Vid-Morp & ReCorrect: 레이블 없는 영상으로 Video Moment Retrieval 모델 사전학습하기
Video Moment Retrieval (VMR)은 대규모 수동 레이블링에 크게 의존하는 문제에 직면해 있습니다. 이 논문은 레이블이 없는 실제 비디오를 활용하는 새로운 사전학습 패러다임을 제안합니다. 이를 위해, 최소한의 인간 개입으로 수집된 대규모 데이터셋 Vid-Morp를 구축하고, 이 데이터셋의 불완전한 의사 레이블(pseudo-annotations)이 가진 노이즈 문제를 해결하기 위해 ReCorrect 알고리즘을 제시합니다. ReCorrect는 semantics-guided refinement를 통해 부정확한 데이터를 정제하고, memory-consensus correction을 통해 점진적으로 시간적 경계를 교정합니다. 이 방법을 통해 사전학습된 모델은 zero-shot 및 unsupervised 환경에서도 높은 성능을 보여주며, VMR의 레이블링 비용 문제를 효과적으로 해결할 수 있는 가능성을 제시합니다. 논문 제목: Vid-Morp: Video Moment Retrieval Pretraining from Unlabeled Videos in the Wild
Bao, Peijun, et al. "Vid-Morp: Video Moment Retrieval Pretraining from Unlabeled Videos in the Wild." arXiv preprint arXiv:2412.00811 (2024).
Vid-Morp: Video Moment Retrieval Pretraining from Unlabeled Videos in the Wild
Peijun Bao, Chenqi Kong, Zihao Shao, Boon Poh Ng, Meng Hwa Er, Life Fellow, IEEE, Alex C. Kot, Life Fellow, IEEE
Abstract
자연어 쿼리가 주어졌을 때, video moment retrieval은 정제되지 않은(untrimmed) 비디오에서 설명된 시간적 순간(temporal moment)을 찾아내는 것을 목표로 한다. 이 task의 주요 과제는 학습을 위한 노동 집약적인 어노테이션에 크게 의존한다는 점이다. 수동으로 큐레이션된 데이터로 모델을 직접 학습시키는 기존 연구들과 달리, 우리는 어노테이션 비용을 줄이기 위한 새로운 패러다임을 제안한다: 레이블이 없는 실제 비디오로 모델을 사전학습(pretraining)하는 것이다.
이를 지원하기 위해 우리는 **최소한의 사람 개입으로 수집된 대규모 데이터셋인 Video Moment Retrieval Pretraining (Vid-Morp)**을 소개한다. 이 데이터셋은 야외에서 촬영된 5만 개 이상의 비디오와 20만 개의 pseudo annotation으로 구성된다. 그러나 이러한 불완전한 pseudo annotation으로 직접 사전학습하는 것은 상당한 도전 과제를 안고 있다. 여기에는 문장-비디오 쌍의 불일치(mismatched sentence-video pairs) 및 부정확한 시간적 경계(imprecise temporal boundaries) 등이 포함된다.
이러한 문제들을 해결하기 위해 우리는 ReCorrect 알고리즘을 제안한다. ReCorrect는 크게 두 가지 주요 단계로 구성된다:
- semantics-guided refinement
- memory-consensus correction
Semantics-guided refinement 단계에서는 비디오 프레임과의 의미론적 유사성(semantic similarity)을 활용하여 pseudo label을 개선한다. 이는 쌍이 맞지 않는 데이터를 제거하고 시간적 경계에 대한 초기 조정을 수행한다. 이어지는 memory-consensus correction 단계에서는 memory bank가 모델의 예측을 추적하며, 메모리 내의 합의(consensus)를 기반으로 시간적 경계를 점진적으로 수정한다.
포괄적인 실험을 통해 ReCorrect가 여러 다운스트림 설정에서 강력한 일반화 능력을 보여주었다. Zero-shot ReCorrect는 두 벤치마크에서 최고 fully-supervised 성능의 75% 이상 및 80% 이상을 달성했으며, unsupervised ReCorrect는 두 벤치마크 모두에서 약 85%에 도달했다.
코드, 데이터셋 및 사전학습된 모델은 https://github.com/baopj/Vid-Morp 에서 확인할 수 있다.
1 Introduction
자연어 쿼리와 untrimmed video가 주어졌을 때, Video Moment Retrieval (VMR) [1], [2] task는 언어 쿼리에 의해 설명되는 비디오 순간(moment)을 시간적으로 지역화(temporally localize)하는 것을 목표로 한다. VMR은 비디오 이해 분야에서 가장 기본적인 task 중 하나이며, 비디오 요약, 로봇 조작, 비디오 감시 분석 등 다양한 실제 응용 분야를 가지고 있다 [3]-[6].
최근 몇 년간 VMR의 성능은 딥러닝 기술 [7]-[18]과 수동으로 주석된 데이터 [1], [2]의 가용성 덕분에 향상되었다. 그러나 문장 쿼리 및 시간적 경계(temporal boundaries)를 포함한 이러한 주석을 수집하는 것은 여전히 비용이 많이 들고, 노동 집약적이며, 확장성이 떨어진다. 또한, 이러한 주석은 종종 언어적 및 시간적 편향 [19]-[21] (예: 쿼리 스타일 및 시간적 경계 분포의 편향)을 보여 실제 적용 가능성을 제한한다.
이러한 도전을 해결하기 위해 최근 연구들 [22]-[24]은 레이블이 없는 비디오에 초점을 맞춰 비지도 학습(unsupervised learning)을 탐구하고 있다. 그러나 이러한 방법들은 잘 주석된 데이터셋 [1], [2], [25]에서 가져온 레이블 없는 비디오에 의존한다는 공통적인 한계를 가지고 있다. 이러한 의존성은 주석자가 수동으로 비디오를 사전 정제해야 하므로 본질적으로 인적 노동을 수반하며, 이는 이러한 방법들의 확장성을 제한한다. 더욱이, 이러한 연구들의 학습 및 테스트 비디오는 종종 유사한 분포를 공유하는데, 이는 실제 환경에서는 거의 발생하지 않는 조건이다. 다양한 실제 환경에서 완전히 레이블이 없는 비디오를 활용할 잠재력은 아직 크게 탐구되지 않았다.
이를 위해, Fig. 1에서 보여주듯이, 우리는 Video Moment Retrieval Pretraining (Vid-Morp) 이라는 대규모 데이터셋을 소개한다. 이 데이터셋은 50K개 이상의 실제 환경에서 촬영된 untrimmed video로 구성된다. 우리는 **GPT-4o와 같은 멀티모달 대규모 언어 모델(LLM)**을 활용하여 맞춤형 prompt를 생성하고, 이를 통해 비디오 순간 검색을 위해 특별히 설계된 200K개 이상의 pseudo-annotation 학습 샘플을 생성한다. 그러나 이러한 샘플을 생성하는 데 인적 개입이 최소화되었기 때문에, 이를 직접 사전학습하는 것은 상당한 어려움을 야기한다. 이러한 샘플에서 흔히 발생하는 문제로는 의미 있는 활동이 거의 없는 비디오, 일치하지 않는 비디오-쿼리 쌍, 그리고 부정확한 시간적 경계 등이 있다.
이러한 문제들을 해결하기 위해 우리는 Refinement and Correction (ReCorrect) 알고리즘을 제안한다. 이 알고리즘은 **의미 기반 정제(semantics-guided refinement)**와 **메모리 합의 보정(memory-consensus correction)**의 두 가지 주요 단계로 구성된다. 의미 기반 정제 단계에서는 비디오 프레임과 pseudo label 간의 의미론적 유사성(semantic similarity)을 활용하여 유휴 비디오(idle videos) 및 불일치 비디오-쿼리 쌍과 같은 오류 발생 가능성이 있는 학습 샘플을 정제하고, 동시에 시간적 경계를 초기 조정함으로써 pseudo label을 개선한다. 이어지는 메모리 합의 보정 단계에서는 메모리 뱅크(memory bank)가 사전학습 동안 모델의 예측을 지속적으로 추적한다. 이 메모리 뱅크는 메모리 내의 합의(consensus)를 기반으로 pseudo label의 시간적 경계를 점진적으로 보정하는 참조 역할을 한다.
Fig. 1에 나타난 바와 같이, 사전학습된 ReCorrect 모델은 zero-shot inference, 비지도 학습(unsupervised learning), 완전 지도 학습(fully supervised learning) 및 out-of-distribution 시나리오를 포함한 VMR의 다양한 다운스트림 설정에 원활하게 적용될 수 있다. 실험 결과, 비지도 ReCorrect는 Charades-STA [1] 및 ActivityNet Captions [2] 벤치마크 모두에서 state-of-the-art 완전 지도 학습 성능의 약 85%를 달성한다. 그리고 zero-shot ReCorrect는 각각 75%와 80%를 초과한다. 이는 VMR에서 수동 주석에 대한 높은 의존성이라는 중요한 문제를 해결할 Vid-Morp의 잠재력을 강조한다. ReCorrect는 또한 주석 편향 문제 [20], [21]를 효과적으로 완화하며, zero-shot 버전은 두 개의 out-of-distribution 벤치마크에서 이 문제를 위해 맞춤화된 완전 지도 학습 방법들을 능가한다.
 Fig. 1: 비디오 순간 검색(VMR)의 중요한 과제는 학습을 위한 광범위한 수동 주석에 대한 높은 의존성이다. 이를 극복하기 위해 우리는 최소한의 인적 개입으로 수집된 대규모 Video Moment Retrieval Pretraining (Vid-Morp) 데이터셋을 소개한다. Vid-Morp는 50K개 이상의 실제 환경 비디오와 200K개의 pseudo 학습 샘플로 구성된다. Vid-Morp로 사전학습된 모델은 주석 비용을 크게 줄이고 다양한 다운스트림 설정에서 강력한 일반화 능력을 보여준다.
Fig. 1: 비디오 순간 검색(VMR)의 중요한 과제는 학습을 위한 광범위한 수동 주석에 대한 높은 의존성이다. 이를 극복하기 위해 우리는 최소한의 인적 개입으로 수집된 대규모 Video Moment Retrieval Pretraining (Vid-Morp) 데이터셋을 소개한다. Vid-Morp는 50K개 이상의 실제 환경 비디오와 200K개의 pseudo 학습 샘플로 구성된다. Vid-Morp로 사전학습된 모델은 주석 비용을 크게 줄이고 다양한 다운스트림 설정에서 강력한 일반화 능력을 보여준다.
우리의 주요 기여는 다음과 같이 요약될 수 있다:
- 우리는 Vid-Morp를 소개한다. Vid-Morp는 50K개 이상의 실제 환경 비디오와 비디오 순간 검색 사전학습을 위해 설계된 200K개의 pseudo 학습 샘플을 포함하는 대규모의 다양한 데이터셋이다.
- 오류 발생 가능성이 있는 pseudo 학습 샘플 문제를 해결하기 위해 ReCorrect 알고리즘을 제안한다. ReCorrect는 **pseudo label을 정제하고 조정하기 위한 의미 기반 정제(semantics-guided refinement)**와 **메모리 뱅크 내의 합의를 기반으로 시간적 경계를 보정하기 위한 메모리 합의 보정(memory consensus correction)**을 통합한다.
- 포괄적인 실험을 통해 ReCorrect가 zero-shot, 비지도 학습, 완전 지도 학습 및 out-of-distribution 시나리오를 포함한 다양한 설정에서 state-of-the-art 성능을 달성함을 입증한다.
2 Related Works
완전 지도 학습 기반 비디오 모먼트 검색 (Fully-Supervised Video Moment Retrieval)
완전 지도 학습 기반 Video Moment Retrieval (VMR)의 성능은 딥러닝 기술의 발전 [7-10, 13, 14, 16]과 수동으로 주석된 데이터의 가용성 [1, 2]에 힘입어 향상되었다. 예를 들어, Liu et al. [7]은 시각적 feature의 중요한 부분을 강조하기 위해 attention mechanism을 적용할 것을 제안한다. Bao et al. [16]은 의미적으로 관련되고 시간적으로 조율된 비디오 모먼트를 검색하기 위해 event propagation network를 개발했다. 쿼리 문장의 **구성적 속성(compositional property)**은 [14, 27, 28]에서 시간적 추론(temporal reasoning)에 활용된다. 이러한 완전 지도 학습 방법들은 유망한 성능을 달성하지만, 수동 주석에 의존하며 이는 노동 집약적이고 주관적인 레이블링을 필요로 한다.
비지도 학습 기반 비디오 모먼트 검색 (Unsupervised Video Moment Retrieval)
높은 주석 비용을 없애기 위해, 비디오 이해의 다양한 task [19, 29-32]에서 비지도 학습이 최근 몇 년간 주목을 받고 있다. 일부 최근 연구들 [22-24]은 레이블이 없는 비디오만을 사용하여 비지도 VMR을 연구한다. 예를 들어, Kim et al. [24]은 언어 데이터 없이 VMR 모델을 학습시키기 위한 language-free training algorithm을 제안한다. 그러나 이러한 모델들의 주요 한계점은 기존의 수동으로 주석된 데이터셋에서 얻은 깨끗한 비디오에 의존하기 때문에 수동 큐레이션(manual curation)의 도입이 불가피하다는 점이다. 의미 있는 활동이 없는 유휴 비디오와 같은 노이즈가 많은 데이터를 포함하는 실제 비디오 시나리오를 처리하도록 이러한 모델을 확장하는 것은 여전히 도전 과제이다. 이와 대조적으로, 제안된 ReCorrect는 야생에서 캡처된 레이블 없는 비디오에만 의존하도록 특별히 설계되었다.
비디오 모먼트 검색 사전학습 (Video Moment Retrieval Pretraining)
우리의 연구와 가장 유사한 작업은 **VMR을 위한 feature extraction backbone을 사전학습하는 ProTeGe [33]**이다. 그러나 우리의 연구는 그들과 다르며 상호 보완적이다: 그들의 접근 방식이 feature extraction backbone의 사전학습에 초점을 맞추는 반면, 우리의 연구는 고정된 backbone을 가진 검색 모델의 사전학습을 목표로 한다. 이러한 차이점은 우리 모델이 추가 fine-tuning 없이 zero-shot 설정을 지원하는 반면, 그들의 모델은 그렇지 않다는 사실에 의해 더욱 강조된다.
UniTVG [34]는 다양한 비디오-언어 task를 위한 범용 사전학습 데이터셋을 소개한다. 그러나 그들의 VMR 성능은 VMR에 특화된 다른 zero-shot 접근 방식보다 현저히 낮으며, 측정 지표의 절반 수준에 불과하다 (Table 2 참조). 이는 VMR을 위한 사전학습 데이터셋을 특별히 설계할 필요성을 시사한다.
3 Vid-Morp Dataset
3.1 Overview
Video Moment Retrieval (VMR) [1], [2]은 정제되지 않은(untrimmed) 비디오에서 언어 쿼리에 의해 설명된 비디오 순간을 시간적으로 식별하는 것을 목표로 한다. fully-supervised 방식이 유망한 성능을 달성하고 있지만, 높은 어노테이션 비용은 여전히 VMR의 실제 적용을 제한한다. 최근 연구들 [22]-[24]이 unsupervised 설정을 탐구하고 있지만, 이들은 잘 어노테이션된 데이터셋에서 추출된 깨끗한(clean) 비디오에 계속 의존하고 있다. 이러한 의존성은 수동 개입을 필요로 하여 실제 시나리오에서는 비실용적이다. 다양한 in-the-wild 환경에서 순수하게 레이블이 없는 비디오를 활용할 잠재력은 아직 크게 탐구되지 않았다.
이를 위해, Fig 2에 제시된 바와 같이, 우리는 **최소한의 사람 개입으로 수집된 5만 개 이상의 in-the-wild 비디오와 20만 개 이상의 학습 어노테이션을 포함하는 대규모 데이터셋인 Video Moment Retrieval Pretraining (Vid-Morp)**을 소개한다. Table 1에 요약된 바와 같이, 우리 데이터셋은 이전 데이터셋인 ActivityNet Captions [2]에 비해 비디오 및 쿼리 수가 5배 더 많으며, 다양한 시각 도메인에 걸친 활동을 포함하여 풍부한 의미론적 콘텐츠를 담고 있다.
TABLE 1: Video moment retrieval 데이터셋의 통계. 학습 분할(training split)에서 우리 데이터셋과 다른 데이터셋을 비교하기 위한 관련 지표들이 보고되었다.
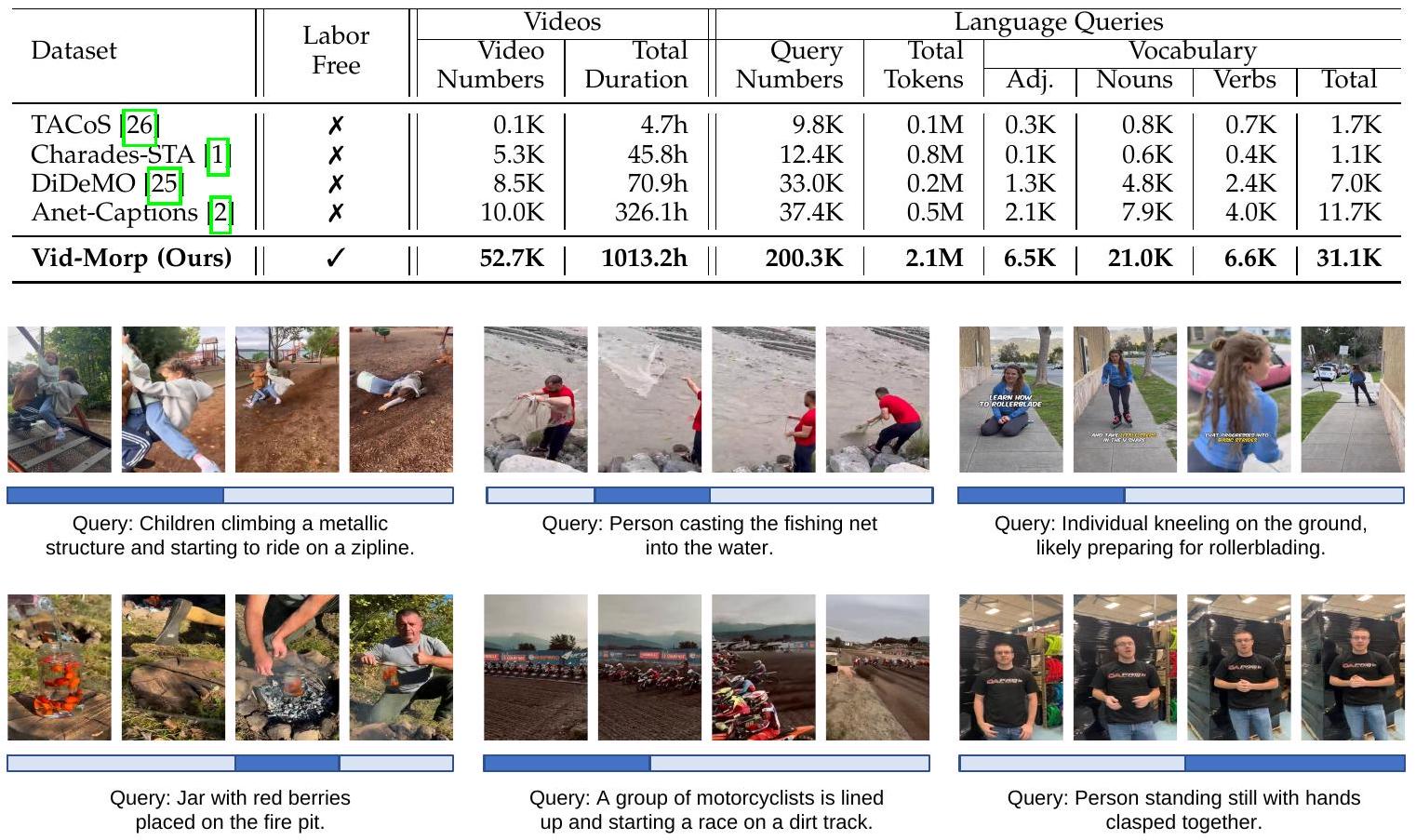
Fig. 2: Video Moment Retrieval Pretraining (Vid-Morp) 데이터셋의 비디오 샘플 및 pseudo-annotation(문장 쿼리 및 시간적 경계 포함) 예시. 진한 파란색 상자는 설명된 비디오 순간의 시간적 경계를 나타낸다.
3.2 Dataset Construction
비디오를 수집하기 위해, 우리는 목표 활동 목록을 정의하고 웹 크롤링을 사용하여 최대 길이의 비디오를 수집한다. 각 비디오는 프레임으로 균일하게 샘플링된 후, 단일 이미지로 연결된다. 우리는 **GPT-4o와 같은 multimodal language model (MLLM)**을 사용하여 pseudo label을 생성하는데, 이때 MLLM이 이미지 내용과 일치하는 프레임 인덱스와 함께 설명적인 문장을 생성하도록 지시하는 신중하게 설계된 prompt를 활용한다. 이 프레임 인덱스는 각 비디오 내의 시작 및 종료 타임스탬프에 매핑된다. 이 과정은 검색 키워드 정의 및 prompt 설계에 주로 제한되는 최소한의 수동 개입으로 높은 확장성을 갖도록 설계되었다.
4 ReCorrect Algorithm
야외에서 촬영된 비디오는 본질적으로 불완전하며, MLLM의 라벨링 정확도 한계로 인해 추가적인 노이즈가 발생한다. 이로 인해 Vid-Morp Dataset의 pseudo annotation에는 Fig. 4에서 보여지듯이 광범위한 오류가 존재한다. 이러한 오류는 크게 세 가지 범주로 나뉜다:
- 의미 있는 이벤트가 없는 Idle 비디오: 아무런 유효한 이벤트가 포함되지 않은 비디오.
- 일치하지 않는 video-query 쌍: pseudo query가 비디오 프레임과 전혀 일치하지 않는 경우.
- 부정확한 temporal boundary: query는 비디오와 일치하지만, 시간적 정렬(temporal alignment)이 정확하지 않은 경우.
이러한 오류들은 pseudo training sample에 대한 직접적인 사전학습에 상당한 어려움을 초래한다.
이러한 문제들을 해결하기 위해, Fig. 3에 나타난 바와 같이, 우리는 Refinement and Correction (ReCorrect) 알고리즘을 제안한다. 이 알고리즘은 다음 두 가지 단계로 구성된다:
- semantics-guided refinement: 오류가 있는 training sample을 제거하고 temporal boundary를 초기 조정한다.
- memory-consensus correction: memory bank가 예측을 추적하여 consensus 기반으로 boundary를 수정한다.
4.1 Pretraining on Vid-Morp
4.1.1 Semantics-Guided Refinement
pseudo query 가 untrimmed video의 비디오 모먼트와 정렬되도록 하기 위해, 우리는 **비디오와 문장의 불일치 쌍을 제거하고 pseudo temporal boundary를 조정하기 위한 의미론 기반 정제(semantics guided refinement)**를 제안한다.
먼저, 사전학습된 **CLIP 모델 [35]**을 사용하여 쿼리 feature 와 -번째 프레임의 visual feature 를 추출하고, 이들 간의 **의미론적 유사도 **를 다음과 같이 계산한다:
여기서 는 비디오의 총 프레임 수이다.
쿼리에 대해 MLLM이 제공하는 pseudo-temporal boundary를 라고 하자. 여기서 와 는 각각 시작 및 종료 시점을 나타낸다.
그런 다음, 우리는 모먼트 contrastive 점수를 계산한다. 이 점수는 비디오 내용이 문장과 얼마나 대조적으로 의미론적 관련성을 가지는지 나타내며, pseudo-temporal 모먼트 내부의 내용과 외부의 내용을 비교한다. 이는 다음과 같이 공식화된다:
 Fig. 3: in-the-wild 비디오로부터 비디오 모먼트 검색 사전학습을 위한 Refinement and Correction (ReCorrect) 알고리즘 개요. ReCorrect는 두 가지 핵심 단계로 구성된다:
Fig. 3: in-the-wild 비디오로부터 비디오 모먼트 검색 사전학습을 위한 Refinement and Correction (ReCorrect) 알고리즘 개요. ReCorrect는 두 가지 핵심 단계로 구성된다:
- 의미론 기반 정제(semantics-guided refinement): 의미론적 유사도를 활용하여 의미 없는 비디오(idle videos) 및 불일치 비디오-쿼리 쌍과 같은 노이즈가 있는 pseudo 학습 샘플을 정제하고, 동시에 temporal boundary를 초기 조정한다.
- 메모리 합의 보정(memory-consensus correction): 메모리 뱅크가 모델 예측을 추적하고, 메모리 내의 합의(consensus)를 기반으로 temporal boundary를 점진적으로 보정한다.
 Fig. 4: 확장 가능하고 수작업 없이 수집된 Vid-Morp 데이터셋은 pseudo 학습 샘플에서 세 가지 일반적인 오류를 보인다:
Fig. 4: 확장 가능하고 수작업 없이 수집된 Vid-Morp 데이터셋은 pseudo 학습 샘플에서 세 가지 일반적인 오류를 보인다:
- 의미 있는 활동이 없는 의미 없는 비디오(idle videos),
- 쿼리 이벤트가 비디오에 나타나지 않는 불일치 비디오-쿼리 쌍(unmatched video-query pairs),
- 비디오-쿼리 매칭은 정확하지만 temporal boundary가 부정확한 정밀하지 않은 temporal boundary.
값이 높다는 것은 pseudo query와 temporal boundary로 정의된 비디오 모먼트 간의 강한 관련성을 나타낸다. 우리는 각 데이터 샘플에 대한 모먼트 contrastive 점수 를 내림차순으로 정렬하고, 하위 퍼센트를 제거하여 나머지 샘플만을 학습 샘플로 선택한다.
이후, 우리는 의미론적 유사도 를 기반으로 시작 시간 를 축소하거나 확장하여 pseudo temporal boundary를 조정한다. 구체적으로, 만약 이면, 를 만큼 축소하여 로 업데이트한다. 그렇지 않고 이면, 를 만큼 확장하여 로 할당한다. 여기서 과 는 미리 정의된 하이퍼파라미터이다. 이 과정은 다음과 같이 공식화될 수 있다:
우리는 에 더 이상 조정이 없을 때까지 이 과정을 반복한다. 동일한 접근 방식이 종료 시점 를 정제하기 위해서도 적용된다. 최종적으로 조정된 pseudo-temporal boundary는 로 표기된다.
4.1.2 Memory Consensus Correction
비록 pseudo temporal boundary가 의미론적 가이드(semantics guided) 정제를 통해 초기적으로 개선되지만, 여전히 부정확하며 문장 쿼리와 완전히 일치하지 않을 수 있다. 이를 해결하기 위해, 우리는 coarse-to-fine 방식으로 boundary를 보정하는 memory consensus correction 방법을 도입한다. 우리는 memory bank 을 유지하여 pseudo temporal boundary의 잠재적 후보들을 저장한다. -번째 데이터 샘플의 경우, 해당 memory bank 는 로 초기화되며, 여기서 는 의미론적 가이드 정제에 의해 조정된 temporal boundary를 나타낸다.
우리는 사전학습을 위해 완전 지도 학습 VMR 모델인 SimBase [12]와 동일한 모델 아키텍처를 사용한다. 모델이 -번째 epoch에서 -번째 데이터 샘플의 문장 쿼리에 대해 개의 temporal boundary 를 예측한다고 가정하자. 만약 -번째 epoch에서 memory bank 가 개의 인스턴스를 포함하고 있다면, 우리는 -번째 memory 인스턴스 에 대한 **consensus score **를 memory bank 내의 다른 개 인스턴스와의 Intersection over Union (IoU)을 합산하여 계산한다:
여기서 는 IoU 연산자를 나타낸다. 여전히 오류가 발생하기 쉬운 temporal boundary 를 pseudo ground truth로 직접 사용하는 대신, 우리는 consensus score 를 사용하여 memory bank에서 가장 신뢰할 수 있는 pseudo ground truth를 결정한다. **가장 높은 consensus를 가진 인스턴스 **가 를 보정하기 위한 pseudo ground truth로 선택되며, 이는 다음과 같다:
다음으로, 우리는 어떤 예측 를 memory bank 에 삽입할지 결정한다. 구체적으로, 우리는 모델이 예측한 confidence score를 사용하고, 가장 높은 confidence score를 가진 를 선택하여 memory bank 에 삽입한다:
여기서 는 -번째 예측에 대한 confidence score이다. 마지막으로, consensus를 가진 memory 인스턴스 를 사용하여, 사전학습 손실 함수는 다음과 같이 정의된다:
여기서 는 손실 항들의 균형을 맞추는 하이퍼파라미터이며, 는 SimBase [12]에 정의된 손실 함수이다.
4.2 Finetuning on Various Settings
사전학습된 ReCorrect 모델은 zero-shot inference, unsupervised learning, fully-supervised learning과 같은 비디오 모멘트 검색을 위한 타겟 데이터셋의 다양한 다운스트림 설정에 원활하게 적용될 수 있다.
Zero-Shot Setting.
사전학습된 모델은 fine-tuning 없이 타겟 데이터셋에 직접 적용된다. 이는 모델이 타겟 데이터셋의 어떤 비디오나 어노테이션에도 접근하지 않고 동작함을 의미한다.
Unsupervised Setting.
타겟 데이터셋의 레이블 없는 비디오만을 사용하여 사전학습된 모델을 fine-tuning한다. 먼저, Vid-Morp를 따라 이 레이블 없는 비디오에 대한 pseudo annotation을 생성한 다음, ReCorrect 알고리즘을 사용하여 사전학습된 모델을 fine-tuning한다. unsupervised fine-tuning을 위한 손실 함수는 다음과 같이 정의된다:
여기서 는 모델의 예측을 나타내고, 는 ReCorrect에 의해 점진적으로 개선되는 pseudo temporal boundary를 나타낸다.
Fully-Supervised Setting.
사전학습된 ReCorrect 모델을 전체 수동 어노테이션을 사용하여 타겟 데이터셋에 fine-tuning한다. 손실 함수는 fully-supervised 방법인 SimBase [12]에서 사용된 것과 동일하다:
여기서 는 모델의 예측을 나타내고, 는 수동 어노테이션에 해당한다.
5 Experiment
5.1 Datasets and Evaluation Metrics
우리는 제안된 방법들의 성능을 두 가지 대규모 데이터셋인 **Charades-STA [1]**와 **ActivityNet Captions [2]**에서 평가한다. 성능 평가를 위해 **비디오 모먼트 검색(video moment retrieval)의 평가 지표인 'R@m'**을 사용한다. 구체적으로, 검색된 시간적 모먼트(temporal moment)와 ground truth 간의 **IoU(Intersection over Union)**를 계산한다. 이때, 'R@m'은 IoU가 보다 큰 경우를 올바른 모먼트 검색 결과로 간주했을 때, 올바른 모먼트 검색 결과를 가진 언어 쿼리의 비율로 정의된다.
5.2 Implementation Details
우리는 사전학습된 CLIP [35] 모델을 사용하여 시각 및 텍스트 feature를 추출한다. 사전학습된 모델의 네트워크 아키텍처는 SimBase [12]와 동일하다. 하이퍼파라미터 **cleaning ratio 은 40%**로 설정된다. semantics-guided refinement를 위한 프레임 수 와 step size 는 각각 256과 5로 설정된다. 하이퍼파라미터 과 는 각각 0.22와 0.92로 구성된다. 우리는 **Adam optimizer [57]**를 사용하여 batch size 256, learning rate 0.0004로 모델을 학습시킨다. 사전학습 epoch 수는 15로 설정된다. loss weight 는 0.7로 설정된다. 비디오 moment retrieval 모델의 경우, state-of-the-art fully-supervised 모델인 SimBase [12]와 동일한 네트워크 아키텍처를 채택한다. 네트워크 아키텍처에 대한 자세한 내용은 [12]를 참조하거나, 우리의 구현 코드(https://github.com/baopj/Vid-Morp)를 통해 확인할 수 있다.
5.3 Performance Comparisons
5.3.1 Zero-Shot Inference
이전의 zero-shot video moment retrieval (VMR) 방법들은 크게 세 가지 범주로 나눌 수 있다: i) 이미지-텍스트 코퍼스에서 사전학습된 CLIP 모델을 VMR task에 적용하는 방식 [36, 37]. ii) [38]-[40]과 같은 대규모 video-language model. iii) VTG-GPT [41]를 포함한 VMR을 위한 멀티모달 language model 앙상블.
Table 2의 첫 번째 부분에서 볼 수 있듯이, 우리의 ReCorrect 방법은 이전의 모든 zero-shot 접근 방식들을 명확한 차이로 능가한다. 예를 들어, 이전 최고 모델인 VTG-GPT보다 R@0.7에서 7점, mIoU에서 5점 이상 높은 성능을 두 데이터셋 모두에서 달성했다. Vid-Morp 데이터셋에서 GPT4o의 원본 pseudo label로 직접 사전학습한 GPT4o Pretraining은 두 데이터셋 모두에서 VTG-GPT 및 Lu et al. [37]과 유사한 결과를 얻는다. 그리고 ReCorrect는 GPT4o Pretraining의 성능을 두 데이터셋 모두에서 일관되게 향상시키는데, 이는 pseudo label의 다양한 유형의 오류를 해결하는 것이 매우 중요함을 강조한다.
5.3.2 Fully-Supervised Learning
Table 2의 두 번째 부분은 완전 supervised 설정에서 SimBase [12]에 GPT4o Pretraining과 ReCorrect를 모두 추가하면 성능이 향상됨을 보여준다. 두 방법 모두 SimBase 대비 Charades에서 R@0.5 기준 1.5점 이상, ActivityNet에서 R@0.3 기준 약 1점의 성능 향상을 보인다. GPT4o Pretraining과 비교했을 때, ReCorrect는 Charades에서 R@0.7 기준 약 2점, ActivityNet에서 R@0.3 기준 0.5점의 추가적인 성능 향상을 가져온다. fine-tuning 데이터셋이 각각 12.8K 및 37.4K의 수동 레이블을 제공하기 때문에, ReCorrect와 GPT4o Pretraining 간의 성능 향상 폭은 zero-shot 설정보다 좁다.
5.3.3 Unsupervised Learning
Table 2의 세 번째 부분은 unsupervised learning 설정에서의 성능 비교를 요약한다. "GPT4o Finetuning" 및 "ReCorrect Finetuning" 방법은 Vid-Morp 데이터셋으로 사전학습되지 않고 Charades 또는 ActivityNet 데이터셋으로만 fine-tuning된 모델을 나타낸다. 이들의 사전학습된 버전은 사전학습되지 않은 버전에 비해 약 3점 및 5점의 성능 향상을 보여준다. 주목할 만한 점은 unsupervised ReCorrect 방법이 mIoU 지표에서 fully-supervised SimBase의 전체 성능의 약 85%를 두 데이터셋 모두에서 달성한다는 것이다. unsupervised 방법과 fully-supervised 방법 간의 이러한 근접한 성능 차이는 VMR task에서 수동 어노테이션 요구 사항을 완화할 수 있는 VidMorp 데이터셋의 잠재력을 강조한다.
TABLE 2: zero-shot, fully-supervised, unsupervised 설정에서의 state-of-the-art 방법 성능 비교. 각각 ZS, Full, Unsup으로 표기한다. "Pretrain"은 모델이 video-language 데이터로 사전학습되었는지 여부를 나타낸다. 회색 행은 이전 최고 fully-supervised 방법인 SimBase 대비 ReCorrect의 성능 비율을 나타낸다.
| Setting | Method | Pretrain | Charades STA | ActivityNet Captions | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| R@0.3 | R@0.5 | R@0.7 | mIoU | R@0.3 | R@0.5 | R@0.7 | mIoU | |||
| ZS | Luo et al. [36] | 56.77 | 42.93 | 20.13 | 37.92 | 48.28 | 27.90 | 11.57 | 32.37 | |
| Lu et al. [37] | 47.74 | 34.62 | 20.16 | 32.97 | 49.26 | 31.45 | 15.27 | 33.25 | ||
| VideoChat-7B |38 | 9.00 | 3.30 | 1.30 | 6.50 | 8.80 | 3.70 | 1.50 | 7.20 | ||
| VideoLLaMA-7B [39] | 10.40 | 3.80 | 0.90 | 7.10 | 6.90 | 2.10 | 0.80 | 6.50 | ||
| VideoChatGPT-7B [40] | 20.00 | 7.70 | 1.70 | 13.70 | 26.40 | 13.60 | 6.10 | 18.90 | ||
| VTG-GPT [41] | 59.48 | 43.68 | 25.94 | 39.81 | 47.13 | 28.25 | 12.84 | 30.49 | ||
| UniVTG [34] | 44.09 | 25.22 | 10.03 | 27.12 | - | - | - | - | ||
| GPT4o Pretraining | 61.77 | 45.46 | 23.10 | 41.43 | 49.15 | 28.28 | 13.52 | 33.21 | ||
| ReCorrect (Ours) | 66.54 | 51.15 | 28.54 | 45.63 | 54.68 | 33.35 | 15.15 | 35.96 | ||
| Relative to SimBase | 85.6% | 76.9% | 64.8% | 81.3% | 85.5% | 67.6% | 49.7% | 76.4% | ||
| Full | UnLoc |42 | - | 60.80 | 38.40 | - | - | 48.00 | 30.20 | - | |
| MESM [43] | - | 61.24 | 38.04 | - | - | - | - | - | ||
| BAM-DETR [44] | 72.93 | 59.95 | 39.38 | 52.33 | - | - | - | - | ||
| SimBase |12| | 77.77 | 66.48 | 44.01 | 56.15 | 63.98 | 49.35 | 30.48 | 47.07 | ||
| SimBase + GPT4o Pretraining | 78.79 | 68.20 | 44.09 | 56.96 | 64.72 | 49.18 | 30.67 | 47.42 | ||
| SimBase + ReCorrect (Ours) | 78.55 | 68.39 | 45.78 | 57.42 | 65.12 | 49.45 | 30.73 | 47.59 | ||
| Unsup | Gao et al |45| | 46.69 | 20.14 | 8.27 | - | 46.15 | 26.38 | 11.64 | - | |
| PSVL [22 | 46.47 | 31.29 | 14.17 | 31.24 | 44.74 | 30.08 | 14.74 | 29.62 | ||
| PZVMR |46| | 46.83 | 33.21 | 18.51 | 32.62 | 45.73 | 31.26 | 17.84 | 30.35 | ||
| Kim et al. [24] | 52.95 | 37.24 | 19.33 | 36.05 | 47.61 | 32.59 | 15.42 | 31.85 | ||
| CoroNet |47 | 49.21 | 34.60 | 17.93 | 32.73 | 46.05 | 28.19 | 12.84 | 31.11 | ||
| SPL |23 | 60.73 | 40.70 | 19.62 | 40.47 | 50.24 | 27.24 | 15.03 | 35.44 | ||
| GPT40 Finetuning | 61.24 | 44.51 | 22.11 | 40.91 | 49.33 | 28.94 | 13.20 | 33.10 | ||
| ReCorrect Finetuning | 65.75 | 47.32 | 25.83 | 44.48 | 55.30 | 35.64 | 17.38 | 37.89 | ||
| ProTeGe [33] | 46.79 | 31.84 | 17.51 | 31.25 | 45.02 | 27.85 | 14.89 | 33.04 | ||
| GPT4o Finetuning + Pretraining | 65.72 | 49.10 | 25.21 | 44.22 | 50.58 | 30.56 | 14.13 | 34.09 | ||
| ReCorrect (Ours) | 70.96 | 54.42 | 31.10 | 48.66 | 58.31 | 37.83 | 18.57 | 39.74 | ||
| Relative to SimBase | 91.2% | 81.9% | 70.7% | 86.7% | 91.1% | 76.7% | 60.9% | 84.4% |
5.3.4 Comparisons to Existing Pretraining Paradigms
여기서 우리는 ReCorrect를 기존의 사전학습 패러다임인 UniTVG [34] 및 ProTeGe [33]와 비교한다.
UniTVG [34]는 비디오 모먼트 검색(video moment retrieval)을 포함한 여러 비디오-언어 시간 이해(temporal understanding) task를 위한 범용 사전학습 접근 방식을 제시한다. 그러나 Table 2의 첫 번째 부분에서 볼 수 있듯이, UniTVG의 zero-shot 성능은 Luo et al. [36]과 같은 VMR(Video Moment Retrieval) 특정 접근 방식뿐만 아니라 우리의 ReCorrect보다도 현저히 낮다. 예를 들어, UniTVG는 Luo et al. [36]의 R@0.7 점수의 절반, ReCorrect의 3분의 1 수준에 불과하며, 이는 VMR에 특화된 사전학습 데이터셋을 설계하는 것의 이점을 강조한다.
ProTeGe [33]는 비디오 모먼트 검색을 위한 feature extraction backbone에 대한 사전학습 패러다임을 소개한다. 이와 대조적으로, ReCorrect는 고정된 backbone을 사용하면서 VMR 모델 자체를 사전학습하는 데 중점을 둔다. 이는 ProTeGe가 지원하지 않는 zero-shot 추론을 우리 모델이 지원할 수 있게 한다. Table 2의 두 번째 부분에 제시된 unsupervised 설정에서 ReCorrect는 ProTeGe에 비해 상당한 이점을 보여준다. 예를 들어, ReCorrect는 Charades에서 R@0.7 점수 78%를 달성하며, 이는 feature extraction backbone만을 사전학습하는 대신 VMR 모델 자체를 사전학습하는 것의 중요성을 강조한다.
5.3.5 Out-of-Distribution Scenarios
Table 3과 4는 세 가지 유형의 out-of-distribution 데이터셋 [20, 21]에 대한 성능 비교를 제시한다: Novel Composition, Novel Word, 그리고 Changing Distribution of temporal boundary.
우리의 ReCorrect 방법은 Novel Composition 및 Novel Word 데이터셋에서 SSL [53]과 VISA [21]를 크게 능가한다.
Changing Distribution 데이터셋, 특히 Charades-CD에서는 ReCorrect가 MomentDETR [56]보다도 우수한 성능을 보인다.
ActivityNet CD에서는 ReCorrect가 MomentDETR와 비슷한 성능을 보이며, R@0.3에서는 5점 우위를 보이지만 R@0.7에서는 2점 열세를 나타낸다.
주목할 점은 DeCo, VISA, SSL과 같은 방법들은 (1) 완전한 supervised 방식이며 (2) 신중하게 설계된 알고리즘을 통해 out-of-distribution 시나리오에 적응하도록 특별히 맞춤화되었다는 것이다.
이와 대조적으로, zero-shot ReCorrect는 fine-tuning이 필요 없으며, 이러한 시나리오를 위한 특정 알고리즘 설계도 없다.
그럼에도 불구하고, zero-shot ReCorrect는 fine-tuning이나 out-of-distribution 시나리오에 대한 특정 알고리즘 수준의 설계 없이도 강력한 성능을 보여준다. 이러한 뛰어난 성능은 Vid-Morp 데이터셋의 규모와 다양성에 기인한다. Vid-Morp는 광범위한 비디오 콘텐츠, 어노테이션, 그리고 어휘를 포함하고 있어 (Table 1 참조), ReCorrect가 다양한 분포 시나리오를 효과적으로 처리할 수 있도록 한다.
TABLE 3: 두 가지 유형의 out-of-distribution 데이터셋 [21]인 Novel Composition과 Novel Words에 대한 성능 비교.
| Method | Setting | Charades-CG | ActivityNet-CG | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Novel Composition | Novel Word | Novel Composition | Novel Word | ||||||||||
| R@0.5 | R@0.7 | mIoU | R@0.5 | R@0.7 | mIoU | R@0.5 | R@0.7 | mIoU | R@0.5 | R@0.7 | mIoU | ||
| WSSL [48] | Weak | 3.61 | 1.21 | 8.26 | 2.79 | 0.73 | 7.92 | 2.89 | 0.76 | 7.65 | 3.09 | 1.13 | 7.10 |
| TSP-PRL [49] | 16.30 | 2.04 | 13.52 | 14.83 | 2.61 | 14.03 | 14.74 | 1.43 | 12.61 | 18.05 | 3.15 | 14.34 | |
| TMN [50] | 8.68 | 4.07 | 10.14 | 9.43 | 4.96 | 11.23 | 8.74 | 4.39 | 10.08 | 9.93 | 5.12 | 11.38 | |
| 2D-TAN [13] | 30.91 | 12.23 | 29.75 | 29.36 | 13.21 | 28.47 | 22.80 | 9.95 | 28.49 | 23.86 | 10.37 | 28.88 | |
| LGI [8] | 29.42 | 12.73 | 30.09 | 26.48 | 12.47 | 27.62 | 23.21 | 9.02 | 27.86 | 23.10 | 9.03 | 26.95 | |
| VLSNet [51] | Full | 24.25 | 11.54 | 31.43 | 25.60 | 10.07 | 30.21 | 20.21 | 9.18 | 29.07 | 21.68 | 9.94 | 29.58 |
| DeCo [52] | 47.39 | 21.06 | 40.70 | - | - | - | 28.69 | 12.98 | 32.67 | - | - | - | |
| VISA [21] | 45.41 | 22.71 | 42.03 | 42.35 | 20.88 | 40.18 | 31.51 | 16.73 | 35.85 | 30.14 | 15.90 | 35.13 | |
| 2D-TAN+SSL [53] | 35.42 | 17.95 | 33.07 | 43.60 | 25.32 | 39.32 | - | - | - | - | - | - | |
| MS-2D-TAN+SSL [53] | 46.54 | 25.10 | 40.00 | 50.36 | 28.78 | 43.15 | - | - | - | - | - | - | |
| Luo et al. [36] | - | - | - | 45.04 | 21.44 | - | - | - | - | 24.57 | 10.54 | - | |
| GPT4o Pretraining | ZS | 40.35 | 18.94 | 38.40 | 48.06 | 25.18 | 43.15 | 24.67 | 10.38 | 29.34 | 24.44 | 10.18 | 29.41 |
| ReCorrect (Ours) | 48.20 | 25.10 | 43.79 | 53.96 | 29.06 | 46.67 | 29.90 | 13.19 | 32.76 | 30.36 | 12.81 | 32.63 |
TABLE 4: Changing Distribution (CD) of temporal boundaries [20] 데이터셋에 대한 성능 비교.
| Method | Setting | Charades CD | ActivityNet CD | ||||
|---|---|---|---|---|---|---|---|
| R@0.3 | R@0.5 | R@0.7 | R@0.3 | R@0.5 | R@0.7 | ||
| WSSL [48] | Weak | 35.86 | 23.67 | 8.27 | 17.00 | 7.17 | 1.82 |
| TSP-PRL [49] | 31.93 | 19.37 | 6.20 | 29.61 | 16.63 | 7.43 | |
| ABLR [54] | 44.62 | 31.57 | 11.38 | 33.45 | 20.88 | 10.03 | |
| 2D-TAN [13] | Full | 43.45 | 30.77 | 11.75 | 30.86 | 18.38 | 9.11 |
| DRN [55] | 40.45 | 30.43 | 15.91 | 36.86 | 25.15 | 14.33 | |
| MomentDETR [56] | 57.34 | 41.18 | 19.31 | 39.98 | 21.30 | 10.58 | |
| GPT4o Pretraining | ZS | 60.68 | 40.84 | 14.12 | 40.57 | 23.45 | 9.81 |
| ReCorrect (Ours) | 65.98 | 46.80 | 21.38 | 45.37 | 26.68 | 12.06 |
 Fig. 5: Pretraining 데이터셋 크기의 확장성(Scability).
Fig. 5: Pretraining 데이터셋 크기의 확장성(Scability).
5.3.6 Qualitative Comparisons
Fig. 7은 zero-shot video moment retrieval에서 GPT-4o 사전학습 모델과 우리의 ReCorrect 알고리즘 간의 정성적 성능 비교를 보여준다. 이 결과는 세 가지 도전적인 시나리오에서 우리의 zero-shot ReCorrect 접근 방식의 강점을 강조한다:
- 흑백 영화 장면 및 저조도 시나리오와 같은 다양한 시각적 조건 처리 능력.
- 동물 행동 및 수중 장면을 포함한 다양한 활동 유형에서 순간을 효과적으로 검색하는 능력.
- 여러 하위 이벤트가 포함되고 시간적 이해를 요구하는 복합적인 이벤트에 대해 정확하게 추론하는 능력.
5.4 Ablation Studies
제안된 ReCorrect 알고리즘의 효과를 평가하기 위해, 우리는 Charades-STA 데이터셋에 대해 ablation study를 수행한다.
 Fig. 6: **클리닝 비율(cleaning ratio)**에 대한 ablation study.
Fig. 6: **클리닝 비율(cleaning ratio)**에 대한 ablation study.
5.4.1 Scability of Pretraining Dataset Size
Fig. 5는 사전학습 데이터 샘플 수에 따른 zero-shot 성능을 반대수(semi-logarithmic) 스케일로 보여준다. 우리는 R@m 값(여기서 )의 평균을 전체 성능으로 평가한다. 사전학습 데이터 크기가 6.3K에서 12.7K로 두 배 증가함에 따라 성능이 선형적으로 증가하는 것이 관찰된다. 이러한 추세는 데이터 크기가 25.3K에서 200.3K로 증가함에 따라 계속되지만, 더 높은 스케일에서는 증가 기울기가 완만해진다. 이러한 결과는 우리의 Vid-Morp 데이터셋이 확장 가능한 성능 향상을 보인다는 것을 입증한다.
5.4.2 Impact of Cleaning Ratio
Vid-Morp 데이터셋은 최소한의 사람 개입으로 수집되었기 때문에, Fig. 4에서 볼 수 있듯이 유휴 비디오(idle videos) 및 **불일치하는 비디오-쿼리 쌍(mismatched video-query pairs)**과 같은 오류를 필연적으로 포함한다. 이를 해결하기 위해 ReCorrect 알고리즘은 의미론 기반 정제(semantics-guided refinement) 단계에서 label-cleaning module을 통합한다. 여기서 cleaning ratio는 필터링되는 데이터 샘플의 비율을 결정한다. Fig. 6은 cleaning ratio가 zero-shot 성능에 미치는 영향을 보여준다. cleaning ratio가 0%에서 30%로 증가함에 따라 pseudo-label 오류가 있는 샘플이 제거되면서 성능이 향상된다. 그러나 cleaning ratio가 50%를 초과하면 성능이 저하된다. 이 곡선은 또한 20%에서 40% 사이의 cleaning ratio가 만족스러운 결과를 제공함을 나타낸다.

-
다양한 활동 유형 (Diverse Activity Types)

-
복합 이벤트 (Compositional Events)
군중이 나타난 후, 축구 경기가 계속되고 쿼리 팀이 골을 넣자, 팬들의 왼쪽 벽 전체가 열광하며 소란스럽게 위아래로 뛰기 시작한다.
여자가 당구대 위에 누워 있고 남자가 쿼리 공을 쳐서 여자의 팔과 다리에 튀었고, 그들은 공을 치면서 키스도 한다.


Fig. 7: GPT4o 사전학습과 우리의 ReCorrect 알고리즘 간의 zero-shot 추론 정성적 비교. 우리의 zero-shot ReCorrect는 다음을 포함한 비디오 모먼트 검색에서 강력한 능력을 보여준다:
- 다양한 시각적 조건: 흑백 영화 세그먼트 및 저조도 시나리오 등.
- 다양한 활동 유형: 동물 행동 및 수중 장면 등.
- 복합 이벤트: 여러 하위 이벤트로 구성되고 시간적 추론이 필요한 경우. 여기서 "GT"는 ground truth를 나타낸다. 더 어두운 노란색 직사각형은 ground-truth 시간 경계를 나타내고, 더 어두운 파란색 직사각형은 모델의 예측을 나타낸다.
TABLE 5: Zero-shot 추론에 대한 ablation study.
| Clean | Adjust | Correct | R@0.3 | R@0.5 | R@0.7 | mIoU |
|---|---|---|---|---|---|---|
| 61.77 | 45.46 | 23.10 | 41.43 | |||
| 64.96 | 48.00 | 23.86 | 42.94 | |||
| 65.27 | 48.28 | 25.63 | 44.17 | |||
| 65.83 | 49.46 | 26.82 | 44.45 | |||
5.4.3 Effectiveness of the Proposed Modules
우리의 ReCorrect 알고리즘은 세 가지 주요 모듈로 구성된다:
- label cleaning,
- semantics-guided refinement 단계에서의 boundary adjustment,
- memory consensus correction.
이 모듈들은 pretraining과 unsupervised learning 모두에 활용된다. 이들의 효과를 평가하기 위해 우리는
TABLE 6: Unsupervised learning에 대한 ablation study.
| Pretrain | Finetune | R@0.3 | R@0.7 | R@0.7 | mIoU | ||
|---|---|---|---|---|---|---|---|
| Clean | Adjust | Correct | |||||
| 61.24 | 44.51 | 22.11 | 40.91 | ||||
| 67.52 | 50.70 | 26.28 | 45.37 | ||||
| 68.62 | 51.89 | 27.27 | 46.35 | ||||
| 69.52 | 53.21 | 30.17 | 47.61 | ||||
| 70.96 | 54.42 | 31.10 | 48.66 |
zero-shot inference와 unsupervised learning 모두에 미치는 영향을 조사한다.
Table 5는 zero-shot inference 성능에 대한 각 모듈의 효과를 보여주며, 세 가지 주요 모듈은 각각 "Clean", "Adjust", "Correct"로 표기된다. Table 6은 unsupervised fine-tuning에 대한 이 모듈들의 효과를 추가적으로 연구한다. 이 결과들은 각 모듈이 pretraining과 unsupervised learning 모두에서 성능에 긍정적으로 기여하며, 어떤 모듈이라도 제거하면 성능이 현저하게 감소한다는 것을 일관되게 보여준다.
6 Conclusion
본 논문은 Video Moment Retrieval Pretraining을 위한 대규모 데이터셋인 Vid-Morp를 소개한다. 이 데이터셋은 최소한의 수동 개입으로 수집되었다. Vid-Morp의 pseudo label에 존재하는 세 가지 유형의 오류를 해결하기 위해, 우리는 Refinement and Correction (ReCorrect) 알고리즘을 제안한다. 이 알고리즘은 다음 두 가지로 구성된다:
- semantics-guided refinement: 쌍이 맞지 않는(unpaired) 데이터를 필터링하고 temporal boundary를 조정한다.
- memory-consensus correction: memory bank가 예측을 추적하여 consensus 기반으로 boundary를 수정한다. 우리의 실험은 다양한 학습 설정에서 ReCorrect의 효과를 입증하며, 강력한 일반화 능력을 보여준다.