InstructBLIP: Instruction Tuning을 통한 범용 Vision-Language 모델
InstructBLIP은 사전 학습된 BLIP-2 모델을 기반으로 Vision-Language Instruction Tuning에 대한 체계적이고 포괄적인 연구를 제시합니다. 26개의 공개 데이터셋을 Instruction Tuning 형식으로 변환하여 학습에 사용했으며, 주어진 Instruction에 맞춰 정보를 추출하는 Instruction-aware Query Transformer를 도입했습니다. 이를 통해 InstructBLIP은 13개의 unseen 데이터셋에서 SOTA zero-shot 성능을 달성하여 BLIP-2 및 Flamingo와 같은 대규모 모델을 능가하는 성능을 보여줍니다. 논문 제목: InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
논문 요약: InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
- 논문 링크: https://arxiv.org/abs/2305.06500
- 저자: Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi (Salesforce Research, Hong Kong University of Science and Technology, Nanyang Technological University, Singapore)
- 발표 시기: 2023년, Advances in Neural Information Processing Systems (NeurIPS) 36
- 주요 키워드: Vision-Language Model, Instruction Tuning, LLM, Multimodal, Zero-shot Learning
1. 연구 배경 및 문제 정의
- 문제 정의: 대규모 언어 모델(LLM) 분야에서 instruction tuning을 통해 범용 모델 구축이 성공적이었지만, 시각 입력의 풍부한 분포와 task 다양성으로 인해 범용 Vision-Language Model(VLM)을 구축하는 것은 여전히 도전적이다. 특히, 학습 시 보지 못한(unseen) 다양한 Vision-Language task에 일반화될 수 있는 통합 모델을 만드는 것이 큰 과제이다.
- 기존 접근 방식:
- Multitask Learning: 다양한 VLM task를 동일한 입출력 형식으로 정식화하여 학습하지만, instruction 없이 수행할 경우 unseen 데이터셋과 task에 대한 일반화 성능이 낮았다.
- 사전학습된 LLM 확장: 사전학습된 LLM에 시각 구성 요소를 추가하고 이미지 캡션 데이터로 학습시키지만, 이는 시각적 설명 이상의 것을 요구하는 광범위한 VLM task에 일반화하기에는 데이터가 너무 제한적이었다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 포괄적이고 체계적인 Vision-Language Instruction Tuning 연구: 26개의 공개 데이터셋을 11개 task 카테고리로 분류하고 instruction tuning 형식으로 변환하여 사용했다. 13개의 held-in 데이터셋으로 학습하고, 13개의 held-out 데이터셋(4개 task 카테고리 포함)으로 zero-shot 평가를 수행하여 InstructBLIP의 효과를 입증했다.
- Instruction-aware Visual Feature Extraction 제안: 주어진 instruction에 따라 유연하고 정보가 풍부한 시각적 특징 추출을 가능하게 하는 새로운 메커니즘을 도입했다. 텍스트 instruction을 Q-Former에 추가 입력으로 제공하여 task와 관련된 시각적 특징 추출을 유도한다.
- 다양한 LLM 백본을 사용한 SOTA 성능 달성 및 오픈 소스 공개: FlanT5 (encoder-decoder) 및 Vicuna (decoder-only) 두 가지 LLM 계열을 사용하여 InstructBLIP 모델을 평가하고 오픈 소스화했다. 광범위한 VLM task에서 SOTA zero-shot 성능을 달성했으며, 다운스트림 fine-tuning에서도 SOTA 성능을 이끌어냈다.
- 제안 방법: InstructBLIP은 사전학습된 BLIP-2 모델을 기반으로 Vision-Language instruction tuning을 수행한다. BLIP-2의 아키텍처(frozen 이미지 인코더, Q-Former, frozen LLM)를 활용하며, 이 중 Q-Former의 파라미터만 fine-tuning하고 이미지 인코더와 LLM은 frozen 상태로 유지한다. 핵심 아이디어는 Instruction-aware Query Transformer로, instruction 텍스트 토큰을 Q-Former의 추가 입력으로 받아 Q-Former가 instruction에 따라 유익한 시각적 특징을 추출하도록 유도한다. 학습 데이터셋의 크기 차이로 인한 과적합/과소적합 문제를 해결하기 위해, 데이터셋 크기의 제곱근에 비례하는 확률로 샘플링하고, 각 데이터셋의 수렴 시간을 고려하여 가중치를 수동으로 조정하는 데이터 균형 샘플링 전략을 사용한다. 모델은 FlanT5-XL/XXL 및 Vicuna-7B/13B를 LLM 백본으로 사용하며, 표준 언어 모델링 손실로 학습된다.
3. 실험 결과
- 데이터셋: 총 26개의 공개 Vision-Language 데이터셋을 수집하여 instruction tuning 형식으로 변환했다. 이 중 13개는 held-in 데이터셋으로 학습에 사용되었고, 13개는 held-out 데이터셋으로 zero-shot 평가에 사용되었다. 실험 환경은 16개의 Nvidia A100 (40G) GPU를 활용하여 모든 모델이 1.5일 이내에 학습 완료되었다.
- 주요 결과:
- Zero-shot 성능: 13개 held-out 데이터셋 전체에서 새로운 SOTA zero-shot 성능을 달성했다. 기존 BLIP-2 및 더 큰 Flamingo 모델들을 크게 능가했으며, 특히 학습 시 접하지 않은 비디오 QA task(MSRVTT-QA)에서도 기존 SOTA 대비 최대 47.1%의 상대적 성능 향상을 보였다. 가장 작은 InstructBLIP FlanT5 (4B 파라미터) 모델조차 Flamingo-80B를 능가했다.
- Ablation Study: Instruction-aware visual feature 추출과 데이터 균형 샘플링 전략이 InstructBLIP의 성능 향상에 필수적임을 입증했다. 이 두 가지 요소가 제거될 경우 held-in 및 held-out 평가 모두에서 성능이 크게 저하되었다.
- 정성적 평가: InstructBLIP은 복잡한 시각적 추론, 지식 기반 이미지 설명, 다중 턴 대화 등 다양한 instruction-following 능력을 보여주었다. 특히, 다른 멀티모달 모델(GPT-4, LLaVA, MiniGPT-4)과 비교했을 때, 더 적절하고 논리적으로 일관된 시각적 세부 정보를 포함하며, 사용자의 의도에 맞춰 응답 길이를 유연하게 조절하는 장점을 보였다.
- Instruction Tuning vs. Multitask Learning: Multitask learning은 held-in 데이터셋에서 instruction tuning과 유사한 성능을 보였으나, 이전에 보지 못한 held-out 데이터셋에서는 instruction tuning이 훨씬 뛰어난 zero-shot 일반화 성능을 보였다. 이는 instruction tuning이 zero-shot 일반화의 핵심임을 시사한다.
- Fine-tuning 성능: InstructBLIP은 다운스트림 task fine-tuning 시 BLIP-2보다 더 나은 초기화 모델을 제공하여, ScienceQA(image-context), OCR-VQA, A-OKVQA에서 새로운 SOTA fine-tuning 성능을 기록했다. 또한, 이미지 인코더를 freeze 상태로 유지하여 fine-tuning 효율성을 크게 높였다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 간단하면서도 효과적인 instruction tuning 프레임워크를 통해 광범위한 미지의 Vision-Language task에 대해 뛰어난 zero-shot 일반화 능력을 보여주었다는 점이 인상 깊다.
- Instruction-aware Q-Former를 통해 task에 맞는 시각적 특징을 유연하게 추출하는 아이디어가 매우 효과적이다.
- 다운스트림 fine-tuning 시에도 효율적인 초기화 모델을 제공하며, 학습 가능한 파라미터 수를 크게 줄여 학습 효율성을 높인 점이 실용적이다.
- 복잡한 시각적 추론, 지식 기반 설명, 다중 턴 대화 등 다재다능한 능력을 정성적으로 입증한 것이 모델의 잠재력을 잘 보여준다.
- 단점/한계:
- 원본 LLM의 한계(예: 근거 없는 텍스트 생성, 편향된 결과)를 그대로 계승할 수 있다는 점.
- LLM의 파라미터를 frozen 상태로 유지하기 때문에, 주어진 instruction을 항상 완벽하게 따르지 못할 가능성이 있다. (향후 LLM 파라미터 fine-tuning을 통해 개선 가능성 제시)
- 응용 가능성:
- 사용자가 임의로 지정하는 다양한 Vision-Language task를 해결하는 범용 멀티모달 AI 개발의 핵심 기반이 될 수 있다.
- 지능형 비서, 이미지 기반 질의응답 시스템, 시각적 스토리텔링, 시각 장애인을 위한 이미지 설명 등 다양한 실제 애플리케이션에 적용될 수 있다.
- 특히, 학습 데이터가 부족한 새로운 도메인이나 task에 대한 zero-shot 적용 가능성이 높아 활용도가 높을 것으로 기대된다.
5. 추가 참고 자료
Dai, Wenliang, et al. "Instructblip: Towards general-purpose vision-language models with instruction tuning." Advances in neural information processing systems 36 (2023): 49250-49267.
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
Wenliang Dai Junnan Li Dongxu Li Anthony Meng Huat Tiong <br>Junqi Zhao Weisheng Wang Boyang Li Pascale Fung Steven Hoi <br> Salesforce Research Hong Kong University of Science and Technology<br> Nanyang Technological University, Singapore<br>https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
Abstract
대규모 사전학습(pre-training)과 instruction tuning은 광범위한 능력을 갖춘 범용 Language Model을 성공적으로 구축하는 데 기여했다. 그러나 추가적인 시각 입력으로 인해 발생하는 풍부한 입력 분포와 task 다양성 때문에 범용 Vision-Language Model을 구축하는 것은 여전히 도전적이다. Vision-Language pretraining은 널리 연구되어 왔지만, Vision-Language instruction tuning은 아직 충분히 탐구되지 않았다.
본 논문에서는 사전학습된 BLIP-2 모델을 기반으로 Vision-Language instruction tuning에 대한 체계적이고 포괄적인 연구를 수행한다. 우리는 26개의 공개 데이터셋을 수집하여 다양한 task와 능력을 포괄하도록 instruction tuning 형식으로 변환한다. 또한, 주어진 instruction에 맞춰 유익한 feature를 추출하는 instruction-aware Query Transformer를 도입한다.
13개의 held-in 데이터셋으로 학습된 InstructBLIP은 13개의 held-out 데이터셋 전체에서 state-of-the-art zero-shot 성능을 달성하며, BLIP-2 및 더 큰 Flamingo 모델들을 크게 능가한다. 우리의 모델은 개별 downstream task에 대해 fine-tuning했을 때도 state-of-the-art 성능을 보인다 (예: 이미지 맥락이 있는 ScienceQA 질문에서 90.7%의 정확도). 나아가, 우리는 InstructBLIP이 동시 개발된 멀티모달 모델들보다 우수하다는 것을 정성적으로 입증한다. 모든 InstructBLIP 모델은 오픈 소스로 공개된다.
1 Introduction
인공지능(AI) 연구의 오랜 염원 중 하나는 사용자가 지정하는 임의의 task를 해결할 수 있는 단일 모델을 구축하는 것이다. 자연어 처리(NLP) 분야에서는 instruction tuning [1, 2]이 이러한 목표를 향한 유망한 접근 방식으로 입증되고 있다. 다양한 task를 자연어 instruction으로 설명하여 대규모 언어 모델(LLM)을 fine-tuning함으로써, instruction tuning은 모델이 임의의 instruction을 따르도록 만든다. 최근에는 instruction-tuned LLM이 vision-language task에도 활용되고 있다. 예를 들어, BLIP-2 [3]는 frozen된 instruction-tuned LLM을 시각 입력 이해에 효과적으로 적용하여, image-to-text 생성에서 instruction을 따르는 초기적인 능력을 보여주었다.
NLP task와 비교할 때, vision-language task는 다양한 도메인의 추가적인 시각 입력으로 인해 본질적으로 더 다양하다. 이는 다양한 vision-language task(학습 중에는 보지 못한 많은 task 포함)에 일반화되어야 하는 통합 모델에 더 큰 도전 과제를 제시한다. 대부분의 이전 연구는 두 가지 접근 방식으로 분류할 수 있다. 첫 번째 접근 방식인 multitask learning [4, 5]은 다양한 vision-language task를 동일한 input-output 형식으로 정식화한다. 그러나 우리는 instruction 없이 multitask learning을 수행할 경우(Table 4) 보지 못한 데이터셋과 task에 잘 일반화되지 않음을 경험적으로 확인했다.

Figure 1: 우리의 InstructBLIP-Vicuna 모델이 생성한 몇 가지 정성적 예시. 여기서는 복잡한 시각 장면 이해 및 추론, 지식 기반 이미지 설명, 다중 턴 시각 대화 등 다양한 능력을 보여준다.
두 번째 접근 방식 [3, 6]은 사전학습된 LLM을 추가적인 시각 구성 요소로 확장하고, 시각 구성 요소를 이미지 캡션 데이터로 학습시킨다. 그럼에도 불구하고, 이러한 데이터는 시각적 설명 이상의 것을 요구하는 vision-language task에 대한 광범위한 일반화를 허용하기에는 너무 제한적이다.
위에서 언급된 도전 과제들을 해결하기 위해, 본 논문은 InstructBLIP을 제시한다. InstructBLIP은 통합된 자연어 인터페이스를 통해 광범위한 vision-language task를 해결할 수 있도록 하는 범용 모델을 가능하게 하는 vision-language instruction tuning 프레임워크이다. InstructBLIP은 다양한 instruction 데이터셋을 사용하여 multimodal LLM을 학습시킨다. 구체적으로, 우리는 이미지 encoder, LLM, 그리고 이 둘을 연결하는 Query Transformer (Q-Former)로 구성된 사전학습된 BLIP-2 모델로 학습을 초기화한다. instruction tuning 동안, 우리는 이미지 encoder와 LLM은 frozen 상태로 유지하면서 Q-Former를 fine-tuning한다. 본 논문의 주요 기여는 다음과 같다:
- 우리는 vision-language instruction tuning에 대한 포괄적이고 체계적인 연구를 수행한다. 26개의 데이터셋을 instruction tuning 형식으로 변환하고, 이를 11개의 task 카테고리로 그룹화한다. instruction tuning을 위해 13개의 held-in 데이터셋을 사용하고, zero-shot 평가를 위해 13개의 held-out 데이터셋을 사용한다. 또한, task 수준의 zero-shot 평가를 위해 4개의 전체 task 카테고리를 보류한다. 철저한 정량적 및 정성적 결과는 vision-language zero-shot generalization에 대한 InstructBLIP의 효과를 입증한다.
- 우리는 instruction-aware visual feature extraction을 제안한다. 이는 주어진 instruction에 따라 유연하고 정보가 풍부한 feature 추출을 가능하게 하는 새로운 메커니즘이다. 구체적으로, 텍스트 instruction은 frozen된 LLM뿐만 아니라 Q-Former에도 제공되어, frozen된 이미지 encoder로부터 instruction-aware visual feature를 추출할 수 있도록 한다. 또한, 데이터셋 간의 학습 진행을 동기화하기 위한 균형 샘플링 전략을 제안한다.
- 우리는 두 가지 LLM 계열을 사용하여 InstructBLIP 모델들을 평가하고 오픈 소스화한다:
- FlanT5 [2]: T5 [7]로부터 fine-tuned된 encoder-decoder LLM.
- Vicuna [8]: LLaMA [9]로부터 fine-tuned된 decoder-only LLM. InstructBLIP 모델들은 광범위한 vision-language task에서 state-of-the-art zero-shot 성능을 달성한다. 또한, InstructBLIP 모델들은 개별 다운스트림 task에서 모델 초기화로 사용될 때 state-of-the-art fine-tuning 성능을 이끌어낸다.
2 Vision-Language Instruction Tuning
InstructBLIP은 vision-language instruction tuning의 고유한 도전 과제를 해결하고, 모델의 미학습 데이터 및 task에 대한 일반화 능력 향상에 대한 체계적인 연구를 제공하는 것을 목표로 한다. 본 섹션에서는 먼저 instruction-tuning 데이터 구축에 대해 소개하고, 이어서 학습 및 평가 프로토콜을 설명한다. 다음으로, 모델 및 데이터 관점에서 instruction-tuning 성능을 향상시키는 두 가지 기술을 설명한다. 마지막으로 구현 세부 사항을 제시한다.
2.1 Tasks and Datasets
명령어 튜닝 데이터의 다양성을 확보하고 접근성을 고려하기 위해, 우리는 공개적으로 사용 가능한 포괄적인 vision-language 데이터셋들을 수집하고, 이를 명령어 튜닝 형식으로 변환한다. Figure 2에서 보여주듯이, 최종 수집된 데이터는 11개의 task 카테고리와 26개의 데이터셋을 포함한다. 여기에는 다음이 포함된다:
- image captioning [10, 11, 12]
- reading comprehension을 포함한 image captioning [13]
- visual reasoning [14, 15, 16]
- image question answering [17, 18]
- 지식 기반 image question answering [19, 20, 21]
- reading comprehension을 포함한 image question answering [22, 23]
- image question generation (QA 데이터셋에서 변형)
- video question answering [24, 25]
- visual conversational question answering [26]
- image classification [27]
- LLaVA-Instruct-150K [28]
각 데이터셋에 대한 자세한 설명과 통계는 Appendix C에 포함되어 있다.
모든 task에 대해 우리는 자연어로 10개에서 15개의 고유한 명령어 템플릿을 세심하게 제작한다. 이 템플릿들은 task와 목표를 명확히 설명하는 명령어 튜닝 데이터를 구성하는 기반이 된다. 본질적으로 짧은 응답을 선호하는 공개 데이터셋의 경우, 모델이 항상 짧은 출력을 생성하도록 과적합되는 위험을 줄이기 위해, 해당 명령어 템플릿 중 일부에 "short" 및 **"briefly"**와 같은 용어를 사용한다. LLaVA-Instruct-150K 데이터셋의 경우, 이미 명령어 형식으로 자연스럽게 구성되어 있으므로 추가적인 명령어 템플릿을 통합하지 않는다. 전체 명령어 템플릿 목록은 Appendix D에서 확인할 수 있다.
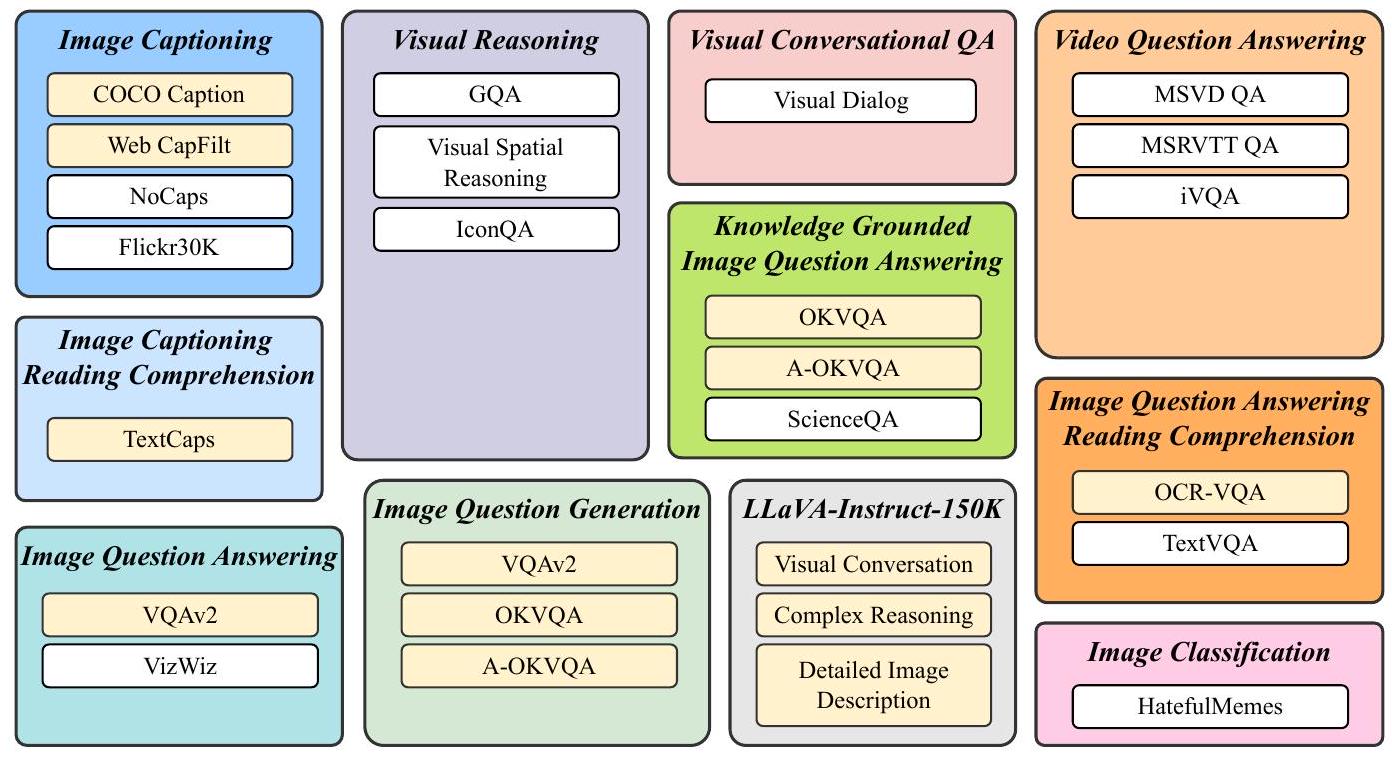
Figure 2: Vision-language instruction tuning에 사용된 task 및 해당 데이터셋.
Held-in 데이터셋은 노란색으로, held-out 데이터셋은 흰색으로 표시되어 있다.
2.2 Training and Evaluation Protocols
충분한 데이터와 task를 확보하여 학습 및 zero-shot 평가를 수행하기 위해, 우리는 26개의 데이터셋을 13개의 held-in 데이터셋과 13개의 held-out 데이터셋으로 나누었다. 이는 Figure 2에서 각각 노란색과 흰색으로 표시되어 있다. 우리는 held-in 데이터셋의 학습 세트를 instruction tuning에 사용하고, held-in 평가를 위해 해당 데이터셋의 validation 또는 test 세트를 활용한다.
held-out 평가의 목표는 instruction tuning이 모델의 unseen 데이터에 대한 zero-shot 성능을 어떻게 향상시키는지 이해하는 것이다. 우리는 두 가지 유형의 held-out 데이터를 정의한다:
- 학습 중 모델에 노출되지 않았지만, 해당 task가 held-in 클러스터에 존재하는 데이터셋.
- 학습 중 완전히 노출되지 않은 데이터셋 및 관련 task.
첫 번째 유형의 held-out 평가는 held-in 및 held-out 데이터셋 간의 **데이터 분포 변화(data distribution shift)**로 인해 쉽지 않다. 두 번째 유형의 경우, 우리는 visual reasoning, video question answering, visual conversational QA, image classification을 포함한 여러 task를 완전히 held-out으로 설정했다.
데이터 오염(data contamination)을 피하기 위해, 우리는 평가 데이터가 held-in 학습 클러스터의 다른 데이터셋에 나타나지 않도록 데이터셋을 신중하게 선택했다. 한 가지 예외는 Visual Dialog [26] 데이터셋인데, 이 데이터셋은 일부 held-in 데이터와 이미지 중복이 있다. Visual Dialog [26] 데이터셋은 일부 학습 데이터와 이미지 중복이 있지만, 정량적 평가를 위해 사용 가능한 거의 유일한 고품질 visual dialog 데이터셋이므로, 우리는 이를 참고용으로 평가에 포함시켰다.
instruction tuning 중에는 모든 held-in 학습 세트를 혼합하고, 각 데이터셋에 대해 instruction template을 균등하게 샘플링한다. 모델은 instruction이 주어졌을 때 응답을 직접 생성하도록 표준 language modeling loss로 학습된다. 또한, 장면 텍스트(scene texts)가 포함된 데이터셋의 경우, 보충 정보로 OCR token을 instruction에 추가한다.
2.3 Instruction-aware Visual Feature Extraction
기존의 zero-shot image-to-text 생성 방법들(BLIP-2 포함)은 시각적 feature를 추출할 때 instruction-agnostic 접근 방식을 취한다. 그 결과, task와 무관하게 정적인 시각적 표현(static visual representations) 세트가 LLM에 입력된다.
이와 대조적으로, instruction-aware vision model은 task instruction에 적응하여 해당 task에 가장 적합한 시각적 표현을 생성할 수 있다. 이는 동일한 입력 이미지에 대해 task instruction이 상당히 다양할 것으로 예상될 때 분명한 이점을 제공한다.
InstructBLIP의 아키텍처는 Figure 3에 나타나 있다. BLIP-2 [3]와 유사하게, InstructBLIP은 Query Transformer (Q-Former)를 활용하여 frozen image encoder로부터 시각적 feature를 추출한다. Q-Former의 입력은 K개의 학습 가능한 query embedding으로 구성되며, 이들은 cross attention을 통해 image encoder의 출력과 상호작용한다.
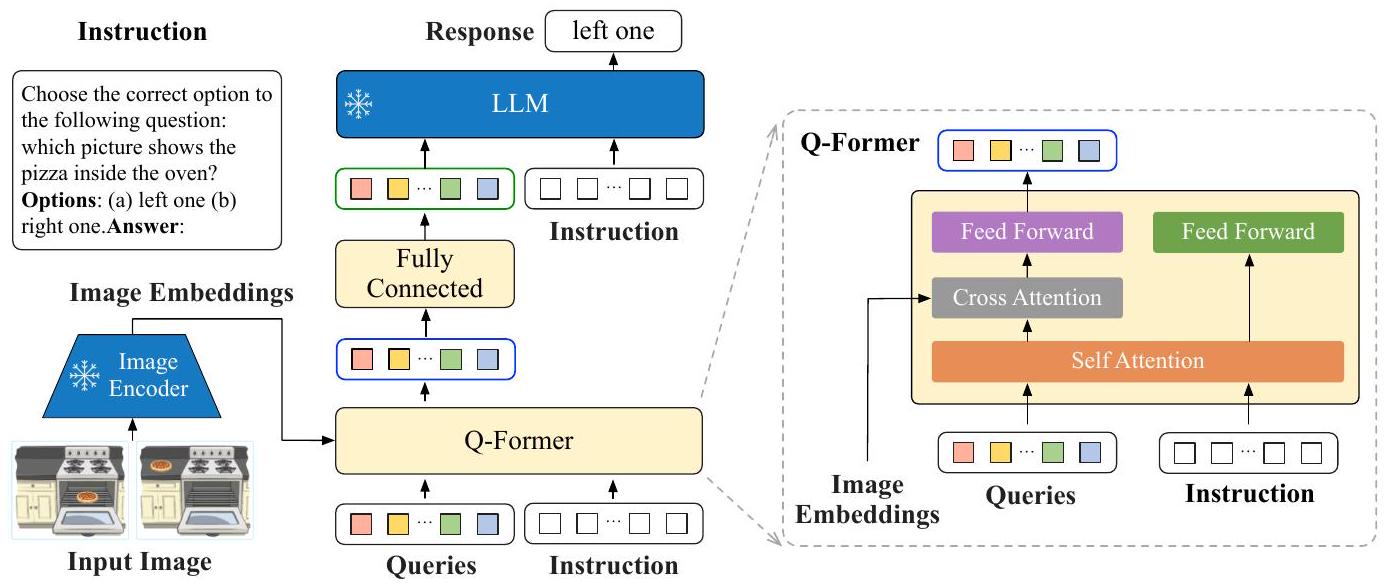
Figure 3: InstructBLIP의 모델 아키텍처. Q-Former는 frozen image encoder의 출력 embedding으로부터 instruction-aware visual feature를 추출하여, 이 visual feature를 frozen LLM에 soft prompt 입력으로 제공한다. 우리는 language modeling loss를 사용하여 모델을 instruction-tune하여 응답을 생성한다.
Q-Former의 출력은 **각 query embedding당 하나의 인코딩된 시각 벡터(총 K개)**로 구성되며, 이 벡터들은 선형 투영(linear projection)을 거쳐 frozen LLM에 입력된다. BLIP-2에서와 마찬가지로, Q-Former는 instruction tuning 전에 이미지-캡션 데이터를 사용하여 두 단계로 사전학습된다.
첫 번째 단계에서는 frozen image encoder와 함께 Q-Former를 vision-language representation learning을 위해 사전학습한다.
두 번째 단계에서는 Q-Former의 출력을 frozen LLM을 위한 텍스트 생성용 soft visual prompt로 적응시킨다.
사전학습 후, 우리는 instruction tuning을 통해 Q-Former를 fine-tune하며, 이때 LLM은 Q-Former로부터의 visual encoding과 task instruction을 입력으로 받는다.
InstructBLIP은 BLIP-2를 확장하여 instruction-aware Q-Former 모듈을 제안한다. 이 모듈은 instruction text token을 추가 입력으로 받는다. instruction은 Q-Former의 self-attention layer를 통해 query embedding과 상호작용하며, task와 관련된 이미지 feature 추출을 유도한다. 결과적으로, LLM은 instruction을 따르는 데 적합한 시각 정보를 수신하게 된다. 우리는 instruction-aware visual feature 추출이 held-in 및 held-out 평가 모두에서 상당한 성능 향상을 제공함을 경험적으로 입증한다 (Table 2).
2.4 Balancing Training Datasets
학습 데이터셋의 수가 많고 각 데이터셋의 크기 차이가 크기 때문에, 이들을 균일하게 혼합하면 모델이 작은 데이터셋에 **과적합(overfit)**되고 큰 데이터셋에는 **과소적합(underfit)**될 수 있다. 이러한 문제를 완화하기 위해, 우리는 데이터셋 크기(또는 학습 샘플 수)의 제곱근에 비례하는 확률로 데이터셋을 샘플링하는 방식을 제안한다.
일반적으로 크기가 인 개의 데이터셋이 주어졌을 때, 학습 중 데이터셋 에서 데이터 샘플이 선택될 확률은 이다.
이 공식 외에도, 우리는 각 데이터셋의 개별적인 수렴 시간을 기반으로 특정 데이터셋의 가중치를 수동으로 조정하여 최적화를 개선한다. 이는 데이터셋과 task의 본질적인 차이로 인해, 유사한 크기임에도 불구하고 다양한 수준의 학습 강도가 필요하기 때문이다.
구체적으로, 우리는 객관식 질문을 특징으로 하는 A-OKVQA의 가중치를 낮추고, open-ended 텍스트 생성을 요구하는 OKVQA의 가중치를 높였다.
Table 2에서 우리는 균형 잡힌 데이터셋 샘플링 전략이 held-in 평가와 held-out 일반화 모두에서 전반적인 성능을 향상시킨다는 것을 보여준다.
2.5 Inference Methods
추론 시, 우리는 다양한 데이터셋 평가를 위해 두 가지 약간 다른 생성 접근 방식을 채택한다. 이미지 캡셔닝 및 open-ended VQA와 같은 대부분의 데이터셋에서는 instruction-tuned 모델이 직접 응답을 생성하도록 prompt되며, 이 응답은 이후 ground truth와 비교되어 metric이 계산된다. 반면, 분류(classification) 및 multi-choice VQA task의 경우, 이전 연구들 [1, 29, 30]을 따라 어휘 순위(vocabulary ranking) 방법을 사용한다. 구체적으로, 모델이 답변을 생성하도록 prompt하지만, 어휘를 후보 목록으로 제한한다. 그런 다음, 각 후보에 대한 log-likelihood를 계산하고 가장 높은 값을 가진 후보를 최종 예측으로 선택한다. 이 순위 방법은 ScienceQA, IconQA, A-OKVQA (multiple-choice), HatefulMemes, Visual Dialog, MSVD, MSRVTT 데이터셋에 적용된다. 또한, **이진 분류(binary classification)**의 경우, 자연어 텍스트의 단어 빈도를 활용하기 위해 긍정 및 부정 레이블을 약간 더 넓은 verbalizer 집합으로 확장한다 (예: 긍정 클래스에는 'yes'와 'true', 부정 클래스에는 'no'와 'false').
비디오 질문-응답(video question-answering) task의 경우, 비디오당 4개의 프레임을 균일하게 샘플링하여 활용한다. 각 프레임은 image encoder와 Q-Former에 의해 개별적으로 처리되며, 추출된 visual feature는 LLM에 입력되기 전에 연결(concatenate)된다.
2.6 Implementation Details
아키텍처 (Architecture)
BLIP-2의 모듈형 아키텍처 설계가 제공하는 유연성 덕분에, 우리는 모델을 다양한 LLM에 빠르게 적용할 수 있다. 실험에서는 동일한 image encoder (ViT-g/14 [31])를 사용하되, FlanT5-XL (3B), FlanT5-XXL (11B), Vicuna-7B, Vicuna-13B 등 서로 다른 frozen LLM을 적용한 4가지 BLIP-2 변형 모델을 사용한다.
**FlanT5 [2]**는 encoder-decoder Transformer인 T5 [7]를 기반으로 instruction-tuning된 모델이다. 반면, **Vicuna [8]**는 최근 출시된 decoder-only Transformer로, LLaMA [9]를 기반으로 instruction-tuning되었다.
vision-language instruction tuning 과정에서, 우리는 사전학습된 BLIP-2 체크포인트로부터 모델을 초기화하고, Q-Former의 파라미터만 fine-tuning하며, image encoder와 LLM은 모두 frozen 상태로 유지한다.
원래 BLIP-2 모델에는 Vicuna용 체크포인트가 포함되어 있지 않으므로, 우리는 BLIP-2와 동일한 절차를 사용하여 Vicuna로 사전학습을 수행한다.
query embedding의 개수는 32개로 설정했으며, 현재 설정에서는 이를 늘려도 성능 향상을 관찰하지 못했다. 그러나 더 복잡한 시각 입력을 다루는 향후 task에서는 잠재적으로 유용할 수 있다.
학습 및 하이퍼파라미터 (Training and Hyper-parameters)
구현, 학습 및 평가는 **LAVIS 라이브러리 [32]**를 사용한다. 모든 모델은 최대 60K 스텝으로 instruction-tuning되며, 3K 스텝마다 모델 성능을 검증한다. 각 모델에 대해 단일 최적 체크포인트를 선택하여 모든 데이터셋 평가에 사용한다.
batch size는 3B 모델에 192, 7B 모델에 128, 11/13B 모델에 64를 사용한다.
AdamW [33] optimizer를 사용하며, , weight decay는 0.05로 설정한다.
추가적으로, 초기 1,000 스텝 동안 학습률(learning rate)을 에서 로 선형적으로 증가시키는 warmup을 적용한 후, **최소 학습률 0으로 코사인 감쇠(cosine decay)**를 적용한다.
디코딩(decoding)의 경우, HatefulMemes, VSR, OCR-VQA에는 beam size 1, NoCaps에는 3, 나머지 task에는 5로 설정된 beam search를 사용한다.
모든 모델은 16개의 Nvidia A100 (40G) GPU를 활용하여 학습되었으며, 1.5일 이내에 완료되었다.
3 Experimental Results and Analysis
3.1 Zero-shot Evaluation
우리는 먼저 InstructBLIP 모델을 Appendix E에 제시된 instruction이 포함된 13개의 held-out 데이터셋에 대해 평가한다. InstructBLIP을 기존의 SOTA 모델인 BLIP-2 및 Flamingo와 비교하였다. Table 1에서 볼 수 있듯이, 우리는 모든 데이터셋에서 새로운 zero-shot SOTA 결과를 달성하였다. InstructBLIP은 모든 LLM 백본에서 기존 백본인 BLIP-2를 상당한 차이로 일관되게 능가하며, 이는 vision-language instruction tuning의 효과를 입증한다. 예를 들어, **InstructBLIP FlanT5**은 **BLIP-2 FlanT5**과 비교했을 때 평균 15.0%의 상대적 성능 향상을 보인다. 더 나아가, instruction tuning은 비디오 QA와 같이 학습 시 접하지 않은 task 카테고리에서도 zero-shot generalization을 향상시킨다. InstructBLIP은 temporal video data로 학습된 적이 없음에도 불구하고 MSRVTT-QA에서 기존 SOTA 대비 최대 47.1%의 상대적 성능 향상을 달성한다. 마지막으로, **가장 작은 InstructBLIP FlanT5 (4B 파라미터)**은 Flamingo-80B를 공유된 6개 평가 데이터셋 모두에서 능가하며, 평균 24.8%의 상대적 성능 향상을 보인다.
Visual Dialog 데이터셋의 경우, 우리는 Normalized Discounted Cumulative Gain (NDCG) 대신 Mean Reciprocal Rank (MRR) 지표를 보고한다. 이는 NDCG가 일반적이고 불확실한 답변을 선호하는 반면, MRR은 확실한 답변을 선호하기 때문이다 [34]. 따라서 MRR이 zero-shot 평가 시나리오에 더 적합하다.
| NoCaps | Flickr 30 K | GQA | VSR | IconQA | TextVQA | Visdial | HM | VizWiz | SciQA image | MSVD QA | MSRVTT QA | iVQA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flamingo-3B [6] | - | 60.6 | - | - | - | 30.1 | - | 53.7 | 28.9 | - | 27.5 | 11.0 | 32.7 |
| Flamingo-9B [6] | - | 61.5 | - | - | - | 31.8 | - | 57.0 | 28.8 | - | 30.2 | 13.7 | 35.2 |
| Flamingo-80B [6] | - | 67.2 | - | - | - | 35.0 | - | 46.4 | 31.6 | - | 35.6 | 17.4 | 40.7 |
| BLIP-2 (FlanT5 ) [3] | 104.5 | 76.1 | 44.0 | 60.5 | 45.5 | 43.1 | 45.7 | 53.0 | 29.8 | 54.9 | 33.7 | 16.2 | 40.4 |
| BLIP-2 (FlanT5 ) [3] | 98.4 | 73.7 | 44.6 | 68.2 | 45.4 | 44.1 | 46.9 | 52.0 | 29.4 | 64.5 | 34.4 | 17.4 | 45.8 |
| BLIP-2 (Vicuna-7B) | 107.5 | 74.9 | 38.6 | 50.0 | 39.7 | 40.1 | 44.9 | 50.6 | 25.3 | 53.8 | 18.3 | 9.2 | 27.5 |
| BLIP-2 (Vicuna-13B) | 103.9 | 71.6 | 41.0 | 50.9 | 40.6 | 42.5 | 45.1 | 53.7 | 19.6 | 61.0 | 20.3 | 10.3 | 23.5 |
| InstructBLIP (FlanT5 ) | 119.9 | 84.5 | 48.4 | 64.8 | 50.0 | 46.6 | 46.6 | 56.6 | 32.7 | 70.4 | 43.4 | 25.0 | 53.1 |
| InstructBLIP (FlanT5 ) | 120.0 | 83.5 | 47.9 | 65.6 | 51.2 | 46.6 | 48.5 | 54.1 | 30.9 | 70.6 | 44.3 | 25.6 | 53.8 |
| InstructBLIP (Vicuna-7B) | 123.1 | 82.4 | 49.2 | 54.3 | 43.1 | 50.1 | 45.2 | 59.6 | 34.5 | 60.5 | 41.8 | 22.1 | 52.2 |
| InstructBLIP (Vicuna-13B) | 121.9 | 82.8 | 49.5 | 52.1 | 44.8 | 50.7 | 45.4 | 57.5 | 33.4 | 63.1 | 41.2 | 24.8 | 51.0 |
Table 1: Held-out 데이터셋에 대한 Zero-shot 결과. 여기서 Visdial, HM, SciQA는 각각 Visual Dialog, HatefulMemes, ScienceQA 데이터셋을 나타낸다. ScienceQA의 경우, 이미지 컨텍스트가 있는 세트만 평가한다. 이전 연구들 [6, 25, 34]에 따라, NoCaps 및 Flickr30K에 대해서는 CIDEr 점수 [35]를, iVQA에 대해서는 iVQA 정확도를, HatefulMemes에 대해서는 AUC 점수를, Visual Dialog에 대해서는 **Mean Reciprocal Rank (MRR)**을 보고한다. 다른 모든 데이터셋에 대해서는 **top-1 정확도(%)**를 보고한다.
| Model | Held-in Avg. | GQA | ScienceQA (image-context) | IconQA | VizWiz | iVQA |
|---|---|---|---|---|---|---|
| InstructBLIP (FlanT5 ) | 94.1 | 48.4 | 70.4 | 50.0 | 32.7 | 53.1 |
| w/o Instruction-aware Visual Features | 89.8 | 63.4 ( ) | 45.8 ( ) | 47.5 ( ) | ||
| w/o Data Balancing | 92.6 | 66.0 ( ) | ||||
| InstructBLIP (Vicuna-7B) | 100.8 | 49.2 | 60.5 | 43.1 | 34.5 | 52.2 |
| w/o Instruction-aware Visual Features | 98.9 | 41.2 ( ) | ||||
| w/o Data Balancing | 98.8 | 47.8 ( ) | 59.4 ( ) |
Table 2: instruction-aware Visual Features (Section 2.3) 및 balanced data sampling 전략 (Section 2.4)을 제거한 ablation study 결과. held-in 평가의 경우, COCO Caption, OKVQA, A-OKVQA, TextCaps의 네 가지 데이터셋에 대한 평균 점수를 계산한다. held-out 평가의 경우, 서로 다른 task의 다섯 가지 데이터셋을 보여준다.
3.2 Ablation Study on Instruction Tuning Techniques
instruction-aware visual feature extraction(Section 2.3)과 balanced dataset sampling strategy(Section 2.4)의 영향을 조사하기 위해, 우리는 instruction tuning 과정에서 ablation study를 수행했다. Table 2에서 볼 수 있듯이, visual feature에서 instruction awareness를 제거하면 모든 데이터셋에서 성능이 크게 저하된다. 이러한 성능 저하는 공간적 시각 추론(예: ScienceQA) 또는 시간적 시각 추론(예: iVQA)을 포함하는 데이터셋에서 더욱 심각하게 나타나는데, 이는 Q-Former에 대한 instruction 입력이 visual feature가 정보가 풍부한 이미지 영역에 집중하도록 유도할 수 있기 때문이다. 데이터 균형 전략을 제거하면 불안정하고 불균일한 학습이 발생하며, 이는 서로 다른 데이터셋이 극적으로 다른 학습 단계에서 최고 성능에 도달하기 때문이다. 여러 데이터셋에 걸쳐 동기화된 진행이 부족하면 전반적인 성능이 저하된다.
3.3 Qualitative Evaluation
공개 벤치마크에 대한 체계적인 평가 외에도, 우리는 더욱 다양한 이미지와 지시(instruction)를 사용하여 InstructBLIP을 정성적으로 추가 검토하였다. Figure 1에서 보여주듯이, InstructBLIP은 복잡한 시각적 추론 능력을 보여준다. 예를 들어, 시각적 장면으로부터 무슨 일이 일어났을지 합리적으로 추론할 수 있으며, 야자수와 같은 시각적 증거를 기반으로 장면의 위치로부터 재난의 유형을 추론할 수 있다. 또한, InstructBLIP은 시각적 입력을 내재된 텍스트 지식과 연결하여 유명한 그림을 소개하는 것과 같은 유익한 응답을 생성할 수 있다. 나아가, 전반적인 분위기를 묘사할 때, InstructBLIP은 시각적 이미지의 은유적 함의를 이해하는 능력을 보여준다.
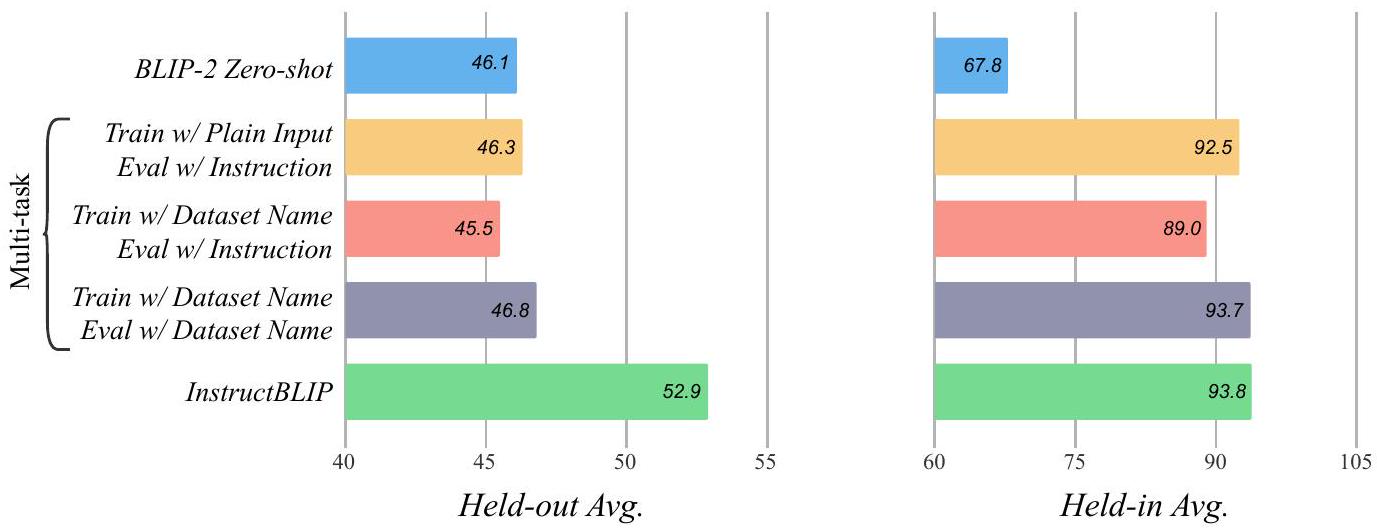
Figure 4: BLIP-2 FlanT5 backbone을 기반으로 한 instruction tuning과 multitask training의 비교. held-in 평가의 경우, 모든 held-in 데이터셋에 대한 평균 점수를 계산한다. held-out 평가의 경우, GQA, TextVQA, VSR, HatefulMemes, IconQA, ScienceQA, iVQA, VizWiz에 대한 평균 점수를 계산한다.
마지막으로, InstructBLIP은 다중 턴 대화(multi-turn conversation)에 참여할 수 있으며, 새로운 응답을 생성할 때 대화 기록을 효과적으로 고려함을 보여준다.
Appendix B에서는 InstructBLIP을 동시 진행된 멀티모달 모델들(GPT4 [36], LLaVA [28], MiniGPT-4 [37])과 정성적으로 비교한다. 모든 모델이 긴 형식의 응답을 생성할 수 있지만, InstructBLIP의 출력은 일반적으로 더 적절한 시각적 세부 정보를 포함하며 논리적으로 일관된 추론 단계를 보여준다. 중요하게도, 우리는 긴 형식의 응답이 항상 선호되는 것은 아님을 주장한다. 예를 들어, Appendix의 Figure 2에서 InstructBLIP은 응답 길이를 적응적으로 조절하여 사용자의 의도를 직접적으로 다루는 반면, LLaVA와 MiniGPT-4는 길고 덜 관련성 있는 문장을 생성한다. InstructBLIP의 이러한 장점은 다양한 instruction tuning 데이터와 효과적인 아키텍처 설계의 결과이다.
3.4 Instruction Tuning vs. Multitask Learning
instruction tuning의 직접적인 유사 개념은 multitask learning이다. 이는 각 개별 데이터셋의 성능 향상을 목표로 여러 데이터셋을 동시에 학습시키는 널리 사용되는 방법이다. zero-shot generalization의 개선이 주로 instruction format에서 비롯되는지, 아니면 단순히 multi-task learning에서 비롯되는지를 조사하기 위해 비교 분석을 수행한다.
[1]을 따라, 우리는 두 가지 multitask training 접근 방식을 고려한다. 첫 번째 접근 방식에서는 instruction 없이 학습 데이터셋의 vanilla input-output format을 사용하여 모델을 학습시킨다. 평가 시에는 어떤 task를 수행할지 지정하기 위해 instruction이 여전히 모델에 제공된다. 그러나 image captioning의 경우, 모델이 이미지를 유일한 입력으로 받을 때 더 나은 성능을 보이므로 예외로 둔다. 두 번째 접근 방식에서는 학습 중에 텍스트 입력 앞에 [Task:Dataset] 식별자를 추가하여 instruction tuning에 한 걸음 더 나아간다. 예를 들어, VQAv2 데이터셋의 경우 **[Visual question answering: VQAv2]**를 앞에 추가한다. 평가 시에는 instruction과 식별자 모두를 탐색한다. 특히, held-out 데이터셋의 경우 모델이 데이터셋 이름을 본 적이 없으므로 task 이름만을 식별자로 사용한다.
Figure 4에서는 zero-shot, multitask training, instruction tuning에 대한 결과를 보여준다. 모든 모델은 BLIP-2 FlanT5 backbone을 기반으로 하며 Section 2의 동일한 학습 구성을 따른다. 전반적으로 두 가지 관찰 결과를 얻었다. 첫째, instruction tuning과 multitask learning은 held-in 데이터셋에서 유사한 성능을 보인다. 이는 모델이 이러한 데이터로 학습되었다면, 이 두 가지 다른 입력 패턴에 대해 비교적 잘 적응할 수 있음을 시사한다. 둘째, instruction tuning은 이전에 보지 못한 held-out 데이터셋에서 multitask learning보다 훨씬 뛰어난 성능을 보이는 반면, multitask learning은 원래 BLIP-2와 비슷한 성능을 보인다. 이는 instruction tuning이 zero-shot generalization의 핵심임을 나타낸다.
| ScienceQA (image-context) | OCR-VQA | OKVQA | A-OKVQA | ||||
|---|---|---|---|---|---|---|---|
| Val | Direct Answer | Val | Multi-choice | ||||
| Previous SOTA | LLaVA [28] | GIT [39] | PaLM-E (562B) [38] | 40 | 41 | [40] | |
| 89.0 | 70.3 | 66.1 | 56.3 | 61.6 | 73.2 | 73.6 | |
| BLIP-2 (FlanT5 ) | 89.5 | 72.7 | 54.7 | 57.6 | 53.7 | 80.2 | 76.2 |
| InstructBLIP (FlanT5 ) | 90.7 | 73.3 | 55.5 | 57.1 | 54.8 | 81.0 | 76.7 |
| BLIP-2 (Vicuna-7B) | 77.3 | 69.1 | 59.3 | 60.0 | 58.7 | 72.1 | 69.0 |
| InstructBLIP (Vicuna-7B) | 79.5 | 72.8 | 62.1 | 64.0 | 62.1 | 75.7 | 73.4 |
Table 3: BLIP-2와 InstructBLIP의 다운스트림 데이터셋 fine-tuning 결과. InstructBLIP은 BLIP-2에 비해 더 나은 가중치 초기화 모델을 제공하며, 4개 데이터셋 중 3개에서 SOTA 성능을 달성한다.
3.5 Finetuning InstructBLIP on Downstream Tasks
우리는 InstructBLIP 모델을 특정 데이터셋 학습 성능을 조사하기 위해 추가로 finetuning하였다. 대부분의 이전 방법들(e.g., Flamingo, BLIP-2)은 입력 이미지 해상도를 증가시키고 downstream task에 대해 visual encoder를 finetuning하는 반면, InstructBLIP은 instruction tuning에서 사용된 동일한 이미지 해상도(224×224)를 유지하고, finetuning 중에도 visual encoder를 freeze 상태로 유지한다. 이로 인해 학습 가능한 파라미터 수가 12억(1.2B)개에서 1억 8800만(188M)개로 크게 줄어들며, finetuning 효율이 크게 향상된다.
결과는 Table 3에 제시되어 있다. BLIP-2와 비교할 때, InstructBLIP은 모든 데이터셋에서 더 나은 finetuning 성능을 보이며, task-specific finetuning을 위한 더 나은 초기화(initialization) 방법임을 입증한다. InstructBLIP은 ScienceQA(image-context), OCR-VQA, A-OKVQA에서 새로운 state-of-the-art finetuning 성능을 기록하였으며, OKVQA에서는 562B 파라미터를 가진 PaLM-E [38]에 의해 성능이 앞지워졌다.
추가적으로, 우리는 FlanT5 기반 InstructBLIP이 multi-choice task에서 우수한 성능을 보이며, 반면 Vicuna 기반 InstructBLIP은 일반적으로 open-ended generation task에서 더 나은 성능을 보인다는 것을 관찰했다. 이러한 차이는 두 모델이 동일한 image encoder를 사용함에도 불구하고, freeze된 LLM의 능력 차이에 주로 기인한다. FlanT5와 Vicuna는 모두 instruction-tuned LLM이지만, 사용된 instruction 데이터가 크게 다르다. FlanT5는 다수의 multi-choice QA 및 분류(classification) 데이터셋을 포함하는 NLP benchmark에 주로 finetuning되어 있으며, Vicuna는 open-ended instruction-following 데이터로 finetuning되어 있다.
4 Related Work
Instruction tuning은 language model이 자연어 지시를 따르도록 학습시키는 것을 목표로 하며, 이는 미학습 task(unseen tasks)에 대한 일반화 성능을 향상시키는 것으로 나타났다. 일부 방법은 기존 NLP 데이터셋을 템플릿을 사용하여 instruction 형식으로 변환하여 instruction tuning 데이터를 수집한다 [1, 2, 42, 43]. 다른 방법들은 LLM(예: GPT-3 [44])을 사용하여 다양성이 향상된 instruction 데이터를 생성한다 [8, 45, 46, 47].
Instruction-tuned LLM은 LLM에 시각 정보를 주입하여 vision-to-language generation task에 적용되어 왔다. BLIP-2 [3]는 frozen된 FlanT5 모델을 사용하고, Q-Former를 학습시켜 LLM의 입력으로 시각 feature를 추출한다. MiniGPT-4 [37]는 BLIP-2와 동일한 사전학습된 visual encoder 및 Q-Former를 사용하지만, LLM으로 Vicuna [8]를 사용하고, BLIP-2 학습 데이터보다 긴 ChatGPT [48]가 생성한 이미지 캡션을 사용하여 학습을 수행한다. LLaVA [28]는 visual encoder의 출력을 LLaMA/Vicuna LLM의 입력으로 직접 투영하고, GPT-4 [36]가 생성한 vision-language 대화 데이터로 LLM을 fine-tuning한다. mPLUG-owl [49]은 LLaMA [9] 모델에 대해 text instruction 데이터와 LLaVA의 vision-language instruction 데이터를 모두 사용하여 low-rank adaption [50]을 수행한다. 별도의 연구인 MultiInstruct [51]는 사전학습된 LLM 없이 vision-language instruction tuning을 수행하여 경쟁력이 낮은 성능을 보인다.
기존 방법들과 비교하여 InstructBLIP은 템플릿 기반 변환 데이터와 LLM 생성 데이터를 모두 포함하는 훨씬 더 광범위한 vision-language instruction 데이터를 사용한다. 아키텍처 측면에서 InstructBLIP은 instruction-aware visual feature extraction 메커니즘을 제안한다. 또한, 본 논문은 vision-language instruction tuning의 다양한 측면에 대한 포괄적인 분석을 제공하여, 미학습 task에 대한 일반화 이점을 검증한다.
5 Conclusion
본 논문에서는 일반화된 vision-language model을 위한 간단하면서도 새로운 instruction tuning 프레임워크인 InstructBLIP을 제시한다. 우리는 vision-language instruction tuning에 대한 포괄적인 연구를 수행하고, InstructBLIP 모델이 광범위한 미지의 task에 대해 state-of-the-art 성능으로 일반화될 수 있는 능력을 입증한다. 정성적 예시들은 또한 InstructBLIP의 다양한 instruction following 능력을 보여준다. 여기에는 복잡한 시각적 추론, 지식 기반 이미지 설명, 다중 턴 대화 등이 포함된다. 나아가, 우리는 InstructBLIP이 다운스트림 task fine-tuning을 위한 향상된 모델 초기화 역할을 할 수 있으며, 이를 통해 state-of-the-art 결과를 달성함을 보여준다. 우리는 InstructBLIP이 범용 멀티모달 AI 및 그 응용 분야에서 새로운 연구를 촉진하기를 기대한다.
6 Acknowledgments
Anthony Meng Huat Tiong은 Salesforce와 싱가포르 경제개발청(Singapore Economic Development Board)의 산업 대학원 프로그램(Industrial Postgraduate Programme) 지원을 받았다. Junqi Zhao와 Boyang Li는 난양 부교수직(Nanyang Associate Professorship)과 싱가포르 국립연구재단 펠로우십(National Research Foundation Fellowship, NRF-NRFF13-2021-0006)의 지원을 받았다. 본 자료에 표현된 의견, 발견, 결론 또는 권고 사항은 전적으로 저자의 것이며, 자금 지원 기관의 견해를 반영하지 않는다.
A Broader Impact
InstructBLIP은 사전학습된(off-the-shelf) frozen LLM을 활용한다. 따라서 **근거 없는 텍스트를 생성(hallucinating ungrounded text)**하거나 편향된 결과물을 생성하는 등 원본 LLM의 일부 단점을 그대로 계승한다. 우리는 모델이 시각 및 지시 입력에 더 잘 grounding되도록 개선하고, 다양한 고품질 데이터셋에 대한 vision-language instruction tuning을 수행하여 이러한 단점을 완화한다. 그럼에도 불구하고, 우리는 InstructBLIP 모델을 해당 애플리케이션에 특화된 안전성 및 공정성 평가 없이 어떠한 다운스트림 애플리케이션에도 적용하는 것을 권장하지 않는다.
또한, 우리는 LLM의 파라미터를 fine-tuning하지 않았기 때문에, InstructBLIP이 주어진 지시를 항상 정확하게 따르지 못할 수 있다. 우리는 더 발전된 LLM을 사용하고 instruction tuning 과정에서 해당 파라미터를 세밀하게 fine-tuning한다면 이 문제를 해결할 수 있을 것으로 생각하며, 이는 향후 연구 과제로 남겨둔다.
B More Case Studies

Figure 5: InstructBLIP의 응답은 GPT-4보다 더 포괄적이고, LLaVA보다 시각적으로 더 근거가 있으며, MiniGPT-4보다 더 논리적이다. GPT-4와 LLaVA의 응답은 각 논문에서 가져왔고, MiniGPT-4는 공식 데모를 사용했다. 출처: https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg
{kind=link}

Figure 6: 이 예시에서는 긴 형식의 응답이 항상 선호되는 것은 아님을 보여준다. InstructBLIP은 응답 길이를 적응적으로 조절하여 사용자의 의도를 직접적으로 다룰 수 있는 반면, 다른 모델들은 관련성이 떨어지는 문장들로 긴 단락을 생성하는 경향이 있다. LLaVA의 응답은 논문에서 가져왔고, MiniGPT-4는 공식 데모를 활용했다.
| [Input Image] |  |
|---|---|
| [Input Instruction] | Introduce me this painting in detail. |
| [Model Response] | |
| InstructBLIP | The painting depicts a young girl with a pearl earring, also known as "The Girl with the Pearl Earring" or "Girl with a Pearl Earring". She is wearing a blue dress and has a pearl earring on her left ear. Her hair is pulled back into a bun, and she is looking directly at the viewer. This painting is a famous work of art by Dutch painter Johannes Vermeer, created in 1665. It is considered one of his masterpieces and is widely recognized for its intricate details and realistic portrayal of the young girl's facial expression. |
| LLaVA | The painting features a woman with a headscarf, possibly of Dutch origin, dressed in blue and white clothing. She is wearing a large blue hat and has a red mouth, which adds a vibrant touch to the portrait. The woman is looking directly at the viewer, creating a sense of connection. The background of the painting is predominantly blue, further emphasizing the color theme of the piece. The overall composition and attire of the woman suggest that the painting might be inspired by the style of Rembrandt. |
| MiniGPT-4 | The painting depicts a young woman with a pearl earring, wearing a blue dress and a white apron. She is shown with a serious expression, looking directly at the viewer. The background is a dark, neutral tone, with no visible objects or elements. The overall mood of the painting is somber and contemplative. <br> The painting is well-executed, with a high level of detail and realism in the depiction of the woman's features and clothing. The use of shading and lighting creates a sense of depth and dimension, making the woman appear three-dimensional. The artist has used a limited color palette, with the woman's dress and apron providing the only sources of color in the painting. <br> The painting is well-composed, with the woman's head and shoulders positioned in the center of the canvas, creating a sense of balance and symmetry. The use of negative space around the woman's figure adds to the overall somber mood of the painting. <br> Overall, this is a well-executed and thought-provoking painting that effectively conveys a sense of contemplation and introspection. |
Figure 7: InstructBLIP은 텍스트 지식과 시각 입력을 연결하는 능력을 보여주는 반면, 다른 모델들은 그림을 단순히 묘사한다. MiniGPT-4는 더 좋지 않은 결과를 보이는데, 이는 긴 캡션으로만 학습되었기 때문일 수 있다. LLaVA와 MiniGPT-4의 응답은 공식 데모를 통해 생성되었다.
C Instruction Tuning Datasets
| Dataset Name | Held-out | Dataset Description |
|---|---|---|
| COCO Caption [10] | 이미지 캡셔닝 task를 위해 대규모 COCO 데이터셋을 사용한다. 특히, Karpathy split [52]을 사용하여 데이터를 train/val/test 세트에 대해 각각 82K/5K/5K 이미지로 나눈다. | |
| Web CapFilt | 웹에서 수집된 1,400만 개의 이미지-텍스트 쌍으로, BLIP [30] 및 BLIP-2 [3]에서 사용된 BLIP 생성 합성 캡션이 추가되어 있다. | |
| NoCaps [11] | (val) | NoCaps는 새로운 객체 이미지 캡셔닝을 위한 15,100개의 이미지와 166,100개의 사람이 작성한 캡션을 포함한다. |
| Flickr30K [12] | (test) | Flickr30k 데이터셋은 Flickr에서 수집된 31K개의 이미지로 구성되며, 각 이미지에는 5개의 ground truth 캡션이 있다. 우리는 1K개의 이미지를 포함하는 test split을 held-out으로 사용한다. |
| TextCaps [13] | TextCaps는 모델이 이미지 내 텍스트를 이해하고 추론해야 하는 이미지 캡셔닝 데이터셋이다. train/val/test 세트는 각각 21K/3K/3K개의 이미지를 포함한다. | |
| VQAv2 [17] | VQAv2는 open-ended 이미지 질문 답변을 위한 데이터셋이다. train/val/test에 대해 82K/40K/81K로 분할되어 있다. | |
| VizWiz [18] | (test-dev) | 시각 장애인이 질문한 시각적 질문을 포함하는 데이터셋이다. held-out 평가를 위해 8K개의 이미지가 사용된다. |
| GQA [14] | (test-dev) | GQA는 장면 이해 및 추론을 위한 이미지 질문을 포함한다. 우리는 balanced test-dev 세트를 held-out으로 사용한다. |
| Visual Spatial Reasoning | (test) | VSR은 이미지 내 두 객체의 공간 관계를 텍스트로 설명하는 이미지-텍스트 쌍 모음이다. 모델은 설명에 대해 true/false를 분류해야 한다. 우리는 공식 github 저장소에 제공된 zero-shot 데이터 분할을 사용한다. |
| IconQA [16] | (test) | IconQA는 모델의 추상 다이어그램 이해 및 포괄적인 인지 추론 능력을 측정한다. held-out 평가를 위해 multi-text-choice task의 test 세트를 사용한다. |
| OKVQA [19] | OKVQA는 답변을 위해 외부 지식을 요구하는 시각적 질문을 포함한다. train 및 test에 대해 9K/5K로 분할되어 있다. | |
| A-OKVQA [20] | A-OKVQA는 OKVQA의 후속작으로, 더 도전적이고 다양한 질문을 포함한다. train/val/test에 대해 17K/1K/6K개의 질문이 있다. | |
| ScienceQA [21] | (test) | ScienceQA는 해당 강의 및 설명과 함께 다양한 과학 주제를 다룬다. 우리의 설정에서는 이미지 컨텍스트(IMG)가 있는 부분만 사용한다. |
| Visual Dialog [26] | (val) | Visual dialog는 대화형 질문 답변 데이터셋이다. 우리는 val split을 held-out으로 사용하며, 이는 2,064개의 이미지와 각 이미지당 10라운드를 포함한다. |
| OCR-VQA [22] | OCR-VQA는 모델이 이미지 내 텍스트를 읽어야 하는 시각적 질문을 포함한다. train/val/test에 대해 각각 800K/100K/100K가 있다. | |
| TextVQA [23] | (val) | TextVQA는 질문에 답하기 위해 모델이 시각적 텍스트를 이해해야 한다. |
| HatefulMemes [27] | (val) | 밈이 혐오스러운 내용을 포함하는지 여부를 판단하는 이진 분류 데이터셋이다. |
| LLaVA-Instruct-150K [28] | 세 부분(상세 캡션(23K), 추론(77K), 대화(58K))으로 구성된 instruction tuning 데이터셋이다. | |
| MSVD-QA [24] | (test) | held-out 테스트를 위해 MSVD-QA의 test 세트(13K 비디오 QA 쌍)를 사용한다. |
| MSRVTT-QA [24] | (test) | MSRVTT-QA는 MSVD보다 더 복잡한 장면을 가지며, test 세트로 72K 비디오 QA 쌍을 포함한다. |
| iVQA [25] | (test) | iVQA는 언어 편향이 완화된 비디오 QA 데이터셋이다. train/val/test에 대해 6K/2K/2K개의 샘플이 있다. |
Table 4: held-in instruction tuning 및 held-out zero-shot 평가에 사용된 데이터셋 설명.
D Instruction Templates
| Task | Instruction Template |
|---|---|
| Image Captioning | <Image>A short image caption: <br> <Image>A short image description: <br> <Image>A photo of <br> <Image>An image that shows <br> <Image>Write a short description for the image. <br> <Image>Write a description for the photo. <br> <Image>Provide a description of what is presented in the photo. <br> <Image>Briefly describe the content of the image. <br> <Image>Can you briefly explain what you see in the image? <br> <Image>Could you use a few words to describe what you perceive in the photo? <br> <Image>Please provide a short depiction of the picture. <br> <Image>Using language, provide a short account of the image. <br> <Image>Use a few words to illustrate what is happening in the picture. |
| VQA | <Image>{Question} <br> <Image>Question: {Question} <br> <Image>{Question} A short answer to the question is <br> <Image>Q: {Question} A: <br> <Image>Question: {Question} Short answer: <br> <Image>Given the image, answer the following question with no more than three words. {Question} <br> <Image>Based on the image, respond to this question with a short answer: {Question}. Answer: <br> <Image>Use the provided image to answer the question: {Question} Provide your answer as short as possible: <br> <Image>What is the answer to the following question? "{Question}" <br> <Image>The question "{Question}" can be answered using the image. A short answer is |
| VQG | <Image>Given the image, generate a question whose answer is: {Answer}. Question: <br> <Image>Based on the image, provide a question with the answer: {Answer}. Question: <br> <Image>Given the visual representation, create a question for which the answer is "{Answer}". <br> <Image>From the image provided, craft a question that leads to the reply: {Answer}. Question: <br> <Image>Considering the picture, come up with a question where the answer is: {Answer}. <br> <Image>Taking the image into account, generate an question that has the answer: {Answer}. Question: |
Table 5: held-in 데이터셋을 instruction tuning 데이터로 변환하는 데 사용된 Instruction Template. OCR token이 있는 데이터셋의 경우, 이미지 쿼리 임베딩 뒤에 단순히 "OCR tokens:"를 추가한다.
E Instructions for Zero-shot Inference
우리는 zero-shot 추론에 사용된 지침을 제공한다. 옵션이 있는 지침의 경우, 예를 들어 (a) blue (b) yellow (c) pink (d) black와 같이 옵션을 알파벳 순서로 구분한다.
GQA, VizWiz, iVQA, MSVD, MSRVTT <Image> Question: { } Short answer: NoCaps, Flickr30k <Image> A short image description: TextVQA <Image> OCR tokens: . Question: Short answer: IconQA <Image> Question: { } Options: { }. Short answer: ScienceQA <Image> Context: { } Question: { } Options: { }. Answer: HatefulMemes <Image> This is an image with: "{}" written on it. Is it hateful? Answer: VSR <Image> Based on the image, is this statement true or false? "{}" Answer: Visual Dialog <Image> Dialog history: {}ไn Question: { } Short answer: