VQ-WAV2VEC: 음성을 이산적인 표현으로 학습하는 자기지도학습 방법
VQ-WAV2VEC은 wav2vec 방식의 자기지도 컨텍스트 예측 과제를 통해 오디오 세그먼트의 이산적인 표현을 학습하는 방법론입니다. 이 알고리즘은 Gumbel-Softmax 또는 온라인 k-means 클러스터링을 사용하여 밀집된 표현을 양자화하며, 이를 통해 자연어 처리(NLP) 커뮤니티의 알고리즘을 음성 데이터에 직접 적용할 수 있게 합니다. 특히, BERT 사전 학습을 적용하여 TIMIT 음소 분류 및 WSJ 음성 인식에서 새로운 최고 성능(SOTA)을 달성했습니다. 논문 제목: VQ-WAV2VEC: Self-Supervised Learning of Discrete Speech Representations
논문 요약: VQ-WAV2VEC: Self-Supervised Learning of Discrete Speech Representations
- 논문 링크: https://arxiv.org/abs/1910.05453
- 저자: Alexei Baevski, Steffen Schneider, Michael Auli (Facebook AI Research, University of Tübingen)
- 발표 시기: 2019 (arXiv preprint)
- 주요 키워드: Speech Representation, Self-Supervised Learning, Discrete Representation, NLP, BERT, Quantization
1. 연구 배경 및 문제 정의
- 문제 정의:
음성 데이터는 본질적으로 연속적인 특성을 가지므로, 이산적인 입력을 요구하는 자연어 처리(NLP) 분야의 강력한 알고리즘(예: BERT)을 음성 데이터에 직접 적용하기 어렵다는 문제가 있었습니다. 기존의 자기지도학습 방식은 주로 연속적인 음성 표현을 학습하거나, 이산적인 단위를 발견하더라도 컨텍스트 예측 과제와 직접적으로 결합되지 않았습니다. - 기존 접근 방식:
- 이산 단위 발견: 오토인코딩(autoencoding) 방식(Wavenet Autoencoders 등)이나 자기회귀 모델(autoregressive model)을 통해 이산적인 음성 단위를 발견하려는 시도가 있었습니다.
- 연속 음성 표현 학습: 컨텍스트 정보를 예측하는 자기지도학습 방식(wav2vec 등)을 통해 연속적인 음성 표현을 학습하는 연구가 진행되었습니다.
- 한계: 기존 방식들은 연속적인 음성 표현을 학습하거나 이산 단위를 발견하더라도, NLP 커뮤니티의 이산 입력 기반 알고리즘을 음성 데이터에 직접적이고 효과적으로 적용하기 위한 명확한 연결 고리가 부족했습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 이산 음성 표현 학습: wav2vec 스타일의 자기지도 컨텍스트 예측 과제를 통해 오디오 세그먼트의 이산적인 표현(discrete representation)을 학습하는 vq-wav2vec을 제안했습니다.
- NLP 알고리즘 적용 가능성 확장: 연속적인 음성 데이터를 이산화함으로써, BERT와 같은 NLP 커뮤니티의 강력한 알고리즘을 음성 데이터에 직접 적용할 수 있는 길을 열었습니다.
- 최고 성능 달성: 이산화된 음성 표현에 BERT 사전 학습을 적용하여 TIMIT 음소 분류 및 WSJ 음성 인식 벤치마크에서 새로운 최고 성능(SOTA)을 달성했습니다.
- 효과적인 양자화 기법 제안: Gumbel-Softmax와 온라인 k-means 클러스터링이라는 두 가지 양자화(quantization) 방법을 사용하여 밀집된 표현을 이산화하는 방법을 제시하고 비교했습니다.
- 모드 붕괴(Mode Collapse) 완화: 여러 변수 그룹을 사용한 벡터 양자화(product quantization과 유사)를 통해 코드북의 모드 붕괴 문제를 완화하고 성능을 향상시켰습니다.
- 제안 방법:
vq-wav2vec은 wav2vec 아키텍처를 기반으로 하며, 특징 추출 및 집계를 위한 두 개의 컨볼루션 네트워크(와 ) 사이에 새로운 양자화 모듈()을 추가합니다.- 인코더 (): 원시 오디오 세그먼트를 밀집 특징 표현 로 매핑합니다.
- 양자화 모듈 (): 밀집 표현 를 고정 크기 코드북 의 이산적인 인덱스로 변환하고, 이를 원본 표현의 재구성인 에 매핑합니다.
- Gumbel-Softmax: 미분 가능한 방식으로 이산 코드북 변수를 선택할 수 있게 하며, 순전파 시에는 argmax를, 역전파 시에는 실제 그래디언트를 사용합니다.
- K-Means: 입력 특징 에 가장 가까운 코드북 변수를 유클리드 거리로 찾아 선택합니다. VQ-VAE와 유사한 보조 손실 항을 사용하여 코드북과 인코더를 업데이트합니다.
- 어그리게이터 (): 양자화된 를 입력으로 받아 wav2vec과 동일한 컨텍스트 예측 과제(미래 타임 스텝 예측)를 최적화합니다.
- 다중 변수 그룹을 통한 양자화: 모드 붕괴를 완화하기 위해 밀집 특징 벡터 를 여러 그룹으로 나누어 각 그룹을 독립적으로 양자화합니다. 이는 더 큰 유효 코드북 크기를 가능하게 합니다.
- 양자화된 음성에 대한 BERT 사전 학습: vq-wav2vec으로 이산화된 레이블 없는 음성 데이터를 BERT 모델의 입력으로 사용합니다. BERT 훈련 시, 개별 토큰이 아닌 연속적인 이산화된 음성 토큰의 "스팬(span)"을 마스킹하여 예측 과제를 더 어렵게 만들고 성능을 향상시킵니다.
3. 실험 결과
- 데이터셋:
- 사전 학습: Librispeech (960시간 전체 데이터셋, 양자화 후 3억 4,500만 토큰; 절제 실험을 위해 100시간 하위 집합 사용).
- 평가: TIMIT (음소 레이블이 있는 5시간 데이터셋), Wall Street Journal (WSJ, 음성 인식을 위한 81시간 데이터셋).
- 모델: vq-wav2vec/wav2vec (3,400만 개 매개변수), BERT base (12 레이어, 768 차원), BERT small (절제 실험용), Wav2letter (음향 모델).
- 주요 결과:
- WSJ 음성 인식: BERT 사전 학습을 적용한 vq-wav2vec은 WSJ 벤치마크(nov92)에서 2.34 WER(단어 오류율)을 달성하며 새로운 최고 성능을 기록했습니다. 이는 기존 wav2vec 모델 및 log-mel 필터뱅크 기준선보다 우수한 결과입니다. 특히 언어 모델을 사용하지 않는 설정에서 가장 큰 성능 향상을 보였습니다.
- TIMIT 음소 인식: vq-wav2vec과 BERT를 결합하여 TIMIT 음소 인식에서 11.64 PER(음소 오류율)을 달성하며 새로운 최고 성능을 기록했습니다. 이는 이전 wav2vec 최고 결과 대비 21%의 오류 감소에 해당합니다.
- 양자화 방식 비교: Gumbel-Softmax와 k-means 클러스터링은 BERT 훈련과 함께 사용될 때 유사한 성능을 보였습니다. 대규모 코드워드를 사용한 k-means 모델은 원래 wav2vec 모델과의 성능 격차를 크게 줄일 수 있음을 보여주었습니다.
- 시퀀스-투-시퀀스 모델링: 이산화된 오디오에 대해 표준 시퀀스-투-시퀀스 모델을 훈련하는 예비 실험에서 유망한 결과를 보였으나, 데이터 증강을 사용하는 최첨단 기술만큼은 아니었습니다.
- 정확도 vs. 비트레이트: vq-wav2vec은 다양한 비트레이트 설정에서 기존 오디오 코덱(Codec2, Opus, MP3, Ogg Vorbis)보다 우수한 음소 인식 정확도를 달성하며, 효율적인 음성 압축 능력을 입증했습니다.
- BERT 마스킹 전략: BERT 훈련 시 개별 토큰이 아닌 연속적인 토큰 "스팬"을 마스킹하는 것이 성능 향상에 훨씬 효과적임을 확인했습니다. 또한, 이산화된 오디오 데이터에 대한 BERT 훈련은 마스킹 확률 변화에 강건했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 연속적인 음성 데이터를 이산적인 형태로 변환하여 NLP 분야의 강력한 모델(BERT)을 음성 데이터에 직접 적용할 수 있게 한 점이 가장 인상 깊습니다. 이는 음성 처리와 NLP 간의 경계를 허물고 새로운 연구 방향을 제시합니다.
- 자기지도학습 방식으로 레이블 없는 대규모 음성 데이터를 효과적으로 활용하여 사전 학습된 표현을 얻는다는 점이 큰 장점입니다.
- WSJ 및 TIMIT 벤치마크에서 새로운 SOTA를 달성하며 제안 방법의 우수성을 명확히 입증했습니다.
- 오디오 압축 측면에서도 기존 코덱 대비 우수한 성능을 보여, 실제 응용 가능성이 높습니다.
- BERT 훈련 시 토큰 "스팬"을 마스킹하는 전략은 음성 데이터의 특성을 잘 반영한 효과적인 방법론이라고 생각합니다.
- 단점/한계:
- vq-wav2vec 단독으로는(BERT 사전 학습 없이) 기존 기준선보다 성능이 떨어지는 경우가 있어, BERT의 역할이 매우 중요함을 시사합니다. 이는 vq-wav2vec이 이산화된 표현을 생성하는 데는 효과적이지만, 그 표현의 강력함은 BERT와 같은 후처리 모델에 크게 의존한다는 의미일 수 있습니다.
- 이산화된 오디오에 대한 시퀀스-투-시퀀스 모델링 결과는 "유망"하지만 아직 최첨단 수준에는 미치지 못해 추가 연구가 필요합니다.
- 대규모 데이터셋에 대한 BERT 훈련은 상당한 컴퓨팅 자원을 요구할 것으로 예상됩니다.
- 응용 가능성:
- 저자원 언어 음성 처리: 레이블 없는 음성 데이터만으로도 강력한 표현을 학습할 수 있어, 레이블된 데이터가 부족한 언어의 음성 인식, 음성 합성 등에 활용될 수 있습니다.
- 음성 압축 및 코덱 개발: 비트레이트 대비 높은 정확도를 유지하는 음성 압축 기술로 활용되어, 통신 및 스트리밍 서비스의 효율성을 높일 수 있습니다.
- 다양한 NLP 모델의 음성 적용: 텍스트 기반으로 개발된 다양한 NLP 모델(예: 감성 분석, 질의응답, 번역 모델)을 이산화된 음성 데이터에 직접 적용하여 새로운 음성 기반 애플리케이션을 개발할 수 있습니다.
- 음성 합성: 이산적인 음성 단위를 활용하여 보다 자연스럽고 제어 가능한 음성 합성 모델을 구축하는 데 기여할 수 있습니다.
5. 추가 참고 자료
Baevski, Alexei, Steffen Schneider, and Michael Auli. "vq-wav2vec: Self-supervised learning of discrete speech representations." arXiv preprint arXiv:1910.05453 (2019).
VQ-WAV2VEC: Self-Supervised Learning of Discrete Speech Representations
Alexei Baevski* Steffen Schneider* Michael Auli <br> Facebook AI Research, Menlo Park, CA, USA<br> University of Tübingen, Germany
Abstract
우리는 wav2vec 스타일의 self-supervised 컨텍스트 예측 과제를 통해 오디오 세그먼트의 이산적인 representation을 학습하는 vq-wav2vec을 제안합니다. 이 알고리즘은 Gumbel-Softmax 또는 온라인 k-means 클러스터링을 사용하여 밀집된 representation을 양자화합니다. 이산화를 통해 이산적인 입력을 요구하는 NLP 커뮤니티의 알고리즘을 직접 적용할 수 있습니다. 실험 결과 BERT pre-training은 TIMIT 음소 분류 및 WSJ speech recognition에서 새로운 최고 성능을 달성했습니다.
1 Introduction
speech의 이산적인 representation을 학습하는 것은 최근 많은 관심을 받고 있습니다 (Versteegh et al., 2016; Dunbar et al., 2019). 이산적인 단위를 발견하는 일반적인 접근 방식은 autoencoding(Tjandra et al., 2019; Eloff et al., 2019; Chorowski et al., 2019)을 통하는 것이며, 때로는 autoregressive model(Chung et al., 2019)과 결합되기도 합니다. 또 다른 연구 분야는 컨텍스트 정보를 예측하여(Chung & Glass, 2018; van den Oord et al., 2018; Schneider et al., 2019) self-supervised 방식으로 연속적인 speech representation을 학습하는 것입니다.
본 논문에서는 입력을 재구성하는 대신 컨텍스트 예측 과제를 통해 speech의 이산적인 representation을 학습함으로써 이 두 연구 분야를 결합합니다. 이를 통해 성능이 우수한 NLP 알고리즘을 speech 데이터에 직접 적용할 수 있습니다 (그림 1a).
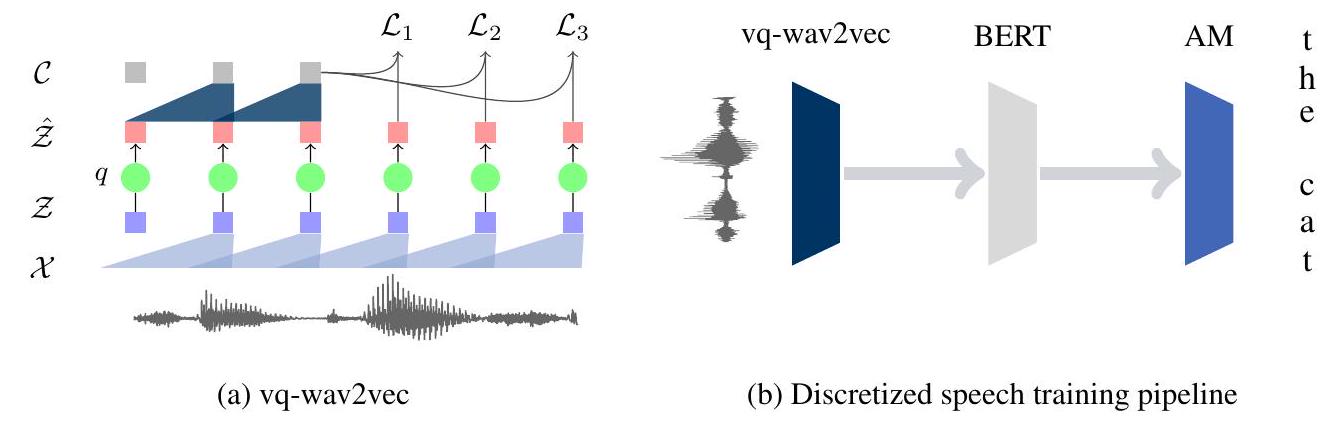
그림 1: (a) vq-wav2vec encoder는 원시 오디오()를 밀집 representation()으로 매핑하고, 이는 양자화(q)되어 가 되며, 컨텍스트 representation()으로 집계됩니다. 훈련에는 미래 타임 스텝 예측이 필요합니다. (b) 음향 모델은 vq-wav2vec으로 원시 오디오를 양자화한 다음, 이산화된 시퀀스에 BERT를 적용하고, 결과 representation을 음향 모델에 입력하여 전사(transcription)를 출력함으로써 훈련됩니다.
우리의 새로운 이산화 알고리즘인 vq-wav2vec은 wav2vec 손실 및 아키텍처(Schneider et al, 2019; §2)를 활용하여 고정 길이 오디오 신호 세그먼트의 이산적인 representation을 학습합니다. 1이산 변수를 선택하기 위해, 우리는 Gumbel-Softmax 접근 방식(Jang et al., 2016)과 VQ-VAE와 유사한 온라인 k-means 클러스터링을 고려합니다 (Oord et al., 2017; Eloff et al., 2019; §3).
그런 다음 이산화된 레이블이 없는 speech 데이터에 대해 Deep Bidirectional Transformer (BERT; Devlin et al., 2018; Liu et al., 2019)를 훈련시키고, 이러한 representation을 표준 음향 모델에 입력합니다 (그림 1b; §4). 우리의 실험은 BERT representation이 TIMIT 및 WSJ 벤치마크 모두에서 log-mel filterbank 입력뿐만 아니라 밀집된 wav2vec representation보다 더 나은 성능을 보인다는 것을 보여줍니다. 오디오의 이산화는 NLP 문헌의 다양한 알고리즘을 speech 데이터에 직접 적용할 수 있게 해줍니다. 예를 들어, NLP 문헌의 표준 시퀀스-투-시퀀스 모델을 사용하여 이산 오디오 토큰에 대한 speech recognition을 수행할 수 있음을 보여줍니다 (§5, §6).
2 BACKGROUND
2.1 WAV2VEC
wav2vec (Schneider et al., 2019)은 word2vec (Mikolov et al., 2013; van den Oord et al., 2018)과 동일한 손실 함수를 사용하는 self-supervised 컨텍스트 예측 과제를 해결하여 오디오 데이터의 representation을 학습합니다. 이 모델은 두 개의 convolutional neural networks를 기반으로 하며, encoder는 100Hz의 속도로 각 타임 스텝 에 대한 representation 를 생성하고 aggregator는 여러 encoder 타임 스텝을 각 타임 스텝 에 대한 새로운 representation 로 결합합니다. 집계된 representation 가 주어지면, 모델은 스텝 미래의 샘플 를 분포 에서 추출한 방해 샘플(distractor sample) 와 구별하도록 훈련되며, 스텝에 대해 contrastive loss를 최소화합니다:
여기서 는 시퀀스 길이, 이며, 는 가 실제 샘플일 확률입니다. 우리는 에 적용되는 스텝별 affine transformation 를 고려합니다 (van den Oord et al., 2018). 우리는 여러 스텝 크기에 걸쳐 (1)을 합산하여 손실 를 최적화합니다. 훈련 후, context network 에 의해 생성된 representation은 log-mel filterbank features 대신 음향 모델에 입력됩니다.
2.2 BERT
BERT (Devlin et al., 2018)는 NLP 과제를 위한 pre-training 접근 방식으로, transformer encoder 모델을 사용하여 텍스트의 representation을 구축합니다. Transformers는 입력 시퀀스와 선택적으로 소스 시퀀스를 인코딩하기 위해 self-attention을 사용합니다 (Vaswani et al., 2017). 원래 BERT 모델은 훈련을 위해 두 가지 과제를 결합했습니다. 첫째, masked language modeling은 입력 토큰 중 일부를 무작위로 제거하고 모델은 이러한 누락된 토큰을 예측해야 합니다. 둘째, next sentence prediction은 두 개의 다른 텍스트 구절을 하나의 예제로 결합하고 모델은 그 구절들이 동일한 문서에서 왔는지 예측해야 합니다.
3 VQ-WAV2VEC
우리의 접근 방식인 vq-wav2vec은 미래 타임 스텝 예측 과제를 사용하여 오디오 데이터의 vector quantized (VQ) representation을 학습합니다. 우리는 특징 추출 및 집계를 위한 두 개의 convolutional networks 와 , 그리고 이산적인 representation을 구축하기 위한 새로운 quantization 모듈 를 사용하여 wav2vec (§2.1)과 동일한 아키텍처 선택을 따릅니다 (그림 1a). 먼저 encoder 네트워크 를 사용하여 10ms의 스트라이드(stride)로 30ms 길이의 원시 speech 세그먼트를 밀집 특징 representation 로 매핑합니다. 다음으로, 양자화기()는 이러한 밀집 representation을 이산적인 인덱스로 변환하고, 이는 원본 representation 의 재구성인 에 매핑됩니다. 우리는 를 aggregator 에 입력하고 §2.1에 설명된 wav2vec과 동일한 컨텍스트 예측 과제를 최적화합니다.
quantization 모듈은 원래 representation 를 개의 크기 representation을 포함하는 고정 크기 코드북 의 로 대체합니다. 우리는 원-핫 representation 계산을 위한 argmax의 미분 가능한 근사치인 Gumbel-Softmax를 고려합니다 (§3.1; 그림 2a).
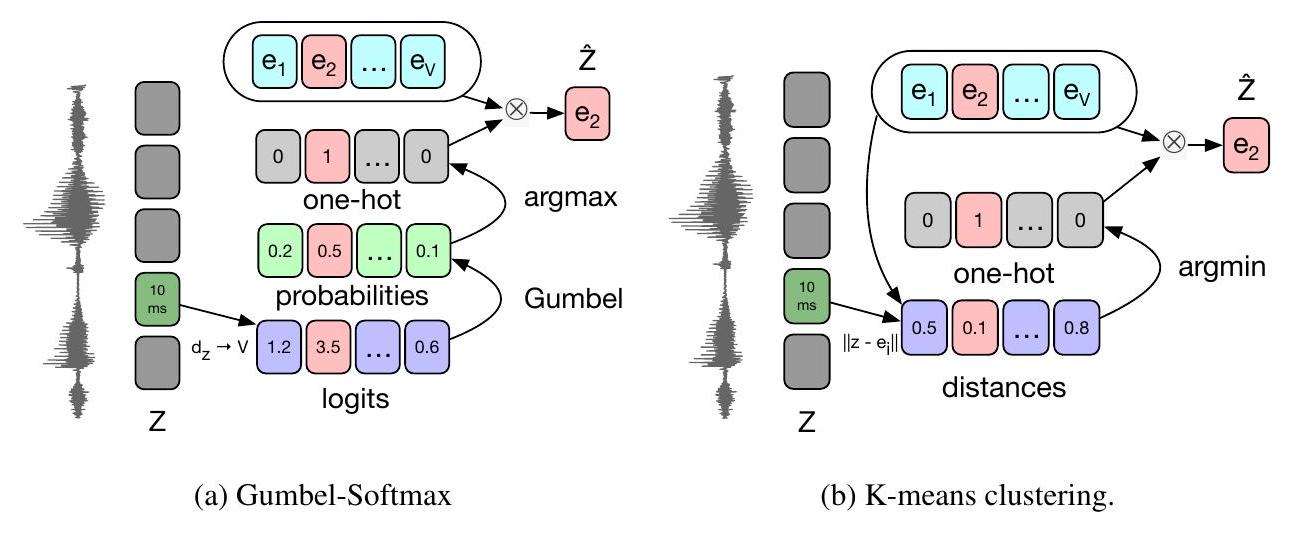
그림 2: (a) Gumbel-Softmax quantization은 코드북 벡터(e)를 나타내는 로짓(logit)을 계산합니다. 순전파(forward pass)에서는 argmax 코드워드()가 선택되고, 역전파(backward pass, 표시되지 않음)에서는 정확한 확률이 사용됩니다. (b) K-means vector quantization은 모든 코드워드 벡터까지의 거리를 계산하고 가장 가까운 것을 선택합니다 (argmin). 또한 vector quantized variational autoencoder (VQVAE; Oord et al., 2017; §3.2; 그림 2b)와 유사한 온라인 k-means 클러스터링도 고려합니다. 마지막으로, 우리는 mode collapse를 완화하기 위해 의 다른 부분에 대해 여러 번의 vector quantization을 수행합니다 (§3.3).
3.1 Gumbel-Softmax
Gumbel-Softmax (Gumbel, 1954; Jang et al., 2016; Maddison et al., 2014)는 완전히 미분 가능한 방식으로 이산 코드북 변수를 선택할 수 있게 하며, 우리는 Jang et al. (2016)의 straight-through estimator를 사용합니다. 밀집 representation 가 주어지면, 우리는 선형 계층, ReLU, 그리고 Gumbel-Softmax를 위한 로짓(logit)을 출력하는 또 다른 선형 계층을 적용합니다. 추론 시에는 단순히 에서 가장 큰 인덱스를 선택합니다. 훈련 시, -번째 변수를 선택하기 위한 출력 확률은 다음과 같습니다.
여기서 이고 는 에서 균등하게 샘플링됩니다. 순전파(forward pass) 동안에는 이고, 역전파(backward pass)에서는 Gumbel-Softmax 출력의 실제 그래디언트가 사용됩니다.
3.2 K-Means
van den Oord et al. (2017)의 vector quantization 접근 방식은 인덱스 선택 절차를 완전히 미분 가능하게 만드는 대안입니다. 그들의 설정과 달리, 우리는 autoencoder의 reconstruction loss 대신 미래 타임 스텝 예측 손실을 최적화합니다.
우리는 유클리드 거리(Euclidean distance) 측면에서 입력 특징 에 가장 가까운 변수를 찾아 코드북 변수 representation을 선택하며, 이는 를 산출합니다. 순전파(forward pass) 동안, 우리는 코드북에서 해당하는 변수를 선택하여 를 선택합니다. 우리는 를 역전파하여 encoder 네트워크에 대한 그래디언트를 얻습니다 (van den Oord et al., 2017). 최종 손실에는 두 가지 추가 항이 있습니다:
여기서 은 stop gradient operator이고 는 하이퍼파라미터입니다. 첫 번째 항은 미래 예측 과제이며, 를 로 매핑하는 straight-through 그래디언트 추정으로 인해 그래디언트가 코드북을 변경하지 않습니다. 두 번째 항 는 코드북 벡터를 encoder 출력에 더 가깝게 이동시키고, 세 번째 항 는 encoder 출력이 중심점(코드워드)에 가깝도록 만듭니다.
3.3 Vector Quantization with multiple variable groups
지금까지 우리는 encoder 특징 벡터 를 코드북의 단일 항목 로 대체하는 것을 고려했습니다. 이것은 일부 코드워드만 실제로 사용되는 mode collapse에 취약합니다. 이전에는 코드워드를 재초기화하거나 손실 함수에 추가적인 정규화 항을 적용하는 것과 같은 해결 방법으로 이 문제가 완화되었습니다 (Caron et al., 2019). 다음으로, 우리는 product quantization(Jegou et al., 2011)과 유사하게 의 파티션을 독립적으로 양자화하는 다른 전략을 설명합니다. 이는 더 큰 사전과 향상된 다운스트림 성능을 가져옵니다 (부록 A). 밀집 특징 벡터 는 먼저 여러 그룹 로 구성되어 행렬 형태 로 만들어집니다. 그런 다음 각 행을 정수 인덱스로 나타내므로 전체 특징 벡터를 인덱스 로 나타낼 수 있습니다. 여기서 는 다시 이 특정 그룹에 대해 가능한 변수의 수를 나타내며 각 요소 는 고정된 코드북 벡터에 해당합니다. 개의 각 그룹에 대해 두 VQ 접근 방식(§3.1 및 §3.2) 중 하나를 적용합니다.
코드북 자체는 두 가지 가능한 방법으로 초기화될 수 있습니다. 코드북 변수는 그룹 간에 공유될 수 있습니다. 즉, 그룹 의 특정 인덱스는 그룹 의 동일한 인덱스와 동일한 벡터를 참조합니다. 이는 코드북 를 산출합니다. 반대로, 코드북 변수를 공유하지 않으면 크기가 인 코드북이 생성됩니다. 실제로는 코드북 변수를 공유하는 것이 일반적으로 공유되지 않은 representation과 경쟁력 있는 결과를 낳는다는 것을 관찰합니다.
4 Bert Pre-Training on Quantized Speech
vq-wav2vec 모델을 훈련시킨 후에는 오디오 데이터를 이산화하여 이산적인 입력을 요구하는 알고리즘에 적용할 수 있습니다. 한 가지 가능성은 이산화된 훈련 데이터를 사용하고, 주변 컨텍스트의 인코딩을 기반으로 마스킹된 입력 토큰을 예측하는 과제인 BERT pre-training을 적용하는 것입니다(Devlin et al., 2018). BERT 모델이 훈련되면, 이를 사용하여 representation을 구축하고 음향 모델에 입력하여 speech recognition을 개선할 수 있습니다. 우리는 마스킹된 입력 토큰 예측만 사용하는 BERT 훈련의 최근 발전을 따릅니다(Liu et al., 2019).
각 이산화된 토큰은 약 10ms의 오디오를 나타내므로 단일 마스킹된 입력 토큰을 예측하는 것은 너무 쉬울 수 있습니다. 따라서 우리는 Joshi et al. (2019)과 유사하게 연속적인 이산화된 speech 토큰의 스팬(span)을 마스킹하여 BERT 훈련을 변경합니다. 입력 시퀀스를 마스킹하기 위해, 우리는 모든 토큰의 를 시작 인덱스로 무작위로 샘플링하고(중복 없음), 샘플링된 모든 인덱스에서 개의 연속 토큰을 마스킹합니다. 스팬은 겹칠 수 있습니다. 이는 마스킹된 토큰 예측을 더 어렵게 만들며, 나중에 개별 토큰을 마스킹하는 것보다 정확도를 향상시킨다는 것을 보여줍니다(§6.5).
5 Experimental Setup
5.1 Datasets
우리는 일반적으로 Librispeech의 전체 960시간(Panayotov et al., 2015)에 대해 vq-wav2vec 및 BERT를 pre-train하며, vq-wav2vec 훈련 후에는 3억 4,500만 개의 토큰으로 이산화됩니다. 표시된 경우, 우리는 3,990만 개의 토큰으로 이산화된 깨끗한 100시간 하위 집합에서 절제 실험(ablation)을 수행합니다. 우리는 두 가지 벤치마크에서 모델을 평가합니다: TIMIT(Garofolo et al., 1993b)는 음소 레이블이 있는 5시간 데이터셋이고 Wall Street Journal(WSJ; Garofolo et al. 1993a)은 speech recognition을 위한 81시간 데이터셋입니다. TIMIT의 경우, 표준 평가 프로토콜을 적용하고 39개의 다른 음소를 고려합니다. WSJ의 경우, 영어 알파벳, 아포스트로피, 무음 토큰 및 반복 문자를 위한 토큰을 포함하여 31개의 graphemes에 대해 직접 음향 모델을 훈련합니다.
5.2 VQ-WAV2VEC
우리는 wav2vec의 fairseq 구현(Schneider et al., 2019; Ott et al., 2019)을 채택하고 개의 매개변수를 가진 vqwav2vec/wav2vec 모델을 사용합니다. encoder는 각각 512개의 채널을 가진 8개의 레이어, 커널 크기 (), 스트라이드 ()를 가지며, 총 스트라이드는 160입니다. 각 레이어는 convolution, dropout, 단일 그룹의 group normalization(Wu & He, 2018) 및 ReLU 비선형성(non-linearity)을 포함합니다. aggregator는 12개의 레이어, 512개의 채널, 스트라이드 1, 그리고 2에서 시작하여 후속 레이어마다 1씩 증가하는 커널 크기로 구성됩니다. 블록 구조는 encoder 네트워크와 동일하지만, 각 후속 블록 사이에 skip connections를 도입합니다.
우리는 40만 업데이트 동안 wav2vec context prediction loss (방정식 1)로 훈련하며, 미래로 단계를 예측하고 동일한 오디오 예제에서 10개의 네거티브를 샘플링합니다. 훈련은 500 단계 동안 워밍업되며, 이 기간 동안 학습률은 에서 으로 증가한 다음 코사인 스케줄(Loshchilov & Hutter, 2016)을 사용하여 으로 어닐링됩니다. 배치 크기는 10이며, 각 예제에 대해 15만 프레임의 무작위 섹션을 잘라냅니다(16kHz 샘플링 속도의 경우 약 9.3초). 모든 모델은 8개의 GPU에서 훈련됩니다.
100시간 Librispeech 하위 집합에 대한 절제 실험 및 실험을 위해, 우리는 encoder에 커널 ()과 스트라이드 ()를, aggregator에 스트라이드 1과 커널 크기 3을 가진 7개의 컨볼루션 레이어를 사용하는 더 작은 모델을 사용합니다. 이 모델은 4만 업데이트 동안 훈련됩니다.
Gumbel-Softmax 모델. 우리는 그룹과 그룹당 개의 잠재 변수(latent)를 사용하며, 선형 계층은 encoder에서 생성된 특징을 개의 로짓(logit)으로 투영합니다. Gumbel-Softmax는 각 그룹 에 대해 원-핫 벡터를 생성합니다. 온도 는 처음 70%의 업데이트 동안 2에서 0.5로 선형적으로 어닐링된 다음 0.5로 일정하게 유지됩니다. 이를 통해 모델은 단일 잠재 변수에 전념하기 전에 각 입력에 가장 적합한 잠재 변수를 학습할 수 있습니다. 이 모델을 960시간의 Librispeech에서 훈련하고 훈련 데이터셋을 양자화한 후, 우리는 13.5k개의 고유한 코드워드 조합을 남깁니다(가능한 코드워드 중). k-means 모델. 우리는 그룹과 그룹당 개의 변수를 사용합니다. 전체 Librispeech에 대한 vq-wav2vec은 23k개의 고유한 코드워드를 생성합니다. van den Oord et al. (2017)을 따라, 우리는 가 VQ 보조 손실의 균형을 맞추는 데 견고한 선택임을 발견했습니다.
5.3 BERT
BERT base 모델은 12개의 레이어, 모델 차원 768, 내부 차원(FFN) 3072, 그리고 12개의 attention heads를 가집니다(Devlin et al., 2018). 학습률은 처음 10,000 업데이트 동안 최대값 까지 워밍업된 다음, 총 250k 업데이트에 걸쳐 선형적으로 감소됩니다. 우리는 128개의 GPU에서 GPU당 3072개의 토큰 배치 크기로 훈련하여 총 배치 크기는 393k 토큰입니다(Ott et al., 2018). 각 토큰은 10ms의 오디오 데이터를 나타냅니다.
BERT small. 절제 실험을 위해 모델 차원 512, FFN 크기 2048, 8개의 attention heads 및 dropout 0.05를 사용하는 더 작은 설정을 사용합니다. 모델은 GPU당 2개의 예제 배치 크기로 250k 업데이트 동안 훈련됩니다.
5.4 Acoustic Model
우리는 wav2letter를 accoustic model로 사용하며 (Collobert et al., 2016; 2019), TIMIT과 WSJ 모두에 대해 8개의 GPU에서 1,000 에포크 동안 auto segmentation criterion을 사용하여 훈련합니다. WSJ의 음향 모델에서 나오는 방출(emission)을 디코딩하기 위해, 우리는 WSJ 언어 모델링 데이터만으로 훈련된 별도의 language model과 lexicon을 사용합니다. 우리는 4-gram KenLM language model (Heafield et al., 2013)과 character based convolutional language model (Likhomanenko et al., 2019)을 고려하고 Schneider et al. (2019)과 동일한 프로토콜로 모델을 튜닝합니다.
6 Results
6.1 WSJ Speech Recognition
먼저 WSJ speech recognition 벤치마크에서 평가합니다. 우리는 Librispeech의 레이블 없는 버전에 대해 vq-wav2vec 모델을 훈련시킨 다음, 결과 모델로 동일한 데이터를 이산화하여 BERT 모델을 추정합니다. 마지막으로, log-mel filterbanks 대신 BERT 또는 vq-wav2vec representation을 입력하여 WSJ에 대해 wav2letter acoustic model을 훈련합니다.
우리는 wav2vec (Schneider et al., 2019)을 포함한 문헌의 다양한 결과와 비교하며, 세 가지 설정을 고려합니다: language model이 없는 성능 (No LM), n-gram LM이 있는 경우 (4-gram LM) 및 character convolutional LM이 있는 경우 (Char ConvLM). 우리는 log-mel filterbanks를 입력으로 사용하는 wav2letter의 정확도(Baseline)와 wav2vec을 보고합니다. vq-wav2vec의 경우, 먼저 Gumbel-Softmax를 사용하여 BERT base 모델(§5.3)을 사용하거나 사용하지 않고 실험합니다.
2| | nov93dev | | nov92 | | | :--- | :--- | :--- | :--- | :--- | | | LER | WER | LER | WER | | Deep Speech 2 (12K h labeled speech; Amodei et al., 2016) | - | 4.42 | - | 3.1 | | Trainable frontend (Zeghidour et al., 2018) | - | 6.8 | - | 3.5 | | Lattice-free MMI (Hadian et al., 2018) | - | | - | | | Supervised transfer-learning (Ghahremani et al., 2017) | - | | - | | | No LM | | | | | | Baseline (log-mel) | 6.28 | 19.46 | 4.14 | 13.93 | | wav2vec (Schneider et al., 2019) | 5.07 | 16.24 | 3.26 | 11.20 | | vq-wav2vec Gumbel | 7.04 | 20.44 | 4.51 | 14.67 | | + BERT base | 4.13 | 13.40 | 2.62 | 9.39 | | 4-GRAM LM (Heafield et al., 2013) | | | | | | Baseline (log-mel) | 3.32 | 8.57 | 2.19 | 5.64 | | wav2vec (Schneider et al., 2019) | 2.73 | 6.96 | 1.57 | 4.32 | | vq-wav2vec Gumbel | 3.93 | 9.55 | 2.40 | 6.10 | | + BERT base | 2.41 | 6.28 | 1.26 | 3.62 | | Char ConvLM (Likhomanenko et al., 2019) | | | | | | Baseline (log-mel) | 2.77 | 6.67 | 1.53 | 3.46 | | wav2vec (Schneider et al., 2019) | 2.11 | 5.10 | 0.99 | 2.43 | | vq-wav2vec Gumbel + BERT base | 1.79 | 4.46 | 0.93 | 2.34 |
표 1: 개발(nov93dev) 및 테스트 세트(nov92)에서의 vq-wav2vec의 WSJ 정확도. 언어 모델링 없음(No LM), 4-gram LM, 문자 컨볼루션 LM에 대한 문자 오류율(LER) 및 단어 오류율(WER)로 표시. BERT pre-training을 사용한 vq-wav2vec은 최고의 wav2vec 모델(Schneider et al., 2019)을 개선합니다.
| nov93dev | nov92 | |||
|---|---|---|---|---|
| LER | WER | LER | WER | |
| No LM | ||||
| wav2vec (Schneider et al., 2019) | 5.07 | 16.24 | 3.26 | 11.20 |
| vq-wav2vec Gumbel | 7.04 | 20.44 | 4.51 | 14.67 |
| + BERT small | 4.52 | 14.14 | 2.81 | 9.69 |
| vq-wav2vec k-means (39M codewords) | 5.41 | 17.11 | 3.63 | 12.17 |
| vq-wav2vec k-means | 7.33 | 21.64 | 4.72 | 15.17 |
| + BERT small | 4.31 | 13.87 | 2.70 | 9.62 |
| 4-GRAM LM (Heafield et al., 2013) | ||||
| wav2vec (Schneider et al., 2019) | 2.73 | 6.96 | 1.57 | 4.32 |
| vq-wav2vec Gumbel | 3.93 | 9.55 | 2.40 | 6.10 |
| + BERT small | 2.67 | 6.67 | 1.46 | 4.09 |
| vq-wav2vec k-means (39M codewords) | 3.05 | 7.74 | 1.71 | 4.82 |
| vq-wav2vec k-means | 4.37 | 10.26 | 2.28 | 5.71 |
| + BERT small | 2.60 | 6.62 | 1.45 | 4.08 |
표 2: WSJ에서 Gumbel-Softmax와 k-means vector quantization 비교 (참조: 표 1). 표 1은 vq-wav2vec이 BERT 훈련과 함께 nov92에서 2.34 WER이라는 새로운 최고 성능을 달성할 수 있음을 보여줍니다. 이득은 가장 빠른 설정인 language model을 사용하지 않을 때 가장 큽니다. Gumbel-Softmax를 사용한 vq-wav2vec은 오디오 신호를 나타내는 데 13.5k개의 고유한 코드워드만 사용하며, 이 제한된 코드워드 집합은 기준선을 능가하기에 충분하지 않습니다. 그러나 상대적으로 작은 어휘를 필요로 하는 BERT 모델 훈련을 가능하게 합니다.
| dev PER | test PER | |
|---|---|---|
| CNN + TD-filterbanks (Zeghidour et al., 2018) | 15.6 | 18.0 |
| Li-GRU + fMLLR (Ravanelli et al., 2018) | - | 14.9 |
| wav2vec (Schneider et al., 2019) | 12.9 | 14.7 |
| Baseline (log-mel) | 16.9 | 17.6 |
| vq-wav2vec, Gumbel | 15.34 | 17.78 |
| + BERT small | 9.64 | 11.64 |
| vq-wav2vec, k-means | 15.65 | 18.73 |
| + BERT small | 9.80 | 11.40 |
표 3: 음소 오류율(PER)로 측정한 TIMIT 음소 인식 성능. 우리의 모든 모델은 CNN-8L-PReLU-do0.7 아키텍처(Zeghidour et al., 2018)를 사용합니다.
| dev clean | dev other | test clean | test other | |
|---|---|---|---|---|
| Mohamed et al. (2019) | 4.8 | 12.7 | 4.7 | 12.9 |
| Irie et al. (2019) | 4.4 | 13.2 | 4.7 | 13.4 |
| Park et al. (2019) | 2.8 | 6.8 | 2.5 | 5.8 |
| vq-wav2vec Gumbel + Transformer Big | 5.6 | 15.5 | 6.2 | 18.2 |
표 4: BERT pre-training 없이 이산화된 오디오로 훈련된 표준 sequence to sequence 모델에 대한 Librispeech 결과 및 문헌의 결과. 모든 결과는 language model이 없습니다.
다음으로, 우리는 Gumbel-Softmax를 k-means와 vector quantization을 위해 비교합니다. 이 실험에서는 훈련이 더 빠른 BERT small 구성(§5.3)을 사용합니다. 우리는 또한 wav2vec과의 격차를 더 표현력 있는 모델이 좁힐 수 있는지 테스트하기 위해 매우 많은 수의 코드워드(39.9M)를 가진 vq-wav2vec k-means 모델을 훈련합니다. 표 2는 Gumbel-Softmax와 k-means 클러스터링이 비교적 비슷하게 수행됨을 보여줍니다: BERT가 없는 No LM 설정에서는 Gumbel-Softmax가 k-means보다 더 정확하지만, BERT를 사용하면 이러한 차이는 사라집니다. 4-gram LM 설정에서는 k-means가 더 낫지만, BERT 훈련 후에는 이러한 차이가 다시 사라집니다. 마지막으로, 대규모 코드워드 모델은 원래 wav2vec 모델과의 격차를 상당히 줄일 수 있습니다.
6.2 TIMIT Phoneme RECOGNITION
다음으로, 우리는 훨씬 작은 TIMIT phoneme recognition 과제에서 실험하며, 여기서도 전체 Librispeech 코퍼스에 대해 vq-wav2vec을 pre-train합니다. 표 3은 vq-wav2vec과 BERT가 11.64 PER이라는 새로운 최고 성능을 달성했음을 보여주며, 이는 이전 wav2vec의 최고 결과보다 21%의 오류 감소에 해당합니다.
6.3 Sequence to Sequence Modeling
지금까지 우리는 vq-wav2vec을 사용하여 discretized speech에 BERT를 훈련시켰습니다. 그러나 오디오가 이산화되면 speech recognition을 수행하기 위해 표준 sequence to sequence 모델을 훈련시킬 수도 있습니다. 예비 실험에서 우리는 vq-wav2vec Gumbel-Softmax로 이산화된 Librispeech 코퍼스에 대해 상용 Big Transformer (Vaswani et al., 2017; Ott et al., 2019)를 훈련시키고 Librispeech 개발/테스트 세트에서 평가했습니다; 우리는 4k BPE 출력 어휘를 사용합니다 (Sennrich et al., 2016). 표 4는 우리가 사용하지 않는 데이터 증강에 의존하는 최첨단 기술(Park et al., 2019)만큼 좋지는 않지만 결과가 유망하다는 것을 보여줍니다.
6.4 Accuracy vs. Bitrate
다음으로, 우리는 vq-wav2vec이 오디오 데이터를 얼마나 잘 압축할 수 있는지 조사합니다. 구체적으로, 우리는 가능한 코드북 크기 를 다양하게 하기 위해 다른 수의 그룹 와 변수 를 가진 모델을 훈련하고 BERT 훈련 없이 TIMIT phoneme recognition에서 정확도를 측정합니다.
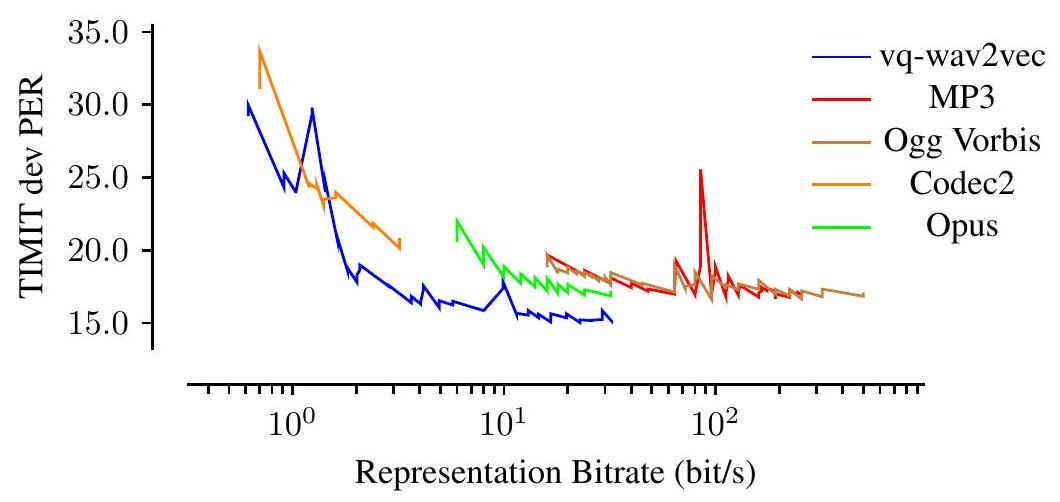
그림 3: Librispeech 100h에서 훈련된 다양한 audio codecs와 vq-wav2vec k-means에 대한 TIMIT 개발 세트의 PER 비교.
우리는 샘플링 속도 에서 bitrate 로 압축을 측정하고 bitrate와 음소 인식 작업의 정확도 사이의 절충 관계를 보고합니다. 우리는 vq-wav2vec k-means로 실험하고 및 32개의 그룹과 개의 변수를 사용하여 에서 까지의 bitrate 범위를 포괄하는 모델을 훈련합니다. 우리는 aggregator 모듈 뒤에 quantization 모듈을 배치하고 100시간 클린 Librispeech 하위 집합에서 작은 vq-wav2vec 설정(§5.2)으로 모든 모델을 훈련합니다. 기준선으로, 우리는 TIMIT 오디오 데이터에 적용된 다양한 손실 압축 알고리즘을 고려하고 결과 오디오에 대해 wav2letter 모델을 훈련합니다: 낮은 bitrate 코덱으로 Codec2 , 중간 bitrate 코덱으로 Opus (Terriberry & Vos, 2012), 높은 bitrate 코덱으로 MP3 및 Ogg Vorbis (Montgomery, 2004). 우리는 코덱의 가변 및 고정 bitrate 설정의 전체 스펙트럼을 사용합니다; 우리는 ffmpeg (ffmpeg developers, 2016)로 인코딩 및 디코딩합니다. 그림 3은 bitrate와 TIMIT 정확도 사이의 절충 관계를 보여줍니다. vq-wav2vec에 대한 음향 모델은 대부분의 bitrate 설정에서 최고의 결과를 달성합니다.
6.5 Ablations
표 5a는 토큰의 전체 스팬을 마스킹하는 것이 개별 토큰()보다 훨씬 더 나은 성능을 보인다는 것을 보여줍니다. 또한, 이산화된 오디오 데이터에 대한 BERT 훈련은 입력의 많은 부분을 마스킹하는 데 상당히 강건합니다(표 5b).
| dev | test | |
|---|---|---|
| 1 | 14.94 | 17.38 |
| 5 | 13.62 | 15.78 |
| 10 | 12.65 | 15.28 |
| 20 | 13.04 | 15.56 |
| 30 | 13.18 | 15.64 |
(a) 마스크 길이.
| dev | test | |
|---|---|---|
| 0.015 | 12.65 | 15.28 |
| 0.020 | 12.51 | 14.43 |
| 0.025 | 12.16 | 13.96 |
| 0.030 | 11.68 | 14.48 |
| 0.050 | 11.45 | 13.62 |
(b) 마스크 확률.
표 5: (a) BERT 훈련에서 인 다른 마스크 크기 에 대한 TIMIT PER 및 (b) 고정된 마스크 길이 에 대한 마스크 확률 .
7 Conclusion
vq-wav2vec은 레이블이 없는 오디오 데이터를 양자화하는 self-supervised 알고리즘으로, 이산적인 데이터를 필요로 하는 알고리즘에 적합하게 만듭니다. 이 접근 방식은 BERT pre-training을 활용하여 WSJ 및 TIMIT 벤치마크에서 최고 수준의 성능을 향상시킵니다. 향후 연구에서는 이산적인 입력을 필요로 하는 다른 알고리즘을 오디오 데이터에 적용하고, 연속적인 오디오 입력의 일부를 마스킹하는 self-supervised pre-training 알고리즘을 탐색할 계획입니다. 또 다른 향후 연구 방향은 사전 훈련된 특징을 맞춤형 ASR 모델에 공급하는 대신, 사전 훈련된 모델을 미세 조정하여 전사(transcription)를 출력하도록 하는 것입니다.
REFERENCES
Dario Amodei, Sundaram Ananthanarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Qiang Cheng, Guoliang Chen, et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proc. of ICML, 2016.
Mathilde Caron, Piotr Bojanowski, Julien Mairal, and Armand Joulin. Unsupervised pre-training of image features on non-curated data. In Proceedings of the International Conference on Computer Vision (ICCV), 2019.
Jan Chorowski, Ron J. Weiss, Samy Bengio, and Aäron van den Oord. Unsupervised speech representation learning using wavenet autoencoders. arXiv, abs/1901.08810, 2019.
Yu-An Chung and James Glass. Speech2vec: A sequence-to-sequence framework for learning word embeddings from speech. arXiv, abs/1803.08976, 2018.
Yu-An Chung, Wei-Ning Hsu, Hao Tang, and James Glass. An unsupervised autoregressive model for speech representation learning. arXiv, abs/1904.03240, 2019.
Ronan Collobert, Christian Puhrsch, and Gabriel Synnaeve. Wav2letter: an end-to-end convnetbased speech recognition system. arXiv, abs/1609.03193, 2016.
Ronan Collobert, Awni Hannun, and Gabriel Synnaeve. A fully differentiable beam search decoder. arXiv, abs/1902.06022, 2019.
FFmpeg Developers. ffmpeg tool software, 2016. URL http: / / ffmpeg.org/. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv, abs/1810.04805, 2018.
Ewan Dunbar, Robin Algayres, Julien Karadayi, Mathieu Bernard, Juan Benjumea, Xuan-Nga Cao, Lucie Miskic, Charlotte Dugrain, Lucas Ondel, Alan W Black, et al. The zero resource speech challenge 2019: Tts without t. arXiv, 1904.11469, 2019.
Ryan Eloff, André Nortje, Benjamin van Niekerk, Avashna Govender, Leanne Nortje, Arnu Pretorius, Elan Van Biljon, Ewald van der Westhuizen, Lisa van Staden, and Herman Kamper. Unsupervised acoustic unit discovery for speech synthesis using discrete latent-variable neural networks. arXiv, abs/1904.07556, 2019.
John S. Garofolo, David Graff, Doug Paul, and David S. Pallett. CSR-I (WSJO) Complete LDC93S6A. Web Download. Linguistic Data Consortium, 1993a.
John S. Garofolo, Lori F. Lamel, William M. Fisher, Jonathon G. Fiscus, David S. Pallett, and Nancy L. Dahlgren. The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus CDROM. Linguistic Data Consortium, 1993b.
Pegah Ghahremani, Vimal Manohar, Hossein Hadian, Daniel Povey, and Sanjeev Khudanpur. Investigation of transfer learning for asr using lf-mmi trained neural networks. In Proc. of ASRU, 2017.
Emil Julius Gumbel. Statistical theory of extreme values and some practical applications: a series of lectures, volume 33. US Government Printing Office, 1954.
Hossein Hadian, Hossein Sameti1, Daniel Povey, and Sanjeev Khudanpur. End-to-end speech recognition using lattice-free mmi. In Proc. of Interspeech, 2018.
Kenneth Heafield, Ivan Pouzyrevsky, Jonathan H. Clark, and Philipp Koehn. Scalable modified Kneser-Ney language model estimation. In Proc. of ACL, 2013.
Appendix A Number of variables vs. Groups
We investigate the relationship between number of variables and groups . Table 6 shows that multiple groups are beneficial compared to a single group with a large number of variables. Table 7 shows that with a single group and many variables, only a small number of codewords survive.
| 1 group | 2 groups | 4 groups | 8 groups | 16 groups | 32 groups | |
|---|---|---|---|---|---|---|
| 40 | ||||||
| 80 | ||||||
| 160 | ||||||
| 320 | ||||||
| 640 | ||||||
| 1280 |
Table 6: PER on TIMIT dev set for vq-wav2vec models trained on Libri100. Results are based on three random seeds.
| 1 group | 2 groups | 4 groups | 8 groups | 16 groups | 32 groups | |
|---|---|---|---|---|---|---|
| 40 | 100 % (40) | 95.3 % (1.6k) | 27.4 % ( 2.56 M ) | 74.8 % (39.9M) | 99.6 % (39.9M) | 99.9 % (39.9M) |
| 80 | 92.5 % (80) | 78.5 % (6.4k) | 11.8 % (39.9M) | 91.5% (39.9M) | 99.3 % (39.9M) | 100 % (39.9M) |
| 160 | 95 % (160) | 57.2 % (25.6k) | 35.2 % (39.9M) | 97.6 % (39.9M) | 99.8 % (39.9M) | 100 % (39.9M) |
| 320 | 33.8 % (320) | 24.6 % (102.4k) | 57.3 % (39.9M) | 98.7 % (39.9M) | 99.9 % (39.9M) | 100 % (39.9M) |
| 640 | 24.6 % (640) | 10 % (409.6k) | 60.2 % (39.9M) | 99.3 % (39.9M) | 99.9 % (39.9M) | |
| 1280 | 7.2 % (1.28k) | 4.9 % (1.63M) | 67.9 % (39.9M) | 99.5 % (39.9M) | 99.9 % (39.9M) |
Table 7: Fraction of used codewords vs. number of theoretically possible codewords in brackets; 39.9 M is the number of tokens in Librispeech 100 h .
Footnotes
-
*동일 기여. 페이스북 AI 레지던시 기간 중 수행된 연구. 코드는 http://github.com/pytorch/fairseq 에서 제공될 예정입니다. ↩
-
vq-wav2vec의 경우 학습된 이산 단위에 해당하는 밀집 표현을 입력합니다. ↩