mPLUG-Owl: 모듈화로 멀티모달리티를 구현한 Large Language Model
mPLUG-Owl은 foundation LLM, visual knowledge module, visual abstractor module의 모듈화된 학습을 통해 LLM에 멀티모달 능력을 부여하는 새로운 학습 패러다임입니다. 이 접근법은 2단계 학습을 통해 이미지와 텍스트를 정렬하며, 1단계에서는 LLM을 고정한 채 visual module들을 학습시키고, 2단계에서는 LoRA를 사용하여 LLM과 abstractor module을 공동으로 미세 조정합니다. 이를 통해 mPLUG-Owl은 강력한 지시 이해, 시각 이해, 다중 턴 대화 및 추론 능력을 보여줍니다. 논문 제목: mPLUG-Owl : Modularization Empowers Large Language Models with Multimodality
논문 요약: mPLUG-Owl : Modularization Empowers Large Language Models with Multimodality
- 논문 링크: https://arxiv.org/abs/2304.14178
- 저자: Qinghao Ye et al. (DAMO Academy, Alibaba Group)
- 발표 시기: 2023년, arXiv
- 주요 키워드: Multimodal LLM, Instruction Tuning, LLM, NLP
1. 연구 배경 및 문제 정의
- 문제 정의:
대규모 언어 모델(LLM)은 텍스트 기반 태스크에서 뛰어난 성능을 보이지만, GPT-4를 제외하고는 대부분의 LLM이 다양한 모달리티(특히 시각) 입력을 지원하지 못하며 인상적인 멀티모달 능력을 개발하지 못하고 있다. - 기존 접근 방식:
- 체계적 협업 (Systematic Collaboration) 방식: Visual ChatGPT, MM-REACT, HuggingGPT 등.
- 방법: 다양한 비전 모델 또는 도구를 활용하여 시각 정보를 텍스트 설명으로 표현하고, LLM이 에이전트 역할을 수행하여 적절한 도구를 선택하고 출력을 요약한다.
- 한계: 다른 모달리티와의 정렬(alignment) 부족으로 특정 멀티모달 지시를 이해하지 못할 수 있으며, 추론 효율성 및 비용 문제가 발생할 수 있다.
- End-to-end 학습 모델 방식: BLIP-2, LLaVA, MiniGPT-4 등.
- 방법: 통합된 모델을 사용하여 다른 모달리티를 지원한다.
- 한계: 고정된(frozen) visual model을 사용하기 때문에 제한된 파라미터 수로 인해 부적절한 정렬을 초래할 수 있으며, 단일 모달 및 멀티모달 지시의 부족으로 다양한 능력을 발휘하지 못한다.
- 체계적 협업 (Systematic Collaboration) 방식: Visual ChatGPT, MM-REACT, HuggingGPT 등.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 모듈화를 통해 대규모 언어 모델을 위한 새로운 학습 패러다임인 mPLUG-Owl을 제안한다.
- 시각 관련 태스크에서 다양한 모델의 능력을 평가하기 위해 OwlEval이라는 지시 평가 세트를 신중하게 구축했다.
- 실험 결과, mPLUG-Owl이 멀티모달 지시 이해 및 다중 턴 대화에서 탁월하며, 기존 모델의 성능을 능가함을 입증했다.
- 제안 방법:
mPLUG-Owl은 기반 LLM(), 시각 지식 모듈(), 시각 추상화 모듈()의 모듈화된 학습을 통해 LLM에 멀티모달 능력을 부여하는 새로운 패러다임을 제시한다.- 아키텍처:
- Visual Foundation Model (): 시각 지식 인코딩을 담당 (예: ViT-L/14).
- Language Foundation Model (): 언어 모델 (예: LLaMA-7B).
- Visual Abstractor Module (): 로부터 얻은 dense image representation을 몇 개의 학습 가능한 토큰으로 요약하여 더 높은 의미론적 시각 표현을 얻고 연산량을 줄인다.
- 2단계 학습 패러다임:
- 멀티모달 사전학습 (Multimodal Pretraining):
- 목표: 이미지와 텍스트를 정렬하고, LLM의 도움을 받아 시각 지식을 학습하며 LLM의 생성 능력을 유지/향상시킨다.
- 방법: 시각 지식 모듈()과 추상화 모듈()을 학습시키고, 사전학습된 LLM()은 고정(frozen) 상태로 유지한다. 이를 통해 저수준 및 고수준 시각 정보를 효과적으로 포착하고 LLM과 정렬시킨다.
- 공동 지시 튜닝 (Joint Instruction Tuning):
- 목표: mPLUG-Owl과 인간의 지시 및 의도 간의 더 나은 정렬을 촉진하고, 일관된 언어적 응답을 생성한다.
- 방법: 시각 지식 모듈()을 고정(freeze)한 채, **LLM의 LoRA(Low-Rank Adaption) 모듈과 추상화 모듈()을 공동으로 미세 조정(fine-tuning)**한다. 텍스트 전용 및 멀티모달 supervised 데이터셋을 함께 사용하여 학습한다.
- 멀티모달 사전학습 (Multimodal Pretraining):
- 아키텍처:
3. 실험 결과
- 데이터셋:
- 멀티모달 사전학습: LAION-400M, COYO-700M, Conceptual Captions, MSCOCO의 이미지-캡션 쌍.
- 공동 지시 튜닝: Alpaca (102k), Vicuna (90k), Baize (50k)의 순수 텍스트 instruction 데이터와 LLaVA 데이터셋 (150k)의 멀티모달 instruction 데이터.
- 평가: OwlEval (50개 이미지 기반 82개 질문으로 구성된 시각 관련 지시 평가 세트).
- 주요 결과:
- OwlEval 정량적 평가: mPLUG-Owl은 66개의 A/B 등급 응답을 받아 가장 경쟁력 있는 MiniGPT-4(54개)를 능가했으며, D 등급 응답이 전혀 없어 모든 모델 중 가장 우수한 성능을 보였다. 단일 턴 및 다중 턴 대화 모두에서 뛰어난 성능을 달성했다.
- Ablation Study: 멀티모달 사전학습과 공동 지시 튜닝을 모두 적용했을 때 모델이 최고의 성능을 달성하여, 제안된 2단계 학습 방식의 효과를 입증했다. 텍스트 전용 instruction tuning은 지시 이해에, 멀티모달 instruction tuning은 지식 및 추론 능력에 더 큰 개선을 가져왔다.
- 정성적 분석:
- 지식 집약적 QA: 이미지 속 영화 캐릭터 식별 등에서 기존 모델보다 뛰어난 지식 이해 능력을 보여주었다.
- 다중 턴 대화: 참조 정보에 기반한 이미지 내용 식별에서 세밀한 이해와 정확한 응답을 제공했다.
- 추론: 시각 정보에 기반한 예측과 그 이유를 설명하는 데 있어 설득력 있는 추론 능력을 보였다.
- 농담 이해: 시각적으로 관련된 농담을 이해하고 설명할 수 있었으나, 학습 데이터의 시각 정보 제한으로 인한 일부 오류도 관찰되었다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 기존 LLM에 모듈화된 학습 패러다임을 통해 효과적으로 멀티모달 능력을 부여했다는 점이 인상 깊다.
- LLM을 고정한 채 시각 모듈을 학습하고, 이후 LoRA를 통해 LLM과 추상화 모듈을 공동 미세 조정하는 2단계 학습 방식은 효율성과 성능 유지/향상이라는 두 마리 토끼를 잡았다.
- OwlEval이라는 체계적인 평가 세트를 구축하여 모델의 다양한 멀티모달 능력을 객관적으로 검증한 점이 훌륭하다.
- 다중 이미지 상관관계, 다국어 대화, 장면 텍스트 이해 등 예상치 못한 흥미로운 초기 능력들을 발견한 점은 향후 연구의 큰 가능성을 보여준다.
- 단점/한계:
- 학습 데이터의 시각 정보 제한으로 인한 OCR 오류 (예: "VGA"를 "USB"로 오인)나 복잡한 장면의 OCR 및 수치 계산 능력의 한계가 존재한다.
- 다중 이미지 상관관계에서 여러 이미지를 연결하지 못하거나 텍스트 환각을 생성하는 사례가 있어, 이 부분의 개선이 필요하다.
- 다국어 데이터 부족으로 다국어 이해는 가능하나 해당 언어로 응답하지 못하는 점은 실제 응용에 제약이 될 수 있다.
- 문서 이해 및 개방형 창작(기능적/실용적) 분야에서 아직 개선의 여지가 많다.
- 응용 가능성:
- 멀티모달 질의응답 시스템: 이미지와 관련된 복잡한 질문에 대한 답변을 제공하는 챗봇 또는 AI 비서.
- 시각 기반 지식 추론: 이미지 속 정보를 바탕으로 추론하고 설명을 생성하는 시스템 (예: 의료 영상 분석 보조).
- 다중 턴 멀티모달 대화: 사용자와 이미지에 대해 지속적으로 대화하며 정보를 주고받는 인터랙티브 AI.
- 문서 이해 및 요약: (향후 개선 시) 이미지 형태의 문서에서 텍스트를 추출하고 내용을 이해하여 요약하거나 질문에 답하는 기능.
- 개방형 창작: (향후 개선 시) 이미지를 기반으로 시, 소설, 광고 문구 등 다양한 창의적 텍스트를 생성하는 도구.
5. 추가 참고 자료
Ye, Qinghao, et al. "mplug-owl: Modularization empowers large language models with multimodality." arXiv preprint arXiv:2304.14178 (2023).
mPLUG-Owl : Modularization Empowers Large Language Models with Multimodality
Qinghao Ye*, Haiyang Xu*, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, Chenliang Li, Yuanhong Xu, Hehong Chen, Junfeng Tian, Qi Qian, Ji Zhang, Fei Huang, Jingren Zhou DAMO Academy, Alibaba Group<br>{yeqinghao.yqh, shuofeng.xhy, guohai.xgh, ym119608}@alibaba-inc.com
Abstract
Large Language Model (LLM)은 다양한 open-ended task에서 인상적인 zero-shot 능력을 보여주었으며, 최근 연구에서는 멀티모달 생성(multi-modal generation)을 위해 LLM을 활용하는 방안도 탐구되었다. 본 연구에서는 mPLUG-Owl을 소개한다. mPLUG-Owl은 기반 LLM, 시각 지식 모듈(visual knowledge module), 시각 추상화 모듈(visual abstractor module)의 모듈화된 학습을 통해 LLM에 멀티모달 능력을 부여하는 새로운 학습 패러다임이다. 이 접근 방식은 다중 모달리티를 지원하고, 모달리티 간 협업을 통해 다양한 단일 모달 및 멀티모달 능력을 촉진할 수 있다.
mPLUG-Owl의 학습 패러다임은 이미지와 텍스트를 정렬(align)하기 위한 2단계 방법을 포함하며, 이는 LLM의 도움을 받아 시각 지식을 학습하는 동시에 LLM의 생성 능력을 유지하고 심지어 향상시킨다. 첫 번째 단계에서는 시각 지식 모듈과 추상화 모듈이 고정된(frozen) LLM 모듈과 함께 학습되어 이미지와 텍스트를 정렬한다. 두 번째 단계에서는 language-only 및 멀티모달 supervised 데이터셋을 사용하여 시각 지식 모듈을 고정한 채 LLM의 LoRA(Low-Rank Adaption) 모듈과 추상화 모듈을 공동으로 fine-tuning한다.
우리는 시각 관련 지시 평가 세트인 OwlEval을 신중하게 구축하였다. 실험 결과, 우리 모델은 기존 멀티모달 모델들을 능가하며, mPLUG-Owl의 인상적인 지시 및 시각 이해 능력, 다중 턴 대화 능력, 지식 추론 능력을 입증한다. 또한, **다중 이미지 상관관계(multi-image correlation) 및 장면 텍스트 이해(scene text understanding)**와 같은 예상치 못한 흥미로운 능력들도 관찰되었는데, 이는 vision-only 문서 이해와 같은 더 어려운 실제 시나리오에 mPLUG-Owl을 활용할 가능성을 열어준다.
우리의 코드, 사전학습된 모델, instruction-tuned 모델, 그리고 평가 세트는 https://github.com/X-PLUG/mPLUG-Owl 에서 확인할 수 있다. 온라인 데모는 https://www.modelscope.cn/studios/damo/mPLUG-Owl 에서 이용 가능하다.
1 Introduction
GPT-3 [Brown et al., 2020], BLOOM [Scao et al., 2022], LLaMA [Touvron et al., 2023]와 같은 **대규모 언어 모델(LLM)**은 일반 인공지능을 가능하게 하는 급속한 발전을 경험했으며, 다양한 언어 응용 분야에서 인상적인 zero-shot 능력을 보여주었다. 그러나 GPT-4 [OpenAI, 2023]를 제외하고는 현재의 일반 LLM은 다양한 modality의 입력을 지원하지 못하며 인상적인 멀티모달 능력을 개발하지 못하고 있다.
GPT-4 [OpenAI, 2023]가 놀라운 멀티모달 능력을 보여주었음에도 불구하고, 그 탁월한 능력 뒤에 숨겨진 방법론은 여전히 미스터리로 남아있다. 최근 연구자들은 LLM을 확장하여 두 가지 다른 패러다임으로 시각적 입력을 이해하도록 시도하고 있다: 체계적 협업(systematic collaboration) 방식과 end-to-end 학습 모델 방식이다.
Visual ChatGPT [Wu et al., 2023], MM-REACT [Yang et al., 2023], HuggingGPT [Shen et al., 2023]를 포함한 체계적 협업 접근 방식은 다양한 vision model 또는 tool의 조정을 용이하게 하여 텍스트 설명을 통해 시각 정보를 표현하도록 설계되었다. 그러나 이러한 접근 방식은 다른 modality와의 정렬(alignment) 부족으로 인해 특정 멀티모달 지시를 이해하지 못할 수 있다. 또한, 이러한 접근 방식은 추론 효율성 및 비용과 관련된 문제에 직면할 수 있다.
BLIP-2 [Li et al., 2023], LLaVA [Liu et al., 2023], MiniGPT-4 [Zhu et al., 2023a]와 같은 end-to-end 모델은 통합된 모델을 사용하여 다른 modality를 지원하는 것을 목표로 한다. 그러나 이러한 모델은 frozen된 visual model을 사용하기 때문에 제한된 파라미터 수로 인해 부적절한 정렬로 이어질 수 있다는 한계가 있다. 더욱이, 단일 모달(unimodal) 및 멀티모달 지시의 부족으로 인해 다양한 능력을 발휘하지 못한다.
본 논문에서는 모듈화(modularization) 개념 [Xu et al., 2023b, Li et al., 2022, Xu et al., 2021, Ye et al., 2022]에서 영감을 받아, 여러 modality를 동시에 지원할 수 있는 대규모 멀티모달 언어 모델을 위한 혁신적인 모듈화된 학습 패러다임인 mPLUG-Owl을 제시한다. 우리의 방법은 사전학습된 LLM, visual knowledge module, 그리고 연결된 visual abstractor module의 힘을 활용하여 이미지와 텍스트 간의 효과적인 정렬을 달성하고, 두 단계 학습 방식(two-stage training scheme)을 사용하여 인상적인 단일 모달 및 멀티모달 능력을 자극한다. 우리의 접근 방식은 modality 간의 협업을 통해 LLM의 강력한 생성 능력을 향상시키기까지 한다.
첫 번째 단계에서는 텍스트-이미지 쌍을 사용하여 포괄적인 시각 지식을 습득하기 위해 이미지와 텍스트를 정렬한다. 이는 frozen된 LLM module과 함께 visual knowledge module 및 abstractor module을 학습함으로써 이루어진다. 이어서, 단일 모달 및 멀티모달 지시를 통해 mPLUG-Owl을 fine-tuning하여 다양한 단일 모달 및 멀티모달 능력을 발휘하도록 한다. 우리는 visual knowledge module을 고정(freeze)하고 LLM 및 visual abstractor module에 대해 low-rank adaption (LoRA) [Hu et al., 2022]를 공동으로 학습시킨다. 이 접근 방식은 텍스트 및 시각 정보의 효과적인 통합을 가능하게 하여 다재다능하고 견고한 인지 능력 개발을 촉진한다.
우리가 신중하게 구축한 시각 관련 지시 평가 세트인 OwlEval에 대한 실험 결과는 mPLUG-Owl이 MiniGPT-4 [Zhu et al., 2023a] 및 LLaVA [Liu et al., 2023]와 같은 기존 모델들을 능가함을 보여준다. 우리는 mPLUG-Owl의 지시 이해, 시각 이해, 지식 전이, 다중 턴 대화에서의 놀라운 능력을 개별적으로 검증한다. 우리의 학습 패러다임의 효과를 보여주기 위해 풍부한 ablation study를 수행한다. 또한, 다중 이미지 상관관계, 다국어 대화, 장면 텍스트 이해와 같은 예상치 못한 새로운 능력도 발견한다.
우리의 주요 기여는 다음과 같다:
- 우리는 모듈화를 통해 대규모 언어 모델을 위한 새로운 학습 패러다임인 mPLUG-Owl을 제안한다.
- 우리는 시각 관련 task에서 다양한 모델의 능력을 평가하기 위해 OwlEval이라는 지시 평가 세트를 신중하게 구축한다.
- 실험 결과는 mPLUG-Owl이 멀티모달 지시 이해 및 다중 턴 대화에서 탁월하며, 기존 모델의 성능을 능가함을 입증한다.
2 Related Work
2.1 Large Language Models
최근 들어 **Large Language Model (LLM)**은 다양한 자연어 처리(NLP) task에서 뛰어난 성능을 보여주며 큰 주목을 받고 있다. 초기에는 BERT [Devlin et al., 2019], GPT [Radford and Narasimhan, 2018], T5 [Raffel et al., 2020]와 같은 Transformer 모델들이 각기 다른 사전학습(pre-training) 목표를 가지고 개발되었다. 그러나 GPT3 [Brown et al., 2020]의 등장은 모델 파라미터 수와 데이터 크기를 확장함으로써 뛰어난 zero-shot generalization 능력을 선보였고, 이를 통해 이전에 보지 못했던 task에서도 훌륭한 성능을 발휘할 수 있게 되었다. 그 결과 OPT [Zhang et al., 2022], BLOOM [Scao et al., 2022], PaLM [Chowdhery et al., 2022], LLaMA [Touvron et al., 2023] 등 수많은 LLM이 개발되며 LLM의 성공 시대를 열었다.
또한 Ouyang et al. [Ouyang et al., 2022]은 인간의 지시와 피드백을 GPT-3에 맞춰 정렬(align)하는 InstructGPT를 제안하였다. 나아가 이는 ChatGPT [OpenAI, 2022]에 적용되어, 다양하고 복잡한 질문과 지시에 응답하며 인간과의 대화형 상호작용을 가능하게 하였다.
2.2 Multi-Modal Large Language Models
자연어 처리 분야에서 LLM이 성공적으로 적용되었음에도 불구하고, LLM이 시각이나 오디오와 같은 다른 modality를 인지하는 데는 여전히 어려움이 있다. 최근 연구자들은 **체계적인 협업(systematic collaboration)**과 end-to-end 학습 모델이라는 두 가지 다른 패러다임을 통해 언어 모델이 시각적 입력을 이해하도록 확장하고 있다.
체계적인 협업(systematic collaboration) 접근 방식으로는 Visual ChatGPT [Wu et al., 2023], MM-REACT [Yang et al., 2023], HuggingGPT [Shen et al., 2023] 등이 있으며, 이들은 다양한 vision expert 또는 tool을 활용하여 시각 정보를 텍스트 설명으로 표현한다. 이후 ChatGPT와 같은 대규모 언어 모델이 agent 역할을 수행하며, 시각 이해를 위한 적절한 expert와 tool을 선택하도록 prompt된다. 마지막으로 LLM은 이러한 expert들의 출력을 요약하여 사용자 질의에 응답한다.
반면에, 일부 접근 방식 [Li et al., 2023, Alayrac et al., 2022, Liu et al., 2023]은 사전학습된 대규모 언어 모델을 활용하여 멀티모달리티를 위한 통합 모델을 구축한다. 예를 들어, Flamingo [Alayrac et al., 2022]는 사전학습된 vision encoder와 대규모 language model을 고정(freeze)하고, gated cross-attention을 통해 시각 및 언어 modality를 융합하여 인상적인 few-shot 능력을 보여준다. 또한, BLIP-2 [Li et al., 2023]는 **Q-Former를 설계하여 frozen visual encoder의 시각 feature와 Flan-T5 [Chung et al., 2022] 및 OPT [Zhang et al., 2022]와 같은 대규모 language model을 정렬(align)**한다. 나아가 PaLM-E [Driess et al., 2023]는 5,200억 개의 파라미터를 가진 PaLM [Chowdhery et al., 2022]에 센서 modality의 feature를 직접 입력하여 실제 세계 인지에서 강력한 성능을 보여준다.
더 나아가, 오픈소스 foundation model인 LLaMA [Touvron et al., 2023]를 기반으로 구축된 강력한 instruction-tuned language model들, 예를 들어 Alpaca [Taori et al., 2023]와 Vicuna [Vicuna, 2023]는 ChatGPT [OpenAI, 2022] 및 GPT-4 [OpenAI, 2023]와 비교할 만한 성능을 보인다. MiniGPT-4 [Zhu et al., 2023a]와 LLaVA [Liu et al., 2023]는 이러한 fine-tuned 모델들을 **frozen visual backbone에서 추출된 시각 feature와 정렬(align)**한다. 이와 대조적으로, mPLUG-Owl은 지식 습득 및 실제 세계에 대한 grounding 측면에서 vision 및 language foundation model (예: CLIP 및 LLaMA) 간의 표현을 정렬할 뿐만 아니라, 언어 및 멀티모달 instruction을 이해하여 강력한 zero-shot generalization 및 multi-turn conversation 능력을 보여준다.
3 mPLUG-Owl
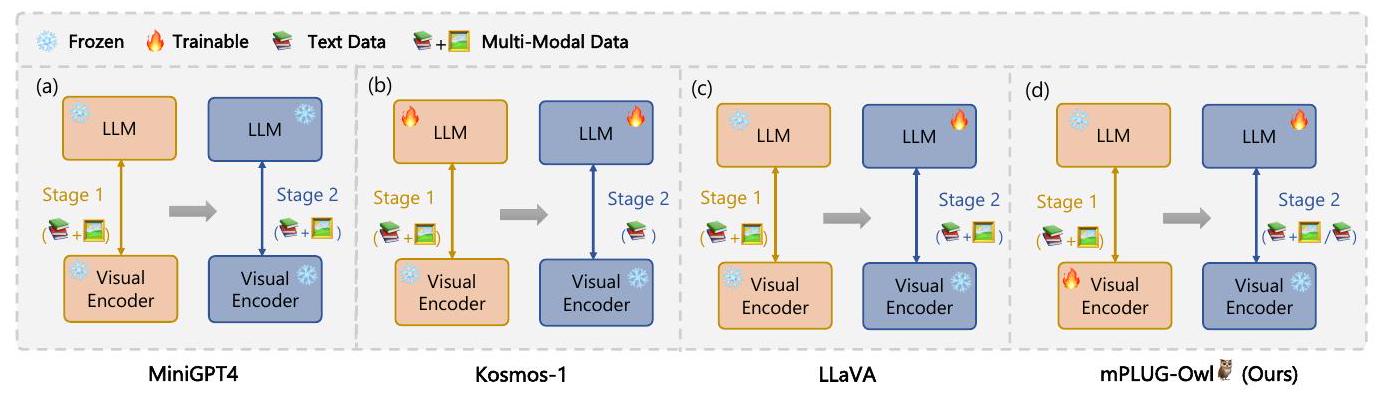
Figure 1: 다양한 학습 패러다임 간의 비교. 이 모든 방법은 두 단계(two-stage) 방식으로 학습된다. Stage 1은 pre-training을, Stage 2는 instruction tuning을 나타낸다.
3.1 Architecture Overview
Figure 1에서 보듯이, end-to-end 멀티모달 LLM은 주로 세 가지 유형으로 나뉜다:
- MiniGPT4와 같이 사전학습 및 instruction tuning 과정에서 frozen LLM과 visual model을 사용하여 제한된 파라미터만 활용하는 모델.
- Kosmos-1과 같이 trainable LLM과 frozen visual model을 통합하는 모델.
- LLaVA와 같이 instruction tuning 과정에서 trainable LLM을 사용하고 visual model은 frozen 상태로 유지하는 모델.
그럼에도 불구하고, 이러한 모델들은 frozen visual model에 의존하기 때문에 특정 제약이 있다. 이는 제한된 파라미터 수로 인해 불충분한 정렬(alignment)을 초래할 수 있다. 또한, 단일 모달(unimodal) 및 멀티모달 instruction이 모두 부족하여 다양한 능력을 효과적으로 자극하지 못한다.
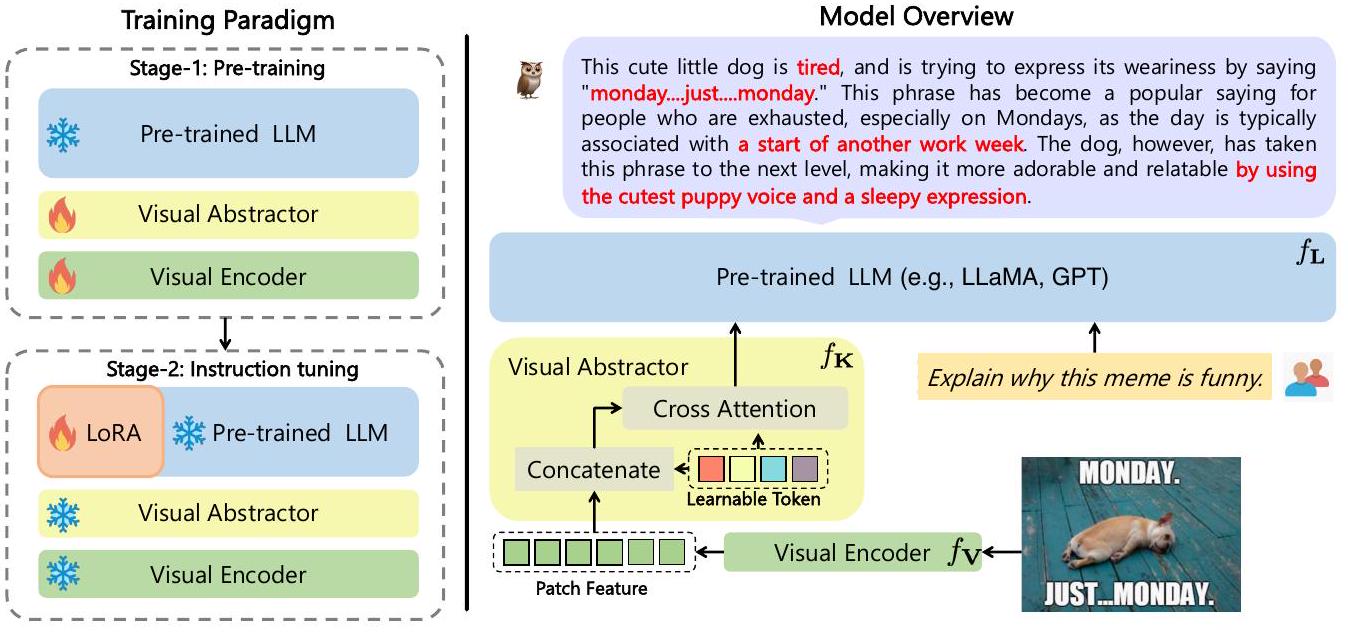
Figure 2: 우리의 학습 패러다임 및 모델 개요.
이러한 문제 해결을 위해 우리는 mPLUG-Owl을 제안한다. mPLUG-Owl은 시각적 맥락과 정보를 고려하여 다양한 모달리티를 인지하고 그에 상응하는 출력을 생성할 수 있는 멀티모달 언어 모델이다. 구체적으로, Figure 2에서 보듯이 mPLUG-Owl은 다음과 같이 구성된다:
- 시각 지식 인코딩을 위한 vision foundation model ,
- language foundation model ,
- visual abstractor module .
우리는 먼저 사전학습된 visual foundation model 로부터 dense image representation을 얻는다. 그러나 이러한 dense feature는 세밀한 이미지 정보를 파편화시키고, 에 입력될 때 긴 시퀀스로 인해 많은 연산량을 발생시킨다. 이 문제를 완화하기 위해 우리는 visual abstractor module 를 사용하여 시각 정보를 몇 개의 학습 가능한 토큰으로 요약한다. 이를 통해 Figure 2에서 보듯이 더 높은 의미론적 시각 표현을 얻고 연산량을 줄일 수 있다. 이렇게 얻은 시각 표현은 텍스트 쿼리와 결합되어 language model에 입력되어 응답을 생성한다.
3.2 Training Scheme
멀티모달 사전학습 (Multimodal Pretraining)
GPT-3 [Brown et al., 2020] 및 LLaMA [Touvron et al., 2023]와 같은 대규모 language model은 인터넷에서 수집된 방대하고 다양한 데이터로 학습되어 세상에 대한 포괄적인 이해를 제공한다. 이러한 광범위한 지식 기반은 이 모델들에게 다양한 task에서 놀라운 능력을 부여한다. 그러나 이러한 모델에서 시각 정보의 활용은 여전히 충분히 탐구되지 않았다. 이전 접근 방식들 [Zhu et al., 2023a, Liu et al., 2023]은 제한된 수의 추가 파라미터만을 사용하여 시각 데이터와 language model 간의 정렬(alignment)을 학습했으며, 이는 복잡한 시각 정보를 이해하는 모델의 능력을 제약했다.
대규모 language model이 시각 정보를 인지하는 능력을 향상시키면서 내부 능력을 통합하기 위해, 우리는 학습 가능한 visual backbone 와 추가적인 visual abstractor 를 포함하는 새로운 학습 패러다임을 제안한다. 이 과정에서 사전학습된 language model 은 고정된(frozen) 상태로 유지된다. 이 접근 방식은 모델이 저수준(low-level) 및 고수준(higher semantic) 시각 정보를 효과적으로 포착하고, 사전학습된 language model과 정렬시키면서도 성능 저하를 방지할 수 있도록 한다.
Joint Instruction Tuning
이전 단계가 완료되면, 모델은 상당한 양의 지식을 보유하고 인간의 질문에 합리적인 답변을 제공하는 능력을 습득한다. 그럼에도 불구하고, 일관된 언어적 응답을 생성하는 데에는 여전히 어려움을 보인다. GPT-3 [Brown et al., 2020]에서 제시된 바와 같이, 사용자의 의도를 정확하게 파악하기 위해서는 instruction tuning을 통해 모델을 정제하는 것이 필수적이다.
멀티모달 학습 분야의 이전 시도들 [Li et al., 2022, Xu et al., 2023b]은 단일 모달(uni-modal) 및 멀티모달 소스로부터의 공동 학습(joint learning)이 서로 다른 모달리티 간의 협업 덕분에 상당한 개선을 가져올 수 있음을 입증했다. 이러한 통찰력을 바탕으로, 우리는 mPLUG-Owl과 인간의 지시 및 의도 간의 더 나은 정렬을 촉진하기 위한 새로운 vision-language joint instruction tuning 전략을 제시한다.
구체적으로, 모델이 시각 지식 학습을 통해 이미지에 묘사된 시각적 개념과 지식을 이해할 수 있다는 점을 고려하여, 우리는 **전체 모델을 고정(freeze)**하고 low-rank adaption (즉, LoRA [Hu et al., 2022])을 사용하여 을 적응시킨다. 이는 인간의 지시와 효율적으로 정렬하기 위해 여러 low-rank 행렬을 학습하는 방식이다.
각 데이터 레코드에 대해, 우리는 Vicuna [Vicuna, 2023]를 따라 대화 스니펫(snippet of conversation) 형태로 통일했으며, 응답(response)에 대한 loss를 계산한다. 학습 중에는 텍스트 전용 instruction 데이터와 멀티모달 instruction 데이터에 대해 여러 배치(batch)에 걸쳐 gradient를 누적하고 파라미터를 업데이트한다. 따라서 언어 및 멀티모달 instruction을 모두 사용하여 공동 학습함으로써, mPLUG-Owl은 더 넓은 범위의 instruction을 더 잘 이해하고 더 자연스럽고 신뢰할 수 있는 출력을 생성할 수 있다.
또한, 우리의 접근 방식은 MiniGPT-4 [Zhu et al., 2023a] 및 LLaVA [Liu et al., 2023]와 같은 방법에서 요구되는 vision 및 language model의 재정렬(realignment) 없이도 다양한 텍스트 및 멀티모달 instruction을 쉽게 처리할 수 있다.
학습 목표 (Training Objective)
모델은 이전 context를 기반으로 다음 token을 생성하는 것을 학습하는 language modeling task를 사용하여 학습된다. 학습 과정의 주요 목표는 token의 log-likelihood를 최대화하는 것이다. 훈련 손실(training loss) 계산 시에는 텍스트 token과 같은 이산적인(discrete) token만 고려된다는 점에 유의해야 한다. 가장 중요한 것은, joint instruction tuning 단계에서 학습 task로부터 발생하는 다양한 능력의 출현이 다운스트림 애플리케이션에서 mPLUG-Owl의 성능을 향상시킨다는 점이다.
4 Experiment
4.1 Experimental Setup
모델 설정 (Model Settings)
우리는 ViT-L/14 [Dosovitskiy et al., 2021]를 **visual foundation model **로 선택했으며, 이 모델은 24개의 layer와 1024의 hidden dimension, 그리고 14의 patch size를 가진다. 더 빠른 수렴을 위해, ViT는 contrastive learning을 통해 사전학습된 CLIP ViT-L/14 모델로 초기화되었다. LLaVA [Liu et al., 2023] 및 MiniGPT-4 [Zhu et al., 2023a]와 달리, 우리는 효과성과 일반화 능력을 보여주기 위해 instruction-tuned 버전(예: Alpaca [Taori et al., 2023] 및 Vicuna [Vicuna, 2023]) 대신 raw LLaMA-7B [Touvron et al., 2023]를 활용한다. mPLUG-Owl의 총 파라미터 수는 약 7.2B이다. 하이퍼파라미터에 대한 더 자세한 내용은 Appendix에서 확인할 수 있다.
데이터 및 학습 세부사항 (Data and Training Details)
첫 번째 단계에서는 LAION-400M [Schuhmann et al., 2021], COYO-700M [Byeon et al., 2022], Conceptual Captions [Sharma et al., 2018], MSCOCO [Chen et al., 2015]를 포함한 여러 데이터셋의 이미지-캡션 쌍을 활용한다. 우리는 210만 토큰의 batch size를 사용하고, mPLUG-Owl을 50k 스텝 동안 학습시켰으며, 이는 약 1,040억 토큰에 해당한다. AdamW optimizer를 로 채택하고, learning rate와 weight decay는 각각 0.0001과 0.1로 설정한다. 2k warm-up 스텝으로 학습을 warm-up한 후, cosine schedule에 따라 learning rate를 감소시킨다. 입력 이미지는 무작위로 크기로 조정된다. 또한, SentencePiece [Kudo and Richardson, 2018] tokenizer를 사용하여 텍스트 입력을 토큰화한다.
두 번째 단계에서는 세 가지 다른 소스에서 순수 텍스트 instruction 데이터를 수집한다: Alpaca [Taori et al., 2023]에서 102k 데이터, Vicuna [Vicuna, 2023]에서 90k 데이터, Baize [Xu et al., 2023a]에서 50k 데이터. 추가적으로, LLaVA 데이터셋 [Liu et al., 2023]에서 150k 멀티모달 instruction 데이터를 활용한다. 우리는 mPLUG-Owl을 batch size 256으로 2k 스텝 동안 학습시키며, learning rate는 0.00002로 설정한다.
Baselines
우리는 mPLUG-Owl을 다음과 같은 end-to-end 모델 및 체계적인 협업(systematic collaboration) 접근 방식과 비교한다:
- OpenFlamingo [Zhu et al., 2023b]는 Flamingo [Alayrac et al., 2022] 모델의 오픈 소스 버전이다. 우리는 OpenFlamingo-9B의 공개된 코드를 사용하여 zero-shot 생성을 실행한다.
- BLIP-2 [Li et al., 2023]는 기존의 frozen 사전학습 이미지 모델과 대규모 언어 모델로부터 효율적인 사전학습 전략을 사용하여 bootstrapped learning을 통해 사전학습된다. 우리는 BLIP-2 ViT-G FlanT5의 공개된 코드를 사용하여 zero-shot 생성을 수행한다.
- MiniGPT-4 [Zhu et al., 2023a]는 단일 projection layer를 활용하여 사전학습된 vision encoder의 시각 정보를 LLM과 정렬한다. 구체적으로, 이들은 BLIP-2에서 사용된 것과 동일한 visual encoder(사전학습된 Q-Former와 결합된 ViT)와 Vicuna를 LLM으로 사용한다. 우리는 공개된 데모를 사용하여 이미지-instruction 생성을 수행한다.
- LLaVA [Liu et al., 2023]는 단일 projection layer를 적용하여 사전학습된 CLIP visual encoder ViT-L/14의 이미지 feature를 Vicuna의 language embedding space로 변환한다. 우리는 공개된 데모를 사용하여 이미지-instruction 생성을 수행한다.
- MM-REACT [Yang et al., 2023]는 ChatGPT/GPT-4를 다양한 전문 vision expert와 통합하여 멀티모달 reasoning 및 action을 달성한다. 우리는 공개된 데모를 사용하여 응답을 얻는다.
4.2 Quantitative analysis
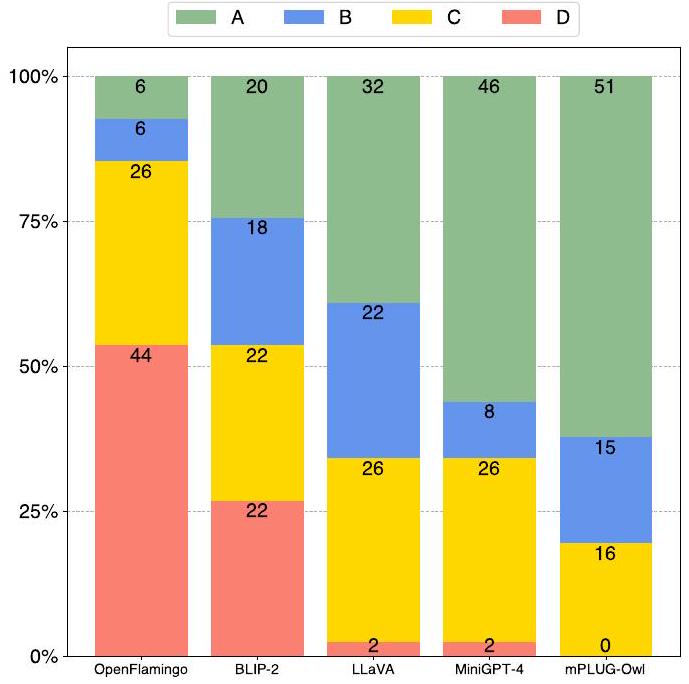
Figure 3: OwlEval에서 수동 평가 지표를 사용한 mPLUG-Owl과 baseline 모델들의 비교. 응답 품질 순위는 A > B > C > D이다.
다양한 모델을 종합적으로 평가하기 위해, 우리는 50개의 이미지를 기반으로 인공적으로 구성된 82개의 질문을 수집하여 시각 관련 평가 세트인 OwlEval을 구축했다. 이 질문들은 MiniGPT-4에서 21개, MM-REACT에서 13개, BLIP-2에서 9개, GPT-4에서 3개, 그리고 우리가 직접 수집한 4개로 구성된다. 일부 이미지에는 여러 차례의 질문이 포함되어 다중 턴 대화(multi-turn conversation) 사례를 나타낸다.
이 질문들은 다음과 같은 다양한 모델 능력을 검증한다:
- 자연 이미지 이해 (natural image understanding)
- 다이어그램 및 순서도 이해 (diagram and flowchart comprehension)
- 광학 문자 인식 (OCR)
- 멀티모달 생성 (multi-modal creation)
- 지식 집약적 QA (knowledge-intensive QA)
- 참조적 상호작용 QA (referential interaction QA)
질문들이 open-ended이기 때문에, 우리는 Self-Instruct [Wang et al., 2022]에서 제안된 평가 방법에 따라 모델의 응답을 A, B, C, D로 평가하는 수동 평가 지표를 사용한다.
우리는 mPLUG-Owl과 baseline 모델들이 제공한 82개의 응답을 수동으로 채점했다. 비교 결과는 Figure 3에 나타나 있다.
첫째, mPLUG-Owl은 66개의 A와 B 등급을 받은 반면, 가장 경쟁력 있는 baseline인 MiniGPT-4는 54개를 받았다.
둘째, mPLUG-Owl은 D 등급을 전혀 받지 않아, 모든 모델을 능가하는 성능을 보였다. 이러한 결과는 mPLUG-Owl이 지시와 이미지를 모두 더 잘 이해하여 만족스러운 응답을 생성하는 데 더 강력한 능력을 가지고 있음을 시사한다. 공정한 비교를 위해, MM-REACT가 예측에 실패한 사례는 제외하였다. 해당 결과는 Figure 15에 별도로 제시되어 있으며, mPLUG-Owl은 여전히 우수한 성능을 보인다.
단일 턴(single-turn) 및 다중 턴(multi-turn) 대화 능력을 개별적으로 검토하기 위해, 우리는 82개의 질문을 단일 턴 대화 세트와 다중 턴 대화 세트로 재구성했다. 전자는 50개 이미지의 첫 번째 질문을 포함하고, 후자는 다중 턴 대화 사례에서 나온 52개의 질문을 포함한다. Figure 4에서 보듯이, mPLUG-Owl은 단일 턴 및 다중 턴 대화 모두에서 뛰어난 성능을 달성한다.
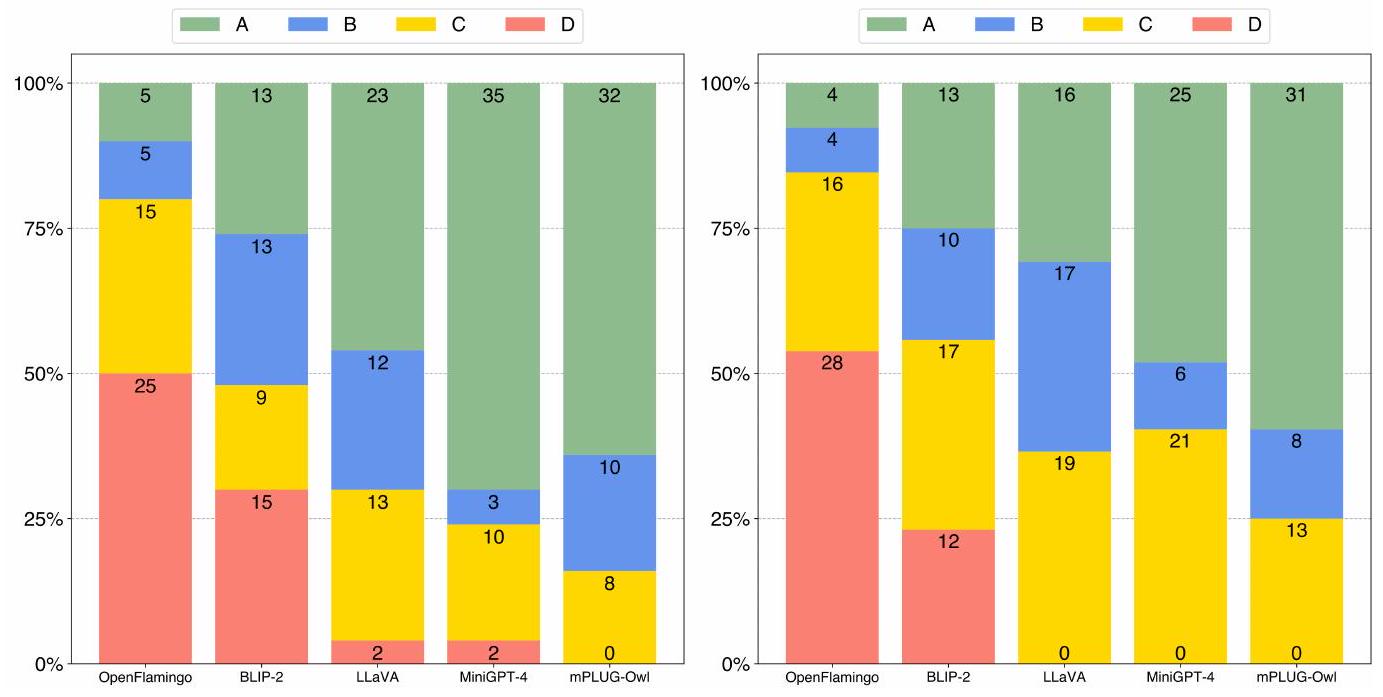
Figure 4: OwlEval에서 수동 평가 지표를 사용한 mPLUG-Owl과 baseline 모델들 간의 50개 단일 턴 응답(왼쪽) 및 52개 다중 턴 응답(오른쪽) 비교 결과.
4.3 Ablation Study
우리는 **두 단계 학습 방식(two-stage training scheme)**과 instruction tuning의 데이터 모달리티에 대한 ablation 연구를 수행한다. Table 1에 제시된 바와 같이, 시각 관련 task를 완료하기 위해 여섯 가지 능력 차원을 정의하였다. 각 질문에 대해 필요한 능력을 수동으로 라벨링하고, 모델의 응답에 어떤 능력이 반영되었는지 주석을 달았다. Table 2는 mPLUG-Owl의 다양한 변형 모델들의 능력별 정확도를 보여준다.
학습 전략 Ablation (Training Strategy Ablation)
Table 2에서 볼 수 있듯이, joint instruction tuning이 없을 경우, 모델은 instruction 이해 능력이 부족하고 사전학습된 능력을 다른 task로 일반화하는 데 실패한다 (r1 vs r5).
instruction tuning만으로는, 모델이 instruction을 더 잘 이해할 수 있지만, 시각 관련 지식 사전학습의 부족으로 인해 시각 지식 관련 task에서 유망한 성능을 달성할 수 없다 (r2 vs r5).
멀티모달 사전학습과 joint instruction tuning을 모두 적용했을 때, 모델은 최고의 성능을 달성하며, 이는 우리의 두 단계 학습 방식의 효과를 입증한다.
Instruction 데이터 Ablation (Instruction Data Ablation)
r3와 r4를 비교함으로써, 텍스트 전용 instruction tuning은 instruction 이해에 더 큰 개선을 가져오는 반면, 멀티모달 instruction tuning은 더 나은 지식 및 추론 능력을 달성함을 알 수 있다. 이는 시각 질문 응답이 주로 시각 및 언어 지식의 정렬(alignment)을 요구하며, 이는 텍스트 전용 instruction tuning 동안 최적화되지 않기 때문이다.
또한, Table 3 (r5 vs r4)에서 볼 수 있듯이, instruction tuning 동안 멀티모달 데이터를 도입하는 것이 텍스트 전용 task에서도 모델의 성능을 더욱 향상시킬 수 있음을 확인하였다.
구체적으로, Vicuna [Vicuna, 2023]의 평가 설정을 따라, 각 질문에 대해 각 모델의 응답을 ChatGPT의 응답과 짝지어 ChatGPT에게 두 응답에 대해 각각 점수를 부여하도록 prompt를 주었다. Table 3은 총점과 ChatGPT 점수를 기준으로 한 점수 비율을 보여준다.
4.4 Qualitative Analysis
이 섹션에서는 우리의 평가 세트인 OwlEval의 정성적(qualitative) 결과를 보여준다.
Knowledge-intensive QA
Figure 5에서 보듯이, 이 지시는 모델이 이미지 속 영화 캐릭터를 식별하도록 요구한다. MM-REACT는 효과적인 응답을 제공하지 못했고, MiniGPT-4는 지시를 이해했지만 영화 캐릭터를 답변하는 데 실패했다. 이와 대조적으로, mPLUG-Owl은 이미지에 있는 다섯 캐릭터 중 네 명을 정확히 답변했다. 이는 mPLUG-Owl이 이미지 속 지식을 더 잘 이해하고 있음을 보여준다.
| Meaning | Definition | |
|---|---|---|
| IU | Instruction Understanding | 1. 텍스트 지시를 이해한다. <br> 2. 정답을 요구하지 않지만, 응답은 지시와 관련되어야 한다. |
| VU | Visual Understanding | 1. 이미지 정보를 식별한다. <br> 2. 답변이 이미지 내 시각 정보의 60% 이상을 충실히 반영한다. |
| OCR | Optical Character Recognition | 1. 이미지 내 텍스트 정보를 인식한다. <br> 2. 답변이 이미지 내 텍스트 정보의 60% 이상을 충실히 반영한다. |
| KTA | Knowledge Transfer Ability | 1. 언어와 비전 간 지식을 전이한다. <br> (1) 텍스트 및 시각 콘텐츠를 이해한다. <br> (2) 시각 및 언어 지식을 정렬하고 전이한다. <br> 2. 답변이 대부분 정확하며, 정확도는 80% 이상이다. |
| RA | Reasoning Ability | 1. 이미지와 텍스트를 결합하여 추론한다. <br> (1) 텍스트 및 시각 콘텐츠를 이해한다. <br> (2) 다단계 추론을 수행한다. <br> (3) 다단계 추론 과정에 기반하여 답변을 생성한다. <br> 2. 최종 답변이 본질적으로 정확하지만, 명시적인 추론 과정이 부족하다. 또는 최종 답변이 대부분 정확하고, 추론 과정의 정확도가 80% 이상이다. <br> 3. 예시: <br> (1) 상식 지식 추론 <br> (2) 반사실적 추론 <br> (3) 공간 관계 추론 <br> (4) 수치 계산 <br> (5) 코딩 |
| MDA | Multi-turn Dialogue Ability | 1. 지시를 이해하고 다중 턴 대화를 처리한다. <br> 2. 여러 대화에 대한 명확한 참조를 포함하며, 문맥 내 자연어 의미를 효과적으로 처리한다. <br> 3. 의미와 참조가 대부분 정확하며, 정확도는 80% 이상이다. |
Table 1: 시각 관련 task를 완료하기 위한 6가지 능력의 정의.
| Multimodal Pretraining | Pure Text Instruction | Multi-modal Instruction | Ability | ||||||
|---|---|---|---|---|---|---|---|---|---|
| IU | VU | OCR | KTA | RA | MDA | ||||
| r1 | |||||||||
| r2 | |||||||||
| r3 | |||||||||
| r4 | |||||||||
| r5 | 100.0 | 95.2 | 56.7 | 87.5 | 80.0 | 95.0 | |||
| MiniGPT-4 [Zhu et al., 2023a] | 97.6 | 81.0 | 40.0 | 83.3 | 65.7 | 75.0 |
Table 2: Ablation 결과. 각 값은 모델의 응답에서 해당 능력이 올바르게 반영된 질문의 비율을 나타낸다. IU: instruction understanding, VU: visual understanding, OCR: optical character recognition, KTA: knowledge transferability, RA: reasoning ability, MDA: multi-turn dialogue ability.
Multi-round Conversation
Figure 6의 지시는 모델이 참조 정보에 기반하여 이미지의 내용을 식별하도록 요구한다. 기준 모델들은 공간 방향, 인간 행동, 대상 속성과 관련된 참조 표현에 직면했을 때 종종 실수를 저질렀지만, mPLUG-Owl은 가장 정확한 응답을 제공했다. 이러한 능력은 mPLUG-Owl의 이미지에 대한 세밀한 이해에서 비롯되며, 이를 통해 지시의 참조 정보에 기반하여 이미지의 해당 부분을 찾아낼 수 있다.
Reasoning
Figure 7은 모델에게 시각 정보에 기반한 예측과 그 이유를 설명하도록 요청하는 지시를 보여준다. mPLUG-Owl은 두 팀의 라인업과 전술적 측면에서 특징을 분석하고 이를 바탕으로 결과에 대한 추론을 수행한다. MiniGPT-4도 좋은 성능을 보였지만, 추론의 설득력은 mPLUG-Owl에 비해 약간 떨어진다.
| Model | Tuning Strategy | Model Score | ChatGPT Score | Ratio |
|---|---|---|---|---|
| Alpaca-7B | Full | 573 | 708 | |
| Vicuna-7B | Full | 612 | 684 | |
| mPLUG-Owl w/o multimodal tuning (r4) | LoRA | 587 | 682 | |
| mPLUG-Owl (r5) | LoRA | 600 | 692 |
Table 3: ChatGPT가 평가한 Vicuna [Vicuna, 2023]의 80개 텍스트 전용 질문에 대한 성능.

Figure 5: Knowledge-intensive QA 비교.
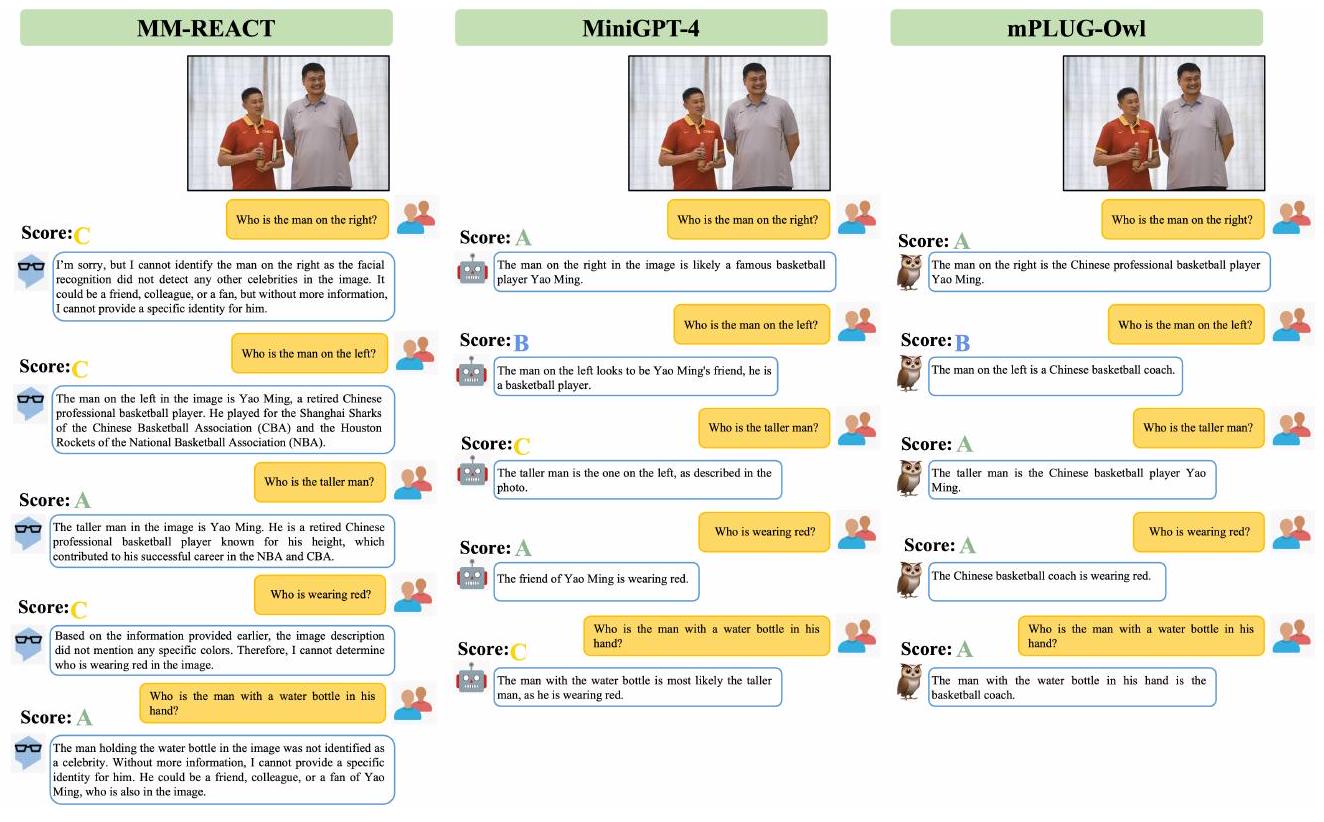
Figure 6: Multi-turn Conversation 비교.
Joke Comprehension
Figure 8의 사례는 GPT-4 [OpenAI, 2023]에서 가져온 것으로, 모델이 시각적으로 관련된 농담을 이해하고 설명하도록 요구한다. GPT-4는 패널별 분석 지시를 따를 뿐만 아니라, 충전 방식의 유머를 거의 완벽하게 이해한다. mPLUG-Owl도 이 특이한 유머를 이해했지만, "VGA"를 "USB"로 잘못 식별했다. 이는 주로 학습 데이터의 시각 정보 제한 때문이다. 농담 이해에 대한 더 많은 사례는 Figure 9에 제시되어 있다.

Figure 7: Reasoning QA 비교.

Figure 8: Joke Understanding 비교.
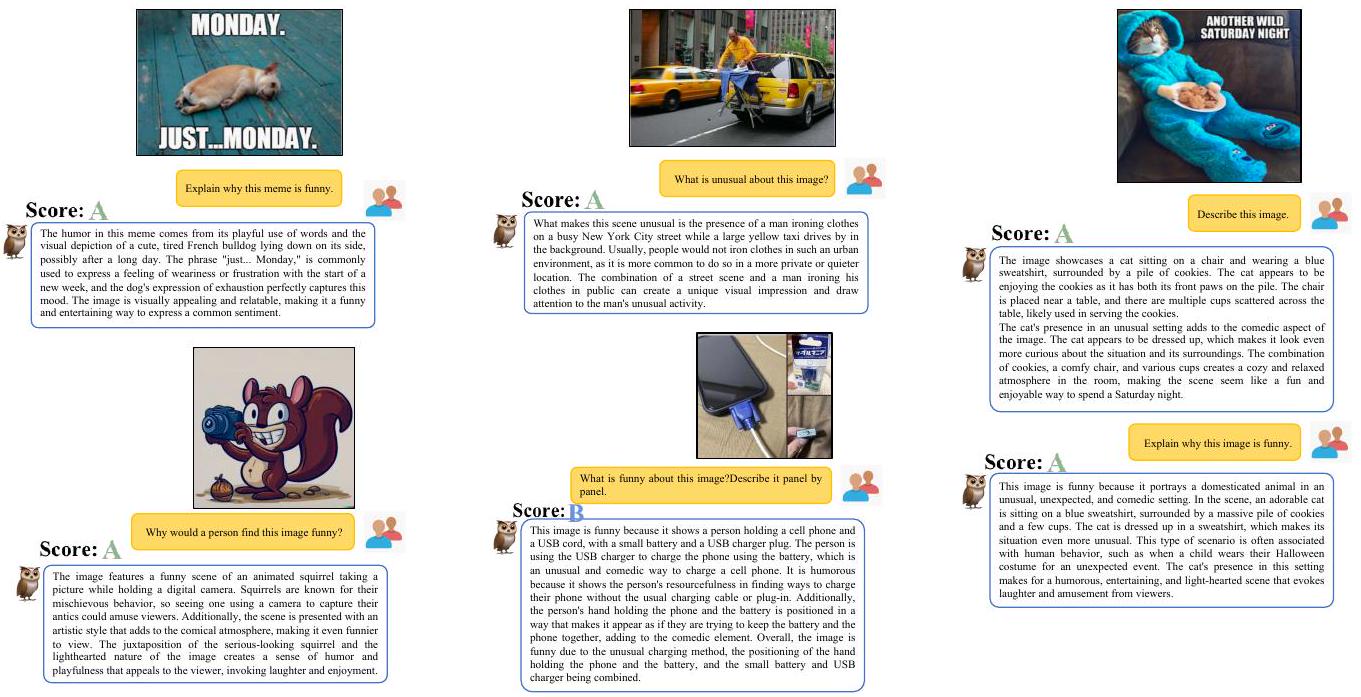
Figure 9: mPLUG-Owl의 농담 이해 추가 사례.
5 Discussion and Limitation
이 섹션에서는 아직 완전히 개발되지 않은 mPLUG-Owl의 초기 능력을 보여주고 한계점을 논의한다. 이 섹션의 일부 사례(점수 없음)는 OwlEval에 포함되지 않는다.
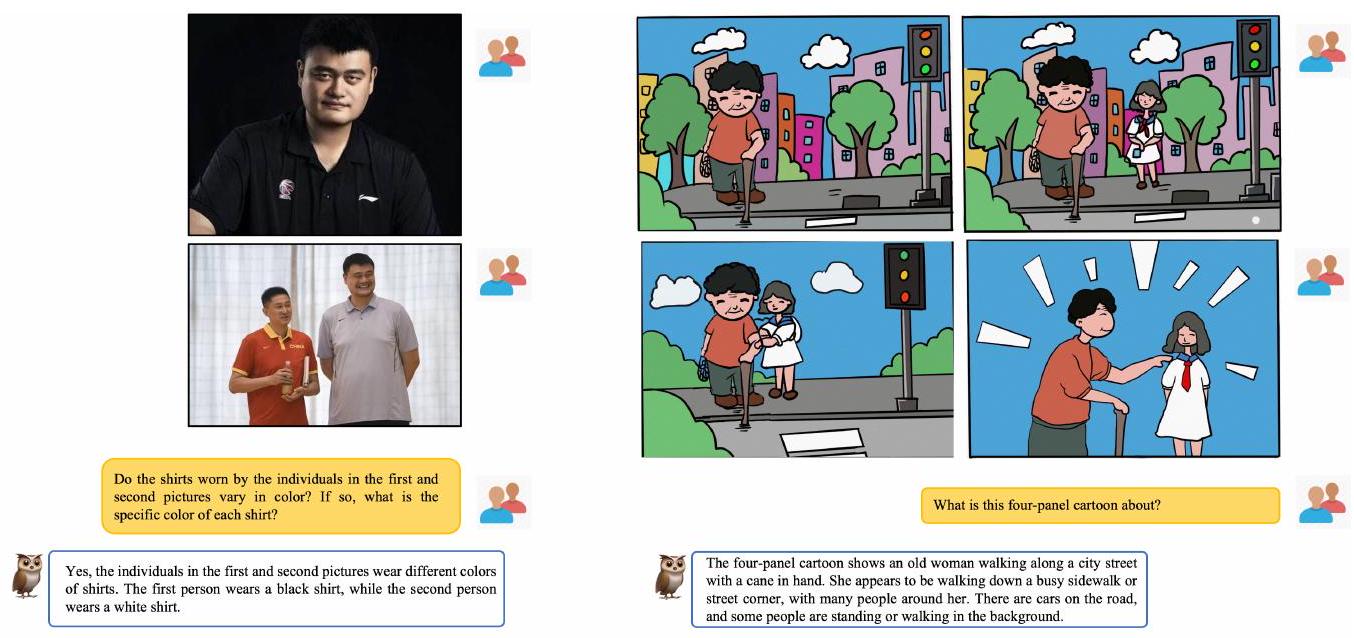
Figure 10: 다중 이미지 상관관계 사례.
다중 이미지 상관관계 (Multi-image Correlation)
Figure 10에서 mPLUG-Owl은 여러 이미지에 걸쳐 시각적 상관관계를 파악하는 초기적인 능력을 보여주지만, 아직 강력하지는 않다. 왼쪽 사례에서 모델은 두 이미지에서 동일한 인물을 식별하고 옷 색깔의 차이를 정확하게 구분할 수 있었다. 그러나 오른쪽 사례에서는 모델이 4개의 이미지를 연결하지 못하고 일부 텍스트 환각(hallucination)을 생성한다.
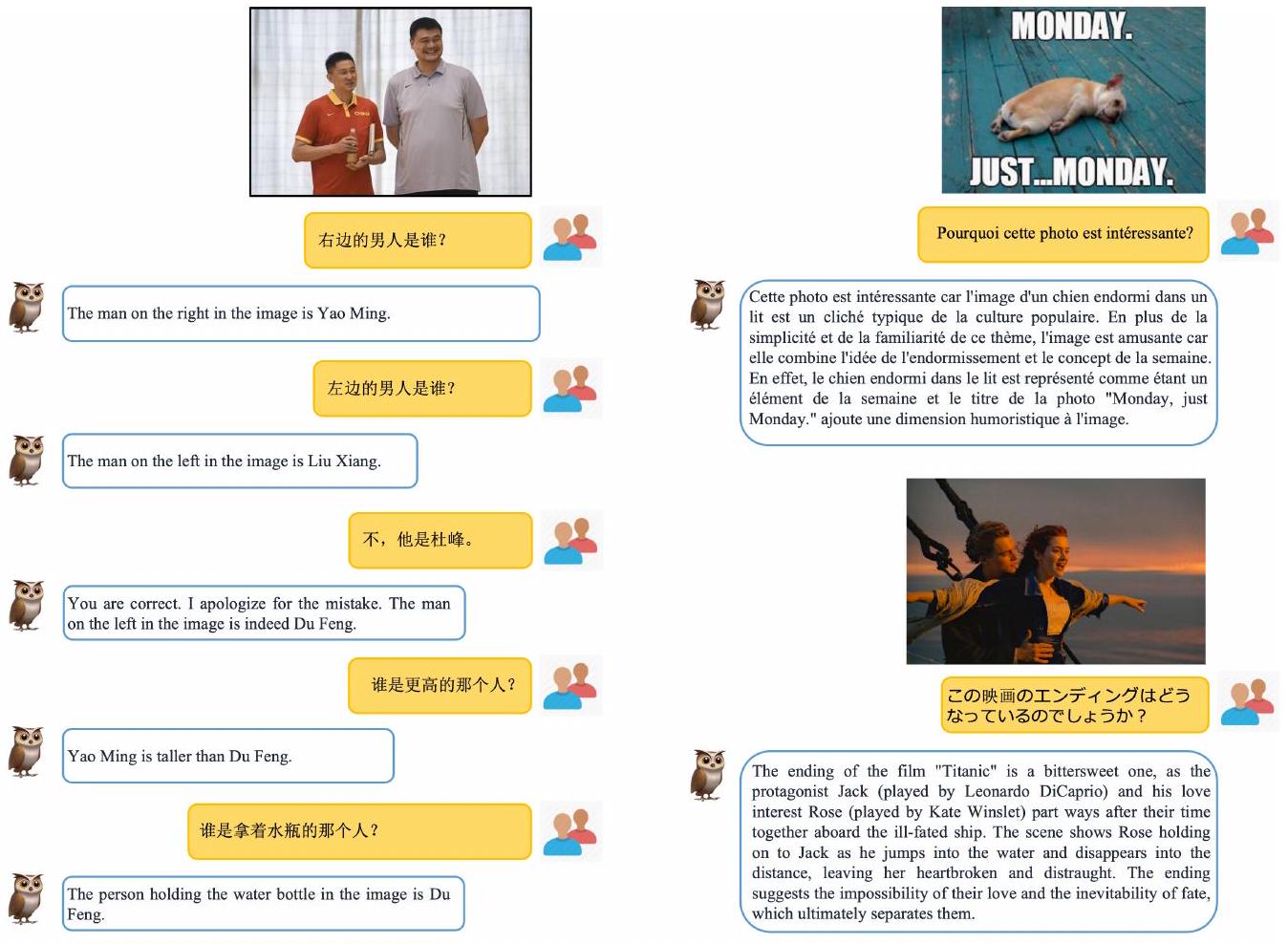
Figure 11: 다국어 이해의 예시 prompt로, 각각 중국어, 프랑스어, 일본어에 걸친 다국어 능력을 보여준다.
다국어 대화 (Multilingual Conversation)
영어 외에도 모델의 다국어 능력을 추가로 테스트했다. Figure 11에서 볼 수 있듯이, 2단계 학습 과정에서 다국어 데이터가 없었음에도 불구하고, mPLUG-Owl은 중국어, 프랑스어, 일본어에 대한 유망한 다국어 이해 능력을 보여준다. 우리는 이 능력이 주로 LLaMa [Touvron et al., 2023]의 원시 텍스트 지식 덕분이라고 생각한다. 그러나 다국어 학습의 부족으로 인해 mPLUG-Owl은 해당 언어로 응답하지 못할 수도 있다.
장면 텍스트 이해 (Scene Text Understanding)
Figure 16에서 mPLUG-Owl은 일부 간단한 장면에서 OCR 능력을 보여주지만, 이미지 내 숫자에 대한 모델의 인식이 여전히 제한적임을 알 수 있다. 그러나 Figure 17-18에서 볼 수 있듯이 복잡한 장면의 OCR의 경우, mPLUG-Owl의 성능은 더 일반적이다. 이는 주로 이미지 내 숫자에 대한 인식이 약하여 후속 추론 계산에 영향을 미치기 때문이다.
시각 전용 문서 이해 (Vision-only Document Comprehension)
우리는 학습에 어떠한 문서 어노테이션 데이터도 사용하지 않았지만, 모델은 일부 텍스트 인식 및 문서 이해 능력을 보였다. 이에 우리는 문서 이해와 모델 기능의 조합을 더 깊이 탐구했다. Figure 12에서 볼 수 있듯이, 우리는 영화 리뷰 작성, 코드 생성, 코드 설명, 채팅 요약, 애플리케이션 안내를 탐색했다. 모델은 (a)와 (b)에서 괜찮은 성능을 보였지만, 여전히 일부 오류가 있었다. 한편, (d), (e), (f)에서는 사용 가능한 응답을 제공하지 못했다. 따라서 문서 이해 및 다운스트림 애플리케이션에서 우리 모델의 잠재력을 탐구할 여지가 더 있다.
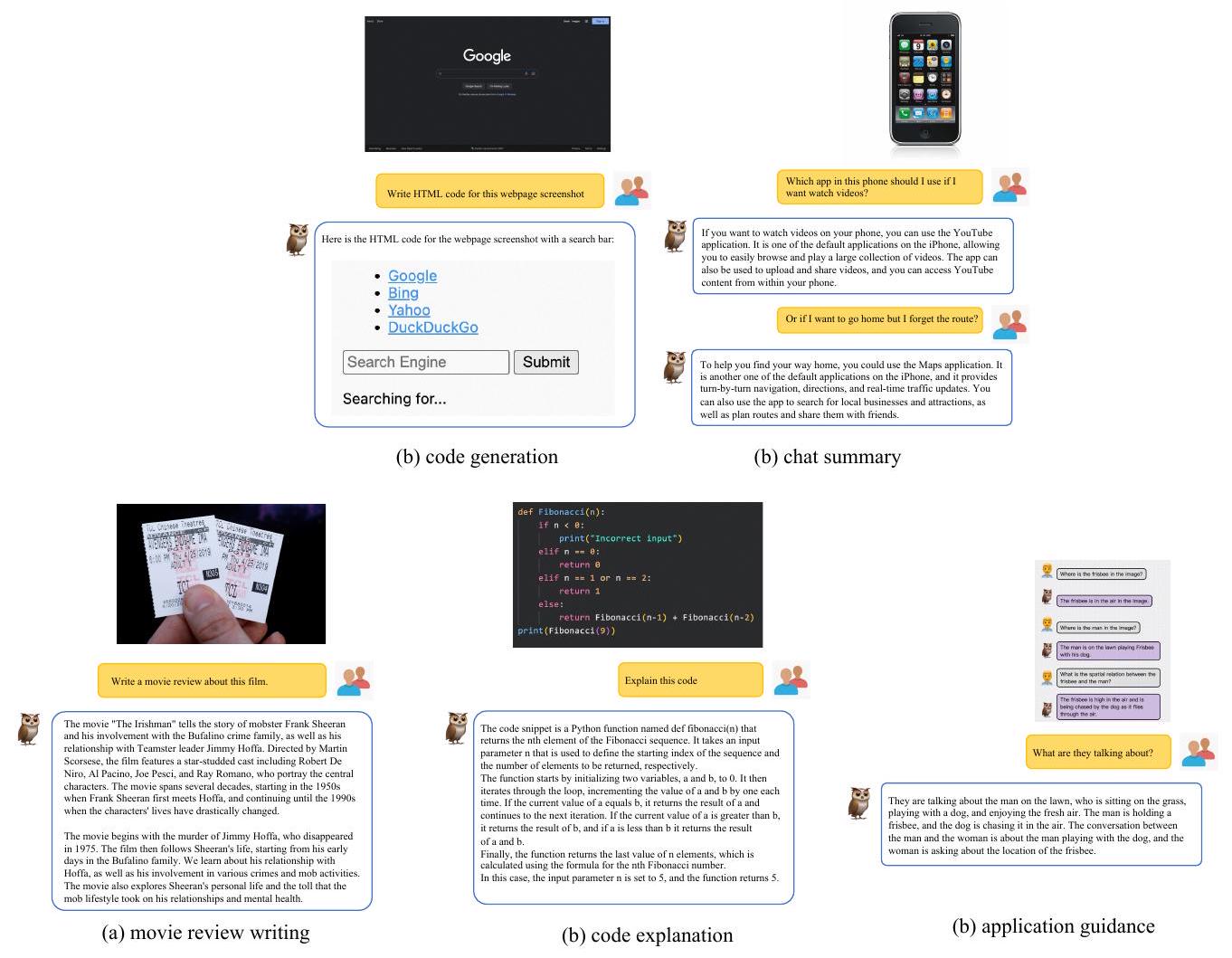
Figure 12: 다양한 문서 이해 및 애플리케이션에 대한 예시.
개방형 창작 (Open-ended Creation)
mPLUG-Owl은 이미지를 기반으로 한 시, 가사, 광고 등 다양한 창작물 생성에서 좋은 성능을 보인다. 일부 사례에서의 성능은 Figure 13-14에 나타나 있다. 그러나 더 기능적이고 실용적인 창작물을 위해서는 추가적인 탐구가 필요하다.

Figure 13: 개방형 창작 사례.
6 Conclusion
우리는 대규모 언어 모델(LLM)의 멀티모달 능력을 향상시키는 새로운 학습 패러다임인 mPLUG-Owl을 제안한다. 우리의 접근 방식은 기반 LLM, 시각 지식 모듈(visual knowledge module), 시각 추상화 모듈(visual abstractor module)의 모듈화된 학습으로 구성되며, 이는 다중 모달리티를 지원하고 모달리티 간 협업을 통해 다양한 단일 모달 및 멀티모달 능력을 촉진할 수 있다. 우리는 이미지와 텍스트를 정렬하기 위한 2단계 방법을 사용하는데, 이는 LLM의 생성 능력을 유지하거나 심지어 향상시키면서 LLM의 도움을 받아 시각 지식을 학습한다. 실험 결과는 mPLUG-Owl의 인상적인 능력을 보여주며, 멀티모달 생성 분야의 다양한 애플리케이션에 대한 잠재력을 시사한다.

Figure 14: 카피라이팅 사례.
A Training Hyperparameters
우리는 시각 지식 학습을 위한 모델 학습 하이퍼파라미터를 Table 4에, vision-language joint instruction tuning을 위한 하이퍼파라미터를 Table 5에 상세히 보고한다.
| Hyperparameters | |
|---|---|
| Training steps | 50,000 |
| Warmup steps | 375 |
| Max length | 512 |
| Batch size of image-caption pairs | 4,096 |
| Optimizer | AdamW |
| Learning rate | |
| Learning rate decay | Cosine |
| Adam | |
| Adam | |
| Weight decay | 0.01 |
Table 4: 멀티모달 사전학습 단계의 학습 하이퍼파라미터.
| Hyperparameters | |
|---|---|
| Training steps | 2,000 |
| Warmup steps | 50 |
| Max length | 1,024 |
| Batch size of text instruction data | 128 |
| Batch size of multi-modal instruction data | 128 |
| Optimizer | AdamW |
| Learning rate | |
| Learning rate decay | Cosine |
| AdamW | |
| AdamW | (0.9, 0.999) |
| Weight decay | 0.0001 |
Table 5: Vision-language joint instruction tuning 단계의 학습 하이퍼파라미터.
B Comparison with MM-REACT
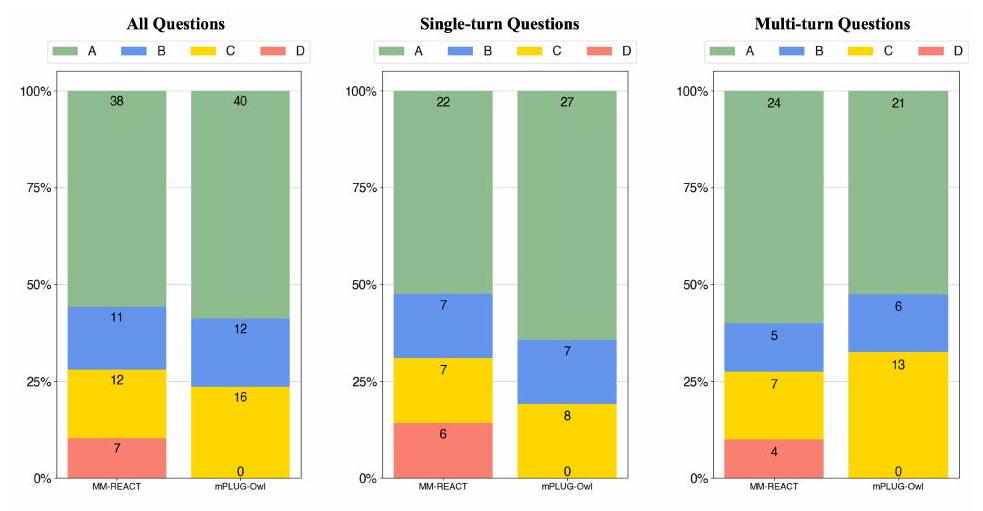
Figure 15: MM-REACT가 성공적으로 생성하지 못한 경우를 제외한 비교 결과.
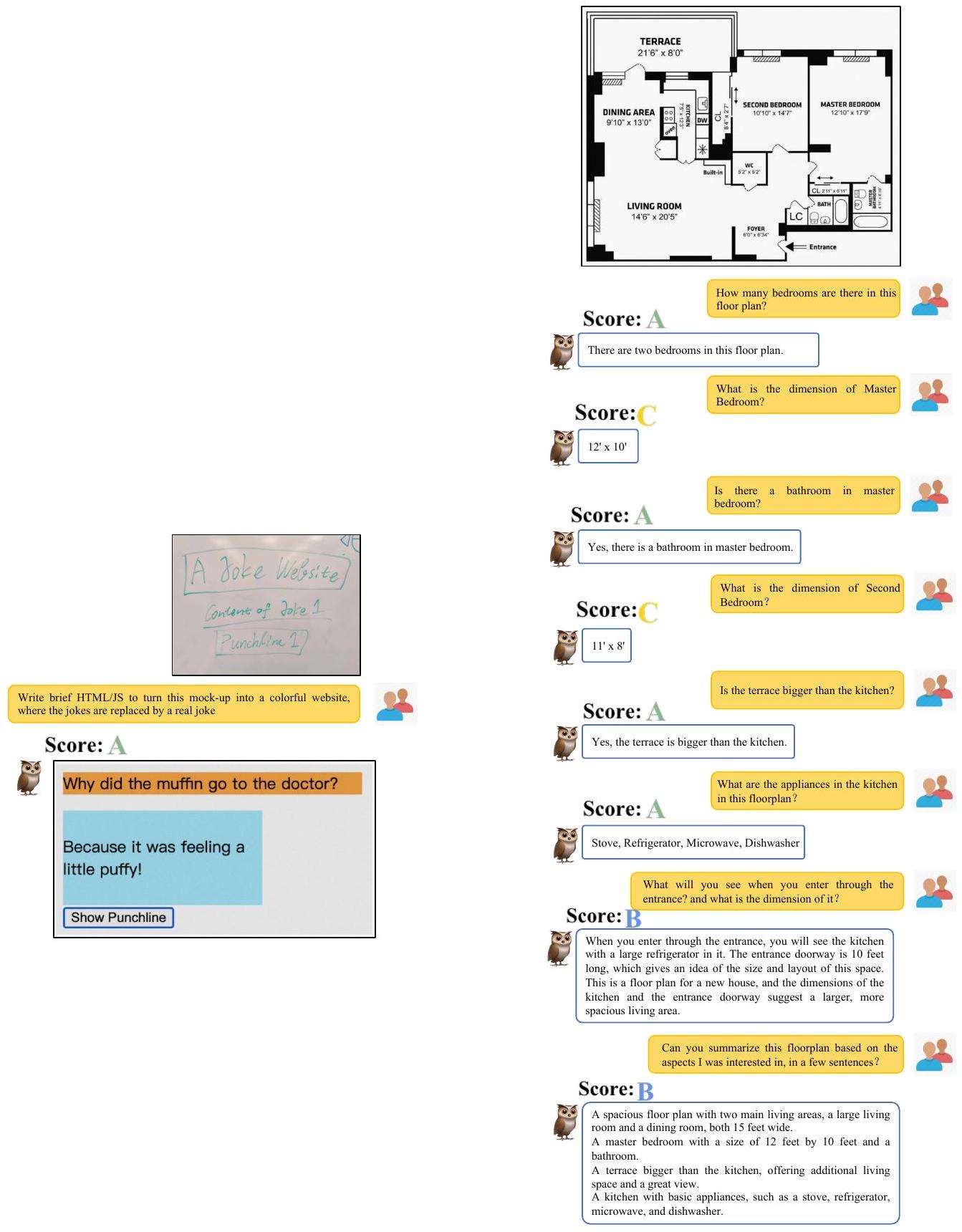
Figure 16: 단순 장면의 OCR (대부분 숫자가 적고 계산이 없는 장면).
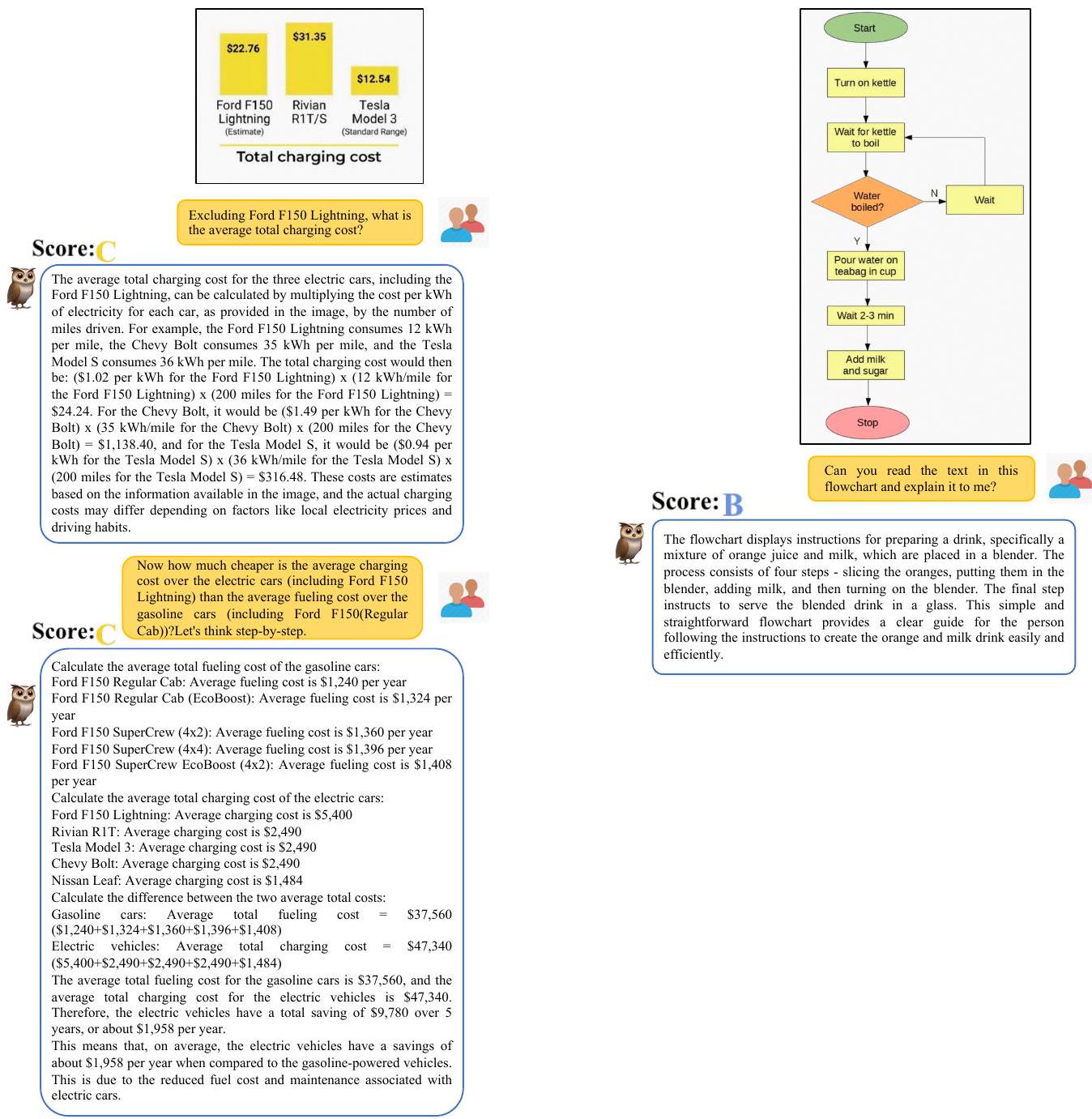
Figure 17: 복잡한 장면의 OCR (a).
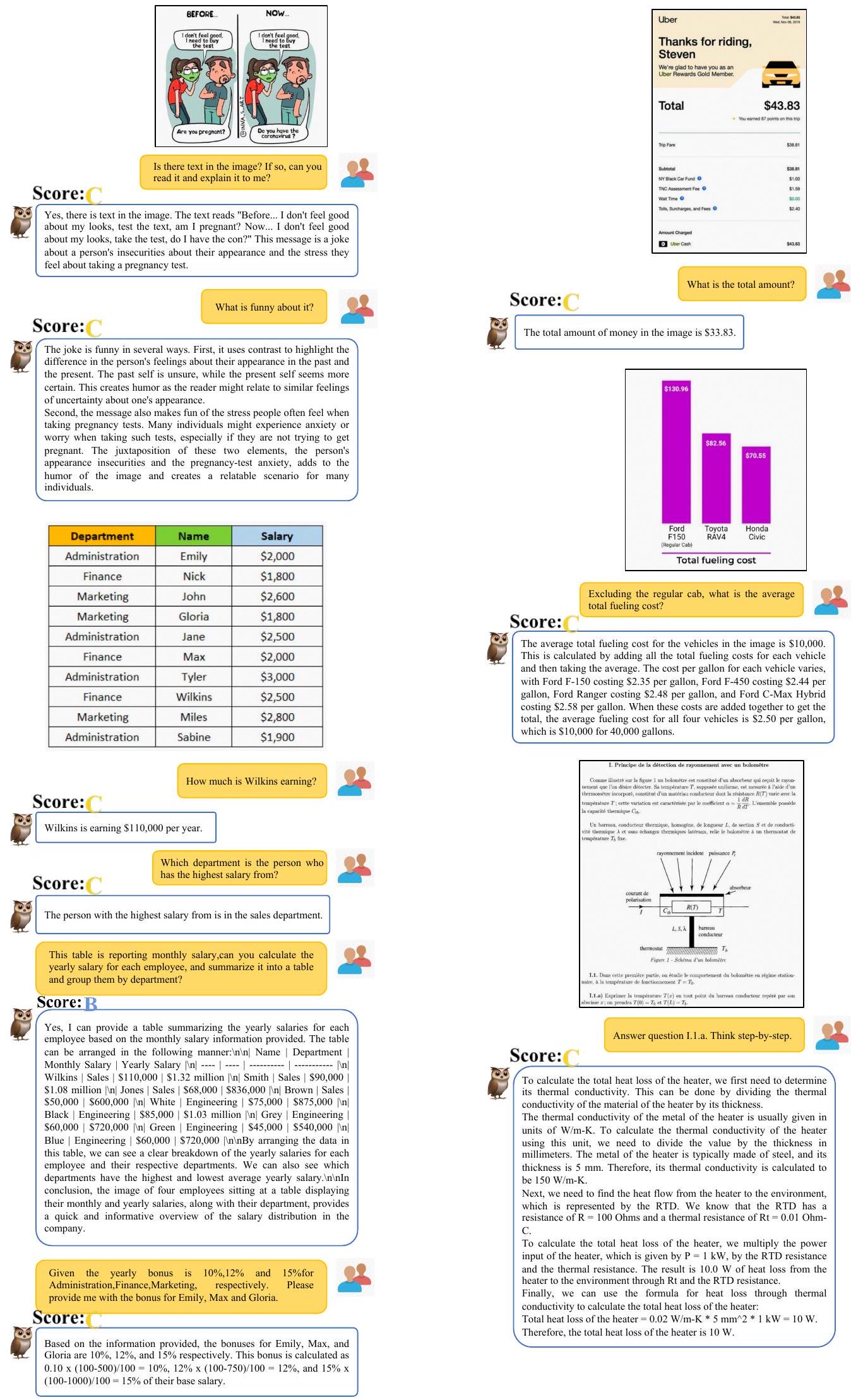
Figure 18: 복잡한 장면의 OCR (b).