오디오 합성과 오디오-비주얼 멀티모달 처리 기술 동향
이 논문은 딥러닝과 인공지능의 발전에 따른 오디오 합성 및 오디오-비주얼 멀티모달 처리에 대한 최신 연구 동향을 다룹니다. Text to Speech(TTS), 음악 생성과 같은 오디오 합성 기술과 Lipreading, Audio-visual speech separation 등 시각과 청각 정보를 결합하는 멀티모달 연구를 종합적으로 소개하고, 관련 기술 방법론을 분류하여 미래 발전 방향을 전망합니다. 논문 제목: A Survey on Audio Synthesis and Audio-Visual Multimodal Processing
논문 요약: A Survey on Audio Synthesis and Audio-Visual Multimodal Processing
- 논문 링크: https://arxiv.org/abs/2108.00443
- 저자: Zhaofeng Shi (University of Electronic Science and Technology of China)
- 발표 시기: 2021년 (arXiv preprint)
- 주요 키워드: Audio Synthesis, Multimodal Processing, Text to Speech (TTS), Music Generation, Lipreading, Audio-visual speech separation, Deep Learning
1. 연구 배경 및 문제 정의
- 문제 정의: 딥러닝과 인공지능의 발전과 함께 오디오 합성 및 오디오-비주얼 멀티모달 처리 분야의 최신 연구 동향을 종합적으로 조사하고, 관련 기술 방법론을 분류하여 미래 발전 방향을 제시함으로써 해당 분야 연구자들에게 지침을 제공하는 것을 목표로 한다.
- 기존 접근 방식: 초기 오디오 합성은 STFT, Griffin-Lim과 같은 순수한 신호 처리 방법을 활용했으나, 최근 딥러닝 기술의 발전과 함께 파이프라인을 단순화하고 성능을 향상시키기 위해 딥 뉴럴 네트워크 기반 모델들이 등장했다. 멀티모달 처리 분야에서도 시각과 청각 정보의 이질성(차원, 시간 해상도 등)으로 인한 어려움이 존재하며, 이를 해결하기 위한 딥러닝 기반 모델들이 활발히 연구되고 있다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- TTS(Text to Speech), 음악 생성, 멀티모달 오디오-비주얼 처리 작업의 배경과 기술적 방법을 종합적으로 소개하고 요약한다.
- 이 방향에 관심 있는 연구자들에게 실질적인 지침을 제공한다.
- 제안 방법:
논문은 오디오 합성(TTS, 음악 생성)과 오디오-비주얼 멀티모달 처리의 세 가지 주요 영역에 대한 딥러닝 기반 방법론을 분류하고 소개한다.
- 텍스트 음성 변환 (TTS):
- 2단계 방법: 텍스트를 중간 표현(음향 특징, 멜-스펙트로그램)으로 변환하는 음향 모델과 이를 원시 오디오 파형으로 변환하는 보코더로 구성된다. 음향 모델에는 자기회귀(Tacotron, Tacotron 2) 및 비자기회귀(FastSpeech, Glow-TTS) 모델이 있으며, 보코더에는 자기회귀(WaveNet, SampleRNN) 및 비자기회귀(WaveGlow, MelGAN, HiFi-GAN 등 GAN 기반) 모델이 있다.
- 엔드투엔드 방법: 중간 표현 없이 텍스트에서 원시 오디오 파형을 직접 생성한다. 효율성과 정확성 때문에 현재 연구의 주요 방향이며, Char2Wav, FastSpeech 2s, VITS 등이 대표적이다.
- 음악 생성:
- 상징적 음악 생성: 음표 시퀀스 형태로 음악을 생성(MIDI 형식)하며, RNN 기반(DeepBach, MusicVAE) 및 CNN 기반(MidiNet, MuseGAN) 모델이 있다.
- 오디오 음악 생성: 원시 오디오 샘플 수준에서 직접 음악을 생성하며, WaveNet, MelGAN 등 TTS 모델과 Jukebox와 같이 보컬까지 합성 가능한 전용 모델이 있다.
- 오디오-비주얼 멀티모달 처리: 음향 및 시각 정보의 상관관계를 모델링하여 다양한 작업을 수행한다.
- 립리딩 (Lipreading): 소리 없는 비디오에서 입술 움직임을 통해 음성 또는 텍스트를 인식한다 (WLAS, Vid2Speech).
- 오디오-비주얼 음성 분리: 시끄러운 환경에서 특정 화자의 음성을 분리한다 (AV-CVAE, Acapella, VisualSpeech).
- 말하는 얼굴 생성: 주어진 음성에 맞춰 입술 동기화된 자연스러운 말하는 얼굴을 생성한다 (DAVS, ATVGnet).
- 비디오에서 소리 생성: 비디오 콘텐츠에 기반하여 소리를 자동으로 생성한다 (I2S, Foley Music).
- 텍스트 음성 변환 (TTS):
3. 실험 결과
- 데이터셋:
- TTS: LJ speech, VCTK, LibriTTS corpus, Blizzard
- 음악 생성: Lakh MIDI Dataset, Lakh Pianoroll Dataset, MAESTRO
- 오디오-비주얼 멀티모달 처리: GRID, LRW, TCD-TIMID, LRS, VoxCeleb
- 주요 결과:
- 오디오 합성: 딥러닝 기반 모델들이 고충실도 및 자연스러운 음성/음악 생성에서 상당한 발전을 이루었으며, 특히 엔드투엔드 TTS 모델과 Jukebox와 같은 오디오 음악 생성 모델은 높은 성능을 보여준다.
- 멀티모달 처리: 시각 정보(입술 움직임, 얼굴 이미지)를 활용하여 립리딩, 음성 분리, 말하는 얼굴 생성, 비디오에서 소리 생성 등 복잡한 오디오-비주얼 작업에서 성능 향상을 달성했다.
4. 개인적인 생각 및 응용 가능성
- 장점: 이 논문은 오디오 합성 및 오디오-비주얼 멀티모달 처리라는 두 가지 광범위한 분야의 최신 딥러닝 기반 연구 동향을 매우 체계적이고 포괄적으로 정리하여, 관련 분야에 대한 이해를 돕고 새로운 연구 아이디어를 얻는 데 큰 도움이 된다. 각 분야별로 주요 모델과 그 특징, 그리고 당면 과제를 명확히 제시하는 점이 인상 깊다.
- 단점/한계: 2021년 발표된 논문이므로, 이후 2~3년간의 최신 연구 동향(예: Diffusion Model 기반의 오디오 생성, 대규모 멀티모달 모델의 발전)은 포함되지 않았다는 한계가 있다. 또한, 각 모델의 기술적 세부 사항보다는 개요에 집중하여, 특정 모델의 깊이 있는 이해를 위해서는 추가적인 자료 조사가 필요하다.
- 응용 가능성:
- TTS: 오디오북, 자동차 내비게이션, 자동 응답 서비스, 가상 비서 등 다양한 음성 인터페이스.
- 음악 생성: 맞춤형 배경 음악 생성, 게임/영화 사운드트랙 자동 생성, 개인의 창작 활동 지원.
- 오디오-비주얼 멀티모달 처리: 청각 장애인을 위한 보조 기술, 시끄러운 환경에서의 화상 회의/통화 품질 향상, 가상 현실/증강 현실 콘텐츠의 몰입감 증대, 가상 캐릭터 생성, 비디오 콘텐츠 자동 더빙/음향 효과 추가.
Shi, Zhaofeng. "A survey on audio synthesis and audio-visual multimodal processing." arXiv preprint arXiv:2108.00443 (2021).
A Survey on Audio Synthesis and Audio-Visual Multimodal Processing
Zhaofeng Shi<br>2017020912015@std.uestc.edu.cn<br>University of Electronic Science and Technology of China
Abstract
딥러닝과 인공지능의 발전과 함께, 오디오 합성은 머신러닝 분야에서 중추적인 역할을 하며 산업계에서 강력한 적용 가능성을 보여주고 있습니다. 한편, 현재 연구자들은 오디오-비주얼 멀티모달 처리와 같은 멀티모달 작업을 처리하기 위해 상당한 노력을 기울이고 있습니다. 본 논문에서는 오디오 합성과 오디오-비주얼 멀티모달 처리에 대한 설문 조사를 수행하여 현재 연구와 미래 동향을 이해하는 데 도움을 줍니다. 이 리뷰는 텍스트 음성 변환(TTS), 음악 생성 및 시각적 정보와 음향 정보를 결합하는 일부 작업에 중점을 둡니다. 해당 기술적 방법들을 종합적으로 분류하고 소개하며, 미래 발전 동향을 전망합니다. 이 설문 조사는 오디오 합성과 오디오-비주얼 멀티모달 처리와 같은 분야에 관심이 있는 연구자들에게 약간의 지침을 제공할 수 있습니다.
1 introduction
음성, 음악과 같은 다양하고 자연스러우며 이해 가능한 형태의 소리를 합성하는 것을 목표로 하는 오디오 합성은 인간 사회와 산업에서 광범위한 적용 시나리오를 가집니다. 초기에 연구자들은 순수한 신호 처리 방법을 활용하여 오디오에 대한 편리한 표현을 찾았는데, 이는 쉽게 모델링하고 시간적 오디오로 변환할 수 있습니다. 예를 들어, 단시간 푸리에 변환(STFT)은 오디오를 주파수 영역으로 변환하는 효율적인 방법이며, Griffin-Lim [31]은 STFT 시퀀스를 시간적 파형으로 디코딩할 수 있는 순수한 신호 처리 알고리즘의 한 종류입니다. Griffin-Lim과 유사한 방법으로는 WORLD [62] 등이 있습니다. 최근 몇 년간, 딥러닝 기술의 급속한 발전과 함께 연구자들은 파이프라인을 단순화하고 모델의 성능을 향상시키기 위해 오디오 합성 및 기타 멀티모달 작업을 위한 딥 뉴럴 네트워크를 구축하기 시작했습니다. 텍스트 음성 변환(TTS) 및 음악 생성과 같은 작업을 위해 수많은 신경망 모델이 현재까지 등장했습니다. Parallel WaveGAN [103], MelGAN [45], FastSpeech2/2s [80], EATs [21], VITS [40]와 같이 보고된 TTS용 모델이 많이 있습니다. 동시에, song from PI [12], C-RNN-GAN [60], MidiNet [104], MuseGAN [23] 및 Jukebox [18]와 같은 음악 생성을 위한 많은 모델이 있습니다. 이러한 모델들은 인간의 생산과 생활에 큰 편의를 가져다주며, 미래 연구에 핵심적인 참고 자료를 제공합니다.
시각은 생리학적 단어입니다. 인간과 동물은 외부 물체의 크기, 밝기, 색상 등을 시각적으로 인지하고 생존에 필수적인 정보를 얻습니다. 시각은 인간에게 가장 중요한 감각입니다. 최근 몇 년 동안, 딥러닝은 이미지 디헤이징/디레이닝, 객체 탐지 및 이미지 분할과 같은 다양한 이미지 처리 및 컴퓨터 비전 작업에서 널리 탐구되어 사회 생산성 발전에 기여했습니다. 이미지 디헤이징/디레이닝은 안개/비로 흐려진 이미지가 주어졌을 때, 알고리즘을 사용하여 이미지의 안개/비를 제거하여 선명하게 만드는 것을 의미합니다. [95, 46, ]은 각각 이미지 디헤이징/디레이닝을 위한 신경망 기반 모델을 제안했습니다. 객체 탐지는 이미지에서 관심 있는 모든 대상을 찾아내고 그 위치와 클래스를 결정하는 것을 의미합니다.
에서는 객체 탐지를 위한 고성능의 여러 신경망 기반 모델을 찾을 수 있습니다. 이미지 분할은 이미지를 고유한 속성을 가진 여러 특정 영역으로 나누고 관심 있는 객체를 제시하는 것을 의미합니다. 이미지 분할에 대한 연구에는 [108, 32, 85, 106, 105, 58, 107, 101, 82, 55, 84]가 포함됩니다.
모달리티는 시각, 청각, 촉각과 같은 모든 종류의 정보의 형태나 출처를 의미합니다. 우리 삶에서 다른 모달리티의 정보는 종종 밀접하게 관련되어 있습니다. 예를 들어, 대화할 때 상대방의 감정을 판단하기 위해 얼굴 표정과 말을 결합해야 합니다. 딥러닝의 발전과 함께, 멀티모달 머신러닝은 연구의 핫스팟이 되었습니다. 이 리뷰에서는 광범위한 응용 분야를 가진 오디오-비주얼 멀티모달 처리에 중점을 둡니다. 지난 몇 년 동안 오디오-비주얼 멀티모달 처리를 위한 많은 성능 좋은 모델이 제안되었습니다. 예를 들어, Ephrat 등이 보고한 Vid2Speech [24]는 립리딩 작업을 처리할 수 있습니다. Acapella [61]는 노래 음성 분리를 위한 모델입니다. VisualSpeech [29]는 다목적 모델로, 음성 분리 및 음성 향상 작업에서 최첨단 성능을 달성합니다. 오디오-비주얼 멀티모달 처리를 위한 더 많은 모델은 섹션 4에서 종합적으로 요약될 것입니다. 이 리뷰에서는 주로 딥러닝 기술을 기반으로 한 TTS, 음악 생성 및 오디오-비주얼 멀티모달 처리의 세 가지 측면에 대한 연구 작업을 검토합니다. 섹션 2, 섹션 3 및 섹션 4에서는 각각 세 가지 작업에 해당하는 배경 및 기술적 방법을 소개합니다. 섹션 5에서는 각기 다른 영역의 연구에서 가장 일반적으로 사용되는 몇 가지 데이터셋을 제시합니다. 마지막으로, 섹션 6에서는 위에서 설명하고 논의한 내용을 바탕으로 결론을 제시합니다. 이 리뷰의 기여는 다음과 같습니다:
- TTS, 음악 생성 및 멀티모달 오디오-비주얼 처리 작업의 배경과 기술적 방법을 소개하고 요약합니다.
- 이 리뷰는 이 방향에 관심이 있는 연구자들에게 약간의 지침을 제공합니다.
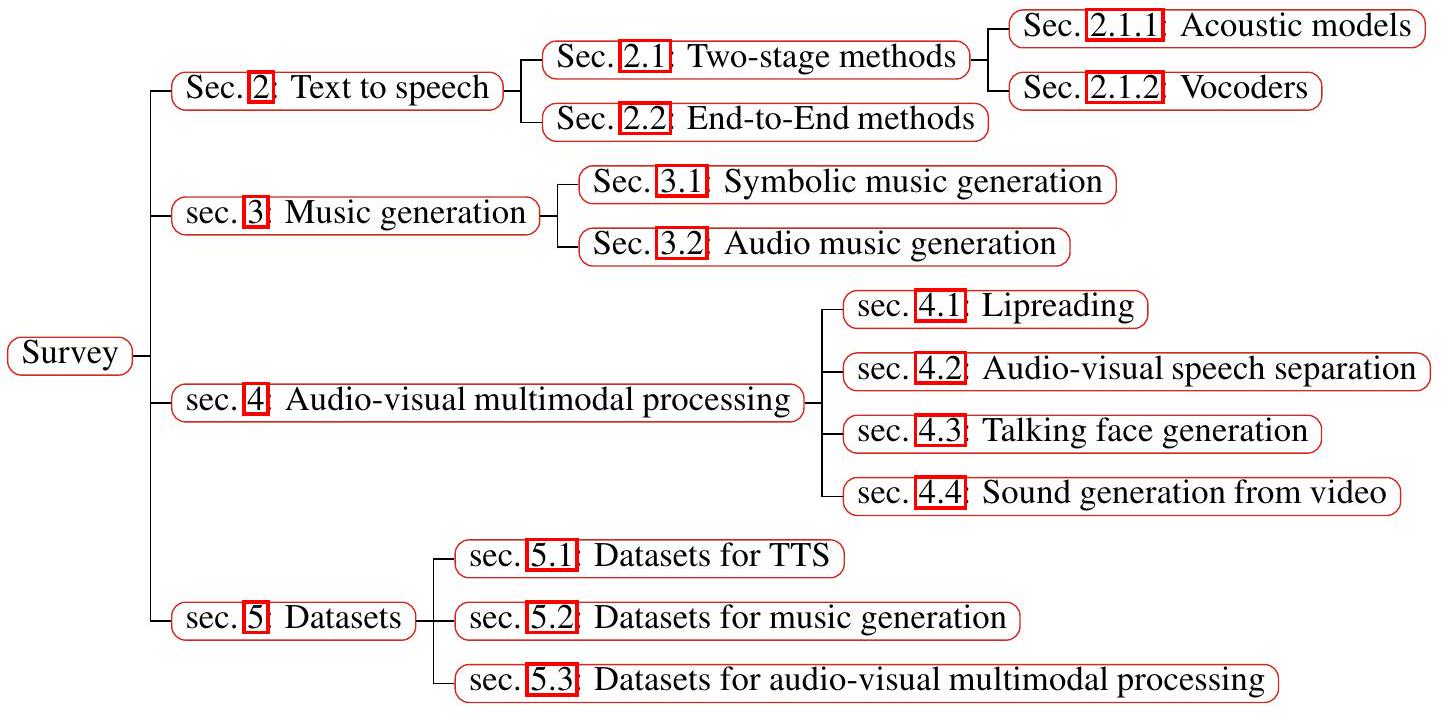
Figure 1: Organization of this paper.
2 Text to Speech
음성 합성으로도 알려진 텍스트 음성 변환(Text to speech)은 입력 텍스트 [88] 조건 하에서 자연스럽고 이해하기 쉬운 음성 파형을 생성하는 것을 목표로 합니다. 인공지능 기술의 지속적인 발전과 함께, TTS는 점차 뜨거운 연구 주제가 되었으며 오디오북 서비스, 자동차 내비게이션 서비스, 자동 응답 서비스 등의 분야에서 널리 채택되었습니다. 그러나 TTS 시스템에 의해 생성되는 음성의 자연스러움과 정확성에 대한 요구 사항도 점점 높아지고 있습니다. 이러한 요구 사항을 충족시키기 위해서는 잘 설계된 신경망이 필요합니다.
원시 오디오 파형을 모델링하는 것은 오디오 데이터의 시간 해상도가 매우 높기 때문에 어려운 문제입니다. 오디오의 샘플링 속도는 최소 16000Hz입니다. 그리고 또 다른 과제는 오디오 파형에 장기 및 단기 의존성이 존재하며, 이를 모델링하기 어렵다는 것입니다. 이 외에도 정렬 문제와 일대다 문제와 같은 TTS 작업에 대한 다른 어려움이 있습니다. 정렬 문제는 출력 음성 오디오 콘텐츠가 입력 텍스트 또는 음소 시퀀스와 시간적으로 정렬되어야 한다는 것을 의미합니다. 현재 이 문제에 대한 주류 해결책은 Monotonic Alignment Search(MAS) [39]를 채택하는 것입니다. 일대다 문제에 관해서는, 텍스트 입력이 지속 시간, 피치와 같은 다양한 변형으로 여러 방식으로 발화될 수 있음을 의미하며, 이 문제를 처리하기 위해 많은 종류의 신경망 구조가 설계되었습니다. TTS 작업의 프레임워크는 주로 2단계 방법과 엔드투엔드 방법을 기반으로 합니다. 대부분의 이전 연구는 텍스트 정규화 및 텍스트에서 음소로의 변환과 같은 텍스트 전처리 외에 2단계 파이프라인을 구성합니다. 첫 번째 단계는 언어적 특징 [66] 또는 멜-스펙트로그램 [83]과 같은 음향 특징과 같은 중간 표현을 음소, 문자 등으로 구성된 입력 시퀀스의 조건 하에 생성하는 것입니다. 두 번째 단계의 모델은 보코더라고도 하며, 입력 중간 표현을 조건으로 원시 오디오 파형을 생성합니다. 2단계 파이프라인의 각 부분에 대한 수많은 모델이 독립적으로 개발되었습니다. 2단계 방법을 활용하여 고충실도 오디오를 얻을 수 있습니다. 그럼에도 불구하고, 2단계 파이프라인은 모델이 미세 조정을 필요로 하고 이전 모듈의 오류가 다음 모듈에 영향을 주어 오류 누적을 유발할 수 있기 때문에 문제가 남아 있습니다. 이 문제를 해결하기 위해 연구자들에 의해 점점 더 많은 엔드투엔드 모델이 개발되었습니다. 엔드투엔드 모델은 중간 표현 없이 직접 원시 오디오 파형을 출력합니다. 매개변수 조정에 많은 시간을 들이지 않고 짧은 시간에 병렬로 오디오를 생성하고 오류 누적 문제를 완화할 수 있기 때문에, 엔드투엔드 방법은 TTS 분야에서 현재의 연구 방향이 되었습니다. 이 두 가지 방법에 대한 세부 사항은 아래에서 소개될 것입니다.
2.1 Two-stage methods
위에서 언급했듯이, 2단계 방법의 첫 번째 단계는 입력 텍스트 시퀀스를 중간 표현으로 변환하고 두 번째 단계는 원시 오디오 파형을 생성하는 것입니다. 첫 번째 단계에서는 언어 모델 또는 음향 모델이 배치되어 언어적 특징 또는 음향 특징을 중간 특징으로 생성합니다. 두 번째 단계의 모델은 보코더라고도 하며, 중간 표현을 원시 오디오 파형으로 변환합니다. 고품질 음성 오디오를 생성하기 위해 이 두 모델은 함께 잘 작동해야 합니다. 2단계 방법에 해당하는 모델은 아래에서 소개되고 요약될 것입니다.
2.1.1 Acoustic models
요즘, 음향 특징은 일반적으로 TTS 작업에서 중간 특징으로 사용됩니다. 결과적으로, 이 섹션에서는 음향 모델에 대한 연구 작업에 중점을 둡니다. 음향 특징은 언어적 특징에서 또는 문자나 음소에서 직접 음향 모델에 의해 생성됩니다 [88]. 음향 모델의 목표는 TTS 작업의 2단계 방법에서 보코더를 사용하여 원시 오디오 파형으로 추가 변환될 음향 특징을 생성하는 것입니다. 최근 몇 년 동안 보고된 음향 모델은 아래에서 종합적으로 요약될 것입니다.
Tacotron과 Tacotron 2 [94, 83]는 원시 텍스트 문자를 입력으로 받아 멜-스펙트로그램을 출력하는 자기회귀 신경망 기반 모델입니다. 멜-스펙트로그램을 출력으로 하는 이들과 유사한 다른 자기회귀 모델에는 DeepVoice 3, Transformer TTS, Flowtron, MelNet [68, 49, 90, 91] 등이 있습니다. MelNet은 시간과 주파수를 모두 고려하는 자기회귀 모델이라는 점은 주목할 가치가 있습니다. Geoffrey 등이 지식 증류 [36]를 제안한 후, 점점 더 많은 연구자들이 ParaNet [67] 및 Fastspeech [79]와 같은 음향 모델을 훈련시키기 위해 지식 증류를 활용하려고 시도했습니다. 이들은 모두 비자기회귀 모델입니다. 또한, Flow-TTS [59], Glow-TTS [39] 등은 flow-기반 비자기회귀 모델이며, Fastspeech 2 [80]는 Transformer [92]를 기반으로 한 비자기회귀 모델입니다.
2.1.2 Vocoders
보코더는 첫 번째 단계에서 생성된 중간 표현을 원시 오디오 파형으로 변환하는 모델입니다. 최근 몇 년 동안, 고충실도 음성 오디오 합성을 달성하기 위해 많은 신경망 기반 보코더가 설계되었습니다. 우리는 아래에서 보코더와 관련된 연구 작업을 요약하고, 이 모델들을 자기회귀 모델과 비자기회귀 모델의 두 가지 범주로 분류할 것입니다.
자기회귀 모델 WaveNet [66]은 언어적 특징을 입력으로 받아 원시 오디오 파형을 자기회귀적으로 생성하는 최초의 신경망 기반 보코더입니다. WaveNet은 완전히 컨볼루션적입니다. 확장된 인과적 컨볼루션을 사용하여 WaveNet은 큰 수용 필드를 달성할 수 있으며, 이는 높은 시간 해상도 오디오 파형 모델링 문제를 해결하는 데 중요한 역할을 합니다. SampleRNN [57]은 RNN을 기반으로 한 또 다른 자기회귀 모델입니다. 이는 서로 다른 시간 해상도에서 작동하는 RNN 모듈의 계층을 사용하여 서로 다른 시간 해상도에서 원시 오디오 파형을 모델링하는 과제를 처리하는 무조건적인 엔드투엔드 신경 오디오 생성 모델입니다. DeepVoice [2]와 LPCNet [89]도 위에서 언급한 두 모델과 같은 자기회귀 모델입니다. 그러나 자기회귀 모델의 경우, 각 출력 샘플 포인트는 이전에 생성된 샘플 포인트에 의존합니다. 결과적으로, 오디오 샘플 포인트가 순차적으로 생성되어야 하므로 이러한 모델을 사용한 추론은 시간이 많이 걸립니다. 이러한 문제에 대응하여 연구자들은 병렬로 오디오를 생성할 수 있는 비자기회귀 모델을 설계했습니다.
비자기회귀 모델 비자기회귀 모델은 실시간 요구 사항을 충족시키기 위해 음성 오디오를 신속하게 생성하기 위해 원시 오디오 샘플을 병렬로 생성할 수 있습니다. 비자기회귀 모델에 적용 가능한 것으로 입증된 많은 기술적 방법이 있습니다. WaveGlow, FloWaveNet 및 WaveFlow [72, 41, 70]는 flow-기반 비자기회귀 모델입니다. Parallel WaveNet [65]도 flow-기반 모델로, 지식 증류 [36]를 결합하여 역 자기회귀 flow(IAF) [43] 네트워크를 학생 네트워크로, 사전 훈련된 WaveNet을 교사 네트워크로 사용합니다. ClariNet [69]도 지식 증류 [36]를 사용하는 보코더입니다. 그러나 증류 기반 방법을 사용한 훈련 과정에는 문제가 남아 있습니다. 견고한 교사 모델뿐만 아니라 복잡한 증류 과정을 최적화하기 위한 방법론도 필요합니다. 생성적 적대 신경망(GANs) [30]의 최근 많은 발전이 가속화되었으며 WaveGAN [20]은 DCGAN [76]의 구조를 수정하여 오디오 합성을 실현한 최초의 GAN 기반 보코더입니다. 또한, Parallel WaveGAN [103]은 자연 음성 오디오의 시간-주파수 분포를 포착하기 위해 다중 해상도 단시간 푸리에 변환(STFT)을 사용하는 GAN 기반 모델입니다. MelGAN [45]은 입력 멜-스펙트로그램을 원시 음성 오디오로 역변환하는 GAN 기반의 또 다른 비자기회귀 피드-포워드 보코더입니다. 다른 GAN 기반 보코더에는 GAN-TTS [5], HiFi-GAN [44] 등이 있습니다.
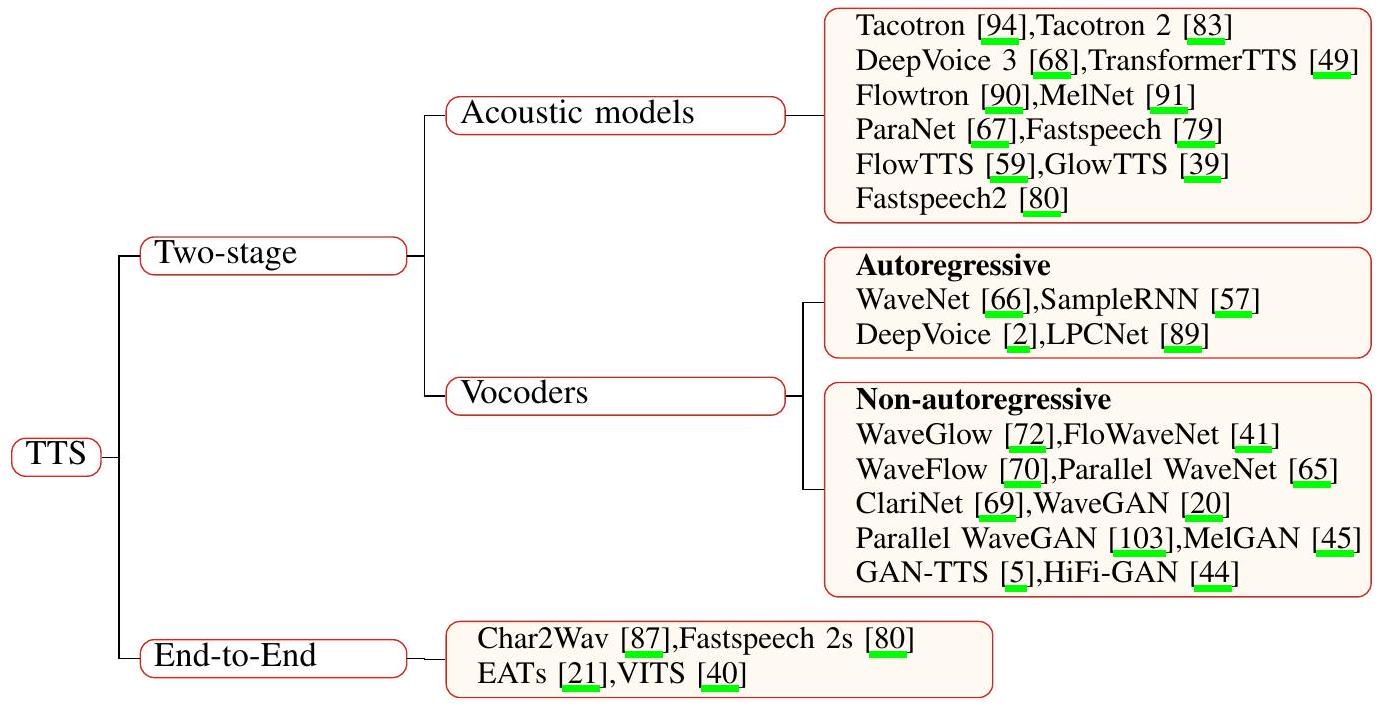
Figure 2: A taxonomy of TTS.
2.2 End-to-End methods
엔드투엔드 TTS 모델은 중간 표현 없이 입력 텍스트 또는 음소 시퀀스를 음성 오디오 파형으로 직접 변환할 수 있으며 이러한 종류의 프레임워크는 많은 간단한 확장을 허용합니다. 완전한 엔드투엔드 모델은 훈련 및 참조의 시간 비용을 줄일 수 있을 뿐만 아니라 캐스케이드 모델에서의 오류 전파를 피할 수 있습니다. 또한, 데이터셋에서 더 적은 인간 주석을 필요로 합니다. 그러나 이러한 장점에는 도전 과제가 따릅니다. 첫 번째는 텍스트와 파형의 모달리티 간의 큰 차이입니다. 예를 들어, 텍스트와 파형의 시간 해상도는 매우 다릅니다. 발화 중 평균적으로 초당 5개의 단어가 있지만, 해당 음소 시퀀스의 길이는 약 20에 불과합니다. 그러나 음성 오디오의 샘플 속도는 보통 16000Hz 이상으로 높습니다. 시간 해상도의 극심한 차이로 인해 텍스트-오디오 상관 관계를 모델링하기가 어렵습니다. 그리고 오디오의 높은 시간 해상도로 인해 메모리 요구량이 높습니다. 게다가, 정렬된 중간 표현의 부족으로 텍스트와 오디오 간의 정렬이 더 어려워집니다. 이러한 도전에 대응하여 연구자들은 우수한 성능을 달성하는 다양한 엔드투엔드 TTS 네트워크를 설계했습니다. Char2Wav [87]는 RNN을 기반으로 한 최초의 엔드투엔드 모델이며, 보고된 이후 다양한 엔드투엔드 솔루션이 등장했습니다. Fastspeech 2s [80]는 피드-포워드 Transformer [92] 블록과 1D-컨볼루션을 인코더와 디코더의 기본 구조로 사용하는 GAN 기반 비자기회귀 모델입니다. 또한, 일대다 문제를 처리하고 텍스트와 음성의 정렬을 용이하게 하기 위해 분산 어댑터가 설계되었습니다. EATs [21]는 Fastspeech 2s와 같은 GAN 기반 비자기회귀 엔드투엔드 TTS 모델입니다. 잘 설계된 정렬기는 입력 음소 시퀀스에서 정렬된 표현을 얻고 이를 원시 오디오 파형으로 디코딩하는 전체 프레임워크의 핵심 부분입니다. 일대다 문제를 해결하기 위해 동적 시간 왜곡이 적용됩니다. VITS [40]는 flow와 Variational Autoencoder(VAE) [42]를 기반으로 한 TTS 모델로, Monotonic Alignment Search(MAS) [39]와 확률적 지속 시간 예측기를 채택하여 각각 정렬 문제와 일대다 문제를 해결하고 최첨단 성능을 달성합니다. 우수한 성능을 가진 많은 2단계 TTS 모델이 있었지만, 엔드투엔드 모델은 그 효율성과 정확성 때문에 최근 몇 년 동안 뜨거운 연구 주제가 되었습니다. 따라서, 고효율 엔드투엔드 모델은 TTS 분야의 미래 연구 동향이 될 것입니다.
3 Music generation
최근 몇 년 동안, 연구자들은 인공지능을 활용하여 이미지, 텍스트, 비디오와 같은 현실적이고 미적인 작품을 생성하려고 시도하기 시작했습니다. 음악은 실제 생활에서 인간의 감정을 반영하는 예술입니다. 알고리즘 작곡을 위한 컴퓨터 기술의 사용은 지난 세기로 거슬러 올라갑니다. 딥러닝 기술의 발전과 함께, 딥 뉴럴 네트워크로 음악을 생성하는 것은 유행하는 연구 주제가 되었습니다. 딥러닝 기술을 사용하여 음악을 생성하는 것은 의미가 있습니다. 생활 속에서 음악 이론 지식이 전혀 없는 사람들도 이 기술을 사용하여 자신을 편안하게 할 음악을 생성할 수 있습니다. 상업 분야에서는 이 기술을 통해 낮은 시간 및 경제적 비용으로 대규모 맞춤형 음악 생성을 실현할 수 있습니다. 또한, 신경망 기반 음악 생성 기술은 교육, 의료 및 기타 분야에서 넓은 전망을 가지고 있습니다. 따라서, 이는 유망한 연구 주제입니다. 이미지 생성 및 텍스트 생성과 달리, 음악 생성은 독특한 과제를 가지고 있습니다. 첫째, 음악은 시간의 예술입니다 [23]. 음악은 계층적이며, 한 곡의 음악 내에는 일반적으로 장기 및 단기 의존성이 있습니다. 따라서 음악의 계층적 구조와 시간적 의존성은 잘 모델링되어야 합니다. 둘째, 음악은 보통 여러 트랙과 악기로 구성됩니다. 자연스럽고 즐거운 음악을 생성하기 위해서는 다른 트랙과 악기를 유기적으로 구성해야 합니다. 셋째, 음악에는 화음과 멜로디가 있으며, 이는 특정 순서로 배열된 일련의 음표로 구성됩니다. 화음과 멜로디의 형성은 음악 생성에서 중추적인 역할을 합니다. 요약하자면, 위에서 언급한 세 가지 점은 음악 생성을 위한 신경망 구조를 설계할 때 신중하게 고려되어야 합니다.
신경망 기반 음악 생성의 현재 연구 현황을 바탕으로, 음악 생성 접근 방식은 상징적 음악 생성과 오디오 음악 생성의 두 가지 클래스로 나눌 수 있습니다. 상징적 음악 생성은 음악이 음높이, 길이, 악기 등의 정보를 지정하는 음표 시퀀스의 형태로 상징적으로 생성되는 것을 의미합니다. 이러한 음표들은 더 나아가 멜로디와 코드를 구성하고 생성된 음악은 최종적으로 미디 형식으로 저장됩니다. 이 접근법을 활용하면, 음악을 저차원 공간에서 모델링할 수 있어 음악 생성 작업의 난이도를 크게 줄일 수 있습니다. 또한, 음악은 일련의 음악적 이벤트로 구성되므로 거친 노이즈가 도입되지 않습니다. 오디오 음악 생성의 경우, 음악이 오디오 샘플 포인트 수준에서 생성되는 것을 의미합니다. 음악 오디오 파형의 샘플링 속도는 보통 44100Hz입니다.
따라서, 오디오 음악 생성의 핵심 병목 현상은 이렇게 높은 시간 해상도에서 장기 및 단기 의존성을 모델링하는 것입니다. 이 접근 방식에는 몇 가지 장점이 있습니다. 첫째, 음악의 원시 오디오 파형을 직접 생성하면 데이터셋의 복잡한 인간 주석을 대량으로 피할 수 있습니다. 둘째, 오디오 음악 생성은 여러 특정 악기에 국한되지 않고 전례 없는 소리, 심지어 가수의 목소리까지 생성할 수 있습니다. 아래에서 이 두 가지 접근 방식과 관련된 연구 작업을 각각 소개하겠습니다.
3.1 Symbolic music generation
상징적 음악 생성은 모델이 음표, 악기, 음높이, 길이와 같은 일련의 음악적 이벤트를 생성하고 이를 미디 형식의 음악으로 구성하는 것을 의미합니다. 오늘날, 신경망 기반의 일부 상징적 음악 생성 모델이 제안되었으며, 이는 네트워크 구조에 따라 RNN 기반 모델과 CNN 기반 모델의 두 종류로 나눌 수 있습니다. 아래에서 이 두 종류 각각의 몇 가지 대표적인 모델을 제시하겠습니다.
RNN 기반 모델 지금까지 상징적 도메인 음악의 많은 우수한 생성 모델이 제안되었습니다. DeepBach [33]는 매우 자연스러운 바흐 스타일의 합창곡을 생성할 수 있는 RNN 기반 모델입니다. Song from PI [12]는 드럼, 코드, 프레스, 키에 각각 해당하는 다른 레이어를 가진 4계층 계층적 RNN 모델로, 상징적 팝 음악을 생성합니다. C-RNN-GAN [60]은 GAN [30]을 사용한 최초의 상징적 도메인 음악 생성 모델입니다. 이 모델의 생성기와 판별기에서 사용되는 순환 신경망은 상징적 음악의 장기 의존성을 모델링하기 위해 장단기 기억(LSTM) [37] 네트워크입니다. HRNN [97]은 3계층 계층적 RNN 모델로, 다른 계층적 레이어에서 마디 프로필, 비트 프로필 및 음표를 출력하여 높은 수준에서 낮은 수준으로 음악을 모델링합니다. MusicVAE [81]는 VAE [42]를 기반으로 한 모델입니다. 이 연구는 장기 의존성을 가진 시퀀스를 모델링하는 어려움을 해결하기 위해 새로운 순차적 오토인코더와 계층적 순환 디코더를 도입했습니다. RNN 기반 상징적 음악 생성 모델의 대부분이 음악의 장기 및 단기 구조를 모델링하기 위해 일종의 계층적 구조를 설계한다는 것을 어렵지 않게 알 수 있습니다.
CNN 기반 모델 현재 제안된 CNN 기반 상징적 음악 생성 모델은 일반적으로 GAN을 활용합니다. 이러한 프레임워크는 GAN 네트워크의 판별기와 생성기 구조로 컨볼루션 신경망을 채택했습니다. MidiNet [104]은 CNN을 핵심 구조로 하는 최초의 GAN 기반 모델입니다. MidiNet은 1차원 조건과 2차원 조건이라는 두 가지 조건부 입력을 교묘하게 추가합니다. 구체적으로, 1차원 조건은 생성의 코드를 조건으로 하는 데 사용되는 반면, 2차원 조건은 현재 마디를 조건으로 하기 위한 이전에 생성된 마디입니다. 이 두 조건의 도입은 생성된 음악의 자연스러움과 연속성을 향상시킵니다. MuseGAN [23]은 다중 트랙 시퀀스 생성을 위한 GAN 기반 모델입니다. 이 모델은 Jamming 모델, Composer 모델, Hybrid 모델의 세 가지 GAN 모델을 제안했습니다. 또한, 시간적 관계를 모델링하기 위한 두 가지 모델도 제안되었습니다. MuseGAN은 앞서 언급한 모델들을 결합하여 높은 성능을 달성합니다. Binary MuseGAN [22]은 MuseGAN을 개선하여, 하드 임계값 처리나 베르누이 샘플링과 같은 후처리 방법을 사용하는 대신 이진 출력을 달성하기 위해 생성기에 추가적인 정제기를 추가할 것을 제안했습니다. 제안된 정제기는 생성된 음악의 성능을 향상시키는 데 유익한 것으로 입증되었습니다. RNN 기반 모델과 비교할 때, CNN 기반 모델의 계산 비용은 보통 더 낮습니다. 결과적으로, CNN 기반 상징적 도메인 음악 생성 모델은 더 편리하게 훈련될 수 있습니다.
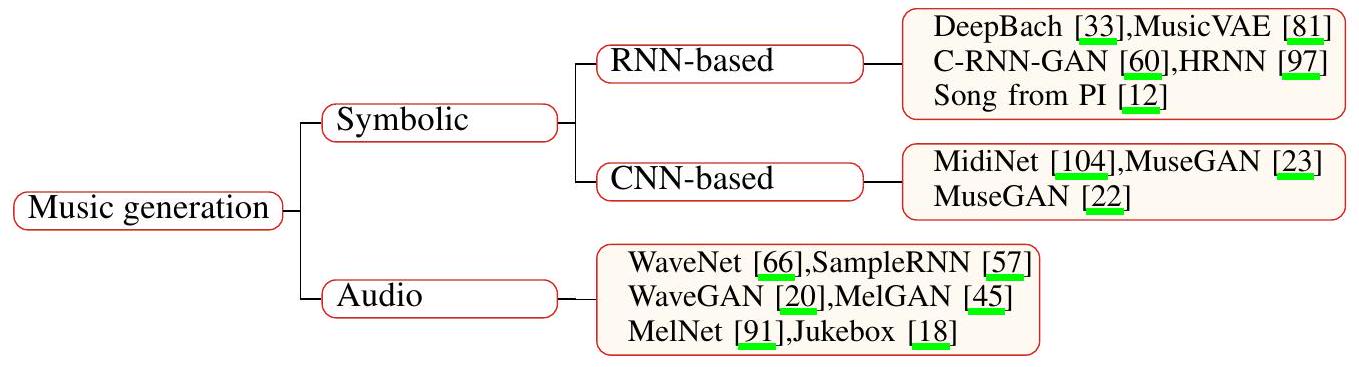
Figure 3: A taxonomy of music generation.
3.2 Audio music generation
상징적 음악 생성과 달리, 오디오 음악 생성 접근 방식은 원시 오디오 샘플 포인트 수준에서 직접 음악을 생성하므로 더 다양한 음악과 심지어 보컬까지 생성할 수 있습니다. 지금까지 오디오 음악 생성을 위한 모델의 핵심 구조에는 CNN과 GAN이 포함되지만 이에 국한되지는 않습니다. 다음에서는 오디오 음악 생성을 위한 몇 가지 신경망 기반 모델을 소개하겠습니다. TTS 작업에 사용되는 여러 모델, 예를 들어 WaveNet, WaveGAN, MelGAN, MelNet 및 SampleRNN [66, 20, 45, 91, 57]은 원시 오디오 도메인에서 음악을 생성하는 능력도 갖추고 있다는 점에 유의해야 합니다. WaveNet [66]은 다중 화자 음성 생성, TTS, 음악 생성 및 음성 인식과 같은 작업을 수행할 수 있는 다재다능한 모델입니다. 음악 생성 측면에서 WaveNet은 확장된 인과적 컨볼루션 레이어를 채택하여 수용 필드를 확대하는데, 이는 음악처럼 들리는 샘플을 얻는 데 중요합니다. SampleRNN [57]은 계층적 RNN 구조 덕분에 원시 오디오 샘플 포인트 수준에서 베토벤 스타일의 피아노 소나타를 생성할 수 있습니다. WaveGAN [20]은 DCGAN [76]의 구조를 개선하여 피아노 및 드럼과 같은 일부 악기의 소리를 생성합니다. MelGAN [45]은 멜-스펙트로그램을 디코딩하여 음악 생성을 실현하는 GAN 기반 모델입니다. MelNet [91]은 주파수 도메인에서 음악을 위한 생성 모델로, RNN을 기반으로 합니다. Jukebox [18]는 VQ-VAE [78]를 기반으로 한 오디오 음악 생성 전용 모델입니다. Jukebox는 매우 강력하여 가수의 보컬까지 합성할 수 있습니다. 원시 오디오의 긴 컨텍스트를 다루기 위해 연구자들은 서로 다른 시간 척도를 가진 세 개의 개별 VQ-VAE 모델을 사용하고 자기회귀 Transformer를 인코더와 디코더의 핵심 구성 요소로 만듭니다. 따라서 Jukebox는 원시 오디오 도메인에서 수 분까지 일관성을 유지하며 고충실도의 다양한 노래를 생성할 수 있습니다. 그러나 그 대가로 너무 많은 계산 비용이 필요합니다. 주크박스 모델 하나를 훈련시키는 데는 수백 개의 GPU가 몇 주 동안 병렬로 훈련되어야 합니다. 마찬가지로, 추론에도 많은 시간과 GPU가 소요됩니다.
원시 오디오 도메인에서의 음악 생성에 대한 연구는 적지만, 이 분야는 연구자들로부터 점점 더 많은 관심을 받고 있습니다. 오디오 음악 생성 모델은 사전 음악 이론과 다수의 인간 주석을 필요로 하지 않을 뿐만 아니라, 더 다양한 음악과 심지어 가수의 보컬까지 모델링할 수 있습니다. 그러나 이러한 모델에 의해 생성된 음악에 수반되는 오디오 노이즈와 스크래치는 우리가 무시할 수 없는 부분입니다. 미래에는 오디오 음악 생성 모델의 노이즈 감소와 계산 비용 절감에 더 많은 노력을 기울여야 할 것입니다.
4 Audio-visual multimodal processing
오디오-비주얼 멀티모달 처리는 음향 및 시각 정보의 저차원 특징을 정확하게 추출한 다음, 두 특징 간의 상관 관계를 모델링하여 립리딩과 같은 일부 작업을 달성하는 것을 의미합니다. 컴퓨터에게 이러한 문제를 해결하는 것은 오디오와 비디오 간의 이질성 때문에 여전히 큰 도전입니다. 오디오와 시각 모달리티는 차원 및 시간 해상도와 같은 여러 측면에서 서로 매우 다릅니다. 이 리뷰에서는 오디오-비주얼 멀티모달 처리와 관련된 네 가지 작업인 립리딩, 오디오-비주얼 음성 분리, 말하는 얼굴 생성 및 비디오에서 소리 생성에 중점을 둡니다. 이들은 아래에서 종합적으로 소개되고 요약될 것입니다.
4.1 Lipreading
립리딩(Lipreading)은 소리 없는 비디오에서 무슨 말이 오가는지를 인식하는 인상적인 기술이며, 인간이 수행하기에는 악명 높게 어려운 작업입니다. 연구자들은 최근 몇 년 동안 딥러닝 기술을 활용하여 립리딩 작업을 처리하는 모델을 훈련시킵니다. 구체적으로, 신경망 기반 립리딩 모델은 소리 없는 얼굴(입술) 비디오를 입력으로 받아 해당 음성 오디오나 문자를 출력합니다. 자동 립리딩 모델에 대한 몇 가지 응용 프로그램이 떠오릅니다: 시끄러운 환경 내에서 화상 회의를 가능하게 하고, 감시 비디오를 원거리 청취 장치로 사용하며, 시끄러운 파티에서 사람들 간의 대화를 용이하게 하는 것 등입니다 [24]. 결과적으로, 우리 일상 생활에 편의를 가져다주는 자동 립리딩 모델을 개발하는 것은 의미가 있습니다. 고성능의 여러 신경망 기반 립리딩 모델이 아래에 소개될 것입니다. WLAS [15]는 오디오 유무에 관계없이 입술 움직임 비디오를 문자로 변환할 수 있는 립리딩 모델입니다. CNN, LSTM [37] 및 Attention 메커니즘이 입술 비디오와 오디오 간의 상관 관계를 모델링하여 문자를 생성하는 데 채택되었습니다. LRS 데이터셋도 이 연구에서 제안되었습니다. LiRA [56]는 자기 지도 모델로, 사전 훈련 단계에서 입술 이미지 시퀀스와 오디오 파형을 각각 고차원 표현으로 투영하고 그들 사이의 손실을 계산한 다음, 모델을 미세 조정하여 단어 수준 및 문장 수준 립리딩을 달성합니다. Ephrat 등 [25]은 이 작업을 음향 회귀 문제로 모델링하는 것이 시각-텍스트 모델링보다 많은 이점을 가지고 있다고 제안했습니다. 예를 들어, 인간의 감정은 음향 신호로 표현될 수 있습니다. Vid2Speech [24]는 얼굴 이미지 시퀀스를 입력으로 받아 해당 음성 원시 오디오 파형을 출력하는 CNN 기반 모델입니다. [25]는 2-타워 CNN 기반 모델을 제안했습니다. 한 타워는 얼굴 그레이스케일 이미지를 입력하고 다른 타워는 얼굴 이미지 프레임 간에 계산된 광학 흐름을 입력합니다. 또한, 이 모델은 오디오 파형의 표현으로 멜-스케일 스펙트로그램과 선형-스케일 스펙트로그램을 모두 채택합니다. [3, 15] 또한 립리딩 작업을 위한 모델을 제안했습니다.
4.2 Audio-visual speech separation
인간은 시끄러운 환경 속에서 단일 음원에 청각적 주의를 집중할 수 있는 능력이 있으며, 이를 "칵테일 파티 효과"라고도 합니다. 최근 몇 년 동안 칵테일 파티 문제는 컴퓨터 음성 인식 분야에서 대표적인 문제가 되었습니다. 입력된 오디오 신호를 개별 음원으로 분리하는 것이 자동 음성 분리의 정의입니다. Ephrat 등 [26]은 화자의 얼굴을 보는 것이 모델이 인지된 모호성을 해결하는 능력을 향상시키기 때문에 오디오-비주얼 음성 분리가 오디오 전용 음성 분리보다 더 높은 성능을 달성할 수 있다고 제안했습니다. 자동 음성 분리는 청각 장애인을 위한 보조 기술 및 시끄러운 회의 시나리오를 위한 헤드 마운트 보조 장치와 같은 많은 응용 분야를 가지고 있습니다. 이 섹션에서는 오디오-비주얼 음성 분리에 중점을 두고 관련 연구의 양을 아래에 소개합니다. [26]은 화자 독립적인 오디오-비주얼 음성 분리에 대한 최초의 시도로, 입력된 얼굴 이미지와 음성 오디오 스펙트로그램을 인코딩하고 음성 분리를 위한 복소 마스크를 출력하는 CNN 기반 모델을 제안했습니다. 또한 이 연구에서는 AVspeech 데이터셋도 제안되었습니다. AV-CVAE [64]는 VAE [42]를 기반으로 한 오디오-비주얼 음성 분리 모델로, 화자의 입술 움직임을 감지하고 개별적으로 분리된 음성 오디오를 예측합니다. Acapella [61]는 오디오-비주얼 노래 분리를 위한 것입니다. 아키텍처는 Y-Net이라고 불리는 2-스트림 CNN으로, 각각 오디오와 비디오를 처리합니다. Y-Net은 복소 스펙트로그램과 입술 영역 프레임을 입력으로 받아 복소 마스크를 출력합니다. 또한, 솔로 노래 비디오의 대규모 데이터셋도 제안되었습니다. VisualSpeech [29]는 얼굴 이미지, 입술 움직임의 이미지 시퀀스 및 혼합된 오디오를 입력으로 받아 복소 마스크를 출력합니다. 또한 오디오 및 시각 모달리티의 정보를 더욱 연관시키기 위해 교차 모달 임베딩 공간을 혁신적으로 제안했습니다. Facefilter [16]는 정지 이미지를 시각 정보로 사용하며 [1,27] 또한 오디오-비주얼 음성 분리 작업을 위한 방법을 제안했습니다.
4.3 Talking face generation
말하는 얼굴 생성은 대상 얼굴 이미지와 임의의 음성 오디오 클립이 주어졌을 때, 주어진 음성을 입술 동기화와 함께 말하는 대상 캐릭터의 자연스러운 말하는 얼굴을 생성하는 것을 의미합니다. 동시에, 얼굴 이미지의 부드러운 전환이 보장되어야 합니다. 이는 활발한 주제가 되어온 신선하고 흥미로운 작업입니다. 말하는 얼굴을 생성하는 것은 지속적으로 변화하는 얼굴 영역이 시각적 정보(주어진 얼굴 이미지)뿐만 아니라 음향 정보(주어진 음성 오디오)에도 의존하고, 입술-음성 동기화를 달성해야 하기 때문에 어렵습니다. 동시에, 원격 회의, 특정 얼굴 움직임을 가진 가상 캐릭터 생성, 음성 이해 향상과 같은 많은 잠재적 응용 분야가 있습니다. 말하는 얼굴 생성 작업과 관련된 많은 연구가 아래에 소개될 것입니다.
이전의 노력에서, 연구들은 특정 얼굴의 3D 모델링을 수행한 다음, 3D 메시를 조작하여 말하는 얼굴을 생성했습니다. 그러나 이 방법은 시간이 많이 걸리는 3D 모델링에 크게 의존하며, 임의의 정체성으로 확장될 수 없습니다. 우리가 아는 한, [14]는 말하는 얼굴 생성을 위해 심층 생성 모델을 사용한 첫 번째 연구입니다. DAVS [110]는 말하는 얼굴 생성을 위한 엔드투엔드 훈련 가능한 심층 신경망입니다. 이 네트워크는 먼저 공동 오디오-비주얼 표현을 학습한 다음, 잠재 공간 분리를 실현하기 위해 적대적 훈련 전략을 사용합니다. [8]은 ATVGnet을 제안했으며, 그 아키텍처는 음향 및 시각 정보를 각각 처리하기 위해 오디오 변환 네트워크(AT-net)와 시각 생성 네트워크(VG-net)의 두 부분으로 나눌 수 있습니다. 또한, 회귀 기반 판별기와 주의 메커니즘을 갖춘 새로운 동적 조절 가능한 픽셀 단위 손실이 제안되었습니다.
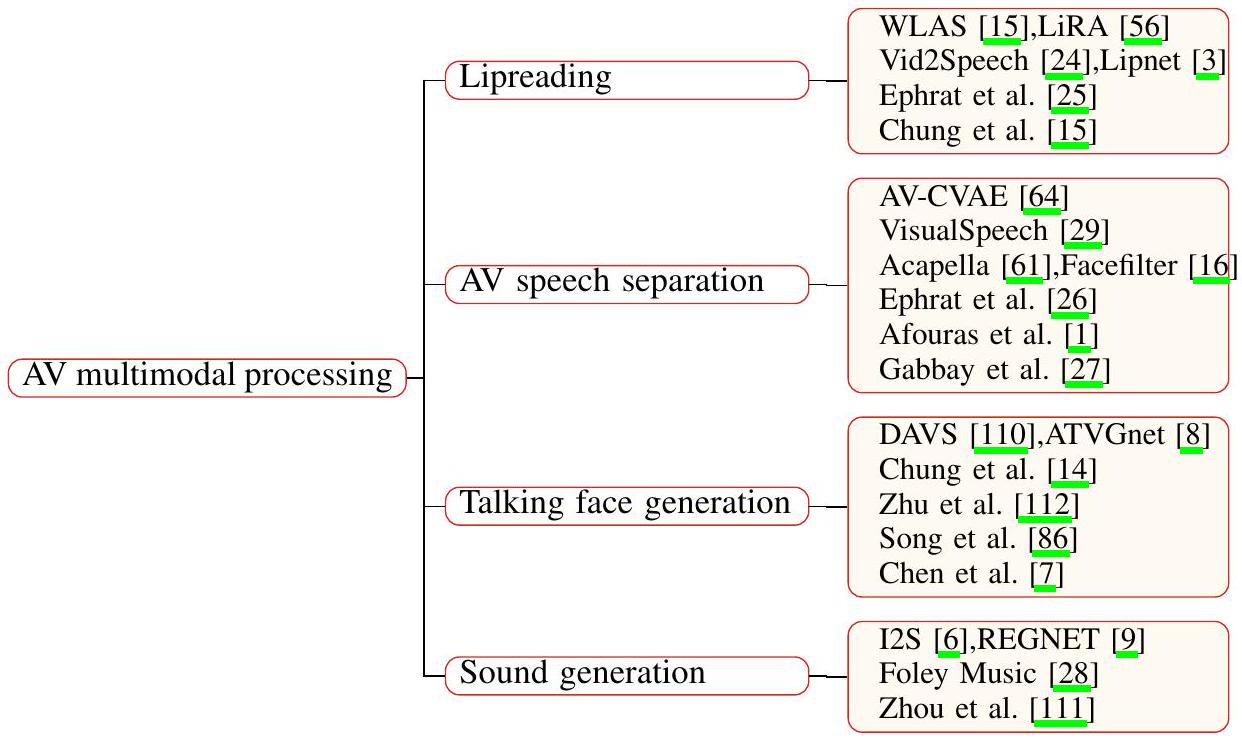
Figure 4: A taxonomy of audio-visual multimodal processing. 112]는 비대칭 상호 정보 추정기를 통해 오디오-비주얼 일관성을 발견하는 새로운 말하는 얼굴 생성 프레임워크를 제안했습니다. [86, 7]도 각각 말하는 얼굴 생성을 위한 방법을 제안했습니다.
4.4 Sound generation from video
시각과 청각은 인간이 주변 환경을 인지하는 데 있어 틀림없이 가장 중요한 두 채널이며, 종종 서로 밀접하게 연관되어 있습니다. 자연 환경에 대한 장기간의 관찰을 통해 사람들은 오디오와 비전 사이의 연관성을 배울 수 있습니다. 최근 몇 년 동안 연구자들은 학습 가능한 네트워크를 활용하여 이를 달성하려고 시도했습니다. 비디오에서 자동으로 소리를 생성하는 것은 많은 응용 시나리오가 있습니다. 예를 들어, 자동으로 생성된 소리와 비디오를 결합하여 가상 현실의 환경을 향상시키거나, 비디오에 배경 음향 효과를 자동으로 추가하여 많은 수작업을 피하는 것 등입니다. 몇 가지 관련 연구가 아래에 소개될 것입니다. [6]은 심층 생성 신경망을 활용하여 오디오-비주얼 멀티모달 생성 문제를 해결하려는 최초의 시도입니다. CNN과 GAN을 기반으로 한 I2S와 S2I라는 두 모델이 제안되었습니다. 이 두 모델은 각각 사운드-이미지 및 이미지-사운드 생성 작업을 수행합니다. 또한, 이 논문의 실험 부분에서는 원시 오디오 파형의 다섯 가지 표현에 대한 해당 생성 결과를 비교했습니다. [111]에서는 SampleRNN [57] 스타일 모델이 사운드 생성기로 채택되었고, 비디오 인코더의 세 가지 변형이 제안되고 비교되었습니다. 10개 카테고리에 걸쳐 28109개의 정리된 비디오를 포함하는 VEGAS 데이터셋도 공개되었습니다. Foley Music [28]은 비디오에서 MIDI 음악을 생성하는 법을 배우는 Graph-Transformer 기반 프레임워크입니다. 신체 및 손의 키 포인트를 감지하여 달성된 신체 움직임을 포착하기 위해 인간 포즈 특징이 추출되었습니다. Transformer 스타일 디코더도 채택되었습니다. REGNET은 [9]에 의해 제안되었으며, 주어진 비디오에서 정렬된 사운드를 생성하기 위해 정보 병목 현상을 도입했습니다. 위에서 언급한 작업 외에도, 음향 및 시각 정보 간의 연결을 활용하여 멀티모달 학습 방법은 오디오에서 얼굴 재구성, 감정 인식, 화자 식별과 같은 광범위한 흥미로운 작업을 탐구합니다. 미래에는 오디오-비주얼 멀티모달 처리가 딥러닝 분야 내의 연구자들로부터 더 많은 주목을 받을 것입니다.
5 Datasets
이 섹션에서는 TTS, 음악 생성 및 오디오-비주얼 멀티모달 처리 영역에서 널리 채택되는 몇 가지 데이터셋을 각각 제시합니다.
5.1 Datasets for TTS
LJ speech LJ speech 데이터셋 [38]은 단일 화자가 7권의 논픽션 책에서 발췌한 구절을 읽는 13,100개의 짧은 오디오 클립으로 구성된 공개 음성 데이터셋으로 총 길이는 약 24시간입니다. 클립의 길이는 1초에서 10초까지 다양합니다. 오디오 형식은 16비트 PCM이며 오디오의 샘플 속도는 22kHz입니다.
VCTK VCTK 데이터셋 [102]은 서로 다른 억양을 가진 110명의 영어 화자가 발화한 음성 데이터를 포함합니다. 각 화자는 신문, 무지개 구절 및 음성 억양 아카이브에 사용된 유도 단락에서 약 400개의 문장을 읽습니다. 오디오 형식은 16비트 PCM이며 샘플 속도는 44kHz입니다.
LibriTTS corpus LibriTTS 데이터셋 [109]은 약 585시간의 읽기 영어 음성으로 구성된 다중 화자 영어 코퍼스이며 샘플 속도는 24kHz입니다. 음성은 문장 중단점에서 분할되며 정규화된 텍스트와 원본 텍스트가 모두 포함됩니다. 또한 상당한 배경 소음이 있는 발화는 제외되고 문맥 정보를 추출할 수 있습니다.
Blizzard Blizzard [71]는 음성 합성 작업을 위한 데이터셋으로, 단일 여성 배우가 315시간 동안 영어 읽기 음성을 녹음한 것으로 구성됩니다. 오디오 형식은 16비트 PCM이며 샘플 속도는 16kHz입니다.
5.2 Datasets for music generation
Lakh MIDI Dataset The Lakh MIDI Dataset [77]은 176,581개의 고유한 미디 형식 파일 모음입니다. 이 데이터셋의 45,129개 파일은 Million Song Dataset [4]의 항목과 일치하고 정렬되었습니다. Lakh MIDI 데이터셋의 목표는 상징적 및 오디오 콘텐츠 기반의 대규모 음악 정보 검색을 용이하게 하는 것입니다.
Lakh Pianoroll Dataset The Lakh Pianoroll Dataset [23]은 Lakh MIDI 데이터셋에서 파생된 174,154개의 다중 트랙 피아노롤로 구성됩니다.
MAESTRO MAESTRO [35]는 10년간의 국제 피아노-e-경연대회에서 얻은 200시간 분량의 오디오 및 MIDI 녹음 쌍으로 구성된 데이터셋입니다. 오디오 및 MIDI 파일은 약 3ms 정확도로 정렬되고 개별 작품으로 분할됩니다. 비압축 오디오는 CD 품질 이상을 달성할 수 있으며 오디오 형식은 샘플 속도 의 16비트 PCM입니다.
Figure 5: A taxonomy of datasets.
5.3 Datasets for audio-visual multimodal processing
GRID GRID 오디오-비주얼 문장 코퍼스 [17]는 34명의 화자가 말하는 1000개의 문장을 포함하는 오디오 및 얼굴 비디오의 대규모 데이터셋입니다. 화자는 남성 18명과 여성 16명으로 구성됩니다. 각 문장은 6단어 시퀀스로 구성되며 이 데이터셋의 총 어휘는 51개입니다.
LRW LRW 데이터셋 [13]은 수백 명의 다른 화자가 말한 500개의 다른 단어를 포함하는 약 1000개의 발화로 구성됩니다. 데이터셋의 모든 비디오는 길이가 29프레임(1.16초)이며 단어는 비디오의 중간에 나타납니다. 데이터셋은 훈련 세트, 검증 세트 및 테스트 세트로 나뉩니다.
TCD-TIMID TCD-TIMID 데이터셋 [34]은 오디오-비디오 음성 처리 연구에서 널리 사용되며, 약 60명의 화자로부터의 고품질 오디오-비디오 발화로 구성됩니다. 모든 화자는 98개의 문장을 발화합니다.
LRS LRS 데이터셋 [15]은 시각적 음성 인식을 위한 데이터셋으로, 영국 텔레비전에서 가져온 100,000개 이상의 자연스러운 문장으로 구성됩니다.
VoxCeleb VoxCeleb 데이터셋 [63]은 1251명의 유명인에 대한 100,000개 이상의 발화를 포함하는 대규모 텍스트 독립적인 화자 식별 데이터셋입니다. 비디오는 유튜브 웹사이트에서 추출되었습니다. 화자는 다양한 인종, 억양, 연령 및 직업을 포함하며 성별 분포가 균형을 이룹니다. 오디오 형식은 16비트 PCM이며 샘플 속도는 16kHz입니다.
6 Conclusion
이 리뷰에서는 오디오 합성과 오디오-비주얼 멀티모달 처리에 대한 연구에 주목했습니다. 오디오 합성 분야의 유지에 중요한 역할을 하는 텍스트 음성 변환(TTS)과 음악 생성 작업을 각각 종합적으로 요약했습니다. TTS 작업에서는 2단계 및 엔드투엔드 방법을 구별하여 소개했습니다. 음악 생성 작업에 대해서는 상징적 도메인과 원시 오디오 도메인 생성 모델을 각각 제시했습니다. 오디오-비주얼 멀티모달 처리 분야에서는 립리딩, 오디오-비주얼 음성 분리, 말하는 얼굴 생성, 비디오에서 소리 생성이라는 네 가지 대표적인 작업에 중점을 두었습니다. 이러한 작업과 관련된 프레임워크를 소개했습니다. 마지막으로, 널리 채택되는 몇 가지 데이터셋도 제시했습니다. 전반적으로, 이 리뷰는 관련 연구자들에게 상당한 지침을 제공합니다.
References
[1] Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman. The conversation: Deep audio-visual speech enhancement. arXiv preprint arXiv:1804.04121, 2018. [2] Sercan Ö Arık, Mike Chrzanowski, Adam Coates, Gregory Diamos, Andrew Gibiansky, Yongguo Kang, Xian Li, John Miller, Andrew Ng, Jonathan Raiman, et al. Deep voice: Real-time neural text-to-speech. In International Conference on Machine Learning, pages 195-204. PMLR, 2017. [3] Yannis M Assael, Brendan Shillingford, Shimon Whiteson, and Nando De Freitas. Lipnet: End-to-end sentence-level lipreading. arXiv preprint arXiv:1611.01599, 2016. [4] Thierry Bertin-Mahieux, Daniel PW Ellis, Brian Whitman, and Paul Lamere. The million song dataset. 2011. [5] Mikołaj Bińkowski, Jeff Donahue, Sander Dieleman, Aidan Clark, Erich Elsen, Norman Casagrande, Luis C Cobo, and Karen Simonyan. High fidelity speech synthesis with adversarial networks. In International Conference on Learning Representations, 2019. [6] Lele Chen, Sudhanshu Srivastava, Zhiyao Duan, and Chenliang Xu. Deep cross-modal audiovisual generation. In Proceedings of the on Thematic Workshops of ACM Multimedia 2017, pages 349-357, 2017. [7] Lele Chen, Zhiheng Li, Ross K Maddox, Zhiyao Duan, and Chenliang Xu. Lip movements generation at a glance. In Proceedings of the European Conference on Computer Vision (ECCV), pages 520-535, 2018. [8] Lele Chen, Ross K Maddox, Zhiyao Duan, and Chenliang Xu. Hierarchical cross-modal talking face generation with dynamic pixel-wise loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7832-7841, 2019.