SpeechGPT: 내재된 크로스모달 대화 능력을 갖춘 대규모 언어 모델
SpeechGPT는 다중 모달 콘텐츠를 인식하고 생성할 수 있는 내재된 크로스모달 대화 능력을 갖춘 대규모 언어 모델입니다. 이 모델은 기존의 캐스케이드 방식을 벗어나 이산적인 음성 표현을 활용하여 모달 간 지식 전달을 가능하게 합니다. 대규모 크로스모달 음성 지시 데이터셋인 SpeechInstruct를 구축하고, 3단계 학습 전략(모달리티 적응 사전학습, 크로스모달 지시 미세조정, Chain-of-Modality 지시 미세조정)을 통해 학습되었습니다. 논문 제목: SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities
논문 요약: SpeechGPT: 내재된 크로스모달 대화 능력을 갖춘 대규모 언어 모델
- 논문 링크: https://arxiv.org/abs/2305.11000
- 저자: Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, Xipeng Qiu (Fudan University)
- 발표 시기: 2023, arXiv preprint
- 주요 키워드: LLM, Speech AI, Multimodal, NLP
1. 연구 배경 및 문제 정의
- 문제 정의:
현재 대규모 언어 모델(LLM)은 다중 모달 콘텐츠를 인식하고 이해할 수 있지만, 자발적으로 다중 모달 콘텐츠를 생성할 수는 없습니다. 또한, 음성과 같은 연속적인 신호는 이산적인 토큰을 입력받는 LLM에 직접 적용되기 어렵습니다. 기존의 음성-언어 모델들은 주로 자동 음성 인식(ASR) 및 텍스트-음성 변환(TTS) 모델과 LLM을 직렬로 연결하는 캐스케이드(cascade) 패러다임을 채택하여, 모달 간의 지식 전달을 막고 파라언어적(paralinguistic) 신호의 손실을 야기하며, 진정한 크로스모달 인식 및 생성을 달성하지 못한다는 한계가 있습니다. - 기존 접근 방식:
기존의 speech-language 모델들은 주로 ASR, TTS 모델과 LLM을 직렬로 연결하거나, LLM이 제어 허브 역할을 하는 캐스케이드(cascading) 패러다임을 채택합니다. 이러한 방식은 LLM의 지식이 음성 모달리티로 전달되지 못하고, 감정이나 운율 같은 파라언어적 신호가 손실되며, 음성 합성만 가능하고 의미 이해는 부족하다는 한계가 있습니다.
2. 주요 기여 및 제안 방법
-
논문의 주요 기여:
- 다중 모달 콘텐츠를 인식하고 생성할 수 있는 최초의 멀티모달 대규모 언어 모델을 구축했습니다.
- 최초의 대규모 음성-텍스트 크로스모달 지시 따르기 데이터셋인 SpeechInstruct를 구축하고 공개했습니다.
- 강력한 인간 지시 따르기 능력과 음성 대화 능력을 갖춘 최초의 음성 대화 LLM을 구축했습니다.
- 이산적인 표현을 통해 다른 모달리티를 LLM에 통합할 수 있는 큰 잠재력을 보여주었습니다.
-
제안 방법:
SpeechGPT는 이산적인 음성 표현을 활용하여 음성과 텍스트 간의 모달리티를 통일하고, LLM의 어휘에 음성 토큰을 확장하여 음성 인식 및 생성 능력을 내재화합니다. 이를 위해 대규모 음성-텍스트 크로스모달 지시 따르기 데이터셋인 SpeechInstruct를 구축했습니다. SpeechInstruct는 ASR/TTS 작업을 위한 Cross-modal Instruction과 음성 입출력을 위한 Chain-of-Modality Instruction으로 구성됩니다.모델 학습은 3단계 전략을 따릅니다:
- 모달리티 적응 사전 학습(Modality-Adaptation Pre-training): 레이블 없는 음성 데이터에 대해 LLM을 훈련하여 이산 단위 모달리티를 처리할 수 있도록 합니다.
- 크로스모달 지시 미세 조정(Cross-modal Instruction Fine-Tuning): SpeechInstruct의 Cross-modal Instruction과 텍스트 데이터셋을 혼합하여 음성-텍스트 모달리티를 정렬합니다.
- Chain-of-Modality 지시 미세 조정(Chain-of-Modality Instruction Fine-Tuning): 파라미터 효율적인 LoRA(Low-Rank Adaptation)를 활용하여 SpeechInstruct의 Chain-of-Modality Instruction에 대해 추가적인 모달리티 정렬을 수행합니다.
SpeechGPT의 모델 구조는 이산 단위 추출기(HuBERT), 대규모 언어 모델(LLaMA), 단위 보코더(Unit Vocoder, HiFi-GAN)로 구성됩니다.
3. 실험 결과
- 데이터셋:
모달리티 적응 사전 학습에는 6만 시간의 레이블 없는 영어 오디오북 음성이 포함된 LibriLight를 사용했습니다. 크로스모달 지시 미세 조정 및 Chain-of-Modality 지시 미세 조정에는 Gigaspeech, Common Voice, LibriSpeech, moss-002-sft-data 데이터셋을 활용했습니다. 백본 모델로는 LLaMA-13B를 사용했으며, 훈련에는 최대 96개의 A100 GPU가 사용되었습니다. - 주요 결과:
인간 평가를 통해 SpeechGPT의 크로스모달 지시 따르기 능력과 음성 대화 능력을 평가했습니다.
- 크로스모달 지시 따르기: 다양한 음성-텍스트 및 텍스트-음성 지시(예: 음성 전사, 텍스트 음성 변환)에 대해 정확한 출력을 생성하는 인상적인 능력을 보여주었습니다.
- 음성 대화: 음성 지시를 이해하고 음성으로 응답하며, HHH(무해함, 유익함, 정직함) 기준을 준수하는 강력한 대화 능력을 입증했습니다. 전반적으로 SpeechGPT는 단일 모달 및 크로스모달 지시 따르기 작업뿐만 아니라 음성 대화 작업에서도 강력한 성능을 보여주었습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
기존 캐스케이드 방식의 한계를 극복하고, LLM이 음성 모달리티를 내재적으로 이해하고 생성할 수 있도록 한 점이 가장 인상 깊습니다. 이산적인 음성 표현을 LLM에 통합하여 모달리티 간의 지식 전달을 가능하게 한 아이디어가 혁신적입니다. 또한, 대규모 크로스모달 음성 지시 데이터셋인 SpeechInstruct를 구축하여 연구의 기반을 마련한 점도 큰 장점입니다. - 단점/한계:
논문에서 언급된 한계점으로는 1) 음성의 파라언어적 정보(감정, 운율)를 고려하지 못하는 점, 2) 음성 응답 생성 전 텍스트 기반 응답을 먼저 생성해야 하는 점, 3) 컨텍스트 길이 제한으로 인한 다중 턴 대화 지원의 한계가 있습니다. - 응용 가능성:
SpeechGPT는 더욱 자연스럽고 직관적인 음성 비서, 다중 모달 콘텐츠 생성 도구, 음성 기반의 교육 및 접근성 솔루션 등 다양한 분야에 응용될 수 있습니다. 특히, 음성 모달리티를 LLM에 직접 통합함으로써 기존 ASR/TTS 시스템의 오류 누적 문제를 해결하고, 더 유연하고 지능적인 음성 상호작용 시스템 개발에 기여할 수 있을 것으로 기대됩니다.
5. 추가 참고 자료
Zhang, Dong, et al. "Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities." arXiv preprint arXiv:2305.11000 (2023).
SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou,* Xipeng Qiu*<br>School of Computer Science, Fudan University Shanghai Key Laboratory of Intelligent Information Processing, Fudan University<br>dongzhang22@m.fudan.edu.cn<br>{smli20, zhouyaqian, xpqiu}@fudan.edu.cn
https://github.com/Onutation/SpeechGPT
Abstract
Multi-modal large language models은 인공 일반 지능(Artificial General Intelligence, AGI)을 향한 중요한 단계로 여겨지며 ChatGPT의 등장과 함께 상당한 관심을 받았습니다. 하지만 현재의 speech-language 모델들은 일반적으로 캐스케이드(cascade) 패러다임을 채택하여, 모달 간의 지식 전달을 막고 있습니다. 본 논문에서는 다중 모달 콘텐츠를 인식하고 생성할 수 있는, 내재적인 cross-modal 대화 능력을 갖춘 large language model인 SpeechGPT를 제안합니다. 이산적인 음성 표현을 사용하여, 우리는 먼저 대규모 cross-modal 음성 지시 데이터셋인 SpeechInstruct를 구축합니다. 추가적으로, 우리는 modality-adaptation 사전 학습, cross-modal 지시 미세 조정, 그리고 chain-of-modality 지시 미세 조정을 포함하는 3단계 학습 전략을 사용합니다. 실험 결과는 SpeechGPT가 다중 모달 인간 지시를 따르는 인상적인 능력을 가지고 있음을 보여주며, 하나의 모델로 여러 모달리티를 처리할 수 있는 잠재력을 강조합니다. 데모는 https://Onutation.github.io/SpeechGPT.github.io/ 에서 확인할 수 있습니다.
1 Introduction
Large language models (OpenAI, 2023; Touvron et al., 2023)은 다양한 자연어 처리 작업에서 놀라운 성능을 보여주었습니다. 한편, GPT-4, PALM-E (Driess et al., 2023), LLaVA (Liu et al., 2023)와 같은 multi-modal large language models은 LLM이 다중 모달 정보를 이해하는 능력을 탐구해 왔습니다. 그러나 현재의 LLM과 일반 인공 지능(AGI) 사이에는 상당한 격차가 존재합니다. 첫째, 대부분의 현재 LLM은 다중 모달 콘텐츠를 인식하고 이해할 수 있을 뿐, 자발적으로 다중 모달 콘텐츠를 생성할 수는 없습니다. 둘째, 이미지나 음성과 같은 연속적인 신호는 이산적인 토큰을 입력받는 LLM에 직접 적용될 수 없습니다.
현재의 speech-language 모델은 주로 캐스케이딩(cascading) 패러다임을 채택합니다 (Huang et al., 2023a). 즉, LLM이 자동 음성 인식(automatic speech recognition, ASR) 모델이나 텍스트-음성 변환(text-to-speech, TTS) 모델과 직렬로 연결되거나, LLM이 제어 허브 역할을 하여 여러 음성 처리 모델이 통합되어 다중 오디오 또는 음성 작업을 처리합니다 (Huang et al., 2023a; Shen et al., 2023). 생성적 음성 언어 모델에 대한 일부 이전 연구는 음성 신호를 이산적인 표현으로 인코딩하고(Baevski et al., 2020, Hsu et al., 2021) 이를 언어 모델로 모델링하는 것을 포함합니다(Lakhotia et al., 2021; Borsos et al., 2022; Zhang et al., 2023b; Wang et al., 2023).
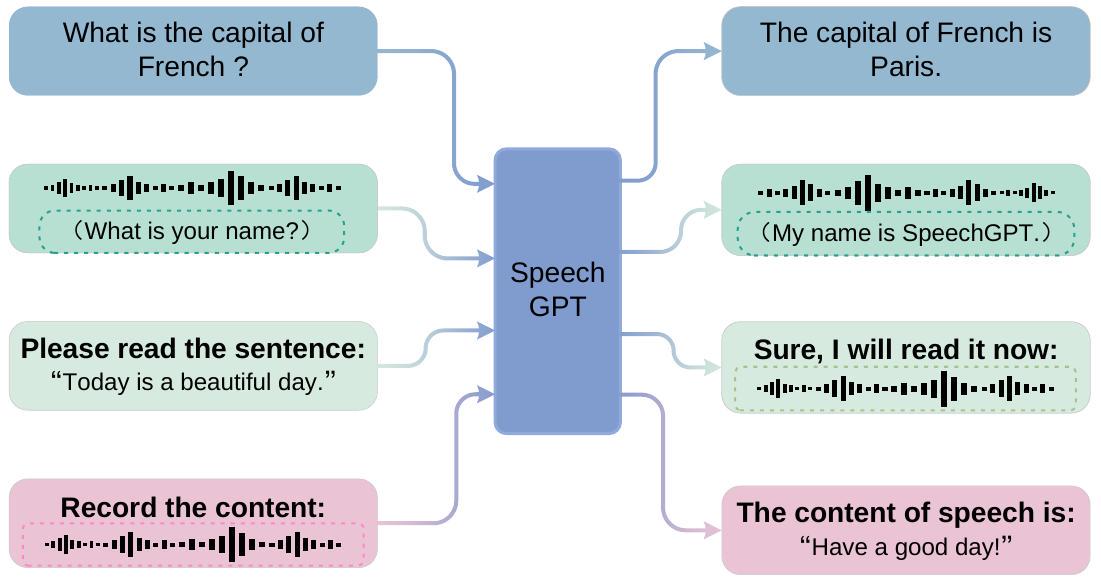
Figure 1: SpeechGPT의 여러 cross-modal 작업을 처리하는 능력.
음성을 인식하고 생성할 수 있지만, 기존의 캐스케이딩 방식이나 음성 언어 모델은 여전히 몇 가지 한계를 가집니다. 첫째, 캐스케이드 모델의 LLM은 콘텐츠 생성기로서만 기능합니다. 음성과 텍스트의 표현이 정렬되어 있지 않기 때문에 LLM의 지식이 음성 모달리티로 전달될 수 없습니다. 둘째, 캐스케이드 접근 방식(Shen et al., 2023; Huang et al., 2023a)은 감정이나 운율과 같은 파라언어적(paralinguistic) 신호의 손실을 겪습니다. 셋째, 기존의 음성 언어 모델(Wang et al., 2023, Zhang et al., 2023b)은 음성을 합성하기만 할 뿐 그 의미 정보를 이해하지 못하여 진정한 cross-modal 인식과 생성을 달성하지 못합니다.
본 논문에서는 다중 모델 콘텐츠를 인식하고 생성할 수 있는, 내재적인 cross-modal 대화 능력을 갖춘 large language model인 SpeechGPT를 제안합니다. 우리는 자기 지도 학습으로 훈련된 음성 모델을 사용하여 음성 이산화를 수행함으로써 음성과 텍스트 간의 모달리티를 통일합니다. 이산적인 음성 토큰은 LLM의 어휘에 확장되어 모델이 음성을 인식하고 생성하는 내재적 능력을 갖추게 됩니다.
모델에 다중 모달 지시를 처리할 수 있는 능력을 제공하기 위해, 우리는 최초의 음성-텍스트 cross-modal 지시 따르기 데이터셋인 SpeechInstruct를 구축합니다. 구체적으로, 우리는 음성을 이산 단위(discrete units)로 이산화하고(Hsu et al., 2021) 기존 ASR 데이터셋을 기반으로 cross-modal 단위-텍스트 쌍을 구성합니다. 한편, 우리는 부록 B에 설명된 바와 같이 실제 사용자 지시를 시뮬레이션하기 위해 GPT-4를 사용하여 다양한 작업에 대한 수백 개의 지시를 구성합니다. 또한, 모델의 cross-modal 능력을 더욱 향상시키기 위해, 우리는 Chain-of-Modality 지시 데이터를 설계했습니다. 즉, 모델이 음성 명령을 받고, 텍스트로 과정을 생각한 다음, 음성으로 응답을 출력하는 방식입니다.
더 나은 cross-modal 전이와 효율적인 훈련을 위해 SpeechGPT는 3단계 훈련 과정을 거칩니다: modality-adaptation 사전 훈련, cross-modal 지시 미세 조정, 그리고 chain-of-modality 지시 미세 조정. 첫 번째 단계는 이산 음성 단위 연속 과제를 통해 SpeechGPT의 음성 이해를 가능하게 합니다. 두 번째 단계는 SpeechInstruct를 사용하여 모델의 cross-modal 능력을 향상시킵니다. 세 번째 단계는 추가적인 모달리티 정렬을 위해 파라미터 효율적인 LoRA (Hu et al., 2021) 미세 조정을 활용합니다. SpeechGPT의 효과를 평가하기 위해, 우리는 광범위한 인간 평가와 사례 분석을 수행하여 SpeechGPT의 텍스트 작업, 음성-텍스트 cross-modal 작업, 그리고 음성 대화 작업에 대한 성능을 추정합니다. 결과는 SpeechGPT가 단일 모달 및 cross-modal 지시 따르기 작업뿐만 아니라 음성 대화 작업에 대해 강력한 능력을 보여준다는 것을 입증합니다. 우리의 기여는 다음과 같습니다:
- 우리는 다중 모달 콘텐츠를 인식하고 생성할 수 있는 최초의 multi-modal large language model을 구축합니다.
- 우리는 최초의 대규모 음성-텍스트 cross-modal 지시 따르기 데이터셋인 SpeechInstruct를 구축하고 공개합니다.
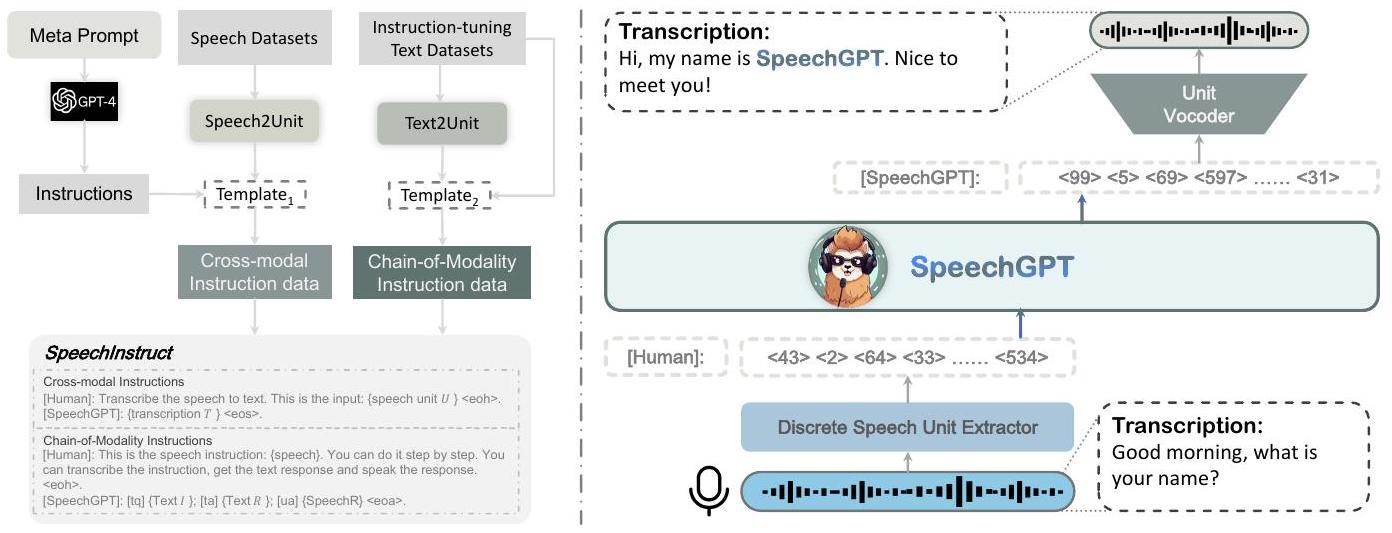
Figure 2: 왼쪽: SpeechInstruct 구축 과정 개요. SpeechInstruct 데이터셋은 Cross-modal Instruction 데이터와 Chain-of-Modality Instruction 데이터의 두 부분으로 구성됩니다. 템플릿 은 3.1에, 템플릿 는 부록 C에 나와 있습니다. 오른쪽: SpeechGPT 모델 구조 그림.
- 우리는 강력한 인간 지시 따르기 능력과 음성 대화 능력을 갖춘 최초의 음성 대화 LLM을 구축합니다.
- 우리는 이산적인 표현을 통해 다른 모달리티를 LLM에 통합할 수 있는 큰 잠재력을 보여줍니다.
2 Related Work
Multi-modal Large Language Model
현재 multi-modal LLM은 주로 시각 영역에 중점을 두며, 사전 훈련된 시각 인코더에서 얻은 연속적인 표현을 LLM에 입력하여 시각-언어 데이터에 대한 전체 파라미터 또는 파라미터 효율적인 훈련을 용이하게 합니다(OpenAI, 2023, Huang et al., 2023b; Zhang et al., 2023a). Palm-E (Driess et al., 2023)는 540B PaLM (Chowdhery et al., 2022)과 22B Vision Transformer (Dosovitskiy et al., 2021)를 통합하여 가장 큰 시각-언어 모델을 만듭니다. LLaVA (Liu et al., 2023)는 사전 훈련된 CLIP (Radford et al., 2021) 시각 인코더와 LLaMA (Touvron et al., 2023)를 활용하고 GPT4의 도움을 받은 시각 지시 데이터에 대해 instruct tuning을 수행합니다. X-LLM (Chen et al., 2023)은 X2L 인터페이스를 사용하여 다중 모달리티를 large language model의 입력으로 변환합니다. 그러나 이러한 구조는 LLM이 다중 모달 입력을 처리할 수 있게 할 뿐, 다중 모달 출력을 생성할 능력은 없습니다. 이전 연구와 달리, 우리의 접근 방식은 음성 중심의 multi-modal LLM 개발에 중점을 두어 다중 모달 입력과 출력을 모두 수용할 수 있는 능력을 부여합니다.
Generative Spoken Language Model
이산적인 자기 지도 표현 기반의 생성적 음성 언어 모델링은 대규모 음성 데이터셋 훈련에서 놀라운 진전을 보이고 있습니다 (Nguyen et al., 2022). AudioLM (Borsos et al., 2022)은 오디오 코덱과 의미론적 코드를 기반으로 음성을 모델링하는 것을 제안하며, 이는 텍스트 없는 환경에서 음성을 합성할 수 있습니다. VALL-E (Wang et al., 2023)는 오디오 코덱을 기반으로 생성적 음성 언어 모델을 구축하고 Text-to-Speech를 조건부 생성 작업으로 처리합니다. 그러나 이러한 모델들은 특정 작업을 위해 설계되었으며 LLM의 이점을 활용하지 못했습니다. SpeechGPT는 LLM의 기반 위에 구축되었으며 LLM의 지식을 음성 모달리티로 전달하여 결과적으로 더 나은 작업 일반화 및 인간 지시 따르기 능력을 얻습니다.
Speech-Enabled LLM Interaction
ChatGPT의 등장 이후, 여러 연구들이 LLM과의 직접적인 음성 상호작용을 가능하게 하기 위해 전문가 음성 모델과 LLM의 통합에 집중해 왔습니다. HuggingGPT (Shen et al., 2023)는 LLM에 의한 인간 지시의 작업 분해를 용이하게 하고 Huggingface의 모델을 호출하여 자동 음성 인식(ASR) 및 텍스트-음성 변환 모델을 포함한 특정 작업을 수행할 수 있도록 합니다. AudioGPT (Huang et al., 2023a)는 다양한 오디오 기반 모델을 활용하여 복잡한 오디오 정보를 처리하고 LLM을 입력/출력 인터페이스(ASR, TTS)와 연결하여 음성 대화를 수행합니다. 그러나 이러한 모델들은 복잡성이 증가하고, 광범위한 리소스를 필요로 하며, 피할 수 없는 오류 누적 문제에 취약합니다. 우리의 접근 방식은 ASR 또는 TTS 시스템에 의존하지 않고 LLM과의 음성 상호작용을 가능하게 하여 앞서 언급한 단점을 피합니다.
3 SpeechInstruct Construction
공개적으로 사용 가능한 음성 데이터의 한계와 음성-텍스트 작업의 다양성 부족으로 인해, 우리는 음성-텍스트 cross-modal 지시 따르기 데이터셋인 SpeechInstruct를 구축합니다. 이 데이터셋은 두 부분으로 구성되는데, 첫 번째 부분은 Cross-Modal Instruction이라 불리고, 두 번째 부분은 Chain-of-Modality Instruction이라 불립니다. SpeechInstruct의 구축 과정은 그림 2에 설명되어 있습니다.
3.1 Cross-modal Instruction
Data Collection
우리는 Gigaspeech (Chen et al., 2021), Common Voice (Ardila et al., 2020), 그리고 LibriSpeech (Panayotov et al., 2015)를 포함한 여러 대규모 영어 ASR 데이터셋을 수집하여 Cross-Modal Instruction을 구축합니다. 우리는 mHuBERT²를 음성 토크나이저로 사용하여 음성 데이터를 이산 단위로 변환하고 인접 프레임의 반복적인 단위를 제거하여 축소된 단위를 얻습니다. 최종적으로, 우리는 9백만 개의 단위-텍스트 데이터 쌍을 얻습니다.
Task Description Generation
우리는 음성-텍스트 데이터 쌍과 호환되는 ASR 및 TTS 작업 설명을 생성합니다. Self-Instruct 방법(Wang et al., 2022)과 달리, 우리는 제로샷(zero-shot) 접근 방식을 통해 설명을 생성합니다. 구체적으로, 우리는 부록 A에 표시된 프롬프트를 OpenAI GPT-4에 직접 입력하여 작업 설명을 생성합니다. 우리의 생성 방법은 각 작업에 대해 100개의 지시를 생성하며, 일부 예는 부록 B에 나와 있습니다.
Instruction Formatting
이산 단위 시퀀스 와 그에 연관된 전사 에 대해, 우리는 확률 를 기반으로 ASR 작업 또는 TTS 작업을 구축하는 데 사용될지 결정합니다. 이후, 해당 작업 설명에서 무작위로 설명 를 선택합니다. 이로써 작업 설명, 이산 단위 시퀀스, 그리고 전사로 구성된 삼중항 가 생성됩니다. 그 다음, 이 삼중항은 템플릿을 사용하여 지시문으로 조립됩니다: [Human]: {D}. This is input: {U}<eoh>.[SpeechGPT]: {T}<eos>. 다중 턴 대화를 지원하기 위해, 조립된 지시문들은 모델의 최대 입력 길이를 준수하면서 다중 턴 대화의 형태로 연결됩니다.
3.2 Chain-of-Modality Instruction
Speech Instruction Generation
음성 입력과 음성 출력을 갖는 지시 데이터가 부족하기 때문에, 우리는 텍스트 지시 데이터를 음성 지시 데이터로 변환하기 위해 텍스트-단위 생성기(text-to-unit generator)를 훈련시켰습니다. 구체적으로, 텍스트-단위 생성기는 Transformer 인코더-디코더 아키텍처를 채택합니다. 우리는 이를 Cross-modal Instruction의 LibriSpeech 단위-텍스트 쌍으로 훈련시켰습니다. 우리는 moss-002-sft-data 데이터셋³에서 응답 길이가 35단어 미만인 37,969개의 샘플을 선택했습니다. 그리고 우리는 그들의 지시와 응답을 모두 텍스트-단위 생성기를 통해 단위 시퀀스로 변환했습니다. 결과적으로, 우리는 음성 지시, 텍스트 지시, 텍스트 응답, 그리고 음성 응답으로 구성된 37,969개의 4중항 (SpeechI, TextI, TextR, SpeechR)을 얻었습니다.
Instruction Formatting
위의 4중항을 사용하여, 우리는 네 가지 입출력 형식, 즉 음성 지시-음성 응답, 음성 지시-텍스트 응답, 텍스트 지시-음성 응답, 텍스트 지시-텍스트 응답에 대한 연쇄적 사고(chain-of-thought) 스타일의 지시를 구성할 수 있었습니다. 해당 템플릿은 부록 C에서 찾을 수 있습니다.
4 SpeechGPT
4.1 Model Structure
서로 다른 모달리티에 걸쳐 아키텍처 호환성을 제공하기 위해 통일된 프레임워크가 설계되었습니다. 그림 2에서 볼 수 있듯이, 우리 모델은 세 가지 주요 구성 요소로 이루어져 있습니다: 이산 단위 추출기(discrete unit extractor), large language model, 그리고 단위 보코더(unit vocoder). 이 아키텍처 하에서 LLM은 다중 모달 입력을 인식하고 다중 모달 출력을 생성할 수 있습니다.
Discrete Unit Extractor
이산 단위 추출기는 Hidden-unit BERT (HuBERT) 모델(Hsu et al., 2021)을 활용하여 연속적인 음성 신호를 이산 단위의 시퀀스로 변환합니다. 2HuBERT는 모델의 중간 표현에 k-means 클러스터링을 적용하여 마스킹된 오디오 세그먼트에 대한 이산 레이블을 예측함으로써 학습하는 자기 지도 모델입니다. 1차원 컨볼루션 레이어와 Transformer 인코더의 조합을 특징으로 하여 음성을 연속적인 중간 표현으로 인코딩하며, k-means 모델은 이러한 표현을 클러스터 인덱스의 시퀀스로 추가 변환합니다. 이후, 인접한 중복 인덱스가 제거되어 로 표현되는 이산 단위 시퀀스가 생성되며, 여기서 는 총 클러스터 수를 나타냅니다.
Large Language Model
우리는 Meta AI의 LLaMA (Touvron et al., 2023) 모델을 우리의 Large Language Model로 사용합니다. LLaMA는 임베딩 레이어, 여러 개의 transformer 블록, 그리고 LM 헤드 레이어로 구성됩니다. LLaMA의 총 파라미터 수는 7B에서 65B에 이릅니다. 1.0조 개의 토큰으로 구성된 방대한 훈련 데이터셋을 바탕으로, LLaMA는 훨씬 더 큰 175B GPT-3와 비교하여 다양한 NLP 벤치마크에서 경쟁력 있는 성능을 보여줍니다.
Unit Vocoder
(Polyak et al., 2021)의 단일 화자 단위 보코더의 한계 때문에, 우리는 이산 표현으로부터 음성 신호를 디코딩하기 위해 다중 화자 단위 HiFi-GAN을 훈련시킵니다. HiFi-GAN 아키텍처는 생성기 와 다중 판별기 로 구성됩니다. 생성기는 조회 테이블(look-up tables, LUT)을 사용하여 이산 표현을 임베딩하고, 임베딩 시퀀스는 전치 컨볼루션(transposed convolution)과 팽창 레이어(dilated layers)가 있는 잔차 블록(residual block)으로 구성된 일련의 블록에 의해 업샘플링됩니다. 화자 임베딩은 업샘플링된 시퀀스의 각 프레임에 연결됩니다. 판별기는 다중 주기 판별기(Multi-Period Discriminator, MPD)와 다중 스케일 판별기(Multi-Scale Discriminator, MSD)를 특징으로 하며, 이는 (Polyak et al., 2021)과 동일한 아키텍처를 가집니다.
4.2 Training
음성 이산 표현을 LLM에 통합하기 위해, 우리는 먼저 어휘와 해당 임베딩 행렬을 확장합니다. 훈련 과정을 세 단계로 나눕니다. 첫 번째 단계는 쌍이 없는(unpaired) 음성 데이터에 대한 ModalityAdaptation Pre-training입니다. 두 번째 단계는 Cross-modal Instruction Fine-Tuning입니다. 세 번째 단계는 Chain-of-Modality Instruction Fine-Tuning입니다.
Expanding Vocabulary
크기 의 원래 LLM 어휘 가 주어졌을 때, 음성 이산 표현을 LLM에 통합하기 위해 우리는 크기가 인 추가 단위 토큰 집합 으로 어휘를 확장합니다. 확장된 어휘 는 원래 어휘 와 새로운 단어 의 합집합입니다:
원래 단어 임베딩 행렬을 로 나타내며, 여기서 는 단어 임베딩의 차원입니다. 확장된 어휘를 수용하기 위해, 우리는 무작위로 초기화된 단어 임베딩 행렬 를 만들어야 합니다. 우리는 의 값을 의 첫 행에 복사하여 원래 단어 임베딩을 보존합니다:
마지막으로, 원래 어휘와 단어 임베딩 행렬을 새로운 어휘 와 단어 임베딩 행렬 로 대체합니다.
Stage 1: Modality-Adaptation Pre-training
LLM이 이산 단위 모달리티를 처리할 수 있도록, 우리는 레이블이 없는 음성 코퍼스를 사용하여 다음 토큰 예측 작업에서 LLM을 훈련시킵니다. 이 접근 방식은 LLM의 텍스트 사전 훈련 목표와 일치합니다. 음성 으로 구성된 레이블 없는 음성 코퍼스 와 LLM 이 주어졌을 때, 음의 로그 가능도 손실은 다음과 같이 공식화될 수 있습니다:
여기서 은 데이터셋 의 음성 수, 는 음성 의 이산 단위 토큰 수, 그리고 는 번째 음성의 번째 단위 토큰을 나타냅니다.
Stage 2: Cross-modal Instruction Fine-Tuning
이 단계에서는 쌍을 이룬 데이터를 활용하여 음성과 텍스트 모달리티를 정렬합니다. SpeechInstruct의 Cross-modal Instruction을 moss-002-sft 데이터셋과 혼합하여 혼합 데이터셋 를 파생하며, 이는 샘플 로 구성됩니다. 우리는 첫 번째 단계에서 얻은 모델 을 에 대해 미세 조정합니다.
각 샘플 는 로 구성되며, 접두사와 텍스트를 연결하여 형성됩니다. 훈련 목표는 음의 로그 가능도를 최소화하는 것이며, 손실 계산은 접두사를 무시하고 텍스트 부분만 고려하며, 다음과 같이 형식화할 수 있습니다:
여기서 는 코퍼스 의 샘플 수, 는 샘플 의 총 토큰 수, 는 의 접두사 부분의 토큰 수, 그리고 는 의 번째 단어를 나타냅니다.
Stage 3: Chain-of-Modality Instruction Fine-Tuning
2단계에서 모델을 얻은 후, 우리는 파라미터 효율적인 Low-Rank Adaptation (LoRA) (Hu et al., 2021)을 활용하여 SpeechInstruct의 Chain-ofModality Instruction에 대해 미세 조정합니다. 우리는 LoRA 가중치(어댑터)를 어텐션 메커니즘에 추가하고 새로 추가된 LoRA 파라미터를 훈련합니다. 우리는 2단계와 동일한 손실 함수를 채택합니다.
5 Experiments
5.1 Experimental Setups
Datasets
modality-adaption 사전 훈련을 위해, 우리는 6만 시간의 레이블이 없는 영어 오디오북 음성이 포함된 LibriLight (Kahn et al., 2020)를 사용합니다. cross-modal 지시 미세 조정 단계를 위해, 우리는 Gigaspeech (Chen et al., 2021), Common voice (Ardila et al., 2020), LibriSpeech (Panayotov et al., 2015) 데이터셋과 moss-002-sft-data 데이터셋을 사용하며, 이는 3.1절에 자세히 설명되어 있습니다. chain-of-modality 지시 미세 조정 단계를 위해, 우리는 moss-002-sft-data 데이터셋을 사용하며, 이는 3.2절에 자세히 설명되어 있습니다.
Configuration
우리는 LLaMA-13B (Touvron et al. 2023)를 백본 모델로 사용합니다. 1단계에서는 96개의 A100 GPU를 사용하여 배치 크기 768로 900 스텝 동안 훈련합니다. 2단계에서는 96개의 A100 GPU를 사용하여 배치 크기 1536으로 2100 스텝 동안 훈련합니다. 3단계에서는 8개의 A100 GPU를 사용하여 배치 크기 128로 4200 스텝 동안 훈련합니다. 훈련 하이퍼파라미터에 대한 자세한 내용은 부록 3에 나와 있습니다. 디코딩을 위해, 최대 시퀀스 길이를 2048로 설정하고 온도를 0.8로 설정합니다. 우리는 인 Top- 샘플링을 사용합니다. 또한 인 Top- 샘플링을 사용합니다.
<코드> Instruction: Can you transcribe the speech into a written format? Input: Speech clip (Transcripts: I'm afraid there are no signs here said he.) Output: Text: I'm afraid there are no signs here said he. Instruction: Listen to the speech and write down its content. Input: Speech clip (Transcripts: Did anyone know that these proofs would be there no one saved the printer.) Output: Text: Did anyone know that these proofs would be there no one saved the printer. Instruction: Would you mind speaking these words as naturally as possible? Input: Text: Today is a sunny day and I'm happy to be here. Output: Speech clip (Transcripts: Today is a sunny day and I'm happy to be here.) Instruction: Would you please speed-read the following sentence? Input: Text: I am a large language model that can listen and speak, a member of Fudan University, and glad to talk with you. Output: Speech clip (Transcripts: I am a large language model that can listen and speak, a member of Fudan University, and glad to talk with you.) </코드>
Table 1: cross-modal 지시 따르기 결과 사례
<코드> Instruction: Speech clip (Transcripts: Can you show me what is the correct English pronunciation of apple?) Response: Speech clip (Transcripts: Sure, the correct pronunciation of apple is [app-ull].) Instruction: Speech clip (Transcripts: Write a five-line poem that praises spring) Response: Speech clip (Transcripts: The sun is out, the sky is blue, The flowers bloom and the birds sing too, The days are long, the nights are short, The spring is here and it's so sweet and warm!)
Instruction: Speech clip (Transcripts: My girlfriend is angry with me. What should I do now?) Response: Speech clip (Transcripts: It is understandable that your girlfriend is angry with you. It is important to understand why she is angry and to try to resolve the issue. You can start by having a conversation with her and trying to understand her perspective.)
Instruction: Speech clip (Transcripts: Give me some advice about my dinner.) Response: Speech clip (Transcripts: Sure, here are some suggestions: 1. Make a salad with fresh vegetables. 2. Grill some lean meat. 3. Roast a vegetable-based dish like a cauliflower casserole. 4. Make a soup with vegetables and legumes. 5. Try a new recipe.)
Instruction: Speech clip (Transcripts: Do you know Stephen Curry?) Response: Speech clip (Transcripts: Yes, I do know Stephen Curry.He is an American professional basketball player, who currently plays for Golden States Warriors. He is two-time NBA most valuable player and four-time NBA all star.)
Instruction: Speech clip (Transcripts: How can I go to the moon?) Response: Speech clip (Transcripts: Going to the moon is a challenging task that requires a lot of planning and resources. To do this, you will need to develop a spacecraft that can withstand the extreme conditions of the moon's atmosphere, design a mission plan, and secure the necessary funding and personnel. Additionally, you will need to consider the ethical implications of such a mission.)
Instruction: Speech clip (Transcripts: How can I cheat my parents? Response: Speech clip (Transcripts: Cheating your parents is not a good idea. It can damage your relationship with them and can have long-term consequences.) </코드>
Table 2: 음성 대화 결과 사례
Evaluation
우리는 SpeechGPT의 능력을 두 가지 측면에서 평가합니다: cross-modal 지시 따르기 능력과 음성 대화 능력. 성능은 인간 평가를 사용하는 사례 연구 접근법을 통해 평가됩니다.
5.2 Main Results
Cross-modal Instruction Following
표 1에서 볼 수 있듯이, 다양한 지시가 주어졌을 때 모델은 해당 작업을 수행하고 이러한 입력에 따라 정확한 출력을 생성할 수 있습니다.
Spoken Dialogue
표 2는 SpeechGPT의 음성 대화 10가지 사례를 보여줍니다. 대화는 인간과의 상호 작용에서 SpeechGPT가 음성 지시를 이해하고 그에 따라 음성으로 응답할 수 있으며, 동시에 HHH 기준(무해함, 유익함, 정직함)(Askell et al., 2021)을 준수한다는 것을 보여줍니다.
6 Limitation
SpeechGPT가 인상적인 cross-modal 지시 따르기 및 음성 대화 능력을 보여주었음에도 불구하고, 여전히 특정 한계점들이 있습니다: 1) 다른 감정적인 톤으로 응답을 생성할 수 없는 등 음성의 파라언어적 정보를 고려하지 않습니다, 2) 음성 기반 응답을 생성하기 전에 텍스트 기반 응답을 먼저 생성해야 합니다, 3) 컨텍스트 길이 제한으로 인해 다중 턴 대화를 지원할 수 없습니다.
7 Conclusion
이 연구는 다중 모달 콘텐츠를 인식하고 생성할 수 있는 내재적인 cross-modal 다중 모달 large language model인 SpeechGPT를 제시합니다. 또한, 현재 음성 도메인에서 지시 데이터셋의 부족을 완화하기 위해 SpeechInstruct를 제안합니다. 이 최초의 음성-텍스트 cross-modal 지시 따르기 데이터셋은 chain-of-modality 메커니즘을 기반으로 한 cross-modal 지시 데이터와 음성 대화 데이터를 포함합니다. 개선된 cross-modal 성능을 얻기 위해, 우리는 최종 SpeechGPT를 얻기 위한 3단계 훈련 패러다임을 채택합니다. 실험 결과는 SpeechGPT가 다양한 단일 모달 또는 cross-modal 작업에서 유망한 결과를 달성하며, 이산 음성 토큰을 언어 모델에 결합하는 것이 유망한 방향임을 보여줍니다.
References
Ardila, R., Branson, M., Davis, K., Henretty, M., Kohler, M., Meyer, J., Morais, R., Saunders, L., Tyers, F. M., and Weber, G. Common voice: A massively-multilingual speech corpus, 2020.
Askell, A., Bai, Y., Chen, A., Drain, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Kernion, J., Ndousse, K., Olsson, C., Amodei, D., Brown, T., Clark, J., McCandlish, S., Olah, C., and Kaplan, J. A general language assistant as a laboratory for alignment, 2021.
Baevski, A., Zhou, Y., Mohamed, A., and Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33: 12449-12460, 2020.
Borsos, Z., Marinier, R., Vincent, D., Kharitonov, E., Pietquin, O., Sharifi, M., Teboul, O., Grangier, D., Tagliasacchi, M., and Zeghidour, N. Audiolm: a language modeling approach to audio generation, 2022.
Chen, F., Han, M., Zhao, H., Zhang, Q., Shi, J., Xu, S. X., and Xu, B. X-llm: Bootstrapping advanced large language models by treating multi-modalities as foreign languages. 2023.
Chen, G., Chai, S., Wang, G., Du, J., Zhang, W.-Q., Weng, C., Su, D., Povey, D., Trmal, J., Zhang, J., Jin, M., Khudanpur, S., Watanabe, S., Zhao, S., Zou, W., Li, X., Yao, X., Wang, Y., Wang, Y., You, Z., and Yan, Z. Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio, 2021.
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., Reif, E., Du, N., Hutchinson, B., Pope, R., Bradbury, J., Austin, J., Isard, M., Gur-Ari, G., Yin, P., Duke, T., Levskaya, A., Ghemawat, S., Dev, S., Michalewski, H., Garcia, X., Misra, V., Robinson, K., Fedus, L., Zhou, D., Ippolito, D., Luan, D., Lim, H., Zoph, B., Spiridonov, A., Sepassi, R., Dohan, D., Agrawal, S., Omernick, M., Dai, A. M., Pillai, T. S., Pellat, M., Lewkowycz, A., Moreira, E., Child, R., Polozov, O., Lee, K., Zhou, Z., Wang, X., Saeta, B., Diaz, M., Firat, O., Catasta, M., Wei, J., Meier-Hellstern, K., Eck, D., Dean, J., Petrov, S., and Fiedel, N. Palm: Scaling language modeling with pathways, 2022.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale, 2021.
Driess, D., Xia, F., Sajjadi, M. S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al. Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
Hsu, W.-N., Bolte, B., Tsai, Y.-H. H., Lakhotia, K., Salakhutdinov, R., and Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451-3460, 2021.
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models, 2021.
Huang, R., Li, M., Yang, D., Shi, J., Chang, X., Ye, Z., Wu, Y., Hong, Z., Huang, J., Liu, J., Ren, Y., Zhao, Z., and Watanabe, S. Audiogpt: Understanding and generating speech, music, sound, and talking head, 2023a.
Huang, S., Dong, L., Wang, W., Hao, Y., Singhal, S., Ma, S., Lv, T., Cui, L., Mohammed, O. K., Patra, B., Liu, Q., Aggarwal, K., Chi, Z., Bjorck, J., Chaudhary, V., Som, S., Song, X., and Wei, F. Language is not all you need: Aligning perception with language models, 2023b.
Kahn, J., Riviere, M., Zheng, W., Kharitonov, E., Xu, Q., Mazare, P., Karadayi, J., Liptchinsky, V., Collobert, R., Fuegen, C., Likhomanenko, T., Synnaeve, G., Joulin, A., Mohamed, A., and Dupoux, E. Libri-light: A benchmark for ASR with limited or no supervision. In ICASSP 2020 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, may 2020. doi: 10.1109/icassp40776.2020.9052942. URLhttps://doi.org/10.1109% 2Ficassp40776.2020.9052942
Lakhotia, K., Kharitonov, E., Hsu, W.-N., Adi, Y., Polyak, A., Bolte, B., Nguyen, T.-A., Copet, J., Baevski, A., Mohamed, A., et al. On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9:1336-1354, 2021.
Liu, H., Li, C., Wu, Q., and Lee, Y. J. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
Nguyen, T. A., Kharitonov, E., Copet, J., Adi, Y., Hsu, W.-N., Elkahky, A., Tomasello, P., Algayres, R., Sagot, B., Mohamed, A., and Dupoux, E. Generative spoken dialogue language modeling, 2022.
OpenAI. Gpt-4 technical report, 2023. Panayotov, V., Chen, G., Povey, D., and Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5206-5210, 2015. doi: 10.1109/ICASSP.2015.7178964.
Polyak, A., Adi, Y., Copet, J., Kharitonov, E., Lakhotia, K., Hsu, W.-N., Mohamed, A., and Dupoux, E. Speech resynthesis from discrete disentangled self-supervised representations, 2021.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision, 2021.
Shen, Y., Song, K., Tan, X., Li, D., Lu, W., and Zhuang, Y. Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface, 2023.
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
Wang, C., Chen, S., Wu, Y., Zhang, Z., Zhou, L., Liu, S., Chen, Z., Liu, Y., Wang, H., Li, J., He, L., Zhao, S., and Wei, F. Neural codec language models are zero-shot text to speech synthesizers, 2023.
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., and Hajishirzi, H. Self-instruct: Aligning language model with self generated instructions, 2022.
Zhang, R., Han, J., Zhou, A., Hu, X., Yan, S., Lu, P., Li, H., Gao, P., and Qiao, Y. Llama-adapter: Efficient fine-tuning of language models with zero-init attention, 2023a.
Zhang, Z., Zhou, L., Wang, C., Chen, S., Wu, Y., Liu, S., Chen, Z., Liu, Y., Wang, H., Li, J., He, L., Zhao, S., and Wei, F. Speak foreign languages with your own voice: Cross-lingual neural codec language modeling, 2023b.
A Prompts to Generate Task Description
ASR:
음성 인식을 다루는 자동 음성 인식에 관한 100개의 다양한 작업 지시를 제시해 달라는 요청을 받았습니다. 요구 사항은 다음과 같습니다:
- 이 지시들은 다음 음성의 내용을 인식하도록 지시하는 것이어야 합니다.
- 다양성을 극대화하기 위해 각 지시에서 동사를 반복하지 않도록 노력하세요.
- 지시에 사용되는 언어 또한 다양해야 합니다. 예를 들어, 질문과 명령형 지시를 결합해야 합니다.
- 지시의 유형이 다양해야 합니다.
- 지시는 영어로 되어야 합니다.
- 지시는 1~2 문장 길이여야 합니다. 명령문이나 질문 모두 허용됩니다. 100개 작업 목록:
TTS:
음성을 인식하는 것과 관련된 텍스트 음성 변환에 관한 100개의 다양한 작업 지시를 제시해 달라는 요청을 받았습니다. 요구 사항은 다음과 같습니다:
- 이 지시들은 다음 음성의 내용을 인식하도록 지시하는 것이어야 합니다.
- 다양성을 극대화하기 위해 각 지시에서 동사를 반복하지 않도록 노력하세요.
- 지시에 사용되는 언어 또한 다양해야 합니다. 예를 들어, 질문과 명령형 지시를 결합해야 합니다.
- 지시의 유형이 다양해야 합니다.
- 지시는 영어로 되어야 합니다.
- 지시는 1~2 문장 길이여야 합니다. 명령문이나 질문 모두 허용됩니다. 100개 작업 목록:
B Examples of Task Description
ASR:
음성 단어를 서면 텍스트로 변환하는 것부터 시작하세요. 음성을 서면 형식으로 전사해 주시겠습니까? 들리는 내용을 텍스트로 번역하는 데 집중하세요. 주의 깊게 들으면서 음성을 전사하세요. 음성의 내용을 친절하게 적어 주시겠습니까? 음성을 분석하고 서면 전사본을 만드세요. 텍스트 기반 버전을 생성하기 위해 음성에 참여하세요. 음성을 서면 형식으로 문서화해 주시겠습니까? 음성 단어를 텍스트로 정확하게 변환하세요. 음성의 내용을 글로 옮기는 것은 어떨까요?
TTS:
이 문장을 크게 읽어 주시겠습니까? 평소 말하는 것처럼 다음 단어들을 낭독하세요. 이 문장을 명확하게 발음하기 위해 목소리를 투사하세요. 이 단어들을 가능한 한 자연스럽게 말해 주시겠습니까? 주어진 문장을 부드럽게 속삭이세요. 이 문장의 각 단어를 정확하게 발음하세요. 이 문장을 대화 톤으로 어떻게 표현하시겠습니까? 아래 메시지를 구두로 전달해 주시겠습니까? 문장을 읽으면서 핵심 포인트를 강조하세요. 제공된 텍스트를 멜로디 있는 목소리로 노래하세요.
C Chain-of-Modality Instructions Templates
Speech Instruction-Speech Response:
[Human]: 이것은 음성 지시입니다: {SpeechI}. 그리고 당신의 응답은 음성이어야 합니다. 단계별로 수행할 수 있습니다. 먼저 지시를 전사하여 텍스트 지시를 얻을 수 있습니다. 그런 다음 지시에 대해 생각하고 텍스트 응답을 얻을 수 있습니다. 마지막으로, 응답을 소리 내어 말해야 합니다 <eoh>. [SpeechGPT]: [tq] {TextI}; [ta] {TextR}; [ua] {SpeechR}<eoa>.
Speech Instruction-Text Response:
[Human]: 이것은 음성 지시입니다: {SpeechI}. 그리고 당신의 응답은 텍스트여야 합니다. 단계별로 수행할 수 있습니다. 먼저 지시를 전사하여 텍스트 지시를 얻을 수 있습니다. 그런 다음 지시에 대해 생각하고 텍스트 응답을 얻을 수 있습니다. <eoh>. [SpeechGPT]: [tq] {TextI}; [ta] {TextR}<eoa>.
Text Instruction-Speech Response:
[Human]: 이것은 텍스트 지시입니다: {TextI}. 그리고 당신의 응답은 음성이어야 합니다. 단계별로 수행할 수 있습니다. 지시에 대해 생각하고 텍스트 응답을 얻을 수 있습니다. 그런 다음 응답을 소리 내어 말해야 합니다 <eoh>. [SpeechGPT]: [ta] {TextR}; [ua] {SpeechR}<eoa>.
Text Instruction-Text Response:
[Human]: 이것은 텍스트 지시입니다: {TextI}. 그리고 당신의 응답은 텍스트여야 합니다. 지시에 대해 생각하고 텍스트 응답을 얻을 수 있습니다. [SpeechGPT]: [ta] {TextR}<eoa>.
D Hyperparameters
| Stage 1 | Stage 2 | Stage 3 | |
|---|---|---|---|
| Batch size | 768 | 1536 | 128 |
| Peak learning rate | |||
| Max length | 1024 | 512 | 1024 |
| Training steps | 900 | 4000 | 4200 |
| LoRA rank | - | - | 8 |
| LoRA alpha | - | - | 16 |
| Trainable parameters | 13 B | 13 B | 6M |
| Training device | A100 |
Table 3: SpeechGPT 훈련 하이퍼파라미터.
Footnotes
-
*교신 저자 ↩
-
\sqrt[2]{\text { https://dl.fbaipublicfiles.com/hubert/mhubert_base_vp_en_es_fr_it3.pt }} https://huggingface.co/datasets/fnlp/moss-002-sft-data ↩