MMAudio: 고품질 비디오-오디오 합성을 위한 멀티모달 공동 학습
비디오 및 선택적 텍스트 조건이 주어졌을 때, 새로운 멀티모달 공동 학습 프레임워크(MMAudio)를 사용하여 고품질의 동기화된 오디오를 합성하는 방법을 제안합니다. MMAudio는 대규모 텍스트-오디오 데이터와 공동으로 학습하여 의미적으로 정렬된 고품질 오디오 샘플 생성을 학습하며, 조건부 동기화 모듈을 통해 오디오-비디오 동기화를 개선합니다. 논문 제목: MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
논문 요약: MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
- 논문 링크: https://arxiv.org/abs/2412.15322
- 저자: Ho Kei Cheng (University of Illinois Urbana-Champaign), Masato Ishii (Sony AI), Akio Hayakawa (Sony AI), Takashi Shibuya (Sony AI), Alexander Schwing (University of Illinois Urbana-Champaign), Yuki Mitsufuji (Sony AI, Sony Group Corporation)
- 발표 시기: 2025년, CVPR (Computer Vision and Pattern Recognition Conference)
- 주요 키워드: Video-to-Audio Synthesis, Multimodal Learning, Audio Generation, Deep Learning
1. 연구 배경 및 문제 정의
- 문제 정의:
- 주어진 비디오에 대해 주변 소리(예: 비, 강물) 및 시각적 사건으로 인한 음향 효과(예: 개 짖는 소리, 테니스공 치는 소리)를 합성하는 Foley 작업에 초점을 맞춘다.
- 합성된 오디오는 1) 의미적으로 비디오에 정렬되고, 2) 시간적으로 동기화되어야 한다. 인간은 25ms의 미세한 오디오-비주얼 불일치도 인지할 수 있어 정밀한 동기화가 필수적이다.
- 기존 접근 방식:
- 오디오-비주얼 데이터만으로 학습: VGGSound와 같은 데이터셋은 약 550시간으로 양이 제한적이며, 대규모 수집 비용이 높다. 또한, 음악이나 사람의 말, 비디오와 무관한(non-diegetic) 사운드가 포함되어 Foley 모델 학습에 적합하지 않은 경우가 많다.
- 사전 학습된 text-to-audio 모델에 "control modules" 추가 파인튜닝: 대규모 오디오-텍스트 데이터의 지식을 활용할 수 있지만, 네트워크 아키텍처를 복잡하게 만들고 설계 공간을 제한하며, 모든 video-to-audio 시나리오를 지원할 충분한 자유도가 부족할 수 있다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 비디오, 오디오, 텍스트 모달리티를 공동으로 고려하는 새로운 멀티모달 공동 학습 프레임워크(MMAudio)를 제안하여 효과적인 데이터 확장과 교차 모달 이해를 가능하게 하고, 오디오 품질 및 의미적 정렬을 크게 향상시켰다.
- 정확한 오디오-비주얼 동기화를 위한 조건부 동기화 모듈(Conditional Synchronization Module)을 제안하여 시간적 정렬 성능을 획기적으로 개선했다.
- 공개적으로 접근 가능한 데이터셋에서 학습하여 기존 공개 모델 중 video-to-audio 합성에서 새로운 최첨단(SOTA) 성능을 달성했으며, text-to-audio 생성에서도 경쟁력 있는 성능을 보여 공동 학습이 단일 모달리티 성능을 저해하지 않음을 입증했다.
- 제안 방법:
- MMAudio 프레임워크: 단일 멀티모달 트랜스포머 네트워크에서 비디오, 오디오, 텍스트를 함께 고려하며, 학습 중 누락된 모달리티를 마스킹하는 패러다임을 사용한다. Conditional Flow Matching 목표로 학습된다.
- 오디오 인코딩: 오디오 파형을 STFT를 통해 멜 스펙트로그램으로 변환하고, 사전 훈련된 VAE(Variational Autoencoder)를 통해 잠재 변수로 인코딩한다. 생성된 잠재 변수는 VAE와 보코더를 통해 오디오 파형으로 변환된다.
- 멀티모달 트랜스포머:
- SD3의 MM-DiT 블록 디자인을 채택하여 시각/텍스트/오디오 분기 간의 상호 작용을 모델링한다.
- Aligned RoPE positional embeddings: 시각(8fps) 및 오디오(31.25fps) 스트림의 서로 다른 프레임 속도를 정렬하기 위해 시각 스트림의 위치 임베딩 주파수를 비례적으로 스케일링한다.
- 1D ConvMLPs: 로컬 시간 구조를 더 잘 포착하기 위해 MLP 대신 1D 컨볼루션(커널 크기 3)을 사용한다.
- Global Conditioning: 흐름 타임스텝, 평균 풀링된 시각적 특징, 텍스트 특징으로부터 계산된 전역 조건 벡터를 adaLN(adaptive layer normalization) 레이어를 통해 네트워크에 주입한다.
- 조건부 동기화 모듈 (Conditional Synchronization Module):
- 오디오-비주얼 동기화를 더욱 향상시키기 위해 Synchformer [19]의 시각 인코더를 사용하여 높은 프레임률(24fps)의 동기화 특징()을 추출한다.
- 이 프레임 정렬된 동기화 특징을 오디오 스트림의 adaLN 레이어에 토큰별로 주입하여 세밀한 제어와 정확한 동기화를 유도한다.
3. 실험 결과
- 데이터셋:
- Video-to-Audio 학습: VGGSound (약 500시간 분량의 비디오, 310개 클래스 레이블).
- Audio-to-Text 학습: AudioCaps (약 128시간), Clotho (약 31시간), WavCaps (약 7,600시간). (시각적 모달리티는 학습 가능한 빈 토큰으로 대체).
- 공정한 비교를 위해 모든 훈련 데이터에서 VGGSound 및 AudioCaps의 테스트 세트 중복을 제거했다.
- 주요 결과:
- Video-to-Audio (VGGSound 테스트 세트):
- 가장 작은 모델(MMAudio-S-16kHz, 157M 파라미터)이 기존 SOTA 모델들(ReWaS, Seeing&Hearing, V-AURA, VATT, Frieren, FoleyCrafter, V2A-Mapper) 대비 분포 일치(FD), 오디오 품질(IS), 의미적 정렬(IB-score), 시간적 정렬(DeSync)에서 모두 우수한 성능을 달성했다.
- 8초 클립 생성에 1.23초가 소요되는 빠른 추론 속도를 보였다.
- 더 큰 모델(M-44.1kHz, L-44.1kHz)은 FD_Passt 및 IB-score에서 추가적인 개선을 보였다.
- 사용자 연구 결과, MMAudio는 오디오 품질, 의미적 정렬, 시간적 정렬 세 가지 측면 모두에서 기존 베이스라인보다 훨씬 높은 평가를 받았다.
- Movie Gen Audio (130억 파라미터, 비공개 데이터 훈련)와 비교 시, 주관적/객관적 지표에서 유사하거나 약간 우위(특히 동기화)를 보였다.
- Text-to-Audio (AudioCaps 테스트 세트):
- 미세 조정 없이도 최첨단 의미적 정렬(CLAP) 및 오디오 품질(IS)을 달성하여, 멀티모달 공동 훈련이 단일 모달리티 성능을 저해하지 않음을 입증했다.
- Ablation Studies:
- 멀티모달 공동 훈련(AVT+AT)이 오디오 품질, 의미적 정렬, 시간적 정렬 모두에서 가장 좋은 성능을 보였다. 텍스트 모달리티를 마스킹하거나 오디오-텍스트 데이터를 사용하지 않을 경우 성능이 저하되었다.
- 오디오-텍스트 데이터의 양이 많을수록 성능이 향상되었다.
- 제안된 조건부 동기화 모듈, 정렬된 RoPE 임베딩, ConvMLP가 동기화 및 전반적인 성능 향상에 기여함을 확인했다.
- Video-to-Audio (VGGSound 테스트 세트):
4. 개인적인 생각 및 응용 가능성
- 장점:
- 멀티모달 공동 학습이라는 혁신적인 접근 방식을 통해 제한적인 비디오-오디오 데이터의 한계를 극복하고, 대규모 오디오-텍스트 데이터의 이점을 효과적으로 활용했다.
- 특히 오디오-비주얼 동기화 측면에서 Conditional Synchronization Module의 기여가 매우 인상적이다. 인간이 인지하는 미세한 불일치까지 고려한 설계가 돋보인다.
- 경량 모델로도 최첨단 성능을 달성하고 빠른 추론 속도를 제공하여 실제 응용 가능성이 높다.
- Video-to-Audio 뿐만 아니라 Text-to-Audio에서도 뛰어난 성능을 보여 모델의 범용성과 견고성을 입증했다.
- 객관적 지표와 함께 사용자 연구를 통해 주관적인 품질까지 검증하여 신뢰도를 높였다.
- 단점/한계:
- 사람의 말(human speech) 생성 시 이해할 수 없는 중얼거림을 생성하는 한계가 있다. 이는 Foley에 집중한 모델의 특성상 언어의 복잡성을 충분히 반영하지 못했기 때문으로 보인다.
- Movie Gen Audio와의 비교에서, 훈련 데이터에 익숙하지 않은 개념의 비디오에 대해서는 의미적 정렬(IB-score)이 낮아지는 경향을 보였다. 이는 훈련 데이터셋의 다양성 확장이 필요함을 시사한다.
- 데이터셋 간의 중복 문제에 대한 언급은 연구 커뮤니티 전반의 과제임을 보여준다.
- 응용 가능성:
- 영화, 드라마, 애니메이션 등 미디어 콘텐츠의 후반 작업에서 Foley 사운드 및 음향 효과를 자동으로 생성하여 제작 효율성을 높일 수 있다.
- VR/AR 콘텐츠, 게임 등 인터랙티브 미디어 환경에서 사용자의 행동이나 시각적 장면에 동기화된 동적인 사운드스케이프를 실시간으로 생성하는 데 활용될 수 있다.
- 시각 장애인을 위한 비디오 콘텐츠의 오디오 설명 생성 등 접근성 향상 분야에 기여할 수 있다.
- MovieGen과 같은 합성 비디오 생성 모델과 결합하여 더욱 사실적이고 몰입감 있는 멀티미디어 콘텐츠를 제작하는 데 활용될 수 있다.
5. 추가 참고 자료
- 프로젝트 페이지: https://hkchengrex.github.io/MMAudio/
Cheng, Ho Kei, et al. "MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis." Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
Ho Kei Cheng Masato Ishii Akio Hayakawa Takashi Shibuya <br>Alexander Schwing Yuki Mitsufuji <br> University of Illinois Urbana-Champaign Sony AI Sony Group Corporation<br>{hokeikc2, aschwing}@illinois.edu, {masato.a.ishii,akio.hayakawa,takashi.tak.shibuya,yuhki.mitsufuji}@sony.com
Abstract
본 논문에서는 새로운 multimodal joint training 프레임워크(MMAudio)를 사용하여 비디오와 선택적 텍스트 조건이 주어졌을 때 고품질의 동기화된 오디오를 합성하는 방법을 제안합니다. 제한적인 비디오 데이터에만 의존하는 단일 모달리티 학습과 달리, MMAudio는 더 큰 규모의 쉽게 구할 수 있는 텍스트-오디오 데이터와 공동으로 학습하여 의미적으로 정렬된 고품질 오디오 샘플을 생성하는 법을 배웁니다. 추가적으로, 우리는 프레임 수준에서 비디오 조건과 오디오 잠재 공간을 정렬하는 conditional synchronization module을 통해 오디오-비주얼 동기화를 개선합니다. flow matching 목표로 학습된 MMAudio는 오디오 품질, 의미적 정렬, 오디오-비주얼 동기화 측면에서 공개 모델 중 새로운 video-to-audio 최고 성능을 달성했으며, 짧은 추론 시간(8초 클립 생성에 1.23초)과 157M개의 파라미터만을 가집니다. MMAudio는 또한 text-to-audio 생성에서도 놀라울 정도로 경쟁력 있는 성능을 보여, 공동 학습이 단일 모달리티 성능을 저해하지 않음을 입증합니다. 코드, 모델 및 데모는 다음에서 확인할 수 있습니다: hkchengrex.github.io/MMAudio.
1. Introduction
우리는 Foley, 즉 주어진 비디오에 대해 주변 소리(예: 비, 강물 흐르는 소리)와 눈에 보이는 사건으로 인해 발생하는 음향 효과(예: 개 짖는 소리, 라켓이 테니스공을 치는 소리)를 합성하는 데 관심이 있습니다. Foley는 종종 후반 작업에서 추가되는 배경 음악이나 사람의 말을 합성하는 데는 초점을 맞추지 않습니다. 중요한 것은, Foley는 1) 의미적으로, 그리고 2) 시간적으로 입력 비디오에 정렬된 설득력 있는 고품질 오디오를 합성해야 한다는 점입니다. 의미적 정렬을 위해, 방법들은 장면의 맥락과 오디오와의 연관성을 이해해야 합니다 - 비라는 시각적 개념은 튀는 빗방울 소리와 연관되어야 합니다. 시간적 정렬을 위해, 방법들은 오디오-비주얼 동기화를 이해해야 합니다. 인간은 25ms만큼의 미세한 오디오-비주얼 불일치도 인지할 수 있기 때문입니다 [51]. 최근 연구들[8, 21, 53]에서 입증된 학습 데이터 확장의 효과에 영감을 받아, 우리는 이 두 가지 유형의 정렬을 준수하는 고품질 오디오를 합성하기 위해 데이터 중심 접근 방식을 추구합니다.
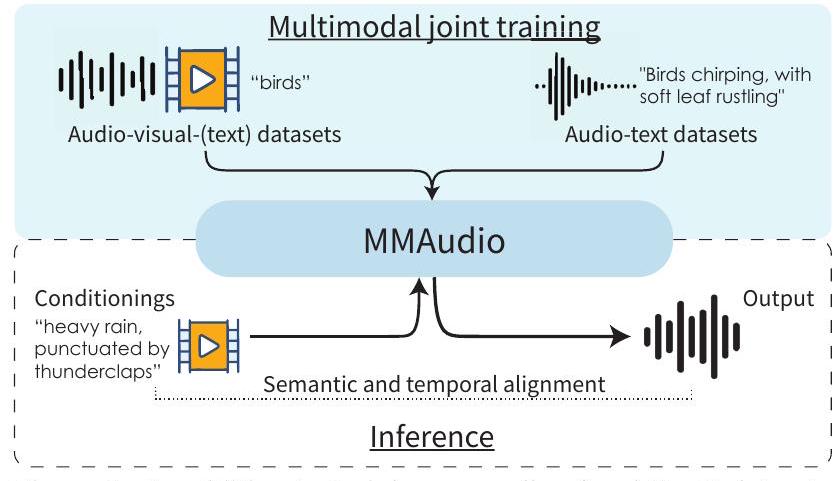
Figure 1. 오디오-비주얼-(텍스트) 데이터셋 학습 외에도, 우리는 효과적인 데이터 확장을 가능하게 하는 고품질의 풍부한 오디오-텍스트 데이터로 multimodal joint training을 수행합니다. 추론 시, MMAudio는 비디오 및/또는 텍스트 안내를 통해 조건에 정렬된 오디오를 생성합니다.
현재 최첨단 video-to-audio 방법들은 오디오-비주얼 데이터 [1]만으로 처음부터 학습하거나 [67], 사전 학습된 text-to-audio 모델을 위해 오디오-비주얼 데이터에 새로운 "control modules" [20, 66, 69, 73]을 학습시킵니다. 전자는 사용 가능한 학습 데이터의 양에 의해 제한됩니다: 가장 일반적으로 사용되는 오디오-비주얼 데이터셋인 VGGSound [1]는 약 550시간 분량의 비디오만을 포함하고 있습니다. 오디오-비주얼 데이터는 대규모로 수집하기에 비용이 많이 듭니다. 인터넷의 야생 비디오들은 1) 일반적인 Foley 모델 학습에 제한적인 유용성을 갖는 음악과 말¹을 포함하고 있으며, 2) 후반 작업에서 추가된 배경 음악이나 음향 효과와 같은 non-diegetic [58] 사운드를 포함하고 있어 Foley 모델에 적합하지 않기 때문입니다. 후자, 즉 사전 학습된 text-to-audio 모델을 (추가된 control modules과 함께) 오디오-비주얼 데이터에 파인튜닝하는 것은 모델이 더 큰 규모의 오디오-텍스트 데이터(예: 7,600시간의 WavCaps [46])로부터 얻은 오디오 생성 지식을 활용할 수 있게 해줍니다. 그러나 사전 학습된 text-to-audio 모델에 control modules을 추가하는 것은 네트워크 아키텍처를 복잡하게 만들고 설계 공간을 제한합니다. 또한 사전 학습된 text-to-audio 모델이 처음부터 학습하는 것에 비해 모든 video-to-audio 시나리오를 지원할 충분한 자유도를 가지고 있는지도 불분명합니다.
이러한 한계를 피하기 위해, 우리는 단일 멀티모달 트랜스포머 네트워크에서 비디오, 오디오, 텍스트를 함께 고려하고 학습 중에 누락된 모달리티를 마스킹하는 multimodal joint training 패러다임(Figure 1)을 제안합니다. 이는 간단한 end-to-end 프레임워크를 사용하여 오디오-비주얼 및 오디오-텍스트 데이터셋 모두에서 처음부터 학습할 수 있게 해줍니다. 대규모 멀티모달 데이터셋에서 공동으로 학습하면 통합된 의미 공간을 가능하게 하고, 모델이 자연스러운 오디오의 분포를 학습하기 위해 더 많은 데이터에 노출되도록 합니다. 경험적으로, 공동 학습을 통해 우리는 오디오 품질(10% 낮은 Fréchet Distance [23] 및 15% 높은 Inception Score [56]), 의미적 정렬(4% 높은 ImageBind [11] 점수), 그리고 시간적 정렬(14% 더 나은 동기화 점수)에서 상당한 상대적 개선을 관찰했습니다.
시간적 정렬을 더욱 향상시키기 위해, 우리는 높은 프레임률의 시각적 특징(자기 지도 오디오-비주얼 비동기화 감지기 [19]에서 추출)을 사용하고 적응형 레이어 정규화(adaLN) 레이어 [50]의 스케일과 바이어스 공간에서 작동하는 conditional synchronization module을 도입하여 정확한 동기화를 이끌어냅니다(동기화 점수에서 50%의 상대적 개선).
요약하자면, 우리는 먼저 video-to-audio를 위한 multimodal joint training 패러다임인 MMAudio를 제안합니다. 이는 접근 가능한 데이터 확장과 교차 모달 이해를 가능하게 하여 오디오 품질과 의미적 정렬을 크게 향상시킵니다. 또한 우리는 더 정확한 오디오-비주얼 동기화를 가능하게 하는 conditional synchronization module을 제안합니다. 우리는 공개적으로 접근 가능한 데이터셋에서 MMAudio를 학습시키고, 두 가지 오디오 샘플링 속도(16 kHz 및 44.1 kHz)와 세 가지 모델 크기(157M, 621M, 1.03B)로 확장했으며, 가장 작은 모델조차도 이미 공개 모델 중 video-to-audio 합성에서 새로운 최첨단 성능을 달성했습니다. 놀랍게도, 우리의 멀티모달 접근 방식은 전용 text-to-audio 방법에 비해 text-to-audio 생성에서도 경쟁력 있는 성능을 달성하여, 공동 학습이 단일 모달리티 성능을 저해하지 않음을 보여줍니다.
2. Related Works
Semantic alignment. 오디오와 비디오 간의 의미적 정렬은 생성 목표 [2, 6, 18, 44, 49, 60, 66, 71] 또는 대조 목표 [42]를 사용하여 쌍을 이룬 오디오-비주얼 데이터에 대한 학습을 통해 학습됩니다. 오디오 의미를 더 잘 이해하기 위해, 우리는 추가적으로 쌍을 이룬 오디오-텍스트 데이터에 대해 학습합니다. 우리는 오디오-텍스트 쌍에서 학습된 의미적 이해가 비디오-텍스트 쌍으로 전이될 수 있다고 주장합니다. 공동 학습은 공유된 의미 공간(ImageBind [11] 및 LanguageBind [74]와 유사)으로 이어지고, 네트워크가 더 다양한 데이터로부터 더 풍부한 의미를 학습할 수 있게 하기 때문입니다. Temporal alignment. 오디오-비주얼 쌍에서 직접 시간적 정렬을 학습하는 것 외에도, 일부 최근 연구들은 비디오로부터 오디오 온셋 [54, 73], 에너지 [17, 20], 또는 파형의 root-mean-square [4, 34]와 같은 수작업 프록시 특징을 예측하기 위해 별도의 모델을 먼저 학습합니다. 우리는 이러한 수작업 특징에서 벗어나 사전 학습된 자기 지도 비동기화 감지기 Synchformer [19]의 심층 특징 임베딩으로부터 직접 정렬을 학습하여, 입력 신호에 대한 더 미묘한 해석을 가능하게 합니다. 최근 연구인 V-AURA [65]도 autoregressive 프레임워크에서 동기화를 위해 Synchformer [19]를 사용합니다. 그러나 [65]는 텍스트에 대한 멀티모달 학습을 수행하지 않으며 짧은 컨텍스트 창(2.56초)을 가지는 반면, 우리는 더 장기적인(8-10초) 시간적으로 일관된 생성을 만들어냅니다. 시간적 정렬을 위한 위치 임베딩 개선과 관련하여, Mei 등 [45]은 동시에 고주파 (오디오) 위치 임베딩을 서브샘플링할 것을 제안하는 반면, 우리는 저주파 (시각) 위치 임베딩의 주파수를 스케일업할 것을 제안합니다 - 고주파가 저주파의 정수배일 때 그 효과는 동일합니다. Multimodal conditioning. 멀티모달 조건부 생성을 지원하는 가장 일반적인 방법은 사전 학습된 text-to-audio 네트워크에 시각적 특징을 주입하는 "control modules"을 추가하는 것입니다 [13, 17, 20, 34, 47, 54, 73]. 그러나 이는 파라미터 수를 증가시킵니다. 게다가, video-to-audio 학습 동안 텍스트 모달리티가 고정되어 있기 때문에, 공동 의미 공간을 학습하는 것이 더 어려워집니다 - 비디오 모달리티는 두 모달리티가 협력하는 법을 배우는 대신 텍스트의 의미에 결합해야 합니다. 대조적으로, 우리는 멀티모달 학습 공식에서 모든 모달리티를 동시에 학습하여 공동 의미를 배우고 모달리티 간의 전방향 특징 공유를 가능하게 합니다. 대안적으로, 학습 없이 다른 모달리티를 정렬하기 위해, Seeing-and-Hearing [69]은 사전 학습된 text-to-audio 모델을 사용하고 테스트 시에 정렬 점수(즉, ImageBind [11])에 대한 경사 상승을 수행합니다. 우리는 테스트 시간 최적화가 느리고 때로는 저품질 및 시간적으로 정렬되지 않은 출력을 초래한다는 점에 주목합니다. 실제로, 우리 모델은 테스트 시간에 더 빠르고 더 일관되게 동기화된 오디오를 생성합니다. 우리 연구와 동시에, VATT [40]와 MultiFoley [3]는 공동으로 학습된 멀티모달 조건화를 탐구합니다. VATT [40]는 오디오를 생성하기 위해 비디오와 텍스트를 모두 사용하지만 학습 중에는 항상 비디오 조건을 요구합니다. MultiFoley [3]는 우리와 유사하게 공식화되었지만, MMAudio는 훨씬 높은 프레임률의 시각적 특징(24 FPS, MultiFoley는 8 FPS 특징 사용)을 사용하여 훨씬 더 나은 오디오-비주얼 동기화를 이끌어냅니다. Multimodal generation. 멀티모달 조건화와 관련하여, 멀티모달 생성 모델은 여러 모달리티(예: 비디오와 오디오)로 구성된 샘플을 생성합니다. 멀티모달 생성은 더 어렵고 기존 접근 방식 [25,55,61,62]은 아직 전용 video-to-audio 모델과 경쟁력이 없습니다. 이 연구에서, 우리는 멀티모달 조건부 오디오 생성에 초점을 맞춥니다. 우리는 우리의 멀티모달 공식과 아키텍처가 멀티모달 생성의 미래 연구를 위한 기초 역할을 할 것이라고 믿습니다.
3. MMAudio
3.1. Preliminaries
Conditional flow matching. 우리는 생성 모델링을 위해 conditional flow matching 목표 [37, 63]를 사용하며, 독자들에게 자세한 내용은 [63]을 참조하도록 안내합니다. 요약하자면, 테스트 시에 샘플을 생성하기 위해, 우리는 표준 정규 분포에서 노이즈 를 무작위로 추출하고 ODE solver를 사용하여 학습된 시간에 의존적인 조건부 속도 벡터 필드 를 따라 시간 에서 까지 수치적으로 적분합니다. 여기서 는 타임스텝, 는 조건(예: 비디오와 텍스트), 는 벡터 필드의 한 점입니다. 우리는 속도 벡터 필드를 로 매개변수화된 심층 신경망을 통해 표현합니다.
학습 시, 우리는 조건부 flow matching 목표를 고려하여 를 찾습니다.
여기서 , 는 표준 정규 분포이고, 는 훈련 데이터에서 샘플링합니다. 또한,
는 노이즈와 데이터 사이의 선형 보간 경로를 정의하고,
는 에서의 해당 흐름 속도를 나타냅니다. Audio encoding. 계산 효율성을 위해, 우리는 일반적인 관행 [38, 67]에 따라 잠재 공간에서 생성 과정을 모델링합니다. 이를 위해, 우리는 먼저 Short-Time Fourier Transform (STFT)을 통해 오디오 파형을 변환하고 mel spectrograms [57]을 추출하며, 이는 사전 훈련된 variational autoencoder (VAE) [27]에 의해 잠재 변수 로 인코딩됩니다. 테스트 중, 생성된 잠재 변수는 VAE에 의해 스펙트로그램으로 디코딩된 후, 사전 훈련된 vocoder [35]에 의해 오디오 파형으로 변환됩니다.
3.2. Overview
conditional flow matching에 따라, 테스트 시에 우리는 에서 까지 잡음 를 학습 시간에 Eq. (1)을 최적화하여 학습된 흐름 를 따라 수치적으로 적분합니다. 테스트 시의 수치 적분은 잠재 변수 에 도달하며, 이는 바람직하게는 고품질이고 비디오 및 텍스트 조건에 의미적으로 그리고 시간적으로 정렬된 오디오로 디코딩됩니다.
현재 잠재 변수 에 대한 흐름 를 추정하기 위해, MMAudio는 비디오/텍스트 조건과 흐름 타임스텝 에 대해 작동합니다. Figure 2는 우리의 네트워크 아키텍처를 보여줍니다. 다른 모달리티의 입력을 결합하기 위해, MMAudio는 시각/텍스트/오디오 분기를 가진 일련의 () multimodal transformer 블록 [8]과, 이어서 일련의 () 오디오 전용 transformer 블록 [32]으로 구성됩니다. 추가적으로, 오디오-비주얼 동기화를 위해, 우리는 시간적 정렬을 위해 높은 프레임률(초당 24 프레임(fps))의 시각적 특징을 추출하고 생성 과정에 통합하는 conditional synchronization module을 고안했습니다. 다음으로, 두 구성 요소를 자세히 설명합니다.
3.3. Multimodal Transformer
우리 접근 방식의 핵심은 비디오, 오디오, 텍스트 모달리티 간의 상호 작용을 모델링하려는 욕구입니다. 이를 위해, 우리는 SD3 [8]의 MM-DiT 블록 디자인을 대부분 채택하고 시간적 정렬을 위해 두 가지 새로운 구성 요소, 즉 서로 다른 프레임 속도의 시퀀스를 정렬하기 위한 aligned RoPE positional embeddings와 로컬 시간 구조를 포착하기 위한 1D convolutional MLPs (ConvMLPs)를 도입합니다. Figure 2 (오른쪽)는 우리의 블록 디자인을 보여줍니다. 참고로, 우리는 FLUX [32]를 따라 일련의 오디오 전용 단일 모달리티 블록도 포함하는데, 이는 단순히 다른 두 모달리티의 스트림을 제거하여 (즉, joint attention이 self-attention이 됨) 구현됩니다. 모든 레이어에서 모든 모달리티를 고려하는 것과 비교하여, 이 디자인은 동일한 파라미터 수와 계산으로 멀티모달리티를 희생하지 않으면서 더 깊은 네트워크를 구축할 수 있게 해줍니다. 이 멀티모달 아키텍처는 모델이 입력에 따라 선택적으로 다른 모달리티에 주의를 기울이고 집중할 수 있게 하여, 오디오-비주얼 및 오디오-텍스트 데이터 모두에 대한 효과적인 공동 학습을 가능하게 합니다. 다음으로, 우리 네트워크의 특징 표현과 블록 디자인의 핵심 구성 요소를 설명합니다. Representations. 우리는 모든 특징을 1차원 토큰으로 표현합니다. 의도적으로 절대 위치 인코딩을 사용하지 않았으며, 이는 테스트 시에 다른 길이에 일반화할 수 있게 해줍니다. 따라서 우리는 주어진 길이에 대한 토큰 수를 결정하기 위해 프레임 속도 측면에서 시간 시퀀스를 지정합니다. 시각적 특징 (프레임당 하나의 토큰, 8fps)와 텍스트 특징 (77개 토큰)는 CLIP [53]에서 1024d 특징으로 추출됩니다. 오디오 잠재 변수 는 VAE 잠재 공간(섹션 3.1)에 있으며, 기본적으로 31.25fps에서 20d 잠재 변수입니다. 동기화 특징 은 Synchformer [19]로 24fps에서 768d 특징으로 추출되며, 이는 섹션 3.4에서 자세히 설명할 것입니다. 텍스트 토큰을 제외하고 다른 모든 토큰은 서로 다른 프레임 속도이긴 하지만 동일한 시간 순서를 따릅니다. 초기 ConvMLP/MLP 레이어 이후, 모든 특징은 은닉 차원 로 투영됩니다. Joint attention. 서로 다른 모달리티의 이러한 토큰들은 joint attention (Figure 2, 오른쪽)을 통해 통신합니다. [8]을 따라, 우리는 세 가지 다른 모달리티의 쿼리, 키, 값 표현을 연결하고 scaled dot product attention [64]을 적용합니다. 출력은 입력 파티션에 따라 세 가지 모달리티로 분할됩니다. 자세한 내용은 [8]을 참조하시기 바랍니다. joint attention만으로는 시간적 정렬을 포착하지 못하며, 이는 다음에 다룰 것입니다.
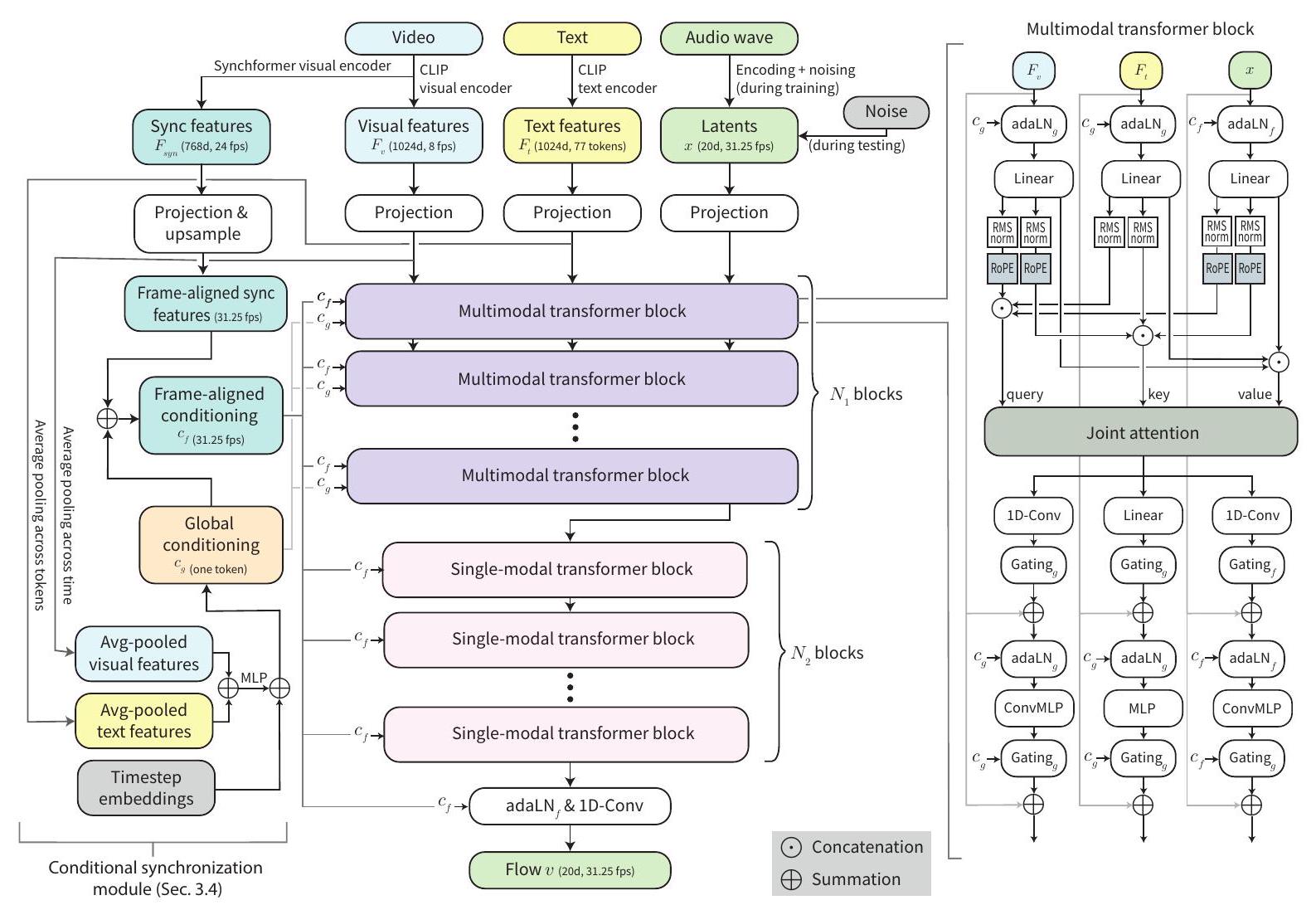
Figure 2. MMAudio 흐름 예측 네트워크 개요. 비디오 조건, 텍스트 조건 및 오디오 잠재 변수가 멀티모달 트랜스포머 네트워크에서 상호 작용합니다. 동기화 모델(섹션 3.4)은 정확한 오디오-비주얼 동기화를 위해 프레임 정렬된 동기화 특징을 주입합니다.
Aligned RoPE position embedding. 오디오-비주얼 동기화를 위해 정확한 시간적 정렬은 매우 중요합니다. 트랜스포머[64]에서 일반적으로 그렇듯이, 우리는 어텐션 레이어에 시간을 알리기 위해 위치 임베딩을 채택합니다. 구체적으로, 우리는 joint attention(Figure 2) 전에 시각 및 오디오 스트림의 쿼리와 키에 RoPE [59] 임베딩을 적용합니다. 텍스트 스트림은 비디오나 오디오의 시간적 순서를 따르지 않기 때문에 적용하지 않습니다. 또한, 프레임 속도가 정렬되지 않기 때문에(시각 스트림은 8fps, 오디오 스트림은 31.25fps), 우리는 시각 스트림의 위치 임베딩 주파수를 비례적으로, 즉 로 스케일링합니다. 우리는 기본(정렬되지 않은) RoPE와 제안된 정렬된 RoPE를 Figure A5에서 시각화합니다. 이러한 정렬된 임베딩은 유익하지만 좋은 동기화를 위해서는 불충분하다는 점에 주목합니다. 따라서 우리는 추가적인 동기화 모듈을 도입하며, 이는 섹션 3.4에서 논의할 것입니다.
ConvMLP. 로컬 시간 구조를 더 잘 포착하기 위해, 우리는 시각 및 오디오 스트림에서 MLP 대신 ConvMLP를 사용합니다. 구체적으로, 우리의 ConvMLP는 선형 레이어 대신 1D 컨볼루션(커널 크기 = 3, 패딩 = 1)을 사용합니다. 다시 말하지만, 이 변경은 텍스트 스트림에는 적용되지 않는데, 이는 비디오나 오디오의 시간적 순서를 따르지 않기 때문입니다.
Global conditioning. Global conditioning은 적응형 레이어 정규화 레이어(adaLN) [50]의 스케일과 바이어스를 통해 네트워크에 전역 특징을 주입합니다. 먼저, 우리는 흐름 타임스텝의 푸리에 인코딩 [64], 평균 풀링된 시각적 특징, 그리고 평균 풀링된 텍스트 특징(Figure 2)으로부터 모든 트랜스포머 블록에 공유되는 전역 조건 벡터 를 계산합니다. 그런 다음, 각 adaLN 레이어는 입력 (은 시퀀스 길이)를 전역 조건 로 다음과 같이 변조합니다:
여기서 는 MLP이고, 은 크기의 모든 원소가 1인 행렬로, 스케일과 바이어스를 시퀀스 길이 에 맞게 "브로드캐스트"하여 시퀀스의 모든 토큰에 동일한 조건이 적용되도록 합니다(따라서 전역적임). 다음으로, 정확한 오디오-비주얼 동기화를 위해 위치에 따른 조건을 어떻게 설계하는지 설명합니다.
3.4. Conditional Synchronization Module
우리는 오디오-비주얼 동기화를 더욱 향상시키기 위해 토큰 수준의 조건화를 개발합니다. 시각 및 오디오 스트림은 이미 교차 모달리티 어텐션 레이어를 통해 통신하지만, 이러한 레이어는 소프트 분포를 통해 특징을 집계하므로 정밀도를 저해하는 것을 발견했습니다. 이 문제를 해결하기 위해, 우리는 먼저 입력 비디오에서 Synchformer [19]의 시각 인코더를 사용하여 높은 프레임률(24fps)의 특징()을 추출합니다. Synchformer를 사용하는 이유는 비디오와 오디오 데이터 간의 시간적 불일치를 감지하도록 자기 지도 방식으로 학습되었기 때문이며, 이는 오디오 이벤트와 관련된 시각적 특징을 산출하여 동기화에 도움이 될 것이라고 가정합니다. 우리는 프레임 정렬된 조건 를 다음을 통해 찾습니다.
Upsample은 최근접 이웃 보간법을 사용하여 동기화 특징 의 프레임 속도를 오디오 잠재 변수 의 프레임 속도와 일치시킵니다. 이 프레임 정렬된 조건 는 특징 변조를 위해 오디오 스트림의 adaLN 레이어를 통해 주입됩니다. Eq. (4)와 유사하게, 우리는 를 다음을 통해 적용합니다.
여기서 는 MLP입니다. Eq. (4)와 달리, 스케일과 바이어스는 브로드캐스팅 없이 토큰별로 적용되어 세밀한 제어를 제공합니다.
3.5. Training and Inference
3.5.1. Multimodal Datasets
VGGSound. 우리는 유일한 오디오-텍스트-비주얼 데이터셋으로 VGGSound [1]에서 학습합니다. 이는 약 500시간 분량의 영상을 제공합니다. 추가적으로, VGGSound는 각 비디오에 대한 클래스 레이블(총 310개 클래스)을 포함하며, 우리는 ReWaS [20]와 VATT [40]를 따라 클래스 이름을 입력으로 사용합니다. 우리는 검증을 위해 훈련 세트에서 2K개의 비디오를 따로 두어, 약 180K개의 10초 비디오로 구성된 훈련 세트를 만듭니다. 우리는 각 비디오의 처음 8초를 학습에 사용합니다. Audio-text datasets. 우리는 학습을 위한 오디오-텍스트 데이터셋으로 AudioCaps [24] (약 128시간, 수동 캡션), Clotho [5] (약 31시간, 수동 캡션), 그리고 WavCaps [46] (약 7,600시간, 메타데이터로부터 자동 캡션)을 사용합니다. 이들은 시각적 모달리티를 포함하지 않기 때문에, 우리는 이 샘플들에 해당하는 모든 시각적 특징과 동기화 특징을 학습 가능한 빈 토큰 와 으로 각각 설정합니다. 짧은 오디오(<16초)의 경우, VGGSound에서와 같이 학습을 위해 8초로 자릅니다. 더 긴 오디오의 경우, 8초짜리 겹치지 않는 크롭을 최대 5개까지 취합니다. 이로 인해 총 951K개의 오디오 클립-텍스트 쌍이 생성됩니다. Overlaps. 우리는 이 데이터셋들 간에 사소한(< 테스트 세트의 1%) 훈련/테스트 데이터 오염이 있음을 발견했습니다. 공정한 비교를 위해, 우리는 모든 훈련 데이터에서 VGGSound와 AudioCaps의 테스트 세트를 제거했습니다. 부록 E에서 더 자세한 내용을 제공합니다.
3.5.2. Implementation Details
Model variants. 우리의 기본 모델은 20차원의 31.25fps 잠재 변수로 인코딩된 16kHz 오디오를 생성하며(Frieren [67]을 따름), 입니다. 우리는 이 기본 모델을 'S-16kHz'라고 부릅니다. 추가적으로 우리는 더 큰 모델과 더 높은 오디오 샘플링 속도를 가진 모델을 훈련시킵니다: 'S-44.1kHz', 'M-44.1kHz', 'L-44.1kHz'는 부록 G.1에 자세히 설명되어 있습니다. 이 모델들의 파라미터 수와 실행 시간은 표 1에 요약되어 있습니다. 추가적인 구현 세부 사항은 부록 F에서 H까지 설명합니다. Classifier-free guidance. 추론 중 classifier-free guidance [14]를 활성화하기 위해, 우리는 훈련 중에 10%의 확률로 시각적 토큰( 및 ) 또는 텍스트를 무작위로 마스킹합니다. 마스킹된 시각적 토큰은 학습 가능한 토큰( 및 )으로 대체되고, 마스킹된 텍스트는 빈 문자열 로 대체됩니다. Inference. 기본적으로, 우리는 25 단계의 수치 적분을 위해 Euler's method를 사용하며, classifier-free guidance 강도는 4.5입니다. 비디오 및 텍스트 조건은 테스트 시 선택 사항입니다 - 누락된 모달리티는 빈 토큰 또는 로 대체합니다. 우리는 의도적으로 절대 위치 인코딩을 사용하지 않으므로 테스트 시 다른 길이(예: 섹션 4.2의 VGGSound에서는 8초, AudioCaps에서는 10초)에 일반화할 수 있습니다.
4. Experiments
4.1. Metrics
우리는 네 가지 다른 차원에서 생성 품질을 평가합니다: 분포 매칭, 오디오 품질, 의미적 정렬 및 시간적 정렬. Distribution matching은 일부 임베딩 모델 하에서 원본 오디오와 생성된 오디오 간의 특징 분포 유사성을 평가합니다. 일반적인 관행[18, 67]에 따라, 우리는 Fréchet Distance (FD)와 Kullback-Leibler (KL) 거리를 계산합니다. FD의 경우, 우리는 PaSST [30] (FD), PANNs [29] (FD), VGGish [9] (FD)를 임베딩 모델로 채택합니다. PaSST는 32kHz에서 작동하는 반면, PANNs와 VGGish는 모두 16kHz에서 작동합니다. 또한, PaSST와 PANNs는 모두 전역 특징을 생성하는 반면, VGGish는 겹치지 않는 0.96초 클립을 처리합니다. KL 거리의 경우, 우리는 PANNs (KL)와 PaSST (KL)를 분류기로 채택합니다. 우리는 Liu 등[38]의 구현을 따릅니다. Audio quality는 Inception Score [56]를 사용하여 원본과 비교하지 않고 생성 품질을 평가합니다. 우리는 Wang 등[67]을 따라 PANNs를 분류기로 채택합니다. Semantic alignment는 입력 비디오와 생성된 오디오 간의 의미적 유사성을 평가합니다. 우리는 Viertola 등[65]을 따라 ImageBind [11]를 사용하여 입력 비디오에서 시각적 특징을, 생성된 오디오에서 오디오 특징을 추출하고 평균 코사인 유사도를 "IB-score"로 계산합니다. Temporal alignment는 동기화 점수(DeSync)로 오디오-비주얼 동기화를 평가합니다. DeSync는 Synchformer [19]에 의해 오디오와 비디오 간의 불일치(초 단위)로 예측됩니다. Viertola 등[65]도 동기화 점수를 사용하지만, Synchformer의 컨텍스트 창(4.8초)보다 짧은 오디오(2.56초)에 대해 평가한다는 점에 유의해야 합니다.
| Method | Params | Distribution matching | Audio quality Semantic align. Temporal align. | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FDvgg | IS | IB-score | DeSync | Time (s) | ||||||
| ReWaS [20]* | 619 M | 141.38 | 17.54 | 1.79 | 2.87 | 2.82 | 8.51 | 14.82 | 1.062 | 15.97 |
| Seeing&Hearing [69]* | 415M | 219.01 | 24.58 | 5.40 | 2.26 | 2.30 | 8.58 | 33.99 | 1.204 | 14.55 |
| V-AURA [65]* | 695 M | 218.50 | 14.80 | 2.88 | 2.42 | 2.07 | 10.08 | 27.64 | 0.654 | 16.55 |
| VATT [40] | - | 131.88 | 10.63 | 2.77 | 1.48 | 1.41 | 11.90 | 25.00 | 1.195 | - |
| Frieren [67] | 159M | 106.10 | 11.45 | 1.34 | 2.73 | 2.86 | 12.25 | 22.78 | 0.851 | - |
| FoleyCrafter [73]* | 1.22 B | 140.09 | 16.24 | 2.51 | 2.30 | 2.23 | 15.68 | 25.68 | 1.225 | 1.67 |
| V2A-Mapper [66] | 229 M | 84.57 | 8.40 | 0.84 | 2.69 | 2.56 | 12.47 | 22.58 | 1.225 | - |
| MMAudio-S-16kHz | 157M | 70.19 | 5.22 | 0.79 | 1.65 | 1.59 | 14.44 | 29.13 | 0.483 | 1.23 |
| MMAudio-S-44.1kHz | 157M | 65.25 | 5.55 | 1.66 | 1.67 | 1.44 | 18.02 | 32.27 | 0.444 | 1.30 |
| MMAudio-M- 44.1 kH z | 621 M | 61.88 | 4.74 | 1.13 | 1.66 | 1.41 | 17.41 | 32.99 | 0.443 | 1.35 |
| MMAudio-L-44.1kHz | 1.03 B | 60.60 | 4.72 | 0.97 | 1.65 | 1.40 | 17.40 | 33.22 | 0.442 | 1.96 |
Table 1. VGGSound 테스트 세트에 대한 video-to-audio 결과. 일반적인 관행[67]에 따라 파라미터 수는 사전 훈련된 특징 추출기(예: CLIP), 잠재 공간 인코더/디코더 및 보코더를 제외합니다. 시간은 H100 GPU에서 워밍업 후 배치 크기가 1인 샘플 하나를 생성하는 데 걸리는 총 실행 시간이며 디스크 I/O 작업은 제외합니다. *: 공식 평가 코드를 사용하여 재현. †: 저자로부터 직접 얻은 생성 샘플을 사용하여 평가. : 테스트 중에 텍스트 입력을 사용하지 않음. 참고로, Seeing&Hearing [69]는 테스트 시간에 직접 ImageBind 점수를 최적화하므로 가장 높은 IB 점수를 얻습니다.
대신, 우리는 두 개의 크롭(처음 4.8초와 마지막 4.8초)을 취하고 결과를 평균하여 더 긴(8초) 오디오를 평가합니다. 따라서 Viertola 등 [65]의 점수는 우리와 직접 비교할 수 없습니다.
4.2. Main Results
Video-to-audio. 표 1은 VGGSound [1] 테스트 세트(약 15K개의 비디오)에 대한 우리의 주요 결과를 기존의 최첨단 모델들과 비교합니다. 우리는 Wang 등 [67]에 따라 긴 오디오를 8초로 잘라서 모든 생성을 8초에서 평가합니다. V-AURA [65]의 경우, 공식 자기회귀 코드를 사용하여 8초 오디오를 생성합니다. ReWaS [20]는 5초 오디오만 생성하므로, 우리는 원본도 5초로 잘라서 그대로 평가합니다 - 이 불일치는 표에서 회색 글꼴로 표시합니다. 우리의 가장 작은 모델(157M)은 이전 방법들보다 더 나은 분포 일치, 오디오 품질, 의미적 정렬 및 시간적 정렬을 보여주면서도 빠릅니다. 주목할 만한 예외는 Seeing-and-Hearing [69] (SAH)와의 IB-점수 비교입니다. 우리는 SAH가 테스트 시간에 IB 점수를 직접 최적화한다는 점에 주목하며, 우리는 이를 수행하지 않습니다. 더 나아가, 우리의 더 큰 모델들은 FD_Passt와 IB-점수에서 계속 개선되지만, 데이터 품질과 오디오-비주얼 데이터의 양에 의해 제한될 수 있는 점감 수익을 관찰합니다. 우리의 방법이 멀티모달 공동 훈련을 위해 더 많은 데이터를 사용하지만, 일부 기존 방법들보다 전체적으로 더 많은 데이터를 사용하는 것은 아닙니다: FoleyCrafter [73], V2A-Mapper [66], ReWaS [20], SAH [69]는 모두 우리가 사용하는 것과 유사한 오디오-텍스트 데이터로 훈련된 text-to-audio 모델을 미세 조정/통합합니다. 공정한 평가를 위해, 우리는 [40,66,67]에서 제공한 사전 계산된 샘플을 사용하고, [20, 65, 69, 73]에 대한 공식 추론 코드를 사용하여 결과를 재현합니다. 그림 3은 우리의 결과를 시각화하고 이전 연구들과 비교합니다. 사용자 연구 결과와 Movie Gen Audio [52]와의 비교는 부록 A와 B에 제시합니다. 모델 기반 DeSync 메트릭을 사용하여 발생할 수 있는 잠재적 편향을 해결하기 위해, 우리는 부록 C에 자세히 설명된 Greatest Hits [48]에서 모델 없는 메트릭을 통해 동기화를 추가로 평가합니다 (표 2).
| Method | Acc. | AP | F1 | DeSync |
|---|---|---|---|---|
| Frieren [67] | 0.6949 | 0.7846 | 0.6550 | 0.851 |
| V-AURA [65] | 0.5852 | 0.8567 | 0.6441 | 0.654 |
| FoleyCrafter [73] | 0.4533 | 0.6939 | 0.4319 | 1.225 |
| Seeing&Hearing [69] | 0.1156 | 0.8342 | 0.1591 | 1.204 |
| MMAudio-S-16kHz | 0.9010 | 0.483 | ||
| MMAudio-S-44.1kHz | 0.7150 | 0.7666 | 0.444 | |
| MMAudio-M-44.1kHz | 0.7226 | 0.9054 | 0.7620 | 0.443 |
| MMAudio-L-44.1kHz | 0.7158 | 0.9064 | 0.7535 |
표 2. Greatest Hits에서의 Onset 정확도, 평균 정밀도(AP), F1-점수, 그리고 참고용으로 VGGSound에서의 DeSync.
Text-to-audio. 우리의 멀티모달 프레임워크는 미세 조정 없이 text-to-audio 합성에 적용될 수 있습니다. 표 3은 AudioCaps [24] 테스트 세트를 사용하여 우리의 방법을 최첨단 text-to-audio 모델과 비교합니다. 공정한 비교를 위해, 우리는 GenAU [12]의 평가 프로토콜에 따라 AudioCaps [24] 테스트 세트에서 10초 샘플을 평가하며, CLAP 재순위화(AudioLDM [38]에서 사용)는 사용하지 않습니다. 우리는 공식적으로 공개된 체크포인트를 동일한 평가 프로토콜 하에서 재현한 Haji-Ali 등 [12]의 결과를 직접 인용합니다. 우리는 FDPANNS, FDvgg, IS, CLAP [68]을 평가합니다. CLAP은 생성된 오디오와 입력 캡션 간의 의미적 정렬을 측정합니다. 우리의 주요 초점은 video-to-audio 합성에 있지만, MMAudio는 멀티모달 공동 훈련으로부터 학습된 풍부한 의미적 특징 공간 덕분에 최첨단 의미적 정렬(CLAP)과 오디오 품질(IS)을 달성합니다. 우리는 최근 연구들에 비해 더 나쁜 FDVGG 점수를 얻었다는 점에 주목합니다. 우리는 VGGish가 지역적 특징(0.96초 클립)을 처리하는 반면 우리의 강점은 전역적이고 의미적으로 일관된 오디오를 생성하는 데 있기 때문이라고 가정합니다.
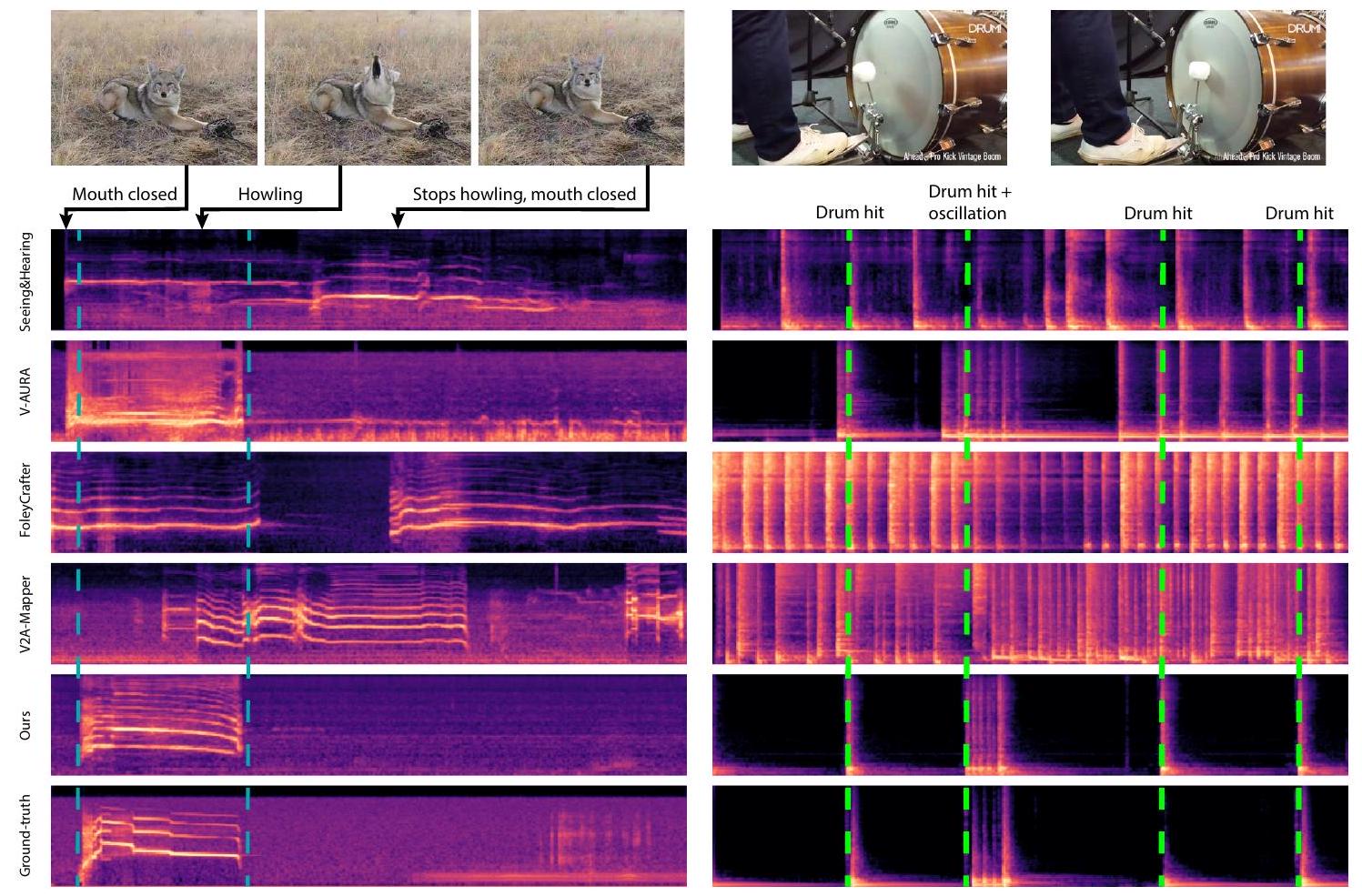
Figure 3. 우리는 생성된 오디오(이전 연구들과 우리 방법)와 원본의 스펙트로그램을 시각화합니다. 우리 방법은 원본에 가장 가깝게 정렬된 오디오 효과를 생성하는 반면, 다른 방법들은 종종 시각적 입력으로 설명되지 않고 원본에 존재하지 않는 소리를 생성합니다.
| Method | Params | FDPANNs | FDvgg | IS | CLAP |
|---|---|---|---|---|---|
| AudioLDM 2-L [39] | 712 M | 32.50 | 5.11 | 8.54 | 0.212 |
| TANGO [10] | 866M | 26.13 | 1.87 | 8.23 | 0.185 |
| TANGO 2 [43] | 866M | 19.77 | 2.74 | 8.45 | 0.264 |
| Make-An-Audio [16] | 453M | 27.93 | 2.59 | 7.44 | 0.207 |
| Make-An-Audio 2 [15] | 937M | 15.34 | 1.27 | 9.58 | 0.251 |
| GenAU-Large [12] | 1.25 B | 16.51 | 1.21 | 11.75 | 0.285 |
| MMAudio-S-16kHz | 157M | 14.42 | 2.98 | 11.36 | 0.282 |
| MMAudio-S-44.1kHz | 157M | 15.26 | 2.74 | 11.32 | 0.331 |
| MMAudio-M- 44.1 kHz | 621 M | 14.38 | 4.07 | 12.02 | 0.351 |
| MMAudio-L-44.1kHz | 1.03 B | 15.04 | 4.03 | 12.08 | 0.348 |
Table 3. AudioCaps 테스트 세트에 대한 Text-to-audio 결과. 공정한 비교를 위해, [12]의 평가 프로토콜을 따르고 모든 베이스라인은 공식적으로 릴리스된 체크포인트를 동일한 평가 프로토콜 하에서 재현한 [12]에서 직접 인용합니다.
| Training modalities | FD | IS | IB-score | DeSync |
|---|---|---|---|---|
| AVT+AT | ||||
| AV+AT | 72.77 | 12.88 | 28.10 | 0.502 |
| AVT+A | 71.01 | 14.30 | 28.72 | 0.496 |
| AVT | 77.38 | 12.53 | 27.98 | 0.562 |
| AV | 77.27 | 12.69 | 28.10 | 0.502 |
표 4. 학습 모달리티를 변경했을 때의 결과. A: 오디오, V: 비디오, T: 텍스트. 두 번째와 세 번째 행에서는 오디오-비주얼 데이터 또는 오디오-텍스트 데이터에서 텍스트 토큰을 마스킹합니다. 마지막 두 행에서는 오디오-텍스트 데이터를 사용하지 않습니다. 전역적으로 그리고 의미적으로 일관된 오디오.
4.3. Ablations
모든 절제 연구는 small-16kHz 모델을 기반으로 하며, VGGSound [1] 테스트 세트에서 분포 일치(), 오디오 품질(IS), 의미적 정렬(IB-score), 시간적 정렬(DeSync)을 평가합니다. 기본 설정은 파란색 배경으로 강조 표시합니다. Cross-modal alignment. 공동 멀티모달 훈련의 이점을 명확히 하기 위해, 훈련 중에 일부 모달리티를 마스킹하고 그 효과를 결과에 관찰하며, 이는 표 4에 요약되어 있습니다. 우리는 설정을 (오디오-비주얼-텍스트 데이터에 사용된 모달리티 + 오디오-텍스트 데이터에 사용된 모달리티)로 표기하며, 여기서 A: 오디오, V: 비디오, T: 텍스트입니다. 우리의 기본 설정(AVT+AT)은 오디오-비주얼-텍스트 데이터(VGGSound 클래스 레이블을 텍스트 입력으로 사용)와 오디오-텍스트 데이터로 훈련함을 의미합니다. 우리는 세 가지 관찰을 합니다:
- 전자(AV+AT) 또는 후자(AVT+A)에서 텍스트 모달리티를 마스킹하면 결과가 더 나빠집니다. 이는 공동 "텍스트 특징 공간"을 갖는 것이 멀티모달 훈련에 유익하다는 것을 시사합니다.
- 캡션이 없는 오디오 데이터를 추가하면 결과가 개선됩니다 (AVT
| % audio-text data | FD Passt | IS | IB-score | DeSync |
|---|---|---|---|---|
| 14.44 | ||||
| 71.03 | 29.11 | 0.489 | ||
| 71.67 | 14.41 | 28.75 | 0.505 | |
| 79.21 | 13.55 | 27.47 | 0.514 | |
| None | 77.38 | 12.53 | 27.98 | 0.562 |
표 5. 멀티모달 훈련 데이터의 양을 변경했을 때의 결과. 처음 네 행에서는 훈련 중 오디오-비주얼 데이터와 오디오-텍스트 데이터를 1:1 비율로 샘플링합니다. 마지막 행에서는 오디오-비주얼 데이터만 사용됩니다.
vs. AVT+A). 이는 우리 네트워크가 자연스러운 소리의 분포를 학습함으로써 조건 없는 생성 데이터에 대한 훈련에서도 이점을 얻는다는 것을 시사합니다. 3. 오디오-텍스트 데이터를 사용하지 않을 때, VGGSound의 간단한 클래스 레이블을 사용하는 것은 결과에 큰 영향을 미치지 않습니다 (AVT vs. AV). 이는 네트워크에 트랜스포머 분기를 추가하거나 클래스 레이블을 사용하는 것보다 대규모 멀티모달 데이터셋에서 훈련하는 것이 핵심임을 시사합니다. Multimodal data. 대규모 멀티모달 데이터 모음에서 학습하는 것은 매우 중요합니다. 표 5는 오디오-텍스트 학습 데이터의 양을 변경했을 때 우리 모델의 성능을 보여줍니다. 오디오-텍스트 데이터를 사용하지 않을 때를 제외하고는 항상 오디오-비주얼 데이터와 오디오-텍스트 데이터를 동일한 비율(대략 1:1, 부록 H 참조)로 샘플링합니다. 오디오-텍스트 데이터를 사용하지 않을 때는 과적합을 관찰하고 조기 종료합니다. 더 많은 멀티모달 데이터를 사용하면 분포 일치(FD_Passt), 의미적 정렬(IB-score), 시간적 정렬(DeSync)이 점감하는 수익과 함께 향상됩니다. Conditional synchronization module. 우리는 동기화 기능을 통합하기 위한 여러 가지 방법을 비교합니다: 1) 조건부 동기화 모듈(섹션 3.4)을 사용하는 우리의 기본 방법; 2) 동기화 기능을 멀티모달 트랜스포머의 시각적 분기에 통합하는 방법. 구체적으로, 우리는 CLIP 특징을 24fps로 업샘플링(최근접 이웃 사용)한 다음, 선형 투영 후 CLIP 특징과 Sync 특징을 합하여 최종 시각적 특징으로 사용합니다. 이 아키텍처를 그림 A4에 설명합니다; 마지막으로, 3) 동기화 기능을 사용하지 않는 방법. 표 6(상단)은 우리의 동기화 모듈이 최고의 시간적 정렬을 달성함을 보여줍니다. "sum sync with visual" 방법이 더 높은 오디오 품질(IS)을 달성하는 것을 주목합니다 - CLIP 특징을 업샘플링하면 시각적 스트림의 토큰 수가 세 배로 증가했기 때문에, 모델이 더 미세한 계산을 위해 더 긴 시퀀스를 사용하는 것에서 이점을 얻는다고 가정합니다. RoPE embeddings. 우리는 정렬된 RoPE 공식을 1) RoPE 임베딩을 사용하지 않는 경우와 2) 정렬되지 않은 RoPE 임베딩, 즉 시각적 분기에서 주파수 스케일링이 없는 경우와 비교합니다. 표 6(하단)은 정렬된 RoPE 임베딩[59]을 사용하면 오디오-비주얼 동기화가 향상됨을 보여줍니다. ConvMLP. 표 7(상단)은 MLP 대 ConvMLP 사용의 성능 차이를 요약합니다. MLP 모델의 경우,
| Variant | FD PassT | IS | IB-score | DeSync |
|---|---|---|---|---|
| With sync module | 70.19 | 14.44 | 29.13 | |
| Sum sync with visual | 73.59 | 28.65 | 0.490 | |
| No sync features | 15.05 | 0.973 | ||
| Aligned RoPE | 14.44 | 29.13 | ||
| No RoPE | 70.24 | 29.23 | 0.509 | |
| Non-aligned RoPE | 70.25 | 0.496 |
Table 6. 동기화 기능이나 RoPE 임베딩을 다르게 사용할 때의 결과.
| Variant | FD PassT | IS | IB-score | DeSync |
|---|---|---|---|---|
| ConvMLP | ||||
| MLP | 73.84 | 13.01 | 28.99 | 0.533 |
| 14.44 | 29.13 | |||
| 70.33 | 0.487 | |||
| 72.53 | 13.75 | 29.06 | 0.509 |
표 7. MLP 아키텍처 또는 다중/단일 모달리티 트랜스포머 블록 간의 비율을 변경했을 때의 결과.
ConvMLP 모델의 파라미터 수와 거의 일치하도록 를 로, 을 으로, 를 으로 증가시켰습니다. ConvMLP 모델은 지역적 시간 구조를 더 잘 포착하여 특히 동기화에서 더 나은 성능을 보입니다. Ratio between and . 표 7(하단)은 거의 동일한 파라미터 예산으로 멀티모달() 및 단일모달() 트랜스포머 블록 수의 다른 할당을 비교합니다. 우리의 기본 할당()은 더 많은 단일모달 블록을 사용하는 것()과 유사하게 수행되며, 더 적은 단일모달 블록을 사용하는 것()보다 더 낫다는 것을 알 수 있습니다. 우리는 단일모달 블록을 사용하는 것이 동일한 파라미터 수로 더 깊은 네트워크를 구축할 수 있게 해주기 때문이라고 생각합니다.
4.4. Limitations
우리 모델은 사람의 말(입 움직임을 보거나 텍스트 입력으로부터)을 생성하라는 지시를 받았을 때 이해할 수 없는 중얼거림을 생성합니다. 우리는 사람의 말이 본질적으로 더 복잡하며(예: 언어, 톤, 문법 등), 일반적인 오디오 효과(Foley)를 목표로 하는 우리 모델이 이를 적절히 수용하지 못한다고 생각합니다.
5. Conclusion
우리는 오디오, 비디오, 텍스트 모달리티를 공동으로 고려하는 최초의 멀티모달 학습 파이프라인인 MMAudio를 제안하여 효과적인 데이터 확장과 교차 모달 의미 정렬을 달성했습니다. 조건부 동기화 모듈과 결합하여, 우리의 방법은 공개 모델 중 새로운 최첨단 성능을 달성했으며 Movie Gen Audio와 비교할 만한 성능을 보입니다. 우리는 멀티모달 공식화가 어떤 모달리티의 데이터 합성에 있어서도 핵심이라고 믿으며, MMAudio는 오디오-비디오-텍스트 공간에서 그 기초를 마련합니다.
Table of Contents
1 Introduction ..... 1 2 Related Works ..... 2 3 MMAudio ..... 3 3.1 Preliminaries ..... 3 3.2 Overview ..... 3 3.3 Multimodal Transformer ..... 3 3.4 Conditional Synchronization Module ..... 4 3.5 Training and Inference ..... 5 3.5.1 Multimodal Datasets ..... 5 3.5.2 Implementation Details ..... 5 4 Experiments ..... 5 4.1 Metrics ..... 5 4.2 Main Results ..... 6 4.3 Ablations ..... 7 4.4 Limitations ..... 8 5 Conclusion ..... 8 A User Study ..... 13 B Comparisons with Movie Gen Audio ..... 13 C Evaluation on the Greatest Hits Dataset ..... 14 D Ablations on Filling in Missing Modalities ..... 15 E Details on Data Overlaps ..... 15 F Details on the Audio Latents ..... 16 G Network Details ..... 16 G. 1 Model Variants ..... 16 G. 2 Projection Layers ..... 16 G. 3 Gating ..... 17 G. 4 Details on Synchronization Features ..... 17 G. 5 Illustration of the "sum sync with visual" Ablation ..... 17 G. 6 Visualization of Aligned RoPE ..... 18 H Training Details ..... 18 I Additional Visualizations ..... 20
A. User Study
표 1에 제시된 객관적인 지표 외에도, 우리는 VGGSound [1] 테스트 세트에 대한 주관적인 평가를 위해 사용자 연구를 수행했습니다. 비교를 위해, 우리는 우리의 최고 모델(MMAudio-L-44.1kHz)과 네 개의 최고 베이스라인을 선택했습니다:
- Seeing and Hearing [69], 우리 것을 제외하고 가장 높은 ImageBind (즉, 비디오와의 최고의 의미적 정렬) 점수를 가졌기 때문입니다.
- V-AURA [65], 우리 것을 제외하고 비디오와 가장 낮은 DeSync (즉, 최고의 시간적 정렬)를 가졌기 때문입니다.
- VATT [40], 우리 것을 제외하고 가장 낮은 Kullback-Leibler 발산 (즉, 및 )을 가졌기 때문입니다.
- V2A-Mapper [66], 우리 것을 제외하고 가장 낮은 Fréchet 거리 (즉, , 및 )를 가졌기 때문입니다.
우리는 VGGSound [1] 테스트 세트에서 저해상도(360p 미만)이거나 사람의 말이 포함된 비디오를 제외한 후 8개의 비디오를 샘플링합니다. 총, 각 참가자는 40개의 비디오(8개 비디오 × 5개 방법)를 평가합니다. 우리는 동일한 비디오에 대한 샘플을 그룹화하고, 편향을 피하기 위해 각 그룹의 순서를 무작위로 섞습니다. 우리는 각 참가자에게 다음 지침을 제공하며 리커트 척도 [36] (1-5; 매우 동의하지 않음, 동의하지 않음, 보통, 동의함, 매우 동의함)를 사용하여 세 가지 측면에서 생성을 평가하도록 요청합니다: (a) 오디오는 고품질입니다.
설명: 오디오는 잡음이 있거나, 불분명하거나, 뭉개지면 저품질입니다. 이 측면에서는 시각 정보를 무시하고 오디오에 집중하십시오. (b) 오디오는 비디오와 의미적으로 정렬되어 있습니다.
설명: 오디오 효과가 비디오에 묘사된 시나리오에서 발생할 가능성이 낮은 경우(예: 도서관에서의 폭발음), 오디오는 비디오와 의미적으로 정렬되지 않은 것입니다. (c) 오디오는 비디오와 시간적으로 정렬되어 있습니다.
설명: 오디오가 비디오에 비해 지연되거나 앞서 들리거나, 오디오 이벤트가 잘못된 시간에 발생하는 경우(예: 비디오에서는 드러머가 드럼을 두 번 치고 멈추지만, 오디오에서는 드럼 소리가 계속 발생하는 경우), 오디오는 비디오와 시간적으로 정렬되지 않은 것입니다. 총 23명의 참가자로부터 각 측면에서 920개의 응답을 수집했습니다. 표 A1은 사용자 연구 결과를 요약합니다. MMAudio는 사용자로부터 세 가지 측면 모두에서 훨씬 높은 평가를 받았으며, 이는 본 논문의 표 1에 제시된 객관적인 지표와 일치합니다.
| Method | Audio quality | Semantic alignment | Temporal alignment |
|---|---|---|---|
| Seeing&Hearing [69] | |||
| V-AURA [65] | |||
| VATT [40] | |||
| V2A-Mapper [66] | |||
| MMAudio-L-44.1kHz |
표 A1. 사용자 연구에서 각 방법에 대한 평균 평점. 각 측면에서 평균 ± 표준 편차를 보여줍니다.
B. Comparisons with Movie Gen Audio
최근, 입력 비디오에 대한 음향 효과와 음악 생성을 위해 Movie Gen Audio [52]가 소개되었습니다. Movie Gen Audio의 기술적 세부 사항은 부족하지만, 업계의 현재 최첨단 video-to-audio 합성 알고리즘을 대표합니다. 130억 파라미터 모델은 우리보다 100배 이상 큰 비공개 데이터로 훈련되었습니다. 그럼에도 불구하고, 우리는 공개 모델과 비공개 모델 간의 차이를 벤치마킹하기 위해 MMAudio를 Movie Gen Audio [52]와 비교합니다.
작성 시점에서 Movie Gen Audio에서 접근 가능한 유일한 출력은 "Movie Gen Audio Bench" 데이터셋의 527²개 생성물입니다. Movie Gen Audio Bench의 모든 비디오는 MovieGen [52]에 의해 생성되었으며, 이는 실제 비디오의 분포(예: 과도하게 부드러운 텍스처, 느린 움직임)와는 다릅니다. 이들은 합성 비디오이므로 해당되는 실제 오디오는 없습니다. 우리는 최고의 모델인 MMAudio-L-44.1kHz를 이 비디오들과 해당 오디오 프롬프트(Movie Gen Audio도 사용함)에 대해 실행하고 우리의 생성물을 Movie Gen Audio와 비교합니다.
원본 오디오가 없기 때문에, 본 논문에서 사용한 표준 지표 중에서는 Inception Score (IS, 오디오 품질), IB-score (ImageBind [11]와 유사하게, 비디오와 오디오 간의 의미적 정렬), DeSync (SynchFormer [19]에 의해 예측된 비디오와 오디오 간의 불일치), 그리고 CLAP [7, 68] (텍스트와 오디오 간의 정렬)만 평가할 수 있습니다. 추가적으로, 우리는 부록 A의 프로토콜에 따라 사용자 연구를 수행했으며, 편향을 방지하기 위해 Movie Gen Audio가 생성한 매우 낮은 볼륨(보통 볼륨에서 명확하게 들리지 않음)의 오디오는 제외했습니다. 우리는 총 5개의 비디오를 샘플링했고 23명의 참가자로부터 각 측면에 대해 230개의 응답을 받았습니다.
표 A2는 우리의 결과를 요약합니다. 주관적 지표에서 MMAudio는 Movie Gen Audio와 비슷합니다 - 의미적 정렬에서는 약간 더 나쁘고 시간적 정렬에서는 약간 더 좋습니다. 객관적 지표에서는 동일한 추세를 관찰합니다 - MMAudio와 Movie Gen Audio는 동일한 오디오 품질(IS) 점수를 얻고, Movie Gen Audio는 더 나은 의미적 정렬(IB-score 및 CLAP)을 가지며, MMAudio는 더 나은 비디오-오디오 동기화(DeSync)를 가집니다.
| Method | Param | Training data | Subjective metrics | Objective metrics | |||||
|---|---|---|---|---|---|---|---|---|---|
| Audio qual. | Semantic align. | Temporal align. | IS | IB-score | CLAP | DeSync | |||
| Movie Gen Audio [52] | 13B | 8.40 | 36.26 | 0.4409 | 1.006 | ||||
| MMAudio-L-44.1kHz | 1.03 B | 8.40 | 27.01 | 0.4324 | 0.771 |
표 A2. Movie Gen Audio와 MMAudio 간의 주관적 지표(사용자 연구) 및 객관적 지표 비교. 주관적 지표의 경우 평균 ± 표준편차를 표시합니다.
또한, IB-점수 측면에서, 우리는 MMAudio가 일부 비디오에서 더 어려움을 겪는 반면, Movie Gen Audio는 더 일관된 결과를 제공한다는 것을 발견했습니다. 우리는 그림 A1(왼쪽)에서 MMAudio와 Movie Gen Audio를 비교하는 정렬된 IB-점수를 그립니다. Movie Gen Audio는 저성능 영역에서 일관되게 더 나은 성능을 보이지만, 고성능 영역에서는 격차가 좁혀집니다. 이는 우리의 제한된 훈련 데이터가 Movie Gen Audio Bench의 데이터를 적절히 포함하지 못하여 익숙하지 않은 비디오 유형에서 부족하기 때문이라고 생각합니다. 참고로, 우리의 유일한 비디오-오디오 훈련 데이터셋은 310개 클래스의 비디오를 포함하는 VGGSound [1]입니다. 우리는 이 클래스를 넘어서는 공개 데이터를 수집하는 것이 이 성능 격차를 효과적으로 줄일 수 있다고 가정합니다. CLAP 점수의 경우 훨씬 작은 규모로 동일한 현상이 발생하는데, 이는 우리가 더 많은 오디오-텍스트 데이터를 사용하기 때문일 수 있습니다. 그림 A2는 훈련 데이터에 의해 잘/잘 다루어지지 않는 개념을 가진 비디오에서 우리가 상당히 높거나 낮은 IB-점수를 얻는 예시를 보여줍니다.
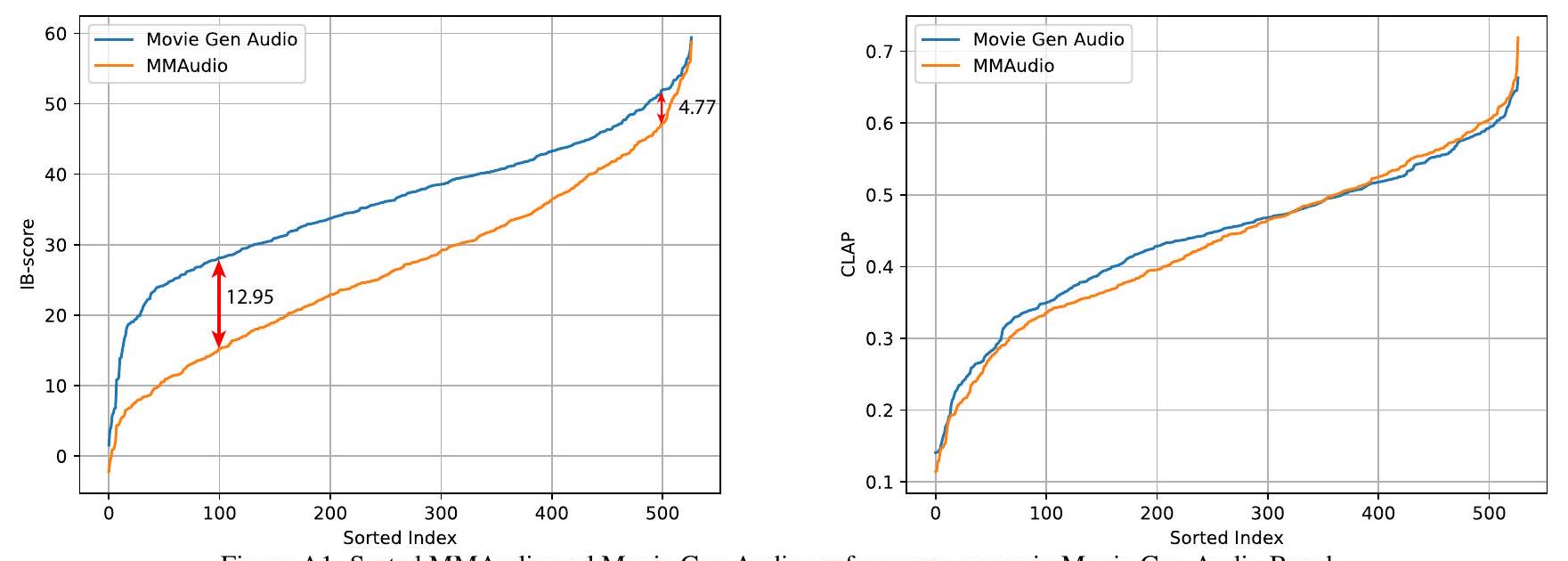
Figure A1. Movie Gen Audio Bench에서 정렬된 MMAudio 및 Movie Gen Audio 성능 점수.
C. Evaluation on the Greatest Hits Dataset
모델 기반 DeSync 메트릭을 사용하여 발생할 수 있는 잠재적 편향을 해결하기 위해, 우리는 생성된 오디오의 시작점과 실제 레이블을 비교하여 시간적 정렬을 평가하는 추가 실험을 수행합니다. 구체적으로, 우리는 뚜렷하고 레이블이 지정된 사운드 이벤트(드럼 스틱이 <물체>를 치는 것)가 포함된 비디오가 있는 Greatest Hits [48] 테스트 세트(244개 비디오)를 사용합니다. 특히, 우리 모델이나 베이스라인 모두 이 데이터 세트에서 훈련되지 않았습니다. 우리는 각 비디오의 처음 8초(모델의 제약으로 인해)에 대해 우리 방법과 베이스라인(사용 가능한 코드 사용)을 모두 테스트합니다: 우리는 [6]에 따라 생성된 오디오에서 시작점을 추출하고 레이블이 지정된 사운드 이벤트와 비교합니다. 우리는 정확도, 평균 정밀도(AP), F1-점수를 사용하여 성능을 평가합니다. 표 2에 결과를 제공하고 그림 A8에 스펙트로그램을 시각화합니다. MMAudio는 이러한 모델 없는 메트릭에서 훨씬 더 나은 성능을 달성합니다. Seeing&Hearing의 경우와 같이 매우 적은 시작점을 생성하여 높은 AP(정확도나 F1이 아님)를 달성할 수 있다는 점에 유의해야 합니다.

그림 A2. 훈련 데이터에 의해 잘/잘 다루어지지 않는 Movie Gen Audio Bench의 비디오 예시. 왼쪽: 훈련 데이터에 익숙한 개념(VGGSound 훈련 세트에 516개의 수영 비디오)이 있는 경우, MMAudio는 더 높은 IB 점수를 달성합니다. 오른쪽: 익숙하지 않은 개념(제공된 레이블에 따르면 VGGSound [1]에는 으깬 감자에 대한 비디오가 없음)이 있는 경우, MMAudio는 상당히 낮은 IB 점수를 얻습니다.
D. Ablations on Filling in Missing Modalities
우리 훈련 데이터 중에서, VGGSound는 유일한 삼중 모달(클래스 이름을 텍스트로 사용) 데이터셋인 반면, 다른 모든 데이터는 오디오-텍스트입니다. 다른 데이터의 경우, 누락된 시각적 모달리티(CLIP 및 Sync 특징)를 종단 간 학습 가능한 임베딩( 및 )으로 대체하고, 누락된 텍스트 모달리티를 빈 문자열()로 대체합니다. 우리는 심층 신경망이 적응할 가능성이 높기 때문에 누락된 모달리티를 채우는 다른 방법도 유사하게 효과적일 것이라고 생각합니다. 실제로, 누락된 모달리티를 모두 학습 가능한 임베딩이나 0으로 대체해도 큰 차이가 없습니다(표 A3). 참고로, 우리는 또한 classifier-free guidance를 가능하게 하기 위해 훈련 중에 무작위로 모달리티를 제거하여, 모델이 누락된 모달리티에 대한 견고성을 향상시킵니다.
| Method | FD Pass | IS | IB-score | DeSync |
|---|---|---|---|---|
| Ours | 70.19 | 14.44 | 29.13 | 0.483 |
| With all learnable | 70.13 | 14.63 | 29.23 | 0.494 |
| With zeros | 69.91 | 14.60 | 29.22 | 0.496 |
표 A3. 누락된 모달리티를 채우는 다른 방법들의 비교. 예상대로, 심층 신경망이 적응하는 법을 배우기 때문에 큰 차이는 없습니다.
E. Details on Data Overlaps
video-to-audio 생성을 위해 일반적으로 사용되는 데이터셋 간에 훈련 및 테스트 데이터 중복이 있음을 주목합니다. 예를 들어, AudioSet [9]은 VAE 인코더/디코더를 훈련하는 데 일반적으로 사용되지만 VGGSound [1] 및 AudioCaps [24]의 테스트 세트 데이터를 포함합니다. 또한, AudioCaps는 종종 text-to-audio 모델 [70]을 훈련하는 데 사용되며, 이는 VGGSound [1]에서 평가되는 video-to-audio 모델의 백본으로 사용됩니다. 그러나 VGGSound 테스트 세트의 일부는 AudioCaps 훈련 세트와 겹칩니다. 더욱이, 때때로 video-to-audio 알고리즘 [73]의 훈련/평가를 위해 VGGSound와 함께 사용되는 AVSync15 [72]는 VGGSound와 심각한 교차 오염을 포함합니다. 이로 인해 VGGSound와 AVSync15 모두에서 편향된 평가가 발생합니다. 우리가 아는 한, 이 데이터 오염 문제는 video-to-audio 커뮤니티에서 아직 해결되지 않았습니다. 오디오 캡셔닝 분야에서 이 문제를 제기하여 우리가 이 문제를 식별하는 데 도움을 준 Labb 등 [31]에게 감사합니다.
표 A4는 관찰된 중복을 요약합니다. WavCaps [46] 및 Freesound [33]와의 중복은 해당 릴리스의 일부로 포함되었으므로 우리 표에서 반복하지 않습니다.
우리는 훈련 데이터(AudioSet [9], AudioCaps [24], Clotho [5], Freesound [33], WavCaps [46], VGGSound [1])에서 테스트 세트(VGGSound 및 AudioCaps)와 겹치는 모든 것을 신중하게 제거했습니다. 또한 훈련 데이터에서 Clotho [5]의 테스트 세트도 제거했습니다. 대부분의 베이스라인이 VGGSound에서 훈련되었기 때문에 AVSync15에서는 평가하지 않기로 결정했습니다.
| Test sets (number of samples) | Training sets | |||
|---|---|---|---|---|
| AudioSet | AudioCaps | VGGSound | AVSync15 | |
| AudioCaps (975) | 580 (59.5%) | - | 147 (15.1%) | - |
| VGGSound | 132 (0.9%) | 13 (0.1%) | - | 59 (0.4%) |
| AVSync-15 (150) | - | - | 144 (96.0%) | - |
Table A4. 다른 데이터셋의 훈련 세트와 테스트 세트 간의 중복. 백분율은 전체 테스트 세트에서 중복되는 데이터의 비율을 나타냅니다. "-"는 이 데이터를 계산하지 않았음을 의미합니다(AVSync15에서 훈련하거나 테스트하지 않음).
F. Details on the Audio Latents
본 논문에서 언급했듯이, 우리는 먼저 단시간 푸리에 변환(STFT)으로 오디오 파형을 변환하고 크기 성분을 멜 스펙트로그램[57]으로 추출하여 오디오 잠재 변수를 얻습니다. 그런 다음, 스펙트로그램은 사전 훈련된 변이형 오토인코더(VAE)[27]에 의해 잠재 변수로 인코딩됩니다. 테스트 중, 생성된 잠재 변수는 VAE에 의해 스펙트로그램으로 디코딩되고, 이는 사전 훈련된 보코더[35]에 의해 오디오 파형으로 변환됩니다. 표 A5는 우리의 STFT 파라미터와 잠재 정보를 표로 나타냅니다.
VAE의 경우, 우리는 Make-An-Audio 2 [15]의 1D 컨볼루션 네트워크 설계를 따르며, 다운샘플링 계수는 2이고 재구성, 적대적, 쿨백-라이블러 발산(KL) 목표로 훈련되었습니다. 기본 설정이 모든 시퀀스의 끝에서 잠재 공간의 극단적인 값(±10σ 떨어져 있음)으로 이어진다는 점에 주목합니다. 이 문제를 해결하기 위해, 우리는 EDM2 [22]의 크기 보존 네트워크 설계를 적용하여 컨볼루션, 정규화, 덧셈, 연결 레이어를 크기 보존 등가물로 대체했습니다. 이 변경은 극단적인 값을 제거하지만, 경험적 성능에 큰 차이를 가져오지는 않습니다. 우리는 Make-An-Audio 2 [15]를 따라 AudioSet [9]에서 16kHz 모델을 훈련합니다. 44.1kHz 모델의 경우, 은닉 차원을 384에서 512로 늘리고 더 높은 샘플링 속도로 인한 재구성 어려움을 수용하기 위해 AudioSet [9]과 Freesound [33]에서 훈련합니다.
보코더의 경우, 16kHz 모델에서는 Make-An-Audio 2 [15]가 훈련한 BigVGAN [35]를 사용합니다. 44.1kHz 모델의 경우, BigVGAN-v2 [35] (bigvgan_v2_44khz_128band_512x 체크포인트)를 사용합니다.
| Model variants | Latent frame rate | # latent channels | # mel bins | # FFTs | Hop size | Window size | Window function |
|---|---|---|---|---|---|---|---|
| 16 kHz | 31.25 | 20 | 80 | 1024 | 256 | 1024 | Hann |
| 44.1 kHz | 43.07 | 40 | 128 | 2048 | 512 | 2048 | Hann |
표 A5. 단시간 푸리에 변환(STFT) 파라미터 및 잠재 정보.
G. Network Details
G.1. Model Variants
우리의 기본 모델은 20차원, 31.25fps 잠재 변수(Frieren [67]에 따름)로 인코딩된 16kHz 오디오를 생성하며, 입니다. 우리는 이 기본 모델을 'S-16kHz'라고 부릅니다. 더 높은 주파수를 충실하게 포착하기 위해, 우리는 40차원, 43.07fps 잠재 변수를 생성하는 44.1kHz 모델('S-44.1kHz')도 훈련시키며, 다른 모든 설정은 기본과 동일합니다. 고주파수 모델을 확장하기 위해, 우리는 먼저 두 배가 된 잠재 차원과 일치하도록 은닉 차원을 두 배로 늘립니다. 즉, 을 사용하며 이 모델을 'M-44.1kHz'로 지칭합니다. 마지막으로, 우리는 레이어 수를 확장합니다. 즉, 이며 이 모델을 'L-44.1kHz'로 지칭합니다. 이러한 모델 변형은 표 A6에 요약되어 있습니다.
G.2. Projection Layers
우리는 입력 텍스트, 시각 및 오디오 특징을 은닉 차원 로 투영하고 시간적 맥락의 초기 집계를 위해 투영 레이어를 사용합니다. Text feature projection. 우리는 로 투영하는 선형 레이어 다음에 MLP를 사용합니다. Clip feature projection. 우리는 로 투영하는 선형 레이어 다음에 커널 크기가 3이고 패딩이 1인 ConvMLP를 사용합니다.
| Model variants | Params | # multimodal blocks | # single-modal blocks | Hidden | Latent dim | Time (s) |
|---|---|---|---|---|---|---|
| S-16kHz | 157 M | 4 | 8 | 448 | 20 | 1.23 |
| S-44.1kHz | 157 M | 4 | 8 | 448 | 40 | 1.30 |
| M-44.1kHz | 621 M | 4 | 8 | 896 | 40 | 1.35 |
| L-44.1kHz | 1.03 B | 7 | 14 | 896 | 40 | 1.96 |
표 A6. 다른 MMAudio 모델 변형에 대한 요약. 시간은 H100 GPU에서 워밍업 후 배치 크기가 1인 샘플 하나를 생성하는 총 실행 시간이며 디스크 I/O 작업은 제외합니다.
Sync feature projection. 우리는 커널 크기 7, 패딩 3으로 에 투영하는 1D 컨볼루션 레이어, SELU [28] 활성화 레이어, 그리고 커널 크기 3, 패딩 1의 ConvMLP를 사용합니다. Audio feature projection. 우리는 커널 크기 7, 패딩 3으로 에 투영하는 1D 컨볼루션 레이어, SELU [28] 활성화 레이어, 그리고 커널 크기 7, 패딩 3의 ConvMLP를 사용합니다.
G.3. Gating
게이팅 레이어는 적응형 정규화 레이어(adaLN)와 유사합니다. 각 전역 게이팅 레이어는 입력 (은 시퀀스 길이)를 전역 조건 로 다음과 같이 변조합니다:
여기서 는 MLP이고, 은 크기의 모든 원소가 1인 행렬로, 스케일을 시퀀스 길이 에 맞게 "브로드캐스트"하여 시퀀스의 모든 토큰에 동일한 조건이 적용되도록 합니다(따라서 전역적임).
유사하게, 토큰별 게이팅 레이어의 경우, 프레임 정렬된 조건 는 정밀한 특징 변조를 위해 다음을 통해 오디오 스트림에 주입됩니다.
여기서 는 MLP입니다. 식 (A1)과 달리, 스케일은 브로드캐스팅 없이 토큰별로 적용됩니다.
G.4. Details on Synchronization Features
우리는 동기화 특징을 추출하기 위해 Synchformer [19]의 시각적 인코더를 사용합니다. 우리는 Iashin 등 [19]이 제공한 AudioSet에서 훈련된 사전 훈련된 오디오-비주얼 동기화 모델을 사용합니다. 입력으로 25fps의 프레임을 얻습니다. Synchformer는 이 프레임들을 16 프레임의 겹치는 클립으로 분할하고(스트라이드 8), 각 클립에 대해 길이 8의 특징을 생성합니다. 따라서 길이가 초인 비디오의 경우, 동기화 특징의 시퀀스 길이는 다음과 같습니다.
해당하는 특징 fps는 다음과 같습니다.
본 논문에서는 과 으로 실험했습니다. 두 경우 모두 는 정확히 24입니다. 또한, 우리는 그림 A3에서 설명한 바와 같이 Synchformer 특징에 추가되는 길이 8(Synchformer가 처리하는 각 클립의 특징 수와 일치)의 학습 가능한 위치 임베딩을 도입합니다.
G.5. Illustration of the "sum sync with visual" Ablation
그림 A4는 "conditional synchronization module" 단락의 "sum sync with visual" 절제 연구를 위한 네트워크 아키텍처를 보여줍니다. 시각적 특징은 동기화 특징의 프레임 속도와 일치하도록 최근접 이웃을 사용하여 업샘플링됩니다. 이 아키텍처는 FD_Passt, IB-score, 동기화(DeSync)가 더 나쁘지만, 더 나은 인셉션 스코어(IS)를 가집니다. 이는 업샘플링 단계에서 시각적 토큰 수가 증가하여 더 세밀한 계산으로 이어진다는 가설을 세웁니다.
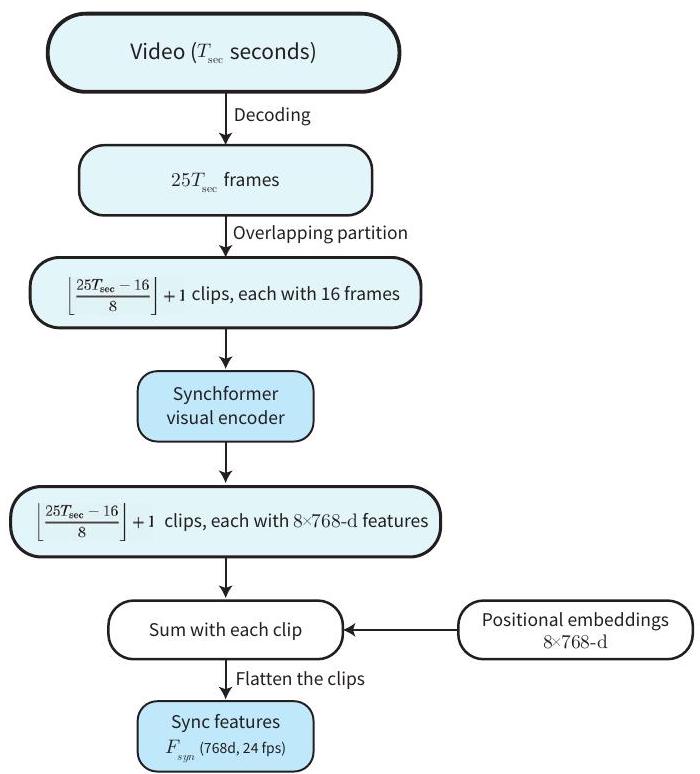
Figure A3. Synchformer 특징 추출.
G.6. Visualization of Aligned RoPE
정렬된 RoPE [59] 사용의 효과를 시각화하기 위해, RoPE가 적용되었을 때 두 시퀀스 와 의 내적 유사도를 비교합니다. 여기서 250은 오디오 시퀀스 길이(8초 동안 31.25fps), 64는 시각 시퀀스 길이(8초 동안 8fps), 그리고 는 채널 크기를 나타냅니다. 구체적으로, 우리는 다음을 시각화합니다.
그리고,
그림 A5에서. 정렬된 RoPE를 사용할 때 시간적 정렬이 달성됩니다.
H. Training Details
Training setup. 별도로 명시되지 않는 한, 모든 모델 크기에 대해 동일한 하이퍼파라미터 세트를 사용했습니다. 모델을 훈련하기 위해, 우리는 기본 학습률 1e-4, 1K 단계의 선형 워밍업 스케줄, 300K 반복, 배치 크기 512를 사용했습니다. 우리는 및 가중치 감쇠 1e-6의 AdamW 옵티마이저 [26,41]를 사용했습니다. 기본 가 대신 사용되었다면, 때때로 훈련 붕괴(NaN으로)를 관찰했습니다. 학습률 스케줄링의 경우, 훈련 단계의 80% 후에 학습률을 1e-5로 줄이고, 훈련 단계의 90% 후에 다시 한 번 1e-6으로 줄입니다. 모델 지수 이동 평균(EMA)의 경우, 모든 모델에 대해 상대적 너비 의 사후 EMA [22] 공식을 사용합니다. 훈련 효율성을 위해, 우리는 bf16 혼합 정밀도 훈련을 사용하며, 모든 오디오 잠재 변수 및 시각적 임베딩은 오프라인으로 사전 계산되어 훈련 중에 로드됩니다. 표 A7은 각 모델 크기에 대해 사용한 훈련 리소스를 요약합니다.
| Model | Number of GPUs used | Number of hours to train | Total GPU-hours |
|---|---|---|---|
| MMAudio-S-16kHz | 2 | 22 | 44 |
| MMAudio-S-44.1kHz | 2 | 26 | 52 |
| MMAudio-M-44.1kHz | 8 | 21 | 168 |
| MMAudio-L-44.1kHz | 8 | 38 | 304 |
표 A7. 각 모델 크기에 사용된 훈련 자원의 양. 모든 설정에서 H100 GPU가 사용되었습니다.
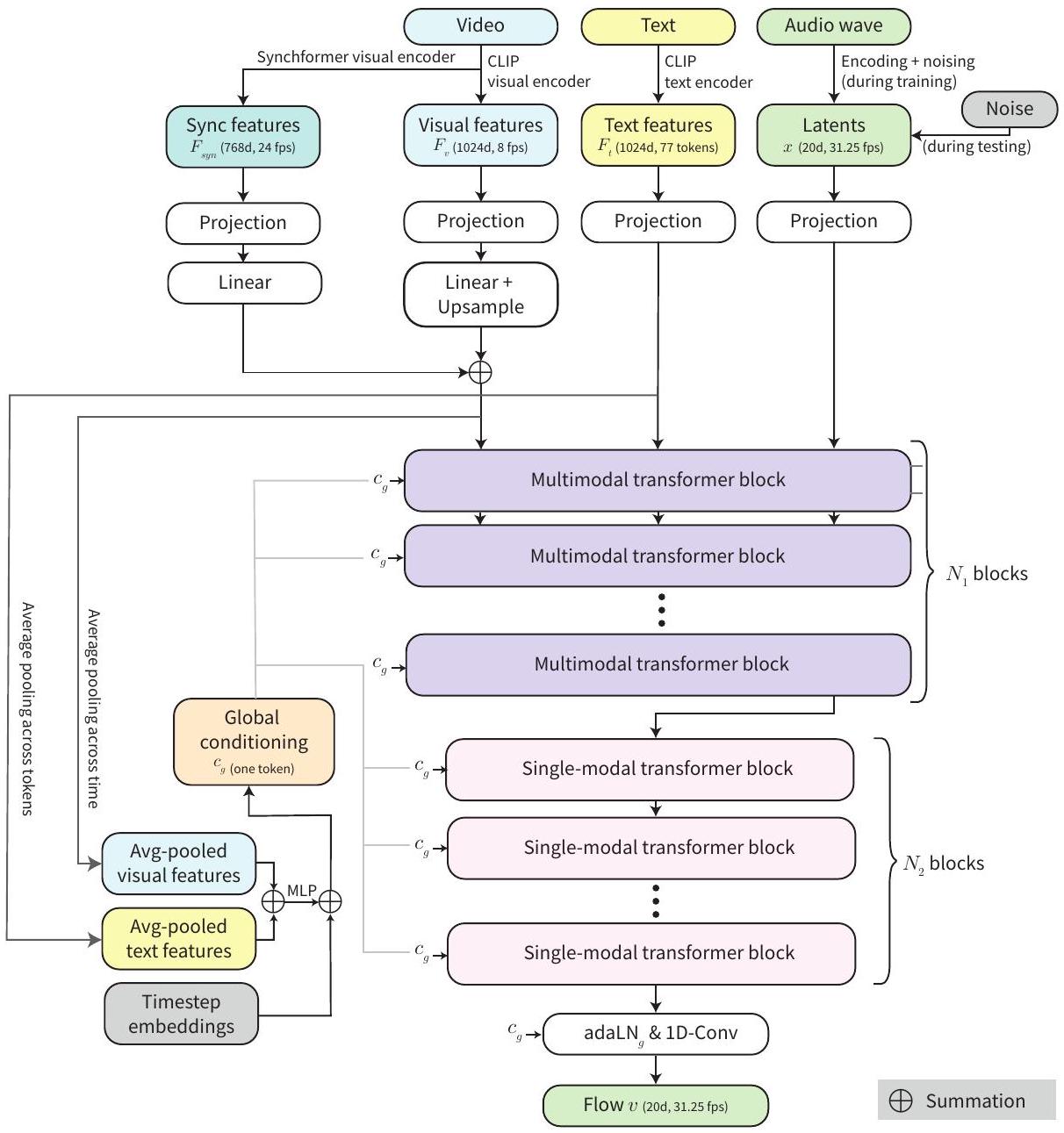
Figure A4. "시각과 동기화 합산" 절제 연구의 그림.
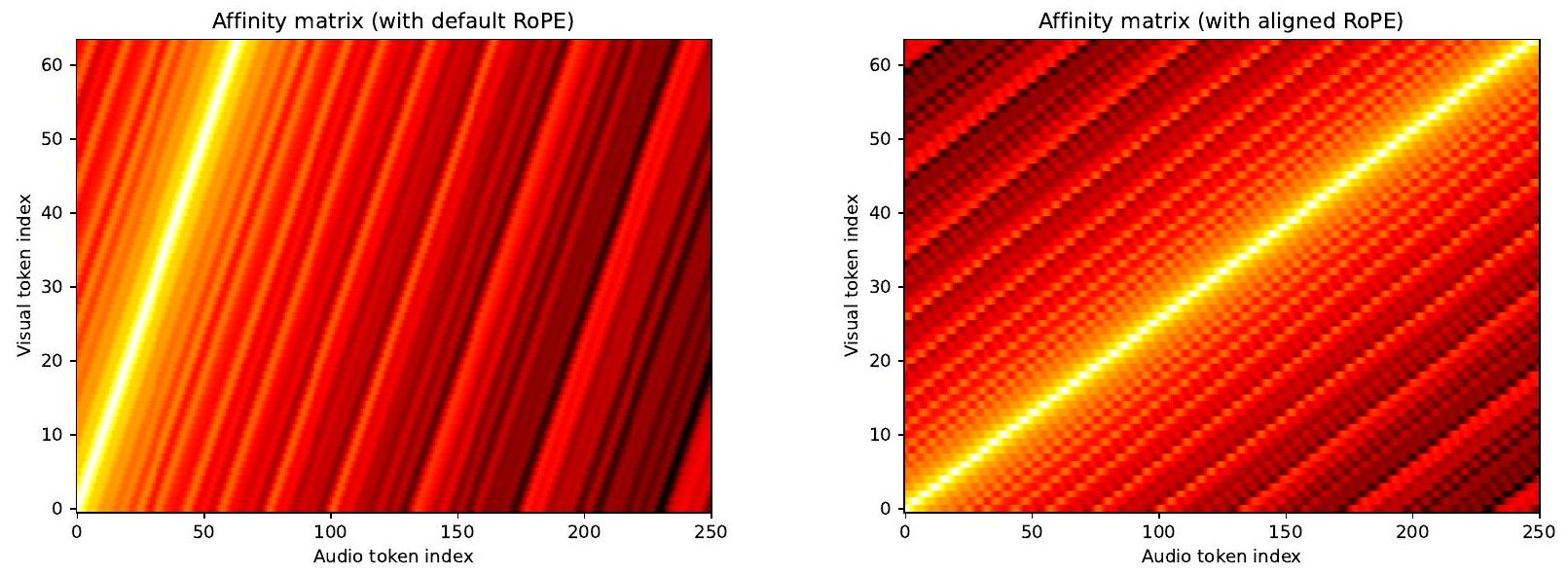
Figure A5. 기본/정렬된 RoPE 임베딩이 사용될 때 다른 프레임 속도를 가진 두 시퀀스 간의 유사도 시각화. 왼쪽: 기본 RoPE를 사용하면 시퀀스가 정렬되지 않습니다. 오른쪽: 제안된 정렬된 RoPE를 사용하면 시간적 정렬을 달성합니다.
Balancing multimodal training data. 오디오-텍스트-시각 데이터(180K)보다 오디오-텍스트 훈련 데이터(951K)가 훨씬 많기 때문에, 각 에포크에서 무작위 섞기 전에 오디오-텍스트-시각 샘플을 복제하여 데이터셋의 균형을 맞춥니다.
기본적으로 대략 1:1 데이터 샘플링 비율을 위해 5배 복제를 적용합니다. "중형" 및 "대형" 모델의 경우 과적합을 완화하기 위해 복제 비율을 3배로 줄입니다. Duplicated videos. VGGSound 데이터셋 [1]에 중복된 비디오가 포함되어 있음을 관찰했는데, 이는 동일한 비디오가 다른 비디오 ID로 YouTube에 여러 번 업로드되었기 때문일 가능성이 높습니다. 예를 들어, 비디오 4PjEi5fFD6A(훈련 세트)와 FhaYvI1yrUM(테스트 세트)은 동일한 비디오입니다. ³ 부록 E에서는 비디오 ID를 비교하여 훈련-테스트 세트 중복을 제거하지만, 이 방법은 반복된 업로드를 제거하지는 않습니다. 이전 연구들이 동일한 데이터셋에서 훈련되었기 때문에, 우리의 훈련 방식은 공정한 비교를 유지합니다.
I. Additional Visualizations
우리는 프로젝트 페이지 https://hkchengrex.com/MMAudio/video_main.html 에서 생성된 샘플과 최첨단 방법들과의 비교를 제공합니다. 아래에서는 그림 A6에서 A8까지 우리 방법과 이전 연구들을 비교하는 추가적인 스펙트로그램 시각화를 제공합니다.
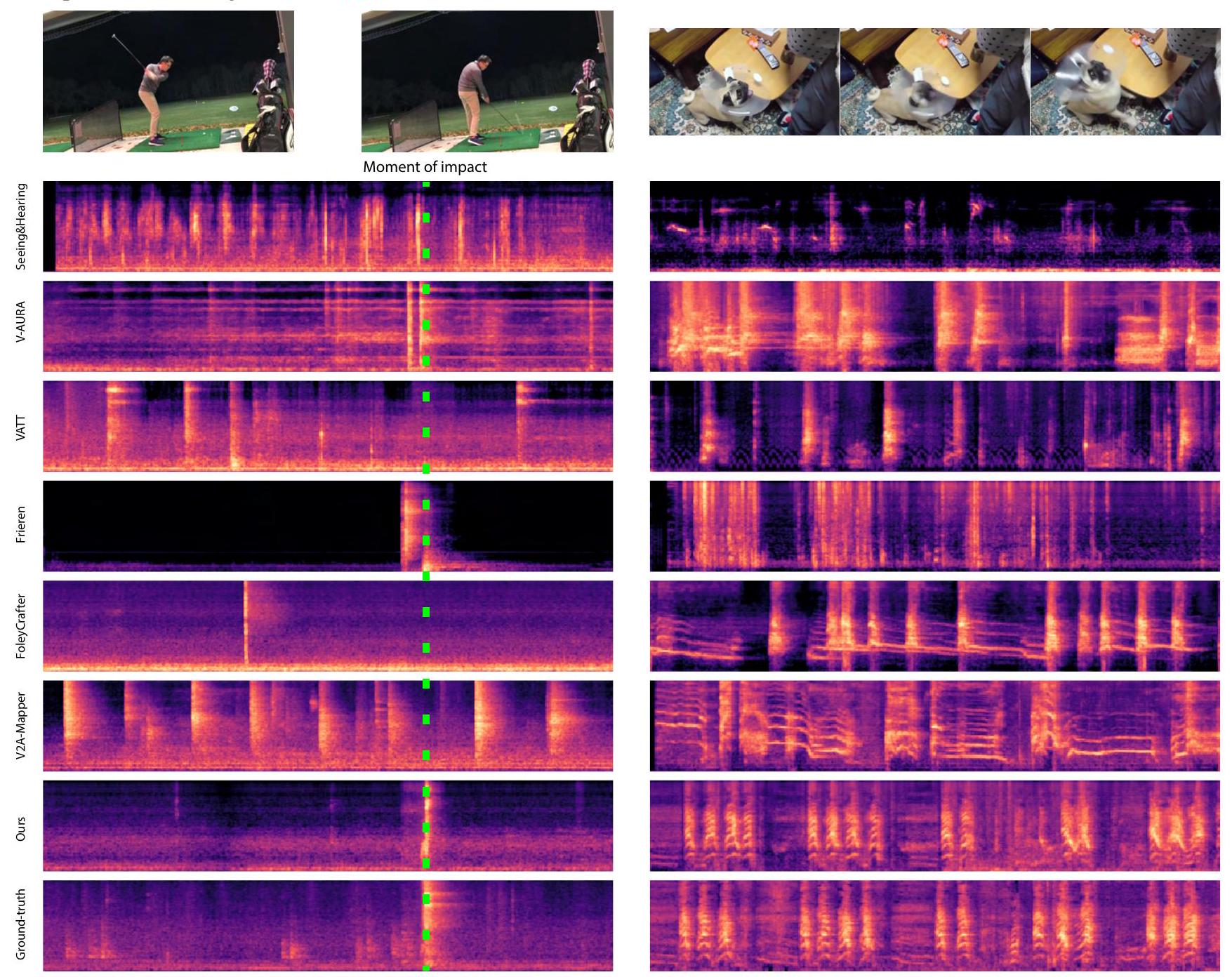
Figure A6. 왼쪽: 우리 방법은 골프공을 치는 독특한 오디오 이벤트를 정확하게 포착할 수 있습니다. 오른쪽: 개가 연속적인 폭발음으로 짖습니다. video-to-audio 생성의 모호한 특성 때문에 우리 생성은 원본과 정확하게 일치하지는 않지만, 빠른 폭발음을 포착합니다.
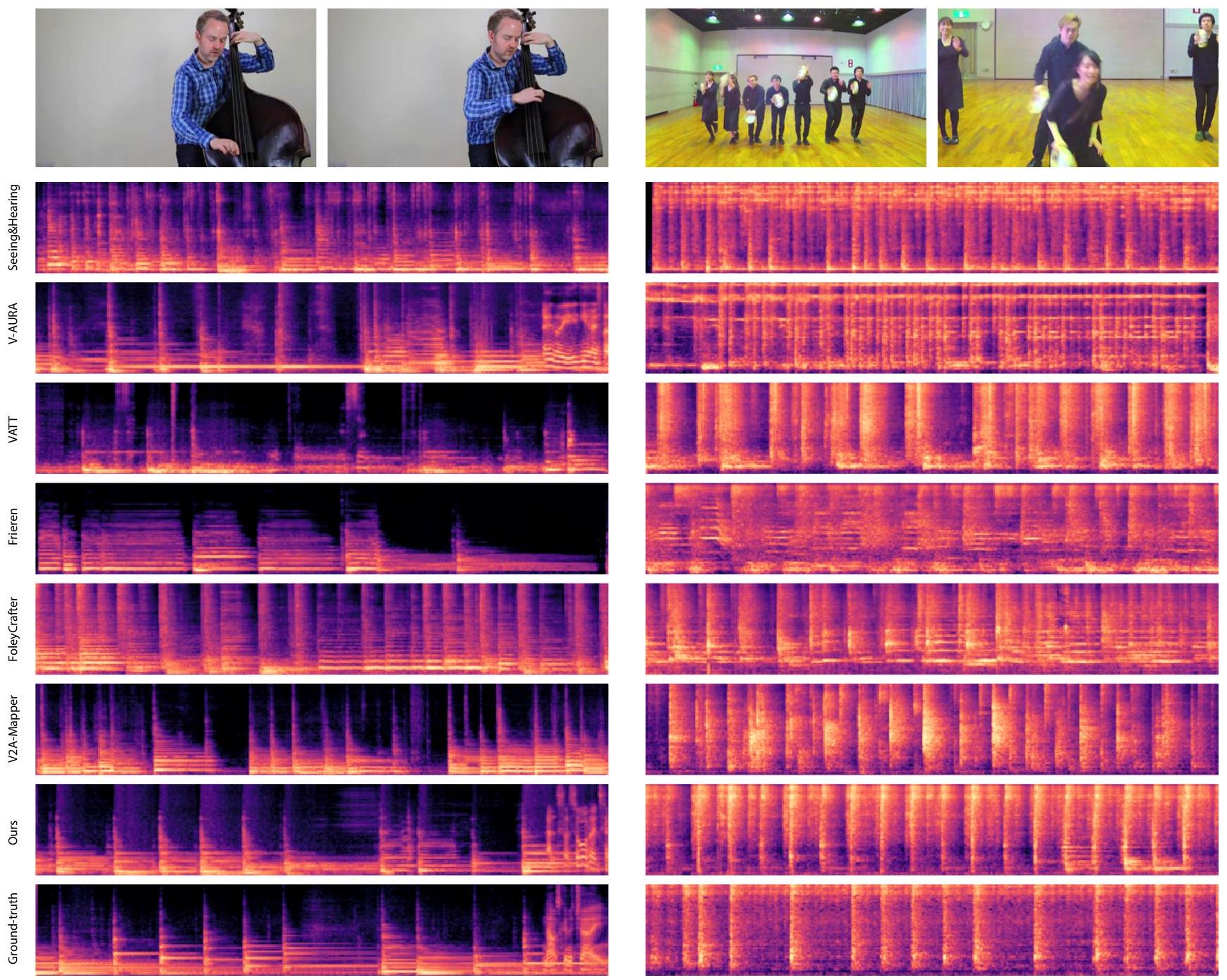
그림 A7. 왼쪽: 현을 연주하는 것과 같은 가시적인 오디오 이벤트가 명확하게 보일 때, MMAudio는 기존 방법보다 훨씬 더 정확하게 이를 포착합니다. 오른쪽: 복잡한 시나리오에서 MMAudio는 항상 원본과 정렬된 오디오를 생성하지는 않지만(생성 설정에서 흔히 볼 수 있듯이) 생성물은 종종 여전히 그럴듯합니다.
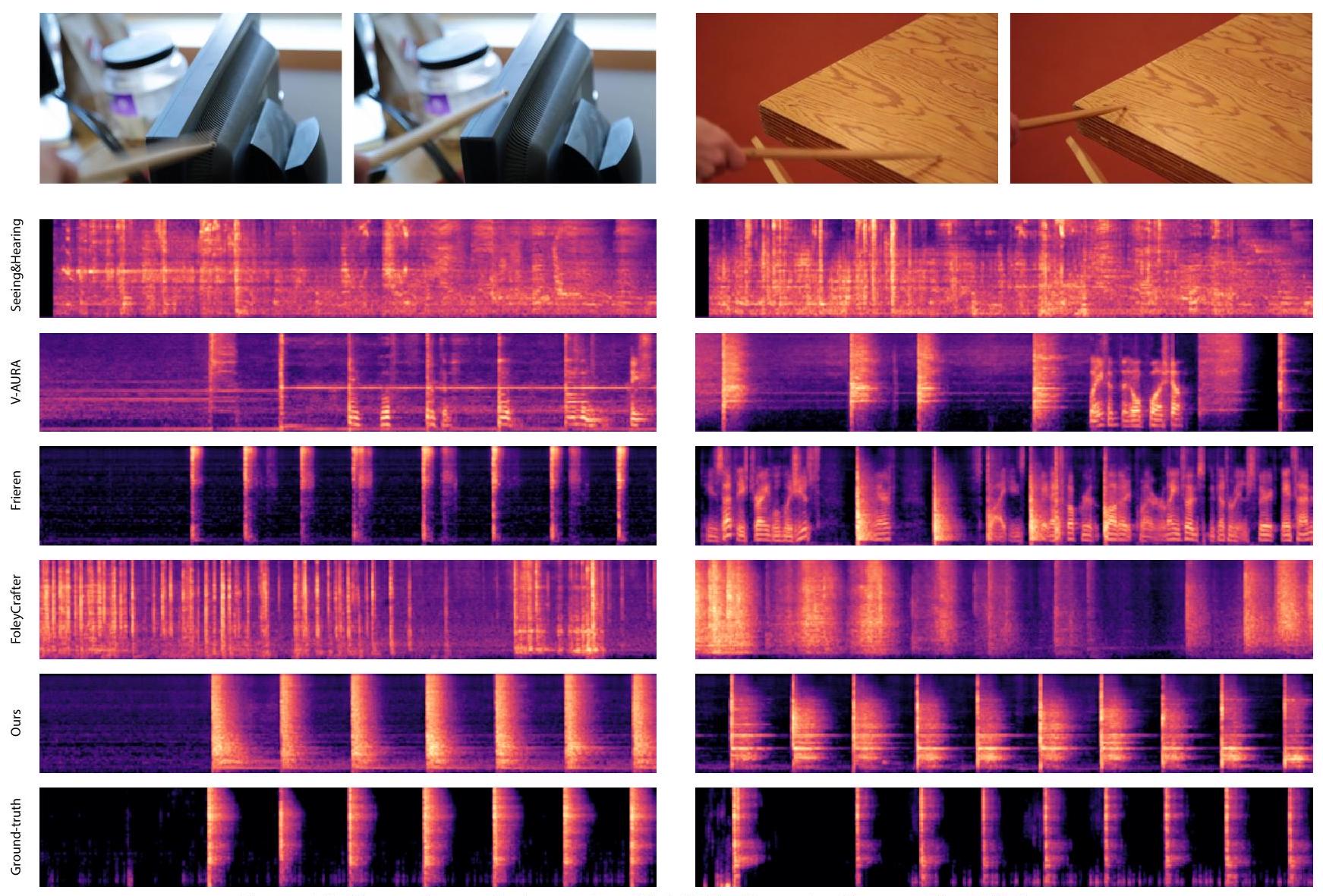
Figure A8. Greatest Hits [48] 데이터셋에서 이전 연구들과 MMAudio의 비교.