Let's Go Real Talk: 얼굴을 마주보고 대화하는 음성 대화 모델
본 논문은 사용자의 시청각 음성 입력을 처리하고 시청각 음성으로 응답을 생성하는 새로운 Face-to-Face 음성 대화 모델을 소개합니다. 이는 텍스트를 거치지 않는 아바타 챗봇 시스템을 향한 첫걸음입니다. 이를 위해 340시간 분량의 MultiDialog 데이터셋을 구축했으며, 사전 학습된 LLM을 음성-텍스트 공동 사전 학습을 통해 시청각 대화 도메인에 적용했습니다. 논문 제목: Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
논문 요약: Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
- 논문 링크: arXiv:2406.07867
- 저자: Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim, Joanna Hong, Jeong Hun Yeo, Yong Man Ro (KAIST Integrated Vision and Language Lab)
- 발표 시기: 2024 (arXiv preprint)
- 주요 키워드: Spoken Dialogue System, Multimodal, Face-to-Face Conversation, Audio-Visual Speech, LLM, MultiDialog Dataset
1. 연구 배경 및 문제 정의
- 문제 정의: 기존 음성 대화 시스템(SDS)은 주로 텍스트 기반이거나 오디오에만 초점을 맞춰, 인간이 얼굴을 마주보고 대화할 때 활용하는 시각적(표정, 제스처, 감정) 및 비언어적 단서를 처리하고 생성하는 데 한계가 있습니다. 이는 실제와 같은 자연스러운 인간-컴퓨터 상호작용을 방해합니다.
- 기존 접근 방식:
- 대부분의 대화 시스템은 풍부한 텍스트 대화 데이터셋에 기반합니다.
- 최근에는 오디오 대화 데이터셋이 등장했지만, 시각적 요소를 포함하는 데이터셋은 규모가 매우 제한적입니다(총 15시간 미만).
- 멀티모달 대규모 언어 모델(MM-LLM)은 이미지 캡셔닝 등 시각 정보를 보충 자료로 사용하지만, 음성 관련 얼굴 움직임을 포함하는 시청각 음성 대화 시스템과는 목적이 다릅니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 사용자 입력에서 멀티모달 음성을 처리하고 멀티모달 음성 응답을 생성하는 최초의 직접적인 Face-to-Face 대화 모델을 제안합니다.
- 얼굴을 마주보고 대화하는 시스템 구축을 위해, 약 9,000개의 시청각 대화 스트림으로 구성된 340시간 분량의 최초 대규모 멀티모달(오디오, 시각, 텍스트) 대화 코퍼스인 MultiDialog를 구축했습니다.
- 텍스트로 사전 훈련된 대규모 언어 모델(LLM)을 활용한 음성-텍스트 공동 사전 훈련이 기존 LLM의 지식을 유지하는 데 있어 직접 초기화보다 효과적임을 입증했습니다.
- 제안 방법:
논문은 중간 텍스트 변환 없이 사용자의 시청각 음성 입력을 직접 처리하고 시청각 음성 응답을 생성하는 시스템을 제안합니다.
- 시청각(AV) 음성 인코딩: AV-HuBERT 모델을 사용하여 원시 시청각 얼굴 비디오에서 이산적인 "AV 음성 토큰"을 추출합니다. 이 토큰은 의사 텍스트(pseudo-text)처럼 활용됩니다.
- AV 음성 대화 언어 모델링:
- 사전 훈련된 LLM (OPT-1.3B)으로 모델을 초기화합니다.
- 새로운 "음성-텍스트 공동 사전 훈련" 방식을 도입합니다.
- 1단계 (AVSR/TTS 사전 훈련): LLM이 AV 음성 토큰을 해석하고 생성하도록 임베딩 및 투영 계층을 훈련합니다. 이는 AV 음성 인식(AVSR) 및 텍스트-음성 생성(TTS) 목표를 포함합니다.
- 2단계 (혼합 텍스트-AV 음성 대화 훈련 및 미세 조정): 텍스트와 AV 음성 토큰의 균형 잡힌 혼합을 사용하여 대화 언어 모델링을 수행한 후, 실시간 상호작용을 위해 순수 AV 음성 토큰 기반 대화에 대해 미세 조정합니다. 이는 텍스트 기반 LLM의 대화 생성 품질을 유지하면서 AV 음성 토큰에 점진적으로 적응하도록 돕습니다.
- 오디오-비주얼 생성: 생성된 AV 음성 토큰을 말하는 얼굴 비디오로 변환하기 위해 길이 예측기, 토큰 기반 음성 디코더, 토큰 기반 얼굴 디코더를 사용합니다. 화자 임베딩 및 얼굴/포즈 사전 정보를 통합하여 화자 신원을 유지합니다.
3. 실험 결과
- 데이터셋:
- MultiDialog 데이터셋: 약 9,000개의 대화, 340시간 분량의 시청각 녹음으로 구성된 대규모 멀티모달(오디오, 시각, 텍스트, 감정 주석 포함) 음성 대화 코퍼스. TopicalChat 데이터셋을 기반으로 구축되었습니다.
- 비교 대상: SpeechGPT, d-GSLM (오디오 전용 음성 대화 시스템), 캐스케이드 시스템 (AVSR + LM + TTS + TFG).
- 실험 환경: 6개의 A6000 GPU (인코딩), 4개의 A6000 GPU (LM 훈련).
- 주요 결과:
- 의미론적 평가 (표 3): 제안된 방법은 BLEU, D-1, D-2 지표에서 최첨단 음성 대화 시스템(SpeechGPT, d-GSLM)보다 우수한 성능을 보여, 문맥적으로 일관되고 다양한 응답을 생성할 수 있음을 입증했습니다. 특히, 중간 텍스트 생성 없이 오디오 및 시각 음성 비디오 모두에서 직접 응답을 인식하고 생성하는 최초의 접근 방식입니다.
- 사전 훈련 방식 분석 (표 3): LLM 초기화가 의미 품질을 향상시키고, AVSR/TTS 사전 훈련이 이를 더욱 개선하며, 혼합 텍스트-AV 음성 사전 훈련이 전반적인 의미 품질 향상에 기여하여 점진적 적응의 효과를 검증했습니다.
- 오디오 및 비주얼 생성 품질 평가 (표 4): 제안된 방법은 화자 음성 유사성(SIM)에서 캐스케이드 시스템 및 다른 음성 대화 시스템을 능가하여 화자 정보 유지에 효과적임을 보였습니다. 또한, 이산화된 시청각 토큰 활용 덕분에 캐스케이드 시스템 대비 우수한 시청각 동기화(LSE-C, LSE-D)를 달성했습니다.
- 음향 노이즈에 대한 견고성 (표 5): 시청각 입력은 오디오 전용 입력에 비해 노이즈 환경에서 성능 저하가 적어 시스템의 견고성을 향상시켰습니다. 이는 시각적 양식이 음향 노이즈에 영향을 받지 않고 오디오 양식의 누락된 정보를 보완하기 때문입니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 기존 음성 대화 시스템의 한계(시각 정보 부재)를 극복하고, 실제 인간 대화와 유사한 얼굴을 마주보는 대화 경험을 제공하려는 시도가 매우 인상적입니다.
- 340시간 규모의 MultiDialog 데이터셋 구축은 멀티모달 대화 연구 분야에 큰 기여를 할 것으로 보이며, 다양한 후속 연구의 기반이 될 수 있습니다.
- 사전 훈련된 LLM을 AV 음성 토큰과 공동으로 훈련하는 점진적 접근 방식은 모델이 텍스트 기반 지식을 유지하면서 새로운 멀티모달 도메인에 효과적으로 적응하도록 돕는 영리한 전략입니다.
- 음향 노이즈 환경에서도 견고한 성능을 보여 실제 적용 가능성이 높습니다.
- 단점/한계:
- MultiDialog 데이터셋에 포함된 감정 레이블을 아직 모델 학습에 활용하지 않았다는 점이 한계로 언급되었습니다. 감정 인식을 통해 더 풍부하고 감성적인 응답 생성이 가능할 것입니다.
- 화자와 청자의 병렬 녹음이 있음에도 불구하고, 현재 모델은 한 명의 얼굴 생성에 초점을 맞추고 있습니다. 두 얼굴의 동시 생성을 모델링하여 더욱 즉흥적이고 자연스러운 대화를 구현할 수 있는 잠재력이 있습니다.
- 응용 가능성:
- 중간 텍스트를 거치지 않는 아바타 챗봇 시스템 개발에 핵심적인 역할을 할 수 있습니다.
- 가상 비서, 고객 서비스, 교육용 챗봇 등 다양한 인간-컴퓨터 상호작용 분야에서 더욱 자연스럽고 몰입감 있는 경험을 제공할 수 있습니다.
- 말하는 얼굴 합성, 청자 얼굴 합성, 감정 조건부 얼굴 합성 등 멀티모달 합성 연구에 새로운 기회를 제공할 것입니다.
- 노이즈 환경에서의 견고성 덕분에 실제 생활 환경에서의 적용 가능성이 높습니다.
5. 추가 참고 자료
- 데모 페이지: https://multidialog.github.io
- MultiDialog 데이터셋: https://huggingface.co/datasets/IVLLab/MultiDialog
Park, Se Jin, et al. "Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation." arXiv preprint arXiv:2406.07867 (2024).
Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
Se Jin Park* Chae Won Kim* Hyeongseop Rha Minsu Kim<br>Joanna Hong Jeong Hun Yeo Yong Man <br>Integrated Vision and Language Lab, KAIST<br>{jinny960812, chaewonkim, ryool_1832, sedne246, ymro}@kaist.ac.kr<br>ms.k@ieee.org joanna2587@gmail.com
Abstract
본 논문에서는 새로운 Face-to-Face 음성 대화 모델을 소개합니다. 이 모델은 사용자 입력으로부터 audio-visual speech를 처리하고 응답으로 audio-visual speech를 생성하며, 중간 텍스트에 의존하지 않는 avatar chatbot system을 만드는 첫 단계를 표시합니다. 이를 위해, 우리는 개방형 도메인 대화 데이터셋인 TopicalChat을 기반으로 녹음된 약 9,000개의 대화, 340시간 분량의 최초의 대규모 멀티모달(즉, 오디오 및 시각) 음성 대화 코퍼스인 MultiDialog를 새롭게 소개합니다. MultiDialog는 감정 주석과 함께 주어진 스크립트에 따라 연기하는 대화 파트너의 병렬 시청각 녹음을 포함하고 있으며, 이는 멀티모달 합성에 대한 연구 기회를 열 것으로 기대합니다. 우리의 Face-to-Face 음성 대화 모델은 텍스트로 사전 훈련된 large language model을 통합하고, 음성-텍스트 공동 사전 훈련을 통합하여 시청각 음성 대화 도메인에 적용합니다. 광범위한 실험을 통해, 우리는 우리 모델이 얼굴을 마주한 대화를 촉진하는 데 효과적임을 검증합니다. 데모 및 데이터는 각각 https://multidialog.github.io와 https://huggingface.co/datasets/IVLLab/MultiDialog에서 확인할 수 있습니다.
1 Introduction
Spoken Dialogue System (SDS)은 종종 대화형 에이전트라고도 불리며, 사용자 입력에서 음성을 인식하고 문맥에 적절하고 정확한 음성 응답을 제공함으로써 인간과 자연스러운 음성 대화를 나눕니다. 1음성 언어를 기본 인터페이스로 사용하여 고객 서비스 및 음성 비서와 같은 인간-컴퓨터 상호 작용에 수많은 응용 프로그램을 가지고 있습니다.
그러나 사람들이 얼굴을 마주하고 소통할 때, 우리는 음성 단어와 비언어적 단서(즉, 표정, 제스처, 감정)를 처리하기 위해 대화 상대의 오디오 정보뿐만 아니라 시각 정보도 활용합니다 (Petridis et al., 2018; Hong et al., 2023). 이러한 멀티모달 정보는 음성 내용과 화자의 의도에 대한 이해를 향상시킵니다. 더욱이, 오디오에 대한 시각적 상대가 있으면 실제 얼굴을 마주한 대화 경험을 시뮬레이션하여 사용자가 더 연결되고 참여하는 느낌을 받을 수 있습니다.
본 논문에서는 처음으로 직접적인 얼굴 맞대고 대화를 촉진하기 위한 시청각 음성 대화 시스템을 탐구합니다. 대화 시스템 개발의 핵심은 대량의 고품질 대화 데이터입니다. 현재 대화 시스템은 텍스트 대화 데이터셋의 풍부함에 힘입어 주로 텍스트 기반입니다 (Lowe et al., 2015; Li et al., 2017; Zhang et al., 2018; Rashkin et al., 2018; Budzianowski et al., 2018; Zhou et al., 2018; Reddy et al., 2019; Lambert et al.; Ding et al., 2023; Köpf et al., 2023). 최근에는 기존 텍스트 대화 데이터(Li et al., 2017; Budzianowski et al., 2018)에 음성을 추가한 여러 오디오 대화 데이터셋이 출시되었습니다(Lee et al., 2023; Si et al., 2023; Nguyen et al., 2023a). 그러나 시각적 요소를 가진 데이터셋은 총 15시간 미만으로 규모가 제한적입니다 (Busso et al., 2008; Poria et al., 2018). 이러한 데이터 격차를 해소하기 위해, 우리는 최초의 대규모 시청각 음성 대화 코퍼스인 MultiDialog를 소개합니다. 이는 약 9,000개의 대화, 340시간 분량의 시청각 녹음으로 구성되어 있으며, 개방형 도메인 텍스트 대화 데이터셋인 TopicalChat (Gopalakrishnan et al., 2023)에서 파생되었습니다. TopicalChat은 9개의 광범위한 주제를 다루는 실제 대화에서 수집된 광범위한 다중 턴 대화 코퍼스입니다. 제안된 MultiDialog는 각 발화에 대한 감정 주석과
| 데이터셋 | 대화 수 | 턴 수 | 길이 (시간) | 오디오 | 텍스트 | 비디오 | 감정 |
|---|---|---|---|---|---|---|---|
| IEMOCAP (Busso et al., 2008) | 151 | 10,039 | 12 | ||||
| DSTC2 (Henderson et al., 2014) | 1,612 | 23,354 | 32 | ||||
| MELD (Poria et al., 2018) | 1,433 | 13,000 | 13.7 | ||||
| DailyTalk (Lee et al., 2023) | 2,514 | 23,774 | 21.7 | ||||
| Expresso (Nguyen et al., 2023a) | 391 | 2,400 | 47 | ||||
| SpokenWOZ (Si et al., 2023) | 5,700 | 203,074 | 249 | ||||
| MultiDialog | 8,733 | 187,859 | 340 |
표 1: MultiDialog 데이터셋과 공개적으로 사용 가능한 멀티모달 대화 데이터셋의 비교. 청자와 화자 모두의 동시 녹음을 포함하여, 얼굴 맞대고 대화 시스템부터 말하는 얼굴 합성 (Park et al., 2022; Zhang et al., 2023b), 청자의 얼굴 합성 (Song et al., 2023; Zhou et al., 2023), 감정 조건부 얼굴 합성 (Goyal et al., 2023)에 이르기까지 다양한 연구 기회를 제공합니다.
MultiDialog 데이터셋을 기반으로, 우리는 사용자 입력으로 시청각 음성을 직접 처리하고 출력 응답으로 시청각 음성을 생성할 수 있는 최초의 시청각 음성 대화 모델을 제안합니다. 이산화된 음성 토큰을 사용하는 직접 음성 대화 모델의 최근 성공에 동기 부여 받아 (Nguyen et al., 2023b; Zhang et al., 2023a), 우리는 자기 지도 모델 (Shi et al., 2021)에서 시청각 음성 특징을 양자화하여 추출한 시청각 (AV) 음성 토큰을 소개합니다. AV 음성 토큰을 의사 텍스트로 활용하여, 우리는 사전 훈련된 대규모 언어 모델 (LLM) (Zhang et al., 2022)에 AV 음성을 통합하고 공동 음성-텍스트 사전 훈련을 통해 이를 통합합니다. 응답은 또한 AV 음성 토큰으로 반환되며, 이는 시스템과의 직접적인 상호 작용을 위해 출력으로 말하는 얼굴 비디오로 합성됩니다.
우리의 기여는 세 가지입니다: (1) 우리는 사용자 입력에서 멀티모달 음성을 처리하고 출력 응답으로 멀티모달 음성을 생성하여 얼굴 맞대고 대화 시스템을 촉진하는 최초의 직접적인 Face-to-Face 대화 모델을 소개합니다. (2) 얼굴 맞대고 대화 시스템을 구축하기 위해, 우리는 약 9,000개의 시청각 대화 스트림으로 구성된 340시간 분량의 최초의 대규모 멀티모달 (즉, 오디오, 시각, 텍스트) 대화 코퍼스인 MultiDialog를 제안합니다. (3) 우리는 사전 훈련된 대규모 언어 모델을 활용한 공동 음성-텍스트 사전 훈련이 원래 대규모 언어 모델의 지식을 유지하는 데 있어 직접 초기화보다 개선됨을 보여줍니다.
2 Related Work
2.1 Spoken Dialogue Dataset
최근 몇 년 동안, 음성 대화 데이터셋의 개발은 인간 행동을 이해하고 실제 대화를 모방하는 음성 대화 시스템을 구축하는 데 중추적인 역할을 해왔습니다. 초기 음성 데이터셋은 음성에서의 감정 및 의도와 같은 인간 행동 분석에 중점을 두어 음성 대화 시스템의 기초를 마련했습니다. IEMOCAP (Busso et al., 2008) 및 MELD (Poria et al., 2018)는 대화의 오디오 및 비디오 녹음으로 구성되어 대화에서의 감정적 역학을 연구하도록 설계되었습니다. 감정 이해 외에도 DSTC2 (Henderson et al., 2014)는 사용자의 목표를 예측하기 위한 대화 상태 추적을 위해 전화 기반 음성 대화를 제시합니다. 음성에서의 인간 행동을 연구하는 데이터셋을 기반으로, 최근 음성 대화 데이터셋은 현실적인 대화 시스템을 모델링하기 위해 구축되었습니다. Expresso (Nguyen et al., 2023a)는 자연스러운 음성 합성을 위해 26가지 표현 스타일을 아우르는 음성 대화를 소개합니다. DailyTalk (Lee et al., 2023) 및 SpokenWOZ (Si et al., 2023) 데이터셋은 음성 대화를 위한 음성-텍스트 대화를 소개합니다. 기존 연구들이 음성 대화 시스템 발전에 기여했지만, 대화 데이터셋은 규모가 제한적이고 오디오와 텍스트로만 구성되어 있어 시각적 단서를 통합하는 시청각 음성 대화 시스템의 개발을 제약합니다. 이러한 한계를 해결하기 위해, 우리는 음성 대화를 규모와 시각적 양식으로 확장하고, 대규모 멀티모달 음성 대화 데이터셋인 MultiDialog를 소개합니다. 기존 멀티모달 대화 데이터셋과 MultiDialog의 요약은 표 1에 나와 있습니다.
2.2 Spoken Dialogue Models
Audio Language Model은 transformer 기반 아키텍처에 의해 구동되며 음성 처리에서 놀라운 발전을 이루었습니다. 연속적인 음성을 이산적인 표현 집합으로 취급함으로써, 음성은
| MultiDialog | 훈련 | 검증 Freq | 검증 Rare | 테스트 Freq | 테스트 Rare | 총계 |
|---|---|---|---|---|---|---|
| # 대화 | 7,011 | 448 | 443 | 450 | 381 | 8,733 |
| # 발화 | 151,645 | 8,516 | 9,556 | 9,811 | 8,331 | 187,859 |
| 평균 # 발화/대화 | 21.63 | 19.01 | 21.57 | 21.80 | 21.87 | 21.51 |
| 평균 길이/발화 (초) | 6.50 | 6.23 | 6.40 | 6.99 | 6.49 | 6.51 |
| 평균 길이/대화 (분) | 2.34 | 1.97 | 2.28 | 2.54 | 2.36 | 2.33 |
| 총 길이 (시간) | 273.93 | 14.74 | 17.00 | 19.04 | 15.01 | 339.71 |
표 2: MultiDialog의 상세 통계 텍스트처럼 효과적으로 모델링될 수 있으며, 이는 Natural Language Processing (NLP) 기술의 적용을 가능하게 합니다. 음성 합성(Lakhotia et al., 2021; Borsos et al., 2023; Wang et al., 2023a; Hassid et al., 2023; Nachmani et al., 2023), 음성 번역(Barrault et al., 2023; Dong et al., 2023; Rubenstein et al., 2023), 음성 인식(Wang et al., 2023b)에서 주목할 만한 진전을 이루었지만, 음성 대화 시스템은 음성 대화 데이터셋의 부족으로 인해 상대적으로 미개척 연구 분야입니다. 여러 연구들이 large language models (LLMs)의 힘을 활용하여 데이터 문제를 해결하려는 노력을 했습니다. SpeechGPT (Zhang et al., 2023a)는 먼저 음성을 이산적인 음성 토큰으로 변환한 다음, 쌍을 이룬 음성 데이터, 음성 지시 데이터, 양식 체인 지시 데이터에 대한 3단계 훈련 파이프라인을 설계합니다. AudioGPT (Huang et al., 2023)는 LLM에 외부 도구를 제어하기 위한 명령을 생성하도록 지시한 후 LLM에 입력합니다. dGSLM (Nguyen et al., 2023b)은 자연스러운 턴테이킹 대화를 생성하기 위해 2채널 대화를 모델링합니다.
시각적 입력과 출력을 모두 처리할 수 있는 Multimodal Large Language Models (MM-LLM) (Wu et al., 2023; Gong et al., 2023)이 있습니다. 그러나 이들은 이미지 캡셔닝 및 이미지 편집과 같은 작업을 위해 시각적 정보를 보충 자료로 사용하는 시각적 기반 대화 시스템입니다. 이와 대조적으로, 우리는 음성 내용의 이해를 향상시키고 실제 얼굴을 마주한 대화를 모방하여 커뮤니케이션 경험을 풍부하게 하기 위해 (음성과 관련된 얼굴 움직임) 시청각 음성 대화 시스템을 구축하는 것을 목표로 합니다.
3 MultiDialog Dataset
3.1 Preparation
대화의 시청각 녹음을 얻기 위해, 우리는 다양한 성별, 연령, 국적을 가진 12명의 유창한 영어 화자를 모았습니다. 참가자들은 20세에서 30세 사이이며, 6개국 출신으로 6명의 여성 배우와 6명의 남성 배우로 구성되었으며, 부록 A.2에 나와 있습니다. 우리는 실제 인간-인간 대화에서 수집된 풍부한 지식 기반 데이터셋인 개방형 도메인 대화 데이터셋, TopicalChat (Gopalakrishnan et al., 2023)에서 대화 스크립트를 파생했습니다. 이는 패션, 정치, 책, 스포츠, 일반 엔터테인먼트, 음악, 과학 및 기술, 영화 등 8개의 광범위한 주제를 포괄합니다. 이는 8가지 감정(혐오, 분노, 두려움, 행복, 슬픔, 놀람, 중립, 더 깊이 파고들고 싶은 호기심)에 대해 주석이 달려 있습니다. 대화 파트너는 '화자'나 '청자'와 같이 명시적으로 정의된 역할이 없으므로 사람들이 실제 대화에서 참여하는 방식과 유사하게 자연스럽게 상호 작용합니다. 주제의 다양성, 감정 주석 및 자연스러운 인간 대화의 표현으로 인해, 우리는 TopicalChat을 멀티모달 대화 데이터셋 구축의 기반으로 선택했습니다.
3.2 Recording
데이터는 녹색 스크린과 최소한의 배경 소음이 있는 전문 녹음 스튜디오에서 녹음되었으며, 부록 A.4에 나와 있습니다. 녹음 세션 동안 두 명의 대화 파트너는 나란히 앉아 별도의 카메라와 마이크로 녹음되었습니다. 카메라 위치는 어깨부터 시작하는 상체를 포착하기 위해 개인의 키에 따라 조정되었습니다. 참가자들은 각 발화에 대한 원하는 감정 주석을 전달하는 주어진 스크립트에 따라 연기하도록 요청받았습니다. 우리는 각 감정에 대해 Facial Action Coding System (Ekman and Friesen, 1978) 및 톤 (Gangamohan et al., 2016)에 기반한 시각 및 오디오 단서에 대한 구체적인 지침을 다음과 같이 제공했습니다:
- 중립: 정상적인 쉬는 얼굴, 무표정, 자연스러운 정보로 여전히 말함.
- 행복: 입꼬리 당김, 볼 올림, 입술 벌림, 높은 톤으로 쾌활하게 말함.
- 슬픔: 처진 윗눈꺼풀, 입꼬리 약간 내림, 슬픈 낮은 톤으로 말함.
- 두려움: 눈썹을 올리고 모음, 눈을 크게 뜸, 부드럽고 낮은 톤으로 말함.
- 놀람: 눈썹 올림, 눈 크게 뜸, 입을 더 크게 벌림, 높은 톤으로 흥분해서 말함.
- 혐오: 눈썹을 내리고 모음, 코에 주름, 볼 올림, 윗입술 올림, 혐오스러운 억양으로 보통 톤으로 말함.
- 분노: 눈썹을 내리고 모음, 눈을 부릅뜸, 높은 톤으로 힘있게 말함.
녹음을 위해, 우리는 두 감정 레이블 '중립'과 '더 깊이 파고들고 싶은 호기심'을 시각적으로 뚜렷한 차이가 없기 때문에 단일 레이블 '중립'으로 결합했습니다. 지침 외에도, 우리는 배우들이 감정에 해당하는 표정을 모방할 수 있도록 화면에 샘플 이미지를 표시했습니다. 또한, 다른 참가자에게 턴이 넘어갈 때, 그들은 들으면서 자연스럽게 반응합니다. 참가자들은 다음 발화로 진행하기 위해 버튼을 누르도록 지시받았고, 이는 후처리를 위해 각 턴의 시작 및 종료 시간을 기록했습니다. 오디오 스트림은 48kHz의 모노 WAV 형식으로, 비디오 스트림은 30fps의 풀 HD로 녹음되었습니다.
3.3 Post-Processing
데이터를 정제하기 위해, 우리는 주석가가 시청각 녹음을 검토하여 오디오와 시각 스트림 사이에 불일치가 있는지 확인하도록 했습니다. 우리는 주석가에게 시작 시간을 슬라이드하여 불일치를 수동으로 조정하도록 요청했습니다. 또한, 오디오 또는 시각 스트림이 누락된 녹음을 필터링했습니다. 그런 다음, 각 턴의 기록된 타임스텝을 기반으로 녹음을 대화와 턴으로 분할했습니다. 그 결과, 후처리된 MultiDialog 데이터셋은 6쌍의 대화 파트너 간의 약 9,000개 대화에 대한 약 340시간의 시청각 비디오로 구성됩니다. 우리 데이터셋의 최종 통계는 표 2에 나와 있습니다. 또한, 우리는 엄격한 주석 평가를 기반으로 선택된 골드 감정 대화 하위 집합을 공개합니다. 자세한 내용은 부록 A.3.1을 참조하십시오.
4 Audio-Visual Spoken Dialogue System
제안된 MultiDialog 데이터셋을 기반으로, 우리는 사용자의 얼굴 비디오의 시청각을 직접 이해하고 시청각 얼굴 비디오로 적절한 응답을 생성하는 시청각 음성 대화 시스템을 소개합니다. 이것은 세 가지 주요 부분으로 구성됩니다: 1) 시청각 음성을 이산적인 표현, 즉 시청각(AV) 음성 토큰으로 인코딩. 2) AV 음성 토큰을 의사 텍스트로 사용하여 멀티모달 음성 대화 언어 모델링 수행. 3) 출력 AV 음성 토큰을 직접적인 얼굴 맞대고 대화를 위해 오디오 및 시각 공간으로 투영.
4.1 Audio-Visual Speech Encoding
오디오와 시각 양식을 모두 통합함으로써, 우리는 대화 시스템의 음성 내용 이해를 향상시킬 수 있습니다. 이는 음성이 청각 신호뿐만 아니라 화자의 입 움직임에서 오는 시각적 단서도 포함하기 때문입니다. 이러한 시각적 정보는 특히 시끄러운 환경에서 청각 신호를 보완하여 더 견고한 성능을 낳습니다 (Afouras et al., 2018).
이를 위해, 우리는 말하는 얼굴 입력의 오디오와 시각을 모두 시청각 음성 토큰으로 모델링하는 통합된 접근 방식을 채택합니다. 자기 지도 음성 모델(Schneider et al., 2019; Baevski et al., 2020; Hsu et al., 2021; Chung et al., 2021; Babu et al., 2021)에서 추출한 이산 음성 토큰을 활용하는 음성 처리의 최근 성공에 영감을 받아(Lakhotia et al., 2021; Lee et al., 2021; Maiti et al., 2023; Kim et al., 2023), 우리는 오디오 및 시각 스트림을 시청각 음성 토큰(일명 AV 음성 토큰)으로 토큰화합니다. 구체적으로, 우리는 멀티모달 음성 모델 중 하나인 AV-HuBERT(Shi et al., 2021)를 사용합니다. 이는 보고 듣는 것으로 음성을 이해하기 위한 최첨단 자기 지도 프레임워크입니다. 이는 음성에서 이산 클러스터를 예측하기 위해 원시 시청각 얼굴 비디오로 훈련됩니다 (Hassid et al., 2023). 시청각 음성 특징은 (Lakhotia et al., 2021; Popuri et al., 2022; Kim et al., 2024)에서와 같이 이산 토큰으로 추출 및 양자화됩니다. 시각적 단서와 청각 정보를 결합함으로써, 시청각 음성 토큰은 언어적 정보와 음성적 정보를 모두 추출합니다. 그런 다음, 우리는 AV 음성 토큰을 의사 텍스트로 취급하여 우리의 Audio-Visual Spoken Dialogue LM을 훈련합니다.
4.2 Audio-Visual Spoken Dialogue Language Modeling
그림 1에서 볼 수 있듯이, 우리의 시청각 음성 대화 언어 모델은 MultiDialog 데이터셋의 AV 음성 토큰으로 훈련됩니다. 이전 연구 (Hassid et al., 2023)는 음성 언어 모델을 텍스트로 사전 훈련된 언어 모델 (LLM)로 초기화하는 것이 더 나은 성능과 더 빠른 수렴으로 이어진다는 것을 보여주었습니다. 따라서 우리는 사전 훈련된 LLM인 OPT-1.3B (Zhang et al., 2022)를 사용하여 모델을 초기화하고, (Zhang et al., 2023a; Nachmani et al., 2023; Maiti et al., 2023)에서와 같이 AV 음성 토큰의 어휘를 원래 텍스트 어휘와 결합합니다. 이를 통해 AV 음성 토큰과 텍스트 토큰 의 확률을 공동으로 모델링할 수 있으며, 손실은 다음과 같이 나타낼 수 있습니다.
이는 길이 토큰의 시퀀스에서 다음 토큰을 예측하는 음의 로그 우도입니다.
음성 번역, 오디오 음성 인식, 텍스트-음성 합성과 같은 음성 처리 작업에서 사용되는 공동 음성-텍스트 훈련에 동기 부여 받아 (Cheng et al., 2023; Maiti et al., 2023; Dong et al., 2023; Wang et al., 2023b), 우리는 음성 대화 언어 모델링에 맞춰진 새로운 공동 음성-텍스트 사전 훈련 체계를 소개합니다. 우리의 설정에서, 각 대화 는 AI와 사용자로 무작위로 지정한 두 화자 사이의 라운드의 턴 로 구성됩니다. 이 사전 훈련의 목표는 텍스트 기반 LLM을 AV 음성 토큰 기반 LLM으로 효과적으로 변환하여 대화 컨텍스트가 주어졌을 때 AI 측에서 관련 AV 음성 응답을 생성할 수 있도록 하는 것입니다. 이는 다음 두 단계로 진행됩니다:
첫 번째 단계는 LLM이 AV 음성 토큰을 해석하고 생성하도록 지시하는 것입니다. 우리는 대화를 턴 로 분할하고 쌍을 이룬 AV 음성 토큰 와 텍스트 토큰 를 준비합니다. 그런 다음 AV 음성 및 텍스트 토큰의 시작을 나타내기 위해 각자의 양식 접두사 토큰 <speech>와 <text>를 사용하여 쌍을 연결합니다. 연결의 역순을 추가하여 그림 2(a)와 (b)에 표시된 대로 시청각 음성 인식(AVSR) 및 텍스트-음성 생성(TTS) 훈련 목표를 모두 구성하며, 손실 함수는 각각 다음과 같이 나타낼 수 있습니다:
간결함을 위해 접두사 토큰을 생략했습니다. 첫 번째 단계에서는 임베딩 계층과 투영 계층만 훈련되며, 이는 LLM이 대화 생성에 필요한 주어진 LLM 지식을 완전히 유지하면서 AV 음성 토큰을 이해하고 생성하도록 안내합니다.
두 번째 단계는 텍스트와 공동으로 학습하는 것입니다.
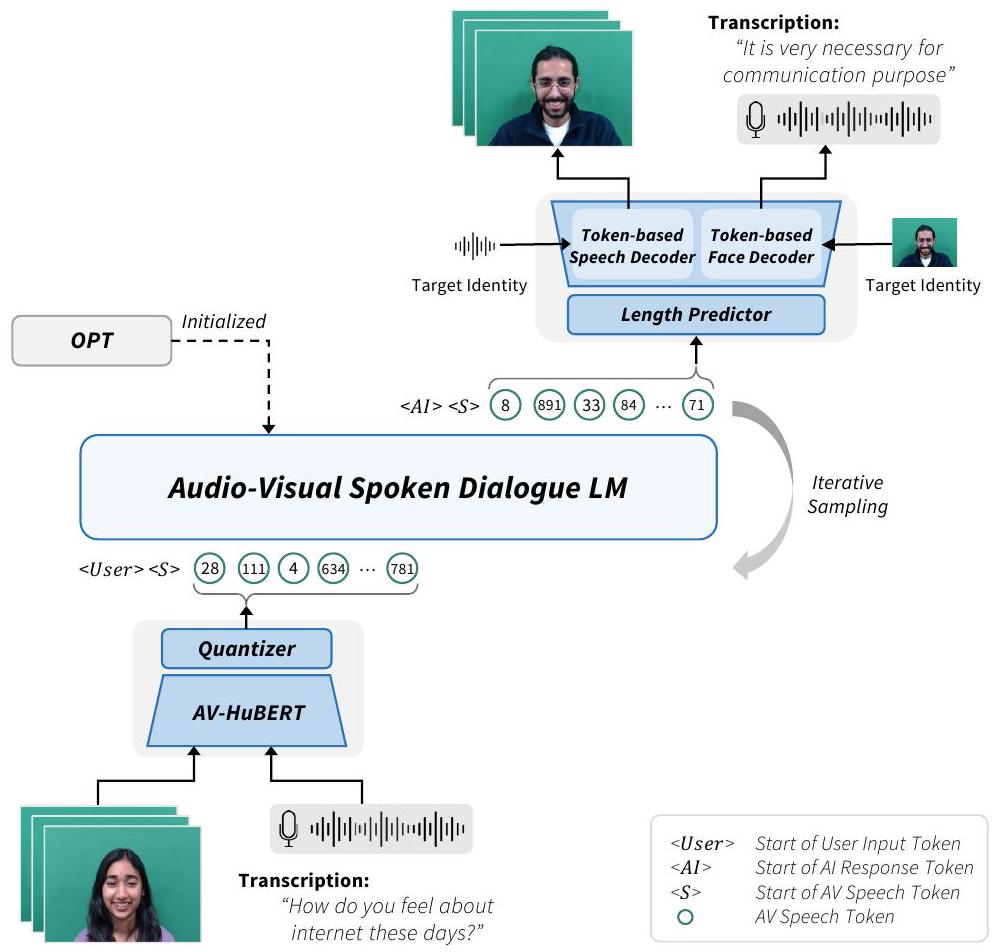
그림 1: 멀티모달 음성 대화 언어 모델링을 위한 제안된 프레임워크 개요. AV 음성 토큰을 의사 텍스트로 사용하여 사용자 입력의 시청각 얼굴 비디오를 처리하고 해당 응답을 시청각 얼굴 비디오로 생성할 수 있습니다.
<코드> (a) AV 음성 대 텍스트 토큰 (AVSR) . <Speech> 7 495 123 495 7 21 495 21 495 ... 118 <Text> 축구 팬이세요? (b) 텍스트 대 AV 음성 토큰 (TTS)
- <Text> 알아요. 제 생각엔 요즘 리그가 수비보다 공격을 선호해서 그런 것 같아요. <Speech> 7 381 17 338 21 123 57 123 329 ... 11 (c) 혼합 텍스트 및 AV 음성 토큰 대화
- <User> <Text> 드라마 좋아하세요? <AI> <Speech> 7 278 123 7 21 278 123 21 7 ... 212 <User> <Text> 네. 짐 캐리 좋아하세요? <AI> <Speech> 7 278 123 278 123 278 1617 406 ... 2 <User> <Text> 네 긍정적인 영향을 주지 않으니까요. <AI> <Text> 네. 라디오 드라마 들으세요? (d) AV 음성 토큰 대화 . <User> <Text> 7 123 381 123 7 402 437 21 413 ... 38 <AI> <Speech> 7 278 123 7 21 278 123 21 7 ... 212 <User> <Text> 7 445 123 7 123 329 57 437 161 ... 2 <AI> <Speech> 7 278 123 278 123 278 161 7 406 ... 2 <User> <Text> 7 17 7 437 23 437 7 437 161 ... 225 <AI> <Text> 7 278 123 278 123 21 7 437 380 ... 385 </코드>
그림 2: 오디오-비주얼 음성 대화 모델 훈련에 사용된 MultiDialog 데이터셋 기반의 구성된 데이터. (a-c)는 오디오-비주얼 음성과 텍스트 토큰의 공동 사전 훈련이고, (d)는 모델 미세 조정에 사용됩니다.
AV 음성 토큰 기반 대화. 우리는 화자 중 한 명을 모델이 예측하고자 하는 AI로 선택하고, 추가적인 화자 접두사 토큰 <User>와 <AI>로 응답의 시작을 나타냅니다. 화자 접두사 토큰 다음에는 발화가 AV 음성인지 텍스트인지를 나타내는 양식 접두사 토큰 <Speech>와 <Text>가 옵니다. 대화 언어 모델링의 손실 함수는 다음과 같습니다:
여기서 는 총 라운드 수, 는 k번째 라운드의 토큰 수, 는 k번째 라운드에서 AI의 n번째 토큰, 은 동일한 라운드 k 내에서 AI의 모든 이전 토큰을 나타내고, 는 이전 라운드의 모든 이전 토큰입니다. 간결성을 위해 방정식에서 접두사 토큰을 생략했습니다. 사전 훈련 중에는 AV 음성 토큰과 텍스트의 균형 잡힌 혼합을 활용하여 모델이 그림 2(c)에서와 같이 두 토큰 지식을 모두 활용하여 대화 응답을 생성할 수 있도록 합니다. 그런 다음, 우리는 실시간 얼굴 맞대고 상호 작용을 위해 그림 2(d)에서와 같이 순수 AV 음성 토큰 기반 대화에 대해 나중에 미세 조정합니다. 이러한 점진적인 전환은 텍스트 기반 LLM의 대화 생성 품질을 손상시키지 않으면서 모델이 AV 음성 토큰에 점진적으로 적응하는 데 도움이 됩니다.
<코드> 평가 프롬프트
- <User> 안녕하세요, 오늘 어떻게 지내세요? <AI>
- <User> 안녕하세요, 오늘 어떻게 지내세요? <AI> 저는 잘 지내요, 고마워요. 저처럼 축구 팬이신지 궁금하네요. 많은 사람들이 시즌이 끝나서 슬퍼하는 걸 알아요, 특히 판타지 풋볼이 그렇게 인기가 많으니까요. <User> 저는 축구를 좋아하지만, 볼 기회가 많지 않아요. 보통 SB를 보려고 노력해요. <AI>
- <User> 안녕하세요, 오늘 어떻게 지내세요? <AI> 저는 잘 지내요, 고마워요. 저처럼 축구 팬이신지 궁금하네요. 많은 사람들이 시즌이 끝나서 슬퍼하는 걸 알아요, 특히 판타지 풋볼이 그렇게 인기가 많으니까요. <User> 저는 축구를 좋아하지만, 볼 기회가 많지 않아요. 보통 SB를 보려고 노력해요. <AI> SB가 뭐예요? 판타지 풋볼에서는 선택이 전부이고 사람들이 몇 주 동안 계획을 세운다고 알고 있어요. <User> 슈퍼볼이요. 죄송해요, 명확하게 말했어야 했는데. 저는 판타지 스포츠를 해본 적이 없어요. 목표가 뭐예요? 어떻게 이기나요? 뭘 이기나요? <AI> </코드>
그림 3: 멀티모달 대화 언어 모델링의 평가 프롬프트. 설명을 위해 텍스트로 작성되었지만 실제 프롬프트는 오디오와 비주얼로 주어집니다.
4.3 Audio-Visual Generation
생성된 AV 음성 토큰은 말하는 얼굴 비디오로 응답을 생성하기 위해 오디오와 비주얼로 투영됩니다. 그림 1에서 볼 수 있듯이, 오디오-비주얼 생성기는 길이 예측기, 토큰 기반 음성 디코더, 토큰 기반 얼굴 디코더로 구성됩니다. 우리 언어 모델은 중복 감소된 AV 음성 토큰으로 훈련되었기 때문에, 우리는 먼저 원래 길이로 복원하기 위해 길이 예측기를 훈련합니다. 토큰 기반 음성 디코더와 토큰 기반 얼굴 디코더는 기존의 오디오 생성기 (Kong et al., 2020)와 말하는 얼굴 생성기 (Prajwal et al., 2020)에서 각각 채택되었으며, 우리는 원시 오디오 대신 AV 음성 토큰을 입력으로 처리하도록 훈련합니다. 추가적으로, 우리는 대상 신원 샘플 오디오에서 화자 임베딩 (Jia et al., 2018)을 추출하여 화자 신원 정보를 통합합니다. 또한, (Prajwal et al., 2020)에서와 같이 대상 신원의 얼굴 및 포즈 사전이 활용되어 원하는 신원으로 말하는 얼굴 비디오 생성을 가능하게 합니다.
5 Experimental Setup
5.1 Evaluation Metrics
우리는 오디오와 비디오 모두의 의미론적 품질과 생성 품질을 평가합니다. 의미론적 품질을 위해, 우리는 먼저 기존 ASR 모델(Shi et al., 2021)을 사용하여 합성된 시청각 출력에서 전사문을 생성하고, 텍스트 기반 대화 생성에 사용되는 표준 메트릭을 사용합니다: log-perplexity (PPL), BLEU, METEOR, F1, D-1, 및 D-2. log-perplexity는 Dialo-GPT 모델(Zhang et al., 2019)을 사용하여 계산되며 각 발화에 대해 계산되고 테스트 세트 전체에 걸쳐 평균화됩니다. 비디오의 생성 품질을 측정하기 위해, 우리는 TFG에 사용되는 메트릭을 채택합니다. 여기에는 시각적 품질을 측정하기 위한 Fréchet Inception Distance (FID) (Heusel et al., 2017)와 시청각 동기화를 측정하기 위한 LSEC 및 LSE-D (Prajwal et al., 2020)가 포함됩니다. 음향 품질을 평가하기 위해, 우리는 주어진 대상 샘플과 생성된 음성 사이의 화자 유사성(SIM)을 화자 검증을 위한 WavLM-Base 모델(Chen et al., 2022)을 사용하여 계산합니다. 각 메트릭에 대한 자세한 설명은 부록을 참조하십시오.
5.2 Implementation Details
AV 음성 토큰을 인코딩하기 위해, 우리는 얼굴 탐지기 (Deng et al., 2020)와 얼굴 랜드마크 탐지기 (Bulat and Tzimiropoulos, 2017)를 사용하여 비디오를 크기의 입 영역으로 자르고 오디오를 16kHz로 리샘플링합니다. 우리는 영어로 훈련된 AVHuBERT (Shi et al., 2021)를 사용하여 HuBERT 토크나이저 (Hassid et al., 2023)에서 해당 대상 클러스터를 예측하도록 미세 조정하며, 이는 500개의 클러스터로 25Hz에서 작동합니다. 우리는 6개의 A6000 GPU에서 최대 토큰 길이 2,000으로 100k 단계 동안 훈련합니다.
우리는 사전 훈련된 언어 모델인 OPT-1.3B (Zhang et al., 2022)로 모델을 초기화합니다. 우리는 먼저 AVSR 및 TTS 목표에 대해 200K 단계 동안 입력 임베딩 계층과 투영 계층을 사전 훈련합니다. 그런 다음, 텍스트와 AV 음성 토큰 대화의 혼합에 대해 전체 모델을 5K 단계 동안 계속 훈련하고, 이어서 AV 음성 토큰 대화에 대해서만 추가로 3K 단계 동안 미세 조정합니다. 우리는 4개의 A6000 GPU에서 최대 토큰 길이 700을 사용합니다.
오디오-비주얼 생성기는 실제(ground truth) AV 음성 토큰을 사용하여 훈련됩니다. 토큰 기반 음성 디코더와 길이 예측기는 배치 크기 32로 450K 단계 동안 공동으로 훈련됩니다. AV 토큰 기반 얼굴 디코더를 훈련하기 위해, 우리는 (Choi et al., 2023)의 재프로그래밍 전략을 사용하고 AV 음성 토큰과 TFG 모델 (Prajwal et al., 2020)의 해당 오디오 특징 사이를 연결하기 위해 두 개의 transformer 인코더 계층으로 구성된 어댑터 계층을 훈련합니다. 이를 통해 생성기를 추가로 미세 조정하지 않고도 사전 훈련된 TFG 모델의 얼굴 생성 능력을 활용할 수 있으며 다른 TFG 모델에도 적용할 수 있습니다. 배치 크기 256으로 250K 단계 동안 훈련됩니다. 우리는 또한 생성된 얼굴 비디오를 고해상도로 업샘플링하기 위해 얼굴 향상기 (Wang et al., 2021b)를 추가로 통합합니다.
5.3 Baselines
직접적으로 시청각 음성 대화 합성을 수행할 수 있는 이전 방법이 없기 때문에, 우리는 최근에 제안된 음성 대화 시스템인 Speech-GPT (Zhang et al., 2023a) 및 d-GSLM (Nguyen et al., 2023b)과 비교합니다. 이들은 입력과 출력 모두에서 오디오 음성만 지원합니다. 추가적으로, 우리는 일련의 기존 사전 훈련된 모델을 통합하여 캐스케이드 시스템을 구축합니다: AVSR (Anwar et al., 2023), LM (Tang et al., 2022), TTS (Casanova et al., 2022), 및 TFG (Prajwal et al., 2020). 캐스케이드 방법과의 비교 목적은 최첨단 성능을 달성하는 것이 아니라, 제안된 시스템의 성능이 직접 전략을 통해 어느 정도 달성될 수 있는지 평가하는 것입니다. 공정한 비교를 위해, 우리는 MultiDialog 데이터셋에서 SpeechGPT와 dGSLM을 미세 조정하고, 캐스케이드 시스템의 LM으로 TopicalChat에서 훈련된 대화 언어 모델 (Tang et al., 2022)을 사용합니다.
6 Results
6.1 Semantic Evaluation
생성된 응답의 의미론적 품질을 정확하게 평가하기 위해, 우리는 텍스트 기반 대화 언어 모델에 사용되는 평가 전략을 사용합니다. 우리는 MultiDialog의 테스트 세트에서 평가를 수행하며, 여기서 모델은 대화의 각 턴에 대한 응답을 순차적으로 생성하도록 프롬프트됩니다. 샘플 평가 프롬프트는 그림 3에 설명되어 있습니다. 생성된 응답은 텍스트로 변환된 후 그 의미론적 품질을 평가하기 위해 실제 응답과 비교됩니다. 표 3에서 볼 수 있듯이, 최첨단 음성 대화 시스템인 SpeechGPT (Zhang et al., 2023a) 및 d-GSLM (Nguyen et al., 2023b)과 비교할 때, 우리 제안 방법은 BLEU, D-1, 및 D-2에서 최고의 성능을 보이며, 이는 우리 방법이 문맥적으로 일관되고 다양한 응답을 생성할 수 있음을 보여줍니다. SpeechGPT는 방대한 양의 음성 데이터로 훈련되고 MultiDialog에서 PEFT-미세 조정되었기 때문에 가장 높은 PPL을 가지며 (Hu et al., 2021), 이는 더 유창한 음성을 생성할 수 있지만 낮은 BLEU 점수에서 알 수 있듯이 참조 응답과 일치하지 못합니다. 또한, 텍스트로 응답을 생성하기 위해 입력의 텍스트 전사를 생성해야 합니다. 특히, 우리 제안 방법은 중간 텍스트 생성 없이 오디오 및 시각 음성 비디오 모두에서 직접 응답을 인식하고 생성하는 최초의 접근 방식입니다.
| 방법 | 입력 양식 | 출력 양식 | 의미 평가 | |||||
|---|---|---|---|---|---|---|---|---|
| PPL | BLEU | METEOR | F1 | D-1 | D-2 | |||
| - Ground Truth | ||||||||
| GT AV 음성 토큰 <br> - 계단식 시스템 | - | - | 1054.643 | 76.326 | 0.565 | 0.474 | 0.947 | 0.996 |
| AVSR + LM + TTS + TFG <br> - 음성 대화 시스템 | AV | AV | 1157.586 | 47.287 | 0.075 | 0.100 | 0.959 | 0.977 |
| SpeechGPT (Zhang et al., 2023a) | A | A | 930.401 | 20.536 | 0.064 | 0.054 | 0.743 | 0.876 |
| d-GSLM (Nguyen et al., 2023b) | A | A | 1085.265 | 8.197 | 0.065 | 0.064 | 0.883 | 0.876 |
| - 시청각 음성 대화 시스템 | ||||||||
| Scratch | AV | AV | 1898.864 | 13.305 | 0.058 | 0.064 | 0.945 | 0.955 |
| + LLM 초기화 | AV | AV | 1237.757 | 17.098 | 0.059 | 0.058 | 0.936 | 0.963 |
| + AVSR/TTS 사전 훈련 | AV | AV | 1068.904 | 22.090 | 0.062 | 0.066 | 0.943 | 0.965 |
| + 혼합 텍스트-AV 음성 사전 훈련 | AV | AV | 1248.001 | 24.094 | 0.063 | 0.065 | 0.945 | 0.957 |
표 3: MultiDialog에서 최첨단 음성 대화 시스템 간의 의미론적 품질 비교. 제안된 방법은 중간 텍스트에 의존하지 않고 대화 시스템의 입력 및 출력에서 오디오와 비주얼을 모두 지원하는 유일한 방법입니다.
| 방법 | FID | LSE-C | LSE-D | SIM |
|---|---|---|---|---|
| - 캐스케이드 시스템 | ||||
| AVSR + LM + TTS + TFG | 30.581 | 7.041 | 7.640 | 0.433 |
| - 음성 대화 시스템 | ||||
| SpeechGPT (Zhang et al., 2023a) | - | - | - | 0.194 |
| d-GSLM (Nguyen et al., 2023b) | - | - | - | 0.211 |
| - 시청각 음성 대화 시스템 | ||||
| 제안됨 | 30.323 | 7.298 | 7.390 | 0.624 |
표 4: 오디오 및 비주얼 생성 품질 평가. MultiDialog의 테스트 세트에서 무작위로 선택된 300개 비디오의 재구성된 오디오 및 비주얼 출력을 평가합니다.
6.2 Ablation on the Pretraining Scheme
우리는 표 3의 아래쪽 섹션에서 우리의 시청각 음성 대화 모델에 사용된 사전 훈련 체계를 분석합니다. 결과는 모델을 텍스트로 사전 훈련된 LLM으로 초기화하는 것이 향상된 의미 품질을 산출하며, 이는 AVSR/TTS 사전 훈련에 의해 더욱 향상된다는 것을 보여줍니다. 단순히 임베딩 레이어와 프로젝션 레이어를 훈련하여 해당 AV 음성 토큰과 텍스트 토큰을 예측하도록 하는 것이 응답을 향상시킵니다. 혼합 텍스트-AV 음성 토큰 사전 훈련을 추가로 통합했을 때, 우리는 의미 품질의 전반적인 향상을 관찰하며, AV 음성 토큰을 LLM에 점진적으로 적응시키는 효과를 검증합니다. 그러나 PPL 점수에서 약간의 감소가 있는데, 이는 모델의 복잡성 증가와 멀티모달 입력에 대한 적응성 때문이라고 생각합니다.
6.3 Audio and Visual Evaluation
우리는 표 4에서 오디오 및 비주얼 생성 품질을 평가합니다. 화자 음성 유사성 (SIM) 측면에서, 우리 제안 방법은 캐스케이드 시스템을 능가할 뿐만 아니라 음성 대화 시스템도 능가합니다. 이는 화자 임베딩으로 강화된 우리의 AV 토큰 기반 음성 디코더가 참조 비디오에서 화자 정보를 유지하는 데 효과적임을 보여줍니다. 비주얼 품질을 평가할 때, 우리는 우리와 동일한 TFG 모델 (Prajwal et al., 2020)을 사용하는 캐스케이드 시스템과 비교했습니다. 우리의 FID 점수는 비슷하지만, 우리의 접근 방식은 이산화된 시청각 토큰의 활용으로 인해 우수한 시청각 동기화를 보여주며, 이는 원시 오디오보다 오디오와 비주얼 구성 요소 간의 더 명확한 정렬을 제공합니다.
그림 4에서는 두 파트너 간의 생성된 시청각 응답과 ASR (Shi et al., 2021)로 생성된 전사문을 보여줍니다. 대화 컨텍스트가 주어지면, 우리 모델은 문맥적으로 일관되고 적절한 다음 응답을 생성합니다. 예를 들어, 그림 4 (a)에서는 이전 턴에서 사용자가 한 질문에 답하고 채팅 주제인 NFL에 대해 적절하게 응답합니다. 또한, 참조 얼굴의 음성 관련 움직임을 성공적으로 합성하여 매끄러운 말하는 얼굴 비디오를 생성합니다. 더 많은 데모는 데모를 참조하십시오.
6.4 Robustness to Acoustic Noise
표 5에서는 대화 시스템에 추가적인 시각적 양식을 통합하는 효과를 분석합니다. (Shi et al., 2021)에 따라, 우리는 다양한 SNR 수준(-5, 0, 5 및 깨끗한)의 무작위 잡음으로 입력 음성을 손상시킵니다. 오디오 전용

그림 4: 제안된 방법의 시청각 대화 생성 결과, 마지막 턴은 생성된 시청각 응답입니다. 설명을 위해 각 턴에서 세 개의 비디오 프레임을 무작위로 샘플링했습니다. (a-d)는 네 턴의 대화이고 (e-f)는 두 턴의 대화입니다. 생성된 응답은 이탤릭체로 표시되며 아래에 ASR 전사문을 제공합니다.
| 방법 | 입력 | SNR (dB) | |||
|---|---|---|---|---|---|
| 양식 | -5 | 0 | 5 | 깨끗함 | |
| 제안됨 | 11.340 | 14.751 | 21.143 | 23.089 | |
| 13.853 | 18.144 | 21.186 | 24.094 |
표 5: 다른 SNR 레벨(dB)의 음향 잡음 손상 하에서 다른 입력 양식을 사용한 대화 응답 생성 성능 (BLEU). 입력과 비교할 때, 시청각 입력은 잡음 하에서 성능 저하가 적다는 점에서 시스템의 견고성을 향상시킵니다. 이는 음향 잡음에 영향을 받지 않는 시각적 양식이 오디오 양식의 누락된 정보를 보완하여 음성 내용을 더 잘 인식하고 응답을 출력할 수 있기 때문입니다. 이는 우리 시스템이 불안정한 음성 입력 시나리오에서 실제 사용에 적용 가능하다는 것을 더욱 입증합니다.
7 Conclusion and Limitation
우리는 사용자 입력에서 시청각 음성을 직접 처리하고 시청각 음성 응답을 생성하는 새로운 얼굴 대 얼굴 음성 대화 모델을 소개합니다. 이는 생성 과정에서 중간 텍스트 없이 말하는 얼굴 아바타 챗봇 시스템을 만드는 첫 번째 단계입니다. 또한, 우리는 현재까지 가장 큰 멀티모달 대화 데이터셋인 MultiDialog를 공개하며, 이는 삼중 모드(즉, 오디오, 시각, 텍스트) 음성 대화 데이터를 포함합니다. 광범위한 주제를 다루는 실제 인간-인간 대화를 포착하는 광범위한 데이터셋이므로, 말하는 얼굴 합성에서 멀티모달 대화 언어 모델링에 이르기까지 멀티모달 합성에 대한 다양한 연구 기회를 가져올 것으로 믿습니다.
우리 연구의 한계점은 데이터셋이 각 발화에 대한 감정 레이블을 포함하고 있지만, 아직 이 레이블을 활용하지 않았다는 것입니다. 향후 연구에서는 사용자의 얼굴 표정에서 감정을 인식하여 음성 내용과 생성의 뉘앙스 모두에서 더 감정을 인식하는 응답을 생성함으로써 이 문제를 해결할 계획입니다. 또한, 우리 데이터는 화자와 청자의 병렬 녹음을 제공하므로, 더 즉흥적이고 자연스러운 대화를 위해 두 얼굴의 생성을 동시에 모델링할 수 있습니다.
References
Triantafyllos Afouras, Joon Son Chung, Andrew Senior, Oriol Vinyals, and Andrew Zisserman. 2018. Deep audio-visual speech recognition. IEEE transactions on pattern analysis and machine intelligence, 44(12):8717-8727.
Mohamed Anwar, Bowen Shi, Vedanuj Goswami, Wei-
Ning Hsu, Juan Pino, and Changhan Wang. 2023. Muavic: A multilingual audio-visual corpus for robust speech recognition and robust speech-to-text translation. arXiv preprint arXiv:2303.00628.
Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, et al. 2021. Xls-r: Self-supervised cross-lingual speech representation learning at scale. arXiv preprint arXiv:2111.09296.
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems, 33:12449-12460.
Satanjeev Banerjee and Alon Lavie. 2005. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65-72.
Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, et al. 2023. Seamlessm4t-massively multilingual & multimodal machine translation. arXiv preprint arXiv:2308.11596.
Yoshua Bengio, Réjean Ducharme, and Pascal Vincent. 2000. A neural probabilistic language model. Advances in neural information processing systems, 13.
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. 2023. Audiolm: a language modeling approach to audio generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing.
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Inigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gašić. 2018. Multiwoz-a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. arXiv preprint arXiv:1810.00278.
Adrian Bulat and Georgios Tzimiropoulos. 2017. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of facial landmarks). In International Conference on Computer Vision.
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N Chang, Sungbok Lee, and Shrikanth S Narayanan. 2008. Iemocap: Interactive emotional dyadic motion capture database. Language resources and evaluation, 42:335-359.
Edresson Casanova, Julian Weber, Christopher D Shulby, Arnaldo Candido Junior, Eren Gölge, and
Moacir A Ponti. 2022. Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone. In International Conference on Machine Learning, pages 2709-2720. PMLR.
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. 2022. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16(6):1505-1518.
Yong Cheng, Yu Zhang, Melvin Johnson, Wolfgang Macherey, and Ankur Bapna. 2023. slam: Multitask, multilingual speech and language models. In International Conference on Machine Learning, pages 5504-5520. PMLR.
Jeongsoo Choi, Minsu Kim, Se Jin Park, and Yong Man Ro. 2023. Reprogramming audio-driven talking face synthesis into text-driven. arXiv preprint arXiv:2306.16003.
Yu-An Chung, Yu Zhang, Wei Han, Chung-Cheng Chiu, James Qin, Ruoming Pang, and Yonghui Wu. 2021. W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training. In 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 244-250. IEEE.
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. 2020. Retinaface: Singleshot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5203-5212.
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. 2023. Enhancing chat language models by scaling high-quality instructional conversations. arXiv preprint arXiv:2305.14233.
Qianqian Dong, Zhiying Huang, Chen Xu, Yunlong Zhao, Kexin Wang, Xuxin Cheng, Tom Ko, Qiao Tian, Tang Li, Fengpeng Yue, et al. 2023. Polyvoice: Language models for speech to speech translation. arXiv preprint arXiv:2306.02982.
Paul Ekman and Wallace V Friesen. 1978. Facial action coding system. Environmental Psychology & Nonverbal Behavior.
Paidi Gangamohan, Sudarsana Reddy Kadiri, and B Yegnanarayana. 2016. Analysis of emotional speech-a review. Toward Robotic Socially Believable Behaving Systems-Volume I: Modeling Emotions, pages 205-238.
Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. 2023. Multimodal-gpt: A vision and language model for dialogue with humans. arXiv preprint arXiv:2305.04790.
Karthik Gopalakrishnan, Behnam Hedayatnia, Qinlang Chen, Anna Gottardi, Sanjeev Kwatra, Anu Venkatesh, Raefer Gabriel, and Dilek HakkaniTur. 2023. Topical-chat: Towards knowledgegrounded open-domain conversations. arXiv preprint arXiv:2308.11995.
Sahil Goyal, Sarthak Bhagat, Shagun Uppal, Hitkul Jangra, Yi Yu, Yifang Yin, and Rajiv Ratn Shah. 2023. Emotionally enhanced talking face generation. In Proceedings of the 1st International Workshop on Multimedia Content Generation and Evaluation: New Methods and Practice, pages 81-90.
Michael Hassid, Tal Remez, Tu Anh Nguyen, Itai Gat, Alexis Conneau, Felix Kreuk, Jade Copet, Alexandre Defossez, Gabriel Synnaeve, Emmanuel Dupoux, et al. 2023. Textually pretrained speech language models. arXiv preprint arXiv:2305.13009.
Matthew Henderson, Blaise Thomson, and Jason D Williams. 2014. The second dialog state tracking challenge. In Proceedings of the 15th annual meeting of the special interest group on discourse and dialogue (SIGDIAL), pages 263-272.
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30.
Joanna Hong, Minsu Kim, Jeongsoo Choi, and Yong Man Ro. 2023. Watch or listen: Robust audiovisual speech recognition with visual corruption modeling and reliability scoring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18783-18794.
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451-3460.
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
Guosheng Hu, Li Liu, Yang Yuan, Zehao Yu, Yang Hua, Zhihong Zhang, Fumin Shen, Ling Shao, Timothy Hospedales, Neil Robertson, et al. 2018. Deep multitask learning to recognise subtle facial expressions of mental states. In Proceedings of the European conference on computer vision (ECCV), pages 103119.
Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, et al. 2023. Audiogpt: Understanding and generating speech, music, sound, and talking head. arXiv preprint arXiv:2304.12995.
Ye Jia, Yu Zhang, Ron Weiss, Quan Wang, Jonathan Shen, Fei Ren, Patrick Nguyen, Ruoming Pang, Ignacio Lopez Moreno, Yonghui Wu, et al. 2018. Transfer learning from speaker verification to multispeaker text-to-speech synthesis. Advances in neural information processing systems, 31.
Minsu Kim, Jeongsoo Choi, Dahun Kim, and Yong Man Ro. 2023. Many-to-many spoken language translation via unified speech and text representation learning with unit-to-unit translation. arXiv preprint arXiv:2308.01831.
Minsu Kim, Jeong Hun Yeo, Jeongsoo Choi, Se Jin Park, and Yong Man Ro. 2024. Multilingual visual speech recognition with a single model by learning with discrete visual speech units. arXiv preprint arXiv:2401.09802.
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. 2020. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33:1702217033.
Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, et al. 2023. Openassistant conversations-democratizing large language model alignment. arXiv preprint arXiv:2304.07327.
Kushal Lakhotia, Eugene Kharitonov, Wei-Ning Hsu, Yossi Adi, Adam Polyak, Benjamin Bolte, Tu-Anh Nguyen, Jade Copet, Alexei Baevski, Abdelrahman Mohamed, et al. 2021. On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9:13361354.
Nathan Lambert, Nazneen Rajani Lewis Tunstall, and Tristan Thrush. Huggingface h4 stack exchange preference dataset. 2023. URL https://huggingface. co/datasets/HuggingFaceH4/stack-exchangepreferences.
Ann Lee, Hongyu Gong, Paul-Ambroise Duquenne, Holger Schwenk, Peng-Jen Chen, Changhan Wang, Sravya Popuri, Yossi Adi, Juan Pino, Jiatao Gu, et al. 2021. Textless speech-to-speech translation on real data. arXiv preprint arXiv:2112.08352.
Keon Lee, Kyumin Park, and Daeyoung Kim. 2023. Dailytalk: Spoken dialogue dataset for conversational text-to-speech. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1-5. IEEE.
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016. A diversity-promoting objective function for neural conversation models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 110-119, San Diego, California. Association for Computational Linguistics.
Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang Cao, and Shuzi Niu. 2017. Dailydialog: A manually labelled multi-turn dialogue dataset. arXiv preprint arXiv:1710.03957.
Ryan Lowe, Nissan Pow, Iulian Serban, and Joelle Pineau. 2015. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dialogue systems. arXiv preprint arXiv:1506.08909.
Soumi Maiti, Yifan Peng, Shukjae Choi, Jee-weon Jung, Xuankai Chang, and Shinji Watanabe. 2023. Voxtlm: unified decoder-only models for consolidating speech recognition/synthesis and speech/text continuation tasks. arXiv preprint arXiv:2309.07937.
Eliya Nachmani, Alon Levkovitch, Julian Salazar, Chulayutsh Asawaroengchai, Soroosh Mariooryad, RJ Skerry-Ryan, and Michelle Tadmor Ramanovich. 2023. Lms with a voice: Spoken language modeling beyond speech tokens. arXiv preprint arXiv:2305.15255.
Tu Anh Nguyen, Wei-Ning Hsu, Antony d'Avirro, Bowen Shi, Itai Gat, Maryam Fazel-Zarani, Tal Remez, Jade Copet, Gabriel Synnaeve, Michael Hassid, et al. 2023a. Expresso: A benchmark and analysis of discrete expressive speech resynthesis. arXiv preprint arXiv:2308.05725.
Tu Anh Nguyen, Eugene Kharitonov, Jade Copet, Yossi Adi, Wei-Ning Hsu, Ali Elkahky, Paden Tomasello, Robin Algayres, Benoit Sagot, Abdelrahman Mohamed, et al. 2023b. Generative spoken dialogue language modeling. Transactions of the Association for Computational Linguistics, 11:250-266.
Se Jin Park, Minsu Kim, Joanna Hong, Jeongsoo Choi, and Yong Man Ro. 2022. Synctalkface: Talking face generation with precise lip-syncing via audio-lip memory. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 2062-2070.
Stavros Petridis, Themos Stafylakis, Pingehuan Ma, Feipeng Cai, Georgios Tzimiropoulos, and Maja Pantic. 2018. End-to-end audiovisual speech recognition. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 65486552. IEEE.
Sravya Popuri, Peng-Jen Chen, Changhan Wang, Juan Pino, Yossi Adi, Jiatao Gu, Wei-Ning Hsu, and Ann Lee. 2022. Enhanced direct speech-to-speech translation using self-supervised pre-training and data augmentation. In Proc. Interspeech.
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. 2018. Meld: A multimodal multi-party dataset for emotion recognition in conversations. arXiv preprint arXiv:1810.02508.
Matt Post. 2018. A call for clarity in reporting bleu scores. arXiv preprint arXiv:1804.08771.
KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar. 2020. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM international conference on multimedia, pages 484-492.
Hannah Rashkin, Eric Michael Smith, Margaret Li, and Y-Lan Boureau. 2018. Towards empathetic opendomain conversation models: A new benchmark and dataset. arXiv preprint arXiv:1811.00207.
Siva Reddy, Danqi Chen, and Christopher D Manning. 2019. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249-266.
Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. 2023. Audiopalm: A large language model that can speak and listen. arXiv preprint arXiv:2306.12925.
Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. 2019. wav2vec: Unsupervised pre-training for speech recognition. arXiv preprint arXiv:1904.05862.
Bowen Shi, Wei-Ning Hsu, Kushal Lakhotia, and Abdelrahman Mohamed. 2021. Learning audio-visual speech representation by masked multimodal cluster prediction. In International Conference on Learning Representations.
Shuzheng Si, Wentao Ma, Haoyu Gao, Yuchuan Wu, Ting-En Lin, Yinpei Dai, Hangyu Li, Rui Yan, Fei Huang, and Yongbin Li. 2023. Spokenwoz: A largescale speech-text benchmark for spoken task-oriented dialogue agents. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
Luchuan Song, Guojun Yin, Zhenchao Jin, Xiaoyi Dong, and Chenliang Xu. 2023. Emotional listener portrait: Realistic listener motion simulation in conversation. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 20782-20792. IEEE.
Tianyi Tang, Junyi Li, Wayne Xin Zhao, and Ji-Rong Wen. 2022. Mvp: Multi-task supervised pre-training for natural language generation. arXiv preprint arXiv:2206.12131.
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. 2023a. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111.
Shaocong Wang, Yuan Yuan, Xiangtao Zheng, and Xiaoqiang Lu. 2021a. Local and correlation attention learning for subtle facial expression recognition. Neurocomputing, 453:742-753.
Tianrui Wang, Long Zhou, Ziqiang Zhang, Yu Wu, Shujie Liu, Yashesh Gaur, Zhuo Chen, Jinyu Li, and Furu Wei. 2023b. Viola: Unified codec language models for speech recognition, synthesis, and translation. arXiv preprint arXiv:2305.16107.
Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. 2021b. Towards real-world blind face restoration with generative facial prior. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and TatSeng Chua. 2023. Next-gpt: Any-to-any multimodal 1lm. arXiv preprint arXiv:2309.05519.
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. 2023a. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. arXiv preprint arXiv:2305.11000.
Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Personalizing dialogue agents: I have a dog, do you have pets too? arXiv preprint arXiv:1801.07243.
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. 2022. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. 2023b. Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8652-8661.
Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. 2019. Dialogpt: Large-scale generative pre-training for conversational response generation. arXiv preprint arXiv:1911.00536.
Kangyan Zhou, Shrimai Prabhumoye, and Alan W Black. 2018. A dataset for document grounded conversations. arXiv preprint arXiv:1809.07358.
Mohan Zhou, Yalong Bai, Wei Zhang, Ting Yao, and Tiejun Zhao. 2023. Interactive conversational head generation. arXiv preprint arXiv:2307.02090.
A MultiDialog Dataset
A. 1 Dataset Statistics
표 2는 MultiDialog의 상세 통계를 보여줍니다. MultiDialog는 9,920개의 인간-인간 대화, 106,624개의 턴, 218,248개의 발화로 구성되어 있으며, 총 약 340시간의 시청각 대화 데이터입니다. 단일 대화는 여러 턴을 포함하며, 각 턴은 두 개의 발화를 포함합니다. 발화는 한 사람이 말하고 침묵하거나 다른 사람이 말하는 경우의 음성 인스턴스입니다. 우리 데이터셋에서 대화는 평균 11.0 턴, 21.9 발화, 140.2초 길이였습니다. 12명의 화자는 한 사람당 평균 826.7개의 대화를 녹음하기 위해 짝을 이루었습니다.
A. 2 Participant Information
데이터셋을 녹음하기 전에, 우리는 인간 멀티모달 대화 기술을 구축하기 위해 얼굴 비디오, 음성 및 텍스트 데이터를 수집하는 것에 대한 IRB 승인을 받았습니다. 우리는 영어가 유창하고 지정된 대화 부분을 수행할 수 있는 대학생들을 모집했습니다. 모집 공고에는 녹음될 데이터셋인 TopicalChat에 대한 일반 정보, 참가자의 파도와 책임, 멀티모달 대화 데이터셋 구축의 잠재적 효과와 기여가 포함되었습니다. 25개의 지원서를 받은 후, 모든 지원자에 대해 인터뷰를 실시했습니다. 인터뷰 동안, 우리는 녹음 세션 동안 참가자의 시청각 데이터를 수집할 것이며, 이는 향후 연구 분야에 공개될 것이라고 통지했습니다. 우리는 또한 인종, 성별, 국적 및 연령과 같은 참가자 정보, 시청각 데이터 공개 동의, 영어 유창성 및 감정을 담아 주어진 대화 스크립트를 읽고 연기하는 능력을 평가했습니다. 데이터셋 수집을 담당하는 두 명의 면접관은 각 참가자를 각 기준에 대해 1에서 5까지의 척도로 순위를 매기고 참가자 인구 통계의 다양성을 고려하여 배우를 선택했습니다. 따라서 6개국 출신의 6명의 여성 및 6명의 남성 배우와 20세에서 30세 사이의 연령대가 선택되었습니다. 참가자 정보에 대한 자세한 내용은 표 6에 요약되어 있습니다.
모든 참가자가 선택된 후, 우리는 참가자들에게 녹음 절차에 대해 안내하기 위해 오리엔테이션을 열었습니다. 3시간의 단일 녹음 세션을 위해, 두 명의 참가자는 TopicalChat에서 50~60개의 대화를 촬영하도록 예정되었습니다. 한 세션에서 촬영할 대화 수는 시험 녹음 세션을 기반으로 계산되었으며, 두 명의 화자는 약 60개의 대화를 촬영했습니다.
| Id | 성별 | 나이 | 국적 | # 대화 수 | 정확도 |
|---|---|---|---|---|---|
| a | F | 24 | 인도네시아 | 1,453 | 69.3 |
| b | F | 25 | 대한민국 | 1,454 | 63.6 |
| c | M | 23 | 카자흐스탄 | 1,772 | 59.3 |
| d | M | 23 | 카자흐스탄 | 1,108 | 33.8 |
| e | F | 24 | 인도 | 1,718 | 41.5 |
| f | M | 24 | 파키스탄 | 1,083 | 43.8 |
| g | F | 20 | 카자흐스탄 | 1,774 | 50.0 |
| h | M | 21 | 파키스탄 | 1,642 | 37.0 |
| i | F | 23 | 파키스탄 | 995 | 60.0 |
| j | M | 24 | 방글라데시 | 1,661 | 44.7 |
| k | M | 20 | 대한민국 | 1,449 | 44.0 |
| 1 | F | 20 | 파키스탄 | 1,357 | 21.2 |
표 6: MultiDialog의 참가자 정보. 3시간 동안, 휴식 시간을 포함합니다. 참가자들은 대화 녹음을 시작하고 끝내고 다음 발화로 진행하기 위해 대화 표시 프로그램을 탐색하는 방법을 배웠습니다. 표시 프로그램은 각 발화에 대한 해당 감정과 함께 대화 스크립트와 현재 세션에서 촬영할 남은 대화 수를 보여주었습니다. 우리는 각 참가자에게 녹음 전에 입에서 약 15~20cm 떨어진 곳에 마이크를 부착하고 카메라를 어깨 높이로 조정하도록 통지했습니다. 마지막으로, 우리는 보상을 위한 개인 정보 제공 동의서와 인간 대상 연구 참가자를 위한 정보 제공 동의서를 수집했습니다.
A. 3 Annotation Evaluation
우리는 25명의 참가자가 참여하는 포괄적인 사용자 연구를 수행했으며, 데이터셋에서 무작위로 70개의 발화를 샘플링하고 참가자들이 감정의 질을 검증하기 위해 각 발화 내에서 전달되는 감정을 예측했습니다.
표 6은 각 배우가 발화에서 의도한 감정을 전달하는 정확도를 포함합니다. 실제 대화에는 종종 미묘하고 다층적인 감정 표현이 포함된다는 점을 감안할 때, 데이터셋은 이러한 복잡성을 반영하도록 설계되었습니다. 미묘한 감정 인식에 대한 이전 연구(Hu et al., 2018; Wang et al., 2021a)를 바탕으로, 우리의 사용자 연구 결과는 배우들이 이러한 미묘한 감정을 묘사하는 데 효과적임을 강조합니다. 향후 연구에 사용될 감정 주석의 품질을 향상시키기 위해, 우리는 낮은 예측 점수를 보이는 배우의 녹음을 걸러내고 MultiDialog의 하위 집합을 공개합니다.
표 7은 사용자 연구에서 추정된 감정 범주 간의 혼동 행렬이며, 이상의 감정 정확도를 달성한 배우의 결과에 초점을 맞추고 있습니다.
| NEU | HAP | FEAR | ANG | DISG | SUR | SAD | |
|---|---|---|---|---|---|---|---|
| NEU | 0.88 | 0.04 | 0.01 | 0.03 | 0.00 | 0.03 | 0.02 |
| HAP | 0.18 | 0.75 | 0.00 | 0.01 | 0.01 | 0.05 | 0.001 |
| FEAR | 0.09 | 0.02 | 0.39 | 0.03 | 0.13 | 0.22 | 0.13 |
| ANG | 0.07 | 0.00 | 0.07 | 0.76 | 0.14 | 0.02 | 0.00 |
| DISG | 0.02 | 0.00 | 0.02 | 0.11 | 0.83 | 0.02 | 0.00 |
| SUR | 0.14 | 0.13 | 0.00 | 0.04 | 0.01 | 0.68 | 0.00 |
| SAD | 0.12 | 0.00 | 0.14 | 0.04 | 0.10 | 0.00 | 0.59 |
표 7: 사용자 연구에서 추정된 감정 범주의 혼동 행렬. 결과는 인간의 시청각에서 감정을 인식하는 타고난 능력과 밀접하게 일치하며(Busso et al., 2008), MultiDialog가 발화 내에서 감정을 전달하는 데 효과적임을 강조합니다. 두려움과 슬픔과 같은 특정 감정은 낮은 정확도를 보였는데, 이는 자연스러운 대화에서 이러한 감정의 고유한 복잡성과 미묘함 때문이라고 생각합니다 (Poria et al., 2018).
A.3.1 Gold Emotion Dialogue Subset
우리는 MultiDialog 데이터셋에 골드 감정 대화 하위 집합을 제공하며, 이는 대화에서 감정적 역학을 연구하기 위한 더 신뢰할 수 있는 리소스입니다. 이전 연구(Hu et al., 2018; Wang et al., 2021a)는 미묘한 감정을 인식하는 정확도가 약간 밑도는 것을 나타냅니다. 따라서 우리는 이상의 감정 정확도를 보이는 배우의 대화를 골드 감정 대화로 분류합니다. 우리는 https://huggingface.co/datasets/IVLLab/MultiDialog에서 데이터셋과 함께 배우 ID의 골드 감정 주석을 공개합니다.
A. 4 Recording Setup
그림 5는 녹음 세션을 위한 스튜디오 설정을 보여줍니다.
B Evaluation Metrics
BLEU (Post, 2018)는 n-gram 중복을 기반으로 생성된 응답의 유창성과 적절성을 평가합니다. 더 높은 BLEU 점수는 더 자연스럽고 매력적인 대화 모델을 나타냅니다.
PPL (Bengio et al., 2000)은 언어 모델이 생성된 응답을 얼마나 잘 예측하는지 측정합니다. 더 낮은 perplexity는 모델이 다음 단어를 예측하는 데 더 자신감 있고 정확하다는 것을 나타내며, 일관되고 문맥적으로 관련된 응답을 생성하는 데 더 높은 품질을 시사합니다.
DISTINCT-n (Li et al., 2016)은 응답 집합에서 고유한 n-gram의 백분율을 계산하여 생성된 응답의 다양성을 평가합니다.

그림 5: MultiDialog 데이터셋을 위한 녹음 스튜디오 설정 구체적으로, D-1은 생성된 텍스트에서 고유한 유니그램의 백분율을 측정하고, D-2는 고유한 바이그램의 백분율을 측정합니다. METEOR (Banerjee and Lavie, 2005) (명시적 순서가 있는 번역 평가를 위한 메트릭)은 동의어와 의역을 고려하여 생성된 출력과 실제 값 사이의 정렬 기반 정밀도와 재현율을 계산하여 생성된 응답의 품질을 평가합니다. F1 (Banerjee and Lavie, 2005)은 생성된 응답의 정확도(정밀도)와 관련 응답의 적용 범위(재현율)를 결합합니다. 이는 모델이 관련성 있고 정확한 응답을 생성하는 데 얼마나 잘 수행되는지에 대한 균형 잡힌 척도를 제공합니다.
Footnotes
-
*동일 기여. 교신 저자. 이 연구는 한국연구재단(NRF)의 지원을 받아 수행되었으며, 이는 한국 정부(MSIT)가 지원하는 연구비(No. NRF-2022R1A2C2005529)와 정보통신기술기획평가원(IITP)이 지원하는 연구비(No.2022-0-00124, 자기 개선 역량 인식 학습 능력 인공지능 기술 개발)로 수행되었습니다. ↩