언어 모델의 Multimodal Chain-of-Thought 추론
기존의 Chain-of-Thought (CoT) 연구는 주로 언어 modality에 집중되어 있었습니다. 이 논문에서는 언어(텍스트)와 비전(이미지) modality를 통합하는 2단계 프레임워크인 Multimodal-CoT를 제안합니다. 이 프레임워크는 논리적 근거(rationale) 생성과 답변 추론을 분리하여, 다중 모드 정보를 기반으로 생성된 더 나은 논리적 근거를 답변 추론에 활용할 수 있도록 합니다. 10억개 미만의 파라미터를 가진 모델로 ScienceQA 벤치마크에서 SOTA 성능을 달성했으며, 이 접근법이 hallucination을 완화하고 수렴 속도를 높이는 이점이 있음을 보여줍니다. 논문 제목: Multimodal Chain-of-Thought Reasoning in Language Models
논문 요약: Multimodal Chain-of-Thought Reasoning in Language Models
- 논문 링크: https://arxiv.org/abs/2302.00923
- 저자: Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
- 발표 시기: 2023년, arXiv
- 주요 키워드: Multimodal, Chain-of-Thought, LLM, NLP, Vision-Language
1. 연구 배경 및 문제 정의
- 문제 정의: 기존 Chain-of-Thought (CoT) 연구는 주로 언어 모달리티에 집중되어 멀티모달 시나리오에 대한 고려가 부족했다. 특히 10억 개 미만의 파라미터를 가진 소형 언어 모델(1B-model)은 멀티모달 환경에서 효과적인 CoT 추론 능력을 이끌어내기 어렵고, 종종 환각적인(hallucinated) 또는 오해의 소지가 있는 추론 과정을 생성하여 최종 답변 정확도를 저해하는 문제가 있었다.
- 기존 접근 방식:
- 대규모 언어 모델(LLM) 프롬프팅: 이미지를 캡션으로 변환하여 텍스트 입력과 함께 LLM에 프롬프팅하는 방식.
- 한계: 이미지 캡션 생성 과정에서 시각 정보 손실이 크고, 대규모 LLM은 자원 소모가 크거나 유료 서비스로 접근성이 낮다.
- 소형 언어 모델(LM) 파인튜닝: 멀티모달 피처를 융합하여 소형 LM을 파인튜닝하는 방식.
- 한계: 1B-모델은 비논리적인 CoT를 생성하여 오답으로 이어지는 경향이 있으며, 단순히 캡션을 사용하는 방식으로는 성능 향상이 미미했다.
- 대규모 언어 모델(LLM) 프롬프팅: 이미지를 캡션으로 변환하여 텍스트 입력과 함께 LLM에 프롬프팅하는 방식.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 과학 분야에서 시각 및 언어 모달리티를 통합한 Chain-of-Thought(CoT) 추론을 연구한 최초의 사례이다.
- 소형 언어 모델의 환각(hallucination) 문제 완화 및 수렴 속도 향상에 기여하는 2단계 Multimodal-CoT 프레임워크를 제안한다.
- 제안된 접근 방식이 다양한 태스크와 백본 모델에 걸쳐 일반적으로 효과적임을 입증했다.
- 제안 방법:
Multimodal-CoT는 **추론 과정 생성(Rationale Generation)**과 **답변 추론(Answer Inference)**의 두 단계로 구성된 프레임워크이다.
- Rationale Generation 단계: 질문, 맥락, 선택지 등의 언어 입력()과 이미지 시각 입력()을 모델에 제공하여 추론 과정(rationale, )을 생성한다. 이 단계에서는 ViT(Vision Transformer)를 통해 추출된 시각 피처를 언어 인코더의 출력과 융합하여 활용한다.
- Answer Inference 단계: 첫 번째 단계에서 생성된 rationale()을 원래의 언어 입력()에 추가하여 새로운 언어 입력()을 구성한다. 이 업데이트된 언어 입력()과 원본 시각 입력()을 다시 모델에 제공하여 최종 답변()을 추론한다. 두 단계 모두 동일한 Transformer 기반 모델 구조를 공유하며, 언어 및 시각 피처 인코딩, 상호작용(단일 헤드 어텐션 및 게이티드 퓨전), 그리고 디코딩 과정을 거쳐 멀티모달 정보를 효과적으로 활용한다.
3. 실험 결과
- 데이터셋: ScienceQA (21,000개 멀티모달 객관식 질문) 및 A-OKVQA (25,000개 지식 기반 VQA 질문) 벤치마크 데이터셋을 사용했다. 두 데이터셋 모두 주석된 추론 과정(reasoning chain)을 포함한다.
- 주요 결과:
- ScienceQA 벤치마크에서 10억 개 미만의 파라미터를 가진 모델(Multimodal-CoT_Large, 738M)로 90.45%의 정확도를 달성하여 기존 SOTA(86.54%)를 크게 능가했다.
- A-OKVQA 벤치마크에서도 기존 베이스라인 대비 우수한 성능을 보였다.
- 시각 피처 통합을 통해 추론 과정 생성의 RougeL 점수가 93.46%로 크게 향상되었고, 이는 답변 정확도(85.31%) 개선으로 이어졌다.
- 환각(hallucination) 오류의 60.7%를 교정하고, 모델 수렴 속도를 향상시키는 이점을 보였다.
- 인간이 주석한 추론 과정이 없는 시나리오에서도 대규모 모델이 생성한 추론 과정을 활용하여 유사한 성능을 달성할 수 있음을 입증했다.
- UnifiedQA, FLAN-T5 등 다양한 백본 언어 모델과 ViT, CLIP 등 다양한 시각 피처에 대해 일반적인 효과를 보였다.
- MMMU와 같은 학습 도메인 외부의 멀티모달 추론 벤치마크에서도 효과적인 일반화 능력을 입증했다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 멀티모달 CoT에서 소형 모델의 환각 문제를 효과적으로 해결하고, 이를 통해 SOTA 성능을 달성했다는 점이 인상 깊다.
- 추론 과정 생성과 답변 추론을 분리한 2단계 프레임워크 설계가 합리적이며, 시각 피처를 효과적으로 융합하여 추론 과정의 품질을 높인 점이 강점이다.
- 상대적으로 작은 모델(1B 미만)로도 뛰어난 성능을 보여 자원 효율적이며, 다양한 백본 모델과 생성된 추론 과정에도 일반화 가능하다는 점이 실용적이다.
- 모델 수렴 속도를 향상시키는 이점도 있다.
- 단점/한계:
- 가장 큰 한계는 상식(commonsense) 지식 부족으로 인한 오류(전체 오류의 80%)이다. 지도 해석, 객체 수 세기, 알파벳 활용 등 기본적인 상식 추론에서 약점을 보인다.
- 추론 과정 자체의 논리적 모순이나 비교 오류와 같은 논리적 오류도 여전히 존재한다.
- 때로는 올바른 추론 과정을 생성했음에도 불구하고 최종 답변이 틀리는
Zhang, Zhuosheng, et al. "Multimodal chain-of-thought reasoning in language models." arXiv preprint arXiv:2302.00923 (2023).
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang*<br>zhangzs@sjtu.edu.cn<br>School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University
Aston Zhang*<br>az@astonzhang.com<br>GenAI, Meta<br>Mu Li<br>muli@cs.cmu.edu<br>Amazon Web Services
Hai Zhao<br>zhaohai@cs.sjtu.edu.cn<br>Department of Computer Science and Engineering, Shanghai Jiao Tong University
George Karypis
gkarypis@amazon.com Amazon Web Services
Alex Smola<br>alex@smola.org<br>Amazon Web Services
Reviewed on OpenReview: https://openreview.net/forum?id=y1pPWFVfvR
Abstract
대규모 Language Model (LLM)은 chain-of-thought (CoT) prompting을 활용하여 중간 추론 과정(reasoning chain)을 생성하고 이를 답변 추론의 근거로 삼음으로써 복잡한 추론 task에서 인상적인 성능을 보여주었다. 그러나 기존의 CoT 연구는 주로 언어 modality에 초점을 맞추어 왔다.
우리는 Multimodal-CoT를 제안한다. 이는 언어(텍스트) 및 시각(이미지) modality를 통합하여 근거 생성(rationale generation)과 답변 추론(answer inference)을 분리하는 2단계 프레임워크이다. 이러한 방식을 통해, 답변 추론은 멀티모달 정보에 기반하여 더 잘 생성된 근거를 활용할 수 있다.
ScienceQA 및 A-OKVQA 벤치마크 데이터셋에 대한 실험 결과는 우리가 제안하는 접근 방식의 효과를 보여준다. Multimodal-CoT를 통해, 10억 개 미만의 파라미터를 가진 우리 모델은 ScienceQA 벤치마크에서 state-of-the-art 성능을 달성한다. 우리의 분석에 따르면 Multimodal-CoT는 hallucination을 완화하고 수렴 속도를 향상시키는 장점을 제공한다.
코드는 https://github.com/amazon-science/mm-cot 에서 공개적으로 이용 가능하다.
1 Introduction
그림이나 표가 없는 교과서를 읽는다고 상상해 보라. 우리의 지식 습득 능력은 시각, 언어, 오디오와 같은 다양한 데이터 양식을 공동으로 모델링함으로써 크게 강화된다. 최근 대규모 language model (LLM) (Brown et al., 2020, Thoppilan et al., 2022, Rae et al., 2021, Chowdhery et al., 2022)은 답변을 추론하기 전에 중간 추론 단계(intermediate reasoning steps)를 생성함으로써 복잡한 추론에서 인상적인 성능을 보여주었다. 이 흥미로운 기술을 chain-of-thought (CoT) reasoning이라고 한다 (Wei et al., 2022b, Kojima et al., 2022, Zhang et al., 2023d).
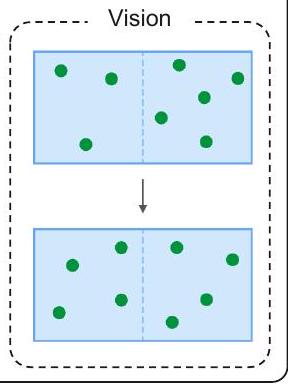
그러나 CoT reasoning과 관련된 기존 연구들은 대부분 언어 양식에만 국한되어 있으며 (Wang et al., 2022c, Zhou et al., 2022, Lu et al., 2022b, Fu et al., 2022), 멀티모달 시나리오에 대한 고려는 거의 없다. 멀티모달리티에서 CoT reasoning을 유도하기 위해 우리는 Multimodal-CoT 패러다임을 제안한다. Multimodal-CoT는 다양한 양식의 입력을 받아 다단계 문제를 중간 추론 단계(rationale)로 분해한 다음 답변을 추론한다. 시각과 언어가 가장 널리 사용되는 양식이므로, 본 연구에서는 이 두 가지 양식에 중점을 둔다. 예시는 Figure 1에 나와 있다.
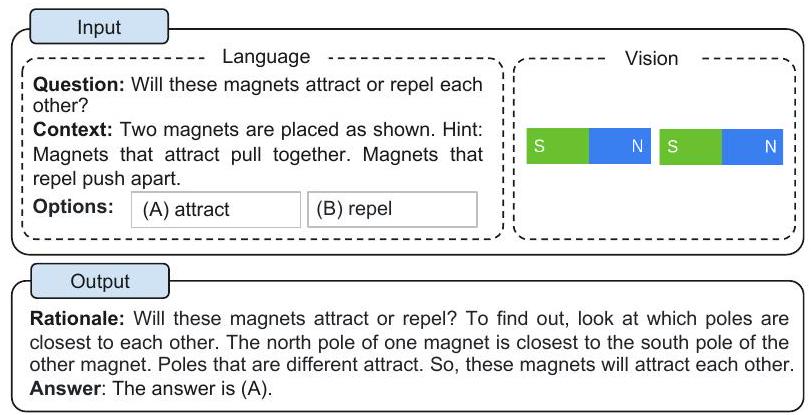
Figure 1: Multimodal CoT task의 예시.
일반적으로 Multimodal-CoT reasoning은 두 가지 주요 패러다임을 통해 유도될 수 있다: (i) LLM에 prompting하는 방식과 (ii) 더 작은 모델을 fine-tuning하는 방식. 우리는 이러한 패러다임들을 자세히 살펴보고 그와 관련된 도전 과제들을 다음과 같이 설명할 것이다.
Multimodal-CoT를 수행하는 가장 직접적인 방법은 다른 양식의 입력을 통합된 양식으로 변환하고 LLM에 CoT를 수행하도록 prompting하는 것이다 (Zhang et al., 2023a, Lu et al., 2023; Liu et al., 2023; Alayrac et al., 2022, Hao et al., 2022, Yasunaga et al., 2022). 예를 들어, captioning 모델을 통해 이미지에 대한 캡션을 생성한 다음, 이 캡션을 원래의 언어 입력과 연결하여 LLM에 입력할 수 있다 (Lu et al., 2022a). GPT-4V (OpenAI, 2023) 및 Gemini (Reid et al., 2024)와 같은 대규모 멀티모달 모델의 개발은 생성된 캡션의 품질을 크게 향상시켜 더 세밀하고 상세한 설명을 가능하게 했다. 그러나 캡션 생성 과정은 시각 신호를 텍스트 설명으로 변환할 때 여전히 상당한 정보 손실을 초래한다. 결과적으로, 시각 feature 대신 이미지 캡션을 사용하는 것은 다른 양식의 표현 공간에서 상호 시너지 부족으로 이어질 수 있다. 또한, LLM은 유료 서비스이거나 로컬에 배포하기에 자원 소모가 크다.
양식 간의 상호작용을 촉진하기 위한 또 다른 잠재적인 해결책은 멀티모달 feature를 융합하여 더 작은 language model (LM)을 fine-tuning하는 것이다 (Zhang et al., 2023c, Zhao et al., 2023). 이 접근 방식은 멀티모달 feature를 통합하기 위해 모델 아키텍처를 유연하게 조정할 수 있도록 허용하므로, 본 연구에서는 LLM에 prompting하는 대신 모델 fine-tuning을 연구한다. 핵심적인 도전 과제는 1000억 개 미만의 파라미터를 가진 language model이 답변 추론을 오도하는 환각적인 rationale를 생성하는 경향이 있다는 것이다 (Ho et al., 2022, Magister et al., 2022, Ji et al., 2022, Zhang et al., 2023b).
환각 문제를 완화하기 위해 우리는 rationale 생성과 답변 추론을 분리하는 2단계 프레임워크에 언어(텍스트) 및 시각(이미지) 양식을 통합하는 Multimodal-CoT를 제안한다. 이러한 방식으로 답변 추론은 멀티모달 정보에 기반한 더 잘 생성된 rationale를 활용할 수 있다. 우리의 실험은 ScienceQA (Lu et al., 2022a) 및 A-OKVQA (Schwenk et al. 2022) 데이터셋에서 수행되었으며, 이들은 annotated reasoning chain을 포함하는 최신 멀티모달 추론 벤치마크이다.
우리의 방법은 출시 시점에 ScienceQA 벤치마크에서 state-of-the-art 성능을 달성한다. 우리는 Multimodal-CoT가 환각을 완화하고 수렴을 가속화하는 데 유익하다는 것을 발견했다. 우리의 기여는 다음과 같이 요약된다: (i) 우리가 아는 한, 본 연구는 과학 분야의 동료 심사 문헌에서 다양한 양식의 CoT reasoning을 연구한 최초의 사례이다. (ii) 우리는 vision 및 language representation을 융합하여 Multimodal-CoT를 수행하기 위해 language model을 fine-tuning하는 2단계 프레임워크를 제안한다. 이 모델은 최종 답변 추론을 용이하게 하는 유익한 rationale를 생성할 수 있다. (iii) 우리는 CoT를 사용하는 순진한 방식이 이 맥락에서 왜 실패하는지, 그리고 vision feature를 통합하는 것이 어떻게 문제를 완화하는지에 대한 분석을 제시한다. 이 접근 방식은 task와 backbone model 전반에 걸쳐 일반적으로 효과적인 것으로 나타났다.
Table 1: 대표적인 CoT 기술 (FT: fine-tuning; KD: knowledge distillation). Segment 1: in-context learning 기술; Segment 2: fine-tuning 기술. 우리가 아는 한, 본 연구는 과학 분야의 동료 심사 문헌에서 다양한 양식의 CoT reasoning을 연구한 최초의 사례이다. 또한, 우리는 LLM의 출력에 의존하지 않고 1B-모델에 중점을 둔다.
| Models | Mutimodal | Model / Engine | Training | CoT Role | CoT Source | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Zero-Shot-CoT | (Kojima et al. | 2022) | GPT-3.5 ( 175 B ) | ICL | Reasoning | Template | ||||
| Few-Shot-CoT | ( | Wei et | 2022b | PaLM (540B) | ICL | Reasoning | Hand-crafted | |||
| Self-Consistency | -CoT | Wang | et al. | 2022b | Codex (175B) | ICL | Reasoning | Hand-crafted | ||
| Least-to-Most P | rompt | ing | (Z) | hou et al., | Codex (175B) | ICL | Reasoning | Hand-crafted | ||
| Retrieval-CoT ( | Zhang | et al., | 2023d | GPT-3.5 (175B) | ICL | Reasoning | Auto-generated | |||
| PromptPG-CoT | (Lu et al., | 2022b | GPT-3.5 ( 175 B ) | ICL | Reasoning | Hand-crafted | ||||
| Auto-CoT (Zhang | g et al | 20 | 23d | Codex (175B) | ICL | Reasoning | Auto-generated | |||
| Complexity-CoT | (Fu et al., | 2022 | GPT-3.5 ( 175 B ) | ICL | Reasoning | Hand-crafted | ||||
| Few-Shot-PoT | Chen et al., | 2022 | GPT-3.5 | (175B) | ICL | Reasoning | Hand-crafted | |||
| UnifiedQA (Lu et al., | 2022a | T5 (770M) | FT | Explanation | Crawled | |||||
| Fine-Tuned T5 XXL | Magister et al., | 2022 | T5 (11B) | KD | Reasoning | LLM-generated | ||||
| Fine-Tune-CoT | Ho et | al., | 2022 | GPT-3 ( 6.7 B ) | KD | Reasoning | LLM-generated | |||
| Multimodal-CoT | (our | work) | T5 (770M) | FT | Reasoning | Crawled |
2 Background
이 섹션에서는 prompting 및 fine-tuning을 통해 CoT reasoning을 유도하는 언어 모델 연구들을 검토한다.
2.1 CoT Reasoning with LLMs
최근 CoT는 LLM의 다단계 추론 능력을 이끌어내는 데 널리 사용되어 왔다 (Wei et al., 2022b). 구체적으로 CoT 기술은 LLM이 문제를 해결하기 위한 중간 추론 체인(reasoning chain)을 생성하도록 유도한다. 연구에 따르면 LLM은 두 가지 주요 패러다임의 기술로 CoT 추론을 수행할 수 있다: Zero-Shot-CoT (Kojima et al., 2022)와 Few-Shot-CoT (Wei et al., 2022b, Zhang et al., 2023d).
Zero-Shot-CoT의 경우, Kojima et al. (2022)는 테스트 질문 뒤에 "Let's think step by step"과 같은 prompt를 추가하여 CoT 추론을 유도함으로써 LLM이 괜찮은 zero-shot reasoner임을 보여주었다. Few-Shot-CoT의 경우, 몇 가지 단계별 추론 시연(demonstration)이 추론을 위한 조건으로 사용된다. 각 시연은 질문과 최종 답변으로 이어지는 추론 체인을 포함한다. 이러한 시연은 일반적으로 수작업 또는 자동 생성으로 얻어진다. 따라서 이 두 가지 기술, 즉 수작업과 자동 생성은 각각 Manual-CoT (Wei et al., 2022b)와 Auto-CoT (Zhang et al., 2023d)로 불린다.
효과적인 시연을 통해 Few-Shot-CoT는 종종 Zero-Shot-CoT보다 더 강력한 성능을 달성하며 더 많은 연구 관심을 끌었다. 따라서 대부분의 최근 연구는 Few-Shot-CoT를 개선하는 방법에 초점을 맞추었다. 이러한 연구는 크게 두 가지 주요 연구 라인으로 분류된다: (i) 시연 최적화; (ii) 추론 체인 최적화. Table 1은 대표적인 CoT 기술들을 비교한다.
시연 최적화 (Optimizing Demonstrations)
Few-Shot-CoT의 성능은 시연의 품질에 달려 있다. Wei et al. (2022b)에서 보고된 바와 같이, 다른 주석자가 작성한 시연을 사용하면 추론 task에서 정확도에 상당한 차이가 발생한다. 시연을 수작업으로 만드는 것을 넘어, 최근 연구들은 시연 선택 프로세스를 최적화하는 방법들을 탐구해왔다. 특히 Rubin et al. (2022)은 테스트 인스턴스와 의미적으로 유사한 시연을 검색했다. 그러나 이 접근 방식은 추론 체인에 오류가 있을 때 성능 저하를 보였다 (Zhang et al., 2023d). 이러한 한계를 해결하기 위해 Zhang et al. (2023d)은 시연 질문의 다양성이 핵심임을 발견하고 Auto-CoT를 제안했다: (i) 주어진 데이터셋의 질문들을 몇 개의 클러스터로 분할하고; (ii) 각 클러스터에서 대표 질문을 샘플링하고 간단한 휴리스틱을 사용하여 Zero-Shot-CoT로 해당 추론 체인을 생성한다. 또한, 효과적인 시연을 얻기 위해 강화 학습(RL) 및 복잡성 기반 선택 전략이 제안되었다. Fu et al. (2022)은 복잡한 추론 체인(즉, 더 많은 추론 단계를 가진)을 가진 예시들을 시연으로 선택했다. Lu et al. (2022b)는 GPT-3.5와 상호 작용할 때 후보 풀에서 최적의 in-context 예시를 찾아 주어진 학습 예시에서 예측 보상을 최대화하도록 에이전트를 학습시켰다.
추론 체인 최적화 (Optimizing Reasoning Chains)
추론 체인을 최적화하는 주목할 만한 방법은 **문제 분해(problem decomposition)**이다. Zhou et al. (2022)은 복잡한 문제를 하위 문제로 분해한 다음 이 하위 문제들을 순차적으로 해결하기 위해 least-to-most prompting을 제안했다. 그 결과, 주어진 하위 문제를 해결하는 것은 이전에 해결된 하위 문제들의 답변에 의해 용이해진다. 유사하게, Khot et al. (2022)은 다양한 분해 구조를 사용하고 각 하위 질문에 답하기 위해 다른 prompt를 설계했다. 추론 체인을 자연어 텍스트로 prompting하는 것 외에도, Chen et al. (2022)은 추론 과정을 프로그램으로 모델링하고 LLM이 생성된 프로그램을 실행하여 답변을 도출하도록 prompting하는 **program-of-thoughts (PoT)**를 제안했다. 또 다른 경향은 테스트 질문에 대해 여러 추론 경로에 걸쳐 투표(vote)하는 것이다. Wang et al. (2022b)은 LLM의 여러 출력을 샘플링한 다음 최종 답변에 대해 다수결을 취하는 self-consistency decoding 전략을 도입했다. Wang et al. (2022c)와 Li et al. (2022c)는 투표를 위해 더 다양한 출력을 생성하도록 입력 공간에 무작위성을 도입했다.
2.2 Eliciting CoT Reasoning by Fine-Tuning Models
최근에는 language model을 fine-tuning하여 CoT(Chain-of-Thought) reasoning을 유도하는 연구에 관심이 집중되고 있다. Lu et al. (2022a)는 encoder-decoder T5 모델을 CoT 어노테이션이 포함된 대규모 데이터셋으로 fine-tuning했다. 그러나 CoT를 사용하여 답을 추론할 때, 즉 답변(reasoning) 전에 추론 과정을 생성할 때 성능이 급격히 저하되는 현상이 관찰되었다. 대신 CoT는 답변 후에 설명으로만 사용되었다. Magister et al. (2022)와 Ho et al. (2022)는 더 큰 teacher model이 생성한 chain-of-thought 출력을 사용하여 student model을 fine-tuning하는 지식 증류(knowledge distillation) 방식을 사용했다. Wang et al. (2022a)는 현재 단계의 context에 따라 prompt를 동적으로 합성하는 반복적인 context-aware prompting 접근 방식을 제안했다.
1B-모델을 CoT reasoner로 학습시키는 데에는 핵심적인 도전 과제가 있다. Wei et al. (2022b)가 관찰했듯이, 1000억 개 미만의 파라미터를 가진 모델은 비논리적인 CoT를 생성하여 오답으로 이어지는 경향이 있다. 다시 말해, 1B-모델이 답변을 직접 생성하는 것보다 효과적인 CoT를 생성하는 것이 더 어려울 수 있다. 질문에 답하기 위해 멀티모달 입력을 이해해야 하는 멀티모달 환경에서는 이러한 도전이 더욱 커진다. 다음 부분에서는 Multimodal-CoT의 도전 과제를 탐색하고 효과적인 다단계 reasoning을 수행하는 방법을 조사할 것이다.
3 Challenge of Multimodal-CoT
기존 연구들은 CoT (Chain-of-Thought) reasoning 능력이 특정 규모, 예를 들어 1,000억 개 이상의 파라미터를 가진 language model에서 나타날 수 있다고 제안해왔다 (Wei et al., 2022a). 그러나 1B-model에서 이러한 reasoning 능력을 이끌어내는 것은 여전히 해결되지 않은 과제이며, 멀티모달 시나리오에서는 더욱 그러하다. 본 연구는 소비자용 GPU(예: 32G 메모리)로 fine-tuning 및 배포가 가능한 1B-model에 초점을 맞춘다. 이 섹션에서는 1B-model이 CoT reasoning에서 실패하는 이유를 조사하고, 이러한 문제를 극복하기 위한 효과적인 접근 방식을 설계하는 방법을 연구할 것이다.
3.1 Towards the Role of CoT
우선, 우리는 ScienceQA 벤치마크 (Lu et al., 2022a)에서 CoT (Chain-of-Thought) reasoning을 위해 텍스트 전용 baseline 모델을 fine-tuning한다. 우리는 FLAN-Alpaca-base를 backbone language model로 채택한다. 우리의 task는 텍스트 생성 문제로 모델링되며, 모델은 텍스트 정보를 입력으로 받아 rationale과 answer로 구성된 출력 시퀀스를 생성한다.
Figure 1에 제시된 예시처럼, 모델은 질문 텍스트(Q), 맥락 텍스트(C), 그리고 여러 옵션(M)의 토큰들을 연결한 시퀀스를 입력으로 받는다. CoT의 효과를 연구하기 위해, 우리는 세 가지 변형 모델의 성능을 비교한다:
(i) No-CoT: answer를 직접 예측하는 방식 () (ii) Reasoning: answer 추론이 rationale에 조건화되는 방식 () (iii) Explanation: rationale이 answer 추론을 설명하는 데 사용되는 방식 ()
Table 2: One-stage 설정에서 CoT의 효과.
| Method | Format | Accuracy |
|---|---|---|
| No-CoT | QCM A | 81.63 |
| Reasoning | QCM RA | 69.32 |
| Explanation | QCM AR | 69.68 |
Problem
Question: Will these magnets attract or repel each other?
Context: Two magnets are placed as shown. Hint: Magnets that attract pull together. Magnets that repel push apart.
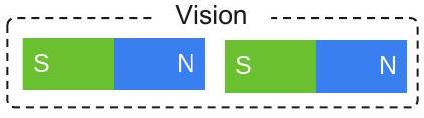
Options: (B) repel
Gold Rationale: Will these magnets attract or repel? To find out, look at which poles are closest to each other. The north pole of one magnet is closest to the south pole of the other magnet. Poles that are different attract. So, these magnets will attract each other. Answer: The answer is (A).
Baseline
생성된 추론: 이 자석들은 서로 끌어당길까, 아니면 밀어낼까? 이를 알아내려면 어떤 극들이 서로 가장 가까이 있는지 확인해야 한다. 한 자석의 남극이 다른 자석의 남극과 가장 가깝다. 같은 극은 서로 밀어낸다. 따라서 이 자석들은 서로 밀어낼 것이다. 정답: 정답은 (B)이다.
+ Vision Features
생성된 추론: 이 자석들은 서로 끌어당길까, 밀어낼까? 이를 알아내려면 어떤 극들이 가장 가까이 있는지 살펴보세요. 한 자석의 북극이 다른 자석의 남극에 가장 가깝습니다. 다른 극들은 서로 끌어당깁니다. 따라서 이 자석들은 서로 끌어당길 것입니다. 정답: 정답은 (A)입니다.

Figure 2: **Vision feature가 없는 2단계 프레임워크(baseline)**와 **vision feature가 포함된 2단계 프레임워크(우리의 방법)**를 사용하여 추론을 생성하고 정답을 예측하는 예시이다. 상단은 정답 추론(gold rationale)이 포함된 문제 세부 정보를 보여주며, 하단은 baseline과 vision feature가 통합된 우리 방법의 출력을 보여준다. 우리는 baseline이 환각(hallucinated) 추론으로 인해 올바른 정답을 예측하지 못하는 것을 관찰할 수 있다. 더 많은 예시는 Appendix A.1에 제시되어 있다.
놀랍게도, Table 2에서 보듯이, 모델이 정답보다 추론을 먼저 예측하는 경우(QCM → RA) 정확도가 **12.31% 감소(81.63% → 69.32%)**하는 것을 관찰했다. 이 결과는 추론이 반드시 올바른 정답 예측에 기여하지 않을 수도 있음을 시사한다. Lu et al. (2022a)에 따르면, 그럴듯한 이유는 모델이 필요한 정답을 얻기 전에 최대 토큰 제한을 초과하거나 예측 생성을 일찍 중단하기 때문일 수 있다. 그러나 우리는 생성된 출력(RA)의 최대 길이가 항상 400토큰 미만이며, 이는 language model의 길이 제한(예: T5 모델의 512토큰)보다 낮음을 확인했다. 따라서 추론이 정답 추론에 해를 끼치는 이유에 대한 더 심층적인 조사가 필요하다.
3.2 Misleading by Hallucinated Rationales
합리적인 설명(rationale)이 답변 예측에 어떻게 영향을 미치는지 심층적으로 분석하기 위해, 우리는 CoT 문제를 **합리적인 설명 생성(rationale generation)**과 **답변 추론(answer inference)**의 두 단계로 분리하였다. 우리는 각각의 단계에 대해 RougeL 점수와 **정확도(accuracy)**를 보고한다. Table 3은 두 단계 프레임워크 기반의 결과를 보여준다. 두 단계 baseline 모델은 합리적인 설명 생성에서 90.73의 RougeL 점수를 달성했지만, 답변 추론 정확도는 78.57%에 불과하다. Table 2의 QCM → A 변형(81.63%)과 비교했을 때, 이 결과는 두 단계 프레임워크에서 생성된 합리적인 설명이 답변 정확도를 향상시키지 못했음을 보여준다.
Table 3: (i) 합리적인 설명 생성(RougeL) 및 (ii) 답변 추론(Accuracy)의 두 단계 설정.
| Method | (i) | ii |
|---|---|---|
| Two-Stage Framework | 90.73 | 78.57 |
| w/ Captions | 90.88 | 79.37 |
| w/ Vision Features | 93.46 | 85.31 |
이어서, 우리는 50개의 오류 사례를 무작위로 샘플링하여 모델이 답변 추론을 오도하는 환각적인(hallucinated) 합리적인 설명을 생성하는 경향이 있음을 발견했다. Figure 2의 예시(왼쪽 부분)에서 볼 수 있듯이, 모델은 시각적 내용에 대한 참조가 부족하여 "한 자석의 남극이 다른 자석의 남극에 가장 가깝다"는 환각적인 설명을 생성한다. 우리는 이러한 종류의 오류가 오류 사례 중 56%의 비율로 발생함을 확인했다 (Figure 3(a)).
3.3 Multimodality Contributes to Effective Rationales
우리는 이러한 환각(hallucination) 현상이 효과적인 Multimodal-CoT를 수행하는 데 필요한 시각적 맥락(vision contexts)의 부족 때문이라고 추측한다. 시각 정보를 주입하는 간단한 방법은 이미지를 캡션으로 변환하고 (Lu et al., 2022a), 이 캡션을 두 단계의 입력에 모두 추가하는 것이다.
하지만 Table 3에서 보듯이, **캡션만을 사용하는 것은 미미한 성능 향상(0.80% 증가)**만을 가져온다. 이에 우리는 vision feature를 language model에 통합하는 고급 기술을 탐구한다. 구체적으로, 우리는 ViT 모델 (Dosovitskiy et al., 2021b)에 이미지를 입력하여 vision feature를 추출한다. 그런 다음, 추출된 vision feature를 인코딩된 언어 표현과 융합하여 decoder에 입력한다 (자세한 내용은 Section 4에서 제시될 것이다). 흥미롭게도, vision feature를 활용하자 rationale 생성의 RougeL 점수가 93.46% (QCM→R)로 크게 향상되었으며, 이는 85.31% (QCMR→A)의 더 나은 답변 정확도로 이어졌다.
 (a) hallucination mistakes 비율
(a) hallucination mistakes 비율
Figure 3: (a) hallucination mistakes 비율 및 (b) vision feature를 사용한 교정률.
이러한 효과적인 rationale 덕분에 환각 현상이 완화되었다. Section 3.2에서 발생했던 환각 오류의 60.7%가 교정되었으며 (Figure 3(b)), Figure 2 (오른쪽 부분)에 그 예시가 나타나 있다. 지금까지의 분석은 vision feature가 효과적인 rationale 생성과 정확한 답변 추론에 실제로 유익하다는 것을 강력하게 보여준다. 두 단계(two-stage) 방식이 한 단계(one-stage) 방식보다 더 나은 성능을 달성하므로, 우리는 Multimodal-CoT 프레임워크에서 두 단계 방식을 채택한다.
4 Multimodal-CoT
Section 3의 논의를 바탕으로, 우리는 Multimodal-CoT를 제안한다. 핵심 동기는 멀티모달 정보에 기반하여 더 잘 생성된 rationale이 답변 추론에 활용될 수 있을 것이라는 기대이다. 이 섹션에서는 프레임워크의 절차를 개괄하고 모델 아키텍처의 기술적 설계를 상세히 설명할 것이다.
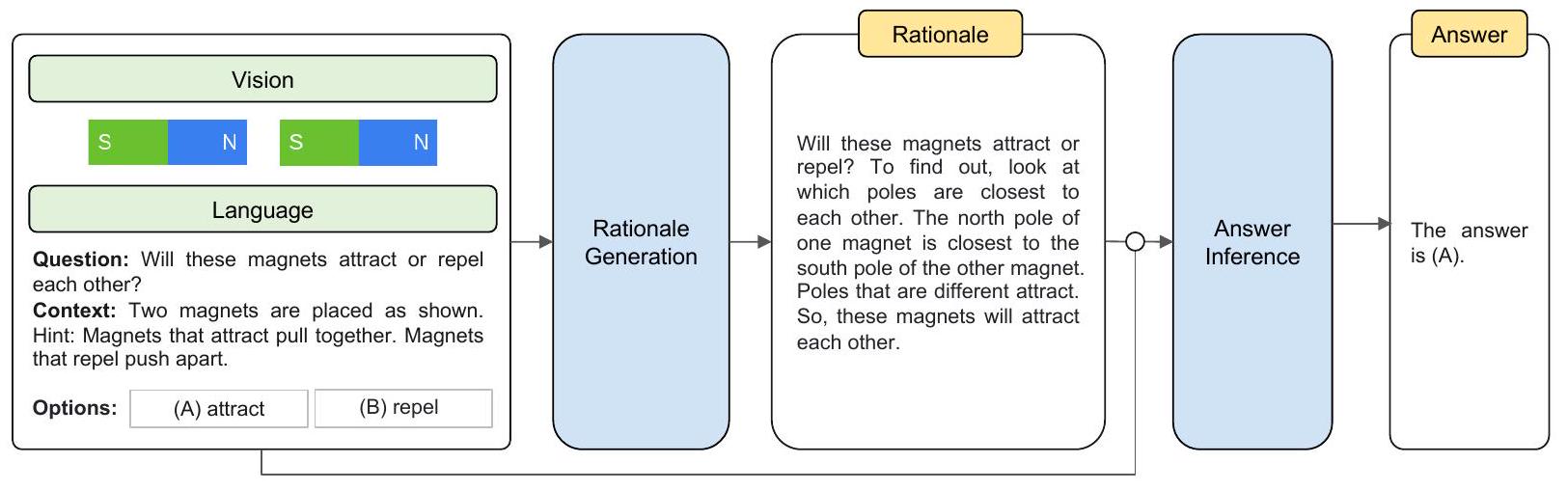
Figure 4: 우리의 Multimodal-CoT 프레임워크 개요. Multimodal-CoT는 두 가지 단계로 구성된다: (i) Rationale 생성(rationale generation) (ii) 답변 추론(answer inference)
두 단계는 동일한 모델 구조를 공유하지만, 입력과 출력에서 차이를 보인다. 첫 번째 단계에서는 언어 및 시각 입력을 모델에 제공하여 rationale을 생성한다. 두 번째 단계에서는 원래의 언어 입력에 첫 번째 단계에서 생성된 rationale을 추가한다. 그 다음, 업데이트된 언어 입력과 원래의 시각 입력을 모델에 제공하여 답변을 추론한다.
4.1 Framework Overview
Multimodal-CoT는 두 가지 운영 단계로 구성된다: (i) Rationale Generation (추론 과정 생성) (ii) Answer Inference (답변 추론)
두 단계는 동일한 모델 구조를 공유하지만, 입력 와 출력 에서 차이가 있다. 전체 과정은 Figure 4에 설명되어 있다. Multimodal-CoT가 어떻게 작동하는지 보여주기 위해 vision-language를 예시로 들어 설명하겠다.
Rationale Generation 단계에서는 모델에 를 입력으로 제공한다. 여기서 는 첫 번째 단계의 언어 입력을 나타내고, 는 시각 입력, 즉 이미지를 나타낸다. 예를 들어, Figure 4에서 보여지듯이 는 질문, 맥락, 그리고 객관식 추론 문제의 선택지들을 연결(concatenation)한 형태로 구성될 수 있다. 이 단계의 목표는 Rationale Generation 모델 를 학습하는 것이며, 여기서 은 추론 과정(rationale)이다.
Answer Inference 단계에서는 생성된 rationale 이 원래의 언어 입력 에 추가되어 두 번째 단계의 언어 입력 를 구성한다 (여기서 는 연결을 의미한다). 그런 다음, 업데이트된 입력 를 Answer Inference 모델에 입력하여 최종 답변 를 추론한다.
두 단계 모두에서 우리는 동일한 아키텍처를 가진 두 개의 모델을 독립적으로 학습시킨다. 이 모델들은 supervised learning을 위해 학습 세트에서 주석된 요소들(예: 각각 )을 사용한다. 추론 시에는 가 주어졌을 때, 테스트 세트에 대한 rationale은 첫 번째 단계에서 학습된 모델을 사용하여 생성되며, 이 rationale은 답변 추론을 위해 두 번째 단계에서 사용된다.
4.2 Model Architecture
주어진 언어 입력 와 시각 입력 에 대해, 우리는 길이 의 목표 텍스트 (Figure 4의 rationale 또는 answer)를 생성할 확률을 다음과 같이 계산한다:
여기서 는 Transformer 기반 네트워크 (Vaswani et al., 2017)로 구현된다. 이 네트워크는 **인코딩(encoding), 상호작용(interaction), 디코딩(decoding)**의 세 가지 주요 절차를 가진다. 구체적으로, 우리는 언어 텍스트를 Transformer encoder에 입력하여 **텍스트 표현(textual representation)**을 얻고, 이 표현은 시각 표현(vision representation)과 상호작용 및 융합된 후 Transformer decoder에 입력된다.
인코딩 (Encoding)
모델 는 언어 및 시각 입력을 모두 받아 다음 함수를 통해 **텍스트 표현 와 이미지 feature **을 얻는다:
여기서 LanguageEncoder 는 Transformer 모델로 구현된다. 우리는 Transformer encoder의 마지막 레이어의 hidden state를 언어 표현 로 사용하며, 여기서 은 언어 입력의 길이, 는 hidden dimension이다. 한편, VisionExtractor 는 입력 이미지를 vision feature로 벡터화하는 데 사용된다. Vision Transformer (Dosovitskiy et al., 2021a)의 최근 성공에 영감을 받아, 우리는 ViT (Dosovitskiy et al., 2021b)와 같은 frozen vision extraction model을 통해 patch-level feature를 추출한다. patch-level vision feature를 얻은 후, 학습 가능한 projection matrix 를 적용하여 VisionExtractor ( )의 형태를 와 동일하게 변환한다. 따라서 가 되며, 여기서 은 patch의 개수이다.
우리의 접근 방식은 이미지 context가 있거나 없는 두 시나리오 모두에 일반적이다. 관련 이미지가 없는 질문의 경우, 모델이 이를 무시하도록 일반 이미지 feature와 동일한 형태의 모든 값이 0인 벡터를 "blank feature"로 사용한다.
상호작용 (Interaction)
언어 및 시각 표현을 얻은 후, 우리는 단일 헤드 어텐션(single-head attention) 네트워크를 사용하여 텍스트 토큰과 이미지 패치를 연관시킨다. 여기서 **query , key , value 는 각각 **이다. 어텐션 출력 는 다음과 같이 정의된다: , 여기서 는 단일 헤드가 사용되므로 의 차원과 동일하다.
그 다음, 우리는 gated fusion mechanism (Zhang et al., 2020, Wu et al., 2021, Li et al., 2022a)을 적용하여 와 을 융합한다. 융합된 출력 는 다음을 통해 얻어진다:
여기서 과 는 학습 가능한 파라미터이다.
디코딩 (Decoding)
마지막으로, 융합된 출력 는 Transformer decoder에 입력되어 목표 를 예측한다.
5 Experiments
이 섹션에서는 벤치마크 데이터셋, 우리 기술의 구현 방식, 그리고 비교를 위한 baseline을 제시한다. 이어서 주요 결과와 발견 사항을 보고한다.
5.1 Dataset
우리의 방법은 ScienceQA (Lu et al., 2022a) 및 A-OKVQA (Schwenk et al., 2022) 벤치마크 데이터셋으로 평가되었다. 이 데이터셋들을 선택한 이유는 annotated reasoning chain을 포함하는 최신 멀티모달 추론 벤치마크이기 때문이다.
ScienceQA는 annotated lecture와 explanation을 포함하는 대규모 멀티모달 과학 질문 데이터셋이다. 이 데이터셋은 3가지 주제, 26가지 토픽, 127가지 카테고리, 379가지 스킬에 걸쳐 풍부한 도메인 다양성을 가진 21,000개의 멀티모달 객관식 질문을 포함한다. 학습, 검증, 테스트 분할에는 각각 12,000개, 4,000개, 4,000개의 질문이 포함되어 있다.
A-OKVQA는 지식 기반 visual question answering 벤치마크로, 답변을 위해 광범위한 상식 및 세계 지식을 요구하는 25,000개의 질문을 포함한다. 학습/검증/테스트 세트에는 각각 17,000개 / 1,000개 / 6,000개의 질문이 있다. A-OKVQA는 객관식 및 직접 답변 평가 설정을 제공하지만, 우리는 ScienceQA와의 일관성을 유지하기 위해 객관식 설정을 사용한다.
5.2 Implementation
다음 부분에서는 Multimodal-CoT 및 baseline 방법들의 실험 설정을 제시한다.
실험 설정
우리는 우리의 프레임워크에서 T5 encoder-decoder 아키텍처 (Raffel et al., 2020)를 Base (200M) 및 Large (700M) 설정으로 채택한다. 모델 가중치는 FLAN-Alpaca로 초기화한다. Multimodal-CoT는 UnifiedQA (Khashabi et al., 2020) 및 FLAN-T5 (Chung et al., 2022)와 같은 다른 backbone LM에서도 일반적으로 효과적임을 보여줄 것이다 (Section 6.3). vision feature는 frozen ViT-large encoder (Dosovitskiy et al., 2021b)를 통해 얻는다. 우리는 5e-5의 learning rate로 최대 20 epoch까지 모델을 fine-tuning한다. 최대 입력 시퀀스 길이는 512이며, batch size는 8이다. 우리의 실험은 8개의 NVIDIA Tesla V100 32G GPU에서 실행된다. 더 자세한 내용은 Appendix B에 제시되어 있다.
Baseline 모델
우리는 세 가지 범주의 방법을 baseline으로 활용했다:
(i) Visual Question Answering (VQA) 모델: MCAN (Yu et al., 2019), Top-Down (Anderson et al., 2018), BAN (Kim et al., 2018), DFAF (Gao et al., 2019), ViLT (Kim et al., 2021), Patch-TRM (Lu et al., 2021), VisualBERT (Li et al., 2019)를 포함한다. 이 VQA baseline들은 질문, 맥락, 선택지를 텍스트 입력으로 사용하고, 이미지를 시각 입력으로 활용한다. 이들은 선형 분류기(linear classifier)를 사용하여 선택지 후보에 대한 점수 분포를 예측한다.
(ii) LM: text-to-text UnifiedQA 모델 (Khashabi et al., 2020)과 few-shot learning LLM (GPT-3.5, ChatGPT, GPT-4, Chameleon (Lu et al., 2023))을 포함한다. UnifiedQA (Khashabi et al., 2020)는 Lu et al. (2022a)에서 최고의 fine-tuning 모델로 채택되었기 때문에 우리도 이를 사용한다. UnifiedQA는 텍스트 정보를 입력으로 받아 답변 선택지를 출력한다. 이미지는 Lu et al. (2022a)에 따라 이미지 캡셔닝 모델로 추출된 캡션으로 변환된다. UnifiedQA는 우리의 task를 텍스트 생성 문제로 취급한다. Lu et al. (2022a)에서 UnifiedQA는 목표 답변 텍스트, 즉 후보 옵션 중 하나를 생성하도록 학습된다. 그런 다음, 질문 답변 정확도를 평가하기 위해 가장 유사한 옵션이 최종 예측으로 선택된다. GPT-3.5 모델 (Chen et al., 2020)의 경우, 강력한 성능 때문에 text-davinci-002 및 text-davinci-003 엔진을 사용한다. 또한, ChatGPT 및 GPT-4와의 비교도 포함한다. 추론은 few-shot prompting을 기반으로 하며, 학습 세트에서 두 개의 in-context 예시가 테스트 인스턴스 앞에 연결된다. few-shot demonstration은 Lu et al. (2022a)의 것과 동일하다.
(iii) Fine-tuned 대규모 vision-language 모델: 최근 출시된 LLaMA-Adapter (Zhang et al., 2023a), LLaVA (Liu et al., 2023), InstructBLIP (Dai et al., 2023)을 경쟁력 있는 대규모 vision-language baseline으로 선정한다. LLaMA-Adapter의 경우, backbone 모델은 52k self-instruct demonstration으로 fine-tuning된 7B LLaMA 모델이다. 우리의 task에 적응하기 위해, 이 모델은 ScienceQA 데이터셋에서 추가로 fine-tuning된다.
| Model | Size | NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| Human | - | 90.23 | 84.97 | 87.48 | 89.60 | 87.50 | 88.10 | 91.59 | 82.42 | 88.40 |
| MCAN (Yu et al., 2019 | 95 M | 56.08 | 46.23 | 58.09 | 59.43 | 51.17 | 55.40 | 51.65 | 59.72 | 54.54 |
| Top-Down (Anderson et al., 2018) | 70 M | 59.50 | 54.33 | 61.82 | 62.90 | 54.88 | 59.79 | 57.27 | 62.16 | 59.02 |
| BAN (Kim et al., 2018 | 112 M | 60.88 | 46.57 | 66.64 | 62.61 | 52.60 | 65.51 | 56.83 | 63.94 | 59.37 |
| DFAF (Gao et al., 2019) | 74 M | 64.03 | 48.82 | 63.55 | 65.88 | 54.49 | 64.11 | 57.12 | 67.17 | 60.72 |
| ViLT (Kim et al., 2021 | 113 M | 60.48 | 63.89 | 60.27 | 63.20 | 61.38 | 57.00 | 60.72 | 61.90 | 61.14 |
| Patch-TRM (Lu et al., | 90 M | 65.19 | 46.79 | 65.55 | 66.96 | 55.28 | 64.95 | 58.04 | 67.50 | 61.42 |
| VisualBERT (Li et al., 2019 | 111 M | 59.33 | 69.18 | 61.18 | 62.71 | 62.17 | 58.54 | 62.96 | 59.92 | 61.87 |
| UnifiedQA (Lu et al., 2022a) | 223 M | 71.00 | 76.04 | 78.91 | 66.42 | 66.53 | 81.81 | 77.06 | 68.82 | 74.11 |
| GPT-3.5 (text-davinci-002) | 173 B | 75.44 | 70.87 | 78.09 | 74.68 | 67.43 | 79.93 | 78.23 | 69.68 | 75.17 |
| GPT-3.5 (text-davinci-003) | 173 B | 77.71 | 68.73 | 80.18 | 75.12 | 67.92 | 81.81 | 80.58 | 69.08 | 76.47 |
| ChatGPT (Lu et al., 2023) | - | 78.82 | 70.98 | 83.18 | 77.37 | 67.92 | 86.13 | 80.72 | 74.03 | 78.31 |
| GPT-4 (Lu et al., 2023) | - | 85.48 | 72.44 | 90.27 | 82.65 | 71.49 | 92.89 | 86.66 | 79.04 | 83.99 |
| Chameleon (ChatGPT) (Lu et al., 2023) | - | 81.62 | 70.64 | 84.00 | 79.77 | 70.80 | 86.62 | 81.86 | 76.53 | 79.93 |
| Chameleon (GPT-4) (Lu et al., 2023, | - | 89.83 | 74.13 | 89.82 | 88.27 | 77.64 | 92.13 | 88.03 | 83.72 | |
| LLaMA-Adapter (Zhang et al., 2023a | 6B | 84.37 | 88.30 | 84.36 | 83.72 | 80.32 | 86.90 | 85.83 | 84.05 | 85.19 |
| LLaVA (Liu et al., | 13 B | 90.36 | 95.95 | 88.00 | 89.49 | 88.00 | 90.66 | 90.93 | 90.90 | 90.92 |
| InstructBLIP (Dai et al., 2023, | 11 B | - | - | - | - | 90.70 | - | - | - | |
| Mutimodal-CoT | 223 M | 84.06 | 92.35 | 82.18 | 82.75 | 82.75 | 84.74 | 85.79 | 84.44 | 85.31 |
| Mutimodal-CoT | 738 M | 91.03 | 93.70 | 86.64 | 90.13 | 88.25 | 89.48 | 91.12 | 89.26 | 90.45 |
Table 4: 주요 결과 (%). Size = ScienceQA 리더보드의 backbone 모델 크기 ("-"는 사용 불가 또는 알 수 없음을 의미). 질문 클래스: NAT = 자연 과학, SOC = 사회 과학, LAN = 언어 과학, TXT = 텍스트 맥락, IMG = 이미지 맥락, NO = 맥락 없음, G1-6 = 1-6학년, G7-12 = 7-12학년. Segment 1: 인간 성능; Segment 2: VQA baseline; Segment 3: LM baseline, 즉 UnifiedQA 및 few-shot learning LLM; Segment 4: Fine-tuned 대규모 vision-language 모델; Segment 5: 우리의 Multimodal-CoT 결과. 이전에 발표된 최고 결과는 밑줄로 표시. 우리의 최고 평균 결과는 굵게 표시. 는 Multimodal-CoT와의 인용 또는 비교를 통한 동시 연구를 나타낸다.
5.3 Main Results
Table 4는 ScienceQA 벤치마크의 주요 결과를 보여준다. 우리는 Multimodal-CoT 가 기존 출판된 최고 모델 대비 상당한 성능 향상(86.54% → 90.45%)을 달성했음을 확인한다. Multimodal-CoT의 효능은 Table 5의 A-OKVQA 벤치마크 결과에서도 추가적으로 입증된다.
Chameleon, LLaMA-Adapter, LLaVA, InstructBLIP은 본 연구보다 몇 달 후에 발표된 동시 진행 연구들임을 주목할 필요가 있다. 이어지는 Section 6.2에서 우리는 우리의 방법이 이러한 멀티모달 모델(예: InstructBLIP)들과 직교하며, 인간이 주석한 rationales를 사용할 수 없는 시나리오까지 확장하여 일반성을 더욱 향상시키기 위해 잠재적으로 함께 사용될 수 있음을 보여줄 것이다. 이를 통해 다양한 task에 걸쳐 효과를 입증할 수 있다.
Table 6의 ablation study 결과는 vision feature의 통합과 두 단계 프레임워크 설계 모두가 전반적인 성능에 기여함을 보여준다.
또한, 우리는 Multimodal-CoT가 환각(hallucination)을 완화하고(Section 3.3) 수렴을 개선하는(Section 6.1) 능력을 보여준다는 것을 발견했다.
Table 5: A-OKVQA 결과. Baseline 결과는 (Chen et al., 2023) 및 Schwenk et al. (2022)에서 가져왔다.
| Model | Accuracy |
|---|---|
| BERT | 32.93 |
| GPT-3 (Curie) | 35.07 |
| IPVR (OPT-66B) | 48.6 |
| ViLBERT | 49.1 |
| Language-only Baseline | 47.86 |
| Multimodal-CoT | 50.57 |
| Table 6: Multimodal-CoT의 Ablation 결과. | Base | Large |
|---|---|---|
| Model | 85.31 | 90.45 |
| Multimodal-CoT | 82.62 | 84.56 |
| w/o Two-Stage Framework | 78.57 | 83.97 |
6 Analysis
다음 분석에서는 먼저 Multimodal-CoT가 수렴 속도를 향상시키고 사람이 주석한 rationale이 없는 시나리오에도 적응 가능하다는 것을 보여줄 것이다. 그 다음, 우리는 다양한 backbone 모델과 vision feature를 사용하여 Multimodal-CoT의 일반적인 효과를 조사할 것이다. 또한, 미래 연구에 영감을 주기 위해 한계점을 탐색하는 오류 분석도 수행할 것이다. 별도로 명시되지 않는 한, 분석에는 base size 모델을 사용한다.
6.1 Multimodality Boosts Convergence
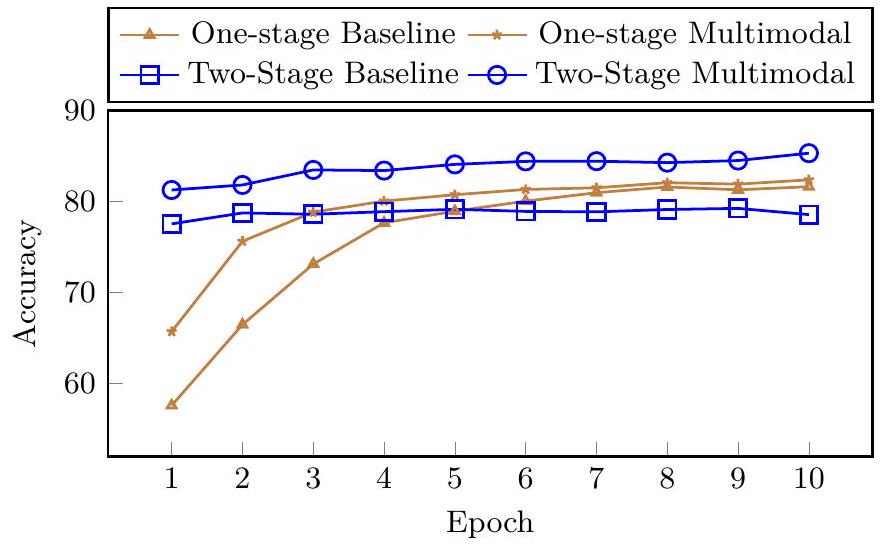
Figure 5: No-CoT baseline 및 Multimodal-CoT variant의 정확도 곡선.
Figure 5는 baseline과 Multimodal-CoT의 학습 epoch에 따른 validation 정확도 곡선을 보여준다. "One-stage"는 Table 2에서 가장 좋은 성능을 달성한 QCM→A 입력-출력 형식을 기반으로 하며, "Two-stage"는 우리의 two-stage framework이다. 우리는 two-stage 방식이 CoT 없이 직접 답변을 생성하는 one-stage baseline보다 초기에 상대적으로 높은 정확도를 달성함을 확인했다. 그러나 vision feature가 없는 two-stage baseline은 (Section 3에서 관찰된 바와 같이) 낮은 품질의 rationale로 인해 학습이 진행될수록 더 나은 결과를 내지 못했다. 이와 대조적으로, vision feature를 사용하는 것은 더 효과적인 rationale를 생성하는 데 도움이 되며, 이는 우리의 two-stage multimodal variant에서 더 나은 답변 정확도에 기여한다.
6.2 When Multimodal-CoT Meets Large Models
최근의 주요 연구 방향 중 하나는 대규모 language model 또는 대규모 vision-language model을 활용하여 멀티모달 질문 답변 문제에 대한 reasoning chain을 생성하는 것이다 (Zhang et al., 2023a, Lu et al., 2023, Liu et al., 2023; Alayrac et al., 2022; Hao et al., 2022, Yasunaga et al., 2022). 우리는 대규모 모델을 사용하여 Multimodal-CoT의 rationales를 생성할 수 있는지, 즉 인간이 주석한 rationales 데이터셋의 필요성을 없앨 수 있는지에 관심을 가졌다.
Multimodal-CoT의 1단계 학습 동안, 우리의 목표 rationales는 벤치마크 데이터셋의 인간 주석에 기반한다. 이제 우리는 목표 rationales를 생성된 rationales로 대체한다. ScienceQA는 이미지와 이미지가 없는 질문을 모두 포함하므로, 우리는 InstructBLIP과 ChatGPT를 각각 이미지와 쌍을 이루는 질문 및 이미지가 없는 질문에 대한 rationales를 생성하는 데 활용한다. 그런 다음, 생성된 두 가지 pseudo-rationales를 결합하여 학습을 위한 목표 rationales로 사용한다 (Multimodal-CoT w/ Generation). 이는 인간이 주석한 reasoning chain에 의존하는 방식(Multimodal-CoT w/ Annotation)을 대체한다.
Table 7은 비교 결과를 보여준다. 우리는 생성된 rationales를 사용하는 것이 인간이 주석한 rationales를 사용하여 학습하는 것과 비슷한 성능을 달성함을 확인했다. 또한, 성능은 해당 baseline 모델에 직접 prompt를 주어 답변을 얻는 방식(QCM A 추론 형식)보다 훨씬 우수하다.
Table 7: 대규모 모델과의 결과 비교. 참고를 위해 InstructBLIP 및 ChatGPT baseline 결과도 제시한다. 두 baseline의 추론 형식은 QCM A이다.
| Model | IMG | TXT | AVG |
|---|---|---|---|
| InstructBLIP | 60.50 | - | - |
| ChatGPT | 56.52 | 67.16 | 65.95 |
| Multimodal-CoT w/ Annotation | 88.25 | 90.13 | 90.45 |
| Multimodal-CoT w/ Generation | 83.54 | 85.73 | 87.76 |
우리는 Multimodal-CoT가 대규모 모델과 효과적으로 작동할 수 있음을 확인했다. 위의 결과는 인간이 주석한 rationales가 없는 시나리오에 대한 적응 가능성을 설득력 있게 보여주며, 이를 통해 다양한 task에서 우리 접근 방식의 효과성을 입증한다.
6.3 Effectiveness Across Backbones
우리의 접근 방식이 다른 backbone 모델에도 적용될 수 있는지 그 일반성을 테스트하기 위해, 우리는 다양한 유형의 다른 LM 변형들을 기반 LM으로 변경하여 실험하였다. Table 8에서 보여주듯이, 우리의 접근 방식은 널리 사용되는 backbone 모델에 대해 일반적으로 효과적이다.
Table 8: 다른 backbone LM 사용.
| Method | Accuracy |
|---|---|
| Prior Best (Lu et al., 2022a) | 75.17 |
| MM-CoT on UnifiedQA | 82.55 |
| MM-CoT on FLAN-T5 | 83.19 |
| MM-CoT on FLAN-Alpaca | 85.31 |
Table 9: 다른 vision feature 사용.
| Feature | Feature Shape | Accuracy |
|---|---|---|
| ViT | 85.31 | |
| CLIP | 84.27 | |
| DETR | 83.16 | |
| ResNet | 82.86 |
6.4 Using Different Vision Features
다양한 vision feature는 모델 성능에 영향을 미칠 수 있다. 우리는 널리 사용되는 세 가지 유형의 vision feature인 ViT (Dosovitskiy et al., 2021b), CLIP (Radford et al., 2021), DETR (Carion et al., 2020), 그리고 ResNet (He et al., 2016)을 비교한다. ViT, CLIP, DETR는 patch-like feature이다. ResNet feature의 경우, ResNet-50의 pooled feature를 텍스트 시퀀스와 동일한 길이로 반복하여 patch-like feature를 모방한다. 여기서 각 patch는 pooled image feature와 동일하다. vision feature에 대한 더 자세한 내용은 Appendix B.1에 제시되어 있다.
Table 9는 vision feature들의 비교 결과를 보여준다. 우리는 ViT가 상대적으로 더 나은 성능을 달성함을 관찰했다. 따라서 Multimodal-CoT에서는 기본적으로 ViT를 사용한다.
6.5 Alignment Strategies for Multimodal Interaction
우리는 멀티모달 상호작용을 위한 다른 정렬(alignment) 전략이 multimodal-CoT의 다양한 동작에 기여할 수 있는지에 관심을 가졌다. 이를 위해, 우리는 BLIP [Li et al. (2022b)]에서 사용된 또 다른 정렬 전략, 즉 image-grounded text encoder를 시도했다. 이 정렬 접근 방식은 텍스트 encoder의 각 Transformer 블록에 대해 self-attention layer와 feed-forward network 사이에 하나의 추가적인 cross-attention layer를 삽입하여 시각 정보를 주입한다. 본 논문에서 사용된 현재 전략은 비교를 위해 사용된 BLIP의 unimodal encoder와 유사하다. Table 10에서 우리는 다른 정렬 전략을 사용하는 것이 직접 답변하는 것보다 더 나은 성능에 기여함을 확인할 수 있다.
Table 10: 멀티모달 상호작용을 위한 다른 정렬 전략과의 결과 비교.
| Model | Accuracy |
|---|---|
| Direct Answering | 82.62 |
| Unimodal encoder | 85.31 |
| Image-grounded text encoder | 84.60 |
6.6 Generalization to Other Multimodal Reasoning Benchmarks
우리는 Multimodal-CoT의 학습 도메인 외부 데이터셋에 대한 일반화 능력을 평가하는 데 관심이 있다. 이를 위해 널리 알려진 멀티모달 추론 벤치마크인 **MMMU (Yue et al., 2024)**를 활용하며, 추가 학습 없이 MMMU에서 Multimodal-CoT의 성능을 평가한다.
Table 11: MMMU에서의 일반화 성능.
| Model | Size | Accuracy |
|---|---|---|
| Kosmos-2 (Peng et al., 2024) | 1.6 B | 24.4 |
| Fuyu (Bavishi et al., 2024) | 8 B | 27.9 |
| OpenFlamingo-2 (Awadalla et al., 2023) | 9B | 28.7 |
| MiniGPT4-Vicuna (Zhu et al., 2023) | 13 B | 26.8 |
| Multimodal-CoT | 738 M | 28.7 |
| GPT-4V(ision) (OpenAI | - | 56.8 |
| Gemini Ultra (Reid et al., 2024) | - | 59.4 |
Table 11에서 볼 수 있듯이, Multimodal-CoT는 MMMU에 대해 효과적인 일반화 능력을 보여주며, 약 8B 규모의 다양한 대형 모델들보다 더 나은 성능을 달성한다.
6.7 Error Analysis
Multimodal-CoT의 동작에 대한 더 깊은 통찰력을 얻고 향후 연구를 촉진하기 위해, 우리는 우리의 접근 방식으로 생성된 예시들을 무작위로 선택하여 수동으로 분석하였다. 분류 결과는 Figure 6에 나타나 있다. 우리는 오답을 생성한 50개의 샘플을 검토하고 그에 따라 분류하였다. 각 카테고리의 예시는 Appendix D에서 확인할 수 있다.
가장 흔한 오류 유형은 **상식 오류(commonsense mistakes)**로, **전체 오류의 80%**를 차지한다. 이러한 오류는 모델이 지도 해석, 이미지 내 객체 수 세기, 알파벳 활용과 같이 상식 지식을 요구하는 질문에 직면했을 때 발생한다. 두 번째 오류 유형은 **논리적 오류(logical mistakes)**로, **전체 오류의 14%**를 차지하며, 추론 과정에서의 모순을 포함한다. 또한, CoT가 비어 있거나 올바른데도 불구하고 오답이 제공되는 경우도 관찰되었으며, 이는 **전체 오류의 6%**에 해당한다. 이러한 경우의 CoT는 최종 답변에 반드시 영향을 미치지는 않을 수 있다.
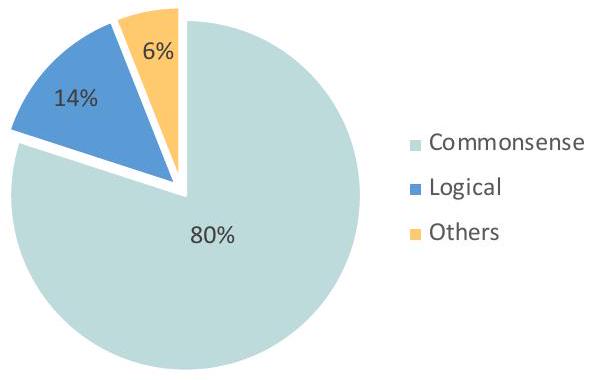
Figure 6: 분류 분석.
이러한 분석은 향후 연구를 위한 잠재적인 방향을 제시한다. Multimodal-CoT는 다음과 같은 방법으로 개선될 수 있다: (i) 더 유익한 시각적 feature를 통합하고, 언어와 비전 간의 상호작용을 강화하여 지도 이해 및 숫자 세기 능력을 향상시킨다. (ii) 상식 지식을 통합한다. (iii) 관련성 있는 CoT만을 사용하여 답변을 추론하고 관련 없는 CoT는 무시하는 필터링 메커니즘을 구현한다.
7 Conclusion
본 논문은 멀티모달 CoT(Chain-of-Thought) 문제를 공식적으로 연구한다. 우리는 Multimodal-CoT를 제안하는데, 이는 언어 및 시각 양식(modality)을 두 단계 프레임워크에 통합하여 추론(rationale) 생성과 답변 추론(answer inference)을 분리한다. 이를 통해 답변 추론은 멀티모달 정보로부터 더 잘 생성된 추론을 활용할 수 있다. Multimodal-CoT를 통해 우리의 모델은 10억 개 미만의 파라미터로 ScienceQA 벤치마크에서 state-of-the-art 성능을 달성한다. 분석 결과, Multimodal-CoT는 환각(hallucination)을 완화하고 수렴 속도를 향상시키는 장점이 있음을 보여준다. 우리의 오류 분석은 향후 연구에서 더 효과적인 vision feature를 활용하고, 상식(commonsense) 지식을 주입하며, 필터링 메커니즘을 적용하여 CoT reasoning을 개선할 잠재력이 있음을 시사한다.
A Extended Analysis for the Challenge of Multimodal-CoT
A. 1 Additional Examples of Misleading through Hallucinated Rationales
우리의 사례 연구(Section 3.2)에 따르면, baseline 모델이 환각적인(hallucinated) 근거를 생성하는 경향이 있음을 관찰했다. Figure 7에 묘사된 바와 같이, 이러한 현상을 설명하기 위한 추가 예시들을 제시한다.
Problem
질문: 어떤 용액이 노란색 입자의 농도가 더 높은가? 맥락: 아래 그림은 두 용액의 모델이다. 각 노란색 공은 용질 입자 하나를 나타낸다. 선택지: (A) 용액 B (B) 용액 A (C) 둘 다 아님; 농도가 같다
Gold Rationale: 용액 A와 용액 B에서 노란색 입자는 용질을 나타낸다. 어떤 용액이 노란색 입자의 농도가 더 높은지 파악하려면, 각 용기 내의 노란색 입자 수와 용매의 부피를 모두 살펴봐야 한다. 농도 공식을 사용하여 밀리리터당 노란색 입자 수를 구한다. 용액 B는 밀리리터당 노란색 입자 수가 더 많다. 따라서 용액 B가 노란색 입자의 농도가 더 높다.
정답: 정답은 (A)이다.
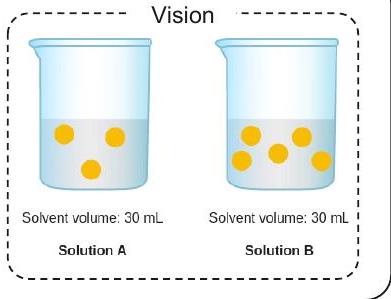
Baseline
Rationale: Solution A와 Solution B에서 노란색 입자는 용질을 나타낸다. 어떤 용액이 노란색 입자의 농도가 더 높은지 파악하려면, 각 용기 내의 노란색 입자 수와 용매의 부피를 모두 확인해야 한다. 농도 공식을 사용하여 밀리리터당 노란색 입자 수를 구한다. Solution A는 밀리리터당 노란색 입자 수가 더 많다. 따라서 Solution A가 노란색 입자의 농도가 더 높다. Answer: 정답은 (B)이다.
+ Vision Features
Rationale: Solution A와 Solution B에서 노란색 입자는 용질을 나타낸다. 어떤 용액이 노란색 입자의 농도가 더 높은지 파악하려면, 각 용기 내의 노란색 입자 수와 용매의 부피를 모두 확인해야 한다. 농도 공식을 사용하여 밀리리터당 노란색 입자 수를 구한다. Solution B는 밀리리터당 노란색 입자 수가 더 많다. 따라서 Solution B가 노란색 입자의 농도가 더 높다. Answer: 정답은 (A)이다.
Problem
Question: 각 쌍의 자석들 사이에 작용하는 자기력에 대해 생각해 보십시오. 다음 진술 중 어느 것이 사실입니까? Context: 아래 이미지는 두 쌍의 자석을 보여줍니다. 다른 쌍의 자석들은 서로 영향을 주지 않습니다. 표시된 모든 자석은 동일한 재료로 만들어졌습니다.
Options:
(A) 자기력의 크기는 Pair 2에서 더 작습니다.
(B) 자기력의 크기는 Pair 1에서 더 작습니다.
(C) 자기력의 크기는 두 쌍 모두에서 동일합니다.
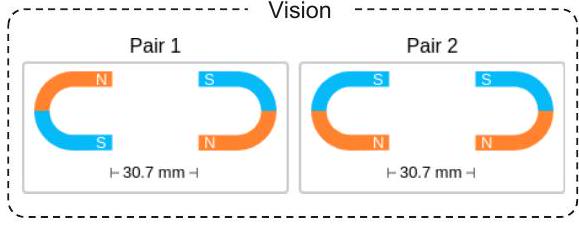
Gold Rationale: Pair 1의 자석들은 서로 끌어당깁니다(attract). Pair 2의 자석들은 서로 밀어냅니다(repel). 하지만 자석이 끌어당기거나 밀어내는 것은 자기력의 방향에만 영향을 미칩니다. 자기력의 크기에는 영향을 주지 않습니다. 자석의 크기와 거리는 자기력의 크기에 영향을 미칩니다. Pair 1의 자석 크기는 Pair 2와 동일합니다. 자석들 사이의 거리 또한 동일합니다. 따라서 자기력의 크기는 두 쌍 모두에서 동일합니다. Answer: 정답은 (C)입니다.
Baseline
Rationale: 거리는 자기력의 크기에 영향을 미친다. 자석 사이의 거리가 멀어질수록 자기력의 크기는 작아진다. Pair 2는 Pair 1보다 자석 사이의 거리가 더 멀다. 따라서 Pair 2의 자기력 크기가 Pair 1보다 작다. Answer: 정답은 (B)이다.
+ Vision Features
근거 (Rationale): Pair 1의 자석들은 서로 끌어당긴다(attract). Pair 2의 자석들은 서로 밀어낸다(repel). 하지만 자석이 끌어당기든 밀어내든 이는 자기력의 방향에만 영향을 미칠 뿐이다. 자기력의 크기에는 영향을 주지 않는다. 자석의 크기와 거리는 모두 자기력의 크기에 영향을 미친다. Pair 1의 자석 크기는 Pair 2와 동일하다. 자석 사이의 거리 또한 동일하다. 따라서 두 쌍 모두에서 자기력의 크기는 같다. 정답 (Answer): 정답은 (C)이다.

Figure 7: **시각 feature가 없는 2단계 프레임워크(baseline)**와 **시각 feature가 있는 2단계 프레임워크(본 연구)**가 근거를 생성하고 정답을 예측하는 예시. 상단은 문제 세부 정보를 제시하고, 하단은 baseline과 본 연구 방법의 출력을 보여준다.
A. 2 Two-Stage Training Performance with Different Sizes of LMs
Section 3에서 우리는 시각 feature의 포함이 더 효과적인 rationale 생성에 긍정적인 영향을 미치며, 결과적으로 답변 정확도를 향상시킨다는 것을 관찰했다. 시각 feature를 통합하는 것 외에도, 잘못된 rationale 문제를 해결하는 또 다른 접근 방식은 language model (LM)의 크기를 확장하는 것이다. Figure 8은 시각 feature 통합 여부에 따른 우리의 2단계 학습 프레임워크의 답변 정확도를 보여준다. 특히, 더 큰 LM을 사용할 때, baseline 정확도(시각 feature 없음)가 크게 향상되는 것을 확인할 수 있다. 이러한 결과는 LM 크기를 확장하는 것이 잘못된 rationale 문제를 완화할 수 있음을 시사한다. 그러나 성능이 여전히 시각 feature를 활용하는 경우에 비해 상당히 부족하다는 점을 인지하는 것이 중요하다. 이 결과는 다양한 LM 크기에서도 우리의 Multimodal-CoT 방법론의 효과를 더욱 입증한다.
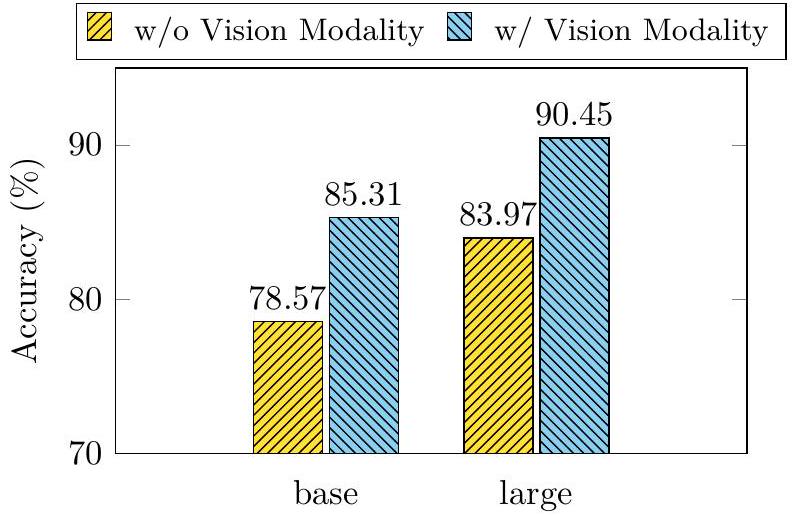
Figure 8: 다양한 LM 크기에 따른 답변 정확도.
A. 3 Discussion of the Possible Paradigms to Achieve Multimodal-CoT
Section 1에서 논의된 바와 같이, Multimodal-CoT reasoning을 촉진하는 두 가지 주요 접근 방식이 있다: (i) LLM에 prompting하는 방식, (ii) 작은 모델을 fine-tuning하는 방식.
첫 번째 접근 방식에서 흔히 사용되는 방법은 서로 다른 modality의 입력을 통합하여 LLM에 prompting하여 reasoning을 수행하는 것이다 (Zhang et al., 2023a, Lu et al., 2023, Liu et al., 2023, Alayrac et al. 2022 Hao et al., 2022 Yasunaga et al., 2022). 예를 들어, 이를 달성하는 한 가지 방법은 captioning 모델을 사용하여 이미지의 caption을 추출한 다음, 이 caption을 원래의 언어 입력과 연결하여 LLM에 입력하는 것이다. 이렇게 함으로써 시각 정보가 텍스트 형태로 LLM에 전달되어 modality 간의 간극을 효과적으로 메울 수 있다. 이 접근 방식은 <image caption, question + caption answer> 와 같은 입출력 형식으로 표현될 수 있다. 우리는 이 접근 방식을 Caption-based Reasoning이라고 부른다 (Figure 9a). 이 접근 방식의 효과는 이미지 caption의 품질에 따라 달라지며, 이미지 captioning에서 답변 추론으로의 전환 과정에서 발생할 수 있는 오류에 취약할 수 있다는 점에 주목할 필요가 있다.
대조적으로, CoT의 흥미로운 측면은 복잡한 문제를 일련의 더 간단한 문제로 분해하고 단계별로 해결하는 능력이다. 이러한 변환은 표준 형식인 <question answer> 를 <question rationale answer> 로 변경시킨다. Rationale은 답변으로 이어지는 reasoning 프로세스를 더 잘 반영할 가능성이 높으므로 이 패러다임에서 중요한 역할을 한다. 결과적으로, 우리는 이 패러다임을 따르는 접근 방식을 CoT-based Reasoning이라고 부른다. 이 명칭은 문헌에서 널리 채택되어 왔다 (Huang & Chang, 2022, Zhang et al., 2023d, Lu et al., 2022c).
우리의 연구는 멀티모달 시나리오에서 CoT-based Reasoning 패러다임과 일치하며, 특히 <question + image rationale answer> 프레임워크를 사용한다 (Figure 9b). 이 접근 방식은 두 가지 측면에서 이점을 제공한다. 첫째, Multimodal-CoT 프레임워크는 vision 및 language 입력 간의 feature-level 상호 작용을 활용하여, 모델이 입력 정보를 더 깊이 이해하고 타당한 rationale를 통합하여 답변을 더 효과적으로 추론할 수 있도록 한다. 우리의 분석은 Multimodal-CoT가 hallucination을 완화하고 수렴을 향상시켜 벤치마크 데이터셋에서 우수한 성능을 달성함으로써 주목할 만한 이점을 제공함을 입증했다. 둘째, Multimodal-CoT의 경량 특성은 자원 제약과 호환되며 잠재적인 paywall을 우회한다.
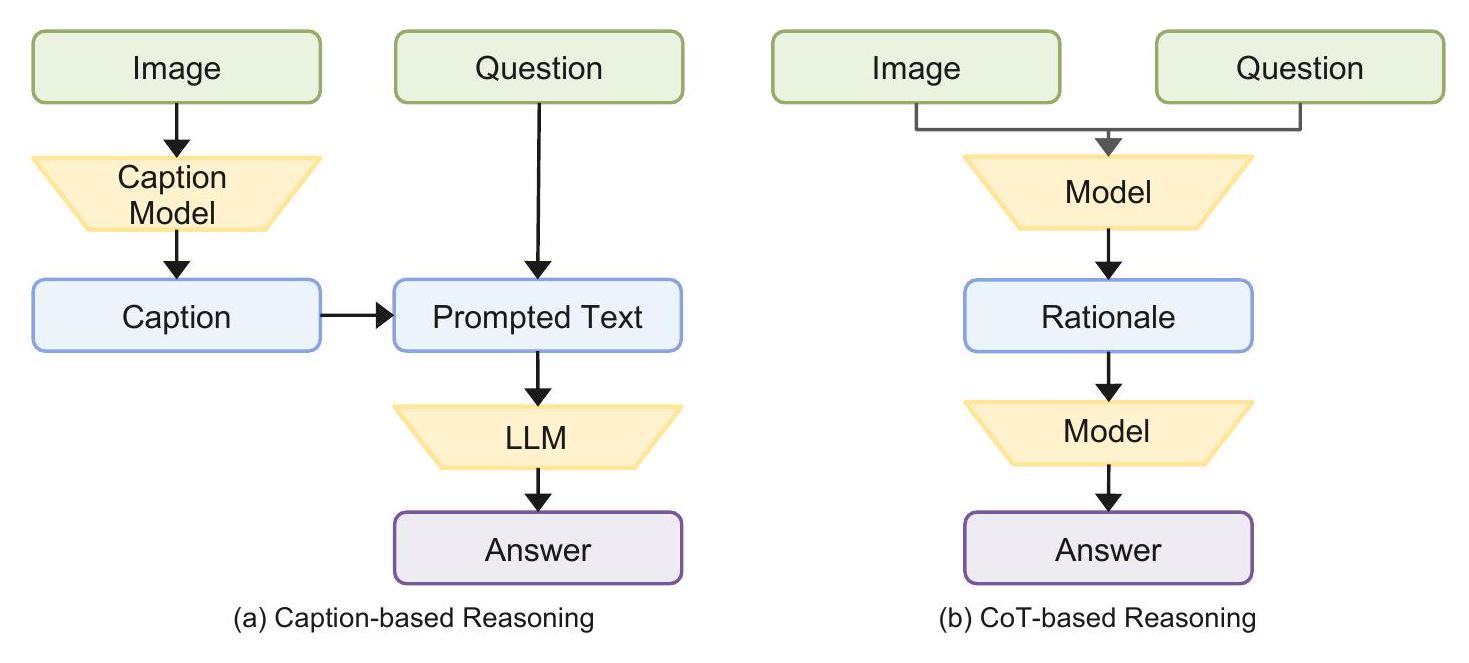
Figure 9: Multimodal-CoT를 달성하기 위한 패러다임.
B Experimental Details
B. 1 Details of Vision Features
Section 6.2에서는 **ViT (Dosovitskiy et al., 2021b), CLIP (Radford et al., 2021), DETR (Carion et al., 2020), ResNet (He et al., 2016)**의 네 가지 유형의 vision feature를 비교하였다. 구체적인 모델은 다음과 같다: (i) ViT: vit_large_patch32_384 (ii) CLIP: RN101 (iii) DETR: detr_resnet101_dc5 (iv) ResNet: 사전학습된 ResNet50 CNN의 평균 풀링된(averaged pooled) feature를 사용한다.
Table 12는 vision feature의 차원을 보여준다 (Eq. 3의 VisionExtractor(•) 함수를 거친 후). ResNet-50의 경우, 패치와 유사한 feature를 모방하기 위해 ResNet-50의 풀링된 feature를 텍스트 시퀀스와 동일한 길이로 반복한다. 여기서 각 패치는 풀링된 이미지 feature와 동일하다.
Table 12: Vision feature의 Feature Shape
| Method | Feature Shape |
|---|---|
| ViT | |
| CLIP | |
| DETR | |
| ResNet |
B. 2 Datasets
우리의 방법은 ScienceQA (Lu et al., 2022a) 및 A-OKVQA (Schwenk et al., 2022) 벤치마크 데이터셋으로 평가되었다.
- ScienceQA는 annotated lecture와 explanation을 포함하는 대규모 멀티모달 과학 질문 데이터셋이다. 이 데이터셋은 3개의 주제, 26개의 토픽, 127개의 카테고리, 379개의 스킬에 걸쳐 풍부한 도메인 다양성을 가진 21k개의 멀티모달 객관식 질문을 포함한다. 데이터셋은 각각 12k, 4k, 4k개의 질문으로 구성된 학습, 검증, 테스트 분할로 나뉜다.
- A-OKVQA는 지식 기반 Visual Question Answering 벤치마크로, 답변을 위해 광범위한 상식 및 세계 지식을 요구하는 25k개의 질문을 포함한다. 각 질문은 필요한 사실이나 지식에 따라 특정 답변이 왜 올바른지 설명하는 rationale과 함께 주석되어 있다. 이 데이터셋은 학습/검증/테스트를 위해 17k / 1k / 6k개의 질문을 포함한다.
ScienceQA의 경우, 우리 모델은 테스트 세트에서 평가되었다. A-OKVQA의 경우, 테스트 세트가 숨겨져 있으므로 우리 모델은 검증 세트에서 평가되었다.
B. 3 Implementation Details of Multimodal-CoT
Multimodal-CoT task는 추론 과정(reasoning chains)을 생성하고 시각 feature를 활용해야 하므로, 우리는 프레임워크에서 Base (200M) 및 Large (700M) 설정의 T5 encoder-decoder 아키텍처 (Raffel et al. 2020)를 채택한다. 우리는 FLAN-Alpaca를 사용하여 모델 가중치를 초기화한다. 우리는 Multimodal-CoT가 UnifiedQA (Khashabi et al., 2020) 및 FLAN-T5 (Chung et al., 2022)와 같은 다른 backbone LM에서도 일반적으로 효과적임을 보여줄 것이다 (Section 6.1).
시각 feature는 frozen된 ViT-large encoder (Dosovitskiy et al., 2021b)로부터 얻는다. Section 3.3에서 보여주듯이 이미지 캡션을 사용하는 것이 모델 성능을 약간 향상시킬 수 있으므로, Lu et al. (2022a)를 따라 이미지 캡션을 context에 추가한다. 캡션은 InstructBLIP (Dai et al., 2023)에 의해 생성된다.
모델은 최대 20 epoch까지 fine-tuning하며, 학습률은 중에서 선택한다. rationale 생성 및 답변 추론을 위한 최대 입력 시퀀스 길이는 각각 512와 64이다. batch size는 8이다. 우리의 실험은 8개의 NVIDIA Tesla V100 32G GPU에서 실행된다.
C Further Analysis
C. 1 Examples of Rationale Generation with Large Models
최근의 연구 동향은 대규모 language model 또는 대규모 vision-language model을 활용하여 멀티모달 질문 응답 문제에 대한 reasoning chain을 생성하는 것이다 (Zhang et al., 2023a, Lu et al., 2023, Liu et al., 2023 ; Alayrac et al., 2022; Hao et al., 2022; Yasunaga et al., 2022). 우리는 대규모 모델을 사용하여 Multimodal-CoT의 rationales를 생성할 수 있는지에 관심을 가졌다. 이는 인간이 주석한 rationales 데이터셋의 필요성을 없애는 것을 의미한다.
Multimodal-CoT의 1단계 학습 동안, 우리의 목표 rationales는 벤치마크 데이터셋의 **인간 주석(human annotation)**에 기반한다. 이제 우리는 목표 rationales를 LLM 또는 vision-language model이 생성한 것으로 대체한다. 구체적으로, 우리는 **이미지가 포함된 질문(IMG)**과 **이미지가 없는 질문(TXT)**을 각각 InstructBLIP (Dai et al., 2023) (Figure 10a)과 ChatGPT (Figure 10b)에 zero-shot inference 방식으로 입력한다. 그런 다음, 생성된 pseudo-rationales를 학습을 위한 목표 rationales로 사용하며, 추론 체인에 대한 인간 주석에 의존하지 않는다.
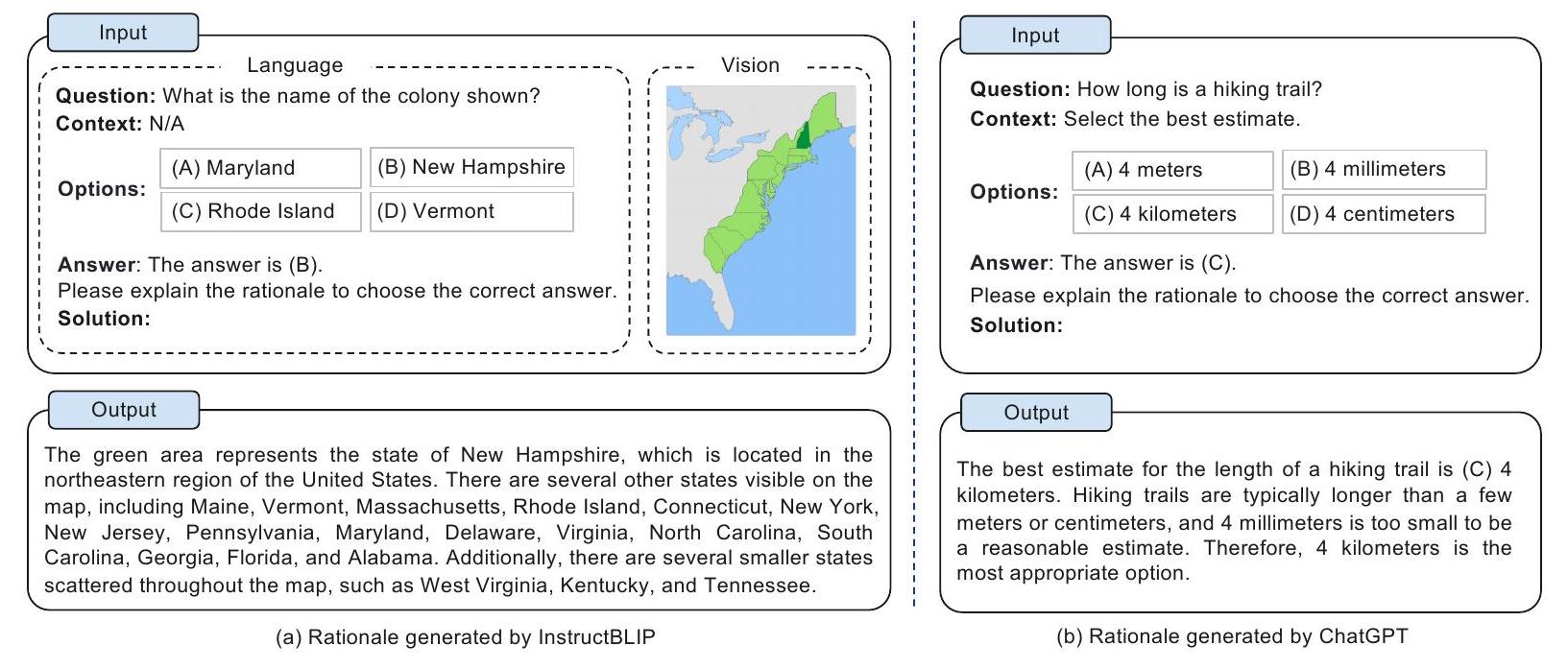
Figure 10: Rationale 생성 예시.
C. 2 Detailed Results of Multimodal-CoT on Different Backbone Models
다른 backbone 모델에 대한 우리 접근 방식의 이점의 일반성을 테스트하기 위해, 우리는 기반 LM을 다른 유형의 변형 모델로 변경하였다. Table 13에 제시된 상세 결과에서 보듯이, 우리 접근 방식은 널리 사용되는 backbone 모델에 대해 일반적으로 효과적이다.
Table 13: 다양한 backbone 모델에 대한 Multimodal-CoT의 상세 결과.
| Model | NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | Avg |
|---|---|---|---|---|---|---|---|---|---|
| MM-CoT on UnifiedQA | 80.60 | 89.43 | 81.00 | 80.50 | 80.61 | 81.74 | 82.38 | 82.86 | 82.55 |
| MM-CoT on FLAN-T5 | 81.39 | 90.89 | 80.64 | 80.79 | 80.47 | 82.58 | 83.48 | 82.66 | 83.19 |
| MM-CoT on FLAN-Alpaca | 84.06 | 92.35 | 82.18 | 82.75 | 82.75 | 84.74 | 85.79 | 84.44 | 85.31 |
D Examples of Case Studies
Multimodal-CoT의 동작에 대한 더 깊은 통찰력을 얻고 향후 연구를 촉진하기 위해, 우리는 우리 접근 방식이 생성한 무작위 샘플을 수동으로 분석했다. 분류 결과는 Figure 11에 나타나 있다. 우리는 오답을 생성한 50개의 샘플을 검토하고 그에 따라 분류했다.
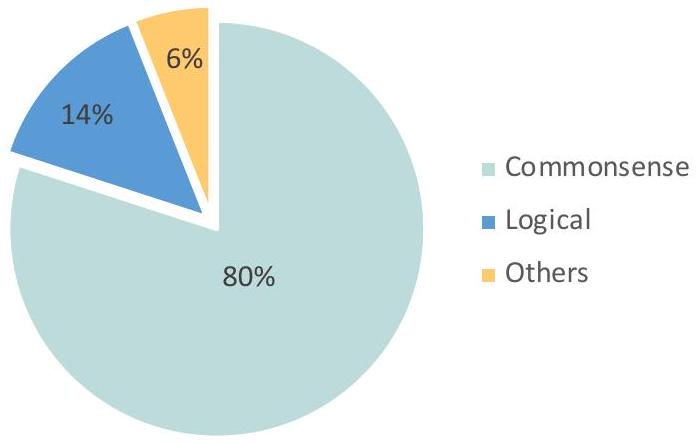
Figure 11: 분류 분석.
가장 흔한 오류 유형은 **상식 오류(commonsense mistakes)**로, 전체 오류의 **80%**를 차지한다. 이러한 오류는 모델이 **지도 해석(Figure 12a), 이미지 내 객체 수 세기(Figure 12b), 또는 알파벳 활용(Figure 12c)**과 같이 상식 지식을 요구하는 질문에 직면했을 때 발생한다.
두 번째 오류 유형은 **논리 오류(logical mistakes)**로, 전체 오류의 **14%**를 차지하며, 비교 오류(Figure 13a) 및 **추론 과정에서의 모순(Figure 13b)**을 포함한다.
또한, CoT가 비어 있거나 올바른데도 불구하고 오답이 제공되는 경우가 관찰되었으며, 이는 전체 오류의 **6%**에 해당한다. 이러한 경우의 CoT는 최종 답변에 반드시 영향을 미 미치지 않을 수 있다 (Figure 14).
이 분석은 향후 연구를 위한 잠재적인 방향을 제시한다. Multimodal-CoT는 다음을 통해 개선될 수 있다: (i) 더 유익한 visual feature를 통합하고 언어와 비전 간의 상호작용을 강화하여 지도 이해 및 숫자 세기를 가능하게 하는 것; (ii) 상식 지식 통합; (iii) 관련 CoT만을 사용하여 답변을 추론하고 관련 없는 CoT는 무시하는 필터링 메커니즘 구현.
Problem
Question: 지도에 표시된 도시 중 어느 도시인가요? Context: N/A Options: (A) Las Vegas (B) San Francisco (C) Phoenix (D) Salt Lake City
Rationale: 해당 도시는 네바다주의 Las Vegas이다. Salt Lake City, Phoenix, San Francisco는 아래 지도에 회색 원으로 표시되어 있다.
Answer: 정답은 (A)이다.
Prediction
Rationale: 도시는 샌프란시스코, 캘리포니아이다. 솔트레이크시티, 라스베이거스, 피닉스는 아래 지도에 회색 원으로 표시되어 있다. Answer: 정답은 (B)이다. (a) 지도에 대한 오류.
Problem
질문: 다음 다이어그램을 설명하는 텍스트를 완성하시오. 용질 입자는 투과성 막을 가로질러 양방향으로 이동했다. 그러나 더 많은 용질 입자가 막을 가로질러 ( ) 이동했다. 양쪽에 동일한 농도가 되었을 때, 입자들은 평형에 도달했다.
맥락: 아래 다이어그램은 하나의 용질을 포함하는 용액을 보여준다. 각 용질 입자는 녹색 공으로 표현된다. 용액은 막에 의해 절반으로 나뉜 밀폐된 용기에 채워져 있다. 점선으로 표현된 막은 용질 입자에 투과성이다. 이 다이어그램은 확산 과정 동안 용액이 시간이 지남에 따라 어떻게 변할 수 있는지를 보여준다.
선택지: (A) 오른쪽보다 왼쪽으로 (B) 왼쪽보다 오른쪽으로
추론: (발췌) 이 다이어그램은 확산 과정 동안 용액이 어떻게 변했는지를 보여준다. 용질 입자가 평형에 도달하기 전에는 막의 왼쪽에 3개의 용질 입자가 있었고, 막의 오른쪽에는 5개의 용질 입자가 있었다. 용질 입자가 평형에 도달했을 때는 막의 각 측면에 4개의 용질 입자가 있었다. 막의 왼쪽에는 이전보다 1개의 용질 입자가 더 많았다. 따라서 용질 입자가 평형에 도달하려면, 오른쪽보다 왼쪽으로 더 많은 용질 입자가 막을 가로질러 이동했어야 한다.
정답: 정답은 (A)이다.
Prediction
Rationale: (extract) 이는 확산 과정에서 용액이 어떻게 변화했는지를 보여준다. 용질 입자가 평형에 도달하기 전에는 막의 왼쪽에 5개의 용질 입자가 있었고, 막의 오른쪽에는 4개의 용질 입자가 있었다. 용질 입자가 평형에 도달했을 때는 막의 각 측면에 5개의 용질 입자가 있었다. 막의 오른쪽에는 이전보다 1개의 용질 입자가 더 많았다. 따라서 용질 입자가 평형에 도달하려면, 오른쪽으로 이동한 용질 입자의 수가 왼쪽으로 이동한 용질 입자의 수보다 더 많았어야 한다. Answer: 정답은 (B)이다. (b) 이미지 내 숫자 세기에 대한 오류.
Problem
Question: 다음 가이드 워드가 있는 사전 페이지에서 어떤 단어를 찾을 수 있을까요? helping - hunter Context: 아래 그림은 하나의 용질(solute)을 포함하는 용액(solution)을 보여줍니다. 각 용질 입자는 녹색 공으로 표현됩니다. 용액은 점선으로 표시된 막(membrane)에 의해 절반으로 나뉜 밀폐된 용기에 채워져 있습니다. 이 막은 용질 입자에 투과성(permeable)입니다. 이 그림은 확산(diffusion) 과정 동안 용액이 시간이 지남에 따라 어떻게 변할 수 있는지를 보여줍니다. Options: (A) hospital (B) hardship
Rationale: 단어들을 알파벳 순서로 배열합니다. hospital은 가이드 워드인 helping - hunter 사이에 있으므로, 해당 페이지에서 찾을 수 있습니다. Answer: 정답은 (A)입니다.
Prediction
근거: 단어들을 알파벳 순서로 배열한다. 'hardship'은 가이드 워드 'helping - hunter' 사이에 있으므로 해당 페이지에서 찾을 수 있다. 정답: (B)이다. (c) 알파벳 활용에 대한 오류.
Figure 12: 상식적인 오류의 예시.
Problem
질문: 두 자동차의 움직임을 비교하시오. 어떤 자동차가 더 낮은 속도로 움직였는가? 맥락: N/A 맥락: (A) 10시간 동안 445마일을 이동한 자동차 (B) 10시간 동안 170마일을 이동한 자동차
N/A
추론: 각 자동차가 이동한 거리와 그 거리를 이동하는 데 걸린 시간을 살펴보자. 한 자동차는 10시간 동안 170마일을 이동했다. 다른 자동차는 10시간 동안 445마일을 이동했다. 각 자동차가 움직인 시간이 동일하다는 점에 주목하자. 170마일을 이동한 자동차는 같은 시간 동안 더 짧은 거리를 이동했다. 따라서 그 자동차가 더 낮은 속도로 움직였을 것이다. 정답: 정답은 (B)이다.
Prediction
Rationale: 각 자동차가 이동한 거리와 그 거리를 이동하는 데 걸린 시간을 살펴보자. 한 자동차는 10시간 동안 445마일을 이동했다. 다른 자동차는 10시간 동안 170마일을 이동했다. 각 자동차가 이동하는 데 동일한 시간을 보냈다는 점에 주목하자. 445마일을 이동한 자동차는 그 시간 동안 더 짧은 거리를 이동했다. 따라서 그 자동차는 더 낮은 속도로 이동했을 것이다. Answer: 정답은 (A)이다. (a) 모델이 비교에 실패하는 논리적 오류.
Problem
질문: 이 정보를 바탕으로, 털 색깔 특성에 대한 Sage의 표현형은 무엇인가?
맥락: 한 무리의 말들 중 일부는 검은색 털을 가지고 있고, 다른 일부는 적갈색 털을 가지고 있다. 이 무리에서 털 색깔 특성을 결정하는 유전자는 두 개의 대립유전자(allele)를 가진다. 적갈색 털을 나타내는 대립유전자(I)는 검은색 털을 나타내는 대립유전자(L)에 대해 열성이다.
Sage는 이 무리에 속한 말이다. Sage는 털 색깔 유전자에 대해 동형 접합 유전자형 II를 가진다.
 선택지:
(A) 검은색 털
(B) 적갈색 털
선택지:
(A) 검은색 털
(B) 적갈색 털
근거: Sage의 털 색깔 유전자에 대한 유전자형은 II이다. Sage의 유전자형 II는 I 대립유전자만을 가지고 있다. I 대립유전자는 적갈색 털을 나타낸다. 따라서 Sage의 털 색깔 특성에 대한 표현형은 적갈색 털이어야 한다. 이 답을 확인하기 위해 Sage의 대립유전자가 우성인지 열성인지 고려해보자. 적갈색 털을 나타내는 대립유전자(I)는 검은색 털을 나타내는 대립유전자(L)에 대해 열성이다. 이는 L이 우성 대립유전자이고, I가 열성 대립유전자임을 의미한다. Sage의 유전자형 II는 열성 대립유전자만을 가지고 있다. 어떤 유전자에 대해 열성 대립유전자만 가진 생물은 열성 대립유전자의 특성 버전을 나타낼 것이다. 따라서 Sage의 털 색깔 특성에 대한 표현형은 적갈색 털이어야 한다. 정답: 정답은 (B)이다.
Prediction
근거: Sage의 털 색깔 유전자형은 II이다. Sage의 유전자형 II는 I 대립유전자만을 가지고 있다. I 대립유전자는 적갈색 털을 나타낸다. 따라서 Sage의 털 색깔 표현형은 적갈색 털이어야 한다. 이 답을 확인하기 위해 Sage의 대립유전자가 우성인지 열성인지 고려해보자. 적갈색 털(I) 대립유전자는 검은색 털(L) 대립유전자에 대해 열성이다. 이는 L이 우성 대립유전자이고, I가 열성 대립유전자임을 의미한다. Sage의 유전자형 II는 열성 대립유전자만을 가지고 있다. 어떤 유전자에 대해 열성 대립유전자만을 가진 유기체는 열성 대립유전자의 특성 버전을 가질 것이다. 따라서 Sage의 털 색깔 표현형은 검은색 털이어야 한다. 답변: 정답은 (A)이다. (b) 근거에 모순이 있는 논리적 오류.

Figure 13: 논리적 오류의 예시.
Problem
질문: Palaeopython은 어떤 특징을 가지고 있었는가? 화석에서 관찰할 수 있는 특징을 선택하시오. 맥락: 이 사진은 Palaeopython이라는 고대 동물의 화석을 보여준다. Palaeopython은 나무에서 살았으며 길이가 6피트 이상 자랄 수 있었다. 선택지: (A) 피부에 검은 줄무늬 (B) 몸에 큰 지느러미 (C) 길고 가는 몸
근거: 유기체의 모습이나 행동 방식을 **특징(trait)**이라고 한다. 과학자들은 화석을 사용하여 고대 유기체의 특징에 대해 더 많이 알아낸다. 화석은 몸의 부분이나 활동의 흔적을 보존할 수 있다. 꼬리나 날개와 같은 몸의 부분 화석은 유기체가 어떻게 생겼는지 알려줄 수 있다. 굴이나 발자국과 같은 유기체의 활동 화석은 유기체의 행동에 대해 알려줄 수 있다. 다음은 화석과 그로부터 관찰할 수 있는 특징의 세 가지 예시이다:
- 이것은 동물의 화석이다. 이 화석은 그 동물이 나선형 껍데기를 가지고 있었음을 알려준다.
- 이것은 식물의 화석이다. 이 화석은 그 식물이 가지 모양으로 배열된 작은 잎을 가지고 있었음을 알려준다.
- 이것은 동물의 발자국 화석이다. 이 화석은 그 동물이 땅 위를 걸을 수 있었음을 알려준다.
유기체의 화석이 유기체의 모든 특징을 보여주지는 않을 수 있다. 이는 대부분의 몸 부분이 화석 형성 과정에서 파괴되기 때문이다. 유기체의 몸이 화석으로 변할 때, 일반적으로 소수의 몸 부분만이 보존된다. 정답: 정답은 (C)이다.
Prediction
Rationale : 유기체의 모습이나 행동 방식을 **특징(trait)**이라고 한다. 과학자들은 화석을 사용하여 고대 유기체의 특징에 대해 더 많이 알아낸다. 화석은 신체 부위와 활동의 흔적을 보존할 수 있다. 꼬리나 날개와 같은 신체 부위의 화석은 유기체가 어떻게 생겼는지 알려줄 수 있다. 굴이나 발자국과 같은 유기체의 활동 화석은 유기체의 행동에 대해 알려줄 수 있다. 다음은 화석과 그로부터 관찰할 수 있는 특징의 세 가지 예시이다: 이것은 동물의 화석이다. 이 화석은 그 동물이 나선형 껍데기를 가지고 있었음을 알려준다. 이것은 식물의 화석이다. 이 화석은 그 식물이 가지 모양으로 배열된 작은 잎을 가지고 있었음을 알려준다. 이것은 동물의 발자국 화석이다. 이 화석은 그 동물이 육지에서 걸을 수 있었음을 알려준다. 유기체의 화석은 유기체의 모든 특징을 보여주지 못할 수도 있다. 이는 대부분의 신체 부위가 화석 형성 과정에서 파괴되기 때문이다. 유기체의 몸이 화석으로 변할 때, 일반적으로 소수의 신체 부위만 보존된다. Answer: 정답은 (B)이다.

Figure 14: CoT는 올바르지만, 답변이 틀린 예시들.