InternVideo2.5: 긴밀하고 풍부한 컨텍스트 모델링으로 비디오 MLLM 역량 강화
본 논문은 길고 풍부한 컨텍스트(Long and Rich Context, LRC) 모델링을 통해 비디오 멀티모달 대형 언어 모델(MLLM)의 성능을 향상시키는 InternVideo2.5를 소개합니다. 이 모델은 Direct Preference Optimization을 사용하여 밀도 높은 비전 과제 주석을 통합하고, 적응형 계층적 토큰 압축을 통해 시공간 표현을 최적화하여 비디오의 미세한 디테일 인식 및 장기적인 시간 구조 포착 능력을 강화합니다. 이를 통해 기존 모델보다 6배 더 긴 비디오 입력을 처리하고 객체 추적과 같은 전문적인 비전 기능을 수행할 수 있습니다. 논문 제목: InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
논문 요약: InternVideo2.5: 긴밀하고 풍부한 컨텍스트 모델링으로 비디오 MLLM 역량 강화
- 논문 링크: https://arxiv.org/abs/2501.12386
- 저자: Yi Wang, Xinhao Li, Ziang Yan 외 다수 (Shanghai AI Laboratory, Nanjing University, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences)
- 발표 시기: 2025년 (arXiv)
- 주요 키워드: Video MLLM, Long Context, Multimodal, LLM, Computer Vision
1. 연구 배경 및 문제 정의
- 문제 정의:
멀티모달 대형 언어 모델(MLLM)은 다양한 감지 신호를 통합하여 인공 일반 지능에 중요한 진전을 이루었지만, 기본적인 시각 관련 작업(객체 인식, 위치 파악, 회상 등)에서 여전히 인간보다 성능이 떨어지는 한계를 보인다. 특히 비디오 MLLM은 긴 비디오의 시공간적 의존성과 미세한 디테일을 포착하는 데 어려움을 겪으며, 이는 복잡한 내러티브 이해나 전문적인 비전 능력 수행을 저해한다. 기존 연구는 모델 크기나 데이터 양을 확장하거나, 컨텍스트 창을 늘리거나, 토큰 압축을 시도했지만, 계산 비용, 통신 장벽, 또는 의미 보존의 한계에 부딪혔다. - 기존 접근 방식:
- 컨텍스트 창 확장: MLLM의 컨텍스트 창 용량을 늘려 더 긴 시퀀스를 처리하지만, 통신 비용과 실제 비디오 길이로 인해 장벽이 존재한다.
- 효율적인 토큰 압축: 계산 효율성을 높이지만, 상세한 비디오 이해 작업에서 성능이 부족하여 압축 중 의미 유지에 개선의 여지가 있다.
- 에이전트 기반 방법: 긴 비디오 이해를 여러 하위 작업으로 분해하여 처리하지만, MLLM 자체의 직접적인 능력 향상과는 거리가 있다.
- 픽셀-투-시퀀스(P2S) 및 픽셀-투-임베딩(P2E): 시각적 캡셔닝 및 질의응답에는 강하지만, 분할 및 시간적 위치 특정과 같은 세분화된 시각 작업에는 어려움을 겪는다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- MLLM의 기억력(길이)과 집중력(세밀함)을 향상시키기 위한 길고 풍부한 컨텍스트(LRC) 모델링에 대한 최초의 포괄적인 연구를 제시한다.
- 계층적 토큰 압축(HiCo)과 작업 선호도 최적화(TPO)를 통합하여 효율적인 학습과 풍부한 비전 주석을 통해 MLLM을 확장 가능하게 향상시킨다.
- InternVideo2.5는 비디오 이해에서 눈에 띄는 성능 향상을 보이며, 기존 MLLM보다 최소 6배 더 긴 비디오 입력을 처리하고 객체 추적 및 분할과 같은 전문가 수준의 시각적 인식 능력을 부여한다.
- 제안 방법:
InternVideo2.5는 비디오 길이 적응형 토큰 표현과 작업 선호도 최적화를 통해 MLLM의 컨텍스트 길이와 세밀함을 향상시킨다.- 비디오 길이 적응형 토큰 표현 (HiCo):
- 적응형 시간 샘플링: 짧은 비디오는 조밀하게(15fps), 긴 비디오는 희소하게(1fps) 샘플링하여 다양한 시간 스케일에서 적절한 움직임 포착을 보장한다.
- 시공간 토큰 병합: 비전 인코더와 언어 모델 사이에 토큰 병합(ToMe)을 사용하여 시공간적 중복성을 압축하고 필수 세부 사항을 보존한다. (Q-Former 대비 학습 효율성 강조)
- 멀티모달 토큰 드롭아웃: 언어 모델 처리 중 토큰 가지치기를 적용하여 계산 오버헤드를 줄이고 관련 없는 시각 정보를 제거한다.
- 특징: HiCo의 모든 단계는 학습 불가능하지만, HiCo와 함께 MLLM을 학습하면 성능이 크게 향상된다.
- 작업 선호도 최적화 (TPO):
- 다중 작업 선호도 학습(MPL)을 통해 MLLM에 특화된 시각적 인식 모듈(시간적 이해, 인스턴스 분할)을 통합하여 정밀한 위치 파악 및 시간적 이해 능력을 가능하게 한다.
- 시각적 인식 모듈은 시간적 구성 요소(비디오 특징 추출 및 시간적 정렬)와 분할 모듈(SAM2 기반)을 포함한다.
- MLLM의 일반적인 능력을 보존하면서 특화된 능력을 통합하기 위해, 기본 MLLM 손실과 작업별 손실을 결합한 총 손실 함수로 최적화한다.
- 점진적 다단계 학습:
- 기초 학습: LLM의 작업 인식 지시 튜닝 및 기본적인 시각-언어 정렬 학습.
- 세밀한 인식 학습: 작업별 데이터셋을 사용하여 작업 토큰, 영역/시간적 헤드, 마스크 어댑터 등 작업별 구성 요소를 통합 및 학습.
- 통합된 정확하고 장편 컨텍스트 학습: 멀티모달 대화와 특정 작업 데이터를 결합한 혼합 코퍼스에 대한 다중 작업 학습 및 포괄적인 데이터셋에 대한 지시 튜닝.
- 분산 시스템 구현: XTuner 기반의 멀티모달 시퀀스 병렬 처리 시스템을 개발하여 긴 비디오의 확장 가능한 컴퓨팅을 가능하게 한다. (2D-어텐션 전략, 동적 패킹 등 활용)
- 비디오 길이 적응형 토큰 표현 (HiCo):
3. 실험 결과
- 데이터셋:
- 비디오 이해 벤치마크: MVBench, PerceptionTest, EgoSchema, LongVideoBench, MLVU, VideoMME, LVBench (단편 및 장편 비디오 질의응답).
- 특정 시각 작업 벤치마크: Charades-STA (시간적 그라운딩), Highlight Detection, Ref-YouTube-VOS (비디오 참조 분할), MeViS J&F, LaSOT (추적), GOT-10k (추적).
- 장기 기억력 평가: Needle-In-The-Haystack (NIAH) 작업 (5,000 프레임, 16 A100 (80G) GPU 사용).
- 학습 데이터: 7백만 이미지-텍스트 쌍, 370만 비디오-텍스트 쌍, 14만 3천 텍스트 데이터, LongVid 포함 긴 비디오 지시 데이터, MeViS, SAMv2 등 작업별 시각 데이터.
- 주요 결과:
- 비디오 이해: InternVideo2.5 (약 7B LLM)는 모든 인기 있는 단편 및 장편 비디오 질의응답 벤치마크에서 거의 최고의 성능을 달성하며, 기본 InternVL2.5 대비 MVBench에서 +3.7, EgoSchema에서 +12.4 등 전반적인 성능 향상을 보인다. 기존 모델보다 최소 6배 더 긴 비디오 입력을 처리할 수 있다.
- Needle-In-The-Haystack (NIAH): InternVL2.5-8B가 500프레임 이상에서 어려움을 겪고 1,000프레임 초과 시 OOM이 발생하는 반면, InternVideo2.5는 최대 3,000프레임 시퀀스에서 프레임을 정확하게 회상하고 10,000프레임 이상을 OOM 없이 처리한다.
- 특정 시각 작업: TPO 최적화 후, InternVideo2.5는 추적, 비디오 참조 분할, 시간적 그라운딩 등 특정 조밀하게 주석이 달린 시각적 작업을 전문가 모델 수준의 성능으로 수행하며, 대부분의 작업에서 다른 MLLM을 능가한다.
- 어블레이션 연구: HiCo와 TPO의 결합이 MLLM 성능을 눈에 띄게 향상시키고 NIAH를 가능하게 함을 검증했다. 다만, TPO의 효과는 매우 긴 비디오(약 15분 이상)에서는 감소하는 경향을 보인다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- MLLM의 핵심 한계인 긴 비디오 컨텍스트 처리 능력과 세밀한 시각적 이해 능력을 동시에 향상시킨 점이 인상 깊다.
- HiCo(효율성)와 TPO(정밀성)라는 두 가지 독창적인 방법론의 시너지를 통해 MLLM의 성능을 비약적으로 끌어올린 점이 뛰어나다.
- 특히, 기존 MLLM이 처리하기 어려웠던 전문가 수준의 객체 추적, 분할 등의 비전 작업을 MLLM 프레임워크 내에서 가능하게 한 것은 큰 발전이다.
- NIAH 평가를 통해 장기 기억력이 획기적으로 개선되었음을 정량적으로 보여준 점이 강력하다.
- 단점/한계:
- 긴 비디오 시퀀스 처리에 대한 계산 비용이 여전히 상당하다는 점은 개선이 필요하다.
- 현재 연구는 주로 시각적 컨텍스트 속성에 초점을 맞추고 있어, 추론 관련 영역으로 LRC를 확장하는 것은 향후 연구 과제로 남아있다.
- 매우 긴 비디오(15분 이상)에서는 TPO의 이점이 줄어드는 경향이 있어, 이 부분에 대한 추가적인 최적화가 필요해 보인다.
- 독점 모델(GPT4-o, Gemini-1.5-Pro)과의 성능 격차가 일부 장편 비디오 벤치마크에서 여전히 존재한다.
- 응용 가능성:
- 고급 비디오 감시 시스템: 장시간 비디오에서 비정상적인 이벤트 감지, 특정 객체 장기 추적 등에 활용될 수 있다.
- 미디어 및 콘텐츠 분석: 영화, TV 쇼 등 긴 영상 콘텐츠의 줄거리 이해, 특정 장면 검색, 상세한 내용 요약 등에 적용될 수 있다.
- 로봇 공학 및 자율 시스템: 복잡하고 장시간 지속되는 환경에서의 이벤트 이해 및 상황 인지에 기여할 수 있다.
- 교육 및 훈련: 긴 강의 비디오에서 특정 개념 설명, 시연 추적 등에 활용하여 학습 효율을 높일 수 있다.
- 개인 비디오 관리: 방대한 개인 비디오 아카이브에서 특정 순간을 검색하거나, 이벤트별로 자동 분류하는 데 사용될 수 있다.
5. 추가 참고 자료
Wang, Yi, et al. "Internvideo2. 5: Empowering video mllms with long and rich context modeling." arXiv preprint arXiv:2501.12386 (2025).
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Yi Wang1 , Xinhao Li , Ziang Yan1 , Yinan He1 Jiashuo Yu1<br>Xiangyu Zeng , Chenting Wang , Changlian Ma , Haian Huang Jianfei Gao , Min Dou , Kai Chen , Wenhai Wang <br>Yu Qiao , Yali Wang , Limin Wang <br> Shanghai AI Laboratory Nanjing University<br> Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences
https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5

Figure 1: Demonstrations of InternVideo2.5. Left: open-source model (8B) performance on MVBench and VideoMME; right: an example of InternVideo2.5 about it monitors the target requested by users and analyzes it.
Abstract
이 논문은 길고 풍부한 컨텍스트(LRC) 모델링을 통해 비디오 멀티모달 대형 언어 모델(MLLM)의 성능을 향상시키는 것을 목표로 합니다. 결과적으로, 저희는 비디오에서 세밀한 디테일을 인식하고 긴 형식의 시간적 구조를 포착하는 MLLM의 기존 능력을 강화하는 데 중점을 둔 새로운 버전의 InternVideo2.5를 개발합니다. 구체적으로, 저희의 접근 방식은 직접 선호도 최적화를 사용하여 조밀한 비전 작업 주석을 MLLM에 통합하고, 적응형 계층적 토큰 압축을 통해 압축된 시공간 표현을 개발합니다. 실험 결과는 이 독특한 LRC 설계가 주류 비디오 이해 벤치마크(단편 및 장편)에서 비디오 MLLM의 결과를 크게 향상시켜, MLLM이 훨씬 더 긴 비디오 입력(기존보다 최소 6배 이상)을 기억하고, 객체 추적 및 분할과 같은 전문적인 비전 능력을 마스터할 수 있게 함을 보여줍니다. 저희의 연구는 MLLM의 타고난 능력(집중과 기억)을 강화하는 데 있어 멀티모달 컨텍스트의 풍부함(길이와 세밀함)의 중요성을 강조하며, 비디오 MLLM에 대한 미래 연구에 새로운 통찰력을 제공합니다.
1 Introduction
멀티모달 대형 언어 모델(MLLM)은 인공 일반 지능에 도달하는 데 있어 중요한 이정표를 세웠습니다. 이 모델들은 다양한 감지 신호를 통합된 LLM 기반 프레임워크로 통합하여, 대부분의 인식 및 인지 문제를 멀티모달 다음 토큰 예측 작업으로 재구성합니다. 이는 멀티모달 문서 분석 [OpenAI, 2024, Reid et al., 2024, Chen et al., 2024c], 비디오 이해 [Li et al., 2023, Wang
1et al., 2024f, Li et al., 2024e], 에이전트 상호작용, 과학적 발견 [Chen et al., 2023a], 세계 모델링 [Agarwal et al., 2025], 자율 주행 [Hu et al., 2023], 그리고 실시간 지원 [Mu et al., 2024, Driess et al., 2023]에 이르는 애플리케이션들을 성공적으로 다룹니다. 이러한 발전에도 불구하고, MLLM은 기본적인 비전 관련 작업에서 여전히 인간보다 성능이 떨어지며, 이는 이해 및 추론 성능을 저해합니다. 이들은 일반적인 시나리오에서 객체, 장면, 움직임을 정확하게 인식하고, 위치를 파악하며, 회상하는 데 어려움을 자주 보이며, 이는 사용자들이 받아들이기 어려운 한계입니다. 연구에서는 시각 관련 데이터와 모델 크기를 늘림으로써 멀티모달 이해 벤치마크에서 지속적인 개선을 보이는 등, 비전-언어 모델링에 스케일링 법칙이 적용됨을 보여주었지만, 이 추세는 MLLM이 인간 수준의 시각적 이해에 도달할 명확한 시점을 제공하지 않습니다. 현재 연구는 고화질 처리를 위한 지능형 문서 분석 및 해상도 적응에 중점을 둡니다. 이러한 접근 방식들이 유망한 성능 향상을 보이고 있지만, 이러한 문제들을 체계적으로 해결하는 데 있어 새로운 능력을 결정적으로 보여주지는 못합니다.
이 논문에서는 모델 크기나 데이터 양을 직접적으로 확장하는 데 초점을 맞추는 대신, 멀티모달 컨텍스트의 길이와 세밀함이 MLLM의 비전 중심 능력과 성능에 어떻게 영향을 미치는지 조사합니다. 여기서 길이와 세밀함은 모델이 멀티모달 입력(예: 비디오 프레임, 오디오, 텍스트)을 긴 컨텍스트에서 세밀한 디테일로 처리하고 해석하는 능력을 의미합니다. 직관적으로, 이는 모델의 이해와 추론에 직접적인 영향을 미칩니다. 더 긴 컨텍스트는 모델이 비디오의 스토리 아크나 다단계 이벤트와 같은 확장된 시간적 의존성과 일관성을 포착할 수 있게 합니다. 이는 복잡한 내러티브를 이해하거나 그에 대해 추론하는 데 중요합니다. 한편, 객체 디테일, 시공간적 관계와 같은 세밀한 컨텍스트는 모델이 미묘한 디테일을 인식할 수 있게 합니다. 이는 특정 행동, 상호작용 또는 장면의 이해를 향상시키고, 인과 관계를 추론하거나 미래 행동을 예측하는 단기적 추론을 개선합니다. 더 높은 컨텍스트 해상도와 풍부함(길이와 세밀함 모두)이 모델의 멀티모달 입력 인식 및 인코딩 능력을 향상시키므로, 우리는 확장 가능한 방식으로 세밀하고 확장된 멀티모달 컨텍스트를 명시적으로 모델링하여 MLLM을 향상시키는 방법을 탐구합니다. 정확한 시공간 이해를 위해, 우리는 직접 선호도 최적화(DPO) [Rafailov et al., 2024]를 사용하여 광범위한 조밀한 시각적 주석을 MLLM으로 전달하며, 비전 전문가 모델을 선호도 모델로 활용합니다 |Yan et al., 2024|. 확장된 멀티모달 컨텍스트를 처리하기 위해, 우리는 시각적으로나 의미적으로 멀티모달 토큰을 적응적으로 압축하여 압축되고 호환 가능한 시공간 표현을 사용합니다 [Li et al., 2024e]. 일반적으로, 우리는 멀티모달 컨텍스트의 길이와 세밀함을 개선하는 것이 채팅 기반 및 기본적인 비전 인식 성능 모두에서 빠른 결과를 가져오는 실행 가능하고 쉽게 구현할 수 있는 해결책임을 보여줍니다, 그림 11에서 볼 수 있듯이. MLLM의 온라인 상호작용이 그 기억(멀티모달 컨텍스트가 얼마나 오래 처리할 수 있는지)과 집중(컨텍스트가 얼마나 정확하게 포착할 수 있는지)에 다소 의존하는지를 고려할 때, 우리는 InternVideo2.5가 이러한 고급 기능과 애플리케이션을 위한 능력 기반을 구축한다고 믿습니다. 구체적으로, 우리의 기여는 다음과 같습니다:
- 저희가 아는 한, 저희는 MLLM의 기억력과 집중력을 향상시키기 위해 길고 풍부한 컨텍스트(LRC)를 실현하는 방법에 대한 첫 번째 포괄적인 연구를 제시합니다. 계층적 토큰 압축(HiCo)과 작업 선호도 최적화(TPO)를 하나의 스키마로 통합함으로써, 우리는 고도로 효율적인 학습과 풍부한 비전 주석을 통해 현재의 MLLM을 규모에 맞게 향상시킬 수 있습니다.
- InternVideo2.5는 기존 MLLM을 비디오 이해에서 눈에 띄는 성능으로 향상시킬 뿐만 아니라 전문가 수준의 시각적 인식 능력을 부여할 수 있습니다. 구체적으로, InternVideo2.5는 여러 단편 및 장편 비디오 벤치마크에서 선도적인 성능을 달성합니다. InternVideo2.5의 비디오 메모리 용량은 크게 향상되어, 원본보다 최소 6배 더 긴 입력을 유지할 수 있습니다.
2 Related Work
Multimodal Large Language Models. 멀티모달 대형 언어 모델(MLLM)은 보통 비전 인코더, LLM, 그리고 이들을 연결하는 커넥터를 명령어 튜닝을 통해 결합하며, 정확한 사진 설명을 생성하고 시각적 질문에 응답하는 것과 같은 정교한 작업을 처리할 수 있습니다. 모델 아키텍처 [Zohar et al., 2024, Liu et al., 2025, Li et al., 2023, Wang et al., 2022, Ye et al., 2023, 2024], 크기 [Chen et al., 2024c, Zhang et al., 2024c], 능력 [Wang et al., 2024d], 학습 코퍼스 [Li et al., 2024d, Wang et al., 2023, GLM et al., 2024], 선호도 최적화 [Yan et al., 2024, Yu et al., 2024] 등에서 발전이 이루어졌습니다. 현대의 비디오 처리 가능 MLLM은 순차적인 시각 자료를 처리하고 시공간적 변화를 이해하는 능력을 보여주었습니다. 연구들은 서로 다른 비전 인코더 [Zohar et al., 2024]와 커넥터 [Liu et al., 2025]가 MLLM의 성능에 어떻게 영향을 미치는지 논하며, 비디오 인코더가 여전히 이미지 인코더로 대체될 수 없음을 발견했습니다. 또한, MLP 관련 커넥터가 Q-Former, 풀링 및 기타 압축 선호 커넥터만큼 효과적임이 입증되었지만, 후자는 더 효율적인 솔루션을 제공하여 잠재적으로 긴 시각 자료 처리에 이점을 줍니다 [Li et al., 2024e].
Long Video Understanding. 긴 비디오 이해는 멀티모달 대형 언어 모델(MLLM)을 통해 빠른 발전을 보았습니다. 이는 확장된 비디오 콘텐츠를 처리하는 데 어려움을 겪으며, 연구자들이 세 가지 주요 접근 방식을 추구하게 만들었습니다. 첫 번째 방법 [Reid et al., 2024, Wei and Chen, 2024, Xue et al., 2024, Zhang et al., 2024a]은 더 긴 시퀀스를 처리하기 위해 MLLM의 컨텍스트 창 용량을 확장하는 데 중점을 둡니다. 두 번째는 계산량을 줄이기 위한 효율적인 토큰 압축을 강조합니다 [Li et al., 2024f, Fei et al., 2024b, Weng et al., 2025, Tan et al., 2024, Song et al., 2024, Shu et al., 2024]. 세 번째는 계산 복잡성을 관리하기 위해 에이전트를 활용하며, 주로 긴 비디오 이해를 시간적 위치 특정, 시공간적 인식, 그리고 관찰된 증거에 대한 추론으로 분리합니다 [Fan] et al., 2025, Wang et al., 2025]. 컨텍스트 창 확장은 더 긴 비디오 시퀀스를 처리하는 데 유망한 결과를 보여주었습니다. 예를 들어, 병렬 컴퓨팅 [Contributors, 2023]과 같은 고급 학습 시스템은 시간적 및 텐서 차원에서 계산 분포를 최적화하여 더 많은 장치를 사용하여 계산 확장성을 향상시키도록 개발되었습니다. 그러나 이러한 접근 방식 [Reid et al., 2024, Wei and Chen, 2024, Xue et al., 2024, Zhang et al., 2024a]은 더 긴 비디오를 처리할 수 있게 하지만, 통신 비용과 실제 비디오 길이로 인해 장벽에 부딪히는 경우가 많습니다. 토큰 압축은 필수적인 요소를 보존하면서 압축된 비디오 표현을 생성합니다. 이러한 방법들 [Li] et al., 2024f, Fei et al., 2024b, Weng et al., 2025, Tan et al., 2024, Song et al., 2024, Shu et al., 2024]은 높은 압축률을 달성하여 계산적으로 더 효율적입니다. 그러나 상세한 비디오 이해 작업에서의 성능은 종종 부족하며, 때로는 이미지 중심의 MLLM보다 성능이 낮아 압축 중 의미 유지에 개선의 여지가 있음을 시사합니다.
에이전트 기반 방법은 긴 비디오 이해를 기존 전문가 모델과 LLM을 위한 여러 하위 작업으로 분해합니다. 이러한 방법들 |Fan et al., 2025, Wang et al., 2025, Fei et al., 2024a|은 답변 성능과 해석 가능성을 향상시키기 위해 자기 성찰이나 사고의 연쇄와 자주 통합됩니다.
긴 비디오 이해의 평가는 객체 인식, 시간적 추론, 기억력 유지 등 여러 측면을 요구합니다. 최근 벤치마크 개발은 주로 질의응답(QA) 작업에 집중되어 있습니다. 이러한 [Rawal et al., 2024, Song et al., 2024, Zhang et al., 2023b, Huang et al., 2024b, Zhang et al., 2025, Chandrasegaran et al., 2024, Hong et al., 2023, Fang et al., 2024, Li et al., 2024g] 평가는 자기중심적 비디오, 온라인 콘텐츠, 영화, TV 쇼, 감시 영상 등을 포함합니다. 일부 벤치마크는 시간적 추론 [Zhou et al., 2024] 및 줄거리 이해 [Wu et al., 2024a]와 같은 특정 측면에 초점을 맞추는 반면, 다른 벤치마크는 확장된 시퀀스에서 세분화된 정보 검색을 강조합니다 [Zhao et al., 2024, Fu et al., 2024]. 이러한 다양한 평가 방법은 장편 콘텐츠를 처리하는 데 있어 지각적 정확성과 추론 능력을 모두 평가하는 데 도움이 됩니다.
MLLMs for Specific Vision Problems. 기존의 MLLM은 시각적 캡셔닝 및 질의응답과 같은 작업에서 강력한 성능을 보여주었지만, 정확한 예측을 요구하는 분할 및 시간적 위치 특정과 같은 세분화된 시각적 작업을 처리하는 데는 어려움을 겪습니다. 이러한 한계를 해결하기 위해 연구자들은 두 가지 주요 접근 방식을 개발했습니다: 1) 픽셀-투-시퀀스(P2S) 방법론 [Chen et al., 2023b, Ren et al., 2024, Wang et al., 2024a g, Ye et al., 2023]은 MLLM이 직접 텍스트 예측을 생성할 수 있게 합니다. 이러한 시스템은 시간 인식 인코더 및 슬라이딩 비디오 프로세서와 같은 특수 구성 요소를 통합하여 시간적 정보 이해를 향상시킵니다. 2) 픽셀-투-임베딩(P2E) 접근 방식 |Bai et al., 2024, Lai et al., 2024, Wang et al., 2024d, Wu et al., 2024b, Zhang et al., 2023a]은 최종 예측을 위해 전문화된 다운스트림 디코더로 전달하기 전에 시각적 정보를 압축하는 데 중점을 둡니다. 최근 구현에서는 프롬프트 기반 메커니즘을 통해 고급 분할 도구를 활용하며, MLLM을 분할 모듈과 연결하기 위해 특수 토큰을 사용합니다. 일부 시스템은 MLLM과 다양한 디코더 구성 요소 간의 연결을 용이하게 하기 위해 여러 라우팅 토큰과 향상된 쿼리 메커니즘을 사용합니다. 이러한 개발은 더 유능하고 다재다능한 시각적 이해 시스템을 만드는 데 있어 상당한 진전을 나타냅니다.
3 InternVideo2.5: Long and Rich Context Modeling
MLLM을 사용하여 길고 정확한 비디오 이해를 가능하게 하기 위해, 저희는 MLLM 컨텍스트 길이와 세밀함을 향상시키기 위해 InternVideo2.5를 구축하며, 비디오 길이에 적응하는 토큰 표현과 작업 선호도 최적화를 사용합니다. 이는 그림 2에 나와 있습니다. 전체 모델은 단편 및 장편 비디오 데이터뿐만 아니라 고전적인 비전 작업 데이터를 활용하여 세 단계로 학습됩니다. 전체 방법은 아래에 자세히 설명되어 있습니다.
3.1 Video Length Adaptive Token Representation For Long Multimodal Context
우리의 접근 방식은 임의 길이의 비디오 시퀀스를 효율적으로 처리하기 위한 실용적인 길이 적응형 토큰 표현 접근 방식을 도입합니다. 이 방법은 비전 인코더, 비전-언어 커넥터, 언어 모델의 세 가지 주요 구성 요소로 구성된 일반적인 MLLM 아키텍처를 기반으로 합니다. 동적 프레임 샘플링 후, 주어진 파이프라인은
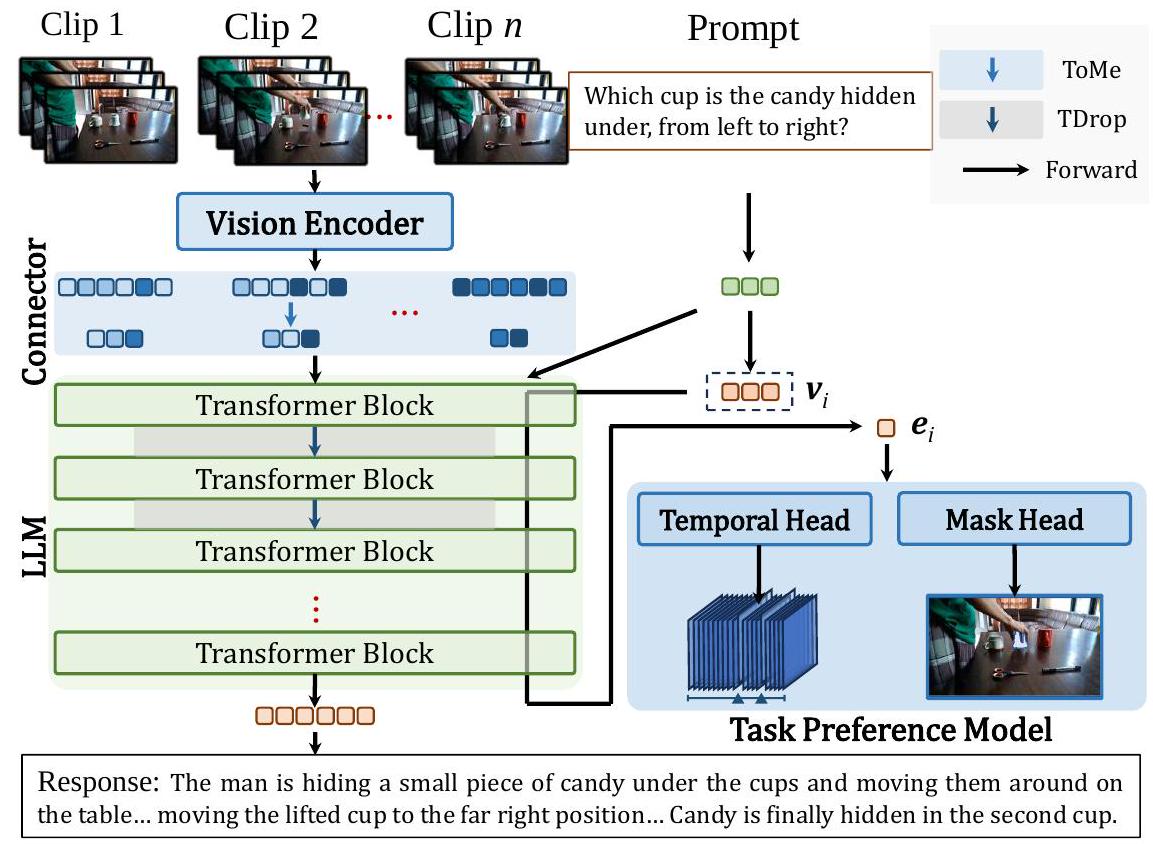
Figure 2: Framework of InternVideo2.5 with the long and rich context (LRC) modeling. 두 가지 독특한 단계로 구성된 계층적 토큰 압축(HiCo)을 구현합니다: 1) 시각적 인코딩 동안의 시공간 인식 압축, 그리고 2) 언어 모델 처리 동안의 적응형 멀티모달 컨텍스트 통합.
Adaptive Temporal Sampling. 저희는 비디오 길이와 콘텐츠 특성에 따라 조정되는 컨텍스트 인식 샘플링 메커니즘을 구현합니다. 움직임의 세밀함이 중요한 짧은 시퀀스의 경우, 조밀한 시간적 샘플링(초당 15프레임)을 사용합니다. 반대로, 이벤트 수준의 이해에 초점을 맞춘 긴 시퀀스(예: 분/시간 단위 비디오)의 경우, 희소 샘플링(초당 1프레임)을 활용합니다. 이 적응형 접근 방식은 다양한 시간적 스케일에서 적절한 움직임 포착을 보장합니다.
Hierarchical Token Compression. 우리는 이벤트의 시공간적 중복성과 이벤트 간의 의미적 중복성을 통해 긴 시각 신호를 압축합니다.
- Spatiotemporal Token Merging. 비디오 시퀀스에 내재된 시간적 중복성을 해결하기 위해, 우리는 입력을 계층적 압축 체계를 통해 처리합니다. 개의 시간적 세그먼트로 나누어진 비디오 시퀀스가 주어지면, 각 세그먼트는 비전 인코더 에 의해 처리되어 번째 세그먼트에 대해 개의 초기 토큰 을 생성합니다. 이 토큰들은 토큰 커넥터 를 통해 적응적 압축을 거쳐 인 개의 압축된 토큰 을 생성합니다:
시공간 토큰의 본질을 유지하기 위해, 토큰 병합 [Bolya et al., 2022]은 의미적 풀링 연산으로 간주될 수 있으며, 가까운 위치 대신 높은 유사도를 가진 토큰을 풀링합니다. 이러한 관계 계산은 몇 번의 반복을 통한 이분 소프트 매칭으로 실현됩니다. 다양한 압축 구성(풀링, MLP, Q-Former 등)에 대한 우리의 경험적 분석(섹션 X)은 의미적 유사도 기반 토큰 병합 [Bolya et al., 2022] (ToMe)을 로서 시공간 스케일에 걸쳐 활용하는 것이 필수적인 세부 사항을 보존하면서 시각적 압축에서 우월함을 보여줍니다. 한편, 우리는 Q-Former에 의한 쿼리 조건부 시각적 토큰 압축이 최신 LLM의 맥락에서 더 이상 성능적으로 경쟁력 있거나 사용자 친화적이지 않다고 주장합니다. Q-Former는 보통 300M개의 학습 가능한 파라미터를 가지며, 최소 10M개의 시각-텍스트 쌍에 대해 여러 에포크의 학습을 요구합니다. 이러한 학습은 비전 또는 언어 모델의 사전 학습이나 지도 미세 조정(SFT)과는 독립적인 반면, ToMe는 풀링처럼 추가적인 튜닝 없이 학습 또는 테스트에 연결하여 사용할 수 있습니다.
- Multimodal Token Dropout. 우리는 장거리 시각적 이해를 더욱 최적화하기 위해 언어 모델 처리 중에 작동하는 토큰 드롭아웃을 도입합니다. 이는 2단계 토큰 감소 전략을 구현합니다: (1) 계산 오버헤드를 줄이면서 구조적 무결성을 유지하기 위한 초기 레이어에서의 균일한 토큰 가지치기, 그리고 (2) 작업 관련 본질을 유지하기 위한 깊은 레이어에서의 주의 기반 토큰 선택.
비디오 시퀀스로부터의 개의 압축된 토큰 에 대해, 우리는 언어 모델 계산 중에 이 가지치기를 적용합니다. 번째 레이어에서의 토큰 표현을 로 표기할 때, 가지치기 연산은 다음과 같이 정의됩니다:
여기서 는 토큰 보존 확률을 나타냅니다. 이 적응형 가지치기 메커니즘은 계산 효율성을 향상시킬 뿐만 아니라 토큰 표현에서 관련 없는 시각적 정보를 줄여 모델 성능을 향상시킵니다.
주어진 비디오 길이 적응형 토큰 표현의 세 단계 모두 학습 불가능하다는 점에 유의하십시오. 그러나 HiCo로 MLLM을 학습하면 HiCo가 더 많은 컨텍스트 적응적 특징에서 학습의 이점을 얻기 때문에 훨씬 더 나은 성능을 낼 것입니다.
3.2 Enhancing Visual Precision in Multimodal Context through Task Preference Optimization
저희는 다중 작업 선호도 학습(MPL)을 통해 멀티모달 언어 모델(MLLM)의 정밀한 시각적 이해 능력을 향상시킵니다. 저희의 접근 방식은 특화된 시각적 인식 모듈을 기본 MLLM 아키텍처와 통합하여 정밀한 위치 파악 및 시간적 이해와 같은 세분화된 시각적 분석 능력을 가능하게 합니다. 이 프레임워크는 시각적 인코더(), 교차 모달 커넥터(), 언어 모델()을 포함하는 핵심 MLLM()으로 구성되며, 작업별 헤드 (여기서 )로 구성된 특화된 시각적 인식 모듈()로 강화됩니다. 이 헤드들은 학습 가능한 작업 토큰 에서 파생된 학습된 작업 임베딩 를 통해 MLLM과 상호 작용합니다.
Visual Perception Preference. 시각적 인식 모듈은 정밀한 시각적 이해에 필수적인 두 가지 기본 기능을 통합합니다:
- Temporal Understanding. 동적 시각 콘텐츠 처리를 위해, 저희는 비디오 특징 추출과 시간적 정렬 기능을 결합한 시간적 구성 요소를 개발합니다. 이 모듈은 시각적 시퀀스와 텍스트 쿼리를 모두 입력받아, 작업별 시간적 임베딩을 통합하여 정확한 시간적 경계와 관련성 점수를 예측합니다.
- Instance Segmentation. 픽셀 수준의 정밀한 이해와 인스턴스 수준의 구별을 가능하게 하기 위해, 저희는 분할을 위한 기초 모델의 최신 발전을 기반으로 한 분할 모듈을 설계합니다. 이 모듈은 이미지 인코더, 마스크 디코더, 그리고 MLLM 임베딩과 픽셀 수준 예측을 연결하는 적응형 투영 레이어로 구성됩니다.
MLLM의 일반적인 능력을 보존하면서 이러한 특화된 능력을 효과적으로 통합하기 위해, 저희는 시각적 인식 모듈 와 함께 MLLM 를 다음과 같이 최적화합니다:
여기서 는 입력 쿼리를, 는 작업 레이블을, 그리고 는 작업별 주석을 나타냅니다. 우리의 프레임워크는 특정 시각 분석 작업에서 MLLM의 정밀도를 크게 향상시켜 일반적인 능력을 개선합니다. 모듈식 설계는 효율적인 계산 및 학습 동역학을 유지하면서 추가적인 시각적 이해 능력으로의 유연한 확장을 허용합니다.
3.3 Training Video Corpus for Multimodal Context Modeling
학습 과정은 세 단계로 구성되며, 시각-텍스트 정렬 데이터, 장편 비디오 데이터 및 작업별 시각 데이터가 사용됩니다. 학습 데이터는 표 1에서 확인할 수 있습니다.
Visual-Text Data For Crossmodal Alignment. 우리는 7백만 개의 이미지-텍스트 쌍과 370만 개의 비디오-텍스트 쌍으로 구성된 시각-텍스트 데이터 컬렉션을 큐레이팅하며, 언어 능력 향상을 위해 14만 3천 개의 텍스트 데이터도 포함합니다. 시각-캡션 쌍의 경우, 학습 편의를 위해 질의응답(QA) 형식으로 변환합니다. 구체적으로,
- Image-Text. 저희는 COCO118K, BLIP558K, CC3M 데이터셋 [Li et al., 2024a]에서 LLava-NeXT-34B [Zhang et al., 2024c]로 다시 캡션된 350만 개의 상세 이미지 설명을 활용합니다. 지시 데이터로는 LLava-NeXT [Zhang et al., 2024c], Allava [Chen et al., 2024a], ShareGPT4O [Chen et al., 2024c, Wang et al., 2024f]의 단일 이미지 지시와 LLaVA-Interleave [Li et al., 2024b]의 다중 이미지 지시를 사용합니다. 추가적으로, LCS-558K [Liu et al., 2024]에서 55만 8천 개의 이미지-텍스트 쌍을 통합합니다.
- Video-Text. 우리의 비디오-텍스트 데이터는 VideoChat2 [Li et al., 2024c]로 다시 캡션된 WebVid2M [Bain et al., 2021] 설명과, Gemini [Reid et al., 2024][Share, 2024]로 다시 캡션된 WebVid [Bain et al., 2021] 및 Kinetics [Kay] et al., 2017]의 32만 3천 개의 상세 설명으로 구성됩니다. 지시 미세 조정을 위해 VideoChat2[Li et al., 2024c]와 InternVideo2 [Wang et al., 2024f]의 단편 비디오 데이터를 사용하며, ShareGPT4o [Chen et al., 2024c, Wang et al., 2024f], VideoChatGPT-Plus [Maaz et al., 2024], LLaVA-Video-178K [Zhang et al., 2024d], LLava-Hound [Zhang et al., 2024b]의 GPT4o 주석 데이터를 보완합니다.
- Text. 저희는 Evo-Instruct 데이터셋 [Chen et al., 2024a]에서 14만 3천 개의 샘플을 통합합니다.
Long Video Corpus for Context Extension. 저희는 주로 MoiveChat [Song] et al., 2024], Cineplie [Rawal et al., 2024], Vript [Yang et al., 2024] 및 저희의 LongVid에서 제공하는 긴 비디오 지시 데이터를 활용했습니다. 긴 비디오 모델을 훈련하는 데 있어 중요한 과제는 대규모의 고품질 데이터가 부족하다는 점입니다. 최근의 발전이 비디오-텍스트 쌍의 장편 데이터셋을 통해 이 문제를 어느 정도 완화했지만, 이러한 데이터셋은 멀티모달 추론에 필수적인 (비디오, 지시, 답변) 삼중항과 같은 지시-따르기 패러다임이 부족합니다. 이 문제를 해결하기 위해, 저희는 [Li et al., 2024e]에서 제공하는 LongVid라는 이름의 대규모 긴 비디오 지시-튜닝 데이터셋을 사용합니다. 이 데이터셋은 114,228개의 긴 비디오와 5가지 다른 작업 유형에 걸친 3,444,849개의 질의응답(QA) 쌍으로 구성되어, 모델이 다양한 긴 비디오 시나리오를 처리할 수 있도록 합니다.
| Stage | Task | Samples | Datasets |
|---|---|---|---|
| Stage 1 | Segmentation | 50 K | SAMv2, MeViS |
| Temporal Grounding | 50 K | DiDeMo, QuerYD | |
| Spatial Grounding | 50 K | RefCOCO, RefCOCOg, RefCOCO+ | |
| Alignment data | 1M | LCS-558K, S-MiT | |
| Stage 2 | Segmentation | 114.6 K | SAMv2, MeViS |
| Temporal Grounding | 116.5 K | DiDeMo, QuerYD, HiRest, ActivityNet, TACoS, NLQ | |
| Spatial Grounding | 540.0 K | AS-V2, Visual Genome, RefCOCO, RefCOCO+, RefCOCOg | |
| Visual Concept | 6M | VideoChat2-IT, WebVid2M, Share-Gemini, LLaVA-NexT, Evo-Instruct | |
| Stage 3 | Temporal Grounding | 7.5 K | QVHighlight |
| Segmentation | 116.5 K | MeViS, SAMv2 | |
| Temporal Reasoning | 40 K | YouCook2, ActivityNet | |
| Spatial Grounding | 400 K | AS-V2, Visual Genome, RefCOCO, RefCOCO+, RefCOCOg | |
| Conversation | 3.5 M | VideoChatGPT-Plus, LLaVA-Video, LLaVA-Hound, MovieChat, Vript, LongVid |
Table 1: The training data specifications encompass more than the standard public video question-answering datasets. In addition to common data, we incorporate annotations from lengthy videos and typical vision task data.
Task-Specific Data for Accurate Perception.
- Segmentation. 저희는 참조 분할(referring segmentation) 작업을 위해 MeViS [Ding et al., 2023]와 SAMv2 [Ravi et al., 2024]를 사용합니다.
- Spatial Grounding. 저희는 AS-V2 [Wang et al., 2024c], Visual Genome [Krishna et al., 2017], RefCOCO [Yu et al., 2016], RefCOCOg [Yu et al., 2016], RefCOCO+ [Yu et al., 2016]를 총 배치 크기 128로 한 에포크 동안 사용하여 영역 헤드와 토큰을 학습합니다.
- Temporal Grounding. 저희는 DiDeMo [Hendricks et al., 2017], QuerYD [Oncescu et al., 2021], HiRest [Zala et al., 2023], ActivityNet [Caba Heilbron et al., 2015], TACoS [Regneri et al., 2013], NLQ [Grauman et al., 2022]를 활용합니다.
3.4 Progressive Multi-stage Training
우리는 MLLM의 세밀한 인식 능력과 시간적 이해 능력을 공동으로 향상시키는 통합된 점진적 학습 체계를 제안합니다. 우리의 접근 방식은 작업의 복잡성과 비디오 입력의 시간적 길이를 점진적으로 증가시키는 세 가지 주요 단계로 구성됩니다.
Stage 1: Foundation Learning. 이 초기 단계는 두 가지 병렬 목표에 초점을 맞춥니다: (a) 다양한 대화 템플릿을 사용하여 LLM을 위한 작업 인식 지시 튜닝을 통해 모델이 다양한 시각적 작업을 식별하고 라우팅할 수 있도록 합니다; 그리고 (b) 시각적 인코더와 LLM을 고정하고 압축기와 MLP를 최적화하여 기본적인 시각-언어적 연결을 설정하는 비디오-언어 정렬 학습입니다. 이 단계에서는 비디오당 4프레임의 0.5M 이미지-텍스트 쌍과 0.5M 단편 비디오-텍스트 쌍을 활용합니다.
Stage 2: Fine-grained Perception Training. 이 단계는 다음을 통해 모델의 시각적 이해 능력을 향상시킵니다: (a) 작업 토큰, 영역 헤드, 시간적 헤드, 마스크 어댑터를 포함한 작업별 구성 요소를 작업별 데이터셋을 사용하여 통합 및 학습합니다; 그리고 (b) 3.5M 이미지와 비디오당 8프레임의 2.5M 단편 비디오-텍스트 쌍을 사용하여 시각적 개념 사전 학습을 수행합니다. 이 단계 동안 LLM은 새로운 시각적 기술을 습득하면서 일반적인 능력을 유지하기 위해 LoRA를 사용하여 업데이트됩니다.
Stage 3: Integrated Accurate and Long-form Context Training. 마지막 단계는 다음을 통해 모든 모델 구성 요소를 공동으로 최적화합니다: (a) 멀티모달 대화와 특정 작업 데이터를 결합한 혼합 코퍼스에 대한 다중 작업 학습을 통해, 작업 감독 그래디언트가 특화된 헤드에서 MLLM으로 흐르도록 합니다; 그리고 (b) 1.1M 이미지, 1.7M 단편 비디오(<60s), 0.7M 장편 비디오(60-3600s)를 포함한 3.5M 샘플의 포괄적인 데이터셋에 대한 지시 튜닝을 수행합니다. 우리는 64-512 프레임의 동적 비디오 샘플링을 사용하고, 비전 인코더, 커넥터, 작업 토큰, 특화된 헤드 및 LoRA를 사용하는 LLM을 포함한 전체 모델을 튜닝합니다. 이 점진적 학습 전략은 모델이 세밀한 인식과 장편 비디오 이해를 모두 개발하면서 일반적인 능력의 잠재적 저하를 완화할 수 있게 합니다. 컨텍스트 창을 확장하기 위해 장문 텍스트에 의존하는 이전 접근 방식과 달리, 장편 비디오에 대한 직접적인 학습은 학습과 배포 시나리오 간의 격차를 최소화합니다.
3.5 Implementation
Distributed System. 우리는 수백만 개의 멀티모달 토큰(대부분 시각적)에 대한 학습 및 테스트를 위해 XTuner를 기반으로 한 멀티모달 시퀀스 병렬 처리 시스템을 개발합니다. 여러 오픈 소스 솔루션 [Xue et al., 2024, Fang and Zhao, 2024, Jacobs et al., 2023, Rasley et al., 2020, Liu et al., 2023]을 기반으로, 우리는 시퀀스 및 텐서 분산 처리와 멀티모달 동적 (소프트) 데이터 패킹을 통합하여 긴 비디오의 확장 가능한 컴퓨팅을 가능하게 합니다.
멀티모달 토큰 시퀀스를 효율적으로 분배하기 위해, 우리는 이를 멀티 헤드 셀프 어텐션(MHSA)의 헤드 처리와 입력 시퀀스 길이로 나눕니다. 구체적으로, 우리는 DeepSpeed-Ulysses [Jacobs et al., 2023]의 텐서 병렬 컴퓨팅을 위해 All-to-All(A2A) 통신을 사용합니다. 이것이 어텐션의 헤드 수에 제한되므로, 우리는 Peer-to-Peer(P2P) 통신에서 병렬 처리 수준을 높이기 위해 시퀀스에 대한 동시 컴퓨팅을 실현하기 위해 링-어텐션 [Liu et al., 2023]을 추가로 통합합니다. 노드 간 높은 전송 속도와 노드 내 낮은 속도 설정을 고려하여, 우리는 A2A를 노드 간 컴퓨팅에 할당하고 P2P를 노드 내 컴퓨팅에 할당하는 2D-어텐션 전략 [Fang and Zhao, 2024]을 활용합니다. A2A를 위해서는 모든 장치가 다른 모든 장치와 통신해야 하지만, P2P를 위해서는 링 구조의 두 이웃과만 통신하면 되기 때문입니다.
학습 비디오 길이의 분산에 관해서, 우리는 데이터를 묶어서 (또는 일부 연구에서는 샤딩하여) 배치 학습을 위한 데이터 크기를 통일해야 합니다. 주류 MLLM 학습에서 널리 채택되는 간단한 패딩 전략은 동일한 배치에서 짧은 시퀀스는 패딩하고 긴 시퀀스는 목표 길이로 자르는 것입니다. 단순함에도 불구하고, 입력에 너무 많은 자리 표시자를 채우기 때문에 데이터 활용 효율성에는 개선의 여지가 있습니다. 대조적으로, 우리는 동적 패킹 전략을 사용합니다. 각 학습 반복에서 고정된 시퀀스 길이가 주어지면, 입력 시퀀스를 순서대로 동적으로 병합하여 새로운 시퀀스를 만듭니다 (총 길이가 목표를 초과하지 않도록 보장). 이는 특히 학습 비디오 길이의 분포가 균일하지 않을 때 GPU 메모리 사용량을 최대화하여 속도 향상 비율을 달성할 수 있음을 유의하십시오.
Model Configuration. 우리의 멀티모달 아키텍처에서는 고급 비디오 처리 및 언어 모델링 기능을 결합한 포괄적인 프레임워크를 활용합니다. 이 시스템은 동적 비디오 샘플링을 구현하여 64512 프레임을 처리하며, 각 8프레임 클립은 128개의 토큰으로 압축되어 프레임당 약 16개의 토큰 표현을 생성합니다. 아키텍처는 시각적 인코딩을 위해 InternViT [Chen et al., 2024b]를 통합하고, MLP 기반 토큰 병합 메커니즘과 언어 모델로 InternLM2.5-7B [Cai et al., 2024]를 함께 사용합니다. 프레임워크는 CG-DETR 아키텍처 [Moon et al., 2023] 기반의 시간적 헤드(Temporal Head)와 SAM2의 사전 훈련된 가중치를 활용하는 마스크 헤드(Mask Head) 등 여러 전문 구성 요소를 통합합니다. 시간적 처리를 위해 시스템은 비디오 특징 추출에 InternVideo2 [Wang et al., 2024f]를 활용하고, 쿼리 특징은 언어 모델을 통해 처리됩니다. 시공간 기능을 향상시키기 위해, 우리는 위치 지정 프롬프트와 공간 입력 인코딩 모두를 멀티모달 언어 모델에 통합하기 위해 2계층 MLP를 구현합니다.
4 Experiments
우리는 InternVideo2.5-7B를 기본 모델 및 기타 비교 대상과 함께 주류 멀티모달 비디오 이해 및 고전적인 비전 작업에 대해 평가합니다. HiCo 및 TPO를 MLLM에 통합함으로써, InternVideo2.5는 단편 및 장편 비디오 대화(표 2)와 추적과 같은 일반적인 비전 작업(표 3)을 처리할 수 있습니다.
| Model | Size | #Tokens | MVBench | PerceptionTest | EgoSchema | LongVideoBench | MLVU | VideoMME | LVBench |
|---|---|---|---|---|---|---|---|---|---|
| Average duration (sec) | 16 | 23 | 180 | 473 | 651 | 1010 | 4101 | ||
| Proprietary Models | |||||||||
| GPT4-V OpenAI, 2023 | - | - | 43.7 | - | - | 59.1 | 49.2 | 59.9 | - |
| GPT4-o |OpenAI, 2024 | - | - | 64.6 | - | 72.2 | 66.7 | 64.6 | 71.9 | 30.8 |
| Gemini-1.5-Pro |Reid et al., 2024] | - | - | 60.5 | - | 71.2 | 64.0 | - | 75.0 | 33.1 |
| Open-Source MLLMs | |||||||||
| InternVL2 | 8B | 256 | 66.4 | - | - | - | - | 54.0 | - |
| InternVL2 | 76B | 256 | 69.6 | - | - | - | - | 61.2 | - |
| LLaVA-NeXT-Video |Zhang et al., 2024c | 7B | 144 | 53.1 | 48.8 | - | 49.1 | - | 46.5 | - |
| LLaVA-OneVision L1 et al., 2024a | 7B | 196 | 56.7 | 57.1 | 60.1 | 56.3 | 64.7 | 58.2 | - |
| LLaVA-OneVision L1 et al., 2024a | 72B | 196 | 59.4 | 66.9 | - | 61.3 | 68.0 | 66.2 | 26.9 |
| VideoLLaMA2 |Cheng et al., 2024 | 7B | 72 | 54.6 | 51.4 | 51.7 | - | 48.5 | 47.9 | - |
| VideoLLaMA2 Cheng et al., 2024 | 72B | 72 | 62.0 | 57.5 | 63.9 | - | - | 62.4 | - |
| mPLUG-Owl3 Ye et al., 2024 | 7B | - | 54.5 | - | - | 52.1 | - | 53.5 | 43.5 |
| QwenVL2 | 7B | - | 67.0 | 62.3 | 66.7 | - | - | 63.3 | - |
| QwenVL2 | 72B | - | 73.6 | 68.0 | 77.9 | - | - | 71.2 | 41.3 |
| VideoChat2-HD L1 et al., 2024c | 7B | 72 | 62.3 | - | - | - | 47.9 | 45.3 | - |
| InternVideo2-HD Wang et al., 2024f | 7B | 72 | 67.2 | 63.4 | 60.0 | - | - | 49.4 | - |
| VideoChat-TPO Yan et al., 2024 | 7B | 64 | 66.8 | - | - | - | 54.7 | - | - |
| InternVL2.5 Chen et al., 2024b | 7B | 256 | 72.0 | 68.2 | 51.5 | 60.0 | 68.9 | 64.2 | 38.4 |
| Open-Source Long Video MLLMs | |||||||||
| LLaMA-VID Li et al., 2024f | 7B | 2 | 41.9 | 44.6 | - | - | 33.2 | 25.9 | 23.9 |
| LongVILA | Xue et al., 2024 | 7B | 196 | - | - | 67.7 | - | - | 57.5 | - |
| LongVA Zhang et al., 2024a | 7B | 144 | - | - | - | - | 56.3 | 52.6 | - |
| LongLLa VA Wang et al., 2024e] | 9B | 144 | 49.1 | - | - | - | - | 43.7 | - |
| LongVU Shen et al., 2024 | 7B | 64 | 66.9 | - | 67.6 | - | 65.4 | - | - |
| VideoChat-Flash L1 et al., 2024e | 7B | 16 | 73.2 | 75.6 | - | 64.2 | 74.5 | 64.0 | 47.2 |
| InternVideo2.5 (internVL2.5+LRC) | 7B | 16 |
Table 2: Performance on video question-answering benchmarks, covering both short and long videos. The models and their corresponding results, displayed in gray font, are based on LLMs of over 7 billion parameters in size.
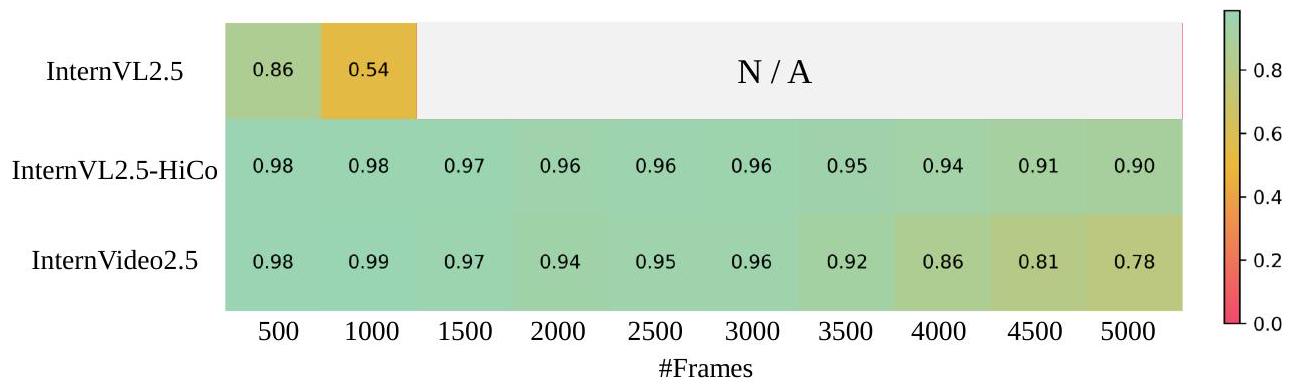
Figure 3: Single-hop Needle-in-a-haystack evaluation results using 5,000 frames using 16 A100 (80G) GPUs.
4.1 Video Understanding
표 2에서 볼 수 있듯이, InternVideo2.5는 약 7B LLM 용량 수준에서 모든 인기 있는 단편 및 장편 비디오 질의응답 벤치마크에서 거의 최고의 성능을 달성합니다. 사용된 기본 MLLM인 InternVL2.5와 비교할 때, InternVideo2.5는 단편 또는 장편 예측에 관계없이 전반적인 증가를 보입니다. 단편 비디오를 다룰 때 상승폭이 두드러지며, InternVideo2.5는 InternVL2.5를 기반으로 MVBench와 Perception Test에서 3포인트 이상 증가합니다. 장편 비디오 이해에 관해서는 전체적인 추세는 여전히 상승하고 있지만 변동은 다른 벤치마크에서 다르게 나타납니다. EgoSchema (test) [Mangalam et al. 2023], MLVU (+3.9) [Zhou et al., 2024], LVBench (+8.0) [Wang et al., 2024b]에서는 가져온 증가가 명확하지만, LongVideoBench (+0.6) |Wu et al., 2024a| 및 VideoMME (wo sub) (+0.9) [Fu et al., 2024]에서는 상대적으로 미미합니다. 우리는 이것이 후자의 두 벤치마크의 질문이 인지된 증거보다는 세계 지식과 추론에 더 의존하기 때문이라고 생각합니다. 왜냐하면 이들에 대한 성능 증가는 더 큰 언어 모델에서 더 분명하기 때문입니다.
GPT4-o와 Gemini-1.5-Pro와 같은 유명한 독점 모델과의 비교에서, InternVideo2.5는 단기간 시공간 이해에서 우월성을 보이는 반면 장편 비디오에서는 (MLVU를 제외하고) 열등한 결과를 보입니다. 이는 우리가 학계와 오픈 소스 관점에서 비전 분야에서 큰 진전을 이루었음에도 불구하고 비전-언어 융합 및 긴 컨텍스트 모델링을 위해 탐구할 여지가 아직 많다는 것을 의미할 수 있습니다.

Figure 4: An example of InternVideo2.5: it can depict spatiotemporal movements with precise temporal references.

Figure 5: An example of InternVideo2.5: it can track the target specified by users and reason over it.
Needle-In-The-Haystack (NIAH). HiCo와 긴 비디오 학습 코퍼스를 통해 InternVideo2.5는 InternVL2.5의 암묵적 기억(8B 모델)을 현저히 향상시킵니다. 5,000 프레임을 사용한 단일 홉 건초더미에서 바늘 찾기(NiAH) 작업을 통해 InternVideo2.5는 우수한 회상 능력을 보여줍니다. 모든 모델은 16개의 A100(80GB) GPU에서 평가되었습니다.
그림 3에서 볼 수 있듯이, InternVL2.5-8B는 500 프레임 내에서도 목표 프레임을 정확하게 회상하는 데 어려움을 겪으며, [Zhang et al., 2024a, Xue et al., 2024]에서 설정된 기억력에 대한 95% 정확도 기준에 미치지 못합니다. 더욱이 긴 비디오 입력을 처리하면 1,000 프레임을 초과할 때 메모리 부족(OOM) 오류가 발생합니다. 반면, HiCo와 긴 비디오 학습의 이점을 얻은 InternVideo2.5는 최대 3,000 프레임 시퀀스에서 프레임을 정확하게 회상하고 OOM 문제없이 10,000 프레임 이상을 처리합니다. LRC 변형()은 최대 3,000 프레임까지 높은 회상률을 유지하지만, 이 지점을 넘어서면 성능이 저하되는데, 이는 훈련 데이터(주로 짧은 비디오)와 긴 비디오 평가 설정 간의 불일치 때문일 가능성이 높습니다. 향후 연구에서는 데이터 비율을 조정하고 TPO에 대한 긴 형식 비디오 주석을 통합하여 이 문제를 완화하는 방안을 탐색할 수 있습니다. 또한 LLM의 컨텍스트 모델링은 MLLM의 컨텍스트에 직접적인 영향을 미칩니다. 따라서 LLM의 컨텍스트를 강화하거나 더 효과적인 것을 활용하면 성능을 더욱 향상시킬 수 있습니다.
Qualitative Evaluations. 그림 4, 5, 6에서 InternVideo2.5와 VideoChat2 |Li et al., 2024c|에 의해 평가된 몇 가지 실제 사례를 제시합니다. InternVideo2.5는 상세한 동작 설명과 구체적인 시간을 제공하고, 추가적인 추론을 위해 목표를 추적(또는 분할)하며, 긴 시각적 입력을 이해할 수 있습니다.
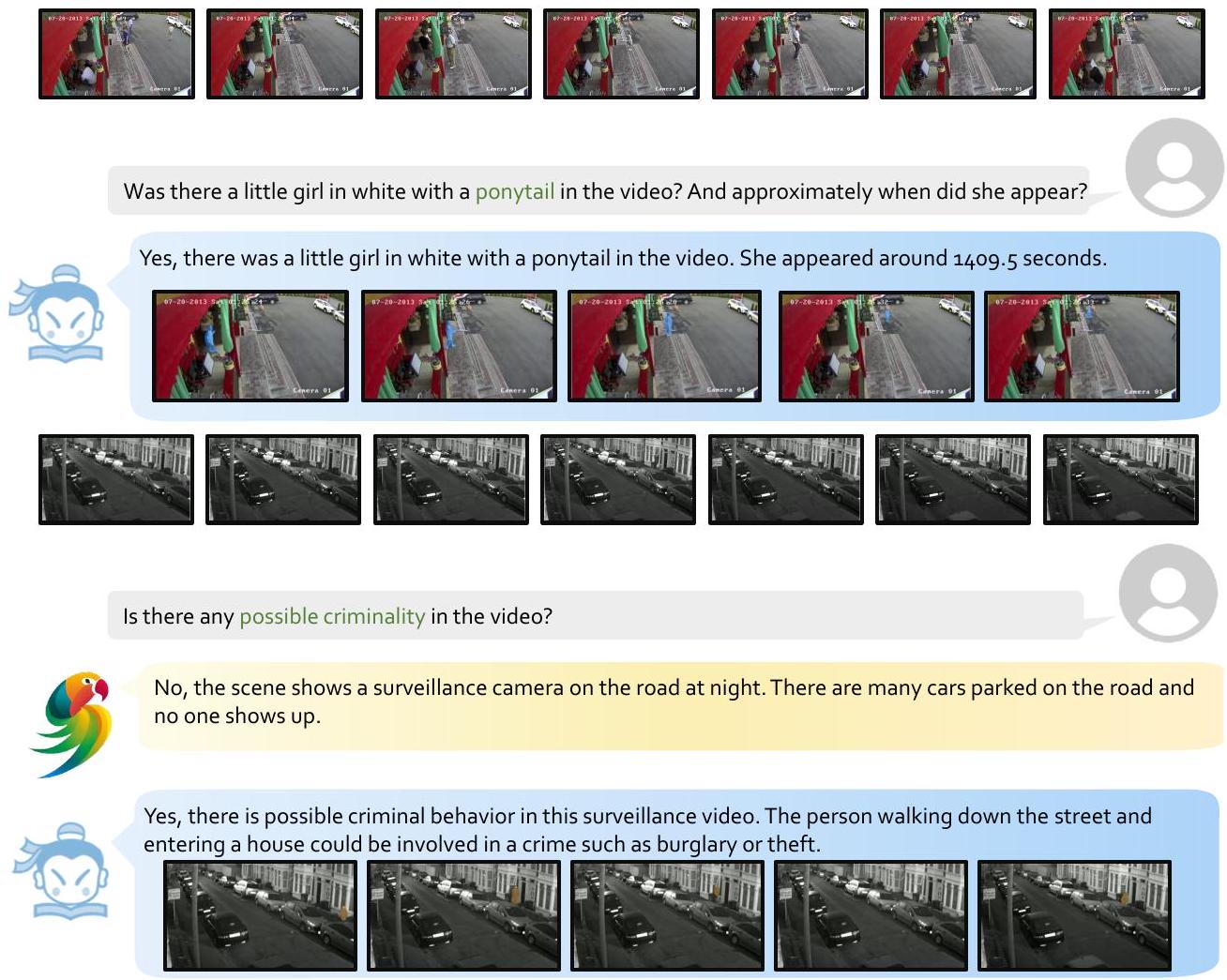
Figure 6: Examples of InternVideo2.5: it can can comprehend extended surveillance videos for moment retrieval or abnormal event detection.
4.2 Specific Vision Tasks
TPO의 최적화 이후, MLLM은 비디오 대화의 이해 능력을 향상시킬 뿐만 아니라, 모멘트 검색, 참조 추적 등과 같은 특정 조밀하게 주석이 달린 시각적 작업을 처리할 수 있는 능력을 갖게 됩니다. TPO를 통해 MLLM은 추적과 같은 고전적인 시각 능력을 마스터합니다. 표 3은 InternVideo2.5가 추적, 비디오 참조 분할, 시간적 그라운딩 및 기타 작업을 전문가 모델 수준의 성능으로 수행할 수 있으며, 대부분의 작업에서 다른 MLLM을 명확하게 능가함을 보여줍니다. 또한 [Yan et al., 2024]에서와 같이 멀티모달 질의응답과 일반적인 시각 작업 간의 공동 학습이 서로에게 이익이 될 수 있음을 검증합니다.
4.3 Ablation Studies
How token representation length affects Model Performance. 표 4는 HiCo에서 각 프레임에 대한 토큰 수가 비디오 벤치마크에서 InternVL2.5에 미치는 영향을 보여줍니다. HiCo에서 더 적은 토큰 수로 인한 감소는 단편 비디오 벤치마크에서는 상대적으로 미미하지만(약 0.5포인트), 장편 비디오 벤치마크에서는 무시할 수 없는 수준(약 1-3포인트)입니다. 이는 긴 멀티모달 컨텍스트에서 탐색할 성능의 여지가 여전히 상당히 남아 있음을 경험적으로 검증합니다.
The compatibility between HiCo and TPO. 저희는 표 5에서 HiCo와 TPO가 MLLM을 개선하는 데 있어 호환 가능하고 직교적임을 추가로 보여줍니다. HiCo와 TPO의 훈련을 함께 결합하면 세 단계로 전체 학습을 단순화할 뿐만 아니라, 단편 및 장편 비디오 벤치마크 결과를 눈에 띄게 향상시키고 MLLM의 NIAH를 가능하게 합니다. InternVL2.5-HiCo와 비교하여, InternVideo2.5는 MVBench, Percpetion Test, EgoSchema, LongVideoBench, MLVU에서 각각 1.7, 3.5, 1.0, 1.0, 1.3 포인트의 무시할 수 없는 증가를 얻습니다. VideoMME에서의 효과는 증가가 0.2에 불과하여 거의 관찰되지 않았습니다. 이는 TPO가 고전적인 비전 감독을 통해 단편 및 장편 비디오 인식을 모두 향상시킬 수 있지만, 입력 비디오가 매우 길어지면(약 15분 이상) 이러한 이점이 사라진다는 것을 보여줍니다.
| Method | Charades-STA | Highlight Detection | Ref-YouTube-VOS | MeViS J&F | LaSOT | GOT-10k | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@0.5 | mIoU | mAP | HIT@1 | J&F | Success | Overlap | ||||||
| UniVTG |Lin et al., 2023 | 25.2 | 27.1 | 40.5 | 66.3 | - | - | - | - | - | - | ||
| ReferFormer | Wu et al. | 2022 | - | - | - | - | 62.9 | 31.0 | - | - | - | - |
| OnlineRefer | Wu et an., 2023 | - | - | - | - | 62.9 | - | - | - | - | - | |
| TFVTG(GPT | -4T) 11 | 49.9 | 44.5 | - | - | - | - | - | - | - | - | |
| VideoChat2 | Li et al., 2024c | 14.3 | 24.6 | - | - | - | - | - | - | - | - | |
| VTimeLLM | Huang et al., 2024a | 27.5 | 31.2 | - | - | - | - | - | - | - | - | |
| TimeChat Ren et al., 2024 | 32.2 | - | 21.7 | 37.9 | - | - | - | - | - | - | ||
| HawkEye Wang et al., 2024g. | 31.4 | 33.7 | - | - | - | - | - | - | - | - | ||
| ChatVTG Qu et al., 2024 | 33.0 | 34.9 | - | - | - | - | - | - | - | - | ||
| LISA |Lai et al., 2024 | - | - | - | - | 52.6 | - | - | - | - | - | ||
| VideoLISA |Ba1 et al., 2024 | - | - | - | - | 63.7 | 44.4 | - | - | - | - | ||
| SiamFC |Bertinetto et al., 2016 | - | - | - | - | - | - | 33.6 | 42.0 | 34.8 | 35.3 | ||
| ATOM [Danelljan et al., 2019 | - | - | - | - | - | - | 51.5 | - | 55.6 | 63.4 | ||
| SiamRPN++ L1 et al.. 2019 | - | - | - | - | - | - | 49.6 | 56.9 | 51.8 | 61.8 | ||
| SiamFC++ Xu et al., 2020 | - | - | - | - | - | - | 54.4 | 62.3 | 59.5 | 69.5 | ||
| LLaVA-1.5 |Liu et al., 2024 | - | - | - | - | - | - | 19.4 | 16.5 | 23.5 | 20.2 | ||
| Merlin |Yu et al., 2025 | - | - | - | - | - | - | 39.8 | 40.2 | 51.4 | 55.9 | ||
| VideoChat-TPO | 40.2 | 38.8 | 66.2 | 63.9 | 47.0 | 69.4 | 70.6 | 79.8 | ||||
| InternVideo2.5 | 43.3 | 41.7 | 34.7 | 60.3 | 34.2 | 32.0 | 71.5 | 82.1 | 72.4 | 83.0 |
Table 3: Performance on Specific Visual Tasks. The grey means is an expert model without LLM, and the tasks they can handle are limited to those that are fine-tuned.
| Base Model | #Tokens | MVBench | PerceptionTest | EgoSchema | LongVideoBench | MLVU | VideoMME |
|---|---|---|---|---|---|---|---|
| InternVL2.5-HiCo | 64 | 74.4 | 71.9 | 65.7 | 62.7 | 72.6 | 66.4 |
| InternVL2.5-HiCo | 16 | 74.0 | 71.4 | 62.9 | 59.6 | 71.5 | 64.9 |
Table 4: Performance of InternVL2.5 using HiCo with varying numbers of tokens per frame.
| Base Model | LRC | MVBench | PerceptionTest | EgoSchema | LongVideoBench | MLVU | VideoMME | |
|---|---|---|---|---|---|---|---|---|
| HiCo | TPO | |||||||
| InternVL2.5 | 72.0 | 68.2 | 51.5 | 60.0 | 68.9 | 64.2 | ||
| InternVL2.5 | 74.0 | 71.4 | 62.9 | 59.6 | 71.5 | 64.9 | ||
| InternVL2.5 | 75.7 | 74.9 | 63.9 | 60.6 | 72.8 | 65.1 |
Table 5: Evaluating HiCo and TPO compatibility on InternVL2.5.
5 Concluding Remarks
이 논문은 길고 풍부한 컨텍스트(LRC) 모델링을 통해 기존의 인식 및 이해 능력을 향상시키기 위한 새로운 버전의 비디오 MLLM인 InternVideo2.5를 소개했습니다. 컨텍스트 해상도—길이(메모리)와 세밀함(집중) 측면에서—를 개선하는 데 초점을 맞춤으로써, InternVideo2.5는 현재의 MLLM이 세부 사항을 강조하며 더 긴 비디오를 이해할 수 있도록 합니다. 우리의 접근 방식은 직접 선호도 최적화를 활용하여 조밀한 시각적 주석을 MLLM으로 전달하고, 효율적인 시공간 표현을 위해 적응형 계층적 토큰 압축을 사용합니다. 실험 결과는 InternVideo2.5가 약 7B 모델 크기에서 다양한 비디오 이해 벤치마크에서 최첨단 성능을 달성하며, 적용된 MLLM에 비해 입력 비디오 시퀀스 길이를 6배 증가시켰음을 보여줍니다. 또한, InternVideo2.5는 객체 추적을 포함한 향상된 시각적 능력을 보여주며, LRC가 기본 비전 작업과 상위 수준 추론 모두를 개선하는 데 효과적임을 보여줍니다. 이 연구는 멀티모달 컨텍스트 해상도와 풍부함이 MLLM 능력을 발전시키는 데 중요한 역할을 한다는 점을 강조하며, 향상된 컨텍스트 처리를 통한 MLLM 성능 개선에 대한 유망한 연구 방향을 제공합니다.
Limitations. 저희는 긴 비디오 시퀀스에서 향상된 성능을 보여주었지만, 이렇게 확장된 컨텍스트를 처리하는 계산 비용은 여전히 상당합니다. 이러한 오버헤드를 줄이기 위해 더 효율적인 학습 기술을 탐색하는 추가 연구가 필요합니다. 또한, 현재 구현은 주로 시각적 컨텍스트 속성에 초점을 맞추고 있습니다. LRC를 추론 관련 영역으로 확장하는 것은 향후 연구를 위한 유망한 길을 제시하며 MLLM 능력을 더욱 검증할 수 있을 것입니다.
Footnotes
-
*Equal contribution. Corresponding authors. ↩