InternVideo2: 멀티모달 비디오 이해를 위한 파운데이션 모델 스케일링
새로운 비디오 파운데이션 모델(ViFM) 제품군인 InternVideo2를 소개합니다. 이 모델은 Masked video modeling, Cross-modal contrastive learning, Next token prediction을 통합하는 점진적 학습 접근 방식을 통해 비디오, 비디오-텍스트, 비디오 중심 대화 작업에서 최고의 성능을 달성합니다. 6B 파라미터까지 확장된 이 모델은 의미적으로 분할된 비디오와 비디오-오디오-음성 캡션을 사용하여 시공간적 일관성을 우선시하고 비디오와 텍스트 간의 정렬을 개선합니다. 논문 제목: InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
논문 요약: InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
- 논문 링크: https://arxiv.org/abs/2403.15377
- 저자: Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Chenting Wang, Guo Chen, Baoqi Pei, Ziang Yan, Rongkun Zheng, Jilan Xu, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, Limin Wang (OpenGVLab, Shanghai AI Laboratory, Nanjing University, Shenzhen Institutes of Advanced Technology, CAS)
- 발표 시기: 2024년, European Conference on Computer Vision (ECCV)
- 주요 키워드: Video Foundation Model, Multimodal Learning, Masked Video Modeling, Cross-modal Contrastive Learning, Next Token Prediction, Video Understanding
1. 연구 배경 및 문제 정의
- 문제 정의: 컴퓨터 비전 분야에서 전이 가능한 시공간 표현을 학습하는 것은 중요하며, 비디오를 대규모 모델(LLM, MLLM)에 효과적으로 임베딩하고 그 능력을 활용하여 비디오 이해 성능을 향상시키는 것이 핵심 과제로 부상했습니다.
- 기존 접근 방식: 기존 연구들은 마스크된 입력을 이용한 비디오 재구성, 비디오와 언어 정렬, 비디오를 활용한 다음 토큰 예측 등 효과적인 비디오 표현 학습 방식을 제시했습니다. InternVideo, UMT, VideoPrism과 같은 모델들은 마스크된 재구성 및 멀티모달 대조 학습을 포함하는 2단계 훈련 접근 방식을 활용하여 성능을 향상시켰지만, 비디오 기반 다음 토큰 예측을 통합하고 모델 및 데이터 스케일을 확장하는 포괄적인 접근 방식이 필요했습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 마스크된 재구성, 교차 모드 대조 학습, 다음 토큰 예측을 통합하여 지각적, 의미론적, 추론 가능한 비디오 파운데이션 모델(InternVideo2) 제품군을 제안합니다.
- 60개 이상의 비디오 및 오디오 작업에서 최첨단 성능을 달성하며, 특히 비디오 관련 대화 및 긴 비디오 이해에서 뛰어난 능력을 보여 고수준 세계 지식 모델링 잠재력을 강조합니다.
- 훈련 중 오디오 데이터 검증 및 통합, 개선된 캡셔닝 방법을 포함하는 향상된 멀티모달 비디오 데이터셋(InternVid2)을 제공하여 모델 성능 및 일반화 능력을 크게 향상시킵니다.
- 제안 방법:
InternVideo2는 세 단계의 점진적 훈련 방식을 통해 구축됩니다.
- Stage 1: 마스크되지 않은 비디오 토큰 재구성: 비디오 인코더가 InternVL-6B 및 VideoMAEv2-g와 같은 전문가 모델의 지침에 따라 마스크되지 않은 비디오 토큰을 재구성하는 방법을 학습하여 기본적인 시공간 인식 능력을 개발합니다.
- Stage 2: 비디오를 오디오-음성-텍스트에 정렬: 아키텍처를 오디오 및 텍스트 인코더로 확장하고, 교차 모드 대조 학습, 매칭 손실, 마스크된 언어 모델링 손실을 사용하여 비디오와 텍스트 간의 정렬을 개선하고 비디오-오디오 작업 처리 능력을 부여합니다.
- Stage 3: 비디오 중심 입력으로 다음 토큰 예측: QFormer 디자인으로 LLM에 연결하여 미세 조정합니다. 비디오 중심 대화 시스템 및 명령어 미세 조정 데이터셋을 구축하여 VQA 및 비디오 설명과 같은 개방형 작업에 대한 능력을 향상시킵니다. 또한 고화질 사후 훈련 단계를 통해 미세하고 긴 시공간 능력을 향상시킵니다.
3. 실험 결과
- 데이터셋:
- Stage 1 (비디오 전용): KMash (2백만 개의 레이블 없는 웹 비디오).
- Stage 2 (멀티모달 정렬): LAION, WebVid2M, WebVid10M, InternVid, InternVid2 (총 4억 2백만 개의 데이터 항목, 2백만 비디오, 5천만 비디오-텍스트 쌍, 5천만 비디오-오디오-음성-텍스트 쌍, 3억 이미지-텍스트 쌍 포함). 특히 InternVid2는 의미론적으로 분할된 클립과 비디오-오디오-음성 캡션을 사용합니다.
- Stage 3 (지침 튜닝): LLaVA 등 (210만 개의 이미지/비디오, 대화, QA 데이터). MVBench, Egoschema, PerceptionTestQA, TVQA, NTU-RGB-D, EgotaskQA, DiDeMo, COCO 기반의 접지 데이터셋도 포함됩니다.
- 주요 결과:
- 액션 인식: Kinetics, Something-Something V2, Moments in Time, ActivityNet, HACS 등에서 엔드-투-엔드 미세 조정, 어텐티브 프로빙, 선형 프로빙, 제로샷 설정 모두에서 최첨단 성능을 달성했습니다. 특히 K400에서 92.1%, MiT에서 51.2%를 기록하며 이전 SOTA를 능가했습니다.
- 시간적 행동 지역화: THUMOS14를 제외한 ActivityNet, HACS Segment, FineAction에서 가장 높은 mAP를 달성했습니다.
- 비디오 인스턴스 분할: Youtube-VIS 2019에서 가장 높은 mAP를 기록하며 세분화된 시공간 인식에서의 효과를 입증했습니다.
- 비디오 검색: MSR-VTT, LSMDC, DiDeMo, MSVD, ActivityNet, VATEX 등 6개 벤치마크에서 텍스트-비디오 및 비디오-텍스트 검색 모두에서 다른 최첨단 기술보다 우수한 성능을 보였습니다.
- 오디오 관련 작업: AudioCaps, Clothov1/v2 (오디오-텍스트 검색), ClothoAQA, Audio-MusicAVQA (오디오 QA), ESC-50 (오디오 분류) 등 모든 다운스트림 오디오 작업에서 최첨단 성능을 달성했습니다.
- 비디오 중심 대화: MVBench, Egoschema, Perception Test 벤치마크에서 InternVideo2 인코더를 장착한 VideoChat2-HD-F16이 독점 상용 모델(GPT-4V, Gemini)을 능가하며, 단기 세분화된 비디오 이해 및 고수준 추론 능력을 입증했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 마스크된 비디오 모델링, 교차 모드 대조 학습, 다음 토큰 예측이라는 세 가지 핵심 학습 기술을 통합한 포괄적인 프레임워크를 제시하여 비디오 이해의 다양한 측면을 효과적으로 다룹니다.
- 의미론적 일관성이 높은 시간적으로 분할된 클립과 비디오-오디오-음성 융합 캡션을 포함하는 새로운 고품질 멀티모달 데이터셋(InternVid2)을 구축하여 모델 학습의 기반을 강화했습니다.
- 60개 이상의 비디오 및 오디오 작업에서 최첨단 성능을 달성하며, 특히 비디오 관련 대화 및 긴 비디오 이해와 같은 고수준 추론 작업에서 뛰어난 능력을 보여줍니다.
- 단점/한계:
- 특별히 새로운 아키텍처 설계를 도입하지 않고 기존 기술의 확장에 중점을 두었습니다.
- 고정된 입력 해상도, 샘플링 속도, 고도로 압축된 토큰으로 인해 풍부한 비디오 정보를 표현하고 세분화된 세부 사항을 포착하는 능력에 한계가 있습니다.
- 점진적 학습 방식은 효율적이지만, 세 가지 최적화 목표를 동시에 공동으로 학습하는 것은 계산적으로 어렵고 제한된 리소스에서 확장성 문제가 발생할 수 있습니다.
- 시각적 추론의 일관성을 보장하는 암묵적인 세계 모델을 완전히 보장하지는 못합니다.
- 응용 가능성:
- 비디오 검색, 게임 제어, 로봇 학습, 자율 주행, 과학 연구 등 비디오 중심 AI의 다양한 도메인에 광범위하게 응용될 수 있습니다.
- 비디오 이해의 미래 탐색을 위한 강력하고 일반적인 비디오 인코더 역할을 할 수 있어, 향후 연구의 기반이 될 잠재력이 큽니다.
Wang, Yi, et al. "Internvideo2: Scaling foundation models for multimodal video understanding." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024.
InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
Yi Wang1 Kunchang Li , Xinhao Li , Jiashuo Yu1 Yinan He1 Chenting Wang2,1<br>Guo Chen , Baoqi Pei , Ziang Yan , Rongkun Zheng , Jilan Xu , Zun Wang Yansong Shi , Tianxiang Jiang , Songze Li , Hongjie Zhang , Yifei Huang <br>Yu Qiao , Yali Wang , Limin Wang <br> OpenGVLab, Shanghai AI Laboratory, Shanghai, China Nanjing University, Nanjing, China<br> Shenzhen Institutes of Advanced Technology, CAS, Shenzhen, China
https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2
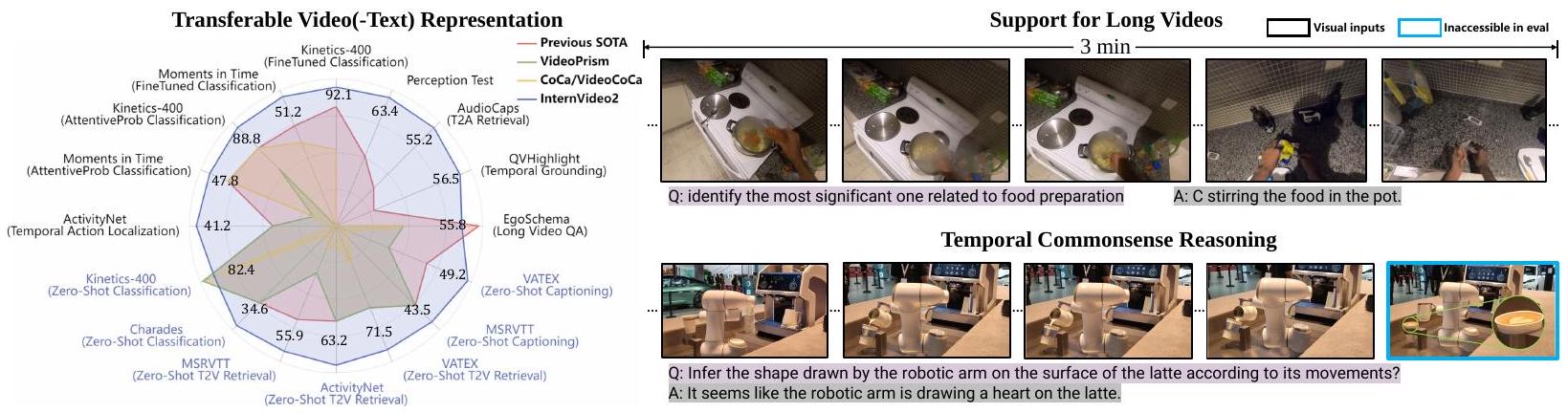
Figure 1: InternVideo2는 액션 인식, 비디오-텍스트 이해, 비디오 중심 대화에 이르기까지 총 70개의 비디오 이해 작업에서 강력한 전이 가능한 시각 및 시각-언어 표현을 산출합니다. 또한 장편 비디오 이해 및 절차 인식 추론 능력도 보여줍니다.
Abstract
InternVideo2는 비디오 인식, 비디오-텍스트 작업 및 비디오 중심 대화에서 최첨단 결과를 달성하는 새로운 비디오 파운데이션 모델(ViFM) 제품군을 소개합니다. 우리의 핵심 설계는 마스크된 비디오 모델링, 교차 모드 대조 학습 및 다음 토큰 예측을 통합하는 점진적인 훈련 접근 방식으로, 비디오 인코더 크기를 6B 파라미터로 확장합니다. 데이터 수준에서는 비디오를 의미론적으로 분할하고 비디오-오디오-음성 캡션을 생성하여 시공간 일관성을 우선시합니다. 이는 비디오와 텍스트 간의 정렬을 개선합니다. 광범위한 실험을 통해 우리는 우리의 설계를 검증하고 60개 이상의 비디오 및 오디오 작업에서 우수한 성능을 입증합니다. 특히, 우리 모델은 다양한 비디오 관련 대화 및 긴 비디오 이해 벤치마크에서 다른 모델을 능가하며, 더 긴 컨텍스트를 추론하고 이해하는 능력을 강조합니다.
1 Introduction
전이 가능한 시공간 표현을 학습하는 것은 컴퓨터 비전에서 중요한 연구 분야이며, 비디오 검색 [Gabeur et al., 2020], 게임 제어 [Bruce et al., 2024], 로봇 학습 [Driess et al., 2023], 자율 주행 [Zablocki et al., 2022], 과학 연구 [Team et al., 2023]와 같은 다양한 도메인에 걸쳐 응용됩니다. 최근 대규모 언어 모델(LLM) [Brown et al., 2020, OpenAI, 2023a, Touvron et al., 2023a b]과 그 멀티모달 변형(MLLM) [OpenAI, 2023b, Gong et al., 2023, Liu et al., 2023, Team et al., 2023]의 발전은 비전 연구 및 기타 학문 분야에 깊은 영향을 미쳤습니다. 비디오를 이러한 대규모 모델에 효과적으로 임베딩하고 그 능력을 활용하여 비디오 이해 성능을 향상시키는 것이 중추적인 과제로 부상했습니다 [Li et al., 2023c, Maaz et al., 2023].
이전 연구에서는 마스크된 입력을 사용하여 비디오를 재구성하는 것 [He et al., 2022, Tong et al., 2022, Wang et al., 2023b, Feichtenhofer et al., 2022], 비디오를 언어와 정렬하는 것 [Li and Wang, 2020, Xu et al., 2021, Yan et al., 2022, Li et al., 2023e], 비디오를 사용하여 다음 토큰을 예측하는 것 [Alayrac et al., 2022, Sun et al., 2023c, Li et al., 2023d]을 포함하여 비디오 표현을 위한 몇 가지 효과적인 학습 방식을 확인했습니다. 이러한 접근 방식은 상호 보완적인 것으로 밝혀졌으며 점진적인 훈련 방식을 통해 통합될 수 있습니다. 특히, InternVideo [Wang et al., 2022], UMT [Li et al., 2023e], VideoPrism [Zhao et al., 2024]과 같은 방법은 마스크된 재구성 및 멀티모달 대조 학습을 포함하는 2단계 훈련 접근 방식을 활용하여 다운스트림 작업에서 향상된 성능을 이끌어 냈습니다. 이 라인을 따라, 우리는 비디오 기반 다음 토큰 예측을 통합하고 모델과 데이터를 포함한 전체 훈련 과정을 확장하여 새로운 비디오 파운데이션 모델 제품군을 구축하는 것을 목표로 합니다.
InternVideo2라고 명명된 제안된 비디오 파운데이션 모델은 점진적인 훈련 방식을 통해 구축됩니다. 학습은 (1) 마스크되지 않은 비디오 토큰 재구성을 통해 시공간 구조를 포착하고, (2) 다른 모달리티의 의미와 정렬하며, (3) 다음 토큰 예측을 통해 개방형 대화 능력을 향상시키는 세 단계로 구성됩니다. 초기 단계에서 모델은 마스크되지 않은 비디오 토큰을 재구성하는 방법을 학습하여 비디오 인코더가 기본적인 시공간 인식 능력을 개발할 수 있도록 합니다. 기존 토큰을 추정하기 위해 다르게 훈련된 비전 인코더(InternViT [Chen et al., 2023c] 및 VideoMAE-g [Wang et al., 2023b])가 프록시로 사용됩니다. 교차 모드 학습의 다음 단계에서는 아키텍처가 오디오 및 텍스트 인코더를 포함하도록 확장됩니다. 이는 비디오와 텍스트 간의 정렬을 개선할 뿐만 아니라 InternVideo2에 비디오-오디오 작업을 처리하는 능력을 부여합니다. 이러한 추가 모달리티를 통합함으로써 모델의 비디오 이해가 풍부해지고 그 의미와 정렬됩니다. 마지막으로, 다음 토큰 예측 단계에서는 비디오 중심 대화 시스템과 해당 명령어 미세 조정 데이터셋이 구축되어 InternVideo2를 추가로 조정합니다. InternVideo2를 LLM에 연결함으로써 비디오 인코더는 다음 토큰 예측 훈련을 통해 추가로 업데이트되어 VQA 및 비디오 설명과 같은 개방형 작업에 대한 능력을 향상시킵니다.
InternVideo2의 훈련을 위해 우리는 데이터의 시공간 일관성과 레이블링 품질을 강조합니다. 우리는 2백만 개의 비디오, 5천만 개의 비디오-텍스트 쌍(WebVid [Bain et al., 2021] 및 InternVid [Wang et al., 2023d]에서), 5천만 개의 비디오-오디오-음성-텍스트 쌍(InternVid2), 3억 개의 이미지-텍스트 쌍을 포함하는 4억 2백만 개의 데이터 항목으로 구성된 대규모 멀티모달 비디오 중심 데이터셋을 구축합니다. 특히 InternVid2의 경우, 비디오를 의미적으로 클립으로 분할하고 오디오, 비디오, 음성의 세 가지 모달리티를 사용하여 클립 설명을 재조정하는 데 중점을 둡니다. 먼저 이 세 가지 모달리티에 대해 개별적으로 캡션을 생성합니다. 그런 다음 개별 캡션을 융합하여 더 포괄적인 설명을 만들어 모델이 비디오를 정확하게 이해하고 해석하는 능력을 향상시킵니다.
우리는 다양한 비디오 관련 작업에서 InternVideo2를 평가합니다. 이러한 작업은 액션 인식과 같은 기본적인 시공간 인식에서부터 그림 1에 제시된 바와 같이 긴 비디오 또는 절차 인식 질의응답(QA)과 같은 고수준 추론 작업에 이르기까지 다양합니다. 결과(섹션 5)는 InternVideo2가 여러 작업에서 최첨단 성능을 달성하고 일련의 행동을 분석하고 추론할 수 있음을 보여줍니다. 이 최고의 성능은 비디오 콘텐츠를 효과적으로 포착하고 이해하는 능력을 의미합니다. 이러한 경험적 발견은 InternVideo2가 비디오 이해의 향후 탐색을 위한 일반적인 비디오 인코더 역할을 할 수 있음을 검증합니다. 요약하면, 비디오 이해에 대한 우리의 기여는 다음과 같습니다.
- 이 논문은 마스크된 재구성, 교차 모드 대조 학습 및 다음 토큰 예측을 활용하여 비디오 이해에서 모델을 지각적이고, 의미론적이며, 추론 가능하게 만드는 경쟁력 있는 비디오 파운데이션 모델 제품군인 InternVideo2를 소개합니다.
- InternVideo2는 60개 이상의 비디오/오디오 작업에서 최첨단 성능을 달성합니다. 우리 모델은 비디오 관련 대화 및 긴 비디오 이해에서 우수한 성능을 보여주며, 고수준 세계 지식을 모델링하는 잠재력을 강조합니다.
- 우리는 InternVideo2를 훈련시키기 위한 향상된 데이터셋을 제공합니다. 여기에는 훈련 중 오디오 데이터의 검증 및 통합과 개선된 캡셔닝 방법이 포함됩니다. 이러한 개선은 모델 성능 및 일반화 능력에서 상당한 향상을 가져옵니다.
2 Related Work
Video Foundation Models. 비디오 파운데이션 모델 학습에 대한 연구는 광범위한 응용 분야를 고려할 때 점점 더 중요해지고 있습니다 [Li and Wang, 2020, Xu et al., 2021, Li et al., 2023e, Wang et al., 2022, Zhao et al., 2024, Wang et al., 2023c, Yan et al., 2022, Feichtenhofer et al., 2022, Wang et al., 2023a, Tong et al., 2022, Wang et al., 2023bl. 비디오 파운데이션 모델(ViFM)을 구축하는 일반적인 방법에는 비디오-텍스트 대조 학습 [Li and Wang, 2020, Xu et al., 2021, Wang et al., 2022], 마스크된 비디오 모델링 [Tong et al., 2022, Wang et al., 2023b, 2022, Fu et al., 2021], 다음 토큰 예측 [Alayrac et al. 2022, Sun et al., 2023c|a|]이 포함됩니다. 특히, All-in-one [Wang et al., 2023a]은 통합된 여러 사전 훈련 목표를 가진 단일 백본을 활용했습니다. 반면에 UMT [Li et al. 2023e]는 마스크된 모델링과 비디오-텍스트 대조 학습을 결합하여 액션 인식 및 비디오-언어 작업 모두에서 강력한 성능을 보여주었습니다. 또 다른 접근 방식은 mPLUG-2 [Xu et al., 2023]로, 다른 모달리티를 조절하기 위한 새로운 설계를 도입했습니다. 이는 모달리티 간의 관계를 향상시키기 위해 공통 모듈을 공유하면서 차별화를 위해 모달리티별 모듈을 통합했습니다. 비디오-텍스트 사전 훈련 외에도 연구자들은 성능을 향상시키기 위해 비디오의 오디오 정보를 사용하는 것을 탐색했습니다. MERLOT Reserve [Zellers et al., 2022]는 대규모 비디오-음성-대본 쌍 데이터셋을 사용하여 비디오 표현을 학습했습니다. VALOR [Chen et al., 2023b]는 비디오, 오디오 및 텍스트에 대해 독립적인 인코더를 사용하고 공동 시각-오디오-텍스트 표현을 훈련시킵니다. VAST [Chen et al., 2024b]는 오디오-시각-음성 데이터셋을 구축하고 비디오-오디오 관련 작업에 뛰어난 멀티모달 백본을 개발합니다. VideoPrism [Zhao et al., 2024]은 공개 및 독점 비디오의 조합에 대해 비디오-텍스트 대조 학습과 비디오 토큰 재구성을 결합하여 다양한 비디오 작업에서 최고의 결과를 달성했습니다.

Figure 2: InternVideo2의 프레임워크. 마스크되지 않은 비디오 토큰 재구성, 멀티모달 대조 학습, 다음 토큰 예측의 세 가지 연속적인 훈련 단계로 구성됩니다. 1단계에서는 비디오 인코더가 처음부터 훈련되고, 2단계와 3단계에서는 이전 단계에서 사용된 버전으로 초기화됩니다.
Multimodal Large Language Models. 대규모 언어 모델(LLM) [Devlin et al., 2018, Raffel et al., 2020, Brown et al., 2020]의 발전으로, 개방형 세계 작업을 처리할 수 있는 멀티모달 버전(MLLM)이 인기를 얻고 있습니다. Flamingo [Alayrac et al., 2022]와 같은 선구적인 연구는 다양한 멀티모달 작업 [Goyal et al., 2017b, Plummer et al., 2015, Xu et al., 2016, Marino et al., 2019]에서 뛰어난 제로/소수 샷 성능을 보여주었습니다. LLaVA [Liu et al., 2023] 및 InstructBLIP [Dai et al., 2023]과 같은 공개 MLLM [Zhu et al., 2023b, Liu et al., 2023, Gong et al., 2023]은 시각적 대화 능력을 향상시키기 위해 시각적 지침 튜닝 데이터를 사용할 것을 제안했습니다. VideoChat [Li et al., 2023c], VideoChatGPT [Maaz et al., 2023], Valley [Luo et al., 2023]과 같은 비디오 중심 MLLM이 제안되었으며, 이는 지침 데이터를 사용하여 비디오 인코더를 LLM에 연결하여 개방형 세계 비디오 이해를 위한 것입니다.
3 Method
우리는 그림 2에 설명된 대로 세 단계로 InternVideo2를 학습합니다. 단계에는 시공간 토큰 재구성, 비디오-오디오-음성-언어 대조 학습, 그리고 공동 훈련을 위해 대규모 언어 모델(LLM)에 연결하는 것이 포함됩니다.
Video Encoder. InternVideo2에 사용된 비디오 인코더는 Vision Transformer(ViT) [Dosovitskiy et al. 2020]를 따르며 증류를 위한 추가 투영 레이어를 포함합니다. 이전 연구 [Chen et al., 2023c, Yu et al., 2022]에서 영감을 받아 ViT에 어텐션 풀링을 도입했습니다. 입력 비디오의 경우 8개 프레임을 드물게 샘플링하고 [Wang et al., 2016] 공간 다운샘플링을 수행합니다. 이러한 시공간 토큰은 클래스 토큰과 연결되고 3D 위치 임베딩과 결합됩니다. ViT-6B 아키텍처의 세부 사항은 부록에 나와 있습니다.
3.1 Stage1: Reconstructing Unmasked Video Tokens
우리는 비디오 인코더가 마스크되지 않은 영역에 대한 토큰 수준 재구성을 수행하도록 안내하기 위해 두 개의 전문가 모델을 활용합니다. 구체적으로, 우리는 InternVL-6B [Chen et al., 2023c] 및 VideoMAEv2-g [Wang et al., 2023b]를 채택하여 간단한 투영 레이어를 통해 마스크되지 않은 지식을 전달합니다. 훈련할 때, 우리는 전체 비디오를 다른 교사에게 입력하고 멀티모달 모델 InternVL과 모션 인식 모델 VideoMAEv2의 의미론적 지침에 따라 프레임별로 토큰의 를 마스크합니다. 우리는 학생과 교사 간의 평균 제곱 오차(MSE)를 최소화하여 마스크되지 않은 토큰만 정렬합니다. 학습 목표는 다음과 같이 나머지 토큰을 재구성하는 것입니다:
여기서 , 그리고 는 각각 우리의 비디오 인코더, InternViT-6B [Chen et al. 2023c], 그리고 VideoMAEv2의 ViT-g입니다. 는 토큰 인덱스를 나타내고 는 입력 비디오 에 대해 InternVideo2에 의해 추출된 해당 토큰입니다. 는 정규화 계수입니다. 과 는 사용된 모델 간의 영향력을 균형 있게 조절합니다. 우리의 구현에서는 비디오 인코더를 무작위로 초기화한 다음, 다른 레이어의 출력(학습 가능한 다층 퍼셉트론으로 변환됨)을 전문가 모델의 출력과 정렬합니다. 구체적으로, 우리는 다음을 정렬합니다: 1) InternVL의 마지막 6개 레이어, 2) VideoMAEv2의 마지막 4개 레이어, 그리고 3) InternVL의 최종 출력 토큰. 이러한 정렬은 놈을 사용하여 비디오 인코더의 해당 출력에 대해 이루어집니다. 다른 손실 항은 최적화를 위해 단순히 합산됩니다. 사전 훈련 후, 우리는 해당 투영 레이어를 버리고 기본 인코더만 사용합니다. UMT 및 VideoPrism에서 멀티모달 모델만 사용하는 것과 비교하여, 우리의 전략은 비전 인코더를 멀티모달 친화적으로 만들 뿐만 아니라 액션 모델링을 위한 시간적 민감도를 향상시킵니다.
3.2 Stage 2: Aligning Video to Audio-Speech-Text
InternVideo2가 더 많은 의미를 학습하도록 장려하기 위해 비디오와 오디오, 음성 및 텍스트 간의 대응 관계를 활용합니다. 실제로 InternVideo2는 거대한 비디오 인코더를 가지고 있으며 사용된 오디오 및 텍스트 인코더는 상대적으로 가볍습니다. 사용된 오디오 인코더는 BEATs [Chen et al., 2023a] (90M)로 초기화된 12개 레이어의 트랜스포머입니다. 10초 길이의 클립(0으로 패딩됨)에서 25ms Hamming 창을 사용하여 생성된 64차원 로그 멜 필터뱅크 스펙트로그램을 입력으로 받습니다. 텍스트 및 음성 인코더의 경우 BERT-Large [Devlin et al., 2018]를 사용하여 텍스트 인코더와 멀티모달 디코더를 초기화합니다. 구체적으로, BERT-Large의 초기 19개 레이어를 텍스트 인코더로 활용하고, 이후 5개 레이어에는 cross-attention 레이어를 장착하여 멀티모달 디코더로 사용합니다.
사전 훈련 목표를 위해 비디오, 오디오, 이미지 및 음성을 포함한 텍스트를 통해 다른 모달리티 간의 정렬을 설정합니다. 우리는 다음과 같이 마스크된 언어 재구성 손실과 함께 교차 모달 대조 및 매칭 손실을 사용합니다:
사용된 와 은 [Cheng et al., 2022]의 표준 손실입니다. 구체적으로, 교차 모달 대조 학습은 다음과 같이 주어집니다:
여기서 와 는 각각 학습된 비디오와 텍스트 임베딩을 나타냅니다. 과 는 각각 입력 신호의 모달리티와 이를 설명하는 텍스트 설명을 나타냅니다. 은 두 특징 간의 코사인 유사도를 계산합니다. 는 학습 가능한 온도입니다.
매칭 부분은 다음과 같이 주어집니다:
여기서 는 와 사이의 매칭 가능성을 계산합니다. 는 주어진 비디오와 텍스트가 쌍을 이루는지() 아닌지()를 나타냅니다.
사용된 마스크된 언어 모델링 손실은 다음과 같습니다:
여기서 는 이전 토큰을 기반으로 번째 텍스트 토큰의 가능성을 계산합니다. 여기서 는 비디오 캡션을 의미합니다.
훈련 효율성을 향상시키기 위해, 우리는 마스크된 학습 전략을 사용하여, 먼저 마스크되지 않은 비디오 토큰을 다른 모달리티의 토큰에 정렬한 다음, 곧바로 전체 비디오 토큰 재구성을 사용합니다. 구체적으로, 다음과 같은 두 단계로 구성됩니다:
마스크된 시각-언어-오디오 정렬. 우리는 오디오 인코더를 동결하고 시각, 오디오 및 텍스트 특징을 정렬하는 데 집중합니다. 사전 훈련을 위해 이미지, 비디오 및 오디오-비디오 데이터의 포괄적인 세트를 사용합니다. 사용된 모달리티의 조합은 로 표현되며, 각 쌍은 해당 모달리티에서 연결된 특징을 나타냅니다.
마스크되지 않은 시각-오디오-언어 사후 사전 훈련. 우리는 비전 인코더를 동결하여 오디오, 시각 및 텍스트 특징을 공동으로 정렬합니다. 사후 사전 훈련은 더 작은 이미지 및 비디오 데이터 하위 집합(2,500만 샘플)과 전체 오디오(50만 샘플) 및 오디오-비디오 데이터(5,000만 샘플) 세트를 사용하여 수행됩니다. 가장 큰 ViT-6B 모델의 매개변수가 동결되었기 때문에, 이 단계에서는 추론 과정과의 일관성을 보장하고 다운스트림 작업에서의 성능 저하를 최소화하기 위해 마스킹 전략을 사용하지 않습니다. 여기서 사용되는 모달리티 조합은 입니다.
Table 1: InternVideo2 사전 훈련 과정에서 사용된 데이터셋 요약.
| Pretraining Stage | Dataset | Domain | # of clips | Annotation |
|---|---|---|---|---|
| Stage 1 | KMash | Web Video | 2M | - |
| Stage 2 (img-txt) | LAION, etc | Web Image | 300M | Alt-text / Generated Caps |
| Stage 2 (vid-txt) | WebVid2M | Web Video | 250 k | Alt-text |
| WebVid10M | Web Video | 9.7 M | Alt-text | |
| InternVid | Youtube Video | 40M | Generated Caption | |
| InternVid2 | Youtube Video | 50M | Generated Caption | |
| Stage 3 | LLaVA, etc | Web Image/Video | 2.1 M | Conversation, QA |
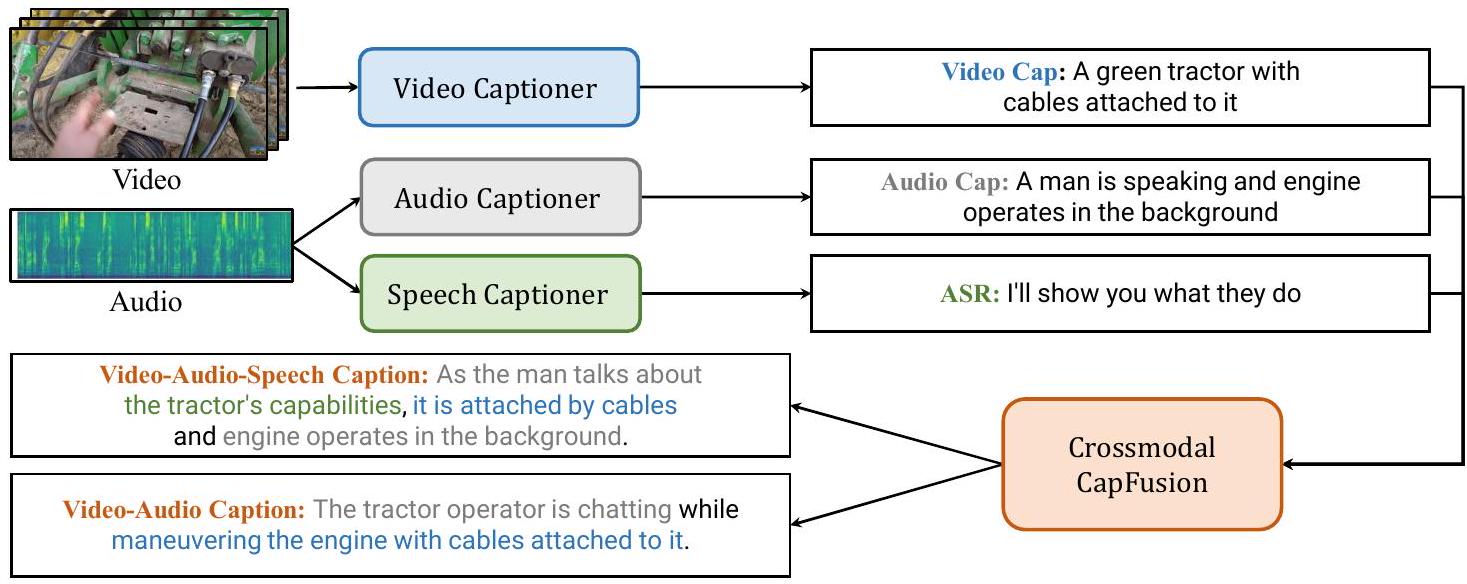
Figure 3: VidCap이라고 불리는 우리의 비디오 멀티모달 주석 시스템의 프레임워크는 비디오, 오디오, 음성 캡셔너와 이러한 모달리티의 캡션을 통합하기 위한 LLM의 네 가지 주요 구성 요소로 이루어져 있습니다.
3.3 Stage3: Predicting Next Token with Video-Centric Inputs
InternVideo2에 내장된 의미를 더욱 풍부하게 하고 비디오 중심 대화 지원을 개선하기 위해 QFormer 디자인 [Li et al., 2022a b]으로 LLM에 연결하여 미세 조정합니다. InternVideo2를 비디오 인코더로 사용하고 공개된 LLM [Zheng et al., 2023, Jiang et al., 2023]과 통신하기 위한 비디오 blip을 훈련하여 [Li et al., 2023d]의 점진적 학습 체계를 사용합니다. 또한 모델의 미세하고 긴 시공간 능력을 향상시키기 위해 고화질 사후 훈련 단계를 구현합니다. 이 단계 동안 입력 비디오는 각각 픽셀 해상도의 최대 6개의 하위 비디오와 동일한 해상도의 전역 크기 조정된 하위 비디오 하나로 나뉩니다. 그런 다음 두 번의 추가 에포크 동안 모델을 훈련합니다. 첫 번째 에포크는 8프레임 비디오 입력을 사용하고 두 번째 에포크는 16프레임 입력을 사용합니다. 추가 훈련 과정 동안 비디오 인코더와 BLIP Qformer를 업데이트하고 LLM은 LoRA [Hu et al., 2021]를 사용하여 업데이트됩니다.
4 Multimodal Video Data
표 1에 훈련 데이터를 나열합니다. 사용된 데이터셋 중 KMash와 InternVid2는 새로 구축되었으며 나머지는 공개적으로 사용 가능합니다.
4.1 Video-only Data for Masked Autoencoders
우리는 액션 인식 데이터셋 [Carreira and Zisserman, 2017, Goyal et al., 2017a, Monfort et al., 2020, Heilbron et al., 2015, Zhao et al., 2019]에서 레이블이 없는 새로운 비디오 세트인 -Mash를 큐레이션했습니다(자세한 내용은 부록 참조). 여기에는 1인칭 및 3인칭 시점, 짧고 긴 지속 시간, 다양한 설정을 특징으로 하는 광범위한 비디오 유형이 포함됩니다. 또한, 다양성을 위해 YouTube에서 추가로 소싱하고 선택한 844K 비디오를 포함하는 을 제공합니다.
4.2 Videos with Audio-Speech Modalities
우리는 다른 모달리티를 통해 비디오 인식을 강화하기 위해 비디오-오디오-음성 정보와 그 설명을 포함하는 InternVid2라는 멀티모달 비디오 데이터셋을 구축합니다. 이는 1억 개의 비디오와 그들의 VAS 캡션으로 구성됩니다. InternVid2에서는 여러 소스(부록에 자세히 설명)에서 비디오를 수집하고, 클립으로 분할하며, 단일 모드 또는 교차 모드 입력을 기반으로 자동으로 주석을 답니다. 우리는 클립 생성에서의 시간적 분할의 중요성과 우리의 비디오 멀티모달 주석 시스템을 강조합니다. 우리는 이들을 개선하는 것이 다운스트림에서 상당한 개선을 가져온다는 것을 발견했습니다.
Temporal Consistency Matters. FFmpeg의 SceneDet 필터 대신 AutoShot [Zhu et al., 2023c]이라는 시간적 경계 탐지 모델을 사용하여 비디오를 클립으로 분할합니다. 이는 픽셀 차이가 아닌 시간적 의미 변화에 기반하여 경계를 예측하며, 일관성 없는 컨텍스트를 가진 추가 프레임을 섞지 않고 의미적으로 완전한 컷을 생성할 수 있습니다.
Video Multimodal Annotation. 우리는 VidCap이라는 비디오 멀티모달 주석 시스템을 설계하여 다양한 인식에서 비디오를 텍스트화하기 위한 적절한 단일 모달 및 교차 모달 설명을 제공합니다. 이는 InternVid2의 시각, 오디오 및 음성을 자동으로 캡션하고, 이를 수정하고 LLM을 통해 교차 모달 캡션을 위해 융합합니다. 시스템 프레임은 그림 3에 나와 있습니다. VidCap은 독립적인 비디오, 오디오, 음성 캡셔너와 캡션 정제 및 융합을 위한 LLM을 가지고 있습니다. 비디오, 음성 및 캡션 후처리를 위해 [Wang et al., 2023d]의 비디오 캡셔닝 파이프라인, WhisperV2-large 모델 [Radford et al., 2023], Vicuna-1.5 [Zheng et al., 2023]와 같은 기존 방법을 사용합니다. 오디오의 경우, 공개된 것이 없기 때문에 VideoChat [Li et al., 2023c]을 기반으로 오디오 캡셔너를 제작합니다. 이는 Beats [Chen et al., 2023a]를 통해 입력에서 오디오 특징을 추출합니다. 대규모 오디오-텍스트 코퍼스인 WavCaps [Mei et al., 2023] 데이터셋의 조합을 사용하여 Qformer만 튜닝하여 학습합니다. 자세한 내용은 보충 자료에 나와 있습니다.
4.3 Instruction-Tuning Data for Video Dialogue
MVBench [Li et al., 2023d]의 업데이트된 훈련 버전을 사용합니다. 원래 34개의 서로 다른 소스에서 190만 개의 샘플(이미지 및 비디오 모두)로 구성되었습니다. WebVid 및 CoCo의 캡션 데이터 양을 각각 80k 및 100k로 줄이고 S-MiT의 새로운 데이터를 추가하여 지침 데이터셋의 양보다는 다양성을 높였습니다. 추가 HD 훈련 단계에서는 [Chen et al., 2024a]의 해당 GPT-4 주석이 있는 비디오를 훈련 세트에 통합합니다. PerceptionTestQA [Patraucean et al., 2024], TVQA [Lei et al., 2018], NTU-RGB-D [Liu et al., 2020], EgotaskQA [Grauman et al., 2022]의 데이터셋과 DiDeMo [Anne Hendricks et al., 2017] 및 COCO [Lin et al., 2014]를 기반으로 하는 그라운딩 데이터셋을 포함하여 훈련 세트를 더욱 확장합니다. 이 훈련 데이터는 1) 대화, 2) 캡션, 3) 시각적 질의 응답, 4) 추론, 5) 분류 등 중요한 작업 전반에 걸친 이미지 및 비디오 이해의 핵심 기능을 포함합니다.
5 Experiments
InternVideo2 평가에서는 세 가지 학습 단계의 모델을 평가합니다. 평가는 비디오 인식, 비디오 검색, 질의응답 등 광범위한 작업을 포함합니다. 제로샷 학습, 미세 조정, 선형 프로빙과 같은 다양한 시나리오를 포함합니다. 1, 2, 3단계에서 훈련된 InternVideo2에 대해 각각 InternVideo2, InternVideo2, InternVideo2으로 표기합니다. 또한 InternVideo2으로 표시되는 CLIP 스타일의 InternVideo2도 학습합니다. 이는 InternVideo2에서 비디오 및 텍스트 인코더와 대조 손실만 보존하여 사후 사전 훈련됩니다.
InternVideo2-6B의 각 훈련 단계는 다른 구성과 리소스를 사용합니다. 첫 번째 단계에서는 256개의 NVIDIA A100 GPU를 사용하여 18일 동안 모델을 훈련합니다. 두 번째 단계에서도 256개의 A100 GPU를 활용하며 훈련 기간은 14일입니다. 마지막으로 세 번째 단계에서는 64개의 A100 GPU를 사용하여 3일 동안 모델을 훈련합니다. 훈련과 추론을 위해 DeepSpeed와 FlashAttention [Dao et al., 2022]을 도입합니다. 더 많은 구현 세부 사항과 실험 결과는 부록에 나와 있습니다.
5.1 Video Classification
5.1.1 Action Recognition
InternVideo2를 Kinetics (즉, K400, 600, 700 [Carreira and Zisserman, 2017, Carreira et al., 2018, 2019]), Moments in Time V1 (MiT) [Monfort et al., 2020], Something-Something V2 (SSv2) [Goyal et al., 2017a], UCF [Soomro et al., 2012], HMDB [Kuehne et al., 2011], Charades [Gao et al., 2017], ActivityNet [Heilbron et al., 2015] (ANet), HACS [Zhao et al., 2019]에서 테스트합니다. 네 가지 설정으로 평가합니다: (a) 전체 백본을 엔드-투-엔드로 미세 조정;
Table 2: Kinetics, SomethingSomething, Moments in Time에서의 종단 간 미세 조정 액션 인식 결과 (top-1 정확도). 는 결과가 다른 해상도 또는 프레임 속도로 달성되었음을 나타냅니다.
| Method | Training Data | Setting | K400 | K600 | K700 | Sth-Sthv2 | MiT | ANet | HACS | |
|---|---|---|---|---|---|---|---|---|---|---|
| CoVeR | Zhang et al., | IV-3B | 87.1 | 87.9 | 79.8 | 70.8 | 46.1 | - | - | |
| Hiera-H | Ryalı et al., | V-0.25M | 87.8 | 88.8 | 81.1 | 76.5 | - | - | - | |
| CoCa-g | Yu et al., | I-3B | 88.9 | 89.4 | 82.7 | - | 49.0 | - | - | |
| MTV-H | Wang et al., | IV-370M | 89.9 | 90.3 | 83.4 | - | - | - | - | |
| VideoMAEv2-g | Wang et al., 2023b | V-1.35M | 90.0 | 89.9 | - | - | - | - | ||
| V-JEPA-H |Bardes et al., 2024 | V-2M | - | - | - | 77.0 | - | - | - | ||
| MVD-H | Wang et al., 2023c] | IV-1.25M | - | - | - | 77.3 | - | - | - | |
| UniFormerV2-L |Li et al., 2022c | IV-401M | 90.0 | 90.1 | 82.7 | 94.7 | 95.4 | ||||
| InternVideo |Wang et al., 2022 | V-12M | ensemble | 91.1 | 91.3 | 84.0 | 77.2 | - | - | - | |
| InternVideo2 | IV-1.1M | 91.3 | 91.4 | 85.0 | 77.1 | 50.8 | - | - | ||
| InternVideo2 | IV-1.1M | 91.6 | 91.6 | 85.4 | 77.1 | 50.9 | - | - | ||
| InternVideo2 | IV-2M | 91.9 | 91.7 | 85.7 | 77.5 | 51.0 | - | - | ||
| InternVideo2 | IV-2M | 92.1 | 91.9 | 85.9 | 77.4 | 51.2 | 95.9 | 97.0 |
Table 3: Kinetics-400/600/700, Moments in Time 및 Something-Something V2에 대한 어텐티브 프로빙 인식 결과(top-1 정확도).
| Method | Training Data | Setting | K400 | K600 | K700 | MiT | SSV2 | ||
|---|---|---|---|---|---|---|---|---|---|
| UMT-L |Li et al., | 2023e | IV-25M | - | 82.8 | - | - | 40.3 | 54.5 | |
| VideoMAEv2-g | Wang et al., | 2023b | V-1.35M | - | 82.1 | - | - | 35.0 | 56.1 |
| V-JEPA-H |Bardes et al., | 2024 | V-2M | 81.9 | - | - | - | 72.2 | ||
| DINOv2-g |Oquab et al., | 2023 | I-142M | 83.4 | - | - | - | 50.0 | ||
| VideoPrism-g | Zhao et al., | 2024 | V-619M | 87.2 | - | - | 45.5 | 68.5 | |
| ViT-e |Dehghanı et al., 2023 | I-4B | 86.5 | - | - | 43.6 | - | |||
| ViT-22B |Dehghanı et al., | 2023 | I-4B | 88.0 | - | - | 44.9 | - | ||
| CoCa-g [Yu et al., 2022 | I-3B | 88.0 | 88.5 | 81.1 | 47.4 | - | |||
| InternVideo2 | IV-25.5M | 87.9 | 88.0 | 79.5 | 46.3 | 67.3 | |||
| InternVideo2 | IV-400M | 88.8 | 89.1 | 81.0 | 47.8 | 67.7 |
(b) attentive probing은 선형 풀링과 유사하지만 추가적으로 어텐션 풀링 레이어를 훈련합니다 [Yu et al., 2022]. (c) 선형 프로빙은 백본을 고정하고 태스크 헤드만 훈련합니다. 그리고 (d) 제로샷입니다.
End-to-end Finetuning. 표 2는 InternVideo2-6B가 Kinetics ( on K400/600/700, 각각), SthSthv2, MiT, ANet, HACS에서 단 16프레임만으로 새로운 최첨단(SOTA) 결과를 얻는 것을 보여주며, 이전 SOTA들은 더 큰 해상도(224 vs. 576) 또는 모델 앙상블을 필요로 합니다. 표 2의 MiT에 관해서는 InternVideo2-6B가 이전 SOTA인 CoCa-g를 ( vs. )의 큰 차이로 능가합니다. 표 2의 시간 관련 행동에 관해서는, 우리의 InternVideo2-6B가 SSv2에서 MVD [Wang et al., 2023c]를 능가합니다( vs. ). 또한, 우리의 InternVideo2-6B는 표 2에 나타난 바와 같이 다듬어지지 않은 비디오 분석에서 최고의 성능을 보여주며, ActivityNet에서 95.9%, HACS에서 97.0%를 기록합니다. 이러한 결과는 다양한 장면에서 복잡한 행동을 견고하게 식별하는 우리 모델의 우수한 능력을 확인시켜 줍니다. "I"와 "V"는 각각 이미지와 비디오를 나타냅니다. "IV-3B"는 사용된 이미지와 비디오의 총 수가 3B임을 의미하며, "I-3B"는 3B 이미지를 사용함을 의미합니다.
Attentive Probing. 표 3에서 볼 수 있듯이, InternVideo2-6B는 장면 중심 데이터셋에서 ViT-22B [Dehghani et al., 2023] 및 CoCa-g [Yu et al., 2022]를 능가할 뿐만 아니라, 시간적 동역학을 강조하는 데이터셋(SthSthV2)에서도 최신 비디오 기반 모델 [Bardes et al., 2024, Zhao et al., 2024]의 성능을 능가하거나 필적합니다. 이는 우리 모델이 공간 및 시간 정보를 효과적으로 이해하고 해석하는 뛰어난 능력을 강조합니다.
Linear Probing. 표 4에서 InternVideo2-1B는 이전 SOTA인 DINOv2-g [Oquab et al., 2023]를 K400에서 +3.2%, SthSthV2에서 +8.0%, UCF-101에서 +4.8%의 상당한 차이로 크게 능가합니다. 모델을 확장함에 따라 결과에서 상승 추세가 관찰되며, 이는 모델 향상의 이점을 강조합니다. 특히, 멀티모달 사전 훈련(2단계)의 통합은 결과에서 추가적인 상승을 가져옵니다. 우리는 2단계가 특징 차별화를 향상시킨다고 가정합니다.
Zero-shot. 표 5와 6은 InternVideo2가 K400/600/700에서 각각 / / 를 얻어 K400(76.4%)에서 VideoPrism을 제외한 다른 모델들을 능가함을 보여줍니다. UCF [Soomro et al., 2012], HMDB [Kuehne et al., 2011], MiT [Monfort et al., 2020], SSv2-MC, Charades에서 InternVideo2는 다른 모델들보다 우위를 점합니다. K400에서 VideoPrism과 InternVideo2 사이의 명확한 격차는 VideoPrism의 사전 훈련 코퍼스(수동으로 레이블이 지정된 36.1M을 포함한 311M 비디오와 텍스트)의 중요성을 나타낼 수 있습니다. Kinetics, UCF101, HMDB51 데이터셋은 1단계에서 사용된 사전 훈련 데이터셋과 분포가 더 가깝기 때문에, Internvideo2-6B의 성능이 Internvideo2-1B보다 약간 열등합니다. 이는 Internvideo2-6B가 2단계에서 더 풍부한 사전 훈련 데이터셋을 사용하여 1단계의 사전 훈련 데이터를 잊어버렸기 때문이라고 가정합니다.
5.1.2 Temporal Action Localization
우리는 네 가지 시간적 행동 지역화(TAL) 데이터셋인 THUMOS14 [Idrees et al., 2017], ActivityNet [Krishna et al., 2017], HACS Segment [Zhao et al., 2019], FineAction [Liu et al., 2022]에서 미세 조정을 통해 특징 기반 방식으로 모델을 평가합니다. 우리는 다른 어떤 것도 융합하지 않고 해당 특징으로 InternVideo2의 7번째 레이어 출력을 입력으로 사용합니다. ActionFormer [Anne Hendricks et al., 2017]가 탐지 헤드로 사용됩니다. 우리는 [Lin et al., 2019, Chen et al., 2022a, Anne Hendricks et al., 2017, Yang et al., 2023]과 같이 여러 tIoU 하에서 평균 평균 정밀도(mAP)를 보고합니다. 표 7에서 InternVideo2-6B는 THUMOS14를 제외한 모든 데이터셋에서 모든 비교 대상 중 가장 높은 mAP를 얻었으며, InternVideo2-1B는 다른 방법들을 거의 능가합니다. 우리는 InternVideo2-6B가 FineAction을 제외하고 InternVideo2-1B로부터 상당한 차이로 mAP를 거의 일관되게 향상시키는 것을 발견했습니다. 우리는 데이터 정제 없이 모델 용량을 확장하는 것이 모델의 세분화된 차별 능력을 중요하지 않게 향상시킬 수 없다고 가정합니다. 훈련에서 상세한 주석을 확장하는 것이 이 문제를 해결할 수 있습니다.
5.1.3 Video Instance Segmentation
우리는 Video Instance Segmentation (VIS) 데이터셋인 Youtube-VIS 2019 [Yang et al., 2019]에서 평가를 수행합니다. Mask2Former [Cheng et al., 2021]를 기반으로, InternVideo2의 비디오 인코더를 ViT-adapter [Chen et al. 2022b]와 함께 백본으로 사용합니다. 비교를 위해 InternViT [Chen et al., 2023c]도 시도합니다. 표 8에서 InternVideo2는 모든 것 중에서 가장 높은 mAP를 얻습니다. 이는 비교적 세분화된 시공간 인식에서의 효과를 검증합니다.
5.2 Video-Audio-Language Tasks
InternVideo2를 비디오 검색, 캡셔닝, 다중 선택 질의응답(QA)에서 평가합니다. 이전 두 작업은 2단계의 텍스트 인코더를 사용하여 비디오 표현과 후보 텍스트를 매칭하여 수행됩니다. 후자는 3단계에서 학습된 VideoLLM으로 테스트됩니다. 오디오 작업도 테스트합니다.
5.2.1 Video Retrieval
MSR-VTT [Xu et al., 2016], LSMDC [Rohrbach et al. 2015], DiDeMo [Anne Hendricks et al., 2017], MSVD [Chen and Dolan, 2011], ActivityNet (ANet) [Heilbron et al., 2015], VATEX [Wang et al., 2019] 등 6개의 인기 있는 벤치마크에서 비디오 검색을 평가합니다. 평가에서는 입력 비디오에서 8개의 프레임을 균일하게 샘플링합니다. 표 9와 10에서 텍스트-비디오(t2v) 및 비디오-텍스트(v2t) 작업 모두에 대해 R@1 점수를 보고합니다. R@5와 R@10은 부록에 나와 있습니다.
표 9와 10은 InternVideo2가 VideoPrism이 최고의 결과를 보인 MSR-VTT의 v2t를 제외하고는 제로샷 또는 미세 조정 설정에 관계없이 사용된 모든 데이터셋의 t2v 및 v2t 모두에서 다른 최첨단 기술보다 상당한 차이로 성능이 우수함을 보여줍니다. 이는 InternVideo2의 전이 가능성의 비디오-언어 의미론적 정렬을 보여줍니다.
5.2.2 Video Temporal Grounding
QVhighlight [Lei et al., 2021]와 Charade-STA [Gao et al., 2017] 두 개의 비디오 시간적 그라운딩(VTG) 데이터셋에서 InternVideo2를 평가합니다. 평가 설정 및 사용된 특징은 TAL과 동일합니다. 그라운딩 헤드로 CG-DETR [Moon et al., 2023]을 사용합니다. [Lei et al., 2021, Moon et al., 2023, Lin et al., 2023]에서와 같이 순간 검색을 위해 R1@0.3, R1@0.5, R1@0.7 및 mAP를 보고합니다. 하이라이트 탐지는 "Very Good" mAP 및 HiT@1로 평가됩니다. 표 11에서 InternVideo2-1B와 InternVideo2-6B는 CLIP [Radford et al., 2021] 및 CLIP [Radford et al., 2021]+Slowfast [Feichtenhofer et al., 2019]에 비해 점진적인 성능 향상을 가져옵니다. 이는 더 큰 시공간 모델이 단기 비디오 의미론적 정렬 능력에 더 유익하다는 것을 시사합니다.
5.2.3 Audio-related Tasks
InternVideo2의 오디오 및 텍스트 인코더를 오디오 작업에서 평가합니다. 여기에는 AudioCaps [Kim et al., 2019], Clothov1, Clothov2 [Drossos et al., 2020]에서의 오디오-텍스트 검색, ClothoAQA [Lipping et al., 2022] 및 Audio-MusicAVQA [Behera et al., 2023]에서의 audioQA, ESC-50 [Piczak, 2015]에서의 오디오 분류가 포함됩니다. 표 12, 13a, 13b에서 볼 수 있듯이 우리 모델은 모든 다운스트림 작업에서 최첨단 성능을 달성합니다. 사용된 오디오 및 텍스트 인코더의 제한된 크기를 고려할 때, 이러한 오디오 관련 결과는 교차 모드 대조 학습의 이점이 사용된 모달리티에 상호적임을 보여줍니다. 오디오 및 해당 텍스트 모델도 이 학습에서 이점을 얻습니다.
Table 14: MVBench [Li et al., 2023d], Egoschema [Mangalam et al., 2023], Perception Test [Patraucean et al., 2024]에서의 다중 선택 비디오-QA에 대한 채팅 중심 평가 결과.
| Model | ViEncoder | LLM | MVBench | Egoschema | Perception Test |
|---|---|---|---|---|---|
| GPT-4V OpenAI, 2023b | - | GPT-4 | 43.5 | - | - |
| Gemini 1.0 Pro |Team et al., 2023 | - | - | 37.7 | 55.7 | 51.1 |
| Gemini 1.0 Ultra |Team et al., 2023 | - | - | - | 61.5 | 54.7 |
| Gemini 1.5 Pro |Team et al., 2023 | - | - | - | 72.2 | - |
| LLaVA-Next-Video |Liu et al., 2024 | CLIP-L | Vicuna-7B | 46.5 | 43.9 | 48.8 |
| VideoLLaMA2 |Cheng et al., 2024 | CLIP-L-336 | Mistral-7B | 54.6 | 51.7 | 51.4 |
| VideoLLaMA2 |Cheng et al., 2024 | CLIP-L-336 | Mistral-8*7B | 53.9 | 53.3 | 52.2 |
| VideoChat2 | UMT-L | Vicuna-7B | 51.1 | - | - |
| VideoChat2 | InternVideo2 | Mistral-7B | 60.3 | 55.8 | 53.0 |
| VideoChat2-HD | InternVideo2 | Mistral-7B | 65.4 | 60.2 | 60.1 |
| VideoChat2-HD-F16 | InternVideo2 | Mistral-7B | 67.2 | 60.0 | 63.4 |
Table 15: 제로샷 및 미세 조정 설정을 사용한 액션 인식(K400, SSv2, MiT) 및 비디오 검색(MSR-VTT, LSMDC, DiDeMo, MSVD, ANet, VATEX t2v)의 평균 top-1 정확도. *는 InternVideo2의 결과임을 나타냅니다.
| Model | Zero-shot | Finetuning | |
|---|---|---|---|
| Action Recognition | Video Retrieval | Action Recognition | |
| InternVideo2-1B | 55.5 | 55.0 | |
| InternVideo2-6B |
Table 16: Kinetics, MiT, SthSthv2에서 미세 조정된 행동 인식을 통해 수행된 Stage1의 절제 연구. 모든 모델은 입력으로 테스트되었습니다.
| Model | Teacher | Data | K400 | K600 | K700 | MiT | SSv2 | Avg |
|---|---|---|---|---|---|---|---|---|
| ViT-L | CLIP-L | K710 | 90.3 | 90.4 | 83.2 | 48.0 | 74.7 | 77.3 |
| ViT-L | CLIP-L | K-Mash | 90.5 | 90.4 | 83.4 | 48.1 | 74.7 | 77.4 |
| ViT-1B | InternVL-6B | K710 | 90.9 | 91.0 | 84.7 | 49.8 | 75.9 | 78.5 |
| ViT-1B | InternVL-6B | K-Mash | 91.4 | 91.5 | 85.1 | 50.5 | 76.5 | 79.0 |
| ViT-1B | InternVL-6B+VideoMAE-g | K-Mash | 91.3 | 91.4 | 85.0 | 50.8 | 77.1 | 79.1 |
| ViT-1B | InternVL-6B | 91.3 | 91.5 | 85.1 | 50.6 | 76.6 | 79.0 | |
| ViT-6B | InternVL-6B+VideoMAE-g | 91.9 | 91.7 | 85.7 | 51.0 | 77.5 | 79.6 |
5.3 Video-centric Dialogue and its Applications
표 14는 MVBench [Li et al., 2023d], Egoschema [Mangalam et al., 2023], Perception Test [Patraucean et al., 2024]에 대한 결과를 보여주며, VideoChat2 [Li et al., 2023d]에 우리의 InternVideo2 인코더를 장착하여 다른 MLLM과 비교합니다. InternVideo2가 포함된 VideoChat2-HD-F16은 독점 상용 모델(GPT4 & Gemini)과 비교하여 Egoschema를 제외하고 Perception Test와 MVBench에서 다른 시스템보다 명확한 차이로 성능이 뛰어납니다(F16은 모델이 16프레임 입력으로 훈련 및 테스트되었음을 나타냅니다). 우리의 방법은 오픈 소스 및 상용 방법 모두와 비교하여 우수한 단기 세분화된 비디오 이해를 보여줍니다. Egoschema는 더 긴 컨텍스트 활용을 필요로 하며, 우리는 긴 멀티모달 시퀀스 모델링을 위해 LLM을 활용하는 것을 추가로 탐색할 계획입니다. 이러한 벤치마크가 인식뿐만 아니라 추론도 포함한다는 점을 고려할 때, 이러한 결과는 InternVideo2가 세계를 부분적으로 모델링하기 위한 지식을 내장하고 있음을 시사합니다. 또한 현재 비디오 관련 MLLM에 대한 전이 가능한 비디오 표현 학습의 중요성을 검증합니다. 또한 인기 있는 GPT-4V 및 GeminiPro와의 몇 가지 정성적 평가를 제공하며, 여기에는 행동 순서(그림 4), 혼동된 행동(그림 5), 시간 순서 이해(그림 6), 시간적 사건 계산(그림 7), 예상치 못한 행동 추론(그림 8), 비전-언어 탐색(그림 9)에 대한 대화가 포함됩니다.
5.4 Ablation Studies
5.4.1 Scaling Video Encoder
표 15는 행동 인식 및 비디오 검색에 대한 InternVideo2의 평균 성능을 보여줍니다. 비디오 인코더를 1B에서 6B로 확장하면 행동 인식 및 비디오 검색의 일반화에서 여전히 상당한 개선이 이루어짐을 보여줍니다.

Figure 4: 시간적 행동 인식 작업. 행동이 일어나기 전의 행동에 대한 질문에서 Gemini Pro와 InternVideo2-Chat은 모두 행동을 정확하게 설명하는 반면 GPT-4V는 환각을 일으킵니다.

Figure 5: 혼동된 행동 인식. 비디오 속 사람은 바나나를 들고 오해의 소지가 있는 행동을 하고 있습니다. Gemini Pro는 잘못된 답을 내놓습니다. GPT-4V는 오해의 소지가 있는 행동을 식별하지만 정답을 내놓지는 못합니다. InternVideo2-Chat은 정답을 내놓습니다. 및 (제로샷에서) 각각. 한편, 미세 조정된 행동 인식 결과의 증가는 모델 규모의 성장과 함께 상대적으로 미미합니다().
5.4.2 Training Data and used Teachers in Stage 1
표 16에서는 증류 교사와 사용된 데이터셋 크기가 모델 성능에 미치는 영향을 검토합니다. (a) 데이터 규모: MAE의 사전 훈련 데이터 규모는 모델 규모가 커짐에 따라 함께 증가해야 하며, 그렇지 않으면 다운스트림 성능이 포화될 수 있습니다. 예를 들어 ViT-L의 경우 K710(0.66M 비디오), ViT-1B의 경우 K-Mash, ViT-6B의 경우 K-Mash입니다. (b) 교사: 표 16은 멀티모달 교사(예: CLIP [Radford et al., 2021])와 모션 인식 교사(예: MAE [Tong et al., 2022]) 간의 시너지 효과가 특히 SthSthV2에서 성능을 현저히 향상시킨다는 것을 보여줍니다. 이는 증류 과정에서 전략적인 교사 모델 선택의 중요성을 강조합니다.
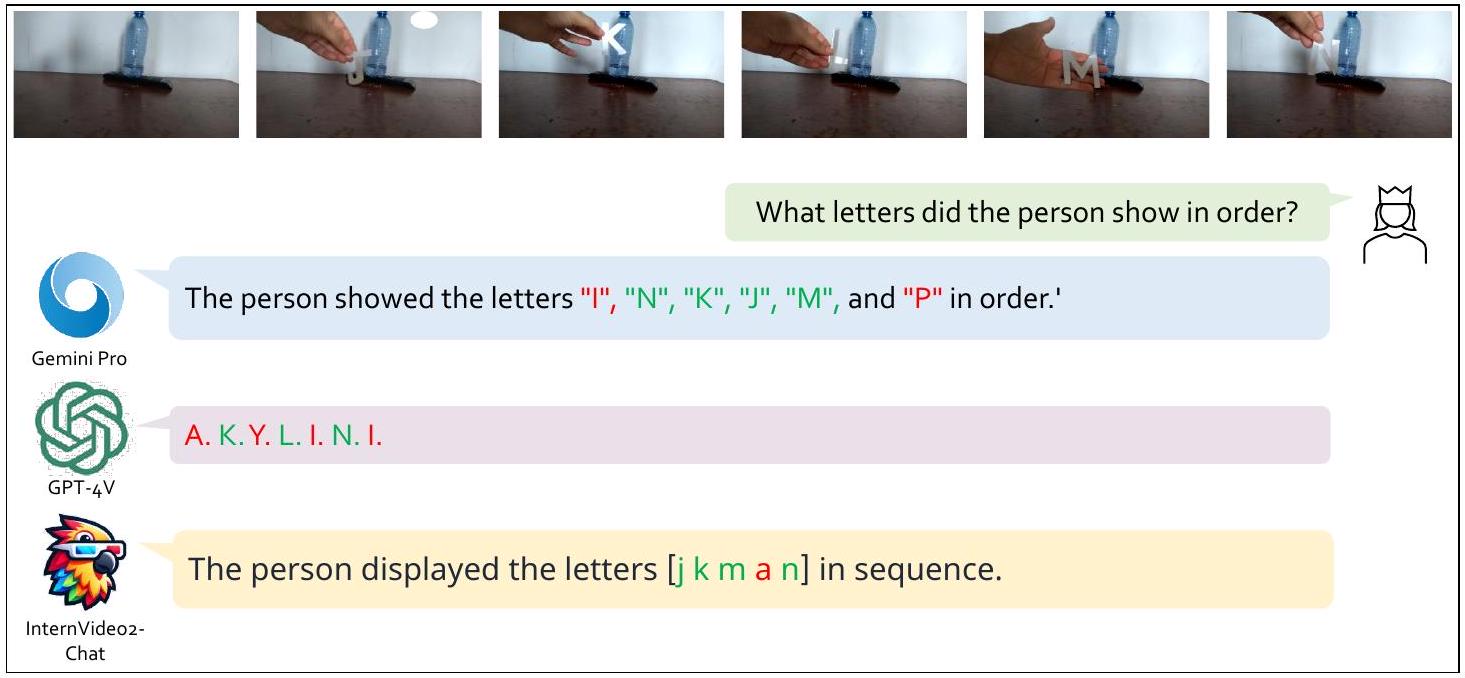
Figure 6: 비디오 객체 시간 인식. 이 비디오의 사람은 시간 순서대로 다른 글자를 꺼냅니다. Gemini Pro는 4개의 글자를 인식하지만 순서가 완전히 반대입니다. GPT-4V는 3개의 글자만 인식하고 결과가 오답과 섞여 있습니다. InternVideo2-Chat은 그중 오류가 가장 적고 순서가 맞습니다.

Figure 7: 이벤트 카운팅 작업. GPT-4V와 InternVideo2-Chat은 모두 행동 횟수를 정확하게 포착하고 중복 프레임 및 기타 행동에 혼동되지 않습니다.
5.4.3 Training Arch, Method, and Data in Stage 2
2단계에서 오디오 인코더 도입의 필요성을 분석합니다. 비디오와 텍스트 인코더에 각각 ViT-B와 Bert-B를 사용합니다. 사용된 텍스트는 간단한 비디오 캡션입니다. 기준선은 비디오와 텍스트 인코더만으로 훈련하면서 비디오-텍스트 대조 및 매칭과 마스킹된 언어 생성 손실을 수행하는 것입니다. 다른 설정으로는 오디오 또는 음성 인코더 또는 둘 다 추가하는 것, 그리고 새로 추가된 인코더를 업데이트하는 방법, 즉 텍스트 인코더만으로 훈련할지 아니면 비디오와 텍스트 인코더 둘 다로 훈련할지가 있습니다. 표 17은 오디오 인코더만 도입하고 비디오와 텍스트 인코더 둘 다와 함께 학습하는 것이 비디오-텍스트 검색 성능을 가장 잘 향상시킬 수 있음을 보여줍니다. 음성 인코더는 이러한 효과를 다소 해칩니다.
또한, 표 18에서 2단계의 비디오 시간 분할 및 텍스트 입력으로 사용된 캡션의 영향을 검증합니다. 우리는 여전히 비디오-텍스트 훈련에 ViT-B와 Bert-B를 사용합니다. 표 18은 비디오-오디오-음성에서 융합된 텍스트가 다른 것과 비교하여 검색 작업에 가장 효과적이며, MSR-VTT의 제로샷 t2v R1을 24.7에서 27.1로 상승시킵니다. 더욱이, SceneDet 대신 AutoShot을 사용하면 t2v 검색이 현저하게 향상됩니다(거의 7포인트 증가). 이는 도입된 비디오-텍스트 데이터셋과 그 주석 시스템의 효과를 검증합니다.

Figure 8: 예상치 못한 행동 인식 작업. 모델은 비디오의 마법 같은 부분을 인식해야 합니다. Gemini Pro와 InternVideo2-Chat은 모두 비디오의 전환 부분을 포착하고 비디오의 촬영 기술을 추론할 수 있습니다. GPT-4V는 전환을 인식하지만 전환 과정을 성공적으로 설명하지 못합니다.

Figure 9: 시각 언어 탐색 작업. GPT-4V와 InternVideo2-Chat은 지침을 이해하고 비디오의 내용을 기반으로 다음 단계에 대한 결정을 내릴 수 있는 반면, Gemini Pro는 환각을 일으키기 쉽습니다.
5.4.4 Training and Evaluation in Stage 3
표 19에서 볼 수 있듯이, 3단계 훈련 중 QFormer에 질문(즉, 'QA'의 'q')을 통합하는 것은 [Dai et al., 2023]에서 유용하다고 밝혀졌지만, 실제로는 확장된 VideoLLM의 도메인 외부 성능을 저해합니다. NextQA 훈련 데이터는 이미 훈련 코퍼스에 포함되어 있으며, 이것이 질문 주입 버전이 더 나은 성능을 보이는 유일한 벤치마크입니다. 따라서 우리는 확장된 VideoChat 모델의 지침 튜닝 단계에서 QFormer에 질문을 추가하는 것이 어느 정도 과적합을 유발한다고 생각합니다.
6 Conclusion and Discussion
우리는 다양한 비디오 및 오디오 작업에서 최첨단 성능을 달성하는 InternVideo2라는 새로운 비디오 파운데이션 모델 제품군을 소개했습니다. InternVideo2에서는 마스크된 비디오 모델링, 비디오-오디오-텍스트 대조 학습 및 다음 토큰 예측을 통합된 프레임워크로 결합합니다. 또한 비디오-오디오-음성 융합 캡션을 설명으로 포함하는 새로운 비디오-텍스트 데이터셋을 만듭니다. 이 데이터셋에는 의미론적 일관성이 높은 시간적으로 분할된 클립이 포함되어 있습니다. InternVideo2의 이러한 설계는 인식 및 추론 작업 모두에서 비디오 이해를 향상시키는 데 기여합니다. 특히 InternVideo2는 비디오 관련 대화 및 긴 비디오 이해에 뛰어나 고수준 의미론을 포착하는 데 효과적임을 보여줍니다.
Limitations and Discussions. 성과에도 불구하고, InternVideo2는 특별히 새로운 아키텍처 설계를 도입하지 않았습니다. 대신, 기존 학습 기술을 활용하여 비디오 파운데이션 모델을 확장하는 동시에 데이터 처리를 개선하여 시공간적 인식, 의미적 정렬 및 기본 지식 임베딩을 향상시키는 데 중점을 둡니다. 이전 연구 [Li et al., 2023e, Ye et al., 2023]와 유사하게, InternVideo2는 고정된 입력 해상도, 샘플링 속도 및 고도로 압축된 토큰에서 비롯되는 한계와 여전히 씨름하고 있으며, 이는 풍부한 비디오 정보를 표현하고 세분화된 세부 사항을 포착하는 능력을 제한합니다. InternVideo2가 채택한 점진적 학습 방식은 모델 능력과 훈련 컴퓨팅 사이의 균형을 맞춥니다. 세 가지 최적화 목표를 동시에 공동으로 학습하는 것은 계산적으로 가능하지만, 제한된 리소스에 직면하면 확장성이 문제가 됩니다. InternVideo2가 일부 비디오 이해 및 추론 벤치마크에서 선도적인 성능을 입증했지만, 시각적 추론의 일관성을 보장하는 암묵적인 세계 모델을 보장할 수는 없습니다. 고정된 입력 표현에 의해 부과된 내재된 제약과 시각적 추론 작업의 복잡성은 시각적 세계에 대한 포괄적이고 일관된 이해를 달성하는 데 어려움을 제시합니다.
Potential Biases. 여기서 잠재적인 편향을 조사합니다. 우리는 연령, 성별, 인종 분포에 초점을 맞춥니다. 이들은 편향이 발생할 수 있는 일반적으로 인식되는 영역이기 때문입니다. 사용된 캡션에서 이러한 범주와 관련된 키워드를 계산합니다. 이러한 합성 캡션은 해당 비디오의 진실을 완전히 반영하지 않을 수 있으므로 우리의 분석과 실제 현실 사이에 격차가 생길 수 있다는 점에 유의해야 합니다. 분석 결과는 다음과 같습니다.
- 연령: 대다수가 성인()에 관한 것이었고, 그 다음이 어린이()였으며, 노인(0.04%)에 대한 언급은 거의 없었습니다.
- 성별: 는 남성에 관한 것이었고, 는 여성에 관한 것이었습니다.
- 인종: 는 아시아인, 는 흑인, 는 백인, 는 중동인, 는 라틴 아메리카인입니다.
7 Broader Impact
다른 기초 모델과 마찬가지로 InternVideo2도 훈련 데이터와 신경망 교사 [Tong et al., 2022, Chen et al., 2023c] 및 언어 모델(LLM) [Jiang et al., 2023, Zheng et al., 2023]과 같은 훈련 중에 사용된 관련 모델에 존재하는 편견을 내포할 가능성이 있다는 점을 인정하는 것이 중요합니다. 이러한 편견은 데이터 제작자의 개인적인 생각, 선호도, 가치관, 관점 및 활용된 훈련 코퍼스를 포함한 다양한 요인으로 인해 나타날 수 있습니다. AI 모델에 편견이 존재하면 사회적 영향을 미치고 기존의 불평등이나 편견을 강화할 수 있습니다. InternVideo2 내의 편견은 불공정하거나 차별적인 출력의 형태로 나타날 수 있으며, 훈련 데이터에 존재하는 사회적 편견이나 고정관념을 잠재적으로 영속시킬 수 있습니다. 따라서 실제 응용 프로그램에 InternVideo2를 배포할 때 잠재적인 영향을 신중하게 고려하고 편견을 완화하고 공정성을 보장하기 위한 선제적인 조치를 취하는 것이 중요합니다.
References
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. Flamingo: a visual language model for few-shot learning. ArXiv, abs/2204.14198, 2022. Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in video with natural language. In ICCV, 2017. Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In ICCV, 2021. Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. V-JEPA: Latent video prediction for visual representation learning, 2024. URL https://openreview. net/forum?id=WFYbBOEOtv. Swarup Ranjan Behera, Krishna Mohan Injeti, Jaya Sai Kiran Patibandla, Praveen Kumar Pokala, and Balakrishna Reddy Pailla. Aquallm: Audio question answering data generation using large language models. arXiv preprint arXiv:2312.17343, 2023. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In NeurIPS, 2020. Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. arXiv preprint arXiv:2402.15391, 2024. Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 2017.
João Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. A short note about kinetics-600. ArXiv, abs/1808.01340, 2018. João Carreira, Eric Noland, Chloe Hillier, and Andrew Zisserman. A short note on the kinetics-700 human action dataset. ArXiv, abs/1907.06987, 2019. David L Chen and William B Dolan. Collecting highly parallel data for paraphrase evaluation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, pages 190-200. Association for Computational Linguistics, 2011. Guo Chen, Yin-Dong Zheng, Limin Wang, and Tong Lu. Dcan: improving temporal action detection via dual context aggregation. In , volume 36, pages 248-257, 2022a. Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, et al. Sharegpt4video: Improving video understanding and generation with better captions. arXiv preprint arXiv:2406.04325, 2024a. Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, Wanxiang Che, Xiangzhan Yu, and Furu Wei. BEATs: Audio pre-training with acoustic tokenizers. In ICML, volume 202 of Proceedings of Machine Learning Research, pages 5178-5193. PMLR, 23-29 Jul 2023a. Sihan Chen, Xingjian He, Longteng Guo, Xinxin Zhu, Weining Wang, Jinhui Tang, and Jing Liu. Valor: Vision-audiolanguage omni-perception pretraining model and dataset. arXiv preprint arXiv:2304.08345, 2023b.
Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset. NeurIPS, 36, 2024b. Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong Lu, Jifeng Dai, and Yu Qiao. Vision transformer adapter for dense predictions. arXiv preprint arXiv:2205.08534, 2022b. Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. arXiv preprint arXiv:2312.14238, 2023c. Bowen Cheng, Alexander G. Schwing, and Alexander Kirillov. Per-pixel classification is not all you need for semantic segmentation. In NeurIPS, 2021. Feng Cheng, Xizi Wang, Jie Lei, David J. Crandall, Mohit Bansal, and Gedas Bertasius. Vindlu: A recipe for effective video-and-language pretraining. ArXiv, abs/2212.05051, 2022. Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. In CVPR, pages 2818-2829, 2023. Seamless Communication, Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, PaulAmbroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, Brian Ellis, Gabriel Mejia Gonzalez, Justin Haaheim, Prangthip Hansanti, Russ Howes, Bernie Huang, Min-Jae Hwang, Hirofumi Inaguma, Somya Jain, Elahe Kalbassi, Amanda Kallet, Ilia Kulikov, Janice Lam, Daniel Li, Xutai Ma, Ruslan Mavlyutov, Benjamin Peloquin, Mohamed Ramadan, Abinesh Ramakrishnan, Anna Sun, Kevin Tran, Tuan Tran, Igor Tufanov, Vish Vogeti, Carleigh Wood, Yilin Yang, Bokai Yu, Pierre Andrews, Can Balioglu, Marta R. Costa-jussà, Onur Celebi, Maha Elbayad, Cynthia Gao, Francisco Guzmán, Justine Kao, Ann Lee, Alexandre Mourachko, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Paden Tomasello, Changhan Wang, Jeff Wang, and Skyler Wang. Seamlessm4t: Massively multilingual & multimodal machine translation, 2023. Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Albert Li, Pascale Fung, and Steven C. H. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. In NeurIPS, 2023. Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. NeurIPS, 35:16344-16359, 2022. Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Steiner, Mathilde Caron, Robert Geirhos, Ibrahim M. Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme, Matthias Minderer, Joan Puigcerver, Utku Evci, Manoj Kumar, Sjoerd van Steenkiste, Gamaleldin F. Elsayed, Aravindh Mahendran, Fisher Yu, Avital Oliver, Fantine Huot, Jasmijn Bastings, Mark Collier, Alexey A. Gritsenko, Vighnesh Birodkar, Cristina Nader Vasconcelos, Yi Tay, Thomas Mensink, Alexander Kolesnikov, Filip Paveti'c, Dustin Tran, Thomas Kipf, Mario Luvci'c, Xiaohua Zhai, Daniel Keysers, Jeremiah Harmsen, and Neil Houlsby. Scaling vision transformers to 22 billion parameters. In ICML, 2023. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. ArXiv, abs/1810.04805, 2018. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. ArXiv, abs/2010.11929, 2020. Danny Driess, F. Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Ho Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Peter R. Florence. Palm-e: An embodied multimodal language model. In ICML, 2023. Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. Clotho: An audio captioning dataset. In ICASSP, pages 736-740. IEEE, 2020. Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In ICCV, 2019.
Christoph Feichtenhofer, Haoqi Fan, Yanghao Li, and Kaiming He. Masked autoencoders as spatiotemporal learners. NeurIPS, 2022. Tsu-Jui Fu, Linjie Li, Zhe Gan, Kevin Lin, William Yang Wang, Lijuan Wang, and Zicheng Liu. Violet: End-to-end video-language transformers with masked visual-token modeling. arXiv preprint arXiv:2111.12681, 2021. Valentin Gabeur, Chen Sun, Karteek Alahari, and Cordelia Schmid. Multi-modal transformer for video retrieval. In ECCV, pages 214-229. Springer, 2020. J. Gao, Chen Sun, Zhenheng Yang, and Ramakant Nevatia. Tall: Temporal activity localization via language query. In ICCV, 2017. Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qianmengke Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. Multimodal-gpt: A vision and language model for dialogue with humans. ArXiv, abs/2305.04790, 2023. Yuan Gong, Yu-An Chung, and James Glass. Ast: Audio spectrogram transformer. arXiv preprint arXiv:2104.01778, 2021.
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fründ, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The "something something" video database for learning and evaluating visual common sense. In ICCV, 2017a. Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In CVPR, 2017b. Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh K. Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Z. Xu, Chen Zhao, Siddhant Bansal, Dhruv Batra, Vincent Cartillier, Sean Crane, Tien Do, Morrie Doulaty, Akshay Erapalli, Christoph Feichtenhofer, Adriano Fragomeni, Qichen Fu, Christian Fuegen, Abrham Gebreselasie, Cristina González, James M. Hillis, Xuhua Huang, Yifei Huang, Wenqi Jia, Weslie Khoo, Jáchym Kolár, Satwik Kottur, Anurag Kumar, Federico Landini, Chao Li, Yanghao Li, Zhenqiang Li, Karttikeya Mangalam, Raghava Modhugu, Jonathan Munro, Tullie Murrell, Takumi Nishiyasu, Will Price, Paola Ruiz Puentes, Merey Ramazanova, Leda Sari, Kiran K. Somasundaram, Audrey Southerland, Yusuke Sugano, Ruijie Tao, Minh Vo, Yuchen Wang, Xindi Wu, Takuma Yagi, Yunyi Zhu, Pablo Arbeláez, David J. Crandall, Dima Damen, Giovanni Maria Farinella, Bernard Ghanem, Vamsi Krishna Ithapu, C. V. Jawahar, Hanbyul Joo, Kris Kitani, Haizhou Li, Richard A. Newcombe, Aude Oliva, Hyun Soo Park, James M. Rehg, Yoichi Sato, Jianbo Shi, Mike Zheng Shou, Antonio Torralba, Lorenzo Torresani, Mingfei Yan, and Jitendra Malik. Ego4d: Around the world in 3,000 hours of egocentric video. In CVPR, 2022. Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In CVPR, 2022. Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. In CVPR, 2015. J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In ICLR, 2021. Haroon Idrees, Amir R Zamir, Yu-Gang Jiang, Alex Gorban, Ivan Laptev, Rahul Sukthankar, and Mubarak Shah. The thumos challenge on action recognition for videos "in the wild". CVIU, 2017. Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023. Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759, 2016. Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 119-132, 2019. Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In ICCV, 2017. Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio, and Thomas Serre. Hmdb: a large video database for human motion recognition. In ICCV, pages 2556-2563. IEEE, 2011.
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. Jie Lei, Licheng Yu, Mohit Bansal, and Tamara L. Berg. Tvqa: Localized, compositional video question answering. In EMNLP, 2018. Jie Lei, Tamara L. Berg, and Mohit Bansal. Qvhighlights: Detecting moments and highlights in videos via natural language queries, 2021. Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726, 2023a. Guangyao Li, Yixin Xu, and Di Hu. Multi-scale attention for audio question answering. arXiv preprint arXiv:2305.17993, 2023b. Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, 2022a. Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022b. Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Limin Wang, and Yu Qiao. Uniformerv2: Spatiotemporal learning by arming image vits with video uniformer. arXiv preprint arXiv:2211.09552, 2022c. KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023c. Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. arXiv preprint arXiv:2311.17005, 2023d. Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, and Yu Qiao. Unmasked teacher: Towards training-efficient video foundation models. arXiv preprint arXiv:2303.16058, 2023e. Tianhao Li and Limin Wang. Learning spatiotemporal features via video and text pair discrimination. CoRR, abs/2001.05691, 2020. URLhttps://arxiv.org/abs/2001.05691. Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. Univtg: Towards unified video-language temporal grounding. In ICCV, pages 2794-2804, 2023. Tianwei Lin, Xiao Liu, Xin Li, Errui Ding, and Shilei Wen. Bmn: Boundary-matching network for temporal action proposal generation, 2019. Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. Samuel Lipping, Parthasaarathy Sudarsanam, Konstantinos Drossos, and Tuomas Virtanen. Clotho-aqa: A crowdsourced dataset for audio question answering. In EUSIPCO, pages 1140-1144. IEEE, 2022. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023. Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, 2024. Jun Liu, Amir Shahroudy, Mauricio Perez, Gang Wang, Ling-Yu Duan, and Alex C Kot. Ntu rgb+d 120: A large-scale benchmark for 3d human activity understanding. TPAMI, 2020. Yi Liu, Limin Wang, Yali Wang, Xiao Ma, and Yu Qiao. Fineaction: A fine-grained video dataset for temporal action localization. TIP, 31:6937-6950, 2022. Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021. Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing, 2022. Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Ming-Hui Qiu, Pengcheng Lu, Tao Wang, and Zhongyu Wei. Valley: Video assistant with large language model enhanced ability. ArXiv, abs/2306.07207, 2023. Muhammad Maaz, Hanoona Abdul Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. ArXiv, abs/2306.05424, 2023. Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, NeurIPS, pages 46212-46244, 2023.
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In CVPR, 2019. Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D. Plumbley, Yuexian Zou, and Wenwu Wang. Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research, 2023. Mathew Monfort, Bolei Zhou, Sarah Adel Bargal, Alex Andonian, Tom Yan, Kandan Ramakrishnan, Lisa M. Brown, Quanfu Fan, Dan Gutfreund, Carl Vondrick, and Aude Oliva. Moments in time dataset: One million videos for event understanding. TPAMI, 2020. WonJun Moon, Sangeek Hyun, SuBeen Lee, and Jae-Pil Heo. Correlation-guided query-dependency calibration in video representation learning for temporal grounding. arXiv preprint arXiv:2311.08835, 2023. OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023a. OpenAI. Gpt-4v(ision) system card. https://api.semanticscholar.org/CorpusID:263218031, 2023b. Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Recasens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Perception test: A diagnostic benchmark for multimodal video models. In NeurIPS, 2024. Karol J Piczak. Esc: Dataset for environmental sound classification. In Proceedings of the 23rd ACM international conference on Multimedia, pages 1015-1018, 2015. Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In ICCV, 2015. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, 2021. Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In ICML, pages 28492-28518. PMLR, 2023. Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR, 2020. Anna Rohrbach, Marcus Rohrbach, Niket Tandon, and Bernt Schiele. A dataset for movie description. In CVPR, pages 3202-3212, 2015. Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, and Christoph Feichtenhofer. Hiera: A hierarchical vision transformer without the bells-and-whistles, 2023. Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012. Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiying Yu, Zhengxiong Luo, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, et al. Generative multimodal models are in-context learners. arXiv preprint arXiv:2312.13286, 2023a. Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389, 2023b. Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative pretraining in multimodality. arXiv preprint arXiv:2307.05222, 2023c. Quan Sun, Jinsheng Wang, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, and Xinlong Wang. Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252, 2024. Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023. Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. NeurIPS, 35:10078-10093, 2022.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971, 2023a. Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Cantón Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony S. Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel M. Kloumann, A. V. Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288, 2023b. Du Tran, Hong xiu Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. In CVPR, 2018. Jinpeng Wang, Yixiao Ge, Rui Yan, Yuying Ge, Kevin Qinghong Lin, Satoshi Tsutsui, Xudong Lin, Guanyu Cai, Jianping Wu, Ying Shan, et al. All in one: Exploring unified video-language pre-training. In CVPR, pages 6598-6608, 2023a. Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In ECCV, 2016. Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yinan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. In CVPR, 2023b. Rui Wang, Dongdong Chen, Zuxuan Wu, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Lu Yuan, and Yu-Gang Jiang. Masked video distillation: Rethinking masked feature modeling for self-supervised video representation learning. In CVPR, pages 6312-6322, 2023c. Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In ICCV, 2019. Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, and Yu Qiao. Internvideo: General video foundation models via generative and discriminative learning. arXiv preprint arXiv:2212.03191, 2022. Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation. arXiv preprint arXiv:2307.06942, 2023d. Haiyang Xu, Qinghao Ye, Ming Yan, Yaya Shi, Jiabo Ye, Yuanhong Xu, Chenliang Li, Bin Bi, Qi Qian, Wei Wang, et al. mplug-2: A modularized multi-modal foundation model across text, image and video. arXiv preprint arXiv:2302.00402, 2023. Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding. arXiv preprint arXiv:2109.14084, 2021. Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In CVPR, pages 5288-5296, 2016. Shen Yan, Tao Zhu, Zirui Wang, Yuan Cao, Mi Zhang, Soham Ghosh, Yonghui Wu, and Jiahui Yu. Video-text modeling with zero-shot transfer from contrastive captioners. ArXiv, abs/2212.04979, 2022. Linjie Yang, Yuchen Fan, and Ning Xu. Video instance segmentation. In ICCV, 2019. Min Yang, Guo Chen, Yin-Dong Zheng, Tong Lu, and Limin Wang. Basictad: an astounding rgb-only baseline for temporal action detection. CVIU, page 103692, 2023. Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, Chaoya Jiang, Chenliang Li, Yuanhong Xu, Hehong Chen, Junfeng Tian, Qian Qi, Ji Zhang, and Fei Huang. mplug-owl: Modularization empowers large language models with multimodality, 2023. Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917, 2022.
Éloi Zablocki, Hédi Ben-Younes, Patrick Pérez, and Matthieu Cord. Explainability of deep vision-based autonomous driving systems: Review and challenges. IJCV, 130(10):2425-2452, 2022. Rowan Zellers, Jiasen Lu, Ximing Lu, Youngjae Yu, Yanpeng Zhao, Mohammadreza Salehi, Aditya Kusupati, Jack Hessel, Ali Farhadi, and Yejin Choi. Merlot reserve: Neural script knowledge through vision and language and sound. In CVPR, pages 16375-16387, 2022. Ziyun Zeng, Yixiao Ge, Zhan Tong, Xihui Liu, Shu-Tao Xia, and Ying Shan. Tvtsv2: Learning out-of-the-box spatiotemporal visual representations at scale. arXiv preprint arXiv:2305.14173, 2023. Biao Zhang and Rico Sennrich. Root mean square layer normalization. NeurIPS, 32, 2019. Bowen Zhang, Jiahui Yu, Christopher Fifty, Wei Han, Andrew M. Dai, Ruoming Pang, and Fei Sha. Co-training transformer with videos and images improves action recognition. ArXiv, abs/2112.07175, 2021. Hongjie Zhang, Yi Liu, Lu Dong, Yifei Huang, Zhen-Hua Ling, Yali Wang, Limin Wang, and Yu Qiao. Movqa: A benchmark of versatile question-answering for long-form movie understanding. arXiv preprint arXiv:2312.04817, 2023.
Hang Zhao, Antonio Torralba, Lorenzo Torresani, and Zhicheng Yan. Hacs: Human action clips and segments dataset for recognition and temporal localization. In ICCV, 2019. Long Zhao, Nitesh B. Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J. Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, Rachel Hornung, Florian Schroff, Ming-Hsuan Yang, David A. Ross, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko, Ting Liu, and Boqing Gong. Videoprism: A foundational visual encoder for video understanding, 2024. Yanpeng Zhao, Jack Hessel, Youngjae Yu, Ximing Lu, Rowan Zellers, and Yejin Choi. Connecting the dots between audio and text without parallel data through visual knowledge transfer. arXiv preprint arXiv:2112.08995, 2021. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023. Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, HongFa Wang, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, et al. Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment. arXiv preprint arXiv:2310.01852, 2023a. Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. ArXiv, abs/2304.10592, 2023b. Wentao Zhu, Yufang Huang, Xiufeng Xie, Wenxian Liu, Jincan Deng, Debing Zhang, Zhangyang Wang, and Ji Liu. Autoshot: A short video dataset and state-of-the-art shot boundary detection. In CVPR, pages 2237-2246, 2023c.
A Model
Table 20: 비전 인코더 아키텍처 (6B).
| Stage | ViT-6B | Output Size | |||
|---|---|---|---|---|---|
| Video | sparse sampling | ||||
| Patch Embedding | stride | ||||
| Position Embedding | learnable, 3D sine-cosine initialization | ||||
| Mask | semantic mask w/ mask ratio | ||||
| Encoder | |||||
| Projection |
Video Encoder. 표 20에서는 ViT-6B를 예로 들고 간단한 설명을 위해 클래스 토큰을 생략했습니다. "MHSA", "MLP", "AttnPool", "LN"은 시공간 다중 헤드 자기 어텐션, 다층 퍼셉트론, 어텐션 풀링 [Yu et al., 2022], 제곱 평균 제곱근 레이어 정규화 [Zhang and Sennrich, 2019]를 의미합니다. 와 는 멀티모달 및 모션 인식 교사와의 마스크되지 않은 토큰 정렬을 위한 레이어 수를 의미합니다. 채널 수, 프레임 수, 공간 크기 및 토큰 수를 다른 색상으로 표시했습니다. 투영 레이어는 1단계 훈련 후에 제거됩니다.
B Video-centric Multimodal Data
우리는 학습 계획의 세 단계의 학습 목표에 따라 훈련 데이터를 준비합니다. 구체적으로, 마스크된 비디오 토큰 재구성을 위한 비디오 전용 사전 훈련 세트, 멀티모달 정렬을 위한 비디오-오디오-음성-텍스트 세트, 인간-컴퓨터 상호 작용 정렬을 위한 비디오 지침 데이터셋으로 구성됩니다. 이에 대한 자세한 내용은 다음과 같습니다.
B. 1 Video-only Data
K-Mash라는 이름의 선별된 비디오 컬렉션을 만들기 위해 Kinetics-400(K400) [Carreira and Zisserman, 2017], Something-Something(Sth) [Goyal et al., 2017a], Moments in Time(MIT) [Monfort et al., 2020], ActivityNet [Heilbron et al., 2015], HACS [Zhao et al., 2019]와 같은 유명한 행동 인식 데이터셋에서 비디오를 소싱했습니다. 이러한 데이터셋은 1인칭 및 3인칭 시점, 짧고 긴 길이, 풍부하고 다양한 캐릭터와 설정을 특징으로 하는 광범위한 비디오 유형을 제공합니다.
데이터셋의 향상된 버전인 의 경우, 한 단계 더 나아가 YouTube에서 추가로 844,000개의 비디오를 신중하게 선택하여 데이터셋의 다양성을 더욱 향상시켰습니다. 이 데이터셋의 모든 비디오는 레이블 없이 훈련에 활용되어 모델이 비지도 방식으로 레이블이 없는 데이터로부터 학습할 수 있도록 한다는 점에 유의하는 것이 중요합니다. 이 접근 방식은 모델이 다양한 시각적 개념에 대한 이해를 넓히고 다양한 비디오 관련 작업에서 성능을 향상시키는 데 도움이 됩니다.
B. 2 Videos with Audio-Video-Speech Modalities
공개적으로 이용 가능한 비디오-텍스트 데이터셋(예: InternVid [Wang et al., 2023d] 및 WebVid [Bain et al., 2021]) 외에도, 오디오-시각-음성 정보와 해당 텍스트 설명을 모두 통합한 새로운 비디오 데이터셋을 소개합니다. 이 데이터셋은 InternVideo2의 훈련 과정에 포함됩니다. InternVid2라는 이 멀티모달 데이터셋을 만들기 위해 여러 비디오 소스를 활용하고 상세한 주석을 제공합니다. InternVid2에는 동기화된 오디오, 시각 및 음성 정보와 해당 텍스트 설명이 포함된 비디오가 포함됩니다. 이 멀티모달 데이터셋은 InternVideo2가 다양한 모달리티 간의 연결을 더 잘 이해하고 포착하도록 훈련하여 오디오, 시각 및 음성 이해가 필요한 다양한 비디오 관련 작업에서 성능을 향상시킬 수 있도록 합니다.
Collection. InternVid2 데이터셋에서 비디오의 약 절반은 YouTube에서 가져왔고 나머지 비디오는 익명의 소스에서 수집되었습니다. 이는 데이터셋의 다양성을 향상시키기 위한 것으로, YouTube에만 의존하면 데이터셋의 깊이가 제한될 수 있기 때문입니다. 또한, 학습된 모델에 대한 비디오 문화 배경의 영향을 연구하기 위해 데이터셋의 일부는 중국어 데이터로 구성됩니다. 이러한 비디오는 법적 및 윤리적 고려 사항을 준수하여 학술적 사용에 대한 적절한 허가를 받아 수집되었습니다.
Table 21: Stagel 데이터 통계. 모든 비디오는 레이블 없이 사용됩니다.
| Dataset | K710 | SthSthV2 | HACS | ANet | MiT | Self-collected |
|---|---|---|---|---|---|---|
| K-Mash | 658 K | 169 K | 106 K | 15 K | 152 K | 0 |
| K-Mash | 658 K | 169 K | 106 K | 15 K | 207 K | 844 K |
다양한 소스의 비디오를 통합하고 중국어 데이터의 일부를 포함함으로써 InternVid2는 InternVideo2 훈련을 위한 더 다양하고 대표적인 데이터셋을 제공합니다. 이 접근 방식을 통해 모델은 다양한 문화적 배경을 포괄하는 광범위한 비디오 콘텐츠로부터 학습하여 다양한 소스의 비디오를 이해하고 처리하는 능력을 더욱 향상시킬 수 있습니다.
Trimming. 우리의 접근 방식에서는 널리 사용되는 FFMPEG의 SceneDet 필터에 의존하는 대신, AutoShot [Zhu et al., 2023c]이라는 시간적 경계 감지 모델을 사용하여 비디오를 클립으로 분할합니다. AutoShot은 픽셀 차이가 아닌 시간적 의미 변화에 따라 클립 경계를 예측할 수 있습니다. 이를 통해 일관되지 않은 컨텍스트를 포함할 수 있는 추가 프레임을 혼합하지 않고 의미적으로 완전한 컷을 생성할 수 있습니다. AutoShot을 사용함으로써, 명백한 전환이 있는 클립을 줄여 캡션 오류를 줄이고, 비디오 캡션 모델에 더 일관된 입력을 제공하는 것을 목표로 합니다. AutoShot의 추론에서는 AutoShot의 추정에 대한 샷 경계를 결정하기 위해 0.5의 임계값을 사용합니다. 비디오 데이터셋의 경우, 먼저 2초보다 긴 클립을 보존합니다. 30초보다 긴 비디오 클립의 경우, 클립 내의 세그먼트가 동일한 샷에서 나온 것이므로 30초 세그먼트를 무작위로 선택합니다. 이 과정에서 사진 갤러리를 탐색하는 것과 같이 정지되거나 극단적인 역학을 가진 클립도 폐기합니다.
Table 22: 융합 프롬프트. 위 프롬프트는 2개의 멀티모달 캡션을 생성하기 위한 것이고, 아래 프롬프트는 3개의 멀티모달 캡션을 생성하기 위한 것입니다.
당신은 텍스트 분석 전문가입니다. 한 비디오에 대해, 여기 1개의 비전 캡션: vid_cap, 1개의 오디오 캡션:aud_cap이 있습니다. 당신은 그것들을 이해하고 1개의 문장으로 인코딩해야 합니다. 단순히 그것들을 함께 연결하지 마십시오. 비디오/오디오의 가중치는 동일합니다. 이해할 수 없는 경우 오디오 캡션을 삭제하는 것을 고려하십시오. 출력은 완전하고 자연스러운 문장이어야 합니다. 문장은 다음과 같습니다: ...
당신은 텍스트 분석 전문가입니다. 한 비디오에 대해, 여기 1개의 비전 캡션: vid_cap, 1개의 오디오 캡션:aud_cap, 그리고 1개의 음성 자막: asr_cap이 있습니다. 당신은 그것들을 이해하고 1개의 완전한 문장으로 인코딩해야 합니다. 비디오/오디오/음성의 가중치는 동일합니다. 이해할 수 없는 경우 오디오 캡션이나 음성 자막을 삭제하는 것을 고려하십시오. 출력은 완전하고 자연스러운 문장이어야 하며, 단순히 그것들을 함께 연결하지 마십시오. 완전한 문장은 다음과 같습니다:
Annotation. InternVid2의 시각, 오디오 및 음성을 자동으로 캡션합니다. 그런 다음 이를 수정하고 LLM을 사용하여 훈련용 교차 모달 캡션으로 융합합니다. 그림 10에 우리 방법의 여러 주석 예를 나열합니다.
- Vision Captioner. 우리는 InternVid의 비디오 캡셔닝 파이프라인을 사용하여 데이터를 주석 처리합니다. 비디오를 설명하기 위해 VideoLLM [Li et al., 2023c, Maaz et al., 2023]을 사용하는 대신, 더 나은 다운스트림 결과 때문에 이 검증된 방법을 선택합니다.
- Audio Captioner. 신뢰할 수 있는 것을 찾지 못했기 때문에 VideoChat [Li et al., 2023c]을 기반으로 오디오 캡셔너를 제작합니다. Beats [Chen et al., 2023a]에 의해 입력에서 오디오 기능을 추출합니다. 대규모 오디오-텍스트 코퍼스 WavCaps [Mei et al. 2023] 데이터셋의 조합을 사용하여 Qformer(오디오 인코더와 LLM 사이의 인터페이스)만 조정하여 학습합니다.
- Speech Captioner. Whisper [Radford et al., 2023] 오디오 전사 모델을 사용하여 비디오에서 음성을 얻습니다. 구체적으로, 동시 최첨단 성능 때문에 WhisperV2-large 모델을 사용합니다. 데이터 수집 과정에서 데이터의 일부는 이미 잘 정렬된 타임스탬프와 조정된 음성 인식 콘텐츠를 가진 YT-Temporal-180M에서 직접 채택됩니다. 나머지 데이터는 먼저 사전 훈련된 언어 식별 모델 Fasttext-lid [Joulin et al., 2016]를 통과하여 언어 범주를 결정한 다음, 사전 훈련된 Seamless M4T [Communication et al., 2023] 모델을 사용하여 영어가 아닌 텍스트를 영어로 번역합니다. 언어 식별 신뢰도가 0.95 미만인 텍스트의 경우 Vicuna-1.5를 번역 대안으로 사용합니다.
- Caption Triming & Fusion with LLM. 주어진 비디오에서 오디오, 비디오, 음성 캡션을 얻은 후, LLM(Vicuna-1.5 [Zheng et al., 2023])을 활용하여 단일 모달 캡션을 멀티모달 캡션으로 통합합니다. 다중 대조 목표에 대한 요청을 충족시키기 위해 오디오 캡션을 비디오 캡션과 결합합니다.

| Video Cap: 한 여성이 가게 안에서 기자에게 이야기하고 있습니다. |
|---|
| Audio Cap: 한 여성이 이야기하고 있고 |
| 배경에서 음악이 재생됩니다. |
| ASR: 그녀는 우리의 두 번째 경쟁자가 될 것입니다. |
| 한 바퀴 도세요. 그녀는 69 파운드를 감량했고 |
| 체중의 31%를 감량했습니다. 이봐요, |
| 저는 흥분되지만 긴장되지만 흥분됩니다, 캐롤린. |
Video-Audio-Speech Cap:
가게 안에서, 배경 음악이 흐르는 가운데 한 여성이 흥분과 긴장이 섞인 목소리로 기자에게 캐롤린에 대해 이야기합니다. 캐롤린은 그들의 두 번째 경쟁자가 될 것이며, 69파운드와 체중의 31%를 감량했습니다.
Video-Audio Cap:
가게 안에서, 한 여성이 기자와 이야기하는 동안 배경에서 음악이 들립니다.
 Video Cap: 빨간 셔츠를 입은 남자가 사자 앞에 서 있습니다.
Audio Cap: 한 남자가 라디오에서 음악이 나오는 동안 이야기하고 있습니다.
Video-Audio-Speech Cap:
빨간 셔츠를 입은 남자는 이미 방 안에 대부분의 줄이 있는 방에서 야생 사자로부터 자신을 바리케이드로 막으려고 시도하고 있으며, 한 남자는 이야기하고 라디오에서는 음악이 흘러나옵니다.
ASR: 장면은 덴버가 야생 사자로부터 자신을 바리케이드로 막으려는 시도로 구성되었으며, 대부분의 줄이 이미 그와 함께 방에 있습니다.
Video-Audio Cap:
빨간 셔츠를 입은 남자는 사자 앞에 서서 라디오에서 음악이 나오는 동안 이야기합니다.
Video Cap: 빨간 셔츠를 입은 남자가 사자 앞에 서 있습니다.
Audio Cap: 한 남자가 라디오에서 음악이 나오는 동안 이야기하고 있습니다.
Video-Audio-Speech Cap:
빨간 셔츠를 입은 남자는 이미 방 안에 대부분의 줄이 있는 방에서 야생 사자로부터 자신을 바리케이드로 막으려고 시도하고 있으며, 한 남자는 이야기하고 라디오에서는 음악이 흘러나옵니다.
ASR: 장면은 덴버가 야생 사자로부터 자신을 바리케이드로 막으려는 시도로 구성되었으며, 대부분의 줄이 이미 그와 함께 방에 있습니다.
Video-Audio Cap:
빨간 셔츠를 입은 남자는 사자 앞에 서서 라디오에서 음악이 나오는 동안 이야기합니다.
 불행히도.
Video Cap: 한 무리의 사람들이 별이 빛나는 밤하늘 아래 들판에 서 있습니다.
Video-Audio-Speech Cap:
한 무리의 사람들이 별이 빛나는 밤하늘 아래 들판에 서 있고, 배경에서는 한 여성이 한 무리의 사람들이 망원경으로 달을 관찰하며 그 분화구에 감탄하고 있다고 이야기하고 있습니다.
Video-Audio Cap:
한 무리의 사람들이 별이 빛나는 밤하늘 아래 들판에 서 있고 배경에서는 한 여성이 이야기하고 있습니다.
불행히도.
Video Cap: 한 무리의 사람들이 별이 빛나는 밤하늘 아래 들판에 서 있습니다.
Video-Audio-Speech Cap:
한 무리의 사람들이 별이 빛나는 밤하늘 아래 들판에 서 있고, 배경에서는 한 여성이 한 무리의 사람들이 망원경으로 달을 관찰하며 그 분화구에 감탄하고 있다고 이야기하고 있습니다.
Video-Audio Cap:
한 무리의 사람들이 별이 빛나는 밤하늘 아래 들판에 서 있고 배경에서는 한 여성이 이야기하고 있습니다.
 Video-Audio-Speech Cap:
배경에서 새가 지저귀는 동안, 작은 검은 물고기가 연못에서 헤엄치고 있고 한 남자가 '이봐, 친구'라고 말하고 있습니다.
Video-Audio Cap:
작은 검은 물고기가 연못에서 헤엄치는 동안 새가 지저귀고 한 남자가 배경에서 이야기합니다.
Video-Audio-Speech Cap:
배경에서 새가 지저귀는 동안, 작은 검은 물고기가 연못에서 헤엄치고 있고 한 남자가 '이봐, 친구'라고 말하고 있습니다.
Video-Audio Cap:
작은 검은 물고기가 연못에서 헤엄치는 동안 새가 지저귀고 한 남자가 배경에서 이야기합니다.
Figure 10: 캡셔닝 접근 방식을 사용한 주석 예시. 오디오-시각 캡션으로, 또한 오디오, 비디오 및 음성 캡션을 오디오-시각-자막 캡션으로 통합합니다. 이러한 방식으로 각 비디오에 대해 자동으로 5가지 유형의 캡션(3개의 단일 모드 캡션(A, V, S) 및 2개의 다중 모드 캡션(AV, AVS))을 획득합니다. 특히, 신중하게 설계된 프롬프트 템플릿(그림 22)을 사용하고 추론 가속화를 위해 vLLM [Kwon et al., 2023]을 사용하여 자연스러운 인간과 같은 자막 스타일을 유지하면서 시각 캡션, 오디오 캡션, 자막, 오디오-시각 캡션 및 오디오-시각-음성 캡션을 효과적으로 얻습니다.
Filtering & Sampling. 캡션을 얻은 후 비디오 세그먼트와 캡션 간의 CLIP 유사도를 계산합니다. 상위 6천만 개의 데이터를 InternVid2의 비디오 세그먼트 데이터로 선택합니다. LAION-2B의 경우 CLIP 유사도가 상위 1억 5천 8백만 개인 샘플만 훈련용으로 선택합니다.
C Experiments
C. 1 Ablations
C.1.1 How InternVideo2 Works in Feature-based Tasks.
InternVideo2의 예측 중 어느 부분이 특징 기반 작업, 즉 시간적 행동 지역화에 적합한지 연구합니다. 본 논문과 동일한 훈련 및 테스트 프로토콜을 따릅니다. 표 C.1.1에서 가장 효과적인 특징은 비디오 인코더의 마지막 몇 개 레이어 내에 위치하는 경향이 있습니다. 이 관찰은 특징 기반 시간적 작업과 선형 프로빙 분류 간의 유사성과 일치하며, 이는 합리적입니다. 표 23에 자세히 설명된 대로 다양한 레이어의 특징이 미치는 영향을 조사하기 위해 포괄적인 실험을 수행했습니다. 결과는 마지막 5번째 레이어와 7번째 레이어 사이에서 최상의 특징이 나타남을 보여줍니다.
Table 23: 마지막 7개 레이어에서 추출한 특징의 효과.
| Layer Index | THUMOS-14 | ActivityNet | HACS Segment | FineAction | ||||
|---|---|---|---|---|---|---|---|---|
| 1B@mAP | 6B@mAP | 1B@mAP | 6B@mAP | 1B@mAP | 6B@mAP | 1B@mAP | 6B@mAP | |
| -1 | 67.9 | 70.3 | 39.0 | 40.7 | 39.5 | 42.1 | 25.4 | 25.3 |
| -2 | 68.4 | 71.0 | 39.3 | 40.5 | 41.0 | 42.7 | 26.2 | 26.4 |
| -3 | 69.0 | 71.3 | 39.7 | 40.5 | 41.2 | 42.7 | 27.0 | 26.6 |
| -4 | 69.3 | 71.4 | 39.6 | 41.1 | 41.3 | 43.1 | 27.1 | 27.1 |
| -5 | 69.9 | 71.8 | 39.7 | 40.9 | 41.4 | 43.1 | 27.2 | 27.7 |
| -6 | 69.6 | 72.0 | 39.6 | 41.2 | 40.7 | 43.3 | 27.0 | 27.7 |
| -7 | 69.5 | 71.9 | 40.0 | 41.1 | 40.6 | 42.8 | 26.9 | 27.7 |
Table 24: MSR-VTT, DiDeMo, LSMDC, ActivityNet, VATEX, MSVD에서의 비디오 검색 결과. R@1, R@5, R@10을 보고합니다. #F는 평가 시 입력 프레임 수를 나타냅니다. (a) MSR-VTT (d) DiDeMo
| Method | Text-to-Video | Video-to-Text | |||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| InternVideo2-1B | 51.9 | 74.6 | 81.7 | 49.6 | 73.6 | 81.2 | |
| InternVideo2-1B | 8 | 51.9 | 75.3 | 82.5 | 50.9 | 73.4 | 81.8 |
| InternVideo2-6B | 4 | 54.5 | 77.5 | 83.7 | 52.3 | 75.3 | 83.5 |
| InternVideo2-6B | 8 | 55.9 | 78.3 | 85.1 | 53.7 | 77.5 | 84.1 |
| Method | Text-to-Video | Video-to-Text | |||||
|---|---|---|---|---|---|---|---|
| #F | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| InternVideo2-1B | 4 | 56.7 | 78.7 | 83.9 | 54.4 | 74.4 | 80.6 |
| InternVideo2-1B | 8 | 57.0 | 80.0 | 85.1 | 54.3 | 77.2 | 83.5 |
| InternVideo2-6B | 4 | 56.2 | 77.6 | 83.6 | 53.2 | 76.8 | 82.7 |
| InternVideo2-6B | 8 | 57.9 | 80.0 | 84.6 | 57.1 | 79.9 | 85.0 |
(b) LSMDC (e) ActivityNet
| Method | Text-to-Video | Video-to-Text | |||||
|---|---|---|---|---|---|---|---|
| #F | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| InternVideo2-1B | 4 | 31.5 | 51.3 | 59.5 | 27.1 | 44.8 | 51.8 |
| InternVideo2-1B | 8 | 32.0 | 52.4 | 59.4 | 27.3 | 44.2 | 51.6 |
| InternVideo2-6B | 4 | 34.8 | 54.0 | 61.6 | 30.1 | 48.0 | 55.0 |
| InternVideo2-6B | 8 | 33.8 | 55.9 | 62.2 | 30.1 | 47.7 | 54.8 |
| Method | #F | Text-to-Video | Video-to-Text | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| InternVideo2-1B | 56.9 | 81.7 | 89.8 | 53.6 | 80.0 | 88.5 | |
| InternVideo2-1B | 8 | 60.4 | 83.9 | 90.8 | 54.8 | 81.5 | 89.5 |
| InternVideo2-6B | 4 | 59.4 | 83.2 | 90.3 | 53.7 | 80.5 | 88.9 |
| InternVideo2-6B | 8 | 63.2 | 85.6 | 92.5 | 56.5 | 82.8 | 90.3 |
(c) VATEX (f) MSVD
| Method | #F | Text-to-Video | Video-to-Text | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| InternVideo2-1B | 70.7 | 93.7 | 96.9 | 85.9 | 97.6 | 99.2 | |
| InternVideo2-1B | 8 | 70.4 | 93.4 | 96.9 | 85.4 | 97.6 | 99.1 |
| InternVideo2-6B | 4 | 71.1 | 93.8 | 97.0 | 85.2 | 97.7 | 99.4 |
| InternVideo2-6B | 8 | 71.5 | 94.0 | 97.1 | 85.3 | 97.9 | 99.3 |
| Method | #F | Text-to-Video | Video-to-Text | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| InternVideo2-1B | 58.9 | 83.0 | 88.7 | 83.6 | 94.8 | 97.0 | |
| InternVideo2-1B | 8 | 58.1 | 83.0 | 88.4 | 83.3 | 94.3 | 96.9 |
| InternVideo2-6B | 4 | 59.8 | 84.2 | 89.7 | 82.5 | 94.6 | 97.2 |
| InternVideo2-6B | 8 | 59.3 | 84.4 | 89.6 | 83.1 | 94.2 | 97.0 |
C. 2 Video Retrieval
참고용으로 InternVideo2의 제로샷 비디오 검색의 R@1, R@5, R@10을 표 24a-24f에 자세히 설명합니다.
Table 25: MSR-VTT 및 LSMDC에 대한 제로샷 비디오 QA(다지선다형)의 top-1 정확도. 미세 조정된 결과는 회색으로 표시됩니다.
| Method | MSR-VTT | LSMDC | | :--- | :---: | :---: | :---: | | VIOLET |Fu et al., 2021. | 91.9 | 82.8 | | InternVideo | Wang et al., 2022. | 93.4 | | | InternVideo2-6B | | 76.9 |
Table 26: MoVQA의 다양한 질문 유형 및 장면에 대한 멀티모달 LLM의 성능.
| Method | Backbone | Synopsis | Temporal | Spatial | Causal | Hypothetical | Knowledge | Single-Scene | Multi-Scene | Full-Scene | Overall | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mplug-Owl | Ye et al., 2023 | CLIP ViT-L | 25.1 | 19.9 | 25.3 | 21.9 | 23.5 | 27.5 | 25.2 | 23.5 | 22.1 | 24.8 |
| Otter | Li | CLIP ViT-L | 22.6 | 20.7 | 19.6 | 26.1 | 24.2 | 21.8 | 23.1 | 22.1 | 21.3 | 22.6 |
| VideoChatGPI | Maaz et al., 2023] | CLIP ViT-L | 23.8 | 20.2 | 22.1 | 22.1 | 21.4 | 24.1 | 23.4 | 22.7 | 22.3 | 22.9 |
| VideoChat | Li et al., 2025 c | Eva-g | 33.6 | 24.3 | 34.5 | 36.6 | 35.5 | 32.0 | 35.3 | 32.9 | 33.3 | 34.7 |
| VideoChat2 | L1 et al., 2025d | InternVideo2 | 42.6 | 27.8 | 39.9 | 44.3 | 442.5 | 41.2 | 40.9 | 39.3 | 38.6 | 40.1 |
C. 3 Multi-Choice Video Question Answering
2단계에서 InternVideo2를 사용하여 MSR-VTT와 VATEX에 대한 제로샷 다지선다(MC) 비디오 QA를 평가합니다. 표 25는 InternVideo2가 LSMDC에서 InternVideo와 비슷한 결과를 얻은 것을 제외하고 이전 SOTA에 비해 MC 정확도를 일관되게 향상시켰음을 보여줍니다.
C. 4 Movie Understanding
MoVQA에서 영화 이해를 위해 InternVideo2를 평가합니다. 이것은 긴 형식의 영화 질의응답 데이터셋입니다[Zhang et al., 2023]. MoVQA는 비디오 길이와 단서 길이를 모두 고려하여 다단계 시간적 길이(단일 장면, 다중 장면 및 전체 장면)에 의존하여 멀티모달 시스템의 다양한 인지 능력을 평가합니다. 정보 요약, 시간적 인식, 공간적 인식, 인과 추론, 가상 추론 및 외부 지식 등 6가지 유형의 QA가 있습니다. 우리는 InternVideo2-6B를 개방형 QA 형식으로 평가하며, 자세한 결과는 표 26에 나와 있습니다.