M³IT: 대규모 다중모드 다국어 Instruction Tuning 데이터셋
본 논문은 Vision-Language Model (VLM)의 발전을 위해 Multi-Modal, Multilingual Instruction Tuning (M³IT) 데이터셋을 제안합니다. M³IT는 40개의 데이터셋, 240만 개의 인스턴스, 400개의 수동 작성된 task instruction을 포함하는 대규모 데이터셋으로, VLM이 인간의 지시를 더 잘 따르도록 학습시키는 것을 목표로 합니다. 주요 task들은 80개 언어로 번역되어 언어적 다양성을 확보했습니다. 이 데이터셋으로 학습된 Ying-VLM 모델은 외부 지식이 필요한 복잡한 VQA task와 보지 못한 비디오 및 중국어 task에 대해서도 뛰어난 일반화 성능을 보여줍니다. 논문 제목: M³IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning
논문 요약: M³IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning
- 논문 링크: https://arxiv.org/abs/2306.04387
- 저자: Lei Li, Yuwei Yin, Shicheng Li, Liang Chen, Peiyi Wang, Shuhuai Ren, Mukai Li, Yazheng Yang, Jingjing Xu, Xu Sun, Lingpeng Kong, Qi Liu
- 홍콩대학교 (The University of Hong Kong)
- 멀티미디어 정보 처리 국가 핵심 연구소, 베이징대학교 컴퓨터 과학부 (National Key Laboratory for Multimedia Information Processing, School of Computer Science, Peking University)
- 상하이 AI 랩 (Shanghai AI Lab)
- 발표 시기: 2023년 (arXiv preprint)
- 주요 키워드: Multi-modal, Instruction Tuning, VLM, LLM, NLP, Multilingual
1. 연구 배경 및 문제 정의
- 문제 정의: ChatGPT와 같은 대규모 언어 모델(LLM)의 성공에 instruction tuning이 크게 기여했지만, Vision-Language Model (VLM) 분야에서는 고품질의 멀티모달 instruction 데이터셋이 부족하여 VLM의 발전이 제한적입니다. 기존 데이터셋은 공개적으로 이용하기 어렵거나(예: GPT-4), task 및 언어 범위(주로 영어)가 제한적이라는 한계를 가집니다. 이러한 데이터셋의 부족은 VLM이 인간의 지시를 따르는 능력을 향상시키는 데 큰 걸림돌이 됩니다.
- 기존 접근 방식:
LLaVA, MiniGPT-4, MultiInstruct, InstructBLIP 등 여러 연구에서 VLM을 위한 멀티모달 instruction tuning을 시도했습니다. 이들은 이미지 캡션 데이터를 활용하여 시각 콘텐츠 관련 대화를 생성하거나, 시각 분류 task를 instruction-tuning 형식으로 재구성했습니다.
- 기존 접근 방식의 한계:
- 제한적인 task 커버리지: 멀티모달 분야의 다양한 task 유형을 충분히 포괄하지 못했습니다.
- 인스턴스의 다양성과 품질 부족: 데이터 인스턴스의 양적, 질적 다양성이 부족했습니다.
- 다국어 지원 부족: 광범위한 언어적 다양성을 위한 다국어 포함이 미흡했습니다.
- 기존 접근 방식의 한계:
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 오픈 소스 대규모 Multimodal, Multilingual Instruction Tuning (M³IT) 데이터셋 제안: 범용 멀티모달 에이전트 개발을 가능하게 하는 고품질의 대규모 데이터셋을 공개했습니다.
- Ying-VLM 모델 개발: M³IT 데이터셋으로 학습된 VLM 모델인 Ying-VLM이 지식 기반 VQA task에서 뛰어난 성능을 보이고, 미학습 비디오 QA 및 중국어 멀티모달 task에 대한 강력한 일반화 능력을 입증하여 향후 연구에 귀중한 통찰력을 제공했습니다.
- 제안 방법:
논문은 VLM이 인간의 지시에 더 잘 부합하도록 설계된 M³IT (Multi-Modal, Multilingual Instruction Tuning) 데이터셋을 제안합니다.
- M³IT 데이터셋 구성:
- 규모: 신중하게 선별된 40개의 데이터셋, 240만 개의 인스턴스, 400개의 수동으로 작성된 task instruction을 포함합니다.
- 구조: 모든 데이터는 통합된 vision-to-text 구조로 재구성되었습니다.
- 다국어 지원: 주요 task들은 고급 번역 시스템을 통해 80개 언어로 번역되어 언어적 다양성을 확보했습니다.
- Task 커버리지: 이미지 캡셔닝, VQA, 지식 기반 VQA (KVQA), 추론, 분류, 생성, 중국어 Vision-Language task, 비디오-언어 task 등 광범위한 멀티모달 task를 포괄합니다.
- 데이터셋 구축 4단계:
- Instruction 작성: 각 task의 핵심 특성을 포괄하는 10개의 다양한 task instruction을 수동으로 작성 (총 400개).
- 데이터 형식 통합: 이미지와 텍스트를 통합된 스키마로 처리. 특히, 바운딩 박스는 이미지에 직접 빨간색 사각형으로 태그하여 시각적 힌트를 제공하고, 짧은 답변은 ChatGPT를 활용하여 추가 맥락 정보를 포함한 자연스러운 응답으로 의역했습니다.
- 품질 검사: 각 task에 대해 다른 어노테이터가 예시를 검토하여 형식 불일치를 해결하고 데이터의 정확성을 재확인했습니다.
- 다국어 세트 구축: OK-VQA, ImageNet, Winoground, VQAv2, VIST, MSRVTT, MSRVTT-QA 등 주요 데이터셋의 평가 데이터를 NLLB-1.3B 번역 모델을 통해 80개 언어로 번역하고, BLEU 점수 20 이상인 언어만 유지했습니다.
- Ying-VLM 모델 개발:
- 아키텍처: 강력한 Vision Encoder인 BLIP-2의 Q-former 아키텍처와 LLaMA에서 파생된 이중 언어(영어 및 중국어) LLM인 Ziya-13B를 통합했습니다.
- 학습 프로세스:
- Visual-Text Alignment (1단계): LAION400M 데이터셋에서 이미지 캡셔닝을 통해 시각 feature를 텍스트 임베딩과 정렬합니다 (Q-former와 language projection 학습).
- Multi-modal Instruction Tuning (2단계): M³IT 데이터셋의 선택된 task에 대해 instruction tuning을 수행하여 모델을 향상시킵니다. 이 단계에서는 LoRa 튜닝을 활용하여 LLM의 특정 가중치만 학습 가능하게 설정했습니다.
- M³IT 데이터셋 구성:
3. 실험 결과
- 데이터셋:
- 학습 데이터셋: M³IT 데이터셋 (총 240만 개 이상의 인스턴스, 40개 task).
- 평가 데이터셋 (Held-out):
- 지식 기반 VQA (KVQA): OK-VQA, A-OKVQA, ViQuAE.
- 중국어 Vision-Language: Flickr-8k-CN (캡셔닝), FM-IQA (VQA), Chinese-FoodNet (분류).
- 비디오-언어: MSRVTT (캡셔닝), iVQA, ActivityNet-QA, MSRVTT-QA, MSVD-QA (VQA).
- 실험 환경: 8개의 NVIDIA 80GB A100 GPU.
- 주요 결과:
- 지식 기반 VQA (KVQA) 성능 향상: Ying-VLM은 OK-VQA, A-OKVQA, ViQuAE 등 모든 KVQA 벤치마크에서 BLIP2-Flan-T5-XXL, MiniGPT4, InstructBLIP 등 강력한 baseline 모델들을 일관되게 능가했습니다 (예: OK-VQA에서 27.5 ROUGE-L). 이는 M³IT 데이터셋을 통한 instruction tuning이 LLM으로부터 세계 지식을 효과적으로 활용하고 응답 품질을 향상시킴을 보여줍니다.
- 중국어 Vision-Language Task로의 Zero-Shot 전이 능력: Ying-VLM은 학습에 영어 데이터셋만 사용했음에도 불구하고, 이전에 보지 못한 중국어 캡셔닝, VQA, 분류 task에서 MiniGPT4와 InstructBLIP을 크게 능가하는 주목할 만한 개선을 보였습니다. 이는 영어 데이터셋을 사용한 instruction tuning이 다른 언어에도 효과적으로 일반화될 수 있음을 시사합니다.
- 비디오-언어 Task로의 Zero-Shot 전이 능력: Ying-VLM은 학습 데이터셋에 비디오와 같은 시각 입력이 포함되지 않았음에도 불구하고, 비디오 캡셔닝 및 비디오 질문 답변 task에서 BLIP-series baseline을 크게 능가하는 뛰어난 성능을 보였습니다. 이는 instruction tuning이 모델이 시간적 차원을 가진 비디오 입력으로 일반화하는 데 효과적으로 도움이 된다는 것을 의미합니다.
- GPT-4 평가 결과: GPT-4를 평가자로 활용한 결과, Ying-VLM은 가장 강력한 baseline인 MiniGPT4에 비해 55.6%의 승률을, InstructBLIP에 비해 65.5%의 승률을 기록하며 더 정확하고 매력적인 응답을 생성함을 입증했습니다.
- Task 수 및 Instruction 다양성 분석:
- Task 수의 영향: 학습에 사용되는 task 수가 증가할수록 일반화 성능이 크게 향상되며, 성능 향상이 줄어들지 않아 더 많은 task를 학습에 도입함으로써 지속적인 성능 향상이 가능함을 보여주었습니다.
- Instruction 다양성의 영향: task당 4개의 instruction을 사용하는 것이 적절한 성능을 달성하기에 충분함을 시사했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 대규모, 다국어, 다중모드 데이터셋의 공개: VLM 연구의 발전을 위한 핵심적인 자원을 오픈 소스로 제공하여 연구 커뮤니티에 큰 기여를 했습니다. 특히 80개 언어를 지원하는 다국어 데이터셋은 글로벌 AI 서비스 개발에 필수적입니다.
- 체계적인 데이터셋 구축 과정: 수동 instruction 작성, 바운딩 박스 시각화, ChatGPT를 활용한 답변 의역 등 고품질 데이터셋을 만들기 위한 세심한 노력이 돋보입니다.
- 강력한 일반화 능력 입증: 이미지 기반 학습만으로 비디오 task에 대한 zero-shot 전이, 영어 학습만으로 중국어 task에 대한 zero-shot 전이 능력을 보여준 것은 VLM의 범용성을 크게 확장할 수 있는 잠재력을 시사합니다.
- Ying-VLM의 우수성: 지식 기반 VQA와 같은 복잡한 task에서 기존 모델들을 능가하는 성능을 보여주어, M³IT 데이터셋의 효과를 명확히 입증했습니다.
- 단점/한계:
- 다국어 번역 품질의 한계: 자동 번역 시스템(NLLB-1.3B)과 BLEU 점수 필터링에 의존했기 때문에, 원어민 검증이 없는 상황에서 모든 80개 언어의 번역 품질이 완벽하다고 보기는 어렵습니다. 미묘한 뉘앙스나 문화적 맥락이 손실될 가능성이 있습니다.
- GPT-4 평가의 대리자 한계: GPT-4를 인간 평가자의 대리자로 사용했지만, 여전히 인간의 복잡한 판단을 완전히 대체할 수는 없습니다. 특히 창의성이나 미묘한 오류 감지에서는 한계가 있을 수 있습니다.
- LLM 튜닝 방식의 잠재적 한계: LoRa 튜닝은 효율적이지만, LLM의 모든 파라미터를 튜닝하는 것에 비해 모델의 잠재력을 완전히 끌어내지 못할 수도 있습니다.
- 응용 가능성:
- 범용 멀티모달 AI 비서 개발: M³IT 데이터셋과 같은 고품질 instruction tuning 데이터는 이미지, 비디오 이해, 질문 답변, 캡셔닝, 추론 등 다양한 시각-언어 task를 수행할 수 있는 범용 AI 비서 개발의 기반이 될 수 있습니다.
- 글로벌 서비스 확장: 다국어 지원을 통해 전 세계 사용자를 대상으로 하는 멀티모달 AI 서비스(예: 다국어 이미지 검색, 시각 기반 고객 지원 챗봇) 개발에 기여할 수 있습니다.
- 교육 및 접근성 향상: 시각 자료를 기반으로 한 교육 콘텐츠 생성, 시각 장애인을 위한 이미지/비디오 설명 생성 등 다양한 분야에서 활용될 수 있습니다.
- 산업 분야 적용: 제조, 의료, 보안 등 다양한 산업 분야에서 시각 데이터를 분석하고 이해하여 의사결정을 돕는 지능형 시스템 구축에 응용될 수 있습니다.
5. 추가 참고 자료
- M³IT 프로젝트 페이지: https://m3it.github.io/
Li, Lei, et al. "M IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning." arXiv preprint arXiv:2306.04387 (2023).
M IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning
Lei , Yuwei Yin , Shicheng Li , Liang Chen , Peiyi Wang , Shuhuai Ren , Mukai <br>Yazheng Yang , Jingjing Xu , Xu Sun , Lingpeng Kong , Qi Liu <br> 홍콩대학교 (The University of Hong Kong)<br> 멀티미디어 정보 처리 국가 핵심 연구소 (National Key Laboratory for Multimedia Information Processing),<br>베이징대학교 컴퓨터 과학부 (School of Computer Science, Peking University)<br> 상하이 AI 랩 (Shanghai AI Lab)<br>nlp.lilei@gmail.com<br>jingjingxu@pku.edu.cn {lpk, liuqi}@cs.hku.hk
Abstract
Instruction tuning은 ChatGPT와 같은 대규모 언어 모델(LLM)이 다양한 task에서 인간의 지시에 부합하도록 하는 데 크게 기여했다. 그러나 고품질 instruction 데이터셋의 부족으로 인해 open vision-language model (VLM)의 발전은 제한적이었다. 이러한 문제를 해결하고 vision-language 분야의 연구를 촉진하기 위해, 우리는 VLM이 인간의 지시에 더 잘 부합하도록 설계된 Multi-Modal, Multilingual Instruction Tuning (IT) 데이터셋을 소개한다.
우리의 IT 데이터셋은 신중하게 선별된 40개의 데이터셋으로 구성되며, 여기에는 240만 개의 인스턴스와 400개의 수동으로 작성된 task instruction이 포함되어 있다. 이들은 vision-to-text 구조로 재구성되었다. 주요 task들은 고급 번역 시스템을 통해 80개 언어로 번역되어 더 넓은 접근성을 보장한다. IT는 task 커버리지, instruction 수, 인스턴스 규모 면에서 기존 데이터셋을 능가한다.
또한, 우리는 IT 데이터셋으로 학습된 VLM 모델인 Ying-VLM을 개발했으며, 이 모델은 세계 지식을 요구하는 복잡한 질문에 답하고, 이전에 보지 못한 비디오 task에 일반화하며, 중국어로 된 새로운 instruction을 이해하는 잠재력을 보여준다. 우리는 추가 연구를 장려하기 위해 데이터셋을 오픈 소스로 공개했다.
1 Introduction
인간의 지시를 따를 수 있는 지능형 비서 개발에 대한 관심이 지속적으로 증가하고 있다 [3, 36, 37]. 자연어 처리(NLP) 분야에서 instruction tuning [35, 53]은 대규모의 잘 정제된 인스턴스를 활용하여 대규모 언어 모델(LLM)을 인간의 지시에 맞게 정렬(align)하는 성공적인 패러다임이다. 특정 task 설명이 포함된 인스턴스로 fine-tuning함으로써, LLM은 다양한 task를 수행하기 위해 지시를 따르는 방법을 학습하고, 미학습(unseen) task에 대해서도 강력한 일반화 능력을 보여준다 [29]. NLP를 넘어, 범용 지능형 에이전트는 비전과 같은 다양한 양식을 포괄해야 하며, 이는 최근 vision-language 영역에서 instruction tuning을 연구하려는 노력으로 이어지고 있다 [63, 28, 7]. 강력한 **vision-language model (VLM)**을 개발하기 위해서는 다양한 vision-language task를 포괄하고 인간의 지시와 일치하는 잘 구축된 데이터셋이 필수적이다. 그러나 기존 VLM을 지원하는 instruction 데이터는 공개적으로 이용할 수 없거나(예: GPT-4), task 및 언어 범위가 제한적이다(예: 영어 task만 고려됨). 이러한 포괄적인 데이터셋의 부족은 개방형 vision-language model의 발전을 저해했으며, 멀티모달 instruction tuning의 중요성과 고품질 데이터셋의 필요성을 강조한다.
본 논문에서는 다재다능한 범용 비서 구축을 위한 필수 단계로서, 오픈 데이터셋 IT, 즉 Multi-Modal Multilingual Instruction Tuning 데이터셋을 소개함으로써 멀티모달 영역에서의 instruction tuning 연구를 발전시키는 것을 목표로 한다. 우리는 기존 데이터셋을 통합된 vision-to-text 스키마로 변환하는 네 단계를 거쳐 이 데이터셋을 구축한다: (1) 수동 instruction 작성, (2) 데이터셋 전처리, (3) 신중한 품질 검사, (4) 주요 task에 대한 데이터셋 번역. 우리의 데이터셋은 이미지 분류, visual question answering, 이미지 캡셔닝과 같은 고전적인 이미지-텍스트 task를 포함하여 광범위한 task를 포괄한다. 비디오 질문 응답과 같은 비디오 관련 task도 여러 양식에 걸쳐 포괄적인 범위를 보장하기 위해 통합되었다. 우리는 또한 해당하는 중국어 instruction과 함께 중국어 vision-language 데이터셋을 통합한다. 결과적으로 이 데이터셋은 40개의 다양한 task와 400개의 instruction을 포함한다. 마지막으로, 주요 vision-language task는 강력한 번역 시스템을 통해 80개 언어로 번역되어 다국어 연구를 지원한다.
제안된 데이터셋의 효과를 평가하기 위해, 우리는 강력한 vision encoder인 BLIP-2 [23]와 LLaMA [49]에서 파생된 대규모 언어 모델인 Ziya-13B [61]를 통합하여 vision-language model인 Ying-VLM을 개발한다. 시각 토큰을 LLM의 텍스트 prompt로 통합하는 성공적인 접근 방식 [7, 63, 28]을 기반으로, 우리는 두 단계의 학습 프로세스를 사용한다: (1) 초기 단계는 LAION400M [41]에서 이미지 캡셔닝을 통해 시각 feature를 텍스트 embedding과 정렬하고, (2) 두 번째 단계는 우리 데이터셋의 선택된 task에 대한 instruction tuning을 수행하여 모델을 향상시킨다. 실험 결과, Ying-VLM은 지식 기반 VQA task에서 강력한 baseline 모델을 능가하며, 미학습 비디오 및 교차 언어 task에 대한 향상된 일반화 성능을 보여준다. 추가 분석에 따르면, 향상된 성능은 instruction tuning을 위한 task 증가에 해당하며, instruction의 다양성 또한 결과에 영향을 미친다.
본 논문은 두 가지 주요 기여를 제시한다: (1) 우리는 범용 멀티모달 에이전트 개발을 가능하게 하는 오픈 소스 대규모 Multimodal, multilingual Instruction Tuning (IT) 데이터셋을 소개한다. (2) 우리는 지식 기반 VQA task에서 뛰어난 성능을 보이고, 미학습 비디오 QA 및 중국어 멀티모달 task에 대한 강력한 일반화 능력을 입증하며, 향후 연구에 귀중한 통찰력을 제공하는 시각 비서인 Ying-VLM을 개발한다.
2 Related Work
Table 1: 멀티모달 instruction tuning 데이터셋 요약
| Dataset | # Tasks | Multi-Lingual | # of Instances | Avg. # of Manual Instructions / Task | Open-Sourced |
|---|---|---|---|---|---|
| MiniGPT4 | N / A | 5 K | N / A | ||
| LLaVA | 3 | 1.15 M | N / A | ||
| MultiModalGPT | 3 | 6 K | 5 | ||
| MultiInstruct | 26 | 5 | |||
| InstructBLIP | 28 | 9.7 | |||
| IT (Ours) | 40 | 2.4 M | 10 |
우리의 연구는 최근 언어 instruction tuning 벤치마크 [53, 35]에서 영감을 얻었다. 이 벤치마크들은 언어 모델의 cross-task generalization 능력을 향상시키는 데 효과적임이 입증되었다 [29, 52]. 본 논문에서는 LLM의 instruction tuning 패러다임을 멀티모달 에이전트로 확장하는 데 중점을 둔다. 텍스트 전용 task와 달리, vision-language task는 일반적으로 더 다양한 형식을 가지며, 이는 vision-language instruction tuning 벤치마크에 새로운 도전 과제를 제시한다.
범용적인 vision-language model을 개발하기 위해서는 다양한 task, 언어, instruction을 포괄하는 고품질의 멀티모달 instruction tuning 데이터셋을 구축하는 것이 중요하다. 몇몇 연구들이 VLM을 위한 멀티모달 instruction tuning을 탐구해왔다. LLaVA [28]와 MiniGPT-4 [63]는 이미지 캡션 데이터를 GPT-4/ChatGPT 모델에 통합하여 시각 콘텐츠 관련 대화를 생성한다. MultiInstruct [56]는 일련의 시각 분류 task를 instruction-tuning 형식으로 재구성했으며, InstructBLIP [7]은 기존 28개의 image-to-text task를 적용했다. 그러나 이러한 데이터셋들은 다음과 같은 제한적인 특성으로 인해 이상적인 멀티모달 instruction tuning 데이터셋을 제공하지 못한다:
- 멀티모달 분야의 다양한 task 유형에 대한 제한적인 커버리지,
- 인스턴스의 다양성과 품질 부족,
- 광범위한 언어적 다양성을 위한 다국어 포함 부족.
본 논문에서는 task 커버리지를 40개 데이터셋으로 확장하고, 10개의 수동으로 작성된 task instruction으로 인스턴스를 보완하며, 다양한 언어의 task를 포함함으로써 개선된 멀티모달 instruction tuning 데이터셋을 구축한다. Table 1은 기존 멀티모달 instruction tuning 데이터셋과 IT의 특성을 비교한 것이다.
3 M IT: A Multi-Modal Multilingual Instruction Tuning Dataset
이 섹션에서는 우리가 제안하는 데이터셋을 소개한다. 먼저 데이터셋의 범위에 대해 상세히 설명하고(§3.1), 이어서 어노테이션 과정의 세부 사항을 다룬다(§3.2). 마지막으로, 데이터셋 형식을 제시하고 제작된 데이터셋 지침의 통계를 제공한다(§3.3).
3.1 Task Coverage
우리의 데이터셋은 captioning, visual question answering (VQA), visual conditioned generation, reasoning, classification을 포함한 다양한 고전적인 vision-language task들을 통합한다.
Captioning
이 task는 주어진 이미지에 대해 다양한 요구사항에 맞춰 설명을 생성하는 것을 목표로 한다. 우리는 일반적인 이미지 설명을 위해 **MS COCO [27] (Karpathy split)**를 포함한다. **TextCaps [44]**는 모델이 이미지에 제시된 텍스트를 파악하고 그에 따라 caption을 생성하도록 요구한다. **Image-Paragraph-Captioning [21]**은 이미지에 대한 상세한 설명을 생성하는 데 중점을 둔다.
Reasoning
이 task는 특정 reasoning 능력을 평가한다. 우리는 **공간 추론(spatial reasoning)을 위해 CLEVR [19]와 NLVR [46]**을, **상식 추론(commonsense reasoning)을 위해 Visual Commonsense Reasoning (VCR) [60]**을, **이미지에 대한 독해(reading comprehensive)를 위해 Visual MRC [47]**를, 그리고 **텍스트 설명과 이미지 내용에 대한 미세한 의미 추론(fine-grained semantics reasoning)을 위해 Winoground [48]**를 포함한다.
Visual Question Answering (VQA)
이것은 가장 널리 연구되는 멀티모달 task로, 모델이 이미지에 기반하여 주어진 질문에 올바르게 답변하도록 요구한다. 포함된 task는 **VQA v2 [15], Shapes VQA [1], DocVQA [33], OCR-VQA [34], ST-VQA [2], Text-VQA [45], GQA [18]**이다.
Knowledgeable Visual Question Answering (KVQA)
전통적인 VQA task가 이미지 내용과 관련된 질문에 초점을 맞추는 것과 달리, **Knowledgeable Visual Question Answering (KVQA)**는 모델이 외부 지식(outside knowledge)을 활용하여 질문에 답변하도록 요구한다. 우리는 두 가지 외부 지식 VQA 데이터셋인 OK-VQA [32]와 A-OK-VQA [42], 멀티모달 과학 질문을 포함하는 ScienceQA [31], 그리고 이미지 내 명명된 개체(named entities)의 지식 사실에 초점을 맞춘 **ViQuAE [22]**를 포함한다.
Classification
이 task는 주어진 후보 레이블 집합에 따라 이미지를 분류하는 것을 포함한다. **ImageNet [40], Grounded Object Identification (COCO-GOI) [27], COCO-Text [50], Image Text Matching (COCO-ITM) [27], e-SNLI-VE [20], Multi-modal Fact Checking (Mocheg) [58], IQA [9]**가 포함된다. 언어 모델 입력 길이 제약으로 인해, ImageNet과 같이 광범위한 후보 레이블을 가진 일부 데이터셋에서는 옵션 수를 줄였다.
Generation
Visual conditional generation은 모델이 시각적 내용을 이해하고 task 요구사항을 충족하는 구성을 만들도록 요구한다. 이 범주에는 **Visual Storytelling (VIST) [17], Visual Dialog (VisDial) [8], 멀티모달 기계 번역 Multi30k [10]**가 있다.
중국어 및 다국어 Vision-Language Task
instruction tuning이 다른 언어에 미치는 영향을 조사하기 위해, 우리는 VQA를 위한 FM-IQA [11], captioning을 위한 COCO-CN [25] 및 Flickr8k-CN [24], 분류를 위한 Chinese Food Net [4], **생성을 위한 MMChat [62]**을 포함한 여러 중국어 vision-language task를 통합한다.
Video-Language Task
정지 이미지 외에도, instruction tuning이 비디오-텍스트 task에도 적용될 수 있는지에 관심이 있다. 우리는 비디오 캡셔닝을 위한 고전적인 MSR-VTT 데이터셋 [55], 비디오 질문 답변을 위한 MSRVTT-QA [54], ActivityNet-QA [59], iVQA [57] 및 MSVD-QA [54], **비디오 액션 분류를 위한 Something-Something [14]**를 포함한다.
Figure 1에서 보여지듯이, 우리의 데이터셋은 현재 존재하는 시각-언어 및 비디오-언어 벤치마크를 광범위하게 포괄하며, 단순한 이미지 캡셔닝부터 이미지 콘텐츠를 넘어선 복잡한 reasoning에 이르기까지 언어 모델을 위한 다양한 기술 세트를 가능하게 한다.
3.2 Annotation Process
고품질의 멀티모달 instruction 데이터셋을 구축하기 위해, 우리는 다양한 데이터셋을 vision-to-text 형식으로 재작성한다. 어노테이션 과정은 다음 네 단계로 구성된다: (1) 각 task에 대한 instruction 작성, (2) 이미지와 텍스트를 통합된 스키마로 구조화, (3) 전체 데이터셋 품질 확인, (4) 다국어 세트 구축. 본 연구의 저자 8명은 인간 어노테이터로 고용되었으며, 각자 관련 문헌에 익숙한 대학원생들이다.
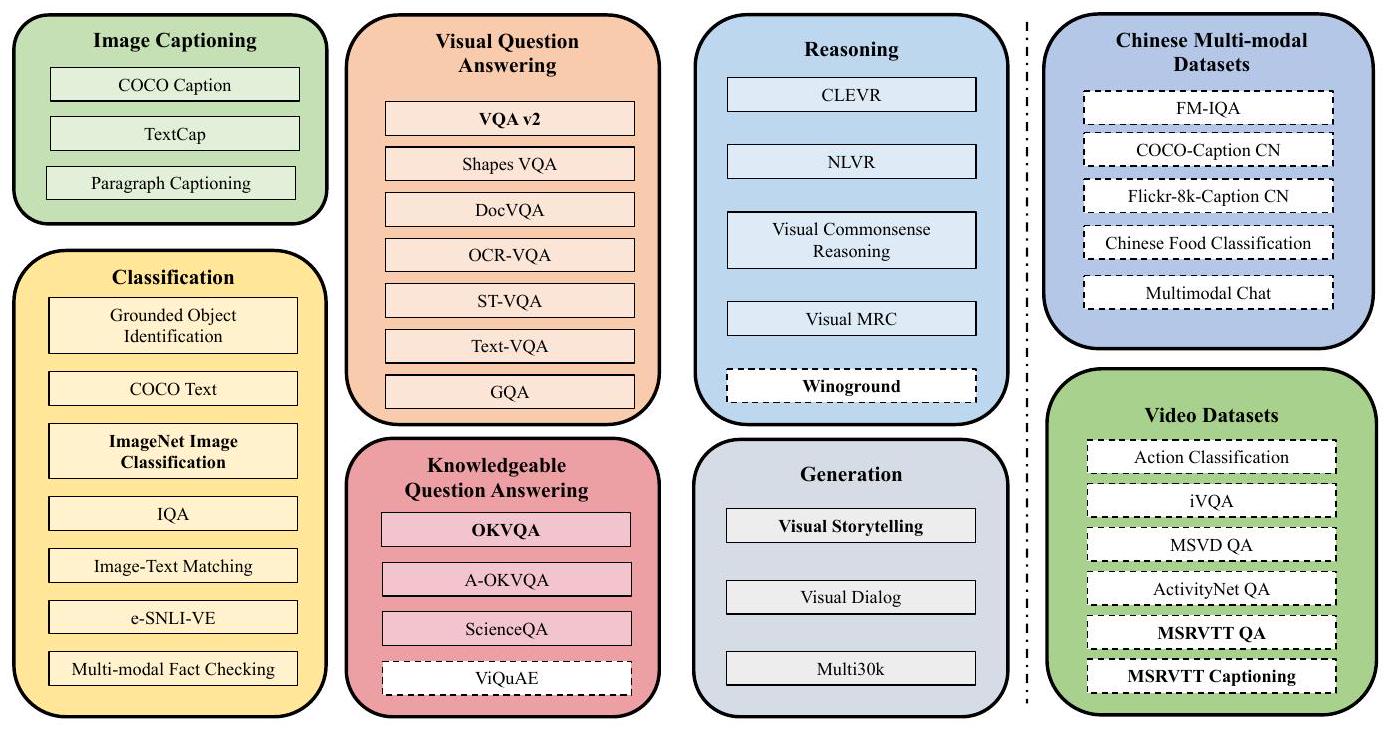
Figure 1: 우리가 제안하는 멀티모달 다국어 instruction tuning 데이터셋의 task들. 점선 흰색 상자 안의 task들은 학습 시 사용되지 않는 held-out 평가 세트이다. 이름이 굵게 표시된 task들은 80개 언어로 번역되었다.
Table 2: Instruction 통계.
| Number of different instructions | 400 |
|---|---|
| - Image Captioning | 52 |
| - Classification | 113 |
| - Visual Question Answering | 95 |
| - Knowledgeable Visual QA | 40 |
| - Reasoning | 60 |
| - Generation | 40 |
| Tokens per instruction | |
| Instruction edit distance among the same task | |
| Instruction edit distance across tasks |
Stage I: Instruction Writing
고품질의 instruction을 구축하기 위해, 우리는 먼저 어노테이터들에게 데이터셋 논문을 주의 깊게 읽고 몇몇 인스턴스를 통해 원본 데이터셋을 확인하여 task를 명확히 이해하도록 요청한다. 그 후, task의 핵심 특성을 포괄하는 10개의 다양한 task instruction을 수동으로 작성하도록 요구한다. Table 2는 각 task에 대해 작성된 instruction의 통계를 보여준다. 총 400개의 instruction을 모든 task에 대해 어노테이션하였다. instruction당 평균 길이는 24.4 토큰이다. 어노테이션된 instruction의 다양성을 평가하기 위해, 우리는 두 문자열 간의 유사도를 측정하는 평균 edit distance를 사용한다. 동일한 task 내에서의 평균 edit distance는 76.6으로, instruction 다양성이 양호한 범위임을 나타낸다.
Stage II: Data Format Unification
instruction이 task 특성에 따라 작성된 후, 우리는 통합된 인스턴스 스키마를 위해 이미지와 해당 텍스트를 추가로 처리한다. 대부분의 데이터셋에 대해, 우리는 원본 이미지와 텍스트를 유지하며, 이미지는 쉬운 데이터 로딩을 위해 해당 base64 인코딩된 문자열로 변환된다. 우리는 잠재적인 예시에 대해 두 가지 수정을 수행한다:
(1) 이미지에 Bounding Box 추가: 이미지 내 특정 영역을 위해 설계된 task의 경우, 관심 영역을 language model에 알리기 위해 자연어로 bounding box 정보를 제공하는 것이 간단한 해결책이다. 그러나 다른 vision encoder가 채택한 이미지 전처리 기술은 원본 이미지를 **크기 조정(resize)**할 수 있으며, 따라서 원본 bounding box 어노테이션은 추가 조정이 필요하다. CLIP [39]과 같은 일반적인 vision encoder가 visual prompt [43]에 민감하다는 최근 관찰에서 영감을 받아, 우리는 bounding box를 이미지에 직접 빨간색 사각형으로 태그하여, VLM이 대상 영역에 집중하도록 힌트 역할을 한다.
(2) 짧은 답변 의역(Short Answer Paraphrasing): 최근 연구에서 일반적인 VQA 데이터셋의 원본 짧고 간결한 답변이 모델 생성 성능에 부정적인 영향을 미칠 수 있음이 밝혀짐에 따라 [7], 우리는 ChatGPT [36] 모델을 활용하여 원본 질문과 답변에 잠재적인 추가 맥락 정보를 제공함으로써 원본 답변을 의역하도록 제안한다. 맥락 정보에는 원본 이미지의 캡션과 장면 관련 질문에 대한 OCR 토큰이 포함된다. 답변 의역에 사용된 prompt는 Appendix에서 찾을 수 있다. Figure 2는 우리가 데이터셋에 수행한 데이터 수정을 보여준다.

Figure 2: (왼쪽) 영역 기반 task에서, 모델에 관심 영역을 알리기 위해 원본 이미지에 bounding box가 추가된다. (오른쪽) 응답 품질 향상을 위한 짧은 답변 의역.
Stage III: Quality Check
이 단계에서는 각 task에 대해 다른 어노테이터를 배정하여 각 split에서 10개의 예시를 검토한다. 이 단계에서 우리는 task 간의 사소한 형식 불일치를 식별하고 task 형식을 표준화하여 해결한다. 또한, 일부 답변(검토된 인스턴스의 3% 미만)이 불충분한 이미지 정보로 인해 ChatGPT에 의해 효과적으로 의역되지 않았음을 관찰했다. 우리는 이러한 의역된 답변을 필터링하기 위해 간단한 휴리스틱을 사용하고, 원본 답변을 문장으로 변환하기 위해 기본 템플릿을 사용한다. 우리는 이 작은 부분의 의역 실패 답변이 무시할 수 있는 영향을 미친다는 것을 발견했다. 마지막으로, 어노테이터가 성공적으로 데이터셋을 로드하고 검토된 각 인스턴스의 instruction, 입력 및 출력의 정확성을 재확인할 수 있을 때 task 데이터셋은 완료된 것으로 간주된다.
Stage IV: Key Datasets Translation
언어 다양성을 높이고 다양한 언어에 걸쳐 평가를 지원하기 위해, 우리는 다양한 task를 포괄하는 데이터셋의 하위 집합(OK-VQA, ImageNet, Winoground, VQAv2, VIST, MSRVTT 및 MSRVTT-QA)을 선택하고, FLORES-101 [13]에 따라 해당 평가 데이터를 100개 언어로 번역한다. 첫 번째 버전에서는 각 task의 각 split에 대해 500개의 샘플을 번역한다. 향후 더 많은 다국어 샘플이 지원될 예정이다. 우리는 번역을 위해 state-of-the-art 오픈 다국어 번역 모델 중 하나인 distillation 버전 NLLB-1.3B [6]를 채택한다. 다양한 언어에 대한 원어민이 없으므로, 번역 품질을 보장하기 위해 자동 필터링 메커니즘을 채택하며, FLORES-101 결과를 기반으로 영어로부터의 번역 BLEU 점수가 20보다 큰 언어만 유지된다. 이 단계 후, 80개 언어만 유지된다 (자세한 언어 이름은 Appendix 참조).
3.3 Dataset Format
우리 데이터셋의 각 인스턴스는 다섯 가지 필드로 구성된다: (1) Images: 잠재적으로 바운딩 박스가 추가된 이미지를 base64 문자열로 표현한다. (2) Instruction: 각 인스턴스에 대해 task instruction pool에서 무작위로 instruction을 선택한다. (3) Inputs: 이 필드는 모델에 제공되는 task-specific 입력(예: VQA task의 질문)을 위해 할당된다. captioning과 같은 task의 경우 추가 입력이 없으므로 해당 필드는 빈 문자열로 남겨진다. (4) Outputs: captioning task의 이미지 설명이나 이미지 관련 질문에 대한 답변과 같이 특정 task에 필요한 출력이다. (5) Meta Data: 원본 데이터셋을 참조하기 위한 이미지 ID와 같은 중요한 정보를 보존하기 위해 이 필드를 제공한다.
Figure 3은 통합 형식의 인스턴스를 보여준다. 이러한 필드들의 명확한 구분을 통해, 우리 벤치마크의 사용자는 필요한 학습 인스턴스를 유연하게 구성하고 모델을 편리하게 평가할 수 있다. Table 3은 task별로 집계된 통계를 제공하며, 자세한 통계 및 각 데이터셋의 라이선스는 Appendix를 참조하라.

Figure 3: 우리 데이터셋에서 사용된 통합 데이터 인스턴스 스키마로 표현된 ViQuAE 인스턴스.
Table 3: IT task 설명 및 통계. 이미지 캡셔닝(CAP), 분류(CLS), 시각 질문 답변(VQA), 지식 기반 시각 질문 답변(KVQA), 추론(REA), 생성(GEN), 중국어 vision-language, 그리고 비디오-언어 task를 포함한다. 학습, 검증, 테스트 세트의 인스턴스 수를 모든 task에 걸쳐 집계하였으며, 총 2,429,264개의 인스턴스이다.
| Task | Description | Total #samples | ||
|---|---|---|---|---|
| Train | Val | Test | ||
| CAP | Given an image, write a description for the image. | 679,087 | 41,462 | 27,499 |
| CLS | Given an image, classify the image into pre-defined categories. | 238,303 | 100,069 | 21,206 |
| VQA | Given an image, answer a question relevant to the image. | 177,633 | 46,314 | 10,828 |
| KVQA | Given an image, answer the question requires outside knowledge. | 39,981 | 11,682 | 5,477 |
| REA | Given an image, conduct reasoning over the images. | 99,372 | 11,500 | 10,000 |
| GEN | Given an image, make compositions with certain requirements. | 145,000 | 11,315 | 17,350 |
| Chinese | CAP, CLS, VQA, and GEN tasks in Chinese. | 192,076 | 77,306 | 4,100 |
| Video | CAP, CLS, and VQA tasks on video-language datasets. | 20,868 | 7,542 | 9,294 |
| Multi-lingual | Translated tasks in 80 languages | 0 | 240,000 | 184,000 |
4 Experiments
이 섹션에서는 멀티모달 에이전트를 위한 제안된 IT 데이터셋의 효과를 검증하기 위해 VLM을 구축한다. 먼저 실험 설정을 소개하고(§4.1), 이어서 결과를 보고하고 논의한다(§4.2). 마지막으로 task 수와 instruction 다양성의 영향을 분석하고, 정성적 결과를 제시한다(§4.3).
4.1 Experimental Settings
구현 세부 사항 (Implementation Details)
최근 BLIP [23]의 성공에 영감을 받아, 우리는 이미지에서 관련 visual feature를 추출하기 위해 BLIP2-OPT-2.7B [23] 모델의 vision encoder와 Q-former 아키텍처를 채택한다. 대규모 language model로는 LLaMA [49]에서 파생된 Ziya-13B [61]를 활용하며, 이는 이중 언어(영어 및 중국어) 능력을 갖추고 있다. 우리는 두 단계의 학습을 사용한다.
Stage I: Visual-Text Alignment
시각 및 텍스트 feature 공간을 정렬하기 위해, 우리는 COCO captioning의 지침을 활용하고 LAION 400M [41] 데이터셋에서 초기 정렬 학습을 수행한다. 이 단계에서는 Q-former와 language projection을 학습시키며, 총 1억 3천만 개의 파라미터를 AdamW [30]로 최적화한다. 배치 크기는 GPU 활용을 극대화하기 위해 256으로 설정하고, 모델은 30만 스텝 동안 학습된다. 학습률은 처음 2000 스텝 동안 의 최고 값으로 선형적으로 증가한 후 cosine decay scheduler를 따른다. Weight decay는 0.05로 설정된다.
Stage II: Multi-modal Instruction Tuning
LLM의 잠재력을 활성화하기 위해, 우리는 벤치마크에서 멀티모달 instruction tuning을 추가로 수행한다. 정렬 학습 후 모델을 3 epoch 동안 학습시키며, 더 낮은 학습률인 와 1000 스텝의 warmup 단계를 사용한다. LoRa tuning [16]에서 영감을 받아, 이 단계에서는 LLM의 attention layer에서 query 및 value 벡터를 매핑하는 가중치를 학습 가능하게 설정하여 instruction tuning 데이터셋에 더 잘 적응하도록 한다. 다른 학습 파라미터는 Stage I과 동일하다. 모든 실험은 8개의 NVIDIA 80GB A100 GPU로 수행되었다. Stage I은 약 10일이 소요되었고, Stage II는 하루 만에 완료될 수 있었다.
Table 4: KVQA task의 ROUGE-L 평가 결과. 우리의 Ying-VLM은 모든 baseline을 일관되게 능가한다.
| Model | OK-VQA | A-OKVQA | ViQuAE |
|---|---|---|---|
| BLIP2-Flan-T5-XXL | 9.1 | 15.6 | 9.7 |
| MiniGPT4 | 23.3 | 21.8 | 24.4 |
| InstructBLIP | 7.1 | 5.9 | 7.3 |
| Ying-VLM (Ours) |
Table 5: 중국어 vision-language task로의 zero-shot 전이. 우리 모델은 보지 못한 중국어 captioning, VQA 및 classification task에서 가장 높은 ROUGE-L 점수로 잘 일반화된다.
| Model | Flickr-8k-CN | FM-IQA | Chinese-FoodNet |
|---|---|---|---|
| MiniGPT4 | 9.6 | 20.1 | 5.0 |
| InstructBLIP | 5.2 | 2.3 | 1.0 |
| Ying-VLM (Ours) |
Table 6: 비디오-언어 task로의 zero-shot 전이. 모든 task에 대한 ROUGE-L 점수를 보고한다.
| Model | Video Captioning | Video Question Answer | |||
|---|---|---|---|---|---|
| MSRVTT | iVQA | ActivityNet-QA | MSRVTT-QA | MSVD-QA | |
| BLIP-2-Flan-T5-XXL | 8.8 | 11.1 | 8.9 | 10.3 | 13.2 |
| InstructBLIP | 6.3 | 9.3 | 4.0 | 7.0 | |
| Ying-VLM (Ours) | 14.2 |
평가 설정 (Evaluation Setup)
instruction tuning의 일반화 능력을 검증하기 위해, 일부 task는 평가를 위해 held-out되었다 (held-in/out task는 Figure 1 참조). 우리는 다음 연구 질문에 관심이 있다:
(RQ1) 멀티모달 instruction tuning이 LLM으로부터 세계 지식(world knowledge)을 이끌어낼 수 있는가?
(RQ2) 영어 전용 instruction tuning이 중국어와 같은 다른 언어로 일반화될 수 있는가?
(RQ3) 이미지 전용 멀티모달 instruction tuning이 비디오-언어 task로 일반화될 수 있는가?
RQ1을 위해, 우리는 데이터셋의 세 가지 KVQA task, 즉 OK-VQA [32], A-OKVQA [42], ViQuAE에서 모델을 평가한다. RQ2와 RQ3을 위해, 우리는 각각 중국어 vision-language 및 비디오-언어 데이터셋에 대한 zero-shot 전이 평가를 수행한다. 특별한 언급이 없는 한, 추론 시에는 greedy decoding을 사용한다.
평가 지표 (Metrics)
우리는 예측과 ground-truth 답변 간의 일관성을 평가하기 위한 자동 지표로 ROUGE-L [26]을 채택하며, 모델의 대화 능력 평가에 중점을 둔다. 자동 지표가 대화 품질의 미묘한 차이를 완전히 포착하지 못할 수 있으므로, 우리는 GPT-4를 인간 평가자의 대리인으로 추가 도입한다 (§ 4.2).
Baseline 모델 (Baselines)
우리는 우리의 모델을 최근 제안된 강력한 멀티모달 에이전트들과 비교한다:
(1) BLIP-2-Flan-T5-XXL [23]: instruction-tuned된 Flan-T5 [53]가 강력한 vision encoder와 연결되어 일련의 멀티모달 task를 수행한다.
(2) MiniGPT-4: CLIP visual encoder를 인공적으로 수집된 대화 데이터셋으로 frozen된 Vicuna [5]와 정렬시킨다.
(3) InstructBLIP: 최근 제안된 instruction tuning이 강화된 멀티모달 에이전트로, Vicuna-13B와 변환된 멀티모달 데이터셋 및 GPT-4에 의해 생성된 LLaVA [28] 데이터셋을 사용한다.
4.2 Main Results
RQ1: 지식 기반 Visual Question Answer 평가
KVQA 벤치마크 결과는 Table 4에 제시되어 있다. 가장 강력한 baseline과 비교했을 때, 우리 모델은 OK-VQA에서 3.2 ROUGE-L 포인트, A-OKVQA에서 2.7 ROUGE-L 포인트의 성능 향상을 달성했다. 또한, Ying-VLM은 held-out ViQuAE 데이터셋에서 최고의 성능을 보인다. 이러한 결과는 IT에 대한 instruction tuning이 LLM으로부터 지식을 효과적으로 활용하고 응답 품질을 향상시킨다는 것을 나타낸다.
RQ2: 중국어 Vision-Language Task로의 Zero-Shot 전이
우리는 instruction tuning의 교차 언어 일반화 능력을 조사하기 위해 세 가지의 이전에 보지 못한 중국어 vision-language task에서 모델을 평가했다. BLIP-2는 Flan-T5가 중국어를 지원하지 않으므로 고려하지 않았다. Table 5에 나타난 바와 같이, 우리 모델은 평가된 모든 task에서 MiniGPT4와 InstructBLIP을 능가하며, 주목할 만한 개선을 보여준다. 이러한 결과는 영어 데이터셋을 사용한 instruction tuning이 다른 언어에도 효과적으로 일반화될 수 있음을 나타내며, 추가 탐색의 유망한 잠재력을 보여준다.
RQ3: 비디오-언어 Task로의 Zero-Shot 전이
비디오-언어 task에서의 성능을 평가하기 위해, 우리는 각 비디오에서 8개의 프레임을 균일하게 샘플링한다. MiniGPT4는 비디오 입력을 지원하지 않으므로 비교에서 제외되었다. InstructBLIP [7]의 접근 방식을 따라, 우리는 각 프레임의 Q-former에서 추출된 visual embedding을 language model의 prefix embedding으로 연결한다. Table 6에서 보여지듯이, 우리 모델은 이러한 도전적인 설정에서 뛰어난 성능을 보이며, BLIP-series baseline을 크게 능가한다. 학습 데이터셋에 비디오와 같은 시각 입력이 포함되지 않았다는 점은 주목할 만하다. 이는 우리의 instruction tuning이 모델이 시간적 차원을 가진 비디오 입력으로 일반화하는 데 효과적으로 도움이 된다는 것을 의미한다.
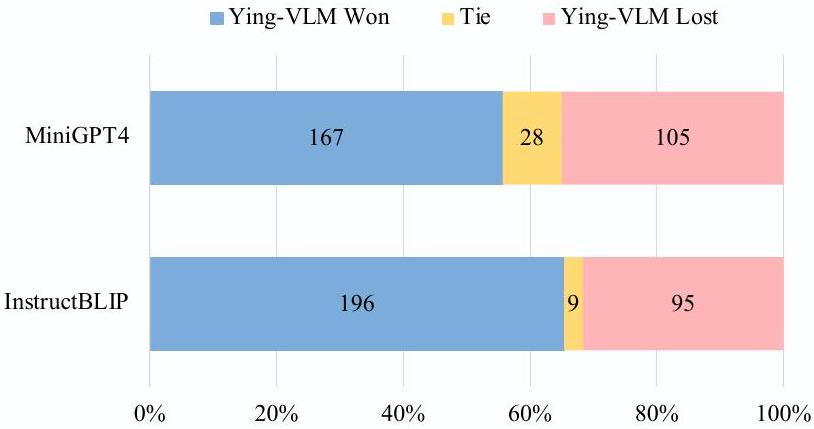
Figure 4: GPT-4를 평가자로 사용한 평가 결과. 우리 모델은 MiniGPT-4와 InstructBLIP을 각각 55.6% 및 65.5%의 승률로 능가한다.
GPT-4 평가 결과
생성된 응답의 품질을 추가로 검증하기 위해, 우리는 강력한 GPT-4 모델을 인간 평가자의 대리자 [38, 12]로 활용할 것을 제안한다. 구체적으로, Vicuna [5]를 따라, 우리는 GPT-4를 사용하여 다양한 모델의 성능을 우리 Ying-VLM과 비교하여 평가한다. GPT-4 API 비용을 고려하여, OK-VQA, A-OKVQA, ViQuAE 데이터셋에서 300개의 예시를 무작위로 샘플링하여 평가용 서브셋으로 사용한다. 각 샘플에 대해, 원래 질문, 해당 참조 답변, 우리 Ying-VLM이 생성한 응답, 그리고 baseline 시스템 출력으로 구성된 prompt를 구성한다. GPT-4는 주어진 질문과 참조 답변을 기반으로 두 응답을 10점 척도로 평가하도록 쿼리된다. 평가는 주로 응답의 정확성, 관련성, 자연스러움을 기반으로 하며, 이는 인간이 멀티모달 에이전트와 상호작용할 때의 요구 사항을 충족시키기 위함이다 (자세한 평가 템플릿은 Appendix 참조). 우리는 응답 순서에 대한 잠재적 평가 편향을 완화하기 위해 Wang et al. [51]이 제안한 전략을 사용한다. Figure 4는 우리 Ying-VLM이 대부분의 샘플에서 모든 baseline 모델을 능가함을 보여준다. 특히, Ying-VLM은 테스트된 300개 샘플 중 167개에서 가장 강력한 baseline인 MiniGPT4를 능가했다. 이전 ROUGE-L 평가와 일관되게, 이 결과는 우리의 instruction 데이터셋으로 fine-tuning된 모델이 도전적인 KVQA task에서 더 정확하고 매력적인 응답을 생성할 수 있음을 나타낸다.
4.3 Analysis
우리는 학습된 모델의 성능에 대한 task 수와 instruction 다양성의 영향을 조사하여, 향후 연구들이 우리 벤치마크를 더 잘 활용할 수 있도록 통찰력을 제공한다.
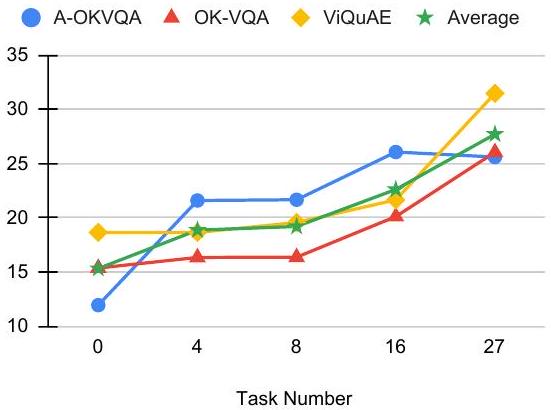
Figure 5: 더 많은 instruction tuning 데이터셋을 사용할수록 성능이 증가한다.
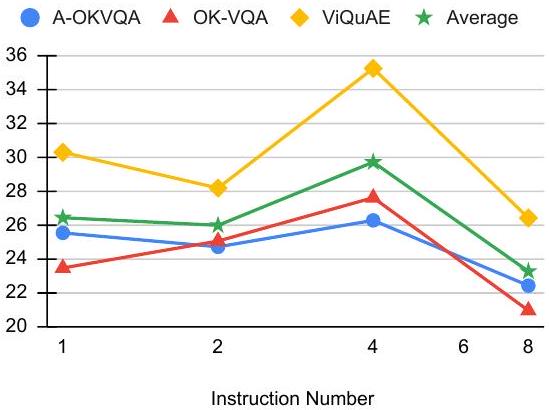
Figure 6: 학습에 사용된 instruction 수의 변화에 따라 성능이 달라진다.

Figure 7: 모델 출력의 사례 연구.
정답은 녹색으로 굵게 표시되었고, 오답은 빨간색, 관련 없는 답변은 회색으로 표시되었다.
우리 데이터셋으로 학습된 모델은 개체 중심 질문에 대해 자연스럽고 유익한 답변을 제공할 수 있으며, 중국어 음식 분류 task에도 일반화된다 (시각화를 위한 영어 번역만 제공).
Task 수의 영향 (Effect of Task Number)
우리는 task들을 무작위로 섞은 다음, instruction tuning 단계에서 모델을 학습시키기 위한 부분집합을 선택하여 task 수의 영향을 조사한다. 계산 자원 제약으로 인해, 각 task당 최대 5,000개의 예시를 설정하고, 모든 모델을 batch size 64로 5,000 step 동안 학습시킨다. 학습을 위해 0, 4, 8, 16개 및 전체 27개 task를 선택하고, 개별 ROUGE-L 점수와 평균 점수를 보고한다. Figure 5에서 볼 수 있듯이, task 수가 증가할수록 일반화 성능이 크게 향상된다. 또한, task 수가 증가하더라도 성능 향상이 줄어들지 않는다. 이는 더 많은 task를 학습에 도입함으로써 지속적으로 성능을 향상시킬 수 있음을 나타내므로 매우 고무적이다. 다양한 task 클러스터의 영향을 조사하는 것은 흥미로운 연구가 될 것이며, 이는 향후 연구로 남겨둔다.
Instruction 다양성의 영향 (Effect Instruction Diversity)
instruction 다양성의 영향을 조사하기 위해, 각 데이터셋에서 사용되는 instruction 수를 1, 2, 4, 8개로 제한하여 각 task에 대한 다양성 수준을 변화시켰다. 다른 학습 파라미터는 task 수 조사에 사용된 이전 실험과 동일하게 유지되었다. Figure 6은 다양성 수준에 따라 성능이 달라짐을 보여준다. 구체적으로, 우리 결과는 task당 4개의 instruction을 사용하는 것이 적절한 성능을 달성하기에 충분함을 시사한다. instruction 다양성에 대한 더 심층적인 분석은 향후 연구로 남겨둔다.
정성적 결과 (Qualitative Results)
우리는 instruction-tuned 모델에 대한 더 직관적인 이해를 제공하기 위해 사례 연구를 수행한다. 사례는 held-out ViQuAE 및 ChineseFoodNet 데이터셋에서 선택되었다. Figure 7에서 볼 수 있듯이, 우리 모델은 모든 질문에 대해 정확한 답변을 생성한다. 대조적으로, MiniGPT4는 왼쪽의 경기장 질문에 대해 오답을 생성하고, 이후 사례에서는 지시를 따르지 못하고 일반적인 이미지 설명을 제공한다. 또한, 외부 지식을 요구하는 두 질문에 대해 간결하지만 덜 매력적인 답변을 제공하는 InstructBLIP과 비교할 때, 우리 모델은 더 자연스럽고 매력적인 답변을 제공하여 우리 데이터셋의 가치를 강조한다. 우리 모델은 또한 중국어 입력에도 성공적으로 일반화되어, 지시에 따라 음식 이미지를 정확하게 분류한다. 이러한 사례들은 instruction tuning의 중요성을 강조하며, 우리 데이터셋이 VLM의 능력을 효과적으로 향상시킬 수 있음을 보여준다.
5 Conclusion
본 논문에서는 멀티모달 대규모 언어 모델(multi-modal large language models) 개발을 지원하기 위한 **멀티모달 다국어 instruction tuning 데이터셋인 **를 소개한다. 이 데이터셋은 40개의 task에 걸쳐 240만 개의 신중하게 선별된 인스턴스와 400개의 수동으로 작성된 task instruction으로 구성된다. 우리는 이 데이터셋의 효과를 검증하기 위해 Ying-VLM을 구축하였다.
정량적 및 정성적 결과는 우리 데이터셋으로 학습된 모델이 사람의 지시를 성공적으로 따르고, 더 매력적인 응답을 제공하며, 이전에 보지 못한 비디오 및 중국어 task에서 강력한 일반화 성능을 달성함을 보여준다. 추가 분석에 따르면 task 수가 증가할수록 성능이 지속적으로 향상될 수 있으며, instruction의 다양성이 결과에 영향을 미칠 수 있다. 우리는 제안하는 벤치마크, 학습된 모델, 그리고 실험 결과가 강력한 멀티모달 지능형 에이전트를 구축하기 위한 향후 연구를 촉진할 수 있기를 기대한다.
A Dataset Statistics
Table 7: 우리의 instruction tuning task에 대한 상세한 task 설명 및 통계. 모든 유형의 task에 포함된 모든 데이터셋을 포함한다. "Used" 열은 instruction tuning 단계에서 이 데이터셋을 사용했는지 여부를 나타낸다.
| Task | Dataset | Used | #samples | License | ||
|---|---|---|---|---|---|---|
| Captioning | MS COCO [27] | Yes | 566,747 | 25,010 | 25,010 | Custom |
| TextCaps [44] | Yes | 97,765 | 13,965 | 0 | Unknown | |
| Image-Paragraph-Captioning [21] | Yes | 14,575 | 2,487 | 2,489 | Custom | |
| Classification | COCO-GOI [27] | Yes | 30,000 | 2,000 | 0 | Custom |
| COCO-Text [50 | Yes | 118,312 | 27,550 | 0 | Custom | |
| ImageNet [40] | Yes | 30,000 | 50,000 | 0 | Non-commercial | |
| COCO-ITM [27] | Yes | 30,000 | 5,000 | 5,000 | Custom | |
| e-SNLI-VE [20] | Yes | 20,000 | 14,339 | 14,740 | Unknown | |
| Mocheg [58] | Yes | 4,991 | 180 | 466 | CC BY 4.0 | |
| IQA [9] | Yes | 5,000 | 1,000 | 1,000 | Custom | |
| VQA | VQA v2 [15] | Yes | 30,000 | 30,000 | 0 | CC-BY 4.0 |
| Shapes VQA [1] | Yes | 13,568 | 1,024 | 1,024 | Unknown | |
| DocVQA [33] | Yes | 39,463 | 5,349 | 0 | Unknown | |
| OCR-VQA [34] | Yes | 11,414 | 4,940 | 0 | Unknown | |
| ST-VQA [2] | Yes | 26,074 | 0 | 4,070 | Unknown | |
| Text-VQA [45] | Yes | 27,113 | 0 | 5,734 | CC BY 4.0 | |
| GQA [18] | Yes | 30,001 | 5,001 | 0 | CC BY 4.0 | |
| KVQA | OK-VQA [32] | Yes | 9,009 | 5,046 | 0 | Unknown |
| A-OK-VQA [42] | Yes | 17,056 | 1,145 | 0 | Unknown | |
| ScienceQA [31 | Yes | 12,726 | 4,241 | 4,241 | CC BY-NC-SA | |
| ViQuAE [22] | No | 1,190 | 1,250 | 1,236 | CC By 4.0 | |
| Reasoning | CLEVR [19] | Yes | 30,000 | 2,000 | 0 | CC BY 4.0 |
| NLVR [46 | Yes | 29,372 | 2,000 | 0 | Unknown | |
| VCR [60] | Yes | 25,000 | 5,000 | 5,000 | Custom | |
| VisualMRC [47] | Yes | 15,000 | 2,500 | 5,000 | Unknown | |
| Winoground [48] | No | 0 | 0 | 800 | Unknown | |
| Generation | Visual Storytelling [17] | Yes | 5,000 | 4,315 | 4,350 | Unknown |
| Visual Dialog [8] | Yes | 50,000 | 1,000 | 1,000 | CC By 4.0 | |
| Multi30k [10] | Yes | 90,000 | 6,000 | 12,000 | Non-commercial | |
| Chinese | FM-IQA [11] | No | 164,735 | 75,206 | 0 | Unknown |
| COCO-Caption CN 125 | No | 18,341 | 1,000 | 1,000 | Non-commercial | |
| Flickr-8k-Caption CN [24] | No | 6,000 | 1,000 | 1,000 | CC By 3.0 | |
| Chinese Food Classification [4] | No | 0 | 0 | 1,100 | Unknown | |
| Multimodal Chat 62 | No | 3,000 | 1,000 | 1,000 | Unknown | |
| Video | Action-Classification [14] | No | 2,000 | 2,000 | 2,000 | Custom |
| iVQA [57] | No | 5,994 | 2,000 | 2,000 | Unknown | |
| MSVD QA [54] | No | 1,161 | 245 | 504 | Unknown | |
| ActivityNet QA [59] | No | 3,200 | 1,800 | 800 | Unknown | |
| MSRVTT QA [54] | No | 6,513 | 497 | 2,990 | Unknown | |
| MSRVTT Captioning [55] | No | 2,000 | 1,000 | 1,000 | Unknown |
Table 7은 우리 벤치마크의 상세 통계를 나열한다. 우리는 PaperWithCode에서 데이터셋 라이선스를 수집했다. Unknown 및 Custom 라이선스 데이터셋의 경우, 사용자는 사용 전에 프로젝트 페이지를 확인하거나 데이터셋 소유자에게 문의할 것을 권장한다.
B Template for Answer Paraphrase
우리는 ChatGPT에 원본 짧은 답변을 다시 작성하도록 쿼리하기 위한 paraphrase 템플릿을 Table 8에 제공한다. 여기서 와 는 각각 질문과 paraphrase해야 할 답변으로 채워진다. 우리는 모델에 paraphrase task를 더 잘 알리기 위해 예시를 포함한다. VQAv2 task의 경우, paraphrase에 도움이 되는 추가적인 context 정보를 제공하기 위해 해당 COCO 데이터셋의 caption으로 채워진 추가적인 {Caption} 필드를 템플릿에 추가한다.
Table 8: 답변 paraphrase를 위해 ChatGPT에 쿼리하는 데 사용된 템플릿.
You are an AI visual assistant. Now you are given a question related to an image and a short ground-truth answer. Your task is to transform the ground-truth answer into a natural and convincing response. Make sure the response is accurate, highly relevant to the question, and consistent with the original answer.
Question:
Which NASA space probe was launched to this planet in 1989 ?
Answer:
Magellan
Transformed Answer:
NASA sent the Magellan spacecraft to Venus in 1989, which was the first planetary spacecraft launched from a space shuttle.
Question:
\{\mathrm{Q}\}
Answer:
\{A\}
Transformed Answer:
C Dataset Translation
우리는 ImageNet, Winoground, VQAv2, OKVQA, VIST, MSRVTT, MSRVTT-QA의 모든 task instruction과 evaluation set을 Table 9에 나타난 바와 같이 80개 언어로 번역하였다. 계산 자원 제약으로 인해, Winoground의 전체 테스트 세트(800개 예시)는 모두 번역하였고, 다른 task의 각 split에 대해서는 최대 500개의 인스턴스 수로 제한하였다.
D Prompt for Zero-Shot Chinese Vision-Language Tasks
실험에서 모든 Vision-Language 모델은 오직 영어 데이터만을 사용하여 fine-tuning되었다. 예비 연구에서 우리는 입력과 지시가 중국어로 작성되었음에도 불구하고, 이 모델들이 영어 응답을 생성하는 경향이 있음을 관찰했다.
이에 우리는 모든 모델의 zero-shot 중국어 Vision-Language Task 평가 시, Table 10에 나타난 바와 같이 간단한 중국어 대화 맥락(dialogue context)을 도입하였다. 흥미롭게도, 이러한 작은 조정만으로도 모델이 합리적인 중국어 출력을 생성하도록 유도할 수 있었다.
instruction-tuned VLM 모델의 다국어 능력에 대한 분석은 향후 연구 과제로 남겨둔다.
E Template for GPT-4 Evaluation
우리는 Table 11의 템플릿을 사용하여 GPT-4에 쿼리하고, FairEval을 통해 평가 결과를 얻어 더 안정적인 결과를 확보한다. 구체적으로, 각 테스트 인스턴스는 **(question, reference, response1, response2)**의 쿼터니언(quaternion) 형태를 가진다. 여기서 response1은 우리의 Ying-VLM 모델의 응답이고, response2는 baseline 모델의 응답이다. 각 인스턴스에 대해 GPT-4에 쿼리하여 정확성(accuracy), 관련성(relevance), 자연스러움(naturalness) 측면에서 어떤 응답이 더 나은 품질을 가지는지 판단한다. 우리는 이 쿼터니언을 평가 템플릿에 채워 넣어 다음과 같은 두 가지 쿼리 prompt를 구성한다:
[^4]Table 9: 번역된 데이터셋의 언어 코드, 스크립트, 언어 이름 목록.
| Language Code | Script | Language Name |
|---|---|---|
| af | amh_Ethi | Afrikaans |
| ar | arb_Arab | Modern Standard Arabic |
| as | asm_Beng | Assamese |
| ast | ast_Latn | Asturian |
| be | bel_Cyrl | Belarusian |
| bg | bul_Cyrl | Bulgarian |
| bn | ben_Beng | Bengali |
| bs | bos_Latn | Bosnian |
| ca | cat_Latn | Catalan |
| ceb | ceb_Latn | Cebuano |
| cs | ces_Latn | Czech |
| cy | cym_Latn | Welsh |
| da | dan_Latn | Danish |
| de | deu_Latn | German |
| el | ell_Grek | Greek |
| es | spa_Latn | Spanish |
| et | est_Latn | Estonian |
| fi | fin_Latn | Finnish |
| fr | fra_Latn | French |
| fuv | fuv_Latn | Nigerian Fulfulde |
| gl | glg_Latn | Galician |
| gu | guj_Gujr | Gujarati |
| ha | hau_Latn | Hausa |
| he | heb_Hebr | Hebrew |
| hi | hin_Deva | Hindi |
| hr | hrv_Latn | Croatian |
| hu | hun_Latn | Hungarian |
| hy | hye_Armn | Armenian |
| id | ind_Latn | Indonesian |
| ig | ibo_Latn | Igbo |
| is | isl_Latn | Icelandic |
| it | ita_Latn | Italian |
| ja | jpn_Jpan | Japanese |
| jv | jav_Latn | Javanese |
| ka | kat_Geor | Georgian |
| kk | kaz_Cyrl | Kazakh |
| km | khm_Khmr | Khmer |
| kn | kan_Knda | Kannada |
| ko | kor_Hang | Korean |
| ky | kir_Cyrl | Kyrgyz |
| lb | ltz_Latn | Luxembourgish |
| lg | lug_Latn | Ganda |
| lij | lij_Latn | Ligurian |
| li | lim_Latn | Limburgish |
| ln | lin_Latn | Lingala |
| lo | lao_Laoo | Lao |
| lt | lit_Latn | Lithuanian |
| lv | lvs_Latn | Standard Latvian |
| mi | mri_Latn | Maori |
| mk | mkd_Cyrl | Macedonian |
| ml | mal_Mlym | Malayalam |
| mr | mar_Deva | Marathi |
| mt | mlt_Latn | Maltese |
| my | mya_Mymr | Burmese |
| nl | nld_Latn | Dutch |
| ny | nya_Latn | Nyanja |
| oc | oci_Latn | Occitan |
| pa | pan_Guru | Eastern Panjabi |
| pl | pol_Latn | Polish |
| pt | por_Latn | Portuguese |
| ro | ron_Latn | Romanian |
| ru | rus_Cyrl | Russian |
| sd | snd_Arab | Sindhi |
| sk | slk_Latn | Slovak |
| sn | sna_Latn | Shona |
| so | som_Latn | Somali |
| sr | srp_Cyrl | Serbian |
| sv | swe_Latn | Swedish |
| ta | tam_Taml | Tamil |
| te | tel_Telu | Telugu |
| tg | tgk_Cyrl | Tajik |
| th | tha_Thai | Thai |
| tl | tgl_Latn | Tagalog |
| tr | tur_Latn | Turkish |
| uk | ukr_Cyrl | Ukrainian |
| ur | urd_Arab | Urdu |
| vi | vie_Latn | Vietnamese |
| wo | wol_Latn | Wolof |
| zh | zho_Hans | Chinese (Simplified) |
question, reference, response1, response2)와 question, reference, response2, response1). 우리는 GPT-4의 temperature를 1로 설정하고, 각 쿼리 prompt에 대해 세 개의 completion을 샘플링한다. 따라서 각 응답은
Table 10: 중국어 출력을 유도하기 위한 Prompt.
<human>: 请根据我的指示,以及所给的图片,做出相应的回答。
<bot>:
好的。
<human>:
{Instruction}
{Input}
<bot>:
好的。
총 6개의 점수를 받게 되며, 우리는 이 점수들의 평균을 각 응답의 최종 점수로 사용한다. 최종 점수가 더 높은 응답이 더 나은 응답으로 간주된다. GPT-4 평가에 소요된 비용은 InstructBlip의 경우 20.90였다.
Table 11: 다양한 모델의 응답 품질을 평가하기 위해 GPT-4에 쿼리하는 데 사용된 템플릿.
[Question]
\(\{\mathrm{Q}\}\)
[The Start of Reference Answer]
\{R\}
[The End of Reference Answer]
[The Start of Assistant 1's Answer]
\{R1\}
[The End of Assistant 1's Answer]
[The Start of Assistant 2's Answer]
\{R2\}
[The End of Assistant 2's Answer]
[System]
We would like to request your feedback on the performance of two AI assistants in response
to the user's multimodal question displayed above. We provided no multimodal inputs other
than question text, but we provided a reference answer for this question. You need to evaluate
the quality of the two responses based on the question and the reference answer.
Please rate the on the follow aspects:
1. Accuracy: whether the candidate's response is consistent with the original answer, this is
important as we do not want a misleading result;
2. Relevance: whether the candidate's response is highly relevant to the question and image
content;
3. Naturalness: whether the candidate's response is engaging, providing a great communica- tion experience for the user when interacting with the AI visual assistant. of the two Assistants'responses.
Each assistant receives an overall score on a scale of 1 to 10 ,where a higher score indicates better overall performance.
Please first provide a comprehensive explanation of your evaluation,avoiding any potential bias and ensuring that the order in which the responses were presented does not affect your judgment.
Then,output two lines indicating the scores for Assistant 1 and 2,respectively.
Output with the following format:
Evaluation evidence:<evaluation explanation here>
The score of Assistant 1:<score>
The score of Assistant 2:<score>