FLARE: 환경에 기반한 멀티모달 계획과 효율적인 재계획을 통한 Embodied Agent 학습
FLARE는 소수의 예시 데이터만으로 Embodied Agent를 학습시키기 위한 멀티모달 기반 계획 및 효율적인 재계획 프레임워크입니다. 기존 LLM 기반 planner들이 주로 언어적 상식에 의존하여 환경 상태를 무시하는 문제를 해결하기 위해, FLARE는 언어 지시와 에이전트의 시각적 인식을 모두 활용하는 'Multi-Modal Planner (MMP)'를 통해 환경에 기반한 초기 계획을 생성합니다. 또한, 계획 실행 중 오류가 발생하면 'Environment Adaptive Replanning (EAR)' 모듈이 LLM 재호출 없이 시각적 단서만으로 계획을 빠르고 효율적으로 수정하여 실제 환경과의 불일치를 해결합니다. 논문 제목: Multi-Modal Grounded Planning and Efficient Replanning For Learning Embodied Agents with A Few Examples
Kim, Taewoong, Byeonghwi Kim, and Jonghyun Choi. "Multi-Modal Grounded Planning and Efficient Replanning For Learning Embodied Agents with A Few Examples." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 39. No. 4. 2025.
Multi-Modal Grounded Planning and Efficient Replanning For Learning Embodied Agents with A Few Examples
Abstract
로봇 보조 장치가 자연어 지침에 따라 복잡한 task를 수행하기 위한 단계를 계획하도록 인식 및 추론 모듈을 학습시키는 것은 종종 대규모의 자유 형식 언어 주석을 필요로 하며, 특히 짧은 고수준 지침의 경우 더욱 그렇다. 주석 비용을 줄이기 위해 **대규모 언어 모델(LLM)**이 소수의 데이터로 **플래너(planner)**로 사용된다. 그러나 단계를 상세화할 때, LLM을 사용하는 최신 플래너조차도 대부분 언어적 상식에 의존하며, 명령 수신 시 환경 상태를 종종 무시하여 부적절한 계획을 초래한다. 환경에 기반한 계획을 생성하기 위해, 우리는 **언어 명령과 환경 인식을 모두 사용하여 task 계획을 개선하는 FLARE (Few-Shot Language with environmental Adaptive Replanning EMBODIED AGENT)**를 제안한다. 언어 지침은 종종 모호하거나 부정확한 표현을 포함하므로, 우리는 에이전트의 **시각적 단서(visual cues)**를 사용하여 이러한 오류를 수정하는 방법을 추가로 제안한다. 제안된 방식은 시각적 단서 덕분에 소수의 언어 쌍만으로도 최신 접근 방식보다 뛰어난 성능을 보인다. 우리의 코드는 https://github.com/snumprlab/flare 에서 확인할 수 있다.
1 Introduction
컴퓨터 비전, 자연어 처리, 그리고 embodied AI 분야의 급속한 발전 덕분에, 우리는 일상적인 task를 수행할 수 있는 로봇 보조 장치의 핵심 기능에서 상당한 개선을 목격하고 있다. 이러한 기능에는 시뮬레이션된 3D 공간에서의 내비게이션 (Anderson et al. 2018; Chaplot et al. 2017; Uppal et al. 2024), 객체 조작 (Zhu et al. 2017; Ryu et al. 2024), 그리고 반응형 추론 (Das et al. 2018; Gordon et al. 2018; Majumdar et al. 2024)이 포함된다 (Ge et al. 2024; Chang et al. 2017; Xia et al. 2018; Kim et al. 2024). 실용적인 로봇 보조 장치는 언어 지시를 이해하고 환경을 능동적으로 인지하기 위해 위에서 언급된 모든 능력을 필요로 한다.
이러한 복잡한 task를 수행하는 agent를 학습시키기 위한 직접적인 접근 방식은 대량의 자연어 지시와 행동 쌍으로 agent를 supervised 방식으로 훈련하는 것이다 (Shridhar et al. 2020; Ehsani et al. 2024; Pashevich et al. 2021; Blukis et al. 2021; Kim et al. 2023). 그러나 지시를 주석(annotate)하고 전문가 행동 시퀀스(즉, 내비게이션 궤적)를 제공하는 것은 비용이 많이 들고 시간이 소모되며, 따라서 충분한 양의 언어 주석을 수집하는 것은 종종 불가능하다. 데이터가 불충분할 경우, 위에서 언급된 데이터 기반 접근 방식은 효과적이지 않을 것이다 (Min et al. 2022; Inoue and Ohashi 2022; Bhambri, Kim, and Choi 2023; Song et al. 2022).
 Figure 1: 제안하는 FLARE의 개요. 우리의 agent는 (1) 'Multi-Modal Planner (MMP)'와 (2) 'Environment Adaptive Replanning (EAR)'으로 구성된다. MMP는 agent의 초기 주변 시야와 수신된 지시를 모두 고려하여 LLM (예: GPT-4)에 prompt를 주어 하위 목표(subgoals) 시퀀스를 생성한다. agent가 계획을 실행하는 동안 막히면, EAR은 시각적 단서를 통해 ungrounded plan을 물리적으로 grounded된 plan으로 조정한다.
Figure 1: 제안하는 FLARE의 개요. 우리의 agent는 (1) 'Multi-Modal Planner (MMP)'와 (2) 'Environment Adaptive Replanning (EAR)'으로 구성된다. MMP는 agent의 초기 주변 시야와 수신된 지시를 모두 고려하여 LLM (예: GPT-4)에 prompt를 주어 하위 목표(subgoals) 시퀀스를 생성한다. agent가 계획을 실행하는 동안 막히면, EAR은 시각적 단서를 통해 ungrounded plan을 물리적으로 grounded된 plan으로 조정한다.
소량의 주석된 데이터로 long-horizon task를 수행하는 agent를 학습시키기 위한 최근 접근 방식 (Min et al. 2022; Inoue and Ohashi 2022)은 특정 task 유형에 대해 수동으로 설계된 행동 시퀀스를 활용한다. 그러나 이러한 정의된 행동은 다양한 유형의 task로 확장되지 않는다. 또 다른 연구 분야는 대규모 언어 모델(LLMs)을 사용하여 불충분한 데이터를 해결하며, LLMs 내에 인코딩된 사전 지식이 다양한 도메인에서 달성한 놀라운 발전을 활용한다 (Zeng et al. 2023; Singh et al. 2023; Driess et al. 2023; Song et al. 2023; Sarch et al. 2023; Wu et al. 2023). 특히 (Song et al. 2023)은 LLMs를 high-level planner로 사용하고, 기존 agent (Blukis et al. 2021) 위에 동적인 grounded replanning을 추가하여 인간이 주석한 언어가 매우 부족한 상황을 다룬다. 그러나 그들은 환경 상태를 무시하는데, 이는 그럴듯하지 않은 계획을 생성할 수 있다. 왜냐하면 계획은 지시를 받을 때 종종 환경의 상태(예: agent가 어디에 있었는지, 시야에서 무엇이 보이는지 등)를 고려해야 하기 때문이다. 부적절한 계획을 수정하기 위해 (Song et al. 2023)은 관찰된 객체 목록을 포함하는 prompt로 LLM을 여러 번 호출하여 grounded plan을 생성한다. 그러나 대규모 모델에 대한 과도한 의존은 불필요하게 비용이 많이 드는데, 이는 부분적인 하위 목표만 잘못되었을 때 전체 시퀀스를 수정하기 때문이다.
 Figure 2: FLARE의 상세 아키텍처. 'Multi-Modal Planner (MMP)'와 'Environment Adaptive Replanning (EAR)'으로 구성된다. 1 MMP는 agent의 초기 파노라마 주변 시야와 언어 지시를 기반으로 관련성 높은 상위 개의 훈련 데이터 쌍(지시 및 전문가 시연(Expert Demon.으로 표시))을 검색한 다음, 이 예시들을 사용하여 LLM (예: GPT-4)을 통해 일련의 행동을 계획한다. 2 agent가 목표 객체(예: 'TrashCan')를 찾지 못하면 EAR을 통해 재계획을 요청한다. 3 EAR은 시각적 관찰과 의미론적 유사성을 사용하여 장면 내에서 사용 가능한 가장 유사한 객체를 식별하고 누락된 객체를 대체한다(예: 'GarbageCan').
Figure 2: FLARE의 상세 아키텍처. 'Multi-Modal Planner (MMP)'와 'Environment Adaptive Replanning (EAR)'으로 구성된다. 1 MMP는 agent의 초기 파노라마 주변 시야와 언어 지시를 기반으로 관련성 높은 상위 개의 훈련 데이터 쌍(지시 및 전문가 시연(Expert Demon.으로 표시))을 검색한 다음, 이 예시들을 사용하여 LLM (예: GPT-4)을 통해 일련의 행동을 계획한다. 2 agent가 목표 객체(예: 'TrashCan')를 찾지 못하면 EAR을 통해 재계획을 요청한다. 3 EAR은 시각적 관찰과 의미론적 유사성을 사용하여 장면 내에서 사용 가능한 가장 유사한 객체를 식별하고 누락된 객체를 대체한다(예: 'GarbageCan').
이러한 문제들을 해결하기 위해, 우리는 FLARE (Few-shot Language with environmental Adaptive Replanning Embodied agent) 를 제안한다. FLARE는 가정용 task를 완료하기 위한 하위 목표 시퀀스를 계획하기 시작할 때 멀티모달 환경 컨텍스트(즉, 시각 입력 및 언어 지시)를 고려하며, LLM을 사용하지 않고 시각 입력을 활용하여 효율적으로(즉, 부분적으로) 계획을 수정한다. 우리 접근 방식의 효과를 실증적으로 검증하기 위해, 우리는 embodied instruction following을 위한 널리 사용되는 벤치마크 (Shridhar et al. 2020)를 채택한다. 우리는 FLARE가 단 100개의 언어 및 시연 쌍과 같은 소수의 데이터만으로도 그럴듯한 계획을 생성할 수 있음을 관찰했으며, test unseen split에서 최대 +24.46%의 절대 이득으로 기존 state-of-the-art 방법들을 눈에 띄게 능가한다. 우리의 기여는 다음과 같이 요약된다:
- 환경 상태와 언어 지시를 모두 고려하는 멀티모달 planner를 제안하여, 소수의 데이터로 long-horizon task를 수행한다.
- 시각적 단서를 통해 잘못된 하위 목표를 수정하는 계산적으로 효율적인 환경 적응형 replanner를 제안하여, LLM 없이도 환경의 상태에 grounded된 계획 생성을 가능하게 한다.
- ALFRED 벤치마크 (Shridhar et al. 2020)의 few-shot 설정에서 모든 지표에서 state-of-the-art 성능을 달성한다.
2 Related Work
우리는 먼저 로봇 공학에서 LLM을 사용하는 시도, 특히 task planning에 대한 연구들을 검토한다. 그런 다음, 복잡한 instruction-following task를 해결하기 위한 최근 접근 방식들을 논의한다.
Task planning을 위한 Foundation Model
최근 대규모 foundation model (즉, LLM 및 VLM)의 발전과 함께 (Brown et al. 2020; Chen et al. 2021; Zhang et al. 2022; Liu et al. 2023), 이들은 로봇 시스템에서 reasoning (Zeng et al. 2023; Singh et al. 2023; Driess et al. 2023), planning (Song et al. 2023; Sarch et al. 2023; Yang et al. 2024; Szot et al. 2024), 그리고 manipulation (Wu et al. 2023; Fang et al. 2024)을 위한 도구로 사용되고 있다. LLM을 활용한 로봇 planning의 초기 접근 방식 (Huang et al. 2022)은 입력 prompt의 반복적인 개선을 통해 subtask를 계획한다. 예를 들어, 에이전트가 계획된 행동을 실행하지 못할 때, (Huang et al. 2023)은 여러 환경 피드백을 사용하여 초기 계획을 조정하고 실패를 복구한다.
유사하게, (Ahn et al. 2022)는 planning을 위한 skill affordance value function을 사용하여 로봇 planning을 가능하게 했다. 실행 가능한 로봇 정책을 직접 생성하기 위해, (Singh et al. 2023; Liang et al. 2023)은 프로그래밍 방식의 LLM prompt를 구성했다. 한편, VIMA (Jiang et al. 2023)와 PaLM-E (Driess et al. 2023)는 multimodal prompt를 사용하여 로봇을 제어한다.
다양한 task로 확장하기 위해, (Wang et al. 2024b)는 잘 구성된 instruction을 통해 LLM이 사족보행 로봇의 locomotion task를 효과적으로 지시할 수 있음을 보여준다. open-ended 환경으로 확장하기 위해 (Fan et al. 2022), 에이전트 (Wang et al. 2024a; Zheng et al. 2024)는 LLM을 사용하여 continual learning agent를 구축한다.
이러한 방법들은 LLM을 사용하여 로봇 planning에서 상당한 진전을 이루었지만, 로봇의 행동을 개선하거나 적응시키기 위해 LLM과의 여러 상호작용에 의존하며, 이는 API 호출로 사용될 경우 높은 inference 비용이나 네트워크 오버헤드로 이어진다. 이와 대조적으로, 우리의 FLARE는 현재 환경에 에이전트를 적응시키는 데 있어 계산 효율성을 높이기 위해 replanning에 LLM을 사용하지 않는다.
Instruction Following Embodied Agent
Embodied instruction following task는 에이전트가 주어진 환경 내에서 자연어 instruction에 부합하는 일련의 행동을 생성하도록 요구한다. 많은 이전 연구들 (Singh et al. 2021; Nguyen et al. 2021; Pashevich et 2021)은 end-to-end 방식으로 에이전트를 학습시켜 자연어 instruction으로부터 저수준(low-level) 행동을 직접 생성한다. 동시에, long-horizon task planning을 위한 템플릿 기반 접근 방식이 제안되었다 (Min et al. 2022; Inoue and Ohashi 2022). 이 방식은 데이터 효율적이지만, 미리 정의된 task를 해결하는 데 제한적이며 새로운 task로 일반화되지 않는다.
계층적(hierarchical) 또는 모듈식(modular) planning 접근 방식이 instruction following task에서 효과적임이 입증됨에 따라 (Min et al. 2022; Blukis et al. 2021; Kim et al. 2023; Xu et al. 2024), LLM을 planner로 활용하려는 시도가 있었다. (Song et al. 2023; Sarch et al. 2023)은 few-shot in-context 예시로 LLM에 prompt를 제공하여 이러한 task에서 LLM을 고수준(high-level) planner로 사용하며, 이는 매우 효과적인 것으로 나타났다 (Brown et al. 2020). 두 방법 모두 임베딩된 언어 instruction의 거리를 기반으로 여러 prompting 예시를 검색한다.
3 Approach
실행 가능한 grounded plan을 생성하는 것은 성공적인 embodied AI agent를 개발하는 데 핵심적인 구성 요소 중 하나이다 (Murray and Cakmak 2022; Inoue and Ohashi 2022; Kim et al. 2023). State-of-the-art 방법들 (Kim et al. 2023; Min et al. 2022; Blukis et al. 2021; Pashevich et al. 2021)은 방대한 데이터에 크게 의존하므로, 데이터가 부족한 학습 시나리오에서는 효과적이지 않을 것이다. 그러나 자유 형식 언어 지시를 주석 처리하는 데 드는 높은 비용을 고려할 때, 소량의 데이터로 agent를 학습시키는 보다 실용적인 접근 방식을 개발하는 것이 바람직하다. LLM을 planner로 활용하려는 노력 (Ahn et al. 2022; Huang et al. 2022, 2023; Sarch et al. 2023) 외에도, Song et al. (2023)은 LLM을 사용하여 소수의 예시로 agent를 학습시킨다.
그러나 LLM은 적절한 prompt 없이는 항상 그럴듯한 plan을 생성하지 못하며, 이는 무의미하거나 비실용적인 subgoal 생성으로 이어진다. 예를 들어, '요리된 감자를 냉장고에 넣어라'라는 task에 대해 LLM은 agent에게 '감자를 호일로 싸라'고 지시할 수 있지만, '싸는(wrapping)' 행위는 agent가 지원하지 않는 동작일 수 있다. LLM이 실행 가능한 plan을 꽤 성공적으로 생성하더라도, open-vocabulary 설명의 본질적인 모호성과 어휘 다양성은 언어 기반 지시와 물리적 세계 간의 연결을 덜 명확하게 만드는 경향이 있다. 구체적으로, 소파(sofa)를 학습한 agent는 카우치(couch)를 인식하지 못할 것이다. 이는 환경에 잘 grounded되지 않은 plan으로 이어질 수 있으며, agent가 실제 시나리오에 직면했을 때 grounded되지 않은 plan에 효과적으로 대처하지 못하게 할 수 있다 (예: 장면에 없는 물체를 끝없이 찾아 헤매는 경우). 이 문제를 해결하기 위해 우리는 시각 및 텍스트 입력을 사용하여 embodied AI agent의 task planning을 개선하는 FLARE를 제안한다. 또한, 우리의 접근 방식은 agent의 시각적 관찰(visual observations)을 활용하여 시각적으로 적응 가능한 grounded replanning을 가능하게 한다.
 Figure 3: Multi-Modal Planner. MMP는 'multi-modal similarity' (Eq. (1))를 기반으로 상위 개의 expert demonstration을 선택한 다음, 이를 subgoal triplet ()으로 변환한다. MMP는 subgoal triplet과 텍스트 prompt를 사용하여 LLM이 자연어 지시로부터 task-specific subgoal sequence를 생성하도록 안내한다.
Figure 3: Multi-Modal Planner. MMP는 'multi-modal similarity' (Eq. (1))를 기반으로 상위 개의 expert demonstration을 선택한 다음, 이를 subgoal triplet ()으로 변환한다. MMP는 subgoal triplet과 텍스트 prompt를 사용하여 LLM이 자연어 지시로부터 task-specific subgoal sequence를 생성하도록 안내한다.
마지막으로, 우리의 agent는 두 가지 제안된 구성 요소인 **'Multi-Modal Planner'**와 **'Environment Adaptive Replanning'**을 통합한다. Figure 2는 우리 FLARE의 아키텍처를 보여준다.
3.1 Multi-Modal Planner
자연어 명령을 통해 에이전트의 해석 가능한 subgoal 시퀀스를 생성하기 위해 LLM이 널리 사용된다 (Zeng et al. 2023; Singh et al. 2023; Driess et al. 2023; Wu et al. 2023; Sarch et al. 2023). 예를 들어, (Song et al. 2023; Sarch et al. 2023)는 언어 명령의 유사성으로부터 in-context 예시를 검색하여 LLM에 prompt로 제공한다. 이들로부터 영감을 받아, 우리는 소수의 annotated 데이터만으로 환경 상태를 반영하기 위해 자연어 명령과 에이전트의 현재 시점 egocentric 주변 시야를 모두 고려하는 **'Multi-Modal Planner (MMP)'**를 제안한다. Figure 3에 MMP를 도식화하였다.
Multi-modal Similarity.
LLM의 in-context learning은 광범위한 언어 task에서 모델 성능을 크게 향상시킨다 (Brown et al. 2020). 이는 prompt 내의 명시적인 context를 사용하여 모델의 이해력과 상세한 언어 명령에 대한 반응성을 정교하게 만든다. LLM을 few-shot learner로 활용하기 위해서는 현재 task와 관련된 예시를 신중하게 선택해야 한다. 이러한 관련 예시들은 LLM이 적절한 subgoal을 생성하는 능력을 돕는다. 예를 들어, task가 '천을 닦는 것'이라면, '포크 닦기'나 '설거지하기'와 같은 유사한 주제의 예시를 모델에 prompt로 제공하는 것이 '사과 데우기'와 같은 관련 없는 task보다 전략적으로 타당하다. (Song et al. 2023; Sarch et al. 2023)는 임베딩된 언어 명령 간의 거리를 측정하여 이를 달성하지만, 계획을 생성할 때 환경 상태(즉, 시각 정보)를 고려하지 않는다.
 Figure 4: Environment Adaptive Replanning (EAR). EAR은 감지된 객체를 나열하고 의미론적 유사성을 계산하여 부정확하게 참조된 항목(예: TrashCan)을 대체함으로써 계획을 수정한다. 이는 계획이 환경에 기반하도록 보장한다.
Figure 4: Environment Adaptive Replanning (EAR). EAR은 감지된 객체를 나열하고 의미론적 유사성을 계산하여 부정확하게 참조된 항목(예: TrashCan)을 대체함으로써 계획을 수정한다. 이는 계획이 환경에 기반하도록 보장한다.
이는 현재 task에 부적절한 예시 선택으로 이어질 수 있다 (예: 칼이 없을 때 칼로 사과를 자르는 것).
환경 상태를 고려하기 위해, 우리는 명령을 받을 때 에이전트의 주변 시야를 사용한다. 그런 다음 frozen BERT 모델 (Devlin et al. 2018)로 텍스트 명령을 임베딩하고, frozen CLIP-ViT encoder (Radford et al. 2021)로 이미지를 임베딩하여 각 학습 예시가 현재 task와 얼마나 밀접하게 일치하는지 측정한다.
정식으로, 와 를 각각 언어 유사성과 환경 유사성이라고 하자. 여기서 와 는 현재 task와 학습 세트의 예시 간의 언어 및 환경 유사성을 각 임베딩 벡터에 대한 코사인 유사성으로 나타낸다. 그런 다음, 우리는 **현재 task와 학습 세트의 task 간의 multi-modal 유사성 ()**을 이러한 개별 유사성 점수의 정규화된 합으로 다음과 같이 계산한다:
여기서 과 는 각각 각 명령 및 환경 유사성의 가중치를 나타낸다. Multi-modal 유사성 점수를 사용하여 학습 데이터에서 가장 관련성이 높은 상위 개의 예시를 검색한다. 이 예시들은 LLM의 생성 과정 동안 in-context learning 예시로 사용되어, LLM이 더 정확한 subgoal을 생성하도록 안내한다.
Subgoal Representation.
언어 명령을 subgoal로 변환하는 것은 로봇 추론의 핵심 구성 요소 중 하나이다. 예를 들어, '조리대에서 식탁으로 사과를 옮겨라'라는 task는 **[Navigate, CounterTop], [Pickup, Apple], [Navigate, DiningTable], [Put, DiningTable]**과 같이 탐색 및 객체 상호작용을 모두 포함하는 subgoal로 분해될 수 있다. 우리는 명령 세트의 총 길이를 줄이기 위해 [Pickup, Apple, CounterTop] 및 **[Put, Apple, DiningTable]**의 트리플릿을 사용하는 중간 subgoal 표현을 제안한다.
Algorithm 1: FLARE algorithm
Input: Time step \(t\), Subgoal index \(k\), Uncertainty \(u\), Uncertainty
threshold \(\tau\), Language instruction \(\mathcal{I}\), Camera input \(\mathcal{C}_{t}\), Subgoal
sequences \(\mathcal{P}\), Semantic map \(\mathcal{S}\), Detected object set \(\mathcal{V}\), Current
object in interest \(O_{k}\)
\(t, k, u \leftarrow 0 \quad \triangleright\) Initialize
\(\mathcal{P} \leftarrow \operatorname{MMP}\left(\mathcal{I}, \mathcal{C}_{t}\right) \quad \triangleright\) Generate initial plan (Sec. 3.1)
\(\mathcal{S} \leftarrow \operatorname{SemanticMapping}\left(\mathcal{C}_{t}\right) \quad \triangleright\) Semantic map (Sec. B.1)
\(a_{t} \leftarrow \operatorname{ActionPolicy}\left(\mathcal{P}_{k}, \mathcal{S}\right) \quad \triangleright\) First action (Sec. 3.3)
while \(k<\operatorname{length}(\mathcal{P})\) do
\(\mathcal{C}_{t} \leftarrow \operatorname{Execute}\left(a_{t}\right)\)
\(\mathcal{S} \leftarrow\) SemanticMapping \(\left(\mathcal{C}_{t}\right) \quad-\) Update semantic map
\(\mathcal{V} . \operatorname{add}\left(\operatorname{ObjectDetector}\left(\mathcal{C}_{t}\right)\right) \quad \triangleright\) Update detected object set
if \(O_{k} \operatorname{not}\) in \(\mathcal{O}\) then
\(u \leftarrow u+1\)
if \(u>\tau\) then
\(O_{k} \leftarrow \operatorname{EAR}\left(O_{k}, \mathcal{V}\right) \quad \triangleright\) Replanning (Eq. (3))
end if
else if Complete \(\left(P_{k}\right)\) then
\(k \leftarrow k+1 \quad \triangleright\) Update subgoal index
end if
\(t \leftarrow t+1\)
\(a_{t} \leftarrow \operatorname{ActionPolicy}\left(\mathcal{P}_{k}, \mathcal{S}\right) \quad \quad \triangleright\) Next action (Sec. 3.3)
end while
정식으로, 주어진 task 명령 에 대해 subgoal을 다음과 같이 나타낸다:
여기서 는 시퀀스의 총 subgoal 수이며, 은 고수준 액션(예: '집기' 또는 '닦기'), 은 액션의 대상 객체, 은 이 위치한 **수용체(receptacle)**를 나타낸다. 이 접근 방식은 (Song et al. 2023)에 비해 토큰 사용량을 25% 감소시킨다.
3.2 Environment Adaptive Replanning
대규모 언어 모델(LLM)의 계획 수립(planning) 능력이 부상하고 있음에도 불구하고, 에이전트가 배치되는 환경에서 충분히 grounding되지 않은 계획을 생성할 수 있다. 이러한 문제는 자연어 지시(natural language instructions)에 내재된 어휘적 다양성에 기인할 수 있다. 예를 들어, "버터 나이프와 과일 조각이 담긴 쟁반을 테이블 위에 놓으세요."라는 task를 생각해보자. 이 task를 완료하려면 에이전트는 썰어야 할 과일을 찾아야 한다. 그러나 에이전트가 훈련 중에 탐색을 위한 과일 객체 클래스를 학습하지 않았다면, 이는 탐색 실패로 이어질 수 있으며, 궁극적으로 task 실패를 초래할 수도 있다.
이러한 문제를 해결하기 위해 제안된 **'Environment Adaptive Replanning (EAR)'**은 감지되지 않은 객체를 지금까지 관찰된 객체 중 가장 의미적으로 유사한 객체로 대체하여 하위 목표(subgoal)를 수정한다. 하위 목표를 수정하기 위해 EAR은 먼저 task를 완료하는 동안 지금까지 관찰된 모든 감지된 객체 목록을 유지한다. 각 하위 목표에 대해 에이전트가 탐색 목표(즉, 또는 )에 도달할 수 없는 경우, EAR은 지정된 객체가 환경에 없다고 추론하고 의미적으로 유사한 객체로 대체한다.
현재 사용할 수 없는 객체를 다른 객체로 대체하기 위해 EAR은 후보 객체(즉, 지금까지 관찰된 객체) 중에서 가장 의미적으로 유사한 객체를 찾는다. 의미적 유사성을 측정하기 위해 우리는 두 객체 클래스 이름의 언어 표현(language representations) 간의 코사인 유사도(cosine similarity)를 계산한다. 구체적으로, EAR은
Table 1: State-of-the-art 방법들과의 비교. 각 지표에 대한 path-length-weighted (PLW) 지표는 괄호 안에 제시되어 있다. 'SR'과 'GC'는 (Song et al. 2023)에서 발췌하였다. PLW 지표를 보고하지 않은 모델의 경우, 비교에서 'N/A'로 표기하였다.
| Setting | Model | Goal instructions + Sequential instructions | Goal instruction only | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Test Seen | Test Unseen | Test Seen | Test Unseen | ||||||
| SR | GC | SR | GC | SR | GC | SR | GC | ||
| Few-shot (0.5%) | HLSM (Blukis et al. 2021) | N/A | |||||||
| FILM (Min et al. 2022) | 4.23 ( ) | 6.71 ( ) | N/A | N/A | |||||
| CAPEAM (Kim et al. 2023) | 0.00 (0.00) | 3.90 (2.29) | 0.20 (0.00) | 6.63 (2.36) | N/A | ||||
| LLM-Planner (Song et al. 2023) | 18.20 ( ) | 26.77 ( ) | 16.42 ( ) | 23.37 ( ) | 15.33 (N/A) | 24.57 ( ) | 13.41 ( ) | 22.89 (N/A) | |
| FLARE-LLaMA2 | 16.96 (4.60) | 24.84 (8.09) | 17.79 (5.62) | 27.40 (9.46) | 12.00 (3.01) | 20.05 (7.22) | 13.73 (4.27) | 21.98 (8.46) | |
| FLARE-Vicuna | 20.61 (6.28) | 29.57 (10.17) | 22.04 (7.61) | 33.57 (12.06) | 16.37 (4.57) | 23.68 (8.84) | 18.05 (5.98) | 26.75 (10.75) | |
| FLARE-GPT-3.5 | 32.55 (12.17) | 42.02 (16.94) | 31.79 (12.21) | 43.94 (17.44) | 23.48 (8.71) | 33.40 (14.40) | 25.38 (9.37) | 36.02 (15.28) | |
| FLARE-GPT-4 (Ours) | 40.05 (16.68) | 48.84 (21.31) | 40.88 (18.14) | 51.72 (22.78) | 31.96 (12.93) | 41.36 (18.55) | 32.57 (12.72) | 43.23 (18.40) | |
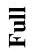 | HLSM (Blukis et al. 2021) | 29.94 (8.74) | 41.21 (14.58) | 20.27 (5.55) | 30.31 (9.99) | 25.11 (6.69) | 35.79 (11.53) | 16.29 (4.34) | 27.24 (8.45) |
| FILM (Min et al. 2022) | 28.83 (11.27) | 39.55 (15.59) | 27.80 (11.32) | 38.52 (15.13) | 25.77 (10.39) | 36.15 (14.17) | 24.46 (9.67) | 34.75 (13.13) | |
| CAPEAM (Kim et al. 2023) | 51.79 (21.60) | 60.50 (25.88) | 46.11 (19.45) | 57.33(24.06) | 47.36 (19.03) | 54.38 (23.78) | 43.69 (17.64) | 55.66 (22.76) |
사전학습된 언어 모델(Devlin et al. 2018; Raffel et al. 2020; Brown et al. 2020)을 사용하여 현재 목표 객체와 관찰된 객체 이름의 언어 표현을 먼저 얻는다. 일단 얻어지면, EAR은 현재 목표 객체에 대한 관찰된 객체들의 유사도 점수를 계산한다.
공식적으로, 우리는 다음과 같이 유사도 점수를 계산하고 가장 의미적으로 유사한 객체를 얻는다:
여기서 는 를 최대화하는 객체이고, 는 현재 객체이며, 는 지금까지 감지된 객체이다. Enc()는 language encoder를 나타내고, 는 두 embedding의 코사인 유사도를 나타낸다. 는 또는 일 수 있음에 유의하라. 우리는 Figure 4에서 EAR을 자세히 설명한다.
3.3 Action Policy
**객체 상호작용(object interaction)**을 위해, 에이전트는 먼저 **목표 객체로 이동(navigate)**하여 가까운 근처에 도달한다. **내비게이션(navigation)**을 위한 유효한 접근 방식은 **모방 학습(imitation learning)**을 사용하는 것이다 (Shridhar et al. 2020; Singh et al. 2021; Pashevich et al. 2021; Nguyen et al. 2021). 그러나 이는 수용 가능한 성능을 위해 많은 수의 훈련 에피소드를 필요로 하지만, 이러한 에피소드를 수집하는 것이 항상 가능한 것은 아니며, 특히 훈련 데이터 수집이 종종 비용이 많이 들고 시간이 오래 걸리는 우리의 경우에는 더욱 그렇다.
이러한 문제를 피하기 위해, 최근 접근 방식들 (Inoue and Ohashi 2022; Kim et al. 2023)은 확정적 알고리즘(deterministic algorithms) (예: A* algorithm, FMM (Sethian 1996) 등)을 **장애물 없는 경로 계획(obstacle-free path planning)**에 통합하여, 모방 학습으로 학습된 방식에 비해 상당한 성능 향상을 이끌어냈다. 최근 관찰에서 영감을 받아, 우리는 효과적인 경로 계획을 위해 확정적 접근 방식(Sethian 1996)을 채택한다.
4 Experiments
4.1 Experimental Setup
우리는 제안된 방법들의 다양한 모델과의 호환성을 검증하기 위해, FLARE에 4개의 대형 language model을 사용했으며, 여기에는 proprietary 모델과 opensource 모델이 모두 포함된다. 구체적으로, GPT-4와 GPT-3.5를 proprietary 모델로, **LLaMA2-13B (Touvron et al. 2023)와 Vicuna-13B (Zheng et al. 2023)**를 opensource 모델로 사용한다.
Song et al. (2023)과의 공정한 비교를 위해 개의 in-context example을 선택했으며, 각 modality를 동등하게 처리하기 위해 equation (1)에서 과 를 동일한 값으로 설정하였다.
4.2 Dataset and metrics
우리는 ALFRED (Shridhar et al. 2020) 벤치마크에서 FLARE의 효과를 평가한다. 이 벤치마크는 에이전트가 언어 지시와 1인칭 시점(egocentric) 관찰을 기반으로 상호작용적인 3D 환경 (Kolve et al. 2017) 내에서 가정용 task를 완료하도록 요구한다. 검증(validation) 및 테스트(test) 세트 모두 seen 및 unseen 시나리오를 포함한다. 여기서 seen 시나리오는 학습 데이터의 일부이며, unseen 시나리오는 평가를 위한 새롭고 익숙하지 않은 환경을 나타낸다.
인간 언어 쌍이 부족한 환경에서 FLARE의 효율성을 평가하기 위해, 우리는 이전 연구 (Song et al. 2023)와 동일한 **few-shot 설정 (0.5%)**을 따랐다. 이전 방법들과의 공정한 비교를 위해, 우리는 **동일한 수의 예시 (100개)**를 사용했다 (Song et al. 2023). 선택된 100개의 예시는 21,023개의 학습 예시를 공정하게 대표하기 위해 모든 7가지 task 유형을 포함한다.
평가를 위해 우리는 (Shridhar et al. 2020)와 동일한 평가 프로토콜을 따른다. **주요 지표는 성공률(SR)**이며, 완료된 task의 비율을 측정한다. **목표 조건 성공률(GC)**은 충족된 목표 조건의 비율을 측정한다. 또한, 우리는 에이전트가 취한 경로 길이(path length)로 SR 및 GC에 페널티를 부여하여 (즉, PLWSR 및 PLWGC) 에이전트의 효율성을 평가한다. 데이터셋 및 지표에 대한 자세한 내용은 Section A에 제공되어 있다.
4.3 Comparison with State of the Arts
우리는 먼저 우리의 방법을 state-of-the-art 방법들(Blukis et al. 2021; Min et al. 2022; Kim et al. 2023; Song et al. 2023)과 비교하고, 그 결과를 Table 1에 요약하였다. (Min et al. 2022; Kim et al. 2023; Blukis et al. 2021)을 따라, 우리는 에이전트의 성능을 다음 두 가지 설정으로 보고한다:
- **'Goal instruction only'**로 표시된 목표 진술(goal statement)만 사용하는 경우,
- **'Goal instructions+Sequential instructions'**로 표시된 목표 진술과 단계별 지시(step-by-step instructions)를 모두 사용하는 경우.
첫째, 우리는 **플래너 학습에 많은 양의 데이터를 요구하는 방법들(HLSM, FILM, CAPEAM)**에서 full-shot 설정에서 few-shot 설정으로 전환할 때 성능이 크게 하락하는 것을 관찰했다. 이는 제한된 학습 예시만으로 task 수행 에이전트를 학습하는 것이 상당한 도전 과제임을 시사한다. 데이터 부족은 다양한 task, 객체, 환경에 대한 모델 학습을 방해하여 일반화에 어려움을 초래할 수 있기 때문이다.
우리는 이어서 LLM을 사용하여 소수의 학습 예시만으로 task를 학습하는 최근 연구(Song et al. 2023)와 결과를 비교한다. 우리는 (Zheng et al. 2023)에서 보여주듯이, 성능이 낮은 비교 모델을 포함하여 독점 및 오픈 소스 language model 모두를 탐색한다.
비교적 성능이 낮은 language model (예: LLaMA2 (Touvron et al. 2023))을 사용했음에도 불구하고, 우리가 제안하는 에이전트는 'Goal instructions + Sequential instructions'와 'Goal instruction only' 두 가지 설정 모두에서 unseen 환경의 모든 지표에서 여전히 우수한 성능을 보인다. 이는 우리의 방법이 효과적임을 의미한다. 또한, 예상대로 GPT-4와 같은 더 우수한 language model을 사용하면 우리 에이전트의 성능을 최대 24.46%까지 크게 향상시킬 수 있다.
플래너 정확도 비교 (Planner Accuracy Comparison)
**정적 계획(static planning)**으로 불리는 초기 액션 시퀀스 생성 플래너의 성능을 조사하기 위해, 우리는 각 에이전트의 replanning 전략을 제거하고 우리 에이전트와 최근 LLM 기반 계획 방법들(Song et al. 2023; Ahn et al. 2022)의 정확도를 비교하여 그 결과를 Table 2에 보고한다.
계획(planning)에서 LLM의 영향을 분리하기 위해, 우리는 다양한 LLM을 사용하여 방법들을 검증한다. 우리는 **MMP를 탑재한 우리 에이전트('FLARE (w/o EAR)'로 표시)**가 모든 LLM에 걸쳐 seen 및 unseen 환경 모두에서 이전 연구(Song et al. 2023)보다 눈에 띄는 정확도 차이로 지속적으로 우수한 성능을 보인다는 것을 관찰했다. 이는 우리 MMP의 개선이 특정 LLM 선택에 기인한 것이 아님을 시사한다.
Table 2: 플래너 정확도 비교. 'Seen Acc.'와 'Unseen Acc.'는 각각 valid seen 및 unseen fold에서의 플래너 정확도를 나타낸다. 계획은 ground-truth 계획과 일치할 때 정확한 것으로 간주된다. 플래너 정확도만을 비교하기 위해, LLM-Planner와 FLARE에서 replanning을 생략했으며, 이는 각각 'Static'과 'w/o EAR'로 표시된다.
| LLM | Method | Seen Acc. | Unseen Acc. |
|---|---|---|---|
| LLaMA2 | LLM-Planner (Static) (Song et al. 2023) | 0.006 | 0.002 |
| LLaMA2 | FLARE (w/o EAR) | 18.54 | 22.29 |
| Vicuna | LLM-Planner (Static) (Song et al. 2023) | 8.17 | 7.06 |
| Vicuna | FLARE (w/o EAR) | 24.51 | 33.62 |
| GPT-3.5 | LLM-Planner (Static) (Song et al. 2023) | 29.78 | 31.67 |
| GPT-3.5 | FLARE (w/o EAR) | 46.10 | 55.66 |
| GPT-4 | LLM-Planner (Static) (Song et al. 2023) | 31.54 | 30.12 |
| GPT-4 | FLARE (w/o EAR) | 61.34 | 67.48 |
Table 3: Ablation study. 각 지표에 대해 PLW 지표가 괄호 안에 제시되어 있다. MMP와 EAR은 각각 'Multi-Modal Planner'와 'Environment Adaptive Replanning'을 나타낸다. 각 구성 요소가 에이전트 성능에 기여함을 관찰할 수 있다.
| # | MMP | EAR | Test Seen | Test Unseen | ||
|---|---|---|---|---|---|---|
| SR | GC | SR | GC | |||
| (a) | 32.55 (12.17) | 42.02 (16.94) | 31.79 (12.21) | 43.94 (17.44) | ||
| (b) | 30.20 (12.13) | 41.26 (17.27) | 30.35 (11.62) | 42.40 (16.66) | ||
| (c) | 30.79 (11.98) | 40.20 (16.51) | 30.28 (12.01) | 42.48 (17.03) | ||
| (d) | 28.05 (11.48) | 38.64 (16.23) | 28.58 (11.82) | 39.92 (16.13) |
4.4 Ablation Study
우리는 FLARE에서 제안된 구성 요소들을 분석하기 위해 정량적인 ablation study를 수행했으며, 그 결과를 Table 3에 요약하였다. 언어 모델로는 GPT-4의 토큰 생성 비용이 훨씬 높기 때문에 GPT-3.5를 선택하였다.
Instruction: Put clean soap on the counter.

Figure 5: 제안된 multi-modal planner (MMP)의 이점. MMP가 없는 에이전트는 task를 잘못 해석하여 단순히 SoapBar를 SinkBasin에 놓는다. 이와 대조적으로, MMP를 갖춘 에이전트는 청소라는 목표를 이해하는 것처럼 보이며, 그럴듯한 계획을 생성하고 성공적으로 task를 완료한다.
Multi-Modal Planner (MMP) 없이
먼저, 우리 방법에서 'MMP'를 제거하고 실험을 진행했다. 이 경우 에이전트는 환경 상태를 고려하지 않고 unimodal 유사성만을 이용해 데이터셋에서 in-context 예시를 검색한다. 제안된 구성 요소가 없으면, 우리는 instruction 유사성에 기반하여 in-context 예시를 선택한다. prompt가 단일 모달리티만을 반영하기 때문에, 에이전트는 환경적 단서를 놓치고 task 요구 사항을 잘못 해석할 수 있으며, 이는 seen 및 unseen split 모두에서 성능 저하로 이어진다 ((#(a) vs. (#b)) 참조).
Environment Adaptive Replanning (EAR) 없이
다음으로, 에이전트에서 'EAR'를 제거하고 실험을 진행했다. EAR가 없으면 에이전트는 언어 변형을 처리할 수 없으며, 종종 자연어 instruction을 잘못 해석하여 잘못된 subgoal을 설정하게 된다. 우리는 seen 및 unseen split 모두에서 SR(Success Rate)이 눈에 띄게 하락하는 것을 관찰했다 (각각 1.76%p, 1.51%p 하락) ((#(a) vs. (#c)) 참조). 이는 LLM이 에이전트가 배치된 환경에서 grounded plan을 생성하는 데 종종 실패하여, 에이전트가 존재하지 않을 수 있는 객체를 찾아 헤매게 되고 결국 task 실패로 이어짐을 시사한다.
두 구성 요소 모두 없이
제안된 구성 요소가 모두 없으면, 에이전트는 현재 task와 일치하지 않을 수 있는 초기 계획에만 고수한다. 예상대로, 'MMP'와 'EAR'가 모두 없는 우리 에이전트는 둘 중 하나라도 갖춘 에이전트들 중에서 가장 낮은 성능을 달성한다 ((#(d) vs. (#a,b,c)) 참조). 또한, 멀티모달 플래닝과 환경 적응형 리플래닝을 모두 사용하는 것이 둘 중 하나만 사용하는 것보다 성능을 향상시킨다는 것을 관찰했다 ((#(d) #(b, c)) vs. (#(d) #(a))). 이는 두 구성 요소가 서로 보완적임을 의미한다.
4.5 Qualitative Analysis
우리는 여러 정성적 결과들을 통해 우리의 방법을 분석하고, 그 결과를 Figure 5, 6 및 Section C에 제시한다.
Instruction: Place a box with a remote in it on the step with the statue on it.
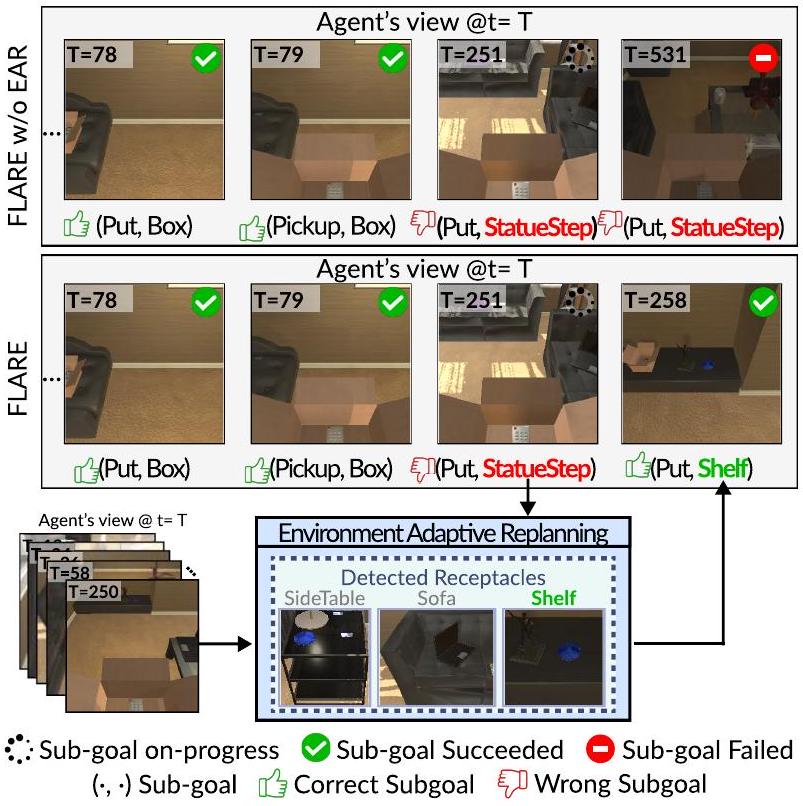
Figure 6: 제안된 **Environment Adaptive Replanning (EAR)**의 이점. 에이전트가 특정 단계에서 지정된 객체를 찾지 못하면, EAR이 계획을 조정한다. EAR은 내비게이션 중 오해의 소지가 있는 객체(misleading object)와 감지된 객체(detected object) 간의 유사성을 측정한다. 그런 다음 이전 객체를 대체할 가장 의미적으로 유사한 객체를 선택한다.
Multi-Modal Planner (MMP). 멀티모달 플래닝의 이점을 조사하기 위해 Figure 5에 정성적 예시를 제시한다. MMP는 멀티모달 쿼리를 통해 현재 task와 관련된 예시를 검색하므로, 대규모 언어 모델이 더 그럴듯한 subgoal을 생성하도록 유도한다.
MMP가 없는 에이전트는 언어 지시의 task context를 이해하지 못하여 부적절한 subgoal을 생성하고, 이는 SoapBar를 SinkBasin에 놓는 결과로 이어진다. 그 결과, 에이전트는 빈 손으로 Put 액션을 실행할 수 없으므로 생성된 subgoal 시퀀스를 진행하지 못한다. 대조적으로, MMP를 갖춘 에이전트는 LLM으로부터 사전 지식을 성공적으로 추출하는 것으로 보인다. 에이전트는 SoapBar를 집어 들고, SinkBasin에서 닦은 다음, 최종적으로 CounterTop에 놓는 만족스러운 subgoal 시퀀스를 생성한다.
Environment Adaptive Replanning (EAR). 다음으로 EAR의 이점을 조사한다. 에이전트가 지정된 객체를 찾지 못할 때, EAR은 시각적 단서를 통해 ungrounded plan을 조정한다.
객체를 지칭하는 다양한 방식 때문에, 이러한 다양성으로 인해 혼란을 겪는 LLM은 ungrounded subgoal을 생성할 수 있다. 예를 들어, Figure 6은 에이전트에게 Box를 '조각상이 있는 계단(the step with the statue on it)'에 놓으라고 지시하는 시나리오를 보여준다. 주어진 정보를 최대화하는 LLM은 **(Put, Box, StatueStep)**을 subgoal로 생성하여, 에이전트가 Box를 들고 StatueStep을 찾아 헤매게 만든다.
EAR이 없는 에이전트는 현재 subgoal이 부적절한지(즉, StatueStep이 존재하지 않는지) 구별하지 못하고, 장면을 끝없이 헤매며 수용 객체를 지정하지 못하는 것을 관찰했다. 반대로, EAR을 갖춘 에이전트는 처음에는 StatueStep을 찾기 시작하고, StatueStep이 장면에 없을 수 있다는 것을 인지한다. 부적절한 객체를 장면에 있는 가장 관련성 높은 객체(즉, StatueShelf Shelf)로 교체한 후, 에이전트는 수정된 subgoal을 실행한다.
 Figure 7: 로봇 task 애플리케이션의 예시. Baseline 모델 (Zeng et al. 2023)은 모호한 지시(예: tool)로 인해 ungrounded plan을 생성한다. 대조적으로, FLARE는 grounded plan을 생성하고 액션을 성공적으로 실행한다.
Figure 7: 로봇 task 애플리케이션의 예시. Baseline 모델 (Zeng et al. 2023)은 모호한 지시(예: tool)로 인해 ungrounded plan을 생성한다. 대조적으로, FLARE는 grounded plan을 생성하고 액션을 성공적으로 실행한다.
4.6 Application in Robotic Task Planning
우리는 제안하는 FLARE의 다른 로봇 task 애플리케이션에 대한 일반화 가능성을 입증한다. 구체적으로, 우리는 UR5 로봇 팔이 있는 시뮬레이션된 테이블탑 환경을 사용하며, Figure 7에서 FLARE와 baseline 모델 간의 비교를 보여준다. 우리는 few-shot 로봇 계획(robot planning)에서의 효과성 때문에 **(Zeng et al. 2023)**을 baseline 모델로 선택한다. 두 모델 모두 GPT-3.5를 LLM으로 사용하여 sub-goal을 생성하고, 환경의 메타데이터를 사용하여 end effector pose를 예측하는 privileged low-level policy를 사용한다.
우리는 FLARE가 지시된 대로 객체를 성공적으로 재배치하는 것을 관찰했으며, 이는 grounded execution을 위한 계획 능력을 보여준다. 이와 대조적으로, baseline (Zeng et al. 2023)은 ungrounded plan(예: 환경에 존재하지 않는 ScrewDriver를 집으려고 시도)으로 인해 실패한다.
5 Conclusion
우리는 시각 입력으로 얻은 환경 상태와 언어 지시를 모두 반영하여 장기적인 task를 소수의 데이터만으로 달성하기 위한 상세 계획(즉, subgoal)을 생성하는 멀티모달 planner를 갖춘 FLARE를 제안한다. 또한, 이 모델은 LLM을 사용하지 않고도 물리적으로 grounding된 계획을 생성하기 위해 잘못된 subgoal의 부분집합만을 수정하여 계산적으로 효율적인 replanning을 가능하게 한다. 우리는 ALFRED (Shridhar et al. 2020) 벤치마크에서 제안된 구성 요소들의 효과를 실증적으로 검증했으며, 우리의 FLARE가 few-shot 설정에서 모든 지표에서 기존 state-of-the-art 방법들을 상당한 차이로 능가함을 확인했다.
한계점 및 향후 연구 (Limitations and future work)
우리의 방법은 매우 적은 양의 학습 데이터(0.5%)만을 필요로 하지만, 여전히 학습 데이터가 필요하다는 한계가 있다. 우리는 어떠한 학습 데이터도 필요 없이, 대규모 언어 모델(LLM)의 도움을 받아 탐색을 통해 환경을 학습하는 agent를 개발하는 것을 목표로 한다.
Acknowledgments
본 연구는 한국 정부(MSIT)의 IITP 보조금(No.RS-2022-II220077, No.RS-2022-II220113, No.RS-2022II220959, No.RS-2022-II220871, No.RS-2021-II211343 (SNU AI), No.RS-2021-II212068 (AI Innov. Hub), No.RS-2022-II220951) 지원을 받아 수행되었다.
Supplemenatry Materials for Multi-Modal Grounded Planning and Efficient Replanning For Learning Embodied Agents with A Few Examples
A Details of ALFRED Benchmark
ALFRED (Action Learning From Realistic Environments and Directives) 벤치마크 (Shridhar et al. 2020)는 시뮬레이션된 가정 환경 내에서 다양한 자연어 지시를 이해하고 실행하는 embodied agent의 능력을 테스트하기 위해 설계되었다. 이 벤치마크는 115가지의 고유한 객체 유형을 포함하는 7가지 task 유형으로 구성된다. 목표는 자연어 지시를 이해하고 long-horizon task를 완료하는 것이다. 미리 정의된 task 조건을 충족하기 위해 agent는 일련의 action을 실행하고 환경 내 객체와 상호작용하기 위한 객체 마스크를 생성해야 한다. 각 task는 높은 수준의 자연어 지시와 함께, **agent의 action을 구체적으로 안내하는 상세하고 낮은 수준의 지시(directive)**를 포함한다. 이러한 조건 중 하나라도 충족하지 못하면 해당 task는 실패로 간주된다.
ALFRED는 세 가지 고유한 split을 제공한다: 'training', 'validation', 'test'. Agent는 'training' split으로 학습할 수 있으며, 'validation' split에서는 해당 split의 task에 대한 ground-truth 정보에 접근하여 접근 방식을 검증할 수 있다. 이후 agent는 task와 관련된 ground-truth 데이터 없이 'validation' 및 'test' split에서 평가된다.
매 timestep마다 환경 내 agent는 이미지 형태의 egocentric RGB 시각 입력을 기반으로 작동한다. 이 입력으로부터 agent는 미리 정의된 action space에서 적절한 action을 선택해야 하며, 여기에는 탐색(navigational) 및 객체 상호작용(object interaction) 명령이 모두 포함된다. 이러한 action과 함께 agent는 시각 입력과 동일한 해상도(즉, )에 해당하는 이진 객체 마스크를 생성하여 상호작용 대상을 지정한다.
Action 명령은 MoveAhead, RotateRight, RotateLeft, LookUp, LookDown과 같은 탐색 action으로 구성된다. 상호작용 action에는 PickupObject, PutObject, OpenObject, CloseObject, ToggleObjectOn, ToggleObjectOff, SliceObject가 포함된다. Stop action은 agent가 task를 종료하기로 결정했음을 나타내며, 이상적으로는 모든 조건이 충족되었을 때 수행된다.
ALFRED는 agent의 성능을 포괄적으로 정량화하기 위해 여러 metric을 사용한다. **주요 metric은 Success Rate (SR)**이며, 이는 완전히 완료된 task의 비율을 측정한다. **보조 metric인 Goal-Condition Success Rate (GC)**는 agent가 필요한 조건 중 일부만 충족한 부분적으로 완료된 task를 고려한다. 마지막으로, Path Length Weighted (PLW) 점수는 agent가 수행한 action 시퀀스의 길이를 기반으로 SR 및 GC metric(즉, PLWSR 및 PLWGC)을 조정한다. 불필요한 탐색 없이 최단 경로를 사용하는 expert demonstration은 일반적으로 최적으로 간주된다. agent가 expert보다 두 배 더 오래 걸려 task를 완료하면, 절반의 점수만 얻는다.
B Additional Implementation Details
B. 1 Semantic Mapping
우리는 먼저 에이전트의 egocentric RGB 입력으로부터 instance segmentation과 depth를 예측한다. 그런 다음 이 예측들을 point cloud로 변환하고, 각 point에 해당 semantic label을 할당하여 labeled voxel을 생성한다. 2D semantic map을 생성하기 위해, 마지막으로 이 3D voxel들을 수직 차원을 따라 합산하여 집계한다. 모델은 매 단계마다 새로 얻은 partial map들을 통합하여 global map을 지속적으로 업데이트한다.
B. 2 LLM and Prompt
우리는 FLARE 구현을 위해 네 가지 대규모 언어 모델을 사용한다. 독점 모델로는 GPT-3.5-turbo-instruct (본문에서는 GPT-3.5로 지칭)와 GPT-4-0125-PREVIEW (본문에서는 GPT-4로 지칭)를 사용한다. 재현성을 보장하기 위해 temperature를 0으로 설정하고, 허용되는 모든 출력 토큰(예: Sec. 3.1의 허용 가능한 A, O, R)에 0.1의 logit bias를 적용한다. 오픈소스 모델로는 LLAMA-2-13B-CHAT (본문에서는 LLaMa2-13B로 지칭)와 VICUNA-13B-V1.5 (본문에서는 Vicuna-13B로 지칭)를 사용한다. 두 오픈소스 모델 모두 temperature 값을 기본값으로 설정한다.
Figure 8은 MMP (Sec. 3.1)에서 사용된 prompt의 예시를 보여준다. 우리는 먼저 task에 대한 설명과 허용되는 모든 action 및 object 목록을 제공한다 (분홍색으로 표시된 블록). 그런 다음, 'Task description', 'Step-by-step instructions', 'Next plan' 헤더와 함께 검색된 예시들을 in-context 예시로 제시한다 (파란색으로 표시된 블록). 마지막으로, 현재 task를 in-context 예시와 동일한 형식으로 보여주며, 'Next plan' 헤더 뒤는 비워둔다 (녹색으로 표시된 블록). 'Goal instruction only' 설정에서는 step-by-step instructions 사용이 금지되므로, 검색된 예시와 현재 task 모두에서 prompt 내의 step-by-step instructions를 제거한다.
C Additional Qualitative Examples
우리는 Figure 6과 동일한 방식으로 Figure 9와 10에 추가적인 정성적 예시를 제공한다. task를 성공적으로 완료하려면 단 하나의 subgoal도 실패해서는 안 된다. Figure 9는 EAR이 없는 에이전트(즉, FLARE w/o EAR)가 머그잔을 성공적으로 찾아 데우는 예시를 보여준다. 그러나 의도한 수납 공간에 물건을 놓는 데 실패하여 task는 실패로 간주된다. 이와 대조적으로, FLARE는 CoffeeMaker를 찾을 수 없으므로 EAR에 replanning을 요청한다. EAR은 CoffeMachine이 CoffeeMaker와 가장 의미적으로 유사하다고 추론하고 subgoal을 수정한다.
첫 번째 subgoal이 잘못되면 에이전트는 후속 subgoal을 달성하지 못하고, 감지할 수 없는 개체를 목적 없이 검색하게 된다. Figure 10은 EAR이 없는 에이전트(즉, FLARE w/o EAR)가 목표 조건(GC)을 전혀 달성하지 못함을 보여준다. 유사한 외형과 기능 때문에 오퍼레이터가 개체를 머그잔이 아닌 컵으로 잘못 식별하여, 에이전트는 컵을 끝없이 찾아 방을 헤매게 된다.
Create a high-level plan for completing a household task using
the allowed actions and objects.
Allowed actions: ToggleObject, CleanObject, HeatObject,
PickupObject, SliceObject, CoolObject, PutObject
Allowed objects: AlarmClock, Apple, AppleSliced, ArmChair,
BaseballBat, BasketBall, Bathtub, Bed, Book, Bowl, Box, Bread,
BreadSliced, ButterKnife, CD, Cabinet, Candle, Cart,
CellPhone, Cloth, CoffeeMachine, CoffeeTable, CounterTop,
CreditCard, Cup, Desk, DeskLamp, DiningTable, DishSponge,
Drawer, Dresser, Egg, FloorLamp, Fork, Fridge, GarbageCan,
Glassbottle, HandTowel, Kettle, KeyChain, Knife, Ladle,
Laptop, Lettuce, LettuceSliced, Microwave, Mug, Newspaper,
Ottoman, Pan, Pen, Pencil, PepperShaker, Pillow, Plate,
Plunger, Pot, Potato, PotatoSliced, RemoteControl, Safe,
SaltShaker, Shelf, SideTable, Sink, SoapBar, SoapBottle, Sofa,
Spatula, Spoon, SprayBottle, Statue, StoveBurner, TennisRacket,
TissueBox, Toilet, ToiletPaper, ToiletPaperHanger, Tomato,
TomatoSliced, Vase, Watch, WateringCan, WineBottle
Task description: pick up a pencil and view it in the light of
the lamp
Step-by-step instructions: turn around and walk a little bit
towards the bed and turn left and walk straight towards the
shelf and turn left pick up the pencil on the bottom shelf
turn left and walk straight then turn left again towards the
bed and walk straight towards the door then turn right and
walk straight towards the mirror and turn right at the table
edge turn the lamp on at the edge of the table
Next plan: PickupObject, Pencil, 0, ToggleObject, DeskLamp, 0
!
Task description: examine keys with the lamp
Step-by-step instructions: walk across room to the wall, turn
right to face lamp turn the lamp on pick up the keys that are
on the table
Next plan: ToggleObject, DeskLamp, 0, PickupObject, KeyChain, 0
Task description: examine a grey bowl in the light of a lamp
Step-by-step instructions: turn right and begin walking across
the room, then hang a right and walk up to the end table to
the left of the couch . pick up the grey bowl off of the end
table . turn left and take a step forward, then turn right to
face the lamp . turn on the small lamp on the end table.
Next plan:
Figure 8: Multi-Modal Planner에서 사용된 prompt 예시. 분홍색으로 표시된 블록은 task에 대한 설명을 제공한다. 파란색으로 표시된 블록은 in-context 예시 역할을 한다. 마지막으로, 녹색으로 표시된 블록은 현재 task를 나타낸다.
이와 대조적으로, EAR을 갖춘 에이전트(즉, FLARE)는 지시된 Cup이 오해의 소지가 있음을 인지하고, 장면에 제시된 Mug로 대체한다. 그에 따라 계획을 조정한 후, 에이전트는 나머지 subgoal을 수행하고 궁극적으로 task를 완료한다.
D Robotic Application
우리는 시뮬레이션 환경으로 PyBullet을, 로봇으로는 병렬 그리퍼가 장착된 UR5 로봇을 사용하여 시뮬레이션된 로봇 task에서 FLARE의 효과를 평가한다. 먼저 GPT-4o를 사용하여 65개의 instruction과 subgoal 쌍으로 구성된 작은 훈련 데이터셋을 생성한다. 각 시나리오에서는 3개에서 6개의 객체가 테이블 위에 무작위로 배치되어 로봇에게 다양한 task를 제공한다. UR5 로봇의 목표는 "레몬과 도구를 각 모서리에 놓으세요"와 같은 instruction을 정확하게 따르고, 객체를 정확하게 집어 옮기는 것이다.
FLARE와 baseline 모델(Zeng et al. 2023) 모두 **GPT-3.5-TURBO-INSTRUCT (본문에서는 GPT3.5로 지칭)**를 LLM으로 사용하여 고수준 subgoal을 생성한다. 저수준 액션 예측을 위해 두 모델 모두 privileged policy를 사용한다. 각 고수준 subgoal이 주어지면 로봇은 시뮬레이션 환경의 메타데이터를 사용하여 목표 좌표를 얻고, **역기구학(inverse kinematics)**을 통해 관절을 작동시킨다.
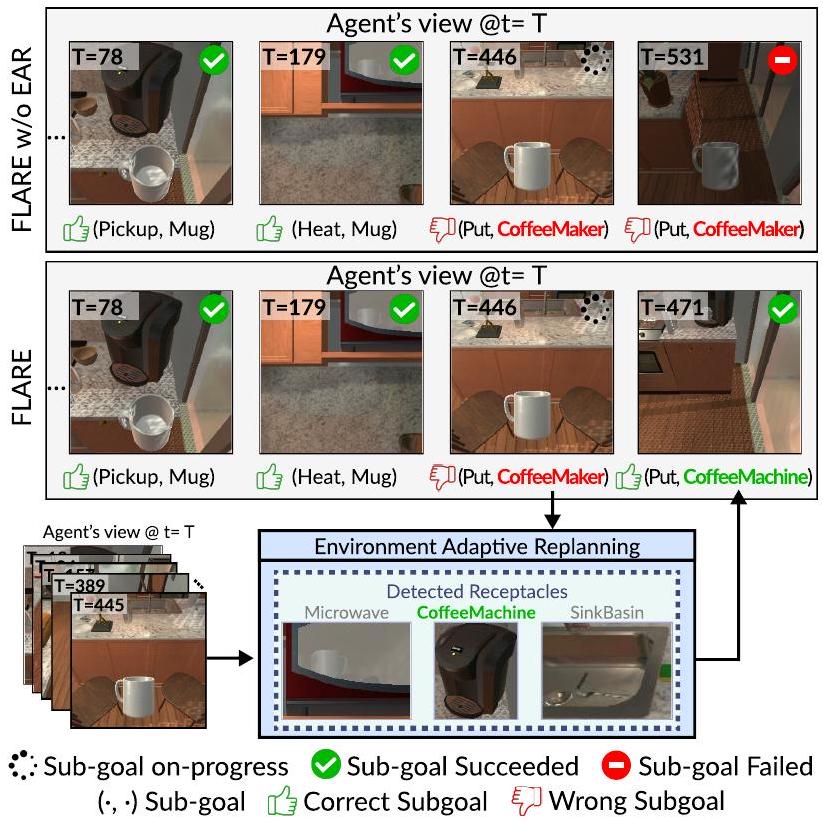
Figure 9: 'Environmental Adaptive Replanning' (EAR) 유무에 따른 우리 에이전트의 정성적 예시. EAR이 없는 FLARE는 CoffeMaker를 찾지 못해 task 실패로 이어진다. 반대로, FLARE는 EAR에 재계획(replanning)을 요청하고, EAR은 부분적으로 잘못된 subgoal의 하위 집합(즉, CoffeeMaker CoffeeMachine)을 교체한다.
Figure 10: 'Environmental Adaptive Replanning' (EAR) 유무에 따른 우리 에이전트의 또 다른 정성적 예시. EAR이 없는 FLARE는 Cup을 찾지 못하고 목표 조건(GC)을 전혀 달성하지 못한다. 반대로, FLARE는 EAR에 재계획(replanning)을 요청하고, EAR은 부분적으로 잘못된 subgoal의 하위 집합(즉, Cup Mug)을 교체한다.