Slot Attention: 경쟁적 Attention 메커니즘을 통한 객체 중심 표현 학습
Slot Attention은 CNN과 같은 perceptual representation을 입력받아, slots이라 불리는 task-dependent한 추상적 표현 집합을 생성하는 모듈입니다. 이 slots들은 여러 라운드에 걸친 경쟁적인 attention 절차를 통해 입력 내의 객체에 바인딩됩니다. 이를 통해 비지도 객체 발견 및 지도 속성 예측과 같은 task에서 보지 못한 구성에 대한 일반화가 가능한 객체 중심 표현을 추출할 수 있습니다. 논문 제목: Object-Centric Learning with Slot Attention
논문 요약: Object-Centric Learning with Slot Attention
- 논문 링크: https://arxiv.org/abs/2006.15055
- 저자: Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, Thomas Kipf
- 발표 시기: 2020
- 주요 키워드: Object-Centric Learning, Slot Attention, Unsupervised Object Discovery, Set Prediction, Attention Mechanism
1. 연구 배경 및 문제 정의
- 문제 정의:
대부분의 딥러닝 모델은 자연 장면의 구성적 속성(compositional properties)을 포착하지 못하는 분산 표현(distributed representations)을 학습하여, 원시 지각 입력으로부터 객체 중심(object-centric) 표현을 효율적으로 학습하기 어렵다. - 기존 접근 방식:
기존 연구들은 원시 지각 입력으로부터 객체 중심 표현을 얻기 위해 종종 지도 학습(supervision)이나 태스크별(task-specific) 아키텍처를 필요로 하거나, 시뮬레이터나 게임 엔진의 구조화된 내부 표현에 의존하여 학습 단계에서 객체 중심 표현 학습을 생략하는 경우가 많았다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- CNN 출력과 같은 지각 표현과 집합으로 구조화된 표현 사이의 인터페이스 역할을 하는 간단한 아키텍처 구성 요소인 Slot Attention 모듈을 제안한다.
- Slot Attention 기반 아키텍처를 비지도 객체 발견에 적용하여, 기존 SOTA 접근 방식과 동등하거나 더 뛰어난 성능을 보이면서도 메모리 효율성이 높고 학습 속도가 훨씬 빠름을 입증한다.
- Slot Attention 모듈이 지도 객체 속성 예측에 사용될 수 있으며, 이 경우 직접적인 객체 분할(segmentation) 감독 없이도 개별 객체를 강조하는 방법을 학습함을 보여준다.
- 제안 방법:
Slot Attention 모듈은 CNN의 출력과 같은 지각 표현을 입력으로 받아, "슬롯(slots)"이라고 불리는 태스크 의존적인 추상 표현 집합을 생성한다. 이 슬롯들은 교환 가능하며, 여러 차례의 반복적인 경쟁적 어텐션(attention) 절차를 통해 입력 내의 어떤 객체에도 바인딩될 수 있도록 전문화된다.- 비지도 객체 발견: Slot Attention을 오토인코더의 인코더로 사용하여 이미지를 슬롯 집합으로 인코딩하고, 각 슬롯은 공간 브로드캐스트 디코더(spatial broadcast decoder)를 통해 개별적으로 디코딩되어 원본 이미지를 재구성한다.
- 지도 집합 예측: Slot Attention을 사용하여 입력 이미지의 분산 표현을 슬롯 집합으로 변환하고, 각 슬롯에 공유 파라미터를 가진 MLP를 적용하여 객체 속성을 예측한다. 예측과 레이블의 순서가 임의적이므로 헝가리안 알고리즘(Hungarian algorithm)을 사용하여 매칭한다.
3. 실험 결과
- 데이터셋:
- 객체 발견: CLEVR (with masks) (CLEVR6), Multi-dSprites, Tetrominoes
- 집합 예측: CLEVR (CLEVR10)
- 주요 결과:
- 객체 발견: IODINE 및 MONet과 같은 기존 SOTA 모델 대비 우수한 Adjusted Rand Index (ARI) 점수를 달성했다 (예: CLEVR6에서 98.8% ARI). 또한, 기존 모델 대비 훨씬 높은 메모리 효율성(배치 크기 64 vs 4)과 빠른 학습 속도(24시간 vs 7일)를 보였다. 학습 시 본 적 없는 더 많은 객체를 포함하는 장면에서도 테스트 시 반복 횟수를 늘려 일반화가 가능함을 입증했다.
- 집합 예측: DSPN과 동등하거나 더 나은 Average Precision (AP) 결과를 달성했다 (예: CLEVR10에서 94.3% AP). 직접적인 분할 감독 없이도 어텐션 마스크가 객체를 자연스럽게 분할하는 능력을 보여주었다 (CLEVR10 마스크에서 78.0% ARI).
4. 개인적인 생각 및 응용 가능성
- 장점:
Slot Attention은 저수준 지각 입력으로부터 객체 중심 표현을 학습하는 데 매우 다재다능하고 효율적인(메모리 및 연산 측면에서) 아키텍처 구성 요소이다. 비지도 객체 발견과 지도 속성 예측 모두에서 SOTA에 필적하는 성능을 달성하며, 구현 및 튜닝이 비교적 용이하다. 어텐션 마스크를 통해 모델의 예측을 시각적으로 해석할 수 있다는 점도 큰 장점이다. - 단점/한계:
배경 처리에 대한 특별한 메커니즘이 없어 배경이 여러 슬롯에 분산될 수 있다. 사용된 위치 인코딩이 절대적이므로 병진 대칭성(translation symmetry)을 가지지 않는다. 슬롯이 객체 자체를 구분하지 않고 다운스트림 태스크에 따라 클러스터링 유형이 결정된다. 슬롯 간 통신이 입력 키에 대한 어텐션을 통해서만 이루어져, 동적으로 상호작용하는 객체 시스템 모델링을 위해서는 더 명시적인 슬롯 간 통신(예: GNN)이 필요할 수 있다. 복잡한 배경이나 텍스처가 있는 장면에서는 어려움을 겪을 수 있다. - 응용 가능성:
비디오 데이터, 그래프 노드 클러스터링, 포인트 클라우드 처리, 텍스트나 음성 데이터와 같은 다른 데이터 양식에 적용될 수 있다. 또한 보상 예측, 시각적 추론, 제어, 계획과 같은 다양한 다운스트림 태스크에 활용될 가능성이 크다.
Locatello, Francesco, et al. "Object-centric learning with slot attention, 2020."
Object-Centric Learning with Slot Attention
Francesco Locatello , Dirk Weissenborn , Thomas Unterthiner , Aravindh Mahendran , Georg Heigold , Jakob Uszkoreit , Alexey Dosovitskiy , and Thomas Kipf <br> Google Research, Brain Team<br> Dept. of Computer Science, ETH Zurich<br> Max-Planck Institute for Intelligent Systems
Abstract
복잡한 장면의 객체 중심(object-centric) 표현을 학습하는 것은 저수준 지각 feature로부터 효율적인 추상적 추론을 가능하게 하는 유망한 단계이다. 그러나 대부분의 딥러닝 접근 방식은 자연 장면의 구성적 속성(compositional properties)을 포착하지 못하는 분산 표현(distributed representations)을 학습한다. 본 논문에서는 Slot Attention 모듈을 제안한다. 이 모듈은 Convolutional Neural Network의 출력과 같은 지각 표현(perceptual representations)과 상호작용하여, 우리가 **슬롯(slots)**이라고 부르는 task-dependent 추상 표현 집합을 생성하는 아키텍처 구성 요소이다. 이 슬롯들은 **교환 가능(exchangeable)**하며, 여러 차례의 attention을 통한 경쟁적 절차(competitive procedure)를 통해 전문화(specializing)됨으로써 입력 내의 어떤 객체에도 바인딩(bind)될 수 있다. 우리는 Slot Attention이 비지도 객체 발견(unsupervised object discovery) 및 지도 속성 예측(supervised property prediction) task로 학습되었을 때, 보지 못한 구성(unseen compositions)으로의 일반화를 가능하게 하는 객체 중심 표현을 추출할 수 있음을 경험적으로 입증한다.
1 Introduction
Object-centric representation는 visual reasoning [1], 구조화된 환경 모델링 [2], multi-agent 모델링 [3-5], 상호작용하는 물리 시스템 시뮬레이션 [6-8]과 같은 다양한 응용 분야에서 머신러닝 알고리즘의 sample efficiency와 일반화 능력을 향상시킬 잠재력을 가지고 있다. 이미지나 비디오와 같은 원시 지각 입력(raw perceptual input)으로부터 object-centric representation을 얻는 것은 어렵고, 종종 supervision [1, 3, 9, 10]이나 task-specific 아키텍처 [2, 11]를 필요로 한다. 결과적으로, object-centric representation을 학습하는 단계는 종종 완전히 생략되기도 한다. 대신, 모델은 일반적으로 시뮬레이터 [6, 8]나 게임 엔진 [4, 5]의 내부 표현으로부터 얻은 환경의 구조화된 표현을 기반으로 동작하도록 학습된다.
이러한 어려움을 극복하기 위해, 우리는 Slot Attention 모듈을 소개한다. Slot Attention 모듈은 지각 표현(예: CNN의 출력)과 슬롯(slot)이라고 불리는 변수 집합 사이의 미분 가능한 인터페이스이다. 반복적인 attention 메커니즘을 사용하여, Slot Attention은 permutation symmetry를 가진 출력 벡터 집합을 생성한다. Capsule Network [12, 13]에서 사용되는 capsule과 달리, Slot Attention이 생성하는 슬롯은 특정 유형이나 클래스의 객체에 특화되지 않아, 일반화에 해를 끼칠 수 있는 문제를 피한다. 대신, 이들은 object file [14]과 유사하게 작동한다. 즉, 슬롯은 공통적인 표현 형식을 사용한다: 각 슬롯은 입력 내의 어떤 객체든 저장(및 바인딩)할 수 있다. 이를 통해 Slot Attention은 보지 못한 구성, 더 많은 객체, 더 많은 슬롯에 대해 체계적인 방식으로 일반화할 수 있다.
Slot Attention은 간단하고 구현하기 쉬운 아키텍처 구성 요소로, 예를 들어 CNN [15] encoder 위에 배치하여 이미지에서 객체 표현을 추출할 수 있으며, 다운스트림 task와 함께 end-to-end로 학습된다. 본 논문에서는 **이미지 재구성(image reconstruction)과 집합 예측(set prediction)**을 다운스트림 task로 고려하여, 도전적인 비지도 객체 발견(unsupervised object discovery) 설정과 집합 구조의 객체 속성 예측을 포함하는 지도 학습 task 모두에서 우리 모듈의 다용성을 보여준다.
 Figure 1: (a) Slot Attention 모듈 및 (b) 비지도 객체 발견, (c) 레이블이 지정된 타겟 를 사용한 지도 집합 예측에 대한 예시 적용. 자세한 내용은 본문 참조.
Figure 1: (a) Slot Attention 모듈 및 (b) 비지도 객체 발견, (c) 레이블이 지정된 타겟 를 사용한 지도 집합 예측에 대한 예시 적용. 자세한 내용은 본문 참조.
우리의 주요 기여는 다음과 같다: (i) 지각 표현(예: CNN의 출력)과 집합으로 구조화된 표현 사이의 인터페이스에 위치하는 간단한 아키텍처 구성 요소인 Slot Attention 모듈을 소개한다. (ii) Slot Attention 기반 아키텍처를 비지도 객체 발견에 적용하여, 기존의 관련 state-of-the-art 접근 방식 [16, 17]과 동등하거나 더 뛰어난 성능을 보이면서도, 메모리 효율성이 높고 학습 속도가 훨씬 빠름을 입증한다. (iii) Slot Attention 모듈이 지도 객체 속성 예측(supervised object property prediction)에 사용될 수 있음을 보여준다. 이 경우, attention 메커니즘은 객체 분할에 대한 직접적인 supervision 없이도 개별 객체를 강조하는 방법을 학습한다.
2 Methods
이 섹션에서는 Slot Attention 모듈(Figure 1a; Section 2.1)을 소개하고, 이 모듈이 비지도 객체 발견(unsupervised object discovery) 아키텍처(Figure 1b; Section 2.2)와 집합 예측(set prediction) 아키텍처(Figure 1c; Section 2.3)에 어떻게 통합될 수 있는지 보여준다.
2.1 Slot Attention Module
Slot Attention 모듈(Figure 1a)은 N개의 입력 feature 벡터 집합을 K개의 출력 벡터(슬롯) 집합으로 매핑한다. 이 출력 집합의 각 벡터는 예를 들어, 입력 내의 객체(object) 또는 개체(entity)를 설명할 수 있다. 전체 모듈은 Algorithm 1에 pseudo-code로 설명되어 있다.
Slot Attention은 반복적인 attention 메커니즘을 사용하여 입력을 슬롯으로 매핑한다. 슬롯은 무작위로 초기화되며, 이후 각 반복 에서 입력 feature의 특정 부분(또는 그룹)에 바인딩되도록 정제된다. 공통 분포에서 초기 슬롯 표현을 무작위로 샘플링함으로써 Slot Attention은 테스트 시 다른 수의 슬롯으로 일반화할 수 있다.
각 반복에서 슬롯은 softmax 기반 attention 메커니즘 [18-20]을 통해 입력의 일부를 설명하기 위해 경쟁하며, 순환 업데이트 함수를 사용하여 자신의 표현을 업데이트한다. 각 슬롯의 최종 표현은 비지도 객체 발견(unsupervised object discovery) (Figure 1b) 또는 지도 집합 예측(supervised set prediction) (Figure 1c)과 같은 다운스트림 task에 사용될 수 있다.
이제 입력 feature 집합, inputs 에 대해 Slot Attention의 단일 반복을 설명한다. 이때 개의 출력 슬롯은 차원을 가진다 (명확성을 위해 배치 차원은 생략한다). 우리는 학습 가능한 선형 변환 를 사용하여 입력과 슬롯을 공통 차원 로 매핑한다.
Slot Attention은 dot-product attention [19]을 사용하며, attention 계수는 슬롯(즉, attention 메커니즘의 쿼리)에 대해 정규화된다. 이러한 정규화 방식은 슬롯들 간에 입력의 일부를 설명하기 위한 경쟁을 유도한다.
Algorithm 1 Slot Attention module. The input is a set of \(N\) vectors of dimension \(D_{\text {inputs }}\) which is
mapped to a set of \(K\) slots of dimension \(D_{\text {slots }}\). We initialize the slots by sampling their initial values
as independent samples from a Gaussian distribution with shared, learnable parameters \(\mu \in \mathbb{R}^{D_{\text {slots }}}\)
and \(\sigma \in \mathbb{R}^{D_{\text {slots }}}\). In our experiments we set the number of iterations to \(T=3\).
Input: inputs \(\in \mathbb{R}^{N \times D_{\text {inputs }}}\), slots \(\sim \mathcal{N}(\mu, \operatorname{diag}(\sigma)) \in \mathbb{R}^{K \times D_{\text {slots }}}\)
Layer params: \(k, q, v\) : linear projections for attention; GRU; MLP; LayerNorm ( x 3 )
inputs = LayerNorm (inputs)
for \(t=0 \ldots T\)
slots_prev = slots
slots = LayerNorm (slots)
attn \(=\operatorname{Softmax}\left(\frac{1}{\sqrt{D}} k(\right.\) inputs \() \cdot q(\text { slots })^{T}\), axis='slots') # norm. over slots
updates \(=\) WeightedMean (weights=attn \(+\epsilon\), values= \(v\) (inputs) ) # aggregate
slots = GRU (state=slots_prev, inputs=updates) # GRU update (per slot)
slots += MLP (LayerNorm (slots)) # optional residual MLP (per slot)
return slots
우리는 또한 softmax temperature를 [20]의 고정 값으로 설정하는 일반적인 관행을 따른다:
다시 말해, 이 정규화는 각 개별 입력 feature 벡터에 대해 attention 계수의 합이 1이 되도록 보장하여, attention 메커니즘이 입력의 일부를 무시하는 것을 방지한다. 입력 값을 할당된 슬롯으로 **집계(aggregate)**하기 위해 다음과 같이 **가중 평균(weighted mean)**을 사용한다:
가중 평균은 attention 계수가 슬롯에 대해 정규화되기 때문에 attention 메커니즘의 안정성을 향상시키는 데 도움이 된다 (가중 합을 사용하는 것과 비교하여). 실제 구현에서는 수치적 불안정성을 피하기 위해 attention 계수에 작은 오프셋 을 추가한다.
집계된 updates는 최종적으로 학습된 순환 함수를 통해 슬롯을 업데이트하는 데 사용되며, 이를 위해 개의 hidden unit을 가진 Gated Recurrent Unit (GRU) [21]를 사용한다. 우리는 GRU 출력에 ReLU 활성화 함수와 residual connection [22]을 가진 (선택적) **multi-layer perceptron (MLP)**을 적용하는 것이 성능 향상에 도움이 된다는 것을 발견했다. GRU와 residual MLP는 모두 공유된 파라미터를 사용하여 각 슬롯에 독립적으로 적용된다. 우리는 모듈의 입력과 각 반복 시작 시 슬롯 feature, 그리고 residual MLP를 적용하기 전에 Layer Normalization (LayerNorm) [23]을 적용한다. 이는 엄격하게 필수적인 것은 아니지만, 학습 수렴 속도를 높이는 데 도움이 된다는 것을 발견했다. 모듈의 전체 시간 복잡도는 이다.
우리는 Slot Attention의 두 가지 핵심 속성을 식별한다: (1) 입력에 대한 순열 불변성(permutation invariance) (즉, 출력은 입력에 적용된 순열과 무관하며 따라서 집합에 적합하다) (2) 슬롯 순서에 대한 순열 동변성(permutation equivariance) (즉, 초기화 후 슬롯의 순서를 바꾸는 것은 모듈의 출력을 바꾸는 것과 동일하다). 더 형식적으로: Proposition 1. Slot Attention 모듈(Algorithm 1)의 출력을 SlotAttention(inputs, slots) 라고 하자. 여기서 inputs 이고 slots 이다. 와 를 임의의 순열 행렬이라고 하자. 그러면 다음이 성립한다:
증명은 supplementary material에 있다. 순열 동변성 속성은 슬롯이 공통적인 표현 형식을 학습하고 각 슬롯이 입력 내의 어떤 객체에도 바인딩될 수 있도록 보장하는 데 중요하다.
2.2 Object Discovery
Set-structured hidden representation은 비지도 학습 방식으로 객체를 학습하는 데 매력적인 선택지이다. 각 set element는 객체가 설명되는 특정 순서를 가정하지 않고도 장면 내 객체의 속성을 포착할 수 있기 때문이다. Slot Attention은 입력 representation을 벡터 집합으로 변환하므로, 비지도 객체 발견을 위한 autoencoder 아키텍처의 encoder 일부로 사용될 수 있다.
Autoencoder는 이미지를 숨겨진 representation 집합(즉, slot)으로 인코딩하는 역할을 하며, 이 slot들은 함께 디코딩되어 이미지 공간으로 다시 변환되어 원본 입력을 재구성한다. 이 과정에서 slot은 representation bottleneck 역할을 하며, decoder(또는 디코딩 프로세스)의 아키텍처는 일반적으로 각 slot이 이미지의 특정 영역 또는 일부만을 디코딩하도록 선택된다 [16, 17, 24-27]. 이렇게 디코딩된 영역/부분들은 결합되어 완전한 재구성된 이미지를 생성한다.
Encoder
우리의 encoder는 두 가지 구성 요소로 이루어져 있다:
(i) positional embedding이 추가된 CNN backbone,
(ii) 이어서 Slot Attention 모듈.
Slot Attention의 출력은 slot들의 집합이며, 이는 장면의 그룹화(예: 객체별 그룹화)를 표현한다.
Decoder
각 slot은 IODINE [16]에서 사용된 spatial broadcast decoder [28]의 도움을 받아 개별적으로 디코딩된다.
Slot representation은 2D 그리드(slot당 하나)로 broadcast되고 position embedding이 추가된다.
각 그리드는 **CNN(slot 간 파라미터 공유)**을 사용하여 디코딩되어 크기의 출력을 생성한다. 여기서 와 는 각각 이미지의 너비와 높이를 나타낸다.
출력 채널은 RGB 색상 채널과 (정규화되지 않은) alpha mask를 인코딩한다.
우리는 이어서 Softmax를 사용하여 slot 전체에 걸쳐 alpha mask를 정규화하고, 이를 혼합 가중치(mixture weights)로 사용하여 개별 재구성 결과들을 단일 RGB 이미지로 결합한다.
2.3 Set Prediction
Set representation은 point cloud prediction [29, 30], 이미지 내 다중 객체 분류 [31], 또는 원하는 속성을 가진 분자 생성 [32, 33]과 같이 다양한 데이터 양식의 task에서 일반적으로 사용된다. 본 논문에서 고려하는 예시에서는 입력 이미지와 예측 대상 집합이 주어지며, 각 예측 대상은 장면 내의 객체를 설명한다.
Set을 예측하는 데 있어 핵심적인 과제는 개의 요소를 가진 set에 대해 개의 동등한 표현이 가능하다는 점이다. 이는 대상들의 순서가 임의적이기 때문이다. 이러한 inductive bias는 학습 과정에서 불연속성(discontinuity)을 피하기 위해 아키텍처에 명시적으로 모델링되어야 한다. 예를 들어, 두 개의 의미적으로 특화된 slot이 학습 과정에서 내용물을 서로 교환하는 경우 [31, 34]가 발생할 수 있다. Slot Attention의 출력 순서는 무작위이며 입력 순서와 독립적이므로, 이러한 문제를 해결할 수 있다. 따라서 Slot Attention은 입력 장면의 분산 표현(distributed representation)을 set representation으로 변환하는 데 사용될 수 있으며, Figure 1c에서 보여주듯이 각 객체는 표준 classifier로 개별적으로 분류될 수 있다.
Encoder
우리는 객체 발견 설정(Section 2.2)과 동일한 encoder 아키텍처를 사용한다. 즉, CNN backbone에 positional embedding을 추가하고, 그 뒤에 Slot Attention을 적용하여 slot representation 집합을 얻는다.
Classifier
각 slot에 대해 slot 간에 파라미터를 공유하는 MLP를 적용한다. 예측과 레이블의 순서가 모두 임의적이므로, 우리는 Hungarian algorithm [35]을 사용하여 이들을 매칭한다. 다른 매칭 알고리즘 [36, 37]에 대한 탐구는 향후 연구로 남겨둔다.
3 Related Work
객체 발견 (Object discovery)
우리의 객체 발견 아키텍처는 **동일한 표현 형식의 잠재 변수 집합으로 장면을 표현하는 구성적 생성 장면 모델(compositional generative scene models)**에 대한 최근 연구 [16, 17, 24-27, 38-44]와 밀접하게 관련되어 있다.
우리의 접근 방식과 가장 유사한 모델은 **IODINE [16]**으로, 이 모델은 반복적인 variational inference [45]를 사용하여 이미지 내 각 객체를 설명하는 잠재 변수 집합을 추론한다.
각 inference 반복에서 IODINE은 디코딩 단계, 픽셀 공간에서의 비교, 그리고 후속 인코딩 단계를 수행한다.
**MONet [17] 및 GENESIS [27]**와 같은 관련 모델들도 유사하게 여러 encode-decode 단계를 사용한다.
반면, 우리 모델은 이 절차를 반복적인 attention을 사용하는 단일 인코딩 단계로 대체하여 계산 효율성을 향상시킨다.
또한, 이를 통해 우리 아키텍처는 디코더가 없는 상태에서도 객체 표현 및 attention mask를 추론할 수 있어, auto-encoding을 넘어선 확장 가능성을 열어준다. 예를 들어, **객체 발견을 위한 contrastive representation learning [46]**이나 제어 또는 계획과 같은 다운스트림 task의 직접 최적화 등이 가능하다.
우리의 attention 기반 라우팅 절차는 AIR [26], SQAIR [40] 및 관련 접근 방식 [41-44]과 같은 아키텍처에서 사용되는 patch 기반 디코더와 함께 사용될 수도 있으며, 이는 일반적으로 사용되는 autoregressive encoder [26, 40]의 대안이 될 수 있다.
우리의 접근 방식은 객체 발견을 위해 adversarial training [47-49] 또는 contrastive learning [46]을 사용하는 방법들과는 직교적이다. 이러한 설정에서 Slot Attention을 활용하는 것은 향후 연구를 위한 흥미로운 방향이다.
집합을 위한 신경망 (Neural networks for sets)
최근의 다양한 방법들은 **집합 인코딩 [34, 50, 51], 생성 [31, 52], 그리고 집합 간 매핑 [20, 53]**을 탐구한다.
그래프 신경망 [54-57], 특히 Transformer 모델 [20]의 self-attention 메커니즘은 고정된 cardinality(즉, 집합 요소의 수)를 가진 요소 집합을 변환하는 데 자주 사용된다.
Slot Attention은 입력 및 출력 집합 모두의 순열 대칭성을 존중하면서, 하나의 집합에서 다른 cardinality를 가진 다른 집합으로 매핑하는 문제를 다룬다.
**Deep Set Prediction Network (DSPN) [31, 58]**는 각 예시에 대해 내부 gradient descent 루프를 실행하여 순열 대칭성을 존중하지만, 이는 수렴을 위해 많은 단계와 여러 loss hyperparameter의 세심한 튜닝을 필요로 한다.
대신, Slot Attention은 단 몇 번의 attention 반복과 단일 task-specific loss function만을 사용하여 집합에서 집합으로 직접 매핑한다.
동시 진행된 연구에서 DETR [59]와 TSPN [60] 모델 모두 조건부 집합 생성을 위해 Transformer [20]를 사용할 것을 제안한다.
DiffPool [61], Set Transformers [53], DSPN [31], DETR [59]를 포함한 대부분의 관련 접근 방식은 **학습된 요소별 초기화(즉, 각 집합 요소에 대한 별도의 파라미터)**를 사용하는데, 이는 이러한 접근 방식이 테스트 시 더 많은 집합 요소로 일반화되는 것을 방해한다.
반복적 라우팅 (Iterative routing)
우리의 반복적인 attention 메커니즘은 일반적으로 Capsule Networks [12, 13, 62]의 변형에서 사용되는 반복적인 라우팅 메커니즘과 유사점을 공유한다.
가장 유사한 변형은 **inverted dot-product attention routing [62]**으로, 이 역시 dot product attention 메커니즘을 사용하여 표현들 간의 할당 계수를 얻는다.
그러나 그들의 방법(다른 캡슐 모델과 마찬가지로)은 각 입력-출력 쌍에 별도로 파라미터화된 변환이 할당되므로 순열 대칭성을 가지지 않는다.
attention 메커니즘이 정규화되는 방식, 업데이트가 집계되는 방식, 그리고 고려되는 응용 분야에 있어서도 두 접근 방식은 크게 다르다.
상호작용 메모리 모델 (Interacting memory models)
Slot Attention은 상호작용 메모리 모델 [9, 39, 46, 63-68]의 변형으로 볼 수 있으며, 이 모델들은 슬롯 집합과 그 쌍별 상호작용을 활용하여 입력의 요소(예: 비디오의 객체)에 대해 추론한다.
이러한 모델들의 공통 구성 요소는 (i) 개별 슬롯에 독립적으로 작용하는 recurrent update function과 (ii) 슬롯 간의 통신을 도입하는 interaction function이다.
일반적으로 이 모델들의 슬롯은 모든 슬롯에 대해 공유되는 recurrent update function과 interaction function을 가진 완전한 대칭성을 가지며, RIM 모델 [67]만이 각 슬롯에 대해 별도의 파라미터 집합을 사용한다.
특히 RMC [63]와 RIM [67]은 입력에서 슬롯으로 정보를 집계하기 위해 attention 메커니즘을 도입한다.
Slot Attention에서는 입력에서 슬롯으로의 attention 기반 할당이 슬롯에 걸쳐 정규화되며(입력에만 정규화되는 것과 반대), 이는 입력의 클러스터링을 수행하기 위해 슬롯 간의 경쟁을 유도한다.
또한, 본 연구에서는 시간적 데이터를 고려하지 않고, 대신 recurrent update function을 사용하여 단일의 정적 입력에 대한 예측을 반복적으로 정제한다.
전문가 혼합 모델 (Mixtures of experts)
**전문가 모델 [67, 69-72]**은 우리의 슬롯 기반 접근 방식과 관련이 있지만, 개별 전문가들 간에 파라미터를 완전히 공유하지는 않는다.
이로 인해 개별 전문가들이 예를 들어 다른 task나 객체 유형에 특화된다.
Slot Attention에서는 슬롯들이 공통적인 표현 형식을 사용하며, 각 슬롯은 입력의 어떤 부분에도 바인딩될 수 있다.
Soft clustering
우리의 라우팅 절차는 soft k-means clustering [73](여기서 슬롯은 클러스터 중심에 해당)과 관련이 있지만, 두 가지 주요 차이점이 있다:
우리는 학습된 선형 투영을 사용한 dot product 유사성을 사용하며, 파라미터화되고 학습 가능한 update function을 사용한다.
학습 가능한 클러스터별 파라미터를 가진 soft k-means clustering의 변형은 컴퓨터 비전 [74] 및 음성 인식 커뮤니티 [75]에서 도입되었지만, 이들은 반복적인 다단계 업데이트를 사용하지 않고 순열 대칭성을 존중하지 않는다는 점(클러스터 중심이 학습 후 고정된 순서의 사전처럼 작동)에서 우리의 접근 방식과 다르다.
Set Transformer [53]의 inducing point 메커니즘과 DETR [59]의 image-to-slot attention 메커니즘은 각 클러스터 할당에 대해 여러 attention head(즉, 여러 유사성 함수)를 사용하는 이러한 순서화된 단일 단계 접근 방식의 확장으로 볼 수 있다.
Recurrent attention
우리의 방법은 **이미지 모델링 및 장면 분해 [26, 40, 76-78]**와 집합 예측 [79]에 사용되는 recurrent attention 모델과 관련이 있다.
집합 예측을 위한 recurrent 모델은 attention 메커니즘을 사용하지 않고도 이 맥락에서 고려되어 왔다 [80, 81].
이러한 연구들은 순열 불변 손실 함수 [79, 80, 82]를 자주 사용하지만, 각 시간 단계에서 하나의 슬롯, 표현 또는 레이블을 autoregressive 방식으로 추론하는 데 의존한다.
반면, Slot Attention은 각 단계에서 모든 슬롯을 동시에 업데이트하므로 순열 대칭성을 완전히 존중한다.
| CLEVR6 | Multi-dSprites | Tetrominoes | |
|---|---|---|---|
| Slot Attention | |||
| IODINE [16] | |||
| MONet [17] | - | ||
| Slot MLP |
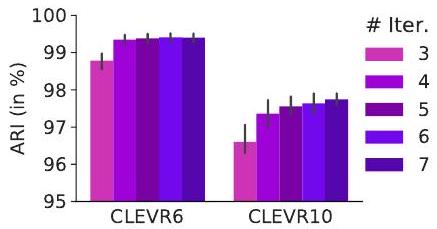
Table 1 & Figure 2: (왼쪽) 다중 객체 데이터셋에서 비지도 객체 발견을 위한 Adjusted Rand Index (ARI) 점수(%, 5개 시드에 대한 평균 표준편차). 이전 연구들 [16, 17, 27]과 마찬가지로, ARI 평가에서 배경 레이블은 제외하였다. *는 평가에서 하나의 이상치(outlier)가 제외되었음을 나타낸다. (오른쪽) 테스트 시 Slot Attention 반복 횟수 를 증가시켰을 때의 효과(CLEVR6에서 , 슬롯으로 학습된 모델에 대해 CLEVR6() 및 CLEVR10()에서 테스트).
4 Experiments
이 섹션의 목표는 Section 2.2와 2.3에서 설명된 두 가지 객체 중심 task(하나는 supervised, 다른 하나는 unsupervised)에서 Slot Attention 모듈의 성능을 평가하는 것이다. 우리는 각 task에 대해 특화된 state-of-the-art 방법들 [16, 17, 31]과 비교한다. 실험 및 구현에 대한 추가 세부 정보, 그리고 추가적인 정성적 결과 및 ablation study는 supplementary material에 제공된다.
Baselines
unsupervised object discovery 실험에서는 최근의 두 가지 state-of-the-art 모델인 **IODINE [16]과 MONet [17]**과 비교한다. supervised object property prediction의 경우, **Deep Set Prediction Networks (DSPN) [31]**과 비교한다. DSPN은 우리가 제안하는 모델 외에 permutation symmetry를 존중하는 유일한 set prediction 모델이다. 두 task 모두에서 우리는 간단한 MLP 기반 baseline인 Slot MLP와도 비교한다. 이 모델은 Slot Attention을 CNN feature map(크기 조정 및 평탄화됨)을 (이제 순서가 지정된) slot representation으로 매핑하는 MLP로 대체한다. MONet, IODINE, DSPN baseline의 경우, 동일한 실험 설정을 사용하므로 [16, 31]에 공개된 수치와 비교한다.
Datasets
object discovery 실험을 위해 다음 세 가지 multi-object dataset [83]을 사용한다: CLEVR (with masks), Multi-dSprites, Tetrominoes.
**CLEVR (with masks)**는 segmentation mask annotation이 추가된 CLEVR dataset 버전이다. IODINE [16]과 유사하게, 우리는 CLEVR (with masks) dataset에서 처음 70K개의 샘플만 학습에 사용하고, 객체가 중앙에 강조되도록 이미지를 자른다. Multi-dSprites와 Tetrominoes의 경우, 처음 60K개의 샘플을 사용한다. [16]에서와 같이, object discovery를 위해 320개의 테스트 예시로 평가한다.
set prediction의 경우, **원래 CLEVR dataset [84]**을 사용한다. 이 데이터셋은 각각 70K 및 15K개의 렌더링된 객체 이미지로 구성된 학습-검증 분할을 포함한다. 각 이미지는 3개에서 10개 사이의 객체를 포함할 수 있으며, 각 객체에 대한 속성(위치, 모양, 재질, 색상, 크기) 주석을 가지고 있다. 일부 실험에서는 CLEVR dataset을 최대 6개의 객체만 포함하도록 필터링했으며, 이 데이터셋을 CLEVR6라고 부르고, 원래 전체 데이터셋은 명확성을 위해 CLEVR10이라고 지칭한다.
4.1 Object Discovery
학습 (Training)
학습 설정은 비지도 학습(unsupervised) 방식이며, 학습 신호는 **(평균 제곱) 이미지 재구성 오차(mean squared image reconstruction error)**를 통해 제공된다. 우리는 **Adam optimizer [85]**를 사용하여 모델을 학습시켰으며, 학습률(learning rate)은 , 배치 크기(batch size)는 64로 설정하였다 (단일 GPU 사용). 또한, **attention mechanism의 초기 포화(early saturation)를 방지하기 위해 learning rate warmup [86]**을 사용했으며, 분산을 줄이는 데 효과적임을 확인한 learning rate의 exponential decay schedule을 적용하였다.
학습 시에는 Slot Attention의 iteration을 사용한다.
slot의 개수 를 제외하고는 모든 데이터셋에 동일한 학습 설정을 적용하였다:
- CLEVR6에는 slots,
- Multi-dSprites (장면당 최대 5개 객체)에는 slots,
- Tetrominoes (장면당 3개 객체)에는 slots를 사용하였다.
Slot Attention에서 slot의 개수는 각 입력 예시마다 다르게 설정할 수 있지만, 배치 처리를 용이하게 하기 위해 학습 세트의 모든 예시에 동일한 값을 사용하였다.
평가 지표 (Metrics)
이전 연구들 [16, 17]과 마찬가지로, 우리는 **decoder가 생성한 alpha mask (각 개별 object slot에 대해)**를 **ground truth segmentation (배경 제외)**과 **Adjusted Rand Index (ARI) 점수 [87, 88]**를 사용하여 비교한다. ARI는 클러스터링 유사도를 측정하는 점수로, 0 (무작위)부터 1 (완벽 일치)까지의 범위를 가진다. ARI 점수를 계산하기 위해 Kabra et al. [83]이 제공한 구현을 사용하였다.
 Figure 3: (a) 비지도 학습 설정(객체 발견)에서의 slot별 재구성 및 alpha mask 시각화. 상단 행: CLEVR6, 중간 행: Multi-dSprites, 하단 행: Tetrominoes. (b) CLEVR6에서 테스트 시 4개의 object slot만 사용했을 때의 각 iteration별 attention mask (attn). (c) iteration별 재구성 및 재구성 마스크 (decoder로부터). slot의 테두리 색상은 결합된 마스크 시각화(세 번째 열)에 사용된 segmentation mask의 색상과 일치한다. 우리는 [16]의 시각화 스크립트를 사용하여 개별 slot 재구성을 해당 alpha mask와 곱한 결과를 시각화한다.
Figure 3: (a) 비지도 학습 설정(객체 발견)에서의 slot별 재구성 및 alpha mask 시각화. 상단 행: CLEVR6, 중간 행: Multi-dSprites, 하단 행: Tetrominoes. (b) CLEVR6에서 테스트 시 4개의 object slot만 사용했을 때의 각 iteration별 attention mask (attn). (c) iteration별 재구성 및 재구성 마스크 (decoder로부터). slot의 테두리 색상은 결합된 마스크 시각화(세 번째 열)에 사용된 segmentation mask의 색상과 일치한다. 우리는 [16]의 시각화 스크립트를 사용하여 개별 slot 재구성을 해당 alpha mask와 곱한 결과를 시각화한다.
 Figure 4: CLEVR6의 그레이스케일 버전으로 학습된 Slot Attention 모델의 (slot별) 재구성 및 마스크 시각화. 이 모델은 98.5 ± 0.3% ARI를 달성한다. 여기서는 각 slot의 전체 재구성(즉, 해당 alpha mask와의 곱셈 없이)을 보여준다.
Figure 4: CLEVR6의 그레이스케일 버전으로 학습된 Slot Attention 모델의 (slot별) 재구성 및 마스크 시각화. 이 모델은 98.5 ± 0.3% ARI를 달성한다. 여기서는 각 slot의 전체 재구성(즉, 해당 alpha mask와의 곱셈 없이)을 보여준다.
결과 (Results)
정량적 결과는 Table 1과 Figure 2에 요약되어 있다. 전반적으로, 우리 모델이 두 가지 최신 state-of-the-art baseline인 IODINE [16]과 MONet [17]에 비해 우수한 성능을 보임을 확인하였다. 또한, **단순한 MLP 기반 baseline (Slot MLP)**과도 비교했는데, 이 모델은 무작위보다 나은 성능을 보이지만, 정렬된 표현(ordered representation)으로 인해 이 task의 구성적 특성(compositional nature)을 모델링할 수 없었다.
우리 모델의 실패 모드도 발견했다: 드물게 Tetrominoes 데이터셋에서 이미지를 줄무늬로 분할하는 등 suboptimal한 솔루션에 갇힐 수 있다. 이는 학습 세트에서 재구성 오차를 상당히 높게 만들므로, 이러한 이상치(outlier)는 학습 시 쉽게 식별할 수 있다. 우리는 Table 1의 최종 점수에서 단 하나의 이러한 이상치(5개 seed 중 1개)를 제외하였다. 특히 이 데이터셋에 대한 학습 하이퍼파라미터를 신중하게 튜닝하면 이 문제가 완화될 수 있을 것으로 예상하지만, 우리는 단순화를 위해 모든 데이터셋에 걸쳐 단일 설정을 선택했다.
IODINE [16]과 비교했을 때, Slot Attention은 메모리 사용량과 런타임 모두에서 훨씬 더 효율적이다. CLEVR6에서 우리는 단일 V100 GPU (16GB RAM)에서 최대 64의 배치 크기를 사용할 수 있었는데, 이는 [16]에서 동일한 하드웨어 유형을 사용했을 때의 4와 대조된다. 유사하게, 8개의 V100 GPU를 병렬로 사용할 때, CLEVR6에서 Slot Attention의 모델 학습은 약 24시간이 걸리는 반면, IODINE [16]은 약 7일이 걸린다.
Figure 2에서는 iteration으로 고정된 상태로 학습된 모델이 테스트 시 더 많은 Slot Attention iteration을 사용했을 때 얼마나 일반화되는지를 조사한다. 또한, 학습 세트(CLEVR6)와 비교하여 더 많은 객체(CLEVR10)에 대한 일반화도 평가한다. 우리는 더 많은 iteration을 사용했을 때 Table 1에 보고된 수치 이상으로 segmentation 점수가 크게 향상됨을 관찰했다. 이러한 향상은 더 많은 객체를 포함하는 CLEVR10 장면에서 테스트할 때 더 강력했다. 이 실험을 위해 우리는 테스트 시 slot의 개수를 (학습)에서 로 증가시켰다. 전반적으로, 학습 시 본 것보다 더 많은 객체를 포함하는 장면에서 테스트할 때도 segmentation 성능은 강력하게 유지되었다.
 Figure 5: (왼쪽) CLEVR10에서 다양한 거리 임계값에서의 AP (K=10). (중앙) 다양한 iteration 수에 대한 Slot Attention 모델의 AP. 모델은 3 iteration으로 학습되었고, 3에서 7 iteration 범위로 테스트되었다. (오른쪽) CLEVR6 (K=6)으로 학습되고 정확히 N개의 객체(N=K, 6에서 10까지)를 포함하는 장면에서 테스트된 Slot Attention의 AP.
Figure 5: (왼쪽) CLEVR10에서 다양한 거리 임계값에서의 AP (K=10). (중앙) 다양한 iteration 수에 대한 Slot Attention 모델의 AP. 모델은 3 iteration으로 학습되었고, 3에서 7 iteration 범위로 테스트되었다. (오른쪽) CLEVR6 (K=6)으로 학습되고 정확히 N개의 객체(N=K, 6에서 10까지)를 포함하는 장면에서 테스트된 Slot Attention의 AP.
 Figure 6: 속성 예측 task로 학습된 모델에 대해 9개 및 4개 객체를 각각 포함하는 두 가지 CLEVR10 예시의 attention mask 시각화. 이 시각화를 위해 마스크는 입력 이미지의 해상도와 일치하도록 128x128로 업샘플링되었다.
Figure 6: 속성 예측 task로 학습된 모델에 대해 9개 및 4개 객체를 각각 포함하는 두 가지 CLEVR10 예시의 attention mask 시각화. 이 시각화를 위해 마스크는 입력 이미지의 해상도와 일치하도록 128x128로 업샘플링되었다.
우리는 Figure 3에서 세 가지 데이터셋 모두에 대해 발견된 객체 segmentation을 시각화한다. 모델은 **객체보다 slot이 더 많을 경우 slot을 비워두는 것(배경만 포착)**을 학습한다. 우리는 Slot Attention이 균일한 배경을 단일 slot에 포착하는 대신 모든 slot에 걸쳐 분산시키는 경향이 있음을 발견했는데, 이는 객체 분리(object disentanglement)나 재구성 품질에 해를 끼치지 않는 attention mechanism의 특성으로 보인다. 우리는 또한 attention mechanism이 개별 attention iteration에 걸쳐 장면을 어떻게 분할하는지를 시각화하고, 각 개별 iteration으로부터의 장면 재구성을 검사한다 (모델은 최종 iteration 후에만 재구성하도록 학습되었다). attention mechanism이 이미 두 번째 iteration에서 개별 객체 추출에 특화되는 것을 학습하는 반면, 첫 번째 iteration의 attention map은 여전히 여러 객체의 일부를 단일 slot에 매핑하는 것을 볼 수 있다.
Slot Attention이 색상 단서에 의존하지 않고 segmentation을 수행할 수 있는지 평가하기 위해, 우리는 검은색 배경에 흰색 객체가 있는 이진화된 multi-dSprites 버전과 그레이스케일 CLEVR6 버전에 대한 추가 실험을 수행했다. 우리는 Kabra et al. [83]의 이진화된 multi-dSprites 데이터셋을 사용했으며, Slot Attention은 slots를 사용하여 69.4 ± 0.9% ARI를 달성했다. 이는 [16]에 보고된 IODINE [16]의 64.8 ± 17.2% 및 R-NEM [39]의 68.5 ± 1.7%와 비교된다. Slot Attention은 형태 단서만을 기반으로 장면을 객체로 분해하는 데 경쟁력 있는 성능을 보인다. 우리는 Figure 4에서 그레이스케일 CLEVR6로 학습된 Slot Attention 모델의 발견된 객체 segmentation을 시각화했는데, Slot Attention은 객체 색상이라는 구별 특징이 없음에도 불구하고 문제없이 처리한다.
우리의 객체 발견 아키텍처는 IODINE [16]과 동일한 decoder 및 재구성 손실을 사용하므로, 더 복잡한 배경과 텍스처를 포함하는 장면에서는 유사하게 어려움을 겪을 것으로 예상된다. 다른 지각적 [49, 89] 또는 contrastive 손실 [46]을 활용하면 이러한 한계를 극복하는 데 도움이 될 수 있다. 추가적인 한계점과 향후 연구는 Section 5와 보충 자료에서 논의한다.
요약 (Summary)
Slot Attention은 **비지도 장면 분해(unsupervised scene decomposition)**에서 객체 segmentation의 품질, 학습 속도 및 메모리 효율성 측면에서 기존 접근 방식과 매우 경쟁력이 있다. 테스트 시, Slot Attention은 decoder 없이도 보지 못한 장면에서 객체 중심 표현(object-centric representations)을 얻는 데 사용될 수 있다.
4.2 Set Prediction
학습 (Training)
우리는 Section 4.1과 동일한 하이퍼파라미터를 사용하여 모델을 학습시켰지만, batch size는 512를 사용하고 encoder에 striding을 적용했다. CLEVR10에서는 [31]과 일치하도록 개의 object slot을 사용했다. Slot Attention 모델은 16GB RAM을 가진 단일 NVIDIA Tesla V100 GPU를 사용하여 학습되었다.
평가 지표 (Metrics)
Zhang et al. [31]을 따라, 우리는 객체 탐지에서 일반적으로 사용되는 Average Precision (AP) [90]을 계산한다. 예측(객체 속성 및 위치)은 특정 거리 임계값 내에서 정확히 동일한 속성(모양, 재질, 색상, 크기)을 가진 일치하는 객체가 있을 경우 올바른 것으로 간주된다 (는 임계값을 강제하지 않음을 의미한다). 예측된 위치 좌표는 으로 스케일링된다. 우리는 타겟을 zero-pad하고, 객체의 존재 확률에 해당하는 범위의 추가 지표 점수(1은 객체가 있음을 의미)를 예측하며, 이를 AP 계산을 위한 예측 신뢰도로 사용한다.
결과 (Results)
Figure 5 (왼쪽)에서 우리는 CLEVR10에서 supervised object property prediction에 대한 Average Precision 결과를 보고한다 (학습 및 테스트 시 Slot Attention에 대해 사용). 우리는 [31]의 DSPN 결과와 Slot MLP baseline 모두와 비교한다. 전반적으로, 우리의 접근 방식이 DSPN baseline과 동등하거나 더 나은 성능을 보임을 관찰한다. 우리 방법의 성능은 더 도전적인 거리 임계값(객체 위치 feature의 경우)에서 점진적으로 저하되지만, 합리적으로 작은 분산을 유지한다. DSPN baseline [31]은 상당히 더 깊은 ResNet 34 [22] 이미지 encoder를 사용한다는 점에 유의하라. Figure 5 (중앙)에서 우리는 테스트 시 attention iteration 수를 늘리면 일반적으로 성능이 향상됨을 관찰한다. Slot Attention은 slot 수를 변경함으로써 테스트 시 더 많은 객체를 자연스럽게 처리할 수 있다. Figure 5 (오른쪽)에서 우리는 CLEVR6 (K=6 slot)으로 모델을 학습시키고 더 많은 객체로 테스트할 경우 AP가 점진적으로 저하됨을 관찰한다.
직관적으로, 이 집합 예측(set prediction) task를 해결하기 위해 각 slot은 다른 객체에 attend해야 한다. Figure 6에서 우리는 두 CLEVR 이미지에 대한 각 slot의 attention map을 시각화한다. 일반적으로, attention map이 객체를 자연스럽게 분할(segment)함을 관찰한다. 우리는 이 방법이 어떤 segmentation mask 없이 객체의 속성을 예측하도록만 학습되었다는 점을 강조한다. 정량적으로, 우리는 attention mask의 Adjusted Rand Index (ARI) 점수를 평가할 수 있다. CLEVR10 (마스크 포함)에서 Slot Attention이 생성한 attention mask는 78.0% ± 2.9의 ARI를 달성한다 (ARI 계산을 위해 입력 이미지를 로 다운스케일링한다). Table 1에서 평가된 마스크는 attention map이 아니라 object discovery decoder에 의해 예측된 마스크라는 점에 유의하라.
요약 (Summary)
Slot Attention은 집합 구조 속성 예측 task를 위한 객체 표현을 학습하며, 구현 및 튜닝이 훨씬 쉬우면서도 기존 state-of-the-art 접근 방식과 경쟁력 있는 결과를 달성한다. 또한, attention mask는 장면을 자연스럽게 분할하며, 이는 모델의 예측을 디버깅하고 해석하는 데 유용할 수 있다.
5 Conclusion
우리는 Slot Attention 모듈을 제안하였다. 이는 저수준의 지각적 입력으로부터 객체 중심의 추상적 표현을 학습하는 다재다능한 아키텍처 구성 요소이다. Slot Attention에 사용된 반복적인 attention 메커니즘은 우리 모델이 입력 feature를 일련의 slot representation으로 분해하는 그룹화 전략을 학습할 수 있도록 한다. 비지도 시각 장면 분해(unsupervised visual scene decomposition) 및 지도 객체 속성 예측(supervised object property prediction) 실험을 통해, Slot Attention이 기존 관련 접근 방식들과 비교하여 매우 경쟁력 있는 성능을 보이며, 메모리 소비 및 연산 측면에서 더 효율적임을 입증하였다.
다음 단계는 Slot Attention을 비디오 데이터나 **다른 데이터 양식(modality)**에 적용하는 것이다. 예를 들어, 그래프의 노드 클러스터링, 포인트 클라우드 처리 backbone 위에 적용, 또는 텍스트나 음성 데이터에 적용할 수 있다. 또한 **보상 예측(reward prediction), 시각적 추론(visual reasoning), 제어(control), 또는 계획(planning)**과 같은 다른 다운스트림 task를 탐구하는 것도 유망하다.
Broader Impact
Slot Attention 모듈은 지각 입력(perceptual input)으로부터 객체 중심(object-centric) 표현을 학습할 수 있게 한다. 따라서 이는 다양한 도메인과 애플리케이션에서 사용될 수 있는 범용 모듈이다. 본 논문에서는 slot이 객체에 특화될 것으로 예상되는 잘 제어된 환경의 인공적으로 생성된 데이터셋만을 고려한다. 그러나 우리 모델의 특화(specialization)는 암묵적이며 전적으로 다운스트림 task에 의해 결정된다. 모듈이 원치 않는 방식으로 특화되었는지 평가하는 구체적인 방법으로, attention mask를 시각화하여 입력 feature가 slot에 어떻게 분포되는지 이해할 수 있음을 언급한다 (Figure 6 참조). 네트워크의 전체 예측을 설명하는 데 있어 attention 계수의 유용성을 적절히 다루기 위해서는 더 많은 연구가 필요하지만 (특히 입력 feature가 인간이 해석하기 어려운 경우), 우리는 이들이 더 투명하고 해석 가능한 예측을 향한 한 단계가 될 수 있다고 주장한다.
Acknowledgements
우리는 본 논문에 대한 전반적인 조언과 피드백을 제공해 준 Nal Kalchbrenner에게 감사하며, 유익한 논의를 함께 해 준 Mostafa Dehghani, Klaus Greff, Bernhard Schölkopf, Klaus-Robert Müller, Adam Kosiorek, Peter Battaglia에게, 그리고 DeepMind Multi-Object Datasets에 대한 조언을 해 준 Rishabh Kabra에게도 감사를 표한다.
Supplementary Material for Object-Centric Learning with Slot Attention
Section A에서는 본 연구의 몇 가지 한계점과 향후 연구 방향을 제시한다. Section B에서는 Slot Attention에 대한 ablation study 결과를 보고한다. Section C에서는 추가적인 정성적 및 정량적 결과를 보고한다. Section D에서는 Proposition 1에 대한 증명을 제공한다. Section E에서는 구현 및 실험 설정에 대한 세부 정보를 보고한다.
A Limitations
우리는 Slot Attention 모듈의 몇 가지 한계점을 강조하며, 이는 향후 연구에서 다루어질 수 있다:
배경 처리 (Background treatment)
Slot Attention에서는 모든 slot이 동일한 표현 형식을 사용하므로, 장면의 배경에 특별한 처리가 없다. **배경에 대한 특별한 처리(예: 별도의 배경 slot 할당)**를 제공하는 것은 향후 연구에 흥미로운 주제이다.
병진 대칭 (Translation symmetry)
우리 실험에서 사용된 위치 인코딩(positional encoding)은 절대적이므로, 우리 모듈은 병진(translation)에 대해 equivariant하지 않다. [44]에서와 같은 패치 기반 객체 추출 프로세스를 사용하거나, 상대적 위치 인코딩 [91]을 갖춘 attention 메커니즘을 사용하는 것은 유망한 확장이다.
클러스터링 유형 (Type of clustering)
Slot Attention은 객체 자체에 대해 알지 못한다: 분할(segmentation)은 전적으로 다운스트림 task에 의해 결정된다. 즉, Slot Attention은 객체, 색상 또는 단순히 공간 영역을 클러스터링하는 것을 구분하지 않으며, 객체에 대한 특화는 다운스트림 task에 의존한다.
Slot 간 통신 (Communication between slots)
Slot Attention에서 slot들은 입력 key에 대한 softmax attention을 통해서만 통신하며, 이는 slot들 간에 정규화된다. 이러한 정규화 방식은 입력의 일부를 설명하기 위한 slot들 간의 경쟁을 유발하며, 이는 slot들이 객체에 특화되도록 유도할 수 있다.
일부 시나리오에서는 slot들 간에 더 명시적인 형태의 통신을 도입하는 것이 합리적일 수 있다. 예를 들어, [9, 46]에서와 같은 그래프 신경망(graph neural network) 형태의 slot-to-slot 메시지 전달이나, [20, 53, 60, 63, 67]에서와 같은 self-attention을 사용하는 방식이다. 이는 동적으로 상호작용하는 객체 시스템을 모델링하거나 [9, 46, 67], 단일 벡터(이미지 또는 벡터 집합과 반대되는)에 조건화된 집합 생성에 유용할 수 있다 [60].
B Model Ablations
이 섹션에서는 Slot Attention 모듈의 개별 구성 요소 및 모델링 선택의 중요성을 조사하고, 우리의 기본 선택을 다양한 합리적인 대안들과 비교한다. 단순화를 위해, 모든 결과는 속성 예측(property prediction)의 경우 500개의 validation 이미지(기존 15K 대신), 객체 발견(object discovery)의 경우 320개의 training 이미지로 구성된 더 작은 validation set에서 보고한다. 비지도 학습(unsupervised)의 경우, training set과 held-out validation 예시에서의 결과는 거의 동일하다.
Value aggregation
Figure 7에서, 우리는 Algorithm 1의 8번째 줄에서 가중 평균(weighted average) 대신 가중합(weighted sum)을 취했을 때의 효과를 보여준다. 가중 평균은 학습을 안정화시키고 훨씬 더 높은 ARI 및 Average Precision 점수를 산출한다 (특히 더 엄격한 거리 임계값에서). 우리는 가중 평균을 Layer Normalization (LayerNorm) [23]이 뒤따르는 가중합으로 대체함으로써 유사한 효과를 얻을 수 있다.
 Figure 7: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 Aggregation function 변형 (8번째 줄).
Figure 7: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 Aggregation function 변형 (8번째 줄).
Position embedding
Figure 8에서, 우리는 position embedding이 categorical object property 예측에는 필수적이지 않음을 관찰한다. 그러나 position embedding을 제거하면 객체 위치 예측 성능이 명확히 감소한다. 유사하게, Slot Attention 모듈 이전에 CNN feature map에 위치 정보를 추가하지 않으면 비지도 객체 발견에서의 ARI 점수가 현저히 낮아진다.
 Figure 8: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 position embedding에 대한 ablation.
Figure 8: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 position embedding에 대한 ablation.
Slot initialization
Figure 9에서, 우리는 각 slot의 초기화를 위해 별도의 Gaussian 평균 및 분산 파라미터 세트를 학습하는 것과 모든 slot에 대해 공유된 파라미터 세트를 사용하는 기본 설정을 비교한 효과를 보여준다. 우리는 slot별 파라미터화가 지도 학습 task에서는 성능을 약간 향상시킬 수 있지만, 비지도 학습 task에서는 기본 공유 파라미터화에 비해 성능을 감소시킨다는 것을 관찰한다. 각 slot에 대해 별도의 파라미터 세트를 학습할 경우, 재학습 없이는 테스트 시 추가 slot을 추가할 수 없다는 점을 언급한다.
 Figure 9: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 slot 초기화 변형.
Figure 9: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 slot 초기화 변형.
Attention normalization axis
Figure 10에서, 우리는 attention 메커니즘에서 softmax 축의 역할, 즉 어떤 차원에 대해 정규화가 수행되는지를 강조한다. slot 축에 대해 softmax를 취하는 것은 입력의 일부를 설명하기 위해 slot들 간의 경쟁을 유도한다. 대신 입력 축에 대해 softmax를 취하면 (일반적인 self-attention에서처럼), 각 slot에 대한 attention 계수는 다른 모든 slot과 독립적이게 되므로, slot들이 정보를 교환할 수단이 없어 두 task 모두에서 성능이 크게 저하된다.
 Figure 10: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 softmax 축 선택.
Figure 10: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 softmax 축 선택.
Recurrent update function
Figure 11에서, 우리는 slot의 업데이트 함수를 학습하는 데 있어 GRU의 역할을 강조한다. 이는 단순히 8번째 줄의 출력을 slot의 다음 값으로 취하는 것과 대조된다. 우리는 학습된 업데이트 함수가 눈에 띄는 성능 향상을 가져옴을 관찰한다.
 Figure 11: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 slot 업데이트 함수 변형.
Figure 11: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 slot 업데이트 함수 변형.
Attention iterations
Figure 12에서, 우리는 학습 중 attention 반복 횟수의 영향을 보여준다. 우리는 단일 attention 반복보다 더 많은 반복을 가질 때 명확한 이점이 있음을 관찰한다. 3회 이상의 attention 반복은 학습 수렴을 상당히 늦추어, 동일한 스텝 수로 학습했을 때 성능 저하를 초래한다. 이는 마지막 반복에서만 손실을 적용하는 대신 모든 attention 반복에서 디코딩하고 손실을 적용함으로써 완화될 수 있다. 우리는 테스트 시 3회 이상의 attention 반복을 사용하면 (3회 반복으로만 학습되었더라도) 일반적으로 성능이 향상된다는 점에 주목한다.
 Figure 12: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 학습 중 attention 반복 횟수.
Figure 12: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 학습 중 attention 반복 횟수.
Layer normalization
Figure 13에서, 우리는 Slot Attention 모듈의 각 반복에서 입력 및 slot 표현에 Layer Normalization (LayerNorm) [23]을 적용하는 것이 예측 성능을 향상시킨다는 것을 보여준다. set prediction의 경우, 특히 위치를 정확하게 예측하는 능력을 향상시키는데, 이는 학습 시 더 빠른 수렴으로 이어지기 때문일 가능성이 높다.
 Figure 13: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 Slot Attention 모듈의 LayerNorm.
Figure 13: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 Slot Attention 모듈의 LayerNorm.
Feedforward network
Figure 14에서, 우리는 GRU 이후의 residual MLP가 선택 사항이며 속성 예측에서 수렴을 늦출 수 있지만, 객체 발견에서는 성능을 약간 향상시킬 수 있음을 보여준다.
 Figure 14: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 선택적 feedforward MLP.
Figure 14: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 선택적 feedforward MLP.
Softmax temperature
Figure 15에서, 우리는 softmax temperature의 효과를 보여준다. 스케일링은 두 task 모두에서 성능을 명확히 향상시킨다.
 Figure 15: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 Slot Attention 모듈의 softmax temperature.
Figure 15: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 Slot Attention 모듈의 softmax temperature.
Offset for numerical stability
Figure 16에서, 우리는 Algorithm 1에서처럼 attention map에 작은 offset을 추가하는 것(수치적 안정성을 위해)이, 가중 평균의 분모에 offset을 추가하는 대안과 비교했을 때 두 task 모두에서 결과를 크게 변경하지 않음을 보여준다.
 Figure 16: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 attention map 또는 가중 평균의 분모에 대한 offset.
Figure 16: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 attention map 또는 가중 평균의 분모에 대한 offset.
Learning rate schedules
Figure 17과 18에서, 우리는 우리의 decay 및 warmup schedule의 효과를 보여준다. decay schedule에서 명확한 이점을 관찰하는 반면, warmup은 주로 객체 발견 설정에서 유용한 것으로 보이며, 이는 최적 이하의 솔루션에 갇히는 실패 사례(예: 이미지를 객체 대신 줄무늬로 클러스터링하는 경우)를 피하는 데 도움이 된다.
 Figure 17: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 learning rate decay.
Figure 17: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 learning rate decay.
 Figure 18: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 learning rate warmup.
Figure 18: CLEVR6에서의 객체 발견(왼쪽) 및 CLEVR10에서의 속성 예측(오른쪽)을 위한 learning rate warmup.
Number of training slots
Figure 19에서, 우리는 필요한 것보다 더 많은 수의 slot으로 학습했을 때의 효과를 보여준다. 우리는 CLEVR6에서 CLEVR10 실험에서 사용한 slot 수로 객체 발견 및 속성 예측 방법을 모두 학습시킨다 (객체 발견의 경우 baseline과 일관성을 유지하기 위해 추가 slot을 사용한다). 우리는 데이터셋의 정확한 객체 수를 아는 것이 일반적으로 필요하지 않음을 관찰한다. 더 많은 slot으로 학습하는 것이 속성 예측 실험에서는 도움이 될 수 있으며, 객체 발견에서는 약간 해로울 수 있다. 전반적으로, 이는 모델이 slot 수에 대해 상당히 강건함을 나타낸다 (각 객체를 독립적으로 모델링하기에 충분한 slot이 주어진 경우). 데이터셋의 객체 수에 대한 (대략적인) 상한을 사용하는 것이 slot 수에 대한 합리적인 선택 전략으로 보인다.
 Figure 19: CLEVR6에서의 객체 발견(왼쪽) 및 속성 예측(오른쪽)을 위한 학습 slot 수.
Figure 19: CLEVR6에서의 객체 발견(왼쪽) 및 속성 예측(오른쪽)을 위한 학습 slot 수.
Soft k-means
Slot Attention은 soft k-means 알고리즘 [73]의 일반화된 버전으로 볼 수 있다. 우리는 GRU 업데이트, 모든 LayerNorm 함수 및 key/query/value projection을 identity 함수로 동시에 대체함으로써 Slot Attention을 dot-product scoring function (negative Euclidean distance와 대조적으로)을 가진 soft k-means 버전으로 축소할 수 있다. 구체적으로, GRU 업데이트 대신 Algorithm 1의 8번째 줄의 출력을 slot의 다음 값으로 취한다. 이러한 ablation을 통해, 모델은 CLEVR6에서 75.5 ± 3.8% ARI를 달성하며, 이는 Slot Attention의 전체 버전의 **98.8 ± 0.3%**와 비교된다.
C Further Experimental Results
C. 1 Object Discovery
런타임 실험
단일 V100 GPU (RAM 16GB)에서 500k 스텝, 배치 크기 64로 실험을 수행했을 때, Tetrominoes는 약 7.5시간, multi-dSprites는 24시간, CLEVR6는 5일 13시간이 소요되었다 (벽시계 시간 기준).
정성적 결과 (Qualitative results)
Figure 20에서는 object discovery task로 학습된 Slot Attention 모델의 정성적 segmentation 결과를 보여준다. 이 모델은 CLEVR6로 학습되었지만, 학습 및 테스트 시 기본 설정인 대신 개의 slot을 사용했으며, 다른 모든 설정은 동일하게 유지되었다. 이 특정 실험에서는 모델 파라미터 초기화를 위해 5개의 다른 random seed를 사용하여 이 설정으로 5개의 모델을 학습시켰다. 이 5개 모델 중, 단 하나의 모델만이 배경을 별도의 slot에 배치하는 해결책을 학습했다 (이것이 우리가 시각화한 결과이다). Slot Attention 기반 모델이 (대부분의 random seed에서) 찾는 일반적인 해결책은 배경을 모든 slot에 균등하게 분배하는 것이며, 이는 본 논문에서 강조한 해결책이다. Figure 20 (하단 두 행)에서는 CLEVR6, 즉 최대 6개의 객체를 포함하는 장면으로 학습되었음에도 불구하고, 모델이 더 많은 객체(최대 10개)가 있는 장면에 어떻게 일반화되는지를 추가로 보여준다.
 Figure 20: CLEVR6 (즉, 최대 6개의 객체를 포함하는 장면)로 학습되었지만, 최대 10개의 객체를 포함하는 장면에서 테스트된 Slot Attention 모델의 전체 재구성, alpha mask, 그리고 slot별 재구성 시각화. 학습 및 테스트 시 개의 slot을 사용했으며, 학습 시 회, 테스트 시 회 반복을 수행했다. 객체가 회 반복 후 성공적으로 클러스터링된 예시만 시각화했다. 일부 무작위 slot 초기화의 경우, 더 많은 반복을 수행하면 클러스터링 결과가 여전히 향상된다. 이 특정 모델은 배경을 모든 slot에 균등하게 분배하는 대신, 별도의 (그러나 무작위) slot으로 분리하는 것을 학습했다는 점에 주목한다.
Figure 20: CLEVR6 (즉, 최대 6개의 객체를 포함하는 장면)로 학습되었지만, 최대 10개의 객체를 포함하는 장면에서 테스트된 Slot Attention 모델의 전체 재구성, alpha mask, 그리고 slot별 재구성 시각화. 학습 및 테스트 시 개의 slot을 사용했으며, 학습 시 회, 테스트 시 회 반복을 수행했다. 객체가 회 반복 후 성공적으로 클러스터링된 예시만 시각화했다. 일부 무작위 slot 초기화의 경우, 더 많은 반복을 수행하면 클러스터링 결과가 여전히 향상된다. 이 특정 모델은 배경을 모든 slot에 균등하게 분배하는 대신, 별도의 (그러나 무작위) slot으로 분리하는 것을 학습했다는 점에 주목한다.
C. 2 Set Prediction
런타임 실험
단일 V100 GPU (16GB RAM)에서 150k 스텝, 배치 크기 512로 CLEVR 데이터셋을 학습했을 때 약 2일 3시간이 소요되었다 (wall-clock time 기준).
정성적 결과 (Qualitative results)
Table 2는 supervised property prediction task에서 Slot Attention 모델이 몇몇 어려운 테스트 예시에 대해 예측한 결과와 attention 계수를 보여준다. 이 모델은 **기본 설정(T=3 attention iteration)**으로 학습되었으며, 이미지는 **특히 어려운 경우(예: 동일한 객체가 여러 개 있거나, 한 장면에 부분적으로 겹치는 객체가 많은 경우)**를 강조하기 위해 수동으로 선택되었다.
전반적으로, 더 많은 iteration을 거칠수록 property prediction의 정확도가 높아지는 경향을 보이지만, 위치 예측의 정확도는 감소할 수 있음을 확인할 수 있다. 이는 우리가 손실(loss)을 T=3에서만 적용하고, 테스트 시 더 많은 time step으로의 일반화가 보장되지 않기 때문에 놀라운 결과는 아니다.
참고로, 학습 중에 모든 iteration에서 손실을 적용하는 대안도 있으며, 이는 정확도를 향상시킬 잠재력이 있지만 계산 비용을 증가시킬 것이다.
모델이 동일한 객체의 여러 복사본을 잘 처리하는 것으로 보인다 (상단). **매우 혼잡한 장면(중간 및 하단)**에서는 slot들이 장면을 분할하는 데 어려움을 겪어 예측 오류로 이어질 수 있음을 확인했다. 그러나 더 많은 iteration은 분할을 더 선명하게 하여 예측을 향상시키는 것으로 보인다.
Table 2: T=3으로 학습된 Slot Attention 모델의 예측 예시. 4개의 객체(그 중 2개는 동일하고 부분적으로 겹침)가 있는 어려운 예시와 10개의 객체가 있는 혼잡한 장면을 보여준다. 잘못된 속성 예측과 0.5보다 큰 거리를 강조 표시했다.
| Image | Attn. | Attn. | Attn. | Attn. | Attn. | ||
|---|---|---|---|---|---|---|---|
 |  |  |  |  | |||
| True Y | Pred. | Pred. | Pred. | Pred. | Pred. | ||
| (-2.11, -0.69, 0.70) large blue rubber cylinder (2.41, -0.82, 0.70) large yellow metal cube (-2.57, 1.88, 0.35) small purple rubber cylinder (0.69, -1.51, 0.70) large blue rubber cylinder | ( ), large blue rubber cylinder (2.57, -0.64, 0.72), d=0.24 | (-2.42, -0.55, 0.71), d=0.34 | (-2.41, -0.35, 0.71), d=0.45 large blue rubber cylinder (2.55, -0.79, 0.70), | ||||
| (-2.82, -0.19, 0.71), d=0.87 large blue rubber cylinder (2.52, -0.35, 0.66), d=0.48 | large blue rubber cylinder (2.53, -0.83, 0.71), d=0.12 | (-2.42, -0.48, 0.71), d=0.36 large blue rubber cylinder (2.54, -0.82, 0.71), d=0.13 | |||||
| large yellow metal cube (-2.19, 2.23, 0.37), d=0.52 | large yellow metal cube (-2.70, 2.31, 0.34), d=0.45 | large yellow metal cube (-2.57, 2.35, 0.33), d=0.47 | large yellow metal cube (-2.58, 2.35, 0.34), d=0.48 | large yellow metal cube (-2.58, 2.35, 0.34), d=0.48 | |||
| small purple rubber cylinder | large blue rubber cylinder | large blue rubber cylinder | small purple rubber cylinder | small purple rubber cylinder |
| Image | Attn. | Attn. | Attn. | Attn. | Attn. | ||
|---|---|---|---|---|---|---|---|
 |  |  |  |  | |||
| True Y | Pred. | Pred. | Pred. | Pred. | Pred. | ||
| (-2.92, 0.03, 0.70) | (-2.36, -1.24, 0.68), d=1.39 | (-0.90, 0.35, 0.57), d=2.05 | (-2.24, 0.16, 0.71), d=0.70 | (-2.38, -0.04, 0.68), d=0.55 | (-2.36, 0.03, 0.69), | ||
| large green metal cylinder | large green metal cylinder | (-1.58, 2.11, 0.25), d=0.50 | (-1.65, 1.99, 0.34), d=0.63 | (-1.98, 2.10, 0.36), d=0.74 | large green metal cylinder <br> (-1.92, 2.24, 0.36), | ||
| small gray metal cylinder (0.33, 2.72, 0.35) | small gray metal cylinder | 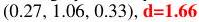 | small gray metal cylinder | ||||
| small blue metal sphere | (2.05, -1.94, 0.37), d=0.38 | 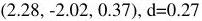 | (2.10, -2.03, 0.36), d=0.28 | (2.10, -2.01, 0.36), d=0.30 | |||
| small red rubber cube | (2.03, -0.31, 0.68), d=0.62 | small red rubber cube <br> (1.54, -1.04, 0.72), d=0.47 | small red rubber cube <br> (1.90, -0.95, 0.72), d=0.09 | small red rubber cube (1.83, -0.90, 0.72), d=0.17 | small red rubber cube (1.86, -0.91, 0.72), d=0.14 | ||
| large blue rubber cube (-1.50, -0.34, 0.35) | large blue rubber cube | (-2.06, 1.66, 0.28), d=2.08 | large blue rubber cube <br> (-0.60, 1.13, | large blue rubber cube <br> (-0.55, 1.04, 0.32), d=1.68 | |||
| small blue metal sphere | small gray metal cylinder | 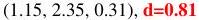 |  | small blue metal sphere <br> (1.81, 2.34, 0.37), small green metal sphere | |||
| small green metal sphere (-2.05, -2.99, 0.70) | (-0.45, -1.37, 0.43), d=2.30 | small green metal sphere | |||||
| large gray metal cylinder (-0.31, -2.95, 0.70) | large blue rubber cylinder | (-0.25, -2.50, 0.70), d=0.45 | large gray metal cylinder | (-0.26, -2.60, 0.69), d=0.35 | large gray rubber cylinder | (-0.26, -2.69, 0.69), d=0.26 | (-0.29, -2.64, 0.69), d=0.31 |
| large gray rubber cylinder | large gray rubber cube (1.16, -1.06, 0.37), d=2.01 large blue rubber cube | small brown rubber sphere | small brown rubber sphere | small brown rubber sphere | large gray rubber cylinder |
| Image | Attn. | Attn. | Attn. | ||
|---|---|---|---|---|---|
 |  |  |  | ||
| True Y | Pred. | Pred. | Pred. | Pred. | Pred. |
| (-2.28, 2.76, 0.70) | (-2.40, 2.30, 0.69), d=0.47 | (-1.96, 2.15, 0.67), d=0.69 | (-2.01, 2.16, 0.66), | (-1.99, 2.12, 0.66), d=0.70 | (-1.98, 2.10, 0.66), d=0.73 |
| large cyan metal sphere | (0.00, 1.31, 0.37), d=1.55 | large cyan metal sphere <br> (0.60, 2.43, 0.33), d=0.35 | large cyan metal sphere <br> (0.85, 2.28, 0.33), d=0.29 | (0.76, 2.39, 0.33), d=0.24 | (0.71, 2.39, 0.33), d=0.28 |
| small purple rubber cube | large blue metal cylinder | small purple rubber cube <br> (-2.61, -2.59, -2.50), d=5.65 | small purple rubber cube | (0.81, -1.73, -0.11), d=1.69 | (2.46, -2.34, 0.38), d=0.22 |
| small purple rubber sphere | large cyan metal cylinder | ( ), d=0.31 | (-0.31, -1.93, 0.35), d=0.44 | small purple rubber sphere | |
| small yellow metal sphere (-0.46, 1.75, 0.70) | (-1.03, 0.70, 0.25), | (-0.46, 1.61, 0.52), d=0.23 | small yellow metal sphere | small yellow metal sphere | small yellow metal sphere (-0.70, 2.29, 0.65), d=0.59 |
| large brown metal sphere (1.14, -0.91, 0.70) | large yellow metal sphere | (0.66, -0.88, 0.71), d=0.48 | (0.74, -0.96, 0.70), d=0.40 | (0.73, -0.91, 0.70), d=0.41 | (0.74, -0.95, 0.69), d=0.40 |
| large green rubber cylinder | large green rubber cylinder | (-2.56, 1.25, 0.66), <br> (-2.56, 1.25, 0.66), | (-2.71, 0.56, 0.68), d=0.35 | <br> arge brown rubber cylinder | large green rubber cylinder |
| large brown rubber cylinder (-2.51, -2.02, 0.35) | large brown metal cylinder (-2.39, 2.31, 0.57), | large brown rubber cylinder (-2.81, -0.77, 0.36), d=1.29 | large brown rubber cylinder (-2.35, -1.36, 0.33), d=0.68 | (-2.26, -1.45, 0.32), d=0.63 | |
| small red rubber sphere | large red rubber cube <br> (2.27, -2.65, 0.37), d=1.07 | (2.24, -2.76, 0.36), | (1.86, -2.38, 0.37), | (2.03, -2.66, 0.35), d=0.85 | (1.41, -2.55, 0.34), d=0.36 |
| small cyan rubber cube | small cyan rubber cube (2.59, 1.99, 0.72), d=0.81 | small cyan rubber cube (2.57, 2.72, 0.75), d=0.12 | small cyan rubber cube (2.61, 2.52, 0.75), d=0.30 | small cyan rubber cube (2.60, 2.52, 0.74), d=0.30 | small cyan rubber cube (2.59, 2.51, 0.73), d=0.30 |
| large yellow metal cylinder | large yellow metal cylinder | large yellow metal cylinder | large yellow metal cylinder | large yellow metal cylinder | large yellow metal cylinder |
Table 3: CLEVR10에서 다양한 거리 임계값에 대한 평균 정밀도(Average Precision) (%, 5개 시드에 대한 평균 표준편차). 신뢰 구간 내에서 각 임계값에 대한 최상의 결과를 강조 표시했다.
| Slot Attention | |||||
| DSPN T=30 | |||||
| DSPN T=10 | |||||
| Slot MLP |
수치 결과 (Numerical results)
우리 방법과의 비교를 용이하게 하기 위해, 본 논문의 Figure 5 (왼쪽 하위 그림)의 결과를 Table 3에 수치 형태로 보고하며, **DSPN [31]의 10 iteration 성능(30 iteration과 대조)**도 함께 제시한다.
우리의 접근 방식이 DSPN에 비해 전반적으로 더 높은 평균 AP와 낮은 분산을 보임을 확인할 수 있다.
DSPN의 공개된 구현은 우리 모델보다 **상당히 깊은 이미지 인코더(ResNet 34 [22] vs. 4개 레이어의 CNN)**를 사용한다는 점에 주목한다. 또한, 우리는 **모든 속성에 대해 동일한 스케일(예측 벡터의 각 좌표는 [0,1] 범위)**을 사용하는 반면, DSPN에서는 객체 좌표가 [-1,1]로 재조정되고 다른 모든 속성은 [0,1] 범위에 있다.
객체 수에 따른 결과 분할 (Results partitioned by number of objects)
여기서는 Slot Attention 모델에 대한 Table 3의 결과를 특정 고정된 객체 수를 가진 이미지에 대해서만 AP 점수를 측정하는 별도의 bin으로 분류한다. 이는 테스트 시 더 많은 객체로의 일반화를 테스트하는 본 논문의 Figure 5 (오른쪽 하위 그림)와는 다르다.
장면 내 객체 수가 증가할수록 오류율이 증가함을 관찰할 수 있다.
이러한 문제가 Slot Attention 모듈에서 사용되는 iteration 수를 늘림으로써 어느 정도 해결될 수 있는지 분석하기 위해, 우리는 동일한 실험을 수행하여 iteration 수를 늘렸다.
 Figure 21: 객체 수에 따른 AP 점수.
Figure 21: 객체 수에 따른 AP 점수.
 Figure 22: 장면 내 객체 수에 따라 분류된 AP 점수. 많은 객체를 포함하는 어려운 장면은 더 많은 Slot Attention iteration을 필요로 한다.
Figure 22: 장면 내 객체 수에 따라 분류된 AP 점수. 많은 객체를 포함하는 어려운 장면은 더 많은 Slot Attention iteration을 필요로 한다.
단계별 손실 및 좌표 스케일링 (Step-wise loss & coordinate scaling)
우리는 최종 단계에서만 손실을 적용하는 대신, attention 메커니즘의 모든 iteration에서 set prediction 구성 요소와 손실을 적용하는 모델 변형을 조사한다. 유사한 실험이 DSPN 모델에 대해 [31]에서 보고되었다. DSPN은 기본적으로 객체의 위치 좌표에 대해 다른 스케일을 사용하므로, 우리는 유사하게 다른 스케일을 사용하는 우리 모델 버전과도 비교한다. 객체 위치에 대해 다른 스케일을 사용하면 손실에서 해당 가중치가 증가한다.
Figure 23에서 좌표 스케일과 각 단계에서 손실을 계산하는 것의 효과를 관찰한다.
스케일 1은 우리의 기본 좌표 정규화인 [0,1]에 해당하며, 더 큰 스케일은 좌표의 [0, scale] 정규화(또는 임의의 상수로 이동)에 해당한다. 전반적으로, Slot Attention에서 각 단계에서 손실을 계산하는 것이 모든 거리 임계값에서 AP 점수를 향상시키는 반면, DSPN에서는 작은 거리 임계값에서만 유익하다. 우리는 이것이 DSPN의 최적화 문제라고 추측한다. 예상대로, 손실에서 위치 모델링의 중요성을 높이는 것은 작은 거리 임계값에서 AP에 긍정적인 영향을 미치지만, 다른 객체 속성을 올바르게 예측하는 데는 부정적인 영향을 미칠 수 있다.
 Figure 23: 각 iteration에서 손실을 계산하는 것은 일반적으로 Slot Attention과 DSPN 모두에서 결과를 향상시킨다 (계산 비용도 증가). 예상대로, 손실에서 더 높은 가중치를 갖도록 좌표를 재조정하는 것은 객체 위치를 더 정확하게 예측해야 하는 작은 거리 임계값에서 AP에 긍정적인 영향을 미친다.
Figure 23: 각 iteration에서 손실을 계산하는 것은 일반적으로 Slot Attention과 DSPN 모두에서 결과를 향상시킨다 (계산 비용도 증가). 예상대로, 손실에서 더 높은 가중치를 갖도록 좌표를 재조정하는 것은 객체 위치를 더 정확하게 예측해야 하는 작은 거리 임계값에서 AP에 긍정적인 영향을 미친다.
D Permutation Invariance and Equivariance
D. 1 Definitions
Proposition 1의 증명을 제시하기 전에, 우리는 permutation invariance와 equivariance를 공식적으로 정의한다.
정의 1 (Permutation Invariance). 함수 가 임의의 permutation matrix 에 대해 다음을 만족하면 permutation invariant하다고 한다:
정의 2 (Permutation Equivariance). 함수 가 임의의 permutation matrix 에 대해 다음을 만족하면 permutation equivariant하다고 한다:
D. 2 Proof
증명은 간단하며 완전성을 위해 보고한다. 우리는 합(sum) 연산이 permutation invariant하다는 사실에 의존한다.
Linear projections
linear projection은 slot/input element별로 독립적으로 공유 파라미터와 함께 적용되므로, permutation equivariant하다.
Equation 1
attention mechanism의 dot product (즉, 행렬 를 계산하는 과정)는 feature 축(차원 )에 대한 합(sum)을 포함하므로, 입력(input)과 slot 모두에 대해 permutation equivariant하다. softmax의 출력 또한 equivariant하며, 그 이유는 다음과 같다:
여기서 는 permutation matrix 에 의한 좌표 의 변환을 나타낸다. 두 번째 등식은 합(sum)이 permutation invariant하다는 사실에서 도출된다.
Equation 2
업데이트 계산에서의 행렬 곱은 입력 요소에 대한 합(sum)을 포함하므로, 입력 순서()에 대해서는 invariant하고, slot 순서()에 대해서는 equivariant하다.
Slot update:
slot update는 동일한 네트워크를 공유 파라미터와 함께 각 slot에 적용한다. 따라서 이는 slot 순서에 대해 permutation equivariant한 연산이다.
모든 단계 결합:
알고리즘의 모든 단계가 에 대해 permutation equivariant하므로, 전체 모듈은 permutation equivariant하다. 반면에 Equation 2는 에 대해 permutation invariant하다. 따라서 첫 번째 iteration 이후에는 알고리즘이 입력 순서에 대해 permutation invariant하게 된다.
E Implementation and Experimental Details
Slot Attention 모듈의 경우, slot feature dimension을 로 설정하였다. GRU는 64차원의 hidden state를 가지며, feedforward block은 단일 hidden layer (크기 128)와 ReLU activation, 그리고 linear layer로 구성된 MLP이다.
E. 1 CNN Encoder
실험에 사용된 CNN Encoder는 CLEVR의 경우 Table 4에, Tetrominoes 및 Multi-dSprites의 경우 Table 5에 나타나 있다. CLEVR의 속성 예측(property prediction) task에서는 CNN backbone에 stride를 사용하여 표현의 크기를 줄였다. 모든 convolutional layer는 SAME padding을 사용하며 bias weight를 가진다. 이 backbone 이후에는 position embedding(Section E.2)을 추가한 다음, **공간 차원(spatial dimensions)을 평탄화(flatten)**한다. Layer Normalization을 적용한 후, 마지막으로 convolution을 추가한다. 이 convolution은 각 공간 위치에 적용되는 공유 MLP로 구현되며, 64개 유닛(Tetrominoes 및 Multi-dSprites의 경우 32개)의 하나의 hidden layer와 ReLU 비선형성을 가진다. 그 뒤에는 출력 차원이 64(Tetrominoes 및 Multi-dSprites의 경우 32)인 linear layer가 이어진다.
Table 4: CLEVR 실험에 사용된 CNN encoder. CLEVR10의 속성 예측 실험에서는 *로 표시된 layer에 stride 2를 사용하여 메모리 사용량을 줄였다.
| Type | Size/Channels | Activation | Comment |
|---|---|---|---|
| Conv | 64 | ReLU | stride: 1 |
| Conv | 64 | ReLU | stride: 1* |
| Conv | 64 | ReLU | stride: 1* |
| Conv | 64 | ReLU | stride: 1 |
| Position Embedding | - | - | See Section E. 2 |
| Flatten | axis: | - | flatten x , y pos. |
| Layer Norm | - | - | - |
| MLP (per location) | 64 | ReLU | - |
| MLP (per location) | 64 | - | - |
Table 5: Tetrominoes 및 Multi-dSprites 실험에 사용된 CNN encoder.
| Type | Size/Channels | Activation | Comment |
|---|---|---|---|
| Conv | 32 | ReLU | stride: 1 |
| Conv | 32 | ReLU | stride: 1 |
| Conv | 32 | ReLU | stride: 1 |
| Conv | 32 | ReLU | stride: 1 |
| Position Embedding | - | - | See Section E. 2 |
| Flatten | axis: | - | flatten x , y pos. |
| Layer Norm | - | - | - |
| MLP (per location) | 32 | ReLU | - |
| MLP (per location) | 32 | - | - |
E. 2 Positional Embedding
Slot Attention은 입력 요소의 순서에 불변하기 때문에(즉, 이미지를 벡터 집합으로 처리함), 위치 정보에 직접 접근할 수 없다. Slot Attention이 위치 정보에 접근할 수 있도록, 우리는 다음과 같이 **입력 feature(CNN feature map)**에 **위치 임베딩(positional embedding)**을 추가한다:
(i) 우리는 텐서를 구성한다. 여기서 와 는 CNN feature map의 너비와 높이이며, 네 개의 기본 방향(cardinal directions) 각각에 대해 범위의 선형 그라디언트를 가진다. 다시 말해, 그리드의 각 지점은 4차원 feature vector와 연결되며, 이 벡터는 **feature map의 각 경계까지의 거리( 로 정규화됨)**를 네 개의 기본 방향을 따라 인코딩한다.
(ii) 우리는 각 feature vector를 학습 가능한 선형 맵을 사용하여 **이미지 feature vector와 동일한 차원(즉, feature map의 수)**으로 투영하고, 그 결과를 CNN feature map에 더한다.
E. 3 Deconvolutional Slot Decoder
객체 발견(object discovery) task를 위해, 우리의 아키텍처는 auto-encoder를 기반으로 한다. 여기서 우리는 Slot Attention이 생성한 표현(representation)을 slot 간 파라미터를 공유하는 slot-wise spatial broadcast decoder [28]의 도움을 받아 디코딩한다.
각 spatial broadcast decoder는 width height 크기의 출력을 생성하는데, 여기서 처음 3개의 출력 채널은 재구성된 이미지의 RGB 채널을 나타내고, 마지막 출력 채널은 예측된 alpha mask를 나타낸다. 이 alpha mask는 나중에 개별 slot 재구성(reconstruction)을 단일 이미지로 재결합(recombine)하는 데 사용된다.
CLEVR에 사용된 전체 아키텍처는 Table 6에, Tetrominoes 및 Multi-dSprites에 사용된 아키텍처는 Table 7에 설명되어 있다.
Spatial broadcast decoder
**spatial broadcast decoder [28]**는 각 slot representation에 대해 slot 간 파라미터를 공유하며 독립적으로 적용된다. 우리는 먼저 차원의 slot representation 벡터를 width height 형태의 그리드에 복사한 후, 위치 임베딩(positional embedding)을 추가한다 (Section E.2 참조). 마지막으로, 이 representation은 여러 de-convolutional layer를 통과한다.
Slot recombination
각 slot에 대한 spatial broadcast decoder의 최종 출력은 width height 형태이다 (slot 및 batch 차원은 무시). 우리는 먼저 최종 채널을 3개의 RGB 채널과 1개의 alpha mask 채널로 분리한다. alpha mask에 대해 slot 간 softmax 활성화 함수를 적용하고, 마지막으로 각 alpha mask를 해당 재구성된 이미지(slot별)와 곱한 다음, slot 차원에 대해 이 해당 출력에 대한 합계 감소(sum reduction)를 수행하여 모든 개별 slot 기반 재구성을 단일 재구성된 이미지로 재결합한다. 단일 이미지 내에서 재구성 마스크를 시각화하기 위해, 각 개별 재구성된 이미지(slot별)를 고유한 slot별 색상으로 대체한다 (예: Figure 20의 세 번째 열 참조).
Table 6: CLEVR 실험을 위한 Deconv 기반 slot decoder.
| Type | Size/Channels | Activation | Comment |
|---|---|---|---|
| Spatial Broadcast | - | - | |
| Position Embedding | - | - | See Section E. 2 |
| Conv | 64 | ReLU | stride: 2 |
| Conv | 64 | ReLU | stride: 2 |
| Conv | 64 | ReLU | stride: 2 |
| Conv | 64 | ReLU | stride: 2 |
| Conv | 64 | ReLU | stride: 1 |
| Conv | 4 | - | stride: 1 |
| Split Channels | RGB (3), alpha mask (1) | Softmax (on alpha masks) | - |
| Recombine Slots | - | - | - |
Table 7: Tetrominoes 및 Multi-dSprites 실험을 위한 Deconv 기반 slot decoder.
| Type | Size/Channels | Activation | Comment |
|---|---|---|---|
| Spatial Broadcast | width height | - | - |
| Position Embedding | - | - | See Section E. 2 |
| Conv | 32 | ReLU | stride: 1 |
| Conv | 32 | ReLU | stride: 1 |
| Conv | 32 | ReLU | stride: 1 |
| Conv | 4 | - | stride: 1 |
| Split Channels | RGB (3), alpha mask (1) | Softmax (on alpha masks) | - |
| Recombine Slots | - | - | - |
E. 4 Set Prediction Architecture
속성 예측(property prediction) task의 경우, 우리는 각 slot에 MLP를 적용하고(slot 간 파라미터 공유), [31]에 따라 Huber loss로 전체 네트워크를 학습시킨다. Huber loss는 인 값에 대해서는 제곱 오차 형태를 취하고, 인 값에 대해서는 기울기 1로 선형적으로 증가하는 오차 형태를 취한다. 이 MLP는 64개의 유닛과 ReLU 활성화 함수를 가진 하나의 hidden layer를 갖는다.
이 MLP의 출력은 sigmoid 활성화 함수를 사용하는데, 이는 우리가 이산 feature를 one-hot encoding하고 연속 feature를 사이로 정규화하기 때문이다. 전체 네트워크는 Table 8에 제시되어 있다.
Table 8: 속성 예측 실험을 위한 MLP.
| Type | Size/Channels | Activation |
|---|---|---|
| MLP (per slot) | 64 | ReLU |
| MLP (per slot) | output size | Sigmoid |
E. 5 Slot MLP Baseline
Slot MLP baseline의 경우, Tables 9와 10에 나타난 바와 같이 MLP를 사용하여 slot representation을 예측한다. 이 모듈은 우리의 Slot Attention 모듈을 대체하며, 그 뒤에는 동일한 decoder/classifier가 이어진다. MLP의 파라미터 수를 줄이기 위해, 이미지를 16x16 크기로 조정한 후 단일 feature vector로 평탄화(flatten)한다.
Table 9: Set prediction을 위한 Slot MLP 아키텍처. 이 블록은 Slot Attention 모듈을 대체한다.
| Type | Size/Channels | Activation |
|---|---|---|
| Resize | - | |
| Flatten | - | - |
| MLP | 512 | ReLU |
| MLP | 512 | ReLU |
| MLP | slot size num slots | - |
| Reshape | [slot size, num slots] | - |
Table 10: Object discovery를 위한 Slot MLP 아키텍처. 이 블록은 Slot Attention 모듈을 대체한다. object discovery task에서 더 간단한 MLP baseline에 비해 성능이 크게 향상되는 것을 확인했기 때문에, 이 설정에서는 더 깊은 MLP와 더 많은 hidden unit, 그리고 파라미터를 공유하는 별도의 slot-wise MLP를 사용한다.
| Type | Size/Channels | Activation |
|---|---|---|
| Resize | - | |
| Flatten | - | - |
| MLP | 512 | ReLU |
| MLP | 1024 | ReLU |
| MLP | 1024 | ReLU |
| MLP | slot size num slots | - |
| Reshape | [slot size, num slots] | - |
| MLP (per slot) | 64 | ReLU |
| MLP (per slot) | 64 | - |
E. 6 Other Hyperparameters
각 실험에 공통적으로 사용된 모든 하이퍼파라미터는 Table 11a에서 확인할 수 있다. object discovery 및 property prediction 실험에 특화된 하이퍼파라미터는 각각 Table 11b와 Table 11c에서 확인할 수 있다.
Table 11: 모든 실험에 사용된 기타 하이퍼파라미터.
| Name | Value |
|---|---|
| attn: | |
| Adam: | 0.9 |
| Adam: | 0.999 |
| Adam: | |
| Adam: learning rate | 0.0004 |
| Exponential decay | rate 0.5 |
| Slot dim. | 64 |
(b) object discovery를 위한 하이퍼파라미터.
| Name | Value |
|---|---|
| Warmup iters. | 10 K |
| Decay steps | 100 K |
| Batch size | 64 |
| Train steps | 500 K |
(c) property prediction을 위한 하이퍼파라미터.
| Name | Value |
|---|---|
| Warmup iters. | 1 K |
| Decay steps | 50 K |
| Batch size | 512 |
| Train steps | 150 K |
두 실험 모두에서 우리는 learning rate warm-up과 exponential decay schedules를 사용한다. learning rate warm-up의 경우, 학습의 초기 단계에서 learning rate를 0부터 최종 learning rate까지 선형적으로 증가시킨다. decay의 경우, learning rate를 지수적으로 감소하는 decay rate를 곱하여 줄인다:
\text { learning_rate } * \text { decay_rate }{ }^{(\text {step } / \text { decay_steps })}여기서 decay rate는 learning rate를 얼마나 줄일지를 결정한다. 두 스케줄의 파라미터는 Table 11을 참조하라.
E. 7 Hyperparameter Optimization
우리는 [16]의 아키텍처 및 하이퍼파라미터 설정과 유사한 지점에서 시작했다. CLEVR 데이터셋의 작은 학습 이미지 서브셋(320개)에서 얻은 ARI 점수를 기반으로 객체 발견(object discovery) task의 하이퍼파라미터를 튜닝했다. 학습률(learning rate)은 [1e-4, 4e-4, 2e-4, 4e-5, 1e-5]의 5가지 값만 고려했으며, 배치 크기(batch size)는 **[32, 64, 128]**을 사용했다. 속성 예측(property prediction)의 경우, 객체 발견과 동일한 학습률을 사용했으며, 작은 학습 이미지 서브셋(500개)에서 AP(Average Precision)를 계산했다. 배치 크기는 **[64, 128, 512]**를 고려했다 (이 모델은 메모리 사용량이 적어 단일 GPU에 더 큰 배치를 올릴 수 있었기 때문).
E. 8 Datasets
Set Prediction
우리는 여러 객체를 포함하는 렌더링된 장면으로 구성된 CLEVR [84] 데이터셋을 사용한다. 각 객체는 **위치( 좌표, 범위는 [-3,3]), 색상(8가지), 모양(3가지), 재질, 크기(2가지)**에 대한 어노테이션을 가지고 있다. 객체의 수는 3개에서 10개 사이로 다양하며, [31]과 유사하게 batch 내에서 객체 수가 일정하도록 target을 zero-padding하고, label이 실제 객체에 해당하는지 padding에 해당하는지를 나타내는 추가 차원을 더한다. 이 task를 위해, 우리는 [31]과의 일관성을 유지하고 그들의 보고된 수치 및 우리의 재구현 결과와 비교하기 위해 CLEVR [84]의 원본 버전을 사용한다. 객체 위치는 [0,1] 범위로 전처리하고, 이미지는 128x128 해상도로 크기를 조정한다. 이미지 feature(RGB 값)는 [-1,1]로 정규화된다.
Object Discovery
Object discovery를 위해, 우리는 **Multi-Object Datasets 라이브러리 [83]**에서 제공하는 세 가지 데이터셋을 사용한다 (https://github.com/deepmind/multi_object_datasets에서 확인 가능). 데이터셋에 대한 자세한 설명은 해당 저장소를 참조하라. 우리는 CLEVR (with masks), Multi-dSprites, Tetrominoes를 사용한다. CLEVR (with masks) 데이터셋의 TFRecords 파일은 디스크에서 더 빠르게 로드할 수 있도록 여러 shard로 분할하였다. 모든 이미지 feature(RGB 값)는 [-1,1]로 정규화된다. Tetrominoes와 Multi-dSprites의 이미지 해상도는 각각 35x35와 64x64이다. **CLEVR (with masks)**의 경우, [16]에서와 같이 너비 [29,221] 및 높이 [64,256] 범위로 center-crop을 수행한 후, 크롭된 이미지를 128x128 해상도로 조정한다. [16]에서와 같이, 우리는 CLEVR (with masks) 데이터셋을 최대 6개의 객체를 포함하는 장면만 유지하도록 필터링했으며, 이 데이터셋을 CLEVR6라고 부르고, 원본 데이터셋은 CLEVR10이라고 부른다.
E. 9 Metrics
ARI (Adjusted Rand Index)
이전 연구 [16]에 따라, 우리는 디코더가 생성한 예측 alpha mask와 ground truth instance segmentation mask를 비교하기 위해 Adjusted Rand Index (ARI) [87, 88] 점수를 사용한다.
ARI는 클러스터링 유사도를 측정하는 점수로, 1은 완벽한 일치를, 0은 무작위 수준을 의미한다.
[16]에서와 같이, ARI 점수 계산 시 배경 레이블은 제외한다.
우리는 Multi-Object Datasets 라이브러리 [83]에서 제공하는 구현을 사용하며, 이는 https://github.com/deepmind/multi_object_datasets 에서 확인할 수 있다.
ARI 점수에 대한 자세한 설명은 해당 저장소를 참조하라.
Average Precision (AP)
우리는 Zhang et al. [31]과 동일한 설정을 고려하며, validation set의 모든 이미지에 걸쳐 average precision을 계산한다.
네트워크는 각 detection에 대한 confidence를 예측하므로(실제 객체는 target 1, padding 객체는 0), 먼저 예측 confidence를 기준으로 예측들을 정렬한다.
각 예측에 대해, 우리는 해당 ground truth 이미지에 일치하는 속성을 가진 객체가 있었는지 확인한다.
예측된 이산 속성(argmax로 얻음)이 ground truth와 정확히 일치하고, 예측된 객체의 위치가 ground truth의 거리 임계값 내에 있을 경우, 해당 detection은 true positive로 간주된다. 그렇지 않으면 false positive로 간주된다.
그 다음, [90]에서와 같이 고유한 recall 값에서 smoothed precision recall curve 아래의 면적을 계산한다.
우리의 AP 점수 구현은 [31]에 설명된 내용을 최대한 재구현한 것이다.
[31]에서 제공하는 구현은 https://github.com/Cyanogenoid/dspn 에서 찾을 수 있다.