TriSense: 시각, 청각, 음성 정보를 통합한 멀티모달 LLM 비디오 이해
TriSense는 시각, 오디오, 음성 세 가지 양식을 통합하여 비디오를 종합적으로 이해하는 트리플 모달리티 LLM입니다. 핵심 기술인 Query-Based Connector는 입력 쿼리에 따라 각 양식의 기여도를 동적으로 조절하여, 일부 양식이 누락된 상황에서도 강건한 성능을 보장합니다. 이 모델을 위해 2백만 개 이상의 고품질 샘플로 구성된 TriSense-2M 데이터셋도 함께 소개합니다. 논문 제목: Watch and Listen: Understanding Audio-Visual-Speech Moments with Multimodal LLM
논문 요약: TriSense: 시각, 청각, 음성 정보를 통합한 멀티모달 LLM 비디오 이해
- 논문 링크: https://arxiv.org/abs/2505.18110
- 저자: Zinuo Li 외 (소속은 논문에 명시되지 않음)
- 발표 시기: 2025년 (arXiv)
- 주요 키워드: LLM, NLP, Multimodal, 비디오 이해, 시간적 추론
1. 연구 배경 및 문제 정의
- 문제 정의: 인간은 시각, 청각, 음성 등 다양한 단서를 통합하여 비디오를 이해하지만, 기존 멀티모달 LLM(MLLM)은 오디오 정보 통합 및 누락된 양식에 대한 견고성 측면에서 한계를 보입니다. 특히, 오디오 및 음성 정보의 효과적인 융합과 해석에 어려움을 겪어 포괄적인 비디오 시간적 이해 능력이 부족합니다.
- 기존 접근 방식: 대부분의 기존 MLLM은 시각적 입력에만 의존하거나, 여러 양식을 통합하더라도 정보 손실이 발생하거나(LongVALE), 미세한 시간적 의존성을 포착하지 못하는(Qwen2.5-Omni) 등 적응성이 부족합니다. 또한, 기존 데이터셋은 짧은 클립 위주이며, 시각, 오디오, 음성 세 가지 양식 모두에 걸쳐 대규모의 완전하고 일관성 있는 주석이 부족하여 실제 시나리오의 불완전한 양식 입력에 대한 모델의 견고성을 저해합니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 시각, 오디오, 음성 양식에 걸쳐 이벤트 기반 주석을 포함하며, 유연한 양식 조합과 자연스러운 양식 부재를 특징으로 하는 2백만 개 이상의 고품질 다중 양식 데이터셋인 TriSense-2M을 구축했습니다.
- 입력 쿼리에 따라 각 양식의 기여도를 동적으로 조절하는 Query-Based Connector를 포함하여, 다양한 양식 구성 하에서 비디오 세그먼트 캡셔닝 및 순간 검색을 위해 설계된 삼중 양식 MLLM인 TriSense를 제안했습니다.
- 두 가지 핵심 작업(비디오 세그먼트 캡셔닝, 순간 검색)에 대해 8가지 양식 구성에 걸쳐 광범위한 실험을 수행하여 TriSense의 효과와 다중 양식 비디오 분석 발전 가능성을 입증했습니다.
- 제안 방법:
TriSense는 시각, 오디오, 음성 정보를 처리하기 위해 세 가지 특화된 전문가 인코더(CLIP, BEATs, Whisper)를 사용합니다. 핵심은 Query-Based Connector로, 각 양식의 특징을 인코딩된 쿼리 표현과 Cross-Attention을 통해 통합하고, 쿼리 내용에 따라 각 양식의 중요도를 동적으로 결정하는 적응형 가중치 메커니즘을 적용합니다. 이를 통해 모델은 가장 유익한 양식을 강조하고 관련 없거나 누락된 양식의 가중치를 낮출 수 있어, 불완전한 양식 조건에서도 강력한 성능을 발휘합니다. 또한, 인과적 이벤트 예측과 특수
<sync>토큰을 통한 적응형 헤드 전환을 도입하여 시간적 추론 능력과 비디오 서사 정렬을 향상시킵니다. 훈련은 특징 정렬, 커넥터 일반화, 지시 튜닝의 3단계로 진행됩니다.
3. 실험 결과
- 데이터셋: 새롭게 구축된 TriSense-2M 데이터셋 (평균 비디오 길이 905초, 2백만 개 샘플)을 주로 사용했으며, Charades-STA, ActivityNet-Captions, LongVALE, VideoMME 등 공개 벤치마크에서도 제로샷 평가를 수행했습니다. 평가 작업은 세그먼트 캡셔닝(SC)과 순간 검색(MR)이며, AVS(오디오-시각-음성), VS(시각-음성), AV(오디오-시각), V(시각 전용)의 네 가지 양식 조합에서 평가되었습니다.
- 주요 결과:
- TriSense-2M 데이터셋에서 기존 비디오 LLM 및 최신 옴니모달 모델(LongVALE, Qwen2.5-Omni)을 세그먼트 캡셔닝 및 순간 검색 작업에서 일관되게 능가했습니다.
- 공개 벤치마크(Charades-STA, ActivityNet-Captions)의 제로샷 순간 검색에서도 경쟁력 있는 성능을 보였으며, 특히 적은 프레임 수에도 불구하고 높은 IoU 임계값에서 우수한 정확도를 달성했습니다.
- 절제 연구를 통해 Query-Based Connector의 적응형 가중치 메커니즘과 3단계 훈련 전략이 모델 성능에 결정적인 기여를 함을 확인했습니다. 특히, 양식을 단순히 더하거나 고정 가중치를 사용하는 것보다 동적 가중치가 더 우수했습니다.
- 입력 프레임 수를 늘리면 성능이 향상되는 경향을 보였으며, 이는 특히 순간 검색 작업에서 두드러졌습니다.
- 일반 비디오 이해 벤치마크(VideoMME)에서도 적은 훈련 데이터에도 불구하고 경쟁력 있는 성능을 보여, 모델의 일반화 능력을 입증했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 시각, 오디오, 음성 세 가지 양식을 통합하여 비디오를 종합적으로 이해하려는 시도와 이를 위한 TriSense-2M이라는 대규모 고품질 데이터셋 구축이 인상 깊습니다.
- 특히 Query-Based Connector를 통해 입력 쿼리에 따라 각 양식의 기여도를 동적으로 조절하고, 일부 양식이 누락된 상황에서도 강건한 성능을 보장하는 점이 실제 환경 적용에 매우 중요하다고 생각합니다.
- 장편 비디오에 대한 이해 능력을 강화하고, 세그먼트 캡셔닝과 순간 검색이라는 핵심 시간적 이해 작업을 동시에 다루는 점도 큰 장점입니다.
- 단점/한계:
- 시각 전용 시나리오에서는 최첨단 시각 전용 모델에 비해 약간 낮은 성능을 보이는 경향이 있어, 특정 단일 양식에 대한 최적화는 추가 연구가 필요할 수 있습니다.
- 모델이 사용하는 프레임 수가 제한적(64프레임)이라는 점이 장편 비디오의 미세한 시간적 이해에 여전히 한계로 작용할 수 있습니다. 더 많은 프레임을 처리할 수 있도록 효율성을 높이는 연구가 필요해 보입니다.
- 데이터셋 구축에 LLM(Generator, Judger)을 활용했지만, 이 LLM들의 편향이나 한계가 데이터셋 품질에 영향을 미칠 가능성도 고려해야 합니다.
- 응용 가능성:
- 비디오 콘텐츠 분석 및 요약: 긴 비디오에서 특정 이벤트나 순간을 정확하게 찾아내고 설명하는 데 활용될 수 있습니다 (예: 뉴스 영상 분석, 강의 요약).
- 스마트 감시 시스템: 이상 행동 감지 시 시각, 청각, 음성 단서를 종합적으로 분석하여 더 정확한 상황 인식을 제공할 수 있습니다.
- 멀티미디어 검색 및 추천: 사용자의 복합적인 쿼리(예: '음악이 흐르고 사람이 춤추는 장면')에 맞춰 비디오를 검색하고 추천하는 데 사용될 수 있습니다.
- 접근성 향상: 청각 장애인을 위한 비디오 설명 생성, 시각 장애인을 위한 오디오 기반 비디오 탐색 등 접근성 기술에 기여할 수 있습니다.
Li, Zinuo, et al. "Watch and Listen: Understanding Audio-Visual-Speech Moments with Multimodal LLM." arXiv preprint arXiv:2505.18110 (2025).
Watch and Listen: Understanding Audio-Visual-Speech Moments with Multimodal LLM

Figure 1: TriSense는 오디오, 시각, 음성 양식뿐만 아니라 이들의 모든 조합으로부터 비디오의 세그먼트 캡셔닝과 순간 검색을 지원하여 총 8개의 다른 작업을 다룹니다.
Abstract
인간은 시각적 및 청각적 단서를 통합하여 비디오 속의 순간들을 자연스럽게 이해합니다. 예를 들어, "과학자가 야생 동물 보존에 대해 열정적으로 연설하고 극적인 오케스트라 음악이 연주되며, 청중은 고개를 끄덕이고 박수를 친다"와 같은 장면을 비디오에서 찾아내려면 시각, 오디오, 음성 신호를 동시에 처리해야 합니다. 그러나 기존 모델들은 오디오 정보를 효과적으로 융합하고 해석하는 데 어려움을 겪는 경우가 많아, 포괄적인 비디오 시간적 이해 능력에 한계가 있습니다. 이를 해결하기 위해, 우리는 시각, 오디오, 음성 양식을 통합하여 전체적인 비디오 시간적 이해를 위해 설계된 삼중 양식 대규모 언어 모델인 TriSense를 제시합니다. TriSense의 핵심은 입력 쿼리에 따라 양식 기여도를 적응적으로 재조정하는 Query-Based Connector로, 양식 누락 시에도 견고한 성능을 보장하고 사용 가능한 입력의 유연한 조합을 가능하게 합니다. TriSense의 다중 양식 능력을 지원하기 위해, 우리는 미세 조정된 LLM으로 구동되는 자동화된 파이프라인을 통해 생성된 2백만 개 이상의 고품질 큐레이션 샘플로 구성된 데이터셋인 TriSense-2M을 소개합니다. TriSense-2M은 장편 비디오와 다양한 양식 조합을 포함하여 광범위한 일반화를 촉진합니다. 여러 벤치마크에 걸친 광범위한 실험은 TriSense의 효과와 다중 양식 비디오 분석을 발전시킬 잠재력을 보여줍니다. 코드와 데이터셋은 공개될 예정입니다.
1 Introduction
실세계 사건에 대한 인간의 이해는 본질적으로 다중 양식적입니다: 우리는 비디오에서 무슨 일이 일어나고 있는지 이해하기 위해 시각뿐만 아니라 음성 언어와 오디오 단서에도 의존합니다. 이 통합을 통해 우리는 의도, 감정, 그리고 사건의 중요성을 해석할 수 있으며, 이는 보이는 것을 넘어 들리고 말하는 것까지 포함합니다. 그러나 기존의 다중 양식 대규모 언어 모델(MLLM)은 이러한 미묘한 수준의 비디오 시간적 이해를 달성하는 데 종종 미치지 못합니다. 비전-언어 모델링과 시간적 지역화의 발전이 언어-시각적 정렬을 개선했지만 , 대부분의 모델은 여전히 시각적 입력에만 의존합니다. 결과적으로, 이들은 오디오와 음성의 통합이 필요한 작업, 특히 하나 이상의 양식이 누락되거나, 잡음이 많거나, 문맥적으로 관련이 없을 때 성능이 저조합니다. 이는 인간의 지각적 견고성과 대조되며, 사건을 정확하게 지역화하거나 풍부한 다중 양식 설명을 생성하는 것과 같은 실제 시나리오에서 모델 일반화를 크게 제한합니다. 도전 과제와 현재 한계. 위에서 강조했듯이, 다중 양식 시간적 이해의 현재 상태는 여전히 제한적입니다. 이러한 관찰을 바탕으로, 다중 양식 시간적 이해의 진전을 계속해서 방해하는 두 가지 핵심 도전 과제가 있습니다: 1) 불충분하고 불완전한 훈련 데이터: 현재 데이터셋은 종종 짧은 클립으로 구성되어 있으며, 효과적인 다중 양식 사전 훈련에 필수적인 시각, 오디오, 음성 세 가지 양식 모두에 걸쳐 대규모의 완전한 주석이 달린 예제가 부족합니다 . 이러한 부족함은 견고한 MLLM의 개발을 저해합니다. 더욱이, 실제 비디오는 다양한 녹화 설정, 의도적인 누락(예: 무성 영상 또는 배경 음악), 또는 특정 장면에서 특정 신호의 자연스러운 부재와 같은 요인으로 인해 불완전하거나 일관성 없는 양식 범위를 포함하는 경우가 많습니다. 모델이 모든 양식이 존재하는 비디오에서 주로 훈련될 때, 실제 상황에서 흔히 발생하는 누락되거나 저하된 입력에 직면하면 추론 시에 실패하는 경우가 많습니다. 2) 양식 적응의 부족: 현재 MLLM은 일반적으로 작업 또는 쿼리 컨텍스트에 따라 각 양식의 상대적 중요성을 평가할 수 있도록 갖추어져 있지 않습니다. LongVALE [10] 및 Qwen2.5-Omni [34]와 같은 최근 모델들은 여러 양식을 통합하려고 시도하지만 적응성 면에서 부족합니다. 예를 들어, LongVALE은 모든 양식 토큰을 단일 표현으로 압축하여 정보 손실과 누락된 양식의 부실한 처리를 초래합니다. 또한 적응형 드롭아웃 전략이 부족하여 양식 가용성이 변할 때 성능이 불안정합니다. Qwen2.5-Omni는 시간적 위치 임베딩을 도입했지만, 여전히 미세한 시간적 의존성을 포착하지 못하여, 우리 실험에서 입증된 바와 같이 복잡한 순간 수준의 작업에서 효과가 제한됩니다. 주요 기여. 우리는 비디오 속 복잡한 순간을 이해하기 위해서는 더 넓은 양식 범위뿐만 아니라 작업과 쿼리에 따라 가장 관련성 있는 양식을 선택적으로 강조하는 적응형 메커니즘이 필요하다고 주장합니다. 우리의 접근 방식은 다음과 같은 주요 기여를 통해 이러한 도전 과제를 해결합니다:
- 우리는 2백만 개의 주석을 포함하는 대규모 다중 양식 데이터셋인 TriSense-2M을 소개합니다. 데이터셋의 각 비디오 인스턴스는 시각, 오디오, 음성 양식에 걸쳐 이벤트 기반 주석을 포함하며, 유연한 조합과 양식의 자연스러운 부재를 특징으로 합니다. 이 데이터셋은 다양한 장면을 지원하며 평균 905초 길이의 장편 비디오를 포함하는데, 이는 기존 데이터셋의 비디오보다 훨씬 길어 더 깊고 현실적인 시간적 이해를 가능하게 합니다. 중요하게도, 쿼리는 고품질의 자연어로 표현되고, 시간적 주석과 정렬되며, 견고한 다중 양식 학습을 촉진하기 위해 다양한 양식 구성을 포괄합니다.
- 우리는 다양한 양식 구성 하에서 비디오 세그먼트 캡셔닝과 순간 검색 모두를 위해 설계된 삼중 양식 MLLM인 TriSense를 제안합니다. 그림 1에 묘사된 바와 같이, TriSense는 시간 차원에 걸쳐 시각, 오디오, 음성의 가용성이 다양한 다중 양식 비디오 데이터를 처리하도록 설계되었습니다. 결정적으로, 이는 쿼리의 내용과 컨텍스트에 따라 동적으로 양식 가중치를 조정하는 Query-Based Connector를 포함합니다. 이를 통해 모델은 가장 유익한 양식(예: 가장 관련성이 높은 경우 시각을 우선시)을 강조하면서 관련 없거나 누락된 양식의 가중치를 낮출 수 있어, 불완전한 양식 조건 하에서도 강력한 성능을 발휘할 수 있습니다.
- 우리는 두 가지 핵심 작업—비디오 세그먼트 캡셔닝과 순간 검색—에 대해 8가지 양식 구성에 걸쳐 광범위한 실험을 수행하며, 공개 벤치마크에 대한 제로샷 평가도 포함합니다. TriSense는 새로운 TriSense-2M 데이터셋과 기존 벤치마크 모두에서 강력한 성능을 달성하여, 다중 양식 시간적 비디오 이해 분야의 미래 연구를 위한 견고한 기반을 마련합니다.
2 Related Work
2.1 Video Temporal Understanding MLLMs
비디오 시간적 이해는 비디오 내에서 이벤트가 시간에 따라 어떻게 전개되는지를 모델링하는 데 초점을 맞추며, 순간 검색, 세그먼트 캡셔닝, 밀집 비디오 캡셔닝과 같은 작업을 가능하게 합니다. 비전-언어 모델(VLM)은 작업별 미세 조정 없이 제로샷 시나리오를 포함하여 실제 문제를 해결하는 데 강력한 능력을 보여주었습니다. 그러나 이러한 모델 중 다수는 여전히 시간적 역학을 이해하는 데 어려움을 겪고 있습니다 [36, 5]. 이를 해결하기 위해, 여러 모델들이 시간적 구조를 강조하는 비디오 그라운딩 데이터셋—예를 들어 TimeChat [27], VTimeLLM [15]—에서 미세 조정되어 시간적 추론 능력을 향상시켰습니다. 더 최근에는, Momentor [23]가 시간 토큰 양자화로 인한 오류를 수정하기 위해 시간 인코더를 도입했으며, VTGLLM [12]은 비디오 LLM이 이벤트의 타이밍을 더 잘 포착할 수 있도록 특수 시간 토큰과 시간적 위치 임베딩을 사용했습니다. 다른 접근 방식으로, TRACE [11]는 인과적 언어 모델링의 원리를 적용하여 비디오에 대한 인과적 이벤트 모델링을 제안했습니다. 또한 시간적 정보 인코딩을 위한 경량 시간 타워를 도입하여 시간적 이해에서 견고한 성능을 달성했습니다.
비전-언어 모델링을 넘어, 다중 양식 대규모 언어 모델(MLLM)은 더 풍부한 비디오 분석을 가능하게 하기 위해 시각, 오디오, 음성 양식을 통합합니다. 성능을 향상시키기 위해, 최근의 노력들은 이러한 추가적인 양식을 통합하는 데 초점을 맞추었습니다. 예를 들어, LongVALE [10]은 모든 양식 토큰을 단일 토큰으로 압축하지만, 이는 오디오 컨텍스트나 음성 억양과 같은 미세한 세부 정보의 손실로 이어집니다. 반면에 Qwen2.5-Omni [34]는 텍스트, 이미지, 오디오, 비디오 입력을 처리하는 완전한 종단 간 다중 양식 시스템인 Thinker-Talker 아키텍처를 도입합니다. 시간 차원에 따라 오디오와 비디오를 더 잘 정렬하기 위해, 저자들은 타이밍 인식 위치 인코딩 기술인 TMRoPE를 제안합니다. 그러나 우리 실험에 따르면 이 모델은 여전히 장편 비디오에서의 그라운딩에 어려움을 겪습니다. 이러한 발전에도 불구하고, 많은 기존 모델들은 시각 양식에만 국한되거나 다른 양식의 유연한 조합을 지원하지 못합니다. 이는 시간적 이해 작업, 특히 일부 양식이 부재하거나 잡음이 많을 수 있는 시나리오에서 그 효과를 제한합니다. 이러한 도전 과제들은 강력한 시간적 추론과 일반적인 이해 성능을 유지하면서 다양한 양식 조합을 견고하게 처리할 수 있는 MLLM을 추구하도록 동기를 부여합니다.
2.2 Benchmarks for Temporal Understanding
벤치마크 데이터셋의 개발은 비디오 시간적 이해를 발전시키는 데 중요한 역할을 해왔습니다. DiDeMo [14]와 같은 초기 기여는 비디오에서 순간 지역화를 위한 자연어 쿼리를 도입했습니다. 이후의 데이터셋인 Charades-STA [8]와 ActivityNet Captions [18]는 더 넓은 범위의 행동과 더 긴 비디오 길이를 다루면서 이 분야를 크게 발전시켰습니다. 더 최근에는, InternVid2 [32]가 6,100만 개의 오디오-시각-음성 주석을 제공하는 대규모 기초 데이터셋으로 등장했습니다. 그러나 이러한 주석 중 다수는 양식 간의 일관성이 부족하게 분리되어 있으며, 데이터셋은 그 규모로 인해 상당수의 저품질 캡션을 포함하고 있습니다.
이러한 한계를 해결하기 위해 VAST-27M [3]과 VALOR [2]가 도입되었습니다. 두 데이터셋 모두 InternVid2보다 더 나은 상호 관련 기능을 갖춘 고품질의 전방위적(오디오-시각-음성) 주석을 제공하여 MLLM을 위한 포괄적인 다중 양식 이해를 지원합니다. 그럼에도 불구하고, 이들은 양식 간의 캡션을 단순히 연결하는 데 의존하며 교차 양식 추론을 통합하지 않습니다. 더욱이, 이러한 벤치마크는 짧은 클립에 대한 대략적인 캡션만 제공하여 장편 비디오의 미세한 이해에는 부적합합니다. 두 데이터셋 모두 InternVid2를 개선했지만, 비슷한 한계를 반복합니다: 주석이 양식 간에 문맥적으로 통합되지 않았고, 시간적 세분성이 긴 비디오에서 미묘한 이벤트 전환을 모델링하기에는 너무 거칩니다. 이러한 단점에 대응하여, LongVALE [10]이 제안되었으며, 108K 개의 고품질 전방위적 주석을 특징으로 합니다. 이는 주목할 만한 개선을 제공하지만, VAST-27M, VALOR, LongVALE 모두 중요한 문제를 간과합니다: 양식의 동적 존재. 실제 비디오에서 오디오, 시각, 음성 입력이 항상 동시에 사용 가능한 것은 아니므로, 누락된 양식에 대한 모델 견고성에 대한 중요한 질문을 제기합니다. 결론적으로, 기존 벤치마크는 종종 시각적 정보에만 초점을 맞추거나 유연한 다중 양식 통합을 적절하게 지원하지 못합니다. 이러한 한계는 개선된 데이터셋의 필요성을 강조하며 우리 연구의 핵심 동기가 됩니다.
3 Data Construction
섹션 1과 2에서 논의한 바와 같이, 일부 기존 데이터셋은 시각, 오디오, 음성의 세 가지 양식을 모두 포함하지만, 일반적으로 이러한 양식들이 항상 동시에 존재한다고 가정합니다 [3, 2, 10]. 이는 임의의 조합을 지원하는 것의 중요성을 간과하는 것입니다. 이러한 가정은 누락되거나 부분적인 입력을 효과적으로 처리할 수 있는 모델의 개발을 제한합니다. 이를 해결하기 위해, 우리는 완전한 다중 양식 및 부분적인 다중 양식 시나리오를 모두 지원하도록 설계된 새로운 대규모 고품질 데이터셋을 소개합니다.
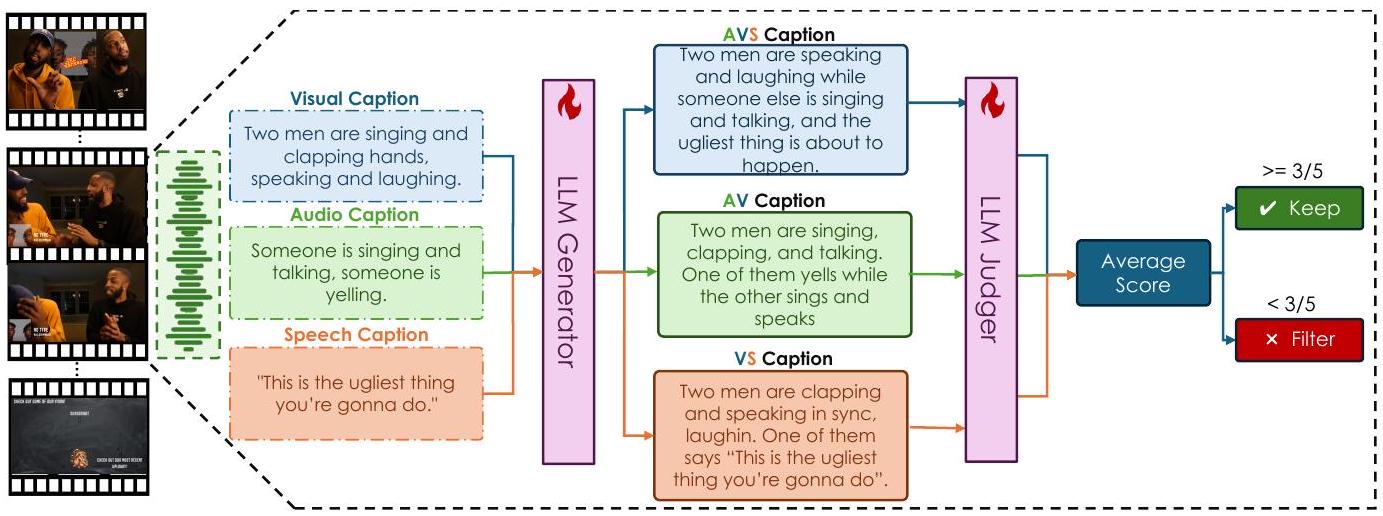
Figure 2: 우리는 시각, 오디오, 음성 스트림에서 얻은 양식별 캡션을 활용하여 데이터셋을 구축하기 위해 자동화된 프레임워크를 사용합니다. 이 과정에는 두 개의 대규모 언어 모델(LLM)이 훈련됩니다: 세 개의 입력 캡션을 다중 모드 출력(AVS, AV, VS)으로 융합하는 생성자(Generator)와 생성된 캡션의 의미적 품질을 평가하는 심판자(Judger). 심판자는 원본 입력과의 정렬을 기반으로 0에서 5 사이의 평균 품질 점수를 할당합니다. 3점 이상인 샘플은 유지되고, 3점 미만인 샘플은 폐기됩니다.
우리 데이터셋은 더 긴 비디오 길이를 포함하여 현실적이고 미세한 시간적 그라운딩 작업에 적합합니다. 이는 모델이 인간과 유사한 방식으로 "보고 들으며", 사용 가능한 시각적, 청각적, 음성적 단서에 유연하게 주의를 기울여 관련 순간을 식별할 수 있도록 합니다. 또한, 더 깊은 비디오 이해와 서사 생성을 촉진하기 위해 캡션 데이터를 포함합니다. 확장 가능하고 일관된 주석을 지원하기 위해, 그림 2와 같이 완전 자동화된 데이터 구성 파이프라인을 개발했습니다. 우리는 InternVid [32]와 VAST [3]에서 부분 집합을 선택하여 비디오 콘텐츠와 초기 캡션의 원시 소스로 사용하는 것으로 시작합니다. 각 비디오 클립에는 세 가지 다른 캡션이 주석으로 달려 있습니다: 관찰 가능한 장면과 행동을 설명하는 시각적 캡션, 음향 요소를 상세히 설명하는 오디오 캡션, 그리고 음성 콘텐츠를 전사하는 음성 캡션입니다. 이러한 양식별 캡션은 이전 연구[32, 3]에서 채택된 전문 주석 파이프라인을 사용하여 생성됩니다.
양식 간 추론을 가능하게 하기 위해, 우리의 목표는 개별적인 단일 양식 주석을 유연하게 결합하는 전방위적 캡션을 합성하는 것입니다. 이는 포괄적인 시간적 이해가 가능한 모델을 훈련하는 데 매우 중요합니다. 이러한 캡션을 생성하기 위해, 우리는 Qwen2.5-72B [35]를 기반으로 한 두 개의 맞춤 훈련된 대규모 언어 모델을 사용합니다: 생성자(Generator)와 심판자(Judger). 생성자는 양식별 캡션을 AVS (Audio-Visual-Speech), AV (Audio-Visual), VS (Visual-Speech)의 세 가지 조합에 대한 통합된 표현으로 병합합니다. 이러한 캡션은 음성 리듬과 일치하는 박수 소리나 시각적 맥락과 일치하는 음성과 같은 교차 양식 상호 작용을 포착하도록 설계되었습니다. 심판자는 각 합성된 캡션의 품질을 원래의 단일 양식 주석과의 의미적 정렬을 측정하여 평가합니다. 0에서 5까지의 품질 점수를 할당하고, 시각적 행동과 관련 없는 음성이나 일치하지 않는 오디오-시각적 설명과 같은 불일치가 있는 샘플을 걸러냅니다. 이 모델들을 훈련시키기 위해, 우리는 먼저 GPT-o1 [16]을 사용하여 고품질 참조 말뭉치를 구축한 다음, 수동으로 정제하고 필터링합니다. 이 큐레이션된 세트에서, 우리는 생성기를 훈련시키기 위해 10,000개의 샘플을 선택하고 심판자를 훈련시키기 위해 3,000개의 샘플을 선택합니다. 추가적인 훈련 세부 정보는 부록에 제공됩니다.
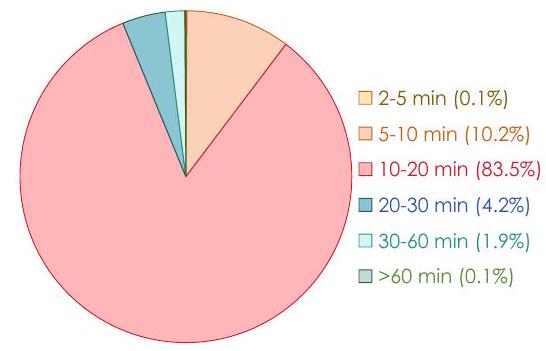
Figure 3: 비디오 길이 분포. 대부분의 비디오는 10-20분 길이(83.5%)로, 장편 시간적 이해를 지원합니다.
Table 1: 시간적 이해 데이터셋 비교. TriSense-2M은 긴 비디오 길이와 양식 드롭아웃의 명시적 처리를 통해 세 가지 양식을 모두 고유하게 지원합니다.
| 데이터셋 | 주석 | 평균 길이 | 시각 | 오디오 | 음성 | 양식 드롭아웃 |
|---|---|---|---|---|---|---|
| VALOR [2] | 1.32M | 10초 | ||||
| VAST [3] | 27M | 30초 | ||||
| UnAV-100 [9] | 30K | 42.1초 | ||||
| Charades-STA [8] | 16K | 30초 | ||||
| ActivityNet-Captions [13] | 20K | 180초 | ||||
| LongVALE [10] | 108K | 235초 | ||||
| TriSense-2M | 2M | 905초 |
데이터 구축 파이프라인은 시각, 오디오 및 음성 캡션을 포함하는 5백만 개의 다중 모드 비디오 샘플 초기 풀을 처리합니다. 여러 차례의 생성, 평가 및 필터링을 통해 심판자는 고품질 출력만 유지하여 약 38,000개의 긴 비디오에서 추출한 2백만 개의 샘플로 최종 데이터셋을 만듭니다. 비디오 길이의 분포는 그림 3에 나와 있습니다. 평균 비디오 길이는 905초로, 평균 235초인 가장 가까운 기존 데이터셋[10]보다 거의 4배 더 깁니다. 이 선별된 데이터셋은 다양한 양식 조합에 걸쳐 견고한 시간적 추론을 가능하게 하고 TriSense 모델의 훈련 및 평가를 위한 기초를 형성합니다. 기존 데이터셋과의 전반적인 비교는 표 1에 제공되며, 더 자세한 예는 부록에 포함되어 있습니다.
4 TriSense Architecture
TriSense 모델의 전체 아키텍처는 그림 4에 설명되어 있습니다. 이 모델은 텍스트 기반 쿼리에 답하기 위해 비디오에서 추출된 시각, 오디오 및 음성 정보를 처리하도록 설계되었습니다. 각 양식은 먼저 세 개의 특화된 전문가 인코더[24, 26, 4] 중 하나에 의해 처리됩니다. 결과적인 특징 표현은 그 다음 양식별 프로젝터를 통과하고 Cross-Attention 메커니즘을 사용하여 쿼리와 통합되어 모델이 각 양식과 쿼리 간의 미세한 상호 작용을 포착할 수 있도록 합니다. Query-Based Connector는 이후 양식 표현을 융합하고 쿼리의 내용에 따라 기여도를 적응적으로 조정합니다. 이 융합된 다중 모드 표현은 시간 정보로 보강된 다음 최종 출력을 생성하는 대규모 언어 모델(LLM) 백본에 입력됩니다. 시간적 종속성을 효과적으로 모델링하기 위해 아키텍처는 전용 시간 인코더[11]를 포함하고 작업별 헤드를 사용하여 출력이 시간적으로 정렬되고 작업과 관련되도록 보장합니다.
4.1 Multimodal Information Extraction
훈련 중에, 비디오 가 주어지면(여기서 는 총 프레임 수를 나타냄), 우리는 먼저 추가 처리 및 메모리 사용량 제어를 위해 개의 프레임을 균일하게 선택합니다. 선택된 각 프레임에 대해 타임스탬프를 기록하고 프레임 주변으로 초의 오디오 세그먼트를 추출하여, 각각 2초 길이의 오디오 세그먼트 시퀀스 를 생성합니다. 예를 들어, 프레임이 123.4초에 샘플링되면 해당 오디오 세그먼트는 122.4초에서 124.4초까지입니다. 그런 다음 사전 훈련된 전문가 인코더를 사용하여 시각, 오디오, 음성에 대한 양식별 토큰인 를 각각 추출합니다. 모델의 시간적 인식을 향상시키기 위해, 선택된 타임스탬프를 시간 인코더[11]를 사용하여 인코딩합니다. 각 타임스탬프는 먼저 네 개의 정수 숫자, 소수점 하나, 그리고 소수점 이하 한 자리 숫자로 구성된 고정 길이 문자 시퀀스로 토큰화되어 프레임당 6개의 토큰이 생성됩니다. 예를 들어, 타임스탬프 [123.4]는 로 토큰화됩니다. 그런 다음 이러한 토큰은 시간 특징 를 형성하기 위해 임베딩됩니다. 세 가지 양식에서 오는 높은 토큰 수를 감안할 때, 우리는 입력의 차원을 줄이기 위해 Slot-Based Compression[12]을 Modality Projector로 적용합니다. 이 기술은 비전 토큰 , 오디오 토큰 , 음성 토큰 를 각각 16개 토큰의 고정 길이 벡터인 및 로 압축합니다.
4.2 Query-Based Connector
다중 모드 입력을 쿼리와 더 효과적으로 통합하고 두드러진 특징에 대한 민감도를 높이기 위해, 우리는 그림 4에 설명된 대로 쿼리의 내용에 따라 각 양식의 기여도를 적응적으로 조절하는 Query-Based Connector를 도입합니다.
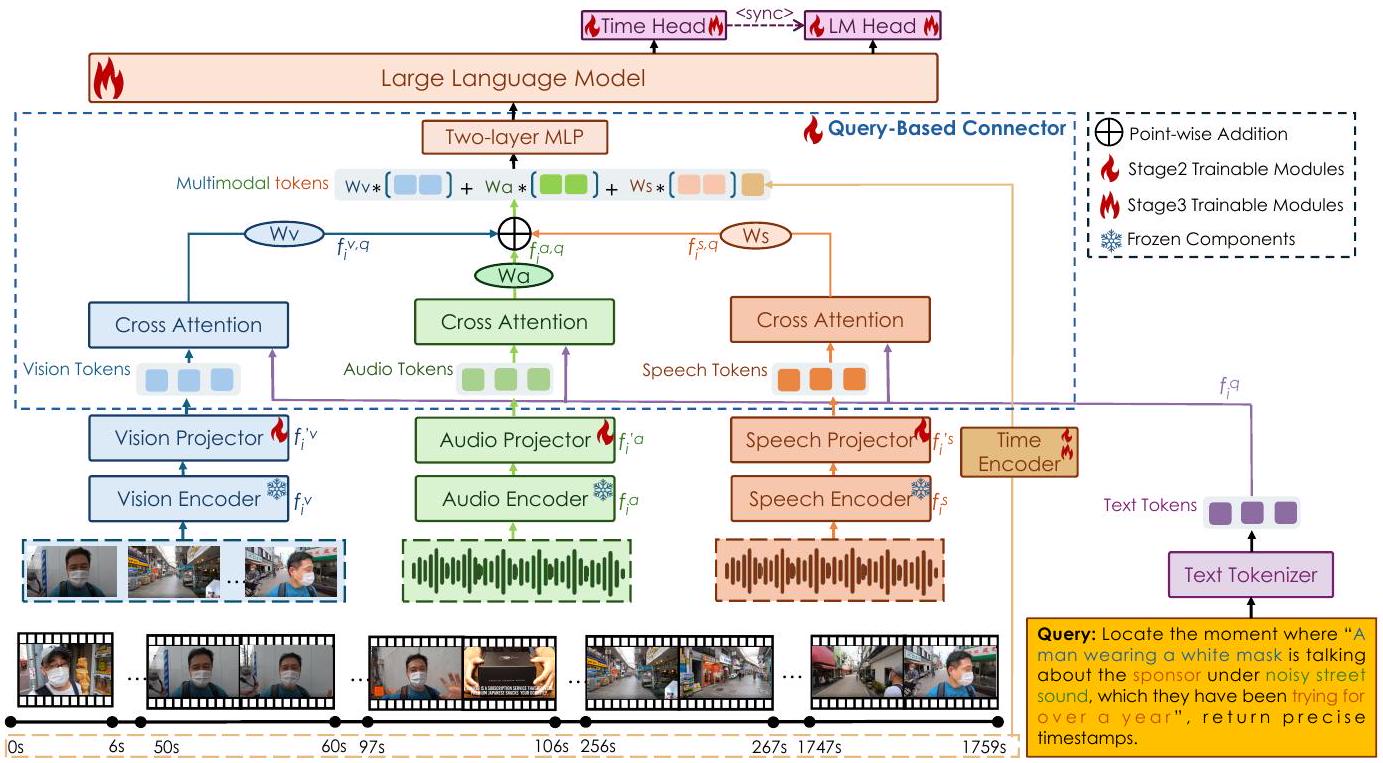
Figure 4: TriSense 모델의 아키텍처. 이 모델은 전용 인코더를 통해 시각, 오디오, 음성을 처리하고 쿼리를 기반으로 가중치를 할당하는 Query-Based Connector를 사용하여 이들을 융합합니다. 융합된 출력은 시간적 임베딩과 결합되어 타임스탬프가 찍힌 응답 또는 텍스트 응답을 생성하기 위해 LLM으로 전달됩니다. 자세한 의사 코드는 부록에 제공됩니다. 섹션 4.1에서 얻은 압축된 양식 특징 및 는 Cross-Attention 레이어를 통과하며, 여기서 인코딩된 쿼리 표현 와 상호 작용합니다. 목표는 각 어텐션 레이어가 쿼리에 가장 관련 있는 특징을 강조하는 것입니다. 이 레이어의 출력은 각 양식과 쿼리 간의 정렬을 반영하는 쿼리 관련 특징 및 로 표시됩니다. 쿼리와 관련하여 각 양식의 중요도를 동적으로 결정하기 위해 적응형 가중치 메커니즘을 도입합니다. 먼저 각 양식의 시퀀스 차원에 대해 전역 평균 풀링을 적용하여 간결한 전역 표현 , 를 도출합니다. 이 벡터들은 연결되어 단일 레이어 MLP 에 입력되어 정규화되지 않은 가중치 , 를 생성합니다. 그런 다음 가중치는 softmax 함수를 사용하여 정규화되어 제약 조건을 만족하는 유효한 확률 분포를 생성합니다. 계산은 다음과 같이 공식화됩니다:
여기서 은 전역 평균 풀링 후의 압축된 양식 벡터이고, 은 고유한 양식 의 시퀀스 길이를 나타내며, 는 벡터 연결을 나타내고, 과 은 각각 정규화되지 않은 가중치와 정규화된 가중치를 나타냅니다. 가중치를 계산한 후, 가중 합계를 적용하여 양식별 쿼리 정렬 토큰을 단일 다중 모드 표현으로 융합합니다. 이 표현은 LLM의 입력 차원과 일치시키고 표현력을 향상시키기 위해 2계층 MLP 를 사용하여 정제됩니다:
이러한 적응형 융합을 통해 모델은 특정 쿼리에 따라 가장 유익한 양식을 강조하면서 덜 관련된 양식의 영향을 줄일 수 있습니다. 결과 표현 은 해당 시간 임베딩 (섹션 4.1에서 소개)와 결합되어 LLM 백본으로 전달되며, 이는 문맥적 추론 능력을 사용하여 최종 출력을 생성합니다.
Table 2: 세그먼트 캡셔닝 결과. 성능은 BLEU-4(B), METEOR(M), ROUGE-L(R), CIDEr(C)를 사용하여 네 가지 양식 설정에 대해 보고됩니다. 최고 및 차선 결과는 각각 굵은 글씨와 밑줄로 표시됩니다.
| 모델 | AVS-SC | VS-SC | AV-SC | V-SC | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | M | R | C | B | M | R | C | B | M | R | C | B | M | R | C | |
| VTimeLLM (7B) | 0.8 | 8.2 | 16.1 | 2.4 | 1.2 | 8.8 | 16.9 | 3.1 | 1.3 | 10.3 | 17.9 | 2.6 | 1.4 | 10.4 | 18.2 | 4.0 |
| TimeChat (7B) | 0.6 | 4.0 | 8.7 | 0.6 | 0.9 | 4.9 | 9.8 | 1.4 | 1.1 | 5.5 | 10.5 | 1.5 | 0.8 | 6.7 | 12.5 | 5.7 |
| VTG-LLM (7B) | 0.3 | 4.8 | 9.6 | 0.6 | 0.3 | 4.9 | 10.0 | 0.9 | 0.4 | 5.2 | 10.2 | 0.9 | 0.3 | 5.0 | 9.8 | 1.4 |
| TRACE (7B) | 1.0 | 7.6 | 13.5 | 1.1 | 1.4 | 7.8 | 14.3 | 2.3 | 1.6 | 9.0 | 16.3 | 2.6 | 1.3 | 9.4 | 16.8 | 9.5 |
| TRACE-uni (7B) | 1.1 | 8.2 | 14.7 | 1.4 | 1.5 | 8.3 | 15.1 | 2.2 | 1.6 | 9.5 | 16.3 | 2.3 | 1.3 | 9.9 | 17.6 | 8.8 |
| LongVALE (7B) | 1.2 | 8.6 | 16.7 | 4.9 | 10.0 | 20.1 | 5.5 | 11.4 | 21.3 | 5.9 | 11.5 | 18.8 | 0.9 | |||
| Qwen2.5-Omni (7B) | 0.8 | 8.8 | 13.1 | 1.7 | 0.8 | 8.6 | 13.1 | 0.8 | 1.2 | 9.8 | 15.1 | 1.3 | 1.1 | 10.1 | 14.6 | 1.1 |
| TriSense (7B) | 3.4 | 10.1 | 20.1 | 8.3 | 3.0 | 10.0 | 22.2 | 11.8 | 5.3 | 12.2 | 26.3 | 15.4 | 7.3 | 12.6 | 30.7 | 36.3 |
4.3 Causal Event Prediction
모델의 시간적 추론 능력을 향상시키고 예측을 비디오 서사의 기본 구조와 더 잘 정렬하기 위해, 이전 연구[11]에서 효과적인 것으로 나타난 방법인 인과적 이벤트 예측을 사용합니다. 이 접근법은 모델이 시간에 따른 원인과 결과 관계에 대해 추론하고, 이전 컨텍스트를 기반으로 다가오는 이벤트를 예측할 수 있게 합니다. 구체적으로, 비디오 V가 주어지면, 이를 이벤트 시퀀스 로 분할하며, 각 이벤트 는 타임스탬프 와 비디오 세그먼트를 설명하는 관련 캡션 로 구성됩니다:
우리의 목표는 이전 이벤트 시퀀스 , 사용자 제공 쿼리 , 그리고 Query-Based Connector에 의해 생성된 다중 모드 특징 에 조건부로 다음 이벤트 를 예측하는 것입니다:
시간적 및 텍스트 출력을 모두 지원하기 위해, LLM 생성 중에 특수 sync 토큰을 통한 적응형 헤드 전환을 도입합니다. 이 토큰은 어휘에 추가되며, 그림 4에서 설명한 바와 같이 모델이 시간 헤드와 언어 모델(LM) 헤드 사이를 전환하도록 안내하는 제어 신호 역할을 합니다. sync 토큰이 나타나면, LLM은 작업에 따라 타임스탬프에 정렬된 예측 또는 자유 형식의 텍스트 출력을 생성하기 위해 디코딩 양식 간에 전환합니다.
5 Experiments
이 섹션에서는 제안된 모델의 성능을 평가하기 위해 수행된 핵심 실험들을 제시합니다. 공간 제약으로 인해 구현 세부 정보, 훈련 절차 및 추가 실험 결과는 부록에 제공됩니다.
5.1 Evaluation Datasets, Metrics and Baseline Models
TriSense의 효과를 엄격하게 평가하기 위해, 우리는 두 가지 주요 시간적 이해 작업에 대한 평가를 수행합니다:
- 세그먼트 캡셔닝 (SC). 이 작업은 비디오 전체에서 발생하는 이벤트를 정확하게 요약하는 설명적인 캡션을 생성하는 것을 포함합니다. 우리는 새롭게 도입된 TriSense-2M 데이터셋에서 우리 모델을 평가하고, 부록에 추가 데이터셋을 제공합니다. 성능은 생성된 캡션의 품질과 정확도를 측정하기 위해 BLEU-4 [22], CIDEr [30], ROUGE_L [20] 및 METEOR [1]로 보고됩니다.
- 순간 검색 (MR). 이 작업에서 모델은 주어진 텍스트 쿼리에 해당하는 비디오 내의 특정 세그먼트를 검색해야 합니다. 우리는 TriSense-2M뿐만 아니라 널리 사용되는 두 가지 공개 벤치마크인 Charades-ST [8]와 ActivityNet-Captions [13]에서 성능을 평가합니다. 검색 효과는 Recall@IoU=0.5, Recall@IoU=0.7 및 평균 IoU (mIoU)를 사용하여 보고되며, 다양한 중첩 임계값에서 모델의 위치 파악 정확도에 대한 포괄적인 관점을 제공합니다. 양식 조합은 오디오-시각-음성(AVS), 시각-음성(VS), 오디오-시각(AV) 및 시각-전용(V)으로 설정됩니다. 견고한 비교 기준선을 설정하기 위해, 우리는 비디오 시간적 그라운딩(VTG) 작업을 위해 특별히 설계된 대표적인 모델들을 선택합니다. 여기에는 VTimeLLM [15]이 포함됩니다.
Table 3: 64 프레임을 사용한 순간 검색 결과. 성능은 네 가지 양식 설정에서 IoU 0.5와 0.7에서의 Recall로 보고됩니다. 최고 및 차선 결과는 각각 굵은 글씨와 밑줄로 표시됩니다.
| 모델 | AVS-MR | VS-MR | AV-MR | V-MR | ||||
|---|---|---|---|---|---|---|---|---|
| IoU=0.7 | IoU=0.7 | IoU=0.5 | IoU=0.7 | IoU=0.7 | ||||
| VTimeLLM (7B) | 0.21 | 0.09 | 0.28 | 0.14 | 0.23 | 0.08 | 0.41 | 0.14 |
| TimeChat (7B) | 0.28 | 0.12 | 0.27 | 0.09 | 0.22 | 0.08 | 0.34 | 0.12 |
| VTG-LLM (7B) | 0.19 | 0.08 | 0.15 | 0.05 | 0.21 | 0.07 | 0.23 | 0.06 |
| TRACE (7B) | 0.39 | 0.12 | 0.31 | 0.15 | 0.24 | 0.13 | 0.42 | 0.21 |
| TRACE-uni (7B) | 0.30 | 0.17 | 0.35 | 0.17 | 0.24 | 0.48 | 0.22 | |
| LongVALE (7B) | 0.08 | 0.01 | 0.07 | 0.01 | 0.07 | 0.01 | 0.05 | 0.01 |
| Qwen2.5-Omni (7B) | 0.61 | 0.21 | 0.61 | 0.16 | 0.28 | 0.07 | 0.18 | 0.06 |
| TriSense (7B) | 1.12 | 0.42 | 0.80 | 0.28 | 0.57 | 0.21 | 0.43 | 0.22 |
Table 4: 공개 벤치마크에서의 제로샷 순간 검색 결과 (64 프레임 사용). "*"는 이 모델이 TriSense보다 더 많은 프레임을 사용함을 나타냅니다. 최고 및 차선 결과는 각각 굵은 글씨와 밑줄로 강조 표시됩니다.
| 모델 | Charades-STA | ActivityNet-Caption | ||||
|---|---|---|---|---|---|---|
| IoU=0.5 | mIoU | IoU=0.5 | IoU=0.7 | mIoU | ||
| VTimeLLM* (7B) | 27.5 | 11.4 | 31.2 | 27.8 | 14.3 | 30.4 |
| VTimeLLM* (13B) | 34.3 | 14.7 | 34.6 | 29.5 | 14.2 | 31.4 |
| TimeChat* (7B) | 32.2 | 13.4 | - | 4.6 | 2.0 | 6.9 |
| Momentor* (7B) | 26.6 | 11.6 | 28.5 | 23.0 | 12.4 | 29.3 |
| HawkEye (7B) | 31.4 | 14.5 | 33.7 | 29.3 | 10.7 | 32.7 |
| VTG-LLM* (7B) | 33.8 | 15.7 | - | 8.3 | 3.7 | 12.0 |
| TRACE* (7B) | 40.3 | 19.4 | 38.7 | 37.7 | 24.0 | 39.0 |
| TRACE-uni* (7B) | 43.7 | 41.5 | 38.2 | 24.7 | 39.4 | |
| NumPro-FT* (7B) | 42.0 | 20.6 | 37.5 | 20.6 | 38.8 | |
| TriSense (7B) | 27.6 | 39.8 | 39.6 | 27.2 | 40.1 |
TimeChat [27], VTG-LLM [12], TRACE [11], 그리고 최근의 두 가지 옴니모달 모델인 LongVALE [10]과 Qwen2.5-Omni [34]. Momentor [23], Hawkeye [31] 및 NumPro-FT [33]는 모델 체크포인트의 부재와 캡셔닝 지원 부족으로 TriSense-2M 벤치마크에는 포함되지 않았지만, 공식 논문에 보고된 바와 같이 공개 벤치마크 평가에서는 고려됩니다. 다양한 작업과 평가 지표에 걸쳐 우리 모델을 이러한 기준선과 비교함으로써, 우리는 TriSense의 능력과 비디오 시간적 이해에서의 발전에 대한 포괄적인 평가를 제공하고자 합니다.
5.2 Results and Analysis
전방위 모달 데이터셋에서의 우수한 성능. 우리는 제안된 TriSense-2M 데이터셋에 대한 성능을 평가합니다. 표 2와 표 3에서 볼 수 있듯이, TriSense는 평가된 거의 모든 작업에서 기존 비디오 LLM을 일관되게 능가합니다. 또한 LongVALE [10] 및 Qwen2.5-Omni [34]와 같은 최신 전방위 모달 모델을 특히 세 가지 모드가 모두 활용되는 오디오-시각-음성(AVS) 설정에서 크게 능가합니다. 페이지 제한으로 인해 LongVALE 벤치마크에 대한 추가 제로샷 성능 결과는 부록에 제공됩니다. 우리는 모델이 최첨단 비전 모델에 비해 시각 전용 순간 검색에서 약간 낮은 성능을 보이는 것을 관찰했는데, 이는 시각 전용 시나리오보다는 다중 모드 설정에 최적화되었기 때문일 가능성이 높습니다. 또한, 우리 모델은 테스트 중에 64개의 입력 프레임만 사용하는 반면, TRACE [11]의 128개 프레임이나 VTimeLLM [15]의 100개 프레임과 같이 다른 모델에서는 더 큰 입력 크기를 사용한다는 점에 유의하는 것이 중요합니다. TriSense-2M은 대부분 긴 비디오로 구성되어 있으므로, 더 적은 프레임을 사용하면 모델이 긴 비디오 순간 검색 작업에서 높은 정확도를 달성하기가 더 어려워집니다. 비디오가 짧아지거나 더 많은 프레임이 사용되면 성능이 향상되며, 이는 표 4와 표 5의 결과에서도 뒷받침됩니다. 공개 Moment Retrieval 벤치마크에서의 제로샷 성능. 우리는 기존의 시각 전용 데이터셋인 Charades-STA [8]와 ActivityNet-Captions [13]에서 TriSense를 제로샷 설정으로 평가하며, 그 결과는 표 4에 나와 있습니다. 결과는 TriSense가 표 3에서 약간 열등한 성능을 보였음에도 불구하고, 시각 전용 설정에서 여전히 경쟁력 있는 성능을 달성하며, 특히 더 적은 프레임을 사용함에도 불구하고 다른 모델보다 더 높은 정확도()를 보인다는 것을 보여줍니다. Table 5: 순간 검색에 대한 절제 연구. 최고 및 차선 결과는 각각 굵은 글씨와 밑줄로 강조 표시됩니다.
| 모델 | 프레임 수 | AVS-MR | VS-MR | AV-MR | V-MR | ||||
|---|---|---|---|---|---|---|---|---|---|
| IoU=0.5 | IoU=0.5 | ||||||||
| 훈련 단계 | |||||||||
| 1단계만 | 64 | 0.07 | 0.01 | 0.06 | 0.01 | 0.06 | 0.00 | 0.02 | 0.00 |
| 1+2 단계 | 64 | 0.52 | 0.19 | 0.43 | 0.18 | 0.32 | 0.12 | 0.27 | 0.14 |
| 커넥터 | |||||||||
| 덧셈 | 64 | 0.71 | 0.22 | 0.69 | 0.21 | 0.41 | 0.11 | 0.22 | 0.19 |
| 고정 가중치 | 64 | 0.89 | 0.38 | 0.77 | 0.24 | 0.52 | 0.19 | ||
| 프레임 수 | |||||||||
| TriSense (7B) | 32 | 0.74 | 0.27 | 0.68 | 0.18 | 0.39 | 0.13 | 0.24 | 0.11 |
| TriSense (7B) | 64 | 1.12 | 0.43 | 0.22 | |||||
| TriSense (7B) | 128 | 1.12 | 0.43 | 0.87 | 0.31 | 0.64 | 0.32 | 0.49 | 0.26 |
절제 연구. 우리는 훈련 전략, Query-Based Connector, 그리고 모델이 처리하는 프레임 수를 포함한 다양한 구성 요소의 기여도를 평가하기 위해 절제 실험을 수행합니다. 페이지 제한으로 인해, 순간 검색 절제 결과만 본문에 포함하고, 세그먼트 캡셔닝 절제는 부록에 제시합니다. 표 5에서 볼 수 있듯이, 우리는 우리의 적응형 가중치 전략을 더 간단한 대안들과 비교합니다. Addition 기준선은 가중치 없이 양식 특징들을 직접 더합니다. Fixed Weights 기준선은 AVS에서 각각 0.33과 같이 동일한 가중치를 할당하거나, VS/AV에서 활성 양식 각각에 0.5, 비활성 양식에 0과 같이 양식 쌍에 따라 고정된 값을 할당하고, 시각 전용 작업에서는 시각 스트림만 사용합니다 (가중치 1, 나머지는 0으로 설정). 이러한 비교는 우리의 쿼리-적응형 가중치 메커니즘의 효과를 확인시켜 줍니다. 우리는 훈련 단계 섹션에서 1단계가 양식 정렬에만 초점을 맞추고 시간 정보가 포함되지 않기 때문에 순간 검색에서 좋은 성능을 보이지 않는다는 것을 관찰할 수 있습니다. 그러나 2단계 훈련 후, 모델은 순간 검색 능력의 약 50%를 습득합니다. 커넥터 절제 연구에서는, 모든 양식을 단순히 더하는 것이 모델이 더 중요한 양식을 강조하는 것을 허용하지 않아 성능 저하를 초래한다는 것을 발견했습니다. 유사하게, AVS/VS/AV 작업에 대한 고정 가중치 절제 연구에서, 양식에 동일한 가중치를 할당하는 것은 그들의 다양한 중요도를 효과적으로 포착하지 못하여 동적 양식 가중치를 사용하는 것에 비해 열등한 성능을 보였습니다. 그러나 시각적 가중치를 1로 고정하는 것은 실제로 시각 전용(V) 설정에서 약간 더 나은 성능을 이끌어 냈습니다. 우리는 또한 모델이 사용하는 프레임 수를 (64에서 128로) 늘리면 모든 시나리오에서 성능이 향상되는 것을 관찰했습니다. 이 경향은 부록에 제시된 세그먼트 캡셔닝의 결과와도 일치합니다.
6 Conclusion
본 연구에서는 시각, 오디오, 음성 양식을 통합하여 포괄적인 비디오 이해를 발전시키기 위해 설계된 새로운 다중 양식 대규모 언어 모델인 TriSense를 소개했습니다. 우리 모델의 핵심에는 동적이고 양식에 적응적인 융합을 가능하게 하는 Query-Based Connector가 있어, 시스템이 임의의 입력 양식 조합에 걸쳐 효과적으로 작동할 수 있도록 합니다. 이 능력은 특정 양식이 부분적으로만 사용 가능하거나 완전히 부재할 수 있는 실제 시나리오에 필수적입니다. 이 분야의 발전을 지원하기 위해, 우리는 2백만 개 이상의 신중하게 선별된 샘플을 포함하는 대규모 데이터셋인 TriSense-2M을 구축했습니다. 이 샘플들은 다양한 장면, 기간, 양식 정렬을 포괄하며, 훈련 및 평가를 위한 풍부한 기반을 제공합니다. 광범위한 실험을 통해, 우리는 TriSense가 순간 검색 및 장편 비디오 세그먼트 캡셔닝을 포함한 주요 시간적 비디오 이해 작업에서 일관되게 최첨단 성능을 달성함을 입증했습니다. 우리의 양식 적응형 프레임워크는 더 유연하고 인간과 유사한 비디오 이해 시스템을 향한 상당한 진전을 나타냅니다. 이는 통제된 평가에서 강력한 성능을 제공할 뿐만 아니라, 다양한 입력 구성을 가진 실제 조건에서도 견고한 적용 가능성을 보여줍니다. 우리는 TriSense와 TriSense-2M 데이터셋 모두가 다중 양식 학습 및 시간적 추론에 대한 향후 연구에 귀중한 자원이 되어, 다양한 비디오 이해 응용 분야 전반에 걸쳐 더 넓은 발전을 가능하게 할 것이라고 믿습니다.
References
[1] Satanjeev Banerjee and Alon Lavie. Closer look at summarization evaluations. In Proceedings of the workshop on empirical modeling of semantic equivalence and entailment, pages 1-8, 2005. 7 [2] Sihan Chen, Xingjian He, Longteng Guo, Xinxin Zhu, Weining Wang, Jinhui Tang, and Jing Liu. Valor: Vision-audio-language omni-perception pretraining model and dataset. arXiv preprint arXiv:2304.08345, 2023. 3, 4, 5 [3] Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset. Advances in Neural Information Processing Systems, 36, 2024. 3, 4, 5 [4] Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, and Furu Wei. Beats: Audio pre-training with acoustic tokenizers. 2022. 5, 13 [5] Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. 3 [6] Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. Clotho: An audio captioning dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 736-740. IEEE, 2020. 12, 13 [7] Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075, 2024. 17 [8] Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. In Proceedings of the IEEE international conference on computer vision, pages 5267-5275, 2017. 2, 3, 5, 7, 8 [9] Tiantian Geng, Teng Wang, Jinming Duan, Runmin Cong, and Feng Zheng. Dense-localizing audio-visual events in untrimmed videos: A large-scale benchmark and baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22942-22951, 2023. 5 [10] Tiantian Geng, Jinrui Zhang, Qingni Wang, Teng Wang, Jinming Duan, and Feng Zheng. Longvale: Vision-audio-language-event benchmark towards time-aware omni-modal perception of long videos. arXiv preprint arXiv:2411.19772, 2024. 2, 3, 4, 5, 8, 16 [11] Yongxin Guo, Jingyu Liu, Mingda Li, Xiaoying Tang, Qingbin Liu, and Xi Chen. Trace: Temporal grounding video 1 lm via causal event modeling, 2024. 2, 3, 5, 7, 8, 13, 17 [12] Yuchen Guo, Linchao Liu, Xin Li, and Ping Luo. Vtg-llm: Efficient temporal grounding in long videos with compressed visual cues. In arXiv preprint arXiv:2401.07684, 2024. 2, 3, 5, 8 [13] Fabian Caba Heilbron and Juan Carlos Niebles. Activitynet captions: A dense-captioning dataset for evaluating understanding of complex video activities. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5246-5255, 2015. 2, 5, 7, 9 [14] Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in video with natural language. In Proceedings of the IEEE international conference on computer vision, pages 5803-5812, 2017. 2, 3 [15] Junjie Huang, Ming Wu, Linchao Li, Yi Zhu, Yu Chen, Siwei Yan, Yi Liu, and Ping Luo. Vtimellm: Compression of time into a latent embedding for efficient video-language modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16694-16704, 2023. 2, 3, 7, 8 [16] Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai ol system card. arXiv preprint arXiv:2412.16720, 2024. 4, 14 [17] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. 13 [18] Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In Proceedings of the IEEE international conference on computer vision, pages 706-715, 2017. 3 [19] Jiabo Lei, Licheng Yu, Mohit Bansal, and Tamara L Berg. Tallyqa: Answering complex counting questions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14168-14178, 2021. 2 [20] Chin-Yew Lin and Franz Josef Och. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In Proceedings of the 42nd annual meeting of the association for computational linguistics (ACL-04), pages 605-612, 2004. 7 [21] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023. 12, 13 [22] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311-318, 2002.7 [23] Yiyuan Qian, Linchao Liu, Xin Li, and Ping Luo. Momentor: Advancing video understanding with temporal reasoning in large language models. In arXiv preprint arXiv:2401.03923, 2024. 2, 3, 8 [24] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748-8763. PmLR, 2021. 5 [25] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748-8763. PmLR, 2021. 13 [26] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision, 2022. 5, 13 [27] Junjie Ren, Can Li, Ming Zhao, Jinhui Liu, Junchi Yang, and Jian Wang. Timechat: A time-aware large language model for video question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16726-16736, 2023. 3, 8 [28] Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. Videoclip: Contrastive pre-training for zero-shot video-text understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16632-16642, 2022. 2 [29] Cassia Valentini-Botinhao et al. Noisy speech database for training speech enhancement algorithms and tts models. University of Edinburgh. School of Informatics. Centre for Speech Technology Research (CSTR), 2017. 12, 13 [30] Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4566-4575, 2015. 7 [31] Hao Wang, Linchao Liu, Xin Li, and Ping Luo. Hawkeye: Visually explainable reasoning in video question answering. In arXiv preprint arXiv:2401.04705, 2024. 8 [32] Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Jilan Xu, Zun Wang, et al. Internvideo2: Scaling video foundation models for multimodal video understanding. arXiv preprint arXiv:2403.15377, 2024. 3, 4 [33] Yongliang Wu, Xinting Hu, Yuyang Sun, Yizhou Zhou, Wenbo Zhu, Fengyun Rao, Bernt Schiele, and Xu Yang. Number it: Temporal grounding videos like flipping manga. arXiv preprint arXiv:2411.10332, 2024. 8 [34] Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report. arXiv preprint arXiv:2503.20215, 2025. 2, 3, 8 [35] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024. 4 [36] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023. 3 [37] Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024. 12, 13 [38] Bolei Zhou, Yu Guo, Meng Zhang, Xiongwei Wang, Siyuan Pu, Yuan Wu, Yan Zhang, Yan Wang, and Li Li. Recent advances in video understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023. 2
Contents of Appendix
A 구현 세부사항 ..... 12 A.1 훈련 레시피 ..... 12 A.2 데이터셋 ..... 12 A.3 상세 훈련 설정 ..... 13 B 데이터 포맷 ..... 14 B.1 생성자 및 심판자 훈련 ..... 14 B.2 훈련 데이터 포맷 ..... 15 C 추가 실험. ..... 15 C.1 세그먼트 캡셔닝에 대한 절제 연구 ..... 15 C.2 전방위 모달 데이터셋 및 일반 이해 데이터셋 ..... 16 C.3 Query-Based Connector의 의사 코드 ..... 17 D 다른 시나리오에 대한 사례 연구 ..... 18
A Implementation Details
A. 1 Training Recipe
우리의 훈련 과정은 구조화된 3단계 접근법을 따릅니다: 특징 정렬, 커넥터 일반화, 그리고 지시 튜닝—모델에 강력한 다중 모드 및 시간적 추론 능력을 점진적으로 갖추게 하기 위함입니다. 각 단계에서 훈련되는 특정 구성 요소는 그림 4에 설명되어 있습니다. 특징 정렬. 첫 번째 단계에서는 Query-Based Connector와 LM Head만 훈련 가능하도록 설정하고 다른 모든 구성 요소는 고정된 상태로 둡니다. 이 단계에서는 단일 양식 입력을 사용하여 모델이 세 가지 양식 각각을 개별적으로 초기 이해할 수 있도록 합니다. 또한 다중 양식 컨텍스트가 없는 상태에서 모델이 가중치를 효과적으로 할당하는 법을 배우도록 도와 다른 구성 요소의 간섭 없이 양식별 특징에 대한 집중적인 파악을 촉진합니다. 커넥터 일반화. 두 번째 단계에서는 혼합 양식 데이터를 통합하고 Query-Based Connector, Time Encoder, Time Head, LM Head에 대한 훈련을 허용하면서 LLM 백본은 고정시킵니다. 이 단계는 커넥터가 여러 양식에 걸쳐 가중치 할당을 처리하도록 하여 고립된 양식을 넘어선 일반화를 향상시킵니다. 동시에 Time Encoder와 Time Head를 훈련시켜 모델에 시간적 구조를 도입하고 시간에 따른 양식 간 역학을 포착하기 위한 기반을 마련합니다. 지시 튜닝. 마지막 단계에서는 Query-Based Connector를 고정하고 Time Encoder, Time Head, LM Head, LLM 백본을 포함한 나머지 구성 요소들을 혼합 양식 입력을 사용하여 훈련합니다. 커넥터를 고정함으로써 이전 단계에서 학습한 양식 정렬을 유지합니다. 이 단계는 시간적 추론과 언어 이해 능력을 정제하는 데 집중하여, 다양한 시나리오에 걸쳐 다중 양식의 시간 민감성 쿼리를 해석하고 처리하는 LLM의 능력을 강화합니다.
A. 2 Datasets
앞서 설명한 3단계 훈련 과정의 목표에 맞춰, 각 단계에서 다양한 데이터셋과 데이터 양을 사용합니다. 가장 큰 목표는 견고한 일반 비디오 이해 능력을 유지하면서 모델의 시간적 비디오 이해 능력을 향상시키는 것입니다. 각 단계에서 사용된 데이터셋의 개요는 표 6에 제공됩니다.
Table 6: 세 가지 훈련 단계에 걸쳐 사용된 데이터셋 및 샘플 크기.
| 단계 | 데이터셋 | 총 수량 |
|---|---|---|
| 1단계 | Clotho [6], LLaVA-LCS558K [21], Valentini-Botinhao Speech Dataset [29] | 600 K |
| 2단계 | TriSense-2M (880K), LLaVA-Video-178K (120K) [37] | 1 M |
| 3단계 | TriSense-2M (1.12M), LLaVA-Video-178K (380K) [37] | 1.5 M |
1단계. 초기 단계를 위해, 우리는 Clotho [6], LLaVA-LCS558K [21], 그리고 Valentini-Botinhao Speech Dataset [29]의 조합을 훈련 데이터셋으로 사용합니다:
- Clotho는 4,981개의 오디오 클립을 포함하는 오디오 캡셔닝 데이터셋으로, 각 클립은 5개의 고유한 캡션과 짝을 이루어 총 24,905개의 주석이 있습니다. 오디오 클립은 15초에서 30초 사이이며, 각 캡션은 8~20개의 단어로 구성됩니다.
- LLaVA-LCS558K는 BLIP 생성 캡션을 사용하여 주석이 달린 558,000개의 이미지-텍스트 쌍으로 구성된 개념 균형 다중 모드 데이터셋입니다. 이는 비전-언어 모델의 사전 훈련 중 특징 정렬을 지원하도록 설계되었습니다.
- Valentini-Botinhao Speech Dataset은 깨끗한 음성 녹음과 잡음이 섞인 음성 녹음의 병렬 말뭉치입니다. 음성 향상 및 텍스트-음성 변환(TTS) 시스템의 훈련 및 평가에 널리 사용되며, 다양한 소음 조건에서 여러 화자의 48kHz 오디오를 특징으로 합니다.
2단계와 3단계. 이 단계들에서는 새로 제안된 TriSense-2M 데이터셋을 채택하여 9:1의 훈련 대 테스트 분할을 적용합니다. 이로 인해 190만 개의 훈련 샘플과 10만 개의 테스트 샘플이 생성됩니다. 훈련 데이터는 2단계에 약 88만 개, 3단계에 112만 개의 샘플로 추가 분할됩니다.
모델이 일반적인 비디오 이해 능력도 유지하도록 하기 위해, 우리는 LLaVA-Video-178K [37]의 일부를 훈련 데이터에 보충하는데, 이는 비디오 캡셔닝, 개방형 QA, 그리고 다지선다형 QA 작업을 포함합니다. 이 혼합된 작업 데이터셋은 모델이 시간적 추론을 넘어 더 넓은 이해 기술을 개발하는 데 도움을 줍니다. 대규모 평가 시간을 피하기 위해, 우리는 10만 개의 테스트 세트에서 두 가지 필터링 기준을 사용하여 11,415개의 어려운 샘플을 추출합니다: 1) 대부분의 이벤트는 비디오의 시작 부분이 아닌 중간 부분에서 발생해야 합니다. 2) 캡션은 최소 20 단어를 포함해야 합니다. 평가는 단일 A100 SXM4 80GB GPU를 사용하여 배치 크기 1로 수행되며, 완료하는 데 약 8-10 시간이 필요합니다. 비교 대상의 모든 모델은 이 동일한 테스트 하위 집합에서 공식적으로 권장되는 하이퍼파라미터(예: 프레임 수, 온도, top-p 등)를 사용하여 평가됩니다.
A. 3 Detailed training settings
우리의 다중 모드 프레임워크는 각 양식에 대해 전용 인코더를 통합합니다. 시각 양식에는 openai/clip-vit-large-patch14-336 [25]을 채택하고, 오디오 및 음성 양식에는 각각 BEATs_iter3 + (AS2M) (cpt2) [4]와 Whisper-large-V3 [26]을 사용합니다. 대규모 언어 모델(LLM) 백본으로는 다른 LLM 백본을 사용하는 대신 TRACE [11]에서 초기화된 Mistral-7B [17]를 선택했습니다. 이 선택은 TRACE가 대규모 시간적 이해 데이터에 대해 사전 훈련되어 더 강력한 시간적 추론 능력을 갖추고 있다는 점에 기인합니다. 최대 컨텍스트 길이는 4096 토큰으로 구성됩니다.
Table 7: 단계별 훈련 구성 및 하이퍼파라미터.
| 설정 | 1단계 | 2단계 및 3단계 |
|---|---|---|
| 비전 인코더 | clip-vit-large-patch14-336 | clip-vit-large-patch14-336 |
| 오디오 인코더 | BEATs_iter3+ (AS2M) (cpt2) | BEATs_iter3+ (AS2M) (cpt2) |
| 음성 인코더 | Whisper-large-V3 | Whisper-large-V3 |
| DeepSpeed 단계 | Zero2 오프로드 | Zero2 오프로드 |
| LLM 백본 | Mistral-7B-v0.2 | Mistral-7B-v0.2 |
| 배치 크기 | 512 | 128 및 256 |
| 프레임 수 | 1 | 64 |
| 프레임 샘플 | 균일 | 균일 |
| 훈련 에포크 | 2 | 1 |
| 학습률 | ||
| LR 스케줄러 | 코사인 | 코사인 |
| 모델 최대 길이 | 4096 | 4096 |
| 훈련 기간 | 10시간 | 3.5일 및 7일 |
훈련 중에는 효율성을 높이기 위해 비디오를 초당 1 프레임(fps)으로 리샘플링합니다. 이 단계는 추론 중에는 전체 충실도를 유지하기 위해 생략됩니다. 이 리샘플링은 입력 중복성을 줄이고 훈련을 가속화합니다. 1단계에서는 배치 크기 512와 단일 프레임 입력으로 모델을 훈련하며, 4대의 A100SXM4-80GB GPU를 사용하여 10시간 이내에 완료합니다. 2단계와 3단계는 16대의 A100SXM4-80GB GPU에서 각각 배치 크기 128과 256으로 수행됩니다. 2단계는 완료하는 데 약 3.5일이 걸리고, 3단계는 완료하는 데 7일이 걸립니다. BEATs 모델이 Zero3 설정에서 제대로 작동하지 않기 때문에 DeepSpeed Zero2를 사용합니다. 데이터셋 및 하이퍼파라미터에 대한 자세한 내용은 7절에 제공됩니다.
B Data Format
B. 1 Training Generator and Judger
이 섹션에서는 생성자(Generator)와 심판자(Judger) 모두를 위한 훈련 데이터를 준비하는 데 사용되는 데이터 생성 및 수동 필터링 과정을 설명합니다. 전방위적 캡션 생성의 효율성과 품질을 보장하기 위해, 우리는 먼저 GPTo1 [16]을 활용하여 감독 미세 조정(SFT)을 위한 고품질 주석 샘플을 생성합니다. 이 과정에 사용된 특정 프롬프트는 5에 나와 있습니다. 이 프롬프트는 두 가지 목적을 가집니다: GPT를 통해 훈련 데이터를 생성하는 데 사용되며, 생성자와 심판자 모두의 SFT 동안 시스템 프롬프트로도 기능합니다.
캡션 품질을 더욱 향상시키기 위해 2단계 채점 메커니즘을 구현합니다. 캡션이 생성된 후 GPT는 자체 평가를 수행합니다. 그런 다음 별도의 GPT 인스턴스가 추가 평가를 제공하여 저품질 샘플을 걸러냅니다. 이 자동화된 채점 이후, 일관성을 확인하고 높은 품질 기준을 충족하는지 확인하기 위해 수동 샘플링을 수행합니다. 데이터는 1,000개 샘플 배치로 생성됩니다. 각 배치에서 500개 샘플을 무작위로 선택하여 생성된 콘텐츠와 GPT 채점의 신뢰성을 평가하기 위해 수동으로 검토합니다. 검토된 샘플의 80% 이상이 우리의 품질 기준을 충족하면 해당 배치는 유지되고, 그렇지 않으면 폐기됩니다.
궁극적으로, 우리는 생성기를 위해 10,000개의 훈련 샘플을, 심판자를 위해 3,000개의 샘플을 선별합니다. 두 모델 모두 효과적인 캡셔닝 및 판단 능력을 확립하기 위해 3 에포크 동안 훈련됩니다.

Figure 5: 생성자(Generator)와 심판자(Judger) 훈련에 사용된 프롬프트. 왼쪽 프롬프트는 GPT가 오디오, 시각, 음성 입력을 사용하여 생성자를 위한 전방위 모달 캡션을 생성하도록 안내합니다. 오른쪽 프롬프트는 GPT에게 생성된 캡션의 커버리지, 정확성, 의역을 기반으로 품질을 평가하도록 지시하여 심판자를 훈련하는 데 사용됩니다. 데이터 생성 중, 샘플은 무작위로 선택되고 수동으로 필터링되어 고품질 훈련 데이터를 보장합니다.
B. 2 Training data format
이 섹션에서는 TriSense 훈련에 사용되는 데이터 형식을 설명합니다. 우리는 ShareGPT 스타일 형식을 채택하며, 각 훈련 샘플은 8개의 대화 라운드로 구성되며, 각 라운드는 다른 양식 조합에 해당합니다. 이 라운드 내의 작업과 설정은 무작위로 지정됩니다. 예를 들어, 한 라운드는 VS-SC 작업을 포함할 수 있고, 다음 라운드는 AVS-SC 또는 V-MR 작업일 수 있습니다. TRACE의 접근 방식을 따라, 우리는 sync 및 time과 같은 특수 토큰을 사용하여 모델이 다른 예측 헤드 사이를 전환하도록 신호를 보냅니다. 데이터 구조의 예는 6에 설명되어 있습니다.
<코드> ShareGPT의 데이터셋 형식 예시 { "video": "zEqicUE2ROI.mp4", "conversations": [ "from": "human", "value": "<video>\n1070.8초에서 1081.9초까지, 필수적인 시각 자료와 소리를 강조하며 시각-음향 이벤트를 자세히 설명해주세요." }, { "value": "<sync><time><time><time><time><time><time><time><time><time><time><time><time><time><time>한 남자가 무대에서 열정적으로 연설하는 동안 관객은 극장에서 웃고 이야기하고 있습니다. 군중은 몰입하고 반응적입니다." }, "from": "human", "value": "비디오의 [1070.8, 1081.9] 구간에 대한 요약을 제공해주시겠어요? 시각, 오디오, 음성 요소에 초점을 맞춰주세요." }, "from": "gpt", "value": "<sync><time><time><time><time><time><time><time><time><time><time><time><time><time><time>한 사람이 무대에서 공연하고 있고, 관객은 극장에서 웃고 이야기하고 있지만, 음성 자막에는 그 사람이 라따뚜이 영화에 나오는 쥐처럼 생겨서 숨어야 한다고 언급되어 있습니다." }, "from": "human", "value": "<sync><time><time><time><time><time><time><time><time><time><time><time><time><time><time>'한 남자가 무대에서 노래하고 있다'고 묘사된 내용이 비디오에서 일어나는 정확한 시간을 초 단위로 찾아 이 타임스탬프를 보고해주세요." }, "from": "gpt", "value": "<sync><time><time><time><time><time><time><time><time><time><time><time><time><time><time>한 남자가 무대에서 노래하고 있다" } <남은 대화들......> ] "times": [[1070.8, 1081.9], [1070.8, 1081.9], [1070.8, 1081.9], <남은 시간들......>] } </코드>
Figure 6: 훈련 중에 사용된 ShareGPT 스타일 주석 형식의 예. 각 샘플에는 동기화된 양식 단서가 있는 비디오 세그먼트에 대한 다중 턴 대화가 포함됩니다. 공간 제약으로 인해 처음 세 라운드만 표시됩니다.
C Additional Experiments.
C. 1 Ablation study on Segment Captioning
세그먼트 캡셔닝 작업에 대한 절제 연구 결과를 표 8에 제시합니다. 훈련 단계 섹션에서, 1단계가 시간적 모델링을 포함하지 않음에도 불구하고 모델이 여전히 세그먼트 캡셔닝에서 어느 정도 효과를 보인다는 것을 관찰합니다. 이는 쌍을 이룬 훈련을 통해 가능해진 양식-텍스트 정렬 덕분이며, 이는 양식 전반에 걸친 기본적 이해를 촉진합니다. 2단계 이후, 훈련이 Query-Based Connector, 시간 모듈, 그리고 LM 헤드(LLM 백본은 여전히 고정됨)를 통합하면서, 모델은 전체 모델 성능의 약 70-80%에 도달하며, 이는 시간적 구성 요소 훈련의 이점을 나타냅니다.
커넥터 절제 연구에서 적응형 가중치를 제거하면 성능이 저하됩니다. Addition 변형과 Fixed Weights 설정의 처음 세 구성은 약한 결과를 보이며, Addition이 최악의 성능을 보입니다. 그러나 순간 검색 작업에서의 발견과 유사하게, 시각 전용 설정에서 시각 토큰에 고정 가중치 1을 할당하면 약간의 성능 향상을 가져옵니다.
프레임 수 분석에서 입력 프레임 수를 늘리면 대부분의 경우 중간 정도의 이득을 얻으며, 이는 섹션 5.2에서 본 경향을 반영합니다. 그러나 이 개선은 비교적 제한적입니다. 잠재적인 설명은 세그먼트 캡셔닝과 순간 검색 사이의 본질적인 차이에 있습니다. 둘 다 시간적 추론이 필요하지만, 세그먼트 캡셔닝은 공간 정보에 더 의존하며, 프레임을 늘리면 모델의 64프레임 훈련 설정과 충돌하는 공간적 중복성을 도입할 수 있습니다. 반대로, 순간 검색은 더 긴 시간적 컨텍스트에서 더 많은 이점을 얻으며, 추가 프레임이 순차적 이해를 풍부하게 하여 더 상당한 성능 향상을 가져옵니다.
Table 8: 세그먼트 캡셔닝에 대한 절제 연구 결과. 훈련 단계, 커넥터 디자인, 입력 프레임 수의 효과를 네 가지 양식 설정(AVS, VS, AV, V)에 걸쳐 분석합니다. 지표에는 BLEU-4(B), METEOR(M), ROUGE-L(R), CIDEr(C)가 포함됩니다.
| 모델 | 프레임 수 | AVS-SC | VS-SC | AV-SC | V-SC | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | M | R | C | B | M | R | C | B | M | R | C | B | M | R | C | ||
| 훈련 단계 | |||||||||||||||||
| 1단계만 | 64 | 0.0 | 1.5 | 4.3 | 0.1 | 0.0 | 1.4 | 4.1 | 0.1 | 0.0 | 1.3 | 4.1 | 0.1 | 0.0 | 1.3 | 4.0 | 0.1 |
| 1+2 단계 | 64 | 2.1 | 9.3 | 19.8 | 6.6 | 1.8 | 8.6 | 20.2 | 6.7 | 3.0 | 11.1 | 21.5 | 8.2 | 5.3 | 6.2 | 11.8 | 13.8 |
| 커넥터 | |||||||||||||||||
| 덧셈 | 64 | 1.6 | 9.9 | 18.0 | 5.8 | 1.8 | 9.1 | 19.3 | 5.8 | 3.8 | 11.2 | 22.0 | 11.5 | 5.7 | 11.1 | 28.5 | 21.9 |
| 고정 가중치 | 64 | 3.1 | 9.8 | 19.4 | 6.6 | 2.4 | 9.3 | 20.7 | 7.9 | 4.3 | 11.8 | 26.1 | 15.3 | 7.4 | 12.7 | 30.6 | 36.7 |
| 프레임 수 | |||||||||||||||||
| TriSense (7B) | 32 | 3.2 | 9.7 | 19.9 | 7.7 | 2.1 | 9.3 | 19.5 | 7.9 | 3.4 | 11.1 | 22.5 | 9.6 | 6.3 | 11.7 | 29.8 | 29.2 |
| TriSense (7B) | 64 | 3.4 | 10.1 | 20.1 | 8.3 | 3.0 | 10.0 | 22.2 | 11.8 | 5.3 | 12.2 | 26.3 | 15.4 | 7.3 | 12.6 | 30.7 | |
| TriSense (7B) | 128 | 3.4 | 10.2 | 20.2 | 8.5 | 3.1 | 9.9 | 22.8 | 11.5 | 5.4 | 12.3 | 26.7 | 15.4 | 7.3 | 12.8 | 30.8 | 36.1 |
C. 2 Omni-modal dataset & General understanding dataset
우리는 공개 Omni-Modal 벤치마크인 LongVALE [10]에 대한 추가 실험을 수행합니다. LongVALE은 시각, 오디오, 언어 양식에 걸친 이벤트 이해를 위해 설계되었으며, 8,400개의 고품질 장편 비디오에서 수집된 정확한 시간적 주석과 관계 인식 캡션을 갖춘 105,000개의 omni-modal 이벤트를 포함합니다. LongVALE의 공식 보고서에서 명명된 Omni-VTG 및 Omni-SC 작업은 우리 논문의 AVS-MR 및 AVS-SC와 동일합니다. 표 9에 요약된 바와 같이, 순간 검색 작업에 대한 우리의 제로샷 성능은 LongVALE의 모델이 동일한 데이터셋에서 훈련되었음에도 불구하고 그들의 성능과 비슷합니다. 세그먼트 캡셔닝 작업에서 더 큰 격차가 있지만, 이는 우리의 SC 훈련 데이터와 LongVALE의 SC 데이터 간의 캡셔닝 스타일 패턴 차이 때문이라고 생각합니다. 이러한 캡션 패턴의 차이는 네 가지 평가 지표 모두에서 눈에 띄는 하락으로 이어질 수 있습니다.
Table 9: 공개 옴니모달 벤치마크 LongVALE [10]에서의 성능. "*"는 이 모델이 LongVALE 데이터셋으로 훈련되었음을 나타냅니다. ZS와 FT는 각각 제로샷과 미세 조정을 나타냅니다. 최고 및 차선 결과는 각각 굵은 글씨와 밑줄로 강조 표시됩니다.
| 모델 | Omni-VTG (AVS-MR) | Omni-SC (AVS-SC) | ||||||
|---|---|---|---|---|---|---|---|---|
| R@0.3 | R@0.5 | R@0.7 | mIoU | B | M | R | C | |
| VideoChat (ZS) | 2.2 | 0.9 | 0.4 | 3.0 | 0.5 | 9.6 | 0.0 | 8.2 |
| VideoChatGPT (ZS) | 4.9 | 2.9 | 0.9 | 5.0 | 0.4 | 14.0 | 0.9 | 5.9 |
| VideoLLaMA (ZS) | 2.5 | 1.1 | 0.3 | 1.9 | 0.9 | 11.5 | 0.1 | 8.9 |
| PandaGPT (ZS) | 2.5 | 1.0 | 0.3 | 2.2 | 0.6 | 14.9 | 0.3 | 8.9 |
| NExT-GPT (ZS) | 4.3 | 1.9 | 0.7 | 4.0 | 0.4 | 10.2 | 0.0 | 8.1 |
| TimeChat (ZS) | 5.8 | 2.6 | 1.1 | 5.2 | 1.2 | 16.1 | 1.6 | 10.0 |
| VTimeLLM (ZS) | 7.5 | 3.4 | 1.3 | 6.4 | 1.0 | 14.5 | 1.6 | 5.5 |
| LongVALE (FT) * | 15.7 | 8.6 | 3.9 | 11.0 | 5.6 | 22.4 | 20.3 | 10.9 |
| TriSense (ZS) | 14.8 | 9.3 | 4.7 | 11.2 | 4.8 | 21.9 | 18.8 | 10.4 |
일반 비디오 이해 평가를 위해, 우리는 비디오 분석에서 다중 모드 대규모 언어 모델(MLLM)을 평가하기 위해 설계된 대규모 벤치마크인 VideoMME [7]에 대한 결과를 보고합니다. VideoMME는 900개의 비디오(총 254시간)와 2,700개의 인간 주석 QA 쌍을 포함하여 광범위한 시각적 도메인, 시간적 규모 및 양식을 다룹니다. 표 10에서 볼 수 있듯이, 우리 모델은 다중 모드 시나리오에서 상당한 이점을 보일 뿐만 아니라 일반적인 이해 작업에서도 경쟁력 있는 성능을 보입니다. 우리 모델이 공식 논문에 보고된 TRACE-uni [11]가 사용하는 0.9M에 비해 훨씬 적은 일반 이해 데이터(500K)를 사용한다는 점은 주목할 가치가 있습니다.
Table 10: 일반 이해 데이터셋 Video-MME [7]에서의 제로샷 성능. 우리 모델은 TRACE-uni에 비해 일반 이해 데이터의 55%만 사용합니다.
| 모델 | VideoMME (자막 없는 전체 점수) |
|---|---|
| VideoChat2 (7B) | 33.7 |
| Video-LLaVA (7B) | 39.9 |
| VideoLLaMA2 (7B) | 46.6 |
| TRACE (7B) | 43.8 |
| TRACE-uni (7B) | |
| TriSense (7B) |
C. 3 Pseudo-code of Query-Based Connector
<코드> 알고리즘 1 Query-Based Connector의 순전파 요구사항: (A, S, V \in \mathbb{R}^{B \times F \times T \times D}, Q \in \mathbb{R}^{B \times L \times D} \quad \triangleright) 양식 및 쿼리 특징 보장: (Z \in \mathbb{R}^{B \times L \times D}) function (\operatorname{Forward}(A, S, V, Q)) for (X \in{A, S, V}) do (\square) 2-D 사인파형 PE (X \leftarrow X+\operatorname{PE}(X)) (X \leftarrow \operatorname{reshape}(X) \quad \triangleright[L, B, D]) end for (Q \leftarrow \operatorname{reshape}(Q) \quad \triangleright[L, B, D]) (A^{\prime}, S^{\prime}, V^{\prime} \leftarrow \operatorname{CrossAttn}(A, Q), \operatorname{CrossAttn}(S, Q), \operatorname{CrossAttn}(V, Q)) (A^{\prime}, S^{\prime}, V^{\prime} \leftarrow) LayerNorm (\left(A^{\prime}\right)), LayerNorm (\left(S^{\prime}\right)), LayerNorm (\left(V^{\prime}\right)) (\hat{S} \leftarrow \operatorname{AW}\left(A^{\prime}, S^{\prime}, V^{\prime}\right) \quad) D Alg. 2 (\hat{S} \leftarrow) LayerNorm ((\hat{S})) (Z \leftarrow 2 \mathrm{xMLP}(\hat{S})+\hat{S} \quad \triangleright) 2계층 MLP (Z \leftarrow) LayerNorm ((Z)) return (Z) end function </코드>
<코드> 알고리즘 2 적응형 가중치 요구사항: (S_{A}, S_{S}, S_{V} \in \mathbb{R}^{B \times L \times D} \quad \triangleright) 쿼리 관련 특징 보장: (\hat{S} \in \mathbb{R}^{B \times L \times D} \quad \triangleright) 융합된 시퀀스 function (\operatorname{FDG}\left(S_{A}, S_{S}, S_{V}\right) \quad \triangleright \tau) : 온도 (m_{a}, m_{s}, m_{v} \leftarrow \operatorname{globpool}\left(S_{A}, 1\right), \operatorname{globpool}\left(S_{S}, 1\right), \operatorname{globpool}\left(S_{V}, 1\right)) (F \leftarrow \operatorname{stack}\left(m_{a}, m_{s}, m_{v}\right) \quad \triangleright[B, 3, D]) (p \leftarrow \operatorname{softmax}(1 \times \operatorname{MLP}(F) / \tau, \operatorname{dim}=1) \quad \triangleright[B, 3]) (\hat{S} \leftarrow p_{1} \odot S_{A}+p_{2} \odot S_{S}+p_{3} \odot S_{V}) return (\hat{S}) end function </코드>
D Case studies on diferent scenarios
우리는 그림 7부터 12까지 다양한 시나리오에서 TriSense의 사례 연구를 제공합니다.
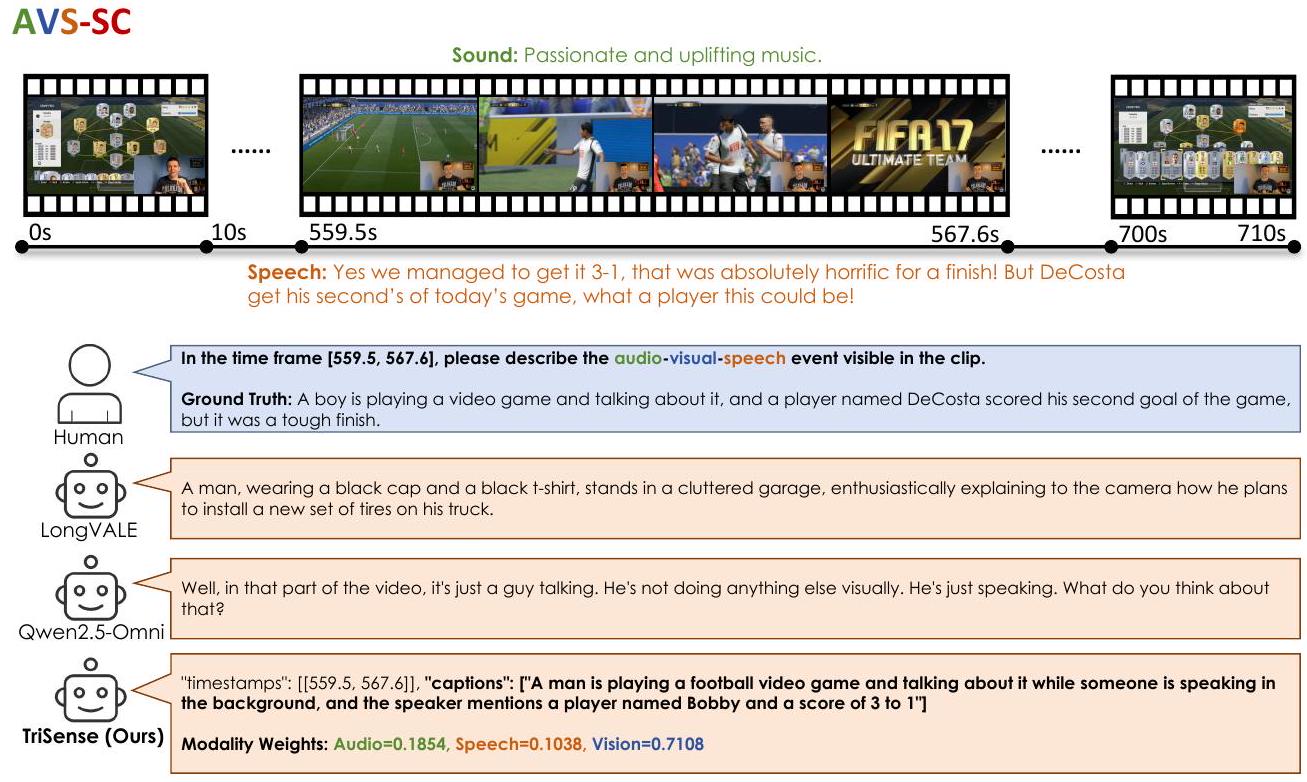
Figure 7: AVS-SC 작업에 대한 TriSense의 사례 연구.
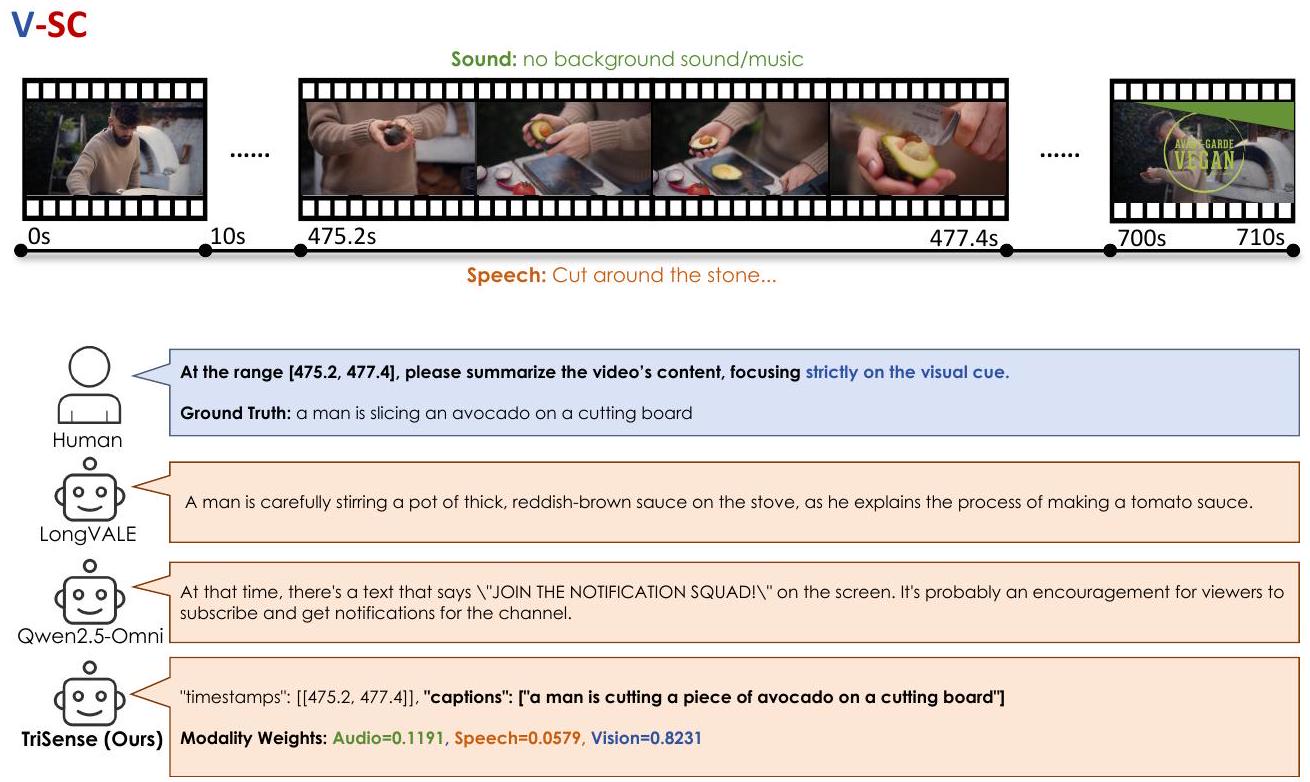
Figure 8: V-SC 작업에 대한 TriSense의 사례 연구.
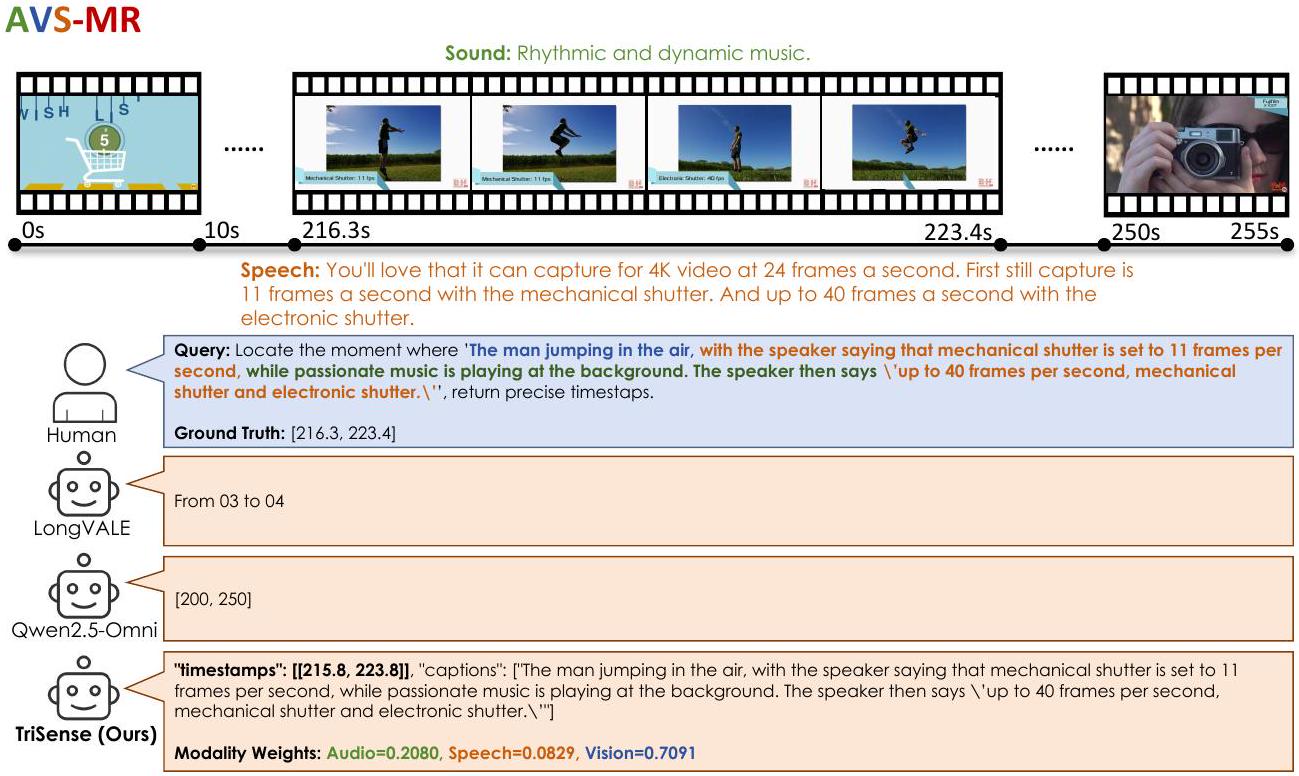
Figure 9: AVS-MR 작업에 대한 TriSense의 사례 연구.
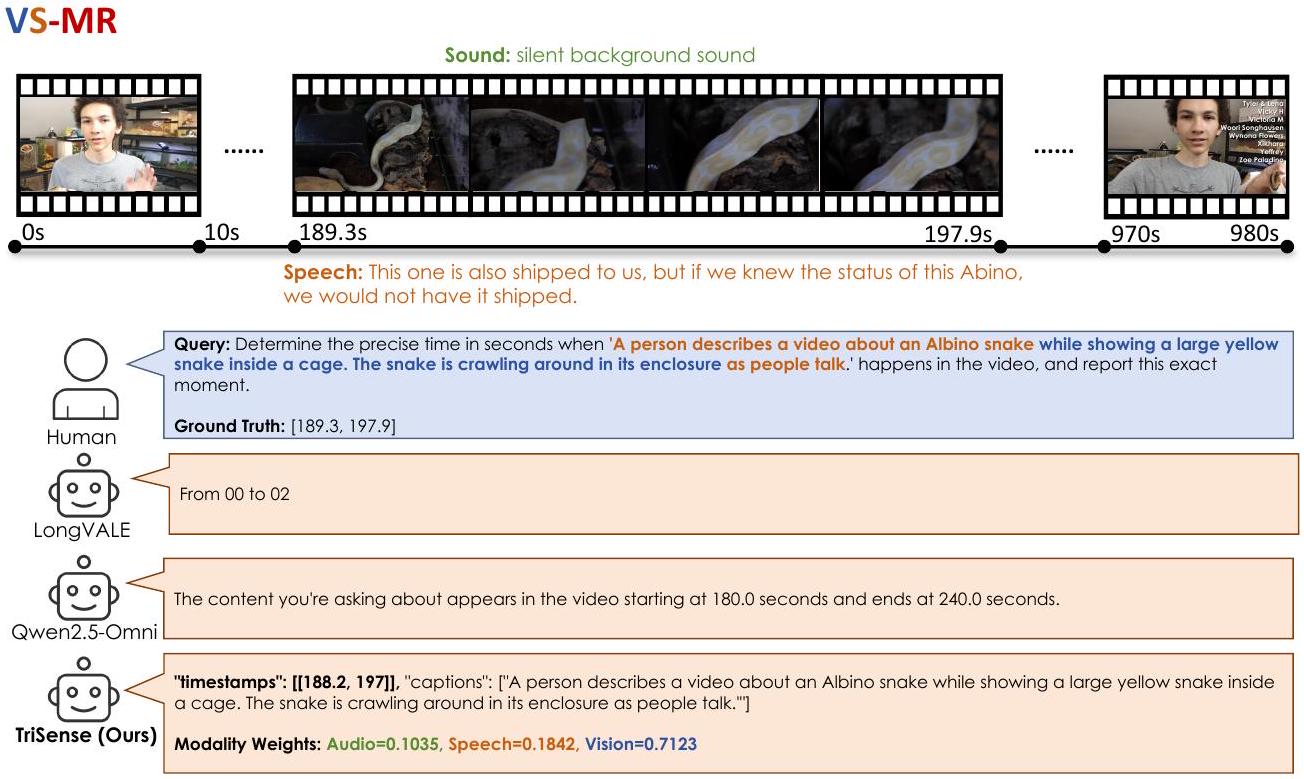
Figure 10: VS-MR 작업에 대한 TriSense의 사례 연구.
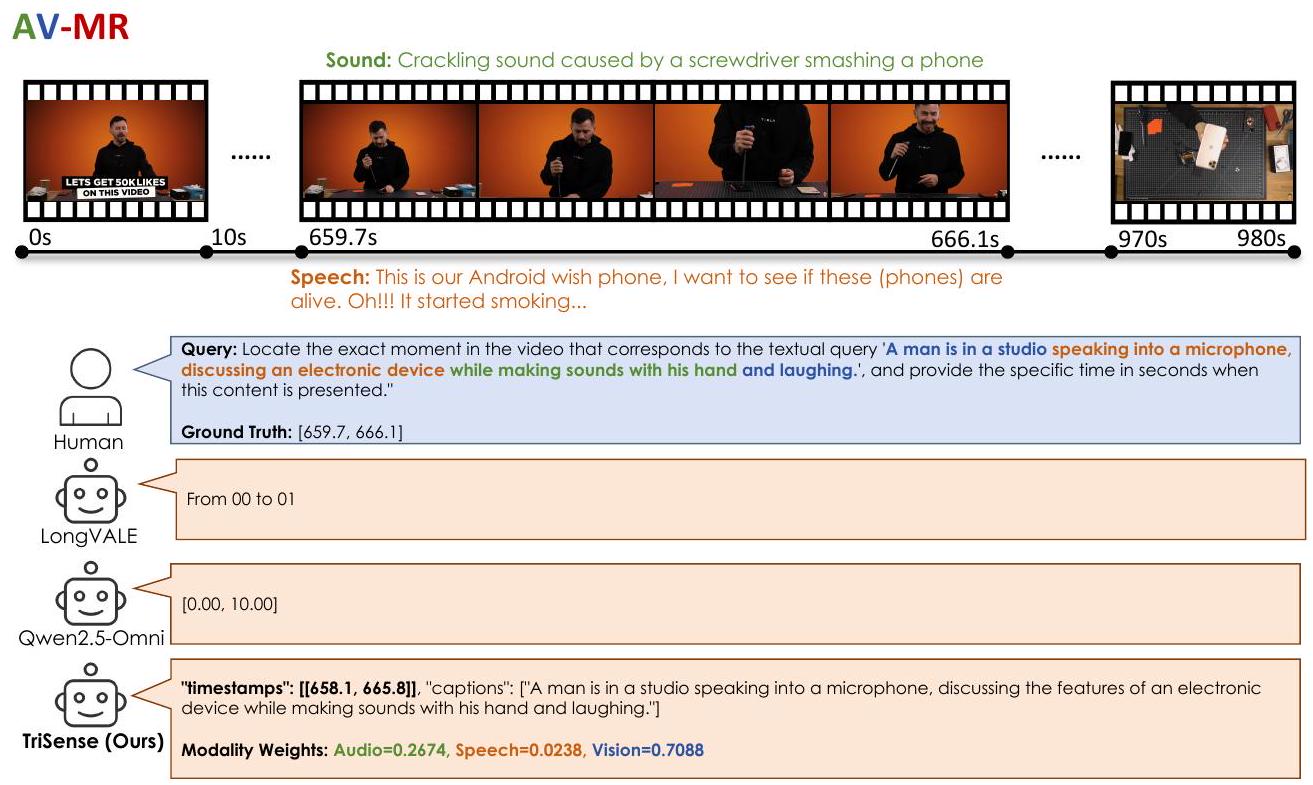
Figure 11: AV-MR 작업에 대한 TriSense의 사례 연구.
General Understanding

Figure 12: 일반 이해 작업에 대한 TriSense의 사례 연구.
Footnotes
-
- 해당 저자