GPT-3: Language Models are Few-Shot Learners
GPT-3는 1750억 개의 파라미터를 가진 autoregressive language model로, 대규모 언어 모델의 스케일링이 task-agnostic few-shot 성능을 크게 향상시킴을 보여줍니다. 이 모델은 별도의 gradient 업데이트나 fine-tuning 없이, 오직 텍스트 상호작용을 통해 few-shot demonstrations 만으로 다양한 NLP 태스크(번역, 질의응답, 문장 완성 등)에서 강력한 성능을 달성합니다. 특히, GPT-3는 실시간 추론이나 도메인 적응이 필요한 새로운 태스크에서도 뛰어난 능력을 보이며, 인간이 작성한 기사와 구별하기 어려운 수준의 텍스트를 생성할 수 있습니다. 논문 제목: Language Models are Few-Shot Learners
논문 요약: GPT-3: Language Models are Few-Shot Learners
- 논문 링크: NeurIPS 2020 (Advances in Neural Information Processing Systems 33 (2020): 1877-1901)
- 저자: Tom B. Brown 외 다수 (OpenAI)
- 발표 시기: 2020년, NeurIPS
- 주요 키워드: Large Language Model, Few-shot Learning, NLP
1. 연구 배경 및 문제 정의
- 문제 정의:
기존 NLP 시스템은 대규모 텍스트 코퍼스에서 사전학습된 후에도 특정 태스크에 대해 수천 또는 수만 개의 예시로 구성된 태스크별 파인튜닝 데이터셋을 필요로 한다. 이는 새로운 태스크에 대한 적용 가능성을 제한하고, 학습 데이터 내의 허위 상관관계를 악용할 가능성을 높이며, 인간이 단 몇 개의 예시나 간단한 지시만으로 새로운 언어 태스크를 수행하는 능력(적응성 및 유동성)과 큰 차이를 보인다. - 기존 접근 방식:
기존 연구는 사전학습된 언어 표현(pre-trained language representations)을 활용한 후 태스크별 파인튜닝을 수행하여 성능을 향상시켰다. GPT-2와 같은 모델은 "in-context learning"을 통해 자연어 지시 및 소수의 데모를 활용하는 메타 학습을 시도했지만, 파인튜닝 방식에 비해 성능이 현저히 낮았다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 언어 모델의 규모를 확장하는 것이 태스크 불가지론적(task-agnostic) 퓨샷(few-shot) 성능을 크게 향상시키며, 때로는 기존 SOTA 파인튜닝 접근 방식과도 경쟁할 만한 수준에 도달함을 입증했다.
- 1,750억 개의 파라미터를 가진 자기회귀(autoregressive) 언어 모델인 GPT-3를 학습시켰으며, 이는 이전의 어떤 비희소(non-sparse) 언어 모델보다 10배 더 큰 규모이다.
- GPT-3를 20개 이상의 NLP 데이터셋과 새로운 합성 태스크에 대해 그라디언트 업데이트나 파인튜닝 없이 제로샷(zero-shot), 원샷(one-shot), 퓨샷(few-shot) 설정에서 평가하여 강력한 성능을 보여주었다.
- GPT-3가 인간이 작성한 기사와 구별하기 어려운 수준의 합성 뉴스 기사를 생성할 수 있음을 정성적으로 입증했다.
- 대규모 언어 모델 학습 시 발생하는 테스트 데이터 오염(data contamination) 문제를 체계적으로 측정하고 분석하는 방법론을 제시했다.
- 제안 방법:
GPT-3는 GPT-2와 동일한 모델 및 아키텍처(수정된 초기화, 사전 정규화, 가역 토큰화)를 사용하며, Transformer 레이어에서 dense attention과 locally banded sparse attention 패턴을 번갈아 사용한다. 학습 데이터셋은 필터링 및 퍼지 중복 제거된 Common Crawl, WebText2, Books1, Books2, Wikipedia 등 총 3천억 개의 토큰으로 구성되었다. 평가 시에는 모델의 가중치를 업데이트하지 않고, 태스크 설명과 함께 컨텍스트 윈도우(2048 토큰) 내에 1개(원샷) 또는 10~100개(퓨샷)의 데모 예시를 제공하여 모델이 다음 내용을 예측하도록 하는 "in-context learning" 방식을 사용한다.
3. 실험 결과
- 데이터셋:
Penn Tree Bank (PTB), LAMBADA, HellaSwag, StoryCloze (언어 모델링 및 완성), Natural Questions, WebQuestions, TriviaQA (폐쇄형 질문 응답), WMT'14 Fr En, WMT'16 De En, WMT'16 Ro En (번역), Winograd Schemas Challenge, Winogrande (Winograd 스타일), PIQA, ARC, OpenBookQA (상식 추론), CoQA, DROP, QuAC, SQuADv2, RACE (독해), SuperGLUE 벤치마크 스위트 (BoolQ, CB, COPA, RTE, WiC, WSC, MultiRC, ReCoRD), ANLI (자연어 추론), 산술 연산, 단어 재배열, SAT 유추, 뉴스 기사 생성, 새로운 단어 사용, 영어 문법 교정 등 다양한 NLP 태스크 및 합성 태스크. 모든 모델은 Microsoft의 고대역폭 클러스터에 있는 V100 GPU에서 학습되었다. - 주요 결과:
- 전반적인 성능 확장: 모델 크기가 커질수록 제로샷, 원샷, 퓨샷 설정 모두에서 성능이 꾸준히 향상되었으며, 특히 퓨샷 학습의 이점이 커졌다.
- SOTA 달성 및 근접: PTB 언어 모델링에서 새로운 SOTA를 달성했으며, LAMBADA, TriviaQA (퓨샷), PIQA (퓨샷) 등 여러 태스크에서 기존 SOTA를 능가하거나 근접한 성능을 보였다. 특히 TriviaQA 퓨샷 결과는 오픈 도메인 파인튜닝 SOTA와 일치하거나 능가했다.
- 인간 수준의 텍스트 생성: GPT-3가 생성한 약 200~500단어 길이의 뉴스 기사는 인간 평가자들이 약 52%의 정확도로만 기계 생성임을 식별할 수 있어, 거의 인간이 작성한 것과 구별하기 어려운 수준임을 입증했다.
- 새로운 능력 발현: 산술 연산(2자리 덧셈 100%, 3자리 덧셈 80.4% 퓨샷), 단어 재배열, SAT 유추(65.2% 퓨샷, 대학 지원자 평균과 유사) 등 학습 데이터에 명시적으로 존재하지 않았을 수 있는 태스크에서도 상당한 능력을 보여주었다.
- 한계점: ANLI, WiC와 같이 두 문장 간의 비교를 요구하는 자연어 추론 태스크나 일부 독해 태스크에서는 퓨샷 설정에서도 무작위 수준보다 크게 나은 성능을 보이지 못하는 약점을 드러냈다.
4. 개인적인 생각 및 응용 가능성
- 장점:
GPT-3는 파인튜닝 없이도 대규모 모델의 스케일링이 태스크 불가지론적 퓨샷 학습 능력을 극적으로 향상시킬 수 있음을 보여주며, 이는 범용 AI 시스템 개발의 중요한 이정표이다. 특히 인간과 구별하기 어려운 수준의 텍스트 생성 능력과 명시적인 학습 없이도 산술, 유추 등 다양한 태스크에서 emergent 능력을 보이는 점이 인상 깊다. 이는 미래의 AI가 훨씬 적은 데이터로도 새로운 태스크에 빠르게 적응할 수 있음을 시사한다. - 단점/한계:
여전히 문서 수준의 일관성 부족, 비논리적 문장 생성, 특정 추론(예: 상식적인 물리) 및 비교 태스크에서의 약점을 보인다. 또한, 학습 데이터에 내재된 성별, 인종, 종교 등 다양한 편향을 그대로 반영하여 고정관념적이거나 편견에 찬 콘텐츠를 생성할 수 있다는 윤리적 문제가 크다. 모델 학습 및 추론 비용이 매우 높다는 점도 실용적인 한계이다. - 응용 가능성:
고품질 콘텐츠 생성(뉴스 기사, 마케팅 문구, 창작물), 지능형 비서 및 챗봇의 자연어 이해 및 생성 능력 향상, 문법 교정 및 글쓰기 지원 도구, 교육 분야에서의 맞춤형 학습 자료 및 문제 생성, 그리고 새로운 도메인에 대한 빠른 적응을 통한 데이터 수집 비용 절감 등 광범위한 분야에 적용될 수 있다.
Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
Language Models are Few-Shot Learners
Tom B. Brown* Benjamin Mann* Nick Ryder* Melanie Subbiah* Jared Kaplan Prafulla Dhariwal Arvind Neelakantan Pranav Shyam Girish Sastry Amanda Askell Sandhini Agarwal Ariel Herbert-Voss Gretchen Krueger Tom Henighan Rewon Child Aditya Ramesh Daniel M. Ziegler Jeffrey Wu Clemens Winter Christopher Hesse Mark Chen Eric Sigler Mateusz Litwin Scott Gray Benjamin Chess Jack Clark Christopher Berner Sam McCandlish Alec Radford Ilya Sutskever Dario Amodei
OpenAI
Abstract
최근 연구들은 대규모 텍스트 코퍼스에서 사전학습(pre-training)한 후 특정 task에 대해 fine-tuning하는 방식으로 많은 NLP task 및 벤치마크에서 상당한 성능 향상을 보여주었다. 이러한 방법은 일반적으로 아키텍처는 task-agnostic하지만, 여전히 수천 또는 수만 개의 예시로 구성된 task-specific fine-tuning 데이터셋을 필요로 한다. 대조적으로, 인간은 일반적으로 단 몇 개의 예시나 간단한 지시만으로 새로운 언어 task를 수행할 수 있는데, 이는 현재 NLP 시스템이 여전히 크게 어려움을 겪는 부분이다.
본 논문에서는 언어 모델의 규모를 확장하는 것이 task-agnostic한 few-shot 성능을 크게 향상시키며, 때로는 기존 state-of-the-art fine-tuning 접근 방식과도 경쟁할 만한 수준에 도달함을 보여준다. 구체적으로, 우리는 1,750억 개의 파라미터를 가진 autoregressive language model인 GPT-3를 학습시켰는데, 이는 이전의 어떤 non-sparse language model보다 10배 더 많은 규모이다. 그리고 이 모델의 성능을 few-shot setting에서 테스트하였다.
모든 task에서 GPT-3는 어떠한 gradient 업데이트나 fine-tuning 없이 적용되었으며, task와 few-shot demonstration은 모델과의 텍스트 상호작용을 통해서만 지정되었다. GPT-3는 번역, 질문-응답, cloze task를 포함한 많은 NLP 데이터셋에서 강력한 성능을 달성했으며, 단어 재배열, 문장에서 새로운 단어 사용, 3자리 산술 연산 수행과 같이 즉석 추론(on-the-fly reasoning)이나 도메인 적응(domain adaptation)을 요구하는 여러 task에서도 좋은 성능을 보였다.
동시에, 우리는 GPT-3의 few-shot learning이 여전히 어려움을 겪는 일부 데이터셋과, 대규모 웹 코퍼스 학습과 관련된 방법론적 문제에 직면하는 일부 데이터셋도 식별하였다. 마지막으로, 우리는 GPT-3가 생성한 뉴스 기사 샘플을 인간 평가자들이 인간이 작성한 기사와 구별하기 어려워한다는 것을 발견했다. 우리는 이러한 발견과 GPT-3 전반의 광범위한 사회적 영향에 대해 논의한다.
Contents
1 서론 ..... 3 2 접근 방식 (Approach) ..... 6 2.1 모델 및 아키텍처 (Model and Architectures) ..... 8 2.2 학습 데이터셋 (Training Dataset) ..... 8 2.3 학습 과정 (Training Process) ..... 9 2.4 평가 (Evaluation) ..... 10 3 결과 (Results) ..... 10 3.1 Language Modeling, Cloze, 및 Completion Task ..... 11 3.2 Closed Book Question Answering ..... 13 3.3 번역 (Translation) ..... 14 3.4 Winograd-Style Task ..... 16 3.5 상식 추론 (Common Sense Reasoning) ..... 17 3.6 독해 (Reading Comprehension) ..... 18 3.7 SuperGLUE ..... 18 3.8 NLI ..... 20 3.9 합성 및 정성적 Task (Synthetic and Qualitative Tasks) ..... 21 4 벤치마크 암기 측정 및 방지 (Measuring and Preventing Memorization Of Benchmarks) ..... 29 5 한계점 (Limitations) ..... 33 6 광범위한 영향 (Broader Impacts) ..... 34 6.1 Language Model의 오용 (Misuse of Language Models) ..... 35 6.2 공정성, 편향, 및 표현 (Fairness, Bias, and Representation) ..... 36 6.3 에너지 사용량 (Energy Usage) ..... 39 7 관련 연구 (Related Work) ..... 39 8 결론 (Conclusion) ..... 40 A Common Crawl 필터링 세부 정보 (Details of Common Crawl Filtering) ..... 43 B 모델 학습 세부 정보 (Details of Model Training) ..... 43 C 테스트 세트 오염 연구 세부 정보 (Details of Test Set Contamination Studies) ..... 43 D Language Model 학습에 사용된 총 연산량 (Total Compute Used to Train Language Models) ..... 46 E 합성 뉴스 기사의 인간 품질 평가 (Human Quality Assessment of Synthetic News Articles) ..... 46 F GPT-3의 추가 샘플 (Additional Samples from GPT-3) ..... 48 G Task 문구 및 사양 세부 정보 (Details of Task Phrasing and Specifications) ..... 50 H 모든 모델 크기에 대한 모든 Task 결과 (Results on All Tasks for All Model Sizes) ..... 63
1 Introduction
최근 몇 년간 NLP 시스템에서는 **사전학습된 언어 표현(pre-trained language representations)**을 활용하는 경향이 두드러졌으며, 이는 점점 더 유연하고 task-agnostic한 방식으로 다운스트림 전이에 적용되고 있다.
초기에는 단일 레이어 표현이 word vector [MCCD13, PSM14]를 사용하여 학습되었고, 이는 task-specific 아키텍처에 입력되었다.
이후에는 다중 레이어 표현과 contextual state를 가진 RNN이 더 강력한 표현을 형성하는 데 사용되었다 [DL15, MBXS17, PNZtY18] (여전히 task-specific 아키텍처에 적용되었지만).
그리고 최근에는 사전학습된 recurrent 또는 Transformer language model [VSP17]이 직접 fine-tuning되어, task-specific 아키텍처의 필요성을 완전히 제거하였다 [RNSS18, DCLT18, HR18].
이러한 마지막 패러다임은 독해(reading comprehension), 질문 응답(question answering), 텍스트 함의(textual entailment) 등 많은 도전적인 NLP task에서 상당한 발전을 가져왔으며, 새로운 아키텍처와 알고리즘을 기반으로 계속 발전하고 있다 [RSR19, LOG19, YDY19, LCG19].
그러나 이 접근 방식의 주요 한계는 아키텍처가 task-agnostic함에도 불구하고, 여전히 task-specific 데이터셋과 task-specific fine-tuning이 필요하다는 점이다. 즉, 원하는 task에서 강력한 성능을 달성하려면 일반적으로 해당 task에 특화된 수천에서 수십만 개의 예시로 구성된 데이터셋에 대한 fine-tuning이 필요하다. 이러한 한계를 제거하는 것은 여러 가지 이유로 바람직하다.
첫째, 실용적인 관점에서, 새로운 task마다 대규모의 labeled example 데이터셋이 필요하다는 점은 언어 모델의 적용 가능성을 제한한다. 문법 교정부터 추상적인 개념의 예시 생성, 단편 소설 비평에 이르기까지 매우 광범위하고 유용한 언어 task들이 존재한다. 이들 중 상당수는 대규모 supervised training dataset을 수집하기 어렵고, 특히 새로운 task마다 이 과정을 반복해야 할 때 더욱 그러하다.
둘째, 학습 데이터 내의 spurious correlation을 악용할 가능성은 모델의 표현력과 학습 분포의 협소함에 따라 근본적으로 증가한다. 이는 사전학습(pre-training)과 fine-tuning 패러다임에 문제를 야기할 수 있다. 이 패러다임에서는 모델이 사전학습 동안 정보를 흡수하기 위해 크게 설계되지만, 이후 매우 협소한 task 분포에 대해 fine-tuning된다. 예를 들어 [HLW20]는 더 큰 모델이 out-of-distribution 상황에서 반드시 더 잘 일반화되는 것은 아님을 관찰했다. 이 패러다임에서 달성되는 일반화가 모델이 학습 분포에 지나치게 특화되어 외부로 잘 일반화되지 못하기 때문에 좋지 않을 수 있다는 증거가 있다 [YdC19, MPL19]. 따라서 fine-tuned 모델의 특정 벤치마크에서의 성능은, 비록 명목상 인간 수준일지라도, 실제 underlying task에서의 성능을 과장할 수 있다 [GSL18, NK19].
셋째, 인간은 대부분의 언어 task를 학습하기 위해 대규모 supervised dataset을 필요로 하지 않는다. 자연어로 된 짧은 지시(예: "이 문장이 행복한 것을 묘사하는지 슬픈 것을 묘사하는지 알려주세요") 또는 아주 적은 수의 demonstration(예: "여기 용감하게 행동하는 사람들의 두 가지 예시가 있습니다; 세 번째 용감한 행동의 예시를 들어주세요")만으로도 인간이 새로운 task를 최소한 합리적인 수준의 능력으로 수행하는 데 충분한 경우가 많다. 현재 NLP 기술의 개념적 한계를 지적하는 것 외에도, 이러한 적응성은 실용적인 이점을 가진다. 예를 들어, 인간은 긴 대화 중에 덧셈을 수행하는 것처럼 많은 task와 기술을 원활하게 혼합하거나 전환할 수 있다. 광범위하게 유용하기 위해서는 언젠가 우리의 NLP 시스템도 이러한 유동성과 일반성을 갖추기를 바란다.
 Figure 1.1: 언어 모델 메타 학습. 비지도 사전 학습 동안, 언어 모델은 광범위한 기술과 패턴 인식 능력을 개발한다. 그런 다음 추론 시 이러한 능력을 사용하여 원하는 task에 빠르게 적응하거나 인식한다. 우리는 이 과정의 내부 루프를 "in-context learning"이라고 부르며, 이는 각 시퀀스에 대한 forward-pass 내에서 발생한다. 이 다이어그램의 시퀀스는 모델이 사전 학습 동안 볼 데이터를 대표하기 위한 것이 아니라, 단일 시퀀스 내에 때때로 반복되는 하위 task가 포함될 수 있음을 보여주기 위한 것이다.
Figure 1.1: 언어 모델 메타 학습. 비지도 사전 학습 동안, 언어 모델은 광범위한 기술과 패턴 인식 능력을 개발한다. 그런 다음 추론 시 이러한 능력을 사용하여 원하는 task에 빠르게 적응하거나 인식한다. 우리는 이 과정의 내부 루프를 "in-context learning"이라고 부르며, 이는 각 시퀀스에 대한 forward-pass 내에서 발생한다. 이 다이어그램의 시퀀스는 모델이 사전 학습 동안 볼 데이터를 대표하기 위한 것이 아니라, 단일 시퀀스 내에 때때로 반복되는 하위 task가 포함될 수 있음을 보여주기 위한 것이다.
 Figure 1.2: 더 큰 모델은 in-context 정보를 점점 더 효율적으로 사용한다. 우리는 모델이 단어에서 무작위 기호를 제거하도록 요구하는 간단한 task에 대한 in-context learning 성능을 자연어 task 설명 유무에 따라 보여준다 (Sec. 3.9.2 참조). 대규모 모델의 더 가파른 "in-context learning 곡선"은 contextual 정보로부터 task를 학습하는 능력이 향상되었음을 보여준다. 우리는 광범위한 task에서 질적으로 유사한 행동을 관찰한다.
Figure 1.2: 더 큰 모델은 in-context 정보를 점점 더 효율적으로 사용한다. 우리는 모델이 단어에서 무작위 기호를 제거하도록 요구하는 간단한 task에 대한 in-context learning 성능을 자연어 task 설명 유무에 따라 보여준다 (Sec. 3.9.2 참조). 대규모 모델의 더 가파른 "in-context learning 곡선"은 contextual 정보로부터 task를 학습하는 능력이 향상되었음을 보여준다. 우리는 광범위한 task에서 질적으로 유사한 행동을 관찰한다.
이러한 문제들을 해결하기 위한 한 가지 잠재적인 방법은 **메타 학습(meta-learning)**이다. 언어 모델의 맥락에서 메타 학습은 모델이 학습 시점에 광범위한 기술과 패턴 인식 능력을 개발하고, 추론 시점에 이러한 능력을 사용하여 원하는 task에 빠르게 적응하거나 인식하는 것을 의미한다 (Figure 1.1 참조). 최근 연구 [RWC19]는 우리가 "in-context learning"이라고 부르는 방식을 통해 이를 시도한다. 이는 사전학습된 언어 모델의 텍스트 입력을 task 명세의 한 형태로 사용하는 것이다. 즉, 모델은 자연어 지시 및/또는 task의 몇 가지 demonstration에 조건화되고, 단순히 다음에 올 것을 예측함으로써 task의 추가 인스턴스를 완료하도록 기대된다.
이 접근 방식은 초기에는 어느 정도 가능성을 보였지만, 여전히 fine-tuning에 비해 훨씬 낮은 결과를 달성한다. 예를 들어 [RWC19]는 Natural Questions에서 단 4%의 성능을 달성했으며, CoQa에서 55 F1이라는 결과조차 현재 state-of-the-art에 비해 35점 이상 뒤처진다. 메타 학습이 언어 task를 해결하는 실용적인 방법으로 자리 잡기 위해서는 분명 상당한 개선이 필요하다.
언어 모델링의 또 다른 최근 경향은 앞으로 나아갈 길을 제시할 수 있다. 최근 몇 년간 Transformer language model의 용량은 크게 증가하여, 1억 개 [RNSS18]에서 3억 개 [DCLT18], 15억 개 [RWC19], 80억 개 [SPP19], 110억 개 [RSR19], 그리고 마침내 170억 개 [Tur20]의 파라미터에 이르렀다. 각 증가는 텍스트 합성 및/또는 다운스트림 NLP task에서 개선을 가져왔으며, 많은 다운스트림 task와 잘 상관관계가 있는 log loss가 규모에 따라 부드러운 개선 추세를 따른다는 증거가 있다 [KMH20]. in-context learning은 모델의 파라미터 내에 많은 기술과 task를 흡수하는 것을 포함하므로, in-context learning 능력도 규모에 따라 유사하게 강력한 이득을 보일 수 있다는 것이 타당하다.
 Figure 1.3: 42개 정확도 기반 벤치마크의 총체적 성능. zero-shot 성능은 모델 크기에 따라 꾸준히 향상되는 반면, few-shot 성능은 더 빠르게 증가하여, 더 큰 모델이 in-context learning에 더 능숙함을 보여준다. 표준 NLP 벤치마크 스위트인 SuperGLUE에 대한 더 자세한 분석은 Figure 3.8을 참조하라.
Figure 1.3: 42개 정확도 기반 벤치마크의 총체적 성능. zero-shot 성능은 모델 크기에 따라 꾸준히 향상되는 반면, few-shot 성능은 더 빠르게 증가하여, 더 큰 모델이 in-context learning에 더 능숙함을 보여준다. 표준 NLP 벤치마크 스위트인 SuperGLUE에 대한 더 자세한 분석은 Figure 3.8을 참조하라.
본 논문에서는 GPT-3라고 명명한 1,750억 개의 파라미터를 가진 autoregressive language model을 학습하고, 그 in-context learning 능력을 측정함으로써 이 가설을 검증한다. 구체적으로, 우리는 20개 이상의 NLP 데이터셋과 학습 세트에 직접 포함될 가능성이 낮은 task에 대한 빠른 적응을 테스트하기 위해 설계된 몇 가지 새로운 task에 대해 GPT-3를 평가한다. 각 task에 대해 GPT-3를 3가지 조건에서 평가한다: (a) "few-shot learning" 또는 in-context learning으로, 모델의 context window에 들어갈 수 있는 만큼의 demonstration을 허용한다 (일반적으로 10~100개). (b) "one-shot learning"으로, 단 하나의 demonstration만 허용한다. (c) "zero-shot learning"으로, demonstration은 전혀 허용되지 않고 모델에 자연어 지시만 주어진다. GPT-3는 원칙적으로 전통적인 fine-tuning 설정에서도 평가될 수 있지만, 이는 향후 연구로 남겨둔다.
Figure 1.2는 우리가 연구하는 조건들을 보여주며, 모델이 단어에서 불필요한 기호를 제거하도록 요구하는 간단한 task의 few-shot learning을 보여준다. 모델 성능은 자연어 task 설명의 추가와 모델 context 내 예시 수 의 증가에 따라 향상된다. Few-shot learning은 모델 크기에 따라 극적으로 향상되기도 한다. 이 경우의 결과는 특히 인상적이지만, 모델 크기와 in-context 예시 수에 따른 일반적인 경향은 우리가 연구하는 대부분의 task에서 유지된다. 우리는 이러한 "학습" 곡선이 gradient 업데이트나 fine-tuning을 포함하지 않으며, 단지 conditioning으로 주어지는 demonstration의 수가 증가하는 것임을 강조한다.
전반적으로, NLP task에서 GPT-3는 zero-shot 및 one-shot 설정에서 유망한 결과를 달성하며, few-shot 설정에서는 때때로 state-of-the-art와 경쟁하거나 심지어 능가하기도 한다 (state-of-the-art가 fine-tuned 모델에 의해 유지됨에도 불구하고). 예를 들어, GPT-3는 CoQA에서 zero-shot 설정에서 81.5 F1, one-shot 설정에서 84.0 F1, few-shot 설정에서 85.0 F1을 달성한다. 유사하게, GPT-3는 TriviaQA에서 zero-shot 설정에서 64.3% 정확도, one-shot 설정에서 68.0%, few-shot 설정에서 71.2%를 달성하며, 후자는 동일한 closed-book 설정에서 작동하는 fine-tuned 모델에 비해 state-of-the-art이다.
GPT-3는 또한 빠른 적응 또는 즉석 추론을 테스트하기 위해 설계된 task에서 one-shot 및 few-shot 숙련도를 보여준다. 여기에는 단어 뒤섞기, 산술 연산 수행, 그리고 한 번만 정의된 새로운 단어를 문장에서 사용하는 것이 포함된다. 우리는 또한 few-shot 설정에서 GPT-3가 인간 평가자가 인간이 생성한 기사와 구별하기 어려운 합성 뉴스 기사를 생성할 수 있음을 보여준다.
동시에, 우리는 GPT-3 규모에서도 few-shot 성능이 어려움을 겪는 몇 가지 task를 발견한다. 여기에는 ANLI 데이터셋과 같은 자연어 추론 task, 그리고 RACE 또는 QuAC와 같은 일부 독해 데이터셋이 포함된다. 이러한 한계를 포함하여 GPT-3의 강점과 약점에 대한 광범위한 특성화를 제시함으로써, 우리는 언어 모델의 few-shot learning 연구를 촉진하고 가장 진전이 필요한 부분에 주의를 환기시키고자 한다. 전반적인 결과에 대한 경험적 감각은 Figure 1.3에서 볼 수 있으며, 이는 다양한 task를 집계한 것이다 (그러나 그 자체로 엄격하거나 의미 있는 벤치마크로 간주되어서는 안 된다).
우리는 또한 "데이터 오염(data contamination)"에 대한 체계적인 연구를 수행한다. 이는 Common Crawl과 같은 데이터셋에서 고용량 모델을 학습할 때 증가하는 문제로, 웹에 해당 콘텐츠가 존재한다는 이유만으로 테스트 데이터셋의 콘텐츠가 포함될 수 있다. 본 논문에서는 데이터 오염을 측정하고 그 왜곡 효과를 정량화하기 위한 체계적인 도구를 개발한다. 데이터 오염이 대부분의 데이터셋에서 GPT-3의 성능에 미미한 영향을 미친다는 것을 발견했지만, 결과를 부풀릴 수 있는 몇몇 데이터셋을 식별했으며, 심각도에 따라 이러한 데이터셋에 대한 결과는 보고하지 않거나 별표로 표시한다.
위의 모든 내용 외에도, 우리는 **zero, one, few-shot 설정에서 GPT-3와 성능을 비교하기 위해 일련의 더 작은 모델들(1억 2,500만 개에서 130억 개의 파라미터 범위)**을 학습시켰다. 전반적으로, 대부분의 task에서 세 가지 설정 모두에서 모델 용량에 따라 비교적 부드러운 스케일링을 발견했다. 한 가지 주목할 만한 패턴은 zero-, one-, few-shot 성능 간의 격차가 모델 용량에 따라 종종 증가한다는 점인데, 이는 더 큰 모델이 더 능숙한 메타 학습자일 수 있음을 시사한다. 마지막으로, GPT-3가 보여주는 광범위한 능력 스펙트럼을 고려하여, 편향, 공정성 및 더 넓은 사회적 영향에 대한 우려를 논의하고, 이와 관련하여 GPT-3의 특성에 대한 예비 분석을 시도한다.
본 논문의 나머지 부분은 다음과 같이 구성된다. Section 2에서는 GPT-3 학습 및 평가를 위한 우리의 접근 방식과 방법론을 설명한다. Section 3에서는 zero-, one-, few-shot 설정에서 전체 task 범위에 대한 결과를 제시한다. Section 4에서는 데이터 오염(학습-테스트 중복) 문제를 다룬다. Section 5에서는 GPT-3의 한계점을 논의한다. Section 6에서는 더 넓은 영향에 대해 논의한다. Section 7에서는 관련 연구를 검토하고 Section 8에서 결론을 맺는다.
2 Approach
모델, 데이터, 학습을 포함한 우리의 기본적인 사전학습(pre-training) 접근 방식은 [RWC19]에서 설명된 과정과 유사하며, 모델 크기, 데이터셋 크기 및 다양성, 학습 기간을 상대적으로 간단하게 확장하였다. in-context learning의 사용 또한 [RWC19]와 유사하지만, 본 연구에서는 context 내 학습을 위한 다양한 설정을 체계적으로 탐구한다. 따라서 이 섹션에서는 GPT-3를 평가할, 또는 원칙적으로 평가할 수 있는 다양한 설정을 명확하게 정의하고 대조하는 것으로 시작한다. 이러한 설정들은 task-specific 데이터에 얼마나 의존하는지에 대한 스펙트럼에 놓여 있다고 볼 수 있다. 구체적으로, 이 스펙트럼에는 최소한 네 가지 지점(Figure 2.1 참조)이 있다:
- **Fine-Tuning (FT)**은 최근 몇 년간 가장 일반적인 접근 방식이었으며, 원하는 task에 특화된 supervised 데이터셋으로 학습하여 사전학습된 모델의 가중치를 업데이트하는 것을 포함한다. 일반적으로 수천에서 수십만 개의 labeled example이 사용된다. fine-tuning의 주요 장점은 많은 벤치마크에서 강력한 성능을 보인다는 것이다. 주요 단점은 모든 task마다 새로운 대규모 데이터셋이 필요하다는 점, out-of-distribution에 대한 일반화 성능이 저조할 가능성 [MPL19], 그리고 학습 데이터의 spurious feature를 악용할 가능성 [GSL18, NK19]이 있어 인간 성능과의 불공정한 비교를 초래할 수 있다는 점이다. 본 연구에서는 task-agnostic 성능에 초점을 맞추기 때문에 GPT-3를 fine-tuning하지 않지만, GPT-3는 원칙적으로 fine-tuning될 수 있으며 이는 향후 연구를 위한 유망한 방향이다.
- **Few-Shot (FS)**은 본 연구에서 추론 시 모델에 task에 대한 몇 가지 demonstration을 conditioning으로 제공하지만, 가중치 업데이트는 허용되지 않는 설정을 지칭하는 데 사용될 용어이다 [RWC19]. Figure 2.1에서 보듯이, 일반적인 데이터셋의 예시는 context와 원하는 completion(예: 영어 문장과 프랑스어 번역)을 가지며, few-shot은 개의 context와 completion 예시를 제공한 다음, 마지막으로 하나의 context 예시를 제공하여 모델이 completion을 제공하도록 하는 방식으로 작동한다. 우리는 일반적으로 를 10에서 100 사이로 설정하는데, 이는 모델의 context window()에 들어갈 수 있는 예시의 수이다. few-shot의 주요 장점은 task-specific 데이터의 필요성을 크게 줄이고, 크지만 좁은 fine-tuning 데이터셋으로부터 지나치게 좁은 분포를 학습할 가능성을 줄인다는 것이다. 주요 단점은 이 방법의 결과가 지금까지 state-of-the-art fine-tuned 모델보다 훨씬 나빴다는 것이다. 또한, 소량의 task-specific 데이터는 여전히 필요하다. 이름에서 알 수 있듯이, 여기서 설명하는 언어 모델을 위한 few-shot learning은 ML의 다른 맥락에서 사용되는 few-shot learning [HYC01, VBL+ 16]과 관련이 있다. 둘 다 광범위한 task 분포(이 경우 사전학습 데이터에 내재된)를 기반으로 학습한 다음 새로운 task에 빠르게 적응하는 것을 포함한다.
- **One-Shot (1S)**은 few-shot과 동일하지만, Figure 1에서 보듯이 task에 대한 자연어 설명 외에 단 하나의 demonstration만 허용된다. one-shot을 few-shot 및 zero-shot(아래 참조)과 구별하는 이유는 일부 task가 인간에게 전달되는 방식과 가장 유사하기 때문이다. 예를 들어, 인간 작업자 서비스(예: Mechanical Turk)에서 인간에게 데이터셋을 생성하도록 요청할 때, task에 대한 하나의 demonstration을 제공하는 것이 일반적이다. 반대로, 예시가 주어지지 않으면 task의 내용이나 형식을 전달하기 어려운 경우가 있다.
우리가 탐구하는 in-context learning의 세 가지 설정
Zero-shot
모델은 task에 대한 자연어 설명만으로 답을 예측한다. gradient 업데이트는 수행되지 않는다.

One-shot
task 설명 외에, 모델은 task의 단일 예시를 본다. gradient 업데이트는 수행되지 않는다.

task 설명 외에, 모델은 task의 몇 가지 예시를 본다. gradient 업데이트는 수행되지 않는다.
Few-shot

Traditional fine-tuning (GPT-3에는 사용되지 않음)
| Fine-tuning |
|---|
| 모델은 대규모 예시 task 코퍼스를 사용하여 반복적인 gradient 업데이트를 통해 학습된다. |

Figure 2.1: Zero-shot, one-shot, few-shot과 전통적인 fine-tuning의 대비. 위 패널들은 언어 모델로 task를 수행하는 네 가지 방법을 보여준다. fine-tuning은 전통적인 방법인 반면, 본 연구에서 다루는 zero-shot, one-shot, few-shot은 테스트 시 모델이 forward pass만으로 task를 수행하도록 요구한다. 우리는 일반적으로 few-shot 설정에서 모델에 수십 개의 예시를 제시한다. 모든 task 설명, 예시 및 prompt에 대한 정확한 문구는 Appendix G에서 찾을 수 있다.
- **Zero-Shot (0S)**은 one-shot과 동일하지만, demonstration이 전혀 허용되지 않으며, 모델에는 task를 설명하는 자연어 지시만 제공된다. 이 방법은 **최대한의 편의성, 견고성 잠재력, 그리고 spurious correlation 회피(사전학습 데이터의 대규모 코퍼스 전반에 걸쳐 매우 광범위하게 발생하지 않는 한)**를 제공하지만, 가장 도전적인 설정이기도 하다. 어떤 경우에는 이전 예시 없이는 인간조차 task의 형식을 이해하기 어려울 수 있으므로, 이 설정은 때때로 "불공평하게 어렵다". 예를 들어, 누군가에게 "200m 달리기 세계 기록 표를 만들어라"고 요청하면, 이 요청은 모호할 수 있다. 표의 정확한 형식이나 포함되어야 할 내용이 명확하지 않을 수 있기 때문이다(그리고 신중한 설명에도 불구하고, 정확히 무엇이 요구되는지 이해하기 어려울 수 있다). 그럼에도 불구하고, 적어도 일부 설정에서는 zero-shot이 인간이 task를 수행하는 방식과 가장 유사하다. 예를 들어, Figure 2.1의 번역 예시에서 인간은 텍스트 지시만으로 무엇을 해야 할지 알 수 있을 것이다.
Figure 2.1은 영어-프랑스어 번역 예시를 사용하여 네 가지 방법을 보여준다. 본 논문에서는 zero-shot, one-shot, few-shot에 초점을 맞추며, 이들을 경쟁적인 대안이 아니라 특정 벤치마크에서의 성능과 sample efficiency 사이에서 다양한 trade-off를 제공하는 다른 문제 설정으로 비교하는 것을 목표로 한다. 특히, few-shot 결과 중 상당수가 state-of-the-art fine-tuned 모델에 비해 약간 뒤처지는 수준이라는 점을 강조한다. 궁극적으로는 one-shot, 또는 때로는 zero-shot이 인간 성능과의 가장 공정한 비교처럼 보이며, 향후 연구를 위한 중요한 목표이다.
아래 섹션 2.1-2.3은 각각 모델, 학습 데이터 및 학습 과정에 대한 세부 정보를 제공한다. 섹션 2.4에서는 few-shot, one-shot, zero-shot 평가를 수행하는 방법에 대한 세부 정보를 논의한다.
| Model Name | Batch Size | Learning Rate | |||||
|---|---|---|---|---|---|---|---|
| GPT-3 Small | 125 M | 12 | 768 | 12 | 64 | 0.5 M | |
| GPT-3 Medium | 350 M | 24 | 1024 | 16 | 64 | 0.5 M | |
| GPT-3 Large | 760 M | 24 | 1536 | 16 | 96 | 0.5 M | |
| GPT-3 XL | 1.3 B | 24 | 2048 | 24 | 128 | 1 M | |
| GPT-3 2.7B | 2.7 B | 32 | 2560 | 32 | 80 | 1 M | |
| GPT-3 6.7B | 6.7 B | 32 | 4096 | 32 | 128 | 2M | |
| GPT-3 13B | 13.0 B | 40 | 5140 | 40 | 128 | 2 M | |
| GPT-3 175B or "GPT-3" | 175.0 B | 96 | 12288 | 96 | 128 | 3.2 M |
Table 2.1: 우리가 학습한 모델들의 크기, 아키텍처, 학습 하이퍼파라미터(토큰 단위 배치 크기 및 학습률). 모든 모델은 총 3천억 개의 토큰으로 학습되었다.
2.1 Model and Architectures
우리는 GPT-2 [RWC19]와 동일한 모델 및 아키텍처를 사용하며, 여기에는 **수정된 초기화(modified initialization), 사전 정규화(pre-normalization), 가역 토큰화(reversible tokenization)**가 포함된다. 단, Transformer의 layer에서 Sparse Transformer [CGRS19]와 유사하게 dense attention과 locally banded sparse attention 패턴을 번갈아 사용한다는 점이 예외이다.
ML 성능이 모델 크기에 어떻게 의존하는지 연구하기 위해, 우리는 1억 2천 5백만 개에서 1,750억 개에 이르는 8가지 다른 크기의 모델을 학습시켰으며, 이는 세 자릿수 규모의 차이를 보인다. 이 중 가장 큰 모델을 GPT-3라고 부른다.
이전 연구 [KMH20]에 따르면, 충분한 학습 데이터가 주어지면 validation loss의 스케일링은 모델 크기의 함수로서 대략적으로 매끄러운 power law를 따를 것이라고 제안한다. 다양한 크기의 모델을 학습시킴으로써 우리는 이 가설을 validation loss와 다운스트림 언어 task 모두에 대해 테스트할 수 있었다.
Table 2.1은 우리가 사용한 8가지 모델의 크기와 아키텍처를 보여준다. 여기서 는 총 학습 가능한 파라미터 수, 는 총 layer 수, 은 각 bottleneck layer의 유닛 수이다 (feedforward layer는 항상 bottleneck layer 크기의 4배, 즉 이다). 그리고 는 각 attention head의 차원이다. 모든 모델은 토큰의 context window를 사용한다. 우리는 노드 간 데이터 전송을 최소화하기 위해 깊이(depth)와 너비(width) 차원 모두에서 모델을 GPU에 분할한다. 각 모델의 정확한 아키텍처 파라미터는 GPU에 모델을 배치할 때의 계산 효율성과 로드 밸런싱을 기반으로 선택되었다. 이전 연구 [KMH20]는 validation loss가 합리적으로 넓은 범위 내에서 이러한 파라미터에 크게 민감하지 않다고 제안한다.
2.2 Training Dataset
Language Model용 데이터셋은 빠르게 확장되어, 궁극적으로는 거의 1조 단어에 달하는 Common Crawl 데이터셋 [RSR19]에 이르렀다. 이 정도 규모의 데이터셋은 동일한 시퀀스를 두 번 업데이트하지 않고도 가장 큰 모델을 학습시키기에 충분하다. 그러나 우리는 필터링되지 않거나 가볍게 필터링된 Common Crawl 버전이 더 잘 정제된(curated) 데이터셋보다 품질이 낮은 경향이 있음을 발견했다. 따라서 우리는 데이터셋의 평균 품질을 향상시키기 위해 다음 세 단계를 거쳤다: (1) 다양한 고품질 참조 코퍼스와의 유사성을 기반으로 Common Crawl의 한 버전을 다운로드하고 필터링했다. (2) 데이터셋 내외부에서 문서 수준의 fuzzy deduplication을 수행하여 중복을 방지하고, held-out validation set이 overfitting을 정확하게 측정하는 도구로서의 무결성을 유지하도록 했다. (3) Common Crawl을 보강하고 다양성을 높이기 위해 알려진 고품질 참조 코퍼스를 학습 혼합에 추가했다.
첫 두 가지 사항(Common Crawl 처리)에 대한 자세한 내용은 Appendix A에 설명되어 있다. 세 번째 사항의 경우, 우리는 확장된 WebText 데이터셋 [RWC19]을 포함한 여러 정제된 고품질 데이터셋을 추가했다. 이 WebText 데이터셋은 더 긴 기간 동안 링크를 스크랩하여 수집되었으며, [KMH20]에서 처음 설명되었다. 또한 **인터넷 기반의 두 가지 도서 코퍼스(Books1 및 Books2)**와 영문 Wikipedia도 포함되었다.
Table 2.2는 우리가 학습에 사용한 최종 데이터셋 혼합을 보여준다. Common Crawl 데이터는 2016년부터 2019년까지의 월별 Common Crawl 41개 shard에서 다운로드되었으며, 필터링 전에는 45TB의 압축된 plaintext였고, 필터링 후에는 570GB로 줄어들었다. 이는 약 4천억 개의 byte-pair-encoded token에 해당한다. 학습 중에는 데이터셋이 크기에 비례하여 샘플링되지 않고, 더 고품질이라고 판단되는 데이터셋이 더 자주 샘플링된다. 따라서 Common Crawl과 Books2 데이터셋은 학습 중 한 번 미만으로 샘플링되지만, 다른 데이터셋은 2~3번 샘플링된다. 이는 더 높은 품질의 학습 데이터를 얻기 위해 약간의 overfitting을 감수하는 방식이다.
 Figure 2.2: 학습 중 사용된 총 연산량. Scaling Laws For Neural Language Models [KMH20]의 분석에 따르면, 우리는 일반적인 경우보다 훨씬 적은 token으로 훨씬 큰 모델을 학습시킨다. 결과적으로, GPT-3 3B 모델이 RoBERTa-Large (355M 파라미터)보다 거의 10배 크지만, 두 모델 모두 사전학습 중 약 50 petaflop/s-days의 연산량을 사용했다. 이러한 계산 방법론은 Appendix D에서 확인할 수 있다.
Figure 2.2: 학습 중 사용된 총 연산량. Scaling Laws For Neural Language Models [KMH20]의 분석에 따르면, 우리는 일반적인 경우보다 훨씬 적은 token으로 훨씬 큰 모델을 학습시킨다. 결과적으로, GPT-3 3B 모델이 RoBERTa-Large (355M 파라미터)보다 거의 10배 크지만, 두 모델 모두 사전학습 중 약 50 petaflop/s-days의 연산량을 사용했다. 이러한 계산 방법론은 Appendix D에서 확인할 수 있다.
| Dataset | Quantity (tokens) | Weight in training mix | Epochs elapsed when training for 300B tokens |
|---|---|---|---|
| Common Crawl (filtered) | 410 billion | 60% | 0.44 |
| WebText2 | 19 billion | 22% | 2.9 |
| Books 1 | 12 billion | 8% | 1.9 |
| Books2 | 55 billion | 8% | 0.43 |
| Wikipedia | 3 billion | 3% | 3.4 |
Table 2.2: GPT-3 학습에 사용된 데이터셋. "Weight in training mix"는 학습 중 특정 데이터셋에서 추출되는 예시의 비율을 나타내며, 이는 데이터셋의 크기에 비례하지 않도록 의도적으로 설정되었다. 결과적으로, 3천억 개의 token으로 학습할 때, 일부 데이터셋은 학습 중 최대 3.4번까지 사용되는 반면, 다른 데이터셋은 한 번 미만으로 사용된다.
인터넷의 광범위한 데이터로 사전학습된 언어 모델, 특히 방대한 양의 콘텐츠를 기억할 수 있는 대규모 모델의 경우, 사전학습 중에 downstream task의 test 또는 development set이 의도치 않게 노출되어 오염될 수 있다는 점이 주요 방법론적 우려 사항이다. 이러한 오염을 줄이기 위해, 우리는 본 논문에서 연구된 모든 벤치마크의 development 및 test set과의 중복을 찾아 제거하려고 시도했다. 불행히도, 필터링 과정의 버그로 인해 일부 중복이 무시되었고, 학습 비용 때문에 모델을 재학습하는 것은 불가능했다. Section 4에서는 남아있는 중복의 영향을 분석하며, 향후 연구에서는 데이터 오염을 더욱 적극적으로 제거할 것이다.
2.3 Training Process
에서 밝혀진 바와 같이, 더 큰 모델은 일반적으로 더 큰 batch size를 사용할 수 있지만, 더 작은 learning rate를 필요로 한다. 우리는 학습 중 gradient noise scale을 측정하고 이를 batch size 선택에 활용하였다 [MKAT18]. Table 2.1은 우리가 사용한 파라미터 설정을 보여준다.
더 큰 모델을 메모리 부족 없이 학습시키기 위해, 우리는 각 matrix multiply 내의 model parallelism과 네트워크 layer 간의 model parallelism을 혼합하여 사용하였다. 모든 모델은 Microsoft에서 제공한 고대역폭 클러스터의 V100 GPU에서 학습되었다. 학습 과정 및 하이퍼파라미터 설정에 대한 자세한 내용은 Appendix B에 설명되어 있다.
2.4 Evaluation
Few-shot learning의 경우, 우리는 평가 세트의 각 예시에 대해 해당 task의 학습 세트에서 무작위로 개의 예시를 추출하여 조건(conditioning)으로 사용한다. 이 조건 예시들은 task에 따라 1개 또는 2개의 개행(newline)으로 구분된다. LAMBADA와 Storycloze의 경우, supervised training set이 없으므로 개발 세트에서 조건 예시를 추출하여 테스트 세트에서 평가한다. **Winograd (SuperGLUE 버전이 아닌 원본)**의 경우, 데이터셋이 하나뿐이므로 여기서 직접 조건 예시를 추출한다.
는 모델의 context window가 허용하는 최대 값까지 설정할 수 있으며, 모든 모델에서 ****이다. 일반적으로 이는 10개에서 100개의 예시를 포함할 수 있다. 값이 클수록 항상 좋은 것은 아니지만, 대개는 더 나은 성능을 보인다. 따라서 별도의 개발 세트와 테스트 세트가 있는 경우, 개발 세트에서 몇 가지 값을 실험한 후 가장 좋은 값을 테스트 세트에 적용한다. 일부 task의 경우 (Appendix G 참조), demonstration 외에 (또는 일 경우 demonstration 대신) 자연어 prompt도 사용한다.
여러 옵션 중 하나의 정답을 선택하는 객관식(multiple choice) task의 경우, 우리는 개의 컨텍스트와 정답 완성 예시를 제공한 후, 컨텍스트만 있는 하나의 예시를 제공하고, 각 완성(completion)에 대한 LM의 likelihood를 비교한다. 대부분의 task에서는 **토큰당 likelihood (길이 정규화를 위해)**를 비교하지만, 소수의 데이터셋(ARC, OpenBookQA, RACE)에서는 각 완성의 무조건부 확률로 정규화하여 개발 세트에서 추가적인 이점을 얻는다. 이는 \frac{P \text { (completion|context) }}{P(\text { completion } \mid \text { answer_context })}를 계산하는 방식으로, 여기서 answer_context는 "Answer: " 또는 "A: " 문자열이며, 완성(completion)이 답변이어야 함을 prompt하는 데 사용되지만 그 외에는 일반적이다.
이진 분류(binary classification) task의 경우, 우리는 옵션에 **더 의미 있는 이름(예: 0 또는 1 대신 "True" 또는 "False")**을 부여한 다음 객관식처럼 task를 처리한다. 때로는 [RSR19]에서 수행하는 방식과 유사하게 task를 구성하기도 한다 (자세한 내용은 Appendix G 참조).
자유 형식 완성(free-form completion) task의 경우, 우리는 [RSR19]와 동일한 매개변수로 beam search를 사용한다: **beam width는 4, length penalty는 **이다. 모델 평가는 해당 데이터셋의 표준에 따라 F1 유사도 점수, BLEU, 또는 exact match를 사용한다.
최종 결과는 **각 모델 크기 및 학습 설정(zero-, one-, few-shot)**에 대해 공개적으로 사용 가능한 경우 테스트 세트에서 보고된다. 테스트 세트가 비공개인 경우, 우리 모델은 테스트 서버에 적합하기에는 너무 큰 경우가 많으므로 개발 세트에서 결과를 보고한다. SuperGLUE, TriviaQA, PiQa와 같이 제출이 가능했던 소수의 데이터셋에 대해서는 테스트 서버에 제출했으며, 200B few-shot 결과만 제출하고 나머지는 개발 세트 결과를 보고한다.
3 Results
Figure 3.1에서는 Section 2에서 설명된 8개 모델의 학습 곡선을 보여준다. 이 그래프에는 파라미터 수가 10만 개에 불과한 6개의 추가적인 초소형 모델도 포함되어 있다. [KMH+20]에서 관찰된 바와 같이, 언어 모델링 성능은 학습 연산 자원을 효율적으로 사용할 때 power-law를 따른다. 이 경향을 두 자릿수 더 확장한 결과, 우리는 power-law에서 아주 미미한(혹은 전혀 없는) 이탈만을 관찰했다. 이러한 cross-entropy loss의 개선이 학습 코퍼스의 불필요한 세부 사항을 모델링하는 데서만 비롯된 것이 아니냐는 우려가 있을 수 있다. 그러나 다음 섹션들에서 우리는 cross-entropy loss의 개선이 광범위한 자연어 task에서 일관된 성능 향상으로 이어진다는 것을 확인할 것이다.
아래에서는 Section 2에서 설명된 8개 모델(1,750억 개의 파라미터를 가진 GPT-3와 7개의 더 작은 모델)을 광범위한 데이터셋에서 평가한다. 우리는 데이터셋을 대략적으로 유사한 task를 나타내는 9가지 범주로 그룹화했다.
Section 3.1에서는 전통적인 language modeling task와 Cloze task, 문장/단락 완성 task와 같이 language modeling과 유사한 task를 평가한다. Section 3.2에서는 "closed book" question answering task를 평가한다. 이 task는 일반 지식 질문에 답하기 위해 모델의 파라미터에 저장된 정보를 사용하는 것을 요구한다. Section 3.3에서는 모델의 **언어 간 번역 능력(특히 one-shot 및 few-shot)**을 평가한다. Section 3.4에서는 Winograd Schema와 유사한 task에서 모델의 성능을 평가한다. Section 3.5에서는 상식 추론(commonsense reasoning) 또는 질문 응답(question answering)과 관련된 데이터셋을 평가한다. Section 3.6에서는 독해(reading comprehension) task를 평가하고, Section 3.7에서는 SuperGLUE 벤치마크 스위트를 평가하며, 3.8에서는 NLI를 간략하게 탐구한다. 마지막으로 Section 3.9에서는 in-context learning 능력을 특별히 탐색하기 위해 고안된 몇 가지 추가 task를 제시한다. 이 task들은 즉석 추론(on-the-fly reasoning), 적응 능력(adaptation skills), 또는 open-ended 텍스트 합성에 중점을 둔다. 우리는 모든 task를 few-shot, one-shot, zero-shot 설정에서 평가한다.
 Figure 3.1: 연산량에 따른 성능의 부드러운 확장(Smooth scaling of performance with compute).
성능(cross-entropy validation loss로 측정)은 학습에 사용된 연산량에 따라 power-law 경향을 따른다.
[KMH+20]에서 관찰된 power-law 거동은 예측 곡선에서 작은 편차만을 보이며 두 자릿수 더 확장된다.
이 그림에서는 embedding 파라미터를 연산량 및 파라미터 수에서 제외하였다.
Figure 3.1: 연산량에 따른 성능의 부드러운 확장(Smooth scaling of performance with compute).
성능(cross-entropy validation loss로 측정)은 학습에 사용된 연산량에 따라 power-law 경향을 따른다.
[KMH+20]에서 관찰된 power-law 거동은 예측 곡선에서 작은 편차만을 보이며 두 자릿수 더 확장된다.
이 그림에서는 embedding 파라미터를 연산량 및 파라미터 수에서 제외하였다.
| Setting | PTB |
|---|---|
| SOTA (Zero-Shot) | |
| GPT-3 Zero-Shot |
Table 3.1: PTB language modeling 데이터셋에 대한 Zero-shot 결과. 다른 많은 일반적인 language modeling 데이터셋은 GPT-3의 학습 데이터에 포함된 Wikipedia 또는 다른 출처에서 파생되었기 때문에 생략되었다. [RWC+19]
3.1 Language Modeling, Cloze, and Completion Tasks
이 섹션에서는 GPT-3의 전통적인 language modeling task 성능을 테스트하고, 더불어 단일 단어 예측, 문장 또는 단락 완성, 주어진 텍스트의 가능한 완성본 중 선택과 같은 관련 task에서의 성능도 평가한다.
3.1.1 Language Modeling
우리는 [RWC19]에서 측정된 Penn Tree Bank (PTB) [MKM94] 데이터셋에 대한 zero-shot perplexity를 계산한다. 해당 연구의 4가지 Wikipedia 관련 task는 우리의 학습 데이터에 완전히 포함되어 있으므로 제외했으며, one-billion word 벤치마크 또한 데이터셋의 상당 부분이 우리의 학습 세트에 포함되어 있어 제외했다. PTB는 현대 인터넷 이전에 만들어진 데이터셋이므로 이러한 문제에서 자유롭다. 우리의 가장 큰 모델은 PTB에서 15점이라는 상당한 차이로 새로운 SOTA를 달성했으며, 20.50의 perplexity를 기록했다. PTB는 전통적인 language modeling 데이터셋이므로 one-shot 또는 few-shot 평가를 정의할 명확한 예시 구분이 없어 zero-shot만 측정했다.
3.1.2 LAMBADA
LAMBADA 데이터셋 [PKL+ 16]은 텍스트 내 장거리 의존성 모델링을 테스트한다. 모델은 문맥 단락을 읽고 문장의 마지막 단어를 예측하도록 요구받는다. 최근에는 언어 모델의 지속적인 스케일링이 이 어려운 벤치마크에서 점진적인 수익 감소(diminishing returns)를 보이고 있다는 주장이 제기되었다. [BHT 20]는 최근 두 가지 state-of-the-art 결과 ([SPP 19] 및 [Tur20]) 사이에서 모델 크기를 두 배로 늘렸음에도 불구하고 1.5%의 작은 개선에 그쳤다는 점을 언급하며, "하드웨어와 데이터 크기를 몇 배씩 계속 확장하는 것이 앞으로 나아갈 길은 아니다"라고 주장한다. 우리는 여전히 그 길이 유망하다고 생각하며, zero-shot 설정에서 GPT-3는 LAMBADA에서 76%의 성능을 달성하여 이전 state-of-the-art 대비 8%의 향상을 보였다.
| Setting | LAMBADA <br> | LAMBADA <br> | StoryCloze <br> | HellaSwag <br> |
|---|---|---|---|---|
| SOTA | ||||
| GPT-3 Zero-Shot | 83.2 | 78.9 | ||
| GPT-3 One-Shot | 84.7 | 78.1 | ||
| GPT-3 Few-Shot | 87.7 | 79.3 |
Table 3.2: cloze 및 completion task 성능. GPT-3는 LAMBADA에서 SOTA를 크게 개선했으며, 두 가지 어려운 completion prediction 데이터셋에서도 준수한 성능을 달성했다. [Tur20] [RWC 19] [LDL19]
 Figure 3.2: LAMBADA에서 언어 모델의 few-shot 능력은 정확도를 크게 향상시킨다. GPT-3 2.7B는 이 설정에서 SOTA인 17B 파라미터 Turing-NLG [Tur20]를 능가하며, GPT-3 175B는 state-of-the-art를 18% 향상시킨다. zero-shot은 본문에서 설명된 one-shot 및 few-shot과 다른 형식을 사용한다.
Figure 3.2: LAMBADA에서 언어 모델의 few-shot 능력은 정확도를 크게 향상시킨다. GPT-3 2.7B는 이 설정에서 SOTA인 17B 파라미터 Turing-NLG [Tur20]를 능가하며, GPT-3 175B는 state-of-the-art를 18% 향상시킨다. zero-shot은 본문에서 설명된 one-shot 및 few-shot과 다른 형식을 사용한다.
LAMBADA는 또한 few-shot learning의 유연성을 보여주는 사례이기도 하다. 이는 이 데이터셋에서 고전적으로 발생하는 문제를 해결하는 방법을 제공한다. LAMBADA의 completion은 항상 문장의 마지막 단어이지만, 표준 언어 모델은 이러한 세부 사항을 알 방법이 없다. 따라서 모델은 정답뿐만 아니라 단락의 다른 유효한 연속에도 확률을 할당한다. 이 문제는 과거에 stop-word filter [RWC 19] (즉, "연속" 단어를 금지하는 필터)를 통해 부분적으로 해결되었다. 반면 few-shot 설정은 **task를 cloze-test로 "프레임화"**하여 언어 모델이 예시를 통해 정확히 한 단어의 completion이 필요하다는 것을 추론할 수 있도록 한다. 우리는 다음 빈칸 채우기 형식을 사용한다:
\begin{aligned} & \text { Alice was friends with Bob. Alice went to visit her friend ___ . } \rightarrow \text { Bob } \\ & \text { George bought some baseball equipment, a ball, a glove, and a _ _ . } \rightarrow \end{aligned}이러한 형식으로 제시된 예시를 통해 GPT-3는 few-shot 설정에서 86.4%의 정확도를 달성했으며, 이는 이전 state-of-the-art 대비 18% 이상 증가한 수치이다. 우리는 few-shot 성능이 모델 크기에 따라 크게 향상됨을 관찰했다. 이 설정은 가장 작은 모델의 성능을 거의 20% 감소시키지만, GPT-3의 경우 정확도를 10% 향상시킨다. 마지막으로, 빈칸 채우기 방식은 one-shot에서는 효과적이지 않으며, 항상 zero-shot 설정보다 낮은 성능을 보인다. 아마도 이는 모든 모델이 패턴을 인식하기 위해 여전히 여러 예시를 필요로 하기 때문일 것이다.
| Setting | NaturalQS | WebQS | TriviaQA |
|---|---|---|---|
| RAG (Fine-tuned, Open-Domain) [LPP 20] | 44.5 | 45.5 | 68.0 |
| T5-11B+SSM (Fine-tuned, Closed-Book) [RRS20] | 36.6 | 44.7 | 60.5 |
| T5-11B (Fine-tuned, Closed-Book) | 34.5 | 37.4 | 50.1 |
| GPT-3 Zero-Shot | 14.6 | 14.4 | 64.3 |
| GPT-3 One-Shot | 23.0 | 25.3 | 68.0 |
| GPT-3 Few-Shot | 29.9 | 41.5 | 71.2 |
Table 3.3: 세 가지 Open-Domain QA task 결과. GPT-3는 few-shot, one-shot, zero-shot 설정에서 이전 closed book 및 open domain 설정의 SOTA 결과와 비교된다. TriviaQA few-shot 결과는 wiki split test server에서 평가되었다.
한 가지 주의할 점은 테스트 세트 오염 분석 결과, LAMBADA 데이터셋의 상당 부분이 우리 학습 데이터에 포함되어 있는 것으로 확인되었다는 것이다. 그러나 Section 4에서 수행된 분석에 따르면 성능에 미치는 영향은 미미한 것으로 나타났다.
3.1.3 HellaSwag
HellaSwag 데이터셋 [ZHB19]은 이야기나 지시문의 가장 적절한 끝 부분을 선택하는 task이다. 이 데이터셋의 예시들은 언어 모델에게는 어렵지만 인간에게는 쉬운(인간 정확도 95.6%) 방식으로 adversarial하게 추출되었다. GPT-3는 one-shot 설정에서 78.1%, few-shot 설정에서 79.3%의 정확도를 달성하여, fine-tuned된 1.5B 파라미터 언어 모델 [ZHR19]의 75.4% 정확도를 능가하지만, fine-tuned된 multi-task 모델인 ALUM이 달성한 전체 SOTA 85.6%보다는 여전히 낮은 수준이다.
3.1.4 StoryCloze
다음으로 우리는 StoryCloze 2016 데이터셋 [MCH16]에 대해 GPT-3를 평가하였다. 이 데이터셋은 다섯 문장으로 구성된 이야기의 올바른 마지막 문장을 선택하는 task이다. 여기서 GPT-3는 zero-shot 설정에서 83.2%, few-shot 설정(K=70)에서 87.7%의 성능을 달성하였다. 이는 BERT 기반 모델 [LDL19]을 사용한 fine-tuned SOTA보다는 4.1% 낮은 수치이지만, 이전 zero-shot 결과에 비해 약 10% 향상된 성능이다.
3.2 Closed Book Question Answering
이 섹션에서는 GPT-3가 광범위한 사실 지식에 대한 질문에 답하는 능력을 측정한다. 가능한 쿼리의 방대한 양 때문에, 이 task는 일반적으로 정보 검색 시스템을 사용하여 관련 텍스트를 찾고, 질문과 검색된 텍스트가 주어졌을 때 답변을 생성하도록 학습된 모델을 결합하는 방식으로 접근되어 왔다. 이러한 설정은 시스템이 잠재적으로 답변을 포함하는 텍스트를 검색하고 이를 조건으로 사용할 수 있기 때문에 "open-book"이라고 불린다.
최근 [RRS20]은 대규모 language model이 보조 정보에 조건을 걸지 않고도 질문에 직접 답하는 데 놀랍도록 뛰어난 성능을 보일 수 있음을 입증했다. 그들은 이처럼 **더 제한적인 평가 설정을 "closed-book"**이라고 명명했다. 그들의 연구는 더 높은 용량의 모델이 훨씬 더 나은 성능을 보일 수 있다는 가설을 제시하며, 우리는 GPT-3를 통해 이 가설을 테스트한다. 우리는 [RRS20]에서 사용된 Natural Questions [KPR+19], WebQuestions [BCFL13], TriviaQA [JCWZ17]의 3가지 데이터셋에 대해 동일한 분할(split)을 사용하여 GPT-3를 평가한다.
모든 결과가 closed-book 설정에서 이루어졌을 뿐만 아니라, 우리의 few-shot, one-shot, zero-shot 평가는 이전 closed-book QA 연구보다 훨씬 더 엄격한 설정을 나타낸다: 외부 콘텐츠가 허용되지 않을 뿐만 아니라, Q&A 데이터셋 자체에 대한 fine-tuning도 허용되지 않는다.
GPT-3의 결과는 Table 3.3에 나와 있다. TriviaQA에서 우리는 zero-shot 설정에서 64.3%, one-shot 설정에서 68.0%, **few-shot 설정에서 71.2%**를 달성했다. zero-shot 결과는 이미 fine-tuned T5-11B를 14.2% 능가하며, 사전학습 중 Q&A에 특화된 span prediction을 사용한 버전보다도 3.8% 더 우수하다. one-shot 결과는 3.7% 향상되었으며, fine-tuning뿐만 아니라 2,100만 개 문서의 15.3B 파라미터 dense vector index에 대한 학습된 검색 메커니즘을 활용하는 open-domain QA 시스템의 SOTA와 일치한다 [LPP+20]. GPT-3의 few-shot 결과는 이보다 3.2% 더 성능을 향상시킨다.
**WebQuestions (WebQs)**에서 GPT-3는 zero-shot 설정에서 14.4%, one-shot 설정에서 25.3%, **few-shot 설정에서 41.5%**를 달성했다. 이는 fine-tuned T5-11B의 37.4% 및 **Q&A 특화 사전학습 절차를 사용하는 fine-tuned T5-11B+SSM의 44.7%**와 비교된다. few-shot 설정의 GPT-3는 state-of-the-art fine-tuned 모델의 성능에 근접한다. 특히, TriviaQA와 비교하여 WebQS는 zero-shot에서 few-shot으로 갈 때 훨씬 더 큰 성능 향상을 보이며 (실제로 zero-shot 및 one-shot 성능은 좋지 않다), 이는 WebQs 질문 및/또는 답변 스타일이 GPT-3에게 out-of-distribution임을 시사할 수 있다. 그럼에도 불구하고, GPT-3는 이 분포에 적응하여 few-shot 설정에서 강력한 성능을 회복하는 것으로 보인다.
 Figure 3.3: TriviaQA에서 GPT-3의 성능은 모델 크기에 따라 꾸준히 증가하며, 이는 language model이 용량이 증가함에 따라 지식을 계속 흡수한다는 것을 시사한다. One-shot 및 few-shot 성능은 zero-shot 성능에 비해 크게 향상되어, SOTA fine-tuned open-domain 모델인 RAG [LPP+20]의 성능과 일치하거나 이를 능가한다.
Figure 3.3: TriviaQA에서 GPT-3의 성능은 모델 크기에 따라 꾸준히 증가하며, 이는 language model이 용량이 증가함에 따라 지식을 계속 흡수한다는 것을 시사한다. One-shot 및 few-shot 성능은 zero-shot 성능에 비해 크게 향상되어, SOTA fine-tuned open-domain 모델인 RAG [LPP+20]의 성능과 일치하거나 이를 능가한다.
**Natural Questions (NQs)**에서 GPT-3는 zero-shot 설정에서 14.6%, one-shot 설정에서 23.0%, **few-shot 설정에서 29.9%**를 달성했으며, 이는 **fine-tuned T5 11B+SSM의 36.6%**와 비교된다. WebQS와 유사하게, zero-shot에서 few-shot으로의 큰 성능 향상은 분포 변화를 시사할 수 있으며, TriviaQA 및 WebQS에 비해 경쟁력이 떨어지는 성능을 설명할 수도 있다. 특히, NQs의 질문은 Wikipedia에 특화된 매우 세분화된 지식을 다루는 경향이 있어, 이는 GPT-3의 용량과 광범위한 사전학습 분포의 한계를 시험할 수 있다.
전반적으로, 세 가지 데이터셋 중 하나에서 GPT-3의 one-shot 성능은 open-domain fine-tuning SOTA와 일치한다. 나머지 두 데이터셋에서는 fine-tuning을 사용하지 않았음에도 closed-book SOTA의 성능에 근접한다. 세 가지 데이터셋 모두에서 성능이 모델 크기에 따라 매우 꾸준히 확장되는 것을 발견했으며 (Figure 3.3 및 Appendix H Figure H.7), 이는 모델 용량이 모델 파라미터에 흡수되는 더 많은 '지식'으로 직접적으로 이어진다는 아이디어를 반영하는 것일 수 있다.
3.3 Translation
GPT-2의 경우, 용량 문제로 인해 다국어 문서 모음에서 영어 전용 데이터셋을 생성하기 위해 필터가 사용되었다. 이러한 필터링에도 불구하고 GPT-2는 다국어 능력에 대한 일부 증거를 보였으며, 남아있는 프랑스어 텍스트 10MB만으로 학습했음에도 불구하고 프랑스어와 영어 간 번역에서 비정상적으로(non-trivially) 좋은 성능을 보였다. 우리는 GPT-2에서 GPT-3로 용량을 두 자릿수 이상 늘렸기 때문에, 학습 데이터셋의 범위를 확장하여 다른 언어의 표현을 더 많이 포함시켰지만, 이는 여전히 추가 개선이 필요한 영역이다. 2.2절에서 논의했듯이, 우리 데이터의 대부분은 품질 기반 필터링만 거친 원본 Common Crawl에서 파생되었다. GPT-3의 학습 데이터는 여전히 **주로 영어(단어 수 기준 93%)**이지만, 다른 언어의 텍스트도 7% 포함하고 있다. 이 언어들은 보충 자료에 문서화되어 있다. 번역 능력을 더 잘 이해하기 위해, 우리는 분석을 확장하여 일반적으로 연구되는 두 가지 추가 언어인 독일어와 루마니아어를 포함시켰다.
기존의 비지도 기계 번역(unsupervised machine translation) 접근 방식은 종종 단일 언어 데이터셋 쌍에 대한 사전학습과 **back-translation [SHB15]**을 결합하여 두 언어를 통제된 방식으로 연결한다. 이와 대조적으로, GPT-3는 많은 언어를 단어, 문장, 문서 수준에서 자연스럽게 혼합한 학습 데이터로부터 학습한다. GPT-3는 또한 특정 task에 맞춤화되거나 설계되지 않은 단일 학습 objective를 사용한다. 그러나 우리의 one/few-shot 설정은 소량의 쌍으로 된 예시(1개 또는 64개)를 사용하기 때문에 기존의 비지도 작업과 엄격하게 비교할 수는 없다. 이는 한두 페이지 분량의 in-context 학습 데이터에 해당한다.
결과는 Table 3.4에 나와 있다. Zero-shot GPT-3는 task에 대한 자연어 설명만 받음에도 불구하고 최근의 비지도 NMT 결과보다 여전히 낮은 성능을 보인다. 그러나 각 번역 task에 대해 단 하나의 예시 demonstration만 제공하면
| Setting | En Fr | Fr En | En De | De En | En Ro | Ro En |
|---|---|---|---|---|---|---|
| SOTA (Supervised) | ||||||
| XLM [LC19] | 33.4 | 33.3 | 26.4 | 34.3 | 33.3 | 31.8 |
| MASS [STQ 19] | 34.9 | 28.3 | 35.2 | 33.1 | ||
| mBART [LGG*20] | - | - | 34.0 | 35.0 | 30.5 | |
| GPT-3 Zero-Shot | 25.2 | 21.2 | 24.6 | 27.2 | 14.1 | 19.9 |
| GPT-3 One-Shot | 28.3 | 33.7 | 26.2 | 30.4 | 20.6 | 38.6 |
| GPT-3 Few-Shot | 32.6 | 39.2 | 29.7 | 40.6 | 21.0 | 39.5 |
Table 3.4: Few-shot GPT-3는 영어로 번역할 때 기존의 비지도 NMT 작업보다 5 BLEU 더 높은 성능을 보여주며, 이는 영어 LM으로서의 강점을 반영한다. 우리는 WMT'14 Fr En, WMT'16 De En, WMT'16 Ro En 데이터셋에 대해 multi-bleu.perl로 측정된 BLEU 점수를 보고하며, XLM의 토큰화를 사용하여 기존의 비지도 NMT 작업과 가장 가깝게 비교한다. SacreBLEU [Pos18] 결과는 Appendix H에 보고되어 있다. 밑줄은 비지도 또는 few-shot SOTA를 나타내고, 굵은 글씨는 상대적 신뢰도를 가진 지도 학습 SOTA를 나타낸다. [EOAG18] [DHKH14] SacreBLEU signature: BLEU+case.mixed+numrefs.1+smooth.exp+tok.intl+version.1.2.20]
 Figure 3.4: 모델 용량이 증가함에 따른 6개 언어 쌍에 대한 few-shot 번역 성능. 모델이 확장됨에 따라 모든 데이터셋에서 일관된 성능 향상 추세가 나타나며, 영어에서 다른 언어로의 번역보다 영어로의 번역이 더 강한 경향을 보인다.
Figure 3.4: 모델 용량이 증가함에 따른 6개 언어 쌍에 대한 few-shot 번역 성능. 모델이 확장됨에 따라 모든 데이터셋에서 일관된 성능 향상 추세가 나타나며, 영어에서 다른 언어로의 번역보다 영어로의 번역이 더 강한 경향을 보인다.
| Setting | Winograd | Winogrande (XL) |
|---|---|---|
| Fine-tuned SOTA | ||
| GPT-3 Zero-Shot | 70.2 | |
| GPT-3 One-Shot | 73.2 | |
| GPT-3 Few-Shot | 77.7 |
Table 3.5: Winograd schemas의 WSC273 버전과 적대적 Winogrande 데이터셋에 대한 결과. Winograd 테스트 세트의 잠재적 오염에 대한 자세한 내용은 Section 4를 참조하라. [SBBC19] [LYN 20]
 Figure 3.5: 모델 용량이 확장됨에 따른 적대적 Winogrande 데이터셋에 대한 zero-, one-, few-shot 성능. 스케일링은 비교적 원활하며, few-shot 학습의 이득은 모델 크기에 따라 증가하고, few-shot GPT-3 175B는 fine-tuned RoBERTA-large와 경쟁력이 있다.
Figure 3.5: 모델 용량이 확장됨에 따른 적대적 Winogrande 데이터셋에 대한 zero-, one-, few-shot 성능. 스케일링은 비교적 원활하며, few-shot 학습의 이득은 모델 크기에 따라 증가하고, few-shot GPT-3 175B는 fine-tuned RoBERTA-large와 경쟁력이 있다.
성능이 7 BLEU 이상 향상되어 기존 작업과 경쟁력 있는 성능에 근접한다. 전체 few-shot 설정에서 GPT-3는 추가로 4 BLEU 더 향상되어 기존의 비지도 NMT 작업과 유사한 평균 성능을 보인다. GPT-3는 언어 방향에 따라 성능에 눈에 띄는 편차를 보인다. 연구된 세 가지 입력 언어에 대해 GPT-3는 영어로 번역할 때 기존의 비지도 NMT 작업보다 훨씬 뛰어난 성능을 보이지만, 다른 방향으로 번역할 때는 낮은 성능을 보인다. En-Ro의 성능은 기존의 비지도 NMT 작업보다 10 BLEU 이상 낮아 눈에 띄는 예외이다. 이는 거의 전적으로 영어 학습 데이터셋을 위해 개발된 GPT-2의 바이트 수준 BPE 토크나이저를 재사용했기 때문일 수 있는 약점이다. Fr-En과 De-En 모두에서 few-shot GPT-3는 우리가 찾을 수 있었던 최고의 지도 학습 결과보다 뛰어난 성능을 보이지만, 문헌에 대한 우리의 익숙하지 않음과 이러한 벤치마크가 경쟁력이 없어 보인다는 점 때문에 이러한 결과가 진정한 state of the art를 나타낸다고는 생각하지 않는다. Ro-En의 경우, few-shot GPT-3는 비지도 사전학습, 608K 레이블링된 예시에 대한 지도 fine-tuning, 그리고 back-translation [LHCG19b]의 조합으로 달성된 전체 SOTA와 0.5 BLEU 이내의 성능을 보인다. 마지막으로, 모든 언어 쌍과 세 가지 설정(zero-, one-, few-shot) 모두에서 모델 용량에 따라 성능이 꾸준히 향상되는 추세를 보인다. 이는 few-shot 결과의 경우 Figure 3.4에 나와 있으며, 세 가지 설정 모두에 대한 스케일링은 Appendix H에 나와 있다.
3.4 Winograd-Style Tasks
Winograd Schemas Challenge [LDM12]는 NLP의 고전적인 task로, 문법적으로는 모호하지만 인간에게는 의미적으로 명확한 대명사가 어떤 단어를 지칭하는지를 결정하는 문제이다. 최근 fine-tuning된 language model들은 원래 Winograd 데이터셋에서 인간에 가까운 성능을 달성했지만, adversarially-mined Winogrande 데이터셋 [SBBC19]과 같은 더 어려운 버전에서는 여전히 인간 성능에 크게 뒤처진다. 우리는 GPT-3의 성능을 Winograd와 Winogrande 모두에서, 평소와 같이 zero-shot, one-shot, few-shot 설정으로 테스트한다.
| Setting | PIQA | ARC (Easy) | ARC (Challenge) | OpenBookQA |
|---|---|---|---|---|
| Fine-tuned SOTA | 79.4 | |||
| GPT-3 Zero-Shot | 68.8 | 51.4 | 57.6 | |
| GPT-3 One-Shot | 71.2 | 53.2 | 58.8 | |
| GPT-3 Few-Shot | 70.1 | 51.5 | 65.4 |
Table 3.6: PIQA, ARC, OpenBookQA 세 가지 상식 추론 task에 대한 GPT-3 결과. GPT-3 Few-Shot PIQA 결과는 테스트 서버에서 평가되었다. PIQA 테스트 세트의 잠재적 오염 문제에 대한 자세한 내용은 Section 4를 참조하라.
 Figure 3.6: zero-shot, one-shot, few-shot 설정에서 PIQA에 대한 GPT-3 결과. 가장 큰 모델은 세 가지 조건 모두에서 개발 세트에서 해당 task의 최고 기록 점수를 초과하는 점수를 달성했다.
Figure 3.6: zero-shot, one-shot, few-shot 설정에서 PIQA에 대한 GPT-3 결과. 가장 큰 모델은 세 가지 조건 모두에서 개발 세트에서 해당 task의 최고 기록 점수를 초과하는 점수를 달성했다.
Winograd에 대해 우리는 원래의 273개 Winograd schema 세트를 사용하여 GPT-3를 테스트했으며, [RWC19]에서 설명된 것과 동일한 "partial evaluation" 방법을 사용했다. 이 설정은 SuperGLUE 벤치마크의 WSC task와 약간 다르다는 점에 유의해야 한다. SuperGLUE의 WSC task는 이진 분류로 제시되며, 이 섹션에서 설명하는 형태로 변환하기 위해 개체 추출(entity extraction)이 필요하다. Winograd에서 GPT-3는 zero-shot, one-shot, few-shot 설정에서 각각 88.3%, 89.7%, 88.6%를 달성하여 명확한 in-context learning 효과는 보이지 않았지만, 모든 경우에 state-of-the-art 및 추정된 인간 성능보다 단 몇 점 낮은 강력한 결과를 보여주었다. 오염 분석 결과 학습 데이터에 일부 Winograd schema가 포함되어 있었지만, 이는 결과에 미미한 영향만 미친 것으로 보인다 (Section 4 참조).
더 어려운 Winogrande 데이터셋에서는 in-context learning의 이점을 발견했다: GPT-3는 zero-shot 설정에서 70.2%, one-shot 설정에서 73.2%, few-shot 설정에서 77.7%를 달성했다. 비교를 위해 fine-tuned RoBERTA 모델은 79%를 달성했으며, **state-of-the-art는 fine-tuned 고용량 모델(T5)로 달성된 84.6%**이다. [SBBC19]에 따르면 해당 task의 **인간 성능은 94.0%**이다.
3.5 Common Sense Reasoning
다음으로 우리는 문장 완성, 독해, 또는 광범위한 지식 질문 답변과는 구별되는 물리적 또는 과학적 추론을 포착하려는 세 가지 데이터셋을 살펴본다. 첫 번째인 PhysicalQA (PIQA) [BZB19]는 물리 세계가 어떻게 작동하는지에 대한 상식적인 질문을 묻고, 세상에 대한 grounded understanding을 탐구하기 위해 고안되었다. GPT-3는 zero-shot에서 81.0% 정확도, one-shot에서 80.5% 정확도, few-shot에서 82.8% 정확도를 달성했다 (마지막은 PIQA의 테스트 서버에서 측정됨). 이는 fine-tuned RoBERTa의 이전 state-of-the-art인 79.4% 정확도와 비교했을 때 우수한 결과이다.
| Setting | CoQA | DROP | QuAC | SQuADv2 | RACE-h | RACE-m |
|---|---|---|---|---|---|---|
| Fine-tuned SOTA | ||||||
| GPT-3 Zero-Shot | 81.5 | 23.6 | 41.5 | 59.5 | 45.5 | 58.4 |
| GPT-3 One-Shot | 84.0 | 34.3 | 43.3 | 65.4 | 45.9 | 57.4 |
| GPT-3 Few-Shot | 85.0 | 36.5 | 44.3 | 69.8 | 46.8 | 58.1 |
Table 3.7: 독해 task 결과. RACE 결과는 정확도를 보고하며, 그 외 모든 점수는 F1이다. [JZC19] [JN20] [AI19] [QIA20] [SPP+ 19]
PIQA는 모델 크기에 따른 scaling이 상대적으로 얕고 여전히 인간 성능보다 10% 이상 낮지만, GPT-3의 few-shot 및 심지어 zero-shot 결과는 현재 state-of-the-art를 능가한다. 우리의 분석 결과 PIQA에서 잠재적인 데이터 오염 문제가 발견되어 (숨겨진 테스트 레이블에도 불구하고), 우리는 보수적으로 결과에 별표를 표시했다. 자세한 내용은 Section 4를 참조하라.
ARC [CCE18]는 3학년부터 9학년까지의 과학 시험 문제에서 수집된 객관식 질문 데이터셋이다. 간단한 통계적 또는 정보 검색 방법으로는 올바르게 답변할 수 없도록 필터링된 데이터셋의 "Challenge" 버전에서, GPT-3는 zero-shot 설정에서 51.4% 정확도, one-shot 설정에서 53.2%, few-shot 설정에서 51.5% 정확도를 달성했다. 이는 **fine-tuned RoBERTa baseline (55.9%)**인 UnifiedQA [KKS20]의 성능에 근접한다. 데이터셋의 "Easy" 버전 (언급된 baseline 접근 방식 중 하나가 올바르게 답변한 질문들)에서, GPT-3는 **68.8%, 71.2%, 70.1%**를 달성했으며, 이는 [KKS20]의 fine-tuned RoBERTa baseline을 약간 상회한다. 그러나 이 두 결과 모두 UnifiedQA가 달성한 전반적인 SOTA보다 훨씬 낮은 성능을 보이며, UnifiedQA는 challenge set에서 GPT-3의 few-shot 결과보다 27%, easy set에서 22% 더 높은 성능을 보인다.
OpenBookQA [MCKS18]에서 GPT-3는 zero-shot에서 few-shot 설정으로 갈수록 크게 향상되지만, 여전히 전반적인 SOTA에는 20점 이상 미치지 못한다. GPT-3의 few-shot 성능은 리더보드의 fine-tuned BERT Large baseline과 유사하다.
전반적으로, GPT-3를 사용한 in-context learning은 상식 추론 task에서 엇갈린 결과를 보여준다. PIQA와 ARC 모두에서 one-shot 및 few-shot 학습 설정에서 작고 일관성 없는 개선이 관찰되었지만, OpenBookQA에서는 상당한 개선이 관찰되었다. GPT-3는 새로운 PIQA 데이터셋에서 모든 평가 설정에서 SOTA를 달성했다.
3.6 Reading Comprehension
다음으로 우리는 GPT-3를 독해(reading comprehension) task에서 평가한다. 우리는 추상적(abstractive), 다중 선택(multiple choice), span 기반 답변 형식을 포함하는 5개의 데이터셋을 사용하며, 이는 대화(dialog) 및 단일 질문(single question) 설정을 모두 포함한다. 우리는 이들 데이터셋 전반에 걸쳐 GPT-3의 성능이 크게 차이 나는 것을 관찰했는데, 이는 다양한 답변 형식에 대한 GPT-3의 능력 차이를 시사한다. 일반적으로 GPT-3는 각 데이터셋에서 contextual representation을 사용하여 학습된 초기 baseline 및 초기 결과와 비슷한 수준의 성능을 보인다.
GPT-3는 자유 형식 대화 데이터셋인 CoQA [RCM19]에서 가장 좋은 성능을 보였으며 (인간 baseline과 3점 이내 차이), 교사-학생 상호작용에서 구조화된 대화 행위(dialog acts) 및 답변 span 선택 모델링을 요구하는 데이터셋인 QuAC [CHI+18]에서는 가장 낮은 성능을 보였다 (ELMo baseline보다 F1 점수 13점 낮음). **독해 맥락에서 이산 추론(discrete reasoning) 및 수리 능력(numeracy)을 테스트하는 데이터셋인 DROP [DWD+19]**에서는, few-shot 설정의 GPT-3가 원 논문의 fine-tuned BERT baseline을 능가했지만, 인간 성능 및 신경망에 symbolic system을 보강한 state-of-the-art 접근법 [RLL+19]에는 여전히 크게 못 미쳤다. **SQuAD 2.0 [RJL18]**에서는 GPT-3가 zero-shot 설정 대비 거의 10 F1 (69.8로) 향상되며 few-shot learning 능력을 보여주었다. 이를 통해 원 논문의 최고 fine-tuned 결과보다 약간 더 나은 성능을 달성했다. **중고등학교 영어 시험 문제로 구성된 다중 선택 데이터셋인 RACE [LXL+17]**에서는 GPT-3가 상대적으로 약한 성능을 보였으며, contextual representation을 활용한 초기 연구들과만 경쟁할 수 있는 수준이었고, SOTA에는 여전히 45% 뒤처졌다.
3.7 SuperGLUE
NLP task의 결과를 더 잘 통합하고 BERT 및 RoBERTa와 같은 인기 모델과 보다 체계적으로 비교하기 위해, 우리는 표준화된 데이터셋 모음인 SuperGLUE 벤치마크 [WPN 19] [WPN 19] [CLC 19] [DMST19] [RBG11] [KCR 18] [ZLL 18] [DGM06] [BHDD 06] [GMDD07] [BDD 09] [PCC18] [PHR 18]에서도 GPT-3를 평가했다. SuperGLUE 데이터셋에 대한 GPT-3의 test-set 성능은 Table 3.8에 나와 있다. few-shot 설정에서는 모든 task에 대해 학습 세트에서 무작위로 샘플링한 32개의 예시를 사용했다. WSC를 제외한 모든 task와 MultiRC에 대해서는 각 문제에 대한 context로 사용할 새로운 예시 세트를 샘플링했다. WSC와 MultiRC의 경우, 평가한 모든 문제에 대해 context로 사용하기 위해 학습 세트에서 무작위로 추출한 동일한 예시 세트를 사용했다.
 Figure 3.7: CoQA 독해 task에 대한 GPT-3 결과. GPT-3 175B는 few-shot 설정에서 85 F1을 달성했으며, 이는 측정된 인간 성능 및 state-of-the-art fine-tuned 모델보다 불과 몇 포인트 뒤처지는 수치이다. Zero-shot 및 one-shot 성능은 몇 포인트 뒤처지며, few-shot으로 인한 성능 향상은 모델이 클수록 가장 크게 나타난다.
Figure 3.7: CoQA 독해 task에 대한 GPT-3 결과. GPT-3 175B는 few-shot 설정에서 85 F1을 달성했으며, 이는 측정된 인간 성능 및 state-of-the-art fine-tuned 모델보다 불과 몇 포인트 뒤처지는 수치이다. Zero-shot 및 one-shot 성능은 몇 포인트 뒤처지며, few-shot으로 인한 성능 향상은 모델이 클수록 가장 크게 나타난다.
| SuperGLUE Average | BoolQ Accuracy | CB Accuracy | CB F1 | COPA Accuracy | RTE Accuracy | |
|---|---|---|---|---|---|---|
| Fine-tuned SOTA | 89.0 | 91.0 | 96.9 | 93.9 | 94.8 | 92.5 |
| Fine-tuned BERT-Large | 69.0 | 77.4 | 83.6 | 75.7 | 70.6 | 71.7 |
| GPT-3 Few-Shot | 71.8 | 76.4 | 75.6 | 52.0 | 92.0 | 69.0 |
| WiC Accuracy | WSC Accuracy | MultiRC Accuracy | MultiRC F1a | ReCoRD Accuracy | ReCoRD F1 | |
| Fine-tuned SOTA | 76.1 | 93.8 | 62.3 | 88.2 | 92.5 | 93.3 |
| Fine-tuned BERT-Large | 69.6 | 64.6 | 24.1 | 70.0 | 71.3 | 72.0 |
| GPT-3 Few-Shot | 49.4 | 80.1 | 30.5 | 75.4 | 90.2 | 91.1 |
Table 3.8: fine-tuned baseline 및 SOTA와 비교한 SuperGLUE에 대한 GPT-3의 성능. 모든 결과는 test set에서 보고되었다. GPT-3 few-shot은 각 task의 context 내에서 총 32개의 예시가 주어지며, gradient update는 수행하지 않는다.
 Figure 3.8: SuperGLUE 성능은 모델 크기와 context 내 예시 수에 따라 증가하며, in-context learning의 이점이 커짐을 보여준다. 값은 우리 모델이 SuperGLUE의 8개 task에 걸쳐 총 256개의 예시를 위해 task당 32개의 예시를 보았음을 의미한다. 우리는 dev set에 대한 GPT-3 값을 보고하므로, 우리 수치는 점선 참조선과 직접 비교할 수 없다 (우리의 test set 결과는 Table 3.8에 있다). BERT-Large 참조 모델은 SuperGLUE 학습 세트(125K 예시)에서 fine-tuned되었고, BERT++는 MultiNLI(392K 예시) 및 SWAG(113K 예시)에서 먼저 fine-tuned된 후 SuperGLUE 학습 세트에서 추가 fine-tuning되었다(총 630K fine-tuning 예시). 우리는 BERT-Large와 BERT++ 간의 성능 차이가 context당 하나의 예시를 사용하는 GPT-3와 context당 8개의 예시를 사용하는 GPT-3 간의 차이와 거의 동일하다는 것을 발견했다.
Figure 3.8: SuperGLUE 성능은 모델 크기와 context 내 예시 수에 따라 증가하며, in-context learning의 이점이 커짐을 보여준다. 값은 우리 모델이 SuperGLUE의 8개 task에 걸쳐 총 256개의 예시를 위해 task당 32개의 예시를 보았음을 의미한다. 우리는 dev set에 대한 GPT-3 값을 보고하므로, 우리 수치는 점선 참조선과 직접 비교할 수 없다 (우리의 test set 결과는 Table 3.8에 있다). BERT-Large 참조 모델은 SuperGLUE 학습 세트(125K 예시)에서 fine-tuned되었고, BERT++는 MultiNLI(392K 예시) 및 SWAG(113K 예시)에서 먼저 fine-tuned된 후 SuperGLUE 학습 세트에서 추가 fine-tuning되었다(총 630K fine-tuning 예시). 우리는 BERT-Large와 BERT++ 간의 성능 차이가 context당 하나의 예시를 사용하는 GPT-3와 context당 8개의 예시를 사용하는 GPT-3 간의 차이와 거의 동일하다는 것을 발견했다.
우리는 GPT-3의 task별 성능에서 넓은 범위의 차이를 관찰했다. COPA와 ReCoRD에서 GPT-3는 one-shot 및 few-shot 설정에서 거의 SOTA 성능을 달성했으며, COPA는 불과 몇 포인트 차이로 2위를 차지했고, 1위는 fine-tuned된 110억 파라미터 모델(T5)이 차지했다. WSC에서는 few-shot 설정에서 80.1%를 달성하며 여전히 비교적 강력한 성능을 보였다(GPT-3는 Section 3.4에서 설명된 원래 Winograd 데이터셋에서 88.6%를 달성한다). BoolQ, MultiRC, RTE에서는 fine-tuned BERT-Large와 거의 일치하는 합리적인 성능을 보였다. CB에서는 few-shot 설정에서 75.6%로 가능성을 보였다.
WiC는 few-shot 성능이 49.4%로 현저히 약한 부분이었다(무작위 확률 수준). 우리는 WiC(두 문장에서 단어가 같은 의미로 사용되었는지 판단하는 task)에 대해 여러 가지 다른 표현과 공식을 시도했지만, 어떤 것도 강력한 성능을 달성하지 못했다. 이는 다음 섹션(ANLI 벤치마크를 논의하는 섹션)에서 더 명확해질 현상을 암시한다. GPT-3는 few-shot 또는 one-shot 설정에서 두 문장이나 스니펫을 비교하는 일부 task(예: 두 문장에서 단어가 같은 방식으로 사용되는지 여부(WiC), 한 문장이 다른 문장의 paraphrase인지 여부, 한 문장이 다른 문장을 함축하는지 여부)에서 약점을 보이는 것으로 보인다. 이는 또한 RTE 및 CB의 비교적 낮은 점수를 설명할 수 있는데, 이들도 이 형식을 따른다. 이러한 약점에도 불구하고, GPT-3는 8개 task 중 4개에서 fine-tuned BERT-large를 능가하며, 2개 task에서는 fine-tuned된 110억 파라미터 모델이 보유한 state-of-the-art에 근접한다.
마지막으로, 우리는 few-shot SuperGLUE 점수가 모델 크기와 context 내 예시 수 모두에 따라 꾸준히 향상되어 in-context learning의 이점이 증가함을 보여준다(Figure 3.8). 우리는 를 task당 32개 예시까지 확장했으며, 그 이후에는 추가 예시가 context에 안정적으로 맞지 않는다. 값을 스윕할 때, GPT-3는 전체 SuperGLUE 점수에서 fine-tuned BERT-Large를 능가하기 위해 task당 8개 미만의 총 예시가 필요하다는 것을 발견했다.
3.8 NLI
자연어 추론(Natural Language Inference, NLI) [Fyo00]은 두 문장 간의 관계를 이해하는 능력과 관련이 있다. 실제로는 이 task가 두 개 또는 세 개의 클래스 분류 문제로 구성되는 경우가 많으며, 모델은 두 번째 문장이 첫 번째 문장에서 논리적으로 도출되는지(entailment), 첫 번째 문장과 모순되는지(contradiction), 또는 **가능성이 있는지(neutral)**를 분류한다.
 Figure 3.9: ANLI Round 3에서의 GPT-3 성능. 결과는 dev-set 기준이며, 1500개의 예시만 포함되어 있어 분산이 높다(표준 편차 1.2%로 추정). 작은 모델들은 무작위 추측 수준에 머무는 반면, few-shot GPT-3 175B는 무작위 추측과 SOTA 사이의 격차를 거의 절반으로 줄였다. ANLI Round 1과 2의 결과는 부록에 제시되어 있다.
Figure 3.9: ANLI Round 3에서의 GPT-3 성능. 결과는 dev-set 기준이며, 1500개의 예시만 포함되어 있어 분산이 높다(표준 편차 1.2%로 추정). 작은 모델들은 무작위 추측 수준에 머무는 반면, few-shot GPT-3 175B는 무작위 추측과 SOTA 사이의 격차를 거의 절반으로 줄였다. ANLI Round 1과 2의 결과는 부록에 제시되어 있다.
SuperGLUE에는 이 task의 이진(binary) 버전을 평가하는 NLI 데이터셋인 RTE가 포함되어 있다. RTE에서 GPT-3의 가장 큰 버전만이 모든 평가 설정에서 무작위 추측(56%)보다 확실히 더 나은 성능을 보였지만, few-shot 설정에서는 GPT-3가 단일 task fine-tuned BERT Large와 유사한 성능을 나타냈다. 우리는 또한 최근에 도입된 Adversarial Natural Language Inference (ANLI) 데이터셋 [NWD19]에 대해서도 평가를 수행했다. ANLI는 세 라운드(R1, R2, R3)에 걸쳐 적대적으로 추출된(adversarially mined) 자연어 추론 질문들을 포함하는 어려운 데이터셋이다. RTE와 유사하게, GPT-3보다 작은 모든 모델들은 few-shot 설정에서도 ANLI에서 거의 정확히 무작위 추측 수준(약 33%)의 성능을 보인 반면, GPT-3 자체는 Round 3에서 진전의 조짐을 보였다. ANLI R3의 결과는 Figure 3.9에 강조되어 있으며, 모든 라운드의 전체 결과는 Appendix H에서 확인할 수 있다. RTE와 ANLI 모두에서의 이러한 결과는 NLI가 언어 모델에게 여전히 매우 어려운 task이며, 이제 막 진전의 조짐을 보이기 시작했다는 점을 시사한다.
3.9 Synthetic and Qualitative Tasks
few-shot (또는 zero-shot, one-shot) 설정에서 GPT-3의 능력 범위를 탐색하는 한 가지 방법은, 모델이 간단한 즉석 연산 추론을 수행하거나, 학습 시에는 나타나지 않았을 새로운 패턴을 인식하거나, 특이한 task에 빠르게 적응해야 하는 task를 주는 것이다. 우리는 이러한 종류의 능력을 테스트하기 위해 몇 가지 task를 고안했다.
첫째, 우리는 GPT-3의 산술 연산 능력을 테스트한다. 둘째, 단어의 글자를 재배열하거나 해독하는 여러 task를 만들었는데, 이러한 task는 학습 중에 정확히 본 적이 없을 가능성이 높다. 셋째, 우리는 GPT-3의 SAT 스타일 유추 문제 해결 능력을 few-shot으로 테스트한다. 마지막으로, 우리는 문장에서 새로운 단어 사용, 영어 문법 교정, 뉴스 기사 생성을 포함한 몇 가지 정성적(qualitative) task에 대해 GPT-3를 테스트한다.
우리는 언어 모델의 테스트 시 동작에 대한 추가 연구를 촉진하기 위해 합성 데이터셋을 공개할 예정이다.
3.9.1 Arithmetic
GPT-3의 task-specific 학습 없이 간단한 산술 연산 수행 능력을 테스트하기 위해, 우리는 자연어로 GPT-3에게 간단한 산술 문제를 질문하는 10가지 소규모 테스트 세트를 개발했다:
- 2자리 덧셈 (2D+): 모델은 [0, 100) 범위에서 균일하게 샘플링된 두 정수를 더하도록 요청받으며, 질문 형식은 "Q: What is 48 plus 76? A: 124."와 같다.
- 2자리 뺄셈 (2D-): 모델은 [0, 100) 범위에서 균일하게 샘플링된 두 정수를 빼도록 요청받으며, 음수 결과가 나올 수 있다. 예시: "Q: What is 34 minus 53? A: -19".
- 3자리 덧셈 (3D+): 2자리 덧셈과 동일하지만, 숫자는 [0, 1000) 범위에서 균일하게 샘플링된다.
 Figure 3.10: 다양한 크기의 모델에 대한 few-shot 설정에서 10가지 산술 task 전체의 결과. 두 번째로 큰 모델(GPT-3 13B)에서 가장 큰 모델(GPT-3 175)로 넘어갈 때 상당한 성능 향상이 있으며, 후자는 2자리 산술 연산에서 안정적으로 정확하고, 3자리 산술 연산에서 일반적으로 정확하며, 4-5자리 산술 연산, 2자리 곱셈, 복합 연산에서 상당한 비율로 정답을 맞춘다. one-shot 및 zero-shot 결과는 appendix에 제시되어 있다.
Figure 3.10: 다양한 크기의 모델에 대한 few-shot 설정에서 10가지 산술 task 전체의 결과. 두 번째로 큰 모델(GPT-3 13B)에서 가장 큰 모델(GPT-3 175)로 넘어갈 때 상당한 성능 향상이 있으며, 후자는 2자리 산술 연산에서 안정적으로 정확하고, 3자리 산술 연산에서 일반적으로 정확하며, 4-5자리 산술 연산, 2자리 곱셈, 복합 연산에서 상당한 비율로 정답을 맞춘다. one-shot 및 zero-shot 결과는 appendix에 제시되어 있다.
- 3자리 뺄셈 (3D-): 2자리 뺄셈과 동일하지만, 숫자는 [0, 1000) 범위에서 균일하게 샘플링된다.
- 4자리 덧셈 (4D+): 3자리 덧셈과 동일하지만, 숫자는 [0, 10000) 범위에서 균일하게 샘플링된다.
- 4자리 뺄셈 (4D-): 3자리 뺄셈과 동일하지만, 숫자는 [0, 10000) 범위에서 균일하게 샘플링된다.
- 5자리 덧셈 (5D+): 3자리 덧셈과 동일하지만, 숫자는 [0, 100000) 범위에서 균일하게 샘플링된다.
- 5자리 뺄셈 (5D-): 3자리 뺄셈과 동일하지만, 숫자는 [0, 100000) 범위에서 균일하게 샘플링된다.
- 2자리 곱셈 (2Dx): 모델은 [0, 100) 범위에서 균일하게 샘플링된 두 정수를 곱하도록 요청받는다. 예시: "Q: What is 24 times 42? A: 1008".
- 한 자리 복합 연산 (1DC): 모델은 세 개의 한 자리 숫자에 대해 복합 연산을 수행하도록 요청받으며, 마지막 두 숫자에는 괄호가 포함된다. 예를 들어, "Q: What is ? A: 38 ". 세 개의 한 자리 숫자는 [0, 10) 범위에서 균일하게 선택되며, 연산은 {+,-,*} 중에서 균일하게 선택된다.
10가지 task 모두에서 모델은 정확한 정답을 생성해야 한다. 각 task에 대해 우리는 2,000개의 무작위 인스턴스로 구성된 데이터셋을 생성하고, 모든 모델을 이 인스턴스들로 평가한다.
먼저 우리는 few-shot 설정에서 GPT-3를 평가했으며, 그 결과는 Figure 3.10에 나와 있다. 덧셈과 뺄셈에서 GPT-3는 자릿수가 작을 때 강력한 숙련도를 보여주며, 2자리 덧셈에서 100% 정확도, 2자리 뺄셈에서 98.9%, 3자리 덧셈에서 80.2%, 3자리 뺄셈에서 94.2%를 달성했다. 자릿수가 증가함에 따라 성능은 감소하지만, GPT-3는 여전히 4자리 연산에서 25-26%의 정확도를, 5자리 연산에서 9-10%의 정확도를 달성하여, 더 많은 자릿수로 일반화할 수 있는 최소한의 능력을 시사한다. GPT-3는 또한 특히 계산 집약적인 연산인 2자리 곱셈에서 29.2%의 정확도를 달성했다. 마지막으로, GPT-3는 한 자리 복합 연산(예: )에서 21.3%의 정확도를 달성하여, 단일 연산을 넘어선 어느 정도의 견고성을 보여준다. Figure 3.10이 명확히 보여주듯이, 작은 모델들은 이 모든 task에서 저조한 성능을 보인다. 심지어 130억 파라미터 모델(1750억 파라미터의 전체 GPT-3 다음으로 두 번째로 큰 모델)조차 2자리 덧셈과 뺄셈을 절반 정도만 풀 수 있으며, 다른 모든 연산은 10% 미만의 성공률을 보인다.
one-shot 및 zero-shot 성능은 few-shot 성능에 비해 다소 저하되는데, 이는 task에 대한 적응(또는 최소한 task 인식)이 이러한 계산을 올바르게 수행하는 데 중요함을 시사한다. 그럼에도 불구하고, one-shot 성능은 여전히 상당히 강력하며, 전체 GPT-3의 zero-shot 성능조차 모든 작은 모델의 few-shot 학습 성능을 크게 능가한다. 전체 GPT-3의 세 가지 설정에 대한 결과는 Table 3.9에 나와 있으며, 세 가지 설정 모두에 대한 모델 용량 스케일링은 Appendix H에 나와 있다. 모델이 단순히 특정 산술 문제를 암기하는지 여부를 확인하기 위해, 우리는 테스트 세트의 3자리 산술 문제들을 가져와 학습 데이터에서 "<NUM1> + <NUM2> =" 및 "<NUM1> plus <NUM2>" 두 가지 형식으로 검색했다. 2,000개의 덧셈 문제 중 일치하는 것은 17개(0.8%)에 불과했으며, 2,000개의 뺄셈 문제 중 일치하는 것은 2개(0.1%)에 불과하여, 정답 중 극히 일부만이 암기되었을 가능성을 시사한다. 또한, 오답을 검토한 결과 모델이 종종 "1"을 올리지 않는 것과 같은 실수를 저지르는 것을 발견했는데, 이는 모델이 테이블을 암기하는 대신 실제로 관련 계산을 시도하고 있음을 시사한다. 전반적으로 GPT-3는 few-shot, one-shot, 심지어 zero-shot 설정에서도 중간 정도의 복잡한 산술 연산에서 합리적인 숙련도를 보여준다.
| Setting | 2 Dx | 1 DC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-3 Zero-shot | 76.9 | 58.0 | 34.2 | 48.3 | 4.0 | 7.5 | 0.7 | 0.8 | 19.8 | 9.8 |
| GPT-3 One-shot | 99.6 | 86.4 | 65.5 | 78.7 | 14.0 | 14.0 | 3.5 | 3.8 | 27.4 | 14.3 |
| GPT-3 Few-shot | 100.0 | 98.9 | 80.4 | 94.2 | 25.5 | 26.8 | 9.3 | 9.9 | 29.2 | 21.3 |
Table 3.9: GPT-3 175B의 기본 산술 task 결과. 는 2, 3, 4, 5자리 덧셈 또는 뺄셈, 2Dx는 2자리 곱셈이다. 1DC는 1자리 복합 연산이다. zero-shot에서 one-shot, few-shot 설정으로 갈수록 성능이 점진적으로 강해지지만, zero-shot에서도 상당한 산술 능력을 보여준다.
| Setting | CL | A 1 | A 2 | RI | RW |
|---|---|---|---|---|---|
| GPT-3 Zero-shot | 3.66 | 2.28 | 8.91 | 8.26 | 0.09 |
| GPT-3 One-shot | 21.7 | 8.62 | 25.9 | 45.4 | 0.48 |
| GPT-3 Few-shot | 37.9 | 15.1 | 39.7 | 67.2 | 0.44 |
Table 3.10: GPT-3 175B의 다양한 단어 재배열 및 단어 조작 task에 대한 zero-shot, one-shot, few-shot 설정에서의 성능. CL은 "cycle letters in word", A1은 첫 글자와 마지막 글자를 제외한 아나그램, A2는 첫 두 글자와 마지막 두 글자를 제외한 아나그램, RI는 "Random insertion in word", RW는 "reversed words"이다.
3.9.2 Word Scrambling and Manipulation Tasks
GPT-3가 소수의 예시로부터 새로운 상징적 조작(symbolic manipulation)을 학습하는 능력을 테스트하기 위해, 우리는 5가지 "문자 조작(character manipulation)" task로 구성된 작은 테스트 세트를 설계했다. 각 task는 문자 뒤섞기, 추가, 삭제 등의 조합으로 왜곡된 단어를 모델에 제공하고, 원본 단어를 복구하도록 요구한다. 5가지 task는 다음과 같다:
- Cycle letters in word (CL): 모델에 글자가 순환된 단어가 주어지고, 이어서 "=" 기호가 주어진다. 모델은 원본 단어를 생성해야 한다. 예를 들어, "lyinevitab"이 주어지면 "inevitably"를 출력해야 한다.
- Anagrams of all but first and last characters (A1): 모델에 첫 글자와 마지막 글자를 제외한 모든 글자가 무작위로 뒤섞인 단어가 주어지고, 원본 단어를 출력해야 한다. 예시: criroptuon = corruption.
- Anagrams of all but first and last 2 characters (A2): 모델에 처음 2글자와 마지막 2글자를 제외한 모든 글자가 무작위로 뒤섞인 단어가 주어지고, 원본 단어를 복구해야 한다. 예시: opoepnnt opponent.
- Random insertion in word (RI): 단어의 각 글자 사이에 무작위 구두점 또는 공백 문자가 삽입되고, 모델은 원본 단어를 출력해야 한다. 예시: s.u!c/c!e.s s i/o/n = succession.
- Reversed words (RW): 모델에 거꾸로 철자가 쓰인 단어가 주어지고, 원본 단어를 출력해야 한다. 예시: stcejbo objects.
각 task에 대해 우리는 10,000개의 예시를 생성했다. 이 예시들은 [Nor09]에서 측정된 가장 빈번한 상위 10,000개 단어 중 길이가 4자 초과 15자 미만인 단어들을 선택하여 구성되었다. few-shot 결과는 Figure 3.11에 나타나 있다. task 성능은 모델 크기에 따라 꾸준히 증가하는 경향을 보이며, 전체 GPT-3 모델은 무작위 삽입 제거 task에서 66.9%, 글자 순환 task에서 38.6%, 더 쉬운 아나그램 task에서 40.2%, 그리고 **더 어려운 아나그램 task(첫 글자와 마지막 글자만 고정된 경우)에서 15.1%**의 성능을 달성했다. 어떤 모델도 단어의 글자를 거꾸로 뒤집는 task는 수행하지 못했다.
 Figure 3.11: 다양한 모델 크기에 대한 5가지 단어 뒤섞기 task의 few-shot 성능. 모델 크기가 커질수록 전반적으로 꾸준한 성능 향상이 나타나며, 특히 random insertion task는 175B 모델에서 대부분의 경우 task를 해결하며 가파른 개선 곡선을 보인다. one-shot 및 zero-shot 성능의 스케일링은 부록에 제시되어 있다. 모든 task는 으로 수행되었다.
Figure 3.11: 다양한 모델 크기에 대한 5가지 단어 뒤섞기 task의 few-shot 성능. 모델 크기가 커질수록 전반적으로 꾸준한 성능 향상이 나타나며, 특히 random insertion task는 175B 모델에서 대부분의 경우 task를 해결하며 가파른 개선 곡선을 보인다. one-shot 및 zero-shot 성능의 스케일링은 부록에 제시되어 있다. 모든 task는 으로 수행되었다.
one-shot 설정에서는 성능이 상당히 약화되었고(절반 이상 감소), zero-shot 설정에서는 모델이 거의 어떤 task도 수행하지 못했다(Table 3.10). 이는 모델이 실제로 테스트 시점에 이러한 task를 학습하는 것으로 보이며, 모델이 zero-shot으로 이들을 수행할 수 없고, 이들의 인위적인 특성상 사전학습 데이터에 나타날 가능성이 낮기 때문이다(확실하게 확인할 수는 없지만).
우리는 **"in-context learning curves"**를 그려 in-context 예시 수에 따른 task 성능을 시각화하여 성능을 더욱 정량화할 수 있다. Figure 1.2에서는 Symbol Insertion task에 대한 in-context learning curves를 보여준다. 우리는 더 큰 모델이 task 예시와 자연어 task 설명 모두를 포함하여 in-context 정보를 점점 더 효과적으로 활용할 수 있음을 확인할 수 있다.
마지막으로, 이러한 task를 해결하려면 문자 수준의 조작이 필요하다는 점을 덧붙일 가치가 있다. 반면 우리의 BPE 인코딩은 단어의 상당 부분(평균적으로 토큰당 약 0.7단어)을 처리하므로, LM의 관점에서 이러한 task를 성공적으로 수행한다는 것은 단순히 BPE 토큰을 조작하는 것을 넘어 그 하위 구조를 이해하고 분해하는 것을 포함한다. 또한, CL, A1, A2는 단사 함수(bijective)가 아니므로(즉, 뒤섞인 단어로부터 원래 단어가 결정론적으로 결정되지 않으므로), 모델이 올바른 원래 단어를 찾기 위해 어느 정도의 탐색을 수행해야 한다. 따라서 관련된 기술은 사소하지 않은 패턴 매칭과 계산 능력을 요구하는 것으로 보인다.
3.9.3 SAT Analogies
일반적인 텍스트 분포와는 다소 이례적인 다른 task에서 GPT-3를 테스트하기 위해, 우리는 374개의 "SAT 유추(analogy)" 문제 세트를 수집했다 [TLBS03]. 유추 문제는 2005년 이전 SAT 대학 입학 시험의 한 섹션을 구성했던 객관식 질문 유형이다. 일반적인 예시는 다음과 같다: "audacious is to boldness as (a) sanctimonious is to hypocrisy, (b) anonymous is to identity, (c) remorseful is to misdeed, (d) deleterious is to result, (e) impressionable is to temptation". 학생은 원래 단어 쌍과 동일한 관계를 가진 다섯 단어 쌍 중 하나를 선택해야 한다. 이 예시의 정답은 "sanctimonious is to hypocrisy"이다.
이 task에서 GPT-3는 few-shot 설정에서 65.2%, one-shot 설정에서 59.1%, **zero-shot 설정에서 53.7%**의 정확도를 달성했으며, 이는 대학 지원자들의 평균 점수 57% [TL05]와 비교된다 (무작위 추측은 20%의 정확도를 보인다). Figure 3.12에서 볼 수 있듯이, 모델 규모가 커질수록 결과가 향상되며, 1,750억 파라미터 모델은 130억 파라미터 모델에 비해 10% 이상 성능이 향상되었다.
 Figure 3.12: SAT 유추 task에서 모델 크기별 zero-shot, one-shot, few-shot 성능. 가장 큰 모델은 few-shot 설정에서 65%의 정확도를 달성했으며, 작은 모델에서는 나타나지 않는 in-context learning의 상당한 이점을 보여준다.
Figure 3.12: SAT 유추 task에서 모델 크기별 zero-shot, one-shot, few-shot 성능. 가장 큰 모델은 few-shot 설정에서 65%의 정확도를 달성했으며, 작은 모델에서는 나타나지 않는 in-context learning의 상당한 이점을 보여준다.
3.9.4 News Article Generation
생성형 language model에 대한 이전 연구에서는 사람이 작성한 뉴스 기사의 첫 문장으로 구성된 그럴듯한 prompt를 모델에 제공하여 조건부 샘플링을 통해 합성 "뉴스 기사"를 생성하는 능력을 정성적으로 테스트했다 [RWC19]. [RWC19]와 비교했을 때, GPT-3 학습에 사용된 데이터셋은 뉴스 기사에 대한 가중치가 훨씬 낮기 때문에, 조건 없이(unconditional) raw 샘플을 통해 뉴스 기사를 생성하는 것은 덜 효과적이다. 예를 들어, GPT-3는 종종 "뉴스 기사"의 첫 문장을 트윗으로 해석하고 합성 응답이나 후속 트윗을 게시하기도 한다. 이 문제를 해결하기 위해 우리는 모델의 context에 세 개의 이전 뉴스 기사를 제공하여 GPT-3의 few-shot learning 능력을 활용했다. 제안된 다음 기사의 제목과 부제목이 주어지면, 모델은 "뉴스" 장르의 짧은 기사를 안정적으로 생성할 수 있다.
GPT-3의 뉴스 기사 생성 품질(이는 일반적으로 조건부 샘플 생성 품질과 관련이 있을 것으로 판단됨)을 측정하기 위해, 우리는 GPT-3가 생성한 기사와 실제 기사를 사람이 구별하는 능력을 측정하기로 결정했다. 유사한 연구는 Kreps et al. [KMB20]과 Zellers et al. [ZHR+19]에 의해 수행되었다. 생성형 language model은 사람이 생성한 콘텐츠의 분포와 일치하도록 학습되므로, 사람이 둘을 구별하는 (불)능력은 품질의 잠재적으로 중요한 척도가 될 수 있다.
모델이 생성한 텍스트를 사람이 얼마나 잘 감지할 수 있는지 알아보기 위해, 우리는 newser.com 웹사이트에서 임의로 25개의 기사 제목과 부제목을 선택했다 (평균 길이: 215단어). 그런 다음 125M에서 175B(GPT-3) 파라미터에 이르는 4개의 language model로부터 이 제목과 부제목에 대한 완성을 생성했다 (평균 길이: 200단어). 각 모델에 대해 우리는 약 80명의 미국 기반 참가자에게 실제 제목과 부제목 뒤에 사람이 작성한 기사 또는 모델이 생성한 기사가 이어지는 퀴즈를 제시했다. 참가자들은 기사가 "매우 높은 확률로 사람이 작성함", "높은 확률로 사람이 작성함", "모르겠음", "높은 확률로 기계가 작성함", 또는 "매우 높은 확률로 기계가 작성함" 중 하나를 선택하도록 요청받았다.
우리가 선택한 기사들은 모델의 학습 데이터에 포함되지 않았으며, 모델 출력은 사람이 임의로 선택하는 것을 방지하기 위해 프로그램적으로 형식화되고 선택되었다. 모든 모델은 출력을 조건화하기 위해 동일한 context를 사용했으며, 동일한 context 크기로 사전학습되었고, 각 모델의 prompt로 동일한 기사 제목과 부제목이 사용되었다. 그러나 우리는 참가자의 노력과 주의를 통제하기 위한 실험도 수행했는데, 이는 동일한 형식을 따르지만 의도적으로 품질이 낮은 모델 생성 기사를 포함했다. 이는 **"control model"**에서 기사를 생성함으로써 이루어졌다: context가 없고 출력 무작위성이 증가된 160M 파라미터 모델이다.
| Mean accuracy | 95% Confidence Interval (low, hi) | compared to control ( -value) | "I don't know" assignments | |
|---|---|---|---|---|
| Control (deliberately bad model) | 86% | 83%-90% | - | 3.6 % |
| GPT-3 Small | 76% | 72%-80% | 3.9 (2e-4) | 4.9% |
| GPT-3 Medium | 61% | 58%-65% | 10.3 (7e-21) | 6.0% |
| GPT-3 Large | 68% | 64%-72% | 7.3 (3e-11) | 8.7% |
| GPT-3 XL | 62% | 59%-65% | 10.7 (1e-19) | 7.5% |
| GPT-3 2.7B | 62% | 58%-65% | 10.4 (5e-19) | 7.1% |
| GPT-3 6.7B | 60% | 56%-63% | 11.2 (3e-21) | 6.2% |
| GPT-3 13B | 55% | 52%-58% | 15.3 (1e-32) | 7.1% |
| GPT-3 175B | 52% | 49%-54% | 16.9 (1e-34) | 7.8% |
Table 3.11: 짧은 (~200단어) 뉴스 기사가 모델에 의해 생성되었는지 여부를 식별하는 인간의 정확도. 인간의 정확도(정확한 할당과 비중립적 할당의 비율로 측정)는 control model에서 86%에서 GPT-3 175B에서 52%까지 다양하다. 이 표는 5가지 다른 모델 간의 평균 정확도를 비교하고, 각 모델과 control model(출력 무작위성이 증가된 조건 없는 GPT-3 Small 모델) 간의 평균 정확도 차이에 대한 두 표본 T-Test 결과를 보여준다.
의도적으로 품질이 낮은 기사가 모델에 의해 생성되었음을 감지하는 **인간의 평균 정확도(참가자당 정확한 할당과 비중립적 할당의 비율)는 약 86%**였으며, 50%는 우연 수준의 성능이다. 대조적으로, 175B 파라미터 모델이 생성한 기사를 감지하는 인간의 평균 정확도는 약 52%로 우연 수준을 겨우 넘는 수준이었다 (Table 3.11 참조). 모델이 생성한 텍스트를 감지하는 인간의 능력은 모델 크기가 증가함에 따라 감소하는 것으로 보이며: 모델 크기에 따라 우연 수준의 정확도로 향하는 경향이 있는 것으로 보이며, GPT-3에 대한 인간의 감지 능력은 우연 수준에 가깝다. 이는 참가자들이 모델 크기가 증가함에 따라 각 출력에 더 많은 시간을 할애했음에도 불구하고 사실이다 (Appendix E 참조).
GPT-3가 생성한 합성 기사의 예시는 Figure 3.14 및 3.15에 제시되어 있다. 평가에서 나타났듯이, 텍스트의 상당 부분은 사람이 실제 인간 콘텐츠와 구별하기 어렵다. 사실적 부정확성은 기사가 모델에 의해 생성되었음을 나타내는 지표가 될 수 있는데, 이는 인간 저자와 달리 모델은 기사 제목이 참조하는 특정 사실이나 기사가 작성된 시점에 접근할 수 없기 때문이다. 다른 지표로는 반복, 비논리적 비약(non sequiturs), 특이한 표현 등이 있지만, 이러한 것들은 종종 너무 미묘하여 눈치채지 못하는 경우가 많다.
Ippolito et al. [IDCBE19]의 language model 감지에 대한 관련 연구는 Grover [ZHR19] 및 GLTR [GSR19]와 같은 자동 판별기가 인간 평가자보다 모델 생성 텍스트를 감지하는 데 더 큰 성공을 거둘 수 있음을 나타낸다. 이러한 모델의 자동 감지는 향후 연구의 유망한 분야가 될 수 있다.
Ippolito et al. [IDCBE19]은 또한 사람이 더 많은 토큰을 관찰할수록 모델 생성 텍스트를 감지하는 인간의 정확도가 증가한다고 언급한다. GPT-3 175B가 생성한 더 긴 뉴스 기사를 사람이 얼마나 잘 감지하는지에 대한 예비 조사를 위해, 우리는 평균 길이 569단어의 로이터 통신 세계 뉴스 기사 12개를 선택하고, 평균 길이 498단어(초기 실험보다 298단어 더 김)의 GPT-3로 이 기사들의 완성을 생성했다. 위 방법론에 따라, 우리는 각각 약 80명의 미국 기반 참가자를 대상으로 두 가지 실험을 수행하여 GPT-3와 control model이 생성한 기사를 감지하는 인간의 능력을 비교했다.
control model에서 의도적으로 품질이 낮은 더 긴 기사를 감지하는 **인간의 평균 정확도는 약 88%**였지만, GPT-3 175B가 생성한 더 긴 기사를 감지하는 인간의 평균 정확도는 여전히 약 52%로 우연 수준을 겨우 넘는 수준이었다 (Table 3.12 참조). 이는 약 500단어 길이의 뉴스 기사의 경우, GPT-3가 사람이 작성한 뉴스 기사와 구별하기 어려운 기사를 계속해서 생성한다는 것을 나타낸다.
3.9.5 Learning and Using Novel Words
발달 언어학에서 연구되는 task 중 하나는 새로운 단어를 학습하고 활용하는 능력이다 [CB78]. 예를 들어, 단어의 정의를 한 번만 보고도 문장에서 그 단어를 사용하거나, 반대로 단어의 사용 예시를 한 번만 보고도 그 의미를 추론하는 능력 등이 이에 해당한다. 여기서 우리는 GPT-3가 전자의 능력을 수행하는지 정성적으로 테스트한다. 구체적으로, 우리는 GPT-3에게 "Gigamuru"와 같은 존재하지 않는 단어의 정의를 제공한 다음, 그 단어를 문장에서 사용하도록 요청한다. 우리는 (별개의)
 Figure 3.13: 뉴스 기사가 모델 생성인지 여부를 식별하는 사람들의 능력(정확한 할당 대 비중립적 할당 비율로 측정)은 모델 크기가 증가함에 따라 감소한다. 의도적으로 품질이 낮은 대조 모델(출력 무작위성이 높은 무조건 GPT-3 Small 모델)의 출력에 대한 정확도는 상단의 점선으로 표시되어 있으며, 무작위 확률(50%)은 하단의 점선으로 표시되어 있다. 최적 적합선은 95% 신뢰 구간을 가진 멱법칙(power law)이다.
Figure 3.13: 뉴스 기사가 모델 생성인지 여부를 식별하는 사람들의 능력(정확한 할당 대 비중립적 할당 비율로 측정)은 모델 크기가 증가함에 따라 감소한다. 의도적으로 품질이 낮은 대조 모델(출력 무작위성이 높은 무조건 GPT-3 Small 모델)의 출력에 대한 정확도는 상단의 점선으로 표시되어 있으며, 무작위 확률(50%)은 하단의 점선으로 표시되어 있다. 최적 적합선은 95% 신뢰 구간을 가진 멱법칙(power law)이다.
| Mean accuracy | 95% Confidence <br> Interval (low, hi) | compared to <br> control ( -value) | "I don't know" <br> assignments | |
|---|---|---|---|---|
| Control | - | |||
| GPT-3 175B |
Table 3.12: 약 500단어 분량의 기사가 모델 생성인지 여부를 식별하는 사람들의 능력(정확한 할당 대 비중립적 할당 비율로 측정)은 **대조 모델에서 88%였고, GPT-3 175B에서는 52%**였다. 이 표는 GPT-3 175B와 대조 모델(출력 무작위성이 증가된 무조건 GPT-3 Small 모델) 간의 평균 정확도 차이에 대한 두 표본 T-검정 결과를 보여준다.
Title: United Methodists Agree to Historic Split Subtitle: Those who oppose gay marriage will form their own denomination Article: After two days of intense debate, the United Methodist Church has agreed to a historic split - one that is expected to end in the creation of a new denomination, one that will be "theologically and socially conservative," according to The Washington Post. The majority of delegates attending the church's annual General Conference in May voted to strengthen a ban on the ordination of LGBTQ clergy and to write new rules that will "discipline" clergy who officiate at same-sex weddings. But those who opposed these measures have a new plan: They say they will form a separate denomination by 2020, calling their church the Christian Methodist denomination. The Post notes that the denomination, which claims 12.5 million members, was in the early 20th century the "largest Protestant denomination in the U.S.," but that it has been shrinking in recent decades. The new split will be the second in the church's history. The first occurred in 1968, when roughly 10 percent of the denomination left to form the Evangelical United Brethren Church. The Post notes that the proposed split "comes at a critical time for the church, which has been losing members for years," which has been "pushed toward the brink of a schism over the role of LGBTQ people in the church." Gay marriage is not the only issue that has divided the church. In 2016, the denomination was split over ordination of transgender clergy, with the North Pacific regional conference voting to ban them from serving as clergy, and the South Pacific regional conference voting to allow them.
Figure 3.14: 사람들이 인간이 작성한 기사와 구별하는 데 가장 어려움을 겪었던 GPT-3 생성 뉴스 기사 (정확도: 12%).
Title: Star's Tux Promise Draws Megyn Kelly's Sarcasm Subtitle: Joaquin Phoenix pledged to not change for each awards event Article: A year ago, Joaquin Phoenix made headlines when he appeared on the red carpet at the Golden Globes wearing a tuxedo with a paper bag over his head that read, "I am a shape-shifter. I can't change the world. I can only change myself." It was a promise to not change to fit into the Hollywood mold: "I think that's a really special thing, to not change yourself. I think it's a really special thing to say, 'This is what's inside of me, I'm proud of it, and I'm not going to be ashamed because of the way that someone else thinks I should be.'" Now, it's the Oscars, and Phoenix is at it again. But this time, his publicist is saying he'll be wearing a tux no matter what. Megyn Kelly was not impressed, and she let him have it on The Tonight Show. "You know, I feel like, I feel like you could have worn the tux," she says. "But you're saying you're a shape-shifter. I don't know if you can change your tux, but you can change your mind. You can change your mind. You can change your mind." Phoenix says he did, but it didn't stick. "I was like, 'Okay, I'm going to wear a tuxedo to this thing.' And then I thought, 'I don't want to wear a tuxedo to this thing.'" Kelly goes on to encourage him to change his mind again, but Phoenix says it's too late: "I'm committed to wearing this."
Figure 3.15: 사람들이 인간이 작성한 기사와 구별하기 가장 쉬웠던 GPT-3 생성 뉴스 기사 (정확도: 61%).
A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that uses
the word whatpu is:
We were traveling in Africa and we saw these very cute whatpus.
To do a "farduddle" means to jump up and down really fast. An example of a sentence that uses
the word farduddle is:
One day when I was playing tag with my little sister, she got really excited and she
started doing these crazy farduddles.
A "yalubalu" is a type of vegetable that looks like a big pumpkin. An example of a sentence
that uses the word yalubalu is:
I was on a trip to Africa and I tried this yalubalu vegetable that was grown in a garden
there. It was delicious.
A "Burringo" is a car with very fast acceleration. An example of a sentence that uses the
word Burringo is:
In our garage we have a Burringo that my father drives to work every day.
A "Gigamuru" is a type of Japanese musical instrument. An example of a sentence that uses the
word Gigamuru is:
I have a Gigamuru that my uncle gave me as a gift. I love to play it at home.
To "screeg" something is to swing a sword at it. An example of a sentence that uses the word
screeg is:
We screeghed at each other for several minutes and then we went outside and ate ice cream.
Figure 3.16: 새로운 단어를 문장에서 사용하는 few-shot task에 대한 GPT-3의 대표적인 완성 예시. 굵은 글씨는 GPT-3의 완성 부분이고, 일반 텍스트는 인간의 prompt이다. 첫 번째 예시에서는 prompt와 완성 모두 인간이 제공했으며, 이는 이후 GPT-3가 추가 prompt를 받고 완성을 제공하는 예시들의 조건으로 사용된다. 여기에 제시된 조건 외에는 GPT-3에 task-specific한 어떤 것도 제공되지 않았다. 존재하지 않는 단어가 정의되고 문장에서 사용된 이전 예시를 1개에서 5개까지 제공한다. 따라서 이 task는 광범위한 task의 이전 예시 측면에서는 few-shot이고, 특정 단어 측면에서는 one-shot이다. Table 3.16은 우리가 생성한 6가지 예시를 보여준다. 모든 정의는 인간이 생성했으며, 첫 번째 답변은 조건으로 인간이 생성했고, 이후 답변들은 GPT-3가 생성했다. 이 예시들은 한 번에 연속적으로 생성되었으며, 우리는 어떠한 prompt도 생략하거나 반복적으로 시도하지 않았다. 모든 경우에 생성된 문장은 단어의 정확하거나 적어도 그럴듯한 사용으로 보인다. 마지막 문장에서 모델은 "screeg"라는 단어에 대해 그럴듯한 활용형("screeghed")을 생성하지만, 단어의 사용은 약간 어색하다("screeghed at each other"). 그럼에도 불구하고 장난감 칼싸움을 묘사할 수 있다는 점에서 그럴듯하다. 전반적으로 GPT-3는 새로운 단어를 문장에서 사용하는 task에 적어도 능숙한 것으로 보인다.
3.9.6 Correcting English Grammar
Few-shot learning에 적합한 또 다른 task는 영어 문법 교정이다. 우리는 GPT-3를 사용하여 few-shot 설정에서 이를 테스트했으며, "Poor English Input: <문장> Good English Output: <문장>" 형식의 prompt를 제공했다. 우리는 GPT-3에 사람이 생성한 교정 예시 하나를 주고, 그 다음 5개의 문장을 교정하도록 요청했다 (이때도 누락이나 반복 없이). 결과는 Figure 3.17에 나와 있다.
4 Measuring and Preventing Memorization Of Benchmarks
우리의 학습 데이터셋은 인터넷에서 수집되었기 때문에, 일부 벤치마크 테스트 세트가 학습 데이터에 포함되었을 가능성이 있다. 인터넷 규모의 데이터셋에서 테스트 데이터 오염(contamination)을 정확하게 탐지하는 것은 아직 확립된 모범 사례가 없는 새로운 연구 분야이다. 대규모 모델을 학습할 때 오염 여부를 조사하지 않는 것이 일반적인 관행이지만, 사전학습 데이터셋의 규모가 증가함에 따라 이 문제가 점점 더 중요해지고 있다고 우리는 생각한다.
이러한 우려는 단순히 가설에 그치지 않는다. Common Crawl 데이터로 언어 모델을 학습시킨 최초의 논문 중 하나인 [TL18]은 평가 데이터셋과 겹치는 학습 문서를 탐지하여 제거하였다. GPT-2 [RWC 19]와 같은 다른 연구에서도 사후(post-hoc) 중복 분석을 수행했다. 그들의 연구는 비교적 고무적이었는데, 학습 데이터와 테스트 데이터가 겹치는 부분에서 모델 성능이 다소 더 좋았지만, 오염된 데이터의 비율이 작았기 때문에(대부분 몇 퍼센트에 불과) 보고된 결과에 큰 영향을 미치지 않았다는 것을 발견했다.
GPT-3는 다소 다른 환경에서 작동한다. 한편으로는 데이터셋과 모델 크기가 GPT-2에 사용된 것보다 약 두 자릿수 더 크며, Common Crawl 데이터가 대량 포함되어 있어 오염 및 암기(memorization) 가능성이 증가한다. 다른 한편으로는, 방대한 데이터 양 덕분에 GPT-3 175B조차도 중복 제거된 held-out validation set에 비해 학습 데이터셋에 크게 과적합되지 않는다 (Figure 4.1). 따라서 우리는 오염이 빈번하게 발생할 가능성이 높지만, 그 영향은 우려했던 것만큼 크지 않을 수 있다고 예상한다. 우리는 처음에 학습 데이터와 본 논문에서 연구된 모든 벤치마크의 개발 및 테스트 세트 간의 중복을 사전에 검색하고 제거하여 오염 문제를 해결하려고 시도했다. 불행히도, 버그로 인해 탐지된 모든 중복이 학습 데이터에서 부분적으로만 제거되었다. 학습 비용 때문에 모델을 재학습하는 것은 불가능했다. 이를 해결하기 위해, 우리는 남아있는 탐지된 중복이 결과에 미치는 영향을 자세히 조사했다.
각 벤치마크에 대해, 우리는 잠재적으로 유출된 모든 예시를 제거한 '클린(clean)' 버전을 생성했다. 이는 대략적으로 **사전학습 세트의 어떤 내용과 13-gram 중복이 있는 예시(또는 13-gram보다 짧을 경우 전체 예시와 중복되는 경우)**로 정의된다. 목표는 잠재적인 오염 가능성이 있는 모든 것을 매우 보수적으로 플래그하여, 높은 신뢰도로 오염이 없는 클린 서브셋을 생성하는 것이다. 정확한 절차는 Appendix C에 자세히 설명되어 있다.
그런 다음 우리는 이러한 클린 벤치마크에서 GPT-3를 평가하고, 원래 점수와 비교했다. 클린 서브셋에서의 점수가 전체 데이터셋에서의 점수와 유사하다면, 이는 오염이 존재하더라도 보고된 결과에 유의미한 영향을 미치지 않음을 시사한다. 클린 서브셋에서의 점수가 낮다면, 이는 오염이 결과를 부풀리고 있을 수 있음을 시사한다. 결과는 Figure 4.2에 요약되어 있다. 잠재적 오염 수준이 종종 높음에도 불구하고(벤치마크의 1/4이 50% 이상), 대부분의 경우 성능 변화는 미미했으며, 오염 수준과 성능 차이가 상관관계가 있다는 증거는 발견되지 않았다. 우리는 우리의 보수적인 방법이 오염을 상당히 과대평가했거나, 오염이 성능에 거의 영향을 미치지 않는다고 결론 내린다.
아래에서는 (1) 클린 버전에서 모델 성능이 현저히 떨어지는 경우 또는 (2) 잠재적 오염이 매우 높아 성능 차이를 측정하기 어려운 경우의 몇 가지 특정 사례를 더 자세히 검토한다.
우리의 분석은 추가 조사를 위해 6개 벤치마크 그룹을 플래그했다: Word Scrambling, Reading Comprehension (QuAC, SQuAD2, DROP), PIQA, Winograd, language modeling tasks (Wikitext tasks, 1BW), 그리고 German to English translation. 우리의 중복 분석은 극도로 보수적으로 설계되었기 때문에, 일부 오탐(false positive)을 생성할 것으로 예상한다. 각 task 그룹에 대한 결과는 다음과 같다:
- Reading Comprehension: 우리의 초기 분석은 QuAC, SQuAD2, DROP의 task 예시 중 90% 이상이 잠재적으로 오염된 것으로 플래그했으며, 그 정도가 너무 커서 클린 서브셋에서 차이를 측정하는 것조차 어려웠다. 그러나 수동 검사 결과, 검사한 모든 중복 사례에서 3개 데이터셋 모두에서 원본 텍스트는 학습 데이터에 존재했지만 질문/답변 쌍은 존재하지 않았다. 이는 모델이 배경 정보만 얻고 특정 질문에 대한 답을 암기할 수 없었음을 의미한다.
- German translation: WMT16 독일어-영어 테스트 세트의 예시 중 25%가 잠재적으로 오염된 것으로 플래그되었으며, 관련 총 효과 크기는 1-2 BLEU였다. 검사 결과, 플래그된 예시 중 어떤 것도 NMT 학습 데이터와 유사한 쌍을 이루는 문장을 포함하지 않았으며, 충돌은 대부분 뉴스에서 논의된 사건의 단편적인 단일 언어 일치였다.
- Reversed Words and Anagrams: 이 task들은 "alaok = koala"와 같은 형태임을 상기하라. 이 task들의 길이가 짧기 때문에, 우리는 **2-gram 필터링(구두점 무시)**을 사용했다. 플래그된 중복을 검사한 결과, 이들은 일반적으로 학습 세트에서 실제 역전(reversal) 또는 스크램블 해제(unscrambling) 사례가 아니라, "kayak = kayak"과 같은 회문(palindrome) 또는 사소한 스크램블 해제였다. 중복 양은 적었지만, 사소한 task들을 제거하면 난이도가 증가하여 가짜 신호(spurious signal)가 발생했다. 이와 관련하여, symbol insertion task는 높은 중복을 보였지만 성능에는 영향이 없었다. 이는 해당 task가 단어에서 비문자 문자를 제거하는 것을 포함하며, 중복 분석 자체가 그러한 문자를 무시하여 많은 가짜 일치를 유발하기 때문이다.
- PIQA: 중복 분석은 예시의 29%를 오염된 것으로 플래그했으며, 클린 서브셋에서 **성능이 3%p 절대 감소(4% 상대 감소)**하는 것을 관찰했다. 테스트 데이터셋은 우리의 학습 세트가 생성된 후에 공개되었고 그 레이블은 숨겨져 있지만, 크라우드소싱 데이터셋 생성자가 사용한 일부 웹페이지가 우리의 학습 세트에 포함되어 있다. 우리는 암기 능력이 훨씬 적은 25배 작은 모델에서도 유사한 감소를 발견했으며, 이는 이러한 변화가 암기보다는 통계적 편향일 가능성이 높다는 것을 시사한다. 즉, 작업자들이 복사한 예시들이 단순히 더 쉬웠을 수 있다. 불행히도, 우리는 이 가설을 엄격하게 증명할 수 없다. 따라서 우리는 PIQA 결과에 잠재적 오염을 나타내는 별표(*)를 표시한다.
- Winograd: 중복 분석은 예시의 45%를 플래그했으며, 클린 서브셋에서 성능이 2.6% 감소하는 것을 발견했다. 중복 데이터 포인트를 수동으로 검사한 결과, 132개의 Winograd 스키마가 실제로 우리의 학습 세트에 존재했지만, 모델에 task를 제시하는 방식과는 다른 형식으로 제시되었다. 성능 감소는 작지만, 우리는 본 논문의 Winograd 결과에 별표(*)를 표시한다.
- Language modeling: 우리는 GPT-2에서 측정된 4개의 Wikipedia 언어 모델링 벤치마크와 Children's Book Test 데이터셋이 거의 전적으로 우리의 학습 데이터에 포함되어 있음을 발견했다. 여기서는 클린 서브셋을 안정적으로 추출할 수 없으므로, 이 연구를 시작할 때 의도했음에도 불구하고 이러한 데이터셋에 대한 결과는 보고하지 않는다. Penn Tree Bank는 오래되었기 때문에 영향을 받지 않았으며, 따라서 우리의 주요 언어 모델링 벤치마크가 되었다.
우리는 또한 오염 수준은 높지만 성능에 미치는 영향이 거의 0에 가까운 데이터셋도 검사하여 실제 오염이 얼마나 존재하는지 확인했다. 이러한 데이터셋들은 종종 오탐(false positive)을 포함하는 것으로 나타났다. 실제 오염이 없거나, task의 답을 유출하지 않는 오염이 있었다. 한 가지 주목할 만한 예외는 LAMBADA였는데, 상당한 실제 오염이 있는 것으로 보였지만 성능에 미치는 영향은 매우 작았으며, 클린 서브셋의 점수가 전체 데이터셋의 0.5% 이내였다. 또한, 엄밀히 말하면, 우리의 빈칸 채우기(fill-in-the-blank) 형식은 가장 단순한 형태의 암기를 배제한다. 그럼에도 불구하고, 본 논문에서 LAMBADA에서 매우 큰 성능 향상을 이루었기 때문에, 잠재적 오염은 결과 섹션에 명시되어 있다. 우리의 오염 분석의 중요한 한계는 클린 서브셋이 원본 데이터셋과 동일한 분포에서 추출되었는지 확신할 수 없다는 점이다. 암기가 결과를 부풀리지만 동시에 클린 서브셋을 더 쉽게 만드는 통계적 편향에 의해 정확히 상쇄될 가능성은 여전히 존재한다. 그러나 0에 가까운 변화의 수가 매우 많다는 점은 이러한 가능성이 낮음을 시사하며, 우리는 암기할 가능성이 낮은 작은 모델에서도 변화에 눈에 띄는 차이가 없음을 관찰했다. 전반적으로, 우리는 데이터 오염의 영향을 측정하고 문서화하며, 문제성 있는 결과를 심각도에 따라 명시하거나 완전히 제거하기 위해 최선을 다했다. 벤치마크를 설계할 때와 모델을 학습할 때 모두, 이 중요하고 미묘한 문제를 해결하기 위해 일반적으로 이 분야에서 많은 연구가 남아있다. 우리의 분석에 대한 더 자세한 설명은 Appendix C를 참조하라.
Poor English input: I eated the purple berries.
Good English output: I ate the purple berries.
Poor English input: Thank you for picking me as your designer. I'd appreciate it.
Good English output: Thank you for choosing me as your designer. I appreciate it.
Poor English input: The mentioned changes have done. or I did the alteration that you
requested. or I changed things you wanted and did the modifications.
Good English output: The requested changes have been made. or I made the alteration that you
requested. or I changed things you wanted and made the modifications.
Poor English input: I'd be more than happy to work with you in another project.
Good English output: I'd be more than happy to work with you on another project.
Poor English input: Please provide me with a short brief of the design you're looking for and
that'd be nice if you could share some examples or project you did before.
Good English output: Please provide me with a brief description of the design you're
looking for and that would be nice if you could share some examples or projects you have
done before.
Poor English input: The patient was died.
Good English output: The patient died.
Poor English input: We think that Leslie likes ourselves.
Good English output: We think that Leslie likes us.
Poor English input: Janet broke Bill on the finger.
Good English output: Janet broke Bill's finger.
Poor English input: Mary arranged for, in St. Louis, John to rent a house cheap.
Good English output: Mary arranged for John to rent a house in St. Louis.
Poor English input: Today I have went to the store to to buys some many bottle of water.
Good English output: Today I went to the store to buy some bottles of water.
Poor English input: I have tried to hit ball with bat, but my swing is has miss.
Good English output: I tried to hit the ball with the bat, but my swing missed.
Figure 3.17: 영어 문법 교정 few-shot task에 대한 대표적인 GPT-3 완성 예시. 굵은 글씨는 GPT-3의 완성 부분이고, 일반 텍스트는 사람이 제공한 prompt이다. 처음 몇 예시에서는 prompt와 완성 모두 사람이 제공했으며, 이는 GPT-3가 연속적으로 추가 prompt를 받고 완성을 제공하는 후속 예시들의 조건으로 사용된다. GPT-3에는 처음 몇 예시와 "Poor English input/Good English output"이라는 틀 외에는 task-specific한 어떤 것도 제공되지 않는다. 우리는 "poor"와 "good" 영어(및 그 용어 자체)의 구분이 복잡하고, 맥락적이며, 논쟁의 여지가 있음을 지적한다. 집 임대와 관련된 예시에서 볼 수 있듯이, 모델이 "good"이 무엇인지에 대해 만드는 가정은 심지어 오류를 유발할 수도 있다(여기서 모델은 문법을 조정할 뿐만 아니라 의미를 변경하는 방식으로 "cheap"이라는 단어를 제거한다).
 Figure 4.1: GPT-3 학습 곡선. 우리는 학습 분포의 중복 제거된 검증 분할에서 학습 중 모델 성능을 측정한다. 학습과 검증 성능 사이에 약간의 차이가 있지만, 이 차이는 모델 크기와 학습 시간에 따라 최소한으로만 증가하며, 이는 대부분의 차이가 과적합보다는 난이도 차이에서 비롯됨을 시사한다.
Figure 4.1: GPT-3 학습 곡선. 우리는 학습 분포의 중복 제거된 검증 분할에서 학습 중 모델 성능을 측정한다. 학습과 검증 성능 사이에 약간의 차이가 있지만, 이 차이는 모델 크기와 학습 시간에 따라 최소한으로만 증가하며, 이는 대부분의 차이가 과적합보다는 난이도 차이에서 비롯됨을 시사한다.
 Figure 4.2: 벤치마크 오염 분석. 우리는 학습 세트의 잠재적 오염을 확인하기 위해 각 벤치마크의 클린 버전을 구성했다. x축은 데이터셋 중 높은 신뢰도로 클린하다고 알려진 부분의 보수적인 하한선이며, y축은 검증된 클린 서브셋에서만 평가했을 때의 성능 차이를 보여준다. 대부분의 벤치마크에서 성능은 미미하게 변했지만, 일부는 추가 검토를 위해 플래그되었다. 검사 결과 PIQA 및 Winograd 결과의 오염에 대한 일부 증거를 발견했으며, 해당 결과는 섹션 3에 별표로 표시한다. 다른 벤치마크가 영향을 받았다는 증거는 발견되지 않았다.
Figure 4.2: 벤치마크 오염 분석. 우리는 학습 세트의 잠재적 오염을 확인하기 위해 각 벤치마크의 클린 버전을 구성했다. x축은 데이터셋 중 높은 신뢰도로 클린하다고 알려진 부분의 보수적인 하한선이며, y축은 검증된 클린 서브셋에서만 평가했을 때의 성능 차이를 보여준다. 대부분의 벤치마크에서 성능은 미미하게 변했지만, 일부는 추가 검토를 위해 플래그되었다. 검사 결과 PIQA 및 Winograd 결과의 오염에 대한 일부 증거를 발견했으며, 해당 결과는 섹션 3에 별표로 표시한다. 다른 벤치마크가 영향을 받았다는 증거는 발견되지 않았다.
5 Limitations
GPT-3와 이에 대한 우리의 분석은 여러 한계점을 가지고 있다. 아래에서는 이러한 한계점 중 일부를 설명하고 향후 연구 방향을 제안한다.
첫째, GPT-3는 특히 이전 모델인 GPT-2에 비해 정량적, 정성적으로 크게 개선되었음에도 불구하고, 텍스트 합성 및 여러 NLP task에서 여전히 눈에 띄는 약점을 보인다. 텍스트 합성의 경우, 전반적인 품질은 높지만, GPT-3가 생성한 텍스트는 문서 수준에서 의미적으로 반복되거나, 충분히 긴 구절에서 일관성을 잃거나, 스스로 모순되거나, 때로는 비논리적인 문장이나 단락을 포함하기도 한다. 우리는 GPT-3의 텍스트 합성 능력의 한계와 강점을 더 잘 이해할 수 있도록 선별되지 않은(uncurated) 무조건적(unconditional) 샘플 500개를 공개할 예정이다. 이산 언어(discrete language) task 영역 내에서, 우리는 GPT-3가 "상식적인 물리(common sense physics)" 문제에 특히 어려움을 겪는 것으로 비공식적으로 관찰했다. 비록 이 영역을 테스트하는 일부 데이터셋(예: PIQA [BZB19])에서는 좋은 성능을 보였음에도 말이다. 구체적으로 GPT-3는 "치즈를 냉장고에 넣으면 녹을까?"와 같은 유형의 질문에 어려움을 겪는다. 정량적으로, GPT-3의 in-context learning 성능은 Section 3에서 설명된 바와 같이 우리의 벤치마크 스위트에서 몇 가지 눈에 띄는 격차를 보인다. 특히, **두 단어가 문장에서 같은 방식으로 사용되었는지, 또는 한 문장이 다른 문장을 함의하는지(각각 WIC 및 ANLI)**와 같은 일부 "비교" task, 그리고 읽기 이해(reading comprehension) task의 일부 하위 집합에서는 one-shot 또는 심지어 few-shot 평가에서도 무작위 수준보다 거의 나은 성능을 보이지 못한다. 이는 GPT-3가 다른 많은 task에서 강력한 few-shot 성능을 보이는 것을 고려할 때 특히 두드러진다.
GPT-3는 몇 가지 구조적 및 알고리즘적 한계를 가지고 있으며, 이는 위에서 언급된 문제들의 일부 원인이 될 수 있다. 우리는 autoregressive language model에서 in-context learning 행동을 탐구하는 데 중점을 두었다. 이는 이 모델 클래스로 샘플링 및 likelihood 계산이 모두 간단하기 때문이다. 결과적으로 우리의 실험에는 어떤 bidirectional 아키텍처나 denoising과 같은 다른 학습 목표가 포함되지 않았다. 이는 최근 문헌의 많은 부분과 눈에 띄는 차이점인데, 최근 연구들은 이러한 접근 방식이 표준 언어 모델보다 fine-tuning 성능을 향상시킨다고 보고하고 있다 [RSR19]. 따라서 우리의 설계 결정은 경험적으로 bidirectionality의 이점을 얻는 task에서 잠재적으로 더 나쁜 성능을 초래할 수 있다. 여기에는 빈칸 채우기(fill-in-the-blank) task, 두 가지 내용을 비교하는 task, 또는 긴 구절을 다시 읽거나 신중하게 고려한 후 매우 짧은 답변을 생성해야 하는 task가 포함될 수 있다. 이는 GPT-3가 **WIC(두 문장에서 단어의 사용을 비교하는 task), ANLI(두 문장을 비교하여 하나가 다른 하나를 함의하는지 확인하는 task), 그리고 여러 읽기 이해 task(예: QuAC 및 RACE)**와 같은 몇몇 task에서 few-shot 성능이 뒤처지는 가능한 설명이 될 수 있다. 우리는 또한 과거 문헌을 바탕으로, 대규모 bidirectional 모델이 GPT-3보다 fine-tuning에서 더 강력할 것이라고 추측한다. GPT-3 규모의 bidirectional 모델을 만들거나, few-shot 또는 zero-shot 학습으로 bidirectional 모델을 작동시키려는 시도는 향후 연구를 위한 유망한 방향이며, "두 가지 장점을 모두 얻는(best of both worlds)" 데 도움이 될 수 있다.
본 논문에서 설명된 일반적인 접근 방식, 즉 autoregressive든 bidirectional이든 LM과 유사한 모델을 확장하는 것의 더 근본적인 한계는 **궁극적으로 사전학습 목표의 한계에 부딪힐 수 있다(또는 이미 부딪히고 있을 수 있다)**는 점이다. 우리의 현재 목표는 모든 토큰에 동일한 가중치를 부여하며, 무엇이 가장 중요하게 예측되어야 하고 무엇이 덜 중요한지에 대한 개념이 부족하다. [RRS20]은 관심 있는 개체에 대한 예측을 맞춤화하는 것의 이점을 보여준다. 또한, self-supervised 목표를 사용할 때, task 명세는 원하는 task를 예측 문제로 강제하는 방식에 의존하지만, 궁극적으로 유용한 언어 시스템(예: 가상 비서)은 단순히 예측을 하는 것보다 목표 지향적인 행동을 취하는 것으로 더 잘 생각될 수 있다. 마지막으로, 대규모 사전학습 언어 모델은 비디오나 실제 물리적 상호작용과 같은 다른 경험 영역에 기반을 두지 않으므로, 세상에 대한 많은 맥락이 부족하다 [BHT20]. 이러한 모든 이유로, 순수한 self-supervised 예측을 확장하는 것은 한계에 부딪힐 가능성이 높으며, 다른 접근 방식과의 증강이 필요할 가능성이 높다. 이러한 맥락에서 유망한 향후 방향으로는 인간으로부터 목표 함수를 학습하는 것 [ZSW19a], 강화 학습을 통한 fine-tuning, 또는 이미지와 같은 추가적인 modality를 추가하여 grounding을 제공하고 세상에 대한 더 나은 모델을 구축하는 것 [CLY19] 등이 있을 수 있다.
언어 모델이 광범위하게 공유하는 또 다른 한계는 사전학습(pre-training) 중 낮은 sample efficiency이다. GPT-3는 테스트 시점의 sample efficiency를 인간에 더 가깝게(one-shot 또는 zero-shot) 만드는 단계를 밟았지만, 사전학습 중에는 인간이 평생 보는 것보다 훨씬 더 많은 텍스트를 접한다 [Lin20]. 사전학습 sample efficiency를 향상시키는 것은 향후 연구를 위한 중요한 방향이며, 추가 정보를 제공하기 위한 물리적 세계에서의 grounding 또는 알고리즘적 개선을 통해 이루어질 수 있다.
GPT-3의 few-shot learning과 관련된 한계, 또는 적어도 불확실성은 few-shot learning이 추론 시점에 새로운 task를 "처음부터" 실제로 학습하는지, 아니면 단순히 학습 중에 학습한 task를 인식하고 식별하는지에 대한 모호성이다. 이러한 가능성은 스펙트럼 상에 존재한다. 즉, 학습 세트의 demonstration이 테스트 시점의 demonstration과 정확히 동일한 분포에서 추출되는 경우부터, 동일한 task를 다른 형식으로 인식하는 경우, QA와 같은 일반적인 task의 특정 스타일에 적응하는 경우, 완전히 새로운 기술을 학습하는 경우까지 다양하다. GPT-3가 이 스펙트럼의 어느 지점에 있는지는 task마다 다를 수 있다. 단어 뒤섞기(wordscrambling) 또는 무의미한 단어 정의와 같은 합성 task는 특히 처음부터 학습될 가능성이 높지만, 번역은 분명히 사전학습 중에 학습되어야 한다. 비록 테스트 데이터와는 조직 및 스타일이 매우 다른 데이터로부터 학습되었을 가능성이 있지만 말이다. 궁극적으로, 인간이 무엇을 처음부터 배우고 무엇을 이전 demonstration으로부터 배우는지조차 명확하지 않다. 사전학습 중에 다양한 demonstration을 조직하고 테스트 시점에 이를 식별하는 것만으로도 언어 모델에게는 발전이 될 것이지만, few-shot learning이 정확히 어떻게 작동하는지 이해하는 것은 향후 연구를 위한 중요한 미탐구 방향이다.
GPT-3 규모의 모델과 관련된 한계, 즉 목표 함수나 알고리즘에 관계없이 추론을 수행하는 데 비용이 많이 들고 불편하다는 점은 현재 형태의 이 규모 모델의 실용적 적용 가능성에 도전 과제를 제시할 수 있다. 이를 해결하기 위한 한 가지 가능한 향후 방향은 특정 task를 위해 대규모 모델을 관리 가능한 크기로 distillation하는 것 [HVD15]이다. GPT-3와 같은 대규모 모델은 매우 광범위한 기술을 포함하고 있으며, 대부분은 특정 task에 필요하지 않으므로, 원칙적으로 공격적인 distillation이 가능할 수 있음을 시사한다. Distillation은 일반적으로 잘 탐구되어 왔지만 [LHCG19a], 수천억 개의 파라미터 규모에서는 시도되지 않았다. 이 규모의 모델에 적용할 때 새로운 도전 과제와 기회가 발생할 수 있다.
마지막으로, GPT-3는 대부분의 딥러닝 시스템에 공통적인 몇 가지 한계점을 공유한다. 즉, 결과를 쉽게 해석할 수 없고, 새로운 입력에 대한 예측이 반드시 잘 보정되지 않으며(표준 벤치마크에서 인간보다 훨씬 높은 성능 분산으로 관찰됨), 학습된 데이터의 편향을 유지한다. 이 마지막 문제, 즉 모델이 고정관념적이거나 편견적인 콘텐츠를 생성하게 할 수 있는 데이터의 편향은 사회적 관점에서 특히 우려되는 사항이며, 다음 섹션인 **"더 넓은 영향(Broader Impacts)"(Section 6)**에서 다른 문제들과 함께 논의될 것이다.
6 Broader Impacts
Language Model은 코드 및 글쓰기 자동 완성, 문법 지원, 게임 내러티브 생성, 검색 엔진 응답 개선, 질문 답변 등 사회에 유익한 광범위한 응용 분야를 가지고 있다. 그러나 잠재적으로 해로운 응용 분야도 존재한다. GPT-3는 소규모 모델에 비해 텍스트 생성 품질과 적응성을 향상시키며, 합성 텍스트와 사람이 작성한 텍스트를 구별하기 어렵게 만든다. 따라서 Language Model의 유익한 응용과 해로운 응용 모두를 발전시킬 잠재력을 가지고 있다.
여기서 우리는 향상된 Language Model의 잠재적 해악에 초점을 맞춘다. 이는 해악이 반드시 더 크다고 믿기 때문이 아니라, 해악을 연구하고 완화하기 위한 노력을 촉진하기 위함이다. GPT-3와 같은 Language Model의 광범위한 영향은 매우 다양하다. 우리는 두 가지 주요 문제에 집중한다: Section 6.1에서는 GPT-3와 같은 Language Model의 고의적인 오용 가능성, Section 6.2에서는 GPT-3와 같은 모델 내의 편향, 공정성, 표현 문제이다. 또한 에너지 효율성 문제에 대해서도 간략하게 논의한다 (Section 6.3).
6.1 Misuse of Language Models
Language Model의 악의적인 사용은 연구자들이 의도한 것과는 매우 다른 환경이나 목적으로 Language Model을 재활용하는 경우가 많기 때문에 예측하기 다소 어려울 수 있다. 이를 돕기 위해 우리는 전통적인 보안 위험 평가 프레임워크를 활용할 수 있다. 이 프레임워크는 위협 및 잠재적 영향 식별, 가능성 평가, 그리고 가능성과 영향의 조합으로 위험 결정과 같은 핵심 단계를 제시한다 [Ros12]. 우리는 다음 세 가지 요소를 논의한다: 잠재적 오용 애플리케이션, 위협 행위자, 외부 인센티브 구조.
6.1.1 Potential Misuse Applications
텍스트 생성에 의존하는 모든 사회적으로 유해한 활동은 강력한 language model에 의해 증강될 수 있다. 예를 들어, 허위 정보, 스팸, 피싱, 법적 및 정부 프로세스 남용, 사기성 학술 에세이 작성, 소셜 엔지니어링 pretexting 등이 있다. 이러한 많은 응용 분야는 충분히 높은 품질의 텍스트를 작성하는 데 있어 인간에게 병목 현상이 발생한다. 고품질 텍스트 생성을 하는 language model은 이러한 활동을 수행하는 데 기존의 장벽을 낮추고 그 효율성을 높일 수 있다.
텍스트 합성의 품질이 향상될수록 language model의 오용 가능성은 증가한다. GPT-3가 3.9.4에서 사람들이 인간이 작성한 텍스트와 구별하기 어렵다고 느끼는 몇 단락의 합성 콘텐츠를 생성하는 능력은 이와 관련하여 우려스러운 이정표를 나타낸다.
6.1.2 Threat Actor Analysis
위협 행위자들은 기술 및 자원 수준에 따라 분류될 수 있으며, 악성 제품을 만들 수 있는 낮거나 중간 정도의 기술과 자원을 가진 행위자부터 **'고급 지속 위협(Advanced Persistent Threats, APTs)'**에 이르기까지 다양하다. APT는 고도로 숙련되고 자원이 풍부한 (예: 국가 지원을 받는) 그룹으로, 장기적인 목표를 가지고 있다 [].
낮은 및 중간 수준의 기술을 가진 행위자들이 language model에 대해 어떻게 생각하는지 이해하기 위해, 우리는 허위 정보 전술, 악성코드 배포, 컴퓨터 사기 등이 자주 논의되는 포럼과 채팅 그룹을 모니터링해왔다. 2019년 봄 GPT-2가 처음 출시된 이후에는 오용에 대한 상당한 논의를 발견했지만, 그 이후로는 실험 사례가 적었고 성공적인 배포는 없었다. 또한, 이러한 오용 논의는 language model 기술에 대한 언론 보도와 상관관계를 보였다. 이를 통해 우리는 이러한 행위자들로부터의 오용 위협이 즉각적이지는 않지만, 신뢰성이 크게 향상되면 상황이 달라질 수 있다고 평가한다.
APTs는 일반적으로 공개적으로 작전을 논의하지 않기 때문에, 우리는 language model 사용과 관련된 APT 활동 가능성에 대해 전문 위협 분석가들과 상담했다. GPT-2 출시 이후 language model을 사용하여 잠재적 이득을 볼 수 있는 작전에서 눈에 띄는 변화는 없었다. 분석가들의 평가는 다음과 같았다: 현재 language model이 텍스트 생성에 있어 기존 방법보다 훨씬 우수하다는 설득력 있는 시연이 없었고, language model의 콘텐츠를 "타겟팅"하거나 "제어"하는 방법이 아직 매우 초기 단계에 있기 때문에, language model에 상당한 자원을 투자할 가치가 없을 수 있다는 것이다.
6.1.3 External Incentive Structures
각 위협 행위자 그룹은 자신들의 목표를 달성하기 위해 의존하는 전술, 기술, 절차(TTPs) 세트를 가지고 있다. TTPs는 **확장성(scalability) 및 배포 용이성(ease of deployment)**과 같은 경제적 요인에 영향을 받는다. **피싱(phishing)**은 모든 그룹에서 매우 인기가 있는데, 이는 악성코드 배포 및 로그인 자격 증명 탈취에 있어 저비용, 적은 노력, 높은 수익을 제공하기 때문이다. Language model을 사용하여 기존 TTPs를 강화한다면 배포 비용이 더욱 낮아질 가능성이 있다.
사용 용이성(ease of use) 또한 중요한 유인 요소이다. 안정적인 인프라는 TTPs의 채택에 큰 영향을 미친다. 그러나 **language model의 출력은 확률적(stochastic)**이며, 개발자가 이를 제약할 수 있지만(예: top-k truncation 사용), 사람의 피드백 없이는 일관된 성능을 유지하기 어렵다. 만약 소셜 미디어 허위 정보 봇이 99%의 시간 동안 신뢰할 수 있는 출력을 생성하지만, 1%의 시간 동안 일관성 없는 출력을 생성한다면, 이는 이 봇을 운영하는 데 필요한 인력(human labor)을 줄일 수 있다. 하지만 여전히 출력을 필터링할 사람이 필요하며, 이는 운영의 확장성(scalability)을 제한한다.
이 모델에 대한 분석과 위협 행위자 및 전반적인 환경에 대한 분석을 바탕으로, 우리는 AI 연구자들이 결국 악의적인 행위자들에게 더 큰 관심을 끌 만큼 충분히 일관되고 조종 가능한(steerable) language model을 개발할 것이라고 예상한다. 우리는 이것이 더 넓은 연구 커뮤니티에 도전 과제를 제시할 것으로 예상하며, 완화 연구(mitigation research), 프로토타이핑, 그리고 다른 기술 개발자들과의 협력을 통해 이 문제에 대처하기를 희망한다.
6.2 Fairness, Bias, and Representation
학습 데이터에 존재하는 편향은 모델이 고정관념적이거나 편견에 찬 콘텐츠를 생성하도록 유도할 수 있다. 이는 모델 편향이 기존의 고정관념을 강화하고 비하적인 묘사를 생성하는 등 다양한 방식으로 관련 그룹의 사람들에게 해를 끼칠 수 있기 때문에 우려되는 부분이다 [Cra17]. 우리는 공정성, 편향, 표현 측면에서 GPT-3의 한계를 더 잘 이해하기 위해 모델의 편향에 대한 분석을 수행하였다.
우리의 목표는 GPT-3를 완벽하게 특성화하는 것이 아니라, 일부 한계점과 동작에 대한 예비 분석을 제공하는 것이다. 우리는 성별, 인종, 종교와 관련된 편향에 초점을 맞추었지만, 다른 많은 범주의 편향도 존재할 가능성이 높으며 후속 연구에서 다룰 수 있을 것이다. 이는 예비 분석이며, 연구된 범주 내에서도 모델의 모든 편향을 반영하지는 않는다.
전반적으로 우리의 분석은 인터넷으로 학습된 모델이 인터넷 규모의 편향을 가지고 있음을 보여준다. 즉, 모델은 학습 데이터에 존재하는 고정관념을 반영하는 경향이 있다. 아래에서는 성별, 인종, 종교 차원에 따른 편향에 대한 예비 결과를 논의한다. 우리는 1,750억 개 파라미터 모델과 유사한 소규모 모델에서 편향을 조사하여, 이 차원에서 어떤 차이가 있는지, 그리고 어떻게 다른지를 확인한다.
6.2.1 Gender
GPT-3의 성별 편향 연구에서 우리는 성별과 직업 간의 연관성에 초점을 맞췄다. "The {occupation} was a" (Neutral Variant)와 같은 맥락이 주어졌을 때, **대부분의 직업이 여성 성별 식별자보다 남성 성별 식별자가 뒤따를 확률이 더 높다(즉, 남성 편향적)**는 것을 발견했다. 우리가 테스트한 388개 직업 중 83%가 GPT-3에 의해 남성 식별자가 뒤따를 가능성이 더 높았다. 우리는 모델에 "The detective was a"와 같은 맥락을 입력한 다음, 모델이 남성을 나타내는 단어(예: man, male 등) 또는 여성을 나타내는 단어(예: woman, female 등)를 뒤이어 생성할 확률을 측정하여 이를 확인했다. 특히, 입법자, 은행가, 명예 교수와 같이 높은 수준의 교육을 요구하는 직업은 벽돌공, 기계공, 보안관과 같이 육체노동을 요구하는 직업과 함께 강하게 남성 편향적이었다. 여성 식별자가 뒤따를 가능성이 더 높은 직업으로는 산파, 간호사, 접수원, 가정부 등이 있었다.
또한 우리는 데이터셋의 각 직업에 대해 맥락을 "The competent {occupation} was a" (Competent Variant)로 변경했을 때와 "The incompetent {occupation} was a" (Incompetent Variant)로 변경했을 때 이러한 확률이 어떻게 변하는지 테스트했다. "The competent {occupation} was a"라는 prompt가 주어졌을 때, 대부분의 직업이 원래의 중립적인 prompt인 "The {occupation} was a"보다 남성 식별자가 뒤따를 확률이 훨씬 더 높았다. "The incompetent {occupation} was a"라는 prompt가 주어졌을 때도 대부분의 직업은 원래의 중립적인 prompt와 유사한 확률로 여전히 남성 편향적이었다. 직업 편향은 로 측정되었으며, Neutral Variant의 경우 -1.11, Competent Variant의 경우 -2.14, Incompetent Variant의 경우 -1.15였다.
우리는 또한 Winogender 데이터셋 [RNLVD18]에 대해 두 가지 방법을 사용하여 대명사 해결(pronoun resolution)을 수행했으며, 이는 대부분의 직업을 남성과 연관시키는 모델의 경향을 더욱 뒷받침했다. 한 가지 방법은 모델이 대명사를 직업 또는 참가자로 올바르게 할당하는 능력을 측정하는 것이었다. 예를 들어, 우리는 모델에 "The advisor met with the advisee because she wanted to get advice about job applications. 'She' refers to the"와 같은 맥락을 입력한 다음, 두 가지 가능한 옵션(직업 옵션: advisor; 참가자 옵션: advisee) 중에서 가장 낮은 확률을 가진 옵션을 찾았다. 직업 및 참가자 단어는 대부분의 직업이 기본적으로 남성이라는 가정과 같은 사회적 편향을 종종 내포한다. 우리는 언어 모델이 여성 대명사를 남성 대명사보다 참가자 위치와 더 많이 연관시키는 경향과 같은 이러한 편향 중 일부를 학습했음을 발견했다. **GPT-3 175B는 이 task에서 모든 모델 중 가장 높은 정확도(64.17%)**를 보였다. 또한 **여성의 Occupant 문장(정답이 직업 옵션인 문장)에 대한 정확도가 남성보다 높은 유일한 모델(81.7% 대 76.7%)**이었다. 다른 모든 모델은 남성 대명사를 사용한 Occupant 문장에서 여성 대명사를 사용한 경우보다 정확도가 높았으며, 두 번째로 큰 모델인 GPT-3 13B는 동일한 정확도(60%)를 보였다는 점만 예외였다. 이는 편향 문제가 언어 모델을 오류에 취약하게 만들 수 있는 곳에서 더 큰 모델이 더 작은 모델보다 더 강력하다는 예비적인 증거를 제공한다.
우리는 또한 공동 발생(co-occurrence) 테스트를 수행하여, 다른 미리 선택된 단어 근처에서 어떤 단어가 발생할 가능성이 높은지 분석했다. 우리는 데이터셋의 모든 prompt에 대해 temperature 1과 top_p 0.9로 각각 길이 50의 출력 800개를 생성하여 모델 출력 샘플 세트를 만들었다. 성별의 경우, "He was very", "She was very", "He would be described as", "She would be described as"와 같은 prompt를 사용했다. 우리는 기성 POS tagger [LB02]를 사용하여 가장 선호되는 상위 100개 단어에서 형용사와 부사를 조사했다. 그 결과, 여성은 "beautiful" 및 "gorgeous"와 같은 외모 지향적인 단어로 더 자주 묘사되는 반면, 남성은 더 넓은 스펙트럼에 걸쳐 있는 형용사로 더 자주 묘사되는 것을 발견했다.
[^5]Table 6.1: 175B 모델에서 가장 편향된 묘사 단어
| 원시 공동 발생 횟수를 포함한 상위 10개 가장 편향된 남성 묘사 단어 | 원시 공동 발생 횟수를 포함한 상위 10개 가장 편향된 여성 묘사 단어 |
|---|---|
| 모든 단어에 대한 평균 공동 발생 횟수: | 모든 단어에 대한 평균 공동 발생 횟수: |
| 17.5 | 23.9 |
| Large (16) | Optimistic (12) |
| Mostly (15) | Bubbly (12) |
| Lazy (14) | Naughty (12) |
| Fantastic (13) | Easy-going (12) |
| Eccentric (13) | Petite (10) |
| Protect (10) | Tight (10) |
| Jolly (10) | Pregnant (10) |
| Stable (9) | Gorgeous (28) |
| Personable (22) | Sucked (8) |
| Survive (7) | Beautiful (158) |
Table 6.1은 모델에서 가장 선호되는 상위 10개 묘사 단어와 각 단어가 대명사 지표와 공동 발생한 원시 횟수를 보여준다. 여기서 "가장 선호되는"은 다른 범주에 비해 해당 범주와 더 높은 비율로 공동 발생하여 한 범주로 가장 많이 치우친 단어를 의미한다. 이러한 수치를 이해하기 위해, 각 성별에 대해 모든 적격 단어에 대한 공동 발생 횟수의 평균도 포함했다.
6.2.2 Race
GPT-3의 인종 편향을 조사하기 위해, 우리는 모델에 다음과 같은 prompt를 주입하고, 각 prompt에 대해 800개의 샘플을 생성하였다:
- "The {race} man was very"
- "The {race} woman was very"
- "People would describe the {race} person as"
여기서 {race}는 White 또는 Asian과 같은 인종 범주를 나타내는 용어로 대체되었다. 그 후, 생성된 샘플에서 **단어 동시 발생(word co-occurrence)**을 측정하였다. 언어 모델이 직업과 같은 특징을 변경할 때 서로 다른 감정의 텍스트를 생성한다는 이전 연구 [HZJ19]를 바탕으로, 우리는 인종이 감정에 미치는 영향을 탐구하였다. 각 인종과 불균형적으로 동시 발생한 단어들에 대해 SentiWordNet [BES10]을 사용하여 감정을 측정하였다. 각 단어의 감정 점수는 100에서 -100까지 다양했으며, 양수 점수는 긍정적인 단어 (예: wonderfulness: 100, amicable: 87.5), 음수 점수는 부정적인 단어 (예: wretched: -87.5, horrid: -87.5), 0점은 중립적인 단어 (예: sloping, chalet)를 나타냈다.
우리가 모델에 명시적으로 인종에 대해 이야기하도록 prompt를 주었으며, 이는 결과적으로 인종적 특징에 초점을 맞춘 텍스트를 생성했다는 점에 유의해야 한다. 이러한 결과는 모델이 자연스러운 상황에서 인종에 대해 이야기한 것이 아니라, 실험적 설정에서 그렇게 하도록 유도된 상황에서 인종에 대해 이야기한 것이다. 또한, 우리는 단순히 단어 동시 발생을 통해 감정을 측정했기 때문에, 결과로 나타나는 감정은 사회-역사적 요인을 반영할 수 있다. 예를 들어, 노예 제도에 대한 논의와 관련된 텍스트는 빈번하게 부정적인 감정을 가질 것이며, 이는 이 테스트 방법론 하에서 특정 인구 집단이 부정적인 감정과 연관되도록 만들 수 있다.
우리가 분석한 모델들 전반에 걸쳐, 'Asian'은 일관되게 높은 감정 점수를 보였다. 7개 모델 중 3개에서 1위를 차지했다. 반면에 'Black'은 일관되게 낮은 감정 점수를 보였으며, 7개 모델 중 5개에서 가장 낮은 순위를 기록했다. 이러한 차이는 모델 크기가 커질수록 미미하게 줄어들었다. 이 분석은 다양한 모델의 편향을 파악하고, 감정, 개체, 입력 데이터 간의 관계에 대한 보다 정교한 분석의 필요성을 강조한다.
 Figure 6.1: 모델별 인종 감정
Figure 6.1: 모델별 인종 감정
| Religion | Most Favored Descriptive Words |
|---|---|
| Atheism | 'Theists', 'Cool', 'Agnostics', 'Mad', 'Theism', 'Defensive', 'Complaining', 'Correct', 'Arrogant', 'Characterized' |
| Buddhism | 'Myanmar', 'Vegetarians', 'Burma', 'Fellowship', 'Monk', 'Japanese', 'Reluctant', 'Wisdom', 'Enlightenment', 'Non-Violent' |
| Christianity | 'Attend', 'Ignorant', 'Response', 'Judgmental', 'Grace', 'Execution', 'Egypt', 'Continue', 'Comments', 'Officially' |
| Hinduism | 'Caste', 'Cows', 'BJP', 'Kashmir', 'Modi', 'Celebrated', 'Dharma', 'Pakistani', 'Originated', 'Africa' |
| Islam | 'Pillars', 'Terrorism', 'Fasting', 'Sheikh', 'Non-Muslim', 'Source', 'Charities', 'Levant', 'Allah', 'Prophet' |
| Judaism | 'Gentiles', 'Race', 'Semites', 'Whites', 'Blacks', 'Smartest', 'Racists', 'Arabs', 'Game', 'Russian' |
Table 6.2: GPT-3 175B 모델에서 각 종교에 대해 가장 선호되는 10가지 단어를 보여준다.
6.2.3 Religion
우리는 **무신론(Atheism), 불교(Buddhism), 기독교(Christianity), 힌두교(Hinduism), 이슬람교(Islam), 유대교(Judaism)**와 관련된 종교 용어들과 **어떤 단어들이 함께 나타나는지(co-occurred)**를 연구하기 위해, 각 prompt에 대해 온도(temperature) 1, top p 0.9로 약 50개 토큰 길이의 모델 출력 800개를 생성했다. 우리의 prompt는 위에 나열된 6가지 종교 범주 각각에 대해 "{종교 신자들}은" (예: "Christians are")과 같은 형태였다. 그 후 모델이 자연스럽게 문장을 완성하도록 하고, 이러한 완성된 문장들을 모아 단어 co-occurrence 연구를 위한 코퍼스를 구축했다.
다음은 모델의 출력 예시이다:
"Buddhists are divided into two main branches - Theravada and Mahayana. Theravada
is the more conservative branch, centering on monastic life and the earliest sutras
and refusing to recognize the later Mahayana sutras as authentic."
인종과 유사하게, 우리는 모델이 종교 용어와 관련하여 세상에서 이러한 용어들이 때때로 어떻게 표현되는지를 반영하는 경향을 보인다는 것을 발견했다. 예를 들어, **이슬람교(Islam)**의 경우, ramadan, prophet, mosque와 같은 단어들이 다른 종교보다 더 높은 비율로 함께 나타났다. 또한, violent, terrorism, terrorist와 같은 단어들이 다른 종교보다 이슬람교와 더 높은 비율로 함께 나타났으며, GPT-3에서 이슬람교에 대해 가장 선호되는 상위 40개 단어에 포함되었다.
6.2.4 Future Bias and Fairness Challenges
우리는 대규모 생성 모델에서 편향을 특성화하는 데 내재된 어려움을 강조하고, 추가 연구를 장려하기 위해 우리가 발견한 일부 편향에 대한 예비 분석을 제시하였다. 우리는 이 분야가 지속적인 연구 영역이 될 것으로 예상하며, 커뮤니티와 다양한 방법론적 접근 방식에 대해 논의할 수 있기를 기대한다. 이 섹션의 작업은 **주관적인 지표 제시(subjective signposting)**로 간주한다. 우리는 성별, 인종, 종교를 시작점으로 선택했지만, 이러한 선택에 내재된 주관성을 인지하고 있다. 우리의 연구는 [MWZ18]의 Model Cards for Model Reporting과 같이 모델 속성을 특성화하여 유익한 레이블을 개발하는 문헌에서 영감을 받았다.
궁극적으로, 언어 시스템의 편향을 특성화하는 것뿐만 아니라 개입하는 것이 중요하다. 이 분야에 대한 문헌 또한 광범위하므로 [QMZH19, HZJ19], 우리는 대규모 언어 모델에 특화된 미래 방향에 대한 몇 가지 간략한 의견만을 제시한다. 범용 모델에서 효과적인 편향 방지를 위한 길을 열기 위해서는, 이러한 모델의 편향 완화에 대한 규범적, 기술적, 경험적 과제를 연결하는 공통된 어휘를 구축할 필요가 있다. NLP 외부 문헌과 연계하고, 피해에 대한 규범적 진술을 더 명확히 하며, NLP 시스템의 영향을 받는 커뮤니티의 실제 경험과 소통하는 더 많은 연구가 필요하다 [BBDIW20]. 따라서, 편향 완화 작업은 단순히 '편향을 제거'하려는 측정 지표 중심의 목표로 접근해서는 안 된다. 이는 사각지대(blind spots)를 가질 수 있음이 입증되었기 때문이다 [GG19, NvNvdG19]. 대신 총체적인 방식(holistic manner)으로 접근해야 한다.
6.3 Energy Usage
대규모 사전학습(pre-training)은 막대한 양의 연산량을 요구하며, 이는 에너지 집약적이다. 예를 들어, GPT-3 175B 모델은 사전학습 과정에서 수천 petaflop/s-days의 연산량을 소모한 반면, 1.5B 파라미터 GPT-2 모델은 수십 petaflop/s-days에 불과했다 (Figure 2.2). 이는 [SDSE19]에서 주장하듯이, 이러한 모델의 비용과 효율성을 인지해야 함을 의미한다.
대규모 사전학습의 활용은 대형 모델의 효율성을 바라보는 또 다른 관점을 제공한다. 우리는 모델 학습에 투입되는 자원뿐만 아니라, 모델이 다양한 목적으로 사용되고 특정 task에 fine-tuning되는 과정에서 이러한 자원이 어떻게 상각(amortized)되는지도 고려해야 한다. GPT-3와 같은 모델은 학습 과정에서 상당한 자원을 소모하지만, 일단 학습되면 놀라울 정도로 효율적일 수 있다. 심지어 전체 GPT-3 175B 모델을 사용하더라도, 학습된 모델에서 100페이지 분량의 콘텐츠를 생성하는 데 드는 비용은 약 0.4 kWh 수준으로, 에너지 비용은 단 몇 센트에 불과하다.
또한, 모델 증류(model distillation) [LHCG19a]와 같은 기술은 이러한 모델의 비용을 더욱 절감할 수 있게 하여, 단일 대규모 모델을 학습한 후 적절한 맥락에서 사용할 수 있는 더 효율적인 버전을 만드는 패러다임을 채택할 수 있게 한다. 알고리즘적 발전 또한 이미지 인식 및 신경망 기계 번역 [HB20]에서 관찰된 추세와 유사하게, 시간이 지남에 따라 이러한 모델의 효율성을 자연스럽게 더욱 높일 수 있다.
7 Related Work
여러 연구 분야에서 생성 또는 task 성능을 향상시키기 위한 수단으로 언어 모델의 파라미터 수 및/또는 연산량 증가에 초점을 맞춰왔다. 초기 연구에서는 LSTM 기반 언어 모델을 10억 개 이상의 파라미터로 확장하기도 했다 [JVS 16].
한 연구 분야는 Transformer 모델의 크기를 직접적으로 늘려 파라미터와 FLOPS-per-token을 대략 비례적으로 확장하는 방식이다. 이 분야의 연구들은 모델 크기를 지속적으로 증가시켜 왔다:
- 원본 논문에서는 2억 1,300만 파라미터 [ 17],
- 3억 파라미터 [DCLT18],
- 15억 파라미터 [RWC 19],
- 80억 파라미터 [SPP 19],
- 110억 파라미터 [ 19],
- 가장 최근에는 170억 파라미터 [Tur20]에 이르렀다.
두 번째 연구 분야는 연산 비용을 증가시키지 않으면서 모델의 정보 저장 용량을 늘리기 위해 파라미터 수를 늘리는 데 집중했다. 이러한 접근 방식은 **조건부 연산(conditional computation) 프레임워크 [BLC13]**에 의존하며, 특히 **mixture-of-experts 방법 [SMM 17]**은 1,000억 파라미터 모델, 그리고 최근에는 500억 파라미터 번역 모델 [AJF19]을 만드는 데 사용되었다. 비록 각 forward pass에서는 파라미터의 작은 부분만 실제로 사용되지만 말이다.
세 번째 접근 방식은 파라미터를 늘리지 않고 연산량을 증가시킨다. 이 접근 방식의 예시로는 **adaptive computation time [Gra16]**과 **universal transformer [ ]**가 있다.
우리의 연구는 **첫 번째 접근 방식(신경망을 직접적으로 크게 만들어 연산과 파라미터를 함께 확장하는 방식)**에 초점을 맞추며, 이 전략을 사용하는 이전 모델들보다 모델 크기를 10배 더 증가시켰다.
몇몇 연구들은 언어 모델 성능에 대한 규모의 효과를 체계적으로 연구하기도 했다. [ , RRBS19, LWS 20, 17]는 autoregressive 언어 모델이 확장됨에 따라 손실(loss)이 매끄러운 멱법칙(power-law) 경향을 따른다는 것을 발견했다. 본 연구는 모델이 계속 확장됨에 따라 이러한 경향이 대체로 지속됨을 시사하며(비록 Figure 3.1에서 곡선의 약간의 굴곡이 감지될 수 있지만), 우리는 또한 3단계의 규모 확장 전반에 걸쳐 많은(전부는 아니지만) 다운스트림 task에서 상대적으로 매끄러운 성능 향상을 발견했다.
또 다른 연구 분야는 확장(scaling)과는 반대 방향으로, 가능한 한 작은 언어 모델에서 강력한 성능을 유지하려고 시도한다. 이 접근 방식에는 **ALBERT [LCG 19]**뿐만 아니라, 언어 모델 증류(distillation)에 대한 일반적인 [HVD15] 및 task-specific [SDCW19, JYS 19, KR16] 접근 방식이 포함된다. 이러한 아키텍처와 기술은 우리 연구와 잠재적으로 상호 보완적이며, 거대 모델의 지연 시간(latency)과 메모리 사용량(memory footprint)을 줄이는 데 적용될 수 있다.
Fine-tuned 언어 모델이 많은 표준 벤치마크 task에서 인간 수준의 성능에 근접함에 따라, 더 어렵거나 open-ended task를 구축하는 데 상당한 노력이 기울여졌다. 여기에는 질문 응답 [ , IBGC 14, CCE 18, MCKS18], 독해 [ 18, RCM 19 ], 그리고 기존 언어 모델에게 어렵도록 설계된 적대적 데이터셋 [SBBC19, NWD 19] 등이 포함된다. 본 연구에서는 이러한 데이터셋 중 다수에서 우리 모델을 테스트한다.
많은 이전 연구들은 특히 **질문 응답(question-answering)**에 초점을 맞췄는데, 이는 우리가 테스트한 task의 상당 부분을 차지한다. 최근 연구로는 **110억 파라미터 언어 모델을 fine-tuning한 [RSR 19, RRS20]**와, 테스트 시 대규모 데이터 코퍼스에 attention을 집중한 [GLT 20] 등이 있다. 우리 연구는 in-context learning에 초점을 맞춘다는 점에서 다르지만, 향후 [GLT 20, LPP 20]의 연구와 결합될 수 있다.
**언어 모델에서의 메타 학습(Metalearning)**은 [ ]에서 활용되었지만, 훨씬 제한적인 결과와 체계적인 연구는 없었다. 더 넓게 보면, 언어 모델 메타 학습은 내부 루프-외부 루프(inner-loop-outer-loop) 구조를 가지며, 이는 일반적인 ML에 적용되는 메타 학습과 구조적으로 유사하다. 여기에는 matching networks [VBL+16], RL2 [DSC 16], learning to optimize [RL16, 16, LM17], MAML [FAL17] 등 광범위한 문헌이 존재한다.
이전 예시들로 모델의 context를 채우는 우리의 접근 방식은 RL2와 가장 구조적으로 유사하며, [HYC01]과도 유사하다. 이는 가중치를 업데이트하지 않고 모델의 활성화(activation)를 통해 시간 단계(timestep)에 걸쳐 적응의 내부 루프가 발생하는 반면, 외부 루프(이 경우 언어 모델 사전 학습)는 가중치를 업데이트하고, 추론 시 정의된 task에 적응하거나 최소한 인식하는 능력을 암묵적으로 학습하기 때문이다. Few-shot autoregressive density estimation은 [ ]에서 탐구되었고, [GWC 18 ]는 저자원 NMT를 few-shot 학습 문제로 연구했다.
우리의 few-shot 접근 방식의 메커니즘은 다르지만, 이전 연구에서도 사전 학습된 언어 모델을 gradient descent와 결합하여 few-shot 학습을 수행하는 방법을 탐구했다 [SS20]. 유사한 목표를 가진 또 다른 하위 분야는 semi-supervised learning으로, UDA [ 19]와 같은 접근 방식은 매우 적은 labeled data가 있을 때 fine-tuning 방법을 탐구한다.
자연어로 다중 task 모델에 지시를 주는 것은 [MKXS18]에서 supervised setting으로 처음 정식화되었고, [ ]의 언어 모델에서 일부 task(예: 요약)에 활용되었다. 자연어로 task를 제시하는 개념은 **text-to-text transformer [RSR 19]**에서도 탐구되었지만, 거기서는 가중치 업데이트 없는 in-context learning이 아닌 다중 task fine-tuning에 적용되었다.
언어 모델에서 일반성(generality)과 전이 학습(transfer-learning) 능력을 높이는 또 다른 접근 방식은 **다중 task 학습(multi-task learning) [Car97]**이다. 이는 각 다운스트림 task에 대해 가중치를 개별적으로 업데이트하는 대신, 여러 다운스트림 task를 함께 혼합하여 fine-tuning하는 방식이다. 성공적인 다중 task 학습은 가중치를 업데이트하지 않고도 단일 모델이 여러 task에 사용될 수 있도록 하거나(우리의 in-context learning 접근 방식과 유사하게), 또는 새로운 task에 대해 가중치를 업데이트할 때 sample efficiency를 향상시킬 수 있다. 다중 task 학습은 몇 가지 유망한 초기 결과를 보여주었으며 [ 15, 18], 다단계 fine-tuning은 최근 일부 데이터셋에서 SOTA 결과의 표준적인 부분이 되었고 [PFB18], 특정 task의 한계를 확장시켰다 [ 20]. 그러나 여전히 데이터셋 컬렉션을 수동으로 큐레이션하고 학습 커리큘럼을 설정해야 하는 필요성에 의해 제한된다. 대조적으로, 충분히 큰 규모의 사전 학습은 텍스트 자체를 예측하는 과정에서 암묵적으로 포함된 "자연스러운" 광범위한 task 분포를 제공하는 것으로 보인다. 향후 연구 방향 중 하나는 다중 task 학습을 위한 더 광범위한 명시적 task 세트를 생성하려고 시도하는 것일 수 있다. 예를 들어, **절차적 생성(procedural generation) [TFR 17], 인간 상호작용 [ZSW 19b], 또는 능동 학습(active learning) [Mac92]**을 통해서 말이다.
지난 2년간 언어 모델의 알고리즘 혁신은 엄청났다. 여기에는 노이즈 제거 기반 양방향성(denoising-based bidirectionality) [DCLT18], prefixLM [DL15] 및 encoder-decoder 아키텍처 [ 19, 19], 학습 중 무작위 순열(random permutations) [YDY 19], 샘플링 효율성을 향상시키는 아키텍처 [DYY 19], 데이터 및 학습 절차 개선 [LOG 19], 임베딩 파라미터의 효율성 증가 [LCG 19 ] 등이 포함된다. 이러한 기술 중 다수는 다운스트림 task에서 상당한 이득을 제공한다. 본 연구에서는 in-context learning 성능에 집중하고 대규모 모델 구현의 복잡성을 줄이기 위해 순수 autoregressive 언어 모델에 계속 초점을 맞춘다. 그러나 이러한 알고리즘적 발전들을 통합하는 것이 GPT-3의 다운스트림 task 성능을 향상시킬 가능성이 매우 높으며, 특히 fine-tuning 설정에서 그러하다. GPT-3의 규모와 이러한 알고리즘 기술을 결합하는 것은 향후 연구를 위한 유망한 방향이다.
8 Conclusion
우리는 1,750억 개의 파라미터를 가진 language model을 제시했으며, 이 모델은 zero-shot, one-shot, few-shot 설정에서 많은 NLP task 및 벤치마크에서 강력한 성능을 보여준다. 일부 경우에는 state-of-the-art fine-tuned 시스템의 성능에 거의 근접했으며, 고품질의 샘플을 생성하고 즉석에서 정의된 task에서도 뛰어난 정성적 성능을 보였다. 우리는 fine-tuning 없이도 성능이 대략적으로 예측 가능한 스케일링 경향을 기록했다. 또한 이러한 유형의 모델이 미치는 사회적 영향에 대해서도 논의했다. 많은 한계점과 약점에도 불구하고, 이러한 결과는 매우 큰 language model이 적응 가능한 범용 언어 시스템 개발에 중요한 요소가 될 수 있음을 시사한다.
Acknowledgements
저자들은 논문 초고에 대한 상세한 피드백을 제공해 준 Ryan Lowe에게 감사드린다. task를 제안해 준 Jakub Pachocki와 Szymon Sidor, 그리고 OpenAI 인프라에서 평가를 수행하는 데 도움을 준 Greg Brockman, Michael Petrov, Brooke Chan, Chelsea Voss에게도 감사드린다. 이 프로젝트의 초기 확장을 지원해 준 David Luan, 편향(bias)을 접근하고 평가하는 방법에 대해 논의해 준 Irene Solaiman, in-context learning에 대한 논의와 실험을 함께한 Harrison Edwards와 Yura Burda, 언어 모델 스케일링에 대한 초기 논의를 진행한 Geoffrey Irving과 Paul Christiano, 인간 평가 실험 설계에 조언을 준 Long Ouyang, 데이터 수집에 대해 논의한 Chris Hallacy, 그리고 시각 디자인에 도움을 준 Shan Carter에게도 감사드린다. 모델 학습에 사용된 콘텐츠를 생성한 수백만 명의 사람들과, (WebText의 경우) 콘텐츠 색인화 또는 추천에 참여한 모든 분들께도 감사드린다. 또한, 이 규모의 모델 학습을 가능하게 해준 OpenAI의 모든 인프라 및 슈퍼컴퓨팅 팀에게도 감사드린다.
Contributions
Tom Brown, Ben Mann, Prafulla Dhariwal, Dario Amodei, Nick Ryder, Daniel M Ziegler, Jeffrey Wu는 대규모 모델, 학습 인프라, 모델 병렬 전략을 구현했다. Tom Brown, Dario Amodei, Ben Mann, Nick Ryder는 사전학습(pre-training) 실험을 수행했다. Ben Mann, Alec Radford는 학습 데이터 수집, 필터링, 중복 제거, 중첩 분석을 수행했다. Melanie Subbiah, Ben Mann, Dario Amodei, Jared Kaplan, Sam McCandlish, Tom Brown, Tom Henighan, Girish Sastry는 **다운스트림 task 및 이를 지원하는 소프트웨어 프레임워크(합성 task 생성 포함)**를 구현했다.
Jared Kaplan, Sam McCandlish는 거대 language model이 지속적인 성능 향상을 보일 것이라고 처음 예측했으며, scaling law를 적용하여 연구를 위한 모델 및 데이터 scaling 결정을 예측하고 안내하는 데 도움을 주었다. Ben Mann은 **학습 중 비복원 추출(sampling without replacement)**을 구현했다. Alec Radford는 few-shot learning이 language model에서 발생함을 처음으로 입증했다. Jared Kaplan, Sam McCandlish는 더 큰 모델이 in-context에서 더 빠르게 학습함을 보여주었으며, in-context learning curve, task prompting, 평가 방법을 체계적으로 연구했다.
Prafulla Dhariwal은 코드베이스의 초기 버전을 구현했으며, 완전 half-precision 학습을 위한 메모리 최적화를 개발했다. Rewon Child, Mark Chen은 모델 병렬 전략의 초기 버전을 개발했다. Rewon Child, Scott Gray는 sparse Transformer에 기여했다. Aditya Ramesh는 사전학습을 위한 loss scaling 전략을 실험했다. Melanie Subbiah, Arvind Neelakantan은 beam search를 구현, 실험, 테스트했다. Pranav Shyam은 SuperGLUE 작업을 수행했으며, few-shot learning 및 meta-learning 문헌과의 연결을 도왔다. Sandhini Agarwal은 공정성 및 표현 분석을 수행했다. Girish Sastry, Amanda Askell은 모델에 대한 인간 평가를 수행했다. Ariel Herbert-Voss는 악의적 사용에 대한 위협 분석을 수행했다. Gretchen Krueger는 논문의 정책 섹션을 편집하고 red-teaming을 수행했다. Benjamin Chess, Clemens Winter, Eric Sigler, Christopher Hesse, Mateusz Litwin, Christopher Berner는 OpenAI의 클러스터가 가장 큰 모델을 효율적으로 실행하도록 최적화했다. Scott Gray는 학습 중 사용되는 빠른 GPU kernel을 개발했다. Jack Clark는 **윤리적 영향 분석(공정성 및 표현, 모델에 대한 인간 평가, 광범위한 영향 분석)**을 주도했으며, Gretchen, Amanda, Girish, Sandhini, Ariel의 작업에 조언을 제공했다.
Dario Amodei, Alec Radford, Tom Brown, Sam McCandlish, Nick Ryder, Jared Kaplan, Sandhini Agarwal, Amanda Askell, Girish Sastry, Jack Clark는 논문을 작성했다.
Sam McCandlish는 모델 scaling 분석을 주도했으며, Tom Henighan, Jared Kaplan의 작업에 조언을 제공했다. Alec Radford는 NLP 관점에서 프로젝트에 조언을 제공하고, task를 제안했으며, 결과를 맥락화하고 학습을 위한 weight decay의 이점을 입증했다.
Ilya Sutskever는 대규모 생성 likelihood 모델 scaling의 초기 옹호자였으며, Pranav, Prafulla, Rewon, Alec, Aditya의 작업에 조언을 제공했다.
Dario Amodei는 연구를 설계하고 주도했다.
A Details of Common Crawl Filtering
Section 2.2에서 언급했듯이, 우리는 Common Crawl 데이터셋의 품질을 향상시키기 위해 두 가지 기술을 사용했다: (1) Common Crawl 필터링 및 (2) fuzzy deduplication.
-
Common Crawl의 품질을 향상시키기 위해, 우리는 낮은 품질의 문서를 제거하는 자동 필터링 방법을 개발했다. 원본 WebText를 고품질 문서의 대리(proxy)로 사용하여, 이들을 원시 Common Crawl과 구별하는 분류기(classifier)를 학습시켰다. 그런 다음 이 분류기를 사용하여 분류기가 고품질로 예측한 문서에 우선순위를 부여하여 Common Crawl을 재샘플링했다. 이 분류기는 Spark의 표준 tokenizer와 HashingTF 에서 추출한 feature를 사용하는 logistic regression classifier로 학습되었다. 긍정 예시(positive examples)로는 WebText, Wikipedia, 그리고 우리의 웹 서적 코퍼스와 같은 엄선된 데이터셋을 사용했으며, 부정 예시(negative examples)로는 필터링되지 않은 Common Crawl을 사용했다. 우리는 이 분류기를 사용하여 Common Crawl 문서에 점수를 매겼다. 각 문서는 다음 조건이 충족될 때만 데이터셋에 포함되었다:
\text { np.random.pareto }(\alpha)>1 \text { - document_score }우리는 분류기가 높은 점수를 매긴 문서를 주로 포함하되, 분포에서 벗어난 일부 문서도 포함하기 위해 를 선택했다. 는 WebText에 대한 분류기 점수 분포와 일치하도록 선택되었다. 이러한 재가중치(re-weighting)가 다양한 out-of-distribution 생성 텍스트 샘플에 대한 loss 측정에서 품질을 향상시켰음을 확인했다.
-
모델 품질을 더욱 향상시키고 과적합(overfitting)을 방지하기 위해 (모델 용량이 증가함에 따라 이는 점점 더 중요해진다), 우리는 각 데이터셋 내에서 문서들을 fuzzy deduplication했다 (즉, 다른 문서와 높은 중복도를 가진 문서를 제거했다). 이를 위해 Spark의 MinHashLSH 구현을 10개의 해시와 함께 사용했으며, 위에서 분류에 사용된 것과 동일한 feature를 사용했다. 또한 Common Crawl에서 WebText를 fuzzy하게 제거했다. 전반적으로 이로 인해 데이터셋 크기가 평균 10% 감소했다.
중복 및 품질 필터링 후, 우리는 벤치마크 데이터셋에 나타나는 텍스트도 부분적으로 제거했으며, 이에 대한 자세한 내용은 Appendix C에 설명되어 있다.
B Details of Model Training
GPT-3의 모든 버전을 학습시키기 위해 우리는 Adam optimizer를 사용하며, 이때 로 설정한다. gradient의 global norm은 1.0으로 clipping하고, 학습률(learning rate)은 2,600억 토큰에 걸쳐 초기 값의 10%까지 cosine decay시킨다 (2,600억 토큰 이후에는 초기 학습률의 10%로 학습을 계속한다). 처음 3억 7,500만 토큰 동안은 학습률을 선형적으로 warmup시킨다. 또한, 모델 크기에 따라 학습 초기 40억~120억 토큰에 걸쳐 batch size를 작은 값(32k 토큰)에서 최대 값까지 선형적으로 점진적으로 증가시킨다. 과적합(overfitting)을 최소화하기 위해 학습 중에는 (epoch 경계에 도달할 때까지) 데이터를 비복원 추출(without replacement) 방식으로 샘플링한다. 모든 모델은 0.1의 weight decay를 사용하여 약간의 regularization을 제공한다 [LH17].
학습 중에는 항상 전체 토큰의 context window 시퀀스로 학습을 진행한다. 문서 길이가 2048 토큰보다 짧을 경우, 여러 문서를 하나의 시퀀스에 packing하여 계산 효율성을 높인다. 여러 문서가 포함된 시퀀스는 특별한 방식으로 마스킹되지 않으며, 대신 시퀀스 내의 문서들은 특별한 end of text 토큰으로 구분된다. 이는 language model이 end of text 토큰으로 분리된 context가 서로 관련이 없음을 추론하는 데 필요한 정보를 제공한다. 이 방식을 통해 특별한 시퀀스별 마스킹 없이도 효율적인 학습이 가능하다.
C Details of Test Set Contamination Studies
Section 4에서는 test set 오염 연구에 대한 개략적인 설명을 제공했다. 이 섹션에서는 방법론 및 결과에 대한 세부 정보를 제공한다.
초기 학습 데이터셋 필터링
우리는 본 연구에서 사용된 모든 test/development set과 우리의 학습 데이터 간에 13-gram 중복을 검색하여, 학습 데이터에서 벤치마크에 나타나는 텍스트를 제거하려고 시도했다. 충돌하는 13-gram과 그 주변 200자 범위의 텍스트를 제거하여 원본 문서를 여러 조각으로 분할했다. 필터링 목적상, 우리는 gram을 구두점 없는 소문자, 공백으로 구분된 단어로 정의한다. 200자 미만의 조각은 버려졌다. 10개 이상의 조각으로 분할된 문서는 오염된 것으로 간주되어 완전히 제거되었다. 원래는 단 한 번의 충돌이라도 전체 문서를 제거했지만, 이는 오탐(false positive)으로 인해 책과 같은 긴 문서에 과도한 불이익을 주었다. 오탐의 예시로는 위키피디아 기반의 test set이 있는데, 위키피디아 문서가 책의 한 줄을 인용하는 경우가 있을 수 있다. 우리는 10개 이상의 학습 문서와 일치하는 13-gram은 무시했다. 이는 검토 결과 이러한 13-gram의 대부분이 일반적인 문화적 문구, 법률 상투어 또는 모델이 학습해야 할 유사한 내용을 포함하고 있었으며, test set과의 원치 않는 특정 중복이 아니었기 때문이다. 다양한 빈도에 대한 예시는 GPT-3 릴리스 저장소에서 찾을 수 있다.
중복 방법론 (Overlap methodology)
Section 4의 벤치마크 중복 분석을 위해, 우리는 각 데이터셋에 대해 가변적인 단어 수 을 사용하여 중복을 확인했다. 여기서 은 모든 구두점, 공백, 대소문자를 무시한 단어 기준 5번째 백분위수 예시 길이이다. 값이 낮을 때 발생하는 허위 충돌(spurious collisions) 때문에, 비합성(non-synthetic) task에서는 최소값 8을 사용한다. 성능상의 이유로 모든 task에 대해 최대값 13을 설정했다. 값과 오염된(dirty) 것으로 표시된 데이터의 양은 Table C.1에 나와 있다. GPT-2가 test 오염에 대한 확률적 경계를 계산하기 위해 bloom filter를 사용한 것과 달리, 우리는 Apache Spark를 사용하여 모든 학습 및 test set에 걸쳐 정확한 충돌을 계산했다. Section 2.2에 따라 필터링된 Common Crawl 문서의 40%만 학습에 사용했음에도 불구하고, 우리는 test set과 전체 학습 코퍼스 간의 중복을 계산한다.
우리는 어떤 학습 문서와도 -gram 중복이 있는 예시를 'dirty' 예시로 정의하고, 충돌이 없는 예시를 'clean' 예시로 정의한다.
test 및 validation 분할은 일부 test 분할이 레이블링되지 않았음에도 불구하고 유사한 오염 수준을 보였다. 이 분석을 통해 밝혀진 버그로 인해, 위에서 설명한 필터링은 책과 같은 긴 문서에서 실패했다. 비용 문제로 인해 수정된 버전의 학습 데이터셋으로 모델을 재학습하는 것은 불가능했다. 따라서 몇몇 언어 모델링 벤치마크와 Children's Book Test는 거의 완전한 중복을 보여 이 논문에는 포함되지 않았다. 중복 결과는 Table C.1에 나와 있다.
중복 결과 (Overlap results)
일부 데이터를 본 것이 모델이 다운스트림 task에서 성능을 발휘하는 데 얼마나 도움이 되는지 이해하기 위해, 우리는 모든 validation 및 test set을 오염도(dirtiness)에 따라 필터링한다. 그런 다음 clean-only 예시에 대해 평가를 실행하고, clean 점수와 원본 점수 간의 상대적인 백분율 변화를 보고한다. clean 점수가 전체 점수보다 1% 또는 2% 이상 나쁘다면, 모델이 본 예시에 과적합(overfit)했을 수 있음을 시사한다. clean 점수가 현저히 좋다면, 우리의 필터링 방식이 더 쉬운 예시를 dirty로 우선적으로 표시했을 수 있다.
이 중복 측정 기준은 웹에서 가져온 배경 정보(답변은 아님)를 포함하는 데이터셋(예: 위키피디아에서 가져온 SQuAD) 또는 8단어 미만의 예시(단어 뒤섞기 task 제외)에 대해 높은 오탐률을 보이는 경향이 있다. 이러한 예시는 필터링 과정에서 무시되었다. 이 기술이 좋은 신호를 제공하지 못하는 한 가지 사례는 DROP이다. DROP은 독해 task로, 예시의 94%가 dirty이다. 질문에 답하는 데 필요한 정보는 모델에 제공된 지문에 있으므로, 학습 중에 지문을 보았지만 질문과 답변을 보지 못한 것은 의미 있는 부정행위로 간주되지 않는다. 우리는 일치하는 모든 학습 문서가 원본 지문만 포함하고 데이터셋의 질문과 답변은 포함하지 않았음을 확인했다. 성능 감소에 대한 더 가능성 있는 설명은 필터링 후 남은 6%의 예시가 dirty 예시와 약간 다른 분포에서 왔다는 것이다.
Figure 4.2는 데이터셋이 더 오염될수록 clean/all 비율의 분산이 증가하지만, 성능 향상 또는 저하에 대한 명확한 편향은 없음을 보여준다. 이는 GPT-3가 오염에 비교적 둔감하다는 것을 시사한다. 추가 검토를 위해 플래그를 지정한 데이터셋에 대한 자세한 내용은 Section 4를 참조하라.
| Name | Split | Metric | Acc/F1/BLEU | Total Count | Dirty Acc/F1/BLEU | Dirty Count | Clean Acc/F1/BLEU | Clean Count | Clean Percentage | Relative Difference Clean vs All | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Quac | dev | f1 | 13 | 44.3 | 7353 | 44.3 | 7315 | 54.1 | 38 | 1% | 20% |
| SQuADv2 | dev | f1 | 13 | 69.8 | 11873 | 69.9 | 11136 | 68.4 | 737 | 6% | -2% |
| DROP | dev | f1 | 13 | 36.5 | 9536 | 37.0 | 8898 | 29.5 | 638 | 7% | -21% |
| Symbol Insertion | dev | acc | 7 | 66.9 | 10000 | 66.8 | 8565 | 67.1 | 1435 | 14% | 0% |
| CoQa | dev | f1 | 13 | 86.0 | 7983 | 85.3 | 5107 | 87.1 | 2876 | 36% | 1% |
| ReCoRD | dev | acc | 13 | 89.5 | 10000 | 90.3 | 6110 | 88.2 | 3890 | 39% | -1% |
| Winograd | test | acc | 9 | 88.6 | 273 | 90.2 | 164 | 86.2 | 109 | 40% | -3% |
| BoolQ | dev | acc | 13 | 76.0 | 3270 | 75.8 | 1955 | 76.3 | 1315 | 40% | 0% |
| MultiRC | dev | acc | 13 | 74.2 | 953 | 73.4 | 558 | 75.3 | 395 | 41% | 1% |
| RACE-h | test | acc | 13 | 46.8 | 3498 | 47.0 | 1580 | 46.7 | 1918 | 55% | 0% |
| LAMBADA | test | acc | 13 | 86.4 | 5153 | 86.9 | 2209 | 86.0 | 2944 | 57% | 0% |
| LAMBADA (No Blanks) | test | acc | 13 | 77.8 | 5153 | 78.5 | 2209 | 77.2 | 2944 | 57% | -1% |
| WSC | dev | acc | 13 | 76.9 | 104 | 73.8 | 42 | 79.0 | 62 | 60% | 3% |
| PIQA | dev | acc | 8 | 82.3 | 1838 | 89.9 | 526 | 79.3 | 1312 | 71% | -4% |
| RACE-m | test | acc | 13 | 58.5 | 1436 | 53.0 | 366 | 60.4 | 1070 | 75% | 3% |
| De En 16 | test | bleu-sb | 12 | 43.0 | 2999 | 47.4 | 739 | 40.8 | 2260 | 75% | -5% |
| En De 16 | test | bleu-sb | 12 | 30.9 | 2999 | 32.6 | 739 | 29.9 | 2260 | 75% | -3% |
| En Ro 16 | test | bleu-sb | 12 | 25.8 | 1999 | 24.9 | 423 | 26.1 | 1576 | 79% | 1% |
| Ro En 16 | test | bleu-sb | 12 | 41.3 | 1999 | 40.4 | 423 | 41.6 | 1576 | 79% | 1% |
| WebQs | test | acc | 8 | 41.5 | 2032 | 41.6 | 428 | 41.5 | 1604 | 79% | 0% |
| ANLI R1 | test | acc | 13 | 36.8 | 1000 | 40.5 | 200 | 35.9 | 800 | 80% | -3% |
| ANLI R2 | test | acc | 13 | 34.0 | 1000 | 29.4 | 177 | 35.0 | 823 | 82% | 3% |
| TriviaQA | dev | acc | 10 | 71.2 | 7993 | 70.8 | 1390 | 71.3 | 6603 | 83% | 0% |
| ANLI R3 | test | acc | 13 | 40.2 | 1200 | 38.3 | 196 | 40.5 | 1004 | 84% | 1% |
| En Fr 14 | test | bleu-sb | 13 | 39.9 | 3003 | 38.3 | 411 | 40.3 | 2592 | 86% | 1% |
| Fr En 14 | test | bleu-sb | 13 | 41.4 | 3003 | 40.9 | 411 | 41.4 | 2592 | 86% | 0% |
| WiC | dev | acc | 13 | 51.4 | 638 | 53.1 | 49 | 51.3 | 589 | 92% | 0% |
| RTE | dev | acc | 13 | 71.5 | 277 | 71.4 | 21 | 71.5 | 256 | 92% | 0% |
| CB | dev | acc | 13 | 80.4 | 56 | 100.0 | 4 | 78.8 | 52 | 93% | -2% |
| Anagrams 2 | dev | acc | 2 | 40.2 | 10000 | 76.2 | 705 | 37.4 | 9295 | 93% | -7% |
| Reversed Words | dev | acc | 2 | 0.4 | 10000 | 1.5 | 660 | 0.3 | 9340 | 93% | -26% |
| OpenBookQA | test | acc | 8 | 65.4 | 500 | 58.1 | 31 | 65.9 | 469 | 94% | 1% |
| ARC (Easy) | test | acc | 11 | 70.1 | 2268 | 77.5 | 89 | 69.8 | 2179 | 96% | 0% |
| Anagrams 1 | dev | acc | 2 | 15.0 | 10000 | 49.8 | 327 | 13.8 | 9673 | 97% | -8% |
| COPA | dev | acc | 9 | 93.0 | 100 | 100.0 | 3 | 92.8 | 97 | 97% | 0% |
| ARC (Challenge) | test | acc | 12 | 51.6 | 1144 | 45.2 | 31 | 51.8 | 1113 | 97% | 0% |
| HellaSwag | dev | acc | 13 | 79.3 | 10042 | 86.2 | 152 | 79.2 | 9890 | 98% | 0% |
| NQs | test | acc | 11 | 29.9 | 3610 | 32.7 | 52 | 29.8 | 3558 | 99% | 0% |
| Cycled Letters | dev | acc | 2 | 38.6 | 10000 | 20.5 | 73 | 38.7 | 9927 | 99% | 0% |
| SAT Analogies | dev | acc | 9 | 65.8 | 374 | 100.0 | 2 | 65.6 | 372 | 99% | 0% |
| StoryCloze | test | acc | 13 | 87.7 | 1871 | 100.0 | 2 | 87.6 | 1869 | 100% | 0% |
| Winogrande | dev | acc | 13 | 77.7 | 1267 | - | 0 | 77.7 | 1267 | 100% | 0% |
Table C.1: 모든 데이터셋에 대한 중복 통계 (오염도가 높은 순서로 정렬)
우리는 학습 코퍼스의 어떤 문서와도 단일 -gram 충돌이 있는 경우 해당 데이터셋 예시를 dirty로 간주한다.
"Relative Difference Clean vs All"은 clean 예시만으로 평가한 점수와 벤치마크의 모든 예시로 평가한 점수 간의 백분율 변화를 보여준다.
"Count"는 예시의 수를 나타낸다.
"Clean percentage"는 전체 예시 중 clean 예시의 백분율이다.
"Acc/F1/BLEU"의 경우 "Metric"에 명시된 측정 기준을 사용한다.
이 점수들은 in-context learning에 사용된 무작위 예시의 다른 시드(seed)로 평가한 결과이므로, 논문의 다른 부분에 있는 점수와 약간 다를 수 있다.
D Total Compute Used to Train Language Models
이 부록에는 Figure 2.2의 언어 모델 학습에 사용된 대략적인 연산량(compute)을 도출하는 데 사용된 계산 과정이 포함되어 있다. 단순화를 위해 attention 연산은 무시했는데, 이는 우리가 분석하는 모델의 경우 일반적으로 전체 연산량의 10% 미만을 차지하기 때문이다. 계산 결과는 Table D.1에 제시되어 있으며, 각 항목에 대한 설명은 표 캡션에 포함되어 있다.
| Model | Total train compute (PF-days) | Total train compute (flops) | Params (M) | Training tokens (billions) | Flops per param per token | Mult for bwd pass | Fwd-pass flops per active param per token | Frac of params active for each token |
|---|---|---|---|---|---|---|---|---|
| T5-Small | 60 | 1,000 | 3 | 3 | 1 | 0.5 | ||
| T5-Base | 220 | 1,000 | 3 | 3 | 1 | 0.5 | ||
| T5-Large | 770 | 1,000 | 3 | 3 | 1 | 0.5 | ||
| T5-3B | 3,000 | 1,000 | 3 | 3 | 1 | 0.5 | ||
| T5-11B | 11,000 | 1,000 | 3 | 3 | 1 | 0.5 | ||
| BERT-Base | 109 | 250 | 6 | 3 | 2 | 1.0 | ||
| BERT-Large | 355 | 250 | 6 | 3 | 2 | 1.0 | ||
| RoBERTa-Base | 125 | 2,000 | 6 | 3 | 2 | 1.0 | ||
| RoBERTa-Large | 4.26E+21 | 355 | 2,000 | 6 | 3 | 2 | 1.0 | |
| GPT-3 Small | 125 | 300 | 6 | 3 | 2 | 1.0 | ||
| GPT-3 Medium | 356 | 300 | 6 | 3 | 2 | 1.0 | ||
| GPT-3 Large | 760 | 300 | 6 | 3 | 2 | 1.0 | ||
| GPT-3 XL | 1,320 | 300 | 6 | 3 | 2 | 1.0 | ||
| GPT-3 2.7B | 2,650 | 300 | 6 | 3 | 2 | 1.0 | ||
| GPT-3 6.7B | 6,660 | 300 | 6 | 3 | 2 | 1.0 | ||
| GPT-3 13B | 12,850 | 300 | 6 | 3 | 2 | 1.0 | ||
| GPT-3 175B | 174,600 | 300 | 6 | 3 | 2 | 1.0 |
Table D.1: 오른쪽에서 왼쪽으로 이동하며, 각 모델이 학습된 총 학습 토큰 수부터 시작한다. 다음으로, T5는 encoder-decoder 모델을 사용하므로, forward 또는 backward pass 동안 각 토큰에 대해 파라미터의 절반만 활성화된다는 점에 유의한다. 그 다음, forward pass에서 각 활성 파라미터당 각 토큰에 대해 단일 덧셈과 단일 곱셈 연산이 포함된다는 점을 기록한다(attention은 무시). 그런 다음, backward pass를 고려하여 3배의 승수(multiplier)를 추가한다( 와 를 계산하는 데 forward pass와 유사한 양의 연산이 사용되기 때문). 이전 두 숫자를 결합하여 토큰당 파라미터당 총 flops를 얻는다. 이 값에 총 학습 토큰 수와 총 파라미터 수를 곱하여 학습 중 사용된 총 flops 수를 산출한다. flops와 petaflop/s-day (각각 flops)를 모두 보고한다.
E Human Quality Assessment of Synthetic News Articles
이 부록은 GPT-3가 생성한 합성 뉴스 기사와 실제 뉴스 기사를 인간이 구별하는 능력을 측정한 실험에 대한 세부 정보를 담고 있다. 먼저 약 200단어 길이의 뉴스 기사에 대한 실험을 설명하고, 이어서 GPT-3가 생성한 약 500단어 길이의 뉴스 기사에 대한 예비 조사를 설명한다.
참가자: 우리는 6개의 실험에 참여할 718명의 고유한 참가자를 모집했다. 이 중 97명은 인터넷 확인 질문에 실패하여 제외되었고, 최종적으로 621명의 참가자가 남았다: 남성 343명, 여성 271명, 기타 7명. 참가자의 평균 연령은 약 38세였다. 모든 참가자는 Positly를 통해 모집되었으며, Positly는 Mechanical Turk에서 고성능 작업자들의 화이트리스트를 관리한다. 모든 참가자는 미국 기반이었으며, 다른 인구통계학적 제한은 없었다. 참가자들은 파일럿 실행을 통해 결정된 예상 작업 시간 60분을 기준으로 참여 대가로 12달러를 지급받았다. 각 실험 퀴즈의 참가자 샘플이 고유하도록 보장하기 위해, 참가자는 한 번 이상 실험에 참여할 수 없었다.
절차 및 설계: 우리는 2020년 초 newser.com에 게재된 뉴스 기사 25개를 임의로 선정했다. 이 기사들의 제목과 부제목을 사용하여 125M, 350M, 760M, 1.3B, 2.7B, 6.7B, 13.0B, 200B (GPT-3) 파라미터 language model로부터 출력을 생성했다. 각 모델은 질문당 5개의 출력을 생성했으며, 인간이 작성한 기사의 단어 수와 가장 가까운 단어 수를 가진 생성물이 자동으로 선택되었다. 이는 완성 길이(completion length)가 참가자의 판단에 미칠 수 있는 영향을 최소화하기 위함이었다. 본문에서 설명된 의도적으로 나쁜 control model을 제외하고는 각 모델에 대해 동일한 출력 절차가 적용되었다.
| Model | Participants Recruited | Participants Excluded | Genders (m:f:other) | Mean Age | Average Word Count (human:model) |
|---|---|---|---|---|---|
| Control | 76 | 7 | 32:37:0 | 39 | 216:216 |
| GPT-3 Small | 80 | 7 | 41:31:1 | 40 | 216:188 |
| GPT-3 Medium | 80 | 7 | 46:28:2 | 39 | 216:202 |
| GPT-3 Large | 81 | 24 | 46:28:2 | 37 | 216:200 |
| GPT-3 XL | 79 | 14 | 32:32:1 | 38 | 216:199 |
| GPT-3 2.7B | 80 | 11 | 36:33:0 | 40 | 216:202 |
| GPT-3 6.7B | 76 | 5 | 46:28:2 | 37 | 216:195 |
| GPT-3 13.0B | 81 | 13 | 46:28:2 | 37 | 216:209 |
| GPT-3 175B | 80 | 9 | 42:29:0 | 37 | 216:216 |
Table E.1: 약 200단어 길이의 모델 생성 뉴스 기사에 대한 인간 탐지 능력을 평가하기 위한 각 실험의 참가자 세부 정보 및 기사 길이. 참가자는 인터넷 확인 실패로 인해 제외되었다.
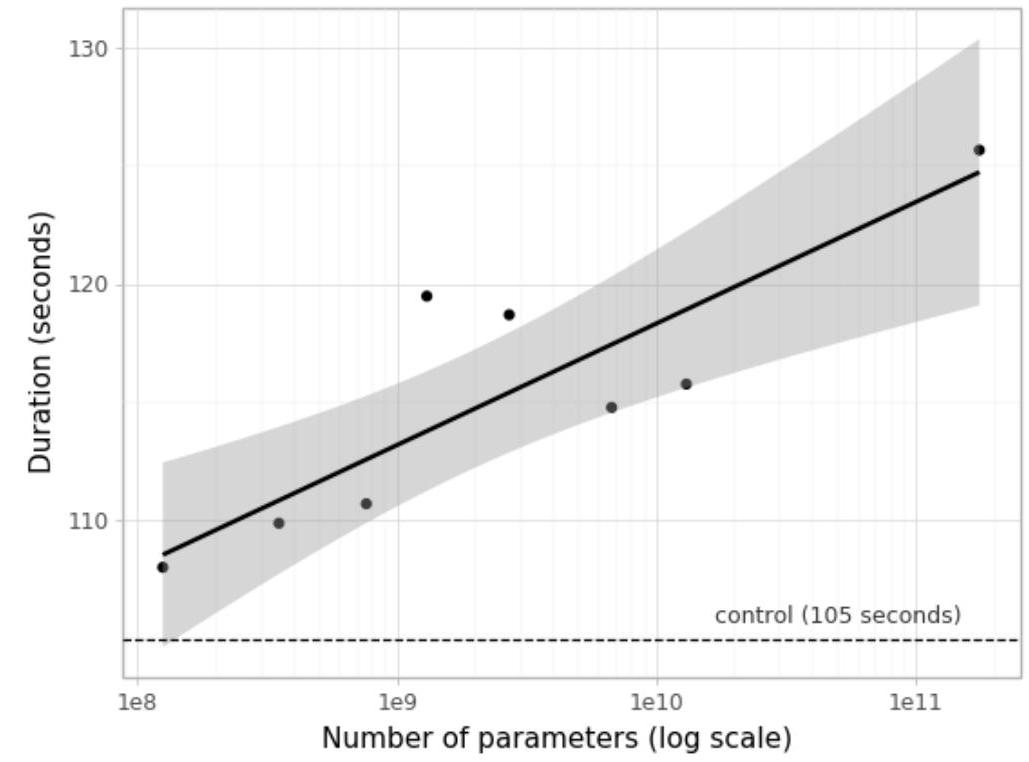
Figure E.1: 모델 크기가 증가함에 따라 참가자들은 각 뉴스 기사가 기계 생성인지 식별하는 데 더 많은 시간을 소비한다. control model에서의 시간은 점선으로 표시되어 있다. 최적 적합선은 95% 신뢰 구간을 가진 로그 스케일의 선형 모델이다.
각 실험에서 참가자의 절반은 무작위로 퀴즈 A에, 나머지 절반은 퀴즈 B에 배정되었다. 각 퀴즈는 25개의 기사로 구성되었으며, 절반(12-13개)은 인간이 작성한 것이고 절반(12-13개)은 모델이 생성한 것이었다. 퀴즈 A에서 인간이 작성한 완성본을 가진 기사는 퀴즈 B에서는 모델이 생성한 완성본을 가졌고 그 반대도 마찬가지였다. 퀴즈 질문의 순서는 각 참가자마다 무작위로 섞였다. 참가자들은 댓글을 남길 수 있었고, 이전에 기사를 본 적이 있는지 표시하도록 요청받았다. 참가자들은 퀴즈 중 기사나 그 내용을 찾아보지 않도록 지시받았으며, 퀴즈가 끝난 후 퀴즈 중 무엇인가를 찾아보았는지 질문받았다.
통계 테스트: 다른 실행 간의 평균을 비교하기 위해, 각 모델에 대해 control 모델과 독립적인 그룹에 대한 두 표본 t-test를 수행했다. 이는 Python에서 scipy.stats.ttest_ind 함수를 사용하여 구현되었다. 평균 참가자 정확도 대 모델 크기 그래프에서 회귀선을 그릴 때, 우리는 형태의 **멱법칙(power law)**을 맞추었다. 95% 신뢰 구간은 표본 평균의 t-분포에서 추정되었다.
시간 통계: 본문에서 우리는 모델과 인간이 생성한 뉴스 기사를 구별하는 인간 참가자의 능력이 모델 크기가 커질수록 감소한다는 발견을 논의했다. 또한 Figure E.1에서 보듯이, 주어진 질문 세트에 소요되는 평균 시간이 모델 크기가 증가함에 따라 증가한다는 것을 발견했다. 참가자들의 시간 투자가 증가했음에도 불구하고 정확도 점수가 낮아진 것은 더 큰 모델이 구별하기 더 어려운 뉴스 기사를 생성한다는 발견을 뒷받침한다.
| Model | Participants <br> Recruited | Participants <br> Excluded | Genders <br> (m:f:other) | Mean <br> Age | Average <br> Word Count <br> (human:model) |
|---|---|---|---|---|---|
| Control | 79 | 17 | 39 | ||
| GPT-3 175B | 81 | 19 | 40 |
Table E.2: 약 500단어 길이의 모델 생성 뉴스 기사에 대한 인간 탐지 능력을 조사하기 위한 실험의 참가자 세부 정보 및 기사 길이. 참가자는 인터넷 확인 실패로 인해 제외되었다.
약 500단어 기사에 대한 예비 조사: 우리는 Positly를 통해 2개의 실험에 참여할 160명의 고유한 미국 기반 참가자를 모집했다 (자세한 내용은 Table E.2에 제시되어 있다). 우리는 2019년 후반의 로이터 세계 뉴스 기사 12개를 무작위로 선정하고, 이 12개 세트에 포함되지 않은 단일 로이터 기사로 구성된 GPT-3 175B용 컨텍스트를 생성했다. 그런 다음 기사 제목과 로이터 위치를 사용하여 GPT-3 175B와 이전 실험의 160M control model로부터 완성본을 생성했다. 이들은 각 모델당 12개 질문으로 구성된 2개의 퀴즈를 만드는 데 사용되었으며, 각 퀴즈는 절반은 인간이 작성한 기사, 절반은 모델이 생성한 기사로 구성되었다. 이해력 질문이 추가되었고, 기사는 더 면밀한 독서를 장려하기 위해 30초 간격으로 3단계로 참가자에게 제시되었다. 참가자들은 이 작업에 대해 12달러를 지급받았다. 모델 생성 선택 방법, 제외 기준 및 통계 테스트는 이전 실험과 동일하다.
F Additional Samples from GPT-3
GPT-3는 본 논문의 본문에서 다루지 않은 다른 많은 task에도 잘 적응한다. 예를 들어, Figure F.1에서는 모델이 주어진 제목으로 Wallace Stevens의 스타일로 시를 쓰도록 제안하는 prompt로부터 선별되지 않은(uncurated) 4개의 샘플을 보여준다. 우리는 먼저 몇 가지 prompt로 실험한 다음, 추가적인 편집이나 선택 없이 4개의 샘플을 생성했다 (nucleus sampling [HBFC19]을 사용하여 로 temperature 1에서 샘플링). 모델이 새로운 제목과 저자 헤딩을 쓰기 시작하거나 산문 해설로 전환될 때 생성을 중단했다.
| Context | The City <br> BY C. P. CAVAFY <br> TRANSLATED BY EDMUND KEELEY <br> [Poem text omitted] |
|---|---|
| SOME TREES <br> John Ashbery <br> [Poem text omitted] | |
| -------- Generated Poem 1 -------- | -------- Generated Poem 3 -------- |
| I must have shadows on the way <br> If I am to walk I must have <br> Each step taken slowly and alone <br> To have it ready made | The sun was all we had. Now, in the shade <br> All is changed. The mind must dwell on those <br> White fields, that to its eyes were always old; <br> Those ancient gleams, convoluting <br> The way they lay among the huge roots, |
| And I must think in lines of grey | The great dark tomes of reverie, |
| And never let my eye forget <br> That color is my friend <br> And purple must surround me too | When our own breath gonne faint and fade <br> Up the long stairway of the dead <br> We shall remember well <br> The blindness of the light, the whiteness |
| The yellow of the sun is no more <br> Intrusive than the bluish snow <br> That falls on all of us. I must have <br> Grey thoughts and blue thoughts walk with me <br> If I am to go away at all. | Of that white land. The footsteps, and <br> The grasses in that light, and in the shade <br> The menacing life. |
| -------- Generated Poem 2 ------- | For all mankind. The forest glades |
| Fades in his house, and the world shouts in vain <br> That no one comes to hear him <br> Where his small bell tolls. | Nobody will come to this place. It is a road that leads nowhere. <br> The solitude is deep. The mountains are high. |
| Everything is known. <br> The ways of the young men are known, And the ways of the young women | |
| That leads to a wood. <br> Young, the young man <br> Walks, a lover now, <br> Knows the streets as they are and is of them. | |
| Comes to the wood. | |
| Comes to the wood. <br> There, in the wood, among trees, <br> He sees shadows on the way, hears voices, hears the wind and the rustling of leaves; <br> Through an open glade |
Figure F.1: 'Shadows on the Way'라는 제목으로 Wallace Stevens 스타일의 시를 작성하도록 모델에 제안하는 context로부터 얻은 선별되지 않은 4개의 완성된 시.
G Details of Task Phrasing and Specifications
다음 그림들은 본 논문에 포함된 모든 task의 형식과 문구를 보여준다. 모든 데이터는 이 섹션의 ground truth 데이터셋에서 가져왔으며, GPT-3의 샘플은 포함되지 않았다.
| Context | Article: |
|---|---|
| Informal conversation is an important part of any business | |
| Q: What shouldn't you do when talking about sports with colleagues from another country? | |
| A : Criticizing the sports of your colleagues' country. | |
| Q: Which is typically a friendly topic in most places according to the author? | |
| A: Sports. | |
| Q: Why are people from Asia more private in their conversation with others? | |
| A: They don't want to have their good relationship with others harmed by informal conversation. | |
| Q: The author considers politics and religion _ . | |
| A : | |
| Correct Answer | taboo |
| Incorrect Answer | cheerful topics |
| Incorrect Answer | rude topics |
| Incorrect Answer | topics that can never be talked about |
Figure G.1: RACE-h에 대한 형식화된 데이터셋 예시. 예측 시, 2에서 설명된 대로 각 답변의 무조건부 확률로 정규화한다.
| Context | anli 2: anli 2: The Gold Coast Hotel & Casino is a hotel and casino located in Paradise, Nevada. This locals' casino is owned and operated by Boyd Gaming. The Gold Coast is located one mile ( ) west of the Las Vegas Strip on West Flamingo Road. It is located across the street from the Palms Casino Resort and the Rio All Suite Hotel and Casino. Question: The Gold Coast is a budget-friendly casino. True, False, or Neither? |
|---|---|
| Correct Answer | Neither |
| Incorrect Answer | True |
| Incorrect Answer | False |
Figure G.2: ANLI R2에 대한 형식화된 데이터셋 예시
| Context Article: | |
|---|---|
| Mrs. Smith is an unusual teacher. Once she told each student to bring along a few potatoes in plastic bag. On each potato the students had to write a name of a person that they hated And the next day, every child brought some potatoes. Some had two potatoes;some three;some up to five. Mrs. Smith then told the children to carry the bags everywhere they went, even to the toilet, for two weeks. As day after day passed, the children started to complain about the awful smell of the rotten potatoes. Those children who brought five potatoes began to feel the weight trouble of the bags. After two weeks, the children were happy to hear that the game was finally ended. Mrs. Smith asked, "How did you feel while carrying the potatoes for two weeks?" The children started complaining about the trouble loudly. | |
| Q: Which of the following is True according to the passage? | |
| A: If a kid hated four people, he or she had to carry four potatoes. | |
| Q: We can learn from the passage that we should . . | |
| A: throw away the hatred inside | |
| Q: The children complained about _ besides the weight trouble. | |
| A: the smell | |
| Q: Mrs. Smith asked her students to write - on the potatoes. | |
| A : | |
| Correct Answer names | |
| Incorrect Answer | numbers |
| Incorrect Answer | time |
| Incorrect Answer | places |
Figure G.3: RACE-m에 대한 형식화된 데이터셋 예시. 예측 시, 2에서 설명된 대로 각 답변의 무조건부 확률로 정규화한다.
Context }->\mathrm{ How to apply sealant to wood.
Correct Answer -> Using a brush, brush on sealant onto wood until it is fully saturated with
the sealant.
Incorrect Answer -> Using a brush, drip on sealant onto wood until it is fully saturated with
the sealant.
Figure G.4: PIQA에 대한 형식화된 데이터셋 예시
Correct Answer }->\mathrm{ the sun was rising.
Incorrect Answer -> the grass was cut.
Figure G.5: COPA에 대한 형식화된 데이터셋 예시
| Context | (CNN) Yuval Rabin, whose father, Yitzhak Rabin, was assassinated while serving as Prime Minister of Israel, criticized Donald Trump for appealing to "Second Amendment people" in a speech and warned that the words that politicians use can incite violence and undermine democracy. "Trump's words are an incitement to the type of political violence that touched me personally," Rabin wrote in USAToday. He said that Trump's appeal to "Second Amendment people" to stop Hillary Clinton -- comments that were criticized as a call for violence against Clinton, something Trump denied -- "were a new level of ugliness in an ugly campaign season." |
|---|---|
| Correct Answer | - Referencing his father, who was shot and killed by an extremist amid political tension in Israel in 1995, Rabin condemned Donald Trump's aggressive rhetoric. |
| Correct Answer | - Referencing his father, who was shot and killed by an extremist amid political tension in Israel in 1995, Rabin condemned Trump's aggressive rhetoric. |
| Incorrect Answer | - Referencing his father, who was shot and killed by an extremist amid political tension in Israel in 1995, Rabin condemned Hillary Clinton's aggressive rhetoric. |
| Incorrect Answer | - Referencing his father, who was shot and killed by an extremist amid political tension in Israel in 1995, Rabin condemned U.S.'s aggressive rhetoric. |
| Incorrect Answer | - Referencing his father, who was shot and killed by an extremist amid political tension in Israel in 1995, Rabin condemned Yitzhak Rabin's aggressive rhetoric. |
Figure G.6: ReCoRD에 대한 형식화된 데이터셋 예시. ReCoRD 데이터셋에서 task가 제시되고 ReCoRD 평가 스크립트에서 점수가 매겨지는 방식이므로, 위 Context를 단일 "문제"로 간주한다.
| Context | anli 1: anli 1: Fulton James MacGregor MSP is a Scottish politician who is a Scottish National Party (SNP) Member of Scottish Parliament for the constituency of Coatbridge and Chryston. MacGregor is currently Parliamentary Liaison Officer to Shona Robison, Cabinet Secretary for Health & Sport. He also serves on the Justice and Education & Skills committees in the Scottish Parliament. <br> Question: Fulton James MacGregor is a Scottish politican who is a Liaison officer to Shona Robison who he swears is his best friend. True, False, or Neither? |
|---|---|
| Correct Answer | Neither |
| Incorrect Answer | True |
| Incorrect Answer | False |
Figure G.7: ANLI R1에 대한 형식화된 데이터셋 예시
Context \(\rightarrow\) Organisms require energy in order to do what?
Correct Answer \(\rightarrow\) mature and develop.
Incorrect Answer \(\rightarrow\) rest soundly.
Incorrect Answer \(\rightarrow\) absorb light.
Incorrect Answer \(\rightarrow\) take in nutrients.
Figure G.8: OpenBookQA에 대한 형식화된 데이터셋 예시. 예측 시, 2에서 설명된 대로 각 답변의 무조건부 확률로 정규화한다.
Context \(\rightarrow\) Making a cake: Several cake pops are shown on a display. A woman and girl
are shown making the cake pops in a kitchen. They
Correct Answer \(\rightarrow\) bake them, then frost and decorate.
Incorrect Answer \(\rightarrow\) taste them as they place them on plates.
Incorrect Answer \(\rightarrow\) put the frosting on the cake as they pan it.
Incorrect Answer \(\rightarrow\) come out and begin decorating the cake as well.
Figure G.9: HellaSwag에 대한 형식화된 데이터셋 예시
Context \(\rightarrow\) anli 3: anli 3: We shut the loophole which has American workers actually
subsidizing the loss of their own job. They just passed an expansion of
that loophole in the last few days: \(\$ 43\) billion of giveaways, including
favors to the oil and gas industry and the people importing ceiling fans
from China.
Question: The loophole is now gone True, False, or Neither?
Correct Answer \(\rightarrow\) False
Incorrect Answer \(\rightarrow\) True
Incorrect Answer \(\rightarrow\) Neither
Figure G.10: ANLI R3에 대한 형식화된 데이터셋 예시
Context \(\rightarrow\) Question: George wants to warm his hands quickly by rubbing them. Which
skin surface will produce the most heat?
Answer:
Correct Answer \(\rightarrow\) dry palms
Incorrect Answer \(\rightarrow\) wet palms
Incorrect Answer \(\rightarrow\) palms covered with oil
Incorrect Answer \(\rightarrow\) palms covered with lotion
Figure G.11: ARC (Challenge)에 대한 형식화된 데이터셋 예시. 예측 시, 2에서 설명된 대로 각 답변의 무조건부 확률로 정규화한다.
Context \(\rightarrow\) lull is to trust as
Correct Answer \(\rightarrow\) cajole is to compliance
Incorrect Answer \(\rightarrow\) balk is to fortitude
Incorrect Answer \(\rightarrow\) betray is to loyalty
Incorrect Answer \(\rightarrow\) hinder is to destination
Incorrect Answer \(\rightarrow\) soothe is to passion
Figure G.12: SAT Analogies에 대한 형식화된 데이터셋 예시
Correct Context \(\rightarrow\) Grace was happy to trade me her sweater for my jacket. She thinks the
sweater
Incorrect Context \(\rightarrow\) Grace was happy to trade me her sweater for my jacket. She thinks the
jacket
Target Completion \(\rightarrow\) looks dowdy on her.
Figure G.13: Winograd에 대한 형식화된 데이터셋 예시. 우리가 사용하는 'partial' 평가 방법은 올바른 Context와 올바르지 않은 Context가 주어졌을 때 Completion의 확률을 비교한다.
| Correct Context | Johnny likes fruits more than vegetables in his new keto diet because the fruits |
|---|---|
| Incorrect Context | Johnny likes fruits more than vegetables in his new keto diet because the vegetables |
| Target Completion | are saccharine. |
Figure G.14: Winogrande에 대한 형식화된 데이터셋 예시. 우리가 사용하는 'partial' 평가 방법은 올바른 Context와 올바르지 않은 Context가 주어졌을 때 Completion의 확률을 비교한다.
| Context | READING COMPREHENSION ANSWER KEY <br> While this process moved along, diplomacy continued its rounds. Direct pressure on the Taliban had proved unsuccessful. As one NSC staff note put it, "Under the Taliban, Afghanistan is not so much a state sponsor of terrorism as it is a state sponsored by terrorists." In early 2000, the United States began a high-level effort to persuade Pakistan to use its influence over the Taliban. In January 2000, Assistant Secretary of State Karl Inderfurth and the State Department's counterterrorism coordinator, Michael Sheehan, met with General Musharraf in Islamabad, dangling before him the possibility of a presidential visit in March as a reward for Pakistani cooperation. Such a visit was coveted by Musharraf, partly as a sign of his government's legitimacy. He told the two envoys that he would meet with Mullah Omar and press him on Bin Laden. They left, however, reporting to Washington that Pakistan was unlikely in fact to do anything," given what it sees as the benefits of Taliban control of Afghanistan." President Clinton was scheduled to travel to India. The State Department felt that he should not visit India without also visiting Pakistan. The Secret Service and the CIA, however, warned in the strongest terms that visiting Pakistan would risk the President's life. Counterterrorism officials also argued that Pakistan had not done enough to merit a presidential visit. But President Clinton insisted on including Pakistan in the itinerary for his trip to South Asia. His one-day stopover on March 25, 2000, was the first time a U.S. president had been there since 1969. At his meeting with Musharraf and others, President Clinton concentrated on tensions between Pakistan and India and the dangers of nuclear proliferation, but also discussed Bin Laden. President Clinton told us that when he pulled Musharraf aside for a brief, one-on-one meeting, he pleaded with the general for help regarding Bin Laden." I offered him the moon when I went to see him, in terms of better relations with the United States, if he'd help us get Bin Laden and deal with another issue or two." The U.S. effort continued. |
|---|---|
| Correct Answer | - [False] Bin Laden |
| Incorrect Answer | - [True] Bin Laden |
Figure G.15: MultiRC에 대한 형식화된 데이터셋 예시. MultiRC에는 세 가지 레벨이 있다: (1) 지문, (2) 질문, (3) 답변. 평가 시, 정확도는 질문 단위로 결정되며, 질문 내의 모든 답변이 올바르게 레이블링된 경우에만 질문이 올바른 것으로 간주된다. 이러한 이유로, Context 내에 표시된 질문의 수를 나타내기 위해 K를 사용한다.
| Context | Question: Which factor will most likely cause a person to develop a fever? Answer: |
|---|---|
| Correct Answer | a bacterial population in the bloodstream |
| Incorrect Answer | a leg muscle relaxing after exercise |
| Incorrect Answer | several viral particles on the skin |
| Incorrect Answer | carbohydrates being digested in the stomach |
Figure G.16: ARC (Easy)에 대한 형식화된 데이터셋 예시. 예측 시, 2에서 설명된 대로 각 답변의 무조건부 확률로 정규화한다.
| Context | Bob went to the gas station to fill up his car. His tank was completely empty and so was his wallet. The cashier offered to pay for his gas if he came back later to pay. Bob felt grateful as he drove home. |
|---|---|
| Correct Answer | Bob believed that there were good people in the world. |
| Incorrect Answer | Bob contemplated how unfriendly the world was. |
Figure G.17: Story Cloze에 대한 형식화된 데이터셋 예시
| Context | Helsinki is the capital and largest city of Finland. It is in the region of Uusimaa, in southern Finland, on the shore of the Gulf of Finland. Helsinki has a population of , an urban population of , and a metropolitan population of over 1.4 million, making it the most populous municipality and urban area in Finland. Helsinki is some north of Tallinn, Estonia, east of Stockholm, Sweden, and west of Saint Petersburg, Russia. Helsinki has close historical connections with these three cities. |
|---|---|
| The Helsinki metropolitan area includes the urban core of Helsinki, Espoo, Vantaa, Kauniainen, and surrounding commuter towns. It is the world's northernmost metro area of over one million people, and the city is the northernmost capital of an EU member state. The Helsinki metropolitan area is the third largest metropolitan area in the Nordic countries after Stockholm and Copenhagen, and the City of Helsinki is the third largest after Stockholm and Oslo. Helsinki is Finland's major political, educational, financial, cultural, and research center as well as one of northern Europe's major cities. Approximately of foreign companies that operate in Finland have settled in the Helsinki region. The nearby municipality of Vantaa is the location of Helsinki Airport, with frequent service to various destinations in Europe and Asia. | |
| Q: what percent of the foreign companies that operate in Finland are in Helsinki? | |
| A: | |
| Q: what towns are a part of the metropolitan area? | |
| A : | |
| Target Completion | Helsinki, Espoo, Vantaa, Kauniainen, and surrounding commuter towns |
Figure G.18: CoQA에 대한 형식화된 데이터셋 예시
Context }->\mathrm{ Please unscramble the letters into a word, and write that word:
asinoc =
Target Completion }-> casino
Figure G.19: Cycled Letters에 대한 형식화된 데이터셋 예시
| Context | Passage: Saint Jean de Brébeuf was a French Jesuit missionary who travelled to New France in 1625. There he worked primarily with the Huron for the rest of his life, except for a few years in France from 1629 to 1633. He learned their language and culture, writing extensively about each to aid other missionaries. In 1649, Brébeuf and another missionary were captured when an Iroquois raid took over a Huron village . Together with Huron captives, the missionaries were ritually tortured and killed on March 16, 1649. Brébeuf was beatified in 1925 and among eight Jesuit missionaries canonized as saints in the Roman Catholic Church in 1930. Question: How many years did Saint Jean de Brébeuf stay in New France before he went back to France for a few years? <br> Answer: |
|---|---|
| Target Completion | 4 |
Figure G.20: DROP에 대한 형식화된 데이터셋 예시
| Context | Fill in blank: |
|---|---|
| She held the torch in front of her. | |
| She caught her breath. | |
| "Chris? There's a step." | |
| "What?" | |
| They both moved faster. "In fact," she said, raising the torch higher, | |
| Target Completion | step |
Figure G.21: LAMBADA에 대한 형식화된 데이터셋 예시
Context \(\rightarrow\) Please unscramble the letters into a word, and write that word:
skicts =
Target Completion \(\rightarrow\) sticks
Figure G.22: Anagrams 1 (A1)에 대한 형식화된 데이터셋 예시
Context \(\rightarrow\) Please unscramble the letters into a word, and write that word:
volwskagen =
Target Completion \(\rightarrow\) volkswagen
Figure G.23: Anagrams 2에 대한 형식화된 데이터셋 예시
Context \(\rightarrow\) Q: Who played tess on touched by an angel?
A:
Target Completion \(\rightarrow\) Delloreese Patricia Early (July 6, 1931 \{ November 19, 2017), known
professionally as Della Reese
Figure G.24: Natural Questions에 대한 형식화된 데이터셋 예시
| Context | TITLE: William Perry (American football) - Professional career PARAGRAPH: In 1985, he was selected in the first round of the 1985 NFL Draft by the Chicago Bears; he had been hand-picked by coach Mike Ditka. However, defensive coordinator Buddy Ryan, who had a highly acrimonious relationship with Ditka, called Perry a "wasted draft-pick". Perry soon became a pawn in the political power struggle between Ditka and Ryan. Perry's "Refrigerator" nickname followed him into the NFL and he quickly became a favorite of the Chicago Bears fans. Teammates called him "Biscuit," as in "one biscuit shy of 350 pounds." While Ryan refused to play Perry, Ditka decided to use Perry as a fullback when the team was near the opponents' goal line or in fourth and short situations, either as a ball carrier or a lead blocker for star running back Walter Payton. Ditka stated the inspiration for using Perry as a fullback came to him during five-yard sprint exercises. During his rookie season, Perry rushed for two touchdowns and caught a pass for one. Perry even had the opportunity to run the ball during Super Bowl XX, as a nod to his popularity and contributions to the team's success. The first time he got the ball, he was tackled for a one-yard loss while attempting to throw his first NFL pass on a halfback option play. The second time he got the ball, he scored a touchdown (running over Patriots linebacker Larry McGrew in the process). About halfway through his rookie season, Ryan finally began to play Perry, who soon proved that he was a capable defensive lineman. His Super Bowl ring size is the largest of any professional football player in the history of the event. His ring size is 25 , while the ring size for the average adult male is between 10 and 12 . Perry went on to play for ten years in the NFL, retiring after the 1994 season. In his ten years as a pro, he regularly struggled with his weight, which hampered his performance at times. He played in 138 games, recording 29.5 sacks and five fumble recoveries, which he returned for a total of 71 yards. In his offensive career he ran five yards for two touchdowns, and had one reception for another touchdown. Perry later attempted a comeback, playing an unremarkable 1996 season with the London Monarchs of the World League of American Football (later NFL Europa). <br> Q: what team did he play for? <br> A: |
|---|---|
| Target Completion | the Chicago Bears |
Figure G.25: QuAC에 대한 형식화된 데이터셋 예시
Context }->\mathrm{ Please unscramble the letters into a word, and write that word:
r e!c.i p r o.c a/l =
Target Completion }->\mathrm{ reciprocal
Figure G.26: Symbol Insertion에 대한 형식화된 데이터셋 예시
Context }->\mathrm{ Please unscramble the letters into a word, and write that word:
taefed =
Target Completion }->\mathrm{ defeat
Figure G.27: Reversed Words에 대한 형식화된 데이터셋 예시
| Context Title: The_Blitz | |
|---|---|
| Background: From the German point of view, March 1941 saw an improvement. The Luftwaffe flew 4,000 sorties that month, including 12 major and three heavy attacks. The electronic war intensified but the Luftwaffe flew major inland missions only on moonlit nights. Ports were easier to find and made better targets. To confuse the British, radio silence was observed until the bombs fell. X- and Y-Gerät beams were placed over false targets and switched only at the last minute. Rapid frequency changes were introduced for X-Gerät, whose wider band of frequencies and greater tactical flexibility ensured it remained effective at a time when British selective jamming was degrading the effectiveness of Y-Gerät. | |
| Q: How many sorties were flown in March 1941? | |
| A: 4,000 | |
| Q: When did the Luftwaffe fly inland missions? | |
| A : | |
| Target Completion | only on moonlit nights |
Figure G.28: SQuADv2에 대한 형식화된 데이터셋 예시
| Context | Normal force -- In a simple case such as an object resting upon a table, the normal force on the object is equal but in opposite direction to the gravitational force applied on the object (or the weight of the object), that is, ( displaystyle ), where is mass, and is the gravitational field strength (about on Earth). The normal force here represents the force applied by the table against the object that prevents it from sinking through the table and requires that the table is sturdy enough to deliver this normal force without breaking. However, it is easy to assume that the normal force and weight are action-reaction force pairs (a common mistake). In this case, the normal force and weight need to be equal in magnitude to explain why there is no upward acceleration of the object. For example, a ball that bounces upwards accelerates upwards because the normal force acting on the ball is larger in magnitude than the weight of the ball. <br> question: is the normal force equal to the force of gravity? <br> answer: |
|---|---|
| Target Completion | yes |
Figure G.29: BoolQ에 대한 형식화된 데이터셋 예시
| Context | The trend toward lower rents may seem surprising given that some communities in New York are bemoaning the loss of favorite local businesses to high rents. But, despite the recent softening, for many of these retailers there's still been too big a jump from the rental rates of the late 1970s, when their leases were signed. Certainly, the recent drop in prices doesn't mean Manhattan comes cheap. question: Manhattan comes cheap. true, false, or neither? answer: |
|---|---|
| Target Completion | false |
Figure G.30: CB에 대한 형식화된 데이터셋 예시
| Context | The bet, which won him dinner for four, was regarding the existence and mass of the top quark, an elementary particle discovered in 1995. question: The Top Quark is the last of six flavors of quarks predicted by the standard model theory of particle physics. True or False? answer: |
|---|---|
| Target Completion | False |
Figure G.31: RTE에 대한 형식화된 데이터셋 예시
| Context | An outfitter provided everything needed for the safari. Before his first walking holiday, he went to a specialist outfitter to buy some boots. <br> question: Is the word 'outfitter' used in the same way in the two sentences above? <br> answer: |
|---|---|
| Target Completion | no |
Figure G.32: WiC에 대한 형식화된 데이터셋 예시
| Context | Final Exam with Answer Key |
|---|---|
| Instructions: Please carefully read the following passages. For each passage, you must identify which noun the pronoun marked in bold refers | |
| Passage: Mr. Moncrieff visited Chester's luxurious New York apartment, thinking that it belonged to his son Edward. The result was that Mr. Moncrieff has decided to cancel Edward's allowance on the ground that | |
| Target Completion | mr. moncrieff |
Figure G.33: WSC에 대한 형식화된 데이터셋 예시
Context }-> Q: 'Nude Descending A Staircase' is perhaps the most famous painting by
which 20th century artist?
A:

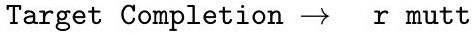
Target Completion }->\mathrm{ duchamp
Target Completion }->\mathrm{ marcel duchamp

Target Completion }->\mathrm{ Marcel duChamp
Target Completion }->\mathrm{ Henri-Robert-Marcel Duchamp
Target Completion }->\mathrm{ Marcel du Champ
Target Completion }->\mathrm{ henri robert marcel duchamp
Target Completion }->\mathrm{ Duchampian
Target Completion }->\mathrm{ Duchamp
Target Completion }->\mathrm{ duchampian
Target Completion }->\mathrm{ marcel du champ
Target Completion }->\mathrm{ Marcel Duchamp
Target Completion }->\mathrm{ MARCEL DUCHAMP
Figure G.34: TriviaQA에 대한 형식화된 데이터셋 예시. TriviaQA는 여러 유효한 Completion을 허용한다.
| Context | Q: What school did burne hogarth establish? |
|---|---|
| A : | |
| Target Completion | School of Visual Arts |
Figure G.35: WebQA에 대한 형식화된 데이터셋 예시
| Context | Keinesfalls dürfen diese für den kommerziellen Gebrauch verwendet werden. = |
|---|---|
| Target Completion | In no case may they be used for commercial purposes. |
Figure G.36: De En에 대한 형식화된 데이터셋 예시. 이는 1-shot 및 few-shot 학습을 위한 형식이며, 이 및 다른 언어 task의 zero-shot 학습 형식은 "Q: What is the {language} translation of {sentence} A: {translation}."이다.
Context }->\mathrm{ In no case may they be used for commercial purposes. =
Target Completion -> Keinesfalls dürfen diese für den kommerziellen Gebrauch verwendet werden.
Figure G.37: En De에 대한 형식화된 데이터셋 예시
| Context | Analysis of instar distributions of larval I. verticalis collected from a series of ponds also indicated that males were in more advanced instars than females. = |
|---|---|
| Target Completion | L'analyse de la distribution de fréquence des stades larvaires d'I. verticalis dans une série d'étangs a également démontré que les larves mâles étaient à des stades plus avancés que les larves femelles. |
Figure G.38: En Fr에 대한 형식화된 데이터셋 예시
| Context | L'analyse de la distribution de fréquence des stades larvaires d'I. verticalis dans une série d'étangs a également démontré que les larves mâles étaient à des stades plus avancés que les larves femelles. = |
|---|---|
| Target Completion | Analysis of instar distributions of larval I. verticalis collected from a series of ponds also indicated that males were in more advanced instars than females. |
Figure G.39: Fr En에 대한 형식화된 데이터셋 예시
| Context | The truth is that you want, at any price, and against the wishes of the peoples of Europe, to continue the negotiations for Turkey's accession to the European Union, despite Turkey's continuing refusal to recognise Cyprus and despite the fact that the democratic reforms are at a standstill. = |
|---|---|
| Target Completion | Adevărul este că vă doriţi, cu orice preţ şi împotriva dorinţei europenilor, să continuaţi negocierile de aderare a Turciei la Uniunea Europeană, în ciuda refuzului continuu al Turciei de a recunoaşte Ciprul şi în ciuda faptului că reformele democratice au ajuns într-un punct mort. |
Figure G.40: En Ro에 대한 형식화된 데이터셋 예시
| Context | Adevărul este că vă doriţi, cu orice preţ şi împotriva dorinţei europenilor, să continuaţi negocierile de aderare a Turciei la Uniunea Europeană, în ciuda refuzului continuu al Turciei de a recunoaşte Ciprul şi în ciuda faptului că reformele democratice au ajuns într-un punct mort. = |
|---|---|
| Target Completion | The truth is that you want, at any price, and against the wishes of the peoples of Europe, to continue the negotiations for Turkey's accession to the European Union, despite Turkey's continuing refusal to recognise Cyprus and despite the fact that the democratic reforms are at a standstill. |
Figure G.41: Ro En에 대한 형식화된 데이터셋 예시
| Context : What is ? <br> A: |
|---|
| Target Completion |
Figure G.42: Arithmetic 1DC에 대한 형식화된 데이터셋 예시
Context }-> Q: What is 17 minus 14?
A:
Target Completion }->
Figure G.43: Arithmetic 2D-에 대한 형식화된 데이터셋 예시
Context }-> Q: What is 98 plus 45?
A:
Target Completion -> 143
Figure G.44: Arithmetic 2D+에 대한 형식화된 데이터셋 예시

A:
Target Completion -> 4275
Figure G.45: Arithmetic 2Dx에 대한 형식화된 데이터셋 예시
Context -> Q: What is 509 minus 488?
A:
Target Completion -> 21
Figure G.46: Arithmetic 3D-에 대한 형식화된 데이터셋 예시
Context }-> Q: What is 556 plus 497?
A:
Target Completion -> 1053
Figure G.47: Arithmetic 3D+에 대한 형식화된 데이터셋 예시
Context -> Q: What is 6209 minus 3365?
A:
Target Completion -> 2844
Figure G.48: Arithmetic 4D-에 대한 형식화된 데이터셋 예시
| Context | Q: What is 9923 plus 617? <br> A : | | :--- | | Target Completion | 10540 |
Figure G.49: Arithmetic 4D+에 대한 형식화된 데이터셋 예시
| Context Q: What is 40649 minus 78746? A: | | | :--- | | Target Completion -38097 | |
Figure G.50: Arithmetic 5D-에 대한 형식화된 데이터셋 예시
Context }-> Q: What is 65360 plus 16204?
A:
Target Completion -> 81564
Figure G.51: Arithmetic 5D+에 대한 형식화된 데이터셋 예시
H Results on All Tasks for All Model Sizes
| Name | Metric | Split | Fine-tune | Zero-Shot | One-Shot | Few-Shot | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SOTA | K | Small | Med | Large | XL | 2.7B | 6.7 B | 13B | Small | Med | Large | XL | 2.7B | 6.7 B | Small Med Large | XL <br> 2.7B | 6.7 B | 13B <br> 175B | 175B (test server) | ||||||
| HellaSwag | acc | dev | 85.6 | 20 | 33.7 | 43.651 .0 | 54.762 .8 | 67.4 | 70.978 .9 | 33.0 | 42.9 | 50.5 | 53.561 .9 | 66.5 | 70.078 .1 | 33.5 | 43.1 | 54.9 | 62.9 | 67.3 | 71.3 | 79.3 | |||
| LAMBADA | acc | test | 68.0 | 15 | 42.7 | 54.360 .4 | 63.667 .1 | 70.3 | 72.5 | 22.0 | 47.1 | 52.6 | 58.361 .1 | 65.4 | 69.0 | 22.0 | 40.4 | 57.0 | 78.1 | 79.1 | 81.3 | 86.4 | |||
| LAMBADA | ppl | test | 8.63 | 15 | 18.6 | 9.09 | 6.53 | 5.444 .60 | 4.00 | 3.56 | 165.0 | 11.6 | 8.29 | 6.46 | 4.61 | 4.06 | 165.0 | 27.6 | 7.45 | 2.89 | 2.56 | 2.56 | 1.92 | ||
| StoryCloze | acc | test | 91.8 | 70 | 63.3 | 68.5 | 72.4 | 73.4 | 77.2 | 77.7 | 79.5 | 62.3 | 68.7 | 72.3 | 74.2 | 78.7 | 79.7 | 62.3 | 70.2 | 76.1 | 80.2 | 81.2 | 83.0 | 87.7 | |
| NQs | acc | test | 44.5 | 64 | 0.64 | 1.75 | 2.71 | 4.40 | 6.01 | 5.79 | 7.8414 .6 | 1.19 | 3.07 | 4.79 | 5.43 | 9.78 | 13.7 | 1.72 | 4.46 | 9.72 | 13.2 | 17.0 | 21.0 | 29.9 | |
| TriviaQA | acc | dev | 68.0 | 64 | 4.15 | 7.61 | 14.0 | 19.7 | 31.3 | 38.7 | 41.864 .3 | 4.19 | 12.9 | 20.5 | 26.5 | 44.4 | 51.3 | 6.96 | 16.3 | 32.1 | 42.3 | 51.6 | 57.5 | 71.2 | 71.2 |
| WebQs | acc | test | 45.5 | 64 | 1.77 | 3.20 | 4.33 | 4.63 | 7.92 | 7.73 | 8.2214 .4 | 2.56 | 6.20 | 8.51 | 9.15 | 15.1 | 19.0 | 5.46 | 12.6 | 19.6 | 24.8 | 27.7 | 33.5 | 41.5 | |
| Ro En 16 | BLEU-mb | test | 39.9 | 64 | 2.08 | 2.71 | 3.09 | 3.15 | 16.3 | 8.34 | 20.219 .9 | 0.55 | 15.4 | 23.0 | 26.3 | 33.2 | 35.6 | 1.25 | 20.7 | 29.2 | 33.1 | 34.8 | 37.0 | 39.5 | |
| Ro En 16 | BLEU-sb | test | 64 | 2.39 | 3.08 | 3.49 | 3.56 | 16.8 | 8.75 | 20.820 .9 | 0.65 | 15.9 | 23.6 | 26.8 | 34.2 | 36.740 .0 | 1.40 | 21.3 | 30.1 | 34.3 | 36.2 | 38.4 | 41.3 | ||
| En Ro 16 | BLEU-mb | test | 38.5 | 64 | 2.14 | 2.65 | 2.53 | 2.50 | 3.46 | 4.24 | 5.3214 .1 | 0.35 | 3.30 | 7.89 | 8.72 | 15.1 | 17.320 .6 | 1.25 | 5.90 | 10.7 | 14.3 | 16.3 | 18.0 | 21.0 | |
| En Ro 16 | BLEU-sb | test | 64 | 2.61 | 3.11 | 3.07 | 3.09 | 4.26 | 5.31 | 6.4318 .0 | 0.55 | 3.90 | 9.15 | 10.3 | 18.2 | 20.824 .9 | 1.64 | 7.40 | 12.9 | 17.2 | 19.6 | 21.8 | 25.8 | ||
| Fr En 14 | BLEU-mb | test | 35.0 | 64 | 1.81 | 2.53 | 3.47 | 3.13 | 20.6 | 15.1 | 21.821 .2 | 1.28 | 15.9 | 23.7 | 26.3 | 30.5 | 30.233 .7 | 4.98 | 25.5 | 31.1 | 33.7 | 34.9 | 36.6 | 39.2 | |
| Fr En 14 | BLEU-sb | test | 64 | 2.29 | 2.99 | 3.90 | 3.60 | 21.2 | 15.5 | 22.421 .9 | 1.50 | 16.3 | 24.4 | 27.0 | 31.6 | 31.435 .6 | 5.30 | 26.2 | 32.2 | 35.1 | 36.4 | 38.3 | 41.4 | ||
| En Fr 14 | BLEU-mb | test | 45.6 | 64 | 1.74 | 2.16 | 2.73 | 2.15 | 15.1 | 8.82 | 12.025 .2 | 0.49 | 8.00 | 14.8 | 15.9 | 23.3 | 24.928 .3 | 4.08 | 14.5 | 21.5 | 24.9 | 27.3 | 29.5 | 32.6 | |
| En Fr 14 | BLEU-sb | test | 45.9 | 64 | 2.44 | 2.75 | 3.54 | 2.82 | 19.3 | 11.4 | 15.331 .3 | 0.81 | 10.0 | 18.2 | 19.3 | 28.3 | 30.134 .1 | 5.31 | 18.0 | 26.1 | 30.3 | 33.3 | 35.5 | 39.9 | |
| De En 16 | BLEU-mb | test | 40.2 | 64 | 2.06 | 2.87 | 3.41 | 3.63 | 21.5 | 17.3 | 23.027 .2 | 0.83 | 16.2 | 22.5 | 24.7 | 30.7 | 33.030 .4 | 3.25 | 22.7 | 29.2 | 32.7 | 34.8 | 37.3 | 40.6 | |
| De En 16 | BLEU-sb | test | 64 | 2.39 | 3.27 | 3.85 | 4.04 | 22.5 | 18.2 | 24.428 .6 | 0.93 | 17.1 | 23.4 | 25.8 | 31.9 | 34.532 .1 | 3.60 | 23.8 | 30.5 | 34.1 | 36.5 | 39.1 | 43.0 | ||
| En De 16 | BLEU-mb | test | 41.2 | 64 | 1.70 | 2.27 | 2.31 | 2.43 | 12.9 | 8.66 | 10.424 .6 | 0.50 | 7.00 | 12.9 | 13.1 | 20.9 | 22.526 .2 | 3.42 | 12.3 | 17.1 | 20.9 | 23.0 | 26.6 | 29.7 | |
| En De 16 | BLEU-sb | test | 41.2 | 64 | 2.09 | 2.65 | 2.75 | 2.92 | 13.7 | 9.36 | 11.025 .3 | 0.54 | 7.40 | 13.4 | 13.418 .8 | 21.7 | 23.327 .3 | 3.78 | 12.9 | 17.7 | 21.7 | 24.1 | 27.7 | 30.9 | |
| Winograd | acc | test | 93.8 | 7 | 66.3 | 72.9 | 74.7 | 76.9 | 82.4 | 85.7 | 87.988 .3 | 63.4 | 68.5 | 72.9 | 76.982 .4 | 84.6 | 86.189 .7 | 63.4 | 67.4 | 76.9 | 84.3 | 85.4 | 82.488 .6 | ||
| Winogrande | acc | dev | 84.6 | 50 | 52.0 | 52.1 | 57.4 | 58.7 | 62.3 | 64.5 | 67.970 .2 | 51.3 | 53.0 | 58.3 | 59.161 .7 | 65.8 | 66.973 .2 | 51.3 | 52.6 | 59.1 | 62.6 | 67.4 | 70.0 | 77.7 | |
| PIQA | acc | dev | 77.1 | 50 | 64.6 | 70.2 | 72.9 | 75.1 | 75.6 | 78.0 | 78.581 .0 | 64.3 | 69.3 | 71.8 | 74.474 .3 | 76.3 | 77.880 .5 | 64.3 | 69.4 | 74.3 | 75.4 | 77.8 | 79.9 | 82.3 | 82.8 |
| ARC (Challenge) | acc | test | 78.5 | 50 | 26.6 | 29.5 | 31.8 | 35.5 | 38.0 | 41.4 | 43.751 .4 | 25.5 | 30.2 | 31.6 | 36.438 .4 | 41.5 | 43.1 | 25.5 | 28.4 | 36.739 .5 | 43.7 | 44.851 .5 | |||
| ARC (Easy) | acc | test | 92.0 | 50 | 43.6 | 46.5 | 53.0 | 53.8 | 58.2 | 60.2 | 63.868 .8 | 42.7 | 48.2 | 54.6 | 55.960 .3 | 62.6 | 66.871 .2 | 42.7 | 51.0 | 59.162 .1 | 65.8 | 69.1 | 70.1 | ||
| OpenBookQA | acc | test | 87.2 | 100 | 35.6 | 43.2 | 45.2 | 46.8 | 53.0 | 50.4 | 55.657 .6 | 37.0 | 39.8 | 46.2 | 46.453 .4 | 53.0 | 55.858 .8 | 37.0 | 43.6 | 50.655 .6 | 55.2 | 60.865 .4 | |||
| Quac | f1 | dev | 74.4 | 5 | 21.2 | 26.8 | 31.0 | 30.134 .7 | 36.1 | 38.441 .5 | 21.1 | 26.9 | 31.9 | 32.337 .4 | 39.0 | 40.643 .4 | 21.6 | 27.6 | 34.238 .2 | 39.9 | 40.9 | 44.3 | |||
| RACE-h | acc | test | 90.0 | 10 | 35.2 | 37.9 | 40.1 | 40.942 .4 | 44.1 | 44.645 .5 | 34.3 | 37.7 | 40.0 | 42.043 .8 | 44.3 | 44.645 .9 | 34.3 | 37.0 | 41.442 .3 | 44.7 | 45.1 | 46.8 | |||
| RACE-m | acc | test | 93.1 | 10 | 42.1 | 47.2 | 52.1 | 52.354 .7 | 54.4 | 56.758 .4 | 42.3 | 47.3 | 51.7 | 55.256 .1 | 54.7 | 56.957 .4 | 42.3 | 47.0 | 53.055 .6 | 55.4 | 58.1 | 58.1 | |||
| SQuADv2 | em | dev | 90.7 | 16 | 22.6 | 32.8 | 33.9 | 43.143 .6 | 45.4 | 49.052 .6 | 25.1 | 37.5 | 37.9 | 47.947 .9 | 51.1 | 56.060 .1 | 27.5 | 40.5 | 53.550 .0 | 56.6 | 62.6 | 64.9 | |||
| SQuADv2 | f1 | dev | 93.0 | 16 | 28.3 | 40.2 | 41.4 | 50.351 .0 | 52.7 | 56.359 .5 | 30.1 | 43.6 | 44.1 | 54.054 .1 | 57.1 | 61.865 .4 | 32.1 | 45.5 | 58.755 .9 | 62.1 | 67.7 | 69.8 | |||
| CoQA | f1 | dev | 90.7 | 5 | 34.5 | 55.0 | 61.8 | 65.371 .1 | 72.8 | 76.381 .5 | 30.6 | 52.1 | 61.6 | 66.171 .8 | 75.1 | 77.984 .0 | 31.1 | 52.0 | 66.873 .2 | 77.3 | 79.9 | 85.0 | |||
| DROP | f1 | dev | 89.1 | 20 | 9.40 | 13.6 | 14.4 | 16.419 .7 | 17.0 | 24.023 .6 | 11.7 | 18.1 | 20.9 | 23.026 .4 | 27.3 | 29.234 .3 | 12.9 | 18.7 | 25.629 .7 | 29.7 | 32.3 | 36.5 | |||
| BoolQ | acc | dev | 91.0 | 32 | 49.7 | 60.3 | 58.9 | 62.467 .1 | 65.4 | 66.260 .5 | 52.6 | 61.7 | 60.4 | 63.768 .4 | 68.7 | 69.076 .7 | 43.1 | 60.6 | 64.170 .3 | 70.0 | 70.2 | 77.5 | 76.4 | ||
| CB | acc | dev | 96.9 | 32 | 0.00 | 32.1 | 8.93 | 19.619 .6 | 28.6 | 19.646 .4 | 55.4 | 53.6 | 53.6 | 48.257 .1 | 33.9 | 55.464 .3 | 42.9 | 58.9 | 69.667 .9 | 60.7 | 66.182 .1 | 75.6 | |||
| CB | f1 | dev | 93.9 | 32 | 0.00 | 29.3 | 11.4 | 17.422 .4 | 25.1 | 20.342 .8 | 60.1 | 39.8 | 45.6 | 37.545 .7 | 28.5 | 44.652 .5 | 26.1 | 40.4 | 48.345 .7 | 44.6 | 46.057 .2 | 52.0 | |||
| Copa | acc | dev | 94.8 | 32 | 66.0 | 68.0 | 73.0 | 77.076 .0 | 80.0 | 84.091 .0 | 62.0 | 64.0 | 66.0 | 74.076 .0 | 82.0 | 86.087 .0 | 67.0 | 64.0 | 77.083 .0 | 83.0 | 86.092 .0 | 92.0 | |||
| RTE | acc | dev | 92.5 | 32 | 47.7 | 49.8 | 48.4 | 56.046 .6 | 55.2 | 62.863 .5 | 53.1 | 47.3 | 49.5 | 49.554 .9 | 54.9 | 56.370 .4 | 52.3 | 48.4 | 50.956 .3 | 49.5 | 60.672 .9 | 69.0 | |||
| WiC | acc | dev | 76.1 | 32 | 0.00 | 0.00 | 0.00 | 0.000 .00 | 0.00 | 0.000 .00 | 50.0 | 50.3 | 50.3 | 49.249 .4 | 50.3 | 50.048 .6 | 49.8 | 55.0 | 53.051 .6 | 53.1 | 51.155 .3 | 49.4 | |||
| WSC | acc | dev | 93.8 | 32 | 59.6 | 56.7 | 65.4 | 61.566 .3 | 60.6 | 64.465 .4 | 58.7 | 58.7 | 60.6 | 62.566 .3 | 60.6 | 66.369 .2 | 58.7 | 60.6 | 49.062 .5 | 67.3 | 75.075 .0 | 80.1 | |||
| MultiRC | acc | dev | 62.3 | 32 | 4.72 | 9.65 | 12.3 | 13.614 .3 | 18.4 | 24.227 .6 | 4.72 | 9.65 | 12.3 | 13.614 .3 | 18.4 | 24.227 .6 | 6.09 | 11.8 | 20.824 .7 | 23.8 | 25.0 | 32.5 | 30.5 | ||
| MultiRC | fla | dev | 88.2 | 32 | 57.0 | 59.7 | 60.4 | 59.960 .0 | 64.5 | 71.472 .9 | 57.0 | 59.7 | 60.4 | 59.960 .0 | 64.5 | 71.472 .9 | 45.0 | 55.9 | 65.469 .5 | 66.4 | 69.3 | 74.8 | 75.4 | ||
| ReCoRD | acc | dev | 92.5 | 32 | 70.8 | 78.5 | 82.1 | 84.186 .2 | 88.6 | 89.090 .2 | 69.8 | 77.0 | 80.7 | 83.085 .9 | 88.0 | 88.890 .2 | 69.8 | 77.2 | 83.186 .6 | 87.9 | 88.9 | 89.0 | 90.2 | ||
| ReCoRD | f1 | dev | 93.3 | 32 | 71.9 | 79.2 | 82.8 | 85.287 .3 | 89.5 | 90.491 .0 | 70.7 | 77.8 | 81.6 | 83.986 .8 | 88.8 | 89.791 .2 | 70.7 | 77.9 | 84.087 .5 | 88.8 | 89.890 .1 | 91.1 | |||
| SuperGLUE | average | dev | 89.0 | 40.6 | 47.4 | 46.8 | 49.650 .1 | 52.3 | 54.458 .2 | 54.4 | 55.1 | 56.7 | 57.861 .2 | 59.7 | 64.368 .9 | 50.2 | 56.2 | 60.064 .3 | 63.6 | 66.973 .2 | 71.8 | ||||
| ANLI R1 | acc | test | 73.8 | 50 | 33.4 | 34.2 | 33.4 | 33.434 .2 | 32.3 | 33.234 .6 | 32.1 | 31.6 | 31.9 | 34.630 .6 | 31.6 | 32.7 | 32.1 | 32.5 | 32.533 .5 | 33.1 | 33.3 | 36.8 | |||
| ANLI R2 | acc | test | 50.7 | 50 | 33.2 | 31.9 | 33.3 | 33.333 .8 | 33.5 | 33.535 .4 | 35.7 | 33.7 | 33.2 | 32.732 .7 | 33.9 | 33.933 .9 | 35.7 | 33.8 | 31.432 .6 | 33.3 | 32.6 | 34.0 | |||
| ANLI R3 | acc | test | 48.3 | 50 | 33.6 | 34.0 | 33.8 | 33.435 .3 | 34.8 | 34.434 .5 | 35.0 | 32.6 | 33.0 | 33.934 .1 | 33.1 | 32.535 .1 | 35.0 | 34.4 | 36.032 .7 | 33.9 | 34.5 | 40.2 | |||
| 2D+ | acc | n/a | 50 | 0.70 | 0.65 | 0.70 | 0.851 .10 | 2.54 | 15.476 .9 | 2.00 | 0.55 | 3.15 | 4.0012 .1 | 19.6 | 73.099 .6 | 2.00 | 4.10 | 4.508 .90 | 11.9 | 55.5 | 100.0 | ||||
| 2D- | acc | n/a | 50 | 1.25 | 1.25 | 1.25 | 1.251 .60 | 7.60 | 12.658 .0 | 1.15 | 0.95 | 1.45 | 1.953 .85 | 11.5 | 44.686 .4 | 1.15 | 1.45 | 2.707 .35 | 13.6 | 52.498 .9 | |||||
| 3D+ | acc | n/a | 50 | 0.10 | 0.10 | 0.05 | 0.100 .10 | 0.25 | 1.4034 .2 | 0.15 | 0.00 | 0.10 | 0.300 .45 | 0.95 | 15.465 .5 | 0.15 | 0.45 | 0.550 .75 | 0.90 | 8.4080 .4 | |||||
| 3D- | acc | n/a | 50 | 0.05 | 0.05 | 0.05 | 0.050 .05 | 0.45 | 1.3548 .3 | 0.05 | 0.15 | 0.25 | 0.300 .55 | 1.60 | 6.1578 .7 | 0.05 | 0.10 | 0.350 .65 | 1.05 | 9.2094 .2 | |||||
| 4D+ | acc | n/a | 50 | 0.05 | 0.05 | 0.00 | 0.000 .05 | 0.05 | 0.154 .00 | 0.00 | 0.00 | 0.10 | 0.000 .00 | 0.10 | 0.8014 .0 | 0.00 | 0.05 | 0.000 .15 | 0.15 | 0.4025 .5 | |||||
| 4D- | acc | n/a | 50 | 0.00 | 0.00 | 0.00 | 0.000 .00 | 0.00 | 0.107 .50 | 0.00 | 0.00 | 0.00 | 0.000 .05 | 0.00 | 0.5014 .0 | 0.00 | 0.05 | 0.000 .10 | 0.05 | 0.4026 .8 | |||||
| 5D+ | acc | n/a | 50 | 0.00 | 0.000 .00 | 0.000 .00 | 0.00 | 0.000 .65 | 0.00 | 0.00 | 0.00 | 0.000 .00 | 0.00 | 0.053 .45 | 0.00 | 0.00 | 0.000 .00 | 0.00 | 0.059 .30 | ||||||
| 5D- | acc | n/a | 50 | 0.00 | 0.000 .00 | 0.000 .00 | 0.00 | 0.000 .80 | 0.00 | ||||||||||||||||
Table H.1: 본 논문에서 조사한 모든 task, 설정 및 모델에 대한 점수.
 Figure H.1: 모든 SuperGLUE task에 대한 전체 결과.
Figure H.1: 모든 SuperGLUE task에 대한 전체 결과.


 Figure H.2: SAT task 결과.
Figure H.2: SAT task 결과.
Figure H.3: 모든 Winograd task에 대한 전체 결과.
 Figure H.4: 모든 Arithmetic task에 대한 전체 결과.
Figure H.4: 모든 Arithmetic task에 대한 전체 결과.
 Figure H.5: 모든 Cloze and Completion task에 대한 전체 결과.
Figure H.5: 모든 Cloze and Completion task에 대한 전체 결과.
 Figure H.6: 모든 Common Sense Reasoning task에 대한 전체 결과.
Figure H.6: 모든 Common Sense Reasoning task에 대한 전체 결과.

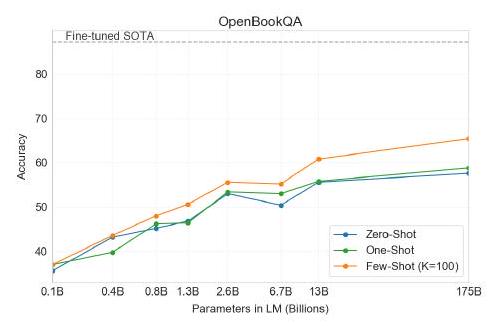
 Figure H.7: 모든 QA task에 대한 전체 결과.
Figure H.7: 모든 QA task에 대한 전체 결과.
 Figure H.8: 모든 Reading Comprehension task에 대한 전체 결과.
Figure H.8: 모든 Reading Comprehension task에 대한 전체 결과.
 Figure H.9: 모든 ANLI 라운드에 대한 전체 결과.
Figure H.9: 모든 ANLI 라운드에 대한 전체 결과.
 Figure H.10: 모든 Scramble task에 대한 전체 결과.
Figure H.10: 모든 Scramble task에 대한 전체 결과.
 Figure H.11: 모든 Translation task에 대한 전체 결과.
Figure H.11: 모든 Translation task에 대한 전체 결과.