MiniGPT-4: 고급 LLM을 활용한 시각-언어 이해 능력의 향상
MiniGPT-4는 frozen visual encoder와 frozen advanced LLM (Vicuna)를 단 하나의 projection layer로 연결하여, GPT-4와 유사한 고급 멀티모달 능력을 구현하는 모델입니다. 이 논문은 별도의 복잡한 모듈 없이, 시각적 특징을 강력한 LLM과 정렬하는 것만으로도 이미지 상세 묘사, 손으로 그린 초안으로 웹사이트 제작, 이미지 기반 시 작성 등 다양한 emergent abilities를 발현할 수 있음을 보여줍니다. 특히, 초반 학습에서 발생하는 부자연스러운 언어 생성을 해결하기 위해, 2단계에서 고품질 이미지 설명 데이터셋으로 미세 조정하여 모델의 신뢰성과 사용성을 크게 향상시켰습니다. 논문 제목: MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
논문 요약: MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
- 논문 링크: https://arxiv.org/abs/2304.10592
- 저자: Deyao Zhu*, Jun Chen*, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny (King Abdullah University of Science and Technology)
- 발표 시기: 2023년, arXiv preprint
- 주요 키워드: Vision-Language Model, Large Language Model, Multimodal, Emergent Abilities, LLM
1. 연구 배경 및 문제 정의
- 문제 정의:
GPT-4와 같은 최신 멀티모달 모델이 놀라운 시각-언어 이해 및 생성 능력(예: 손글씨 텍스트로부터 웹사이트 생성, 이미지 내 유머 식별)을 보여주었으나, 그 기술적 세부 사항은 공개되지 않고 있습니다. 이 논문은 이러한 고급 능력이 정교한 대규모 언어 모델(LLM)의 활용에서 비롯된다는 가설을 검증하고, 기존 Vision-Language 모델(VLM)에서는 보기 어려웠던 고급 멀티모달 능력을 구현하는 것을 목표로 합니다. - 기존 접근 방식:
기존 VLM(예: BLIP-2, Kosmos-1)은 GPT-4와 같은 고급 멀티모달 능력을 보여주지 못했으며, 이는 상대적으로 덜 강력한 LLM을 사용했기 때문으로 추정됩니다. 또한, 단순히 대규모 이미지-캡션 쌍으로 학습할 경우 부자연스러운 언어 생성(반복, 단편화) 문제가 발생하여 인간과 유창한 시각적 대화를 수행하기 어렵다는 한계가 있었습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 고정된 시각 인코더와 고정된 고급 LLM(Vicuna)을 단 하나의 선형 투영 레이어로 정렬하는 것만으로 GPT-4와 유사한 고급 멀티모달 능력(상세 이미지 묘사, 손글씨 초안 웹사이트 생성 등)을 구현할 수 있음을 최초로 입증했습니다.
- 이미지 기반 시/이야기 작성, 요리 레시피 생성, 이미지 속 제품 광고 생성 등 기존 모델에서 볼 수 없었던 다양한 새로운 멀티모달 능력(emergent abilities)을 발견했습니다.
- 초기 학습 단계의 부자연스러운 언어 생성 문제를 해결하기 위해, 고품질의 상세 이미지 설명 데이터셋을 큐레이션하고 이를 활용한 2단계 미세 조정(fine-tuning) 과정을 제안하여 모델의 생성 신뢰성과 유용성을 크게 향상시켰습니다.
- 단일 투영 레이어 학습만으로 효율적인 학습(4 A100 GPU로 약 10시간)이 가능함을 보여주었습니다.
- 제안 방법:
MiniGPT-4는 사전 학습된 BLIP-2의 시각 인코더(ViT-G/14 및 Q-Former)와 사전 학습된 고급 LLM인 Vicuna를 단 하나의 선형 투영(projection) 레이어로 연결합니다. 시각 인코더와 LLM은 고정(frozen)하고, 투영 레이어만 학습합니다. 모델은 다음의 2단계 학습 전략을 통해 구축됩니다:- 1단계 (사전 학습): 대규모의 정렬된 이미지-텍스트 쌍(LAION, Conceptual Captions, SBU 등 약 500만 쌍)을 사용하여 투영 레이어를 학습시켜 시각적 특징을 Vicuna LLM에 정렬합니다. 이 단계에서 모델은 풍부한 지식을 습득하지만, 부자연스러운 언어 출력(반복, 단편화 등) 문제가 발생합니다.
- 2단계 (미세 조정): 1단계의 문제 해결을 위해, 1단계 모델과 ChatGPT를 활용하여 3,500개의 고품질 상세 이미지 설명 데이터셋을 큐레이션합니다. 이 데이터셋과 설계된 대화형 템플릿을 사용하여 모델을 미세 조정합니다. 이 과정을 통해 모델의 언어 생성 신뢰성과 유용성이 크게 향상됩니다.
3. 실험 결과
- 데이터셋:
- 학습 데이터셋:
- 1단계 사전 학습: LAION, Conceptual Captions, SBU 등 약 500만 개의 이미지-텍스트 쌍. (4 A100 GPU, 약 10시간 소요)
- 2단계 미세 조정: 자체 큐레이션한 3,500개의 고품질 상세 이미지 설명 쌍. (1 A100 GPU, 약 7분 소요)
- 평가 데이터셋:
- 정성적 평가: BLIP-2와 비교하여 상세 이미지 묘사, 밈 해석, 광고 생성, 요리 레시피 생성, 시 작성, 손글씨 초안 웹사이트 생성 등 8가지 다양한 예시.
- 정량적 평가 (고급 능력): 밈 해석, 레시피 생성, 광고 제작, 시 작문 4가지 태스크에 대해 각 25개 이미지로 구성된 총 100개 이미지의 자체 구축 데이터셋. (인간 평가)
- 정량적 평가 (이미지 캡셔닝): COCO caption 벤치마크. (ChatGPT를 활용한 생성 캡션의 Ground Truth 포함 여부 평가)
- 정량적 평가 (VQA): AOK-VQA, GQA.
- 학습 데이터셋:
- 주요 결과:
- 고급 멀티모달 능력: MiniGPT-4는 상세 이미지 묘사, 밈 해석, 이미지 기반 광고/레시피/시 생성, 손글씨 초안 웹사이트 제작 등 다양한 고급 멀티모달 능력에서 BLIP-2를 크게 능가했습니다. 특히, 4가지 고급 태스크(밈 해석, 레시피 생성, 광고 제작, 시 작문)에서 요청의 65%를 성공적으로 처리하여 BLIP-2(5%) 대비 압도적인 성능을 보였습니다.
- 이미지 캡셔닝: COCO 캡션 벤치마크에서 MiniGPT-4는 생성된 캡션이 Ground Truth의 모든 시각 객체 및 관계를 포함하는 비율이 66.2%로, BLIP-2(27.5%)보다 훨씬 정확했습니다.
- 2단계 미세 조정의 효과: 2단계 미세 조정을 통해 상세 캡션 생성의 실패율이 35%에서 2%로, 시 생성의 실패율이 32%에서 1%로 크게 감소하여 언어 생성의 자연스러움과 신뢰성이 향상됨을 확인했습니다.
- 아키텍처 분석: 단일 선형 투영 레이어만으로도 시각 인코더와 LLM을 효과적으로 정렬할 수 있음을 확인했습니다. Q-Former 제거 시에도 유사한 고급 능력을 보여, Q-Former가 이러한 고급 능력에 결정적인 역할을 하지 않음을 시사했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 효율성과 단순성: 고정된 시각 인코더와 LLM 사이에 단 하나의 선형 투영 레이어만 학습하여 GPT-4와 유사한 고급 멀티모달 능력을 달성했다는 점이 매우 인상적입니다. 이는 복잡한 아키텍처나 방대한 학습 데이터 없이도 강력한 성능을 낼 수 있음을 보여줍니다.
- LLM의 중요성 입증: 강력한 LLM(Vicuna)을 활용하는 것이 고급 시각-언어 이해 능력 발현의 핵심임을 명확히 입증했습니다.
- 새로운 능력 발현: 이미지 기반 시/이야기 작성, 요리 레시피 생성, 손글씨 초안으로 웹사이트 제작 등 기존 모델에서는 볼 수 없었던 다양한 'emergent abilities'를 보여준 점이 흥미롭습니다.
- 2단계 학습의 효과: 초기 학습에서 발생하는 부자연스러운 언어 생성 문제를 고품질 데이터셋을 통한 2단계 미세 조정으로 효과적으로 해결하여 모델의 실용성을 크게 높였습니다.
- 단점/한계:
- 환각(Hallucination) 문제: LLM의 고질적인 문제인 환각 현상을 그대로 물려받아, 이미지에 존재하지 않는 정보를 생성하는 경향이 있습니다. 특히 긴 설명을 생성할 때 환각률이 높아집니다.
- 공간 정보 이해의 한계: 이미지 내 객체의 정확한 공간적 위치를 파악하는 데 어려움이 있습니다. 이는 공간 정보 이해를 위한 정렬된 데이터 부족에서 기인할 수 있습니다.
- 전통적인 VQA 벤치마크 성능: 논문의 주 목표는 아니지만, 전통적인 VQA 벤치마크에서는 BLIP-2 등 기존 모델에 비해 성능이 뒤처지는 한계가 있습니다. 이는 학습 용량 및 데이터 확장을 통해 개선될 여지가 있습니다.
- 응용 가능성:
- 고급 이미지 캡셔닝 및 설명: 시각 장애인을 위한 상세 이미지 설명, 콘텐츠 제작(블로그, 소셜 미디어), 이미지 검색 정확도 향상 등 다양한 분야에서 활용될 수 있습니다.
- 창의적 콘텐츠 생성: 이미지에서 영감을 받은 시, 이야기, 광고 문구 등을 자동으로 생성하여 작가, 마케터, 디자이너의 창작 활동을 지원할 수 있습니다.
- 지능형 멀티모달 챗봇: 이미지의 유머를 설명하거나, 음식 사진으로 레시피를 제공하는 등 시각 정보를 기반으로 더욱 정교하고 인간적인 대화가 가능한 챗봇 개발에 기여할 수 있습니다.
- 전문 분야 응용: 식물 질병 진단, 의료 영상 분석(추가 학습 필요), 이커머스 제품 설명 자동화 등 특정 도메인에서의 시각 정보 처리 및 응용 가능성이 높습니다.
- 웹 개발 보조: 손글씨 초안을 기반으로 웹사이트 코드를 생성하는 기능은 프론트엔드 개발의 초기 단계를 가속화하는 데 활용될 수 있습니다.
5. 추가 참고 자료
- https://minigpt-4.github.io/ (공식 프로젝트 페이지, 코드, 사전학습 모델, 데이터셋 제공)
Zhu, Deyao, et al. "Minigpt-4: Enhancing vision-language understanding with advanced large language models." arXiv preprint arXiv:2304.10592 (2023).
MiniGPT-4: <br> Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu*, Jun Chen*, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny<br>King Abdullah University of Science and Technology<br>{deyao.zhu, jun.chen, xiaoqian.shen,<br>xiang.li.1,mohamed.elhoseiny}@kaust.edu.sa
Abstract
최근 GPT-4는 손글씨 텍스트로부터 웹사이트를 직접 생성하거나 이미지 내의 유머러스한 요소를 식별하는 등 놀라운 멀티모달 능력을 보여주었다. 이러한 기능들은 이전의 vision-language model에서는 거의 관찰되지 않았다. 그러나 GPT-4의 기술적 세부 사항은 여전히 공개되지 않고 있다. 우리는 GPT-4의 향상된 멀티모달 생성 능력이 정교한 대규모 언어 모델(LLM)의 활용에서 비롯된다고 믿는다.
이러한 현상을 검증하기 위해, 우리는 고정된(frozen) visual encoder를 고정된(frozen) 고급 LLM인 Vicuna와 하나의 projection layer를 사용하여 정렬(align)하는 MiniGPT-4를 제시한다. 우리의 연구는 시각적 feature를 고급 대규모 언어 모델과 적절히 정렬하는 것만으로도 GPT-4가 보여준 수많은 고급 멀티모달 능력(예: 상세한 이미지 설명 생성, 손으로 그린 초안으로부터 웹사이트 생성 등)을 가질 수 있음을 처음으로 밝혀냈다.
나아가, 우리는 MiniGPT-4에서 다음과 같은 다른 새로운 능력들도 관찰했다:
- 주어진 이미지에서 영감을 받아 이야기나 시를 쓰는 능력,
- 음식 사진을 기반으로 사용자에게 요리법을 가르치는 능력 등.
실험에서 우리는 짧은 이미지 캡션 쌍으로 학습된 모델이 부자연스러운 언어 출력(예: 반복 및 단편화)을 생성할 수 있음을 발견했다. 이 문제를 해결하기 위해, 우리는 두 번째 학습 단계에서 상세한 이미지 설명 데이터셋을 큐레이션하여 모델을 fine-tune했으며, 그 결과 모델의 생성 신뢰성과 전반적인 유용성이 향상되었다.
우리의 코드, 사전학습된 모델 및 수집된 데이터셋은 https://minigpt-4.github.io/ 에서 확인할 수 있다.
1 Introduction
최근 몇 년간 **대규모 언어 모델(LLM)**은 급속한 발전을 경험했다 [Ouyang et al., 2022; OpenAI, 2022; Brown et al., 2020; Scao et al., 2022a; Touvron et al., 2023; Chowdhery et al., 2022; Hoffmann et al., 2022]. 탁월한 언어 이해 능력을 바탕으로, 이 모델들은 zero-shot 방식으로 다양한 복잡한 언어 task를 수행할 수 있다. 특히, 최근에는 대규모 멀티모달 모델인 GPT-4가 소개되었으며, vision-language 이해 및 생성 분야에서 인상적인 능력을 보여주었다 [OpenAI, 2023]. 예를 들어, GPT-4는 상세하고 정확한 이미지 설명을 생성하고, 특이한 시각 현상을 설명하며, 심지어 손글씨 텍스트 지시를 기반으로 웹사이트를 구축할 수도 있다.
GPT-4가 놀라운 vision-language 능력을 보여주었음에도 불구하고, 그 탁월한 능력의 배경이 되는 방법론은 여전히 미스터리이다 [OpenAI, 2023]. 우리는 이러한 인상적인 기술이 더욱 발전된 대규모 언어 모델(LLM)의 활용에서 비롯되었을 것이라고 믿는다. LLM은 GPT-3의 few-shot prompting 설정 [Brown et al., 2020]과 Wei et al. (2022)의 연구 결과 [Wei et al., 2022]에서 입증되었듯이, 다양한 emergent ability를 보여주었다. 이러한 emergent property는 소규모 모델에서는 찾기 어렵다. 이러한 emergent ability가 멀티모달 모델에도 적용될 수 있으며, 이것이 GPT-4의 인상적인 시각 설명 능력의 기반이 될 수 있다고 추측된다.
우리의 가설을 입증하기 위해, 우리는 MiniGPT-4라는 새로운 vision-language 모델을 제시한다. 이 모델은 LLaMA [Touvron et al., 2023]를 기반으로 구축되었으며, GPT-4의 평가에 따르면 ChatGPT 품질의 90%를 달성했다고 보고된 고급 대규모 언어 모델(LLM)인 Vicuna [Chiang et al., 2023]를 언어 decoder로 활용한다.
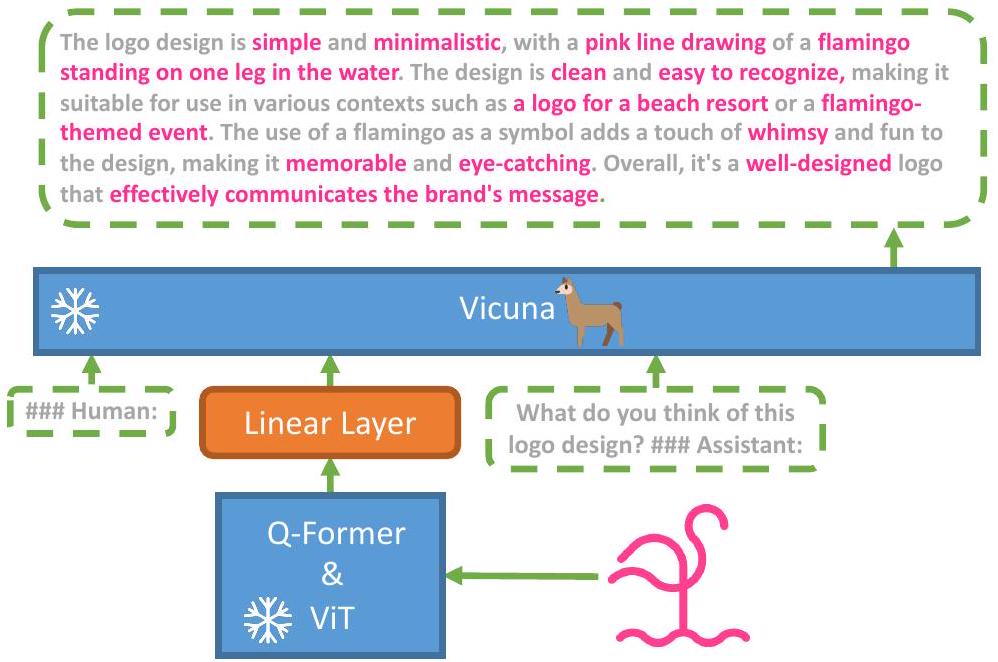
Figure 1: MiniGPT-4의 아키텍처. MiniGPT-4는 사전학습된 ViT와 Q-Former를 포함하는 vision encoder, 단일 linear projection layer, 그리고 고급 Vicuna large language model로 구성된다. MiniGPT-4는 visual feature를 Vicuna에 정렬하기 위해 linear projection layer만 학습하면 된다.
시각적 인지 측면에서는 BLIP-2 [Li et al., 2023]의 사전학습된 vision component를 동일하게 사용한다. 이 component는 EVA-CLIP [Fang et al., 2022]의 ViT-G/14와 Q-Former 네트워크로 구성된다. MiniGPT-4는 인코딩된 visual feature를 Vicuna language model에 정렬하기 위한 단일 projection layer를 추가하며, **다른 모든 vision 및 language component는 고정(freeze)**시킨다.
MiniGPT-4는 초기 20,000 스텝 동안 batch size 256으로 4개의 A100 GPU를 사용하여 학습된다. 이 학습은 LAION [Schuhmann et al., 2021], Conceptual Captions [Changpinyo et al., 2021; Sharma et al., 2018], SBU [Ordonez et al., 2011]의 이미지를 포함하는 결합된 이미지 캡셔닝 데이터셋을 활용하여 visual feature를 Vicuna language model에 정렬한다.
그럼에도 불구하고, 단순히 visual feature를 language model(LLM)에 정렬하는 것만으로는 **강력한 시각 대화 능력(visual conversation capabilities)**을 보장하기에 불충분하며, 이는 챗봇과 유사한 수준이다. 원시 이미지-텍스트 쌍에 내재된 노이즈는 저조한 언어 출력으로 이어질 수 있다. 따라서 우리는 생성된 언어의 자연스러움과 유용성을 향상시키기 위해, 3,500개의 상세한 이미지 설명 쌍을 추가로 수집하여 설계된 대화 템플릿으로 모델을 fine-tuning한다.
실험 결과, MiniGPT-4는 GPT-4가 보여준 것과 유사한 수많은 능력을 가지고 있음을 발견했다. 예를 들어, MiniGPT-4는 복잡한 이미지 설명을 생성하고, 손글씨 텍스트 지시를 기반으로 웹사이트를 생성하며, 특이한 시각 현상을 설명할 수 있다. 또한, 우리의 연구 결과는 MiniGPT-4가 GPT-4 시연에서는 보여지지 않은 다양한 흥미로운 능력도 가지고 있음을 밝혀냈다. 예를 들어, MiniGPT-4는 음식 사진으로부터 상세한 요리 레시피를 직접 생성하고, 이미지에서 영감을 받은 이야기나 시를 작성하며, 이미지 속 제품에 대한 광고를 작성하고, 사진에 나타난 문제를 식별하고 해당 해결책을 제공하며, 이미지로부터 사람, 영화 또는 예술에 대한 풍부한 사실을 직접 검색하는 등의 능력을 가지고 있다. 이러한 능력은 덜 강력한 language model을 사용하는 Kosmos-1 [Huang et al., 2023] 및 BLIP-2 [Li et al., 2023]와 같은 이전 vision-language 모델에서는 찾아볼 수 없었다. 이는 visual feature를 고급 language model과 통합하는 것이 vision-language 모델을 향상시키는 핵심 중 하나임을 더욱 입증한다.
우리의 주요 발견 사항을 요약하면 다음과 같다:
- 우리의 연구는 visual feature를 Vicuna와 같은 고급 large language model에 정렬함으로써, MiniGPT-4가 GPT-4 시연에서 나타난 것과 유사한 고급 vision-language 능력을 달성할 수 있다는 강력한 증거를 제시한다.
- 우리의 연구 결과는 단 하나의 projection layer를 학습하는 것만으로도 사전학습된 vision encoder를 large language model에 효과적으로 정렬할 수 있음을 시사한다. MiniGPT-4는 4개의 A100 GPU에서 약 10시간의 학습 시간만을 필요로 한다.
- 우리는 짧은 이미지 캡션 쌍을 사용하여 visual feature를 large language model에 단순히 정렬하는 것만으로는 충분히 좋은 성능의 모델을 개발할 수 없으며, 이는 부자연스러운 언어 생성으로 이어진다는 것을 발견했다. 작지만 상세한 이미지 설명 쌍으로 추가 fine-tuning을 수행하면 이러한 한계를 해결하고 유용성을 크게 향상시킬 수 있다.
2 Related Works
최근 몇 년간 **대규모 언어 모델(LLM)**은 학습 데이터의 확장과 파라미터 수의 증가에 힘입어 엄청난 성공을 거두었다. 초기 모델인 BERT (Devlin et al., 2018), GPT-2 (Radford et al., 2019), T5 (Raffel et al., 2020)는 이러한 발전의 토대를 마련했다. 이후 1,750억 개의 파라미터를 가진 GPT-3 (Brown et al., 2020)가 등장하여 수많은 언어 벤치마크에서 상당한 돌파구를 마련했다. 이러한 발전은 MegatronTuring NLG (Smith et al., 2022), Chinchilla (Hoffmann et al., 2022), PaLM (Chowdhery et al., 2022), OPT (Zhang et al., 2022), BLOOM (Scao et al., 2022b), LLaMA (Touvron et al., 2023) 등 다양한 대규모 언어 모델의 개발로 이어졌다. Wei et al. (Wei et al., 2022)은 대규모 모델에서만 나타나는 여러 emergent abilities를 추가로 발견했다. 이러한 능력의 출현은 대규모 언어 모델 개발에서 확장(scaling up)의 중요성을 강조한다. 더욱이, 사전학습된 대규모 언어 모델인 GPT-3를 인간의 의도, 지시 및 인간 피드백에 맞춰 정렬(align)함으로써, InstructGPT (Ouyang et al., 2022)와 ChatGPT (OpenAI, 2022)는 인간과의 대화형 상호작용을 가능하게 하고 다양하고 복잡한 질문에 답할 수 있게 되었다. 최근에는 Alpaca (Taori et al., 2023)와 Vicuna (Chiang et al., 2023)와 같은 여러 오픈소스 모델이 LLaMA (Touvron et al., 2023)를 기반으로 개발되었으며, 유사한 성능을 보인다.
사전학습된 LLM을 Vision-Language Task에 활용하기. 최근 몇 년 동안 autoregressive language model을 vision-language task의 decoder로 사용하는 경향이 크게 증가했다 (Chen et al., 2022; Huang et al., 2023; Yang et al., 2022; Tiong et al., 2022; Alayrac et al., 2022; Li et al., 2023; 2022; Driess et al., 2023). 이 접근 방식은 cross-modal transfer를 활용하여 언어 도메인과 멀티모달 도메인 간에 지식을 공유할 수 있게 한다. VisualGPT (Chen et al., 2022) 및 Frozen (Tsimpoukelli et al., 2021)과 같은 선구적인 연구들은 사전학습된 language model을 vision-language model의 decoder로 사용하는 것의 이점을 입증했다. 이어서 Flamingo (Alayrac et al., 2022)는 gated cross-attention을 사용하여 사전학습된 vision encoder와 language model을 정렬하도록 개발되었으며, 수십억 개의 이미지-텍스트 쌍으로 학습되어 인상적인 in-context few-shot learning 능력을 보여주었다. 그 후 BLIP-2 (Li et al., 2023)가 도입되었는데, 이는 Q-Former와 함께 Flan-T5 (Chung et al., 2022)를 사용하여 시각적 feature를 language model과 효율적으로 정렬한다. 가장 최근에는 5,620억 개의 파라미터를 특징으로 하는 PaLM-E (Driess et al., 2023)가 개발되어 실세계의 연속적인 센서 모달리티를 LLM에 통합함으로써 실세계 인식과 인간 언어 간의 연결을 구축했다. GPT-4 (OpenAI, 2023) 또한 최근 출시되었으며, 방대한 양의 정렬된 이미지-텍스트 데이터로 사전학습된 후 더욱 강력한 시각 이해 및 추론 능력을 보여주고 있다.
ChatGPT와 같은 LLM은 다른 전문화된 모델들과 협력하여 vision-language task의 성능을 향상시키는 강력한 도구임이 입증되었다. 예를 들어, Visual ChatGPT (Wu et al., 2023) 및 MM-REACT (Yang* et al., 2023)는 ChatGPT가 다양한 시각 foundation model과 통합되고 이들의 협업을 촉진하여 더 복잡한 문제를 해결하는 코디네이터 역할을 할 수 있음을 보여준다. ChatCaptioner (Zhu et al., 2023)는 ChatGPT를 질문자로 취급하여 BLIP-2가 답변할 다양한 질문을 제시한다. 다중 라운드 대화를 통해 ChatGPT는 BLIP-2에서 시각 정보를 추출하고 이미지 내용을 효과적으로 요약한다. Video ChatCaptioner (Chen et al., 2023)는 이 접근 방식을 확장하여 비디오 시공간 이해에 적용한다. ViperGPT (Surís et al., 2023)는 LLM과 다양한 vision model을 결합하여 복잡한 시각 쿼리를 프로그래밍 방식으로 해결할 수 있는 잠재력을 보여준다. 이와 대조적으로 MiniGPT-4는 외부 vision model을 사용하지 않고 시각 정보를 language model과 직접 정렬하여 다양한 vision-language task를 수행한다.
3 Method
MiniGPT-4는 사전학습된 vision encoder의 시각 정보를 **고급 대규모 언어 모델(LLM)**과 정렬(align)하는 것을 목표로 한다. 구체적으로, 우리는 **Vicuna (Chiang et al., 2023)**를 언어 decoder로 활용한다. Vicuna는 **LLaMA (Touvron et al., 2023)**를 기반으로 구축되었으며, 광범위하고 복잡한 언어 task를 수행할 수 있다. 시각적 인식을 위해서는 **BLIP-2 (Li et al., 2023)**에서 사용된 것과 동일한 visual encoder를 사용한다. 이는 **ViT backbone (Fang et al., 2022)**과 사전학습된 Q-Former가 결합된 형태이다. 언어 모델과 비전 모델 모두 오픈 소스로 공개되어 있다. 우리는 선형 projection layer를 사용하여 visual encoder와 LLM 간의 간극을 연결하는 것을 목표로 하며, 모델의 전체적인 개요는 Fig.1에 나타나 있다.
효과적인 MiniGPT-4를 구축하기 위해 우리는 두 단계의 학습 접근 방식을 제안한다. 첫 번째 단계는 대규모의 정렬된 이미지-텍스트 쌍 데이터셋으로 모델을 사전학습하여 vision-language 지식을 습득하는 것이다. 두 번째 단계에서는 더 작지만 고품질의 이미지-텍스트 데이터셋과 설계된 대화형 템플릿을 사용하여 사전학습된 모델을 fine-tuning함으로써 생성 신뢰성과 유용성을 향상시킨다.
3.1 First pretraining stage
초기 pretraining 단계 동안, 모델은 정렬된 대규모 image-text pair로부터 vision-language 지식을 학습하도록 설계되었다. 우리는 주입된 projection layer의 출력을 LLM에 대한 soft prompt로 간주하며, 이는 LLM이 해당 ground-truth text를 생성하도록 유도한다.
전체 pretraining 과정 동안, pretrained vision encoder와 LLM은 모두 고정(frozen)된 상태로 유지되며, 오직 linear projection layer만이 학습된다. 우리는 Conceptual Caption (Changpinyo et al., 2021; Sharma et al., 2018), SBU (Ordonez et al., 2011), 그리고 LAION (Schuhmann et al., 2021)으로 구성된 결합 데이터셋을 사용하여 모델을 학습시킨다. 모델은 총 20,000 training step 동안 batch size 256으로 학습되며, 이는 약 500만 개의 image-text pair를 포함한다. 전체 과정은 4개의 A100 (80GB) GPU를 사용하여 약 10시간이 소요된다.
첫 번째 pretraining 단계의 문제점. 첫 번째 pretraining 단계를 거친 후, MiniGPT-4는 풍부한 지식을 보유하고 인간의 질문에 대해 합리적인 응답을 생성할 수 있는 능력을 보여준다. 그러나, 우리는 모델이 반복적인 단어나 문장, 단편적인 문장, 또는 무관한 내용을 생성하는 등 언어적으로 일관되지 않은 출력을 생성하는 사례들을 관찰했다. 이러한 문제는 MiniGPT-4가 인간과 유창한 시각적 대화를 수행하는 데 방해가 된다.
이와 유사한 문제는 GPT-3에서도 관찰된 바 있다. GPT-3는 방대한 language dataset으로 pretraining 되었음에도 불구하고, 사용자의 의도에 정확히 부합하는 언어 출력을 생성하는 데 어려움을 겪는다. Instruction fine-tuning과 reinforcement learning from human feedback 과정을 통해, GPT-3는 GPT-3.5(Ouyang et al., 2022; OpenAI, 2022)로 발전하였고, 보다 인간 친화적인 출력을 생성할 수 있게 되었다. 이 현상은 초기 pretraining 단계를 마친 현재의 MiniGPT-4와 유사하다. 따라서, 이 단계에서 우리 모델이 유창하고 자연스러운 인간 언어 출력을 생성하는 데 어려움을 겪는 것은 놀라운 일이 아니다.
3.2 Curating a high-QUALITY ALIGNMENT DATASET FOR VISION-LANGUAGE DOMAIN.
생성된 언어의 자연스러움을 높이고 모델의 유용성을 향상시키기 위해서는 2단계 정렬(alignment) 과정이 필수적이다. NLP 분야에서는 instruction fine-tuning 데이터셋(Taori et al., 2023)과 대화 데이터셋(sha, 2023)이 쉽게 접근 가능하지만, vision-language 도메인에는 이에 상응하는 데이터셋이 존재하지 않는다. 이러한 부족함을 해결하기 위해 우리는 vision-language 정렬 목적에 특별히 맞춰진 상세 이미지 설명 데이터셋을 신중하게 큐레이션하였다. 이 데이터셋은 이후 2단계 정렬 과정에서 MiniGPT-4를 fine-tuning하는 데 활용된다.
초기 정렬된 이미지-텍스트 생성 (Initial aligned image-text generation)
초기 단계에서는 1단계 사전학습(pretraining)에서 얻은 모델을 사용하여 입력 이미지에 대한 포괄적인 설명을 생성한다. 모델이 더 상세한 이미지 설명을 생성할 수 있도록, 우리는 아래와 같이 Vicuna (Chiang et al., 2023) language model의 대화 형식을 따르는 prompt를 설계하였다. 이 prompt에서 <ImageFeature>는 선형 투영(linear projection) layer에 의해 생성된 시각적 feature를 나타낸다.
###Human: <Img><ImageFeature></Img>Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
불완전한 문장을 식별하기 위해, 우리는 생성된 문장이 80 토큰을 초과하는지 여부를 확인한다. 만약 초과하지 않는다면, 추가적인 prompt인 ###Human: Continue ###Assistant:를 삽입하여 MiniGPT-4가 생성 과정을 확장하도록 유도한다. 이 두 단계의 출력을 연결함으로써, 우리는 더욱 포괄적인 이미지 설명을 생성할 수 있다. 이 접근 방식은 상세하고 정보가 풍부한 이미지 설명이 포함된 이미지-텍스트 쌍을 생성할 수 있게 한다. 우리는 Conceptual Caption 데이터셋 (Changpinyo et al., 2021; Sharma et al., 2018)에서 5,000개의 이미지를 무작위로 선택하고, 사전학습된 모델을 사용하여 각 이미지에 대한 해당 언어 설명을 생성한다.
데이터 후처리 (Data post-processing)
위에서 자동으로 생성된 이미지 설명에는 단어나 문장의 반복, 단편적인 문장, 또는 관련 없는 내용과 같은 노이즈가 많거나 일관성 없는 설명이 포함되어 있다. 이러한 문제를 해결하기 위해 우리는 ChatGPT를 활용하여 다음 prompt를 사용하여 설명을 수정한다:
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
후처리 단계를 완료한 후, 우리는 각 이미지 설명의 정확성을 수동으로 검증하여 높은 품질을 보장한다. 구체적으로, 우리는 먼저 자주 나타나는 오류("I'm sorry I made a mistake...", 또는 "I apologize for that ...")를 식별한 다음, 하드코딩된 규칙을 사용하여 이를 자동으로 필터링하였다. 또한, ChatGPT가 감지하지 못하는 중복 단어나 문장을 제거하여 생성된 캡션을 수동으로 다듬었다. 최종적으로, 5,000개의 이미지-텍스트 쌍 중 약 3,500개만이 우리의 요구 사항을 충족했으며, 이 쌍들은 이후 2단계 정렬 과정에 활용된다.
3.3 Second-stage finetuning
두 번째 단계에서는 사전학습된 모델을 선별된 고품질 이미지-텍스트 쌍으로 fine-tuning한다. fine-tuning 시에는 다음 템플릿의 미리 정의된 prompt를 사용한다: ###Human: <Img><ImageFeature></Img><Instruction>###Assistant: 이 prompt에서 <Instruction>은 "이 이미지를 자세히 설명해 주세요" 또는 "이 이미지의 내용을 설명해 주시겠어요?"와 같은 다양한 형태의 지시문을 포함하는 미리 정의된 지시문 세트에서 무작위로 샘플링된 지시문을 나타낸다. 이 특정 텍스트-이미지 prompt에 대해서는 regression loss를 계산하지 않는다는 점이 중요하다.
그 결과, MiniGPT-4는 이제 더 자연스럽고 신뢰할 수 있는 언어 출력을 생성할 수 있게 되었다. 또한, 이 fine-tuning 과정은 놀랍도록 효율적이어서, batch size 12로 단 400 training step만 필요하며, 이는 단일 A100 GPU로 약 7분밖에 걸리지 않는다.
4 Experiments
실험에서는 다양한 정성적 예시를 통해 MiniGPT-4 모델의 다양하고 새로운(emergent) 능력을 보여주고자 한다. 이러한 능력에는 상세한 이미지 설명 생성, 밈(meme) 내의 재미있는 요소 식별, 사진으로부터 음식 레시피 제공, 이미지에 대한 시(poem) 작성 등이 포함된다. 또한, 이미지 캡셔닝 task에 대한 정량적 결과도 제시한다.
4.1 Uncovering emergent abilities with MiniGPT-4 through qualitative EXAMPLES
MiniGPT-4는 기존의 vision-language model에 비해 다양한 고급 능력을 보여준다. 예를 들어, 이미지를 상세하게 묘사하고 주어진 밈(meme)의 유머러스한 측면을 해석할 수 있다. 여기서는 선도적인 vision-language model 중 하나인 BLIP-2 (Li et al., 2023)와 우리의 모델을 8가지의 다른 예시를 통해 정성적으로 비교했으며, 각 예시는 MiniGPT-4의 다른 능력을 강조한다.
Figure 2의 예시에서는 MiniGPT-4가 이미지 내의 다양한 요소들을 효과적으로 식별함을 보여준다. 예를 들어, 번잡한 도시 거리, 시계탑, 상점, 식당, 오토바이, 사람들, 가로등, 구름 등을 식별한다. 이와 대조적으로, BLIP-2는 이미지 캡션 생성에서 도시 거리, 사람들, 오토바이만을 언급할 수 있다. Figure 4a에 제시된 또 다른 예시에서는 MiniGPT-4가 밈이 왜 유머러스한지 성공적으로 설명한다. MiniGPT-4는 누워있는 개가 많은 사람들이 한 주의 가장 두려운 날로 여겨지는 월요일에 느끼는 것과 같은 감정을 느끼고 있다고 해석한다. 이와 대조적으로, BLIP-2는 이미지 내용을 간략하게 설명할 뿐, 이미지의 재미있는 측면을 이해하지 못한다.
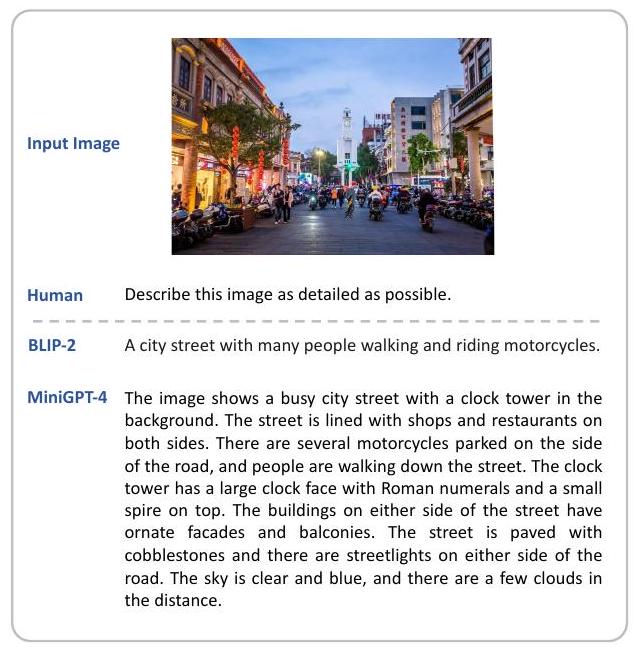
Figure 2: 상세 묘사

Figure 3: 광고 프로모션
우리는 MiniGPT-4의 다른 독특한 능력들을 시연함으로써 그 외의 능력들도 선보인다. 이러한 능력에는 다음이 포함된다:
- 주어진 이미지를 기반으로 광고 프로모션 생성 (Fig.3),
- 영화 사진에서 사실 정보 검색 (Fig.8),
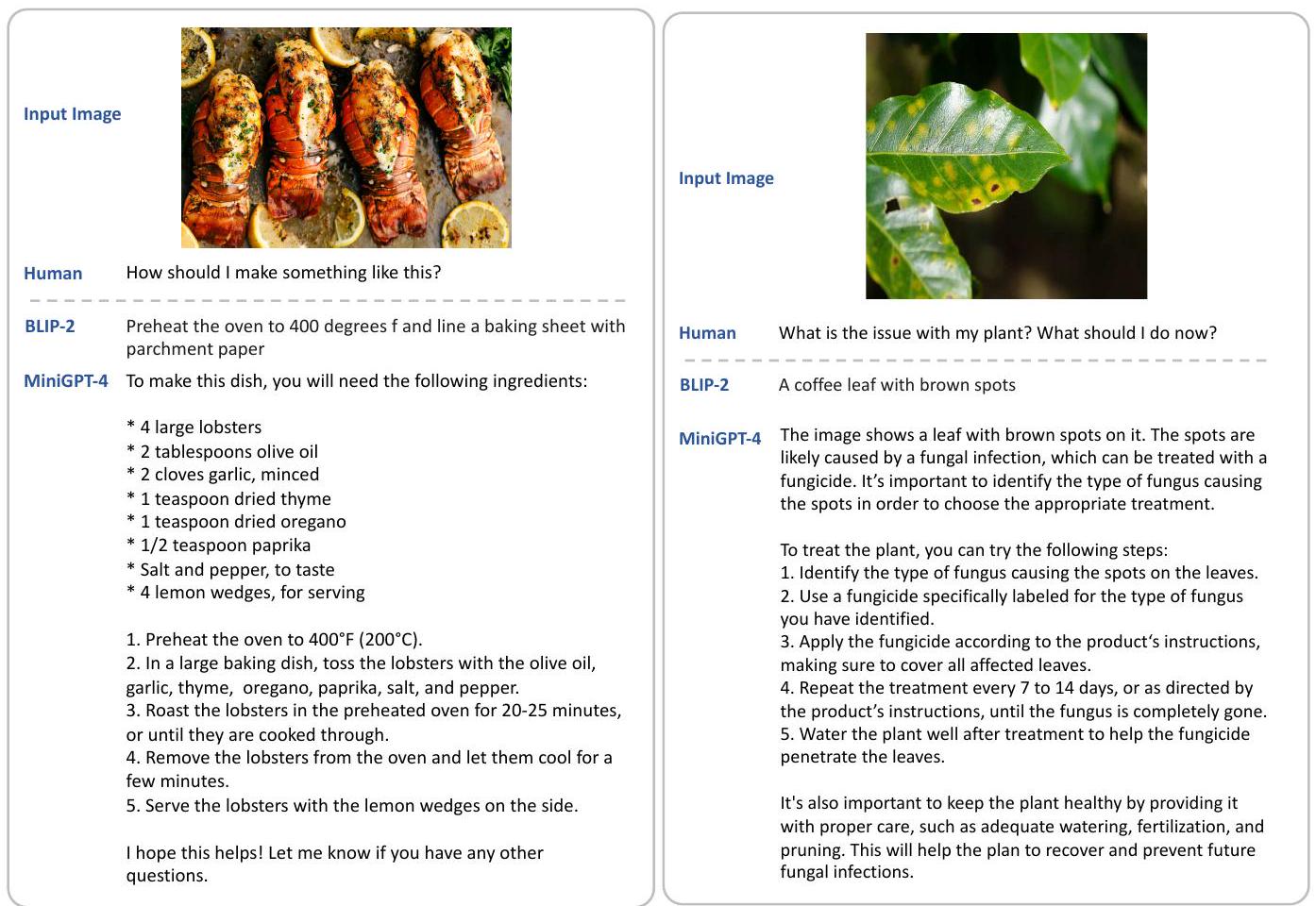
- 음식 이미지에서 요리 레시피 생성 (Fig.11),
- 식물 질병 진단 및 치료 계획 제안 (Fig.12),
- 손글씨 초안에서 웹사이트 생성 (Fig.4b),
- 이미지에서 영감을 받아 시 작성 (Fig.10).
이러한 능력들은 Flan-T5 XXL (Chung et al., 2022)을 language model로 사용하는 BLIP-2와 같은 기존의 vision-language model에는 부재하며, 이는 덜 강력한 Large Language Model (LLM)을 사용하기 때문이다. 이러한 대조는 고급 vision-language 능력들이 Vicuna (Chiang et al., 2023)와 같은 고급 LLM과 시각적 feature가 적절하게 정렬될 때만 나타남을 시사한다.
4.2 Quantitative analysis
고급 능력 (Advanced Abilities)
고급 vision-language task에서의 성능을 정량화하기 위해, 우리는 4가지 task로 구성된 소규모 평가 데이터셋을 구축했다:
- 밈 해석 (meme interpretation): "이 밈이 왜 웃긴지 설명해줘."라는 질문.
- 레시피 생성 (recipe generation): "이런 걸 어떻게 만들 수 있을까?"라는 질문.
- 광고 제작 (advertisement creation): "이것에 대한 전문적인 광고 초안을 작성하는 것을 도와줘."라는 prompt.
- 시 작문 (poem composition): "이 이미지에 대한 아름다운 시를 지어줄 수 있을까?"라는 질문.
총 100개의 다양한 이미지를 수집했으며, 각 task에 25개의 이미지를 할당했다. 우리는 인간 평가자들에게 모델의 생성물이 요청을 만족하는지 여부를 판단하도록 요청했다. 우리의 결과를 BLIP-2 (Li et al., 2023)와 비교했으며, 그 결과는 Table 1에 제시되어 있다.
밈 해석, 시 작문, 광고 제작 task에서 BLIP-2는 대부분의 요청을 수행하는 데 어려움을 겪었다. 레시피 생성의 경우, BLIP-2는 25개 중 4개 사례에서 성공했다. 이와 대조적으로, MiniGPT-4는 레시피, 광고, 시 생성 task에서 거의 80%의 사례에서 요청을 처리했다. 또한, MiniGPT-4는 25개 중 8개 사례에서 밈의 어려운 유머를 정확하게 이해했다.
이미지 캡셔닝 (Image Captioning)
우리는 COCO caption 벤치마크에서 MiniGPT-4의 성능을 평가하고 BLIP-2 (Li et al., 2023)와 비교했다. 우리 모델이 생성한 캡션은 일반적으로 풍부한 시각적 세부 정보를 포함한다. 따라서 기존의 유사도 기반 이미지-캡션 평가 지표는 우리 모델에 대한 정확한 평가를 제공하는 데 어려움을 겪는다. 이와 관련하여, 우리는 ChatGPT의 도움을 받아 생성된 캡션이 모든 ground truth 캡션 정보를 포함하는지 확인하는 방식으로 성능을 평가했으며, 자세한 내용은 Appx.A.3에서 확인할 수 있다. Table 2의 결과는 MiniGPT-4가 ground-truth 시각 객체 및 관계와 더 밀접하게 일치하는 캡션을 생성하는 데 있어 BLIP-2를 능가함을 보여준다. MiniGPT-4는 66.2%의 성공률을 보이며, 27.5%에 불과한 BLIP-2보다 훨씬 더 정확하다. 전통적인 VQA task에 대한 추가 평가는 Appx.A.2에서 확인할 수 있다.
Table 1: 고급 vision-language task에 대한 정량적 결과. MiniGPT-4는 강력한 성능을 보이며 요청의 65%에 성공적으로 응답한다.
| Meme | Recipes | Ads | Poem | Avg. | |
|---|---|---|---|---|---|
| BLIP-2 | |||||
| MiniGPT-4 |
 (a) Meme explaining
(a) Meme explaining
 (b) Website Creating
(b) Website Creating
Figure 4: BLIP-2, BLIP-2를 2단계 데이터로 fine-tuning한 모델 (BLIP-2 FT), 2단계에서 Local Narrative 데이터로 MiniGPT-4를 fine-tuning한 모델 (MiniGPT-4 LocNa), Q-Former가 없는 MiniGPT-4 모델 (MiniGPT-4 No Q-Former), 그리고 MiniGPT-4의 모델 생성 결과.
4.3 AnAlysis on the second-stage finetuning
2단계 fine-tuning의 효과
첫 번째 사전학습 단계 이후에만 사전학습된 모델을 활용할 경우, 반복적인 단어나 문장, 단편적인 문장, 또는 관련 없는 내용의 발생과 같은 실패가 발생할 수 있다. 그러나 이러한 문제들은 2단계 fine-tuning 프로세스를 통해 대부분 완화되었다. 이는 Figure 5에서 확인할 수 있는데, 2단계 fine-tuning 이전의 MiniGPT-4는 불완전한 캡션을 생성한다. 하지만 2단계 fine-tuning 이후 MiniGPT-4는 완전하고 유창한 캡션을 생성할 수 있게 된다. 이 섹션에서는 2단계 fine-tuning 접근 방식의 중요성과 효과를 조사한다.
Table 2: COCO 캡션 평가. 생성된 캡션이 ground-truth 캡션의 모든 시각적 객체와 관계를 포함하는지 여부를 ChatGPT를 사용하여 판단한다.
| BLIP-2 | MiniGPT-4 | |
|---|---|---|
| Correctness | ||
| Percentage |
Table 3: 2단계 fine-tuning 전후의 상세 캡션 및 시 생성 task의 실패율. fine-tuning 단계는 생성 실패를 크게 줄인다.
| Failure rate | Detailed caption | Poem |
|---|---|---|
| Before stage-2 | ||
| After stage-2 |
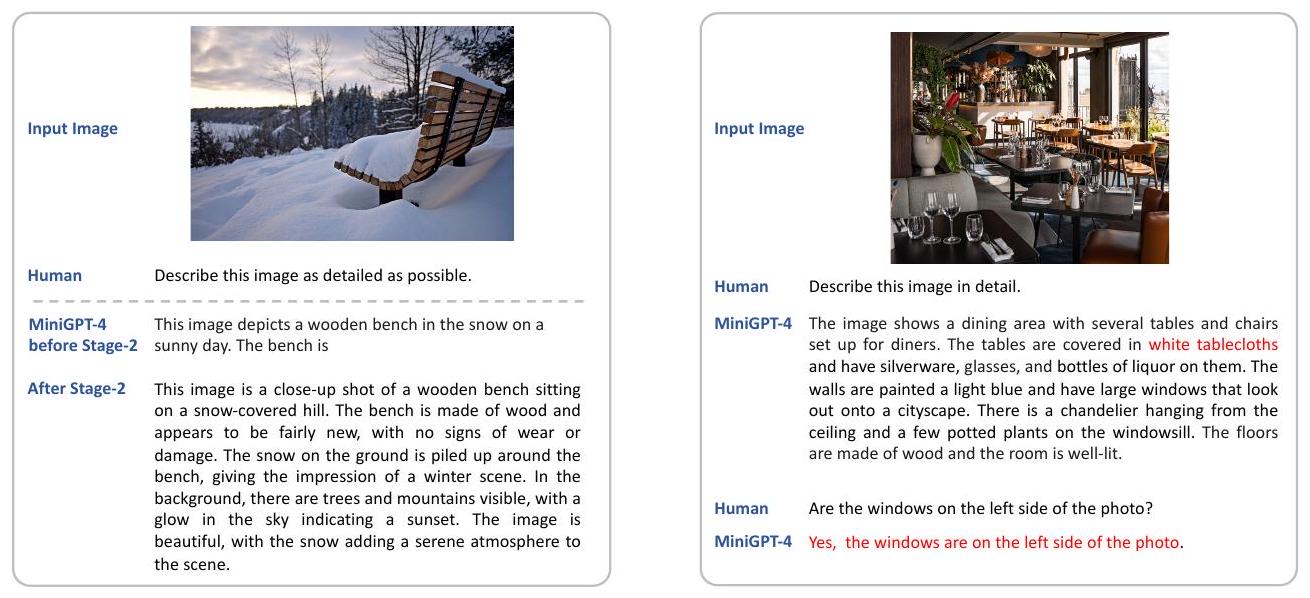
Figure 5: 2단계 fine-tuning 이전의 MiniGPT-4는 불완전한 텍스트를 출력한다. fine-tuning 이후 생성 능력이 향상된다. Figure 6: MiniGPT-4의 한계 예시. MiniGPT-4는 존재하지 않는 식탁보를 환각하고 창문의 위치를 정확히 파악하지 못한다.
2단계 fine-tuning의 영향을 정량화하기 위해, 우리는 COCO test set에서 100개의 이미지를 무작위로 샘플링하고 상세 설명 생성과 시 쓰기라는 두 가지 task에 대한 모델 성능을 조사했다. 사용된 prompt는 각각 "Describe the image in detail."과 "Can you write a beautiful poem about this image?"였다. 이 task들은 2단계 fine-tuning 전후의 모델 모두에 의해 수행되었다. 우리는 각 단계에서 모델의 실패 생성 횟수를 수동으로 세었다. 결과는 Table 3에 제시되어 있다. 2단계 fine-tuning 이전에는 생성된 출력의 약 1/3이 ground truth 캡션이나 시와 일치하지 않았다. 대조적으로, 2단계 fine-tuning 이후의 모델은 두 task 모두에서 100개의 테스트 이미지 중 실패 사례가 2개 미만이었다. 이러한 실험 결과는 2단계 fine-tuning이 생성된 출력의 품질에 상당한 개선을 가져옴을 보여준다. 2단계 fine-tuning 전후 모델 생성의 질적 예시는 Figure 5에 나와 있다.
원래 BLIP-2도 2단계 데이터의 이점을 얻을 수 있는가?
이 연구에서는 BLIP-2 (Li et al., 2023)를 MiniGPT-4와 동일한 방식으로 2단계 데이터로 fine-tuning하고, MiniGPT-4와 유사한 고급 능력을 얻을 수 있는지 확인한다. fine-tuning된 BLIP-2는 BLIP-2 FT로 표기한다. MiniGPT-4는 BLIP-2와 동일한 visual module을 사용하지만, BLIP-2는 MiniGPT-4 모델에 사용된 Vicuna (Chiang et al., 2023) 모델만큼 강력하지 않은 FlanT5 XXL (Chung et al., 2022)을 language model로 사용한다는 점에 유의해야 한다. 우리는 모델의 고급 능력을 평가하기 위해 동일한 prompt를 사용한다. 질적 결과는 Figure 4, 13, 14에 나와 있다. 우리는 BLIP-2 FT가 여전히 짧은 응답을 생성하고 밈 설명 및 웹사이트 코딩과 같은 고급 task로 일반화하는 데 실패함을 발견했다 (Figure 4). 우리의 발견은 BLIP-2의 상대적으로 약한 language model인 FlanT5 XXL이 이러한 작은 데이터셋으로부터 이점을 덜 얻으며, VLM 시스템에서 더 고급 LLM의 효과를 강조한다.
Localized Narratives를 사용한 2단계
Localized Narratives (Pont-Tuset et al., 2020) 데이터셋은 주석자가 해당 영역을 동시에 지역화하면서 이미지를 설명하는 상세 이미지 설명 데이터셋이다. 여기서는 2단계에서 자체 수집한 데이터셋을 Localized Narratives 데이터셋으로 대체하여 모델 성능을 테스트한다. 이 모델은 MiniGPT-4 LocNa로 표기한다.
Table 4: 아키텍처 설계에 대한 Ablation
| Model | AOK-VQA | GQA |
|---|---|---|
| MiniGPT-4 | 58.2 | 32.2 |
| (a) MiniGPT-4 w/o Q-Former | 56.9 | 33.4 |
| (b) MiniGPT-4 + 3 Layers | 49.7 | 31.0 |
| (c) MiniGPT-4 + Finetune Q-Former | 52.1 | 28.0 |
Table 5: 환각 평가
| CHAIR | Avg. Length | |
|---|---|---|
| Blip-2 | 1.3 | 6.5 |
| MiniGPT-4 (short) | 7.2 | 28.8 |
| MiniGPT-4 (long) | 9.6 | 175 |
Figure 4, 13, 14의 질적 결과는 MiniGPT-4 LocNa가 긴 이미지 설명을 생성할 수 있음을 보여준다 (Figure 14). 그러나 생성된 출력은 단조로운 표현으로 인해 품질이 낮다. 게다가 MiniGPT-4 LocNa는 밈이 왜 재미있는지 설명하는 것과 같은 다른 복잡한 task에서 원래 MiniGPT-4만큼 잘 일반화되지 않는다 (Figure 4a). 이러한 성능 차이는 Localized Narratives의 단조롭고 반복적인 이미지 설명 때문일 수 있다.
4.4 Ablation on the architecture designs
LLM에 시각적 feature를 정렬하기 위해 단일 선형 레이어를 사용하는 것의 효과를 추가적으로 입증하기 위해, 우리는 다양한 아키텍처 설계로 실험을 수행했다. 여기에는 다음이 포함된다: (a) Q-Former를 제거하고 VIT의 출력을 Vicuna의 임베딩 공간에 직접 매핑하는 방식 (즉, Q-Former 없음), (b) 단일 레이어 대신 세 개의 선형 레이어를 사용하는 방식, (c) vision 모듈에서 Q-Former를 추가적으로 fine-tuning하는 방식.
모든 변형 모델은 원래 설계와 동일한 방식으로 학습되었다. Tab. 4의 AOK-VQA (Schwenk et al., 2022) 및 GQA (Hudson & Manning, 2019) 데이터셋에 대한 결과는 (a) MiniGPT-4 w/o Q-Former 변형이 원래 설계와 유사한 성능을 보임을 나타낸다. Fig. 4, 13, 14의 이 변형에 대한 정성적 결과 또한 유사한 고급 기술을 보여준다. 이는 BLIP-2의 Q-Former가 고급 기술에 결정적인 역할을 하지 않음을 시사한다. 또한, (b) MiniGPT-4+3 Layers 및 (c) MiniGPT-4 + finetuning Q-Former 변형 모두 원래 MiniGPT-4보다 약간 더 나쁜 성능을 보인다. 이는 제한된 학습 데이터 설정에서 vision encoder와 large language model을 정렬하는 데 단일 projection layer로 충분함을 나타낸다.
4.5 Limitation analysis
환각 (Hallucination)
MiniGPT-4는 LLM을 기반으로 구축되었기 때문에, 존재하지 않는 지식을 환각하는 LLM의 한계를 그대로 물려받는다. Figure 6의 예시에서 MiniGPT-4는 이미지에 흰색 식탁보가 없음에도 불구하고, 잘못된 정보를 생성하는 것을 볼 수 있다.
여기서 우리는 생성된 텍스트의 환각률을 측정하기 위해 (Rohrbach et al., 2018) 지표를 사용했으며, 모델 생성 길이 제어를 위해 두 가지 다른 prompt를 사용했다:
- MiniGPT-4 (long): 이 이미지를 가능한 한 자세하게 설명해 주세요.
- MiniGPT-4 (short): 이미지를 20단어 이내로 짧고 정확하게 설명해 주세요.
Table 5의 결과는 캡션 길이가 길수록 환각률이 높아지는 경향이 있음을 보여준다. 예를 들어, MiniGPT-4 (long)은 평균 175단어의 캡션을 생성하며 더 높은 환각률을 보이는 반면, MiniGPT-4 (short)은 평균 28.8단어의 캡션을 생성하며 더 낮은 환각률을 보인다. BLIP-2는 평균 6.5단어를 생성하며 환각률이 더 낮지만, Table 2에서 볼 수 있듯이 다루는 객체 수가 더 적다. 상세한 이미지 설명에서의 환각은 여전히 해결되지 않은 문제이다. 환각 감지 모듈을 포함한 AI 피드백 기반의 Reinforcement Learning이 잠재적인 해결책이 될 수 있다.
공간 정보 이해 (Spatial Information Understanding)
MiniGPT-4의 시각적 인지 능력은 여전히 제한적이다. 특히 공간적 위치를 구별하는 데 어려움을 겪을 수 있다. 예를 들어, Figure 6의 MiniGPT-4는 창문의 위치를 정확히 식별하지 못한다. 이러한 한계는 공간 정보 이해를 위해 정렬된(aligned) 이미지-텍스트 데이터의 부족에서 비롯될 수 있다. RefCOCO (Kazemzadeh et al., 2014) 또는 Visual Genome (Krishna et al., 2017)과 같은 데이터셋으로 학습하면 이 문제를 잠재적으로 완화할 수 있을 것이다.
5 Discussion
MiniGPT-4는 어떻게 이러한 고급 능력을 얻게 되었을까? GPT-4가 보여준 많은 고급 vision-language 능력들은 **이미지 이해(image understanding)**와 **언어 생성(language generation)**이라는 두 가지 기초적인 기술에 뿌리를 둔 구성적(compositional) 기술로 이해될 수 있다. 예를 들어, 이미지 기반 시 쓰기(image-based poem writing) task를 생각해보자. ChatGPT나 Vicuna와 같은 고급 LLM은 이미 사용자의 지시에 따라 시를 창작할 수 있다. 만약 이들이 이미지를 이해하는 능력을 습득한다면, 학습 데이터에 이미지-시 쌍이 없더라도 이미지 기반 시 쓰기 task로 구성적으로 일반화(compositionally generalizing)하는 것이 가능하다.
첫 번째 사전학습(pretraining) 단계에서 MiniGPT-4는 이미지 캡션 데이터셋의 이미지와 짧은 이미지 설명 간의 상관관계를 모델링하여 이미지를 이해하는 방법을 학습한다. 그러나 이러한 이미지 캡션 데이터셋의 언어 스타일은 최신 LLM의 생성 언어 스타일과 다르다. 이는 왜곡된 언어 생성으로 이어지고 성공적인 구성적 일반화를 방해한다. 따라서 우리는 언어 생성 능력을 복원하기 위해 두 번째 fine-tuning 단계를 도입한다. 두 단계 학습을 거친 MiniGPT-4는 초안으로부터 웹사이트 코딩이나 밈 해석과 같은 많은 고급 구성적 vision-language 능력으로 성공적으로 일반화되었으며, 이는 우리의 가정을 입증한다. 향후 연구는 구성적 일반화의 메커니즘을 더 깊이 탐구하고 이를 향상시키는 방법을 모색할 수 있을 것이다. 우리는 vision-based LLM 능력에 대한 초기 탐구로서 우리의 연구가 이 분야의 추가적인 연구를 촉진하기를 희망한다.
A Appendix
A. 1 More Qualitative Results

Figure 7: 광고 홍보 (Advertisement promotion)

Figure 9: 웹사이트 생성 (Website creating)

Figure 8: 사실 검색 (Factual retrieval)
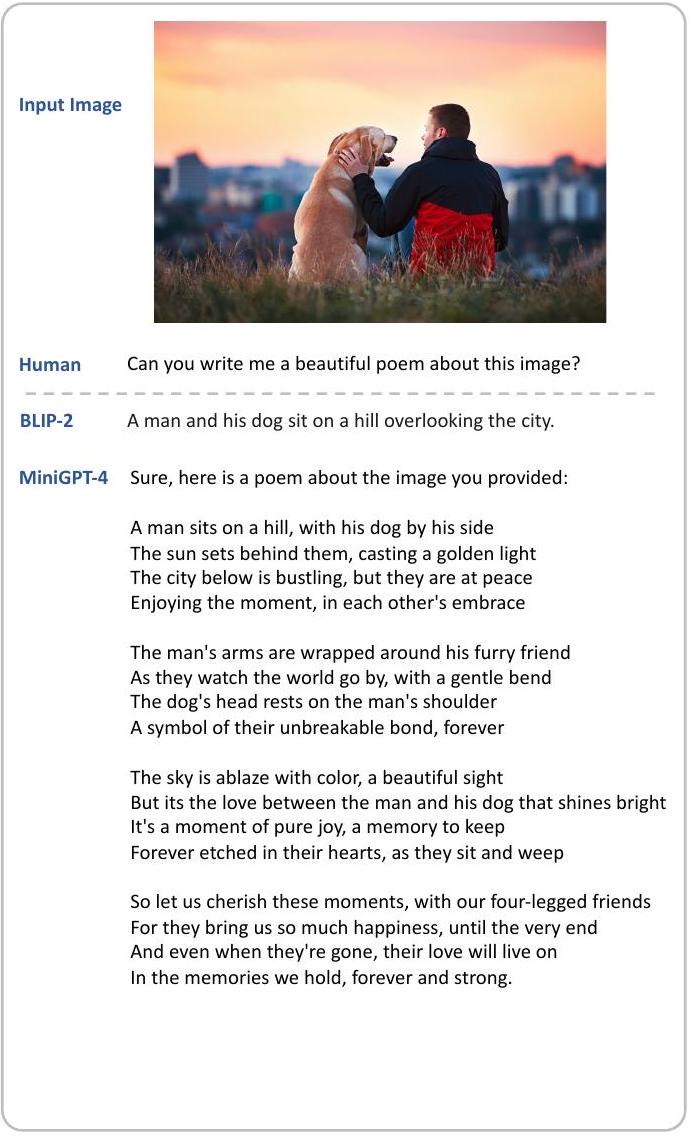
Figure 10: 시 쓰기 (Poem writing)
A. 2 Evaluation in traditional VQA benchmarks
본 연구의 목표는 GPT-4에서 시연된 놀라운 멀티모달 능력, 즉 상세한 이미지 설명 생성이나 손으로 그린 초안으로부터 웹사이트를 제작하는 능력 등을 재현하는 것이다. 고급 vision-language 능력의 가장 중요한 구성 요소를 강조하기 위해, MiniGPT-4의 방법론은 의도적으로 최소한으로 유지되었다. 예를 들어, 학습 가능한 모델 용량은 단 하나의 선형 레이어로 제한되었으며, MiniGPT-4는 5백만 쌍의 데이터로만 학습되었다. 이는 1억 2천 9백만 개의 이미지-텍스트 쌍을 사용하는 BLIP-2와 대조적이다. 이러한 간소화된 접근 방식은 전통적인 벤치마크에서 최적화되지 않은 결과를 가져올 것으로 예상된다. 비록 이것이 우리의 주된 목표는 아니지만, 우리는 VQA 데이터셋인 A-OKVQA (multi-choice) (Schwenk et al., 2022)와 GQA (Hudson & Manning, 2019)에 대한 정량적 분석을 제공한다. 또한, MiniGPT-4의 전통적인 벤치마크에서의 잠재력을 보여주기 위해, 우리는 간단한 ablation study를 수행한다. 여기서 우리는 LoRA (Hu et al., 2021)를 사용하여 LLM을 단순히 unfreeze하고, 두 번째 fine-tuning 단계에서 VQAv2, OKVQA, A-OKVQA 데이터셋으로부터 더 많은 학습 데이터를 통합한다. Tab. 6의 결과는 원래 MiniGPT-4가 BLIP-2에 비해 상당한 차이로 뒤처지며, 학습 용량과 학습 데이터를 단순히 늘리는 것만으로도 상당한 성능 향상이 있음을 보여주며, 이는 우리의 예상을 확인시켜 준다. 우리는 신중하게 설계된 학습 전략 (예: 데이터셋 샘플 비율, 학습률 스케줄 등), 더 많은 학습 데이터/데이터셋, 그리고 추가적인 학습 가능한 파라미터를 통해 전통적인 vision 벤치마크에서 우리 모델의 성능을 향상시킬 수 있다고 믿는다. 전통적인 vision 벤치마크에서의 성능 향상이 이 프로젝트의 목표가 아니므로, 이 부분은 향후 연구를 위해 남겨둔다.
| Model | Training data | AOK-VQA | GQA |
|---|---|---|---|
| Blip-2 | 129M image-text pairs | 80.2 | 42.4 |
| MiniGPT-4 | 5M image-text pairs | 58.2 | 32.2 |
| MiniGPT-4 (Finetune Vicuna) | 5M image-text pairs | 67.2 | 43.5 |
Table 6: BLIP-2와 MiniGPT-4의 성능 비교
A. 3 Details of Caption Evaluation
우리는 ChatGPT를 활용하여 baseline 모델이 ground-truth caption에 제시된 모든 객체와 시각적 관계를 포함하는지 여부를 판단한다. COCO 평가 데이터셋의 경우, 우리는 하나의 ground-truth caption을 무작위로 선택하여 이를 참조(reference) caption으로 간주한다. 평가를 수행하기 위해 다음 prompt를 적용한다:
There is one image caption1 ' { ground-truth caption}', and there is another image caption2 '{comparison caption}'. Does image caption2 cover all the objects and visual relations shown in image caption1? Only answer yes or no without any explanation.
A. 4 More qualitative ablation results

Figure 13: Ablation Study on Recipe Generation

Figure 14: Ablation Study on Detailed Description