Self-Supervised Multimodal Learning (SSML) 핵심 개념 정리
이 글은 Self-Supervised Multimodal Learning (SSML) 분야의 최신 연구 동향을 종합적으로 리뷰합니다. SSML은 라벨이 없는 멀티모달 데이터로부터 표현을 학습하는 방법으로, (1) 라벨 없는 데이터에서의 표현 학습, (2) 다양한 modality의 Fusion, (3) 정렬되지 않은 데이터 학습이라는 세 가지 주요 과제를 다룹니다. 본문에서는 이러한 과제들을 해결하기 위한 다양한 self-supervised 목적 함수, 모델 아키텍처, 그리고 정렬 학습 전략에 대해 자세히 설명합니다. 논문 제목: Self-Supervised Multimodal Learning: A Survey
논문 요약: Self-Supervised Multimodal Learning: A Survey
- 논문 링크: https://arxiv.org/abs/2304.01008
- 저자: Yongshuo Zong, Oisin Mac Aodha, Timothy Hospedales
- 발표 시기: 2024년, IEEE Transactions on Pattern Analysis and Machine Intelligence
- 주요 키워드: Self-Supervised Learning, Multimodal Learning, Deep Learning, Representation Learning, Alignment
1. 연구 배경 및 문제 정의
- 문제 정의:
멀티모달 학습은 다양한 정보 양식을 이해하고 분석하는 데 큰 발전을 이루었지만, 효과적인 모델 훈련을 위해 비용이 많이 드는 인간 주석 데이터에 과도하게 의존하는 한계가 있습니다. 이는 모델 확장을 방해하는 주요 병목 현상으로 작용합니다. - 기존 접근 방식:
기존의 지도 멀티모달 학습은 값비싼 수동 주석에 의존하며, 기존의 설문 논문들은 주로 지도 멀티모달 학습이나 단일 모달 자기 지도 학습에 초점을 맞추거나, SSML의 특정 하위 분야(예: 비전-언어 사전 훈련)에만 집중하여 SSML 고유의 과제를 포괄적으로 다루지 못했습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 자기 지도 멀티모달 학습(SSML) 분야의 최신 연구 동향에 대한 포괄적인 검토를 제공합니다.
- 멀티모달 데이터를 사용한 자기 지도 학습에 내재된 세 가지 주요 과제(레이블 없는 데이터에서의 표현 학습, 다양한 모달리티의 융합, 정렬되지 않은 데이터 학습)를 식별하고 설명합니다.
- 이러한 과제들을 해결하기 위한 기존의 다양한 자기 지도 목적 함수, 모델 아키텍처, 그리고 정렬 학습 전략에 대해 자세히 설명합니다.
- SSML 알고리즘의 실제 적용 사례를 검토하고, SSML의 과제와 향후 연구 방향을 논의합니다.
- 제안 방법:
본 논문은 SSML 분야를 다음 세 가지 핵심 과제와 그 해결책을 중심으로 분류하고 분석합니다.- 레이블 없는 멀티모달 데이터로부터 표현 학습:
- Instance Discrimination: 각 인스턴스를 구별하거나, 두 모달리티 샘플이 동일한 인스턴스에서 왔는지 예측하는 방식 (대조 학습, 매칭 예측).
- Clustering: 인코딩된 표현의 클러스터 할당을 반복적으로 예측하고 이를 감독 신호로 사용하여 특징 표현을 업데이트하는 방식.
- Masked Prediction: 입력 데이터의 일부 요소를 마스킹하고 모델이 누락된 정보를 예측하도록 훈련하는 방식 (자동 인코딩, 자동 회귀).
- Hybrid: 상호 보완적인 강점을 활용하기 위해 여러 목표 함수를 조합하는 방식.
- 다양한 모달리티의 융합:
- 사전 훈련 중 융합:
- 모달리티별 인코더: 각 입력 유형에 모달리티별 인코더를 사용하고, 이후 명시적인 융합 모듈(후기 융합)을 사용하거나 융합 없이 유사도 계산(융합 없음)을 수행.
- 통합 인코더: 여러 양식을 처리할 수 있는 단일 인코더(주로 트랜스포머 기반)를 사용하여 초기 단계에서 융합을 수행.
- 디코더: 마스크 예측과 같은 생성 작업을 위해 사전 훈련 단계에서 디코더를 활용.
- 스티칭(Stitching)을 통한 융합: 별도로 사전 훈련된 단일 모달 모델을 고정된 상태로 통합하고, 추가적인 학습 가능한 "스티칭" 모듈을 통해 양식 간 상호 작용을 중재 (얕은 스티칭, 깊은 상호 작용 스티칭).
- 사전 훈련 중 융합:
- 정렬되지 않은 데이터 학습:
- 조밀한(Coarse-grained) 정렬: 인스턴스 수준의 페어링.
- 잡음이 있는 쌍(Noisy-Paired): 자연적으로 또는 우연히 생성된 잡음이 있는 쌍 데이터 활용.
- 쌍을 이루지 않은(Unpaired): 외부 모델 사용 또는 주기 일관성(cycle-consistency) 강제를 통해 정렬 유도.
- 혼합(Mixed): 쌍을 이룬 데이터와 쌍을 이루지 않은 데이터를 혼합하여 훈련.
- 세밀한(Fine-grained) 정렬: 인스턴스의 하위 구성 요소 간의 대응.
- 암시적 정렬: 임베딩 공간에서 교차 모달 연결을 강제 (교차 모달 어텐션, 최적 수송).
- 명시적 정렬: 다중 인스턴스 학습 또는 외부 모델(객체 탐지기 등)을 통해 세분화된 페어링 도입.
- 조밀한(Coarse-grained) 정렬: 인스턴스 수준의 페어링.
- 레이블 없는 멀티모달 데이터로부터 표현 학습:
3. 실험 결과
- 데이터셋:
본 논문은 SSML 분야의 설문 조사 논문으로, 새로운 실험 결과를 제시하지는 않습니다. 대신, SSML 알고리즘의 응용 분야에서 사용되는 다양한 데이터셋과 해당 모델들의 성능을 종합적으로 검토합니다. 언급된 주요 데이터셋으로는 이미지-텍스트 검색을 위한 COCO, Flickr30K, 비디오-텍스트 검색을 위한 MSRVTT, YouCook2, MSVD, 시각적 질의응답을 위한 VQAv2, Vizwiz VQA, VQA-CP, TVQA, How2QA, TGIF-QA 등이 있습니다. 또한 의료 영상 데이터셋, 원격 감지 데이터셋 등 다양한 분야의 데이터셋이 언급됩니다. - 주요 결과:
- 상태 표현 학습(State Representation Learning) for Control: 순방향/역방향 모델링, 마스크 예측 등을 통해 환경 관찰 및 에이전트 행동 양식 간의 상호 작용을 포착하여 강화 학습 및 제어 작업에 기여합니다.
- 헬스케어(Healthcare): 의료 영상 및 보고서 등 다양한 양식의 정보를 통합하여 정확한 진단, 예후, 치료 계획 수립에 활용됩니다 (예: ConVIRT, GLoRIA, CheXzero, MEDCLIP).
- 원격 감지(Remote Sensing): 초분광, 다중 분광, 라이다, SAR 데이터 등 다른 센서의 보완적인 정보를 통합하여 토지 피복 분류, 변화 탐지 등에 활용됩니다.
- 전반적인 응용: SSML 알고리즘은 자율 주행, 기계 번역 등 다양한 실제 시나리오에서 효과적인 멀티모달 표현 학습을 가능하게 합니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 확장성: 대규모 언어 모델(LLM)의 발전과 함께 자기 지도 학습은 멀티모달 LLM의 확장을 촉진하며, 자동 회귀 및 스티칭 기술은 효율적인 확장을 가능하게 합니다.
- 통합: 아키텍처, 목적 함수, 작업 측면에서 통합된 접근 방식은 효율성을 높이고 다양한 양식에 대한 적응성을 용이하게 하며, 이전에 보지 못한 작업에 대한 제로샷 성능을 가능하게 합니다.
- 창발적 능력: 모델 크기가 커짐에 따라 멀티모달 추론과 같은 어려운 작업에서 창발적 능력이 나타날 수 있으며, 이는 범용 AI에 더 가까워지는 길을 열어줍니다.
- 단점/한계:
- 높은 계산 요구 사항: 수십억 개의 매개변수를 가진 모델 훈련에는 방대한 양의 데이터와 계산 자원이 필요하며, 공개 데이터셋의 부족은 AI의 비민주화 위험을 초래합니다.
- 데이터 품질 및 노이즈: 웹에서 수집된 "무료 레이블" 데이터는 잡음이 있는 경우가 많아 모델의 효능을 제한할 수 있으며, 데이터 필터링 절차에 대한 연구가 부족합니다.
- 정렬되지 않은 데이터의 어려움: 쌍을 이루지 않았거나 혼합된 데이터는 여전히 대응 모호성으로 인해 학습이 어렵고, 외부 모델 의존성 및 불균형 데이터셋 처리 문제가 존재합니다.
- 견고성 및 공정성: SSML 모델은 구성적 이해가 제한적이고, 추론 시 임의의 양식이 추가되거나 제거될 때 안정적인 성능을 유지하기 어려울 수 있으며, 데이터 및 아키텍처 편향으로 인한 공정성 문제가 발생할 수 있습니다.
- 이론적 분석의 부족: SSML에 대한 현재 연구는 주로 경험적이며, 멀티모달 맥락에 적합한 포괄적인 이론적 프레임워크가 아직 부족합니다.
- 응용 가능성:
- 로봇 공학 및 자율 시스템: 환경의 다양한 센서 데이터를 통합하여 로봇의 상태 표현 학습 및 제어 능력을 향상시킬 수 있습니다.
- 의료 진단 및 치료: 의료 영상, 환자 기록, 유전체 데이터 등 이종 데이터를 결합하여 보다 정확하고 개인화된 진단 및 치료 계획을 지원할 수 있습니다.
- 환경 모니터링 및 재난 관리: 위성 이미지, 라이다, 음향 데이터 등 원격 감지 데이터를 분석하여 환경 변화를 감지하고 재난 피해를 평가하는 데 활용될 수 있습니다.
- 다중 모달 콘텐츠 생성 및 이해: 이미지 캡셔닝, 비디오 요약, 시각적 질의응답 등 인간과 유사하게 다양한 양식의 정보를 이해하고 생성하는 AI 시스템 개발에 기여할 수 있습니다.
5. 추가 참고 자료
Zong, Yongshuo, Oisin Mac Aodha, and Timothy Hospedales. "Self-supervised multimodal learning: A survey." IEEE Transactions on Pattern Analysis and Machine Intelligence (2024).
Self-Supervised Multimodal Learning: A Survey
Yongshuo Zong, Oisin Mac Aodha, and Timothy Hospedales, Senior Member, IEEE
Abstract
여러 양식의 정보를 이해하고 분석하는 것을 목표로 하는 멀티모달 학습은 최근 몇 년 동안 지도 학습 체제에서 상당한 발전을 이루었습니다. 그러나 비용이 많이 드는 인간의 주석이 달린 데이터에 대한 과도한 의존은 모델 확장을 방해합니다. 한편, 야생에서 대규모의 주석 없는 데이터를 사용할 수 있다는 점을 감안할 때, 자기 지도 학습은 주석 병목 현상을 완화하기 위한 매력적인 전략이 되었습니다. 이 두 가지 방향을 기반으로, 자기 지도 멀티모달 학습(SSML)은 원시 멀티모달 데이터로부터 학습하는 방법을 제공합니다. 이 설문조사에서는 SSML의 최신 기술에 대한 포괄적인 검토를 제공하며, 멀티모달 데이터를 사용한 자기 지도 학습에 내재된 세 가지 주요 과제를 설명합니다: (1) 레이블 없이 멀티모달 데이터로부터 표현 학습, (2) 서로 다른 양식의 융합, (3) 정렬되지 않은 데이터로 학습. 그런 다음 이러한 과제에 대한 기존 해결책을 자세히 설명합니다. 구체적으로, 우리는 다음을 고려합니다: (1) 자기 지도(self-supervision)를 통해 멀티모달 비표지 데이터로부터 학습하기 위한 목표, (2) 다양한 멀티모달 융합 전략의 관점에서 본 모델 아키텍처, (3) 조밀한(coarse-grained) 및 세밀한(fine-grained) 정렬을 위한 쌍 없는(pair-free) 학습 전략. 또한 제어, 의료 및 원격 감지와 같은 다양한 분야에서 SSML 알고리즘의 실제 적용 사례를 검토합니다. 마지막으로 SSML의 과제와 향후 방향에 대해 논의합니다. 관련 리소스 모음은 다음에서 찾을 수 있습니다: https://github.com/ys-zong/awesome-self-supervised-multimodal-learning.
Index Terms-Self-Supervised Learning, Multimodal Learning, Deep Learning, Alignment, Representation Learning.
1 Introduction
인간은 시각, 청각, 촉각, 후각 등 여러 감각을 통해 세상을 인식합니다. 우리는 이 모든 양식(modalities)에서 상호 보완적인 정보를 활용하여 주변 환경에 대한 포괄적인 이해를 얻습니다. 인공지능(AI) 연구는 오랫동안 인간의 행동을 모방하고 유사한 방식으로 세상을 이해하는 에이전트를 개발하는 것을 목표로 해왔습니다. 이를 위해, 멀티모달 기계 학습 [1], [2] 분야는 여러 양식의 데이터를 처리하고 통합할 수 있는 모델을 개발하는 것을 목표로 합니다. 최근 몇 년 동안 멀티모달 학습은 상당한 발전을 이루었으며, 비전 및 언어 학습 [3], 비디오 이해 [4], [5], 생의학 [6], 자율 주행 [7] 등과 같은 분야에서 다양한 응용을 이끌어냈습니다. 더 근본적으로, 멀티모달 학습은 AI의 오랜 문제인 접지 문제(grounding problem) [8]를 발전시켜, 우리를 보다 범용적인 AI에 한 걸음 더 다가가게 하고 있습니다.
그러나 멀티모달 방법은 효과적인 훈련을 위해 여전히 값비싼 인간의 주석(annotation)을 필요로 하는 경우가 많아 확장을 방해합니다. 최근, 자기 지도 학습(SSL) [9], [10]은 쉽게 구할 수 있는 주석 없는 데이터로부터 감독(supervision)을 생성함으로써 이 문제를 완화하기 시작했습니다. 단일 모달 학습에서 자기 지도(self-supervision)의 정의는 훈련 목표에만 의존하고 수동 주석을 활용하는지 여부에 따라 꽤 잘 확립되어 있습니다. 그러나 멀티모달 학습의 맥락에서는 더 미묘합니다. 멀티모달 학습에서 한 양식은 종종 다른 양식에 대한 감독 신호 역할을 합니다. 확장(scaling up)을 위한 수동 주석 병목 현상을 제거하는 목표 측면에서, 자기 지도(self-supervision)의 범위를 정의하는 중요한 문제는 교차 모달 페어링(cross-modal pairing)이 본질적으로 자유롭게 사용 가능한지(예: 영화의 비디오+오디오 트랙처럼) 아닌지(예: 이미지의 텍스트 설명처럼) 여부입니다.
1자유롭게 사용 가능한 멀티모달 데이터와 자기 지도 목표를 활용함으로써, 자기 지도 멀티모달 학습(SSML)은 멀티모달 모델의 능력과 성능을 크게 향상시켰습니다. 이 설문조사에서는 자기 지도(self-supervision)와 멀티모달 데이터의 교차점에 내재된 세 가지 주요 과제를 식별하는 것부터 시작하여 SSML 분야를 검토합니다: (1) 레이블 없이 멀티모달 데이터에서 표현 학습을 수행하는 방법, (2) 서로 다른 양식을 융합하는 방법, (3) 부분적으로 또는 완전히 정렬되지 않은 멀티모달 데이터로 학습하는 방법. 이러한 상호 관련된 질문에서 시작하여, 우리는 그림 1의 분류법으로 요약된 최첨단 솔루션과 미해결 질문에 대해 논의합니다.
레이블이 없는 멀티모달 데이터로부터 표현을 학습하기 위해, 우리는 다양한 자기 지도 목표 함수를 고려합니다. pretext tasks를 기반으로, 훈련 목표를 instance discrimination, clustering, masked prediction 카테고리로 분류합니다. 이러한 접근 방식 중 두 가지 이상을 결합한 하이브리드 방법도 논의됩니다.
자기 지도 멀티모달 융합은 두 가지 방식으로 달성될 수 있습니다: 융합 아키텍처를 사용한 멀티모달 사전 훈련 또는 독립적으로 사전 훈련된 단일 모달 모델의 통합(즉, "stitching"). 우리는 먼저 멀티모달 사전 훈련을 위한 최신 SSML 아키텍처의 설계를 면밀히 검토합니다. 구체적으로, 우리는 인코더 및 융합 모듈의 설계 공간을 고려하며, 양식별 인코더(융합 없거나 후기 융합)와 초기 융합이 있는 통합 인코더를 대조합니다. 우리는 또한 특정 디코더 설계를 검토하고 이러한 설계 선택의 영향을 논의합니다. 대조적으로, 모델 스티칭(model stitching)은 자기 지도(self-supervision)를 통해 둘 이상의 개별적으로 사전 훈련된 단일 모달 모델을 연결하여 멀티모달 모델을 구성하는 것을 의미합니다.
마지막 독특한 과제는 정렬되지 않은 데이터로 학습하는 것인데, 이는 정렬 자체가 멀티모달 데이터에서 종종 중요한 누락된 주석이기 때문에 자기 지도(self-supervision)에 핵심적입니다. 멀티모달 데이터는 두 가지 다른 수준에서 (정렬되지 않음) 정렬될 수 있습니다: 조밀한(coarse-grained) 수준(예: 이미지-캡션)과 세밀한(fine-grained) 수준(예: 경계 상자-단어). 우리는 이러한 수준에서 정렬을 달성하는 것을 목표로 하는 쌍 없는(pair-free) 학습 전략을 개략적으로 설명합니다.
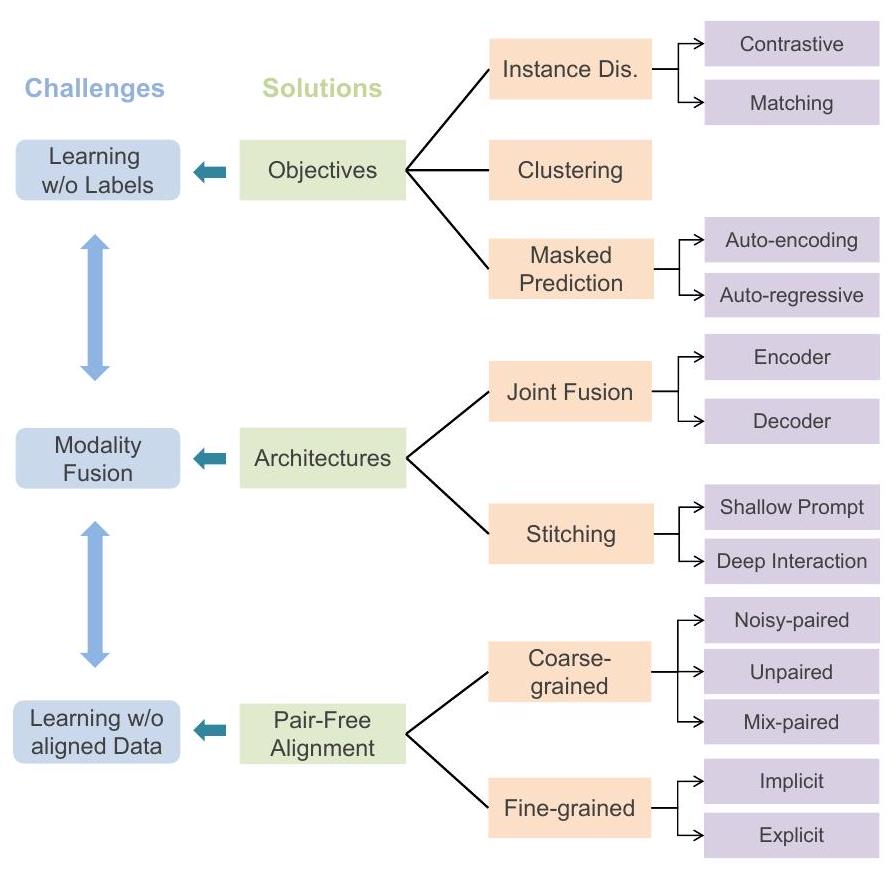
Fig. 1. Challenges and solutions for self-supervised multimodal learning. 조밀한(coarse-grained) 데이터의 경우, 잡음이 있는 쌍(noisy-paired), 혼합된 쌍(mixed-paired), 완전히 쌍이 없는(unpaired) 데이터를 포함한 다양한 페어링 시나리오로부터 학습하기 위한 접근법에 대해 논의합니다. 반면에, 세밀한(fine-grained) 데이터의 경우, 우리의 초점은 암시적이거나 명시적인 세밀한 정렬을 도출하는 방법론에 있습니다.
마지막으로, 의료, 원격 감지, 기계 번역 등 다양한 실제 분야에서 이러한 알고리즘의 응용에 대해 논의하고, SSML의 기술적 과제와 사회적 영향에 대한 심층적인 논의를 제공하며, 잠재적인 미래 연구 방향을 강조합니다. 우리는 이 분야의 연구자들과 실무자들을 위한 출발점을 제공하기 위해 방법, 데이터셋, 구현에 대한 최신 발전을 요약합니다.
기존의 설문 논문들은 지도 멀티모달 학습 [1], [2], [11], [12] 또는 단일모달 자기 지도 학습 [9], [10], [13]에만 초점을 맞추거나, SSML의 특정 하위 분야, 예를 들어 비전-언어 사전 훈련 [14]에만 초점을 맞춥니다. 가장 관련 있는 리뷰는 [15]이지만, 주로 시간적 데이터에 초점을 맞추고 SSML에서 융합과 정렬의 핵심 고려 사항을 생략합니다. 대조적으로, 우리는 SSML의 독특한 과제와 해결책을 다루는 새로운 분류법을 통해 SSML 알고리즘에 대한 포괄적이고 최신 리뷰를 제공합니다.
2 Background
먼저 이 설문조사에서 사용되는 표기법을 소개하고, 그 다음 학습 패러다임을 공식적으로 소개합니다. 마지막으로 우리가 다룰 SSML 알고리즘의 범위를 정의합니다.
2.1 Notation
Unimodal and Multimodal Data. 양식(modality)은 그것이 수신되고, 표현되고, 이해되는 방식에 의해 정의되는 데이터의 한 범주입니다. 단일모달 데이터는 이미지와 같이 단 하나의 양식에서 온 데이터를 의미합니다. 단일모달 데이터셋 는 입력 와 선택적으로 실제 참(ground-truth) 레이블 로 구성되며, 여기서 은 총 데이터 포인트의 수입니다. 대조적으로, 멀티모달 데이터는 이미지와 텍스트와 같이 서로 다른 () 양식에서 온 데이터로, 공유되거나 보완적인 정보를 포함할 수 있습니다. 멀티모달 데이터셋은 으로 표현될 수 있으며, 여기서 는 입력 양식의 수입니다. 이것은 쌍을 이룬(paired) 멀티모달 데이터인데, 각 양식의 샘플이 튜플 로 쌍을 이루어 관측치가 동일한 실제 사건을 참조하거나 그렇지 않으면 상응하기 때문입니다.
쌍을 이룬 멀티모달 데이터를 얻기 어려운 경우, 특정 알고리즘을 설계하여 쌍을 이루지 않은(unpaired) 데이터도 사용할 수 있습니다. 쌍을 이루지 않은 멀티모달 데이터는 각 양식이 독립적으로 기록되어 각 입력 양식에서 상응하는 관측 쌍을 생성하지 않는 데이터셋을 의미합니다. 공식적으로, 개의 양식과 개의 샘플을 가진 데이터셋 에 대해, 샘플을 개의 개별 데이터셋 으로 나눌 수 있으며, 여기서 입니다. 또한, 혼합 멀티모달 데이터는 쌍을 이룬 데이터와 쌍을 이루지 않은 데이터의 조합으로 간주될 수 있습니다.
Unimodal and Multimodal Models. 일반성을 잃지 않고, 예측 작업을 해결하고 싶다고 가정해 봅시다. 단일모달 학습의 경우, 목표는 예측 모델 를 학습하는 것이며, 여기서 는 일반적으로 표현 인코더 와 작업별 예측 헤드 로 구성됩니다. 즉, 입니다. 멀티모달 학습의 경우, 우리는 또한 예측 모델 를 학습하고자 합니다. 대조적으로, 는 일반적으로 각 입력 에 대한 양식별 인코더 , 서로 다른 양식의 인코딩된 정보를 통합하기 위한 잠재적인 융합 모듈 , 그리고 예측 헤드 로 구성됩니다. 간단히 하기 위해, 다음 텍스트에서는 로 표기합니다. 즉, 입니다. , , 는 해당 모델의 파라미터입니다. 구체적인 아키텍처 설계는 섹션 4에서 논의됩니다. 파라미터는 손실 함수 에 의해 최적화되며, 학습 절차는 섹션 2.2에서 자세히 설명됩니다.
2.2 Learning Paradigms
여기서는 관련된 네 가지 기계 학습 패러다임인 지도 단일 모드 학습, 자기 지도 단일 모드 학습, 지도 다중 모드 학습, 자기 지도 다중 모드 학습을 요약합니다. 그림 2에서 다중 모드 학습 패러다임을 설명합니다.
Supervised Unimodal Learning. 지도 단일 모드 학습은 인간이 주석을 단 ground-truth 레이블 의 감독을 사용하여 예측 모델 를 학습하는 것을 목표로 합니다. 인코더 와 예측 헤드 의 매개변수는 지도 손실 함수 을 통해 최적화됩니다: 지도 단일 모드 학습은 이미 많은 분야를 혁신했으며 컴퓨터 비전 [16]과 같이 인간 수준의 인식 능력을 달성했습니다. 그러나 모델의 성공적인 훈련에는 일반적으로 많은 수의 ground-truth 레이블이 필요하며, 이는 항상 사용 가능한 것은 아닙니다.
Self-supervised Unimodal Learning. 지도 학습과는 반대로, 자기 지도 단일 모드 학습은 사전 훈련 중에 ground-truth 레이블 를 필요로 하지 않으므로 값비싼 인간 주석의 필요성을 완화합니다.
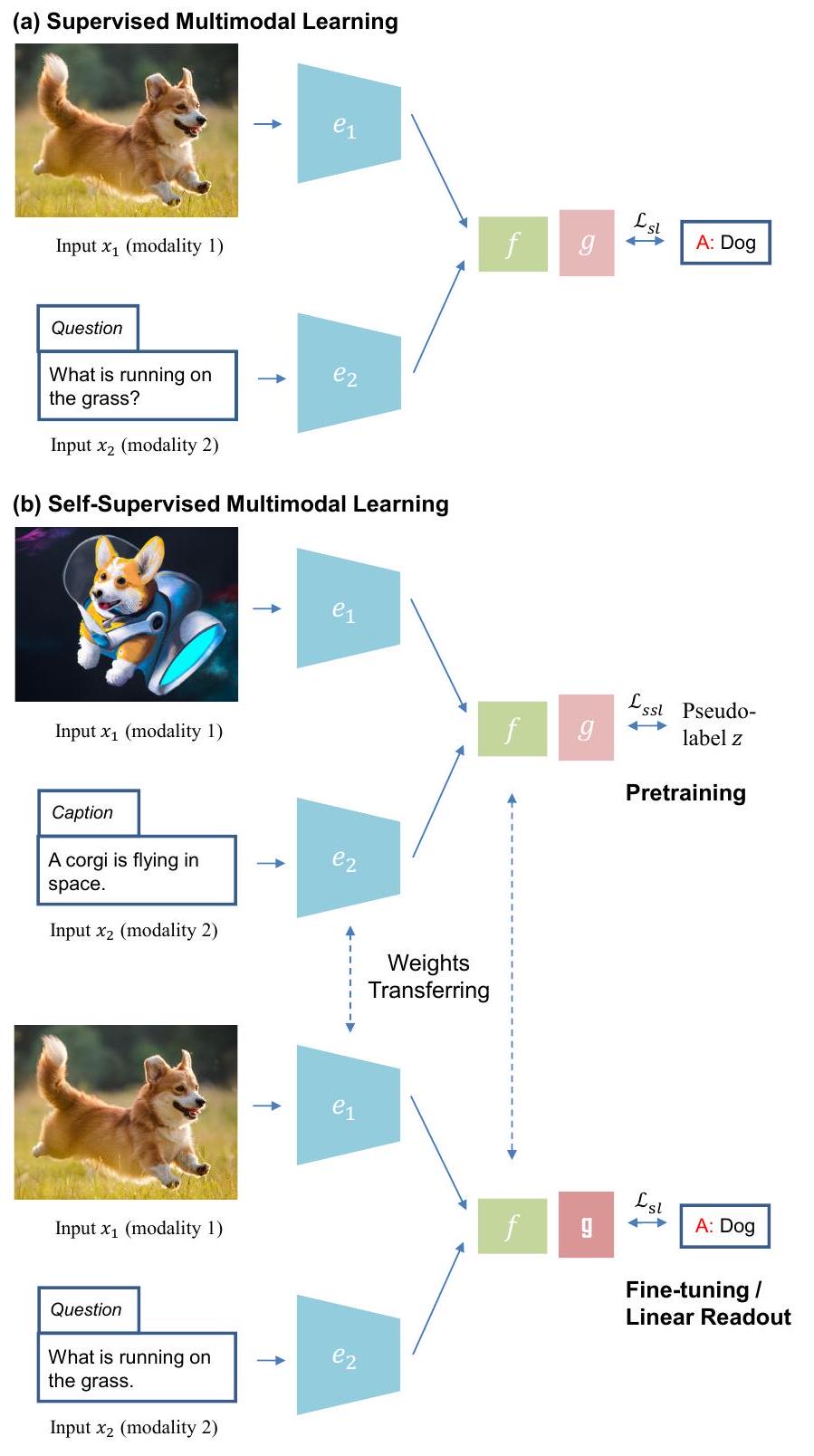
Fig. 2. (a) 지도 멀티모달 학습과 (b) 자기 지도 멀티모달 학습을 위한 학습 패러다임; 수동 주석이 없는 자기 지도 사전 훈련(상단)과 다운스트림 작업을 위한 지도 미세 조정 또는 선형 판독(하단)을 보여줍니다. 대신 입력 에 pretext 프로세스 를 적용하여 의사 레이블 를 생성하여 훈련을 감독합니다(예: [17]). 유사하게, 인코더 와 pretext 헤드 의 매개변수는 자기 지도 손실 함수 을 통해 최적화됩니다: 다운스트림 작업으로 전이할 때, pretext 헤드 는 버려지고 인코더 는 새로운 작업별 헤드 를 사용하여 대상 문제를 해결하기 위한 부분적인 솔루션으로 유지됩니다. 이들은 작은 레이블이 있는 데이터셋 에서 전체 모델을 업데이트하기 위해 미세 조정하거나 인코더 의 가중치가 고정되고 작업별 헤드 만 지도 손실로 훈련되는 선형 판독을 통해 효과적으로 훈련될 수 있습니다. 공식적으로, 미세 조정의 경우: 그리고 선형 판독의 경우: Supervised Multimodal Learning. 지도 멀티모달 학습은 지도 단일 모드 학습과 유사한 학습 패러다임을 따릅니다. ground-truth 레이블 는 모달리티별 인코더 , 융합 모듈 , 예측 헤드 의 매개변수 최적화를 감독하는 데 사용됩니다: 지도 멀티모달 학습 작업의 예는 그림 2(a)에 설명된 시각적 질문 답변입니다.
Self-supervised Multimodal Learning. 자기 지도 단일모달 학습과 유사하게, ground-truth 레이블 는 사전 훈련 중에 사용할 수 없습니다. 의사 레이블 는 입력 양식 중 하나에 의해 생성되거나 일부 또는 모든 입력 양식에서 공동으로 생성될 수 있습니다(예: ). 일반성을 위해 자기 지도 멀티모달 학습에 대한 의사 레이블 변환을 로 나타냅니다. 그러면 인코더 , 융합 모듈 , 예측 헤드 의 매개변수는 자기 지도 손실 을 최소화하여 훈련할 수 있습니다: 사전 훈련 후, 다운스트림 전이 과정은 다운스트림 단일 모드 사례의 과정과 유사합니다. 작업별 헤드 를 사용하여 다음과 같이 미세 조정할 수 있습니다: 또는 선형 판독의 경우 인코더 와 융합 모델 를 고정할 수 있습니다: 그림 2(b)에는 시각적 질의응답을 위한 다운스트림 지도 학습에 앞선 자기 지도 시각 및 언어 사전 훈련을 보여주는 예가 나와 있습니다.
2.3 Scope of the Survey
2.3.1 Self-supervision in Multimodal Learning
우리는 이 용어가 문헌에서 일관성 없이 사용되어 왔기 때문에 이 설문조사에서 고려되는 SSML의 범위를 먼저 설명합니다. 자기 지도(Self-supervision)는 단일모달(unimodal) 맥락에서 레이블이 없는 특성을 가진 다양한 pretext tasks에 의존함으로써 정의하기가 더 간단합니다. 예를 들어, instance discrimination [18]이나 masked prediction objectives [19]에 의해 유명하게 실현되었습니다. 대조적으로, 멀티모달 학습에서의 상황은 모달리티와 레이블의 역할이 모호해지기 때문에 더 복잡합니다. 예를 들어, 텍스트는 일반적으로 지도 이미지 캡셔닝 [20]에서 레이블로 간주되지만, 자기 지도 멀티모달 비전 및 언어 표현 학습 [21]에서는 입력 모달리티로 간주됩니다.
멀티모달 맥락에서, '자기 지도(self-supervision)'라는 용어는 적어도 네 가지 상황을 지칭하는 데 사용되었습니다: (1) 비디오 및 오디오 트랙이 있는 영화 [22]나 RGBD 카메라의 이미지 및 깊이 데이터 [23]와 같이 자동으로 쌍을 이루는 멀티모달 데이터로부터의 레이블 없는 학습. (2) 한 모달리티가 수동으로 주석 처리되었거나 두 모달리티가 수동으로 쌍을 이루었지만, 이 주석이 이미 다른 목적으로 생성되어 SSML 사전 훈련 목적으로는 무료로 간주될 수 있는 멀티모달 데이터로부터의 학습. 예를 들어, 웹에서 수집된 이미지-캡션 쌍을 일치시키는 것(CLIP [21]의 선구적인 예시)은 실제로는 쌍을 이루는 것이 감독인 지도 메트릭 학습 [24], [25]의 한 예입니다. 그러나 모달리티와 쌍이 모두 대규모로 자유롭게 사용할 수 있기 때문에 종종 자기 지도라고 설명됩니다. 이러한 선별되지 않은 우연히 생성된 데이터는 COCO [20] 및 Visual Genome [26]과 같이 목적에 맞게 생성되고 선별된 데이터셋보다 품질이 낮고 노이즈가 많습니다. (3) COCO [20]에서 수동으로 캡션이 달린 이미지와 같이 고품질의 목적에 맞게 주석이 달린 멀티모달 데이터로부터 학습하지만, Pixel-BERT [27]와 같이 자기 지도 스타일의 목표를 사용합니다. (4) 마지막으로, 무료 및 수동으로 주석이 달린 멀티모달 데이터의 혼합을 사용하는 '자기 지도' 방법이 있습니다 [28], [29].
이 설문조사의 목적을 위해, 우리는 수동 주석 병목 현상을 극복하여 규모를 확장하려는 자기 지도(self-supervision)의 정신을 따릅니다. 따라서 우리는 자유롭게 사용할 수 있는 데이터로 훈련할 수 있다는 점에서 위의 첫 번째, 두 번째 및 네 번째 범주에 속하는 방법을 포함합니다. 우리는 일반적으로 "자기 지도" 목표(예: 마스크 예측)를 선별된 데이터셋에 적용하기 때문에 선별된 데이터셋에서만 작동하는 것으로 나타난 방법은 제외합니다.
2.3.2 Multimodal v.s. Multiview
멀티모달 학습과 멀티뷰 학습은 관련이 있지만, 일부 문헌 [30], [31]에서 서로 바꿔 사용할 수 있는 별개의 개념입니다. 둘 다 작업 성능을 향상시키기 위해 둘 이상의 데이터 소스에서 상호 보완적인 정보를 추출하는 것을 목표로 합니다. 그러나 멀티모달 학습은 텍스트, 이미지, 오디오 또는 유전자 서열과 같이 여러 이종 모달리티의 데이터로부터 학습하는 데 초점을 맞춘다는 점에서 다릅니다 (예: [32], [33], [34]). 반면에, 멀티뷰 학습은 동일한 모달리티에서 얻은 데이터의 여러 뷰를 다룹니다. 예를 들어, 다른 시점에서 본 물체의 사진이나 공간적으로 떨어진 마이크에서 녹음된 오디오 (예: [35], [36], [37]) 등이 있습니다. 멀티뷰 학습은 또한 단일 모달리티 관찰에서 다른 특징이 추출되는 상황도 포함합니다 - 예를 들어 입력의 푸리에 변환 후 진폭과 위상과 같은. 이 설문조사에서는 입력이 뚜렷한 이종 모달리티인 멀티모달 학습에만 초점을 맞춥니다.
2.3.3 Generative vs Self-Supervised Models
생성적 적대 신경망(GANs) [38] 및 확산 모델(diffusion models) [39]과 같은 생성 모델은 비지도 학습기입니다. 우리는 주로 표현 학습을 위한 자기 지도 알고리즘에 초점을 맞춥니다.
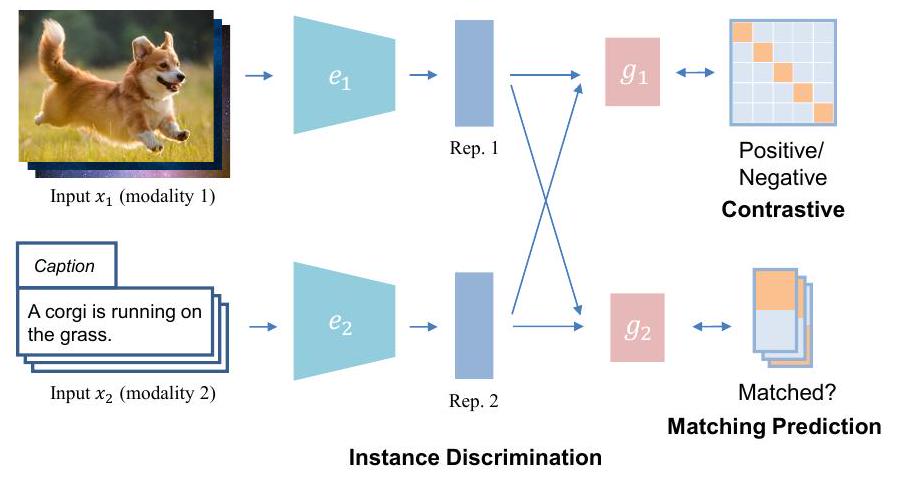
Fig. 3. instance discrimination 목표의 예시적 개략도. 따라서, 우리는 이 설문조사에서 이러한 모델에 대한 논의를 제외하고 대신 이러한 주제에 초점을 맞춘 다른 설문조사 [40], [41], [42]를 독자들에게 참조하도록 하겠습니다.
3 Multimodal Learning without Labels
레이블이 없는 데이터로부터 멀티모달 표현을 학습하는 과제는 맞춤형 솔루션을 요구합니다. 레이블의 부재는 명시적인 지도 레이블 정보에 접근하지 않고도 다른 양식에서 의미 있는 표현을 추출할 수 있는 학습 전략을 필요로 합니다. 자기 지도 멀티모달 목표를 활용함으로써, 우리는 학습 과정을 이끌기 위해 데이터 내의 고유한 구조와 동시 발생 패턴을 활용할 수 있습니다. 단일모달 SSL과 달리, 멀티모달 목표는 다른 양식과 그들의 고유한 특성을 고려해야 합니다. 이 측면은 그것을 별개의 과제로 구별하며, 전문화된 솔루션을 필요로 합니다. 구체적으로, 우리는 세 가지 주요 범주에 걸쳐 자기 지도 멀티모달 알고리즘을 훈련하기 위해 설계된 목표 함수를 자세히 설명합니다: instance discrimination, clustering, 및 masked prediction, 고전적인 단일모달 목표가 멀티모달 입력을 처리하기 위해 어떻게 확장될 수 있는지에 초점을 맞춥니다. 또한, 끝에서 하이브리드 목표에 대해서도 논의합니다.
3.1 Instance Discrimination
단일모달 학습에서, instance discrimination(ID)은 원본 데이터의 각 인스턴스를 별개의 클래스로 취급하며, 모델은 서로 다른 인스턴스를 구별하도록 훈련됩니다. 멀티모달 학습의 맥락에서, instance discrimination은 종종 두 입력 모달리티의 샘플이 동일한 인스턴스에서 왔는지, 즉 쌍을 이루는지 여부를 결정하는 것을 목표로 합니다. 그렇게 함으로써, 쌍을 이룬 모달리티의 표현 공간을 정렬하려고 시도하면서 다른 인스턴스 쌍의 표현 공간을 더 멀리 밀어냅니다. 입력이 어떻게 샘플링되는지에 따라 contrastive와 matching prediction이라는 두 가지 유형의 instance discrimination 목표가 있습니다.
3.1.1 Contrastive
대조적 방법은 일반적으로 서로 다른 양식의 해당 샘플을 긍정적인 예시 쌍으로 사용하고 해당하지 않는 샘플을 부정적인 쌍으로 사용합니다. 이러한 쌍은 대조적 훈련 목표를 사용하여 모델이 긍정적인 쌍과 부정적인 쌍을 정확하게 구별하도록 훈련하는 데 사용됩니다.
모달리티 에서 추출된 앵커 데이터 포인트 가 주어지면, 동일한 인스턴스의 다른 모달리티가 긍정 샘플 로 선택되고, 비대응 포인트는 부정 샘플 로 간주됩니다. 인코딩 후, 앵커, 긍정 및 부정 샘플에 대해 추출된 표현은 특징 공간 에서 , 및 로 정의될 수 있습니다. 그런 다음, 대조 목표의 일반적인 형태는 다음과 같이 쓸 수 있습니다: 여기서 은 두 입력 사이의 유사도 함수이고, 은 음성 샘플의 수입니다.
Contrastive Multiview Coding (CMC) [23]은 멀티모달 환경에서 대조 학습의 적용을 탐구한 최초의 연구 중 하나입니다. 이 프레임워크는 동일한 장면의 다른 뷰(모달리티)의 표현 간의 상호 정보를 최대화하면서 일치하지 않는 샘플을 밀어냅니다. 서로 다른 모달리티 간의 상호 정보를 최대화하고 교차 모달 인스턴스 판별을 수행하는 아이디어는 다양한 방식으로 더욱 발전하고 확장되었습니다. AVTS [43]는 시간적으로 동기화된 오디오-비디오 쌍을 긍정으로 간주하고 curriculum Learning을 활용하여 점진적으로 어려운 부정 샘플을 학습합니다. 공간적 정렬을 달성하기 위해, AVSA [44]는 서로 다른 공간적 시야 방향에서 비디오 및 오디오 클립을 샘플링하고 동일한 방향의 시청각 쌍의 상호 정보를 최대화합니다. MultiModal Versatile (MMV) 네트워크 [45]는 시간적으로 동시 발생하는 비전, 오디오 및 텍스트 쌍 간의 상호 정보를 최대화합니다. Video-Audio-Text transformer (VATT) [46]는 유사한 대조 목표를 사용하지만, 세 가지 모달리티 간에 가중치를 공유하여 모달리티에 구애받지 않는 단일 백본 transformer를 연구합니다.
대조 학습(Contrastive learning)은 더 큰 모델과 데이터셋으로 확장하는 데 큰 잠재력을 보여주었습니다. CLIP [21]은 4억 개의 이미지-언어 쌍으로 구성된 대규모 데이터셋에서 사전 훈련 시 쌍을 예측하는 것만으로 강력한 제로샷 성능을 달성합니다. 이 패러다임은 AudioCLIP [47], VideoCLIP [48], CLIP4CLIP [49], pointCLIP [50]과 같은 다른 다양한 영역에서 성공적으로 채택되었습니다. 쌍을 이룬 데이터를 수집하는 데 추가적인 큐레이션 단계가 필요할 수 있으므로, ALIGN [51]은 노이즈가 있는 쌍에서 사전 훈련하는 것이 여전히 강력한 성능을 달성하는지 연구하고 그렇다는 것을 확인합니다. 모델 및 데이터셋 크기가 증가함에 따라 훈련이 계산적으로 더 비싸지고 효율성을 향상시키는 방법이 개발됩니다. CLIPPO [52]는 이미지, 텍스트 및 멀티모달 작업을 위해 픽셀 기반 접근 방식을 사용하여 CLIP 모달리티를 통합하는 반면, FLIP [53]은 대규모 이미지 패치 세트를 마스킹하여 훈련 효율성을 향상시켜 CLIP과 동등하거나 우수한 성능을 제공합니다.
정렬을 위한 모달 간 대조 학습 외에도, 기존의 모달 내 학습은 추가적인 단서를 제공할 수 있습니다. SLIP [54]과 CrossCLR [55]은 교차 모달 학습과 함께 모달 내 대조 손실을 추가하여 이미지-텍스트 및 비디오-텍스트 문제에서 향상된 성능을 이끌어냅니다. CrossPoint [56]는 포인트 클라우드와 렌더링된 이미지로부터 교차 모달 대응을 학습하고 3D 포인트 클라우드의 다른 뷰로부터 모달 내 대응을 학습합니다. 그러나 모달 내 인스턴스 판별의 추가가 항상 유익한 것은 아닙니다. 예를 들어, AVID [57]는 교차 모달 판별에 비해 더 쉬운 pretext task이고 낮은 수준의 데이터 통계를 일치시켜 부분적으로 해결할 수 있기 때문에 모달 내 인스턴스 판별을 순진하게 추가하면 전체 성능에 해를 끼칠 수 있음을 보여줍니다.
3.1.2 Matching Prediction
정합 예측(matching prediction)은 정렬 예측(alignment prediction)이라고도 하며, 두 입력 양식에서 온 한 쌍의 샘플이 정합되었는지(긍정 쌍) 아닌지(부정 쌍) 예측하는 것을 목표로 합니다. 예를 들어, 텍스트가 이미지의 캡션에 해당하는지 여부입니다. 대조 학습과 정합 예측의 주요 차이점은 미니 배치에서 전자는 긍정 쌍과 다른 모든 부정 쌍 간의 유사성을 계산하는 반면, 후자는 개별 튜플을 긍정 또는 부정으로 레이블링한다는 것입니다. 를 정합 쌍의 두 클래스 확률로 나타내면, 정합 예측 손실은 이진 교차 엔트로피 손실(BCE)을 최소화합니다:
여기서 의사 레이블 는 입력이 일치하는지 여부를 나타내는 원-핫 벡터입니다.
정합 예측은 시청각 대응(AVC) 모델링에 널리 사용됩니다. AVC는 -Net [22]에 의해 도입되었으며, 오디오와 비디오의 융합된 표현을 사용하여 오디오-이미지 쌍이 동일한 비디오 클립에서 왔는지 이진 예측을 합니다. 이 전략은 AVE-Net [58]에 의해 융합 없이 유클리드 거리 정렬만 사용하여 채택되어 이미지 내에서 소리가 나는 객체를 국지화합니다. Owens와 Efros [59]도 이 pretext task를 활용하지만, 대신 시간적 비디오 프레임과 오디오를 입력으로 사용합니다. 그들은 동일한 비디오에서 부정적인 쌍을 구성하여 pretext task의 난이도를 높여 학습된 표현과 국지화 정확도를 향상시킵니다.
더 나은 시청각 지역화 및 분리를 달성하기 위해, 픽셀 단위 정합 예측이 pretext task로 제안되었습니다. 한 예로 mix-and-separate 방법 [60]이 있으며, 이는 다른 비디오의 오디오 신호를 결합하여 입력 혼합물을 만듭니다. 네트워크는 해당 비디오 프레임에 기반하여 이진 스펙트로그램 마스크를 예측함으로써 오디오 소스를 분리하도록 훈련됩니다. 유사한 접근 방식이 [61], [62]에서도 제안되었습니다. 이 아이디어를 바탕으로, Sound of Motions [63]는 모션 궤적 모델링을 통합하고, Music Gesture [64]는 인간의 신체 및 손 움직임을 사용하여 분리를 안내합니다.
Image-text matching (ITM)은 CLIP 이전에 UNITER [65]에 의해 처음 제안된 비전-언어 사전 훈련을 위한 효과적인 목표입니다. 이는 전역 교차 모달 표현을 이진 분류기에 공급하여 입력 쌍이 일치하는지 예측했습니다. ITM은 ViLBERT [66], BLIP [67], FLAVA [68] 등 다양한 알고리즘에 채택되었습니다. ITM은 또한 대조 학습을 보완할 수 있습니다. 예를 들어, ALBEF [69]는 대조 배치에서 어려운 부정 샘플을 샘플링하여 ITM 목표를 더 유익한 부정 샘플로 훈련합니다.
Discussion. 인스턴스 판별은 여러 양식에서 표현을 학습하기 위한 효과적이고 다재다능한 프레임워크로 부상했습니다. 많은 멀티모달 인스턴스 판별 방법의 핵심 측면은 양식 간에 긍정 및 부정 샘플을 샘플링하는 전략이며, 이는 학습된 표현에 상당한 영향을 미칠 수 있습니다. 예를 들어, 두 개의 비대응 샘플은 의미적 유사성에 관계없이 부정적인 쌍으로 처리됩니다. 이 과정은 거짓 긍정 및 거짓 부정 쌍을 모두 생성하여 레이블 노이즈 [70], [71]를 유발할 수 있습니다. 또한 대부분의 부정적인 샘플은 구별하기 매우 쉽다는 것을 의미하며, 이로 인해 어려운 부정적인 샘플 채굴이 지속적인 연구 주제가 되었습니다 [72], [73]. 대조 학습은 효과적이지만 모드 붕괴를 피하기 위해 충분한 부정적인 샘플을 얻기 위해 종종 큰 배치 크기가 필요합니다. 이는 특히 메모리 측면에서 리소스 집약적이며 더 효율적인 대조 학습에 대한 활발한 연구로 이어졌습니다 [74]. 양식 간의 대응 또는 상호 작용을 모델링하는 경우, 대조 모델은 일반적으로 양식별 인코더에서 임베딩을 얻은 후 교차 모달 점곱을 취합니다. 이는 단순하다는 장점이 있지만 양식 간의 풍부한 상호 작용을 모델링하는 능력이 부족합니다. 반면에, 일치 예측은 두 양식의 공동 표현에 대해 수행될 수 있습니다. 후자의 접근 방식은 더 풍부한 교차 모달 상호 작용을 가능하게 합니다. 따라서 이 두 목표는 때때로 보완적인 효과를 얻기 위해 결합됩니다.
3.2 Clustering
클러스터링 방법은 종단 간 훈련된 클러스터링을 적용하면 의미적으로 두드러진 특성에 따라 데이터가 그룹화될 것이라고 가정합니다. 실제로 이러한 방법은 인코딩된 표현의 클러스터 할당을 반복적으로 예측하고, 의사 레이블이라고도 하는 이러한 예측을 사용하여 특징 표현을 업데이트하는 감독 신호로 사용합니다. 멀티모달 클러스터링은 멀티모달 표현을 학습할 기회를 제공하고 각 모달리티의 의사 레이블을 사용하여 다른 모달리티를 감독함으로써 기존 클러스터링을 개선합니다.
형식적으로, 예측 헤드 를 K-means와 같은 표준 클러스터링 방법(즉, 학습 가능한 매개변수 없음)이라고 가정합시다. 기하학적 유사성을 기반으로 인코딩된 표현을 개의 고유한 클러스터로 클러스터링합니다. 입력 에 대한 클러스터 예측을 로 나타냅니다. 클러스터링 기반 방법은 예측된 클러스터 할당 와 의사 레이블 사이의 교차 엔트로피 손실을 최소화합니다. DeepCluster [75]에서 제안된 의사 레이블을 생성하는 널리 사용되는 접근 방식은 다음 목표를 최적화하여 중심 행렬 와 각 데이터 샘플 의 클러스터 할당 를 공동으로 학습하는 것입니다.
\begin{gathered} \min _{T \in \mathbb{R}^{d \times M}} \frac{1}{n} \sum_{i=1}^{n} \min _{z^{i} \in\{0,1\}}\left\|f_{\psi}\left(e_{\theta}\left(x_{1}^{i}, \ldots, x_{k}^{i}\right)\right)-T z^{i}\right\|_{2}^{2} \\ \text{ s.t. } z_{i}^{\top} 1_{k}=1 \end{gathered} $$이것은 최적의 할당 집합 $\left(z^{i *}\right)_{n \leq N}$과 중심 행렬 $T^{*}$를 산출합니다. 우리는 이 할당을 의사 레이블로 사용하고, 중심 행렬은 폐기합니다. 그 후에, 모델은 다음을 사용하여 최적화될 수 있습니다:$$ \begin{aligned} & \mathcal{L}_{\text {Clustering }}=\frac{1}{n} \sum_{\left(x_{k}^{i}\right) \in \mathcal{D}_{m}} \mathcal{L}_{C E}\left(C^{i}, z^{i}\right) \\ & \text{ and } C^{i}=g\left(f_{\psi}\left(e_{\theta}\left(x_{1}^{i}, \ldots, x_{k}^{i}\right)\right)\right) \end{aligned}그런 다음 클러스터링 프로세스는 업데이트된 표현에 대해 반복되므로 모델을 반복적으로 업데이트할 수 있습니다.
Cross-Modal Deep Clustering (XDC) [76]은 비디오 및 오디오 표현 학습을 위한 대표적인 클러스터링 기반 방법입니다. 한 양식의 클러스터 할당의 의사 레이블을 사용하여 다른 양식의 훈련을 감독합니다. 저자들은 또한 Multi-Head Deep Clustering (MDC)와 Concatenation Deep Clustering (CDC)를 탐구하는데, 이들은 각각 두 양식의 클러스터 할당과 두 양식의 공동 표현을 감독으로 사용합니다. 세 가지 방법 모두 다양한 다운스트림 작업에서 좋은 성능을 달성하는 표현을 산출합니다.
SeLaVi [77]는 최적 수송 문제를 해결하여 클러스터링을 학습하는 단일 모달 SeLa [78]를 기반으로 하며, 비디오 레이블링을 위해 구축되었습니다. SeLaVi는 추출된 오디오 및 시각 정보를 다른 뷰로 간주한 다음 뷰 불변성을 학습함으로써 이를 멀티모달 데이터로 확장합니다. 비퇴화 클러스터링은 최적 수송을 통해 보장됩니다. DMC [79]는 이미지와 오디오 스펙트로그램을 별도의 표현으로 인코딩한 다음 공동으로 클러스터링합니다. 그런 다음 모델은 모달리티 간의 유사성을 훈련을 위한 감독으로 사용합니다.
클러스터링을 위한 대안적인 pretext tasks도 설계되었습니다. AV-HuBERT [80]는 인코딩된 마스킹된 오디오 및 이미지 시퀀스 표현을 사용하여 미리 결정된 이산 클러스터 할당 시퀀스를 예측하는 마스크된 클러스터 예측을 사용합니다. 마스크되지 않은 클러스터 예측에 비해 잘못된 클러스터 할당에 더 탄력적입니다. u-HuBERT [81]는 다양한 입력을 공유된 모달리티 불가지론적 임베딩 공간에 매핑하여 마스크된 클러스터 예측을 위해 멀티모달 및 단일모달 음성과 모두 호환되도록 AV-HuBERT를 일반화합니다.
Discussion. 클러스터링 목표는 클러스터 할당을 감독 신호로 사용하여 모델이 데이터의 기본 구조를 포착할 수 있도록 하여 교차 모달 검색과 같은 다운스트림 작업에서 강력한 성능을 제공합니다. 클러스터 할당은 공동으로 융합된 표현 또는 모달리티별 표현과 같은 다양한 방식으로 생성될 수 있습니다. 동일한 인스턴스의 다른 뷰가 동일한 클러스터 할당을 갖도록 강제하는 단일 모달 클러스터링과 달리, 쌍을 이룬 모달리티가 완벽하게 일치하지 않을 수 있으므로 다양성을 높이기 위해 다른 모달리티가 다른 클러스터 할당을 갖도록 허용할 수 있습니다. 그러나 주어진 데이터셋에 대해 얼마나 많은 유연성을 갖는 것이 최적인지 선험적으로 알기는 어렵습니다. 마찬가지로, 노이즈가 있는 쌍을 이룬 데이터셋의 경우, 클러스터링은 대조 학습이 겪는 거짓 긍정 및 어려운 부정의 문제를 완화할 수 있습니다. 그러나 단점으로는 매개변수 초기화, 클러스터링 알고리즘 선택 및 선택된 클러스터 수에 대한 민감성이 포함되며, 이는 과적합과 과소적합의 균형을 맞추기 위해 신중하게 선택해야 합니다.
3.3 Masked Prediction
마스크된 예측 작업은 자동 인코딩 방식(BERT [82]와 유사) 또는 자동 회귀 방식(GPT [83]와 유사)으로 수행될 수 있습니다.
3.3.1 Auto-encoding Masked Prediction
자동 인코딩 마스크 예측기는 일부 요소가 무작위로 마스킹된 입력 데이터를 제공하고 모델이 누락된 정보를 예측하도록 훈련함으로써 모델을 사전 훈련합니다. 이는 모델이 데이터의 다른 조각 간의 관계를 이해하도록 강요하여 풍부한 의미론적 특징을 학습하는 것을 목표로 합니다. 이 접근 방식은 BERT [82]에서 제안한 마스크 언어 모델링(MLM) 기술로 자연어 처리를 위해 처음 도입되었으며 현재는 멀티모달 작업에 널리 사용되고 있습니다.
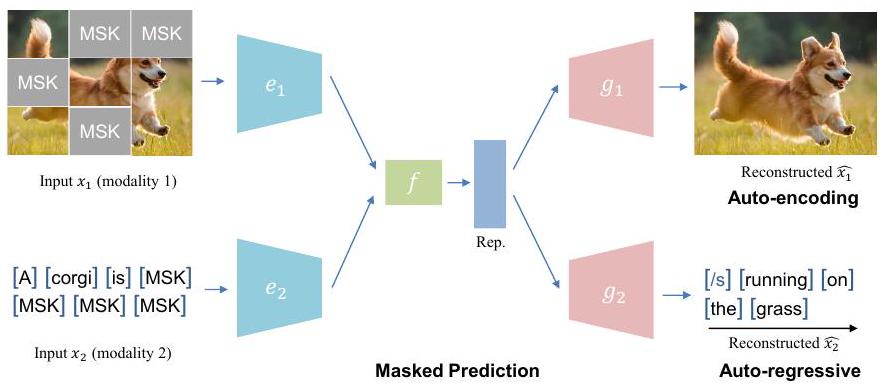
Fig. 4. 마스크 예측 프레임워크의 예시적 개략도. 멀티모달 학습의 경우, 마스크된 예측 작업은 종종 교차 모달 맥락에서 사용되며, 여기서 모델은 그림 4에서 설명된 바와 같이 다른 모달리티를 조건으로 누락된 정보를 예측해야 합니다. 예를 들어, 모델은 컨텍스트로 이미지를 제공받고 누락된 텍스트를 예측하도록 훈련될 수 있으며, 그 반대도 마찬가지입니다. 이를 위해서는 모델이 서로 다른 모달리티 간의 관계와 상호 작용을 이해해야 합니다. 일반성을 잃지 않고, 입력 모달리티 를 다른 모달리티 에 조건부로 재구성하는 것을 목표로 하는 pretext task를 고려해 봅시다. 여기서 입력에 마스킹 함수를 적용합니다. 즉, : 여기서 은 일반적으로 원래 입력과 재구성된 출력 간의 차이를 측정하기 위한 교차 엔트로피 또는 평균 제곱 오차(MSE) 손실입니다.
어떤 경우에는 모달 내 마스크 예측이 교차 모달 마스크 예측을 보완합니다. 즉, 모델은 동일한 모달리티 내에 포함된 정보만을 기반으로 모달 내 마스크된 콘텐츠를 예측해야 합니다. 이는 다른 모달리티의 부재에 강건한 표현을 학습하는 데 도움이 될 수 있습니다 [84], [85].
문서 이미지 이해를 위해 제안된 SelfDoc [86]은 언어 또는 비전 특징을 무작위로 마스킹하여 예측하는 마스킹 함수를 도입하여 문맥 단서와 멀티모달 정보를 추론하는 데 도움을 줍니다. 비디오와 텍스트를 위해 설계된 VideoBERT [85]는 원시 입력을 모두 이산 토큰 시퀀스로 변환하여 동일한 언어 모델에서 사용할 수 있도록 합니다. 모델은 모달 내 마스크 완성 목표를 사용하여 비디오 전용 또는 텍스트 전용 코퍼스에서 사전 훈련될 수 있습니다. VL-BEIT [84]는 공유된 transformer를 사용하여 단일모달 및 멀티모달 데이터 모두에 대해 마스크된 예측을 수행합니다. 이는 하나의 통합된 사전 훈련 작업, 하나의 공유된 백본, 하나의 단계 훈련으로 처음부터 학습할 수 있는 간단하고 효과적인 설계를 사용합니다. BEiT-3 [29]는 마스크된 예측 목표만 사용하여 다양한 다운스트림 작업에서 최첨단 전이 성능을 달성함을 추가로 보여줍니다. 이미지를 언어로 취급하고 이미지, 텍스트, 이미지-텍스트 쌍에 대해 통합된 방식으로 마스크된 "언어" 모델링을 수행합니다. Unified-IO [87]는 마스크된 언어 모델링과 마스크된 이미지 모델링을 수행하며, 이는 개별적으로 또는 여러 양식이 존재할 때 함께 훈련될 수 있습니다.
정확한 재구성 외에도, 고수준 특징을 더 잘 모델링하기 위해 항목에 대한 분포를 일치시키는 방법이 제안되었습니다. 예를 들어, ViLBERT [66]는 해당 이미지 영역에 대한 마스크된 텍스트 입력의 의미론적 클래스에 대한 분포를 예측하며, 여기서 목표 분포는 사전 훈련된 객체 탐지기에 의해 얻어집니다. 두 분포 사이의 KL 발산이 최소화됩니다. 유사하게, ActBERT [88]는 이 분포 일치 전략을 채택하여 비디오와 텍스트를 모델링합니다.
3.3.2 Auto-regressive Masked Prediction
PixelCNN [89]과 GPT [83]에 의해 대중화된 자기회귀 사전 훈련 방법은 왼쪽에서 오른쪽으로 한 번에 한 단계씩 다음 (마스킹된) 토큰을 예측합니다. 형식적으로, 특정 양식 입력 가 인코더 에 의해 토큰 집합 으로 토큰화되고 (예: 텍스트의 단어 집합 또는 이미지의 패치 집합), 유사하게 입력 양식 에 대해 토큰 을 갖는다고 가정합니다. 를 컨텍스트 창 크기로 나타내면, 자기회귀 프로세스의 목표는 다른 양식의 특정 융합을 조건으로 하는 우도를 최대화하는 것입니다:
SimVLM [90]은 접두사 시퀀스에 대한 양방향 주의를 활성화하고 나머지 토큰에 대해서만 AR 인수분해를 수행하여 PrefixLM 목표를 통해 자기 회귀(AR) 사전 훈련을 개선합니다. 이는 훈련 복잡성을 줄이면서 교차 모드 정보를 효과적으로 활용합니다.
사전 훈련을 위해 자동 인코딩과 자동 회귀 재구성을 모두 수행하는 방법도 있습니다. 예를 들어, OPT [91]는 오디오, 비전, 언어를 다른 세분성으로 모델링합니다. 토큰 수준에서 모델은 자동 인코딩 방식으로 훈련되는 반면, 모달리티 수준에서 모델은 생성 능력을 향상시키기 위해 모달리티별 디코더를 사용하여 자동 회귀를 수행합니다. UNIMO [92]는 마스크된 언어 모델링과 seq2seq 자동 회귀 마스크 예측을 모두 채택합니다.
Discussion. Masked prediction은 언어(BERT [82], GPT [83]) 및 비전(MAE [19])과 같은 단일 모드 영역에서 성공적이었으며, 다양한 모드를 통합하는 능력으로 인해 멀티모달 영역에서 인기가 높아지고 있습니다. 동일한 마스크 예측 목표는 원시 입력을 토큰으로 토큰화한 후 모든 모드에 편리하게 적용할 수 있으므로 더 많은 모드로 쉽게 확장할 수 있습니다. 한편, 마스크 예측을 위한 조건으로 다양한 모드 토큰을 혼합하면 교차 모드 상호 작용을 더욱 향상시킬 수 있습니다. 그러나 마스크 예측 접근 방식의 일반적인 단점은 입력을 재구성하기 위해 추가 디코더가 필요하므로 계산 비용이 많이 든다는 것입니다.
자동 인코딩 기반 마스크 예측 목표는 자동 회귀 기반 방법보다 멀티모달 학습에 비교적 더 널리 채택됩니다. 그 이유 중 하나는 AE 기반 목표가 AR 기반 방법보다 훈련 속도가 빠르기 때문입니다. AR 기반 방법은 한 번에 하나씩 출력을 생성하므로 대규모 데이터셋에서 사전 훈련할 때 특히 중요합니다. 또한 AE 기반 방법은 교차 모달 상호 작용을 향상시키기 위해 양방향 정보를 더 잘 활용할 수 있습니다. 그럼에도 불구하고 AR 기반 방법은 생성 능력을 향상시키는 장점이 있으며, 이는 이미지 합성이나 캡셔닝과 같은 생성적인 다운스트림 작업에 유용합니다.
3.4 Hybrid
단일 목표만으로도 좋은 성능을 얻을 수 있지만, 많은 방법들은 상호 보완적인 강점을 활용하기 위해 위에서 언급한 접근법들을 조합하여 사용합니다. 이는 여러 개의 pretext task를 가진 다중 작업 학습 문제로 볼 수 있습니다. 개의 개별적인 목표로 구성된 하이브리드 목표는 가중 합으로 공식화할 수 있습니다: 여기서 는 가중 계수입니다. 대조 및 클러스터링 목표의 조합은 유익할 수 있습니다. 앞서 언급했듯이, 대조 목표는 샘플 간의 의미적 유사성을 무시하여 거짓 음성으로 고통받을 수 있습니다. 반면에, 클러스터링 목표는 의미적으로 유사한 샘플을 동일한 클러스터로 그룹화하여 의미적 유사성을 고려합니다. MCN [93]은 공동 멀티모달 표현 공간에서 클러스터링을 수행하고(별도의 표현 공간에서 클러스터링하는 XDC [76]와 대조적으로), 오디오, 비디오 및 텍스트에 대해 쌍으로 대조 손실을 계산합니다. 결과적으로 생성된 고품질 임베딩 공간은 보지 못한 데이터셋 및 도메인에서도 샘플을 효과적으로 검색할 수 있게 합니다. 또한, 음원 위치 파악에서 대조 학습의 성공(예: [58], [60])과 클래스 식별에서 클러스터링 목표의 성공에 영감을 받아, Afouras 등 [94]은 오디오-비디오 히트맵 및 클러스터 레이블에서 의사 레이블을 사용하여 객체 감지기를 학습하기 위해 두 목표를 결합합니다.
연구자들은 시각-언어 사전 훈련을 위한 하이브리드 목표를 탐구했으며, 특히 인스턴스 판별과 마스크 예측을 결합했습니다. 예를 들어, UNITER [65]는 인스턴스 및 객체 수준 모두에서 마스크 예측과 매칭 예측 학습을 모두 사용합니다. 대조 학습은 매칭 예측과 함께 널리 사용되며, 여기서 매칭 예측은 대조 목표에서 계산된 어려운 부정 샘플을 활용하여 보다 근거 있는 표현 학습을 가능하게 합니다. ALBEF [69]는 이미지 및 텍스트 표현을 융합하기 전에 대조 학습을 사용하고 융합된 표현을 MLM 및 매칭 예측에 사용합니다. FLAVA [68]는 유사한 목표 조합을 포함하지만, 별도로 쌍을 이루지 않은 데이터를 처리하기 위해 모드 내 마스크 모델링도 사용합니다. VLMO [95]도 이 목표를 채택하지만, 모드별 전문가와 함께 입력을 인코딩하기 위해 mixture-of-modality-experts (MOME) transformer를 사용합니다. BLIP [67]는 대조 학습과 매칭 예측을 모두 채택하고 생성 능력을 향상시키기 위해 자동 회귀 마스크 예측을 수행합니다.
비디오 및 언어 사전 훈련 분야에서도 하이브리드 목표가 탐구되었습니다. ActBERT [88]는 전역 행동, 지역적 객체, 텍스트 설명 수준에서 마스크 예측을 수행합니다. UniVL [96]은 자동 인코딩 방식으로 마스크된 언어 모델링과 마스크된 프레임 모델링을 적용하고, 자동 회귀 방식으로 언어 재구성을 적용합니다. 또한 텍스트와 비디오 표현을 정렬하기 위해 대조적 방법을 적용합니다. MERLOT Reserve [97]는 새로운 대조적 스팬 목표를 제시합니다: 모든 양식이 시간적으로 정렬된 비디오가 주어지면, 텍스트와 오디오의 한 영역이 마스킹됩니다. 모델은 예측된 마스킹된 영역의 유사성을 특정 시점(긍정)의 텍스트와 오디오의 독립적인 인코딩에 대해서만 최대화해야 합니다.
하이브리드 목표는 비디오-오디오 사전 훈련에서도 점점 더 인기를 얻고 있습니다. CAV-MAE [98]는 비디오-오디오 대응의 대조 학습과 교차 모달 마스크 데이터 모델링을 수행합니다. MAViL [99]은 세 가지 멀티모달 목표를 제안합니다: (1) 마스크된 오디오-비디오 모델링; (2) 마스크된 모드 간/내 대조 학습; (3) 멀티모달 특징에 대한 마스크된 자기 훈련.
Discussion. 하이브리드 목표는 상호 보완적인 개별 패러다임을 결합하는 것을 목표로 합니다. 훈련 중에 서로 다른 목표가 상호 작용할 수 있습니다. 예를 들어, 대조 학습은 일치 예측을 위한 부정적인 쌍 선택을 향상시킬 수 있습니다. 또한, 서로 다른 목표는 서로 다른 다운스트림 작업에 도움이 될 수 있으며, 이를 결합하면 보다 유연한 범용 표현으로 이어질 수 있습니다 [67], [69]. 그러나 하이브리드 목표를 사용하면 개별 목표의 중요도와 수렴 속도가 다르기 때문에 하이퍼파라미터 튜닝이 복잡해집니다. 그리고 한 목표를 최적화하는 것이 다른 목표를 약화시킬 수 있는 목표 간섭의 잠재적인 위험이 있습니다. 또한, 이러한 접근 방식은 서로 다른 목표를 계산하기 위해 여러 번의 순방향 패스가 필요하므로 훈련 속도를 늦출 수 있습니다.
4 Modality Fusion
모달리티 융합(Modality fusion)은 다양한 모달리티의 정보를 통합하여 그들 사이의 관계를 설명하고 다중 모달 작업을 지원하는 통합된 표현으로 만드는 과정입니다. 두 가지 독특한 방법론이 이를 가능하게 합니다: 다양한 융합 단계를 갖춘 다중 모달 공동 사전 훈련; 그리고 독립적으로 사전 훈련된 단일 모달 모델의 통합인 "stitching". 사전 훈련 중 다른 단계에서 다중 모달 융합을 수행하기 위해 다양한 아키텍처 설계가 존재합니다. 반면에 스티칭(Stitching)은 별도로 사전 훈련되고 고정된 단일 모달 모델을 상호 연결하여 다중 모달 인식이 가능한 모델을 구성하는 것을 수반합니다. "Stitching"은 자기 지도(self-supervision)를 사용하여 단일 모달 모델을 사전 훈련한 다음, 다중 모달리티의 자기 지도 융합을 활용하기 때문에 SSML에서 두드러집니다. 우리는 SSML에서 독특하거나 더 널리 사용되는 융합 전략에 특히 초점을 맞춥니다.
4.1 Fusion during Pretraining
이 하위 섹션에서는 인코더, 융합 및 디코더 모듈을 검토하여 SSML 모델의 아키텍처를 탐색합니다. 전체 모델을 로 표기하고 아래에서 각 주요 아키텍처 제품군에 대해 논의합니다.
4.1.1 Encoders and Fusion
4.1.1.1 Modality-specific Encoder
이러한 방법들은 각 입력 유형을 인코딩하기 위해 모달리티별 인코더를 채택합니다. 예를 들어, 시각적 입력에는 CNN을, 텍스트에는 transformer를 사용합니다.

Fig. 5. 다양한 양식 융합 아키텍처의 그림. 그런 다음, 인코딩된 표현은 단순한 점곱 정렬이나 추가적인 후기 융합에 사용될 수 있습니다.
Fusion-free. 퓨전 없는 방법은 명시적인 퓨전 모듈 를 포함하지 않는 모델입니다. 대신, 대조 손실을 사용하는 것과 같이 유사도를 계산하여 교차 모달 정렬을 달성합니다. 즉, 예를 들어, CLIP [21]과 ALIGN [51]은 대규모 데이터셋에서 대조 학습으로 사전 훈련하기 위해 별도의 이미지 및 텍스트 인코더를 사용합니다. MMV [45]는 시각, 오디오 및 텍스트 입력을 세 가지 다른 인코더로 인코딩한 다음 사전 훈련을 위해 멀티모달 대조 손실을 적용합니다. 이 아키텍처는 또한 일치 예측을 사용하여 훈련될 수 있으며, 여기서 AVE-Net [58]은 별도의 임베딩의 유클리드 거리를 기반으로 시각과 오디오의 정렬을 예측합니다. 또한, XDC [76]에서는 각 인코더의 임베딩의 클러스터 할당이 추가적인 퓨전 없이 다른 인코더에 대한 감독 신호로 활용됩니다.
Late Fusion. 후기 융합은 모달리티별 인코더를 사용한 후 명시적인 융합 모듈을 사용하여 교차 모달 상호 작용을 모델링하는 모델을 의미하며, 일반적으로 transformer 계층이나 간단히 완전 연결(FC) 계층을 통해 이루어집니다: 이것은 표현 융합을 의미하며, 다른 모델의 예측 확률을 융합하는 전통적인 정의와는 다릅니다. 예를 들어, 다른 인코더의 임베딩은 공유 잠재 공간으로 투영된 다음, 공동 표현은 클러스터 할당을 생성하거나 [93] 몇 개의 FC 계층 후에 예측을 정렬하는 데 사용될 수 있습니다 [59]. transformer 계층을 사용하면 주의 메커니즘을 사용하여 잠재적으로 더 깊은 모달리티 상호 작용을 달성할 수 있습니다. 예를 들어, ALBEF [69]와 FLAVA [68]는 시각 및 텍스트 표현을 모두 입력으로 사용하고 교차 주의로 융합하는 추가 멀티모달 transformer를 사용하여 교차 주의가 시각적 접지/함의/추론과 같이 심층적인 모달리티 상호 작용이 필요한 다운스트림 작업에 이점을 준다는 것을 보여줍니다. 융합 계층은 다른 형태를 취할 수도 있습니다. 예를 들어, Dragon [100]은 정보 교환을 위해 FC 계층을 사용하는 모달리티 상호 작용 모듈이 있는 융합 계층을 특징으로 합니다. 융합 계층은 여전히 텍스트와 지식 그래프를 각각 인코딩하기 위한 언어 인코더와 그래프 신경망을 유지합니다.
Discussion. 융합 없는 아키텍처는 간단하고 확장이 용이하여 교차 모달 정렬에 널리 사용됩니다. 효율적인 검색과 같은 다운스트림 작업에서 강력한 성능을 보여주었습니다. 그러나 멀티모달 융합이 부족하면 모달리티 상호 작용이 완전히 모델링되지 않아 시각적 추론, VQA 또는 더 복잡한 교차 모달 이해가 필요한 이산 접지와 같은 작업에서 성능이 저하됩니다. 이 문제는 교차 주의를 통해와 같이 다른 모달리티 간의 상호 작용을 명시적으로 장려하는 후기 융합 모듈을 통합하여 해결할 수 있습니다. 그러나 융합 모듈은 융합 없는 모델에 비해 훈련 속도를 늦출 수 있는 추가 계산을 도입합니다.
4.1.1.2 Unified Encoder with Early Fusion
여러 양식을 처리할 수 있는 인코더를 통합 인코더(unified encoder)라고 합니다. 이러한 모델은 일반적으로 다양한 양식의 입력 토큰을 처리하기 위해 transformer 기반 아키텍처를 사용하여 단일 매개변수 집합으로 다양한 유형의 데이터를 처리할 수 있습니다: 여기서는 융합이 전체 인코더에 걸쳐 발생하기 때문에 융합 모듈 의 표기를 생략합니다. 후기 융합의 정의와 유사하게, 초기 융합은 통합 인코더의 초기 단계에서 표현의 융합을 의미하지만, 양식별 토크나이저는 여전히 필요할 수 있습니다.
토크나이저는 오프라인으로 사전 훈련된 외부 모델이거나 종단 간 공동으로 훈련된 모델일 수 있습니다. 외부 모델은 초기 연구에서 원시 모달리티로부터 상세한 특징을 추출하는 데 널리 사용되었으며, 이 특징은 입력 토큰 시퀀스로 변환됩니다. 예를 들어, 객체 탐지기는 이미지 특징 [65], [101]과 비디오 특징 [88]에 사용되었습니다. 자세한 논의는 섹션 5.2.2.2를 참조하십시오. 종단 간 토크나이저는 함께 훈련되며, 그 출력은 통합 인코더의 입력 토큰입니다. 이는 시각적 입력에 대한 패치 임베딩, CNN 또는 ViT [28], [90]일 수 있으며, 텍스트에 대한 MLP 또는 transformer [46], [84]일 수 있습니다. 종단 간 모델은 추가적인 오프라인 모델이 필요하지 않아 훈련 과정을 단순화하고 종종 더 나은 성능을 산출하기 때문에 더 널리 채택되었습니다.
통합 아키텍처는 다른 모달리티의 입력 토큰을 입력으로 받는 공유된 self-attention을 통해 암묵적으로 모달리티 상호 작용을 학습할 수 있습니다. 다른 모달리티의 입력 토큰은 필요한 경우 특정 위치 인코딩이나 추가 모달리티 유형 임베딩을 설계하여 구별할 수 있습니다. 이 설계는 유연하여 단일 모달 입력이 가능하며, 따라서 단일 모달 데이터만 사용 가능하고 쉽게 얻을 수 있는 단일 모달 데이터셋을 [85], [90]과 같은 연구에서 입증된 바와 같이 활용할 수 있습니다. 비디오-오디오 [102] 및 비디오-오디오-텍스트 [46]를 위한 통합 백본을 설계하려는 시도도 있었습니다. 이를 통해 다른 모달리티의 토큰을 혼합할 수 있으며, 예를 들어 특정 텍스트 토큰을 해당 이미지 객체 토큰으로 교체하는 것과 같습니다 [103]. HiP [104]는 아키텍처에 지역성을 다시 구축하면서 모달리티 독립성을 보존함으로써 Perceiver 유형 모델 [105]을 고해상도 원시 멀티모달 입력으로 확장합니다. 통합 아키텍처의 변형은 전문가 혼합 모델이며, 최근 이미지, 텍스트, 비디오, 오디오, 소스 코드 등 다양한 모달리티에 활용되었습니다 [29], [95], [106], [107]. 이 설계는 self-attention을 공유하는 동일한 다중 방식 transformer 내에서 다른 모달리티에 대해 다른 전문가를 활용합니다. 이를 통해 특정 모달리티 전문가가 더 정밀한 처리에 사용될 수 있으며, 동시에 통합 아키텍처의 이점을 누릴 수 있습니다.
Discussion. 일반적으로, 통합 아키텍처는 모델의 주요 구성 요소에 대해 서로 다른 양식 간에 매개변수 공유를 허용하여 매개변수 수를 줄입니다. 또한, 양식별 인코더에 비해 누락된 양식에 대해 일반적으로 더 견고합니다. 그러나 이러한 방법의 주요 단점은 검색과 같은 작업에서 비효율적이라는 것입니다. 순위를 매기기 위해 유사성 점수를 계산하기 위해 모든 가능한 교차 양식 쌍을 인코딩해야 하기 때문입니다. 하지만 경쟁력 있는 성능을 달성할 수 있습니다(예: [84]).
4.1.2 Decoders
많은 방법들이 디코더가 없지만, 다른 방법들은 pretext tasks의 성격에 따라 사전 훈련 단계에서 디코더를 필요로 합니다. 여기서 pretext head 가 디코더 역할을 합니다. 그러면 디코더는 폐기되거나 다른 다운스트림 작업을 위해 유지될 수 있습니다. 예를 들어, [87], [90], [91], [96], [108], [109]에서 사용된 자동 회귀 마스크 예측은 마스크된 입력을 재구성하기 위해 디코더를 필요로 합니다. 재구성된 입력의 멀티모달 정보를 조건으로 한 성공적인 생성은 다른 양식의 융합을 강제합니다.
Discussion. 추가적인 디코더는 모델의 생성 능력을 향상시켜 이미지/비디오 캡셔닝 및 개방형 질문 답변과 같은 다운스트림 작업에 이점을 줄 수 있습니다. 대규모 언어 모델의 인기로 인해, 그 중 다수는 transformer 디코더 전용 아키텍처 [83], [110]를 활용하며, 디코더 아키텍처는 동시에 멀티모달 학습에서 수용도가 높아지고 있습니다. 이는 pretext 설계에 더 많은 가능성과 멀티모달 융합에 대한 유연성을 제공합니다. 그러나 디코더를 포함하면 훈련이 계산적으로 더 비싸지고 잠재적으로 MLP를 출력 레이어로만 사용하는 디코더 없는 방법(예: [21], [22], [69])에 비해 덜 안정적일 수 있습니다.
4.2 Fusion by Stitching
GPT [83]와 같은 자기 지도 학습 전략을 통해 사전 훈련된 단일 모달 기반 모델 [111]은 상당한 능력과 광범위한 가용성으로 인해 현대 연구에서 중추적인 역할을 하게 되었습니다. 그러나 그들의 성공은 설득력 있는 과제를 낳았습니다: 어떻게 이러한 단일 모달 모델의 힘을 활용하여 멀티모달 모델을 구축할 수 있을까요? 처음에는 CNN에 추가 레이어를 삽입하는 것을 의미했던 "stitching" 개념 [112]이 이 과제에 대한 해결책으로 탐구되었습니다. 멀티모달 맥락에서, stitching은 별도로 사전 훈련된 단일 모달 모델을 고정된 상태로 통합하는 과정을 의미합니다. 이 모델들 사이의 연결은 추가적인 훈련 가능한 "stitching" 모듈을 통해 설정됩니다. 이 모듈은 양식 간의 상호 작용을 중재하는 작업을 수행하여, 단일 모달 인식을 일관된 멀티모달 이해로 변환합니다. 이 접근 방식은 기존 단일 모달 모델의 강점을 활용하고 멀티모달 이해를 향한 효율적인 경로를 제공합니다. 스티칭에는 두 가지 주요 접근 방식이 있습니다: 입력 레이어에서의 얕은 스티칭과 깊은 상호 작용을 통한 스티칭.
4.2.1 Shallow Stitching at the Input Layer
얕은 스티칭은 융합의 초기 단계에서 이루어집니다. 한 양식의 사전 훈련된 단일모달 모델의 출력 표현이 다른 양식의 다른 단일모달 모델의 입력으로 재사용되며, 변환은 일반적으로 학습된 투영 네트워크에 의해 달성됩니다.
Frozen [113]은 시각적 양식을 언어적 맥락에 접지시키려는 최초의 시도 중 하나입니다. 시각적 표현을 소프트 프롬프트로 처리함으로써 사전 훈련된 언어 모델의 의미론적 지식을 효과적으로 활용하여, 언어 전용 능력을 제로샷 방식으로 멀티모달 작업으로 이전할 수 있는 잠재력을 보여줍니다. 한 걸음 더 나아가, LiMBeR [114]는 두 모델 모두 고정된 상태에서 선형 계층만으로 시각적 의미 표현을 소프트 프롬프트로 언어 공간에 매핑할 수 있음을 보여줍니다. FROMAGe [115]는 소규모 훈련 데이터로도 선형 투영을 통해 모델이 강력한 소수 샷 멀티모달 능력을 학습할 수 있음을 보여줍니다. BLIP-2 [116]는 BLIP [67]과 동일한 목표를 사용하는 Querying Transformer로 양식 간의 격차를 해소할 것을 제안합니다. 두 단계로 사전 훈련된 이미지 모델과 언어 모델을 부트스트랩하여 최첨단 성능을 달성합니다. 쌍을 이룬 훈련 데이터에 대한 의존도를 완화하기 위해, ESPER [117]는 모든 모델이 고정된 강화 학습에 대한 보상 신호를 얻기 위해 CLIP을 활용하여 쌍을 이루지 않은 멀티모달 입력을 언어 모델 생성물에 정렬합니다. 이러한 발전은 경량 및 효율적인 멀티모달 학습을 위한 유망한 궤적을 보여줍니다.
4.2.2 Stitching with Deep Interactions
연구자들은 또한 더 깊은 상호작용을 가진 모델을 연결하는 것을 탐구했습니다. 입력 계층에서만 연결하는 대신, 깊은 연결은 고정된 모델 내에서 융합됩니다. 이는 일반적으로 추가 어댑터를 통합하여 달성되며, 풍부한 상호작용으로 깊은 융합을 장려합니다. CLIPCap [118]은 시각적 토큰을 언어 모델의 접두사 임베딩으로 매핑하기 위해 transformer를 사용하고, 각 계층에서 접두사를 추가할 것을 제안합니다. Frozen과 유사하게, MAGMA [119]는 시각적 토큰을 더 잘 해석하기 위해 언어 모델의 각 블록 사이에 스케일링된 잔차 병목 MLP 형태의 추가 어댑터 모듈을 도입합니다. Flamingo [120]는 perceiver 기반 [105] 모듈로 고정된 비전 및 언어 모델을 연결하고, 교차 주의를 통해 각 계층에 걸쳐 시각적 토큰을 언어 모델과 인터리브합니다. 놀랍게도, 의도적으로 주석이 달린 데이터를 사용하지 않고도 강력한 성능을 달성하며 일부 작업에서는 미세 조정된 최첨단 기술을 능가하기도 합니다. 그러나 여전히 수십억 규모의 훈련 가능한 매개변수가 필요합니다.
Discussion. 스티칭(Stitching)은 효율성과 단순성 덕분에 멀티모달 융합에 대한 강력한 솔루션을 제공합니다. 사전 훈련된 단일 모달 모델의 힘을 활용함으로써, 스티칭은 계산 및 메모리 오버헤드를 크게 줄이고 훈련을 간소화합니다. 단순성은 자동 회귀 언어 모델링 목표의 일반적인 사용으로 더욱 뒷받침되어 간단한 훈련 절차로 강력한 성능을 발휘합니다. 스티칭은 또한 문맥 내 학습 [121] 및 사고의 연쇄 [122]와 같은 대규모 사전 훈련된 단일 모달 모델의 고급 기능을 활용하고 유지할 수 있으며, 이는 미세 조정으로 인한 망각의 위험 없이 상속될 수 있습니다.
딥 스티칭(Deep stitching)은 고정된 모델 내부에 융합을 통합함으로써 양식 간에 비교적 풍부하고 복잡한 상호 작용을 도입합니다. 그러나 일반적으로 더 복잡한 훈련 절차를 포함하며 추가적인 계산 자원이 필요합니다. 딥 스티칭을 위해 도입된 추가 어댑터는 또한 프로세스를 잠재적으로 덜 투명하고 해석하기 어렵게 만듭니다. 반면에 얕은 스티칭(shallow stitching)은 고유한 단순성으로 인해 효율적인 구현과 간단한 훈련을 가능하게 하여 멀티모달 작업으로의 능력 전이를 효과적으로 촉진합니다. 그럼에도 불구하고 양식의 융합은 비교적 피상적이어서 잠재적으로 양식 간의 융합 정도를 제한합니다. 사전 훈련된 단일 모달 모델에서 지식을 부트스트랩하고 고정된 양식별 표현을 융합하는 방법은 미래 연구를 위한 유망한 길로 남아 있습니다.
비전 및 언어 영역에서의 진전을 고려할 때, 다른 양식으로 스티칭을 확장하는 것은 미래 연구를 위한 흥미로운 기회를 제공합니다. 그러나 사전 훈련된 단일 모달 모델에 내재된 편향을 무심코 상속할 위험이 있습니다. 이는 스티칭 중 면밀한 조사와 적극적인 편향 완화 전략을 요구합니다. 또한, 우리는 고정된 단일 모달 표현의 뚜렷한 속성과 가능한 상호 작용에 대한 더 나은 이해가 필요합니다. 다른 양식의 표현에서 차이점과 유사점을 분석하면 스티칭된 멀티모달 모델의 해석 가능성과 투명성을 향상시킬 수 있습니다.
5 Unaligned Multimodal Learning
정렬되지 않은 멀티모달 데이터의 문제는 SSML에 대한 독특한 차원입니다. 정렬은 조밀한(coarse-grained) 및 미세한(fine-grained) 스케일 모두에서 발생합니다(그림 6). 조밀한 정렬은 인스턴스 수준의 페어링, 즉 다른 모달리티에 걸쳐 데이터 샘플의 페어링과 관련이 있습니다. 대조적으로, 미세한 정렬은 이미지의 객체를 문장의 해당 단어와 연결하는 것과 같이 이러한 인스턴스의 하위 구성 요소 간의 대응을 포함합니다. 위의 대응을 정의하는 것은 종종 수동 주석 프로세스이며, 따라서 자기 지도 학습은 이상적으로 정렬이 주석 처리될 필요가 없는 방법을 요구합니다.
5.1 Coarse-grained
우리는 조밀한(coarse-grained) 입력 페어링에 대해 세 가지 시나리오를 고려합니다: 모든 모달리티가 대략적으로 정렬된 경우(paired), 모달리티 간에 알려진 대응 관계가 없는 경우(unpaired), 그리고 이 두 데이터 유형이 혼합된 경우(mixed). 우리는 더 큰 어려움을 제기하는 후자의 두 경우에 더 많은 관심을 기울입니다.
5.1.1 Noisy-Paired
각 양식의 샘플 간에 알려진 대응 관계가 있는 쌍을 이룬 데이터를 가정하는 것은 멀티모달 학습에서 가장 널리 사용되는 설정입니다.
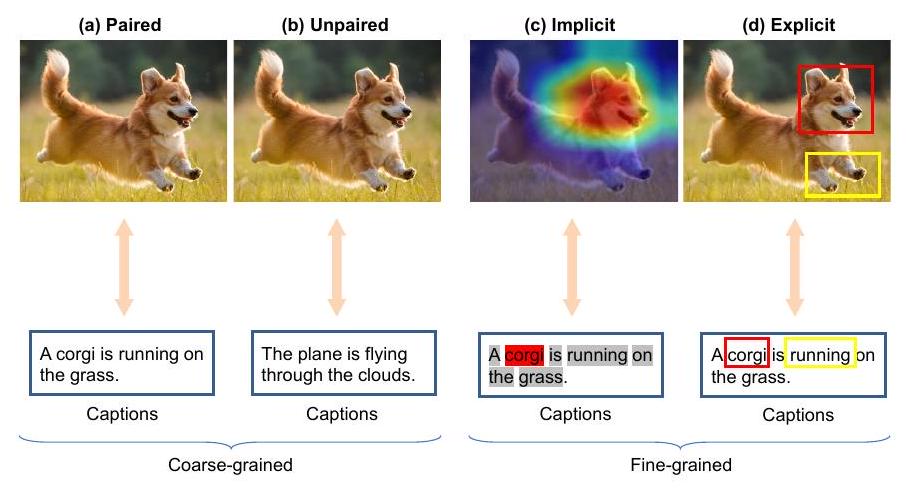
Fig. 6. (a) 조밀한 쌍을 이룬 입력, (b) 조밀한 쌍을 이루지 않은 입력, (c) 세밀한 암시적 정렬, (d) 세밀한 명시적 정렬의 그림. 쌍을 이룬 데이터는 양식이 동기적으로 기록되는 경우(예: 비디오 클립의 오디오 및 비디오 양식)에 자연적으로 발생하지만, 다른 경우(예: 웹 이미지의 alt 텍스트 태그)에도 우연히 생성될 수 있습니다. 그러나 데이터 페어링은 두 경우 모두 잡음이 있을 수 있습니다. 예를 들어, 오디오-비디오와 같은 자연적으로 쌍을 이룬 데이터에서 화자는 물리적으로 시연하기 전에 주제에 대해 논의하거나 보이는 행동을 설명하는 것을 소홀히 할 수 있습니다. 유사하게, 웹에서 수집한 이미지-텍스트 쌍에서 텍스트는 이미지 내용의 일부만 다룰 수 있습니다.
잡음이 있는 쌍이 발생할 수 있는 비디오로부터 표현을 학습하기 위해, 시각, 오디오 또는 텍스트 모달리티 간의 시간적 정렬을 다른 전략을 사용하여 활용하는 방법이 개발되었습니다. 예를 들어, 부정적인 쌍은 다른 비디오 [22], [45], [58]에서, 동일한 비디오이지만 다른 프레임의 모달리티를 사용하여 [59], 또는 여러 개의 올바른 긍정적인 쌍을 선택하면서 잘못된 것을 경감하여 [123] 선택할 수 있습니다. 이미지-텍스트 쌍은 캡션이 이미지에서 수동으로 생성되어야 하기 때문에 특별한 경우입니다. 그러나 많은 양의 잡음이 있는 이미지-텍스트 쌍을 인터넷에서 쉽게 수집할 수 있기 때문에, 연구원들은 잡음이 있는 쌍을 이룬 데이터로도 섹션 3에 설명된 다양한 목표를 사용하여 유망한 결과를 얻었습니다(예: [21], [29], [52], [67]).
Discussion. 멀티모달 학습에서 대략적으로 쌍을 이룬 데이터를 사용하는 것은 알려진 페어링을 가정하는 간단한 pretext task의 이점을 누릴 수 있지만, 이러한 정렬 노이즈가 궁극적으로 이러한 모델의 효능을 제한하는지는 아직 밝혀지지 않았습니다. 더욱이, 많은 영역에서 쌍을 이룬 데이터를 얻는 것은 여전히 병목 현상입니다. 예를 들어, 의료 분야에서는 개인 정보 보호 문제로 인해 쌍을 이룬 데이터를 얻는 것이 불가능할 수 있습니다. 상당한 양의 쌍을 이룬 데이터가 존재하는 이미지-텍스트 설정에서도, 쌍을 이루지 않은 이미지와 텍스트의 양은 쌍을 이룬 예의 양을 훨씬 능가합니다. 따라서 데이터의 일부 또는 전체가 쌍을 이루지 않은 경우 학습할 수 있는 방법을 개발하는 것이 바람직합니다.
5.1.2 Unpaired
비쌍(unpaired) 학습은 잘 정렬된 멀티모달 데이터 쌍에 대한 의존도를 줄이고 대규모 단일모달 데이터 코퍼스를 멀티모달 학습에 직접 활용하는 것을 목표로 합니다. 비쌍 멀티모달 알고리즘의 핵심 목표는 정렬되지 않은 데이터에서 정렬을 유도하는 방법을 찾는 것입니다. 기존 접근 방식은 주로 두 가지 방식으로 이를 달성합니다: (1) 외부 모델 사용, 또는 (2) 사이클 일관성(cycle-consistency) 강제.
외부 모델은 종종 한 양식의 인스턴스를 다른 양식의 유사한 인스턴스와 연결할 수 있는 개념을 감지하는 데 사용되어, 멀티모달 학습을 위한 추가적인 감독을 제공하기 위해 잡음이 있는 조밀한(coarse-grained) 쌍을 만듭니다. 개념 탐지기라고도 하는 객체 탐지기는 종종 영역 특징과 객체 태그를 추출하여 시각 및 언어 데이터를 정렬하는 데 사용됩니다. 예를 들어, U-VisualBERT [124], VLMixer [103] 및 -VLA [125]는 객체 탐지기를 활용하여 이미지에서 객체 태그를 추출한 다음 개념 단어로 텍스트에 연결합니다. 장면 그래프 탐지기와 같은 다른 도구도 상호 관계를 추출하는 데 사용되었습니다. 예를 들어, Graph-Align [126]은 텍스트와 이미지 모두에서 장면 그래프를 추출하여 비지도 이미지 캡셔닝을 가능하게 합니다. 명시적으로 세밀한(fine-grained) 페어링을 추출하기 위한 외부 모델 사용에 대해서는 섹션 5.2.2.2에서 자세히 논의합니다.
주기 일관성(cycle consistency) [127]을 강제하는 것은 다른 양식의 표현을 정렬하는 또 다른 접근 방식입니다. 멀티모달 맥락에서, 두 양식 A와 B를 고려할 때, 우리는 매핑 와 를 학습하고자 합니다. 주기 일관성의 개념은 이러한 매핑이 서로의 역이어야 하고 두 매핑 모두 전단사 함수여야 한다는 직관을 인코딩합니다. 구체적으로, 주기 일관성 손실은 를 장려하고 그 반대도 마찬가지입니다. DM2C [128]는 먼저 단일 모달 데이터에서 사전 훈련된 특수 모달 간 자동 인코더를 사용하여 잠재 표현의 쌍을 이루지 않은 교차 모달 매핑을 학습하기 위해 주기 일관성을 활용합니다. MACK [129]는 공개적으로 사용 가능한 데이터셋에서 개념 단어 집합과 관련 이미지 영역을 수집한 다음, 사전 훈련된 일반 지식을 얻기 위해 프로토타입 영역 표현을 계산합니다. 특정 데이터셋에 대해 모델을 추가로 미세 조정하기 위해 영역 수준 주기 일관성 손실을 적용할 수 있습니다. 유사하게, Graph-Align [126]도 모달리티 정렬을 위해 이 손실을 채택합니다.
Discussion. 쌍을 이루지 않은 멀티모달 데이터로 학습하는 것은 대규모 단일 모달 데이터 코퍼스를 사용할 수 있게 하므로 도전적이지만 실용적인 가치가 큽니다. 최근 몇 년 동안 점점 더 많은 관심을 받고 있지만 아직 미성숙합니다. 외부 사전 훈련된 모델에 의존하는 접근 방식은 외부 모델의 품질에 의해 제한되며, 이는 사용되는 특정 작업이나 데이터셋에 잘 일반화되지 않을 수 있습니다. 또한 외부 모델은 관심 있는 모든 개념이나 도메인을 다루는 사전 훈련된 모델이 존재하지 않을 수 있으므로 일반성과 확장성을 제한합니다. 한편, 주기 일관성 손실은 일반적으로 디코더와 같은 추가 모델 구성 요소를 필요로 합니다. 이는 모델에 추가적인 복잡성을 더하고 필요한 계산량을 증가시킵니다.
5.1.3 Mixed
쌍을 이룬 데이터와 쌍을 이루지 않은 멀티모달 데이터를 혼합하여 훈련하는 것은 종종 가장 현실적인 시나리오입니다. 왜냐하면 이는 종종 약간의 쌍을 이룬 데이터와 더 많은 양의 쌍을 이루지 않은 데이터를 사용할 수 있다는 현실을 반영하기 때문입니다. 혼합 페어링 데이터를 처리하는 방법은 일반적으로 쌍을 이루지 않은 데이터에 대해 별도의 pretext task를 적용하고 다중 작업 방식으로 쌍을 이룬 입력에 대해 쌍을 이룬 데이터 pretext task를 적용합니다.
마스크 예측은 유연성으로 인해 혼합 페어링 데이터를 처리하는 데 널리 사용됩니다. VATLM [130]은 텍스트에 대한 모달리티 내 마스크 예측과 시각-오디오-텍스트 쌍의 조합에서 멀티모달 마스크 예측을 사용하여 통합 마스크 예측 목표를 사용합니다. BEiT-3 [29]는 이미지, 텍스트 및 이미지-텍스트 쌍에 대해 마스크된 데이터 모델링을 수행하여 다중 방식 transformer를 사전 훈련합니다.
클러스터링 방법도 활용되었습니다. 예를 들어, u-HuBERT [81]는 별도의 오디오 및 비디오 인코더를 채택하고, 융합 모듈에 의해 연결된 후 마스킹된 입력 프레임의 클러스터 할당을 예측합니다. 만약 어떤 모달리티가 누락된 경우, 더미 연결(즉, 0을 추가하여)이 수행되고, 동일한 목적 함수가 평소와 같이 사용될 수 있습니다.
쌍을 이룬 데이터와 쌍을 이루지 않은 데이터에 대해 서로 다른 목표를 사용하는 측면에서, VideoBERT [85]는 통합 아키텍처를 특징으로 하며 텍스트 전용 및 비디오 전용 데이터 모두에 대해 마스크 예측을 수행합니다. 쌍을 이룬 데이터를 사용할 수 있는 경우, 교차 모달 대응을 학습하기 위해 매칭 예측을 활용합니다. FLAVA [68]는 이미지 전용 및 텍스트 전용 데이터에 대해 마스크된 이미지 모델링 및 마스크된 언어 모델링을 사용하고, 쌍을 이룬 데이터에 대해 마스크된 멀티모달 모델링 및 대조 학습을 사용합니다. UNIMO [92]는 이미지 전용 데이터에 대해 마스크된 이미지 모델링을 적용하고, 텍스트 전용 데이터에 대해 AE 기반 및 AR 기반 마스크 예측을 모두 적용합니다. 이는 단일 모달 및 멀티모달 데이터를 모두 활용하여 교차 모달 대조 학습을 위한 긍정적인 쌍으로 유사한 단일 모달 샘플을 검색합니다. VLMO [95]는 마스크 예측을 사용하여 이미지 전용 및 텍스트 전용 모달리티 전문가를 훈련하는 것으로 시작하여 이미지-텍스트 쌍에 대한 인스턴스 판별을 수행하는 단계적 훈련 접근 방식을 채택합니다. 특히, SkillNet [106]은 5가지 다른 모달리티에 대해 전문가 혼합을 활용하며, 대조 학습을 사용하여 쌍을 이룬 이미지-텍스트 및 비디오-텍스트에서 훈련될 수 있으며, 클러스터링 및 마스크 예측을 사용하여 쌍을 이루지 않은 사운드 및 코드에서 훈련될 수 있습니다.
Discussion. 혼합 쌍 학습 방법은 쉽게 구할 수 있는 단일 모달 데이터셋을 효과적으로 활용하여 확장성을 향상시키고 결과적으로 더 나은 다운스트림 성능을 이끌어낼 수 있습니다. 그러나 몇 가지 한계가 존재합니다. 예를 들어, 단일 모달 데이터의 양이 불균형하면 훈련된 모델은 다른 다운스트림 작업에서 불균형한 성능을 겪거나 특정 모달리티에 과적합될 수 있습니다.
5.2 Fine-grained
이전 하위 섹션에서는 감독으로서의 제한된 조밀한(coarse-grained) 페어링을 다루었습니다. 이 하위 섹션에서는 조밀한 감독(그림 6(a))으로부터 세밀한(fine-grained) 멀티모달 정렬(그림 6(c,d))을 유도하는 기술에 대해 논의합니다. 우리는 각 모달리티 내의 하위 요소 또는 토큰 간의 이산적인 접지 또는 대응을 추론하는 명시적 정렬 방법(그림 6(d))과 각 모달리티의 토큰 간의 부드러운 연관성을 추론하는 암시적 정렬 방법(그림 6(c))을 구별합니다.
여기에서는 세분화된 정렬에 대한 일반적인 공식화를 제시합니다. 각 인스턴스에 대해, 각 양식 에서 세분화된 요소(임베딩/토큰/패치) 집합 가 있다고 가정합니다. 여기서 은 요소의 수입니다. 명확성을 위해, 요소의 수는 다른 양식에 대해 동일하다고 가정합니다. 양식 와 에 대해, 세분화된 정렬은 에 대한 순열 함수 를 찾는 것을 시도하며, 이를 통해 의 요소가 의 임베딩과 정렬됩니다. 우리는 해당 순열 행렬을 로 쓸 수 있습니다. 암시적 및 명시적 정렬은 에 부과된 제약 조건에 해당합니다. 암시적 정렬의 경우, 우리는 및 을 가지며, 여기서 은 모두 1인 차원 벡터입니다. 다중 인스턴스 학습을 통한 명시적 정렬의 경우, 우리는 및 이라는 이산적인 대응을 강제합니다. 는 양식 의 토큰 가 양식 의 토큰 에 해당하면 1로 설정되고, 그렇지 않으면 0으로 설정됩니다(값은 암시적의 경우 연속적이고 명시적의 경우 이산적임). 요소의 수가 양식에 따라 다를 때, 순열 행렬의 제약 조건은 완화됩니다. 대부분의 세분화된 정렬 방법은 다음 형식의 손실을 최적화하는 것에 해당합니다: 와 를 생성하는 표현 매개변수에 대해, 그리고 여기서 은 L2-norm과 같은 거리를 측정하는 함수입니다. I.E: 동시 대응 및 표현 학습.
5.2.1 Implicit
암시적 정렬은 종종 임베딩 공간에서 교차 모달 연결을 강제함으로써 달성됩니다. 교차 모달 주의(cross-modal attention)와 최적 수송(optimal transport)은 이러한 연결을 달성하기 위해 일반적으로 사용되는 두 가지 기술입니다 (즉, 순열 함수의 실현).
Self-attention은 입력 집합의 요소들이 상호 작용할 수 있도록 하는 강력한 메커니즘입니다 [110]. 멀티모달 학습에서, self-attention은 cross-attention으로 확장되며, 추론된 어텐션 맵은 모달리티 간의 세분화된 대응을 유도합니다. LLA-CMA의 [131] 공동 어텐션 모듈은 오디오 유도 어텐션과 시각 유도 어텐션으로 구성되어 모델이 시청각 동시 발생을 활용할 수 있도록 합니다. ViLBERT [66]는 이미지와 텍스트 모달리티 모두에 대해 어텐션 풀링된 특징을 생성하기 위해 공동 어텐션 레이어를 도입하여, 그들 사이의 희소한 상호 작용을 가능하게 합니다. 유사하게, 공동 어텐션은 FLAVA [68]와 SelfDoc [86]에서도 모달 간 관계를 밝히는 데 사용됩니다.
Cross-attention은 또한 전역-지역 상호작용을 모델링할 수 있습니다. 예를 들어, ActBERT [88]는 원래의 키-값 쌍을 다른 양식의 값과 쌓음으로써 디자인에 추가적인 전역-지역 대응을 통합하여, 공동 비디오-텍스트 표현이 세밀한 객체와 전역 정보를 모두 인식하도록 보장합니다. COOT [132]는 지역 표현을 키-값 쌍으로, 전역 표현을 쿼리로 입력함으로써 지역 특징(클립/단어)과 전역 컨텍스트(프레임/문장) 간의 상호작용에 대해 표현을 최적화합니다.
교차 모달 어텐션은 한 양식이 다른 양식에 주목하지만 그 반대는 아닌 방향성 있는 방식으로 수행될 수도 있습니다. 이 접근 방식은 일부 양식은 더 복잡한 모델링이 필요한 반면 다른 양식은 더 얕은 모델로 적절하게 인코딩될 수 있다는 생각으로 설계되었습니다. 예를 들어, ALBEF [69]는 단일 모달 텍스트 표현을 정렬하기 위해 이미지 표현을 멀티모달 인코더에 융합합니다. 유사하게, BLIP [67]는 이미지 기반 텍스트 인코더와 디코더를 사용하여 교차 어텐션을 통해 시각적 표현을 텍스트와 융합합니다.
최근의 방법들인 [29], [95]는 전문가 혼합(mixture of experts)에 의해 인코딩된 다른 양식에 대해 공유된 self-attention을 사용합니다. 명시적으로 연구되지는 않았지만, 공유된 self-attention 가중치는 다른 양식들 사이에 연결을 설정할 잠재력을 가지고 있습니다. 양식들 사이의 세밀한 정렬을 보여주기 위해, Oscar [101], UNITER [65], Hero [133], 그리고 -VLA [125]와 같은 여러 방법들이 학습된 어텐션 가중치를 시각화했습니다. 그들은 어텐션이 단어를 이미지 영역에 매핑하는 것과 같은 교차 모달 정렬을 학습할 수 있음을 보여줍니다.
최적 수송(Optimal transport, OT) [134], [135]은 확률 측정 간의 거리를 정의하며, 교차 도메인 세분화 정렬에도 사용됩니다. 교차 도메인 정렬을 위한 OT는 한 분포를 다른 분포로 변환하는 비용을 최소화하여 분포를 일치시키는 것을 목표로 합니다. UNITER [65]는 이미지 영역에서 문장의 단어로 (그리고 그 반대로) 표현을 수송하는 비용을 최소화하기 위해 OT를 사용하여 교차 모달 정렬을 개선합니다. 최적 수송을 위한 빠른 부정확 근사점 방법(IPOT) [136]은 다루기 힘든 계산의 어려움을 극복하기 위해 OT 거리를 근사하는 데 사용됩니다. 유사하게, ViLT [28]는 UNITER [65]와 달리 외부 모델에 의해 추출되지 않은 텍스트 하위 집합과 시각적 하위 집합을 정렬하기 위해 이 접근 방식을 채택합니다.
정준 상관 분석(Canonical correlation analysis, CCA) [137]은 두 변수 집합 간의 선형 관계를 찾는 고전적인 접근 방식이며, 직교성을 보장합니다. 그 목적은 다른 양식의 표현의 해당 차원 간의 상관 관계를 최대화하는 것입니다. CCA의 심층 확장 [138], [139]이 존재하고 미세 오디오-시각 상관 관계 [140]와 같은 작업에 적용되었지만, 전반적으로 SSML에서 널리 사용되지는 않았습니다.
5.2.2 Explicit
암시적 정렬과는 대조적으로, 명시적 정렬을 도입하기 위한 방법들도 개발되었습니다. 명시적 세분화 페어링은 이미지의 객체와 문장의 단어와 같이 인스턴스의 더 작고 더 구체적인 구성 요소 간의 대응을 의미합니다. 이러한 유형의 대응은 외부 모델이나 다중 인스턴스 학습을 통해 도입될 수 있습니다.
5.2.2.1 Multi-instance Learning
암시적 대응과는 대조적으로, 명시적 정렬 기반 방법은 보통 현저성 탐지와 같은 다른 프로세스의 결과로 생성되는 미세한 요소 를 사용합니다. 다중 인스턴스 학습(Multiple Instance Learning, MIL) [141]은 양식 간에 요소들 사이에 일대다 대응이 있는 명시적 정렬에 일반적으로 사용되는 접근 방식입니다. 음원을 국지화하기 위해 AVOLNet [58]은 공간 그리드에서 지역 영역 수준 이미지 설명자를 추출한 다음 오디오 임베딩과 각 비전 설명자 간의 유사도 점수를 계산합니다. 최대 유사도 점수는 네트워크를 훈련시키기 위한 이미지-오디오 일치 측정, 즉 대응 점수로 사용됩니다. 이 접근 방식은 하나의 이미지 영역이 해당 오디오에 높게 반응하도록 장려하여 객체를 국지화합니다. DMC [79]는 특징 맵의 요소들이 동일한 단일 모달 구성 요소에 대해 유사한 활성화 확률을 갖는다는 가정에 기초하여 오디오 및 시각 양식 간의 유사한 특징 벡터를 집계하여 시청각 엔티티를 추출할 것을 제안합니다. 따라서, 그것은 단일 모달 특징 벡터를 객체 수준 표현으로 클러스터링하고 시청각 환경에서 정렬합니다.
명시적 정렬 방법은 암시적 대응 방법보다 덜 일반적으로 연구되지만, 학습된 대응의 해석 가능성이 더 크다는 이점이 있습니다. 그러나 대응을 위한 집합 를 생성하는 데 사용되는 프로세스와 대응 가정(일대일, 일대다 등)의 타당성에 민감합니다.
5.2.2.2 External Models
명시적인 세분화된 입력 페어링은 모델이 다른 양식 간의 상세한 관계를 학습하는 데 도움이 될 수 있습니다. 이 설문조사에서는 SSML 방법을 수동 주석이 필요하지 않은 방법으로 정의합니다. 따라서 이러한 방법은 외부 모델이 감독을 사용하여 데이터셋에서 훈련될 수 있으므로 엄밀히 말해 자기 지도(self-supervised)로 간주되지 않을 수 있습니다. 그러나 오픈 소스 커뮤니티를 통해 쉽게 접근할 수 있고 완전성을 위해 포함되었습니다.
시각 데이터의 경우, 객체 탐지기(예: Faster R-CNN [142])는 관심 영역(ROI)과 객체 클래스를 추출하는 데 자주 사용됩니다. 그런 다음 다른 모달리티의 해당 부분과 정렬하는 데 사용될 수 있습니다. 이미지-텍스트 사전 훈련의 경우, 추출된 ROI는 단어-영역 정렬 [65], [66], [92], [103], [143], 마스크된 객체 분류 [143], [144], 특징 회귀 [145]에 사용될 수 있습니다. 또한 설정된 프레임 속도로 모든 정지 프레임에서 비디오의 ROI를 추출하는 데 사용될 수도 있습니다. 예: ActBERT [88]. 문서 이해의 경우, SelfDoc [86]은 문서 객체 제안을 추출하고 OCR을 적용하여 각 제안에 대한 단어를 얻습니다.
객체 탐지기는 쌍을 이루지 않은 데이터를 정렬하는 데에도 사용될 수 있습니다. 잡음이 있는 정렬을 달성하기 위해, U-VisualBERT [124]는 사전 훈련된 탐지기를 사용하여 이미지에서 객체 태그를 추출하고, 이를 공간 좌표와 함께 토큰 임베딩에 추가합니다. 그런 다음 탐지된 태그에도 마스크된 예측 목표가 적용되어 재구성을 통해 잡음이 있는 접지 신호를 제공합니다. VLMixer [103]는 문장에서 일부 개념 단어를 무작위로 지우고 탐지기에 의해 생성된 동일한 개념 레이블을 가진 시각적 패치를 붙여 혼합된 문장을 얻을 것을 제안하며, 이는 원래 문장의 교차 모달 표현 역할을 합니다. 그런 다음, 마스크된 언어 모델링과 대조 학습을 사용하여 교차 모달 정렬을 학습합니다. -VLA [125]는 검색 기반 방법으로 이미지-텍스트 코퍼스를 약하게 정렬하고 마스크된 예측, 대조 학습, 탐지된 객체 레이블 분류를 포함한 다중 세분화 정렬 pretext task를 사용합니다.
언어에서 다양한 수준의 특징을 추출하기 위해, 사전 훈련된 의미 분석기는 명시적으로 분해된 의미 공간을 얻는 데 사용됩니다. 예를 들어, UNIMO [92]는 장면 그래프 분석기를 적용하여 객체, 속성 및 관계를 어휘로 수집하고, 이는 다양한 수준에서 텍스트 재작성을 통해 데이터 증강을 돕습니다. 추출된 장면 그래프는 문장을 구문적으로 분석하여 언어 및 이미지 정보를 정렬함으로써 쌍을 이루지 않은 이미지 캡셔닝 [126]과 같은 작업에도 적용될 수 있습니다.
6 Theoretical Considerations
SSML에 대한 현재 연구는 주로 경험적이며, 이론적 분석은 제한적입니다. 특히, 단일 모드 자기 지도 학습을 위해 개발된 많은 저명한 이론적 프레임워크 [71]는 멀티모달 맥락에 직접 적용되지 않습니다. SSML로의 확장이 알려진 몇 안 되는 이론적 프레임워크 중 하나는 정보 병목 원리(IB) [146]입니다. 고전적인 IB는 지도 학습을 정보 이론적 용어로 해석하며, 인코딩과 레이블 Y 간의 MI를 최대화하면서 입력 X와 숨겨진 표현 R 간의 정보를 최소화하는 표현을 학습하는 과정으로 봅니다. 여기서 는 와 사이의 상호 정보를 나타내고, 는 압축과 관련성 사이의 균형을 조절하는 트레이드오프 파라미터입니다. SSML에서 목표는 모달리티별 관련 없는 정보를 압축하면서 모달리티 전반에 걸쳐 관련 공유 정보를 보존하는 것으로 확장됩니다. 를 번째 모달리티, 를 의 잠재 표현, 를 의사 목표라고 가정합시다. 멀티모달 데이터에 대한 IB 목표는 다음과 같이 표현될 수 있습니다: 여기서 는 에 보존된 모달리티 에 대한 정보를 정량화하고, 는 에 대한 의 공동 정보를 측정하며, 와 는 트레이드오프 파라미터입니다.
단일 모드 다중 뷰 SSL [147]과 달리, SSML에는 상당한 모달리티별 정보가 존재하여 모든 관련 정보가 뷰 간에 공유된다는 가정을 위반합니다. 이러한 불일치는 공유 정보와 고유 정보를 모두 처리하도록 IB 프레임워크를 조정할 필요가 있습니다: , 여기서 는 모달리티별 정보와 공유 정보 사이의 균형을 조절하는 트레이드오프 파라미터입니다. 는 다른 모달리티의 표현 간의 상호 정보를 측정합니다. 이 목표는 모델이 모달리티별 세부 사항을 보존하면서 필수적인 공유 정보를 포착하도록 장려하여 학습된 표현의 일반화 가능성을 향상시킵니다.
그러나 SSML의 전반적인 이론적 분석은 여전히 미해결 과제로 남아 있으며, 멀티모달 데이터의 복잡성을 적절하게 해결할 수 있는 포괄적인 이론적 프레임워크를 개발하기 위한 미래 연구에 중요한 기회를 제공합니다.
7 Applications
SSML 알고리즘은 상태 표현 학습, 의료, 원격 감지 및 자율 주행 [148], [149] 및 기계 번역 [150]과 같은 다른 많은 분야를 포함한 실제 시나리오에 널리 적용되었습니다.
7.1 State Representation Learning for Control
상태 표현 학습(SRL)은 환경 관찰 양식과 에이전트의 행동 양식 간의 상호 작용을 포착하는 특별한 유형의 멀티모달 표현 학습입니다. SRL은 작업에 따라 달라질 필요가 없으며 SSML 목표로 해결할 수 있습니다. 학습된 표현은 다운스트림 강화 학습 및 제어 작업에 도움이 되도록 이전될 수 있습니다.
SRL에 대한 일반적인 접근 방식은 마스크 예측입니다. 제어에서 순방향 모델과 역방향 모델 [151], [152]은 자동 회귀 마스크 예측의 특별한 형태로 간주될 수 있습니다. 고전적인 강화 학습 프레임워크 [153]에서 관찰은 원시 센서 정보이고 상태는 행동 선택에 필요한 정보를 포함하는 이 정보의 압축된 묘사입니다. 순방향 모델은 현재 행동 와 현재 관찰 또는 상태 로부터 미래 상태 을 예측하는 반면, 역방향 모델은 관찰 와 또는 상태 와 이 주어졌을 때 행동 를 예측합니다. 관찰되지 않은 상태/행동은 마스크된 것으로 간주될 수 있으며 SRL은 SSML 마스크 예측에 해당합니다. 예를 들어, [154]는 미래의 상태를 예측하는 행동 조건부 비디오 순방향 모델을 제안합니다. 월드 모델 [155]은 과거 시각적 관찰과 행동이 주어졌을 때 미래 표현을 예측하도록 훈련됩니다. 그런 다음 에이전트는 보상을 받기 위해 학습된 표현에만 기초하여 어떤 행동을 취할지 결정합니다. 유사하게, PlaNet [156]은 이미지로부터 환경 동역학을 학습하고 잠재 공간에서 계획을 통해 행동을 선택하며, 여기서 결정론적 및 확률적 전환 구성 요소를 모두 포함하는 동역학 모델은 여러 시간 단계에 대한 보상을 예측하도록 학습합니다. [157]은 로봇이 무작위로 물체를 찌르고 시각적 상태 전후를 기록하여 동역학의 순방향 및 역방향 모델을 추정함으로써 모델을 훈련합니다. 마스크 예측 목표는 인스턴스 판별과 함께 사용될 수도 있습니다. 예를 들어, Contrastive Forward Modeling [158]은 예측과 긍정 사이의 상호 정보를 최대화하기 위해 예측과 긍정 사이의 상호 정보를 최대화하는 대조적 예측 코딩 [159]과 미래 상태 예측을 결합합니다. [160]은 이미지, 힘 및 고유 수용 감각의 표현을 융합한 다음, 각각 자동 인코딩 및 일치 예측을 사용하여 다음 제어 주기의 광학 흐름 및 잠재적인 환경 접촉을 예측하도록 학습할 것을 제안합니다.
7.2 Healthcare
임상의는 종종 진단, 예후 및 치료 계획에서 여러 출처 및 양식의 정보에 의존합니다. 따라서 다양한 데이터에 대한 표현 학습은 정확한 진단과 효과적인 환자 치료에 중요합니다. 의료 영상은 자동 진단에 널리 사용되며, 영상 및 기타 양식을 사용하여 다운스트림 진단을 개선하기 위한 다양한 방법이 제안되었습니다. 예를 들어, ConVIRT [161], GLoRIA [162], CheXzero [163]는 의료 영상 및 의료 보고서에 대한 대조 학습을 채택합니다. MEDCLIP [164]는 이미지와 텍스트를 분리하여 쉽게 사용할 수 있는 이미지 전용 및 텍스트 전용 훈련 데이터를 활용합니다. ContIG [165]는 망막 이미지와 유전 양식을 대조 손실로 정렬합니다. CoMIR [166]은 회전 등분산을 강제하여 대조 손실로 등록을 가능하게 합니다.
7.3 Remote Sensing
원격 감지에서, 다른 센서는 지구 관측을 위한 보완적인 정보를 제공할 수 있으며, 여기에는 초분광 데이터, 다중 분광 데이터, 라이다(LiDAR), 합성 개구 레이더(SAR) 데이터 등이 포함됩니다 [167]. 예를 들어, 초분광 이미지는 스펙트럼 서명을 통해 토지 피복 범주를 포착하는 반면, SAR 이미지는 유전 특성을 제공합니다. 이러한 데이터셋을 통합하는 기술에는 SAR 및 광학 이미지에 대한 대조 손실 사용 [168]과 다중 분광 및 SAR 데이터에 대한 마스크 예측 [169]이 포함됩니다. 피해 평가와 같은 분야에 중요한 변화 탐지는 다른 센서의 이중 시간 장면을 분석하기 위해 대조 학습과 클러스터링을 사용하는 방법 등을 사용합니다 [170]. 또한, 지리 태그가 지정된 오디오 녹음은 대조 학습을 통해 이미지 데이터와의 대응 관계를 설정하는 데 사용됩니다 [171].
8 Challenges and Future Directions
Scaling. 자기 지도(self-supervision)의 가장 매력적인 속성 중 하나는 확장성입니다. 대규모 언어 모델(LLM) [121], [172]의 발전은 자기 지도를 통해 훈련된 멀티모달 LLM의 확장을 더욱 장려했습니다 [173]. 목표와 관련하여, 자동 회귀 접근 방식은 다음 멀티모달 "단어"를 예측함으로써 대규모 멀티모달 모델을 훈련하는 데 효과적임을 입증했습니다 [174], [175], [176]. 통합된 목표는 또한 확장이 용이합니다. 모달리티 융합 측면에서, "stitching" 기술은 사전 훈련된 단일 모달 모델을 활용하고, 이후 멀티모달 훈련으로 향상시켜 자원 요구 사항을 줄이면서 더 큰 멀티모달 모델을 효율적으로 확장합니다. 특정 기술은 미해결 과제로 남아 있지만, 스티칭과 자동 회귀는 더 큰 멀티모달 모델을 확장하기 위한 인기 있는 레시피 역할을 합니다.
Resources. SSML의 주요 과제는 높은 계산 요구 사항과 대규모의 공개적으로 사용 가능한 데이터셋에 대한 제한된 접근을 포함합니다. 수십억 개의 매개변수를 가진 모델을 훈련하려면 방대한 양의 데이터가 필요하며, LAION [177]과 같은 노력이 존재하지만 공개 데이터셋의 부족은 독점 데이터가 없는 조직을 방해하여 AI의 비민주화 위험을 초래합니다 [178]. SSML 훈련 효율성을 향상시키기 위한 노력에는 마스킹된 토큰 삭제 [53] 및 분리된 그래디언트 누적 [179]이 포함됩니다. 모달리티 간의 매개변수 공유 [85], [143], [180] 및 전문가 혼합을 통한 주의 가중치 공유 [29], [95]도 매개변수 수를 줄이는 데 도움이 됩니다. 계산 자원을 줄이기 위해 데이터 및 모델 가지치기 기술 [181], [182]과 기존 쌍 데이터의 더 나은 활용 [183]을 적용할 수 있습니다. 그러나 최첨단 성능과 효율성의 균형을 맞추는 것은 미해결 문제로 남아 있습니다.
Data Acquisition and Noise. 웹에서 수집한 데이터와 같은 "무료 레이블"에 의존하기 때문에, 많은 SSML 방법들은 실제로는 잡음이 있는 쌍을 이룬 샘플로 훈련되며, 이는 단일 모드 데이터에 비해 독특한 과제입니다. 잡음이 있는 레이블로부터 학습하는 것과 관련하여 [184], [185], 훈련 데이터 크기와 품질을 절충하기 위해 좋은 표현을 학습하면서 얼마나 많은 잡음을 허용할 수 있는지 연구하는 것이 중요합니다. 현재 방법들은 많은 수의 잡음이 있는 쌍으로 확장하거나 [51] 잡음이 있는 데이터셋으로부터 고품질 데이터 쌍을 부트스트래핑하는 것을 탐구했습니다 [67]. 그러나 많은 방법에서 데이터 필터링 단계는 기계 학습 과정의 일부로 명시적으로 논의되지 않습니다. 우리는 데이터 수집 및 필터링 절차가 최종 성능에 결정적인 영향을 미칠 수 있으므로 신경망 아키텍처 및 목표와 마찬가지로 연구 및 보급을 위한 일급 알고리즘으로 간주되어야 한다고 권장합니다. 마지막으로, SSML을 포함한 생성 모델의 출력이 인터넷에 공유됨에 따라, 이러한 모델의 향후 반복은 인공적으로 생성된 데이터로 훈련될 가능성이 있으며, 이는 성능에 해로울 수 있습니다. 이러한 피드백 주기가 데이터셋에 미치는 영향은 아직 이해되지 않았습니다.
Unpaired, Mixed, and Interleaved Data. 쌍을 이루지 않았거나 혼합 페어링된 데이터를 모델링하는 것은 추가적인 대응 모호성으로 인해 여전히 어렵습니다. 일부 방법은 객체 탐지기를 사용하여 문장과의 정렬을 위해 객체 태그를 추출하는 것과 같이 [92], [103], [125], [164] 다른 양식 간의 연결을 만들기 위해 외부 모델에 의존합니다. 그러나 이러한 접근 방식은 사전 훈련된 모델의 품질에 의존합니다. 또한, 쌍을 이루지 않은 양식 간에 중복되는 의미적 내용이 있다는 가정에 의존하며, 이는 각 양식이 독립적으로 샘플링되는 모델의 적용 가능성을 제한할 수 있습니다. 완전히 제한되지 않거나 선별되지 않은 경우는 이전 연구에서 적절하게 연구되지 않은 어려운 문제로 남아 있는 반면, 쌍을 이루지 않은 모델이 다양한 수준의 기본 대응에 얼마나 견고한지 정량화하는 것이 중요합니다. 또한, 현재 쌍을 이루지 않았거나 혼합된 방법은 일반적으로 각 양식의 샘플 수가 비교적 균형 잡힌 데이터셋에서 훈련됩니다. 그러나 실제로는 불균형 데이터셋이 더 일반적이므로 불균형 훈련 샘플에 대한 민감도를 평가하고 이 문제를 해결하기 위한 새로운 방법을 개발하는 것이 중요합니다. 또한, 이미지와 텍스트가 있는 웹 페이지와 같이 임의로 인터리브된 데이터는 SSML에 귀중한 기회를 제공합니다. 이러한 자연적으로 동시 발생하는 멀티모달 예제는 풍부하고 쉽게 얻을 수 있으며, 양식 간의 다양한 문맥적 연관성을 제공하여 성능을 상당히 향상시킬 수 있습니다 [120]. 그러나 이러한 형태의 데이터는 비교적 덜 탐구되었습니다. 향후 노력은 더 많은 인터리브된 멀티모달 데이터셋을 만들고 잠재력을 실현하기 위한 새로운 방법론을 고안하는 것을 고려해야 합니다.
Robustness and Fairness. SSML 모델이 더 널리 사용됨에 따라 배포 전에 신뢰성을 보장하는 것이 중요합니다. 그러나 최첨단 모델은 이 점에서 여전히 제한적입니다. 예를 들어, 비전-언어 모델은 구성적 이해가 제한적이며 "뒤에"와 같은 간단한 개념에 어려움을 겪는 것으로 나타났습니다 [186]. 견고성의 또 다른 중요한 과제는 추론 시 임의의 조합의 양식이 추가되거나 제거될 때 안정적인 성능을 유지하는 것입니다. SSL은 견고한 멀티모달 표현을 향상시키는 데 유망한 것으로 나타났습니다 [187]. 또한 생성 모델의 공정성 문제에 대한 관심이 증가하고 있음에도 불구하고 [188] 차별적인 SSML 모델은 편향에 면역이 아닙니다. 예를 들어, 멀티모달 데이터 [191], 모델 아키텍처 및 목적 함수 [192]에서 편향을 집계하여 성별 [189] 또는 인종 [190]에 기반한 편향을 나타내는 것으로 밝혀졌습니다. 편향의 원인을 식별하고 제거하기 위한 향후 연구가 필요합니다.
Unification. SSML의 통합 추세는 아키텍처, 목적 함수, 작업이라는 세 가지 주요 축에 걸쳐 나타났습니다. 첫 번째 측면인 아키텍처 통합은 모든 입력 양식을 처리하기 위해 특정 양식 인코더(예: 언어를 인코딩하는 비전 모델 [193])를 사용하거나 여러 양식을 인코딩하도록 특별히 설계된 아키텍처를 사용하는 것을 포함합니다 [106], [194]. 이 통합은 효율성을 높여 다양한 양식에 대응할 수 있는 적응형 아키텍처를 용이하게 합니다. 유사하게, data2vec [195] 및 BEiT-v3 [29]와 같은 접근 방식에서 볼 수 있듯이 사전 훈련 목표를 공통 목표로 통합하면 양식의 통합이 더 쉬워졌습니다. 다른 양식에 걸쳐 공통 목표를 사용함으로써 학습 프로세스가 더욱 간소화되고 단백질에 대한 언어 모델 [196]과 같이 광범위한 데이터 유형에 더 간단하게 적응할 수 있습니다. 마지막으로, SSML의 통합은 다양한 작업을 일관된 형태로 제시하는 것을 의미하기도 합니다. 예를 들어, 이미지 분류, 분할 및 탐지는 텍스트 생성으로 통합될 수 있습니다. 이러한 작업의 조화는 이전에 보지 못한 작업에 대한 제로샷 성능을 허용하여 다양한 도메인에서 멀티모달 모델의 일반화 가능성을 현저하게 향상시킵니다.
Emergent Abilities. 대규모 언어 모델은 모델 크기가 특정 규모에 도달했을 때만 특정 작업에 대한 의미 있는 성능을 관찰할 수 있는 창발적 능력을 보입니다 [197]. 그러나 멀티모달 모델의 창발적 능력은 비교적 미개척 상태로 남아 있습니다. SSL은 멀티모달 모델의 확장을 허용하며, 이는 멀티모달 추론과 같은 어려운 작업에서 창발적 능력으로 이어져 우리를 범용 모델에 더 가깝게 만들 수 있습니다. 특히, 창발적 능력은 양식 간에 다르게 나타날 수 있습니다. 예를 들어, 언어 모델은 확장으로부터 상식과 논리 능력을 얻는 것처럼 보이는 반면 [121], 멀티모달 모델은 창발적 제로샷 인식을 보여줄 수 있습니다 [198]. 이러한 속성이 양식 전반에 걸쳐 어떻게 그리고 언제 나타나는지 분석하면 학습된 표현에 대한 통찰력을 제공할 수 있습니다. 또한, 창발적 멀티모달 능력은 양식을 융합하거나 정렬 메커니즘에 고유하게 적합한 모델 아키텍처에서 발생할 수 있습니다. 새로운 능력을 발휘하는 융합 및 정렬 기술을 식별하는 것은 미래의 멀티모달 모델 설계를 뒷받침할 것입니다.
Rethinking Self-supervision in the Multimodal Context and Beyond. SSL의 핵심 매력은 널리 사용 가능한 레이블 없는 데이터를 활용하는 것입니다 [199]. 그러나 이 원칙을 멀티모달 데이터에 적용하는 것은 미해결 질문을 제기합니다. 첫째, 멀티모달 데이터는 SSL 패러다임이 잘 확립된 단일 모드 데이터와 다릅니다. 섹션 2.3에서 논의했듯이, 자유롭게 사용할 수 있는 동시 발생 웹 수집 데이터 쌍을 자기 감독 기준을 충족하는 것으로 간주해야 할까요? 둘째, 특히 대규모 언어 모델과 함께 새로운 패러다임이 등장하고 있으며, 그 출력은 잠재적으로 규모에 따라 무한한 감독 소스를 제공할 수 있습니다. 예를 들어, ChatGPT [200]와 같은 모델에 의해 생성된 텍스트가 수동으로 설계된 템플릿을 고려할 때 유효한 자기 감독 형태로 간주될 수 있을까요? 한편으로, 이러한 출력은 수동으로 제공된 프롬프트 템플릿의 약간을 필요로 합니다. 다른 한편으로, 프롬프트 템플릿의 설계는 웹 데이터 수집을 위한 수동으로 정의된 규칙이나 pretext task의 설계(예: 프롬프트 템플릿: 이미지 캡션 재작성 대 다른 증강을 사용한 대조 학습)와 유사할 수 있습니다. SSML 연구가 진행됨에 따라 "자기 감독"을 구성하는 것에 대한 우리의 이해는 진화할 가능성이 높습니다. SSL의 정신과 목표를 신중하게 고려하는 것은 풍부한 데이터로부터 풍부한 멀티모달 표현을 학습하는 방법을 개발하는 데 중요할 것입니다.
보충 자료에는 (1) 멀티모달 다운스트림 작업 개요와 (2) 표 1-4가 포함되어 있으며, 이는 다양한 목표를 가진 방법 모음과 정렬 및 아키텍처에 대한 정보를 제공합니다. 또한, 방법, 데이터셋 및 구현에 대한 최신 발전 요약을 제공하며, 이는 https://github.com/ys-zong/awesome-self-supervised-multimodal-learning에서 찾을 수 있습니다.
Appendix A
Multimodal Downstream Tasks
A. 1 Vision-Language Downstream Tasks
이 하위 섹션에서는 교차 모달 검색, 시각적 질의응답, 시각적 추론, 캡셔닝을 포함한 인기 있는 비전-언어 다운스트림 작업에 대해 논의합니다. 또한 그림 7에 요약된 성능, 사전 훈련된 데이터셋, 모델 매개변수의 관점에서 최첨단 모델의 개요를 제시합니다.
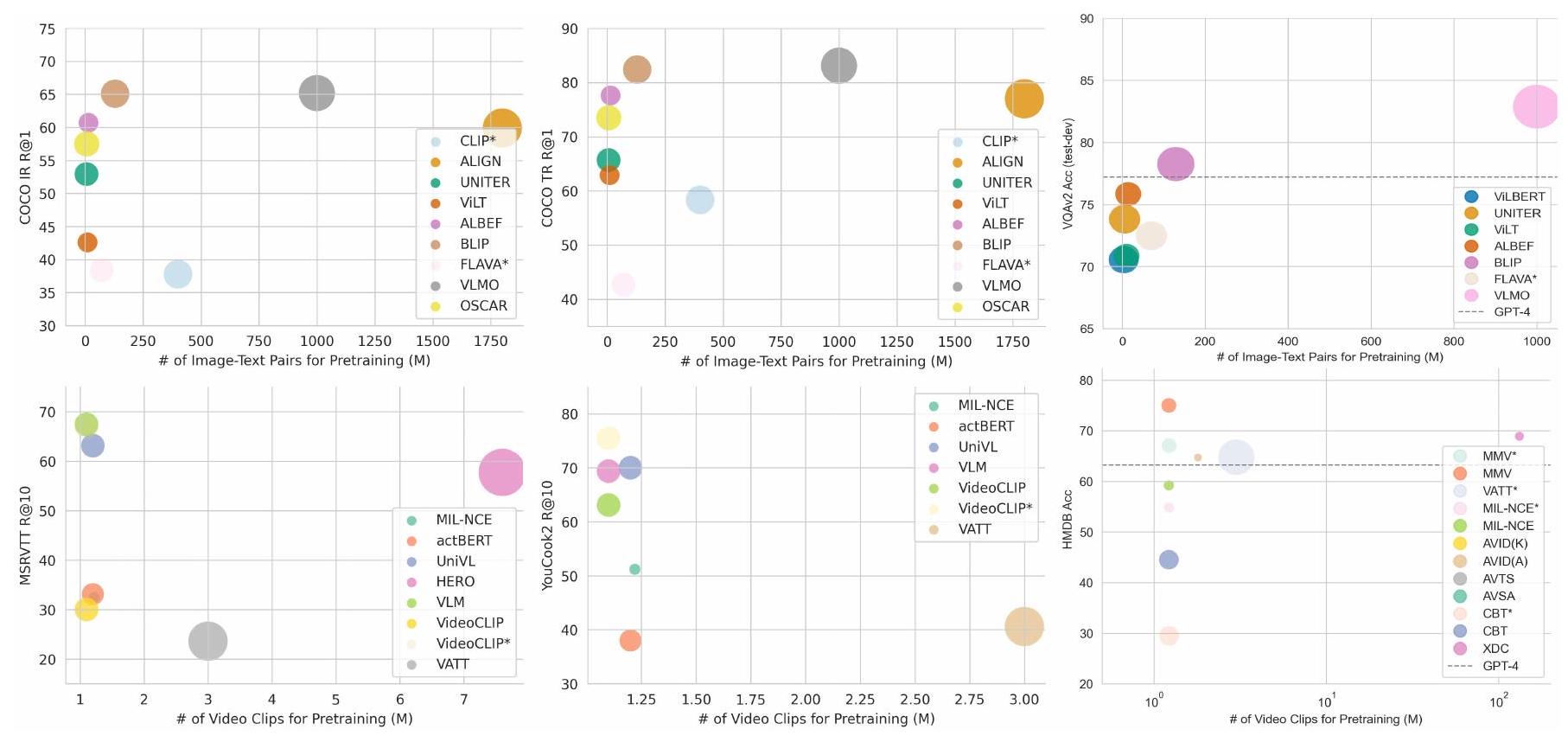
Fig. 7. 다운스트림 작업에 대한 이미지-텍스트 모델 및 멀티모달 비디오 모델의 결과. 각 산점도의 크기는 추정된 모델 매개변수의 수에 해당합니다. 상단 행, COCO 데이터셋에서 텍스트-이미지 및 이미지-텍스트 검색의 recall@1, VQAv2 데이터셋에서 VQA의 정확도. 별표(*)가 있는 방법은 제로샷 성능을 나타내고, 다른 방법은 미세 조정 결과를 보여줍니다. 하단 행, MSRVTT 및 YouCook2 데이터셋에서 비디오 검색의 recall@10, HMDB 데이터셋에서 행동 인식의 정확도. 비디오 검색 작업의 경우 별표는 미세 조정 성능을 나타내고 별표가 없는 방법은 제로샷 성능을 나타냅니다. 행동 인식 작업의 경우 그 반대입니다. VQAv2 및 HMDB 데이터셋에 대한 GPT-4 제로샷 성능도 참고용으로 포함했습니다.
A.1.1 Cross-modal Retrieval
Image-text Retrieval. 이미지-텍스트 검색은 이미지-텍스트와 텍스트-이미지 검색의 두 가지 형태로 이루어질 수 있으며, 이는 각각 이미지와 텍스트를 쿼리 양식으로 사용하는 것에 해당합니다. 성능 측정에 사용되는 평가 지표는 Recall@K이며, K는 일반적으로 1, 5 또는 10으로 설정됩니다. 인기 있는 평가 데이터셋에는 COCO [20]와 Flickr30K [201]가 포함됩니다.
Video-text Retrieval. 비디오-텍스트 검색은 주로 텍스트-비디오 검색에 중점을 두며, 두 가지 하위 작업이 있습니다: (a) 텍스트 쿼리를 기반으로 관련 비디오 검색, 또는 (b) 주어진 비디오 내에서 특정 텍스트 설명과 일치하는 비디오 세그먼트 검색. 두 경우 모두 평가 지표는 recall@K입니다. (a)에 대한 인기 있는 데이터셋에는 MSRVTT [202], YouCook2 [203], MSVD [204] 등이 포함되며, (b)에는 [205], ActivityNet Captions [206] 등이 포함됩니다.
A.1.2 Visual Question Answering and Visual Reasoning
Visual Question Answering (VQA). VQA는 모델이 함께 제공되는 이미지나 비디오를 기반으로 질문에 답해야 합니다. VQA의 두 가지 일반적인 설정은 다음과 같습니다: (a) 모델이 미리 정의된 목록에서 답변을 선택하는 객관식, (b) 모델이 제약 없이 답변을 생성해야 하는 개방형. 그러나 작업을 단순화하기 위해 많은 연구에서 VQA를 분류 작업으로 취급하며, 이는 훈련 세트에서 가장 빈번한 답변을 선택한 다음 답변 후보 세트를 구축하는 것을 포함합니다. 평가 지표는 정확도 또는 VQA 점수 [207]일 수 있습니다. 이미지 VQA에 대한 인기 있는 데이터셋에는 VQAv2 [208], Vizwiz VQA [209], VQA-CP [210] 등이 포함되며, 비디오 VQA에는 TVQA [211], How2QA [133], TGIF-QA [212] 등이 포함됩니다.
Visual Reasoning. 시각적 추론 과제는 공간 추론, 논리적 추론, 상식 지식을 포함한 모델의 고수준 인지 능력을 평가하기 위해 설계되었습니다. VQA와 유사하게 정확도 또는 VQA 점수로 평가됩니다. 인기 있는 데이터셋에는 NLVR [213], GQA [214], VCR [215] 등이 있습니다.
TABLE 1 인스턴스 판별 목표를 가진 알고리즘 목록. 목표(obj.) 열에서 C는 대조적(contrastive)을, M은 일치 예측(matching prediction)을 나타냅니다. CG/FG 페어링은 각각 조밀한(coarse-grained) 및 세밀한(fine-grained) 입력 페어링을 나타냅니다. 양식(Modalities) 열에서 I, V, A, L, PC, K는 각각 이미지, 비디오, 오디오, 언어, 포인트 클라우드, 키포인트를 나타냅니다.
| Method | Obj. | CG/FG Pairing | FG Alignment | Encoder/Decoder | Loss | Modalities |
|---|---|---|---|---|---|---|
| CMC [23] | C | Paired/ | None | Spec.(w/o fus.)/ | InfoNCE | RGB, depth |
| AVTS [43] | C | Paired/ | None | Spec.(w/o fus.)/ | InfoNCE | V, A |
| AVSA [44] | C | Paired/ | None | Spec.(w/o fus.)/ | InfoNCE | V, A |
| StereoCRW [218] | C | Paired/ | None | Spec.(w/o fus.)/ | InfoNCE | V, A |
| CLIP [21] | C | Paired/ | None | Spec.(w/o fus.)/ | InfoNCE | I, L |
| MMV [45] | C | Paired/ | None | Spec.(w/o fus.)/ | NCE + MIL-NCE | V, L, A |
| MIL-NCE [123] | C | Mixed/X | None | Spec.(w/o fus.)/ | MIL-NCE | V, L |
| ALIGN [51] | C | Paired/ | None | Spec.(w/o fus.)/ | Normalized Softmax | I, L |
| VATT [46] | C | Paired/X | None | Unified/ | NCE+MIL-NCE | V, L, A |
| SLIP [54] | C | Paired/X | None | Spec.(w/o fus.)/ | InfoNCE+NT-Xent | I, L |
| COOKIE [219] | C | Paired/ | Implicit | Spec.(late fus.)/ | InfoNCE | I, L |
| CrossCLR [55] | C | Paired/ | None | Spec.(late fus.)/ | CrossCLR loss | V, L |
| CrossPoint [56] | C | Paired/ | None | Spec.(w/o fus.)/ | NT-Xent | I, PC |
| CM-CV [220] | C+M | Paired/ | None | Spec.(late fus.)/ | Triplet Loss+CE | I, PC |
| Learnable PIN [221] | C | Paired/ | None | Spec.(w/o fus.)/ | [24] | I, A |
| AVID [57] | C | Paired/ | None | Spec.(w/o fus.)/ | NCE | V, L, A |
| FG-MMSSL [222] | C | Paired/ | Implicit | Spec.(late fus.)/ | MIL-NCE+FG-NCE | V, L, A |
| -Net [22] | M | Paired/ | None | Spec.(late fus.)/ | BCE | V, A |
| AVE-Net [58] | M | Paired/ | Explicit | Spec.(w/o fus.)/ | BCE | V, A |
| Multisensory [59] | M | Paired/ | Explicit | Spec.(late fus.)/ | BCE | V, A |
| LLA-CMA [131] | M | Paired/ | Implicit | Spec.(late fus.)/ | BCE | V, A |
| Sound of Pixels [60] | M | Paired/ | Explicit | Spec.(late fus.)/ | Per-pixel BCE | V, A |
| Sound of motions [63] | M | Paired/ | Explicit | Spec.(late fus.)/ | Per-pixel BCE | V, A |
| Music Gesture [64] | M | Paired/X | Explicit | Spec.(late fus.)/ | Per-pixel BCE | V, A, K |
TABLE 2 클러스터링 목표를 가진 알고리즘 목록. 목표(obj.) 열에서 C는 대조적(contrastive)을, M은 일치 예측(matching prediction)을 나타냅니다. CG/FG 페어링은 각각 조밀한(coarse-grained) 및 세밀한(fine-grained) 입력 페어링을 나타냅니다. 양식(Modalities) 열에서 I, V, A, L은 각각 이미지, 비디오, 오디오, 언어를 나타냅니다.
| Method | CG/FG Pairing | FG Alignment | Encoder/Decoder | Loss | Modalities |
|---|---|---|---|---|---|
| XDC [76] | Paired/X | None | Spec.(w/o fus.) | CE | V, A |
| SeLaVi [77] | Paired/X | None | Spec.(w/o fus.)/ | CE | V, A |
| u-HuBERT [81] | Mixed/x | None | Spec.(late fus.)/ | CE | V, A |
| DMC [79] | Paired/ | Explicit | Spec.(w/o fus.)/ | Max-margin | V, A |
| AV-HuBERT [80] | Paired/X | None | Spec.(late fus.)/ | CE | I, L |
A.1.3 Visual Captioning
캡셔닝(Captioning)은 주어진 이미지나 비디오에 대해 자유 형식의 텍스트 캡션을 생성하는 작업입니다. 평가는 일반적으로 BLEU, METEROR, CIDEr 등과 같은 표준 텍스트 생성 지표를 따릅니다. 이미지 캡셔닝의 경우, 일반적인 데이터셋에는 COCO [20], Vizwiz Caption [216], TextCaps [217] 등이 있습니다. 비디오의 경우, 데이터셋에는 MSRVTT [202], YouCook2 [203], MSVD [204] 등이 있습니다.
Appendix B
Supplementary TablesTABLE 3 마스크 예측 목표를 가진 알고리즘 목록. CG/FG 페어링은 각각 조밀한(coarse-grained) 및 세밀한(fine-grained) 입력 페어링을 나타냅니다. 양식(Modalities) 열에서 I, V, A, L, PC, KG는 각각 이미지, 비디오, 오디오, 언어, 포인트 클라우드, 지식 그래프를 나타냅니다.
| Method | AE/AR | Inter-/intra-MP | CG/FG Pairing | FG Alignment | Encoder/Decoder | Loss | Modalities |
|---|---|---|---|---|---|---|---|
| VideoBERT [85] | AE | Mixed/X | None | Unified/ | CE | V, L | |
| selfDoc [86] | AE | Paired/ | Implicit | Spec.(late fus.)/ | Smooth L1 | I, L | |
| BEiT-3 [29] | AE | Mixed/ | Implicit | Unified/ | CE | I, L | |
| Unified-IO [87] | AE | Mixed/ | None | Unified/ | CE | I, L | |
| VL-BEiT [84] | AE | Mixed/ | Implicit | Unified/ | CE | I, L | |
| VATLM [130] | AE | Mixed/ | None | Spec.(late fus.)/ | CE | V, L, A | |
| MAG [223] | AE/AR | Paired/ | None | Spec.(late fus.)/ | CE | I, L, A | |
| SimVLM [90] | AR | Paired/ | None | Unified/ | PrefixLM | I, L | |
| Pix2struct [224] | AE | Paired/X | Implicit | Unified/ | CE | I, L, HTML | |
| OPT [91] | AE+AR | Paired/ | Implicit | Spec.(late fus.)/ | CE | I, L, A | |
| U-VisualBERT [124] | AE | Unpaired/ | None | Unified/ | CE | I, L | |
| VLM [108] | AE | Mixed/ | None | Unified/ | CE | V, L, A | |
| ERNIE [225] | AE+AR | Paired/ | None | Unified/ | CE | L, KG | |
| Dragon [100] | AE | Paired/ | None | Spec.(late fus.)/ | CE+KG triplet | L, KG |
TABLE 4 하이브리드 목표를 가진 알고리즘 목록. CG/FG 페어링은 각각 조밀한(coarse-grained) 및 세밀한(fine-grained) 입력 페어링을 나타냅니다. 양식(Modalities) 열에서 I, V, A, L, C는 각각 이미지, 비디오, 오디오, 언어, 코드를 나타냅니다.
| Method | Objective | CG/FG Pairing | FG Align. | Encoder/Decoder | Loss | Modalities |
|---|---|---|---|---|---|---|
| MCN [93] | ID(C)+Cluster. | Paired/ | None | Spec.(late fus.)/ | [226]+L2 | V, L, A |
| self-detector [94] | ID(C)+Cluster. | Paired/ | Explicit | Spec.(w/o fus.)/ | NCE+CE | V, L |
| MDA [227] | Cluster.+MP(AE) | Paired/ | None | Spec.(w/o fus.)/ | L2 | I, Pose |
| UNITER [65] | ID(M)+MP(AE) | Paired/ | Implicit | Unified/ | CE+KLD | I, L |
| ViLBERT [66] | ID(M)+MP(AE) | Paired/ | Implicit | Spec.(late fus.)/ | CE+KLD | I, L |
| Oscar [101] | ID(M)+MP(AE) | Paired/ | Implicit | Unified/ | CE | I, L |
| UNIMO [92] | ID(C)+MP(AE+AR) | Mixed/ | None | Unified/ | CE | I, L |
| VLMixer [103] | ID(C)+MP(AE) | Unpaired/ | Implicit | Unified/ | InfoNCE+CE | I, L |
| -VLA [125] | ID(M)+MP(AE) | Unpaired/ | Implicit | Unified/ | CE+L2 | I, L |
| ALBEF [69] | Paired/ | Implicit | Spec.(late fus.)/ | CE+NT-Xent | I, L | |
| FLAVA [68] | Mixed/ | Implicit | Spec.(late fus.)/ | CE+InfoNCE | I, L | |
| VLMO [95] | Mixed/ | Implicit | Unified/ | InfoNCE+CE | I, L | |
| BLIP [67] | ID(C+M)+MP(AR) | Mixed/X | Implicit | Spec.(late fus.)/ | CE+NT-Xent | I, L |
| ActBERT [88] | ID(M)+MP(AE) | Paired/ | Implicit | Unified/ | CE+KLD | V, L |
| UniVL [96] | ID(C)+MP(AE+AR) | Paired/ | Implicit | Spec.(late fus.) | MIL-NCE+CE+NCE | V, L |
| HERO [133] | ID(M)+MP(AE) | Paired/ | Implicit | Spec.(late fus.)/ | CE+L2 | V, L |
| MERLOT Reserve [97] | ID(C)+MP(AE) | Paired/ | None | Unified/ | CE+KLD | V, L, A |
| CAV-MAE [98] | ID(C)+MP(AE) | Paired/ | Implicit | Spec.(late fus.)/ | InfoNCE+L2 | V, A |
| MAViL [99] | ID(C)+MP(AE) | Paired/ | Implicit | Spec.(late fus.) | InfoNCE+L2 | V, A |
| SkillNet [106] | ID(C)+Cluster.+MP(AE) | Mixed/X | Implicit | Unified/ | InfoNCE+CE | V, I, A, L, C |
Footnotes
-
Y.Z., O.M.A., T.H.는 에든버러 대학교 정보학부에 소속되어 있습니다. T.H.는 케임브리지 삼성 AI 연구 센터에도 소속되어 있습니다. 이메일: yongshuo.zong@ed.ac.uk ↩