UNITER: 범용 이미지-텍스트 표현 학습(UNiversal Image-TExt Representation Learning)
UNITER는 다양한 Vision-and-Language (V+L) 태스크에 범용적으로 적용 가능한 UNiversal Image-TExt Representation 모델입니다. 대규모 이미지-텍스트 데이터셋을 기반으로 사전 학습되며, 4가지 태스크(Masked Language Modeling, Masked Region Modeling, Image-Text Matching, Word-Region Alignment)를 통해 이미지와 텍스트의 joint multimodal embedding을 학습합니다. 특히 이 모델은 한 modality의 전체 정보를 조건으로 다른 modality를 예측하는 Conditional Masking과, Optimal Transport (OT)를 이용해 단어와 이미지 영역 간의 정렬을 명시적으로 학습하는 Word-Region Alignment (WRA)를 제안하여 기존 모델들과 차별점을 두었습니다. 이를 통해 UNITER는 6개의 V+L 벤치마크에서 최고 성능을 달성했습니다. 논문 제목: UNITER: UNiversal Image-TExt Representation Learning
논문 요약: UNITER: 범용 이미지-텍스트 표현 학습(UNiversal Image-TExt Representation Learning)
- 논문 링크: https://arxiv.org/abs/1909.11740
- 저자: Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu (Microsoft Dynamics 365 AI Research)
- 발표 시기: 2020년 (European Conference on Computer Vision, ECCV 2020)
- 주요 키워드: Vision-and-Language, Representation Learning, Multimodal, Pre-training, Transformer, Optimal Transport
1. 연구 배경 및 문제 정의
- 문제 정의:
Vision-and-Language (V+L) 태스크는 이미지와 텍스트 간의 통합적인 이해를 위한 joint multimodal embedding에 의존하지만, 기존 모델들은 특정 태스크에 맞춰져 있어 학습된 표현이 해당 태스크에만 특화되고 다른 태스크로의 일반화가 어렵다는 한계가 있다. 이 논문은 모든 V+L 태스크에 범용적으로 적용 가능한 이미지-텍스트 표현을 학습하는 것을 목표로 한다. - 기존 접근 방식:
기존 V+L 모델들은 Visual Question Answering (VQA), Image-Text Retrieval, Referring Expression Comprehension 등 특정 태스크에 최적화된 아키텍처(예: MCB, BAN, DFAF의 멀티모달 융합, SCAN, MAttNet의 잠재적 정렬 학습)와 사전학습 방식(예: ViLBERT, LXMERT의 two-stream, VisualBERT, VL-BERT의 single-stream)을 사용했다. 이러한 모델들은 각 벤치마크에서 SOTA를 달성했지만, 아키텍처가 다양하고 학습된 표현이 태스크에 특화되어 일반화 능력이 부족했다.
2. 주요 기여 및 제안 방법
-
논문의 주요 기여:
- 다양한 V+L 태스크를 위한 강력한 범용 이미지-텍스트 표현 학습 모델인 UNITER (UNiversal Image-TExt Representation)를 제안한다.
- Masked Language Modeling (MLM) 및 Masked Region Modeling (MRM)을 위한 조건부 마스킹(Conditional Masking)과, Optimal Transport (OT) 기반의 새로운 Word-Region Alignment (WRA) 사전학습 태스크를 제안한다.
- 광범위한 V+L 벤치마크(6가지 태스크, 9개 데이터셋)에서 새로운 SOTA 성능을 달성하며, 기존 멀티모달 사전학습 방법들을 큰 차이로 능가함을 입증하고, 각 사전학습 태스크 및 데이터셋의 효과에 대한 심층적인 분석을 제공한다.
-
제안 방법:
UNITER는 Transformer를 핵심으로 하는 단일 스트림(single-stream) 아키텍처를 사용하며, 대규모 이미지-텍스트 데이터셋(COCO, Visual Genome, Conceptual Captions, SBU Captions)으로 사전 학습된다. 모델은 이미지 영역(시각적 특징 및 바운딩 박스)과 텍스트 단어(토큰 및 위치)를 Image Embedder와 Text Embedder를 통해 공통 임베딩 공간으로 인코딩한 후, Transformer 모듈을 통해 cross-modality contextualized embedding을 학습한다.네 가지 주요 사전학습 태스크는 다음과 같다:
- Masked Language Modeling (MLM): 이미지 영역에 조건화되어 마스킹된 단어를 예측한다.
- Masked Region Modeling (MRM): 입력 텍스트에 조건화되어 마스킹된 이미지 영역을 재구성한다 (Masked Region Classification (MRC), Masked Region Feature Regression (MRFR), KL-divergence를 사용한 Masked Region Classification (MRC-kl)의 세 가지 변형).
- Image-Text Matching (ITM): 전체 이미지와 문장 간의 인스턴스 수준 정렬을 학습한다.
- Word-Region Alignment (WRA): Optimal Transport (OT)를 활용하여 단어와 이미지 영역 간의 세밀한 정렬을 명시적으로 유도한다.
특히, 기존 연구들이 두 모달리티에 동시에 무작위 마스킹을 적용했던 것과 달리, UNITER는 한 모달리티의 전체 정보를 조건으로 다른 모달리티를 예측하는 조건부 마스킹을 사용한다. 또한, OT 기반 WRA를 통해 이미지 영역 임베딩을 단어 임베딩으로 운반하는 비용을 최소화하여 더 나은 cross-modal alignment를 유도한다.
3. 실험 결과
- 데이터셋:
사전학습에는 COCO, Visual Genome (In-domain), Conceptual Captions, SBU Captions (Out-of-domain) 등 4가지 대규모 이미지-텍스트 데이터셋을 활용했다. 평가는 Visual Question Answering (VQA), Visual Commonsense Reasoning (VCR), NLVR, Visual Entailment (SNLI-VE), Image-Text Retrieval (COCO, Flickr30K), Referring Expression Comprehension (RefCOCO, RefCOCO+, RefCOCOg) 등 6가지 V+L 태스크(총 9개 데이터셋)에서 UNITER-base (12 레이어) 및 UNITER-large (24 레이어) 모델로 진행되었다. PyTorch 기반으로 구현되었으며, Nvidia V100/Titan RTX GPU를 사용했다. - 주요 결과:
- UNITER-large 모델은 6가지 V+L 태스크(9개 데이터셋) 모두에서 새로운 SOTA를 달성했으며, UNITER-base 모델 또한 VQA를 제외한 대부분의 태스크에서 기존 모델들을 크게 능가했다.
- 구체적으로, VCR Q→AR에서 약 +2.8%, NLVR에서 +2.5%, SNLI-VE에서 +7%, Image-Text Retrieval R@1에서 +4% (zero-shot에서는 +15%), RE Comprehension에서 +2%의 성능 향상을 보였다.
- Ablation Study를 통해 조건부 마스킹이 joint random masking보다 더 빠르게 수렴하고 높은 정확도를 달성하며, 다운스트림 태스크에서도 더 나은 성능을 보임을 입증했다. 또한, Optimal Transport 기반 WRA가 VQA 및 RefCOCO+와 같이 영역 수준의 인식 및 추론이 필요한 태스크에서 모델 성능을 크게 향상시켰다.
- In-domain 및 Out-of-domain 데이터를 모두 활용한 사전학습이 가장 좋은 성능을 보였다.
- UNITER의 단일 스트림(single-stream) 아키텍처가 LXMERT(183M), ViLBERT(221M)보다 훨씬 적은 파라미터 수(UNITER-base: 86M)로도 새로운 SOTA 결과를 달성하여 효율성을 입증했다.
- VCR과 NLVR와 같이 사전학습 데이터와 특성이 다른 태스크에 대해서도 2단계 사전학습 및 아키텍처 수정(Pair-biattn)을 통해 효과적으로 적응하고 높은 성능을 달성했다.
4. 개인적인 생각 및 응용 가능성
- 장점:
UNITER는 범용적인 이미지-텍스트 표현 학습이라는 목표를 성공적으로 달성하며, 다양한 V+L 태스크에서 SOTA 성능을 기록했다. 특히, 기존 two-stream 모델보다 적은 파라미터로도 우수한 성능을 보인 점이 인상 깊다. 제안된 조건부 마스킹과 Optimal Transport 기반 WRA가 멀티모달 정렬 학습에 효과적임을 명확히 입증했으며, 어텐션 맵 시각화를 통해 모델의 cross-modality alignment 학습 능력을 보여주었다. - 단점/한계:
현재 모델은 Faster R-CNN을 통해 추출된 이미지 영역 특징을 사용하므로, raw 픽셀 수준에서의 이미지-텍스트 상호작용 학습은 향후 연구 과제로 남아있다. 또한, 객체 탐지기의 학습 데이터셋과 RefCOCO 등 일부 다운스트림 평가 데이터셋 간의 잠재적 중복 문제가 언급되었는데, 이는 엄밀한 의미에서 공정한 비교를 저해할 수 있는 부분이다. - 응용 가능성:
UNITER는 범용적인 이미지-텍스트 표현을 학습하므로, VQA, 이미지 캡셔닝, 이미지-텍스트 검색, 시각적 추론, 시각적 질의응답 등 다양한 Vision-and-Language 태스크에 직접적으로 응용될 수 있다. 특히, 특정 태스크에 대한 추가적인 대규모 사전학습 없이도 높은 성능을 기대할 수 있어, 새로운 V+L 태스크 개발 및 연구에 기반 모델로 활용될 가능성이 크다.
Chen, Yen-Chun, et al. "Uniter: Universal image-text representation learning." European conference on computer vision. Cham: Springer International Publishing, 2020.
UNITER: UNiversal Image-TExt Representation Learning
Yen-Chun Chen , Linjie Li , Licheng Yu*, Ahmed El Kholy<br>Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu<br>Microsoft Dynamics 365 AI Research<br>{yen-chun.chen,lindsey.li,licheng.yu,ahmed.elkholy,fiahmed,<br>zhe.gan, yu.cheng, jingjl}@microsoft.com
Abstract
Joint image-text embedding은 대부분의 Vision-and-Language (V+L) task의 기반이 되며, 여기서는 멀티모달 입력이 동시에 처리되어 시각 및 텍스트를 통합적으로 이해한다. 본 논문에서는 UNITER (UNiversal Image-TExt Representation) 를 소개한다. UNITER는 4개의 대규모 이미지-텍스트 데이터셋(COCO, Visual Genome, Conceptual Captions, SBU Captions)을 통해 사전학습되었으며, 통합된 멀티모달 embedding을 활용하여 다양한 다운스트림 V+L task에 적용될 수 있다.
우리는 4가지 사전학습 task를 설계했다:
- Masked Language Modeling (MLM)
- Masked Region Modeling (MRM, 3가지 변형)
- Image-Text Matching (ITM)
- Word-Region Alignment (WRA)
두 가지 모달리티에 동시에 무작위 마스킹을 적용했던 이전 연구들과 달리, 우리는 사전학습 task에 조건부 마스킹(conditional masking)을 사용한다 (즉, masked language/region modeling은 이미지/텍스트의 전체 관찰에 조건화된다).
전역적인 이미지-텍스트 정렬(global image-text alignment)을 위한 ITM 외에도, 우리는 Optimal Transport (OT)를 활용한 WRA를 제안하여 사전학습 과정에서 단어와 이미지 영역 간의 세밀한 정렬(fine-grained alignment)을 명시적으로 유도한다.
종합적인 분석 결과, 조건부 마스킹과 OT 기반 WRA 모두 더 나은 사전학습에 기여하는 것으로 나타났다. 또한, 우리는 사전학습 task의 최적 조합을 찾기 위해 철저한 ablation study를 수행했다.
광범위한 실험 결과, UNITER는 **Visual Question Answering, Image-Text Retrieval, Referring Expression Comprehension, Visual Commonsense Reasoning, Visual Entailment, NLVR**를 포함한 6가지 V+L task (9개 데이터셋) 에서 새로운 state of the art를 달성했다.
1 Introduction
대부분의 Vision-and-Language (V+L) task는 이미지와 텍스트 내 시각적, 텍스트적 단서 사이의 의미적 간극(semantic gap)을 연결하기 위해 joint multimodal embedding에 의존한다. 하지만 이러한 표현(representation)은 일반적으로 특정 task에 맞춰져 있다. 예를 들어, MCB [11], BAN [19], DFAF [13]는 Visual Question Answering (VQA) [3]를 위한 고급 멀티모달 융합(fusion) 방법을 제안했다. SCAN [23]과 MAttNet [55]은 Image-Text Retrieval [50] 및 Referring Expression Comprehension [18]을 위해 단어와 이미지 영역 간의 잠재적 정렬(latent alignment) 학습을 연구했다.
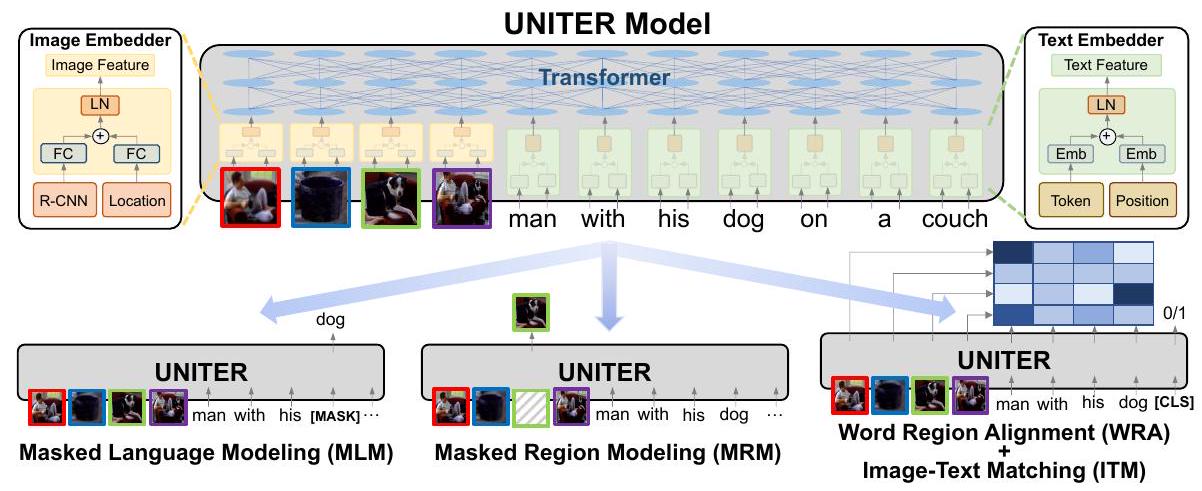
Fig. 1: 제안된 UNITER 모델의 개요 (컬러로 보는 것이 가장 좋음). Image Embedder, Text Embedder 및 다중 레이어 Transformer로 구성되며, 네 가지 사전학습 task를 통해 학습된다.
이러한 각 모델들이 해당 벤치마크에서 state of the art를 경신했지만, 그들의 아키텍처는 다양하고 학습된 표현은 매우 task-specific하여 다른 task로 일반화하기 어렵다. 이는 다음과 같은 중요한 질문을 제기한다: 모든 V+L task를 위한 범용적인 이미지-텍스트 표현을 학습할 수 있을까?
이러한 목표를 가지고, 우리는 **joint multimodal embedding을 위한 대규모 사전학습 모델인 UNiversal Image-TExt Representation (UNITER)**을 소개한다. 우리는 Transformer [49]를 모델의 핵심으로 채택하여, contextualized representation 학습을 위해 설계된 우아한 self-attention 메커니즘을 활용한다. 대규모 언어 모델링을 통해 Transformer를 NLP task에 성공적으로 적용한 BERT [9]에서 영감을 받아, 우리는 UNITER를 다음 네 가지 사전학습 task를 통해 사전학습한다: (i) 이미지에 조건화된 Masked Language Modeling (MLM); (ii) 텍스트에 조건화된 Masked Region Modeling (MRM); (iii) Image-Text Matching (ITM); (iv) Word-Region Alignment (WRA). MRM의 효과를 추가로 탐구하기 위해, 우리는 세 가지 MRM 변형을 제안한다: (i) Masked Region Classification (MRC); (ii) Masked Region Feature Regression (MRFR); (iii) KL-divergence를 사용한 Masked Region Classification (MRC-kl).
Figure 1에서 보여지듯이, UNITER는 먼저 이미지 영역(시각적 feature 및 bounding box feature)과 텍스트 단어(token 및 position)를 Image Embedder와 Text Embedder를 통해 공통 embedding 공간으로 인코딩한다. 그런 다음, Transformer 모듈이 적용되어 잘 설계된 사전학습 task를 통해 각 영역과 각 단어에 대한 일반화 가능한 contextualized embedding을 학습한다. 기존의 멀티모달 사전학습 연구들 [47, 29, 1, 24, 42, 60, 25]과 비교했을 때: (i) 우리의 masked language/region modeling은 두 modality에 joint random masking을 적용하는 대신, 이미지/텍스트의 전체 관찰에 조건화된다; (ii) 우리는 Optimal Transport (OT) [37, 7]를 사용하여 단어와 이미지 영역 간의 fine-grained alignment를 명시적으로 장려하는 새로운 WRA 사전학습 task를 도입한다. 직관적으로, OT 기반 학습은 하나의 분포를 다른 분포로 운반하는 비용을 최소화함으로써 분포 매칭을 최적화하는 것을 목표로 한다. 우리의 맥락에서는, 이미지 영역의 embedding을 문장의 단어(및 그 반대)로 운반하는 비용을 최소화하여, 더 나은 cross-modal alignment를 향해 최적화하는 것을 목표로 한다. 우리는 조건부 마스킹(conditional masking)과 OT 기반 WRA 모두 이미지와 텍스트 간의 misalignment를 성공적으로 완화하여, 다운스트림 task를 위한 더 나은 joint embedding을 생성할 수 있음을 보여준다.
UNITER의 일반화 능력을 입증하기 위해, 우리는 다음을 포함한 9개 데이터셋에 걸쳐 6가지 V+L task를 평가한다: (i) VQA; (ii) Visual Commonsense Reasoning (VCR) [58]; (iii) NLVR [44]; (iv) Visual Entailment [52]; (v) Image-Text Retrieval (zero-shot 설정 포함) [23]; (vi) Referring Expression Comprehension [56]. 우리의 UNITER 모델은 다음 네 가지 하위 데이터셋으로 구성된 대규모 V+L 데이터셋으로 학습된다: (i) COCO [26]; (ii) Visual Genome (VG) [21]; (iii) Conceptual Captions (CC) [41]; (iv) SBU Captions [32]. 실험 결과, UNITER는 모든 9개 다운스트림 데이터셋에서 상당한 성능 향상과 함께 새로운 state of the art를 달성한다. 또한, 추가적인 CC 및 SBU 데이터(다운스트림 task에서 보지 못한 이미지/텍스트 포함)로 학습하면 COCO 및 VG로만 학습했을 때보다 모델 성능이 더욱 향상된다.
우리의 기여는 다음과 같이 요약된다: (i) 우리는 V+L task를 위한 강력한 UNiversal Image-TExt Representation인 UNITER를 소개한다. (ii) 우리는 masked language/region modeling을 위한 Conditional Masking을 제시하고, 사전학습을 위한 새로운 Optimal-Transport 기반 Word-Region Alignment task를 제안한다. (iii) 우리는 광범위한 V+L 벤치마크에서 새로운 state of the art를 달성하며, 기존 멀티모달 사전학습 방법들을 큰 차이로 능가한다. 또한, 멀티모달 encoder 학습을 위한 각 사전학습 task/데이터셋의 효과에 대한 유용한 통찰력을 제공하기 위해 광범위한 실험 및 분석을 제시한다.
2 Related Work
Self-supervised learning은 원본 데이터를 자체적인 supervision 소스로 활용하며, 이는 이미지 색상화 [59], 직소 퍼즐 풀기 [31, 48], 인페인팅 [35], 회전 예측 [15], 상대 위치 예측 [10] 등 다양한 컴퓨터 비전 task에 적용되어 왔다.
최근에는 ELMo [36], BERT [9], GPT2 [39], XLNet [54], RoBERTa [27], ALBERT [22]와 같은 사전학습된 language model들이 NLP task에서 큰 발전을 이끌었다. 이러한 성공의 두 가지 핵심 요소는 다음과 같다:
- 대규모 언어 코퍼스에 대한 효과적인 사전학습 task,
- Transformer [49]를 사용하여 contextualized text representation을 학습하는 방식.
최근에는 대규모 이미지/비디오-텍스트 쌍 데이터로 사전학습한 후, 다운스트림 task에 fine-tuning하는 방식으로 멀티모달 task를 위한 self-supervised learning에 대한 관심이 급증하고 있다.
예를 들어, VideoBERT [46]와 CBT [45]는 BERT를 적용하여 비디오-텍스트 쌍으로부터 비디오 프레임 feature와 언어 token의 joint distribution을 학습하였다.
ViLBERT [29]와 LXMERT [47]는 two-stream 아키텍처를 도입했는데, 이는 두 개의 Transformer를 이미지와 텍스트에 독립적으로 적용한 후, 후반 단계에서 세 번째 Transformer를 통해 융합하는 방식이다.
반면, B2T2 [1], VisualBERT [25], Unicoder-VL [24], VL-BERT [42]는 single-stream 아키텍처를 제안했으며, 이는 단일 Transformer를 이미지와 텍스트 모두에 적용하는 방식이다.
VLP [60]는 사전학습된 모델을 이미지 캡셔닝과 VQA 모두에 적용하였다.
더 최근에는 multi-task learning [30]과 adversarial training [12]이 성능 향상을 위해 추가로 사용되었다.
VALUE [6]는 사전학습된 모델을 이해하기 위한 일련의 probing task를 개발하였다.
우리의 기여 (Our Contributions)
우리의 UNITER 모델과 다른 방법들 간의 주요 차이점은 두 가지이다:
(i) UNITER는 MLM(Masked Language Modeling)과 MRM(Masked Region Modeling)에 조건부 마스킹(conditional masking)을 사용한다. 즉, 한 가지 모달리티만 마스킹하고 다른 모달리티는 손상되지 않은 상태로 유지한다.
(ii) Optimal Transport를 활용한 새로운 Word-Region Alignment 사전학습 task를 제안한다. 이전 연구에서는 이러한 정렬이 task-specific loss에 의해 암묵적으로만 강제되었다.
또한, 우리는 철저한 ablation study를 통해 사전학습 task의 최적 조합을 탐색하였으며, 여러 V+L 데이터셋에서 새로운 state of the art를 달성하여, 종종 기존 연구보다 훨씬 뛰어난 성능을 보여준다.
3 UNiversal Image-TExt Representation
이 섹션에서는 먼저 UNITER의 모델 아키텍처(Section 3.1)를 소개한 다음, 사전학습을 위해 설계된 pre-training task와 V+L 데이터셋(Section 3.2 및 3.3)에 대해 설명한다.
3.1 Model Overview
UNITER의 모델 아키텍처는 Figure 1에 나타나 있다. 이미지와 문장 쌍이 주어졌을 때, UNITER는 이미지의 visual region과 문장의 textual token을 입력으로 받는다. 우리는 각각의 embedding을 추출하기 위해 Image Embedder와 Text Embedder를 설계한다. 이 embedding들은 multi-layer Transformer에 입력되어 visual region과 textual token 간의 cross-modality contextualized embedding을 학습한다. Transformer의 self-attention 메커니즘은 순서에 구애받지 않으므로, token의 위치와 region의 위치를 추가 입력으로 명시적으로 인코딩하는 것이 필요하다.
구체적으로, Image Embedder에서는 먼저 Faster R-CNN을 사용하여 각 region에 대한 visual feature (pooled ROI feature) 를 추출한다. 또한 각 region에 대한 location feature를 7차원 벡터를 통해 인코딩한다. visual feature와 location feature는 모두 fully-connected (FC) layer를 통과하여 동일한 embedding 공간으로 투영된다. 각 region에 대한 최종 visual embedding은 두 FC 출력값을 합산한 후 layer normalization (LN) layer를 통과시켜 얻는다. Text Embedder의 경우, BERT [9]를 따라 입력 문장을 WordPieces [51]로 토큰화한다. 각 sub-word token에 대한 최종 표현은 해당 word embedding과 position embedding을 합산한 후 또 다른 LN layer를 통과시켜 얻는다.
우리는 모델을 사전학습하기 위해 네 가지 주요 task를 도입한다:
- Masked Language Modeling (MLM): 이미지 region에 조건화된 MLM
- Masked Region Modeling (MRM): 입력 텍스트에 조건화된 MRM (세 가지 변형)
- Image-Text Matching (ITM)
- Word-Region Alignment (WRA)
Figure 1에서 보듯이, 우리의 MRM과 MLM은 BERT와 유사하게, 입력에서 일부 단어나 region을 무작위로 마스킹하고 Transformer의 출력으로 해당 단어나 region을 복구하도록 학습한다. 구체적으로, 단어 마스킹은 토큰을 특수 토큰 [MASK]로 대체하여 구현되며, region 마스킹은 visual feature 벡터를 모두 0으로 대체하여 구현된다. 다른 사전학습 방법에서 사용되는 것처럼 두 가지 양식을 무작위로 마스킹하는 대신, 각각의 경우 한 가지 양식만 마스킹하고 다른 양식은 그대로 유지한다. 이는 마스킹된 region이 마스킹된 단어에 의해 설명되는 경우 발생할 수 있는 잠재적인 불일치를 방지한다 (자세한 내용은 Section 4.2 참조).
또한 우리는 ITM을 통해 전체 이미지와 문장 간의 instance-level alignment를 학습한다. 학습 중에는 긍정 및 부정 이미지-문장 쌍을 모두 샘플링하고 그 매칭 점수를 학습한다. 나아가, 단어 토큰과 이미지 region 간의 더 세밀한 alignment를 제공하기 위해, Optimal Transport를 사용하여 WRA를 제안한다. 이는 contextualized image embedding을 word embedding으로 (또는 그 반대로) 운반하는 최소 비용을 효과적으로 계산한다. 따라서 추론된 transport plan은 더 나은 cross-modal alignment를 위한 추진체 역할을 한다. 경험적으로, 우리는 조건부 마스킹(conditional masking) 과 WRA가 모두 성능 향상에 기여함을 보여준다 (Section 4.2 참조). 이러한 task들로 UNITER를 사전학습하기 위해, 우리는 각 미니배치마다 하나의 task를 무작위로 샘플링하고, SGD 업데이트당 하나의 objective로만 학습한다.
3.2 Pre-training Tasks
Masked Language Modeling (MLM)
우리는 이미지 영역을 로, 입력 단어를 로, 마스크 인덱스를 로 표기한다.
MLM에서는 입력 단어의 15%를 무작위로 마스킹하고, 마스킹된 단어 를 특수 토큰 **[MASK]**로 대체한다. 목표는 주변 단어 와 모든 이미지 영역 를 기반으로 이 마스킹된 단어를 예측하는 것이며, 이는 negative log-likelihood를 최소화함으로써 달성된다:
여기서 는 학습 가능한 파라미터이다. 각 쌍 는 전체 학습 데이터셋 에서 샘플링된다.
Image-Text Matching (ITM)
ITM에서는 추가적인 특수 토큰 **[CLS]**가 모델에 입력되는데, 이는 두 가지 모달리티의 융합된 표현을 나타낸다. ITM의 입력은 문장과 이미지 영역 집합이며, 출력은 샘플링된 쌍이 일치하는지 여부를 나타내는 이진 레이블 이다. 우리는 [CLS] 토큰의 표현을 입력 이미지-텍스트 쌍의 결합 표현으로 추출한 다음, 이를 FC layer와 sigmoid 함수에 입력하여 0과 1 사이의 점수를 예측한다. 출력 점수를 로 표기한다. ITM supervision은 [CLS] 토큰에 대해 이루어진다. 학습 중에는 매 단계마다 데이터셋 에서 긍정 또는 부정 쌍 을 샘플링한다. 부정 쌍은 쌍을 이룬 샘플의 이미지 또는 텍스트를 다른 샘플에서 무작위로 선택된 것으로 대체하여 생성된다. 최적화를 위해 이진 cross-entropy loss를 적용한다:
Word-Region Alignment (WRA)
WRA를 위해 **Optimal Transport (OT)**를 사용하며, 여기서 와 간의 정렬을 최적화하기 위해 transport plan 가 학습된다. OT는 WRA에 적합한 몇 가지 독특한 특성을 가지고 있다:
(i) Self-normalization: 의 모든 요소의 합은 1이다 [37].
(ii) Sparsity: 정확하게 해결될 때, OT는 최대 개의 0이 아닌 요소를 포함하는 sparse solution 를 생성하며, 여기서 이다. 이는 더 해석 가능하고 견고한 정렬을 가능하게 한다 [37].
(iii) Efficiency: 기존의 선형 프로그래밍 솔버와 비교하여, 우리의 솔루션은 행렬-벡터 곱셈만 필요한 반복 절차를 사용하여 쉽게 얻을 수 있으므로 [53], 대규모 모델 사전학습에 쉽게 적용할 수 있다.
구체적으로, 는 두 개의 이산 분포 로 간주될 수 있으며, 및 로 공식화된다. 여기서 는 에 중심을 둔 Dirac 함수이다. 가중치 벡터 와 는 각각 -차원 및 -차원 simplex에 속한다 (즉, ). 이는 와 가 모두 확률 분포이기 때문이다. 와 사이의 OT 거리 (따라서 쌍에 대한 정렬 손실)는 다음과 같이 정의된다:
여기서 이고, 은 -차원 all-one 벡터를 나타내며, 는 와 사이의 거리를 평가하는 비용 함수이다. 실험에서는 cosine distance 가 사용된다. 행렬 는 transport plan으로 표시되며, 두 모달리티 간의 정렬을 해석한다. 불행히도, 에 대한 정확한 최소화는 계산적으로 다루기 어렵기 때문에, 우리는 OT 거리를 근사하기 위해 IPOT 알고리즘 [53]을 고려한다 (자세한 내용은 supplementary file에 제공된다). 를 해결한 후, OT 거리는 파라미터 를 업데이트하는 데 사용될 수 있는 WRA loss로 사용된다.
Masked Region Modeling (MRM)
MLM과 유사하게, 우리는 이미지 영역을 샘플링하고 시각적 feature를 15% 확률로 마스킹한다. 모델은 나머지 영역 와 모든 단어 가 주어졌을 때 마스킹된 영역 를 재구성하도록 학습된다. 마스킹된 영역의 시각적 feature는 0으로 대체된다. 이산 레이블로 표현되는 텍스트 토큰과 달리, 시각적 feature는 고차원적이고 연속적이므로 클래스 likelihood를 통해 감독될 수 없다. 대신, 우리는 동일한 목적 함수 기반을 공유하는 MRM의 세 가지 변형을 제안한다:
-
Masked Region Feature Regression (MRFR)
MRFR은 각 마스킹된 영역 의 Transformer 출력을 해당 시각적 feature로 회귀하도록 학습한다. 구체적으로, 우리는 FC layer를 적용하여 Transformer 출력을 입력 ROI pooled feature 와 동일한 차원의 벡터 로 변환한다. 그런 다음 둘 사이에 L2 regression을 적용한다: . -
Masked Region Classification (MRC)
MRC는 각 마스킹된 영역에 대한 객체 semantic class를 예측하도록 학습한다. 우리는 먼저 마스킹된 영역 의 Transformer 출력을 FC layer에 입력하여 개의 객체 클래스 점수를 예측하고, 이는 softmax 함수를 통해 정규화된 분포 로 변환된다. 객체 카테고리가 제공되지 않으므로 groundtruth label은 없다. 따라서 우리는 Faster R-CNN의 객체 감지 출력을 사용하고, 감지된 객체 카테고리(가장 높은 신뢰도 점수 포함)를 마스킹된 영역의 레이블로 사용하며, 이는 one-hot 벡터 로 변환된다. 최종 목적은 cross-entropy (CE) loss를 최소화하는 것이다: . -
Masked Region Classification with KL-Divergence (MRC-kl)
MRC는 객체 감지 모델에서 가장 가능성이 높은 객체 클래스를 hard label (확률 0 또는 1)로 취하며, 감지된 객체 클래스가 해당 영역의 groundtruth label이라고 가정한다. 그러나 ground-truth label이 없으므로 이는 사실이 아닐 수 있다. 따라서 MRC-kl에서는 이러한 가정을 피하고, detector의 원시 출력(즉, 객체 클래스의 분포 )인 soft label을 supervision 신호로 사용한다. MRC-kl은 [16]과 같이 두 분포 간의 KL divergence를 최소화하여 이러한 지식을 UNITER로 증류하는 것을 목표로 한다: .
3.3 Pre-training Datasets
우리는 기존의 4가지 V+L 데이터셋인 **COCO [26], Visual Genome (VG) [21], Conceptual Captions (CC) [41], SBU Captions [32]**를 기반으로 사전학습 데이터셋을 구축한다. 사전학습에는 이미지-문장 쌍만 사용되는데, 이는 추가적인 이미지-문장 쌍을 쉽게 수집하여 추가 사전학습에 활용할 수 있어 모델 프레임워크의 확장성을 높여준다.
| In-domain | Out-of-domain | ||||
|---|---|---|---|---|---|
| Split | COCO Captions VG Dense Captions | Conceptual Captions SBU Captions | |||
| train | |||||
| val |
Table 1: 사전학습에 사용된 데이터셋 통계. 각 셀은 #이미지-텍스트 쌍 (#이미지)을 나타낸다.
사전학습에 대한 다양한 데이터셋의 효과를 연구하기 위해, 우리는 네 가지 데이터셋을 두 가지 범주로 나눈다. 첫 번째 범주는 COCO의 이미지 캡셔닝 데이터와 VG의 dense 캡셔닝 데이터로 구성된다. 대부분의 V+L task가 이 두 데이터셋을 기반으로 구축되기 때문에, 우리는 이를 "In-domain" 데이터라고 부른다. "공정한" 데이터 분할을 얻기 위해, 우리는 COCO의 원본 학습 및 검증 분할을 병합하고, 다운스트림 task에 나타나는 모든 검증 및 테스트 이미지를 제외한다. 또한, COCO와 Flickr30K 이미지 모두 Flickr에서 크롤링되었고 중복될 수 있으므로, URL 매칭을 통해 모든 중복 Flickr30K [38] 이미지를 제외한다. 동일한 규칙이 Visual Genome에도 적용되었다. 이러한 방식으로, 우리는 학습을 위해 5.6M 이미지-텍스트 쌍과 내부 검증을 위해 131K 이미지-텍스트 쌍을 얻는다. 이는 중복 이미지 필터링 및 이미지-텍스트 쌍만 사용했기 때문에 LXMERT [47]에서 사용된 데이터셋 크기의 절반에 해당한다. 우리는 또한 모델 학습을 위해 Conceptual Captions [41] 및 SBU Captions [32]에서 추가적인 Out-of-domain 데이터를 사용한다. 정리된 분할에 대한 통계는 Table 1에 제공된다.
4 Experiments
우리는 사전학습된 모델을 각 target task로 전이(transfer)시키고 end-to-end fine-tuning을 통해 6가지 V+L task에서 UNITER를 평가한다. 우리는 두 가지 모델 크기에 대한 실험 결과를 보고한다:
- UNITER-base: 12개 layer
- UNITER-large: 24개 layer
4.1 Downstream Tasks
VQA, VCR, NLVR task에서는 입력 이미지(또는 이미지 쌍)와 자연어 질문(또는 설명)이 주어졌을 때, 모델은 이미지의 시각적 내용을 기반으로 답변을 예측한다(또는 설명의 정확성을 판단한다). Visual Entailment의 경우, SNLI-VE 데이터셋으로 평가한다. 목표는 주어진 이미지가 입력 문장을 의미론적으로 수반하는지 여부를 예측하는 것이다. 모델 성능 측정에는 세 가지 클래스("Entailment", "Neutral", "Contradiction")에 대한 분류 정확도가 사용된다. Image-Text Retrieval의 경우, 두 가지 데이터셋(COCO 및 Flickr30K)을 고려하며, Image Retrieval(IR)과 Text Retrieval(TR)의 두 가지 설정에서 모델을 평가한다. Referring Expression (RE) Comprehension은 쿼리 설명이 주어졌을 때, 모델이 이미지 영역 제안(image region proposal) 세트에서 대상을 선택하도록 요구한다. 모델은 ground-truth 객체와 감지된 제안 (MAttNet [55]) 모두에서 평가된다.
| Pre-training Data | Meta-Sum | VQA test-dev | IR (Flickr) | TR (Flickr) | NLVR | Ref | ||
|---|---|---|---|---|---|---|---|---|
| val | val | dev | val | |||||
| None | 1 | None | 314.34 | 67.03 | 61.74 | 65.55 | 51.02 | 68.73 |
| Wikipedia + BookCorpus | 2 | MLM (text only) | 346.24 | 69.39 | 73.92 | 83.27 | 50.86 | 68.80 |
| 9 | 3 | MRFR | 344.66 | 69.02 | 72.10 | 82.91 | 52.16 | 68.47 |
| 4 | ITM | 385.29 | 70.04 | 78.93 | 89.91 | 74.08 | 72.33 | |
| MLM | 386.10 | 71.29 | 77.88 | 89.25 | 74.79 | 72.89 | ||
| MLM + ITM | 393.04 | 71.55 | 81.64 | 91.12 | 75.98 | 72.75 | ||
| MLM + ITM + MRC | 393.97 | 71.46 | 81.39 | 91.45 | 76.18 | 73.49 | ||
| MLM + ITM + MRFR | 396.24 | 71.73 | 81.76 | 92.31 | 76.21 | 74.23 | ||
| MLM + ITM + MRC-kl | 397.09 | 71.63 | 82.10 | 92.57 | 76.28 | 74.51 | ||
| 10 MLM + ITM + MRC-kl + MRFR | 399.97 | 71.92 | 83.73 | 92.87 | 76.93 | 74.52 | ||
| 11 MLM + ITM + MRC-kl + MRFR + WRA | 400.93 | 72.47 | 83.72 | 93.03 | 76.91 | 74.80 | ||
| 12 <br> MLM + ITM + MRC-kl + MRFR (w/o cond. mask) | 396.51 | 71.68 | 82.31 | 92.08 | 76.15 | 74.29 | ||
| Out-of-domain (SBU+CC) | 13 MLM + ITM + MRC-kl + MRFR + WRA | 396.91 | 71.56 | 84.34 | 92.57 | 75.66 | 72.78 | |
| In-domain + Out-of-domain | 405.24 | 72.70 | 85.77 | 94.28 | 77.18 | 75.31 |
Table 2: VQA, Flickr30K의 Image-Text Retrieval, NLVR , RefCOCO+를 벤치마크로 사용하여 사전학습 task 및 데이터셋에 대한 평가. 모든 결과는 UNITER-base에서 얻어졌다. Image Retrieval(IR) 및 Text Retrieval(TR)에 대한 Flickr30K의 R@1, R@5, R@10 평균이 보고된다. 짙은 회색과 옅은 회색은 In-domain 데이터로 학습된 모든 task에서 각각 최고 및 두 번째 최고 결과를 강조한다.
VQA, VCR, NLVR , Visual Entailment 및 Image-Text Retrieval의 경우, [CLS] 토큰의 표현으로부터 multi-layer perceptron (MLP)을 통해 입력 이미지-텍스트 쌍의 joint embedding을 추출한다. RE Comprehension의 경우, MLP를 사용하여 region-wise alignment score를 계산한다. 이러한 MLP layer는 fine-tuning 단계에서 학습된다. 구체적으로, VQA, VCR, NLVR , Visual Entailment 및 RE Comprehension은 분류 문제(classification problem)로 공식화되며, ground-truth 답변/응답에 대한 cross-entropy를 최소화한다. Image-Text Retrieval의 경우, 랭킹 문제(ranking problem)로 공식화한다. Fine-tuning 동안, 우리는 이미지와 텍스트 쌍 3개를 샘플링한다. 하나는 데이터셋에서 가져온 positive pair이고, 나머지 두 개는 문장/이미지를 다른 것으로 무작위로 대체하여 만든 negative pair이다. 우리는 positive pair와 negative pair 모두에 대해 **유사도 점수(joint embedding 기반)**를 계산하고, triplet loss를 통해 그들 간의 margin을 최대화한다.
4.2 Evaluation on Pre-training Tasks
우리는 대표적인 V+L benchmark인 VQA, NLVR, Flickr30K, RefCOCO+에 대한 ablation study를 통해 다양한 pre-training 설정의 효과를 분석하였다. 각 benchmark에 대한 standard metric 외에도, 모든 benchmark 점수를 합한 Meta-Sum을 global metric으로 사용하였다.
우선, 두 가지 baseline을 설정한다. Table 2의 Line 1 (L1)은 pretraining을 전혀 수행하지 않은 경우이며, L2는 [9]에서 pre-trained된 weight로 초기화된 MLM 결과를 나타낸다. 비록 MLM이 text만으로 학습되어 pre-training 중에 image 정보를 전혀 학습하지 않았음에도 불구하고, L1 대비 약 +30의 Meta-Sum 향상을 보인다. 따라서 이후 실험에서는 L2의 pre-trained weight를 모델 초기화에 사용한다.
다음으로, 각 pre-training task의 효과를 철저한 ablation study를 통해 검증한다. L2와 L3을 비교하면, MRFR (L3)은 NLVR에서만 MLM (L2)보다 더 나은 결과를 보인다. 반면, ITM (L4) 또는 MLM (L5)만으로 pre-trained한 경우, L1 및 L2 baseline보다 모든 task에서 유의미한 성능 향상이 나타난다. 여러 pre-training task를 결합하면, MLM + ITM (L6)이 단일 task인 ITM (L4) 또는 MLM (L5)보다 향상된 성능을 보인다. MLM, ITM, MRM을 함께 학습시킨 경우 (L7-L10), 모든 benchmark에서 일관된 성능 향상이 관찰된다. MRM의 세 가지 variant 중 (L7-L9), MRC-kl (L9)이 MLM + ITM과 함께 사용될 때 가장 높은 성능 (397.09)을 보이며, MRC (L7)는 가장 낮은 성능 (393.97)을 보인다. MRC-kl과 MRFR을 MLM 및 ITM과 함께 결합한 경우 (L10), 두 task는 서로 보완적으로 작용하여 두 번째로 높은 Meta-Sum 점수를 달성한다. 가장 높은 Meta-Sum 점수는 MLM + ITM + MRC-kl + MRFR + WRA (L11) 설정에서 얻어진다. 특히 VQA와 RefCOCO+에서 WRA를 추가함으로써 상당한 성능 향상이 있었는데, 이는 WRA를 통해 학습된 단어와 영역 간의 정밀한 정렬이 region-level recognition 또는 reasoning이 필요한 downstream task에 도움이 되었음을 나타낸다. 우리는 이후 실험에서 이 optimal한 pre-training 설정을 사용한다.
추가적으로, conditional masking의 기여도를 비교 실험을 통해 검증한다. pre-training 중 두 modality를 동시에 random masking하는 경우, 즉 conditional masking이 없는 설정 (L12)에서는 conditional masking을 사용한 설정 (399.97)보다 낮은 Meta-Sum 점수 (396.51)를 보인다. 이는 conditional masking 전략이 joint image-text representation을 보다 효과적으로 학습하게 함을 시사한다.
마지막으로, pre-training dataset의 영향을 분석한다. 지금까지의 실험은 In-domain 데이터를 중심으로 진행되었다. 이번 실험에서는 Out-of-domain 데이터 (Conceptual Captions + SBU Captions)로 pre-training을 수행하였다. Out-of-domain 데이터는 더 많은 image를 포함하고 있음에도 불구하고, In-domain 데이터 (COCO + Visual Genome)로 학습된 모델 (400.93 in L11) 대비 낮은 성능 (396.91 in L13)을 보였다. 이는 모델이 pre-training 중 downstream task와 유사한 이미지에 노출될 때 더 많은 이점을 얻는다는 것을 보여준다. 마지막으로 In-domain과 Out-of-domain 데이터를 모두 활용하여 pre-training한 경우, 데이터의 양이 두 배가 되면서 모델 성능은 계속 향상되어 Meta-Sum 점수는 405.24 (L14)에 도달하였다.
4.3 Results on Downstream Tasks
Table 3는 모든 다운스트림 task에 대한 UNITER의 결과를 보여준다. 우리의 base 모델과 large 모델 모두 In-domain+Out-of-domain 데이터셋으로 사전학습되었으며, 최적의 사전학습 설정인 MLM+ITM+MRC-kl+MRFR+WRA를 사용하였다. 각 task의 구현 세부사항은 supplementary file에 제공된다. 우리는 각 다운스트림 task에서 task-specific 모델과 다른 사전학습 모델들을 비교한다.
SOTA task-specific 모델은 다음과 같다:
- VQA의 MCAN [57],
- NLVR 의 MaxEnt [44],
- VCR의 B2T2 [1],
- Image-Text Retrieval의 SCAN [23],
- SNLI-VE의 EVE-Image [52],
- RE Comprehension (RefCOCO, RefCOCO+ 및 RefCOCOg)의 MAttNet.
다른 사전학습 모델에는 **ViLBERT [29], LXMERT [47], Unicoder-VL [24], VisualBERT [25], VLBERT [42]**가 포함된다.
결과는 우리의 UNITER-large 모델이 모든 벤치마크에서 새로운 state of the art를 달성했음을 보여준다. UNITER-base 모델 또한 VQA를 제외한 모든 task에서 다른 모델들을 큰 차이로 능가한다. 구체적으로, 우리의 UNITER-base 모델은 SOTA 대비 다음과 같은 성능 향상을 보인다:
- VCR의 Q→AR에서 약 +2.8%,
- NLVR 에서 +2.5%,
- SNLI-VE에서 +7%,
- Image-Text Retrieval의 R@1에서 +4% (zero-shot 설정에서는 +15%),
- RE Comprehension에서 +2%.
LXMERT는 다운스트림 VQA (+VG+GQA) 데이터로 사전학습되는데, 이는 VQA task에 모델을 적응시키는 데 도움이 될 수 있다. 그러나 NLVR 와 같이 학습 시 보지 못한(unseen) task에서 평가했을 때, UNITER-base는 LXMERT보다 3% 더 높은 성능을 달성한다. 또한, 이미지-텍스트 쌍으로만 사전학습된 모든 모델 중에서, 우리의 UNITER-base는 VQA에서 다른 모델들보다 1.5% 이상 더 우수한 성능을 보인다.
ViLBERT와 LXMERT 모두 two-stream 모델이 single-stream 모델보다 우수하다고 관찰했지만, 우리의 결과는 제안된 사전학습 설정에서 single-stream 모델이 훨씬 적은 파라미터 수(UNITER-base: 86M, LXMERT: 183M, ViLBERT: 221M)로도 새로운 state-of-the-art 결과를 달성할 수 있음을 경험적으로 보여준다.
VCR의 경우, 우리는 두 단계의 사전학습 접근 방식을 제안한다: (i) 표준 사전학습 데이터셋으로 사전학습; (ii) 다운스트림 VCR 데이터셋으로 추가 사전학습. 흥미롭게도, VLBERT와 B2T2는 VCR에서 사전학습이 크게 도움이 되지 않는다고 관찰했지만, 우리는 2단계 사전학습이 모델 성능을 크게 향상시킬 수 있음을 발견했다. 반면, 1단계 사전학습도 여전히 도움이 되지만 그 효과는 제한적이었다 (결과는 Table 4 참조). 이는 제안된 2단계 접근 방식이 사전학습 데이터셋에 없던 새로운 데이터에 대해 우리의 사전학습 모델에서 매우 효과적임을 시사한다.
| Tasks | SOTA ViLBERT | VLBERT Unicoder | VisualBERT LXMERT | UNITER | |||||
|---|---|---|---|---|---|---|---|---|---|
| (Large) | -VL | Base | Large | ||||||
| VQA | test-dev | 70.63 | 70.55 | 71.79 | - | 70.80 | 72.42 | ||
| test-std | 70.90 | 70.92 | 72.22 | - | 71.00 | 72.54 | 72.91 | 74.02 | |
| VCR | 72.60 | 73.30 | 75.80 | - | 71.60 | - | 75.00 | 77.30 | |
| 75.70 | 74.60 | 78.40 | - | 73.20 | - | 77.20 | 80.80 | ||
| Q AR | 55.00 | 54.80 | 59.70 | - | 52.40 | - | 58.20 | 62.80 | |
| NLVR | dev | 54.80 | - | - | - | 67.40 | 74.90 | 77.18 | 79.12 |
| test-P | 53.50 | - | - | - | 67.00 | 74.50 | 77.85 | 79.98 | |
| SNLIVE | val | 71.56 | - | - | - | - | - | 78.59 | 79.39 |
| test | 71.16 | - | - | - | - | - | 78.28 | 79.38 | |
| ZS IR (Flickr) | R@1 | - | 31.86 | - | 48.40 | - | - | 66.16 | 68.74 |
| R@5 | - | 61.12 | - | 76.00 | - | - | 88.40 | 89.20 | |
| R@10 | - | 72.80 | - | 85.20 | - | - | 92.94 | 93.86 | |
| IR (Flickr) | R@1 | 48.60 | 58.20 | - | 71.50 | - | - | 72.52 | 75.56 |
| R@5 | 77.70 | 84.90 | - | 91.20 | - | - | 92.36 | 94.08 | |
| R@10 | 85.20 | 91.52 | - | 95.20 | - | - | 96.08 | 96.76 | |
| IR (COCO) | R@1 | 38.60 | - | - | 48.40 | - | - | 50.33 | 52.93 |
| R@5 | 69.30 | - | - | 76.70 | - | - | 78.52 | 79.93 | |
| R@10 | 80.40 | - | - | 85.90 | - | - | 87.16 | 87.95 | |
| ZS TR (Flickr) | R@1 | - | - | - | 64.30 | - | - | 80.70 | 83.60 |
| R@5 | - | - | - | 85.80 | - | - | 95.70 | 95.70 | |
| R@10 | - | - | - | 92.30 | - | - | 98.00 | 97.70 | |
| TR (Flickr) | R@1 | 67.90 | - | - | 86.20 | - | - | 85.90 | 87.30 |
| R@5 | 90.30 | - | - | 96.30 | - | - | 97.10 | 98.00 | |
| R@10 | 95.80 | - | - | 99.00 | - | - | 98.80 | 99.20 | |
| TR (COCO) | R@1 | 50.40 | - | - | 62.30 | - | - | 64.40 | 65.68 |
| R@5 | 82.20 | - | - | 87.10 | - | - | 87.40 | 88.56 | |
| R@10 | 90.00 | - | - | 92.80 | - | - | 93.08 | 93.76 | |
| RefCOCO | val | 87.51 | - | - | - | - | 91.64 | 91.84 | |
| testA | 89.02 | - | - | - | - | - | 92.26 | 92.65 | |
| testB | 87.05 | - | - | - | - | - | 90.46 | 91.19 | |
| val | 77.48 | - | - | - | - | - | 81.24 | 81.41 | |
| testA | 83.37 | - | - | - | - | - | 86.48 | 87.04 | |
| testB | 70.32 | - | - | - | - | - | 73.94 | 74.17 | |
| Ref- | val | 75.38 | - | 80.31 | - | - | - | 83.66 | 84.25 |
| testA | 80.04 | - | 83.62 | - | - | - | 86.19 | 86.34 | |
| testB | 69.30 | - | 75.45 | - | - | - | 78.89 | 79.75 | |
| val | 68.19 | 72.34 | 72.59 | - | - | - | 75.31 | 75.90 | |
| testA | 75.97 | 78.52 | 78.57 | - | - | - | 81.30 | 81.45 | |
| testB | 57.52 | 62.61 | 62.30 | - | - | - | 65.58 | 66.70 | |
| RefCOCOg | val | 81.76 | - | - | - | - | - | 86.52 | 87.85 |
| test | 81.75 | - | - | - | - | - | 86.52 | 87.73 | |
| val | 68.22 | - | - | - | - | - | 74.31 | 74.86 | |
| test | 69.46 | - | - | - | - | - | 74.51 | 75.77 |
Table 3: UNITER 모델의 다운스트림 V+L task 결과, task-specific state-of-the-art (SOTA) 및 이전 사전학습 모델들과 비교. ZS: Zero-Shot, IR: Image Retrieval, TR: Text Retrieval.
다른 task들과 달리, NLVR 는 두 개의 이미지를 입력으로 받는다. 따라서 이미지 쌍 간의 상호작용이 사전학습 단계에서 학습되지 않았기 때문에, 이미지-문장 쌍으로 사전학습된 UNITER를 직접 fine-tuning하는 것은 최적의 성능으로 이어지지 않을 수 있다. 이에 우리는 NLVR 에 대해 세 가지 수정된 설정으로 실험을 진행했다: (i) Triplet: 이미지 쌍과 쿼리 캡션의 joint embedding; (ii) Pair: 각 이미지와 각 쿼리 캡션의 개별 embedding; (iii) Pair-biattn: Pair 모델에 bidirectional attention을 추가하여 쌍을 이룬 이미지들 간의 상호작용을 학습.
| Stage I Stage II | ||||
|---|---|---|---|---|
| N | N | 72.44 | 73.71 | 53.52 |
| N | Y | 73.52 | 75.34 | 55.6 |
| Y | N | 72.83 | 75.25 | 54.94 |
| Y | Y |
Table 4: VCR에 대한 2단계 사전학습 실험. 결과는 VCR val split에 대한 UNITER-base 모델의 성능이다. Stage I과 Stage II는 각각 1단계 및 2단계 사전학습을 나타낸다.
| Setting | dev | test-P |
|---|---|---|
| Triplet | 73.03 | 73.89 |
| Pair | 75.85 | 75.80 |
| Pair-biattn |
Table 5: NLVR 에 대한 세 가지 수정된 설정 실험. 모든 모델은 사전학습된 UNITER-base를 사용한다.
비교 결과는 Table 5에 제시되어 있다. Pair 설정은 이미지 쌍 간의 cross-attention이 없음에도 불구하고 Triplet 설정보다 더 나은 성능을 달성한다. 우리는 이것이 우리의 UNITER가 이미지-텍스트 쌍으로 사전학습되었기 때문이라고 가정한다. 따라서 쌍 기반으로 사전학습된 모델을 Triplet 입력에 fine-tuning하는 것은 어렵다. 그러나 Pair-biattn 설정의 bidirectional attention 메커니즘은 이미지 간 cross-attention의 부족을 보완하여 큰 차이로 최고의 성능을 보인다. 이는 UNITER의 최상위 레이어에 최소한의 수정만으로도, 우리의 사전학습 모델이 사전학습 task와 매우 다른 새로운 task에 적응할 수 있음을 보여준다.
4.4 Visualization
[20]과 유사하게, 우리는 Fig. 2에서 보여지는 것처럼 UNITER 모델의 attention map에서 여러 가지 패턴을 관찰하였다. [20]과는 다르게, 우리의 attention mechanism은 inter-modality와 intra-modality 양쪽 모두에서 작동한다는 점에 주목해야 한다. 완전성을 위해, 각 패턴에 대해 간단히 설명하면 다음과 같다: • Vertical: special token인 [CLS] 또는 [SEP]에 대한 attention • Diagonal: 해당 token/region 자체 또는 앞뒤의 token/region에 대한 attention • Vertical + Diagonal: vertical과 diagonal의 혼합 형태 • Block: intra-modality attention, 즉 text 내부 또는 image 내부의 self-attention • Heterogeneous: 특정한 분류가 어려운 다양한 attention으로, 입력에 따라 크게 달라짐 • Reversed Block: inter-modality attention, 즉 text-to-image 또는 image-to-text attention
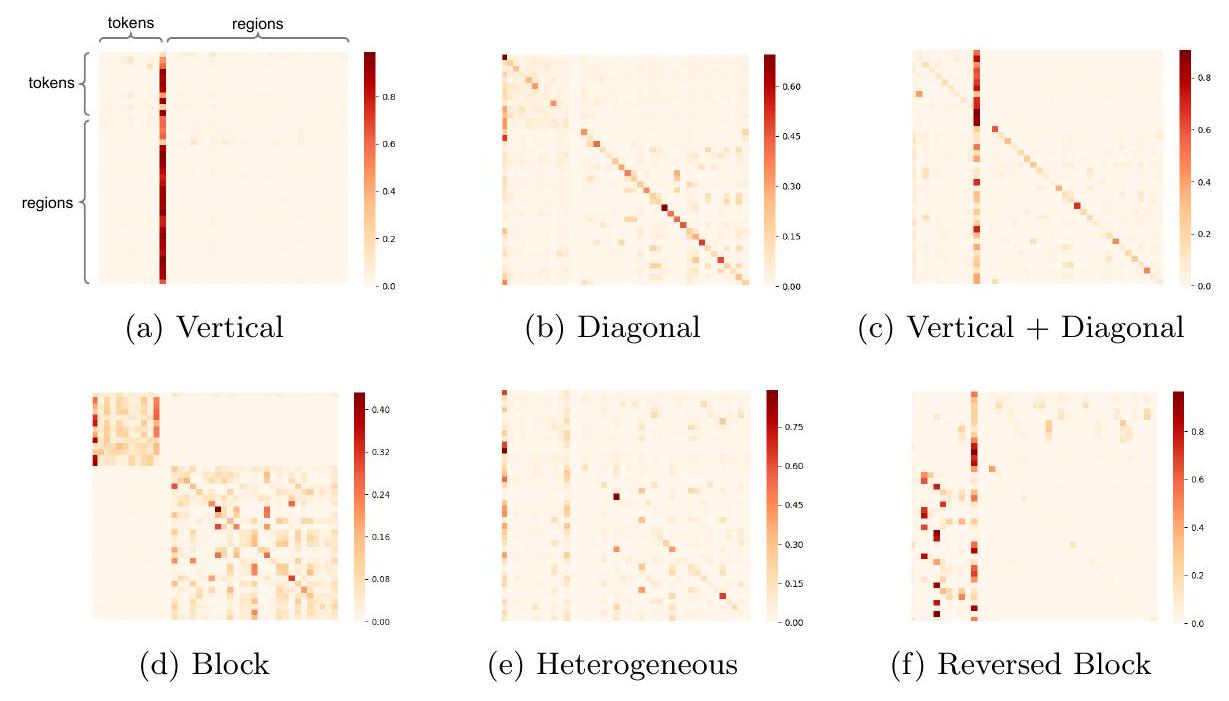
Fig. 2: UNITER-base 모델이 학습한 attention map 시각화

Fig. 3: text-to-image attention 시각화 예시
Reversed Block (Fig. 2f)은 token과 region 사이의 cross-modality alignment를 보여준다. Fig. 3에서는 region과 token 사이의 local cross-modality alignment를 보여주기 위해 여러 text-to-image attention 예시를 시각화하였다.
5 Conclusion
본 논문에서는 Vision-and-Language (V+L) task를 위한 UNiversal Image-TExt Representations를 제공하는 대규모 사전학습 모델인 UNITER를 소개한다. 네 가지 주요 사전학습 task가 제안되었으며, 광범위한 ablation study를 통해 평가되었다. in-domain 및 out-of-domain 데이터셋으로 학습된 UNITER는 여러 V+L task에서 state-of-the-art 모델들을 상당한 차이로 능가하는 성능을 보인다. 향후 연구에는 raw image pixel과 sentence token 간의 초기 상호작용을 연구하고, 더 효과적인 사전학습 task를 개발하는 것이 포함된다.
A Appendix
이 보충 자료는 총 8개의 섹션으로 구성되어 있다.
- Section A.1에서는 데이터셋 수집에 대한 세부 사항을 설명한다.
- Section A.2에서는 각 다운스트림 task에 대한 구현 세부 사항을 설명한다.
- Section A.3에서는 conditional masking과 joint random masking 간의 상세한 정량적 비교를 제공한다.
- Section A.5에서는 VCR 및 NLVR에 대한 추가 결과를 제공한다.
- Section A.6에서는 VLBERT 및 ViLBERT와의 직접적인 비교를 제공한다.
- Section A.7에서는 최적 수송(Optimal Transport, OT) 및 OT 거리를 계산하는 데 사용되는 IPOT 알고리즘에 대한 배경 지식을 제공한다.
- Section A.8에서는 추가적인 시각화 예시를 제공한다.
A. 1 Dataset Collection
서론에서 언급했듯이, 우리의 전체 데이터셋은 COCO, Visual Genome, Conceptual Captions, SBU Captions의 네 가지 기존 V+L 데이터셋으로 구성된다. 데이터셋 수집은 단순히 이들을 결합하는 것이 아니라, 사전학습(pre-training) 중에 어떠한 다운스트림 평가 이미지도 노출되지 않도록 해야 한다. 이 중 COCO는 여러 다운스트림 task가 이를 기반으로 구축되어 있어 정제하기 가장 까다로운 데이터셋이다. Figure 4는 VQA, Image-Text Retrieval, COCO Captioning, RefCOCO/RefCOCO+/RefCOCOg, 그리고 bottom-up top-down (BUTD) detection [2] 등 COCO 이미지를 기반으로 하는 다양한 task의 데이터 분할(split)을 보여준다.
관찰된 바와 같이, 서로 다른 task의 validation 및 test split은 원본 COCO split에 흩어져 있다. 따라서 우리는 다운스트림 task에 나타나는 모든 평가 이미지를 제외한다. 또한, URL 매칭을 통해 Flickr30K 이미지도 모두 제외하여, Flickr에서의 zero-shot image-text retrieval 평가가 공정하게 이루어지도록 한다. 남은 이미지들은 Figure 4 하단 행에 표시된 대로 전체 데이터셋 내의 COCO 서브셋이 된다. 우리는 Visual Genome, Conceptual Captions, SBU Captions에도 동일한 규칙을 적용한다.
| MS COCO (raw) | train | val | test | |||
|---|---|---|---|---|---|---|
| VQA | train | train / val | test | |||
| Img-Txt Retrieval | train | train | val | test | ||
| Img Captioning | train | train | val | test | test | |
| RefCOCO(+/g) | val | train | ||||
| BUTD | train | train | val | test | ||
| UNITER | train | train | val |
Fig. 4: COCO 이미지를 기반으로 하는 다운스트림 task의 다양한 데이터 분할. 우리의 UNITER 사전학습은 어떠한 다운스트림 평가 이미지도 보지 않도록 한다.
| Task | Datasets | Image Src. | #Images #Text Metric | ||
|---|---|---|---|---|---|
| 1 VQA | VQA | COCO | 204 K | 1.1 M | VQA-score |
| 2 VCR | VCR | Movie Clips | 110 K | 290 K | Accuracy |
| 3 NLVR | NLVR | Web Crawled | 214 K | 107 K | Accuracy |
| 4 Visual Entailment | SNLI-VE | Flickr30K | 31 K | 507 K | Accuracy |
| 5 Image-Text Retrieval | COCO | COCO | 92 K | 460 K | Recall@1,5,10 |
| Flickr30K | Flickr30K | 32 K | 160 K | ||
| 6 RE Comprehension | RefCOCO | 20 K | 142 K | ||
| RefCOCO+ COCO | 20 K | 142 K | Accuracy | ||
| RefCOCOg | 26 K | 95 K |
Table 6: 다운스트림 task 데이터셋 통계
A. 2 Implementation Details
우리 모델은 PyTorch [34]를 기반으로 구현되었다. 학습 속도 향상을 위해 mixed precision training을 위해 Nvidia Apex를 사용한다. 모든 사전학습(pre-training) 실험은 Nvidia V100 GPU (16GB VRAM; PCIe connection)에서 실행된다. Fine-tuning 실험은 동일한 하드웨어 또는 Titan RTX GPU (24GB VRAM)에서 구현된다. 학습 속도를 더욱 높이기 위해, padding을 줄이고 입력 단위(텍스트 토큰 + 이미지 영역) 수에 따라 batch 예시를 처리하는 동적 시퀀스 길이를 구현한다. 대규모 사전학습 실험의 경우, 최대 4개의 V100 서버 노드(이더넷을 통한 TCP 연결)를 사용하여 multi-node 통신을 위해 Horovod + NCCL을 사용한다. multi-GPU 통신 오버헤드를 줄이기 위해 Gradient accumulation [33]도 적용된다.
Visual Question Answering (VQA)
우리는 [57]을 따라 가장 빈번한 3129개의 답변을 답변 후보로 사용하고, 10개의 사람 응답과의 관련성을 기반으로 각 후보에 soft target score를 할당한다. VQA 데이터셋에 fine-tuning하기 위해, 우리는 binary cross-entropy loss를 사용하여 최대 5K step 동안 10240 입력 단위의 batch size로 multi-label classifier를 학습시킨다. AdamW optimizer [28]를 사용하며, learning rate는 , weight decay는 0.01이다. 추론 시에는 최대 확률 답변이 예측 답변으로 선택된다. test-dev 및 test-std split 결과의 경우, 학습 및 검증 세트 모두 학습에 사용되며, [57]에서와 같이 Visual Genome의 추가 질문-답변 쌍이 데이터 증강에 사용된다.
Visual Commonsense Reasoning (VCR)
VCR은 두 가지 다중 선택 하위 task로 분해될 수 있다: 질문-답변 task (Q→A) 및 답변-정당화 task (QA→R). 전체적인 설정 (Q→AR)에서 모델은 먼저 답변 선택지에서 답변을 선택한 다음, 선택한 답변이 올바른 경우 정당화 선택지에서 supporting rationale을 선택해야 한다. 우리는 두 가지 설정에서 모델을 동시에 학습시킨다. 전체적인 설정에서 테스트할 때, 우리는 먼저 모델을 적용하여 답변을 예측한 다음, 주어진 질문과 예측된 답변을 기반으로 동일한 모델에서 rationale을 얻는다. VCR 데이터셋에 fine-tuning하기 위해, 우리는 질문(질문과 ground truth 답변)과 네 가지 가능한 답변(rationale) 후보 각각에서 답변(rationale) 선택지를 연결한다. 'modality embedding'은 질문, 답변 및 rationale을 구별하는 데 도움이 되도록 확장된다. cross-entropy loss는 최대 5K step 동안 4096 입력 단위의 batch size로 각 질문-답변 쌍(질문-답변-rationale triplet)에 대해 두 클래스('right' 또는 'wrong')를 분류하는 classifier를 학습시키는 데 사용된다. AdamW optimizer를 사용하며, learning rate는 , weight decay는 0.01이다.
VCR 데이터셋의 이미지와 텍스트는 우리의 사전학습 데이터셋과 매우 다르기 때문에, 우리는 MLM, MRFR 및 MRC-kl을 사전학습 task로 사용하여 VCR에서 모델을 추가로 사전학습한다. VCR의 텍스트가 이미지를 명시적으로 설명하지 않기 때문에 ITM은 제외된다. VCR에 대한 두 가지 사전학습 결과는 Table 4 (본 논문)에 보고되어 있으며 본문에서 논의된다. 결론적으로, 사전학습 데이터셋과 매우 다른 새로운 데이터를 포함하는 다운스트림 task의 경우, 2단계 사전학습은 성능을 더욱 향상시키는 데 도움이 된다.
우리의 구현에서 2단계 사전학습은 최대 60K step 동안 4096 입력 단위의 batch size, 의 learning rate, 0.01의 weight decay로 구현된다. 2단계 사전학습 후, 우리는 최대 8K step 동안 의 learning rate로 모델을 fine-tuning한다.
Natural Language for Visual Reasoning for Real (NLVR2)
NLVR2는 시각적 추론을 위한 새롭고 도전적인 task이다. 목표는 자연어 문장이 주어진 이미지 쌍에 대해 참인지 여부를 결정하는 것이다. 여기서는 NLVR2 fine-tuning의 세 가지 아키텍처 변형에 대해 자세히 논의한다. UNITER는 사전학습 시 하나의 이미지와 하나의 텍스트 입력만 처리하므로, NLVR2 task에 제시된 추가 이미지를 구별하는 데 도움이 되도록 'modality embedding'이 확장된다. Triplet 설정의 경우, 이미지 영역을 연결한 다음 UNITER 모델에 입력한다. 이진 분류를 위해 [CLS] 출력에 MLP transform이 적용된다. Pair 설정의 경우, 텍스트를 반복하여 하나의 입력 예시를 두 개의 텍스트-이미지 쌍으로 처리한다. UNITER의 두 [CLS] 출력은 예시에 대한 joint embedding으로 깊이 연결된다. 또 다른 MLP는 최종 분류를 위해 이 embedding을 추가로 변환한다. Pairbiattn 설정의 경우, 입력 형식은 Pair 설정과 동일하다. joint representation의 경우, 두 개의 [CLS] 출력에만 의존하는 대신, 우리는 하나의 joint image-text embedding 시퀀스에 multi-head attention layer [49]를 적용하여 다른 embedding 시퀀스에 attend하고, 그 반대도 마찬가지이다. 이러한 '양방향' attention 상호 작용 후, 각 출력 시퀀스에 간단한 attentional pooling이 적용된 다음, 최종 concat+MLP layer가 cross-attended joint representation을 참/거짓 분류를 위해 변환한다.
우리는 NLVR2에서 UNITER를 10K 입력 단위의 batch size로 8K step 동안 fine-tuning한다. AdamW optimizer는 의 learning rate와 0.01의 weight decay로 사용된다.
Image-Text Retrieval
이 task를 위해 COCO와 Flickr30K 두 가지 데이터셋이 고려된다. COCO는 123K개의 이미지로 구성되며, 각 이미지에는 5개의 사람이 작성한 캡션이 함께 제공된다. 우리는 [17]을 따라 데이터를 82K/5K/5K 학습/검증/테스트 이미지로 분할한다. [23]에서와 같이 학습 개선을 위해 MSCOCO 검증 세트의 추가 30K 이미지도 포함된다. Flickr30K 데이터셋은 Flickr 웹사이트에서 수집된 31K개의 이미지와 이미지당 5개의 텍스트 설명으로 구성된다. 우리는 [17]을 따라 데이터를 30K/1K/1K 학습/검증/테스트 분할로 나눈다. fine-tuning 동안, 우리는 이미지 및 텍스트 측면에서 각각 긍정 샘플당 두 개의 부정 이미지-텍스트 쌍을 샘플링한다. COCO의 경우, 60개의 예시 batch size, 의 learning rate를 사용하고 모델을 20K step 동안 fine-tuning한다. Flickr30K의 경우, 120개의 예시 batch size와 의 learning rate로 모델을 최대 16K step 동안 fine-tuning한다.
본문의 Table 3에서 최종 결과를 얻기 위해, 우리는 fine-tuning을 용이하게 하기 위해 hard negative를 추가로 샘플링한다. 매 N step마다, 우리는 텍스트 입력당 128개의 negative 이미지를 무작위로 샘플링하고 전체 학습 세트에 대한 sparse scoring matrix를 얻는다. 각 이미지에 대해, 우리는 상위 20개의 negative 문장을 hard negative 샘플로 선택한다. 유사하게, 우리는 점수에 따라 각 문장에 대해 20개의 hard negative 이미지를 얻는다. hard negative는 추가 negative 샘플로 모델에 전송된다. 결국, 우리는 긍정 샘플당 두 개의 무작위 샘플링된 negative와 두 개의 hard negative 샘플을 갖는다. N은 COCO의 경우 4000, Flickr30K의 경우 2500으로 설정된다.
Visual Entailment (SNLI-VE)
Visual Entailment는 Flickr30K 이미지와 Stanford Natural Language Inference (SNLI) 데이터셋에서 파생된 task로, 자연어 문장과 이미지 간의 논리적 관계를 결정하는 것이 목표이다. Natural Language Inference (NLI)를 위한 BERT와 유사하게, 우리는 SNLI-VE를 3방향 분류 문제로 처리하고 [CLS] 출력에 MLP Transform을 적용한다. UNITER 모델은 cross-entropy loss를 사용하여 fine-tuning된다. batch size는 10K 입력 단위로 설정되며, 의 learning rate로 AdamW를 사용하여 3K step 동안 학습한다.
Referring Expression Comprehension
우리는 평가를 위해 RefCOCO, RefCOCO+, RefCOCOg 세 가지 referring expression 데이터셋을 사용하며, 모두 COCO 이미지에서 수집되었다. 이 task에서 UNITER를 fine-tuning하기 위해, Transformer의 region 출력 위에 MLP layer를 추가하여 쿼리 구/문장과 각 region 간의 alignment score를 계산한다. 쿼리 구/문장과 하나의 객체만 쌍을 이루므로, 정규화된 alignment score에 cross-entropy loss를 적용한다. fine-tuning은 효율적이다. 우리는 64개의 예시 batch size와 의 learning rate로 모델을 단 5 epoch 동안 학습시키고 state-of-the-art 성능을 달성한다.
우리를 포함한 모든 연구는 시각적 feature를 추출하기 위해 COCO (및 Visual Genome)에서 학습된 off-the-shelf object detector를 사용한다. 이는 다른 다운스트림 task에는 영향을 미치지 않지만, RefCOCO, RefCOCO+, RefCOCOg의 val/test 이미지가 COCO의 학습 split의 하위 집합이므로 RE comprehension에 문제를 제기한다. 엄밀히 말하면, 우리의 object detector는 이러한 val/test 이미지로 학습할 수 없다. 그러나 동시 연구들과의 "공정한" 비교를 위해, 우리는 이 문제를 무시하고 다른 연구들과 동일한 feature [2]를 사용한다. 우리는 또한 이 "오염된" feature를 사용하여 MAttNet의 결과를 업데이트했으며, 그 정확도는 원래보다 1.5% 더 높다. 앞서 언급했듯이, 문장과 이미지 간의 상호 작용은 추출된 feature 대신 토큰과 픽셀에서 시작될 수 있다. 우리는 이 연구와 엄격하게 올바른 feature를 사용한 RE comprehension을 향후 연구로 남겨둔다.
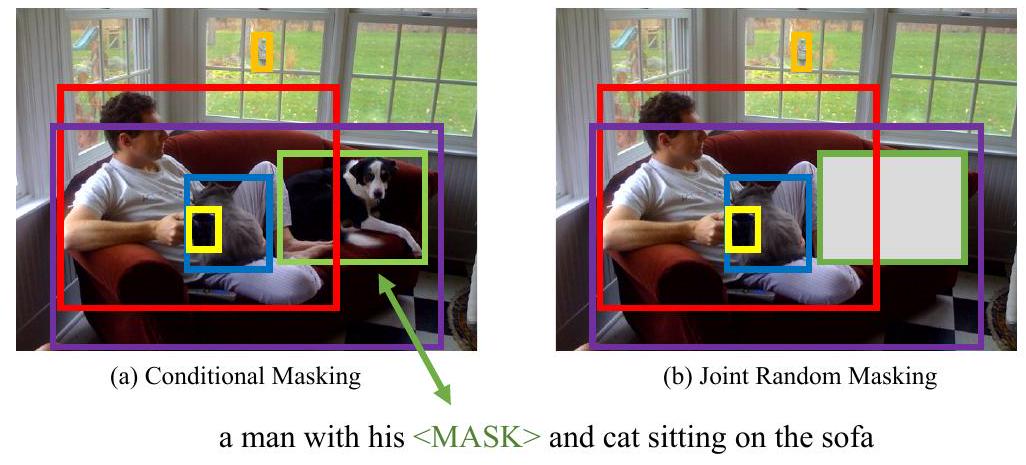
Fig. 5: 조건부 마스킹과 joint random 마스킹 간의 차이를 보여주는 예시
A. 3 Conditional Masking vs. Joint Random Masking
우리는 [47, 29]에서 사용된 joint random masking 방식에 비해 우리가 제안하는 conditional masking의 장점을 추가로 논의한다. 직관적으로, 우리의 conditional masking은 두 가지 양식(modality)에 걸쳐 개체(영역 및 단어)의 잠재적 정렬(latent alignment)을 더 잘 학습한다. Figure 5는 "man with his dog and cat sitting on a sofa"라는 문장과 함께 제시된 이미지 예시를 보여준다. conditional masking을 사용하면, 개의 영역이 마스킹되었을 때, 우리 모델은 주변 영역과 전체 문맥(full sentence)을 기반으로 해당 영역이 개임을 추론할 수 있어야 하며 (Figure 5(a)), 그 반대도 마찬가지이다. 그러나 joint masking 구현에서는 개의 영역과 "dog"라는 단어가 동시에 마스킹될 수 있다 (Figure 5(b)). 이러한 경우, 모델은 맹목적으로 예측해야 하므로 잘못된 정렬(mis-alignment)로 이어질 수 있다.
이러한 직관을 검증하기 위해, Figure 6에서 사전학습 중 MLM 및 MRC-kl의 validation curve를 보여준다. 각 하위 그림은 UNITER의 사전학습 중 conditional masking과 joint random masking을 적용했을 때의 비교를 나타낸다. MLM accuracy는 UNITER가 마스킹된 단어를 얼마나 잘 재구성하는지를 측정하며, MRC-kl accuracy는 UNITER가 마스킹된 영역을 얼마나 잘 분류하는지를 측정한다. Figure 6에서 볼 수 있듯이, 두 경우 모두 우리의 conditional masking이 joint random masking보다 더 빠르게 수렴하고 더 높은 최종 정확도를 달성한다. 또한, 본 논문의 Table 2 (10행 및 11행)는 우리의 conditional masking이 fine-tuned downstream task에서도 더 나은 성능을 보임을 보여준다.
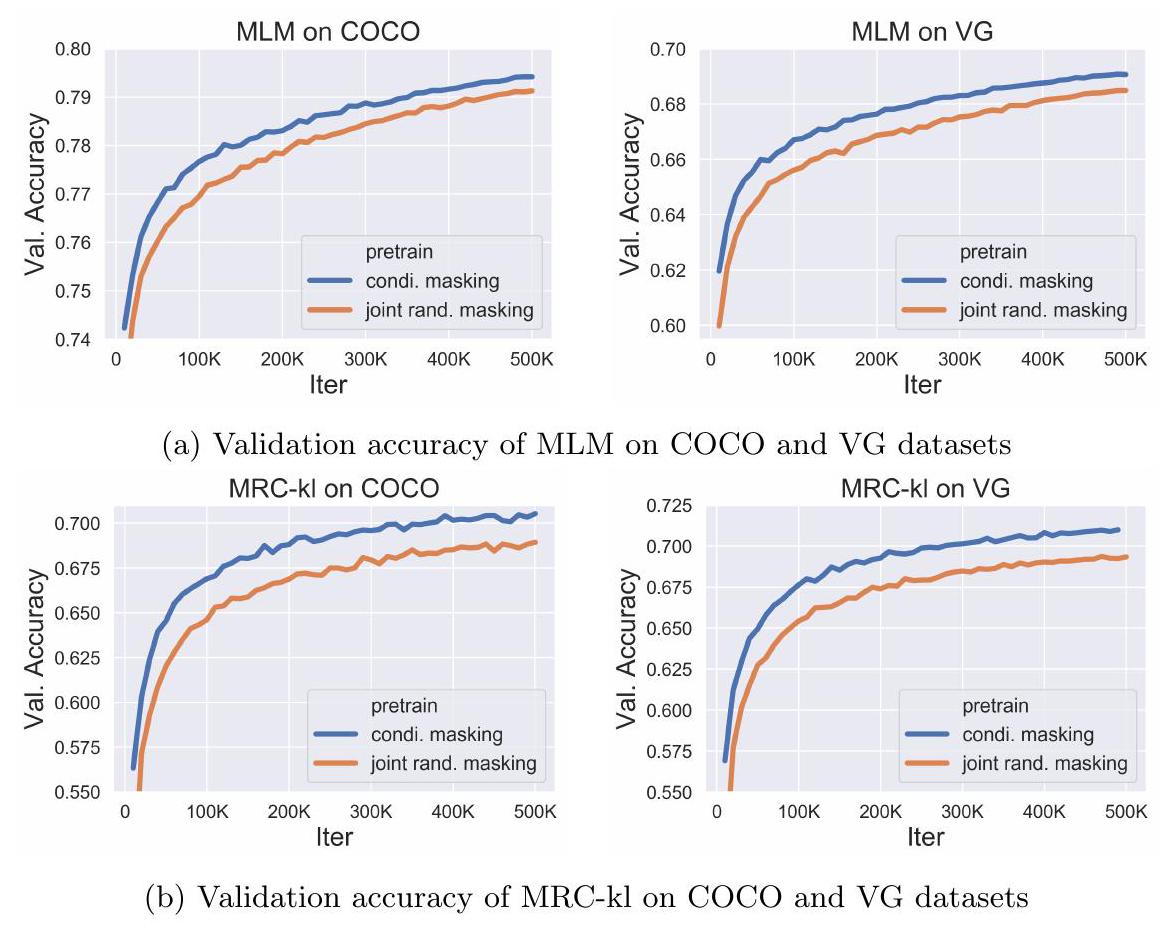
Fig. 6: joint masking과 우리가 제안하는 conditional masking을 사용한 MLM 및 MRC-kl validation accuracy 비교.
A. 4 More Ablation Studies on Pre-training Settings
MRC-only Pre-training
본 논문의 Table 2에 제시된 ablation 외에도, 우리는 in-domain 데이터에 대해 MRC만으로 사전학습된 UNITER-base의 결과를 추가로 포함한다. Table 7은 MRC-only 사전학습이 MRFR-only 사전학습과 유사한 다운스트림 성능을 보임을 나타낸다. 이는 in-domain 데이터를 사용한 다른 모든 사전학습 설정(Table 2의 4-12행)과 비교했을 때 약한 baseline이다.
WRA의 중요성
본 논문의 Table 2에서 우리는 WRA를 추가하는 것이 VQA 및 RefCOCO+에서 모델 성능을 크게 향상시키는 반면, Flickr 및 NLVR2에서는 비슷한 결과를 얻음을 보여준다. 설계상 WRA는 각 이미지 영역과 문장의 각 단어 간의 지역적 정렬(local alignment)을 촉진한다. 따라서 WRA는 VQA와 같이 영역 수준의 인식 및 추론에 의존하는 다운스트림 task에 주로 이점을 제공하는 반면, Flickr 및 NLVR2는 지역적 정렬보다는 전역적 정렬(global alignment)에 더 중점을 둔다. 우리는 Table 8에서 In-domain 및 Out-of-domain 데이터를 모두 사용하여 사전학습된 UNITER-large의 WRA에 대한 추가 ablation 결과를 제시한다. 우리는 이미지/텍스트 검색의 zero-shot 설정에서 큰 성능 향상을 관찰했으며, 다른 모든 task에서도 일관된 성능 향상을 확인했다.
| Pre-training Data Pre-training Tasks Meta-Sum | VQA | IR (Flickr) | TR (Flickr) | NLVR | Ref | ||
|---|---|---|---|---|---|---|---|
| test-dev | val | val | dev | val | |||
| In-domain ( ) | MRC | 350.97 | 66.23 | 77.17 | 84.57 | 52.31 | 70.69 |
Table 7: In-domain 데이터를 사용한 UNITER-base의 MRC-only 사전학습에 대한 추가 ablation 결과.
| WRA pre-train | VQA | NLVR | SNLI-VE | ZS IR (flickr) | ZS TR (flickr) | RefCOCO | Ref | RefCOCOg |
|---|---|---|---|---|---|---|---|---|
| test-std | test | test | val | val | testB | testB | test | |
| N | 73.40 | 79.50 | 78.98 | 65.82 | 77.50 | 74.17 | 78.89 | 87.73 |
| Y | 74.02 | 79.98 | 79.38 | 68.74 | 83.60 | 74.98 | 79.75 | 88.47 |
Table 8: UNITER-large를 사용한 WRA 사전학습 task에 대한 직접적인 ablation 결과. 모든 모델은 In-domain + Out-of-domain 데이터로 MLM + ITM + MRC-kl + MRFR (+ WRA)를 사용하여 사전학습되었다. 단순화를 위해 ZS IR 및 ZS TR에 대해서는 R@1만 보고되었다.
| Model | |||
|---|---|---|---|
| VLBERT-large (single) | 75.8 | 78.4 | 59.7 |
| ViLBERT (10 ensemble) | 76.4 | 78.0 | 59.8 |
| UNITER-large (single) | 77.3 | 80.8 | 62.8 |
| UNITER-large (10 ensemble) |
Table 9: VLBERT [42], ViLBERT [29], 및 UNITER의 VCR 결과.
| Model | Balanced Unbalanced Overall Consistency | |||
|---|---|---|---|---|
| VisualBERT | 67.3 | 68.2 | 67.3 | 26.9 |
| LXMERT | 76.6 | 76.5 | 76.2 | 42.1 |
| UNITER-large |
Table 10: VisualBERT [25], LXMERT [47], 및 UNITER의 NLORR2 test-U 분할 결과.
A. 5 More Results on VCR and NLVR2
VCR 세팅(Table 4, main paper 기준)에 따라, 우리는 10개의 UNITER-large 모델을 이용한 ensemble 모델을 추가로 구성하였다. Table 9는 VCR에서의 VLBERT, ViLBERT, UNITER의 성능 비교를 보여준다. 우리의 ensemble 모델은 ViLBERT [29] ensemble보다 무려 7.0% 높은 정확도를 보인다. 특히, 단일 UNITER-large 모델조차도 ViLBERT ensemble 및 VLBERT-large보다 3.0% 더 높은 성능을 기록한다는 점에 주목할 필요가 있다.
또한, 우리는 UNITER-large 모델을 LXMERT [47], VisualBERT [25]와 비교하여 NLVR²의 추가 테스트 세트에서 성능을 측정하였고, 그 결과는 Table 10에 제시되어 있다. 우리의 결과는 모든 평가 지표에서 기존 SOTA를 약 4.0% 차이로 크게 능가한다.
| Model | VQA | RefCOCO+ (det) | ||||
|---|---|---|---|---|---|---|
| test-dev | val | testA | testB | |||
| ViLBERT | 70.55 | 72.34 | 78.52 | 62.61 | ||
| VLBERT-base | 71.16 | 71.60 | 77.72 | 60.99 | ||
| UNITER-base |
Table 11: Conceptual Captions [41] 데이터셋으로만 학습된 ViLBERT [29], VLBERT [42], 그리고 UNITER 간의 직접 비교
A. 6 Direct Comparison to VLBERT and ViLBERT
우리의 아이디어를 추가적으로 입증하기 위해, 우리는 Conceptual Captions [41]으로 학습된 ViLBERT [29] 및 VLBERT [42]와 직접적인 비교를 수행한다. 우리는 제안된 conditional masking과 최적의 사전학습 task만을 사용하여 Conceptual Captions 데이터셋으로 UNITER를 사전학습시켰다. Table 11은 UNITER가 VQA 및 RefCOCO+에서 다른 모델들을 눈에 띄는 차이로 일관되게 능가함을 보여준다.
A. 7 Review of Optimal Transport and the IPOT Algorithm
Optimal Transport
먼저 **Optimal Transport (OT)**에 대해 간략히 설명한다. OT는 domain (본 연구에서는 시퀀스 공간) 상의 확률 측정(probability measure) 간의 거리를 정의한다. 두 확률 측정 와 에 대한 Optimal Transport 거리는 다음과 같이 정의된다 [37]:
여기서 는 주변 분포(marginal distribution)가 와 인 모든 결합 분포(joint distribution) 의 집합을 나타낸다. 는 를 로 이동시키는 데 드는 **비용 함수(cost function)**이며, 예를 들어 유클리드 거리 또는 코사인 거리가 사용될 수 있다. 직관적으로, Optimal Transport 거리는 에서 로 수송하기 위해 가 유도하는 최소 비용이다. 가 상의 metric일 때, 는 상에 support를 가지는 확률 분포 공간에 적절한 metric을 유도하며, 이는 일반적으로 Wasserstein 거리로 알려져 있다. 가장 널리 사용되는 선택 중 하나는 **2-Wasserstein 거리 **이며, 이 경우 제곱 유클리드 거리 가 비용 함수로 사용된다.
IPOT 알고리즘
불행히도, 에 대한 정확한 최소화는 일반적으로 계산적으로 다루기 어렵다(computationally intractable) [4, 14, 40]. 이러한 비효율성을 극복하기 위해, 우리는 OT 거리를 근사하기 위한 효율적인 반복적 접근 방식을 고려한다. 우리는 최근에 소개된 Inexact Proximal point method for Optimal Transport (IPOT) 알고리즘을 사용하여 OT 행렬 를 계산하고, 이를 통해 OT 거리도 계산할 것을 제안한다 [53]. 구체적으로, IPOT는 proximal point method [5]를 사용하여 다음 최적화 문제를 반복적으로 해결한다:
여기서 근접성 metric 항(proximity metric term) 는 최신 근사치로부터 너무 멀리 떨어진 해에 페널티를 부과하며, 는 **일반화된 스텝 사이즈(generalized stepsize)**로 이해된다. 이는 정확한 OT 해를 향한 다루기 쉬운 반복적 스킴을 제공한다. 본 연구에서는 일반화된 KL Bregman divergence 를 근접성 metric으로 사용한다. Algorithm 1은 IPOT의 구현 세부 사항을 설명한다.
Algorithm 1 IPOT algorithm
Input: Feature vectors \(\mathbf{S}=\left\{\mathbf{w}_{i}\right\}_{i=1}^{n}, \mathbf{S}^{\prime}=\left\{\mathbf{v}_{j}\right\}_{j=1}^{m}\) and generalized stepsize \(1 / \beta\),
\(\boldsymbol{\sigma}=\frac{1}{m} \mathbf{1}_{\mathbf{m}}, \mathbf{T}^{(1)}=\mathbf{1}_{\mathbf{n}} \mathbf{1}_{\mathbf{m}}{ }^{\top}\)
\(\mathbf{C}_{i j}=c\left(\mathbf{w}_{i}, \mathbf{v}_{j}\right), \mathbf{A}_{i j}=\mathrm{e}^{-\frac{\mathbf{C}_{i j}}{\beta}}\)
for \(t=1,2,3 \ldots\) do
\(\mathbf{Q}=\mathbf{A} \odot \mathbf{T}^{(t)} / / \odot\) is Hadamard product
for \(k=1, \ldots K\) do \(/ / K=1\) in practice
\(\boldsymbol{\delta}=\frac{1}{n \mathbf{Q} \boldsymbol{\sigma}}, \boldsymbol{\sigma}=\frac{1}{m \mathbf{Q}^{\top} \boldsymbol{\delta}}\)
end for
\(\mathbf{T}^{(t+1)}=\operatorname{diag}(\boldsymbol{\delta}) \mathbf{Q} \operatorname{diag}(\boldsymbol{\sigma})\)
end for
Return \(\langle\mathbf{T}, \mathbf{C}\rangle\)
Sinkhorn 알고리즘 [8] 또한 OT 행렬을 계산하는 데 사용될 수 있다는 점에 유의해야 한다. 구체적으로, Sinkhorn 알고리즘은 엔트로피 정규화된 최적화 문제를 해결하려고 시도한다: , 여기서 는 **엔트로피 정규화 항(entropy regularization term)**이며 는 **정규화 강도(regularization strength)**이다. 그러나 우리의 실험에서, 우리는 Sinkhorn 알고리즘의 수치적 안정성(numerical stability)과 성능이 하이퍼파라미터 의 선택에 매우 민감하다는 것을 경험적으로 발견했으며, 따라서 우리 모델 학습에서는 IPOT만 고려되었다.
A. 8 Additional Visualization

Fig. 7: 추가적인 text-to-image attention 시각화 예시