PaLM: Pathways를 이용한 언어 모델링 스케일링
PaLM은 5400억 개의 파라미터를 가진 대규모 고밀도 Transformer 언어 모델로, Pathways라는 새로운 ML 시스템을 사용하여 6144개의 TPU v4 칩에서 효율적으로 학습되었습니다. 이 모델은 수백 개의 언어 이해 및 생성 벤치마크에서 최첨단 few-shot 학습 성능을 달성했으며, 특히 chain-of-thought prompting과 결합되었을 때 다단계 추론 작업에서 획기적인 성능을 보여줍니다. 또한 모델 규모가 커짐에 따라 특정 작업에서 성능이 급격히 향상되는 불연속적인 개선(discontinuous improvements) 현상을 나타내며, 이는 대규모 모델에서 새로운 능력이 나타날 수 있음을 시사합니다. 논문 제목: PaLM: Scaling Language Modeling with Pathways
Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." Journal of Machine Learning Research 24.240 (2023): 1-113.
PaLM: Scaling Language Modeling with Pathways
Abstract
대규모 language model은 few-shot learning을 사용하여 다양한 자연어 task에서 놀라운 성능을 달성하는 것으로 나타났으며, 이는 특정 애플리케이션에 모델을 적용하는 데 필요한 task-specific 학습 예시의 수를 획기적으로 줄여준다. few-shot learning에서 규모(scale)의 영향에 대한 이해를 더욱 심화하기 위해, 우리는 5,400억 개의 파라미터를 가진 densely activated Transformer language model을 학습시켰으며, 이를 **Pathways Language Model (PaLM)**이라고 명명한다.
우리는 Pathways라는 새로운 ML 시스템을 사용하여 6144개의 TPU v4 칩으로 PaLM을 학습시켰다. Pathways는 여러 TPU Pod에 걸쳐 매우 효율적인 학습을 가능하게 한다. 우리는 수백 개의 언어 이해 및 생성 벤치마크에서 state-of-the-art few-shot learning 결과를 달성함으로써 규모 확장(scaling)의 지속적인 이점을 입증한다. 이들 task 중 상당수에서 PaLM 540B는 획기적인 성능을 달성했으며, 일련의 multi-step reasoning task에서 fine-tuned state-of-the-art를 능가하고, 최근 공개된 BIG-bench 벤치마크에서 평균적인 인간 성능을 능가한다. 상당수의 BIG-bench task에서 **모델 규모에 따른 불연속적인 성능 향상(discontinuous improvements)**이 나타났는데, 이는 가장 큰 모델로 확장함에 따라 성능이 급격히 증가했음을 의미한다. PaLM은 또한 다국어 task 및 소스 코드 생성에서도 강력한 능력을 가지고 있으며, 이를 다양한 벤치마크에서 입증한다. 우리는 추가적으로 편향(bias) 및 유해성(toxicity)에 대한 포괄적인 분석을 제공하고, 모델 규모에 따른 학습 데이터 암기(memorization) 정도를 연구한다. 마지막으로, 우리는 대규모 language model과 관련된 윤리적 고려 사항을 논의하고 잠재적인 완화 전략을 제시한다.
1 Introduction
지난 몇 년간, 언어 이해 및 생성 분야에서 학습된 매우 큰 규모의 신경망은 다양한 task에서 놀라운 결과를 달성해왔다. BERT (Devlin et al., 2019) 및 T5 (Raffel et al., 2020)와 같은 많은 모델들은 encoder-only 또는 encoder-decoder 아키텍처를 사용하여 대규모 텍스트 코퍼스에서 infilling ("masked LM" 또는 "span corruption") 사전학습 objective로 학습되며, 일반적으로 fine-tuning을 통해 하나 이상의 특정 task에 적응된다. 이러한 모델들이 수천 개의 자연어 task에서 거의 보편적인 state of the art를 달성했지만, 단점은 모델을 fine-tuning하기 위해 상당한 수의 task-specific 학습 예시가 필요하다는 것이다. 또한, 모델 파라미터의 최소한 일부는 task에 맞게 업데이트되어야 하므로, 모델 fine-tuning 및 배포의 복잡성이 증가한다.
GPT-3 (Brown et al., 2020)는 **매우 큰 autoregressive language model (LM)**이 few-shot 예측에 사용될 수 있음을 보여주었다. 이 경우 모델에는 자연어 task 설명과 (선택적으로) task가 어떻게 완료되어야 하는지를 보여주는 소수의 예시만 제공된다. 이 클래스의 모델은 decoder-only 아키텍처와 표준적인 left-to-right language modeling objective로 대규모 텍스트 코퍼스에서 학습되며, objective는 예시에서 선행하는 토큰이 주어졌을 때 다음 토큰을 예측하는 것이다. Few-shot 평가는 대규모 task-specific 데이터 수집이나 모델 파라미터 업데이트 없이도 매우 강력한 결과를 달성하는 것으로 나타났다.
GPT-3 이후, 여러 다른 대규모 autoregressive language model이 개발되어 state of the art를 계속해서 발전시켰다. 이들 GPT-3 이후 모델 중 가장 강력한 모델은 GLaM (Du et al., 2021), Gopher (Rae et al., 2021), Chinchilla (Hoffmann et al., 2022), Megatron-Turing NLG (Smith et al., 2022), 그리고 LaMDA (Thoppilan et al., 2022)이며, 이들 모두 출시 당시 상당수의 task에서 few-shot state-of-the-art 결과를 달성했다. 이들 모델은 GPT-3와 마찬가지로 모두 Transformer 아키텍처 (Vaswani et al., 2017)의 변형이다. 이들 모델의 개선은 주로 다음 접근 방식 중 하나 이상에서 비롯되었다: (1) 깊이와 너비 모두에서 모델 크기 확장; (2) 모델이 학습된 토큰 수 증가; (3) 더 다양한 소스에서 얻은 더 깨끗한 데이터셋으로 학습; (4) 희소하게 활성화된 모듈을 통해 계산 비용을 증가시키지 않고 모델 용량 증가.
본 연구에서는 language modeling 개선의 스케일링 라인을 계속 이어가며, 5,400억 개의 파라미터를 가진 densely activated autoregressive Transformer를 7,800억 개의 고품질 텍스트 토큰으로 학습시켰다. 이는 **Pathways (Barham et al., 2022)**라는 새로운 ML 시스템을 사용하여 달성되었는데, 이 시스템은 수천 개의 가속기 칩(여러 Tensor Processing Unit (TPU) v4 Pod에 걸쳐 있는 칩 포함)에 걸쳐 매우 큰 신경망을 고효율로 학습할 수 있게 한다. **Pathways Language Model (PaLM)**이라고 불리는 이 새로운 모델은 수백 개의 자연어, 코드, 수학적 추론 task에서 state-of-the-art few-shot 결과를 달성한다. 우리는 이들 task 중 다수에서 획기적인 성능을 달성했다.
본 연구의 주요 시사점은 다음과 같다:
- 효율적인 스케일링: 우리는 **Pathways (Barham et al., 2022)**의 첫 대규모 사용을 시연한다. Pathways는 수천 또는 수만 개의 가속기 칩에 걸쳐 단일 모델을 고효율로 학습할 수 있게 하는 새로운 ML 시스템이다. Pathways를 통해 우리는 6144개의 TPU v4 칩에서 5,400억 개의 파라미터를 가진 language model을 학습시켰으며, 이는 이 규모의 모델에서는 이전에 도달할 수 없었던 효율성 수준이다. 대부분의 이전 대규모 language model은 단일 TPU 시스템에서 학습되었거나 (Du et al., 2021; Thoppilan et al., 2022) **pipeline parallelism (Huang et al., 2019)**을 사용하여 GPU 클러스터 (Smith et al., 2022) 또는 여러 TPU v3 pod (Rae et al., 2021)에 걸쳐 확장되었으며, 최대 4096개의 TPU v3 칩 규모였다. Section 4에서는 PaLM 540B의 pipeline-free 학습을 두 개의 TPU v4 Pod에 걸쳐 6144개의 칩으로 확장하면서, 모델 FLOPs 활용률에서 46.2% (관찰된 처리량 대비 이론적 최대 처리량) 및 하드웨어 FLOPs 활용률에서 57.8%의 매우 높은 효율성을 달성할 수 있었던 방법을 설명한다.
- 스케일링을 통한 지속적인 개선: Section 6에서 우리는 PaLM을 수백 개의 자연어, 코드, 수학적 추론 task에 걸쳐 평가하고, 대부분의 벤치마크에서 일반적으로 상당한 차이로 state-of-the-art 결과를 달성한다. 이는 대규모 LM의 스케일링 개선이 정체되거나 포화점에 도달하지 않았음을 결정적으로 보여준다. 예를 들어, Table 4에서는 GLaM (Du et al., 2021), GPT-3 (Brown et al., 2020), Megatron-Turing NLG (Smith et al., 2022), Gopher (Rae et al., 2021), Chinchilla (Hoffmann et al., 2022), 그리고 LaMDA (Thoppilan et al., 2022)의 task별 최고 결과와 비교하여, 가장 널리 평가되는 29개 영어 언어 이해 벤치마크 중 28개에서 새로운 few-shot state of the art를 제시한다.
 Figure 1: 이 예시들은 **chain-of-thought prompting (Wei et al., 2022b)**을 사용하여 PaLM이 설명을 생성하도록 유도하는 탐색적 능력을 보여준다. 모든 예시는 PaLM 540B의 greedy (1-best) decoding으로 생성되었다. Prompting은 2-shot exemplars로 수행되었으며, 이는 Section 9에 제시되어 있으며, 동일한 exemplars를 사용한 더 많은 예시에 대한 출력도 함께 제공된다.
Figure 1: 이 예시들은 **chain-of-thought prompting (Wei et al., 2022b)**을 사용하여 PaLM이 설명을 생성하도록 유도하는 탐색적 능력을 보여준다. 모든 예시는 PaLM 540B의 greedy (1-best) decoding으로 생성되었다. Prompting은 2-shot exemplars로 수행되었으며, 이는 Section 9에 제시되어 있으며, 동일한 exemplars를 사용한 더 많은 예시에 대한 출력도 함께 제공된다.
- 획기적인 능력: 우리는 여러 어려운 task에서 언어 이해 및 생성의 획기적인 능력을 시연한다. 특히 Section 6.3에서는 정확한 답을 생성하기 위해 다단계 수학적 또는 상식적 추론을 요구하는 추론 task 모음에 대한 평가를 제시한다. 이전의 state-of-the-art 결과는 강력한 결과를 달성하기 위해 task-specific fine-tuning, domain-specific 아키텍처, task-specific verifier의 조합을 사용했다. 본 연구에서는 모델 스케일링이 chain-of-thought prompting (Wei et al., 2022b)과 결합될 때, 단순한 few-shot 평가가 광범위한 추론 task에서 fine-tuned state of the art를 능가하거나 일치할 수 있음을 보여준다. Section 6.2에서는 최근 출시된 **150개 이상의 새로운 언어 이해 및 생성 task 모음인 BIG-bench (BIG-bench collaboration, 2021)**에서 획기적인 성능을 추가로 강조한다. 이들 중 다수는 인간조차도 정확하게 답하기 매우 어려운 task이다. Figure 1과 Section 9에서는 PaLM이 복잡한 추론 체인을 명시적으로 해석하고 설명하는 능력에 대한 탐색적 능력을 시연한다.
- 불연속적인 개선: 스케일링 동작을 더 잘 이해하기 위해, 우리는 8B, 62B, 540B의 세 가지 다른 파라미터 규모에서 결과를 제시한다. 일반적으로 62B에서 540B로 스케일링하는 것은 8B에서 62B로 스케일링하는 것과 유사한 성능을 가져오며, 이는 신경망 스케일링에서 종종 관찰되는 "멱법칙(power law)" 경험 법칙 (Kaplan et al., 2020)과 일치한다. 그러나 특정 task의 경우, 불연속적인 개선을 관찰하는데, 62B에서 540B로 스케일링하는 것이 8B에서 62B로 스케일링하는 것과 비교하여 정확도에서 급격한 도약을 가져온다. 이러한 동작은 Section 6.2의 BIG-bench task 중 약 25%에서 관찰된다. 이는 모델이 충분한 규모를 달성할 때 대규모 LM의 새로운 능력이 나타날 수 있으며, 이러한 능력은 이전에 연구된 규모를 넘어서 계속해서 나타난다는 것을 시사한다.
- 다국어 이해: 대규모 language model에 대한 이전 연구는 다국어 도메인에서 제한적인 평가를 수행했다. 본 연구에서는 **기계 번역 (Section 6.5), 요약 (Section 6.6), 질문 응답 (Section 6.7)**을 포함한 다양한 언어의 다국어 벤치마크에 대한 보다 철저한 평가를 수행한다. 학습 코퍼스에서 비영어 데이터의 비율이 상대적으로 작음에도 불구하고 (약 22%), 540B 모델의 few-shot 평가 결과는 비영어 요약 task에서 이전 fine-tuned state of the art와의 격차를 줄이고 번역 task에서 이전 state of the art를 능가할 수 있다. 영어 및 다국어 task에서 다국어 데이터의 비율을 늘리는 것의 영향을 이해하기 위한 추가 연구가 필요하다.
- 편향 및 유해성: 우리는 또한 분포 편향 및 유해성에 대한 모델 성능을 평가했으며, 이는 몇 가지 통찰력을 제공했다 (Section 10). 첫째, 성별 및 직업 편향에 대해, 우리는 Winogender coreference task의 정확도가 모델 규모에 따라 향상되며, PaLM 540B가 1-shot 및 few-shot 설정에서 새로운 state-of-the-art 결과를 달성한다는 것을 발견했다. 둘째, 인종/종교/성별 prompt continuation에 대해 수행된 동시 발생 분석은 모델이 고정관념을 잘못 확증할 가능성을 보여준다. 예를 들어, 무슬림을 테러, 극단주의, 폭력과 연관시키는 것이다. 이러한 행동은 모델 규모에 걸쳐 일관적이었다. 마지막으로, prompt continuation task에 대한 유해성 분석은 8B 모델에 비해 62B 및 540B 모델에서 약간 더 높은 전반적인 유해성 수준을 보여준다. 그러나 모델이 생성한 continuation의 유해성은 prompting 텍스트의 유해성과 높은 상관관계를 가지는 반면, 인간이 생성한 continuation은 강한 유해성 상관관계를 가지지 않는다. 이는 모델이 인간이 생성한 텍스트의 경우보다 prompt의 스타일에 더 크게 영향을 받는다는 것을 시사한다. 향후 연구에서는 이러한 벤치마크를 비영어 언어로 확장하고 잠재적 위험을 보다 철저하게 설명할 계획이다.
2 Model Architecture
PaLM은 표준 Transformer 모델 아키텍처 (Vaswani et al., 2017)를 decoder-only 설정 (즉, 각 timestep은 자신과 이전 timestep에만 attend할 수 있음)으로 사용하며, 다음과 같은 수정 사항을 적용했다:
-
SwiGLU Activation – 우리는 MLP의 중간 activation으로 SwiGLU activation (Swish )을 사용한다. 이는 표준 ReLU, GeLU 또는 Swish activation에 비해 품질을 크게 향상시키는 것으로 나타났기 때문이다 (Shazeer, 2020). 이 방식은 MLP에서 두 번이 아닌 세 번의 행렬 곱셈을 필요로 하지만, Shazeer (2020)는 연산량 동등 실험 (즉, 표준 ReLU 변형이 비례적으로 더 큰 차원을 가졌던 실험)에서 품질 향상을 입증했다.
-
Parallel Layers – 우리는 각 Transformer 블록에서 표준 "serialized" 방식 대신 "parallel" 방식을 사용한다 (Wang & Komatsuzaki, 2021). 구체적으로, 표준 방식은 다음과 같이 표현될 수 있다:
반면, parallel 방식은 다음과 같이 표현될 수 있다:
parallel 방식은 MLP와 Attention 입력 행렬 곱셈을 융합(fuse)할 수 있기 때문에 대규모에서 약 15% 더 빠른 학습 속도를 제공한다. ablation 실험 결과, 8B 규모에서는 작은 품질 저하가 있었지만 62B 규모에서는 품질 저하가 없었으므로, 우리는 parallel layer의 효과가 540B 규모에서는 품질에 중립적일 것으로 추정했다.
-
Multi-Query Attention – 표준 Transformer 방식은 개의 attention head를 사용하며, 각 timestep의 입력 벡터는 형태의 "query", "key", "value" 텐서로 선형 투영된다 (여기서 는 attention head 크기이다). 여기서는 key/value 투영이 각 head에 대해 공유된다. 즉, "key"와 "value"는 로 투영되지만, "query"는 여전히 형태로 투영된다. 우리는 이 방식이 모델 품질과 학습 속도에 중립적인 영향을 미치지만 (Shazeer, 2019), autoregressive decoding 시 상당한 비용 절감을 가져온다는 것을 발견했다. 이는 표준 multi-headed attention이 autoregressive decoding 동안 가속기 하드웨어에서 효율성이 낮기 때문이다. key/value 텐서가 예시 간에 공유되지 않고, 한 번에 하나의 토큰만 디코딩되기 때문이다.
-
RoPE Embeddings – 우리는 절대 또는 상대 위치 임베딩 대신 RoPE embeddings (Su et al., 2021)를 사용한다. RoPE embeddings가 긴 시퀀스 길이에서 더 나은 성능을 보이는 것으로 나타났기 때문이다.
-
Shared Input-Output Embeddings – 우리는 입력 및 출력 임베딩 행렬을 공유하는데, 이는 이전 연구에서 자주 (항상 그런 것은 아니지만) 사용되었다.
-
No Biases – 어떤 dense kernel이나 layer norm에서도 bias는 사용되지 않았다. 우리는 이 방식이 대규모 모델의 학습 안정성을 향상시키는 결과를 가져온다는 것을 발견했다.
-
Vocabulary – 우리는 256k 토큰을 가진 SentencePiece (Kudo & Richardson, 2018a) vocabulary를 사용한다. 이는 과도한 토큰화 없이 학습 코퍼스의 많은 언어를 지원하기 위해 선택되었다. vocabulary는 학습 데이터로부터 생성되었으며, 이는 학습 효율성을 향상시키는 것으로 나타났다. 이 vocabulary는 완전히 손실이 없고 가역적이다. 즉, 공백(whitespace)이 vocabulary 내에서 완전히 보존되며 (특히 코드에 중요), 어휘 외(out-of-vocabulary) Unicode 문자는 UTF-8 바이트로 분할되고 각 바이트에 대한 vocabulary 토큰이 존재한다. 숫자는 항상 개별 숫자 토큰으로 분할된다 (예: "123.5 ").
2.1 Model Scale Hyperparameters
본 연구에서는 세 가지 다른 모델 규모를 비교한다: 540B 파라미터, 62B 파라미터, 8B 파라미터. 이 모델들은 표준 dense Transformer이므로, 토큰당 FLOPs 수는 파라미터 수와 거의 동일하다. 이 모델들은 Table 1의 하이퍼파라미터를 사용하여 구축되었다. 세 모델은 동일한 데이터와 vocabulary를 사용하여 동일하게 학습되었다 (batch size 제외). 학습에 대한 자세한 내용은 Section 3과 5에서 설명한다.
| Model | Layers | # of Heads | # of Parameters (in billions) | Batch Size | |
|---|---|---|---|---|---|
| PaLM 8B | 32 | 16 | 4096 | 8.63 | |
| PaLM 62B | 64 | 32 | 8192 | 62.50 | |
| PaLM 540B | 118 | 48 | 18432 | 540.35 |
Table 1: 모델 아키텍처 세부 정보. 레이어 수, , attention head 수 및 attention head 크기를 나열한다. feed-forward 크기 는 항상 이고 attention head 크기는 항상 256이다.
2.2 Model Card
PaLM에 대한 Model Card (Mitchell et al., 2019)는 Appendix E에 제공되어 있다. 여기에는 모델의 아키텍처, 학습 설정, 학습 데이터, 그리고 의도된 사용 목적에 대한 개략적인 요약이 포함되어 있다.
3 Training Dataset
PaLM의 사전학습 데이터셋은 다양한 자연어 사용 사례를 대표하는 7,800억 개의 토큰으로 구성된 고품질 코퍼스이다. 이 데이터셋은 필터링된 웹페이지, 책, Wikipedia, 뉴스 기사, 소스 코드, 소셜 미디어 대화 등의 혼합으로 이루어져 있다. 이 데이터셋은 LaMDA (Thoppilan et al., 2022) 및 GLaM (Du et al., 2021) 학습에 사용된 데이터셋을 기반으로 한다. 우리는 세 가지 모델 모두를 데이터의 정확히 한 epoch 동안 학습시키며 (모든 모델에 대해 동일하게 섞음), 어떤 하위 구성 요소에서도 데이터가 반복되지 않도록 혼합 비율을 선택한다.
자연어 데이터 외에도, 사전학습 데이터셋에는 코드도 포함되어 있다. 사전학습 데이터셋의 소스 코드는 GitHub의 오픈 소스 저장소에서 얻었다. 우리는 저장소에 포함된 라이선스를 기준으로 파일을 필터링했으며, copyleft 라이선스는 제외되었다. 파일 확장자를 기준으로 필터링하여 Java, HTML, Javascript, Python, PHP, C#, XML, C++, C를 포함한 24가지 일반적인 프로그래밍 언어 중 하나로 제한했으며, 그 결과 196GB의 소스 코드가 생성되었다. 또한, 소스 코드 저장소에서 중복 파일이 흔하다는 점을 고려하여 (Lopes et al., 2017; Allamanis, 2019), 파일 간의 Levenshtein distance를 기반으로 중복을 제거했다.
Table 2는 최종 PaLM 데이터셋 혼합을 생성하는 데 사용된 다양한 데이터 소스의 비율을 나열한다. 우리는 Section 8에서 데이터 오염 여부를 확인하고, 학습 데이터셋과 평가 데이터 간의 중복 분석을 제시한다. Appendix D에는 언어 비율 분석을 포함한 추가 정보가 담긴 데이터시트 (Gebru et al., 2021)가 포함되어 있다.
| Total dataset size billion tokens | |
|---|---|
| Data source | Proportion of data |
| Social media conversations (multilingual) | 50% |
| Filtered webpages (multilingual) | 27% |
| Books (English) | 13% |
| GitHub (code) | 5% |
| Wikipedia (multilingual) | 4% |
| News (English) | 1% |
Table 2: 학습 데이터셋에서 각 소스의 데이터 비율.
다국어 코퍼스는 100개 이상의 언어로 된 텍스트를 포함하며, 그 분포는 Appendix Table 29에 제시되어 있다.
4 Training Infrastructure
우리의 학습 및 평가 코드베이스는 JAX (Bradbury et al., 2018)와 T5X (Roberts et al., 2022)를 기반으로 하며, 모든 모델은 TPU v4 Pods (Jouppi et al., 2020)에서 학습된다. PaLM 540B는 model parallelism과 data parallelism (Xu et al., 2021)의 조합을 사용하여 데이터센터 네트워크(DCN)로 연결된 두 개의 TPU v4 Pods에서 학습되었다. 우리는 각 Pod에 768개의 호스트에 연결된 3072개의 TPU v4 칩을 사용한다. 현재까지 설명된 가장 큰 TPU 구성인 이 시스템은 pipeline parallelism (Huang et al., 2019)을 사용하지 않고도 6144개의 칩으로 학습을 효율적으로 확장할 수 있게 해주었다.
이전의 유사한 규모의 end-to-end 모델 학습 보고서들은 두 가지 접근 방식 중 하나를 사용했다. LaMDA (Thoppilan et al., 2022)와 GLaM (Du et al., 2021)은 각각 pipeline parallelism이나 DCN을 활용하지 않고 단일 TPU 시스템에서 학습되었다. Megatron-Turing NLG 530B (Smith et al., 2022)는 2240개의 A100 GPU에서 model, data, pipeline parallelism의 조합을 사용하여 학습되었고, Gopher (Rae et al., 2021)는 DCN으로 연결된 4개의 TPU v3 Pods (각각 1024개의 TPU v3 칩 포함)에서 Pod 간 pipelining을 사용하여 학습되었다.
Pipelining은 일반적으로 DCN (Smith et al., 2022)과 함께 사용되는데, 이는 대역폭 요구 사항이 낮고 model 및 data parallelism이 허용하는 최대 효율적인 규모를 넘어 추가적인 병렬화를 제공하기 때문이다. Pipelining은 일반적으로 학습 batch를 "micro-batch"로 분할하지만, 중요한 단점이 있다. 첫째, forward 및 backward pass의 시작과 끝에서 파이프라인을 채우고 비울 때 많은 장치가 완전히 유휴 상태가 되는 pipelining "bubble"로 인한 step time 오버헤드가 발생한다. 둘째, mini-batch 내의 각 micro-batch에 대해 메모리에서 가중치를 다시 로드해야 하므로 더 높은 메모리 대역폭이 필요하다. 어떤 경우에는 추가적인 소프트웨어 복잡성도 수반한다. 우리는 다음 전략을 사용하여 PaLM 540B의 pipeline-free 학습을 6144개의 칩으로 효율적으로 확장할 수 있었다.
각 TPU v4 Pod는 모델 파라미터의 전체 복사본을 포함하며, 각 가중치 텐서는 12-way model parallelism과 256-way fully sharded data parallelism (Xu et al. (2021)에서 "2D finalized"라고 명명된 접근 방식)을 사용하여 3072개의 칩에 분할된다. Forward pass 동안, 가중치는 data parallel 축을 따라 all-gather되고, 각 layer에서 하나의 fully sharded activation 텐서가 저장된다. Backward pass 동안, 나머지 activation은 rematerialize되는데, 이는 다른 재계산 선택지에 비해 더 큰 batch size에서 더 높은 학습 처리량을 가져오기 때문이다.
우리는 Pathways 시스템 (Barham et al., 2022)을 사용하여 단일 TPU v4 Pod를 넘어 학습을 확장한다. PaLM 540B는 Pathways의 client-server 아키텍처를 활용하여 Pod 수준에서 2-way data parallelism을 달성한다. 여기서 단일 Python 클라이언트는 학습 batch의 절반을 각 Pod에 분배하고, 각 Pod는 표준 Pod 내 data 및 model parallelism을 사용하여 forward 및 backward 계산을 병렬로 실행하여 gradient를 계산한다. 그런 다음 Pod들은 (자신들의 batch 절반에서 계산된) gradient를 원격 Pod와 전송하고, 마지막으로 각 Pod는 로컬 및 원격 gradient를 누적하고 파라미터 업데이트를 병렬로 적용하여 다음 timestep에 대한 bitwise-identical 파라미터를 얻는다.
 Figure 2: Pathways 시스템 (Barham et al., 2022)은 Pod 수준에서 2-way data parallelism을 사용하여 두 개의 TPU v4 Pod에 걸쳐 학습을 확장한다.
Figure 2: Pathways 시스템 (Barham et al., 2022)은 Pod 수준에서 2-way data parallelism을 사용하여 두 개의 TPU v4 Pod에 걸쳐 학습을 확장한다.
Figure 2는 Pathways 시스템이 2-way Pod 수준 data parallelism을 실행하는 방법을 보여준다. 단일 Python 클라이언트는 sharded dataflow 프로그램 (Figure 2의 왼쪽에 표시)을 구성하여 각각 TPU Pod로 구성된 원격 서버에서 JAX/XLA (XLA, 2019) 작업을 시작한다. 이 프로그램은 Pod 내 forward+backward 계산 (Pod 내 gradient reduction 포함)을 위한 컴포넌트 A, Pod 간 gradient 전송을 위한 전송 서브그래프, 그리고 옵티마이저 업데이트 (로컬 및 원격 gradient 합산 포함)를 위한 컴포넌트 B를 포함한다. Pathways 프로그램은 각 Pod에서 컴포넌트 A를 실행한 다음, 출력 gradient를 다른 Pod로 전송하고, 마지막으로 각 Pod에서 컴포넌트 B를 실행한다. Pathways 시스템 설계는 수천 개의 가속기 칩으로 프로그램 실행을 확장할 수 있는 여러 기능을 가지고 있다. 첫째, 단일 Python 클라이언트에서 원격 서버로 JAX/XLA 작업을 디스패치하는 지연 시간을 Pod별 스케줄러에서 비동기 gang-scheduling을 통해 마스킹하고 (Figure 2의 오른쪽에 표시), 둘째, sharded-dataflow 실행 모델을 통해 데이터 전송 관리 비용을 상각한다 (자세한 내용은 Barham et al. (2022) 참조).
2-way Pod 수준 data parallelism의 흥미로운 측면은 두 Pod에 걸쳐 총 1536개의 호스트에 연결된 6144개의 TPU v4 칩 규모에서 Pod 간 gradient 전송에 대한 높은 학습 처리량을 달성하는 과제이다. Pod 간 gradient 전송은 각 코어가 모델 sharded 파라미터에 대한 원격 gradient만 필요하므로 두 Pod의 해당 호스트 간에 1:1 전송만 필요하다는 점에 유의해야 한다. 또한, 두 Pod 간의 호스트는 Google 데이터센터 네트워크 (Singh et al., 2015)를 통해 연결된다. 각 코어가 gradient 계산을 완료할 때까지 전송이 시작되지 않으므로 (Figure 2에 표시된 대로), 이는 모든 호스트가 데이터센터 네트워크 링크를 통해 동시에 gradient를 전송하는 매우 bursty한 워크로드를 초래한다. 특히, 각 호스트 쌍은 매 학습 단계마다 약 1.3GB의 gradient를 교환하며, 이는 모든 호스트에 걸쳐 총 81Tbps의 aggregate burst에 해당한다. 이 워크로드의 bursty한 특성은 최적의 DCN 링크 활용을 가능하게 하는 Pathways 네트워킹 스택의 신중한 설계를 통해 해결하는 과제를 제시한다. 예를 들어, 혼잡의 영향을 완화하기 위해 gradient 전송을 위한 데이터는 더 작은 청크로 분할되고 다양한 DCN 링크를 통해 여러 개의 더 작은 흐름으로 라우팅된다. 이러한 최적화를 통해 우리는 학습 중 단일 Pod에서의 처리량 대비 약 1.95배의 학습 처리량을 달성한다 (이는 단일 Pod 대비 두 Pod에 걸쳐 batch size를 두 배로 늘렸기 때문에 완벽한 weak scaling의 97%에 해당한다). 이론적인 2배 처리량 대비 성능 격차는 backward pass와 Pod 간 gradient reduction 간의 오버랩 부족으로 인해 발생한다. 우리는 이를 향후 연구에서 다룰 예정이다.
4.1 Training Efficiency
대부분의 이전 연구에서 언어 모델의 가속기 효율성에 대해 보고된 수치들은 우리가 **hardware FLOPs utilization (HFU)**이라고 부르는 지표를 사용한다. 이는 일반적으로 주어진 장치에서 관찰된 FLOPs와 이론적인 최대 FLOPs의 비율을 추정한 것이다. 그러나 hardware FLOPs utilization에는 몇 가지 문제가 있다.
첫째, 실행되는 hardware FLOPs의 수는 시스템 및 구현에 따라 달라지며, 컴파일러의 설계 선택에 따라 다른 수의 연산이 발생할 수 있다. Rematerialization은 메모리 사용량과 연산량 간의 trade-off를 위해 널리 사용되는 기술이다. gradient descent를 사용하여 대부분의 신경망 아키텍처의 역전파(backward pass)를 효율적으로 계산하려면, 배치에 대한 많은 중간 활성화(intermediate activations)가 메모리에 저장되어야 한다. 이들이 모두 저장될 수 없는 경우, 일부 순전파(forward pass) 연산을 재계산할 수 있다 (일부 활성화를 저장하는 대신 rematerialize할 수 있도록 함). 이는 추가적인 hardware FLOPs를 사용하여 메모리를 절약할 수 있는 trade-off를 생성하지만, 훈련 시스템의 궁극적인 목표는 초당 토큰 처리량(throughput)을 높여 (따라서 훈련 시간을 단축하여) 빠른 훈련 시간을 달성하는 것이지, 가능한 한 많은 hardware FLOPs를 사용하는 것이 아니다.
둘째, 관찰된 hardware FLOPs를 측정하는 것은 이를 계산하거나 추적하는 데 사용되는 방법론에 따라 달라진다. 관찰된 hardware FLOPs는 분석적 계산 (Narayanan et al., 2021b)뿐만 아니라 하드웨어 성능 카운터 (Xu et al., 2021)를 사용하여 보고되었다.
이러한 문제들을 고려할 때, 우리는 HFU가 LLM 훈련 효율성을 위한 일관되고 의미 있는 지표가 아님을 인식한다. 우리는 **구현에 독립적이며 시스템 효율성을 더 명확하게 비교할 수 있는 새로운 효율성 지표인 model FLOPs utilization (MFU)**을 제안한다. 이는 관찰된 처리량(초당 토큰 수)과 시스템이 최대 FLOPs로 작동할 때의 이론적 최대 처리량의 비율이다. 결정적으로, "이론적 최대" 처리량은 순전파(forward pass)와 역전파(backward pass)를 계산하는 데 필요한 연산만을 고려하며, rematerialization은 포함하지 않는다. 따라서 MFU는 서로 다른 시스템에서의 훈련 실행 간에 공정한 비교를 가능하게 한다. 분자는 단순히 관찰된 초당 토큰 수이며, 분모는 모델 아키텍처와 주어진 시스템에 대한 공개된 최대 FLOPs에만 의존하기 때문이다. MFU를 계산하는 수학적 공식은 Appendix B에서 자세히 설명한다.
| Model | # of Parameters <br> (in billions) | Accelerator chips | Model FLOPS <br> utilization |
|---|---|---|---|
| GPT-3 | 175 B | V100 | |
| Gopher | 280 B | 4096 TPU v3 | |
| Megatron-Turing NLG | 530 B | 2240 A100 | |
| PaLM | 540 B | 6144 TPU v4 |
Table 3: PaLM 및 이전 대규모 모델의 Model FLOPs utilization.
PaLM은 모델, 컴파일러 및 병렬화 전략 전반에 걸친 여러 최적화 덕분에 현저히 높은 MFU를 달성한다. PaLM의 해당 **hardware FLOPs utilization은 57.8%**이다. 계산 세부 사항은 Appendix B에 있다.
우리는 PaLM 540B 모델의 model FLOPs utilization을 제시하고, Table 3에서 이전 대규모 모델들과 비교하여 설명한다. MFU는 다양한 모델 파라미터 수, 아키텍처 및 모델 품질의 맥락에서 모델과 시스템을 비교하는 데 유용하다. GPT-3의 MFU 수치는 OpenAI가 Patterson et al. (2021)을 통해 보고한 GPU당 24.6 non-attention model TFLOP/s를 기반으로 **21.3%**이다. Gopher의 MFU 수치는 초당 0.0152 스텝의 훈련 속도를 기반으로 **32.5%**이다. Megatron-Turing NLG 530B의 MFU 수치는 65.43 K tokens/sec의 훈련 처리량을 기반으로 self-attention을 포함하지 않을 경우 29.7%, 포함할 경우 **30.2%**이다 (Smith et al., 2022). 이에 비해 PaLM 540B는 배치 크기 2048에서 평균 238.3 K tokens/sec의 훈련 처리량을 달성한다. PaLM 540B의 훈련은 rematerialization을 사용하는데, 이는 rematerialization을 통해 더 높은 배치 크기를 사용할 수 있어 더 높은 훈련 처리량을 가능하게 하기 때문이다. PaLM 540B의 MFU는 self-attention을 포함하지 않을 경우 45.7%, 포함할 경우 **46.2%**이다. rematerialization FLOPs를 포함하는 우리의 분석적으로 계산된 hardware FLOPs utilization은 **57.8%**이다. PaLM은 병렬화 전략과 XLA TPU 컴파일러 최적화, "parallel layers" 사용 (Section 2 참조)을 포함한 여러 요인 덕분에 높은 가속기 활용도를 달성한다. 우리는 PaLM이 LLM 훈련 효율성에서 중요한 진전을 나타낸다고 믿는다.
5 Training Setup
모델 학습은 대규모 Transformer language model에 대한 상당히 표준적인 설정을 따랐다. 자세한 내용은 다음과 같다:
- 가중치 초기화 (Weight initialization): kernel 가중치(즉, embedding과 layer norm scale을 제외한 모든 것)는 "fan-in variance scaling" 방식으로 초기화된다. 즉, 이며, 여기서 은 kernel의 입력 차원이다. 입력 embedding은 로 초기화되는데, 이는 embedding에 layer normalization이 적용되지 않기 때문이다. 입력 및 출력 embedding layer가 공유되므로, pre-softmax 출력 logits은 로 스케일링되며, 여기서 은 embedding 크기이다.
- Optimizer: 모델은 Adafactor optimizer (Shazeer & Stern, 2018)를 사용하여 학습되었으며, factorization은 사용하지 않았다. 이는 사실상 Adam (Kingma & Ba, 2014)에 "parameter scaling"을 적용한 것과 동일하다. parameter scaling은 학습률(learning rate)을 파라미터 행렬의 root-mean-square로 스케일링한다. 가중치 초기화가 에 비례하므로, 이는 Brown et al. (2020)에서처럼 Adam 학습률을 수동으로 스케일 다운하는 것과 유사한 효과를 가진다. 그러나 parameter scaling은 서로 다른 스케일에서 작동하는 파라미터 행렬(embedding 및 layer norm scale)의 학습률이 동일한 비율로 스케일 다운되지 않는다는 장점이 있다.
- 최적화 하이퍼파라미터 (Optimization hyperparameters): 우리는 처음 10,000 스텝 동안 의 Adafactor 학습률을 사용했으며, 이후에는 스텝 번호 에 따라 의 비율로 감소시켰다. 모멘텀 로 학습했다. 2차 모멘트 보간 값은 로 계산되며, 여기서 는 스텝 번호이다. 우리는 대규모 language model을 학습할 때 이것이 표준 보다 더 안정적이라는 것을 발견했는데, 이는 희귀한 embedding token이 짧은 윈도우에서 2차 모멘트 추정치가 좋지 않을 수 있기 때문이다. 모든 모델에 대해 1.0 값으로 global norm gradient clipping (Pascanu et al. (2012))을 사용했다. 학습 중에는 현재 학습률 에 따라 의 동적 weight decay를 사용했다.
- 손실 함수 (Loss function): 모델은 표준 language modeling loss function으로 학습되었으며, 이는 label smoothing 없이 모든 token의 평균 로그 확률이다. 우리는 추가적으로 **의 보조 손실(auxiliary loss)**을 사용하여 softmax normalizer 가 0에 가깝도록 유도했는데, 이는 학습의 안정성을 높이는 것으로 나타났다.
- 시퀀스 길이 (Sequence length): 모든 모델에 대해 2048의 시퀀스 길이를 사용했다. 입력 예시는 서로 연결된 다음 정확히 2048 token의 시퀀스로 분할되므로, padding token은 없지만 예시가 중간에 분할될 수 있다. 입력 예시는 특수
[eod]token으로 서로 구별된다. - Batch size: 모든 모델에 대해 학습 중 batch size를 증가시켰다. 가장 큰 모델의 경우, 50k 스텝까지 batch size 512 (1M token)를 사용한 다음, 115k 스텝까지 1024 (2M token)로 두 배 늘리고, 마지막으로 255k 스텝에서 학습이 완료될 때까지 다시 2048 (4M token)로 두 배 늘렸다. 더 작은 모델들도 유사한 스케줄을 따랐다. 이러한 batch size 스케줄을 사용하는 이유는 두 가지이다: (1) 학습 초반에는 더 작은 batch size가 sample efficient(즉, 본 token 수에 대한 더 나은 손실)하며, 학습 후반에는 더 큰 batch size가 더 나은 gradient 추정치로 인해 유리하다 (Smith et al., 2018; McCandlish et al., 2018). (2) 더 큰 batch size는 더 큰 행렬 곱셈 차원을 초래하여 TPU 효율성을 높인다.
- 비트 단위 결정론 (Bitwise determinism): 모델은 모든 체크포인트에서 완전히 비트 단위로 재현 가능하다. 즉, 모델이 단일 실행에서 17,000 스텝까지 학습되었고, 15,000 체크포인트에서 다시 시작하면, 학습 프레임워크는 15,000에서 17,000 스텝까지 두 실행에서 동일한 결과를 생성하도록 보장된다. 이는 두 가지 방식으로 달성된다: (1) JAX+XLA+T5X가 제공하는 비트 단위 결정론적 모델링 프레임워크, (2) 셔플된 데이터가 랜덤 액세스 형식으로 기록되어 주어진 학습 batch의 내용이 스텝 번호의 함수일 뿐인 결정론적 데이터셋 파이프라인 (Roberts et al., 2022).
- Dropout: 모델은 dropout 없이 학습되었지만, 대부분의 경우 fine-tuning에는 0.1의 dropout이 사용된다.
5.1 Training Instability
가장 큰 모델의 경우, gradient clipping이 활성화되었음에도 불구하고 학습 중에 손실(loss)이 약 20회 급증하는 현상을 관찰했다. 이러한 급증은 매우 불규칙한 간격으로 발생했으며, 때로는 학습 후반부에 나타나기도 했고, 더 작은 모델들을 학습할 때는 관찰되지 않았다. 가장 큰 모델을 학습하는 데 드는 비용 때문에, 이러한 급증을 완화하기 위한 원칙적인 전략을 결정할 수는 없었다.
대신, 우리는 이 문제를 효과적으로 완화하는 간단한 전략을 발견했다: 급증이 시작되기 약 100단계 전의 체크포인트에서 학습을 다시 시작하고, 급증 전후에 사용된 약 200~500개의 데이터 배치(batch)를 건너뛰는 것이다. 이 완화 전략을 사용하자, 동일한 지점에서 손실이 다시 급증하지 않았다. 우리는 이 급증이 "나쁜 데이터" 자체 때문에 발생했다고는 생각하지 않는다. 왜냐하면 급증을 유발한 데이터 배치들을 가져와서, 다른 더 이전의 체크포인트에서 동일한 데이터 배치들로 학습을 진행했을 때, 급증 현상이 나타나지 않았기 때문이다. 이는 급증이 특정 데이터 배치와 특정 모델 파라미터 상태의 조합으로 인해 발생한다는 것을 시사한다. 앞으로 우리는 매우 큰 language model에서 손실 급증에 대한 보다 원칙적인 완화 전략을 연구할 계획이다.
6 Evaluation
6.1 English NLP tasks
이전의 대규모 language model들과 비교하기 위해, 우리는 Du et al. (2021) 및 Brown et al. (2020)과 동일한 29개의 영어 벤치마크 세트에서 PaLM 모델을 평가한다. 벤치마크는 다음과 같다:
- Open-Domain Closed-Book Question Answering task: TriviaQA (Joshi et al., 2017), Natural Questions (Kwiatkowski et al., 2019), Web Questions (Berant et al., 2013)
- Cloze and Completion task: LAMBADA (Paperno et al., 2016), HellaSwag (Zellers et al., 2019), StoryCloze (Mostafazadeh et al., 2016)
- Winograd-style task: Winograd (Levesque et al., 2012), WinoGrande (Sakaguchi et al., 2020)
- Common Sense Reasoning: PIQA (Bisk et al., 2019), ARC (Clark et al., 2018), OpenBookQA (Mihaylov et al., 2018)
- In-context Reading Comprehension: DROP (Dua et al., 2019), CoQA (Reddy et al., 2018), QuAC (Choi et al., 2018), SQuADv2 (Rajpurkar et al., 2018), RACE (Lai et al., 2017)
- SuperGLUE (Wang et al., 2019a)
- Natural Language Inference (NLI): Adversarial NLI (Nie et al., 2019)
Table 4는 PaLM 540B 모델과 다른 대규모 language model들의 이전 state-of-the-art (SOTA) 결과를 포함한다. 이 표에서는 사전학습된 language model의 단일 체크포인트 결과만 고려한다. fine-tuning 또는 multi-task adaptation (Wei et al. (2022a), Sanh et al. (2021))을 사용하는 모델은 표에 포함되지 않는다.
PaLM 540B는 1-shot 설정에서 29개 task 중 24개에서, few-shot 설정에서는 29개 task 중 28개에서 이전 SOTA를 능가한다. 흥미롭게도, PaLM 540B는 few-shot 설정에서 일부 Reading Comprehension 및 NLI task에서 이전 SOTA보다 10점 이상 높은 성능을 보인다. 모델 크기가 이러한 결과를 달성하는 데 중요한 역할을 했지만, PaLM 540B는 유사한 크기의 모델(Megatron-Turing NLG 530B)을 모든 벤치마크에서 능가한다. 이는 사전학습 데이터셋, 학습 전략, 그리고 학습 중 관찰된 token의 수가 이러한 결과를 달성하는 데 중요한 역할을 한다는 것을 시사한다.
Table 5는 Natural Language Understanding (NLU) 및 Natural Language Generation (NLG) task의 평균 점수를 보여준다. PaLM 540B는 두 범주 모두에서 평균 점수를 5점 이상 향상시킨다. 표에서 보듯이, 각 범주의 평균 점수는 PaLM 모델의 규모가 커질수록 향상된다. 흥미롭게도, PaLM 62B는 두 범주 모두에서 GPT-3 175B를 능가한다. 8B 및 62B 모델의 모든 task에 대한 결과는 Appendix H.1에서 확인할 수 있다.
| Task | 0-shot | 1-shot | Few-shot | |||
|---|---|---|---|---|---|---|
| Prior SOTA | PaLM 540 B | Prior SOTA | PaLM 540B | Prior SOTA | PaLM 540 B | |
| TriviaQA (EM) | 76.9 | 81.4 | ||||
| Natural Questions (EM) | 24.7 | 21.2 | 29.3 | |||
| Web Questions (EM) | 10.6 | 22.6 | ||||
| Lambada (EM) | 77.9 | 81.8 | ||||
| HellaSwag | 83.4 | 83.6 | ||||
| StoryCloze | 84.6 | 86.1 | ||||
| Winograd | 90.1 | 87.5 | ||||
| Winogrande | 81.1 | 83.7 | ||||
| Drop (F1) | 69.4 | 70.8 | ||||
| CoQA (F1) | 81.5 | 77.6 | 79.9 | |||
| QuAC (F1) | 45.2 | 47.7 | ||||
| SQuADv2 (F1) | 80.8 | 82.9 | ||||
| SQuADv2 (EM) | 75.5 | 78.7 | ||||
| RACE-m | 68.1 | 69.3 | ||||
| RACE-h | 49.1 | 52.1 | ||||
| PIQA | 82.3 | 83.9 | (5) | |||
| ARC-e | 76.6 | 85.0 | ||||
| ARC-c | 53.0 | 60.1 | ||||
| OpenbookQA | 53.4 | 53.6 | ||||
| BoolQ | 88.0 | 88.7 | ||||
| Copa | 93.0 | 92.0 | 91.0 | |||
| RTE | 72.9 | 78.7 | ||||
| WiC | 59.1 | 63.2 | ||||
| Multirc (F1a) | 83.5 | 84.9 | ||||
| WSC | 89.1 | 86.3 | ||||
| ReCoRD | 92.9 | 92.8 | ||||
| CB | 51.8 | 83.9 | ||||
| ANLI R1 | 48.4 | 52.6 | ||||
| ANLI R2 | 44.2 | 48.7 | ||||
| ANLI R3 | 45.7 | 52.3 |
Table 4: 29개 NLP 벤치마크에서 PaLM 540B 모델이 얻은 결과. few-shot 결과의 경우, 각 task에 대한 shot 수는 괄호 안에 명시되어 있다. 각 task의 split은 Du et al. (2021) 및 Brown et al. (2020)에서 사용된 것과 동일하다. 위첨자는 과거 연구의 결과를 나타낸다: GLaM 62B/64E (Du et al., 2021), GPT-3 175B (Brown et al., 2020), Megatron-Turing NLG 530B (Smith et al., 2022), Gopher (Rae et al., 2021), LaMDA (Thoppilan et al., 2022) (Wei et al. (2022a)에서 보고된 결과), Chinchilla (Hoffmann et al., 2022)). Rae et al. (2021) 및 Hoffmann et al. (2022)의 연구는 RACE-m/h에서 훨씬 높은 점수를 달성했지만, 해당 논문의 저자들은 task 설정의 차이로 인해 그들의 점수를 GPT-3 및 다른 대규모 LM과 비교할 수 없다고 언급한다. 우리는 RACE-m/h에 대해 GPT-3 스타일의 task 설정을 따르며, 동일한 설정을 사용한 이전 결과와 비교한다.
| Model | Avg NLG | Avg NLU |
|---|---|---|
| GPT-3 175B | 52.9 | 65.4 |
| GLaM 64B/64E | 58.4 | 68.7 |
| PaLM 8B | 41.5 | 59.2 |
| PaLM 62B | 57.7 | 67.3 |
| PaLM 540B | 63.9 | 74.7 |
Table 5: 1-shot 평가를 사용한 29개 벤치마크에 대한 Natural Language Generation (NLG) 및 Natural Language Understanding (NLU) 평균(Avg) 결과. NLG 벤치마크는 TriviaQA, NQS, WebQS, SQuADv2, LAMBADA, DROP, QuAC, CoQA의 8개 task를 포함하며, 나머지는 NLU 벤치마크이다. GPT-3 및 GLaM의 결과는 Du et al. (2021)에서 가져왔다.
6.1.1 Massive Multitask Language Understanding
우리는 또한 Massive Multitask Language Understanding (MMLU) (Hendrycks et al., 2021) 벤치마크에서 PaLM 모델을 평가한다. 이 객관식 질문 응답 벤치마크는 수학, 역사, 법률과 같은 주제를 포함하는 57가지의 다양한 task를 다룬다. Table 6에서 볼 수 있듯이, PaLM 540B는 MMLU 벤치마크의 평균 점수를 약 2점 향상시킨다. PaLM 540B는 'Other tasks' 카테고리를 제외한 모든 카테고리에서 Chinchilla 모델보다 우수한 성능을 보인다.
| Model | Average | Humanities | STEM | Social Sciences | Other |
|---|---|---|---|---|---|
| Chinchilla 70B (Prior SOTA) | 67.5 | 63.6 | 54.9 | 79.3 | 73.9 |
| PaLM 8B | 25.3 | 25.6 | 23.8 | 24.1 | 27.8 |
| PaLM 62B | 53.7 | 59.5 | 41.9 | 62.7 | 55.8 |
| PaLM 540B | 69.3 | 77.0 | 55.6 | 81.0 | 69.6 |
Table 6: MMLU (Hendrycks et al., 2021) 벤치마크에서 Chinchilla (Hoffmann et al., 2022) 및 PaLM 모델의 결과 (5-shot). Chinchilla는 이 벤치마크에서 이전 state of the art 결과를 나타낸다. 결과는 각 task의 test set에서 보고되었다.
6.1.2 Finetuning
우리는 SuperGLUE 벤치마크에서 PaLM 모델에 대한 fine-tuning 실험을 수행한다. PaLM은 Adafactor optimizer를 사용하여 의 learning rate와 32의 batch size로 fine-tuning된다. PaLM은 일반적으로 15K fine-tuning step 이내에 수렴한다.
Table 7은 SuperGLUE task들의 task-proportionate mixture에 대한 fine-tuning의 validation 결과를 보고한다. SuperGLUE에서 우리는 T5-11B (Raffel et al., 2020) 및 **ST-MoE-32B (Zoph et al., 2022)**와 같은 state-of-the-art 모델들과 비교하며, PaLM이 경쟁력 있는, SotA에 근접한 성능을 얻음을 보여준다. SuperGLUE에서 최고 성능을 보이는 두 모델 모두 span corruption objective를 사용하여 학습된 encoder-decoder 모델이라는 점은 주목할 만하다. 이러한 아키텍처는 학습 비용이 동일할 때 분류 task fine-tuning에서 autoregressive decoder-only 모델보다 일반적으로 우수한 성능을 보인다는 것이 입증되었다 (Raffel et al., 2020). 이러한 결과는 모델 규모(scale)가 성능 격차를 줄이는 데 도움이 될 수 있음을 보여준다. Table 8은 또한 few-shot 결과와 fine-tuned 결과 사이에 여전히 상당한 격차가 있음을 보여준다. 마지막으로, Table 9는 SuperGLUE 리더보드의 test set 결과를 보고한다. 우리는 PaLM이 state-of-the-art와 경쟁력 있는 성능을 보이며, 리더보드에서 최고의 decoder-only autoregressive language model을 큰 차이로 능가함을 보여준다.
| Model | Avg | BoolQ | CB | CoPA | MultiRC | Record | RTE | WiC | WSC |
|---|---|---|---|---|---|---|---|---|---|
| T5-11B | 89.9 | 90.8 | 98.0 | 93.9 | 77.3 | 96.2 | |||
| ST-MoE-32B | 93.2 | 93.1 | 100 | 95.7 | 81.0 | 100 | |||
| PaLM 540B (finetuned) | 92.6 | 92.2 | 100 | 95.7 | 78.8 | 100 |
Table 7: SuperGLUE dev set 결과. T5-11B (Raffel et al., 2020) 및 ST-MoE-32B (Zoph et al., 2022)와 비교한다. 보고된 점수는 task별 최고 validation 점수이다.
| Model | BoolQ | CB | CoPA | MultiRC | Record | RTE | WiC | WSC |
|---|---|---|---|---|---|---|---|---|
| Few-shot | 89.1 | 89.3 | 95 | 81.2 | 64.6 | 89.5 | ||
| Finetuned | 92.2 | 100 | 95.7 | 78.8 | 100 |
Table 8: SuperGLUE dev set에서 PaLM-540B의 few-shot 및 fine-tuned 결과 비교.
| Model | Avg | BoolQ | CB | CoPA | MultiRC | Record | RTE | WiC | WSC |
|---|---|---|---|---|---|---|---|---|---|
| ST-MoE-32B | 91.2 | 92.4 | 96.9/98.0 | 99.2 | 89.6/65.8 | 95.1/94.4 | 93.5 | 77.7 | 96.6 |
| Best Decoder-only LM | 71.8 | 76.4 | 52.0/75.6 | 92.0 | 75.4/30.5 | 91.1/90.2 | 69.0 | 49.4 | 80.1 |
| PaLM 540B (finetuned) | 90.4 | 91.9 | 94.4/96.0 | 99.0 | 88.7/63.6 | 94.2/93.3 | 95.9 | 77.4 | 95.9 |
Table 9: SuperGLUE test set (리더보드) 결과. state-of-the-art span corruption 기반 Encoder-Decoder (Zoph et al., 2022) 및 최고의 decoder-only language model (Brown et al., 2020)과 비교한다.
6.2 BIG-bench
BIG-bench는 대규모 language model을 위한 도전적인 task를 생성하는 것을 목표로 하는 협력 벤치마크이다 (BIG-bench collaboration, 2021). 여기에는 논리적 추론, 번역, 질문 응답, 수학 등 다양한 언어 모델링 task를 다루는 150개 이상의 task가 포함되어 있다. 이 섹션에서는 BIG-bench에서 PaLM 모델 계열의 few-shot 평가 결과를 제시하고 분석한다. BIG-bench는 텍스트 task와 프로그래밍 task를 모두 포함하지만, 이 평가에서는 텍스트 task만 고려되었다.
BIG-bench 데이터 릴리스에는 인간 성능 지표가 포함되어 있는데, 이는 크라우드소싱 플랫폼의 작업자들(일반적으로 10명)에게 각 task를 풀도록 요청한 결과이다. 이 작업자들은 few-shot 모델이 보는 것과 유사한 **task 설명과 예시(exemplar)**를 제공받았으며, 답변을 제공하기 위해 원하는 외부 도구(검색 엔진, 계산기 등)를 사용할 수 있었다. 모델과 인간의 성능은 모두 각 task의 원본 생성자가 제공한 gold label에 대해 동일한 지표를 사용하여 측정되었다. "최고" 인간 성능은 가장 높은 예시별 지표 점수를 가진 인간 생성 답변을 사용하여 계산되었고, "평균" 인간 성능은 모든 인간 생성 답변의 평균 지표 점수를 사용하여 계산되었다.
Figure 3-왼쪽은 PaLM 모델 계열의 BIG-bench 평가 결과를 이전에 발표된 결과(Rae et al., 2021)와 비교하여 보여준다. BIG-bench 데이터셋이 최근에 공개되었고, 이전 모델들은 task 및 shot의 일부만 벤치마킹했기 때문에, 비교는 다른 더 확립된 벤치마크보다 제한적이라는 점에 유의해야 한다. 세 모델은 공통적으로 58개 task에서 평가되었으므로, 이 그림은 이 58개 task에 대한 결과만 제시한다. 우리는 PaLM이 GPT-3, Gopher, Chinchilla를 크게 능가하며, 5-shot PaLM 540B가 동일한 task를 풀도록 요청받은 인간의 평균 점수보다 더 높은 점수를 달성하는 것을 확인했다. PaLM 540B 5-shot은 58개 공통 task 중 44개에서 이전 SOTA를 능가하며, task별 결과는 Figure 4에 나와 있다. 또한, PaLM 모델의 성능은 규모에 따라 log-linear 행동을 따르는 것으로 보이며, 이는 추가적인 스케일업이 성능 향상으로 이어질 가능성이 있음을 나타낸다. Figure 3-오른쪽은 BIG-bench 텍스트 task 컬렉션(150개 task)에 대한 PaLM 결과를 제시하며, 이는 유사한 성능 특성을 보인다.
 Figure 3: PaLM의 BIG-bench 평가.
(왼쪽) PaLM, GPT-3, Gopher, Chinchilla의 평가. 이전 모델들은 task의 일부만 평가했으므로, 이 그래프는 세 모델 모두가 평가한 58개 task에 대한 종합 결과를 보여준다.
(오른쪽) 더 큰 150개 BIG-bench 텍스트 task 세트에 대한 PaLM 평가. 각 task에 대해 선호하는 지표의 결과가 사용된다. 결과는 최대 점수를 100으로, 다중 선택 task의 무작위 기회 점수를 0으로 설정하여 정규화되었으며, 모델이 무작위 기회보다 성능이 낮으면 음수 값을 갖는다. 정규화된 결과는 모든 task에 대해 평균화된다.
Figure 3: PaLM의 BIG-bench 평가.
(왼쪽) PaLM, GPT-3, Gopher, Chinchilla의 평가. 이전 모델들은 task의 일부만 평가했으므로, 이 그래프는 세 모델 모두가 평가한 58개 task에 대한 종합 결과를 보여준다.
(오른쪽) 더 큰 150개 BIG-bench 텍스트 task 세트에 대한 PaLM 평가. 각 task에 대해 선호하는 지표의 결과가 사용된다. 결과는 최대 점수를 100으로, 다중 선택 task의 무작위 기회 점수를 0으로 설정하여 정규화되었으며, 모델이 무작위 기회보다 성능이 낮으면 음수 값을 갖는다. 정규화된 결과는 모든 task에 대해 평균화된다.
PaLM 540 B vs. Prior SOTA: 58 BIG-bench Tasks in common
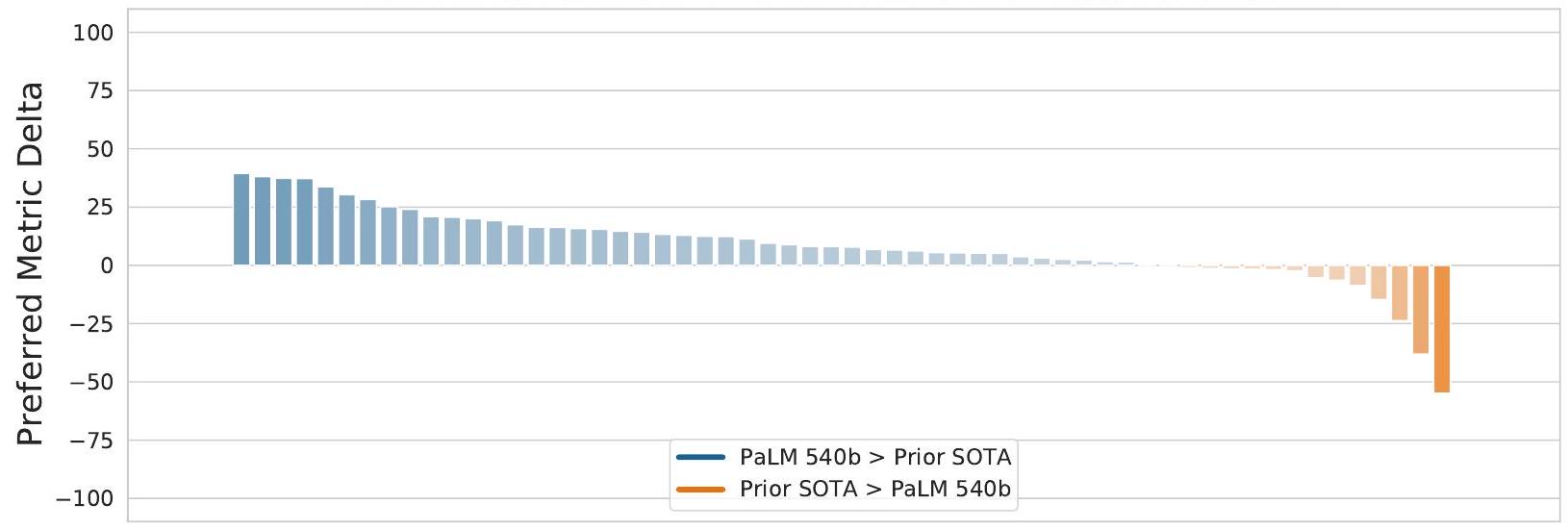
Figure 4: PaLM 540B 5-shot과 이전 SOTA 간의 "정규화된 선호 지표" 점수 차이 분포를 58개 BIG-bench 텍스트 task의 공통 하위 집합에 걸쳐 보여준다. **양수 값(파란색)**은 PaLM 540B가 이전 SOTA보다 높은 점수를 달성했음을 나타내고, **음수 값(주황색)**은 이전 SOTA가 PaLM 540B보다 높았음을 나타낸다. 이전 SOTA에는 GPT-3 175B 1-shot (Brown et al., 2020), Gopher 5-shot (Rae et al., 2021), Chinchilla 5-shot (Hoffmann et al., 2022)이 포함된다. 시각적 명확성을 위해 개별 task 이름은 여기에 표시되지 않았다.
다음으로, PaLM이 특히 흥미로운 성능 특성을 보인 BIG-bench의 몇 가지 task를 강조한다. 이 task들에 대한 개별 평가는 Figure 5에 나와 있다. 아래에서 각 task를 간략하게 설명한다:
- goal_step_wikihow - 이벤트 간의 목표-단계 관계를 추론하는 것이 목표이다. 예시: 입력: "은을 닦기" 위해 어떤 단계를 먼저 해야 할까요? (a) 은을 말린다 (b) 은을 손으로 씻는다 답변: (b) 은을 손으로 씻는다
- logical_args - 구절에서 올바른 논리적 추론을 예측하는 것이 목표이다. 예시: 입력: 학생들은 대체 교사에게 삼각법을 배우고 있다고 말했다. 대체 교사는 삼각형에 대한 쓸모없는 사실을 가르치는 대신 확률을 다루는 방법을 가르치겠다고 말했다. 그가 암시하는 것은 무엇인가? (a) 그는 수학이 흥미롭기 위해 유용할 필요는 없다고 믿는다. (b) 그는 확률을 이해하는 것이 삼각법보다 더 유용하다고 생각한다. (c) 그는 확률 이론이 쓸모없는 과목이라고 믿는다. 답변: (b) 그는 확률을 이해하는 것이 삼각법보다 더 유용하다고 생각한다.
- english_proverbs - 텍스트 구절을 가장 잘 설명하는 속담을 추측하는 것이 목표이다. 예시: 입력: 바네사는 몇 년 동안 주말마다 지역 노숙자 지원 센터에서 자원봉사를 했다. 최근 그녀가 직장을 잃었을 때, 센터는 즉시 그녀에게 새로운 일자리를 제안할 준비가 되어 있었다. 다음 속담 중 이 상황에 가장 잘 적용되는 것은 무엇인가? (a) 저주도 닭처럼 제자리로 돌아온다. (b) 연기 나는 곳에 불이 있다 (c) 뿌린 대로 거둔다. 답변: (c) 뿌린 대로 거둔다.
- logical_sequence - 일련의 "것들"(월, 행동, 숫자, 문자 등)을 논리적 순서로 정렬하는 것이 목표이다. 예시: 입력: 다음 목록 중 시간순으로 올바르게 정렬된 것은 무엇인가? (a) 물 마시기, 목마름 느끼기, 물병 밀봉하기, 물병 열기 (b) 목마름 느끼기, 물병 열기, 물 마시기, 물병 밀봉하기 (c) 물병 밀봉하기, 물병 열기, 물 마시기, 목마름 느끼기 답변: (b) 목마름 느끼기, 물병 열기, 물 마시기, 물병 밀봉하기
- navigate - 일련의 간단한 길 안내 지시를 따르고, 어디에 도착할지 알아내는 것이 목표이다. 예시: 입력: 이 지시를 따르면 시작점으로 돌아오나요? 항상 앞을 보세요. 왼쪽으로 6걸음. 앞으로 7걸음. 왼쪽으로 8걸음. 왼쪽으로 7걸음. 앞으로 6걸음. 앞으로 1걸음. 앞으로 4걸음. 답변: 아니요
- mathematical_induction - 실제 수학과 모순되더라도 논리적 추론 수학적 귀납법 규칙을 수행하는 것이 목표이다. 예시: 입력: 어떤 홀수에 2를 더하면 또 다른 홀수가 생성된다는 것이 알려져 있다. 2는 홀수이다. 따라서 6은 홀수이다. 이것은 올바른 귀납 논증인가 (일부 가정이 틀릴 수 있더라도)? 답변: 예
Figure 5에서 goal_step_wikihow와 logical_args의 성능은 log-linear 스케일링 곡선을 따르며, PaLM 540B 모델은 최고 인간 성능에 가까운 정확도를 달성하는 것을 볼 수 있다. english_proverbs와 logical_sequence의 성능 또한 매우 강력하지만, 불연속적인 개선 곡선을 따른다. 즉, 62B에서 540B로의 개선이 8B에서 62B로의 개선보다 훨씬 크다. 이러한 task는 모델의 특정 능력이 특정 규모에 도달해야만 나타나기 때문에 특히 흥미롭다. 예를 들어, english_proverbs는 복잡한 은유를 이해하기 위해 매우 높은 수준의 추상적 추론 능력을 요구하므로, PaLM 62B의 25%에서 PaLM 540B의 87%로의 개선은 매우 고무적인 결과이다.
BIG-bench에서 불연속적인 개선을 더 정량화하기 위해, 먼저 예시를 사용하여 불연속성의 정의를 설명한다. logical_sequence task는 PaLM 8b, 62b, 540b에 대해 각각 13%, 25%, 87%의 정규화된 정확도 점수를 가졌다. 따라서 8b 62b를 사용한 log-linear 투영은 540b에 대해 대략 37%(=25%+(25%-13%))의 정확도를 예측할 것이다. 실제 정확도는 87%이므로, 불연속성은 **+50%(=87%-37%)**이다. 전체 150개 task 중 25%의 task는 +10%보다 큰 불연속성을 가졌고, 15%의 task는 +20%보다 큰 불연속성을 가졌다. 이는 규모에 따른 불연속적인 개선이 도전적인 few-shot 언어 task에서 흔한 현상임을 보여준다.
 Figure 5: 흥미로운 스케일링 특성을 가진 6개 개별 task에 대한 5-shot 평가. 각 task에 대해 "정규화된 선호 지표"가 사용되며, 다중 선택 task의 경우 0%는 무작위 추측에 해당한다. (a)는 규모에 따른 log-linear 개선을 보여주고, (b)는 규모에 따른 "불연속적인" 개선을 보여주며, (c)는 규모에 따른 상대적으로 평탄한 개선을 보여준다.
Figure 5: 흥미로운 스케일링 특성을 가진 6개 개별 task에 대한 5-shot 평가. 각 task에 대해 "정규화된 선호 지표"가 사용되며, 다중 선택 task의 경우 0%는 무작위 추측에 해당한다. (a)는 규모에 따른 log-linear 개선을 보여주고, (b)는 규모에 따른 "불연속적인" 개선을 보여주며, (c)는 규모에 따른 상대적으로 평탄한 개선을 보여준다.
그러나 규모가 모든 task에 도움이 되는 것은 아니다. navigate와 mathematical_induction의 경우, PaLM 540B는 PaLM 62B를 약간만 능가하며, 둘 다 여전히 최고 인간 성능 점수와는 거리가 멀다. 이는 task의 예시 수준 난이도에 높은 분산이 있음을 시사한다. 예를 들어, mathematical_induction에서는 일부 예시가 올바른 가정("2는 짝수이다.")을 가지고 있고, 일부는 잘못된 가정("2는 홀수이다.")을 가지고 있다. 이 task의 여러 예시를 분석한 결과, 모든 PaLM 모델(및 task를 풀도록 요청받은 인간)은 가정의 정확성이 관련이 없다는 지시에도 불구하고 가정이 잘못된 경우에 어려움을 겪는 것으로 보인다.
Figure 6은 PaLM 540B를 인간 평가의 평균 성능 점수와 비교할 때 task별 개선 분포를 보여준다. PaLM 540B가 전체적으로 평균 인간 성능을 능가하지만, 개별 task의 35%에서는 평균 인간 성능이 여전히 PaLM 540B보다 높다는 것을 알 수 있다 (부록의 Table 43에서 예시 참조). 이는 BIG-bench에서 개선의 여지가 여전히 크다는 것을 나타낸다.
우리는 PaLM 540B 성능이 평균 인간 성능을 초과하는 몇 가지 task를 고려한다 (자세한 결과는 부록의 Table 42 참조). 우리는 이 task들 중 일부가 PaLM의 다국어 능력을 보여준다는 것을 관찰한다. 예를 들어, persian_idioms와 swedish_to_german_proverbs의 경우, 이 task를 평가한 인간 집단이 모든 언어에 능숙하지 않을 수 있다. periodic_elements task 중 하나는 암기 위주이므로, 대규모 language model의 암기 능력을 활용한다. common_morpheme, sufficient_information, logical_args와 같은 대부분의 다른 task는 PaLM 540B의 인상적인 자연어 처리 능력을 강조한다. 이 점을 더 설명하기 위해, 우리는 cause_and_effect task를 고려한다. 이 task는 모델에게 제시된 두 이벤트 중 어느 것이 다른 것을 유발했는지 결정하도록 요청한다. 이 task에는 두 가지 버전이 있다:
PaLM 540b 5-shot vs. Human (Avg.): 150 BIG-bench Tasks

Figure 6: PaLM 540B와 평균 인간 성능 간의 "정규화된 선호 지표" 점수 차이 분포를 150개 BIG-bench 텍스트 task 전체에 걸쳐 보여준다. **양수 값(파란색)**은 PaLM 540B가 평균 인간 성능보다 높은 점수를 달성했음을 나타내고, **음수 값(주황색)**은 평균 인간 성능이 PaLM 540B보다 높았음을 나타낸다. 시각적 명확성을 위해 개별 task 이름은 여기에 표시되지 않았다.
- cause_and_effect (one_sentence_no_prompt) - one_sentence_no_prompt 하위 task에서는 이벤트가 두 가지 다른 순서로 하나의 문장으로 결합되며, 각 문장의 log-likelihood가 모델로 채점된다. prompt는 제공되지 않는다. 예시: 입력 A: 내 차가 더러워졌기 때문에 차를 세차했다. 입력 B: 내가 차를 세차했기 때문에 내 차가 더러워졌다. 더 높은 likelihood 문장: 내 차가 더러워졌기 때문에 차를 세차했다.
- cause_and_effect (two_sentence) - two_sentence 하위 task에서는 모델에게 두 가지 이벤트가 제시되며, 어느 문장이 다른 것을 유발한 이벤트에 해당하는지 선택해야 한다. 예시: 입력: 각 예시에 대해 두 가지 이벤트가 주어진다. 어느 이벤트가 다른 것을 유발했는가? (a) 내 차가 더러워졌다. (b) 나는 차를 세차했다. 올바른 예측: (a) 내 차가 더러워졌다.
우리는 모든 PaLM 모델이 이 task의 one_sentence_no_prompt 버전에서 잘 수행하며, 8B 모델이 80% 이상의 정확도를 달성하는 것을 확인했지만, 더 작은 PaLM 모델은 이 task의 two_sentence 버전에서 성능이 좋지 않으며, 8B 모델은 무작위 기회에 가까운 점수를 기록했다. 대조적으로, 540B 모델은 two_sentence 버전을 해결할 수 있으며 90% 이상의 정확도를 달성하여, 규모가 해제할 수 있는 일반적인 언어 모델링 능력을 보여준다.
마지막으로, Figure 7은 경량 평가 대상 역할을 하는 24개 BIG-bench task의 큐레이션된 하위 집합인 BIG-bench Lite에 대한 자세한 평가 결과를 제시한다. BIG-bench Lite task 중 일부는 해결되었거나 해결에 가까워졌지만, 다른 task는 인간 평가의 최고 성능 점수와 비교할 때 여전히 해결과는 거리가 멀다.
 Figure 7: BIG-bench Lite의 24개 task에 대한 모델 규모별 5-shot 평가 성능. PaLM 540B는 모든 모델 규모 중에서 가장 좋은 성능을 보이지만, 3개 task에서만 최고 인간 성능 점수보다 높은 성능을 달성하여 추가 개선의 여지가 있음을 시사한다. Task t24는 모델과 인간 모두에게 어려우며 성능이 0.0에 가깝다. task 이름은 각주를, task별 데이터는 부록 H.2를 참조하라.
Figure 7: BIG-bench Lite의 24개 task에 대한 모델 규모별 5-shot 평가 성능. PaLM 540B는 모든 모델 규모 중에서 가장 좋은 성능을 보이지만, 3개 task에서만 최고 인간 성능 점수보다 높은 성능을 달성하여 추가 개선의 여지가 있음을 시사한다. Task t24는 모델과 인간 모두에게 어려우며 성능이 0.0에 가깝다. task 이름은 각주를, task별 데이터는 부록 H.2를 참조하라.
우리는 이러한 결과의 유효성을 확립하기 위해 몇 가지 단계를 거쳤으며, 특히 모델이 BIG-bench 데이터를 암기하여 이를 달성했을 가능성을 배제했다. 첫째, BIG-bench task 파일에는 고유한 canary 문자열이 포함되어 있다. 우리는 이 문자열이 PaLM 학습 데이터에 나타나지 않도록 했다. 둘째, BIG-bench 데이터셋은 학습 데이터가 수집될 당시 인터넷에서 사용할 수 없었으며, BIG-bench task의 대다수는 task 작성자가 BIG-bench에 포함하기 위해 특별히 구성한 완전히 새로운 벤치마크이다. 마지막으로, 모델이 강력한 성능을 보인 몇 가지 task에서 모델 입력 및 출력을 무작위로 확인하고, 디코딩 중에 gold label에서 정보가 유출되지 않았음을 수동으로 확인했다.
6.3 Reasoning
우리는 PaLM을 다단계 산술 또는 상식적인 논리적 추론을 통해 정답을 도출해야 하는 추론 task 모음으로 평가한다. 언어 모델은 광범위한 task를 수행하는 것으로 나타났지만, 다단계 추론이 필요한 task에서는 여전히 어려움을 겪는다는 것이 일반적으로 받아들여지고 있다 (Rae et al., 2021). 본 연구에서 평가된 추론 벤치마크의 두 가지 주요 범주는 다음과 같다:
- 산술 추론 (Arithmetic reasoning): 이 task들은 종종 다단계 논리적 추론을 요구하는 초등학교 수준의 자연어 수학 문제들을 포함한다. 수학 자체는 일반적으로 사소하며, 어려운 부분은 자연어를 수학 방정식으로 변환하는 것이다. 본 연구에서는 **계산기 형태(calculator form)**와 **모델 자체가 수학을 수행하는 직접 추론 형태(direct inference form)**를 모두 평가했다.
- 입력: Q: Roger는 테니스 공 5개를 가지고 있다. 그는 테니스 공 2캔을 더 산다. 각 캔에는 테니스 공 3개가 들어있다. 그는 지금 몇 개의 테니스 공을 가지고 있는가?
- 답변: 정답은 11이다.
- 상식 추론 (Commonsense reasoning): 이 task들은 강력한 세상 지식을 요구하지만, 단순히 사실적인 질문 답변이 아닌 질문 답변 task이다. 오히려, 세상에 대한 여러 논리적 추론을 연결해야 한다.
- 입력: Q: Sean은 서둘러 집에 가고 있었지만, 신호등이 노란색으로 바뀌었고 그는 무엇을 해야만 했는가?
- 선택지: (a) 시간을 들이다 (b) 꾸물거리다 (c) 천천히 가다 (d) 바다 (e) 속도를 줄이다
- 답변: 정답은 (e) 속도를 줄이다.
 Figure 8: Chain-of-thought prompting은 언어 모델이 수학 단어 문제와 같은 다단계 추론 task를 더 잘 수행하도록 돕는다.
Figure 8: Chain-of-thought prompting은 언어 모델이 수학 단어 문제와 같은 다단계 추론 task를 더 잘 수행하도록 돕는다.
최근 여러 논문들은 대규모 언어 모델이 최종 답변을 생성하기 전에 중간 추론 단계(intermediate reasoning steps)를 생성함으로써 상당한 정확도 향상을 이룰 수 있음을 보여주었다 (Nye et al., 2021; Cobbe et al., 2021; Wei et al., 2022b). 본 연구에서는 이 기법을 chain-of-thought prompting이라고 부른다. few-shot 설정에서, 이러한 중간 추론 단계는 few-shot exemplars에 대해 수동으로 작성되며, 모델은 테스트 예시에 대해 자체적인 chain-of-thoughts를 생성한다. 비록 이러한 생성된 chain-of-thoughts가 오류 분석 및 모델 해석 가능성에 유용할 수 있지만, 평가에는 최종 답변만 사용된다. GSM8K 벤치마크(초등학교 수학 문제)에 대한 chain-of-thought prompting의 예시는 아래 Figure 8에 제시되어 있다.
6.3.1 Results
본 연구에서는 모델 규모(model scale)와 chain-of-thought (CoT) prompting만으로도 다양한 산술 및 상식 추론 task에서 SOTA 정확도를 달성할 수 있다는 놀라운 결과를 보여준다. 대부분의 이전 연구들은 추론 task에서 강력한 결과를 얻기 위해 domain-specific 아키텍처, task-specific fine-tuning, task-specific verifier를 결합했다. 본 연구에서는 이러한 task들을 few-shot prompting을 통해 간단하게 표현한다. Cobbe et al. (2021)과 마찬가지로, 산술 추론 데이터셋의 경우 post-hoc 외부 계산기(external calculator)를 사용하여 모델 예측을 보강했지만, 이러한 계산기 사용이 어떤 데이터셋에서도 성능을 5% 이상 향상시키지는 못했다는 것을 발견했다.
chain-of-thought prompting을 사용하여, 우리는 산술 데이터셋인 GSM8K (Cobbe et al., 2021), SVAMP (Patel et al., 2021), MAWPS (Koncel-Kedziorski et al., 2016), AQuA (Ling et al., 2017)와 상식 추론 데이터셋인 CommonsenseQA (Talmor et al., 2019), StrategyQA (Geva et al., 2021)에 대한 PaLM의 성능을 평가했다. 이 prompting 설정은 Wei et al. (2022b)에서 제시된 것과 동일하게 8-shot exemplars만을 사용한다.
Figure 10-left에서 GSM8K에 대한 PaLM의 결과를 강조한다. GSM8K의 이전 SOTA인 Cobbe et al. (2021)은 모델 fine-tuning, chain-of-thought prompting, 외부 계산기, task-specific verifier를 조합하여 사용했다. 8-shot chain-of-thought prompting과 외부 계산기를 조합하여, PaLM 540B는 58%의 성능을 달성했으며, 이는 Table 10에서 보여지듯이 Cobbe et al. (2021)의 이전 SOTA인 55%를 능가한다. 이는 또한 chain-of-thought가 없는 PaLM 540B와 chain-of-thought가 있는 PaLM 62B의 성능을 모두 크게 능가한다. 우리는 PaLM 62B 모델이 틀린 문제들의 오류를 분석했으며, 이들은 일반적으로 의미 이해(semantic understanding), 한 단계 누락(one-step missing), 기타 오류의 세 가지 범주에 속한다는 것을 발견했다. Figure 9에서 보여지듯이, 540B 모델 크기로 확장하면서 이러한 오류의 상당 부분이 수정되었다. Appendix의 Figure 28과 29는 모델 크기 확장으로 수정된 오류의 샘플 예시를 보여준다.
| Model+Technique | Accuracy |
|---|---|
| PaLM 540B+chain-of-thought+calculator | |
| PaLM 540B+chain-of-thought | |
| PaLM 540B w/o chain-of-thought | |
| PaLM 62B+chain-of-thought | |
| GPT-3+finetuning+chain-of-thought+calculator | |
| GPT-3+finetuning+chain-of-thought+calculator+verifier |
Table 10: GSM8K에 대한 PaLM의 8-shot 평가 (chain-of-thought 포함)와 이전 SOTA와의 비교.
 Figure 9: 우리는 150개의 무작위 GSM8K 예시를 분석했으며, PaLM 62B가 그 중 45개에서 추론 오류를 범한다는 것을 발견했다. 이 오류들은 수동으로 세 가지 일반적인 오류 유형으로 분류되었다. "기타(Other)" 범주의 오류에는 환각(hallucinations), 반복 출력(repetitive outputs), 기호 매핑 오류(symbol mapping errors)가 포함되었다. 이 그림은 PaLM 540B로 확장함으로써 각 유형의 오류 중 수정된 비율을 보여주며, 모든 범주에서 상당한 수정이 이루어졌다.
Figure 9: 우리는 150개의 무작위 GSM8K 예시를 분석했으며, PaLM 62B가 그 중 45개에서 추론 오류를 범한다는 것을 발견했다. 이 오류들은 수동으로 세 가지 일반적인 오류 유형으로 분류되었다. "기타(Other)" 범주의 오류에는 환각(hallucinations), 반복 출력(repetitive outputs), 기호 매핑 오류(symbol mapping errors)가 포함되었다. 이 그림은 PaLM 540B로 확장함으로써 각 유형의 오류 중 수정된 비율을 보여주며, 모든 범주에서 상당한 수정이 이루어졌다.
Figure 10은 다른 추론 데이터셋에 대한 결과도 보여준다. 7개의 추론 데이터셋 전반에 걸쳐, PaLM 540B+chain-of-thought를 사용한 8-shot 예측은 4개 task (GSM8K, MAWPS, SVAMP, StrategyQA)에서 SOTA 정확도를 달성했으며, 나머지 3개 task (ASDiv, AQuA, CommonsenseQA)에서도 SOTA에 근접한 성능을 보였다. GSM8K 데이터셋에는 중간 추론 단계가 포함되었지만, 다른 벤치마크에는 포함되지 않았으므로, 완전성을 위해 직접 prompting을 사용한 GSM8K에 대한 PaLM 결과도 포함한다. 이러한 7개 벤치마크의 이전 SOTA는 일반적으로 domain-specific 아키텍처와 task-specific fine-tuning을 사용했다는 점에 유의해야 한다. 또한 chain-of-thought와 모델 스케일링 모두 모든 task에서 크게 도움이 된다는 것을 알 수 있는데, 두 기술이 모두 없었다면 PaLM은 단일 task (SVAMP)에서만 SOTA를 달성했을 것이다. n-gram 중복 분석을 통해 모델 학습 코퍼스와 추론 평가 세트 사이에 데이터 오염이 없었음을 확인했다.
 Figure 10: chain-of-thought prompting을 통해 PaLM은 다양한 산술 및 상식 추론 task에서 강력한 성능을 달성한다. PaLM은 GSM8K, MAWPS, SVAMP, StrategyQA에서 새로운 SOTA를 달성한다. 이전 SOTA와의 비교는 다음과 같다. GSM8K: Cobbe et al. (2021), MAWPS 및 ASDiv: Lan et al. (2021), SVAMP: Pi et al. (2022), AQuA: Piekos et al. (2021), CommonsenseQA: Talmor et al. (2019) 리더보드, StrategyQA: Geva et al. (2021).
Figure 10: chain-of-thought prompting을 통해 PaLM은 다양한 산술 및 상식 추론 task에서 강력한 성능을 달성한다. PaLM은 GSM8K, MAWPS, SVAMP, StrategyQA에서 새로운 SOTA를 달성한다. 이전 SOTA와의 비교는 다음과 같다. GSM8K: Cobbe et al. (2021), MAWPS 및 ASDiv: Lan et al. (2021), SVAMP: Pi et al. (2022), AQuA: Piekos et al. (2021), CommonsenseQA: Talmor et al. (2019) 리더보드, StrategyQA: Geva et al. (2021).
6.4 Code Tasks
최근 연구에 따르면 대규모 language model은 경쟁 프로그래밍 (Li et al., 2022), 코드 완성 (Chen et al., 2021), 자연어 사양으로부터 프로그램 합성 (Chen et al., 2021; Austin et al., 2021)을 포함한 코딩 task에 유용하다는 것이 밝혀졌다. 이 섹션에서는 PaLM 모델이 다양한 코딩 task에서 뛰어난 결과를 달성함을 보여준다:
- Text-to-code: 우리는 자연어 설명이 주어졌을 때 코드를 작성하는 것을 목표로 하는 세 가지 task를 고려한다.
- HumanEval (Chen et al., 2021) 및 MBPP (Austin et al., 2021) 데이터셋에서는 모델에 몇 문장으로 된 영어 설명과 소수의 입출력 예시가 주어지며, 목표는 일반적으로 단일 함수인 짧은 Python 프로그램을 생성하는 것이다.
- 우리는 또한 Cobbe et al. (2021)의 GSM8K 데이터셋에서 파생된 GSM8K-Python task를 소개한다. GSM8K 데이터셋은 수학 단어 문제로 구성되어 있으며, 이 데이터에 대한 결과는 Section 6.3을 참조하라. GSM8K-Python은 이 task의 변형으로, 정답을 생성하는 대신 정확한 솔루션을 반환하는 Python 프로그램을 생성하는 것을 목표로 한다. 우리는 few-shot 예시로 사용하기 위해 데이터셋의 문제 중 4개를 Python 프로그램으로 수동 변환했다. MathQA 데이터셋 (Amini et al., 2019)을 사용한 유사한 실험은 Austin et al. (2021)을 참조하라.
- Code-to-code: TransCoder (Lachaux et al., 2020)는 C++ 프로그램을 Python으로 번역하는 task이다. 우리는 GitHub에서 TransCoder 데이터를 다운로드하고 데이터셋의 Python 및 C++ 하위 디렉토리에 모두 나타나는 함수들을 수집했다. 이 중에서 우리는 세 가지 다른 유형의 함수를 few-shot prompt로 선택하고 나머지를 테스트 세트를 만드는 데 사용했다. 이로써 560개의 샘플을 얻었다.
- 우리는 또한 DeepFix (Gupta et al., 2017) 코드 수정 task를 평가한다. 컴파일에 실패하는 학생이 작성한 손상된 C 프로그램에서 시작하여, 목표는 프로그램이 성공적으로 컴파일되도록 수정하는 것이다. 이전 연구 (Yasunaga & Liang, 2020, 2021)와 마찬가지로, 우리는 모델에 손상된 코드에 대한 컴파일러 오류를 제공하고 (이를 손상된 코드에 주석으로 삽입함) 1260개의 프로그램에 대해 테스트한다.
 Figure 11: PaLM-Coder 540B 모델의 예시. (왼쪽 상단) OpenAI GSM8K 수학 데이터셋에서 변환된 GSM8K-Python 질문. (왼쪽 하단) C++에서 Python으로 간단한 함수를 번역하는 TransCoder 예시. (오른쪽) 변환된 HumanEval 예시.
Figure 11: PaLM-Coder 540B 모델의 예시. (왼쪽 상단) OpenAI GSM8K 수학 데이터셋에서 변환된 GSM8K-Python 질문. (왼쪽 하단) C++에서 Python으로 간단한 함수를 번역하는 TransCoder 예시. (오른쪽) 변환된 HumanEval 예시.
Kulal et al. (2019)에 따라, 우리는 pass@k 메트릭을 사용하여 결과를 보고한다. 이 메트릭은 테스트 세트의 각 문제에 대해 모델에서 개의 소스 코드 샘플을 추출하고, 어떤 샘플이라도 문제를 해결하면 해당 문제가 해결된 것으로 간주한다. 우리는 Chen et al. (2021)의 pass@k 추정치를 사용하지 않고, 대신 task를 해결하는 샘플의 비율을 단순히 보고한다. MBPP 및 GSM8K의 경우, 데이터셋의 테스트 분할을 사용하여 측정했다. pass@1을 보고할 때는 greedy decoding을 사용한다. 의 경우, 의 nucleus sampling과 온도 0.8을 사용한다.
우리는 PaLM 모델을 코드용으로 여러 다른 language model과 비교한다. 첫째, LaMDA 137B 파라미터 모델 (Thoppilan et al., 2022)과 비교한다. LaMDA는 GitHub 코드로 학습되지 않았지만, LaMDA 사전학습 혼합의 약 12.5%는 Q&A 사이트 및 튜토리얼과 같은 코드 관련 웹사이트에서 가져왔으며, 이를 "code web docs"라고 부른다. 이는 LaMDA에게 프로그램 합성을 수행할 수 있는 일부 능력을 부여하는 것으로 나타났다 (Austin et al., 2021). 둘째, Chen et al. (2021)에 설명된 초기 Codex 모델 12B와 비교하며, 이 모델은 HumanEval 데이터셋에 대한 결과만 보고한다.
다른 데이터셋에서 Codex의 결과를 얻기 위해 우리는 OpenAI Davinci Codex API에 쿼리했다. 우리는 2021년 9월 1일부터 2022년 3월 10일 사이에 Davinci Codex 측정을 수행했다. 우리는 실험을 실행할 당시 가장 최신 버전이었던 Davinci 모델 버전 1 (code-davinci-001)을 사용했다. 불행히도 Davinci Codex 모델에 대해 공개적으로 알려지지 않은 많은 것들이 있다: 우리는 이 모델의 크기, 단일 모델인지 앙상블인지, 얼마나 많은 데이터로 학습되었는지, 모델 출력에 어떤 (만약 있다면) 후처리가 수행되는지, 그리고 Davinci Codex 학습 데이터가 우리의 평가 데이터셋과 얼마나 오염되었는지 알지 못한다. 이러한 불확실성으로 인해 성능 차이의 원인을 이해하는 것은 불가능하지만, 이 비교는 우리가 고려하는 task의 본질적인 어려움을 이해하는 데 여전히 유용하다.
| Code tokens | Code web docs | |||
|---|---|---|---|---|
| LaMDA 137B | - | - | 18 B | |
| Codex 12B | 100 B | 100 B | - | |
| PaLM 540B | 39 B | 2.7 B | - | |
| PaLM-Coder 540B | 46.8 B | 8.7 B | - |
Table 11: 우리가 고려하는 코드 language model이 학습 중에 처리한 코드 토큰의 양. Davinci Codex 모델의 경우, 학습 데이터셋 혼합은 알려져 있지 않다. PaLM-Coder의 경우, 표는 사전학습 및 fine-tuning 데이터의 합계를 보여준다. 대시는 해당 유형의 데이터가 포함되지 않았음을 나타낸다. Codex 12B의 데이터는 Chen et al. (2021)에서 보고되었다. Codex, PaLM 및 PaLM-Coder는 소량의 code web docs를 포함할 수 있다; 각주를 참조하라.
데이터셋
PaLM 모델은 Section 3에 설명된 대로 학습 세트에 GitHub 코드를 포함했다. 사전학습 데이터셋에는 총 39B개의 코드 토큰이 있었다. 대부분의 평가 데이터셋이 Python 프로그래밍 기술을 테스트하기 때문에, 우리는 특히 Python 코드만으로 구성된 추가 데이터셋을 수집했다. 이 추가 데이터셋을 ExtraPythonData라고 부르며, 사전학습에 사용되지 않은 GitHub 저장소에서 가져온 5.8B개의 토큰을 포함한다. Table 12는 사용된 코드 학습 데이터의 양을 요약한다: PaLM 540B 행은 사전학습에 사용된 토큰 수를 보여주고, PaLM-Coder 540B는 사전학습 및 fine-tuning 데이터의 총 토큰 수를 보여준다. 비교를 위해 다른 최신 모델의 코드 토큰 양도 포함되어 있다. Table 28은 데이터의 프로그래밍 언어 분포를 보여준다. 가장 일반적인 언어는 Java, HTML, Javascript, Python, C, PHP, C# 및 C++이다.
PaLM 540B
PaLM 모델의 성능은 Table 12에 0에서 4-shot prompt로 표시되어 있다. 첫째, LaMDA 모델은 GitHub 코드로 학습되지 않았음에도 불구하고 모든 task에서 0이 아닌 성능을 보인다. 이는 LaMDA 학습에 사용된 code web documents가 이러한 task에 유용하다는 것을 보여준다. 이는 Chen et al. (2021)에 따르면 HumanEval에서 성능이 0인 GPT-3와는 대조적이다. 그럼에도 불구하고 PaLM 모델은 LaMDA보다 모든 task에서 더 나은 성능을 보이며, HumanEval에서는 Codex 12B와 필적한다. 이는 Codex와 달리 PaLM 모델이 코드에 특화되지 않았고, 동일한 모델이 코드 및 자연어 task 모두에서 뛰어난 성능을 달성한다는 점에서 특히 놀랍다. 우리가 아는 한, 이는 단일 모델에서 자연어 및 코드 task 모두에서 state-of-the-art 성능을 목표로 하는 최초의 대규모 language model이며, 실제로 PaLM은 둘 다에서 최고의 공개된 성능을 달성한다. PaLM 코드 코퍼스의 약 7%가 Python이며, 이는 PaLM이 약 2.7B개의 Python 코드로 학습되었음을 의미한다. 이는 Chen et al. (2021)에서 보고된 Codex 모델의 100B Python 토큰과 비교된다. PaLM 모델은 이전에 공개된 결과보다 50배 적은 Python 코드로 few-shot 평가에서 필적하는 성능을 달성한다. 우리는 이를 (a) 다른 프로그래밍 언어 및 자연어 데이터로부터의 전이 학습과 (b) Kaplan et al. (2020)의 관찰, 즉 더 큰 모델이 더 작은 모델보다 샘플 효율적일 수 있다는 특히 놀라운 사례의 조합으로 해석한다.
PaLM-Coder
이제 Chen et al. (2021)이 수행한 것과 유사하게 코드에 대해서만 추가 fine-tuning의 효과를 평가한다. Table 12에서 결과 모델을 PaLM-Coder라고 부른다. 우리는 8B, 62B 및 540B PaLM 모델을 두 단계로 fine-tuning한다: (a) 첫째, ExtraPythonData에서 가져온 60% Python 코드, 언어 전반의 30% 코드 (사전학습 코드 데이터와 동일한 소스에서 가져왔지만 사전학습에는 포함되지 않음), 그리고 10% 자연어의 혼합으로 6.5B 토큰에 대해 fine-tuning하고, (b) ExtraPythonData에서 가져온 더 많은 Python 코드로 1.9B 토큰에 대해 추가 fine-tuning한다. 두 단계를 통틀어 fine-tuning 데이터는 7.75B 토큰을 포함했으며, 이 중 5.9B는 Python이었다. 사전학습 및 두 단계의 fine-tuning을 포함한 총 코드 데이터 양은 Table 11에 나와 있다. PaLM-Coder 540B의 성능은 더욱 향상되어 HumanEval에서 88.4% pass@100, MBPP에서 80.8% pass@80을 달성한다 (Table 12). Figure 12는 8B에서 62B, 그리고 최종적으로 540B 모델로의 성능 스케일링을 보여준다. 540B 모델의 경우, fine-tuning되지 않은 모델에 비해 HumanEval pass@100에서 12% 절대 개선, MBPP pass@80에서 5% 절대 개선을 제공한다. 스케일이 증가할 때마다 모든 데이터셋에서 성능이 향상되며, 540B까지도 스케일이 성능에 미치는 영향은 포화되지 않는 것으로 보인다.
| Pretraining only | Code Finetuning | Other Work | |||||
|---|---|---|---|---|---|---|---|
| LaMDA 137 B | PaLM 540B | Codex | Davinci Codex* | PaLM Coder 540B | |||
| HumanEval (0) | pass@100 | 47.3 | 76.2 | 72.3 | 81.7 | 88.4 | - |
| MBPP (3) | pass@80 | 75.0 | - | 84.4 | 80.8 | - | |
| TransCoder (3) | pass@25 | - | 79.8 | - | 71.7 | 82.5 | |
| HumanEval (0) | pass@1 | 14.0 | 26.2 | 28.8 | 36.0 | 36.0 | - |
| MBPP (3) | pass@1 | 36.8 | - | 50.4 | 47.0 | - | |
| GSM8K-Python | pass@1 | 7.6 | 51.3 | - | 32.1 | 50.9 | - |
| TransCoder (3) | pass@1 | 30.2 | 51.8 | - | 54.4 | 55.1 | |
| DeepFix (2) | pass@1 | 4.3 | 73.7 | - | 81.1 | 82.1 |
Table 12: PaLM 540B 및 PaLM-Coder 540B 모델이 코드 합성 및 소프트웨어 엔지니어링 task에서 얻은 결과. few-shot 결과의 경우, 각 task에 대한 shot 수는 괄호 안에 언급되어 있다. 위첨자는 이전 연구에서 인용된 결과를 나타낸다: Chen et al. (2021); Austin et al. (2021); Lachaux et al. (2020); Yasunaga & Liang (2021). *Davinci Codex 결과는 OpenAI Codex API 및 Chen et al. (2021)에 명시된 Codex 권장 설정을 사용하여 얻은 자체 계산 결과이다.
 Figure 12: PaLM 및 PaLM-Coder 모델의 8B, 62B, 540B 스케일에 대한 HumanEval, MBPP, GSM8K-Python, TransCoder 및 DeepFix 데이터셋의 스케일링 결과. DeepFix의 경우 컴파일 성공률의 스케일링을 보고한다.
Figure 12: PaLM 및 PaLM-Coder 모델의 8B, 62B, 540B 스케일에 대한 HumanEval, MBPP, GSM8K-Python, TransCoder 및 DeepFix 데이터셋의 스케일링 결과. DeepFix의 경우 컴파일 성공률의 스케일링을 보고한다.
GSM8K-Python 데이터셋의 경우, Section 6.3의 결과와 비교하기 위해 동일한 문제를 사용하여 8-shot prompt도 평가했다. PaLM-Coder 540B는 8-shot prompt에 대해 57.5의 pass@1 점수를 달성한 반면, PaLM 540B 모델은 Figure 10에서 58.1의 pass@1 점수를 얻었다.
#include <stdio.h>
int main() {
int a[i];
int i;
int i;
scanf("%d", &n);
scanf("%d", &a[i]);
int count = 0;
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
if (a[i] == a[j])
count = count + 1;
}
}
if (count == a[i])
printf("Yes");
else
printf("No");
return 0;
}
#include <stdio.h>
int main() {
int a[100], i, n, count = 0;
scanf("%d", &n);
for (i = 0; i < n; i++)
scanf("%d", &a[i]);
for (i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (a[i] == a[j])
count = count + 1;
}
}
if (count == n)
printf("Yes");
else
printf("No");
return 0;
}
Figure 13: DeepFix 문제의 예시로, 왼쪽에는 원래의 손상된 코드가 있고 오른쪽에는 PaLM-Coder 540B 모델의 예측이 있다. 예측된 코드에는 모든 컴파일 오류 (선언되지 않은 변수)에 대한 수정 사항뿐만 아니라 다른 스타일 개선 (변수 함께 선언) 및 논리 개선 (루프에서 배열 a에 숫자를 읽고 루프 외부에서 인덱스 i를 사용하지 않음)이 포함되어 있다.
#include <stdio.h>
int main() {
int n;
scanf("%d", &n);
int i, num[400];
for (i = 0; i < 2 * n; i++)
scanf("%d", &num[i]);
int min = 400;
for (i = 0; i < n; i++) {
for (int j = 0; j < (2 * n - 1); j++) {
if (num[i] == num[j])
int t;
(j - i);
t = (j - i);
if (t <= min)
min = t;
t = 0;
}
}
printf("%d", min);
return 0;
}
#include <stdio.h>
int main() {
int n, i, min = 400;
int num[400];
scanf("%d", &n);
for (i = 0; i < 2 * n; i++)
scanf("%d", &num[i]);
for (i = 0; i < n; i++) {
for (int j = 0; j < (2 * n - 1); j++) {
if (num[i] == num[j]) {
int t = (j - i);
if (t <= min)
min = t;
}
}
}
printf("%d", min);
return 0;
}
Figure 14: 또 다른 DeepFix 문제 예시. 예측된 코드는 컴파일 오류 (if 블록에 중괄호가 없어 변수 t에 대한 스코프 오류 발생)를 수정하고 다른 개선 사항 (변수 함께 선언 및 효과 없는 줄 ; 제거)을 적용한다.
DeepFix 코드 수정
PaLM-Coder 540B 모델은 DeepFix 코드 수정 task에서 인상적인 성능을 보여주며, 이전 연구 (Yasunaga & Liang, 2021)가 달성한 71.7%에 비해 82.1%의 컴파일 성공률을 달성한다. Figure 13과 14는 PaLM-Coder의 성공적인 예측을 보여주는 DeepFix 문제 예시이다. prompt를 위해 우리는 다양한 일반적인 오류를 포함하는 손상된 C 프로그램과 수정된 C 프로그램 쌍 두 개를 수동으로 작성했으며, prompt 예시를 더 이상 반복하지 않았다. 우리는 손상된 코드를 코드 포맷터를 통해 전달한 후 포맷된 결과를 모델에 제공하고, 모델은 전체 수정된 코드를 예측한다.
코드 수정의 경우, 모델이 변경한 코드의 양을 평가하는 것이 중요하다. 이상적으로는 손상된 코드의 작은 부분만 수정하기를 원한다. Table 13에서 "작은" 편집을 정의하는 다양한 메트릭을 사용하여 결과를 분석한다. 흥미롭게도 PaLM은 가장 작은 편집을 생성하는 반면, PaLM-Coder는 작은 정규화된 편집 거리만 고려할 때 가장 높은 성공률을 보이고, Davinci Codex는 변경된 줄 수가 적은 편집만 고려할 때 가장 높은 성공률을 보인다. 즉, PaLM-Coder는 Codex에 비해 더 많은 줄에 걸쳐 더 적은 문자를 변경하는 경향이 있다. 우리는 예측에서 이러한 행동을 질적으로 관찰하는데, PaLM-Coder는 Codex보다 사소한 스타일 변경을 할 가능성이 더 높다. 예를 들어, 을 로 변경하고 int int b ;를 int ; (변수 선언 결합)로 변경하는 반면, Codex는 줄을 급격하게 변경할 가능성이 더 높다.
우리는 이 기회를 통해 PaLM-Coder의 예측이 변경된 prompt에 어떻게 반응하는지 관찰한다. 우리는 동일한 두 가지 prompt 예시를 사용하여 PaLM-Coder를 다시 실행했는데, 단, 동일한 줄에 있는 두 변수 선언 중 하나가 손상된 코드와 수정된 코드 모두에서 두 줄로 분할되어 PaLM-Coder가 변수 선언을 결합하지 않도록 의도했다. 새로운 prompt를 사용하자 Table 13의 모든 메트릭이 향상되었으며, "정규화된 편집 거리" 메트릭에 비해 "변경된 줄 수" 메트릭에서 더 큰 개선이 있었다. 예를 들어, 전체 컴파일 성공률은 82.1%에서 83.4%로 향상되었고, 최대 5줄 변경에 대한 성공률은 66.8%에서 70.2%로 향상되었다. 질적으로는, 새로운 prompt를 사용할 때 PaLM-Coder가 변수 선언을 결합할 가능성이 훨씬 적다는 것을 관찰했다. 이는 단지 하나의 일화적인 실험이지만, prompt 예시에 대한 작고 목표 지향적인 변경이 예상대로 예측을 개선했다는 점은 고무적이다.
| Pretraining only | Code Finetuning | |||
|---|---|---|---|---|
| LaMDA 137B | PaLM 540B | Davinci Codex | PaLM-Coder 540B | |
| Compile Rate (any edit size) | 4.3 | 73.7 | 81.1 | 82.1 |
| Normalized Edit Distance | 1.7 (1.9) | 68.0 (93.1) | 70.5 (86.7) | 71.7 (87.5) |
| Normalized Edit Distance | 2.1 (2.7) | 71.0 (96.5) | 74.7 (91.7) | 77.0 (94.0) |
| Normalized Edit Distance | 2.5 (3.4) | 72.4 (98.1) | 77.1 (94.7) | 79.4 (96.7) |
| Lines Changed | 1.7 (2.1) | 63.8 (87.8) | 67.9 (83.3) | 66.8 (81.1) |
| Lines Changed | 2.1 (3.1) | 66.6 (91.4) | 71.5 (87.9) | 70.1 (85.5) |
| Lines Changed | 2.5 (4.1) | 68.4 (93.7) | 73.9 (90.9) | 72.9 (88.7) |
Table 13: DeepFix 성공률을 백분율로 나타낸 것으로, "성공"은 예측된 코드가 컴파일되고 예측에 작은 편집이 포함됨을 의미하며, "작은" 편집을 정의하는 다양한 방식이 적용되었다. 괄호 안에는 작은 편집을 나타내는 예측의 백분율을 보여준다. "Normalized Edit Distance"는 문자열 와 에 대해 LevenshteinDistance 로 계산된다. "Lines Changed"는 줄 삽입, 삭제 및 편집의 총 수를 계산한다. 두 경우 모두 모든 들여쓰기 변경은 무시한다.
논의
소프트웨어 개발에 LM 기반 시스템을 배포할 때, 주요 위험은 생성된 코드가 부정확하거나 미묘한 버그를 도입할 수 있다는 것이다. 이는 코드 완성 시스템에 대한 데이터셋 오염 공격 (Schuster et al., 2020)의 발견과, LM이 prompt에 버그가 있는 코드가 있을 때 버그가 있는 코드를 생성할 가능성이 더 높다는 관찰 (Chen et al., 2021)을 고려할 때 특히 시급한 문제이다. 이 위험에 대한 현재의 완화책은 불완전하다. 개발자는 제안된 코드를 프로그램에 추가하기 전에 검토해야 하지만, 제안된 코드에서 미묘한 버그를 항상 찾지 못할 수도 있다. 또한, 코드 제안은 테스트 스위트로 확인할 수도 있지만, 소수의 테스트 케이스만으로 솔루션이 기능적으로 올바르다고 추론하는 것이 항상 안전하지는 않다. 실제로, 여기서 고려하는 벤치마크에서도 우리는 소수의 테스트를 기반으로 기능적 정확성을 측정하는 이전 작업을 따르지만, 이는 방법의 성능을 과대평가할 수 있다. 기능적 정확성에 대한 더 철저한 테스트가 바람직할 것이다. 프로그램 수정 문헌에서 이 문제는 특히 심각했다. 부분적으로 테스트 스위트의 한계로 인해, 당시 시스템이 생성한 패치의 압도적인 대다수는 올바르지 않았다 (Qi et et al., 2015).
기능적 정확성은 소스 코드 품질의 한 측면에 불과하다. LM이 생성한 제안은 또한 읽기 쉽고, 견고하며, 빠르고, 안전해야 한다. DeepFix는 PaLM-Coder의 현재 예측에 대한 한 가지 문제를 보여준다. Figure 13과 14에서 "수정된" 프로그램은 컴파일되지만, 입력의 형식과 크기에 대한 가정에 의존하기 때문에 반드시 안전하지는 않다. DeepFix 데이터셋은 C 프로그래밍 과정의 연습 문제에 대한 학생이 작성한 제출물에서 가져온 것으로, 학생들은 그러한 가정을 할 수 있다. 이러한 제안은 더 일반적인 설정에서는 바람직하지 않을 수 있다. 일반적으로 개발자가 제안된 코드를 이해하고 신뢰하도록 돕는 것은 미해결 문제이다. 가독성 (Allamanis et al., 2018) 및 보안 (Pearce et al., 2021) 평가에 대한 이전 연구가 존재하지만, 해당 연구 분야는 아직 초기 단계이며 코드 모델이 발전함에 따라 추가 작업이 필요하다.
6.5 Translation
**기계 번역(Machine translation)**은 모델이 입력 텍스트의 내용, 의미, 스타일을 보존하면서 한 언어의 텍스트를 다른 언어로 다시 작성하는 task이다. GPT-3와 같은 다른 대형 Language Model(LM)들은 명시적으로 병렬 텍스트 코퍼스로 학습되지 않았음에도 불구하고 기계 번역에서 어느 정도의 능력을 보여주었다. 특히 영어로 번역할 때 인상적인 결과를 보였지만, 영어가 아닌 다른 언어로 번역할 때는 다소 부진한 결과를 나타냈다.
이 섹션에서는 다양한 언어 쌍과 설정에서 PaLM의 번역 능력을 평가한다. 다른 대형 LM과 마찬가지로, PaLM은 명시적으로 병렬 텍스트로 학습되지 않았지만, 학습 코퍼스에 일부 병렬 데이터가 자연적으로 존재할 가능성이 있다. 우리는 WMT에서 개발 및 테스트 세트가 제공되는 언어 쌍에만 집중하며, 특히 다음 세 가지 유형의 언어 쌍에 초점을 맞춘다:
- 영어 중심 언어 쌍 (English-centric language pairs): 이는 과거 모델들이 주로 다루었던 전통적인 언어 쌍이다. 이 언어 쌍들은 영어를 원본(source) 또는 대상(target) 언어로 포함하며, 다양한 수준의 병렬 데이터를 사용할 수 있다. 쌍에 포함된 비영어권 언어에 따라 번역 task는 **고자원(high-resource, 1천만 개 이상의 예시), 중자원(mid-resource, 1백만 개 초과 1천만 개 미만 예시), 또는 저자원(low-resource, 1백만 개 미만 예시)**일 수 있다. 이 설정에서는 **WMT'14 영어-프랑스어(고), WMT'16 영어-독일어(중), WMT'16 영어-루마니아어(저)**를 언어 쌍으로 사용한다.
- 직접 언어 쌍 (Direct language pairs): 번역 시스템이 영어를 거치지 않고 어떤 언어 쌍 간에도 직접 번역할 수 있는 능력은 점점 더 중요해지고 있다 (Freitag & Firat, 2020; Fan et al., 2020). 기계 번역에서 영어는 원본/대상 언어가 아닐 때도 번역에 관여할 수 있는데, 이는 기계 번역 시스템이 종종 영어를 "pivot" 언어로 사용하여 번역하기 때문이다 (예: 프랑스어 → 영어 → 독일어). 우리는 WMT'19 프랑스어-독일어 언어 쌍을 사용하여 직접 번역 능력을 테스트할 것이다.
- 극히 저자원 언어 쌍 (Extremely-low resource language pairs): 모델에 명시적인 병렬 데이터가 제공되지 않았으므로 모든 언어 쌍은 기술적으로 zero-resource이지만, 고려 중인 언어 중 하나가 매우 적은 단일 언어 데이터를 가지고 있는 경우를 살펴보는 것은 흥미롭다. 본 연구에서는 카자흐어를 저자원 언어로 선택한다. 비교를 위해, 학습 세트에서 프랑스어와 독일어는 각각 약 240억 및 260억 토큰을 가지고 있는 반면, 카자흐어는 약 1억 3,400만 토큰만을 가지고 있다. 평가를 위해 WMT'19 영어-카자흐어를 사용할 것이다.
| Src | Tgt | 0-shot | 1-shot | Few-shot | Supervised | |||
|---|---|---|---|---|---|---|---|---|
| Prior SOTA | PaLM 540B | Prior SOTA | PaLM 540 B | Prior SOTA | PaLM 540 B | Finetuned SOTA | ||
| en | fr | 38.5 | 37.5 | 44.0 | ||||
| en | de | 31.8 | 31.8 | 37.4 | ||||
| en | ro | 24.2 | 28.2 | 28.7 | ||||
| fr | en | 41.1 | 37.4 | 42.8 | ||||
| de | en | 43.8 | 43.9 | |||||
| ro | en | 39.9 | 42.1 | 43.8 |
Table 14: 전통적인 WMT 언어 쌍에 대한 번역 BLEU 점수. 위첨자는 과거 연구의 결과를 나타낸다: FLAN(Wei et al., 2022a); GPT-3 175B (Brown et al., 2020); (Edunov et al., 2018); (Wang et al., 2019b); (Caswell et al., 2019); Lin et al. (2020); (Wang et al., 2019b); (Song et al., 2019). PaLM의 few-shot 설정에서는 5 shots를 사용한다. 가장 좋은 zero/few-shot 결과는 굵게 표시하고, 전체적으로 가장 좋은 결과는 밑줄로 표시한다. PaLM의 few-shot 평가는 5 shots에 해당한다. 0-shot prompt는 prompt에 원본 및 대상 언어 이름을 포함하는 반면, 1-shot 및 few-shot은 포함하지 않는다 (언어는 예시에서 추론되어야 함). 이는 일부 언어 쌍에서 0-shot 성능이 강하게 나타나는 이유를 설명할 수 있다.
 Figure 15: 0-shot 번역 task에서 PaLM의 비교. (왼쪽) 이전 대규모 언어 모델과의 비교. (오른쪽) 다른 PaLM 모델 규모의 비교.
Figure 15: 0-shot 번역 task에서 PaLM의 비교. (왼쪽) 이전 대규모 언어 모델과의 비교. (오른쪽) 다른 PaLM 모델 규모의 비교.
영어 중심 언어 쌍에 대한 평가
우리는 먼저 다른 대규모 언어 모델들이 일반적으로 평가하는 전통적인 영어 중심 언어 쌍에 대해 PaLM을 평가한다. 0-shot, 1-shot, few-shot 설정을 고려하고, 유사한 설정의 다른 모델들과 비교한다. 비교를 위해 **GPT-3 (Brown et al., 2020) 및 FLAN (Wei et al., 2022a)**과 비교하여 각 설정에서 가장 좋은 결과를 포함한다. 결과는 Table 14에 보고하고 Figure 15-left에 그래프로 나타낸다. PaLM은 모든 baseline을 능가하며, 때로는 최대 13 BLEU 차이로 매우 결정적인 우위를 보인다. 비교를 위해 각 언어 쌍에 대한 전용 번역 모델의 SOTA 결과도 포함한다. 독일어-영어 및 루마니아어-영어의 경우 PaLM이 supervised baseline보다도 우수한 성능을 보이지만, WMT task의 초점이 최근 변경되었으므로 이러한 baseline이 오래되었을 수 있다는 점도 인정한다.
Figure 15-right에서는 모델 크기를 8B에서 62B, 540B로 확장했을 때의 0-shot 번역 결과를 제시한다. PaLM을 62B에서 540B로 확장하면 BLEU 점수에서 여러 급격한 상승이 나타나며, 이는 8B에서 62B로 모델 크기를 확장했을 때 예상되는 "power law" 경험 법칙 (Kaplan et al., 2020)을 따르지 않는다. 예를 들어, 영어-독일어 언어 쌍은 13 BLEU 증가를, 영어-프랑스어 언어 쌍은 17 BLEU 증가를 보인다.
| Src | Tgt | 0-shot | 1-shot | Few-shot | Supervised |
|---|---|---|---|---|---|
| PaLM 540B | PaLM 540B | PaLM 540B | Finetuned SOTA | ||
| en | kk | 1.8 | 4.2 | 5.1 | |
| de | fr | 28.6 | 20.9 | 25.7 | |
| kk | en | 18.0 | 20.3 | 20.8 | |
| fr | de | 25.2 | 9.5 | 17.4 |
Table 15: 비영어 중심 및 극히 저자원 언어 쌍에 대한 번역 BLEU 점수. (Toral et al., 2019); (Xia et al., 2019); (Li et al., 2019). 0-shot prompt는 prompt에 원본 및 대상 언어 이름을 포함하는 반면, 1-shot 및 few-shot은 포함하지 않는다 (언어는 예시에서 추론되어야 함). 이는 일부 언어 쌍에서 0-shot 성능이 강하게 나타나는 이유를 설명할 수 있다.
직접 및 극히 저자원 언어 쌍에 대한 평가
다음으로, PaLM을 직접 및 극히 저자원 언어 쌍에 대해 평가한다. 다른 언어 모델들은 이러한 설정을 연구하지 않으므로, 우리는 대신 WMT'19에서 각 언어 쌍에 대해 가장 높은 점수를 받은 제출물을 활용한다. 이 모델들은 일반적인 supervised 번역 모델을 넘어선 다양한 기술과 기법 (예: 보조 모델을 사용한 재점수화, 대규모 역번역, 앙상블 등)을 사용한다. PaLM-540B의 결과는 Table 15에 제시되어 있다. 이 더 도전적인 설정에서 PaLM은 프랑스어-독일어 설정에서만 supervised 성능과 일치할 수 있었지만, 독일어-프랑스어 및 카자흐어-영어에서는 여전히 강력한 성능을 제공한다.
6.5.1 Further findings and analysis
우리는 실험 결과를 다음과 같은 관찰 내용으로 요약한다:
- 번역 품질은 영어가 아닌 다른 언어에서 영어로 번역할 때 더 좋다. 이는 모든 영어 중심 언어 모델에서 관찰되는 일반적인 패턴이며, PaLM의 성능을 검토할 때도 유사하게 나타난다. 우리는 다국어 데이터의 우선순위를 높이면 이러한 효과가 완화될 것으로 예상한다.
- Prompt는 단일 예시보다 더 큰 가치를 제공할 수 있다. 우리는 대부분의 경우, 언어 이름을 사용하여 번역을 유도하는 (0-shot 설정) 방식이 input-output 예시만 사용하는 (1-shot 및 few-shot 설정) 방식보다 더 강력한 성능을 제공한다는 것을 발견했으며, 이는 이전 연구 (Reynolds & McDonell, 2021)와 일치한다.
- Self-supervision에만 의존하는 Generalist 모델은 더 작은 규모에서 Specialized 모델과 동등한 성능을 낼 수 있다. 우리가 고려한 전용 번역 baseline 모델들은 대부분 10억 개 미만의 파라미터를 가지고 있으며, 이는 우리의 가장 큰 PaLM 구성보다 두 자릿수 더 작다. 반면에, 우리는 대규모 번역 모델이 다양한 다운스트림 task에 적응될 수 있음을 확인했으며 (Siddhant et al., 2020), 이는 Specialist 모델도 Generalist 역할을 할 수 있음을 시사한다. 이는 다음과 같은 질문을 제기한다: 자원이 풍부한 시나리오(예: 다국어 번역)에서 우리는 Specialist를 훈련해야 하는가, 아니면 Generalist를 훈련해야 하는가?
6.6 Multilingual Natural Language Generation
자연어 생성(Natural language generation) task는 문서, 테이블 또는 기타 구조화된 형태와 같은 텍스트 또는 비언어적 정보를 입력으로 받아 이해 가능한 텍스트를 자동으로 생성하는 것을 요구한다. 이러한 텍스트는 특정 의사소통 목표(예: 문서 요약, 개념 집합을 언어로 표현)를 달성하고자 한다.
과거에는 유사한 크기의 모델에 대해 few-shot 조건부 자연어 생성(conditional natural language generation)이 탐구되지 않았다. 일반적으로 생성 평가는 생성형 질문 응답(generative question answering) 및 다중 선택 언어 모델링(multiple-choice language modeling) task에 국한되었으며, 이는 완전한 문장이나 단락을 생성할 필요가 없는 task이다. 우리가 다른 섹션에서 비교하는 대규모 언어 모델들(GPT-3, GLaM, Gopher, LaMDA, Megatron-Turing NLG) 중 어떤 모델도 조건부 자연어 생성 task(영어 또는 다국어)에 대한 few-shot 또는 fine-tuning 결과를 보고하지 않았다.
따라서 본 연구는 조건부 자연어 생성 task의 few-shot 모델링을 위한 대규모 LM의 첫 번째 벤치마크를 제시한다. 비교 대상으로 LaMDA 137B를 평가했는데, 이 모델은 Thoppilan et al. (2022)에서 해당 벤치마크에 대한 결과를 보고하지 않았지만, 우리가 직접 실행할 수 있었다.
Fine-tuning의 경우, 이전의 SOTA 결과는 주로 **T5 (Raffel et al., 2020), mT5 (Xue et al., 2021b), 또는 BART (Lewis et al., 2020)**를 fine-tuning하여 얻어졌는데, 이들은 infilling objective (masked LM 또는 span corruption)로 사전학습된 encoder-decoder 모델이다. 이 모델들은 PaLM보다 훨씬 작으며, 130M에서 13B 파라미터 범위에 있다. Section 6.1.2에서 언급했듯이, infilling을 위해 학습된 encoder-decoder 모델은 fine-tuning 설정에서 더 큰 decoder-only LM보다 우수한 성능을 보이는 경우가 많다. 따라서 본 연구에서 중요한 비교 지점은 대규모 decoder-only language model을 fine-tuning할 때, 모델의 규모가 알려진 약점을 보완할 수 있는지 여부이다.
데이터
우리는 PaLM을 **Generation Evaluation and Metrics 벤치마크 (GEM, Gehrmann et al., 2021)**에서 가져온 세 가지 요약(summarization) task와 세 가지 데이터-투-텍스트(data-to-text) 생성 task에 대해 평가했다. 데이터셋은 **체코어(cz), 영어(en), 독일어(de), 러시아어(ru), 스페인어(es), 터키어(tr), 베트남어(vi)**를 포함한다. 데이터셋, 언어 및 간략한 task 설명은 다음과 같다:
- MLSum (Scialom et al., 2020) - 여러 문장으로 뉴스 기사를 요약한다. [de/es]
- WikiLingua (Ladhak et al., 2020) - WikiHow의 단계별 지침을 매우 간결한 문장으로 요약한다. [en/es/ru/tr/vi en]
- XSum (Narayan et al., 2018) - 단일 문장으로 뉴스 기사를 요약한다. [en]
- Clean E2E NLG (Novikova et al., 2017; Dušek et al., 2019) - 키-값 속성 쌍 집합이 주어졌을 때, 한두 문장으로 레스토랑을 설명한다. [en]
- Czech Restaurant response generation (Dušek & Jurčíček, 2019) - 대화 맥락과 대화 행위 표현이 주어졌을 때, 스마트 어시스턴트가 제공할 응답을 생성한다. [cz]
- WebNLG 2020 (Gardent et al., 2017; Castro Ferreira et al., 2020) - 주어-술어-목적어 삼중항을 문법적이고 자연스러운 방식으로 하나 이상의 문장으로 표현한다. [en/ru]
모델의 추론 시간을 최소화하기 위해, 여러 문장 생성 task의 테스트 세트가 5,000개를 초과할 때마다 (MLSum de/es 및 WikiLingua en/ru/es) 5,000개의 테스트 예시를 균일하게 샘플링했다. 공개된 결과는 전체 테스트 분할에 대해 보고되므로, 정확한 수치는 약간 다를 수 있음을 명시한다.
평가 지표 (Metrics)
Gehrmann et al. (2022)의 제안에 따라, 우리는 **ROUGE-2, ROUGE-L (Lin, 2004), 및 BLEURT-20 (Pu et al., 2021)**을 보고한다. 간결성을 위해, 이 섹션의 본문에서는 ROUGE-2의 F-measure에 중점을 두며, ROUGE의 정밀도(precision) 및 재현율(recall) 수치를 포함한 나머지 결과는 Appendix H.3에 있다.
Few-shot 평가 방법론 (Few-shot evaluation methodology)
PaLM을 few-shot 추론에 사용하기 위해, task-specific prompt 를 입력에 연결하고, 출력 prompt를 출력에 추가한다. 요약 task의 종종 매우 긴 입력을 처리하기 위해, 입력은 2048 토큰으로 잘렸다. Few-shot 예시는 이중 줄 바꿈(double linebreaks)으로 구분되며, 이는 평가를 위한 출력 예측을 자르는 데에도 사용된다. 모든 few-shot demonstration은 학습 코퍼스에서 무작위로 샘플링된다.
Fine-tuning 방법론 (Finetuning methodology)
fine-tuning 동안 decoder-only 아키텍처를 사용하기 위해, 입력과 타겟은 연결되지만 손실은 시퀀스의 타겟 섹션에서만 계산된다. 연결된 시퀀스는 사전학습 동안 사용된 학습 컨텍스트인 2048 토큰으로 잘리며, 512 토큰은 타겟을 위해 예약된다. 요약 task만 입력 자르기가 필요했다.
PaLM을 fine-tuning하기 위해, 우리는 사전학습 시보다 20배 작은 의 상수 학습률을 사용하고, 옵티마이저(Adafactor)의 누적기(accumulators)를 재설정했다. 각 데이터셋에 대한 최고의 모델 체크포인트는 검증 세트에서 ROUGE-1, ROUGE-2, ROUGE-L 점수의 기하 평균이 가장 높은 모델로 선택되었다. 추론은 인 top-k 샘플링을 사용하여 수행되었다. T5 XXL baseline은 PaLM과 동일한 파라미터로 fine-tuning되었고, **빔 크기가 4인 빔 서치(beam-search)**를 사용하여 디코딩되었다.
6.6.1 Results
1-shot과 fine-tuning 간의 비교는 ROUGE-2의 F-measure를 사용하여 Table 16에 제시되어 있으며, 아래에서 더 자세히 설명한다. 동일한 결과는 추가적인 metric과 함께 Appendix H.3의 표에 제시되어 있다.
| Task | 1-shot | Finetuning | |||||||
|---|---|---|---|---|---|---|---|---|---|
| LaMDA 137B | PaLM 8 B | PaLM 62B | PaLM 540B | Prior SOTA | T5 XXL | PaLM 8 B | PaLM 62B | PaLM 540B | |
| Data-To-Text | |||||||||
| Czech Restaurant (cs) | 6.6 | 8.2 | 12.2 | 16.1 | 28.8 | 30.2 | 30.3 | 30.6 | |
| E2E (en) | 29.2 | 27.7 | 33.5 | 35.2 | 45.3 | 45.7 | 45.2 | 45.3 | |
| WebNLG (en) | 30.5 | 29.1 | 38.6 | 44.4 | 39.6 | 47.6 | 48.6 | 49.3 | |
| WebNLG (ru) | 5.4 | 4.5 | 8.5 | 14.9 | 23.2 | 22.4 | 23.3 | 23.4 | |
| Summarization | |||||||||
| MLSum (de) | 0.9 | 4.6 | 10.5 | 12.8 | 35.9 | 26.5 | 30.0 | 33.1 | |
| MLSum (es) | 0.5 | 2.3 | 3.2 | 3.6 | 12.0 | 10.6 | 11.2 | 12.0 | |
| WikiLingua (en en) | 5.4 | 5.6 | 8.9 | 9.9 | - | 23.8 | 19.3 | 22.1 | 23.2 |
| WikiLingua (es en) | 2.2 | 3.4 | 5.8 | 7.7 | 17.9 | 16.1 | 18.2 | 20.9 | |
| WikiLingua (ru en) | 0.1 | 2.3 | 5.2 | 6.6 | 12.5 | 13.9 | 16.6 | 18.6 | |
| WikiLingua ( en) | 1.8 | 1.8 | 5.6 | 8.5 | 13.8 | 16.7 | 21.4 | 23.1 | |
| WikiLingua (vi en) | 0.3 | 1.5 | 4.0 | 5.5 | 9.7 | 13.4 | 16.3 | 19.1 | |
| XSum (en) | 5.4 | 7.9 | 11.2 | 12.2 | 21.0 | 16.3 | 18.5 | 21.2 |
Table 16: GEM data-to-text 및 summarization 데이터셋의 ROUGE-2 결과.
우리는 fine-tuning 결과를 이전 보고된 SOTA 및 T5 XXL fine-tuned baseline과 비교하여 제시한다. 또한 few-shot 결과는 LaMDA baseline과 비교하여 제시한다.
(Dusek & Jurvc'ivcek, 2019), (Xue et al., 2021b), (Bakshi et al., 2021), (Gehrmann et al., 2021), (Zhang et al., 2020).
본 연구는 few-shot 모델링에 중점을 두며, 이러한 task에 대한 공개된 few-shot 결과는 없지만, 이 결과들로부터 몇 가지 흥미로운 시사점을 얻을 수 있다:
- Fine-tuning의 효과 - summarization task에서 540B fine-tuned PaLM은 모든 영어 생성 task에서 가장 우수하다고 보고된 이전 결과와 거의 일치하거나 이를 능가한다. 이는 PaLM이 막대한 규모 증가를 통해 아키텍처적 단점을 보완할 수 있음을 보여준다. 62B 모델은 종종 이전 최고 결과에 근접한 성능을 보이며, 540B 모델은 이를 능가한다. 우리는 대량의 task-specific 학습 데이터가 존재하는 경우, decoder-only LM의 fine-tuning이 모든 task에 대해 계산적으로 최적의 접근 방식이 아닐 수 있음을 인정하지만, 이는 few-shot 예측의 중요한 상한선 역할을 한다고 믿는다.
- 영어 vs. 비영어 생성 품질 - PaLM은 입력이 비영어일지라도 영어 텍스트를 생성하는 6개의 summarization task 중 4개에서 새로운 fine-tuning state-of-the-art 결과를 달성한다. 그러나 비영어 summarization (MLSum) fine-tuning은 SOTA를 달성하지 못하며, 비영어 생성의 경우 few-shot과 fine-tuning 간의 상대적 차이가 더 크다. 이는 PaLM이 비영어 출력을 생성하는 것보다 비영어 입력을 처리하는 데 더 능숙하다는 것을 시사하며, 이는 향후 비영어 텍스트의 큰 비중(현재 모델에서는 22%)으로 사전학습을 수행함으로써 개선될 수 있을 것이다.
- 1-shot vs. fine-tuning 격차 - Data-to-Text 결과를 살펴보면, few-shot 결과는 summarization과 유사한 경향을 보이지만, 최고 fine-tuned 결과와의 격차가 크게 줄어든다. 또 다른 비교점으로, few-shot과 fine-tuning의 하이브리드 형태로 볼 수 있는 FLAN (Wei et al., 2022a)은 instruction tuning 후 12-shot E2E-NLG에서 33.2, 10-shot WebNLG (en)에서 48.0의 ROUGE-2 점수를 보고했다. PaLM은 어떠한 튜닝 없이 1-shot 설정에서 35.2와 44.4를 얻는다. 우리는 Data-to-Text task가 작은 규모와 사전학습 코퍼스와의 상당한 불일치로 인해 (따라서 이러한 task에 대한 언어 사전학습의 효과를 제한함) fine-tuning 벤치마크로서의 가치가 제한적일 수 있음을 지적한다.
- Few-shot summarization - 다양한 PaLM 규모에서 few-shot summarization 결과를 비교할 때, 8B에서 62B로 갈 때 큰 폭의 개선을 볼 수 있으며, 62B에서 540B로 갈 때도 작지만 유의미한 개선이 나타난다. 그러나 few-shot과 fine-tuning 간의 격차는 여전히 상당하며, 1-shot 성능은 비영어 task의 경우 T5-base 또는 T5-large와 같은 더 작은 fine-tuned 모델, 영어 task의 경우 T5-small과 유사하다. 우리가 아는 한, 이것이 대규모 언어 모델을 사용한 few-shot summarization의 첫 번째 시연이므로, 우리는 이것이 조건부 생성 task에서 few-shot 모델과 fine-tuned 모델 간의 격차를 줄이는 강력한 출발점이 될 것이라고 믿는다.
6.7 Multilingual Question Answering
우리는 **TyDiQA-GoldP 벤치마크 (Clark et al., 2020)**를 사용하여 few-shot 및 fine-tuning 설정 모두에서 다국어 질문 응답(Multilingual Question Answering)에 대한 모델을 평가한다. few-shot 설정에서는 context, question, answer를 모두 개행 문자(new line characters)로 구분하여 제공한다. 모든 언어에 대해 질문은 "Q:", 답변은 "A:"로 표시한다. 다른 task와 마찬가지로, few-shot 예시들은 개행 문자로 구분된다. fine-tuning의 경우, English SuperGLUE fine-tuning 실험과 동일한 하이퍼파라미터 세트를 사용한다. 구체적으로, 학습률(learning rate)은 , Adafactor accumulators는 재설정하고, batch size는 32를 사용한다. 우리는 전체적으로 가장 좋은 checkpoint의 결과를 보고한다.
| Model | Ar | Bn | En | Fi | Id | Ko | Ru | Sw | Te | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| mT5 XXL | 76.9 | 80.5 | 75.5 | 76.3 | 81.8 | 75.7 | 76.8 | 84.4 | 83.9 | 79.1 |
| ByT5 XXL | 80.0 | 85.0 | 77.7 | 78.8 | 85.7 | 78.3 | 78.2 | 84.0 | 85.5 | 81.4 |
| PaLM 540B (finetuned) | 75.0 | 83.2 | 75.5 | 78.9 | 84.1 | 75.7 | 77.1 | 85.2 | 84.9 | 80.0 |
| PaLM 540B (few-shot) | 65.5 (10) | 60.5 |
Table 17: TyDiQA-GoldP validation set에 대한 SOTA 비교 (exact match metric).
Table 17은 TyDiQA-GoldP 벤치마크에 대한 결과를 보고한다. 예상대로, few-shot과 fine-tuning 품질 사이에 평균적으로 큰 격차가 있음을 발견했다. 흥미롭게도, 스와힐리어(Swahili) 및 핀란드어(Finnish)와 같은 특정 언어에서는 그 격차가 작다. 다국어 데이터셋에 대한 prompt engineering 및 multi-task adaptation에 대한 추가 연구는 few-shot 결과 개선에 도움이 될 수 있다.
우리는 PaLM 540B가 비영어 데이터(총 780B 학습 토큰 중 약 22%)를 많이 학습하지 않았음에도 불구하고 이 task에서 매우 경쟁력 있는 결과를 달성했음을 보여준다. 이에 비해 mT5 (Xue et al., 2021b)와 ByT5 (Xue et al., 2021a)는 PaLM보다 각각 6배, 1.5배 많은 비영어 텍스트로 학습되었다. PaLM 540B는 mT5 XXL을 능가하지만, ByT5 XXL에는 미치지 못한다. 우리는 SuperGLUE 실험과 유사하게, causal language model loss objective와 decoder-only architecture가 discriminative fine-tuning에 최적화되지 않았을 수 있다고 추측한다. 또한, 사전학습 데이터셋에서 비영어 데이터의 비율을 늘리면 fine-tuning 결과도 향상될 수 있다. 그러나 autoregressive language model을 540B 규모로 확장하는 것이 많은 잘 확립된 벤치마크에서 SOTA에 가까운 성능을 달성하고, 어느 정도 특정 아키텍처적 단점이나 inductive bias를 극복할 수 있다는 점은 고무적이다.
6.8 Analysis
이 섹션에서는 PaLM 모델의 few-shot 성능에 대한 심층 분석을 제시한다. 먼저, Section 6.1에서 평가된 **5가지 task(RTE, Natural Questions, Lambada, Story Cloze, Trivia QA)**에 대해 **세 가지 모델(8B, 62B, 540B)**을 연구한다. 이 task들은 **지식 중심(knowledge-heavy) task(Natural Questions, Trivia QA)**부터 **추론 중심(reasoning-heavy) task(RTE, Lambada, Story Cloze)**까지 다양하게 분포한다. Trivia QA와 Natural Questions는 "closed book" 변형으로, 질문 자체만 입력으로 제공되며 (context document 없음) 별도의 외부 지식 없이 모델의 내재된 지식으로 답변해야 한다. Figure 16은 5가지 task에 대한 3가지 모델 크기의 결과를 보여준다.
또한, 0-shot, 1-shot, 5-shot, 8-shot 학습을 평가하여 모델에 더 많은 예시가 제시될 때 성능이 어떻게 향상되거나 때로는 저하되는지 확인한다. 거의 모든 task와 모델에서 더 많은 예시가 제시될수록 성능이 향상된다. 예외적으로 Trivia QA task에서는 1-shot 학습이 세 가지 모델 크기 모두에서 5-shot 및 8-shot 학습보다 우수한 성능을 보인다.
 Figure 16: 3가지 모델 크기(8B, 62B, 540B)에 대한 5가지 task의 few-shot 학습 성능.
대부분의 task는 few-shot 예시의 수가 증가함에 따라 단조적으로 성능이 향상된다.
Trivia QA와 같은 특정 task는 이러한 경향에서 벗어난다.
few-shot task의 성능은 모델 크기에 따라 잘 확장되며, 540B 모델이 모든 task에서 최고의 성능을 달성한다.
Figure 16: 3가지 모델 크기(8B, 62B, 540B)에 대한 5가지 task의 few-shot 학습 성능.
대부분의 task는 few-shot 예시의 수가 증가함에 따라 단조적으로 성능이 향상된다.
Trivia QA와 같은 특정 task는 이러한 경향에서 벗어난다.
few-shot task의 성능은 모델 크기에 따라 잘 확장되며, 540B 모델이 모든 task에서 최고의 성능을 달성한다.
다음으로, Section 6.1에 제시된 StoryCloze, Natural Questions, Web Questions 벤치마크에서 **few-shot 학습 성능의 분산(variance)**을 연구한다. 우리는 사전학습 과정에서 15개의 서로 다른 균등 간격의 모델 checkpoint를 선택한다. 그런 다음, 모든 다른 checkpoint를 1-shot 학습을 사용하여 평가한다. 각 checkpoint가 2B 사전학습 토큰만큼만 차이가 나기 때문에, 모델 품질에는 큰 영향이 없을 것으로 예상한다. Figure 17은 이 세 가지 task에 대한 1-shot 성능을 비교한다. StoryCloze와 Natural Questions의 경우, 특히 모델 규모 간의 성능 차이와 비교할 때 checkpoint 간의 변동이 상대적으로 미미하다. 그러나 Web Questions의 경우, checkpoint 간의 결과에서 훨씬 더 큰 변동을 관찰한다. 흥미롭게도, PaLM 540B는 7700억 토큰 학습 시점의 checkpoint에서 SOTA 결과를 달성하지만, 그 이후의 checkpoint에서는 더 나쁜 결과를 보인다. 참고로, 다른 섹션에서 제시된 모든 결과는 동일한 checkpoint에서 평가되었다 (checkpoint 선택의 오류로 인해 PaLM 8B 및 540B는 780B, PaLM 62B는 795B).
 Figure 17: 사전학습 과정에서 1-shot 학습의 분산 분석.
checkpoint는 최종 모델 checkpoint까지 2B 토큰 간격으로 배치되어 있다.
540B 모델의 WebQuestions를 제외하고는 유사한 단계에서 점수의 변동이 상대적으로 낮음을 알 수 있다.
참고로, 다른 곳에서는 결과가 이전 checkpoint보다 나쁘더라도 항상 최종 checkpoint의 결과를 제시한다.
Figure 17: 사전학습 과정에서 1-shot 학습의 분산 분석.
checkpoint는 최종 모델 checkpoint까지 2B 토큰 간격으로 배치되어 있다.
540B 모델의 WebQuestions를 제외하고는 유사한 단계에서 점수의 변동이 상대적으로 낮음을 알 수 있다.
참고로, 다른 곳에서는 결과가 이전 checkpoint보다 나쁘더라도 항상 최종 checkpoint의 결과를 제시한다.
7 Memorization
신경망이 훈련 데이터를 암기할 수 있다는 것은 잘 알려진 사실이며, 이는 과적합(overfitting)의 정의이기도 하다. 일반적으로 이러한 유형의 암기는 모델이 작은 훈련 세트를 여러 번 통과할 때 발생한다. 그러나 우리의 경우, PaLM은 780B 토큰 코퍼스를 단 한 번 통과하여 훈련된다. 반면에 우리 모델은 극도로 큰 용량을 가지고 있으므로, 단 한 번의 통과로도 훈련 데이터의 상당 부분을 암기할 수 있다는 것이 타당하다. 또한, 웹에서 파생된 코퍼스에 거의 중복되는 텍스트가 존재하기 때문에, 일부 구절(사소한 변형 포함)은 훈련 중에 여러 번 나타난다 (Lee et al., 2021).
이 섹션에서는 PaLM 모델이 훈련 데이터를 어느 정도 암기했는지 분석한다. 이를 평가하기 위해, 훈련 예시에서 무작위로 100개의 토큰 시퀀스를 선택하고, 시퀀스의 처음 50개 토큰을 모델에 prompt로 제공했다. 우리는 greedy decoding을 실행하고, 모델이 훈련 예시와 정확히 일치하는 50개 토큰의 연속(continuation)을 얼마나 자주 생성하는지 측정했다. 이 방법론은 **Carlini et al. (2022)**의 연구를 따르며, 그들은 50개에서 500개 토큰까지의 prompt 길이를 실험했다.
Figure 18(a)는 세 가지 모델 규모에 걸친 암기 일치율을 보여준다. 8B 모델은 데이터의 **1.6%**에 대해 50개 토큰 연속을 정확히 재현할 수 있었고, 540B 모델은 데이터의 **2.4%**에 대해 연속을 재현할 수 있었다. 우리는 또한 훈련 데이터와 동일한 분포에서 샘플링된 held-out 데이터에 대한 "암기"율도 평가했다. held-out 데이터의 암기율이 0%보다 큰 이유는 일부 held-out 예시가 훈련 세트 예시와 매우 유사하기 때문이다. 예를 들어, 연도만 변경된 상용구 오픈 소스 코드 라이선스와 같은 경우이다.
 Figure 18: (a) 세 가지 모델 크기에 대해 암기된 훈련 예시의 비율. Held-out 데이터는 훈련 데이터와 동일한 분포에서 가져왔지만, 훈련에서 정확히 관찰되지는 않았다. (b) 훈련에서 예시가 관찰된 횟수를 기반으로 한 암기율의 log-log 플롯. (c) 코퍼스별로 분류된 암기된 예시의 비율.
Figure 18: (a) 세 가지 모델 크기에 대해 암기된 훈련 예시의 비율. Held-out 데이터는 훈련 데이터와 동일한 분포에서 가져왔지만, 훈련에서 정확히 관찰되지는 않았다. (b) 훈련에서 예시가 관찰된 횟수를 기반으로 한 암기율의 log-log 플롯. (c) 코퍼스별로 분류된 암기된 예시의 비율.
Figure 18(b)는 훈련 예시가 훈련 데이터에서 정확히 관찰된 횟수의 함수로서 암기율을 보여준다. 훈련에서 정확히 한 번 관찰된 예시는 가장 큰 모델에서 0.75%의 암기율을 보인 반면, 500번 이상 관찰된 예시는 40% 이상의 암기율을 보였다. 이렇게 높은 중복율을 가진 예시가 존재하는 이유는 우리의 훈련이 전체 문서에 대해서만 중복 제거를 수행하며, 여기서는 100개 토큰 범위에 대한 암기를 평가하기 때문이다.
Figure 18(c)는 훈련 데이터 코퍼스별로 분류된 세 가지 모델의 암기율을 보여준다. 암기된 예시들을 분석한 결과, 가장 큰 차이점은 훈련 데이터 내에서 예시의 정확한 중복, 거의 중복, 또는 템플릿화된 정도라는 결론을 내렸다. 코드 코퍼스에는 상당량의 상용구 라이선스 문자열, 다른 곳에서 복사된 공유 코드 스니펫, 그리고 자동으로 생성된 코드가 포함되어 있다. 책 코퍼스는 주로 진정으로 고유한 텍스트 문자열을 포함한다.
이러한 결과로부터 암기에 대해 다음과 같은 결론을 내릴 수 있다:
- 더 큰 모델은 더 작은 모델보다 더 높은 암기율을 보인다. log-linear fit의 기울기는 Carlini et al. (2022)에서 이전에 관찰된 것과 매우 유사하다 (우리는 PaLM에 대해 인 0.002의 기울기를 발견했으며, Carlini et al. (2022)는 GPT-Neo 모델 계열에 대해 인 0.002의 기울기를 발견했다).
- held-out 결과에서 입증되었듯이, 일정량의 "암기"는 예상된다. 모델이 일반적인 템플릿과 상용구에 대해 정확히 일치하는 연속을 생성할 것이기 때문이다. 그러나 훈련 데이터에 대한 암기율은 held-out 데이터보다 훨씬 높으며, 이는 모델이 데이터의 일부를 실제로 암기한다는 것을 나타낸다.
- 예시가 암기될 가능성은 훈련에서의 고유성과 강하게 상관관계를 가진다. 한 번만 관찰된 예시는 여러 번 관찰된 예시보다 암기될 가능성이 훨씬 낮다. 이는 이전 연구 (Lee et al., 2021; Kandpal et al., 2022; Carlini et al., 2022)와 일치한다.
우리는 대부분의 암기 사례가 Table 39에 표시된 예시와 같이 우려를 유발할 가능성이 낮은 정형화된 텍스트임을 발견했다. 그러나 우리는 이야기, 뉴스 기사, 사실의 암기도 관찰했다. 실제로 추출 가능한 암기된 콘텐츠의 양은 훈련 데이터셋, 모델 크기, 그리고 추출 공격을 수행하는 사람들이 prompt로 사용할 훈련 세트의 텍스트에 대한 지식을 가지고 있는지 여부에 따라 달라진다. 예를 들어, Carlini et al. (2022)는 더 긴 prompt가 더 많은 암기 사례를 발견한다는 것을 보여준다. 그러나 단순히 추출 가능한 훈련 세트 텍스트의 양을 측정하는 것만으로는 이러한 암기가 문제가 되는지 여부에 대해 아무것도 알 수 없다.
암기가 문제가 되는지 여부는 **데이터셋의 속성("데이터셋에 표면화될 경우 유해할 수 있는 텍스트가 포함되어 있는가?")**과 **대상 애플리케이션("암기된 텍스트가 생성될 경우 부정적인 결과가 있는가?")**에 따라 달라진다. 따라서 대규모 language model의 다운스트림 애플리케이션을 선택할 때는 항상 신중해야 한다. 생성 시 암기를 방지하기 위한 계산적으로 효율적이지만 메모리 집약적인 접근 방식 중 하나는 훈련 데이터에 대한 bloom filter를 구현하고, 훈련 데이터셋에 정확히(verbatim) 나타나는 시퀀스가 생성되지 않도록 제한하는 것이다. 일부 소스의 데이터는 다른 소스보다 암기될 경우 더 문제가 될 수 있으므로, 이러한 접근 방식은 데이터의 일부에 대해서만 bloom filter를 구축하여 메모리 효율성을 높일 수 있다. 이 접근 방식은 정확히 암기된 콘텐츠를 제거하지만, 대략적으로 암기된 콘텐츠(훈련 세트 텍스트와 한두 단어만 다른 생성물)는 여전히 생성될 수 있다. 궁극적으로, 최고의 완화 전략은 대규모 language model을 긴 시퀀스 생성에 사용하는 것이 적절한 시기를 신중하고 의도적으로 선택하는 것이다.
8 Dataset Contamination
이전 연구들(Brown et al., 2020; Wei et al., 2022a; Du et al., 2021)은 벤치마크 평가 세트와 학습 데이터 간에 매우 높은 데이터 중복률을 보고했다. 이 연구들은 단순히 전체 평가 예시 텍스트와 학습 데이터 간의 고차 n-gram(예: 13-gram) 발생 여부를 확인하고, 중복이 있는 모든 예시를 "오염된(contaminated)" 것으로 간주했다. 그러나 많은 벤치마크는 오픈 웹에서 일부 context를 가져온 다음, annotator에게 해당 context에 대한 새로운 질문/답변을 생성하도록 요청하거나(또는 자동으로 생성된 질문에 답변하도록 요청) 하여 구성된다. 이러한 task의 경우 평가 시점에 context가 제공되므로, 모델이 이전에 language modeling objective를 위해 해당 context로 학습했더라도 평가 시점에 불공정한 이점을 얻는 것은 아니다.
여기서는 단순히 고차 n-gram 중복을 찾는 대신, 29개의 주요 영어 NLP 벤치마크 task에 대한 통계를 계산하고, 각 task에서 많은 수의 예시를 수동으로 검토하여 오염된 예시의 비율이 높은 것을 식별했다. 이는 각 데이터셋이 원래 어떻게 구성되었는지에 대한 지식과 함께 수행되었다.
29개의 벤치마크 task는 대략 네 가지 범주로 나눌 수 있다:
- 전체 오염(Wholesale contamination): 데이터셋의 상당 부분이 오픈 웹에 나타나는 데이터셋. 이들은 오염된 것으로 간주한다. 예시: SQuADv2, Winograd.
- 웹에서 구성(Constructed from web): 질문 + 답변(또는 prefix + continuation)이 오픈 웹에서 자동으로 추출된 데이터셋으로, 많은 평가 예시가 학습 데이터에 포함될 가능성이 높다. 이들은 오염된 것으로 간주한다. 예시: Web Questions, ReCoRD, Lambada.
- 웹상의 Context(Context on web): context는 웹에서 가져왔지만 질문은 그렇지 않은 질문-답변 데이터셋. 이들은 오염된 것으로 간주하지 않는다. 예시: BoolQ, Multirc, ANLI.
- 유의미한 중복 없음(No significant overlap): 일반적인 n-gram 외에는 학습 데이터와 유의미한 중복이 없는 데이터셋. 이러한 n-gram은 어떤 대규모 학습 코퍼스에서도 예상되는 것이다. 예시: StoryCloze, OpenbookQA.
우리는 29개 세트 중 10개가 처음 두 범주에 속한다는 것을 발견했다. 이 세트들 중 실제로 학습 데이터에서 발견된 평가 예시는 일부에 불과했다. 이는 우리의 학습 코퍼스가 약 2천억 단어의 샘플링/필터링된 영어 웹 데이터만 포함하는 반면, 전체 웹은 수조 개의 토큰을 포함하기 때문이다. 따라서 우리는 질문, prompt 또는 target에 있는 8-gram 중 최소 70%가 학습 데이터에서 한 번 이상 발견되었는지 여부에 따라 각 데이터셋을 "오염된(contaminated)" 하위 세트와 "깨끗한(clean)" 하위 세트로 나눌 수 있었다. Table 18에서는 깨끗한 부분과 전체 세트에 대한 결과를 보고한다.
깨끗한 하위 세트에서 양의 정확도 delta와 음의 정확도 delta를 가진 세트의 수가 동일하다는 것을 알 수 있으며, 이는 데이터 오염이 보고된 결과에 의미 있는 인플레이션을 유발하지 않음을 시사한다. 양의 delta는 데이터 오염이 결과를 부풀리지 않는다는 증거로 작용하는 반면, 음의 delta는 데이터 오염으로 인해 결과가 부풀려졌을 가능성에 대한 증거로 작용한다. 물론, 우리는 데이터의 다른 하위 세트를 평가하고 있으므로(CB와 같은 일부 테스트 세트는 상당히 작음) 이는 동일한 조건에서의 비교(apples-to-apples comparison)는 아니다. 그러나 540B 모델이 평가 세트의 많은 부분을 단순히 암기했다면, 540B 모델이 훨씬 더 큰 암기 용량을 가지고 있기 때문에 깨끗한 하위 세트에서 8B 모델보다 더 큰 음의 delta를 보일 것으로 예상할 수 있다. Table 18에서 보듯이, 8B와 540B 모델 모두 깨끗한 검증 세트와 전체 검증 세트 간에 거의 비슷한 수의 음의 delta를 가지고 있다.
| Dataset | Clean Proportion | PaLM 8B 1-Shot | PaLM 540B 1-Shot | ||
|---|---|---|---|---|---|
| Full Set Accuracy | Clean Subset Delta | Full Set Accuracy | Clean Subset Delta | ||
| TriviaQA (Wiki) | 80.1% | 48.5 | +0.5 | 81.4 | +0.1 |
| WebQuestions | 73.3% | 12.6 | +1.1 | 22.6 | +0.3 |
| Lambada | 70.7% | 57.8 | +0.6 | 81.8 | +0.0 |
| Winograd | 61.5% | 82.4 | -4.4 | 87.5 | -1.8 |
| SQuADv2 (F1) | 14.8% | 50.1 | -2.5 | 82.9 | +1.1 |
| ARC-e | 69.6% | 71.3 | -0.3 | 85.0 | -0.4 |
| ARC-c | 75.3% | 42.3 | +0.4 | 60.1 | -1.1 |
| WSC | 63.2% | 81.4 | -1.4 | 86.3 | -3.5 |
| ReCoRD | 56.6% | 87.8 | -2.0 | 92.8 | -1.6 |
| CB | 51.8% | 41.1 | -3.1 | 83.9 | +5.8 |
Table 18: 10개의 부분적으로 오염된 영어 NLP task의 "깨끗한" 하위 세트에 대한 성능. 예를 들어, WebQuestions의 경우 dev 세트 예시의 73.3%가 깨끗했으며, 깨끗한 하위 세트의 PaLM 540B 1-shot dev 정확도는 22.6 + 0.3 = 22.9였다.
우리는 기계 번역에 대해서도 유사한 분석을 수행했다. 전체 오염은 발견되지 않았지만, 이러한 데이터셋이 구성된 방식 때문에 학습 데이터에 나타나는 다수의 target reference sentence가 있음을 발견했다. 이러한 예시들은 일반적으로 학습 데이터에 source와 target이 모두 포함되어 있지 않다는 점에 유의해야 한다. 따라서 우리는 target reference sentence가 학습 데이터와 높은 n-gram 중복을 보이는 평가 예시를 제거하여 이러한 세트의 깨끗한 하위 세트를 만들었다. 결과는 Table 19에 제시되어 있다. 6개 세트 중 5개 세트에서 깨끗한 세트와 전체 세트 간에 BLEU 점수가 매우 유사하다는 것을 알 수 있다. De-En에 대한 결과는 깨끗한 세트에서 약 3.0 BLEU 더 나쁘지만, 이 delta는 규모에 따라 일관적이다. Section 7에서 8B 모델이 540B보다 훨씬 적은 암기 용량을 가지고 있음을 알고 있으므로, 이 차이가 주로 암기 때문이라면 8B에서 delta가 더 작을 것으로 예상할 수 있다.
| Language Pair | Clean Proportion | PaLM 8B 0-shot | PaLM 62B 0-shot | PaLM 540B 0-shot | |||
|---|---|---|---|---|---|---|---|
| Full Set BLEU | Clean Set BLEU | Full Set BLEU | Clean Set BLEU | Full Set BLEU | Clean Set BLEU | ||
| En-Fr | 88.9% | 21.4 | 21.6 | 25.5 | 25.0 | 38.2 | 38.4 |
| En-De | 96.5% | 17.8 | 17.9 | 15.0 | 14.8 | 31.8 | 31.8 |
| En-Ro | 94.3% | 7.6 | 7.6 | 15.2 | 15.1 | 24.3 | 24.2 |
| Fr-En | 64.0% | 33.9 | 34.2 | 35.3 | 36.4 | 40.2 | 41.1 |
| De-En | 74.2% | 31.7 | 34.9 | 31.5 | 34.8 | 40.4 | 43.8 |
| Ro-En | 75.2% | 31.9 | 31.6 | 31.8 | 32.0 | 39.6 | 39.9 |
Table 19: 0-shot 기계 번역 task의 "깨끗한" 하위 세트에 대한 성능.
9 Exploring Explanations
Section 6.3에서는 **chain-of-thought prompting (Wei et al., 2022b)**이 다단계 추론 task에서 예측 정확도를 어떻게 크게 향상시킬 수 있는지 경험적으로 입증하였다. 이 경우, 모델이 생성한 추론 체인(reasoning chain)은 평가 시 사용되지 않았지만, 오류 분석은 Appendix Figures 28과 29에 제시되어 있다. 물론, 이러한 설명적 생성(explanatory generation)은 정확도 향상 외에도 여러 면에서 유용할 수 있다. 첫째, 모델이 단순히 표면적인 통계적 추론을 하는 것이 아니라, "올바른 이유"로 정답을 도출하는지 여부를 아는 것은 과학적으로 매우 흥미로운 일이다. 둘째, 설명은 시스템의 최종 사용자에게 제공되어 주어진 예측에 대한 신뢰도를 높이거나 낮추는 데 활용될 수 있다. 셋째, 많은 상황(예: 농담 설명)에서 설명 자체가 원하는 출력이기도 하다.
이 섹션의 목표는 chain-of-thought prompting을 활용한 PaLM의 설명적 언어 생성 능력을 보여주는 것이다. 우리가 제시하는 예시들은 **논리적 추론 연결, 세계 지식, 추상적 언어 이해, 그리고 어휘적 언어 이해(예: 말장난)**의 복잡한 조합을 요구한다. 이를 위해 우리는 "농담 설명하기(Explaining a Joke)"와 "논리적 추론(Logical Inference)"이라는 두 가지 예비 task에 대한 모델 출력을 제시한다. 각 task에 대해 우리는 원하는 출력 스타일을 보여주는 2-shot exemplars와 모델에 prompt로 제공할 여러 예시를 작성했다. exemplars와 평가된 예시 모두 저자들이 작성하고 선택했지만, 우리는 이러한 결과가 PaLM의 언어 이해 능력에서 획기적인 숙련도를 보여준다고 믿는다. 이는 이 분석이 수행된 방식과 관련된 몇 가지 핵심 요소 때문이다:
- 모든 예측은 동일한 2-shot exemplars로 생성되었으며, 이 exemplars는 우리가 평가하는 예시들과 내용이 아닌 스타일적인 측면에서만 관련이 있다. 또한, 전체 exemplar prompt는 어떤 예시도 평가하기 전에 작성되었으며, 모델 출력 검토를 기반으로 수정된 적이 없다.
- 모든 출력은 temperature sampling이 아닌 greedy decoding으로 생성되었다. 이는 매우 중요한데, 각 출력이 모델의 정규적인 1-best 예측이며, 지수적으로 많은 가능한 출력 중 하나가 아니라는 것을 의미하기 때문이다.
- 이러한 task의 목적이 모델이 철저한 자연어 설명을 생성하도록 유도하는 것이기 때문에, 단순한 통계적 상관관계나 "운 좋은 추측"을 통해 greedy decoding이 완전히 정확한 설명을 생성할 가능성은 극히 낮다.
- prompt가 저자들에 의해 작성되었기 때문에, 직접적인 데이터 오염 및 암기(memorization)가 주요 요인이 될 가능성을 완화한다.
이러한 task의 예시는 Figure 19에 제시되어 있다. 우리는 이 섹션의 가장 큰 가치가 단순히 이 예시들을 읽는 것에서 얻어질 수 있다고 믿는다. 비록 이러한 결과가 철저한 정량적 분석과 동일하지는 않지만, 우리는 이것이 정말로 놀라운 수준의 깊이 있는 언어 이해 능력을 보여준다고 생각한다.
Explaining a Joke
나는 이 농담들을 설명할 것이다:
(1) 도벽 환자의 문제는 그들이 항상 모든 것을 **문자 그대로(literally) 가져간다(take)**는 것이다.
 하지만 도벽(kleptomania)의 정의는 말 그대로(literally) 물건을 가져가는(takes things) 사람이다.
하지만 도벽(kleptomania)의 정의는 말 그대로(literally) 물건을 가져가는(takes things) 사람이다.
 그들에게 돈을 빌려주면, 어차피 갚지 않을 것이라고 예상할 것이다.
그들에게 돈을 빌려주면, 어차피 갚지 않을 것이라고 예상할 것이다.
Input: 나는 오후 5시에 논문 작성을 시작하기로 되어 있었다. 그런데 이 멋진 새 language model을 가지고 10분 동안 놀기 시작했다. 10분 후, 갑자기 밤 9시 30분이 되었다! Model Output: 이 농담은 즐거운 시간을 보낼 때 시간이 얼마나 빨리 흐르는지에 대한 것이다. 이 사람은 오후 5시에 논문 작성을 시작하기로 되어 있었지만, 대신 language model을 가지고 놀기 시작했다. 그들은 단 10분만 가지고 놀았다고 생각했지만, 실제로는 4.5시간이 지난 것이었다.
Input: 나는 4월 6일에 가족을 만나러 비행기를 타고 갈 예정이었다. 엄마가 "오, 잘됐다, 그날 밤에 네 새아빠의 시 낭독회가 있어!"라고 말했다. 그래서 이제 나는 4월 7일에 비행기를 타고 간다. Model Output: 이 농담은 화자의 엄마가 새아빠의 시 낭독회에 가도록 설득하려 하지만, 화자는 가고 싶지 않아서 시 낭독회 다음 날로 비행 일정을 변경한다는 내용이다.
Input: 나와 내 파트너가 왜 그렇게 잘 맞는지 알 것 같다. 나는 음식 냄새를 맡으면 흥분하고, 초인종이 울리면 엄청나게 경계한다. 내 여자친구 셸리는 5시간 전에 본 사람을 다시 보면 황홀해한다. Model Output: 이 농담은 개에 대한 것이다. 개는 음식 냄새를 맡거나 초인종이 울리면 흥분한다. 여자친구는 5시간 전에 본 사람을 다시 보고 흥분하는데, 이것은 개의 특징이다.
Input: 나는 neural network를 10,000번 무작위로 재시작했지만, overfitting으로 비난받았다. 좋은 seed는 벌받지 않는 법이 없나 보다. Model Output: 이 농담은 **말장난(pun)**이다. neural network는 데이터로부터 학습할 수 있는 컴퓨터 프로그램이다. "seed"는 난수 생성기를 초기화하는 데 사용되는 숫자이다. "good seed"는 좋은 난수 생성기를 생성하는 숫자이다. "no good deed goes unpunished"라는 문구는 좋은 일을 하면 벌을 받는다는 뜻이다.
Input: 얼룩말과 우산의 차이점은 무엇일까? 하나는 줄무늬가 있는 말과 관련된 동물이고, 다른 하나는 비가 내리는 것을 막기 위해 사용하는 장치이다. Model Output: 이 농담은 **반(反)농담(anti-joke)**이다. 농담의 요점은 답이 너무나 명백하다는 것이며, 당신이 재미있는 답변을 기대했을 것이라는 점이 농담이다.
Input: "전쟁과 평화"를 읽는 것은 나를 두렵게 하지 않는다. 나는 인턴의 마지막 날에 그의 전체 프로젝트에 대한 CL을 검토해야 했다! Model Output: '전쟁과 평화'는 매우 긴 책이므로, 그것을 읽는 것은 벅찬 일이다. 그러나 화자는 인턴의 마지막 날에 그의 프로젝트 코드를 검토해야 했다고 말하는데, 이는 훨씬 더 벅찬 일이다.
Logical Inference
논리적 추론을 하는 방법을 설명하겠다:
 년. 존이 버락 오바마의 취임 전에 태어났다고 추론할 수 있는가?
년. 존이 버락 오바마의 취임 전에 태어났다고 추론할 수 있는가?

 10살이었다. 따라서 존은 오바마의 취임 전에 태어났다고 추론할 수 있다. 답은 "예"이다.
10살이었다. 따라서 존은 오바마의 취임 전에 태어났다고 추론할 수 있다. 답은 "예"이다.
 파티?" 존이 줄리아드에서 피아노를 전공했다고 추론할 수 있는가?
파티?" 존이 줄리아드에서 피아노를 전공했다고 추론할 수 있는가?

 샘이 줄리아드에서 피아노를 전공했다는 것이다. 답은 "아니오"이다.
샘이 줄리아드에서 피아노를 전공했다는 것이다. 답은 "아니오"이다.
Input: 할머니가 병원에 입원했다는 소식을 들었을 때 나는 특정 색깔을 느꼈다. 운전 중에 누군가 내 차를 가로막았을 때 나는 다른 색깔을 느꼈다. 이 두 색깔을 합치면 가장 가능성이 높은 색깔은 무엇일까? Model Output: 할머니가 병원에 입원했다는 소식을 들었을 때 느꼈던 색깔은 슬픈 색깔, 예를 들어 파란색일 가능성이 높다. 운전 중에 누군가 내 차를 가로막았을 때 느꼈던 색깔은 화난 색깔, 예를 들어 빨간색일 가능성이 높다. 이 두 색깔을 합치면 보라색을 볼 가능성이 높다. 답은 "보라색"이다.
Input: 마이클은 프랑스의 아주 유명한 박물관에서 가장 유명한 그림을 보고 있다. 그런데 이 그림을 그린 화가는 마이클에게 어린 시절 가장 좋아했던 만화 캐릭터를 떠올리게 한다. 그 만화 캐릭터가 보통 손에 들고 다니는 물건의 원산지는 어디인가? Model Output: 루브르 박물관에서 가장 유명한 그림은 모나리자이다. 모나리자를 그린 화가는 레오나르도 다빈치이다. 레오나르도 다빈치는 만화 닌자 거북이의 주인공 이름이기도 하다. 레오나르도 다빈치는 이탈리아 출신이다. 레오나르도 다빈치가 보통 손에 들고 다니는 물건은 카타나이다. 카타나의 원산지는 일본이다. 답은 "일본"이다.
Input: 귀도는 Python 프로그램을 작성하고 있었다. 그는 계속해서 변수 스코프 때문에 혼란스러워하며 StackOverflow를 찾아보고 있다. prompt에 나오는 귀도가 Guido van Rossum일 가능성이 있는가? Model Output: Guido van Rossum은 Python의 창시자이다. 그는 변수 스코프를 StackOverflow에서 찾아볼 필요가 없을 것이다. 답은 "아니오"이다.
Input: 트레버는 오랫동안 머리 조각들이 있는 산을 보고 싶어 했고, 마침내 차를 몰고 가서 보았다. 트레버가 현재 있는 주 바로 동쪽에 있는 주의 수도는 어디인가? Model Output: 머리 조각들이 있는 산은 러시모어 산이다. 러시모어 산은 사우스다코타에 있다. 사우스다코타 바로 동쪽에 있는 주는 미네소타이다. 미네소타의 수도는 세인트폴이다. 답은 "세인트폴"이다.
Input: 제니퍼는 창밖을 내다보니 멋진 구름이 아래에 보였다. 그녀는 안전벨트를 풀고 화장실로 향했다. 제니퍼는 지구에 대해 시속 300마일 이상으로 이동하고 있을 가능성이 높은가? Model Output: 시속 300마일은 약 480km/h이다. 이는 상업용 비행기의 속도와 비슷하다. 구름은 보통 비행기 아래에 있으므로, 제니퍼는 아마 비행기 안에 있을 것이다. 답은 "예"이다.
Figure 19: 각 "Input"은 상단에 표시된 동일한 2-shot 예시와 함께 독립적으로 추가되었으며, "Model Output"은 PaLM 540B의 greedy decoding 출력을 보여준다. 두 가지 예시 농담은 잘 알려진 농담이며 (설명은 저자가 작성), 평가된 모든 농담은 저자가 작성했다. 물론, 이 농담들은 기존 농담들과 추상적인 전제(말장난, 신뢰성, 유머러스한 비유, 예상 뒤집기)를 공유한다. 추론 연결 예시 또한 저자가 작성했다.
10 Representational Bias Analysis
사전학습된 language model은 기저 데이터에 존재하는 편향을 포함하고 증폭시키는 것으로 나타났다 (Sheng et al., 2021; Kurita et al., 2019; Dev et al., 2019). 또한, 모델의 인프라를 명확히 전달하는 것의 중요성도 강조되어 왔다 (Mitchell et al., 2019). 우리는 Appendix D에 데이터시트를, Appendix E에 모델 카드를 제공하여 모델의 의도된 사용법, 사용된 데이터셋 등을 상세히 설명한다. 이 섹션에서는 PaLM에 대해 **사회 집단과 관련된 분포적 편향(distributional biases)**과 **open-ended 언어 생성에서의 유해성(toxicity)**을 분석한다. 이 분석은 모델의 잠재적 위험 중 일부를 개략적으로 설명하는 데 도움이 되지만, 실질적인 피해를 측정하고, 맥락화하며, 완화하기 위해서는 domain 및 task별 분석이 필수적이다.
10.1 Distributional bias in social groups
10.1.1 Gender and occupation bias
Coreference resolution은 질문 응답, 요약, 번역과 같은 언어 시스템에 있어 중요한 언어학적 능력이다 (Stanovsky et al., 2019; Webster & Pitler, 2020). 영어에서 대명사는 의미론적 성별로 표시되며, coreference resolution 성능은 성별과 선행 명사 간의 의도치 않은 편향에 의해 영향을 받을 수 있다. 우리는 Winogender 벤치마크를 사용하여 이러한 편향의 한 측면을 평가한다. 이 벤치마크는 "nurse" 및 "electrician"과 같은 영어 직업 명사에서 성별 편향을 측정한다 (Rudinger et al., 2018).
Winogender에서는 multiple choice scoring이 일반적으로 사용되며 (Brown et al., 2020; Rae et al., 2021; Du et al., 2021), 이는 모델이 해당 답변을 생성할 확률로 각 잠재적 답변의 점수를 매기는 방식이다. 정답 옵션의 확률이 해당 예시에 대해 정의된 다른 옵션보다 높을 때 예시는 정답으로 채점된다. 중요한 점은, 이 채점 방식은 모델이 정답을 생성할 절대 확률이 상당히 낮더라도 예시가 정답으로 채점될 수 있다는 것이다. 일반적으로 사용되지만, 우리는 이 채점 방식으로부터 정확도를 계산하는 것이 모델 성능을 과대평가하며, 특히 옵션이 거의 정의되지 않은 0-shot 설정에서 그렇다는 것을 발견했다. 540B 모델의 multiple choice scoring 및 generative output 예시는 다음과 같다:
Input (0-shot): The nurse notified the patient that his shift would be ending in an hour. "his" refers to: Multiple choice scoring: p(nurse) = 0.0395 (patient) = 0.0197 Multiple choice evaluation: Correct answer [Ground truth = nurse, and p(nurse) > p(patient)] Generative prediction: a. the patient b. the nurse c. the shift d. the hour
0-shot generative의 경우, 모델이 task를 이해하지 못하고 객관식 시험을 작성하는 것을 모방하기 시작한다는 점에 유의해야 한다. generative scoring의 경우, 우리는 대소문자를 구분하지 않는 정확한 문자열 일치(case-insensitive exact string matching)를 사용한다. 모델 출력은 구두점 또는 줄 바꿈에서 잘린다.
Winogender에 대한 전체 결과는 Figure 20에 제시되어 있다. 우리는 정확도가 모델 규모에 따라 향상되며, PaLM 540B가 1-shot 및 few-shot 설정에서 새로운 state-of-the-art를 달성한다는 것을 발견했다. 1-shot 설정에서 PaLM 540B는 multiple choice scoring으로 79.4%의 정확도를 (GLaM 1-shot 71.7%), 더 엄격한 generative scoring으로는 69.7%의 정확도를 보인다. 특히 주목할 만한 점은 PaLM 540B의 성능이 4-shot 설정에서 84.7%의 정확도로 향상된다는 것이다. 이는 더 엄격한 generative scoring 방식을 사용했을 때도 마찬가지이다. 이러한 개선은 유망하지만, 이 성능은 여전히 task-adapted 모델 (예: Sanh et al. (2021)의 entailment task로 구성된 경우) 및 인간 성능인 95.9% (Rudinger et al., 2018)에는 미치지 못한다.
 Figure 20: PaLM 62B 및 540B의 Winogender 전체 정확도를 다양한 채점 방식을 사용하여 나타낸 그래프. PaLM 540B는 generative scoring 방식을 사용했을 때도 1-shot 및 few-shot 설정에서 새로운 state-of-the-art 성능을 달성한다.
Figure 20: PaLM 62B 및 540B의 Winogender 전체 정확도를 다양한 채점 방식을 사용하여 나타낸 그래프. PaLM 540B는 generative scoring 방식을 사용했을 때도 1-shot 및 few-shot 설정에서 새로운 state-of-the-art 성능을 달성한다.
이전 연구와 마찬가지로, 우리는 Winogender를 고정관념적(stereotypical) 또는 함정(gotcha) 하위 집합으로 분리한 비집계(disaggregated) 정확도도 추가로 보고한다 (Rudinger et al., 2018). 고정관념적 어노테이션의 경우, 선행사가 직업일 때 성별+직업 쌍은 2015년 미국 BLS 직업 통계에 따라 직업의 다수 성별과 일치한다 (예: "nurse"와 "her"). 반면, 함정 어노테이션의 경우 이 관계가 반전된다 (예: "nurse"와 "his"). 참가자가 선행사인 경우, 반전된 예시는 고정관념적 집합의 일부이며, 함정의 경우 그 반대이다. Winogender는 또한 성 중립 대명사 ("they", "their", "them")를 포함하며, 이는 중립(neutral) 분할의 일부이다. 모든 경우에, 올바른 예측은 제공된 맥락에서 (인간에 의해) 명확하게 추론될 수 있으므로, 고정관념적 하위 집합과 함정 하위 집합 간의 격차는 모델이 통계적 지름길(statistical shortcuts)에 얼마나 의존하는지를 측정하는 강력한 척도이다 (Geirhos et al., 2020). 모든 경우에, few-shot 예시는 전체 720개 예시 세트에서 무작위로 샘플링되었으며, 현재 평가 중인 예시는 제외되었다.
 Figure 21: PaLM 540B의 비집계(disaggregated) Winogender 정확도를 나타낸 그래프. "Stereotypical"과 "gotcha"는 2016년 미국 BLS 직업 데이터에 기반하여 정답을 추론할 수 있는지 여부를 나타낸다 (Rudinger et al., 2018). "gotcha" 예시에서 성능이 더 낮다.
Figure 21: PaLM 540B의 비집계(disaggregated) Winogender 정확도를 나타낸 그래프. "Stereotypical"과 "gotcha"는 2016년 미국 BLS 직업 데이터에 기반하여 정답을 추론할 수 있는지 여부를 나타낸다 (Rudinger et al., 2018). "gotcha" 예시에서 성능이 더 낮다.
Figure 21은 성별로 세분화된 비집계(disaggregated) 정확도를 제시한다 (Barocas et al., 2021). 우리는 고정관념적 예시에서 함정 예시보다 정확도가 더 높으며, 여성 성별에 대한 함정 예시에서 정확도가 가장 낮다는 것을 발견했다. 고무적인 점은, 이러한 슬라이스 전반에 걸쳐 성능 격차가 shot 수에 따라 개선된다는 것이다: 1-shot 설정에서는 14.1%에서 10.1% 포인트로, 4-shot 설정에서는 18.3%에서 9.2% 포인트로 개선된다. 성능 차이는 학습 세트의 영어 대명사 빈도 차이 (중립 7억 7천만, 남성 6억 2천만, 여성 3억 8천 1백만)와 관련이 있을 수 있지만, 우리는 정확도와 Appendix C에서 식별된 직업 순위 사이에 명확한 관계를 발견하지 못했다.
10.1.2 Toxicity and bias
Brown et al. (2020)에서 설명된 것과 유사한 절차에 따라, 우리는 "{term} was very..." 와 같은 prompt가 주어졌을 때 모델의 생성 텍스트(continuation)에서 자주 함께 나타나는 단어들을 분석한다. 여기서 **{term}**은 성별, 종교, 인종 및 민족 정체성을 나타낸다. 각 prompt (Table 34)에 대해 top-k 샘플링 (k=40) 및 온도(temperature) 1.0을 사용하여 800개의 출력을 생성한다. **기성 POS tagger (Bird & Loper, 2004)**를 사용하여 불용어(stop words)를 제거하고 서술적인 단어(즉, 형용사 및 부사)만 선택한다. Brown et al. (2020)과 유사하게, 우리는 분석의 투명성과 재현성을 높이기 위해 어떠한 수동적인 사람 라벨링도 생략한다.
정체성 그룹을 지칭하지 않는 서술적인 단어들을 세는 것에서 발생하는 노이즈를 줄이기 위해, 우리는 128개의 디코딩 스텝을 사용하여 생성된 전체 텍스트가 아닌, 첫 번째 완전한 문장에만 존재하는 형용사와 부사의 개수를 계산한다. 우리는 동일한 라이브러리 (Bird & Loper, 2004)를 사용하여 단락을 문장으로 토큰화한다. Table 35는 성별 대명사에 대한 prompt-template에 대한 응답으로 가장 자주 나타나는 서술적인 단어들을 보여주며, Table 36과 37은 인종 및 종교 prompt에 대한 동일한 결과를 보여준다.
우리는 이 방법을 사용했을 때 특정 차원에서 다른 차원보다 편향이 더 두드러지게 나타남을 확인했다. 특히 Table 37에서 이슬람은 'terrorist', 'violent', 'radical'과 같은 매우 강렬한 용어 및 고정관념과 연관되어 있음을 볼 수 있으며, 이는 anti-Muslim 편향을 드러낸 다른 decoder-only 모델 평가 (Abid et al., 2021)와 유사하다. 인종 정체성 동시 발생 분석은 몇 가지 통찰을 제공한다. 첫째, 인종 정체성 용어들은 종종 서로 함께 나타나, 해당 문장에서 정체성들 간의 관계(있다면)에 대한 의문을 제기한다. 둘째 통찰은 prompt 언어의 작은 변화가 결과에 극적인 변화를 가져온다는 것이다. 특히, "The term was" (대신 "The term was very") prompt를 사용했을 때, Latinx는 'shot', 'allegedly', 'dead', 'unarmed', 'arrested', 'fatally' 와 같이 잠재적으로 폭력적이거나 공격적인 뉘앙스를 가진 여러 동시 발생 단어들을 생성한다.
놀랍게도, Indian은 White와 함께 가장 많이 동시 발생하는 용어였다. 두 용어를 모두 포함하는 문장들을 비포괄적으로 살펴보면, 백인 식민주의자를 지칭하는 "the white man"이라는 문구가 원주민 역사를 묘사하는 글이나 서술에서 흔히 사용되는 미국 기원 콘텐츠에 뿌리를 두고 있음을 시사한다. 한 prompt continuation은 "The White man was very nice to the Indian and told him his name was Columbus, in return the Chief told them the land was called the New World but the White people still called them Indians" 를 생성한다. 많은 continuation은 백인과 아메리카 원주민 간의 식민지 역학 관계를 묘사하는데, 이는 역사적으로 관련성이 있지만, 사용자가 북미 식민지화에 대한 설명에 지나치게 국한되지 않는 언어를 생성하고자 하는 창의적인 애플리케이션의 경우 추가 분석이 필요할 수 있다.
우리의 결과를 검토할 때 정체성 용어가 명확하게 구분되지 않는다는 점을 주목하는 것이 중요하다. prompt의 Indian은 아메리카 원주민과 인도 출신 또는 인도 혈통의 사람들을 구별하지 않는다. 이는 Black과 White에도 해당되며, 이들은 인종 정체성 외의 다른 것들을 지칭하는 데 자주 사용된다. 또한, 사회 인구학적 서술어로서의 white는 다른 인종 및 민족 정체성 용어와 질적으로 다르다. 일반적으로 백인에 대해 묘사할 때 사용되지 않기 때문이다 (Sue, 2006). 이로 인해 white와의 동시 발생은 다른 동시 발생과 비교하기 더 복잡할 수 있는데, white 정체성에 대한 암묵적인 언급은 식별하기 훨씬 어렵고 종종 불가능하기 때문이다.
또한 우리는 62B 및 540B 모델이 매우 유사한 동시 발생 횟수를 보인다는 것을 발견했다. 평균적으로, 인종, 종교, 성별 차원에서 62B 및 540B 모델의 상위 10개 단어 중 70%가 동일하다. 따라서 우리는 기본 학습 데이터가 모델 크기보다 결과에 더 많은 영향을 미친다고 가정한다.
동시 발생 분석은 어떤 용어가 나타나는지뿐만 아니라 다른 용어와 관련하여 어떻게 나타나는지를 조사하기 위한 보완적인 접근 방식의 중요성과 가치를 보여준다. 여기에 사용된 한 가지 접근 방식은 정체성 용어가 포함된 prompt template을 사용하여 모델 완성 텍스트의 유해성(toxicity)을 분석하는 것이다. 종교적 정체성 용어에 대한 동시 발생 분석에서 우리는 **이슬람에 대한 상위 용어로 'terrorist'**를 본다. 다른 용어들은 즉시 두드러진 고정관념을 불러일으키지는 않지만, 우리는 이 결과를 이슬람과 무신론을 포함하는 prompt에 대해 약간 더 높은 유해성 점수를 보여주는 유해성 분석으로 맥락화할 수 있다. 유해성을 바람직하지 않은 설명이나 연관성의 대리 지표로 삼으면, 모델 완성 텍스트가 무슬림을 테러리스트, 극단주의자, 폭력적인 사람으로 잘못 확증하는 고정관념을 강화할 가능성을 볼 수 있다.
따라서 동시 발생 횟수를 계산하는 것 외에도, 우리는 Perspective API를 사용하여 생성 텍스트의 유해성을 분류한다. Perspective API는 텍스트가 무례하거나, 무례하거나, 또는 사람들이 대화를 떠나고 싶게 만들 가능성이 있는 것으로 간주될 확률을 할당한다. Perspective API는 비어 있지 않은 문자열을 요구하므로, 생성 텍스트가 빈 문자열일 경우 유해성 점수를 0.0으로 할당한다. Figure 22는 다양한 종교 그룹에 대해 모델 응답의 유해성 확률 분포를 보여준다. 우리는 유해성 확률에서 높은 분산을 관찰하지만, 이슬람과 유대교가 "All {practitioners} are" prompt에 대한 응답에서 유해한 응답을 생성할 전체 확률이 더 높다는 점에 주목한다. 우리는 Perspective API의 사회적 편향에 영향을 받는다는 점에 유의한다. Perspective API는 특정 정체성 그룹에 대한 무해한 언급에도 더 높은 유해성을 할당할 수 있다 (Dixon et al., 2018; Röttger et al., 2021). 특히, 우리는 "religion practitioners are" prompt에 대한 응답이 "called Jews." (각각 "called Buddhists.")와 같이 짧고 무해한 continuation을 생성하며, 유해성 확률은 0.31 (각각 0.16)로 다양하다는 것을 발견했다.
우리가 수행한 편향 및 유해성 평가는 모든 언어 모델 애플리케이션에 걸쳐 포괄적이지는 않지만, 잠재적인 다운스트림 위험에 대한 중요한 통찰을 제공한다. 우리는 우리의 분석이 편향을 강조하더라도, prompt 구성에 따른 결과의 분산은 template 기반 접근 방식이 prompt 언어의 작은 변화에 매우 취약하다는 것을 강조한다. 강력한 벤치마크와 측정 지표는 편향을 측정하고 완화 전략을 효과적으로 결정하는 데 필수적이다.
 Figure 22: PaLM 540B의 다양한 종교 그룹에 대한 첫 번째 문장에서의 생성 텍스트 유해성 확률 분포.
Figure 22: PaLM 540B의 다양한 종교 그룹에 대한 첫 번째 문장에서의 생성 텍스트 유해성 확률 분포.
10.2 Toxicity in open-ended generation
Toxicity degeneration은 언어 모델이 유해하다고 인식할 수 있는 텍스트를 생성하는 현상을 의미한다. 우리는 toxicity degeneration을 평가하기 위해 Welbl et al. (2021); Rae et al. (2021)에서 사용된 방법론을 적용한다. 우리는 문장 단위의 prompt와 그에 대한 continuation으로 구성된 RealToxicityPrompts 데이터셋 (Gehman et al., 2020)을 활용한다. Perspective API를 사용하여 continuation에 toxicity probability를 할당한 후,
 Figure 23: **Continuation의 toxicity probability (TPC)**를 **Prompt의 toxicity probability (TPP)**의 함수로 나타낸 그래프. Human baseline은 원본 문장 continuation의 toxicity probability를 나타낸다. 모델의 TPC는 human TPC보다 TPP와 더 일관된 경향을 보이는데, 이는 모델이 prompt 스타일에 강하게 영향을 받으며 유사한 방식으로 응답할 가능성이 높음을 시사한다. PaLM 62B와 540B 모델은 매우 유사한 toxicity profile을 가지고 있음에 주목하라.
Figure 23: **Continuation의 toxicity probability (TPC)**를 **Prompt의 toxicity probability (TPP)**의 함수로 나타낸 그래프. Human baseline은 원본 문장 continuation의 toxicity probability를 나타낸다. 모델의 TPC는 human TPC보다 TPP와 더 일관된 경향을 보이는데, 이는 모델이 prompt 스타일에 강하게 영향을 받으며 유사한 방식으로 응답할 가능성이 높음을 시사한다. PaLM 62B와 540B 모델은 매우 유사한 toxicity profile을 가지고 있음에 주목하라.
prompt의 toxicity likelihood에 따라 모델 continuation의 toxicity probability 분포를 연구한다.
무작위로 샘플링된 10,000개의 prompt 세트에 대해, 각 prompt당 25개의 continuation을 생성하며, 각 continuation은 **top-k 샘플링 (k=40)**과 온도(temperature) 1.0을 사용하여 최대 128 decoding step으로 생성한다. 여러 decoding step을 사용했음에도 불구하고, 우리는 첫 번째 완전한 문장 continuation의 toxicity metric만 보고한다. 그 이유는 두 가지이다: (1) human baseline은 단일 문장 continuation으로 구성되어 있어, 단일 문장을 넘어선 담론이 어떻게 전개될지 예측하기 어렵고, (2) Perspective API가 할당하는 toxicity score는 생성된 토큰 수에 비례하여 증가하는 경향이 있는데, 이는 모델이 유해한 콘텐츠를 생성할 기회가 더 많아지고 결과가 텍스트 길이에 대해 정규화되지 않기 때문이다.
Figure 23은 다양한 모델 크기에 대한 prompt의 binned toxicity probability (TPP) 함수로서 continuation의 평균 toxicity probability (TPC)를 나타내는 scaling plot이다. 이전 연구 Rae et al. (2021)에서 관찰된 바와 같이, 우리는 TPC가 TPP에 따라 증가하는 것을 발견했으며, 이는 prompt toxicity와 human baseline보다 일관되게 낮다 (가장 높은 수준의 prompt toxicity를 제외하고). 우리는 8B 모델과 두 개의 더 큰 모델 (62B 및 540B) 사이에서 toxicity probability의 눈에 띄는 증가를 확인했다. 이는 toxicity 수준과 모델 크기 사이에 상관관계가 있음을 시사하지만, 62B 및 540B PaLM 모델의 toxicity profile이 매우 유사하다는 점을 고려할 때 특정 지점까지만 해당된다. 낮은 TPP의 경우, 상대적으로 높은 human TPC는 기본 데이터셋을 생성하는 데 사용된 계층적 샘플링 전략 (Gehman et al., 2020) 때문임을 밝힌다. 우리는 모델 TPC가 human TPC보다 TPP와 더 일관적임을 관찰했다. 이는 모델이 prompt 스타일에 강하게 영향을 받으며 prompt와 유사한 수준의 toxicity를 가진 continuation을 생성할 가능성이 높음을 나타낸다. Table 38에서 모델과 human continuation의 side-by-side 샘플을 공유한다.
TPC는 일반적으로 다른 유사한 연구 (Rae et al., 2021; Gehman et al., 2020)에서 보고된 것보다 낮지만, 이는 toxicity 측정 대상을 첫 번째 완전한 문장으로 제한했기 때문이며, 모델이 유해한 콘텐츠를 생성하는 경향이 낮다는 것을 나타내는 것은 아니다. 이전 연구와의 side-by-side 비교는 다음과 같은 이유로 어렵다: (1) 무작위로 샘플링된 10,000개의 prompt가 다르며, (2) continuation 길이가 보고된 결과에 영향을 미친다. 이는 Table 20에서 첫 번째 문장과 128 decoding step 모두에 대해 유해한 prompt와 비유해한 prompt가 주어졌을 때 최소한 하나의 유해한 댓글을 생성할 확률을 보고함으로써 입증된다.
| First-sentence | 128-decode steps | ||||
|---|---|---|---|---|---|
| Model | Toxic | Non-toxic | Toxic | Non-toxic | |
| PaLM 8B | 0.78 | 0.44 | 0.90 | 0.53 | |
| PaLM 62B | 0.81 | 0.46 | 0.91 | 0.58 | |
| PaLM 540B | 0.80 | 0.46 | 0.91 | 0.56 |
Table 20: 다양한 모델 크기에 대해 25개의 continuation 중 최소 한 번 유해하다고 인식될 수 있는 댓글 (즉, toxicity score > 0.5)을 생성할 확률. 우리는 "Toxic" 및 "Non-Toxic" prompt에 대한 toxicity probability를 계산하고 그 결과를 보고한다. Rae et al. (2021)과 유사하게, 첫 번째 완전한 문장 완성 및 전체 128 decoding step 모두에 대해 metric을 보고한다. Perspective API가 할당하는 toxicity score는 생성된 토큰 수에 비례하여 증가하는 경향이 있는데, 이는 결과가 텍스트 길이에 대해 정규화되지 않기 때문임을 주목하라.
10.3 Limitations
이 섹션에서 제시된 공정성 분석의 주요 한계점은 영어 데이터에 대해서만 수행되었다는 것이다. 반면 PaLM은 다국어 데이터로 학습되었고 다국어 언어 처리 task에서 평가되었다. 대규모 언어 모델을 활용하는 언어 기술이 전 세계의 다양한 지리-문화적 맥락에서 점점 더 많이 사용되고 있다는 점을 고려할 때, 다른 언어 및 사회-문화적 맥락에 대한 편향 벤치마크를 개발하고 활용하는 것이 중요하다. 또한, Sambasivan et al. (2021)이 지적했듯이, 서구 세계에서 개발된 공정성 평가 및 벤치마크는 사회적 불평등이 완전히 다른 축을 따라 나타날 수 있는 다른 지리-문화적 맥락에 쉽게 적용되지 않을 수 있다. 따라서 우리는 현재 측정 가능한 범위를 넘어서는 잠재적 편향이 존재한다는 점을 밝힌다.
더 나아가, 영어 언어 기술의 편향을 조사하는 연구가 증가하고 있음에도 불구하고 (Dev et al., 2021b), 공정성 벤치마크의 표준화가 부족하고, NLP에서 다양한 편향 측정치가 어떤 해악과 관련되는지에 대한 이해가 부족하며 (Blodgett et al., 2020, 2021; Jacobs & Wallach, 2021), 유동적이고 포괄적인 방식으로 정체성을 다루는 범위가 제한적이라는 점을 주목하는 것이 중요하다 (Cao & Daumé III, 2020; Dev et al., 2021a). 따라서 이 섹션의 공정성 평가 역시 동일한 문제점들로 인해 제한되며, 측정 가능한 범위를 넘어서는 잠재적 위험이 존재한다. 우리는 의도치 않은 편향을 평가하기 위한 이전 노력들을 확장하였으며, 우리의 평가는 대명사 해결(pronoun resolution) (Winogender) (Rudinger et al., 2018) 및 동시 발생 분석(co-occurrence analysis)과 같은 일반적인 task에 국한된다. 이러한 벤치마크는 번역, 코드 생성, 상식 추론, open-ended 대화, 산술 추론 및 질문 답변과 같은 task에서 발생할 수 있는 편향(및 그에 따른 해악의 위험)에 대한 대리 지표(proxies)일 수 있다.
또한, 편향은 특정 다운스트림 애플리케이션, 특정 학습 파이프라인, 그리고 애플리케이션 수준의 보호 장치(예: 안전 필터)에 따라 시스템 전반에 퍼질 수 있다. 우리는 여기에서 사전학습된 모델의 공정성과 특정 축을 따른 유해성을 평가하지만, 이러한 편향은 모델이 어떻게 사용되는지에 따라 다양한 다운스트림 영향을 미 미칠 수 있다. 또한, 사전학습된 언어 모델에 대한 평가가 모델이 fine-tuning된 후의 다운스트림 task 평가에 영향을 미치는지도 불분명하다. 따라서, 배포 전에 애플리케이션 맥락에서 공정성 격차를 평가하기 위한 적절한 조치를 취할 것을 권장한다.
11 Ethical Considerations
이처럼 대규모 및 고품질의 언어 모델링 능력은 의료 및 교육 분야를 포함한 다양한 실제 응용 분야에서 잠재력을 발휘할 수 있다 (Bommasani & et. al., 2021).
그러나 최근 연구들은 웹 텍스트로 학습된 이러한 대규모 범용 언어 모델과 관련된 다양한 잠재적 위험을 지적해왔다 (Bender et al., 2021; Bommasani & et. al., 2021). 예를 들어, 학습 데이터에 반영된 사회적 고정관념과 불평등을 영속화하거나 악화시키거나 (Sheng et al., 2021), 개인 정보를 기억하고 노출하거나 (Carlini et al., 2022), 또는 다운스트림에서 해를 끼칠 수 있다 (Weidinger et al., 2021). 이러한 모든 사회적 편향을 데이터와 모델에서 완전히 제거하는 것이 불가능할 수 있으므로, 모델 카드 (Mitchell et al., 2019) 및 데이터시트 (Gebru et al., 2021)와 같은 투명성 아티팩트를 통해 이러한 잠재적인 바람직하지 않은 연관성 및 위험을 분석하고 문서화하는 것이 필수적이다. 이를 위해 우리는 데이터셋 (Appendix C) 및 모델 출력 (Section 7 및 Section 10)에 대한 이러한 편향 및 위험에 대한 철저한 분석을 보고한다. 또한, PaLM의 다운스트림 사용자를 위한 투명성 증대를 위해 데이터시트 (Appendix D) 및 모델 카드 (Appendix E)를 제공한다.
우리의 분석에 따르면, 학습 데이터와 그 결과인 PaLM은 정체성 용어(identity terms)와 관련된 다양한 사회적 고정관념 및 유해성 연관성을 반영하고 있다. 그러나 이러한 연관성을 제거하는 것은 쉽지 않다. 예를 들어, 자동화된 도구에 의해 유해하다고 판단된 콘텐츠를 필터링하면, 학습 데이터에서 소외된 하위 그룹에 대한 또는 그들이 작성한 콘텐츠가 불균형적으로 제외될 수 있다 (Dodge et al., 2021). 향후 연구에서는 데이터 내의 이러한 바람직하지 않은 편향과 모델 행동에 미치는 영향을 효과적으로 다루는 방법을 모색해야 한다. 한편, 다운스트림 task를 위한 PaLM의 모든 실제 사용은 잠재적 피해를 평가하고 적절한 완화 및 보호 조치를 도입하기 위해 추가적인 맥락화된 공정성 평가를 수행해야 한다.
더 나아가, Section 10.3에서 논의했듯이, 우리의 공정성 분석은 범위가 좁으며 다양한 잠재적 위험에 대한 포괄적인 설명을 제공하지 않는다. 예를 들어, 우리는 성별, 인종, 민족 및 종교 축을 따른 편향에 초점을 맞추지만, 영어 데이터 및 모델 출력에 대해서만 분석을 수행한다. 우리는 성적 지향 (Dixon et al., 2018) 또는 장애 (Hutchinson et al., 2020)와 같은 다른 사회적 불평등 축을 따른 편향이나, 카스트 (Sambasivan et al., 2021)와 같이 비서구 사회문화적 맥락에서 두드러지는 편향은 살펴보지 않았다. 따라서, 잠재적 위험을 의미 있게 평가하기 위해서는 대상 응용 도메인 및 사회문화적 맥락과 관련된 불평등 축을 따라 공정성 분석을 수행하는 것이 중요하다.
마찬가지로, 우리의 분석은 데이터 및 모델의 편향에 초점을 맞추지만, 이들이 야기하는 다운스트림 피해는 모델이 실제로 어떻게 사용되는지에 따라 달라질 것이다 (Blodgett et al., 2020; Hutchinson et al., 2020). 예를 들어, 학습 데이터의 유해한 콘텐츠가 추상적으로는 바람직하지 않게 보일 수 있지만, 만약 PaLM이 유해한 콘텐츠를 탐지하는 데 사용된다면 (예: 온라인 콘텐츠 중재), 사전학습된 모델이 그러한 콘텐츠에 노출되었던 것이 중요하다고 주장할 수 있다.
표현 편향 분석 외에도, PaLM의 언어 능력은 학습 데이터 및 평가 벤치마크에 존재하는 언어의 한계에 의해 제약될 가능성이 높다는 점에 유의하는 것이 중요하다. Raji et al. (2021)이 지적했듯이, 벤치마크 평가는 종종 구성 타당성(construct validity)이 부족하여, 언어 이해 능력의 전체 복잡성과 격차를 포착하지 못하고, 일반적인 적용 가능성에 대한 주장을 충족시키지 못할 수 있다. 우리가 제시하는 벤치마크 평가는 이 분야의 과학적 진보를 평가하는 데 유용하지만, 측정하려는 것과 실제로 측정하는 것 사이에는 격차가 있으며, 다양한 실제 응용 맥락에서 유사한 수준의 성능이 보장되지 않는다.
PaLM은 우리가 평가한 벤치마크에서 인상적인 다국어 능력을 보여주지만, 대부분의 벤치마크 (모든 공정성 평가 포함)는 영어로 되어 있다. PaLM이 비영어권 언어에서 사용되기 전에 비영어권 언어에서의 성능 및 잠재적 편향에 대한 보다 강력한 평가가 필요하다. 마찬가지로, 학습 데이터셋에 포함된 웹 페이지는 품질을 평가하기 위해 분류기를 사용하여 필터링되었으며, 이는 콘텐츠 유해성을 제한하고 전문적으로 작성된 콘텐츠를 포함하는 것을 목표로 했다. 그러나 이로 인해 비격식적인 언어, 코드 스위칭, 또는 방언 다양성 (예: Sap et al. (2019))이 불균형적으로 제외되었을 수 있으며, 전 세계 영어권 지역의 비지배적인 방언을 모델링하는 PaLM의 능력을 제한할 수 있다. 마찬가지로, PaLM은 특정 시점 (매우 오래된 텍스트부터 2021년 말까지)의 언어 사용을 나타내므로, 현대적인 비격식 언어나 속어를 모델링하려는 task, 또는 변화하는 언어 규범에 민감할 수 있는 task에서는 시간이 지남에 따라 성능이 저하될 수 있다. 표준 벤치마크는 언어 데이터의 이러한 다양한 측면을 포착하거나 구별하지 못하므로, 우리는 이 부분에서 PaLM의 능력을 평가할 수 없다.
또한, 모델의 다양한 표현 편향 및 능력 불균형을 완화한 후에도, 인간의 언어 행동을 모방할 수 있는 이러한 대규모 LM의 악의적인 사용 가능성이 존재한다는 점에 유의하는 것이 중요하다. 예를 들어, 이러한 고품질 언어 생성 능력에 쉽게 접근할 수 있다는 것은 허위 정보 캠페인과 같은 악의적인 사용 사례에 사용될 수 있다. 마찬가지로, 이러한 모델은 온라인 공간에서 소외된 정체성에 대한 표적 괴롭힘에도 사용될 수 있다. 이러한 위험은 PaLM에만 국한된 것이 아니며, 일반적으로 대규모 LM에 존재한다. 따라서, 이러한 악의적인 사용에 대한 안전장치를 마련할 수 있는 확장 가능한 솔루션을 제공하기 위해 더욱 협력적인 노력이 필요하다.
PaLM-Coder를 소프트웨어 개발 지원에 배포하는 것은 추가적인 복잡성과 윤리적 고려 사항을 수반하며, 이에 대해서는 Section 6.4에서 논의한다. LM 기반 제안이 정확하고, 견고하며, 안전하고, 보안성이 있는지 확인하는 것과, 개발자들이 이러한 제안이 이러한 속성을 가지고 있다고 확신하도록 하는 것은 모두 미해결 문제이다.
12 Related Work
지난 몇 년간 대규모 language modeling을 통해 자연어 처리(natural language capabilities) 능력은 크게 발전했다. 넓은 의미에서 language modeling은 시퀀스 내 다음 토큰을 예측하거나 마스킹된 스팬(masked spans)을 예측하는 접근 방식을 의미한다 (Devlin et al., 2019; Raffel et al., 2020). 인터넷, 서적, 포럼 등에서 수집된 방대한 코퍼스에 이러한 self-supervised objective를 적용한 결과, 고급 언어 이해 및 생성 능력을 갖춘 모델들이 탄생했다. 데이터 양, 파라미터 수, 연산량을 확장함에 따라 모델 품질의 예측 가능한 power-law가 나타나면서, 이는 점점 더 강력한 모델을 구축하는 신뢰할 수 있는 접근 방식이 되었다 (Kaplan et al., 2020).
Transformer 아키텍처 (Vaswani et al., 2017)는 현대 가속기에서 비할 데 없는 효율성을 발휘하며 language model의 사실상 표준 접근 방식이 되었다. 불과 4년 만에 가장 큰 모델들은 크기와 총 연산량 면에서 수십 배 증가했다. 규모 확장의 첫 번째 주요 성공 사례 중 하나는 3억 4,500만 개의 파라미터를 가진 encoder-only BERT 모델 (Devlin et al., 2019)로, SuperGLUE를 포함한 분류 task 전반에서 언어 이해 능력을 크게 향상시켰다. decoder-only 모델인 Generative Pretrained Transformer (GPT) 시리즈 (Radford et al., 2018; Raffel et al., 2020)는 state-of-the-art language modeling 성능을 달성했다. Raffel et al. (2020)은 이후 최대 110억 개의 파라미터를 가진 encoder-decoder 모델을 사전학습하고 fine-tuning하여 transfer learning의 새로운 기준을 세웠다. GPT 시리즈의 가장 최신 모델인 1,750억 개의 파라미터를 가진 GPT-3 모델 (Brown et al., 2020)은 추론 전용(inference-only) few-shot 기법을 통해 새로운 능력을 발견했다. GPT-3 이후에도 규모는 계속 증가하여, 1,780억 개의 파라미터를 가진 Jurassic-1 (Lieber et al., 2021), 2,800억 개의 파라미터를 가진 Gopher 모델 (Rae et al., 2021), 5,300억 개의 Megatron-Turing NLG (Smith et al., 2022)뿐만 아니라 Switch Transformers (Fedus et al., 2021) 및 GLaM (Du et al., 2021)을 포함한 조 단위 파라미터를 가진 sparse 모델들이 연이어 등장했다. 이러한 핵심 자연어 처리 능력의 발전은 코드 이해 및 생성 (Chen et al., 2021; Austin et al., 2021)을 포함한 다른 영역에서도 개선을 동반했다. 또한, 대화 애플리케이션도 규모 확장을 통해 발전했으며, 가장 최근에는 1,370억 개의 decoder-only 모델인 LaMDA (Thoppilan et al., 2022)가 이를 입증했다. 마지막으로, 추가 연구를 통해 language model이 지시를 따르도록 (Ouyang et al., 2022; Wei et al., 2022a) 하여 이러한 모델의 유용성과 신뢰성을 향상시켰다.
이러한 대규모 모델들은 더 이상 단일 가속기의 메모리에 효율적으로 학습되거나 심지어 들어가지도 않는다. 따라서, 모델 텐서를 여러 가속기에 분할하거나 (Shazeer et al., 2018) 또는 모델의 레이어를 가속기별로 분리한 후 단계별로 활성화(activations)를 파이프라인 처리하는 (Huang et al., 2019) 기술들이 등장했다. 다른 많은 연구들은 통신 오버헤드를 제한하면서 모델의 규모를 늘리는 것을 목표로 한다 (Rajbhandari et al., 2020; Lepikhin et al., 2020; Li et al., 2020; Rasley et al., 2020; Rajbhandari et al., 2021; Ren et al., 2021; Narayanan et al., 2021a). PaLM은 Pathways 인프라 (Barham et al., 2022)를 통해 데이터 병렬 처리와 모델 병렬 처리의 혼합을 사용한다.
모델을 더 효율적으로 확장하는 데 도움이 되는 아키텍처 변형들이 제안되었다. 한 분야는 모델이 나중에 접근할 수 있는 방대한 양의 텍스트를 임베딩하여 모델 크기를 대폭 줄이는 것을 목표로 하는 retrieval model이다 (Guu et al., 2020; Borgeaud et al., 2021). Mixture-of-Experts와 같은 모델 sparsity는 다른 예시들이 다른 파라미터 서브셋을 사용하도록 허용함으로써 모델 크기를 확장할 수 있게 한다 (Shazeer et al., 2017; Lepikhin et al., 2020; Fedus et al., 2021; Du et al., 2021; Zoph et al., 2022). 시퀀스 길이의 sparsity는 매우 긴 시퀀스로 효율적으로 학습할 수 있도록 하는 분야이다 (Zaheer et al., 2020; Tay et al., 2020; Choromanski et al., 2020; Kitaev et al., 2020; Roy et al., 2020; Child et al., 2019; Gale et al., 2019). 향후 연구에서는 이러한 연구 라인의 개선 사항들을 Pathways language model의 미래 버전에 통합할 수 있을 것이다.
13 Open Questions in Scaling
서론에서 우리는 few-shot learning을 위한 대규모 LM의 품질 향상에 기여한 네 가지 주요 축을 설명했다. 이는 다음과 같이 요약할 수 있다: (1) 모델의 깊이(depth)와 너비(width), (2) 학습된 토큰의 수, (3) 학습 코퍼스의 품질, (4) 연산량 증가 없이 모델 용량 증대 (즉, sparse model).
본 논문의 나머지 부분에서는 주로 (1)번 요인 탐구에 초점을 맞추지만, 본 연구와 이전 연구를 통해 이것이 유일하게 중요한 요인이 아님은 분명하다. 예를 들어, PaLM 62B는 GPT-3 및 다른 대규모 LM보다 훨씬 낮은 총 학습 FLOP 수를 가졌음에도 불구하고 상당수의 task에서 더 나은 성능을 보인다. 이는 (3)번 요인이 주요한 역할을 한다는 것을 시사하지만, 우리는 이를 결정적으로 말하기 위한 필요한 ablation study를 수행하지 않았다. 그러나 Du et al. (2021)은 동일한 학습 코퍼스에 대해 ablation study를 수행했으며, 신중한 데이터 필터링을 통한 few-shot learning 성능 향상이 매우 중요함을 보여주었다.
마찬가지로, 우리는 (1)번과 (2)번 요인의 효과를 분리하기 위한 ablation study를 전체 규모에서 수행하는 데 드는 높은 학습 비용 때문에 진행하지 않았다. 다시 말해, 중요한 미해결 스케일링 질문은 다음과 같다: "7조 토큰으로 학습된 62B 파라미터 모델이 7800억 토큰으로 학습된 우리의 540B 파라미터 모델과 어떻게 비교될까? 3.6조 토큰으로 학습된 120B 모델은? 1.8조 토큰으로 학습된 240B 모델은?" 이러한 모델은 PaLM 540B와 거의 동일한 총 학습 비용을 가질 것이 분명하다. 그러나 다운스트림 task 성능이 비슷하다면, 추론 비용이 모델 크기에 비례하므로 더 작은 모델이 확실히 선호될 것이다.
최근 Hoffmann et al. (2022)은 바로 이 질문을 탐구하기 위해 발표되었다. 이 연구에서 저자들은 Chinchilla라는 새로운 language model을 학습시켰는데, 이는 1.4조 토큰의 데이터로 학습된 70B 파라미터 모델이다. 이 모델은 동일한 학습 코퍼스와 일반적인 학습 설정을 사용하여 3000억 토큰의 데이터로 학습된 280B 파라미터 모델인 Gopher와 비교되었다. 두 모델 모두 유사한 학습 비용을 가졌지만, Chinchilla는 광범위한 언어 task에서 Gopher를 큰 차이로 능가했다.
우리는 이러한 결과를 PaLM의 맥락에서 논의한다. Chinchilla가 보고한 많은 벤치마크 task가 PaLM이 평가한 task와 겹치지 않지만, 겹치는 벤치마크에 대해서는 결과를 비교할 수 있다. 특히, Chinchilla와 PaLM은 58개의 BIG-bench task와 9개의 영어 NLP task에서 비슷한 결과를 보였다. 9개 영어 NLP 벤치마크에 대한 task별 결과는 Table 21에 나와 있다. 공간 제약으로 인해 BIG-bench에 대한 task별 결과는 제외되었다.
Figure 24에서는 총 학습 FLOP 수에 따른 두 가지 task 세트에 대한 종합 결과를 제시한다. Chinchilla는 BIG-bench에서 PaLM의 보간된 스케일링 곡선을 중간 정도로 능가하며, 9개 영어 NLP task에서는 스케일링 곡선보다 약간 낮은 성능을 보인다. Gopher는 두 스케일링 곡선 모두에서 크게 뒤처진다. 또한 Gopher와 Chinchilla에 사용된 학습 코퍼스는 동일했으므로, (1)번과 (2)번 요인만을 사용하여 최소한으로 비교할 수 있는 반면, PaLM은 다른 코퍼스를 사용했기 때문에 (3)번 요인으로 인해 결론 도출에 추가적인 복잡성이 발생한다. 이러한 결과는 Hoffmann et al. (2022)에서 도출된 결론, 즉 Gopher가 그 크기의 모델에 비해 충분히 학습되지 않았다는 결론을 확실히 뒷받침한다. 그러나 우리는 이러한 결과를 사용하여 우리의 중요한 스케일링 질문("크기 의 모델이 토큰으로 학습되었을 때 PaLM 540B와 어떻게 비교될까?")에 대한 답을 외삽할 수는 없다. 이 질문에 답하기 어려운 몇 가지 이유는 다음과 같다:
- 강력한 결론을 도출하려면 이러한 실험을 대규모로 수행해야 하며, 이는 막대한 계산 비용을 수반한다.
- 만약 더 작은 모델이 더 큰 모델보다 적은 TPU 칩을 사용하여 학습된다면, 총 학습 FLOP 수가 동일하더라도 학습의 실제 소요 시간(wall-clock time)이 비례적으로 증가할 것이다. 만약 | | PaLM 8B | PaLM 62B | PaLM 540B | Chinchilla | Gopher | | :--- | :--- | :--- | :--- | :--- | :--- | | Model Size (Billions of Parameters) | 8 | 62 | 540 | 70 | 280 | | Num Tokens (Billions of Tokens) | 780 | 795 | 780 | 1400 | 300 | | Training FLOP Count (Zettaflops) | 37.4 | 295.7 | 2527.2 | 588.0 | 504.0 | | Lambada 0-shot | 69.5 | 75.4 | 77.9 | 77.4 | 74.5 | | HellaSWAG 0-shot | 68.7 | 79.7 | 83.6 | 80.8 | 79.2 | | PIQA 0-shot | 77.1 | 80.5 | 82.3 | 81.8 | 81.8 | | Winogrande 0-shot | 66.3 | 77.0 | 81.1 | 74.9 | 70.1 | | BoolQ 0-shot | 68.3 | 84.8 | 88.7 | 83.7 | 79.3 | | Natural Questions 0-shot | 8.4 | 18.1 | 21.2 | 16.6 | 10.1 | | Natural Questions few-shot | 14.6 | 27.6 | 39.6 | 31.5 | 24.5 | | Trivia QA 0-shot | 39.5 | 67.3 | 76.9 | 67.0 | 52.8 | | Trivia QA few-shot | 48.5 | 72.7 | 81.4 | 73.2 | 63.6 | | Average Task Metric | 51.2 | 64.8 | 70.3 | 65.2 | 59.5 |
Table 21: PaLM, Chinchilla, Gopher의 영어 NLP task 비교.
 Figure 24: 총 학습 FLOP 수에 따른 모델 성능. PaLM 라인은 PaLM 8B, 62B, 540B의 스케일링 곡선을 나타낸다. BIG-bench는 "Normalized Preferred Metrics"를 사용하는데, 이는 BIG-bench에서 제공하는 점수 정규화 방식으로, 모든 결과를 선형적으로 스케일링하여 0.0점은 무작위 추측과 동일하고 100.0점은 완벽한 성능과 동일하게 만든다.
Figure 24: 총 학습 FLOP 수에 따른 모델 성능. PaLM 라인은 PaLM 8B, 62B, 540B의 스케일링 곡선을 나타낸다. BIG-bench는 "Normalized Preferred Metrics"를 사용하는데, 이는 BIG-bench에서 제공하는 점수 정규화 방식으로, 모든 결과를 선형적으로 스케일링하여 0.0점은 무작위 추측과 동일하고 100.0점은 완벽한 성능과 동일하게 만든다.
동일한 수의 TPU 칩을 사용하여 학습된다면, 배치 크기를 급격히 늘리지 않고는 TPU 연산 효율성을 유지하기 매우 어려울 것이다. PaLM 540B의 배치 크기는 이미 4백만 토큰이며, 이보다 더 큰 배치 크기가 샘플 효율성을 유지할 수 있을지는 불분명하다. 3. 웹에는 매우 고품질의 방대한 텍스트 데이터가 존재하지만, 무한한 양은 아니다. PaLM에 선택된 코퍼스 혼합 비율의 경우, 7800억 토큰 이후 일부 하위 코퍼스에서 데이터가 반복되기 시작하며, 이것이 우리가 학습 종료 지점으로 7800억 토큰을 선택한 이유이다. 대규모 language model 학습에서 반복된 데이터의 "가치"가 보지 못한 데이터와 어떻게 비교되는지는 불분명하다. Appendix F의 ablation study에서 우리는 PaLM 62B에서 7800억 토큰 이후 반복된 데이터 소스로부터 이점을 보지 못했지만, 새로 고쳐진 데이터셋으로 더 오래 학습했을 때 성능 향상을 보여주었다.
향후 연구에서는 여러 task에 걸쳐 잘 일반화되는 더 유능한 LM을 만드는 데 기여하는 다양한 요인들 간의 trade-off를 조사할 계획이다. 우리는 여기서 설명된 네 가지 요인 외에도 모델 아키텍처, 사전학습 task, 옵티마이저 구성과 같은 다른 요인들도 더 탐구하기를 희망한다.
14 Conclusion
본 연구에서는 PaLM을 학습시켜 few-shot 언어 이해 및 생성의 한계를 계속해서 확장한다. PaLM은 5,400억 개의 파라미터를 가진 dense Transformer language model로, 7,800억 개의 고품질의 다양한 텍스트 토큰으로 학습되었다. Section 6.1의 평가 결과는 뛰어난 few-shot 성능을 보여주며, 가장 널리 평가되는 29개의 영어 NLP task 중 28개에서 기존의 어떤 대규모 language model보다 최고의 task별 결과를 달성하여 state-of-the-art 성능을 기록했다. 최근 개발된 150개 이상의 도전적인 새로운 언어 task를 포함하는 벤치마크인 **BIG-bench (Section 6.2)**에서 PaLM은 5-shot 설정에서 동일한 task를 수행하도록 요청받은 인간의 평균 성능 점수보다 높은 성능을 달성했다. 또한, **소스 코드 이해/생성 (Section 6.4), 다국어 NLP (Section 6.6 및 Section 6.7), 기계 번역 (Section 6.5)**에서도 추가적인 state-of-the-art 성능을 입증했다.
본 연구의 또 다른 중요한 시사점은 다단계 논리적 추론을 요구하는 reasoning task에서의 획기적인 성능이다. 우리의 few-shot 결과는 여러 산술 및 상식 추론 task에서 fine-tuned state-of-the-art 성능과 일치하거나 이를 능가한다. reasoning task에서의 이러한 결과는 모델 규모만으로 달성된 것이 아니라, 규모와 chain-of-thought prompting의 조합을 통해 이루어졌다. chain-of-thought prompting은 모델이 예측을 하기 전에 자연어 논리 추론 체인을 명시적으로 생성하도록 유도하는 방식이다. Section 9에서는 PaLM이 농담을 설명하고 시나리오에 대한 복잡한 질문에 답하기 위해 명시적인 논리 추론 체인을 작성할 수 있었던 몇 가지 흥미로운 예시를 제시한다.
이러한 결과들로부터 몇 가지 결론을 도출할 수 있다. 첫째, 여기에 제시된 결과는 few-shot 언어 이해를 위한 규모 확장의 개선이 아직 정체되지 않았음을 시사한다. PaLM 540B의 결과를 동일하게 학습된 62B 및 8B 모델 변형과 비교했을 때, 개선은 일반적으로 로그-선형적이다. 이것만으로도 우리는 아직 스케일링 곡선의 정점에 도달하지 않았음을 시사한다. 그러나 여러 벤치마크에서 개선은 실제로 불연속적이다. 즉, 8B에서 62B로의 개선은 매우 미미하지만, 540B로 확장할 때 엄청나게 도약한다. 이는 언어 모델의 특정 능력은 충분한 규모로 학습될 때만 나타나며, 미래 세대 모델에서 나타날 수 있는 추가적인 능력이 있음을 시사한다.
둘째, reasoning task에서의 획기적인 성능 (Section 6.3)은 중요한 의미를 갖는다. 모델이 예측을 설명하기 위해 자연어를 생성할 수 있다는 것은 시스템의 최종 사용자가 모델이 특정 예측을 한 이유를 더 잘 이해하는 데 유익하다는 것은 분명하다. 그러나 이러한 결과는 그 이상으로 나아가, 모델이 명시적인 추론 체인을 생성하도록 유도하는 것이 예측 자체의 품질을 크게 향상시킬 수 있음을 보여준다. 다시 말해, **모델의 생성 능력 (단순한 이해 능력뿐만 아니라)**은 일반적으로 상당한 언어 생성을 요구하지 않는 범주형 예측 또는 회귀로 모델링되는 task에서도 엄청나게 유익할 수 있다.
마지막으로, few-shot 언어 모델링을 위한 규모 확장의 한계를 뛰어넘는 목표를 달성했지만, 미래 세대 모델을 위한 이상적인 네트워크 아키텍처 및 학습 방식에 대해서는 여전히 많은 미해결 질문이 남아 있다. PaLM은 Google 및 그 외에서 Pathways를 ML 스케일링의 미래로 확립하려는 우리의 비전에서 첫 번째 단계일 뿐이다. 이를 위해 우리는 잘 확립된 방식, 즉 dense, decoder-only, full-attention Transformer 모델을 사용하여 autoregressive language modeling을 수행하도록 학습함으로써 이러한 스케일링 능력을 입증하기로 선택했다. 그러나 우리의 더 넓은 목표는 다양한 새로운 아키텍처 선택 및 학습 방식을 탐색하고, 가장 유망한 시스템을 Pathways의 스케일링 능력과 결합하는 것이다. 우리는 PaLM이 다중 모달리티에 걸쳐 광범위한 일반화 능력을 가질 대규모 모듈화 시스템을 개발하려는 우리의 궁극적인 목표에 강력한 기반을 제시한다고 믿는다.