멀티모달 정렬 및 융합 기술 심층 분석: 최신 연구 동향 서베이
본 게시물은 텍스트, 이미지, 오디오, 비디오 등 다양한 데이터 유형의 증가에 따라 기계 학습에서 Multimodal Alignment 및 Fusion의 최신 발전에 대한 포괄적인 검토를 제공합니다. 200편 이상의 관련 논문을 바탕으로 기존 정렬 및 융합 기술을 체계적으로 분류하고 분석하며, 소셜 미디어 분석, 의료 영상, 감정 인식과 같은 분야의 응용에 중점을 둡니다. 논문 제목: Multimodal Alignment and Fusion: A Survey
논문 요약: 멀티모달 정렬 및 융합 기술 심층 분석: 최신 연구 동향 서베이
- 논문 링크: https://arxiv.org/abs/2411.17040
- 저자: Songtao Li (Northeastern University, China), Hao Tang (Peking University, China)
- 발표 시기: 2024년, arXiv
- 주요 키워드: 멀티모달, 정렬, 융합, 기계 학습, AI
1. 연구 배경 및 문제 정의
- 문제 정의:
텍스트, 이미지, 오디오, 비디오 등 다양한 데이터 유형의 증가에 따라 기계 학습 모델의 성능을 향상시키기 위한 멀티모달 데이터 통합의 중요성이 커지고 있습니다. 그러나 서로 다른 양식 간의 의미론적 관계를 설정하는 **정렬(Alignment)**과 이질적인 정보를 효과적으로 결합하는 **융합(Fusion)**이라는 두 가지 주요 기술적 과제가 존재합니다. 기존의 피상적인 통합 방식으로는 복잡한 실제 시나리오에서 깊이 있는 이해와 상호작용을 달성하기 어렵습니다. - 기존 접근 방식:
기존 연구에서는 각 양식을 독립적으로 처리하고 간단한 연산(덧셈, 곱셈, 내적 등)을 통해 임베딩을 결합하는 방식(Two-Tower 아키텍처)이 주로 사용되었습니다. 이는 검색 기반 작업에는 효과적일 수 있으나, 양식 간의 깊은 이해와 상호작용이 필요한 정교한 멀티모달 과제에는 한계가 있었습니다. 또한, 전용 융합 네트워크를 사용하더라도 양식별 특징이 의미적으로 정렬되지 않아 최적의 결과를 얻기 어려운 문제가 있었습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 멀티모달 정렬 및 융합 기술에 대한 200개 이상의 논문을 포괄적으로 검토하고 체계적으로 분류했습니다.
- 멀티모달 데이터 통합의 주요 과제(정렬 문제, 노이즈 복원력, 특징 표현 불일치) 및 응용 분야(소셜 미디어 분석, 의료 영상, 감성 인식 등)를 심층적으로 분석했습니다.
- 기존 융합 분류의 한계를 지적하고, 현대 방법론을 더 잘 반영하는 새로운 융합 기술 분류 프레임워크(인코더-디코더, 커널 기반, 그래픽, 어텐션 기반)를 제안했습니다.
- 멀티모달 학습 시스템 최적화를 위한 미래 연구 방향을 제시하여 이 분야의 추가 혁신을 안내합니다.
- 제안 방법:
이 논문은 새로운 방법론을 제안하기보다는, 멀티모달 정렬 및 융합 분야의 최신 연구 동향을 체계적으로 분석하고 분류합니다. 주요 분석 대상 방법론은 다음과 같습니다.- 정렬 (Alignment):
- 명시적 정렬: Dynamic Time Warping (DTW), Canonical Correlation Analysis (CCA)와 같은 통계적 방법을 사용하여 양식 간 유사성을 직접 측정합니다.
- 암시적 정렬: 그래픽 모델 기반(예: 그래프 구조를 통한 복잡한 관계 모델링) 및 신경망 기반(예: 어텐션 메커니즘, GAN, VAE 등을 통해 공유 잠재 공간 학습) 방법을 통해 기본 작업 수행 중 간접적으로 양식을 정렬합니다.
- 융합 (Fusion):
- 인코더-디코더 융합: 원시 데이터 수준, 특징 수준, 또는 모델 수준에서 정보를 통합하여 압축된 표현을 학습하고 재구성합니다.
- 커널 기반 융합: 커널 트릭을 활용하여 비선형 관계를 처리하고 이종 데이터 소스를 효과적으로 통합합니다.
- 그래픽 융합: 그래프 모델을 사용하여 양식 간의 복잡한 관계를 포착하고 불완전한 멀티모달 데이터를 처리합니다.
- 어텐션 기반 융합: 어텐션 메커니즘을 사용하여 여러 양식의 정보에 동적으로 가중치를 부여하고 선택적으로 결합하여 효과적인 정보 통합을 달성합니다 (Transformer 기반 모델 포함).
- 정렬 (Alignment):
3. 실험 결과
- 데이터셋:
이 논문은 새로운 실험 결과를 제시하는 서베이 논문이므로, 특정 데이터셋을 사용하여 자체적인 실험을 수행하지는 않았습니다. 대신, 서베이 대상 논문들에서 사용된 다양한 멀티모달 데이터셋(예: LAION-5B, WIT, MS-COCO, YFCC-100M 등)의 특성과 활용 사례를 분석하고 있습니다. - 주요 결과:
- 양식 특징 정렬 문제: 초기 모델은 사전 훈련된 객체 감지 모델에 의존하여 시각적 특징과 언어적 특징 간의 불일치가 발생했습니다. 노이즈 주입 임베딩, 유한 이산 토큰(FDT) 등의 방법으로 이 문제를 완화하려는 시도가 있었습니다.
- 계산 효율성 문제: 대규모 모델과 객체 감지기의 사용으로 인한 높은 계산 요구량이 문제였습니다. Vision Transformer (ViT)의 패치 기반 특징 사용, 어텐션 병목 현상, TokenFusion, PMF(Prompt-based Multimodal Fusion)와 같은 효율적인 융합 방법이 제안되었습니다.
- 데이터 품질 문제: 웹에서 수집된 대규모 멀티모달 데이터셋(예: 이미지-캡션 쌍)은 불일치하거나 관련 없는 내용을 포함하는 경우가 많아 모델 일반화에 어려움을 줍니다. 합성 캡션 생성, 데이터 필터링(LAION-5B) 등의 접근 방식이 데이터 품질 개선에 기여했습니다.
- 훈련 데이터셋 규모 문제: 비전 및 언어 작업을 결합하는 모델 훈련을 위한 충분히 크고 고품질의 데이터셋 확보가 중요합니다. LAION-5B, WIT와 같은 대규모 데이터셋의 도입과 데이터 압축, 전문가 혼합(MoE)과 같은 확장 기술이 이 문제를 해결하는 데 도움이 되었습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
이 서베이 논문은 멀티모달 AI 분야의 핵심인 정렬과 융합 기술에 대한 매우 포괄적이고 체계적인 분석을 제공합니다. 200편 이상의 논문을 검토하여 방대한 지식을 응축하고, 기존 분류의 한계를 지적하며 새로운 융합 분류 프레임워크를 제시한 점이 인상 깊습니다. 또한, 현재 직면한 주요 과제들을 명확히 제시하고 미래 연구 방향을 제안하여 이 분야에 대한 깊이 있는 이해를 돕고 연구자들에게 실질적인 가이드를 제공합니다. - 단점/한계:
논문 자체의 한계라기보다는, 서베이 대상인 멀티모달 학습 분야의 현재 한계점을 명확히 보여줍니다. 특히, 다양한 양식을 완벽하게 정렬하고 통합하는 프레임워크의 부재, 데이터 품질의 가변성, 그리고 대규모 모델 훈련에 필요한 막대한 계산 자원 요구는 여전히 해결해야 할 큰 과제입니다. 노이즈가 많은 데이터와 양식 불일치를 효과적으로 관리하는 기술의 발전이 지속적으로 필요합니다. - 응용 가능성:
멀티모달 정렬 및 융합 기술은 다양한 실제 응용 분야에서 혁신적인 가능성을 제공합니다.- 소셜 미디어 분석: 텍스트, 이미지, 비디오를 결합하여 사용자 감성 및 행동을 더 정확하게 이해.
- 의료 영상: MRI, PET 등 다양한 의료 영상 데이터를 통합하여 질병 진단 및 예측 정확도 향상.
- 감성 인식: 시각, 청각, 텍스트 정보를 결합하여 인간의 감정을 더 미묘하게 파악.
- 자율 주행: 카메라, LiDAR, 레이더 등 센서 데이터를 융합하여 환경 인식 및 객체 감지 성능 개선.
- 로봇 공학: 센서 데이터와 언어 지시를 통합하여 로봇의 순차 계획 및 시각적 질문 답변 능력 향상.
- 교차 모달 검색: 텍스트 쿼리로 이미지나 비디오를 검색하는 등 다른 양식 간의 정보 검색.
5. 추가 참고 자료
- [1] T. Baltrusaitis, C. Ahuja, and L.-P. Morency, "Multimodal machine learning: A survey and taxonomy," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 2, 2018.
- [13] A. Radford et al., "Learning transferable visual models from natural language supervision," in Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021. (CLIP)
- [39] W. Kim, B. Son, and I. Kim, "ViLT: Vision-and-language transformer without convolution or region supervision." 2021.
- [41] J. Li et al., "BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation," in Proceedings of the 39th International Conference on Machine Learning. PMLR, 2022.
- [49] J. Li et al., "Align before fuse: Vision and language representation learning with momentum distillation," in Advances in Neural Information Processing Systems, vol. 34, 2021. (ALBEF)
- [57] A. Vaswani et al., "Attention is all you need." 2017. (Transformer)
Li, Songtao, and Hao Tang. "Multimodal alignment and fusion: A survey." arXiv preprint arXiv:2411.17040 (2024).
Multimodal Alignment and Fusion: A Survey
Songtao Li Hao Tang*
Abstract
이 설문 조사는 텍스트, 이미지, 오디오, 비디오와 같은 데이터 유형의 다양성이 증가함에 따라 촉발된 기계 학습 내 멀티모달 정렬 및 융합의 최근 발전에 대한 포괄적인 검토를 제공합니다. 멀티모달 통합은 다양한 양식에 걸쳐 보완적인 정보를 활용하여 모델 정확도를 향상시키고 적용 가능성을 넓힐 뿐만 아니라 데이터가 제한된 상황에서 지식 전달을 용이하게 합니다. 200개 이상의 관련 논문에 대한 광범위한 검토를 통해 얻은 통찰력을 바탕으로 기존 정렬 및 융합 기술을 체계적으로 분류하고 분석합니다. 또한 이 설문 조사는 소셜 미디어 분석, 의료 영상, 감성 인식과 같은 영역의 응용에 중점을 두면서 정렬 문제, 노이즈 복원력, 특징 표현의 불일치를 포함한 멀티모달 데이터 통합의 과제를 다룹니다. 제공된 통찰력은 다양한 응용 분야에서 확장성, 견고성 및 일반성을 향상시키기 위해 멀티모달 학습 시스템을 최적화하는 미래 연구를 안내하기 위한 것입니다.
Index Terms-Multimodal Alignment, Multimodal Fusion, Multimodality, Machine Learning, Survey
1 Introduction
기술의 급속한 발전으로 이미지, 텍스트, 오디오, 비디오 등 멀티모달 데이터 생성이 기하급수적으로 증가했습니다 [1]. 이러한 풍부한 데이터는 컴퓨터 비전 및 자연어 처리(NLP)와 같은 다양한 분야의 연구원과 실무자에게 기회와 과제를 제시합니다. 여러 양식의 정보를 통합하면 기계 학습 모델의 성능을 크게 향상시켜 복잡한 실제 시나리오를 이해하는 능력을 향상시킬 수 있습니다 [2].
이러한 양식의 조합은 일반적으로 두 가지 주요 목표를 가지고 추구됩니다: (i) 서로 다른 데이터 양식은 서로를 보완하여 특정 작업에 대한 모델의 정밀도와 효율성을 향상시킬 수 있습니다 [3], [4], [5]. (ii) 일부 양식은 데이터 가용성이 제한되거나 대량으로 수집하기 어려울 수 있습니다. 따라서 LLM 기반 모델에서의 훈련은 지식 전달을 활용하여 데이터가 희소한 작업에서 만족스러운 성능을 달성할 수 있습니다 [5], [6].
예를 들어, 소셜 미디어 분석에서 텍스트 콘텐츠를 관련 이미지나 비디오와 결합하면 사용자 감성과 행동에 대한 보다 포괄적인 이해를 제공합니다 [1], [7]. 소셜 네트워크 외에도 멀티모달 방법은 의료 이미지에 대한 자동 캡션 생성, 비디오 요약, 감성 인식과 같은 응용 분야에서 유망한 결과를 보여주었습니다 [8], [9], [10], [11], [12]. 이러한 발전에도 불구하고 멀티모달 데이터를 효과적으로 통합하고 활용하는 데에는 정렬과 융합이라는 두 가지 주요 기술적 과제가 남아 있습니다. 정렬은 다른 양식 간의 의미적 관계를 설정하여 각 양식의 표현이 공통 공간 내에서 정렬되도록 하는 데 중점을 둡니다. 반면에 융합은
- Songtao Li는 중국 친황다오 066006, 동북대학교 시드니 스마트 기술 대학에 소속되어 있습니다. 이메일: songtao.li.0x00@gmail.com
- Hao Tang은 중국 베이징 100871, 베이징 대학교 컴퓨터 과학 대학에 소속되어 있습니다. 이메일: haotang@pku.edu.cn *교신 저자: Hao Tang. 멀티모달 정보를 통합된 예측으로 통합하여 각 양식의 강점을 활용하여 전반적인 모델 성능을 향상시킵니다.
첫 번째 구성 요소인 멀티모달 정렬은 다른 양식 간의 관계를 설정하는 것을 포함합니다 [1], [49], [50], [51]. 예를 들어, 비디오의 행동 단계를 해당 텍스트 설명과 정렬하려면 입력-출력 분포의 변화와 양식 간의 정보 충돌 가능성으로 인해 정교한 방법이 필요합니다 [52]. 멀티모달 정렬은 명시적 방법과 암시적 방법으로 광범위하게 분류할 수 있습니다 [1], [53]. 명시적 정렬은 유사성 행렬을 사용하여 모달 간 관계를 직접 측정하는 반면, 암시적 정렬은 번역이나 예측과 같은 작업에서 중간 단계 역할을 합니다.
두 번째 구성 요소인 멀티모달 융합은 다른 양식의 정보를 결합하여 통합된 예측을 만드는 것을 포함하며, 노이즈 변동성 및 양식 간의 신뢰도 차이와 같은 과제를 해결합니다 [1], [54], [55]. 전통적으로 융합 방법은 데이터 처리 파이프라인에서 발생하는 단계를 기준으로 분류됩니다 [53], [56]. 예를 들어, 초기 융합은 특징 추출 단계에서 여러 양식의 데이터를 통합하여 모달 간 상호 작용을 조기에 포착합니다 [56]. 이 설문 조사는 현재 융합 기술의 핵심 특성에 중점을 두어 현대 방법론을 보다 효과적으로 나타내고 미래의 발전을 안내합니다. 우리는 커널 기반, 그래픽, 인코더-디코더 및 어텐션 기반 융합 프레임워크 내에서 융합 방법을 분석합니다.
그림 1은 멀티모달 모델의 세 가지 일반적인 구조를 보여줍니다. (a)에서 간단한 작업은 양식 간의 상호 작용이 불충분하여 깊고 효과적인 융합을 달성하지 못합니다. (b)에서는 전용 융합 네트워크의 설계에도 불구하고 정렬 문제가 여전히 중요합니다. 구체적으로, 각각의 양식별 모델에 의해 이미지와 텍스트에서 파생된 특징은 의미적으로 정렬되지 않을 수 있으며, 이러한 특징을 융합 모듈에 직접 전달하는 것이 최적의 결과를 낳지 않을 수 있습니다. (c)에서 모델은 공유 인코더 또는 통합된 인코딩-디코딩 프로세스를 사용하여 멀티모달 입력을 동시에 처리합니다. 이를 통해 이미지와
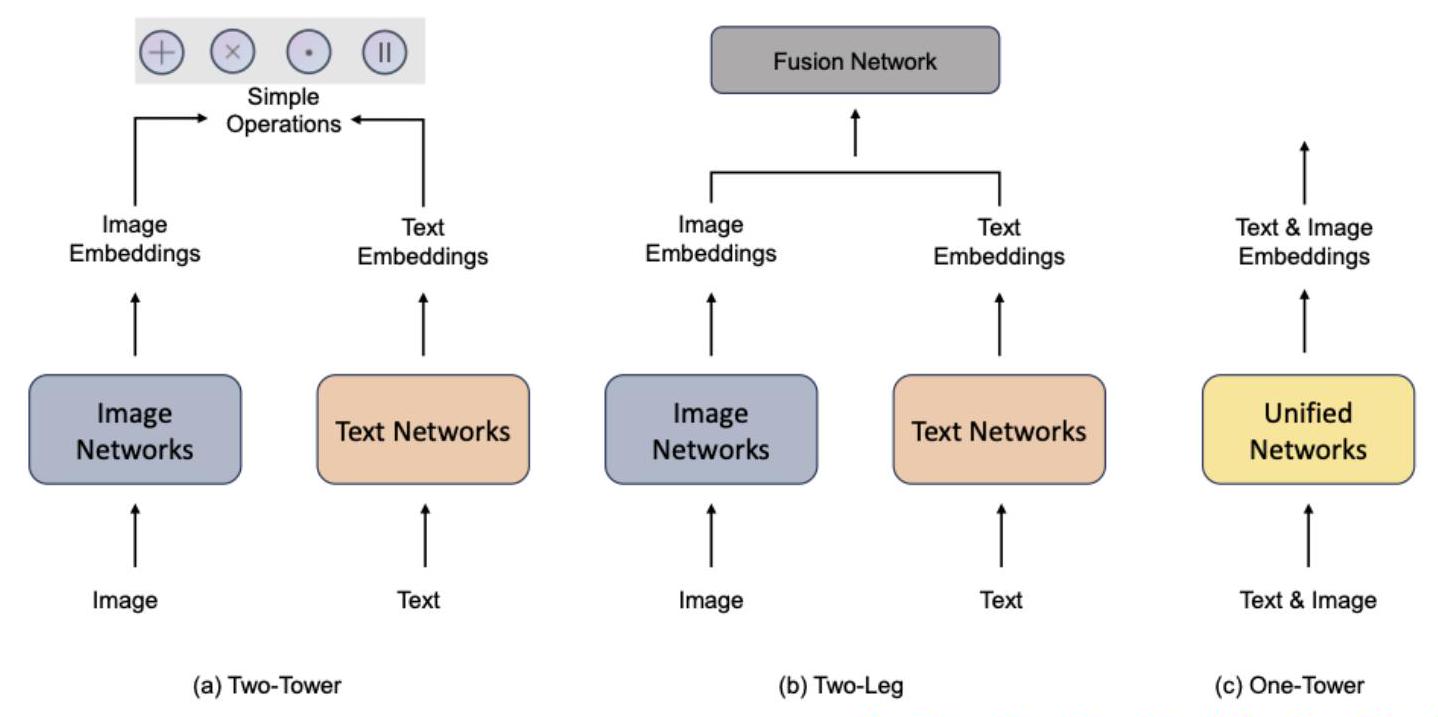
그림 1: 멀티모달 모델 아키텍처 개요: (a) Two-Tower [13], [14], [15], [16], [17], [18], [19], [20], [21], [22], [23], [24]: 이미지와 텍스트를 별도로 처리하고 간단한 연산(더하기, 곱하기, 내적 및 연결)을 통해 임베딩을 결합합니다. (b) Two-Leg [25], [26], [27], [28], [29], [30], [31], [32], [33], [34], [35], [36], [37], [38], [39]: 별도의 이미지 및 텍스트 임베딩을 Fusion Network를 사용하여 결합합니다. (c) One-Tower [12], [40], [41], [42], [43], [44], [45], [46], [47], [48]: 통합된 네트워크를 활용하여 이미지 및 텍스트 입력을 공동으로 임베딩합니다. 텍스트 데이터를 공통 표현 공간으로 변환하여 보다 자연스럽게 결합하기 쉽게 만듭니다. 이러한 설계는 일반적으로 양식 간의 관계가 잘 이해되고 효과적으로 모델링될 때 모델의 단순성과 효율성을 우선시합니다.
이 연구는 200개 이상의 관련 논문을 검토한 결과를 바탕으로 기존 방법, 최근 발전, 그리고 잠재적인 미래 방향에 대한 포괄적인 개요를 제공함으로써 이 분야에 기여하는 것을 목표로 합니다. 이 설문 조사는 연구자들이 멀티모달 정렬 및 융합의 기본 개념, 핵심 방법론, 현재 진행 상황을 이해하는 데 도움을 주며, 시각 및 언어 양식에 중점을 두면서 비디오 및 오디오와 같은 다른 유형으로 확장합니다.
이 설문 조사의 구성은 다음과 같습니다. 섹션 2에서는 대규모 언어 모델(LLM)과 비전 모델의 최근 발전을 포함하여 멀티모달 학습의 기본 개념에 대한 개요를 제시하여 융합 및 정렬에 대한 논의의 토대를 마련합니다. 섹션 3에서는 정렬 및 융합에 대한 설문 조사를 수행하는 이유에 대해 중점을 둡니다. 섹션 4에서는 서로 다른 양식 간의 관계를 설정하기 위한 명시적 및 암시적 기술에 초점을 맞춰 정렬 방법을 검토합니다. 섹션 5에서는 융합 전략을 탐색하고 초기, 후기 및 하이브리드 융합으로 분류하며 커널 기반, 그래픽 및 어텐션 기반 융합 프레임워크와 같은 고급 방법을 소개합니다. 섹션 6에서는 특징 정렬, 계산 효율성, 데이터 품질 및 확장성을 포함하여 멀티모달 융합 및 정렬의 주요 과제를 다룹니다. 마지막으로 섹션 7에서는 미래 연구의 잠재적 방향을 설명하고 실제적 의미를 논의하며, 이 분야에서 추가적인 혁신을 이끌어내는 것을 목표로 합니다.
2 PRELIMINARIES
이 섹션에서는 우리 작업에 대한 이해를 높이기 위해 주요 주제 및 개념에 대한 간략한 개요를 제공합니다.
2.1 MLLM
최근 자연어 처리(NLP)와 컴퓨터 비전(CV) 모두 어텐션 메커니즘과 Transformer [57], [58], [59], [60], [61], [62]의 도입 이후 급속한 발전을 경험했습니다. 이 프레임워크를 기반으로 OpenAI의 GPT 시리즈 [63], [64], [65] 및 Meta의 Llama 시리즈 [66]와 같은 수많은 대규모 언어 모델(LLM)이 등장했습니다. 마찬가지로 비전 분야에서는 Segment Anything [67], DINO [68], DINOv2 [69]를 포함한 대규모 비전 모델(LVM)이 제안되었습니다.
그러나 이러한 LLM은 시각 정보를 이해하고 오디오나 센서 입력과 같은 다른 양식을 처리하는 데 어려움을 겪는 반면, LVM은 추론에 한계가 있습니다 [70]. 상호 보완적인 강점을 고려할 때, LLM과 LVM은 점점 더 결합되어 멀티모달 대규모 언어 모델(MLLM)이라는 새로운 분야의 출현으로 이어지고 있습니다. 텍스트 처리에서 LLM의 강력한 성능을 다른 양식을 포함하는 작업으로 확장하기 위해 대규모 멀티모달 모델을 개발하기 위한 상당한 연구 노력이 이루어졌습니다.
텍스트 처리에서 LLM의 강력한 성능을 다른 양식을 포함하는 작업으로 확장하기 위해, 대규모 멀티모달 모델 개발에 상당한 연구 노력이 집중되었습니다 [71]. Kosmos-2 [72]는 텍스트 설명을 시각적 맥락과 연결하여 더 정확한 객체 감지 및 구 인식를 허용함으로써 접지(grounding) 기능을 도입합니다. PaLM-E [73]는 이러한 기능을 실제 응용 프로그램에 추가로 통합하여 순차 계획 및 시각적 질문 답변과 같은 로봇 공학의 구체화된(embodied) 작업에 센서 데이터를 사용합니다. 또한 ContextDET [74]와 같은 모델은 시각적 요소를 언어 입력에 직접 연결하여 시각-언어 연관의 이전 한계를 극복함으로써 맥락적 객체 감지에서 탁월합니다.
여러 모델이 멀티모달 데이터의 복잡성을 관리하기 위해 계층적 접근 방식을 채택했습니다. 예를 들어 SEED-Bench-2는 계층적 MLLM 기능을 벤치마킹하여 인식 및 인지 작업 모두에서 모델 성능을 평가하고 개선하기 위한 구조화된 프레임워크를 제공합니다 [75]. 또한 X-LLM은 각 양식을 "외국어"로 취급하여 오디오, 시각 및 텍스트 입력을 대규모 언어 모델과 보다 효과적으로 정렬함으로써 멀티모달 정렬을 향상시킵니다 [76].
MLLM이 계속 발전함에 따라 UnifiedVisionGPT와 같은 기본 프레임워크는 여러 비전 모델을 통합 플랫폼으로 통합하여 멀티모달 AI의 발전을 가속화합니다 [77]. 이러한 프레임워크는 MLLM이 방대한 멀티모달 데이터 세트를 활용할 뿐만 아니라 광범위한 작업에 적응할 수 있는 잠재력을 보여주며 인공 일반 지능을 달성하기 위한 중요한 단계를 나타냅니다.
2.2 Multimodal Data
2.2.1 Multimodal Dataset
서로 다른 양식은 고유한 특성을 제공합니다. 예를 들어, 이미지는 시각적 정보를 제공하지만 조명 및 시점의 변화에 취약합니다 [93]. 텍스트 데이터는 언어적으로 다양하며 모호성을 포함할 수 있습니다 [94]. 오디오 데이터는 감정적인 내용과 기타 비언어적 단서를 전달합니다 [1].
멀티모달 데이터 세트는 이미지 캡셔닝, 텍스트-이미지 검색, 제로샷 분류와 같은 다양한 작업에서 모델 학습을 가능하게 하는 대규모 쌍을 이루는 이미지-텍스트 데이터를 제공함으로써 비전-언어 모델(VLM)을 훈련하기 위한 기본입니다. 주요 데이터 세트에는 LAION-5B, WIT 및 특정 도메인이나 멀티모달 학습 내의 과제를 목표로 하는 RS5M과 같은 새로운 특수 데이터 세트가 포함됩니다. 표 1은 일반적으로 사용되는 데이터 세트와 그 특성을 요약합니다.
예를 들어, LAION-5B 데이터 세트는 50억 개 이상의 CLIP 필터링된 이미지-텍스트 쌍을 포함하여 연구자들이 CLIP 및 GLIDE와 같은 모델을 미세 조정하여 오픈 도메인 생성 및 강력한 제로샷 분류 작업을 지원할 수 있도록 합니다 [90]. 108개 언어로 3,700만 개 이상의 이미지-텍스트 쌍을 가진 WIT(Wikipedia-based Image Text) 데이터 세트는 다국어 및 다양한 검색 작업을 지원하도록 설계되었으며, 교차 언어 이해에 중점을 둡니다 [87]. 500만 개의 원격 감지 이미지-텍스트 쌍으로 구성된 RS5M 데이터 세트는 지리 공간 데이터의 의미론적 위치 파악 및 비전-언어 검색과 같은 도메인별 학습 작업에 최적화되어 있습니다 [92]. 또한 ViLLA와 같은 세분화된 데이터 세트는 의료 또는 합성 이미지의 객체 감지와 같은 작업에 중요한 복잡한 영역-속성 관계를 포착하도록 맞춤화되었습니다 [95].
2.2.2 Characteristics and Challenges
멀티모달 학습의 각 양식은 고유한 과제를 제시합니다. 예를 들어, 이미지 데이터는 종종 조명 변화, 가려짐, 원근 왜곡과 같은 문제에 직면하여 다양한 조건에서 객체와 장면을 인식하는 모델의 능력에 영향을 미칠 수 있습니다 [96]. 텍스트 데이터는 모호성, 속어, 다의성을 포함한 자연어의 가변성으로 인해 복잡성을 야기하며, 이는 정확한 해석과 다른 양식과의 정렬을 복잡하게 만듭니다 [94]. 마찬가지로 오디오 데이터는 배경 소음, 잔향, 환경 간섭에 취약하여 의도된 신호를 왜곡하고 모델 정확도를 저하시킬 수 있습니다 [97].
이러한 과제를 해결하기 위해 멀티모DAL 학습에서는 표현과 정렬을 모두 최적화하기 위해 특정 손실 함수가 사용됩니다. 주목할만한 예는 다음과 같습니다.
- Contrastive Loss는 이미지-텍스트 매칭과 같은 작업에서 일반적으로 사용되며, 의미적으로 유사한 쌍을 임베딩 공간에서 더 가깝게 만들고 유사하지 않은 쌍을 멀리 밀어내는 것을 목표로 합니다. 이 접근 방식은 멀티모달 특징의 표현을 개선하고 노이즈가 많은 데이터를 처리하는 데 특히 효과적입니다 [13], [98], [99].
- Cross-Entropy Loss는 널리 사용되는 분류 손실로, 예측된 확률 분포와 실제 확률 분포 사이의 발산을 계산하여 여러 양식에 걸쳐 레이블 기반 학습을 가능하게 합니다. 이는 지도 분류 작업의 기본이며, 집합 교차 엔트로피와 같은 변형은 여러 대상 답변을 처리하여 멀티모달 작업에 더 큰 유연성을 제공합니다 [100], [101].
- Reconstruction Loss는 오토인코더 및 멀티모달 융합 작업에서 사용되며, 입력 데이터를 재구성하거나 노이즈를 마스킹하여 모델이 양식별 왜곡에 더 탄력적으로 대처할 수 있도록 합니다. 이러한 유형의 손실은 시각-텍스트 및 시청각 융합과 같이 강력한 특징 정렬 및 노이즈 복원력이 필요한 멀티모달 작업에 필수적입니다 [102].
- Angular Margin Contrastive Loss (AMC-Loss)는 클래스 간의 각도 분리를 향상시키기 위해 기하학적 제약을 도입하여 임베딩 공간에서 더 명확한 클래스 경계를 이끌어냅니다. 이 손실 함수는 정량적 정확도와 전통적인 대조 손실을 기반으로 구축된 지도 대조 손실 모두를 향상시키는 데 효과적인 것으로 입증되었습니다. 지도 대조 손실은 대조 손실과 교차 엔트로피 손실의 요소를 결합하여 레이블이 지정된 데이터를 활용하고, 특히 어려운 멀티모DAl 조건에서 성능과 안정성을 향상시킵니다 [104], [105].
3 Why Alignment and Fusion
정렬과 융합은 멀티모달 학습에서 두 가지 기본 개념으로, 별개이면서도 깊이 상호 연결되어 있으며 종종 상호 보강적입니다 [1], [50]. 정렬은 서로 다른 양식이 적절하게 일치하고 동기화되도록 하여 전달하는 정보를 일관성 있고 통합에 적합하게 만드는 것을 포함합니다. 반면에 융합은 서로 다른 양식의 정보를 결합하여 포괄적인 방식으로 데이터의 본질을 포착하는 통일된 표현을 만드는 것을 의미합니다 [1], [54], [55]. 또한, 최근의 많은 방법들은 정렬 과정 없이는 융합이 어렵다는 것을 발견했습니다 [49].
3.1 Enhancing Comprehensiveness and Robustness
정렬은 서로 다른 출처의 데이터가 시간, 공간 또는 맥락 측면에서 동기화되도록 보장하여 의미 있는 조합을 가능하게 합니다. 적절한 정렬 없이는 융합 과정에서 오해나 중요한 정보 손실이 발생할 수 있습니다 [53].
정렬이 이루어지면 융합은 정렬된 데이터를 활용하여 더 견고하고 포괄적인 표현을 생성합니다 [49]. 여러 관점을 통합함으로써 융합은 개별 양식의 약점을 완화하여 정확도와 신뢰성을 향상시킵니다.
표 1: 다양한 데이터 세트의 특성 개요.
| 데이터 세트 | 크기 | 언어 | 양식 | 특징 |
|---|---|---|---|---|
| SBU Captions [78] | 1M | 영어 | 이미지-텍스트 | CC-3M보다 고유한 단어는 많지만 캡션은 적습니다. |
| MS-COCO [79] | 1.64 M | 영어 | 이미지-텍스트 | 크라우드 워커가 이미지에 대한 캡션을 제공하여 생성되었습니다. |
| YFCC-100M [80] | 100M | 영어 | 이미지-텍스트 | 1억 개의 이미지-텍스트 쌍을 포함하며, 텍스트와 이미지 간의 평균 일치 정도는 불분명합니다. |
| YFCC-15M [80] | 15 M | 영어 | 이미지-텍스트 | Redford 등이 정리한 YFCC-100M의 하위 집합입니다. |
| Flickr30k [81] | 30k | 영어 | 이미지-텍스트 | 크라우드 워커가 약 30,000개의 이미지에 대한 캡션을 제공하여 생성되었습니다. |
| Visual Genome [82] | 5.4 M | 영어 | 이미지-텍스트 | 영역 설명, 객체 인스턴스, 관계 등과 같은 구조화된 이미지 개념을 포함합니다. |
| Conceptual Captions [83] | - | 영어 | 이미지-텍스트 | SBU보다 약 3배 더 많은 캡션을 가지고 있지만 고유한 단어는 더 적습니다. |
| MulRan [84] | - | - | 포인트 클라우드 | 도시 환경을 대상으로 하는 레이더 및 라이다 데이터를 위한 멀티모달 범위 데이터 세트입니다. 장소 인식 지상 실측 자료를 위한 6D 기준 궤적을 제공합니다. 범위 센서를 기반으로 한 장소 인식의 시간적 및 구조적 다양성을 포착합니다. |
| RedCaps [85] | 12.01 M | 영어 | 이미지-텍스트 | 긴 꼬리 분포를 가진 350개의 서브레딧에 분포되어 있습니다. 미리 정의된 객체 클래스 온톨로지 없이 인간이 일상 생활에서 마주치는 시각적 개념의 분포를 포함합니다. CC-3M 및 SBU와 같은 다른 데이터 세트에 비해 언어적 다양성이 더 높습니다. |
| CC-12M [86] | 12.4 M | 영어 | 이미지-텍스트 | RedCaps에 비해 언어적 다양성이 낮습니다. |
| WIT [87] | 37.6 M | 다국어 | 이미지-텍스트 | 다국어 위키백과 이미지-텍스트 데이터 세트의 하위 집합입니다. |
| CLIP [13] | 400 M | 영어 | 이미지-텍스트 | 공개적으로 출시되지 않았습니다. |
| TaiSu [88] | 166 M | 중국어 | 이미지-텍스트 | TaiSu는 1억 6,600만 개의 이미지와 2억 1,900만 개의 중국어 캡션을 포함하는 대규모 고품질 중국어 교차 모달 데이터 세트로, 비전-언어 사전 훈련을 위해 설계되었습니다. |
| COYO-700M [89] | 700M | 영어 | 이미지-텍스트 | HTML 문서에서 가져온 7억 개의 유익한 이미지-대체 텍스트 쌍 모음입니다. |
| LAION-5B [90] | 5.85 B | 영어 | 이미지-텍스트 | LAION-5B는 CLIP으로 필터링된 58억 개 이상의 이미지-텍스트 쌍을 포함하는 공개적으로 사용 가능한 대규모 데이터 세트로, 차세대 이미지-텍스트 모델 훈련을 위해 설계되었습니다. |
| LAION-2B [90] | 2.3 B | 영어 | 이미지-텍스트 | LAION-5B에서 가져온 23억 2천만 개의 영어 쌍의 하위 집합입니다. |
| LAION-COCO [90] | 600M | 영어 | 이미지-텍스트 | LAION-5B에서 가져온 6억 개의 이미지와 합성 캡션의 하위 집합입니다. |
| LAION-A [90] | 900M | 영어 | 이미지-텍스트 | LAION-2B에서 가져온 9억 개의 하위 집합으로, 미학적으로 필터링되고 pHash를 사용하여 중복 제거되었습니다. |
| DATACOMP-1B [91] | 1.4B | 영어 | 이미지-텍스트 | 간단한 필터링을 사용하여 Common Crawl에서 수집되었습니다. 이 데이터 세트에서 훈련된 모델은 이전 결과에 비해 더 적은 MAC을 사용하여 더 높은 정확도를 달성합니다. |
| RS5M [92] | 5M | 영어 | 이미지-텍스트 | RS5M 데이터 세트는 500만 개의 원격 감지 이미지와 해당 영어 설명을 함께 포함하는 대규모 원격 감지 이미지-텍스트 쌍 데이터 세트입니다. |
3.2 Addressing Data Sparsity and Imbalance
많은 실제 응용 프로그램에서 특정 양식의 데이터는 부족하거나 얻기 어려울 수 있습니다. 정렬은 제한적이더라도 사용 가능한 데이터를 동기화하여 효과적으로 활용할 수 있도록 도와줍니다 [106], [107].
그런 다음 융합은 양식 간의 지식 전달을 가능하게 하여 모델이 한 양식의 강점을 활용하여 다른 양식의 약점을 보완할 수 있도록 합니다. 이는 한 양식에 풍부한 데이터가 있는 반면 다른 양식은 제한적인 시나리오에서 특히 유용합니다.
3.3 Improving Model Generalization and Adaptability
정렬은 서로 다른 양식 간의 관계가 잘 이해되고 정확하게 모델링되도록 보장하며, 이는 모델이 다양한 맥락과 응용 분야에서 일반화하는 능력에 매우 중요합니다 [1], [53].
융합은 데이터의 미묘한 차이를 보다 효과적으로 포착하는 통일된 표현을 만들어 모델의 적응성을 향상시킵니다. 이 통일된 표현은 새로운 작업이나 환경에 더 쉽게 적응할 수 있어 모델의 전반적인 유연성을 향상시킵니다 [1], [53].
3.4 Enabling Advanced Applications
정렬과 융합은 함께 교차 모달 검색과 같은 고급 응용 프로그램을 가능하게 하며, 여기서 한 양식(예: 텍스트)의 정보는 다른 양식(예: 이미지)에서 관련 정보를 검색하는 데 사용됩니다 [108]. 이러한 프로세스는 시각적 및 청각적 단서를 결합하는 것이 단독으로 어느 한 양식을 사용하는 것보다 인간의 감정을 더 정확하게 이해하는 데 도움이 되는 감정 인식과 같은 작업에도 중요합니다 [109].
4 Multimodal Alignment
멀티모달 정렬은 둘 이상의 다른 양식 간의 의미적 관계를 설정하는 것을 포함합니다. 이는 네트워크 정렬 [110], 이미지 융합 [50], 멀티모달 학습의 특징 정렬 [111] 등 다양한 분야에서 널리 연구되어 왔습니다.
서로 다른 양식을 동일한 의미 표현으로 정렬하기 위해, 잠재적인 장거리 의존성과 모호성을 고려하여 이러한 양식 간의 유사성을 측정합니다. 간단히 말해, 목표는 한 양식의 표현을 동일한 의미를 공유하는 다른 양식의 해당 표현에 정렬하는 매핑을 구성하는 것입니다. [1]에 따르면, 정렬은 암시적과 명시적 두 가지 유형으로 분류될 수 있습니다. 명시적 정렬은 일반적으로 유사성 행렬을 사용하여 유사성을 직접 측정하는 반면, 암시적 정렬은 번역이나 예측과 같은 작업의 중간 단계인 경우가 많습니다.
4.1 Explicit Alignment
명시적 정렬은 초기 기반을 가지고 있으며, 종종 Dynamic Time Warping (DTW) [112], [113] 및 Canonical Correlation Analysis (CCA) [114]와 같은 통계적 방법에 의존합니다. DTW는 시퀀스를 정렬하기 위해 프레임을 삽입하는 시간 왜곡을 통해 최적의 일치를 찾아 두 시퀀스 간의 유사성을 측정합니다 [112]. 그러나 원래의 DTW 공식은 사전 정의된 유사성 메트릭을 필요로 하므로, 1936년 Harold Hotelling이 도입한 Canonical Correlation Analysis (CCA) [114]로 확장되어 선형 변환을 통해 두 개의 서로 다른 공간을 공통 공간으로 투영합니다. CCA의 목표는 투영을 최적화하여 두 공간 간의 상관 관계를 최대화하는 것입니다. CCA는 멀티모달 응용 프로그램(예: 비디오-텍스트 및 비디오-오디오 정렬)에서 볼 수 있듯이 (DTW를 통한) 정렬과 비지도 방식으로 양식 간 매핑의 공동 학습을 모두 용이하게 합니다. 그림 2는 CCA 방법을 시각화합니다. 구체적으로, CCA의 목적 함수는 다음과 같이 표현될 수 있습니다.
여기서:
- 와 는 두 개의 다른 공간에서 온 데이터 행렬입니다.
- 와 는 와 를 공통 공간으로 투영하는 선형 변환 벡터 (또는 정준 벡터)입니다.
- 는 투영된 와 간의 상관 계수입니다.
- 목표는 투영된 데이터 간의 상관 관계 를 최대화하는 와 를 찾는 것입니다. 그러나 CCA는 두 양식 간의 선형 관계만 포착할 수 있어 비선형 관계를 포함하는 복잡한 시나리오에서의 적용 가능성이 제한됩니다. 이 한계를 해결하기 위해 커널 방법을 사용하여 원래 데이터를 고차원 특징 공간으로 매핑하여 비선형 종속성을 처리하기 위해 Kernel Canonical Correlation Analysis (KCCA)가 도입되었습니다 [115], [116]. 다중 레이블 KCCA 및 Deep Canonical Correlation Analysis (DCCA)와 같은 확장은 원래 CCA 방법을 더욱 개선했습니다 [115], [116], [117], [118], [119].
또한 Verma와 Jawahar는 서포트 벡터 머신(SVM)을 사용하여 멀티모달 검색을 달성할 수 있음을 보여주었습니다 [120]. 또한, 복잡한 공간 변환을 통해 멀티모달 정렬을 해결하기 위해 특징 양식 간의 선형 매핑과 같은 방법이 개발되었습니다 [121].
4.2 Implicit Alignment
암시적 정렬은 기본 작업 실행 중에 종종 잠재적인 방식으로 중간 단계로 사용되는 방법을 말합니다. 서로 다른 양식의 데이터를 직접 정렬하는 대신 이러한 방법은 공유 잠재 공간을 학습하여 기본 작업의 성능을 향상시킵니다. 암시적 정렬 기술은 그래픽 모델 기반 방법과 신경망 기반 방법의 두 가지 유형으로 광범위하게 분류할 수 있습니다.
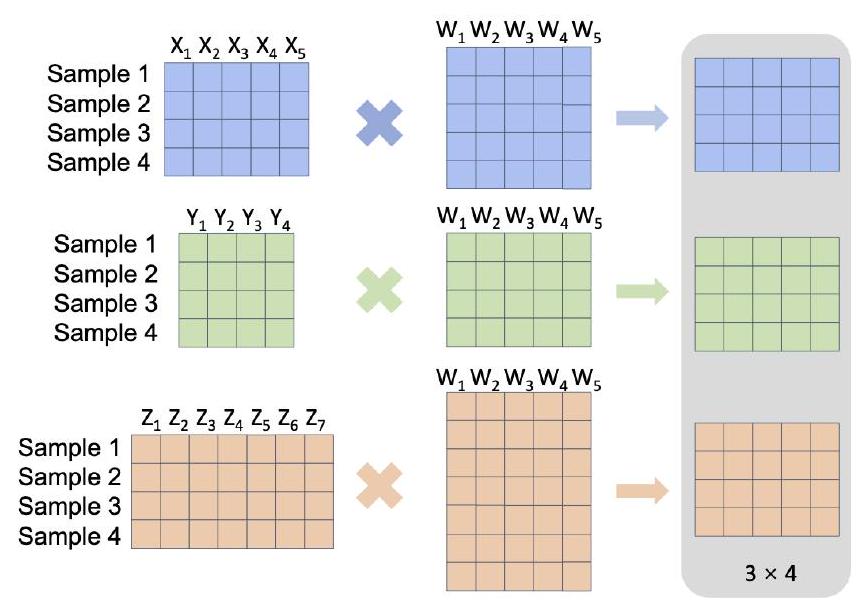
그림 2: 정준 상관 분석(Canonical Correlation Analysis, CCA)은 고전적인 정렬 방법으로, 공유 가중치 행렬을 사용하여 특징 차원이 다른 다양한 샘플 행렬을 정렬하여 통일된 표현을 생성합니다. 기본 작업. 다른 양식의 데이터를 직접 정렬하는 대신, 이러한 방법은 공유 잠재 공간을 학습하여 기본 작업의 성능을 향상시킵니다. 암시적 정렬 기술은 그래픽 모델 기반 방법과 신경망 기반 방법의 두 가지 유형으로 광범위하게 분류할 수 있습니다.
4.2.1 Graphical Model-Based Methods
그래프 구조의 통합은 다른 양식 간의 복잡한 관계를 더 잘 모델링하여 멀티모달 데이터의 더 정확하고 효율적인 처리를 가능하게 합니다. 이러한 방법은 일반적으로 이미지를 텍스트 또는 이미지와 신호로 정렬하는 데 적용됩니다. 예를 들어, 특정 모델은 객체의 그래프 표현을 정렬하여 몇 번의 샷으로 컨텍스트 내 모방 학습을 가능하게 하여 로봇이 사전 훈련 없이 새로운 객체에 대한 작업을 수행할 수 있도록 합니다 [122]. 명시적인 진화 모델을 기반으로 하는 GraphAlignment 알고리즘은 상동 정점을 식별하고 파라로그를 해결하는 데 강력한 성능을 보여 특정 시나리오에서 대안을 능가합니다 [123]. 그림 3은 정렬에 그래프가 사용되는 방식을 보여줍니다.
이러한 작업에서 중요한 과제는 멀티모달 신호가 항상 서로 직접적으로 대응하지 않는 양식 간의 암시적 정보를 정렬하는 것입니다. 그래프 기반 모델은 노드가 데이터 요소(예: 단어, 객체 또는 프레임)를 나타내고 에지가 이들 간의 관계(예: 의미적, 공간적 또는 시간적)를 나타내는 그래프로 양식 간의 복잡한 관계를 나타냄으로써 이 과제를 해결하는 데 효과적인 것으로 입증되었습니다.
최근 연구에서는 그래프 구조를 사용하여 멀티모달 정렬의 다양한 측면을 탐색했습니다. 예를 들어, Tang 등 [124]은 수화 번역을 개선하기 위해 그래프 기반 멀티모달 순차 임베딩 접근 방식을 도입했습니다. 멀티모달 데이터를 통합된 그래프 구조로 임베딩함으로써 그들의 모델은 복잡한 관계를 더 잘 포착합니다.
또 다른 응용 분야는 감성 분석으로, 암시적 멀티모달 정렬이 중요한 역할을 합니다. Yang 등 [125]은 명시적 측면(예: 객체, 감성)과 암시적 멀티모달 상호작용(예: 이미지-텍스트 관계)을 공동으로 모델링하는 멀티모달 그래프 기반 정렬
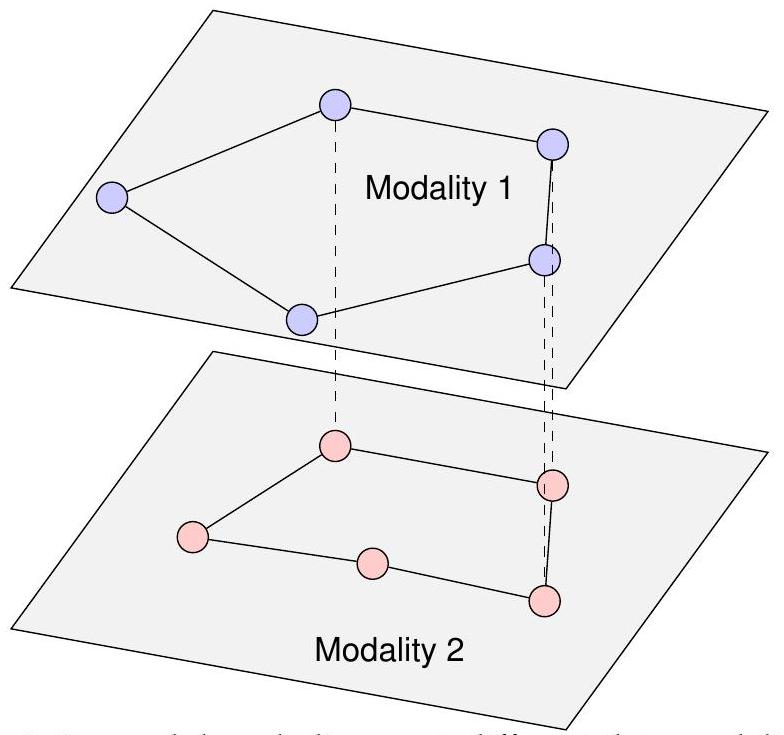
그림 3: 그래프 기반 정렬에서 서로 다른 데이터 양식은 고유한 의미를 가진 그래프를 형성할 수 있으며, 여기서 에지와 노드의 해석이 다를 수 있습니다. 예를 들어, [123]에서 정점과 에지의 해석은 비교되는 생물학적 네트워크의 유형에 따라 달라집니다. 모델(MGAM)을 제안했습니다.
구현된 AI 분야에서 Song 등 [126]은 복잡한 멀티모달 작업에서 암묵적 관계를 모델링하기 위해 장면 기반 지식 그래프를 어떻게 구성할 수 있는지 탐구합니다. 그들의 연구는 텍스트 및 시각 정보를 지식 그래프로 통합하며, 여기서 멀티모달 의미는 그래프 기반 추론을 통해 정렬됩니다. 장면에서 객체 간의 공간적 및 시간적 관계와 같은 암묵적 단서를 정렬하는 것은 구현된 AI 시스템에서 의사 결정 및 상호 작용을 개선하는 데 중요합니다.
개체명 인식(NER)을 위해 Zhang 등 [127]은 텍스트와 관련된 이미지의 암묵적인 시각적 정보를 통합하는 토큰 단위 그래프 기반 접근 방식을 제안합니다. 이 방법은 시각적 도메인의 공간적 관계를 활용하여 고립된 텍스트 데이터를 사용할 때 종종 모호한 명명된 개체의 식별을 개선합니다.
이미지 캡셔닝 및 시각적 질문 응답(VQA)과 같은 작업에서 장면 그래프도 중요한 역할을 합니다. Xiong 등 [128]은 양식 전반에 걸친 의미론적 정렬을 위한 장면 그래프 기반 모델을 도입합니다. 객체와 그 관계를 그래프의 노드와 에지로 표현함으로써 모델은 시각적 및 텍스트 양식의 정렬을 개선합니다.
요약하면, 그래프 기반 방법은 다양한 데이터 유형을 나타내는 강력한 프레임워크를 제공하며 멀티모달 정렬에 큰 잠재력을 가지고 있습니다. 그러나 이러한 유연성은 상당한 과제를 제시하기도 합니다.
그래프 구조의 희소성과 동적인 특성은 최적화를 복잡하게 만듭니다. 행렬이나 벡터와 달리 그래프는 불규칙한 비구조적 연결을 가지고 있어 높은 계산 복잡성과 메모리 제약으로 이어집니다. 이러한 문제는 고급 하드웨어 플랫폼에서도 지속됩니다. 또한 그래프 신경망(GNN)은 특히 하이퍼파라미터에 민감합니다. 네트워크 아키텍처, 그래프 샘플링, 손실 함수 최적화와 관련된 선택은 성능에 직접적인 영향을 미치며 GNN 설계 및 실제 배포의 어려움을 증가시킵니다.
4.2.2 Neural Network-Based Methods
최근 몇 년 동안 신경망 기반 방법은 암시적 정렬 문제를 해결하는 지배적인 접근 방식이 되었습니다. 특히 번역과 같은 작업에서 정렬을 잠재적 중간 단계로 통합하면 종종 더 나은 결과를 얻을 수 있습니다. 일반적인 신경망 접근 방식에는 인코더-디코더 모델 및 교차 모달 검색이 포함됩니다. 암시적 정렬 없이 번역이 수행되면 인코더에 더 큰 부담을 주어 전체 이미지, 문장 또는 비디오를 벡터 표현으로 요약해야 합니다.
한 가지 인기 있는 해결책은 디코더가 소스 인스턴스의 특정 하위 구성 요소에 집중할 수 있도록 하는 어텐션 메커니즘을 사용하는 것입니다. 이는 모든 소스 하위 구성 요소를 함께 인코딩하는 기존의 인코더-디코더 모델과 대조됩니다. 어텐션 모듈은 디코더가 번역되는 소스의 특정 하위 구성 요소(예: 이미지 영역, 문장 단어, 오디오 세그먼트, 비디오 프레임 또는 지침 일부)에 더 집중하도록 안내합니다. 예를 들어, 이미지 캡션 생성에서 어텐션 메커니즘은 디코더(일반적으로 순환 신경망)가 전체 이미지를 한 번에 인코딩하는 대신 각 단어를 생성할 때 이미지의 특정 부분에 집중할 수 있도록 합니다 [129]. 이전 연구에서는 입력에서 출력까지 사전 훈련된 모델과 인터페이스하기 위해 양식별 임베더 및 예측기를 설계하여 이를 달성했습니다.
생성적 적대 신경망(GAN)은 고차원 데이터 공간 간의 복잡한 매핑을 학습하는 능력으로 인해 멀티모달 데이터 합성에 성공적으로 적용되었습니다 [130], [131], [132], [133], [134]. 예를 들어, MRI 양식에서 단일 생성기가 양식 간 매핑을 학습하는 통합 프레임워크를 사용하면 여러 데이터 유형에 걸쳐 정렬 정확도를 향상시킬 수 있습니다 [130].
또 다른 심층 생성 방법인 C-Flow는 3D 포인트 클라우드 재구성과 같은 작업에서 멀티모달 정렬을 위해 정규화 흐름을 활용하여 생성 프로세스에 대한 더 세분화된 제어를 허용합니다 [135]. 오토인코더와 그 변형인 Variational Autoencoders (VAEs)도 양식 전반에 걸친 기본 의미 구조를 포착하는 잠재 표현을 학습하는 데 사용되었습니다. 이 접근 방식은 VAE가 이미지와 텍스트 양식을 공유 잠재 공간에 매핑하여 정렬하는 데 도움이 되는 구성적 표현 학습에서 효과적인 것으로 입증되었습니다 [136]. 마찬가지로 VAE를 사용한 교차 모달 양자화를 사용한 멀티모달 이미지-텍스트 쌍 생성은 신경망이 양자화된 공동 표현을 학습하여 텍스트 및 시각적 데이터를 정렬할 수 있는 방법을 보여줍니다 [137].
또한, Diffusion Transport Alignment (DTA)와 같은 준지도 매니폴드 정렬 방법은 소량의 사전 지식을 활용하여 뚜렷하지만 관련된 구조를 가진 멀티모달 데이터 도메인을 정렬합니다 [138]. 이 접근 방식은 도메인 간의 기하학적 유사성에 의존하기 때문에 부분적인 데이터 정렬만 가능한 상황에서 특히 유용합니다.
최근 개발에서, Sinkhorn 메트릭과 어텐션 메커니즘을 결합한 Att-Sinkhorn 방법은 서로 다른 양식의 확률 분포 간의 최적 수송 문제를 해결함으로써 멀티모달 특징 정렬에서 향상된 정확도를 보여주었습니다 [139].
요약하면, 명시적 및 암시적 정렬 기술은 모두 멀티모달 기계 학습 분야에서 중요합니다. 명시적 방법은 유사성을 측정하고 대응 관계를 설정하기 위한 명확한 프레임워크를 제공하지만, 암시적 방법은 종종 더 유연하며 특히 복잡하거나 모호한 데이터 관계를 포함하는 광범위한 시나리오에 적응할 수 있습니다. 향후 연구는 멀티모달 데이터가 제시하는 다양한 과제를 해결하기 위해 두 정렬 전략의 강점을 결합한 하이브리드 접근 방식을 계속 탐색할 가능성이 높습니다 [110], [111], [139].
5 Multimodal Fusion
멀티모달 데이터는 이미지, 텍스트, 오디오와 같은 다양한 유형의 정보 통합을 포함하며, 기계 학습 모델에 의해 처리되어 수많은 작업에서 성능을 향상시킬 수 있습니다 [1], [53], [140], [141], [142], [143]. 다양한 유형의 정보를 결합함으로써 멀티모달 융합은 단일 유형의 데이터에 의존함으로써 발생할 수 있는 약점이나 격차를 해결하면서 각 양식의 강점을 활용합니다 [1], [53], [144]. 예를 들어, 각 양식은 최종 예측에 다르게 기여할 수 있으며, 하나는 특정 시간에 다른 것보다 잠재적으로 더 유익하거나 덜 잡음이 있을 수 있습니다.
융합 방법은 다른 양식의 정보를 효과적으로 결합하는 데 중요합니다. 초기 접근 방식에서는 이미지와 텍스트가 종종 별도로 처리되었으며 두 데이터 유형 간의 기본적인 통합만 있었습니다. CLIP [13]과 같은 아키텍처는 시각적 정보와 텍스트 정보가 독립적으로 인코딩되고 그 상호 작용이 일반적으로 내적 계산을 포함하는 간단한 연산을 통해 처리되는 이중 인코더 프레임워크를 사용했습니다 [145], [146]. 결과적으로 이 두 양식의 융합은 인코더 자체가 지배하는 전체 모델 아키텍처에서 비교적 작은 역할을 했습니다. 이 제한된 통합 전략은 검색 기반 작업에는 효과적이었지만 [147], [148], 양식 간의 깊은 이해와 상호 작용이 필요한 더 정교한 멀티모달 과제에는 미치지 못합니다 [149], [150].
만약 각 양식에 대해 특화된 인코더를 독립적으로 훈련시킨 후 피상적인 통합만으로 강력한 성능을 달성할 수 있다면 [4], [151], 심층 멀티모달 학습의 필요성은 의문스러울 것입니다. 그러나 경험적 증거에 따르면 시각적 질문 응답 및 시각적 추론과 같이 미묘한 이해가 필요한 작업의 경우, 시각적 인식과 언어 처리 간의 상호 관계를 적절하게 포착하기 위해서는 두 양식의 더 복잡하고 깊은 융합이 필수적입니다 [152].
전통적으로 융합 방법은 융합이 발생하는 데이터 처리 파이프라인의 단계를 기반으로 분류되었습니다. 초기 융합은 특징 수준에서 데이터를 통합하고, 후기 융합은 결정 수준에서, 하이브리드 융합은 둘 다의 측면을 결합합니다 [1], [53].
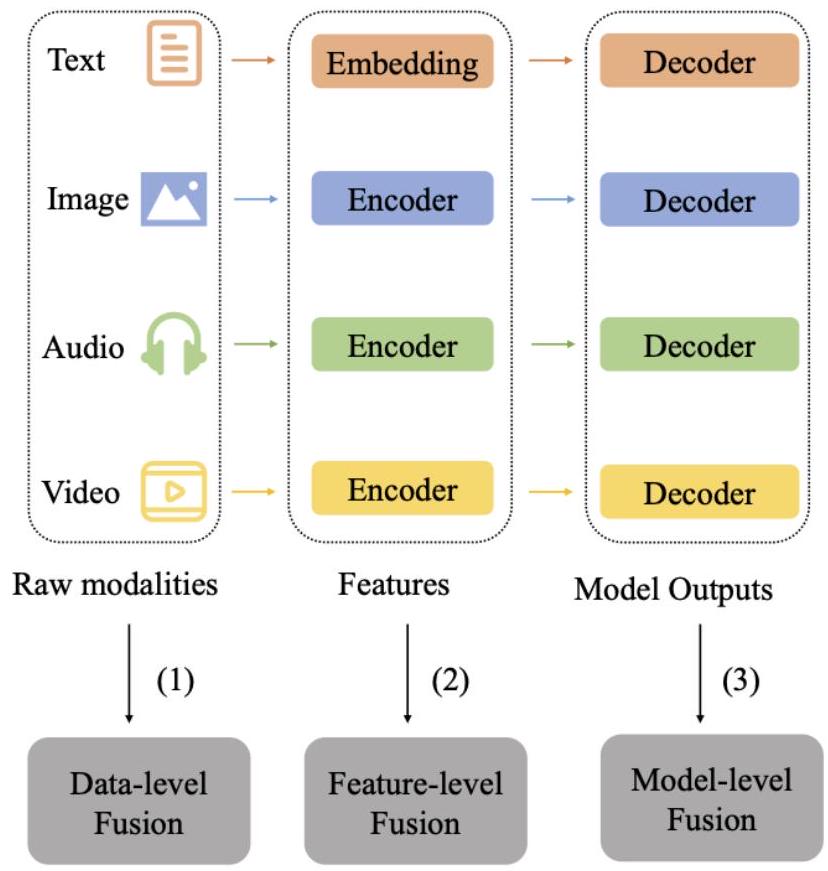
그림 4: 인코더-디코더 융합의 세 가지 유형: (1) 데이터 수준 융합: 여러 양식의 원시 데이터를 직접 결합합니다. (2) 특징 수준 융합: 각 양식에서 인코딩된 특징을 통합합니다. (3) 모델 수준 융합: 개별 양식 디코더의 출력을 융합하여 최종 결과를 생성합니다.
초기 융합은 특징 추출 단계에서 다른 양식의 데이터를 병합하여 양식 간의 상호 작용을 조기에 포착할 수 있도록 합니다 [56]. Zhao 등 [93]이 설명했듯이 통합은 특징 수준에서 발생합니다. 반면에 후기 융합은 결정 단계에서 개별 양식 모델의 출력을 결합하는데, 이는 Morvant 등 [153]이 보여준 것처럼 예측 중에 하나 이상의 양식이 누락될 때 유리합니다. 하이브리드 융합은 초기 및 후기 융합의 측면을 모두 통합하며, Zhao 등은 딥 러닝 맥락에서 그 구현을 탐구합니다 [93].
기술과 융합 기술이 발전함에 따라 초기, 후기, 하이브리드 융합을 구별하는 것이 점점 더 복잡해졌습니다. 고급 방법은 종종 전통적인 시간 기반 범주를 넘어 특징 및 결정 수준 모두에서 동시에 작동하여 엄격한 분류에 도전합니다.
이 복잡성을 해결하기 위해 현재 융합 기술의 핵심 특성에 기반한 새로운 분류 프레임워크를 제안하여 현대적인 방법을 더 정확하게 표현하고 미래 발전을 안내합니다. 특히, 많은 어텐션 기반 방법이 인코더-디코더 또는 인코더 전용 프레임워크에 적합할 수 있지만, 최근의 중요한 발전과 기존 범주로는 적절하게 포착되지 않는 독특한 혁신으로 인해 별도로 분류합니다.
5.1 Encoder-Decoder Fusion
인코더-디코더 융합 아키텍처는 입력 데이터에서 필수적인 특징을 포착하고 이를 압축된 형태로 압축하는 인코더와, 이 압축된 표현에서 출력을 재구성하는 디코더를 포함합니다 [26].
이 아키텍처에서 시스템은 주로 인코더와 디코더라는 두 가지 주요 구성 요소로 구성됩니다. 인코더는 일반적으로 입력 데이터를 중요한 특징의 잠재 공간으로 변환하는 고급 특징 추출기로 기능합니다 [26], [37]. 즉, 인코딩 프로세스는 중복성을 줄이면서 중요한 의미 정보를 보존합니다. 인코딩 단계가 완료되면 디코더는 잠재 표현을 기반으로 해당 "재구성된" 출력을 생성합니다 [26], [31]. 의미론적 분할과 같은 작업에서 디코더의 출력은 일반적으로 입력 크기와 일치하는 의미론적 레이블 맵입니다.
Encoder-decoder 융합은 일반적으로 세 가지 형태로 나타납니다: (1) 데이터 수준 융합, 여기서 서로 다른 양식의 원시 데이터가 연결되어 공유 인코더에 공급됩니다; (2) 특징 수준 융합, 여기서 특징은 각 양식에서 별도로 추출되고, 잠재적으로 중간 레이어를 포함하며, 디코더에 입력되기 전에 결합됩니다; 그리고 (3) 모델 수준 융합, 여기서 개별 양식별 모델의 출력이 처리 후 연결됩니다. 그림 4는 이러한 세 가지 유형의 인코더-디코더 융합 구조를 보여줍니다. 특징 수준 융합은 피상적인 조합이 아닌 더 깊은 통합을 가능하게 하는 서로 다른 양식 간의 관계를 고려하기 때문에 종종 가장 효과적입니다.
5.1.1 Data-level Fusion
이 방법에서는 각 양식의 데이터 또는 각 양식의 고유한 전처리 단계에서 처리된 데이터가 입력 수준에서 결합됩니다 [27]. 이 통합 후 모든 양식의 통합된 입력은 단일 인코더를 통해 전달되어 더 높은 수준의 특징을 추출합니다. 본질적으로 다른 양식의 데이터는 입력 단계에서 병합되고 단일 인코더가 멀티모달 정보에서 포괄적인 특징을 추출하는 데 사용됩니다.
최근 연구는 자율 주행 차량의 객체 감지 및 인식을 개선하기 위해 데이터 수준 융합에 초점을 맞추었습니다. 연구에서는 신경망 아키텍처의 초기 단계에서 카메라 및 LiDAR 데이터를 융합하는 것을 탐구했으며, 특히 희소한 포인트 클라우드에서 자전거 타는 사람에 대한 3D 객체 감지 정확도가 향상되었음을 보여주었습니다 [35]. 원시 카메라 및 LiDAR 데이터를 공동으로 처리하는 YOLO 기반 프레임워크는 기존의 결정 수준 융합에 비해 차량 감지에서 개선을 보였습니다 [27]. 또한, 특히 원시 레이더 데이터를 활용하는 저수준 센서 융합을 위한 개방형 하드웨어 및 소프트웨어 플랫폼이 이 분야의 연구를 촉진하기 위해 개발되었습니다 [36]. 이러한 연구는 원시 데이터 수준 융합이 센서 간 시너지를 활용하고 전반적인 시스템 성능을 개선할 수 있는 잠재력을 강조합니다.
5.1.2 Feature-level Fusion
이 융합 기술의 기본 개념은 여러 추상화 수준의 데이터를 결합하여 계층적 심층 신경망의 다른 계층에서 추출된 특징을 활용하여 궁극적으로 모델 성능을 향상시키는 것입니다. 많은 응용 프로그램에서 이 융합 전략을 구현했습니다 [32], [163].
특징 수준 융합은 다양한 컴퓨터 비전 작업에서 강력한 접근 방식으로 부상했습니다. 이는 성능 향상을 위해 다양한 추상화 수준에서 특징을 결합하는 것을 포함합니다. 예를 들어, 성별 분류에서는 로컬 패치를 융합한 2단계 계층 구조가 효과적이었습니다 [163]. 두드러진 객체 감지를 위해, 다양한 VGG 수준의 특징을 계층적으로 융합한 네트워크는 의미론적 정보와 에지 정보를 모두 보존했습니다 [30]. 멀티모달 감성 컴퓨팅에서는 "분할, 정복, 결합" 전략이 로컬 및 글로벌 상호 작용을 모두 탐색하여 최첨단 성능을 달성했습니다 [32]. 적응형 시각 추적을 위해, 객체 모델을 계층적으로 업데이트하여 매개변수 공간에서 검색을 안내하고 계산 복잡성을 줄이는 계층적 모델 융합 프레임워크가 개발되었습니다 [33]. 이러한 접근 방식은 다양한 영역에 걸쳐 계층적 특징 융합의 다재다능함을 보여주며, 복잡한 시각적 작업에서 향상된 성능을 위해 미세한 정보와 높은 수준의 정보를 모두 포착하는 능력을 보여줍니다.
5.1.3 Model-level Fusion
모델 수준 융합은 여러 모델의 출력을 통합하여 다양한 응용 분야에서 정확도를 향상시키는 기술입니다. 예를 들어, 지면 투과 레이더(GPR)를 사용한 지뢰 탐지에서 Missaoui 등 [34]은 다중 스트림 연속 은닉 마르코프 모델(HMM)을 통해 에지 히스토그램 디스크립터와 가버 웨이블릿을 융합하는 것이 개별 특징 및 동일 가중치 조합보다 성능이 우수함을 입증했습니다.
멀티모달 객체 감지에서 Guo와 Zhang [28]은 이미지, 음성, 비디오를 처리하는 모델의 결과를 결합하기 위해 평균화, 가중치 부여, 계단식 연결, 스태킹과 같은 융합 방법을 적용하여 복잡한 환경에서의 성능을 향상시켰습니다. 안면 활동 단위(AU) 감지를 위해 Jaiswal 등 [29]은 인공 신경망(ANN)을 사용한 모델 수준 융합이 간단한 특징 수준 접근 방식보다 더 효과적이라는 것을 발견했습니다.
또한, 다중 충실도 컴퓨터 모델을 포함하는 물리적 시스템의 경우, Allaire와 Willcox [25]는 모델 불충분 정보와 합성 데이터를 사용하는 융합 방법론을 개발하여 개별 모델에 비해 더 나은 추정치를 얻었습니다. 품질 관리 및 예측 유지 보수에서 새로운 모델 수준 융합 접근 방식은 기존 방법을 능가하여 예측 분산을 줄이고 정확도를 증가시켰습니다 [38]. 이러한 연구는 다양한 영역에서 모델 수준 융합의 효과를 보여줍니다.
이 섹션에서는 인코더-디코더 아키텍처를 기반으로 한 융합 모델을 검토합니다. 인코더-디코더 프레임워크는 인코더가 먼저 특징을 추출한 다음, 이러한 더 표현력 있는 표현을 사용하여 상관 관계를 학습하여 서로 다른 양식 간의 상호 작용을 가능하게 하고 다양한 소스의 특징을 통합하는 직관적인 접근 방식입니다. 그러나 이 방법의 융합 프로세스는 종종 덧셈이나 연결과 같은 비교적 간단한 연산에 의존합니다. 점점 더 많은 연구자들이 서로 다른 양식의 특징을 통합하여 그들 사이의 관계를 더 잘 드러내는 더 정교한 방법을 모색하고 있습니다. 요약하자면, 대표적인 모델에 대한 자세한 정보는 표 2에 제시되어 있습니다.
표 2: 인코더-디코더 모델 요약.
| 모델 | 연도 | 범주 | 시각적 인코더 | 주요 목표 | 방법 |
|---|---|---|---|---|---|
| Missaoui et al. [34] | 2010 | 모델 수준 | - | 지뢰 탐지 | 다중 스트림 연속 은닉 마르코프 모델(MSCHMM)을 사용하여 에지 히스토그램 디스크립터(EHD) 및 가버 웨이블릿을 별도의 스트림으로 처리합니다. |
| Makris et al. [33] | 2011 | 특징 수준 | - | 시각적 표적 추적 | 여러 모델(예: 키포인트, 패치 및 등고선)을 사용하여 대상을 계층적으로 표현하고 파티클 필터를 사용하여 추적합니다. |
| Chen et al. [154] | 2014 | 모델 수준 | DeepLab | 도로 감지 | Deeplab을 사용하여 도로를 별도로 감지하고 조건부 랜덤 필드(CRF)를 사용하여 결과를 융합합니다. |
| SegNet [26] | 2017 | 특징 수준 | VGG16 | 이미지 분할 | 디코더가 인코더의 최대 풀링 인덱스를 사용하여 업샘플링하는 인코더-디코더 구조를 사용합니다. |
| SegNet-Basic [26] | 2017 | 특징 수준 | VGG16 (축소 버전) | 이미지 분할 | 분석 및 비교를 위한 SegNet의 소규모 버전입니다. |
| FCN [155] | 2017 | 특징 수준 | VGG16 | 이미지 분할 | 널리 사용되는 디코딩 기술이지만 메모리 집약적입니다. |
| PointFusion [156] | 2018 | 모델 수준 | ResNet, PointNet | 차량 감지 | PointNet으로 포인트 클라우드 데이터를 처리하고 ResNet으로 이미지 데이터를 처리하며, 심층 융합 모듈을 사용하여 결과를 융합합니다. |
| Steinbaeck et al. [36] | 2018 | 데이터 수준 | - | 환경 인식 | ToF 및 레이더 데이터를 공통 좌표계로 통합하여 추가 데이터 처리 및 알고리즘 개발을 수행합니다. |
| Rvid et al. [35] | 2019 | 데이터 수준 | - | 자율 주행 환경 인식 | 카메라 및 LiDAR 센서의 데이터를 거의 원시 데이터 추상화 수준에서 융합하여 3D 객체 감지 정확도를 향상시킵니다. |
| DenseFuse [31] | 2019 | 특징 수준 | - | 적외선 및 가시광선 이미지 융합 | 인코더-디코더 구조와 덧셈 및 11-노름 전략을 사용하여 인코더가 추출한 특징을 융합합니다. |
| HFFN [32] | 2019 | 특징 수준 | 3D-CNN, Facet | 멀티모달 감성 컴퓨팅 | 멀티모달 융합을 위해 "분할-정복, 통합-통일" 전략을 채택하고, 로컬 및 글로벌 상호 작용을 고려하여 계층적 융합을 수행합니다. |
| Uezato et al. [37] | 2020 | 특징 수준 | - | 이미지 융합 | 정규화기로 Guided Depth Decoder (GDD)를 사용하여 가이드 이미지의 다중 스케일 공간 세부 정보와 의미론적 특징을 더 잘 활용할 수 있습니다. |
| YOLO-RF [27] | 2020 | 데이터 수준 | YOLOv3 (수정 버전) | 차량 감지 | LiDAR 반사율 및 깊이 맵을 수정된 YOLOv3에 입력되는 카메라 데이터의 네 번째 및 다섯 번째 채널로 추가합니다. |
| WM-YOLO [157] | 2020 | 모델 수준 | YOLO | 차량 감지 | 컬러 이미지 및 포인트 클라우드 데이터를 기반으로 객체 감지를 별도로 수행하고, 가중 평균을 사용하여 결과를 결합합니다. |
| HFFNet [30] | 2020 | 특징 수준 | VGG | 두드러진 객체 감지 | 계층적 특징 융합 네트워크를 활용하여 낮은 수준의 에지 정보와 높은 수준의 의미론적 정보를 결합하여 현저성 맵을 생성합니다. |
| Guo et al. [28] | 2023 | 모델 수준 | Faster R-CNN, Optical Flow Estimation Model | 멀티모달 객체 감지 및 인식 | 이미지, 오디오 및 비디오 양식의 결과를 융합하여 객체 감지 및 인식 정확도를 향상시킵니다. |
| I2I-Mamba [158] | 2024 | 데이터 수준 | CNN | 합성 성능 향상 | SSM의 장거리 컨텍스트에 대한 민감성과 CNN의 로컬 정확도를 활용하여 데이터 수준에서 다른 양식의 입력 이미지를 연결하고 융합합니다. |
| GFE-Mamba [159] | 2024 | 특징 수준 | 3D GAN-Vit | 질병 진행 예측 | 3D GAN-Vit 모델, 멀티모달 Mamba 분류기 및 픽셀 수준 이중 교차 어텐션 메커니즘을 통합하여 특징 수준에서 MRI 및 PET 이미지의 특징과 스케일 정보를 융합합니다. |
| JambaTalk [160] | 2024 | 특징 수준 | Jamba (하이브리드 Transformer-Mamba 모델) | 애니메이션 향상 | Transformer와 Mamba 방법의 장점을 결합하여 특징 수준에서 오디오 특징과 얼굴 특징을 융합합니다. |
| UV-Mamba [161] | 2024 | 특징 수준 | DCN 강화 상태 공간 모델 | 경계 인식 개선 | 변형 가능한 상태 공간 증강(DSSA) 모듈을 채택하여 특징 수준에서 다중 스케일 특징을 융합합니다. |
| PyramidMamba [162] | 2024 | 특징 수준 | ResNet18 또는 SwinBase | 다중 스케일 표현 향상 | 풍부한 다중 스케일 의미론적 특징을 인코딩하기 위해 밀집 공간 피라미드 풀링(DSPP)을 개발하고, 다중 스케일 특징 융합에서 의미론적 중복성을 줄이기 위해 피라미드 융합 Mamba(PFM)를 개발하는 플러그 앤 플레이 디코더를 설계하여 특징 수준에서 다중 스케일 특징을 융합합니다. |
5.2 Kernel-based Fusion
커널 기반 융합 기술은 비선형 관계를 처리하고 이종 데이터 소스를 효과적으로 통합하는 능력으로 인해 다양한 영역에서 두각을 나타냈습니다. 이러한 방법은 데이터를 고차원 공간으로 매핑하기 위해 커널 트릭을 활용하여 특징 표현 및 분석을 향상시킵니다 [164], [165]. 다항식 커널 또는 방사형 기저 함수 커널과 같은 적절한 커널 함수를 선택함으로써 이러한 방법은 모델 복잡성과 정확도를 유지하면서 계산 효율성을 달성할 수 있습니다.
커널 교차 모달 요인 분석은 특히 이중 모드 감정 인식을 위한 멀티모달 융합을 위한 새로운 접근 방식으로 도입되었습니다 [166]. 이 기술은 서로 다른 특징 하위 집합 간의 결합된 패턴을 나타내기 위한 최적의 변환을 식별합니다. 신약 개발에서 서포트 벡터 머신(SVM) 내의 커널 함수를 통해 여러 데이터 소스를 통합하면 약물-단백질 상호 작용 예측이 향상됩니다 [167]. 시청각 음성 활동 감지를 위해 최적화된 대역폭 선택을 통한 커널 기반 융합은 잡음이 많은 환경에서 기존 접근 방식을 능가합니다 [168]. 멀티미디어 의미론적 인덱싱에서 커널 기반 정규화된 조기 융합 및 문맥적 후기 융합 방식은 표준 융합 방법에 비해 개선된 성능을 보여줍니다 [169]. 약물 재배치를 위해 커널 기반 데이터 융합은 이종 정보 소스를 효과적으로 통합하여 순위 기반 융합을 능가하고 기존 약물의 새로운 치료 응용 분야를 식별하는 독특한 솔루션을 제공합니다 [164].
커널 트릭을 사용하여 이러한 방법은 계산 효율성을 달성하고 패턴을 더 잘 나타내어 예측 정확도를 향상시킵니다. 그러나 올바른 커널을 선택하고 매개변수를 조정하는 데 어려움, 대규모 데이터 세트의 잠재적인 확장성 문제, 고차원 투영으로 인한 해석 가능성 감소, 적절하게 정규화되지 않은 경우 과적합 위험 등 과제가 존재합니다.
5.3 Graphical Fusion
그래픽 모델은 멀티모달 데이터를 표현하고 융합하는 강력한 접근 방식을 제공하여 서로 다른 양식 간의 복잡한 관계를 효과적으로 포착합니다 [170]. 이러한 모델은 불완전한 멀티모달 데이터를 처리하는 데 특히 유용합니다. 예를 들어, 이종 그래프 기반 멀티모달 융합(HGMF) 방법 [171]은 불완전한 멀티모달 데이터를 모델링하고 융합하기 위해 이종 하이퍼노드 그래프를 구성합니다. HGMF는 하이퍼노드 그래프를 활용하여 데이터 대체를 요구하지 않고 다양한 데이터 조합을 수용하여 다양한 양식에 걸쳐 강력한 표현을 가능하게 합니다 [171]. 그림 5는 [171]에서 하이퍼노드 구성을 보여줍니다.
그래픽 융합 방법은 알츠하이머병(AD) 진단 및 표적 추적과 같은 다양한 응용 분야에서 여러 양식의 데이터를 결합하는 데 점점 더 많이 사용되고 있습니다 [172], [173]. 예를 들어, AD 진단에서 이종 그래프 기반 모델은 MRI 및 PET와 같은 신경 영상 양식을 통합하여 복잡한 뇌 네트워크 구조를 포착하여 예측 정확도를 향상시킵니다 [174]. 추천 시스템에서 이종 그래프는 텍스트, 이미지 및 소셜 미디어 데이터의 효과적인 통합을 가능하게 하여
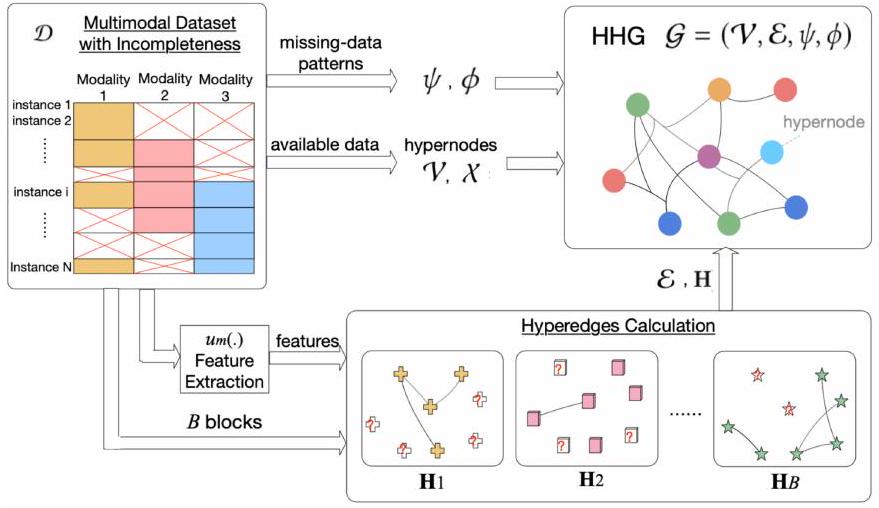
그림 5: [171]의 그림은 그래프 모델이 일부 데이터가 누락된 경우에도 양식을 효과적으로 융합할 수 있음을 보여줍니다. 멀티모달 관계를 포착하여 추천 품질을 향상시킵니다 [175]. 그러나 멀티모달 융합을 위한 전통적인 선형 조합 접근 방식은 보완적인 정보를 포착하는 데 한계가 있으며 종종 양식 가중치에 민감합니다 [176].
이러한 문제를 해결하기 위해 연구자들은 멀티모달 상호보완성을 효율적으로 활용하는 비선형 그래프 융합 기술을 개발했습니다 [176], [177]. 이종 그래프의 조기 융합 연산자와 같은 이러한 기술은 모드 간 상호 작용을 포착하여 선형 접근 방식을 능가하며 단일 클래스 학습 및 멀티모달 분류 작업에서 개선된 성능을 보여주었습니다 [178]. 예를 들어, 비선형 융합 방법은 AD 및 그 전구 단계인 경도 인지 장애(MCI)에 대한 분류 정확도를 향상시켰습니다 [177].
최근의 발전에는 적대적 표현 학습 및 그래프 융합 네트워크가 포함되며, 이는 양식 불변 임베딩 공간을 학습하고 양식 간의 다단계 상호 작용을 탐색하는 것을 목표로 합니다 [179]. 이러한 접근 방식은 멀티모달 융합 작업에서 최첨단 성능을 보여주었으며 융합 결과의 향상된 시각화를 제공합니다 [172], [179].
요약하면, 그래프 기반 멀티모달 융합 분야는 전통적인 선형 융합 모델을 넘어 더 정교한 비선형 및 적응형 접근 방식으로 크게 발전했습니다. 그래프 구조를 활용함으로써 이러한 모델은 양식 전반에 걸쳐 복잡하고 고차원적인 상호 작용을 포착하여 의료 진단, 사회적 추천 및 감성 분석과 같은 응용 분야에 매우 효과적입니다. 지속적인 발전을 통해 그래프 기반 융합 방법은 불완전하고 이종적인 데이터를 처리하고 AI 기반 멀티모달 응용 분야에서 혁신을 주도할 큰 가능성을 가지고 있습니다.
5.4 Attention-based Fusion
어텐션 기반 융합은 어텐션 메커니즘을 사용하여 여러 소스의 정보를 선택적으로 결합하는 방법으로, 모델이 처리 중에 데이터의 가장 관련성 높은 부분에 동적으로 집중할 수 있도록 합니다 [57], [58], [192]. 이 접근 방식은 여러 양식의 정보를 통합하는 것이 효과적인 정보 통합에 필수적인 멀티모달 융합에서 특히 중요합니다.
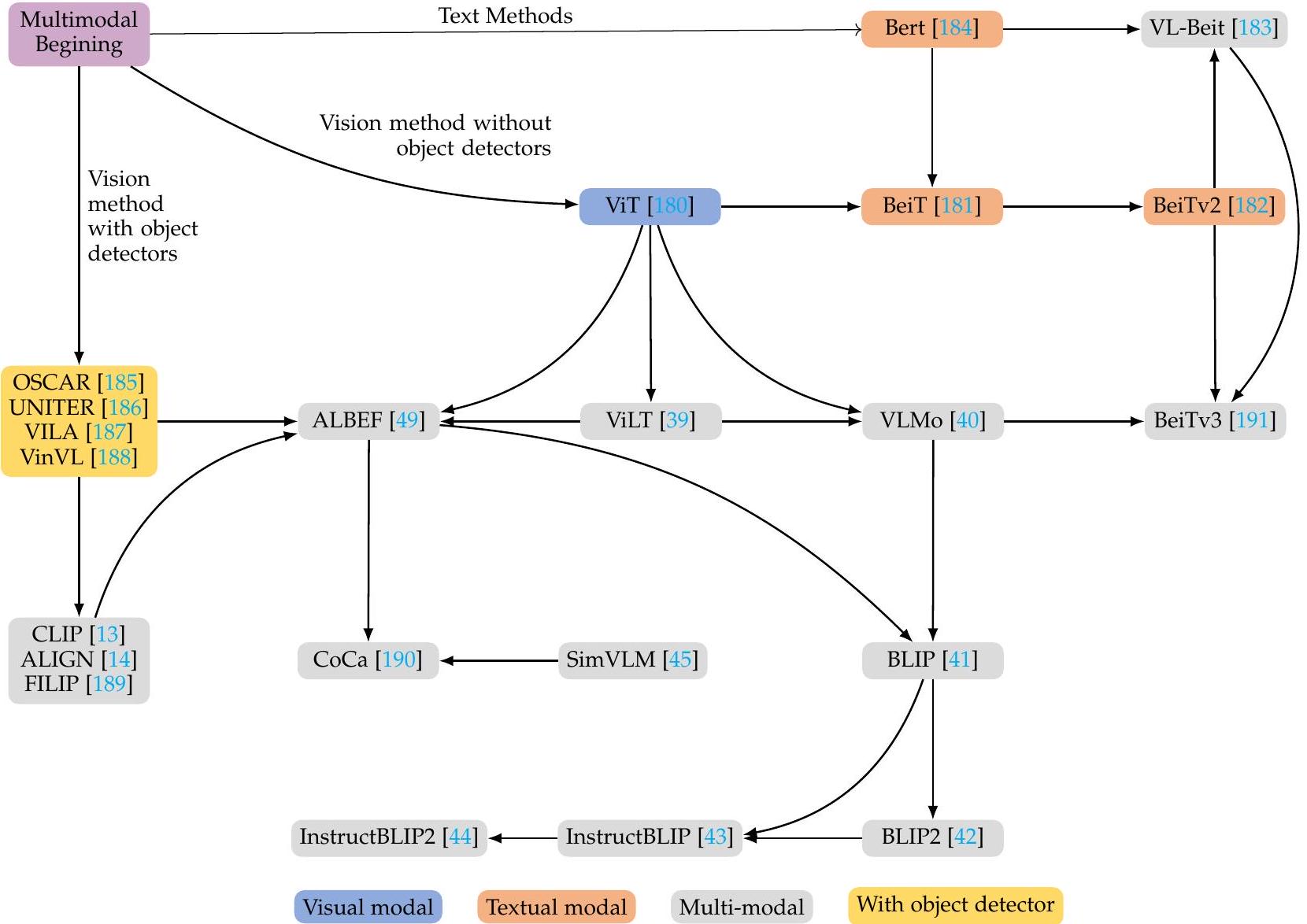
그림 6: 멀티모달 융합의 핵심 문헌 진화 및 계승 관계. 이 다이어그램은 시각, 텍스트, 멀티모달 및 객체 감지 강화 모델로 원래 분류된 다양한 모델 간의 관계 및 개발 경로를 보여줍니다. 화살표는 한 모델에서 다른 모델로의 영향 또는 진행을 나타냅니다. 각 모델의 초점은 범주를 설명하는 하단의 범례와 함께 해당 양식을 나타내도록 색상으로 구분됩니다.
어텐션 메커니즘의 개념은 Vaswani 등이 획기적인 연구인 "Attention Is All You Need"에서 Transformer 아키텍처를 도입한 후 두드러지게 되었습니다 [57]. 그 이후로 어텐션 메커니즘은 장거리 의존성을 모델링하고 다양한 작업에서 성능을 향상시키는 능력으로 인해 딥 러닝 커뮤니티에서 주요 주제가 되었습니다.
멀티모달 융합의 맥락에서 어텐션 메커니즘은 모델이 서로 다른 양식에 걸쳐 특징의 중요성을 동적으로 가중치를 부여할 수 있도록 합니다. 어텐션 메커니즘은 쿼리(Q), 키(K), 값(V)으로 구성된 입력에 대해 작동합니다. 쿼리와 각 키의 내적을 계산하고 결과를 (여기서 는 키의 차원)로 스케일링한 다음 소프트맥스 함수를 적용하여 값에 대한 가중치를 얻습니다 [57]. 이 연산은 다음과 같이 공식화됩니다.
어텐션 기반 융합은 멀티모달 데이터에 내재된 노이즈와 불확실성을 처리할 수 있기 때문에 멀티모달 응용 분야에서 특히 효과적입니다 [193], [194]. 그러나 이 방법론은 또한 계산 복잡성을 증가시키고 일반적으로 더 큰 데이터 세트를 필요로 합니다.
이러한 모델의 표현력이 커짐에 따라 관련 계산 비용도 증가합니다.
그림 6은 어텐션 메커니즘 및 Transformer와 관련된 주요 연구 간의 관계를 보여줍니다. OSCAR [185], UNITER [186], VILA [187], VinVL [188]과 같은 이전 방법들은 객체 감지기를 사용하여 양식 특징을 추출한 다음 간단한 융합 과정을 거쳤습니다. CLIP [13]과 같은 이후 모델들은 효율적인 이미지-텍스트 매칭 기능으로 상당한 발전을 이루었으며, 이전 객체 감지기를 능가했습니다. 그러나 양식 특징의 심층 융합은 종종 간과되었습니다. 예를 들어, CLIP의 양식 간 상호 작용은 간단한 내적 연산에 국한되어 심층 융합을 달성하는 데 방해가 되었습니다 [39].
이러한 한계를 해결하기 위해, 더 깊은 모달 간 상호작용에 초점을 맞춘 방법들이 개발되었으며, 종종 Transformer 인코더나 다른 복잡한 아키텍처를 사용하여 더 높은 수준의 양식 통합을 달성했습니다 [1]. Vision Transformer (ViT)의 도입은 멀티모달 학습에 있어 중요한 전환점이 되었습니다. ViLT [39]는 컨볼루션 네트워크나 영역 감독 없이도 멀티모달 작업을 수행할 수 있다는 것을 보여주었으며, 특징 추출 및 처리에 Transformer를 독점적으로 사용했습니다.
그러나 ViLT의 단순한 구조는 특히 더 깊은 모달 간 상호 작용과 융합을 강조한 방법들과 비교했을 때 성능 문제를 야기했습니다.
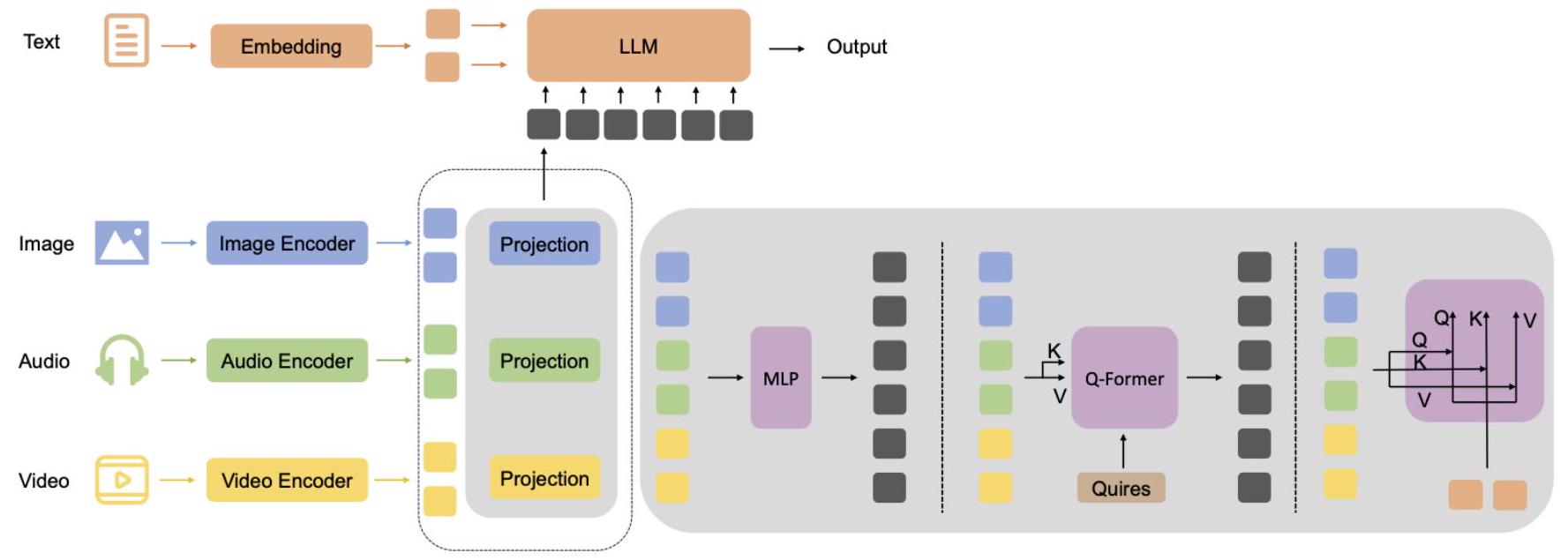
그림 7: 어텐션 기반 커넥터. 이 파이프라인은 대규모 언어 모델(LLM)을 사용한 멀티모달 융합을 보여줍니다. 텍스트 입력은 임베딩되어 LLM에 의해 처리되는 반면, 이미지, 오디오, 비디오 입력은 인코딩되어 공유 임베딩 공간으로 투영되고 MLP 및 Q-Former와 같은 모듈을 통과합니다. Q-Former는 어텐션 메커니즘(쿼리, 키, 값)을 사용하여 LLM을 통해 최종 출력을 생성하기 전에 멀티모달 특징을 정렬합니다. 심층적인 모달 간 상호작용과 융합을 강조한 방법들과 비교했을 때 [1], [49]. ViLT는 데이터셋 편향이나 더 강력한 시각적 기능에 대한 내재된 필요성 때문에 많은 작업에서 이러한 방법들보다 뒤쳐졌습니다 [49]. 일반적으로 시각적 모델은 더 나은 결과를 얻기 위해 텍스트 모델보다 커야 하며, 성능 저하는 주로 경량 시각적 임베딩 전략으로 인해 발생하지 않았습니다.
ALBEF [49]와 같은 후속 연구에서는 더 정교한 모델 설계를 도입했습니다. ALBEF는 대조 손실을 사용하여 융합하기 전에 이미지와 텍스트 표현을 정렬하는 것을 강조했습니다. 모멘텀 증류를 사용하여 노이즈가 많은 데이터 세트로 인한 문제를 완화하기 위해 의사 레이블을 생성했습니다. 이어서 BLIP [41]은 부트스트래핑 메커니즘을 채택하여 모델에서 처음 생성된 캡션을 사용하여 데이터 세트 노이즈를 필터링함으로써 후속 훈련의 품질을 향상시켰습니다.
CoCa [190]는 대조적 손실과 캡셔닝 손실을 결합하여 놀라운 성능을 달성했습니다. 특히 CoCa는 멀티모달 작업뿐만 아니라 ImageNet 분류와 같은 단일 모달 작업에서도 90% 이상의 top-1 정확도를 달성했습니다. BEIT-3 [191]는 이미지, 텍스트, 이미지-텍스트 쌍을 동시에 처리할 수 있는 Multiway Transformer를 구현하여 멀티모달 학습을 더욱 발전시켰습니다. 이러한 입력에 마스크 데이터 모델링을 적용함으로써 BEIT-3는 다양한 시각 및 시각-언어 작업에서 최첨단 성능을 달성했습니다.
그림 7은 어텐션 기반 융합의 일반적인 시나리오를 보여줍니다. 인코더가 각 양식에서 특징을 추출한 후, 커넥터는 이러한 특징을 텍스트 공간으로 매핑하고, 여기서 LLM에 의해 함께 처리됩니다. 이전에는 이 커넥터가 종종 간단한 MLP였지만, 이제는 더 복잡한 어텐션 메커니즘이 될 수 있습니다. 최근 연구자들은 교차 모달 기능을 향상시키기 위한 다양한 아키텍처와 기술을 제안했습니다. 그들은 고정된 LLM에 어댑터를 내장하여 양식 간의 상호 작용을 용이하게 합니다. 그림 8은 이 접근 방식의 기본 구조를 보여줍니다. 이전 방법과의 주요 차이점은 어댑터가 LLM에 직접 내장되어 정렬을 포함한 종단 간 훈련이 가능하다는 것입니다.

그림 8: 어텐션 기반 어댑터. 각 양식(텍스트, 이미지, 오디오 및 비디오)은 해당 인코더 및 양식별 어댑터에 의해 처리됩니다. 이러한 어댑터는 인코딩된 특징을 LLM에 공급하여 최종 출력을 생성합니다. 종단 간 훈련이 가능합니다. 예를 들어, Qwen-VL 시리즈 모델 [47]은 시각 수용체, 입출력 인터페이스, 다단계 훈련 파이프라인 설계를 통해 교차 모달 학습을 발전시켜 이미지 및 텍스트 이해, 위치 파악, 텍스트 읽기에서 주목할 만한 성능을 달성했습니다. 비디오 이해에서 ViLA 네트워크 [195]는 학습 가능한 텍스트 유도 프레임 프롬프터와 교차 모달 증류 모듈(QFormer-Distiller)을 도입하여 주요 프레임 선택에 최적화되어 비디오-언어 정렬의 정확도와 효율성을 모두 향상시켰습니다. 또한 CogVLM [196]은 Transformer를 사용하여 사전 훈련된 언어 모델에 시각적 전문성을 통합했습니다. 감정 인식 작업에서 COLD Fusion은 멀티모달 감정 인식을 위해 불확실성 인식 구성 요소를 추가했습니다 [197].
멀티모달 융합을 용이하게 하기 위해 다양한 사전 훈련 전략이 개발되었습니다. 예를 들어, BLIP-2 [42]는 고정된 이미지 인코더와 대규모 언어 모델을 비전-언어 사전 훈련에 사용하여 매개변수 수를 줄이면서 제로샷 학습 성능을 향상시키는 부트스트래핑 접근 방식을 도입했습니다. 마찬가지로, VAST 모델 [198]은 비전, 오디오, 자막, 텍스트를 포함하는 포괄적인 멀티모달 설정을 탐색하여 대규모 데이터 세트를 구축하고 이러한 모든 양식을 인식하고 처리할 수 있는 기본 모델을 훈련했습니다. 또한, ONE-PEACE 모델 [199]은 모듈식 어댑터 설계와 공유 자기 주의 계층을 사용하여 더 많은 양식으로 확장할 수 있는 유연하고 확장 가능한 아키텍처를 제공했습니다. Zhang 등의 연구 [200]는 종단 간 해부학적 및 기능적 이미지 융합을 위해 Transformer를 사용하여 자기 주의를 활용하여 전역적 맥락 정보를 통합했습니다.
이러한 발전에도 불구하고, 이 분야는 여전히 여러 가지 과제에 직면해 있습니다. 주요 과제 중 하나는 훈련 데이터 세트의 내재된 편향이 모델 성능을 제한하는 데이터 편향입니다. 또 다른 우려는 정보 손실이나 불일치 없이 일관된 정보 통합을 보장하기 위해 양식 간의 일관성을 유지하는 것입니다. 또한, 모델 규모가 커짐에 따라 계산 자원에 대한 수요가 증가하여 더 효율적인 알고리즘과 하드웨어 지원이 필요합니다. 표 3은 일부 최첨단(SOTA) 또는 인기 있는 어텐션 기반 모델을 요약합니다.
결론적으로, 멀티모달 융합은 어텐션 기반 메커니즘과 모델 아키텍처의 발전에 힘입어 역동적이고 진화하는 연구 분야로 남아 있습니다. 여러 양식의 정보를 효과적으로 통합하는 모델 개발에 상당한 진전이 있었지만, 데이터 편향, 양식 일관성, 계산 요구량과 같은 지속적인 과제가 남아 있습니다. 보다 지능적이고 적응 가능한 멀티모달 시스템을 달성하고, 인공 지능 기술을 발전시키며, 실제 응용 분야에 강력한 도구를 제공하기 위해서는 새로운 이론적 프레임워크와 기술적 해결책에 대한 지속적인 탐구가 필요합니다.
6 Challenges in Multimodal Alignment and Fusion
6.1 Modal Feature Alignment Challenge
멀티모달 학습에서 시각적 및 언어적 특징을 정렬하는 것은 중요한 과제이며, 특히 초기 모델은 멀티모달 작업에 특별히 맞춤화되지 않은 시각적 특징을 추출하기 위해 사전 훈련된 객체 감지 모델에 의존하는 경우가 많았기 때문입니다. 이러한 불일치는 텍스트 특징과의 정렬 불량으로 이어져 [5], 멀티모달 인코더가 강력한 이미지-텍스트 상호 작용을 효과적으로 포착하는 능력을 저해했습니다. 예를 들어, Ma 등 [5]은 양식 불일치를 서로 다른 양식 간의 지식 전달에 대한 중요한 장벽으로 식별했으며, 사전 훈련된 모델은 양식 간에 상당한 의미적 격차가 있을 때 지식 전달에 자주 어려움을 겪는다고 강조했습니다.
최근의 접근 방식은 노이즈 주입 임베딩과 같은 혁신적인 방법을 통해 이 문제를 해결하는 것을 목표로 합니다. 예를 들어, CapDec는 CLIP 임베딩에 노이즈 주입을 사용하여 양식 격차를 완화하여 제한된 쌍 데이터로도 공유 의미 공간에서 더 나은 정렬을 가능하게 하며, 제로샷 학습 맥락에서 가능성을 보여줍니다 [209]. 또한, 유한 이산 토큰(FDT)과 같은 방법은 이미지와 텍스트를 모두 공유 공간에 임베딩하여 시각적 패치와 텍스트 토큰 간의 차이에서 흔히 발생하는 세분성 격차를 줄임으로써 정렬을 더욱 구체화합니다 [210].
이러한 발전에도 불구하고, 특히 시각적 특징과 텍스트 특징이 자연스럽게 정렬되지 않는 복잡한 실제 시나리오에서는 양식 불일치 문제가 남아 있습니다. VT-CLIP과 같은 모델은 시각적 및 언어적 특징을 더 잘 연관시키기 위해 이미지에서 정보적인 영역을 적응적으로 탐색하는 시각 유도 텍스트를 도입하여 정렬을 향상시키려고 시도합니다. 그러나 이러한 솔루션은 여전히 공유 임베딩 공간과 같은 단순화 가설에 의존하며, 이는 서로 다른 양식 간의 다양한 의미론적 상호 작용을 완전히 포착하지 못합니다. 이는 향후 연구에서 더 정교한 정렬 기술이 필요함을 강조합니다 [211].
6.2 Computational Efficiency Challenge
초기 멀티모달 모델은 특히 추론 중에 객체 감지기에 의존하기 때문에 상당한 계산 요구량에 직면했습니다. Vision Transformer (ViTs)의 개발은 경계 상자 대신 패치 기반 시각적 특징을 사용하여 계산 복잡성을 크게 줄였습니다. 그러나 텍스트 및 시각적 특징을 단순히 토큰화하는 것만으로는 멀티모달 작업을 효과적으로 처리하기에 충분하지 않습니다. 어텐션 병목 현상 및 교환 기반 융합과 같은 효율적인 양식 융합 방법은 효과적인 양식 상호 작용을 유지하면서 계산 비용을 줄이는 데 필수적입니다 [212], [213].
TokenFusion과 같은 고급 접근 방식은 Transformer 기반 비전 작업을 위해 특별히 설계되었으며, Transformer의 효율성을 최적화하기 위해 정보가 없는 토큰을 융합된 모달 간 특징으로 동적으로 대체합니다 [212]. 마찬가지로 융합 중 어텐션 병목 현상은 모델이 정확도를 희생하지 않고 양식 전반에 걸쳐 중요한 정보를 선택적으로 처리할 수 있도록 하여 계산 부하를 최소화합니다 [213]. 또한 PMF(Prompt-based Multimodal Fusion)와 같은 방법은 Transformer 내에서 심층 레이어 프롬프트를 사용하여 융합 프로세스를 간소화하여 강력한 멀티모달 상호 작용을 유지하면서 메모리 사용량을 효과적으로 줄입니다 [214].
이러한 발전에도 불구하고 모델이 규모와 복잡성이 계속 증가함에 따라 융합 메커니즘을 개선하고 계산 요구 사항을 줄이기 위한 더 많은 연구가 필요합니다.
6.3 Data Quality Challenge
인터넷에서 얻은 대규모 멀티모달 데이터 세트, 예를 들어 이미지-캡션 쌍은 이미지와 해당 텍스트 사이에 불일치하거나 관련 없는 내용이 포함되어 있는 경우가 많습니다. 이 문제는 주로 이러한 이미지-텍스트 쌍이 정밀한 멀티모달 정렬보다는 검색 엔진에 최적화되어 있기 때문에 발생합니다. 결과적으로 이러한 노이즈가 많은 데이터로 훈련된 모델은 효과적으로 일반화하는 데 어려움을 겪을 수 있습니다. 이 문제를 해결하기 위해 데이터 품질을 개선하기 위한 여러 접근 방식이 제안되었습니다.
Nguyen 등 [215]은 이미지 캡셔닝 모델을 통해 생성된 합성 캡션을 사용하여 웹에서 수집한 데이터 세트의 노이즈 문제를 해결했습니다. 합성 설명을 원본 캡션과 통합함으로써 여러 벤치마크 작업에서 데이터 유용성을 향상시켜 캡션 품질 향상이 모델 성능에 크게 기여할 수 있음을 입증했습니다. 마찬가지로 CapsFusion [216]은 대규모 언어 모델을 활용하여 멀티모달 데이터 세트의 합성 및 자연 캡션을 개선하는 프레임워크를 도입했습니다.
표 3: 어텐션 기반 모델 요약.
| 모델 | 연도 | 비전 인코더 | 어댑터 | 사용된 LLM | 훈련 모듈 |
|---|---|---|---|---|---|
| ViLT [39] | 2021 | ViT | - | - | 마스크 언어 모델링; 이미지-텍스트 매칭; 단어-패치 정렬 |
| ALBEF [49] | 2021 | ViT-B/16 | - | BERT-base | 이미지-텍스트 대조 손실; 이미지-텍스트 매칭 손실; 마스크-언어-모델링 손실 |
| Unified-IO [201] | 2022 | VQVAE 인코더 (CNN) | - | - | 객체 분할; 시각적 질문 응답; 깊이 추정; 객체 위치 파악 |
| BEIT-3 [191] | 2022 | 패치 임베딩 | Multiway Transformer | - | 이미지, 텍스트, 이미지-텍스트 쌍에 대한 마스크 "언어" 모델링 |
| BLIP [41] | 2022 | ViT | - | BERT | 이미지-텍스트 대조 손실; 이미지-텍스트 매칭 손실; 언어 모델링 손실 |
| VLMo [40] | 2022 | 패치 임베딩 | Multiway Transformer | - | 이미지-텍스트 대조 학습; 마스크 언어 모델링; 이미지-텍스트 매칭 |
| CoCa [190] | 2022 | ViT | - | - | 캡셔닝 손실; 대조 손실 |
| MiniGPT-4 [12] | 2023 | ViT-L (EVA-CLIP) | 단일 레이어 투영 레이어 | Vicuna | 2단계 훈련: 1단계: 시각적 특징 추출기 고정, Vicuna와 시각적 특징을 정렬하기 위해 투영 레이어 훈련; 2단계: 대화 데이터에 대한 명령어 미세 조정 |
| Qwen-VL [47] | 2023 | ViT-bigG (Openclip) | 단일 레이어 Cross-Attention | Qwen-7B | 1단계: 이미지 캡션 생성; 2단계: 다중 작업 사전 훈련; 3단계: 지도 미세 조정 |
| MiniGPT-v2 [202] | 2023 | ViT-L (EVA-CLIP) | - | Vicuna (7B/13B) | 다중 작업 학습 |
| VAST [198] | 2023 | ViT | BERT | OM-VCC; OM-VCM; OM-VCG | |
| BLIP-2 [42] | 2023 | ViT-L/14 (CLIP), ViT-g/14 (EVACLIP) | Q-Former (학습 가능한 쿼리 임베딩) | OPT, FlanT5 | 1단계: 비전-언어 표현 학습; 2단계: 비전-언어 생성 학습 |
| InstructBLIP [43] | 2023 | ViT-L/14 (CLIP) | Q-Former | Vicuna (7B/13B) | 시각적 명령어 튜닝 |
| LLaVA [7] | 2023 | 고정된 이미지 인코더 | - | GPT-3, GPT-3.5, LLaMA | 시각적 명령어 튜닝 |
| ONE-PEACE [199] | 2023 | hMLP 스템 | V-Adapter, A-Adapter, L-Adapter | - | 마스크 대조 학습 |
| InternLMXComposer [203] | 2023 | EVA-CLIP | LoRA | InternLM-Chat-7B | 사전 훈련, 다중 작업 훈련, 명령어 미세 조정 |
| Yi-VL [204] | 2023 | CLIP ViT-H/14 | 2계층 MLP | Yi-Chat | 3단계 훈련: 1. ViT 및 투영 모듈 훈련 2. 이미지 해상도 증가 및 ViT 및 투영 모듈 훈련 3. 전체 모델 훈련 |
| Qwen2-VL [46] | 2024 | ViT (Qwen-VL의 개선된 비전 인코더) | Cross-Attention | Qwen-2 | 시각적 명령어 튜닝 |
| ViLA [195] | 2024 | 고정된 시각적 인코더 | Teacher/StudentQFormer, FramePrompter | LLM의 고정 및 미세 조정(LoRA) 사용 지원 | 증류 손실; 시각적 질문 응답 손실 |
| CAFuser [205] | 2024 | Swin Tiny | MLP | - | 이미지-텍스트 대조 손실 |
| InternLM-XComposer-2.5 [206] | 2024 | OpenAI ViT-L/14 | 부분 LoRA | InternLM2-7B | 사전 훈련, 다중 작업 훈련, 명령어 미세 조정 |
| MaPPER [207] | 2024 | DINOv2-B/14 | DyPA, LoCA | BERT-base | 미세 조정 |
| ADEM-VL [208] | 2024 | CLIP | Cross-Attention | LLaMA | 미세 조정 |
따라서 캡션 품질과 대규모 모델의 샘플 효율성을 향상시킵니다. 또한 LAION-5B 데이터 세트 [90]는 CLIP으로 필터링된 이미지-텍스트 쌍의 대규모 컬렉션을 제공하여 높은 데이터 볼륨과 효과적인 필터링을 결합하면 비전 언어 모델의 견고성과 제로샷 기능을 향상시킬 수 있음을 보여줍니다.
이러한 개선에도 불구하고 확장 가능한 데이터 필터링 및 다양성 유지에는 여전히 과제가 남아 있습니다. 예를 들어 DataComp [91]는 효과적인 필터링을 사용하더라도 대규모 멀티모달 데이터 세트에서 고품질의 다양한 표현을 달성하는 것이 복잡하다는 것을 보여주었습니다. 이러한 데이터 세트에서 훈련된 모델이 여러 도메인에서 효과적으로 일반화되도록 하려면 데이터 정리 및 품질 평가에서 지속적인 혁신이 필요합니다.
요약하자면, 합성 캡셔닝 및 대규모 필터링 방법이 멀티모달 데이터 세트의 품질을 향상시켰지만, 웹에서 수집한 멀티모달 데이터 세트와 관련된 문제를 완전히 해결하기 위해서는 확장 가능한 필터링 기술 및 다양성 유지에 대한 추가적인 발전이 필요합니다.
6.4 Scale of Training Datasets Challenge
멀티모달 학습의 또 다른 중요한 과제는 특히 비전 및 언어 작업을 결합하기 위한 모델 훈련을 위해 충분히 크고 고품질의 데이터 세트를 확보하는 것입니다. 다양한 작업에서 모델을 효과적으로 훈련하는 데 사용할 수 있는 광범위하고 신뢰할 수 있는 데이터 세트에 대한 시급한 요구가 있습니다. 예를 들어, 수십억 개의 CLIP 필터링된 이미지-텍스트 쌍으로 구성된 LAION-5B 데이터 세트의 도입은 대규모 비전-언어 모델의 훈련 및 미세 조정을 지원하는 확장 가능하고 오픈 소스인 데이터 세트를 제공하여 고품질 데이터에 대한 접근성을 민주화하는 데 도움이 되었습니다 [90]. 마찬가지로 WIT 데이터 세트는 위키피디아에서 공급된 선별된 개체 풍부 데이터 세트를 제공하여 멀티모달, 다국어 학습을 가능하게 하며, 높은 수준의 개념 및 언어 다양성을 특징으로 하여 다운스트림 검색 작업에 유익한 것으로 입증되었습니다 [87].
이러한 데이터 세트는 상당한 진전을 나타내지만 확장성과 데이터 품질은 여전히 어려운 과제로 남아 있습니다. 예를 들어, [217]은 중복성과 불일치를 줄이면서 필수 정보를 유지하기 위해 시각-언어 사전 훈련(VLP) 데이터 세트를 압축하여 더 작지만 고품질의 훈련 세트를 만드는 것을 제안합니다. 또한, 전문가의 희소 혼합(MoE)과 같은 확장 기술 [218]은 통합된 프레임워크 내에서 특화된 하위 모델을 훈련하여 계산 비용과 성능의 균형을 맞추어 대규모 모델의 효율성을 향상시키는 것을 목표로 합니다. 이러한 혁신은 데이터 규모 및 품질 문제를 해결하기 위한 단계이지만, 멀티모달 학습을 위한 다양하고 대규모 데이터 세트에 대한 효율적인 접근은 연구 커뮤니티에 여전히 어려운 과제로 남아 있습니다.
7 Conclusion
멀티모달 정렬 및 융합은 서로 다른 데이터 양식의 고유한 강점을 결합하여 기계 학습 응용 프로그램을 발전시킬 수 있는 상당한 잠재력을 제공합니다. 200개 이상의 학술적 기여에 대한 광범위한 조사에도 불구하고, 원활한 통합 프레임워크의 실현은 다양한 양식을 정렬하는 복잡성, 데이터 품질의 가변성, 필요한 상당한 계산 자원 등 여러 중요한 요인에 의해 계속해서 방해받고 있습니다. 어텐션 기반 메커니즘 및 인코더-디코더 아키텍처와 같은 현재 접근 방식은 이러한 과제를 해결하기 위한 기반을 마련했지만, 노이즈가 많은 데이터 및 양식 불일치 관리의 한계는 여전히 남아 있습니다. 향후 연구는 대규모의 이종 데이터 세트를 효율적으로 처리하고, 모델 해석 가능성을 향상시키며, 계산 비용을 줄일 수 있는 보다 적응적인 프레임워크를 개발하는 데 중점을 두어야 합니다. 이러한 과제를 극복함으로써 멀티모달 학습은 더욱 적응 가능하고 효과적이 되어 점점 더 복잡해지는 실제 시나리오에서 인공 지능을 발전시킬 수 있습니다.
References
[1] T. Baltrusaitis, C. Ahuja, and L.-P. Morency, "Multimodal machine learning: A survey and taxonomy," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 2, 2018. 1, 3, 4, 5, 7, 11, 12 [2] K. Boehm, P. Khosravi, R. Vanguri, J. Gao, and S. Shah, "Harnessing multimodal data integration to advance precision oncology," Nature Reviews Cancer, vol. 22, pp. 114-126, 2021. 1 [3] Y. Li, H. Ding, and H. Chen, "Data processing techniques for modern multimodal models," arXiv preprint arXiv:2407.19180, 2024. 1 [4] W. Zhang, J. Yu, Y. Wang, and W. Wang, "Multimodal deep fusion for image question answering," Knowledge-Based Systems, vol. 212, p. 106639, 2021. 1, 7 [5] W. Ma, S. Li, L. Cai, and J. Kang, "Learning modality knowledge alignment for cross-modality transfer," in Proceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 21-27 Jul 2024, pp. 33 777-33 793. 1, 13 [6] P. P. Liang, A. Zadeh, and L.-P. Morency, "Foundations & trends in multimodal machine learning: Principles, challenges, and open questions," ACM Comput. Surv., vol. 56, no. 10, jun 2024. 1 [7] H. Liu, C. Li, Q. Wu, and Y. J. Lee, "Visual instruction tuning," Advances in neural information processing systems, vol. 36, 2024. 1, 14 [8] V. Gabeur, C. Sun, K. Alahari, and C. Schmid, "Multi-modal transformer for video retrieval," in ECCV, 2020, pp. 214-229. 1 [9] M. Mahmud, M. Kaiser, A. Hussain, and S. Vassanelli, "Applications of deep learning and reinforcement learning to biological data," IEEE Transactions on Neural Networks and Learning Systems, vol. 29, pp. 2063-2079, 2017. 1 [10] K. Chen and Y. Sun, "Llava-med: Medical image understanding with large language models," IEEE Transactions on Neural Networks and Learning Systems, 2023. 1 [11] H. Yang and S. Li, "Videochat: Conversational agents in video understanding," IEEE Transactions on Neural Networks and Learning Systems, 2023. 1 [12] D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, "Minigpt-4: Enhancing vision-language understanding with advanced large language models," arXiv preprint arXiv:2304.10592, 2023. 1, 2, 14 [13] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, "Learning transferable visual models from natural language supervision," in Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021, pp. 8748-8763. 2, 3, 4, 7, 11 [14] C. Jia, Y. Yang, Y. Xia, Y.-T. Chen, Z. Parekh, H. Pham, Q. V. Le, Y. Sung, Z. Li, and T. Duerig, "Scaling up visual and visionlanguage representation learning with noisy text supervision," 2021. 2, 11 [15] Y. Cui, S. Liang, and Y. Zhang, "Multimodal representation learning for tourism recommendation with two-tower architecture," PLoS One, 2024. 2 [16] Y. Vasilakis, R. Bittner, and J. Pauwels, "I can listen but cannot read: An evaluation of two-tower multimodal systems for instrument recognition," 2024. 2 [17] X. Xu, C. Wu, S. Rosenman, V. Lal, and W. Che, "Bridgetower: Building bridges between encoders in vision-language representation learning," in Proceedings of the AAAI Conference on Artificial Intelligence, 2023. 2 [18] L. Su, F. Yan, J. Zhu, X. Xiao, and H. Duan, "Beyond two-tower matching: Learning sparse retrievable cross-interactions for recommendation," in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023. 2 [19] C. Liu, H. Liu, H. Chen, and W. Du, "Touchformer: A transformer-based two-tower architecture for tactile temporal signal classification," IEEE Transactions on Multimedia, 2023. 2 [20] D. Chen, J. Chen, L. Yang, and F. Shang, "Mix-tower: Light visual question answering framework based on exclusive self-attention mechanism," Neurocomputing, 2024. 2 [21] N. Fei, Z. Lu, Y. Gao, G. Yang, Y. Huo, J. Wen, and H. Lu, "Towards artificial general intelligence via a multimodal foundation model," Nature Communications, 2022. 2 [22] H. Wen, H. Zhuang, H. Zamani, A. Hauptmann, and M. Bendersky, "Multimodal reranking for knowledge-intensive visual question answering," 2024. 2 [23] J. Tu, X. Liu, R. Lin, Z.and Hong, and M. Wang, "Differentiable cross-modal hashing via multimodal transformers," in Proceedings of the 30th ACM International Conference on Multimedia, 2022. 2 [24] S. Yuan, P. Bhatia, B. Celikkaya, H. Liu, and K. Choi, "Towards user friendly medication mapping using entity-boosted twotower neural network," in International Workshop on Deep Learning for Human Activity Recognition, 2021. 2 [25] D. L. Allaire and K. E. Willcox, "Fusing information from multifidelity computer models of physical systems," 2012 15th International Conference on Information Fusion, pp. 2458-2465, 2012. 2, 8 [26] V. Badrinarayanan, A. Kendall, and R. Cipolla, "Segnet: A deep convolutional encoder-decoder architecture for image segmentation," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, pp. 2481-2495, 2015. 2, 8, 9 [27] G. Danapal, G. A. Santos, J. P. C. L. da Costa, B. J. G. Praciano, and G. P. M. Pinheiro, "Sensor fusion of camera and lidar raw data for vehicle detection," in 2020 Workshop on Communication Networks and Power Systems (WCNPS), 2020, pp. 1-6. 2, 8, 9 [28] C. Guo and L. Zhang, "A model-level fusion-based multi-modal object detection and recognition method," in 2023 7th Asian Conference on Artificial Intelligence Technology (ACAIT), 2023, pp. 34-38. 2, 8, 9 [29] S. Jaiswal, B. Martínez, and M. F. Valstar, "Learning to combine local models for facial action unit detection," 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), vol. 06, pp. 1-6, 2015. 2, 8 [30] X. Li, D. Song, and Y. Dong, "Hierarchical feature fusion network for salient object detection," IEEE Transactions on Image Processing, vol. 29, pp. 9165-9175, 2020. 2, 8, 9 [31] H. Li and X. Wu, "Densefuse: A fusion approach to infrared and visible images," IEEE Transactions on Image Processing, vol. 28, pp. 2614-2623, 2018. 2, 8, 9 [32] S. Mai, H. Hu, and S. Xing, "Divide, conquer and combine: Hierarchical feature fusion network with local and global perspectives for multimodal affective computing," in Annual Meeting of the Association for Computational Linguistics, 2019. 2, 8, 9 [33] A. Makris, D. I. Kosmopoulos, S. J. Perantonis, and S. Theodoridis, "A hierarchical feature fusion framework for adaptive visual tracking," Image Vis. Comput., vol. 29, pp. 594-606, 2011. 2, 8, 9 [34] O. Missaoui, H. Frigui, and P. D. Gader, "Model level fusion of edge histogram descriptors and gabor wavelets for landmine detection with ground penetrating radar," 2010 IEEE International Geoscience and Remote Sensing Symposium, pp. 3378-3381, 2010. 2, 8, 9 [35] A. Rövid and V. Remeli, "Towards raw sensor fusion in 3d object detection," 2019 IEEE 17th World Symposium on Applied Machine Intelligence and Informatics (SAMI), pp. 293-298, 2019. 2, 8, 9 [36] J. Steinbaeck, C. Steger, G. Holweg, and N. Druml, "Design of a low-level radar and time-of-flight sensor fusion framework," 2018 21st Euromicro Conference on Digital System Design (DSD), pp. 268-275, 2018. 2, 8, 9 [37] T. Uezato, D. Hong, N. Yokoya, and W. He, "Guided deep decoder: Unsupervised image pair fusion," in European Conference on Computer Vision, 2020. 2, 8, 9 [38] Y. Wei, D. Wu, and J. P. Terpenny, "Decision-level data fusion in quality control and predictive maintenance," IEEE Transactions on Automation Science and Engineering, vol. 18, pp. 184-194, 2021. 2, 8 [39] W. Kim, B. Son, and I. Kim, "ViLT: Vision-and-language transformer without convolution or region supervision." 2, 11, 14 [40] H. Bao, W. Wang, L. Dong, Q. Liu, O. K. Mohammed, K. Aggarwal, S. Som, and F. Wei, "Vlmo: Unified vision-language pretraining with mixture-of-modality-experts," 2022. 2, 11, 14 [41] J. Li, D. Li, C. Xiong, and S. Hoi, "BLIP: Bootstrapping languageimage pre-training for unified vision-language understanding and generation," in Proceedings of the 39th International Conference on Machine Learning. PMLR, 2022, pp. [42] J. Li, D. Li, S. Savarese, and S. Hoi, "Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models," 2023. 2, 11, 12, 14 [43] W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi, "Instructblip: Towards general-purpose vision-language models with instruction tuning," 2023. 2, 11, 14 [44] H. Chen and T. Xu, "Instructblip 2: Extending vision-language models with fine-grained instruction tuning," IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023. 2, 11 [45] Z. Wang, J. Yu, A. W. Yu, Z. Dai, Y. Tsvetkov, and Y. Cao, "Simvlm: Simple visual language model pretraining with weak supervision," 2022. 2, 11 [46] P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y. Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin, "Qwen2-vl: Enhancing vision- language model's perception of the world at any resolution," 2024. 2, 14 [47] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, "Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond," 2023. 2, 12, 14 [48] J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Monteiro, J. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Binkowski, R. Barreira, O. Vinyals, A. Zisserman, and K. Simonyan, "Flamingo: A visual language model for few-shot learning," in Proceedings of the Conference on Neural Information Processing Systems (NeurIPS 2022), 2022. 2 [49] J. Li, R. Selvaraju, A. Gotmare, S. Joty, C. Xiong, and S. C. H. Hoi, "Align before fuse: Vision and language representation learning with momentum distillation," in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 9694-9705. 1, 3, 11, 12, 14 [50] A. Akhmerov, A. Vasilev, and A. Vasileva, "Research of spatial alignment techniques for multimodal image fusion," in Proceedings of the SPIE, vol. 11059, 2019, pp. 1105916 - 1 105916-9. 1, 3, 4 [51] J. Wu, H. Liu, Y. Su, W. Shi, and H. Tang, "Learning concordant attention via target-aware alignment for visible-infrared person re-identification," in ICCV, 2023. 1 [52] Y. Li, F.-X. Wu, and A. Ngom, "A review on machine learning principles for multi-view biological data integration," Briefings in Bioinformatics, vol. 19, p. 325-340, 2020. 1 [53] A. Barua, M. U. Ahmed, and S. Begum, "A systematic literature review on multimodal machine learning: Applications, challenges, gaps and future directions," IEEE Access, vol. 11, pp. 14804-14831, 2023. 1, 3, 4, 7 [54] H. Tian, Y. Tao, S. Pouyanfar, S.-C. Chen, and M.-L. Shyu, "Multimodal deep representation learning for video classification," World Wide Web, vol. 22, pp. 1325-1341, 2019. 1, 3 [55] S. Shankar, L. Thompson, and M. Fiterau, "Progressive fusion for multimodal integration," 2022. 1, 3 [56] C. G. M. Snoek, M. Worring, and A. W. M. Smeulders, "Early versus late fusion in semantic video analysis," Proceedings of the 13th annual ACM international conference on Multimedia, 2005. 1, 7 [57] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, "Attention is all you need." 2, 10, 11 [58] S. Islam, H. Elmekki, A. Elsebai, J. Bentahar, N. Drawel, G. Rjoub, and W. Pedrycz, "A comprehensive survey on applications of transformers for deep learning tasks." 2,10 [59] X. Zhang, Z. Xu, H. Tang, C. Gu, W. Chen, S. Zhu, and X. Guan, "Enlighten-your-voice: When multimodal meets zero-shot lowlight image enhancement," arXiv:2312.10109, 2023. 2 [60] T. Lin, Y. Wang, X. Liu, and X. Qiu, "A survey of transformers," AI Open, vol. 3, pp. 111-132, 2022. 2 [61] X. Zhang, C. Shen, X. Yuan, S. Yan, L. Xie, W. Wang, C. Gu, H. Tang, and J. Ye, "From redundancy to relevance: Enhancing explainability in multimodal large language models," arXiv preprint arXiv:2406.06579, 2024. 2 [62] J. Ni, H. Tang, S. T. Haque, Y. Yan, and A. H. Ngu, "A survey on multimodal wearable sensor-based human action recognition," arXiv preprint arXiv:2404.15349, 2024. 2 [63] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, "Language models are unsupervised multitask learners," 2019. 2 [64] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, and et al., "Language models are few-shot learners." 2 [65] OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, and et al., "GPT-4 technical report." 2 [66] A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, and et al., "The llama 3 herd of models." 2 [67] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollár, and R. Girshick, "Segment anything," 2023. 2 [68] H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y. Shum, "Dino: Detr with improved denoising anchor boxes for end-to-end object detection," 2022. 2 [69] M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, and et al., "Dinov2: Learning robust visual features without supervision," 2024. 2 [70] S. Yin, C. Fu, S. Zhao, K. Li, X. Sun, T. Xu, and E. Chen, "A survey on multimodal large language models," 2024. 2 [71] H. et al., "Onellm: One framework to align all modalities with language," in CVPR, 2024. 2 [72] Z. Peng, W. Wang, L. Dong, Y. Hao, S. Huang, S. Ma, and F. Wei, "Kosmos-2: Grounding multimodal large language models to the world," 2023. 2 [73] D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y. Chebotar, P. Sermanet, D. Duckworth, S. Levine, V. Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence, "Palm-e: An embodied multimodal language model," 2023. 2 [74] Y. Zang, W. Li, J. Han, K. Zhou, and C. C. Loy, "Contextual object detection with multimodal large language models," 2024.2 [75] B. Li, Y. Ge, Y. Ge, G. Wang, R. Wang, R. Zhang, and Y. Shan, "Seed-bench-2: Benchmarking multimodal large language models," 2023. 3 [76] F. Chen, M. Han, H. Zhao, Q. Zhang, J. Shi, S. Xu, and B. Xu, "Xllm : Bootstrapping advanced large language models by treating multi-modalities as foreign languages," 2023. 3 [77] C. Kelly, L. Hu, C. Yang, Y. Tian, D. Yang, B. Yang, Z. Huang, Z. Li, and Y. Zou, "Unifiedvisiongpt: Streamlining vision-oriented ai through generalized multimodal framework," 2023.3 [78] V. Ordonez, G. Kulkarni, and T. Berg, "Im2text: Describing images using 1 million captioned photographs," in Advances in Neural Information Processing Systems, J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K. Weinberger, Eds., vol. 24. Curran Associates, Inc., 2011. 4 [79] T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollár, "Microsoft coco: Common objects in context," 2015.4 [80] B. Thomee, D. A. Shamma, G. Friedland, B. Elizalde, K. Ni, D. Poland, D. Borth, and L.-J. Li, "Yfcc100m: the new data in multimedia research," Communications of the ACM, vol. 59, no. 2, p. 64-73, Jan. 2016. 4 [81] B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hockenmaier, and S. Lazebnik, "Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models," 2016. 4 [82] R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y. Kalantidis, L.-J. Li, D. A. Shamma, M. S. Bernstein, and F.-F. Li, "Visual genome: Connecting language and vision using crowdsourced dense image annotations," 2016. 4 [83] P. Sharma, N. Ding, S. Goodman, and R. Soricut, "Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning," in Annual Meeting of the Association for Computational Linguistics, 2018. 4 [84] G. Kim, Y. S. Park, Y. Cho, J. Jeong, and A. Kim, "Mulran: Multimodal range dataset for urban place recognition," in 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 6246-6253. 4 [85] K. Desai, G. Kaul, Z. Aysola, and J. Johnson, "Redcaps: webcurated image-text data created by the people, for the people," 2021. 4 [86] S. Changpinyo, P. Sharma, N. Ding, and R. Soricut, "Conceptual 12 m : Pushing web-scale image-text pre-training to recognize long-tail visual concepts," 2021. 4 [87] K. Srinivasan, K. Raman, J. Chen, M. Bendersky, and M. Najork, "Wit: Wikipedia-based image text dataset for multimodal multilingual machine learning," in Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR '21. ACM, Jul. 2021. 3, 4, 15 [88] Y. Liu, G. Zhu, B. Zhu, Q. Song, G. Ge, H. Chen, G. Qiao, R. Peng, L. Wu, and J. Wang, "Taisu: A 166m large-scale high-quality dataset for chinese vision-language pre-training," in Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 16705-16717. 4 [89] M. Byeon, B. Park, H. Kim, S. Lee, W. Baek, and S. Kim, "Coyo700 m : Image-text pair dataset," 2022. 4 [90] C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, P. Schramowski, S. Kundurthy, K. Crowson, L. Schmidt, R. Kaczmarczyk, and J. Jitsev, "Laion-5b: An open large-scale dataset for training next generation image-text models," [91] S. Y. Gadre, G. Ilharco, A. Fang, J. Hayase, G. Smyrnis, T. Nguyen, R. Marten, M. Wortsman, D. Ghosh, J. Zhang, E. Orgad, R. Entezari, G. Daras, S. Pratt, V. Ramanujan, Y. Bitton, K. Marathe, S. Mussmann, R. Vencu, M. Cherti, R. Krishna, P. W. Koh, O. Saukh, A. Ratner, S. Song, H. Hajishirzi, A. Farhadi, R. Beaumont, S. Oh, A. Dimakis, J. Jitsev, Y. Carmon, V. Shankar, and L. Schmidt, "Datacomp: In search of the next generation of multimodal datasets," 2023. 4, 14 [92] Z. Zhang, T. Zhao, Y. Guo, and J. Yin, "Rs5m and georsclip: A large-scale vision- language dataset and a large vision-language model for remote sensing," IEEE Transactions on Geoscience and Remote Sensing, vol. 62, p. 1-23, 2024. 3, 4 [93] F. Zhao, C. Zhang, and B. Geng, "Deep multimodal data fusion," ACM Computing Surveys, vol. 56, no. 9, pp. 1-36, 2024. 3, 7 [94] S. Yin, C. Fu, S. Zhao, K. Li, X. Sun, T. Xu, and E. Chen, "A survey on multimodal large language models." 3 [95] M. Varma, J.-B. Delbrouck, S. Hooper, A. Chaudhari, and C. Langlotz, "Villa: Fine-grained vision-language representation learning from real-world data," 2023.3 [96] L. Zhao and H. Wang, "Deep multimodal learning with vision, audio, and text: Challenges and innovations," IEEE Transactions on Neural Networks and Learning Systems, vol. 35, pp. 1172-1184, 2024. 3 [97] A. Rahate, R. Walambe, S. Ramanna, and K. Kotecha, "Multimodal co-learning: Challenges, applications with datasets, recent advances and future directions," Information Fusion, vol. 81, p. 203-239, May 2022. 3 [98] F. Qian and J. Han, "Contrastive regularization for multimodal emotion recognition using audio and text," 2022. 3 [99] R. Nakada, H. I. Gulluk, Z. Deng, W. Ji, J. Zou, and L. Zhang, "Understanding multimodal contrastive learning and incorporating unpaired data," 2023. 3 [100] T. Zhou, J. Cao, X. Zhu, B. Liu, and S. Li, "Visual-textual sentiment analysis enhanced by hierarchical cross-modality interaction," IEEE Systems Journal, vol. 15, pp. 4303-4314, 2021. 3 [101] M. Asai, "Set cross entropy: Likelihood-based permutation invariant loss function for probability distributions," 2018. 3 [102] S. Parekh, S. Essid, A. Ozerov, N. Q. K. Duong, P. Pérez, and G. Richard, "Weakly supervised representation learning for audio-visual scene analysis," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 416-428, 2020. 3 [103] H. Choi, A. Som, and P. Turaga, "Amc-loss: Angular margin contrastive loss for improved explainability in image classification," in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2020, pp. 3659-3666. [104] P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, "Supervised contrastive learning," ArXiv, vol. abs/2004.11362, 2020. 3 [105] C. Zang and F. Wang, "Scehr: Supervised contrastive learning for clinical risk prediction using electronic health records," 2021 IEEE International Conference on Data Mining (ICDM), pp. 857-866, 2021. 3 [106] Z. Song, Z. Zang, Y. Wang, G. Yang, K. yu, W. Chen, M. Wang, and S. Z. Li, "Set-clip: Exploring aligned semantic from lowalignment multimodal data through a distribution view," 2024. 4 [107] N. Vouitsis, Z. Liu, S. K. Gorti, V. Villecroze, J. C. Cresswell, G. Yu, G. Loaiza-Ganem, and M. Volkovs, "Data-efficient multimodal fusion on a single gpu," 2024.4 [108] Y. Wan, W. Wang, G. Zou, and B. Zhang, "Cross-modal feature alignment and fusion for composed image retrieval," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2024, pp. 8384-8388. 4 [109] F. Noroozi, M. Marjanovic, A. Njegus, S. Escalera, and G. Anbarjafari, "Audio-visual emotion recognition in video clips," IEEE Transactions on Affective Computing, vol. 10, no. 1, pp. 60-75, 2019. 4 [110] H. Nassar and D. Gleich, "Multimodal network alignment," ArXiv, 2017. 4, 7 [111] J. Qin, Y. Xu, Z. Luo, C. Liu, Z. Lu, and X. Zhang,"Alternative telescopic displacement: An efficient multimodal alignment method," ArXiv, 2023. 4, 7 [112] Unknown, "Dynamic time warping," in Information Retrieval for Music and Motion. Berlin, Heidelberg: Springer, 2007. 5 [113] J. B. Kruskal, "An overview of sequence comparison: Time warps, string edits, and macromolecules," SIAM Rev., vol. 25, no. 2, p. 201-237, Apr. 1983. 5 [114] H. Hotelling, "Relations between two sets of variates," Biometrika, vol. 28, no. 3-4, pp. 321-377, Dec. 1936. 5 [115] F. R. Bach and M. I. Jordan, "Kernel independent component analysis," Journal of Machine Learning Research, vol. 3, pp. 1-48, 2002. 5 [116] D. R. Hardoon, S. Szedmak, and J. Shawe-Taylor, "Canonical correlation analysis: An overview with application to learning methods," Neural Computation, vol. 16, no. 12, pp. 2639-2664, 2004. 5 [117] S. Akaho, "A kernel method for canonical correlation analysis," in Proceedings of the International Meeting on Psychometric Society, 2001. 5 [118] T. Melzer, M. Reiter, and H. Bischof, "Nonlinear feature extraction using generalized canonical correlation analysis," in Proceedings of the International Conference on Artificial Neural Networks (ICANN), 2001. 5 [119] G. Andrew, R. Arora, J. Bilmes, and K. Livescu, "Deep canonical correlation analysis," in Proceedings of the 30th International Conference on Machine Learning, 2013. 5 [120] Y. Verma and C. V. Jawahar, "Im2text and text2im: Associating images and texts for cross-modal retrieval," in Proceedings of the British Machine Vision Conference (BMVC), 2014, p. 2. 5 [121] Y. Jiang, Y. Zheng, S. Hou, Y. Chang, and J. Gee, "Multimodal image alignment via linear mapping between feature modalities," Journal of Healthcare Engineering, 2017. 5 [122] V. Vosylius and E. Johns, "Few-shot in-context imitation learning via implicit graph alignment," in Proceedings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, vol. 229, 2023, pp. 3194-3213. 5 [123] M. Kolář, J. Meier, V. Mustonen et al., "Graphalignment: Bayesian pairwise alignment of biological networks," BMC Syst Biol, vol. 6, p. 144, 2012. 5, 6 [124] S. Tang, D. Guo, R. Hong, and M. Wang, "Graph-based multimodal sequential embedding for sign language translation," IEEE Transactions on Multimedia, vol. 23, pp. 1056-1067, 2021. 5 [125] H. Yang, Y. Wu, Z. Si, Y. Zhao, J. Liu, and B. Qin, "Macsa: A multimodal aspect-category sentiment analysis dataset with multimodal fine-grained aligned annotations," Multimedia Tools and Applications, vol. 82, pp. 3839-3858, 2023. 5 [126] Y. Song, Z. Li, and W. Song, "Scene-driven multimodal knowledge graph construction for embodied ai," IEEE Transactions on Robotics, vol. 39, no. 1, pp. 45-60, 2023. 6 [127] Z. Zhang, W. Mai, H. Xiong, and C. Wu, "A token-wise graphbased framework for multimodal named entity recognition," IEEE Transactions on Knowledge and Data Engineering, vol. 33, no. 10, pp. 3121-3134, 2021. 6 [128] W. Xiong, Y. Zhang, and W. Li, "Scene graph-based semantic alignment for multimodal tasks," IEEE Transactions on Multimedia, vol. 22, no. 5, pp. 1231-1243, 2020. 6 [129] A. Karpathy and F.-F. Li, "Deep visual-semantic alignments for generating image descriptions," in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 3128-3137. 6 [130] X. Dai, Y. Lei, Y. Fu, W. Curran, T. Liu, H. Mao, and X. Yang, "Multimodal mri synthesis using unified generative adversarial networks," Medical Physics, 2020. 6 [131] M. Tao, B.-K. Bao, H. Tang, and C. Xu, "Galip: Generative adversarial clips for text-to-image synthesis," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14214-14223. 6 [132] H. Tang, B. Ren, and N. Sebe, "A pure mlp-mixer-based gan framework for guided image translation," Elsevier PR, vol. 157, p. 110894, 2025. 6 [133] X. Qian, H. Tang, J. Yang, H. Zhu, and X.-C. Yin, "Dual-path transformer-based gan for co-speech gesture synthesis," International Journal of Social Robotics, pp. 1-12, 2024. 6 [134] H. Tang and N. Sebe, "Facial expression translation using landmark guided gans," IEEE Transactions on Affective Computing, vol. 13, no. 4, pp. 1986-1997, 2022. 6 [135] A. Pumarola, S. Popov, F. Moreno-Noguer, and V. Ferrari, "Cflow: Conditional generative flow models for images and 3d point clouds," in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 7946-7955. 6 [136] M. Wu and N. Goodman, "Multimodal generative models for compositional representation learning," 2019. 6 [137] H. Lee, S. Park, and E. Choi, "Unconditional image-text pair generation with multimodal cross quantizer," ArXiv, 2022. 6 [138] A. F. Duque, G. Wolf, and K. R. Moon, "Diffusion transport alignment," 2022. 6 [139] Q. Ma, M. Zhang, Y. Tang, and Z. Huang, "Att-sinkhorn: Multimodal alignment with sinkhorn-based deep attention architecture," in 2023 28th International Conference on Automation and Computing (ICAC), 2023. 7 [140] P. P. Liang, A. Zadeh, and L.-P. Morency, "Foundations and trends in multimodal machine learning: Principles, challenges, and open questions," 2023. 7 [141] H. Tang, H. Liu, W. Xiao, and N. Sebe, "Fast and robust dynamic hand gesture recognition via key frames extraction and feature fusion," Elsevier Neurocomputing, vol. 331, pp. 424-433, 2019. 7 [142] M. Tao, H. Tang, F. Wu, X.-Y. Jing, B.-K. Bao, and C. Xu, "Df-gan: A simple and effective baseline for text-to-image synthesis," in CVPR, 2022. 7 [143] B. Duan, H. Tang, W. Wang, Z. Zong, G. Yang, and Y. Yan, "Audio-visual event localization via recursive fusion by joint coattention," in WACV, 2021. 7 [144] M. B. Rashid, M. S. Rahaman, and P. Rivas, "Navigating the multimodal landscape: A review on integration of text and image data in machine learning architectures," Machine Learning and Knowledge Extraction, 2024. 7 [145] X. Wang, X. Liu, X. Li, and J. Cui, "Multi-granularity text representation and transformer-based fusion method for visual question answering," in 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), 2023, pp. 965-971. 7 [146] M. I. Sarker and M. Milanova, "Deep learning-based multimodal image retrieval combining image and text," in 2022 International Conference on Computational Science and Computational Intelligence (CSCI), 2022, pp. 1543-1546. 7 [147] T. M. Thai, A. T. Vo, H. K. Tieu, L. Bui, and T. Nguyen, "Uitsaviors at medvqa-gi 2023: Improving multimodal learning with image enhancement for gastrointestinal visual question answering," 2023. 7 [148] T. Siebert, K. N. Clasen, M. Ravanbakhsh, and B. Demir, "Multimodal fusion transformer for visual question answering in remote sensing," SPIE, vol. 12267, pp. [149] W. Tang, F. He, Y. Liu, and Y. Duan, "Matr: Multimodal medical image fusion via multiscale adaptive transformer," IEEE Transactions on Image Processing, vol. 31, pp. 5134-5149, 2022. 7 [150] C. Zhang, Z. Yang, X. He, and L. Deng, "Multimodal intelligence: Representation learning, information fusion, and applications," IEEE Journal of Selected Topics in Signal Processing, vol. 14, pp. 478493, 2020. 7 [151] K. E. Ak, G. Lee, Y. Xu, and M. Shen, "Leveraging efficient training and feature fusion in transformers for multimodal classification," in 2023 IEEE International Conference on Image Processing (ICIP), 2023, pp. 1420-1424. 7 [152] N. Srivastava and R. Salakhutdinov, "Multimodal learning with deep boltzmann machines," Journal of Machine Learning Research, vol. 15, pp. 2949-2980, 2012. 7 [153] E. Morvant, A. Habrard, and S. Ayache, "Majority vote of diverse classifiers for late fusion," in Structural, Syntactic