ViLT: 합성곱이나 영역 감독 없이 구현된 Vision-and-Language Transformer
ViLT(Vision-and-Language Transformer)는 기존 Vision-and-Language Pre-training(VLP) 모델들이 의존했던 복잡한 이미지 특징 추출 과정(예: object detection, ResNet)을 제거한 혁신적인 모델입니다. ViLT는 텍스트를 처리하는 방식과 동일하게, 간단한 patch projection을 통해 시각적 입력을 처리하여 모델을 단순화했습니다. 이러한 설계 덕분에 기존 VLP 모델보다 수십 배 빠르면서도, 다양한 vision-and-language downstream task에서 경쟁력 있거나 더 나은 성능을 보여줍니다. 논문 제목: ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
논문 요약: ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- 논문 링크: https://arxiv.org/abs/2102.03334
- 저자: Wonjae Kim, Bokyung Son, Ildoo Kim
- 발표 시기: 2021년, International Conference on Machine Learning (ICML)
- 주요 키워드: Vision-and-Language Pre-training (VLP), Transformer, CNN-free, Efficiency, Multimodal, Image-Text Matching, Masked Language Modeling
1. 연구 배경 및 문제 정의
- 문제 정의:
기존 Vision-and-Language Pre-training (VLP) 모델들은 이미지 특징 추출 과정(예: 객체 탐지, ResNet과 같은 CNN 기반 아키텍처)에 과도하게 의존하여 다음과 같은 두 가지 주요 문제를 야기했습니다.
- 효율성/속도: 이미지 특징 추출에 멀티모달 상호작용 단계보다 훨씬 더 많은 연산량이 필요하여 전체 모델의 속도를 저해합니다. 학습 시에는 특징을 미리 캐싱하여 부담을 줄일 수 있지만, 실제 추론 시에는 여전히 병목 현상이 발생합니다.
- 표현력: 시각 임베더와 미리 정의된 시각적 어휘(vocabulary)의 표현력에 상한선이 있어, 모델의 잠재적 성능을 제한합니다.
- 기존 접근 방식: 대부분의 VLP 모델은 Faster R-CNN과 같은 기성 객체 탐지기(object detector)를 사용하여 이미지에서 Region Feature(bottom-up feature)를 추출하거나, ImageNet으로 사전학습된 ResNet 변형을 사용하여 Grid Feature를 추출했습니다. 이러한 방식은 무거운 CNN 기반의 시각 임베더를 사용하며, 전체 연산량의 대부분을 차지하여 비효율적입니다. 또한, 객체 탐지 기반 방식은 NMS(Non-Maximum Suppression)와 같은 복잡한 후처리 과정을 포함하여 추가적인 지연 시간을 발생시킵니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 최소한의 VLP 아키텍처 제안: 별도의 심층 시각 임베더(deep visual embedder) 없이 Transformer 모듈이 시각 특징을 직접 추출하고 처리하도록 위임하여, 현재까지 Vision-and-Language 모델 중 가장 단순하고 효율적인 아키텍처를 구현했습니다.
- CNN 및 영역 감독 없는 경쟁력 있는 성능 달성: Region Feature 또는 심층 CNN 기반 시각 임베더를 사용하지 않고도 다양한 Vision-and-Language 다운스트림 태스크에서 경쟁력 있거나 더 나은 성능을 최초로 달성했습니다.
- VLP 학습 기법 개선: Whole Word Masking과 이미지 증강(Image Augmentation)이 VLP 모델의 다운스트림 성능을 향상시킨다는 것을 경험적으로 최초로 입증했습니다.
- 제안 방법:
ViLT(Vision-and-Language Transformer)는 시각 입력과 텍스트 입력을 단일하고 통합된 방식으로 처리하는 monolithic, single-stream VLP 모델입니다.
- 시각 입력 처리 간소화: 기존 CNN 기반의 무거운 시각 임베더 대신, ViT(Vision Transformer)에서 사용된 패치(patch)의 단순한 선형 투영(linear projection) 방식을 채택하여 픽셀을 Transformer에 직접 입력합니다. 이는 텍스트 임베딩 방식과 유사하게 시각 임베딩 단계를 대폭 단순화합니다.
- 모델 아키텍처:
- 텍스트 입력은 단어 임베딩과 위치 임베딩을 통해 임베딩됩니다.
- 이미지 입력은 패치로 분할되어 선형 투영과 위치 임베딩을 통해 임베딩됩니다.
- 텍스트 및 이미지 임베딩은 각 모달리티 타입 임베딩 벡터와 합쳐진 후, 하나의 결합된 시퀀스로 연결됩니다.
- 이 결합된 시퀀스는 Multiheaded Self-Attention(MSA) 및 MLP 레이어를 포함하는 Transformer 블록 스택을 통해 처리됩니다.
- 모델은 ImageNet으로 사전학습된 ViT-B/32의 가중치로 초기화됩니다.
- 사전학습 목표 (Pre-training Objectives):
- Image Text Matching (ITM): 이미지와 텍스트 쌍이 정렬되었는지 예측합니다. pooled output feature에 선형 레이어를 적용하며, 추가적으로 텍스트 부분집합과 시각 부분집합 간의 정렬 점수를 계산하는 **Word Patch Alignment (WPA)**를 포함합니다.
- Masked Language Modeling (MLM): 마스킹된 텍스트 토큰의 원본 레이블을 예측합니다.
- Whole Word Masking: MLM 시 하나의 단어를 구성하는 모든 연속적인 subword 토큰을 마스킹하여, 모델이 마스킹된 단어를 예측하기 위해 다른 모달리티(이미지)의 정보를 활용하도록 유도합니다.
- Image Augmentation: fine-tuning 과정에서 RandAugment를 적용하여 모델의 일반화 능력을 향상시킵니다 (color inversion 및 cutout 제외).
3. 실험 결과
- 데이터셋:
- 사전학습: Microsoft COCO (MSCOCO), Visual Genome (VG), SBU Captions (SBU), Google Conceptual Captions (GCC).
- 다운스트림:
- 분류(Classification): VQAv2 (Visual Question Answering), NLVR2 (Natural Language for Visual Reasoning).
- 검색(Retrieval): MSCOCO, Flickr30K (F30K) (Karpathy & Fei-Fei 분할).
- 주요 결과:
- 효율성:
- 추론 지연 시간: 기존 Region 기반 VLP 모델(예: ViLBERT, UNITER)의 약 900ms, Grid 기반 Pixel-BERT-X152의 약 160ms, Pixel-BERT-R50의 약 60ms에 비해 ViLT-B/32는 약 15ms로, 수십 배에서 최소 4배 이상 빠릅니다.
- 파라미터 수: ViLT-B/32는 87.4M 파라미터로, 기존 VLP 모델(150M~270M)보다 훨씬 적습니다.
- FLOPs: ViLT-B/32는 55.9G FLOPs로, 기존 VLP 모델(136G~1023G)보다 현저히 낮습니다.
- 성능 (분류 태스크):
- VQAv2: ViLT-B/32는 71.26%의 test-dev 정확도를 기록하여, 무거운 시각 임베더를 사용하는 SOTA 모델(예: VinVL-Base 75.95%)보다는 낮지만, 뛰어난 속도를 고려할 때 경쟁력 있는 성능을 보였습니다. (객체 탐지기가 VQA에 더 유리할 수 있다고 추측)
- NLVR2: ViLT-B/32는 76.13%의 test-P 정확도를 기록하여, 역시 SOTA 모델(예: VinVL-Base 83.08%)보다는 낮지만 경쟁력 있는 성능을 유지했습니다.
- 성능 (검색 태스크):
- Zero-shot 검색: ViLT-B/32는 ImageBERT(1,400만 개 데이터셋으로 사전학습)보다 전반적으로 더 나은 성능을 보였습니다.
- Fine-tuned 검색: ViLT-B/32는 Flickr30K Text Retrieval R@1에서 83.5%, Image Retrieval R@1에서 64.4%를 기록하며, 두 번째로 빠른 모델(Pixel-BERT-R50)보다 훨씬 우수한 Recall 성능을 보였습니다.
- Ablation Study:
- 학습 스텝 증가(100K -> 200K), Whole Word Masking, RandAugment 이미지 증강은 다운스트림 성능을 지속적으로 향상시켰습니다.
- Masked Patch Prediction (MPP)는 다운스트림 성능에 기여하지 않았습니다.
- 효율성:
4. 개인적인 생각 및 응용 가능성
- 장점:
- 혁신적인 효율성: 기존 VLP 모델의 가장 큰 병목이었던 시각 특징 추출 과정을 획기적으로 단순화하여, 압도적인 속도와 적은 파라미터로도 경쟁력 있는 성능을 달성했습니다. 이는 실제 서비스 환경에서의 적용 가능성을 크게 높입니다.
- Transformer의 확장된 역할: Transformer가 단순히 모달리티 간 상호작용뿐만 아니라 시각적 특징 추출까지 담당할 수 있음을 보여주어, 향후 멀티모달 모델 아키텍처 설계에 새로운 방향을 제시했습니다.
- VLP 학습 기법 개선: Whole Word Masking과 이미지 증강의 효과를 VLP 분야에서 최초로 입증하여, 모델 성능 향상을 위한 실용적인 팁을 제공했습니다.
- 단점/한계:
- 특정 태스크에서의 성능 한계: VQA와 같이 객체에 대한 명시적인 이해가 중요한 태스크에서는 객체 탐지 기반 모델에 비해 성능이 다소 낮을 수 있습니다. 이는 ViLT가 객체 수준의 명시적인 정보를 사용하지 않기 때문으로 보입니다.
- 시각 마스킹 목표의 개선 필요성: Masked Patch Prediction(MPP)이 효과적이지 않았다는 점은, 영역 감독 없이 시각 모달리티에 대한 더 정교하고 효과적인 마스킹 학습 목표 개발이 필요함을 시사합니다.
- 대규모 데이터셋의 필요성: ViLT 계열 모델의 추가적인 확장(ViLT-L, ViLT-H)을 위해서는 정렬된 대규모 Vision-and-Language 데이터셋이 아직 부족하다는 한계가 있습니다.
- 응용 가능성:
- 실시간 멀티모달 애플리케이션: 빠른 추론 속도 덕분에 실시간 이미지-텍스트 검색, 비디오 질의응답, 인터랙티브 AI 에이전트 등 지연 시간에 민감한 애플리케이션에 적용될 수 있습니다.
- 경량화된 온디바이스 AI: 적은 파라미터와 낮은 연산량으로 인해 모바일 기기나 엣지 디바이스와 같이 리소스가 제한적인 환경에서도 멀티모달 AI 기능을 구현하는 데 활용될 수 있습니다.
- 새로운 VLP 연구 방향 제시: 향후 VLP 연구가 단순히 유니모달 임베더의 성능 경쟁보다는, Transformer 내부의 모달리티 상호작용과 효율적인 엔드-투-엔드 학습 방식에 더 집중하도록 유도할 수 있습니다.
5. 추가 참고 자료
Kim, Wonjae, Bokyung Son, and Ildoo Kim. "Vilt: Vision-and-language transformer without convolution or region supervision." International conference on machine learning. PMLR, 2021.
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Wonjae Kim* Bokyung Son* Ildoo Kim
Abstract
**Vision-and-Language Pre-training (VLP)**은 다양한 vision-and-language downstream task에서 성능을 향상시켰다. 현재 VLP 접근 방식은 이미지 feature 추출 과정에 크게 의존하며, 이 과정의 대부분은 **region supervision (예: object detection)과 convolutional architecture (예: ResNet)**를 포함한다.
문헌에서는 간과되었지만, 우리는 이러한 방식이 다음과 같은 두 가지 측면에서 문제가 있다고 판단한다:
- 효율성/속도: 단순히 입력 feature를 추출하는 데 멀티모달 상호작용 단계보다 훨씬 더 많은 연산량이 필요하다는 점.
- 표현력: 시각 embedder와 미리 정의된 시각적 vocabulary의 표현력에 상한선이 있다는 점.
본 논문에서는 **최소한의 VLP 모델인 Vision-and-Language Transformer (ViLT)**를 제시한다. ViLT는 시각 입력 처리 방식이 텍스트 입력 처리 방식과 동일하게 convolution-free 방식으로 대폭 간소화되었다는 점에서 monolithic하다. 우리는 ViLT가 기존 VLP 모델보다 최대 수십 배 빠르면서도, 경쟁력 있거나 더 나은 downstream task 성능을 보임을 입증한다.
우리의 코드와 사전학습된 가중치는 https://github.com/dandelin/vilt에서 확인할 수 있다.
1. Introduction
사전학습-fine-tuning(pre-train-and-fine-tune) 방식은 vision과 language의 공동 영역으로 확장되어, Vision-and-Language Pre-training (VLP) 모델이라는 새로운 범주를 탄생시켰다 (Lu et al., 2019; Chen et al., 2019; Su et al., 2019; Li et al., 2019; Tan & Bansal, 2019; Li et al., 2020a; Lu et al., 2020; Cho et al., 2020; Qi et al., 2020; Zhou et al., 2020; Huang et al., 2020; Li et al., 2020b; Gan et al., 2020; Yu et al., 2020; Zhang et al., 2021). 이러한 모델들은 이미지-텍스트 매칭(image text matching) 및 masked language modeling objective를 사용하여 이미지와 그에 정렬된 설명 텍스트로 사전학습되며, 입력이 두 가지 modality를 포함하는 vision-and-language downstream task에서 fine-tuning된다.
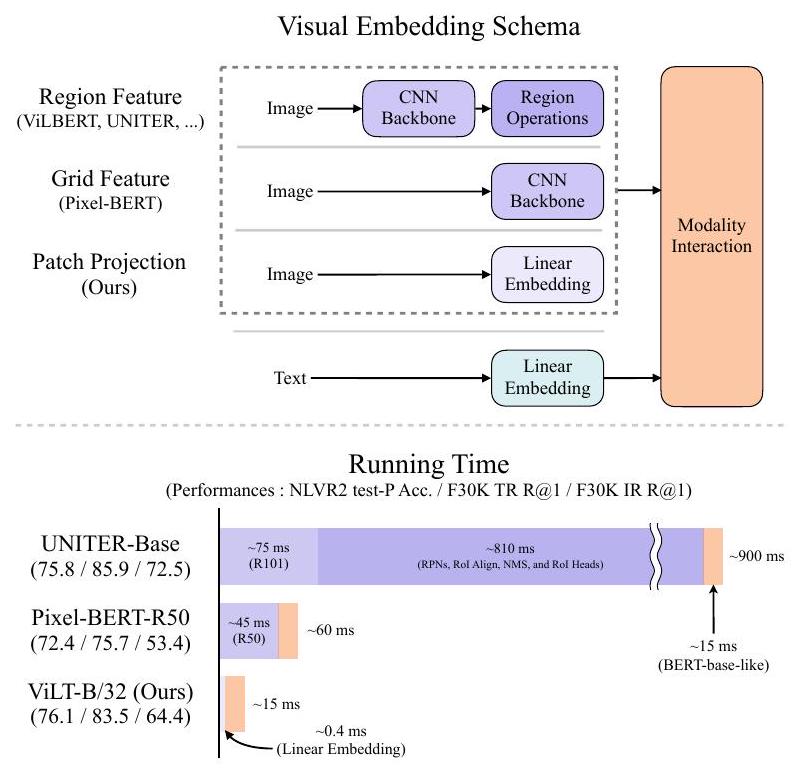
Figure 1. 기존 VLP 아키텍처와 우리가 제안하는 ViLT의 시각적 비교. 우리는 VLP 파이프라인에서 CNN을 완전히 제거했음에도 불구하고 downstream task 성능 저하 없이 이를 달성했다. ViLT는 멀티모달 상호작용을 위한 Transformer 구성 요소보다 modality-specific 구성 요소가 더 적은 연산을 요구하는 최초의 VLP 모델이다.
VLP 모델에 입력되기 위해서는 이미지 픽셀이 언어 토큰과 함께 dense한 형태로 초기 임베딩되어야 한다. Krizhevsky et al. (2012)의 선구적인 연구 이후, **심층 CNN(deep convolutional networks)**은 이러한 시각 임베딩 단계에 필수적인 요소로 간주되어 왔다. 대부분의 VLP 모델은 Anderson et al. (2018)에서처럼 1,600개의 객체 클래스와 400개의 속성 클래스로 주석된 Visual Genome 데이터셋 (Krishna et al., 2017)으로 사전학습된 객체 탐지기(object detector)를 사용한다.
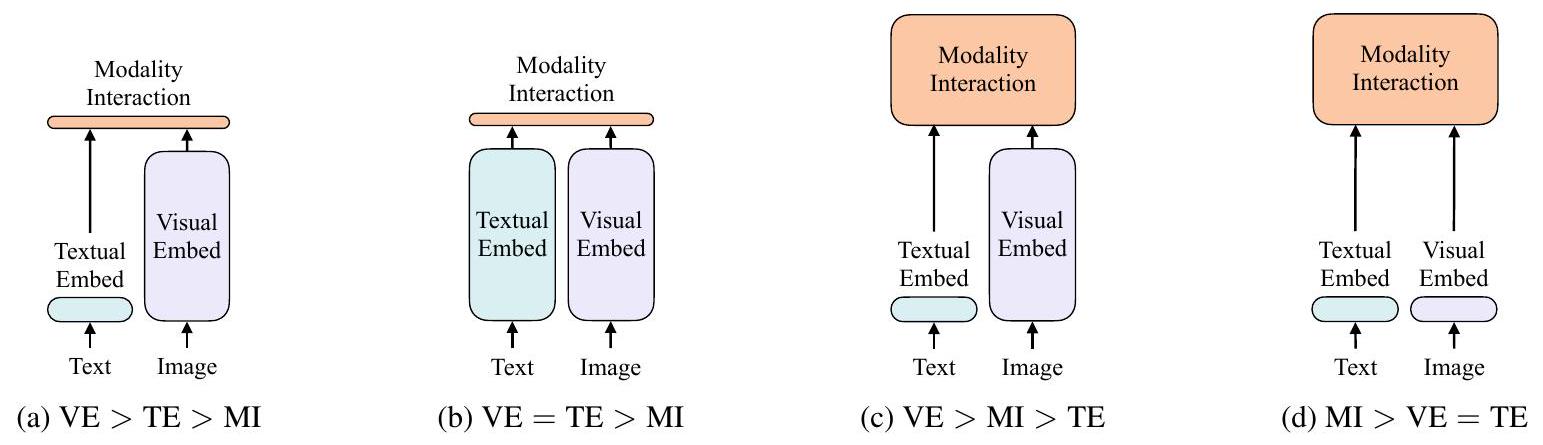
Figure 2. Vision-and-language 모델의 네 가지 범주. 각 직사각형의 높이는 상대적인 연산 크기를 나타낸다. VE, TE, MI는 각각 visual embedder, textual embedder, modality interaction의 약자이다.
**Pixel-BERT (Huang et al., 2020)**는 이러한 경향의 예외 중 하나로, 객체 탐지 모듈 대신 ImageNet 분류 (Russakovsky et al., 2015)로 사전학습된 ResNet 변형 (He et al., 2016; Xie et al., 2017)을 사용하여 픽셀을 임베딩한다.
현재까지 대부분의 VLP 연구는 visual embedder의 성능을 향상시켜 전체 성능을 개선하는 데 집중해왔다. 무거운 visual embedder를 사용하는 단점은 학술 실험에서 종종 간과되는데, 이는 feature 추출 부담을 줄이기 위해 학습 시점에 region feature가 미리 캐싱되는 경우가 많기 때문이다. 그러나 실제 애플리케이션에서는 쿼리가 느린 추출 과정을 거쳐야 하므로 이러한 한계가 여전히 명확하다.
이러한 문제 해결을 위해 우리는 시각 입력의 경량화 및 빠른 임베딩으로 관심을 돌렸다. 최근 연구 (Dosovitskiy et al., 2020; Touvron et al., 2020)는 패치(patch)의 단순한 선형 투영(linear projection)이 픽셀을 Transformer에 입력하기 전에 임베딩하는 데 충분히 효과적임을 입증했다. Transformer (Vaswani et al., 2017)는 텍스트 분야에서는 확고한 주류(Devlin et al., 2019)이지만, 이미지 분야에 사용되기 시작한 것은 최근의 일이다. 우리는 VLP 모델에서 modality interaction에 사용되는 Transformer 모듈이 텍스트 feature를 처리하는 것처럼, CNN 기반의 visual embedder 대신 시각 feature도 처리할 수 있을 것이라고 가정한다.
본 논문은 **두 가지 modality를 단일하고 통합된 방식으로 처리하는 Vision-and-Language Transformer (ViLT)**를 제안한다. ViLT는 기존 VLP 모델과 주로 얕고(shallow), CNN이 없는(convolution-free) 픽셀 수준 입력 임베딩 방식에서 차이가 있다. 시각 입력만을 위한 심층 임베더(deep embedder)를 제거함으로써, 모델 크기와 실행 시간을 설계 단계에서부터 크게 줄일 수 있다. Figure 1은 우리의 파라미터 효율적인 모델이 region feature를 사용하는 VLP 모델보다 수십 배 빠르고, grid feature를 사용하는 모델보다 최소 4배 빠르면서도, vision-and-language downstream task에서 유사하거나 더 나은 성능을 보인다는 것을 보여준다.
우리의 주요 기여는 다음과 같이 요약할 수 있다:
- ViLT는 별도의 심층 visual embedder 대신 Transformer 모듈이 시각 feature를 추출하고 처리하도록 위임함으로써, 현재까지 vision-and-language 모델 중 가장 단순한 아키텍처를 가진다. 이러한 설계는 본질적으로 상당한 실행 시간 및 파라미터 효율성을 가져온다.
- 우리는 region feature 또는 일반적으로 심층 CNN 기반 visual embedder를 사용하지 않고도 vision-and-language task에서 경쟁력 있는 성능을 최초로 달성했다.
- 또한, VLP 학습 방식에서는 전례가 없었던 whole word masking과 이미지 증강(image augmentations)이 downstream 성능을 더욱 향상시킨다는 것을 최초로 경험적으로 보여준다.
2. Background
2.1. Taxonomy of Vision-and-Language Models
우리는 vision-and-language 모델들을 두 가지 기준에 따라 분류하는 taxonomy를 제안한다: (1) 두 modality가 전용 parameter 및/또는 연산 측면에서 동등한 수준의 expressiveness를 가지는지 여부, 그리고 (2) 두 modality가 deep network 내에서 상호작용하는지 여부. 이 두 기준의 조합은 Figure 2에 제시된 네 가지 archetype으로 이어진다.
Visual Semantic Embedding (VSE) 모델들 — 예를 들어 VSE++ (Faghri et al., 2017) 및 SCAN (Lee et al., 2018) — 은 Figure 2a에 해당한다. 이들은 image와 text를 위한 별도의 embedder를 사용하며, 일반적으로 image embedder가 훨씬 더 무겁다. 이후 두 modality로부터 임베딩된 feature들의 유사도를 simple dot product나 shallow attention layer로 표현한다.
CLIP (Radford et al., 2021)은 Figure 2b에 속한다. 이 모델은 modality마다 별도의 transformer embedder를 사용하지만, 두 embedder 모두 유사한 연산량과 parameter 크기를 갖는다. 그러나 pooled image vector와 text vector 간의 상호작용은 여전히 얕은 수준(dot product)에 머문다. CLIP은 image-to-text retrieval에서 zero-shot 성능이 매우 우수함에도 불구하고, 우리는 다른 vision-and-language downstream task에서는 유사한 성능을 관찰하지 못했다. 예를 들어, pooled visual vector와 textual vector 간의 dot product를 multimodal representation으로 사용하여 CLIP의 MLP head를 NLVR2 (Suhr et al., 2018)에서 fine-tuning한 결과, dev accuracy는 (세 개의 seed로 실험)으로 나타났으며, 이는 정답을 랜덤으로 찍는 수준(0.5)과 거의 동일하다. 이로부터 해당 representation은 해당 task를 학습하는 데 부적합하다는 결론을 내릴 수 있다. 이는 Suhr et al. (2018)의 결과와도 일치하며, 그들은 단순히 fused된 multimodal representation을 사용하는 모든 모델들이 NLVR2 학습에 실패했다고 보고하였다.
이러한 결과는 성능이 높은 unimodal embedder의 출력이라 하더라도, 이를 단순히 결합하는 방식만으로는 복잡한 vision-and-language task를 학습하기에 충분하지 않다는 우리의 가설을 뒷받침하며, 보다 정교한 inter-modal interaction scheme의 필요성을 강조한다.
shallow interaction을 사용하는 모델들과 달리, Figure 2c에 해당하는 최근의 VLP 모델들은 image와 text feature 간의 상호작용을 deep transformer를 통해 모델링한다. 그러나 이들 모델에서도 interaction module 외에는 convolutional network가 여전히 image feature를 추출하고 임베딩하는 데 사용되며, Figure 1에서 보이듯 전체 연산량 중 대부분을 차지한다. Modulation 기반 vision-and-language 모델들 (Perez et al., 2018; Nguyen et al., 2020) 또한 Figure 2c에 해당하며, 이들 모델에서 visual CNN stem은 visual embedder에, RNN은 text embedder에 modulation parameter를 제공하며, modulated CNN은 modality interaction에 대응한다.
우리가 제안하는 ViLT는 Figure 2d에 해당하는 최초의 모델로, raw pixel과 text token의 embedding layer가 모두 얕고 계산량이 적다. 따라서 이 아키텍처는 modality 간 상호작용을 모델링하는 데 대부분의 연산을 집중시킨다.
2.2. Modality Interaction Schema
최신 VLP 모델의 핵심에는 Transformer가 있다. Transformer는 시각 및 텍스트 임베딩 시퀀스를 입력으로 받아, layer 전반에 걸쳐 모달 간(inter-modal) 상호작용과 선택적으로 모달 내(intra-modal) 상호작용을 모델링한 후, contextualized feature 시퀀스를 출력한다.
Bugliarello et al. (2020)은 상호작용 스키마를 두 가지 범주로 분류한다: (1) 단일 스트림(single-stream) 접근 방식: VisualBERT (Li et al., 2019), UNITER (Chen et al., 2019)와 같이 이미지 및 텍스트 입력의 연결(concatenation)에 대해 layer들이 함께 작동하는 방식. (2) 이중 스트림(dual-stream) 접근 방식: ViLBERT (Lu et al., 2019), LXMERT (Tan & Bansal, 2019)와 같이 두 모달리티가 입력 수준에서 연결되지 않는 방식.
우리는 단일 스트림 접근 방식을 우리의 interaction Transformer 모듈에 적용한다. 이는 이중 스트림 접근 방식이 추가적인 파라미터를 도입하기 때문이다.
2.3. Visual Embedding Schema
모든 고성능 VLP 모델이 사전학습된 BERT의 동일한 textual embedder-tokenizer(BERT와 유사한 단어 및 위치 임베딩)를 공유하는 반면, visual embedder에서는 차이를 보인다. 그럼에도 불구하고, 대부분의 (전부는 아닐지라도) 경우에 visual embedding은 기존 VLP 모델의 병목 현상을 일으킨다. 우리는 무거운 추출 모듈을 사용하는 region 또는 grid feature 대신 patch projection을 도입하여 이 단계의 병목 현상을 해결하는 데 중점을 둔다.
Region Feature. VLP 모델은 주로 region feature를 활용하며, 이는 bottom-up feature라고도 알려져 있다 (Anderson et al., 2018). 이들은 Faster R-CNN (Ren et al., 2016)과 같은 기성 객체 검출기(off-the-shelf object detector)로부터 얻어진다.
region feature를 생성하는 일반적인 파이프라인은 다음과 같다. 먼저, **Region Proposal Network (RPN)**는 CNN backbone에서 풀링된 grid feature를 기반으로 **관심 영역(Region of Interest, RoI)**을 제안한다. 이어서 **Non-Maximum Suppression (NMS)**는 RoI의 수를 수천 개로 줄인다. RoI Align (He et al., 2017)과 같은 연산을 통해 풀링된 RoI는 RoI head를 거쳐 region feature가 된다. 각 클래스에 대해 NMS가 다시 적용되어 최종적으로 feature의 수를 100개 미만으로 줄인다.
위 과정에는 성능과 런타임에 영향을 미치는 여러 요소가 포함된다: backbone, NMS 방식, RoI head. 이전 연구들은 이러한 요소들을 제어하는 데 관대하여, Table 7에 나열된 것처럼 서로 다른 선택을 해왔다.
- Backbone: ResNet-101 (Lu et al., 2019; Tan & Bansal, 2019; Su et al., 2019)과 ResNext-152 (Li et al., 2019; 2020a; Zhang et al., 2021)는 일반적으로 사용되는 두 가지 backbone이다.
- NMS: NMS는 일반적으로 클래스별(per-class)로 수행된다. 클래스 수가 많을 경우(예: VG 데이터셋의 1.6K 클래스), 각 클래스에 NMS를 적용하는 것은 주요 런타임 병목 현상이 된다 (Jiang et al., 2020). 최근에는 이러한 문제를 해결하기 위해 Class-agnostic NMS가 도입되었다 (Zhang et al., 2021).
- RoI head: 초기에는 C4 head가 사용되었다 (Anderson et al., 2018). 이후 FPN-MLP head가 도입되었다 (Jiang et al., 2018). head는 각 RoI에 대해 작동하므로 상당한 런타임 부담을 초래한다.
아무리 경량화되었다 하더라도, 객체 검출기는 backbone이나 단일 레이어 convolution보다 빠르기 어렵다. visual backbone을 고정하고 region feature를 미리 캐싱하는 것은 학습 시에만 도움이 되며, 추론 시에는 도움이 되지 않을 뿐만 아니라 성능을 저해할 수도 있다.
[^2]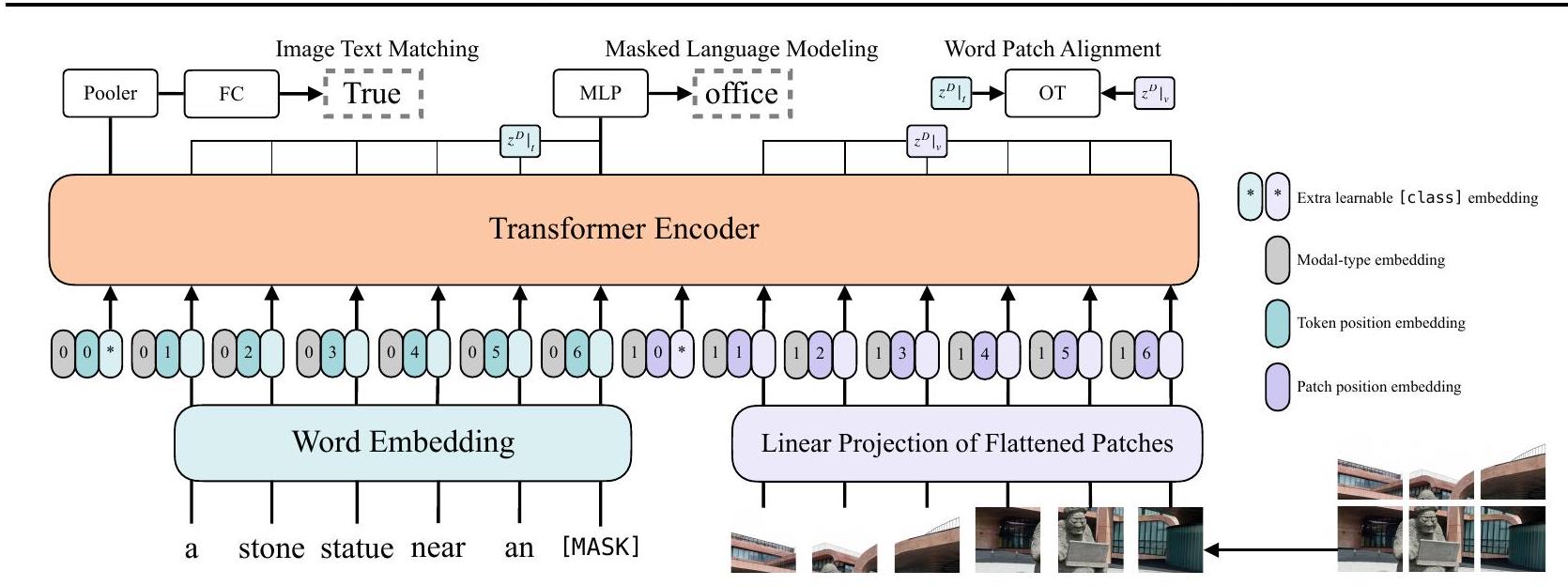
Figure 3. 모델 개요. Dosovitskiy et al. (2020)의 그림에서 영감을 받았다.
Grid Feature. 검출기 head 외에도, ResNet과 같은 Convolutional Neural Network의 출력 feature grid도 vision-and-language pretraining을 위한 visual feature로 사용될 수 있다. grid feature의 직접적인 사용은 주로 매우 느린 region selection 연산을 피하기 위해 VQA-specific 모델에서 처음 제안되었다 (Jiang et al., 2020; Nguyen et al., 2020). X-LXMERT (Cho et al., 2020)는 region proposal network에서 얻은 region proposal 대신 grid로 region proposal을 고정하여 grid feature를 재조명했다. 그러나 이들의 feature 캐싱은 backbone의 추가 튜닝을 배제했다. Pixel-BERT는 VG 사전학습된 객체 검출기를 ImageNet 분류로 사전학습된 ResNet 변형 backbone으로 대체한 유일한 VLP 모델이다. region feature 기반 VLP 모델의 고정된 검출기와 달리, Pixel-BERT의 backbone은 vision-and-language pretraining 동안 튜닝된다. ResNet-50을 사용한 Pixel-BERT의 다운스트림 성능은 region feature 기반 VLP 모델보다 낮지만, 훨씬 무거운 ResNeXt-152를 사용하면 다른 경쟁 모델과 일치한다.
그러나 우리는 grid feature가 최적의 선택이 아니라고 주장한다. Figure 1에서 보듯이, 깊은 CNN은 여전히 전체 계산의 많은 부분을 차지할 정도로 비용이 많이 들기 때문이다.
Patch Projection. 오버헤드를 최소화하기 위해, 우리는 가장 간단한 visual embedding 방식인 이미지 패치에 작동하는 선형 투영(linear projection)을 채택한다. patch projection embedding은 ViT (Dosovitskiy et al., 2020)에 의해 이미지 분류 task를 위해 도입되었다. patch projection은 visual embedding 단계를 텍스트 임베딩 수준으로 대폭 단순화한다. 텍스트 임베딩 또한 간단한 투영(lookup) 연산으로 구성된다.
우리는 2.4M 파라미터만 필요한 32x32 patch projection을 사용한다. 이는 복잡한 ResNe(X)t backbone과 검출 구성 요소와는 극명한 대조를 이룬다. Figure 1에서 보듯이, 그 실행 시간 또한 무시할 수 있는 수준이다. 자세한 런타임 분석은 Section 4.6에서 다룬다.
3. Vision-and-Language Transformer
3.1. Model Overview
ViLT는 최소한의 visual embedding 파이프라인을 갖추고 single-stream 접근 방식을 따르는 간결한 아키텍처의 VLP 모델이다.
우리는 기존 문헌들과 달리 interaction Transformer의 가중치를 BERT 대신 사전학습된 ViT로부터 초기화한다. 이러한 초기화는 별도의 깊은 visual embedder 없이도 interaction layer가 시각적 feature를 처리하는 능력을 활용한다.
ViT는 multiheaded self-attention (MSA) layer와 MLP layer를 포함하는 스택형 블록으로 구성된다. ViT에서 Layer Normalization (LN)의 위치는 BERT와 유일한 차이점이다: BERT에서는 LN이 MSA와 MLP 뒤에 오지만("post-norm"), ViT에서는 그 전에 온다("pre-norm").
입력 텍스트 는 단어 임베딩 행렬 와 위치 임베딩 행렬 를 사용하여 로 임베딩된다.
입력 이미지 는 패치로 분할되어 로 평탄화된다. 여기서 는 패치 해상도이고 이다. 선형 투영 와 위치 임베딩 를 거쳐 는 로 임베딩된다.
텍스트 및 이미지 임베딩은 해당 모달 타입 임베딩 벡터 와 합쳐진 다음, 결합된 시퀀스 로 연결된다. Contextualized 벡터 는 개의 Transformer layer를 통해 최종 contextualized 시퀀스 까지 반복적으로 업데이트된다. 는 전체 멀티모달 입력의 pooled representation이며, 시퀀스 의 첫 번째 인덱스에 선형 투영 와 hyperbolic tangent를 적용하여 얻어진다.
모든 실험에서 우리는 ImageNet으로 사전학습된 ViT-B/32의 가중치를 사용하며, 따라서 모델 이름은 ViLT-B/32이다. Hidden size 는 768, layer depth 는 12, patch size 는 32, MLP size는 3,072, attention head의 수는 12이다.
3.2. Pre-training Objectives
우리는 VLP 모델 학습에 일반적으로 사용되는 두 가지 objective인 **Image Text Matching (ITM)**과 **Masked Language Modeling (MLM)**을 사용하여 ViLT를 학습시킨다.
Image Text Matching (ITM)
우리는 0.5의 확률로 정렬된(aligned) 이미지를 다른 이미지로 무작위로 교체한다.
단일 linear layer로 구성된 ITM head는 pooled output feature 를 이진 클래스에 대한 logits으로 투영하며, 우리는 negative log-likelihood loss를 ITM loss로 계산한다.
또한, Chen et al. (2019)의 word region alignment objective에서 영감을 받아, 우리는 **word patch alignment (WPA)**를 설계하였다. WPA는 의 두 부분집합, 즉 텍스트 부분집합 와 시각 부분집합 간의 정렬 점수(alignment score)를 계산한다. 이를 위해 optimal transports (IPOT)를 위한 inexact proximal point method (Xie et al., 2020)를 사용한다. 우리는 Chen et al. (2019)를 따라 IPOT의 하이퍼파라미터()를 설정하고, approximate wasserstein distance에 0.1을 곱한 값을 ITM loss에 추가한다.
Masked Language Modeling (MLM)
이 objective는 masked text token 의 ground truth label을 해당 contextualized vector 로부터 예측하는 것이다. Devlin et al. (2019)의 휴리스틱을 따라, 우리는 0.15의 확률로 를 무작위로 마스킹한다.
우리는 BERT의 MLM objective와 동일하게, 를 입력으로 받아 vocabulary에 대한 logits을 출력하는 두 개의 layer로 구성된 MLP MLM head를 사용한다. MLM loss는 마스킹된 토큰에 대한 negative log-likelihood loss로 계산된다.
3.3. Whole Word Masking
Whole word masking은 하나의 단어를 구성하는 모든 연속적인 subword token을 마스킹하는 기법이다. 이 기법은 원본 BERT와 중국어 BERT에 적용되었을 때 다운스트림 task에서 효과적임이 입증되었다 (Cui et al., 2019).
우리는 whole word masking이 VLP(Vision-Language Pre-training)에서 다른 modality의 정보를 최대한 활용하는 데 특히 중요하다고 가정한다. 예를 들어, "giraffe"라는 단어는 사전학습된 bert-base-uncased tokenizer에 의해 세 개의 wordpiece token인 ["gi", "##raf", "##fe"]로 토큰화된다. 만약 모든 토큰이 마스킹되지 않고, 예를 들어 ["gi", "[MASK]", "##fe"]와 같이 일부만 마스킹된다면, 모델은 이미지의 정보를 활용하기보다는 인접한 두 언어 토큰인 ["gi", "##fe"]에만 의존하여 마스킹된 "##raf"를 예측할 수 있다.
우리는 사전학습 중에 0.15의 마스크 확률로 whole word masking을 적용한다. 이에 대한 영향은 Section 4.5에서 논의한다.
3.4. Image Augmentation
이미지 증강(Image augmentation)은 vision model의 일반화 능력(generalization power)을 향상시키는 것으로 알려져 있다 (Shorten & Khoshgoftaar, 2019). ViT를 기반으로 하는 DeiT (Touvron et al., 2020)는 다양한 증강 기법들 (Zhang et al., 2017; Yun et al., 2019; Berman et al., 2019; Hoffer et al., 2020; Cubuk et al., 2020)을 실험했으며, 이들이 ViT 학습에 유익하다는 것을 발견했다. 그러나 VLP model 내에서 이미지 증강의 효과는 아직 탐구되지 않았다.
visual feature를 캐싱하는 방식은 region-feature 기반 VLP model이 이미지 증강을 사용하는 것을 제한한다. Pixel-BERT 역시 적용 가능성에도 불구하고 그 효과를 연구하지 않았다.
이에 우리는 fine-tuning 과정에서 RandAugment (Cubuk et al., 2020)를 적용한다. 우리는 두 가지 정책을 제외한 모든 원본 정책을 사용한다:
- color inversion: 텍스트에도 색상 정보가 포함되는 경우가 많기 때문.
- cutout: 작지만 이미지 전체에 분산된 중요한 객체를 지워버릴 수 있기 때문.
하이퍼파라미터로는 N=2, M=9를 사용한다. 이의 영향은 Section 4.5와 Section 5에서 논의한다.
4. Experiments
4.1. Overview
우리는 사전학습을 위해 네 가지 데이터셋을 사용한다: Microsoft COCO (MSCOCO) (Lin et al., 2014), Visual Genome (VG) (Krishna et al., 2017), SBU Captions (SBU) (Ordonez et al., 2011), Google Conceptual Captions (GCC) (Sharma et al., 2018). Table 1은 각 데이터셋의 통계를 보여준다.
Table 1. 사전학습 데이터셋 통계. Caption length는 사전학습된 bert-base-uncased tokenizer의 토큰 길이를 나타낸다. GCC와 SBU는 이미지 URL만 제공하므로, 접근 가능한 URL에서 이미지를 수집하였다.
| Dataset | # Images | # Captions | Caption Length |
|---|---|---|---|
| MSCOCO | 113 K | 567 K | |
| VG | 108 K | 5.41 M | |
| GCC | 3.01 M | 3.01 M | |
| SBU | 867 K | 867 K |
우리는 ViLT를 두 가지 널리 연구된 vision-and-language 다운스트림 task 유형에 대해 평가한다: 분류(classification) task로는 VQAv2 (Goyal et al., 2017)와 NLVR2 (Suhr et al., 2018)를 사용하고, 검색(retrieval) task로는 MSCOCO와 Flickr30K (F30K) (Plummer et al., 2015)를 Karpathy & Fei-Fei (2015)가 재분할한 버전을 사용한다. 분류 task의 경우, head와 데이터 순서에 대해 다른 초기화 seed를 사용하여 세 번 fine-tuning하고 평균 점수를 보고한다. 표준 편차는 ablation study와 함께 Table 5에 보고한다. 검색 task의 경우, 한 번만 fine-tuning한다.
4.2. Implementation Details
모든 실험에서 우리는 **AdamW optimizer (Loshchilov & Hutter, 2018)**를 사용했으며, **기본 learning rate는 , weight decay는 **로 설정했다. learning rate는 전체 학습 스텝의 10% 동안 warm-up되었고, 나머지 학습 기간 동안 선형적으로 0으로 감소되었다. 각 task에 맞게 하이퍼파라미터를 조정하면 다운스트림 성능이 더욱 향상될 수 있음에 유의해야 한다.
입력 이미지의 짧은 변은 384로 크기를 조정하고, 긴 변은 640 미만으로 제한하면서 종횡비(aspect ratio)를 유지했다. 이러한 크기 조정 방식은 다른 VLP 모델의 객체 탐지(object detection)에서도 사용되지만, 짧은 변의 크기가 더 크다(800). ViLT-B/32의 Patch projection은 해상도의 이미지에 대해 개의 patch를 생성한다. 이는 거의 도달하지 않는 상한선이므로, 사전학습(pre-training) 중에는 최대 200개의 patch를 샘플링한다. 우리는 각 이미지 크기에 맞게 ViT-B/32의 를 **보간(interpolate)**하고, 배치 학습을 위해 patch를 **패딩(pad)**한다. 결과적으로 이미지 해상도는 보다 4배 작으며, 이는 다른 모든 VLP 모델이 visual embedder의 입력으로 사용하는 크기이다.
텍스트 입력 토큰화에는 bert-base-uncased tokenizer를 사용한다. 사전학습된 BERT로부터 fine-tuning하는 대신, 텍스트 임베딩 관련 파라미터인 , 는 scratch부터 학습한다. 사전학습된 text-only BERT를 사용하는 것이 표면적으로는 이점이 있어 보이지만, vision 및 language 다운스트림 task에서 성능 향상을 보장하지는 않는다. Tan & Bansal (2019)은 사전학습된 BERT 파라미터로 초기화하는 것이 scratch부터 사전학습하는 것보다 성능이 저하될 수 있음을 이미 보고한 바 있다.
Table 2. 다운스트림 분류 task에서 ViLT-B/32와 다른 모델들의 비교.
VQAv2 및 NLVR2 w/o VLP SOTA 결과에는 MCAN (Yu et al., 2019) 및 MaxEnt (Suhr et al., 2018)를 사용했다.
는 사전학습에 GQA, VQAv2, VG-QA를 추가로 사용했음을 나타낸다.
는 Open Images (Kuznetsova et al., 2020) 데이터셋을 추가로 사용했음을 나타낸다.
(a)는 fine-tuning 중에 RandAugment가 적용되었음을 나타낸다.
는 모델이 200K 사전학습 스텝으로 더 길게 학습되었음을 나타낸다.
| Visual Embed | Model | Time (ms) | VQAv2 test-dev | NLVR2 dev <br> test-P | |
|---|---|---|---|---|---|
| Region | w/o VLP SOTA | ~900 | 70.63 | 54.80 | 53.50 |
| ViLBERT | ~920 | 70.55 | - | - | |
| VisualBERT | ~925 | 70.80 | 67.40 | 67.00 | |
| LXMERT | ~900 | 72.42 | 74.90 | 74.50 | |
| UNITER-Base | ~900 | 72.70 | 75.85 | 75.80 | |
| OSCAR-Base | ~900 | 73.16 | 78.07 | 78.36 | |
| VinVL-Base | 75.95 | 82.05 | 83.08 | ||
| Grid | Pixel-BERT-X152 | ~160 | 74.45 | 76.50 | 77.20 |
| Pixel-BERT-R50 | 71.35 | 71.70 | 72.40 | ||
| Linear | ViLT-B/32 | 70.33 | 74.41 | 74.57 | |
| ViLT-B/32® | 70.85 | 74.91 | 75.57 | ||
| ViLT-B/32 ( + | 71.26 | 75.70 | 76.13 |
우리는 ViLT-B/32를 64개의 NVIDIA V100 GPU에서 100K 또는 200K 스텝 동안 배치 크기 4,096으로 사전학습한다. 모든 다운스트림 task에 대해, VQAv2/retrieval task는 배치 크기 256으로, NLVR2는 배치 크기 128로 10 epoch 동안 학습한다.
4.3. Classification Tasks
우리는 VQAv2와 NLVR2라는 두 가지 일반적으로 사용되는 데이터셋에서 ViLT-B/32를 평가한다. fine-tuning된 다운스트림 head로는 히든 사이즈 1,536의 두 레이어 MLP를 사용한다.
Visual Question Answering (VQA)
VQAv2 task는 이미지와 자연어 질문 쌍이 주어졌을 때 답변을 요구한다. 주석된 답변은 원래 자유 형식의 자연어이지만, 이 task를 3,129개의 답변 클래스를 가진 분류 task로 변환하는 것이 일반적인 관행이다. 이 관행에 따라, 우리는 VQAv2 train 및 validation 세트에서 ViLT-B/32를 fine-tuning했으며, 내부 검증을 위해 1,000개의 validation 이미지와 관련 질문을 따로 남겨두었다.
우리는 평가 서버에 제출한 test-dev 점수 결과를 보고한다. ViLT는 무거운 visual embedder를 사용하는 다른 VLP 모델에 비해 VQA 점수가 낮다. VQA의 질문이 일반적으로 객체에 대해 묻기 때문에, 객체 검출기(object detector)에 의해 생성된 분리된 객체 표현(detached object representation)이 VQA 학습을 용이하게 한다고 우리는 추측한다.
Table 3. 다운스트림 zero-shot retrieval task에서 ViLT-B/32와 다른 VLP 모델들의 비교. 원본 논문에서 zero-shot retrieval 성능이 보고되지 않은 모델은 제외하였다. 는 4M GCC+SBU 데이터셋 외에 10M 독점 vision-and-language 데이터셋으로 사전학습되었다. 는 200K 사전학습 단계를 더 길게 학습한 모델을 나타낸다.
| Visual Embed | Model | Time (ms) | Zero-Shot Text Retrieval | Zero-Shot Image Retrieval | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flickr30k (1K) | MSCOCO (5K) | Flickr30k (1K) | MSCOCO ( 5 K ) | |||||||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| Region | ViLBERT | ~900 | - | - | - | - | - | - | 31.9 | 61.1 | 72.8 | - | - | - |
| Unicoder-VL | ~925 | 64.3 | 85.8 | 92.3 | - | - | - | 48.4 | 76.0 | 85.2 | - | - | - | |
| UNITER-Base | ~900 | 80.7 | 95.7 | 98.0 | - | - | - | 66.2 | 88.4 | 92.9 | - | - | - | |
| ImageBERT | ~925 | 70.7 | 90.2 | 94.0 | 44.0 | 71.2 | 80.4 | 54.3 | 79.6 | 87.5 | 32.3 | 59.0 | 70.2 | |
| Linear | ViLT-B/32 | ~15 | 69.7 | 91.0 | 96.0 | 53.4 | 80.7 | 88.8 | 51.3 | 79.9 | 87.9 | 37.3 | 67.4 | 79.0 |
| ViLT-B/32 | ~15 | 73.2 | 93.6 | 96.5 | 56.5 | 82.6 | 89.6 | 55.0 | 82.5 | 89.8 | 40.4 | 70.0 | 81.1 |
Table 4. 다운스트림 retrieval task에서 ViLT-B/32와 다른 모델들의 비교. w/o VLP SOTA 결과는 SCAN을 사용한다. 는 사전학습에 GQA, VQAv2, VG-QA를 추가로 사용했다. 는 Open Images 데이터셋을 추가로 사용했다. (a)는 fine-tuning 시 RandAugment가 적용되었음을 나타낸다. 는 200K 사전학습 단계를 더 길게 학습한 모델을 나타낸다.
| Visual Embed | Model | Time (ms) | Text Retrieval | Image Retrieval | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flickr30k (1K) MSCOCO (5K) | Flickr30k (1K) | MSCOCO (5K) | ||||||||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| Region | w/o VLP SOTA | ~900 | 67.4 | 90.3 | 95.8 | 50.4 | 82.2 | 90.0 | 48.6 | 77.7 | 85.2 | 38.6 | 69.3 | 80.4 |
| ViLBERT-Base | ~920 | - | - | - | - | - | - | 58.2 | 84.9 | 91.5 | - | - | - | |
| Unicoder-VL | ~925 | 86.2 | 96.3 | 99.0 | 62.3 | 87.1 | 92.8 | 71.5 | 91.2 | 95.2 | 48.4 | 76.7 | 85.9 | |
| UNITER-Base | ~900 | 85.9 | 97.1 | 98.8 | 64.4 | 87.4 | 93.1 | 72.5 | 92.4 | 96.1 | 50.3 | 78.5 | 87.2 | |
| OSCAR-Base | ~900 | - | - | - | 70.0 | 91.1 | 95.5 | - | - | - | 54.0 | 80.8 | 88.5 | |
| VinVL-Base | ~650 | - | - | - | 74.6 | 92.6 | 96.3 | - | - | - | 58.1 | 83.2 | 90.1 | |
| Grid | Pixel-BERT-X152 | ~160 | 87.0 | 98.9 | 99.5 | 63.6 | 87.5 | 93.6 | 71.5 | 92.1 | 95.8 | 50.1 | 77.6 | 86.2 |
| Pixel-BERT-R50 | 75.7 | 94.7 | 97.1 | 59.8 | 85.5 | 91.6 | 53.4 | 80.4 | 88.5 | 41.1 | 69.7 | 80.5 | ||
| Linear | ViLT-B/32 | ~15 | 81.4 | 95.6 | 97.6 | 61.8 | 86.2 | 92.6 | 61.9 | 86.8 | 92.8 | 41.3 | 72.0 | 82.5 |
| ViLT-B/32 | ~15 | 83.7 | 97.2 | 98.1 | 62.9 | 87.1 | 92.7 | 62.2 | 87.6 | 93.2 | 42.6 | 72.8 | 83.4 | |
| ViLT-B/32 ( | ~15 | 83.5 | 96.7 | 98.6 | 61.5 | 86.3 | 92.7 | 64.4 | 88.7 | 93.8 | 42.7 | 72.9 | 83.1 |
Natural Language for Visual Reasoning (NLVR2)
NLVR2 task는 두 개의 이미지와 자연어 질문으로 구성된 세 쌍(triplet)이 주어졌을 때 이진 분류(binary classification)를 수행하는 task이다. 사전학습 설정과 달리 두 개의 입력 이미지가 존재하므로, 여러 전략이 존재한다. OSCAR (Li et al., 2020b) 및 VinVL (Zhang et al., 2021)을 따라 pair method를 사용한다. 이 방법에서는 세 쌍의 입력이 (질문, 이미지1)과 (질문, 이미지2)의 두 쌍으로 재구성되며, 각 쌍은 ViLT를 통과한다. head는 두 개의 pooled representation ()을 연결한 것을 입력으로 받아 이진 예측을 출력한다.
Table 2는 결과를 보여준다. ViLT-B/32는 뛰어난 추론 속도를 고려할 때 두 데이터셋 모두에서 경쟁력 있는 성능을 유지한다.
4.4. Retrieval Tasks
우리는 MSCOCO와 F30K의 Karpathy & Fei-Fei (2015) 분할 데이터셋에 대해 ViLT-B/32를 fine-tuning한다. 이미지-텍스트 및 텍스트-이미지 검색의 경우, zero-shot과 fine-tuned 성능을 모두 측정한다. 유사도 점수 head는 사전학습된 ITM head, 특히 true-pair logits를 계산하는 부분으로 초기화한다. 15개의 무작위 텍스트를 negative sample로 샘플링하고, positive pair에 대한 점수를 최대화하는 cross-entropy loss로 모델을 튜닝한다.
zero-shot 검색 결과는 Table 3에, fine-tuned 결과는 Table 4에 보고한다. zero-shot 검색에서 ViLT-B/32는 ImageBERT가 더 큰(1,400만 개) 데이터셋으로 사전학습되었음에도 불구하고 ImageBERT보다 전반적으로 더 나은 성능을 보인다. fine-tuned 검색에서는 ViLT-B/32의 recall이 두 번째로 빠른 모델(Pixel-BERT-R50)보다 훨씬 높은 마진으로 우수하다.
4.5. Ablation Study
Table 5에서 우리는 다양한 ablation을 수행한다. 더 많은 학습 단계, 전체 단어 마스킹(whole word masking), 이미지 증강(image augmentation)은 유익한 반면, 추가적인 학습 objective는 도움이 되지 않는다.
학습 반복 횟수가 self-supervised 모델의 성능에 영향을 미친다는 보고가 있다 (Devlin et al., 2019; Chen et al., 2020a;b). VLP 또한 self-supervised 학습의 한 형태이므로, 우리는 학습 기간의 영향을 조사한다. 예상대로, 모델을 더 긴 학습 단계 동안 학습시킬수록 성능은 지속적으로 증가한다 (13행). MLM objective를 위한 whole word masking (34행)과 augmentation을 통한 fine-tuning (6행) 또한 성능 향상에 기여한다. 학습 반복 횟수를 200K까지 추가로 늘렸을 때 VQAv2, NLVR2, 그리고 zero-shot retrieval 성능이 향상되었다. fine-tuned text retrieval 성능이 그 이후 감소하기 때문에 우리는 200K 이상의 반복 횟수 증가는 중단한다.
Table 5. ViLT-B/32의 Ablation study. (M)은 사전학습에 whole word masking이 사용되었는지 여부를 나타낸다. (P)는 사전학습에 MPP objective가 사용되었는지 여부를 나타낸다. (A)는 fine-tuning 동안 RandAugment가 사용되었는지 여부를 나타낸다.
| Training | Ablation | VQAv2 | Flickr30k R@1 (1K) | MSCOCO R@1 (5K) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Steps | (M) | (P) | (A) | test-dev | dev | test-P | TR (ZS) | IR (ZS) | TR (ZS) | IR (ZS) |
| 25 K | X | X | X | 75.39 (45.12) | 52.52 (31.80) | 53.72 (31.55) | 34.88 (21.58) | |||
| 50 K | X | X | X | 78.13 (55.57) | 57.36 (40.94) | 57.00 (39.56) | 37.47 (27.51) | |||
| 100 K | X | X | X | 79.39 (66.99) | 60.50 (47.62) | 60.15 (51.25) | 40.45 (34.59) | |||
| 100 K | O | X | X | 81.35 (69.73) | 61.86 (51.28) | 61.79 (53.40) | 41.25 (37.26) | |||
| 100 K | O | O | X | 78.91 (63.67) | 58.76 (46.96) | 59.53 (47.75) | 40.08 (32.28) | |||
| 100 K | O | X | O | 83.69 (69.73) | 62.22 (51.28) | 62.88 (53.40) | 42.62 (37.26) | |||
| 200 K | O | X | O | 83.50 (73.24) | 64.36 (54.96) | 61.49 (56.51) | 42.70 (40.42) |
Table 6. 파라미터 크기, FLOPs, 추론 지연 시간 측면에서 VLP 모델 비교. FLOPs는 입력 크기에 비례하므로, 입력 토큰(이미지+텍스트) 수를 위첨자로 표시한다 (텍스트 길이가 보고되지 않은 경우 "?"로 표시; 임의로 길이 40을 사용). FLOPs 계산이나 파라미터 크기에는 포함되지 않지만 (텐서 연산이 아니기 때문에), 1,600개 클래스에 대한 per-class NMS는 500ms 이상의 지연 시간을 초래할 수 있음에 유의한다. NMS 지연 시간은 감지된 클래스 수에 따라 크게 달라진다.
| Visual Embed | Model | #Params (M) | #FLOPs (G) | Time (ms) |
|---|---|---|---|---|
| Region | ViLBERT | 274.3 | 958.1 | ~900 |
| VisualBERT | 170.3 | 425.0 | ~925 | |
| LXMERT | 239.8 | 952.0 | ~900 | |
| UNITER-Base | 154.7 | 949.9 | ~900 | |
| OSCAR-Base | 154.7 | 956.4 | ~900 | |
| VinVL-Base | 157.3 | 1023.3 | ||
| Unicoder-VL ? | 170.3 | 419.7 | ~925 | |
| ImageBERT | 170.3 | 420.6 | ~925 | |
| Grid | Pixel-BERT-X152146+? | 144.3 | 185.8 | ~160 |
| Pixel-BERT-R50260+? | 94.9 | 136.8 | ||
| Linear | ViLT-B/32 | 87.4 | 55.9 | ~15 |
추가적인 masked region modeling (MRM) objective는 Chen et al. (2019)와 같은 VLP 모델의 성능 향상에 핵심적인 역할을 해왔다. 우리는 patch projection과 호환되는 형태로 MRM의 효과를 모방하는 masked patch prediction (MPP) (Dosovitskiy et al., 2020)을 실험한다. 패치 는 0.15의 확률로 마스킹되며, 모델은 마스킹된 패치의 contextualized vector 로부터 마스킹된 패치의 평균 RGB 값을 예측한다. 그러나 MPP는 다운스트림 성능에 기여하지 않는 것으로 나타났다 (4~5행). 이 결과는 객체 감지(object detection)의 supervision signal에 기반한 MRM objective와는 극명한 대조를 이룬다.
Table 7. VLP 모델 구성 요소. "PC"는 per-class 방식의 NMS를, "CA"는 class-agnostic을 나타낸다. Tan & Bansal (2019)에 따라, 단일 모달리티 레이어는 0.5 멀티 모달리티 레이어로 계산된다.
| Visual Embed | Model | CNN Backbone | RoI Head | NMS | Trans. Layers |
|---|---|---|---|---|---|
| Region | ViLBERT | R101 | C4 | PC | |
| VisualBERT | X152 | FPN | PC | 12 | |
| LXMERT | R101 | C4 | PC | ~12 | |
| UNITER-Base | R101 | C4 | PC | 12 | |
| OSCAR-Base | R101 | C4 | PC | 12 | |
| VinVL-Base | X152 | C4 | CA | 12 | |
| Unicoder-VL | X152 | FPN | PC | 12 | |
| ImageBERT | X152 | FPN | PC | 12 | |
| Grid | Pixel-BERT-X152 | X152 | - | - | 12 |
| Pixel-BERT-R50 | R50 | - | - | 12 | |
| Linear | ViLT-B/32 | - | - | - | 12 |
4.6. Complexity Analysis of VLP Models
우리는 다양한 측면에서 VLP 모델의 복잡성을 분석한다. Table 6에서는 **visual embedder와 Transformer의 파라미터 수, FLOPs(floating-point operations) 수, 그리고 추론 지연 시간(latency)**을 보고한다. 텍스트 embedder는 모든 VLP 모델이 공유하므로 분석에서 제외한다. 지연 시간은 Xeon E5-2650 CPU와 NVIDIA P40 GPU에서 10,000회 평균을 낸 값이다.
이미지 해상도와 연결된 멀티모달 입력 시퀀스의 길이는 FLOPs 수에 영향을 미친다. 우리는 시퀀스 길이를 함께 표기한다. 이미지 해상도는 region-based VLP 모델과 Pixel-BERT-R50의 경우 800x1,333, Pixel-BERT-X152의 경우 600x1,000, 그리고 ViLT-B/32의 경우 384x640이다.
Pixel-BERT와 ViLT에서는 사전학습(pre-training) 중에 visual token이 샘플링되고, fine-tuning 중에는 전체 visual token이 사용된다. 우리는 최대 visual token 수를 보고한다.
우리는 BERT-base와 유사한 Transformer의 런타임이 길이가 300 미만인 입력 시퀀스에 대해 1ms 미만으로만 변동한다는 것을 관찰했다. ViLT-B/32의 patch projection이 최대 240개의 이미지 토큰을 생성하므로, 우리 모델은 이미지와 텍스트 토큰의 조합을 받더라도 여전히 효율적일 수 있다.

Figure 4. 단어 패치 정렬의 전송 계획 시각화. 확대해서 보는 것이 가장 좋다.
4.7. Visualization
Figure 4는 cross-modal alignment의 예시이다. WPA의 transportation plan은 분홍색으로 강조된 텍스트 토큰에 대한 heatmap을 표현한다. 각 사각형 타일은 patch를 나타내며, 그 불투명도(opacity)는 강조된 단어 토큰으로부터 얼마나 많은 mass가 전송되었는지를 나타낸다. 더 많은 IPOT iteration (학습 단계에서 50회 이상)은 시각화 heatmap이 수렴하는 데 도움을 준다. 경험적으로 1,000회의 iteration이면 명확하게 식별 가능한 heatmap을 얻기에 충분하다. 우리는 각 토큰에 대해 plan을 z-normalize하고 값을 [1.0, 3.0]으로 clamp한다.
5. Conclusion and Future Work
본 논문에서는 **최소한의 VLP 아키텍처인 Vision-and-Language Transformer (ViLT)**를 제시한다. ViLT는 convolutional visual embedding network (예: Faster R-CNN 및 ResNet)로 무장한 경쟁 모델들과 견줄 만한 성능을 보여준다. 우리는 향후 VLP 연구가 단순히 unimodal embedder의 성능을 높이는 군비 경쟁에 참여하기보다는, Transformer 모듈 내부의 modality 상호작용에 더 집중할 것을 제안한다.
ViLT-B/32는 놀라운 성능을 보여주지만, **convolution과 region supervision이 없는 효율적인 VLP 모델도 충분히 경쟁력 있을 수 있다는 개념 증명(proof of concept)**에 가깝다. 우리는 ViLT 계열에 추가될 수 있는 몇 가지 요소를 지적하며 논문을 마무리한다.
확장성 (Scalability)
대규모 Transformer에 대한 논문들(Devlin et al., 2019; Dosovitskiy et al., 2020)에서 보여주듯이, 사전학습된 Transformer의 성능은 적절한 양의 데이터가 주어졌을 때 잘 확장된다. 이러한 관찰은 더 나은 성능을 가진 ViLT 변형 모델(예: ViLT-L (large) 및 ViLT-H (huge))의 가능성을 열어준다. 우리는 정렬된 vision-and-language 데이터셋이 아직 부족하기 때문에, 더 큰 모델 학습은 향후 연구 과제로 남겨둔다.
시각 입력에 대한 Masked Modeling
MRM의 성공을 고려할 때, 우리는 시각 modality에 대한 masked modeling objective가 Transformer의 마지막 layer까지 정보를 보존함으로써 도움을 줄 것이라고 추측한다. 그러나 Table 5에서 관찰된 바와 같이, 이미지 패치에 대한 MRM의 단순한 변형(MPP)은 실패한다.
Cho et al. (2020)은 masked object classification (MOC) task에서 grid RoI를 학습할 것을 제안했다. 그러나 이 연구에서 사용된 visual vocabulary cluster는 vision-language pre-training과 visual backbone과 함께 고정되었다. 학습 가능한 visual embedder의 경우, 일회성 클러스터링은 실현 가능한 옵션이 아니다. 우리는 시각 비지도 학습 연구에서 다루어진 alternating clustering (Caron et al., 2018; 2019) 또는 simultaneous clustering (Asano et al., 2019; Caron et al., 2020) 방법이 적용될 수 있다고 생각한다. 우리는 region supervision을 사용하지 않는 향후 연구에서 시각 modality를 위한 더 정교한 masking objective를 고안할 것을 권장한다.
증강 전략 (Augmentation Strategies)
contrastive visual representation learning에 대한 이전 연구(Chen et al., 2020a;b)는 RandAugment에서 사용되지 않은 gaussian blur가 더 단순한 증강 전략(He et al., 2020)에 비해 다운스트림 성능에 상당한 이득을 가져온다는 것을 보여주었다. 텍스트 및 시각 입력에 대한 적절한 증강 전략을 탐구하는 것은 가치 있는 추가 사항이 될 것이다.