멀티모달 대규모 언어 모델(MLLM)의 모든 것: 최신 연구 동향 총정리
최근 GPT-4V와 같은 Multimodal Large Language Model(MLLM)의 최신 연구 동향을 종합적으로 살펴봅니다. 본 논문은 MLLM의 기본 개념, 아키텍처, 학습 전략, 평가 방법을 다루고, Multimodal ICL (M-ICL), Multimodal CoT (M-CoT)와 같은 확장 기술과 멀티모달 환각 현상 및 해결 과제를 논의합니다. 논문 제목: A Survey on Multimodal Large Language Models
논문 요약: A Survey on Multimodal Large Language Models
- 논문 링크: https://arxiv.org/abs/2306.13549
- 저자: Shukang Yin*, Chaoyou Fu* , Sirui Zhao*, Ke Li, Xing Sun, Tong Xu, and Enhong Chen
- 발표 시기: 2024년, National Science Review
- 주요 키워드: Multimodal Large Language Model (MLLM), Vision Language Model, Large Language Model (LLM)
1. 연구 배경 및 문제 정의
- 문제 정의:
최근 LLM은 텍스트 처리에서 놀라운 능력을 보여주지만, 본질적으로 시각 정보에 "맹목적"이다. 반면 Large Vision Models(LVM)은 시각 정보를 잘 처리하지만 추론 능력이 부족하다. 이러한 LLM과 LVM의 상호 보완적인 한계를 극복하고, 멀티모달 정보를 수신, 추론 및 출력할 수 있는 LLM 기반 모델(MLLM)의 필요성이 대두되었다. - 기존 접근 방식:
MLLM 이전에 멀티모달 연구는 판별적 패러다임(예: CLIP)과 생성적 패러다임(예: OFA)으로 나뉘었다. 하지만 기존 모델들은 수십억 개의 매개변수를 가진 LLM을 기반으로 하지 않았으며, 멀티모달 명령어 튜닝과 같은 새로운 훈련 패러다임을 사용하지 않아 MLLM이 보여주는 이미지 기반 웹사이트 코드 작성, 밈 이해, OCR 없는 수학 추론과 같은 놀라운 창발적 능력을 갖추지 못했다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- MLLM의 기본 개념, 아키텍처, 훈련 전략, 데이터, 평가 방법을 포괄적으로 검토하고 요약하여 연구자들에게 MLLM 분야의 핵심 아이디어와 진행 상황을 제공한다.
- MLLM이 더 많은 세분성, 양식, 언어 및 시나리오를 지원하도록 확장될 수 있는 방법과 멀티모달 환각 현상 및 해결 과제를 논의한다.
- Multimodal ICL (M-ICL), Multimodal CoT (M-CoT), LLM-Aided Visual Reasoning (LAVR)을 포함한 핵심 확장 기술을 소개한다.
- MLLM 분야의 기존 과제를 논의하고 유망한 연구 방향을 제시한다.
- 제안 방법:
본 논문은 MLLM의 일반적인 아키텍처를 세 가지 핵심 모듈로 추상화하여 설명한다.- 양식 인코더 (Modality encoder): 이미지(CLIP, EVA-CLIP, ConvNext-L 등), 오디오(CLAP), 기타 양식(ImageBind)과 같은 원시 정보를 압축된 표현으로 변환한다. 사전 훈련된 인코더를 활용하며, 특히 고해상도 입력의 중요성을 강조한다.
- 사전 훈련된 LLM (Pre-trained LLM): 효율성과 강력한 추론 능력을 위해 기존의 대규모 언어 모델(FlanT5, LLaMA, Vicuna, Qwen 등)을 활용한다. LLM의 매개변수 크기 확장(7B에서 70B 이상)이 성능 향상에 기여하며, MoE(Mixture of Experts) 아키텍처 도입이 주목받고 있다.
- 양식 인터페이스 (Modality interface): LLM이 텍스트 외의 양식을 이해할 수 있도록 양식 간의 격차를 해소한다.
- 학습 가능한 커넥터: 인코더에서 출력된 특징을 LLM이 이해할 수 있는 토큰으로 변환한다. 토큰 수준 융합(Q-Former, MLP 기반)과 특징 수준 융합(교차 주의 계층, 시각적 전문가 모듈) 방식이 있다.
- 전문가 모델: 이미지 캡셔닝 모델 등을 사용하여 멀티모달 입력을 언어로 변환하는 방식도 있으나, 정보 손실 가능성이 있다.
3. 실험 결과
- 데이터셋:
MLLM의 훈련 및 평가에 사용되는 다양한 데이터셋과 벤치마크를 소개한다.- 사전 훈련 데이터셋: CC-3M, CC-12M, SBU Captions, LAION-5B, LAION-2B, LAION-COCO, COYO-700M (조밀한 이미지-텍스트 캡션 데이터). ShareGPT4V-PT, LVIS-Instruct4V, ALLaVA (고품질 미세 이미지-텍스트 데이터). MSR-VTT (비디오-텍스트), WavCaps (오디오-텍스트).
- 명령어 튜닝 데이터셋: LLaVA-Instruct, LVIS-Instruct, ALLaVA, Video-ChatGPT, VideoChat, Clotho-Detail (자가-명령어 생성 데이터). 기존 VQA 및 캡션 데이터셋을 명령어 형식으로 변환하여 사용.
- 정렬 튜닝 데이터셋: LLaVA-RLHF, RLHF-V (인간 피드백 기반 선호도 데이터). VLFeedback (GPT-4V를 활용한 AI 피드백 기반 선호도 데이터).
- 평가 벤치마크: MME, MMBench, Video-ChatGPT, Video-Bench (포괄적 MLLM 평가 벤치마크). POPE, HaELM, Woodpecker, FaithScore, AMBER (환각 평가 벤치마크).
- 주요 결과:
- MLLM의 능력: LLM의 강력한 추론 능력과 LVM의 시각 이해 능력을 결합하여 이미지 기반 웹사이트 코드 작성, 밈의 깊은 의미 이해, OCR 없는 수학 추론 등 전통적인 멀티모달 방법에서는 드문 놀라운 창발적 능력을 보여준다.
- 확장된 기능:
- 세분성 지원: 영역(Shikra, Ferret), 픽셀(Osprey, LISA) 단위의 사용자 프롬프트 제어 및 접지 기능 향상.
- 양식 지원: 3D 포인트 클라우드 입력 및 이미지, 오디오, 비디오 등 다양한 양식의 출력 생성(NExT-GPT).
- 언어 지원: 다단계 훈련 체계 및 이중 언어 LLM(VisCPM, Qwen-VL)을 통해 다국어(특히 중국어) 지원 확장.
- 시나리오/작업 확장: 모바일 장치 배포(MobileVLM), GUI 에이전트(CogAgent, AppAgent), 문서 이해(mPLUG-DocOwl, TextMonkey), 의료 분야(LLaVA-Med) 등 특정 도메인 및 실제 시나리오에 적용.
- 평가 방법:
- 폐쇄형 질문: 미리 정의된 답변 옵션이 있는 작업(VQA, 캡셔닝)에 대해 정확도, CIDEr 등의 벤치마크 메트릭으로 정량적 평가.
- 개방형 질문: 챗봇과 같은 유연한 응답에 대해 수동 채점, GPT 채점(GPT-4V 활용), 사례 연구를 통해 정성적 평가.
4. 개인적인 생각 및 응용 가능성
- 장점:
- LLM의 강력한 추론 및 일반화 능력과 LVM의 시각 이해 능력을 효과적으로 결합하여 기존 멀티모달 모델의 한계를 뛰어넘는 창발적 능력을 보여준다.
- 명령어 튜닝, In-Context Learning(ICL), Chain of Thought(CoT)와 같은 LLM의 핵심 기술을 멀티모달 영역으로 확장하여 다양한 복합 추론 작업을 해결할 수 있는 잠재력을 제시한다.
- 빠른 연구 발전 속도와 다양한 아키텍처 및 훈련 전략의 탐색을 통해 지속적인 성능 향상이 기대된다.
- 인공 일반 지능(AGI)으로 가는 중요한 경로 중 하나로 간주될 수 있다.
- 단점/한계:
- 멀티모달 환각: 모델이 이미지 내용과 일치하지 않는 응답을 생성하는 환각 현상이 여전히 중요한 문제로 남아 있으며, 이를 완화하기 위한 연구가 필요하다.
- 긴 컨텍스트 처리의 한계: 긴 비디오나 복잡한 문서와 같이 많은 멀티모달 토큰을 포함하는 정보를 처리하는 데 제한이 있다.
- 복잡한 지시 수행 능력 부족: 고품질의 멀티모달 질의응답 데이터 생성을 위해 여전히 GPT-4V와 같은 비공개 소스 모델에 의존하는 경향이 있다.
- M-ICL 및 M-CoT의 초기 단계: 멀티모달 In-Context Learning 및 Chain of Thought 기술은 아직 초기 단계에 있으며, 관련 기능이 약하여 추가적인 개선과 메커니즘 탐구가 필요하다.
- 안전 문제: LLM과 유사하게, MLLM도 조작된 공격에 취약하여 편향되거나 바람직하지 않은 응답을 생성할 수 있으므로 모델 안전성 향상이 중요하다.
- 응용 가능성:
- 체화 에이전트 개발: 실제 세계와 상호 작용하며 인식, 추론, 계획 및 실행 능력을 갖춘 멀티모달 에이전트(예: 로봇, GUI 에이전트) 개발.
- 전문 분야 적용: 의료 이미지 이해 및 질의응답, 복잡한 문서 구문 분석 및 이해 등 특정 전문 지식이 필요한 도메인에서의 활용.
- 사용자 인터페이스 개선: 자연어 및 시각적 프롬프트를 통한 더욱 직관적이고 세밀한 인간-기계 상호 작용 구현.
- 다국어 지원: 전 세계 사용자들을 위한 다국어 멀티모달 어시스턴트 개발.
- 자원 제한 환경 배포: 모바일 장치와 같은 자원 제한 환경에서도 효율적으로 작동하는 소규모 MLLM 개발.
5. 추가 참고 자료
Yin, Shukang, et al. "A survey on multimodal large language models." National Science Review 11.12 (2024): nwae403.
A Survey on Multimodal Large Language Models
Shukang Yin*, Chaoyou Fu* , Sirui Zhao*, Ke Li, Xing Sun, Tong Xu, and Enhong Chen, Fellow, IEEE
초록
최근 GPT-4V로 대표되는 Multimodal Large Language Model(MLLM)이 새로운 연구 핫스팟으로 떠오르고 있으며, 이는 강력한 Large Language Models(LLM)를 두뇌로 사용하여 멀티모달 작업을 수행합니다. 이미지를 기반으로 이야기를 쓰거나 OCR 없이 수학적 추론을 하는 것과 같은 MLLM의 놀라운 창발적 능력은 전통적인 멀티모달 방법에서는 드문 것으로, 인공 일반 지능으로 가는 잠재적인 경로를 제시합니다. 이를 위해 학계와 산업계 모두 GPT-4V와 경쟁하거나 심지어 더 나은 MLLM을 개발하기 위해 노력하며, 놀라운 속도로 연구의 한계를 넓혀가고 있습니다. 본 논문에서는 MLLM의 최근 발전을 추적하고 요약하는 것을 목표로 합니다. 먼저 MLLM의 기본 공식을 제시하고 아키텍처, 훈련 전략 및 데이터, 평가를 포함한 관련 개념을 설명합니다. 그런 다음 MLLM이 더 많은 세분성, 양식, 언어 및 시나리오를 지원하도록 확장될 수 있는 방법에 대한 연구 주제를 소개합니다. 우리는 계속해서 멀티모달 환각과 Multimodal ICL(M-ICL), Multimodal CoT(M-CoT), LLM-Aided Visual Reasoning(LAVR)을 포함한 확장된 기술에 대해 다룹니다. 논문을 마무리하며, 기존의 과제를 논의하고 유망한 연구 방향을 제시합니다. MLLM의 시대가 이제 막 시작되었다는 사실에 비추어, 우리는 이 설문조사를 계속 업데이트할 것이며 이것이 더 많은 연구에 영감을 주기를 바랍니다. 최신 논문을 수집하는 관련 GitHub 링크는 https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models 에서 확인할 수 있습니다.
색인 용어 - Multimodal Large Language Model, Vision Language Model, Large Language Model.
1 Introduction
최근 몇 년간 LLM [1], [2], [3], [4], [5]의 눈부신 발전을 보았습니다. 데이터 크기와 모델 크기를 확장함으로써 이러한 LLM은 일반적으로 명령어 따르기 [5], [6], In-Context Learning(ICL) [7], 그리고 Chain of Thought(CoT) [8]를 포함하는 특별한 창발적 능력을 보여줍니다. LLM은 대부분의 자연어 처리(NLP) 작업에서 놀라운 제로/퓨샷 추론 성능을 보여주었지만, 이들은 이산적인 텍스트만 이해할 수 있기 때문에 본질적으로 시각에 "맹목적"입니다. 동시에, Large Vision Models(LVM)은 명확하게 볼 수 있지만 [9], [10], [11], [12], 일반적으로 추론에서는 뒤처집니다.
이러한 상호 보완성에 비추어, LLM과 LVM은 서로를 향해 나아가며 Multimodal Large Language Model(MLLM)이라는 새로운 분야로 이어집니다. 공식적으로, 이는 멀티모달 정보를 수신, 추론 및 출력할 수 있는 능력을 갖춘 LLM 기반 모델을 의미합니다. MLLM 이전에, 멀티모달에 전념한 많은 연구들이 있었으며, 이는 판별적 [13], [14], [15] 패러다임과 생성적 [16], [17], [18] 패러다임으로 나눌 수 있습니다. 전자의 대표인 CLIP [13]은 시각 및 텍스트 정보를 통합된 표현 공간으로 투영하여 다운스트림 멀티모달 작업을 위한 다리를 구축합니다. 대조적으로, OFA [16]는 후자의 대표로, 멀티모달 작업을 시퀀스-투-시퀀스 방식으로 통합합니다. MLLM은 시퀀스 작업에 따라 후자로 분류될 수 있지만,
- Chaoyou Fu가 프로젝트 리더입니다.
- *Shukang Yin, Chaoyou Fu, Sirui Zhao는 동등하게 기여했습니다.
- Shukang Yin, Sirui Zhao, Tong Xu, Enhong Chen은 중국 안후이성 허페이시 바오허구 진자이로 96번지 중국과학기술대학교 데이터과학과 소속입니다. 이메일: sirui@mail.ustc.edu.cn, cheneh@ustc.edu.cn
- Chaoyou Fu, Ke Li, Xing Sun은 중국 상하이 200233 텐센트 유투 랩 소속입니다. 이메일: bradyfu24@gmail.com 해당 저자: Chaoyou Fu, Sirui Zhao, Enhong Chen. 전통적인 모델들과 비교하여 두 가지 대표적인 특징을 나타냅니다: (1) MLLM은 수십억 개의 매개변수를 가진 LLM을 기반으로 하며, 이는 이전 모델에서는 사용할 수 없었습니다. (2) MLLM은 멀티모달 명령어 튜닝 [19], [20]을 사용하여 모델이 새로운 명령어를 따르도록 장려하는 등 잠재력을 최대한 발휘하기 위해 새로운 훈련 패러다임을 사용합니다. 이 두 가지 특징으로 무장한 MLLM은 이미지 기반 웹사이트 코드 작성 [21], 밈의 깊은 의미 이해 [22], OCR 없는 수학 추론 [23]과 같은 새로운 능력을 보여줍니다.
GPT-4 [3]가 출시된 이래, 그것이 보여주는 놀라운 멀티모달 예시 때문에 MLLM에 대한 연구 열풍이 있었습니다. 학계와 산업계의 노력으로 빠른 개발이 촉진되었습니다. MLLM에 대한 예비 연구는 텍스트 프롬프트와 이미지 [20], [24]/비디오 [25], [26]/오디오 [27]에 기반한 텍스트 콘텐츠 생성에 중점을 둡니다. 후속 연구는 기능이나 사용 시나리오를 확장했으며, 다음을 포함합니다: (1) 더 나은 세분성 지원. 사용자의 프롬프트에 대한 더 세밀한 제어가 개발되어 상자 [28]를 통해 특정 영역을 지원하거나 클릭 [29]을 통해 특정 객체를 지원합니다. (2) 입력 및 출력 양식에 대한 향상된 지원 [30], [31], 예를 들어 이미지, 비디오, 오디오 및 포인트 클라우드. 입력 외에도 NExT-GPT [32]와 같은 프로젝트는 다른 양식의 출력을 추가로 지원합니다. (3) 향상된 언어 지원. 상대적으로 제한된 훈련 코퍼스 [33], [34]를 가진 다른 언어(예: 중국어)로 MLLM의 성공을 확장하려는 노력이 있었습니다. (4) 더 많은 영역 및 사용 시나리오로의 확장. 일부 연구는 MLLM의 강력한 기능을 의료 이미지 이해 [35], [36], [37] 및 문서 구문 분석 [38], [39], [40]과 같은 다른 도메인으로 이전합니다. 또한, 멀티모달 에이전트는 체화된 에이전트 [41], [42] 및 GUI 에이전트 [43], [44], [45]와 같이 실제 상호 작용을 지원하기 위해 개발되었습니다. MLLM 타임라인은 그림 1에 나와 있습니다.
이 분야의 급속한 발전과 유망한 결과를 고려하여, 우리는 연구자들이 MLLM의 기본 아이디어, 주요 방법 및 현재 진행 상황을 파악할 수 있도록 이 설문 조사를 작성합니다. 우리는 주로 시각 및 언어 양식에 중점을 두지만 비디오 및 오디오와 같은 다른 양식을 포함하는 연구도 포함합니다. 구체적으로, 우리는 MLLM의 가장 중요한 측면을 해당 요약과 함께 다루고 실시간으로 업데이트될 GitHub 페이지를 엽니다. 우리가 아는 한, 이것은 MLLM에 대한 최초의 설문 조사입니다.
이 조사의 다음 부분은 다음과 같이 구성됩니다: 조사는 (1) 주류 아키텍처(§2), (2) 훈련 전략 및 데이터의 전체 레시피(§3), (3) 성능 평가의 일반적인 관행(§4)을 포함하여 MLLM의 필수적인 측면에 대한 포괄적인 검토로 시작합니다. 그런 다음, MLLM에 대한 몇 가지 중요한 주제에 대해 더 깊이 논의하며, 각 주제는 주요 문제에 초점을 맞춥니다: (1) 어떤 측면이 더 개선되거나 확장될 수 있는가(§5)? (2) 멀티모달 환각 문제를 어떻게 완화할 수 있는가(§6)? 이 조사는 세 가지 핵심 기술(§7)의 소개로 이어지며, 각 기술은 특정 시나리오에 특화되어 있습니다: MICL(§7.1)은 추론 단계에서 일반적으로 사용되어 소수 샷 성능을 향상시키는 효과적인 기술입니다. 또 다른 중요한 기술은 복잡한 추론 작업에서 일반적으로 사용되는 M-CoT(§7.2)입니다. 그 후, 우리는 복합 추론 작업을 해결하거나 일반적인 사용자 쿼리를 처리하기 위해 LLM 기반 시스템을 개발하는 일반적인 아이디어를 설명합니다(§7.3). 마지막으로, 우리는 요약 및 잠재적인 연구 방향으로 조사를 마칩니다.
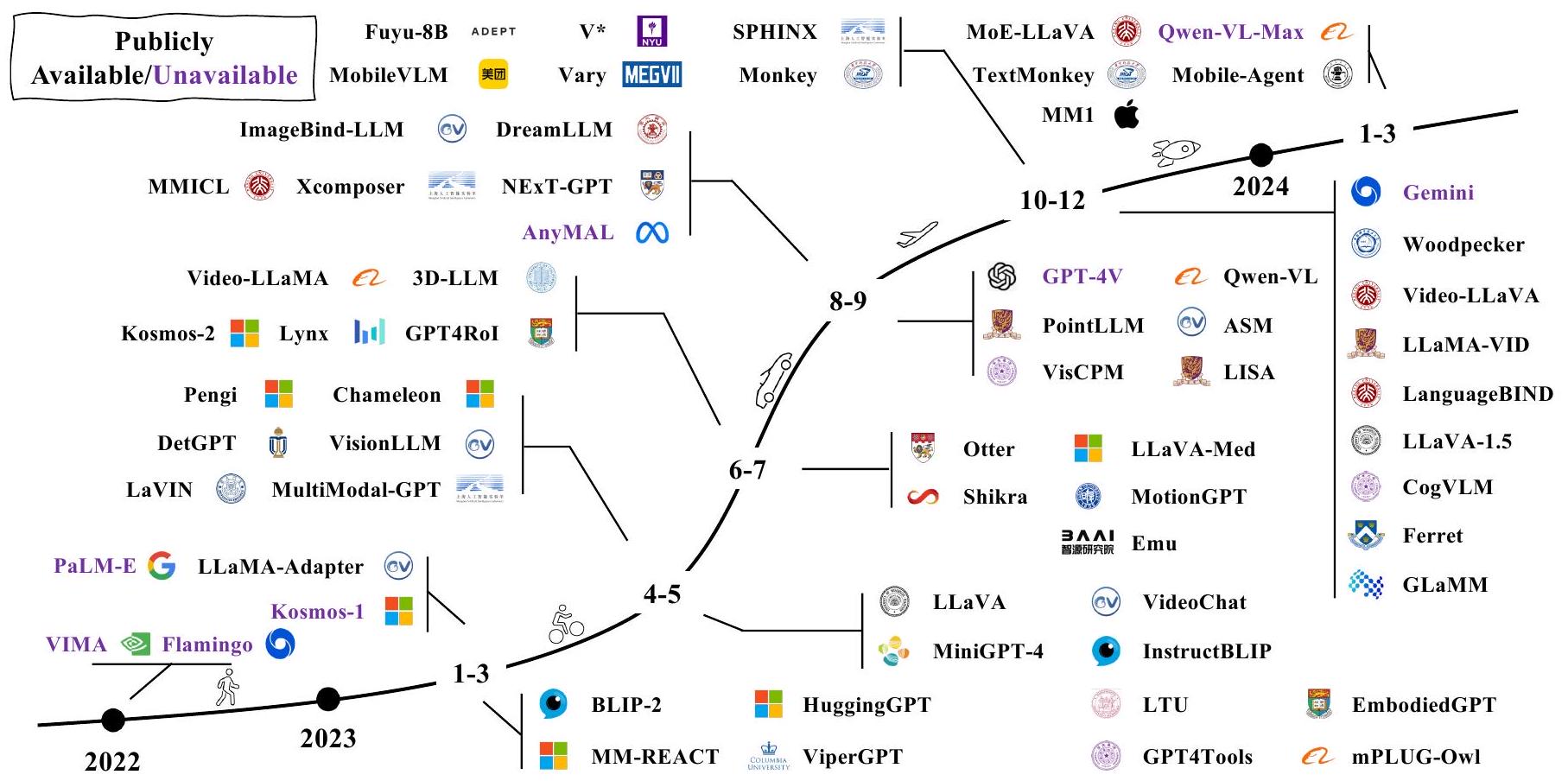
그림 1: 대표적인 MLLM의 타임라인. 우리는 이 분야에서 급속한 성장을 목격하고 있습니다. 더 많은 연구는 매일 업데이트되는 우리 GitHub 페이지에서 찾을 수 있습니다.
2 Architecture
일반적인 MLLM은 사전 훈련된 양식 인코더, 사전 훈련된 LLM, 그리고 이들을 연결하는 양식 인터페이스의 세 가지 모듈로 추상화될 수 있습니다. 인간에 비유하자면, 이미지/오디오 인코더와 같은 양식 인코더는 광학/음향 신호를 수신하고 전처리하는 인간의 눈/귀와 같고, LLM은 처리된 신호를 이해하고 추론하는 인간의 뇌와 같습니다. 그 사이에서 양식 인터페이스는 다른 양식을 정렬하는 역할을 합니다. 일부 MLLM은 텍스트 외에 다른 양식을 출력하기 위한 생성기를 포함하기도 합니다. 아키텍처 다이어그램은 그림 2에 그려져 있습니다. 이 섹션에서는 각 모듈을 순서대로 소개합니다.
2.1 Modality encoder
인코더는 이미지나 오디오와 같은 원시 정보를 더 압축된 표현으로 압축합니다. 처음부터 훈련하는 대신, 다른 양식에 정렬된 사전 훈련된 인코더를 사용하는 것이 일반적인 접근 방식입니다. 예를 들어, CLIP [13]은 이미지-텍스트 쌍에 대한 대규모 사전 훈련을 통해 텍스트와 의미적으로 정렬된 시각적 인코더를 통합합니다. 따라서 이러한 초기에 사전 정렬된 인코더를 사용하여 정렬 사전 훈련(§3.1 참조)을 통해 LLM과 정렬하는 것이 더 쉽습니다.
일반적으로 사용되는 이미지 인코더 시리즈는 표 1에 요약되어 있습니다. 바닐라 CLIP 이미지 인코더 [13] 외에도 일부 연구에서는 다른 변형을 사용하는 것을 탐구합니다. 예를 들어, MiniGPT-4 [21]는 개선된 훈련 기술로 훈련된 EVA-CLIP [47], [48] (ViT-G/14) 인코더를 채택합니다. 대조적으로, Osprey [29]는 더 높은 해상도와 다중 수준 기능을 활용하기 위해 컨볼루션 기반 ConvNext-L 인코더 [46]를 도입합니다. 일부 연구는 인코더 없는 아키텍처를 탐구하기도 합니다. 예를 들어, Fuyu-8b [49]의 이미지 패치는 LLM으로 전송되기 전에 직접 투영됩니다. 따라서 모델은 자연스럽게 유연한 이미지 해상도 입력을 지원합니다.
TABLE 1: 일반적으로 사용되는 이미지 인코더 요약.
| 변형 | 사전 훈련 코퍼스 | 해상도 | 샘플 (B) | 매개변수 크기 (M) |
|---|---|---|---|---|
| OpenCLIP-ConvNext-L [46] | LAION-2B | 320 | 29 | 197.4 |
| CLIP-ViT-L/14 [13] | OpenAI's WIT | 224/336 | 13 | 304.0 |
| EVA-CLIP-ViT-G/14 [47] | LAION-2B,COYO-700M | 224 | 11 | 1000.0 |
| OpenCLIP-ViT-G/14 [46] | LAION-2B | 224 | 34 | 1012.7 |
| OpenCLIP-ViT-bigG/14 [46] | LAION-2B | 224 | 34 | 1844.9 |
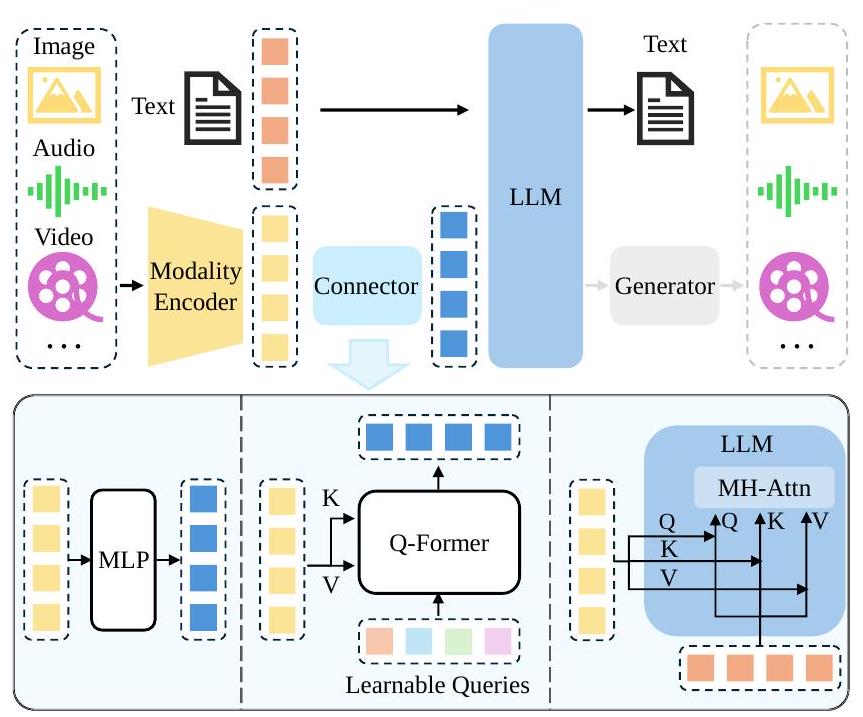
그림 2: 일반적인 MLLM 아키텍처의 그림. 인코더, 커넥터 및 LLM을 포함합니다. 선택적 생성기는 텍스트 외에 더 많은 양식을 생성하기 위해 LLM에 부착될 수 있습니다. 인코더는 이미지, 오디오 또는 비디오를 입력받아 특징을 출력하고, 이는 LLM이 더 잘 이해할 수 있도록 커넥터에 의해 처리됩니다. 커넥터에는 투영 기반, 쿼리 기반, 융합 기반의 세 가지 유형이 있습니다. 앞의 두 유형은 토큰 수준 융합을 채택하여 특징을 텍스트 토큰과 함께 전송될 토큰으로 처리하는 반면, 마지막 유형은 LLM 내부에서 특징 수준 융합을 가능하게 합니다.
인코더를 선택할 때 해상도, 매개변수 크기 및 사전 훈련 코퍼스와 같은 요소를 종종 고려합니다. 특히, 많은 연구에서 더 높은 해상도를 사용하면 현저한 성능 향상을 얻을 수 있음을 경험적으로 검증했습니다 [34], [50], [51], [52]. 입력 해상도를 확장하는 접근 방식은 직접 확장과 패치 분할 방법으로 분류될 수 있습니다. 직접 확장 방식은 더 높은 해상도의 이미지를 인코더에 입력하며, 이는 종종 인코더를 추가로 튜닝하거나 [34] 더 높은 해상도의 사전 훈련된 인코더로 교체하는 것을 포함합니다 [50]. 유사하게, CogAgent [44]는 이중 인코더 메커니즘을 사용하며, 여기서 두 인코더는 각각 고해상도 및 저해상도 이미지를 처리합니다. 고해상도 특징은 교차 주의를 통해 저해상도 분기에 주입됩니다. 패치 분할 방법은 고해상도 이미지를 패치로 자르고 저해상도 인코더를 재사용합니다. 예를 들어, Monkey [51]와 SPHINX [53]는 큰 이미지를 더 작은 패치로 나누고 다운샘플링된 고해상도 이미지와 함께 하위 이미지를 이미지 인코더로 보내며, 여기서 하위 이미지와 저해상도 이미지는 각각 로컬 및 글로벌 특징을 캡처합니다. 대조적으로, 매개변수 크기와 훈련 데이터 구성은 경험적 연구 [52]에 의해 발견된 바와 같이 입력 해상도에 비해 덜 중요합니다.
유사한 인코더는 다른 양식에도 사용할 수 있습니다. 예를 들어, Pengi [27]는 오디오 인코더로 CLAP [54] 모델을 사용합니다. ImageBind-LLM [30]은 이미지, 텍스트, 오디오, 깊이, 열 및 관성 측정 장치(IMU) 데이터 인코딩을 지원하는 ImageBind [55] 인코더를 사용합니다. 강력한 인코더를 갖춘 ImageBind-LLM은 여러 양식의 입력에 응답할 수 있습니다.
2.2 Pre-trained LLM
LLM을 처음부터 훈련하는 대신, 사전 훈련된 것으로 시작하는 것이 더 효율적이고 실용적입니다. 웹 코퍼스에 대한 엄청난 사전 훈련을 통해 LLM은 풍부한 세계 지식을 내장하게 되었고, 강력한 일반화 및 추론 능력을 보여줍니다.
우리는 표 2에서 일반적으로 사용되고 공개적으로 사용 가능한 LLM을 요약합니다. 특히, 대부분의 LLM은 GPT-3 [7]을 따르는 인과적 디코더 범주에 속합니다. 그중 FlanT5 [56] 시리즈는 BLIP-2 [59] 및 InstructBLIP [60]과 같은 연구에서 비교적 초기에 사용된 LLM입니다. LLaMA 시리즈 [5], [57] 및 Vicuna 제품군 [4]은 많은 학문적 관심을 끈 대표적인 오픈 소스 LLM입니다. 두 LLM은 주로 영어 코퍼스에서 사전 훈련되었기 때문에 중국어와 같은 다국어 지원에 제한이 있습니다. 대조적으로, Qwen [58]은 중국어와 영어를 잘 지원하는 이중 언어 LLM입니다.
LLM의 매개변수 크기를 확장하는 것도 입력 해상도를 높이는 경우와 마찬가지로 추가적인 이점을 가져온다는 점에 유의해야 합니다. 구체적으로, Liu 등[50], [61]은 LLM을 7B에서 13B로 단순히 확장하는 것만으로도 다양한 벤치마크에서 포괄적인 개선을 가져온다는 것을 발견했습니다. 더욱이, 34B LLM을 사용할 때, 훈련 중에 영어 멀티모달 데이터만 사용했음에도 불구하고 모델은 창발적인 제로샷 중국어 능력을 보여줍니다. Lu 등[62]은 LLM을 13B에서 35B 및 65B/70B로 확장함으로써 유사한 현상을 관찰했으며, 여기서 더 큰 모델 크기는 MLLM을 위해 특별히 설계된 벤치마크에서 일관된 이득을 가져왔습니다. 모바일 장치에 배포를 용이하게 하기 위해 더 작은 LLM을 사용하는 연구도 있습니다. 예를 들어, MobileVLM 시리즈 [63], [64]는 축소된 LLaMA [5](MobileLLaMA 1.4B/2.7B로 명명됨)를 사용하여 모바일 프로세서에서 효율적인 추론을 가능하게 합니다.
최근, LLM을 위한 전문가 혼합(MoE) 아키텍처에 대한 탐구가 점점 더 많은 주목을 받고 있습니다 [65], [66], [67]. 밀집 모델과 비교하여, 희소 아키텍처는 매개변수의 선택적 활성화를 통해 계산 비용을 증가시키지 않고 총 매개변수 크기를 확장할 수 있게 합니다. 경험적으로, MM1 [52]과 MoE-LLaVA [68]는 MoE 구현이 거의 모든 벤치마크에서 밀집 모델보다 더 나은 성능을 달성한다는 것을 발견했습니다.
TABLE 2: 일반적으로 사용되는 오픈 소스 LLM 요약. en, zh, fr, de는 각각 영어, 중국어, 프랑스어, 독일어를 나타냅니다.
| 모델 | 출시일 | 사전 훈련 데이터 규모 | 매개변수 크기 (B) | 언어 지원 | 아키텍처 |
|---|---|---|---|---|---|
| Flan-T5-XL/XXL [56] | 2022년 10월 | - | 3/ 11 | en, fr, de | 인코더-디코더 |
| LLaMA [5] | 2023년 2월 | 1.4T 토큰 | 7/ 13/ 33/ 65 | en | 인과적 디코더 |
| Vicuna [4] | 2023년 3월 | 1.4T 토큰 | 7/ 13/ 33 | en | 인과적 디코더 |
| LLaMA-2 [57] | 2023년 7월 | 2T 토큰 | 7/ 13/ 70 | en | 인과적 디코더 |
| Qwen [58] | 2023년 9월 | 3T 토큰 | 1.8 / 7/ 14/ 72 | en, zh | 인과적 디코더 |
2.3 Modality interface
LLM은 텍스트만 인식할 수 있으므로 자연어와 다른 양식 간의 격차를 해소하는 것이 필요합니다. 그러나 대규모 멀티모달 모델을 종단 간 방식으로 훈련하는 것은 비용이 많이 듭니다. 더 실용적인 방법은 사전 훈련된 시각적 인코더와 LLM 사이에 학습 가능한 커넥터를 도입하는 것입니다. 다른 접근 방식은 전문가 모델의 도움으로 이미지를 언어로 번역한 다음 해당 언어를 LLM에 보내는 것입니다. 학습 가능한 커넥터. 서로 다른 양식 간의 격차를 해소하는 역할을 합니다. 구체적으로, 이 모듈은 정보를 LLM이 효율적으로 이해할 수 있는 공간으로 투영합니다. 멀티모달 정보가 융합되는 방식에 따라 이러한 인터페이스를 구현하는 방법에는 토큰 수준 및 특징 수준 융합의 두 가지 방법이 있습니다.
토큰 수준 융합의 경우, 인코더에서 출력된 특징은 토큰으로 변환되어 LLM으로 전송되기 전에 텍스트 토큰과 연결됩니다. 일반적이고 실현 가능한 해결책은 학습 가능한 쿼리 토큰 그룹을 활용하여 쿼리 기반 방식으로 정보를 추출하는 것입니다 [69]. 이는 BLIP-2 [59]에서 처음 구현되었으며 이후 다양한 연구 [26], [60], [70]에 의해 계승되었습니다. 이러한 Q-Former 스타일 접근 방식은 시각적 토큰을 더 적은 수의 표현 벡터로 압축합니다. 대조적으로, 일부 방법은 단순히 MLP 기반 인터페이스를 사용하여 양식 격차를 해소합니다 [20], [37], [71], [72]. 예를 들어, LLaVA 시리즈는 하나/두 개의 선형 MLP [20], [50]를 채택하여 시각적 토큰을 투영하고 특징 차원을 단어 임베딩과 정렬합니다.
관련하여 MM1 [52]은 커넥터의 설계 선택에 대해 소거 실험을 수행했으며 토큰 수준 융합의 경우 양식 어댑터 유형이 시각적 토큰 수 및 입력 해상도보다 훨씬 덜 중요하다는 것을 발견했습니다. 그럼에도 불구하고 Zeng 등[73]은 토큰 및 특징 수준 융합의 성능을 비교하고 경험적으로 토큰 수준 융합 변형이 VQA 벤치마크 측면에서 더 나은 성능을 보인다는 것을 밝혔습니다. 성능 격차에 대해 저자들은 교차 주의 모델이 비교 가능한 성능을 달성하기 위해 더 복잡한 하이퍼파라미터 검색 프로세스가 필요할 수 있다고 제안합니다.
또 다른 라인으로, 특징 수준 융합은 텍스트 특징과 시각적 특징 간의 깊은 상호 작용 및 융합을 가능하게 하는 추가 모듈을 삽입합니다. 예를 들어, Flamingo [74]는 LLM의 동결된 Transformer 계층 사이에 추가적인 교차 주의 계층을 삽입하여 외부 시각적 단서로 언어 특징을 증강합니다. 유사하게, CogVLM [75]은 각 Transformer 계층에 시각적 전문가 모듈을 연결하여 시각과 언어 특징 간의 이중 상호 작용 및 융합을 가능하게 합니다. 더 나은 성능을 위해 도입된 모듈의 QKV 가중치 행렬은 사전 훈련된 LLM에서 초기화됩니다. 유사하게, LLaMA-Adapter [76]는 Transformer 계층에 학습 가능한 프롬프트를 도입합니다. 이러한 프롬프트는 먼저 시각적 지식으로 임베딩된 다음 접두사로 텍스트 특징과 연결됩니다.
매개변수 크기 측면에서, 학습 가능한 인터페이스는 일반적으로 인코더 및 LLM에 비해 작은 부분을 차지합니다. 예를 들어 Qwen-VL [34]의 경우 Q-Former의 매개변수 크기는 약 0.08B로 전체 매개변수의 1% 미만을 차지하는 반면, 인코더와 LLM은 각각 약 19.8%(1.9B)와 80.2%(7.7B)를 차지합니다. 전문가 모델. 학습 가능한 인터페이스 외에도 이미지 캡셔닝 모델과 같은 전문가 모델을 사용하는 것도 양식 격차를 해소하는 실현 가능한 방법입니다 [77], [78], [79], [80]. 기본 아이디어는 훈련 없이 멀티모달 입력을 언어로 변환하는 것입니다. 이런 식으로 LLM은 변환된 언어로 멀티모달을 이해할 수 있습니다. 예를 들어 VideoChat-Text [25]는 사전 훈련된 비전 모델을 사용하여 행동과 같은 시각적 정보를 추출하고 음성 인식 모델을 사용하여 설명을 풍부하게 합니다. 전문가 모델을 사용하는 것은 간단하지만 학습 가능한 인터페이스를 채택하는 것만큼 유연하지 않을 수 있습니다. 외부 양식을 텍스트로 변환하면 정보 손실이 발생할 수 있습니다. 예를 들어, 비디오를 텍스트 설명으로 변환하면 공간-시간 관계가 왜곡됩니다 [25].
3 Training Strategy and Data
완전한 MLLM은 사전 훈련, 명령어 튜닝, 정렬 튜닝의 세 가지 훈련 단계를 거칩니다. 각 훈련 단계는 다른 유형의 데이터를 필요로 하고 다른 목표를 달성합니다. 이 섹션에서는 각 훈련 단계에 대한 훈련 목표, 데이터 수집 및 특성에 대해 논의합니다.
3.1 Pre-training
3.1.1 Training Detail
첫 번째 훈련 단계인 사전 훈련은 주로 다양한 양식을 정렬하고 멀티모달 세계 지식을 배우는 것을 목표로 합니다. 사전 훈련 단계는 일반적으로 캡션 데이터와 같은 대규모 텍스트 쌍 데이터를 수반합니다. 일반적으로 캡션 쌍은 자연어 문장으로 이미지/오디오/비디오를 설명합니다.
여기서는 MLLM이 시각과 텍스트를 정렬하도록 훈련되는 일반적인 시나리오를 고려합니다. 표 3에서 볼 수 있듯이, 이미지가 주어지면 모델은 표준 교차 엔트로피 손실에 따라 이미지의 캡션을 자동 회귀적으로 예측하도록 훈련됩니다. 사전 훈련을 위한 일반적인 접근 방식은 사전 훈련된 모듈(예: 시각적 인코더 및 LLM)을 고정하고 학습 가능한 인터페이스 [20], [35], [72]를 훈련하는 것입니다. 아이디어는 사전 훈련된 지식을 잃지 않고 다양한 양식을 정렬하는 것입니다. 일부 방법 [34], [81], [82]은 정렬을 위해 더 많은 훈련 가능한 매개변수를 활성화하기 위해 더 많은 모듈(예: 시각적 인코더)을 고정 해제하기도 합니다.
입력: <image> 응답: {caption}
표 3: 캡션 데이터를 구조화하는 단순화된 템플릿. {<image>}는 시각적 토큰의 자리 표시자이고, {caption}은 이미지의 캡션입니다. 빨간색으로 표시된 부분만 손실 계산에 사용된다는 점에 유의하십시오. 훈련 방식은 데이터 품질과 밀접한 관련이 있다는 점에 유의해야 합니다. 짧고 노이즈가 많은 캡션 데이터의 경우 훈련 프로세스 속도를 높이기 위해 더 낮은 해상도(예: 224)를 채택할 수 있으며, 더 길고 깨끗한 데이터의 경우 환각을 완화하기 위해 더 높은 해상도(예: 448 이상)를 활용하는 것이 좋습니다. 또한 ShareGPT4V [83]는 사전 훈련 단계에서 고품질 캡션 데이터를 사용하면 비전 인코드를 잠금 해제하는 것이 더 나은 정렬을 촉진한다는 것을 발견했습니다.
3.1.2 Data
사전 훈련 데이터는 주로 두 가지 목적을 수행합니다. 즉, (1) 서로 다른 양식을 정렬하고 (2) 세계 지식을 제공하는 것입니다. 사전 훈련 코퍼스는 세분성에 따라 거친 입자 데이터와 미세 입자 데이터로 나눌 수 있으며, 순서대로 소개하겠습니다. 일반적으로 사용되는 사전 훈련 데이터 세트를 표 4에 요약했습니다.
조밀한 캡션 데이터는 다음과 같은 일반적인 특징을 공유합니다: (1) 샘플이 일반적으로 인터넷에서 공급되기 때문에 데이터 양이 많습니다. (2) 웹에서 크롤링된 특성 때문에 캡션은 웹 이미지의 alt-text에서 유래했기 때문에 일반적으로 짧고 노이즈가 많습니다. 이러한 데이터는 자동 도구를 통해 정리 및 필터링할 수 있습니다. 예를 들어 CLIP [13] 모델을 사용하여 유사성이 미리 정의된 임계값보다 낮은 이미지-텍스트 쌍을 필터링합니다. 다음에서는 몇 가지 대표적인 조밀한 데이터 세트를 소개합니다. CC. CC-3M [84]은 330만 개의 이미지-캡션 쌍으로 구성된 웹 규모의 캡션 데이터 세트로, 원시 설명은 이미지와 관련된 alt-text에서 파생됩니다. 저자는 데이터를 정리하기 위해 복잡한 파이프라인을 설계했습니다: (1) 이미지의 경우 부적절한 콘텐츠나 종횡비를 가진 이미지를 필터링합니다. (2) 텍스트의 경우 NLP 도구를 사용하여 텍스트 주석을 얻고, 설계된 휴리스틱에 따라 샘플을 필터링합니다. (3) 이미지-텍스트 쌍의 경우, 분류기를 통해 이미지에 레이블을 할당합니다. 텍스트 주석이 이미지 레이블과 겹치지 않으면 해당 샘플은 삭제됩니다.
CC-12M [85]은 CC-3M의 후속 연구이며 1,240만 개의 이미지-캡션 쌍을 포함합니다. 이전 연구에 비해 CC-12M은 데이터 수집 파이프라인을 완화하고 단순화하여 더 많은 데이터를 수집합니다. SBU Captions [86]. Flickr에서 가져온 이미지와 설명이 포함된 1백만 개의 이미지-텍스트 쌍으로 구성된 캡션이 달린 사진 데이터 세트입니다. 구체적으로, 초기 이미지 세트는 다수의 쿼리 용어로 Flickr 웹사이트를 쿼리하여 얻습니다. 이미지에 첨부된 설명은 캡션 역할을 합니다. 그런 다음 설명이 이미지와 관련이 있는지 확인하기 위해 보존된 이미지는 다음 요구 사항을 충족합니다: (1) 이미지의 설명이 관찰에 의해 결정된 만족스러운 길이입니다. (2) 이미지의 설명에는 미리 정의된 용어 목록에 있는 단어가 최소 2개 이상 포함되어 있으며 일반적으로 공간 관계를 나타내는 전치사(예: "on", "under")가 포함되어 있습니다.
TABLE 4: 사전 훈련에 사용되는 일반적인 데이터 세트.
| 데이터셋 | 샘플 수 | 날짜 |
|---|---|---|
| 조밀한 이미지-텍스트 | ||
| CC-3M [84] | 3.3 M | 2018 |
| CC-12M [85] | 12.4 M | 2020 |
| SBU Captions [86] | 1M | 2011 |
| LAION-5B [87] | 5.9 B | 2022년 3월 |
| LAION-2B [87] | 2.3 B | 2022년 3월 |
| LAION-COCO [88] | 600 M | 2022년 9월 |
| COYO-700M [90] | 747M | 2022년 8월 |
| 세밀한 이미지-텍스트 | ||
| ShareGPT4V-PT [83] | 1.2 M | 2023년 11월 |
| LVIS-Instruct4V [91] | 111 K | 2023년 11월 |
| ALLaVA [92] | 709 K | 2024년 2월 |
| 비디오-텍스트 | ||
| MSR-VTT [93] | 200K | 2016 |
| 오디오-텍스트 | ||
| WavCaps [94] | 24 K | 2023년 3월 |
LAION. 이 시리즈는 인터넷에서 긁어온 이미지와 관련 alt-텍스트를 캡션으로 사용하는 대규모 웹 스케일 데이터셋입니다. 이미지-텍스트 쌍을 필터링하기 위해 다음 단계가 수행됩니다: (1) 길이가 짧은 텍스트나 너무 작거나 너무 큰 이미지는 삭제됩니다. (2) URL 기반 이미지 중복 제거. (3) 이미지와 텍스트에 대한 CLIP [13] 임베딩을 추출하고, 이 임베딩을 사용하여 불법 콘텐츠일 가능성이 있는 것과 임베딩 간의 코사인 유사도가 낮은 이미지-텍스트 쌍을 삭제합니다. 다음은 몇 가지 대표적인 변형에 대한 간략한 요약입니다.
- LAION-5B [87]: 58억 5천만 개의 이미지-텍스트 쌍으로 구성된 연구용 데이터셋입니다. 이 데이터셋은 20억 개의 영어 하위 집합을 포함하는 다국어 데이터셋입니다.
- LAION-COCO [88]: LAION-5B의 영어 하위 집합에서 추출한 6억 개의 이미지를 포함합니다. 캡션은 합성된 것으로, BLIP [89]를 사용하여 다양한 이미지 캡션을 생성하고 CLIP [13]을 사용하여 이미지에 가장 적합한 것을 선택합니다. COYO-700M [90]. CommonCrawl에서 추출한 7억 4,700만 개의 이미지-텍스트 쌍을 포함합니다. 데이터 필터링을 위해 저자들은 다음과 같은 전략을 설계했습니다: (1) 이미지의 경우, 부적절한 크기, 콘텐츠, 형식 또는 가로세로 비율을 가진 이미지는 필터링됩니다. 또한 ImageNet 및 MS-COCO와 같은 공개 데이터셋과 겹치는 이미지를 제거하기 위해 pHash 값을 기반으로 이미지를 필터링합니다. (2) 텍스트의 경우, 만족스러운 길이, 명사 형식 및 적절한 단어를 가진 영어 텍스트만 저장됩니다. 문장 앞뒤의 공백은 제거되고, 연속적인 공백 문자는 단일 공백으로 대체됩니다. 또한 "image for"와 같이 10번 이상 나타나는 텍스트는 삭제됩니다. (3) 이미지-텍스트 쌍의 경우, (이미지 pHash, 텍스트) 튜플을 기반으로 중복된 샘플이 제거됩니다.
최근, 더 많은 연구들[83], [91], [92]이 강력한 MLLM(예: GPT-4V)에 프롬프트를 주어 고품질의 미세한 데이터를 생성하는 것을 탐구했습니다. 거친 데이터와 비교하여, 이러한 데이터는 일반적으로 이미지에 대한 더 길고 정확한 설명을 포함하므로 이미지와 텍스트 양식 간의 미세한 정렬을 가능하게 합니다. 그러나 이 접근 방식은 일반적으로 상업용 MLLM을 호출해야 하므로 비용이 더 높고 데이터 양이 상대적으로 적습니다. 특히, ShareGPT4V [83]는 GPT-4V로 생성된 100K 데이터로 캡셔너를 먼저 훈련시킨 다음 사전 훈련된 캡셔너를 사용하여 데이터 양을 120만으로 확장함으로써 균형을 맞춥니다.
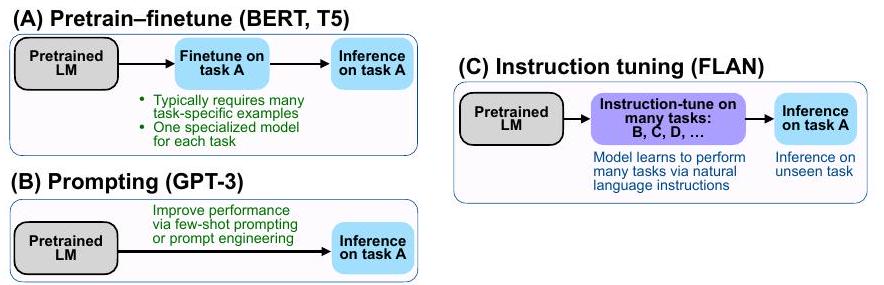
그림 3: 세 가지 대표적인 학습 패러다임 비교. 이미지는 [19]에서 가져왔습니다.
3.2 Instruction-tuning
3.2.1 Introduction
명령어는 작업의 설명을 의미합니다. 직관적으로, 명령어 튜닝은 모델이 사용자의 명령어를 더 잘 이해하고 요구된 작업을 수행하도록 가르치는 것을 목표로 합니다. 이러한 방식으로 튜닝하면 LLM은 새로운 명령어를 따름으로써 보이지 않는 작업에 일반화하여 제로샷 성능을 향상시킬 수 있습니다. 이 간단하면서도 효과적인 아이디어는 ChatGPT [2], InstructGPT [95], FLAN [19], [56], OPT-IML [96]과 같은 후속 NLP 연구의 성공을 촉발시켰습니다.
명령어 튜닝과 관련된 대표적인 학습 패러다임 간의 비교는 그림 3에 나와 있습니다. 지도 미세 조정 접근 방식은 일반적으로 작업별 모델을 훈련하기 위해 많은 양의 작업별 데이터가 필요합니다. 프롬프트 접근 방식은 대규모 데이터에 대한 의존도를 줄이고 프롬프트 엔지니어링을 통해 전문화된 작업을 수행할 수 있습니다. 이러한 경우 소수 샷 성능은 향상되었지만 제로샷 성능은 여전히 상당히 평균적입니다 [7]. 다르게, 명령어 튜닝은 두 가지 대응물처럼 특정 작업에 적합하도록 하는 대신 보이지 않는 작업으로 일반화하는 방법을 배웁니다. 또한 명령어 튜닝은 다중 작업 프롬프트 [97]와 밀접한 관련이 있습니다.
이 섹션에서는 명령어 샘플의 형식, 훈련 목표, 명령어 데이터를 수집하는 일반적인 방법, 그리고 해당되는 일반적으로 사용되는 데이터 세트를 설명합니다.
3.2.2 Training Detail
멀티모달 명령어 샘플은 종종 선택적 명령어와 입출력 쌍을 포함합니다. 명령어는 일반적으로 "이미지를 자세히 설명하세요."와 같이 작업을 설명하는 자연어 문장입니다. 입력은 VQA 작업 [99]과 같은 이미지-텍스트 쌍이거나 이미지 캡션 작업 [100]과 같은 이미지만일 수 있습니다. 출력은 입력에 대한 조건부로 명령어에 대한 답변입니다. 명령어 템플릿은 유연하며 수동 설계에 따라 달라질 수 있습니다 [20], [25], [98]. 표 5에 예시되어 있습니다. 명령어 템플릿은 다중 라운드 대화 [20], [37], [71], [98]의 경우에도 일반화될 수 있다는 점에 유의하십시오.
<코드> 아래는 작업을 설명하는 명령어입니다. 요청을 적절하게 완료하는 응답을 작성하십시오. 명령어: <instruction> 입력: {<image>, <text>} 응답: <output> <코드>
표 5: 멀티모달 명령어 데이터를 구조화하는 단순화된 템플릿. <instruction>은 작업에 대한 텍스트 설명입니다. {<image>, <text>}와 <output>은 데이터 샘플의 입력과 출력입니다. 입력의 <text>는 이미지 캡션 데이터셋과 같이 <image>만 있는 일부 데이터셋에서는 누락될 수 있습니다. 이 예는 [98]에서 가져왔습니다. 공식적으로, 멀티모달 명령어 샘플은 삼중항 형태, 즉 ()로 표기될 수 있으며, 여기서 은 각각 명령어, 멀티모달 입력, 그리고 정답 응답을 나타냅니다. MLLM은 명령어와 멀티모달 입력이 주어졌을 때 답변을 예측합니다:
여기서 는 예측된 답변을, 는 모델의 매개변수를 나타냅니다. 훈련 목표는 일반적으로 LLM을 훈련시키는 데 사용되는 원래의 자동 회귀 목표이며 [20], [37], [71], [101], 이를 기반으로 MLLM은 응답의 다음 토큰을 예측하도록 장려됩니다. 목표는 다음과 같이 표현될 수 있습니다:
여기서 N은 정답 응답의 길이입니다.
3.2.3 Data Collection
명령어 데이터는 형식의 유연성과 작업 구성의 다양성으로 인해 데이터 샘플 수집이 일반적으로 더 까다롭고 비용이 많이 듭니다. 이 섹션에서는 데이터 적응, 자가 명령어, 데이터 혼합이라는 세 가지 대표적인 대규모 명령어 데이터 수집 방법을 요약합니다. 데이터 적응. 작업별 데이터 세트는 고품질 데이터의 풍부한 소스입니다. 따라서 수많은 연구 [60], [70], [76], [82], [101], [102], [103], [104]에서 기존의 고품질 데이터 세트를 활용하여 명령어 형식의 데이터 세트를 구축했습니다. VQA 데이터 세트 변환을 예로 들면, 원본 샘플은 입력이 이미지와 자연어 질문으로 구성되고 출력이 이미지에 대한 질문에 대한 텍스트 답변인 입출력 쌍입니다. 이러한 데이터 세트의 입출력 쌍은 자연스럽게 명령어 샘플의 멀티모달 입력 및 응답을 구성할 수 있습니다(§3.2.2 참조). 작업 설명인 명령어는 수동 설계 또는 GPT의 도움을 받은 반자동 생성에서 파생될 수 있습니다. 구체적으로, 일부 연구 [21], [35], [60], [70], [102], [105]는 후보 명령어 풀을 수작업으로 만들고 훈련 중에 그 중 하나를 샘플링합니다. 표 6에 VQA 데이터 세트에 대한 명령어 템플릿의 예를 제공합니다. 다른 연구에서는 일부 시드 명령어를 수동으로 설계하고 이를 사용하여 GPT가 더 많은 명령어를 생성하도록 프롬프트합니다 [25], [82], [98].
기존 VQA 및 캡션 데이터셋의 답변은 보통 간결하기 때문에, 이러한 데이터셋을 직접 사용하여 명령어 튜닝을 하면 MLLM의 출력 길이가 제한될 수 있다는 점에 유의해야 합니다. 이 문제를 해결하기 위한 두 가지 일반적인 전략이 있습니다. 첫 번째는 명령어에서 명시적으로 지정하는 것입니다. 예를 들어, ChatBridge [104]는 짧은 답변 데이터에 대해 '짧고 간결하게'라고 명시적으로 선언하고, 기존의 거친 캡션 데이터에 대해서는 '문장' 및 '단일 문장'을 사용합니다. 두 번째는 기존 답변의 길이를 확장하는 것입니다 [105]. 예를 들어, M3IT [105]는 원본 질문, 답변, 그리고 이미지의 문맥 정보(예: 캡션 및 OCR)를 사용하여 ChatGPT에 프롬프트를 주어 원본 답변을 재구성할 것을 제안합니다.
- <Image> {Question}
- <Image> Question: {Question}
- <Image> {Question} A short answer to the question is
- <Image> Q: {Question} A:
- <Image> Question: {Question} Short answer:
- <Image> Given the image, answer the following question with no more than three words. {Question}
- <Image> Based on the image, respond to this question with a short answer: {Question}. Answer:
- <Image> Use the provided image to answer the question: {Question} Provide your answer as short as possible:
- <Image> What is the answer to the following question? "{Question}"
- <Image> The question "{Question}" can be answered using the image. A short answer is
표 6: VQA 데이터셋을 위한 명령어 템플릿, [60]에서 인용. <Image>와 {Question}은 각각 원본 VQA 데이터셋의 이미지와 질문입니다.
표 7: 자가 명령어로 생성된 인기 데이터셋 요약. 입/출력 양식에서 I: 이미지, T: 텍스트, V: 비디오, A: 오디오. 데이터 구성에서 M-T와 S-T는 각각 다중 턴과 단일 턴을 나타냅니다.
| 데이터셋 | 샘플 | 양식 | 출처 | 구성 |
|---|---|---|---|---|
| LLaVA-Instruct | 158 K | MS-COCO | 23 K 캡션 +58 K M-T QA +77 K 추론 | |
| LVIS-Instruct | 220 K | LVIS | 110 K 캡션 +110 K M-T QA | |
| ALLaVA | 1.4 M | VFlan, LAION | 709 K 캡션 +709 K S-T QA | |
| Video-ChatGPT | 100K | ActivityNet | 7 K 설명 +4 K M-T QA | |
| VideoChat | 11 K | WebVid | 설명 + 요약 + 생성 | |
| Clotho-Detail | 3.9 K | Clotho | 캡션 |
자가-명령어. 기존의 다중 작업 데이터셋이 풍부한 데이터 소스를 제공할 수 있지만, 다중 대화 라운드와 같은 실제 시나리오에서 인간의 요구를 잘 충족시키지 못하는 경우가 많습니다. 이 문제를 해결하기 위해 일부 연구에서는 자가-명령어 [106]를 통해 샘플을 수집하는데, 이는 소수의 수작업으로 주석이 달린 샘플을 사용하여 LLM이 텍스트 명령어 준수 데이터를 생성하도록 활용합니다. 구체적으로, 일부 명령어 준수 샘플은 시연용으로 수작업으로 제작된 후 ChatGPT/GPT-4가 시연을 지침으로 삼아 더 많은 명령어 샘플을 생성하도록 프롬프트됩니다. LLaVA [20]는 이미지를 캡션 및 경계 상자의 텍스트로 변환하고, 요구 사항 및 시연의 지침에 따라 텍스트 전용 GPT-4에 프롬프트를 주어 새로운 데이터를 생성함으로써 이 접근 방식을 멀티모달 분야로 확장합니다. 이러한 방식으로 LLaVA-Instruct-150k라는 멀티모달 명령어 데이터셋이 구성됩니다. 이 아이디어를 따라 MiniGPT-4 [21], ChatBridge [104], GPT4Tools [107], DetGPT [72]와 같은 후속 연구에서는 다양한 요구에 맞는 다양한 데이터셋을 개발합니다. 최근에는 더 강력한 멀티모달 모델 GPT-4V의 출시로 많은 연구에서 LVIS-Instruct4V [91] 및 ALLaVA [92]에서 예시된 바와 같이 더 높은 품질의 데이터를 생성하기 위해 GPT-4V를 채택했습니다. 우리는 표 7에서 자가-명령어를 통해 생성된 인기 있는 데이터셋을 요약합니다. 데이터 혼합. 멀티모달 명령어 데이터 외에도, 언어 전용 사용자-보조자 대화 데이터는 대화 능력과 명령어 준수 능력을 향상시키는 데 사용될 수 있습니다 [81], [98], [101], [103]. LaVIN [101]은 언어 전용 데이터와 멀티모달 데이터에서 무작위로 샘플링하여 미니배치를 직접 구성합니다. MultiInstruct [102]는 단일 모달 데이터와 멀티모달 데이터의 융합으로 훈련하기 위한 다양한 전략을 탐구하며, 여기에는 혼합 명령어 튜닝(두 유형의 데이터를 결합하고 무작위로 섞음)과 순차적 명령어 튜닝(텍스트 데이터 다음에 멀티모달 데이터)이 포함됩니다.
3.2.4 Data Quality
최근 연구에 따르면 명령어 튜닝 샘플의 데이터 품질이 양보다 중요하지 않다는 것이 밝혀졌습니다. Lynx [73]는 대규모이지만 노이즈가 많은 이미지-텍스트 쌍으로 사전 훈련된 모델이 더 작지만 깨끗한 데이터셋으로 사전 훈련된 모델만큼 성능이 좋지 않다는 것을 발견했습니다. 마찬가지로 Wei 등[108]은 품질이 높은 명령어 튜닝 데이터가 적을수록 더 나은 성능을 달성할 수 있다는 것을 발견했습니다. 데이터 필터링을 위해 이 연구는 데이터 품질을 평가하기 위한 몇 가지 지표와 그에 따라 열등한 시각-언어 데이터를 자동으로 필터링하는 방법을 제안합니다. 여기서는 데이터 품질과 관련된 두 가지 중요한 측면에 대해 논의합니다. 프롬프트 다양성. 명령어의 다양성은 모델 성능에 매우 중요한 것으로 밝혀졌습니다. Lynx [73]는 다양한 프롬프트가 모델 성능과 일반화 능력을 향상시키는 데 도움이 된다는 것을 경험적으로 검증했습니다. 작업 범위. 훈련 데이터에 포함된 작업 측면에서 Du 등[109]은 경험적 연구를 수행하여 시각적 추론 작업이 캡셔닝 및 QA 작업보다 모델 성능을 향상시키는 데 우수하다는 것을 발견했습니다. 또한 이 연구는 작업 다양성을 높이고 세분화된 공간 주석을 통합하는 것보다 명령어의 복잡성을 높이는 것이 더 유익할 수 있다고 제안합니다.
3.3 Alignment tuning
3.3.1 Introduction
정렬 튜닝은 모델을 특정 인간의 선호도, 예를 들어 환각이 적은 응답(§6 참조)에 맞춰 정렬해야 하는 시나리오에서 더 자주 사용됩니다. 현재, 인간 피드백을 이용한 강화 학습(RLHF)과 직접 선호도 최적화(DPO)가 정렬 튜닝을 위한 두 가지 주요 기술입니다. 이 섹션에서는 두 기술의 주요 아이디어를 순서대로 소개하고, 실제 문제 해결에 어떻게 활용되는지에 대한 몇 가지 예를 제공하며, 마지막으로 관련 데이터 세트의 편집본을 제공합니다.
3.3.2 Training Detail
RLHF [110], [111]. 이 기술은 강화 학습 알고리즘을 활용하여 LLM을 인간의 선호도와 일치시키는 것을 목표로 하며, 훈련 루프에서 인간의 주석을 감독으로 사용합니다. InstructGPT [95]에서 예시된 바와 같이, RLHF는 세 가지 주요 단계를 포함합니다:
- 지도 미세 조정. 이 단계는 사전 훈련된 모델을 미세 조정하여 예비적으로 원하는 출력 동작을 제시하는 것을 목표로 합니다. RLHF 설정에서 미세 조정된 모델을 정책 모델이라고 합니다. 이 단계는 지도 정책 모델 가 명령어 튜닝된 모델(§3.2 참조)에서 초기화될 수 있으므로 건너뛸 수 있다는 점에 유의해야 합니다.
- 보상 모델링. 이 단계에서 선호도 쌍을 사용하여 보상 모델이 훈련됩니다. 멀티모달 프롬프트(예: 이미지 및 텍스트) 와 응답 쌍 ()이 주어지면, 보상 모델 는 선호하는 응답 에 더 높은 보상을 부여하고, 에 대해서는 그 반대를 학습합니다. 다음 목표에 따라:
여기서 는 인간 주석가에 의해 레이블이 지정된 비교 데이터 세트입니다. 실제로 보상 모델 는 정책 모델과 유사한 구조를 공유합니다. 3) 강화 학습. 이 단계에서는 Proximal Policy Optimization(PPO) 알고리즘을 채택하여 RL 정책 모델 을 최적화합니다. 원래 정책에서 너무 멀리 벗어나는 것을 피하기 위해 토큰당 KL 페널티가 종종 훈련 목표에 추가되며, 그 결과 목표는 다음과 같습니다:
여기서 는 KL 페널티 항의 계수입니다. 일반적으로 RL 정책 과 참조 모델 는 모두 지도 모델 에서 초기화됩니다. 얻어진 RL 정책 모델은 이 튜닝 과정을 통해 인간의 선호도와 일치할 것으로 예상됩니다. 연구자들은 더 나은 멀티모달 정렬을 위해 RLHF 기술을 사용하는 것을 탐구해 왔습니다. 예를 들어, LLaVARLHF [112]는 인간 선호도 데이터를 수집하고 LLaVA [20]를 기반으로 환각이 적은 모델을 튜닝합니다. DPO [113]. 간단한 이진 분류 손실을 이용하여 인간 선호도 레이블로부터 학습합니다. PPO 기반 RLHF 알고리즘과 비교하여, DPO는 명시적인 보상 모델을 학습할 필요가 없으므로 전체 파이프라인을 인간 선호도 데이터 수집 및 선호도 학습의 두 단계로 단순화합니다. 학습 목표는 다음과 같습니다:
RLHF-V [114]는 모델 응답의 환각을 수정하여 세분화된(세그먼트 수준) 선호도 데이터 쌍을 수집하고 얻은 데이터를 사용하여 조밀한 DPO를 수행합니다. Silkie [115]는 대신 GPT-4V에 프롬프트를 주어 선호도 데이터를 수집하고 DPO를 통해 선호도 감독을 명령어 튜닝된 모델에 증류합니다.
3.3.3 Data
정렬 튜닝을 위한 데이터 수집의 핵심은 모델 응답에 대한 피드백을 수집하는 것입니다. 즉, 어떤 응답이 더 나은지 결정하는 것입니다. 이러한 데이터를 수집하는 것은 일반적으로 더 비싸고, 이 단계에 사용되는 데이터의 양은 일반적으로 이전 단계에서 사용된 양보다 훨씬 적습니다. 이 부분에서는 몇 가지 데이터 세트를 소개하고 표 8에 요약합니다. LLaVA-RLHF [112]. 정직성과 유용성 측면에서 인간의 피드백으로부터 수집된 10K 선호도 쌍을 포함합니다. 이 데이터셋은 주로 모델 응답의 환각을 줄이는 데 사용됩니다. RLHF-V [114]. 세그먼트 수준의 환각 수정을 통해 수집된 5.7K의 세분화된 인간 피드백 데이터를 포함합니다. VLFeedback [115]. 모델 응답에 대한 피드백을 제공하기 위해 AI를 활용합니다. 이 데이터셋은 유용성, 충실성 및 윤리적 문제에 대해 GPT-4V가 채점한 380K 이상의 비교 쌍을 포함합니다.
TABLE 8: 정렬 튜닝을 위한 데이터셋 요약. 입/출력 양식에서 I: 이미지, T: 텍스트.
| 데이터셋 | 샘플 | 양식 | 출처 |
|---|---|---|---|
| LLaVA-RLHF [112] | 10 K | 인간 | |
| RLHF-V [114] | 5.7 K | 인간 | |
| VLFeedback [115] | 380 K | GPT-4V |
4 Evaluation
평가는 모델 최적화를 위한 피드백을 제공하고 다른 모델의 성능을 비교하는 데 도움이 되기 때문에 MLLM 개발의 필수적인 부분입니다. 전통적인 멀티모달 모델의 평가 방법과 비교하여 MLLM의 평가는 몇 가지 새로운 특징을 보입니다: (1) MLLM은 일반적으로 다재다능하기 때문에 MLLM을 포괄적으로 평가하는 것이 중요합니다. (2) MLLM은 특별한 주의가 필요한 많은 창발적 능력(예: OCR 없는 수학 추론)을 나타내므로 새로운 평가 체계가 필요합니다. MLLM의 평가는 질문 장르에 따라 폐쇄형과 개방형의 두 가지 유형으로 광범위하게 분류될 수 있습니다.
4.1 Closed-set
폐쇄형 질문은 가능한 답변 옵션이 미리 정의되어 있고 유한한 집합으로 제한되는 유형의 질문을 말합니다. 평가는 일반적으로 작업별 데이터 세트에서 수행됩니다. 이 경우 응답은 벤치마크 메트릭 [20], [60], [70], [76], [101], [102], [103], [104]에 의해 자연스럽게 판단될 수 있습니다. 예를 들어 InstructBLIP [60]은 ScienceQA [116]에 대한 정확도와 NoCaps [118] 및 Flickr30K [119]에 대한 CIDEr 점수 [117]를 보고합니다. 평가 설정은 일반적으로 제로샷 [60], [102], [104], [105] 또는 미세 조정 [20], [35], [60], [70], [76], [101], [103], [105]입니다. 첫 번째 설정은 종종 다양한 일반 작업을 다루는 광범위한 데이터 세트를 선택하고 이를 보류 데이터 세트와 분할합니다. 전자에 대해 튜닝한 후에는 보이지 않는 데이터 세트 또는 보이지 않는 작업으로 후자에 대해 제로샷 성능이 평가됩니다. 대조적으로, 두 번째 설정은 도메인별 작업 평가에서 종종 관찰됩니다. 예를 들어, LLaVA [20]와 LLaMA-Adapter [76]는 ScienceQA [116]에 대한 미세 조정된 성능을 보고합니다. LLaVA-Med [35]는 생의학 VQA [120], [121], [122]에 대한 결과를 보고합니다.
위의 평가 방법은 일반적으로 선택된 작업이나 데이터셋의 좁은 범위에 국한되어 포괄적인 정량적 비교가 부족합니다. 이를 위해 일부 노력들은 MLLM을 위해 특별히 설계된 새로운 벤치마크를 개발하기 위해 노력해왔습니다 [123], [124], [125], [126], [127], [128], [129]. 예를 들어, Fu 등[123]은 총 14개의 인식 및 인지 작업을 포함하는 포괄적인 평가 벤치마크 MME를 구축합니다. MME의 모든 명령어-답변 쌍은 데이터 유출을 피하기 위해 수동으로 설계되었습니다. MMBench [124]는 개방형 응답을 미리 정의된 선택지와 일치시키기 위해 ChatGPT를 사용하여 모델 능력의 여러 차원을 평가하기 위해 특별히 설계된 벤치마크입니다. Video-ChatGPT [130]와 Video-Bench [131]는 비디오 도메인에 초점을 맞추고 평가를 위한 전문 벤치마크와 평가 도구를 제안합니다. 모델의 특정 측면을 평가하기 위해 설계된 평가 전략도 있으며 [102], 환각 정도 평가를 위한 POPE [132]가 그 예입니다.
4.2 Open-set
폐쇄형 질문과 달리, 개방형 질문에 대한 응답은 더 유연할 수 있으며, MLLM은 보통 챗봇 역할을 합니다. 채팅 내용은 임의적일 수 있으므로 폐쇄형 출력보다 판단하기가 더 까다롭습니다. 기준은 수동 채점, GPT 채점, 사례 연구로 분류될 수 있습니다. 수동 채점은 인간이 생성된 응답을 평가해야 합니다. 이러한 종류의 접근 방식은 종종 특정 차원을 평가하기 위해 설계된 수작업 질문을 포함합니다. 예를 들어, mPLUG-Owl [81]은 자연 이미지 이해, 다이어그램 및 순서도 이해와 같은 능력을 판단하기 위해 시각적으로 관련된 평가 세트를 수집합니다. 유사하게, GPT4Tools [107]은 미세 조정 및 제로샷 성능을 위해 각각 두 개의 세트를 구축하고 사고, 행동, 논증 및 전체 측면에서 응답을 평가합니다.
수동 평가는 노동 집약적이기 때문에 일부 연구자들은 GPT로 채점하는 GPT 채점을 탐색했습니다. 이 접근 방식은 멀티모달 대화 성능을 평가하는 데 자주 사용됩니다. LLaVA [20]는 유용성 및 정확성과 같은 다양한 측면에서 텍스트 전용 GPT-4를 통해 응답을 채점할 것을 제안합니다. 구체적으로, COCO [133] 검증 세트에서 30개의 이미지를 샘플링하고, 각 이미지에 짧은 질문, 자세한 질문 및 복잡한 추론 질문을 GPT-4에 대한 자체 지시를 통해 연결합니다. 모델과 GPT-4 모두에서 생성된 답변은 비교를 위해 GPT-4로 전송됩니다. 후속 연구에서는 이 아이디어를 따르고 ChatGPT [81] 또는 GPT-4 [35], [70], [101], [104], [105]에 프롬프트를 주어 결과를 평가하거나 [35], [70], [81], [101], [104] 어느 것이 더 나은지 판단합니다 [103].
평가자로서 텍스트 전용 GPT-4를 적용하는 데 있어 주요 문제는 심판이 캡션이나 경계 상자 좌표와 같은 이미지 관련 텍스트 콘텐츠에만 기반하고 이미지에 접근하지 않는다는 것입니다 [35]. 따라서 이 경우 GPT-4를 성능 상한으로 설정하는 것이 의문스러울 수 있습니다. GPT의 비전 인터페이스 출시와 함께 일부 연구 [77], [134]는 MLLM의 성능을 평가하기 위해 더 발전된 GPT-4V 모델을 활용합니다. 예를 들어, Woodpecker [77]는 이미지에 기반한 모델 답변의 응답 품질을 판단하기 위해 GPT-4V를 채택합니다. GPT-4V는 이미지에 직접 접근할 수 있으므로 평가는 텍스트 전용 GPT-4를 사용하는 것보다 더 정확할 것으로 예상됩니다.
보충적인 접근 방식은 사례 연구를 통해 MLLM의 다양한 기능을 비교하는 것입니다. 예를 들어, 일부 연구는 두 가지 대표적인 고급 상업용 모델인 GPT-4V와 Gemini를 평가합니다. Yang 등[135]은 캡션 및 객체 계산과 같은 예비 기술에서부터 세계 지식과 추론이 필요한 복잡한 작업(예: 농담 이해 및 체화된 에이전트로서의 실내 탐색)에 이르기까지 다양한 도메인과 작업에 걸쳐 일련의 샘플을 만들어 GPT-4V에 대한 심층적인 정성 분석을 수행합니다. Wen 등[136]은 자동 운전 시나리오를 대상으로 하는 샘플을 설계하여 GPT-4V에 대한 보다 집중적인 평가를 합니다. Fu 등[137]은 모델을 GPT-4V와 비교하여 Gemini-Pro에 대한 포괄적인 평가를 수행합니다. 결과는 GPT-4V와 Gemini가 다른 응답 스타일에도 불구하고 비슷한 시각적 추론 능력을 보인다는 것을 시사합니다.
5 Extensions
최근 연구는 MLLM의 기능을 확장하는 데 상당한 진전을 이루었으며, 이는 더 강력한 기본 능력에서부터 더 넓은 시나리오 범위에 이르기까지 다양합니다. 우리는 이와 관련하여 MLLM의 주요 발전을 추적합니다. 세분성 지원. 에이전트와 사용자 간의 더 나은 상호 작용을 촉진하기 위해 연구자들은 모델 입력 및 출력 측면에서 더 미세한 세분성을 지원하는 MLLM을 개발했습니다. 입력 측면에서는 이미지에서 영역 [28], [138], [139], 심지어 픽셀 [29], [140], [141]로 진화하면서 사용자 프롬프트로부터 더 미세한 제어를 지원하는 모델이 점진적으로 개발되었습니다. 구체적으로, Shikra [28]는 영역 수준의 입력 및 이해를 지원합니다. 사용자는 자연어 형식의 경계 상자로 표현되는 특정 영역을 참조하여 조수와 더 유연하게 상호 작용할 수 있습니다. Ferret [141]는 한 걸음 더 나아가 하이브리드 표현 체계를 고안하여 더 유연한 참조를 지원합니다. 이 모델은 점, 상자 및 스케치를 포함한 다양한 형태의 프롬프트를 지원합니다. 유사하게, Osprey [29]는 분할 모델 [9]을 활용하여 점 입력을 지원합니다. 사전 훈련된 분할 모델의 탁월한 기능을 통해 Osprey는 한 번의 클릭으로 단일 개체 또는 그 일부를 지정할 수 있습니다. 출력 측면에서는 입력 지원의 발전에 맞춰 접지 기능이 개선되었습니다. Shikra [28]는 상자 주석이 있는 이미지에 근거한 응답을 지원하여 더 높은 정밀도와 더 미세한 참조 경험을 제공합니다. LISA [142]는 픽셀 수준의 접지를 가능하게 하는 마스크 수준의 이해 및 추론을 추가로 지원합니다. 양식 지원. 양식에 대한 지원 증가는 MLLM 연구의 경향입니다. 한편으로, 연구자들은 3D 포인트 클라우드 [41], [143], [144], [145]와 같이 더 많은 멀티모달 콘텐츠 입력을 지원하도록 MLLM을 조정하는 것을 탐구했습니다. 다른 한편으로, MLLM은 이미지 [32], [146], [147], [148], 오디오 [32], [147], [149], [150], 비디오 [32], [151]와 같은 더 많은 양식의 응답을 생성하도록 확장되었습니다. 예를 들어, NExT-GPT [32]는 MLLM에 부착된 확산 모델 [152], [153]의 도움으로 텍스트, 이미지, 오디오 및 비디오의 조합과 같은 혼합 양식의 입력 및 출력을 지원하는 프레임워크를 제안합니다. 이 프레임워크는 인코더-디코더 아키텍처를 적용하고 이해와 추론의 중추로서 LLM을 배치합니다. 언어 지원. 현재 모델은 주로 단일 언어이며, 이는 아마도 고품질의 비영어 훈련 코퍼스가 부족하다는 사실 때문일 것입니다. 일부 연구는 더 넓은 범위의 사용자를 포괄할 수 있도록 다국어 모델을 개발하는 데 전념해 왔습니다. VisCPM [33]은 다단계 훈련 체계를 설계하여 모델 기능을 다국어 설정으로 이전합니다. 구체적으로, 이 체계는 풍부한 훈련 코퍼스가 있는 영어를 중추 언어로 삼습니다. 사전 훈련된 이중 언어 LLM을 활용하여, 명령어 튜닝 중에 일부 번역된 샘플을 추가하여 멀티모달 기능이 중국어로 이전됩니다. 유사한 접근 방식을 취하여, Qwen-VL [34]은 이중 언어 LLM Qwen [58]에서 개발되었으며 중국어와 영어를 모두 지원합니다. 사전 훈련 중에, 모델의 이중 언어 기능을 보존하기 위해 중국어 데이터가 훈련 코퍼스에 혼합되며, 전체 데이터 양의 22.7%를 차지합니다. 시나리오/작업 확장. 일반적인 범용 보조 프로그램을 개발하는 것 외에도, 일부 연구는 실제 조건을 고려해야 하는 보다 구체적인 시나리오에 초점을 맞추었으며, 다른 연구는 특정 전문 지식을 가진 다운스트림 작업으로 MLLM을 확장했습니다.
전형적인 경향은 MLLM을 보다 구체적인 실생활 시나리오에 적응시키는 것입니다. MobileVLM [63]은 자원이 제한된 시나리오를 위해 MLLM의 소규모 변형을 개발하는 것을 탐구합니다. 더 작은 크기의 LLM 및 계산 속도를 높이기 위한 양자화 기술과 같은 일부 설계 및 기술이 모바일 장치 배포에 활용됩니다. 다른 연구는 CogAgent [44], AppAgent [43], Mobile-Agent [45]에서 예시된 바와 같이 그래픽 사용자 인터페이스(GUI)를 위해 특별히 설계된 사용자 친화적인 보조 프로그램과 같이 실제 세계와 상호 작용하는 에이전트를 개발합니다 [41], [154], [155]. 이러한 보조 프로그램은 사용자가 지정한 작업을 수행하기 위해 각 단계를 계획하고 안내하는 데 뛰어나며 인간-기계 상호 작용을 위한 유용한 에이전트 역할을 합니다. 또 다른 라인은 문서 이해 [38], [39], [156], [157] 및 의료 분야 [35], [36], [37]와 같은 다양한 영역의 작업을 해결하기 위해 특정 기술로 MLLM을 보강하는 것입니다. 문서 이해를 위해 mPLUG-DocOwl [38]은 튜닝을 위해 다양한 형태의 문서 수준 데이터를 활용하여 OCR 없는 문서 이해에서 향상된 모델을 만듭니다. TextMonkey [39]는 모델 성능을 향상시키기 위해 문서 이해와 관련된 여러 작업을 통합합니다. 기존의 문서 이미지 및 장면 텍스트 데이터 세트 외에도 환각을 줄이고 모델이 시각적 정보에 응답을 기반으로 하는 방법을 배우도록 돕기 위해 위치 관련 작업이 추가됩니다. MLLM은 의료 분야의 지식을 주입하여 의료 분야로 확장될 수도 있습니다. 예를 들어, LLaVA-Med [158]는 바닐라 LLaVA [20]에 의료 지식을 주입하고 의료 이미지 이해 및 질의응답에 특화된 보조 프로그램을 개발합니다.
6 Multimodal Hallucination
멀티모달 환각은 MLLM에 의해 생성된 응답이 이미지 내용과 일치하지 않는 현상을 말합니다[77]. 근본적이고 중요한 문제로서, 이 문제는 점점 더 많은 관심을 받고 있습니다. 이 섹션에서는 몇 가지 관련 개념과 연구 개발을 간략하게 소개합니다.
6.1 Preliminaries
멀티모달 환각에 대한 현재 연구는 세 가지 유형으로 더 분류될 수 있습니다 [159]:
- 존재 환각은 가장 기본적인 형태로, 모델이 이미지에 특정 객체의 존재를 잘못 주장하는 것을 의미합니다.
- 속성 환각은 특정 객체의 속성을 잘못된 방식으로 설명하는 것을 의미합니다. 예를 들어 개의 색깔을 정확하게 식별하지 못하는 경우입니다. 이는 속성에 대한 설명이 이미지에 존재하는 객체에 근거해야 하므로 존재 환각과 일반적으로 관련이 있습니다.
- 관계 환각은 더 복잡한 유형이며 객체의 존재를 기반으로 합니다. 이는 상대적 위치 및 상호 작용과 같은 객체 간의 관계에 대한 잘못된 설명을 의미합니다. 다음으로, 우리는 먼저 몇 가지 구체적인 평가 방법(§6.2)을 소개하며, 이는 환각을 완화하는 방법의 성능을 측정하는 데 유용합니다(§6.3). 그런 다음, 각 방법이 속하는 주요 범주에 따라 환각을 줄이기 위한 현재 방법에 대해 자세히 논의할 것입니다.
6.2 Evaluation Methods
CHAIR [160]는 개방형 캡션의 환각 수준을 평가하는 초기 지표입니다. 이 지표는 환각된 객체가 있는 문장의 비율 또는 언급된 모든 객체 중 환각된 객체의 비율을 측정합니다. 대조적으로, POPE [132]는 폐쇄형 선택지를 평가하는 방법입니다. 구체적으로, 이진 선택지가 있는 여러 프롬프트가 공식화되며, 각 프롬프트는 특정 객체가 이미지에 존재하는지 여부를 쿼리합니다. 이 방법은 또한 MLLM의 견고성을 평가하기 위해 더 어려운 설정을 포함하며, 데이터 통계가 고려됩니다. 최종 평가는 간단한 감시 단어 메커니즘을 사용합니다. 즉, "예/아니오" 키워드를 감지하여 개방형 응답을 폐쇄형 이진 선택지로 변환합니다. 유사한 평가 접근 방식으로, MME [123]는 존재, 개수, 위치 및 색상 측면을 다루는 보다 포괄적인 평가를 제공하며 [77]에 예시되어 있습니다.
환각을 감지하고 결정하기 위해 일치 메커니즘을 사용하는 이전 접근 방식과 달리, HaELM [161]은 MLLM의 캡션이 참조 캡션에 대해 올바른지 여부를 자동으로 결정하기 위해 심판으로 텍스트 전용 LLM을 사용하는 것을 제안합니다. 텍스트 전용 LLM은 제한된 이미지 컨텍스트에만 액세스할 수 있고 참조 주석이 필요하다는 사실에 비추어, Woodpecker [77]는 이미지에 근거한 모델 응답을 직접 평가하기 위해 GPT-4V를 사용합니다. FaithScore [162]는 설명적인 하위 문장을 분해하고 각 하위 문장을 개별적으로 평가하는 루틴에 기반한 보다 세분화된 지표입니다. 이전 연구를 바탕으로, AMBER [163]는 판별적 작업과 생성적 작업을 모두 포함하고 세 가지 유형의 가능한 환각을 포함하는 LLM 없는 벤치마크입니다(§6.1 참조).
6.3 Mitigation Methods
고수준 아이디어에 따르면, 현재 방법은 사전 교정, 처리 중 교정, 사후 교정의 세 가지 범주로 대략적으로 나눌 수 있습니다. 사전 교정. 환각에 대한 직관적이고 간단한 해결책은 특수 데이터(예: 부정적 데이터)를 수집하고 미세 조정을 위해 데이터를 사용하여 환각 응답이 적은 모델을 만드는 것입니다.
LRV-Instruction [164]은 시각적 명령어 튜닝 데이터셋을 소개합니다. 일반적인 긍정적 명령어 외에도, 이 데이터셋은 이미지 내용에 충실한 응답을 장려하기 위해 다양한 의미 수준에서 섬세하게 설계된 부정적 명령어를 통합합니다. LLaVA-RLHF [112]는 인간 선호도 쌍을 수집하고 강화 학습 기술로 모델을 미세 조정하여 환각이 적은 답변에 더 잘 부합하는 모델을 만듭니다. 처리 중 수정. 또 다른 방법은 아키텍처 설계나 특징 표현을 개선하는 것입니다. 이 연구들은 환각의 원인을 탐구하고 생성 과정에서 환각을 완화하기 위한 해당 해결책을 설계하려고 시도합니다.
HallE-Switch [159]는 객체 존재 환각의 가능한 요인에 대한 경험적 분석을 수행하고 존재 환각이 시각적 인코더에 의해 근거가 없는 객체에서 파생되며, 실제로는 LLM에 내장된 지식을 기반으로 추론된다고 가정합니다. 이 가정을 바탕으로 추론 중 모델 출력의 상상 정도를 제어하기 위해 연속적인 제어 요인과 해당 훈련 계획이 도입됩니다.
VCD [165]는 객체 환각이 훈련 코퍼스의 통계적 편향과 LLM에 내장된 강력한 언어 사전 지식이라는 두 가지 주요 원인에서 파생된다고 제안합니다. 저자들은 이미지에 노이즈를 주입할 때 MLLM이 응답 생성을 위해 이미지 내용보다는 언어 사전 지식에 의존하는 경향이 있으며, 이로 인해 환각이 발생한다는 현상에 주목합니다. 이에 따라 이 연구는 잘못된 편향을 상쇄하기 위한 증폭 후 대비 디코딩 방식을 설계합니다.
HACL [166]은 시각과 언어의 임베딩 공간을 조사합니다. 관찰을 바탕으로, 짝을 이룬 교차 모달 표현을 더 가깝게 당기면서 환각이 아닌 텍스트 표현과 환각 텍스트 표현을 멀리 밀어내는 대조 학습 방식을 고안합니다. 사후 교정. 이전 패러다임과 달리, 사후 교정은 사후 치료 방식으로 환각을 완화하고 출력 생성 후 환각을 교정합니다. Woodpecker [77]는 환각 교정을 위한 훈련 없는 일반 프레임워크입니다. 구체적으로, 이 방법은 이미지의 문맥 정보를 보충하기 위해 전문가 모델을 통합하고 단계별로 환각을 교정하는 파이프라인을 만듭니다. 이 방법은 각 단계의 중간 결과를 확인할 수 있고 객체가 이미지에 근거한다는 점에서 해석 가능합니다. 다른 방법인 LURE [167]는 설명에서 불확실성이 높은 객체를 마스킹하고 응답을 다시 생성하도록 특화된 교정자를 훈련시킵니다.
7 Extended Techniques
7.1 Multimodal In-Context Learning
ICL은 LLM의 중요한 창발적 능력 중 하나입니다. ICL에는 두 가지 좋은 특징이 있습니다: (1) 풍부한 데이터로부터 암묵적인 패턴을 학습하는 전통적인 지도 학습 패러다임과 달리, ICL의 핵심은 유추로부터 학습하는 것입니다 [168]. 구체적으로, ICL 환경에서 LLM은 선택적인 명령어와 함께 몇 가지 예제로부터 학습하고 새로운 질문으로 외삽하여 소수 샷 방식으로 복잡하고 보지 못한 작업을 해결합니다 [22], [169], [170]. (2) ICL은 일반적으로 훈련 없이 구현되며 [168] 따라서 추론 단계에서 다른 프레임워크에 유연하게 통합될 수 있습니다. ICL과 밀접하게 관련된 기술은 명령어 튜닝(§3.2 참조)이며, 경험적으로 ICL 능력을 향상시키는 것으로 나타났습니다 [19].
MLLM의 맥락에서 ICL은 더 많은 양식으로 확장되어 Multimodal ICL(M-ICL)로 이어졌습니다. (§3.2)의 설정에 기반하여, 추론 시 M-ICL은 원본 샘플에 데모 세트, 즉 문맥 내 샘플 세트를 추가하여 구현될 수 있습니다. 이 경우 템플릿은 표 9와 같이 확장될 수 있습니다. 설명을 위해 두 개의 문맥 내 예제를 나열했지만 예제의 수와 순서는 유연하게 조정될 수 있다는 점에 유의하십시오. 실제로 모델은 일반적으로 데모의 배열에 민감합니다 [168], [171].
<코드> <BOS> 아래는 몇 가지 예제와 작업을 설명하는 지침입니다. 요청을 적절하게 완료하는 응답을 작성하십시오.
지침: {instruction}
이미지: <image>
응답: {response}
이미지: <image>
응답: {response}
이미지: <image>
응답: <EOS>
<코드>
표 9: M-ICL 쿼리를 구조화하기 위한 템플릿의 단순화된 예시, [98]에서 수정. 설명을 위해, 점선으로 구분된 두 개의 문맥 내 예제와 하나의 쿼리를 나열합니다. {instruction}과 {response}는 데이터 샘플의 텍스트입니다. <image>는 멀티모달 입력(이 경우 이미지)을 나타내는 자리 표시자입니다. <BOS>와 <EOS>는 각각 LLM에 대한 입력의 시작과 끝을 나타내는 토큰입니다.
7.1.1 Improvement on ICL capabilities
최근, 다양한 시나리오에서 ICL 성능을 향상시키는 데 초점을 맞춘 연구가 증가하고 있습니다. 이 섹션에서는 이 분야의 발전을 추적하고 몇 가지 관련 연구를 요약합니다.
MIMIC-IT [172]는 멀티모달 컨텍스트로 형식화된 명령어 데이터셋을 구축하여 문맥 내 학습과 명령어 튜닝을 결합합니다. 도입된 데이터셋에서 명령어 튜닝된 모델은 캡션 작업에서 향상된 소수 샷 성능을 보여줍니다. Emu [173]는 모델 생성 및 해당 훈련 코퍼스에 추가적인 양식을 도입하여 Flamingo [74]의 아이디어를 확장합니다. 도입된 비전 디코더, 즉 Stable Diffusion의 도움으로 모델은 추가적인 비전 감독으로부터 학습하고 출력 형식 및 문맥 내 추론에서 더 많은 유연성을 지원합니다. 구체적으로, 순수 텍스트로 답변하는 것 외에도 모델은 이미지 형식으로 응답을 제공할 수 있습니다. Sheng 등 [174]은 유사한 아이디어를 채택하고 출력 양식을 텍스트와 이미지 모두로 확장하려고 시도합니다. 이미지를 위한 특수 인코더를 채택하는 대신, 이 연구는 공유 임베딩 계층을 가진 통합 양자화 방식을 채택합니다.
일부 다른 연구는 특정 설정 하에서 소수 샷 학습 성능을 향상시키는 것을 탐구합니다. 링크-컨텍스트 학습 [175]은 이미지-레이블 쌍 사이의 인과 관계를 강화하는 데 중점을 두고 긍정적 및 부정적 이미지-설명 쌍을 공식화하여 대조 훈련 방식을 제시합니다. MMICL [176]은 여러 관련 이미지로 추론하는 능력을 증강하는 것을 목표로 합니다. 이미지와 텍스트 간의 연결을 강화하기 위해, 이 연구는 인터리브된 이미지-텍스트 데이터를 균일한 형식으로 변환하는 컨텍스트 방식을 제안합니다. Jeong [177]은 노이즈로 일관성 없는 이미지/텍스트의 작은 부분을 삽입할 때 MLLM이 컨텍스트와 일치하지 않는 응답을 제공하도록 오도될 수 있음을 발견합니다. 이 관찰을 바탕으로, 이 연구는 관련 없는 컨텍스트를 제거하고 보다 일관된 응답을 촉진하기 위한 사전 필터링 방법을 제안합니다.
7.1.2 Applications
멀티모달리티에서의 응용 측면에서, M-ICL은 주로 두 가지 시나리오에서 사용됩니다: (1) 다양한 시각적 추론 작업 해결 [22], [74], [178], [179], [180] 및 (2) LLM에게 외부 도구 사용법 교육 [169], [170], [181]. 전자는 일반적으로 소수의 작업별 예제로부터 학습하고 새롭지만 유사한 질문에 일반화하는 것을 포함합니다. 명령어 및 데모에서 제공된 정보로부터 LLM은 작업이 무엇을 하는지, 출력 템플릿이 무엇인지 파악하고 최종적으로 예상되는 답변을 생성합니다. 대조적으로, 도구 사용 예제는 더 세분화되어 있습니다. 이들은 일반적으로 작업을 수행하기 위해 순차적으로 실행될 수 있는 일련의 단계를 포함합니다. 따라서 두 번째 시나리오는 CoT(§7.2 참조)와 밀접한 관련이 있습니다.
7.2 Multimodal Chain of Thought
선구적인 연구[8]에서 지적했듯이, CoT는 "일련의 중간 추론 단계"이며, 복잡한 추론 작업[8], [182], [183]에서 효과적인 것으로 입증되었습니다. CoT의 주요 아이디어는 LLM이 최종 답변뿐만 아니라 인간의 인지 과정과 유사하게 답변에 이르는 추론 과정도 출력하도록 유도하는 것입니다.
NLP에서의 성공에 영감을 받아, 여러 연구[184], [185], [186], [187]가 단일 모달 CoT를 멀티모달 CoT(M-CoT)로 확장하기 위해 제안되었습니다. 먼저 M-CoT 능력을 습득하기 위한 다양한 패러다임을 소개합니다(§7.2.1). 그런 다음, 체인 구성(§7.2.2)과 패턴(§7.2.3)을 포함하여 M-CoT의 더 구체적인 측면을 설명합니다.
7.2.1 Learning Paradigms
학습 패러다임 또한 조사할 가치가 있는 측면입니다. M-CoT 능력을 습득하는 방법에는 크게 세 가지가 있습니다. 즉, 미세 조정과 훈련 없는 소수/제로 샷 학습을 통해서입니다. 세 가지 방법에 대한 샘플 크기 요구 사항은 내림차순입니다.
직관적으로, 미세 조정 접근 방식은 종종 M-CoT 학습을 위해 특정 데이터셋을 큐레이션하는 것을 포함합니다. 예를 들어, Lu 등[116]은 강의와 설명이 포함된 과학 질의응답 데이터셋 ScienceQA를 구성하여 CoT 추론 학습의 원천으로 삼고, 제안된 데이터셋에서 모델을 미세 조정합니다. Multimodal-CoT [185]도 ScienceQA 벤치마크를 사용하지만, 근거(추론 단계의 사슬)와 근거에 기반한 최종 답변이라는 두 단계로 출력을 생성합니다. CoT-PT [187]는 프롬프트 튜닝과 단계별 시각적 편향의 조합을 통해 암묵적인 추론 사슬을 학습합니다.
미세 조정과 비교할 때, 소수/제로샷 학습은 계산적으로 더 효율적입니다. 이 둘의 주요 차이점은 소수샷 학습은 일반적으로 모델이 단계별로 추론하는 법을 더 쉽게 배울 수 있도록 몇 가지 문맥 내 예제를 수작업으로 만들어야 한다는 것입니다. 대조적으로, 제로샷 학습은 CoT 학습을 위한 특정 예제가 필요하지 않습니다. 이 경우 모델은 "프레임별로 생각해 보자" 또는 "이 두 핵심 프레임 사이에 무슨 일이 일어났는가" [184], [186]와 같이 설계된 명령어를 프롬프트하여 명시적인 안내 없이 내장된 지식과 추론 능력을 사용하도록 학습합니다. 유사하게, 일부 연구[22], [188]는 복잡한 작업을 하위 작업으로 분해하기 위해 작업 및 도구 사용에 대한 설명으로 모델에 프롬프트를 줍니다.
7.2.2 Chain Configuration
구조와 길이는 추론 체인의 두 가지 중요한 측면입니다. 구조 측면에서 현재 방법은 단일 체인과 트리 모양 방법으로 나눌 수 있습니다. 단일 체인으로 추론하는 것은 다양한 방법 [116], [185]에서 널리 사용되는 패러다임입니다. 구체적으로, 단계별 추론 과정은 단일 질문-근거-답변 체인을 형성합니다. 최근 일부 방법은 추론을 위해 트리 모양 체인과 같은 더 복잡한 방식을 사용하는 것을 탐구했습니다. 구체적으로, DDCoT [189]는 질문을 여러 하위 질문으로 분해하고, 각 하위 질문은 LLM 자체 또는 시각적 전문가가 해결하여 근거를 생성합니다. 그런 다음 LLM은 근거를 집계하고 추론하여 최종 답변을 형성합니다. 체인 길이에 관해서는 적응형 및 사전 정의된 구성으로 분류할 수 있습니다. 전자의 구성은 LLM이 추론 체인을 언제 중단할지 스스로 결정해야 하는 반면 [22], [116], [169], [170], [185], [188], 후자의 설정은 사전 정의된 길이로 체인을 중단합니다 [79], [184], [186], [187].
7.2.3 Generation Patterns
사슬이 어떻게 구성되는지는 연구할 가치가 있는 질문입니다. 우리는 현재의 연구를 (1) 채우기 기반 패턴과 (2) 예측 기반 패턴으로 요약합니다. 구체적으로, 채우기 기반 패턴은 논리적 간극을 메우기 위해 주변 문맥(이전 및 다음 단계) 사이의 단계를 추론해야 합니다 [184], [186]. 대조적으로, 예측 기반 패턴은 명령어 및 이전 추론 기록과 같은 주어진 조건 하에서 추론 사슬을 확장해야 합니다 [22], [116], [169], [170], [185], [188]. 두 가지 유형의 패턴은 생성된 단계가 일관되고 정확해야 한다는 요구 사항을 공유합니다.
7.3 LLM-Aided Visual Reasoning
7.3.1 Introduction
도구 증강 LLM[190], [191], [192], [193]의 성공에 영감을 받아, 일부 연구는 시각적 추론 작업을 위해 외부 도구[22], [107], [169], [170] 또는 시각 기초 모델[22], [79], [80], [188], [194], [195], [196]을 호출할 가능성을 탐구해 왔습니다. LLM을 다양한 역할을 하는 도우미로 삼아, 이러한 연구는 작업별[79], [197], [198] 또는 범용[22], [169], [170], [181], [188] 시각적 추론 시스템을 구축합니다.
전통적인 시각적 추론 모델 [199], [200], [201]과 비교하여 이러한 연구는 몇 가지 좋은 특징을 나타냅니다: (1) 강력한 일반화 능력. 대규모 사전 훈련에서 학습한 풍부한 오픈 월드 지식을 갖춘 이러한 시스템은 놀라운 제로/소수 샷 성능 [169], [170], [195], [197], [198], [202]으로 보이지 않는 객체나 개념에 쉽게 일반화할 수 있습니다. (2) 창발적 능력. LLM의 강력한 추론 능력의 도움으로 이러한 시스템은 복잡한 작업을 수행할 수 있습니다. 예를 들어, 이미지가 주어지면 MMREACT [22]는 밈이 왜 웃긴지 설명하는 것과 같이 표면 아래의 의미를 해석할 수 있습니다. (3) 더 나은 상호 작용성 및 제어. 전통적인 모델은 일반적으로 제한된 제어 메커니즘을 허용하며 종종 비싼 큐레이션된 데이터 세트를 수반합니다 [203], [204]. 대조적으로, LLM 기반 시스템은 사용자 친화적인 인터페이스(예: 클릭 및 자연어 쿼리) [79]에서 미세 제어를 할 수 있는 능력을 가지고 있습니다.
이 부분에서는 LLM 지원 시각적 추론 시스템 구축에 사용되는 다양한 훈련 패러다임을 소개하는 것으로 시작합니다(§7.3.2). 그런 다음, 이러한 시스템 내에서 LLM이 수행하는 주요 역할에 대해 자세히 알아봅니다(§7.3.3).
7.3.2 Training Paradigms
훈련 패러다임에 따라, LLM 기반 시각적 추론 시스템은 훈련 없음과 미세 조정의 두 가지 유형으로 나눌 수 있습니다. 훈련 없음. 사전 훈련된 LLM에 저장된 풍부한 사전 지식을 바탕으로, 직관적이고 간단한 방법은 사전 훈련된 모델을 고정하고 다양한 요구를 충족시키기 위해 LLM에 직접 프롬프트를 주는 것입니다. 설정에 따라 추론 시스템은 소수 샷 모델 [22], [169], [170], [181]과 제로 샷 모델 [79], [197]로 더 분류될 수 있습니다. 소수 샷 모델은 LLM이 프로그램이나 일련의 실행 단계를 생성하도록 안내하기 위해 몇 가지 수작업으로 만든 문맥 내 샘플(§7.1 참조)을 수반합니다. 이러한 프로그램이나 실행 단계는 해당 기초 모델이나 외부 도구/모듈에 대한 명령어 역할을 합니다. 제로 샷 모델은 LLM의 언어학적/의미론적 지식이나 추론 능력을 직접 활용하여 한 단계 더 나아갑니다. 예를 들어, PointCLIP V2 [197]는 GPT-3에 프롬프트를 주어 해당 이미지와 더 잘 정렬되도록 3D 관련 의미론이 포함된 설명을 생성합니다. CAT [79]에서 LLM은 사용자 쿼리에 따라 캡션을 수정하도록 지시받습니다. 미세 조정. 일부 연구는 도구 사용과 관련된 계획 능력을 향상시키거나 [107] 시스템의 위치 파악 능력을 향상시키기 위해 [142], [205] 추가적인 미세 조정을 채택합니다. 예를 들어, GPT4Tools [107]는 명령어 튜닝 접근 방식을 도입합니다(§3.2 참조). 이에 따라 새로운 도구 관련 명령어 데이터셋이 수집되고 모델을 미세 조정하는 데 사용됩니다.
7.3.3 Functions
LLM이 LLM 기반 시각적 추론 시스템에서 정확히 어떤 역할을 하는지 더 자세히 살펴보기 위해, 기존 관련 연구는 세 가지 유형으로 나뉩니다:
- 컨트롤러로서의 LLM
- 의사 결정자로서의 LLM
- 의미론 정제자로서의 LLM
처음 두 역할은 CoT(§7.2 참조)와 관련이 있습니다. 복잡한 작업은 중간의 더 간단한 단계로 분해되어야 하기 때문에 자주 사용됩니다. LLM이 컨트롤러 역할을 할 때, 시스템은 종종 작업을 한 번에 끝내지만, 의사 결정자의 경우에는 다중 라운드가 더 일반적입니다. 다음 부분에서는 LLM이 이러한 역할을 어떻게 수행하는지 설명합니다. 컨트롤러로서의 LLM. 이 경우 LLM은 (1) 복잡한 작업을 더 간단한 하위 작업/단계로 분해하고 (2) 이러한 작업을 적절한 도구/모듈에 할당하는 중앙 컨트롤러 역할을 합니다. 첫 번째 단계는 종종 LLM의 CoT 능력을 활용하여 완료됩니다. 구체적으로, LLM은 명시적으로 작업 계획 [181] 또는 더 직접적으로 호출할 모듈 [107], [169], [170]을 출력하도록 프롬프트됩니다. 예를 들어, VisProg [170]은 GPT-3에 시각적 프로그램을 출력하도록 프롬프트하며, 각 프로그램 라인은 하위 작업을 수행하기 위해 모듈을 호출합니다. 또한 LLM은 모듈 입력에 대한 인수 이름을 출력해야 합니다. 이러한 복잡한 요구 사항을 처리하기 위해 일부 수작업으로 만든 문맥 내 예제가 참조로 사용됩니다 [169], [170], [181]. 이는 추론 체인 최적화(§7.2 참조) 또는 더 구체적으로 최소-최대 프롬프팅 [206] 기술과 밀접한 관련이 있습니다. 이러한 방식으로 복잡한 문제는 순차적으로 해결되는 하위 문제로 분해됩니다. 의사 결정자로서의 LLM. 이 경우, 복잡한 작업은 다중 라운드 방식으로, 종종 반복적인 방식으로 해결됩니다 [195]. 의사 결정자는 종종 다음과 같은 책임을 수행합니다: (1) 현재 컨텍스트와 이력 정보를 요약하고, 현재 단계에서 사용 가능한 정보가 질문에 답하거나 작업을 완료하기에 충분한지 결정합니다. (2) 답변을 구성하고 요약하여 사용자 친화적인 방식으로 제시합니다. 의미론 정제자로서의 LLM. LLM이 의미론 정제자로 사용될 때, 연구자들은 주로 그것의 풍부한 언어학 및 의미론 지식을 활용합니다. 구체적으로, LLM은 종종 정보를 일관되고 유창한 자연어 문장으로 통합하도록 지시받거나 [202], 다양한 특정 요구에 따라 텍스트를 생성하도록 지시받습니다 [79], [197], [198].
8 Challenges and Future Directions
MLLM의 개발은 아직 초기 단계에 있으며 개선의 여지가 많으며, 이를 아래에 요약합니다:
- 현재 MLLM은 긴 컨텍스트의 멀티모달 정보를 처리하는 데 제한이 있습니다. 이는 긴 비디오 이해, 이미지와 텍스트가 섞인 긴 문서와 같은 더 많은 멀티모달 토큰을 가진 고급 모델의 개발을 제한합니다.
- MLLM은 더 복잡한 지시를 따르도록 업그레이드되어야 합니다. 예를 들어, 고품질의 질의응답 쌍 데이터를 생성하는 주류 접근 방식은 여전히 고급 명령어 수행 능력 때문에 비공개 소스인 GPT-4V에 프롬프트를 주는 것이지만, 다른 모델들은 일반적으로 이를 달성하지 못합니다.
- M-ICL 및 M-CoT와 같은 기술에는 여전히 개선의 여지가 많습니다. 두 기술에 대한 현재 연구는 아직 초보적이며, MLLM의 관련 기능은 약합니다. 따라서 기본 메커니즘과 잠재적 개선에 대한 탐구는 유망합니다.
- MLLM을 기반으로 한 체화 에이전트 개발은 뜨거운 주제입니다. 실제 세계와 상호 작용할 수 있는 그러한 에이전트를 개발하는 것은 의미가 있을 것입니다. 이러한 노력에는 인식, 추론, 계획 및 실행을 포함한 중요한 능력을 갖춘 모델이 필요합니다.
- 안전 문제. LLM과 유사하게, MLLM은 조작된 공격에 취약할 수 있습니다 [177], [207], [208]. 즉, MLLM은 편향되거나 바람직하지 않은 응답을 출력하도록 오도될 수 있습니다. 따라서 모델 안전성을 향상시키는 것은 중요한 주제가 될 것입니다.
9 Conclusion
본 논문에서는 기존 MLLM 문헌에 대한 조사를 수행하고 기본 레시피 및 관련 확장을 포함한 주요 방향에 대한 광범위한 관점을 제공합니다. 또한, 우리는 채워져야 할 현재의 연구 격차를 강조하고 몇 가지 유망한 연구 방향을 지적합니다. 이 조사가 독자들에게 MLLM의 현재 진행 상황에 대한 명확한 그림을 제공하고 더 많은 연구에 영감을 주기를 바랍니다.