PRVR: 텍스트 쿼리와 부분적으로만 관련된 영상도 정확하게 찾아내는 비디오 검색
기존의 Text-to-Video Retrieval (T2VR)은 검색 대상 비디오가 텍스트 쿼리와 완전히 관련이 있다고 가정하지만, 실제 비디오는 다양한 내용을 포함하고 있어 쿼리와 부분적으로만 일치하는 경우가 많습니다. 이 논문은 이러한 현실적인 문제를 해결하기 위해 부분 관련 비디오 검색(Partially Relevant Video Retrieval, PRVR)이라는 새로운 태스크를 제안합니다. PRVR 문제를 Multiple Instance Learning (MIL)으로 공식화하고, 비디오를 클립(clip-scale)과 프레임(frame-scale)의 다중 스케일에서 분석하여 부분적 관련성을 판단하는 MS-SL++ (Multi-Scale Similarity Learning) 네트워크를 제안합니다. 이 모델은 거친 수준의 클립 유사도와 세밀한 수준의 프레임 유사도를 함께 학습하여, 쿼리와 관련된 일부 장면만 포함된 긴 비디오도 효과적으로 검색할 수 있습니다. 논문 제목: PRVR: Partially Relevant Video Retrieval
Chen, Xianke, et al. "PRVR: Partially Relevant Video Retrieval." IEEE Transactions on Pattern Analysis and Machine Intelligence (2025).
PRVR: Partially Relevant Video Retrieval
Xianke Chen, Daizong Liu, Xun Yang, Xirong Li, Member, IEEE, Jianfeng Dong, Meng Wang, Fellow, IEEE, Xun Wang, Member, IEEE
Abstract
현재의 **text-to-video retrieval (T2VR)**에서는 검색 대상 비디오들이 적절하게 잘려 있어, 비디오와 ad-hoc 텍스트 쿼리 사이에 자연스러운 대응 관계가 존재한다. 그러나 실제 인터넷이나 소셜 미디어 플랫폼에서 유통되는 비디오들은 상대적으로 짧음에도 불구하고, 일반적으로 내용이 풍부하다는 점에 주목해야 한다. 종종 하나의 비디오 안에 여러 장면/액션/이벤트가 포함되어 있어, 비디오 내용의 일부만이 주어진 쿼리와 관련 있는 더욱 도전적인 T2VR 환경이 조성된다. 본 논문은 이러한 환경에 대한 첫 연구를 제시하며, 이를 **부분 관련 비디오 검색(Partially Relevant Video Retrieval, PRVR)**이라고 명명한다.
비디오가 일반적으로 여러 순간(moment)들로 구성된다는 점을 고려할 때, 주어진 쿼리와 관련된 순간을 포함하고 있다면 해당 비디오는 부분적으로 관련성이 있는 것으로 간주된다. 우리는 PRVR task를 multiple instance learning 문제로 공식화하고, 비디오-쿼리 쌍 간의 부분적 관련성을 결정하기 위해 clip-scale과 frame-scale 유사도를 모두 공동으로 학습하는 Multi-Scale Similarity Learning (MS-SL++) 네트워크를 제안한다. 세 가지 다양한 비디오-텍스트 데이터셋(TVshow Retrieval, ActivityNet-Captions, Charades-STA)에 대한 광범위한 실험은 제안된 방법의 실현 가능성을 입증한다. 소스 코드와 데이터셋은 https://github.com/HuiGuanLab/ms-sl-pp 에서 확인할 수 있다.
Index Terms: Video-Text Retrieval, Cross-Modal Retrieval, Partially Relevant, Video Representation Learning.
1 Introduction
TEXT-to-video retrieval (T2VR) [1], [2], [3]은 멀티미디어 분야에서 인기 있는 task이다. 지난 몇 년간 상당한 발전이 있었음에도 불구하고, 현재 T2VR 방법들 [4], [5], [6], [7], [8], [9]은 검색될 비디오가 주어진 텍스트 쿼리에 대해 완전히 관련성이 있다고 가정한다. 또한, 이들은 단순히 MSVD [10], MSR-VTT [11], VATEX [12]와 같은 비디오 캡셔닝 중심 데이터셋으로 평가를 수행한다. 이러한 데이터셋의 핵심 특징은 비디오가 짧은 길이로 시간적으로 미리 잘려져(pretrimmed) 있으며, 제공된 캡션이 비디오 콘텐츠의 핵심을 잘 설명한다고 가정한다는 점이다. 결과적으로, 주어진 비디오-캡션 쌍에 대해 비디오는 Fig. 1 (a)에 나타난 것처럼 캡션과 완전히 관련되어 있다고 간주된다. 그러나 실제로는 쿼리가 사전에 알려지지 않기 때문에, 미리 잘려진 비디오 클립이 쿼리를 완전히 충족시킬 만큼 충분한 콘텐츠를 포함하지 않을 수 있다. 이는 문헌과 실제 세계 사이의 간극을 시사한다.
이 간극을 메우기 위해 우리는 T2VR의 새로운 하위 task인 **Partially Relevant Video Retrieval (PRVR)**을 제안한다. PRVR은 대규모 untrimmed 비디오 컬렉션에서 부분적으로 관련성이 있는 비디오를 검색하는 것을 목표로 한다. Fig. 1 (b)에 나타난 것처럼, untrimmed 비디오는 쿼리와 관련된 (짧은) 순간을 포함하는 한, 주어진 텍스트 쿼리에 대해 부분적으로 관련성이 있다고 간주된다. 이 비디오는 쿼리와 관련 없는 콘텐츠를 포함할 수도 있다. 관련 순간의 위치와 지속 시간이 모두 알려져 있지 않고, 대상 비디오에 관련 없는 콘텐츠가 존재하기 때문에, PRVR은 현재 T2VR task보다 더 도전적이다.
- X. Chen, X. Wang and J. Dong are with the College of Computer and Information Engineering, Zhejiang Gongshang University, Hangzhou 310035, China. E-mail: cxkxk_@outlook.com, wx@zjgsu.edu.cn, dongjf24@gmail.com
- D. Liu is with the Wangxuan Institute of Computer Technology, Peking University, No. 128, Zhongguancun North Street, Beijing 100871, China. E-mail: dzliu@stu.pku.edu.cn
- X. Yang is with the School of Information Science and Technology, University of Science and Technology of China, Hefei 230026, China. Email: xyang21@ustc.edu.cn
- X. Li is with the Key Lab of Data Engineering and Knowledge Engineering, Renmin University of China, and the AI and Media Computing Lab, School of Information, Renmin University of China, Beijing 100872, China. E-mail: xirong@ruc.edu.cn
- M. Wang is with the School of Computer Science and Information Engineering, Hefei University of Technology, Hefei 230009, China. Email: wangmeng@hfut.edu.cn Corresponding authors: Jianfeng Dong, Xirong Li and Xun Wang
 Fig. 1. 현재 T2VR task와 우리가 제안하는 PRVR task의 차이점. T2VR에서는 대상 비디오가 일반적으로 미리 잘려져(pre-trimmed) 있으며 해당 쿼리에 거의 완전히 관련되어 있다고 가정하는데, 이는 실제 검색 시나리오에 비해 너무 이상적이다. 반면, PRVR의 대상 비디오는 untrimmed 상태이며 쿼리와 관련 없는 콘텐츠를 포함하여 다양하며, 쿼리에 부분적으로 관련되어 있다고 간주된다.
Fig. 1. 현재 T2VR task와 우리가 제안하는 PRVR task의 차이점. T2VR에서는 대상 비디오가 일반적으로 미리 잘려져(pre-trimmed) 있으며 해당 쿼리에 거의 완전히 관련되어 있다고 가정하는데, 이는 실제 검색 시나리오에 비해 너무 이상적이다. 반면, PRVR의 대상 비디오는 untrimmed 상태이며 쿼리와 관련 없는 콘텐츠를 포함하여 다양하며, 쿼리에 부분적으로 관련되어 있다고 간주된다.
또한, 우리가 제안하는 PRVR은 Single Video Moment Retrieval (SVMR) [13], [14], [15], [16] 및 Video Corpus Moment Retrieval (VCMR) [17], [18], [19], [20]과 같은 다양한 다운스트림 vision-language task를 위한 중요한 중간 단계 역할을 한다는 점도 주목할 만하다. 구체적으로, SVMR은 untrimmed 비디오에서 주어진 자연어 쿼리와 의미적으로 일치하는 특정 순간을 식별하는 것을 목표로 하며, VCMR은 비디오 컬렉션에서 후보 비디오를 찾아낸 다음 쿼리를 기반으로 해당 비디오 내의 순간을 정확히 찾아내는 것을 포함한다. 두 task 모두 비디오 내에서 세분화된 텍스트 기반 순간 검색을 요구하며, 우리의 PRVR task는 대규모 untrimmed 비디오 세트에서 쿼리와 부분적으로 관련된 비디오를 검색하는 신뢰할 수 있는 사전 단계를 제공하여 기반을 마련한다. Fig. 2에 나타난 것처럼, T2VR의 보다 실용적인 하위 task로서, 우리가 제안하는 PRVR은 VCMR의 첫 번째 단계에서 더 정확하고 부분적으로 관련된 비디오를 검색하는 데 도움을 줄 뿐만 아니라, SVMR 설정의 초기 단계 역할도 수행한다. 따라서 새로운 PRVR task를 탐구하는 것은 이러한 vision-language task의 발전을 위해 가치 있는 일이다.
 Fig. 2. 제안된 PRVR task와 기존 비디오/순간 검색 task 간의 연결성 그림. 특히, PRVR은 T2VR의 더 실용적이지만 도전적인 하위 task로 간주될 수 있으며, 쿼리와 부분적으로 관련된 비디오를 제공함으로써 VCMR 및 SVMR task의 중요한 중간 단계 역할을 한다.
Fig. 2. 제안된 PRVR task와 기존 비디오/순간 검색 task 간의 연결성 그림. 특히, PRVR은 T2VR의 더 실용적이지만 도전적인 하위 task로 간주될 수 있으며, 쿼리와 부분적으로 관련된 비디오를 제공함으로써 VCMR 및 SVMR task의 중요한 중간 단계 역할을 한다.
PRVR을 위한 모델은 부분적으로 관련성이 있는 비디오-텍스트 쌍으로 학습되어야 한다. 사실, 비디오-텍스트가 완전히 관련성이 있는 "고품질" 데이터셋으로 학습하는 것은 학습 데이터와 테스트 데이터 간의 상당한 불일치로 인해 문제가 발생한다. 따라서 우리는 SVMR을 위해 구축된 TVR [17], ActivityNet-Captions [21], Charades-STA [22]의 세 가지 데이터셋을 활용한다. 이 데이터셋들은 텍스트 쿼리와 정렬된 특정 시간적 주석을 포함하는 untrimmed 비디오를 포함하고 있어, 부분적으로 관련성이 있는 특성을 반영하므로 PRVR에 적합하다.
이 실용적이지만 도전적인 PRVR task를 해결하기 위해, 본 논문에서는 현재 T2VR 방법에서 사용되는 전역 매칭(global matching) 패러다임에서 벗어난다. 대신, 우리는 multiple instance learning (MIL) [23], [24] 프레임워크를 사용하는 지역 매칭(local matching) PRVR 방법을 도입한다. 여기서 비디오는 비디오 클립의 bag이자 비디오 프레임의 bag으로 동시에 간주되며, 비디오가 텍스트와 부분적으로 관련되어 있는지 여부를 결정하기 위해 텍스트 관련 프레임/클립이 있는지 여부만 찾으면 된다. 구체적으로, 우리는 다양한 시간적 길이를 가진 순간들을 효과적으로 처리하기 위해 각 비디오를 클립 및 프레임 스케일 모두에서 표현한다. 이러한 표현을 기반으로, 우리는 Multi-Scale Similarity Learning (MS-SL++) 네트워크를 도입한다. 이 네트워크는 클립 스케일 유사성 학습 브랜치와 프레임 스케일 유사성 학습 브랜치를 포함하며, 각각 거친(coarse) 및 세밀한(fine-grained) 시간적 granularity에서 부분적 관련성을 평가하는 것을 목표로 한다. 클립 스케일 브랜치는 관련 순간과 부분적으로 겹치는 핵심 클립을 식별하여 비디오 세그먼트와 쿼리 간의 거칠지만 의미 있는 상관관계를 제공하도록 설계되었다. 한편, 프레임 스케일 브랜치는 프레임 수준에서 세밀한 상관관계를 포착하여 클립에서 놓칠 수 있는 정보를 보완함으로써 이를 향상시킨다. 마지막으로, 클립 스케일과 프레임 스케일의 유사성을 함께 사용하여 전체적인 부분 비디오-텍스트 유사성을 측정한다.
요약하면, 우리의 주요 기여는 다음과 같다:
- 우리는 PRVR이라는 새로운 T2VR 하위 task를 제안한다. 이 task에서는 untrimmed 비디오가 쿼리와 관련된 순간을 포함하는 경우, 주어진 텍스트 쿼리에 대해 부분적으로 관련성이 있다고 간주된다. PRVR은 대규모 untrimmed 비디오 컬렉션에서 이러한 부분적으로 관련성이 있는 비디오를 검색하는 것을 목표로 한다.
- 우리는 PRVR task를 MIL 문제로 공식화하며, 비디오를 비디오 클립의 bag이자 비디오 프레임의 bag으로 동시에 간주한다. 클립과 프레임은 서로 다른 시간적 스케일에서 비디오 콘텐츠를 나타낸다. 다중 스케일 비디오 표현을 기반으로, 우리는 **MS-SL++**를 제안하여 비디오와 쿼리 간의 관련성을 거친(coarse) 것에서 세밀한(fine-grained) 방식으로 계산한다.
- 우리는 sliding window 방법으로 얻은 비디오 클립에서 대표 클립을 선택할 수 있는 길이 인식 클러스터링(length-aware clustering) 모듈을 제안한다. 이는 추론 단계에서 모델의 계산 및 메모리 비용을 절약할 수 있다.
- TVR [17], ActivityNet-Captions [21], Charades-STA [22]의 세 가지 데이터셋에 대한 광범위한 실험은 제안된 PRVR 방법의 실현 가능성을 입증한다. 또한 우리 방법이 비디오 코퍼스 순간 검색(video corpus moment retrieval)을 개선하는 데 사용될 수 있음을 보여준다.
본 연구의 예비 버전은 ACM Multimedia 2022 [25] (구두 발표)에 게재되었다. 저널 확장판은 컨퍼런스 논문 대비 주로 세 가지 측면에서 개선되었다. (1) 이론적으로, 우리는 관련 T2VR, SVMR, VCMR task와 비교하여 제안된 PRVR task의 필요성에 대한 심층 분석을 제공한다. 우리의 PRVR task는 현재 T2VR보다 더 실용적이고 도전적이며, SVMR 및 VCMR의 중요한 중간 단계 역할을 한다. (2) 기술적으로, 우리는 길이 인식 클러스터링(length-aware clustering) 모듈을 도입하여 원래의 클립 스케일 유사성 학습을 향상시켰다. 이 모듈은 시간적 지속 시간 정보를 기반으로 중복되는 클립 스케일 표현을 필터링한다. [25]의 이전 모델과 비교하여, 개선된 MSSL++ 모델은 약간 더 나은 성능을 달성하면서도 훨씬 빠른 검색 시간과 훨씬 적은 저장 공간을 제공한다. 구체적으로, TVR 데이터셋에서 SumR 측면에서 검색 성능을 172.4에서 174.4로 향상시켰고, 쿼리당 검색 시간을 60% 이상 단축했으며 (33ms에서 12ms로), 모든 후보 비디오에 대한 feature 저장 공간을 약 75% 감소시켰다 (4.1GB에서 1.02GB로). 이는 실제 애플리케이션 배포에 더 적합하게 만든다. (3) 실험적으로, 우리는 클러스터링 모듈의 ablation 분석, 클립의 granularity에 대한 연구, 그리고 더 최신 연구 및 baseline 모델과의 비교를 포함하여 평가를 강화했다. 우리는 Contrastive Language-Image Pre-Training (CLIP) [26] 모델로 추출된 feature를 사용한 성능 비교를 제공한다. 또한 인공 노이즈에 대한 모델의 견고성, 보지 못한 데이터에 대한 일반화 능력, 그리고 더 많은 정성적 결과를 추가로 분석한다.
2 Related Work
2.1 Text-to-Video Retrieval (T2VR)
T2VR task는 최근 몇 년간 많은 주목을 받아왔으며 [2, 6, 8, 27, 28, 29, 30, 31, 32], 이는 사전 트리밍된 비디오 클립 세트에서 주어진 쿼리에 해당하는 비디오를 검색하는 것을 목표로 한다. 검색된 클립은 주어진 쿼리와 완전히 관련되어야 한다. T2VR의 일반적인 해결책은 먼저 비디오와 텍스트 쿼리를 인코딩한 다음, cross-modal 유사성을 측정하는 공통 임베딩 공간으로 매핑하는 것이다. 따라서 현재 연구들은 주로 비디오 표현(video representation) [4, 5, 33, 34, 35, 36, 37], 문장 표현(sentence representation) [1, 3, 6], 그리고 이들의 cross-modal 유사성 학습(cross-modal similarity learning) [7, 38, 39, 40, 41]에 초점을 맞추고 있다. 본 연구는 주로 비디오 표현과 cross-modal 유사성 학습에 중점을 두므로, 다음에서는 이 두 가지 측면의 최근 진행 상황을 검토한다.
**비디오 표현(video representation)**의 경우, MSR-VTT [11] 및 VATEX [12]와 같은 기존 T2VR 데이터셋의 비디오 길이가 짧기 때문에, 비디오는 일반적으로 하나 또는 여러 개의 전체론적(holistic) feature vector로 표현된다 [4, 7, 39, 42]. 비디오 표현의 일반적인 방법은 먼저 사전학습된 CNN 모델로 frame-level feature를 추출한 다음, mean pooling [27, 43] 또는 max pooling [44, 45]을 통해 이를 집계(aggregate)하여 video-level feature를 얻는 것이다. 단순한 pooling 전략으로는 전체 비디오에 대한 완전한 정보를 요약하기에 불충분하므로, 더 복잡한 방법들이 제안되었다. Dong et al. [46]은 mean pooling, biGRU, biGRU-CNN을 공동으로 활용하여 세 가지 수준의 feature vector를 얻고 이를 최종 비디오 표현으로 연결한다. Liu et al. [4]은 여러 사전학습된 전문가(expert)를 사용하여 장면, 동작, 오디오, 객체와 같은 multi-modal feature를 추출하고, gating attention mechanism으로 이를 하나의 feature vector로 융합한다. 최근에는 대규모 이미지-언어 사전학습 모델인 CLIP [26]이 T2VR task에 널리 사용되어 상당한 성능 향상을 가져왔다 [9, 47, 48, 49, 50, 51, 52, 53]. 이 연구들에서는 일반적으로 CLIP으로 patch-level 또는 frame-level feature를 추출하고, 이를 video-level feature로 집계한다. 예를 들어, Luo et al. [9]은 mean pooling, Transformer Encoder, LSTM을 각각 사용하여 frame-level feature를 집계하려고 시도했으며, Max et al. [49]은 frame-wise attention을 사용한다. [53]에서는 patch-level feature가 텍스트 쿼리와의 상호작용적 인코딩(interactive encoding) 후 하나의 벡터로 집계된다. 또한, 비디오를 여러 feature vector로 표현하는 경향이 증가하고 있음을 관찰한다 [6, 42, 54, 55, 56]. 예를 들어, Chen et al. [6]은 세 개의 독립적인 변환 행렬을 사용하여 비디오를 전역 이벤트 수준(global event level), 지역 동작 및 개체 수준(local action and entity level)의 세 가지 수준 feature로 인코딩한다. Dong et al. [55]은 previewing branch와 intensive-reading branch를 통해 다양한 granularities의 두 가지 feature로 비디오를 표현한다. Zhang et al. [56]은 클러스터링 방법을 활용하여 비디오의 주요 이벤트를 나타내는 frame-level feature 세트를 선택한다.
**Cross-modal 유사성 학습(cross-modal similarity learning)**의 경우, 기존 T2VR 방법들은 주로 비디오와 텍스트 간의 전체론적(holistic) 유사성에 초점을 맞춘다 [6, 46, 57, 58, 59]. 가장 일반적인 방법은 비디오와 텍스트를 위한 공통 공간을 학습하고, 두 feature vector 간의 표준 유사성 측정(예: cosine similarity [46, 57, 60, 61, 62])으로 cross-modal 유사성을 측정하는 것이다. 최근에는 단일 공통 공간 대신 여러 공통 공간을 학습하는 방식이 점점 더 많은 주목을 받고 있다 [1, 39, 55, 63, 64]. 여러 공통 공간에 투영된 후, 최종 비디오-텍스트 유사성은 여러 공간에서의 유사성들의 가중합으로 계산된다. 예를 들어, Wray et al. [54]은 명사와 비명사 단어에 각각 해당하는 두 개의 다른 잠재 공간(latent space)을 학습한다. [39]에서는 유사성 예측을 위해 잠재 공간과 개념 공간이 공동으로 학습된다.
위 연구들과 달리, 우리는 비디오가 특정 쿼리와 부분적으로만 관련되어 있다고 가정하는 보다 현실적인 시나리오를 고려한다. 따라서 우리는 텍스트와 비디오 간의 부분적 관련성(partial relevance)을 측정하는 방법에 더 중점을 둔다.
2.2 Video Moment Retrieval (VMR)
VMR(Video Moment Retrieval) task는 주어진 단일 untrimmed 비디오 또는 대규모 untrimmed 비디오 컬렉션에서 주어진 쿼리와 의미론적으로 관련된 순간(moment)을 검색하는 것이다. 전자는 단일 비디오 모멘트 검색(SVMR) [65], [66], [67], [68], [69], [70], [71], [72]으로 알려져 있으며, 후자는 비디오 코퍼스 모멘트 검색(VCMR) [18], [73], [74], [75]으로 알려져 있다.
SVMR에서 기존 방법들은 주로 타겟 모멘트의 시간적 경계(temporal bounding)를 얼마나 정확하게 지역화(localize)하는지에 초점을 맞추며, 일반적으로 제안 기반(proposal-based) 방법 [76], [77], [78], [79], [80], [81]과 제안 없는(proposal-free) 방법 [13], [68], [82], [83], [84], [85]으로 분류될 수 있다.
제안 기반 방법은 먼저 여러 모멘트 제안(proposal)을 생성한 다음, 이를 쿼리와 매칭하여 제안 중에서 가장 관련성이 높은 것을 결정한다.
제안 없는 방법은 모멘트 제안을 생성하지 않고, 융합된 비디오-쿼리 feature를 기반으로 타겟 모멘트의 시작 및 종료 시점을 예측한다.
SVMR 방법들이 상당한 발전을 이루었음에도 불구하고, 해당하는 비디오가 먼저 제공되어야만 ground truth 모멘트를 얻을 수 있다는 치명적인 결함이 여전히 존재한다. 이러한 설정은 비디오가 특정적으로 제공되지 않고 일반적으로 대규모 데이터베이스에 수집되는 현실적인 시나리오를 처리하지 못한다.
다행히도, 우리의 PRVR(Partially Related Video Retrieval) task는 대규모 untrimmed 비디오 컬렉션에서 쿼리와 부분적으로 관련된 비디오를 제공함으로써 신뢰할 수 있는 사전 단계 역할을 할 수 있으며, 이를 통해 SVMR을 위한 기반을 마련한다.
SVMR의 확장으로서, VCMR task는 주어진 쿼리와 의미론적으로 관련된 모멘트(또는 비디오 세그먼트)를 untrimmed 비디오 컬렉션에서 검색하는 것이다 [73]. VCMR의 일반적인 방법들은 두 단계의 워크플로우를 가진다.
첫째, 쿼리와 비디오 간의 **전역 feature 정렬(global feature alignment)**을 통해 타겟 모멘트를 포함할 수 있는 여러 후보 비디오(candidate video)를 검색한다.
둘째, 모멘트 선택(moment selection) 접근 방식을 활용하여 후보 비디오에서 올바른 모멘트를 얻는다.
대부분의 VCMR 방법들은 후자의 지역화(localization) 단계에 초점을 맞춘다. 초기 연구들 [73], [74]은 후보 비디오에 temporal convolutional module을 적용하여 가능한 한 많은 제안(proposal)을 얻는다.
제안 생성의 계산 비용을 절약하기 위해 Lei et al. [17]은 각 프레임이 타겟 모멘트의 시작 또는 끝일 확률을 예측하는 새로운 Convolutional Start-End (ConvSE) detector를 구축했다.
Lei et al. [17]이 제안한 모델을 기반으로 Zhang et al. [19]은 쿼리-모멘트 쌍에 contrastive learning을 적용하여 더 높은 성능을 달성했다.
Yoon et al. [86]은 제안 없는(proposal-free) 및 제안 기반(proposal-based) 모멘트 점수 맵을 동시에 구축하여 더 정확한 모멘트 검색을 수행했다.
모멘트와 쿼리를 별도로 인코딩하는 것 외에도 Zhang et al. [18]과 Hou et al. [20]은 cross modal attention을 도입하여 상호작용적인 방식으로 모델링했지만, 상대적으로 높은 성능을 달성했음에도 불구하고 시간 소모적이다.
그러나 위에서 언급했듯이, 대부분의 VMCR 방법들은 최종적으로 관련성 높은 모멘트를 얻는 데 집중하지만, 더 신뢰할 수 있는 후보 비디오를 찾는 중간 단계의 중요성을 간과한다.
대신, 우리의 PRVR은 VCMR의 첫 번째 단계에서 비디오 코퍼스에서 더 정확한 부분적으로 관련된 비디오를 검색하는 데 도움을 준다.
3 Our Method
3.1 Overview
PRVR의 정의.
문장 형태의 쿼리가 주어졌을 때, **PRVR(Partially Relevant Video Retrieval)**은 주어진 쿼리에 의미론적으로 관련된 특정 순간을 포함하는 대상 비디오를 대규모의 untrimmed 비디오 코퍼스에서 검색하는 것을 목표로 한다. 쿼리가 지칭하는 순간은 일반적으로 쿼리와 관련 없는 내용이 포함된 대상 비디오의 작은 부분만을 구성하므로, 우리는 **쿼리가 비디오에 부분적으로 관련되어 있다(partially relevant)**고 주장한다.
PRVR은 현재의 T2VR(Text-to-Video Retrieval) [6], [8], [46] task와는 다르다는 점에 주목할 필요가 있다. T2VR에서는 비디오가 미리 trim되어 훨씬 짧고, 쿼리는 일반적으로 전체 비디오와 완전히 관련되어 있다. PRVR 모델을 구축하기 위해, 학습용으로 untrimmed 비디오 세트가 주어지며, 각 비디오는 여러 자연어 문장과 연결된다. 각 문장은 해당 비디오의 특정 순간의 내용을 설명한다. 우리는 문장이 지칭하는 대상 순간의 시작 및 종료 시점(moment annotations)에 접근할 수 없다는 점을 강조한다.
전체 파이프라인.
우리는 PRVR task를 위해 MS-SL++ 네트워크를 제안한다. 특히, untrimmed 비디오가 주어졌을 때, 관련 콘텐츠가 어디에 위치하는지에 대한 사전 지식이 없으므로, 세밀한(fine-grained) 스케일에서 비디오-텍스트 유사도를 직접 계산하는 것은 어렵다. 따라서 우리는 PRVR을 MIL(Multiple Instance Learning) 문제로 공식화할 것을 제안한다. 여기서 비디오는 비디오 클립들의 bag이자 동시에 비디오 프레임들의 bag으로 간주된다. 우리는 텍스트와 관련된 프레임/클립이 있는지 여부만으로 비디오가 텍스트와 부분적으로 관련되어 있는지 여부를 판단할 수 있다.
우리의 전체 파이프라인은 Fig. 3에 설명되어 있다. 구체적으로, 우리는 먼저 입력 텍스트 쿼리를 전역 문장 표현(global sentence representation)으로 인코딩하고, 비디오를 coarse한 클립 스케일 및 fine-grained한 프레임 스케일 표현으로 인코딩한다. 그런 다음, 문장 표현을 클립 스케일 비디오 표현과 통합하여 부분적으로 관련된 클립이 존재하는지 여부를 결정한다. 다중 클립 추론을 가속화하기 위해, 우리는 클립-텍스트 매칭을 위한 가장 대표적인 클립들을 선택하는 클립 의미론적 클러스터링(clip semantic clustering) 전략을 도입한다. 계산된 클립 스케일 유사도 외에도, 핵심 클립(key clips)의 안내를 받아 프레임 스케일 부분 관련성 추론(frame-scale partial relevance reasoning)을 추가로 계산한다. 마지막으로, 클립 스케일 및 프레임 스케일 컨텍스트 모두 최종 검색 결과에 기여한다.
3.2 Sentence Representation
우리의 초점은 비디오 표현과 부분적으로 관련된 학습에 있기 때문에, 우리는 VCMR task에서 좋은 성능을 보인 [17]의 문장 표현 접근 방식을 채택한다. 구체적으로, 개의 단어로 구성된 텍스트 쿼리가 주어지면, 먼저 사전학습된 RoBERTa [87]를 사용하여 단어 feature를 추출한다. RoBERTa feature는 이미 contextualized되어 있지만, 더 나은 task-specific 적응(즉, 텍스트-비디오 의미론적 정렬)을 위해 Transformer 기반 블록으로 feature를 추가적으로 강화한다.
먼저, ReLU 활성화 함수를 가진 fully connected (FC) layer를 사용하여 단어 feature를 더 낮은 차원의 공간으로 매핑한다. 이렇게 차원이 축소된 feature는 학습된 positional embedding과 함께 표준 Transformer layer에 입력되어, -차원의 단어 feature 벡터 시퀀스 를 얻는다. Transformer 내부에서 이 feature들은 multi-head attention layer에 입력된 후 feed-forward layer를 거치며, 두 layer는 residual connection [88]과 layer normalization [89]을 통해 연결된다. 마지막으로, 에 대한 간단한 attention을 사용하여 문장 수준 표현 를 도출한다:
여기서 Softmax는 softmax layer를 나타내고, 는 학습 가능한 벡터이며, 는 attention 벡터를 나타낸다.
3.3 Multi-Scale Video Representation
주어진 untrimmed video에 대해, 우리는 먼저 이를 -차원 feature vector들의 시퀀스 로 표현한다. 여기서 는 vector의 개수를 나타낸다. 이 feature 시퀀스는 사전학습된 2D CNN을 사용하여 frame-level feature를 추출하거나, 사전학습된 3D CNN을 사용하여 segment-level feature를 추출함으로써 얻어진다. 설명을 단순화하기 위해, 이후의 설명에서는 를 frame-level feature의 시퀀스로 간주한다. 를 기반으로, 우리는 clip-scale similarity learning branch와 frame-scale similarity learning branch를 함께 사용하여 multi-scale video representation을 구축한다.
3.3.1 Clip-scale video representation
비디오 클립을 구성하기 전에, 우리는 모델의 계산 복잡도를 줄이기 위해 입력의 시간 도메인에서 먼저 다운샘플링을 수행하여 feature 시퀀스의 길이를 줄인다. 구체적으로, 입력으로 주어진 프레임 feature 벡터 시퀀스 를 고정된 개의 feature 벡터로 다운샘플링한다. 이때 각 feature 벡터는 **해당하는 여러 연속적인 프레임 feature들을 평균 풀링(mean pooling)**하여 얻어진다. 그러면 비디오는 새로운 feature 벡터 시퀀스 로 표현된다.
feature를 더욱 압축하기 위해, 우리는 ReLU 활성화 함수를 가진 FC layer를 사용한다. 또한, 내의 feature들 간의 시간적 종속성(temporal dependencies)을 모델링하기 위해, 학습된 positional embedding을 포함하는 표준 Transformer를 사용한다. TVR 데이터셋에 대한 예비 실험 결과, Transformer의 사용이 R@1 성능을 12.8에서 13.6으로 향상시키는 데 도움이 됨을 보여주었다.
정식으로, FC layer와 1-layer Transformer를 통해 다음과 같이 를 얻는다:
여기서 는 positional embedding의 출력을 나타낸다.
전체적인 클립 구성을 위해, Fig. 3 (c)에 나타난 바와 같이 에 대해 시간 차원을 따라 stride 1의 유연한 sliding window를 적용한다. 크기 의 sliding window가 주어지면, 클립 feature는 해당 window 내의 feature들을 평균 풀링하여 얻어진다. 결과로 생성되는 feature 시퀀스는 로 표기되며, 이는 개의 클립으로 구성된다.
 Fig. 3. PRVR을 위한 제안 모델 **MS-SL++**의 프레임워크. untrimmed video가 주어지면, multi-scale video representation module은 이를 클립 스케일(clip-scale) 및 프레임 스케일(frame-scale) feature로 인코딩한다. 보다 효율적인 coarse-to-fine 유사도 계산을 위해, length-aware clustering module이 적용되어 대표적인 클립 레벨 feature를 선택한다. 한편, 간단하지만 효과적인 sentence representation module은 텍스트 쿼리를 단일 feature 벡터로 인코딩한다. 그런 다음, 클립 스케일 유사도 학습을 통해 비디오와 텍스트 쿼리 간의 coarse relevance가 얻어지며, 동시에 key clip이 감지된다. 또한, key clip은 프레임 스케일 feature의 aggregation을 안내하는 데 활용되어 비디오와 쿼리의 fine-grained relevance를 출력한다. untrimmed video와 쿼리 간의 **부분 유사도(partial similarity)**는 multi-scale 유사도에 의해 동시에 결정된다.
Fig. 3. PRVR을 위한 제안 모델 **MS-SL++**의 프레임워크. untrimmed video가 주어지면, multi-scale video representation module은 이를 클립 스케일(clip-scale) 및 프레임 스케일(frame-scale) feature로 인코딩한다. 보다 효율적인 coarse-to-fine 유사도 계산을 위해, length-aware clustering module이 적용되어 대표적인 클립 레벨 feature를 선택한다. 한편, 간단하지만 효과적인 sentence representation module은 텍스트 쿼리를 단일 feature 벡터로 인코딩한다. 그런 다음, 클립 스케일 유사도 학습을 통해 비디오와 텍스트 쿼리 간의 coarse relevance가 얻어지며, 동시에 key clip이 감지된다. 또한, key clip은 프레임 스케일 feature의 aggregation을 안내하는 데 활용되어 비디오와 쿼리의 fine-grained relevance를 출력한다. untrimmed video와 쿼리 간의 **부분 유사도(partial similarity)**는 multi-scale 유사도에 의해 동시에 결정된다.
결과적으로, 와 같이 다양한 크기의 sliding window를 함께 사용함으로써, 우리는 시퀀스 집합을 얻는다. 이들을 모두 합쳐서, 다음과 같이 **클립 스케일 비디오 feature **를 얻는다:
여기서 는 번째 클립의 feature 표현을 나타내며, 는 모든 클립 스케일 비디오 feature의 개수로 를 만족한다.
3.3.2 Frame-scale video representation
Clip-scale feature와는 반대로, frame-scale feature는 세밀한 시간적 granularity를 가지는 것으로 간주되므로, 우리는 비디오의 상세한 내용을 보존하기 위해 초기 feature들을 그대로 유지한다. 그러나 초기 frame feature들은 독립적으로 추출되기 때문에, 자연스럽게 시간적 종속성(temporal dependencies)이 부족하다. 이러한 종속성을 다시 도입하기 위해, 우리는 Transformer를 사용하여 self-context를 학습한다. 구체적으로, frame feature 시퀀스 가 주어졌을 때, 우리는 먼저 ReLU 활성화 함수를 가진 FC layer를 사용하여 입력의 차원을 줄인 다음, positional embedding layer가 포함된 표준 Transformer를 적용한다. 재인코딩된 frame feature 는 다음과 같이 계산된다:
여기서 Transformer, FC, PE의 네트워크 구조는 clip-scale visual encoder와 동일하지만, 학습 가능한 파라미터는 공유되지 않는다. 이는 각 visual encoder가 자신의 scale에 적합한 파라미터를 학습할 수 있도록 한다.
3.4 Multi-Scale Similarity Learning
비디오가 텍스트와 관련된 프레임/클립을 포함하는 경우 텍스트와 부분적으로 관련되어 있다고 정의할 때, 거친(coarse) 전역(global) 매칭 대신 세밀한(fine-grained) 클립 및 프레임 스케일에서 비디오-쿼리 쌍을 매칭하는 것이 필요하다. PRVR에서 관련 콘텐츠의 위치에 대한 사전 지식이 없으므로, 세밀한 스케일에서 비디오-텍스트 유사도를 직접 계산하는 것은 어렵다.
이를 위해 우리는 multi-scale similarity learning 접근 방식을 제안한다. 이 방식은 거친(coarse) 스케일에서 세밀한(fine) 스케일로 점진적으로(coarse-to-fine) 유사도를 계산한다. 구체적으로, 먼저 쿼리와 가장 관련성이 높을 것으로 예상되는 key clip을 감지한다. 그런 다음, key clip의 안내에 따라 세밀한 시간 스케일에서 각 프레임의 중요도를 측정한다. 최종 유사도는 key clip과 프레임 모두에 대한 쿼리의 유사도를 공동으로 고려하여 계산된다. multi-scale similarity learning의 프레임워크는 Fig. 3 (c)와 (d)에 설명되어 있다.
3.4.1 Clip-scale similarity learning
clip-scale 비디오 feature 는 다양한 크기의 슬라이딩 윈도우를 통해 생성되어, 길이가 다양하고 시간적 중복이 높으며 정보의 중복성을 가진다. 각 비디오에 대해 모든 clip-scale feature를 추론을 위해 저장해야 하므로, 대규모 비디오 검색 시 상당한 메모리 소비가 발생한다. 이러한 문제들은 실제 애플리케이션에 검색 모델을 배포하는 데 어려움을 초래한다.
더 빠른 추론을 위해, 우리는 에서 대표적인 feature들의 부분집합 을 선택하여 clip-scale 비디오 표현으로 사용할 것을 제안한다. 을 얻기 위한 간단한 아이디어는 에 대해 클러스터링 알고리즘을 수행하는 것이다. 그러나 clip-scale feature는 길이가 다양한 비디오 클립에 해당하므로, 클립 길이를 고려하지 않는 이러한 바닐라 클러스터링 전략은 최적화되지 못한다. 대표 feature와 관련된 비디오 클립 길이의 다양성을 향상시키기 위해, 우리는 길이 인식 클러스터링(length-aware clustering) 전략을 도입한다. 이 전략은 클러스터링 시 의 길이 정보를 강화하기 위해 길이 임베딩(length embedding)을 통합한다.
구체적으로, 우리는 먼저 Transformer [90]에서 사용되는 position embedding과 유사하게, 사인 및 코사인 함수를 사용하여 길이 임베딩 행렬 을 구성한다. 여기서 는 임베딩 차원이고 은 클립의 최대 길이이다. 원본 클립 표현 가 주어졌을 때, **길이 강화 클립 표현(length-enhanced clip representation)**은 다음과 같이 얻어진다:
여기서 는 에서 선택된 길이 의 길이 임베딩 벡터이며, [ , ]는 연결(concatenation) 연산을 나타낸다. 그런 다음, 길이 강화 clip-scale 표현 에 대해 일반적인 클러스터링 알고리즘인 k-medoids 알고리즘 [50]을 수행한다. 이 알고리즘은 각 클러스터 내의 모든 데이터 포인트와 해당 클러스터의 중심 간의 거리 합을 최소화하여 데이터를 개의 클러스터로 분할한다. 특정 클러스터의 중심은 동일 클러스터 내의 다른 모든 포인트에 대한 평균 거리가 최소인 실제 데이터 포인트로 정의된다. 이어서, 클러스터의 중심 feature는 대표 feature로 유지되고, 유사한 clip-scale feature의 중복 계산을 피하기 위해 다른 모든 비중심 feature는 제거된다. 클러스터링 후, 우리는 개의 클러스터 수를 나타내는 **핵심 클립(key clips)**을 얻는다.
그 다음, 우리는 에 대해 쿼리 관련 유사도 학습(query-relevant similarity learning)을 구성할 수 있다. 우리는 과 쿼리 표현 사이의 코사인 유사도를 계산한 후, 유사도에 대해 max-pooling 연산을 적용한다. 더 공식적으로, clip-scale 유사도는 다음과 같이 얻어진다:
여기서 는 코사인 유사도 함수를 나타낸다. max-pooling 연산은 쿼리와 가장 높은 의미론적 관련성을 가진 clip-scale feature를 선택할 수 있으므로, 우리는 이를 후속 frame-scale 유사도 학습을 위한 핵심 클립 feature로 간주한다. max-pooling 연산이 단순하지만, 관련 없는 세그먼트를 무시하면서 부분적인 관련성을 식별할 수 있다는 점은 주목할 만하다.
3.4.2 Frame-scale similarity learning
우리는 모델이 쿼리에 대한 대략적인(coarse) 관련 콘텐츠를 미리 이해하고 있다면, 더 미세한(finer) 스케일에서 더 정확한 관련 콘텐츠를 찾아내는 모델의 능력이 향상될 것이라고 가정한다. 따라서 우리는 Transformer [90]의 multi-head self-attention (MHSA) 메커니즘 아이디어를 활용하여 프레임 스케일 유사도 학습을 위한 Key Clip Guided Attention (KCGA) 메커니즘을 고안한다. 이 메커니즘은 Section 3.4.1에서 얻은 key clip과 의미적으로 가까운 프레임들을 탐색하고, 비디오 내 key clip의 상세 정보를 보완할 수 있다. 구체적으로, 프레임 feature들의 시퀀스 가 입력으로 주어지면, 원래의 MHSA는 이들을 먼저 **query, key, value로 투영(project)**한 다음, value들의 가중합으로 출력을 계산한다. 각 value에 할당되는 가중치는 **query와 해당 key의 호환성 함수(compatibility function)**에 의해 계산된다. MHSA가 동일한 입력을 사용하여 query, key, value를 구성하는 것과 달리, 여기서는 key clip의 feature vector를 query로 사용하고, 비디오 프레임 feature를 key와 value로 사용한다. 정식으로, **집계된(aggregated) 프레임 feature vector **은 다음과 같이 얻어진다:
여기서 는 key clip의 feature vector를 나타내며, 와 는 두 개의 학습 가능한 projection matrix이다. 는 프레임과 key clip 간의 세밀한(fine-grained) 상관관계를 측정하며, 이는 key clip과 더 유사한 프레임에 대해 더 큰 값을 산출하고, 관련 없는 배경 프레임의 영향은 억제할 것으로 예상된다. 따라서 key clip과 더 유사한 프레임은 더 높은 attention 가중치를 받게 된다.
마지막으로, **프레임 스케일 유사도 **는 집계된 프레임 feature vector 과 쿼리 feature vector 간의 코사인 유사도로 측정된다:
3.5 Model Training and Inference
3.5.1 Training stage
이 섹션에서는 먼저 모델 학습을 위한 positive 및 negative 쌍의 정의를 소개한다. MIL [23], [24]에서 영감을 받아, 우리는 쿼리와 비디오 쌍이 쿼리에 관련된 특정 콘텐츠를 포함하면 positive로, 비디오에 관련 콘텐츠가 없으면 negative로 정의한다.
위 정의를 바탕으로, 우리는 retrieval 관련 task에서 널리 사용되며 상호 보완적임이 밝혀진 triplet ranking loss [39], [91]와 infoNCE loss [19], [92]를 함께 사용한다. **Positive 비디오-쿼리 쌍 **가 주어졌을 때, 미니배치 에 대한 triplet ranking loss는 다음과 같이 정의된다:
여기서 은 margin constant이고, 는 clip-scale similarity 또는 frame-scale similarity 를 사용할 수 있는 유사도 함수를 나타낸다. 또한, 와 는 각각 에 대한 negative sentence sample과 에 대한 negative video sample을 의미한다. negative sample은 학습 초기에는 미니배치에서 무작위로 샘플링되지만, 20 epoch 이후에는 가장 어려운 negative sample이 된다.
**Positive 비디오-쿼리 쌍 **가 주어졌을 때, 미니배치 에 대한 infoNCE loss는 다음과 같이 계산된다:
여기서 는 미니배치 내의 비디오 에 대한 모든 negative query를 나타내고, 는 미니배치 내의 쿼리 에 대한 모든 negative video를 나타낸다.
이전 연구 [1]에서 여러 유사도의 합에 하나의 loss를 사용하는 것보다 각 유사도 함수에 대해 하나의 loss를 사용하는 것이 더 나은 성능을 보인다고 결론지었으므로, 우리는 clip-scale similarity와 frame-scale similarity 모두에 대해 위의 두 loss를 적용하며, 이들의 합을 사용하지 않는다. 최종적으로, 우리 모델은 다음 전체 학습 loss를 최소화함으로써 학습된다:
여기서 와 는 각각 clip-scale similarity 와 frame-scale similarity 를 사용한 triplet ranking loss를 나타내며, 와 도 이에 상응한다. 과 는 여러 loss의 균형을 맞추기 위한 하이퍼파라미터이다.
3.5.2 Inference stage
모델 학습이 완료된 후, **untrimmed video와 textual query 간의 부분 유사도(partial similarity)**는 클립 스케일 유사도(clip-scale similarity)와 프레임 스케일 유사도(frame-scale similarity)의 합으로 계산된다. 즉, 다음과 같다:
여기서 는 두 유사도의 중요도를 조절하는 하이퍼파라미터로, 범위의 값을 가진다. 주어진 쿼리에 대해, 우리는 비디오 갤러리 내의 모든 비디오를 해당 쿼리와의 유사도에 따라 내림차순으로 정렬한다.
4 Experiments
4.1 Experimental Setup
4.1.1 Datasets
PRVR에 대한 제안 모델의 타당성을 검증하기 위해서는 비디오와 부분적으로만 관련 있는 쿼리가 필요하다. MSRVTT [11], MSVD [10], VATEX [12]와 같은 일반적인 T2VR 데이터셋의 비디오들은 쿼리와 완전히 관련되어 있다고 가정되므로, 우리의 실험에는 적합하지 않다.
이에 우리는 VCMR(Video Corpus Moment Retrieval)에 일반적으로 사용되는 세 가지 데이터셋, 즉 TVR [17], ActivityNet-Captions [21], Charades-STA [22]를 재활용하였다. 이 데이터셋들은 해당 비디오와 부분적으로만 관련 있는 자연어 쿼리를 포함하고 있기 때문이다 (쿼리는 일반적으로 비디오 내 특정 순간과 연관된다).
Table 1은 이 데이터셋들의 간략한 통계를 요약한 것으로, **순간(moment) 및 비디오의 평균 길이, 그리고 전체 비디오에서 순간 길이의 평균 비율(moment-to-video ratio)**을 포함한다.
우리는 비디오 검색(retrieving videos)에 초점을 맞추고 있으므로, 이 데이터셋들이 제공하는 순간(moment) 주석은 새로 제안하는 PRVR task에서는 사용되지 않는다는 점에 유의해야 한다.
TABLE 1 실험에 사용된 세 가지 공개 데이터셋의 간략한 통계. 길이는 초(seconds) 단위로 측정된다.
| Datasets | Average length | Moment-to-video ratio | ||||
|---|---|---|---|---|---|---|
| moments | videos | |||||
| TVshow Retrieval | 9.1 | 76.2 | ||||
| ActivityNet-Captions | 36.2 | 117.6 | ||||
| Charades-STA | 8.1 | 30.0 |
**TVshow Retrieval (TVR) [17]**은 원래 **비디오 코퍼스 순간 검색(video corpus moment retrieval)**을 위한 멀티모달 데이터셋으로, 자동 음성 인식(automatic speech recognition)으로 생성된 자막과 비디오가 쌍을 이룬다. 이 데이터셋은 6개의 TV 쇼에서 수집된 21.8K개의 비디오를 포함한다. 각 비디오는 비디오 내 특정 순간을 설명하는 5개의 문장과 연관되어 있다. 따라서 이러한 문장은 비디오와 부분적으로만 관련된다. [18], [19]를 따라, 우리는 17,435개의 비디오와 87,175개의 순간을 학습에 사용하고, 2,179개의 비디오와 10,895개의 순간을 테스트에 사용한다.
**ActivityNet-Captions [21]**은 원래 dense video captioning을 위해 개발되었으며, 현재는 SVMR(Single Video Moment Retrieval)을 위한 인기 있는 데이터셋이다. 이 데이터셋은 Youtube에서 약 20K개의 비디오를 포함하며, 비디오의 평균 길이는 우리가 사용한 데이터셋 중 가장 길다. 평균적으로 각 비디오는 약 3.7개의 순간과 해당 문장 설명을 가지고 있다. 우리는 [18], [19]에서 사용된 일반적인 데이터 분할 방식을 사용한다.
**Charades-STA [22]**는 6,670개의 비디오와 16,128개의 문장 설명을 포함한다. 각 비디오는 평균적으로 약 2.4개의 순간과 해당 문장 설명을 가지고 있다. 우리는 모델 학습 및 평가를 위해 공식 데이터 분할 방식을 활용한다.
4.1.2 Evaluation metrics
PRVR 모델을 평가하기 위해, 우리는 현재 T2VR task에서 일반적으로 사용되는 rank-based metric인 **와 Median rank (Med r)**를 활용한다 [31], [39]. ****는 랭킹 리스트의 상위 내에서 원하는 항목을 올바르게 검색한 쿼리의 비율을 나타낸다. 성능은 백분율(%)로 보고된다. Med r은 검색 결과에서 첫 번째 관련 항목의 중앙값 순위이다. 값이 높을수록, Med r 값이 낮을수록 더 좋은 성능을 의미한다. 전반적인 비교를 위해 **모든 Recall 값의 합(SumR)**도 함께 보고한다.
4.1.3 Implementation details
이전 연구들 [17], [19]에 따라, 우리는 CNN 기반 feature를 활용하여 비디오를 표현한다. TVR 데이터셋에서는 [17]에서 제공하는 feature, 즉 프레임 수준의 ResNet152 [88] feature와 세그먼트 수준의 I3D [93] feature를 연결하여 얻은 3,072차원 시각 feature를 사용한다. 편의상 이를 ResNet152-I3D라고 부른다. ActivityNet-Captions 및 Charades-STA 데이터셋에서는 각각 [18]과 [94]에서 제공하는 I3D feature를 사용한다. 문장 feature의 경우, TVR 데이터셋에서는 [17]에서 제공하는 768차원 RoBERTa feature를 사용하며, 여기서 RoBERTa는 TVR의 쿼리 및 자막 문장에 대해 fine-tuning되었다. ActivityNet-Captions 및 Charades-STA 데이터셋에서는 우리가 직접 오픈 RoBERTa 툴킷을 사용하여 추출한 1,024차원 RoBERTa feature를 사용한다. 또한, 시각 및 텍스트 표현을 위해 Contrastive Language-Image Pre-Training (CLIP) [26], [61]의 사용이 증가하고 있음을 관찰하여, 우리 실험에서도 이를 활용한다. 우리는 CLIP (ViT-B/32)의 시각 branch와 텍스트 branch를 각각 프레임 및 문장 feature 추출에 사용하며, fine-tuning 없이 이들을 고정(freeze)시킨다.
TABLE 2 TVR 데이터셋에 대한 Ablation study.
| Model | R@1 | R@5 | R@10 | R100 | SumR | Med |
|---|---|---|---|---|---|---|
| Full setup | 13.6 | 33.1 | 44.2 | 83.5 | 174.4 | 14 |
| w/o frame-scale branch | 12.5 | 31.4 | 41.8 | 82.2 | 167.9 | 18 |
| w/o clip-scale branch | 8.0 | 21.0 | 30.0 | 74.0 | 133.0 | 33 |
| w/o key clip guide | 12.3 | 30.8 | 41.4 | 82.0 | 166.5 | 17 |
| w/o weighted aggregation | 12.0 | 30.2 | 40.8 | 81.5 | 164.5 | 17 |
| w/o infoNCE | 11.5 | 29.4 | 40.5 | 81.2 | 162.6 | 19 |
| w/o Triplet loss | 11.4 | 29.8 | 40.9 | 81.9 | 163.9 | 19 |
비디오 표현 모듈의 경우, 다운샘플링 전략에서 고정된 숫자 를 32로 설정한다. 또한, 최대 프레임 수 를 128로 설정한다. 프레임 수가 를 초과하면 로 다운샘플링된다. 문장의 경우, 쿼리의 최대 길이 를 TVR 및 Charades-STA에서는 32로, ActivityNet-Captions에서는 64로 설정하며, 최대 길이를 초과하는 단어는 단순히 버려진다. 우리 모델에 사용된 Transformer 모듈의 경우, hidden size 를 384로 설정하고 4개의 attention head를 사용한다. k-medoids 알고리즘에서는 유클리드 거리(Euclidean distance)를 사용하여 데이터 포인트 간의 거리를 측정한다.
손실 함수(loss function)의 하이퍼파라미터는 모델 학습 초기에 모든 손실 요소가 유사한 손실 값을 갖도록 및 로 경험적으로 설정한다. 모델 학습을 위해 mini-batch size 128의 Adam optimizer를 사용한다. 초기 학습률(learning rate)은 0.00025로 설정하며, [17]과 유사한 학습률 조정 스케줄을 따른다. 10 epoch 연속으로 validation 성능이 향상되지 않으면 early stop이 발생한다. 최대 epoch 수는 100으로 설정한다.
4.2 Ablation Studies
이 섹션에서는 TVR 데이터셋을 사용하여 제안된 모델의 각 구성 요소의 효과를 평가한다.
4.2.1 The effectiveness of multi-scale similarity learning branches
다중 스케일 브랜치의 유용성을 검증하기 위해, 우리는 clip-scale similarity learning branch 또는 frame-scale similarity learning branch가 없는 모델들과 비교하였다. Table 2에서 볼 수 있듯이, 어떤 브랜치라도 제거하면 성능이 명확하게 저하된다. 이 결과는 다중 스케일 솔루션의 효과성을 입증할 뿐만 아니라, clip-scale과 frame-scale similarity learning branch 간의 상호 보완성도 보여준다.
4.2.2 The effectiveness of key clip guided attention
우리가 제안한 key clip guided attention은 주로 key clip guide와 weighted aggregation으로 구성된다. 이들의 기여도를 평가하기 위해, 먼저 key clip guided attention을 simple attention으로 대체한 variant w/o key clip guide를 비교한다. simple attention은 어떠한 guidance 없이 Eq. 1과 같이 구현된다. 추가적으로, weighted aggregation을 mean-pooling 전략으로 대체한 variant w/o weighted aggregation도 조사한다.
TABLE 3 클러스터 수 가 모델 성능 및 추론 시간에 미치는 영향. 마지막 행은 가속화를 위한 클러스터링을 사용하지 않은 모델의 결과이다.
| Performance (SumR) | Retrieval Time (ms) | Feature Storage (number) | |
|---|---|---|---|
| 8 | 167.3 | 10 | 59 |
| 16 | 171.1 | 11 | 67 |
| 32 | 174.5 | 12 | 83 |
| 64 | 173.2 | 16 | 115 |
| 128 | 172.4 | 21 | 179 |
| 256 | 173.7 | 28 | 307 |
| - | 172.4 | 33 | 579 |
 (a)
(a)
 (b)
(b)
Fig. 4. length-aware clustering과 vanilla clustering의 비교: (a) 검색 성능 및 (b) 클러스터링을 통해 얻은 대표 클립들의 길이 다양성 측면.
Table 2에서 볼 수 있듯이, 완전한 설정을 갖춘 우리 모델은 두 가지 ablation variant보다 우수한 성능을 보인다 (R@1이 각각 13.6 대 12.3 및 12.0). 이러한 결과는 우리의 key clip guided attention 설계의 효과성을 확인할 뿐만 아니라, key clip guide와 weighted aggregation 모두의 중요성을 강조한다.
4.2.3 The effectiveness of the combination of triplet ranking loss and infoNCE loss
두 가지 loss를 함께 사용하는 방식의 유효성을 검증하기 위해, 우리는 triplet ranking loss 또는 infoNCE loss 중 하나만 사용했을 때의 결과를 비교하였다. Table 2에서 볼 수 있듯이, triplet ranking loss와 infoNCE는 단독으로 사용될 때 비슷한 결과를 보였지만, 두 loss를 함께 사용하는 전체 설정의 모델보다 훨씬 낮은 성능을 나타냈다. 이 결과는 두 loss를 함께 사용하는 것의 이점을 명확히 보여준다.
4.2.4 The studies on length-aware clustering
클러스터 수 의 영향.
우리는 먼저 **클러스터 수(즉, 대표 비디오 클립의 수)**가 모델 성능, 검색 시간 및 feature 저장 공간에 미치는 영향을 연구한다.
검색 시간의 경우, 비디오는 미리 오프라인에서 표현될 수 있으므로 비디오 표현에 필요한 시간은 제외한다. 검색 시간은 TVR 데이터셋에서 10,895개의 쿼리에 응답하는 평균 시간으로 평가된다.
feature 저장 공간은 각 비디오에 대해 오프라인으로 추출된 클립 수준 비디오 feature의 수로 측정한다.
클러스터 수에 따른 결과는 Table 3에 요약되어 있다.
클러스터 수 가 감소하면 검색 시간과 feature 저장 공간이 모두 단축된다.
그러나 8개 또는 16개와 같이 클러스터 수가 적으면 성능 저하가 뚜렷하게 나타남을 관찰했다.
이는 클러스터 수가 적으면 대표 클립이 불충분하여 원본 비디오의 내용을 적절하게 표현하지 못하기 때문이라고 생각한다.
클러스터 수가 16보다 많을 때는 클러스터링을 사용하지 않고 가속화한 모델과 성능이 비슷하다.
이 결과는 우리가 제안한 클러스터링 전략의 가속화 효과를 보여준다.
클러스터 수를 32로 설정했을 때 모델 성능과 검색 비용 간의 최적의 균형을 이루므로, 별도로 명시하지 않는 한 이 값을 기본값으로 사용한다.
 Fig. 5. 클립 세분화가 검색 성능에 미치는 영향.
Fig. 5. 클립 세분화가 검색 성능에 미치는 영향.
길이 인식 클러스터링(length-aware clustering)의 효과.
대표 클립 선택에서 길이 인식 클러스터링의 효과를 검증하기 위해, 길이 임베딩을 통합하지 않은 바닐라 클러스터링(vanilla clustering)과 비교를 수행했다.
**Fig. 4 (a)**에서 볼 수 있듯이, 다양한 클러스터 수에 걸쳐 길이 인식 클러스터링이 바닐라 클러스터링보다 일관되게 우수한 성능을 보여주며, 이는 대표 클립 선택에 대한 효과를 입증한다.
이러한 더 나은 성능은 길이 인식 클러스터링이 클립 길이를 고려하여, 클러스터링을 통해 얻은 대표 클립들이 길이 측면에서 더 다양해질 수 있기 때문으로 설명할 수 있다.
길이 인식 클러스터링을 통해 얻은 대표 클립의 다양성을 추가로 확인하기 위해, TVR 데이터셋의 학습 세트에서 모든 비디오의 **클립 길이 분산(clip length variance)**을 계산했다.
Figure 4에 나타난 결과는 길이 인식 클러스터링이 바닐라 클러스터링에 비해 더 높은 길이 분산을 초래함을 명확히 보여준다.
4.2.5 Clip granularity sensitivity analysis
생성된 클립의 다양한 granularity 수준이 성능에 미치는 영향을 확인한다. 클립 granularity는 슬라이딩 윈도우의 개수()와 stride에 의해 함께 결정된다. Figure 5에서 볼 수 있듯이, **더 세분화된 클립(더 큰 와 더 작은 stride)**은 더 나은 성능을 의미하지만, 더 높은 연산 오버헤드를 수반한다. 효과와 효율성 사이의 trade-off를 고려하여, 우리의 기본 와 stride 선택은 각각 32와 1이다.
4.3 Comparison with Simple Baselines
제안된 프레임워크를 추가로 검증하기 위해, 우리는 추가적인 모델 구성 요소 없이 프레임 수준의 CLIP feature에만 의존하는 간단한 baseline과 비교한다. 주어진 비디오에 대해 후보 모멘트(candidate moments)가 어떻게 생성되는지에 따라, 이 간단한 baseline을 세 가지 방식으로 구현한다:
TABLE 4 추가적인 모델 구성 요소 없이 CLIP feature에만 의존하는 간단한 baseline과 제안된 MS-SL++의 비교.
| Dataset | Method | R@1 | R@5 | R@10 | R@100 | SumR | Med r |
|---|---|---|---|---|---|---|---|
| TVR | CLIP-cluster | 9.0 | 19.8 | 26.7 | 60.5 | 116.0 | 54 |
| CLIP-psd | 6.8 | 16.6 | 22.7 | 56.6 | 102.7 | 72 | |
| CLIP-svmr | 8.8 | 19.8 | 26.8 | 60.5 | 115.9 | 54 | |
| MS-SL++ | 23.4 | 47.2 | 58.3 | 90.1 | 219.0 | 6 | |
| ActivityNet | CLIP-cluster | 13.0 | 29.6 | 40.2 | 74.7 | 157.4 | 19 |
| CLIP-psd | 11.8 | 27.7 | 38.4 | 73.1 | 150.9 | 21 | |
| CLIP-svmr | 13.5 | 30.4 | 41.5 | 78.2 | 163.6 | 18 | |
| MS-SL++ | 12.7 | 33.1 | 46.0 | 82.1 | 173.9 | 13 | |
| Charades-STA | CLIP-cluster | 0.9 | 4.2 | 7.0 | 30.3 | 42.4 | 268 |
| CLIP-psd | 1.0 | 3.9 | 6.7 | 27.8 | 39.5 | 298 | |
| CLIP-svmr | 1.2 | 4.7 | 7.5 | 32.0 | 45.4 | 258 | |
| MS-SL++ | 1.5 | 5.2 | 9.3 | 39.2 | 55.2 | 171 |
- CLIP-cluster: 우리가 제안한 길이 인식 클러스터링(length-aware clustering) 방법으로 모멘트를 생성한다.
- CLIP-psd: 공개된 샷 경계 감지 도구인 PySceneDetect를 사용하여 모멘트를 생성한다.
- CLIP-svmr: 쿼리 의존적인 시간적 경계를 예측하기 위해 여러 SVMR 데이터셋으로 사전학습된 **supervised SVMR 모델인 UniVTG [95]**를 사용하여 모멘트를 생성한다.
모멘트의 시간적 경계가 결정되면, 해당 프레임 수준 feature들을 **평균 풀링(average pooling)**하여 모멘트 수준 feature를 얻는다. 그런 다음, 각 모멘트와 텍스트 쿼리 간의 유사도는 **코사인 유사도(cosine similarity)**를 사용하여 측정되며, 모든 모멘트 중에서 가장 높은 유사도 점수가 랭킹을 위한 최종 비디오-텍스트 관련성 점수로 사용된다.
Table 4에서 보듯이, 우리는 세 가지 벤치마크에서 각 방법의 최고 성능 구성을 보고한다. 세 가지 baseline 중에서 CLIP-svmr은 특히 ActivityNet에서 상대적으로 강력한 성능을 보여주는데, 이는 supervised grounding task에 대한 사전 학습 덕분인 것으로 보인다. 우리가 제안한 길이 인식 클러스터링을 사용하는 CLIP-cluster는 PySceneDetect를 사용하는 CLIP-psd보다 일관되게 우수한 성능을 보여주며, 이는 우리의 클립 선택 전략의 효과를 입증한다. **MS-SL++**는 SumR 및 Med r 측면에서 전반적으로 최고의 성능을 달성한다. 이러한 결과는 학습 기반 최적화의 필요성과 PRVR task에서 fine-grained partial similarity를 모델링하는 것의 이점을 강조한다.
4.4 Comparison with the State-of-the-art
PRVR task에서 우리 방법의 효과를 검증하기 위해, 우리는 기존 CNN 기반 feature와 CLIP 기반 feature에 대한 성능 비교를 수행한다.
CNN 기반 feature의 경우, PRVR을 위해 특별히 설계된 모델이 거의 없으므로, 기존 방법인 **JSG [96]**와 비교하는 것 외에도, 현재 T2VR을 목표로 하는 모델들, 즉 **VSE++ [91], W2VV [27], CE [4], W2VV++ [57], DE [46], HTM [44], HGR [6], DE++ [39]**와 VCMR을 위해 개발된 모델들, 즉 **XML [17] 및 ReLoCLNet [19]**을 추가로 도입하여 비교한다.
CLIP 기반 feature의 경우, 우리는 우리 방법을 여러 최신 CLIP 기반 T2VR 모델들과 비교한다. 여기에는 **CLIP4Clip [9], X-Pool [61], X-CLIP [101], MeVTR [56], UCoFiA [100], DiCoSA [98], T-MASS [53] 및 TC-MGC [97]**이 포함되며, 또한 CLIP을 teacher model로 사용하여 PRVR을 위한 distillation learning을 수행하는 **DL-DKD [99]**도 포함된다.
모든 VCMR 방법은 2단계로 구성된다. 첫 번째 단계 모듈은 후보 비디오를 검색하는 데 사용되고, 이어서 두 번째 단계 모듈은 후보 비디오 내에서 특정 순간을 localize하는 데 사용된다. PRVR의 경우 순간 주석(moment annotations)을 사용할 수 없으므로, 우리는 이들을 (moment localization 모듈을 제거한 상태로) 우리와 동일한 비디오 feature를 사용하여 재학습시켰다.
TABLE 5
세 가지 PRVR 벤치마크에 대한 PRVR 성능. 모델은 전체 성능을 기준으로 오름차순으로 정렬되어 있다.
| Method | TVR | ActivityNet-Captions | Charades-STA | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@100 | SumR | Med r | R@1 | R@5 | R@10 | R@100 | SumR | Med r | R@1 | R@5 | R@10 | R@100 | SumR | Med r | |
| CNN-based features: | ||||||||||||||||||
| W2VV [27] | 2.6 | 5.6 | 7.5 | 20.6 | 36.3 | 552 | 2.2 | 9.5 | 16.6 | 45.5 | 73.8 | 134 | 0.5 | 2.9 | 4.7 | 24.5 | 32.6 | 541 |
| HGR [6] | 1.7 | 4.9 | 8.3 | 35.2 | 50.1 | 262 | 4.0 | 15.0 | 24.8 | 63.2 | 107.0 | 41 | 1.2 | 3.8 | 7.3 | 33.4 | 45.7 | 263 |
| HTM [44] | 3.8 | 12.0 | 19.1 | 63.2 | 98.2 | 59 | 3.7 | 13.7 | 22.3 | 66.2 | 105.9 | 44 | 1.2 | 5.4 | 9.2 | 44.2 | 60.0 | 125 |
| CE [4] | 3.7 | 12.8 | 20.1 | 64.5 | 101.1 | 65 | 5.5 | 19.1 | 29.9 | 71.1 | 125.6 | 26 | 1.3 | 4.5 | 7.3 | 36.0 | 49.1 | 210 |
| W2VV++ [57] | 5.0 | 14.7 | 21.7 | 61.8 | 103.2 | 62 | 5.4 | 18.7 | 29.7 | 68.6 | 122.6 | 30 | 0.9 | 3.5 | 6.6 | 34.3 | 45.3 | 265 |
| VSE++ [91] | 7.5 | 19.9 | 27.7 | 66.0 | 121.1 | 44 | 4.9 | 17.7 | 28.2 | 66.4 | 117.8 | 32 | 0.8 | 3.9 | 7.2 | 31.7 | 43.6 | 281 |
| DE [46] | 7.6 | 20.1 | 28.1 | 67.5 | 123.4 | 43 | 5.6 | 18.8 | 29.4 | 68.0 | 121.0 | 30 | 1.5 | 5.7 | 9.5 | 36.9 | 53.7 | 188 |
| DE++ [39] | 8.8 | 21.9 | 30.2 | 67.4 | 128.3 | 38 | 5.3 | 18.4 | 29.2 | 68.0 | 121.0 | 31 | 1.7 | 5.6 | 9.6 | 37.1 | 54.1 | 186 |
| RIVRL [55] | 9.4 | 23.4 | 32.2 | 70.6 | 135.6 | 33 | 5.2 | 18.0 | 28.2 | 66.4 | 117.8 | 28 | 1.6 | 5.6 | 9.4 | 37.7 | 54.3 | 183 |
| XML [17] | 10.0 | 26.5 | 37.3 | 81.3 | 155.1 | 21 | 5.3 | 19.4 | 30.6 | 73.1 | 128.4 | 26 | 1.6 | 6.0 | 10.1 | 46.9 | 64.6 | 117 |
| ReLoCLNet [19] | 10.7 | 28.1 | 38.1 | 80.3 | 157.1 | 20 | 5.7 | 18.9 | 30.0 | 72.0 | 126.6 | 26 | 1.2 | 5.4 | 10.0 | 45.6 | 62.3 | 118 |
| JSG [96] | 11.3 | 29.1 | 39.6 | 80.9 | 161.0 | 19 | 6.7 | 22.5 | 34.8 | 76.2 | 140.3 | 23 | 1.8 | 7.2 | 11.9 | 48.3 | 69.2 | 108 |
| MS-SL++ | 13.6 | 33.1 | 44.2 | 83.5 | 174.5 | 14 | 7.0 | 23.1 | 35.2 | 75.8 | 141.1 | 22 | 1.8 | 7.6 | 12.0 | 48.4 | 69.7 | 108 |
| CLIP-based features: | ||||||||||||||||||
| CLIP4Clip-meanP [9] | 5.5 | 13.8 | 19.4 | 52.3 | 91.0 | 89 | 11.0 | 26.4 | 36.6 | 72.0 | 146.0 | 20 | 0.9 | 3.9 | 6.1 | 26.4 | 37.3 | 565 |
| CLIP4Clip-seqLSTM [9] | 11.0 | 25.3 | 34.0 | 73.8 | 144.1 | 27 | 12.8 | 31.9 | 43.1 | 79.2 | 167.0 | 16 | 1.2 | 4.0 | 6.9 | 32.0 | 44.1 | 235 |
| TC-MGC [97] | 11.5 | 28.1 | 38.5 | 79.9 | 158.0 | 21 | 10.1 | 28.3 | 40.6 | 78.6 | 157.5 | 17 | 0.7 | 3.4 | 6.6 | 31.5 | 42.2 | 226 |
| DiCoSA [98] | 12.1 | 28.9 | 38.9 | 78.4 | 158.4 | 21 | 10.4 | 29.0 | 40.4 | 77.7 | 157.5 | 17 | 0.4 | 2.7 | 5.1 | 29.7 | 37.9 | 246 |
| CLIP4Clip-seqTransf [9] | 12.7 | 30.1 | 39.8 | 79.2 | 161.8 | 19 | 12.7 | 30.1 | 43.8 | 79.8 | 168.5 | 16 | 1.1 | 4.2 | 7.3 | 32.8 | 45.4 | 231 |
| X-Pool [61] | 13.5 | 31.3 | 40.3 | 77.8 | 162.9 | 19 | 13.1 | 33.8 | 45.5 | 80.5 | 172.9 | 13 | 1.2 | 4.3 | 7.6 | 35.5 | 48.7 | 190 |
| T-MASS [53] | 14.1 | 32.6 | 42.8 | 79.1 | 168.6 | 17 | 12.8 | 31.6 | 44.1 | 79.9 | 168.4 | 15 | 0.9 | 3.8 | 6.6 | 31.5 | 47.4 | 231 |
| MeVTR [56] | 13.1 | 32.0 | 40.6 | 79.5 | 165.2 | 18 | 13.0 | 32.3 | 44.5 | 80.8 | 170.6 | 14 | 1.3 | 4.5 | 8.0 | 36.7 | 50.5 | 185 |
| DL-DKD [99] | 14.4 | 34.9 | 45.8 | 84.9 | 179.9 | 13 | 8.0 | 25.0 | 37.5 | 77.1 | 147.6 | 19 | - | - | - | - | - | |
| UCoFiA [100] | 15.0 | 35.3 | 46.2 | 84.6 | 181.1 | 14 | 11.6 | 30.1 | 42.3 | 79.5 | 163.5 | 16 | 0.9 | 3.8 | 6.3 | 31.0 | 41.1 | 234 |
| X-CLIP [101] | 15.5 | 35.8 | 46.7 | 85.0 | 183.1 | 13 | 10.7 | 29.3 | 41.9 | 78.8 | 160.8 | 16 | 0.9 | 3.4 | 6.3 | 31.7 | 42.4 | 232 |
| MS-SL++ | 23.4 | 47.2 | 58.3 | 90.1 | 219.0 | 6 | 12.7 | 33.1 | 46.0 | 82.1 | 173.9 | 13 | 1.5 | 5.2 | 9.3 | 39.2 | 55.2 | 171 |
4.4.1 Overall performance comparison
Table 5는 세 가지 PRVR 벤치마크에 대한 성능 비교를 요약한다. CNN 기반 visual feature를 사용하는 경우, 우리가 제안한 모델은 모든 T2VR 모델을 확실한 차이로 지속적으로 능가한다. T2VR 모델 중 가장 성능이 좋은 RIVRL 모델보다도 우리 모델은 SumR 측면에서 38.9 더 높은 성능을 보인다. 이 모델들은 비디오와 쿼리 간의 전체적인 유사성에 초점을 맞추기 때문에, 이러한 결과는 전체 유사성 모델링이 PRVR에 최적화되지 않았음을 시사한다. VCMR task를 해결하는 XML 및 ReLoCLNet 모델은 T2VR 모델보다 성능이 좋지만, 여전히 우리 모델보다는 떨어진다. 이들은 순간(moment) 검색에 초점을 맞춰 어느 정도 부분적인 관련성을 모델링하지만, 특정 스케일에서만 유사성을 계산한다. PRVR-specific 모델인 JSG는 ActivityNet-Captions 및 Charades-STA 데이터셋에서 우리 모델과 비슷한 결과를 달성하지만, 우리 MSSL++는 TVR 데이터셋에서 확실한 차이로 JSG를 능가한다. 우리는 제안된 모델의 우수한 성능이 클립 및 프레임 스케일 모두에서 유사성을 공동으로 고려하는 데 기인한다고 본다.
ActivityNet-Captions 및 Charades-STA 데이터셋 모두에서 우리 모델은 여전히 최고의 성능을 보인다. 이 결과는 비디오와 쿼리 간의 부분적인 관련성을 측정하는 우리 모델의 효과를 다시 한번 입증한다. 흥미롭게도, HTM은 TVR 및 ActivityNetCaptions에서 좋지 않은 성능을 보이는 반면, Charades-STA에서는 T2VR 모델 중 최고의 SumR 점수를 달성한다. Charades-STA는 세 데이터셋 중 가장 적은 학습 데이터를 가지고 있음을 상기하자. HTM의 극도로 단순한 네트워크 구조는 소규모 데이터로 학습할 때 장점이 된다. 우리 모델은 다양한 수의 학습 샘플을 가진 세 데이터셋에서 일관되게 최고의 성능을 보이며, 이는 우리 모델이 학습 데이터의 규모에 민감하지 않음을 어느 정도 보여준다.
CLIP 기반 visual feature 비교에서는 우리 MS-SL++ 모델 또한 세 데이터셋에서 선두적인 위치에 있다. 우리는 또한 T-MASS와 같이 기존 T2VR task에서 좋은 성능을 보이는 모델들이 우리가 제안한 PRVR task에서는 일관되게 강력한 결과를 달성하지 못함을 관찰한다. 대조적으로, X CLIP 및 UCoFiA와 같이 다중 granularity 유사성 모델링을 통합한 방법들이 상대적으로 더 나은 성능을 보이는 경향이 있다. 이는 PRVR task가 전체적인 매칭에만 의존하기보다는 텍스트 쿼리와 untrimmed 비디오 간의 fine-grained 부분 정렬을 강조한다는 것을 다시 한번 시사한다. 또한, CNN 기반 feature를 사용하는 우리 모델과 달리, CLIP feature를 사용하면 TVR 및 ActivityNetCaptions 데이터셋에서 검색 성능이 분명히 향상되지만, Charades-STA에서는 성능이 감소한다. 우리는 이러한 성능 저하가 주로 동적인 인간 행동에 초점을 맞춘 Charades-STA 비디오의 특성에 기인한다고 본다. 결과적으로, Charades-STA에서는 인간 행동 인식 비디오 데이터셋으로 사전학습된 CNN 기반 I3D feature가 정적 이미지로 학습된 CLIP feature보다 우수하다.
4.4.2 Grouped performance comparison
개별 모델에 대한 추가적인 이해를 얻기 위해, 우리는 쿼리당 moment-to-video ratio (M/V) 를 정의한다. 이는 해당 moment의 길이가 전체 비디오에서 차지하는 비율로 측정된다. M/V가 작을수록 쿼리에 대한 관련 콘텐츠가 적고, 관련 없는 콘텐츠가 많음을 나타낸다. 다시 말해, M/V가 작을수록 쿼리와 해당 비디오 간의 관련성이 낮고, M/V가 클수록 관련성이 높음을 의미한다. M/V에 따라 쿼리들을 자동으로 여러 그룹으로 분류할 수 있으며, 이는 특정 모델이 다양한 유형의 쿼리에 어떻게 반응하는지에 대한 세분화된 분석을 가능하게 한다. TVR 데이터셋의 경우, 우리는 10,895개의 테스트 쿼리를 M/V에 따라 6개 그룹으로 나누었으며, 각 그룹의 성능은 Fig. 6에 나타나 있다. 예상대로, 우리 모델은 모든 그룹에서 일관되게 최고의 성능을 보인다.
 Fig. 6. 다양한 유형의 쿼리에 대한 여러 모델의 성능. 쿼리는 M/V에 따라 그룹화되었다. M/V가 가장 작은 그룹에서 최소 성능을 보이며, 이 그룹에 대한 비디오 검색이 더 어렵다는 것을 나타낸다. 그림을 왼쪽에서 오른쪽으로 보면, 비교된 12개 모델의 평균 성능은 쿼리의 M/V가 증가함에 따라 111.2, 118.1, 117.5, 123.1, 129.5, 129.7로 증가한다. 이는 현재 비디오 검색 baseline 모델들이 더 큰 M/V를 가진 쿼리에 더 잘 대응함을 보여준다.
Fig. 6. 다양한 유형의 쿼리에 대한 여러 모델의 성능. 쿼리는 M/V에 따라 그룹화되었다. M/V가 가장 작은 그룹에서 최소 성능을 보이며, 이 그룹에 대한 비디오 검색이 더 어렵다는 것을 나타낸다. 그림을 왼쪽에서 오른쪽으로 보면, 비교된 12개 모델의 평균 성능은 쿼리의 M/V가 증가함에 따라 111.2, 118.1, 117.5, 123.1, 129.5, 129.7로 증가한다. 이는 현재 비디오 검색 baseline 모델들이 더 큰 M/V를 가진 쿼리에 더 잘 대응함을 보여준다.
그림을 왼쪽에서 오른쪽으로 보면, 비교된 12개 모델의 평균 성능은 M/V가 증가함에 따라 111.2, 118.1, 117.5, 123.1, 129.5, 129.7로 증가한다. 가장 낮은 M/V 그룹에서 성능이 가장 작고, 가장 높은 M/V 그룹에서 성능이 가장 크다. 이 결과는 현재 비디오 검색 baseline 모델들이 해당 비디오에 대한 관련성이 더 큰 쿼리에 더 잘 대응한다는 것을 시사한다. 대조적으로, 우리가 달성한 성능은 모든 그룹에서 더 균형 잡혀 있다. 이 결과는 우리가 제안한 모델이 비디오 내의 관련 없는 콘텐츠에 덜 민감하다는 것을 보여준다.
4.4.3 Robustness analysis
이 섹션에서는 노이즈를 추가하여 각 방법의 강건성(robustness)을 연구한다. 구체적으로, [16]에서 설명된 안정성 검증 실험을 따라, 초 길이의 각 테스트 비디오에 -레벨 노이즈를 추가한다. 즉, 초 길이의 무작위로 생성된 비디오 클립이 비디오의 시작 부분에 삽입된다. 삽입된 비디오 클립의 프레임 feature는 정규 분포에서 무작위로 생성된다. 정규 분포의 평균과 표준 편차는 각각 학습 비디오의 모든 프레임 feature의 평균과 표준 편차로 설정된다. TVR 데이터셋에서 노이즈 레벨에 따른 성능 곡선은 Fig. 7에 나와 있다. 예상대로, 더 많은 노이즈가 추가될수록 모든 방법의 성능은 감소한다. 모든 노이즈 레벨에서 우리의 제안 방법은 다른 방법들보다 여전히 우수하다.
4.5 Generalization Ability on Unseen Data
모델의 미학습 데이터셋(unseen datasets)에 대한 일반화 능력을 평가하기 위해, 우리는 TVR 데이터셋으로 학습하고 ActivityNet-Captions 데이터셋으로 테스트하는 cross-dataset 평가를 수행하였다. CLIP 기반의 baseline 모델들과 비교한 결과, Table 6에서 볼 수 있듯이 제안된 모델이 더 나은 일반화 능력을 보여주었다.
 Fig. 7. TVR 데이터셋에 인위적인 노이즈를 추가했을 때, 다양한 방법들의 성능 곡선을 보여준다. 제안된 방법은 다양한 수준의 노이즈 조건에서도 다른 방법들보다 일관되게 우수한 성능을 보인다.
Fig. 7. TVR 데이터셋에 인위적인 노이즈를 추가했을 때, 다양한 방법들의 성능 곡선을 보여준다. 제안된 방법은 다양한 수준의 노이즈 조건에서도 다른 방법들보다 일관되게 우수한 성능을 보인다.
TABLE 6 Cross-dataset 평가. 학습: TVR. 테스트: ActivityNet-Captions.
| R@1 | R@5 | R@10 | R@100 | SumR | Med R | |
|---|---|---|---|---|---|---|
| X-CLIP [101] | 1.9 | 5.5 | 7.9 | 26.6 | 41.9 | 384 |
| TC-MGC [97] | 2.2 | 8.7 | 13.9 | 44.2 | 69.1 | 142 |
| UCoFiA [100] | 2.9 | 9.8 | 14.8 | 45.2 | 72.7 | 134 |
| DiCoSA [98] | 3.2 | 10.2 | 15.7 | 46.5 | 75.6 | 122 |
| T-MASS [53] | 3.0 | 10.4 | 16.8 | 48.5 | 78.7 | 112 |
| X-Pool [61] | 3.1 | 10.6 | 17.2 | 48.8 | 79.6 | 109 |
| CLIP4clip-seqTransf [9] | 3.3 | 10.9 | 17.1 | 49.0 | 80.2 | 108 |
| MeVTR [56] | 3.5 | 10.8 | 17.8 | 49.3 | 81.3 | 106 |
| MS-SL++ | 3.8 | 12.0 | 18.5 | 50.4 | 84.7 | 98 |
4.6 PRVR for VCMR
우리 모델은 PRVR을 위해 제안되었지만, VCMR의 첫 번째 단계로 사용되어 타겟 순간(target moment)을 포함할 수 있는 비디오를 검색하는 데에도 활용될 수 있다. 이 실험에서는 VCMR에서 일반적으로 사용되는 Recall@ () 지표로 성능을 평가한다.
VCMR에 대한 잠재력을 입증하기 위해, 우리는 두 VCMR 모델(XML [17] 및 ReLoCLNet [19])의 첫 번째 단계를 우리 모델로 대체하고, 나머지 프로세스는 그대로 유지하였다.
 Fig. 8. VCMR을 위한 첫 번째 단계로 우리 모델을 사용했을 때와 사용하지 않았을 때의 XML 및 ReLoCLNet 성능.
Fig. 8. VCMR을 위한 첫 번째 단계로 우리 모델을 사용했을 때와 사용하지 않았을 때의 XML 및 ReLoCLNet 성능.
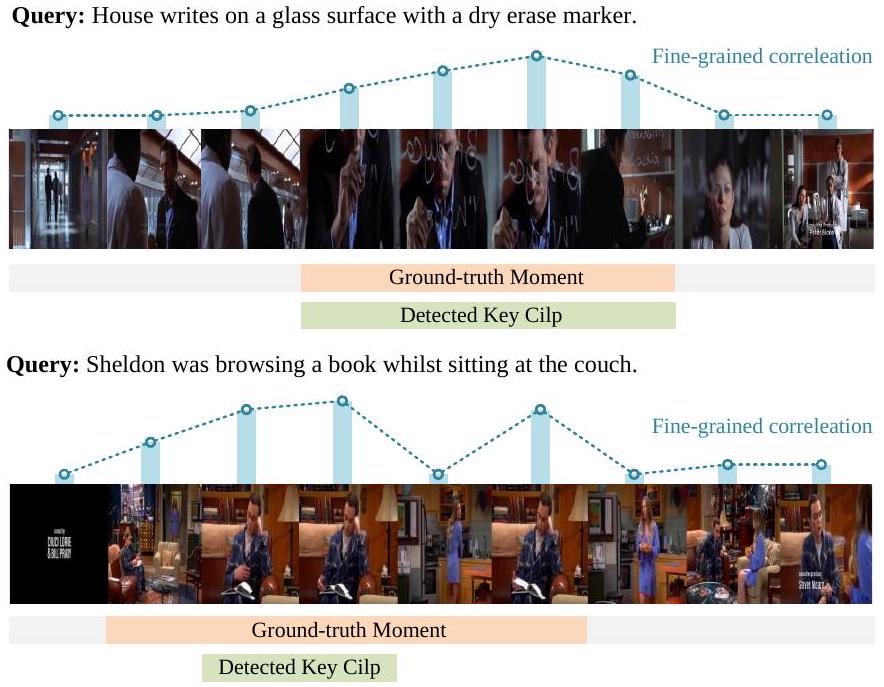
Query: Chandler and Monica sway their babies together in their arms.

Fig. 9. TVR 데이터셋에 대한 PRVR 시각화 결과.
모든 모델은 비디오 표현을 위해 시각 feature와 자막 feature를 모두 사용한다. Fig. 8은 TVR 데이터셋에서 원본 모델과 우리 모델로 첫 단계를 대체한 모델의 성능을 보여준다. 여기서 우리는 서로 다른 IoU에서의 모든 Recall 값의 합인 SumR을 보고한다.
첫 번째 단계를 우리 모델로 대체한 후, 모든 모델에서 일관된 성능 향상이 나타났다. 이는 우리 방법이 VCMR 성능 향상에 사용될 수 있음을 입증한다.
4.7 Qualitative Results
PRVR 결과 시각화.
제안된 PRVR을 더 자세히 조사하기 위해 Figure 9에 시각화 예시를 제공한다. 각 예시에서 우리는 감지된 key clip과 프레임 수준의 fine-grained correlation을 시각화한다. Key clip은 clip-scale SL branch에 의해 감지되며, correlation score는 frame-scale SL branch에 의해 얻어진다.
첫 번째 예시에서, 우리 모델에 의해 감지된 key clip은 ground-truth moment와 잘 정렬되어 있으며, ground-truth moment 내의 대부분의 프레임 또한 높은 correlation score를 보인다. 이 결과는 우리 모델이 거친 clip 수준과 fine-grained frame 수준 모두에서 관련 콘텐츠를 식별할 수 있음을 어느 정도 보여준다.
나머지 두 예시에서는 감지된 key clip이 완벽하지 않고 ground-truth moment와 약간만 겹치지만, 우리 모델의 frame-scale SL branch가 관련 프레임에 대해 높은 correlation score를 예측함으로써 이를 보완하여 query 관련 콘텐츠의 더 미세한 세부 사항을 포착하는 데 도움을 준다. 이러한 결과는 우리 모델의 multi-scale modeling 설계의 효과를 다시 한번 보여준다.
t-SNE를 통한 시각화 분석.
length-aware clustering의 효과를 더 탐색하기 위해 Figure 10에 t-SNE를 사용한 clip feature 시각화를 제공한다. 각 예시에서 우리는 원본 clip, vanilla clustering으로 얻은 selective clip, 그리고 length-aware clustering으로 얻은 selective clip의 분포를 시각화한다.
다른 색상의 점들은 다른 길이의 clip을 나타내며, 서로 가까운 점들은 의미적으로 더 유사하다. Figure 10 (a)에서 보듯이, 많은 점들이 가깝게 군집되어 있어 원본 clip의 중복성을 보여주며 효과적인 clip 선택의 필요성을 강조한다.
Figure 10 (b)와 (c)는 각각 vanilla clustering과 length-aware clustering으로 얻은 selective clip의 결과를 보여준다. Vanilla clustering은 일부 중복성을 줄이지만 clip 길이의 가변성을 완전히 설명하지 못한다. 이에 비해, 제안된 length-aware clustering은 중복성을 해결할 뿐만 아니라 다른 길이의 clip 간의 의미적 차이를 더 잘 포착하여, 더 균형 잡히고 대표적인 key clip 선택으로 이어진다.
5 Concluding Remarks
본 논문에서는 다양한 쿼리 관련 콘텐츠를 포함하는 비디오를 처리하는 데 더 실용적인 새로운 T2VR 하위 task인 PRVR을 제안한다. 기존 T2VR은 검색 대상 비디오가 트리밍되어 주어진 쿼리에 대해 완전히 관련성이 있다고 가정하는 반면, PRVR에서는 비디오가 트리밍되지 않은(untrimmed) 상태이며 쿼리에 대해 부분적으로만 관련성을 가진다. PRVR은 또한 SVMR 및 VCMR과도 다르며, 이 두 다운스트림 task에 대해 대략적으로 검색된 비디오를 제공하는 중요한 중간 단계 역할을 한다. PRVR을 연구하는 것은 의미 있지만 도전적인 과제이다. 비디오 수준의 어노테이션으로부터 학습하기 위해, 우리는 PRVR task를 MIL(Multiple Instance Learning) 문제로 공식화하고, 이에 따라 클립 및 프레임 스케일에서 비디오-쿼리 관련성 점수를 coarse-to-fine 방식으로 계산하는 새로운 MS-SL++ 모델을 개발한다. 세 가지 데이터셋에 대한 광범위한 실험은 PRVR에 대한 MS-SL++의 효과를 검증한다. 이 모델은 VCMR에도 유익한 것으로 나타났다.