VAGUE: 시각적 맥락으로 모호한 표현을 명확히 하다
인간의 의사소통은 모호함을 해결하기 위해 종종 시각적 단서에 의존합니다. VAGUE는 이러한 멀티모달 추론 능력을 평가하기 위한 새로운 벤치마크로, 모호한 텍스트 표현과 이미지를 쌍으로 제공하여 시각적 맥락 없이는 정답을 알 수 없도록 설계되었습니다. 실험 결과, 기존 Multimodal AI 모델들은 화자의 실제 의도를 추론하는 데 어려움을 겪으며, 특히 피상적인 시각 정보에 의존할 뿐 깊이 있는 추론에는 실패하는 경향을 보였습니다. 이는 인간의 수준과 상당한 격차를 나타내며, VAGUE 벤치마크가 향후 멀티모달 추론 연구의 중요한 과제를 제시함을 시사합니다. 논문 제목: VAGUE: Visual Contexts Clarify Ambiguous Expressions
Nam, Heejeong, et al. "VAGUE: Visual Contexts Clarify Ambiguous Expressions." arXiv preprint arXiv:2411.14137 (2024).
VAGUE: Visual Contexts Clarify Ambiguous Expressions
Heejeong Nam* , Jinwoo Ahn , Keummin Ka , Jiwan Chung , and Youngjae <br> Brown University<br> UC Berkeley<br> Yonsei University
Abstract
인간의 의사소통은 종종 **시각적 단서(visual cues)**에 의존하여 **모호성(ambiguity)**을 해소한다. 인간은 이러한 단서들을 직관적으로 통합할 수 있지만, AI 시스템은 **정교한 멀티모달 추론(multimodal reasoning)**을 수행하는 데 어려움을 겪는 경우가 많다. 우리는 멀티모달 AI 시스템이 시각적 맥락(visual context)을 통합하여 의도 모호성(intent disambiguation)을 해소하는 능력을 평가하는 벤치마크인 VAGUE를 소개한다.
VAGUE는 1,600개의 모호한 텍스트 표현으로 구성되며, 각 표현은 이미지 및 다중 선택 해석(multiple-choice interpretations)과 짝을 이룬다. 여기서 정답은 시각적 맥락이 주어져야만 명확해진다. 이 데이터셋은 **연출된 복잡한 장면(Visual Commonsense Reasoning)**과 **자연스러운 개인적 장면(Ego4D)**을 모두 포함하여 다양성을 확보한다.
우리의 실험 결과는 기존 멀티모달 AI 모델들이 화자의 진정한 의도를 추론하는 데 어려움을 겪고 있음을 보여준다. 더 많은 시각적 단서가 도입될수록 성능은 꾸준히 향상되지만, 전반적인 정확도는 인간의 성능에 훨씬 못 미치며, 이는 멀티모달 추론의 중요한 격차를 강조한다. 실패 사례 분석 결과, 현재 모델들은 시각적 장면에서 피상적인 상관관계와 진정한 의도를 구별하지 못하는 것으로 나타났다. 이는 모델이 이미지를 인지(perceive)하지만, 이를 효과적으로 추론(reason)하지 못함을 시사한다.
우리는 코드와 데이터를 https://hazel-heejeong-nam.github.io/vague/ 에서 공개한다.
1. Introduction
인간의 의사소통은 본질적으로 **맥락적(contextual)**이다. 예를 들어, 어질러진 방을 보고 "야, 이거 완전 재앙이네!"라고 외치는 것은 실제 재앙을 의미하기보다는 좌절감이나 과장을 표현하는 것이다. 주변 단서 없이는 텍스트 대화가 모호해져, 모델이 화자의 의도와 뉘앙스를 정확하게 파악하기 어렵다.
우리는 **시각적 맥락 단서(visual contextual cues)**의 경우를 고려한다. 특정 상황에서 화자가 발언하는 모습을 묘사한 Figure 1을 살펴보자.
 Figure 1: 의도 이해에 있어 시각적 맥락의 중요성을 보여주는 동기 부여 예시. 미리 정해진 맥락 없이는 단일 표현이 여러 다른 의도를 전달할 수 있다. 텍스트 표현과 Context 1은 우리 데이터셋에서 가져왔으며, Context 2는 이해를 돕기 위해 DALL•E 3 [2]를 사용하여 생성되었다.
Figure 1: 의도 이해에 있어 시각적 맥락의 중요성을 보여주는 동기 부여 예시. 미리 정해진 맥락 없이는 단일 표현이 여러 다른 의도를 전달할 수 있다. 텍스트 표현과 Context 1은 우리 데이터셋에서 가져왔으며, Context 2는 이해를 돕기 위해 DALL•E 3 [2]를 사용하여 생성되었다.
시각적 단서에서 비롯된 맥락을 명시하지 않으면, 화자의 의도는 다양하게 해석될 수 있어 모호함이 남는다. 이는 시각적 맥락이 의사소통에서 중요한 역할을 한다는 것을 의미하며, 다음과 같은 질문을 제기한다: AI 시스템이 모호한 대화와 시각적 단서를 통합하여 화자의 의도를 추론할 수 있을까?
우리는 **Visual Contexts ClArify ambiGUous Expressions (VAGUE)**라는 벤치마크를 소개한다. 이 벤치마크는 1.6K개의 모호한 텍스트 표현으로 구성되며, 각 표현은 단일 이미지와 짝을 이룬다. VAGUE는 각 이미지를 화자의 시점으로 설정하여 다양하고 자연스러운 인간-인간 상호작용을 모델링하는 것을 목표로 한다. 여기서 화자는 자신의 시야 내에 있는 사람에게 특정 행동을 암묵적으로 요청한다. 우리는 이러한 설정을 통해 다루는 문제를 **Multimodal Intention Disambiguation (MID)**으로 정의하며, 이는 시각적 맥락에 기반하여 가장 그럴듯한 요청을 추론하는 과정을 포함한다. VAGUE의 각 샘플은 4개의 객관식 후보로 주석 처리되어 있으며, 이는 의미의 재구성(paraphrasing)이나 계층적 포함으로 인해 발생할 수 있는 여러 유효한 답변을 방지하고 명확성을 보장한다. 이 데이터셋은 시각적 의존성을 보장하기 위해 세심하게 큐레이션되었다. 즉, 시각적 맥락을 고려할 때만 정답 후보가 선호된다. VAGUE는 인공적인 출처(Visual Commonsense Reasoning [46])와 실제 시나리오(Ego4D [41]) 모두에서 가져온 시각적 장면을 포함하여, 장면 복잡성과 자연스러움의 광범위한 스펙트럼을 포착한다. VAGUE의 텍스트 표현은 초기에 GPT-4o [31]의 지시에 따라 생성된 후, 광범위한 인간 평가 및 필터링을 거쳐 자연스러움과 해당 이미지와의 일치성을 보장한다.
VAGUE에 대한 실험 결과는 기존 멀티모달 AI 모델들이 멀티모달 환경에서 화자의 진정한 의도를 추론하는 데 어려움을 겪고 있음을 보여준다. 첫째, 모델들이 시각적 맥락을 활용할 수 있음에도 불구하고 (텍스트 전용 Language Model (LM)에서 파이프라인 방식의 Socratic Model (SM) [47]로, 궁극적으로는 end-to-end Visual Language Model (VLM)로 성능이 향상되는 것을 통해 확인됨), 전반적인 정확도는 인간보다 현저히 낮아 진정한 의도를 포착하지 못하고 있음을 나타낸다. 실패 사례에 대한 심층 분석은 오류의 주요 원인이 시각적 맥락에 대한 피상적인 이해로부터 진정한 의도를 구별하지 못하는 모델의 능력 부족에 있음을 밝혀낸다. 다시 말해, 이러한 멀티모달 시스템은 이미지 내용을 인지할 수 있지만, 이 정보를 효과적으로 사용하여 화자의 진정한 의도를 추론하지 못한다.
결론적으로, 우리는 현재 모델들이 시각적 단서와 의도 이해를 통합하는 데 한계가 있음을 드러내고, 주요 실패 모드를 식별하는 벤치마크를 소개한다. 우리는 VAGUE가 미래의 멀티모달 대화형 또는 embodied agent 개발을 위한 테스트 베드 역할을 할 것으로 기대한다. 이러한 시스템은 강력한 시각적 인지 능력과 미묘한 대화 추론 능력을 결합하여 복잡한 장면에서 사용자 요청에 효과적으로 응답할 수 있을 것이다.
우리의 기여는 세 가지이다:
- VAGUE: **멀티모달 의도 모호성 해소(Multimodal Intention Disambiguation)**를 평가하기 위한 새로운 벤치마크. 광범위한 인간 필터링을 통해 검증된 VAGUE는 쿼리의 모호성과 답변 후보에 대한 시각적 (비)의존성을 모두 보장하여 강력한 정량적 평가를 위해 설계되었다.
- VCR [46]과 Ego4D [41]에서 엄선된 1,677개의 장면 이미지는 다양한 맥락에서 VAGUE의 일반화 가능성을 보장하기 위해 광범위한 장면 복잡성, 다양성 및 자연스러움을 포착한다.
- 멀티모달 의도 모호성 해소(Multimodal Intention Disambiguation)의 중요한 과제를 강조하는 실험 결과: 기존 모델들은 시각적 단서를 인지할 수 있지만, 이 정보를 추론에 효과적으로 통합하여 화자의 진정한 의도를 추론하는 데 실패한다.
2. Related Work
2.1. Multimodal Theory of Mind
**Theory of Mind (ToM)**은 사용 가능한 정보를 바탕으로 타인의 의도를 추론하고 추론하는 능력을 의미하며 [34], 최근의 language model들은 관련 task에서 여전히 어려움을 겪고 있어 [7] 이 분야에 대한 전용 연구의 필요성을 강조한다. 초기에는 텍스트 기반 접근 방식에 의존하는 [11, 36] 다양한 방법론과 벤치마크가 단일 모달(unimodal) 환경에서 제안되었다. 그러나 이러한 방법들은 언어적 단서와 시각적 단서를 모두 통합해야 하는 실제 세계 상호작용의 풍부함을 포착하는 데 종종 실패한다.
텍스트 전용(text-only) 맥락을 넘어, 최근 연구들은 시각 정보를 통합하고 있다. MMToM [17]은 모델이 ToM 관련 질문-응답 task를 해결하기 위해 시각적 단서와 텍스트 단서를 모두 처리해야 하는 벤치마크를 소개한다. BOSS 데이터셋 [9]은 비언어적 의사소통이 필요한 상황에서 수집된 멀티모달 데이터셋이다. 이 데이터셋은 사회적 상호작용 중 비언어적 단서를 기반으로 인간의 신념을 추론할 수 있는지 여부를 평가하는 데 사용된다. 유사하게, Chen et al. (2024) [5]는 핵심 비디오 프레임과 스크립트를 활용하는 Video ToM 모델을 제안하며, Social-IQ 2.0 데이터셋 [45]에서 향상된 추론 능력을 보여준다. MuMA-ToM [37]은 다중 에이전트(multi-agent) 상호작용에서 ToM 추론을 평가하여, 비디오 및 텍스트 입력을 기반으로 인간의 신념과 목표를 추론하는 모델의 능력을 평가함으로써 이 방향을 더욱 확장한다. MToMnet [3]은 장면 비디오 및 객체 위치와 같은 맥락적 단서를 사람별 단서와 통합하여 특정 시나리오에서 인간의 신념을 예측하는 ToM 기반 신경망을 소개한다.
그러나 멀티모달 ToM의 발전은 고품질 데이터셋의 부족 [5]뿐만 아니라, 인간 의사소통에 내재된 모호성과 간접성에 대한 명시적인 고려 부족으로 인해 여전히 제약을 받고 있다.
2.2. Multimodal Implicature Understanding
**함축(Implicature)**과 그로 인해 발생하는 **모호성(ambiguity)**은 일상적인 인간 대화에서 자연스럽게 나타나며, **화용론적 이해(pragmatic understanding)**를 요구한다 [38]. 함축 이해에 대한 초기 연구는 주로 텍스트 전용(text-only) 환경에서 수행되었으며 [27, 30, 40], 일부 연구는 **비유적 언어(figurative language)와 은유(metaphor)**에 특별히 초점을 맞추었다 [4, 21, 39]. 그러나 단독 텍스트의 모호성은 본질적으로 제한적이므로, 최근 연구들은 다중 모달리티(multiple modalities)로 확장되었다.
한 가지 예시는 **멀티모달 비꼬기 이해(Multimodal Sarcasm Understanding, MSU)**이다. WITS [19]와 MOSES [20]는 비꼬기 설명(sarcasm explanation)을 위한 벤치마크로, 둘 다 화자의 감정과 목소리 톤을 단서로 제공한다. DocMSU [8]는 문서 수준의 비꼬기 위치 파악 및 감지(sarcasm localization and detection)를 위한 벤치마크이다. MSU를 개선하기 위해 그래프 기반 접근 방식인 EDGE [32]는 강력한 성능을 달성했다. UR-FUNNY [13]는 멀티모달 유머 이해(multimodal humor comprehension)를 위한 벤치마크로, MSU [19, 20]에서와 같이 얼굴 표정과 목소리 톤을 통합한다. Hessel et al. (2023) [14]은
 Figure 2. Multimodal Intention Disambiguation (MID) task를 Multiple-Choice Question 형식으로 설명: 입력 이미지()와 간접적인 표현()이 주어졌을 때, 화자의 숨겨진 의도()를 추론하고 가장 가능성 있는 답변을 선택하는 것이 목표이다.
Figure 2. Multimodal Intention Disambiguation (MID) task를 Multiple-Choice Question 형식으로 설명: 입력 이미지()와 간접적인 표현()이 주어졌을 때, 화자의 숨겨진 의도()를 추론하고 가장 가능성 있는 답변을 선택하는 것이 목표이다.
**만화 캡션 콘테스트(Cartoon Caption Contest)**에서 파생된 벤치마크를 도입하여 유머 식별 및 설명을 탐구했다. Baluja et al. (2024) [1]은 유머 이해에서 모델이 멀티모달 단서로부터 이점을 얻는다는 것을 입증했다. 밈(Memes) 또한 함축을 포함하며, MemeCap [15] 및 MultiBully-Ex [16]와 같은 멀티모달 데이터셋이 있다.
그러나 멀티모달 함축 이해에 사용되는 단서들은 여전히 단순하며, 주로 단일 주요 객체나 인물이 있는 이미지에 나타나, 실제 시나리오에서 여러 객체와 인물 간의 상호작용의 중요성을 간과하고 있다. 이러한 한계점들은 VAGUE에서 다루는 바와 같이 더 복잡한 단서의 필요성을 강조한다.
3. Multimodal Intention Disambiguation
이 섹션에서는 우리가 **Multimodal Intention Disambiguation (MID)**라고 명명한 주요 task의 형식에 대한 구조와 근거를 설명한다. 이어서, 해당 task의 기반을 형성하는 필수 구성 요소들을 구체적으로 명시한다.
3.1. Problem Setting
각 MID 문제는 입력 이미지 , 직접 텍스트 표현 , 그리고 **간접 텍스트 표현 **로 구성된다. 여기서 직접 표현 는 해당 의 근본적인 의도를 명확히 보여주며, 를 생성하는 데 필수적인 중간 단계 역할을 한다.
우리의 문제를 명확히 하기 위해, 모든 추론은 묘사된 장면에 국한되며, 각 표현은 청자가 상황에 기반하여 특정 행동을 취하도록 의도하는 사람에 의해 발화된다고 가정한다. 이 task의 궁극적인 목표는 이미지 내의 맥락적 단서들을 활용하여 숨겨진 의도 를 효과적으로 해석하는 것이다.
모델이 이러한 의도를 얼마나 잘 포착하는지 평가하기 위해, Fig. 2에 나타난 바와 같이 객관식(MCQ) 형식을 주요 설정으로 채택한다. 이러한 결정은 특정 prompt가 계층적 관계(예: 칩을 집어라 - 간식 - 음식) 또는 화자의 목표를 가장 잘 만족시키는 행동에 대한 내재된 불확실성(예: 어둠에 대한 간접적인 불평은 불을 켜거나 커튼을 열어 해결될 수 있음)에 의해 여러 그럴듯한 결과로 이어질 수 있다는 사실을 반영한다. 모든 가능한 유효한 해석을 탐색하는 것은 노동 집약적이며 종종 불가능하다. 결과적으로, 각 MID 인스턴스는 네 가지의 개별적인 옵션으로 제시되며, 하나의 정답과 세 가지는 다양한 이유로 의도적으로 오답으로 설계되어 (Sec. 4.2.3 참조) 언어적 및 시각적 추론 모두에서 모델에 도전한다.
정식으로, 를 모든 객관식 옵션 의 집합이라고 하자. 이미지 와 간접 prompt 가 주어졌을 때, task는 의 시각적 맥락에 조건화되어 미리 정의된 옵션 중에서 의 가장 유효한 해석을 선택하는 것이다. 우리는 이 task를 다음과 같이 정의한다:
3.2. Direct and Indirect Expressions
우리가 설계한 task의 특성상, 효과적인 입력 prompt 와 를 큐레이션하는 것은 정확한 해석을 보장하는 데 매우 중요하다. 그렇다면 좋은 prompt란 무엇일까? 이 섹션에서는 직접 및 간접 표현이 모두 충족해야 하는 기준을 정의하고 설명한다. 각 기준에 대한 좋은 예시와 나쁜 예시에 대한 자세한 내용은 Appendix A를 참조하라.
3.2.1. Directness: Relevance and Solvability
관련성 (Relevance)
직접적인 prompt는 화자가 의도하는 바를 모호함 없이 명확하게 전달하는 발화이다. 그러나 이러한 의도가 장면의 시각적 맥락과 일치하는 것 또한 중요하다. 예를 들어, "Hey person1, I want you to stop the fireworks"와 같은 직접적인 prompt 는 의도된 행동을 명확히 표현한다. 하지만 Figure 2에 나타난 것처럼, 해당 이미지에 불꽃놀이와 관련된 요소가 전혀 없다면, 이 prompt는 장면과 일치하지 않는다. 따라서 직접적인 prompt는 의도를 드러내는 것뿐만 아니라 이미지와의 관련성(relevance)을 유지해야 한다. 우리 task의 맥락에서 관련성은 사람이 prompt와 묘사된 장면 사이에 합리적인 연결을 설정할 수 있는지 여부로 결정된다.
해결 가능성 (Solvability)
관련성만으로는 prompt가 유용하다고 보장할 수 없다. Section 3.1에서 설명했듯이, prompt 는 청자가 합리적으로 수행할 수 있는 행동을 명시적으로 요청해야 한다. 이는 **해결 가능성(solvability)**을 도입하며, prompt가 명확하고 실행 가능한 문제를 제시해야 함을 요구한다. 해결 가능한 prompt는 독립적으로 해결될 수 있는 특정 문제를 정의하여, 청자가 여러 경쟁적인 행동 중에서 선택해야 하는 상황에 놓이지 않도록 보장한다.
3.2.2. Indirectness: Consistency and Ambiguity
일관성 (Consistency)
간접적인 prompt는 본래의 의도를 숨기도록 설계되지만, 직접적인 prompt와 동일한 근본적인 의도를 전달해야 한다. 즉, 본질적으로 동일한 해결책을 요청해야 한다. 간접적인 prompt는 직접적인 prompt에서 파생되므로, 일관성은 핵심 기준이 된다. 우리는 직접적인 prompt 와 간접적인 prompt 가 의도 면에서 잠재적으로 일치할 수 있다면 일관적이라고 정의한다. "잠재적으로"라는 용어를 사용하는 이유는 간접적인 prompt의 특성상 여러 가지 유효한 해석이 가능하기 때문이다. 예를 들어, 앞서 언급된 "이건 재앙이야!"라는 예시에서는 곤경에 처했음을 전달하지만, 방을 청소하거나 안심시키는 것과 같이 여러 가지 합리적인 반응을 허용한다.
모호성 (Ambiguity)
만약 간접적인 prompt가 어떠한 추가적인 복잡성도 도입하지 않고 직접적인 prompt와 완전히 일관적이라면, 이는 직접적인 prompt와 구별할 수 없게 된다. 따라서 간접적인 prompt는 그 근본적인 의도를 숨겨야 하며, 우리는 이를 모호성이라고 정의한다. 이 기준의 핵심 원칙은 필요한 특정 행동이나 관련된 핵심 개체가 prompt 내에서 명시적으로든 암시적으로든 언급되어서는 안 된다는 것이다. 이 두 가지 요소가 숨겨지면, 더욱 간접적이거나, 비꼬거나, 유머러스한 어조로 조정하는 것과 같은 추가적인 개선을 통해 전반적인 뉘앙스와 해석의 난이도를 높일 수 있다.
4. VAGUE Benchmark Construction
VAGUE는 **단일 모달 또는 단순 멀티모달 모호성(ambiguity)**을 더 현실적인 도메인으로 확장하고, 최신 vision-language model이 복잡한 시각적 맥락에서 인간과 유사한 추론을 수행할 수 있는지 평가하는 새로운 벤치마크이다. 이 벤치마크는 총 1,677개의 이미지로 구성되어 있으며, 이 중 1,144개는 VCR [46] 데이터셋에서, 533개는 Ego4D [41]에서 가져왔다. 이 이미지들은 다양한 맥락적 시나리오와 실제 인간 상호작용을 포함한다. 평균적으로 VAGUE의 각 이미지에는 7개의 객체와 4명의 사람이 포함되어 있다. 각 이미지는 직접적인 표현(), 간접적인 표현(), 그리고 4개의 객관식 답변과 관련 메타 정보와 함께 짝을 이룬다. 모든 텍스트 구성 요소는 GPT-4o를 사용하여 생성되었으며, 이후 광범위한 인간 평가, 선택 및 필터링을 통해 정제되어, 멀티모달 추론을 테스트하고 발전시키기 위한 신중하게 선별된 벤치마크 데이터셋임을 보장한다. 자세한 벤치마크 통계 및 다양성 분석은 Appendix B.2에 제공되어 있다.
4.1. Visual Data Curation
4.1.1. Sampling
VCR [46]
VCR 데이터셋은 Large Scale Movie Description Challenge [35]와 YouTube 클립에서 가져온 11만 개의 영화 장면으로 구성된다. 이 이미지들은 "흥미로움(interestingness)" 기준 [46]에 따라 선별되었으며, 최소 두 명 이상의 사람이 등장하여 상호작용 시나리오를 촉진하도록 보장한다. 데이터셋의 중복을 방지하기 위해, 우리는 인접 프레임 간의 변화가 미미하다는 점을 고려하여 인접 프레임을 신중하게 피하면서 1만 개의 이미지를 샘플링한다. 이러한 선택 과정은 데이터셋의 문맥적 다양성을 유지하면서도 복잡한 다중 개체(multi-entity) 상호작용에 초점을 맞춘다.
Ego4D [41]
VCR이 광범위한 문맥적 다양성을 제공하지만, 종종 실제 세계의 상호작용을 완전히 포착하지 못하는 인위적으로 구성된 설정을 포함한다. 이를 해결하기 위해 우리는 인간 상호작용을 보다 자연스럽게 묘사하는 Ego4D 데이터셋의 프레임을 통합한다. 우리는 특히 개인 간의 대화 교환을 나타내는 AV(Audio-Visual) 부분을 활용하여 선택된 프레임에 사람이 존재하도록 보장한다. VCR과 유사하게, 우리는 다양성을 유지하기 위해 인접 프레임을 피하고, 데이터 품질을 향상시키기 위해 심하게 흐릿한 이미지를 필터링한다. 이 과정을 통해 94개의 비디오에서 888개의 후보 이미지를 얻었으며, 이는 추가 텍스트 처리의 기반이 된다.
4.1.2. Object Extraction
시각 정보의 복잡성을 확보하기 위해, 우리는 태깅 모델인 RAM [49]을 사용하여 각 이미지에 존재하는 물리적 객체 목록을 추출한다. 이 단계를 통해 충분한 시각적 디테일을 가진 장면들을 쉽게 식별할 수 있다. VCR의 경우, 많은 장면이 상대적으로 단순하며 종종 몇 개의 객체만 포함하고 있다. 따라서 우리는 VCR 이미지를 감지된 객체 수에 따라 정렬하고, 상위 4,000개를 텍스트 처리 후보로 유지하여, 우리 벤치마크가 맥락적으로 다양한 장면에서 풍부한 시각적 단서로 주로 구성되도록 보장한다. 자세한 내용은 Appendix B.3을 참조하라.
4.1.3. Person Indicator
우리의 task에서는 화자가 장면에 밖에 있으며, 이미지를 보고 그 안에 있는 사람에게 말을 건네는 상황을 가정한다. 그러나 이미지에는 여러 사람이 포함되어 있는 경우가 많아 청자(addressee)를 식별하는 것이 항상 간단하지는 않다. 발화에서 언급된 특정 사람을 grounding하는 것은 추가적인 복잡성을 야기할 수 있지만, 이는 우리 평가의 주요 초점은 아니다.
청자를 명확히 하기 위해, 우리는 Fig. 3에 나타난 것처럼 이미지 속 각 사람에게 지시자 태그(indicator tag)를 할당한다. VCR의 경우, 기존의 어노테이션 [46]을 사용하며, bounding box가 완전히 제공되지 않는 Ego4D의 경우, YOLOv11 [18]을 사용하여 사람을 감지하고 어노테이션한다. 이 방법은 대상 인물을 grounding하는 간단한 방법을 제공하지만, 모델이 기본적인 Optical Character Recognition (OCR)을 수행해야 한다. 따라서 우리는 본 연구에서 사용된 모델들의 OCR 능력을 평가하기 위한 실험을 수행한다. 자세한 내용은 Appendix B.4를 참조하라.
 Figure 3. 데이터 생성 과정 개요.
인간이 정의한 기준과 지침에 따라 GPT-4o [31]가 초기 데이터를 생성하고, 이 데이터는 품질 보장을 위해 인간에 의해 평가 및 필터링된다. 원본 이미지에서 고품질의 간접 표현을 생성하는 것은 어렵기 때문에, 이 과정은 다음 단계를 따른다:
Figure 3. 데이터 생성 과정 개요.
인간이 정의한 기준과 지침에 따라 GPT-4o [31]가 초기 데이터를 생성하고, 이 데이터는 품질 보장을 위해 인간에 의해 평가 및 필터링된다. 원본 이미지에서 고품질의 간접 표현을 생성하는 것은 어렵기 때문에, 이 과정은 다음 단계를 따른다:
- 이미지로부터 직접적인 표현과 의도 생성,
- 이전 단계의 정보를 사용하여 간접 표현 생성,
- 지금까지 수집된 모든 정보를 기반으로 답변 후보 생성.
답변 후보에서 FS는 Fake Scene Understanding, SU는 Superficial Understanding, NE는 Nonexistent Entity를 의미한다. **FS는 모델이 완전히 다른 이미지의 시각적 맥락을 오해하는 전역적 환각(global hallucination)**을 평가한다 (예: 양초가 있는 야외 캠핑 장면). 반면 **NE는 특정 객체만 조작된 것으로 대체되는 지역적 환각(local hallucination)**을 다룬다 (예: 커튼).
4.2. Multimodal Expression Synthesis
Fig. 3에서 볼 수 있듯이, VAGUE의 텍스트 표현은 먼저 모델에 의해 생성된 후, 광범위한 인간 평가 및 필터링 과정을 거친다. 우리는 모든 텍스트 처리에 **GPT-4o [31]**를 사용한다. 직접(direct) 표현() 및 간접(indirect) 표현() 생성에 사용된 지침은 Appendix B.5에 제공되어 있으며, 객관식 질문의 답변 후보 생성 지침은 Appendix B.7에 자세히 설명되어 있다.
4.2.1. Direct Expressions
직접 표현 는 간접 표현 를 생성하는 데 중요한 기반이 된다. 이는 두 표현이 동일한 근본적인 의도를 공유하기 때문이다. 가 Sec. 3.2.1에서 논의된 관련성(relevance)과 해결 가능성(solvability) 원칙을 준수하도록 하기 위해, 우리는 입력 이미지 와 이러한 기준을 명시적으로 정의하는 task prompt를 조건으로 를 생성한다. 생성 과정에서 모델에게 (subject, action, object) 형식의 해결책 triplet을 출력하도록 지시한다. 직접 표현은 의도를 명시적으로 나타내므로, 해결책 triplet의 각 구성 요소를 추출하는 것은 간단하다. 시각적 맥락과의 일관성을 유지하기 위해, triplet의 "object"는 Sec. 4.1.2에서 추출한 **물리적 객체(physical objects)**로 제한된다.
모든 후보 이미지에 대해 를 생성한 후, 인간 평가자들은 각 prompt를 **관련성(relevance)과 해결 가능성(solvability)**을 기준으로 평가하여 1점에서 5점까지의 점수를 부여한다. 4점 또는 5점을 받은 prompt만 추가 사용을 위해 유지된다. 인간 검증을 위한 상세한 평가 기준과 평가 과정의 예시는 Fig. J13에 제공되어 있다.
4.2.2. Indirect Expressions
간접적인 표현 가 모호성과 유창성을 유지하면서 실제 의도 와 일치하도록 하기 위해, 우리는 제안(proposal) 및 선택(selection)의 두 단계 프로세스를 채택한다.
첫 번째 단계에서는 모델이 세 가지의 서로 다른 후보 옵션을 생성하도록 prompt를 제공한다. 각 후보는 Section 3.2.2에 명시된 기준을 따르지만, 각각 비꼬는 말(sarcasm), 유머(humor), 밈/관용적 표현(meme/idiomatic expressions)과 같은 다른 언어적 전략을 명시적으로 포함하도록 지시한다. 이 접근 방식은 생성된 응답의 다양성을 보장한다. 두 번째 단계에서는 인간 어노테이터가 세 후보를 평가하고 의도된 간접성에 가장 잘 부합하는 것을 선택한다. 선택된 prompt는 더 구체적인 기준에 따라 1에서 5까지의 척도로 평가된다. 3점 이상을 받은 prompt만 데이터셋에 사용하기 위해 유지된다. 인간 검증을 위한 상세한 평가 기준과 평가 프로세스의 예시는 Fig. J14에 제공되어 있다.
4.2.3. Counterfactual Choices
고품질의 반사실적 선택지(counterfactual choices)를 생성하는 것은 매우 중요하다. 멀티모달 의도 모호성 해소(multimodal intent disambiguation)에서 모델의 약점을 상세히 분석하기 위해, 우리는 더욱 그럴듯한 대안을 제공하는 해석 가능한 반사실적 선택지를 설계한다.
Fake Scene Understanding (가짜 장면 이해)
첫 번째 반사실적 선택지는 모델이 이미지를 크게 오해했을 때 발생할 수 있는 해석이다. 이 과정은 두 단계로 진행된다. 첫 번째 단계에서는 간접적인 표현과 일치하지만 실제 의도와는 모순되는 가상의 장면을 가정하여 가짜 캡션(fake caption)을 생성한다. 그런 다음, 가짜 장면의 캡션을 화자의 간접적인 진술과 결합하여 가장 그럴듯한 해석을 도출한다.
Superficial Understanding (표면적 이해)
다음 선택지는 모델이 문장의 암묵적인 의도를 깊이 추론하지 못하고, 대신 표면적인 의미에 의존하여 생성된 해석에 해당한다. 우리는 모델이 간접 문장의 함축적이거나 더 깊은 의미를 고려하지 않고, 문자 그대로의 표현에만 집중하도록 강제한다. 이러한 답변 선택지들은 간접 표현 와 함께 생성된다. 간접 선택 단계에서는 해당 표면적으로 이해된 선택지가 함께 선택되어, 그들 간의 일관성을 유지한다.
Nonexistent Entity (존재하지 않는 개체)
마지막 선택지는 모델이 텍스트를 올바르게 해석했지만, 이미지의 세부 사항을 적절히 고려하지 못하여 그럴듯하지만 잘못된 선택지를 생성할 때 발생한다. 이는 구조적으로 정답과 유사하지만, 해결책의 핵심 객체를 이미지에 존재하지 않는 객체로 대체한다. 매우 관련 없는 객체를 생성하여 task가 너무 쉬워지는 것을 방지하기 위해, 우리는 대체되는 객체가 이미지에는 없지만, 장면에 존재할 것으로 매우 예상되며 원래 개체를 대체할 수 있는 객체로 제한한다. 이러한 개체를 식별하기 위해, 모델은 장면의 맥락과 일치하는 객체를 선택하도록 이미지를 입력으로 제공받는다. 이 방법은 반사실적 선택지가 장면과 잠재적 개체 간의 예상되는 일관성을 활용하면서도, 시각적 세부 사항에 대한 모델의 주의력을 엄격하게 테스트하도록 보장한다.
5. Experiments
모델 (Models)
우리는 실험에서 다음 모델들을 사용한다. 각 모델에 대한 자세한 설명은 Appendix C에 있다.
- Phi3.5-Vision-Instruct (4B) [29]
- LLaVA Onevision (7B) [23]
- Qwen2.5-VL-Instruct (7B, 72B) [43]
- InternVL-2.5-MPO (8B, 26B) [6]
- Idefics2 (8B) [22]
- LLaVA NeXT Vicuna (13B) [24]
- Ovis2 (16B) [28]
- GPT-4o [31]
- Gemini 1.5 Pro [12]
- InternVL-3 (38B) [42]
5.1. MLLMs Benefit from Visual Cues
우리의 첫 번째 목표는 MLLM이 시각적 단서(visual cues)를 얼마나 효과적으로 활용하여 발화(utterance)의 모호성을 해결하는지 평가하는 것이다. 이를 위해 우리는 모델에 제공되는 시각적 단서의 세부 수준을 체계적으로 제어하고, 화자의 실제 의도를 추론하는 모델의 정확도를 측정한다. 성능은 객관식(multiple-choice) 및 자유 형식(free-form) 설정 모두에서 평가된다. 명확성을 위해 주로 객관식 정확도를 보고하며, 자유 형식 결과는 Appendix I로 미룬다.
우리는 세 가지 수준의 시각적 단서를 고려한다:
- Language Model (LM): 시각적 입력을 전혀 받지 않으므로, 모델은 풍자나 유머에 대한 상식과 같은 표면적인 텍스트 사전 지식(textual priors)에 의존하여 의도를 결정해야 한다.
- Socratic Model (SM) [47]: 텍스트 전용 LM을 사용하지만, **짧은 이미지 캡션(최대 두세 문장)**을 추가 입력으로 통합한다. 이 짧고 일반적인 캡션은 충분한 세부 정보가 부족하여 의도를 정확하게 추론하기에 불충분할 수 있다. 각 SM 모델은 자체적으로 이미지 캡션을 생성하고 이를 후속 처리에서 사용했다.
- Visual Language Model (VLM): 원시 이미지 입력(raw image input)을 받아 시각적 단서를 보다 직접적으로 해석할 수 있다.
결과
Tab. 1의 결과는 MLLM이 시각적 단서를 활용할 수 있음을 보여주지만, 그 정도는 제한적이다. SM과 VLM이 모든 평가 모델에서 LM보다 지속적으로 우수한 성능을 보이기 때문이다. 또한, 더 상세한 시각적 입력은 일반적으로 성능을 향상시키며, 대부분의 경우 VLM이 SM을 능가한다. 다만, 독점 모델(proprietary models)의 경우 예외가 있는데, 이 예외는 Sec. 5.2에서 추가로 분석된다. VCR 및 Ego4D 서브셋 모두 유사한 성능 경향을 보여주며, 이는 우리의 발견이 연출된(staged) 시나리오와 실제(real-world) 시나리오 모두에 일반화될 수 있음을 입증한다. 마지막으로, LM의 지속적으로 낮은 성능은 멀티모달 벤치마크로서 우리 데이터셋의 유효성을 더욱 강화한다.
5.2. Analysis on Failure Modes
여기서는 모델이 진정한 의도를 추론하는 데 실패하는 방식과 이러한 실패 패턴이 제공되는 시각적 단서의 수준에 따라 어떻게 달라지는지를 살펴본다. Fig. 3에서 보듯이, 우리의 multiple-choice 질문에는 세 가지 유형의 오답 후보가 포함된다. 우리는 Fake Scene Understanding (FS) 및 Nonexistent Entity (NE) 후보를 사용하여 모델의 원시적인 시각 이해 능력을 평가한다. 이는 모델이 조작되거나 존재하지 않는 요소에 현혹되지 않고 장면을 올바르게 해석할 수 있는지를 테스트한다. 반대로, Superficial Understanding (SU) 후보는 모델의 추론 능력을 평가하며, 표면적인 인식을 넘어 의도를 추론할 수 있는지를 테스트한다. MCQ 설정에서의 실패 모드 전체 표는 Appendix I에 제공되어 있다.
결과
Figure 4는 각 모델이 올바른 의도 대신 다양한 유형의 오답을 얼마나 자주 선택하는지를 보여준다. 오류 유형 중 Superficial Understanding (SU)이 가장 흔하게 발생한다. 이는 모델이 기본적인 시각적 세부 사항을 인식하는 데는 일반적으로 성공하지만, 화자의 근본적인 의도를 정확하게 추론하기 위해 시각적 단서를 깊이 있게 추론하는 데는 종종 실패한다는 것을 나타낸다. 그러나 proprietary 모델들은 SU 관련 오류가 더 적게 나타나, 더 강력한 추론 능력을 보여준다.
또한, 더 강력한 시각적 단서는 모든 모델과 실패 유형에서 정확도를 향상시킨다. 이러한 개선은 시각적 조건화(visual conditioning)가 시각 기반 오류(FS 및 NE)와 추론 관련 실패(SU)를 모두 줄이는 데 중요한 역할을 한다는 것을 강조한다.
| Model | VAGUE-VCR | VAGUE-Ego4D | ||||
|---|---|---|---|---|---|---|
| LM (L) | SM (L+V) | VLM (L+V) | LM (L) | SM (L+V) | VLM (L+V) | |
| Phi3.5-Vision-Instruct (4B) | 26.6 | 35.3 ( 8.7) | 46.0 ( 19.4) | 22.5 | 31.1 ( 8.6) | 42.4 ( 19.9) |
| LLaVA-Onevision (7B) | 13.1 | 29.4 ( ) | 43.1 ( ) | 11.3 | 29.5 ( 18.2) | 43.2 ( ) |
| Qwen2.5-VL-Instruct (7B) | 11.1 | 25.6 ( ) | 46.8 ( ) | 9.8 | 28.0 ( 18.2) | 48.4 ( ) |
| InternVL-2.5-MPO (8B) | 23.0 | 48.4 ( ) | 63.9 ( ) | 24.2 | 54.0 ( ) | 66.8 ( ) |
| Idefics2 (8B) | 13.9 | 21.1 ( ) | 58.7 ( ) | 14.8 | 18.2 ( ) | 58.3 ( ) |
| LLaVA-NeXT-vicuna (13B) | 24.2 | 37.2 ( ) | 46.4 ( ) | 20.3 | 34.1 ( ) | 52.5 ( ) |
| Ovis2 (16B) | 21.9 | 23.8 ( ) | 24.5 ( ) | 20.5 | 25.3 ( ) | 25.7 ( ) |
| InternVL-2.5-MPO (26B) | 21.2 | 48.5 ( ) | 63.7 ( ) | 21.8 | 55.2 ( ) | 68.7 ( ) |
| InternVL-3 (38B) | 24.8 | 47.2 ( ) | 63.6 ( ) | 18.0 | 47.5 ( ) | 59.8 ( ) |
| Qwen2.5-VL-Instruct (72B) | 29.6 | 55.6 ( ) | 74.2 ( ) | 26.8 | 59.3 ( ) | 69.8 ( ) |
| GPT-4o | 46.4 | 65.1 ( ) | 48.2 | 67.5 ( ) | 63.6 ( ) | |
| Gemini-1.5-Pro | 43.2 | 62.4 ( 19.2) | 60.6 ( 17.4) | 40.3 | 60.6 ( 20.3) | 60.6 ( 20.3) |
Table 1. 다양한 수준의 시각적 단서를 사용한 Multimodal Intention Disambiguation (MID) task 실험.
Multiple-Choice Question의 정확도(%)를 보고한다. 는 시각적 단서로부터 얻은 성능 향상, 즉 LM 설정 대비 증가량을 나타낸다. (L)은 언어 입력만 사용한 경우를 의미하며, (L+V)는 시각적 단서가 통합된 경우를 나타낸다. LM, SM, VLM 전반에 걸쳐 정확도가 눈에 띄게 증가하는 것은 상세한 시각적 단서의 도입이 task에 유익함을 보여준다.
 Figure 4. 각 모델이 선택한 오답 선택지의 분포를 분석하기 위한 막대 그래프를 제시한다. 각 숫자는 데이터셋의 1,677개 항목 중 주어진 선택지가 선택된 빈도를 나타낸다. 반사실적 선택지 범주는 FS (Fake Scene Understanding), SU (Superficial Understanding), NE (Nonexistent Entity)이다. LM (Language Models), SM (Socratic Models), VLM (Visual-Language Models)을 나타내기 위해 서로 다른 색상을 사용한다.
Figure 4. 각 모델이 선택한 오답 선택지의 분포를 분석하기 위한 막대 그래프를 제시한다. 각 숫자는 데이터셋의 1,677개 항목 중 주어진 선택지가 선택된 빈도를 나타낸다. 반사실적 선택지 범주는 FS (Fake Scene Understanding), SU (Superficial Understanding), NE (Nonexistent Entity)이다. LM (Language Models), SM (Socratic Models), VLM (Visual-Language Models)을 나타내기 위해 서로 다른 색상을 사용한다.
특히, proprietary 모델들은 원시 이미지(VLM)보다 캡션이 있는 입력(SM)에서 더 나은 성능을 보인다. Fig. 4를 자세히 살펴보면, 이러한 불일치는 추론 중심의 실패(SU)보다는 시각 기반의 실패(FS 및 NE)에서 비롯됨을 알 수 있다. 이는 캡션 생성 능력이 이미지의 환각(hallucination)을 줄이면서 더 정교한 정보를 얻을 수 있도록 돕는 잠재력을 가지고 있음을 시사한다. 관련 실험 및 설명은 Appendix F에 제공되어 있다.
5.3. Comparison with human
벤치마크를 검증하고 성능의 상한선을 설정하기 위해, 우리는 인간의 정확도를 평가하여 기존 모델과 인간 능력 간의 격차를 강조한다. 이 평가는 VLM 설정 내의 multiple-choice 방식을 따르며, 400개의 샘플로 구성된 서브셋을 사용한다.
Table 2에서 보듯이, 인간의 성능은 94%에 달하며 거의 완벽한 정확도를 보여준다. 비록 proprietary 모델들과 일부 대형 모델들이 괜찮은 성능을 보이지만, 인간 평가자와 비교했을 때 여전히 약 20%에 달하는 상당한 성능 격차가 존재한다.
이 결과는 AI 모델의 멀티모달 추론 능력과 인간 수준의 숨겨진 의도 추론 능력 사이에 큰 격차가 있음을 강조한다. 이는 시각적 인식이 정확하더라도 더 깊은 인지적 통합 없이는 불충분하다는 것을 시사한다. 이러한 성능 격차는 모델이 더 깊은 시각-텍스트적 함의를 이해하기보다는 표면적인 텍스트에 의존하는 경향이 있기 때문이다. 따라서 멀티모달 추론의 발전은 모델이 상식 추론(commonsense reasoning) 및 실용적 이해(pragmatic understanding)와 같은 고차원 인지 과정을 시각 해석 task에 통합해야 할 가능성이 높다.
선택된 서브셋 및 인간 평가 설정에 대한 자세한 내용은 Appendix E를 참조하라.
| Model | Acc (%) | FS | SU | NE | Correct |
|---|---|---|---|---|---|
| Ovis2 (16B) | 23.0 | 119 | 171 | 18 | 92 |
| LLaVA-Onevision (7B) | 41.0 | 43 | 183 | 10 | 164 |
| Phi3.5-Vision-Instruct (4B) | 44.3 | 60 | 132 | 31 | 177 |
| Qwen2.5-VL-Instruct (7B) | 47.0 | 47 | 152 | 13 | 188 |
| LLaVA-NeXT-icuna (13B) | 48.0 | 48 | 143 | 17 | 192 |
| Idefics2 (8b) | 57.0 | 28 | 120 | 24 | 228 |
| Gemini-1.5-Pro | 60.3 | 60 | 73 | 26 | 241 |
| InternVL-3 (38B) | 61.5 | 38 | 94 | 22 | 246 |
| InternVL-2.5-MPO (8B) | 61.8 | 42 | 95 | 16 | 247 |
| GPT-4o | 62.3 | 61 | 63 | 27 | 249 |
| InternVL-2.5-MPO (26B) | 63.0 | 36 | 101 | 11 | 252 |
| Qwen2.5-VL-Instruct (72B) | 72.3 | 39 | 60 | 12 | 289 |
| Human | 94.0 | 12 | 4 | 8 | 374 |
Table 2. 400개 질문 샘플 세트에 대한 모델 및 인간의 성능. 결과는 인간이 모델보다 20% 이상 높은 성능을 보임을 나타낸다.
| Model | Type | Acc (%) | Incorrect count | ||
|---|---|---|---|---|---|
| FS | SU | NE | |||
| GPT-4o | SM | 68.9 | 165 | 240 | 117 |
| SM+CoT | 69.5 ( ) | 165 | 241 | 105 | |
| VLM | 64.6 | 226 | 226 | 141 | |
| VLM+CoT | 66.4 ( ) | 162 | 156 | 85 | |
| Gemini-1.5-Pro | SM | 61.8 | 176 | 374 | 83 |
| 190 | 367 | 94 | |||
| VLM | 60.6 | 249 | 264 | 145 | |
| VLM+CoT | 64.4 ( ) | 213 | 267 | 117 |
Table 3. proprietary 모델에 대한 Chain-of-Thought (CoT) 실험 결과 (SM 및 VLM 설정 모두). 및 는 zero-shot CoT 적용 시 정확도 증가 및 감소를 나타낸다.
5.4. Chain-of-Thought Experiments
멀티모달 의도 추론(multimodal intent deduction)의 강력한 추론 요구 사항을 고려하여, 우리는 MLLM의 추론 능력을 향상시키는 데 있어 Chain-of-Thought (CoT) prompting [44]의 효과를 추가적으로 탐구한다. Fig. J21과 Fig. J22에 제시된 CoT prompt 템플릿은 추론 과정을 명시적으로 grounding하여 환각(hallucination)을 줄이도록 설계되었다. 우리의 주요 결과는 zero-shot CoT 추론에 더 적합한 proprietary model에 초점을 맞추고 있지만, 4B에서 72B에 이르는 open-source model에 대한 실험 및 분석도 Appendix G에 제시한다.
결과
Tab. 3에서 볼 수 있듯이, CoT prompting은 raw image input (VLM)에 대한 성능을 향상시키는 반면, image caption input (SM)의 경우에는 명확한 경향을 보이지 않고 유사한 수준을 유지한다. 이러한 불일치에 대한 한 가지 가능한 설명은 CoT가 주로 grounding을 개선하고 환각을 줄임으로써 추론 능력을 향상시킨다는 것이다. Image caption은 본질적으로 환각이 적기 때문에, SM은 세부 정보 감소라는 대가를 치르더라도 CoT prompting으로부터 약간의 이점을 얻는다. 또한, CoT prompting에서 관찰된 성능 향상은 다양한 유형의 오답 후보(false answer candidates)에 걸쳐 일관적이며, 이는 추론 품질 향상에 있어 일반화 가능한 효과를 시사한다.
6. Conclusion
우리는 복잡한 멀티모달 시나리오에서 미묘한 의사소통을 해석하는 모델의 능력을 평가하기 위한 새로운 벤치마크인 **VAGUE (Visual Contexts ClArify ambiGUous Expressions)**를 제시한다. 우리의 결과는 모델이 간접적인 표현의 기저 의도를 추론할 때 시각 정보로부터 이점을 얻는다는 것을 보여준다. 이는 시각적 단서 수준이 증가함에 따라 성능이 향상되는 것으로 입증된다. 그러나 기계의 능력과 인간의 능력 사이에는 상당한 격차가 여전히 존재한다. 모델의 부정확성에 대한 더 깊은 통찰력을 얻기 위해, 우리는 실패 지점을 명시적으로 다루는 객관식 질문을 설계하여 성능 저하의 원인을 체계적이고 정량적으로 평가할 수 있도록 했다. 확인된 주요 과제는 멀티모달 모델이 시각적 단서를 불충분하게 통합하고, 대신 텍스트 정보의 문자적 해석에 의존하는 경향이 있다는 것이다. 이러한 단점은 추가 연구의 필요성을 강조하며, 우리는 VAGUE가 AI가 인간과 유사한 상호작용에 참여하는 능력을 향상시키기 위해 더 깊은 멀티모달 추론이 가능한 시스템을 개발하는 유망한 길을 열어줄 것으로 기대한다.
7. Limitations
첫째, 우리는 문화적, 언어적 한계가 있음을 인정한다. 우리는 **비꼬는 표현(sarcastic), 유머러스한 표현(humorous), 관용적인 함축(idiomatic implicatures)**을 간접적인 표현 생성에 통합하였다. 그러나 초기 데이터 초안이 GPT-4o [31] 모델에 의해 생성되었기 때문에, 학습 데이터에 존재하는 문화적 편향을 반영할 수 있다. 잠재적인 윤리적 문제를 방지하기 위해, 모든 인간 어노테이터는 평가 및 필터링 과정에서 문제적이거나 차별적이라고 판단되는 모든 콘텐츠를 제거하도록 지시받았다. 또한, VAGUE의 모든 텍스트 표현은 영어에 한정된다. 따라서, 우리는 다양한 언어와 문화에 걸친 간접 표현에 대한 향후 연구를 장려한다.
둘째, 특정 메타 정보가 상위 데이터셋의 품질과 데이터셋 생성 과정에서 활용된 모델의 성능에 의존한다는 한계가 있다. 우리는 YOLOv11 [18]의 bounding box 어노테이션이 때때로 중복되어 실제보다 더 많은 사람 수가 보고되는 경우를 관찰했다. 마찬가지로, 태깅 모델 RAM [49]이 때때로 객체를 잘못 식별하기도 했다. 따라서, 우리는 인간 평가 및 필터링 과정에서 task의 무결성을 훼손할 수 있는 손상된 인스턴스를 모두 제거하였다.
VAGUE: Visual Contexts Clarify Ambiguous Expressions
Supplementary Material
A. Directness & Indirectness Examples
Figure J3은 본문에서 정의된 직접적(direct) 및 간접적(indirect) 표현에 대한 보다 구체적이고 현실적인 예시를 제공한다. 각 표현은 두 가지 핵심 기준을 따르며, "Bad" 열의 예시와 같은 경우는 피하고 "Good" 열의 경우를 우선시한다.
B. VAGUE Benchmark
이 섹션에서는 VAGUE Benchmark 데이터셋에 대한 세부 정보를 소개한다. 우리는 이미지와 그에 해당하는 객관식 질문의 예시를 제공하며, direct, indirect expression, correct understanding expression, superficial understanding expression을 생성하는 데 사용된 prompt도 함께 제시한다. 또한, 객관식 보기 중 **두 가지 오답 선택지(fake scene understanding expression, nonexistent entity expression)**를 생성하는 데 사용된 prompt와 direct 및 indirect expression의 품질을 평가하는 데 사용된 인간 평가(human rating) 기준도 제시한다.
B.1. Samples in VAGUE
Figures J5부터 J7은 우리 벤치마크 데이터셋의 여섯 가지 예시를 보여준다. Visual Language Model (VLM) 설정에서, 모델은 그림에 나타난 바와 같이 사람 지시 태그가 포함된 이미지, 질문, 그리고 화자의 간접 발화를 제공받아 객관식 질문에 답해야 한다. 참고로, 각 샘플 아래에는 해당 **직접 표현(direct expression)**이 포함되어 있다.
B.2. Benchmark Statistics
Table B1은 VAGUE-VCR과 VAGUE-Ego4D를 구성하는 데이터셋의 평균 통계를 보여준다. "Average object counts"는 이미지당 감지된 객체의 평균 개수를 나타내며, "Average people counts"는 이미지당 감지된 사람의 평균 개수를 나타낸다. "Average word counts"는 각 이미지에 대해 생성된 직접(direct) 및 간접(indirect) 표현의 평균 단어 수를 의미한다. 특히, "Average object counts"와 "Average people counts"의 높은 값은 이미지들이 단순하지 않음을 시사한다.
| VAGUE-VCR | VAGUE-Ego4D | |
|---|---|---|
| Average object counts | 7.4 | 6.89 |
| Average people counts | 4.48 | 2.59 |
| Average word counts (direct) | 9.69 | 15.9 |
| Average word counts (indirect) | 11.52 | 12.27 |
Table B1. 데이터셋 통계표
또한, Fig. B1은 두 parent 데이터셋에서 생성된 의도(intention)의 다양성을 보여준다. 각 데이터셋의 solution triplet (person, action, object)에서 가장 자주 등장하는 동사 20개를 사용하여 radial diagram을 생성하였다. VAGUE-VCR과 VAGUE-Ego4D 모두 유사한 수준의 다양성을 보였으며, 이는 데이터셋이 완벽하게 균일하지는 않지만 광범위한 맥락을 포괄하고 있음을 입증한다.
B.3. Details of Object Extraction
우리의 prompt는 직접적이든 간접적이든, 장면 내 특정 객체에 대한 조작을 요청하는 지시문으로 구성된다. 이러한 task prompt의 구성은 장면에 충분한 객체가 존재해야 함을 전제로 한다. VCR [46] 데이터셋은 COCO [26] 객체 태그를 메타 정보로 포함하고 있지만, COCO 객체는 매우 제한적이며 실제 장면의 모든 객체를 포괄적으로 담아내지 못하는 경우가 많다. 따라서 우리는 각 이미지에 존재하는 물리적 객체를 식별하기 위해 Recognize Anything Model (RAM) [49]을 사용하여 이미지를 처리한다. 그러나 RAM [49]은 장소, 감정, 색상 등 엄밀히 물리적 객체가 아닌 엔티티에 대한 태그를 자주 생성한다. 이 문제를 해결하기 위해, 우리는 RAM [49]이 감지할 수 있는 총 4,585개의 항목 중에서 2,403개의 물리적 객체 목록을 수동으로 선별하였다. 이 정제된 목록을 사용하여 이미지에서 초기 추출된 엔티티들을 필터링하여 추가적으로 활용한다.
B.4. OCR Experiments for Testing Person Tags
Sec. 4.1.3에서는 다양한 context에서 prompt를 해석할 때 개인을 구별하기 위해 이미지에 사람 지시자(person indicator)를 통합한다. 이는 대상 인물을 grounding하는 직접적인 방법을 제공하지만, 모델이 "Hey person2"와 같은 문구를 해석하기 위해 기본적인 OCR(Optical Character Recognition)을 수행해야 한다. 이 능력을 평가하기 위해, 우리는 COCO [26] 데이터셋에서 각기 다른 수의 사람이 포함된 세 개의 이미지를 선택했다. Fig. B2는 다양한 색상의 티셔츠를 입은 두 명, 다섯 명, 열 명의 사람이 등장하는 이 이미지들을 보여준다. 모델에게 특정 인물의 티셔츠 색상을 식별하도록 요청함으로써, 우리는 선택된 모델들이 Tab. B2에 나타난 바와 같이 사람 지시자를 인식하는 데 완벽하게 일관된 성능을 보였다고 결론 내린다.
B.5. Model Instruction for Direct and Indirect prompts
Fig. J8은 직접적인 표현(direct expressions)을 생성하는 데 사용된 prompt이다. 또한, Fig. J9는 이 직접적인 표현을 기반으로 의도를 이해하여 객관식 정답(Correct)을 생성하는 prompt이다. Fig. J10은
 Figure B1. VAGUE-VCR 데이터셋과 VAGUE-Ego4D 데이터셋에서 가장 빈번한 20가지 action의 다양성 다이어그램.
Figure B1. VAGUE-VCR 데이터셋과 VAGUE-Ego4D 데이터셋에서 가장 빈번한 20가지 action의 다양성 다이어그램.
Table B2
| model | response | ||
|---|---|---|---|
| (a) | (b) | (c) | |
| Phi3.5-Vision-Instruct (4B) LLaVA-Onevision (7B) | Person1 is wearing a red shirt. red | Person1 is wearing a red shirt. red | Person5 is wearing a red shirt. red |
| Qwen2.5-VL-Instruct (7B) | Person1 is wearing a red shirt. | Person1 is wearing a red shirt. | Person5 is wearing a red shirt. |
| InternVL-2.5-MPO (8B) Idefics2 (8B) | Person 1 is wearing a red shirt. Red. | Person 1 is wearing a red shirt. Red. | Person 5 is wearing a red shirt. Red. |
| LLaVA-NeXT-vicuna (13B) Ovis2 (16B) | Person 1 is wearing a red -shirt. Person1 is wearing a red shirt. | Person 1's t -shirt is red. Person1 is wearing a red shirt. | Person 5 is wearing a red t -shirt. Person5 is wearing a red shirt. |
| InternVL-2.5-MPO (26B) | Person 1 is wearing a red shirt. | Person 1 is wearing a red shirt. | Person 5 is wearing a red shirt. |
| InternVL-3 (38B) | Person 1 is wearing a red shirt. | Person 1 is wearing a red shirt. | Person 5 is wearing a red shirt. |
| Qwen2.5-VL-Instruct (72B) | Person 1 is wearing a red shirt. | Person 1 is wearing a red shirt. | Person5 is wearing a red shirt. |
| GPT-4o | Person 1 is wearing a red shirt. | Person 1 is wearing a red shirt. | Person 5 is wearing a red shirt. |
| Gemini-1.5-Pro | Person 1 is wearing a red t -shirt. | Person 1 is wearing a red t -shirt. | Person 5 is wearing a red t-shirt. |
 Figure B2. COCO [26] 데이터셋에서 OCR 능력 평가에 사용된 세 장의 이미지. (a)와 (b)에서는 Person 1의 티셔츠 색깔에 대해, (c)에서는 Person 5의 티셔츠 색깔에 대해 질문했다. 테스트 시 모든 모델이 정답인 "red"를 정확하게 식별했다.
Figure B2. COCO [26] 데이터셋에서 OCR 능력 평가에 사용된 세 장의 이미지. (a)와 (b)에서는 Person 1의 티셔츠 색깔에 대해, (c)에서는 Person 5의 티셔츠 색깔에 대해 질문했다. 테스트 시 모든 모델이 정답인 "red"를 정확하게 식별했다.
직접적인 표현과 그 의도된 의미를 기반으로 간접적인 표현을 생성하는 prompt이다. 또한, 표면적으로 잘못 해석된 의도(SU)를 생성한다.
B.6. Human Rating for Direct and Indirect prompts
이 섹션에서는 인간 평가(human rating) 및 필터링 과정을 자세히 설명한다. 인간 어노테이터들은 Figure J13과 J14의 표에 제시된 채점 가이드라인을 따르도록 지시받았다. 우리는 고품질의 어노테이션을 효율적으로 수행하기 위해 Label Studio (https://labelstud.io/)를 사용한다. Figure J13은 직접적인 표현(direct expressions)을 평가하는 UI를 보여주며, Figure J14는 간접적인 표현(indirect expressions)을 선택하고 평가하는 UI를 보여준다.
B.7. Model Instruction for Counterfactual Choices
Fig. J11은 간접 표현과 일치하지만 직접 표현과는 모순되는 가짜 caption을 생성하여 오답 선택지를 만드는 데 사용된 prompt이다. 이 가짜 caption은 간접 표현과 결합되어 **그럴듯한 의도(plausible intention)를 도출(FS)**한다.
Fig. J12는 이미지에 없는 객체를 도입하여 오답 선택지를 생성하는 prompt이며, 이는 **간접 표현의 의도된 의미를 의도적으로 왜곡(NE)**한다.
C. Baseline Models
기존의 멀티모달 언어 모델(MLLM)을 폭넓게 다루기 위해, 우리는 다양한 파라미터 크기를 가진 10개의 오픈소스 모델과 2개의 클로즈드소스 모델을 평가한다.
오픈소스 모델로는 다음을 사용한다:
- Phi3.5-Vision-Instruct (4B) [29]: 간결한 instruction-following task에 최적화되어 있으며, 낮은 파라미터 설정에서도 강력한 text-image alignment를 제공한다.
- LLaVA Onevision (7B) [23]: 고해상도 이미지 해석에 중점을 두며, 정교한 attention mechanism을 통해 멀티모달 대화 능력을 향상시킨다.
- Qwen2.5-VL-Instruct (7B, 72B) [43]: 고급 vision-language pretraining을 사용하여 다양한 이미지 기반 쿼리 및 텍스트 지시를 처리한다.
- InternVL-2.5-MPO (8B, 26B) [6]: 다목적 최적화(multi-purpose optimizations)를 위해 설계되었으며, 향상된 멀티모달 reasoning을 지원한다.
- InternVL-3 (38B) [42]: 이전에 출시된 모델들보다 다양한 task에서 더 나은 성능을 제공한다.
- Idefics2 (8B) [22]: 효율적인 학습을 위한 컴팩트한 아키텍처를 채택하며, domain-specific 이미지 이해 및 텍스트 생성에 중점을 둔다.
- LLaVA NeXT Vicuna (13B) [24]: 개선된 vision encoder와 정제된 instruction tuning을 활용하여 향상된 상식 reasoning을 제공한다.
- Ovis2 (16B) [28]: 강력한 textual grounding과 visual alignment를 기반으로 이미지 캡셔닝 및 추론에서 뛰어난 성능을 보인다.
독점 모델 중에서는 다음을 사용한다:
- GPT-4o [31]: 시각적 인지(visual perception)와 결합된 고급 언어 이해 능력을 통해 미묘한 멀티모달 상호작용을 보여준다.
- Gemini 1.5 Pro [12]: 고해상도 비전 처리와 강력한 언어 모델을 통합하여 정교한 instruction-following 및 cross-domain reasoning을 제공한다.
D. Free-From Answering
D.1. Metrics
BLEU [33]
BLEU 점수는 기계 생성 텍스트의 품질을 참조 텍스트와 비교하여 평가하는 metric이다. 이는 n-gram precision을 측정하여, 생성된 텍스트의 n-gram이 참조 텍스트에 얼마나 많이 나타나는지를 확인한다. 그러나 자유 형식으로 생성된 텍스트를 BLEU로 평가할 때, 문구의 높은 가변성 때문에 2-gram부터 점수가 급격히 하락한다. 더 의미 있는 측정을 위해 우리는 개별 단어 중복을 포착하고 텍스트 유사성의 합리적인 근사치를 제공하는 1-gram BLEU를 사용한다.
BERT-F1 [48]
BERT-F1은 BERT 모델의 contextual embedding을 활용하는 semantic similarity metric이다. 이는 정확한 단어 일치에 의존하는 대신, embedding 공간에서의 token 유사도를 기반으로 F1-score를 계산한다. 이를 통해 paraphrasing과 synonymy를 포착할 수 있어, 표면적인 유사성보다는 의미를 평가하는 데 더 효과적이다.
D.2. Limitations of Free-form Answering
전통적인 텍스트 유사도 측정 지표인 BLEU [33]와 BERT-F1 [48]은 언어 모델 평가에 널리 사용된다. 그러나 이들은 멀티모달 의도 모호성 해소(multimodal intent disambiguation) task에서 의도 유사성(intent similarity)을 평가하는 데는 적합하지 않은 경우가 많다.
BLEU는 문장 간의 **n-gram 중첩(overlap)**을 계산하며, 모든 토큰을 동일하게 취급하기 때문에 미묘한 의도 차이를 포착하는 데 비효율적이다. 유사하게, **문맥 임베딩(contextual embedding)**을 사용하는 BERT-F1은 반의어(antonymy) 문제에 직면한다. 반대되는 의미의 단어들이 종종 유사한 문맥에 나타나기 때문이다. 예를 들어, "open the window"와 "close the window"는 완전히 반대되는 의도를 가지지만, BERT-F1은 공유되는 구조와 중복되는 단어들 때문에 0.939라는 높은 유사도 점수를 부여한다.
이러한 문제를 해결하기 위해, 우리는 주요 평가 설정으로 객관식 질문(MCQ) 형식을 채택한다. 이 방식은 근사적인 유사도 점수에 의존하는 대신, 모델이 올바른 의도를 선택하는지 여부를 직접적으로 평가한다. MCQ 구조는 그럴듯하지만 틀린 오답(distractor)을 명시적으로 포함하여, 모델이 단순한 어휘 중첩(lexical overlap)에만 의존하지 않고 멀티모달 단서(multimodal cues)를 통합하여 모호성을 해결하도록 강제한다. 이러한 구조화된 접근 방식은 더욱 견고하고 의도 인지적인 평가를 가능하게 한다.
D.3. Qualitative Example
Fig. J4는 InternVL-2.5-8B-MPO 모델을 사용하여 VLM, SM, LM 설정에서 자유 형식 답변(free-form answering)의 결과를 보여준다. 이 결과는 주어진 이미지의 간접적인 표현 뒤에 숨겨진 의도가 잘 보존되며, 다른 설정에서 생성된 응답들이 매우 유사함을 나타낸다.
E. Details of Human Evaluation
인간 평가를 위해 우리는 VAGUE 데이터셋에서 400개의 고품질 항목으로 구성된 subset을 사용한다. 이 항목들은 의도된 정답이 이미지와 잘 일치하고, 간접적인 표현이 충분히 모호하도록 신중하게 선택되었다.
저품질 샘플은 이미 필터링되어, 직접적인 표현은 4점 또는 5점, 간접적인 표현은 3점에서 5점 사이의 점수를 갖는다. 이러한 필터링으로 인해 직접 및 간접 표현의 평균 점수가 종종 동일하게 나타난다. 이러한 경우, 우리는 최종 400개 항목 subset을 구성하기 위해 무작위로 항목을 선택한다.
우리의 인간 평가자는 다양한 modality와 language model에 걸쳐 인간 인지 분야에 전문성을 가진 학생 연구원이다. 이 평가자는 원어민 수준으로 영어에 능통한 한국인이며, 400개 항목 전체를 독립적으로 주석하였다.
F. Why does SM setting outperform in proprietary models?
Table F3. 는 GPT-4o가 생성한 caption으로 전환했을 때 SM에서의 MCQ 성능 향상을 나타낸다.
| Models | Self captioning | GPT-4o captioning |
|---|---|---|
| Phi3.5-Vision-Instruct (4b) | 34.0 | |
| LLaVA-Onevision (7b) | 29.4 | |
| LLaVA-NeXT-vicuna (13B) | 36.3 | |
| InternVL-2.5-MPO (26B) | 50.6 |
proprietary 모델의 우수한 SM 성능은 vision 관련 오류(FS, NE)가 적기 때문이다. 이를 두 가지 관점에서 설명할 수 있다:
- caption에 필요한 세부 정보가 부족할 경우, VLM은 자연스럽게 뛰어난 성능을 보인다. Table F3은 SM 설정에서 더 작은 open-source 모델들이 GPT-4o의 caption을 활용했을 때 성능이 향상되는 것을 보여줌으로써, proprietary 모델들이 더 나은 caption을 생성한다는 것을 암시한다.
- caption이 이미지와 세부 정보 면에서 동등한 수준에 도달한다면 (실제로는 길이 제약으로 인해 모든 뉘앙스를 포착하기는 어렵다), 텍스트 토큰이 이미지 토큰보다 시각 정보를 더 효과적으로 처리한다 [25]. 실제로 CoT reasoning에서 VLM은 화자의 rationale에 더 의존하는 반면, SM은 장면 중심적인 접근 방식을 취하는 것을 관찰했다.
G. CoT Open-source
우리는 오픈소스 모델에 대한 CoT ablation을 제공하고 이를 SM 및 VLM baseline과 비교한다. Table G4는 CoT가 대부분의 경우 SM 성능을 약간 저하시키는 반면, VLM은 훨씬 더 큰 성능 저하를 겪으며 모든 유형의 오류(FS, SU, NE)가 함께 증가함을 보여준다. 일관된 성능 저하는 오픈소스 모델이 심층적인 reasoning 능력에서 proprietary 모델에 뒤처짐을 시사한다. 우리는 VLM에서 더 급격한 성능 저하가 더 긴 생성 시퀀스로 인한 conditioning dilution [10]에서 비롯된다고 생각한다.
H. Model Instruction for Experiments
이 섹션에서는 Visual Language Model (VLM), Socratic Model (SM), **Language Model (LM)**의 세 가지 모델 유형에 대해, 객관식 질문과 자유 형식 답변 task 모두에서 사용된 다양한 설정의 prompt를 제시한다. 또한, 이러한 실험을 통해 얻은 전체 결과도 제공한다.
| Model | Type | Acc (%) | Incorrect count | ||
|---|---|---|---|---|---|
| FS | SU | NE | |||
| Phi3.5-Vision-Instruct (4B) | SM | 34.0 | 292 | 678 | 137 |
| SM+CoT | 31.5 ( 2.5) | 291 | 603 | 148 | |
| VLM | 44.8 | 266 | 501 | 158 | |
| VLM+CoT | 295 | 510 | 154 | ||
| LLaVA-Onevision (7B) | SM | 29.4 | 215 | 885 | 84 |
| 28.0 ( 1.4) | 291 | 795 | 101 | ||
| VLM | 43.1 | 169 | 727 | 58 | |
| VLM+CoT | 187 | 736 | 76 | ||
| LLaVA-NeXT-vicuna (13B) | SM | 36.3 | 228 | 730 | 111 |
| 259 | 598 | 149 | |||
| VLM | 48.4 | 206 | 564 | 96 | |
| VLM+CoT | 206 | 541 | 139 | ||
| InternVL-2.5-MPO (26B) | SM | 50.6 | 209 | 530 | 89 |
| 45.1 ( 5.5) | 213 | 584 | 106 | ||
| VLM | 65.3 | 147 | 377 | 58 | |
| VLM+CoT | 58.1 ( 7.2) | 17 | 440 | 67 | |
| InternVL-3 (38B) | SM | 47.3 | 259 | 478 | 136 |
| SM+CoT | 54.3 ( ) | 166 | 359 | 102 | |
| VLM | 62.4 | 153 | 374 | 102 | |
| VLM+CoT | 211 | 387 | 107 | ||
| Qwen2.5-VL-Instruct (72B) | SM | 56.8 | 175 | 457 | 92 |
| 213 | 428 | 100 | |||
| VLM | 72.8 | 142 | 236 | 78 | |
| VLM+CoT | 154 | 272 | 78 |
Table G4. 오픈소스 모델에 대한 Chain-of-Thought (CoT) 실험 결과 (SM 및 VLM 설정 모두). 및 는 zero-shot CoT 적용 시 정확도의 증가 및 감소를 나타낸다.
객관식 질문 (Multiple Choice Questions)
Fig. J15, Fig. J16, Fig. J17은 VLM, SM, LM 설정에서 객관식 질문 실험에 사용된 prompt를 보여준다.
자유 형식 답변 (Free-form Answering)
Fig. J18, Fig. J19, Fig. J20은 VLM, SM, LM 설정에서 자유 형식 답변 실험에 사용된 prompt를 보여준다.
Chain-of-Thoughts
또한, Fig. J24, Fig. J22는 Socratic Model을 사용한 zero-shot chain-of-thought 실험에 사용된 prompt이며, Fig. J23, Fig. J21은 Visual-Language Model을 사용한 경우의 prompt이다.
I. Full Results
Table J5와 Table J6은 각각 VAGUE-VCR 및 VAGUE-Ego4D 데이터셋에 대해 본 논문에서 수행된 완전한 실험 결과를 제시한다. VAGUE-VCR의 총 항목 수는 1,144개이고, VAGUE-Ego4D의 총 항목 수는 533개이다. 그러나 'valid count' 열의 항목 수가 항상 이 총계와 일치하지는 않는다. 이러한 불일치는 모델이 'I don't know'라고 응답하거나 답변을 거부할 때 발생한다. 정확도를 계산할 때, 우리는 이러한 경우를 오답으로 처리하며, 각 데이터셋의 총 항목 수로 정답 수를 나누어 정확도를 산출한다.
J. Full structure of VAGUE
Fig. J25는 우리의 벤치마크 데이터셋인 VAGUE의 구조를 보여준다.
| Bad | Good | ||
|---|---|---|---|
| Direct | Relevance | Irrelevant <br> 시각 정보와 무관함. <br> 텍스트 prompt와 이미지 사이에 연관성을 찾을 수 없음. <br> 예: (이미지: 창문 없는 방) <br> Hey person1, please close that window. | Relevant <br> 시각 정보와 명확히 관련됨. <br> prompt와 이미지 사이에 명확한 연관성을 한눈에 찾을 수 있음. <br> 예: (이미지: 창문이 열려 있고 밖에 눈이 쌓인 방) <br> Hey person1, please close that window because it's cold. |
| Solvability | Unsolvable <br> 여러 독립적인 해결책이 가능함. <br> prompt로부터 여러 독립적인 해결책을 도출할 수 있음. <br> 예: Hey person2, 1) put the gun down immediately and 2) get behind the car for cover. | Solvable <br> 단 하나의 독립적인 해결책만 가능함. <br> 단 하나의 명확히 해결 가능한 사건을 도출할 수 있음. <br> 예: Hey person3, please bring the refreshments over here faster. | |
| Indirect | Consistency | Inconsistent <br> 간접적인 의도 직접적인 의도 <br> 간접적인 prompt의 어떤 해석도 직접적인 prompt의 의도와 일치하지 않음. <br> 예: (Direct : Hey person13, stop standing by the wall.) <br> Hey person13, are we building an igloo here? | Consistent <br> 간접적인 의도 = 직접적인 의도 <br> 간접적인 prompt의 의도가 직접적인 prompt의 의도와 일치함. <br> 예: (Direct : Hey person3, listen to what person2 has to say!) <br> Hey person3, I believe person2 has some important words to share with you. |
| Ambiguity | Direct <br> 반복됨. <br> prompt가 직접적인 재표현을 통해 직접적인 prompt를 단순히 재구성함. <br> 예: (Direct: Hey person2, stop distracting the horse while person 18 is talking.) <br> Hey person2, maybe now isn't the best time to bond with our four-legged friend. | Ambiguous <br> 잘 보호됨. <br> prompt가 수행될 행동과 조정될 대상을 거의 완벽하게 모호하게 만듦. <br> 예: (Direct: Hey person3, can you hurry up with the refrigerator?) <br> Hey person3, is it just me or is the energy bill increasing lately? |
Figure J3. 이 표는 직접적인 표현에 대한 두 가지 평가 기준과 간접적인 표현에 대한 두 가지 평가 기준을 설명 및 해당 bad/good 사례와 함께 제시한다. bad/good 사례의 예시는 주어진 기준에 기반한 사람의 평가로부터 도출되었다.
[Free-form Answer] oo13_Halloween_oo.15.15.492-00.15.17.652@o_annot.jpg
{kind=link}
 Figure J4. 이 그림은 InternVL-2.5-8B-MPO가 VLM, SM, LM 설정에서 간접적인 표현과 자유 형식 응답에 대해 생성한 결과를 보여준다.
Figure J4. 이 그림은 InternVL-2.5-8B-MPO가 VLM, SM, LM 설정에서 간접적인 표현과 자유 형식 응답에 대해 생성한 결과를 보여준다.
간접적인 표현: 이봐, person1, 차이점을 찾아봐, 이 주차는 좀 너무 특별하지 않아?
[Answers]
LM: 화자는 person1이 주차 상황의 특이한 점을 알아차리기를 원한다.
SM: 화자는 person1이 주차 공간의 특별한 점을 알아차리기를 원한다.
VLM: 화자는 person1이 장애인 주차 공간의 특별한 점을 알아차리기를 원한다.
[Question] Select the option that best explains the underlying intention of the speaker's utterance based on the given image.
Utterance: 이봐, person1, 다른 점을 찾아봐, 이 주차는 좀 특별하지 않아?
 A) 화자는 person1이 주차장에 있는 특별하게 장식된 오토바이를 감상하기를 원한다. (Fake Scene Understanding)
B) 화자는 person1이 퍼즐 게임을 즐기며 다른 점을 찾기를 원한다. (Superficial Understanding)
C) 화자는 person1이 장애인 주차 공간에 세워진 세단을 옮기기를 원한다. (Correct)
D) 화자는 person1이 소화전 앞에 주차된 세단을 옮기기를 원한다. (Nonexistent Entity)
A) 화자는 person1이 주차장에 있는 특별하게 장식된 오토바이를 감상하기를 원한다. (Fake Scene Understanding)
B) 화자는 person1이 퍼즐 게임을 즐기며 다른 점을 찾기를 원한다. (Superficial Understanding)
C) 화자는 person1이 장애인 주차 공간에 세워진 세단을 옮기기를 원한다. (Correct)
D) 화자는 person1이 소화전 앞에 주차된 세단을 옮기기를 원한다. (Nonexistent Entity)
Direct expression (reference): 이봐 person1, 장애인 주차 공간에서 세단을 옮겨야 해.
[Question] Select the option that best explains the underlying intention of the speaker's utterance based on the given image.
Utterance: Hey, person1, I hope you're ready to swim with the fishes today!
 Figure J5. 이들은 이미지와 그에 해당하는 생성된 직접적인 표현(direct expression) 및 객관식 질문 세트의 예시이다.
Figure J5. 이들은 이미지와 그에 해당하는 생성된 직접적인 표현(direct expression) 및 객관식 질문 세트의 예시이다.
A) 화자는 person1이 구명 조끼를 사용하여 물에 빠지지 않도록 하기를 원한다. (Nonexistent Entity) B) 화자는 person1이 자세를 조절하여 난간에 너무 기대지 않도록 하기를 원한다. (Correct) C) 화자는 person1이 스노클을 잡고 다이빙을 준비하기를 원한다. (Fake Scene Understanding) D) 화자는 person1이 물에 뛰어들어 수영하기를 원한다. (Superficial Understanding)
Direct expression (reference): Hey person1, please be careful not to lean too heavily on the rail.
[Question] 주어진 이미지를 바탕으로 화자의 발화에 담긴 근본적인 의도를 가장 잘 설명하는 보기를 선택하시오.
Utterance: Hey, person1, did someone forget to pay the electricity bill?
 A) 화자는 person1이 전기 요금 납부에 실수가 있었는지 확인하기를 원한다. (Superficial Understanding)
B) 화자는 person1이 방의 효과적인 조명을 위해 촛불을 확인하기를 원한다. (Fake Scene Understanding)
C) 화자는 person1이 더 많은 자연광을 들이기 위해 커튼을 열기를 원한다. (Nonexistent Entity)
D) 화자는 person1이 식탁의 조명을 개선하기 위해 램프를 조절하기를 원한다. (Correct)
A) 화자는 person1이 전기 요금 납부에 실수가 있었는지 확인하기를 원한다. (Superficial Understanding)
B) 화자는 person1이 방의 효과적인 조명을 위해 촛불을 확인하기를 원한다. (Fake Scene Understanding)
C) 화자는 person1이 더 많은 자연광을 들이기 위해 커튼을 열기를 원한다. (Nonexistent Entity)
D) 화자는 person1이 식탁의 조명을 개선하기 위해 램프를 조절하기를 원한다. (Correct)
Direct expression (reference): Hey person1, please adjust the lamp so it provides better lighting on the dining table.
[Question] 주어진 이미지를 바탕으로 화자의 발화에 담긴 근본적인 의도를 가장 잘 설명하는 보기를 선택하시오.
Utterance: Hey person2, feeling like a dragon today, aren't we?

A) 화자는 person2가 흐르는 붉은 스카프를 용의 날개처럼 조절하기를 원한다. (Fake Scene Understanding) B) 화자는 person2가 분위기 개선을 위해 담배를 끄기를 원한다. (Correct) C) 화자는 person2가 내면의 용을 받아들이고 계속 '불을 뿜기'를 원한다. (Superficial Understanding) D) 화자는 person2가 분위기 개선을 위해 향초를 끄기를 원한다. (Nonexistent Entity)
Direct expression (reference): Hey, person2, please put out the cigarette.
Figure J6. 이들은 이미지와 그에 해당하는 생성된 직접적인 표현(direct expression) 및 객관식 질문 세트의 예시이다.
[Question] 주어진 이미지를 바탕으로 화자의 발화에 담긴 근본적인 의도를 가장 잘 설명하는 보기를 선택하시오.
Utterance: Hey, person1, looks like you're planning a party for the neighborhood squirrels.

A) 화자는 person1이 다람쥐를 위한 작은 피크닉 테이블 세팅을 설명하기를 원한다. (Fake Scene Understanding) B) 화자는 person1이 시리얼 상자를 닫아 신선하게 보관하기를 원한다. (Correct) C) 화자는 person1이 시리얼 상자를 밀봉하기 위해 칩 클립을 사용하기를 원한다. (Nonexistent Entity) D) 화자는 person1이 이웃 다람쥐들을 시리얼 파티로 즐겁게 해주기를 원한다. (Superficial Understanding)
Direct expression (reference): Hey, person1, please close the cereal box to keep the contents fresh.
[Question] 주어진 이미지를 바탕으로 화자의 발화에 담긴 근본적인 의도를 가장 잘 설명하는 보기를 선택하시오.
Utterance: Hey, person1, please close the fridge door to keep the food fresh.

A) 화자는 person1이 부엌에 이글루를 만들기를 원한다. (Superficial Understanding) B) 화자는 person1이 베개를 깔끔하게 배열하여 장난스러운 요새를 만들기를 원한다. (Fake Scene Understanding) C) 화자는 person1이 뜨거운 물건을 안전하게 다루기 위해 오븐 장갑을 사용하기를 원한다. (Nonexistent Entity) D) 화자는 person1이 음식의 신선도를 유지하기 위해 냉장고를 닫기를 원한다. (Correct)
Direct expression (reference): Hey, person1, please close the fridge door to keep the food fresh.
Figure J7. 이들은 이미지와 그에 해당하는 생성된 직접적인 표현(direct expression) 및 객관식 질문 세트의 예시이다.
Prompt for Direct Generation
당신의 임무는 두 가지입니다.
- 이미지를 기반으로 직접적인 불만 사항을 생성합니다. 생성된 prompt는 다음 두 가지 기준을 염두에 두어야 합니다: a. 수신자 지정: 화자는 장면을 보고 있는 사람입니다. 이미지에 있는 사람을 수신자로 지정합니다 ("이봐, person1..."으로 시작). 각 사람에게는 이미지에 숫자 태그가 있습니다. b. 직접적인 prompt 생성: 불만 사항에는 "주체", "행동", "객체", "이유"가 포함되어야 합니다: "누가 무엇을 왜 해야 하는지"를 전달해야 합니다.
- prompt를 해결하는 솔루션 triplet을 생성합니다. 생성된 솔루션은 다음 세 가지 기준을 염두에 두어야 합니다: a. Triplet: 출력 형식은 (주체, 행동, 객체)여야 합니다. b. 문제 완화: 생성된 솔루션은 prompt의 불만 사항을 해결하는 방식으로 prompt를 해결해야 합니다. c. 물리적 객체로 해결 가능: triplet-(주체, 행동, 객체)-의 객체는 제공된 "Entity" 목록의 물리적 객체여야 합니다.
Entity: {entities} Prompt: (하나의 문장) Solution: (주체, 행동, 객체) Caption: (장면을 묘사하는 2-3 문장)
Figure J8. 이 prompt는 엔티티 목록 중 하나를 선택하고 이미지 속 인물에게 직접적인 요청을 생성합니다. 또한 세 가지 솔루션을 생성하고 장면에 대한 캡션을 생성합니다.
Prompt for mcq-correct Generation
The speaker wants to {action} (figure out) {obj} (the true intention) {direct} (based on the given prompt).
Prompt for Indirect, mcq-Superficial Understanding(SU) Generation
주어진 문장을 세 가지 다른 간접적인 문장으로 바꾸고, 각 문장의 오해될 수 있는 의도를 파악하는 것이 당신의 임무입니다. 생성된 문장의 오해될 수 있는 의도는 원래 의도와 명확하게 달라서는 안 됩니다. 원문, 원래 의도, 그리고 장면 설명이 주어질 것입니다. 간접 문장에 대한 요구사항은 다음과 같습니다:
- 간접성: 프롬프트는 직접적인 버전과 달리 간접적이어야 하며, 약간의 비꼬는 듯한 어조, 유머, 또는 심지어 관용구를 사용하여 진정한 의도를 숨길 수 있습니다.
- 객체 부재: 프롬프트는 원래 의도에 있는 "OBJECT" 또는 "ACTION", 또는 이와 유사하거나 동의어인 어떤 것도 포함해서는 안 됩니다.
- 자연스러운 의사소통: 프롬프트는 학술적이지 않고, 간단하고 자연스러운 일상 대화문이어야 합니다.
생성된 간접 문장은 표면적으로 명확히 다른 의미를 가져야 합니다. 매우 중요하게, 오해될 수 있는 의도는 주어진 상황에서 (문자 그대로 이해했을 때) 어색하게 들려야 합니다.
예를 들어, "Hey Person1, please clean your room!"은 간접 문장으로 바뀔 수 있습니다: "Hey Person1, this is a disaster!" 여기서 오해될 수 있는 의도는 다음과 같을 수 있습니다: "화자는 Person1이 재난으로부터 탈출하기를 원한다." 이것은 지저분한 방을 마주한 상황에서 분명히 우스꽝스럽습니다. 위의 예시처럼, 오해될 수 있는 의도는 다음으로 시작해야 합니다: "The speaker wants Person N to ..." 원문: {direct} 원래 의도: {correct} 간접 문장에서 금지된 단어: {action}, {obj}, 그리고 {obj}의 동의어. 장면 설명: {caption}
-
간접 문장 (비꼬는 어조 사용): Hey person{p}, (당신의 답변)
오해될 수 있는 의도 (표면적인 이해): The speaker wants person{p} to (당신의 답변)
-
간접 문장 (유머 사용): Hey person{p}, (당신의 답변)
오해될 수 있는 의도 (표면적인 이해): The speaker wants person{p} to (당신의 답변)
-
간접 문장 (밈 또는 속어 사용): Hey person{p}, (당신의 답변)
오해될 수 있는 의도 (표면적인 이해): The speaker wants person{p} to (당신의 답변)
Figure J10. 이 프롬프트는 직접적인 표현, 진정한 의도, 그리고 캡션을 입력으로 받아 의도된 의미를 전달하는 간접적인 표현을 생성합니다. 또한, 간접적인 표현의 표면적으로 해석된 버전을 생성합니다.
Prompt for mcq-Fake Scene Understanding(FS) Generation
주어진 상황에서 화자의 숨겨진 의도를 추측하는 것이 당신의 임무입니다. 생성된 답변은 다음 5가지 기준을 따라야 합니다:
- 현재 상황: {fake_caption}
- 다음 특정 prompt에 답해야 합니다: {indirect}
- 답변은 15단어를 초과하지 않아야 하며, 'The speaker wants to'로 시작해야 합니다.
- 답변은 주어진 상황에 있는 하나의 물리적 객체에 대해 언급해야 합니다.
- 답변은 "{answer}"와 동일한 의미를 가져서는 안 됩니다.
예시 a. {icls[o]} b. {icls[1]} c. {icls[2]}
Figure J11. 이 prompt는 가짜 캡션과 간접적인 표현을 사용하여 직접적인 표현의 실제 의도와 일치하지 않는 가장 그럴듯한 의도를 도출합니다.
Prompt for mcq-Nonexistent Entity(NE) Generation
주어진 이미지에 묘사된 상황에 대한 간접적인 불만과 프롬프트의 올바른 해석이 있습니다. 당신의 임무는 객관식 질문의 오답으로 사용될 잘못된 해석을 의도적으로 만들어내는 것입니다. 잘못된 해석은 합리적이지만 이미지에는 존재하지 않는 객체를 사용하여 특별히 설계되어야 합니다. 이미지에는 없지만, 해당 장면에서 매우 높은 확률로 존재할 것으로 예상되며 불만을 해결하는 데 사용될 수 있는 객체여야 합니다.
답변은 15단어를 초과해서는 안 되며, 'The speaker wants'로 시작해야 합니다.
[Example 1]
Prompt: Hey person1, I guess we're all going to be sharing more than just food today. Interpretation: The speaker wants person1 to use a fork to pick the food from the platter. Assistant: The speaker wants person1 to make use of the serving spoon when picking up shared food.
[Example 2]
Prompt: Hey person1, I guess we're all going to be sharing more than just food today. Interpretation: The speaker wants person1 to use a fork to pick the food from the platter. Assistant: 화자는 person1이 플라스틱 장갑을 사용하여 세균 공유를 피하기를 원한다.
[You]
Prompt: {text} Interpretation:{interpretation}
Figure J12. 이 prompt는 **간접적인 표현(indirect expression)**과 그에 대한 **해석(interpretation)**을 입력으로 받아, **이미지에 존재하지 않는 객체에 기반한 잘못된 의도(incorrect intention)**를 생성한다.
Direct: Evaluated by two main criteria. Rating from 1 to 5
[Criteria]
a. 관련성(Relevance): 표현은 이미지와 함께 보았을 때 의미가 통해야 한다. b. 해결 가능성(Solvability): 해결책을 도출할 수 있어야 한다.
[Rating]
1: 이미지 자체에 윤리적 문제가 있거나 품질이 좋지 않아 인식할 수 없는 경우. 2: 직접적인 표현이 이미지에 존재하지 않는 대상을 지칭하여 관련성이 부적절한 경우. 3: 직접적인 표현이 이미지 내 대상을 지칭하지만, 요청 자체가 부자연스러운 경우. 4: 요청이 명확하게 어떤 행동을 기대하며, 그 행동이 이미지 내에서 수행될 수 있는 경우. 5: 요청이 명확하게 어떤 행동을 기대하며, 그 행동이 이미지 상황과 완벽하게 일치하는 경우.
 (1) ن (ㅜ)
(1) ن (ㅜ)
Direct
Hey, person2, please pick up the shopping bag from the floor to keep the area tidy.

Figure J13. 직접 표현에 대한 사람의 평가에 사용된 실제 인터페이스. 직접 표현에 대한 두 가지 평가 기준과 1점에서 5점 척도에 대한 자세한 채점 가이드라인이 포함되어 있다.
Indirect: Comprehensive judgment based on two criteria. Rating from 1 to 5
[Criteria]
a. 일관성(Consistency): 간접 표현은 직접 표현과 동일한 의미로 해석될 여지가 있어야 한다. b. 모호성(Ambiguity): 직접 표현을 단순히 바꿔 말한 것이 아니어야 하며, 해결책의 행동이나 대상이 명시적으로 언급되어서는 안 된다.
[Rating]
1: 직접적인 표현과 의미가 다르게 해석되거나 매우 부자연스럽다.
2: 직접적인 표현과 같은 의미로 해석될 수 있지만, 대상이나 행동이 재구성되거나 명시적으로 드러난다.
3: 대상이 이미지에 없고 행동이 명시적으로 나타나지 않지만, 비꼬는 의미나 시각적 단서를 통해 추론할 수 있다.
4: 직접적인 표현과 같은 의미로 해석될 수 있지만, 문자 그대로 해석하면 다른 의미가 되고, 대상이나 행동이 드러나지 않는다.
5: 직접적인 표현과 같은 의미로 해석될 수 있지만, 문자 그대로 해석하면 완전히 다른 의미가 되고, 대상이나 행동이 드러나지 않으면서 자연스럽다.
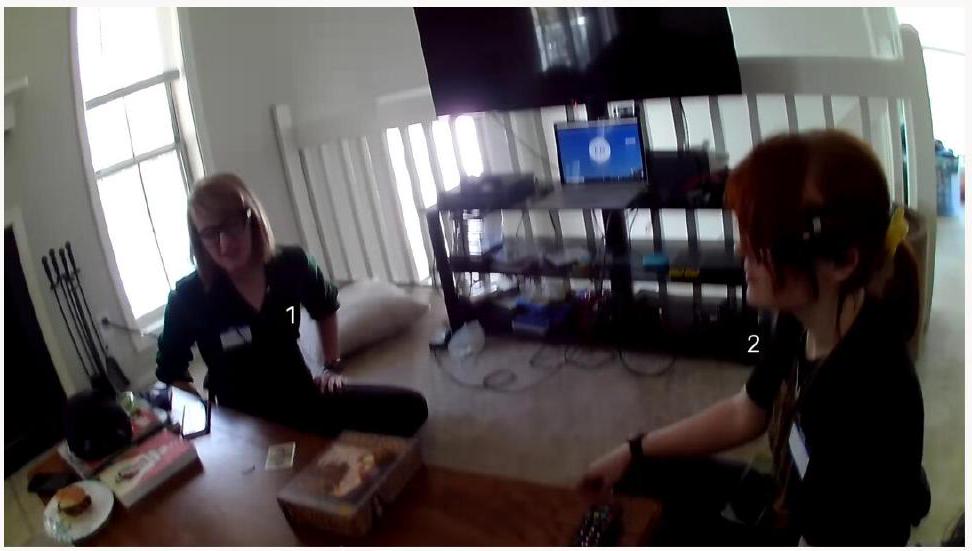
Original Information
Direct: Hey, person1, could you please pick up the cables on the floor to prevent anyone from tripping over them? Triplet (Object Prohibited) : (person1, pick up, floor)
1. Sarcasm
Indirect: 이봐 person1, 우리 여기서 장애물 코스 설치하는 거야? Surface: (표면적인 이해로) 의도를 잘못 해석했을 가능성: 화자는 person1이 케이블을 재미있는 활동의 일부로 즐겁게 헤쳐나가기를 원한다.
2. Humor
간접적(Indirect): 이봐 person1, 우리 방이 미래형 정글짐을 위한 무대인 줄 몰랐네! 표면적(Surface): (표면적인 이해로) 의도를 잘못 해석했을 가능성: 화자는 person1이 케이블을 놀이터 시설의 일부인 것처럼 타고 올라가기 시작하기를 원한다.
3. Meme
Indirect: Hey person1, let's not turn this place into a hazard audition for 'Wipeout!' Surface: Likely misinterpreted intention (superficial understanding) : The speaker wants person1 to prepare for participating in the 'Wipeout' show by practicing with the cables. Selection and Scoring
- Sarcasm
- Humor
- Meme

Figure J14. 간접 표현에 대한 인간 평가에 사용된 실제 인터페이스. 간접 표현에 대한 두 가지 평가 기준과 1점부터 5점까지의 상세한 채점 가이드라인이 포함되어 있다.
VLM 다중 선택 질문 답변을 위한 Prompt
주어진 이미지를 바탕으로 화자의 발화에 담긴 근본적인 의도를 가장 잘 설명하는 옵션을 선택하시오.
이미지 외부의 어떠한 상황도 선택에 영향을 미치지 않도록 하십시오.
화자는 청자가 상황에 적절한 특정 행동을 취하기를 원한다고 가정합니다.
발화: {utt}
[선택지]
{mcq}
당신의 답변: (A, B, C, D 중 문자만 출력하시오)

Figure J15. 다중 선택 질문 task에서 VLM 설정에 사용되는 prompt이다. 모델은 이미지, 발화, 그리고 답변 선택지들을 입력으로 받아 가장 적절한 답변을 선택한다.
SM 다중 선택 질문 답변을 위한 Prompt
장면 묘사를 바탕으로 화자의 발화에 담긴 근본적인 의도를 가장 잘 설명하는 옵션을 선택하시오.
장면 외부의 어떠한 상황도 선택에 영향을 미치지 않도록 하십시오.
화자는 청자가 상황에 적절한 특정 행동을 취하기를 원한다고 가정합니다.
장면 묘사: {cap}
발화: {utt}
[선택지]
{mcq}
당신의 답변: (A, B, C, D 중 문자만 출력하시오)

Figure J16. 다중 선택 질문 task에서 SM 설정에 사용되는 prompt이다. 모델은 먼저 이미지에 대한 caption을 생성한다. 그런 다음, caption, 발화, 그리고 답변 선택지들을 입력으로 받아 가장 적절한 답변을 선택한다.
LM 다중 선택 질문 답변을 위한 Prompt
화자의 발화에 담긴 근본적인 의도를 가장 잘 설명하는 옵션을 선택하시오.
화자는 청자가 특정 행동을 취하기를 원한다고 가정합니다.
발화: {utt}
[선택지]
{mcq}
당신의 답변: (A, B, C, D 중 문자만 출력하시오)

Figure J17. 다중 선택 질문 task에서 LM 설정에 사용되는 prompt이다. 모델은 발화와 답변 선택지들을 입력으로 받아 가장 적절한 답변을 선택한다.
Prompt for VLM Free-form Answering
주어진 이미지에 기반하여 화자의 발화에 담긴 근본적인 의도는 무엇이라고 생각하십니까? 이미지 외부의 어떠한 상황도 답변에 영향을 미치지 않아야 합니다. 화자는 청자가 상황에 적절한 특정 행동을 취하기를 원한다고 가정합니다. 답변은 15단어를 초과해서는 안 됩니다.
발화: {utt} 귀하의 답변: (문장을 "화자는 {p}가..."로 시작하십시오)
Figure J18. 다음 prompt는 자유 형식 답변 task의 VLM 설정에 사용된다. 모델은 이미지와 발화를 입력으로 받아 근본적인 의도를 추론하는 task를 수행한다.
Prompt for SM Free-form Answering
장면 설명에 기반하여 화자의 발화에 담긴 근본적인 의도는 무엇이라고 생각하십니까? 장면 밖의 어떠한 상황도 답변에 영향을 미치지 않아야 합니다. 화자는 청자가 상황에 적절한 특정 행동을 취하기를 원한다고 가정합니다. 답변은 15단어를 초과해서는 안 됩니다. 장면 설명: {cap} 발화: {utt} 귀하의 답변: (문장을 "화자는 {p}가..."로 시작하십시오)
Figure J19. 다음 prompt는 free-form 답변 task의 SM 설정에 사용된다. 모델은 먼저 이미지에 대한 caption을 생성한다. 그런 다음, caption과 발화를 입력으로 받아 근본적인 의도를 추론하는 task를 수행한다.
Prompt for LM Free-form Answering
화자가 말한 내용의 근본적인 의도는 무엇이라고 생각하십니까? 우리는 화자가 청자에게 특정 행동을 취하기를 원한다고 가정합니다. 귀하의 답변은 15단어를 초과해서는 안 됩니다. 발화: {utt} 귀하의 답변: (문장을 "화자는 {p}가..."로 시작하십시오.)
Figure J20. 다음 prompt는 free-form 답변 task의 LM 설정에 사용된다. 모델은 발화를 입력으로 받아 그 기저에 있는 의도를 추론하도록 지시받는다.
VLM+CoT 다중 선택 질문 답변을 위한 Prompt
주어진 이미지를 바탕으로 화자의 발화에 담긴 근본적인 의도를 가장 잘 설명하는 옵션을 선택하세요.
이미지 외부의 어떤 상황도 선택에 영향을 미치지 않도록 하세요.
우리는 화자가 청자에게 상황에 적절한 특정 행동을 취하기를 원한다고 가정합니다.
또한, 답변의 추론 과정을 설명하세요.
발화: {utt}
[선택지]
{mcq}
귀하의 답변1 (추론): (2~3문장으로 추론 과정을 출력하세요. "단계별로 생각해 봅시다."로 시작합니다.)
귀하의 답변2 (의도): (A, B, C, D 중 문자만 출력하세요.)
Figure J21. 다음 prompt는 다중 선택 질문 task의 VLM Chain of Thought 설정에 사용된다. 모델은 이미지, 발화, 그리고 답변 선택지를 입력으로 받아 단계별로 생각하여 가장 적절한 답변을 선택한다.
SM+CoT 다중 선택 질문 답변을 위한 Prompt
장면 설명을 바탕으로 화자의 발화에 담긴 근본적인 의도를 가장 잘 설명하는 옵션을 선택하세요.
장면 외부의 어떤 상황도 선택에 영향을 미치지 않도록 하세요.
우리는 화자가 청자에게 상황에 적절한 특정 행동을 취하기를 원한다고 가정합니다.
또한, 답변의 추론 과정을 설명하세요.
장면 설명: {cap}
발화: {utt}
[선택지]
{mcq}
귀하의 답변1 (추론): (2~3문장으로 추론 과정을 출력하세요. "단계별로 생각해 봅시다."로 시작합니다.)
귀하의 답변2 (의도): (A, B, C, D 중 문자만 출력하세요.)
Figure J22. 다음 prompt는 다중 선택 질문 task의 SM Chain of Thought 설정에 사용된다. 모델은 먼저 이미지에 대한 캡션을 생성한다. 그런 다음, 캡션, 발화, 그리고 답변 선택지를 입력으로 받아 단계별로 생각하여 가장 적절한 답변을 선택한다.
Prompt for VLM+CoT Free-form Answering
주어진 이미지에 기반하여 화자의 발화에 담긴 근본적인 의도가 무엇이라고 생각하는가? 이미지 외부의 어떠한 상황도 답변에 영향을 미치지 않아야 한다. 화자는 청자가 상황에 적절한 특정 행동을 취하기를 원한다고 가정한다. 또한, 답변의 추론 과정을 설명하라.
발화: {utt} 답변1 (추론): (2~3문장으로 추론 과정을 작성하며, "단계별로 생각해 봅시다."로 시작한다.) 답변2 (의도): ("화자는 {p}가..."로 시작하며 15단어를 초과하지 않도록 작성한다.)
Figure J23. 다음 prompt는 free-form 질문 task의 VLM Chain of Thought 설정에 사용된다. 모델은 이미지와 발화를 입력으로 받아 단계별 사고를 통해 근본적인 의도를 추론하는 task를 수행한다.
Prompt for Free-form Answering
어떤 장면 묘사를 바탕으로 화자의 발화 의도가 무엇이라고 생각하십니까? 장면 외부의 어떠한 상황도 답변에 영향을 미쳐서는 안 됩니다. 화자는 청자가 상황에 적절한 특정 행동을 취하기를 원한다고 가정합니다. 또한, 답변의 추론 과정을 설명하십시오. 장면 묘사: {cap} 발화: {utt} Your answer1 (reasoning): (2~3문장으로 추론 과정을 출력하며, "Let's think step by step."으로 시작합니다.) Your answer2 (intention): (문장을 "The speaker wants {p} to..."로 시작하고 15단어를 초과하지 마십시오.)
Figure J24. 자유 형식 질문 task의 SM Chain of Thought 설정에 사용되는 prompt이다. 모델은 먼저 이미지에 대한 caption을 생성한다. 그런 다음, caption과 발화를 입력으로 받아 단계별로 추론하여 근본적인 의도를 추론하는 task를 수행한다.
| VAGUE-VCR | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | Type | Multiple Choice Questions | Free-Form Answering | |||||||
| Accuracy(%) | Incorrect Count | Correct | Valid Count | Bert F1 | BLEU(1gram) | Valid Count | ||||
| FS | SU | WE | ||||||||
| Phi3.5-Vision-Instruct (4B) | VLM | 46.0 | 174 | 349 | 95 | 526 | 1144 | 0.682 | 0.293 | 1144 |
| SM | 35.3 | 198 | 461 | 81 | 404 | 1144 | 0.686 | 0.293 | 1144 | |
| LM | 26.6 | 296 | 440 | 104 | 304 | 1144 | 0.680 | 0.279 | 1144 | |
| LLaVA-Onevision (7B) | VLM | 43.1 | 119 | 503 | 29 | 493 | 1144 | 0.705 | 0.282 | 1144 |
| SM | 29.4 | 148 | 614 | 46 | 336 | 1144 | 0.707 | 0.290 | 1144 | |
| LM | 13.1 | 252 | 698 | 44 | 150 | 1144 | 0.689 | 0.271 | 1144 | |
| Qwen2.5-VL-Instruct (7B) | VLM | 46.8 | 134 | 438 | 37 | 535 | 1144 | 0.690 | 0.312 | 1144 |
| SM | 25.6 | 160 | 651 | 40 | 293 | 1144 | 0.687 | 0.303 | 1144 | |
| LM | 11.1 | 268 | 703 | 46 | 127 | 1144 | 0.666 | 0.278 | 1144 | |
| InternVL-2.5-MPO (8B) | VLM | 63.9 | 106 | 270 | 37 | 731 | 1144 | 0.706 | 0.326 | 1144 |
| SM | 48.4 | 158 | 374 | 58 | 554 | 1144 | 0.695 | 0.310 | 1144 | |
| LM | 23.0 | 290 | 516 | 75 | 263 | 1144 | 0.679 | 0.279 | 1144 | |
| Idefics2 (8B) | VLM | 58.7 | 75 | 338 | 59 | 672 | 1144 | 0.708 | 0.284 | 1144 |
| SM | 21.1 | 171 | 696 | 36 | 241 | 1144 | 0.674 | 0.281 | 1144 | |
| LM | 13.9 | 211 | 723 | 51 | 159 | 1144 | 0.663 | 0.270 | 1144 | |
| LLaVA-NeXT-vicuna (13B) | VLM | 46.4 | 140 | 416 | 57 | 531 | 1144 | 0.716 | 0.311 | 1144 |
| SM | 37.2 | 151 | 509 | 58 | 426 | 1144 | 0.711 | 0.314 | 1144 | |
| LM | 24.2 | 275 | 513 | 79 | 277 | 1144 | 0.594 | 0.287 | 1144 | |
| Ovis2 (16B) | VLM | 24.5 | 327 | 464 | 73 | 280 | 1144 | 0.679 | 0.290 | 1144 |
| SM | 23.8 | 305 | 503 | 64 | 272 | 1144 | 0.681 | 0.293 | 1144 | |
| LM | 21.9 | 306 | 532 | 56 | 250 | 1144 | 0.682 | 0.293 | 1144 | |
| InternVL-2.5-MPO (26B) | VLM | 63.7 | 105 | 280 | 30 | 729 | 1144 | 0.712 | 0.330 | 1144 |
| SM | 48.5 | 153 | 385 | 51 | 555 | 1144 | 0.707 | 0.326 | 1144 | |
| LM | 21.2 | 294 | 537 | 71 | 242 | 1144 | 0.681 | 0.288 | 1144 | |
| InternVL-3 (38B) | VLM | 63.6 | 99 | 263 | 54 | 728 | 1144 | 0.699 | 0.319 | 1144 |
| SM | 47.6 | 186 | 326 | 83 | 540 | 1144 | 0.677 | 0.300 | 1144 | |
| LM | 25.1 | 282 | 489 | 78 | 284 | 1144 | 0.671 | 0.275 | 1144 | |
| Qwen2.5-VL-Instruct (72B) | VLM | 74.2 | 99 | 159 | 37 | 849 | 1144 | 0.742 | 0.372 | 1144 |
| SM | 55.7 | 130 | 331 | 46 | 637 | 1144 | 0.724 | 0.358 | 1144 | |
| LM | 29.6 | 257 | 478 | 70 | 339 | 1144 | 0.687 | 0.293 | 1144 | |
| GPT-4o | VLM | 65.1 | 159 | 160 | 80 | 745 | 1144 | 0.735 | 0.366 | 1144 |
| SM | 69.5 | 112 | 167 | 70 | 795 | 1144 | 0.741 | 0.387 | 1144 | |
| LM | 46.4 | 246 | 254 | 113 | 531 | 1144 | 0.689 | 0.306 | 1144 | |
| Gemini-1.5-Pro | VLM | 60.6 | 168 | 190 | 90 | 693 | 1141 | 0.724 | 0.347 | 1144 |
| SM | 62.4 | 123 | 256 | 49 | 714 | 1142 | 0.705 | 0.324 | 1144 | |
| LM | 43.2 | 278 | 263 | 108 | 494 | 1143 | 0.687 | 0.289 | 1144 |
Table J5. VAGUE-VCR 데이터셋의 전체 결과 표이다. Multiple Choice Questions와 Free-Form Answering 모두에 대해 실험이 수행되었으며, 각 모델에 대해 VLM, SM, LM 세 가지 설정에서 결과가 측정되었다. GPT-4o 및 Gemini 1.5 Pro의 경우, VLM 및 SM 설정에서 CoT reasoning이 추가로 적용되었다.
| VAGUE-Ego4D | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | Type | Multiple Choice Questions | Free-Form Answering | |||||||
| Accuracy(%) | Incorrect Count | Correct | Valid Count | Bert F1 | BLEU(1gram) | Valid Count | ||||
| FS | SU | WE | ||||||||
| Phi3.5-Vision-Instruct (4B) | VLM | 42.4 | 92 | 152 | 63 | 226 | 533 | 0.681 | 0.279 | 533 |
| SM | 31.1 | 94 | 217 | 56 | 166 | 533 | 0.683 | 0.287 | 533 | |
| LM | 22.5 | 131 | 216 | 66 | 120 | 533 | 0.672 | 0.266 | 533 | |
| LLaVA-Onevision (7B) | VLM | 43.2 | 50 | 224 | 29 | 230 | 533 | 0.697 | 0.246 | 533 |
| SM | 29.5 | 67 | 271 | 38 | 157 | 533 | 0.699 | 0.261 | 533 | |
| LM | 11.3 | 108 | 332 | 33 | 60 | 533 | 0.675 | 0.239 | 533 | |
| Qwen2.5-VL-Instruct (7B) | VLM | 48.4 | 56 | 180 | 39 | 258 | 533 | 0.683 | 0.295 | 533 |
| SM | 28.0 | 74 | 273 | 37 | 149 | 533 | 0.687 | 0.292 | 533 | |
| LM | 9.8 | 131 | 326 | 24 | 52 | 533 | 0.660 | 0.269 | 533 | |
| InternVL-2.5-MPO (8B) | VLM | 66.8 | 33 | 110 | 34 | 356 | 533 | 0.701 | 0.308 | 533 |
| SM | 54.0 | 47 | 159 | 39 | 288 | 533 | 0.696 | 0.295 | 533 | |
| LM | 24.2 | 122 | 224 | 58 | 129 | 533 | 0.669 | 0.258 | 533 | |
| Idefics2 (8B) | VLM | 58.3 | 42 | 136 | 44 | 311 | 533 | 0.705 | 0.274 | 533 |
| SM | 18.2 | 69 | 336 | 31 | 97 | 533 | 0.664 | 0.267 | 533 | |
| LM | 14.8 | 85 | 340 | 29 | 79 | 533 | 0.655 | 0.256 | 533 | |
| LLaVA-NeXT-vicuna (13B) | VLM | 52.5 | 66 | 148 | 39 | 280 | 533 | 0.705 | 0.288 | 533 |
| SM | 34.1 | 77 | 221 | 53 | 182 | 533 | 0.701 | 0.291 | 533 | |
| LM | 20.3 | 140 | 235 | 50 | 108 | 533 | 0.680 | 0.255 | 533 | |
| Ovis2 (16B) | VLM | 25.7 | 158 | 197 | 41 | 137 | 533 | 0.668 | 0.268 | 533 |
| SM | 25.3 | 144 | 213 | 41 | 135 | 533 | 0.674 | 0.276 | 533 | |
| LM | 20.5 | 144 | 240 | 40 | 109 | 533 | 0.673 | 0.271 | 533 | |
| InternVL-2.5-MPO (26B) | VLM | 68.7 | 42 | 97 | 28 | 366 | 533 | 0.712 | 0.327 | 533 |
| SM | 55.2 | 56 | 145 | 38 | 294 | 533 | 0.707 | 0.315 | 533 | |
| LM | 21.8 | 130 | 238 | 49 | 116 | 533 | 0.672 | 0.268 | 533 | |
| InternVL-3 (38B) | VLM | 60.0 | 54 | 111 | 48 | 319 | 533 | 0.687 | 0.295 | 533 |
| SM | 47.6 | 73 | 152 | 53 | 253 | 533 | 0.660 | 0.274 | 533 | |
| LM | 18.2 | 136 | 249 | 47 | 96 | 533 | 0.667 | 0.252 | 533 | |
| Qwen2.5-VL-Instruct (72B) | VLM | 69.8 | 43 | 77 | 41 | 372 | 533 | 0.733 | 0.349 | 533 |
| SM | 59.3 | 45 | 126 | 46 | 316 | 533 | 0.724 | 0.340 | 533 | |
| LM | 26.8 | 120 | 216 | 54 | 143 | 533 | 0.684 | 0.274 | 533 | |
| GPT-4o | VLM | 63.6 | 67 | 66 | 61 | 339 | 533 | 0.730 | 0.353 | 533 |
| SM | 67.5 | 53 | 73 | 47 | 360 | 533 | 0.735 | 0.362 | 533 | |
| LM | 48.2 | 100 | 111 | 65 | 257 | 533 | 0.683 | 0.294 | 533 | |
| Gemini-1.5-Pro | VLM | 60.6 | 81 | 74 | 55 | 323 | 533 | 0.716 | 0.318 | 533 |
| SM | 60.6 | 53 | 118 | 34 | 323 | 528 | 0.708 | 0.307 | 533 | |
| LM | 40.3 | 119 | 130 | 68 | 215 | 532 | 0.676 | 0.265 | 533 |
Table J6. VAGUE-Ego4D 데이터셋의 전체 결과 표이다. Multiple Choice Questions와 Free-Form Answering 모두에 대해 실험이 수행되었으며, 각 모델에 대해 VLM, SM, LM 세 가지 설정에서 결과가 측정되었다. GPT-4o 및 Gemini 1.5 Pro의 경우, VLM 및 SM 설정에서 CoT reasoning이 추가로 적용되었다.
Example of full structure
{
"image_name": "oo13_Halloween_oo.15.15.492-00.15.17.652@o",
"direct": "Hey, person1, you should move the sedan from the handicapped parking spot.",
"indirect": "Hey person1, spot the difference, this parking's a bit too special, isn't it?",
"solution": "(person1, move, sedan)",
"mcq": {
"1_correct": "The speaker wants person1 to move the sedan because it's in a handicapped parking
ot.",
"2_fake_scene": "The speaker wants person1 to admire the unusually decorated motorcycle in the
parking lot.",
"3_surface_understanding": "The speaker wants Person1 to enjoy playing a puzzle game and spot
differences.",
"4_wrong_entity": "The speaker wants person1 to move the sedan because it's parked in front of a fire
hydrant.",
"ordering": [
"C",
"A",
"B",
"D"
]
},
"meta":{
"caption": "A man in a business suit stands near a beige sedan parked in a handicapped parking spot.
The area is surrounded by greenery and a building entrance is visible in the background.",
"ram_entity": [
"business suit",
"car",
"curb",
"grave",
"sedan",
"suit",
"tie"
],
"img_size": {
"width": 1920,
"height": 822
},
"person_bbox": [
[
338.989990234375,
112.2576904296875,
578.5294799804688,
717.6659545898438
],
[
1055.5440673828125,
233.45152282714844,
1131.0687255859375,
288.561767578125
]
],
"rating": {
"direct": 5,
"indirect": 4
},
"fake_caption": "In a bustling supermarket parking lot filled with shoppers and carts, person1 stands with
an amused smile, observing an unusually decorated motorcycle parked amidst a sea of ordinary cars. ("Hey
person1, spot the difference, this parking's a bit too special, isn't it?" \(\backslash\)
}
}
Figure J25. 벤치마크 데이터셋인 VAGUE의 샘플을 사용하여 구조를 보여준다. VAGUE는 이미지 이름, 직접 표현, 간접 표현, 세 가지 해결책, 객관식 세트, 이미지에 대한 다양한 정보를 포함하는 메타 데이터, 그리고 가짜 캡션으로 구성된다.
- 이 저자들은 동등하게 기여했습니다. † 교신 저자. ‡ 이 저자들은 이 작업에 동등하게 기여했습니다.