wav2vec: 음성 인식을 위한 비지도 사전 학습(Unsupervised Pre-training)
본 논문은 원시 오디오로부터 표현을 학습하여 음성 인식을 위한 비지도 사전 학습(unsupervised pre-training) 방법인 wav2vec을 제안합니다. wav2vec은 레이블이 없는 대량의 오디오 데이터로 학습되며, 결과 표현은 음향 모델 훈련을 개선하는 데 사용됩니다. 간단한 다층 convolutional neural network를 noise contrastive binary classification 작업을 통해 최적화합니다. WSJ 데이터셋 실험에서 적은 양의 전사 데이터만 있을 때 강력한 문자 기반 로그-멜 필터뱅크 기준 모델의 단어 오류율(WER)을 최대 36%까지 줄였습니다. 이 접근 방식은 기존 문자 기반 시스템인 Deep Speech 2보다 훨씬 적은 레이블 데이터를 사용하면서도 더 나은 성능을 보입니다. 논문 제목: wav2vec: Unsupervised Pre-training for Speech Recognition
논문 요약: wav2vec: 음성 인식을 위한 비지도 사전 학습(Unsupervised Pre-training)
- 논문 링크: https://arxiv.org/abs/1904.05862
- 저자: Steffen Schneider, Alexei Baevski, Ronan Collobert, Michael Auli (Facebook AI Research)
- 발표 시기: 2019년 (arXiv preprint)
- 주요 키워드: Speech Recognition, Unsupervised Learning, Pre-training, ASR, Convolutional Neural Network
1. 연구 배경 및 문제 정의
- 문제 정의:
현재 최첨단 음성 인식(ASR) 모델은 높은 성능을 달성하기 위해 대량의 전사된(labeled) 오디오 데이터를 필요로 합니다. 그러나 이러한 레이블링된 데이터를 얻는 데는 상당한 시간과 노력이 필요하며, 이는 특히 저자원 언어나 특정 도메인에서 ASR 시스템을 구축하는 데 큰 제약이 됩니다. - 기존 접근 방식:
컴퓨터 비전(ImageNet, COCO) 및 자연어 처리(BERT, GPT) 분야에서는 대규모 레이블링되거나 레이블링되지 않은 데이터를 활용한 사전 학습(pre-training)이 다운스트림 작업의 성능을 크게 향상시키는 효과적인 기술로 입증되었습니다. 음성 처리 분야에서도 감정 인식, 화자 식별, 음소 판별 등에서 사전 학습 연구가 있었지만, 대부분의 비지도 학습 연구 결과로 얻어진 표현(representation)이 감독 학습 기반의 음성 인식 시스템 성능을 직접적으로 개선하는 데 적용되지 못했습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 감독 학습 기반 음성 인식 시스템의 성능을 개선하기 위해 원시 오디오 데이터에 대한 비지도 사전 학습(unsupervised pre-training) 방법인
wav2vec을 제안했습니다. wav2vec은 레이블이 없는 대량의 오디오 데이터로부터 일반적인 음성 표현을 학습하며, 이 표현은 음향 모델 훈련을 개선하는 데 사용됩니다.- 기존 연구에서 사용된 순환 모델(recurrent models)과 달리, 최신 하드웨어에서 시간적으로 쉽게 병렬화할 수 있는 완전 컨볼루션(fully convolutional) 아키텍처를 제안했습니다.
- WSJ 벤치마크에서 기존 최고 성능의 문자 기반 시스템인 Deep Speech 2보다 훨씬 적은 레이블 데이터를 사용하면서도 더 나은 WER(단어 오류율)을 달성했습니다.
- 감독 학습 기반 음성 인식 시스템의 성능을 개선하기 위해 원시 오디오 데이터에 대한 비지도 사전 학습(unsupervised pre-training) 방법인
- 제안 방법:
wav2vec모델은 원시 오디오 신호를 입력으로 받아 두 개의 네트워크를 통해 음성 표현을 학습합니다.- 인코더 네트워크 (Encoder Network, ): 5계층 컨볼루션 네트워크로, 원시 오디오 신호()를 저주파 특징 표현()으로 임베딩합니다. 약 30ms의 16kHz 오디오를 10ms 간격의 특징으로 변환합니다.
- 컨텍스트 네트워크 (Context Network, ): 인코더의 출력()에 적용되어 여러 타임 스텝의 잠재 표현을 결합하여 단일 컨텍스트화된 텐서()를 얻습니다. 9계층 컨볼루션 네트워크로 구성되며, 총 수용 필드(receptive field)는 약 210ms입니다. (더 큰 모델인 "wav2vec large"는 12계층, 약 810ms의 수용 필드를 가집니다.)
- 목적 함수 (Objective Function):
- 모델은 각 단계 에 대해 **대조 손실(contrastive loss)**을 최소화하도록 학습됩니다.
- 이 손실은 주어진 컨텍스트()에서 실제 미래 오디오 샘플()을 제안 분포에서 추출한 방해 샘플(negative samples, )과 구별하도록 모델을 최적화합니다.
- 실제로는 각 오디오 시퀀스에서 10개의 네거티브 샘플을 균일하게 샘플링하여 기댓값을 근사합니다.
- 사전 학습 후 활용: 학습된
wav2vec모델의 컨텍스트 네트워크에서 생성된 표현()을 기존의 log-mel filterbank 특징 대신 음향 모델의 입력으로 사용합니다.
3. 실험 결과
- 데이터셋:
- 사전 학습: WSJ 코퍼스(81시간), Librispeech(80시간 하위 집합 또는 전체 960시간), 또는 이들의 조합.
- 음향 모델 훈련 및 평가:
- TIMIT: 음소 인식(Phoneme Recognition)을 위해 표준 훈련/개발/테스트 분할 사용 (훈련 데이터 약 3시간).
- WSJ: 음성 인식(Speech Recognition)을 위해 si284 훈련, nov93dev 검증, nov92 테스트 분할 사용 (약 81시간).
- 평가 지표: 단어 오류율(WER), 문자 오류율(LER), 음소 오류율(PER).
- 환경: wav2letter++ 툴킷, fairseq, 8개 또는 16개의 NVIDIA V100 GPU.
- 주요 결과:
- WSJ 벤치마크 성능 향상:
wav2vec large모델은 Librispeech 960시간 데이터로 사전 학습 후 WSJ nov92 테스트 세트에서 2.43%의 WER을 달성했습니다.- 이는 기존 최고 성능의 문자 기반 시스템인 Deep Speech 2(3.1% WER)를 능가하며, 두 자릿수나 적은 양의 레이블링된 훈련 데이터를 사용했습니다.
- 더 많은 데이터로 사전 학습할수록 WSJ 벤치마크에서 더 나은 정확도를 보였습니다.
- 저자원 환경에서의 강력한 성능:
- 약 8시간의 전사된 오디오 데이터만 사용할 수 있는 시뮬레이션된 저자원 환경에서,
wav2vec사전 학습은 기존 log-mel filterbank 기준 모델 대비 WSJ nov92에서 WER을 최대 36%까지 감소시켰습니다.
- 약 8시간의 전사된 오디오 데이터만 사용할 수 있는 시뮬레이션된 저자원 환경에서,
- TIMIT 음소 인식 성능:
wav2vec사전 학습은 TIMIT 음소 인식 작업에서 최첨단(state-of-the-art) 수준에 필적하는 14.7% PER을 달성했습니다.
- 설계 선택 분석 (Ablation Study):
- 네거티브 샘플의 수는 10개까지 성능 향상에 도움이 되며, 그 이상은 훈련 시간만 증가시키고 성능은 정체됩니다.
- 오디오 시퀀스 자르기(cropping)를 통한 데이터 증강은 성능 향상에 기여하며, 150k 프레임의 자르기 크기가 최적의 성능을 보였습니다.
- 미래 예측 단계 수()는 12단계까지 성능 향상에 도움이 되며, 그 이상은 성능을 더 이상 개선하지 못했습니다.
- WSJ 벤치마크 성능 향상:
4. 개인적인 생각 및 응용 가능성
- 장점:
- 데이터 효율성: 레이블링되지 않은 대량의 오디오 데이터를 활용하여 음성 인식 모델의 성능을 획기적으로 개선했다는 점이 가장 인상 깊습니다. 특히 레이블 데이터가 부족한 저자원 환경에서 WER을 36%까지 줄인 것은 매우 큰 성과입니다.
- 성능 우위: 기존의 강력한 ASR 시스템(Deep Speech 2)을 훨씬 적은 레이블 데이터로 능가했다는 것은
wav2vec이 학습하는 표현의 우수성을 증명합니다. - 병렬화 용이성: 완전 컨볼루션 아키텍처를 채택하여 훈련 속도와 효율성을 높인 점도 실용적인 측면에서 큰 장점입니다.
- 범용성: WSJ와 TIMIT 두 가지 다른 벤치마크에서 모두 뛰어난 성능을 보여, 학습된 표현이 다양한 음성 인식 작업에 범용적으로 적용될 수 있음을 시사합니다.
- 단점/한계:
- 논문 자체에서 명시적인 한계점을 언급하기보다는 "향후 연구"를 제안하지만,
wav2vec large모델의 경우 더 많은 GPU가 필요하다는 점에서 여전히 상당한 컴퓨팅 자원이 요구될 수 있습니다. - 아블레이션 스터디에서 보듯이, 단순히 모델 크기나 특정 파라미터(네거티브 샘플 수, 예측 단계 수)를 늘린다고 해서 성능이 무한정 개선되는 것은 아니며, 최적점을 찾아야 한다는 점이 있습니다.
- 논문 자체에서 명시적인 한계점을 언급하기보다는 "향후 연구"를 제안하지만,
- 응용 가능성:
- 저자원 언어 ASR 개발: 레이블링된 데이터가 부족한 소수 언어 또는 특정 도메인(예: 의료, 법률)의 음성 인식 시스템 구축 비용과 시간을 크게 절감할 수 있습니다.
- 음성 관련 다른 태스크:
wav2vec이 학습하는 일반적인 음성 표현은 음성 합성, 화자 인식, 감정 인식, 음성 분리 등 다양한 음성 처리 태스크의 사전 학습 모델로 활용될 수 있습니다. - 온디바이스 ASR: 효율적인 컨볼루션 아키텍처는 향후 모바일 기기나 엣지 디바이스에서의 경량 ASR 모델 개발에도 기여할 수 있습니다.
Schneider, Steffen, et al. "wav2vec: Unsupervised pre-training for speech recognition." arXiv preprint arXiv:1904.05862 (2019).
wav2vec: Unsupervised Pre-training for Speech Recognition
Steffen Schneider, Alexei Baevski, Ronan Collobert, Michael Auli<br>Facebook AI Research
Abstract
우리는 원시 오디오의 representation을 학습하여 음성 인식을 위한 비지도 pre-training을 탐색합니다. wav2vec은 대량의 레이블 없는 오디오 데이터로 학습되며, 결과 representation은 음향 모델 학습을 개선하는 데 사용됩니다. 우리는 noise contrastive 이진 분류 작업을 통해 최적화된 간단한 다층 convolutional neural network를 pre-train합니다. WSJ에 대한 우리의 실험은 단 몇 시간의 전사된 데이터만 사용할 수 있을 때 강력한 문자 기반 log-mel filterbank 기준선의 WER을 최대 까지 감소시킵니다. 우리의 접근 방식은 nov92 테스트 세트에서 2.43% WER을 달성합니다. 이는 문헌에서 보고된 최고의 문자 기반 시스템인 Deep Speech 2를 능가하며, 두 자릿수나 적은 양의 레이블링된 학습 데이터를 사용합니다.
1 Introduction
현재 음성 인식을 위한 최첨단 모델은 좋은 성능을 얻기 위해 대량의 전사된 오디오 데이터가 필요합니다(Amodei et al., 2016). 최근에는 신경망의 pre-training이 레이블링된 데이터가 부족한 환경에서 효과적인 기술로 부상했습니다. 핵심 아이디어는 상당한 양의 레이블링되거나 레이블링되지 않은 데이터를 사용할 수 있는 설정에서 일반적인 representation을 학습하고, 학습된 representation을 활용하여 데이터 양이 제한된 다운스트림 작업의 성능을 향상시키는 것입니다. 이는 음성 인식과 같이 레이블링된 데이터를 얻는 데 상당한 노력이 필요한 작업에 특히 흥미롭습니다.
컴퓨터 비전에서는 ImageNet(Deng et al., 2009) 및 COCO(Lin et al., 2014)에 대한 representation이 이미지 캡셔닝(Vinyals et al., 2016)이나 자세 추정(Pavllo et al., 2019)과 같은 작업을 위한 모델을 초기화하는 데 유용한 것으로 입증되었습니다. 컴퓨터 비전을 위한 비지도 pre-training 또한 유망함을 보여주었습니다(Doersch et al., 2015; Hénaff et al., 2019). natural language processing(NLP)에서는 언어 모델의 비지도 pre-training(Devlin et al., 2018; Radford et al., 2018; Baevski et al., 2019)이 텍스트 분류, 구문 구조 분석 및 기계 번역과 같은 많은 작업을 개선했습니다(Edunov et al., 2019; Lample & Conneau, 2019). speech processing에서 pre-training은 감정 인식(Lian et al., 2018), 화자 식별(Ravanelli & Bengio, 2018), 음소 판별(Synnaeve & Dupoux, 2016a; van den Oord et al., 2018)뿐만 아니라 ASR representation을 한 언어에서 다른 언어로 전이하는 데 중점을 두었습니다(Kunze et al., 2017). speech에 대한 unsupervised learning 연구가 있었지만, 그 결과로 나온 representation은 supervised speech recognition을 개선하는 데 적용되지 않았습니다(Synnaeve & Dupoux, 2016b; Kamper et al., 2017; Chung et al., 2018; Chen et al., 2018; Chorowski et al., 2019).
이 논문에서는 supervised speech recognition을 개선하기 위해 비지도 pre-training을 적용합니다. 이를 통해 레이블링된 데이터보다 수집하기 훨씬 쉬운 레이블링되지 않은 오디오 데이터를 활용할 수 있습니다. 우리의 모델인 wav2vec은 원시 오디오를 입력으로 받아 음성 인식 시스템에 입력될 수 있는 일반적인 representation을 계산하는 convolutional neural network입니다. 목표는 실제 미래 오디오 샘플을 네거티브 샘플과 구별해야 하는 contrastive loss입니다(Collobert et al., 2011; Mikolov et al., 2013; van den Oord et al., 2018). 이전 연구(van den Oord et al., 2018)와 달리, 우리는 프레임 단위 음소 분류를 넘어 학습된 representation을 강력한 supervised ASR 시스템을 개선하는 데 적용합니다. wav2vec은 이전 연구에서 사용된 recurrent models에 비해 최신 하드웨어에서 시간적으로 쉽게 병렬화할 수 있는 fully convolutional 아키텍처에 의존합니다(§2).

그림 1: 서로 겹쳐 쌓인 두 개의 convolutional neural network로 인코딩되는 오디오 데이터 로부터의 pre-training 그림. 모델은 다음 타임 스텝 예측 작업을 해결하도록 최적화됩니다.
WSJ 벤치마크에 대한 실험 결과는 약 1,000시간의 레이블 없는 음성으로 추정된 pre-trained representation이 문자 기반 ASR 시스템을 상당히 개선하고, 문헌상 최고의 문자 기반 결과인 Deep Speech 2를 능가하여 WER을 3.1%에서 2.43%로 향상시킬 수 있음을 보여줍니다. TIMIT에서 pre-training은 문헌에서 보고된 최고 결과를 달성할 수 있게 해줍니다. 단 8시간의 전사된 오디오 데이터만 있는 시뮬레이션된 저자원 환경에서 wav2vec은 레이블된 데이터에만 의존하는 기준 모델에 비해 WER을 최대 까지 감소시킵니다 (§3, §4).
2 Pre-training Approach
오디오 신호를 입력으로 받아, 우리는 주어진 신호 컨텍스트에서 미래 샘플을 예측하도록 모델을 최적화합니다(§2.1). 이러한 접근 방식의 일반적인 문제는 데이터 분포 를 정확하게 모델링해야 하는 요구 사항이며, 이는 어렵습니다. 우리는 먼저 원시 음성 샘플 를 더 낮은 시간적 주파수에서 특징 representation 로 인코딩한 다음, van den Oord et al. (2018)과 유사하게 밀도 비율 를 암시적으로 모델링하여 이 문제를 피합니다.
2.1 Model
우리 모델은 원시 오디오 신호를 입력으로 받아 두 개의 네트워크를 적용합니다. encoder network는 오디오 신호를 잠재 공간에 임베딩하고, context network는 인코더의 여러 타임 스텝을 결합하여 contextualized representations를 얻습니다(그림 1). 그런 다음 두 네트워크는 목적 함수를 계산하는 데 사용됩니다(§2.2). 원시 오디오 샘플 가 주어지면, 5계층 convolutional network로 매개변수화된 encoder network 를 적용합니다(van den Oord et al., 2018). 대안으로, Zeghidour et al. (2018a)의 학습 가능한 프론트엔드와 같은 다른 아키텍처를 사용할 수 있습니다. 인코더 레이어는 커널 크기가 (10,8,4,4,4)이고 스트라이드가 (5,4,2,2,2)입니다. 인코더의 출력은 약 30ms의 16kHz 오디오를 인코딩하는 저주파 특징 representation 이며, 스트라이딩 결과 10ms마다 representation 가 생성됩니다.
다음으로, context network 를 encoder network의 출력에 적용하여 여러 잠재 representation 를 수용 필드 크기 에 대해 단일 contextualized 텐서 로 혼합합니다. context network는 커널 크기가 3이고 스트라이드가 1인 9개의 레이어로 구성됩니다. context network의 총 수용 필드는 약 210ms입니다.
encoder 및 context network의 레이어는 512 채널의 causal convolution, group normalization 레이어 및 ReLU 비선형성으로 구성됩니다. 우리는 각 샘플에 대해 특징 및 시간 차원 모두에서 정규화하며, 이는 단일 정규화 그룹을 사용하는 group normalization과 동일합니다(Wu & He, 2018). 우리는 입력의 스케일링 및 오프셋에 불변하는 정규화 방식을 선택하는 것이 중요하다고 생각했습니다. 이 선택은 데이터셋 전반에 걸쳐 잘 일반화되는 representation을 낳았습니다.
더 큰 데이터셋에서의 학습을 위해, 우리는 용량을 증가시킨 모델 변형("wav2vec large")도 고려합니다. 이는 인코더에 두 개의 추가적인 선형 변환을 사용하고, 커널 크기가 증가하는 12개의 레이어로 구성된 훨씬 더 큰 context network를 사용합니다. 이 경우 수렴을 돕기 위해 애그리게이터에 skip connections를 도입하는 것이 중요하다고 생각했습니다. 마지막 context network 레이어의 총 수용 필드는 이로써 약 810ms로 증가합니다.
2.2 Objective
우리는 각 단계 에 대한 contrastive loss를 최소화함으로써, 단계 뒤의 샘플 를 제안 분포 에서 추출한 방해 샘플 와 구별하도록 모델을 학습시킵니다:
여기서 sigmoid 를 나타내고, 는 가 실제 샘플일 확률입니다. 우리는 각 단계 에 대해 에 적용되는 단계별 affine transformation 를 고려합니다(van den Oord et al., 2018). 우리는 손실 를 최적화하며, 여러 단계 크기에 대해 (1)을 합산합니다. 실제로, 우리는 각 오디오 시퀀스에서 균일하게 방해 요소를 선택하여 10개의 네거티브 예제를 샘플링함으로써 기댓값을 근사합니다. 즉, 이며, 여기서 는 시퀀스 길이이고 를 네거티브의 수로 설정합니다. 학습 후, 우리는 log-mel filterbank 특징 대신 context network에서 생성된 representation 를 음향 모델에 입력합니다.
3 Experimental Setup
3.1 Data
우리는 다음 코퍼스를 고려합니다: TIMIT(Garofolo et al., 1993b)에서의 음소 인식을 위해 표준 train, dev, test 분할을 사용하며, 훈련 데이터는 3시간이 조금 넘는 오디오 데이터를 포함합니다. Wall Street Journal(WSJ; Garofolo et al. (1993a); Woodland et al. (1994))은 약 81시간의 전사된 오디오 데이터로 구성됩니다. 우리는 si284에서 훈련하고, nov93dev에서 검증하며, nov92에서 테스트합니다. Librispeech(Panayotov et al., 2015)는 훈련을 위해 총 960시간의 깨끗하고 잡음이 있는 음성을 포함합니다. pre-training을 위해, 우리는 WSJ 코퍼스의 전체 81시간, 깨끗한 Librispeech의 80시간 하위 집합, 전체 960시간 Librispeech 훈련 세트 또는 이들 모두의 조합을 사용합니다. 기준 음향 모델을 훈련하기 위해, 우리는 10ms 보폭의 25ms 슬라이딩 윈도우에 대해 80개의 log-mel filterbank 계수를 계산합니다. 최종 모델은 word error rate (WER)과 letter error rate (LER) 모두로 평가됩니다.
3.2 Acoustic Models
우리는 음향 모델의 훈련 및 평가를 위해 wav2letter++ 툴킷을 사용합니다(Pratap et al., 2018). TIMIT 작업의 경우, Zeghidour et al. (2018a)의 문자 기반 wav2letter++ 설정을 따르며, 이는 7개의 연속적인 컨볼루션 블록(커널 크기 5, 채널 1,000개), PReLU 비선형성 및 0.7의 dropout 비율을 사용합니다. 최종 representation은 39차원 음소 확률로 투영됩니다. 모델은 모멘텀이 있는 SGD를 사용하여 Auto Segmentation Criterion(ASG; Collobert et al., 2016)을 통해 훈련됩니다. WSJ 벤치마크에 대한 우리의 기준은 Collobert et al. (2019)에 설명된 wav2letter++ 설정으로, 이는 gated convolutions을 사용한 17개 레이어 모델입니다(Dauphin et al., 2017). 이 모델은 표준 영어 알파벳, 아포스트로피 및 마침표, 두 개의 반복 문자(예: 단어 'ann'은 'an1'로 전사됨), 그리고 단어 경계로 사용되는 묵음 토큰(|)을 포함한 31개 자소의 확률을 예측합니다. 모든 음향 모델은 fairseq 및 wav2letter++의 분산 훈련 구현을 사용하여 8개의 NVIDIA V100 GPU에서 훈련됩니다. WSJ에서 음향 모델을 훈련할 때, 우리는 학습률 5.6의 일반 SGD와
2| | | | nov93dev | | nov92 | | | :--- | :--- | :--- | :--- | :--- | :--- | :--- | | | | | LER | WER | LER | WER | | Deep Speech 2 (12K h labeled speech; Amodei et al., 2016) | | | - | 4.42 | - | 3.1 | | Trainable frontend (Zeghidour et al., 2018a) | | | - | 6.8 | - | 3.5 | | Lattice-free MMI (Hadian et al., 2018) | | | - | | - | | | Supervised transfer-learning (Ghahremani et al., 2017) | | | - | | - | | | 4-GRAM LM (Heafield et al., 2013) | | | | | | | | Baseline | - | - | 3.32 | 8.57 | 2.19 | 5.64 | | wav2vec | Librispeech | 80 h | 3.71 | 9.11 | 2.17 | 5.55 | | wav2vec | Librispeech | 960 h | 2.85 | 7.40 | 1.76 | 4.57 | | wav2vec | Libri + WSJ | | 2.91 | 7.59 | 1.67 | 4.61 | | wav2vec large | Librispeech | 960 h | 2.73 | 6.96 | 1.57 | 4.32 | | Word ConvLM (Zeghidour et al., 2018b) | | | | | | | | Baseline | - | - | 2.57 | 6.27 | 1.51 | 3.60 | | wav2vec | Librispeech | 960 h | 2.22 | 5.39 | 1.25 | 2.87 | | wav2vec large | Librispeech | 960 h | 2.13 | 5.16 | 1.02 | 2.53 | | CHAR CONVLM (Likhomanenko et al., 2019) | | | | | | | | Baseline | - | - | 2.77 | 6.67 | 1.53 | 3.46 | | wav2vec | Librispeech | 960 h | 2.14 | 5.31 | 1.15 | 2.78 | | wav2vec large | Librispeech | 960 h | 2.11 | 5.10 | 0.99 | 2.43 |
표 1: log-mel filterbanks(Baseline)를 pre-trained 임베딩으로 교체하면 LER과 WER 측면에서 테스트(nov92) 및 검증(nov93dev) 세트에서 WSJ 성능이 향상됩니다. 우리는 깨끗한 Librispeech의 일부 및 전체와 이들 모두의 조합에 대한 음향 데이터에 대한 pre-training을 평가합니다. 는 음소 기반 모델의 결과를 나타냅니다. gradient clipping(Collobert et al., 2019)을 사용하고 총 배치 크기 64개의 오디오 시퀀스로 1,000 에포크 동안 훈련합니다. 우리는 조기 종료를 사용하고 4-gram language model로 체크포인트를 평가한 후 검증 WER을 기반으로 모델을 선택합니다. TIMIT의 경우 학습률 0.12, 모멘텀 0.9를 사용하고 배치 크기 16개의 오디오 시퀀스로 8개 GPU에서 1,000 에포크 동안 훈련합니다.
3.3 Decoding
음향 모델의 출력을 디코딩하기 위해, 우리는 WSJ 언어 모델링 데이터만으로 훈련된 별도의 language model뿐만 아니라 lexicon도 사용합니다. 우리는 4-gram KenLM language model(Heafield et al., 2013), 단어 기반 convolutional language model(Collobert et al., 2019), 그리고 문자 기반 convolutional language model(Likhomanenko et al., 2019)을 고려합니다. 우리는 Collobert et al. (2019)의 beam search decoder를 사용하여 context network 또는 log-mel filterbanks의 출력에서 단어 시퀀스 를 디코딩하며, 다음을 최대화합니다.
여기서 은 음향 모델, 은 language model, 은 의 문자들입니다. 하이퍼파라미터 는 language model, 단어 패널티, 묵음 패널티에 대한 가중치입니다. WSJ 디코딩을 위해, 우리는 무작위 탐색을 사용하여 하이퍼파라미터 를 조정합니다. 마지막으로, 우리는 에 대한 최적의 파라미터 설정으로 음향 모델의 출력을 디코딩합니다. 단어 기반 language model의 경우 빔 크기 4,000과 빔 점수 임계값 250을 사용하고, 문자 기반 language model의 경우 빔 크기 1,500과 빔 점수 임계값 40을 사용합니다.
3.4 Pre-training Models
pre-training 모델은 fairseq 툴킷(Ott et al., 2019)의 PyTorch로 구현됩니다. 우리는 Adam(Kingma & Ba, 2015)과 cosine learning rate schedule(Loshchilov
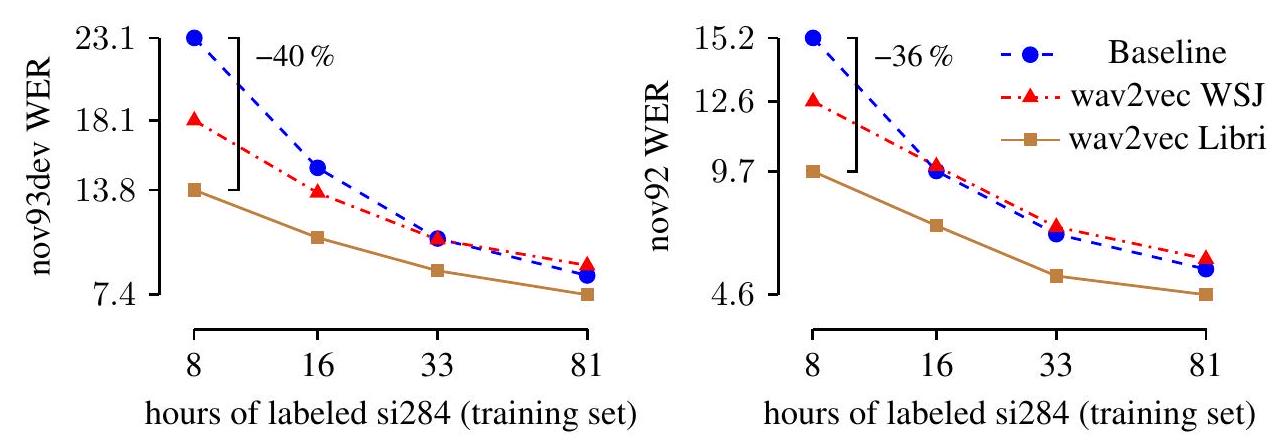
그림 2: Pre-training은 WSJ의 오디오 데이터에 대한 시뮬레이션된 저자원 환경에서 log-mel filterbanks 특징을 사용하는 wav2letter++(Baseline)와 비교하여 WER을 상당히 향상시킵니다. 전체 & Hutter, 2016)으로 최적화하며, WSJ와 깨끗한 Librispeech 훈련 데이터셋 모두에 대해 40k 업데이트 단계 동안, 또는 전체 Librispeech에 대해 400k 단계 동안 어닐링합니다. 우리는 학습률 로 시작하여 500 업데이트 동안 점진적으로 까지 워밍업한 다음 코사인 곡선을 따라 까지 감소시킵니다. 목적 함수를 계산하기 위해, 우리는 개의 각 작업에 대해 10개의 네거티브를 샘플링합니다.
우리는 첫 번째 wav2vec 변형을 8개의 GPU에서 훈련하고 각 GPU에 최대 1.5M 프레임에 달하는 오디오 시퀀스를 배치합니다. 시퀀스는 길이별로 그룹화되며, 각 시퀀스를 최대 150k 프레임 또는 배치에서 가장 짧은 시퀀스의 길이 중 더 작은 크기로 자릅니다. 자르기는 시퀀스의 시작 또는 끝에서 음성 신호를 제거하며 각 샘플에 대한 자르기 오프셋을 무작위로 결정합니다. 우리는 매 에포크마다 다시 샘플링합니다. 이것은 데이터 증강의 한 형태이지만 GPU의 모든 시퀀스가 동일한 길이를 갖도록 보장하고 훈련 데이터의 평균 를 제거합니다. 자르기 후, GPU 전체의 총 유효 배치 크기는 약 556초의 음성입니다. 대규모 모델 변형의 경우, 16개의 GPU에서 훈련하여 유효 배치 크기를 두 배로 늘립니다.
4 Results
van den Oord et al. (2018)과 달리, 우리는 pre-trained representation을 다운스트림 음성 인식 작업에서 직접 평가합니다. 우리는 WSJ 벤치마크에서 음성 인식 성능을 측정하고 다양한 저자원 설정을 시뮬레이션합니다(§4.1). 또한 TIMIT 음소 인식 작업에서도 평가하고(§4.2) 다양한 모델링 선택을 분석합니다(§4.3).
4.1 Pre-training for the WSJ benchmark
우리는 WSJ의 오디오 데이터(레이블 없음), 깨끗한 Librispeech의 일부(약 80시간), 전체 Librispeech 및 모든 데이터셋의 조합에 대한 pre-training을 고려합니다(§3.1). pre-training 실험을 위해 우리는 log-mel filterbank 특징 대신 context network의 출력을 음향 모델에 입력합니다.
표 1은 더 많은 데이터에 대한 pre-training이 WSJ 벤치마크에서 더 나은 정확도로 이어진다는 것을 보여줍니다. pre-trained representation은 log-mel filterbank 특징으로 훈련된 우리의 문자 기반 기준선보다 성능을 상당히 향상시킬 수 있습니다. 이것은 레이블 없는 오디오 데이터에 대한 pre-training이 nov92에서 WER 0.67만큼 최고의 문자 기반 접근 방식인 Deep Speech 2(Amodei et al., 2016)를 개선할 수 있음을 보여줍니다. Hadian et al. (2018)과 비교하여, wav2vec은 그들의 음소 기반 모델과 동등한 성능을 보이며 wav2vec large는 WER 0.37만큼 그것을 능가합니다. Ghahremani et al. (2017)의 음소 기반 접근 방식은 Librispeech의 레이블링된 버전에 대해 pre-train한 다음 WSJ에서 finetune합니다. wav2vec large는 더 약한 기준 모델과 Librispeech 전사를 사용하지 않음에도 불구하고 여전히 Ghahremani et al. (2017)을 능가합니다.
더 적은 양의 전사된 데이터가 있을 때 pre-trained representation의 영향은 무엇일까요? 이를 더 잘 이해하기 위해, 우리는 다양한 양의 레이블링된 훈련 데이터로 음향 모델을 훈련하고 pre-trained representation(log-mel filterbanks) 유무에 따른 정확도를 측정합니다. pre-trained representation은
| dev | test | |
|---|---|---|
| CNN + TD-filterbanks (Zeghidour et al., 2018a) | 15.6 | 18.0 |
| Li-GRU + MFCC (Ravanelli et al., 2018) | - | |
| Li-GRU + FBANK (Ravanelli et al., 2018) | - | |
| Li-GRU + fMLLR (Ravanelli et al., 2018) | - | |
| Baseline | ||
| wav2vec (Librispeech 80h) | ||
| wav2vec (Librispeech 960h) | ||
| wav2vec (Librispeech + WSJ) |
표 2: TIMIT에서의 음소 인식 결과를 PER로 나타낸 표. 우리의 모든 모델은 CNN-8L-PReLU-do0.7 아키텍처를 사용합니다 (Zeghidour et al., 2018a).
| negatives | dev PER | train time (h) |
|---|---|---|
| 1 | 16.3 | 6.1 |
| 2 | 15.8 | 6.3 |
| 5 | 15.9 | 8.2 |
| 10 | 15.5 | 10.5 |
| 20 | 15.7 | 15.3 |
표 3: TIMIT 개발 세트에서 pre-training 중 다른 수의 negative samples의 효과. 전체 Librispeech 코퍼스에서 훈련되었으며, 4-gram language model로 디코딩할 때 WER 측면에서 정확도를 측정합니다. 그림 2는 약 8시간의 전사된 데이터만 사용할 수 있을 때 pre-training이 nov92에서 WER을 36% 감소시킨다는 것을 보여줍니다. WSJ의 오디오 데이터에만 pre-training하는 것(wav2vec WSJ)은 훨씬 더 큰 Librispeech(wav2vec Libri)에 비해 성능이 떨어집니다. 이는 더 많은 데이터에 대한 pre-training이 좋은 성능에 중요하다는 것을 더욱 확인시켜 줍니다. Hénaff et al. (2019)과 유사하게, 우리는 임베딩 네트워크를 fine-tuning하는 것이 음향 모델 훈련 시간을 상당히 증가시키면서 성능을 의미 있게 향상시키지 않는다는 것을 발견했습니다.
4.2 Pre-training for timit
TIMIT 작업에서는 높은 dropout을 가진 7계층 wav2letter++ 모델을 사용합니다(§3; Synnaeve & Dupoux (2016b)). 표 2는 Librispeech와 WSJ 오디오 데이터에 대한 wav2vec pre-training이 최첨단 수준에 필적하는 결과를 낳을 수 있음을 보여줍니다. pre-training을 위한 데이터가 많을수록 정확도가 꾸준히 증가하며, 가장 많은 양의 pre-training 데이터로 최고의 정확도를 달성합니다.
4.3 Ablations
이 섹션에서는 wav2vec에 대해 우리가 내린 몇 가지 설계 선택을 분석합니다. 우리는 깨끗한 Librispeech의 80시간 하위 집합에서 pre-train하고 TIMIT에서 평가합니다. 표 3은 negative samples의 수를 늘리는 것이 10개 샘플까지만 도움이 된다는 것을 보여줍니다. 그 이후에는 훈련 시간이 증가하는 동안 성능이 정체됩니다. 우리는 이것이 negative samples의 수가 증가함에 따라 positive samples로부터의 훈련 신호가 감소하기 때문이라고 의심합니다. 이 실험에서는 negative samples의 수를 제외하고 모든 것이 동일하게 유지됩니다.
다음으로, 오디오 시퀀스를 자르는 것을 통한 데이터 증강의 효과를 분석합니다(§3.4). 배치를 생성할 때 우리는 시퀀스를 미리 정의된 최대 길이로 자릅니다. 표 4는 150k 프레임의 자르기 크기가 최고의 성능을 낳는다는 것을 보여줍니다. 최대 길이를 제한하지 않으면(None) 평균 시퀀스 길이가 약 207k 프레임이 되어 최악의 정확도를 보입니다. 이것은 이 설정이 가장 적은 양의 데이터 증강을 제공하기 때문일 가능성이 높습니다.
표 5는 또한 미래 12단계 이상을 예측하는 것이 더 나은 성능을 낳지 않으며 단계 수를 늘리면 훈련 시간이 증가한다는 것을 보여줍니다.
| Crop size | dev PER |
|---|---|
| None (Avg. 207k) | 16.3 |
| 100k | 16.1 |
| 150k | |
| 200k | 16.0 |
표 4: 다른 자르기 크기의 효과 (참조. 표 3).
| # Tasks | dev PER |
|---|---|
| 8 | 15.9 |
| 12 | |
| 16 | 15.5 |
표 5: 다른 작업 수 의 효과 (참조. 표 3).
5 Conclusions
우리는 fully convolutional 모델을 사용한 음성 인식에 비지도 pre-training을 처음으로 적용한 wav2vec을 소개합니다. 우리의 접근 방식은 WSJ 테스트 세트에서 2.43%의 WER을 달성했으며, 이는 문헌에서 알려진 차선책 문자 기반 음성 인식 모델(Amodei et al., 2016)을 능가하는 결과이면서도 두 자릿수나 적은 전사된 훈련 데이터를 사용했습니다. 우리는 pre-training을 위한 더 많은 데이터가 성능을 향상시키고 이 접근 방식이 자원이 부족한 설정뿐만 아니라 모든 WSJ 훈련 데이터가 사용되는 설정에서도 개선된다는 것을 보여줍니다. 향후 연구에서는 성능을 더욱 향상시킬 가능성이 있는 다른 아키텍처를 조사할 것입니다.
Acknowledgements
FAIR의 Speech 팀, 특히 wav2letter++ 실험에 도움을 주신 Jacob Kahn, Vineel Pratap, Qiantong Xu와 저희 실험을 위해 convolutional language models을 제공해주신 Tatiana Likhomanenko에게 감사드립니다.
References
Dario Amodei, Sundaram Ananthanarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Qiang Cheng, Guoliang Chen, et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proc. of ICML, 2016.
Alexei Baevski, Sergey Edunov, Yinhan Liu, Luke Zettlemoyer, and Michael Auli. Cloze-driven pretraining of self-attention networks. arXiv, abs/1903.07785, 2019.
Yi-Chen Chen, Chia-Hao Shen, Sung-Feng Huang, Hung-yi Lee, and Lin-Shan Lee. Almost-unsupervised speech recognition with close-to-zero resource based on phonetic structures learned from very small unpaired speech and text data. arXiv, abs/1810.12566, 2018.
Jan Chorowski, Ron J. Weiss, Samy Bengio, and Aäron van den Oord. Unsupervised speech representation learning using wavenet autoencoders. arXiv, abs/1901.08810, 2019.
Yu-An Chung, Wei-Hung Weng, Schrasing Tong, and James R. Glass. Unsupervised cross-modal alignment of speech and text embedding spaces. arXiv, abs/1805.07467, 2018.
Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. Natural language processing (almost) from scratch. .
Ronan Collobert, Christian Puhrsch, and Gabriel Synnaeve. Wav2letter: an end-to-end convnet-based speech recognition system. arXiv, abs/1609.03193, 2016.
Ronan Collobert, Awni Hannun, and Gabriel Synnaeve. A fully differentiable beam search decoder. arXiv, abs/1902.06022, 2019.
Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional networks. In Proc. of ICML, 2017.
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In Proc. of CVPR, 2009.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv, abs/1810.04805, 2018.
Footnotes
-
코드는 fairseq의 일부로 제공됩니다 (https://github.com/pytorch/fairseq). ↩
-
van den Oord et al. (2018)과 유사하게, 우리는 다른 시퀀스와 화자로부터 네거티브를 샘플링하는 것이 더 낮은 결과를 낳는다는 것을 발견했습니다. ↩