Aggregate and Discriminate: Pseudo Clips를 활용한 Video Moment Retrieval 경계 인식
본 논문은 Video Moment Retrieval (VMR) 성능 향상을 위해, 쿼리와 관련성이 높거나 낮은 비디오 클립을 의미론적 가이드로 활용하는 점진적 프레임워크를 제안합니다. 이 방법은 먼저 쿼리와 가장 관련 있는 pseudo-positive 클립과 관련 없는 pseudo-negative 클립을 생성하여 비디오와 텍스트 간의 의미적 격차를 해소합니다. 이후 Pseudo Clips Guided Aggregation 모듈이 관련 클립들을 효과적으로 집계하고, Discriminative Boundary-Enhanced Decoder가 혼란스러운 경계 정보를 명확히 구분하여 목표 모멘트의 시작과 끝 타임스탬프를 정확하게 localize합니다. 논문 제목: Aggregate and Discriminate: Pseudo Clips-Guided Boundary Perception for Video Moment Retrieval
Liu, Jin, et al. "Aggregate and Discriminate: Pseudo Clips-Guided Boundary Perception for Video Moment Retrieval." IEEE Transactions on Multimedia (2025).
Aggregate and Discriminate: Pseudo Clips-Guided Boundary Perception for Video Moment Retrieval
Jing Liu , Zongbing Zhang , Yuting Su , Bing Yang , Xiongkuo Min , Member, IEEE, and Guangtao Zhai
Abstract
Video moment retrieval (VMR)은 언어 쿼리(language query)와 의미적으로 관련된 비디오 세그먼트를 untrimmed 비디오에서 찾아내는 것을 목표로 한다. 이 task의 난이도는 복잡하고 정보 밀도가 높은 비디오 모달리티와 간결하게 요약된 텍스트 모달리티를 효과적으로 정렬(align)하고, 나아가 타겟 모먼트의 시작 및 종료 타임스탬프를 정확히 찾아내는 것에 있다.
기존 연구들은 coarse-to-fine 방식으로 비디오와 쿼리의 다중 granularity 정렬을 시도했지만, 이러한 노력들은 비디오와 쿼리 간의 표현 및 정보 밀도에 내재된 불균형을 해결하는 데 여전히 부족하여 모달리티 간의 misalignment를 초래했다.
본 논문에서는 점진적인 video moment retrieval 프레임워크를 제안한다. 이 프레임워크는 먼저 쿼리와 가장 관련성이 높거나 낮은 비디오 클립을 semantic guidance로 검색하여, 비디오 모달리티와 언어 모달리티 간의 semantic gap을 해소한다.
나아가, 우리는 pseudo clips guided aggregation module을 도입하여 **밀접하게 관련된 모먼트 클립들을 더 가깝게 집계(aggregate)**하고, pseudo clips의 guidance를 통해 의미적으로 혼란스러운 proposal들을 밀어내는 discriminative boundary-enhanced decoder를 제안한다.
CharadesSTA, ActivityNet Captions, TACoS 데이터셋에 대한 광범위한 실험을 통해 우리 방법이 기존 방법들보다 우수함을 입증한다.
Index Terms—Pseudo clips, video grounding, video moment retrieval.
I. Introduction
멀티미디어 기술의 급속한 발전과 함께, 비디오는 다양한 유형의 정보를 전달, 공유, 소통하는 데 필수적인 매체로 부상했다 [1]. 비디오는 이미지 프레임의 시퀀스로 구성되며, 오디오와 자막을 포함할 수 있어 이미지나 텍스트보다 더 포괄적인 의미 정보를 제공한다 [2]. 현재 비디오 이해와 관련된 다양한 task들이 존재하며 [3], [4], 특히 짧은 비디오 이해와 관련된 task로는 비디오 액션 인식 [5], [6], 인간 상호작용 인식 [7], 비디오 질문 응답 [8], 비디오-텍스트 검색 [9] 등이 있다. 그러나 현재 온라인 비디오의 대부분은 편집되지 않은 긴 영상이며, 방대한 양의 미편집 비디오에서 관심 있는 순간을 찾는 것은 비디오 편집자와 사용자 모두에게 상당한 도전 과제를 제기한다 [10]. Video moment retrieval [11], [12], [13]은 긴 비디오 내에서 주어진 자연어 쿼리(문장 또는 구문)에 해당하는 비디오 순간을 정확하게 찾아 검색하는 기술이다. 이 도전적인 task는 시각 정보와 텍스트 정보 간의 효과적인 의미론적 연결을 구축하고, 목표 순간의 경계를 정확히 찾아내는 것을 요구한다.
시각 및 텍스트 양식 간의 본질적인 의미론적 불일치는 효과적인 cross-modal alignment를 달성하는 데 장애물이 된다. 이전 연구들 [14], [15], [16]은 coarse-grained 또는 fine-grained alignment 접근 방식을 활용했지만, 두 양식 간의 표현 및 정보 밀도의 근본적인 차이를 간과했다. 구체적으로, 텍스트 양식은 추상적이고 일반화되어 있어 다양한 비디오 콘텐츠를 효과적으로 요약하고 설명할 수 있다. Fig. 1(a)에 나타난 것처럼, 'person runs up the stairs'라는 동일한 텍스트로 두 개의 다른 장면을 모두 설명할 수 있다. 반면, 비디오 양식은 풍부한 시각적 콘텐츠로 인해 높은 수준의 정보 밀도와 세부 사항을 보여준다.
 Fig. 1. 두 양식 간의 표현 및 정보 밀도의 근본적인 차이를 보여주는 예시.
Fig. 1. 두 양식 간의 표현 및 정보 밀도의 근본적인 차이를 보여주는 예시.
 Fig. 2. 단일 비디오 클립 검색과 목표 순간 검색 간의 정확도 비교. 순간 검색을 평가하기 위해 , , 세 가지 지표가 활용된다.
Fig. 2. 단일 비디오 클립 검색과 목표 순간 검색 간의 정확도 비교. 순간 검색을 평가하기 위해 , , 세 가지 지표가 활용된다.
Fig. 1(b)에서 보듯이, 하나의 비디오 시퀀스는 'a person walks in a doorway drinking some coffee'와 'a person drinking a glass of water'라는 두 가지 다른 텍스트 설명에 해당한다. 이러한 다대다(many-to-many) 대응은 cross-modal alignment bias를 초래한다. 다행히도, 시각 및 텍스트 양식 간의 관련성 덕분에, 우리는 쿼리와 관련된 특정 프레임(즉, 비디오 클립)이 전체 관련 순간보다 검색하기 더 쉽다는 것을 발견했으며, 이는 양식 간의 불일치를 해소하는 추가적인 가이드로 활용될 수 있다. Fig. 2에 나타난 것처럼, 우리는 동일한 cross-modal alignment 방법 [17]을 사용하여 쿼리 관련 비디오 클립 검색과 목표 순간 검색의 정확도를 비교했다. 쿼리 관련 비디오 클립의 검색 정확도는 65%에 달하는 반면, 동일한 방법은 조건에서 목표 순간 검색에 대해 54.95%의 정확도만을 보였다. 또한, 인접한 비디오 클립 간의 유사성을 활용하여, 쿼리와 관련 없는 비디오 클립도 동시에 찾아내어 본질적으로 'negative' 샘플로 참조할 수 있음을 발견했다. 따라서 긍정 및 부정 샘플 모두 순간 클립의 의미론적 연결을 촉진하는 데 활용될 수 있다.
cross-modal 의미론적 정렬 외에도, 쿼리와 관련된 정확한 경계 위치 파악(boundary localization)은 여전히 도전적이다. 최근 일부 연구들 [18], [19]은 DETR [20]과 유사한 방법을 구현하여 후보 제안(candidate proposals)을 생성하려는 노력을 기울였다. 이러한 방법들 [21], [22], [18]은 고정된 수의 learnable query를 활용하여 제안의 내용과 위치를 효과적으로 매칭하고, 이 learnable query를 반복적으로 정제하며, 궁극적으로 랭킹 프로세스를 통해 목표 순간의 시작 및 끝 위치를 찾아낸다. 그러나 learnable query 표현은 주로 각 제안과 관련된 주요 정보에 초점을 맞추어 경계 정보에 대한 민감도가 떨어진다. 이로 인해 ground truth와 가깝거나 겹치는 순간에 대해 learnable query 표현이 매우 유사하게 나타나 경계 추정에서 예측 오프셋(prediction offset)이 발생한다. 이는 향상된 경계 위치 파악 성능을 위해 learnable query 내용과 함께 경계 정보를 decoder에 통합하도록 유도한다.
이를 위해 우리는 pseudo clip-guided perception network를 제안한다. 이 네트워크는 pseudo clip을 의미론적 가이드로 생성하여 시각 및 언어 양식 간의 간극을 해소하고 decoding 과정에서 혼란스러운 제안들을 구별한다. 구체적으로, 텍스트와 비디오 양식을 coarse-to-fine granularity 방식으로 직접 정렬하는 대신 [23], [24], 우리는 초기 cross-modal alignment를 사용하여 pseudo clip을 생성한다. 이는 일련의 목표 비디오 클립을 직접 검색하는 것보다 쉽다. pseudo-positive 및 pseudo-negative 샘플로 분류되는 이 pseudo clip들은 텍스트 관련 및 텍스트 비관련 정보의 구체적인 표현이다. 우리는 Gaussian weighted discriminative cross entropy (GW-DCE) loss와 함께 pseudo clip-guided aggregation을 도입하여 ground truth와 positive pseudo clip 간의 간극을 최소화하고 pseudo-negative clip과의 거리를 최대화한다. 또한, 우리는 pseudo clip-guided discriminative boundary information을 decoder에 통합한다. 적응형 gating module은 learnable query의 경계 및 내용 표현을 모두 통합하도록 개발되었다. 이는 learnable query의 표현 정보를 더욱 풍부하게 하여 의미론적으로 혼란스러운 제안들 [25], [26] 간의 거리를 증가시킨다. 결과적으로, decoding 과정에서 보다 정확한 목표 위치 파악 및 경계 정제가 달성된다.
본 논문의 주요 기여는 다음과 같이 요약된다:
- 우리는 비디오 클립을 텍스트 의미 가이드로 사용하여 목표 순간 정보 집계 및 고정밀 경계 인식을 달성하는 비디오 순간 검색을 위한 점진적 프레임워크를 최초로 제안한다.
- 우리는 목표 클립과 언어 쿼리 간의 의미론적 거리를 줄이기 위해 Gaussian weighted discriminative cross-entropy (GW-DCE) loss와 함께 pseudo clip-guided aggregation을 제안한다.
- 우리는 discriminative boundary information을 통합하여 정확한 경계 위치 파악을 위해 의미론적으로 유사한 learnable query 간의 거리를 증가시키는 discriminative boundary-enhanced decoder를 도입한다.
- Charades-STA, ActivityNet Captions, TACoS 세 가지 널리 인정받는 벤치마크에서 수행된 광범위한 실험은 제안된 방법이 state-of-the-art 접근 방식과 비교하여 경쟁력 있는 성능을 달성함을 보여준다.
II. Related Work
A. Video Moment Retrieval
비디오 모먼트 검색(Video moment retrieval) [27], [28], [29]은 정제되지 않은(untrimmed) 비디오 내에서 텍스트로 설명된 타겟 모먼트(target moment)를 찾아내는 것을 목표로 한다.
Proposal-based 방법 [15], [30], [31]은 제안(proposal)을 생성한 후 순위를 매기는 2단계 프로세스를 따른다.
이전에는 비디오 모먼트 검색을 위한 proposal-based 방법들이 특정 모먼트를 식별하기 위해 수동으로 제작된 proposal에 의존했다. 예를 들어, 이 task를 정의하고 벤치마크 데이터셋을 구축한 CTRL [32]과 MCN [33]은 다양한 스케일의 sliding window를 사용하여 proposal을 생성했다. SRM [14]은 temporal actionness grouping을 사용하여 action proposal을 생성했는데, 각 proposal은 비디오에서 완전한 action instance를 포함하며, 이 proposal과 텍스트 설명 간의 세밀한 매칭을 수행했다.
이러한 방법들은 비디오의 전역적인 맥락(global context)을 포착하는 데 어려움이 있다는 것이 밝혀졌고, 이는 예측 단계에서 후보 proposal 생성을 위한 새로운 방법 탐색으로 이어졌다.
그중 2D-TAN [30]은 가장 대표적인 baseline으로 꼽힌다. 이 방법은 2D-map 기반의 새로운 접근 방식을 도입했는데, 이는 시각적 feature를 2D feature map으로 변환하고 문장 수준의 query feature를 통합한다. Convolutional network와 결합하면 2D-map 내에서 맥락적 정보(contextual information)를 효과적으로 통합할 수 있다.
후속 연구들 [26]은 검색 효율성과 정확도를 향상시키기 위해 2D-map 접근 방식에 수많은 개선 사항을 도입했다. 예를 들어, MGPN [24]은 각 모먼트에 대해 content-level feature map과 boundary-level feature map을 모두 구축하여 비디오의 시간적 상관관계를 포괄적으로 포착했다. VLG-CRF [13]는 CRF 기반의 Boundary Predictor를 설계하여 2D-map 상의 후보 proposal 간의 모먼트 관계를 고려함으로써 모델 예측의 집중도를 높였다.
그러나 이러한 proposal-based 방법들은 여전히 비효율성과 계산 중복성이라는 문제에 직면해 있다.
비디오 모먼트 검색 프로세스를 단순화하고 계산 효율성을 최적화하기 위해, proposal-free 방법 [16], [23], [34]은 세밀한 비디오 클립 feature를 사용하여 타겟의 시작 및 끝 경계(boundary)를 직접 추정함으로써, 수많은 후보 proposal을 생성하는 비용을 제거한다.
예를 들어, EAMAT [35]은 entity-aware 및 motion-aware Transformer를 제안했는데, 이는 세부적인 entity 및 motion query를 추출하여 높은 정밀도로 action boundary를 점진적으로 추정했다. HLGT [16]는 새로운 계층적 local-global Transformer를 제시하여 비디오 및 query 도메인 모두에서 다양한 수준의 granularity를 포착하고, 세밀한 grounding을 위한 완전한 의미론(semantics)을 추론했다.
이후 ACRM [23]은 프레임이 내부 프레임으로 분류될 확률을 정확하게 추정하는 추가적인 predictor를 통합하여 모먼트의 내부 프레임에 포함된 정보를 최대한 활용했다.
그러나 시각 및 텍스트 양식(modality) 간의 본질적인 의미론적 불일치(semantic disparity)와 복잡한 대응 관계는 세밀한 정렬(fine-grained alignment)을 달성하는 데 장애물이 된다.
이를 위해 우리는 pseudo video clip의 guidance를 활용하여 타겟 모먼트에 대한 비디오 표현의 식별성(discriminability)을 초기적으로 향상시킨 후, 세밀한 정렬을 수행하는 점진적 전략을 설계한다.
B. Detection Transformer
DETR [20] (Detection Transformer)은 Transformer [36] encoder-decoder 네트워크를 기반으로 하는 end-to-end 학습 가능한 아키텍처를 활용하는 객체 탐지(object detection)를 위한 새로운 방법이다. DETR은 객체 탐지를 **집합 예측 문제(set prediction problem)**로 공식화하여, region proposal network에서 사용되는 후보 제안(candidate proposal) 생성 비용과 **non-maximum suppression (NMS)**과 같은 후처리 단계의 필요성을 제거한다. 뛰어난 성능과 간소화된 모델 아키텍처를 통해 DETR은 객체 탐지 분야에서 state-of-the-art (SOTA) 알고리즘으로 자리매김했다.
이러한 획기적인 성공에도 불구하고, DETR은 느린 학습 수렴 속도와 작은 객체에 대한 성능 저하와 같은 특정 한계점을 여전히 보인다 [37]. 이러한 문제들을 해결하기 위해 수많은 개선 방안 [38], [39]이 제안되었다. 일부 연구 [38]는 **학습 가능한 쿼리(learnable query)**의 현재 패러다임에 **공간적 사전 정보(spatial prior)**를 도입하여 수렴 효율성을 높이려 시도한다. 이러한 노력은 학습 가능한 쿼리로부터 참조점(reference point)을 분리하고, 이 공간적 사전 정보를 활용하여 이미지 context feature에 효율적으로 attend한다. 또한, 여러 연구 [39]는 객체 내의 대표적인 keypoint가 객체 탐지에서 핵심적인 역할을 한다는 것을 입증했으며, 정확한 semantic alignment를 달성하기 위해 각 학습 가능한 쿼리에 대해 여러 대표 keypoint를 사전 정보로 명시적으로 식별하고자 했다.
최근, 객체 탐지에서 DETR의 prompting 성능에 영감을 받아, 일부 연구 [22], [18], [19]는 비디오 모먼트 검색(video moment retrieval)을 위해 학습 가능한 쿼리 기반의 end-to-end 프레임워크를 채택하여, 높은 추론 속도를 유지하면서도 우수한 성능을 보여주었다. 예를 들어, LVTR [40]은 비디오 모먼트 검색을 집합 예측 문제로 모델링하고 여러 문장 쿼리를 동시에 예측할 수 있는 end-to-end 학습 가능한 모델을 제안했다. Moment-DETR [41]은 detection Transformer의 수정된 버전을 도입하여 쿼리와 관련된 모먼트를 효과적으로 지역화했다. MS-DETR [21]은 학습 가능한 템플릿을 모먼트 후보로 디코딩하기 위한 새로운 anchor-guided moment decoder를 도입했으며, 디코딩 프로세스를 안내하기 위해 anchor highlight 메커니즘을 사용했다.
그러나 학습 가능한 쿼리는 주로 전체 모먼트 정보에 초점을 맞추어 경계(boundary)에 대한 민감도가 떨어지는 한계를 보인다. 이러한 한계를 해결하기 위해, 우리는 디코딩 과정에서 판별적인 경계 정보(discriminative boundary information)를 도입하고, 각 학습 가능한 쿼리의 경계 및 내용 표현(boundary and content representations)을 통합하기 위한 적응형 gating 모듈을 개발한다.
III. Proposed Method
이 섹션에서는 Pseudo clips-Guided Boundary Perception (PGBP) network의 구현 세부 사항을 설명한다. Fig. 3에서 볼 수 있듯이, 제안된 PGBP는 네 가지 구성 요소로 이루어져 있다.
- Feature extraction module: 입력으로부터 비디오 feature와 쿼리 feature를 모두 추출한다.
- Pseudo clips 생성: 쿼리와 관련 있는(relevant) pseudo clip과 관련 없는(irrelevant) pseudo clip이 직접적인 cross-modal interaction을 통해 생성된다.
- Pseudo clips guided aggregation module: pseudo clip의 guidance를 받아 점진적인 video-text interaction을 촉진한다.
- Decoder: fine-grained multi-modal feature를 사용하여, 학습 가능한 proposal에 boundary 정보를 도입하여 정확한 moment boundary localization을 달성한다.
모델을 자세히 설명하기 전에, 먼저 video moment retrieval 표기법을 공식화한다. 주어진 untrimmed video 와 query 에 대해, video moment retrieval은 query 와 가장 관련 있는 비디오 moment를 localize하는 것을 목표로 한다. 구체적으로, 입력 비디오는 로 표기되며, 여기서 는 각 비디오 프레임을 나타내고 는 총 비디오 프레임 수를 나타낸다. 마찬가지로, 입력 쿼리는 로 표기되며, 여기서 는 쿼리의 각 단어를 나타내고 는 쿼리의 총 단어 수를 나타낸다. 마지막으로, 는 moment retrieval의 출력, 즉 타겟 moment의 시작 및 종료 타임스탬프를 나타낸다.
A. Feature Extraction
우리는 사전학습된 비디오 feature extractor를 사용하여 비디오 시퀀스 feature 를 추출한다. 여기서 는 feature extractor에 의해 샘플링된 비디오 클립의 수이고, 는 hidden layer의 차원이다. 이어서, FFN layer와 Transformer layer를 사용하여 비디오 feature를 지정된 차원으로 투영하고 비디오 시퀀스의 시간적 정보(temporal information)를 초기적으로 포착한다. 비디오 인코더는 다음과 같이 공식화된다:
 Fig. 3. 제안하는 PGBP 모델의 프레임워크. 이 모델은 네 가지 구성 요소로 이루어져 있다: 비디오 feature와 쿼리 임베딩을 각각 추출하는 두 개의 인코더; pseudo clips를 선택하는 pseudo clips 생성 모듈; 점진적인 비디오-텍스트 상호작용을 촉진하는 pseudo clips guided aggregation 모듈; 그리고 시간적 경계를 추정하는 discriminative boundary-enhanced decoder.
Fig. 3. 제안하는 PGBP 모델의 프레임워크. 이 모델은 네 가지 구성 요소로 이루어져 있다: 비디오 feature와 쿼리 임베딩을 각각 추출하는 두 개의 인코더; pseudo clips를 선택하는 pseudo clips 생성 모듈; 점진적인 비디오-텍스트 상호작용을 촉진하는 pseudo clips guided aggregation 모듈; 그리고 시간적 경계를 추정하는 discriminative boundary-enhanced decoder.
여기서 는 선형 투영 후의 비디오 시퀀스 feature를 나타내고, 는 초기 문맥 상호작용 후의 비디오 시퀀스 feature를 나타낸다.
마찬가지로, 주어진 쿼리는 GloVe 모델 [42]을 통해 매핑되어 해당 임베딩 벡터 를 얻는다. 여기서 은 단어 임베딩의 수를 나타낸다. 쿼리 임베딩 또한 FFN layer를 통과하여 지정된 차원으로 투영되며, LSTMTransformer [35]를 사용하여 쿼리 내의 문맥 정보(contextual information)를 포착한다. 또한, 명사는 행동의 주체와 초점을 나타내는 역할을 하고, 동사는 주체의 행동이나 상태를 설명하여 쿼리 설명에서 중요한 역할을 한다는 점이 주목된다 [43]. 이에 영감을 받아, 핵심 동사와 명사를 쿼리 키워드로 간주하고, 향상된 텍스트 표현을 위해 추가적인 키워드 마스크를 사용한다. 쿼리 인코더는 다음과 같이 표현될 수 있다:
여기서 는 선형 투영 후의 쿼리 feature를 나타내고, 는 LSTMTransformer 와 키워드 마스크 강화 후의 쿼리 feature를 나타낸다. 키워드 마스크는 키워드 위치를 제외하고는 0과 같다.
B. Pseudo Clips Generation
이전 연구들 [14], [15], [24]는 추출된 시각 및 텍스트 feature에 대해 coarse-to-fine granularity alignment에 초점을 맞추었다. 그러나 비디오 클립 feature와 쿼리 feature 사이의 **내재적인 불균형(disparity)**은 정렬 전에 공유 feature 공간으로 투영되더라도 지속된다. 텍스트 modality는 간결한 반면, 비디오 modality는 Fig. 1에서 보여주듯이 더 높은 정보 밀도를 가진 더 구체적인 특성을 갖는다. 이러한 불균형은 정렬 과정에서 정렬 가능한 정보의 비율에 대한 불확실성을 야기한다. 특히 비디오가 복잡한 배경 콘텐츠를 포함할 때, 정렬 가능한 정보는 더 희소해질 수 있으며, 이는 후속 경계 지역화(boundary localization)에 부정적인 영향을 미친다.
이에 동기를 받아, 우리는 추상적인 텍스트 modality를 구체화하여 비디오 내의 관련 없는 배경 정보가 정확한 cross-modal alignment에 미치는 영향을 완화한다. 구체적으로, 우리는 추상적인 텍스트 modality를 효과적으로 구체화하는 pseudo clips 생성 모듈을 제안한다. 이 모듈은 cross-modal alignment를 사용하여 텍스트와 관련이 있거나 없는 비디오 클립을 식별하며, 이를 각각 pseudo-positive 및 pseudo-negative 샘플이라고 한다. 또한, 이러한 샘플 선택을 위한 필터링 전략을 적용하여 더 안정적인 선택을 촉진한다.
Fig. 3에서 보여주듯이, 우리는 **context-query attention (CQA) fusion [17]**을 사용하여 쿼리 feature 를 비디오 feature 에 통합한다. 이어서 FFN을 활용하여 각 비디오 클립과 쿼리 간의 상관관계를 다음과 같이 계산한다:
여기서 는 cross-modal fusion 방법이고, 는 초기 multi-modal feature이며, 는 sigmoid 함수이고, 는 각 비디오 클립과 쿼리의 상관관계 점수이다.
상관관계 계산의 견고성(robustness)을 향상시키기 위해, 우리는 cross-entropy loss와 pairwise margin loss [22]를 함께 상관관계 손실(correlation loss)로 사용하여 상관관계를 제약한다. 이는 다음과 같이 정의된다:
여기서 는 ground truth label이다. 비디오 클립이 ground truth 내에 있으면 , 그렇지 않으면 이다. 와 는 각각 무작위 샘플의 positive 및 negative 쌍에 해당하는 상관관계 점수이다.
 Fig. 4. pseudo clips guided aggregation의 Triple-branch 아키텍처. 처음 두 branch는 Clip-Driven Attention (CDA) 블록을 갖추고 있어, 두드러진 비디오 콘텐츠에 대한 선택적 집중을 최적화하도록 고안되었다. 세 번째 branch는 Transformer Encoder를 사용하여 시간적 정보 교환을 촉진한다.
Fig. 4. pseudo clips guided aggregation의 Triple-branch 아키텍처. 처음 두 branch는 Clip-Driven Attention (CDA) 블록을 갖추고 있어, 두드러진 비디오 콘텐츠에 대한 선택적 집중을 최적화하도록 고안되었다. 세 번째 branch는 Transformer Encoder를 사용하여 시간적 정보 교환을 촉진한다.
무작위로 샘플링된 positive 및 negative 샘플의 수는 이고, 는 margin으로, 모델이 negative 및 positive 쌍 사이에 유지해야 하는 최소 거리를 정의하는 하이퍼파라미터이다.
변동하는 예측으로 인한 부정적인 영향을 피하기 위해, 우리는 를 직접 사용하여 pseudo clips를 선택하지 않는다. 타겟 순간(target moment)은 연속적이므로, 모든 비디오 클립을 순회하기 위해 필터링 윈도우(filtering window)를 사용한다. 윈도우 필터링된 상관관계 점수를 기반으로, pseudo positive clips는 가장 높은 점수를 가진 중심 클립으로 식별되고, pseudo negative clips는 가장 낮은 점수를 가진 중심 클립으로 식별된다. 마지막으로, 선택된 positive 및 negative pseudo clips는 각각 및 로 나타낼 수 있으며, 여기서 K는 negative 샘플의 수이다.
C. Pseudo Clips Guided Aggregation
위에서 생성된 pseudo clip들은 두 가지 측면에서 가이드로 활용된다. 한편으로, positive pseudo clip들은 타겟 순간과 상당한 유사성을 공유하는 풍부한 전경(foreground) 콘텐츠를 특징으로 한다. 따라서 이들은 전경 feature를 강조하는 데 사용될 수 있다. 다른 한편으로, negative pseudo clip들은 쿼리와 관련이 없지만, 광범위한 문맥 정보를 가지고 있으며 특정 비타겟 순간과 높은 유사성을 공유한다. 결과적으로, 이들은 관련 없는 배경 feature를 억제하는 데 동시에 활용될 수 있다. 따라서 positive 및 negative pseudo clip의 가이드를 통해 **쿼리 관련 및 쿼리 비관련 비디오 클립의 의미론적 집계(semantic aggregation)**가 달성될 수 있으며, 이는 후속 cross-modal interaction을 크게 촉진한다.
또한, pseudo clip들이 쿼리 관련 의미론적 정보를 전달하지만, 짧은 지속 시간으로 인해 쿼리 설명에서 표현된 특정 뉘앙스를 간과할 수 있다는 점에 주목할 필요가 있다. 이러한 한계는 종종 포괄적인 표현을 위해 긴 프레임 시퀀스를 필요로 하는 액션 쿼리 시 특히 두드러진다. 따라서 pseudo clip을 사용하여 쿼리 설명의 역할을 완전히 대체하는 대신, 우리는 이러한 pseudo clip을 텍스트 및 시각 모달리티 간의 간극을 메우는 보충 자료로 활용한다.
이를 위해, 우리는 Fig. 4에 나타난 바와 같이 pseudo clip guided aggregation에서 positive amplifier, negative suppressor, inter-frame interaction을 포함하는 세 가지 브랜치 아키텍처를 제안한다.
처음 두 브랜치는 Clip-Driven Attention (CDA) 블록을 갖추고 있으며, 이는 클립 관련성에 따라 모델의 attention을 동적으로 조정하여 모델이 관심 있는 비디오 콘텐츠에 집중하도록 특별히 고안되었다. 또한, 세 번째 브랜치는 Transformer를 활용하여 시간 정보 교환을 촉진하고, 비디오 클립의 문맥 이해를 더욱 풍부하게 한다.
CDA 블록은 클립 상관관계에 따라 모델의 attention을 동적으로 조정하도록 설계되어, 참조(reference)에 가장 관련성이 높은 요소에 초점을 맞추고 비필수적인 배경 정보의 영향을 효과적으로 최소화한다. 참조 feature 와 feature 시퀀스 가 주어졌을 때, CDA 모듈은 와 간의 **내적 유사도(dot product similarity)**를 기반으로 feature 가중치를 계산한 후, 1D convolutional block을 적용한다. 그런 다음 이 가중치는 **내적 연산(dot product operation)**을 통해 시퀀스 feature에 적용된다. CDA 모듈의 연산은 다음과 같이 공식화될 수 있다:
여기서 및 는 1D convolutional layer이며 출력 채널 차원은 각각 및 이고, 및 는 각각 ReLU 및 sigmoid 활성화 함수이다.
positive amplifier 브랜치의 경우, 비디오 feature 와 positive pseudo clip feature 의 CDA 블록을 통한 조합은 비디오 클립 내의 전경 정보(foreground information)를 협력적으로 풍부하게 한다. 이는 다음과 같이 공식화된다:
negative suppressor 브랜치는 두 개의 CDA로 구성된다. pseudo negative clip은 텍스트 쿼리와 관련이 없을 수 있지만, ground truth 텍스트 쿼리 세그먼트와 배경 또는 부분적으로 쿼리 관련 정보를 공유할 가능성이 있다. 따라서 비디오와 negative pseudo clip의 feature 시퀀스에 하나의 CDA를 단순히 적용하면 원치 않게 특정 유용한 feature를 억제할 수 있다. 이를 해결하기 위해 Fig. 4에 나타난 바와 같이 두 개의 CDA 블록을 쌓는다. 첫 번째 CDA는 negative pseudo clip을 feature 시퀀스로, positive pseudo clip을 참조 클립으로 사용한다. 마지막 채널 convolutional layer의 활성화 함수는 로 대체된다. 이러한 방식으로 공유된 배경 또는 부분적으로 쿼리 관련 정보가 선택적으로 제거되고, negative pseudo clip으로부터 **쿼리 비관련 표현(query-irrelevant representations)**을 얻는다. 수정된 CDA 블록은 로 표현된다. 이어서, 두 번째 CDA는 비디오의 feature 시퀀스와 쿼리 비관련 표현을 참조 클립으로 입력받는다. 이는 다음과 같이 공식화된다:
여기서 은 max pooling 연산이다. 는 마지막 채널 convolutional layer의 활성화 함수가 로 대체된 CDA 블록이다.
처음 두 브랜치는 positive 및 negative pseudo clip을 통합하여 프레임 내 정보 상호작용을 촉진하는 반면, 세 번째 브랜치는 입력 클립 시퀀스의 feature 내 상호작용에 중점을 둔다. 우리는 각 클립의 시각 feature에 Transformer Encoder를 사용하여 프레임 간 정보 상호작용을 촉진한다. 이 브랜치는 다음과 같이 공식화될 수 있다:
최종적으로 정제된 비디오 클립 feature는 다음과 같이 공식화될 수 있다:
비디오 클립 feature의 식별력(discriminability)을 향상시키기 위해, 우리는 출력 를 제약하기 위해 두 가지 유형의 CrossEntropy (CE) loss로 구성된 GW-DCE loss를 제안한다. 특히, 타겟 순간을 벗어난 비디오 클립은 다양한 시나리오를 포함할 수 있으며 높은 시간적 연속성을 가지지 않을 수 있다. 결과적으로, 음성 샘플 정보의 집계는 Gaussian 가중치를 사용하여 제약되어야 한다. 이 loss 함수를 사용함으로써, 우리는 타겟 순간의 비디오 클립을 positive pseudo clip 쪽으로 당기고, 다른 비디오 클립을 인접한 negative pseudo clip 쪽으로 당길 수 있다. 이 loss 함수는 다음과 같이 공식화될 수 있다:
여기서 는 ground truth label이고, 는 pseudo clip과 비디오 클립 feature 간의 cosine similarity이며, 는 Gaussian 가중치를 나타낸다.
여기서 는 cosine similarity이고, 이며, 와 는 각각 Gaussian 함수의 평균과 분산이다.
이어서, 우리는 정제된 비디오 feature와 쿼리 feature의 피라미드 cross-modal alignment를 수행한다. 첫째, stacked LSTM-Transformer를 사용하여 비디오 feature에 대한 심층적인 프레임 간 정보 상호작용을 촉진한다. [44]에서 영감을 받아, 우리는 비디오 시퀀스 feature에 max pooling 연산을 통해 비디오와 텍스트를 다른 스케일에서 정렬하여, 모델이 비디오 콘텐츠와 텍스트 설명 간의 의미론적 관계를 더 잘 이해할 수 있도록 한다. 최종 fine-grained multi-modal feature는 로 표현될 수 있다. 마지막으로, 순간의 내부 클립에 포함된 정보를 완전히 활용하기 위해, 디코딩 전에 프레임이 내부 프레임일 확률을 추정하는 추가 예측기(predictor)를 추가한다 [23]. 예측기는 다음과 같이 공식화될 수 있다:
여기서 는 sigmoid 함수이고 이다.
D. Discriminative Boundary-Enhanced Decoder
fine-grained multi-modal feature 로부터 타겟 moment를 식별하기 위해, 기존의 learnable query 기반 방법들은 특정 개수의 learnable query를 proposal로 무작위로 생성한다. 각 query는
 Fig. 5. discriminative boundary-enhanced decoder의 구조. learnable query에 해당하는 boundary semantic information이 도입되어 semantic content를 풍부하게 한다.
Fig. 5. discriminative boundary-enhanced decoder의 구조. learnable query에 해당하는 boundary semantic information이 도입되어 semantic content를 풍부하게 한다.
temporal prior ()와 content 정보를 포함한다. 이어서, 무작위로 생성된 learnable query들은 self-attention 및 cross-attention layer를 통해 처리된다. 이 과정은 다음과 같이 표현될 수 있다:
여기서 와 은 각각 현재 decoder layer와 다음 decoder layer의 learnable query feature이며, MHSA와 MHCA는 각각 self-attention 및 cross-attention layer를 나타낸다. 이 과정은 서로 다른 learnable query feature들 간의 광범위한 상호작용뿐만 아니라, learnable query feature와 cross-modal fusion feature 간의 상호작용을 촉진한다. 그럼에도 불구하고, 이러한 learnable query들은 각 proposal moment에 대한 전역적인 semantic information을 우선시하는 경향이 있어, boundary detail에 대한 민감도가 부족하다.
비디오 moment retrieval에서 주요 목표는 타겟 moment의 boundary 위치를 정확하게 식별하는 것이며, 최종 decoding 단계에서 boundary information에 상당한 강조를 둔다. object detection 분야에서 key point information을 learnable query에 통합하는 것이 [39] detection 정확도를 크게 향상시키는 것으로 나타났다는 점에서 영감을 받아, 여기에 boundary information을 통합하면 성능 향상을 가져올 것으로 기대된다. 이는 semantic적으로 유사한 proposal moment들을 더 멀리 떨어뜨려 놓아 boundary 위치의 discriminability를 향상시키는 데 도움이 될 것이다. 그러나 boundary information을 learnable query에 직접 도입하는 것은 sub-optimal할 수 있다. 한편으로는, boundary information의 도입이 참조 컨텍스트(referential context)를 결여하여, 서로 다른 query의 boundary information 간의 상관관계가 부족해지고, 이로 인해 localization boundary의 최적화를 방해할 수 있다. 다른 한편으로는, boundary information과 global semantic information 간의 균형이 특정 query와 컨텍스트에 따라 적응적으로 결정되어야 한다.
각 learnable query의 정보 내용을 풍부하게 하고 최종 타겟 moment localization의 정확도를 높이기 위해, 우리는 discriminative boundary-enhanced decoder를 제안한다. 구체적으로, Fig. 5에 나타난 바와 같이, MS-DETR [21]을 따라 temporal prior와 content information을 learnable query 정보로 결합한다. 그리고 MHCA 이전에 discriminative boundary information이 query feature에 도입된다. 각 learnable query에 대해, temporal prior (center, width)를 기반으로 cross-modal fusion feature 내에서 해당 boundary feature 가 위치한다. 이어서, positive pseudo clip이 CDA를 통해 boundary information에 referential context로 통합된다. CDA 블록은 channel dimension을 따라 boundary information에 가중치를 부여하여, 정제된 boundary information이 cross-modal fusion feature 와 동일한 feature space 내에 유지되도록 한다. 이는 MHCA에서 와의 후속 정렬을 용이하게 한다. 또한, 각 decoder layer에서 query content feature 와 boundary feature 의 상대적 중요성을 효과적으로 평가하기 위해, 우리는 각 learnable query의 boundary 및 content feature를 병합하는 adaptive gating module을 설계한다. 이 과정은 다음과 같이 공식화될 수 있다:
여기서 Pool 은 maxpool 연산이며, 는 각 query에 해당하는 비디오의 positive pseudo clip들로부터 concatenate된 것이다. ||는 concatenate 연산을 나타낸다.
주류 연구 [21]를 따라, 두 개의 Feed-Forward Network (FFN)가 decoder의 query feature에 적용되어 각 query의 해당 ()에 대한 offset ()과 class score를 각각 예측한다. 각 query와 관련된 positional information ()은 decoder의 layer들을 통해 점진적으로 정제된다. boundary refinement 과정은 다음과 같이 공식화될 수 있다:
여기서 ()은 현재 decoder layer의 learnable query에 대한 positional information의 center와 width이다. 와 는 각각 inverse sigmoid function과 sigmoid function이다.
decoder layer에 의해 예측된 각 moment 에 대해, 예측된 moment와 ground truth 간의 차이는 L1 loss와 GIOU loss 를 사용하여 측정된다. Cross-entropy loss 는 IOU metric을 기반으로 각 query를 foreground 또는 background로 분류하는 데 사용된다. 각 decoder에 대한 loss는 다음과 같이 공식화될 수 있다:
여기서 는 타겟 moment의 ground truth이며, , 는 loss에 대한 가중치이다.
전체 네트워크 loss는 다음과 같이 공식화될 수 있다:
여기서 및 는 loss에 대한 가중치이다. 추론 시, 최종 decoder layer의 가장 높은 점수를 받은 query에 해당하는 center 및 width 값이 출력 예측으로 도출된다. 이 값들은 시작 및 종료 timestamp로 변환된다.
IV. Experiement
A. Datasets and Evaluation Metrics
우리는 세 가지 데이터셋인 CharadesSTA [32], TACoS [45], 그리고 **ActivityNet Captions [11]**를 사용하여 우리의 방법을 평가한다.
- CharadesSTA는 Charades 데이터셋의 확장 버전으로, **시간적 주석(시작 및 종료 타임스탬프)**과 각 비디오 세그먼트에 해당하는 자연어 설명을 포함하며, 일상생활의 다양한 활동을 묘사한다. 이 데이터셋은 총 16,128개의 주석을 포함하며, 이 중 12,408개는 학습용이고 3,720개는 테스트용이다.
- TACoS 데이터셋은 128개의 요리 비디오로 구성되어 있으며, 자르기, 굽기 등 다양한 요리 활동을 다룬다. 총 26시간 이상의 분량과 18,818개의 주석을 포함하며, 이 중 10,146개는 학습용, 4,589개는 검증용, 4,083개는 테스트용이다.
- ActivityNet Captions 데이터셋은 대규모 벤치마크로, 다양한 활동을 다루는 20,000개의 YouTube 비디오를 포함한다. **2D-TAN [30]**을 따라, 우리는 val_1을 검증 세트로, val_2를 테스트 세트로 사용한다. 이 데이터셋은 학습용 37,417쌍, 검증용 17,505쌍, 테스트용 17,031쌍의 쿼리-비디오 쌍을 포함한다.
이전 연구들 [35], [24]를 따라, 우리는 평가 지표로 ""와 ""를 사용한다.
- ****는 상위 n개 결과 중 적어도 하나가 ground truth와 를 만족하는 테스트 샘플의 비율을 측정한다.
- ****는 **모든 테스트 샘플에 대한 평균 **를 계산한다.
우리는 ****로 설정하고 ****를 사용한다. 비교 및 논의에서는 주로 ****에 초점을 맞추는데, 이는 더 높은 가 더 높은 품질의 일치를 나타내기 때문이다.
B. Implementation Details
우리의 모델은 1개의 NVIDIA GeForce RTX 4080 GPU가 장착된 PyTorch 프레임워크에서 구현되었다. 공정한 비교를 위해, TACoS 데이터셋의 비디오 인코딩에는 C3D [46]를 적용하고, Charades-STA 데이터셋의 비디오 feature 추출에는 I3D [47]를 사용한다. 쿼리 인코딩의 경우, Glove 모델을 활용하여 쿼리 내 각 단어에 대해 300차원 벡터 임베딩을 얻는다. 모든 layer의 hidden state dimension은 512로 설정된다.
하이퍼파라미터 설정으로, decoder layer의 학습 가능한 query 수는 10개로, pyramid cross-modal alignment의 stacked LSTM-Transformer layer 수는 3개로 설정된다. [21]을 참조하여, 별도로 언급되지 않는 한 **loss balancing 파라미터는 **로 설정한다. 우리는 Charades-STA, TACoS, ActivityNet Captions 데이터셋에 대해 Adam optimizer와 의 learning rate로 50 epoch 동안 비디오 모멘트 검색 모델을 학습시킨다.
C. Model Performance Comparison
- Baselines: 제안된 모델은 세 가지 그룹으로 분류된 여러 state-of-the-art 방법들과 비교된다:
- proposal-based methods
- proposal-free methods
- proposal-learnable methods
Proposal-based methods는 수동으로 설계된 proposal의 품질에 크게 의존하며, 상당한 계산 오버헤드를 수반한다. 우리는 비교를 위해 대표적인 **SCDM [48], CBP [49], 2D-TAN [30], SMIN [50], VSLNet [51], BAN-APR [25], MGPN [24], BMRN [26]**을 선정하였다.
TABLE I Charades-STA 결과
| method | mIoU | |||
|---|---|---|---|---|
| DEBUG | 54.95 | 37.39 | 17.69 | 36.34 |
| 2D-TAN | 58.76 | 46.02 | 27.4 | 41.25 |
| ACRM | 73.47 | 57.53 | 38.33 | 53.01 |
| SeqPAN | 73.84 | 60.86 | 41.34 | 53.92 |
| VSLNet | 70.46 | 54.19 | 35.22 | 50.02 |
| MGPN | - | 60.82 | 41.16 | - |
| EAMAT | 74.19 | 61.69 | 41.96 | 54.45 |
| BAN-APR | - | 63.68 | 42.28 | - |
| QD-DETR | - | 50.67 | 31.02 | - |
| MS-DETR | 68.68 | 57.72 | 37.4 | 50.12 |
| BMRN | - | 63.09 | - | |
| MomentDiff | - | 53.79 | 30.18 | - |
| HLGT | - | 65.31 | 41.38 | - |
| Ours | 74.24 | 64.03 | 44.78 | 55.18 |
최고 결과는 굵은 글씨로, 두 번째 최고 결과는 밑줄로 표시.
Proposal-free methods는 **temporal boundary를 직접 회귀(regress)**하여, 광범위한 proposal 설계 과정을 피한다. 대표적인 연구로는 DEBUG [17], GDP [52], LGI [53], SeqPAN [54], ACRM [23], CPN [55], EAMAT [35], SAM [56] 등이 있다. 대상 비디오 세그먼트의 다양한 temporal duration과 semantics로 인해, proposal-free methods의 grounding 결과는 종종 충분히 정밀하지 못하다.
또한, 우리의 방법은 현재 인기 있는 proposal-learnable methods인 **MMN [57], GTR [58], QD-DETR [18], MS-DETR [21], MomentDiff [22]**와 비교된다. 이 방법들은 학습 가능한 query를 기반으로 하는 end-to-end 프레임워크를 채택하여 video moment retrieval을 수행하며, proposal-based methods와 proposal-free methods의 장점을 결합한다. 공정하고 엄격한 비교를 위해, 우리는 이 방법들의 원 논문에서 보고된 결과를 직접 인용하였다.
- 성능 분석: Charades-STA, TACOS, ActivityNet Captions 데이터셋에 대한 우리 모델과 다른 방법들의 비교 결과는 각각 Table I-III에 제시되어 있다. 최고 성능은 굵은 글씨로, 두 번째 최고 성능은 밑줄로 강조되어 있다. 모든 표의 결과는 우리 방법이 평가된 모든 metric에서 경쟁력 있는 성능을 제공하며, 이는 대상 moment를 정확하게 localize하고 refine하는 제안 모델의 효과를 입증한다.
Charades-STA 데이터셋에서 제안된 방법은 세 가지 중요한 평가 metric에서 최고의 결과를 달성한다. 특히, 중요한 평가 metric인 R@1, IoU 측면에서 우리 방법은 두 번째로 좋은 방법보다 2.32% 더 우수하다. 이는 pseudo-sample의 guidance를 통해 우리 방법이 대상 비디오 클립을 효과적으로 집계하고 더 정확한 boundary localization을 달성할 수 있음을 추가적으로 나타낸다. 평가 metric R@1, IoU=0.5에서는 HLGT가 우리 방법보다 우수한데, 이는 HLGT가 더 미세한 spatio-temporal feature extraction 전략을 사용하기 때문으로 분석된다.
TACOS 데이터셋에서 우리 방법은 baseline인 EAMAT 방법보다 R@1, IoU , R@1, IoU , mIoU에서 각각 0.9%, 2.7%, 0.4% 우수하지만, R@1, IoU 에서는 1.2% 뒤처진다. 이러한 차이는 TACOS 데이터셋에 내재된 복잡한 텍스트 설명과 관련이 있을 수 있으며, 이는 추가적인 텍스트 탐색의 여지를 시사한다.
ActivityNet Captions 데이터셋에서도 우리 방법은 state-of-the-art 방법들과 비교하여 경쟁력 있는 결과를 달성한다. 최고 성능을 보인 MMN은 negative query에 특별히 주의를 기울였으며, 기존 supervision 외에 모델이 구성된 negative sentence set에서 비디오 moment에 대한 올바른 문장을 선택하도록 요구하는 상호 매칭(mutual matching) 보조 task를 제안했다. 우리 방법은 새로운 관점에서 비디오 클립을 video moment retrieval을 위한 텍스트 semantic guide로 활용한다. MMN과 우리 알고리즘은 서로 다른 관점에서 VMR 문제를 해결한다. 우리는 MMN의 보조 task supervision을 우리 접근 방식에 통합하면 결과를 더욱 향상시킬 수 있다고 생각하지만, 이는 본 논문의 범위를 벗어난다.
TABLE II TACOS 결과
| method | mIoU | |||
|---|---|---|---|---|
| DEBUG | 23.45 | 11.72 | - | 16.03 |
| 2D-TAN | 37.29 | 25.32 | - | - |
| VSLNet | 29.61 | 24.27 | 20.03 | 24.11 |
| SeqPAN | 31.72 | 27.19 | 21.65 | 25.86 |
| GTR | 40.39 | 39.22 | - | - |
| SMIN | 48.01 | 35.24 | - | - |
| CPN | 48.29 | 36.58 | 21.25 | 34.63 |
| MGPN | 48.81 | 36.74 | - | - |
| BAN-APR | 48.24 | 33.74 | - | - |
| EAMAT | 50.11 | 38.16 | 26.82 | |
| MS-DETR | 47.66 | 37.36 | 25.81 | 35.09 |
| MomentDiff | 44.78 | 33.68 | - | - |
| HLGT | 49.33 | 39.17 | - | - |
| Ours | 51.01 | 40.86 | 25.62 | 36.83 |
최고 결과는 굵은 글씨로, 두 번째 최고 결과는 밑줄로 표시.
기본 측정치 R@1, (다양한 IoU 임계값)
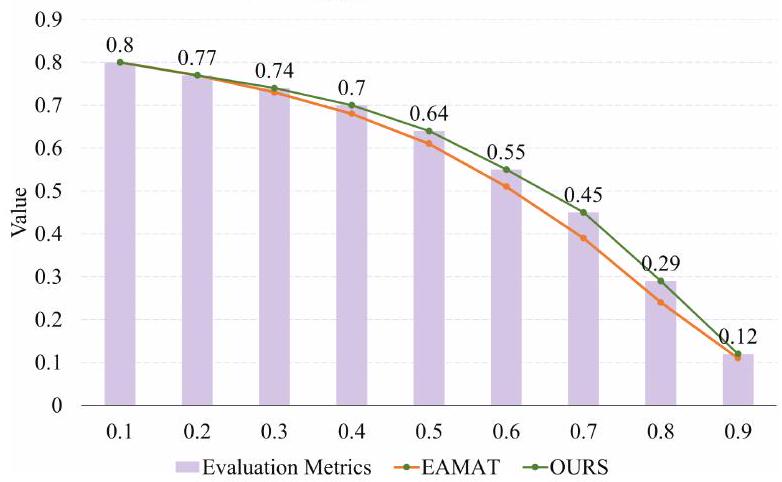
Fig. 6. 에 대한 모델의 평가 결과, IoU 임계값 파라미터 .
우리는 또한 더 미세한 단계에서 다양한 IoU 임계값에 대한 를 비교한다. Fig. 6은 에 대한 모델의 평가 결과를 보여준다. 우리 모델이 더 넓은 범위의 IoU 임계값에서 높은 성능을 제공함을 알 수 있다. 우리는 또한 이를 EAMAT [35]와 비교했으며, 우리 방법은 IoU 임계값이 증가함에 따라 더 높은 성능으로 개선된다.
다른 한편으로, 우리는 **임계값 파라미터 없이 와 일관된 평가를 제공할 수 있는 민감한 평가 metric인 AxIoU [59]**도 사용한다. Fig. 7은 Charades-STA 데이터셋에서 AxIoU 및 기본 평가 metric인 측면에서 우리 방법과 세 가지 state-of-the-art 방법 [35], [30], [48]의 결과를 보여준다. 우리 방법은 다양한 평가 metric에서 더 나은 성능을 보여주며, 이는 그 유효성과 신뢰성을 더욱 입증한다.
 Fig. 7. 민감한 평가 metric AxIoU와 기본 평가 metric 를 사용한 모델 평가 결과.
Fig. 7. 민감한 평가 metric AxIoU와 기본 평가 metric 를 사용한 모델 평가 결과.
TABLE III ActivityNet Captions 결과
| method | mIoU | |||
|---|---|---|---|---|
| DEBUG | 55.91 | 39.72 | - | 39.51 |
| SCDM | 54.80 | 36.75 | 19.86 | - |
| CBP | 54.30 | 35.76 | 17.80 | - |
| GDP | 56.17 | 39.27 | - | 39.80 |
| 2D-TAN | 59.45 | 44.51 | 27.38 | - |
| VSLNet | 63.16 | 43.22 | 26.16 | 43.19 |
| LGI | 58.52 | 41.51 | 23.07 | - |
| MMN | 65.05 | 48.59 | 29.26 | - |
| SAM | 60.08 | 44.65 | 25.75 | - |
| Ours | 60.33 | 45.04 | 28.14 | 43.87 |
최고 결과는 굵은 글씨로, 두 번째 최고 결과는 밑줄로 표시.
D. Ablation Study
우리는 모델의 핵심 구성 요소들의 효과를 평가하기 위해 ablation study를 수행한다. 여기에는 다음 내용들이 포함된다:
- 선택된 긍정 및 부정 pseudo clip 수의 영향 평가,
- pseudo clips guided aggregation 모듈 내 세 가지 병렬 branch의 효과 검토,
- 경계(boundary) 및 의미(semantic) feature 통합 전략 분석,
- 특정 loss function과 관련 하이퍼파라미터의 효과 평가,
- 위치 편향(location bias) 문제 탐색.
특별히 명시되지 않는 한, ablation 실험은 Charades-STA 데이터셋에서 수행된다.
- Pseudo Clips의 효과: pseudo clip의 적절한 선택은 우리 모델에서 비디오의 의미를 정제하고 경계 정보를 구별하는 데 중요한 역할을 한다. 따라서 우리는 선택된 pseudo clip의 수가 모델 성능에 미치는 영향을 평가한다. Fig. 8에서 보듯이, 선택된 긍정 pseudo clip의 수가 증가함에 따라 모델의 성능은 모든 평가 지표에서 전반적으로 감소한다. 긍정 pseudo clip 수가 2일 때 R@1, IOU=0.5에서 64.41%의 최적 성능을 달성했지만, mIoU에서는 긍정 pseudo clip 수가 1일 때보다 0.25%의 성능 감소가 있었다. 이는 Charades-STA 데이터셋이 복잡한 텍스트 설명이 적어 제한된 수의 긍정 pseudo clip만으로도 대부분의 타겟 순간 클립을 집계할 수 있기 때문으로 해석될 수 있다. 반대로, Fig. 9에서 보듯이, 부정 pseudo clip의 수가 증가함에 따라 모델 성능은 향상되며, 6개의 부정 pseudo clip에서 최고점에 도달한다. 이는 비타겟 순간 클립의 의미 정보가 일관적이지 않아 효과적인 표현을 위해 더 많은 부정 pseudo clip이 필요함을 나타낸다. mIoU는 모델 성능의 포괄적인 평가 지표이므로, 긍정 pseudo clip 수 1개, 부정 pseudo clip 수 6개를 최적의 선택으로 간주한다. 또한, 우리는 샘플 선택의 정확도를 평가한다. Fig. 10은 선택된 긍정 pseudo clip의 정확도가 클립 수에 의해 크게 영향받는 반면, 부정 샘플에 미치는 영향은 상대적으로 작음을 보여준다. 이는 선택된 긍정 pseudo clip의 수가 증가함에 따라 모델 성능이 감소하는 주요 요인이다.
 Fig. 8. 긍정 Pseudo clip 수의 영향.
Fig. 8. 긍정 Pseudo clip 수의 영향.
 Fig. 9. 부정 Pseudo clip 수의 영향.
Fig. 9. 부정 Pseudo clip 수의 영향.
 Fig. 10. 선택된 pseudo clip의 정확도. 빨간색 점선은 부정 pseudo clip을, 녹색 선은 긍정 pseudo clip을 나타낸다.
Fig. 10. 선택된 pseudo clip의 정확도. 빨간색 점선은 부정 pseudo clip을, 녹색 선은 긍정 pseudo clip을 나타낸다.
- Pseudo Clips Guide Aggregation의 효과: pseudo clips guided aggregation의 효과를 평가하기 위해, 우리는 모듈에서 긍정 branch, 부정 branch, 그리고 상호작용 branch를 순차적으로 제거한다. Table IV에서 보듯이, 어떤 branch를 제거하더라도 모델 성능이 약간 감소하는데, 이는 pseudo clip이 프레임 내 전경 정보를 강화하고 배경 정보를 억제하는 데 효과적임을 나타낸다.
TABLE IV Pseudo Clip Guided Discrimination Module에 대한 Charades-STA Ablation 결과; PB는 긍정 Branch, NB는 부정 Branch, IB는 프레임 간 상호작용 Branch
| IB | PB | NB | R@ 1, IoU | mIoU | ||
|---|---|---|---|---|---|---|
| 64.03 | ||||||
| 44.09 | ||||||
| 73.65 | 54.94 | |||||
| 74.01 | 63.57 | 43.76 | 54.52 | |||
| 72.18 | 62.18 | 43.82 | 53.56 |
TABLE V 경계 Feature와 의미 Feature의 융합 방법에 대한 Charades-STA Ablation 결과
| B | Fusion | R@1,IoU= | mIoU | ||
|---|---|---|---|---|---|
| 64.08 | 43.87 | 54.87 | |||
| Sum Fusion | 43.76 | ||||
| Max Pool | 74.27 | 55.09 | |||
| Gating mechanism | 74.24 | 64.03 |
TABLE VI Correlation Loss에 대한 Charades-STA Ablation 결과
| PM | CE | R@1,IoU= | mIoU | ||
|---|---|---|---|---|---|
| 73.03 | 63.68 | 44.44 | 54.38 | ||
| 72.58 | 62.37 | 42.44 | 53.35 |
CE는 cross-entropy loss를, PM은 pairwise margin loss를 나타낸다.
프레임 간 상호작용 branch가 제거되었을 때, R@1, IoU=0.3 및 R@1, IoU=0.5에서 모델 성능이 크게 감소하는데, 이는 충분한 contextual 정보 상호작용이 타겟 fragment 의미의 집계에 기여함을 나타낸다. 3) Boundary Integrated Decoder의 효과: 경계 정보의 효율성을 평가하는 동시에, 경계 feature와 내용(content) feature를 통합하는 융합 방법도 평가한다. Table V에서 보듯이, 다양한 융합 방법을 사용하여 최종 제안 feature에 경계 정보를 추가하면 모델 성능이 눈에 띄게 향상된다. sum fusion 방법은 모든 feature를 고려하지만, 핵심 feature를 강조하는 데 한계가 있다. 그리고 R@1, IoU=0.3 및 R@1, IoU=0.5 평가 지표에서 각각 0.11% 및 0.44% 성능을 향상시킨다. max pool 방법은 feature 내에서 가장 중요한 정보를 식별할 수 있지만, 일부 중요한 보조 feature를 상대적으로 무시할 수 있다. 제안된 Gating mechanism은 계산 비용의 작은 증가로 적응형 feature 선택을 가능하게 하며, 인 평가 지표에서 경쟁력 있는 성능을 보여준다. 또한, 더 엄격한 평가 지표인 R@1, IoU=0.7에서 뛰어난 성능을 보인다. 전반적으로, 우리 모델의 "Gating mechanism"은 전반적인 효율성 측면에서 최고의 성능을 보여준다. 동적으로 통합된 경계 및 내용 feature는 더 정확한 경계 위치 파악을 나타낸다. 4) Correlation Loss의 효과: correlation loss는 cross-entropy loss와 pairwise margin loss로 구성된다. Table VI에서 보듯이, 우리는 pseudo clip 선택 과정에서 cross-entropy loss와 pairwise margin loss 모두의 효과를 검증한다. 결과는 두 loss를 모두 통합하는 것이 pseudo clip 선택의 안정성을 보장하고 경계 위치 정확도를 향상시킨다는 것을 나타낸다. 결과적으로, 우리는 pseudo clip 생성을 위한 correlation loss로 cross-entropy loss와 pairwise margin loss의 공동 활용을 채택한다.
 Fig. 11. GW-DCE loss에 대한 Charades-STA Ablation 결과. ""은 GW-DCE loss가 비활성화되었음을 나타낸다.
Fig. 11. GW-DCE loss에 대한 Charades-STA Ablation 결과. ""은 GW-DCE loss가 비활성화되었음을 나타낸다.
- Gaussian Weighted Discriminative Cross-Entropy Loss의 효과: 우리는 GW-DCE loss function의 효과를 평가하고, 그 하이퍼파라미터 를 평가한다. Fig. 11에서 보듯이, GW-DCE loss는 모델 성능에 상당한 영향을 미치며, loss가 없는 모델에 비해 mIoU에서 1.15%의 향상을 보인다. 이는 loss가 긍정 pseudo clip과 타겟 순간 클립 간의 거리를 효과적으로 줄이는 동시에, 부정 pseudo clip을 비타겟 순간 클립에 더 가깝게 당긴다는 것을 나타낸다. 또한, 값이 증가함에 따라 모델 성능이 처음에는 증가하다가 감소하는 경향이 관찰되었다. 최적의 결과는 일 때 얻어진다. 이는 의 추가적인 증가가 성능 향상에 기여하지 않는 임계점이 있음을 나타낸다.
- Location Bias 문제 탐색: location bias 문제를 탐색하기 위해, 우리는 위치 분포 변화가 있는 두 가지 anti-bias 데이터셋인 Charades-STA-Len 및 Charades-STA-Mom [22]에서 우리 모델을 검증한다. Charades-STA-Len 데이터셋은 학습 및 테스트 세트 간의 길이 분포 차이를 강조하고, Charades-STA-Mom 데이터셋은 위치 분포 차이를 강조하여, 모델이 길이 및 위치 변화 모두에 대한 강건성을 강력하게 검증한다.
MomentDiff [22]를 따라, 우리는 VGG 및 Glove 비디오-텍스트 feature를 사용하여 이 두 anti-bias 데이터셋에서 실험을 수행한다. Table VII에서 보듯이, 우리 방법은 anti-bias 데이터셋에서 최적의 성능을 보이며, location bias를 다루는 데 MomentDiff보다 더 강건함을 보여준다. 이러한 실험은 위치 편향을 처리하는 우리 방법의 효과를 검증하며, 분포가 변화하는 데이터셋에 적용될 때 기존 방법들보다 더 강건함을 보여준다.
E. Qualitative Results
비디오 모먼트 현지화 결과의 몇 가지 예시를 그림 12와 13에서 시각화하였다. 여기서 비디오 내 긍정적인 pseudo clip의 예측된 attention score는 jet gradient에 따라 색상이 지정된 막대로 표현된다. "Ours"는 우리 모델이 생성한 시작 및 종료 타임스탬프의 최종 예측을 나타낸다.
그림 12의 첫 번째 예시에서, 비디오는 "계단을 오르는 사람"부터 "가방을 캐비닛에 넣는 사람"이라는 쿼리, 그리고 "옷을 벗기 시작하는 사람"에 이르기까지 다양한 액션 장면을 포함한다. 우리가 제안한 방법은 긍정적인 pseudo clip을 효과적으로 현지화하고, 뚜렷한 장면 변화를 보이는 비디오에 대해 정확한 타겟 모먼트 현지화 결과를 달성한다.
TABLE VII Anti-Bias 데이터셋(Charades-StA-Len 및 Charades-STA-Mom)에 대한 위치 편향 문제 실험 결과 (%)
| Method | Charades-STA-Len | Charades-STA-Mom | ||||
|---|---|---|---|---|---|---|
| 2DTAN | 39.68 | 28.68 | 17.72 | 27.81 | 20.44 | 10.84 |
| MMN | 43.58 | 34.31 | 19.94 | 33.58 | 27.20 | 14.12 |
| MomentDETR | 42.73 | 34.39 | 16.12 | 29.94 | 22.16 | 11.56 |
| MomentDiff | 51.25 | 38.32 | 23.38 | 48.39 | 33.59 | 15.71 |
| Ours | 62.74 | 50.55 | 34.72 | 53.97 | 41.78 | 25.59 |
a. Query: the person was putting the bag into the cabinet.
 Fig. 12. 비디오 모먼트 현지화 시각화의 긍정적인 예시.
a. Query: a person stands in the bathroom holding a glass.
Fig. 12. 비디오 모먼트 현지화 시각화의 긍정적인 예시.
a. Query: a person stands in the bathroom holding a glass.
 Fig. 13. 비디오 모먼트 현지화 시각화의 부정적인 예시.
Fig. 13. 비디오 모먼트 현지화 시각화의 부정적인 예시.
그림 12의 두 번째 예시에서, 비디오는 복잡한 배경 정보를 포함한다. "a person walks through the doorway into the home office"라는 텍스트에 해당하는 모먼트 지속 시간은 상대적으로 짧고, 타겟은 비디오 내에서 눈에 띄는 위치를 차지하지 않는다. 그럼에도 불구하고, 우리 방법은 타겟 모먼트를 정확하게 현지화할 수 있으며, 복잡한 비디오 환경에서의 효능을 보여준다.
그림 13의 첫 번째 예시에서, 프레임들은 서로 매우 유사하며, 쿼리 설명인 "a person stands in the bathroom holding a glass"의 핵심 요소는 감지하기 어려운 작은 타겟을 포함한다. 우리 모델은 긍정적인 pseudo clip을 예측할 때 초기 몇 프레임에만 높은 점수를 할당하는 경향을 보이며, 이후 프레임에 대해서는 점수 차이가 거의 없다. 최종 현지화 결과는 복잡한 시각적 세부 사항을 다룰 때 ground truth와 어느 정도 불일치를 보인다.
또 다른 실패는 복잡한 의도를 가진 긴 텍스트를 다룰 때 발생한다. 그림 13의 두 번째 예시에서 보듯이, 텍스트 설명과 동일한 행동을 하는 다른 남성들도 타겟 모먼트로 간주되어, "the screenshot is unpaused"라는 전제를 무시한다.
V. Conclusion
본 연구에서는 비디오 모멘트 검색(video moment retrieval) task에서 발생하는 **의미론적 간극(semantic gap)**을 해소하기 위해, 비디오 클립을 언어 쿼리(language query)의 의미론적 가이드(semantic guidance)로 혁신적으로 활용하는 점진적 프레임워크를 제안한다.
구체적으로, 우리는 간단하면서도 효과적인 pseudo clip 생성 메커니즘을 설계하고, pseudo clip guided aggregation module을 구축하여 긍정(positive) 및 부정(negative) pseudo clip을 모두 활용한 효율적인 가이드와 cross-modal feature fusion을 달성한다.
또한, 혼란스러운 제안(confusing proposals)의 식별력을 향상시키고 정확한 경계 지역화(boundary localization)를 달성하기 위해 boundary integrated decoder를 제안한다.
Charades-STA, TACoS, ActivityNet Captions 데이터셋에 대한 광범위한 비교 및 ablation 실험을 통해 제안된 방법이 기존 state-of-the-art 방법들에 비해 경쟁력 있는 성능을 보임을 입증하였다.