멀티모달 머신러닝의 모든 것: 최신 연구 동향과 분류
AI가 인간처럼 다양한 정보를 이해하기 위한 핵심 기술, 멀티모달 머신러닝의 최신 연구 동향을 소개합니다. 이 논문은 기존의 초기/후기 통합 방식을 넘어, representation, translation, alignment, fusion, co-learning이라는 5가지 핵심 과제를 중심으로 새로운 분류 체계를 제시하여 연구자들이 분야의 현황을 파악하고 미래 연구 방향을 설정하는 데 도움을 줍니다. 논문 제목: Multimodal Machine Learning: A Survey and Taxonomy (4435회 인용)
논문 요약: Multimodal Machine Learning: A Survey and Taxonomy
- 논문 링크: https://arxiv.org/abs/1705.09406
- 저자: Tadas Baltrušaitis (Microsoft Corporation), Chaitanya Ahuja, Louis-Philippe Morency (Carnegie Mellon University)
- 발표 시기: 2018년 (IEEE Transactions on Pattern Analysis and Machine Intelligence)
- 주요 키워드: Multimodal Machine Learning, Survey, Representation, Translation, Alignment, Fusion, Co-learning
1. 연구 배경 및 문제 정의
- 문제 정의: 인공지능이 인간처럼 다양한 감각(시각, 청각, 언어 등)을 통해 세상을 이해하고 추론하기 위해서는 여러 모달리티의 정보를 함께 처리하고 연관시킬 수 있는 모델을 구축해야 한다. 멀티모달 데이터의 이질성으로 인해 이러한 모델을 구축하는 것은 독특하고 복잡한 기술적 과제들을 야기한다.
- 기존 접근 방식: 기존 멀티모달 머신러닝 연구에서는 주로 '초기 통합(early fusion)'과 '후기 통합(late fusion)'이라는 단순한 분류 체계로 모달리티 통합 방식을 설명해왔다. 그러나 이러한 분류는 멀티모달 머신러닝이 직면한 광범위한 기술적 과제들을 포괄적으로 설명하기에는 한계가 있었다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 멀티모달 머신러닝 분야의 최신 연구 동향을 종합적으로 조사하고 분류했다.
- 기존의 단순한 통합 방식 분류를 넘어, 멀티모달 머신러닝이 직면한 5가지 핵심 기술적 과제(Representation, Translation, Alignment, Fusion, Co-learning)를 중심으로 새로운 분류 체계(Taxonomy)를 제시했다.
- 제시된 분류 체계가 연구자들이 분야의 현황을 더 잘 이해하고 미래 연구 방향을 설정하는 데 도움을 줄 수 있음을 강조했다.
- 제안 방법:
논문은 새로운 방법론을 제안하는 것이 아니라, 멀티모달 머신러닝 분야의 방대한 기존 연구들을 체계적으로 분석하고 재분류하여 제시한다. 제안된 5가지 핵심 기술적 과제는 다음과 같다:
- Representation (표현): 여러 모달리티의 상보성과 중복성을 활용하여 멀티모달 데이터를 표현하고 요약하는 방법 (Joint vs. Coordinated).
- Translation (변환): 한 모달리티의 데이터를 다른 모달리티로 변환(매핑)하는 방법 (Example-based vs. Generative).
- Alignment (정렬): 둘 이상의 모달리티에서 온 (하위) 요소들 사이의 직접적인 관계를 식별하는 방법 (Explicit vs. Implicit).
- Fusion (융합): 예측을 수행하기 위해 둘 이상의 모달리티에서 온 정보를 결합하는 방법 (Model-agnostic vs. Model-based).
- Co-learning (공동 학습): 자원이 부족한 모달리티의 모델링을 돕기 위해 다른 모달리티의 지식을 전달하고 활용하는 방법 (Parallel, Non-parallel, Hybrid data). 각 과제에 대해 상세한 하위 분류와 대표적인 연구 사례들을 제시하며, 각 접근 방식의 장단점을 분석한다.
3. 실험 결과
- 데이터셋: 이 논문은 새로운 방법론을 제안하고 실험하는 것이 아니라, 기존 연구들을 조사하고 분류하는 서베이 논문이므로 특정 데이터셋이나 실험 환경을 사용하지 않는다.
- 주요 결과:
- 논문은 멀티모달 머신러닝의 광범위한 응용 사례(시청각 음성 인식, 멀티미디어 콘텐츠 인덱싱, 감정 인식, 미디어 설명 등)를 역사적 관점에서 분석하고, 각 응용 분야에 필요한 핵심 기술 과제를 식별하여 제시한다.
- 제안된 5가지 기술적 과제(Representation, Translation, Alignment, Fusion, Co-learning) 각각에 대해 다양한 기존 연구들을 분류하고, 각 접근 방식의 특징, 장점, 단점 및 한계점을 상세히 분석한다.
- 특히, 각 과제 섹션의 말미에 해당 과제가 직면한 문제점과 미래 연구 방향에 대한 논의를 포함하여, 연구자들에게 실질적인 통찰을 제공한다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 멀티모달 머신러닝이라는 방대하고 복잡한 분야의 연구들을 5가지 핵심 과제라는 명확하고 체계적인 분류 체계로 정리하여, 분야의 현황을 한눈에 파악하고 이해하는 데 큰 도움을 준다.
- 각 과제별로 상세한 하위 분류와 대표적인 연구들을 제시하여, 특정 문제에 대한 해결책을 찾거나 새로운 연구 아이디어를 얻는 데 매우 유용하다.
- 서베이 논문임에도 불구하고 각 섹션 말미에 해당 과제의 한계점과 미래 연구 방향을 제시하여, 연구자들에게 실질적인 가이드를 제공한다.
- 단점/한계:
- 2018년에 발표된 논문이므로, 이후 딥러닝 기술의 급격한 발전(특히 트랜스포머 기반의 대규모 멀티모달 모델, 생성형 AI 등)을 반영하지 못한다는 시간적 한계가 있다.
- 제시된 분류 체계가 명확하지만, 실제 복합적인 멀티모달 시스템에서는 여러 과제가 유기적으로 얽혀 있어 칼같이 구분하기 어려울 수 있다.
- 응용 가능성:
- 새로운 멀티모달 AI 시스템을 설계할 때, 데이터 표현, 모달리티 간 변환, 정렬, 통합, 지식 공유 등 각 구성 요소를 체계적으로 고려하고 최적의 방법을 선택하는 데 활용될 수 있다.
- 멀티모달 연구를 시작하는 연구자들에게 분야의 지도를 제공하고, 어떤 과제에 집중할지 결정하는 데 기초 자료로 활용될 수 있다.
- 교육 목적으로 멀티모달 머신러닝의 핵심 개념과 분류를 가르치는 데 유용하다.
Baltrušaitis, Tadas, Chaitanya Ahuja, and Louis-Philippe Morency. "Multimodal machine learning: A survey and taxonomy." IEEE transactions on pattern analysis and machine intelligence 41.2 (2018): 423-443.
Multimodal Machine Learning: A Survey and Taxonomy
Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency
Abstract
우리가 세상을 경험하는 방식은 multimodal합니다 - 우리는 사물을 보고, 소리를 듣고, 질감을 느끼고, 냄새를 맡고, 맛을 봅니다. Modality는 어떤 일이 일어나거나 경험되는 방식을 의미하며, 연구 문제는 여러 그러한 modality를 포함할 때 multimodal로 특징지어집니다. 인공지능이 우리 주변의 세계를 이해하는 데 진전을 이루기 위해서는 이러한 multimodal 신호를 함께 해석할 수 있어야 합니다. Multimodal machine learning은 여러 modality의 정보를 처리하고 연관시킬 수 있는 모델을 구축하는 것을 목표로 합니다. 이는 중요성이 증가하고 비범한 잠재력을 지닌 활기찬 다학제적 분야입니다. 이 논문은 특정 multimodal 응용에 초점을 맞추는 대신, multimodal machine learning 자체의 최근 발전을 조사하고 공통된 분류 체계로 제시합니다. 우리는 일반적인 early fusion과 late fusion 분류를 넘어 multimodal machine learning이 직면한 더 넓은 과제들, 즉 representation, translation, alignment, fusion, co-learning을 식별합니다. 이 새로운 분류 체계는 연구자들이 해당 분야의 현황을 더 잘 이해하고 미래 연구 방향을 식별하는 데 도움이 될 것입니다.
Index Terms-Multimodal, machine learning, introductory, survey.
1 Introduction
우리를 둘러싼 세계는 여러 modality를 포함합니다 - 우리는 사물을 보고, 소리를 듣고, 질감을 느끼고, 냄새를 맡는 등 다양한 경험을 합니다. 일반적으로 modality는 어떤 일이 일어나거나 경험되는 방식을 의미합니다. 대부분의 사람들은 modality라는 단어를 시각이나 촉각과 같이 우리의 주요 의사소통 및 감각 채널을 나타내는 감각 modality와 연관시킵니다. 따라서 연구 문제나 데이터셋은 여러 그러한 modality를 포함할 때 multimodal로 특징지어집니다. 이 논문에서는 주로, 그러나 배타적이지는 않게, 세 가지 modality에 초점을 맞춥니다: 쓰이거나 말하는 자연어; 종종 이미지나 비디오로 표현되는 시각 신호; 그리고 운율 및 성대 표현과 같은 준언어적 정보를 인코딩하는 음성 신호입니다.
인공지능이 우리 주변의 세계를 이해하는 데 진전을 이루기 위해서는 multimodal 메시지를 해석하고 추론할 수 있어야 합니다. Multimodal machine learning은 여러 modality의 정보를 처리하고 연관시킬 수 있는 모델을 구축하는 것을 목표로 합니다. 시청각 음성 인식에 대한 초기 연구부터 최근 언어 및 시각 모델에 대한 관심 폭발에 이르기까지, multimodal machine learning은 중요성이 증가하고 비범한 잠재력을 지닌 활기찬 다학제적 분야입니다.
Multimodal Machine Learning 연구 분야는 데이터의 이질성으로 인해 컴퓨터 연구자들에게 몇 가지 독특한 과제를 안겨줍니다. Multimodal 소스로부터 학습하는 것은 modality 간의 대응 관계를 포착하고 자연 현상에 대한 깊이 있는 이해를 얻을 수 있는 가능성을 제공합니다. 이 논문에서는 multimodal machine learning을 둘러싼 다섯 가지 핵심 기술적 과제(및 관련 하위 과제)를 식별하고 탐구합니다.
- T. Baltrušaitis는 영국 케임브리지 Microsoft Corporation 소속입니다. C. Ahuja와 L-P. Morency는 펜실베이니아 피츠버그 카네기 멜런 대학교 언어 기술 연구소 소속입니다. 이메일: tbaltrus, cahuja, morency@cs.cmu.edu 원고 접수일 2017년 5월 18일
이들은 multimodal 환경의 핵심이며, 이 분야를 발전시키기 위해 해결되어야 합니다. 우리의 분류 체계는 일반적인 early fusion과 late fusion의 구분을 넘어서며, 다음 다섯 가지 과제로 구성됩니다:
- Representation 첫 번째 근본적인 과제는 여러 modality의 상보성과 중복성을 활용하는 방식으로 multimodal 데이터를 표현하고 요약하는 방법을 배우는 것입니다. Multimodal 데이터의 이질성 때문에 이러한 표현을 구성하는 것이 어렵습니다. 예를 들어, 언어는 종종 상징적인 반면, 오디오 및 시각 modality는 신호로 표현됩니다.
- Translation 두 번째 과제는 한 modality의 데이터를 다른 modality로 변환(매핑)하는 방법을 다룹니다. 데이터가 이질적일 뿐만 아니라 modality 간의 관계가 종종 개방적이거나 주관적입니다. 예를 들어, 이미지를 설명하는 여러 가지 올바른 방법이 존재하며 완벽한 번역 하나가 존재하지 않을 수 있습니다.
- Alignment 세 번째 과제는 둘 이상의 다른 modality에서 온 (하위) 요소들 사이의 직접적인 관계를 식별하는 것입니다. 예를 들어, 요리법의 단계를 요리가 만들어지는 과정을 보여주는 비디오와 정렬하고 싶을 수 있습니다. 이 과제를 해결하려면 다른 modality 간의 유사성을 측정하고 가능한 장거리 의존성 및 모호성을 처리해야 합니다.
- Fusion 네 번째 과제는 예측을 수행하기 위해 둘 이상의 modality에서 온 정보를 결합하는 것입니다. 예를 들어, 시청각 음성 인식의 경우, 입술 움직임에 대한 시각적 설명이 음성 신호와 융합되어 발화된 단어를 예측합니다. 다른 modality에서 오는 정보는 예측 능력과 노이즈 위상이 다를 수 있으며, 최소한 하나의 modality에서 데이터가 누락될 수 있습니다.
- Co-learning 다섯 번째 과제는 modality, 그 표현, 그리고 예측 모델 간에 지식을 전달하는 것입니다. 이는 cotraining, conceptual grounding, zero shot learning과 같은 알고리즘으로 예시됩니다. Co-learning은 한
Table 1: Multimodal machine learning에 의해 가능해진 응용 프로그램 요약. 각 응용 분야에 대해, 이를 해결하기 위해 다루어야 할 핵심 기술 과제를 식별합니다.
| Challenges | |||||
|---|---|---|---|---|---|
| APPLICATIONS | REPRESENTATION | TRANSLATION | Alignment | FUSION | CO-LEARNING |
| Speech recognition Audio-visual speech recognition | |||||
| Event detection <br> Action classification Multimedia event detection | |||||
| Emotion and affect <br> Recognition Synthesis |  |  | |||
| Media description <br> Image description <br> Video description <br> Visual question-answering <br> Media summarization |  |  |  |  |  |
| Multimedia retrieval <br> Cross modal retrieval <br> Cross modal hashing | |||||
| Multimedia generation <br> (Visual) speech and sound synthesis Image and scene generation |  |
modality에서 학습된 지식이 다른 modality에서 훈련된 컴퓨터 모델에 어떻게 도움을 줄 수 있는지 탐구합니다. 이 과제는 modality 중 하나가 제한된 자원(예: 주석이 달린 데이터)을 가질 때 특히 관련이 있습니다. 이 다섯 가지 과제 각각에 대해, 우리는 이 신흥 연구 분야인 multimodal machine learning의 최근 연구를 구조화하는 데 도움이 되는 분류 클래스와 하위 클래스를 정의합니다. 우리는 multimodal machine learning의 주요 응용 분야에 대한 논의(섹션 2)로 시작하여, multimodal machine learning이 직면한 다섯 가지 핵심 기술 과제 모두에 대한 최근 개발에 대한 논의로 이어집니다: representation(섹션 3), translation(섹션 4), alignment(섹션 5), fusion(섹션 6), co-learning(섹션 7). 우리는 섹션 8에서 논의로 마무리합니다.
2 Applications: A historical perspective
Multimodal machine learning은 시청각 음성 인식에서 이미지 캡셔닝에 이르기까지 광범위한 응용을 가능하게 합니다. 이 섹션에서는 시청각 음성 인식의 시작부터 최근 언어 및 시각 응용에 대한 관심이 다시 높아지기까지 multimodal 응용의 간략한 역사를 제시합니다.
multimodal 연구의 가장 초기 사례 중 하나는 audio-visual speech recognition (AVSR)입니다 [251]. 이는 음성 인식 중 청각과 시각 사이의 상호작용인 McGurk 효과 [143]에 의해 동기를 부여받았습니다. 인간 피험자들이 /ga-ga/라고 말하는 사람의 입술을 보면서 /ba-ba/ 음절을 들었을 때, 그들은 세 번째 소리인 /da-da/를 인지했습니다. 이러한 결과는 음성 커뮤니티의 많은 연구자들이 시각 정보를 추가하여 접근 방식을 확장하도록 동기를 부여했습니다. 당시 음성 커뮤니티에서 hidden Markov models (HMMs)의 중요성을 고려할 때 [99], AVSR을 위한 초기 모델 중 다수가 다양한 HMM 확장 [25], [26]에 기반을 둔 것은 놀라운 일이 아닙니다. 오늘날 AVSR에 대한 연구가 예전만큼 흔하지는 않지만, deep learning 커뮤니티로부터 새로운 관심을 받고 있습니다 [157].
AVSR의 원래 비전은 모든 상황에서 음성 인식 성능(예: 단어 오류율)을 향상시키는 것이었지만, 실험 결과는 시각 정보의 주요 이점이 음성 신호가 잡음이 많을 때(즉, 낮은 signal-to-noise ratio) 나타난다는 것을 보여주었습니다 [78], [157], [251]. 즉, modality 간에 포착된 상호작용은 상보적이기보다는 보충적이었습니다. 동일한 정보가 양쪽에서 포착되어 multimodal 모델의 견고성은 향상되었지만, 잡음이 없는 시나리오에서는 음성 인식 성능이 향상되지 않았습니다.
multimodal 응용의 두 번째 중요한 범주는 멀티미디어 콘텐츠 인덱싱 및 검색 분야에서 비롯됩니다 [11], [196]. 개인용 컴퓨터와 인터넷의 발전으로 디지털화된 멀티미디어 콘텐츠의 양이 급격히 증가했습니다 [2]. 초기에는 이러한 멀티미디어 비디오를 인덱싱하고 검색하는 접근 방식이 키워드 기반이었지만 [196], 시각 및 multimodal 콘텐츠를 직접 검색하려고 시도하면서 새로운 연구 문제가 등장했습니다. 이는 자동 shot-boundary detection [128] 및 video summarization [55]과 같은 멀티미디어 콘텐츠 분석의 새로운 연구 주제로 이어졌습니다. 이러한 연구 프로젝트는 2011년에 시작된 multimedia event detection (MED) 작업을 포함한 많은 고품질 데이터셋을 도입한 미국 국립표준기술원의 TrecVid 이니셔티브에 의해 지원되었습니다 [1].
세 번째 응용 범주는 2000년대 초반 사회적 상호작용 중 인간의 multimodal 행동을 이해하려는 목표를 가진 신흥 분야인 multimodal interaction을 중심으로 확립되었습니다. 이 분야에서 수집된 최초의 획기적인 데이터셋 중 하나는 100시간 이상의 회의 비디오 녹화를 포함하고 모두 완전히 전사되고 주석이 달린 AMI Meeting Corpus입니다 [34]. 또 다른 중요한 데이터셋은 화자와 청자 간의 대인 관계 역학을 연구할 수 있게 해준 SEMAINE corpus입니다 [144]. 이 데이터셋은 2011년에 조직된 최초의 audio-visual emotion challenge (AVEC)의 기초를 형성했습니다 [186]. emotion recognition 및 affective computing 분야는 자동 얼굴 탐지, 얼굴 랜드마크 탐지, 얼굴 표정 인식의 강력한 기술 발전 덕분에 2010년대 초반에 꽃을 피웠습니다 [48]. AVEC 챌린지는 이후 매년 계속되었으며, 이후 버전에는 우울증 및 불안의 자동 평가와 같은 헬스케어 응용 프로그램이 포함되었습니다 [217]. D'Mello 등이 발표한 multimodal 감정 인식의 최근 진전에 대한 훌륭한 요약이 있습니다 [52]. 그들의 메타 분석에 따르면 multimodal 감정 인식에 대한 최근 연구의 대다수는 하나 이상의 modality를 사용할 때 개선을 보이지만, 자연스럽게 발생하는 감정을 인식할 때는 이 개선이 감소합니다.
가장 최근에는 언어와 시각에 중점을 둔 새로운 범주의 multimodal 응용이 등장했습니다: media description. 가장 대표적인 응용 중 하나는 입력 이미지에 대한 텍스트 설명을 생성하는 작업인 image captioning입니다 [86]. 이는 시각 장애인이 일상적인 작업을 수행하는 데 도움이 되는 시스템의 능력에 의해 동기를 부여받았습니다 [21]. 최근에는 텍스트에서 미디어를 생성하는 역작업인 media generation에서도 진전이 있었습니다 [37], [178]. media description과 generation의 주요 과제는 평가입니다: 예측된 설명과 미디어의 품질을 어떻게 평가할 것인가. visual question-answering (VQA) 작업은 정답을 제공함으로써 평가 과제 중 일부를 해결하기 위해 최근에 제안되었습니다 [9].
언급된 응용 프로그램 중 일부를 현실 세계에 도입하기 위해서는 multimodal machine learning이 직면한 여러 기술적 과제를 해결해야 합니다. 위에서 언급한 응용 분야에 대한 관련 기술적 과제를 표 1에 요약했습니다. 가장 중요한 과제 중 하나는 다음 섹션의 초점인 multimodal representation입니다.
3 Multimodal Representations
컴퓨터 모델이 작업할 수 있는 형식으로 데이터를 표현하는 것은 기계 학습에서 항상 어려운 과제였습니다. Bengio 등의 연구 [19]에 따라, 우리는 feature와 representation이라는 용어를 상호 교환적으로 사용하며, 각각은 이미지, 오디오 샘플, 개별 단어 또는 문장과 같은 개체의 벡터 또는 텐서 표현을 의미합니다. multimodal representation은 여러 그러한 개체의 정보를 사용하여 데이터를 표현하는 것입니다. 여러 modality를 표현하는 것은 많은 어려움을 야기합니다: 이질적인 소스의 데이터를 결합하는 방법, 다양한 수준의 노이즈를 처리하는 방법, 누락된 데이터를 처리하는 방법. 의미 있는 방식으로 데이터를 표현하는 능력은 multimodal 문제에 매우 중요하며, 모든 모델의 중추를 형성합니다.
좋은 representation은 기계 학습 모델의 성능에 중요하며, 이는 음성 인식 [82] 및 시각적 객체 분류 [114] 시스템의 최근 성능 도약에서 입증됩니다. Bengio 등 [19]은 좋은 representation의 여러 속성을 식별합니다: smoothness, temporal and spatial coherence, sparsity, 그리고 자연스러운 군집화 등입니다. Srivastava와 Salakhutdinov [206]은 multimodal representation에 대한 추가적인 바람직한 속성을 식별합니다: representation 공간에서의 유사성은 해당 개념의 유사성을 반영해야 하며, 일부 modality가 없는 경우에도 representation을 쉽게 얻을 수 있어야 하고, 마지막으로 관찰된 modality가 주어졌을 때 누락된 modality를 채울 수 있어야 합니다.
unimodal representation의 개발은 광범위하게 연구되었습니다 [4], [19], [127]. 지난 10년 동안 특정 응용 프로그램을 위해 수작업으로 설계된 것에서 데이터 기반으로 전환되었습니다. 예를 들어, 2000년대 초반에 이미지를 표현하는 가장 인기 있는 방법 중 하나는 scale invariant feature transform (SIFT) [132]과 같은 수작업으로 설계된 특징의 bag of visual words representation을 통하는 것이었습니다. 그러나 현재 대부분의 이미지(또는 그 일부)는 convolutional neural networks (CNN) [114]와 같은 신경망 아키텍처를 사용하여 데이터로부터 학습된 설명으로 표현됩니다. 마찬가지로, 오디오 도메인에서는 Mel-frequency cepstral coefficients (MFCC)와 같은 음향 특징이 음성 인식에서 데이터 기반의 deep neural networks [82]와 준언어 분석을 위한 recurrent neural networks [216]에 의해 대체되었습니다. natural language processing에서는 텍스트 특징이 처음에는 문서에서 단어 발생 횟수를 세는 것에 의존했지만, 단어 컨텍스트를 활용하는 데이터 기반 word embeddings로 대체되었습니다 [146]. unimodal representation에 대한 엄청난 양의 연구가 있었지만, 최근까지 대부분의 multimodal representation은 unimodal representation의 단순한 연결을 포함했습니다 [52]. 그러나 이것은 빠르게 변하고 있습니다.
연구의 폭을 이해하는 데 도움이 되도록, 우리는 두 가지 범주의 multimodal representation을 제안합니다: joint와 coordinated. Joint representation은 unimodal 신호를 동일한 representation 공간으로 결합하는 반면, coordinated representation은 unimodal 신호를 별도로 처리하지만, 우리가 coordinated space라고 부르는 공간으로 가져오기 위해 특정 유사성 제약 조건을 적용합니다. 다른 multimodal representation 유형의 그림은 그림 1에서 볼 수 있습니다.
수학적으로, joint representation은 다음과 같이 표현됩니다:
여기서 multimodal representation 은 unimodal representation 에 의존하는 함수 (예: deep neural network, restricted Boltzmann machine, 또는 recurrent neural network)를 사용하여 계산됩니다. 반면 coordinated representation은 다음과 같습니다:
여기서 각 modality는 해당 modality를 coordinated multimodal space로 매핑하는 해당 프로젝션 함수(와 )를 가집니다. multimodal space로의 프로젝션은 각 modality에 대해 독립적이지만, 결과 공간은 그들 사이에서 조정됩니다(로 표시됨). 이러한 조정의 예로는 코사인 거리 최소화 [64], 상관 관계 최대화 [7], 결과 공간 간의 부분 순서 강제 [220] 등이 있습니다.
3.1 Joint Representations
우리는 unimodal representation을 multimodal 공간으로 함께 투영하는 joint representation(방정식 1)에 대한 논의로 시작합니다. Joint representation은 대부분(전부는 아니지만) 훈련 및 추론 단계 모두에서 multimodal 데이터가 존재할 때 사용됩니다. joint representation의 가장 간단한 예는 개별 modality 특징의 연결입니다(early fusion [52]이라고도 함). 이 섹션에서는 신경망으로 시작하여 그래픽 모델 및 순환 신경망에 이르기까지 joint representation을 만드는 고급 방법에 대해 논의합니다(대표적인 연구는 표 2에서 볼 수 있습니다).
Neural networks는 unimodal 데이터 표현을 위한 매우 인기 있는 방법이 되었습니다 [19]. 이들은 시각, 음향 및 텍스트 데이터를 표현하는 데 사용되며, 점점 더
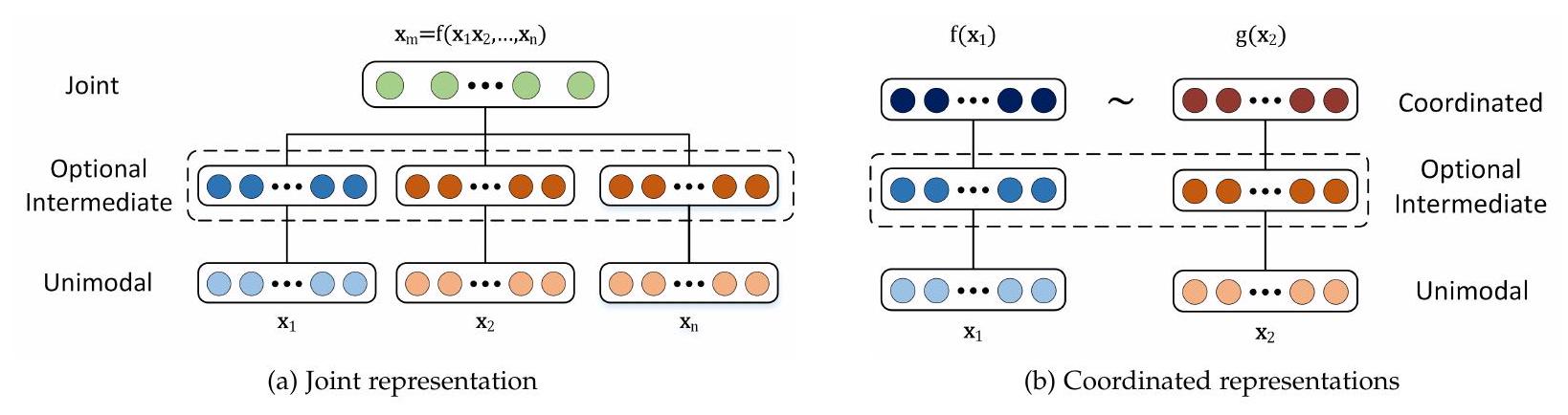
Figure 1: Joint 및 coordinated representation의 구조. Joint representation은 모든 modality를 입력으로 사용하여 동일한 공간으로 투영됩니다. 반면에 Coordinated representation은 자체 공간에 존재하지만 유사성(예: 유클리드 거리) 또는 구조 제약(예: 부분 순서)을 통해 조정됩니다. multimodal 영역 [157], [163], [225]에서 사용되고 있습니다. 이 섹션에서는 신경망을 사용하여 공동 multimodal representation을 구성하는 방법, 이를 훈련하는 방법 및 이들이 제공하는 이점에 대해 설명합니다.
일반적으로 신경망은 내적과 비선형 활성화 함수의 연속적인 빌딩 블록으로 구성됩니다. 신경망을 데이터 표현 방법으로 사용하려면 먼저 특정 작업(예: 이미지에서 객체 인식)을 수행하도록 훈련됩니다. deep neural networks의 다층 특성으로 인해 각 연속적인 계층은 데이터를 더 추상적인 방식으로 표현하는 것으로 가정되므로 [19], 최종 또는 최종에서 두 번째 신경망 계층을 데이터 표현의 한 형태로 사용하는 것이 일반적입니다. 신경망을 사용하여 multimodal representation을 구성하려면 각 modality가 여러 개별 신경망 계층으로 시작한 다음 modality를 공동 공간으로 투영하는 은닉 계층으로 이어집니다 [9], [150], [163], [235]. 공동 multimodal representation은 여러 은닉 계층을 통과하거나 예측에 직접 사용될 수 있습니다. 이러한 모델은 종단 간 훈련될 수 있으며, 데이터 표현과 특정 작업 수행을 모두 학습합니다. 이로 인해 신경망을 사용할 때 multimodal representation 학습과 multimodal fusion 간에 긴밀한 관계가 형성됩니다.
신경망은 레이블이 지정된 훈련 데이터가 많이 필요하기 때문에, 비지도 데이터(예: autoencoder 모델 사용 [12], [83])나 다른 관련 도메인의 지도 데이터 [9], [221]를 사용하여 이러한 표현을 사전 훈련하는 것이 일반적입니다. Ngiam 등 [157]이 제안한 모델은 autoencoder를 multimodal 도메인에 사용하는 아이디어를 확장했습니다. 그들은 각 modality를 개별적으로 표현하기 위해 stacked denoising autoencoders를 사용하고, 다른 autoencoder 계층을 사용하여 multimodal representation으로 융합했습니다. 마찬가지로 Silberer와 Lapata [191]는 semantic concept grounding 작업(섹션 7.2 참조)을 위해 multimodal autoencoder를 사용할 것을 제안했습니다. 표현을 훈련하기 위해 재구성 손실을 사용하는 것 외에도, 그들은 표현을 사용하여 객체 레이블을 예측하는 항을 손실 함수에 도입합니다.
신경망 기반 공동 표현의 주요 이점은 레이블이 지정된 데이터가 지도 학습에 충분하지 않을 때 레이블이 없는 데이터로부터 사전 훈련할 수 있다는 능력에서 비롯됩니다. 또한 비지도 데이터로 구성된 표현은 일반적이며 특정 작업에 반드시 최적인 것은 아니므로 주어진 특정 작업에 대해 결과 표현을 미세 조정하는 것이 일반적입니다 [225]. 단점 중 하나는 모델이 누락된 데이터를 자연스럽게 처리하지 못한다는 점입니다. 비록 이 문제를 완화할 방법이 있지만 말입니다 [157], [225]. 마지막으로, 심층 신경망은 종종 훈련하기 어렵지만 [72], 이 분야는 개선된 정규화 [204], 배치 정규화 [92] 및 적응형 경사 하강법 알고리즘 [109]과 같은 새로운 기술로 진전을 보이고 있습니다. 확률적 그래픽 모델은 잠재 확률 변수를 사용하여 표현을 구성하는 데 사용될 수 있습니다 [19]. 이 섹션에서는 확률적 그래픽 모델이 단일 모드 및 다중 모드 데이터를 표현하는 데 어떻게 사용되는지 설명합니다. 데이터를 표현하는 한 가지 방법은 제한된 볼츠만 머신(RBM) [84]을 빌딩 블록으로 쌓는 심층 볼츠만 머신(DBM) [183]을 통하는 것입니다. 신경망과 유사하게, DBM의 각 연속적인 계층은 데이터를 더 높은 수준의 추상화로 표현할 것으로 예상됩니다. DBM의 매력은 훈련에 지도 데이터가 필요하지 않다는 사실에서 비롯됩니다 [183]. 그래픽 모델이므로 데이터 표현은 확률적이지만, 결정론적 신경망으로 변환할 수 있습니다. 그러나 이는 모델의 생성적 측면을 잃게 합니다 [183].
Srivastava와 Salakhutdinov의 연구 [205]는 다중 모드 심층 신뢰 신경망과 다중 모드 DBM [206]을 다중 모드 표현으로 도입했습니다. Kim 등 [108]은 각 모드에 대해 심층 신뢰 신경망을 사용한 다음 시청각 감정 인식을 위해 공동 표현으로 결합했습니다. Huang과 Kingsbury [89]는 AVSR에 유사한 모델을 사용했고, Wu 등 [233]은 오디오 및 골격 관절 기반 제스처 인식을 위해 사용했습니다. Ouyang 등 [163]은 다중 뷰 데이터로부터 인간 자세 추정 작업을 위해 다중 모드 DBM의 사용을 탐구했습니다. 그들은 단일 모드 데이터가 비선형 변환을 거친 후 나중 단계에서 데이터를 통합하는 것이 모델에 유익하다는 것을 보여주었습니다. 유사하게, Suk 등 [207]은 양전자 방출 단층 촬영 및 자기 공명 영상 데이터로부터 알츠하이머병 분류를 수행하기 위해 다중 모드 DBM 표현을 사용했습니다.
다중 모드 DBM을 사용하여 다중 모드 표현을 학습하는 큰 이점 중 하나는 생성적 특성으로, 누락된 데이터를 쉽게 처리할 수 있다는 점입니다. 전체 모드가 누락되더라도 모델은 자연스럽게 대처할 수 있습니다. 또한 다른 모드가 있는 상태에서 한 모드의 샘플을 생성하거나 표현에서 두 모드를 모두 생성하는 데 사용될 수 있습니다. 오토인코더와 유사하게, 표현은 비지도 방식으로 훈련될 수 있습니다.
Table 2: 멀티모달 표현 기법 요약. 공동 표현의 세 가지 하위 유형(섹션 3.1)과 조정된 표현의 두 가지 하위 유형(섹션 3.2)을 식별합니다. 모달리티에 대해 +는 결합된 모달리티를 나타냅니다.
| REPRESENTATION | Modalities | REFERENCE |
|---|---|---|
| Joint | ||
| Neural networks | Images + Audio <br> Images + Text | [150], [157], [235] [191] |
| Graphical models | Images + Text <br> Images + Audio | [206] <br> [108] |
| Sequential | Audio + Video <br> Images + Text | [100], [158] <br> [173] |
| Coordinated | ||
| Similarity | Images + Text <br> Video + Text | [64], [110] <br> [166], [239] |
| Structured | Images + Text <br> Audio + Articulatory | [33], [220], [256] <br> [228] |
레이블이 없는 데이터의 사용을 가능하게 합니다. DBM의 주요 단점은 높은 계산 비용으로 인해 훈련이 어렵고, 근사 변분 훈련 방법을 사용해야 한다는 것입니다 [206]. Sequential Representation. 지금까지 우리는 고정 길이 데이터를 표현할 수 있는 모델에 대해 논의했지만, 종종 문장, 비디오 또는 오디오 스트림과 같은 가변 길이 시퀀스를 표현해야 합니다. Recurrent neural networks (RNNs)와 그 변형인 long-short term memory (LSTMs) 네트워크 [85]는 최근 다양한 작업에서 시퀀스 모델링의 성공으로 인해 인기를 얻었습니다 [13], [222]. 지금까지 RNN은 주로 단어, 오디오 또는 이미지의 단일 모드 시퀀스를 표현하는 데 사용되었으며, 언어 영역에서 가장 큰 성공을 거두었습니다. 전통적인 신경망과 마찬가지로, RNN의 은닉 상태는 데이터의 표현으로 볼 수 있습니다. 즉, 시간 단계 에서 RNN의 은닉 상태는 해당 시간 단계까지의 시퀀스를 요약한 것으로 볼 수 있습니다. 이는 RNN 인코더-디코더 프레임워크에서 특히 분명하며, 인코더의 작업은 RNN의 은닉 상태에 시퀀스를 표현하여 디코더가 이를 재구성할 수 있도록 하는 것입니다 [13], [244].
RNN 표현의 사용은 단일 모드 영역에 국한되지 않았습니다. RNN을 사용하여 다중 모드 표현을 구성하는 초기 사용은 AVSR에 대한 Cosi 등의 연구에서 비롯됩니다 [45]. 또한 감정 인식을 위한 시청각 데이터 표현 [39], [158] 및 인간 행동 분석을 위한 다양한 시각적 단서와 같은 다중 뷰 데이터 표현 [173]에도 사용되었습니다.
3.2 Coordinated Representations
joint multimodal representation의 대안은 coordinated representation입니다. modality를 joint space로 함께 투영하는 대신, 각 modality에 대해 별도의 representation이 학습되지만 제약 조건을 통해 조정됩니다. 우리는 representation 간의 유사성을 강제하는 coordinated representation에 대한 논의로 시작하여 결과 공간에 더 많은 구조를 강제하는 coordinated representation으로 넘어갑니다(이러한 coordinated representation의 대표적인 연구는 표 2에서 볼 수 있습니다). Similarity models은 coordinated space에서 modality 간의 거리를 최소화합니다. 예를 들어, 이러한 모델은 '개'라는 단어의 표현과 개의 이미지 표현 사이의 거리가 '개'라는 단어와 자동차 이미지 사이의 거리보다 작도록 장려합니다 [64]. 이러한 표현의 초기 예 중 하나는 Weston 등의 WSABIE (web scale annotation by image embedding) 모델에 대한 연구에서 비롯되며 [229], [230], 여기서 이미지와 그 주석을 위한 coordinated space가 구성되었습니다. WSABIE는 이미지와 텍스트 특징으로부터 간단한 선형 맵을 구성하여 해당 주석과 이미지 표현이 해당하지 않는 것들보다 더 높은 내적(더 작은 코사인 거리)을 갖도록 합니다.
최근에는 신경망이 표현을 학습하는 능력 때문에 coordinated representation을 구성하는 인기 있는 방법이 되었습니다. 그들의 장점은 종단 간 방식으로 coordinated representation을 공동으로 학습할 수 있다는 사실에 있습니다. 이러한 coordinated representation의 한 예는 DeViSE - a deep visual-semantic embedding입니다 [64]. DeViSE는 WSABIE와 유사한 내적 및 순위 손실 함수를 사용하지만 더 복잡한 이미지 및 단어 임베딩을 사용합니다. Kiros 등 [110]은 LSTM 모델과 쌍별 순위 손실을 사용하여 특징 공간을 조정함으로써 이를 문장 및 이미지 coordinated representation으로 확장했습니다. Socher 등 [199]은 동일한 작업을 다루지만, 구성 의미론을 통합하기 위해 언어 모델을 dependency tree RNN으로 확장합니다. 유사한 모델이 Pan 등 [166]에 의해 제안되었지만 이미지를 비디오로 대체하여 사용했습니다. Xu 등 [239]도 <주어, 동사, 목적어> 구성 언어 모델과 심층 비디오 모델을 사용하여 비디오와 문장 사이에 coordinated space를 구성했습니다. 이 표현은 이후 교차 모달 검색 및 비디오 설명 작업에 사용되었습니다.
위의 모델들이 표현 간의 유사성을 강제한 반면, structured coordinated space 모델은 그 이상으로 나아가 modality 표현 간에 추가적인 제약을 강제합니다. 강제되는 구조의 유형은 종종 응용 프로그램에 기반하며, hashing, cross-modal retrieval 및 image captioning에 대해 다른 제약을 가집니다.
Structured coordinated spaces는 cross-modal hashing에서 일반적으로 사용됩니다 - 고차원 데이터를 유사한 객체에 대해 유사한 이진 코드를 가진 컴팩트한 이진 코드로 압축하는 것 [226]. cross-modal hashing의 아이디어는 cross-modal retrieval을 위해 그러한 코드를 생성하는 것입니다 [28], [97], [118]. Hashing은 결과적인 multimodal 공간에 특정 제약을 강제합니다: 1) 차원 Hamming space여야 합니다 - 제어 가능한 비트 수를 가진 이진 표현; 2) 다른 modality에서 온 동일한 객체는 유사한 해시 코드를 가져야 합니다; 3) 공간은 유사성을 보존해야 합니다. 데이터를 해시 함수로 표현하는 방법을 학습하는 것은 이 세 가지 요구 사항을 모두 강제하려고 시도합니다 [28], [118]. 예를 들어, Jiang과 Li [96]는 종단 간 훈련 가능한 딥러닝 기술을 사용하여 문장 설명과 해당 이미지 사이에 그러한 공통 이진 공간을 학습하는 방법을 도입했습니다. 반면 Cao 등 [33]은 더 복잡한 LSTM 문장 표현으로 접근 방식을 확장하고 이상치에 둔감한 비트 단위 마진 손실과 관련성 피드백 기반 의미 유사성 제약을 도입했습니다. 유사하게, Wang 등 [227]은 유사한 의미를 가진 이미지(및 문장)가 서로 더 가까운 coordinated space를 구성했습니다.
구조화된 조정 표현의 또 다른 예는 이미지와 언어의 order-embeddings에서 비롯됩니다 [220], [257]. Vendrov 등이 제안한 모델 [220]은 비대칭적인 비유사성 메트릭을 강제하고 다중 모드 공간에서 부분 순서의 개념을 구현합니다. 아이디어는 언어와 이미지 표현의 부분 순서를 포착하여 공간에 계층 구조를 강제하는 것입니다. 예를 들어, "개를 산책시키는 여성"의 이미지 → "개를 산책시키는 여성"이라는 텍스트 → "산책하는 여성"이라는 텍스트입니다. 표기 그래프를 사용하는 유사한 모델이 Young 등 [246]에 의해 제안되었으며, 여기서 표기 그래프는 부분 순서를 유도하는 데 사용됩니다. 마지막으로, Zhang 등은 텍스트와 이미지의 구조화된 표현을 활용하는 것이 어떻게 비지도 방식으로 개념 분류 체계를 생성할 수 있는지 보여줍니다 [257].
구조화된 조정 공간의 특별한 경우는 canonical correlation analysis (CCA) [87]에 기반한 것입니다. CCA는 두 확률 변수(우리의 경우 modality) 간의 상관 관계를 최대화하고 새로운 공간의 직교성을 강제하는 선형 투영을 계산합니다. CCA 모델은 cross-modal retrieval [79], [111], [176] 및 시청각 신호 분석 [184], [195]에 광범위하게 사용되었습니다. CCA에 대한 확장은 상관 관계를 최대화하는 비선형 투영을 구성하려고 시도합니다 [7], [121]. Kernel canonical correlation analysis (KCCA) [121]는 투영을 위해 재생 커널 힐베르트 공간을 사용합니다. 그러나 이 접근 방식은 비모수적이므로 훈련 세트의 크기에 따라 확장성이 좋지 않고 매우 큰 실제 데이터 세트에 문제가 있습니다. Deep canonical correlation analysis (DCCA) [7]는 KCCA의 대안으로 도입되었으며 확장성 문제를 해결하며 더 나은 상관 관계 표현 공간으로 이어진다는 것이 입증되었습니다. 유사한 correspondence autoencoder [61] 및 deep correspondence RBMs [60]도 cross-modal retrieval을 위해 제안되었습니다.
CCA, KCCA 및 DCCA는 비지도 기법이며 표현에 대한 상관 관계만 최적화하므로 주로 모달리티 간에 공유되는 것을 포착합니다. Deep canonically correlated autoencoders [228]는 또한 오토인코더 기반 데이터 재구성 항을 포함합니다. 이는 표현이 모달리티 특정 정보도 포착하도록 장려합니다. Semantic correlation maximization 방법 [256]은 또한 의미적 관련성을 장려하면서 결과 공간의 상관 관계 최대화 및 직교성을 유지합니다. 이는 CCA와 교차 모달 해싱 기법의 조합으로 이어집니다.
3.3 Discussion
이 섹션에서는 multimodal representation의 두 가지 주요 유형인 joint와 coordinated를 식별했습니다. Joint representation은 multimodal 데이터를 공통 공간으로 투영하며, 추론 시 모든 modality가 존재할 때 가장 적합합니다. 이들은 AVSR, 감정 및 multimodal 제스처 인식에 광범위하게 사용되었습니다. 반면에 Coordinated representation은 각 modality를 별도의 조정된 공간으로 투영하므로, 테스트 시에 하나의 modality만 존재하는 응용 프로그램에 적합합니다. 예를 들어, multimodal retrieval 및 translation(섹션 4), grounding(섹션 7.2), zero shot learning(섹션 7.2)이 있습니다. 또한, joint representation은 두 개 이상의 modality의 representation을 구성하는 상황에서 사용되었지만, coordinated space는 지금까지 대부분 두 개로 제한되었습니다. 마지막으로, 우리가 논의한 multimodal 네트워크는 대체로 정적입니다. 미래에는 한 modality가 다른 modality에 적용되는 네트워크의 구조를 구동하는 작업이 더 많이 나타날 수 있습니다 [6].
Table 3: multimodal translation 연구의 분류 체계. 각 클래스 및 하위 클래스에 대해, 참조와 함께 예시 작업을 포함합니다. 우리의 분류 체계에는 번역의 방향성도 포함됩니다: 단방향 및 양방향.
| TASKS | DIR. | REFERENCES | |
|---|---|---|---|
| Example-based | |||
| Retrieval | Image captioning | [58], [162] | |
| Media retrieval | [199], [239] | ||
| Visual speech | [27] | ||
| Image captioning | [102], [103] | ||
| Combination | Image captioning | [77], [119], [124] | |
| Generative | |||
| Grammar based | Video description | [15], [213] | |
| Image description | [53], [126], [147] | ||
| Encoder-decoder | Image captioning | [110], [139] | |
| Video description | [222], [249] | ||
| Text to image | [137], [178] | ||
| Continuous | Sounds synthesis | [161], [164] | |
| Visual speech | [5], [49], [212] |
4 Translation
multimodal machine learning의 큰 부분은 한 modality에서 다른 modality로의 번역(매핑)과 관련이 있습니다. 한 modality의 개체가 주어졌을 때, 다른 modality에서 동일한 개체를 생성하는 것이 과제입니다. 예를 들어, 이미지가 주어지면 이를 설명하는 문장을 생성하거나, 텍스트 설명이 주어지면 그에 맞는 이미지를 생성하는 것입니다. Multimodal translation은 speech synthesis [91], visual speech generation [141], video description [112], cross-modal retrieval [176] 등 초기 연구부터 오랫동안 연구된 문제입니다.
최근, multimodal translation은 컴퓨터 비전과 자연어 처리(NLP) 커뮤니티의 공동 노력 [20]과 최근 대규모 multimodal 데이터셋의 가용성 [40], [214] 덕분에 새로운 관심을 받고 있습니다. 특히 인기 있는 문제는 visual scene description으로, image captioning [223] 및 video captioning [222]으로도 알려져 있으며, 이는 여러 컴퓨터 비전 및 NLP 문제에 대한 훌륭한 테스트 베드 역할을 합니다. 이를 해결하기 위해서는 시각적 장면을 완전히 이해하고 그 두드러진 부분을 식별해야 할 뿐만 아니라, 문법적으로 정확하고 포괄적이면서도 간결한 설명 문장을 생성해야 합니다.
multimodal translation에 대한 접근 방식은 매우 광범위하고 종종 modality에 따라 다르지만, 여러 가지 통일된 요소를 공유합니다. 우리는 이를 example-based와 generative의 두 가지 유형으로 분류합니다. Example-based 모델은 modality 간 번역 시 사전을 사용합니다. 반면에 Generative 모델은 번역을 생성할 수 있는 모델을 구성합니다. 이 구분은 비모수적 기계 학습 접근 방식과 모수적 기계 학습 접근 방식 간의 구분과 유사하며 그림 2에 설명되어 있으며, 대표적인 예는 표 3에 요약되어 있습니다.
생성 모델은 신호나 기호 시퀀스(예: 문장)를 생성하는 능력을 요구하기 때문에 구축하기가 더 어렵습니다. 이는 특히 시간적 및 구조적으로 일관된 시퀀스를 생성해야 할 때 시각, 청각 또는 언어 등 모든 양식에서 어렵습니다. 이로 인해 초기 다중 양식 번역 시스템 중 다수가 예제 기반 번역에 의존하게 되었습니다. 그러나 이미지 [178], [218], 소리 [161], [164], 텍스트 [13]를 생성할 수 있는 딥 러닝 모델의 출현으로 이것이 바뀌고 있습니다.
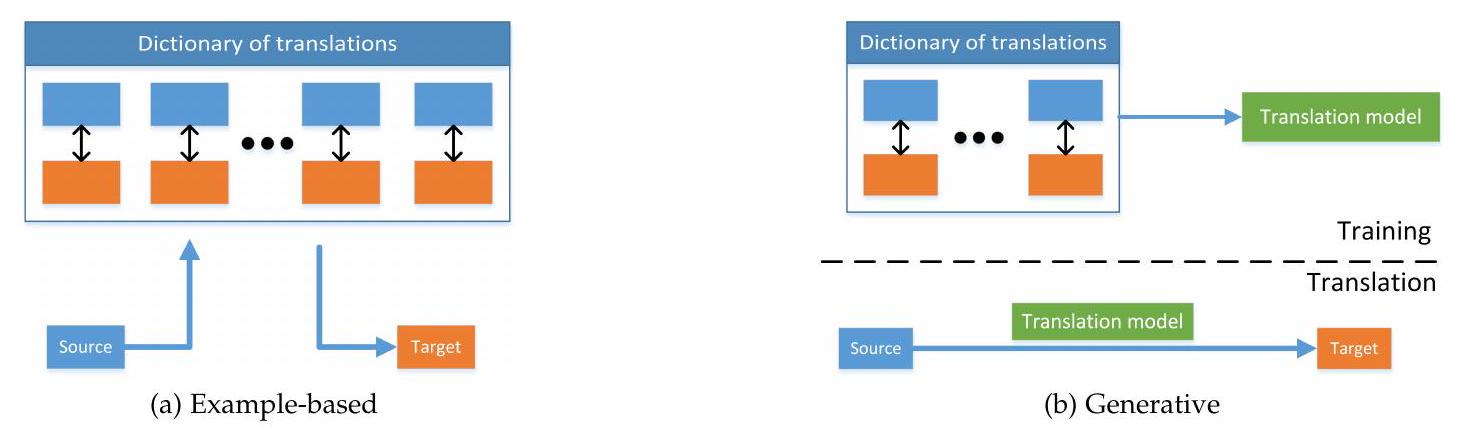
Figure 2: 예제 기반 및 생성적 multimodal translation 개요. 전자는 사전에서 최상의 번역을 검색하는 반면, 후자는 먼저 사전에 대해 번역 모델을 훈련시킨 다음 해당 모델을 번역에 사용합니다.
4.1 Example-based
예제 기반 알고리즘은 훈련 데이터, 즉 사전(그림 2a 참조)에 의해 제한됩니다. 우리는 이러한 알고리즘을 두 가지 유형으로 식별합니다: 검색 기반 및 조합 기반. 검색 기반 모델은 검색된 번역을 수정하지 않고 직접 사용하는 반면, 조합 기반 모델은 여러 검색된 인스턴스를 기반으로 번역을 생성하기 위해 더 복잡한 규칙에 의존합니다. 검색 기반 모델은 아마도 multimodal translation의 가장 간단한 형태일 것입니다. 이들은 사전에서 가장 가까운 샘플을 찾고 그것을 번역된 결과로 사용하는 것에 의존합니다. 검색은 단일 모드 공간 또는 중간 의미 공간에서 수행될 수 있습니다.
번역할 소스 모달리티 인스턴스가 주어지면, 단일 모달리티 검색은 소스의 공간에서 사전에서 가장 가까운 인스턴스를 찾습니다. 예를 들어, 이미지의 경우 시각적 특징 공간입니다. 이러한 접근 방식은 원하는 음소의 가장 일치하는 시각적 예를 검색하여 시각적 음성 합성에 사용되었습니다 [27]. 또한 연결식 텍스트-음성 변환 시스템에도 사용되었습니다 [91]. 최근에는 Ordonez 등이 전역 이미지 특징을 사용하여 캡션 후보를 검색함으로써 이미지 설명을 생성하기 위해 단일 모달리티 검색을 사용했습니다 [162]. Yagcioglu 등 [240]은 적응적 이웃 선택을 사용하여 시각적으로 유사한 이미지를 검색하기 위해 CNN 기반 이미지 표현을 사용했습니다. Devlin 등 [51]은 합의 캡션 선택과 함께 간단한 최근접 이웃 검색이 더 복잡한 생성적 접근 방식과 비교하여 경쟁력 있는 번역 결과를 달성함을 보여주었습니다. 이러한 단일 모달리티 검색 접근 방식의 장점은 검색을 수행하는 단일 모달리티의 표현만 필요하다는 것입니다. 그러나 검색된 번역의 재순위화와 같은 추가적인 다중 모달리티 후처리 단계가 종종 필요합니다 [140], [162], [240]. 이는 이 접근 방식의 주요 문제를 나타냅니다. 즉, 단일 모달리티 공간에서의 유사성이 항상 좋은 번역을 의미하지는 않습니다.
대안은 검색 중 유사성 비교를 위해 중간 의미 공간을 사용하는 것입니다. 수작업으로 만든 의미 공간의 초기 예는 Farhadi 등이 사용한 것입니다 [58]. 그들은 문장과 이미지를 모두 <객체, 행동, 장면> 공간에 매핑하고, 이미지에 대한 관련 캡션 검색은 그 공간에서 수행됩니다. 표현을 수작업으로 만드는 것과 대조적으로, Socher 등 [199]은 문장과 CNN 시각적 특징의 조정된 표현을 학습합니다(조정된 공간에 대한 설명은 섹션 3.2 참조). 그들은 텍스트에서 이미지로, 이미지에서 텍스트로 번역하는 데 모두 이 모델을 사용합니다. 유사하게, Xu 등 [239]은 교차 모드 검색을 위해 비디오와 그 설명의 조정된 공간을 사용했습니다. Jiang과 Li [97] 및 Cao 등 [33]은 이미지에서 문장으로 그리고 그 반대로 다중 모드 번역을 수행하기 위해 교차 모드 해싱을 사용하는 반면, Hodosh 등 [86]은 이미지-문장 검색을 위해 다중 모드 KCCA 공간을 사용합니다. 공통 공간에서 이미지와 문장을 전역적으로 정렬하는 대신, Karpathy 등 [103]은 이미지 조각(시각적 객체)을 문장 조각(의존성 트리 관계)과 내부적으로 정렬하는 다중 모드 유사성 메트릭을 제안합니다.
의미 공간에서의 검색 접근 방식은 두 modality를 모두 반영하고 종종 검색에 최적화된 보다 의미 있는 공간에서 예제를 검색하기 때문에 단일 modality 대응 방식보다 성능이 더 좋은 경향이 있습니다. 또한, 단일 modality 방법으로는 간단하지 않은 양방향 번역을 허용합니다. 그러나 이러한 의미 공간을 수동으로 구성하거나 학습해야 하며, 이는 종종 쌍으로 된 샘플의 대규모 훈련 사전(데이터셋)의 존재에 의존합니다. 조합 기반 모델은 검색 기반 접근법을 한 단계 더 발전시킵니다. 사전에서 예제를 단순히 검색하는 대신, 더 나은 번역을 구성하기 위해 의미 있는 방식으로 조합합니다. 조합 기반 미디어 설명 접근법은 이미지의 문장 설명이 이용될 수 있는 공통적이고 단순한 구조를 공유한다는 사실에 의해 동기 부여됩니다. 대부분의 경우 조합 규칙은 수작업으로 만들어지거나 휴리스틱에 기반합니다.
Kuznetsova 등 [119]은 먼저 시각적으로 유사한 이미지를 설명하는 구문을 검색한 다음, 여러 수작업 규칙과 함께 정수 선형 프로그래밍을 사용하여 쿼리 이미지의 새로운 설명을 생성하기 위해 이를 결합합니다. Gupta 등 [77]은 먼저 소스 이미지와 가장 유사한 개의 이미지를 찾은 다음, 캡션에서 추출한 구문을 사용하여 대상 문장을 생성합니다. Lebret 등 [124]은 CNN 기반 이미지 표현을 사용하여 이를 설명하는 구문을 추론합니다. 예측된 구문은 삼중음 제약 언어 모델을 사용하여 결합됩니다.
예제 기반 번역 접근법이 직면한 큰 문제는 모델이 전체 사전이라는 점입니다. 이로 인해 모델이 크고 추론이 느려집니다(물론 해싱과 같은 최적화가 이 문제를 완화합니다). 예제 기반 번역이 직면한 또 다른 문제는 소스 예제와 관련된 단일의 포괄적이고 정확한 번역이 사전에 항상 존재할 것이라고 기대하는 것이 비현실적이라는 것입니다. 작업이 간단하거나 사전이 매우 크지 않은 한 말입니다. 이는 더 복잡한 구조를 구성할 수 있는 조합 모델에 의해 부분적으로 해결됩니다. 그러나 그들은 한 방향으로만 번역을 수행할 수 있는 반면, 의미 공간 검색 기반 모델은 양방향으로 수행할 수 있습니다.
4.2 Generative approaches
multimodal translation에 대한 생성적 접근법은 단일 모드 소스 인스턴스가 주어졌을 때 multimodal translation을 수행할 수 있는 모델을 구성합니다. 이는 소스 modality를 이해하고 대상 시퀀스 또는 신호를 생성하는 능력을 모두 요구하므로 어려운 문제입니다. 다음 섹션에서 논의된 바와 같이, 이는 또한 가능한 정답의 공간이 크기 때문에 이러한 방법을 평가하기 훨씬 더 어렵게 만듭니다.
이 조사에서는 언어, 시각, 소리의 세 가지 양식 생성에 중점을 둡니다. 언어 생성은 오랫동안 탐구되어 왔으며 [177], 이미지 및 비디오 설명과 같은 작업에 최근 많은 관심이 집중되었습니다 [20]. 음성 및 소리 생성 또한 역사적 [91] 및 현대적 접근법 [161], [164]을 포함하여 많은 연구가 이루어졌습니다. 사실적인 이미지 생성은 덜 탐구되었으며 아직 초기 단계에 있지만 [137], [178], 추상적인 장면 [261], 컴퓨터 그래픽 [47], 말하는 머리 [5] 생성에 대한 여러 시도가 있었습니다.
우리는 생성 모델의 세 가지 광범위한 범주를 식별합니다: 문법 기반, 인코더-디코더, 연속 생성 모델. 문법 기반 모델은 문법을 사용하여 대상 도메인을 제한함으로써 작업을 단순화합니다. 예를 들어, <주어, 목적어, 동사> 템플릿을 기반으로 제한된 문장을 생성합니다. 인코더-디코더 모델은 먼저 소스 양식을 잠재 표현으로 인코딩한 다음, 디코더가 이를 사용하여 대상 양식을 생성합니다. 연속 생성 모델은 소스 양식 입력 스트림을 기반으로 대상 양식을 지속적으로 생성하며, 텍스트 음성 변환과 같이 시간적 시퀀스 간의 변환에 가장 적합합니다. 문법 기반 모델은 특정 modality를 생성하기 위해 미리 정의된 문법에 의존합니다. 이들은 이미지의 객체 및 비디오의 행동과 같은 소스 modality에서 고수준 개념을 감지하는 것으로 시작합니다. 이러한 감지 결과는 미리 정의된 문법에 기반한 생성 절차와 함께 통합되어 대상 modality를 생성합니다.
Kojima 등 [112]은 사람의 머리와 손의 감지된 위치 및 개념과 행동의 계층 구조를 통합하는 규칙 기반 자연어 생성을 사용하여 비디오에서 인간 행동을 설명하는 시스템을 제안했습니다. Barbu 등 [15]은 누가 누구에게 무엇을 어디서 어떻게 했는지 형태의 문장을 생성하는 비디오 설명 모델을 제안했습니다. 이 시스템은 수작업으로 만든 객체 및 이벤트 분류기를 기반으로 하며 작업에 적합한 제한된 문법을 사용했습니다. Guadarrama 등 [76]은 불확실한 경우 더 일반적인 단어를 사용하는 의미 계층 구조를 사용하여 비디오를 설명하는 <주어, 동사, 목적어> 삼중항을 예측합니다. 언어 모델과 함께 이 접근 방식은 사전에 없는 동사와 명사의 번역을 허용합니다.
이미지를 설명하기 위해 Yao 등 [243]은 and-or 그래프 기반 모델을 도메인별 어휘화된 문법 규칙, 대상 시각적 표현 체계 및 계층적 지식 온톨로지와 함께 사용할 것을 제안합니다. Li 등 [126]은 먼저 객체, 시각적 속성 및 객체 간의 공간적 관계를 감지합니다. 그런 다음 시각적으로 추출된 구문에 대해 n-gram 언어 모델을 사용하여 <주어, 전치사, 목적어> 스타일의 문장을 생성합니다. Mitchell 등 [147]은 템플릿을 채우는 대신 구문 트리를 생성하기 위해 더 정교한 트리 기반 언어 모델을 사용하여 더 다양한 설명을 생성합니다. 대부분의 접근 방식은 공간적 및 의미적 관계를 포착하지 않고 전체 이미지를 시각적 객체의 가방으로 공동으로 표현합니다. 이를 해결하기 위해 Elliott 등 [53]은 이미지 설명 생성을 위해 객체의 근접 관계를 명시적으로 모델링할 것을 제안합니다.
일부 문법 기반 접근 방식은 대상 양식을 생성하기 위해 그래픽 모델에 의존합니다. 예를 들어, BabyTalk[117]는 이미지가 주어지면 <객체, 전치사, 객체> 삼중항을 생성하며, 이는 조건부 랜덤 필드와 함께 문장을 구성하는 데 사용됩니다. Yang 등[241]은 이미지에서 추출한 시각적 특징을 사용하여 <명사, 동사, 장면, 전치사> 후보 집합을 예측하고, 통계적 언어 모델과 은닉 마르코프 모델 스타일의 추론을 사용하여 이를 문장으로 결합합니다. Thomason 등[213]에 의해 유사한 접근 방식이 제안되었으며, 여기서 팩터 그래프 모델은 <주어, 동사, 객체, 장소> 형태의 비디오 설명에 사용됩니다. 팩터 모델은 잡음이 있는 시각적 표현을 처리하기 위해 언어 통계를 활용합니다. 반대로 Zitnick 등[261]은 문장에서 추출한 언어 삼중항을 기반으로 추상적인 시각적 장면을 생성하기 위해 조건부 랜덤 필드를 사용할 것을 제안합니다.
문법 기반 방법의 장점은 미리 정의된 템플릿과 제한된 문법을 사용하기 때문에 구문적으로(언어의 경우) 또는 논리적으로 올바른 대상 인스턴스를 생성할 가능성이 더 높다는 것입니다. 그러나 이는 창의적인 번역보다는 정형화된 번역을 생성하도록 제한합니다. 또한, 문법 기반 방법은 개념 탐지를 위한 복잡한 파이프라인에 의존하며, 각 개념은 별도의 모델과 별도의 훈련 데이터 세트를 필요로 합니다. 종단 간 훈련된 신경망 기반 인코더-디코더 모델은 현재 다중 모드 번역에서 가장 인기 있는 기술 중 하나입니다. 모델의 주요 아이디어는 먼저 소스 모드를 벡터 표현으로 인코딩한 다음 디코더 모듈을 사용하여 대상 모드를 생성하는 것입니다. 이 모든 것이 단일 패스 파이프라인에서 이루어집니다. 비록 처음에는 기계 번역[101], [208]에 사용되었지만, 이러한 모델은 이미지 캡셔닝[139], [223] 및 비디오 설명[181], [222]에 성공적으로 사용되었습니다. 인코더-디코더 모델은 주로 텍스트를 생성하는 데 사용되었지만, 이미지[137], [178]와 음성 및 소리[161], [164]도 생성할 수 있습니다.
인코더-디코더 모델의 첫 번째 단계는 소스 객체를 인코딩하는 것이며, 이는 모달리티별 방식으로 수행됩니다. 음향 신호를 인코딩하는 인기 있는 모델에는 RNN [36] 및 DBN [82]이 있습니다. 단어 문장을 인코딩하는 대부분의 연구는 분포 의미론 [146]과 RNN의 변형 [13]을 사용합니다. 이미지는 대부분 컨볼루션 신경망(CNN) [114], [193]을 사용하여 인코딩됩니다. 비디오 표현을 학습하는 방법이 있지만 [59], [192], 수작업으로 만든 특징도 여전히 사용됩니다 [181], [213]. 단일 모달리티 표현을 사용하여 소스 모달리티를 인코딩하는 것이 가능하지만, 조정된 공간(섹션 3.2 참조)을 사용하면 더 나은 결과를 얻을 수 있습니다 [110], [166]. 디코딩은 대부분 RNN 또는 LSTM에 의해 수행되며, 인코딩된 표현을 초기 은닉 상태로 사용합니다 [56], [137], [223], [223]. 번역 작업을 돕기 위해 기존의 LSTM 모델에 여러 확장이 제안되었습니다. 가이드 벡터를 사용하여 이미지 입력의 솔루션을 긴밀하게 결합할 수 있습니다 [95]. Venugopalan 등 [222]은 비디오 설명에 미세 조정하기 전에 이미지 캡셔닝을 위해 디코더 LSTM을 사전 훈련하는 것이 유익하다는 것을 보여줍니다. Rohrbach 등 [181]은 비디오 설명 작업을 위해 다양한 LSTM 아키텍처(단일 계층, 다중 계층, 분해)와 여러 훈련 및 정규화 기술의 사용을 탐구합니다.
RNN을 사용한 번역 생성의 문제는 모델이 이미지, 문장 또는 비디오의 단일 벡터 표현에서 설명을 생성해야 한다는 것입니다. 이러한 모델은 초기 입력을 잊어버리는 경향이 있으므로 긴 시퀀스를 생성할 때 특히 어려워집니다. 이는 디코더의 모든 단계에서 인코딩된 정보를 포함함으로써 부분적으로 해결되었습니다 [95]. 어텐션 모델(섹션 5.2 참조)은 생성 중에 디코더가 이미지 [238], 문장 [13] 또는 비디오 [244]의 특정 부분에 더 잘 집중할 수 있도록 제안되었습니다.
생성적 어텐션 기반 RNN은 문장에서 이미지를 생성하는 작업에도 사용되었으며 [137], 결과는 아직 사실적이지는 않지만 많은 가능성을 보여줍니다. 최근에는 생성적 적대 신경망 [74]을 사용하여 이미지를 생성하는 데 많은 진전이 있었으며, 이는 텍스트에서 이미지를 생성하기 위해 RNN의 대안으로 사용되었습니다 [178].
신경망 기반 인코더-디코더 시스템이 매우 성공적이었음에도 불구하고 여전히 여러 문제에 직면해 있습니다. Devlin 등 [51]은 -최근접 이웃 모델이 생성 기반 모델과 유사하게 수행된다는 관찰에 근거하여, 네트워크가 시각적 장면을 이해하고 생성하는 방법을 배우기보다는 훈련 데이터를 암기하고 있을 가능성이 있다고 제안합니다. 또한 이러한 모델은 종종 훈련을 위해 대량의 데이터가 필요합니다. 연속 생성 모델은 시퀀스 번역을 위한 것이며 온라인 방식으로 모든 시간 단계에서 출력을 생성합니다. 이러한 모델은 텍스트를 음성으로, 음성을 텍스트로, 비디오를 텍스트로 변환하는 것과 같이 시퀀스에서 시퀀스로 변환할 때 유용합니다. 이러한 모델링을 위해 그래픽 모델, 연속 인코더-디코더 접근법, 다양한 기타 회귀 또는 분류 기법 등 여러 가지 다른 기법이 제안되었습니다. 이러한 모델이 해결해야 할 추가적인 어려움은 모달리티 간의 시간적 일관성 요구 사항입니다.
시퀀스 대 시퀀스 번역에 대한 초기 연구의 대부분은 그래픽 또는 잠재 변수 모델을 사용했습니다. Deena와 Galata [49]는 오디오 기반 시각적 음성 합성을 위해 공유 가우시안 프로세스 잠재 변수 모델을 사용할 것을 제안했습니다. 이 모델은 오디오와 시각적 특징 사이에 공유 잠재 공간을 만들어 다른 시간 단계에서 시각적 음성의 시간적 일관성을 강제하면서 한 공간에서 다른 공간을 생성하는 데 사용할 수 있습니다. 은닉 마르코프 모델(HMM)도 시각적 음성 생성 [212] 및 텍스트 음성 변환 [253] 작업에 사용되었습니다. 또한 클러스터 적응 훈련을 사용하여 여러 화자, 언어 및 감정에 대한 훈련을 허용하도록 확장되어 음성 신호 [252] 또는 시각적 음성을 생성할 때 더 많은 제어를 허용합니다. 매개변수 [5]. Encoder-decoder 모델은 최근 시퀀스 대 시퀀스 모델링에서 인기를 얻었습니다. Owens 등 [164]은 비디오를 기반으로 드럼 스틱에서 발생하는 소리를 생성하기 위해 LSTM을 사용했습니다. 그들의 모델은 CNN 시각적 특징에서 코클리오그램을 예측하여 소리를 생성할 수 있지만, 예측된 코클리오그램을 기반으로 가장 가까운 오디오 샘플을 검색하는 것이 최상의 결과를 가져온다는 것을 발견했습니다. 음성 및 음악 생성을 위해 원시 오디오 신호를 직접 모델링하는 것은 van den Oord 등 [161]에 의해 제안되었습니다. 저자들은 계층적 완전 컨볼루션 신경망을 사용할 것을 제안하며, 이는 음성 합성 작업에 대해 이전의 최첨단 기술에 비해 큰 개선을 보여줍니다. RNN은 또한 음성 대 텍스트 번역(음성 인식)에 사용되었습니다 [75]. 최근에는 인코더-디코더 기반 연속 접근 방식이 필터 뱅크 스펙트럼으로 표현된 음성 신호에서 문자를 예측하는 데 효과적이라는 것이 입증되었습니다 [36]. 이는 희귀하고 어휘에 없는 단어의 더 정확한 인식을 가능하게 합니다. Collobert 등 [44]은 오디오 특징의 필요성을 제거하고 원시 오디오 신호를 직접 음성 인식을 위해 사용하는 방법을 보여줍니다.
이전의 많은 연구에서는 연속 신호 간의 다중 모드 번역을 위해 그래픽 모델을 사용했습니다. 그러나 이러한 방법은 신경망 인코더-디코더 기반 기술로 대체되고 있습니다. 특히 최근에는 복잡한 시각 및 음향 신호를 표현하고 생성할 수 있는 것으로 나타났기 때문입니다.
4.3 Model evaluation and discussion
multimodal translation 방법이 직면한 주요 과제는 평가가 매우 어렵다는 것입니다. 음성 인식과 같은 일부 작업은 단일 정답 번역을 갖지만, 음성 합성 및 미디어 설명과 같은 작업은 그렇지 않습니다. 때로는 언어 번역에서와 같이 여러 답변이 정확하며 어떤 번역이 더 나은지 결정하는 것은 종종 주관적입니다. 다행히도 모델 평가에 도움이 되는 여러 근사 자동 메트릭이 있습니다.
주관적인 작업을 평가하는 이상적인 방법은 종종 인간의 판단을 통하는 것입니다. 즉, 한 그룹의 사람들이 각 번역을 평가하도록 하는 것입니다. 이는 각 번역이 특정 차원(음성 합성에 대한 자연스러움 및 평균 의견 점수[161], [252], 시각적 음성 합성에 대한 사실성[5], [212], 미디어 설명에 대한 문법적 및 의미적 정확성, 관련성, 순서 및 세부 사항[40], [117], [147], [222])에서 평가되는 Likert 척도로 수행될 수 있습니다. 또 다른 옵션은 참가자에게 선호도 비교를 위해 두 개(또는 그 이상)의 번역을 제시하는 선호도 연구를 수행하는 것입니다[212], [252]. 그러나 사용자 연구는 인간의 판단에 가장 가까운 평가를 가져올 것이지만 시간이 많이 걸리고 비용이 많이 듭니다. 또한, 유창성, 연령, 성별 및 문화적 편견을 피하기 위해 이를 구성하고 수행할 때 주의가 필요합니다.
인간 연구는 평가의 황금 표준이지만, 미디어 설명 작업을 위해 여러 가지 자동 대안이 제안되었습니다: BLEU [167], ROUGE [129], Meteor [50], CIDEr [219]. 그러나 이러한 사용은 많은 비판에 직면했으며 인간의 판단과 약하게만 일치하는 것으로 나타났습니다 [54], [90].
Hodosh 등 [86]은 인간의 판단을 더 잘 반영하는 방법으로 이미지 캡셔닝 평가의 대리 지표로 검색을 사용할 것을 제안합니다. 캡션을 생성하는 대신, 검색
Table 4: multimodal alignment 과제에 대한 우리 분류 체계 요약. 우리 분류 체계의 각 하위 클래스에 대해, 참조 인용 및 정렬된 modality를 포함합니다.
| Alignment | Modalities | REFERENCE |
|---|---|---|
| Explicit | ||
| Unsupervised | Video + Text <br> Video + Audio | [136], [210], [211] <br> [160], [215], [259] |
| Supervised | Video + Text <br> Image + Text | [24], [260] <br> [113], [138], [168] |
| Implicit | ||
| Graphical models | Audio/Text + Text | [194], [224] |
| Neural networks | Image + Text <br> Video + Text | [102], [236], [238] <br> [244], [249] |
기반 시스템은 사용 가능한 캡션을 이미지에 대한 적합성에 따라 순위를 매기고, 올바른 캡션에 높은 순위가 부여되었는지 평가하여 평가됩니다. 여러 캡션 생성 모델이 생성적이므로 이미지에 대한 캡션의 가능성을 직접 평가하는 데 사용될 수 있으며, 이미지 캡셔닝 커뮤니티에서 채택되고 있습니다 [103], [110]. 이러한 검색 기반 평가 지표는 비디오 캡셔닝 커뮤니티에서도 채택되었습니다 [182].
Visual question-answering (VQA) [135] 과제는 부분적으로 이미지 캡셔닝 평가가 직면한 문제 때문에 제안되었습니다. VQA는 이미지와 그 내용에 대한 질문이 주어졌을 때 시스템이 답해야 하는 과제입니다. 이러한 시스템을 평가하는 것은 정답이 존재하기 때문에 더 쉬우며, 과제를 번역이 아닌 multimodal fusion (섹션 6 참조)으로 전환합니다. Image co-reference 과제 [113], [138]는 과제를 multi-modal alignment (섹션 5 참조)로 구성함으로써 이러한 모호성을 해결하기 위해 제안되었습니다.
우리는 평가 문제를 해결하는 것이 multimodal translation 시스템의 추가적인 성공에 중요할 것이라고 믿습니다. 이는 접근 방식 간의 더 나은 비교를 가능하게 할 뿐만 아니라 최적화할 더 나은 목표를 가능하게 할 것입니다.
5 Alignment
우리는 multimodal alignment를 둘 이상의 modality에서 온 인스턴스의 하위 구성 요소 간의 관계와 대응 관계를 찾는 것으로 정의합니다. 예를 들어, 이미지와 캡션이 주어지면 캡션의 단어 또는 구에 해당하는 이미지 영역을 찾고자 합니다 [102]. 또 다른 예는 영화가 주어졌을 때, 그것이 기반으로 한 스크립트나 책의 장과 정렬하는 것입니다 [260]. 이를 수행하는 능력은 텍스트를 기반으로 비디오 콘텐츠를 검색할 수 있게 하므로 멀티미디어 검색에 특히 중요합니다. 예를 들어, 영화에서 특정 캐릭터가 나타나는 장면을 찾거나 파란색 의자가 포함된 이미지를 찾는 것입니다.
우리는 multimodal alignment를 implicit과 explicit의 두 가지 유형으로 분류합니다. explicit alignment에서는 modality 간의 하위 구성 요소를 명시적으로 정렬하는 데 관심이 있습니다. 예를 들어, 요리법 단계를 해당 교육용 비디오와 정렬하는 것입니다 [136]. implicit alignment는 다른 작업(예: 텍스트 설명을 기반으로 한 이미지 검색)의 중간(종종 잠재적인) 단계로 사용되며, 단어와 이미지 영역 간의 정렬 단계를 포함할 수 있습니다 [103]. 이러한 접근 방식의 개요는 표 4에서 볼 수 있으며 다음 섹션에서 더 자세히 제시됩니다.
5.1 Explicit alignment
우리는 논문들이 그들의 주요 모델링 목표가 둘 이상의 modality에서 온 인스턴스의 하위 구성 요소 간의 정렬일 경우 명시적 정렬을 수행하는 것으로 분류합니다. 명시적 정렬의 매우 중요한 부분은 유사성 메트릭입니다. 대부분의 접근 방식은 다른 modality의 하위 구성 요소 간의 유사성을 측정하는 것을 기본 빌딩 블록으로 의존합니다. 이러한 유사성은 수동으로 정의되거나 데이터로부터 학습될 수 있습니다. 우리는 명시적 정렬을 다루는 두 가지 유형의 알고리즘을 식별합니다 - 비지도 및 (약)지도. 첫 번째 유형은 다른 modality의 인스턴스 간에 직접적인 정렬 레이블(즉, 레이블이 지정된 대응 관계) 없이 작동합니다. 두 번째 유형은 그러한 (때로는 약한) 레이블에 접근할 수 있습니다. 비지도 다중 모드 정렬은 직접적인 정렬 레이블 없이 모달리티 정렬을 다룹니다. 대부분의 접근 방식은 통계적 기계 번역 [29] 및 게놈 서열 [116], [151]에 대한 정렬에 대한 초기 연구에서 영감을 받았습니다. 작업을 더 쉽게 만들기 위해 접근 방식은 시퀀스의 시간적 순서 또는 모달리티 간의 유사성 메트릭 존재와 같은 정렬에 대한 특정 제약을 가정합니다.
Dynamic time warping (DTW) [116], [151]는 다중 시점 시계열을 정렬하는 데 광범위하게 사용되어 온 동적 프로그래밍 접근 방식입니다. DTW는 두 시퀀스 간의 유사성을 측정하고 시간 왜곡(프레임 삽입)을 통해 최적의 일치를 찾습니다. 두 시퀀스의 시간 단계가 비교 가능해야 하며 그들 사이의 유사성 측정치가 필요합니다. DTW는 모달리티 간의 유사성 메트릭을 수작업으로 제작하여 다중 모드 정렬에 직접 사용할 수 있습니다. 예를 들어 Anguera 등 [8]은 문자소와 음소 사이의 수동으로 정의된 유사성을 사용하고, Tapaswi 등 [210]은 TV 쇼와 줄거리 시놉시스를 정렬하기 위해 동일한 문자의 모양에 기반한 시각적 장면과 문장 사이의 유사성을 정의합니다 [210]. DTW와 유사한 동적 프로그래밍 접근 방식은 텍스트-음성 [80] 및 비디오 [211]의 다중 모드 정렬에도 사용되었습니다.
원래의 DTW 공식은 모달리티 간에 미리 정의된 유사성 메트릭을 필요로 하기 때문에, 모달리티를 조정된 공간으로 매핑하기 위해 정준 상관 분석(CCA)을 사용하여 확장되었습니다. 이는 다른 모달리티 스트림 간의 정렬(DTW를 통해)과 매핑 학습(CCA를 통해)을 공동으로 그리고 비지도 방식으로 가능하게 합니다 [187], [258], [259]. CCA 기반 DTW 모델은 선형 변환 하에서 다중 모드 데이터 정렬을 찾을 수 있지만, 비선형 관계를 모델링할 수는 없습니다. 이는 심층 정준 시간 왜곡 접근법 [215]에 의해 해결되었으며, 이는 심층 CCA와 DTW의 일반화로 볼 수 있습니다.
다양한 그래픽 모델은 비지도 방식으로 다중 모드 시퀀스 정렬에 널리 사용되었습니다. Yu와 Ballard의 초기 연구 [247]는 이미지의 시각적 객체를 음성 단어와 정렬하기 위해 생성적 그래픽 모델을 사용했습니다. Cour 등 [46]은 영화 장면과 장면을 해당 시나리오와 정렬하기 위해 유사한 접근 방식을 취했습니다. Malmaud 등 [136]은 요리법을 요리 비디오와 정렬하기 위해 분해된 HMM을 사용했으며, Noulas 등 [160]은 화자를 비디오와 정렬하기 위해 동적 베이지안 네트워크를 사용했습니다. Naim 등 [153]은 문장을 해당하는 비디오 프레임에 해당하는 문장을 계층적 HMM 모델을 사용하여 프레임과 문장을 정렬하고, 단어 및 객체 정렬을 위해 수정된 IBM [29] 알고리즘을 사용합니다 [16]. 이 모델은 나중에 정렬을 위해 잠재 조건부 랜덤 필드를 사용하도록 확장되었으며 [152], 명사와 객체 외에 동사와 행동의 정렬을 통합하도록 확장되었습니다 [203].
DTW 및 그래픽 모델 정렬 접근법은 모두 정렬에 대한 제약(예: 시간적 일관성, 시간의 큰 도약 없음, 단조성)을 허용합니다. DTW 확장은 유사성 메트릭과 정렬을 공동으로 학습할 수 있도록 하는 반면, 그래픽 모델 기반 접근법은 구성에 전문가 지식이 필요합니다 [46], [247]. 지도 정렬 방법은 레이블이 지정된 정렬된 인스턴스에 의존합니다. 이들은 모달리티를 정렬하는 데 사용되는 유사성 측정치를 훈련하는 데 사용됩니다.
여러 지도 시퀀스 정렬 기법은 비지도 기법에서 영감을 얻었습니다. Bojanowski 등 [23], [24]은 정준 시간 왜곡과 유사한 방법을 제안했지만, 모델 훈련을 위해 기존의 (약한) 감독 정렬 데이터를 활용하도록 확장했습니다. Plummer 등 [168]은 이미지 영역과 구문 간의 정렬을 위해 조정된 공간을 찾기 위해 CCA를 사용했습니다. Gebru 등 [68]은 가우시안 혼합 모델을 훈련하고 비지도 잠재 변수 그래픽 모델과 함께 반지도 클러스터링을 수행하여 오디오 채널의 화자를 비디오의 위치와 정렬했습니다. Kong 등 [113]은 3D 장면의 객체를 텍스트 설명의 명사와 대명사와 정렬하기 위해 마르코프 랜덤 필드를 훈련했습니다.
딥러닝 기반 접근법은 최근 언어 및 시각 커뮤니티에서 정렬된 데이터셋의 가용성 덕분에 명시적 정렬(특히 유사성 측정)에 인기를 얻고 있습니다 [138], [168]. Zhu 등 [260]은 장면과 텍스트 간의 유사성을 측정하기 위해 CNN을 훈련하여 책을 해당 영화/대본과 정렬했습니다. Mao 등 [138]은 LSTM 언어 모델과 CNN 시각 모델을 사용하여 참조 표현과 이미지의 객체 간의 일치 품질을 평가했습니다. Yu 등 [250]은 동일한 유형의 객체를 더 잘 구별할 수 있도록 상대적인 외양 및 컨텍스트 정보를 포함하도록 이 모델을 확장했습니다. 마지막으로, Hu 등 [88]은 LSTM 기반 점수 함수를 사용하여 이미지 영역과 그 설명 간의 유사성을 찾았습니다.
5.2 Implicit alignment
명시적 정렬과는 대조적으로, 암시적 정렬은 다른 작업을 위한 중간(종종 잠재적인) 단계로 사용됩니다. 이는 음성 인식, 기계 번역, 미디어 설명 및 시각적 질문 응답을 포함한 여러 작업에서 더 나은 성능을 가능하게 합니다. 이러한 모델은 데이터를 명시적으로 정렬하지 않으며 감독된 정렬 예제에 의존하지 않고, 모델 훈련 중에 데이터를 잠재적으로 정렬하는 방법을 학습합니다. 우리는 암시적 정렬 모델의 두 가지 유형을 식별합니다: 그래픽 모델을 기반으로 한 초기 연구와 더 현대적인 신경망 방법입니다. 그래픽 모델은 기계 번역을 위해 언어 간 단어를 더 잘 정렬하고 [224], 음성 음소를 그 전사와 정렬하는 데 [194] 사용된 초기 연구가 일부 있습니다. 그러나 이들은 음소를 음향 특징에 매핑하는 생성적 음소 모델과 같이 모달리티 간 매핑을 수동으로 구성해야 합니다. [194]. 이러한 모델을 구축하려면 훈련 데이터나 인간 전문가의 수동 정의가 필요합니다. 신경망 번역(섹션 4)은 정렬이 잠재적 중간 단계로 수행될 경우 종종 개선될 수 있는 모델링 작업의 한 예입니다. 앞서 언급했듯이, 신경망은 인코더-디코더 모델을 사용하거나 교차 모드 검색을 통해 이 번역 문제를 해결하는 인기 있는 방법입니다. 암시적 정렬 없이 번역이 수행되면, 전체 이미지, 문장 또는 비디오를 단일 벡터 표현으로 적절히 요약할 수 있도록 인코더 모듈에 많은 부담을 주게 됩니다.
이를 해결하는 매우 인기 있는 방법은 attention [13]을 통하는 것이며, 이는 디코더가 소스 인스턴스의 하위 구성 요소에 집중할 수 있도록 합니다. 이는 기존의 인코더-디코더 모델에서 수행되는 것처럼 모든 소스 하위 구성 요소를 함께 인코딩하는 것과 대조됩니다. attention 모듈은 번역될 소스의 대상 하위 구성 요소, 즉 이미지의 영역 [238], 문장의 단어 [13], 오디오 시퀀스의 세그먼트 [36], [41], 비디오의 프레임 및 영역 [244], [249], 심지어 지침의 일부 [145]에 더 많이 보도록 디코더에게 지시합니다. 예를 들어, 이미지 캡셔닝에서 CNN을 사용하여 전체 이미지를 인코딩하는 대신, attention 메커니즘은 각 연속 단어를 생성할 때 디코더(일반적으로 RNN)가 이미지의 특정 부분에 집중할 수 있도록 합니다 [238]. 이미지의 어느 부분에 집중할지 학습하는 attention 모듈은 일반적으로 얕은 신경망이며 대상 작업(예: 번역)과 함께 종단 간 훈련됩니다.
Attention 모델은 질문에 있는 단어를 텍스트 조각 [236], 이미지 [65] 또는 비디오 시퀀스 [254]와 같은 정보 소스의 하위 구성 요소와 정렬할 수 있기 때문에 질문 응답 작업에도 성공적으로 적용되었습니다. 이는 더 나은 정확도를 가능하게 하고 더 나은 모델 해석 가능성으로 이어집니다 [3]. 특히, 계층적 [133], 스택형 [242] 및 에피소드 메모리 어텐션 [236]을 포함하여 이 문제를 해결하기 위해 다양한 유형의 어텐션 모델이 제안되었습니다.
이미지와 캡션을 교차 모드 검색을 위해 정렬하는 또 다른 신경망 대안은 Karpathy 등[102], [103]에 의해 제안되었습니다. 그들이 제안한 모델은 이미지 영역과 단어 표현 사이의 내적 유사성 측정치를 사용하여 문장 조각을 이미지 영역에 정렬합니다. 어텐션을 사용하지는 않지만, 검색 모델을 훈련함으로써 간접적으로 학습되는 유사성 측정치를 통해 모달리티 간의 잠재적 정렬을 추출합니다.
5.3 Discussion
Multimodal alignment는 여러 가지 어려움에 직면합니다: 1) 명시적으로 주석이 달린 정렬이 있는 데이터셋이 거의 없습니다; 2) modality 간의 유사성 메트릭을 설계하기가 어렵습니다; 3) 여러 가능한 정렬이 존재할 수 있으며 한 modality의 모든 요소가 다른 modality에 대응 관계를 갖는 것은 아닙니다. multimodal alignment에 대한 초기 연구는 그래픽 모델과 동적 프로그래밍 기법을 사용하여 비지도 방식으로 multimodal 시퀀스를 정렬하는 데 중점을 두었습니다. 이는 modality 간의 유사성에 대한 수작업으로 정의된 측정치에 의존하거나 비지도 방식으로 학습했습니다. 최근 레이블이 지정된 훈련 데이터의 가용성으로 modality 간의 유사성을 지도 학습하는 것이 가능해졌습니다.
그러나 데이터를 공동으로 정렬하고 번역하거나 융합하는 방법을 배우는 비지도 기술도 인기를 얻었습니다.
6 Fusion
Multimodal fusion은 multimodal machine learning의 원래 주제 중 하나이며, 이전 조사에서는 early, late 및 hybrid fusion 접근법을 강조했습니다 [52], [255]. 기술적인 용어로, multimodal fusion은 결과 측정치를 예측하는 것을 목표로 여러 modality의 정보를 통합하는 개념입니다: 분류를 통해 클래스(예: 행복 대 슬픔)를 예측하거나, 회귀를 통해 연속적인 값(예: 감정의 긍정성)을 예측합니다. 이는 25년 전으로 거슬러 올라가는 연구와 함께 multimodal machine learning에서 가장 많이 연구된 측면 중 하나입니다 [251].
multimodal fusion에 대한 관심은 그것이 제공할 수 있는 세 가지 주요 이점에서 비롯됩니다. 첫째, 동일한 현상을 관찰하는 여러 modality에 접근할 수 있으면 더 견고한 예측이 가능할 수 있습니다. 이는 AVSR 커뮤니티에서 특히 탐구되고 활용되었습니다 [170]. 둘째, 여러 modality에 접근할 수 있으면 상보적인 정보를 포착할 수 있습니다. 즉, 개별 modality에서는 보이지 않는 정보입니다. 셋째, multimodal 시스템은 modality 중 하나가 없을 때도 작동할 수 있습니다. 예를 들어, 사람이 말하지 않을 때 시각 신호로부터 감정을 인식하는 것입니다 [52].
Multimodal fusion은 audio-visual speech recognition (AVSR) [170], multimodal emotion recognition [200], medical image analysis [93], multimedia event detection [122]을 포함하여 매우 광범위한 응용 분야를 가지고 있습니다. 이 주제에 대한 여러 리뷰가 있습니다 [11], [170], [196], [255]. 대부분은 멀티미디어 분석, 정보 검색 또는 감정 인식과 같은 특정 작업에 대한 multimodal fusion에 집중합니다. 대조적으로, 우리는 기계 학습 접근법 자체와 이러한 접근법과 관련된 기술적 과제에 집중합니다.
일부 이전 연구에서는 multimodal fusion이라는 용어를 모든 multimodal 알고리즘을 설명하는 데 사용했지만, 우리는 multimodal 통합이 결과 측정치를 예측하는 목표를 가지고 후기 예측 단계에서 수행될 때 접근법을 fusion으로 분류합니다. 최근, multimodal representation과 fusion 사이의 경계는 representation 학습이 분류 또는 회귀 목표와 상호 작용하는 심층 신경망과 같은 모델에 대해 흐려졌습니다.
우리는 multimodal fusion을 두 가지 주요 범주로 분류합니다: 특정 기계 학습 방법에 직접 의존하지 않는 모델 불가지론적 접근법(섹션 6.1)과 커널 기반 접근법, 그래픽 모델, 신경망과 같이 구성에서 융합을 명시적으로 다루는 모델 기반 접근법(섹션 6.2)입니다. 이러한 접근법의 개요는 표 5에서 볼 수 있습니다.
6.1 Model-agnostic approaches
역사적으로, multimodal fusion의 대부분은 모델 불가지론적 접근 방식을 사용하여 수행되었습니다 [52]. 이러한 접근 방식은 초기(즉, 특징 기반), 후기(즉, 결정 기반) 및 하이브리드 융합으로 나눌 수 있습니다 [11]. 초기 융합은 특징이 추출된 직후(종종 단순히 표현을 연결함으로써) 통합합니다. 반면에 후기 융합은 각 Table 5: 우리의 다중 모드 융합 접근법 분류 요약. Out - 출력 유형(class - 분류 또는 reg - 회귀), TEMP - 시간적 모델링 가능 여부.
| Fusion Type | Out | TEMP | TASK | Reference |
|---|---|---|---|---|
| Model-agnostic | ||||
| Early | class | no | Emotion rec. | [35] |
| Late | reg | yes | Emotion rec. | [175] |
| Hybrid | class | no | Multimedia event detection | [122] |
| Model-based | ||||
| Kernel-based | class class | no no | Object class. Emotion rec. | [32], [69] [94], [189] |
| Graphical models | class reg class | yes yes no | AVSR Emotion rec. Media class. | [78] [14] [97] |
| Neural networks | class class reg | yes no yes | Emotion rec. AVSR Emotion rec. | [100], [232] [157] [39] |
modality가 결정(예: 분류 또는 회귀)을 내린 후에 통합을 수행합니다. 마지막으로, 하이브리드 융합은 초기 융합의 출력과 개별 단일 모드 예측기의 출력을 결합합니다. 모델 불가지론적 접근 방식의 장점은 거의 모든 단일 모드 분류기 또는 회귀기를 사용하여 구현할 수 있다는 것입니다.
Early fusion은 각 modality의 저수준 특징 간의 상관 관계 및 상호 작용을 활용하는 법을 배울 수 있기 때문에 multimodal 연구자들이 multimodal representation 학습을 수행하려는 초기 시도로 볼 수 있습니다. 또한 단일 모델의 훈련만 필요하므로 late fusion 및 hybrid fusion에 비해 훈련 파이프라인이 더 간단합니다.
반면에, late fusion은 단일 모드 결정 값을 사용하고 평균화 [188], 투표 방식 [149], 채널 노이즈 [170] 및 신호 분산 [55]에 기반한 가중치 부여, 또는 학습된 모델 [71], [175]과 같은 융합 메커니즘을 사용하여 이를 융합합니다. 이는 각 모드에 대해 다른 모델을 사용할 수 있게 하여 다른 예측기가 각 개별 모드를 더 잘 모델링할 수 있도록 하여 더 많은 유연성을 제공합니다. 또한, 하나 이상의 모드가 누락되었을 때 예측을 더 쉽게 만들고 병렬 데이터가 없을 때도 훈련을 허용합니다. 그러나 late fusion은 모드 간의 저수준 상호 작용을 무시합니다.
Hybrid fusion은 위에서 설명한 두 방법의 장점을 공통 프레임워크에서 활용하려고 시도합니다. 이는 multimodal 화자 식별 [234] 및 multimedia event detection (MED) [122]에 성공적으로 사용되었습니다.
6.2 Model-based approaches
모델 불가지론적 접근법은 단일 모드 기계 학습 방법을 사용하여 구현하기 쉽지만, 결국 다중 모드 데이터용으로 설계되지 않은 기술을 사용하게 됩니다. 이 섹션에서는 다중 모드 융합을 수행하도록 설계된 세 가지 범주의 접근법을 설명합니다: 커널 기반 방법, 그래픽 모델 및 신경망입니다. Multiple kernel learning (MKL) 방법은 데이터의 다른 모달리티/뷰에 대해 다른 커널을 사용할 수 있도록 하는 커널 서포트 벡터 머신(SVM)의 확장입니다 [73]. 커널은 데이터 포인트 간의 유사성 함수로 볼 수 있으므로, MKL의 모달리티별 커널은 이종 데이터의 더 나은 융합을 가능하게 합니다.
MKL 접근법은 객체 탐지를 위한 시각적 설명자를 융합하는 데 특히 인기 있는 방법이었으며 [32], [69], 최근에야 딥러닝 방법으로 대체되었습니다. 이 작업에 대한 학습 방법 [114]. 또한 다중 모드 감정 인식 [38], [94], [189], 다중 모드 감성 분석 [169] 및 멀티미디어 이벤트 탐지(MED) [245]에도 사용되었습니다. 또한, McFee와 Lanckriet [142]은 음향, 의미 및 사회적 뷰 데이터에서 음악 아티스트 유사성 순위를 매기기 위해 MKL을 사용할 것을 제안했습니다. 마지막으로, Liu 등 [130]은 알츠하이머병 분류에서 다중 모드 융합을 위해 MKL을 사용했습니다. 그들의 광범위한 적용 가능성은 다양한 영역과 다양한 모달리티에 걸쳐 이러한 접근법의 강점을 보여줍니다.
커널 선택의 유연성 외에도 MKL의 장점은 손실 함수가 볼록하다는 사실로, 표준 최적화 패키지와 전역 최적해를 사용하여 모델 훈련이 가능하다는 것입니다 [73]. 또한 MKL은 회귀와 분류를 모두 수행하는 데 사용될 수 있습니다. MKL의 주요 단점 중 하나는 테스트 시 훈련 데이터(서포트 벡터)에 의존하여 추론이 느리고 메모리 사용량이 크다는 점입니다. 그래픽 모델은 multimodal fusion을 위한 또 다른 인기 있는 방법군입니다. 이 섹션에서는 얕은 그래픽 모델을 사용한 multimodal fusion에 대한 연구를 개괄합니다. 심층 신뢰 네트워크와 같은 심층 그래픽 모델에 대한 설명은 섹션 3.1에서 찾을 수 있습니다.
대부분의 그래픽 모델은 생성적(결합 확률 모델링) 또는 판별적(조건부 확률 모델링) [209] 두 가지 주요 범주로 분류될 수 있습니다. 그래픽 모델을 사용하여 다중 모드 융합을 수행한 초기 접근법 중 일부는 결합된 [155] 및 계승적 은닉 마르코프 모델 [70]과 같은 생성 모델과 동적 베이지안 네트워크 [67]를 포함합니다. 보다 최근에 제안된 다중 스트림 HMM 방법은 AVSR [78]에 대한 모달리티의 동적 가중치를 제안합니다.
아마도 생성 모델은 예측력을 위해 결합 확률 모델링을 희생하는 조건부 랜덤 필드(CRF) [120]와 같은 판별 모델에 인기를 잃었을 것입니다. CRF 모델은 이미지 설명의 시각 및 텍스트 정보를 결합하여 이미지를 더 잘 분할하는 데 사용되었습니다 [63]. CRF 모델은 숨겨진 조건부 랜덤 필드 [172]를 사용하여 잠재 상태를 모델링하도록 확장되었으며 다중 모드 회의 분할에 적용되었습니다 [180]. 잠재 변수 판별 그래픽 모델의 다른 다중 모드 사용에는 다중 뷰 숨겨진 CRF [202] 및 잠재 변수 모델 [201]이 포함됩니다. 최근 Jiang 등 [97]은 멀티미디어 분류 작업에 대한 다중 모드 숨겨진 조건부 랜덤 필드의 이점을 보여주었습니다. 대부분의 그래픽 모델은 분류를 목표로 하지만, CRF 모델은 회귀를 위한 연속 버전 [171]으로 확장되었으며 다중 모드 설정 [14]에서 시청각 감정 인식을 위해 적용되었습니다.
그래픽 모델의 이점은 데이터의 공간적 및 시간적 구조를 쉽게 활용할 수 있다는 점으로, AVSR 및 다중 모드 감정 인식과 같은 시간적 모델링 작업에 특히 인기가 있습니다. 또한 모델에 인간 전문가의 지식을 내장할 수 있으며 종종 해석 가능한 모델로 이어집니다. 신경망은 multimodal fusion 작업에 광범위하게 사용되었습니다 [157]. 신경망을 multi-modal fusion에 사용한 가장 초기 예는 AVSR에 대한 연구에서 비롯됩니다 [170]. 오늘날에는 시각 및 미디어 질문 응답 [66], [135], [237], 제스처 인식 [156], 감정 분석 [100]을 위한 정보 융합에 사용되고 있습니다. [159], 및 비디오 설명 생성 [98], [221]. 얕은 [66] 및 깊은 [159], [221] 신경망 모델 모두 다중 모드 융합을 위해 탐구되었습니다.
신경망은 또한 RNN과 LSTM을 사용하여 시간적 다중 모드 정보를 융합하는 데 사용되었습니다. 이러한 초기 응용 중 하나는 양방향 LSTM을 사용하여 시청각 감정 분류를 수행하는 것이었습니다 [232]. 최근에는 Wöllmer 등 [231]이 연속적인 다중 모드 감정 인식을 위해 LSTM 모델을 사용하여 그래픽 모델과 SVM에 비해 그 장점을 입증했습니다. 유사하게, Nicolaou 등 [158]은 연속적인 감정 예측을 위해 LSTM을 사용했습니다. 그들이 제안한 방법은 모드별(오디오 및 얼굴 표정) LSTM의 결과를 융합하기 위해 LSTM을 사용했습니다.
순환 신경망을 통해 모달리티 융합에 접근하는 것은 다양한 이미지 캡셔닝 작업에서 사용되었습니다. 예를 들어, 신경망 이미지 캡셔닝[223]은 CNN 이미지 표현을 LSTM 언어 모델로 디코딩하고, gLSTM[95]은 시각 및 문장 데이터를 공동 표현으로 융합하여 모든 시간 단계에서 문장 디코딩과 함께 이미지 데이터를 통합합니다. 더 최근의 예는 Rajagopalan 등이 제안한 multi-view LSTM(MV-LSTM) 모델입니다[173]. MV-LSTM 모델은 시간에 따른 모달리티별 및 교차 모달리티 상호 작용을 명시적으로 모델링하여 LSTM 프레임워크에서 모달리티의 유연한 융합을 허용합니다.
딥 뉴럴 네트워크 접근법의 데이터 융합에서의 큰 장점은 대량의 데이터로부터 학습할 수 있는 능력입니다. 둘째, 최근의 신경망 아키텍처는 다중 모드 표현 구성 요소와 융합 구성 요소의 종단 간 훈련을 허용합니다. 마지막으로, 비 신경망 기반 시스템과 비교했을 때 좋은 성능을 보이며 다른 접근법이 어려움을 겪는 복잡한 결정 경계를 학습할 수 있습니다.
신경망 접근 방식의 주요 단점은 해석 가능성이 부족하다는 것입니다. 예측이 무엇에 의존하는지, 어떤 모달리티나 특징이 중요한 역할을 하는지 알기 어렵습니다. 또한 신경망은 성공하기 위해 대규모 훈련 데이터셋이 필요합니다.
6.3 Discussion
Multimodal fusion은 모델 불가지론적 방법, 그래픽 모델, 다중 커널 학습 및 다양한 유형의 신경망을 포함하여 이를 해결하기 위해 제안된 수많은 접근 방식이 있는 광범위하게 연구된 주제입니다. 각 접근 방식은 고유한 강점과 약점을 가지고 있으며, 일부는 더 작은 데이터셋에 더 적합하고 다른 일부는 잡음이 많은 환경에서 더 나은 성능을 보입니다. 가장 최근에는 신경망이 multimodal fusion을 다루는 매우 인기 있는 방법이 되었지만, 그래픽 모델과 다중 커널 학습은 특히 훈련 데이터가 제한적이거나 모델 해석 가능성이 중요한 작업에서 여전히 사용되고 있습니다.
이러한 발전에도 불구하고 다중 모드 융합은 여전히 다음과 같은 과제에 직면해 있습니다: 1) 신호가 시간적으로 정렬되지 않을 수 있음(밀집된 연속 신호와 희소한 이벤트 가능성); 2) 보완적인 정보뿐만 아니라 보충적인 정보를 활용하는 모델을 구축하기 어려움; 3) 각 모드는 다른 시점에서 다른 유형과 다른 수준의 잡음을 나타낼 수 있음.
7 Co-learning
우리의 분류 체계에서 마지막 multimodal 과제는 co-learning입니다. 즉, 자원이 풍부한 다른 modality의 지식을 활용하여 자원이 부족한 modality의 모델링을 돕는 것입니다. 이는 modality 중 하나가 주석이 달린 데이터 부족, 잡음이 많은 입력, 신뢰할 수 없는 레이블과 같은 제한된 자원을 가질 때 특히 관련이 있습니다. 이 과제를 co-learning이라고 부르는 이유는 대부분의 경우 도우미 modality가 모델 훈련 중에만 사용되고 테스트 시에는 사용되지 않기 때문입니다. 우리는 훈련 자원을 기반으로 co-learning 접근법을 세 가지 유형으로 식별합니다: 병렬, 비병렬 및 하이브리드. 병렬 데이터 접근법은 한 modality의 관측치가 다른 modality의 관측치와 직접 연결된 훈련 데이터셋을 필요로 합니다. 즉, multimodal 관측치가 동일한 인스턴스에서 비롯된 경우입니다. 예를 들어, 비디오와 음성 샘플이 동일한 화자에게서 나온 시청각 음성 데이터셋과 같습니다. 대조적으로, 비병렬 데이터 접근법은 다른 modality의 관측치 간에 직접적인 연결을 필요로 하지 않습니다. 이러한 접근법은 일반적으로 범주 측면에서 중복을 사용하여 co-learning을 달성합니다. 예를 들어, zero shot learning에서 기존의 시각적 객체 인식 데이터셋이 위키피디아의 두 번째 텍스트 전용 데이터셋으로 확장되어 시각적 객체 인식의 일반화를 향상시키는 경우입니다. 하이브리드 데이터 설정에서는 modality가 공유 modality 또는 데이터셋을 통해 연결됩니다. co-learning의 방법에 대한 개요는 표 6에서 볼 수 있으며 데이터 병렬 처리에 대한 요약은 그림 3에 있습니다.
7.1 Parallel data
병렬 데이터 co-learning에서는 두 modality가 인스턴스 집합을 공유합니다. 예를 들어, 해당 비디오가 있는 오디오 녹음, 이미지와 그 문장 설명 등이 있습니다. 이를 통해 두 가지 유형의 알고리즘이 해당 데이터를 활용하여 modality를 더 잘 모델링할 수 있습니다: co-training과 representation learning입니다. Co-training은 다중 모드 문제에서 레이블이 지정된 샘플이 거의 없을 때 더 많은 레이블이 지정된 훈련 샘플을 생성하는 프로세스입니다 [22]. 기본 알고리즘은 각 모드에서 약한 분류기를 구축하여 레이블이 없는 데이터에 대한 레이블을 서로 부트스트랩합니다. Blum과 Mitchell의 독창적인 연구에서 웹 페이지 자체와 하이퍼링크를 기반으로 웹 페이지 분류를 위한 더 많은 훈련 샘플을 발견하는 것으로 나타났습니다 [22]. 정의상 이 작업은 다중 모드 샘플의 중복에 의존하기 때문에 병렬 데이터가 필요합니다.
Co-training은 통계적 구문 분석 [185], 더 나은 시각적 탐지기 구축 [125], 시청각 음성 인식 [42]에 사용되었습니다. 또한 신뢰할 수 없는 샘플을 필터링하여 모달리티 간의 불일치를 처리하도록 확장되었습니다 [43]. Co-training은 더 많은 레이블링된 데이터를 생성하는 강력한 방법이지만, 편향된 훈련 샘플로 이어져 과적합을 유발할 수도 있습니다. 전이 학습은 병렬 데이터를 사용하여 공동 학습을 활용하는 또 다른 방법입니다. 다중 모드 심층 볼츠만 머신 [206] 및 다중 모드 오토인코더 [157]와 같은 다중 모드 표현 학습(섹션 3.1) 접근 방식은 한 모드의 표현에서 다른 모드의 표현으로 정보를 전달합니다. 이는 다중 모드 표현뿐만 아니라 더 나은 단일 모드 표현으로 이어지며, 테스트 시에는 하나의 모드만 사용됩니다 [157].
Moon 등 [148]은 음성 인식 신경망(오디오 기반)에서 립리딩 신경망(이미지 기반)으로 정보를 전달하는 방법을 보여주며, 이는 더 나은 시각적 표현과 테스트 시 오디오 정보 없이 립리딩에 사용할 수 있는 모델로 이어집니다. 유사하게, Arora와 Livescu [10]는 음향 및 조음(입술, 혀, 턱의 위치) 데이터에 CCA를 사용하여 더 나은 음향 특징을 구축합니다. 그들은 CCA 구성 중에만 조음 데이터를 사용하고 테스트 시에는 결과적인 음향(단일 모드) 표현만 사용합니다.
7.2 Non-parallel data
비병렬 데이터에 의존하는 방법은 모달리티가 공유 인스턴스를 가질 필요 없이 공유 범주나 개념만 있으면 됩니다. 비병렬 공동 학습 접근법은 표현을 학습할 때 도움이 될 수 있으며, 더 나은 의미 개념 이해를 가능하게 하고 심지어 보이지 않는 객체 인식을 수행할 수도 있습니다. 전이 학습은 비병렬 데이터에서도 가능하며, 데이터가 풍부하거나 깨끗한 modality를 사용하여 구축된 표현에서 데이터가 부족하거나 잡음이 많은 modality로 정보를 전달함으로써 더 나은 표현을 학습할 수 있게 합니다. 이러한 유형의 전이 학습은 종종 조정된 multimodal representation(섹션 3.2 참조)을 사용하여 달성됩니다. 예를 들어, Frome 등 [64]은 별도의 대규모 데이터셋에서 훈련된 word2vec 텍스트 특징 [146]과 CNN 시각적 특징을 조정하여 이미지 분류를 위한 시각적 표현을 개선하기 위해 텍스트를 사용했습니다. 이러한 방식으로 훈련된 시각적 표현은 유사한 범주의 객체로 착각하는 등 더 의미 있는 오류를 발생시킵니다 [64]. Mahasseni와 Todorovic [134]은 은닉 상태 간의 유사성을 강제하여 3D 골격 데이터에서 훈련된 autoencoder LSTM을 사용하여 색상 비디오 기반 LSTM을 정규화하는 방법을 보여주었습니다. 이러한 접근 방식은 원래의 LSTM을 개선하고 행동 인식에서 최첨단 성능을 이끌어낼 수 있습니다. Conceptual grounding은 순수하게 언어에 기반하지 않고 시각, 소리, 심지어 냄새와 같은 추가적인 modality에 기반하여 의미론적 의미나 개념을 학습하는 것을 의미합니다 [17]. 대부분의 개념 학습 접근법이 순수하게 언어 기반이지만, 인간의 의미 표현은 단순히 언어적 노출의 산물이 아니라 감각운동 경험과 지각 시스템을 통해 접지되기도 합니다 [18], [131]. 인간의 의미 지식은 지각 정보에 크게 의존하며
Table 6: 데이터 병렬 처리를 기반으로 한 공동 학습 분류 요약. 병렬 데이터 - 여러 모달리티가 동일한 인스턴스를 볼 수 있습니다. 비병렬 데이터 - 단일 모드 인스턴스는 서로 독립적입니다. 하이브리드 데이터 - 모달리티는 공유 모달리티 또는 데이터 세트를 통해 연결됩니다.
| DATA PARALLELISM | TASK | Reference |
|---|---|---|
| Parallel | ||
| Co-training | Mixture | [22], [115] |
| Transfer learning | AVSR Lip reading | [157] [148] |
| Non-parallel | ||
| Transfer learning | Visual classification Action recognition | [64] [134] |
| Concept grounding | Metaphor class. Word similarity | [188] [107] |
| Zero shot learning | Image class. Thought class. | [64], [198] [165] |
| Hybrid data | ||
| Bridging | MT and image ret. Transliteration | [174] [154] |
많은 개념들이 지각 시스템에 기반을 두고 있으며 순전히 상징적인 것이 아닙니다 [18]. 이는 순전히 텍스트 정보로부터 의미적 의미를 배우는 것이 최적이 아닐 수 있음을 의미하며, 우리의 언어적 표현을 기반으로 시각적 또는 청각적 단서를 사용하는 것을 동기 부여합니다.
Feng과 Lapata의 연구 [62]에서 시작하여, 접지는 일반적으로 표현 간의 공통 잠재 공간을 찾는 것 [62], [190] (병렬 데이터셋의 경우) 또는 단일 모드 표현을 별도로 학습한 다음 이를 연결하여 다중 모드 표현을 만드는 것 [30], [105], [179], [188] (비병렬 데이터의 경우)으로 수행됩니다. 다중 모드 표현이 구성되면 순전히 언어적 작업에 사용될 수 있습니다. Shutova 등 [188]과 Bruni 등 [30]은 은유와 직설적 언어의 더 나은 분류를 위해 접지된 표현을 사용했습니다. 이러한 표현은 또한 개념적 유사성과 관련성을 측정하는 데 유용했습니다. 즉, 두 단어 [31], [105], [190] 또는 행동 [179]이 의미적으로 또는 개념적으로 얼마나 관련이 있는지 식별하는 데 도움이 됩니다. 또한, 개념은 시각적 신호뿐만 아니라 청각적 신호를 사용하여 접지될 수 있으며, 특히 청각적 연관성이 있는 단어 [107] 또는 냄새 연관성이 있는 단어에 대한 후각 신호 [106]에 대해 더 나은 성능을 이끌어냅니다. 마지막으로, 시각적 장면을 설명에 정렬하면 더 나은 텍스트 또는 시각적 표현으로 이어지기 때문에 다중 모드 정렬과 개념적 접지 사이에는 많은 중복이 있습니다 [113], [168], [179], [248].
Conceptual grounding은 여러 작업에서 성능을 향상시키는 효과적인 방법으로 밝혀졌습니다. 또한 언어와 시각(또는 오디오)이 상보적인 정보 소스이며, 이를 multimodal 모델에서 결합하면 종종 성능이 향상됨을 보여줍니다. 그러나 grounding이 항상 더 나은 성능으로 이어지는 것은 아니며 [106], [107], 시각적으로 관련된 개념에 대해 이미지를 사용하는 grounding과 같이 작업에 관련성이 있을 때만 의미가 있다는 점에 주의해야 합니다. Zero shot learning (ZSL)은 어떤 예시도 명시적으로 본 적 없는 개념을 인식하는 것을 의미합니다. 예를 들어, 고양이의 (레이블이 지정된) 이미지를 본 적 없이 이미지에서 고양이를 분류하는 것입니다. 이는 시각적 객체 분류와 같은 여러 작업에서 상상할 수 있는 모든 관심 객체에 대한 훈련 예제를 제공하는 것이 엄청나게 비싸기 때문에 해결해야 할 중요한 문제입니다. ZSL에는 단일 모드와 다중 모드의 두 가지 주요 유형이 있습니다. 단일 모드 ZSL은 객체의 구성 요소나 속성을 살펴봅니다. 예를 들어, 들어보지 못한 단어를 인식하기 위한 음소나, 보이지 않는 시각적 클래스를 예측하기 위한 색상, 크기, 모양과 같은 시각적 속성을 살펴봅니다 [57]. 다중 모드 ZSL은 객체가 보였던 보조 모드의 도움을 받아 주 모드에서 객체를 인식합니다. ZSL의 다중 모드 버전은 본 클래스의 중복이 모드 간에 다르기 때문에 정의상 비병렬 데이터에 직면하는 문제입니다.
Socher 등 [198]은 이미지 특징을 개념적 단어 공간에 매핑하여 본 개념과 보지 못한 개념을 분류할 수 있습니다. 보지 못한 개념은 시각적 표현에 가까운 단어에 할당될 수 있는데, 이는 의미 공간이 더 많은 개념을 본 별도의 데이터셋에서 훈련되었기 때문에 가능합니다. 시각적 공간에서 개념 공간으로의 매핑을 학습하는 대신 Frome 등 [64]은 ZSL을 가능하게 하는 개념과 이미지 사이의 조정된 다중 모드 표현을 학습합니다. Palatucci 등 [165]은 기능적 자기 공명 영상을 기반으로 사람들이 생각하는 단어를 예측하며, 중간 의미 공간을 사용하여 보지 못한 단어를 예측하는 것이 어떻게 가능한지 보여줍니다. Lazaridou 등 [123]은 추출된 시각적 특징 벡터를 신경망을 통해 텍스트 기반 벡터에 매핑하여 ZSL을 위한 빠른 매핑 방법을 제시합니다.
7.3 Hybrid data
하이브리드 데이터 설정에서는 두 개의 비병렬 모달리티가 공유 모달리티 또는 데이터셋에 의해 연결됩니다(그림 3c 참조). 가장 주목할 만한 예는 비병렬 데이터가 있는 상황에서 조정된 다중 모드 표현을 학습하기 위해 피벗 모달리티를 사용하는 Bridge Correlational Neural Network [174]입니다. 예를 들어, 다국어 이미지 캡셔닝의 경우 이미지 모달리티는 모든 언어로 된 최소 하나의 캡션과 쌍을 이룹니다. 이러한 방법은 병렬 코퍼스가 없을 수 있지만 기계 번역 [154], [174] 및 문서 음역 [104]과 같이 공유 피벗 언어에 접근할 수 있는 언어를 연결하는 데에도 사용되었습니다.
브리징을 위해 별도의 모달리티를 사용하는 대신, 일부 방법은 제한된 주석 데이터만 포함하는 작업에서 더 나은 성능을 이끌어내기 위해 유사하거나 관련된 작업의 대규모 데이터셋 존재에 의존합니다. Socher와 Fei-Fei [197]는 이미지 분할을 안내하기 위해 대규모 텍스트 코퍼스의 존재를 사용합니다. 반면 Hendricks 등 [81]은 제한된 데이터만 사용 가능한 이미지 및 비디오 설명 시스템을 개선하기 위해 별도로 훈련된 시각적 모델과 언어 모델을 사용합니다.
7.4 Discussion
Multimodal co-learning은 한 modality가 다른 modality의 훈련에 영향을 미치도록 하여, modality 간의 상보적인 정보를 활용합니다. co-learning은 작업에 독립적이며 더 나은 fusion, translation, alignment 모델을 만드는 데 사용될 수 있다는 점에 유의하는 것이 중요합니다. 이 과제는 co-training, multimodal representation learning, conceptual grounding, zero shot learning (ZSL)과 같은 알고리즘으로 예시되며, 시각적 분류, 행동 인식, 시청각 음성 인식 및 의미적 유사성 추정에서 많은 응용을 발견했습니다.
8 Conclusion
Multimodal machine learning은 여러 modality의 정보를 처리하고 연관시킬 수 있는 모델을 구축하는 것을 목표로 하는 활기찬 다학제적 분야입니다. 이 논문은 multimodal machine learning의 최근 발전을 조사하고, multimodal 연구자들이 직면한 다섯 가지 기술적 과제인 representation, translation, alignment, fusion, co-learning을 기반으로 구축된 공통 분류 체계로 제시했습니다. 각 과제에 대해, 현재 multimodal 연구의 폭을 이해할 수 있도록 분류학적 하위 분류를 제시했습니다. 이 조사 논문의 초점은 주로 지난 10년간의 multimodal 연구에 있었지만, 과거의 성과에 대한 지식을 바탕으로 미래의 과제를 해결하는 것이 중요합니다.
앞으로, 제안된 분류 체계는 연구자들에게 현재 연구를 이해하고 미래 연구를 위한 연구가 부족한 과제를 식별하는 프레임워크를 제공합니다. 우리는 각 기술적 과제를 미래 방향과 연구 문제에 대한 논의로 요약했습니다(섹션 3.3, 및 7.4 참조). 우리는 컴퓨터가 multimodal 신호를 인식, 모델링 및 생성할 수 있도록 하려면 multimodal 연구의 모든 측면이 필요하다고 믿습니다. multimodal machine learning의 한 특정 영역으로, 연구가 부족해 보이는 분야는 co-learning이며, 여기서 한 modality의 지식이 다른 modality의 모델링에 도움이 됩니다. 이 과제는 각 modality가 자체 representation을 유지하지만 지식을 교환하고 조정하는 방법을 찾는 coordinated representations의 개념과 관련이 있습니다. 우리는 이러한 연구 라인을 미래 연구의 유망한 방향으로 봅니다.
References
[1] "TRECVID Multimedia Event Detection 2011 Evaluation," https://www.nist.gov/multimodal-information-group/ trecvid-multimedia-event-detection-2011-evaluation, accessed: 2017-01-21. [2] "YouTube statistics," https://www.youtube.com/yt/press/ statistics.html (accessed Sept. 2016), accessed: 2016-09-30. [3] A. Agrawal, D. Batra, and D. Parikh, "Analyzing the Behavior of Visual Question Answering Models," in EMNLP, 2016. [4] C. N. Anagnostopoulos, T. Iliou, and I. Giannoukos, "Features and classifiers for emotion recognition from speech: a survey from 2000 to 2011," Artificial Intelligence Review, 2012. [5] R. Anderson, B. Stenger, V. Wan, and R. Cipolla, "Expressive visual text-to-speech using active appearance models," in CVPR, 2013. [6] J. Andreas, M. Rohrbach, T. Darrell, and D. Klein, "Neural Module Networks," CVPR, 2016. [7] G. Andrew, R. Arora, J. Bilmes, and K. Livescu, "Deep canonical correlation analysis," in ICML, 2013. [8] X. Anguera, J. Luque, and C. Gracia, "Audio-to-text alignment for speech recognition with very limited resources." in INTERSPEECH, 2014. [9] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. Lawrence Zitnick, and D. Parikh, "VQA: Visual question answering," in ICCV, 2015. [10] R. Arora and K. Livescu, "Multi-view CCA-based acoustic features for phonetic recognition across speakers and domains," ICASSP, 2013. [11] P. K. Atrey, M. A. Hossain, A. El Saddik, and M. S. Kankanhalli, "Multimodal fusion for multimedia analysis: a survey," Multimedia systems, 2010. [12] Y. Aytar, C. Vondrick, and A. Torralba, "Soundnet: Learning sound representations from unlabeled video," in NIPS, 2016. [13] D. Bahdanau, K. Cho, and Y. Bengio, "Neural Machine Translation By Jointly Learning To Align and Translate," ICLR, 2014. [14] T. Baltrušaitis, N. Banda, and P. Robinson, "Dimensional Affect Recognition using Continuous Conditional Random Fields," in IEEE FG, 2013. [15] A. Barbu, A. Bridge, Z. Burchill, D. Coroian, S. Dickinson, S. Fidler, A. Michaux, S. Mussman, S. Narayanaswamy, D. Salvi, L. Schmidt, J. Shangguan, J. M. Siskind, J. Waggoner, S. Wang, J. Wei, Y. Yin, and Z. Zhang, "Video In Sentences Out," in Proc. of the Conference on Uncertainty in Artificial Intelligence, 2012. [16] K. Barnard, P. Duygulu, D. Forsyth, N. de Freitas, D. M. Blei, and M. I. Jordan, "Matching Words and Pictures," JMLR, 2003. [17] M. Baroni, "Grounding Distributional Semantics in the Visual World Grounding Distributional Semantics in the Visual World," Language and Linguistics Compass, 2016. [18] L. W. Barsalou, "Grounded cognition," Annual review of psychology, 2008. [19] Y. Bengio, A. Courville, and P. Vincent, "Representation learning: A review and new perspectives," TPAMI, 2013. [20] R. Bernardi, R. Cakici, D. Elliott, A. Erdem, E. Erdem, N. IkizlerCinbis, F. Keller, A. Muscat, and B. Plank, "Automatic Description Generation from Images: A Survey of Models, Datasets, and Evaluation Measures," JAIR, 2016. [21] J. P. Bigham, C. Jayant, H. Ji, G. Little, A. Miller, R. C. Miller, R. Miller, A. Tatarowicz, B. White, S. White, and T. Yeh, "VizWiz: Nearly Real-Time Answers to Vvisual Questions," in UIST, 2010. [22] A. Blum and T. Mitchell, "Combining labeled and unlabeled data with co-training," Computational learning theory, 1998. [23] P. Bojanowski, R. Lajugie, F. Bach, I. Laptev, J. Ponce, C. Schmid, and J. Sivic, "Weakly supervised action labeling in videos under ordering constraints," in ECCV, 2014. [24] P. Bojanowski, R. Lajugie, E. Grave, F. Bach, I. Laptev, J. Ponce, and C. Schmid, "Weakly-Supervised Alignment of Video With Text," in ICCV, 2015. [25] H. Bourlard and S. Dupont, "A new ASR approach based on independent processing and recombination of partial frequency bands," in International Conference on Spoken Language, 1996. [26] M. Brand, N. Oliver, and A. Pentland, "Coupled hidden Markov models for complex action recognition," CVPR, 1997. [27] C. Bregler, M. Covell, and M. Slaney, "Video rewrite: Driving visual speech with audio," in SIGGRAPH, 1997. [28] M. M. Bronstein, A. M. Bronstein, F. Michel, and N. Paragios, "Data Fusion through Cross-modality Metric Learning using Similarity-Sensitive Hashing," in CVPR, 2010. [29] P. F. Brown, S. A. D. Pietra, V. J. D. Pietra, and R. L. Mercer, "The mathematics of statistical machine translation: Parameter estimation," Computational linguistics, 1993. [30] E. Bruni, G. Boleda, M. Baroni, and N.-K. Tran, "Distributional Semantics in Technicolor," in ACL, 2012. [31] E. Bruni, N. K. Tran, and M. Baroni, "Multimodal Distributional Semantics," JAIR, 2014. [32] S. S. Bucak, R. Jin, and A. K. Jain, "Multiple Kernel Learning for Visual Object Recognition: A Review," TPAMI, 2014. [33] Y. Cao, M. Long, J. Wang, Q. Yang, and P. S. Yu, "Deep VisualSemantic Hashing for Cross-Modal Retrieval," in KDD, 2016. [34] J. Carletta, S. Ashby, S. Bourban, M. Flynn, M. Guillemot, T. Hain, J. Kadlec, V. Karaiskos, W. Kraaij, M. Kronenthal, G. Lathoud, M. Lincoln, A. Lisowska, I. McCowan, W. Post, D. Reidsma, and P. Wellner, "The AMI Meeting Corpus: A Pre-Announcement," in Int. Conf. on Methods and Techniques in Behavioral Research, 2005. [35] G. Castellano, L. Kessous, and G. Caridakis, "Emotion recognition through multiple modalities: Face, body gesture, speech," LNCS, 2008. [36] W. Chan, N. Jaitly, Q. Le, and O. Vinyals, "Listen, Attend, and Spell: a Neural Network for Large Vocabulary Conversational Speech Recognition," in ICASSP, 2016.