MM-Diffusion: 오디오와 비디오를 함께 생성하는 새로운 Multi-Modal Diffusion 모델
본 논문은 고품질의 현실적인 비디오를 목표로, 시청과 청취 경험을 동시에 제공하는 최초의 공동 오디오-비디오 생성 프레임워크인 MM-Diffusion을 제안합니다. 이 모델은 두 개의 결합된 Denoising Autoencoder를 가진 새로운 Multi-Modal Diffusion 모델로, 오디오와 비디오 서브넷이 정렬된 오디오-비디오 쌍을 점진적으로 생성하도록 학습합니다. 모달리티 간의 의미적 일관성을 보장하기 위해 Random-shift 기반의 Cross-modal attention 블록을 도입하여 효율적인 교차 모달 정렬을 가능하게 합니다. 논문 제목: MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
논문 요약: MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
- 논문 링크: https://arxiv.org/abs/2212.09478
- 저자: Ludan Ruan, Yiyang Ma, Huan Yang, Huiguo He, Bei Liu, Jianlong Fu, Nicholas Jing Yuan, Qin Jin, Baining Guo (Renmin University of China, Peking University, Microsoft Research)
- 발표 시기: 2023년, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
- 주요 키워드: Diffusion Model, Multi-Modal Generation, Audio-Video Generation
1. 연구 배경 및 문제 정의
- 문제 정의:
기존 AI 기반 콘텐츠 생성 모델(예: DALL•E 2, DiffWave)은 이미지나 오디오와 같은 단일 모달리티 콘텐츠 생성에 집중하여, 시청각 경험을 동시에 제공하는 고품질의 현실적인 공동 오디오-비디오 생성에는 한계가 있었습니다. 특히, 비디오와 오디오는 데이터 패턴이 다르고 시간적 동기화가 필수적이므로, 하나의 공동 Diffusion 모델 내에서 이들을 병렬 처리하고 의미론적 일관성을 보장하는 것이 주요 과제였습니다. - 기존 접근 방식:
대부분의 기존 Diffusion 모델은 단일 모달리티 콘텐츠 생성에 특화되어 있으며, 다중 모달리티 생성을 위한 Diffusion 모델 활용은 거의 탐구되지 않았습니다. Cross-modal 생성 연구는 존재하지만, 주로 한 모달리티를 다른 모달리티로 변환하는 조건부 생성(예: text-to-image, audio-to-video)에 초점을 맞추었으며, 두 모달리티를 동시에 생성하는 통합 프레임워크는 부재했습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 고품질의 현실적인 오디오와 비디오를 동시에 생성하는 최초의 공동 오디오-비디오 생성 프레임워크인 MM-Diffusion을 제안했습니다.
- 두 개의 결합된 Denoising Autoencoder를 가진 새로운 Multi-Modal Diffusion 모델을 설계하여 공동 노이즈 제거 프로세스를 가능하게 했습니다.
- 모달리티 간의 의미론적 일관성을 보장하고 효율적인 교차 모달 정렬을 위해 Random-shift 기반의 Cross-modal attention 블록을 도입했습니다.
- 무조건부 오디오-비디오 생성뿐만 아니라, 추가 훈련 없이 제로샷 조건부 생성(예: 비디오-투-오디오, 오디오-투-비디오)에서도 우수한 성능을 입증했습니다.
- 제안 방법:
- MM-Diffusion 모델: 순방향 확산은 각 모달리티(오디오, 비디오)에 독립적으로 노이즈를 추가하지만, 역방향 확산은 통합 모델()을 사용하여 오디오와 비디오를 공동으로 노이즈 제거하여 두 모달리티 간의 상호작용을 통해 생성 품질을 강화합니다.
- 결합된 U-Net 아키텍처: 오디오와 비디오 생성을 위한 두 개의 단일 모달 U-Net으로 구성됩니다. 비디오 서브넷은 공간-시간 정보를 효율적으로 모델링하기 위해 1D 컨볼루션 후 2D 컨볼루션을 쌓는 방식을 사용하며, 오디오 서브넷은 장기 의존성 모델링을 위해 확장된 컨볼루션 레이어를 채택합니다.
- Random-Shift 기반 Multi-Modal Attention (RS-MMA): 비디오와 오디오 간의 의미론적 일관성을 보장하기 위해 제안된 메커니즘입니다. 오디오 스트림을 비디오 프레임의 시간 단계에 따라 세그먼트로 분할하고, 랜덤 시프트(Random-shift)를 적용하여 이웃 기간 내에서 오디오 세그먼트와 비디오 세그먼트 간의 교차 어텐션을 수행합니다. 이는 계산 복잡도를 줄이면서도 전역 어텐션 기능을 유지하여 효율적인 교차 모달 상호작용을 촉진합니다.
- 제로샷 조건부 생성: 무조건부 훈련된 MM-Diffusion 모델을 추가 훈련 없이 오디오-투-비디오 또는 비디오-투-오디오와 같은 조건부 생성 작업에 적용할 수 있습니다. 대체 기반 방법과 기울기 유도 방법을 활용하여 강력한 조건부 생성 성능을 보입니다.
3. 실험 결과
- 데이터셋:
고품질 오디오-비디오 데이터셋인 Landscape (자연 장면, 약 2.7시간)와 AIST++ (스트리트 댄스 비디오, 약 5.2시간)를 사용하여 실험을 수행했습니다. 또한, 오픈 도메인 오디오 이벤트 데이터셋인 AudioSet에 대한 추가 실험도 진행했습니다. - 주요 결과:
- 객관적 평가: Landscape 데이터셋에서 기존 SOTA 단일 모달 생성 모델(DIGAN, TATS-base, Diffwave) 대비 FVD (비디오) 및 FAD (오디오) 지표에서 각각 25.0% 및 32.9%의 상당한 성능 향상을 달성했습니다. AIST++ 데이터셋에서도 FVD 56.7%, FAD 37.7%의 큰 성능 향상을 보였습니다. 이는 MM-Diffusion의 공동 학습이 단일 모달리티 생성보다 우수함을 입증합니다.
- 주관적 평가 (User Studies): 사용자 연구(MOS)를 통해 MM-Diffusion이 기존 2단계 파이프라인 방식(Diffwave + TATS)보다 비디오 품질, 오디오 품질, 오디오-비디오 정렬 측면에서 훨씬 우수한 점수를 획득했으며, 실제 데이터와의 격차도 훨씬 작음을 확인했습니다. 튜링 테스트에서는 Landscape 데이터셋의 경우 80% 이상, AIST++의 경우 약 50%의 생성 비디오가 실제와 구별하기 어렵다는 평가를 받아 높은 현실성을 검증했습니다.
- 제로샷 조건부 생성: 추가 훈련 없이도 비디오-투-오디오, 오디오-투-비디오 등 모달리티 전송 능력을 성공적으로 입증하여 모델의 다재다능함을 보여주었습니다.
- 절제 연구: 제안된 Random-Shift 기반 Multi-modal Attention (RS-MMA)이 효율적인 교차 모달 정렬 및 생성 품질 향상에 기여함을 확인했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
오디오와 비디오를 동시에 생성하는 최초의 통합 Diffusion 모델이라는 점이 가장 큰 장점입니다. 특히, Random-shift 기반 Cross-modal attention을 통해 두 모달리티 간의 의미론적 일관성을 효율적으로 학습하고, 이는 생성 품질 향상으로 이어지는 점이 인상 깊습니다. 기존 단일 모달리티 생성 모델을 뛰어넘는 객관적/주관적 성능을 보여주며, 특히 튜링 테스트에서 높은 현실성을 입증한 점은 실제 적용 가능성을 높입니다. 추가 훈련 없이 제로샷 조건부 생성(오디오-투-비디오, 비디오-투-오디오)이 가능하다는 점은 모델의 유연성과 잠재력을 보여줍니다. - 단점/한계:
Diffusion 모델의 일반적인 한계인 샘플링 속도 문제(수백 번의 반복 추론 필요)가 존재합니다. AIST++와 같이 사람의 세밀한 움직임이 포함된 데이터셋에서는 여전히 현실성 측면에서 개선의 여지가 있으며(튜링 테스트 50% 수준), 고품질의 대규모 다중 모달 데이터셋 확보의 어려움도 한계점으로 작용할 수 있습니다. - 응용 가능성:
향후 텍스트 프롬프트를 통한 오디오-비디오 생성(Text-to-Audio-Video)으로 확장하여 사용자 친화적인 콘텐츠 생성 도구 개발에 기여할 수 있습니다. 또한, 비디오 인페인팅, 배경 음악 합성 등 다양한 비디오 편집 기술에 응용하여 다중 모달 콘텐츠 제작 효율성을 증대시킬 수 있습니다. 가상 현실(VR) 및 증강 현실(AR) 콘텐츠 제작, 게임 개발, 영화 및 애니메이션 제작 등 시청각 경험이 중요한 분야에서 폭넓게 활용될 잠재력을 가집니다.
5. 추가 참고 자료
Ruan, Ludan, et al. "Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
Ludan Ruan , Yiyang , Huan Yang , Huiguo , Bei Liu , Jianlong Fu , Nicholas Jing Yuan , Qin Jin , Baining Guo <br> Renmin University of China, Peking University, Microsoft Research<br> {ruanld, qinj}@ruc.edu.cn, myy12769@pku.edu.cn,<br> {huayan,v-huiguohe,bei.liu,nicholas.yuan, jianf,bainguo}@microsoft.com
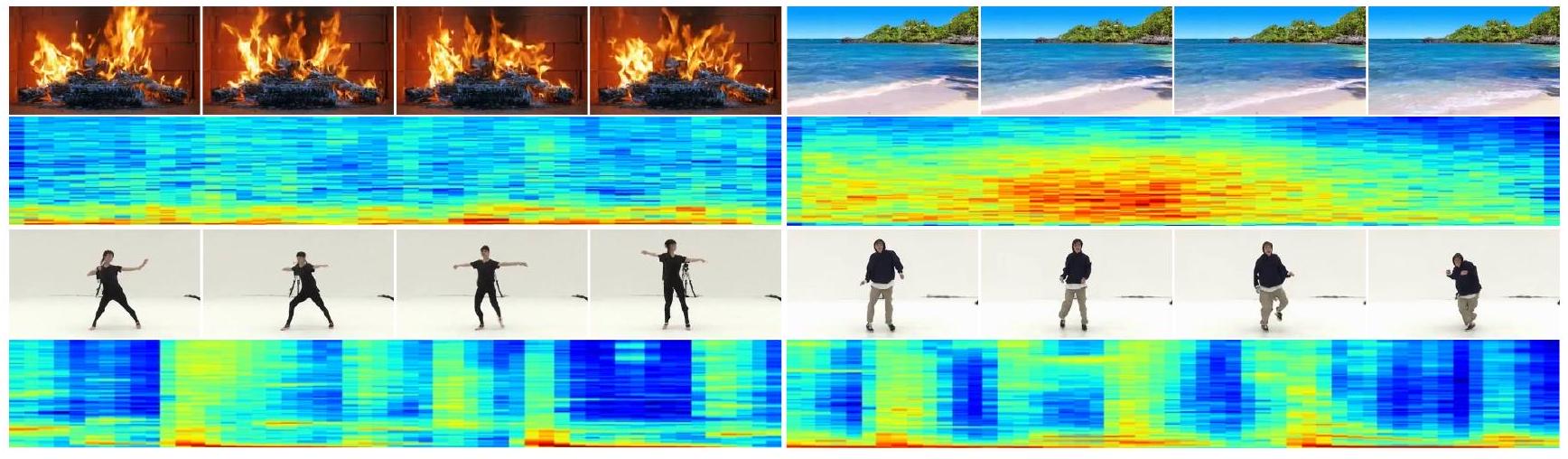
그림 1. Landscape [22] 및 AIST++ 데이터셋 [23]에서 생성된 비디오 프레임(256x256) 및 오디오 스펙트로그램의 예시. 생생한 모닥불이 타오르는 모습, 아름다운 파도가 움직이는 모습, 우아한 춤을 볼 수 있습니다. 비디오의 외형과 일치하는 오디오가 생성됩니다(예: 댄서의 주기적인 리듬). 완전한 고충실도 비디오 및 오디오는 보충 자료에서 확인할 수 있습니다.
Abstract
우리는 고품질의 사실적인 비디오를 향해 매력적인 시청 및 청취 경험을 동시에 제공하는 최초의 공동 오디오-비디오 생성 프레임워크를 제안합니다. 공동 오디오-비디오 쌍을 생성하기 위해, 우리는 두 개의 결합된 노이즈 제거 오토인코더를 갖춘 새로운 Multi-Modal Diffusion 모델(즉, MM-Diffusion)을 제안합니다. 기존의 단일 모달 확산 모델과 달리, MM-Diffusion은 공동 노이즈 제거 프로세스를 위해 설계된 순차적 다중 모드 U-Net으로 구성됩니다. 오디오와 비디오를 위한 두 개의 서브넷은 가우시안 노이즈로부터 정렬된 오디오-비디오 쌍을 점진적으로 생성하는 법을 학습합니다. 모달리티 간의 의미론적 일관성을 보장하기 위해, 우리는 두 서브넷을 연결하는 새로운 random-shift 기반 어텐션 블록을 제안하며, 이는 효율적인 교차 모달 정렬을 가능하게 하여 오디오-비디오 충실도를 상호 강화합니다. 광범위한 실험은 무조건부 오디오-비디오 생성 및 제로샷 조건부 작업(예: 비디오-투-오디오)에서 우수한 결과를 보여줍니다. 특히, 우리는 Landscape 및 AIST++ 댄싱 데이터셋에서 최고의 FVD 및 FAD를 달성했습니다. 1만 표의 튜링 테스트는 우리 모델에 대한 압도적인 선호를 더욱 입증합니다. 코드와 사전 훈련된 모델은 https://github.com/researchmm/MM-Diffusion에서 다운로드할 수 있습니다.
1. Introduction
이미지, 비디오, 오디오 영역에서 AI 기반 콘텐츠 생성은 최근 몇 년 동안 광범위한 주목을 받았습니다. 예를 들어, DALL•E 2 [34]와 DiffWave [20]는 각각 생생한 예술 이미지와 고충실도 오디오를 만들 수 있습니다. 그러나 이러한 생성된 콘텐츠는 시각 또는 청각 중 하나의 단일 모달리티 경험만 제공할 수 있습니다. 웹상의 풍부한 인간이 만든 콘텐츠는 종종 다중 모달 콘텐츠를 포함하며, 인간이 시각과 청각 모두에서 인식할 수 있는 매력적인 경험을 제공할 수 있다는 점에서 여전히 큰 격차가 있습니다. 본 논문에서는 한 걸음 더 나아가 새로운 다중 모달리티 생성 작업을 연구하며, 특히 오픈 도메인에서의 공동 오디오-비디오 생성에 초점을 맞춥니다.
생성 모델의 최근 발전은 diffusion 모델 [15, 41]을 사용하여 달성되었습니다. 작업 수준의 관점에서 이러한 모델은 무조건부 및 조건부 diffusion 모델의 두 가지 범주로 나눌 수 있습니다. 특히, 무조건부 diffusion 모델은 Gaussian 분포 [15]에서 샘플링된 노이즈를 입력으로 받아 이미지와 비디오를 생성합니다. 조건부 모델은 일반적으로 한 모달리티의 임베딩 특징과 결합된 샘플링된 노이즈를 가져와 다른 모달리티를 출력으로 생성합니다. 예를 들어 text-to-image [31, 34, 38], text-to-video [14, 40], audio-to-video [54] 등이 있습니다. 그러나 기존의 대부분의 diffusion 모델은 단일 모달리티 콘텐츠만 생성할 수 있습니다. 다중 모달리티 생성을 위해 diffusion 모델을 활용하는 방법은 아직 거의 탐구되지 않았습니다.
다중 모달 diffusion 모델을 설계하는 데 따르는 어려움은 주로 다음 두 가지 측면에 있습니다. 첫째, 비디오와 오디오는 데이터 패턴이 다른 두 개의 별개 모달리티입니다. 특히, 비디오는 일반적으로 공간(즉, 높이 × 너비) 및 시간 차원 모두에서 RGB 값을 나타내는 3D 신호로 표현되는 반면, 오디오는 시간 차원에 걸쳐 1D 파형 숫자로 표현됩니다. 하나의 공동 diffusion 모델 내에서 이들을 병렬로 처리하는 방법은 여전히 문제로 남아 있습니다. 둘째, 실제 비디오에서 비디오와 오디오는 시간 차원에서 동기화되어 있으므로 모델이 이 두 모달리티 간의 관련성을 포착하고 서로에 대한 상호 영향을 장려할 수 있어야 합니다.
위의 과제를 해결하기 위해, 우리는 공동 오디오-비디오 생성을 위한 두 개의 결합된 노이즈 제거 오토인코더로 구성된 최초의 Multi-Modal Diffusion 모델(즉, MM-Diffusion)을 제안합니다. 시간 단계 에서 각 모달리티(예: 오디오)의 덜 잡음이 있는 샘플은 시간 단계 에서 두 모달리티(오디오 및 비디오)의 출력을 암묵적으로 노이즈 제거하여 생성됩니다. 이러한 설계는 두 모달리티에 대한 공동 분포를 학습할 수 있게 합니다. 의미론적 동기성을 더 학습하기 위해, 우리는 생성된 비디오 프레임과 오디오 세그먼트가 매 순간 상관 관계를 갖도록 보장하는 새로운 교차 모달 어텐션 블록을 제안합니다. 우리는 주어진 비디오 프레임과 이웃 기간에서 무작위로 샘플링된 오디오 세그먼트 간의 교차 어텐션을 수행하는 효율적인 random-shift 메커니즘을 설계하여 비디오 및 오디오의 시간적 중복성을 크게 줄이고 교차 모달 상호 작용을 효율적으로 촉진합니다.
제안된 MM-Diffusion 모델을 검증하기 위해, 우리는 Landscape 데이터셋 [22]과 AIST++ 댄싱 데이터셋 [23]에 대해 광범위한 실험을 수행했습니다. SOTA 모달리티별(비디오 또는 오디오) 무조건부 생성 모델에 대한 평가 결과는 우리 모델의 우수성을 보여주며, Landscape 데이터셋에서 FVD와 FAD로 각각 와 의 상당한 시각적 및 청각적 이득을 얻었습니다. AIST++ 데이터셋 [23]에서도 우수한 성능이 관찰되었으며, 이전 SOTA 모델에 비해 FVD와 FAD에서 각각 와 의 큰 이득을 얻었습니다. 우리는 더 나아가 작업 중심의 미세 조정 없이 우리 모델의 제로샷 조건부 생성 능력을 보여줍니다. 또한, 1만 표의 튜링 테스트는 일반 사용자를 위한 우리 결과의 고충실도 성능을 더욱 검증합니다.
2. Related Work
Diffusion Probabilistic Models. Diffusion Probabilistic Models (DPMs) [15,41]는 인상적인 결과를 달성한 새로운 유형의 생성 모델입니다. 이들은 순방향 프로세스(신호를 노이즈에 매핑)와 역방향 프로세스(노이즈를 신호에 매핑)로 구성됩니다. DPMs의 순방향 및 역방향 프로세스는 미분 방정식 [43]을 풀어 수행할 수 있음이 추가로 입증되었습니다. 이들은 일반적으로 훈련 중에 재가중된 목표 [15]를 사용하면 더 나은 성능을 보입니다. 생성 품질 및 다양성 측면에서 DPMs는 노이즈 제거 모델 [5]의 적절한 설계로 다른 생성 모델을 능가했습니다. DPMs는 이미지 인페인팅 [29], 초해상도 [33,39,51], 이미지 복원 [18], 이미지-투-이미지 변환 [37] 등 여러 이미지 생성 작업에서 잘 수행될 수 있음을 보여주었습니다. DPMs가 노이즈 제거 모델을 수백 번 반복적으로 추론하는 특성 때문에 샘플링 속도는 GANs [10] 및 VAEs [19]와 같은 다른 생성 모델에 비해 느립니다. DPMs를 더 실용적으로 만들기 위해 많은 방법이 제안되었습니다. Denoising Diffusion Implicit Models [42]는 처음으로 DPM을 암시적인 방식으로 샘플링하여 샘플링 속도를 가속화하는 방법을 제안했습니다. DPM Solver [27,28]는 DPMs [43]의 역방향 프로세스의 상미분 방정식을 풀고, 이러한 방정식의 고차 근사 해를 제공했으며, 약 10-20회의 평가만으로 고품질 결과를 얻었습니다. Stable Diffusion [35]은 잠재 공간에 DPMs를 구축하여 픽셀 수를 줄였습니다. DPMs 이론의 탐구와 완성에 따라 diffusion 모델을 여러 도메인에 적용하는 것이 더욱 인기를 얻고 있습니다.
Cross-Modality Generation. text-to-visual [7, 12, 30, 31, 40], text-to-audio [21], audio-to-visual [4, 8, 13], visual-to-audio [4, 6, 13, 53, 54] 및 visual transfer [17,24,25,47-49,52]와 같은 Cross-modal generation은 큰 주목을 받았습니다. audio-to-visual 생성 측면에서 Sound2Sight [3]는 오디오에서 정렬된 비디오를 생성하는 방법을 처음 제안했습니다. TATS [8]는 오디오 잠재 임베딩을 비디오 임베딩에 투영하는 시간 민감성 transformer를 제안하고 SOTA 결과를 달성했습니다. visual-to-audio 생성의 경우, CMT [6]는 음악 리듬을 모델링하고 제어 가능한 음악 transformer로 주어진 비디오에 해당하는 배경 음악을 생성하는 방법을 제안했습니다. CDCD [54]는 DPMs를 적용하고 생성된 오디오와 주어진 비디오의 정렬을 개선하기 위해 대조적 diffusion 손실을 제안했습니다. 양방향 조건부 생성을 위해, Chen 등 [4]은 audio-to-image 및 image-to-audio 생성을 위한 2개의 별도 프레임워크를 처음 제안했습니다. CMCGAN [13]은 오디오-이미지 양방향 전송을 통합된 프레임워크와 결합하고 별도의 프레임워크보다 낫다는 것을 증명했습니다. 그러나 이전 연구는 한 번에 하나의 모달리티만 생성할 수 있었지만, 우리 연구는 두 개의 모달리티를 동시에 생성할 수 있습니다.
3. Approach
이 섹션에서는 현실적인 오디오-비디오 공동 생성을 위해 제안된 새로운 Multi-Modal Diffusion 모델(즉, MM-Diffusion)을 제시합니다. 구체적인 설계에 들어가기 전에, 먼저 섹션 3.1에서 diffusion 모델의 예비 지식을 간략하게 요약합니다. 그런 다음, 섹션 3.2에서 의미론적으로 일관된 다중 모달리티 생성을 가능하게 하기 위해 바닐라 diffusion 모델을 추가로 개발하여 제안된 MMDiffusion을 소개합니다. 그 후, 섹션 3.3에서 공동 오디오-비디오 데이터 모델링을 위해 설계된 결합된 U-Net 아키텍처를 설명합니다. 섹션 3.4에서는 마지막으로 제로샷 방식으로 조건부 다중 모달리티 생성(즉, 오디오-투-비디오 및 비디오-투-오디오)을 위한 우리 모델의 생성 능력에 대해 논의합니다.
3.1. Preliminaries of Vanilla Diffusion
Diffusion 기반 모델 [15,41]은 주어진 데이터 분포 를 비정형 노이즈(실제로는 가우시안 노이즈)로 변환한 다음, 위의 순방향 프로세스를 역전시켜 데이터 분포를 복구하는 법을 배우는 생성 알고리즘 클래스를 말합니다. Denoising Diffusion Probabilistic models (DDPMs) [15]의 원래 순방향 프로세스는 이산적인 시간 단계에 걸쳐 수행됩니다. 을 의 샘플로 정의하고, 를 표준 가우시안 분포에 적합하고 마르코프 순방향 프로세스를 사용하여 과 독립적인 샘플로 정의하며, 이는 다음과 같이 표현될 수 있습니다:
여기서 이고 는 미리 정의된 분산 스케줄 시퀀스입니다. 우리는 이전 연구 [15,43]를 따라 선형 노이즈 스케줄을 사용하여 를 증가시킵니다.
원본 이미지를 복구하기 위해, 순방향 프로세스를 역전시키는 것을 배우는 것은 주어진 모든 와 에 대해 로 근사하는 에 맞게 모델 를 훈련시키는 것으로 단순화될 수 있습니다. 따라서 역방향 프로세스는 방정식 3으로 공식화될 수 있으며, 는 다음과 같이 표시되는 방정식 4를 사용하여 확률 밀도 에서 복구할 수 있습니다:
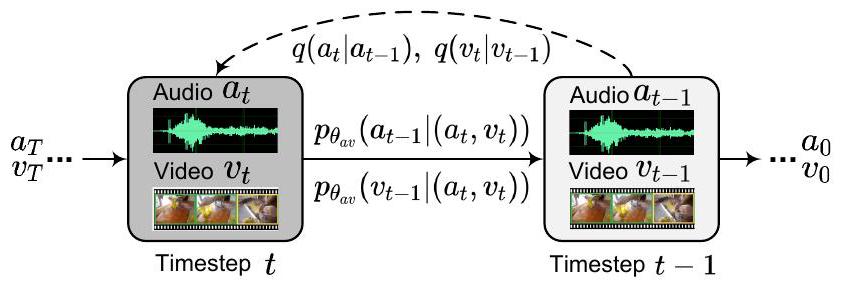
그림 2. 다중 모드 노이즈 제거 확산 과정의 그림. 순방향 확산(점선 화살표)은 오디오 및 비디오 데이터를 독립적으로 노이즈에 매핑하는 반면, 역방향 프로세스(실선 화살표)는 통합 모델 에 의해 다중 모드 콘텐츠를 점진적으로 재구성합니다.
여기서 는 에 의해 예측된 가우시안 평균값을 나타냅니다. 그리고 마침내 을 얻을 수 있습니다. 실제로는 분산 예측이 미미한 개선 [1,32]만을 가져오므로 제거합니다. 다음에서도 이 항을 생략합니다.
3.2. Multi-Modal Diffusion Models
위에서 정의된 diffusion의 순방향 및 역방향 프로세스를 바탕으로, 이 섹션에서는 제안된 MM-Diffusion 공식을 추가로 제시합니다. 그림 2와 같이, 단일 모달리티가 생성되는 바닐라 diffusion과 달리, 우리의 목표는 하나의 diffusion 프로세스 내에서 두 개의 일관된 모달리티(즉, 오디오 및 비디오)를 복구하는 것입니다.
1D 오디오 세트 와 3D 비디오 세트 에서 쌍을 이룬 데이터 ()가 주어졌을 때, 각 모달리티의 순방향 프로세스는 서로 다른 분포에 있기 때문에 독립적이라고 간주합니다. 오디오 를 예로 들면, 시간 단계 에서의 순방향 프로세스는 다음과 같이 정의됩니다:
간단히 하기 위해, 비디오 에 대한 순방향 프로세스는 유사한 공식을 공유하므로 생략합니다. 방정식 2를 사용하여 임의의 를 추가로 계산할 수 있습니다. 프로세스 정의를 단순화하기 위해 오디오와 비디오에 걸쳐 하이퍼파라미터 에 대한 공유 스케줄을 경험적으로 설정했다는 점은 주목할 가치가 있습니다.
오디오와 비디오를 독립적으로 모델링하는 순방향 프로세스와 달리, 두 모달리티 간의 상관 관계는 역방향 프로세스 중에 고려되어야 합니다. 따라서 및 를 직접 맞추는 대신, 두 모달리티를 모두 입력으로 사용하고 서로에 대한 오디오 및 비디오 생성 품질을 강화하는 통합 모델 를 제안합니다. 특히, 주어진 시간 단계 에 대해, 오디오 도메인에서 을 얻기 위한 역방향 프로세스 는 다음과 같이 공식화됩니다:
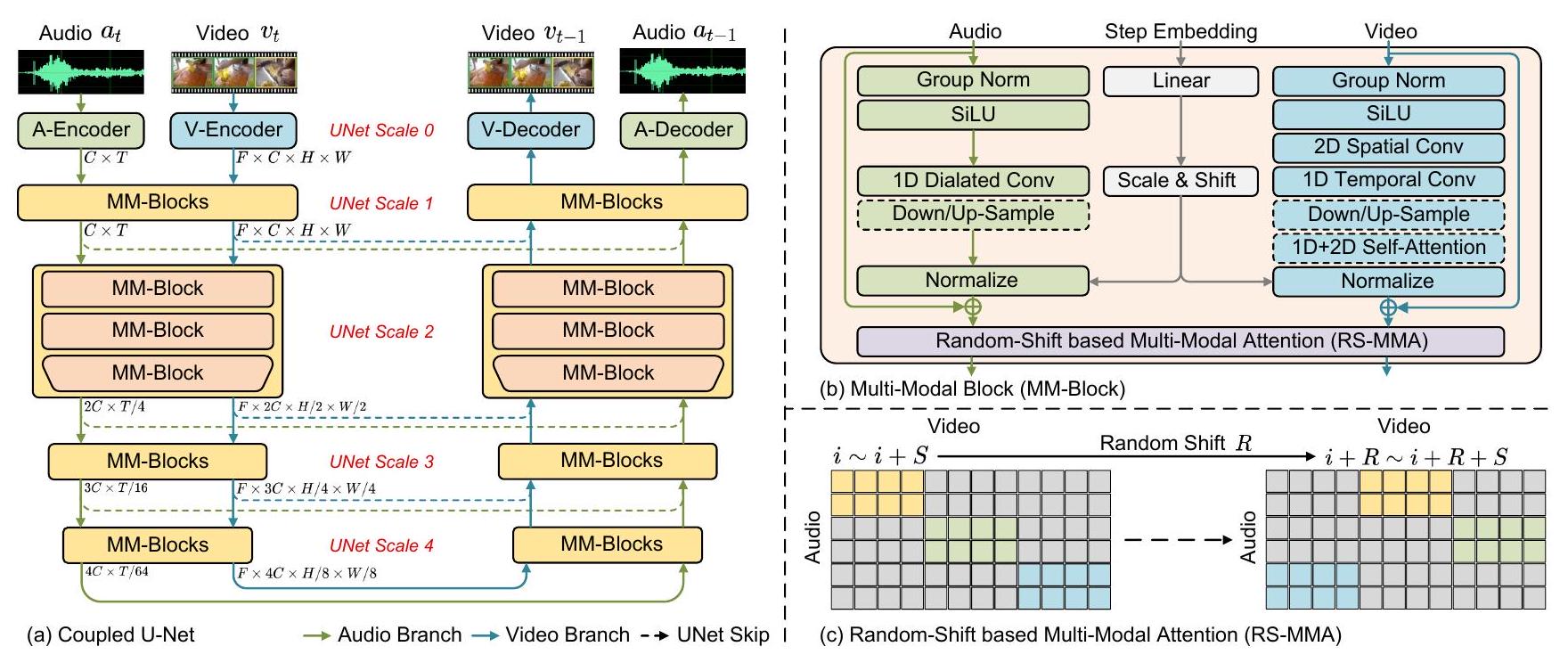
그림 3. 제안된 MM-Diffusion 프레임워크의 개요. 결합된 U-Net은 (a)의 각 노이즈 제거 확산 단계에서 결합된 오디오 및 비디오 스트림(각각 녹색 및 파란색 블록으로 표시)을 포함합니다. 각 MM-Block은 (b)에서 1D 확장 오디오 컨볼루션과 2D+1D 공간-시간 시각 컨볼루션으로 오디오와 비디오를 인코딩합니다. (c)에서는 특정 모달리티 간 정렬을 촉진하고 중복 계산을 피하기 위해 효율적인 random-shift 기반 다중 모드 어텐션 모듈이 추가로 제안됩니다. 여기서 은 와 모두에 의해 공동으로 결정되는 가우시안 분포에서 생성됩니다. 전체 네트워크를 최적화하기 위해, 우리는 다음과 같이 정의되는 -예측을 사용합니다:
여기서 이고, 는 선택적 가중 함수입니다. 비디오 공식은 오디오와 유사한 표현을 공유하므로 생략합니다.
다중 모달리티 생성의 핵심 장점은 독립적인 가우시안 분포에서 오디오-비디오 쌍을 공동으로 재구성할 수 있게 하는 통합 모델 에 있습니다. 우리가 설계한 모델 MM-Diffusion은 완전히 다른 모양과 패턴을 가진 이 두 가지 유형의 입력 모달리티에 적응할 수 있습니다.
3.3. Coupled U-Net for Joint Audio-Video Denoising
이전 연구 [5, 15, 20, 35]는 단일 모달리티(예: 이미지 생성을 위한 2D U-Net [5, 15] 및 오디오 생성을 위한 1D U-Net [20])를 생성하기 위한 모델 아키텍처로 U-Nets를 사용하는 것의 효과를 입증했습니다. 이러한 연구에서 영감을 받아, 우리는 오디오 및 비디오 생성을 위한 두 개의 단일 모달 U-Nets로 구성된 결합된 U-Net(그림 3 (a) 참조)을 제안합니다. 특히, 우리는 입력 오디오 및 비디오를 텐서 쌍 으로 공식화합니다. 한편, 는 오디오 입력을 나타내며, 여기서 와 는 각각 채널 및 시간 차원입니다. 다른 한편, 는 비디오 입력을 나타내며, 여기서 는 각각 프레임 수, 채널, 높이 및 너비 차원입니다.
Efficient Multi-Modal Blocks. 그림 3(b)와 같이, 비디오 서브 네트워크 설계를 위해 공간 및 시간 정보를 효율적으로 모델링하기 위해, Jonathan 등[16]을 따라 공간 및 시간 차원을 분해합니다. 구체적으로, 무거운 3D 컨볼루션을 사용하는 대신 비디오 인코더로 1D 컨볼루션 다음에 2D 컨볼루션을 쌓습니다. 유사하게, 비디오 어텐션 모듈은 2D 및 1D 어텐션으로 구성됩니다. 비디오와 달리, 오디오 신호는 장기 의존성 모델링에 대한 요구가 더 높은 1D 긴 시퀀스입니다. 따라서 오디오 블록에 대한 두 가지 특별한 디자인이 있습니다. 첫째, Kong [20]에서 영감을 받아 순수 1D 컨볼루션을 채택하는 대신 확장된 컨볼루션 레이어를 쌓습니다. 팽창은 1에서 까지 두 배가 되며, 여기서 은 하이퍼파라미터입니다. 둘째, 계산적으로 무겁고 예비 실험에서 제한된 효과를 보인 오디오 블록의 모든 시간적 어텐션을 삭제했습니다. 이전 연구[14,20]에서도 유사한 결론을 도출했습니다.
Random-Shift based Multi-Modal Attention. 오디오와 비디오의 두 서브네트워크를 연결하고 그들의 정렬을 공동으로 학습하기 위해 가장 직접적인 방법은 그들의 특징에 교차 어텐션을 수행하는 것입니다. 그러나 이 두 모달리티에 대한 원래의 어텐션 맵은 계산 복잡도가 로 계산하기에 너무 큽니다. 한편, 비디오와 오디오는 모두 시간적으로 중복되어 있어 모든 교차 모달 어텐션 계산이 필요한 것은 아닙니다.
위의 문제를 해결하기 위해, 우리는 Random Shift 기반 어텐션 마스크를 사용하여 비디오와 오디오를 효율적인 방식으로 정렬하는 Multi-Modal Attention 메커니즘을 제안합니다 (RS-MMA로 표기), 그림 3(c)에 표시된 바와 같습니다. 구체적으로, 결합된 U-Nets의 번째 레이어가 주어졌을 때, 모양이 인 출력으로, 프레임을 가진 3D 비디오 입력 텐서 는 패치로 표현되고, 1D 오디오 입력 텐서는 로 표현됩니다.
비디오 프레임과 오디오 신호를 더 잘 정렬하기 위해, 우리는 다음과 같은 단계를 가진 random-shift 어텐션 체계를 제안합니다: 1단계: 먼저 오디오 스트림을 비디오 프레임의 시간 단계에 따라 세그먼트 로 분할합니다. 여기서 각 세그먼트 는 모양입니다. 2단계: 프레임 수 보다 훨씬 작은 창 크기 를 설정하고, 범위의 random-shift 수 을 설정합니다. 오디오에서 비디오로의 어텐션 가중치는 각 오디오 세그먼트 와 프레임 에서 프레임 까지 시작하는 비디오 세그먼트 사이에서 계산됩니다. 여기서 이고 입니다. 3단계: 오디오 세그먼트 와 샘플링된 비디오 세그먼트 의 교차 어텐션은 다음과 같이 공식화됩니다:
여기서 는 의 차원입니다. 비디오에서 오디오로의 교차 어텐션은 대칭적이므로 는 생략합니다.
이 어텐션 메커니즘은 두 가지 장점을 가져옵니다. 첫째, 이러한 설계를 사용함으로써 계산 복잡도를 로 줄일 수 있습니다. 둘째, 이 설계는 이웃 기간 내에서 전역 어텐션 기능을 유지합니다. Multi-Modal Diffusion은 단계 에서 단계 0까지 반복할 수 있으므로 비디오와 오디오는 역방향 프로세스 중에 서로 완전히 상호 작용할 수 있습니다. 실제로, 우리는 U-Net의 상단에서 미세한 대응을 포착하기 위해 더 작은 를 설정하고, U-Net의 하단에서 높은 수준의 의미적 대응을 적응적으로 포착하기 위해 더 큰 를 설정합니다. 자세한 설정은 실험에서 설명합니다.
3.4. Zero-Shot Transfer to Conditional Generation
MM-Diffusion 모델은 무조건부 오디오-비디오 쌍 생성을 위해 훈련되었지만, 제로샷 전이 방식으로 조건부 생성(즉, 오디오-투-비디오 또는 비디오-투-오디오)에도 활용될 수 있습니다. 모델이 이 두 모달리티 간의 상관 관계를 학습했기 때문에, 강력한 제로샷 조건부 생성 성능은 MM-Diffusion의 우수한 모델링 능력을 검증하는 데 도움이 될 수 있습니다. 실제로 Video Diffusion [16]에서 영감을 받아, 조건부 생성을 위해 대체 기반 방법과 개선된 기울기 유도 방법의 두 가지 방법을 사용합니다.
대체 기반 방법의 경우, 비디오 를 조건으로 하는 오디오 , 즉 를 생성하기 위해, 각 확산 단계 에서 역방향 프로세스 의 를 순방향 프로세스 의 샘플로 대체합니다. 비디오-투-오디오 생성에도 유사한 작업을 수행할 수 있습니다. 그러나 대체 기반 방법은 에서 목표 오디오 분포를 예측하는 반면, 직관적으로 더 강력한 조건부 지침을 제공할 수 있는 원래의 는 무시됩니다. 따라서, 우리는 이 조건을 추가하고 다음과 같이 기울기 유도 방법으로 재구성합니다:
여기서 이고 입니다. 따라서 다음 공식을 통해 생성된 오디오 를 얻습니다:
이 공식은 또한 분류기 없는 조건부 생성 [26]과 유사하며, 여기서 는 조건화의 강도를 제어하는 기울기 가중치의 역할을 합니다. 주요 차이점은 전통적인 조건부 생성 모델은 종종 조건 데이터에 맞게 명시적인 훈련이 필요하다는 것입니다. 따라서 샘플링 절차의 업데이트 프로세스는 조건을 변경할 필요가 없습니다. 반대로, 무조건부 훈련 프로세스에 맞추기 위해, 우리의 기울기 유도 방법의 조건부 입력은 역방향 프로세스가 진행됨에 따라 지속적인 교체가 필요합니다. 결과적으로, 우리는 조건부 입력에 적응하기 위해 추가적인 훈련이 필요하지 않아 상당한 장점을 보입니다.
4. Experiments
이 섹션에서는 제안된 MM-Diffusion 모델을 평가하고, SOTA 생성 모델과 공동 오디오 및 비디오 생성 성능을 비교합니다. 시각적 결과는 그림 4에서 확인할 수 있으며, 오픈 도메인의 더 많은 결과는 보충 자료에서 확인할 수 있습니다.
4.1. Implementation Details
Diffusion model. 공정한 비교를 위해, 이전 연구 [27,28]를 따라 선형 노이즈 스케줄과 섹션 3.1의 노이즈 예측 목표를 모든 실험에 사용합니다. 확산 단계 는 1,000으로 설정됩니다. 샘플링을 가속화하기 위해, 별도로 명시하지 않는 한 DPM-Solver [27]를 기본 샘플링 방법으로 사용합니다. 모델 아키텍처. 우리의 전체 파이프라인은 크기의 비디오와 크기의 오디오를 생성하는 결합된 U-Net과 이미지를 64에서 256으로 스케일링하는 Super Resolution 모델을 포함합니다. 기본 결합 U-Net의 경우, 4개의 MM-Block 스케일을 설정하고, 각 스케일은 2개의 일반 MM-Block과 1개의 다운/업샘플 블록으로 쌓여 있습니다. U-Net 스케일 [2,3,4]에서만 비디오 어텐션과 교차 모달 어텐션이 적용되며, 교차 모달 어텐션의 창 크기는 각 스케일에 해당하는 [1,4,8]입니다.
전체 모델은 115.13 M개의 파라미터를 포함합니다. SR 모델의 경우, ADM [5]의 구조와 설정을 따라 311.03 M개의 파라미터를 가집니다. 모델 아키텍처와 훈련 구성의 모든 세부 사항은 보충 자료를 참조할 수 있습니다. 평가. 일관성을 유지하기 위해, 객관적인 평가에서 각 모델로 2,048개의 샘플을 무작위로 생성합니다. 공정한 비교를 위해, 모든 방법에 대해 해상도에서 메트릭이 계산됩니다. 섹션 4.4의 주요 결과에서는 무작위성을 줄이기 위해 평균 6회 실행을 계산합니다. 섹션 4.5의 절제 연구에서는 효율성을 위해 기본 결합 U-Net에서 2,048개의 샘플을 샘플링합니다.
4.2. Datasets
비디오 또는 오디오 생성에 대한 이전 연구는 주로 하나의 모달리티에 중점을 둡니다. 기존 비디오 데이터셋은 낮은 오디오 품질, 오디오 누락, 시청각 관리 불량(예: UCF101 [44]에서 오디오의 절반 누락)과 같은 문제가 있습니다. 다중 모달 생성을 촉진하고 다양한 방법과 광범위하게 비교하기 위해, 우리는 두 가지 다른 유형의 고품질 비디오-오디오 데이터셋인 Landscape [22]와 AIST++ [23]에 대한 실험을 수행합니다. Landscape 데이터셋은 자연 장면을 담은 고충실도 오디오-비디오 데이터셋입니다. [22]에서 제공한 URL을 사용하여 Youtube에서 928개의 소스 비디오를 크롤링한 다음, 10초짜리 1,000개의 겹치지 않는 클립으로 나눕니다. 총 재생 시간은 약 2.7시간, 30만 프레임입니다. Landscape 데이터셋은 폭발, 불꽃놀이, 비, 물 튀김, 물 철벅거림, 천둥, 수중 거품, 폭포 소리, 바람 소리 등 9가지 다양한 장면을 포함합니다. AIST++ [23]는 AIST 데이터셋 [45]의 하위 집합으로, 60개의 저작권이 해결된 댄스 곡이 포함된 스트리트 댄스 비디오를 포함합니다. 이 데이터셋은 총 5.2시간 분량의 1,020개 비디오 클립으로 구성되어 있으며 약 56만 프레임을 포함합니다. 선명한 캐릭터를 생성하기 위해, 우리는 훈련 시 모든 방법에 대해 비디오 중앙에서 크기의 사진을 균일하게 잘라냅니다.
4.3. Evaluation Metrics
객관적 평가. 객관적 평가를 위해 생성된 오디오와 비디오의 품질을 별도로 측정합니다. 비디오의 경우, 이전 설정[8,50]에 따라 Kinetics-400[2]에서 사전 훈련된 I3D[2] 분류기를 사용하여 Fréchet video distance(FVD)와 kernel video distance(KVD)를 사용합니다. 오디오 평가의 경우, 무조건부 오디오 생성에 대한 이전 연구는 특정 도메인(예: 음성 숫자를 위한 SC09 [46])에서 오디오를 생성하는 경향이 있습니다. 특별히 훈련된 오디오 분류기를 기반으로 한 평가 지표는 오픈 도메인[36]에서 생성된 우리 오디오에 적합하지 않습니다. 이미지 평가를 위한 FID와 비디오 평가를 위한 FVD에서 영감을 받아, 생성된 오디오와 실제 오디오의 특징 간에 유사한 Fréchet audio distance(FAD)를 계산할 것을 제안합니다(모든 FAD 값에 1e4를 곱해야 함). 우리는 환경음 분류 작업에서 SOTA를 달성한 사전 훈련된 오디오 모델인 AudioCLIP [11]을 오디오 특징 추출기로 선택합니다. 주관적 평가. 또한 Amazon Mechanical Turk에서 사용자 연구를 수행하여 생성된 오디오-비디오 쌍의 품질과 관련성을 모두 측정합니다. 구체적으로, 각 오디오-비디오 쌍에 대해 오디오 품질, 비디오 품질, 쌍의 관련성을 측정하기 위해 세 가지 작업이 구성됩니다. 각 작업에 대해 사용자에게 1(나쁨)에서 5(좋음)까지의 점수를 매기도록 요청합니다. 점수를 평균하여 최종 점수, 즉 Mean Opinion Score(MOS)로 합니다. 또한, 우리 모델과 실제 데이터로 생성된 오디오-비디오 쌍에 대해 튜링 테스트를 수행합니다. 이를 섞어서 사용자에게 생성되었는지 여부를 판단하도록 요청합니다.
4.4. Objective Comparison with SOTA methods
MM-Diffusion에 의해 생성된 오디오 및 비디오의 품질을 평가하기 위해, 우리는 SOTA 무조건부 비디오 생성 방법인 DIGAN [50], TATS [8] 및 오디오 생성 방법인 Diffwave [20]와 비교합니다. 이들 베이스라인은 널리 사용되고 우리 데이터셋에서 표준 교체를 위한 공식 코드베이스를 공개했기 때문에 선택했습니다. MM-Diffusion에서 공동 학습의 효과를 추가로 탐색하고 동일한 백본을 사용한 단일 모달리티 생성과 공정한 비교를 하기 위해, 결합된 U-Nets를 오디오 서브네트워크(Ours-a)와 비디오 서브네트워크(Ours-v)로 분해하여 모달리티 독립적인 생성을 수행합니다.
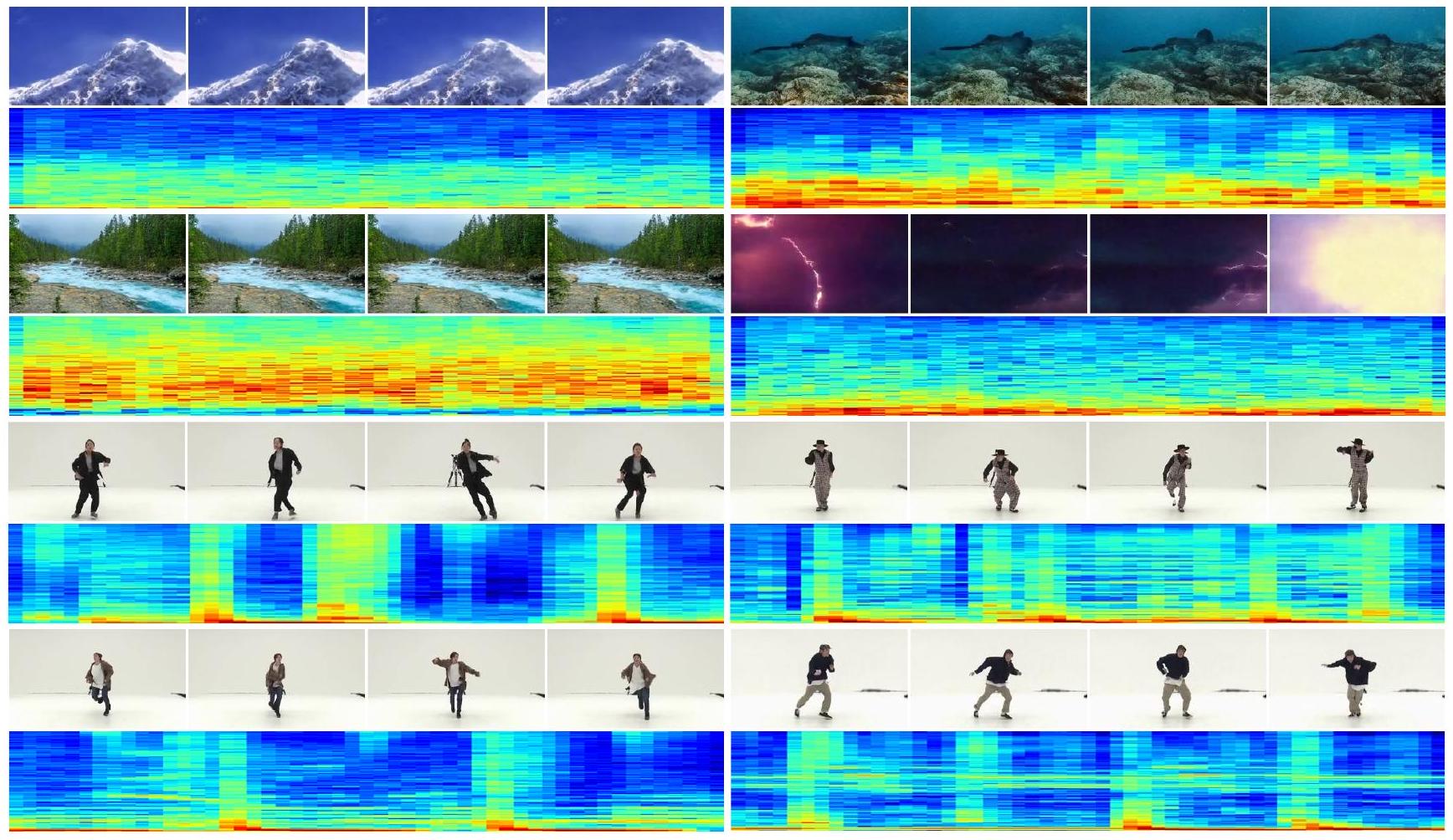
그림 4. 의미적으로 일관된 오디오(스펙트로그램으로 표시됨)와 함께 생성된 비디오 프레임()의 더 많은 시각적 예. 일부 사례는 눈 덮인 산에서 바람이 부는 모습을 생생하게 보여주고, 일부는 아름다운 장면과 함께 지속적인 강물 소리를 보여줍니다. Landscape 및 AIST++에 대한 결과는 표 1과 표 2에 나와 있습니다.
이 두 표에서 다음과 같은 결론을 도출할 수 있습니다: (1) 우리 모델은 비디오 및 오디오 생성 모두에서 SOTA 단일 모달 생성 방법을 훨씬 능가합니다. 특히 우리 모델은 SOTA FAD를 실제 품질에 가깝게 끌어올립니다. 이는 제안된 MM-Diffusion 및 결합된 U-Net의 효과를 입증합니다. (2) 비디오 생성만 있는 우리 모델(Ours-v)조차도 두 표의 대부분의 지표에서 SOTA 방법인 DIGAN 및 TATS-base를 능가합니다(5번을 2번 및 3번과 비교). 이는 diffusion 기반 방법이 기존 방법에 비해 생성된 비디오의 품질을 향상시킬 수 있음을 나타냅니다. (3) 우리의 전체 설정(7번)을 단일 스트림 U-Net(Ours-v 및 Ours-a)과 비교하면, 교차 모달 정렬을 공동으로 학습하는 결합된 U-Nets가 비디오 및 오디오 생성 모두에 추가적인 이점을 제공한다는 것을 알 수 있습니다. 또한, 완전한 샘플링 전략(8번)은 Dpm-Solver보다 더 나은 품질의 샘플을 얻을 것입니다.
4.5. Ablation Studies
Random-Shift based Multi-modal Attention. 우리는 섹션 4.4에서 제안된 Random-shift 기반 다중 모달 어텐션 메커니즘(RS-MMA)의 효과를 입증했습니다. 우리는 다른 창 크기와 random shift 메커니즘의 효과를 탐색하기 위해 두 가지 추가 절제 실험을 수행합니다. (1) 다른 창 크기. 먼저 결합된 U-Net의 스케일 [2,3,4]에 다른 창 크기를 설정합니다. 모든 실험은 비용을 절약하기 위해 80K 단계로 훈련되었으며 결과는 표 3에 나와 있습니다. 처음 세 줄에서 더 큰 창 크기가 더 많은 개선을 가져오는 것을 볼 수 있습니다. U-Net의 채널 스케일에 따른 적응형 창 크기의 최상의 성능은 이 효율적인 설계의 효과를 보여주며, 특히 비디오 생성 품질을 향상시키는 데 효과적입니다. (2) Random shift 메커니즘. 표 4는 훈련 중 random shift(RS) 사용 여부에 대한 결과를 보여줍니다. 비교를 통해 RS가 이동이 없을 때보다 더 나은 품질의 오디오를 생성하는 데 도움이 되며 오디오의 수렴도 가속화된다는 것을 알 수 있습니다. 이는 또한 우리가 제안한 RSMMA가 더 효율적인 공동 교차 모달리티 학습을 장려한다는 것을 보여줍니다.
한편, RS를 사용함으로써 오디오 품질의 개선이 더 크다는 것을 알 수 있습니다. 왜냐하면 비디오의 외형이 쌍을 이루는 오디오에 대해 더 많은 정보를 제공할 수 있기 때문이며, 쌍을 이루는 비디오에 대한 오디오의 효과와 비교됩니다. Zero-Shot Conditional Generation. 우리는 제로샷 전송을 위한 두 가지 방법의 효과를 검증하고 두 방법 모두 비디오를 조건으로 사용하여 고품질 오디오를 생성할 수 있음을 발견했습니다. 오디오 기반 비디오 생성의 경우,
표 1. Landscape 데이터셋에서 단일 모달 방법과의 비교. *는 완전한 ddpm 샘플링을 나타냅니다.
| # | 방법 | FVD | KVD | FAD |
|---|---|---|---|---|
| 1 | Ground-truth | 17.83 | -0.12 | 7.51 |
| 2 | DIGAN [50] | 305.36 | 19.56 | - |
| 3 | TATS-base [8] | 600.30 | 51.54 | - |
| 4 | Diffwave [20] | - | - | 14.00 |
| 5 | Ours-v | 238.33 | 15.14 | - |
| 6 | Ours-a | - | - | 13.6 |
| 7 | Ours | 229.08 | 13.26 | |
| 8 | Ours* | 10.72 |
표 2. AIST++ 댄싱 데이터셋에서 단일 모달 생성 방법과의 비교.
| 방법 | FVD | KVD | FAD | |
|---|---|---|---|---|
| 1 | Ground-truth | 8.73 | 0.036 | 8.46 |
| 2 | DIGAN [50] | 119.47 | 35.84 | - |
| 3 | TATS-base [8] | 267.24 | 41.64 | - |
| 4 | Diffwave [20] | - | - | 15.76 |
| 5 | Ours-v | 184.45 | 33.91 | - |
| 6 | Ours-a | - | - | 13.30 |
| 7 | Ours | 176.55 | 31.92 | 12.90 |
| 8 | Ours* |
표 3. 다중 모달 어텐션의 창 크기에 대한 절제 연구, U-Net 스케일 [2,3,4]에 해당하며, 80k 훈련 단계에서 수행됨.
| # | W-Size | FVD | KVD | FAD |
|---|---|---|---|---|
| 1 | 374.18 | 22.26 | 9.81 | |
| 2 | 361.65 | 21.64 | 9.65 | |
| 3 | 350.60 | 21.47 | ||
| 4 | 10.20 |
표 4. random-shift 어텐션에 의해 영향을 받는 다른 훈련 단계에서의 비디오 및 오디오 품질.
| 방법 | 60K/ 80K/ 100K 반복 | |
|---|---|---|
| FVD | FAD | |
| w/ RS |
구배 유도 방법이 대체 방법보다 주어진 오디오와 의미적, 시간적으로 정렬된 일관된 비디오를 얻는 데 더 좋습니다. 결과는 또한 우리 모델이 추가적인 훈련 없이도 모달리티 전송 능력을 가지고 있음을 보여줍니다. 그림 5는 우리 모델이 유사한 패턴을 가진 오디오에서 유사한 장면(바다)의 비디오를 생성하거나, 입력 댄스 비디오의 리듬에 맞는 오디오를 생성할 수 있음을 보여줍니다. 이는 우리의 공동 학습이 단일 모달리티 생성을 향상시킬 수 있음을 더욱 검증합니다.
4.6. User Studies
다른 방법과의 비교. 우리가 오디오-비디오 쌍을 공동으로 생성하는 최초의 연구이기 때문에 비교할 직접적인 기준선이 없습니다. 따라서 기존의 단일 모달리티 모델을 사용하는 2단계 파이프라인을 선택합니다.
특히, 우리는 노이즈-오디오-비디오 순서를 파이프라인으로 사용합니다. 구체적으로, 무조건부 오디오 생성을 위해 Diffwave [20]를 사용하고 오디오를 비디오로 변환하기 위해 TATS [8]를 사용합니다. 각 데이터셋에 대해, 우리 모델, 기준선 및 실제 데이터에서 각각 500개의 샘플을 포함하여 1,500개의 오디오-비디오 쌍을 무작위로 샘플링했습니다. 섹션 4.3에서 설명했듯이, 각 쌍은 3개의 작업으로 나뉩니다. 각 작업은 5명의 사용자에게 할당되었습니다. 따라서 총 9,000개의 작업에서 45k 표를 얻었습니다. 표 5의 결과에서 볼 수 있듯이, 두 데이터셋에서 우리 방법으로 생성된 오디오-비디오 쌍의 품질은 2단계 기준선 방법보다 훨씬 우수하며, 우리 결과는 실제 데이터와의 격차가 훨씬 작습니다. 튜링 테스트.
생성된 비디오의 현실성을 평가하기 위해 추가로 튜링 테스트를 실시했습니다. 각 데이터셋에 대해 생성된 결과와 실제 데이터에서 각각 500개의 오디오-비디오 쌍을 무작위로 샘플링했습니다. 각 샘플은 5명의 사용자에게 할당되었으며 총 1만 표를 얻었습니다. 표 6에 나타난 결과에서 볼 수 있듯이, Landscape에서 생성된 사운드 비디오의 80% 이상이 성공적으로 피험자를 속였습니다. AIST++에서도 세밀한 부분은 잘 생성되기 어렵지만 생성된 사운드 비디오의 거의 절반이 사용자를 속일 수 있었습니다. 사람들의 세밀한 부분을 잘 생성하기 어려운 경우에도 AIST++에서 생성된 사운드 비디오의 거의 절반이 사용자를 속일 수 있었습니다. 이 테스트는 일반 사용자를 위해 우리가 생성한 사운드 비디오의 높은 품질과 현실성에 대한 강력한 검증을 제공합니다.
5. Conclusion
본 논문에서는 공동 오디오 및 비디오 생성을 위한 새로운 다중 모달 확산 모델인 MM-Diffusion을 제안합니다. 우리의 연구는 단일 모달리티 확산 모델에 기반한 현재의 콘텐츠 생성을 한 단계 발전시키며, 제안된 MM-Diffusion은 현실적인 오디오와 비디오를 공동으로 생성할 수 있습니다. 널리 사용되는 오디오-비디오 벤치마크에서 객관적인 평가와 튜링 테스트를 통해 우수한 성능을 달성했으며, 이는 다중 모달 확산을 위한 새로운 공식과 설계된 결합 U-Net 덕분입니다. 향후에는 보다 사용자 친화적인 인터페이스로 오디오-비디오 생성을 안내하기 위해 텍스트 프롬프트를 추가하고, 다중 모달 확산 모델을 통해 다양한 비디오 편집 기술(예: 비디오 인페인팅, 배경 음악 합성)을 더욱 발전시킬 것입니다.
References
[참고 문헌은 원문 그대로 유지됩니다.]
Supplementary Material
이 보충 자료에서는 섹션 A에서 알고리즘 세부 정보를 소개합니다. 다음으로 섹션 B에서 인간 연구에 대한 자세한 내용을 제안합니다. 마지막으로 섹션 C에서 더 많은 시각화 결과를 보여줍니다.
A. Algorithm Details
이 섹션에서는 결과의 재현성을 보장하기 위해 모든 구현 세부 정보를 소개합니다. 결합된 U-Net 및 초해상도 네트워크의 아키텍처, 확산 프로세스, 훈련 설정에 대한 세부 정보를 표 A.1에 공식적으로 나열합니다.
B. Details of Human Study
MM-diffusion의 생성 품질을 주관적으로 평가하기 위해, 본 논문에 기술된 대로 MOS와 튜링 테스트의 두 가지 종류의 인간 연구를 수행합니다. MOS의 경우, 시험관에게 표 A.2의 기준에 따라 비디오 품질, 오디오 품질 및 비디오-오디오 정렬을 평가하도록 요청했습니다. 튜링 테스트의 경우, 일반 사용자에게 주어진 비디오에 대해 투표하도록 요청했습니다: 1). 기계에 의해 생성됨; 2). 비디오가 기계 생성인지 실제인지 판단할 수 없음; 3). 실제임. 우리는 후자의 두 투표를 튜링 테스트를 통과한 것으로 간주합니다.
C. Additional Samples
이 섹션에서는 Landscape, AIST++ 및 AudioSet [9]에서 비디오-오디오 쌍의 더 많은 무조건부 생성 결과와 더 많은 제로샷 조건부 생성 결과를 보여줍니다. 모든 결과는 최상의 품질을 위해 1,000단계로 샘플링되었습니다. 무조건부 생성 결과 먼저, 그림 C. 1과 그림 C. 2에서 각각 Landscape와 AIST++의 더 많은 무조건부 생성 결과를 보여줍니다. 오픈 도메인에서 MMDiffusion의 생성 능력을 검증하기 위해, 우리는 오픈 도메인의 쌍을 이룬 비디오를 사용하여 가장 큰 오디오 이벤트 데이터셋인 AudioSet [9]에서 결합된 U-Net을 추가로 훈련시켰습니다. 여기에는 총 632개의 이벤트 클래스를 포괄하는 10초짜리 210만 개의 비디오 클립이 포함되어 있습니다. AudioSet의 오디오는 완전하고 데이터 양은 충분하지만 비디오 품질은 높지 않습니다. 따라서 비디오 프레임 속도와 비디오 크기에 따라 고품질의 2만 개 비디오를 필터링합니다. 우리는 기본 채널을 128에서 256으로 확대하여 결합된 U-Net을 확장하고 다른 설정은 변경하지 않습니다. 시각화 결과는 그림 C.3에 나와 있습니다. 모든 해당 비디오는 MP4 형식으로 보충 비디오에 포함되어 있습니다.
제로샷 조건부 생성 결과 이 섹션에서는 AIST++에서 비디오 기반 오디오 생성을 제안합니다. 그림 C. 4 (a)에서 볼 수 있듯이, 동일한 비디오를 입력으로 사용하여 우리 모델은 춤 비트에 해당하는 다른 오디오를 생성할 수 있습니다. 대칭적으로, 다음으로 Landscape에서 오디오 기반 비디오 생성을 제안합니다. 그림 C. 4 (b)의 결과를 통해 우리 모델이 주어진 파도 소리에 대해 바다의 다양한 비디오 장면을 생성할 수 있음을 발견했습니다.
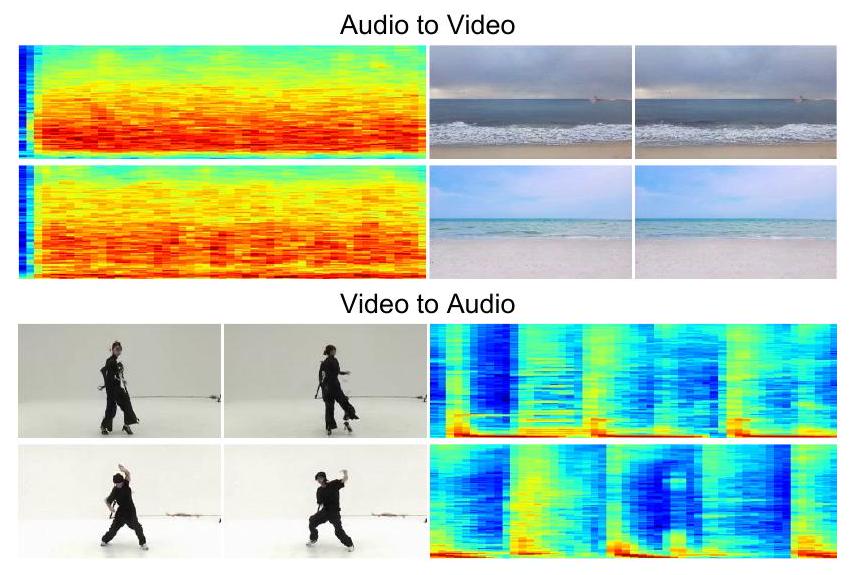
그림 5. 제로샷 전송을 조건부 생성으로 전환하여 생성된 몇 가지 무작위 선택 예시. 더 나은 결과를 위해 경사도 유도 방법을 채택합니다. 사람의 세밀한 부분을 잘 생성하기 어려운 경우에도 AIST++에서 생성된 사운드 비디오의 거의 절반이 사용자를 속일 수 있었습니다. 이 테스트는 일반 사용자를 위해 우리가 생성한 사운드 비디오의 높은 품질과 현실성에 대한 강력한 검증을 제공합니다.
표 5. 평균 의견 점수 (5가 가장 높음). VQ/AQ는 비디오 및 오디오 품질을 나타냅니다. A-V는 교차 모달 정렬을 나타냅니다.
| 방법 | Landscape | AIST++ | ||||
|---|---|---|---|---|---|---|
| 3.84 | 4.22 | 4.52 | 3.79 | 3.89 | 4.15 | |
| 2-Stage | 1.61 | 1.74 | 1.72 | 2.31 | 2.27 | 1.81 |
| Ours | 3.75 | 3.93 | 4.33 | 3.48 | 3.50 | 3.87 |
표 6. Landscape 및 AIST++에 대한 튜링 테스트, 숫자는 실제 세계에서 온 것으로 간주되는 데이터의 백분율입니다.
| Landscape | AIST++ | |
|---|---|---|
| Ours | 84.9 | 49.6 |
| Ground-truth | 92.5 | 84.7 |
| 결합된 U-Net | 초해상도 | |
|---|---|---|
| 아키텍처 | ||
| 기본 채널 | 128 | 192 |
| 채널 스케일 배수 | 1,2,3,4 | 1,1,2,2,4,4 |
| 해상도당 블록 | 2 + 1 다운/업 샘플 | 2 + 1 다운/업 샘플 |
| 비디오 다운샘플 스케일 | H/2, W/2 | H/2, W/2 |
| 오디오 다운샘플 스케일 | T/4 | N/A |
| 비디오 어텐션 스케일 | 2,3,4 | 4,5,6 |
| 오디오 conv 확장 | N/A | |
| 교차 모달 어텐션 스케일 | 2,3,4 | N/A |
| 교차 모달 어텐션 창 크기 | 1,4,8 | N/A |
| 어텐션 헤드 차원 | 64 | 48 |
| 스텝 임베딩 차원 | 128 | 192 |
| 스텝 임베딩 MLP 레이어 | 2 | 2 |
| Diffusion 프로세스 | ||
| Diffusion 노이즈 스케줄 | 선형 | 선형 |
| Diffusion 단계 | 1000 | 1000 |
| 예측 목표 | ||
| 시그마 학습 | False | True |
| 샘플 방법 | DPM solver | DDIM |
| 샘플 단계 | N/A | 25 |
| 훈련 설정 | ||
| 비디오 형태 | LR: , HR: | |
| 비디오 fps | 10 | N/A |
| 오디오 형태 | N/A | |
| 오디오 샘플 속도 | N/A | |
| 증강 | N/A | 가우시안 노이즈, <br> JPEG 압축, <br> 랜덤 플립, |
| 가중치 감쇠 | 0.0 | 0.0 |
| 드롭아웃 | 0.1 | 0.1 |
| 학습률 | ||
| 배치 크기 | 128 | 48 |
| 훈련 단계 | 100,000 | 270,000 |
| 훈련 하드웨어 | ||
| EMA | 0.9999 | 0.9999 |
표 A.1. 결합된 U-Net 및 초해상도 네트워크의 구현 세부 정보.
| 점수 | 비디오/오디오 품질 | 비디오-오디오 정렬 |
|---|---|---|
| 1 | 순수 노이즈, 완전히 인식할 수 없는 내용. | 비디오와 오디오는 완전한 노이즈이며 완전히 관련이 없습니다. |
| 2 | 비디오/오디오는 발전이 있지만 비디오/오디오 유형을 인식할 수 없습니다. | 비디오/오디오 유형을 인식할 수 없으며 관련이 없습니다. |
| 3 | 비디오/오디오는 특정 유형으로 인식될 수 있지만 매우 부자연스럽습니다. | 비디오/오디오 유형은 인식할 수 있지만 정렬되지 않았습니다. |
| 4 | 비디오/오디오는 자연스럽지만 생성된 콘텐츠로 인식될 수 있습니다. | 비디오와 오디오는 기본적으로 일치하지만 대응의 세부 사항이 부족합니다. |
| 5 | 비디오/오디오는 너무 자연스러워서 생성된 것인지 실제 세계의 것인지 인식할 수 없습니다. | 비디오와 오디오는 세부 사항에서 일관되고 매우 자연스럽습니다. |
표 A.2. 비디오/오디오 품질 및 비디오-오디오 정렬에 대한 MOS의 점수 설명.

그림 C.1. 우리 MM-Diffusion의 Landscape에서 더 많은 생성 결과. 주어진 사례는 각각 바람이 부는 장면, 수중, 물 튀김, 비, 물 철벅거림, 폭포, 천둥, 불꽃놀이 장면을 보여줍니다.
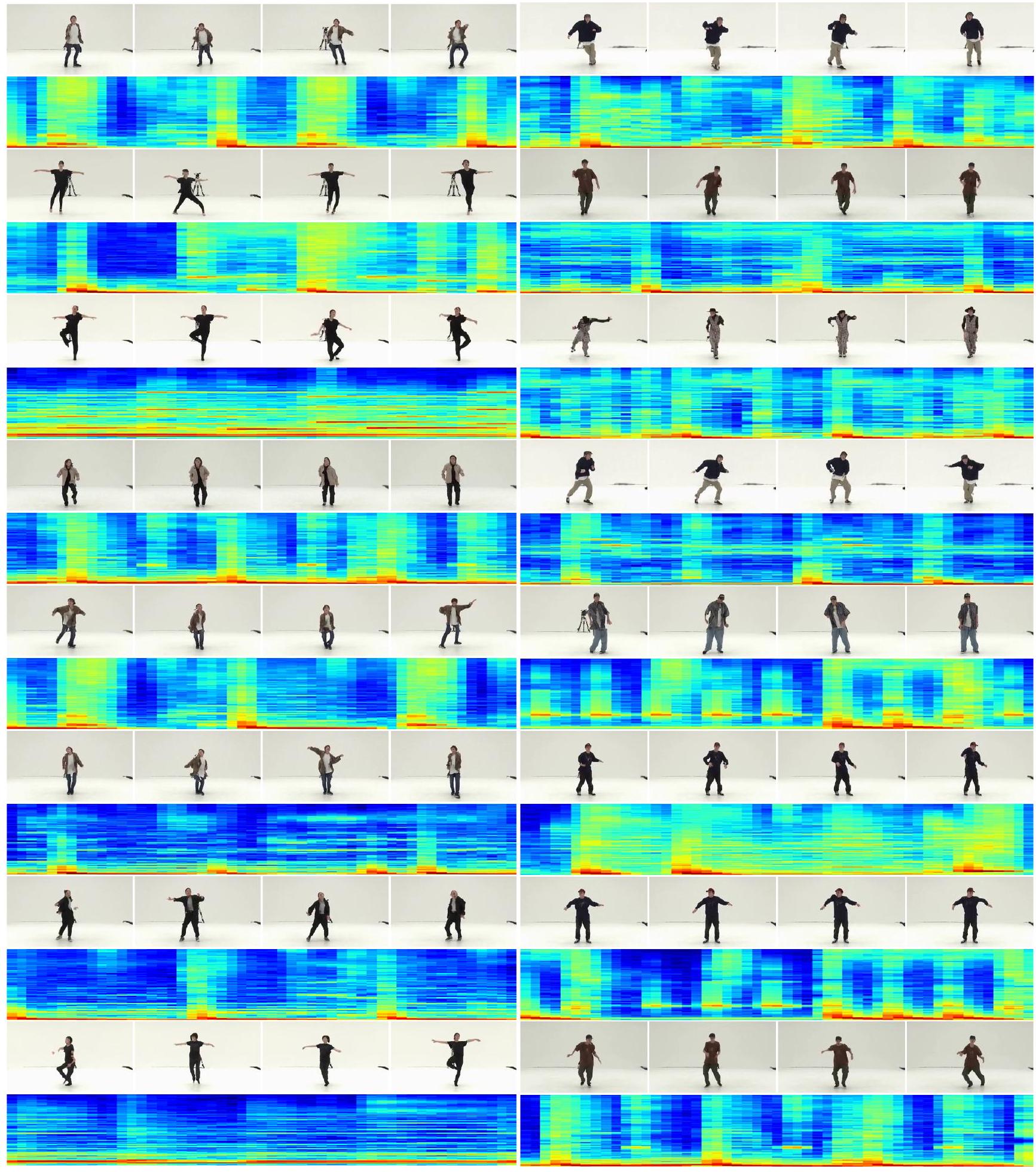
그림 C.2. 우리 MM-Diffusion의 AIST++에서 더 많은 생성 결과. 비디오 외형과 일치하는 오디오가 생성됩니다(예: 댄서의 주기적인 리듬).
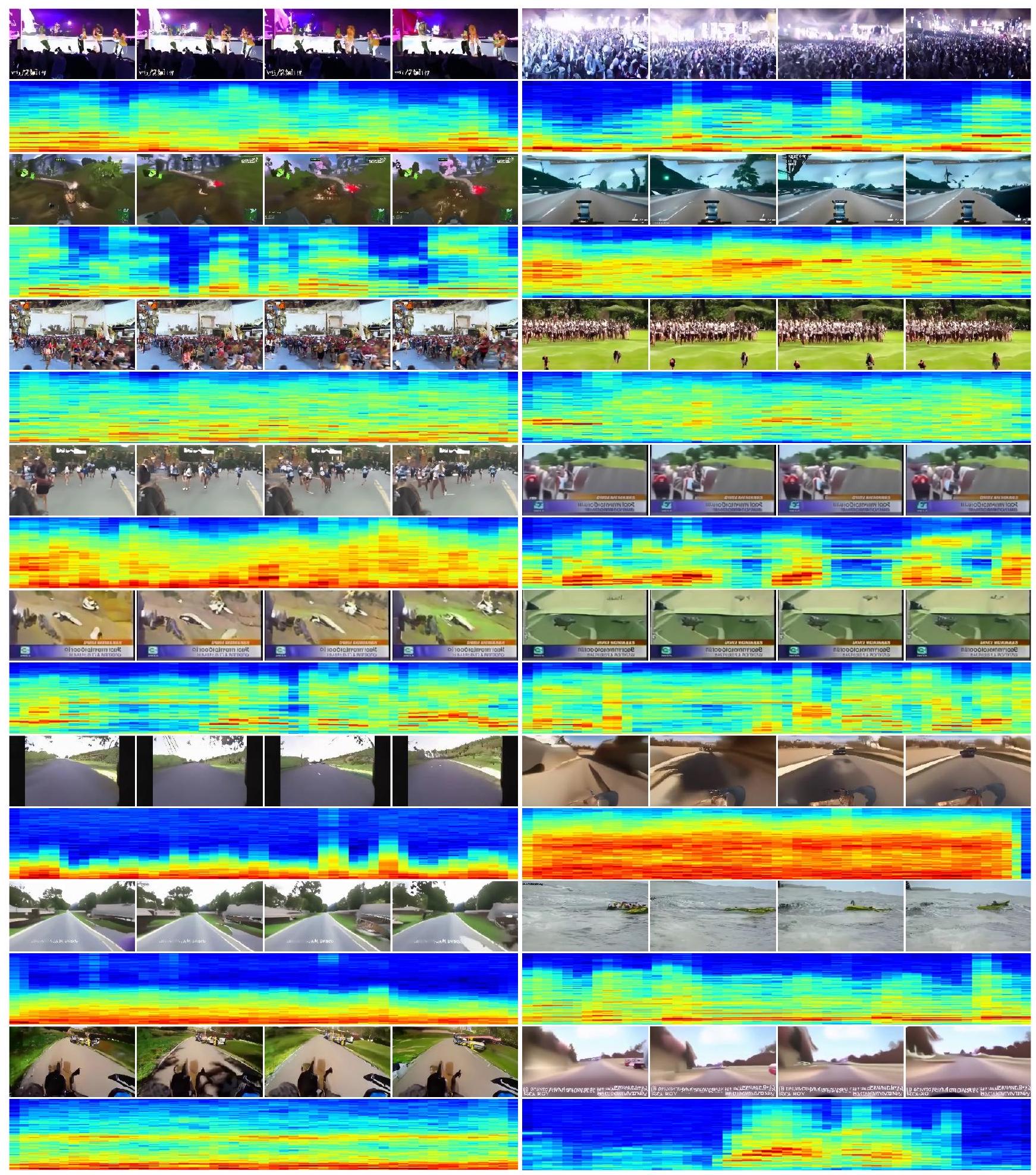
그림 C.3. 우리 MM-Diffusion의 오픈 도메인(AudioSet)에서 더 많은 생성 결과. 주어진 사례는 각각 콘서트, 게임 스트리밍, 마라톤, 뉴스 재생, 서핑 및 1인칭 시점 운전 장면을 보여줍니다.
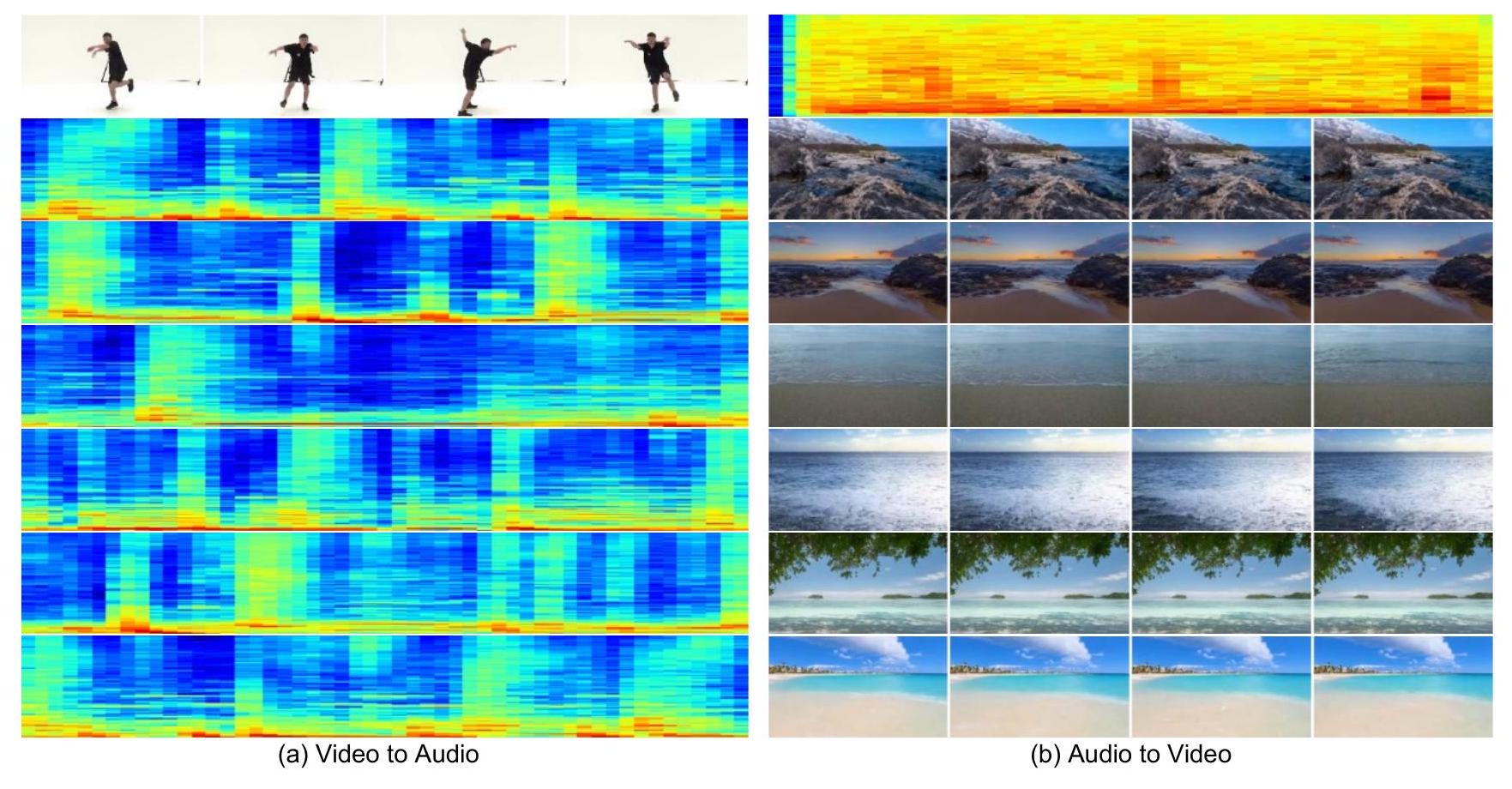
그림 C.4. 우리 MM-diffusion을 사용한 제로샷 조건부 생성의 더 많은 시각적 예.