프로토타입: 효율성과 정확성을 모두 잡는 부분 관련 영상 검색(PRVR) 기법
영상 검색 시스템에서 정확성과 효율성을 동시에 달성하는 것은 어려운 과제입니다. 특히, 부분 관련 영상 검색(Partially Relevant Video Retrieval, PRVR)에서는 다양한 시간적 스케일의 컨텍스트를 표현할수록 정확도는 높아지지만 계산 및 메모리 비용이 증가합니다. 이 논문은 영상 내의 다양한 컨텍스트를 고정된 수의 프로토타입(prototypes)으로 인코딩하는 새로운 프레임워크를 제안하여 이 문제를 해결합니다. 텍스트 연관성과 영상 이해도를 높이기 위해 cross-modal 및 uni-modal 재구성 작업을 도입하고, 프로토타입의 다양성을 확보하기 위한 직교 목적 함수를 사용합니다. 이 접근법을 통해 효율성을 희생하지 않으면서도 TVR, ActivityNet-Captions 등 주요 벤치마크에서 최고의 성능을 달성합니다. 논문 제목: Prototypes are Balanced Units for Efficient and Effective Partially Relevant Video Retrieval
Moon, WonJun, et al. "Prototypes are Balanced Units for Efficient and Effective Partially Relevant Video Retrieval." arXiv preprint arXiv:2504.13035 (2025).
Prototypes are Balanced Units for Efficient and Effective Partially Relevant Video Retrieval
Minho Shim
Taeoh Kim Inwoong Lee NAVER Cloud
Dongyoon Wee Jae-Pil Heo Sungkyunkwan University
Abstract
검색 시스템에서 검색 정확도와 효율성을 동시에 달성하는 것은 본질적으로 어려운 과제이다. 이러한 어려움은 **부분적으로 관련된 비디오 검색(PRVR)**에서 특히 두드러지는데, 각 비디오에 대해 다양한 시간적 스케일에서 더 많은 문맥 표현을 통합할수록 정확도는 향상되지만, 계산 및 메모리 비용이 증가하기 때문이다.
이러한 이분법적 문제를 해결하기 위해, 우리는 비디오 내의 다양한 문맥을 고정된 수의 prototype으로 인코딩하는 prototypical PRVR 프레임워크를 제안한다.
이후, 우리는 prototype 내에서 텍스트 연관성 및 비디오 이해를 향상시키기 위한 여러 전략과, prototype이 다양한 범위의 콘텐츠를 포착하도록 보장하는 orthogonal objective를 도입한다.
prototype이 텍스트 쿼리를 통해 검색 가능하도록 유지하면서도 비디오 문맥을 정확하게 인코딩하기 위해, 우리는 cross-modal 및 uni-modal reconstruction task를 구현한다.
- cross-modal reconstruction task: prototype을 공유 공간 내의 텍스트 feature와 정렬한다.
- uni-modal reconstruction task: 인코딩 과정에서 모든 비디오 문맥을 보존한다.
또한, 우리는 비디오 믹싱(video mixing) 기술을 사용하여 prototype과 관련 텍스트 표현을 더욱 정렬하기 위한 약한 형태의 가이드를 제공한다.
TVR, ActivityNet-Captions, QVHighlights 데이터셋에 대한 광범위한 평가는 효율성을 희생하지 않으면서도 우리 접근 방식의 효과를 입증한다.
1. Introduction
방대한 양의 비디오 콘텐츠로 인해 사용자가 원하는 비디오를 찾는 것이 점점 더 어려워지고 있다. 이는 사용자가 찾고 있는 짧은 순간들로 구성된 비디오를 검색할 수 있는 정확하고 효율적인 비디오 검색 시스템의 필요성을 강조한다 [39]. 이러한 요구에 부응하여, 부분적으로 관련된 비디오 검색(Partially Relevant Video Retrieval, PRVR) [9]이 도입되어, 특정 세그먼트만이 텍스트 쿼리에 해당하는 길고 복잡한 비디오에 대한 텍스트-비디오 검색을 확장하였다.
 Figure 1. 비디오 인코딩 과정 비교. (a) MS-SL은 다양한 시간 스케일에서 컨텍스트를 인코딩하기 위해 다양한 길이의 클립 윈도우를 기반으로 **철저한 클립 모델링(exhaustive clip modeling)**을 활용한다. (b) GMMFormer는 사전 정의된 가우시안 커널로 제약된 self-attention을 통해 유사도 인식 feature aggregation을 수행하여 지역성을 반영한다. 이러한 적응형 방식은 높은 효율성을 제공한다. (c) 효율성을 희생하지 않고 철저한 클립 모델링의 의미적 풍부함을 활용하기 위해, 우리는 비디오 내에서 다양한(길이가 다양하거나 잠재적으로 분리된) 컨텍스트를 집계하는 고정된 수의 프로토타입을 학습한다. (하단) 제안된 방법은 정확도-효율성 trade-off 측면에서 이전 연구들보다 우수하다.
Figure 1. 비디오 인코딩 과정 비교. (a) MS-SL은 다양한 시간 스케일에서 컨텍스트를 인코딩하기 위해 다양한 길이의 클립 윈도우를 기반으로 **철저한 클립 모델링(exhaustive clip modeling)**을 활용한다. (b) GMMFormer는 사전 정의된 가우시안 커널로 제약된 self-attention을 통해 유사도 인식 feature aggregation을 수행하여 지역성을 반영한다. 이러한 적응형 방식은 높은 효율성을 제공한다. (c) 효율성을 희생하지 않고 철저한 클립 모델링의 의미적 풍부함을 활용하기 위해, 우리는 비디오 내에서 다양한(길이가 다양하거나 잠재적으로 분리된) 컨텍스트를 집계하는 고정된 수의 프로토타입을 학습한다. (하단) 제안된 방법은 정확도-효율성 trade-off 측면에서 이전 연구들보다 우수하다.
MS-SL [9]과 같은 일반적인 접근 방식은 Fig. 1 (a)에서 보듯이, 긴 프레임 단위 [10] feature를 저장하고 다양한 윈도우 크기 [22]를 사용하여 다양한 길이의 클립을 철저하게 모델링함으로써 정확도를 우선시한다. 이러한 표현을 통해 입력 텍스트 설명과 가장 높은 유사도를 보이는 비디오가 검색된다. 이러한 접근 방식들이 상당한 발전을 이루었지만, 광범위한 데이터베이스 내에서 작동하는 검색 시스템의 효율성은 종종 간과된다.
효율성 문제를 해결하기 위해 GMMFormer [54]는 Fig. 1(b)에서 보듯이, **선택된 프레임 주변에 사전 정의된 분산을 가진 가우시안 제약(Gaussian constraints)을 적용하는 지역 클립 모델링(local clip modeling)**을 도입했다. 구체적으로, 이러한 제약은 self-attention [11, 51] 내에 통합된다. 이 접근 방식은 주로 지역 컨텍스트를 인코딩하여 효율성을 향상시키지만, 비디오 시퀀스 내에서 복잡하고 확장된 이벤트를 설명하는 쿼리를 매칭할 때 순간을 정확하게 포착하는 데 어려움을 겪는다. 이러한 한계는 지역 컨텍스트가 고정된 길이의 시간 세그먼트 내에 국한되기 때문에 발생한다. 마찬가지로, 우리는 효율성 달성과 콘텐츠에 대한 철저한 이해 달성 사이의 trade-off를 관찰한다.
효율성과 다양한 컨텍스트를 동시에 포용하는 문제를 해결하기 위해, 우리는 PRVR을 위한 **프로토타입 네트워크(prototypical network)**를 제안한다. 구체적으로, 우리는 지역 및 전역 컨텍스트를 모두 인코딩하기 위해 철저한 클립 모델링 전략의 장점을 활용하는 동시에(Fig. 1(a)), 우리의 프로토타입은 Fig. 1(c)에서 보듯이 다양한 시간 스케일에 걸쳐 이러한 feature들을 더 작은 footprint로 효과적으로 집계한다. 그런 다음, 비디오 프레임 또는 클립 표현보다 훨씬 적은 수의 작은 비디오 프로토타입 세트만 효율적인 검색을 위해 저장된다.
프로토타입의 잠재력에도 불구하고, 프로토타입 학습은 각 프로토타입이 특정 정보를 어떻게 인코딩해야 하는지에 대한 명시적인 지침 없이 암묵적인 학습 특성으로 인해 검색에 필요한 모든 컨텍스트 세부 정보의 텍스트 연관성 또는 보존을 본질적으로 보장하지 않는다. 이를 해결하기 위해 우리는 텍스트 설명과의 연관성을 강화하고 비디오 이해를 향상시키기 위해 프로토타입 학습에 몇 가지 개선 사항을 제안한다. 첫째, 우리는 교차 모달(비디오-텍스트) 및 단일 모달(비디오-비디오) 재구성 task로 구성된 이중 재구성 task를 도입한다. 교차 모달 마스크 재구성 task는 텍스트 쿼리에 대한 프로토타입의 이해를 향상시키는 반면, 단일 모달 재구성 task는 프로토타입 집계 중에 시각적 콘텐츠를 보존한다. 또한, 명시적인 순간 감독 없이 텍스트 관련 비디오 세그먼트에 attend하는 텍스트 쿼리와 시각적 프로토타입 간의 정렬을 보장하기 위해, 우리는 더 높은 프레임 속도로 비디오를 연결하는 비디오 믹싱 전략을 사용한다. 이 전략은 주어진 쿼리에 해당하는 비디오 내의 클립에 초점을 맞춘 프로토타입을 식별하고 검색하도록 모델을 훈련시킨다. 마지막으로, 이러한 구성 요소들을 프로토타입 다양화를 위한 orthogonal loss와 결합하여, 우리의 방법은 CNN 및 Transformer 기반 backbone 모두에서 TVR, ActivityNet Captions 및 QVHighlights 데이터셋에 대한 state-of-the-art 결과를 달성한다.
2. Related Work
**Text-to-Video Retrieval (T2VR)**은 쿼리에 관련된 비디오를 검색하는 것을 목표로 한다 [7, 8, 19, 23, 40, 46, 50, 52, 56]. 주목할 만한 한 흐름은 multi-scale spatio-temporal similarity를 활용하는 것이다 [16, 41, 55]. 이 연구들은 비디오와 문장 간의 유사성뿐만 아니라, 정확한 검색을 위해 패치와 단어 간의 지역적 유사성도 고려한다. 또 다른 흐름은 **검색의 불확실성(uncertainty)**을 고려하는 것이다. 텍스트와 비디오 도메인 모두에서 표현의 다양성으로 인해 발생하는 many-to-many 문제를 해결하기 위해, UATVR [12]은 불확실성을 다루기 위해 Gaussian augmentation을 사용했고, PAU [29]는 학습 및 재순위화를 위해 불확실성을 활용했다. 그러나 T2VR은 전체 비디오 수준의 텍스트 설명이 제공된다고 가정하여, 실제 적용 가능성을 제한한다.
Moment Retrieval은 텍스트 설명에 해당하는 비디오 내의 부분적인 순간(moment)을 지역화한다 [2, 4, 14, 21, 27, 32, 34-37, 43, 48, 59-61, 65]. 관련 클립을 지역화해야 한다는 점에서 PRVR과 유사하지만, moment retrieval은 쌍별 검색 문제(pair-wise searching problem)만을 가정한다. 따라서 **비디오-텍스트 상호작용 설계(video-text interactive designs)**가 널리 사용된다 [42, 49, 58]. Video Corpus Moment Retrieval은 여러 비디오를 동시에 고려해야 하므로, 모달리티 상호작용 설계(modality-interactive designs)를 직접적으로 채택하기는 비실용적이다 [17, 64]. 효율성을 유지하고 상호작용 설계의 장점을 활용하기 위해, 비디오 검색 후 moment retrieval이 구현되는 2단계 파이프라인이 널리 채택된다 [18, 63]. PRVR과의 차이점은 지역화 레이블(localization labels)의 존재 여부이다.
**Partially Relevant Video Retrieval (PRVR)**은 부분적으로 관련된 비디오를 검색한다는 점에서 VCMR의 실용적인 목표를 공유한다 [10, 22]. 그러나 PRVR은 비용 문제로 인해 비디오 내 관련 클립의 정확한 순간 정보가 제공되지 않는다고 가정한다는 점에서 차이가 있다. 이는 정확한 비디오-텍스트 정렬을 위해 텍스트 관련 세그먼트를 암묵적으로 식별해야 하는 더 어려운 시나리오를 제시한다. 비디오 내의 다양한 의미를 탐색하기 위해 MS-SL [9]은 다양한 시간 간격을 가진 모든 가능한 부분 비디오를 인코딩하는 방식을 고려했다. 하지만 이러한 전략은 용량과 추론 속도 면에서 효율성을 희생하므로, 최근 연구들은 효율성 향상에 초점을 맞추고 있다. GMMFormer [54]는 Gaussian 분포 계수를 적용하여 각 클립이 temporal attention layer에서 인접 클립에 더 많이 attend하도록 강제함으로써 모든 클립 표현에서 지역적 맥락을 학습하는 것을 목표로 했다. QASIR [44] 또한 여러 프레임 이미지를 포함하는 super-image를 통해 효율성을 다루었다. 우리는 복잡한 맥락을 인코딩하는 능력을 희생하지 않으면서 효율성을 높이려는 이러한 연구들과 동기를 공유한다.
Prototypical learning은 일반적으로 효율성과 맥락별 표현을 조직화하는 능력이라는 두 가지 주요 이점을 제공한다. 이러한 이점 덕분에, 수많은 prototypical learning 변형이 개발되어 다양한 머신러닝 도메인에 적용되어 왔다 [1, 3, 15, 25, 30, 31, 45, 53]. 그중 slot-attention과 perceiver는 유사한 아키텍처 설계를 가진 두 가지 인기 있는 접근 방식이다. Slot-attention [38]은 합성 벤치마크에서 객체 중심 프로토타입(object-centric prototypes)으로 slot을 도입하는 반면, perceiver [20]는 다양한 데이터 유형을 효율적으로 인코딩하기 위해 compact latent bottleneck을 활용한다.
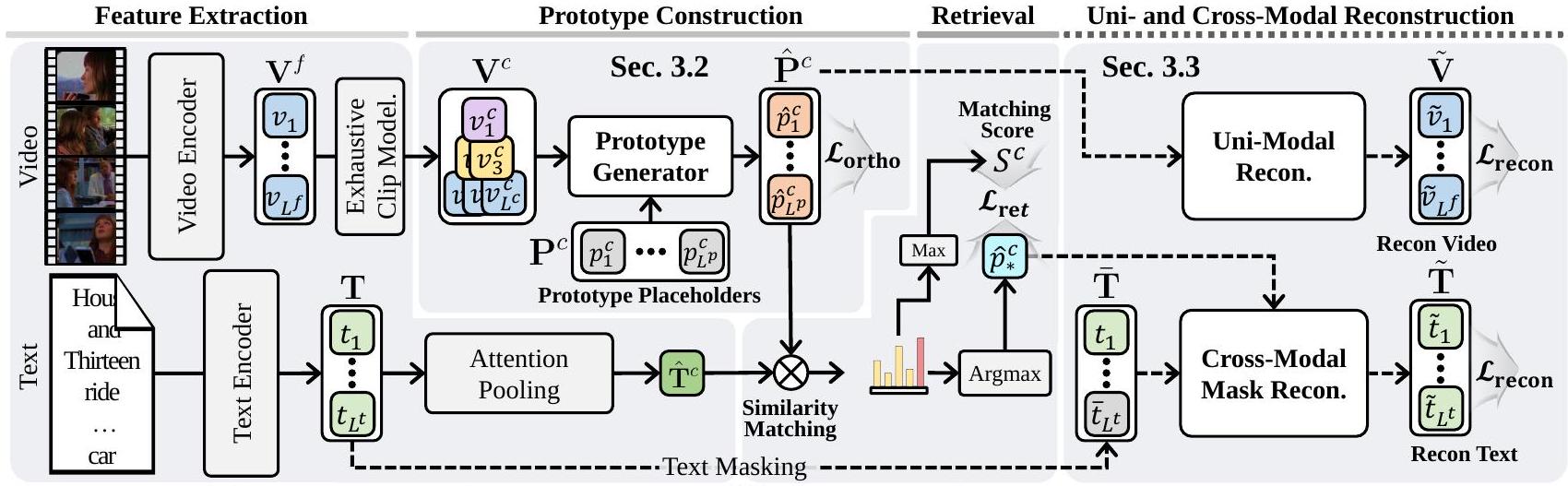
Figure 2. 우리의 prototypical framework에서 clip branch의 개요로, frame branch와 일관되지만 exhaustive clip modeling의 존재가 다르다. Video stream의 경우, prototype aggregation은 exhaustive clip modeling 전략에 의해 형성된 clip feature 위에서 구현된다. Text query는 attention-pooling layer를 통해 encoding 및 aggregation된다. 마지막으로, visual prototype 와 query token 사이의 similarity matching이 구현되어 retrieval을 위한 text-to-video score 를 계산한다. 오른쪽에서는 training 중에 구성된 prototype을 사용하여 uni-modal 및 cross-modal reconstruction이 수행된다. Retrieval된 prototype 중 similarity가 최대인 것만이 masked text word(cross-modal)를 재구성하는 데 활용되며, 모든 prototype은 video frame(uni-modal)을 재구성하는 데 사용된다.
우리의 연구는 PRVR을 위한 **비디오 표현 학습(video representation learning)**으로 prototypical learning을 확장한다. 다음 섹션에서는 프로토타입의 효율성을 활용하기 위한 우리의 아키텍처 설계 선택에 대해 자세히 설명하며, 여기에는 이중 재구성 task, 약한 비디오-텍스트 가이드, 프로토타입 다양화와 같은 개선 사항이 포함된다.
3. Prototypical PRVR
일반성을 잃지 않고 말하자면, 비디오는 종종 여러 context를 포함하며, 대부분의 경우 사용자는 비디오의 일부만 시청하는 데 관심이 있다. 따라서 신뢰할 수 있는 text-video retrieval 시스템을 제공하기 위해서는 막대한 메모리 비용에도 불구하고 데이터베이스에 모든 context를 유지하는 것이 필수적이다. 최근 연구에서 모델링된 local clip을 저장하여 효율성을 부분적으로 개선했지만, 우리는 사용자의 요구가 항상 단일의 짧은 context로 미리 결정되는 것은 아니라고 주장한다.
이러한 관점에서 우리는 PRVR을 위한 prototypical framework를 제안한다. 우리는 추론 시 추가적인 계산 부담 없이 긴 untrimmed 비디오에서 다양한 segment를 활용하여 local 및 복잡한 context를 모두 인코딩할 수 있게 하는 prototypical framework의 장점을 강조한다. 이는 학습된 context들이 저장되기 전에 최종적으로 고정된 수의 prototype으로 집계되어, 효율적이고 compact한 비디오 표현을 보장하기 때문이다. 이러한 이점을 바탕으로 우리는 텍스트 이해도와 시각 이해 능력을 더욱 향상시킨 맞춤형 prototypical framework를 소개한다.
3.1. Overall Architecture
프레임 및 클립 브랜치를 사용하는 이전 연구들 [9, 54]에 따라, 우리는 듀얼 브랜치 아키텍처를 채택한다. 클립 브랜치의 경우, exhaustive clip modeling process [9]가 존재한다는 점을 제외하고는 각 브랜치의 절차는 동일하다.
Figure 2는 클립 브랜치의 개요를 보여준다. 주어진 비디오 세트에 대해, 각 비디오의 개 프레임으로 구성된 프레임 feature 는 인코딩 layer 스택을 통해 인코딩되고, exhaustive clip modeling process를 거쳐 개의 시각 클립 feature 로 변환된다. 그런 다음, 각 비디오의 시각적 context는 개의 prototype으로 집계된다.
한편, 개의 단어로 표현되는 텍스트 쿼리 세트 는 투영(projected)되고 풀링(pooled)되어 단일 쿼리 토큰 를 생성한다. 마지막으로, 텍스트 쿼리 는 각 비디오의 모든 prototype과 비교되며, 가장 높은 유사도()를 가진 prototype이 검색되어 각 비디오가 검색 학습을 위한 텍스트 쿼리에 어떻게 대응하는지를 나타낸다. 우리는 최대 유사도를 가진 prototype을 로 표기한다.
추론 시에는 텍스트 쿼리와 저장된 모든 비디오의 prototype 간의 유사도를 계산한다. 그런 다음, 가장 높은 유사도를 가진 prototype에 해당하는 비디오가 검색된다. 본 논문의 나머지 부분에서는 비디오 브랜치들이 동일한 연산을 공유하므로 브랜치 표기법을 생략한다.
3.2. Prototype Construction
prototypical learning [20, 38]의 효율성과 의미론적 인코딩 능력에 영감을 받아, 우리의 prototype generator는 전역적으로 공유되는 학습 가능한 개의 prototype, 즉 를 기반으로 작동한다. 우리의 prototype generator는 cross-attention만으로 구성된 간결한 디자인을 가지고 있다. cross-attention만을 사용하는 이유는 독립적인 prototype들이 특정 이벤트를 더 정확하게 포착하는 경향이 있어 검색에 더 효과적이기 때문이다. 이러한 단순성은 불필요한 연산을 피하여 더 효율적인 검색에 기여한다. 이 디자인을 통해 prototype들은 번의 반복(iteration)에 걸쳐 각 인스턴스에 점진적으로 적응하며, 비디오 내의 특정 맥락을 총체적으로 캡슐화한다. 공식적으로, 비디오 feature 를 집계(aggregating)하는 번째 반복은 다음과 같이 표현된다:
여기서 CA는 cross-attention을 나타내며, 는 로 초기화된다. 본 논문의 나머지 부분에서는 를 로 줄여서 표기한다.
 Figure 3. 재구성(reconstruction) task의 아키텍처 개요.
(a) cross-modal 시나리오의 경우, 마스킹된 query feature는 검색된 비디오 prototype 를 통해 Transformer 기반 decoder로 재구성된다. 이는 검색된 prototype을 해당 텍스트 feature와 정렬(align)시킨다.
(b) uni-modal 시나리오의 경우, 시각 prototype은 MLP 기반 decoder를 통해 처리되어 프레임별 feature를 재구성함으로써 집계(aggregation) 과정에서 발생하는 시각 정보 손실을 완화한다.
Figure 3. 재구성(reconstruction) task의 아키텍처 개요.
(a) cross-modal 시나리오의 경우, 마스킹된 query feature는 검색된 비디오 prototype 를 통해 Transformer 기반 decoder로 재구성된다. 이는 검색된 prototype을 해당 텍스트 feature와 정렬(align)시킨다.
(b) uni-modal 시나리오의 경우, 시각 prototype은 MLP 기반 decoder를 통해 처리되어 프레임별 feature를 재구성함으로써 집계(aggregation) 과정에서 발생하는 시각 정보 손실을 완화한다.
앞서 논의했듯이, prototypical framework의 핵심 이점은 다양한 시간 스케일에 걸쳐 다양한 시각 콘텐츠를 효율적으로 관리하는 데 있다. 그러나 암묵적인 인코딩 과정은 텍스트와 연관된 prototype을 구축하거나 모든 시각적 세부 사항을 완전히 보존하지 못할 수 있다. 이러한 한계를 극복하기 위해, 우리는 prototype을 개선하기 위한 몇 가지 전략을 제안한다.
3.3. Dual Reconstruction with Prototypes
재구성은 프로토타입 생성 과정에서 발생하는 정보 손실을 완화하기 위해 널리 사용되는 기술이다 [38]. 이는 부분적으로만 관련된 텍스트 설명을 처리하기 위해 프로토타입이 비디오의 다양한 맥락을 보존해야 하는 PRVR에서 특히 중요하다.
우리의 재구성 task는 cross-modal과 uni-modal의 두 가지이다. cross-modal mask reconstruction은 프로토타입과 텍스트 feature 간의 정렬(alignment)을 촉진하는 반면, uni-modal reconstruction은 프로토타입 내에서 시각적 맥락의 보존을 보장한다. 재구성 과정은 Fig. 3에 묘사되어 있다.
3.3.1. Cross-modal Mask Reconstruction: Bridging the Modality Gaps
Modality gap은 효과적인 PRVR을 위한 핵심 과제 중 하나이다. visual prototype이 텍스트 쿼리를 더 잘 이해할 수 있도록, 우리는 visual prototype을 사용하여 masked text token을 예측하는 방식을 제안한다. 그러나 모든 visual prototype을 사용하여 특정 쿼리를 재구성하는 것은 representation collapse로 이어질 수 있다. 이는 텍스트 쿼리가 비디오의 부분적인 의미만을 포함하기 때문이다. 이를 방지하기 위해, 우리는 Fig. 3 (왼쪽)에 나타난 바와 같이, 검색된 visual prototype 만을 사용하여 masked text feature를 재구성한다. Masked text feature는 마스킹된 토큰의 인덱스를 지정하는 집합 을 사용하여 다음과 같이 정의된다:
여기서 와 는 각각 마스킹된 텍스트 토큰과 마스킹되지 않은 텍스트 토큰을 나타낸다. 그런 다음, cross-modal reconstruction은 다음과 같이 공식화된다:
여기서 , 는 마스킹된 입력과 prototype 간의 차원을 정렬하기 위한 함수이며, SA/CA는 각각 multi-head self-attention 및 cross-attention layer를 나타낸다. 명확히 하자면, naive reconstruction 대신 masked reconstruction을 사용하는 직관은 동일한 의미가 다양한 언어 표현을 통해 표현될 수 있다는 점이다. 따라서 우리는 재구성을 위한 구조화된 참조를 제공함으로써 표현의 변화로 인한 재구성 오류를 최소화하는 것을 목표로 한다. 특히, 각 쿼리 내의 마스킹되지 않은 단어 토큰은 attention 기반 decoder 내에서 템플릿 역할을 하며, 여기서 attention 메커니즘은 이들 간의 종속성을 설정한다. 이는 검색된 prototype이 쿼리의 의미를 정확하게 포착하도록 보장하여, 모델이 prototype을 주어진 텍스트 컨텍스트와 정렬할 수 있도록 한다.
각 텍스트 쿼리에 대한 재구성 objective는 **mini-batch 내의 다른 모든 마스킹된 단어 토큰에 대한 infoNCE [5]**를 사용하여 설계되었다. 구체적으로, 가 mini-batch에서 -번째 텍스트 쿼리의 -번째 마스킹된 단어에 해당하는 backbone에서 추출된 단어 토큰을 나타낸다고 하자. 그러면 -번째 재구성된 텍스트 단어 에 대한 손실은 다음과 같이 표현된다:
여기서 는 배치 내의 쿼리 인덱스 집합을 나타낸다. PRVR의 목표가 텍스트-비디오 검색을 위한 cosine distance를 최적화하는 것이므로, 우리는 단순화를 위해 배치 내의 모든 텍스트 쿼리에서 마스킹된 단어 인덱스가 동일하다고 가정하여 을 공유할 수 있도록 한다. Cosine similarity는 메트릭으로 사용된다.
3.3.2. Uni-modal Reconstruction: Context Preservation
cross-modal task를 통한 text-video alignment에는 이점이 있지만, cross-modal reconstruction은 프로토타입 내에서 가장 텍스트와 연관성이 높은 시각적 세부 사항에 선택적으로 집중함으로써 시각적 맥락 보존을 저해할 수 있다. 이러한 정보 손실을 완화하기 위해, 우리는 Fig. 3 (오른쪽)에 나타난 바와 같이 uni-modal reconstruction task를 동시에 수행한다.
Uni-modal encoding은 전체 비디오의 맥락이 visual prototype 내에 보존되도록 보장한다 [38].
Table 1. TVR 및 ActivityNet Captions 데이터셋에 대한 성능 비교. 회색으로 강조된 행은 T2VR 및 VCMR 방법을 나타낸다. VCMR 방법은 moment annotation을 사용하지 않고 학습되었다는 점에 유의하라.
| Method | TVR | ActivityNet Captions | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@100 | SumR | Memory (MB) | R@1 | R@5 | R@10 | R@100 | SumR | Memory (MB) | |
| ResNet152 + I3D + Roberta | ||||||||||||
| CLIP4Clip | 9.9 | 24.3 | 34.3 | 72.5 | 141.0 | - | 5.9 | 19.3 | 30.4 | 71.6 | 127.3 | - |
| Cap4Video | 10.3 | 26.4 | 36.8 | 74.0 | 147.5 | - | 6.3 | 20.4 | 30.9 | 72.6 | 130.2 | - |
| XML | 10.0 | 26.5 | 37.3 | 81.3 | 155.1 | - | 5.3 | 19.4 | 30.6 | 73.1 | 128.4 | - |
| ReLoCLNet | 10.7 | 28.1 | 38.1 | 80.3 | 157.1 | - | 5.7 | 18.9 | 30.0 | 72.0 | 126.6 | - |
| CONQUER | 11.0 | 28.9 | 39.6 | 81.3 | 160.8 | - | 6.5 | 20.4 | 31.8 | 74.3 | 133.1 | - |
| MS-SL | 13.5 | 32.1 | 43.4 | 83.4 | 172.4 | 1.01 | 7.1 | 22.5 | 34.7 | 75.8 | 140.1 | 0.98 |
| PEAN | 13.5 | 32.8 | 44.1 | 83.9 | 174.2 | - | 7.4 | 23.0 | 35.5 | 75.9 | 141.8 | - |
| T-D3N | 13.8 | 33.8 | 45.0 | 83.9 | 176.5 | - | 7.3 | 23.8 | 36.0 | 76.6 | 143.6 | - |
| GMMFormer | 13.9 | 33.3 | 44.5 | 84.9 | 176.6 | 0.05 | 8.3 | 24.9 | 36.7 | 76.1 | 146.0 | 0.05 |
| Ours | 15.4 | 35.9 | 47.5 | 86.4 | 185.1 | 0.09 | 7.9 | 24.9 | 37.2 | 77.3 | 147.4 | 0.09 |
| ResNet152 + I3D + Roberta + CLIP B/32 | ||||||||||||
| DL-DKD | 14.4 | 34.9 | 45.8 | 84.9 | 179.9 | 0.39 | 8.0 | 25.0 | 37.4 | 77.1 | 147.6 | 0.39 |
| CLIP L/14 | ||||||||||||
| QASIR | 23.0 | 45.4 | 56.3 | 88.9 | 213.6 | 0.10 | - | - | - | - | - | - |
| MS-SL | 30.8 | 57.1 | 67.1 | 93.3 | 248.2 | 1.01 | 14.6 | 37.1 | 50.2 | 84.4 | 186.3 | 0.99 |
| GMMFormer | 29.4 | 56.8 | 65.5 | 93.3 | 243.2 | 0.05 | 15.0 | 37.6 | 50.3 | 83.9 | 186.9 | 0.05 |
| Ours | 34.7 | 60.0 | 70.1 | 94.4 | 259.2 | 0.09 | 16.0 | 38.8 | 52.4 | 85.1 | 192.3 | 0.09 |
특히, 인코딩된 visual prototype 는 MLP 기반 decoder를 통해 디코딩되고, 입력 visual feature 의 의미를 재구성하기 위해 차원으로 브로드캐스트된다. 재구성된 출력이 일 때, 예측된 mask token의 오류를 계산하기 위해 L2 distance가 다음과 같이 사용된다:
마지막으로, 이중 재구성(dual reconstruction)을 위한 손실 함수는 과 의 합으로 구성된다:
3.4. Weak Guidance for Where to Focus
전형적인 retrieval 방식에서는 검색된 prototype이 주어진 텍스트 쿼리와 관련된 시각적 context를 포착하는 것이 중요하다. 그러나 PRVR에서는 dense temporal span annotation의 부재로 인해, prototype이 문맥적으로 관련된 segment만을 인코딩하도록 제약하는 것이 어렵다.
이러한 한계를 극복하기 위해, 우리는 두 개의 다른 비디오를 연결(concatenate)하여 어디에 집중해야 할지에 대한 약한 형태의 supervision을 제공한다. 구체적으로, 우리는 연결된 예시를 통해 모델의 attention weight를 유도하는데, 이는 각 쿼리에 해당하는 비디오에 모델이 집중하도록 학습시키는 방식이다. 검색된 prototype이 어떤 비디오에 attend하는지를 결정하기 위해, 우리는 각 비디오에 대한 검색된 prototype의 총 attention weight를 계산한다. 각 비디오에 대한 attention weight의 합을 스칼라 과 로 나타내자. 과 의 합이 1이므로, 우리는 에 대해서만 binary cross-entropy loss를 적용한다. 이때 레이블 은 연결된 인스턴스의 첫 번째 비디오가 쿼리와 관련이 있으면 1, 그렇지 않으면 0으로 할당된다. 이 목적 함수는 다음과 같이 공식화된다:
여기서 는 문맥적으로 유사한 비디오가 섞여 있을 경우 overfitting을 완화하기 위한 margin이다. 이 방법은 모델이 정확히 어떤 비디오 프레임에 attend해야 하는지에 대한 명시적인 신호를 제공하지는 않지만, 완전히 관련 없는 비디오 segment를 고려하지 않도록 간접적으로 유도한다.
3.5. Prototype Diversification
prototypical framework의 장점에도 불구하고, 동일한 비디오 내 프로토타입 간에 의미론적 중복(semantic overlap)이 존재한다면 다양한 텍스트 쿼리에 걸쳐 일반화하는 능력은 제한될 수 있다. 이를 해결하기 위해 우리는 프로토타입 다양화를 촉진하기 위해 prototypical learning에 직교 목적 함수(orthogonal objective)를 통합한다.
정식으로, 프로토타입 내의 직교 손실(orthogonal loss)은 다음과 같이 표현된다:
여기서 는 크기의 항등 행렬(identity matrix)이다.
프로토타입 분리(prototype separation)는 코사인 유사도(cosine similarity)가 양수일 때만 적용된다는 점에 유의해야 한다. 이는 지나치게 엄격한 정규화(regularization)를 방지하고, 부분적인 의미론적 중복을 허용한다. 이는 일부 비디오가 제한된 범위의 이벤트만을 포함할 수 있다는 점을 고려한 것이다.
전체 목적 함수 (Overall Objective)
마지막으로, 우리의 목적 함수는 다음과 같다:
여기서 는 각 에 대한 손실 계수(loss coefficient)를 나타내며, 는 표준 retrieval loss를 의미한다.
이러한 계수들은 이전 연구 [54]를 따라 와 직교 손실(orthogonal loss)을 제외하고는 대부분의 데이터셋에서 일관되게 설정되며, 이는 데이터셋의 특성을 반영하기 위함이다 (자세한 내용은 Appendix 참조).
 Figure 4. 각 프레임에 대한 프로토타입의 attention 가중치 예시. 각 상자는 개별 프로토타입을 나타낸다.
Figure 4. 각 프레임에 대한 프로토타입의 attention 가중치 예시. 각 상자는 개별 프로토타입을 나타낸다.
4. Experiments
데이터셋 및 Backbone
우리는 널리 사용되는 두 가지 대규모 데이터셋인 **TVR [26]**과 **ActivityNet Captions [24]**를 사용한다. 또한, PRVR 평가를 위해 moment retrieval 데이터셋인 **QVHighlights [28]**를 재구성하였다. 자세한 내용은 Appendix에 있다.
TVR 및 ActivityNet Captions에 대한 실험에서는 두 가지 다른 backbone을 활용한다. ResNet152, I3D, Roberta를 사용하는 설정의 경우, MS-SL [9]의 설정을 따른다. 또한, 기존 벤치마크를 넘어, **QASIR [44]에 따라 더 강력한 backbone인 CLIP-L/14 [47]**를 사용하여 방법들을 비교한다. PRVR에 대한 backbone 적합성 비교는 Appendix를 참조하며, 거기서 CLIP이 retrieval에 더 구별 가능한 representation을 추출한다는 점을 강조한다. 모든 데이터셋에 대해 CLIP feature는 3 fps로 추출되며, CLIP-L/14를 사용한 성능 재현을 위해 최신 연구들의 공식 구현을 사용한다. QVHighlights의 경우, 원본 연구 [27]에 따라 Slowfast [13]와 CLIP-B/16을 사용한다.
평가
[9]에 따라, retrieval 정확도를 측정하기 위해 **rank-based metric인 ()**을 보고한다. 은 쿼리가 주어졌을 때 정확한 retrieval의 비율로 정의되며, 검색된 목록의 상위 M개 내에 올바르게 해당하는 비디오가 포함되어 있으면 retrieval이 정확하다고 간주한다. 전반적인 성능 비교를 위해 **Sum of all Recalls (SumR)**을 사용한다.
4.1. Comparison with the State-of-the-arts
결과는 Tab. 1에서 state-of-the-art (SOTA) PRVR 방법들 [6, 9, 10, 22, 44, 54]과 T2VR [39, 57], 그리고 moment annotation 없이 동작하는 VCMR 방법들 [18, 26, 62]과 비교하여 제시되었다. TVR 벤치마크에서, 우리가 제안하는 방법은 ResNet152, I3D, Roberta 조합을 사용했을 때 SumR에서 최대 8.5점, CLIP-L/14를 사용했을 때 SumR에서 11점까지 SOTA 기술들을 크게 능가한다. ActivityNet Captions 데이터셋에서도 일관된 결과가 관찰되었으며, 우리 방법은 기존 SOTA 접근 방식보다 계속해서 우수한 성능을 보인다. 우리는 이러한 향상된 성능이 다양한 비디오 context를 보존하고 관리하는 프로토타입의 효과 덕분이라고 생각한다. 특히, 기존 방법들은 일반적으로 텍스트 쿼리와 가장 유사한 단일 세그먼트만을 비디오당 하나씩 선택하여 텍스트-비디오 검색 학습에 사용한다. 이러한 접근 방식은 모델이 비디오당 단일 대표 요소로부터만 학습하도록 제한하여, 다른 비디오 세그먼트들이 모델 학습에서 제외될 가능성이 있다. 이와 대조적으로, 우리 프로토타입은 Fig. 4에서 보여주듯이 여러 비디오 세그먼트의 혼합으로 구성된다. 이를 통해 모델은 더 넓은 범위의 시각적 표현을 통합할 수 있으며, 단일 비디오 세그먼트로부터만 학습하는 문제점을 완화한다. 또한, 우리는 GMMFormer [54]와 관련된 특정 문제점을 확인했는데, 특히 CLIP과 같이 context가 풍부한 backbone을 활용할 때 두드러진다. 우리는 이 문제가 GMMFormer의 local-biased 인코딩 전략 때문이라고 생각한다. 이 전략은 강력한 CLIP backbone으로부터 얻을 수 있는 이점을 제한적으로 활용한다. 우리의 연구 결과는 제약 없이 모든 가능한 경우를 인코딩하는 것이 foundation backbone (CLIP)에서 추출된 강력한 표현을 더 잘 활용한다는 것을 시사한다.
Table 2. QVHighlights val split 결과.
| Model | R@1 | R@5 | R@10 | R@100 | SumR |
|---|---|---|---|---|---|
| MS-SL [9] | 20.4 | 46.7 | 60.7 | 222.5 | |
| GMMFormer [54] | 18.2 | 43.7 | 56.7 | 92.5 | 211.1 |
| Ours | 93.9 |
Table 3. TVR에서 각 텍스트 쿼리에 대한 추론 시간(ms) 및 매칭 FLOPs(G) 비교. 괄호 안의 매칭 FLOPs는 비디오-텍스트 매칭 프로세스에 대한 FLOPs를 나타낸다.
| Video Size | 1000 | 2000 | 3000 | 4000 |
|---|---|---|---|---|
| MS-SL | ||||
| GMMFormer | ||||
| Ours |
또한, 우리 방법은 다양한 길이의 context 정보를 유사하게 활용하는 MS-SL에 비해 메모리 소비를 90% 절감하여 저장 공간 요구 사항에서 뛰어난 효율성을 보여준다. GMMFormer의 높은 저장 효율성은 다양한 context를 인코딩하는 것을 희생하고 단일 비디오 수준 클립과 로컬 클립만 저장하기 때문이다. 이와 대조적으로, 우리 접근 방식은 풍부한 context 정보를 유지하면서도 효율성을 우선한다. 실제로, Tab. 5의 성능과 메모리 소비 간의 trade-off에 대한 연구는 우리 프로토타입 프레임워크의 이점을 입증한다. 즉, 프로토타입 수를 줄여 메모리 소비를 줄이더라도 SOTA 성능을 달성한다.
추가 검증을 위해, 우리는 QVHighlights를 새로운 PRVR 데이터셋으로 재구성하였다. Tab. 2에서는 최신 방법들과의 비교를 제시한다. 보시다시피, 우리 방법은 R@1 지표에서 2%p 이상의 개선을 달성하며 baseline들을 능가한다. 이와 대조적으로, GMMFormer에서는 강력한 vision-language model인 CLIP에 연결했을 때 제한적인 성능을 보이는 유사한 경향을 발견했다.
마지막으로, Tab. 3에서 계산 효율성을 보고한다. 특히, 텍스트-비디오 검색 과정에서의 추론 시간과 FLOPs는 NVIDIA RTX 3090 GPU와 Intel Xeon Gold 5220R CPU를 사용하여 다양한 비디오 데이터베이스 크기에 걸쳐 측정되었다. 결과는 우리 제안 방법의 효율성이 GMMFormer와 비슷하며, 비디오 저장 크기가 증가함에 따라 MS-SL보다 속도 면에서 훨씬 우수하다는 것을 보여준다.
4.2. Analysis
모든 연구는 CLIP을 사용하여 TVR 데이터셋에서 수행되었다. 구성 요소 Ablation. Table 4는 구성 요소 연구 결과를 보여준다. prototype generator만 포함하는 baseline 모델을 기반으로, (1) cross-modal mask reconstruction, (2) uni-modal reconstruction, (3) weak attention guidance, (4) prototype orthogonal objective의 효과를 점진적으로 도입하고 평가하였다. 우리의 발견은 PRVR의 prototypical network가 첫 번째 행에서 보여주듯이 견고한 baseline을 구축한다는 것을 나타낸다. 이는 exhaustive clip modeling을 통한 implicit prototype aggregation이 의미론적으로 중요한 context를 인코딩하는 강력한 접근 방식이며, 특히 강력한 CLIP-L/14 backbone과 함께 사용될 때 더욱 효과적임을 시사한다. 또한, 두 번째 행부터 마지막 행까지의 결과는 제안된 각 구성 요소가 prototypical learning의 implicit한 특성을 효과적으로 보완하여 전반적인 검색 성능을 향상시킨다는 것을 검증한다.
Table 4. 모델 구성 요소에 대한 ablation study. 왼쪽에서 오른쪽으로, cross-modal mask reconstruction, uni-modal reconstruction, prototype에 대한 weak guidance, prototype diversification objective를 순차적으로 추가한다.
| C.Recon | U.Recon | Guide | P.Div. | R@ 1 | R@ | R@ 10 | R@ 100 | SumR |
|---|---|---|---|---|---|---|---|---|
| - | - | - | - | 32.8 | 58.2 | 68.6 | 93.4 | 253.0 |
| - | - | - | 32.9 | 58.7 | 69.0 | 93.5 | 254.2 | |
| - | - | 33.8 | 58.7 | 68.8 | 93.9 | 255.1 | ||
| - | 34.3 | 60.0 | 69.9 | 94.1 | 258.2 | |||
| 34.7 | 60.0 | 70.1 | 94.4 | 259.2 |
Table 5. prototype 수에 따른 성능.
| Num of Proto. | 10 | 20 | 30 | 60 |
|---|---|---|---|---|
| SumR | 252.9 | 257.8 | 259.2 | 260.2 |
| Memory (MB) | 0.03 | 0.06 | 0.09 | 0.18 |
Table 6. prototype 구성을 위한 다양한 아키텍처 설계와의 성능 비교.
| Model | R@1 | R@5 | R@10 | R@100 | SumR | |
|---|---|---|---|---|---|---|
| (a) | Perceiver | 31.8 | 57.1 | 67.0 | 93.5 | |
| (b) | Slot-attention | 32.3 | 58.4 | 68.9 | 94.1 | |
| (c) | Ours | 34.7 | 60.0 | 70.1 | 94.4 |
다양한 prototype 수. prototype의 수는 성능과 메모리 소비(이는 시간 효율성에도 직접적인 영향을 미침) 사이의 trade-off를 조절하는 중요한 파라미터이다. Table 5에서 우리의 분석은 prototype 수의 영향을 탐구한다. 우리의 관찰에 따르면, 적은 수의 prototype은 성능 감소를 대가로 가장 높은 효율성을 제공한다. 그럼에도 불구하고, 우리는 단 10개의 prototype만으로도 이미 강력한 성능을 달성하여, baseline인 GMMFormer(메모리 요구량 0.05MB로 SumR 243.2 달성)에 비해 더 효율적이고 효과적인 접근 방식을 제공한다고 주장한다. 반면에, prototype 수를 60개로 늘리면 성능은 향상되지만 메모리 소비가 선형적으로 증가한다. 성능과 효율성 사이의 trade-off를 고려할 때, 우리는 30개의 prototype을 사용하는 것이 둘 사이의 최적의 균형을 이룬다고 제안한다.
Prototype 구성을 위한 아키텍처. Sec. 3.2에서 논의했듯이, 우리의 prototype generator는 cross-attention만을 사용하여 의도적으로 설계되었다. 이 연구에서는 우리의 아키텍처를 문헌에서 널리 채택된 더 복잡한 설계 [20, 38]와 비교한다. 특히, Perceiver 및
 Figure 5. 주어진 쿼리와의 유사도 순서로 시각적 prototype에 대한 moment 내 프레임의 참석(attendance). prototype과 텍스트 쿼리 간의 유사도가 높을수록 moment 프레임에 대한 참석도가 높아지는 것을 관찰할 수 있다.
Figure 5. 주어진 쿼리와의 유사도 순서로 시각적 prototype에 대한 moment 내 프레임의 참석(attendance). prototype과 텍스트 쿼리 간의 유사도가 높을수록 moment 프레임에 대한 참석도가 높아지는 것을 관찰할 수 있다.
 Figure 6. TVR 데이터셋에서 prototype의 매칭 빈도.
Figure 6. TVR 데이터셋에서 prototype의 매칭 빈도.
 Figure 7. 비디오 내 moment 비율에 따른 성능.
Figure 7. 비디오 내 moment 비율에 따른 성능.
Slot-attention 아키텍처는 **self-attention 및 Gated Recurrent Unit (GRU)**과 같은 추가 구성 요소를 통합하는데, 이는 prototype 간의 불필요한 상호 작용을 유발하고 계산 오버헤드를 증가시킬 수 있다. Table 6의 결과는 PRVR을 위한 우리의 간소화된 설계의 효과를 강조하며, 그 성능의 우수성을 입증한다.
Prototype의 Attention 분석. 우리는 prototype이 텍스트 관련 의미론을 인코딩하는지 여부를 분석한다. 특히, 텍스트 관련 context를 포함하는 in-moment 프레임에 대한 prototype의 attention 가중치 크기를 시각화한다. moment를 이해하는 데 주변 context가 중요하므로, moment 경계에 시간적 여백(temporal margin)이 추가된다는 점에 유의한다 (즉, moment의 시작 및 끝 인덱스는 [33, 66]에 따라 [st-tm, ed+tm]으로 형성됨. 여기서 tm은 moment 지속 시간의 1/20로 설정됨). Figure 5에서 우리는 각 prototype과 텍스트 설명 간의 유사도 순서로 각 prototype의 moment 프레임 내 attention 크기를 플로팅한다. 구체적으로, 검색 점수(유사도)가 in-moment 프레임에 대한 참석도와 높은 상관관계를 보인다는 것을 관찰한다. 이는 우리의 prototypical framework의 contextual 이해 능력을 검증한다.
 Figure 8. TVR 데이터셋에 대한 정성적 결과. 쿼리의 각 context는 다른 색상으로 표시되며, 해당 context가 비디오에 존재하면 해당 moment는 동일한 색상으로 표시된다.
Figure 8. TVR 데이터셋에 대한 정성적 결과. 쿼리의 각 context는 다른 색상으로 표시되며, 해당 context가 비디오에 존재하면 해당 moment는 동일한 색상으로 표시된다.
 Figure 9. TVR에서 상위 랭크된 검색 비디오의 예시. 쿼리 context가 존재하는 moment는 점선으로 강조 표시된다.
Figure 9. TVR에서 상위 랭크된 검색 비디오의 예시. 쿼리 context가 존재하는 moment는 점선으로 강조 표시된다.
Prototype의 매칭 빈도. 검색 과정에서 각 prototype의 유용성과 효과를 검증하기 위해 Figure 6에 prototype의 매칭 빈도를 제시한다. 이 분석은 각 prototype이 검색되는 횟수를 보여준다. prototype 전반에 걸쳐 균일하게 분포된 빈도는 모든 prototype이 검색 과정에 적극적으로 기여하고 있음을 나타내며, 이는 데이터셋의 다양한 콘텐츠를 표현하는 데 있어 그들의 효과를 확인시켜준다.
Moment 길이에 따른 견고성. Figure 7에서는 다양한 moment 길이에 따른 우리의 성능도 조사한다. 결과는 다양한 지속 시간의 moment를 처리하는 데 있어 우리의 prototypical framework의 견고성을 보여준다. 우리는 이를 유사도를 기반으로 시각적 context를 집계하는 시각적 prototype의 특성에 기인한다고 본다. 이는 길고 짧은 이벤트 모두를 균등하게 고려할 수 있게 한다. 대조적으로, 우리의 관찰에 따르면 baseline 모델은 더 긴 moment에서 어려움을 겪는다. 특히, MS-SL의 경우, 이러한 어려움은 더 짧은 클립이 모델링된 세그먼트를 지배하기 때문에 발생한다. 유사하게, GMMFormer는 더 짧은 moment에 더 집중해야 하는 제약으로 인해 더 긴 moment에서 어려움을 겪는다.
4.3. Qualitative Results
Fig. 8은 GMMFormer와 우리 모델의 검색 결과를 보여준다. 이 예시에서 쿼리는 여러 순차적인 이벤트를 설명하고 있으며, 올바른 비디오를 검색하기 위해서는 모델이 길고 복잡한 시나리오를 이해할 수 있는 능력이 필요하다. 우리 모델은 복잡한 쿼리를 효과적으로 처리함으로써 이러한 도전을 성공적으로 해결한다. 반면, GMMFormer는 가장 유사한 일치로 부분적인 context에만 초점을 맞춰 잘못된 비디오를 검색하는 경향이 있다. 이러한 한계는 GMMFormer가 주로 인접 프레임 내에서만 clip context를 구성하기 때문에 발생한다. 이 비교는 우리 모델의 prototypical framework의 장점을 강조한다. 즉, 긴 이벤트 시퀀스를 인식하는 데 효과적이며, 다양한 context 길이에 적응하고, exhaustive clip modeling의 이점을 활용한다.
Fig. 9에서는 우리 모델의 prototypical framework가 상위 3개 검색 비디오를 통해 주어진 context를 어떻게 해석하는지 보여준다. 특히, 이들 상위 랭크 비디오들이 매우 유사한 contextual alignment를 보인다는 점을 주목할 수 있다. 상위 1위 비디오는 의도된 context를 완벽하게 포착하는 반면, 상위 2위와 3위 비디오는 "Chase가 서서 커피를 들고 있는" 장면을 묘사한다. 이 예시는 prototype이 일관된 contextual feature를 학습하고 표현하는 능력을 가지고 있음을 강조한다.
5. Conclusion
본 연구는 검색 시스템이 흔히 직면하는 핵심 과제인 검색 정확도와 추론 속도 간의 균형 문제를 다룬다. 이러한 trade-off를 극복하기 위해, 우리는 효율성을 저해하지 않으면서도 exhaustive clip modeling 전략의 풍부한 contextual 정보를 활용하는 새로운 prototypical learning framework를 소개한다.
특히, 우리의 prototype들은 다양한 시간적 스케일(temporal scales)에 걸친 feature들을 효율적으로 집계하여 compact한 표현으로 만든다.
그 다음, prototype 내에서 텍스트 이해 능력을 향상시키고 prototype이 비디오 context를 효과적으로 인코딩하도록 보장하기 위해 cross-modal 및 uni-modal reconstruction task를 제안한다.
또한, 검색된 prototype들이 적절한 콘텐츠에 attend하도록 유도하고 prototype 간의 다양성을 장려하기 위해 weak guidance와 orthogonal loss를 제공한다.
광범위한 실험을 통해 우리의 접근 방식이 검색 정확도와 효율성 간의 trade-off를 효과적으로 균형 있게 맞춘다는 것을 입증한다.
Prototypes are Balanced Units for Efficient and Effective Partially Relevant Video Retrieval
Appendix
6. Datasets
PRVR 방법들을 벤치마크하기 위해, 우리는 **각 비디오의 여러 부분집합에 대한 자연어 설명을 포함하는 두 개의 널리 사용되는 대규모 데이터셋(TVR 및 ActivityNet Captions)**을 활용한다.
**TVR [26]**은 19,524개의 비디오로 구성되며, 각 비디오에는 5개의 다른 TV 쇼에서 수집된 5개의 텍스트 설명이 포함되어 있다. 데이터 분할은 이전 연구들을 따라 87,175개의 moment 쌍을 학습용으로, 17,435개의 moment 쌍을 테스트용으로 할당한다.
**ActivityNet Captions [24]**는 9,043개의 학습용 YouTube 비디오와 4,430개의 테스트용 YouTube 비디오를 포함하며, 각각 33,721개와 15,753개의 텍스트 문장이 학습 및 테스트용으로 제공된다. 평균적으로 비디오당 3.7개의 설명이 제공된다.
QVHighlights는 원래 moment retrieval 데이터셋으로 소개되었다 [27]. 이 데이터셋은 일반적으로 사용자가 제작한 YouTube 라이프스타일 브이로그 비디오를 포함하며, 스마트폰이나 GoPro와 같은 다양한 장치로, 1인칭 또는 3인칭과 같은 다양한 각도에서 촬영되었다. 특히, 우리는 PRVR 평가를 위해 QVHighlights의 학습 및 검증 세트를 사용한다. 이는 테스트 세트에 조밀한 주석(향후 분석에 필요할 수 있음)이 제공되지 않기 때문이다. 따라서 PRVR을 위한 QVHighlights는 학습 세트에 7,218개의 moment-text 쌍, 테스트 세트에 1,550개의 쌍으로 구성된다.
부분적으로 관련된 비디오 검색(PRVR) task에 맞추기 위해, 우리는 동일한 소스에서 유래한 비디오들을 병합하여 데이터셋을 재구성했으며, 그 결과 비디오당 평균 3.3개의 텍스트 쿼리가 생성되었다. 결과적으로 PRVR을 위한 QVHighlights는 학습 세트에 2,214개의 비디오, 테스트 세트에 474개의 비디오를 포함하며, 원래의 7,218개 및 1,550개 텍스트 쿼리는 그대로 유지된다. 본 연구에서 사용된 데이터셋은 에서 접근할 수 있다.
마지막으로, Charades는 PRVR 평가에 덜 적합하여 본 연구에서는 사용되지 않았다. 예를 들어, Charades는 주로 다른 비디오의 쿼리와 유사한 문맥적 의미를 공유하는 광범위한 텍스트 쿼리로 구성되어 있다. 예를 들어, 'the person opens the door' (비디오 인덱스: HQ8BB) 쿼리는 'a person opens the door' (비디오 인덱스: 3W1GP), 'person opens the door' (비디오 인덱스: 8007M), 'a person opens a door' (비디오 인덱스: LLTBQ), 'person opens the door' (비디오 인덱스: IUETR) 등과 동일한 의미를 전달한다.
정성적인 관점에서, 텍스트 쿼리의 평균 길이는 6.2단어로, TVR (12.2단어), ActivityNet Captions (13.6단어), QVHighlights (10.5단어)보다 현저히 짧다. 또한, CLIP [47]으로 추출된 텍스트 쿼리 표현 간의 전체 cosine 유사도는 0.84로, TVR (0.56), ActivityNet (0.68), QVHighlights (0.55)보다 훨씬 높아 텍스트 쿼리의 상당한 중복성을 나타낸다. 이러한 한계점들을 고려하여, 우리는 Charades 대신 PRVR 평가를 위해 QVHighlights를 새롭게 도입하였다.
7. Backbone Comparison
이 하위 섹션에서는 TVR 및 ActivityNet Captions 데이터셋에서 벤치마킹 방법에 사용된 다양한 backbone의 적절성을 비교하며, 특히 텍스트 modality에 중점을 둔다. Table 7은 Roberta 및 CLIP 모델을 사용하여 서로 다른 데이터셋 간의 텍스트 표현의 쌍별 코사인 유사도에 대한 통계를 제시한다.
우리의 연구 결과는 텍스트-비전 정렬 모델인 CLIP이 대규모 데이터셋에서 텍스트 주석의 고유한 특성을 효과적으로 포착한다는 것을 보여준다. 이와 대조적으로, **Roberta 모델에서 파생된 텍스트 feature는 높은 유사도(모든 텍스트 쿼리 간의 평균 코사인 유사도는 0.961)**를 나타내며, 이는 다양한 모델의 일반화 능력을 공정하게 평가하는 데 있어 평가 프로토콜을 제한할 수 있다. 우리는 이러한 통찰이 향후 연구에서 PRVR 모델 평가를 위한 backbone을 신중하게 고려하도록 장려하기를 바란다.
Table 7. 서로 다른 backbone을 사용한 데이터셋 간 텍스트 쿼리 표현의 유사도 통계.
모든 쌍별 유사도 중 최대, 평균, 중앙값, 최소값을 보고한다. ANet은 ActivityNet Captions 데이터셋을 나타낸다.
| CLIP | I3D+Roberta | |||
|---|---|---|---|---|
| TVR | ANet | TVR | ANet | |
| max | 1.000 | 1.000 | 1.000 | 1.000 |
| mean | 0.558 | 0.678 | 0.961 | 0.994 |
| median | 0.553 | 0.683 | 0.961 | 0.994 |
| min | 0.218 | 0.245 | 0.877 | 0.974 |
8. Implementation Details
TVR, ActivityNet Captions, QVHighlights 데이터셋에 사용된 하이퍼파라미터는 Table 8에 나열되어 있다. 대부분의 하이퍼파라미터는 데이터셋 전반에 걸쳐 일관되게 유지되었지만, contrastive loss ()의 계수는 [54]를 따라 조정되었다. 이는 TV 프로그램에서 수집된 TVR 데이터셋이 고유 명사와 텍스트-비디오 쌍 전반에 걸쳐 유사한 맥락을 포함하는 특성을 반영하기 위함이다.
또한, Roberta text encoder를 CNN 기반 visual encoder와 함께 사용할 때 구현에 약간의 차이가 있다. 구체적으로, **prototype 구축을 위한 반복 횟수 **는 Roberta text encoder를 사용할 때 6으로 설정되었다.
 Figure 10. Loss 계수에 대한 연구. 왼쪽부터 오른쪽으로, 각 그래프는 , 의 민감도를 조사한다. 각 그래프에서 X축은 계수 값을 나타내고, Y축은 성능을 나타낸다. 빨간색 원은 기본값을 나타낸다.
Figure 10. Loss 계수에 대한 연구. 왼쪽부터 오른쪽으로, 각 그래프는 , 의 민감도를 조사한다. 각 그래프에서 X축은 계수 값을 나타내고, Y축은 성능을 나타낸다. 빨간색 원은 기본값을 나타낸다.
Table 8. 구현 세부 사항. 위에서 아래로, ' *'는 해당 loss (즉, contrastive (InfoNCE) loss, cross-modal reconstruction loss, uni-modal reconstruction loss, attention guidance loss, prototype 내 orthogonal loss)의 계수를 나타낸다. 는 attention guidance loss의 margin을 나타내고, 는 prototype 구축을 위한 반복 횟수를 나타낸다. ANet과 QVH는 각각 ActivityNet Captions와 QVHighlights를 나타낸다.
| TVR | ANet | QVH | |
|---|---|---|---|
| 0.03 | 0.06 | 0.06 | |
| 0.1 | 0.1 | 0.1 | |
| 1.0 | 1.0 | 1.0 | |
| 0.005 | 0.005 | 0.005 | |
| 0.01 | 0.01 | 0.01 | |
| 0.2 | 0.2 | 0.2 | |
| 1 | 1 | 1 |
또한, ActivityNet Captions 데이터셋에 Roberta를 사용할 때는 에 더 높은 값(0.3)을 할당한다. 이는 Table 7에서 보여지듯이, 텍스트 쿼리 간의 평균 유사도가 특히 ActivityNet Captions에서 매우 높기 때문이다 (TVR: 0.961, ANet: 0.994). 따라서 우리는 더 많은 context-specific prototype 형성을 장려하고 (비디오 prototype 간의 더 큰 구별을 촉진), 텍스트 쿼리를 더 잘 분리하기 위해 더 높은 를 설정하기 위해 를 증가시켰다. 이 외의 다른 파라미터는 동일하게 유지되었다.
일반적인 학습을 위해, 우리는 PyTorch 프레임워크를 사용하여 구현했으며, 이전 연구들 [9, 54]에 따라 NVIDIA RTX A6000 GPU에서 batch size 128로 모델을 학습시켰다.
9. Loss Sensitivity
Fig. 10은 loss sensitivity에 대한 우리의 연구를 보여주며, loss 계수들이 합리적인 범위 내에 있는 한 우리 prototypical framework의 견고함을 입증한다. 또한, 우리는 domain-specific한 변화와 관계없이 prototypical framework의 일반화 가능성을 검증하기 위해 모든 데이터셋에 걸쳐 균일한 loss 계수를 유지했음을 밝힌다. 결과적으로, 우리의 기본 설정이 항상 모든 데이터셋에서 최적의 성능을 달성하지는 못할 수 있다. 그러나 우리는 각 데이터셋에 대한 loss 가중치를 조정하면 성능을 더욱 향상시킬 수 있으며, 이는 우리 접근 방식이 데이터셋별 최적화를 통해 적응적으로 더 많은 이득을 가져올 수 있음을 시사한다.
감사의 글 (Acknowledgements)
본 프로젝트는 NAVER Cloud Corporation의 부분적인 지원을 받았다.