KOSMOS-1: 언어 모델과 인식을 결합한 Multimodal Large Language Model
KOSMOS-1은 일반적인 양식을 인식하고, in-context learning (few-shot)을 수행하며, 지시를 따를 수 있는 Multimodal Large Language Model (MLLM)입니다. 이 모델은 임의로 인터리브된 텍스트와 이미지, 이미지-캡션 쌍, 텍스트 데이터를 포함한 웹 스케일의 멀티모달 코퍼스를 기반으로 처음부터 학습됩니다. KOSMOS-1은 별도의 미세 조정 없이 zero-shot, few-shot, multimodal chain-of-thought 프롬프팅 등 다양한 설정에서 언어 이해, 멀티모달 대화, 이미지 캡셔닝, 시각적 질문 답변(VQA) 등 광범위한 작업에서 뛰어난 성능을 보입니다. 또한, 이 연구는 MLLM의 비언어적 추론 능력을 진단하기 위한 Raven IQ 테스트 데이터셋을 소개합니다. 논문 제목: Language Is Not All You Need: Aligning Perception with Language Models
논문 요약: Language Is Not All You Need: Aligning Perception with Language Models
- 논문 링크: https://arxiv.org/abs/2302.14045
- 저자: Shaohan Huang 외 Microsoft 연구진
- 발표 시기: 2023년, NeurIPS (Advances in Neural Information Processing Systems 36)
- 주요 키워드: MLLM, In-context Learning, Multimodal, NLP, Computer Vision, AGI
1. 연구 배경 및 문제 정의
- 문제 정의:
기존 대규모 언어 모델(LLM)은 텍스트 기반 작업에서 뛰어난 성능을 보였지만, 이미지, 오디오와 같은 멀티모달 데이터에 대한 기본적인 인지 및 활용 능력에 한계가 있었습니다. 인공 일반 지능(AGI) 달성을 위해서는 멀티모달 인지 능력이 필수적이며, LLM의 적용 범위를 멀티모달 머신러닝, 문서 지능, 로봇 공학 등으로 확장하기 위해서는 언어 모델에 시각적 인지 능력을 정렬(align)하는 것이 중요합니다. - 기존 접근 방식:
기존 LLM은 텍스트 입력과 출력에만 초점을 맞추어 멀티모달 데이터를 직접적으로 처리하는 데 어려움이 있었습니다. 이는 LLM이 텍스트 설명 이상의 상식 지식을 습득하거나, 로봇 공학 및 문서 지능과 같은 새로운 멀티모달 작업에 적용되는 데 제약이 되었습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- Kosmos-1 모델 제안: 일반적인 양식(modality)을 인지하고, in-context learning (few-shot)을 수행하며, 지시를 따를 수 있는(zero-shot) Multimodal Large Language Model (MLLM)인 Kosmos-1을 처음으로 소개했습니다.
- 웹 규모 멀티모달 코퍼스 학습: 임의로 인터리브된 텍스트와 이미지, 이미지-캡션 쌍, 텍스트 데이터를 포함하는 웹 규모의 멀티모달 코퍼스를 기반으로 Kosmos-1을 처음부터 학습시켰습니다.
- 다양한 작업에서의 뛰어난 성능 입증: 별도의 미세 조정 없이 zero-shot, few-shot, multimodal chain-of-thought 프롬프팅 등 다양한 설정에서 언어 이해, 멀티모달 대화, 이미지 캡셔닝, 시각적 질문 답변(VQA), OCR-free NLP, 이미지 분류 등 광범위한 작업에서 인상적인 성능을 달성했습니다.
- 교차 양식 전이(Cross-modal Transfer) 효과 입증: MLLM이 언어에서 멀티모달로, 멀티모달에서 언어로 지식을 전이함으로써 이점을 얻을 수 있음을 보여주었습니다.
- 비언어적 추론 능력 진단 데이터셋 제안: MLLM의 비언어적 추론 능력을 진단하기 위한 Raven IQ 테스트 데이터셋을 구축하고 평가했습니다.
- 제안 방법:
Kosmos-1은 Transformer 기반의 Causal Language Model을 백본으로 사용하며, 시각 인코더(Vision Encoder)와 Resampler를 통해 이미지 임베딩을 생성하여 언어 모델에 입력합니다. 입력은 특수 토큰으로 장식된 시퀀스로 평탄화(flatten)됩니다. 학습은 다음 토큰 예측(next-token prediction) 방식으로 진행되며, 텍스트 토큰에 대한 log-likelihood를 최대화합니다. 모델 아키텍처는 학습 안정성과 성능을 개선한 Magneto와 긴 컨텍스트 모델링에 유리한 xPos 상대 위치 인코딩을 포함합니다. 학습 데이터는 모노모달 텍스트 데이터(The Pile, Common Crawl), 이미지-캡션 쌍(LAION, COYO, Conceptual Captions), 그리고 임의로 섞인 이미지-텍스트 데이터(Common Crawl 웹 페이지)로 구성됩니다. 또한, 언어 전용 instruction tuning을 통해 모델의 지시 따르기 능력을 향상시키고 이를 다른 양식으로 전이시킵니다.
3. 실험 결과
- 데이터셋:
- 언어 작업: StoryCloze, HellaSwag, Winograd, Winogrande, PIQA, BoolQ, CB, COPA
- 인지-언어 작업: MS COCO Caption, Flickr30k (이미지 캡셔닝), VQAv2, VizWiz (시각적 질문 답변), WebSRC (웹페이지 질문 답변)
- 비전 작업: ImageNet (Zero-shot 이미지 분류), CUB 기반 새 분류 데이터셋 (설명을 포함한 Zero-shot 이미지 분류)
- 비언어적 추론: 자체 구축한 Raven IQ 테스트 데이터셋 (50개 예시)
- OCR-free 언어 이해: Rendered SST-2, HatefulMemes
- 교차 양식 전이 (시각적 상식 추론): RelativeSize, MemoryColor, ColorTerms
- 실험 환경: 이미지 해상도 224x224, 디코딩 방식(beam search, greedy search) 및 프롬프트 템플릿 사용.
- 주요 결과:
- 이미지 캡셔닝: Kosmos-1 (1.6B)은 COCO Karpathy test (CIDEr 84.7) 및 Flickr30k test (CIDEr 67.1)에서 zero-shot으로 Flamingo-3B/9B (각각 73.0/79.4, 60.6/61.5)보다 우수한 성능을 보였습니다.
- 시각적 질문 답변 (VQA): VQAv2 및 VizWiz 데이터셋에서 Flamingo 모델들과 경쟁력 있거나 더 나은 zero-shot 및 few-shot 성능을 달성했습니다.
- Raven IQ 테스트 (비언어적 추론): Kosmos-1은 26%의 정확도를 달성하여 무작위 선택(17%) 대비 유의미한 향상을 보였으며, MLLM의 비언어적 추론 잠재력을 입증했습니다.
- OCR-free 언어 이해: HatefulMemes (ROC AUC 63.9%) 및 Rendered SST-2 (정확도 67.1%)에서 CLIP 및 Flamingo를 능가하며, 이미지 내 텍스트를 직접 읽고 이해하는 내장 능력을 보여주었습니다.
- 웹페이지 질문 답변: Kosmos-1은 LLM 대비 뛰어난 성능(EM 15.8, F1 31.3 vs LLM의 EM 7.6, F1 17.9)을 보이며, 웹페이지의 시각적 레이아웃 및 스타일 정보를 활용할 수 있음을 입증했습니다.
- 멀티모달 Chain-of-Thought 프롬프팅: Rendered SST-2에서 표준 프롬프팅 대비 5.8점 향상된 72.9%의 정확도를 달성하여, 추론 과정 생성을 통한 복잡한 문제 해결 능력을 보여주었습니다.
- 교차 양식 전이: 언어 전용 instruction tuning이 멀티모달 작업(Flickr30k, VQAv2, VizWiz)의 성능을 향상시켰으며, Kosmos-1은 시각적 상식 추론 작업(RelativeSize, MemoryColor, ColorTerms)에서 LLM을 크게 능가하여 시각적 지식이 언어 작업으로 전이될 수 있음을 보여주었습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
Kosmos-1은 단순히 언어 모델에 시각 모듈을 추가하는 것을 넘어, 웹 규모의 멀티모달 데이터를 활용하여 처음부터 진정한 멀티모달 모델로 학습되었다는 점이 인상 깊습니다. 특히, 1.6B라는 비교적 작은 모델 크기에도 불구하고 더 큰 Flamingo 모델들과 경쟁하거나 능가하는 zero-shot 및 few-shot 성능을 보여주며, OCR-free 언어 이해, 멀티모달 CoT, 비언어적 추론 등 MLLM의 새로운 능력을 성공적으로 시연했습니다. 언어 전용 instruction tuning이 멀티모달 작업으로 전이되는 능력과 시각적 상식 지식이 언어 작업에 긍정적인 영향을 미치는 교차 양식 전이성은 모델의 범용성과 확장 가능성을 높게 평가할 수 있는 부분입니다. - 단점/한계:
Raven IQ 테스트에서 무작위 선택보다는 훨씬 높은 성능을 보였지만, 여전히 인간의 평균 수준에는 크게 못 미치는 26%의 정확도를 기록하여 복잡한 비언어적 추론 능력에는 개선의 여지가 있습니다. 또한, 논문에서는 모델 학습에 사용된 컴퓨팅 자원이나 구체적인 하드웨어 환경에 대한 상세한 정보가 부족하여 실제 모델을 재현하거나 활용하는 데 어려움이 있을 수 있습니다. 향후 모델 크기 확장 및 음성 기능 통합을 언급한 것으로 보아, 현재 버전에서는 이러한 부분에 한계가 있음을 시사합니다. - 응용 가능성:
Kosmos-1과 같은 MLLM은 인공 일반 지능(AGI)을 향한 중요한 단계로, 다양한 분야에 혁신적인 응용 가능성을 제공합니다. 예를 들어, 로봇 공학에서 시각적 인지를 통해 실제 세계와 상호작용하거나, 문서 지능 분야에서 영수증이나 웹 페이지의 레이아웃과 텍스트를 동시에 이해하여 정보를 추출하는 데 활용될 수 있습니다. 또한, 그래픽 사용자 인터페이스(GUI)를 직접 읽고 상호작용하는 통합된 인터페이스로서 다양한 API를 통합하는 데 기여할 수 있으며, 지시와 예시를 통해 텍스트-이미지 생성과 같은 멀티모달 콘텐츠 생성 작업에도 응용될 수 있습니다.
5. 추가 참고 자료
Huang, Shaohan, et al. "Language is not all you need: Aligning perception with language models." Advances in Neural Information Processing Systems 36 (2023): 72096-72109.
Language Is Not All You Need: Aligning Perception with Language Models
Shaohan Huang,* Li Dong,* Wenhui Wang,* Yaru Hao,* Saksham Singhal,* Shuming Ma* Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, Qiang Liu, Kriti Aggarwal Zewen Chi, Johan Bjorck, Vishrav Chaudhary, Subhojit Som, Xia Song, Furu Wei Microsoft
https://github.com/microsoft/unilm
 Kosmos-1은 언어와 를 모두 인지하고, in-context 학습, 추론, 생성을 수행할 수 있다.
Kosmos-1은 언어와 를 모두 인지하고, in-context 학습, 추론, 생성을 수행할 수 있다.
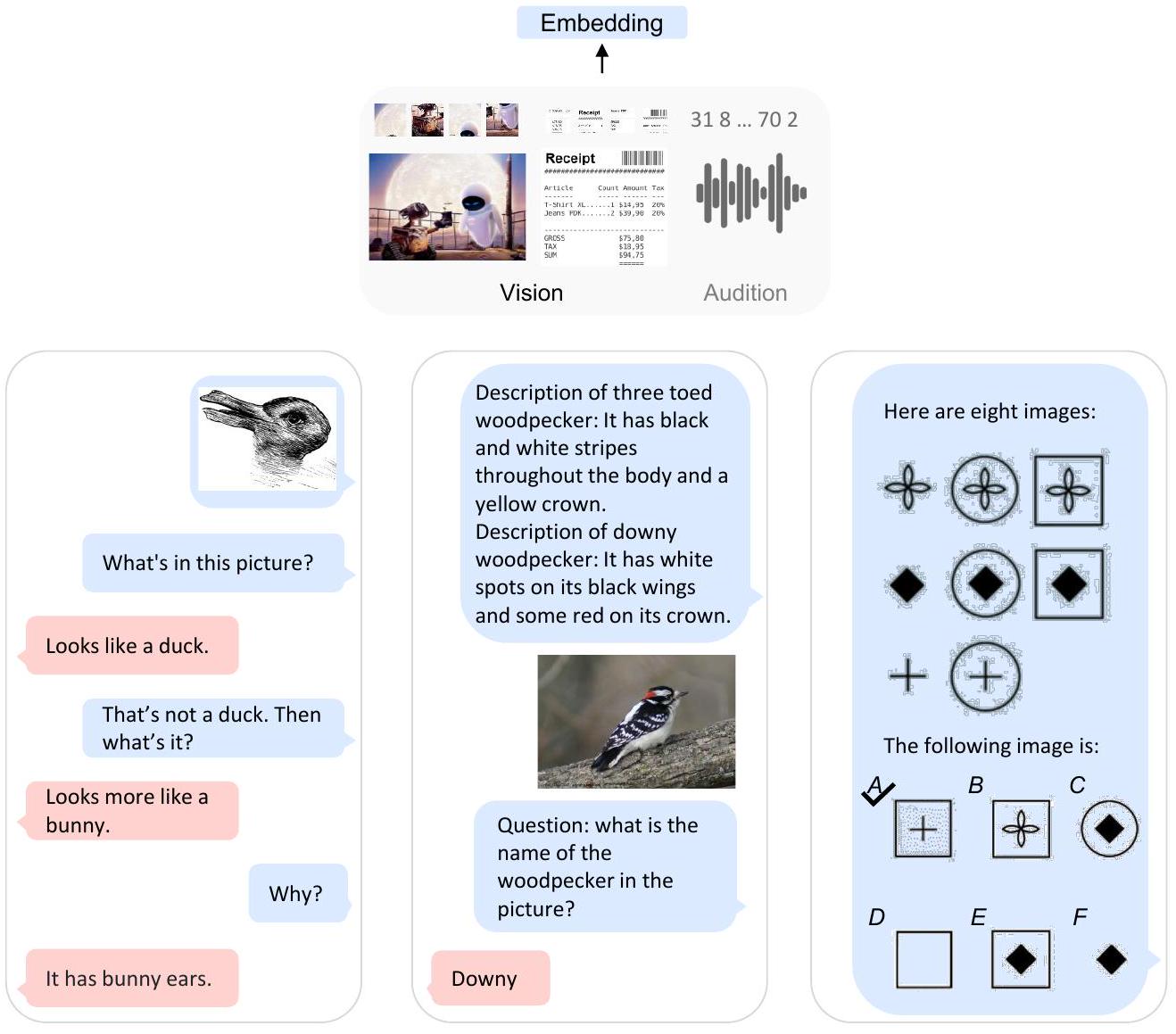
Figure 1: Kosmos-1은 멀티모달 입력을 인지하고, 지시를 따르며, 언어 task뿐만 아니라 멀티모달 task에서도 in-context learning을 수행할 수 있는 **Multimodal Large Language Model (MLLM)**이다. 본 연구에서는 **vision을 large language model (LLM)과 정렬(align)**하여, LLM에서 MLLM으로 나아가는 추세를 발전시킨다.
Abstract
언어, 멀티모달 인지, 행동, 그리고 세계 모델링의 큰 융합은 **인공 일반 지능(artificial general intelligence)**을 향한 핵심 단계이다. 본 연구에서는 **일반적인 양식(modality)을 인지하고, in-context 학습(즉, few-shot)을 수행하며, 지시를 따를 수 있는(즉, zero-shot) Multimodal Large Language Model (MLLM)**인 Kosmos-1을 소개한다. 구체적으로, 우리는 임의로 섞여 있는 텍스트와 이미지, 이미지-캡션 쌍, 그리고 텍스트 데이터를 포함하는 웹 규모의 멀티모달 코퍼스를 사용하여 Kosmos-1을 scratch부터 학습시킨다. 우리는 어떠한 gradient 업데이트나 fine-tuning 없이 zero-shot, few-shot, 그리고 multimodal chain-of-thought prompting을 포함한 다양한 설정에서 광범위한 task에 대해 평가를 수행한다. 실험 결과는 Kosmos-1이 다음과 같은 분야에서 인상적인 성능을 달성했음을 보여준다:
(i) 언어 이해, 생성, 심지어 OCR-free NLP (문서 이미지를 직접 입력으로 사용), (ii) 멀티모달 대화, 이미지 캡셔닝, visual question answering을 포함한 인지-언어(perception-language) task, (iii) 설명(텍스트 지시를 통한 분류 지정)을 포함한 이미지 인식과 같은 비전 task.
우리는 또한 MLLM이 cross-modal transfer, 즉 언어에서 멀티모달로, 그리고 멀티모달에서 언어로 지식을 전이(transfer)함으로써 이점을 얻을 수 있음을 보여준다. 또한, 우리는 MLLM의 비언어적 추론 능력(nonverbal reasoning capability)을 진단하는 Raven IQ test 데이터셋을 소개한다.

Figure 2: Kosmos-1에서 생성된 선택된 예시들. 파란색 상자는 입력 prompt이고, 분홍색 상자는 Kosmos-1의 출력이다. 예시에는 (1)-(2) 시각적 설명, (3)-(4) visual question answering, (5) 웹페이지 질문 응답, (6) 간단한 수학 방정식, 그리고 (7)-(8) 숫자 인식이 포함된다.

| Completion | a girl blowing out a candle on her birthday cake. | a group of people posing for a wedding photo. | Starbucks | Corn |
|---|---|---|---|---|
| (1) | (2) | (3) | (4) |
 (5)
(5)
 (9)
(9)
 (11)
(11)
Figure 3: Kosmos-1에서 생성된 선택된 예시들. 파란색 상자는 입력 prompt이고, 분홍색 상자는 Kosmos-1의 출력이다. 예시에는 (1)-(2) 이미지 캡셔닝, (3)-(6) visual question answering, (7)-(8) OCR, 그리고 (9)-(11) visual dialogue가 포함된다.
| Dataset | Task description | Metric | Zero-shot | Few-shot |
|---|---|---|---|---|
| Language tasks | ||||
| StoryCloze [MRL 17] | Commonsense reasoning | Accuracy | ||
| HellaSwag [ZHB 19] | Commonsense NLI | Accuracy | ||
| Winograd [LDM12a] | Word ambiguity | Accuracy | ||
| Winogrande [SBBC20] | Word ambiguity | Accuracy | ||
| PIQA [BZB 20] | Physical commonsense | Accuracy | ||
| BoolQ [CLC 19] | Question answering | Accuracy | ||
| CB [dMST19] | Textual entailment | Accuracy | ||
| COPA [RBG11] | Causal reasoning | Accuracy | ||
| Rendered SST-2 [ 21] | OCR-free sentiment classification | Accuracy | ||
| HatefulMemes [ 20] | OCR-free meme classification | ROC AUC | ||
| Cross-modal transfer | ||||
| RelativeSize [BHCF16] | Commonsense reasoning (object size) | Accuracy | ||
| MemoryColor [NHJ21] | Commonsense reasoning (object color) | Accuracy | ||
| ColorTerms [BBBT12] | Commonsense reasoning (object color) | Accuracy | ||
| Nonverbal reasoning tasks | ||||
| IQ Test | Raven's Progressive Matrices | Accuracy | ||
| Perception-language tasks | ||||
| COCO Caption [ 14] | Image captioning | CIDEr, etc. | ||
| Flicker30k [YLHH14] | Image captioning | CIDEr, etc. | ||
| VQAv2 [GKSS 17] | Visual question answering | VQA acc. | ||
| VizWiz [GLS 18] | Visual question answering | VQA acc. | ||
| WebSRC [CZC 21] | Web page question answering | F1 score | ||
| Vision tasks | ||||
| ImageNet [DDS 09] | Zero-shot image classification | Top-1 acc. | ||
| CUB [WBW 11] | Zero-shot image classification with descriptions | Accuracy |
Table 1: 우리는 Kosmos-1의 언어, 인지-언어(perception-language), 그리고 비전 task에 대한 능력을 zero-shot 및 few-shot 학습 설정 모두에서 평가한다.
1 Introduction: From LLMs to MLLMs
대규모 언어 모델(LLM)은 다양한 자연어 task에서 범용적인 인터페이스 역할을 성공적으로 수행해왔다 [BMR20]. LLM 기반 인터페이스는 입력과 출력을 텍스트로 변환할 수 있는 한, 어떤 task에도 적용될 수 있다. 예를 들어, 요약 task의 입력은 문서이고 출력은 요약문이므로, 입력 문서를 language model에 입력한 후 생성된 요약문을 얻을 수 있다.
자연어 처리 분야에서의 성공적인 적용에도 불구하고, LLM을 이미지, 오디오와 같은 멀티모달 데이터에 기본적으로 활용하는 것은 여전히 어려운 과제이다. 지능의 기본적인 부분인 **멀티모달 인식(multimodal perception)**은 지식 습득 및 실제 세계에 대한 grounding 측면에서 인공 일반 지능(artificial general intelligence)을 달성하기 위한 필수 요소이다. 더욱 중요하게는, 멀티모달 입력 [TMC21, HSD22, WBD22, ADL22, AHR22, LLSH23]을 활용할 수 있게 되면 language model의 적용 분야가 멀티모달 머신러닝, 문서 지능, 로봇 공학과 같은 더욱 가치 있는 영역으로 크게 확장된다.
본 연구에서는 일반적인 양식(modality)을 인식하고, 지시를 따르며(즉, zero-shot learning), 문맥 내에서 학습할 수 있는(즉, few-shot learning) Multimodal Large Language Model (MLLM)인 Kosmos-1을 소개한다. 목표는 인식(perception)을 LLM과 정렬(align)하여 모델이 보고 말할 수 있도록 하는 것이다. 구체적으로, 우리는 MetaLM [HSD22]을 따라 Kosmos-1 모델을 처음부터 학습시킨다. Figure 1에서 보듯이, Transformer 기반 language model이 범용 인터페이스로 간주되며, 인식 모듈(perception module)이 language model에 도킹(docking)된다. 우리는 웹 규모의 멀티모달 코퍼스, 즉 텍스트 데이터, 임의로 섞인 이미지와 텍스트, 그리고 이미지-캡션 쌍으로 모델을 학습시킨다. 또한, 언어 전용 데이터를 전이(transfer)하여 양식(modality) 전반에 걸쳐 지시 따르기(instruction-following) 능력을 보정한다.
Table 1에서 보듯이, Kosmos-1 모델은 언어, 인식-언어(perception-language), 비전 task를 기본적으로 지원한다. Figure 2와 3에서는 몇 가지 생성된 예시를 제시한다. 다양한 자연어 task 외에도, KOSMOS-1 모델은 시각 대화, 시각 설명, 시각 질의응답, 이미지 캡셔닝, 간단한 수학 방정식, OCR, 설명이 포함된 zero-shot 이미지 분류 등 광범위한 인식 집중(perception-intensive) task를 기본적으로 처리한다. 우리는 또한 MLLM의 비언어적 추론 능력(nonverbal reasoning capability)을 평가하는 Raven's Progressive Matrices [JR03, CJS90]를 따라 IQ 테스트 벤치마크를 구축하였다. 이 예시들은 멀티모달 인식의 기본 지원이 LLM을 새로운 task에 적용할 새로운 기회를 제공함을 보여준다. 더욱이, 우리는 MLLM이 LLM에 비해 더 나은 상식 추론(commonsense reasoning) 성능을 달성함을 보여주는데, 이는 교차 양식 전이(cross-modal transfer)가 지식 습득에 도움이 됨을 시사한다.
핵심 요약은 다음과 같다:
LLM에서 MLLM으로. 인식을 적절히 처리하는 것은 인공 일반 지능을 향한 필수적인 단계이다. 멀티모달 입력을 인식하는 능력은 LLM에 매우 중요하다. 첫째, 멀티모달 인식은 LLM이 텍스트 설명 이상의 상식 지식을 습득할 수 있도록 한다. 둘째, 인식을 LLM과 정렬하는 것은 로봇 공학 및 문서 지능과 같은 새로운 task의 문을 연다. 셋째, 인식 능력은 다양한 API를 통합한다. 이는 그래픽 사용자 인터페이스가 상호 작용하는 가장 자연스럽고 통합된 방법이기 때문이다. 예를 들어, MLLM은 화면을 직접 읽거나 영수증에서 숫자를 추출할 수 있다. 우리는 Kosmos-1 모델을 웹 규모의 멀티모달 코퍼스로 학습시키는데, 이는 모델이 다양한 소스로부터 견고하게 학습하도록 보장한다. 우리는 대규모 텍스트 코퍼스뿐만 아니라, 고품질 이미지-캡션 쌍과 임의로 섞인 이미지 및 텍스트 문서를 웹에서 마이닝한다.
범용 인터페이스로서의 Language Model. MetaLM [HSD22]에서 제안된 철학을 따라, 우리는 language model을 보편적인 task layer로 간주한다. 개방형 출력 공간 덕분에 우리는 다양한 task 예측을 텍스트로 통합할 수 있다. 더욱이, 자연어 지시 및 행동 시퀀스(예: 프로그래밍 언어)는 language model에 의해 잘 처리될 수 있다. LLM은 또한 기본적인 추론기(reasoner) 역할을 하며 [WWS22], 이는 복잡한 task에서 인식 모듈을 보완한다. 따라서 세계, 행동, 멀티모달 인식을 범용 인터페이스, 즉 language model과 정렬하는 것은 자연스러운 일이다.
MLLM의 새로운 능력. Table 1에서 보듯이, 기존 LLM [BMR20, CND22]에서 발견된 능력 외에도, MLLM은 새로운 활용법과 가능성을 제공한다. 첫째, 자연어 지시와 시범 예시를 사용하여 zero-shot 및 few-shot 멀티모달 학습을 수행할 수 있다. 둘째, 인간의 유동 추론 능력(fluid reasoning ability)을 측정하는 Raven IQ 테스트를 평가하여 비언어적 추론의 유망한 신호를 관찰한다. 셋째, MLLM은 멀티모달 대화와 같은 일반적인 양식에 대한 다중 턴 상호 작용을 기본적으로 지원한다.
2 Kosmos-1: A Multimodal Large Language Model
Figure 1에서 보여주듯이, Kosmos-1은 일반적인 modality를 인지하고, 지시를 따르며, in-context 학습을 수행하고, 출력을 생성할 수 있는 멀티모달 language model이다. 주어진 이전 context를 바탕으로, 모델은 auto-regressive 방식으로 텍스트를 생성하도록 학습된다. 구체적으로, Kosmos-1의 backbone은 Transformer 기반의 causal language model이다. 텍스트 외의 다른 modality들은 embedding되어 language model에 입력된다. Transformer decoder는 멀티모달 입력에 대한 범용적인 인터페이스 역할을 한다. 우리는 Kosmos-1을 monomodal 데이터, crossmodal paired 데이터, interleaved multimodal 데이터를 포함하는 멀티모달 코퍼스로 학습시킨다. 모델 학습이 완료되면, zero-shot 및 few-shot 설정에서 언어 task와 멀티모달 task 모두에 대해 모델을 직접 평가할 수 있다.
2.1 Input Representation
Transformer decoder는 일반적인 modality들을 통합된 방식으로 인지한다. 입력 형식의 경우, 우리는 **입력을 특수 토큰으로 장식된 시퀀스로 평탄화(flatten)**한다. 구체적으로, <s>와 </s>는 시퀀스의 시작과 끝을 나타내는 데 사용된다. <image>와 </image> 특수 토큰은 인코딩된 이미지 임베딩의 시작과 끝을 나타낸다. 예를 들어, "<s> document </s>"는 텍스트 입력이며, "<s> paragraph <image> Image Embedding </image> paragraph </s>"는 interleaved 이미지-텍스트 입력이다. Appendix의 Table 21은 입력 형식의 몇 가지 예시를 보여준다.
임베딩 모듈은 텍스트 토큰과 다른 입력 modality들을 벡터로 인코딩하는 데 사용된다. 그런 다음 이 임베딩들은 decoder에 입력된다. 입력 토큰의 경우, 우리는 lookup table을 사용하여 토큰을 임베딩으로 매핑한다. 연속적인 신호(예: 이미지, 오디오)의 modality에 대해서는, 입력을 이산적인 코드(discrete code)로 표현한 다음 이를 "외국어(foreign languages)"로 간주하는 것도 가능하다 [WBD22, WCW23]. 본 연구에서는 [HSD22]를 따라, vision encoder를 입력 이미지의 임베딩 모듈로 사용한다. 또한, Resampler [ADL22]는 이미지 임베딩의 수를 줄이기 위한 attentive pooling mechanism으로 사용된다.
2.2 Multimodal Large Language Models (MLLMs)
입력 시퀀스의 embedding을 얻은 후, 이를 Transformer 기반 decoder에 입력한다. 좌에서 우로 진행되는 causal model은 시퀀스를 auto-regressive 방식으로 처리하며, 이전 timestep에 조건을 부여하여 다음 token을 생성한다. Causal masking은 미래 정보를 가리는 데 사용된다. Transformer 위에 있는 softmax classifier는 vocabulary에 걸쳐 token을 생성하는 데 사용된다.
MLLM은 자연어 및 멀티모달 입력과의 상호작용을 수행할 수 있는 범용 인터페이스 [HSD22] 역할을 한다. 이 프레임워크는 입력을 벡터로 표현할 수 있는 한, 다양한 데이터 유형을 유연하게 처리할 수 있다. MLLM은 두 가지 장점을 결합한다. 첫째, language model은 in-context learning 및 instruction following 능력을 자연스럽게 계승한다. 둘째, 멀티모달 코퍼스 학습을 통해 perception이 language model과 정렬된다.
구현은 대규모 모델 학습을 위해 설계된 라이브러리 TorchScale [MWH22]를 기반으로 한다. 표준 Transformer 아키텍처와 비교하여 다음과 같은 수정 사항을 포함한다:
Magneto
우리는 Transformer 변형인 Magneto [WMH22]를 backbone 아키텍처로 사용한다. Magneto는 더 나은 학습 안정성과 모달리티 전반에 걸쳐 우수한 성능을 제공한다. 이는 각 sublayer(즉, multi-head self-attention 및 feed-forward network)에 추가적인 LayerNorm을 도입한다. 이 방법은 최적화를 근본적으로 개선하기 위한 이론적으로 도출된 초기화 방법 [WMD22]을 가지고 있어, 모델을 효과적으로 고통 없이 확장할 수 있게 한다.
xPos
우리는 더 나은 long-context modeling을 위해 xPos [SDP22] 상대 위치 인코딩을 사용한다. 이 방법은 다양한 길이에 더 잘 일반화될 수 있다. 즉, 짧은 시퀀스로 학습하고 더 긴 시퀀스로 테스트할 수 있다. 또한, xPos는 attention resolution을 최적화하여 위치 정보를 더 정확하게 포착할 수 있도록 한다. xPos 방법은 보간(interpolation) 및 외삽(extrapolation) 설정 모두에서 효율적이고 효과적이다.
2.3 Training Objective
Kosmos-1의 학습은 웹 규모의 멀티모달 코퍼스를 기반으로 진행되며, 여기에는 다음과 같은 데이터가 포함된다:
- 모노모달 데이터 (예: 텍스트 코퍼스)
- 크로스모달 쌍 데이터 (예: 이미지-캡션 쌍)
- interleaved 멀티모달 데이터 (예: 이미지와 텍스트가 임의로 섞여 있는 문서)
구체적으로, 우리는 모노모달 데이터를 **표현 학습(representation learning)**에 사용한다. 예를 들어, 텍스트 데이터를 이용한 language modeling은 instruction following, in-context learning, 그리고 다양한 언어 task를 사전학습한다. 또한, 크로스모달 쌍 데이터와 interleaved 데이터는 일반적인 모달리티의 인식을 language model과 정렬(align)하는 것을 학습한다. Interleaved 데이터는 멀티모달 language modeling task에 자연스럽게 적합하다. 학습 데이터 수집에 대한 더 자세한 내용은 Section 3.1에 제시되어 있다.
모델은 다음 토큰 예측(next-token prediction) task, 즉 이전 context에 따라 다음 토큰을 생성하는 것을 학습하는 방식으로 훈련된다. 학습 목표는 예시 내 토큰들의 log-likelihood를 최대화하는 것이다. 훈련 손실(training loss)에는 텍스트 토큰과 같은 이산적인(discrete) 토큰만 포함된다는 점에 유의해야 한다. 멀티모달 language modeling은 모델을 학습시키는 확장 가능한(scalable) 방법이다. 더 중요한 것은, 다양한 능력의 출현으로 인해 이 학습 task가 다운스트림 애플리케이션에 유리하다는 점이다.
3 Model Training
3.1 Multimodal Training Data
모델은 웹 규모의 멀티모달 코퍼스로 학습된다. 학습 데이터셋은 텍스트 코퍼스, 이미지-캡션 쌍, 그리고 이미지와 텍스트가 섞여 있는(interleaved) 데이터로 구성된다.
텍스트 코퍼스 (Text Corpora)
우리는 **The Pile [GBB20]과 Common Crawl (CC)**로 모델을 학습시킨다. The Pile은 대규모 언어 모델 학습을 위해 구축된 방대한 영어 텍스트 데이터셋으로, 다양한 데이터 소스에서 생성되었다. 우리는 GitHub, arXiv, Stack Exchange, PubMed Central의 데이터 분할은 제외한다. 또한 **Common Crawl 스냅샷 (2020-50 및 2021-04) 데이터셋, CC-Stories, 그리고 RealNews 데이터셋 [SPP19, SPN22]**을 포함한다. 전체 데이터셋은 중복 및 거의 중복되는 문서들을 제거하고, 다운스트림 task 데이터를 제외하도록 필터링되었다. 학습 텍스트 코퍼스에 대한 자세한 설명은 Appendix B.1.1을 참조하라.
이미지-캡션 쌍 (Image-Caption Pairs)
이미지-캡션 쌍은 **English LAION-2B [SBV22], LAION-400M [SVB21], COYO-700M [BPK22], 그리고 Conceptual Captions [SDGS18, CSDS21]**을 포함한 여러 데이터셋으로부터 구축되었다. English LAION-2B, LAION-400M, COYO-700M은 Common Crawl 웹 데이터의 웹 페이지에서 이미지 소스와 해당 alt-text를 추출하여 수집되었다. Conceptual Captions 또한 인터넷 웹 페이지에서 가져온 것이다. 더 자세한 내용은 Appendix B.1.2에서 찾을 수 있다.
Interleaved 이미지-텍스트 데이터 (Interleaved Image-Text Data)
우리는 공개적으로 사용 가능한 웹 페이지 아카이브인 Common Crawl 스냅샷에서 interleaved 멀티모달 데이터를 수집한다. 스냅샷의 원본 20억 개 웹 페이지에서 약 7,100만 개의 웹 페이지를 선택하기 위해 필터링 프로세스를 사용한다. 그런 다음 각 선택된 웹 페이지의 HTML에서 텍스트와 이미지를 추출한다. 각 문서에 대해 노이즈와 중복성을 줄이기 위해 이미지 수를 5개로 제한한다. 또한 다양성을 높이기 위해 이미지가 하나만 있는 문서의 절반을 무작위로 폐기한다. 데이터 수집 과정에 대한 더 자세한 내용은 Appendix B.1.3에 제공되어 있다. 이 코퍼스를 사용함으로써 Kosmos-1이 interleaved 텍스트와 이미지를 처리하고 few-shot 능력을 향상시킬 수 있도록 한다.
3.2 Training Setup
3.3 Language-Only Instruction Tuning
Kosmos-1을 인간의 지시에 더 잘 맞추기 위해, 우리는 언어 전용 instruction tuning을 수행한다 [LHV23, HSLS22]. 구체적으로, 우리는 (instructions, inputs, and outputs) 형식의 instruction 데이터를 사용하여 모델을 계속 학습시킨다. 이 instruction 데이터는 **언어 전용(language-only)**이며, 다른 학습 코퍼스와 혼합된다. 튜닝 과정은 language modeling으로 진행된다. 이때, instructions와 inputs는 loss 계산에 포함되지 않는다는 점에 유의해야 한다. Section 4.9.1에서는 instruction-following 능력의 향상이 여러 modality에 걸쳐 전이될 수 있음을 보여준다.
우리는 Unnatural Instructions [HSLS22]와 FLANv2 [LHV23]를 결합하여 instruction 데이터셋으로 사용한다. Unnatural Instructions는 대규모 language model을 사용하여 다양한 자연어 처리 task에 대한 instruction을 생성함으로써 만들어진 데이터셋이다. 이 데이터셋의 핵심 부분에는 68,478개의 instruction-input-output triplet이 포함되어 있다. FLANv2는 독해, 상식 추론, closed-book question answering과 같은 다양한 유형의 언어 이해 task를 다루는 데이터셋 모음이다. 우리는 instruction 데이터셋을 보강하기 위해 FLANv2에서 54,000개의 instruction 예시를 무작위로 선택한다. 학습 하이퍼파라미터 설정에 대한 자세한 내용은 Appendix A.2에 설명되어 있다.
4 Evaluation
MLLM은 언어 task와 지각(perception) 중심 task를 모두 처리할 수 있다. 우리는 Kosmos-1을 다음과 같은 다양한 유형의 task에서 평가한다:
- 언어 task
- 언어 이해 (Language understanding)
- 언어 생성 (Language generation)
- OCR-free 텍스트 분류 (OCR-free text classification)
- 교차 모달 전이 (Cross-modal transfer)
- 상식 추론 (Commonsense reasoning)
- 비언어적 추론 (Nonverbal reasoning)
- IQ 테스트 (Raven’s Progressive Matrices)
- 지각-언어 task (Perception-language tasks)
- 이미지 캡셔닝 (Image captioning)
- 시각 질문 응답 (Visual question answering)
- 웹페이지 질문 응답 (Web page question answering)
- 비전 task (Vision tasks)
- Zero-shot 이미지 분류 (Zero-shot image classification)
- 설명을 포함한 Zero-shot 이미지 분류 (Zero-shot image classification with descriptions)
4.1 Perception-Language Tasks
우리는 Kosmos-1의 지각-언어(perception-language) 능력을 vision-language 환경에서 평가한다. 구체적으로, **이미지 캡셔닝(image captioning)**과 **시각적 질문 응답(visual question answering)**이라는 두 가지 널리 사용되는 task에 대해 zero-shot 및 few-shot 실험을 수행한다. 이미지 캡셔닝은 이미지에 대한 자연어 설명을 생성하는 task이며, 시각적 질문 응답은 이미지에 대한 자연어 질문에 답하는 것을 목표로 한다.
4.1.1 Evaluation Setup
우리는 MS COCO Caption [LMB14]과 Flickr30k [YLHH14] 데이터셋에서 캡션 생성 성능을 평가한다. COCO Karpathy split [KFF17]의 test set을 사용하는데, 이는 train2014 및 val2014 이미지 [LMB14]를 각각 학습 세트 113,287개, 검증 세트 5,000개, 테스트 세트 5,000개로 재분할한 것이다. Flickr30k의 경우 Karpathy split test set에서 평가를 수행한다. 이미지 해상도는 224x224이며, 캡션 생성을 위해 beam size 5의 beam search를 사용한다. few-shot 설정에서는 학습 세트에서 demonstration을 무작위로 샘플링한다. 평가 지표로는 CIDEr [VLZP15]와 SPICE [AFJG16] 점수를 계산하기 위해 COCOEvalCap을 사용한다. zero-shot 및 few-shot 캡션 생성 실험에서는 Kosmos-1에 "An image of"라는 prompt를 사용한다.
Visual Question Answering (VQA) task의 경우, VQAv2 [GKSS17]의 test-dev set과 VizWiz [GLS18]의 test-dev set에서 각각 zero-shot 및 few-shot 결과를 평가한다.
이미지 해상도는 224x224이며, 디코딩을 위해 greedy search를 사용한다.
VQA 정확도 계산 시에는 VQAv2 평가 코드의 정규화 규칙을 따른다.
VQA 성능은 Kosmos-1이 답변을 생성하고 </s>("end of sequence") 토큰에서 멈추는 open-ended 설정에서 평가한다.
VQA task의 prompt는 **"Question: {question} Answer: {answer}"**이다.
4.1.2 Results
Image Captioning
Table 2는 COCO Karpathy test split과 Flickr30k test set에서의 zero-shot captioning 성능을 보여준다. Kosmos-1은 두 이미지 캡셔닝 데이터셋에서 zero-shot 설정에서 놀라운 결과를 달성한다. 특히, 우리 모델은 Flickr30k 데이터셋에서 67.1의 CIDEr 점수를 달성했으며, 이는 Flamingo-3B의 60.6, Flamingo-9B의 61.5와 비교된다. 주목할 점은 우리 모델이 Flamingo 모델들보다 작은 1.6B의 크기로 이러한 성과를 달성할 수 있었다는 것이다. 이는 zero-shot 이미지 캡셔닝에서 우리 모델의 우수성을 보여준다.
| Model | COCO | Flickr30k | ||
|---|---|---|---|---|
| CIDEr | SPICE | CIDEr | SPICE | |
| ZeroCap | 14.6 | 5.5 | - | - |
| VLKD | 58.3 | 13.4 | - | - |
| FewVLM | - | - | 31.0 | 10.0 |
| Metalm | 82.2 | 15.7 | 43.4 | 11.7 |
| Flamingo-3B* | 73.0 | - | 60.6 | - |
| Flamingo-9B* | 79.4 | - | 61.5 | - |
| Kosmos-1 (1.6B) | 84.7 | 16.8 | 67.1 | 14.5 |
Table 2: COCO caption Karpathy test 및 Flickr30k test에서의 zero-shot 이미지 캡셔닝 결과.
* Flamingo [ADL22]는 다운스트림 task의 두 가지 예시를 prompt로 사용하되, 해당 이미지들은 제거한다 (즉, few-shot text prompt와 유사). 다른 모델들은 prompt에 어떠한 예시도 포함하지 않는다.
Table 3은 few-shot () 설정의 결과를 보고한다. shot 수가 2개에서 4개로 증가함에 따라 전반적인 성능이 향상된다. 이러한 경향은 두 데이터셋 모두에서 일관적이다. 또한, few-shot 결과는 Table 2의 zero-shot 캡셔닝보다 더 우수하다.
| Model | COCO | Flickr30k | ||||
|---|---|---|---|---|---|---|
| Flamingo-3B | - | 85.0 | 90.6 | - | 72.0 | 71.7 |
| Flamingo-9B | - | 93.1 | - | 72.6 | ||
| Kosmos-1 (1.6B) | 96.7 | 68.0 |
Table 3: COCO caption Karpathy test 및 Flickr30k test에서의 few-shot 이미지 캡셔닝 결과. CIDEr 점수가 보고되었다.
Visual Question Answering
Table 4는 VQAv2 및 VizWiz에서의 zero-shot visual question answering 결과를 보고한다. 우리는 Kosmos-1이 VizWiz 데이터셋의 다양성과 복잡성을 더 잘 처리할 수 있음을 보여준다. Kosmos-1은 Flamingo-3B 및 Flamingo-9B 모델보다 더 높은 정확도와 견고성을 달성한다. 또한, 우리 모델은 VQAv2 데이터셋에서 Flamingo와 경쟁력 있는 성능을 보인다.
| Model | VQAv2 | VizWiz |
|---|---|---|
| Frozen | 29.5 | - |
| VLKDViT-B/16 | 38.6 | - |
| MeTALM | 41.1 | - |
| Flamingo-3B* | 49.2 | 28.9 |
| Flamingo-9B* | 28.8 | |
| Kosmos-1 (1.6B) | 51.0 |
Table 4: VQAv2 및 VizWiz에서의 zero-shot visual question answering 결과. VQA 정확도 점수가 제시되었다.
"*": Flamingo [ADL22]는 다운스트림 task의 두 가지 예시를 prompt로 구성하되, 해당 이미지들은 제거한다 (즉, few-shot text prompt와 유사). 반면 다른 모델들은 진정한 zero-shot learning을 평가한다.
Table 5는 visual question answering task에서의 few-shot 성능을 보여준다. Kosmos-1은 VizWiz 데이터셋에서 few-shot () 설정에서 다른 모델들을 능가한다. 또한, 우리는 VizWiz 데이터셋에서 shot 수가 증가함에 따라 결과의 품질이 향상되는 긍정적인 상관관계를 관찰한다. 더욱이, few-shot 결과는 Table 4에 보고된 zero-shot 수치보다 더 우수하다.
| Model | VQAv2 | VizWiz | ||||
|---|---|---|---|---|---|---|
| Frozen | - | 38.2 | - | - | - | - |
| Metalm | - | 45.3 | - | - | - | - |
| Flamingo-3B | - | 53.2 | 55.4 | - | 34.4 | 38.4 |
| Flamingo-9B | - | 56.3 | 58.0 | - | 34.9 | 39.4 |
| Kosmos-1 (1.6B) | 51.4 | 51.8 | 51.4 | 31.4 | 35.3 | 39.0 |
Table 5: VQAv2 및 VizWiz에서의 few-shot visual question answering 결과. VQA 정확도 점수가 보고되었다.
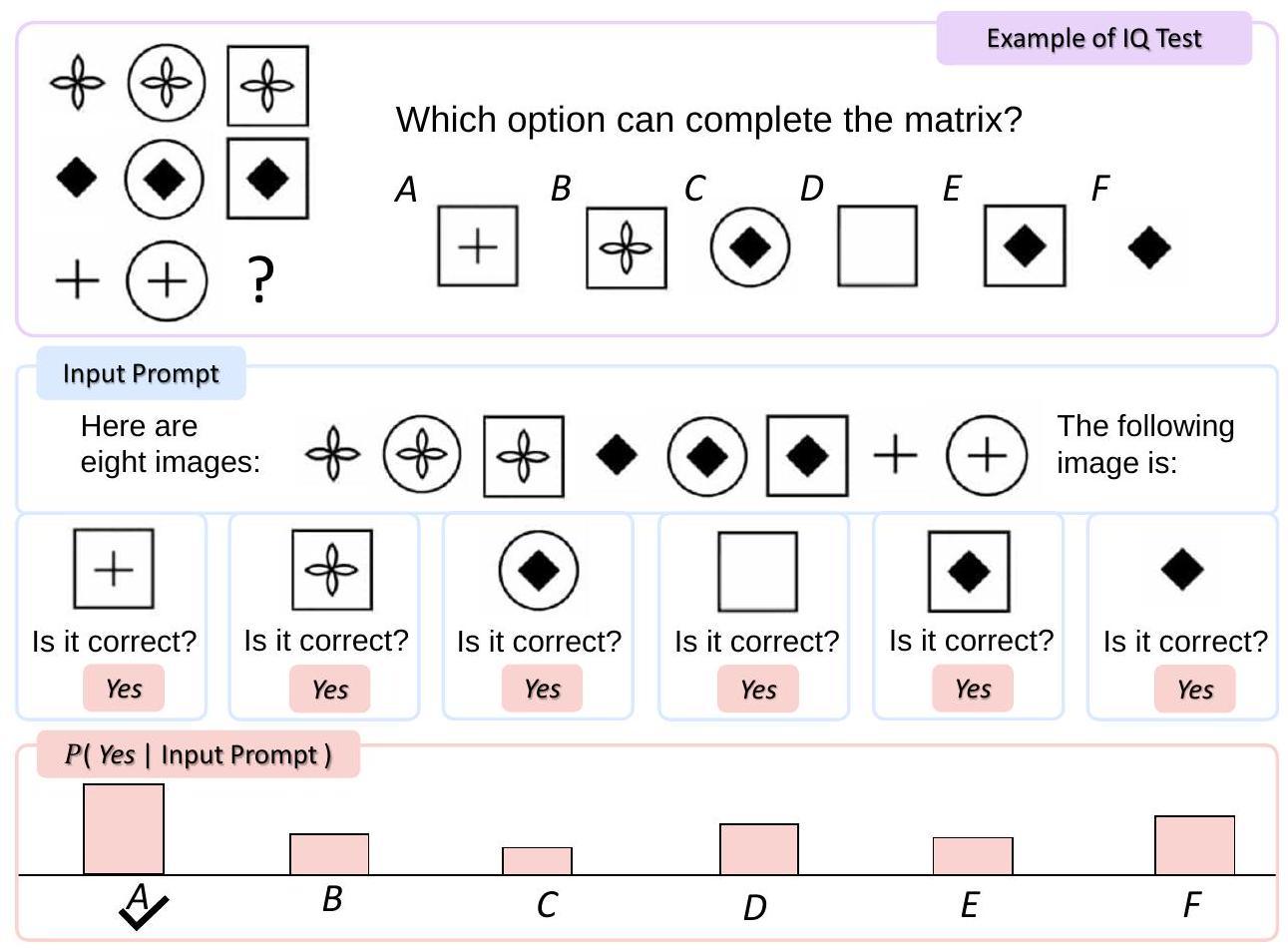
Figure 4: 상단: Raven IQ test의 예시. 하단: Raven IQ test에서 Kosmos-1 평가. 입력 prompt는 평탄화된 이미지 행렬과 언어 지시로 구성된다. 우리는 각 후보 이미지를 prompt에 개별적으로 추가하고, 모델이 올바른지 여부를 쿼리한다. 최종 예측은 모델이 "Yes"에 대한 가장 높은 확률을 유도하는 후보이다.
4.2 IQ Test: Nonverbal Reasoning
Raven's Progressive Matrices [CJS90, JR03]는 비언어적 추론(nonverbal reasoning) 능력을 평가하는 가장 일반적인 테스트 중 하나이다. 비언어적 추론 능력은 일반적으로 개인의 **지능 지수(IQ)**를 반영한다. Figure 4는 그 예시를 보여준다. 행렬로 제시된 8개의 이미지를 보고, 6개의 후보 중에서 다음 요소를 식별하는 것이 task이다.
모델은 명시적인 fine-tuning 없이 zero-shot 비언어적 추론을 수행해야 한다. Raven IQ 테스트는 언어 모델의 in-context learning과 유사하며, 그 차이는 context가 비언어적인지 언어적인지에 있다. 정답을 추론하기 위해 모델은 추상적인 개념을 인식하고 주어진 이미지의 내재된 패턴을 식별해야 한다. 따라서 IQ task는 비언어적 in-context learning 능력을 벤치마킹하기에 좋은 테스트베드이다.
4.2.1 Evaluation Setup
Kosmos-1의 zero-shot 비언어적 추론(nonverbal reasoning) 능력을 평가하기 위해, 우리는 Raven IQ test 데이터셋을 구축하였다. 이 데이터셋은 다양한 웹사이트에서 수집된 50개의 예시로 구성된다. 각 예시는 3개(즉, 2x2 행렬), 4개, 또는 8개(즉, 3x3 행렬)의 주어진 이미지를 포함한다. 목표는 다음 이미지를 예측하는 것이다. 각 인스턴스에는 고유한 정답을 가진 6개의 후보 이미지가 있다. 우리는 모델을 평가하기 위해 정확도(accuracy) 점수를 측정한다. 이 평가 데이터셋은 **https://aka.ms/kosmos-iq50**에서 이용 가능하다.
Figure 4는 Raven IQ test에서 Kosmos-1을 평가하는 방법을 보여준다. 행렬 형태의 이미지들은 평탄화(flatten)되어 모델에 하나씩 입력된다. 모델이 원하는 task를 더 잘 이해할 수 있도록, 우리는 "Here are three/four/eight images:", "The following image is:", "Is it correct?"와 같은 텍스트 지시(textual instruction)를 조건(conditioning)으로 사용한다. 우리는 각 가능한 후보 이미지를 컨텍스트에 개별적으로 추가하고, 모델이 "Yes"를 출력할 확률을 close-ended 설정에서 비교한다. 가장 큰 확률을 보이는 후보가 예측으로 간주된다.
4.2.2 Results
Table 6는 IQ 테스트 데이터셋에 대한 평가 결과를 보여준다. Kosmos-1은 language-only instruction tuning을 적용한 경우와 적용하지 않은 경우 모두 각각 random baseline 대비 5.3% 및 9.3%의 성능 향상을 달성했다. 이 결과는 Kosmos-1이 비언어적 맥락에서 추상적인 개념 패턴을 인지하고, 여러 선택지 중에서 다음 요소를 추론할 수 있음을 나타낸다. 우리가 아는 한, 모델이 이러한 zero-shot Raven IQ 테스트를 수행한 것은 이번이 처음이다. 현재 모델과 성인의 평균 수준 사이에는 여전히 큰 성능 격차가 있지만, Kosmos-1은 지각(perception)을 language model과 정렬함으로써 zero-shot 비언어적 추론을 수행할 수 있는 MLLM의 잠재력을 보여준다.
| Method | Accuracy |
|---|---|
| Random Choice | |
| Kosmos-1 | |
| w/o language-only instruction tuning |
Table 6: Raven IQ 테스트에 대한 zero-shot 일반화 성능.
4.3 OCR-Free Language Understanding
OCR-free language understanding은 OCR(Optical Character Recognition)에 의존하지 않고 텍스트와 이미지를 이해하는 데 초점을 맞춘 task이다. 예를 들어, Rendered SST-2 task에서는 Stanford Sentiment Treebank [SPW13] 데이터셋의 문장들이 이미지로 렌더링된다. 모델은 이미지 내 텍스트의 감성(sentiment)을 예측하도록 요구받는다. 이 task는 이미지로부터 직접 단어와 문장의 의미를 읽고 이해하는 모델의 능력을 평가한다.
4.3.1 Evaluation Setup
우리는 Rendered SST-2 [] 테스트 세트와 HatefulMemes [] validation 세트에서 OCR-free language understanding을 평가한다. Rendered SST-2의 경우 **정확도(accuracy)**를, HatefulMemes 데이터셋의 경우 ROC AUC를 지표로 사용한다.
Rendered SST-2에 사용된 prompt는 "Question: what is the sentiment of the opinion? Answer: {answer}"이며, 여기서 answer는 positive 또는 negative이다. HatefulMemes task의 경우 prompt는 "Question: does this picture contain real hate speech? Answer: {answer}"이며, 여기서 answer는 yes 또는 no이다.
4.3.2 Results
Table 7에서 보여지듯이, Kosmos-1은 HatefulMemes validation set에서 **ROC AUC 63.9%**를 달성했으며, Rendered SST-2 test set에서는 **테스트 정확도 67.1%**를 기록했다. 이는 HatefulMemes task에서 각각 63.3%와 57.0%의 AUC를 달성한 CLIP ViT-L과 Flamingo-9B를 능가하는 성능이다. Flamingo는 prompt에 OCR 텍스트를 명시적으로 제공하는 반면, Kosmos-1은 어떠한 외부 도구나 리소스에도 접근하지 않는다는 점에 주목해야 한다. 이는 Kosmos-1이 렌더링된 이미지 내의 텍스트를 읽고 이해하는 내장된 능력을 가지고 있음을 시사한다.
| Model | HatefulMemes | Rendered SST-2 |
|---|---|---|
| CLIP ViT-B/32 | 57.6 | 59.6 |
| CLIP ViT-B/16 | 61.7 | 59.8 |
| CLIP ViT-L/14 | 63.3 | 64.0 |
| Flamingo-3B | 53.7 | - |
| Flamingo-9B | 57.0 | - |
| Kosmos-1 (1.6B) |
Table 7: OCR-free 언어 이해에 대한 Zero-shot generalization. 정확도 점수를 보고한다.
4.4 Web Page Question Answering
**웹페이지 질문 응답(Web page question answering)**은 웹페이지에서 질문에 대한 답을 찾는 것을 목표로 한다. 이는 모델이 텍스트의 의미론(semantics)과 구조(structure)를 모두 이해해야 함을 요구한다. 웹페이지의 구조(예: 테이블, 목록, HTML 레이아웃)는 정보가 배열되고 표시되는 방식에 핵심적인 역할을 한다. 이 task는 모델이 웹페이지의 의미론과 구조를 이해하는 능력을 평가하는 데 도움이 될 수 있다.
4.4.1 Evaluation Setup
우리는 Web-based Structural Reading Comprehension (WebSRC) 데이터셋 [CZC21]에 대한 성능을 비교한다. 비교를 위해, Kosmos-1과 동일한 텍스트 코퍼스와 동일한 학습 설정으로 language model (LLM)을 학습시켰다. 이 LLM은 웹페이지에서 추출된 텍스트를 입력으로 받는다. Prompt의 템플릿은 다음과 같다: "Given the context below from web page, extract the answer from the given text like this: Qusestion: Who is the publisher of this book? Answer: Penguin Books Ltd. Context: {WebText} Q: {question} A: {answer}". 여기서 {WebText}는 웹페이지에서 추출된 텍스트를 나타낸다. Kosmos-1은 동일한 prompt를 사용하는 것 외에도, prompt 앞에 이미지를 추가한다. WebSRC의 두 가지 예시 이미지는 Appendix C.3에 제시되어 있다. 원본 논문 [CZC21]에 따라, 우리는 정확 일치(Exact Match, EM) 및 F1 점수를 평가 지표로 사용한다.
4.4.2 Results
실험 결과는 Table 8에 요약되어 있다. 우리는 Kosmos-1이 LLM보다 뛰어난 성능을 보이는 것을 관찰했으며, 이는 Kosmos-1이 이미지 내 웹페이지의 레이아웃 및 스타일 정보를 활용할 수 있음을 시사한다. 또한, 우리는 prompt에서 추출된 텍스트를 사용하지 않은 Kosmos-1의 성능을 평가했다. 그 결과, 추출된 텍스트가 Kosmos-1의 EM/F1 점수에 +12.0 / 20.7의 기여를 한다는 것을 보여주며, 이는 이미지 모델링을 통한 이점이 언어 능력을 희생시키지 않음을 나타낸다.
| Models | EM | F1 |
|---|---|---|
| Using extracted text | ||
| LLM | 7.6 | 17.9 |
| Kosmos-1 | ||
| Without using extracted text | ||
| Kosmos-1 | 3.8 | 10.6 |
Table 8: WebSRC task에서의 zero-shot 성능. Exact Match (EM) 및 F1 점수를 보고한다.
4.5 Multimodal Chain-of-Thought Prompting
Chain-of-thought prompting [WWS ]은 대규모 언어 모델이 일련의 추론 단계를 생성하고 다단계 문제를 중간 단계로 분해할 수 있도록 하여, 복잡한 task에서 성능을 크게 향상시킬 수 있다.
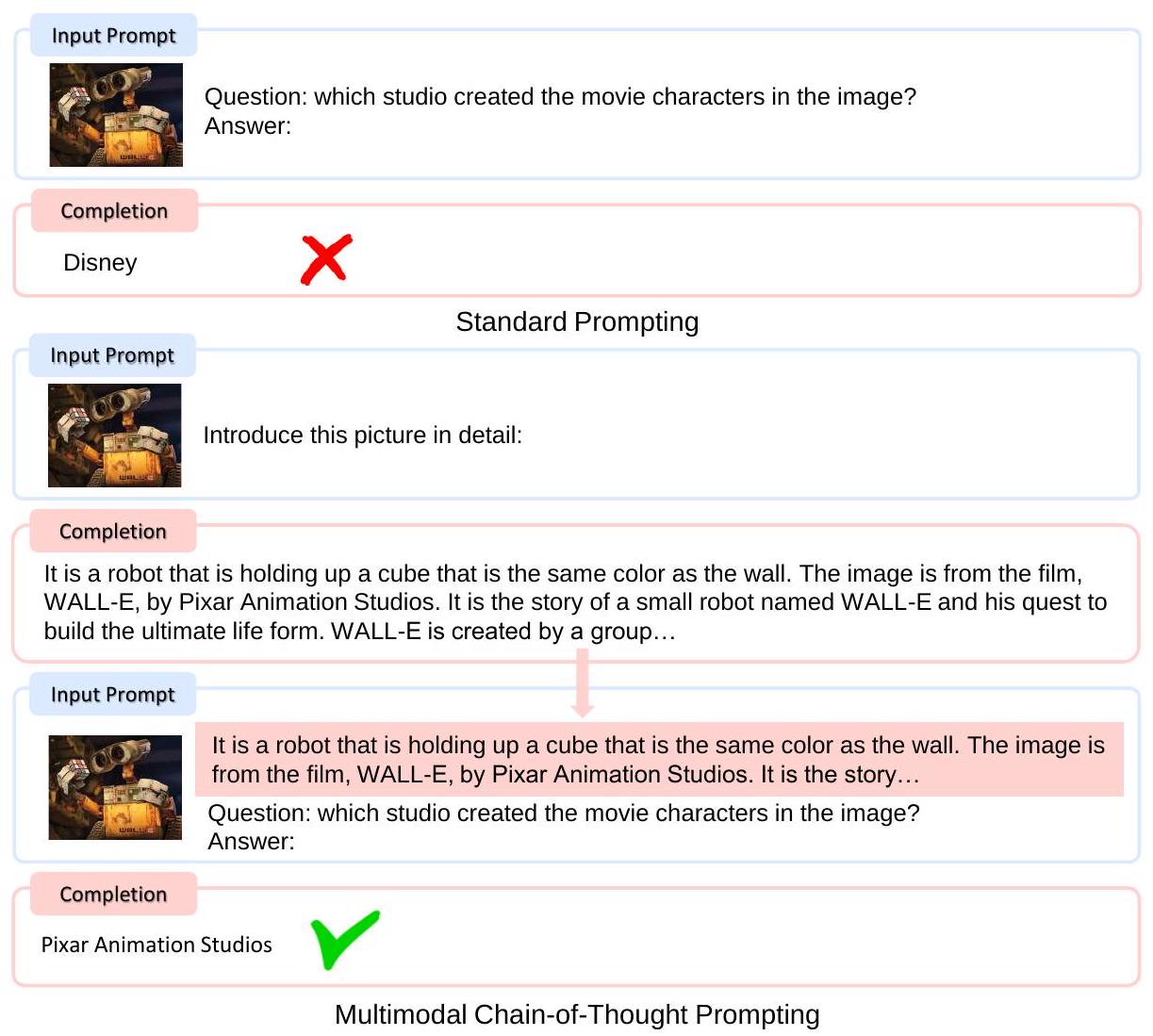
Figure 5: Multimodal Chain-of-Thought prompting은 Kosmos-1이 먼저 추론 과정(rationale)을 생성한 다음, 복잡한 질문-응답 및 추론 task를 해결할 수 있도록 한다. Chain-of-thought prompting에서 영감을 받아, 우리는 Kosmos-1을 사용하여 multimodal chain-of-thought prompting을 연구한다. Figure 5에서 보여주듯이, 우리는 인지-언어(perception-language) task를 두 단계로 분해한다. 첫 번째 단계에서는 이미지가 주어졌을 때, prompt를 사용하여 모델이 추론 과정(rationale)을 생성하도록 유도한다. 그런 다음, 모델은 생성된 rationale과 task-aware prompt를 입력받아 최종 결과를 생성한다.
4.5.1 Evaluation Setup
우리는 Rendered SST-2 데이터셋에서 멀티모달 chain-of-thought prompting의 능력을 평가한다. 먼저, "Introduce this picture in detail:"이라는 prompt를 사용하여 그림의 내용을 rationale로 생성한다. 그 다음, "{rationale} Question: what is the sentiment of the opinion? Answer: {answer}"라는 prompt를 사용하여 감성을 예측한다. 여기서 answer는 positive 또는 negative이다.
4.5.2 Results
우리는 멀티모달 chain-of-thought prompting의 성능을 평가하기 위한 실험을 수행했다. Table 9는 멀티모달 chain-of-thought prompting이 72.9점을 달성했으며, 이는 표준 prompting보다 5.8점 높은 수치임을 보여준다. 중간 콘텐츠를 생성함으로써 모델은 이미지 내 텍스트를 인식하고 문장의 감성을 더 정확하게 추론할 수 있다.
4.6 Zero-Shot Image Classification
우리는 ImageNet [DDS+09]에서의 zero-shot 이미지 분류 성능을 보고한다. 이미지 분류는 전체 이미지를 하나의 단위로 이해하고 이미지에 레이블을 할당하는 것을 목표로 한다. 우리는 각 레이블을 자연어의 카테고리 이름으로 매핑한다. 모델은 zero-shot 이미지 분류를 수행하기 위해 카테고리 이름을 예측하도록 prompt된다.
| Models | Accuracy |
|---|---|
| CLIP ViT-B/32 | 59.6 |
| CLIP ViT-B/16 | 59.8 |
| CLIP ViT-L/14 | 64.0 |
| KosmOS-1 | 67.1 |
| w/ multimodal CoT prompting | 72.9 |
Table 9: Rendered SST-2 task에서의 Multimodal chain-of-thought (CoT) prompting 결과.

Figure 6: In-context verbal description은 Kosmos-1이 시각적 카테고리를 더 잘 인식하도록 도울 수 있다.
4.6.1 Evaluation Setup
입력 이미지가 주어지면, 우리는 이미지와 "The photo of the"라는 prompt를 연결한다. 그런 다음 이 입력을 모델에 넣어 이미지의 카테고리 이름을 얻는다. 우리는 ImageNet [DDS 09] 데이터셋으로 모델을 평가한다. ImageNet은 1,000개의 객체 카테고리에 걸쳐 128만 개의 학습 이미지와 5만 개의 검증 이미지를 포함한다. 예측된 카테고리 이름이 ground-truth 카테고리 이름과 정확히 일치하면 올바른 것으로 분류된다. 평가에 사용된 이미지 해상도는 224x224이다. 카테고리 이름을 생성하기 위해 beam search를 사용하며, beam size는 2이다.
4.6.2 Results
Table 10에서 보여주듯이, 우리는 constrained 및 unconstrained 설정 모두에서 zero-shot 결과를 보고한다. 두 설정의 차이점은 1,000개의 객체 카테고리 이름을 사용하여 decoding을 제한하는지 여부이다. Kosmos-1은 constrained 설정에서 GIT [WYH22]보다 4.6%, unconstrained 설정에서 2.1% 더 뛰어난 성능을 보인다.
| Model | Without Constraints | With Constraints |
|---|---|---|
| GIT [WYH 22] | 1.9 | 33.5 |
| Kosmos-1 |
Table 10: ImageNet에 대한 Zero-shot 이미지 분류 결과.
With Constraints 결과의 경우, 1,000개의 ImageNet 객체 카테고리 이름을 사용하여 constrained decoding을 수행한다. 우리는 top-1 accuracy 점수를 보고한다.
4.7 Zero-Shot Image Classification with Descriptions
위와 같은 이미지 분류의 표준적인 접근 방식은 모델에게 이미지에 묘사된 객체의 특정 이름을 prompt로 제공하는 것이다. 그러나 복잡한 동물 아종의 세분화된 분류와 같이, 다양한 사용자와 시나리오에 맞춰 사용자 정의된 분류 규칙도 존재한다. 우리는 자연어 설명을 활용하여 Kosmos-1이 zero-shot 설정에서 이미지를 구별하도록 유도할 수 있으며, 이는 의사결정 과정을 더욱 해석 가능하게 만든다.
| Category 1 | Category 2 | ||
|---|---|---|---|
| three toed woodpecker | downy woodpecker | ||
 | It has black and white stripes throughout the body and a yellow crown. |  | It has white spots on its black wings and some red on its crown. |
| Gentoo penguin | royal penguin | ||
 | It has a black head and white patch above its eyes. |  | It has a white face and a yellow crown. |
| black throated sparrow | fox sparrow | ||
 | It has white underparts and a distinctive black bib on the throat. |  | It has a reddish-brown plumage and a streaked breast. |
Table 11: In-context 이미지 분류를 위한 다양한 카테고리의 상세 설명.
4.7.1 Evaluation Setup
CUB [WBW11]을 따라, 우리는 이미지와 자연어 카테고리 설명을 포함하는 새 분류 데이터셋을 구축하였다. 이 데이터셋은 세 그룹의 이진 이미지 분류로 구성된다. 각 그룹은 외형이 유사한 두 가지 동물 카테고리를 포함한다. 우리의 목표는 카테고리 설명이 주어졌을 때 이미지를 분류하는 것이다. Table 11은 데이터 샘플을 보여준다. 첫 번째 그룹은 [WBW11]에서 가져왔고, 나머지 두 그룹은 웹사이트에서 수집되었다. 각 카테고리는 20개의 이미지를 포함한다.
평가 절차는 Figure 6에 설명되어 있다. zero-shot 설정의 경우, 우리는 두 특정 카테고리에 대한 상세한 설명을 제공하고, "Question:what is the name of {general category} in the picture? Answer: " 템플릿을 사용하여 모델이 특정 카테고리 이름을 open-ended 방식으로 생성하도록 prompt한다. 문맥 내에서 언어적 설명을 제공하는 효과를 평가하기 위해, 우리는 설명을 prompt로 제공하지 않는 zero-shot baseline도 구현하였다. 대신, prompt에 해당하는 특정 이름을 제공한다.
4.7.2 Results
평가 결과는 Table 12에 제시되어 있다. 우리는 context 내에서 설명을 제공하는 것이 이미지 분류의 정확도를 크게 향상시킬 수 있음을 관찰했다. 이러한 일관된 성능 향상은 Kosmos-1이 지시의 의도를 인지하고, 언어 modality의 개념을 vision modality의 시각적 feature와 잘 정렬시킬 수 있음을 나타낸다.
| Settings | Accuracy |
|---|---|
| Without Descriptions | 61.7 |
| With Descriptions |
Table 12: 언어적 설명 유무에 따른 zero-shot 이미지 분류 결과.
4.8 Language Tasks
모델은 task 지시(zero-shot) 또는 **몇 가지 demonstration 예시(few-shot)**가 주어졌을 때 언어 task에 대해 평가된다. 텍스트 입력은 기존 language model에서와 같이 모델에 직접 입력된다.
4.8.1 Evaluation Setup
우리는 동일한 텍스트 코퍼스와 학습 설정을 사용하여 Language Model (LLM) baseline을 학습시켰다. 우리는 Kosmos-1과 LLM baseline을 8가지 언어 task에서 평가했다. 여기에는 cloze 및 completion task (예: StoryCloze, HellaSwag), Winograd-style task (예: Winograd, Winogrande), commonsense reasoning (예: PIQA), 그리고 SuperGLUE 벤치마크 [WPN19]의 BoolQ, CB, COPA 세 가지 데이터셋이 포함된다. 이 데이터셋들에 대한 자세한 설명은 Appendix C.2에 제공되어 있다. 우리는 zero-shot 및 few-shot 설정에서 실험을 수행했다. 각 테스트 예시는 학습 세트에서 무작위로 demonstration 예시를 샘플링하여 평가했다. 실험에서 shot 수는 0, 1, 4로 설정했다.
4.8.2 Results
Table 13은 언어 task에 대한 in-context learning 성능을 보여준다. Kosmos-1은 cloze completion 및 commonsense reasoning task에서 LLM과 비교하여 유사하거나 더 나은 성능을 달성한다. 이 모든 데이터셋에 대한 평균 결과 측면에서, LLM은 zero-shot 및 one-shot 설정에서 더 나은 성능을 보이는 반면, 우리 모델은 few-shot () 설정에서 더 나은 성능을 보인다. 이 결과는 Kosmos-1이 언어 전용 task도 잘 처리하며, 데이터셋 전반에 걸쳐 유리한 성능을 달성함을 나타낸다. 또한, Section 4.9.2에서는 MLLM이 LLM에 비해 더 나은 시각적 commonsense 지식을 학습한다는 것을 보여준다.
| Task | Zero-shot | One-shot | Few-shot ( ) | |||
|---|---|---|---|---|---|---|
| LLM | Kosmos-1 | LLM | Kosmos-1 | LLM | Kosmos-1 | |
| StoryCloze | 72.9 | 72.1 | 72.9 | 72.2 | 73.1 | 72.3 |
| HellaSwag | 50.4 | 50.0 | 50.2 | 50.0 | 50.4 | 50.3 |
| Winograd | 71.6 | 69.8 | 71.2 | 68.4 | 70.9 | 69.8 |
| Winogrande | 56.7 | 54.8 | 56.7 | 54.5 | 57.0 | 55.7 |
| PIQA | 73.2 | 72.9 | 73.0 | 72.5 | 72.6 | 72.3 |
| BoolQ | 56.4 | 56.4 | 55.1 | 57.2 | 58.7 | 59.2 |
| CB | 39.3 | 44.6 | 41.1 | 48.2 | 42.9 | 53.6 |
| COPA | 68.0 | 63.0 | 69.0 | 64.0 | 69.0 | 64.0 |
| Average | 61.1 | 60.5 | 61.2 | 60.9 | 61.8 | 62.2 |
Table 13: Kosmos-1과 LLM 간의 언어 task 성능 비교. 우리는 동일한 텍스트 데이터와 학습 설정을 사용하여 language model을 재구현하였다. 공정한 비교를 위해 두 모델 모두 instruction tuning을 사용하지 않았다.
4.9 Cross-modal Transfer
Cross-modal transferability는 모델이 하나의 modality(예: 텍스트, 이미지, 오디오 등)로부터 학습한 지식을 다른 modality로 전이할 수 있는 능력을 의미한다. 이러한 능력은 모델이 다양한 modality에 걸쳐 여러 task를 수행할 수 있도록 해준다. 이 부분에서는 Kosmos-1의 cross-modal transferability를 여러 벤치마크에서 평가한다.
4.9.1 Transfer from Language to Multimodal: Language-Only Instruction Tuning
언어 전용 instruction tuning의 효과를 평가하기 위해, 우리는 COCO, Flickr30k, VQAv2, VizWiz의 네 가지 데이터셋을 사용하여 ablation study를 수행한다. 이 데이터셋들은 이미지 캡셔닝 및 시각 질문 답변으로 구성되어 있다. 평가 지표는 COCO/Flickr30k의 CIDEr 점수와 VQAv2/VizWiz의 VQA accuracy이다.
Table 14는 실험 결과를 보여준다. 언어 전용 instruction tuning은 Flickr30k에서 1.9점, VQAv2에서 4.3점, VizWiz에서 1.3점 모델 성능을 향상시킨다. 우리 실험은 언어 전용 instruction tuning이 모델의 instruction-following 능력을 모달리티 전반에 걸쳐 크게 향상시킬 수 있음을 보여준다. 또한 이 결과는 우리 모델이 언어로부터 다른 모달리티로 instruction-following 능력을 **전이(transfer)**할 수 있음을 나타낸다.
| Model | COCO | Flickr30k | VQAv2 | VizWiz |
|---|---|---|---|---|
| Kosmos-1 | 84.7 | |||
| w/o language-only instruction tuning | 65.2 | 46.7 | 27.9 |
Table 14: 언어 전용 instruction tuning에 대한 ablation study. COCO 및 Flickr30k의 CIDEr 점수와 VQAv2 및 VizWiz의 VQA accuracy 점수를 보고한다.
4.9.2 Transfer from Multimodal to Language: Visual Commonsense Reasoning
시각적 상식 추론(Visual commonsense reasoning) task는 색상, 크기, 모양과 같은 현실 세계의 일상적인 객체 속성에 대한 이해를 요구한다. 이러한 task는 텍스트에 있는 정보만으로는 객체 속성에 대한 충분한 정보를 제공하지 못할 수 있기 때문에 language model에게는 도전적이다. 시각적 상식 능력을 조사하기 위해, 우리는 시각적 상식 추론 task에서 Kosmos-1과 LLM의 zero-shot 성능을 비교한다.
평가 설정 (Evaluation Setup)
우리는 세 가지 객체 상식 추론 데이터셋인 RelativeSize [BHCF16], MemoryColor [NHJ21], ColorTERMS [BBBT12] 데이터셋에서 Kosmos-1과 LLM baseline을 비교한다. Table 15는 객체 크기 및 색상 추론 task의 몇 가지 예시를 보여준다. RELATIVESIZE는 41개의 물리적 객체로부터 486개의 객체 쌍을 포함한다. 모델은 "Yes"/"No" 답변을 포함하는 이진 질문-답변 형식으로 두 객체 간의 크기 관계를 예측해야 한다. MemoryColor와 ColorTerms는 모델이 11개의 색상 레이블 세트에서 객체의 색상을 다중 선택 형식으로 예측하도록 요구한다. 우리는 입력으로 텍스트만 사용하며, 이미지는 포함하지 않는다. 우리는 이 세 데이터셋에서 모델의 정확도를 측정한다.
| Task | Example Prompt | Object / Pair | Answer |
|---|---|---|---|
| Object Size Reasoning | Is Item1 larger than Item2 Answer | (sofa, cat) | Yes |
| Object Color Reasoning | The color of {Object} is? {Answer} | the sky | blue |
Table 15: 객체 크기 및 색상 추론의 평가 예시.
결과 (Results)
Table 16은 시각적 상식 추론 task에서 Kosmos-1과 LLM의 zero-shot 성능을 보여준다. Kosmos-1은 RelativeSize에서 1.5%, MemoryColor에서 14.7%, **ColorTerms 데이터셋에서 9.7%**로 LLM을 크게 능가한다. 이러한 일관된 개선은 Kosmos-1이 해당 시각적 상식 추론을 완료하기 위해 시각적 지식으로부터 이점을 얻는다는 것을 나타낸다. Kosmos-1의 우수한 성능의 이유는 **모달리티 전이성(modality transferability)**을 가지고 있기 때문이며, 이는 모델이 시각적 지식을 언어 task로 전이할 수 있도록 한다. 반대로, LLM은 시각적 상식 질문에 답하기 위해 텍스트 지식과 단서에 의존해야 하므로, 객체 속성에 대한 추론 능력이 제한된다.
| Model | Size Reasoning | Color Reasoning | |
|---|---|---|---|
| RelativeSize | MemoryColor | ColorTerms | |
| Using retrieved images | |||
| VALM [WDC 23] | 85.0 | 58.6 | 52.7 |
| Language-only zero-shot evaluation | |||
| LLM | 92.7 | 61.4 | 63.4 |
| Kosmos-1 | 94.2 | 76.1 | 73.1 |
Table 16: RelativeSize, MemoryColor, ColorTerms 데이터셋에 대한 zero-shot 시각적 상식 추론 결과. 정확도 점수가 보고되었다.
5 Conclusion
본 연구에서는 일반적인 modality를 인지하고, 지시를 따르며, in-context learning을 수행할 수 있는 **멀티모달 대규모 언어 모델(multimodal large language model)**인 Kosmos-1을 소개한다. 웹 규모의 멀티모달 코퍼스로 학습된 이 모델은 다양한 언어 task 및 멀티모달 task에서 유망한 결과를 달성한다. 우리는 LLM(Large Language Model)에서 MLLM(Multimodal Large Language Model)으로의 전환이 새로운 능력과 기회를 가능하게 함을 보여준다. 향후에는 Kosmos-1의 모델 크기를 확장하고 [MWH22, WMH22, CDH22], 음성(speech) 기능 [WCW23]을 Kosmos-1에 통합하고자 한다. 또한, Kosmos-1은 멀티모달 학습을 위한 통합 인터페이스로 활용될 수 있으며, 예를 들어 지시와 예시를 사용하여 text-to-image 생성을 제어하는 것이 가능해진다.
A Hyperparameters
A. 1 Training
Table 17과 Table 18에 Kosmos-1의 상세 모델 하이퍼파라미터 설정 및 학습 하이퍼파라미터를 보고한다.
| Hyperparameters | |
|---|---|
| Number of layers | 24 |
| Hidden size | 2,048 |
| FFN inner hidden size | 8,192 |
| Attention heads | 32 |
| Dropout | 0.1 |
| Attention dropout | 0.1 |
| Activation function | GeLU [HG16] |
| Vocabulary size | 64,007 |
| Soft tokens size | 64 |
| Max length | 2,048 |
| Relative position embedding | xPos [SDP 22] |
| Initialization | Magneto [ 22] |
Table 17: Kosmos-1의 causal language model 하이퍼파라미터
| Hyperparameters | |
|---|---|
| Training steps | 300,000 |
| Warmup steps | 375 |
| Batch size of text corpora | 256 |
| Max length of text corpora | 2,048 |
| Batch size of image-caption pairs | 6,144 |
| Batch size of interleaved data | 128 |
| Optimizer | Adam |
| Learning rate | |
| Learning Rate Decay | Linear |
| Adam | |
| Adam | (0.9, 0.98) |
| Weight decay | 0.01 |
Table 18: Kosmos-1의 학습 하이퍼파라미터
A. 2 Language-Only Instruction Tuning
자세한 instruction tuning 하이퍼파라미터는 Table 19에 나열되어 있다.
| Hyperparameters | |
|---|---|
| Training steps | 10,000 |
| Warmup steps | 375 |
| Batch size of instruction data | 256 |
| Batch size of text corpora | 32 |
| Batch size of image-caption pairs | 768 |
| Batch size of interleaved data | 16 |
| Learning rate |
Table 19: Kosmos-1의 instruction tuning 하이퍼파라미터
B Datasets
B. 1 Pretraning
B.1.1 Text Corpora
Kosmos-1은 The Pile [GBB+20]과 Common Crawl로 학습되었다. The Pile은 22개의 다양한 소스를 결합한 800GB 규모의 영어 텍스트 코퍼스이다. 우리는 The Pile에서 7개의 소스만 선택하여 사용했다. Common Crawl 또한 학습 코퍼스에 포함되었다. Common Crawl은 웹의 스냅샷을 담고 있으며, 방대한 양의 언어 데이터를 포함한다. Table 20은 Kosmos-1 모델 학습에 사용된 언어 데이터셋에 대한 전체 개요를 제공한다. 이 데이터 소스는 다음 세 가지 범주로 나눌 수 있다:
- Academic: NIH Exporter
- Internet: Pile-CC, OpenWebText2, Wikipedia (English), CC-2020-50, CC-2021-04, Realnews
- Prose: BookCorpus2, Books3, Gutenberg [RPJ+20], CC-Stories
| Datasets | Tokens (billion) | Weight (%) | Epochs |
|---|---|---|---|
| OpenWebText2 | 14.8 | 21.8% | 1.47 |
| CC-2021-04 | 82.6 | 17.7% | 0.21 |
| Books3 | 25.7 | 16.2% | 0.63 |
| CC-2020-50 | 68.7 | 14.7% | 0.21 |
| Pile-CC | 49.8 | 10.6% | 0.21 |
| Realnews | 21.9 | 10.2% | 0.46 |
| Wikipedia | 4.2 | 5.4% | 1.29 |
| BookCorpus2 | 1.5 | 1.1% | 0.75 |
| Gutenberg (PG-19) | 2.7 | 1.0% | 0.38 |
| CC-Stories | 5.3 | 1.0% | 0.19 |
| NIH ExPorter | 0.3 | 0.2% | 0.75 |
Table 20: Kosmos-1 모델 학습에 사용된 언어 데이터셋.
B.1.2 Image-Caption Pairs
Kosmos-1은 **영어 LAION-2B [SBV 22], LAION-400M [SVB ], COYO-700M [BPK 22], Conceptual Captions [SDGS18, CSDS21]**을 포함한 여러 데이터셋으로부터 구축된 이미지-캡션 쌍으로 학습된다. LAION-2B, LAION-400M, COYO-700M 데이터셋은 Common Crawl 웹 데이터에서 웹페이지의 이미지 URL과 alt-text를 파싱하여 추출된다. LAION-2B는 약 20억 개의 영어 이미지-캡션 쌍을 포함하고, LAION-400M은 4억 개의 영어 이미지-캡션 쌍으로 구성되며, COYO-700M은 7억 개의 영어 이미지-캡션 쌍을 가지고 있다. Conceptual Captions는 1,500만 개의 영어 이미지-캡션 쌍을 포함하며, CC3M과 CC12M 두 개의 데이터셋으로 구성된다. 이들 역시 Flume 파이프라인을 사용하여 인터넷 웹페이지에서 수집되었다. Conceptual Captions의 경우, 캡션에 "<PERSON>"과 같은 특수 태그가 포함된 쌍은 제외하였다.
B.1.3 Interleaved Data
우리는 Common Crawl 스냅샷에서 20억 개의 웹페이지로 구성된 대규모 코퍼스를 수집한다. 품질과 관련성을 보장하기 위해 여러 필터링 기준을 적용한다. 첫째, 영어로 작성되지 않은 페이지는 모두 제외한다. 둘째, 텍스트 중간에 이미지가 삽입되지 않은 페이지는 제외한다. 셋째, 해상도가 64x64 픽셀보다 낮거나 단색인 이미지는 제외한다. 넷째, 스팸이나 의미 없는 텍스트(gibberish)와 같이 의미 없거나 일관성이 없는 텍스트는 제외한다. 우리는 이모지 기호, 해시태그, URL 링크를 포함하는 의미 없는 텍스트를 식별하고 제거하기 위해 몇 가지 휴리스틱을 사용한다. 이러한 필터를 적용한 후, 최종적으로 약 7,100만 개의 문서를 학습에 사용한다.
B. 2 Data Format
학습 데이터는 다음과 같은 형식으로 구성된다:
| Datasets | Format Examples |
|---|---|
| Text | <s> Kosmos-1 can perceive multimodal input, learn in context, and generate output. </s> |
| Image-Caption | <s> <image> Image Embedding </image> WALL-E giving potted plant to EVE. </s> |
| Multimodal | <s> <image> Image Embedding </image> This is WALL-E. <image> Image Embedding </image> This is EVE. </s> |
Table 21: Kosmos-1 모델 학습을 위한 데이터 형식 예시.
C Evaluation
C. 1 Input Format Used for Perception-Language Tasks
Figure 7은 perception-language task에 대해 zero-shot 및 few-shot 평가를 수행하는 방법을 보여준다.
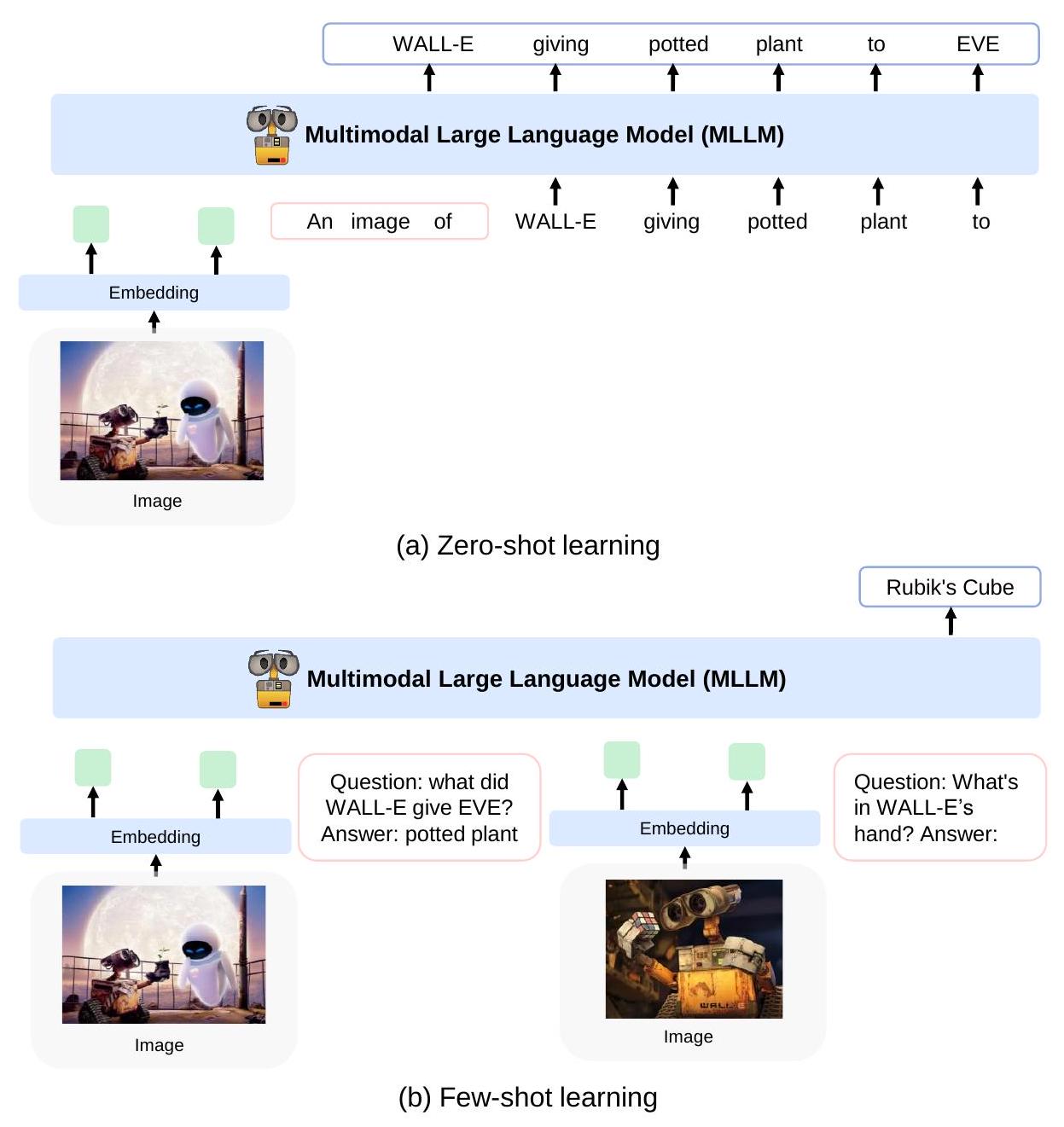
Figure 7: 우리는 Kosmos-1을 perception-language task에 대해 zero-shot 및 few-shot 설정으로 평가한다. (a) Zero-shot learning, 예: language prompt를 사용한 zero-shot image captioning. (b) Few-shot learning, 예: in-context learning을 사용한 visual question answering.
C. 2 Language Tasks
우리는 언어 task를 다음 네 가지 범주로 나누어 실험을 수행한다:
- Cloze 및 completion task: StoryCloze [MRL+17], HellaSwag [ZHB19]
- Winograd-style task: Winograd [LDM12b], Winogrande [SBBC20]
- Commonsense reasoning: PIQA [BZB20]
- SuperGLUE 벤치마크 [WPN19]의 세 가지 데이터셋: BoolQ [CLC19], CB [dMST19], COPA [RBG11]
C. 3 WebSRC Task Examples
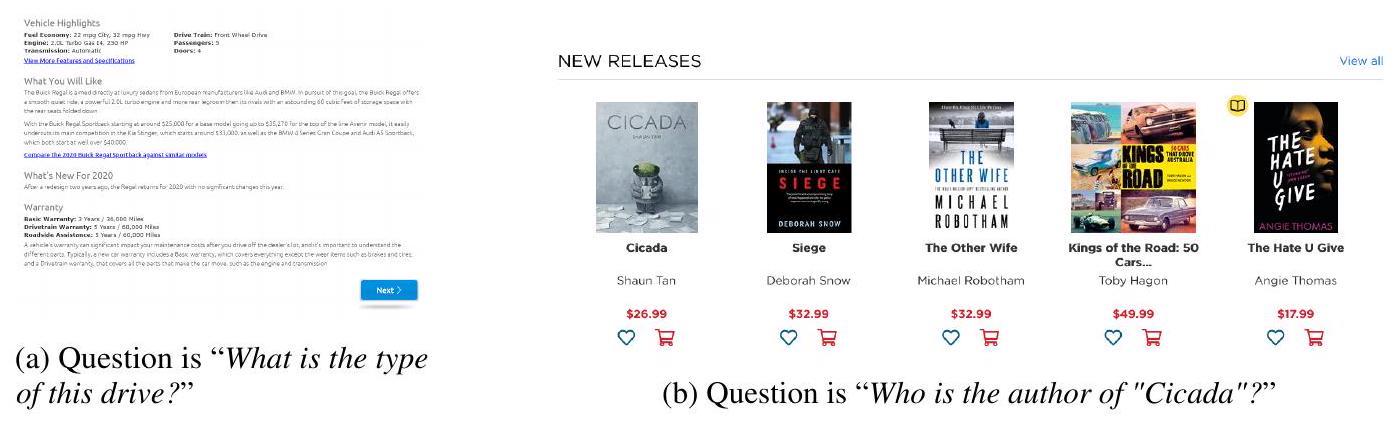
Figure 8: WebSRC [CZC21]의 예시.