InternVideo: 생성 및 판별 학습을 통한 일반 비디오 파운데이션 모델
InternVideo는 생성적(generative) 및 판별적(discriminative) 자기지도 비디오 학습을 활용하여 범용 비디오 파운데이션 모델을 제시합니다. 이 모델은 masked video modeling과 video-language contrastive learning을 사전 학습 목표로 삼아 두 프레임워크의 비디오 표현을 학습 가능한 방식으로 조정하여 다양한 비디오 애플리케이션의 성능을 향상시킵니다. InternVideo는 비디오 액션 인식, 비디오-언어 정렬 등 39개의 비디오 데이터셋에서 최고의 성능을 달성하여 비디오 이해를 위한 일반성을 입증했습니다. 논문 제목: InternVideo: General Video Foundation Models via Generative and Discriminative Learning
논문 요약: InternVideo: General Video Foundation Models via Generative and Discriminative Learning
- 논문 링크: arXiv:2212.03191
- 저자: Wang, Yi 외 (OpenGVLab)
- 발표 시기: 2022년, arXiv preprint
- 주요 키워드: Video Foundation Model, Self-supervised Learning, Generative Learning, Discriminative Learning, Video Understanding
1. 연구 배경 및 문제 정의
- 문제 정의:
- 기존 비전 파운데이션 모델들은 대부분 이미지 수준의 사전 학습에 초점을 맞춰, 동적이고 복잡한 비디오 이해 작업에는 한계가 있었습니다.
- 비디오 처리의 높은 컴퓨팅 부담과 특정 작업에만 집중된 기존 모델들의 좁은 전이 가능성(행동 이해 또는 비디오-언어 정렬)이 문제였습니다.
- 비디오 이해 능력을 측정하기 위한 포괄적인 벤치마크가 부족했습니다.
- 기존 접근 방식:
- 대부분의 기존 비전 파운데이션 모델은 이미지 수준의 사전 학습 및 적응에만 집중했습니다.
- 일부 비디오 데이터셋의 경우, 이미지 특징만으로도 괜찮은 결과를 얻었으며, 특히 CLIP과 같은 멀티모달 모델의 등장이 이러한 경향을 강화했습니다.
- 비디오 마스크 모델링은 행동 이해에 특화되어 있었고, 멀티모달 대조 학습은 시공간 모델링 없이 비디오 표현에 풍부한 의미를 부여했습니다. 하지만 이 두 방식의 통합 및 일반화에는 한계가 있었습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 생성적(마스크 모델링) 및 판별적(대조 모델링) 자기 지도 학습을 모두 활용한 일반적인 비디오 표현 패러다임을 제안하고, 지도 학습에서 경량 모델 상호 작용 학습을 통해 이들의 표현을 통합했습니다. 이를 통해 생성적 및 대조 학습으로 학습된 특징이 상호 보완적임을 입증했습니다.
- 마스크된 비디오 인코더가 적절한 튜닝을 통해 모델 및 데이터 크기에서 확장될 수 있음을 발견했습니다. 또한, 멀티모달 학습을 위해 이미지-텍스트 데이터로 사전 학습된 ViT를 재사용하기 위한 플러그인 가능한 로컬 시간적 및 글로벌 시공간 상호 작용 모듈을 고안하여 학습 부담을 줄이고 더 나은 성능을 달성했습니다.
- 체계적인 비디오 이해 벤치마크를 구축하는 데 기여했으며, 제안된 일반 비디오 파운데이션 모델은 이 벤치마크의 여러 핵심 작업에서 39개 데이터셋에 대해 최첨단 성능을 달성했습니다.
- 제안 방법:
- 통합 비디오 표현(UVR) 학습 패러다임: InternVideo는 생성적(마스크된 비디오 모델링) 및 판별적(비디오-언어 대조 학습) 자기 지도 학습을 모두 활용하여 범용 비디오 파운데이션 모델을 제시합니다.
- 자기 지도 비디오 사전 학습:
- 비디오 마스크 모델링 (Video Masked Modeling): VideoMAE를 기반으로 바닐라 Vision Transformer(ViT)를 비디오 인코더로 학습시킵니다. 비대칭 인코더-디코더 아키텍처를 사용하여 90%와 같은 높은 마스킹 비율로 비디오 재구성 작업을 수행하며, 전역적인 시공간 상호 작용을 특성화합니다.
- 비디오-언어 대조 학습 (Video-Language Contrastive Learning): 사전 학습된 CLIP을 기반으로 멀티모달 구조를 구축하며, UniformerV2를 비디오 인코더로 사용합니다. 비디오/이미지-텍스트 대조 학습과 비디오 캡셔닝 작업을 모두 수행하여 비디오와 텍스트 특징의 임베딩 공간을 정렬하고, 캡션 디코더를 통해 교차 모달 융합을 수행합니다.
- 지도 비디오 후-사전 학습 (Supervised Video Post-Pretraining): 행동 인식이 다양한 다운스트림 애플리케이션으로 전이하기 위한 훌륭한 소스 작업임을 활용하여, 마스크된 비디오 인코더와 멀티모달 인코더를 지도 행동 분류(Kinetics-710 데이터셋 사용)로 개별적으로 학습시킵니다.
- 교차 모델 상호 작용 (Cross-Model Interaction): 마스크된 비디오 인코더와 멀티모달 인코더의 표현을 통합하기 위해 교차 모델 어텐션(CMA) 모듈을 사용합니다. 두 백본은 고정하고, CMA 모듈만 업데이트하여 두 모델의 중간 특징 간 교차 어텐션을 구현하고, 최종 예측을 위해 학습 가능한 선형 조합으로 두 예측 점수를 동적으로 융합합니다.
3. 실험 결과
- 데이터셋:
- 사전 학습: Kinetics-400, WebVid2M, WebVid10M, HowTo100M, AVA, Something-Something V2, 자체 수집 비디오 등 5개 도메인에서 총 1,200만 개의 비디오 클립을 사용했습니다. 멀티모달 학습에는 LAION-400M의 이미지-텍스트 쌍도 공동 훈련에 사용되었습니다.
- 후-사전 학습: Kinetics-710 (710개 행동 레이블, 65만 개 비디오)을 지도 학습에 사용했습니다.
- 다운스트림 평가: 행동 이해(행동 인식, 시간적 행동 지역화, 시공간 행동 지역화), 비디오-언어 정렬(비디오 검색, 비디오 질의응답, 시각 언어 탐색), 개방형 이해(제로샷 행동 인식, 제로샷 비디오 검색, 제로샷 객관식, 개방형 집합 행동 인식) 등 10개 작업에 걸쳐 39개 비디오 데이터셋에서 평가되었습니다.
- 실험 환경: 멀티모달 학습에 128개의 NVIDIA A100 GPU, 마스크된 비디오 학습에 6480개의 G-A100 GPU를 사용했습니다.
- 주요 결과:
- InternVideo는 비디오 액션 인식, 비디오-언어 정렬 및 개방형 비디오 응용 프로그램을 포함한 광범위한 작업의 39개 비디오 데이터셋에서 최첨단 성능을 달성했습니다.
- 특히, Kinetics-400 벤치마크에서 91.1%의 top-1 정확도를, Something-Something V2 벤치마크에서 77.2%의 top-1 정확도를 기록했습니다.
- 행동 인식, 시간적/시공간 행동 지역화, 비디오 검색, 비디오 질의응답, 시각 언어 탐색 등 10개 주요 비디오 작업에서 모든 이전 최첨단 방법을 상당한 차이로 능가했습니다.
- 제로샷 및 개방형 집합 설정에서도 일관되고 상당한 성능 향상을 보여, 모델의 일반화 및 적응 능력을 입증했습니다.
- 훈련 효율성 측면에서, CoCa 모델이 245.76K TPU 시간이 필요했던 반면, InternVideo는 64.5K GPU 시간(A100-80G)으로 일반화된 비디오 표현을 달성하여 CoCa의 23.19% 수준의 전력 소비를 보였습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 생성적 및 판별적 자기 지도 학습을 효과적으로 통합하여 비디오 이해를 위한 강력하고 일반적인 표현을 학습했습니다.
- 매우 광범위한 벤치마크(10개 작업, 39개 데이터셋)에서 압도적인 최첨단 성능을 달성하여 비디오 파운데이션 모델의 일반성을 새로운 수준으로 끌어올렸습니다.
- 기존 파운데이션 모델 대비 훨씬 높은 훈련 효율성을 보여주어, 대규모 비디오 모델 개발의 실용성을 높였습니다.
- 간단한 작업 헤드와 적절한 다운스트림 튜닝만으로도 뛰어난 성능을 발휘하며, 제로샷 및 개방형 집합 시나리오에서도 강력한 일반화 능력을 입증했습니다.
- 단점/한계:
- 새로운 근본적인 공식이나 모델 설계를 제시하기보다는 기존의 효과적인 자기 지도 학습 방법들을 통합하고 확장하는 데 초점을 맞췄습니다.
- 현재는 주로 클립 기반의 비디오 처리 및 인기 있는 비디오 인식 작업에 집중되어 있어, 영화의 줄거리 예측과 같은 장기적인 비디오 작업이나 고차원적인 인지 작업 처리에는 한계가 있습니다.
- 응용 가능성:
- 비디오 이해 분야의 새로운 기준을 제시하며, 다양한 비디오 애플리케이션(예: 스마트 감시, 자율 주행, 비디오 콘텐츠 분석, 로봇 공학의 Embodied AI)에서 핵심적인 기반 기술로 활용될 수 있습니다.
- 향후 모델 조정(Model Alignment) 및 인지 능력(Cognition)을 비디오 파운데이션 모델에 통합하는 연구의 중요한 발판이 될 수 있습니다.
- 장기적인 시공간 분석 및 의사 결정과 결합된 지능형 에이전트 개발(예: 시각-언어 탐색)에 기여할 잠재력이 큽니다.
Wang, Yi, et al. "Internvideo: General video foundation models via generative and discriminative learning." arXiv preprint arXiv:2212.03191 (2022).
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
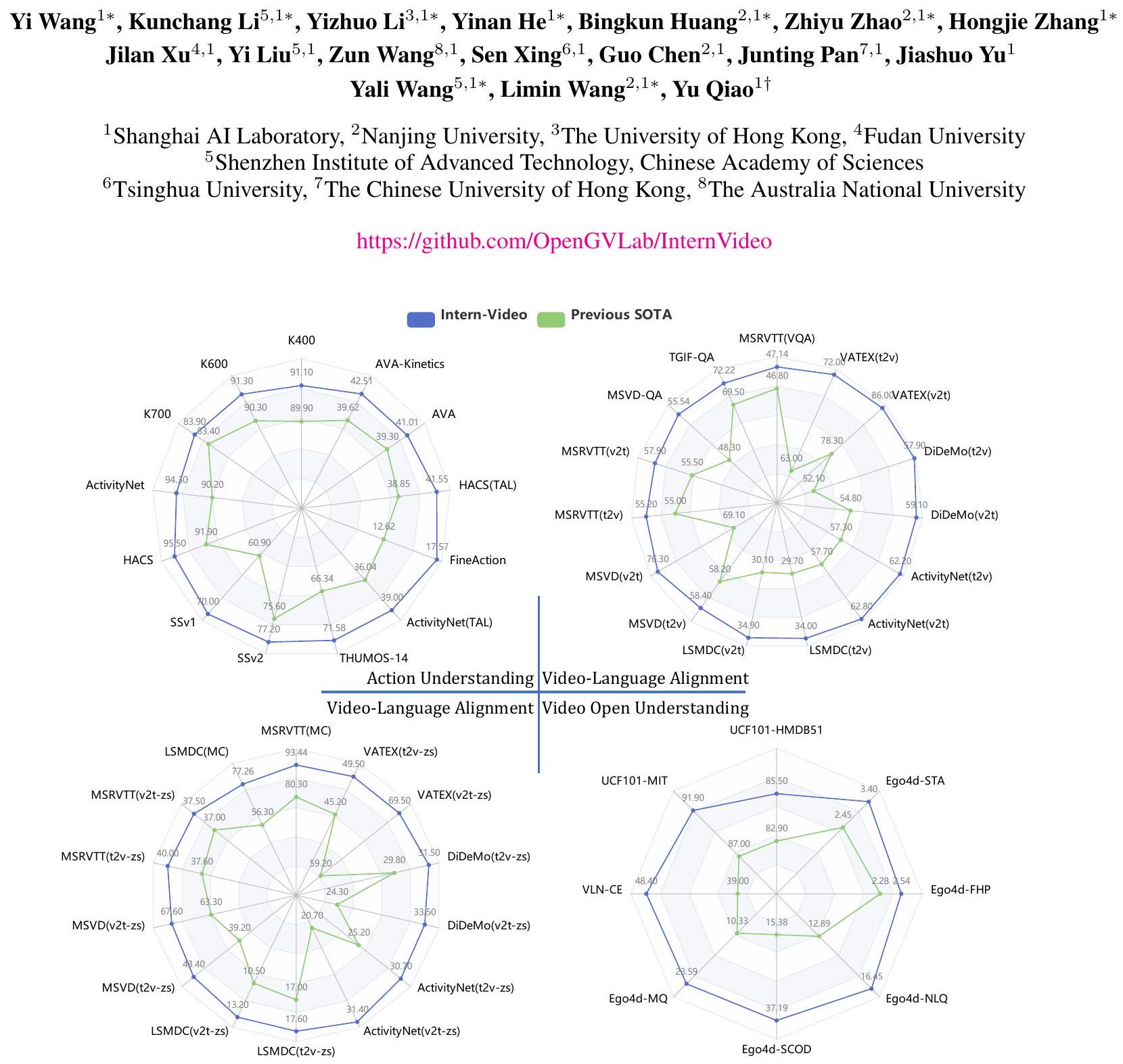
Figure 1: InternVideo는 최첨단 방법(특화된 [1-5] 및 파운데이션 모델 [6-9] 포함)과 비교할 때 광범위한 비디오 관련 작업에서 최고의 성능을 제공합니다. 비교 세부 정보는 섹션 4.3에 나와 있습니다. v2t와 t2v는 각각 비디오-텍스트 검색과 텍스트-비디오 검색을 나타냅니다. STA, FHP, NLQ, SCOD 및 MQ는 각각 Short-term Object Interaction Anticipation, Future Hand Prediction, Natural Language Queries, State Change Object Detection, Moment Queries의 약자입니다.
Abstract
최근 파운데이션 모델은 컴퓨터 비전의 다양한 다운스트림 작업에서 뛰어난 성능을 보여주었습니다. 그러나 대부분의 기존 비전 파운데이션 모델은 이미지 수준의 사전 학습 및 적응에만 초점을 맞추고 있어 동적이고 복잡한 비디오 수준의 이해 작업에는 한계가 있습니다. 이러한 격차를 해소하기 위해, 우리는 생성적 및 판별적 자기 지도 비디오 학습을 모두 활용하여 일반 비디오 파운데이션 모델인 InternVideo를 제시합니다. 구체적으로, InternVideo는 사전 학습 목표로 마스크된 비디오 모델링과 비디오-언어 대조 학습을 효율적으로 탐색하고, 다양한 비디오 응용 프로그램을 향상시키기 위해 학습 가능한 방식으로 이 두 상호 보완적인 프레임워크의 비디오 표현을 선택적으로 조정합니다. 별다른 추가 기능 없이, InternVideo는 비디오 행동 인식/탐지, 비디오-언어 정렬 및 개방형 비디오 응용 프로그램을 포함한 광범위한 작업의 39개 비디오 데이터셋에서 최첨단 성능을 달성합니다. 특히, 우리의 방법은 까다로운 Kinetics-400 및 Something-Something V2 벤치마크에서 각각 91.1% 및 77.2%의 top-1 정확도를 얻을 수 있습니다. 이러한 모든 결과는 비디오 이해를 위한 InternVideo의 일반성을 효과적으로 보여줍니다. 코드는 https://github.com/OpenGVLab/InternVideo 에서 공개될 예정입니다.
1 Introduction
파운데이션 모델은 놀랍도록 좋은 결과로 수많은 인식 작업으로 확장할 수 있는 실용적인 패러다임을 제공하기 때문에 연구 커뮤니티에서 점점 더 많은 주목을 받고 있습니다 [10-12]. 간단한 적응이나 제로/소수 샷 학습을 통해 파운데이션 모델은 높은 용량의 강력한 백본으로 웹 규모 데이터에서 학습한 일반적인 표현을 사용하여 다운스트림 설계 및 학습 비용을 크게 줄입니다. 파운데이션 모델 개발은 인식에서 인지를 배양하여 일반적인 비전 능력을 얻을 수 있을 것으로 기대됩니다. 다양한 비전 파운데이션 모델이 제안되었지만 [7, 13-21], 비디오 이해 및 관련 작업은 이미지 작업에 비해 덜 탐구되었으며, 주로 이러한 모델의 시각적 특징이 시공간 표현에도 유익하다는 것을 검증하는 데 사용됩니다. 우리는 학계의 이러한 상대적으로 부족한 관심이 1) 비디오 처리의 높은 컴퓨팅 부담과 2) 현재의 많은 비디오 벤치마크가 이미지 백본의 외형 특징을 그에 따른 시간적 모델링과 함께 활용하여 처리될 수 있다는 점 때문에 발생했다고 추측합니다. 구체적으로, 효율성 측면에서 비디오 처리의 추가 시간 차원은 공간 해상도가 비슷하고 시간적 샘플링 비율이 보통 16일 때 이미지 처리보다 최소 한 자릿수 높은 복잡성을 야기합니다. 일부 현재 비디오 데이터셋의 경우, 이미지 특징만으로 또는 측면 시간적 모듈과 함께 사용하면 괜찮은 결과를 얻기에 충분하며, 특히 멀티모달 모델인 CLIP [13]의 부상으로 더욱 그렇습니다. 그 다양한 시간적 변형은 여러 핵심 작업에서 경쟁적이거나 최첨단 성능을 보여줍니다 [5, 22]. 이와 관련하여, 동시 시공간 학습자는 연구 개발 비용과 투자 회수 사이의 최적점처럼 보이지 않습니다. 더욱이, 현재 비전 파운데이션 모델의 전이 가능성은 비디오 응용 프로그램의 넓은 스펙트럼을 고려할 때 다소 좁습니다. 이러한 모델 [6, 8, 23, 24]은 행동 이해 작업(예: 행동 인식, 시공간 행동 지역화 등) 또는 비디오-언어 정렬 작업(예: 비디오 검색, 비디오 질의응답 등)에 집중합니다. 우리는 이것이 그들의 학습 방식뿐만 아니라 비디오 이해 능력을 측정하기 위한 포괄적인 벤치마크의 부족에서 비롯된다고 가정합니다. 따라서 이러한 연구 [6, 8, 23, 24]는 그들의 시공간 인식을 입증하기 위해 몇 가지 특정 작업에 초점을 맞춥니다. 커뮤니티는 더 넓은 응용 분야를 가능하게 하는 일반적인 파운데이션 모델을 원합니다.
이 논문에서 우리는 비용 효율적이고 다재다능한 모델인 InternVideo를 통해 비디오 파운데이션 모델 연구를 발전시킵니다. 실현 가능하고 효과적인 시공간 표현을 구축하기 위해, 우리는 널리 사용되는 비디오 마스크 모델링 [23, 25]과 멀티모달 대조 학습 [13, 26]을 모두 연구합니다. 비디오 마스킹 모델링은 행동 이해에 특화되어 있으며, 현재 디코더로 인한 모델 규모의 한계를 고려할 때 여전히 탐구할 가치가 있습니다. 멀티모달 대조 학습의 경우, 구체적인 시공간 모델링을 무시하면서 비디오 표현에 풍부한 의미를 포함시킵니다. 이러한 문제를 해결하기 위해, 우리는 이 두 자기 지도 접근법이 모듈식 설계에서 효율적으로 대규모 학습을 할 수 있도록 만듭니다. 현재 비디오 파운데이션 모델의 일반화를 크게 넓히기 위해, 우리는 이 두 자기 지도 학습 방식을 모두 사용한 통합 표현 학습을 제안합니다. 이러한 일반화된 표현을 검증하기 위해, 우리는 체계적인 비디오 이해 벤치마크를 제안합니다. 여기에는 행동 이해, 비디오-언어 정렬, 그리고 개방형 비디오 응용 프로그램에 대한 평가가 포함되며, 우리는 이것이 일반적인 비디오 인식의 세 가지 핵심 능력이라고 믿습니다. 이 시스템에 새로운 데이터나 주석을 도입하는 대신, 우리는 처음에 39개의 공개 데이터셋을 가진 10개의 대표적인 비디오 작업을 선택하고, 이를 세 가지 유형으로 분류합니다. 우리가 아는 한, InternVideo는 이 세 가지 다른 유형의 비디오 작업 모두에서 최첨단 성능으로 유망한 전이 가능성을 입증한 최초의 비디오 파운데이션 모델입니다.
InternVideo에서는 통합 비디오 표현(Unified Video Representation, UVR) 학습 패러다임을 설계합니다. 이 패러다임은 오토인코더(MAE)를 사용한 마스크된 비디오 모델링과 두 가지 유형의 표현을 위한 멀티모달 대조 학습을 모두 탐색하고, 지도된 행동 분류로 이를 강화하며, 그들 사이의 교차 표현 학습을 기반으로 더 일반적인 표현을 생성합니다. UVR은 경험적으로 비디오 표현이 시간적 캡처를 통해 핵심 비디오 작업에서 이미지 표현을 크게 능가함을 보여줄 뿐만 아니라 학습 효율성도 높습니다. UVR의 MAE는 비디오의 높은 중복성을 활용하여 적은 수의 가시적인 토큰만으로 학습합니다. 한편, InternVideo의 멀티모달 학습은 기존의 이미지 사전 학습된 백본을 비디오 대조 학습을 위해 확장합니다. 이 두 비디오 인코더를 지도 학습한 후, 우리는 거의 고정된 이 두 인코더 간의 특징 정렬을 수행하기 위해 교차 모델 어텐션을 만듭니다. 통합 비디오 표현 학습 패러다임 이상으로, 우리는 또한 대규모 비디오 파운데이션 모델을 다루기 쉽고 효율적인 방식으로 학습하기 위한 실습과 지침을 제시합니다. 우리의 연구는 1) VideoMAE를 확장 가능하게 만들고 모델 및 데이터 규모에서 그 확장성을 탐구하는 것; 2) 기존의 이미지 사전 학습된 백본을 활용하는 방법에 대한 효율적이고 효과적인 멀티모달 아키텍처 설계 및 학습 방법; 3) VideoMAE와 멀티모달 모델의 특징이 상호 보완적임을 경험적으로 발견하고, 다른 기존 모델들을 조정하여 더 강력한 비디오 표현을 추론하는 방법을 연구하는 것을 포함하며 이에 국한되지 않습니다. 구체적으로,
- VideoMAE의 확장성 연구를 위해, 우리는 학습 비디오에서 적절한 다양성과 확장 크기가 사용된 비디오 인코더의 확장성을 향상시킬 수 있음을 보여줍니다. 마스크된 오토인코더 학습 설정에서 새로운 사전 학습된 데이터셋을 사용하면, ViT는 미세 조정을 통해 Kinetics-400 [27]에서의 행동 인식 성능을 기본에서 대형으로 81.01%에서 85.35%로 끌어올렸으며, 거대 설정에서는 86.9%에 도달하여 [23]에서 보고된 성능을 상당한 차이로 능가합니다. VideoMAE의 확장성은 비디오 파운데이션 모델 개발에 사용될 수 있게 합니다.
- 멀티모달 학습을 위해 기존 파운데이션 모델을 재사용하기 위해, 우리는 이미지 사전 학습된 비전 트랜스포머 [28]를 비디오 표현 학습으로 확장합니다. 이 전이 학습은 상당한 구조 및 최적화 사용자 정의 또는 멀티모달 사전 학습을 위한 로컬 및 글로벌 시공간 모듈 사용을 요구합니다. 로컬 모듈은 연속적이고 독립적인 공간 및 시간적 어텐션 계산을 통해 시공간 모델링을 분리합니다. 한편, 글로벌 모듈은 공간과 시간에 걸쳐 토큰 상호 작용을 계산합니다. 실험 결과, 이 재사용 설계는 시공간 표현 학습에 효과적임을 보여줍니다.
- 자기 지도 사전 학습 외에도, 우리는 비디오 표현을 더욱 향상시키기 위해 지도 행동 인식을 사용합니다. 결과는 행동 인식이 다양한 다운스트림 응용 프로그램으로 전이하기 위한 훌륭한 소스 작업임을 보여줍니다.
- 파운데이션 모델을 조정하기 위해, 우리는 마스크된 비디오 인코더를 멀티모달 인코더와 교차 표현 학습을 통해 통합하며, 하나의 공식으로 공동으로 학습하지 않습니다. MAE와 멀티모달 학습(MML)의 최적화가 서로 모순될 수 있다는 점을 고려할 때, 그들의 장점을 손상시키지 않으면서 결합하는 것은 아직 해결되지 않은 문제로 남아 있습니다 [29]. 더 중요한 것은, 대조 학습을 통한 MML은 더 나은 대조 최적화를 위해 거대한 배치를 요구한다는 것입니다. 여기에 MAE를 추가하면 필연적으로 수많은 골치 아픈 구현 문제가 발생할 것입니다. 잠재적인 학습 충돌을 고려하여, 우리는 MAE와 MML을 개별적으로 학습시킵니다. 그들의 학습이 수렴된 후, 우리는 제안된 교차 모델 어텐션(Cross-Model Attention, CMA) 모듈을 사용하여 그들의 표현을 동적으로 결합합니다. 이는 MAE와 MML 중간 수준 특징 간의 교차 어텐션을 구현하여, 예측을 위해 그들의 높은 수준 특징을 적응적으로 융합합니다. 모델 수준의 표현 상호 작용 단계에서는 MAE와 MML로 개별적으로 학습된 백본을 고정하고, 몇 에포크 동안 지도 학습에서 CMA만 업데이트되도록 합니다. 실험 결과, 이는 MAE와 MML 특징을 모두 활용하기 위한 계산적으로 다루기 쉽고 효율적인 수단임이 나타났습니다.
우리는 제안된 비디오 파운데이션 모델을 10개 작업과 39개 데이터셋(핵심 작업인 행동 인식, 시공간 행동 지역화, 비디오 질의응답, 비디오 검색 등 포함)에서 검증했으며, 각 작업에서 모든 최첨단 방법을 상당한 차이로 능가합니다. 우리는 우리의 접근 방식으로 얻은 이러한 전반적인 우수한 결과와 관찰 및 분석이 비디오 이해 커뮤니티에 새로운 기준을 제시한다고 가정합니다. 이 논문의 경험적 증거는 비디오 인식 작업과 부분적인 고차 작업(인식 형태로 공식화됨)이 비디오 파운데이션 모델에 의해 잘 해결될 수 있다는 확신을 높여주며, 다양한 응용 분야에서 성능에 중요한 방법으로 작용합니다.
요약하자면, 우리는 다음과 같은 측면에서 비디오 파운데이션 모델에 기여합니다.
- 우리는 마스크된 모델링과 대조 모델링을 모두 사용한 일반적인 비디오 표현 패러다임을 탐구하고, 지도 학습에서 경량 모델 상호 작용 학습을 통해 그들의 표현을 통합함으로써 이 설계를 실현합니다. 우리는 생성적 및 대조 학습으로 학습된 특징이 실험적으로 상호 보완적이며, 각각 독립적으로 학습된 것보다 더 나은 결과를 제공할 수 있음을 확인합니다.
- 우리는 마스크된 비디오 인코더가 적절한 튜닝을 통해 모델과 데이터 크기에서 확장될 수 있음을 발견했습니다. 우리는 멀티모달 학습을 위해 이미지-텍스트 데이터로 사전 학습된 ViT를 재사용하기 위해 플러그인 가능한 로컬 시간적 및 글로벌 시공간 상호 작용 모듈을 고안하여, 학습 부담을 줄이고 더 나은 다운스트림 성능을 산출합니다.
- 우리는 체계적인 비디오 이해 벤치마크를 구축하는 데 잠정적인 시도를 합니다. 우리의 일반 비디오 파운데이션 모델은 이 벤치마크의 여러 핵심 작업에서 39개 데이터셋에 대해 최첨단 성능을 달성합니다. 예를 들어, 행동 인식의 Kinetics-400과 Something-Something v2가 있습니다. 우리는 경험적으로 학습된 비디오 표현이 경쟁 모델들을 능가하며, 특히 일부 이미지 기반 작업의 경우 큰 차이로 비전-언어 작업을 지배한다는 것을 발견했습니다. 이는 일반적인 비디오 표현이 비디오 작업에서 중심적인 역할을 할 것임을 시사합니다. 우리는 제안된 방법과 모델의 개방성이 연구 커뮤니티에 파운데이션 모델과 그 특징에 대한 손쉬운 접근 도구를 제공할 것이라고 믿습니다.
2 Related Work
Image Foundation Models
현재 대부분의 비전 모델은 특정 작업 및 도메인에만 적합하며, 훈련을 위해 수동으로 레이블이 지정된 데이터셋이 필요합니다. 이와 관련하여 최근 연구에서는 비전 파운데이션 모델을 제안했습니다. CLIP [13]과 ALIGN [14]은 웹 규모의 노이즈가 있는 이미지-텍스트 쌍을 준비하여 대조 학습으로 이중 인코더 모델을 훈련시켜 강력한 제로샷 전이를 위한 견고한 이미지-텍스트 표현을 생성합니다. INTERN [12]은 자기 지도 사전 훈련을 여러 학습 단계로 확장하여 대량의 이미지-텍스트 쌍과 수동으로 주석이 달린 이미지를 사용합니다. INTERN은 CLIP에 비해 더 나은 선형 프로브 성능을 달성하고 다운스트림 이미지 작업에서 데이터 효율성을 향상시킵니다. Florence [15]는 통합된 대조 학습 [16]과 정교한 적응 모델로 이를 확장하여 다양한 전송 설정에서 광범위한 비전 작업을 지원합니다. SimVLM [17]과 OFA [18]는 생성 목표로 인코더-디코더 모델을 훈련하고 일련의 다중 모드 작업에서 경쟁력 있는 성능을 보여줍니다. 또한 CoCa [7]는 CLIP으로서의 대조 학습과 SimVLM으로서의 생성 학습을 통합합니다. 최근 BeiT-3 [19]는 통합된 BeiT [20] 사전 훈련과 함께 Multiway Transformers를 도입하여 여러 비전 및 이미지-언어 작업에서 최첨단 전송 결과를 달성했습니다.
Video Foundation Models
이전의 이미지 파운데이션 모델 [7, 15]은 비디오 인식(특히 Kinetics에서)에 대해서만 유망한 성능을 보여줍니다. 비디오 멀티모달 작업의 경우, VIOLET [30]은 마스크된 언어와 마스크된 비디오 모델링을 결합하고, All-in-one [24]은 공유 백본으로 통합된 비디오-언어 사전 훈련을 제안하며, LAVENDER [31]는 작업을 마스크된 언어 모델링으로 통합합니다. 멀티모달 벤치마크에서는 좋은 성능을 보이지만, 제한된 비디오-텍스트 데이터로 훈련되어 행동 인식과 같은 비디오 전용 작업에는 어려움을 겪습니다. 반면, MERLOT Reserve [32]는 2천만 개의 비디오-텍스트-오디오 쌍을 수집하여 대조적 스팬 매칭으로 공동 비디오 표현을 훈련시켜 최첨단 비디오 인식 및 시각적 상식 추론을 설정합니다. 이미지 파운데이션 모델과 비교할 때, 현재 비디오 파운데이션 모델은 특히 시간적 지역화와 같은 세분화된 시간적 판별 작업에 대해 제한된 비디오 및 비디오-언어 작업을 지원합니다.
Self-supervised Pretraining
자기 지도 학습은 최근 빠르게 발전했습니다. 이는 사전 훈련을 위한 다양한 구실 작업 설계에 중점을 두며 [33-37], 주로 대조 학습과 마스크 모델링으로 나눌 수 있습니다. 대조 학습은 다양한 데이터 증강을 채택하여 이미지의 다른 뷰를 생성한 다음, 긍정적인 쌍을 모으고 부정적인 쌍을 밀어냅니다. 충분한 정보 제공적인 부정적인 샘플을 유지하기 위해 이전 방법은 큰 메모리 뱅크나 배치 크기에 의존했습니다 [38-40]. BYOL [41]과 SimSiam [42]은 부정적인 샘플의 요구 사항을 제거하고 모델 붕괴를 피하기 위한 정교한 기술을 설계합니다. 마스크 모델링의 경우, 가시적인 컨텍스트를 기반으로 한 마스크 예측을 통해 풍부한 시각적 표현을 학습합니다. iGPT [43]는 처음으로 Masked Image Modeling (MIM)을 언급했습니다. BeiT [20]는 사전 훈련된 토크나이저 [44]를 사용한 시각적 토큰 예측을 제안하고, MaskFeat [6]는 수작업으로 만든 이미지 디스크립터를 예측하며, MAE [25]는 원시 픽셀을 직접 재구성합니다. 시공간 표현 학습을 위해 VideoMAE [23]와 BEVT [45]는 각각 MAE와 BeiT를 시공간으로 확장합니다.
Multimodal Pretraining
이미지-텍스트 사전 훈련의 발전과 함께, 특정 다운스트림 작업 미세 조정을 통한 대규모 비디오-텍스트 사전 훈련은 비디오-언어 분야의 표준 패러다임이 되었습니다 [26,30,32,46-51]. 초기 방법들 [52, 53]은 사전 훈련된 시각 및 언어 인코더를 사용하여 오프라인 비디오 및 텍스트 특징을 추출했지만, 최근 방법들 [9,24,26,46,54,55]은 종단 간 훈련의 가능성을 입증했습니다. 또한, 널리 사용되는 방법들은 종종 마스크된 언어 모델링 [31], 비디오-텍스트 매칭 [24], 비디오-텍스트 대조 학습 [47], 비디오-텍스트 마스크 모델링 [30]과 같은 두세 가지 사전 훈련 작업을 포함합니다.
3 InternVideo
InternVideo는 그림 2와 같이 학습 및 내부 협력과 함께 제공되는 일반적인 비디오 파운데이션 모델입니다. 구조적으로 InternVideo는 비전 트랜스포머(ViT) [28]와 그 변형인 UniformerV2 [56]를 채택하고, 다중 수준 표현 상호 작용을 위한 추가적인 로컬 시공간 모델링 모듈을 함께 사용합니다. 학습에서 InternVideo는 자기 지도 학습(마스크 모델링 및 멀티모달 학습)과 지도 학습을 모두 통합하여 점진적으로 표현을 향상시킵니다. 또한, 두 가지 유형의 자기 지도 학습을 탐색하면서 그 장점을 더욱 통합합니다. InternVideo는 학습 가능한 상호 작용을 통해 이 두 트랜스포머에서 새로운 특징을 동적으로 파생하여 생성적 및 대조적 관련성 모두에서 최상의 결과를 얻습니다.
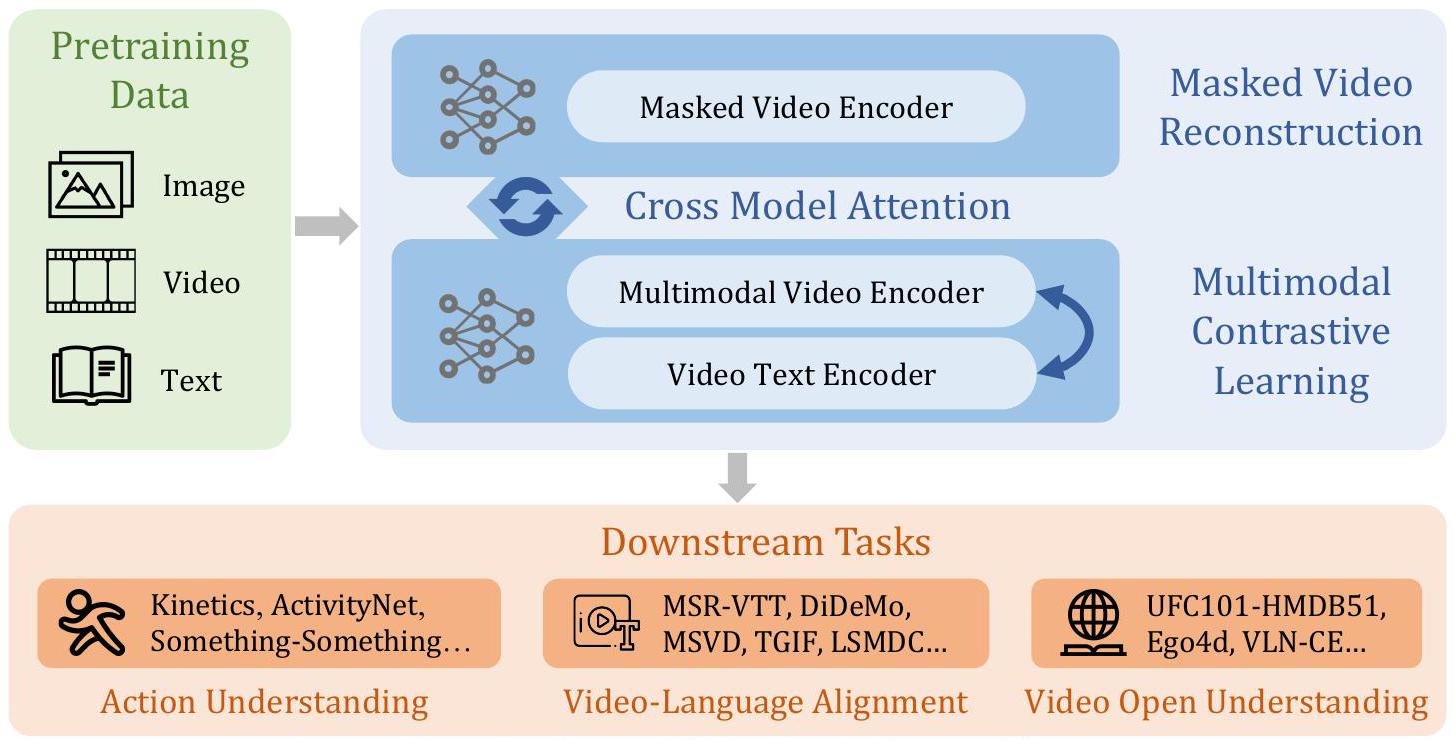
Figure 2: InternVideo의 전체 프레임워크. 새롭게 집계된 특징을 통해 InternVideo는 10개의 주류 비디오 작업에서 34개의 벤치마크에 대한 새로운 성능 기록을 세우고, 최근 Ego4D 대회 [57]에서 5개 트랙의 챔피언십을 획득했습니다.
3.1 Self-Supervised Video Pretraining
InternVideo는 표현 학습을 위해 감독 없이 마스크된 학습과 대조 학습을 모두 수행합니다. [13, 23]에 따르면, 비디오 마스크 모델링은 행동 인식 및 시간적 행동 지역화와 같은 행동 식별에 뛰어난 특징을 생성하고, 비디오-언어 대조 학습은 주석 없이 텍스트의 의미를 가진 비디오를 이해할 수 있습니다. 우리는 이 두 최적화 목표를 더 잘 활용하기 위해 다른 구조를 가진 두 개의 트랜스포머를 사용합니다. 최종 표현은 이 두 가지 유형의 표현을 적응적으로 집계하여 구성됩니다.
3.1.1 Video Masked Modeling
우리는 제안된 VideoMAE [23] 연구의 대부분의 절차를 따라 바닐라 Vision Transformer (ViT)를 시공간 모델링을 위한 비디오 인코더로 학습시킵니다. 이는 그림 3(a)에 나와 있습니다. VideoMAE는 비대칭 인코더-디코더 아키텍처를 사용하여 매우 마스크된 비디오 입력을 가지고 비디오 재구성 작업을 수행합니다. 사용된 인코더와 디코더는 모두 ViT입니다. 디코더의 채널 수는 인코더의 절반이며 기본적으로 4개의 블록이 있습니다. 구체적으로, 우리는 시간적으로 스트라이드 다운샘플링된 비디오 입력을 겹치지 않는 3D 패치로 나누고 이를 선형적으로 큐브 임베딩으로 투영합니다. 그런 다음 튜브 마스킹을 현저히 높은 비율(예: 90%)로 이 임베딩에 적용하고 마스크된 비디오 모델링 사전 학습을 수행하기 위해 비대칭 인코더-디코더 아키텍처에 입력합니다. 시공간 상호 작용을 전역적으로 특성화하기 위해 ViT에 공동 시공간 어텐션 [58, 59]을 사용하여 모든 가시적인 토큰이 서로 전역적으로 상호 작용하도록 합니다. 계산에는 몇 개의 토큰만 보존되므로 계산적으로 다루기 쉽습니다.
3.1.2 Video-Language Contrastive Learning
우리는 사전 학습을 위해 비디오/이미지-텍스트 대조 학습과 비디오 캡셔닝 작업을 모두 수행합니다 (그림 3(b) 참조). 학습 효율성을 위해, 우리는 사전 학습된 CLIP [13]을 기반으로 멀티모달 구조를 구축합니다. 바닐라 ViT를 직접 사용하는 대신, 더 좋고 효율적인 시간적 모델링을 위해 제안된 UniformerV2 [56]를 비디오 인코더로 사용합니다. 또한, 교차 모달 학습을 위해 추가적인 트랜스포머 디코더를 채택합니다. 구체적으로, 우리는 [7, 60]에 제시된 전형적인 정렬-후-융합 패러다임을 따릅니다. 먼저, 비디오와 텍스트는 개별적으로 인코딩됩니다. 그런 다음 대조 손실을 사용하여 비디오와 텍스트 특징의 임베딩 공간을 정렬합니다. 융합 단계에서는, 캡션 디코더를 교차 모달 융합기로 적용하며, 이는 캡셔닝 구실을 위해 교차 어텐션을 사용합니다. 이 정렬-후-융합 패러다임은 모달리티가 동일한 단일 임베딩 공간으로 정렬되도록 보장하여 검색과 같은 작업에 유익할 뿐만 아니라, 모델에 다른 모달리티를 결합하는 능력을 부여하여 질의응답과 같은 작업에도 유익할 수 있습니다. 캡션 디코더의 도입은 원래 CLIP의 잠재력을 확장하고 멀티모달리티 특징의 견고성을 향상시킵니다.
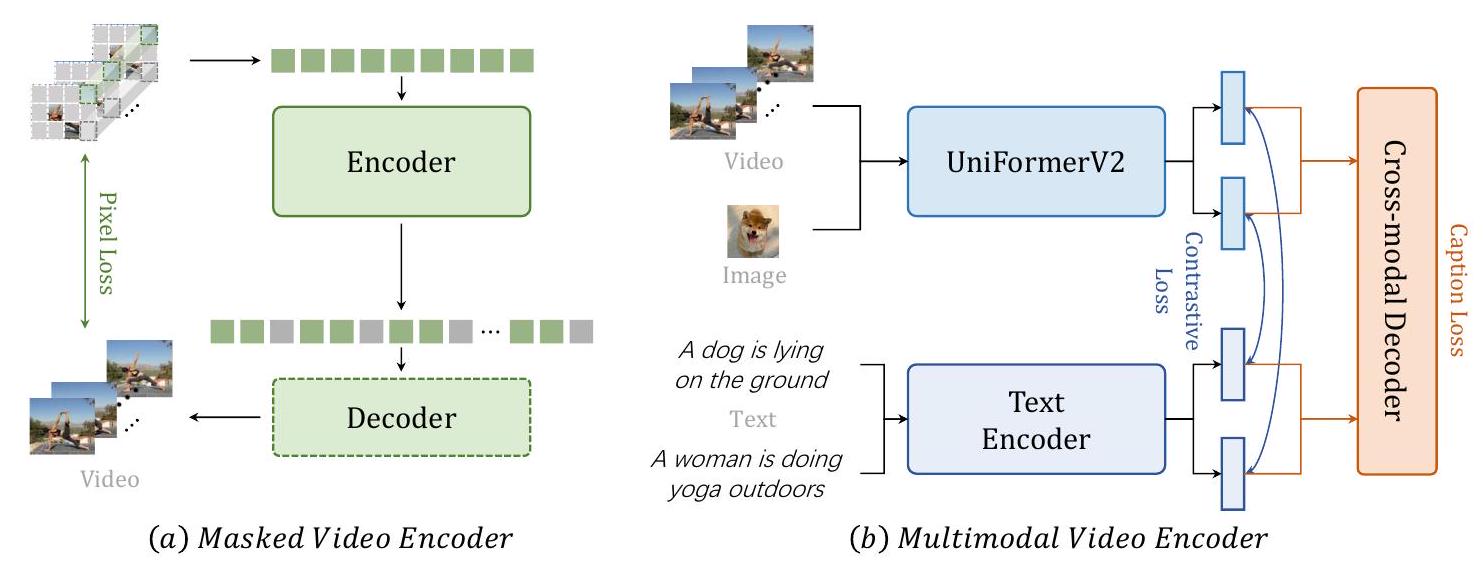
Figure 3: 사전 학습 단계에서 마스크 학습과 멀티모달 학습의 전체 프레임워크.
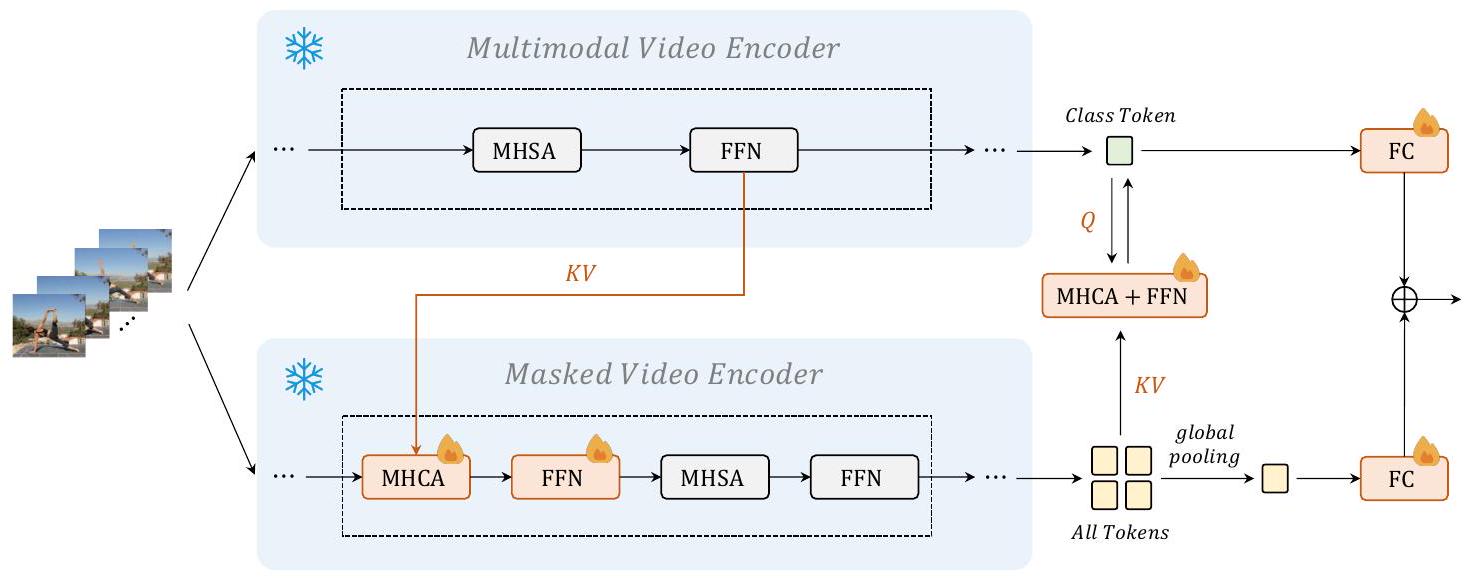
Figure 4: 교차 모델 어텐션을 사용한 모델 상호 작용의 그림.
3.2 Supervised Video Post-Pretraining
경험적으로, 행동 인식은 비디오 다운스트림 응용 프로그램에서 메타 작업으로 잘 작동하며, [61, 62]에서 널리 검증되었습니다. 따라서 우리는 다양한 작업에서 더 나은 성능을 위해 마스크된 비디오 인코더와 멀티모달 인코더를 지도 행동 분류로 개별적으로 학습시키는 것을 후-사전 학습 단계로 사용합니다. 이러한 인코더의 학습 능력을 증진시키기 위해, 우리는 비디오 인코더를 미세 조정하기 위한 통합 비디오 벤치마크 Kinetics-710(K710, 섹션 4.1에 설명됨)을 제안합니다.
Masked Video Encoder
K710에서 32개의 GPU를 사용하여 마스크된 비디오 인코더를 미세 조정합니다. 기본 학습률과 배치 크기에 따라 학습률을 선형적으로 조정합니다. 기본 학습률 . DeepSpeed 프레임워크¹를 채택하여 메모리 사용량을 절약하고 학습 속도를 높입니다. 기본 학습률을 0.001, 드롭 경로율을 0.2, 헤드 드롭아웃율을 0.5, 반복 샘플링[63]을 2, 레이어 감쇠를 0.8로 설정하고 40 에포크 동안 학습했습니다.
Multimodal Video Encoder
UniFormer [64]의 대부분의 훈련 레시피를 따릅니다. 최상의 결과를 위해, 비전-언어 대조 학습으로 사전 훈련된 강력한 표현 때문에 기본적으로 CLIP-ViT [13]를 백본으로 채택합니다. ViT-B/L의 마지막 4개 레이어에 글로벌 UniBlocks를 삽입하여 다단계 융합을 수행합니다. 기본 학습률을 1e-5로, 반복 샘플링을 1로, 배치 크기를 512로 설정하고 40 에포크 동안 훈련했습니다. 모든 데이터셋에 대해 224의 해상도로 희소 샘플링 [65]을 채택했습니다. 후기 사전 훈련에서는 UniformerV2 [56]를 시각적 인코더로 사용하고 추가 매개변수를 초기화하여 출력이 원래 CLIP 모델과 동일하도록 했는데, 이는 좋은 제로샷 성능에 필수적인 것으로 나타났습니다. 비디오 캡셔닝 모듈은 인 표준 6레이어 트랜스포머 디코더 다음에 2레이어 MLP가 이어집니다. 다른 설정은 CLIP Large/14를 그대로 둡니다.
2Table 1: InternVideo 사전 훈련 과정에서 사용된 데이터셋 요약. 대규모 데이터베이스는 일반적인 비전 사전 훈련에 매우 중요합니다. 우리의 사전 훈련 데이터는 5개의 다른 도메인에서 온 1,200만 개의 비디오 클립으로 구성됩니다.
| Pretraining Dataset | Domain | Sample Clips | Frames Sample rate |
|---|---|---|---|
| Kinetics-400 [27] | Youtube Video | 240k | |
| WebVid2M [55] | Web Video | 250 k | |
| WebVid10M [55] | Web Video | 10M | |
| HowTo100M [66] | Youtube Video | 1.2 M | |
| AVA [67] | Movie | 21 k | |
| Something-Something V2 [68] | Shot from scripts | 169k | |
| Self-collected video | Youtube, Instagram | 250 k | |
| Kinetics-710 [56] | Youtube Video | 680k |
3.3 Cross-Model Interaction
비디오 마스크 모델링과 비디오-언어 대조 학습 모두에 기반한 통합 비디오 표현을 학습하기 위해, 그림 4와 같이 추가된 교차 모델 어텐션 모듈을 사용하여 교차 표현 학습을 수행합니다.
두 모델을 동시에 최적화하는 것은 계산 집약적이므로, 우리는 분류 레이어와 멀티모달 비디오 인코더의 쿼리 토큰을 제외한 두 백본을 모두 고정하고, 새로 추가된 구성 요소만 업데이트합니다. 우리는 다른 접근법에서 학습된 표현을 정렬하기 위해 정교한 학습 가능 모듈(교차 모델 어텐션)을 추가합니다. 교차 모델 어텐션(Cross-model attention, CMA)은 피드-포워드 네트워크(Feed-Forward Network, FFN)와 함께 표준 다중 헤드 교차 어텐션(Multi-Head Cross Attention, MHCA)으로 형성됩니다. 이는 멀티모달 비디오 인코더의 중간 토큰을 키와 값으로 사용하고 마스크된 비디오 인코더의 토큰을 쿼리로 사용합니다. CMA에서 계산된 새로운 토큰은 멀티모달 비디오 인코더의 표현과 점진적으로 정렬된 표현으로 취급됩니다. 이 절차는 주로 멀티모달 지식을 마스크된 비디오 인코더의 CMA로 전달합니다. 한 가지 설계 예외는 마지막 CMA 모듈의 경우, 키와 값이 마스크된 비디오 인코더의 토큰에서 오고 쿼리는 멀티모달 비디오 인코더의 클래스 토큰에서 온다는 것입니다. 따라서 클래스 토큰은 마스크된 인코더의 토큰을 기반으로 업데이트됩니다. 이는 단일 모달 지식을 멀티모달 비디오 인코더의 CMA로 전달합니다. 이러한 관점에서, 마스크된 비디오 인코더의 모든 단계의 특징과 멀티모달 비디오 인코더의 최종 단계의 특징은 행동 인식을 통해 서로 협력하도록 강화됩니다. 마지막으로, 우리는 학습 가능한 선형 조합을 사용하여 두 예측 점수를 동적으로 융합합니다.
4 Experiments
먼저 실험 구성을 자세히 설명하고(섹션 4.1), 그 다음 InternVideo의 다운스트림 성능을 세 가지 유형의 작업(행동 이해, 비디오-언어 정렬, 개방형 이해)으로 구성된 제안된 비디오 이해 벤치마크에서 제시합니다(섹션 4.3).
4.1 Data for Pretraining
일반적인 비디오 파운데이션 모델 사전 훈련은 다양한 도메인의 대규모 데이터를 필요로 합니다. 다양성을 갖춘 데이터 분포를 달성하기 위해, 표 1과 같이 6개의 공개 데이터셋과 자체 수집한 비디오 클립을 사용합니다.
Kinetics-710
우리는 지도 학습을 위해 새로운 맞춤형 kinetics 행동 데이터셋인 Kinetics-710 [56]을 채택합니다. 이는 개별 및 공동 학습 모두에 사용됩니다. 이 데이터셋은 710개의 고유한 행동 레이블을 가진 65만 개의 비디오를 포함합니다. 이는 Kinetics 400/600/700 [27, 69, 70]의 모든 고유한 학습 데이터를 결합합니다. 학습 누출을 피하기 위해, 특정 버전의 Kinetics 테스트 세트에 존재하는 일부 학습 데이터는 폐기됩니다.
UnlabeledHybrid
UnlabeledHybrid 데이터셋은 마스크된 비디오 사전 학습에 사용되며, Kinetics710 [56], Something-Something V2 [68], AVA [67], WebVid2M [55], 그리고 우리가 직접 수집한 비디오로 구성됩니다. AVA의 경우, 15분짜리 학습 비디오를 300 프레임씩 잘라 2만 1천 개의 비디오 클립을 얻었습니다. 우리는 직접 수집한 비디오와 WebVid2M에서 각각 25만 개의 비디오를 무작위로 선택했습니다. 자세한 내용은 표 1에서 확인할 수 있습니다.
Table 2: Kinetics & Something-Something에서의 행동 인식 결과. 각 데이터셋에서 비교된 방법들의 top-1 정확도를 보고합니다. InternVideo-D는 마스크된 비디오 인코더 ViT-H와 CLIP으로 사전 학습된 UniFormerV2-L 간의 모델 앙상블로 형성되었음을 나타내며, InternVideo-T는 InternVideo-D와 멀티모달로 사전 학습된 UniFormerV2-L을 기반으로 계산되었음을 나타냅니다.
| Method | #Params | K400 | K600 | K700 |
|---|---|---|---|---|
| MaskFeat-L [6] | 218 M | 87.0 | 88.3 | 80.4 |
| CoCa [7] | 1B+ | 88.9 | 89.4 | 82.7 |
| MTV-H [8] | 1B+ | 89.9 | 90.3 | 83.4 |
| MerlotReserve-L [9] | 644 M | - | 90.1 | - |
| MerlotReserve-L (+Audio) [9] | 644 M | - | 91.1 | - |
| InternVideo-D | 1.0 B | 90.9 | 91.1 | 83.8 |
| InternVideo-T | 1.3 B | 84.0 |
Table 3: Something-Something & ActivityNet & HACS & HMDB51에서의 행동 인식 결과. 각 데이터셋에서 비교된 방법들의 top-1 정확도를 보고합니다.
| Method | SthSthV1 | SthSthV2 | ActivityNet | HACS | HMDB51 |
|---|---|---|---|---|---|
| Previous SOTA | |||||
| InternVideo |
4.2 Implementations
4.2.1 Multimodal Training
CLIP에서 초기화하여 WebVid2M, WebVid10M, HowTo100M으로 다중 모드 모델을 사후 사전 훈련합니다. 비디오-텍스트 데이터셋의 훈련 코퍼스가 CLIP-400M [13]만큼 풍부하지 않기 때문에, 1억 개의 이미지-텍스트 쌍을 포함하는 LAION-400M [71]의 하위 집합인 이미지-텍스트 데이터셋과 함께 비디오 모델을 공동 훈련합니다. 각 반복마다 이미지와 비디오를 번갈아 사용합니다. 비디오-텍스트의 배치 크기는 14,336이고 이미지-텍스트의 배치 크기는 86,016입니다. 128개의 NVIDIA A100 GPU에서 2주 동안 40만 단계 동안 훈련했으며, 학습률은 8 × 10⁻⁵, 가중치 감쇠는 0.2, 코사인 어닐링 스케줄, 4k 워밍업 단계를 사용했습니다.
4.2.2 Masked Video Training
UnlabeledHybrid 데이터셋에서 VideoMAE-Huge를 1200 에포크 동안 6480개의 G-A100 GPU로 훈련합니다. 이 모델은 코사인 어닐링 학습률 스케줄을 적용하고 총 에포크의 10%를 워밍업합니다. 학습률은 2.5e-4로 설정됩니다. 데이터 증강에는 MultiScaleCrop만 사용됩니다.
4.2.3 Model Interaction
그림 4와 같이, 우리는 분류 레이어와 멀티모달 비디오 인코더의 쿼리 토큰을 제외한 두 백본을 모두 고정합니다. 원래 출력을 유지하기 위해 Flamingo [72]에서와 같이 추가 MHCA 및 FFN에 tanh 게이팅 레이어를 추가하고 동적 가중 합계의 매개변수는 0으로 초기화됩니다. 배치 크기 64, 학습률 5 × 10^5, 가중치 감쇠 0.001, 드롭아웃 비율 0.9, EMA 비율 0.9999로 조정된 모델을 훈련합니다. 또한, 1개의 워밍업 에포크와 함께 5 에포크 동안 코사인 어닐링 스케줄을 사용합니다. 사용된 모든 데이터 증강은 UniFormerV2 [56]에서와 동일합니다.
4.3 Downstream Tasks
우리는 InternVideo를 평가하기 위해 다양한 다운스트림 작업에 대한 광범위한 실험을 수행합니다. 사용된 작업은 행동 이해, 비디오-언어 정렬 및 개방형 이해를 고려하는 세 가지 범주입니다. InternVideo는 시공간 변화 특성화에 특화된 마스크된 비디오 인코더와 융합된 다중 모드 비디오 인코더를 포함하므로 행동 이해(섹션 4.3.1) 및 비디오-언어 정렬(섹션 4.3.2) 작업을 크게 향상시킬 수 있습니다. 대규모 훈련 데이터로 인한 일반화는 관련 작업(섹션 4.3.3)에서 인상적인 제로샷 및 개방형 집합 기능을 가능하게 합니다. 자기 중심적 작업으로 이전하더라도 InternVideo는 간단한 헤드로 압도적으로 우호적인 성능을 제공합니다 [57]. 자세한 내용은 다음과 같습니다.
Table 4: THUMOS-14, ActivityNet-v1.3, HACS, FineAction에서의 시간적 행동 지역화 결과. 각 데이터셋에서 비교된 방법들의 평균 mAP를 보고합니다.
| Backbone | Head | THUMOS-14 | ActivityNet-v1.3 | HACS | FineAction |
|---|---|---|---|---|---|
| I3D [27] | ActionFormer [4] | 66.80 | - | - | 13.24 |
| SlowFast [74] | TCANet [75] | - | - | 38.71 | - |
| TSP [76] | ActionFormer [4] | - | 36.60 | - | - |
| InternVideo | ActionFormer [4] | 41.32 | |||
| InternVideo | TCANet [75] | - | - | - |
Table 5: AVA2.2 & AVA-Kinetics (AK)에서의 시공간 행동 지역화 결과. 데이터셋에서 평가된 접근 방식의 mAP를 보고합니다.
| Method | Head | AVA2.2 | AVA-Kinetics |
|---|---|---|---|
| ACAR [77] (ensemble) | ACAR [77] | 33.30 | 40.49 |
| RM [78] (ensemble) | RM [78] | - | 40.97 |
| MaskFeat [6] | - | 38.80 | - |
| InternVideo | Linear |
4.3.1 Action Understanding Tasks
Action Recognition
행동은 시공간 패턴을 파생시킵니다. InternVideo는 적절한 시공간 특징의 표현을 학습하고 동적 패턴의 모델링을 목표로 합니다. 우리는 인기있는 Kinetics 및 Something-Something을 포함하여 8개의 행동 인식 벤치마크에서 InternVideo를 평가합니다. 우리는 Kinetics-400 [27], Kinetics-600 [69], Kinetics-700 [70], Something-in-Something-V1 [68], Something-in-Something-V2 [68], ActivityNet [79], HACS [80], HMDB51 [81]에서 InternVideo의 VideoMAE와 UniFormerV2를 평가합니다. 비교 지표로 상위 1위 정확도를 사용합니다. 표 2와 3에서 InternVideo는 이러한 모든 행동 인식 벤치마크에서 매우 유망한 성능을 보여줍니다. 우리의 InternVideo는 거의 모든 벤치마크에서 이전 SOTA 방법을 크게 능가하며 ActivityNet에서 SOTA 결과와 일치합니다. 추가 융합 모델(InternVideo-D 대 InternVideo-T)에 의해 발생한 정확도 상승은 다른 라인이 성능에서 서로 이익을 주기 때문에 광범위한 기술 로드맵을 탐색하는 것이 필요함을 보여줍니다.
Temporal Action Localization
이 작업(TAL)은 전체 비디오를 완전히 관찰하여 다듬어지지 않은 전체 비디오에서 행동 클립의 시작 및 끝 지점을 찾는 것을 목표로 합니다. 우리는 THUMOS-14 [82], ActivityNet-v1.3 [79], HACS Segment [80], FineAction [83]의 네 가지 고전적인 TAL 데이터셋에서 InternVideo를 평가합니다. 이전의 시간적 행동 지역화 작업과 마찬가지로 정량적 평가를 위해 평균 정밀도(mAP)를 사용합니다. 행동 범주에 대한 제안을 평가하기 위해 각 행동 범주에 대해 평균 정밀도(AP)를 계산합니다. 이는 다른 tIoU 임계값에서 계산됩니다. 우리는 코드가 공개적으로 사용 가능한 최첨단 TAL 방법의 성능을 보고합니다. 여기에는 THUMOS-14, ActivityNet-v1.3 및 FineAction에 대한 ActionFormer [4] 방법과 HACS Segment에 대한 TCANet [75] 방법이 포함됩니다. 우리는 특징 추출을 위해 InternVideo의 ViT-H를 백본으로 사용합니다. 실험에서 ViT-H 모델은 하이브리드 데이터셋에서 사전 훈련되었습니다. 표 4에서 볼 수 있듯이, InternVideo는 이 네 가지 TAL 데이터셋에서 모든 이전 방법보다 뛰어난 성능을 보입니다. 특히 THUMOS-14 및 FineAction과 같은 세분화된 TAL 데이터셋에서 시간적 행동 지역화에서 큰 향상을 달성했습니다.
Spatiotemporal Action Localization
이 작업(STAL)은 비디오 키프레임에서 사람들의 프레임과 해당 행동을 예측하는 것입니다. 우리는 두 개의 고전적인 STAL 데이터셋 AVA2.2 [67]와 AVA-Kinetics [84]에서 InternVideo를 평가합니다. AVA2.2 [67]에서는 각 비디오가 15분 동안 지속되며 초당 키프레임을 제공합니다. 주석은 모든 프레임이 아닌 키프레임에 제공됩니다. 여기서는 이 작업을 처리하기 위해 고전적인 2단계 접근 방식을 적용합니다. 우리는 (MS-COCO [85]에서 잘 훈련된) Mask-RCNN [86]을 적용하여 각 키프레임에서 사람을 감지하고, 키프레임 상자는 Alphaction [87] 프로젝트에서 제공됩니다. 두 번째 단계에서는 키프레임을 중심으로 일정 수의 프레임이 추출되어 비디오 백본에 공급됩니다. 마찬가지로 훈련에서는 훈련을 위해 실제 상자를 사용하고 [87] 테스트를 위해 첫 번째 단계에서 예측된 상자를 사용합니다. 우리는 실험에 InternVideo의 ViT-Huge를 사용했습니다. 구체적인 결과는 표 5에서 볼 수 있습니다. 분류 헤드는 간단한 선형 헤드를 사용하여 두 데이터셋 모두에서 SOTA 성능을 달성합니다. ViT-H 모델을 사용하고 AVA-Kinetics 데이터셋으로 훈련하면 전체 mAP가 향상될 뿐만 아니라 AVA 단독 테스트에서 얻은 mAP도 크게 향상됩니다. 이는 일부 Kinetics 비디오를 AVA에 도입하면 AVA에 대한 모델의 일반화가 향상될 것임을 시사합니다. 반면에 AVA 데이터셋의 다양한 분포를 관찰하면 AVA가 전형적인 롱테일 분포를 나타내는 것을 발견했습니다. Kinetics 비디오의 도입은 더 나은 결과를 위해 이 문제를 완화할 것입니다. AVA-Kinetics 데이터셋에서 검증된 모델 수가 적기 때문에 표 5에는 paperswithcode 웹사이트의 결과만 선택되었습니다.
4.3.2 Video-Language Alignment Tasks
Video Retrieval
InternVideo를 비디오 검색 작업에서 평가합니다. 비디오 집합과 관련 자연어 캡션이 주어지면, 이 작업은 후보 중에서 상호 모달리티 상대방에 해당하는 일치하는 비디오 또는 캡션을 검색해야 합니다. 우리는 시각적 인코더 와 텍스트 인코더 로 시각 및 텍스트 의미를 포착한 다음, 교차 모달리티 유사성 행렬을 검색 지침으로 계산하는 일반적인 패러다임을 따릅니다. 우리는 사전 훈련된 ViT-L/14 [28]를 기본 CLIP [13] 아키텍처로 사용하여 다중 모드 비디오 인코더를 및 로 활용하고 각 검색 데이터셋에서 전체 모델을 미세 조정합니다. 훈련 레시피와 대부분의 하이퍼파라미터 설정은 훈련 일정, 학습률, 배치 크기, 비디오 프레임, 최대 텍스트 길이 등을 포함하여 CLIP4Clip [5]을 따릅니다. 모델 성능을 향상시키기 위해 후처리 작업으로 이중 소프트맥스 손실 [91]도 채택합니다. 우리 모델은 MSR-VTT [92], MSVD [93], LSMDC [94], DiDeMo [95], ActivityNet [79], VATEX [96] 등 6개의 공개 벤치마크에서 평가되었으며, 이전 연구에 따라 표준 분할에 대한 결과를 보고합니다. 텍스트-비디오 및 비디오-텍스트 작업 모두에서 순위-1(R@1) 메트릭으로 검색 결과를 측정했으며, 표 6에 나와 있습니다. 결과는 우리 모델이 모든 이전 방법을 큰 차이로 크게 능가하여 InternVideo가 비디오-언어 관련 작업에서 우수함을 보여줍니다. 순위-5(R@5) 및 순위-10(R@10)을 포함한 더 자세한 검색 결과는 보충 자료에서 찾을 수 있습니다.
Video Question Answering
InternVideo의 시각-언어 능력을 더욱 입증하기 위해, 비디오 질의응답(VQA)에서 InternVideo를 평가합니다. 비디오와 질문 쌍이 주어지면, VQA는 질문에 대한 답을 예측하는 것입니다. 교차 모달리티 융합이 없는 바닐라 CLIP 모델과 달리, 우리의 멀티모달 비디오 인코더는 제안된 캡션 디코더를 통해 모달리티 간의 상호 작용을 포착할 수 있습니다. VQA 분류기에 필요한 특징을 생성하는 세 가지 잠재적인 방법이 있습니다: 비디오 인코더와 텍스트 인코더의 특징을 연결하는 것, 캡션 디코더의 특징만 활용하는 것, 그리고 비디오 인코더, 텍스트 인코더, 캡션 디코더의 모든 특징을 연결하는 것입니다. 비교 후, 우리는 성능을 높이기 위해 세 가지 소스의 특징을 모두 사용하기로 결정했습니다. VQA 분류기는 3계층 MLP입니다. MSR-VTT [92], MSVD [97], TGIF [98] 세 가지 인기 있는 공개 벤치마크에서 평가합니다. 우리는 주로 [24]의 관행을 따릅니다. 결과는 표 7에 나와 있으며 우리 모델은 이전의 모든 SOTA를 능가하여 교차 모달리티 학습자의 효과를 입증합니다.
Visual Language Navigation
Visual-Language Navigation [99]은 에이전트가 자연어 지침에 따라 시각적 인식을 기반으로 미지의 사실적인 환경에서 탐색해야 합니다. 탐색 에이전트는 탐색 기록에서 객체의 상대적인 움직임과 같은 시공간 정보를 포착할 수 있어야 합니다.
Table 6: MSR-VTT, MSVD, LSMDC, ActivityNet, DiDeMo, VATEX에서의 비디오 검색 결과. 텍스트-비디오(T2V) 및 비디오-텍스트(V2T) 검색 작업 모두에서 R@1을 보고합니다.
| Method | MSR-VTT | MSVD | LSMDC | ActivityNet | DiDeMo | VATEX | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | |
| CLIP4Clip [5] | 45.6 | 45.9 | 45.2 | 48.4 | 24.3 | 23.8 | 40.3 | 41.6 | 43.0 | 43.6 | 63.0 | 78.3 |
| TS2Net [88] | 49.4 | 46.6 | - | - | 23.4 | - | 41.0 | - | 41.8 | - | 59.1 | - |
| X-CLIP [22] | 49.3 | 48.9 | 50.4 | 66.8 | 26.1 | 26.9 | 46.2 | 46.4 | 47.8 | 47.8 | - | - |
| InternVideo | 55.2 | 57.9 | 58.4 | 76.3 | 34.0 | 34.9 | 62.2 | 62.8 | 57.9 | 59.1 | 71.1 | 87.2 |
Table 7: MSRVTT, MSVD, TGIF에서의 비디오 질의응답. top-1 정확도를 보고합니다.
| Method | MSRVTT | MSVD | TGIF |
|---|---|---|---|
| ClipBERT [54] | 37.4 | - | 60.3 |
| All-in-one [24] | 42.9 | 46.5 | 64.2 |
| MERLOT [9] | 43.1 | - | 69.5 |
| VIOLET [30] | 43.9 | 47.9 | 68.9 |
| InternVideo |
특히 에이전트가 연속적인 공간에서 짧은 스텝 크기로 탐색할 때 그렇습니다. 우리 모델의 이러한 능력의 효과를 검증하기 위해, 우리는 에이전트가 연속적인 환경에서 기능해야 하는 VLN-CE 벤치마크 [100]에서 실험을 수행합니다. 우리는 90에서 제안된 방법을 사용하여 실험을 수행합니다. 히스토리 강화 플래너는 깊이 임베딩과 RGB 임베딩의 연결을 입력 임베딩으로 사용하는 HAMT [101]의 맞춤형 변형입니다. VLN-CE 설정이 슬라이딩을 허용하므로 여기서는 시도 컨트롤러를 사용하지 않습니다. 이는 이미 이전의 최첨단 방법인 CWP-VLNBERT [89]를 능가하는 강력한 기준선입니다. 각 결정 루프에서 우리는 최신 16프레임 관찰을 수집하여 파노라마 탐색 비디오를 형성한 다음 InternVideo에서 ViT-L을 사용하여 비디오를 인코딩합니다. 비디오 임베딩은 RGB 임베딩 및 깊이 임베딩과 연결되어 최종 이미지 임베딩으로 사용됩니다. 평가를 위해 자세한 메트릭은 [90]을 참조하십시오. InternVideo는 우리의 기준선을 성공률(SR)에서 50.2%에서 52.9%로 향상시킬 수 있었습니다(표 8).
4.3.3 Video Open Understanding Tasks
Zero-shot Action Recognition
제로샷 인식은 원래 CLIP 모델의 뛰어난 능력 중 하나입니다. 우리가 설계한 다중 모드 비디오 인코더를 사용하면 추가 최적화 없이도 뛰어난 제로샷 행동 인식 성능을 달성할 수 있습니다. 우리는 Kinetics-400 데이터셋에서 64.25%의 정확도로 모델을 평가했으며, 이는 이전 SOTA인 56.4% [102]를 큰 차이로 능가합니다.
Zero-shot Video Retrieval
InternVideo를 CLIP과 제로샷 텍스트-비디오 및 비디오-텍스트 검색에서 비교합니다. 공정한 비교를 위해, CLIP의 사전 훈련된 가중치¹를 가진 ViT-L/14 모델을 사용합니다. Wise-finetuning [103]과 모델 앙상블을 사용하여 제로샷 비디오 검색에서 모델 성능을 더욱 향상시킵니다. 우리는 경험적으로 제로샷 검색에 최적의 비디오 프레임 수가 4에서 8 사이임을 발견했으며, 각 벤치마크 데이터셋에서 최상의 성능을 보인 프레임은 그리드 검색을 통해 산출되었습니다. 표 9에서 볼 수 있듯이, InternVideo는 6개의 벤치마크 데이터셋 모두에서 우수한 검색 능력을 보여줍니다. 또한, Florence [15]는 사전 훈련에 9억 개의 이미지-텍스트 쌍을 사용했으며 MSR-VTT에서 37.6 R@1 텍스트-비디오 검색 정확도를 달성했습니다. 이에 비해, 우리 모델은 훨씬 적은 훈련 데이터(1435만 비디오 + 1억 이미지 대 9억 이미지)로 Florence를 4.1% 능가합니다. 이러한 결과는 사전 훈련 중 공동 비디오-텍스트 특징 공간을 학습하는 우리 방법의 효과를 보여줍니다.
Zero-shot Multiple Choice
제로샷 객관식은 모델의 일반성을 보여줄 수 있는 또 다른 제로샷 작업입니다. 객관식 작업은 주어진 선택지(보통 5개 단어와 같은 작은 하위 집합)에서 정답을 찾는 것을 목표로 합니다. 우리는 이미지-텍스트 쌍과의 공동 훈련, 현명한 미세 조정 및 앙상블이 제로샷 객관식 성능에 필수적이라는 것을 발견했습니다. MSR-VTT 및 LSMDC 데이터셋에 대한 제로샷 객관식 결과를 표 10에 보고합니다. 우리는 훈련에서 일반성을 위한 편리한 지표로 제로샷 성능을 사용하며, 결과는 우리 모델이 견고하고 효과적임을 보여줍니다.
Open-set Action Recognition
개방형 집합 행동 인식(OSAR)에서 모델은 훈련 클래스의 알려진 행동 샘플을 인식하고 훈련 클래스 외부의 알려지지 않은 샘플을 거부해야 합니다. 이미지와 비교할 때, 비디오 행동은 불확실한
Table 8: VLN-CE 데이터셋의 결과.
| Agent | Backbone | val-unseen | ||||
|---|---|---|---|---|---|---|
| NE | PL | SR | NDTW | SPL | ||
| CWP-VLNBERT [89] | ResNet50 | 5.52 | 11.85 | 45.19 | 54.20 | 39.91 |
| CWP-HEP [90] | CLIP-ViT-B/16 | 5.21 | 10.29 | 50.24 | 60.39 | 45.71 |
| CWP-HEP [90] | InternVideo | 10.44 |
Table 9: MSR-VTT, MSVD, LSMDC, ActivityNet, DiDeMo, VATEX에서의 제로샷 비디오 검색 결과. 텍스트-비디오(T2V) 및 비디오-텍스트(V2T) 검색 작업 모두에서 R@1을 보고합니다.
| Methods | MSR-VTT | MSVD | LSMDC | ActivityNet | DiDeMo | VATEX | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | T2V | V2T | |
| CLIP [13] | 35.0 | 32.3 | 39.2 | 63.3 | 17.0 | 10.5 | 25.2 | 20.7 | 29.8 | 24.3 | 45.2 | 59.2 |
| InternVideo |
3Table 10: MSR-VTT 및 LSMDC에서의 제로샷 객관식. 회색은 지도 학습을 사용한 방법을 나타냅니다.
| MSR-VTT | LSMDC | |||
|---|---|---|---|---|
| Method | Accuracy | Method | Accuracy | |
| JSFusion [104] | 83.4 | JSFusion [104] | 73.5 | |
| ActBERT [53] | 85.7 | MERLOT [9] | 81.7 | |
| ClipBERT [54] | 88.2 | VIOLET [30] | 82.9 | |
| All-in-one [24] | 80.3 | All-in-one [24] | 56.3 | |
| InternVideo | InternVideo |
Table 11: 알려지지 않은 클래스의 샘플이 각각 HMDB-51과 MiT-v2에서 온 두 개의 다른 개방형 집합에 대한 개방형 집합 행동 인식 결과. 95%의 훈련 비디오(UCF101)가 알려진 것으로 인식되도록 보장하는 임계값에서 결정된 개방형 집합 AUC를 보고합니다.
| Method | Open Set AUC (%) | Closed Set Accuracy (%) | |
|---|---|---|---|
| UCF-101 + HMDB-51 | UCF-101 + MiT-v2 | ||
| OpenMax [105] | 78.76 | 80.62 | 62.09 |
| MC Dropout [106] | 75.41 | 78.49 | 96.75 |
| BNN SVI [107] | 74.78 | 77.39 | 96.43 |
| SoftMax | 79.16 | 82.88 | 96.70 |
| RPL [108] | 74.23 | 77.42 | 96.93 |
| DEAR [109] | 82.94 | 86.99 | 96.48 |
| InternVideo |
시간적 역학 및 인간 행동의 정적 편향 [109]으로 인해 OSR 설정에서 인식하기가 더 어렵습니다. 우리의 InternVideo는 훈련 클래스 외부의 알려지지 않은 클래스로 잘 일반화되며 모델 보정 없이 기존 방법 [109]을 능가합니다.
우리는 InternVideo의 ViT-H/16 모델을 백본으로 사용하고 UCF-101 [110] 훈련 세트에서 간단한 선형 분류 헤드로 미세 조정합니다. InternVideo가 "알려지지 않은 것을 알 수 있도록" 하기 위해, 우리는 [109]에서 제안된 DEAR 방법을 따르고, 증거 기반 딥 러닝(EDL)을 활용하여 불확실성 추정 문제로 공식화합니다. 이는 다중 클래스 분류와 불확실성 모델링을 공동으로 공식화하는 방법을 제공합니다. 구체적으로, 비디오를 입력으로 주었을 때, InternVideo 백본 위의 Evidential Neural Network (ENN) 헤드는 클래스별 증거를 예측하며, 이는 다중 클래스 확률과 입력의 예측 불확실성을 결정할 수 있도록 디리클레 분포를 형성합니다. 개방 집합 추론 중에, 불확실성이 높은 비디오는 알려지지 않은 행동으로 간주될 수 있으며, 불확실성이 낮은 비디오는 학습된 범주형 확률에 의해 분류됩니다. InternVideo는 알려진 행동 클래스를 정확하게 인식할 뿐만 아니라 알려지지 않은 것도 식별할 수 있습니다. 표 11은 InternVideo와 다른 기준선의 폐쇄 집합(폐쇄 집합 정확도) 및 개방 집합(개방 집합 AUC) 성능 결과를 보고합니다. 이는 우리의 InternVideo가 HMDB-51 [81]과 MiT-v2 [111]에서 온 알려지지 않은 샘플이 있는 두 개의 개방 집합 데이터셋 모두에서 다른 기준선을 일관되고 유의하게 능가함을 보여줍니다.
5 Concluding Remarks
이 논문에서 우리는 다재다능하고 훈련 효율적인 비디오 파운데이션 모델인 InternVideo를 제안합니다. 우리가 아는 한, InternVideo는 행동 이해, 비디오-언어 정렬, 비디오 개방형 이해 작업 모두에서 기존 연구 중 최고의 성능을 보이는 첫 번째 연구입니다. 이전 관련 연구 [6, 8, 9]와 비교하여, 10개의 다른 작업을 다루는 거의 40개의 데이터셋에서 최첨단 성능을 달성함으로써 비디오 파운데이션 모델의 일반성을 새로운 수준으로 크게 끌어올렸습니다. 이 모델은 마스크된 비디오 학습(VideoMAE)과 비디오-언어 대조 모델링 간의 교차 모델 학습과 지도 학습을 기반으로 한 통합 비디오 표현을 활용합니다. 이전 파운데이션 모델과 비교하여 훈련 효율성이 높습니다. 간단한 ViT와 그에 상응하는 변형을 사용하여, 우리는 64.5K GPU 시간(A100-80G)으로 일반화된 비디오 표현을 달성한 반면, CoCa [7]는 245.76K TPU 시간(v4)이 필요했습니다. 우리는 다양한 응용 프로그램에서 이러한 일반화된 시공간 표현을 검증합니다. 간단한 작업 헤드(선형 헤드 포함)와 적절한 다운스트림 적응 튜닝을 통해, 우리의 비디오 표현은 사용된 모든 데이터셋에서 기록적인 결과를 보여줍니다. 제로샷 및 개방형 집합 설정에서도 우리의 모델 스펙트럼은 여전히 일관되고 상당한 성능 향상을 보여주며, 일반화와 적응을 더욱 증명합니다.
5.1 Limitations
우리 연구는 새로운 공식이나 모델 설계를 제시하기보다는 비디오 파운데이션 모델의 효과성과 실현 가능성을 보여줍니다. 현재 인기 있는 비디오 인식 작업에 초점을 맞추고 클립을 사용하여 비디오를 처리합니다. 그 설계는 장기적인 비디오 작업뿐만 아니라 영화의 본 부분에서 줄거리를 예측하는 것과 같은 고차원적인 작업을 처리하기 어렵습니다. 이러한 작업을 처리할 수 있는 능력을 얻는 것은 비디오 표현 학습의 일반성을 더욱 발전시키는 데 중요합니다.
5.2 Future Work
비디오 파운데이션 모델의 일반성을 더욱 확장하기 위해, 우리는 모델 조정과 인지를 수용하는 것이 연구에 필요하다고 생각합니다. 구체적으로, 더 나은 표현을 위해 서로 다른 양식, 사전 훈련 작업, 심지어 다양한 아키텍처에서 훈련된 파운데이션 모델을 체계적으로 조정하는 방법은 아직 해결되지 않은 어려운 문제입니다. 이를 해결하기 위한 여러 기술적 경로가 있으며, 예를 들어 모델 증류, 다양한 사전 훈련 목표 통합, 특징 정렬 등이 있습니다. 이전에 학습된 지식을 활용함으로써 우리는 비디오 파운데이션 모델 개발을 지속 가능하게 가속화할 수 있습니다.
장기적으로 파운데이션 모델은 인지 능력보다 인지 능력을 더 많이 습득할 것으로 예상됩니다. 그 실현 가능성을 고려할 때, 우리는 연구 동향 중 하나가 개방된 세계에서 기초적인 동적 인식으로부터 대규모 시공간 분석(장기 및 큰 장면)을 달성하여 필수적인 인지 이해로 이어지는 것이라고 생각합니다. 또한, 파운데이션 모델을 의사 결정과 결합하여 새로운 작업을 탐색하기 위한 지능형 에이전트를 형성하는 흐름을 일으켰습니다. 이 상호 작용에서 데이터 수집과 모델 훈련도 자동화됩니다. 전체 프로세스는 상호 작용 결과가 에이전트 전략과 행동을 조정함에 따라 폐쇄 루프로 들어갑니다. 시각-언어 탐색에 대한 우리의 초기 실험(섹션 4.3.2)은 비디오 파운데이션 모델을 Embodied AI에 통합하는 유망한 미래를 보여줍니다.
6 Broader Impact
우리는 비디오 파운데이션 모델 스펙트럼인 InternVideo를 제공합니다. 이는 약 40개의 데이터셋에서 최첨단 성능을 제공할 수 있으며, 행동 식별, 비디오-언어 정렬, 개방형 이해가 가능합니다. 공개 데이터 외에도 인터넷에서 자체 수집한 데이터를 활용합니다. 데이터 수집에 사용된 쿼리는 윤리적 및 법적 문제에 대해 확인되었으며, 큐레이팅된 데이터도 마찬가지입니다. InternVideo 훈련의 전력 소비는 CoCa [7]보다 훨씬 낮으며, CoCa의 23.19%만 차지합니다. 추가적인 영향 연구를 위해 우리는 편향, 위험, 공정성, 평등 및 더 많은 사회적 주제를 탐색해야 합니다.
References
[1] Boyang Xia, Wenhao Wu, Haoran Wang, Rui Su, Dongliang He, Haosen Yang, Xiaoran Fan, and Wanli Ouyang. Nsnet: Non-saliency suppression sampler for efficient video recognition. In . [2] Alexandros Stergiou and Ronald Poppe. Learn to cycle: Time-consistent feature discovery for action recognition. Pattern Recognition Letters, 141:1-7, 2021. [3] Lei Wang and Piotr Koniusz. Self-supervising action recognition by statistical moment and subspace descriptors. In ACM International Conference on Multimedia, 2021. [4] Chenlin Zhang, Jianxin Wu, and Yin Li. Actionformer: Localizing moments of actions with transformers. In eccv, 2022. [5] Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing, 2022. [6] Chen Wei, Haoqi Fan, Saining Xie, Chao-Yuan Wu, Alan Yuille, and Christoph Feichtenhofer. Masked feature prediction for self-supervised visual pre-training. In CVPR, 2022. [7] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917, 2022. [8] Shen Yan, Xuehan Xiong, Anurag Arnab, Zhichao Lu, Mi Zhang, Chen Sun, and Cordelia Schmid. Multiview transformers for video recognition. In CVPR, 2022. [9] Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, and Yejin Choi. Merlot: Multimodal neural script knowledge models. NeurIPS, 2021. [10] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021. [11] Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. NeurIPS, 2021. [12] Jing Shao, Siyu Chen, Yangguang Li, Kun Wang, Zhenfei Yin, Yinan He, Jianing Teng, Qinghong Sun, Mengya Gao, Jihao Liu, et al. Intern: A new learning paradigm towards general vision. arXiv preprint arXiv:2111.08687, 2021. [13] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021. [14] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In ICML, 2021. [15] Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, et al. Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432, 2021. [16] Jianwei Yang, Chunyuan Li, Pengchuan Zhang, Bin Xiao, Ce Liu, Lu Yuan, and Jianfeng Gao. Unified contrastive learning in image-text-label space. In CVPR, 2022. [17] Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. SimVLM: Simple visual language model pretraining with weak supervision. In . [18] Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In ICML, 2022. [19] Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, et al. Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv preprint arXiv:2208.10442, 2022. [20] Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEit: BERT pre-training of image transformers. In ICLR, 2022. [21] Paul Barham, Aakanksha Chowdhery, Jeff Dean, Sanjay Ghemawat, Steven Hand, Daniel Hurt, Michael Isard, Hyeontaek Lim, Ruoming Pang, Sudip Roy, et al. Pathways: Asynchronous distributed dataflow for ml. Proceedings of Machine Learning and Systems, 2022. [22] Yiwei Ma, Guohai Xu, Xiaoshuai Sun, Ming Yan, Ji Zhang, and Rongrong Ji. X-clip: End-to-end multi-grained contrastive learning for video-text retrieval. In ACM International Conference on Multimedia, 2022. [23] Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In NeurIPS, 2022. [24] Alex Jinpeng Wang, Yixiao Ge, Rui Yan, Yuying Ge, Xudong Lin, Guanyu Cai, Jianping Wu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. All in one: Exploring unified video-language pre-training. arXiv preprint arXiv:2203.07303, 2022. [25] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In CVPR, 2022. [26] Tianhao Li and Limin Wang. Learning spatiotemporal features via video and text pair discrimination. CoRR, abs/2001.05691, 2020. [27] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 2017. [28] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021. [29] Roman Bachmann, David Mizrahi, Andrei Atanov, and Amir Zamir. Multimae: Multi-modal multi-task masked autoencoders. arXiv preprint arXiv:2204.01678, 2022. [30] Tsu-Jui Fu, Linjie Li, Zhe Gan, Kevin Lin, William Yang Wang, Lijuan Wang, and Zicheng Liu. Violet: End-to-end video-language transformers with masked visual-token modeling. arXiv preprint arXiv:2111.12681, 2021. [31] Linjie Li, Zhe Gan, Kevin Lin, Chung-Ching Lin, Zicheng Liu, Ce Liu, and Lijuan Wang. Lavender: Unifying video-language understanding as masked language modeling. arXiv preprint arXiv:2206.07160, 2022. [32] Rowan Zellers, Jiasen Lu, Ximing Lu, Youngjae Yu, Yanpeng Zhao, Mohammadreza Salehi, Aditya Kusupati, Jack Hessel, Ali Farhadi, and Yejin Choi. Merlot reserve: Neural script knowledge through vision and language and sound. In CVPR, 2022. [33] Carl Doersch, Abhinav Gupta, and Alexei A Efros. Unsupervised visual representation learning by context prediction. In ICCV, 2015. [34] Xiaolong Wang and Abhinav Gupta. Unsupervised learning of visual representations using videos. In ICCV, 2015. [35] Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. In ECCV, 2016. [36] Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful image colorization. In ECCV, 2016. [37] Christoph Feichtenhofer, Haoqi Fan, Yanghao Li, and Kaiming He. Masked autoencoders as spatiotemporal learners. arXiv preprint arXiv:2205.09113, 2022. [38] Zhirong Wu, Yuanjun Xiong, Stella X Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. In CVPR, 2018. [39] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020. [40] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In ICML, 2020. [41] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. NeurIPS, 2020. [42] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In CVPR, 2021. [43] Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. In ICML, 2020. [44] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In ICML, 2021. [45] Rui Wang, Dongdong Chen, Zuxuan Wu, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Yu-Gang Jiang, Luowei Zhou, and Lu Yuan. Bevt: Bert pretraining of video transformers. In CVPR, 2022. [46] Antoine Miech, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, and Andrew Zisserman. End-to-end learning of visual representations from uncurated instructional videos. In CVPR, 2020. [47] Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding. arXiv preprint arXiv:2109.14084, 2021. [48] Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Lijuan Wang. Scaling up visionlanguage pre-training for image captioning. In CVPR, 2022. [49] Zi-Yi Dou, Yichong Xu, Zhe Gan, Jianfeng Wang, Shuohang Wang, Lijuan Wang, Chenguang Zhu, Pengchuan Zhang, Lu Yuan, Nanyun Peng, et al. An empirical study of training end-to-end vision-and-language transformers. In CVPR, 2022. [50] Sheng Shen, Liunian Harold Li, Hao Tan, Mohit Bansal, Anna Rohrbach, Kai-Wei Chang, Zhewei Yao, and Kurt Keutzer. How much can clip benefit vision-and-language tasks? arXiv preprint arXiv:2107.06383, 2021. [51] Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training. arXiv preprint arXiv:2111.07783, 2021. [52] Chen Sun, Austin Myers, Carl Vondrick, Kevin P. Murphy, and Cordelia Schmid. Videobert: A joint model for video and language representation learning. ICCV, 2019. [53] Linchao Zhu and Yi Yang. Actbert: Learning global-local video-text representations. CVPR, 2020. [54] Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L Berg, Mohit Bansal, and Jingjing Liu. Less is more: Clipbert for video-and-language learning via sparse sampling. In CVPR, 2021. [55] Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In ICCV, 2021. [56] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Limin Wang, and Yu Qiao. Uniformerv2: Spatiotemporal learning by arming image vits with video uniformer. arXiv preprint arXiv:2211.09552, 2022. [57] Guo Chen, Sen Xing, Zhe Chen, Yi Wang, Kunchang Li, Yizhuo Li, Yi Liu, Jiahao Wang, Yin-Dong Zheng, Bingkun Huang, et al. Internvideo-ego4d: A pack of champion solutions to ego4d challenges. arXiv preprint arXiv:2211.09529, 2022. [58] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. Vivit: A video vision transformer. In ICCV, 2021. [59] Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. In CVPR, 2022. [60] Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. Align before fuse: Vision and language representation learning with momentum distillation. NeurIPS, 2021. [61] Tianwei Lin, Xu Zhao, Haisheng Su, Chongjing Wang, and Ming Yang. Bsn: Boundary sensitive network for temporal action proposal generation. In Proceedings of the European conference on computer vision (ECCV), pages 3-19, 2018. [62] Tianwei Lin, Xiao Liu, Xin Li, Errui Ding, and Shilei Wen. Bmn: Boundary-matching network for temporal action proposal generation. In ICCV, 2019. [63] Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler, and Daniel Soudry. Augment your batch: Improving generalization through instance repetition. CVPR, 2020. [64] Kunchang Li, Yali Wang, Gao Peng, Guanglu Song, Yu Liu, Hongsheng Li, and Yu Qiao. Uniformer: Unified transformer for efficient spatial-temporal representation learning. In ICLR, 2022. [65] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In ECCV, 2016. [66] Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. ICCV, 2019. [67] Chunhui Gu, Chen Sun, David A Ross, Carl Vondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. In CVPR, 2018. [68] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. In ICCV, 2017. [69] Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. A short note about kinetics-600. arXiv preprint arXiv:1808.01340, 2018. [70] Joao Carreira, Eric Noland, Chloe Hillier, and Andrew Zisserman. A short note on the kinetics-700 human action dataset. arXiv preprint arXiv:1907.06987, 2019. [71] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021. [72] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198, 2022. [73] Yuan Tian, Yichao Yan, Guangtao Zhai, Guodong Guo, and Zhiyong Gao. Ean: event adaptive network for enhanced action recognition. IJCV, 2022. [74] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In ICCV, 2019. [75] Zhiwu Qing, Haisheng Su, Weihao Gan, Dongliang Wang, Wei Wu, Xiang Wang, Yu Qiao, Junjie Yan, Changxin Gao, and Nong Sang. Temporal context aggregation network for temporal action proposal refinement. In CVPR, 2021. [76] Humam Alwassel, Silvio Giancola, and Bernard Ghanem. Tsp: Temporally-sensitive pretraining of video encoders for localization tasks. In ICCV, 2021. [77] Junting Pan, Siyu Chen, Mike Zheng Shou, Yu Liu, Jing Shao, and Hongsheng Li. Actor-context-actor relation network for spatio-temporal action localization. In CVPR, 2021. [78] Yutong Feng, Jianwen Jiang, Ziyuan Huang, Zhiwu Qing, Xiang Wang, Shiwei Zhang, Mingqian Tang, and Yue Gao. Relation modeling in spatio-temporal action localization. arXiv preprint arXiv:2106.08061, 2021. [79] Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. In CVPR, 2015. [80] Hang Zhao, Antonio Torralba, Lorenzo Torresani, and Zhicheng Yan. Hacs: Human action clips and segments dataset for recognition and temporal localization. In ICCV, 2019. [81] Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio, and Thomas Serre. Hmdb: a large video database for human motion recognition. In ICCV, 2011. [82] Haroon Idrees, Amir R Zamir, Yu-Gang Jiang, Alex Gorban, Ivan Laptev, Rahul Sukthankar, and Mubarak Shah. The thumos challenge on action recognition for videos "in the wild". CVIU, 2017. [83] Yi Liu, Limin Wang, Yali Wang, Xiao Ma, and Yu Qiao. Fineaction: A fine-grained video dataset for temporal action localization. IEEE Transactions on Image Processing, 2022. [84] Ang Li, Meghana Thotakuri, David A Ross, João Carreira, Alexander Vostrikov, and Andrew Zisserman. The ava-kinetics localized human actions video dataset. arXiv preprint arXiv:2005.00214, 2020. [85] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. [86] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Girshick. Mask r-cnn. In ICCV, 2017. [87] Jiajun Tang, Jin Xia, Xinzhi Mu, Bo Pang, and Cewu Lu. Asynchronous interaction aggregation for action detection. In ECCV, 2020. [88] Yuqi Liu, Pengfei Xiong, Luhui Xu, Shengming Cao, and Qin Jin. Ts2-net: Token shift and selection transformer for text-video retrieval. In . [89] Yicong Hong, Zun Wang, Qi Wu, and Stephen Gould. Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation. In CVPR, 2022. [90] Dong An, Zun Wang, Yangguang Li, Yi Wang, Yicong Hong, Yan Huang, Liang Wang, and Jing Shao. 1st place solutions for rxr-habitat vision-and-language navigation competition (cvpr 2022). arXiv preprint arXiv:2206.11610, 2022. [91] Xing Cheng, Hezheng Lin, Xiangyu Wu, Fan Yang, and Dong Shen. Improving video-text retrieval by multi-stream corpus alignment and dual softmax loss. arXiv preprint arXiv:2109.04290, 2021. [92] Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In CVPR, 2016. [93] Zuxuan Wu, Ting Yao, Yanwei Fu, and Yu-Gang Jiang. Deep learning for video classification and captioning. In Frontiers of Multimedia Research. 2017. [94] Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in video with natural language. In ICCV, 2017. [95] Anna Rohrbach, Marcus Rohrbach, Niket Tandon, and Bernt Schiele. A dataset for movie description. In CVPR, 2015. [96] Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In ICCV, 2019. [97] David Chen and William B Dolan. Collecting highly parallel data for paraphrase evaluation. In ACL, 2011. [98] Yuncheng Li, Yale Song, Liangliang Cao, Joel Tetreault, Larry Goldberg, Alejandro Jaimes, and Jiebo Luo. Tgif: A new dataset and benchmark on animated gif description. In CVPR, 2016. [99] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In CVPR, 2018. [100] Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language navigation in continuous environments. In ECCV, 2020. [101] Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-andlanguage navigation. NeurIPS, 2021. [102] Mengmeng Wang, Jiazheng Xing, and Yong Liu. Actionclip: A new paradigm for video action recognition. ArXiv, abs/2109.08472, 2021. [103] Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, et al. Robust fine-tuning of zero-shot models. In CVPR, 2022. [104] Youngjae Yu, Jongseok Kim, and Gunhee Kim. A joint sequence fusion model for video question answering and retrieval. In ECCV, 2018. [105] Abhijit Bendale and Terrance E Boult. Towards open set deep networks. In CVPR, 2016. [106] Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In ICML, 2016. [107] Ranganath Krishnan, Mahesh Subedar, and Omesh Tickoo. Bar: Bayesian activity recognition using variational inference. arXiv preprint arXiv:1811.03305, 2018. [108] Guangyao Chen, Limeng Qiao, Yemin Shi, Peixi Peng, Jia Li, Tiejun Huang, Shiliang Pu, and Yonghong Tian. Learning open set network with discriminative reciprocal points. In . [109] Wentao Bao, Qi Yu, and Yu Kong. Evidential deep learning for open set action recognition. In ICCV, 2021. [110] Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. A dataset of 101 human action classes from videos in the wild. Center for Research in Computer Vision, 2012. [111] Mathew Monfort, Bowen Pan, Kandan Ramakrishnan, Alex Andonian, Barry A McNamara, Alex Lascelles, Quanfu Fan, Dan Gutfreund, Rogerio Feris, and Aude Oliva. Multi-moments in time: Learning and interpreting models for multi-action video understanding. TPAMI, 2021.
Footnotes
-
- 동등한 기여. † 교신 저자 (qiaoyu@pjlab.org.cn).