wav2vec 2.0: 자기 지도 학습(Self-Supervised Learning)을 통한 음성 표현의 혁신
wav2vec 2.0은 음성 오디오만으로 강력한 표현을 학습한 후, 전사된 데이터로 미세 조정하여 기존의 반지도 학습(semi-supervised) 방법을 능가하는 프레임워크입니다. 이 모델은 잠재 공간(latent space)에서 음성 입력을 마스킹하고, 공동으로 학습된 잠재 표현의 양자화(quantization)를 통해 정의된 Contrastive loss를 해결합니다. 이 방식은 Transformer를 사용하여 문맥화된 표현을 구축하며, 단 10분의 레이블 데이터만으로도 초저자원 음성 인식의 가능성을 입증했습니다. 논문 제목: wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
논문 요약: wav2vec 2.0: 자기 지도 학습(Self-Supervised Learning)을 통한 음성 표현의 혁신
- 논문 링크: https://arxiv.org/abs/2006.11477
- 저자: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli (Facebook AI)
- 발표 시기: 2020년, NeurIPS
- 주요 키워드: 음성 인식(ASR), 자기 지도 학습(Self-Supervised Learning), Transformer, 음성 표현 학습
1. 연구 배경 및 문제 정의
- 문제 정의:
대부분의 언어에서 음성 인식 시스템 구축에 필요한 수천 시간의 전사(transcribed)된 음성 데이터 확보가 어렵습니다. 이는 전 세계 약 7,000개 언어 중 대다수에 음성 인식 기술이 보급되지 못하는 주요 원인입니다. - 기존 접근 방식:
기존의 반지도 학습(semi-supervised learning) 방식은 여전히 많은 양의 레이블링된 데이터를 요구하거나, 이산 단위를 학습한 후 문맥화된 표현을 학습하는 2단계 파이프라인에 의존했습니다. 이는 개념적으로 복잡하고 효율성 측면에서 한계를 가졌습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 음성 오디오만으로 강력한 표현을 자기 지도 학습 방식으로 학습한 후, 전사된 데이터로 미세 조정하여 기존의 반지도 학습 방법을 능가하는 프레임워크를 제안했습니다.
- 단 10분이라는 극히 적은 양의 레이블링된 데이터만으로도 높은 성능의 음성 인식이 가능함을 입증하여 초저자원 언어에 대한 ASR 가능성을 제시했습니다.
- 연속적인 음성 표현에 대해 Transformer를 사용하여 문맥화된 표현을 구축하고, 동시에 이산적인 음성 단위를 공동으로 학습하는 종단간(end-to-end) 방식을 제안했습니다.
- 제안 방법:
wav2vec 2.0은 크게 특징 인코더(Feature Encoder), 양자화 모듈(Quantization Module), 문맥 네트워크(Context Network, Transformer 기반)로 구성됩니다. 원시 음성 오디오를 특징 인코더로 인코딩한 후, 생성된 잠재 음성 표현(latent speech representation)의 일부 구간을 마스킹합니다. 마스킹된 구간에 대해 공동으로 학습된 잠재 표현의 양자화(quantization)를 통해 정의된 대조 학습(Contrastive Loss)을 해결하여 모델을 사전 학습합니다. 이때, 양자화된 잠재 표현의 사용을 균등하게 장려하기 위한 다양성 손실(Diversity Loss)도 함께 사용됩니다. 사전 학습 후에는 레이블링된 데이터에 대해 CTC(Connectionist Temporal Classification) 손실을 사용하여 음성 인식 작업을 위해 미세 조정(fine-tuning)됩니다.
3. 실험 결과
- 데이터셋:
사전 학습에는 Librispeech (LS-960, 960시간) 및 LibriVox (LV-60k, 53.2k 시간)의 레이블링되지 않은 음성 데이터를 사용했습니다. 미세 조정에는 Librispeech의 다양한 레이블링된 하위 집합 (10분, 1시간, 10시간, 100시간, 960시간)과 TIMIT 데이터셋을 사용했습니다. - 주요 결과:
- 단 10분의 레이블링된 데이터만으로도 Librispeech test-clean/other 세트에서 4.8/8.2 WER(단어 오류율)을 달성하여 초저자원 음성 인식의 가능성을 입증했습니다.
- 1시간의 레이블링된 데이터만으로도 기존 최첨단 self-training 방법(Noisy Student)보다 100배 적은 레이블 데이터로 더 우수한 성능을 보였습니다 (test-clean/other 3.9/7.6 WER).
- 전체 Librispeech 960시간 레이블링된 데이터를 사용했을 때, test-clean/other 세트에서 1.8/3.3 WER을 달성하여 새로운 최첨단 성능을 기록했습니다.
- TIMIT 음소 인식에서도 8.3 PER(음소 오류율)을 달성하며 새로운 최첨단 성능을 수립했습니다.
- 연속적인 입력과 양자화된 타겟을 사용하는 방식이 가장 좋은 성능을 보였으며, 이는 이전 연구의 한계를 극복한 핵심 요소임을 입증했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
자기 지도 학습을 통해 극히 적은 양의 레이블링된 데이터만으로도 높은 성능의 음성 인식 모델을 구축할 수 있다는 점이 가장 인상 깊습니다. 이는 데이터 부족 문제로 인해 음성 인식 기술이 적용되기 어려웠던 수많은 저자원 언어에 대한 가능성을 열어줍니다. - 단점/한계:
현재 모델은 CTC 손실과 문자 기반 어휘를 사용하고 있어, seq2seq 아키텍처나 단어 조각(word piece) 어휘를 적용하면 추가적인 성능 향상이 가능할 것으로 보입니다. 또한, 데이터 균형 조정이나 self-training과의 결합을 통해 더 나은 결과를 얻을 수 있을 것입니다. - 응용 가능성:
음성 인식 기술이 부족한 전 세계 수천 개의 저자원 언어 및 방언에 대한 음성 인식 시스템 구축에 크게 기여할 수 있습니다. 이는 언어 다양성 보존 및 디지털 접근성 향상에 중요한 역할을 할 것입니다.
Baevski, Alexei, et al. "wav2vec 2.0: A framework for self-supervised learning of speech representations." Advances in neural information processing systems 33 (2020): 12449-12460.
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
Alexei Baevski Henry Zhou Abdelrahman Mohamed Michael Auli<br>{abaevski,henryzhou7,abdo,michaelauli}@fb.com
Facebook AI
Abstract
우리는 speech audio만으로 강력한 representation을 학습한 후 전사된 speech에 대해 fine-tuning하는 것이 개념적으로 더 간단하면서도 최고의 준지도(semi-supervised) 방법을 능가할 수 있음을 처음으로 보여줍니다. wav2vec 2.0은 latent 공간에서 speech 입력을 마스킹하고, 공동으로 학습되는 latent representation의 양자화(quantization)를 통해 정의된 contrastive task를 해결합니다. Librispeech의 모든 레이블링된 데이터를 사용한 실험은 clean/other 테스트 세트에서 1.8/3.3 WER을 달성합니다. 레이블링된 데이터의 양을 1시간으로 줄였을 때, wav2vec 2.0은 100배 더 적은 레이블링된 데이터를 사용하면서 100시간 부분 집합에서 이전의 최첨단 기술을 능가합니다. 단 10분의 레이블링된 데이터를 사용하고 53k 시간의 레이블링되지 않은 데이터에 대해 pre-training을 해도 여전히 4.8/8.2 WER을 달성합니다. 이는 제한된 양의 레이블링된 데이터로 speech recognition이 가능함을 보여줍니다 1
1 Introduction
신경망은 대량의 레이블링된 훈련 데이터로부터 이점을 얻습니다. 그러나 많은 환경에서 레이블링된 데이터는 레이블링되지 않은 데이터보다 훨씬 얻기 어렵습니다. 현재의 speech recognition 시스템은 수용 가능한 성능에 도달하기 위해 수천 시간의 전사된 speech가 필요하며, 이는 전 세계적으로 사용되는 거의 7,000개 언어 대다수에서는 사용할 수 없습니다 [31]. 레이블링된 예제만으로 학습하는 것은 인간의 언어 습득 과정과 유사하지 않습니다. 유아는 주변 어른들의 말을 들으면서 언어를 배우며, 이 과정은 speech의 좋은 representation을 학습하는 것을 필요로 합니다.
기계 학습에서, self-supervised learning은 레이블링되지 않은 예제로부터 일반적인 데이터 representation을 배우고, 레이블링된 데이터에 모델을 fine-tune하는 패러다임으로 부상했습니다. 이는 특히 자연어 처리에서 성공적이었으며[43, 45, 9], 컴퓨터 비전 분야에서도 활발한 연구 분야입니다[20, 2, 36, 19, 6]. 이 논문에서 우리는 원시 audio 데이터로부터 representation을 학습하기 위한 self-supervised learning 프레임워크를 제시합니다. 우리의 접근 방식은 다층 convolutional 신경망을 통해 speech audio를 인코딩한 다음, 그 결과로 생성된 latent speech representation의 일부 구간을 마스킹합니다 [26, 56]. 이는 masked language modeling [9]과 유사합니다. latent representation은 Transformer 네트워크에 입력되어 문맥화된 representation을 구축하고, 모델은 참인 latent를 방해 요소(distractors)와 구별해야 하는 contrastive task를 통해 훈련됩니다 [54, 49, 48, 28] (§ 2). 훈련의 일부로, 우리는 contrastive task에서 latent representation을 나타내기 위해 gumbel softmax [24, 5]를 통해 이산적인 speech 단위[53, 32, 7, 18]를 학습합니다 (그림 1). 우리는 이것이 양자화되지 않은 타겟보다 더 효과적이라는 것을 발견했습니다. 레이블링되지 않은 speech에 대한 pre-training 후, 모델은 다운스트림 speech recognition 작업을 위해 Connectionist Temporal Classification (CTC) 손실[14, 4]을 사용하여 레이블링된 데이터에 fine-tuning됩니다 (§ 3).
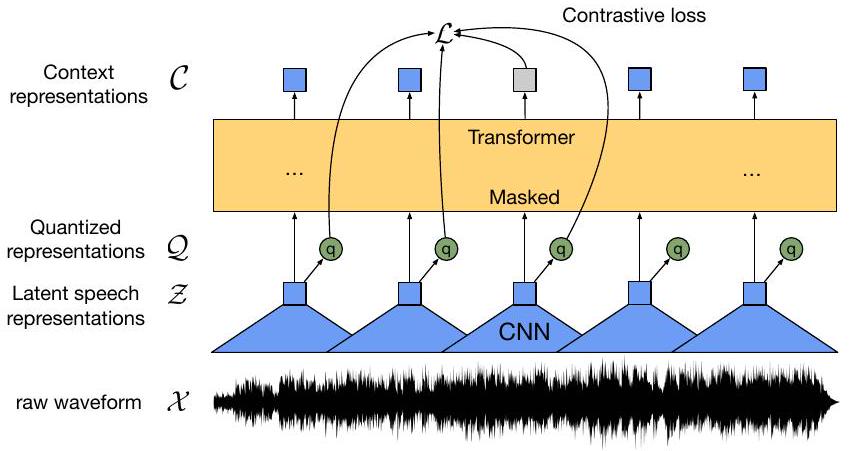
Figure 1: 문맥화된 speech representation과 이산화된 speech 단위의 목록을 공동으로 학습하는 우리 프레임워크의 그림입니다.
이전 연구는 데이터의 양자화를 학습한 후 self-attention 모델로 문맥화된 representation을 학습했지만[5, 4], 우리의 접근 방식은 두 문제를 종단간(end-to-end)으로 해결합니다. speech에 대해 Transformer 네트워크로 입력의 일부를 마스킹하는 것은 탐구되었지만[4, 26], 이전 연구는 2단계 파이프라인에 의존하거나 필터 뱅크 입력 특징을 재구성하여 모델을 훈련시켰습니다. 다른 관련 연구로는 입력 데이터를 auto-encoding하거나[52, 11] 미래의 타임스텝을 직접 예측하여 representation을 학습하는 것이 있습니다[8]. 우리의 결과는 이산적인 speech 단위를 문맥화된 representation과 공동으로 학습하는 것이 이전 단계에서 학습된 고정된 단위보다 훨씬 더 나은 결과를 달성함을 보여줍니다[4]. 우리는 또한 초저자원 speech recognition의 실현 가능성을 보여줍니다: 단 10분의 레이블링된 데이터를 사용할 때, 우리의 접근 방식은 Librispeech의 clean/other 테스트 세트에서 단어 오류율(WER) 4.8/8.2를 달성합니다. 우리는 TIMIT 음소 인식뿐만 아니라 Librispeech의 100시간 clean 부분 집합에서 새로운 최첨단 기술을 수립했습니다. 더욱이, 레이블링된 데이터의 양을 단 1시간으로 줄였을 때, 우리는 [42]의 이전 최첨단 self-training 방법보다 100배 적은 레이블링된 데이터와 동일한 양의 레이블링되지 않은 데이터를 사용하면서도 더 나은 성능을 보입니다. Librispeech의 모든 960시간의 레이블링된 데이터를 사용할 때, 우리 모델은 1.8/3.3 WER을 달성합니다(§ 4, § 5).
2 Model
우리 모델은 원시 audio 를 입력으로 받아 타임스텝에 대한 latent speech representation 를 출력하는 다층 컨볼루션 특징 인코더 로 구성됩니다. 이들은 전체 시퀀스로부터 정보를 포착하는 representation 를 구축하기 위해 Transformer 에 입력됩니다[9, 5, 4]. 특징 인코더의 출력은 self-supervised 목적 함수(§ 3.2)에서 타겟을 나타내기 위해 양자화 모듈 를 사용하여 로 이산화됩니다(그림 1). vq-wav2vec [5]와 비교하여, 우리 모델은 연속적인 speech representation에 대해 문맥 representation을 구축하고 self-attention은 latent representation의 전체 시퀀스에 대한 종속성을 종단간(end-to-end)으로 포착합니다.
Feature encoder. 인코더는 시간적 컨볼루션(temporal convolution)과 그 뒤를 잇는 layer normalization [1] 및 GELU 활성화 함수 [21]를 포함하는 여러 블록으로 구성됩니다. 인코더에 입력되는 원시 파형은 평균이 0이고 단위 분산이 되도록 정규화됩니다. 인코더의 총 스트라이드(stride)는 Transformer에 입력되는 타임스텝 의 수를 결정합니다().
Contextualized representations with Transformers. 특징 인코더의 출력은 Transformer 아키텍처를 따르는 문맥 네트워크(context network)에 입력됩니다[55, 9, 33]. 절대적인 위치 정보를 인코딩하는 고정된 위치 임베딩 대신, 우리는 [37, 4, 57]과 유사한 컨볼루션 레이어를 사용하여 상대적 위치 임베딩 역할을 하도록 합니다. 우리는 GELU를 통과한 컨볼루션의 출력을 입력에 더한 다음 layer normalization을 적용합니다.
Quantization module. self-supervised 훈련을 위해 우리는 특징 인코더 z의 출력을 product quantization [25]을 통해 유한한 집합의 speech representation으로 이산화합니다. 이 선택은 이전 연구에서 좋은 결과를 가져왔으며, 이전 연구에서는 첫 단계에서 이산 단위를 학습하고 그 다음에 문맥화된 representation을 학습했습니다[5]. Product quantization은 여러 코드북 또는 그룹에서 양자화된 representation을 선택하고 이를 연결하는 것에 해당합니다. 개의 코드북(그룹)과 개의 항목 가 주어졌을 때, 우리는 각 코드북에서 하나의 항목을 선택하고 결과 벡터 를 연결한 후 선형 변환 를 적용하여 를 얻습니다.
Gumbel softmax는 완전히 미분 가능한 방식으로 이산 코드북 항목을 선택할 수 있게 합니다[16, 24, 35]. 우리는 straight-through 추정기[26]를 사용하고 개의 하드 Gumbel softmax 연산을 설정합니다[24]. 특징 인코더 출력 는 로짓 에 매핑되고, 그룹 에 대해 번째 코드북 항목을 선택할 확률은 다음과 같습니다.
여기서 는 음이 아닌 온도이고, 이며 는 에서 균일하게 샘플링됩니다. 순전파(forward pass) 동안, 코드워드 는 에 의해 선택되고, 역전파(backward pass)에서는 Gumbel softmax 출력의 실제 그래디언트가 사용됩니다.
3 Training
모델을 pre-train하기 위해 우리는 BERT [9]의 masked language modeling과 유사하게 latent 특징 인코더 공간(§ 3.1)에서 특정 비율의 타임스텝을 마스킹합니다. 훈련 목표는 각 마스킹된 타임스텝(§ 3.2)에 대해 방해 요소 집합에서 올바른 양자화된 latent audio representation을 식별하는 것이며, 최종 모델은 레이블링된 데이터(§ 3.3)에 fine-tuning됩니다.
3.1 Masking
우리는 특징 인코더 출력, 즉 타임스텝의 일부를 문맥 네트워크에 공급하기 전에 마스킹하고, 이를 모든 마스킹된 타임스텝 간에 공유되는 훈련된 특징 벡터로 대체합니다; 양자화 모듈에 대한 입력은 마스킹하지 않습니다. 인코더에서 출력된 latent speech representation을 마스킹하기 위해, 우리는 모든 타임스텝의 특정 비율 를 시작 인덱스로 무작위로 복원 없이 샘플링한 다음, 샘플링된 각 인덱스에서 후속 개의 연속 타임스텝을 마스킹합니다; 구간은 겹칠 수 있습니다.
3.2 Objective
pre-training 동안, 우리는 마스킹된 타임스텝에 대한 실제 양자화된 latent speech representation을 방해 요소 집합 내에서 식별해야 하는 contrastive task 을 해결하여 speech audio의 representation을 학습합니다. 이는 모델이 코드북 항목을 동등하게 사용하도록 장려하기 위한 코드북 다양성 손실 에 의해 보강됩니다.
여기서 는 조정된 하이퍼파라미터입니다. Contrastive Loss. 마스킹된 타임스텝 를 중심으로 하는 문맥 네트워크 출력 가 주어지면, 모델은 와 개의 방해 요소를 포함하는 개의 양자화된 후보 representation 집합에서 실제 양자화된 latent speech representation 를 식별해야 합니다[23, 54]. 방해 요소는 동일한 발화의 다른 마스킹된 타임스텝에서 균일하게 샘플링됩니다. 손실은 다음과 같이 정의됩니다.
여기서 우리는 문맥 representation과 양자화된 latent speech representation 사이의 코사인 유사도 를 계산합니다[19, 6].
Diversity Loss. contrastive task는 긍정 및 부정 예제를 모두 나타내기 위해 코드북에 의존하며, 다양성 손실 는 양자화된 코드북 representation의 사용을 증가시키도록 설계되었습니다[10]. 우리는 발화 배치에 걸쳐 각 코드북 에 대한 코드북 항목의 평균 softmax 분포 l의 엔트로피를 최대화함으로써 개의 코드북 각각에서 개의 항목을 동등하게 사용하도록 장려합니다; softmax 분포는 gumbel 노이즈나 온도를 포함하지 않습니다
3.3 Fine-tuning
pre-trained 모델은 speech recognition을 위해 fine-tuning되며, 문맥 네트워크 위에 작업의 어휘를 나타내는 개의 클래스로 무작위로 초기화된 선형 투영을 추가합니다[4]. Librispeech의 경우, 문자 타겟을 위한 29개의 토큰과 단어 경계 토큰이 있습니다. 모델은 CTC 손실[14]을 최소화하여 최적화되며, 우리는 훈련 중에 타임스텝과 채널에 마스킹을 적용하여 SpecAugment [41]의 수정된 버전을 적용합니다. 이는 과적합을 지연시키고 특히 레이블링된 예제가 거의 없는 Libri-light 부분 집합에서 최종 오류율을 크게 향상시킵니다.
4 Experimental Setup
4.1 Datasets
레이블링되지 않은 데이터로는 960시간의 audio(LS-960)를 포함하는 Librispeech 코퍼스 [40] 또는 LibriVox(LV-60k)의 audio 데이터를 고려합니다. 후자의 경우, [27]의 전처리 과정을 따라 53.2k 시간의 audio를 얻습니다. 우리는 5가지 레이블링된 데이터 설정에서 fine-tune합니다: 960시간의 전사된 Librispeech, 100시간을 포함하는 train-clean-100 부분 집합(100시간 레이블링됨), 그리고 원래 Librispeech에서 추출된 Libri-light의 제한된 자원 훈련 부분 집합들, 즉 train-10h(10시간 레이블링됨), train-1h(1시간 레이블링됨), train-10min(10분 레이블링됨)입니다. 우리는 이러한 분할에 대해 Libri-light의 평가 프로토콜을 따르고 표준 Librispech dev-other/clean 및 test-clean/other 세트에서 평가합니다.
우리는 TIMIT 데이터셋[13]에서 음소 인식을 위해 사전 훈련된 모델을 미세 조정합니다. 이 데이터셋은 상세한 음소 레이블이 있는 5시간 분량의 오디오 녹음을 포함합니다. 우리는 표준 훈련, 개발, 테스트 분할을 사용하고 음소 레이블을 39개 클래스로 축소하는 표준 프로토콜을 따릅니다.
4.2 Pre-training
모델은 fairseq [39]에서 구현됩니다. 마스킹을 위해, 우리는 모든 타임스텝의 를 시작 인덱스로 샘플링하고 후속 타임스텝을 마스킹합니다. 이로 인해 모든 타임스텝의 약 가 마스킹되고 평균 구간 길이는 14.7, 즉 299ms가 됩니다(마스킹에 대한 자세한 내용은 부록 A 참조). 특징 인코더는 7개의 블록을 포함하며 각 블록의 시간적 컨볼루션은 512개의 채널, 스트라이드 ( ) 및 커널 너비 ( )를 가집니다. 이로 인해 인코더 출력 주파수는 49Hz이며 각 샘플 사이의 스트라이드는 약 20ms이고 수용 필드는 400개의 입력 샘플 또는 25ms의 오디오입니다. 상대적 위치 임베딩을 모델링하는 컨볼루션 레이어는 커널 크기 128과 16개의 그룹을 가집니다. 우리는 동일한 인코더 아키텍처를 사용하지만 Transformer 설정이 다른 두 가지 모델 구성으로 실험합니다: BASE는 12개의 transformer 블록, 모델 차원 768, 내부 차원(FFN) 3,072, 8개의 어텐션 헤드를 포함합니다. 배치는 각 예제에서 250k 오디오 샘플 또는 15.6초를 잘라내어 구성됩니다. 잘라낸 샘플들은 GPU당 1.4m 샘플을 초과하지 않도록 배치로 묶이며, 총 64개의 V100 GPU에서 1.6일 동안 훈련합니다[38]; 총 배치 크기는 1.6시간입니다. Large 모델은 24개의 transformer 블록, 모델 차원 1,024, 내부 차원 4,096, 16개의 어텐션 헤드를 포함합니다. 우리는 GPU당 1.2m 샘플 제한으로 320k 오디오 샘플 또는 20초를 잘라내고, Librispeech의 경우 128개의 V100 GPU에서 2.3일 동안, LibriVox의 경우 5.2일 동안 훈련합니다; 총 배치 크기는 2.7시간입니다. 우리는 Transformer, 특징 인코더의 출력, 양자화 모듈의 입력에 dropout 0.1을 사용합니다. 레이어는 BASE의 경우 0.05, LARGE의 경우 0.2의 비율로 드롭됩니다[22, 12]; LV-60k의 경우 레이어 드롭은 없습니다.
2우리는 Adam [29]으로 최적화하며, 업데이트의 첫 8% 동안 학습률을 BASE의 경우 , LARGE의 경우 의 피크까지 워밍업한 다음 선형적으로 감소시킵니다. LARGE는 250k 업데이트, BASE는 400k 업데이트, LV-60k의 LARGE는 600k 업데이트 동안 훈련합니다. 다양성 손실 방정식 2에 대해 가중치 을 사용합니다. 양자화 모듈에 대해 우리는 두 모델 모두 및 을 사용하여 이론적 최대 102.4k 코드워드를 생성합니다. 항목의 크기는 BASE의 경우 , LARGE의 경우 입니다. Gumbel softmax 온도 는 매 업데이트마다 0.999995의 비율로 2에서 최소 0.5(BASE) 및 0.1(LARGE)로 어닐링됩니다. 대조 손실(방정식 3)의 온도는 로 설정됩니다. 더 작은 Librispeech 데이터셋의 경우, 특징 인코더의 최종 레이어 활성화에 L2 페널티를 적용하고 인코더의 그래디언트를 10배로 축소하여 모델을 정규화합니다. 또한 레이어 정규화를 사용하지 않고 원시 파형을 정규화하는 대신 첫 번째 인코더 레이어의 출력을 정규화하는 약간 다른 인코더 아키텍처를 사용합니다. 대조 손실에서는 개의 방해 요소를 사용합니다. 검증 세트에서 가장 낮은 을 가진 훈련 체크포인트를 선택합니다.
4.3 Fine-tuning
pre-training 후, 우리는 레이블이 지정된 데이터에 학습된 representation을 fine-tune하고, Transformer 위에 무작위로 초기화된 출력 레이어를 추가하여 문자(Librispeech/Libri-light) 또는 음소(TIMIT)를 예측합니다. Libri-light의 경우, 모든 부분 집합에 대해 두 가지 다른 학습률( 및 )로 세 개의 시드(seed)를 훈련하고, 공식 4-gram 언어 모델(LM)과 빔 50, 고정된 모델 가중치(LM 가중치 2, 단어 삽입 페널티 -1)로 디코딩했을 때 dev-other 부분 집합에서 가장 낮은 WER을 보인 구성을 선택합니다. 레이블이 지정된 960h 부분 집합의 BASE에 대해서는 의 학습률을 사용합니다.
우리는 Adam과 3단계 비율 스케줄로 최적화합니다. 학습률은 업데이트의 처음 10% 동안 워밍업되고, 다음 40% 동안 일정하게 유지된 다음, 나머지 기간 동안 선형적으로 감소합니다. BASE는 GPU당 3.2m 샘플의 배치 크기를 사용하고 8개의 GPU에서 fine-tune하여 총 배치 크기는 1,600초가 됩니다. Large는 각 GPU에서 1.28m 샘플을 배치하고 24개의 GPU에서 fine-tune하여 유효 배치 크기는 1,920초가 됩니다. 처음 10k 업데이트 동안에는 출력 분류기만 훈련되고, 그 이후에는 Transformer도 업데이트됩니다. 특징 인코더는 fine-tuning 중에 훈련되지 않습니다. 우리는 부록 B에 자세히 설명된 SpecAugment [41]와 유사한 전략으로 특징 인코더 representation을 마스킹합니다.
4.4 Language Models and Decoding
우리는 두 가지 유형의 언어 모델(LM)을 고려합니다: 4-gram 모델과 Librispeech LM 코퍼스에서 훈련된 Transformer [3]입니다. Transformer LM은 [51]과 동일하며 20개의 블록, 모델 차원 1,280, 내부 차원 6,144 및 16개의 어텐션 헤드를 포함합니다. 우리는 베이지안 최적화 를 통해 언어 모델의 가중치(간격 )와 단어 삽입 페널티()를 조정합니다: 4-gram LM에 대해 빔 500으로 128번의 시도를 실행하고 Transformer LM에 대해 빔 50으로 실행하며, dev-other에서의 성능에 따라 최상의 가중치 세트를 선택합니다. 테스트 성능은 n-gram LM의 경우 빔 1,500, Transformer LM의 경우 빔 500으로 측정됩니다. 우리는 [44]의 빔 검색 디코더를 사용합니다.
5 Results
5.1 Low-Resource Labeled Data Evaluation
먼저, 레이블링되지 않은 데이터에서 학습된 representation이 저자원 환경을 어떻게 개선할 수 있는지 파악하기 위해 레이블링된 데이터의 양이 제한된 환경에서 사전 훈련된 모델을 평가합니다. 사전 훈련된 모델이 speech의 구조를 포착한다면, speech recognition을 위해 fine-tune하는 데 적은 레이블링된 예제만 필요할 것입니다. 모델은 Librispeech(LS-960) 또는 LibriVox(LV-60k)의 오디오 데이터에 대해 사전 훈련되었으며, 대부분의 결과는 Transformer 언어 모델(Transf.)로 디코딩하여 얻었습니다. 부록 C는 언어 모델이 전혀 없는 경우와 n-gram 언어 모델을 사용한 결과를 보여줍니다. LV-60k에서 사전 훈련되고 단 10분의 레이블링된 데이터로 fine-tuning된 LARGE 모델은 Librispeech clean/other 테스트 세트에서 5.2/8.6의 단어 오류율을 달성합니다. 10분의 레이블링된 데이터는 평균 길이가 12.5초인 48개의 녹음 파일에 해당합니다. 이는 레이블링되지 않은 데이터에 대한 self-supervised learning으로 초저자원 speech recognition이 가능하다는 것을 보여줍니다.
Table 1: Libri-light의 저자원 레이블 데이터 설정인 10분, 1시간, 10시간 및 Librispeech의 clean 100h 부분 집합으로 훈련할 때 Librispeech dev/test 세트의 WER. 모델은 레이블 없는 데이터로 Librispeech(LS-960) 또는 더 큰 LibriVox(LV-60k)의 오디오를 사용합니다. 두 가지 모델 크기를 고려합니다: BASE(95m 파라미터) 및 Large(317m 파라미터). 이전 연구에서는 860시간의 레이블 없는 데이터(LS-860)를 사용했지만 레이블 있는 데이터를 포함한 총량은 960시간으로 우리의 설정과 비슷합니다.
| Model | Unlabeled data | LM | dev | test | ||
|---|---|---|---|---|---|---|
| clean | other | clean | other | |||
| 10 min labeled | ||||||
| Discrete BERT [4] | LS-960 | 4-gram | 15.7 | 24.1 | 16.3 | 25.2 |
| BASE | LS-960 | 4-gram | 8.9 | 15.7 | 9.1 | 15.6 |
| Transf. | 6.6 | 13.2 | 6.9 | 12.9 | ||
| Large | LS-960 | Transf. | 6.6 | 10.6 | 6.8 | 10.8 |
| LV-60k | Transf. | 4.6 | 7.9 | 4.8 | 8.2 | |
| 1h labeled | ||||||
| Discrete BERT [4] | LS-960 | 4-gram | 8.5 | 16.4 | 9.0 | 17.6 |
| BASE <br> Large | LS-960 | 4-gram | 5.0 | 10.8 | 5.5 | 11.3 |
| Transf. | 3.8 | 9.0 | 4.0 | 9.3 | ||
| LS-960 | Transf. | 3.8 | 7.1 | 3.9 | 7.6 | |
| LV-60k | Transf. | 2.9 | 5.4 | 2.9 | 5.8 | |
| 10h labeled | ||||||
| Discrete BERT [4] | LS-960 | 4-gram | 5.3 | 13.2 | 5.9 | 14.1 |
| Iter. pseudo-labeling [58] | LS-960 | 4-gram+Transf. | 23.51 | 25.48 | 24.37 | 26.02 |
| LV-60k | 4-gram+Transf. | 17.00 | 19.34 | 18.03 | 19.92 | |
| BASE <br> Large | LS-960 | 4-gram | 3.8 | 9.1 | 4.3 | 9.5 |
| Transf. | 2.9 | 7.4 | 3.2 | 7.8 | ||
| LS-960 | Transf. | 2.9 | 5.7 | 3.2 | 6.1 | |
| LV-60k | Transf. | 2.4 | 4.8 | 2.6 | 4.9 | |
| 100h labeled | ||||||
| Hybrid DNN/HMM [34] | - | 4-gram | 5.0 | 19.5 | 5.8 | 18.6 |
| TTS data augm. [30] | - | LSTM | 4.3 | 13.5 | ||
| Discrete BERT [4] | LS-960 | 4-gram | 4.0 | 10.9 | 4.5 | 12.1 |
| Iter. pseudo-labeling [58] | LS-860 | 4-gram+Transf. | 4.98 | 7.97 | 5.59 | 8.95 |
| LV-60k | 4-gram+Transf. | 3.19 | 6.14 | 3.72 | 7.11 | |
| Noisy student [42] | LS-860 | LSTM | 3.9 | 8.8 | 4.2 | 8.6 |
| BASE | LS-960 | 4-gram | 2.7 | 7.9 | 3.4 | 8.0 |
| Transf. | 2.2 | 6.3 | 2.6 | 6.3 | ||
| Large | LS-960 | Transf. | 2.1 | 4.8 | 2.3 | 5.0 |
| LV-60k | Transf. | 1.9 | 4.0 | 2.0 | 4.0 |
이산 단위와 문맥화된 representation을 공동으로 학습하는 우리의 접근 방식은 별도의 단계에서 양자화된 오디오 단위를 학습한 이전 연구[4]보다 명확하게 개선되어 WER을 약 1/3로 줄였습니다.
최근의 반복적 self-training 접근법[42]은 Librispeech의 clean 100시간 부분집합에서 최첨단을 대표하지만, 레이블링, 필터링, 재훈련의 여러 반복을 필요로 합니다. 우리의 접근법은 더 간단합니다: 레이블링되지 않은 데이터에 대해 pre-train하고 레이블링된 데이터에 대해 fine-tune합니다. Librispeech의 100시간 부분집합에서 그들의 방법은 test-clean/other에서 WER 4.2/8.6을 달성하는데, 이는 동일한 조건의 LARGE 모델에서의 WER 2.3/5.0과 비교되며, 상대적 WER 감소는 입니다. Large 모델이 10배 적은 레이블링된 데이터(10h labeled)를 사용할 때, 여전히 WER 3.2/6.1을 달성하며, 이는 반복적 self-training에 비해 의 오류 감소입니다. 단 1시간의 레이블링된 데이터만을 사용하여 동일한 모델은 WER 3.9/7.6을 달성하며, 이는 100배 적은 레이블링된 데이터로 test-clean과 test-other 모두에서 개선된 것입니다. 우리는 Libri-
Table 2: 모든 960시간의 레이블링된 데이터를 사용할 때의 Librispeech에서의 WER (표 1 참조).
| Model | Unlabeled data | LM | dev | test | ||
|---|---|---|---|---|---|---|
| clean | other | clean | other | |||
| Supervised | ||||||
| CTC Transf [51] | - | CLM+Transf. | 2.20 | 4.94 | 2.47 | 5.45 |
| S2S Transf. [51] | - | CLM+Transf. | 2.10 | 4.79 | 2.33 | 5.17 |
| Transf. Transducer [60] | - | Transf. | - | - | 2.0 | 4.6 |
| ContextNet [17] | - | LSTM | 1.9 | 3.9 | 1.9 | 4.1 |
| Conformer [15] | - | LSTM | 2.1 | 4.3 | 1.9 | 3.9 |
| Semi-supervised | ||||||
| CTC Transf. + PL [51] | LV-60k | CLM+Transf. | 2.10 | 4.79 | 2.33 | 4.54 |
| S2S Transf. + PL [51] | LV-60k | CLM+Transf. | 2.00 | 3.65 | 2.09 | 4.11 |
| Iter. pseudo-labeling [58] | LV-60k | 4-gram+Transf. | 1.85 | 3.26 | 2.10 | 4.01 |
| Noisy student [42] | LV-60k | LSTM | 1.6 | 3.4 | 1.7 | 3.4 |
| This work | ||||||
| LARGE - from scratch | - | Transf. | 1.7 | 4.3 | 2.1 | 4.6 |
| Base | LS-960 | Transf. | 1.8 | 4.7 | 2.1 | 4.8 |
| Large | LS-960 | Transf. | 1.7 | 3.9 | 2.0 | 4.1 |
| LV-60k | Transf. | 1.6 | 3.0 | 1.8 | 3.3 |
light 데이터 분할에는 clean 데이터와 noisy 데이터가 모두 포함되어 있어 test-clean에 비해 test-other에서 더 나은 정확도를 보입니다. 모델 크기를 늘리면 모든 설정에서 WER이 감소하며, test-other에서 가장 큰 개선이 나타납니다(LS-960에서 BASE 대 LARGE). 또한 레이블 없는 훈련 데이터의 양을 늘리는 것도 큰 개선으로 이어집니다(LARGE LS-960 대 LV-60k).
5.2 High-Resource Labeled Data Evaluation on Librispeech
이 섹션에서는 대량의 레이블링된 speech가 사용 가능할 때의 성능을 평가하여 고자원 환경에서 우리 접근법의 효과를 평가합니다. 구체적으로, 이전에 사용한 동일한 모델들을 전체 960시간의 레이블링된 Librispeech에 대해 fine-tune합니다: LS-960에서 pre-trained된 BASE와 LARGE, 그리고 LV-60k에서 pre-trained된 LARGE. 표 2는 우리의 접근 방식이 전체 Librispeech 벤치마크의 test-clean/other에서 WER 1.8/3.3을 달성함을 보여줍니다. 이는 약한 기준 아키텍처에도 불구하고 달성된 결과입니다. 우리의 아키텍처를 supervised training한 결과는 WER 2.1/4.6(LARGE - from scratch)을 달성하는 반면, 최첨단 기술의 기준 아키텍처인 ContextNet[17]은 WER 1.9/4.1을 달성합니다[42]. 우리는 seq2seq 모델[51]만큼 성능이 좋지 않은 CTC를 사용한 간단한 Transformer를 사용합니다. 우리의 음향 모델(문자)의 어휘가 LM(단어)의 어휘와 일치하지 않는다는 점에 유의해야 합니다. 이는 LM으로부터의 피드백을 지연시켜 해로울 가능성이 있습니다. 대부분의 최근 연구[51, 58, 17, 42]는 두 모델 모두에 대해 더 나은 성능을 보이는 단어 조각(word pieces)[50]을 사용합니다. 더욱이, 우리의 결과는 [42]와 같은 데이터 균형 조정 없이 달성되었습니다. 마지막으로, self-training은 pre-training과 상호 보완적일 가능성이 있으며, 이 둘의 조합은 훨씬 더 나은 결과를 낳을 수 있습니다. 부록 E는 다양한 레이블링 데이터 설정에서 우리의 pre-trained 모델에 대한 상세한 오류 분석을 제시합니다.
5.3 Phoneme Recognition on TIMIT
다음으로, 우리는 사전 훈련된 모델을 레이블링된 TIMIT 훈련 데이터에 대해 fine-tuning하여 TIMIT 음소 인식의 정확도를 평가합니다. 우리는 Libri-light의 10시간 하위 집합과 마찬가지로 fine-tuning하지만 언어 모델은 사용하지 않습니다. 표 3은 우리의 접근 방식이 이 데이터셋에서 새로운 최첨단 기술을 달성할 수 있음을 보여주며, dev/test 세트에서 다음으로 좋은 결과에 비해 PER을 상대적으로 감소시킵니다. 부록 D는 이산적인 잠재 speech 표현이 음소와 어떻게 관련되는지에 대한 분석을 보여줍니다. TIMIT에서 평가하는 다른 최근의 사전 훈련 연구로는 speech의 좋은 표현을 학습하기 위해 여러 작업을 해결하는 [47]이 있습니다.
Table 3: 음소 오류율(PER)로 본 TIMIT 음소 인식 정확도.
| dev PER | test PER | |
|---|---|---|
| CNN + TD-filterbanks [59] | 15.6 | 18.0 |
| PASE+ [47] | - | 17.2 |
| Li-GRU + fMLLR [46] | - | 14.9 |
| wav2vec [49] | 12.9 | 14.7 |
| vq-wav2vec [5] | 9.6 | 11.6 |
| This work (no LM) | ||
| LARGE (LS-960) | 7.4 | 8.3 |
Table 4: 세 가지 훈련 시드에 대한 Librispeech의 dev-clean/other 결합 세트의 평균 WER 및 표준 편차. contrastive loss에서 문맥 네트워크 입력과 타겟을 양자화하는 것을 절제합니다.
| avg. WER | std. | |
|---|---|---|
| Continuous inputs, quantized targets (Baseline) | 7.97 | 0.02 |
| Quantized inputs, quantized targets | 12.18 | 0.41 |
| Quantized inputs, continuous targets | 11.18 | 0.16 |
| Continuous inputs, continuous targets | 8.58 | 0.08 |
5.4 Ablations
이전 연구[5, 4]와의 차이점은 우리가 contrastive loss를 위해서만, 즉 latent가 타겟으로 사용될 때만 latent audio representation을 양자화하고, latent가 Transformer 네트워크에 입력될 때는 양자화하지 않는다는 것입니다. 우리는 이 선택을 실험적 전환을 늘리기 위해 축소된 훈련 설정을 채택하는 절제를 통해 동기를 부여합니다: 우리는 LS-960에서 BASE를 마스킹 확률 로 250k 업데이트 동안 pre-train하고, train-10h에서 60k 업데이트 동안 단일 GPU에서 배치당 640k 샘플 또는 40초의 speech audio로 fine-tune합니다. 우리는 fine-tuning의 세 가지 시드에 대해 dev-clean과 dev-other의 연결(dev PER)에 대한 평균 WER과 표준 편차를 보고합니다. 표 4는 양자화된 타겟을 사용한 연속 입력(베이스라인) 전략이 가장 좋은 성능을 보임을 보여줍니다. 연속적인 latent speech representation은 더 나은 문맥 representation을 가능하게 하기 위해 더 많은 정보를 유지하며, 타겟 representation을 양자화하면 더 견고한 훈련으로 이어집니다. 입력과 타겟 모두에서 latent를 양자화하는 것은 가장 성능이 낮았으며, 이는 이전 연구[5, 4]의 낮은 성능을 설명합니다. 연속적인 타겟은 self-supervised 훈련의 효과를 감소시킵니다. 왜냐하면 타겟이 현재 시퀀스의 세부적인 인공물, 예를 들어 화자 및 배경 정보를 포착할 수 있어 작업을 더 쉽게 만들고 모델이 speech recognition에 유익한 일반적인 representation을 배우는 것을 방해하기 때문입니다. 올바른 latent audio representation을 식별하는 훈련 정확도는 양자화된 타겟에서 연속적인 타겟으로 전환할 때 에서 로 증가합니다. 연속적인 입력과 연속적인 타겟은 두 번째로 좋은 성능을 보이지만, 이를 개선하려는 다양한 시도는 더 나은 결과로 이어지지 않았습니다(이 실험 및 다양한 하이퍼파라미터에 대한 다른 절제는 부록 F 참조).
6 Conclusion
우리는 원시 파형의 latent representation을 마스킹하고 양자화된 speech representation에 대한 contrastive task를 해결하는 speech representation의 self-supervised learning을 위한 프레임워크인 wav2vec 2.0을 제시했습니다. 우리의 실험은 speech 처리를 위한 레이블 없는 데이터에 대한 pre-training의 큰 잠재력을 보여줍니다: 평균 12.5초의 48개 녹음, 즉 단 10분의 레이블링된 훈련 데이터만 사용할 때, 우리는 Librispeech의 test-clean/other에서 4.8/8.2의 WER을 달성합니다. 우리 모델은 noisy speech에 대한 전체 Librispeech 벤치마크에서 새로운 최첨단 기술을 달성하는 결과를 얻습니다. clean 100시간 Librispeech 설정에서, wav2vec 2.0은 100배 적은 레이블 데이터를 사용하면서 이전의 최고 결과를 능가합니다. 이 접근 방식은 많은 양의 레이블 데이터가 사용 가능할 때도 효과적입니다. 우리는 seq2seq 아키텍처와 단어 조각 어휘로 전환함으로써 성능 향상을 기대합니다.
Broader Impact
전 세계에는 약 7,000개의 언어와 더 많은 방언이 있습니다. 그러나 대부분의 언어에 대해서는 speech recognition 기술이 존재하지 않습니다. 현재 시스템은 수백 또는 수천 시간의 레이블링된 데이터가 필요한데, 이는 대부분의 언어에서 수집하기 어렵기 때문입니다. 우리는 매우 적은 양의 주석 달린 데이터로도 매우 좋은 정확도의 speech recognition 모델을 구축할 수 있음을 보여주었습니다. 우리의 연구가 더 많은 언어와 방언에 speech recognition 기술을 더 널리 보급하는 데 기여하기를 바랍니다.
Acknowledgments
유용한 논의와 wav2letter 통합에 도움을 주신 Tatiana Likhomanenko와 Qiantong Xu에게 감사드립니다.
References
[1] J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization. arXiv, 2016. [2] P. Bachman, R. D. Hjelm, and W. Buchwalter. Learning representations by maximizing mutual information across views. In Proc. of NeurIPS, 2019. [3] A. Baevski and M. Auli. Adaptive input representations for neural language modeling. In Proc. of ICLR, 2018. [4] A. Baevski, M. Auli, and A. Mohamed. Effectiveness of self-supervised pre-training for speech recognition. arXiv, abs/1911.03912, 2019. [5] A. Baevski, S. Schneider, and M. Auli. vq-wav2vec: Self-supervised learning of discrete speech representations. In Proc. of ICLR, 2020. [6] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. arXiv, abs/2002.05709, 2020. [7] J. Chorowski, R. J. Weiss, S. Bengio, and A. van den Oord. Unsupervised speech representation learning using wavenet autoencoders. arXiv, abs/1901.08810, 2019. [8] Y. Chung, W. Hsu, H. Tang, and J. R. Glass. An unsupervised autoregressive model for speech representation learning. arXiv, abs/1904.03240, 2019. [9] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv, abs/1810.04805, 2018. [10] S. Dieleman, A. van den Oord, and K. Simonyan. The challenge of realistic music generation: modelling raw audio at scale. arXiv, 2018. [11] R. Eloff, A. Nortje, B. van Niekerk, A. Govender, L. Nortje, A. Pretorius, E. Van Biljon, E. van der Westhuizen, L. van Staden, and H. Kamper. Unsupervised acoustic unit discovery for speech synthesis using discrete latent-variable neural networks. arXiv, abs/1904.07556, 2019. [12] A. Fan, E. Grave, and A. Joulin. Reducing transformer depth on demand with structured dropout. In Proc. of ICLR, 2020. [13] J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pallett, and N. L. Dahlgren. The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus CDROM. Linguistic Data Consortium, 1993. [14] A. Graves, S. Fernández, and F. Gomez. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proc. of ICML, 2006. [15] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu, and R. Pang. Conformer: Convolution-augmented transformer for speech recognition. arXiv, 2020. [16] E. J. Gumbel. Statistical theory of extreme values and some practical applications: a series of lectures, volume 33. US Government Printing Office, 1954. [17] W. Han, Z. Zhang, Y. Zhang, J. Yu, C.-C. Chiu, J. Qin, A. Gulati, R. Pang, and Y. Wu. Contextnet: Improving convolutional neural networks for automatic speech recognition with global context. arXiv, 2020. [18] D. Harwath, W.-N. Hsu, and J. Glass. Learning hierarchical discrete linguistic units from visually-grounded speech. In Proc. of ICLR, 2020. [19] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick. Momentum contrast for unsupervised visual representation learning. arXiv, abs/1911.05722, 2019. [20] O. J. Hénaff, A. Razavi, C. Doersch, S. M. A. Eslami, and A. van den Oord. Data-efficient image recognition with contrastive predictive coding. arXiv, abs/1905.09272, 2019. [21] D. Hendrycks and K. Gimpel. Gaussian error linear units (gelus). arXiv, 2016. [22] G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Weinberger. Deep networks with stochastic depth. arXiv, 2016. [23] M. G. A. Hyvärinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proc. of AISTATS, 2010. [24] E. Jang, S. Gu, and B. Poole. Categorical reparameterization with gumbel-softmax. arXiv, abs/1611.01144, 2016. [25] H. Jegou, M. Douze, and C. Schmid. Product quantization for nearest neighbor search. IEEE Trans. Pattern Anal. Mach. Intell., 33(1):117-128, Jan. 2011. [26] D. Jiang, X. Lei, W. Li, N. Luo, Y. Hu, W. Zou, and X. Li. Improving transformer-based speech recognition using unsupervised pre-training. arXiv, abs/1910.09932, 2019. [27] J. Kahn et al. Libri-light: A benchmark for asr with limited or no supervision. In Proc. of ICASSP, 2020. [28] K. Kawakami, L. Wang, C. Dyer, P. Blunsom, and A. van den Oord. Learning robust and multilingual speech representations. arXiv, 2020. [29] D. P. Kingma and J. Ba. Adam: A Method for Stochastic Optimization. In Proc. of ICLR, 2015. [30] A. Laptev, R. Korostik, A. Svischev, A. Andrusenko, I. Medennikov, and S. Rybin. You do not need more data: Improving end-to-end speech recognition by text-to-speech data augmentation. arXiv, abs/2005.07157, 2020. [31] M. P. Lewis, G. F. Simon, and C. D. Fennig. Ethnologue: Languages of the world, nineteenth edition. Online version: http://www.ethnologue.com 2016. [32] A. H. Liu, T. Tu, H. yi Lee, and L. shan Lee. Towards unsupervised speech recognition and synthesis with quantized speech representation learning. arXiv, 2019. [33] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019. [34] C. Lüscher, E. Beck, K. Irie, M. Kitza, W. Michel, A. Zeyer, R. Schlüter, and H. Ney. Rwth asr systems for librispeech: Hybrid vs attention. In Interspeech 2019, 2019. [35] C. J. Maddison, D. Tarlow, and T. Minka. A* sampling. In Advances in Neural Information Processing Systems, pages 3086-3094, 2014. [36] I. Misra and L. van der Maaten. Self-supervised learning of pretext-invariant representations. arXiv, 2019. [37] A. Mohamed, D. Okhonko, and L. Zettlemoyer. Transformers with convolutional context for ASR. arXiv, abs/1904.11660, 2019. [38] M. Ott, S. Edunov, D. Grangier, and M. Auli. Scaling neural machine translation. In Proc. of WMT, 2018. [39] M. Ott, S. Edunov, A. Baevski, A. Fan, S. Gross, N. Ng, D. Grangier, and M. Auli. fairseq: A fast, extensible toolkit for sequence modeling. In Proc. of NAACL System Demonstrations, 2019. [40] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur. Librispeech: an asr corpus based on public domain audio books. In Proc. of ICASSP, pages 5206-5210. IEEE, 2015. [41] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le. Specaugment: A simple data augmentation method for automatic speech recognition. In Proc. of Interspeech, 2019. [42] D. S. Park, Y. Zhang, Y. Jia, W. Han, C.-C. Chiu, B. Li, Y. Wu, and Q. V. Le. Improved noisy student training for automatic speech recognition. arXiv, abs/2005.09629, 2020. [43] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer. Deep contextualized word representations. In Proc. of ACL, 2018. [44] V. Pratap, A. Hannun, Q. Xu, J. Cai, J. Kahn, G. Synnaeve, V. Liptchinsky, and R. Collobert. Wav2letter++: A fast open-source speech recognition system. In Proc. of ICASSP, 2019. [45] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever. Improving language understanding by generative pre-training. https://s3-us-west-2.amazonaws.com/openai-assets/ research-covers/language-unsupervised/language_understanding_paper.pdf. 2018. [46] M. Ravanelli, P. Brakel, M. Omologo, and Y. Bengio. Light gated recurrent units for speech recognition. IEEE Transactions on Emerging Topics in Computational Intelligence, 2(2):92-102, 2018. [47] M. Ravanelli, J. Zhong, S. Pascual, P. Swietojanski, J. Monteiro, J. Trmal, and Y. Bengio. Multi-task self-supervised learning for robust speech recognition. arXiv, 2020. [48] M. Rivière, A. Joulin, P.-E. Mazaré, and E. Dupoux. Unsupervised pretraining transfers well across languages. arXiv, abs/2002.02848, 2020. [49] S. Schneider, A. Baevski, R. Collobert, and M. Auli. wav2vec: Unsupervised pre-training for speech recognition. In Proc. of Interspeech, 2019. [50] M. Schuster and K. Nakajima. Japanese and korean voice search. In Proc. of ICASSP, 2012. [51] G. Synnaeve, Q. Xu, J. Kahn, T. Likhomanenko, E. Grave, V. Pratap, A. Sriram, V. Liptchinsky, and R. Collobert. End-to-end ASR: from Supervised to Semi-Supervised Learning with Modern Architectures. arXiv, abs/1911.08460, 2020. [52] A. Tjandra, B. Sisman, M. Zhang, S. Sakti, H. Li, and S. Nakamura. Vqvae unsupervised unit discovery and multi-scale code2spec inverter for zerospeech challenge 2019. arXiv, 1905.11449, 2019. [53] A. van den Oord, O. Vinyals, et al. Neural discrete representation learning. In Advances in Neural Information Processing Systems, pages 6306-6315, 2017. [54] A. van den Oord, Y. Li, and O. Vinyals. Representation learning with contrastive predictive coding. arXiv, abs/1807.03748, 2018. [55] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In Proc. of NIPS, 2017. [56] W. Wang, Q. Tang, and K. Livescu. Unsupervised pre-training of bidirectional speech encoders via masked reconstruction. arXiv, 2020. [57] F. Wu, A. Fan, A. Baevski, Y. N. Dauphin, and M. Auli. Pay less attention with lightweight and dynamic convolutions. In Proc. of ICLR, 2019. [58] Q. Xu, T. Likhomanenko, J. Kahn, A. Hannun, G. Synnaeve, and R. Collobert. Iterative pseudo-labeling for speech recognition. arXiv, 2020. [59] N. Zeghidour, N. Usunier, I. Kokkinos, T. Schaiz, G. Synnaeve, and E. Dupoux. Learning filterbanks from raw speech for phone recognition. In Proc. of ICASSP, 2018. [60] Q. Zhang, H. Lu, H. Sak, A. Tripathi, E. McDermott, S. Koo, and S. Kumar. Transformer transducer: A streamable speech recognition model with transformer encoders and rnn-t loss. arXiv, 2020.
Appendices
A Masking distribution
마스킹할 타임스텝을 선택할 때, 발화 내 각 latent speech representation은 확률 로 시작 타임스텝 후보로 간주되며, 은 각 타임스텝에서 시작하는 각 마스킹된 구간의 길이입니다. 이 둘은 모두 하이퍼파라미터입니다. 샘플링된 시작 타임스텝은 길이 으로 확장되며 구간은 겹칠 수 있습니다.
15초 길이의 오디오 샘플에 대해 평균 마스크 길이는 14.7 타임스텝이며, 이는 299ms의 오디오에 해당하고, 중앙값은 10 타임스텝, 최대값은 약 100 타임스텝입니다. 샘플의 모든 타임스텝 중 약 49%가 마스킹됩니다. 해당 마스크 길이 분포의 플롯은 그림 2에 나와 있으며, 과 의 제거 실험 및 다른 마스킹 전략의 효과는 표 5에 나와 있습니다. 을 줄이면 self-supervised에 대한 예측 정확도가 증가하지만, 길이가 1인 구간이 마스킹될 때 작업이 사소해져 다운스트림 speech recognition 작업에서 성능이 저하됩니다. 우리는 또한 다른 마스킹 전략을 고려합니다: w/o overlap uniform 은 각 시작 인덱스에 대해 구간 에서 까지의 구간 길이 를 샘플링하고 기존 구간과 겹치지 않도록 후속 타임스텝을 마스킹합니다; poisson 및 normal , )은 포아송 및 정규 분포에서 를 샘플링합니다.
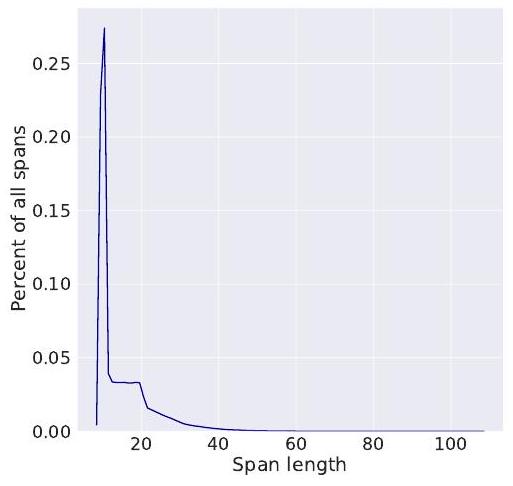
Figure 2: 이고 인 15초 샘플에 대한 마스크 길이 분포.
Table 5: pre-training 중 마스킹 전략 설정에 대한 절제 연구. 중복 없이 마스킹할 때, 우리는 로 시작 타임스텝을 선택하며, 이는 총 마스킹된 토큰 수가 기준선과 일치하도록 합니다.
| avg WER | std | |
|---|---|---|
| Baseline ( ) | 7.97 | 0.02 |
| Mask length | 8.33 | 0.05 |
| Mask length | 8.19 | 0.08 |
| Mask length | 8.43 | 0.19 |
| Mask probability | 7.95 | 0.08 |
| Mask probability | 8.14 | 0.22 |
| Mask w/o overlap, uniform( 1,31 ) | 8.39 | 0.02 |
| Mask w/o overlap, uniform(10,30) | 9.17 | 0.05 |
| Mask w/o overlap, poisson(15) | 8.13 | 0.04 |
| Mask w/o overlap, normal(15, 10) | 8.37 | 0.03 |
| Mask w/o overlap, length 10 | 9.15 | 0.02 |
| Mask w/o overlap, length 15 | 9.43 | 0.26 |
B Fine-tuning Setup
fine-tuning 동안 우리는 SpecAugment [41]와 유사하게 특징 인코더 출력에 마스킹 전략을 적용합니다: 우리는 10개의 연속적인 타임스텝 구간이 마스크 임베딩으로 대체될 시작 타임스텝의 수를 무작위로 선택합니다. 구간은 겹칠 수 있으며 우리는 pre-training과 동일한 마스크된 타임스텝 임베딩을 사용합니다. 우리는 또한 시작 인덱스로 채널 수를 선택한 다음 각각을 확장하여 후속 64개 채널을 덮도록 하여 채널을 마스킹합니다. 구간은 겹칠 수 있으며 선택된 채널 구간은 0 값으로 설정됩니다. 우리는 fine-tuning 동안 BASE의 경우 0.05, LARGE의 경우 0.1의 비율로 LayerDrop [22, 12]을 사용합니다. 표 6은 다른 레이블링된 데이터 설정에 사용된 fine-tuning 하이퍼파라미터 설정을 요약합니다. 표 7은 Librispeech 사전 훈련 모델의 다양한 레이블링된 데이터 설정의 최종 평가에 사용된 디코딩 파라미터를 보여주고 표 8은 LibriVox에 대한 디코딩 파라미터를 보여줍니다.
Table 6: Fine-tuning 하이퍼파라미터
| timestep mask prob. | channel mask prob. | updates | |
|---|---|---|---|
| 10 min | 0.075 | 0.008 | 12 k |
| 1 hour | 0.075 | 0.004 | 13 k |
| 10 hours | 0.065 | 0.004 | 20 k |
| 100 hours | 0.05 | 0.008 | 50 k |
| 960 hours | 0.05 | 0.0016 | 320 k |
| TIMIT | 0.065 | 0.012 | 40 k |
Table 7: Librispeech에서 사전 훈련된 모델에 대한 Librispeech 하위 집합의 디코딩 매개변수
| 4gram LM weight | 4gram word insert. | TransLM weight | TransLM word insert. | |
|---|---|---|---|---|
| 10 min | 3.23 | -0.26 | 1.20 | -1.39 |
| 1 hour | 2.90 | -1.62 | 1.15 | -2.08 |
| 10 hours | 2.46 | -0.59 | 1.06 | -2.32 |
| 100 hours | 2.15 | -0.52 | 0.87 | -1.00 |
| 960 hours | 1.74 | 0.52 | 0.92 | -0.86 |
Table 8: Librivox에서 사전 훈련된 모델에 대한 Librispeech 하위 집합의 디코딩 매개변수.
| 4gram LM weight | 4gram word insert. | TransLM weight | TransLM word insert. | |
|---|---|---|---|---|
| 10 min | 3.86 | -1.18 | 1.47 | -2.82 |
| 1 hour | 3.09 | -2.33 | 1.33 | -0.69 |
| 10 hours | 2.12 | -0.90 | 0.94 | -1.05 |
| 100 hours | 2.15 | -0.52 | 0.87 | -1.00 |
| 960 hours | 1.57 | -0.64 | 0.90 | -0.31 |
C Full results for Libri-light and Librispeech
Table 9: Libri-light 저자원 레이블 데이터 설정으로 훈련 시 Librispeech dev/test 세트의 WER (표 1 참조).
| Model | Unlabeled data | LM | dev | test | ||
|---|---|---|---|---|---|---|
| clean | other | clean | other | |||
| 10 min labeled | ||||||
| BASE | LS-960 | None | 46.1 | 51.5 | 46.9 | 50.9 |
| 4-gram | 8.9 | 15.7 | 9.1 | 15.6 | ||
| Transf. | 6.6 | 13.2 | 6.9 | 12.9 | ||
| Large | LS-960 | None | 43.0 | 46.3 | 43.5 | 45.3 |
| 4-gram | 8.6 | 12.9 | 8.9 | 13.1 | ||
| Transf. | 6.6 | 10.6 | 6.8 | 10.8 | ||
| Large | LV-60k | None | 38.3 | 41.0 | 40.2 | 38.7 |
| 4-gram | 6.3 | 9.8 | 6.6 | 10.3 | ||
| Transf. | 4.6 | 7.9 | 4.8 | 8.2 | ||
| 1h labeled | ||||||
| Base | LS-960 | None | 24.1 | 29.6 | 24.5 | 29.7 |
| 4-gram | 5.0 | 10.8 | 5.5 | 11.3 | ||
| Transf. | 3.8 | 9.0 | 4.0 | 9.3 | ||
| Large | LS-960 | None | 21.6 | 25.3 | 22.1 | 25.3 |
| 4-gram | 4.8 | 8.5 | 5.1 | 9.4 | ||
| Transf. | 3.8 | 7.1 | 3.9 | 7.6 | ||
| Large | LV-60k | None | 17.3 | 20.6 | 17.2 | 20.3 |
| 4-gram | 3.6 | 6.5 | 3.8 | 7.1 | ||
| Transf. | 2.9 | 5.4 | 2.9 | 5.8 | ||
| 10h labeled | ||||||
| Base | LS-960 | None | 10.9 | 17.4 | 11.1 | 17.6 |
| 4-gram | 3.8 | 9.1 | 4.3 | 9.5 | ||
| Transf. | 2.9 | 7.4 | 3.2 | 7.8 | ||
| Large | LS-960 | None | 8.1 | 12.0 | 8.0 | 12.1 |
| 4-gram | 3.4 | 6.9 | 3.8 | 7.3 | ||
| Transf. | 2.9 | 5.7 | 3.2 | 6.1 | ||
| Large | LV-60k | None | 6.3 | 9.8 | 6.3 | 10.0 |
| 4-gram | 2.6 | 5.5 | 3.0 | 5.8 | ||
| Transf. | 2.4 | 4.8 | 2.6 | 4.9 | ||
| 100h labeled | ||||||
| BASE | LS-960 | None | 6.1 | 13.5 | 6.1 | 13.3 |
| 4-gram | 2.7 | 7.9 | 3.4 | 8.0 | ||
| Transf. | 2.2 | 6.3 | 2.6 | 6.3 | ||
| Large | LS-960 | None | 4.6 | 9.3 | 4.7 | 9.0 |
| 4-gram | 2.3 | 5.7 | 2.8 | 6.0 | ||
| Transf. | 2.1 | 4.8 | 2.3 | 5.0 | ||
| Large | LV-60k | None | 3.3 | 6.5 | 3.1 | 6.3 |
| 4-gram | 1.8 | 4.5 | 2.3 | 4.6 | ||
| Transf. | 1.9 | 4.0 | 2.0 | 4.0 |
Table 10: Librispeech의 모든 960시간을 레이블 데이터로 사용할 때 Librispeech의 WER (표 2 참조).
| Model | Unlabeled data | LM | dev | test | ||
|---|---|---|---|---|---|---|
| clean | other | clean | other | |||
| LARGE - from scratch | - | None | 2.8 | 7.6 | 3.0 | 7.7 |
| - | 4-gram | 1.8 | 5.4 | 2.6 | 5.8 | |
| - | Transf. | 1.7 | 4.3 | 2.1 | 4.6 | |
| Base | LS-960 | None | 3.2 | 8.9 | 3.4 | 8.5 |
| 4-gram | 2.0 | 5.9 | 2.6 | 6.1 | ||
| Transf. | 1.8 | 4.7 | 2.1 | 4.8 | ||
| Large | LS-960 | None | 2.6 | 6.5 | 2.8 | 6.3 |
| 4-gram | 1.7 | 4.6 | 2.3 | 5.0 | ||
| Transf. | 1.7 | 3.9 | 2.0 | 4.1 | ||
| Large | LV-60k | None | 2.1 | 4.5 | 2.2 | 4.5 |
| 4-gram | 1.4 | 3.5 | 2.0 | 3.6 | ||
| Transf. | 1.6 | 3.0 | 1.8 | 3.3 |
D Analysis of Discrete Latent Speech Representations
다음으로, 양자화기(quantizer)에 의해 학습된 이산 잠재 음성 표현 가 음성 정보와 관련이 있는지 조사합니다: LV-60k에서 사전 훈련되고 fine-tuning 없이 LARGE를 사용하여 TIMIT의 훈련 데이터에 대한 이산 잠재 표현을 계산하고 인간이 주석을 단 음소와 잠재 표현 간의 동시 발생을 계산합니다. 동점은 의 수용 필드에서 가장 많이 표현되는 음소를 선택하여 해결합니다. 훈련 데이터는 평균 길이 13.6초, 즉 563k개의 이산 잠재 표현을 가진 3696개의 발화를 포함합니다.
그림 3은 를 플롯하며 많은 이산 잠재 표현이 특정 음소 소리에 특화되어 있음을 보여줍니다. 침묵 음소(bcl)는 모든 인간 주석 음성 데이터의 를 차지하므로 여러 다른 잠재 표현에 의해서도 모델링됩니다.
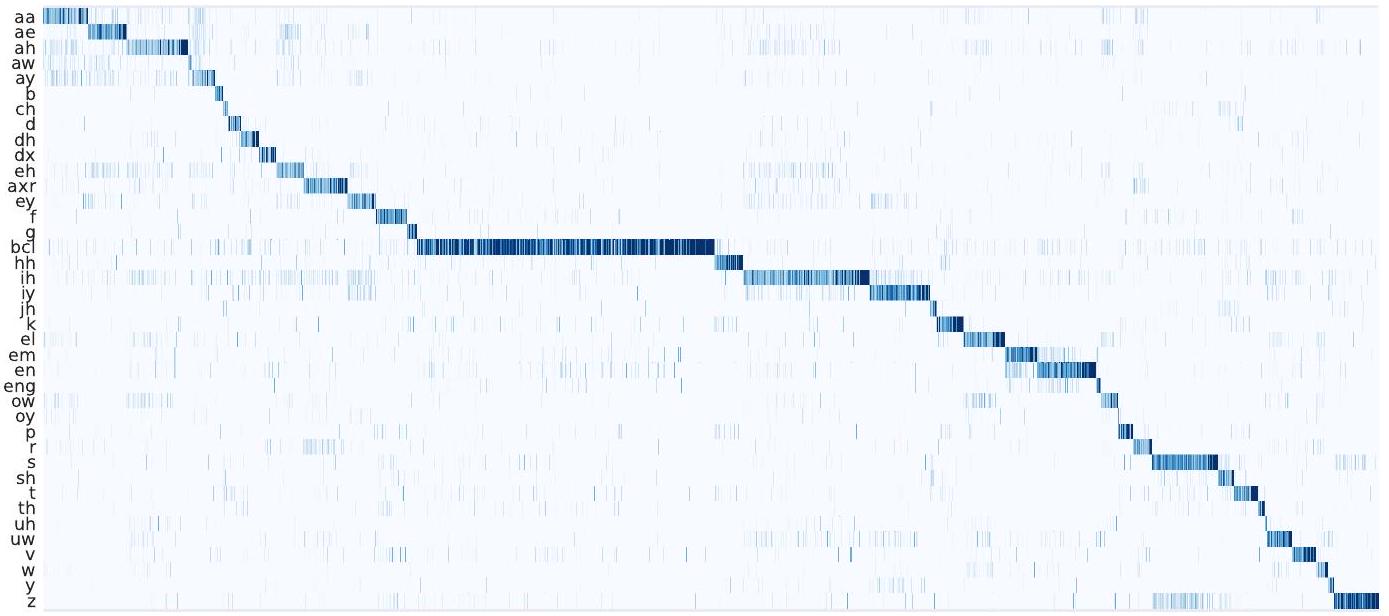
Figure 3: 이산적인 잠재 음성 표현과 음소 간의 동시 발생 시각화. TIMIT 훈련 데이터에서 조건부 확률 를 플롯합니다. y축은 축소된 39개 클래스의 음소를, x축은 다른 이산적인 잠재 표현을 나타냅니다.
E Speech Recognition Error Analysis
이 섹션에서는 다른 양의 레이블링된 데이터로 fine-tuning했을 때 우리 모델이 만드는 가장 흔한 오류를 연구합니다(표 11). 또한 Librispeech의 dev-clean 부분 집합에서 비교적 어려운 몇몇 발화의 전사본을 보여줍니다(표 12). 우리는 어휘집이나 언어 모델 디코딩이 없는 모델을 고려하며, 표 9에서 None으로 표시됩니다. 용량이 클수록 오류율이 감소합니다: LS-960의 LARGE는 dev-clean의 단어 오류율을 BASE에 비해 46.1에서 43으로 향상시킵니다. 레이블 없는 훈련 데이터의 양을 늘리면 LS-960의 LARGE에 대해 오류율이 33.8로 더욱 감소합니다.
10분 레이블 데이터 설정에서, 모델은 여전히 speech의 기본 단위를 인식할 수 있습니다: 표 11은 대부분의 오류가 단어의 철자 주위에 있음을 보여줍니다. 예를 들어, could → coud, know → now와 같은 묵음 문자를 생략하거나, still → stil, little → litle과 같은 반복되는 문자를 무시합니다. LARGE LV-60k 모델은 dev-clean에서 WER 38.3을 달성하며 Transformer 언어 모델을 추가하면 검색 중에 더 가능성 있는 발음을 선택할 수 있어 WER이 5.0으로 크게 향상됩니다. 어휘집과 언어 모델이 없는 10분짜리 모델은 단어를 음성적으로 철자하고 반복되는 글자를 생략하는 경향이 있습니다. 예를 들어, will → wil (표 11). 레이블링된 데이터가 많아질수록 철자 오류가 감소합니다: 1시간의 레이블링된 데이터를 사용하면, heaven과 food와 같이 약간 덜 흔한 단어들이 가장 빈번한 오류 목록으로 이동하며, 음성적으로 철자됩니다. 10시간이 되면, 상위 오류에는 a, the와 같은 관사가 포함되며, 이는 일반적으로 speech recognition에서 흔한 오류의 원인입니다. 또한, color 대 colour와 같은 대체 철자법뿐만 아니라 사람 이름과 같은 비교적 드문 단어들도 여전히 음성적으로 철자됩니다. 예를 들어, phoebe → feeby.
100시간에서는 사람 이름이 가장 빈번한 오류를 지배합니다: phoebe → phebe, 그리고 잘못된 공백 anyone → any one, awhile → a while과 함께. 마지막으로 960시간에서는 단어 오류율이 2%로 떨어지고 상위 오류는 대부분 관사, 잘못된 분할, 그리고 deucalion이나 gryce와 같은 매우 드문 단어나 이름입니다. "from scratch" 960시간 모델은 100시간 사전 훈련 모델과 유사한 단어 오류율을 가지며 유사한 오류 패턴을 보입니다. 사전 훈련된 speech representation은 특정 소리를 인식하도록 쉽게 적응될 수 있으며, fine-tuning은 이러한 representation을 실제 철자에 기반을 둡니다.
Table 11: 의 레이블링된 데이터로 훈련하고 언어 모델이나 어휘집 없이 Librispeech dev-clean 부분 집합에서 디코딩한 모델의 상위 단어 오류 (표 9 및 표 10-None 참조). 괄호 안은 각 오류의 총 발생 횟수입니다.
| 10m Large LV-60k | 1h Large LV-60k | 10h Large LV-60k |
|---|---|---|
| all → al (181) | too → to (26) | in → and (15) |
| are → ar (115) | until → untill (24) | a → the (11) |
| will → wil (100) | new → knew (22) | o → oh (10) |
| you → yo (90) | door → dor (18) | and → in (9) |
| one → on (89) | says → sais (18) | mode → mod (9) |
| two → to (81) | soul → sol (17) | ursus → ersus (9) |
| well → wel (80) | bread → bred (16) | tom → tome (8) |
| been → ben (73) | poor → pore (16) | randal → randol (7) |
| upon → apon (73) | a → the (13) | the → a (7) |
| good → god (67) | either → ither (13) | color → colour (6) |
| see → se (66) | food → fud (13) | flour → flower (6) |
| we → whe (60) | doubt → dout (12) | phoebe → feeby (6) |
| little → litle (54) | earth → erth (12) | an → and (5) |
| great → grate (53) | led → lead (12) | cucumbers → cucombers (5) |
| your → yor (53) | sea → see (12) | egg → eg (5) |
| could → coud (51) | thee → the (12) | macklewain → macklewaine (5) |
| here → hear (51) | tom → tome (12) | magpie → magpi (5) |
| know → now (45) | add → ad (11) | milner → millner (5) |
| there → ther (45) | good → god (11) | stacy → staci (5) |
| three → thre (45) | heaven → heven (11) | trevelyan → trevellion (5) |
| still → stil (42) | mary → marry (11) | verloc → verlock (5) |
| off → of (40) | randal → randel (11) | ann → an (4) |
| don't → dont (37) | answered → ansered (10) | anyone → one (4) |
| shall → shal (36) | blood → blod (10) | apartment → appartment (4) |
| little → litl (35) | bozzle → bosel (10) | basin → bason (4) |
| 100h Large LV-60k | 960h Large LV-60k | 960h Large from scratch |
| a → the (13) | a → the (12) | and → in (20) |
| and → in (10) | and → in (9) | a → the (16) |
| in → and (10) | macklewain → mackelwaine (7) | in → and (13) |
| o → oh (8) | in → and (6) | the → a (10) |
| minnetaki → minnitaki (7) | o → oh (6) | in → an (8) |
| randal → randall (7) | bozzle → bosell (5) | and → an (5) |
| christie → cristy (6) | criss → chris (5) | clarke → clark (4) |
| macklewain → mackelwane (6) | bozzle → bosel (4) | grethel → gretel (4) |
| randal → randoll (6) | clarke → clark (4) | macklewain → mackelwaine (4) |
| bozzle → bosall (5) | colored → coloured (4) | this → the (4) |
| kaliko → calico (5) | grethel → gretel (4) | an → and (3) |
| trevelyan → trevelian (5) | lige → lyge (4) | anyone → one (3) |
| an → and (4) | the → a (4) | bozzle → basell (3) |
| and → an (4) | and → an (3) | buns → bunds (3) |
| anyone → one (4) | ann → marianne (3) | carrie → carry ( 3 ) |
| bozzle → bozall (4) | butte → bute (3) | criss → chris ( 3 ) |
| clarke → clark (4) | color → colour (3) | he's → is (3) |
| gryce → grice (4) | deucalion → ducalion (3) | his → is ( 3 ) |
| i'm → am (4) | forcemeat → meat (3) | honor → honour (3) |
| in → ind (4) | gryce → grice ( 3 ) | lattimer → latimer (3) |
| letty → lettie (4) | honor → honour (3) | millet → mellet (3) |
| phoebe → phebe (4) | kearny → kirney (3) | pyncheon → pension (3) |
| the → a (4) | nuova → noiva ( 3 ) | tad → ted (3) |
| ann → anne (3) | thing → anything (3) | thing → anything (3) |
| awhile → while (3) | this → the ( 3 ) | trevelyan → trevelian (3) |
Table 12: 언어 모델이나 사전 없이 다양한 모델에 의해 dev-clean 서브셋에서 선택된 발화의 전사 예. 대문자 단어는 오류를 나타냅니다.
| Model | Transcription |
|---|---|
| Reference | i'm mister christopher from london |
| 10m LV-60k | IM mister CRESTIFER FROME LUNDEN |
| 1h LV-60k | IM mister CRISTIFFHER from LOUNDEN |
| 10h LV-60k | i'm mister CHRYSTEPHER from london |
| 100h LV-60k | i'm mister christopher from london |
| 960h LV-60k | i'm mister christopher from london |
| 960h scratch | I MISSTER christopher from london |
| Reference | il popolo e una bestia |
| 10m LV-60k | ILPOPULAR ONABESTIA |
| 1h LV-60k | O POPOLAONABASTIA |
| 10h LV-60k | U POPULAONABASTIAR |
| 100h LV-60k | O POPALOON A BASTYA |
| 960h LV-60k | YOU'LL POP A LAWYE ON A BAISTYE |
| 960h scratch | OL POPALOY ON ABESTIA |
| Reference | he smelt the nutty aroma of the spirit |
| 10m LV-60k | he SMELTD the NUDY aroma of the spirit |
| 1 h LV-60k | he SMELTD the NUDDY ARROMA of the spirit |
| 10h LV-60k | he smelt the NUDDY ERROMA of the spirit |
| 100h LV-60k | he smelt the NUDDY aroma of the spirit |
| 960 h LV-60k | he smelt the NUTTIE aroma of the spirit |
| 960h scratch | he smelt the nutty EROMA of the spirit |
| Reference | phoebe merely glanced at it and gave it back |
| 10m LV-60k | FEABY MEARLY glanced at it and gave it BAK |
| 1h LV-60k | FIEABY merely glanced at it and gave it back |
| 10h LV-60k | FEEBY merely glanced at it and gave it back |
| 100h LV-60k | BEBE merely glanced at it and gave it back |
| 960h LV-60k | phoebe merely glanced at it and gave it back |
| 960 h scratch | phoebe merely glanced at it and gave it back |
| Reference | sauterne is a white bordeaux a strong luscious wine the best known varieties being |
| 10m LV-60k | SULTERIN is a white BORDOE a strong LUCHOUS WIN the best NOWN VERIATYS being |
| 1 h LV-60k | CLTEREN is a white BORDO a strong LUCHIOUS wine the best known VERIETIES being |
| 10h LV-60k | SOTERN is a white BOURDO a strong LUCIOUS wine the best known VORIETIES being |
| 100h LV-60k | SOTERN is a white BORDAUX a strong LUCIOUS wine the best known varieties being |
| 960h LV-60k | SOTERN is a white bordeaux a strong luscious wine the best known varieties being |
| 960h scratch | SOTERAN is a white bordeaux a strong luscious wine the best known varieties being |
| Reference | i happen to have mac connell's box for tonight or there'd be no chance of our getting places |
| 10m LV-60k | i HAPEND to have MECONALES BOXS for TONIT ORE THIRLD be no chance of OR GETING places |
| 1h LV-60k | i happen to have MACCONNEL'S BOCXS for tonight or TE'ELD be no chance of our getting places |
| 10h LV-60k | i HAPPENED to have MUKONNEL'S box for tonight or THERED be no chance of our getting places |
| 100h LV-60k | i HAPPENED to have MC CONNEL'S box for TO NIGHT or there'd be no chance of our getting places |
| 960h LV-60k | i happen to have MC CONALL'S box for TO NIGHT or there'd be no chance of our getting places |
| 960h scratch | i HAPPENE to have MACONEL'S box for TO NIGHT or there'd be no chance of our getting places |
F Ablations
표 13은 우리 아키텍처의 다양한 하이퍼파라미터 선택을 제거 분석합니다. 기준 모델의 설정은 § 5.4에 설명되어 있습니다. 먼저, 우리는 연속적인 입력과 연속적인 타겟 모델(§5.4)을 연속적인 타겟 representation 위에 MLP를 추가하여 개선하려고 시도했으며, 또한 입력과 타겟으로 사용되는 representation에 대해 별도의 인코더 파라미터 세트를 사용하려고 시도했습니다(별도 인코더). 둘 다 의미 있는 개선을 이끌어내지 못했습니다. 수용 필드 크기를 25ms에서 30ms로 늘리는 것은 거의 효과가 없었습니다. 다양성 패널티 가중치()를 너무 낮게 설정하면 코드북 사용량이 낮아지고 성능이 저하됩니다. 너무 높게 설정하면 약간의 불안정성이 발생합니다. 상대적 위치 임베딩 수를 256개로 두 배로 늘리는 것도 도움이 되지 않았습니다. 양자화기에서 인코더로의 그래디언트를 중단시키는 것은 인코더가 양자화기로부터도 훈련 신호를 필요로 함을 보여줍니다.
다음으로, 부정 샘플의 수를 늘리는 것은 더 나은 성능을 가져오지 않았고(), 전체 발화 배치에서 부정 샘플을 샘플링하는 것은 성능을 저해했습니다. 이는 아마도 다른 발화의 후보들이 구별하기 쉽기 때문일 것입니다. 마스킹되거나 마스킹되지 않은 발화의 모든 타임스텝에서 부정 샘플을 샘플링하는 것은 도움이 되지 않으며 계산적으로 더 비쌉니다. Gumbel 노이즈는 중요하며 코드북 수를 늘리는 것은 더 나은 성능을 가져오지 않았습니다.
Table 13: 다양한 하이퍼파라미터 선택에 대한 제거 분석. 우리는 세 번의 훈련 시드에 대해 Librispeech의 dev-clean/other 결합 세트의 평균 WER과 표준 편차를 보고합니다.
| avg. WER | std. | |
|---|---|---|
| Baseline ( ) | 7.97 | 0.02 |
| Continuous inputs, continuous targets | 8.58 | 0.08 |
| + MLP on targets | 8.51 | 0.05 |
| + Separate encoders | 8.90 | 0.01 |
| receptive field 30 ms | 7.99 | 0.06 |
| diversity penalty | ||
| 8.48 | 0.08 | |
| 8.34 | 0.08 | |
| 8.58 | 0.45 | |
| Conv pos emb, kernel 256 | 8.14 | 0.05 |
| No gradient to encoder from quantizer | 8.41 | 0.08 |
| Negatives | ||
| same utterance | 8.12 | 0.05 |
| same utterance from batch | 8.79 | 0.06 |
| Sample negatives from any time step | 8.07 | 0.02 |
| No Gumbel noise | 8.73 | 0.42 |
| Codebook | ||
| 9.02 | 0.38 | |
| 8.13 | 0.07 | |
| Predict exactly time steps from edges | ||
| 9.53 | 0.91 | |
| 8.19 | 0.07 | |
| 8.07 | 0.07 | |
| 7.89 | 0.10 | |
| 7.90 | 0.01 |
우리는 또한 각 구간의 마지막 마스킹되지 않은 타임스텝 바로 옆의 타임스텝만 예측하는 것을 조사했습니다. 이는 사전 훈련 작업의 난이도를 더 잘 제어할 수 있게 합니다. 마스킹된 구간 옆의 가장 왼쪽 또는 가장 오른쪽 마스킹되지 않은 타임스텝이 주어지면, 우리는 이러한 마스킹되지 않은 구간 옆의 첫 번째 개의 마스킹된 타임스텝에 대해서만 대조 손실을 계산합니다. 최대 한 타임스텝까지만 예측하는 것은 각 발화에서 훈련 신호가 거의 없기 때문에 성능이 좋지 않으며, 더 많은 타임스텝을 예측하는 것이 더 나은 성능을 보이지만 모든 마스킹된 타임스텝을 예측하는 것보다 크게 뛰어나지는 않습니다. 훈련 업데이트 횟수를 늘리면 도움이 되지만 이는 훈련 시간을 증가시킵니다.
Footnotes
-
코드와 모델은 https://github.com/pytorch/fairseq 에서 확인할 수 있습니다. ↩
-
우리의 구현은 퍼플렉서티(perplexity) 를 최대화하며, 이는 동일한 효과를 가집니다. ↩