HuBERT: 은닉 유닛의 마스크된 예측을 통한 자기지도 음성 표현 학습
HuBERT(Hidden-Unit BERT)는 오프라인 클러스터링을 통해 BERT와 유사한 예측 손실을 위한 정렬된 타겟 레이블을 생성하는 자기지도 음성 표현 학습 접근법입니다. 이 모델의 핵심은 마스킹된 영역에만 예측 손실을 적용하여, 연속적인 음성 입력에 대해 음향 모델과 언어 모델을 결합하여 학습하도록 하는 것입니다. HuBERT는 단순한 k-means 클러스터링으로 시작하여 반복적인 개선을 통해 최첨단 wav2vec 2.0 모델의 성능과 동등하거나 이를 능가하는 결과를 보여줍니다. 논문 제목: HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
논문 요약: HuBERT: 은닉 유닛의 마스크된 예측을 통한 자기지도 음성 표현 학습
- 논문 링크: https://arxiv.org/abs/2106.07447
- 저자: Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed
- 발표 시기: 2021년, IEEE/ACM transactions on audio, speech, and language processing
- 주요 키워드: Self-supervised learning, Speech Representation, BERT, Acoustic Model, Language Model
1. 연구 배경 및 문제 정의
- 문제 정의:
음성 표현 학습을 위한 자기지도(Self-supervised) 접근 방식은 다음과 같은 세 가지 고유한 문제에 직면합니다:- 각 입력 발화에 여러 음성 단위가 존재합니다.
- 사전 학습(pre-training) 단계에서는 입력 음성 단위에 대한 어휘집이 없습니다.
- 음성 단위는 명시적인 분할 없이 가변적인 길이를 가집니다. 이러한 문제들로 인해 컴퓨터 비전(CV)이나 자연어 처리(NLP)에서 성공적인 자기지도 학습 기법을 음성 도메인에 직접 적용하기 어렵습니다.
- 기존 접근 방식:
- Pseudo-labeling (PL) / Self-training: 레이블이 없는 데이터에 대해 "교사(teacher)" 모델이 의사 레이블을 생성하고, 이를 사용하여 "학생(student)" 모델을 학습시키는 방식입니다. 하지만 이는 교사 모델의 지도 데이터 크기와 주석 품질에 제한되며, 단일 다운스트림 작업에 맞춰지는 경향이 있습니다.
- CV/NLP의 자기지도 학습: CV에서는 인스턴스 분류, NLP에서는 마스킹된 예측 또는 자동 회귀 생성을 사용합니다. 그러나 음성은 연속적인 시퀀스이며, 여러 음성 단위가 존재하고, 이산 음향 단위의 사전 어휘집이 없으며, 단위 간 경계가 불분명하다는 점에서 차이가 있습니다.
- 기존 음성 자기지도 학습: 시간적으로 떨어진 특징 구별, 다음 단계 예측, 마스킹되지 않은 문맥이 주어졌을 때 오디오 특징의 마스킹된 예측 등이 있었으나, 위에서 언급한 음성 고유의 문제들을 완전히 해결하지 못했습니다. 특히 DiscreteBERT는 마스킹된 이산 목표를 예측하지만, 양자화된 단위를 입력으로 받아 정보 손실이 발생할 수 있습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 은닉 유닛의 마스크된 예측: BERT와 유사한 마스크된 예측 손실을 위해 오프라인 클러스터링을 통해 정렬된 목표 레이블을 제공하는 HuBERT(Hidden-Unit BERT) 접근 방식을 제안했습니다.
- 음향 및 언어 모델 결합 학습: 마스킹된 영역에만 예측 손실을 적용하여, 모델이 연속적인 음성 입력으로부터 음향 모델과 언어 모델을 모두 학습하도록 강제합니다.
- 반복적 개선을 통한 클러스터 품질 향상: 단순한 k-means 클러스터링으로 시작하여, 사전 학습된 HuBERT 모델의 중간 레이어에서 추출한 특징을 사용하여 클러스터 할당을 반복적으로 개선함으로써 학습된 표현의 품질을 극적으로 향상시켰습니다.
- 최첨단 성능 달성: 다양한 파인튜닝 데이터셋(10분, 1시간, 10시간, 100시간, 960시간)에서 최첨단 wav2vec 2.0 모델과 동등하거나 이를 능가하는 결과를 보여주었습니다.
- 확장성 입증: 10억 개의 매개변수를 가진 X-Large 모델로 확장했을 때, 더 어려운 평가 데이터셋에서 WER(단어 오류율)을 최대 19%까지 상대적으로 감소시키는 등 뛰어난 확장성을 입증했습니다.
- 제안 방법:
HuBERT는 크게 세 가지 단계로 구성됩니다:- 은닉 유닛 학습 (Learning the Hidden Units):
- 음성 발화 에 대해 k-means와 같은 클러스터링 모델 를 사용하여 프레임 수준의 이산 은닉 단위 를 생성합니다.
- 초기에는 MFCC 특징에 대해 k-means를 수행하여 목표 레이블을 얻습니다.
- 이후 반복에서는 이전 HuBERT 모델의 중간 Transformer 레이어에서 추출한 잠재 특징에 대해 k-means를 수행하여 더 나은 품질의 클러스터 할당을 생성합니다.
- 마스크된 예측을 통한 표현 학습 (Representation Learning via Masked Prediction):
- 입력 음성 시퀀스 의 일부 프레임을 무작위로 마스킹하여 손상된 버전 를 만듭니다 (SpanBERT 및 wav2vec 2.0과 유사한 스팬 마스킹 전략 사용).
- HuBERT 모델 는 를 입력으로 받아 마스킹된 타임스텝의 목표 클러스터 할당을 예측합니다.
- 핵심 아이디어는 예측 손실()을 마스킹된 영역에만 적용하는 것입니다 (). 이는 모델이 마스킹되지 않은 입력의 고수준 표현을 학습하고, 이를 통해 마스킹된 부분의 목표를 정확하게 추론하도록 강제합니다. 이를 통해 음향 모델링과 언어 모델링을 동시에 학습하는 효과를 얻습니다.
- 클러스터 앙상블 및 반복적 정제 (Cluster Ensembles & Iterative Refinement):
- 클러스터 앙상블: 여러 클러스터링 모델(예: 다른 코드북 크기를 가진 k-means)을 활용하여 목표 품질을 개선합니다. 이는 다중 작업 학습(multi-task learning)과 유사합니다.
- 반복적 정제: 사전 학습된 HuBERT 모델이 원시 음향 특징(MFCC)보다 더 나은 표현을 제공하므로, 학습된 잠재 표현에 대해 새로운 클러스터링을 수행하여 다음 학습 반복을 위한 더 나은 목표를 생성합니다.
- 구현: wav2vec 2.0 아키텍처를 따르며, 컨볼루션 파형 인코더, BERT 인코더, 프로젝션 레이어, 코드 임베딩 레이어로 구성됩니다. BASE, Large, X-Large 세 가지 모델 크기를 사용합니다. 사전 학습 후에는 컨볼루션 오디오 인코더를 제외한 전체 모델 가중치에 대해 CTC(Connectionist Temporal Classification) 손실을 사용하여 ASR 파인튜닝을 수행합니다.
- 은닉 유닛 학습 (Learning the Hidden Units):
3. 실험 결과
- 데이터셋:
- 비지도 사전 학습: LibriSpeech 960시간 또는 Libri-light 60,000시간 오디오.
- 지도 파인튜닝: Libri-light 10분, 1시간, 10시간 분할 및 LibriSpeech 100시간, 960시간 분할.
- 단위 발견: 39차원 MFCC 특징 (첫 번째 반복), 이전 HuBERT 모델의 중간 Transformer 레이어(6번째 또는 9번째) 출력 (후속 반복).
- 주요 결과:
- 저자원 설정 (10분, 1시간, 10시간, 100시간): HuBERT는 모든 파인튜닝 하위 집합에서 최첨단 wav2vec 2.0 성능과 동등하거나 이를 개선했습니다. 특히 X-Large 모델은 10분 레이블링 데이터에서 test-clean 4.6%, test-other 6.8%의 WER을 달성하여 wav2vec 2.0 Large보다 우수했습니다. DiscreteBERT를 큰 차이로 능가했습니다.
- 고자원 설정 (960시간): HuBERT Large 및 X-Large 모델은 최첨단 지도 및 자기 훈련 방법을 능가했으며, wav2vec 2.0 및 Conformer XXL과 같은 다른 최첨단 사전 학습 결과와 동등한 수준을 보였습니다.
- K-Means 안정성: k-means 클러스터링은 다양한 하이퍼파라미터와 특징에 걸쳐 상당히 안정적이며, HuBERT 특징에 대한 클러스터링이 MFCC 특징보다 훨씬 높은 PNMI(Phone-Normalized Mutual Information) 점수를 보여 반복적 정제의 효과를 입증했습니다.
- 마스크된 프레임 예측의 중요성: 클러스터 품질이 낮을 때 마스킹된 영역에만 손실을 계산하는 것이 최상의 성능을 달성했습니다. 클러스터 품질이 향상됨에 따라 마스킹되지 않은 프레임에서 손실을 계산해도 성능 저하가 적거나 오히려 개선되었습니다.
- 클러스터 앙상블 효과: 여러 k-means 모델을 결합하거나 product quantization을 사용하는 앙상블 방식이 단일 k-means 클러스터링보다 더 나은 성능을 이끌어냈습니다.
- 하이퍼파라미터 영향: 마스크 시작으로 선택된 프레임의 최적 비율은 8%였으며, 배치 크기를 늘리고 훈련 단계를 늘릴수록 성능이 크게 향상되었습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 혁신적인 접근 방식: BERT의 마스크된 예측 아이디어를 음성 도메인에 성공적으로 적용하여, 이산 단위가 없는 연속적인 음성 신호에 대한 자기지도 학습의 새로운 길을 열었습니다.
- 반복적 정제 메커니즘: 사전 학습된 모델의 표현을 활용하여 클러스터 목표를 반복적으로 개선하는 아이디어는 매우 강력하며, 초기 클러스터의 품질이 낮더라도 모델 성능을 지속적으로 향상시킬 수 있음을 보여줍니다.
- 견고성과 확장성: 초기 클러스터 할당의 본질적인 품질보다는 일관성에 더 의존하며, 대규모 모델과 데이터셋에 대해 뛰어난 확장성과 성능을 입증했습니다.
- 단순한 손실 함수: wav2vec 2.0과 같은 다른 최첨단 모델이 복잡한 대조 손실(contrastive loss)이나 보조 손실을 사용하는 반면, HuBERT는 직접적인 예측 손실을 사용하여 모델 학습을 단순화했습니다.
- 단점/한계:
- 오프라인 클러스터링 단계: 클러스터 할당을 생성하기 위한 오프라인 클러스터링 단계가 필요하며, 이는 완전한 엔드-투-엔드 학습이 아니라는 점에서 한계로 볼 수 있습니다.
- 추가 자기 훈련과의 시너지: 논문에서 제시된 HuBERT는 사전 학습(pre-training) 단계에 중점을 두며, 사전 학습된 모델을 추가적인 자기 훈련(self-training, 의사 레이블링)과 결합했을 때의 성능은 아직 완전히 탐구되지 않았습니다. (하지만 논문에서는 결합 시 더 나은 성능을 기대한다고 언급).
- 응용 가능성:
- 저자원 언어 ASR: 레이블링된 데이터가 부족한 언어나 방언에 대한 자동 음성 인식(ASR) 시스템 구축에 매우 유용하게 활용될 수 있습니다.
- 범용 음성 표현 학습: 언어적 자원에 의존하지 않고 음성 표현을 학습하므로, 다양한 방언과 언어에 걸쳐 일반화될 수 있는 범용 음성 표현을 구축하는 데 기여할 수 있습니다.
- 다양한 다운스트림 작업: ASR 외에도 화자 인식, 감정 인식, 음성 합성 등 다양한 음성 관련 인식 및 생성 작업의 강력한 사전 학습 기반 모델로 활용될 수 있습니다.
5. 추가 참고 자료
Hsu, Wei-Ning, et al. "Hubert: Self-supervised speech representation learning by masked prediction of hidden units." IEEE/ACM transactions on audio, speech, and language processing 29 (2021): 3451-3460.
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed
Abstract
음성 표현 학습을 위한 Self-supervised 접근 방식은 세 가지 독특한 문제에 직면합니다: (1) 각 입력 발화에는 여러 음성 단위가 존재하며, (2) pre-training 단계에서는 입력 음성 단위에 대한 어휘집이 없고, (3) 음성 단위는 명시적인 분할 없이 가변적인 길이를 가집니다. 이 세 가지 문제를 해결하기 위해, 우리는 은닉 유닛 BERT (Hidden-Unit BERT, HuBERT) 접근 방식을 제안합니다. 이는 BERT와 유사한 prediction loss를 위해 오프라인 클러스터링 단계를 활용하여 정렬된 목표 레이블을 제공합니다. 우리 접근 방식의 핵심 요소는 마스킹된 영역에만 prediction loss를 적용하여 모델이 연속적인 입력에 대해 결합된 acoustic 및 language model을 학습하도록 강제하는 것입니다. HuBERT는 할당된 클러스터 레이블의 본질적인 품질보다는 비지도 클러스터링 단계의 일관성에 주로 의존합니다. 100개의 클러스터를 가진 간단한 k-means 교사 모델로 시작하여 두 번의 클러스터링 반복을 사용한 HuBERT 모델은 Librispeech (960h) 및 Libri-light (60,000h) 벤치마크에서 10분, 1시간, 10시간, 100시간, 960시간 fine-tuning 하위 집합에 대해 최첨단 wav2vec 2.0 성능과 일치하거나 이를 개선합니다. 10억 개의 매개변수 모델을 사용하여 HuBERT는 더 어려운 dev-other 및 test-other 평가 하위 집합에서 각각 최대 19%와 13%의 상대적 WER 감소를 보여줍니다. ¹
Index Terms-Self-supervised learning, BERT.
I. Introduction
많은 연구 프로그램의 북극성은 아기들이 첫 언어를 배우는 방식과 유사하게, 듣고 상호작용을 통해 speech 및 audio representation을 배우는 것이었습니다. 고충실도 speech representation은 발화 내용의 분리된 측면과 함께 그것이 전달되는 방식에 대한 비어휘적 정보, 예를 들어, speaker identity, emotion, 망설임, 중단을 포함합니다. 더 나아가, 완전한 상황적 이해에 도달하기 위해서는 웃음, 기침, 입맛 다시기, 배경 차량 엔진 소리, 새 지저귐 또는 음식 지글거리는 소리와 같이 speech signal과 섞이고 겹치는 structured noise를 모델링해야 합니다.
이러한 고충실도 representation의 필요성은 speech 및 audio를 위한 self-supervised learning 연구를 주도했으며, 여기서 설계된 pretext task의 학습 과정을 이끄는 목표는 입력 신호 자체에서 추출됩니다. self-supervised speech representation learning을 위한 pretext task의 예로는 시간적으로 멀리 떨어진 특징들로부터 가까운 특징들을 구별하는 것 [1]-[3], 오디오 특징의 다음 단계 예측 [4], 마스킹되지 않은 문맥이 주어졌을 때 오디오 특징의 masked prediction [5], [6]이 포함됩니다. 게다가, self-supervised learning 방법은 훈련 중에 어떠한 언어적 자원에도 의존하지 않아, 레이블, 주석, 그리고 텍스트 전용 자료가 입력 신호의 풍부한 정보를 무시하기 때문에 universal representations를 배울 수 있게 합니다.
대량의 레이블링된 데이터에 의존하지 않고 speech representation을 학습하는 것은 새로운 언어와 도메인의 적용 범위가 계속 증가하는 산업 응용 프로그램 및 제품에 매우 중요합니다. 이러한 각 시나리오를 포괄하는 대규모 레이블링된 데이터셋을 수집하는 데 필요한 시간은 현재 빠르게 움직이는 AI 산업의 실질적인 병목 현상이며, 제품 성공에 있어 시장 출시 시간이 중요한 역할을 합니다. 구어 전용 방언과 언어를 포괄하는 보다 포용적인 응용 프로그램을 구축하는 것은 언어 자원에 대한 의존도를 줄이는 또 다른 중요한 이점입니다. 비표준 철자법 규칙 때문에 이러한 많은 언어와 방언은 자원이 거의 없거나 전혀 없습니다.
Pseudo-labeling (PL)은 자기 훈련(self-training)으로도 알려져 있으며 준지도 학습(semi-supervised learning) 기술군에 속하며, 1990년대 중반으로 거슬러 올라가는 성공적인 적용 사례와 함께 레이블이 없는 음성과 오디오를 활용하는 지배적인 접근 방식이었습니다 [7]-[10]. PL은 특정 downstream task에서 "teacher" 모델을 훈련시키기 위해 일부 지도 데이터를 가지고 시작합니다. 그런 다음 teacher 모델을 사용하여 레이블이 없는 데이터에 대한 pseudo-label이 생성됩니다. 다음으로, 지도 데이터와 교사 레이블링된 데이터를 결합하여 표준 cross-entropy [9] 손실을 사용하거나 교사 생성 레이블의 노이즈를 고려하기 위해 contrastive loss [11]를 사용하여 student model을 훈련합니다. pseudo-labeling 과정은 교사 레이블 품질을 반복적으로 개선하기 위해 여러 번 반복될 수 있습니다 [12].
pseudo-labeling 기술의 엄청난 성공을 무시하지 않으면서도, self-supervised representation은 두 가지 독특한 이점을 제공합니다: (1) Pseudo-label 방법은 student model이 단순히 teacher 모델을 모방하도록 강요하며, 이는 지도 데이터 크기와 제공된 주석 품질에 의해 제한됩니다. 반면에, self-supervised pretext task는 모델이 훨씬 더 많은 정보 비트를 학습된 잠재 표현으로 압축하여 전체 입력 신호를 표현하도록 강요합니다. (2) pseudo-labeling에서, teacher 모델의 지도 데이터는 전체 학습이 단일 downstream task에 맞춰지도록 강요합니다. 반대로, self-supervised 특징은 다수의 downstream 응용 프로그램에 더 나은 일반화를 보여줍니다.
Computer Vision (CV) [13]-[15] 및 Natural Language Processing (NLP) [16]-[18] 응용 프로그램에서 self-supervised learning에 대한 인상적인 성공이 있었습니다. Natural Language Processing (NLP) 응용 프로그램과 같이 이산 입력 시퀀스의 representation을 학습하는 것은 부분적으로 불분명하게 처리된 입력 시퀀스의 masked prediction [19], [20] 또는 auto-regressive generation [18], [21]을 사용합니다. Computer Vision (CV) 응용 프로그램과 같은 연속 입력의 경우, representation은 종종 instance classification을 통해 학습되며, 각 이미지와 그 증강은 함께 모아질 단일 출력 클래스로 처리되거나 [14], [15] 다른 negative samples과 대조됩니다 [22].
Speech 신호는 연속적인 값의 시퀀스라는 점에서 텍스트 및 이미지와 다릅니다. 음성 인식 도메인을 위한 Self-supervised learning은 CV 및 NLP의 그것들과는 다른 독특한 도전에 직면합니다. 첫째, 각 입력 발화에 여러 소리가 존재한다는 점은 많은 CV pre-training 접근법에서 사용되는 instance classification 가정을 깨뜨립니다. 둘째, pre-training 동안에는 단어나 단어 조각이 사용되는 NLP 응용 프로그램에서와 같이 이산 음향 단위의 사전 어휘집이 없어 예측 손실의 사용을 방해합니다. 마지막으로, 음향 단위 간의 경계가 알려져 있지 않아 masked prediction pre-training을 복잡하게 만듭니다.
본 논문에서는 BERT와 유사한 사전 훈련을 위해 잡음이 있는 레이블을 생성하기 위해 오프라인 클러스터링 단계를 활용하는 Hidden unit BERT (HuBERT)를 소개합니다. 구체적으로, BERT 모델은 마스킹된 연속 음성 특징을 소비하여 미리 결정된 클러스터 할당을 예측합니다. 예측 손실은 마스킹된 영역에만 적용되어, 모델이 마스킹되지 않은 입력의 좋은 고수준 표현을 학습하여 마스킹된 것들의 목표를 정확하게 추론하도록 강제합니다. 직관적으로, HuBERT 모델은 연속 입력으로부터 음향 모델과 언어 모델을 모두 학습하도록 강제됩니다. 첫째, 모델은 마스킹되지 않은 입력을 의미 있는 연속 잠재 표현으로 모델링해야 하며, 이는 고전적인 음향 모델링 문제에 해당합니다. 둘째, 예측 오류를 줄이기 위해 모델은 학습된 표현 간의 장거리 시간적 관계를 포착해야 합니다. 이 연구를 동기 부여한 한 가지 중요한 통찰은 목표의 정확성뿐만 아니라 일관성의 중요성으로, 이는 모델이 입력 데이터의 순차적 구조를 모델링하는 데 집중할 수 있게 합니다. 우리의 접근 방식은 self-supervised 시각 학습을 위한 DeepCluster 방법 [23]에서 영감을 얻었지만, HuBERT는 음성 시퀀스의 순차적 구조를 표현하기 위해 masked prediction loss를 활용하는 이점을 가집니다.
HuBERT 모델이 표준 Librispeech 960h [24] 또는 Libri-Light 60k 시간 [25] 중 하나에서 사전 훈련될 때, 및 960 h의 모든 fine-tuning 하위 집합에서 최첨단 wav2vec 2.0 [6] 성능과 일치하거나 이를 개선합니다. 우리는 HuBERT로 사전 훈련된 세 가지 모델 크기인 BASE(90M 매개변수), Large(300M) 및 X-Large(1B)에 대한 체계적인 결과를 제시합니다. X-LARGE 모델은 Libri-Light 60k 시간에 사전 훈련될 때 더 어려운 dev-other 및 test-other 평가 하위 집합에서 LARGE 모델에 비해 최대 및 의 상대적 WER 개선을 보여줍니다.
II. Method
A. Learning the Hidden Units for HuBERT
텍스트와 음성 쌍으로 훈련된 acoustic model은 semi-supervised learning에서 forced alignment를 통해 각 프레임에 대한 pseudo-phonetic 레이블을 제공합니다. 반대로, self-supervised representation learning 설정은 음성 전용 데이터에만 접근할 수 있습니다. 그럼에도 불구하고, k-means 및 가우시안 혼합 모델(Gaussian mixture models, GMMs)과 같은 간단한 이산 잠재 변수 모델은 기본 음향 단위(acoustic units)와 자명하지 않은 상관 관계를 보이는 은닉 단위를 추론합니다 [26] (표 V 참조). 더 발전된 시스템은 더 나은 graphical models [27], [28]을 사용하거나 더 강력한 neural network models [29]-[33]로 분포를 매개변수화하여 더 나은 acoustic unit 발견 성능을 달성할 수 있습니다.
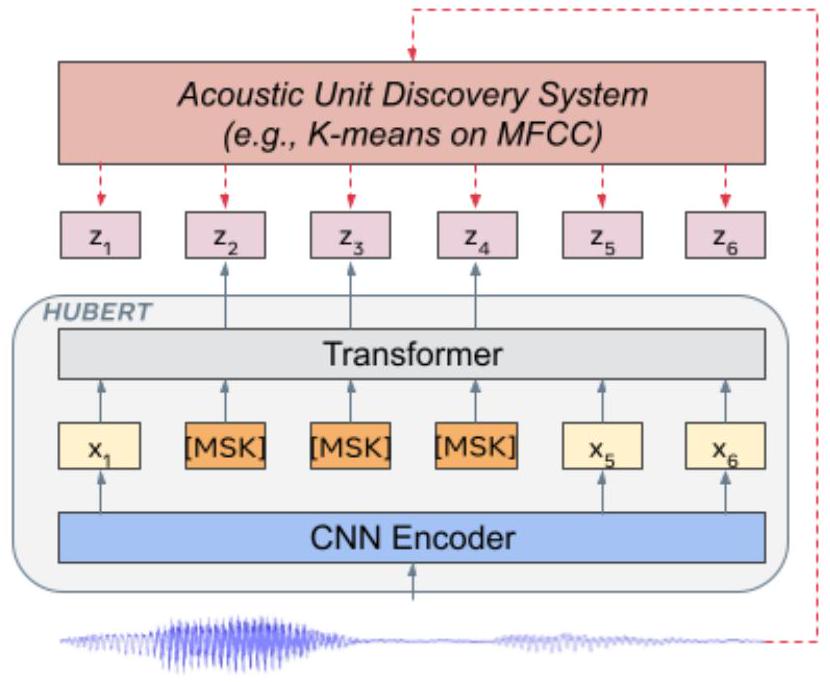
Fig. 1: HuBERT 접근 방식은 하나 이상의 k-means 클러스터링 반복으로 생성된 마스킹된 프레임(그림의 )의 은닉 클러스터 할당을 예측합니다.
이에 영감을 받아, 우리는 프레임 수준의 목표를 제공하기 위해 acoustic unit 발견 모델을 사용할 것을 제안합니다. 를 프레임의 음성 발화 라고 합시다. 발견된 은닉 단위는 로 표시되며, 여기서 는 -클래스 categorical variable이고 는 k-means와 같은 clustering model입니다.
B. Representation Learning via Masked Prediction
길이가 인 시퀀스 에 대해 마스킹될 인덱스 집합을 라 하고, 일 때 가 마스크 임베딩 로 대체된 의 손상된 버전을 이라고 합시다. masked prediction model 는 를 입력으로 받아 각 타임스텝에서 목표 인덱스에 대한 분포 를 예측합니다. masked prediction을 위해 내려야 할 두 가지 결정이 있습니다: 어떻게 마스킹할 것인가와 예측 손실을 어디에 적용할 것인가입니다.
첫 번째 결정에 관해서는, SpanBERT [34]와 wav2vec 2.0 [6]에서 사용된 마스크 생성과 동일한 전략을 채택합니다. 여기서 타임스텝의 가 시작 인덱스로 무작위로 선택되고, 단계의 스팬이 마스킹됩니다. 두 번째 결정을 해결하기 위해, 마스킹된 타임스텝과 마스킹되지 않은 타임스텝에 대해 계산된 cross-entropy loss를 각각 과 로 나타냅니다. 은 다음과 같이 정의됩니다:
그리고 는 에 대해 합산하는 것을 제외하고는 동일한 형태입니다. 최종 손실은 두 항의 가중 합으로 계산됩니다: . 인 극단적인 경우, 손실은 마스킹되지 않은 타임스텝에 대해 계산되며, 이는 하이브리드 음성 인식 시스템(hybrid speech recognition systems)의 음향 모델링과 유사합니다 [35]-[38]. 우리의 설정에서 이것은 학습 과정을 클러스터링 모델을 모방하는 것으로 제한합니다.
다른 극단적인 경우인 에서는, 손실이 마스킹된 타임스텝에 대해서만 계산되며, 모델은 문맥으로부터 보이지 않는 프레임에 해당하는 목표를 예측해야 하며, 이는 언어 모델링과 유사합니다. 이는 모델이 마스킹되지 않은 세그먼트의 acoustic representation과 음성 데이터의 장거리 시간적 구조(long-range temporal structure)를 모두 학습하도록 강제합니다. 우리는 인 설정이 클러스터 목표의 품질에 더 강건하다고 가정하며, 이는 우리의 실험에서 입증되었습니다(표 V 참조).
C. Learning with Cluster Ensembles
목표 품질을 개선하는 간단한 아이디어는 여러 클러스터링 모델을 활용하는 것입니다. 개별 클러스터링 모델의 성능은 끔찍할 수 있지만, cluster ensembles은 representation learning을 용이하게 하기 위해 보완적인 정보를 제공할 수 있습니다. 예를 들어, 다른 codebook 크기를 가진 k-means 모델의 앙상블은 조음 방식 클래스(모음/자음)에서 하위 음소 상태(senones)에 이르기까지 다양한 세분성을 가진 목표를 생성할 수 있습니다. 제안된 프레임워크를 확장하기 위해, 를 번째 클러스터링 모델에 의해 생성된 목표 시퀀스라고 합시다. 이제 을 다음과 같이 다시 쓸 수 있습니다:
그리고 마스킹되지 않은 손실 도 유사합니다. 이는 비지도 클러스터링에 의해 생성된 작업과 함께 multi-task learning과 유사합니다.
또한, 앙상블링은 특징 공간이 여러 하위 공간으로 분할되고 각 하위 공간이 별도로 양자화되는 product quantization (PQ) [39]와 함께 사용될 수 있기 때문에 흥미롭습니다. PQ는 고차원 특징 및 하위 공간 간에 스케일이 크게 다른 이종 특징에 대해 k-means와 같은 효과적인 Euclidean distance-based quantization을 가능하게 합니다. 이 경우, 목표 공간의 이론적 크기는 모든 코드북 크기의 곱입니다.
D. Iterative Refinement of Cluster Assignments
cluster ensembles을 사용하는 것 외에도, 향상된 representation을 위한 또 다른 방향은 학습 과정 전반에 걸쳐 클러스터 할당을 개선하는 것입니다. 사전 훈련된 모델이 MFCC와 같은 원시 음향 특징보다 더 나은 representation을 제공할 것으로 기대하기 때문에, 우리는 학습된 잠재 표현에 대해 이산 잠재 모델을 훈련하여 새로운 세대의 클러스터를 생성할 수 있습니다. 그런 다음 학습 과정은 새로 발견된 단위로 진행됩니다.
E. Implementation
우리의 사전 훈련 모델은 convolutional waveform encoder, BERT encoder [19], projection layer 및 code embedding layer를 갖춘 wav2vec 2.0 architecture [6]를 따릅니다.
우리는 HuBERT를 세 가지 다른 구성, 즉 BASE, Large, X-Large로 고려합니다. 처음 두 가지는 wav2vec 2.0 Base 및 Large의 아키텍처를 밀접하게 따릅니다. X-Large 아키텍처는 [40]의 Conformer XXL 모델 크기와 유사하게 모델 크기를 약 10억 개의 매개변수로 확장합니다. waveform encoder는 세 가지 구성 모두에 대해 동일하며, 보폭 [5,2,2,2,2,2,2]과 커널 너비 [10,3,3,3,3,2,2]를 가진 7개의 512채널 레이어로 구성됩니다. BERT encoder는 많은 동일한 transformer blocks으로 구성되며, 그 매개변수와 후속 projection layer의 매개변수는 표 1에 명시되어 있습니다.
| BASE | Large | X-Large | ||
|---|---|---|---|---|
| CNN Encoder | strides kernel width channel | 5, 2, 2, 2, 2, 2, 2 10, 3, 3, 3, 3, 2, 2 512 | ||
| Transformer | layer | 12 | 24 | 48 |
| embedding dim. | 768 | 1024 | 1280 | |
| inner FFN dim. | 3072 | 4096 | 5120 | |
| layerdrop prob | 0.05 | 0 | 0 | |
| attention heads | 8 | 16 | 16 | |
| Projection | dim. | 256 | 768 | 1024 |
| Num. of Params | 95 M | 317M | 964 M |
TABLE I: Base, Large, X-Large HuBERT 모델에 대한 모델 아키텍처 요약
convolutional waveform encoder는 16kHz로 샘플링된 오디오에 대해 20ms 프레임레이트로 특징 시퀀스를 생성합니다 (CNN encoder 다운샘플링 계수는 320x). 오디오 인코딩된 특징은 그런 다음 섹션 II-B에 설명된 대로 무작위로 마스킹됩니다. BERT encoder는 마스킹된 시퀀스를 입력으로 받아 특징 시퀀스 를 출력합니다. 코드워드에 대한 분포는 다음과 같이 매개변수화됩니다.
여기서 는 projection matrix이고, 는 코드워드 에 대한 임베딩이며, 은 두 벡터 간의 코사인 유사도를 계산하고, 는 로짓을 스케일링하며 0.1로 설정됩니다. cluster ensembles이 사용될 때, 각 클러스터링 모델 에 대해 하나의 projection matrix 가 적용됩니다.
HuBERT pre-training 후, 우리는 고정된 convolutional audio encoder를 제외한 전체 모델 가중치의 ASR fine-tuning을 위해 connectionist temporal classification (CTC) [41] 손실을 사용합니다. projection layer(들)는 제거되고 무작위로 초기화된 softmax layer로 대체됩니다. CTC 목표 어휘는 26개의 영어 문자, 공백 토큰, 아포스트로피 및 특수 CTC 공백 기호를 포함합니다.
III. Related Work
우리는 훈련 목표에 따라 그룹화하여 self-supervised speech representation learning에 대한 최근 연구를 논의합니다. 가장 초기의 연구 라인은 잠재 변수를 가진 음성에 대한 generative model을 가정하여 representation을 학습하며, 이 잠재 변수는 관련 음성 정보를 포착하는 것으로 가정됩니다. 이러한 모델의 훈련은 likelihood maximization에 해당합니다. 연속 [29], 이산 [31], [42] 또는 순차 [28], [30], [32], [33], [43]과 같은 다양한 잠재 구조가 사전 가정을 인코딩하기 위해 적용되었습니다.
Prediction-based self-supervised learning은 최근 점점 더 많은 관심을 모으고 있으며, 여기서 모델은 보이지 않는 영역의 내용을 예측하거나 [4], [44]-[50] 목표 보이지 않는 프레임을 무작위로 샘플링된 것과 대조하도록 [1]-[3], [6] 과제를 받습니다. 일부 모델은 예측 손실과 contrastive losses를 모두 결합합니다 [5], [51]. 이러한 목표는 일반적으로 mutual information maximization [52]으로 해석될 수 있습니다. 다른 목표는 이러한 범주에 속하지 않습니다, 예를 들어 [53].
이 연구는 DiscreteBERT [51]와 가장 관련이 깊습니다: HuBERT와 DiscreteBERT 모두 마스킹된 영역의 이산 목표를 예측합니다. 그러나 몇 가지 중요한 차이점이 있습니다. 첫째, 양자화된 단위를 입력으로 받는 대신, HuBERT는 원시 파형을 입력으로 받아 가능한 한 많은 정보를 transformer 레이어에 전달하며, 이는 [6]에서 중요하다고 나타났습니다. 또한, 실험 섹션에서 우리는 간단한 k-means 목표를 가진 우리 모델이 vq-wav2vec [5] 학습 단위를 사용하는 DiscreteBERT보다 더 나은 성능을 달성할 수 있음을 보여줍니다. 둘째, 우리는 또한 DiscreteBERT에서처럼 단일 고정 교사를 사용하는 대신 교사 품질을 개선하기 위한 많은 기술을 제시합니다.
HuBERT는 또한 wav2vec 2.0 [6]과 관련이 있습니다. 그러나 후자는 음수 프레임을 어디에서 샘플링할지에 대한 신중한 설계, 이산 단위 사용을 장려하기 위한 보조 다양성 손실, 그리고 적절한 Gumbel-softmax 온도 어닐링 스케줄을 요구하는 contrastive loss를 사용합니다. 또한, 파형 인코더 출력을 양자화하는 것만을 탐색하며, 이는 우리의 그림 2의 절제 연구에서 제안된 바와 같이, 컨볼루션 인코더의 제한된 용량으로 인해 양자화에 가장 좋은 특징이 아닐 수 있습니다. 구체적으로, 제안된 방법은 음향 단위 발견 단계를 마스크된 예측 표현 학습 단계와 분리하여 보다 직접적인 예측 손실을 채택하고, 다양한 fine-tuning 규모에서 wav2vec 2.0을 능가하거나 일치하는 최첨단 결과를 달성합니다.
마지막으로, 반복적 정제 목표 레이블의 아이디어는 semi-supervised ASR [12], [54]를 위한 반복적 의사 레이블링과 유사하며, 이는 향상되는 학생 모델을 활용하여 다음 반복 훈련을 위한 더 나은 의사 레이블을 생성합니다. HuBERT 접근법은 이 방법을 마스크된 예측 손실을 가진 self-supervised 설정으로 확장하는 것으로 볼 수 있습니다.
IV. Experimental Details
A. Data
비지도 pre-training을 위해 LibriSpeech 오디오 [24]의 전체 960시간 또는 Libri-light [25] 오디오의 60,000시간을 사용하며, 이 두 가지 모두 인터넷의 자원 봉사자들이 저작권이 없는 오디오북을 녹음한 LibriVox 프로젝트에서 파생되었습니다. 지도 fine-tuning을 위해 다섯 가지 다른 파티션이 고려됩니다: Libri-light 10분, 1시간, 10시간 분할 및 LibriSpeech 100시간 (train-clean-100) 및 960시간 (train-clean-100, train-clean-360, train-other-500 결합) 분할. 세 개의 Libri-light 분할은 LibriSpeech 훈련 분할의 하위 집합이며, 각각은 train-clean-*에서 절반의 오디오를, 다른 절반은 train-other-500에서 가져옵니다.
B. Unsupervised Unit Discovery
제안된 방법이 저품질 클러스터 할당을 활용하는 효과를 입증하기 위해, 우리는 기본적으로 음향 단위 발견을 위해 k-means 알고리즘 [55]을 고려합니다. 이는 각 음향 단위에 대해 동일한 스칼라 분산을 가진 등방성 가우시안을 모델링하는 것으로 취급될 수 있는 가장 순진한 단위 발견 모델 중 하나입니다. 960시간 LibriSpeech 훈련 세트에 대한 첫 번째 반복 HuBERT 훈련을 위한 레이블을 생성하기 위해, 우리는 39차원 MFCC 특징에 대해 100개의 클러스터로 k-means 클러스터링을 실행하며, 이는 1차 및 2차 도함수를 포함한 13개의 계수입니다.
후속 반복을 위한 더 나은 목표를 생성하기 위해, 우리는 이전 반복에서 사전 훈련된(fine-tuned되지 않은) HuBERT 모델의 일부 중간 transformer 레이어에서 추출한 잠재 특징에 대해 500개의 클러스터로 k-means 클러스터링을 실행합니다. transformer 출력의 특징 차원은 MFCC 특징(HuBERT BASE의 경우 768-D)보다 훨씬 높기 때문에 전체 960시간 훈련 분할을 메모리에 로드할 여유가 없습니다. 그래서 대신, k-means 모델을 피팅하기 위해 데이터의 를 무작위로 샘플링합니다.
scikit-learn [56] 패키지에 구현된 MiniBatchKMeans 알고리즘이 클러스터링에 사용되며, 이는 한 번에 샘플의 미니 배치를 맞춥니다². 우리는 미니 배치 크기를 10,000 프레임으로 설정합니다. 더 나은 초기화를 위해 20개의 무작위 시작과 함께 k-means++ [57]가 사용됩니다.
C. Pre-Training
우리는 32개의 GPU에서 LibriSpeech 오디오 960시간에 대해 BASE 모델을 두 번의 반복으로 훈련하며, GPU당 최대 87.5초의 오디오 배치 크기를 사용합니다. 첫 번째 반복은 250k 단계 동안 훈련되고, 두 번째 반복은 첫 번째 반복 모델의 6번째 transformer 레이어 출력을 클러스터링하여 생성된 레이블을 사용하여 400k 단계 동안 훈련됩니다. 100k 단계를 훈련하는 데는 약 9.5시간이 걸립니다.
다음으로 HuBERT Large와 X-Large를 128개와 256개의 GPU에서 각각 400k 단계 동안 60,000시간의 Libri-light 오디오로 한 번의 반복으로 훈련합니다. 배치 크기는 메모리 제약으로 인해 GPU당 56.25초와 22.5초의 오디오로 줄어듭니다. MFCC 특징 클러스터링에서 반복 프로세스를 다시 시작하는 대신, 두 번째 반복 BASE HuBERT의 9번째 transformer 레이어에서 특징을 추출하여 클러스터링하고 해당 레이블을 이 두 모델을 훈련하는 데 사용합니다. 따라서 이 두 모델은 세 번째 반복 모델로도 볼 수 있습니다.
모든 HuBERT 구성에 대해, 마스크 스팬은 으로 설정되고, 달리 언급되지 않는 한 파형 인코더 출력 프레임의 가 마스크 시작으로 무작위로 선택됩니다. Adam [58] 옵티마이저는 과 함께 사용되며, 학습률은 훈련 단계의 처음 동안 0에서 최고 학습률까지 선형적으로 증가한 다음, 다시 0으로 선형적으로 감소합니다. 최고 학습률은 Base/Large/X-Large 모델에 대해 각각 입니다.
D. Supervised Fine-Tuning and Decoding
우리는 IV-A절에 설명된 레이블이 있는 분할에 대해 8개의 GPU에서 각 모델을 fine-tuning합니다. GPU당 배치 크기는 Base/Large/X-Large 모델에 대해 최대 200/80/40초의 오디오입니다. fine-tuning 동안, convolutional waveform audio encoder 매개변수는 고정됩니다. wav2vec 2.0과 마찬가지로, transformer 매개변수가 고정되고 새로운 softmax 행렬만 훈련되는 fine-tuning 단계 수를 제어하기 위해 고정 단계 하이퍼파라미터를 도입합니다. 우리는 각 모델 크기와 fine-tuning 분할 조합에 대해 dev-other 하위 집합의 단어 오류율(WER)을 모델 선택 기준으로 사용하여 최고 학습률([1e-5, 1e-4]), 학습률 스케줄(선형 램프업 및 감쇠 단계의 백분율), fine-tuning 단계 수, 고정 단계 및 파형 인코더 출력 마스킹 확률을 스윕합니다.
우리는 언어 모델 융합 디코딩을 위해 Fairseq [60]에 래핑된 wav2letter++ [59] 빔 검색 디코더를 사용하며, 이는 다음을 최적화합니다:
여기서 는 예측된 텍스트, 는 텍스트의 길이, 과 는 언어 모델 가중치와 단어 점수를 나타냅니다. 디코딩 하이퍼파라미터는 베이지안 최적화 툴킷인 Ax로 검색됩니다. 이 연구에서는 공식 Librispeech 언어 모델링 데이터로 훈련된 n-gram 및 transformer 언어 모델을 모두 고려합니다.
E. Metrics of Target Quality
분석을 위해, 우리는 k-means 클러스터 할당과 실제 음소 단위 간의 상관 관계를 측정하기 위해 하이브리드 ASR 시스템을 사용하여 프레임 수준의 forced-aligned phonetic transcripts를 도출합니다. 정렬된 프레임 수준 음소 레이블 와 k-means 레이블 가 주어지면, 두 변수 사이의 결합 분포는 발생 횟수를 세어 추정할 수 있습니다:
여기서 는 번째 음소 클래스를 나타내고 는 번째 k-means 레이블 클래스를 나타냅니다. 주변 확률은 와 로 계산됩니다.
각 음소 클래스 에 대해, 우리는 가장 가능성 있는 목표 레이블을 다음과 같이 계산합니다:
마찬가지로, 각 k-means 클래스 에 대해, 우리는 가장 가능성 있는 음소 레이블을 다음과 같이 계산합니다:
세 가지 측정 기준이 고려됩니다:
- phone purity (Phn Pur.):
여기서 는 k-means 레이블이 주어졌을 때 음소의 조건부 확률을 나타냅니다. 이 측정 기준은 한 클래스 내의 평균 음소 순도를 측정하며, 각 k-means 클래스를 가장 가능성 있는 음소 레이블로 전사할 경우 프레임 수준의 음소 정확도로 해석될 수 있습니다. 동일한 수의 단위를 가진 다른 목표 레이블 집합을 비교할 때, 순도가 높을수록 품질이 좋습니다. 그러나 이 측정 기준은 다른 수의 단위를 가진 두 집합을 비교할 때 덜 의미가 있습니다: 각 프레임에 고유한 목표 레이블이 할당되는 극단적인 경우, 음소 순도는 100%가 될 것입니다. 2) cluster purity (Cls Pur.): 여기서 는 음소 레이블이 주어졌을 때 k-means 레이블의 조건부 확률을 나타냅니다. 클러스터 순도는 음소 순도의 대응물로, 단위 수가 증가하면 일반적으로 그 값이 감소합니다. 동일한 수의 단위를 가진 목표 레이블을 비교할 때, 클러스터 순도가 높을수록 품질이 더 좋음을 나타내며, 동일한 음소의 프레임이 동일한 k-means 레이블 클래스로 레이블링될 가능성이 더 높습니다. 3) phone-normalized mutual information (PNMI):
PNMI는 k-means 레이블 를 관찰한 후 음소 레이블 에 대한 불확실성이 제거된 비율을 측정하는 정보 이론적 지표입니다. PNMI가 높을수록 k-means 클러스터링 품질이 좋다는 것을 나타냅니다.
V. Results
A. Main Results: Low- and High-Resource Setups
표 II는 저자원 설정에 대한 결과를 제시하며, 여기서 사전 훈련된 모델은 10분, 1시간, 10시간 또는 100시간의 레이블링된 데이터에 대해 fine-tuning됩니다. 우리는 문헌의 준지도(iterative pseudo labeling (IPL) [12], slimIPL [54], noisy student [61]) 및 자기지도 접근법(DeCoAR 2.0 [50], DiscreteBERT [51], wav2vec 2.0 [6])과의 비교를 포함합니다. 레이블이 없는 데이터의 양을 늘리고 모델 크기를 늘리면 성능이 향상되어 제안된 HuBERT self-supervised pre-training 방법의 확장성을 보여줍니다. 단 10분의 레이블링된 데이터만 있는 초저자원 설정에서 HuBERT Large 모델은 test-clean 세트에서 의 WER, test-other 세트에서 의 WER을 달성할 수 있으며, 이는 최첨단 wav2vec 2.0 Large 모델보다 각각 및 낮은 WER입니다. 모델 크기를 10억 개의 매개변수로 더 확장함으로써 HuBERT X-LARGE 모델은 WER을 test-clean 및 test-other에서 각각 및 로 더 줄일 수 있습니다. HuBERT의 우수성은 레이블링된 데이터 양이 다른 설정 전반에 걸쳐 지속되며, 유일한 예외는 100시간의 레이블링된 데이터에 대한 fine-tuning으로, 여기서 HuBERT Large는 test-clean에서 wav2vec 2.0 LARGE보다 WER이 높고, HuBERT BASE는 test-other에서 wav2vec 2.0보다 WER이 높습니다.
| Model | Unlabeled Data | LM | dev-clean | dev-other | test-clean | test-other |
|---|---|---|---|---|---|---|
| 10-min labeled | ||||||
| DiscreteBERT [51] | LS-960 | 4-gram | 15.7 | 24.1 | 16.3 | 25.2 |
| wav2vec 2.0 BASE |6| | LS-960 | 4-gram | 8.9 | 15.7 | 9.1 | 15.6 |
| wav2vec 2.0 Large [6] | LL-60k | 4-gram | 6.3 | 9.8 | 6.6 | 10.3 |
| wav2vec 2.0 Large [6] | LL-60k | Transformer | 4.6 | 7.9 | 4.8 | 8.2 |
| HUBERT BASE | LS-960 | 4-gram | 9.1 | 15.0 | 9.7 | 15.3 |
| HUBERT Large | LL-60k | 4-gram | 6.1 | 9.4 | 6.6 | 10.1 |
| HUBERT Large | LL-60k | Transformer | 4.3 | 7.0 | 4.7 | 7.6 |
| HUBERT X-Large | LL-60k | Transformer | 4.4 | 6.1 | 4.6 | 6.8 |
| 1-hour labeled | ||||||
| DeCoAR 2.0 [50] | LS-960 | 4-gram | - | - | 13.8 | 29.1 |
| DiscreteBERT [51] | LS-960 | 4-gram | 8.5 | 16.4 | 9.0 | 17.6 |
| wav2vec 2.0 BASE [6] | LS-960 | 4-gram | 5.0 | 10.8 | 5.5 | 11.3 |
| wav2vec 2.0 Large [6] | LL-60k | Transformer | 2.9 | 5.4 | 2.9 | 5.8 |
| HUBERT BASE | LS-960 | 4-gram | 5.6 | 10.9 | 6.1 | 11.3 |
| HUBERT Large | LL-60k | Transformer | 2.6 | 4.9 | 2.9 | 5.4 |
| HUBERT X-Large | LL-60k | Transformer | 2.6 | 4.2 | 2.8 | 4.8 |
| 10-hour labeled | ||||||
| SlimIPL [54] | LS-960 | 4-gram + Transformer | 5.3 | 7.9 | 5.5 | 9.0 |
| DeCoAR 2.0 [50] | LS-960 | 4-gram | - | - | 5.4 | 13.3 |
| DiscreteBERT [51] | LS-960 | 4-gram | 5.3 | 13.2 | 5.9 | 14.1 |
| wav2vec 2.0 BASE [6] | LS-960 | 4-gram | 3.8 | 9.1 | 4.3 | 9.5 |
| wav2vec 2.0 Large [6] | LL-60k | Transformer | 2.4 | 4.8 | 2.6 | 4.9 |
| HUBERT BASE | LS-960 | 4-gram | 3.9 | 9.0 | 4.3 | 9.4 |
| HUBERT Large | LL-60k | Transformer | 2.2 | 4.3 | 2.4 | 4.6 |
| HUBERT X-Large | LL-60k | Transformer | 2.1 | 3.6 | 2.3 | 4.0 |
| 100-hour labeled | ||||||
| IPL [12] | LL-60k | 4-gram + Transformer | 3.19 | 6.14 | 3.72 | 7.11 |
| SlimIPL [54] | LS-860 | 4-gram + Transformer | 2.2 | 4.6 | 2.7 | 5.2 |
| Noisy Student [61] | LS-860 | LSTM | 3.9 | 8.8 | 4.2 | 8.6 |
| DeCoAR 2.0 [50] | LS-960 | 4-gram | - | - | 5.0 | 12.1 |
| DiscreteBERT [51] | LS-960 | 4-gram | 4.0 | 10.9 | 4.5 | 12.1 |
| wav2vec 2.0 BASE [6] | LS-960 | 4-gram | 2.7 | 7.9 | 3.4 | 8.0 |
| wav2vec 2.0 Large [6] | LL-60k | Transformer | 1.9 | 4.0 | 2.0 | 4.0 |
| HUBERT BASE | LS-960 | 4-gram | 2.7 | 7.8 | 3.4 | 8.1 |
| HUBERT Large | LL-60k | Transformer | 1.8 | 3.7 | 2.1 | 3.9 |
| HUBERT X-Large | LL-60k | Transformer | 1.7 | 3.0 | 1.9 | 3.5 |
TABLE II: 저자원 설정(-시간, 10-시간 및 100-시간의 레이블링된 데이터)에 대한 결과 및 문헌과의 비교.
BASE는 test-other에서 wav2vec 2.0 BASE보다 0.1% 더 높은 WER을 보입니다. 또한, HuBERT는 모든 설정에서 DiscreteBERT를 큰 차이로 능가하며, 두 모델 모두 발견된 단위의 masked prediction이라는 거의 동일한 목표로 훈련되었습니다. 이 상당한 성능 격차는 두 가지를 시사합니다. 첫째, 모델에 파형을 입력으로 사용하는 것은 양자화 중 정보 손실을 피하는 데 중요합니다. 둘째, DiscreteBERT가 훈련에 사용하는 단위인 vq-wav2vec [5]는 MFCC 특징의 k-means 클러스터링보다 더 나은 단위를 발견할 수 있지만, 제안된 반복적 개선은 개선되는 HuBERT 모델로부터 이점을 얻고 결국 더 나은 단위를 학습합니다. 우리는 절제 연구 섹션에서 이러한 진술을 검증할 것입니다.
우리는 Librispeech 데이터의 전체 960시간에 대해 HuBERT 모델을 fine-tuning한 결과를 보고하고 표 III에서 문헌과 비교합니다. 추가적인 비쌍 음성을 사용한 이전 연구는 다음과 같이 분류됩니다:
- self-training: 먼저 레이블이 있는 데이터로 ASR을 훈련하여 레이블이 없는 음성에 주석을 달고, 그런 다음 황금 표준과 ASR 주석이 달린 텍스트-음성 쌍을 모두 결합하여 지도 훈련을 합니다.
- pre-training: 먼저 레이블이 없는 음성을 사용하여 모델을 pre-training한 다음, 지도 훈련 목표를 사용하여 레이블이 있는 데이터에서 모델을 fine-tuning합니다.
- pre-training + self-training: 먼저 모델을 pre-training하고 fine-tuning한 다음, 이를 사용하여 레이블이 없는 음성에 주석을 달아 지도 데이터와 결합된 self-training을 합니다. HuBERT는 최첨단 지도 및 self-training 방법을 능가하며, 문헌에서 가장 좋은 두 가지 pre-training 결과와 동등한 수준이며, 둘 다 wav2vec 2.0 contrastive learning에 기반합니다. 대조적으로, pre-training과 self-training을 결합한 방법에는 뒤쳐집니다. 그러나 [63]과 [40]에서 관찰된 바와 같이, pre-trained HuBERT 모델이 의사 레이블링에 사용하는 pre-trained 모델과 동등하거나 더 우수하기 때문에, self-training과 결합한 후 HuBERT가 비슷한 또는 더 나은 성능을 달성할 수 있을 것으로 기대합니다.
B. Analysis: K-Means Stability
발견된 단위의 masked prediction이 효과적인 이유를 더 잘 이해하기 위해, 우리는 일련의 분석과 절제 연구를 수행합니다. 우리는 k-means 클러스터링 알고리즘이 다른 클러스터 수와 다른 크기의 훈련 데이터에 대해 얼마나 안정적인지 탐색하는 것으로 시작합니다.
| Model | Unlabeled Data | LM | dev-clean | dev-other | test-clean | test-other |
|---|---|---|---|---|---|---|
| Superivsed | ||||||
| Conformer L [62] | - | LSTM | - | - | 1.9 | 3.9 |
| Self-Training | ||||||
| IPL [12] | LL-60k | 4-gram + Transformer | 1.85 | 3.26 | 2.10 | 4.01 |
| Noisy Student [61] | LV-60k | LSTM | 1.6 | 3.4 | 1.7 | 3.4 |
| Pre-Training | ||||||
| wav2vec 2.0 Large [6] | LL-60k | Transformer | 1.6 | 3.0 | 1.8 | 3.3 |
| pre-trained Conformer XXL [40] | LL-60k | LSTM | 1.5 | 3.0 | 1.5 | 3.1 |
| Pre-Training + Self-Training | ||||||
| wav2vec 2.0 + self-training [63] | LL-60k | Transformer | 1.1 | 2.7 | 1.5 | 3.1 |
| pre-trained Conformer XXL + Noisy Student [40] | LL-60k | LSTM | 1.3 | 2.6 | 1.4 | 2.6 |
| This work (Pre-Training) | ||||||
| HUBERT Large | LL-60k | Transformer | 1.5 | 3.0 | 1.9 | 3.3 |
| HUBERT X-Large | LL-60k | Transformer | 1.5 | 2.5 | 1.8 | 2.9 |
TABLE III: 레이블이 있는 모든 LibriSpeech 데이터 960시간을 사용한 고자원 설정에 대한 문헌과의 비교. 두 가지 특징이 고려됩니다: 39차원 MFCC 특징과 첫 번째 반복 HuBERTBASE 모델의 6번째 transformer 레이어에서 나온 768차원 출력. 이 두 특징은 각각 첫 번째와 두 번째 반복 HUBERT 훈련을 위한 클러스터 할당을 생성하는 데 사용됩니다.
k-means 클러스터링을 위해, 우리는 LibriSpeech 훈련 분할에서 샘플링된 시간의 음성에 대해 피팅된 클러스터를 고려합니다. 하이퍼파라미터와 특징의 각 조합은 10번의 시도에 대해 훈련되며, 개발 세트(LibriSpeech의 dev-clean과 dev-other를 결합)에 대한 지도 PNMI 지표의 평균과 표준 편차는 표 IV에 보고됩니다. 결과는 k-means 클러스터링이 다른 하이퍼파라미터와 특징에 걸쳐 작은 표준 편차를 감안할 때 상당히 안정적이라는 것을 보여줍니다. 또한, k-means 모델 피팅에 사용되는 데이터 양을 늘리면 일반적으로 PNMI가 향상되지만, 이득은 0.012에 불과하여 특징 행렬 크기에 비해 CPU 메모리가 제한된 경우에도 단위 발견에 k-means를 사용하는 것이 가능함을 시사합니다. 마지막으로, PNMI 점수는 MFCC 특징에 대해 클러스터링할 때보다 HuBERT 특징에 대해 클러스터링할 때 훨씬 높으며, 그 격차는 500개 클러스터에서 훨씬 더 커져 반복적 정제가 클러스터링 품질을 크게 향상시킨다는 것을 나타냅니다.
| feature | C | PNMI (mean std) with K-means Training Size | ||
|---|---|---|---|---|
| 1 h | 10 h | 100 h | ||
| MFCC | 100 | |||
| 500 | ||||
| BASE-it1-L6 | 100 | |||
| 500 |
TABLE IV: 비지도 단위 발견 알고리즘으로서의 K-means의 안정성. 다양한 특징, 클러스터 수, 훈련 데이터 크기에 대한 안정성. PNMI는 phone-normalized mutual information의 약자입니다.
C. Analysis: Clustering Quality Across Layers and Iterations
다음으로 우리는 각 반복에서 HuBERT 모델의 각 계층이 훈련 목표를 생성하기 위해 클러스터링에 사용될 때 어떻게 수행되는지 연구합니다.
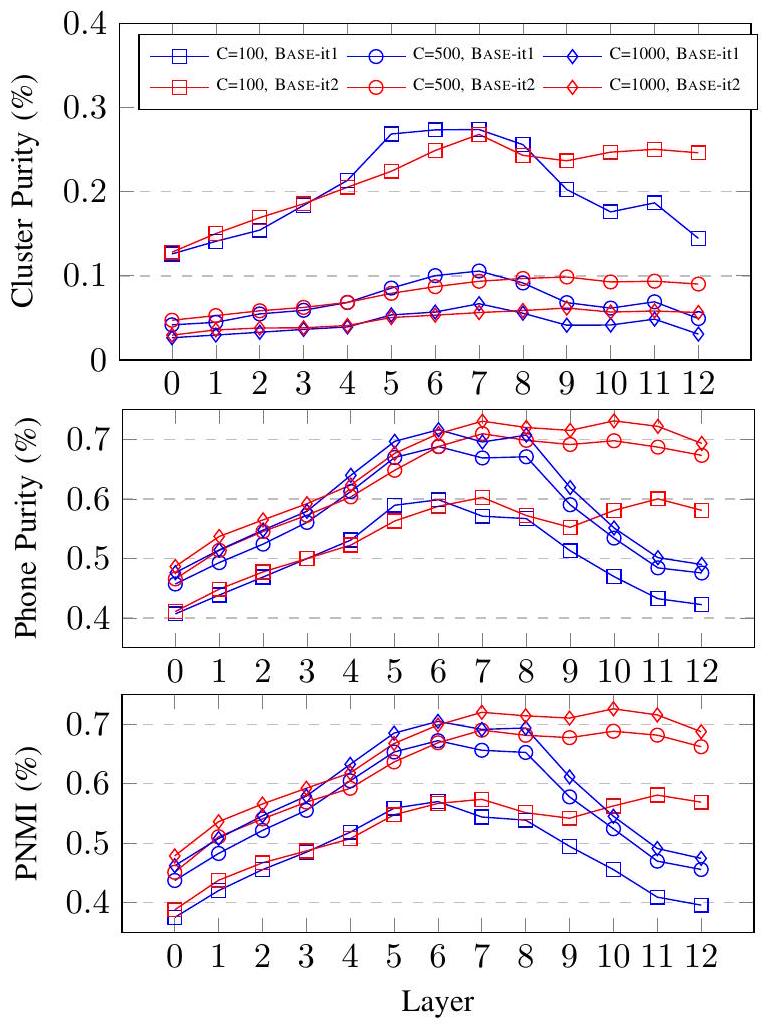
Fig. 2: 첫 번째 및 두 번째 반복 BASE HuBERT 모델의 각 transformer 레이어에서 추출한 특징에 대해 k-means 클러스터링을 실행하여 얻은 클러스터 할당의 품질. 섹션 IV-C에 설명된 처음 두 반복의 두 BASE HuBERT 모델이 고려되며, 각각 BASE-it1 및 BASE-it2로 지칭됩니다. 두 HuBERT 모델의 12개 transformer 레이어와 첫 번째 transformer 레이어의 입력("Layer 0"으로 표시)을 나타내는 26개의 특징이 있습니다. 각 특징에 대해, 우리는 LibriSpeech 훈련 데이터에서 무작위로 샘플링된 100시간 하위 집합에 대해 세 개의 k-means 모델( 클러스터)을 맞춥니다.
| teacher | C | PNMI | dev-other WER (%) | ||
|---|---|---|---|---|---|
| Chenone (supervised top-line) | 8976 | 0.809 | 10.38 | 9.16 | 9.79 |
| K-means on MFCC | 50 | 0.227 | 18.68 | 31.07 | 94.60 |
| 100 | 0.243 | 17.86 | 29.57 | 96.37 | |
| 500 | 0.276 | 18.40 | 33.42 | 97.66 | |
| K-means on BASE-it1-layer6 | 500 | 0.637 | 11.91 | 13.47 | 23.29 |
| K-means on BASE-it2-layer9 | 500 | 0.704 | 10.75 | 11.59 | 13.79 |
TABLE V: 훈련 목표 및 클러스터링 품질이 성능에 미치는 영향. 는 단위 수를 나타내고, 는 마스킹된 프레임에 대한 가중치입니다.
| teacher | WER |
|---|---|
| K-means | 17.81 |
| K-means | 17.56 |
| Product K-means-0-100 | 19.26 |
| Product K-means-1-100 | 17.64 |
| Product K-means-2-100 | 18.46 |
| Product K-means- | 16.73 |
TABLE VI: k-means 및 product k-means를 사용한 클러스터 앙상블.
cluster purity, phone purity, and phone normalized mutual information (PNMI)로 측정된 교사 품질은 그림 2에 나와 있습니다. 기준으로, MFCC는 에 대해 (cluster purity, phone purity, PNMI) = (0.099, 0.335, 0.255)를, 에 대해 (0.031, 0.356, 0.287)를 달성합니다.
BASE-it1과 BASE-it2 특징 모두 동일한 클러스터 수로 MFCC보다 세 가지 지표 모두에서 훨씬 더 나은 클러스터링 품질을 보였습니다. 반면에, 최고의 BASE-it2 특징은 phone purity와 PNMI에서 최고의 BASE-it1보다 낫지만, cluster purity에서는 약간 더 나쁩니다. 마지막으로, BASE-it1과 BASE-it2에서 레이어에 따라 다른 추세를 관찰합니다: BASE-it2 모델 특징은 일반적으로 레이어를 거치면서 개선되지만, BASE-it1은 6번째 레이어 주변의 중간 레이어에서 최고의 특징을 가집니다. 흥미롭게도, 마지막 몇 레이어의 품질은 BASE-it1에 대해 극적으로 저하되는데, 이는 더 나쁜 품질의 목표 할당에 대해 훈련되었기 때문에 마지막 몇 레이어가 그들의 나쁜 레이블 행동을 모방하는 법을 배우기 때문일 수 있습니다.
D. Ablation: The Importance of Predicting Masked Frames
다음 섹션에서는 사전 훈련 목표, 클러스터 품질 및 하이퍼파라미터가 성능에 어떻게 영향을 미치는지 알아보기 위해 일련의 절제 연구를 제시합니다. 절제 연구를 위한 모델은 100k 단계 동안 사전 훈련되고 고정된 하이퍼파라미터를 사용하여 10시간짜리 libri-light 분할에서 미세 조정됩니다. 달리 언급되지 않는 한 C=100인 MFCC 기반 k-means 단위가 사용됩니다. 우리는 고정된 디코딩 하이퍼파라미터를 사용하여 n-gram 언어 모델로 디코딩된 dev-other 세트의 WER을 보고합니다.
마스킹된 프레임만 예측하자는 우리의 제안의 중요성을 이해하기 위해, 우리는 세 가지 조건을 비교합니다: 1) 마스킹된 프레임 예측, 2) 모든 프레임 예측, 3) 마스킹되지 않은 프레임 예측. 이는 각각 를 1.0, 0.5, 0.0으로 설정하여 시뮬레이션할 수 있습니다. 우리는 50, 100, 500개 클러스터로 MFCC 교사를 클러스터링하여 학습한 세 개의 k-means 모델, HuBERT-BASE-it1 6번째 트랜스포머 레이어 특징을 클러스터링하여 학습한 모델, 그리고 문자 기반 HMM 모델(chenone) [64]의 강제 정렬에서 얻은 감독 레이블을 비교하고 있습니다.
표 V에 나타난 결과는 나쁜 클러스터 할당으로부터 학습할 때, 마스킹된 영역에서만 손실을 계산하는 것이 최상의 성능을 달성하는 반면, 마스킹되지 않은 손실을 포함하면 WER이 상당히 높아진다는 것을 나타냅니다. 그러나 클러스터링 품질이 향상됨에 따라, 모델은 마스킹되지 않은 프레임에서 손실을 계산할 때 덜 고통받거나(BASE-it1-layer6) chenone의 경우처럼 더 나은 성능을 달성하기도 합니다.
E. Ablation: The Effect of Cluster Ensembles
목표 생성을 위해 여러 k-means 모델을 결합하는 효과를 이해하기 위해 두 가지 설정을 고려합니다. 첫 번째는 표 V에 제시된 다양한 클러스터 수를 가진 k-means 모델로, KM-{50, 100, 500}으로 표기됩니다. 두 번째는 창 크기가 3인 접합 MFCC 특징으로 훈련된 k-means 모델이므로 각 입력 특징은 117차원 벡터로 표현됩니다. 이 두 번째 경우, 우리는 접합된 특징에 대해 product quantization을 적용하며, 여기서 차원은 0차, 1차, 2차 도함수의 계수로 분할되고 각 39차원 하위 공간은 100개 항목의 코드북으로 양자화됩니다. 우리는 이 코드북을 각각 Product k-means-{0, 1, 2}-100으로 표기합니다. 표 V와 표 VI의 결과를 비교하면 앙상블을 사용하는 것이 단일 k-means 클러스터링이 달성할 수 있는 것보다 더 나은 성능을 이끌어낸다는 것이 분명합니다.
F. Ablation: Impact of Hyperparameters
그림 3과 표 VII는 하이퍼파라미터가 HuBERT 사전 훈련에 어떻게 영향을 미치는지 연구합니다. (1) 마스크 시작으로 선택된 프레임의 비율은 에서 최적이라는 것이 나타났습니다. (2) 배치 크기를 늘리면 성능이 크게 향상될 수 있습니다. (3) 더 오래 훈련하면 C={50, 100}인 두 k-means 모델 모두에 대해 일관되게 도움이 되며, 최고의 모델은 11.68%의 WER을 달성합니다. 이러한 발견은 BERT와 유사한 모델 [20]의 결과와도 일치합니다. 또한, 우리는 표 VII에 DiscreteBERT [51]의 비교 가능한 결과를 포함하며, 이는 동일한 MFCC 특징을 13.5k 단위로 양자화하기 위해 k-means를 적용하고, 이를 BERT 모델의 출력과 입력으로 모두 사용합니다. 이산 단위 대신 연속적인 음성 입력을 사용하는 것 외에도, 우리는 HuBERT가 100 또는 500개의 더 적은 k-means 클러스터가 화자 간/내 변동에 깊이 파고들지 않고 광범위한 음성 개념을 포착하는 데 도움이 되기 때문에 훨씬 더 나은 성능을 달성한다고 가정합니다.
VI. Conclusion
본 논문은 연속 입력의 마스킹된 세그먼트에 대한 K-means 클러스터 할당 예측에 의존하는 음성 표현 학습 접근법인 HuBERT를 제시합니다. Librispeech 960시간 및 60,000시간 Libri-light pre-training 설정 모두에서 HuBERT는 10분, 1시간, 10시간, 100시간 및 960시간의 모든 fine-tuning 하위 집합에서 최첨단 시스템과 동등하거나 이를 능가합니다.
| teacher | C | dev-other WER (%) | |||
|---|---|---|---|---|---|
| steps=100k | 250k | 400k | 800k | ||
| K-means | 50 | 18.68 | 13.65 | 12.40 | 11.82 |
| 100 | 17.86 | 12.97 | 12.32 | 11.68 |
TABLE VII: HuBERT 사전 훈련 단계 수 변경. p는 6.5%로 설정됨.
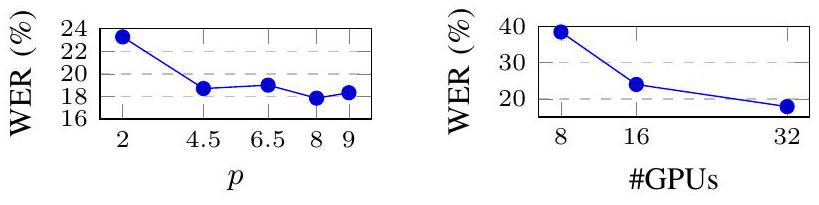
Fig. 3: 마스킹 확률 p(왼쪽)와 GPU 수를 통한 유효 배치 크기(오른쪽) 변경.
10h, 100h, 960h. 또한, 이전 반복에 대해 학습된 잠재 표현을 사용하여 K-means 클러스터 할당을 반복적으로 개선함으로써 학습된 표현 품질이 극적으로 향상됩니다. 마지막으로, HuBERT는 1B transformer 모델로 잘 확장되어 test-other 하위 집합에서 최대 13%의 상대적 WER 감소를 보여줍니다. 향후 연구를 위해 HuBERT 훈련 절차를 단일 단계로 구성하도록 개선할 계획입니다. 또한, 표현의 고품질을 고려하여 ASR을 넘어 여러 다운스트림 인식 및 생성 작업에 HuBERT 사전 훈련된 표현을 사용하는 것을 고려할 것입니다.
References
[1] A. v. d. Oord, Y. Li, and O. Vinyals, "Representation learning with contrastive predictive coding," arXiv preprint arXiv:1807.03748, 2018. [2] S. Schneider, A. Baevski, R. Collobert, and M. Auli, "wav2vec: Unsupervised pre-training for speech recognition," arXiv preprint arXiv:1904.05862, 2019. [3] E. Kharitonov, M. Rivière, G. Synnaeve, L. Wolf, P.-E. Mazaré, M. Douze, and E. Dupoux, "Data augmenting contrastive learning of speech representations in the time domain," arXiv preprint arXiv:2007.00991, 2020. [4] Y.-A. Chung, W.-N. Hsu, H. Tang, and J. Glass, "An unsupervised autoregressive model for speech representation learning," arXiv preprint arXiv:1904.03240, 2019. [5] A. Baevski, S. Schneider, and M. Auli, "vq-wav2vec: Selfsupervised learning of discrete speech representations," arXiv preprint arXiv:1910.05453, 2019. [6] A. Baevski, H. Zhou, A. Mohamed, and M. Auli, "wav2vec 2.0: A framework for self-supervised learning of speech representations," arXiv preprint arXiv:2006.11477, 2020. [7] G. Zavaliagkos and T. Colthurst, "Utilizing untranscribed training data to improve performance," in DARPA Broadcast News Transcription and Understanding Workshop, 1998. [8] J. Ma, S. Matsoukas, O. Kimball, and R. Schwartz, "Unsupervised training on large amounts of broadcast news data," in ICASSP, 2006. [9] J. Kahn, A. Lee, and A. Hannun, "Self-training for end-to-end speech recognition," in ICASSP, 2020. [10] W.-N. Hsu, A. Lee, G. Synnaeve, and A. Hannun, "Semisupervised speech recognition via local prior matching," arXiv preprint arXiv:2002.10336, 2020. [11] A. Xiao, C. Fuegen, and A. Mohamed, "Contrastive semi-supervised learning for asr," arXiv preprint arXiv:2103.05149, 2021. [12] Q. Xu, T. Likhomanenko, J. Kahn, A. Hannun, G. Synnaeve, and R. Collobert, "Iterative pseudo-labeling for speech recognition," arXiv preprint arXiv:2005.09267, 2020. [13] M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, "Unsupervised learning of visual features by contrasting cluster assignments," CoRR, vol. abs/2006.09882, 2020. [14] X. Chen and K. He, "Exploring simple siamese representation learning," CoRR, vol. abs/2011.10566, 2020. [15] J. Grill, F. Strub, F. Altché, C. Tallec, P. H. Richemond, E. Buchatskaya, C. Doersch, B. Á. Pires, Z. D. Guo, M. G. Azar, B. Piot, K. Kavukcuoglu, R. Munos, and M. Valko, "Bootstrap your own latent: A new approach to self-supervised learning," CoRR, vol. abs/2006.07733, 2020. [16] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. HerbertVoss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, "Language models are few-shot learners," CoRR, vol. abs/2005.14165, 2020. [17] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, "Roberta: A robustly optimized bert pretraining approach," arXiv preprint arXiv:1907.11692, 2019. [18] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, "Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension," arXiv preprint arXiv:1910.13461, 2019. [19] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, "Bert: Pre-training of deep bidirectional transformers for language understanding," arXiv preprint arXiv:1810.04805, 2018. [20] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, "Electra: Pretraining text encoders as discriminators rather than generators," arXiv preprint arXiv:2003.10555, 2020. [21] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, "Deep contextualized word representations," in NAACL, 2018. [22] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, "Momentum contrast for unsupervised visual representation learning," in CVPR, 2020. [23] M. Caron, P. Bojanowski, A. Joulin, and M. Douze, "Deep clustering for unsupervised learning of visual features," in . [24] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, "Librispeech: an asr corpus based on public domain audio books," in ICASSP, 2015. [25] J. Kahn et al., "Libri-light: A benchmark for asr with limited or no supervision," in ICASSP, 2020. [26] C.-y. Lee and J. Glass, "A nonparametric bayesian approach to acoustic model discovery," in . [27] L. Ondel, L. Burget, and J. Cernockỳ, "Variational inference for acoustic unit discovery," Procedia Computer Science, vol. 81, pp. 80-86, 2016. [28] J. Ebbers, J. Heymann, L. Drude, T. Glarner, R. Haeb-Umbach, and B. Raj, "Hidden markov model variational autoencoder for acoustic unit discovery." in INTERSPEECH, 2017. [29] W.-N. Hsu, Y. Zhang, and J. Glass, "Learning latent representations for speech generation and transformation," in INTERSPEECH, 2017. [30] -, "Unsupervised learning of disentangled and interpretable representations from sequential data," in NeurIPS, 2017. [31] J. Chorowski, R. J. Weiss, S. Bengio, and A. van den Oord, "Unsupervised speech representation learning using wavenet autoencoders," IEEE/ACM transactions on audio, speech, and language processing, vol. 27, no. 12, pp. 2041-2053, 2019. [32] S. Khurana, S. R. Joty, A. Ali, and J. Glass, "A factorial deep markov model for unsupervised disentangled representation learning from speech," in ICASSP, 2019. [33] S. Khurana, A. Laurent, W.-N. Hsu, J. Chorowski, A. Lancucki, R. Marxer, and J. Glass, "A convolutional deep markov model for unsupervised speech representation learning," arXiv preprint arXiv:2006.02547, 2020. [34] M. Joshi, D. Chen, Y. Liu, D. S. Weld, L. Zettlemoyer, and O. Levy, "Spanbert: Improving pre-training by representing and predicting spans," Transactions of the Association for Computational Linguistics, 2020. [35] S. Young, "Large vocabulary continuous speech recognition: A review," IEEE Signal Processing Magazine, vol. 13, no. 5, pp. 45-57, 1996. [36] O. Abdel-Hamid, A.-r. Mohamed, H. Jiang, and G. Penn, "Applying convolutional neural networks concepts to hybrid nn-hmm model for speech recognition," in 2012 IEEE international conference on Acoustics, speech and signal processing (ICASSP). IEEE, 2012, pp. 42774280. [37] D. Povey, "Discriminative training for large vocabulary speech recognition," Ph.D. dissertation, University of Cambridge, 2005. [38] H. A. Bourlard and N. Morgan, Connectionist speech recognition: a hybrid approach. Springer Science & Business Media, 2012, vol. 247. [39] R. M. Gray and D. L. Neuhoff, "Quantization," IEEE transactions on information theory, vol. 44, no. 6, pp. 2325-2383, 1998. [40] Y. Zhang, J. Qin, D. S. Park, W. Han, C.-C. Chiu, R. Pang, Q. V. Le, and Y . Wu, "Pushing the limits of semi-supervised learning for automatic speech recognition," arXiv preprint arXiv:2010.10504, 2020. [41] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, "Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks," in ICML, 2006. [42] A. van den Oord, O. Vinyals et al., "Neural discrete representation learning," in NeurIPS, 2017. [43] T. Glarner, P. Hanebrink, J. Ebbers, and R. Haeb-Umbach, "Full bayesian hidden markov model variational autoencoder for acoustic unit discovery." in INTERSPEECH, 2018. [44] Y.-A. Chung and J. Glass, "Generative pre-training for speech with autoregressive predictive coding," in ICASSP, 2020. [45] ——, "Improved speech representations with multi-target autoregressive predictive coding," arXiv preprint arXiv:2004.05274, 2020. [46] S. Ling, Y. Liu, J. Salazar, and K. Kirchhoff, "Deep contextualized acoustic representations for semi-supervised speech recognition," in ICASSP, 2020. [47] W. Wang, Q. Tang, and K. Livescu, "Unsupervised pre-training of bidirectional speech encoders via masked reconstruction," in ICASSP, 2020. [48] A. T. Liu, S.-w. Yang, P.-H. Chi, P.-c. Hsu, and H.-y. Lee, "Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders," in ICASSP, 2020. [49] P.-H. Chi, P.-H. Chung, T.-H. Wu, C.-C. Hsieh, S.-W. Li, and H.-y. Lee, "Audio albert: A lite bert for self-supervised learning of audio representation," arXiv preprint arXiv:2005.08575, 2020. [50] S. Ling and Y. Liu, "Decoar 2.0: Deep contextualized acoustic representations with vector quantization," arXiv preprint arXiv:2012.06659, 2020. [51] A. Baevski, M. Auli, and A. Mohamed, "Effectiveness of self-supervised pre-training for speech recognition," arXiv preprint arXiv:1911.03912, 2019. [52] Y.-H. H. Tsai, Y. Wu, R. Salakhutdinov, and L.-P. Morency, "Selfsupervised learning from a multi-view perspective," arXiv preprint arXiv:2006.05576, 2020. [53] S. Pascual, M. Ravanelli, J. Serrà, A. Bonafonte, and Y. Bengio, "Learning problem-agnostic speech representations from multiple selfsupervised tasks," in INTERSPEECH, 2019. [54] T. Likhomanenko, Q. Xu, J. Kahn, G. Synnaeve, and R. Collobert, "slimipl: Language-model-free iterative pseudo-labeling," arXiv preprint arXiv:2010.11524, 2020. [55] S. Lloyd, "Least squares quantization in pcm," IEEE transactions on information theory, vol. 28, no. 2, pp. 129-137, 1982. [56] F. Pedregosa et al., "Scikit-learn: Machine learning in python," the Journal of machine Learning research, 2011. [57] D. Arthur and S. Vassilvitskii, "k-means++: The advantages of careful seeding," Stanford, Tech. Rep., 2006. [58] D. P. Kingma and J. Ba, "Adam: A method for stochastic optimization," arXiv preprint arXiv:1412.6980, 2014. [59] V. Pratap et al., "wav2letter++: The fastest open-source speech recognition system," arXiv preprint arXiv:1812.07625, 2018. [60] M. Ott et al., "fairseq: A fast, extensible toolkit for sequence modeling," in . [61] D. S. Park, Y. Zhang, Y. Jia, W. Han, C.-C. Chiu, B. Li, Y. Wu, and Q. V. Le, "Improved noisy student training for automatic speech recognition," arXiv preprint arXiv:2005.09629, 2020. [62] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu et al., "Conformer: Convolution-augmented transformer for speech recognition," arXiv preprint arXiv:2005.08100, 2020. [63] Q. Xu, A. Baevski, T. Likhomanenko, P. Tomasello, A. Conneau, R. Collobert, G. Synnaeve, and M. Auli, "Self-training and pretraining are complementary for speech recognition," arXiv preprint arXiv:2010.11430, 2020. [64] D. Le, X. Zhang, W. Zheng, C. Fügen, G. Zweig, and M. L. Seltzer, "From senones to chenones: Tied context-dependent graphemes for hybrid speech recognition," in ASRU, 2019.