GPT-5 완전 분석: 똑똑함을 넘어 신뢰성까지 갖춘 통합 AI
OpenAI의 최신 언어 모델 GPT-5는 빠른 응답의 Chat 모드와 깊이 있는 추론의 Thinking 모드를 자동으로 전환하는 통합 AI 시스템입니다. 코딩, 수학, 글쓰기 등 다양한 분야에서 최고 성능(SOTA)을 달성했으며, 특히 환각(hallucination) 현상을 GPT-4 대비 크게 줄여 사실성과 신뢰성을 향상시켰습니다. 향상된 창의성, 강력한 코딩 능력, 전문 지식 활용 능력을 통해 더 유용하고 정확한 답변을 제공하는 GPT-5의 모든 것을 알아봅니다.
GPT-5 출시: 무엇이 달라졌나?
OpenAI의 최신 언어 모델 GPT-5가 마침내 공개되었습니다. 이제 ChatGPT 사용자라면 누구나 GPT-5를 만나볼 수 있는데요. 이번 업데이트는 단순한 성능 향상을 넘어 이전 모델들의 장점을 통합한 통합 AI 시스템으로의 도약을 표방합니다. GPT-5는 이전보다 훨씬 똑똑해지고 빨라진 것은 물론, 복잡한 문제에 대해 스스로 “생각하기(Thinking)” 모드로 전환하여 더 깊이 있는 답변을 제공합니다. 이 글에서는 일반 사용자 분들을 위해 GPT-5의 핵심 변화를 먼저 정리하고, 이어서 전문가 시각에서 본 세부 성능 지표와 기술적 업데이트 내용을 살펴보겠습니다.
한눈에 보는 GPT-5의 핵심 업그레이드
- 단일 통합 모델: GPT-5는 이제 ChatGPT의 기본 모델로 적용되어, 상황에 따라 **빠른 응답(Chat 모드)**과 **심층 추론(Thinking 모드)**을 자동으로 전환합니다. 복잡한 문제에서는 스스로 시간을 들여 깊이 생각하고, 간단한 질문은 즉각 답변하는 똑똑한 라우터가 내장되었습니다. 별도로 모델을 선택할 필요 없이, GPT-5 하나면 됩니다.
- 비약적인 성능 향상: GPT-5는 코딩, 수학, 글쓰기, 의료, 시각 이해 등 다양한 분야에서 현존 최고 수준(SOTA)의 성능을 보입니다. 예를 들어 수학 경시대회(AIME 2025) 문제에서 94.6%의 정답률로 최고 기록을 세웠고, 실제 프로그래밍 테스트(SWE-bench 등)에서도 GPT-4를 크게 앞질렀습니다. 일상적인 글쓰기부터 전문 지식까지 더 유용하고 정확한 답변을 제공합니다.
- 향상된 Factuality 및 신뢰성: GPT-5는 환각(hallucination) 현상이 크게 줄어들어, 사실 오류가 GPT-4 대비 약 45% 더 적게 나타납니다. 특히 복잡한 질문에 **추론 모드(Thinking)**로 답변할 때는 이전 세대 모델(OpenAI o3)에 비해 6배 이상 적은 허위 정보를 생성할 정도로 사실성 면에서 큰 개선을 이루었습니다. 이제 GPT-5는 모르는 것은 모른다고 솔직히 말하는 경향이 강화되어, 불가능한 요청에도 억지로 답을 꾸며내기보다 정직하게 한계를 설명합니다.
- 향상된 Writing 및 창의성: GPT-5는 글쓰기 측면에서도 GPT-4 대비 눈에 띄는 발전을 보였습니다. 복잡한 시나 시문학적 글쓰기에서도 맥락과 운율을 유지하며 깊이 있는 표현을 해내고, 아이디어 수준의 입력을 매끄럽고 완성도 높은 글로 발전시키는 능력이 뛰어납니다. 예를 들어, 같은 주제로 시를 쓸 때 GPT-4가 비교적 평이한 표현에 그쳤다면, GPT-5는 “검은 깃발”, “쿄토의 종소리” 등 인상적인 은유와 이미지를 활용해 감성을 자아내는 글을 만들어냅니다.
- 코딩 능력의 도약: GPT-5는 OpenAI가 밝힌 바에 따르면 역대 최강의 코딩 파트너입니다. 특히 프론트엔드 웹 개발이나 디버깅에 강하며, 한 번의 프롬프트로 완성도 높은 웹사이트나 게임을 통째로 만들어낼 정도의 능력을 보여줍니다. 초기 테스트 사용자들은 GPT-5가 디자인 감각도 탁월해져서, 여백이나 타이포그래피 등의 요소까지 신경 쓰는 모습을 보였다고 전합니다. 실제로 “간단한 HTML5 게임 만들어줘” 같은 요청에 대해, GPT-5는 미적 감각까지 반영된 결과물을 바로 내놓을 수 있습니다.
- 의료/전문 지식 활용: GPT-5는 의료 분야 질문에서도 이전보다 더 나은 성능을 보입니다. OpenAI가 공개한 HealthBench 평가에서 이전 모델들을 제치고 최고 점수를 기록했고, 의료 상담 시 환자의 증상과 배경을 고려하여 주의점이나 추가 질문을 제시하는 등 능동적 조력자 역할을 합니다. 물론 **“의사 대체”**는 아니지만, 의료 정보를 이해하고 의사와 상담 시 올바른 질문을 준비하는 데 GPT-5가 유용하게 활용될 수 있습니다.
- 모든 도구와의 호환: 이제 GPT-5는 ChatGPT의 모든 플러그인 및 툴을 제한 없이 활용할 수 있습니다. 웹 검색, 코드를 실행하는 데이터 해석, 이미지 분석, 파일 읽기, 그림 그리기, 이미지 생성 등 현재 ChatGPT가 제공하는 기능을 GPT-5에서도 모두 사용할 수 있습니다.
- 새로운 사용자 경험: 이번 GPT-5 출시와 함께 ChatGPT 앱에도 여러 편의 기능이 추가되었습니다. 대화 스타일(Personality) 변경 기능이 생겨서, 기본 중립 스타일 외에도 냉소적 조언자(Cynic), 로봇 같은 직답형(Robot), 친근한 청자(Listener), 지식에 탐닉하는 너드(Nerd) 등 4가지 개성적인 응답 톤을 선택할 수 있습니다. 질문에 따라 미묘하게 다른 어조로 답변해주는 재미가 있습니다. 또한 채팅 인터페이스의 **강조 색상(Accent Color)**을 사용자가 취향대로 설정할 수 있게 되었고, 음성 모드(Voice) 역시 개선되어 더 자연스러운 말투와 억양으로 응답합니다 (※ 음성 응답 자체는 아직 GPT-4o 기반으로 동작).
강조색상 지정 & 대화스타일(Personality) 변경
위의 변화만 보더라도, GPT-5는 이전 세대 대비 크게 향상된 지능과 편의성을 겸비하고 있음을 알 수 있습니다. 이제 좀 더 상세한 분석과 함께, 어떤 점들이 기술적으로 개선되었는지 살펴보겠습니다.
GPT-5의 기술적 특징과 성능 분석
(전문가용. 자세한 성능을 알고싶으신 분들만 보시고, 넘어가셔도 괜찮습니다.)
(Limit Rate 등 실제 사용 관련 정보는 4번에 정리되어 있으니, 4번만 보시는 것도 추천합니다.)
1. 통합 AI 시스템 – Chat 모드와 Thinking 모드
GPT-5의 가장 큰 혁신 중 하나는 하나의 모델 안에 서로 다른 두 가지 응답 모드를 결합한 점입니다. 기본적으로 빠르게 답할 수 있는 질문은 곧바로 답변하고, 난이도가 높은 문제나 신중한 분석이 필요한 경우에는 자동으로 **추론 강화 모드(GPT-5 Thinking)**로 전환됩니다. 예를 들어 사용자가 **“이 문제는 시간을 들여 깊이 생각해줘”**라고 요구하거나 질문이 매우 복잡한 경우, GPT-5는 알아서 추론 시간을 길게 가져가며(Thinking longer) 답을 도출합니다. 반대로 간단한 정보 요청에는 지체 없이 Chat 모드로 즉각 대답하지요. 이러한 실시간 라우팅 기술은 사용자들이 일일이 어느 모델을 쓸지 고민하지 않아도 되도록 설계되었습니다. OpenAI에 따르면 이 라우터는 사용자들의 모델 선택 패턴, 답변 평가지표, 답변 정확도 등의 신호로 지속 학습하여 갈수록 똑똑해진다고 합니다.
- GPT-5 Thinking 모드: GPT-5에서는 Thinking 모드가 내장되어 자동/수동으로 활용됩니다. Thinking 모드로 동작하면 **“더 나은 답변을 위해 깊이 생각하는 중”**이라는 표시가 뜨며, 필요시 “빨리 답 받기(Get a quick answer)” 버튼을 눌러 즉시 답변을 받을 수도 있습니다. 추론 모드는 코드 작성, 과학 문제, 데이터 분석처럼 정확도가 중요한 작업에서 빛을 발합니다. 약간의 지연이 생길 수 있지만, 답변 품질이 크게 향상되어 시간을 투자할 가치가 있는 경우에만 이 모드가 사용됩니다.
- GPT-5 Chat (기본) 모드: 대부분의 일상 대화와 간단한 질문에는 기본 모드로 응답합니다. 이는 GPT-4o 대비 속도가 크게 빨라진 모델로, 일반적인 문답에서 매우 쾌적한 반응 속도를 보여줍니다. OpenAI는 GPT-5가 *“사람들이 ChatGPT로 가장 많이 하는 작업 – 글쓰기, 코딩, 의료 상담 등 – 에서 가장 뛰어나고 신뢰할 만한 모델”*이라고 소개하고 있는데요, 이러한 효용은 주로 기본 Chat 모드에서 즉각적으로 체감할 수 있습니다.
- Thinking-Pro: 한편 GPT-5는 고급 사용자를 위해 Thinking Pro라는 더욱 깊이 있는 추론 버전도 제공합니다. ChatGPT의 Pro 요금제 사용자는 GPT-5 Thinking Pro를 선택할 수 있는데, 응답 속도가 느린 대신 최고 수준의 정확도를 내는 모드입니다. 복잡한 프로젝트나 매우 어려운 문제를 풀 때 유용하며, 사실상 현재 OpenAI가 제공하는 최강 성능의 언어 모델이라 할 수 있습니다.
이처럼 GPT-5는 하나의 시스템 안에 경량 모델부터 최고 성능 모델까지 아우르는 구조를 취하고 있습니다. 참고로 OpenAI는 향후 별도 모드 없이 하나의 모델로 이 기능들을 통합할 계획이라고 밝혔습니다. 즉, 지금은 라우터가 Chat/Thinking 두 모델을 스위칭하지만, 궁극적으로는 단일 거대 모델이 상황에 따라 스스로 추론 “강약 조절”을 하는 방향입니다.
2. 비약적인 성능 향상 – 벤치마크로 보는 GPT-5
GPT-5는 출시와 함께 다양한 벤치마크 테스트에서 놀라운 성적을 거두며 학계와 업계의 주목을 받고 있습니다. OpenAI가 공개한 평가 결과를 종합해 보면 GPT-5는 대부분 영역에서 기존 모델들을 뛰어넘는 최고 기록을 달성했습니다. 몇 가지 주목할 만한 수치를 살펴보겠습니다:
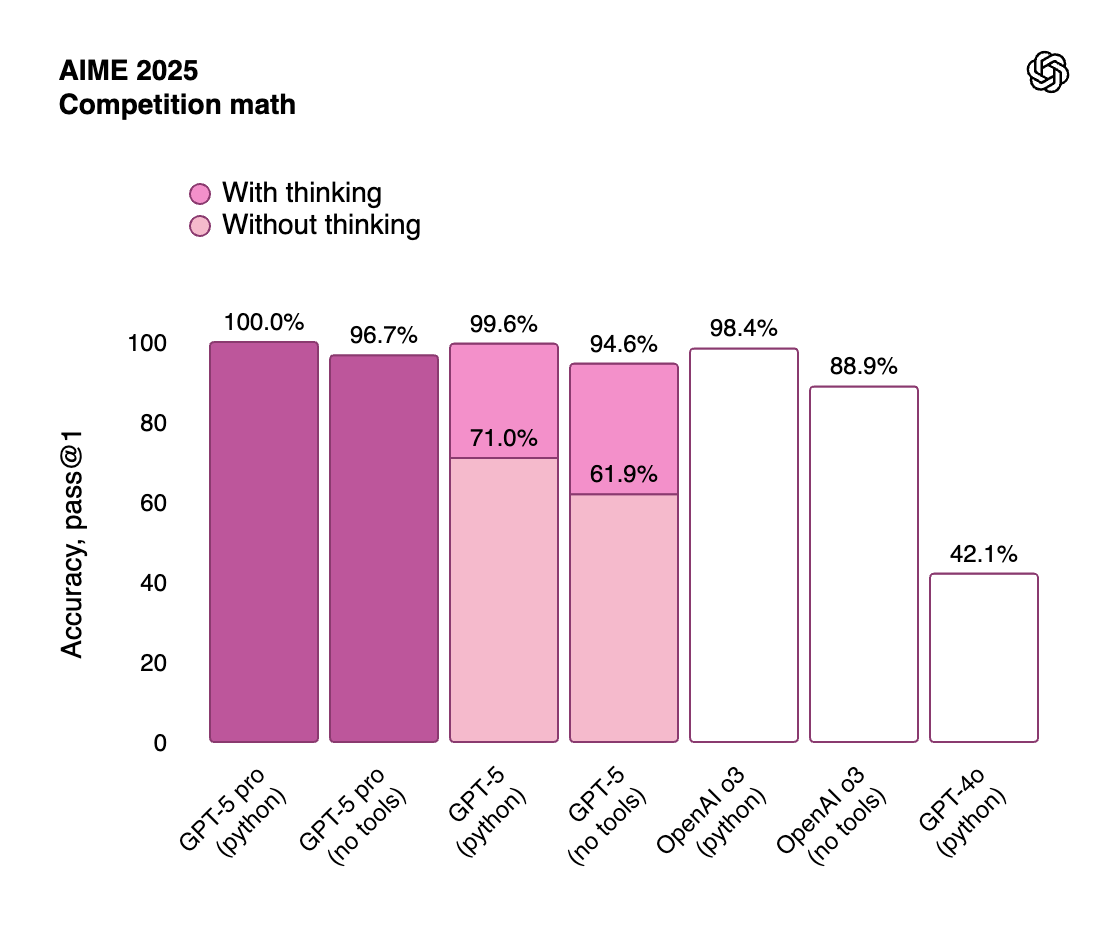
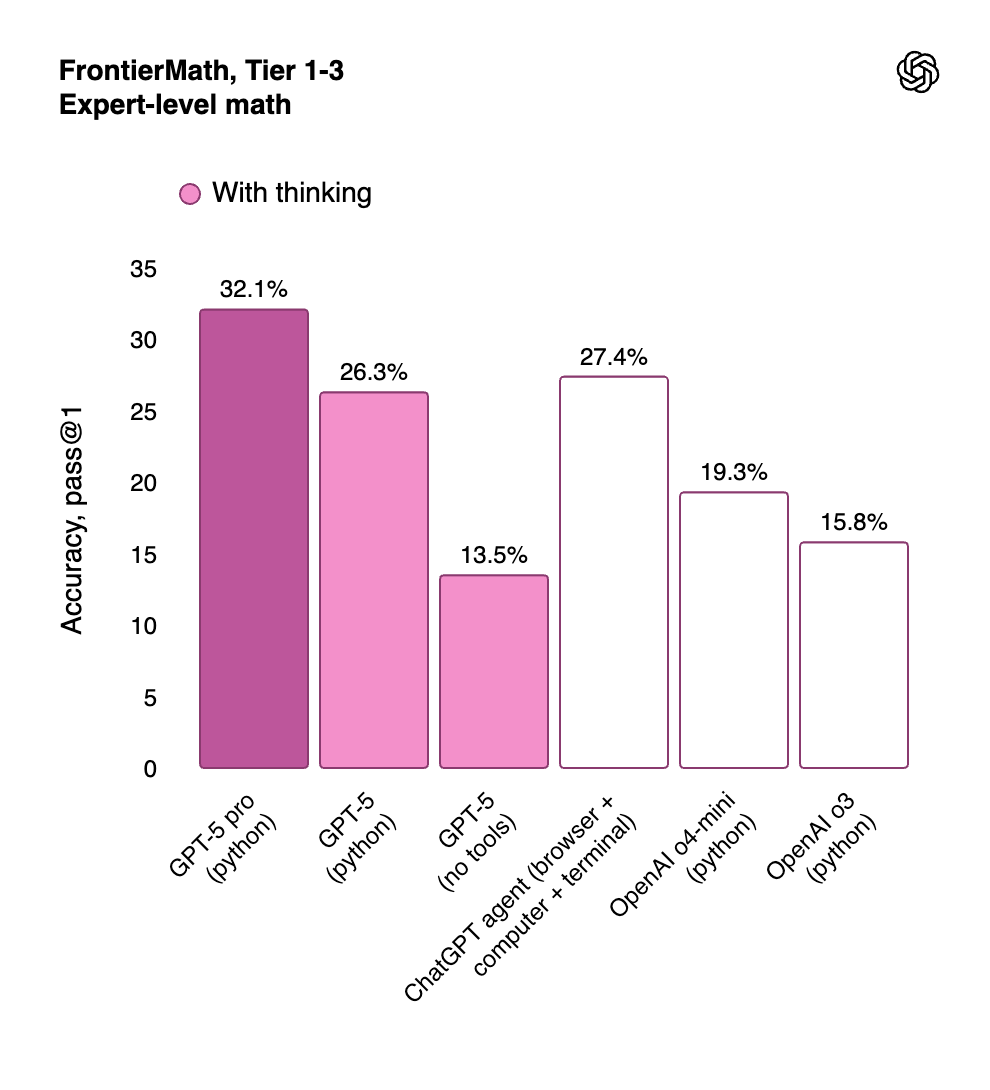
- 수리 및 논리: 미국 수학 경시대회 AIME 2025 문제에서 **94.6%**의 정답률로, GPT-4 계열 모델보다 월등히 높았습니다. 또한 추론형 수학 문제 집합인 Frontier Math에서도 기존 모델 대비 큰 향상을 보였습니다.
- 코딩: 프로그래밍 능력 평가에서 GPT-5의 강점이 두드러집니다. 예를 들어 **SWE-bench (대규모 소프트웨어 엔지니어링 테스트)**에서 **74.9%**의 점수로 OpenAI의 이전 최고 모델(o3)을 앞섰고, **다중언어 코딩 테스트(Aider polyglot)**에서도 **88%**의 높은 정확도를 보였습니다. 실무적인 프론트엔드 개발 과제에서는 내부 테스트 결과 GPT-5가 이전 모델 대비 70% 이상 우수한 코드를 작성했다는 보고도 있습니다.
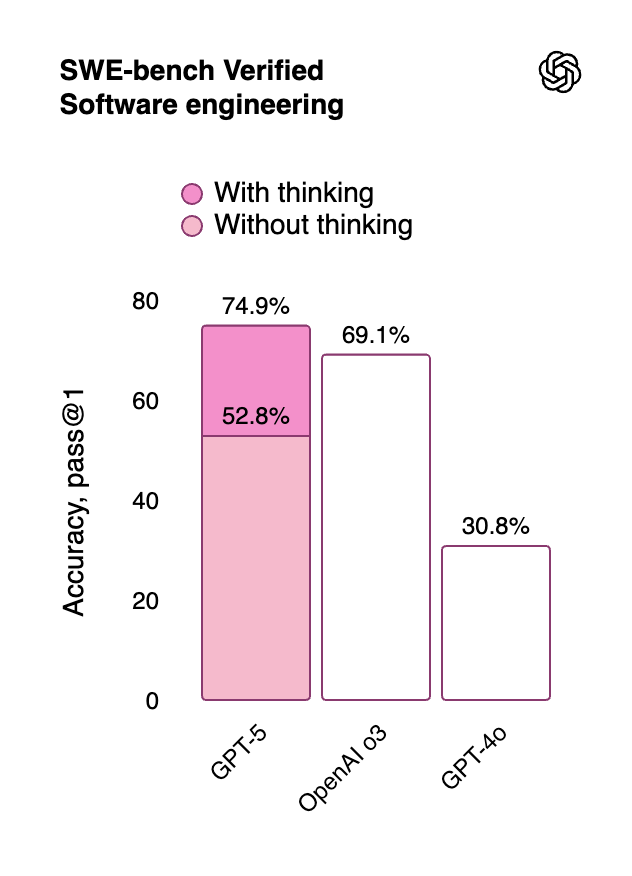
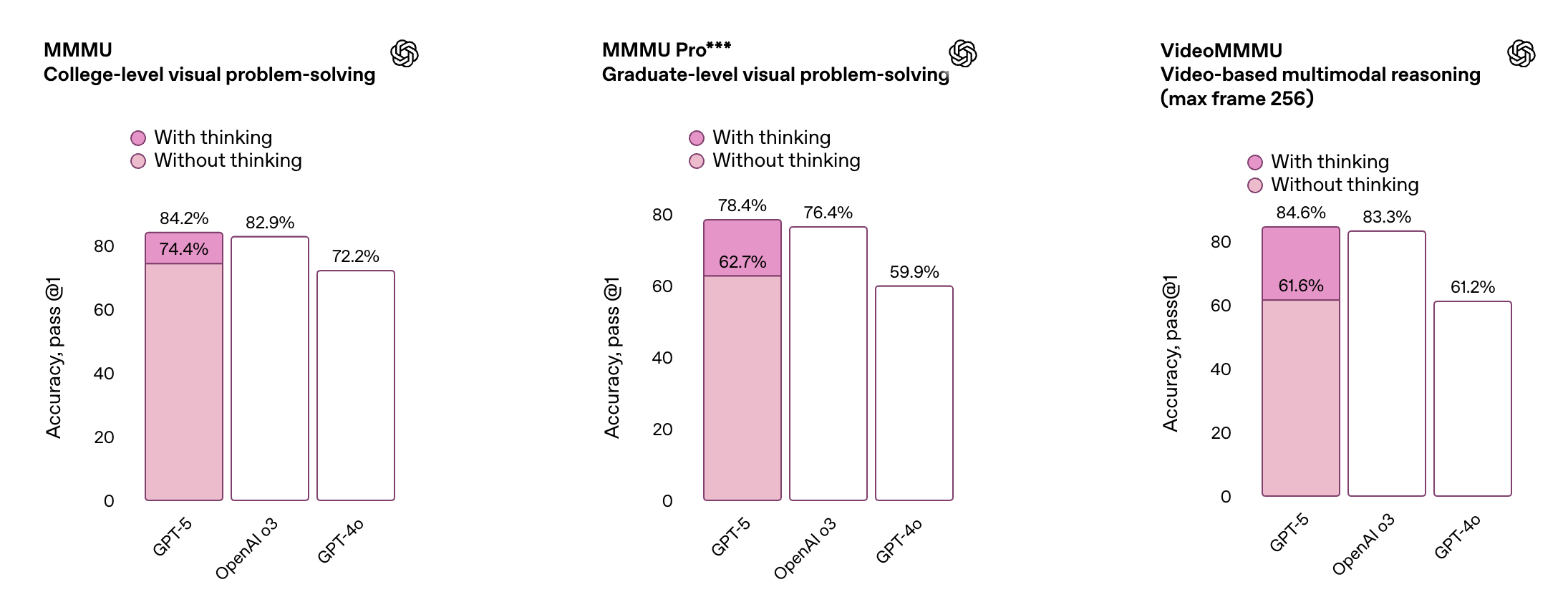
- 멀티모달 이해: 이미지와 텍스트를 함께 다루는 MMMU 벤치마크(Multimodal Massive Multitask Unit)에서 **84.2%**로, 멀티모달 능력 역시 SOTA 수준임을 입증했습니다. 시각 정보를 해석하여 답하는 CharXiv 테스트에서도 GPT-5는 탁월한 성능을 보였고, 동영상 이해 평가(VideoMMMU)에서도 높은 점수를 얻었습니다.
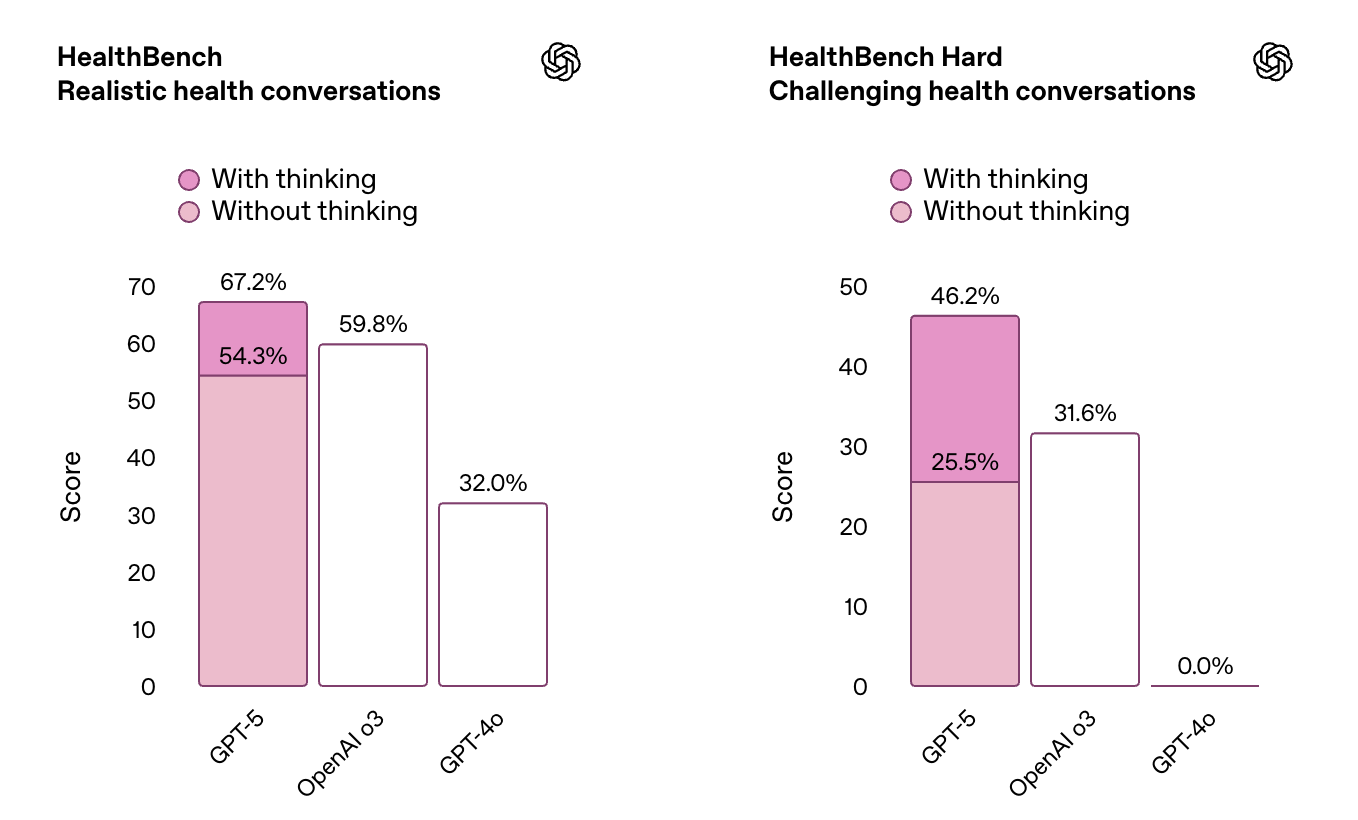
- 의료 및 전문 지식: **의학 지식 평가(HealthBench Hard)**에서 GPT-5는 **46.2%**의 점수로, 이전 GPT-4 모델들을 제치고 최고점을 기록했습니다. 또한 법률, 물류, 영업, 엔지니어링 등 40여 개 직업 분야의 복잡한 업무 수행 평가에서 GPT-5는 고도의 추론 모드 활용 시 약 절반 정도의 작업에서 인간 전문가 수준 혹은 그 이상의 성과를 냈다고 합니다. 이는 생산성 도구로서 GPT-5의 가능성을 보여주는 대목입니다.
- 종합적 지능 지표: OpenAI 내부 종합 평가에서 GPT-5는 전 세대 모델인 GPT-4o 대비 더 적은 토큰으로 동일 작업을 수행하는 효율성까지 겸비했다고 합니다. 동일한 난이도의 문제를 풀 때 GPT-5는 o3 모델보다 50~80% 적은 단어로 답을 산출하면서도 더 나은 성능을 냈다고 합니다. 이는 추론의 효율성이 대폭 개선되었음을 의미합니다.
이러한 수치들은 결국 사용자가 체감하게 될 변화로 이어집니다. GPT-5는 답변의 정확도와 깊이, 그리고 다양한 분야에 걸친 전문성 면에서 확실히 한 단계 업그레이드되었습니다. 이제 실제 사례를 통해 구체적인 향상 내용을 알아보겠습니다.
예시: GPT-5의 향상된 코딩 능력 – 한 사용자가 GPT-5에게 **“장애물을 점프하여 생존 시간을 늘리는 간단한 HTML5 러닝 게임을 만들어줘”**라고 한 프롬프트 하나만 던졌을 때, GPT-5는 캐릭터 애니메이션부터 파라allax 배경이 적용된 컬러풀한 UI, 점수 기록 및 재시작 버튼, 효과음까지 모두 갖춘 완성형 게임 코드를 즉석에서 작성했습니다. 이전 세대에서는 여러 차례의 피드백과 수정이 필요했겠지만, GPT-5는 디자인 감각까지 가미하여 한 번에 결과물을 만든 것입니다. 이는 개발 현장에서 GPT-5가 전문 프론트엔드 엔지니어 수준의 결과물을 빠르게 생성할 수 있음을 보여주는 인상적인 사례입니다.
또 다른 예로, 창의적 글쓰기 분야를 들 수 있습니다. GPT-4 기반 ChatGPT가 “교토의 한 과부가 여기저기서 돌아가신 남편의 양말을 발견한다”는 주제로 쓴 시는 전형적인 서정시 형태였지만, GPT-5는 같은 주제의 시에서 훨씬 선명한 이미지와 메타포로 강렬한 정서를 전달했습니다. “대나무 장대에 걸린 검은 깃발들 – 이제 존재하지 않는 나라”, “쿄토의 종소리가 저녁을 언덕 아래로 굴려 보낸다” 등의 구절은 GPT-4o의 시에서는 볼 수 없었던 수준의 문학적 깊이를 보여줍니다. 일상적인 이메일이나 보고서 작성에서도 GPT-5는 구조적으로 깔끔하고 설득력 있는 문장을 생성하는 데 더욱 능숙해졌습니다.
3. 신뢰성, 사실성(Factuality) 강화 및 안전성
대형 언어 모델을 실무에 활용하면서 가장 우려되던 점 중 하나가 이른바 **“환각(hallucination)”**이라 불리는 현상이었습니다. 모델이 자신있게 엉뚱한 사실을 지어내거나, 불확실한 답을 사실처럼 말하는 문제가 있었지요. GPT-5에서는 이러한 사실 오류와 환각 빈도가 크게 줄어들었다는 점이 여러 평가를 통해 확인됩니다.
예를 들어 LongFact와 FActScore 같은 공개 벤치마크로 측정한 결과를 보면, GPT-5는 이전 세대 모델(OpenAI o3)에 비해 환각 응답 비율이 1/5 ~ 1/8 수준으로 감소했습니다. 이는 GPT-5가 정보를 모를 때 추측으로 채우지 않고, 필요한 경우 웹 검색 등의 도구를 활용하거나 답변을 유보하는 방향으로 훈련되었음을 시사합니다. 아래 그래프는 GPT-5와 이전 모델의 몇 가지 사실성 평가에서의 환각률을 비교한 것입니다 (값이 낮을수록 정확함을 의미):
GPT-5(핑크색)와 OpenAI o3(흰색) 모델의 사실 오류 발생률 비교. GPT-5는 모든 항목에서 o3보다 훨씬 낮은 환각률을 보였다.
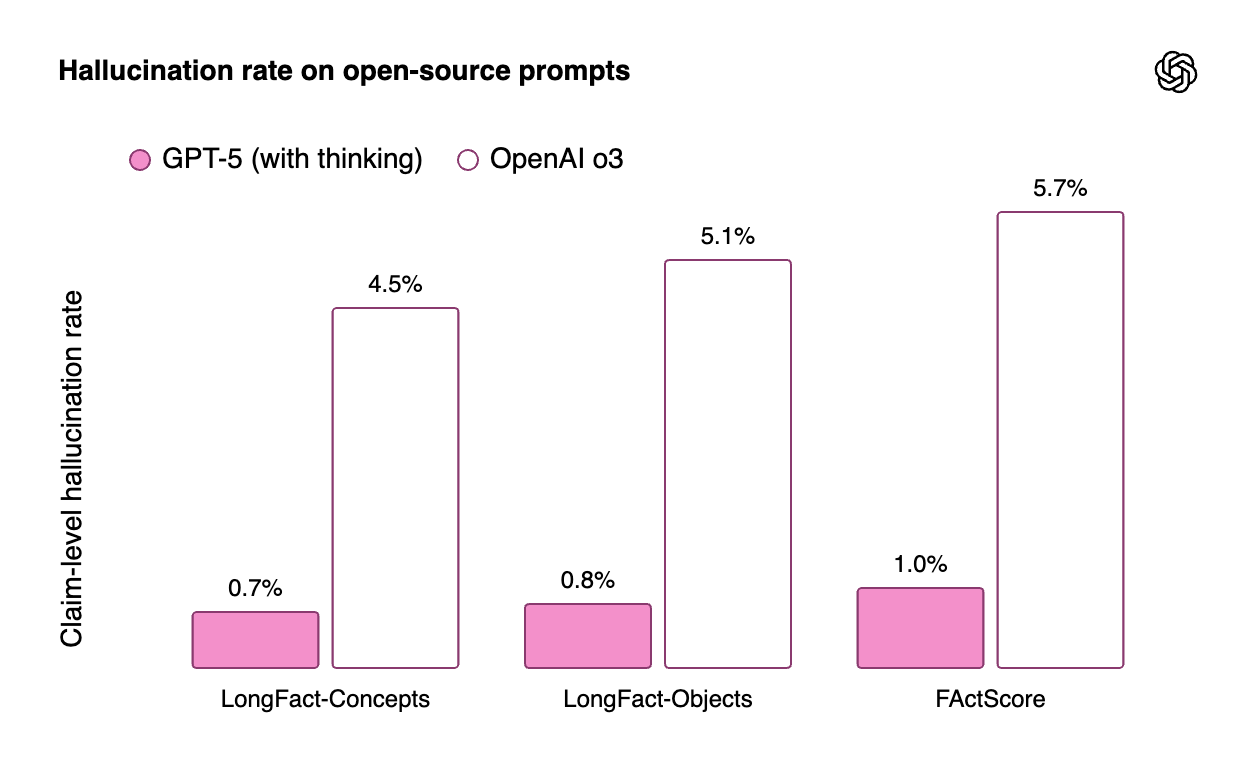
위 그래프에서 알 수 있듯, GPT-5는 이전 모델 대비 지식의 신뢰성 측면에서 큰 도약을 이루었습니다. 실제 OpenAI 내부 테스트에서, 실제 사용자의 복잡한 질의들에 대해 거짓으로 “임무 완료” 식의 답변을 하는 기만적 응답률이 GPT-5(추론 모드 기준)에서는 **2.1%**로, 이전 o3 모델의 **4.8%**에서 절반 이하로 떨어졌다고 합니다. 또한 불가능한 요청에 대한 솔직도도 높아져서, 예컨대 제공된 이미지 없이 이미지 기반 질문을 했을 때 GPT-4 계열은 86.7% 확률로 **“보이지 않는 이미지 내용을 지어낸 답”**을 했지만 GPT-5는 동일한 상황에서 9%만 그런 실수를 했다는 분석도 있습니다. 이런 개선들은 GPT-5가 사용자에게 더욱 정직하고 책임감 있는 응답을 제공하도록 설계되었음을 보여줍니다.
한편, 안전성과 가이드라인 준수 측면에서도 GPT-5는 발전했습니다. OpenAI는 GPT-5에 **새로운 안전 훈련 기법(safe-completion)**을 도입하여, 부적절한 요청에 대해 이전처럼 딱 잘라 거절하는 대신 안전한 대답으로 이끄는 방식을 연구했다고 밝혔습니다. (예: 사용자가 위험한 조언을 구하면 바로 거부하기보다 안전을 우선하며 도움이 되는 방향으로 답변). 이러한 접근은 사용자 경험을 해치지 않으면서도 AI의 출력 통제력을 높이는 방향입니다. GPT-5는 여전히 사용 정책(Usage Policies) 범위 내에서만 동작하지만, 민감한 주제에 좀 더 유연하고 책임감 있게 대응하도록 개선되었습니다.
※참고: GPT-5 개발에는 강력한 안전장치와 테스트가 수반되었습니다. OpenAI 관계자인 Johannes Heidecke는 *“GPT-oss와 GPT-5에서 전례 없는 수준의 안전장치와 테스트를 적용했다”*며, 기능 향상만큼이나 안전성 확보에 공을 들였다고 강조했습니다. 실제 GPT-5의 System Card에는 모델의 잠재적 위험성을 평가하고 완화하기 위한 여러 조치들이 상세히 적혀 있습니다 (모델이 거짓말을 학습하지 않도록 하는 추가 훈련 등).
4. GPT-5 사용법 – ChatGPT에서의 이용 및 한계
일반 사용자로서 GPT-5를 접하는 가장 쉬운 방법은 ChatGPT에서 대화 모델로 사용하는 것입니다. 다행히 GPT-5는 무료 사용자도 기본적으로 이용 가능하도록 배포되었습니다. 다만 몇 가지 이용 제한과 요금제별 차이가 있으므로 알아둘 필요가 있습니다:
기본 제공 및 모델 선택:
현재 ChatGPT에 로그인하면 기본 모델로 GPT-5가 설정되어 있습니다. 무료 플랜 사용자의 경우 모델 선택 메뉴가 따로 없으며 GPT-5로 통일되어 있습니다. 유료 플랜(Plus, Pro, Team) 사용자는 채팅창 상단의 **모델 선택기(model picker)**를 통해 GPT-5 또는 GPT-5 Thinking 모드를 수동으로 고를 수 있습니다. (Free에서는 복잡한 질문 시 자동으로 Thinking이 켜지며, Pro/Team은 Thinking Pro까지 선택 가능).
요금제별 이용량 제한:
📌 GPT-5 Free 요금제
- 5시간마다 GPT-5 메시지 10개, 하루 최대 48개, 주간 최대 336개
- 하루 1개, 주간 최대 7개의 GPT-5-Thinking 메시지
📌 GPT-5 Plus 요금제
- 3시간마다 GPT-5 메시지 80개
- 주간 최대 200개의 GPT-5-Thinking 메시지 (8.11 기준 주당 3000으로 늘린다고 함)
- 앞으로 점차 늘어날 수 있고 변동될 수 있으니, 본 블로그의 글이 8.11 기준이라 업데이트 전의 할당량일 수 있음을 주의.
📌 GPT-5 Pro 요금제
- GPT-5 및 GPT-5-Thinking 메시지 무제한
요금제별 컨텍스트 길이(Context Length)
GPT-5가 처리할 수 있는 대화 문맥의 길이도 요금제에 따라 차이가 있습니다. 무료 사용자는 약 8K 토큰(약 수천 단어)의 컨텍스트를, Plus는 32K 토큰, Pro는 128K 토큰까지 지원하는 것으로 알려졌습니다. 이는 이전 GPT-4의 한계(8K~32K)를 크게 확장한 것으로, Pro의 경우 장문 문서나 대용량 데이터도 한 번에 넣고 질문할 수 있을 정도입니다. (GPT-5 자체는 이보다 훨씬 긴 컨텍스트도 처리 가능하도록 훈련되었으며, OpenAI의 내부 테스트에서는 256K 이상의 토큰 길이에서도 작동함을 확인했습니다.)
응답 속도:
GPT-5는 전반적인 응답 지연이 GPT-4o 대비 감소하여 쾌적하지만, Thinking 모드에서는 복잡성에 따라 답변 생성에 수십 초 이상이 걸릴 수 있습니다. 예컨대 어려운 코딩 문제를 풀 때는 체감상 4~5배 정도 느려질 수 있지만, 대신 정확도는 크게 향상되므로 요구 사항에 따라 적절히 활용하면 됩니다. 빠른 응답이 필요할 땐 “Get a quick answer” 버튼으로 언제든 Thinking을 중단시킬 수 있습니다.
기존 대화 및 모델 호환:
GPT-5 출시와 함께 ChatGPT에서 그동안 쓰이던 여러 구형 모델들이 **지원 중단(deprecate)**되었습니다. GPT-4o, GPT-4.1, GPT-4.5 등 이전 모델로 진행되던 채팅을 불러오면 자동으로 가장 가까운 GPT-5 모델로 대체됩니다. 예를 들어 예전에 GPT-4.1로 작성된 채팅을 열면 GPT-5(Chat)로 전환되고, GPT-o3 모델로 한 대화는 GPT-5 Thinking 모드로 열리는 식입니다. 다만 Voice 음성 응답 모드는 당분간 여전히 GPT-4o 기반으로 작동한다는 점 참고하세요.
5. 개발자를 위한 GPT-5 – API 업데이트
이번 GPT-5 공개는 ChatGPT 서비스뿐만 아니라 OpenAI API 플랫폼에도 동시에 적용되었습니다. 개발자는 이제 자신이 만드는 애플리케이션에서 GPT-5 모델을 호출하여 활용할 수 있습니다. OpenAI는 GPT-5 API를 도입하며 몇 가지 중요한 변경 사항 및 기능 추가를 안내했습니다:
API 모델 옵션
- 모델 크기 선택 (gpt-5 / gpt-5-mini / gpt-5-nano)
gpt-5: 최고 성능을 제공하지만 비용이 가장 높음
gpt-5-mini: 성능과 비용의 균형형
gpt-5-nano: 응답 속도 빠르고 비용 저렴, 성능은 낮음
개발자는 작업 중요도와 예산에 따라 적합한 모델을 선택할 수 있습니다.
ChatGPT vs API 모델
- ChatGPT 내부 구조: 경량 응답 모델 + 심층 추론 모델 + 라우터
- API 제공 모델:
gpt-5: Thinking 모드에서 사용하는 추론 능력 최적화 단일 모델gpt-5-chat-latest: 대화형 응답에 최적화된 경량 모델 (응답 속도 중시)
새로운 API 파라미터
verbosity(low|medium|high)
응답의 길이와 상세도를 조절합니다.reasoning_effort(minimal외 기본값)
사전 사고 과정을 얼마나 거칠지 정합니다.minimal: 최대한 빠른 응답- 기본값 이상: 더 깊은 추론 과정
툴 사용 및 커스텀 툴 확장
- Function Calling 기능을 확장하여 커스텀 툴을 자연어 프롬프트로 호출 가능
- 출력 형식을 CFG (grammar) 제약으로 설정해 문자열 구조를 엄격히 통제
- 병렬 또는 연속 호출을 지원, 복잡한 워크플로우 수행 시에도 맥락 유지
Microsoft 제품군 통합
- OpenAI API뿐 아니라 MS Azure, Microsoft 365 Copilot, GitHub Copilot, Azure AI Foundry 등에서 GPT-5 활용
- Copilot 제품군에서는 문서 요약·생성 능력이 크게 향상되어 이메일 작성, Excel 데이터 요약 등에 응용 가능
6. GPT-5의 장점과 한계 (Pros & Cons)
마지막으로, 이번 GPT-5 업데이트의 장단점을 정리하며 글을 마무리하겠습니다. 새로운 모델의 도입은 분명히 AI 활용에 있어 커다란 진일보를 의미하지만, 동시에 알아두어야 할 한계나 고려사항도 존재합니다.
✅ GPT-5 장점 요약:
- 탁월한 성능 향상: GPT-4를 넘어서는 최첨단(SOTA) 성능을 다수 분야에서 입증하였고, 빠른 응답 + 심층 추론 두 마리 토끼를 잡았습니다. 코딩, 수학, 글쓰기, 의료 상담 등에서 더 정확하고 유용한 답변을 기대할 수 있습니다.
- 향상된 사실성: 환각 및 잘못된 정보가 크게 감소하여, 답변의 신뢰도가 높아졌습니다. 어려운 질문에도 모르는 척 하지 않고 최선의 진실에 가까운 답변을 제공하려는 경향이 강화되었습니다.
- 향상된 사용자 경험: 모델 통합으로 사용 편의성이 좋아졌습니다. 이제 하나의 GPT-5가 자동으로 모드 전환을 하므로, 사용자는 모델을 번갈아 선택할 필요 없이 일관된 경험을 누릴 수 있습니다. 또한 다양한 대화 스타일 선택 등 부가 기능이 추가되어 재미와 활용도가 높아졌습니다.
- 멀티모달 & 도구 활용: GPT-5는 이미지, 표, 파일 등 비언어적 입력에 대한 이해력이 더욱 좋아졌고, ChatGPT의 **모든 플러그인(tool)**을 제약 없이 사용할 수 있습니다. 따라서 정보를 찾거나 데이터를 분석하는 복잡한 작업도 GPT-5 단독으로 end-to-end 수행해낼 가능성이 커졌습니다.
- 개발자 친화성: API를 통한 GPT-5 활용 시, 세분화된 모델 선택과 새 파라미터 도입 등으로 유연성이 높아졌습니다. 또한
gpt-5-chat경량 모델 제공으로 실시간성이 중요한 애플리케이션에도 대응하고, 툴 사용 능력 개선으로 에이전트 개발에도 탄력이 붙을 전망입니다.
❗ GPT-5 한계 및 유의점:
- 일반인들에게는 모델 통합으로 인해 큰 사용자 편의성을 제공해주었지만, 전문가들에게는 기대했던 만큼의 벤치마크 성능 향상이 일어나지는 않았다고 합니다.
- 그래도 OpenAI 측에서는 사용자 편의성을 대폭 강화하는데 초점을 맞췄기 때문에 사용자 입장에서는 많은 편의성을 제공해줄 것이라 예측됩니다.
지금까지 OpenAI GPT-5의 주요 업데이트 내용과 영향을 살펴보았습니다.
즐겁고 유익한 GPT-5 활용 경험이 되시길 바라며, 앞으로 GPT-5를 직접 써보면서 성능을 체감해보시면 좋을 것 같습니다. 감사합니다.