Whisper-Flamingo: 시각 정보를 활용한 Whisper의 진화, 시청각 음성 인식 및 번역
Whisper-Flamingo는 Flamingo 모델에서 영감을 받아 기존 Whisper 모델에 Gated Cross Attention을 사용하여 시각적 특징(입술 움직임)을 통합하는 새로운 오디오-비주얼 음성 인식(AVSR) 모델입니다. 이 모델은 잡음이 많은 환경에서 오디오 전용 Whisper보다 뛰어난 성능을 보이며, LRS3 및 LRS2 데이터셋에서 최첨단(SOTA) 성능을 달성했습니다. 또한, 단일 모델로 영어 음성 인식과 6개 언어로의 번역 작업을 모두 수행할 수 있는 다재다능함을 보여줍니다. 논문 제목: Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
논문 요약: Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
- 논문 링크: arXiv:2406.10082
- 저자: Andrew Rouditchenko 외 (MIT, IBM Research AI, MIT-IBM Watson AI Lab, University of Bonn)
- 발표 시기: 2024년 (arXiv preprint)
- 주요 키워드: AVSR, 음성 인식, 음성 번역, 잡음 강인성, 멀티모달, 대규모 음성 모델
1. 연구 배경 및 문제 정의
- 문제 정의: 자동 음성 인식(ASR) 모델은 대규모 데이터 학습으로 성능이 크게 향상되었지만, 잡음이 많은 환경에서는 여전히 성능이 저하됩니다. 이를 개선하기 위해 입술 움직임과 같은 시각 정보를 활용하는 시청각 음성 인식(AVSR)이 제안되었으나, 비디오 데이터는 오디오 데이터(예: Whisper의 수십만 시간)에 비해 수천 시간 수준으로 매우 제한적이라는 한계가 있습니다. 이로 인해 AVSR 모델의 비디오 학습 데이터가 부족하여 강력한 텍스트 디코더를 학습하기 어렵습니다.
- 기존 접근 방식: 기존 연구들은 수십만 시간의 오디오로 사전 학습된 오디오 전용 모델을 AVSR에 파인튜닝하는 방식을 사용했습니다. 그러나 이러한 방법들은 비디오 모델과 텍스트 디코더를 제한된 수백 시간의 비디오 데이터만으로 처음부터 학습시키는 경우가 많아 대규모 데이터 학습에 비해 성능이 떨어지며, 주로 영어 데이터에만 국한되어 있었습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- Whisper 모델에 AV-HuBERT의 시각적 특징을 효과적으로 통합하여 잡음이 많은 환경에서 오디오 전용 Whisper보다 훨씬 뛰어난 성능을 달성했습니다.
- 단일 모델 파라미터 세트로 영어 음성 인식과 6개 언어(그리스어, 스페인어, 프랑스어, 이탈리아어, 포르투갈어, 러시아어)로의 영어-X 번역 작업을 모두 수행할 수 있는 다재다능함을 보여주었습니다. 이는 각 언어에 대해 별도로 학습해야 했던 이전 방법들과 차별화됩니다.
- LRS3 및 LRS2 데이터셋에서 최첨단(SOTA) ASR 및 AVSR 성능을 달성했습니다.
- 제안 방법:
논문은 Flamingo 모델에서 영감을 받아 Gated Cross Attention 메커니즘을 사용하여 Whisper의 디코더에 시각적 특징을 통합하는 Whisper-Flamingo를 제안합니다.
- Gated Cross Attention: Whisper 디코더의 각 블록 시작 부분(self-attention 레이어 앞)에 Gated Cross Attention 레이어를 삽입합니다. 이 레이어는 학습 가능한 파라미터()를 0으로 초기화하여 처음에는 항등 함수처럼 작동하며, 파인튜닝 과정에서 시각적 특징에 주의를 기울이는 법을 학습합니다. 이 방식은 오디오와 비디오 특징의 샘플링 속도가 다르더라도 유연하게 처리할 수 있습니다.
- 학습 파이프라인:
- 먼저 오디오 전용 Whisper 모델의 모든 레이어를 파인튜닝하여 관심 도메인에 적응시키고 잡음 강인성을 높입니다 (Whisper Fine-tuned).
- 파인튜닝된 Whisper 모델의 가중치를 고정합니다.
- Gated Cross Attention 레이어와 시각적 특징 위에 있는 선형 레이어를 추가하고, 오디오-비주얼 입력으로 이 새로운 레이어들만 파인튜닝합니다. 이를 통해 Whisper의 강력한 오디오 처리 능력을 유지하면서 시각적 모달리티를 효과적으로 통합합니다.
- 다국어 확장: Whisper의 다국어 능력을 활용하여 영어 오디오를 전사하고 다른 언어로 번역하는 다중 작업 스타일로 오디오 모델을 파인튜닝한 후, Whisper-Flamingo를 학습시켜 영어-X 번역 성능을 향상시킵니다.
3. 실험 결과
- 데이터셋:
- 영어 음성 인식: LRS3 (433시간 훈련 세트), LRS3 + VoxCeleb2 (총 1,759시간 훈련 세트).
- 영어-X 번역: MuAViC 데이터셋 (LRS3의 영어 텍스트를 그리스어, 스페인어, 프랑스어, 이탈리아어, 포르투갈어, 러시아어 6개 언어로 번역).
- 추가 검증: LRS2 데이터셋 (223시간 훈련 세트).
- 실험 환경: A6000 GPU, AdamW 옵티마이저, SpecAugment 적용. Clean 조건 및 0-SNR(신호 대 잡음비)의 babble noise가 주입된 noisy 조건에서 성능 평가. WER(단어 오류율) 및 BLEU(번역 품질) 점수 사용.
- 주요 결과:
- 모달리티 융합 방식 비교 (Whisper-Medium): Gated Cross Attention을 사용한 Whisper-Flamingo가 초기 융합 및 후기 융합 방식보다 잡음 환경에서 가장 우수한 성능을 보였습니다 (오디오 전용 Whisper 대비 잡음 WER 12.6%에서 7.0%로 크게 개선).
- 영어 음성 인식 (Whisper-Large):
- LRS3에서 SOTA ASR WER (0.68%) 및 AVSR WER (0.76%)을 달성했습니다. 이는 Llama-AVSR(0.77%)보다 적은 파라미터(25억 vs 80억 이상)로 유사하거나 더 나은 성능입니다.
- 잡음 환경에서 오디오 전용 Whisper 대비 WER을 20.8%에서 5.6%로 크게 개선하여 49.5%의 상대적 성능 향상을 보였습니다.
- 영어-X 음성 번역:
- 오디오 전용 Whisper는 MuAViC 데이터셋에서 SOTA BLEU 점수(22.7)를 달성하며, 이전 SOTA인 Bilingual AV-HuBERT(21.9)를 능가했습니다.
- Whisper-Flamingo는 잡음 환경에서 오디오 전용 모델을 크게 능가했습니다 (평균 BLEU 20.5 vs 18.6, 영어 WER 7.2% vs 13.8%). 단일 모델로 여러 언어 번역 및 전사를 수행하는 강점을 보였습니다.
- 비디오만 사용하는 VSP-LLM보다 우수한 성능을 보이며, 오디오와 비디오를 모두 사용하는 이점을 입증했습니다.
- LRS2 데이터셋: LRS2에서도 SOTA ASR WER (1.3%) 및 AVSR WER (1.4%)을 달성하며, USR(1.9%) 및 AutoAVSR(1.5%)과 같은 최신 방법들을 능가했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- Whisper의 강력한 사전 학습된 오디오-텍스트 디코더와 AV-HuBERT의 시각적 특징을 Gated Cross Attention이라는 효과적인 메커니즘으로 결합하여, 잡음 환경에서의 음성 인식 및 번역 성능을 획기적으로 개선한 점이 매우 인상 깊습니다.
- 단일 모델로 영어 음성 인식과 다국어 번역을 동시에 수행할 수 있다는 점은 실제 응용에서 모델 관리 및 배포의 효율성을 크게 높일 수 있는 중요한 장점입니다.
- Gated Cross Attention이 초기에는 항등 함수로 작동하여 기존 Whisper의 성능을 해치지 않으면서 점진적으로 시각 정보를 통합하도록 학습되는 방식은 모델의 안정적인 학습에 기여했을 것으로 보입니다.
- 단점/한계:
- 다국어 비디오 데이터의 부족으로 인해 다국어 인식 및 X-En 번역(다른 언어 오디오를 영어 텍스트로)에 대한 직접적인 확장이 어려웠다는 점은 향후 연구 과제로 남아 있습니다.
- 매우 낮은 SNR 조건(예: -10dB)에서는 여전히 개선의 여지가 있으며, 특히 LRS2 데이터셋에서의 잡음 강인성 개선 폭이 LRS3에 비해 상대적으로 작았다는 점은 추가적인 최적화가 필요함을 시사합니다.
- AV-HuBERT의 가중치를 훈련 중에 업데이트하지 않고 동결한 점이 특정 데이터셋(LRS2)에서의 성능 개선 폭을 제한했을 가능성도 있습니다.
- 응용 가능성:
- 소음 환경에서의 음성 인식: 공장, 건설 현장, 시끄러운 사무실 등 소음이 심한 환경에서 음성 비서, 회의록 자동 작성, 음성 명령 시스템의 정확도를 크게 향상시킬 수 있습니다.
- 청각 장애인 지원: 입술 움직임을 활용하여 청각 장애인을 위한 실시간 자막 및 번역 서비스를 제공하여 의사소통 장벽을 낮출 수 있습니다.
- 다국어 콘텐츠 처리: 온라인 강의, 국제 회의, 뉴스 등 다국어 비디오 콘텐츠의 자동 전사 및 번역에 활용되어 정보 접근성을 높일 수 있습니다.
- 보안 및 감시: 잡음이 많은 감시 영상에서 특정 인물의 음성을 정확하게 인식하고 분석하는 데 기여할 수 있습니다.
Rouditchenko, Andrew, et al. "Whisper-flamingo: Integrating visual features into whisper for audio-visual speech recognition and translation." arXiv preprint arXiv:2406.10082 (2024).
Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
Andrew Rouditchenko , Yuan Gong , Samuel Thomas , Leonid Karlinsky , Hilde Kuehne , Rogerio Feris , James Glass <br> MIT, USA IBM Research AI, USA MIT-IBM Watson AI Lab, USA<br> University of Bonn, Germany<br>roudi@mit.edu
Abstract
Audio-Visual Speech Recognition (AVSR)은 잡음 속에서 성능을 향상시키기 위해 입술 기반 비디오를 사용합니다. 비디오는 오디오보다 얻기 어렵기 때문에, AVSR 모델의 비디오 학습 데이터는 보통 수천 시간으로 제한됩니다. 반면에, Whisper와 같은 speech 모델은 수십만 시간의 데이터로 학습되므로 더 나은 speech-totext 디코더를 학습합니다. 이러한 엄청난 학습 데이터 차이는 Whisper가 비디오 입력을 처리하도록 조정하는 동기를 부여합니다. 언어 모델에 시각적 특징을 주입하는 Flamingo에서 영감을 받아, 우리는 gated cross attention을 사용하여 Whisper speech recognition 및 번역 모델에 시각적 특징을 통합하는 Whisper-Flamingo를 제안합니다. 우리 모델은 LRS3에서 최첨단 ASR WER(0.68%) 및 AVSR WER(0.76%)을 달성하고, LRS2에서 최첨단 ASR WER(1.3%) 및 AVSR WER(1.4%)을 달성합니다. Audio-visual Whisper-Flamingo는 잡음이 있는 환경에서 6개 언어에 대한 영어 speech recognition 및 En-X 번역에서 오디오 전용 Whisper를 능가합니다. 또한, Whisper-Flamingo는 하나의 파라미터 세트를 사용하여 이러한 모든 작업을 수행하는 반면, 이전 방법들은 각 언어에 대해 별도로 학습됩니다.
Index Terms: audio-visual speech recognition, noise-robust
1. Introduction
최근 몇 년 동안, 대규모 데이터로 학습된 모델에 의해 Automatic Speech Recognition (ASR) 성능이 크게 향상되었지만 [1,2], 잡음 속에서는 여전히 성능이 저하됩니다 [3]. 잡음 속에서 성능을 향상시키기 위해, Audio-Visual Speech Recognition (AVSR)은 오디오 입력 외에 입술 기반 비디오를 사용합니다. AV-HuBERT [4]와 같은 Self-Supervised Learning (SSL) 방법은 레이블이 없는 대규모 비디오 데이터셋에서 pre-train을 하고, 레이블이 지정된 수백 시간의 비디오에서 fine-tune하여 잡음에 강한 AVSR을 수행합니다. 그러나 공개적으로 접근 가능한 비디오를 수집하는 데 어려움이 있기 때문에, 이러한 모델들은 보통 수천 시간의 데이터로만 학습됩니다.
비디오 데이터의 부족을 극복하기 위해, 최근 방법들은 수십만 시간의 오디오로 pre-train된 오디오 전용 모델을 audio-visual speech recognition을 위해 fine-tune합니다 [5-7]. 결과에 따르면 이러한 오디오 모델이 수백 시간의 비디오에 대한 audio-visual fine-tuning과 결합될 경우, 수천 시간의 비디오로 pre-train된 비디오 모델의 성능에 근접할 수 있음을 보여줍니다 [6]. 그러나 이러한 방법들은 종종 비디오 모델과 텍스트 디코더를 수백 시간의 데이터만으로 처음부터 학습시키는데, 이는 대규모 데이터로 학습하는 것에 비해 차선책입니다. 더욱이, 영어 데이터만 사용되었습니다.
본 연구에서는 강력한 다국어 디코더를 갖춘 680,000시간의 speech로 학습된 오디오 전용 모델인 Whisper [1]에 AV-HuBERT의 시각적 특징을 통합할 것을 제안합니다. 이전의 audio-visual 적응 방법과 비교할 때, 우리의 비디오 모델과 텍스트 디코더는 대규모 데이터로 pre-train되었습니다. 이를 통해 우리 방법은 이전 방법들 [5-7]이 탐색하지 않은 작업인 audio-visual speech translation에서 좋은 성능을 발휘할 수 있습니다.
다중 모드 모델에서 modality를 효과적으로 융합하는 방법은 지속적인 연구 과제입니다. 최근 연구인 Flamingo [8]는 gated cross attention을 사용하여 시각적 특징을 텍스트 전용 언어 모델에 융합하고, 쌍을 이룬 텍스트-이미지 데이터셋에서 fine-tuning합니다. gated cross attention 레이어는 항등 함수로 초기화되며 fine-tuning 중에 시각적 특징에 주의를 기울이는 법을 학습합니다. 이러한 레이어는 다른 modality 쌍에도 일반화되는 것으로 나타났습니다. Audio Flamingo [9]는 최근 텍스트-오디오 추론을 위해 이를 적용했습니다. 이 방법에 영감을 받아, 우리는 Whisper의 디코더에 gated cross attention 레이어를 삽입하여 Whisper가 speech recognition을 위해 입술 기반 특징을 사용할 수 있도록 하는 Whisper-Flamingo를 제안합니다.
영어(En) LRS3 비디오 데이터셋 [10]에서, 우리 모델은 State-of-the-Art (SOTA) ASR WER (0.68%) 및 AVSR WER (0.76%)을 달성합니다. LRS2 [11]에서는 SOTA ASR WER (1.3%) 및 AVSR WER (1.4%)를 달성합니다. 우리의 새로운 audio-visual Whisper-Flamingo는 잡음 속에서 오디오 전용 Whisper 기준 모델을 크게 능가합니다. 또한, Whisper-Flamingo는 이전 audio-visual 모델과 비교하여 잡음에 강한 경쟁력 있는 결과를 달성합니다. 다음으로, 우리는 MuAViC 데이터셋 [12]에서 En-X 번역을 위해 Whisper-Flamingo를 확장하여 Whisper의 다국어 능력을 보여줍니다. 우리 모델은 En 전사와 6개 다른 언어로의 En-X 번역을 수행하는 반면, 이전 audio-visual SOTA는 각 언어에 대해 개별적으로 fine-tuning이 필요합니다. 다시 한번, Whisper-Flamingo는 잡음 속에서 En 전사와 En-X 번역 모두에서 오디오 전용 Whisper를 크게 능가합니다. 코드 및 모델은 https://github.com/roudimit/whisper-flamingo 에서 확인할 수 있습니다.
2. Method
이 섹션에서는 AVSR을 위한 audio-visual 융합 방법을 검토한 다음, 우리의 방법을 설명합니다. 두 가지 일반적인 융합 방법은 초기 융합과 후기 융합입니다. 초기 융합에서는 두 modality가 먼저 경량 인코더에 의해 개별적으로 처리된 다음, 특징 덧셈 또는 연결을 통해 결합되어 audio-visual Transformer [11, 13]의 입력으로 사용됩니다. SSL 모델 과 완전 지도 모델 [16-18] 모두 이 설계를 사용합니다. 후기 융합에서는 오디오와 비디오가 Transformer 인코더에 의해 개별적으로 처리된 후, 특징이 MLP로 융합됩니다. audio-visual 특징은 그 다음 선형 레이어 또는 Transformer 디코더로 전달됩니다. 이 접근 방식은 완전 지도 모델 [19-21]에서 일반적입니다. 초기 및 후기 융합 모두 동일한 오디오 및 시각적 특징 비율을 필요로 하므로 각 시간 단계에서 융합될 수 있습니다. 일반적인 설계는 오디오 특징을 25Hz로 다운샘플링하여 비디오의 프레임 속도와 일치시키는 것입니다.
pre-train된 오디오 전용 모델을 audio-visual fine-tuning을 통해 AVSR에 적용하는 대부분의 방법은 초기 융합을 사용합니다. FAVA [6]는 오디오 self-supervised 모델인 BEST-RQ [22]를 처음부터 학습된 비디오 모델과의 초기 융합을 통해 적응시킵니다. Adaptive AV [7]는 Whisper 앞에 audio-visual Transformer를 추가하여 노이즈 제거된 스펙트로그램을 출력하지만, Whisper에서 시각적 특징을 직접 사용하지는 않습니다. 그러나 우리는 pre-train된 AVHuBERT의 특징을 이용한 gated cross attention이 초기 융합보다 더 잘 작동한다는 것을 발견했습니다. 별도의 연구는 이미지나 교육용 비디오의 시각적 특징을 AVSR에 사용하는 데 초점을 맞추고 있으며, 여기서 시각 정보는 맥락을 제공하고 오디오와 느슨하게 동기화됩니다 [23,24].
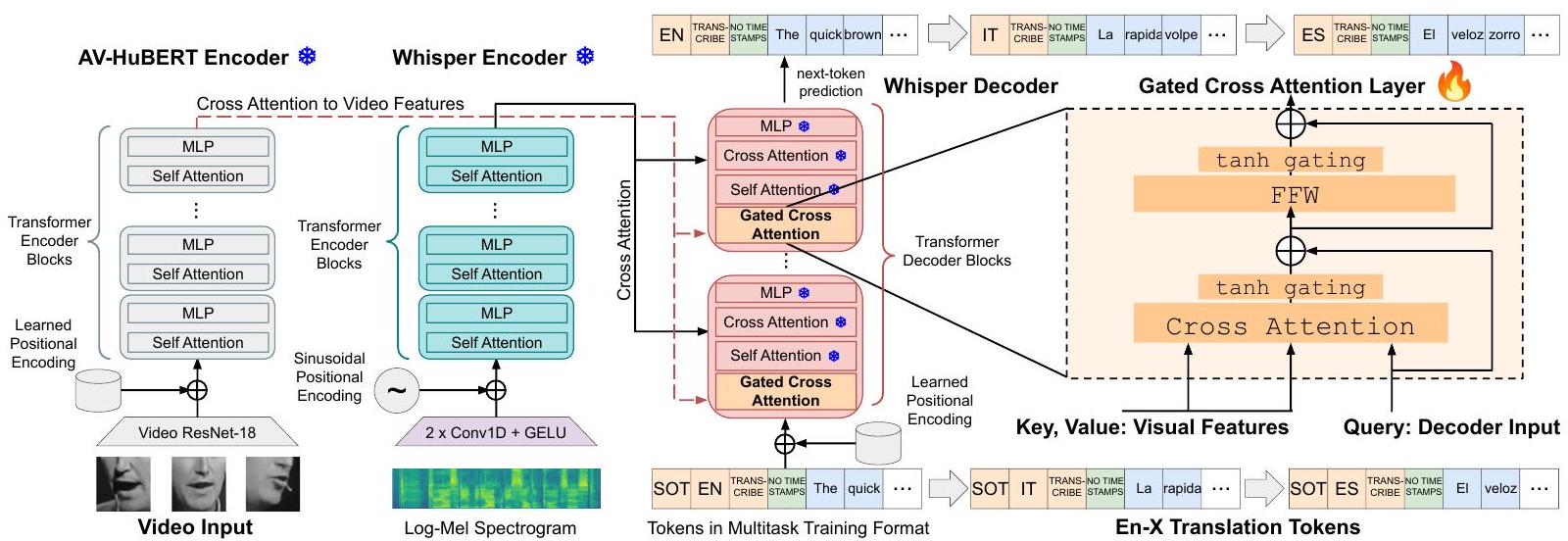
Figure 1: Whisper [1]와 Flamingo [8]에 기반한 Whisper-Flamingo의 다이어그램입니다. 먼저 영어 전사 및 En-X 번역을 위해 모든 Whisper 파라미터를 영어 오디오를 사용하여 fine-tune합니다. Whisper-Flamingo를 학습시키기 위해, 오디오 모델을 동결하고, Whisper의 디코더에 AV-HuBERT의 시각적 특징에 주의를 기울이는 gated cross attention 레이어를 추가하고, audio-visual 입력으로 모델을 학습시킵니다.
Table 1: 하이퍼파라미터 요약. 먼저 WhisperLarge FT (Fine-tune)을 오디오 전용으로 학습시킨 다음, 이를 사용하여 Whisper-Flamingo를 초기화합니다. A=오디오, AV=audio-visual. 샘플당.
| WhisperLarge FT | WhisperLarge FT | WhisperFlamingo | WhisperFlamingo | |
|---|---|---|---|---|
| Test Modalities | A | A | AV | AV |
| En Recognition | ||||
| En-X Translation | ||||
| GPUs | 1 | 4 | 1 | 4 |
| Total Params. | 1.55 B | 1.55 B | 2.5 B | 2.5 B |
| AV-HuBERT Params. | - | - | 325 M | 325 M |
| Gated X-Attn Params. | - | - | 630 M | 630 M |
| Trainable Params. | 1.55 B | 1.55 B | 631 M | 631 M |
| Warmup Steps | 1k | 1k | 5k | 5k |
| Total Steps | 90 k | 225 k | 20 k | 40k |
| Learning Rate | ||||
| Batch per GPU (s) | 80 | 40 | 160 | 30 |
| Max Length (s) | 10 | 10 | 15 | 15 |
| Max Characters | 350 | 300 | 350 | 250 |
우리는 그림 1과 같이 gated cross attention을 사용하여 AV-HuBERT의 시각적 특징을 Whisper의 디코더에 통합할 것을 제안합니다. Whisper의 각 디코더 블록은 self-attention 레이어, 오디오 특징에 주의를 기울이는 cross attention 레이어, 그리고 Multi-Layer Perceptron (MLP)으로 구성됩니다. Flamingo [8]를 기반으로, gated cross attention 레이어는 다음과 같이 정의됩니다. 여기서 는 디코더 블록의 입력, 는 시각적 특징, Attn은 multi-head cross attention, LN은 Layernorm [25], FFW는 MLP입니다:
학습 가능한 파라미터 과 는 0으로 초기화되어, 이므로 레이어는 초기에 항등 함수로 작동합니다. audio-visual fine-tuning을 통해 모델은 과 의 가중치를 조정하고 시각적 특징에 주의를 기울이는 법을 학습합니다. 우리는 gated cross attention 레이어를 Whisper의 디코더에서 각 블록의 시작 부분, 즉 self-attention 레이어 앞에 삽입합니다. 다른 순서로 디코더 블록에 삽입하려고 시도했지만 성능이 약간 더 나빴습니다. 전체 분석은 부록 8.4절에 나와 있습니다. gated cross attention은 비디오 특징에 개별적으로 주의를 기울이기 때문에, 오디오와 비디오 특징은 서로 다른 특징 속도(예: 50Hz 및 25Hz)를 가질 수 있습니다. 학습 파이프라인. gated cross attention을 추가하기 전에, 먼저 오디오 전용 Whisper 모델의 모든 레이어를 fine-tune하여 관심 도메인에 적응시킵니다(Whisper Fine-tuned로 표기). 또한 fine-tuning 중에 노이즈를 추가하여 잡음 강인성을 높입니다. 모델이 예측한 스크립트와 실제 정답 토큰 간의 표준 cross-entropy 손실을 사용합니다. Whisper-Flamingo를 학습시키기 위해, 우리는 fine-tune된 Whisper를 동결하고, gated cross attention 레이어를 삽입한 후, audio-visual 입력으로 모델을 fine-tune합니다. gated cross attention 레이어와 시각적 특징 위에 있는 선형 레이어는 처음부터 학습되는 반면, 다른 모든 파라미터는 동결됩니다. 따라서 새로운 레이어는 (큰) 어댑터 세트로 볼 수 있습니다 [32]. 이들을 제거하면 오디오 전용 Whisper 가중치가 됩니다. 영어에서 다국어로. Whisper는 다국어 전사 및 X-En 번역(다국어 오디오를 En 텍스트로)을 위해 학습되었습니다. 우리는 MuAViC 데이터셋 [12]의 비디오를 사용하여 다국어 speech recognition 및 X-En 번역에 Whisper-Flamingo를 시도했지만 몇 가지 문제를 발견했습니다. 데이터셋의 대부분 언어는 사용 가능한 영어 데이터 시간의 1/3 미만을 가지고 있어 새로운 레이어를 처음부터 학습하기 어렵습니다. 또한 다국어 비디오는 영어 비디오보다 평균적으로 더 깁니다. 이로 인해 GPU 메모리 압력이 증가하고 배치 크기를 줄여야 하므로 학습이 어려워집니다. 따라서 우리는 En-X 번역(영어
Table 2: LRS3에서 Whisper-Medium을 사용한 융합 실험. 원본 테스트 세트(Clean)와 0-SNR로 주입된 배블 노이즈(Noisy)에 대한 결과를 보고합니다. A = 오디오, AV = audio-visual.
| Model | Test <br> Modalities | Clean <br> WER | Noisy <br> WER |
|---|---|---|---|
| Whisper, Zero-shot | A | 2.3 | 22.2 |
| Whisper, Fine-tuned | A | ||
| Whisper-Early-Fusion | AV | 1.7 | 10.0 |
| Whisper-Late-Fusion | AV | 2.1 | 16.5 |
| Whisper-Flamingo | AV |
오디오를 다국어 텍스트로)에 초점을 맞추고 향후 연구에서 다국어 인식 및 번역을 다룰 것을 제안합니다 [29,33-36].
이전 연구에 따르면 Whisper는 EnX 번역을 위해 프롬프트될 수 있지만, 언어별 로짓 필터링이 필요하며 성능이 여전히 만족스럽지 않을 수 있습니다 [24]. Whisper를 fine-tuning하면 보이지 않는 언어의 전사가 가능하다는 것이 밝혀졌기 때문에 [37], 우리는 En-X 번역을 위해 Whisper를 fine-tune할 것을 제안합니다. 우리는 영어 오디오를 전사하고 다른 언어로 번역하도록 다중 작업 스타일로 오디오 모델을 fine-tune합니다. Whisper-Flamingo를 학습시키기 위해, 우리는 fine-tune된 오디오 모델을 동결하고, gated cross attention 레이어와 시각적 특징 위의 선형 레이어를 추가한 다음, audio-visual 입력으로 모델을 학습시킵니다.
3. Experiments on LRS3
3.1. Experimental Setup
모델을 학습시키기 위해, 우리는 영어(En)로 된 가장 크고 공개적으로 이용 가능한 AVSR 데이터셋인 LRS3 [10]을 사용합니다. 이 데이터셋은 TED 강연에서 가져온 것입니다. 우리는 AV-HuBERT [4]를 따라 433시간의 훈련 세트, 1시간의 검증 세트, 1시간의 테스트 세트를 만들었습니다. 또한 LRS3 훈련 비디오를 VoxCeleb2 [40]의 1,326시간의 영어 비디오와 결합하여 훈련에 사용했습니다. VoxCeleb2 비디오의 스크립트는 Whisper Large-v2 [41]에서 얻었습니다. En-X 번역을 위해, 우리는 LRS3의 영어 텍스트를 그리스어(El), 스페인어(Es), 프랑스어(Fr), 이탈리아어(It), 포르투갈어(Pt), 러시아어(Ru)의 6개 언어로 번역한 MuAViC [12] 데이터셋을 사용합니다.
우리는 2억 4,400만, 7억 6,900만, 15억 5,000만 개의 파라미터를 가진 Whisper Small, Medium, Large-v2를 사용합니다 [1]. 16kHz로 샘플링된 오디오에서 10ms의 스트라이드와 25ms의 창 크기를 가진 80-bin log-Mel 스펙트로그램을 추출합니다. LRS3에서 3억 2,500만 개의 파라미터로 fine-tune된 AV-HuBERT Large [4] 인코더에서 비디오 특징을 추출합니다. Whisper Large의 경우, gated cross attention 레이어는 6억 3,000만 개의 파라미터를 추가하여 총 파라미터 수를 25억 개(AV-HuBERT 포함)로 만듭니다. 우리는 AVHuBERT를 동결하지만 Whisper-Flamingo 훈련 중에 dropout과 batch normalization 업데이트를 활성화합니다. 비디오는 25fps의 프레임 속도를 가지며 흑백으로 변환됩니다. Dlib [42]을 사용하여 입술 중앙에 위치한 96x96 크롭을 추출하고 참조 평균 얼굴 [43]에 정렬합니다. 훈련 중에는 무작위 88x88 크롭이 사용되고 비디오는 0.5의 확률로 수평으로 뒤집힙니다. 테스트 시에는 중앙 88x88 크롭이 사용됩니다.
Table 1은 주요 실험에 대한 하이퍼파라미터를 요약합니다. 48GB 메모리를 가진 A6000 GPU를 사용했습니다. 비슷한 길이의 오디오/비디오 샘플은 함께 배치되며, 짧은 샘플은 0으로 채워집니다. AdamW를 옵티마이저로 사용했습니다 [44]. [1]에 따라, Whisper-Large와 함께 SpecAugment [45] (LibrispeechBasic)를 사용했으며 WhisperMedium과는 사용하지 않았습니다. 훈련은 PyTorch [46]와 PyTorch Lightning [47]으로 수행되었습니다. ESPnet [48]의 SpecAugment와 배치 정렬기 구현을 사용했습니다.
우리는 두 가지 조건에서 모델을 훈련합니다: 노이즈가 없는(clean) 조건과 노이즈가 있는(noisy) 조건. clean 훈련의 경우, 오디오에 노이즈를 추가하지 않습니다. noisy 훈련의 경우, 신호 대 잡음비(SNR) 0으로 오디오에 무작위로 노이즈를 추가합니다. 이전 연구 [12,26]에 따라, "자연", "음악", "babble" 노이즈는 MUSAN 데이터셋 [49]에서 샘플링되며, 중첩되는 "speech" 노이즈는 LRS3 [10]에서 샘플링됩니다. 최상의 체크포인트를 선택하기 위해, 1k 단계마다 clean 또는 noisy 검증 세트에서 가장 높은 토큰 예측 정확도를 모니터링합니다. 이전 연구 [12]에 따라 Fairseq normalizer [50]를 사용하여 WER을 계산하기 전에 구두점을 제거하고 텍스트를 소문자로 변환합니다. 번역의 경우, SacreBLEU [51]를 기본 13-a 토크나이저와 함께 사용하여 BLEU [52]를 계산합니다.
3.2. Modality Fusion Ablation with Whisper-Medium
우리는 먼저 Whisper Medium을 사용하여 gated cross attention을 초기 융합 및 후기 융합과 비교했습니다. 초기 융합의 경우, AVHuBERT의 25Hz 비디오 특징을 복제하여 Whisper의 50Hz 오디오 특징(CNN 레이어 이후)과 시간적으로 정렬하고, Whisper의 Transformer 인코더 전에 융합하기 위해 덧셈을 사용합니다. 후기 융합의 경우, MLP를 사용하여 비디오 특징을 Whisper의 Transformer 인코더 이후의 오디오 특징과 융합합니다. 두 경우 모두 Whisper의 모든 파라미터는 fine-tune됩니다. 오디오 전용 기준 모델로는 Whisper zero-shot(fine-tuning 없음)과 LRS3에서 fine-tune된 모델을 사용합니다. 0-SNR로 주입된 babble-noise가 있는 clean 및 noisy 조건 모두에서 모델을 테스트합니다. 결과는 Table 2에 나와 있습니다. 오디오 전용 Whisper를 fine-tuning하면 zero-shot 모델의 noisy WER이 에서 로 감소합니다. 그런 다음 fine-tune된 모델을 초기화로 사용하여 audio-visual 융합 모델을 훈련합니다. 초기 융합은 clean 및 noisy WER 모두에서 약간의 개선을 얻었습니다. 후기 융합은 modality를 잘 융합하지 못했고 clean 및 noisy 조건 모두에서 성능이 악화되었습니다. 마지막으로, gated cross attention을 사용한 Whisper-Flamingo가 가장 좋은 noisy WER을 얻었으며, 오디오 전용 Whisper fine-tune 기준 모델을 에서 로 크게 개선했으며, clean WER은 에서 로 약간 개선되었습니다. Whisper를 동결하면 강력한 오디오 기술을 유지하는 데 도움이 되며, 새로운 cross attention 레이어를 통해 시각적 modality를 더 효과적으로 통합할 수 있습니다.
3.3. Whisper-Flamingo English Speech Recognition
Table 3의 주요 실험에서는 Whisper-Large를 사용합니다. 빔 크기 1과 15의 빔 검색을 사용한 결과를 보고합니다. 잡음이 있는 조건에서는 LRS3의 30명 화자의 오디오를 추가하여 AV-HuBERT [26]에 따라 구성된 0-SNR의 babble noise를 사용합니다. 추가적인 잡음 유형 및 SNR 수준에 대한 결과는 부록 8.2절에 나와 있습니다. 깨끗한 오디오(잡음 없음)로 훈련. zero-shot 오디오 전용 Whisper-Large와 비교하여, 잡음 없이 fine-tuning하면 깨끗한 ASR WER이 2.1%에서 1.0%(LRS3 433h 사용) 및 (LRS3+VoxCeleb2 1,759h 사용)로 향상됩니다. fine-tune된 Whisper-Large는 LRS3에서 SOTA ASR(0.68%)을 달성하며 Fast Conformer [29]의 이전 SOTA인 0.7%와 일치합니다. 그런 다음 fine-tune된 Whisper 모델을 사용하여 audio-visual Whisper-Flamingo를 초기화하고 LRS3 433h / LRS3+VoxCeleb2 를 각각 사용하여 / 0.76% AVSR WER을 달성합니다. 우리의 audio-visual Whisper-Flamingo는 LRS3에서 SOTA AVSR()을 달성하며 LRS3+VoxCeleb2를 사용한 Llama-AVSR(0.77%) 및 추가 데이터를 사용한 Fast Conformer()의 현재 SOTA와 일치합니다. 특히, 우리 방법은 25억 개의 매개변수만 사용하는 반면 Llama-AVSR은 80억 개 이상의 매개변수를 사용합니다. 또한, 우리 방법은 10만 개의 비디오로 훈련된 LP Conformer()보다 더 나은 AVSR 성능을 달성합니다. 깨끗한 오디오로 Whisper를 fine-tuning해도 잡음 있는 WER은 향상되지 않지만, 깨끗한 오디오로 Whisper-Flamingo를 훈련하면 잡음 있는 WER이 향상됩니다. 잡음 있는 오디오로 훈련. zero-shot 오디오 전용 Whisper-Large와 비교하여, 잡음으로 fine-tuning하면 잡음 있는 ASR WER이 에서 (LRS3 433h 사용) 및 (LRS3+VoxCeleb2 1,759h 사용)로 향상됩니다. 깨끗한 ASR WER은 잡음 없이 fine-tune된 Whisper에 비해 약간 나쁘지만, 결과는 비슷합니다( 대 ). 그런 다음 fine-tune된 Whisper 모델을 사용하여 audio-visual WhisperFlamingo를 초기화하고 잡음 있는 WER을 LRS3 433h / LRS3+VoxCeleb2 1,759h를 사용하여 각각 / AVSR WER로 크게 향상시킵니다(fine-tune된 오디오 전용 Whisper에 비해 49.5% 상대적 잡음 있는 WER 개선). 깨끗한 AVSR WER은 잡음 없이 훈련된 Whisper-Flamingo에 비해 약간 나쁘지만, 결과는 비슷합니다( 대 ). 잡음 있는 결과를 SOTA와 비교. Table 3은 또한 LRS3에서 이전 audio-visual SSL 방법 및 audio-visual fine-tuning 방법과의 비교를 보여줍니다. 잡음 있는 조건에서의 직접적인 비교는 다른 잡음 데이터셋이 babble noise를 생성하는 데 사용되었기 때문에 어렵습니다. SSL 방법인 AV-HuBERT [26], u-HuBERT [14], CMA [27]는 LRS3를 사용하여 babble noise를 생성했지만, 그들이 생성한 잡음 파일은 공개적으로 사용할 수 없었습니다. 우리는 그들의 절차를 따라 잡음을 생성했으므로 우리의 잡음 있는 조건은 비슷하지만 동일하지는 않습니다. AV-HuBERT와 비교할 때, Whisper-Flamingo는 더 나은 깨끗한 성능( 대 )과 약간 더 나은 잡음 있는 결과( 대 )를 달성하며, 이는 Whisper-Flamingo가 AVHuBERT의 시각적 특징에 Whisper를 효과적으로 적응시키는 것을 보여줍니다. 또한, AV-HuBERT에 대한 Whisper-Flamingo의 주요 장점은 번역 성능 향상입니다(섹션 3.4). 가장 좋은 잡음 성능은 uHuBERT와 CMA에 의해 보고되었습니다. 우리는 Whisper-Flamingo의 시각적 인코더로 사용해보고 싶지만, 가중치는 공개적으로 사용할 수 없습니다. 마지막으로, Whisper-Flamingo는 audio-visual fine-tuning [6,7]을 통해 오디오 전용 모델을 적응시키는 다른 방법들보다 잡음에서 더 나은 성능을 보이며, 여기에는 12M 시간의 레이블 없는 오디오로 pre-train된 FAVA-USM [6]도 포함됩니다 [2]. 그러나 babble noise가 다른 데이터셋에서 생성되어 결과가 엄격하게 비교할 수는 없습니다.
3.4. Whisper-Flamingo En-X Speech Translation
이 실험들을 위해, 우리는 Whisper를 fine-tune하고 WhisperFlamingo를 노이즈와 함께 학습시킵니다. 빔 크기 15로 결과를 보고합니다. 오디오 결과. Table 4에서, 우리는 MuAViC 데이터셋의 6개 언어를 사용하여 En-X 번역을 위해 오디오 전용 Whisper-Large를 fine-tuning한 결과("Whisper-Large, Fine-tuned")를 보여줍니다. Whisper는 원래 En-X 번역을 위해 학습되지 않았지만, 새로운 작업에 잘 적응합니다. 깨끗한 오디오로 테스트했을 때, 우리는 평균 BLEU 점수 22.7을 달성했으며, 이는 Bilingual AV-HuBERT의 이전 SOTA인 21.9를 능가합니다. 더욱이, 우리 모델은 En 오디오를 전사하고(WER 1.5%) 단일 파라미터 세트로 6개 언어로 번역하는 반면, Bilingual AV-HuBERT는 각 언어 쌍에 대해 별도로 fine-tune하고 언어별 디코더를 처음부터 학습합니다. 우리 모델은 ground-truth 영어 텍스트를 사용하는 기계 번역 모델의 텍스트-텍스트 성능에 거의 도달합니다. 이들 모델은 다국어 모델에서 평균 BLEU 점수 23.1, 이중 언어 모델에서 24.3을 달성합니다. Audio-Visual 결과. 오디오 전용 Whisper를 En-X 번역을 위해 fine-tune한 후, 가중치를 고정하고 gated cross attention 레이어를 추가하여 Whisper-Flamingo를 학습시키는 데 사용합니다. 깨끗한 오디오로 테스트했을 때, Whisper-Flamingo는 평균 BLEU 점수 22.9와 En WER 1.3%로 오디오 전용 모델을 약간 능가합니다. 잡음이 있는 조건에서는 MuAViC [12]에 따라 30명의 화자로부터 9개 언어의 오디오를 추가하여 구성된 다국어 babble noise를 사용합니다. 그들의 잡음 파일은 공개적으로 사용할 수 없었으므로, 우리의 잡음 조건은 비슷하지만 동일하지는 않습니다. 다국어 babble noise를 사용하면 Whisper-Flamingo는 평균 BLEU 점수( 대 18.6)와 En WER( 대 )에서 오디오 전용 Whisper 모델을 크게 능가합니다. 이전 SOTA 이중 언어 AV-HuBERT와 비교할 때, 우리의 오디오 전용 평균 BLEU는 훨씬 더 좋지만(18.6 대 15.0), 우리의 audio-visual 성능은 약간 더 나쁩니다(20.5 대 20.8). 그러나 우리 모델은 단일 모델로 En-X 번역과 En 전사를 모두 수행하는 반면, 그들의 모델은 각 언어 쌍에 대해 별도로 fine-tune합니다. 마지막으로, 우리는 Whisper-Medium 및 Whisper-Small을 사용한 결과를 보여줍니다. Whisper-Flamingo는 오디오 전용 기준 모델에 비해 항상 잡음에서 더 나은 성능을 보이며, 모델 크기가 커짐에 따라 성능이 향상되는 경향이 있습니다. VSP-LLM과의 비교. 마지막으로, 우리는 LLM 기반의 최신 접근 방식인 VSPLLM [39]과 비교합니다. 이 방식은 AV-HuBERT의 특징을 LLM의 입력으로 사용하여 오디오 없이 비디오 입력만으로 립리딩과 번역을 수행합니다. 오디오에 잡음이 있더라도, 우리의 Whisper-Flamingo(Large)는 평가된 4개 언어 모두에서 VSP-LLM을 능가하며, 이는 비디오만 사용하는 대신 오디오와 비디오를 모두 입력으로 사용하는 것의 이점을 보여줍니다. 또한, 우리 모델은 VSP-LLM의 70억 파라미터에 비해 25억 파라미터만 가지고 있습니다.
4. Experiments on LRS2
우리의 프레임워크를 사용하여 LRS2 데이터셋 [11]에 대한 실험을 수행합니다. 우리는 AutoAVSR [21]을 따라 223시간의 훈련 세트, 0.6시간의 검증 세트, 0.5시간의 테스트 세트를 만들었습니다. 모델을 훈련하는 동안 오디오에 노이즈를 추가합니다. LRS2 테스트 세트(clean)에 대한 ASR 및 AVSR WER을 Table 5에 보고합니다. zero-shot Whisper Medium과 Whisper Large V2를 비교하면, medium 모델이 약간 더 나은 성능을 보였으므로( 대 ), 실험에는 Whisper medium을 사용합니다. fine-tune된 Whisper 및 Whisper-Flamingo 모델은 각각 7억 6,900만 및 13억 9,000만 개의 파라미터를 가집니다. zero-shot Whisper와 비교하여, fine-tune된 Whisper는 ASR WER을 5.2%에서 1.3%로 향상시켜 LRS2에서 새로운 SOTA ASR WER을 달성했습니다. 마지막으로, WhisperFlamingo는 의 SOTA AVSR WER을 달성했습니다. WhisperFlamingo는 동일한 시간의 비디오로 훈련된 최근 SSL 방법인 USR 57을 능가하고, 더 많은 시간의 비디오로 훈련된 AutoAVSR 21을 능가합니다. 마지막으로, Whisper-Flamingo는 잡음이 있는 조건에서 Whisper를 능가합니다(부록, 8.3절 참조).
5. Conclusion
우리는 AV-HuBERT와 Whisper의 강점을 gated cross attention을 사용하여 결합한 새로운 audio-visual 모델인 Whisper-Flamingo를 소개했습니다. 우리의 audio-visual Whisper-Flamingo는 잡음 속에서 오디오 전용 Whisper를 크게 능가합니다. 우리는 Whisper가 XEn 번역이라는 새로운 작업에 fine-tune될 수 있음을 보여주었습니다. 우리 모델은 이전 방법들이 각 언어에 대해 개별적으로 fine-tune하는 반면, 하나의 파라미터 세트를 사용하여 En speech recognition 및 En-X speech translation을 모두 수행합니다. 우리의 방법은 시각적 인코더를 ASR 모델의 디코더에 융합하여 AVSR을 가능하게 하는 일반적인 방법이며, 향후 더 많은 데이터로 훈련된 다른 모델과도 함께 작동할 수 있습니다.
6. Acknowledgments
유용한 논의를 해주신 Alex H. Liu, Mohamed Anwar, 그리고 리뷰어들께 감사드립니다. Table A2의 실험에 도움을 주신 Videet Mehta께 감사드립니다. 이 연구는 MIT-IBM Watson AI Lab과 A.R.에 대한 NDSEG Fellowship의 지원을 받았습니다.
7. References
[1] A. Radford et al., "Robust speech recognition via large-scale weak supervision," in ICML, 2023. [2] Y. Zhang et al., "Google usm: Scaling automatic speech recognition beyond 100 languages," arXiv preprint, 2023. [3] Y. Gong, S. Khurana, L. Karlinsky, and J. Glass, "Whisper-AT: Noise-Robust Automatic Speech Recognizers are Also Strong General Audio Event Taggers," in Interspeech, 2023. [4] B. Shi, W.-N. Hsu, K. Lakhotia, and A. Mohamed, "Learning audio-visual speech representation by masked multimodal cluster prediction," in ICLR, 2022. [5] X. Pan, P. Chen, Y. Gong, H. Zhou, X. Wang, and Z. Lin, "Leveraging unimodal self-supervised learning for multimodal audiovisual speech recognition," in . [6] A. May, D. Serdyuk, A. P. Shah, O. Braga, and O. Siohan, "Audiovisual fine-tuning of audio-only asr models," ASRU, 2023. [7] C. Simic and T. Bocklet, "Self-supervised adaptive av fusion module for pre-trained asr models," in ICASSP, 2024. [8] J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds et al., "Flamingo: a visual language model for few-shot learning," NeurIPS, 2022. [9] Z. Kong et al., "Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities," ICML, 2024. [10] T. Afouras, J. S. Chung, and A. Zisserman, "Lrs3-ted: a largescale dataset for visual speech recognition," arXiv preprint, 2018. [11] T. Afouras, J. S. Chung, A. Senior, O. Vinyals, and A. Zisserman, "Deep audio-visual speech recognition," IEEE TPAMI, 2018. [12] M. A. et al., "MuAViC: A Multilingual Audio-Visual Corpus for Robust Speech Recognition and Robust Speech-to-Text Translation," in Interspeech, 2023. [13] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, "Attention is all you need," NeurIPS, 2017. [14] W.-N. Hsu and B. Shi, "u-hubert: Unified mixed-modal speech pretraining and zero-shot transfer to unlabeled modality," NeurIPS, 2022. [15] J.-X. Zhang, G. Wan, Z.-H. Ling, J. Pan, J. Gao, and C. Liu, "Selfsupervised audio-visual speech representations learning by multimodal self-distillation," in ICASSP, 2023. [16] T. Makino, H. Liao, Y. Assael, B. Shillingford, B. Garcia, O. Braga, and O. Siohan, "Recurrent neural network transducer for audio-visual speech recognition," in ASRU, 2019. [17] D. Serdyuk, O. Braga, and O. Siohan, "Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition for Single and Muti-Person Video," in Interspeech, 2022. [18] A. Rouditchenko, R. Collobert, and T. Likhomanenko, "Av-cpl: Continuous pseudo-labeling for audio-visual speech recognition," arXiv preprint, 2023. [19] S. Petridis, T. Stafylakis, P. Ma, F. Cai, G. Tzimiropoulos, and M. Pantic, "End-to-end audiovisual speech recognition," in ICASSP, 2018. [20] P. Ma, S. Petridis, and M. Pantic, "End-to-end audio-visual speech recognition with conformers," in ICASSP, 2021. [21] P. Ma, A. Haliassos, A. Fernandez-Lopez, H. Chen, S. Petridis, and M. Pantic, "Auto-avsr: Audio-visual speech recognition with automatic labels," in ICASSP, 2023. [22] C.-C. Chiu, J. Qin, Y. Zhang, J. Yu, and Y. Wu, "Self-supervised learning with random-projection quantizer for speech recognition," in ICML, 2022. [23] P. H. Seo, A. Nagrani, and C. Schmid, "Avformer: Injecting vision into frozen speech models for zero-shot av-asr," in CVPR, 2023. [24] P. Peng, B. Yan, S. Watanabe, and D. Harwath, "Prompting the Hidden Talent of Web-Scale Speech Models for Zero-Shot Task Generalization," in Interspeech, 2023. [25] J. L. Ba, J. R. Kiros, and G. E. Hinton, "Layer normalization," arXiv preprint, 2016. [26] B. Shi, W.-N. Hsu, and A. Mohamed, "Robust Self-Supervised Audio-Visual Speech Recognition," in Interspeech, 2022. [27] S. Kim, K. Jang, S. Bae, H. Kim, and S.-Y. Yun, "Learning video temporal dynamics with cross-modal attention for robust audiovisual speech recognition," arXiv preprint arXiv:2407.03563, 2024. [28] O. Chang, O. Braga, H. Liao, D. Serdyuk, and O. Siohan, "On robustness to missing video for audiovisual speech recognition," Transactions on Machine Learning Research, 2022. [29] M. Burchi et al., "Multilingual audio-visual speech recognition with hybrid ctc/rnn-t fast conformer," in ICASSP, 2024. [30] A. Haliassos, A. Zinonos, R. Mira, S. Petridis, and M. Pantic, "Braven: Improving self-supervised pre-training for visual and auditory speech recognition," in ICASSP, 2024. [31] U. Cappellazzo, M. Kim, H. Chen, P. Ma, S. Petridis, D. Falavigna, A. Brutti, and M. Pantic, "Large language models are strong audio-visual speech recognition learners," arXiv preprint arXiv:2409.12319, 2024. [32] N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, "Parameter-efficient transfer learning for nlp," in ICML, 2019. [33] X. Cheng et al., "Mixspeech: Cross-modality self-learning with audio-visual stream mixup for visual speech translation and recognition," in ICCV, 2023. [34] J. Hong, S. Park, and Y. Ro, "Intuitive multilingual audio-visual speech recognition with a single-trained model," in Findings of EMNLP, 2023. [35] Z. Li et al., "Parameter-efficient cross-language transfer learning for a language-modular audiovisual speech recognition," in ASRU, 2023. [36] H. Han, M. Anwar, J. Pino, W.-N. Hsu, M. Carpuat, B. Shi, and C. Wang, "Xlavs-r: Cross-lingual audio-visual speech representation learning for noise-robust speech perception," . [37] A. Rouditchenko, S. Khurana, S. Thomas, R. Feris, L. Karlinsky, H. Kuehne, D. Harwath, B. Kingsbury, and J. Glass, "Comparison of Multilingual Self-Supervised and Weakly-Supervised Speech Pre-Training for Adaptation to Unseen Languages," in Interspeech, 2023. [38] A. Fan, S. Bhosale, H. Schwenk, Z. Ma, A. El-Kishky, S. Goyal, M. Baines, O. Celebi, G. Wenzek, V. Chaudhary et al., "Beyond english-centric multilingual machine translation," JMLR, 2021. [39] J. H. Yeo, S. Han, M. Kim, and Y. M. Ro, "Where visual speech meets language: Vsp-1lm framework for efficient and context-aware visual speech processing," arXiv preprint arXiv:2402.15151, 2024. [40] J. S. Chung, A. Nagrani, and A. Zisserman, "VoxCeleb2: Deep Speaker Recognition," in Interspeech, 2018. [41] N. Vaessen and D. A. van Leeuwen, "Towards multi-task learning of speech and speaker recognition," in Interspeech, 2023. [42] D. E. King, "Dlib-ml: A machine learning toolkit," The Journal of Machine Learning Research, 2009. [43] B. Martinez, P. Ma, S. Petridis, and M. Pantic, "Lipreading using temporal convolutional networks," in ICASSP, 2020. [44] I. Loshchilov and F. Hutter, "Decoupled weight decay regularization," in ICLR, 2019. [45] D. S. P. et al., "SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition," in Interspeech, 2019. [46] A. Paszke et al., "Pytorch: An imperative style, high-performance deep learning library," NeurIPS, 2019. [47] W. Falcon and The PyTorch Lightning team, "PyTorch Lightning," 2023. [48] S. W. et al., "ESPnet: End-to-End Speech Processing Toolkit," in Interspeech, 2018. [49] D. Snyder, G. Chen, and D. Povey, "Musan: A music, speech, and noise corpus," arXiv preprint, 2015. [50] C. Wang, Y. Tang, X. Ma, A. Wu, D. Okhonko, and J. Pino, "Fairseq S2T: Fast speech-to-text modeling with fairseq," in AACL: System Demonstrations, 2020. [51] M. Post, "A call for clarity in reporting BLEU scores," in WMT, 2018. [52] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, "Bleu: a method for automatic evaluation of machine translation," in . [53] S. Petridis, T. Stafylakis, P. Ma, G. Tzimiropoulos, and M. Pantic, "Audio-visual speech recognition with a hybrid ctc/attention architecture," in SLT, 2018. [54] J. Yu, S.-X. Zhang, J. Wu, S. Ghorbani, B. Wu, S. Kang, S. Liu, X. Liu, H. Meng, and D. Yu, "Audio-visual recognition of overlapped speech for the lrs2 dataset," in ICASSP, 2020. [55] M. Burchi and R. Timofte, "Audio-visual efficient conformer for robust speech recognition," in WACV, 2023. [56] A. Haliassos, P. Ma, R. Mira, S. Petridis, and M. Pantic, "Jointly learning visual and auditory speech representations from raw data," in ICLR, 2023. [57] A. Haliassos, R. Mira, H. Chen, Z. Landgraf, S. Petridis, and M. Pantic, "Unified speech recognition: A single model for auditory, visual, and audiovisual inputs," arXiv preprint arXiv:2411.02256, 2024. [58] B. Xu, C. Lu, Y. Guo, and J. Wang, "Discriminative multimodality speech recognition," in CVPR, 2020. [59] Y. Hu, R. Li, C. Chen, H. Zou, Q. Zhu, and E. S. Chng, "Crossmodal global interaction and local alignment for audio-visual speech recognition," arXiv preprint arXiv:2305.09212, 2023. [60] Y. Hu, R. Li, C. Chen, C. Qin, Q. Zhu, and E. S. Chng, "Hearing lips in noise: Universal viseme-phoneme mapping and transfer for robust audio-visual speech recognition," ACL, 2023. [61] Y. Hu, C. Chen, R. Li, H. Zou, and E. S. Chng, "Mir-gan: Refining frame-level modality-invariant representations with adversarial network for audio-visual speech recognition," . [62] C. Chen, Y. Hu, Q. Zhang, H. Zou, B. Zhu, and E. S. Chng, "Leveraging modality-specific representations for audio-visual speech recognition via reinforcement learning," in AAAI, 2023.
8. Appendix
8.1. Original Results Table
Table A1은 논문의 원본 버전(ArXiv의 V1)에 보고된 결과를 보여줍니다. 이 결과들에서는 빔 크기가 15인 빔 탐색이 사용되었습니다. Table 3에 있는 현재 Whisper-Flamingo 결과는 Table A1에 보고된 결과의 상위 집합입니다(원본 결과는 동일하게 유지되었고 현재 메인 테이블에 더 많은 결과를 추가했습니다).
8.2. LRS3: Testing Different Noise Types and Noise Levels
Table A2는 다양한 노이즈 유형과 SNR 레벨 에서의 LRS3 433h에 대한 결과를 보여줍니다. 노이즈 설정은 AV-HuBERT [26]와 CMA [27]를 따르며, MuAViC의 오디오를 사용하여 만든 다국어 babble 노이즈에 대해서도 테스트합니다. 그러나 노이즈 파일이 후보 목록에서 샘플링되므로(LRS3의 babble 노이즈와 MuAViC의 babble 노이즈는 테스트에 단 하나의 노이즈 파일만 사용함) 결과의 일부 차이는 다른 랜덤 시드 때문일 수 있습니다. 먼저 오디오만으로 테스트하는 모델을 비교한 다음, 오디오와 시각적 modality를 모두 사용하여 테스트하는 모델을 비교합니다. 노이즈로 fine-tune된 영어 모델의 Large 버전을 사용하고 빔 크기 1과 15로 디코딩 결과를 보고합니다. 다음과 같은 관찰을 할 수 있습니다:
- Audio-visual Whisper-Flamingo는 빔 크기 1과 15 모두에서 오디오 전용 Whisper(fine-tuned)를 크게 능가합니다.
- 빔 크기 1과 15의 결과를 비교하면, 빔 크기 15는 SNR 에서 빔 크기 1을 능가하는 경향이 있지만, 빔 크기 1은 SNR 에서 더 나은 성능을 보입니다.
- 오디오 전용 테스트의 경우, fine-tuned Whisper는 거의 모든 노이즈 유형과 레벨에서 zero-shot Whisper를 능가합니다. Whisper(fine-tuned)는 AV-HuBERT [26]를 능가하는 경향이 있습니다.
- Audio-visual 테스트의 경우, AV-HuBERT와 CMA [27]는 SNR 에서 Whisper-Flamingo를 능가하는 경향이 있는 반면, Whisper-Flamingo는 SNR 에서 그들을 능가하는 경향이 있습니다.
- 세 가지 babble 노이즈 유형에 대한 성능 순서는 최악에서 최고 순으로 다음과 같습니다: (1) MuAViC (2) LRS3 (3) MUSAN. 우리는 MuAViC babble 노이즈가 다국어이기 때문에 더 어렵다고 생각합니다.
- babble 노이즈의 난이도를 다른 유형과 비교하면, LRS3의 speech는 0 SNR에서도 어렵지만, SNR 에서는 babble보다 쉽습니다. 또한, 음악과 자연 노이즈는 babble 노이즈보다 쉽습니다. 전반적으로, 결과는 오디오와 시각적 modality를 사용하는 Whisper-Flamingo의 노이즈 강인성을 확인시켜 줍니다. 향후 연구는 낮은 SNR 조건에서의 성능 향상과 이전 연구 [11, 58-62]와의 보다 포괄적인 비교에 초점을 맞출 수 있습니다.
8.3. LRS2: Testing Different Noise Types and Noise Levels
Table A3는 다양한 노이즈 유형과 SNR 수준 을 가진 LRS2 223h에 대한 결과를 보여줍니다. 노이즈 설정은 AV-HuBERT [26]를 따르며, MuAViC의 오디오를 사용하여 만든 다국어 babble 노이즈에 대해서도 테스트합니다. Whisper Medium zero-shot, Whisper Medium finetuned, Whisper-Flamingo를 비교합니다. 빔 크기 1과 15의 디코딩 결과를 보고합니다. 일반적으로, 관찰 결과는 8.2절의 결과와 유사합니다. 가장 중요한 것은, fine-tuned Whisper가 zero-shot Whisper를 능가하고, Whisper-Flamingo가 대부분의 노이즈 유형과 수준에서 fine-tuned Whisper를 능가한다는 것입니다. 그러나 LRS3 데이터셋에서 달성한 개선 사항(Table A2)에 비해 Whisper-Flamingo의 fine-tuned Whisper에 대한 개선 사항은 그리 크지 않습니다. 잠재적인 이유는 LRS3와 VoxCeleb2에서 훈련된 AV-HuBERT를 사용하고 Whisper-Flamingo를 훈련하는 동안 가중치를 업데이트하지 않기 때문일 수 있습니다. 향후 연구는 LRS2에서 Whisper-Flamingo의 노이즈 강인성을 향상시키는 데 더 많은 주의를 기울여야 합니다.
8.4. Analysis of Gated Cross Attention Position
Table A4는 gated cross attention 레이어를 Whisper에 삽입할 위치에 대한 분석을 보여줍니다. transformer 디코더 및 인코더 블록의 레이어 순서는 Figure 1을 참조하십시오. 먼저 Whisper의 디코더 블록에서 가능한 모든 위치를 시도했으며 각 블록의 시작 부분이 가장 잘 작동한다는 것을 발견했습니다( noisy AVSR WER), 비록 각 블록의 MLP 이후도 잘 작동했지만(5.7% noisy AVSR WER). 그런 다음 Whisper의 디코더와 인코더 블록 모두에 레이어를 삽입하려고 시도했지만 추가적인 이득은 없었습니다.
8.5. Analysis of Training With and Without Noise
Table A5는 LRS3 433h에서 노이즈 유무에 따라 Whisper-Large를 fine-tuning하고 Whisper-Flamingo를 학습하는 전체 분석을 보여줍니다. 결과는 Table 3과 동일하며 audio-visual Whisper-Flamingo에 대한 추가 결과가 포함되어 있습니다. 먼저 오디오 전용 Whisper 기준 모델을 제시합니다: zero-shot(fine-tuning 없음), 노이즈 없이 fine-tuned, 노이즈와 함께 fine-tuned. 빔 크기 1(greedy)과 15의 빔 검색을 사용한 결과를 보고합니다. Whisper-Flamingo audio-visual 학습의 경우, 세 가지 Whisper 모델 각각을 사용하여 모델을 초기화하고 새로운 gated cross attention 레이어를 추가합니다. 그런 다음 노이즈 유무에 따라 WhisperFlamingo를 학습합니다. 핵심 내용은 다음과 같습니다. 첫째, Whisper zero-shot에서 Whisper-Flamingo를 초기화하는 것은 잘 작동하지 않습니다. 깨끗한 오디오에서 테스트하더라도 성능이 좋지 않습니다. 우리는 Whisper-Flamingo가 효과적으로 작동하기 위해 세 가지 문제를 해결해야 한다고 생각합니다: 1. 노이즈가 있는 오디오를 처리해야 하고, 2. 특정 관심 도메인(Ted 강연)에 적응해야 하며, 3. 새로운 modality(시각적 특징)를 통합해야 합니다. 이 세 가지 작업을 모두 해결하는 것은 Whisper를 fine-tuning하지 않고 Whisper-Flamingo에게 너무 어려울 수 있습니다. Whisper를 fine-tuning하면 처음 두 문제를 해결하고 Whisper-Flamingo가 시각적 특징에 적응하는 데 집중할 수 있게 됩니다. 다음으로, 깨끗한 오디오(노이즈 없이)에서 학습된 Whisper-Flamingo의 경우, 노이즈 없이 fine-tuned된 Whisper 또는 노이즈와 함께 fine-tuned된 Whisper에서 초기화하면 모두 좋은 깨끗한 AVSR WER을 달성합니다(각각 및 WER). 흥미롭게도 Whisper-Flamingo는 해당 fine-tuned 오디오 전용 Whisper보다 항상 더 나은 노이즈 WER을 달성하며, 이는 오디오와 비디오 modality를 모두 사용하는 이점을 보여줍니다. 마지막으로, 노이즈가 있는 오디오에서 학습된 Whisper-Flamingo의 경우, 노이즈와 함께 fine-tuned된 Whisper에서 초기화하는 것이 노이즈 없이 fine-tuned된 Whisper에서 초기화하는 것보다 더 나은 성능을 보입니다. 전자는 AVSR WER을 달성하는 반면 후자는 8.5% AVSR WER을 달성합니다. 전반적으로, 노이즈와 함께 학습된 Whisper-Flamingo는 최고의 노이즈 WER()을 달성하고 최고의 fine-tuned Whisper 모델의 깨끗한 WER(1.0% WER)과 일치합니다.