QUAG: 쿼리 중심 오디오-비주얼 인지 네트워크를 통한 비디오 분석
이 논문은 사용자의 선호도에 맞는 비디오 콘텐츠를 깊이 있게 이해하기 위해, 얕은 수준에서 깊은 수준으로 처리하는 원칙에 기반한 QUAG(Query-centric Audio-Visual Cognition) 네트워크를 제안합니다. QUAG는 시각 및 오디오 모달리티 간의 전역적 Contrastive 정렬과 지역적 상호작용을 모델링하는 MSP(Modality-Synergistic Perception)와, 쿼리를 사용하여 오디오-비주얼 표현에서 중요한 정보를 필터링하는 QC²(Query-centric Cognition)를 통해 모멘트 검색, 분할, 및 스텝 캡셔닝 작업을 수행하는 신뢰도 높은 다중 모달 표현을 구축합니다. 논문 제목: Query-centric Audio-Visual Cognition Network for Moment Retrieval, Segmentation and Step-Captioning
논문 요약: Query-centric Audio-Visual Cognition Network for Moment Retrieval, Segmentation and Step-Captioning
- 논문 링크: https://arxiv.org/abs/2412.13543
- 저자: Yunbin Tu, Liang Li, Li Su, Qingming Huang (University of Chinese Academy of Sciences 외)
- 발표 시기: 2025년, AAAI Conference on Artificial Intelligence
- 주요 키워드: 비디오 이해, 다중 모달 학습, 모멘트 검색, 모멘트 분할, 스텝 캡셔닝, HIREST
1. 연구 배경 및 문제 정의
- 문제 정의: 기존 비디오 검색은 전체 비디오를 반환하여 사용자의 특정 관심 순간을 만족시키지 못하는 한계가 있었습니다. 이에 따라 사용자가 텍스트 쿼리를 통해 비디오 내의 가장 관련 있는 순간을 찾고(모멘트 검색), 이를 더 세분화된 단계로 분할하며(모멘트 분할), 각 단계를 간결한 문장으로 설명하는(스텝 캡셔닝) 새로운 계층적 비디오 이해 작업인 HIREST(Hierarchical Retrieval and Step-Captioning)가 제시되었습니다.
- 기존 접근 방식: 선구적인 HIREST 연구는 사전 훈련된 CLIP 기반 모델을 특징 추출기로 사용하고, 시각, 오디오, 텍스트 세 가지 모달리티의 표현을 단순한 요소별 덧셈/곱셈 방식으로 융합했습니다. 이러한 접근 방식은 모달리티 간의 계층적 관계나 시너지 효과를 충분히 활용하지 못하여, 사용자가 선호하는 콘텐츠에 대한 포괄적인 인지를 학습하는 데 한계가 있었습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 인간의 지각 및 인지 원리(얕은 것에서 깊은 것으로)에 기반하여, 쿼리 중심 시청각 표현을 학습하고 세 가지 어려운 작업(모멘트 검색, 분할, 스텝 캡셔닝)을 공동으로 해결하는 QUAG(Query-centric Audio-Visual Cognition) 네트워크를 제안했습니다.
- QUAG 내에서 시각 및 오디오 모달리티 간의 전역적 대조 정렬과 지역적 세분화된 상호 작용을 모델링하여 풍부한 시청각 표현을 얻는 MSP(Modality-Synergistic Perception) 모듈을 설계했습니다.
- 깊은 수준의 쿼리에서 얕은 수준의 시청각 표현으로의 시간적-채널 여과를 구현하여 사용자가 요청한 세부 사항에 주목하는 QC²(Query-centric Cognition) 모듈을 고안했습니다.
- 광범위한 실험을 통해 HIREST 데이터셋에서 모멘트 검색, 분할, 스텝 캡셔닝에 대해 최첨단(SOTA) 결과를 달성했으며, 쿼리 기반 비디오 요약 작업(TVSum)에서도 좋은 일반화 가능성을 검증했습니다.
- 제안 방법:
QUAG는 '얕은 것에서 깊은 것으로'의 원칙에 따라 쿼리 중심 시청각 표현을 학습합니다.
- 다중 모달 입력 임베딩: 사전 훈련된 EVA-CLIP(시각, 텍스트) 및 Whisper/MiniLM(오디오)을 사용하여 시각, 오디오, 텍스트 표현을 추출하고 동일한 임베딩 공간에 투영합니다.
- MSP (Modality-Synergistic Perception):
- 시각 및 오디오 표현 간의 전역적 대조 정렬(InfoNCE 손실 사용)을 통해 동일한 임베딩 공간에 위치하도록 합니다.
- Multi-head cross-attention을 사용하여 두 모달리티의 지역적 세분화된 상호 작용을 학습하고 공동 표현을 발굴하여 시청각 표현으로 융합합니다.
- QC² (Query-centric Cognition):
- 깊은 수준의 쿼리 표현을 사용하여 얕은 수준의 시청각 표현에 대한 관련 정보에 주목합니다.
- 쿼리와 시청각 표현 간의 시간적 및 채널 관계 행렬을 계산하고 이를 융합하여 시간-채널 관계 행렬을 얻습니다.
- 이 관계 행렬을 통해 시청각 표현에서 사소한 세부 사항을 필터링하고, 필터링된 시청각 표현에 쿼리 표현을 통합하여 최종 쿼리 중심 시청각 표현을 구성합니다.
- 다운스트림 작업: 생성된 쿼리 중심 시청각 표현은 다중 모드 인코더, 다중 작업 예측 헤드, 텍스트 디코더에 입력되어 모멘트 검색, 모멘트 분할, 스텝 캡셔닝 작업을 수행합니다.
- 훈련: 라운드-로빈 방식의 다중 작업 학습 설정을 사용하며, 각 작업 손실과 MSP의 대조 손실을 결합하여 모델을 훈련합니다.
3. 실험 결과
- 데이터셋:
- HIREST: 비디오 검색, 모멘트 검색, 모멘트 분할, 스텝 캡셔닝 작업을 포함하는 데이터셋 (3.4K 텍스트-비디오 쌍, 1.8K 모멘트, 8.6K 스텝 캡션).
- TVSum: 쿼리 기반 비디오 요약 작업을 위한 데이터셋 (10개 카테고리, 각 5개 비디오).
- 주요 결과:
- HIREST 데이터셋:
- 모멘트 검색: Joint 모델 대비 R@0.5에서 2.2%, R@0.7에서 4.2% 성능 향상을 보이며 SOTA를 달성했습니다.
- 모멘트 분할: Recall 및 Precision 지표 모두에서 SOTA를 달성하여 정확하고 신뢰할 수 있는 모멘트 분할 능력을 입증했습니다.
- 스텝 캡셔닝: Joint 모델을 모든 지표에서 크게 능가했으며, 특히 CIDEr에서 20.1%, SPICE에서 48.7%의 상대적 개선을 이루었습니다. 기존 캡셔닝 모델(BMT, SwinBERT)과 비교해도 경쟁력 있는 성능을 보였습니다.
- TVSum 데이터셋 (일반화 능력):
- 5개 카테고리에서 최고의 결과를 얻었으며, 평균 전체 성능이 다른 SOTA 방법과 동등하여 쿼리 기반 비디오 요약 작업에서도 좋은 일반화 능력을 검증했습니다.
- 절제 연구 (Ablation Study):
- MSP와 QC² 각 모듈이 개별적으로도 성능 향상에 기여하며, 두 모듈을 함께 사용했을 때 가장 큰 성능 향상(Joint 대비 CIDEr 20.1%, SPICE 48.7% 증가)을 보여, 각 모듈이 상호 보완적인 역할을 함을 입증했습니다.
- HIREST 데이터셋:
4. 개인적인 생각 및 응용 가능성
- 장점:
- 인간의 인지 과정을 '얕은 것에서 깊은 것으로'라는 원칙으로 모델링에 적용한 점이 매우 흥미롭고 직관적입니다.
- 시각과 오디오 모달리티 간의 전역적 정렬과 지역적 상호작용을 모두 고려한 MSP 모듈의 설계가 다중 모달리티 융합의 효과를 극대화한 것으로 보입니다.
- 쿼리를 활용하여 비디오 콘텐츠에서 중요한 정보를 필터링하는 QC² 모듈의 아이디어가 사용자의 의도를 정확히 반영하는 데 큰 도움이 됩니다.
- 모멘트 검색, 분할, 스텝 캡셔닝이라는 세 가지 복잡한 작업을 단일 프레임워크에서 통합적으로 해결하면서도 각 작업에서 SOTA 성능을 달성한 점이 인상 깊습니다.
- 쿼리 기반 비디오 요약에서도 좋은 일반화 능력을 보여 다양한 비디오 이해 작업에 적용될 수 있는 잠재력을 가지고 있습니다.
- 정성적 분석에서 Joint 모델보다 더 정확하고 세분화된 모멘트 검색 및 캡션 생성을 보여주어, 제안 방법의 실제적인 효과를 시각적으로 확인할 수 있었습니다.
- 단점/한계:
- 실패 사례에서 강사가 항상 비디오에 나타나는 경우 모델이 지시 내용이 끝나지 않았다고 오해하거나, '칠리 파우더'와 같은 미세한 객체를 인식하지 못하는 한계가 있었습니다. 이는 모델이 특정 시각적 맥락에 과도하게 의존하거나, 세분화된 객체 인지 능력이 부족할 수 있음을 시사합니다.
- 미세한 객체 인식을 위해 세분화 특징(segmentation features)과 같은 더 미세한 수준의 시각적 특징 도입이 필요하다는 제안은 향후 연구 방향을 제시합니다.
- HIREST의 궁극적인 목표가 일반적인 모델 훈련이므로, 특정 작업별 모델보다는 일부 지표에서 제한적인 개선을 보일 수 있다는 점은 여전히 존재할 수 있는 한계입니다.
- 응용 가능성:
- 사용자 맞춤형 비디오 콘텐츠 서비스: 특정 요리 레시피의 특정 단계 찾기, DIY 비디오에서 특정 작업 과정 추출 등 사용자 쿼리에 기반한 정교한 비디오 검색 및 요약 서비스에 활용될 수 있습니다.
- 교육 및 훈련: 온라인 강의나 튜토리얼 비디오에서 핵심 내용 자동 추출 및 요약, 특정 개념 설명 구간 식별 등에 적용하여 학습 효율을 높일 수 있습니다.
- 콘텐츠 제작 및 편집: 비디오 편집자가 특정 장면을 빠르게 찾거나, 긴 비디오를 자동으로 분할하고 각 장면에 대한 설명을 생성하는 데 도움을 줄 수 있습니다.
- 보안 및 감시: 특정 행동이나 이벤트를 감지하고 그 순간을 정확히 포착하여 설명하는 데 응용될 수 있습니다.
5. 추가 참고 자료
Tu, Yunbin, et al. "Query-centric Audio-Visual Cognition Network for Moment Retrieval, Segmentation and Step-Captioning." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 39. No. 7. 2025.
Query-centric Audio-Visual Cognition Network for Moment Retrieval, Segmentation and Step-Captioning
Yunbin , Liang , Li Su , Qingming Huang <br> School of Computer Science and Technology, University of Chinese Academy of Sciences, Beijing, China<br> Key Laboratory of AI Safety of CAS, Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China<br> Peng Cheng Laboratory, Shenzhen, China<br>tuyunbin22@mails.ucas.ac.cn, liang.li@ict.ac.cn, {suli,qmhuang}@ucas.ac.cn
Abstract
비디오는 인터넷에서 선호되는 멀티미디어 형식으로 부상했습니다. 비디오 콘텐츠를 더 잘 파악하기 위해, 비디오 검색, 모멘트 검색, 모멘트 분할 및 스텝 캡셔닝을 포함하는 새로운 주제인 HIREST가 제시되었습니다. 선구적인 연구는 비디오 검색을 위해 사전 훈련된 CLIP 기반 모델을 선택하고, 다중 작업 학습 패러다임에서 해결되는 다른 세 가지 어려운 작업을 위한 특징 추출기로 이를 활용합니다. 그럼에도 불구하고, 이 연구는 모달리티 간의 계층과 연관 관계를 무시하기 때문에 사용자가 선호하는 콘텐츠에 대한 포괄적인 인지를 학습하는 데 어려움을 겪습니다. 본 논문에서는 얕은 것에서 깊은 것으로의 원칙에 따라, 모멘트 검색, 분할 및 스텝 캡셔닝을 위한 신뢰할 수 있는 다중 모드 표현을 구성하기 위해 쿼리 중심 시청각 인지(QUAG) 네트워크를 제안합니다. 구체적으로, 우리는 먼저 시각 및 오디오 모달리티 간의 전역적 대조 정렬과 지역적 세분화된 상호 작용을 모델링하여 풍부한 시청각 콘텐츠를 얻기 위한 모달리티-시너지 인식을 설계합니다. 그런 다음, 우리는 얕은 수준의 시청각 표현에 대해 시간적-채널 여과를 수행하기 위해 깊은 수준의 쿼리를 사용하는 쿼리 중심 인지를 고안합니다. 이는 사용자가 선호하는 콘텐츠를 인지할 수 있게 하여 세 가지 작업을 위한 쿼리 중심 시청각 표현을 얻을 수 있습니다. 광범위한 실험을 통해 QUAG가 HIREST에서 SOTA 결과를 달성함을 보여줍니다. 또한, 우리는 쿼리 기반 비디오 요약 작업에서 QUAG를 테스트하여 그 좋은 일반화 가능성을 검증합니다. 코드는 https://github.com/tuyunbin/QUAG 에서 확인할 수 있습니다.
Introduction
최근, 우리는 생성 AI(예: Sora)와 비디오 플랫폼의 발전과 함께 비디오의 기하급수적인 성장을 목격하고 있습니다. 이에 따라, 비디오 검색 능력을 향상시키기 위해 수많은 연구(Wu et al. 2023; Li et al. 2024; Wang et al. 2024c)가 제안되었습니다. 그러나 텍스트 쿼리가 주어졌을 때 전체 비디오를 반환하는 것은 항상 만족스럽지 않습니다. 때때로, 사용자들은 쿼리와 가장 관련 있는 순간을 직접적으로 찾고 싶어합니다. 예를 들어, 딸기 파이를 만드는 방법을 배울 때, 사용자들은 그림 1에서 볼 수 있듯이 지시적인 순간에만 집중하는 경향이 있습니다. 더욱이, 이 순간이 복잡하다면, 우리는 기계가 더 나은 이해를 위해 이를 더 세분화된 단계로 분할하고 각각을 간결한 문장으로 캡션하기를 기대합니다. 예를 들어 "접시에 딸기 주스를 추가하세요", "그 위에 반죽을 올리세요" 등입니다. 이러한 사용자 선호도의 변화는 새로운 연구 주제인 계층적 검색 및 스텝 캡셔닝(HIREST) (Zala et al. 2023)을 촉발시켰습니다.
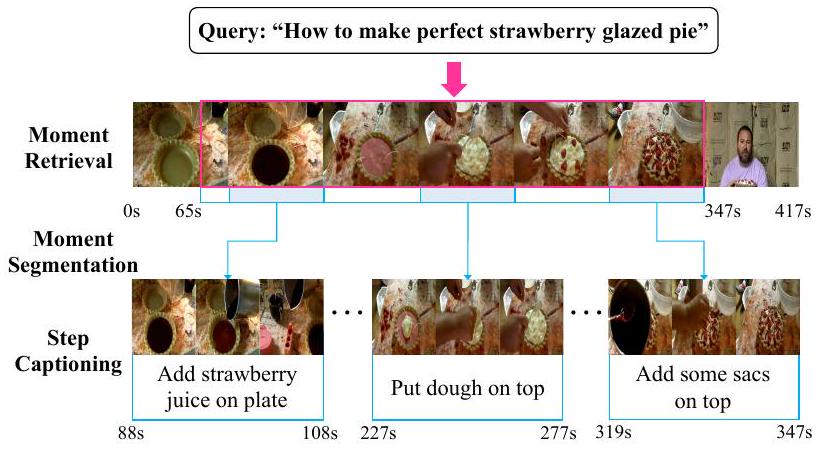
Figure 1: 모멘트 검색, 모멘트 분할, 스텝 캡셔닝으로 구성된 예시. 먼저, "완벽한 딸기 글레이즈드 파이를 만드는 방법"이라는 텍스트 쿼리가 주어지면, 모델은 비디오에서 가장 관련 있는 순간을 찾아야 합니다(모멘트 검색). 그런 다음, 모델은 해당 순간을 더 세분화된 단계로 나눕니다(모멘트 분할). 마지막으로, 모델은 각 단계를 간결한 문장으로 설명해야 합니다(스텝 캡셔닝).
이 주제는 비디오 검색, 모멘트 검색, 모멘트 분할 및 스텝 캡셔닝의 네 가지 작업을 벤치마킹합니다. 선구적인 연구(Zala et al. 2023)에서 Zala 등은 사전 훈련된 CLIP 기반 모델로 비디오 검색을 구현하고 이를 세 가지 다운스트림 작업을 위한 특징 추출기로 사용합니다. 그들의 초점은 단일 아키텍처에서 세 가지 작업을 공동으로 해결하는 것입니다. 이를 위해, 그들은 먼저 사전 훈련된 모델(Fang et al. 2023; Radford et al. 2023; Reimers and Gurevych 2019)을 활용하여 시각적 프레임, 오디오 및 쿼리에 대한 다중 모드 표현을 생성하는 Joint 모델을 제안합니다. 다음으로, 이 표현은 모멘트와 스텝의 경계를 예측하고 각 스텝 캡션을 생성하는 데 사용됩니다. 이 과정에서 모델은 라운드-로빈 방식(Cho et al. 2021)의 다중 작업 설정을 통해 훈련됩니다.
유망한 결과에도 불구하고, 위의 연구는 순진한 다중 모드 융합 전략으로 인해 사용자가 선호하는 비디오 콘텐츠에 대한 포괄적인 인지를 학습하는 데 한계가 있습니다. 첫째, 세 가지 모달리티의 표현이 구별 없이 직접 융합되어 모달리티 간의 계층을 무시합니다. 심리학 연구(Tacca 2011; Yang, Zhuang, and Pan 2021)에 따르면 인간의 지각과 인지는 얕은 것에서 깊은 것으로의 방식으로 이루어집니다. 비디오를 볼 때, 우리는 보통 먼저 객체의 외형이나 소리와 같은 얕은 수준의 감각 정보를 얻어 비디오의 시청각 콘텐츠에 대한 직관적인 인식을 형성합니다. 그런 다음, 우리는 관심 있는 특정 콘텐츠에 대한 포괄적인 인지를 학습하기 위해 의도와 같은 더 깊은 수준의 지식을 감각 정보에 통합합니다. 따라서, 이러한 얕은 것에서 깊은 것으로의 원칙에 기반하여 모달리티 계층을 모델링하는 것이 유익합니다.
둘째, 세 가지 모달리티 간의 융합 전략(요소별 곱셈 및 덧셈)은 그들의 연관 관계를 충분히 활용하지 못합니다. 얕은 수준의 시각 및 오디오 모달리티는 다른 측면에서 비디오 콘텐츠를 나타낼 수 있지만, 직접적인 요소별 덧셈은 그들의 시너지 관계를 잃을 수 있습니다. 그 후, 깊은 수준의 쿼리는 사소한 세부 사항을 필터링하고 얕은 수준의 시청각 콘텐츠 내에서 중요한 것을 강조할 수 있습니다. 그럼에도 불구하고, 요소별 곱셈은 사용자가 선호하는 비디오 콘텐츠를 인지하는 데 도움이 되는 그러한 여과 관계를 모델링할 수 없습니다. 따라서, 모달리티 간의 계층을 모델링하는 동안 이러한 연관 관계를 점진적으로 포착하는 것이 필요합니다.
본 논문에서는 사용자가 선호하는 비디오 콘텐츠를 인지하고 모멘트 검색, 분할 및 스텝 캡셔닝을 해결하기 위한 효과적인 다중 모드 표현을 학습하기 위해 QUery-centric Audio-visual coGnition (QUAG) 네트워크를 제안합니다. QUAG는 modality-synergistic perception (MSP) 및 query-centric cognition () 모듈로 구성됩니다. 구체적으로, 시각적 프레임 및 오디오 표현이 주어지면, MSP는 먼저 그들의 전역적 대조 정렬을 모델링하여 동일한 임베딩 공간에 있도록 합니다. 그런 다음, 그들의 지역적 세분화된 상호 작용을 학습하여 공동 표현을 발굴하고, 이를 시청각 표현으로 융합합니다. 그 후, 깊은 수준의 쿼리에 의해 안내되는 는 얕은 수준의 시청각 표현에 대해 시간적-채널 여과를 수행하여 사용자가 요청한 세부 사항을 강조합니다. 다음으로, 쿼리 표현은 필터링된 시청각 표현에 주입되어 쿼리 중심 시청각 표현을 구성합니다. 이것은 최종적으로 다중 모드 인코더, 다중 작업 예측 헤드 및 텍스트 디코더에 공급되어 세 가지 어려운 작업을 해결합니다.
우리의 주요 기여는 다음과 같이 요약됩니다:
- 인간의 지각과 인지에 대한 조사를 바탕으로, 우리는 얕은 것에서 깊은 것으로의 원칙에 따라 QUAG를 제안하며, 이는 쿼리 중심 시청각 표현을 학습하여 세 가지 어려운 작업을 공동으로 해결합니다.
- QUAG에서, 우리는 먼저 시각 및 오디오 표현 간의 전역적 대조 정렬과 지역적 세분화된 상호 작용을 모델링하여 시청각 표현을 얻기 위해 MSP를 설계합니다. 그런 다음, 깊은 수준의 쿼리에서 얕은 수준의 시청각 표현으로의 시간적-채널 여과를 구현하여 쿼리 중심 시청각 표현에 주목하기 위해 를 고안합니다.
- 광범위한 실험을 통해 QUAG가 HIREST 데이터셋에서 모멘트 검색, 분할 및 스텝 캡셔닝에 대해 최첨단 결과를 달성함을 보여줍니다. 또한, 우리는 TVSum 데이터셋에서 쿼리 기반 비디오 요약에 대해 QUAG를 테스트하여 그 일반화 가능성을 검증합니다.
Related Work
계층적 검색 및 스텝 캡셔닝 작업은 다중 모드 학습 커뮤니티(Cong et al. 2022, 2023; Tu et al. 2023a, 2024a,b,c)에 속합니다. 다음에서는 관련 연구를 네 가지 차원에서 검토합니다.
Video-moment retrieval. 교차 모드 검색은 인공 지능의 근본적인 문제입니다(Zha et al. 2019; Zhang et al. 2020; Liu et al. 2022a; Zhang et al. 2024; Yue et al. 2023; Wang et al. 2024a,b; Tang et al. 2024; Yue et al. 2024). 텍스트 기반 비디오 검색(Dong et al. 2022; Xie et al. 2024; Li et al. 2023)은 텍스트 쿼리를 사용하여 코퍼스에서 관련 비디오를 찾는 것입니다. 최근, 대조 학습의 이점을 활용하여 대부분의 텍스트-이미지/비디오 검색 모델(예: CLIP)이 설계되었습니다(Radford et al. 2021; Fang et al. 2023). 이러한 모델을 사용하면 텍스트 쿼리와 비디오 간의 코사인 유사도를 쉽게 계산할 수 있어 쿼리와 가장 관련 있는 비디오를 찾을 수 있습니다. 그러나 전체 비디오에는 쿼리와 관련 없는 부분이 일부 있기 때문에, 대부분의 방법(Sun et al. 2022; Lei, Berg, and Bansal 2021; Moon et al. 2023)에서는 비디오에서 쿼리 관련 구간을 찾는 모멘트 검색을 연구해 왔습니다.
Video summarization. 전통적인 비디오 요약 방법(Song et al. 2015; Xiong and Grauman 2014)은 중요한 정보를 추출하여 긴 비디오를 압축하는 것입니다. 그러나 이러한 방법들은 요약에 대한 사용자들의 다양한 선호를 무시합니다. 이 한계를 해결하기 위해, 쿼리 중심 접근 방식(Sharghi, Gong, and Shah 2016; Sharghi, Laurel, and Gong 2017; Narasimhan et al. 2022)은 텍스트 쿼리를 통해 사용자 선호를 통합하여 비디오 내에서 가장 관련 있는 프레임을 식별합니다. 요약 과정을 사용자 관심사와 일치시킴으로써, 이러한 쿼리 중심 방법들은 사용자 선호도와 가장 관련 있는 모멘트들의 모음을 찾을 수 있습니다.
Video Captioning. 전통적인 비디오 캡셔닝 방법(Li et al. 2022; Tu et al. 2023b)은 짧은 비디오에 대해 간결한 문장을 생성합니다. 여러 이벤트가 있는 긴 비디오를 설명하기 위해, 일부 방법(Yang et al. 2023; Kim et al. 2024)에서는 긴 비디오에 대한 단락을 생성하는 밀집 비디오 캡셔닝을 연구합니다. 다른 한편으로, 일부 방법(Lei et al. 2020; Li et al. 2020; Tu et al. 2022)들은 TV 쇼 캡셔닝을 연구하려고 합니다. 시각적 모달리티만 사용하는 대신, 그들은 캡션 생성을 위한 시각-언어 표현을 모델링하기 위해 비디오 특징을 보강하는 텍스트 특징(예: 배우의 대화에서 온 자막)을 도입하는 것을 고려합니다.
Hierarchical Retrieval and Step-Captioning. 위의 작업들은 이전 연구에서 개별적으로 연구되었습니다. 사실, 이 작업들은 비디오 코퍼스에서 정보를 추출하는 공통된 목표를 공유합니다. 따라서, Zala 등(Zala et al. 2023)은 사용자들의 다양한 선호도를 충족시키기 위해 이러한 작업들을 HIREST라는 새로운 작업으로 결합했습니다. 이 선구적인 연구에서는, 사전 훈련된 CLIP 기반 모델이 비디오 검색에 활용되고, 다른 세 가지 작업을 위한 특징 추출기로 사용됩니다. 또한, 세 가지 작업을 공동으로 해결하기 위한 통합 프레임워크가 제안됩니다. 이 연구에서, 우리는 이 패러다임을 따라 통합된 아키텍처에서 세 가지 작업을 해결합니다. 여러 모달리티를 요소별 덧셈/곱셈으로 직접 융합하는 선구적인 연구와 비교하여, 우리는 모달리티 간의 계층과 연관 관계를 모델링하여 쿼리 중심 시청각 표현을 학습함으로써 세 가지 다운스트림 작업을 더 잘 해결합니다.
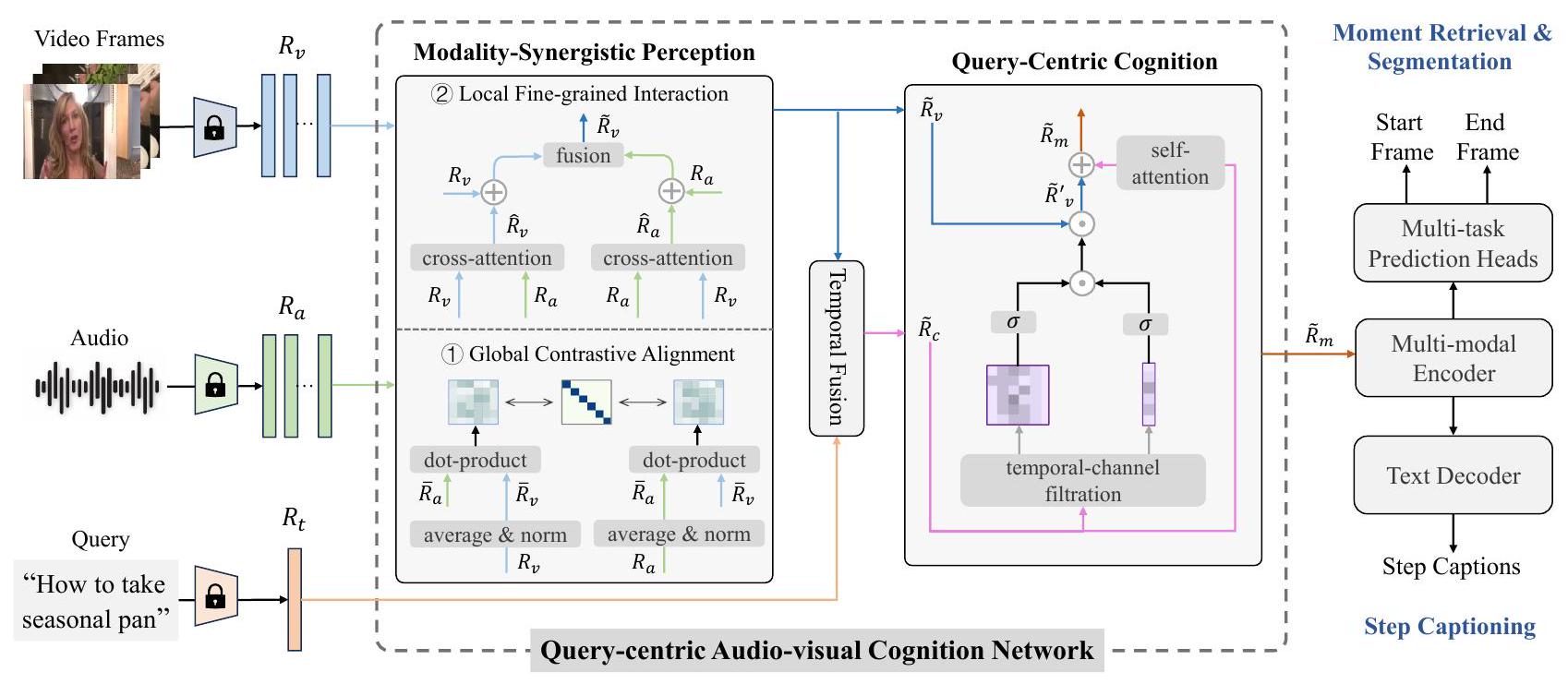
Figure 2: 우리 방법의 개요. 얕은 것에서 깊은 것으로의 원리에 기초하여, 우리는 modality-synergistic perception과 query-centric cognition이라는 핵심 모듈을 가진 query-centric audio-visual cognition (QUAG) 네트워크를 제안합니다. QUAG는 사용자가 선호하는 비디오 콘텐츠에 대한 포괄적인 인지를 학습하고, 이를 통해 모멘트 검색, 모멘트 분할, 그리고 스텝 캡셔닝을 공동으로 해결하기 위한 쿼리 중심 시청각 표현을 얻는 것을 목표로 합니다.
Methodology
그림 2에서 볼 수 있듯이, 우리 방법의 전체적인 프레임워크는 다음 부분들을 포함합니다. 먼저, 시각적 프레임, 오디오, 쿼리가 주어지면, 사전 훈련된 모델을 사용하여 시각, 오디오, 텍스트 표현을 추출합니다. 그런 다음, 이들을 QUAG에 입력하여 쿼리 중심 시청각 표현을 생성합니다. 마지막으로, 이 표현은 내부 관계 모델링을 위해 다중 모드 인코더에 입력되며, 1) 모멘트와 스텝의 경계를 예측하고, 2) 텍스트 디코더가 각 스텝에 대한 캡션을 생성하도록 프롬프트하는 데 사용됩니다.
Multi-modal Input Embedding
프레임을 포함하는 잘리지 않은 비디오와 토큰으로 구성된 텍스트 쿼리가 주어지면, 먼저 사전 훈련된 모델을 사용하여 시각적 표현 와 텍스트 표현 를 각각 추출합니다. 그런 다음, 오디오 정보가 비디오의 주요 객체를 인식하는 데 도움이 된다는 점을 고려하여, 오디오에서 음성 트랜스크립션을 추출하고 이를 오디오 표현 로 임베딩합니다. 이 길이는 비디오 표현과 동일하게 입니다. 다음으로, 세 가지 모달리티 표현을 세 개의 선형 변환 함수를 사용하여 동일한 임베딩 공간에 투영합니다. 즉, , 입니다.
Query-centric Audio-visual Cognition
시각, 오디오 및 텍스트 표현을 얻은 후, 우리는 사용자가 선호하는 비디오 콘텐츠에 대한 포괄적인 인지를 학습하기 위해, 얕은 것에서 깊은 것으로의 원리에 기반하여 쿼리 중심 시청각 표현을 학습하는 modality-synergistic perception (MSP) 및 query-centric cognition () 모듈을 활용하는 query-centric audio-visual cognition (QUAG) 네트워크를 제안합니다.
Modality-Synergistic Perception 쌍으로 주어진 시각적 표현 와 오디오 표현 에 대해, 우리는 MSP를 설계하여 먼저 그들의 전역적 대조 정렬을 최대화함으로써 동일한 임베딩 공간에 상주하도록 합니다. 구체적으로, 우리는 길이 차원에 대해 평균 풀링 연산을 사용하여 그들의 전역 특징을 계산합니다:
여기서 이고 입니다. 그런 다음, 학습 배치에서 개의 쌍으로 된 전역 시각 및 오디오 특징을 샘플링합니다. 번째 전역 시각 특징 에 대해, 번째 전역 오디오 특징 는 양성 샘플이며, 다른 전역 오디오 특징들은 음성 샘플이 됩니다. 즉, 이 배치에는 총 개의 양성 샘플 쌍과 개의 음성 샘플 쌍이 있습니다. 다음으로, InfoNCE 손실(Oord, Li, and Vinyals 2018)을 사용하여 양성 쌍 와 사이의 양방향 유사도를 최대화하고, 음성 쌍 사이의 유사도를 최소화합니다:
여기서 는 온도 하이퍼파라미터입니다. "sim"은 내적 연산을 의미합니다. 이 손실은 시각 및 오디오 표현 간의 전역적 정렬을 향상시키는 자기 지도 신호를 형성하여, 후속 지역적 세분화된 상호 작용을 용이하게 합니다.
이후, 우리는 시각적 표현 와 오디오 표현 에 대한 지역적 특징들을 상호작용시켜 그들의 세분화된 시너지를 학습하고 공동 표현을 발굴합니다. 이는 multi-head cross-attention mechanism (MHCA) (Vaswani et al. 2017)에 의해 수행됩니다:
각 방정식의 괄호 안에서 첫 번째 항은 쿼리를 나타내고, 마지막 두 항은 키와 값 표현을 나타냅니다. 그 후, 두 모달리티의 공동 표현을 연결하여 시청각 표현으로 사용하며, 이는 완전 연결 레이어에 의해 수행됩니다:
여기서 입니다. 및 입니다. 는 연결 연산입니다.
Query-Centric Cognition 우리는 깊은 수준의 쿼리 표현 를 사용하여 얕은 수준의 시청각 표현 에 대한 관련 정보에 주목하기 위해 를 고안합니다. 는 먼저 시간적 및 채널 차원 모두에서 와 사이의 관련성을 측정합니다. 시간적 및 채널 관계 행렬 와 는 다음과 같이 계산됩니다:
여기서 이고 입니다. [; ]는 연결 연산이며, 텍스트 표현 를 로 브로드캐스팅하여 시청각 표현 와 시간적으로 모양을 맞춥니다. Ate , . 및 는 선형 변환 함수입니다.
다음으로, 는 와 를 함께 융합하여 시간-채널 관계 행렬을 계산하며, 이는 요소별 곱셈 함수로 구현됩니다:
여기서 입니다. 에 의해 안내되어, 모델은 시청각 표현 에서 사소한 세부 사항을 필터링할 수 있습니다:
여기서 입니다. 그 후, 필터링된 시청각 표현 에 를 통합하여 쿼리 중심 시청각 표현을 모델링합니다:
여기서 는 multi-head self-attention을 나타냅니다. 마지막으로, 은 향상을 위해 transformer 기반 다중 모드 인코더에 입력된 후, 모멘트 검색, 모멘트 분할 및 스텝 캡셔닝에 활용됩니다.
Moment Retrieval, Moment Segmentation, and Step-captioning
Moment Retrieval은 쿼리와 가장 관련 있는 모멘트를 찾아 그 구간을 출력하는 것입니다. 구체적으로, 이 주어지면, 두 개의 선형 레이어로 구성된 학습 가능한 예측 헤드를 사용하여 시작과 끝 경계를 동시에 예측합니다. 이때 프레임 입력은 마스킹되지 않습니다. 전체 비디오에 대한 시작 및 끝 인덱스의 확률 분포는 다음과 같이 계산됩니다:
여기서 , 그리고 입니다. Moment Segmentation은 검색된 모멘트 내에서 반복적인 프레임이 없는 "핵심 단계"를 식별하는 것을 의미하며, 각 단계의 끝 타임스탬프는 다음 단계의 시작 타임스탬프가 됩니다. 구체적으로, 이 주어지면, 선형 레이어가 있는 학습 가능한 예측 헤드를 사용하여 각 단계의 경계를 자기 회귀 방식으로 예측합니다. 여기서 이전에 예측된 경계는 입력의 일부로 에 통합됩니다. 모멘트 외부 및 이전 단계의 프레임은 마스킹됩니다. 각 단계의 경계 인덱스에 대한 확률 분포는 다음과 같이 계산됩니다:
여기서 이고 입니다. Step-captioning은 분할된 각 단계를 문장으로 설명하는 것을 목표로 합니다. 이를 위해, 먼저 사전 훈련된 캡셔닝 모델 CLIP4Caption (Tang et al. 2021)을 사용하여 텍스트 디코더의 파라미터를 초기화합니다. 그런 다음, 을 텍스트 디코더에 입력하여 자기회귀 방식으로 텍스트 설명을 생성합니다. 이 과정은 다음과 같이 공식화될 수 있습니다:
여기서 는 개의 어휘로 구성된 사전에 대한 번째 디코딩된 분포입니다; 는 이전에 생성된 단어들입니다(학습 중에는 정답 단어, 추론 중에는 예측된 단어). Training. 모멘트 검색의 경우, 정답 시작 및 끝 인덱스가 주어졌을 때, 훈련 손실(최소화 대상)을 예측된 분포에 의한 음의 로그 확률의 합으로 정의하고, 이를 배치의 모든 예제에 대해 평균을 냅니다:
여기서 는 배치 크기이고, 와 는 각각 번째 예제의 정답 시작 및 끝 인덱스입니다.
모멘트 분할의 경우, 정답 스텝 인덱스가 주어지면, 학습 손실(최소화될)을 예측된 분포에 의한 음의 로그 확률의 합으로 정의하며, 이는 배치의 모든 예제에 대해 평균을 냅니다:
여기서 는 배치 크기이고 은 번째 예제의 정답 스텝 인덱스입니다.
스텝 캡셔닝의 경우, 정답 스텝 캡션 단어 가 주어지면, 학습 손실(최소화 대상)을 예측된 분포에 의한 음의 로그 확률의 합으로 정의하고, 이를 배치의 모든 예제에 대해 평균을 냅니다:
여기서 는 식 (11)에 의해 계산됩니다. 은 스텝 캡션의 길이입니다.
저희 방법은 다중 작업 구성으로 학습되며, 라운드-로빈 방식이 활용되고 각 반복마다 세 개의 데이터 로더 중 하나에서 배치가 샘플링됩니다(Zala et al. 2023; Cho et al. 2021). 즉, 각 반복에 대한 학습 손실은 다음과 같이 정의됩니다:
여기서 는 ret, seg, 또는 cap을 나타냅니다. 는 학습 가능한 가중치 집합입니다. 는 작업 손실 중 하나와 대조 손실 사이의 기여도를 균형 있게 조절하는 트레이드오프 파라미터이며, 보충 자료에서 논의됩니다 *.
Experiments
Datasets
HIREST는 비디오 검색, 모멘트 검색, 모멘트 분할 및 스텝 캡셔닝 작업을 포함합니다. 이는 3.4K개의 텍스트-비디오 쌍, 1.8K개의 모멘트, 8.6K개의 스텝 캡션으로 구성됩니다. 우리는 훈련용으로 1,507개의 비디오-쿼리 쌍, 검증용으로 477개의 비디오-쿼리 쌍, 테스트용으로 1,391개의 비디오-쿼리 쌍이 있는 공식 분할을 사용합니다. TVSum은 모멘트 분할과 관련된 쿼리 기반 비디오 요약 작업을 포함합니다. 이 데이터셋은 10개의 다양한 카테고리의 비디오를 포함하며, 각 카테고리는 5개의 비디오로 구성됩니다. 공정한 비교를 위해, 우리는 QDDETR (Moon et al. 2023)을 따라 80%의 비디오를 훈련에 사용하고 나머지는 테스트에 사용합니다.
Evaluation Metrics
HIREST: (1) 우리는 모델의 출력을 정답 모멘트 구간과 비교하여 모멘트 검색을 검증하며, 이는 Intersection over Union (IoU) 임계값 (0.5 및 0.7)의 Recall을 통해 평가됩니다. (2) 모멘트 분할의 경우, 모델은 생성된 스텝 구간과 정답 스텝 구간 간의 유사도를 기반으로 평가되며, 이는 IoU 임계값 (0.5 및 0.7)에 대한 Recall 및 Precision 지표를 통해 이루어집니다. (3)
2스텝 캡셔닝의 경우, 전통적인 지표인 METEOR (Banerjee and Lavie 2005), ROUGE-L (Lin 2004), CIDEr (Vedantam, Lawrence Zitnick, and Parikh 2015), SPICE (Anderson et al. 2016)가 생성된 문장을 평가하는 데 사용됩니다. 또한, (Zala et al. 2023)을 따라, 우리는 ELMo (Peters et al. 2018) 기반의 Decomposable Attention model (Parikh et al. 2016)을 도입하여 생성된 문장과 정답 캡션 간의 함의를 계산합니다. TVSum: 이전 연구들(Moon et al. 2023; Liu et al. 2022b)을 따라, 우리는 상위 5개 mAP를 주요 지표로 활용합니다.
Implementation Details
먼저, 우리는 사전 훈련된 EVA-CLIP (Fang et al. 2023)을 사용하여 시각적 프레임에 대한 시각적 표현을 추출하고, EVA-CLIP의 텍스트 인코더를 사용하여 텍스트 쿼리를 텍스트 표현으로 매핑합니다. 그런 다음, 사전 훈련된 Whisper (Radford et al. 2023)를 사용하여 오디오에서 음성 트랜스크립션을 추출하고, 사전 훈련된 MiniLM (Reimers and Gurevych 2019) 텍스트 인코더를 사용하여 트랜스크립션을 오디오 표현이라는 표현으로 매핑합니다. 은닉 크기는 768로 설정됩니다. 텍스트 디코더는 먼저 사전 훈련된 CLIP4Caption (Tang et al. 2021)에서 초기화된 다음, HIREST 데이터셋에서 미세 조정됩니다. 훈련 중, 배치 크기는 5로 설정되고 학습률은 로 설정되며, AdamW 옵티마이저 (Loshchilov and Hutter 2018)가 식 (15)에 정의된 훈련 손실을 최소화하는 데 사용됩니다. 더 자세한 내용은 보충 자료에 나와 있습니다.
Performance Comparison on HIREST
Results on the Moment Retrieval 이 작업에서, 우리는 QUAG를 선구적인 연구인 Joint model (Zala et al. 2023)과 비교합니다. 또한 QUAG를 세 가지 작업별 모멘트 검색 모델인 QD-DETR (Moon et al. 2023), TR-DETR (Sun et al. 2024), 그리고 UVCOM (Xiao et al. 2024)과 비교합니다. 언급된 모델들은 공개된 코드를 기반으로 구현되었습니다. 또한, Zala et al. (Zala et al. 2023)을 따라, 우리는 QUAG를 텍스트-이미지 검색 모델인 EVA-CLIP (Fang et al. 2023)과 비교합니다.
비교 결과는 표 1에 나와 있습니다. 우리의 QUAG는 두 지표 모두에서 모멘트 검색에서 최고의 성능을 얻습니다. 이는 우리 방법이 정답 구간과 50% 중첩 및 70% 중첩으로 관련 모멘트를 식별하는 데 높은 재현율을 가지고 있음을 나타냅니다. 특히, 우리 방법은 Joint 모델에 비해 에서 2.2%, 에서 4.2%의 성능 향상을 보였으며, 이는 QUAG의 효과를 더욱 검증합니다.
Table 1: HIREST 테스트 세트에서의 모멘트 검색 결과.
| Model | Recall @ IoU | |
|---|---|---|
| 0.5 | 0.7 | |
| EVA-CLIP-G/14 (Fang et al. 2023) | 38.27 | 19.33 |
| QD-DETR (Moon et al. 2023) | 71.52 | 38.34 |
| UVCOM (Xiao et al. 2024) | ||
| TR-DETR (Sun et al. 2024) | 72.07 | 38.40 |
| Joint (Zala et al. 2023) | 70.98 | 37.31 |
| QUAG |
Table 2: HIREST 데이터셋의 테스트 세트에서의 모멘트 분할 결과.
| Model | Recall @ IoU | Precision @ IoU | ||
|---|---|---|---|---|
| 0.5 | 0.7 | 0.5 | 0.7 | |
| 34.24 | 16.27 | 28.32 | 12.05 | |
| UVCOM | 37.03 | 16.79 | ||
| TR-DETR | 37.07 | 16.35 | 29.71 | 12.93 |
| Joint | 28.52 | 12.84 | ||
| QUAG |
Table 3: HIREST 테스트 세트에서의 스텝 캡셔닝 결과. M, R, C, S는 METEOR, ROUGE-L, CIDEr, SPICE를 나타냅니다.
| Model | M | R | C | S | Entail. (%) |
|---|---|---|---|---|---|
| BMT | 3.84 | - | 6.72 | 1.05 | 30.68 |
| SWinBERT | - | 24.66 | 35.09 | ||
| Joint | 4.14 | 11.85 | 21.19 | 3.02 | 35.97 |
| QUAG |
Results on the Moment Segmentation 이 작업에서, 우리는 제안된 QUAG를 Joint 모델(Zala et al. 2023)과 비교합니다. 또한, 세 가지 작업별 모델인 QD-DETR(Moon et al. 2023), TR-DETR(Sun et al. 2024), 그리고 UVCOM(Xiao et al. 2024)이 그들의 코드를 기반으로 구현되어 우리의 QUAG와 비교되었습니다.
결과는 표 2에 나와 있습니다. QUAG는 IoU 임계값 0.5와 0.7에서 Recall에서 뛰어난 성능을 보입니다. QUAG의 두 IoU 임계값에서의 높은 재현율은 모멘트 분할에 대한 강력한 능력을 보여줍니다. 정밀도 지표의 경우, 우리의 QUAG는 IoU 임계값 0.5와 0.7 모두에서 최고의 결과를 얻었으며, 이는 우리 방법이 높은 정확도로 모멘트를 분할할 수 있음을 나타냅니다. 전반적으로, 재현율과 정밀도 모두에서 우수한 결과는 QUAG가 정확하고 신뢰할 수 있는 모멘트 분할을 달성하는 데 효과적임을 입증하며, 이는 후속 스텝 캡셔닝 작업에 필수적입니다.
Results on the Step-captioning 이 과제에서 우리는 제안된 QUAG를 Joint model (Zala et al. 2023), BMT (Iashin and Rahtu 2020) (ActivityNet 데이터셋 (Krishna et al. 2017)에서 사전 훈련된 밀집 비디오 캡셔닝 모델), 그리고 SwinBERT (Lin et al. 2022) (YouCook2 데이터셋 (Zhou, Xu, and Corso 2018)에서 사전 훈련된 비디오 캡셔닝 모델)와 비교합니다. 비교 결과는 표 3에 나와 있습니다.
우리 QUAG의 전반적인 성능이 이 과제에서 더 우수하다는 점에 주목할 필요가 있습니다. 우리 QUAG는 모든 지표에서 Joint 모델을 큰 차이로 능가합니다. 두 캡셔닝 기반 모델인 BMT와 SwinBERT에 대해, 우리 QUAG는 모든 지표에서 BMT를 능가하고 SwinBERT에 대해 필적하는 성능을 달성합니다. 특히, 캡션 중심 지표인 CIDEr에서 우리 QUAG는 SwinBERT와 BMT에 비해 각각 3.2%와 280%의 상대적 개선을 이룹니다. 함의 점수에서도 QUAG는 SwinBERT와 BMT에 비해 각각 14.3%와 30.7%의 상대적 개선을 보입니다.
전반적인 성능 분석. HIREST에 대한 선구적인 연구인 Joint와 비교했을 때, 우리 방법은 각 하위 작업의 모든 지표에서 이를 능가하여 그 효과를 증명합니다. 우리 접근법을 종합적으로 평가하기 위해, 일부 작업별 방법과도 비교되었습니다. 우리 방법이 스텝 캡셔닝의 특정 지표에서 제한적인 개선을 보인다는 것을 알 수 있는데, 이는 사실 예상된 상황입니다. HIREST의 궁극적인 목표는 여러 관련된 비디오 이해 작업에 일반화될 수 있는 일반적인 모델을 훈련하는 것이므로, 특정 작업별 방법보다 성능이 떨어질 수 있습니다.
Ablation Study
우리는 각 모듈과 전체 모델의 기여도를 조사하기 위해 절제 연구를 수행합니다. 여기서는 스텝 캡셔닝 작업을 주요 절제 작업으로 선택했는데, 이는 모델이 다중 모드 콘텐츠에 대한 인지, 정렬 및 생성을 위한 포괄적인 능력을 갖추어야 하기 때문입니다. 기준선은 Joint이며, 이는 세 가지 모달리티 표현을 요소별 덧셈과 곱셈으로 직접 융합합니다.
절제 결과는 표 4에 나와 있습니다. 각 모듈과 전체 QUAG의 성능은 Joint 기준선보다 우수하여 그 효과를 입증합니다. 그러나 각 모듈을 개별적으로 사용했을 때 성능 향상은 크지 않습니다. 만 사용했을 때, CIDEr 지표에서는 성능이 감소하는 현상까지 나타났습니다. 우리의 추측은 각 모듈이 시너지 관계 또는 여과 관계 중 하나만 학습한다는 것입니다. 게다가 모달리티 간의 계층 구조가 간과되었습니다. 전체 QUAG 모델을 사용했을 때, 그 성능은 다른 모델들을 현저히 능가했으며, 특히 Joint 기준선에 비해 CIDEr와 SPICE에서 각각 20.1%와 48.7% 증가했습니다. 절제 결과는 설계된 각 모듈이 고유한 역할을 할 뿐만 아니라 서로를 보완한다는 것을 나타냅니다.
Table 4: 스텝 캡셔닝에 대한 각 모듈의 애블레이션 연구.
| Model | MSP | QC | M | R | C | S |
|---|---|---|---|---|---|---|
| Joint | 4.14 | 11.85 | 21.19 | 3.02 | ||
| QUAG | 4.70 | 13.05 | 23.18 | 3.49 | ||
| QUAG | 4.50 | 12.65 | 20.43 | 3.87 | ||
| QUAG |
Performance Comparison on TVsum
우리는 추가적으로 모멘트 분할과 관련된 쿼리 기반 비디오 요약에 대한 QUAG의 일반화 능력을 검증합니다. 실험은 TVsum 데이터셋에서 수행되었으며 비교 방법은 TGG (Ye et al. 2021), UMT (Liu et al. 2022b), QD-DETR (Moon et al. 2023), UVCOM (Xiao et al. 2024), 그리고 TR-DETR (Sun et al. 2024)입니다. 모든 비교 방법에 대한 입력은 시각, 오디오, 그리고 텍스트 쿼리 표현입니다.
결과는 표 5에 나와 있습니다. QUAG는 5개 카테고리에서 최고의 결과를 얻었으며, 이는 다른 방법들보다 우수합니다. 게다가, 우리 방법의 평균 전체 성능은 TR-DETR(87.0 대 87.1)과 동등하여 좋은 일반화 능력을 보여줍니다.
Table 5: TVsum 데이터셋에서의 성능 비교
| Model | VT | VU | GA | MS | PK | PR | FM | BK | BT | DS | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TGG (Ye et al. 2021) | 85.0 | 71.4 | 81.9 | 78.6 | 80.2 | 75.5 | 71.6 | 77.3 | 78.6 | 68.1 | 76.8 |
| UMT (Liu et al. 2022b) | 87.5 | 81.5 | 88.2 | 78.8 | 81.4 | 87.0 | 76.0 | 86.9 | 84.4 | 83.1 | |
| QD-DETR (Moon et al. 2023) | 87.6 | 91.7 | 90.2 | 88.3 | 84.1 | 88.3 | 78.7 | 91.2 | 87.8 | 77.7 | 86.6 |
| UVCOM (Xiao et al. 2024) | 87.6 | 91.6 | 91.4 | 86.7 | 86.9 | 86.9 | 76.9 | 92.3 | 87.4 | 75.6 | 86.3 |
| TR-DETR (Sun et al. 2024) | 90.6 | 92.4 | 91.7 | 81.3 | 85.5 | 79.8 | 93.4 | 81.0 | 87.1 | ||
| QUAG | 89.8 | 93.1 | 92.9 | 85.6 | 87.9 | 86.1 | 76.7 | 91.4 | 89.0 | 77.7 | 87.0 |
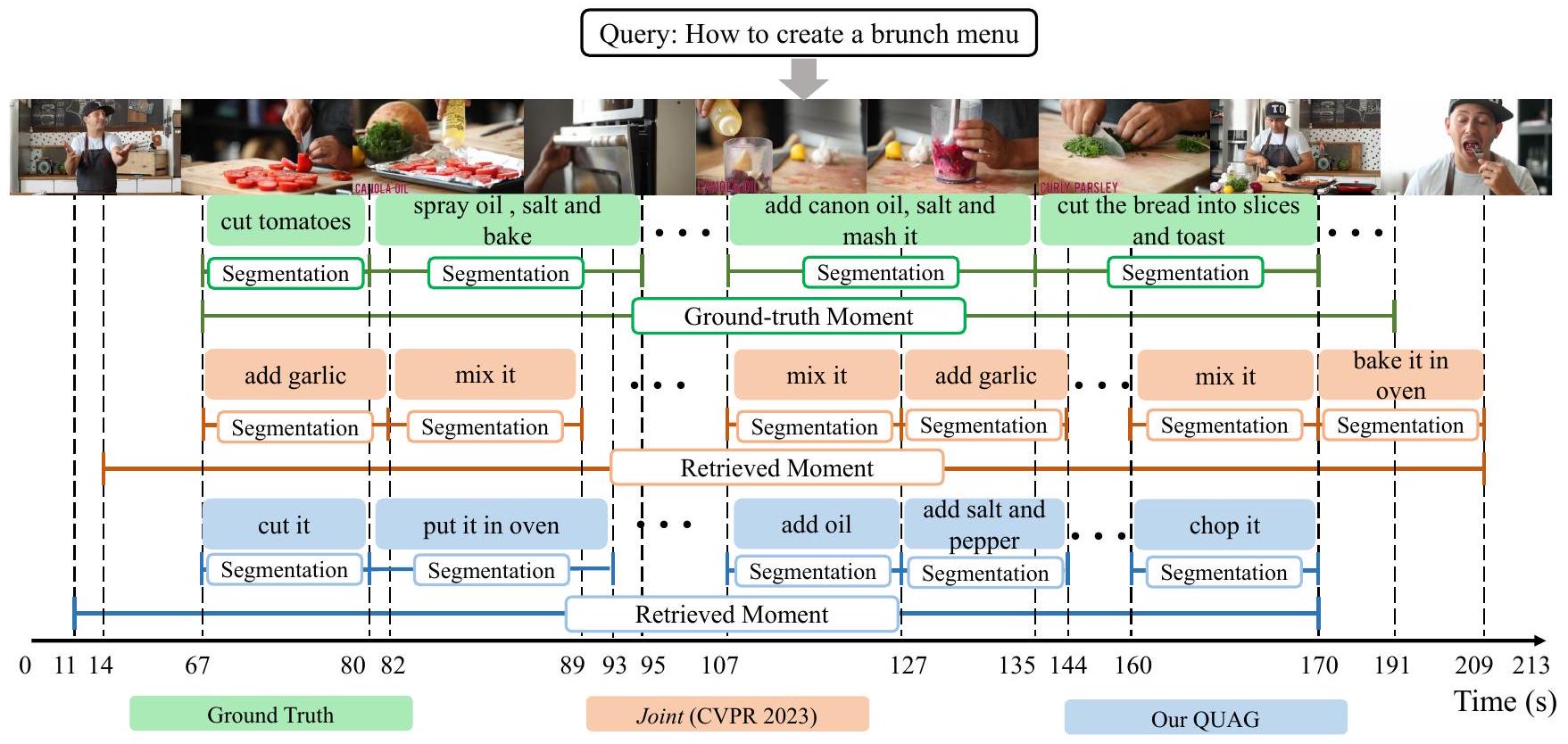
Figure 3: "브런치 메뉴 만드는 법"이라는 텍스트 쿼리와 정답 주석이 주어졌을 때, 우리는 모멘트 검색, 분할, 스텝 캡셔닝에 대한 우리 QUAG와 Joint(Zala et al. 2023)의 예측 및 생성된 출력을 비교합니다.
우수한 결과는 주로 우리 방법이 쿼리 중심의 시청각 표현을 구성한다는 점에서 비롯됩니다. 이로 인해 모델은 비디오의 어느 부분이 중요한지를 더 잘 학습할 수 있고, 따라서 쿼리를 기반으로 비디오에서 가장 관련 있는 프레임을 추출할 수 있습니다.
Qualitative Analysis
우리 방법에 대한 직관적인 관찰을 위해 그림 3에서 모멘트 검색, 분할 및 스텝 캡셔닝에 대한 시각화 사례를 제공합니다. 우리 QUAG에 의해 검색된 모멘트는 Joint의 그것보다 사소한 세부 사항을 덜 포함하는 것을 관찰합니다. 또한, QUAG는 스텝 경계를 더 잘 예측하고 스텝 캡션을 생성합니다. 예를 들어, Joint 모델에 의해 생성된 스텝 캡션은 중복되며 검색된 모멘트의 세부 정보가 부족합니다. 대조적으로, 우리 QUAG는 정답 캡션 "토마토를 자른다"(67-80초)와 일치하는 "자른다"를 생성하고, 정답 캡션 "캐논 오일, 소금을 넣고 으깬다"(107-135초)와 의미적 일관성을 보이는 "기름을 추가한다" 및 "소금과 후추를 추가한다"를 생성합니다. 또한, 우리 QUAG는 배우가 빵을 조각으로 자르는 동안 "그것을 다진다"라는 미세한 내용까지 설명할 수 있습니다.
요컨대, 시각화 결과는 QUAG의 효과를 보여줍니다. 이러한 우수성은 쿼리 중심의 시청각 표현을 구별 없이 직접 융합하는 대신 점진적으로 모델링하는 사실에서 비롯됩니다. 더 많은 예시는 보충 자료에 나와 있습니다.
Conclusion
본 논문은 얕은 것에서 깊은 것으로의 원칙을 따라 QUAG를 제안하며, 이는 모멘트 검색, 분할 및 스텝 캡셔닝을 위한 쿼리 중심 시청각 표현을 학습합니다. QUAG에서, 우리는 먼저 시각 및 오디오 모달리티 간의 전역적 대조 정렬과 지역적 세분화된 상호 작용을 모델링하여 시청각 표현을 얻기 위해 MSP를 고안합니다. 그런 다음, 깊은 수준의 쿼리에서 얕은 수준의 시청각 콘텐츠로의 시간적-채널 여과를 모델링하여 사용자가 선호하는 콘텐츠에 대한 포괄적인 인지를 학습하도록 가 설계되었습니다. 광범위한 실험은 QUAG가 HIREST 데이터셋에서 세 가지 어려운 작업에 대해 SOTA 성능을 달성함을 보여줍니다. 또한, 우리는 쿼리 기반 비디오 요약 작업에 대해 QUAG를 테스트했습니다. 결과는 그 좋은 일반화 능력을 검증합니다.
Acknowledgements
이 연구는 중국 국립 자연과학재단(National Natural Science Foundation of China): 62322211, 62336008, U21B2038, 저장성(Zhejiang Province)의 "Pionee" 및 "Leading Goose" R&D 프로그램(2024C01023), 중앙 대학 기본 연구 기금(Fundamental Research Funds for the Central Universities) (E2ET1104), 문화관광부(Ministry of Culture and Tourism) 디지털 음악 지능형 처리 기술 핵심 연구소(Key Laboratory of Intelligent Processing Technology for Digital Music (Zhejiang Conservatory of Music)) (2023DMKLB004)의 지원을 받았습니다.
References
Anderson, P.; Fernando, B.; Johnson, M.; and Gould, S. 2016. Spice: Semantic propositional image caption evaluation. In ECCV, 382-398. Banerjee, S.; and Lavie, A. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In , 65-72. Carreira, J.; and Zisserman, A. 2017. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 6299-6308. Cho, J.; Lei, J.; Tan, H.; and Bansal, M. 2021. Unifying vision-and-language tasks via text generation. In , 1931-1942.
Cong, G.; Li, L.; Liu, Z.; Tu, Y.; Qin, W.; Zhang, S.; Yan, C.; Wang, W.; and Jiang, B. 2022. Ls-gan: iterative languagebased image manipulation via long and short term consistency reasoning. In . Cong, G.; Li, L.; Qi, Y.; Zha, Z.-J.; Wu, Q.; Wang, W.; Jiang, B.; Yang, M.-H.; and Huang, Q. 2023. Learning to dub movies via hierarchical prosody models. In CVPR, 1468714697.
Dong, J.; Chen, X.; Zhang, M.; Yang, X.; Chen, S.; Li, X.; and Wang, X. 2022. Partially relevant video retrieval. In ACM MM, 246-257. Fang, Y.; Wang, W.; Xie, B.; Sun, Q.; Wu, L.; Wang, X.; Huang, T.; Wang, X.; and Cao, Y. 2023. Eva: Exploring the limits of masked visual representation learning at scale. In CVPR, 19358-19369. Gemmeke, J. F.; Ellis, D. P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R. C.; Plakal, M.; and Ritter, M. 2017. Audio set: An ontology and human-labeled dataset for audio events. In ICASSP, 776-780. Iashin, V.; and Rahtu, E. 2020. A Better Use of Audio-Visual Cues: Dense Video Captioning with Bi-modal Transformer. In .
Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. 2017. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950. Kim, M.; Kim, H. B.; Moon, J.; Choi, J.; and Kim, S. T. 2024. Do You Remember? Dense Video Captioning with Cross-Modal Memory Retrieval. In CVPR, 13894-13904. Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A. C.; Lo, W.Y.; et al. 2023. Segment anything. In ICCV, 4015-4026.
Kong, Q.; Cao, Y.; Iqbal, T.; Wang, Y.; Wang, W.; and Plumbley, M. D. 2020. Panns: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28: 2880-2894. Krishna, R.; Hata, K.; Ren, F.; Fei-Fei, L.; and Carlos Niebles, J. 2017. Dense-captioning events in videos. In ICCV, 706-715. Lei, J.; Berg, T. L.; and Bansal, M. 2021. Detecting moments and highlights in videos via natural language queries. NeurIPS, 34: 11846-11858. Lei, J.; Yu, L.; Berg, T. L.; and Bansal, M. 2020. Tvr: A large-scale dataset for video-subtitle moment retrieval. In ECCV, 447-463. Li, H.; Yang, S.; Zhang, Y.; Tao, D.; and Yu, Z. 2023. Progressive Feature Mining and External KnowledgeAssisted Text-Pedestrian Image Retrieval. arXiv preprint arXiv:2308.11994. Li, L.; Chen, Y.-C.; Cheng, Y.; Gan, Z.; Yu, L.; and Liu, J. 2020. HERO: Hierarchical Encoder for Video+ Language Omni-representation Pre-training. In , 2046-2065. Li, L.; Gao, X.; Deng, J.; Tu, Y.; Zha, Z.-J.; and Huang, Q. 2022. Long short-term relation transformer with global gating for video captioning. IEEE Transactions on Image Processing, 31: 2726-2738. Li, Q.; Su, L.; Zhao, J.; Xia, L.; Cai, H.; Cheng, S.; Tang, H.; Wang, J.; and Yin, D. 2024. Text-Video Retrieval via Multi-Modal Hypergraph Networks. In WSDM, 369-377. Lin, C.-Y. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, 74-81. Lin, K.; Li, L.; Lin, C.-C.; Ahmed, F.; Gan, Z.; Liu, Z.; Lu, Y.; and Wang, L. 2022. Swinbert: End-to-end transformers with sparse attention for video captioning. In CVPR, 1794917958.
Liu, X.; Li, L.; Wang, S.; Zha, Z.-J.; Li, Z.; Tian, Q.; and Huang, Q. 2022a. Entity-enhanced adaptive reconstruction network for weakly supervised referring expression grounding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3): 3003-3018. Liu, Y.; Li, S.; Wu, Y.; Chen, C.-W.; Shan, Y.; and Qie, X. 2022b. Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection. In CVPR, 3042-3051. Loshchilov, I.; and Hutter, F. 2018. Decoupled Weight Decay Regularization. In . Moon, W.; Hyun, S.; Park, S.; Park, D.; and Heo, J.-P. 2023. Query-dependent video representation for moment retrieval and highlight detection. In CVPR, 23023-23033. Narasimhan, M.; Nagrani, A.; Sun, C.; Rubinstein, M.; Darrell, T.; Rohrbach, A.; and Schmid, C. 2022. Tl; dw? summarizing instructional videos with task relevance and crossmodal saliency. In ECCV, 540-557. Oord, A. v. d.; Li, Y.; and Vinyals, O. 2018. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748.
Parikh, A.; Täckström, O.; Das, D.; and Uszkoreit, J. 2016. A Decomposable Attention Model for Natural Language Inference. In EMNLP, 2249-2255. Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. 2019. Pytorch: An imperative style, high-performance deep learning library. NeurIPS, 32. Peters, M. E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; and Zettlemoyer, L. 2018. Deep Contextualized Word Representations. In NAACL-HLT, 2227-2237. Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. 2021. Learning transferable visual models from natural language supervision. In ICML, 8748-8763. Radford, A.; Kim, J. W.; Xu, T.; Brockman, G.; McLeavey, C.; and Sutskever, I. 2023. Robust speech recognition via large-scale weak supervision. In ICML, 28492-28518. Reimers, N.; and Gurevych, I. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In EMNLP-IJCNLP, 3982-3992. Sharghi, A.; Gong, B.; and Shah, M. 2016. Query-focused extractive video summarization. In . Sharghi, A.; Laurel, J. S.; and Gong, B. 2017. Queryfocused video summarization: Dataset, evaluation, and a memory network based approach. In CVPR, 4788-4797. Song, Y.; Vallmitjana, J.; Stent, A.; and Jaimes, A. 2015. Tvsum: Summarizing web videos using titles. In CVPR, 51795187.
Sun, H.; Zhou, M.; Chen, W.; and Xie, W. 2024. Tr-detr: Task-reciprocal transformer for joint moment retrieval and highlight detection. In , volume 38, 4998-5007. Sun, X.; Wang, X.; Gao, J.; Liu, Q.; and Zhou, X. 2022. You need to read again: Multi-granularity perception network for moment retrieval in videos. In SIGIR, 1022-1032. Tacca, M. C. 2011. Commonalities between perception and cognition. Frontiers in psychology, 2: 358. Tang, M.; Wang, Z.; Liu, Z.; Rao, F.; Li, D.; and Li, X. 2021. Clip4caption: Clip for video caption. In 4862.
Tang, W.; Li, L.; Liu, X.; Jin, L.; Tang, J.; and Li, Z. 2024. Context Disentangling and Prototype Inheriting for Robust Visual Grounding. IEEE Transactions on Pattern Analysis & Machine Intelligence, 46(05): 3213-3229. Tu, Y.; Li, L.; Su, L.; Gao, S.; Yan, C.; Zha, Z.-J.; Yu, Z.; and Huang, Q. 2022. I2 Transformer: Intra-and interrelation embedding transformer for TV show captioning. IEEE Transactions on Image Processing, 31: 3565-3577. Tu, Y.; Li, L.; Su, L.; Yan, C.; and Huang, Q. 2024a. Distractors-Immune Representation Learning with Crossmodal Contrastive Regularization for Change Captioning. In ECCV, 311-328. Tu, Y.; Li, L.; Su, L.; Zha, Z.-J.; and Huang, Q. 2024b. SMART: Syntax-Calibrated Multi-Aspect Relation Transformer for Change Captioning. IEEE Transactions on Pattern Analysis & Machine Intelligence, 46(07): 4926-4943.
Tu, Y.; Li, L.; Su, L.; Zha, Z.-J.; Yan, C.; and Huang, Q. 2023a. Self-supervised cross-view representation reconstruction for change captioning. In ICCV, 2805-2815. Tu, Y.; Li, L.; Su, L.; Zha, Z.-J.; Yan, C.; and Huang, Q. 2024c. Context-aware Difference Distilling for Multichange Captioning. In , 7941-7956. Tu, Y.; Zhou, C.; Guo, J.; Li, H.; Gao, S.; and Yu, Z. 2023b. Relation-aware attention for video captioning via graph learning. Pattern Recognition, 136: 109204. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. In NeurIPS, 5998-6008. Vedantam, R.; Lawrence Zitnick, C.; and Parikh, D. 2015. Cider: Consensus-based image description evaluation. In CVPR, 4566-4575. Wang, L.; Huang, X.; Yu, Z.; Peng, H.; Gao, S.; Mao, C.; Huang, Y.; Dong, L.; and Yu, P. S. 2024a. Zero-Shot Text Normalization via Cross-Lingual Knowledge Distillation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32: 4631-4646. Wang, L.; Yu, Z.; Gao, S.; Mao, C.; and Huang, Y. 2024b. DETS: End-to-End Single-Stage Text-to-Speech Via Hierarchical Diffusion Gan Models. In ICASSP, 10916-10920. Wang, M.; Li, H.; Zhang, Y.; Li, J.; Xie, M.; and Tao, D. 2024c. Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding. arXiv preprint arXiv:2411.17481.
Wu, W.; Luo, H.; Fang, B.; Wang, J.; and Ouyang, W. 2023. Cap4video: What can auxiliary captions do for text-video retrieval? In CVPR, 10704-10713. Xiao, Y.; Luo, Z.; Liu, Y.; Ma, Y.; Bian, H.; Ji, Y.; Yang, Y.; and Li, X. 2024. Bridging the gap: A unified video comprehension framework for moment retrieval and highlight detection. In CVPR, 18709-18719. Xie, M.; Wang, M.; Li, H.; Zhang, Y.; Tao, D.; and Yu, Z. 2024. Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction for Visual Grounding. arXiv preprint arXiv:2410.23570. Xiong, B.; and Grauman, K. 2014. Detecting snap points in egocentric video with a web photo prior. In . Yang, A.; Nagrani, A.; Seo, P. H.; Miech, A.; Pont-Tuset, J.; Laptev, I.; Sivic, J.; and Schmid, C. 2023. Vid2seq: Largescale pretraining of a visual language model for dense video captioning. In CVPR, 10714-10726. Yang, Y.; Zhuang, Y.; and Pan, Y. 2021. Multiple knowledge representation for big data artificial intelligence: framework, applications, and case studies. Frontiers of Information Technology & Electronic Engineering, 22(12): 15511558.
Ye, Q.; Shen, X.; Gao, Y.; Wang, Z.; Bi, Q.; Li, P.; and Yang, G. 2021. Temporal cue guided video highlight detection with low-rank audio-visual fusion. In ICCV, 7950-7959. Yue, S.; Tu, Y.; Li, L.; Gao, S.; and Yu, Z. 2024. Multigrained Representation Aggregating Transformer with Gating Cycle for Change Captioning. ACM Transactions on
Multimedia Computing, Communications and Applications, 20(10): 321:1-321:23. Yue, S.; Tu, Y.; Li, L.; Yang, Y.; Gao, S.; and Yu, Z. 2023. I3n: Intra-and inter-representation interaction network for change captioning. IEEE Transactions on Multimedia, 25: 8828-8841. Zala, A.; Cho, J.; Kottur, S.; Chen, X.; Oguz, B.; Mehdad, Y.; and Bansal, M. 2023. Hierarchical video-moment retrieval and step-captioning. In CVPR, 23056-23065. Zha, Z.-J.; Liu, D.; Zhang, H.; Zhang, Y.; and Wu, F. 2019. Context-aware visual policy network for fine-grained image captioning. IEEE transactions on pattern analysis and machine intelligence, 44(2): 710-722. Zhang, B.; Li, L.; Wang, S.; Cai, S.; Zha, Z.-J.; Tian, Q.; and Huang, Q. 2024. Inductive State-Relabeling Adversarial Active Learning With Heuristic Clique Rescaling. IEEE Transactions on Pattern Analysis & Machine Intelligence, 46(12): 9780-9796. Zhang, D.; Zhang, H.; Tang, J.; Hua, X.-S.; and Sun, Q. 2020. Causal intervention for weakly-supervised semantic segmentation. NeurIPS, 33: 655-666. Zhou, L.; Xu, C.; and Corso, J. 2018. Towards automatic learning of procedures from web instructional videos. In , volume 32.
Supplementary Material
Experiment
이 보충 자료에서는 TVsum 데이터셋에 대한 구현 세부 정보를 제공합니다. 또한, 트레이드오프 파라미터 선택에 대한 더 많은 실험적 분석과 논의를 제공합니다. 여기서는 스텝 캡셔닝 작업을 주요 절제 작업으로 선택했는데, 이는 모델이 다중 모드 콘텐츠에 대한 인지, 정렬 및 생성을 위한 포괄적인 능력을 갖추어야 하기 때문입니다. 또한, 더 많은 시각화 결과와 실패 사례에 대한 논의를 제공합니다.
Implementation Details 제안된 QUAG는 TVsum 데이터셋에서 종단간 방식으로 학습됩니다. TVSum에서, 클립 수준의 시각적 특징은 Kinetics 400 (Carreira and Zisserman 2017)에서 사전 훈련된 I3D 모델 (Kay et al. 2017)을 사용하여 추출됩니다. 오디오 특징은 AudioSet (Gemmeke et al. 2017)에서 사전 훈련된 PANN 모델 (Kong et al. 2020)에 의해 추출됩니다. 은닉 크기는 256으로 설정되고, 어텐션 레이어와 어텐션 헤드는 각각 2와 8로 설정됩니다. TVsum에서 배치 크기와 학습률은 4와 으로 설정됩니다. AdamW 옵티마이저 (Loshchilov and Hutter 2018)는 훈련 손실을 최소화하는 데 사용됩니다. 모델 훈련은 RTX 3090 GPU에서 PyTorch (Paszke et al. 2019)로 구현됩니다.
Study on the Trade-off Parameter 우리는 본 논문의 식 (15)에 있는 트레이드오프 파라미터 의 효과에 대해 논의합니다. 본 논문에서 언급했듯이, 는 세 가지 작업 손실 중 하나와 전역 대조 정렬 손실 사이의 중요도를 균형 있게 조절하는 트레이드오프 파라미터입니다. 표 6에서, 우리는 대조 손실이 없는 QUAG (즉, 를 0으로 설정)와 비교하여 대조 손실의 정규화를 사용한 QUAG (다른 값들 하에서)가 더 나은 결과를 얻을 수 있음을 발견했습니다. 결과는 시각 및 오디오 표현 간의 지역적 세분화된 상호 작용을 모델링하기 전에 전역 대조 정렬 손실을 추가하는 것이 도움이 된다는 것을 나타냅니다. 그 이유는 이 손실이 시각 및 오디오 모달리티를 동일한 임베딩 공간에 상주하게 만들 수 있기 때문입니다. 또한, 값을 0.0001에서 0.0006으로 설정했을 때 결과가 비슷하며, 모델의 전반적인 성능은 0.0003 값에서 더 좋다는 점에 주목할 필요가 있습니다. 이는 제안된 QUAG가 이 하이퍼파라미터에 대해 견고하고 그다지 민감하지 않다는 것을 보여줍니다. 경험적으로, 우리는 HIREST 데이터셋에서 값을 0.0003으로 설정합니다. 이러한 방식으로, 우리는 TVsum 데이터셋에서 값을 0.3으로 선택합니다.
Table 6: 스텝 캡셔닝 작업에서 트레이드오프 파라미터 에 대한 연구, 여기서 M, R, C, S는 METEOR, ROUGE-L, CIDEr, SPICE의 약자입니다.
| Model | M | R | C | S | |
|---|---|---|---|---|---|
| QUAG | 0 | 4.61 | 12.96 | 23.40 | 3.83 |
| QUAG | 0.0001 | 4.71 | 13.17 | 24.08 | |
| QUAG | 0.0002 | 4.69 | 13.32 | 25.29 | |
| QUAG | 0.0003 | 13.20 | |||
| QUAG | 0.0004 | 4.69 | 13.03 | 24.05 | 4.44 |
| QUAG | 0.0005 | 4.56 | 12.94 | 23.67 | 3.91 |
| QUAG | 0.0006 | 4.60 | 25.24 | 4.24 |
Ablation Study for Query-Centric Cognition ( ) 는 깊은 수준의 쿼리 표현을 사용하여 얕은 수준의 시청각 표현에 대해 시간적-채널 어텐션을 수행하여 사용자가 요청한 세부 사항을 강조하는 것을 목표로 합니다. 이 방법의 핵심 구성 요소는 시간적 및 채널 어텐션 행렬인 와 입니다. 와 에 대한 절제 연구는 본 논문의 표 4에 나와 있으며, 와 를 모두 사용하는 것의 효과를 검증합니다. 우리는 또한 와 중 하나만 사용하여 그 영향을 조사합니다. 여기서 스텝 캡셔닝 결과를 보고하는데, Base는 와 를 평균 풀링 연산으로 대체합니다. 결과는 어느 한 구성 요소를 단독으로 사용하는 것이 Base의 성능을 향상시키며, 시간적 및 채널 어텐션을 모두 사용할 때 가장 큰 이득을 얻는다는 것을 보여줍니다.
Table 7: 스텝 캡셔닝에 대한 애블레이션 연구 결과. M: METEOR, R: ROUGE-L, S: SPICE.
| Ablation | M | R | S |
|---|---|---|---|
| Base | 3.14 | 11.19 | 2.88 |
| w/o | 4.28 | 12.09 | 3.56 |
| w/o | 4.42 | 12.40 | 3.72 |
Qualitative Analysis 이 보충 자료에서는 공동 모멘트 검색, 모멘트 분할 및 스텝 캡셔닝에 대한 더 많은 시각화 사례를 제공하며, 이는 그림 4-6에 나와 있습니다. 이 사례들은 텍스트 쿼리, 정답 주석, 그리고 우리의 QUAG와 현재 최첨단 방법인 Joint (Zala et al. 2023)에 의해 생성된 출력 결과를 포함합니다. 이 사례들로부터, 우리는 QUAG에 의해 검색된 모멘트가 Joint에서 얻은 것들보다 사소한 세부 사항을 덜 포함한다는 것을 발견할 수 있습니다. 또한, 우리의 QUAG는 스텝 경계를 더 잘 예측하고 해당하는 스텝 캡션을 생성할 수 있습니다. 예를 들어, 그림 6에서 Joint 모델에 의해 생성된 스텝 캡션은 중복되며 검색된 모멘트의 세부 사항이 부족합니다. 대조적으로, 우리의 QUAG는 정답 캡션 "보석을 붙인다" 및 "핀을 붙인다"(60-83초)와 일치하는 "위에 풀을 붙인다"를 생성합니다. 이러한 우수성은 우리 방법이 사용자가 선호하는 비디오 콘텐츠에 대한 포괄적인 인지를 학습하고 따라서 세 가지 어려운 작업을 위해 점진적으로 쿼리 중심 시청각 표현을 모델링할 수 있다는 사실에서 비롯됩니다.
그림 7에서는 제안된 QUAG에서 파생된 실패 사례를 보여줍니다. 우리는 QUAG가 정답 모멘트에 비해 관련 없는 세부 정보가 더 많은 모멘트를 찾는다는 것을 발견했습니다. 우리의 추측은 강사가 항상 비디오에 나타난다는 것입니다. 이 경우, 우리 모델은 지시 내용이 아직 끝나지 않았다고 오해할 수 있습니다. 또한, 우리 QUAG는 "오븐"과 같은 일부 핵심 객체를 설명할 수 있지만, "칠리 파우더" 및 "핫 소스"와 같은 미세한 세부 사항을 설명하는 데 실패하는 스텝 캡션을 생성합니다. 미세한 객체 인식에 대한 이 실패에 대해, 가능한 해결책은 세분화 특징(Kirillov et al. 2023)과 같은 더 미세한 수준의 시각적 특징을 도입하여 그러한 미세한 객체를 식별하는 데 도움을 주는 것입니다.
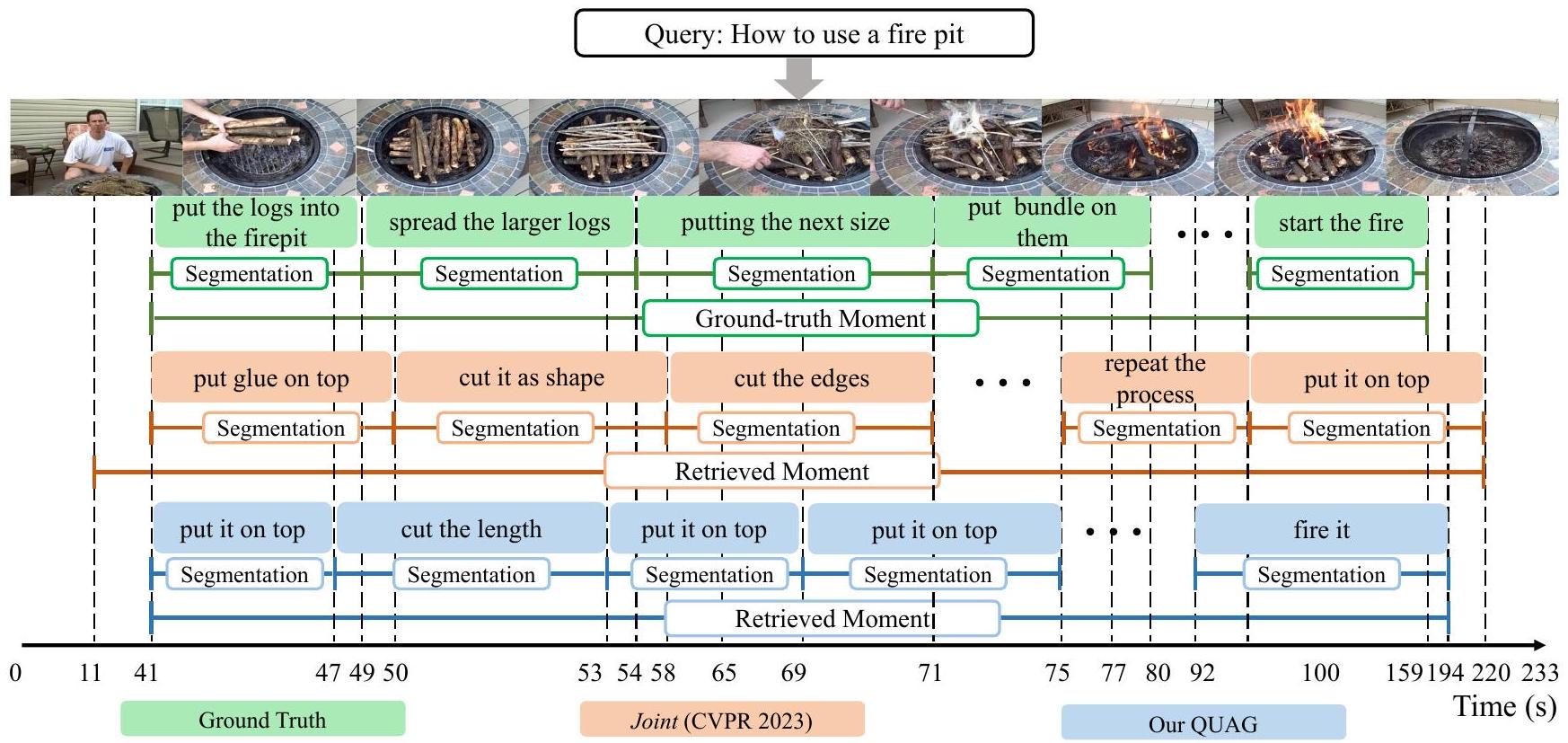
Figure 4: "화덕 사용법"이라는 텍스트 쿼리와 정답 주석이 주어졌을 때, 모멘트 검색, 분할, 스텝 캡셔닝에 대한 우리 QUAG와 Joint(Zala et al. 2023)의 예측 및 생성된 결과를 비교합니다.
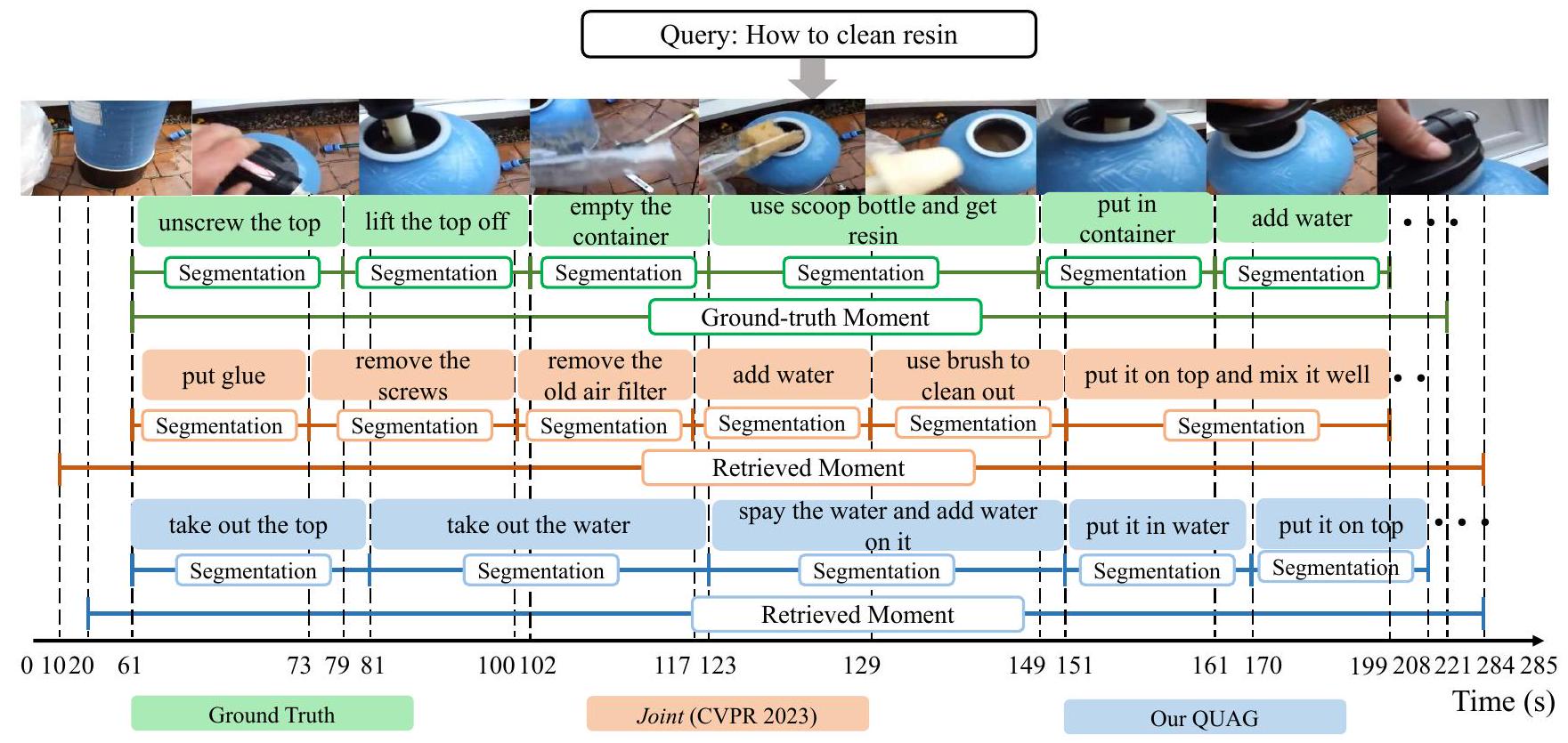
Figure 5: "레진 청소 방법"이라는 텍스트 쿼리와 정답 주석이 주어졌을 때, 모멘트 검색, 분할, 스텝 캡셔닝에 대한 우리 QUAG와 Joint(Zala et al. 2023)의 예측 및 생성된 결과를 비교합니다.
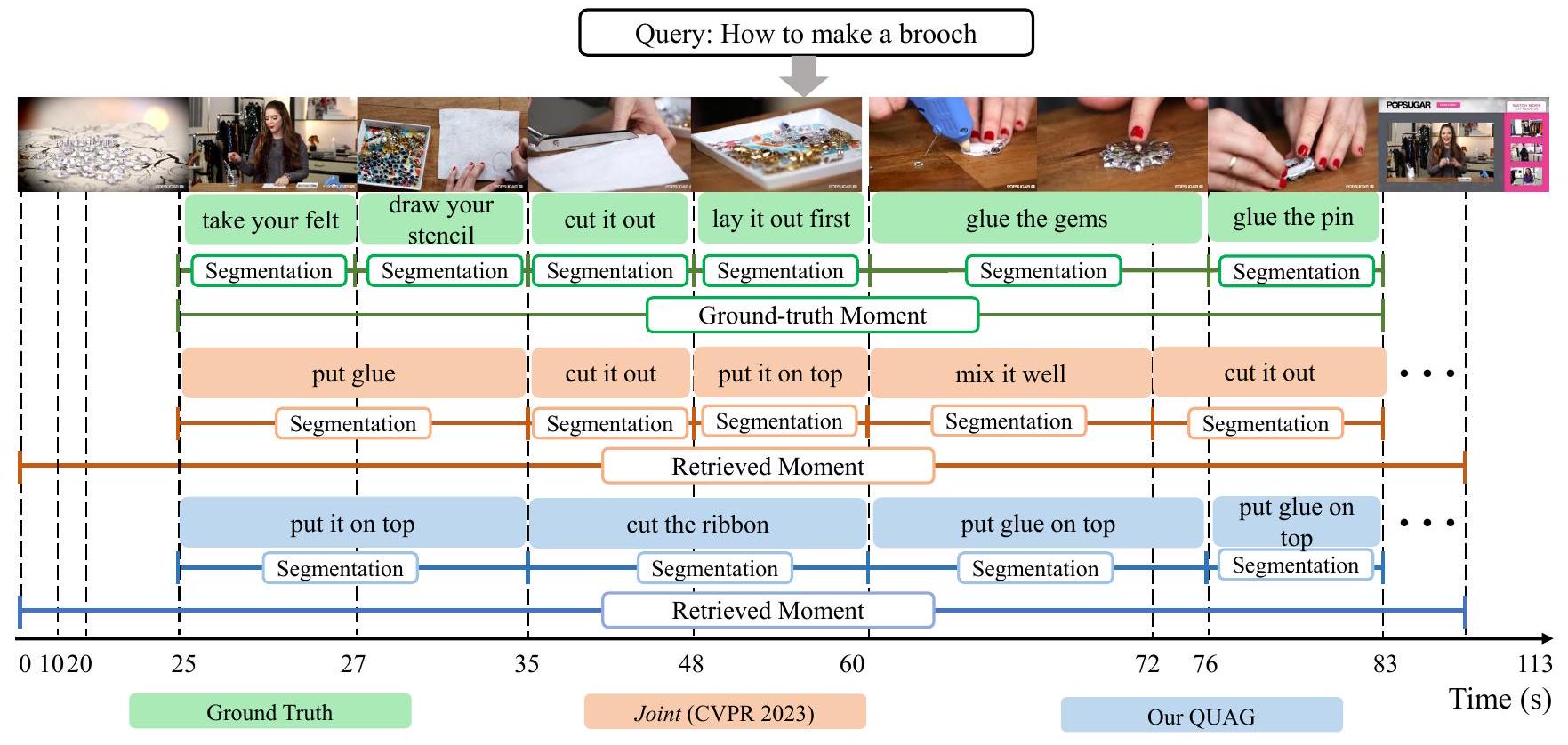
Figure 6: "브로치 만드는 법"이라는 텍스트 쿼리와 정답 주석이 주어졌을 때, 모멘트 검색, 분할, 스텝 캡셔닝에 대한 우리 QUAG와 Joint(Zala et al. 2023)의 예측 및 생성된 결과를 비교합니다.
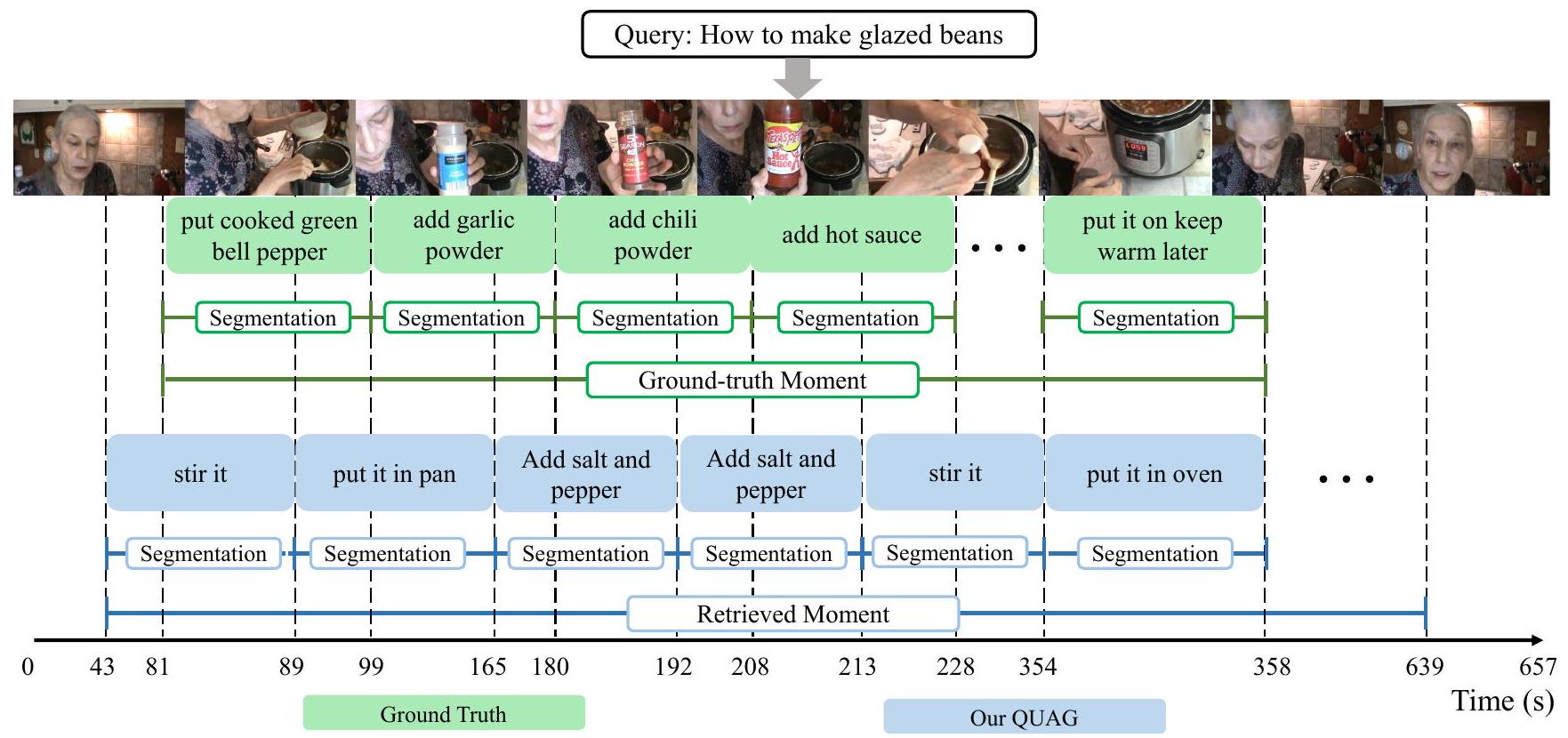
Figure 7: "유약을 바른 콩 만드는 법"이라는 텍스트 쿼리와 정답 주석이 주어졌을 때, 모멘트 검색, 분할 및 스텝 캡셔닝에 대한 우리 QUAG의 실패 사례를 보여줍니다.
Footnotes
-
Copyright © 2025, Association for the Advancement of Artificial Intelligence (www.aaai.org). All rights reserved. *Corresponding authors. ↩
-
*보충 자료는 arXiv 버전에 포함되어 있습니다. ↩