Flan Collection: 효과적인 Instruction Tuning을 위한 데이터와 방법론 설계
이 논문은 효과적인 Instruction Tuning을 위한 데이터 및 방법론 설계에 대해 다루는 Flan Collection을 소개합니다. 저자들은 Flan 2022 모델의 개발 과정을 상세히 분석하고, ablation studies를 통해 어떤 설계 결정이 성능 향상에 기여했는지 밝혀냅니다. 연구 결과, task balancing, 데이터 증강 기법, 그리고 특히 zero-shot, few-shot, Chain-of-Thought (CoT) 프롬프트를 혼합하여 훈련하는 것이 모든 평가 환경에서 성능을 크게 향상시킨다는 점을 발견했습니다. 이렇게 훈련된 Flan-T5는 이전의 공개 Instruction Tuning 방법론들보다 우수한 성능을 보였으며, 새로운 단일 downstream task에 대해 미세 조정할 때 더 적은 계산 비용으로 더 빠르고 높은 성능에 도달하는 효율적인 시작점(checkpoint)이 됨을 입증합니다. 논문 제목: The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
Longpre, Shayne, et al. "The flan collection: Designing data and methods for effective instruction tuning." International Conference on Machine Learning. PMLR, 2023.
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
Abstract
우리는 공개된 instruction tuning 방법들의 설계 결정을 연구하고, Flan 2022 모델(Chung et al., 2022)의 개발 과정을 분석한다. Flan Collection의 instruction tuning task 및 방법에 대한 신중한 ablation study를 통해, Flan-T5가 평가 설정 전반에 걸쳐 기존 연구보다 3-17%+ 더 나은 성능을 발휘하게 하는 설계 결정들의 효과를 밝혀낸다. 우리는 task balancing 및 enrichment 기법들이 간과되었지만 효과적인 instruction tuning에 매우 중요하다는 것을 발견했으며, 특히 mixed prompt 설정(zero-shot, few-shot, chain-of-thought)으로 학습하는 것이 모든 설정에서 실제로 더 강력한(2%+) 성능을 제공한다는 것을 확인했다. 추가 실험에서, 우리는 Flan-T5가 단일 다운스트림 task에서 T5보다 더 적은 fine-tuning으로 더 높고 빠르게 수렴한다는 것을 보여주며, 이는 instruction-tuned 모델이 새로운 task를 위한 더 계산 효율적인 시작 체크포인트가 될 수 있음을 시사한다. 마지막으로, instruction tuning 연구를 가속화하기 위해, 우리는 Flan 2022 데이터셋, 템플릿, 방법 컬렉션을 공개한다.
 Figure 1: Held-In, Held-Out (BIG-Bench Hard (Suzgun et al., 2022) 및 MMLU (Hendrycks et al., 2020)), 그리고 Chain-of-Thought 평가 스위트에서 공개된 instruction tuning 컬렉션들을 비교한 결과는 Appendix A.3에 자세히 설명되어 있다. OPT-IML-Max (175B)를 제외한 모든 모델은 3B 파라미터의 T5-XL이다. 녹색 텍스트는 다음으로 가장 좋은 비교 가능한 T5-XL (3B) 모델 대비 절대적인 성능 향상을 나타낸다.
Figure 1: Held-In, Held-Out (BIG-Bench Hard (Suzgun et al., 2022) 및 MMLU (Hendrycks et al., 2020)), 그리고 Chain-of-Thought 평가 스위트에서 공개된 instruction tuning 컬렉션들을 비교한 결과는 Appendix A.3에 자세히 설명되어 있다. OPT-IML-Max (175B)를 제외한 모든 모델은 3B 파라미터의 T5-XL이다. 녹색 텍스트는 다음으로 가장 좋은 비교 가능한 T5-XL (3B) 모델 대비 절대적인 성능 향상을 나타낸다.
1 Introduction
PaLM (Chowdhery et al., 2022), Chinchilla (Hoffmann et al., 2022), ChatGPT (Brown et al., 2020; Ouyang et al., 2022) 등과 같은 대규모 language model들은 지시적인 prompt를 읽고 자연어 처리(NLP) task를 수행하는 새로운 능력을 열었다. 선행 연구들은 instruction tuning (즉, 지시문으로 형식화된 NLP task 모음으로 language model을 fine-tuning하는 것)이 지시문으로부터 이전에 보지 못한 task를 수행하는 language model의 능력을 더욱 향상시킨다는 것을 보여주었다 (Wei et al., 2021; Sanh et al., 2021; Min et al., 2022).
본 연구에서는 오픈 소스 instruction generalization 노력들의 방법론과 결과들을 평가하고, 그들의 fine-tuning 기법과 방법들을 비교한다. 특히, 우리는 **"Flan 2022 Collection"**의 핵심적인 방법론적 개선 사항들을 식별하고 평가한다. Flan 2022 Collection은 Chung et al. (2022)에서 처음 구현되고 사용된 데이터 증강 및 instruction tuning을 위한 데이터 및 방법들의 집합을 지칭하는 용어이다. Chung et al. (2022)가 Flan 2022와 PaLM 540B를 결합한 결과의 새로운(emergent) 및 state-of-the-art 성능에 초점을 맞춘 반면, 본 연구는 instruction tuning 방법론 자체의 세부 사항에 집중하여, 개별 요인들을 ablation하고, 사전학습된 모델 크기와 체크포인트를 일관되게 유지함으로써 선행 연구들과 직접적으로 비교한다.
Flan 2022 Collection은 instruction tuning을 위한 가장 광범위한 공개 task 및 방법 세트를 제공하며, 우리는 이를 한곳에 모았다. 또한 우리는 수백 개의 자체 고품질 템플릿, 더 풍부한 형식화 패턴 및 데이터 증강으로 이를 보완했다. 우리는 이 Collection으로 학습된 모델이 기존의 Flan 2021 (Wei et al., 2021), T0++ (Sanh et al., 2021), Super-Natural Instructions (Wang et al., 2022c), 그리고 동시 연구인 OPT-IML (Iyer et al., 2022)을 포함한 모든 테스트된 평가 벤치마크에서 다른 공개 Collection들을 능가함을 보여준다. Figure 1에서 보듯이, 이는 동일한 크기의 모델에 대해 MMLU (Hendrycks et al., 2020)에서 4.2%+ 개선, BIG-Bench Hard (Suzgun et al., 2022) 평가 벤치마크에서 8.5% 개선을 포함한다.
Flan 2022 방법론에 대한 분석은 강력한 결과가 더 크고 다양한 task 세트뿐만 아니라, 일련의 간단한 fine-tuning 및 데이터 증강 기법에서 비롯된다는 것을 시사한다. 특히, zero-shot, few-shot, 그리고 chain-of-thought prompt로 템플릿화된 예시들의 혼합으로 학습하는 것은 이러한 모든 설정에서 함께 성능을 향상시킨다. 예를 들어, 단 10%의 few-shot prompt를 추가하는 것만으로 zero-shot prompting 결과가 2%+ 향상된다. 또한, (Sanh et al., 2021; Min et al., 2022)에서 사용된 것처럼 입력-출력 쌍을 반전시켜 task 다양성을 풍부하게 하는 것과 task 소스를 균형 있게 조정하는 것 모두 성능에 중요함이 입증되었다. 결과적으로 Flan-T5 모델은 단일 task fine-tuning에서 T5 모델보다 더 빠르게 수렴하고 더 높은 성능을 보인다. 이는 instruction-tuned 모델이 다운스트림 애플리케이션을 위한 더 계산 효율적인 시작 체크포인트를 제공함을 시사하며, Aribandi et al. (2021) 및 Liu et al. (2022b)의 연구를 뒷받침한다.
우리는 이러한 연구 결과와 리소스를 공개함으로써 instruction tuning에 대한 리소스를 통합하고 더 범용적인 language model 연구를 가속화하기를 희망한다. 본 연구의 핵심 기여는 다음과 같이 요약된다:
- 방법론적: zero-shot 및 few-shot prompt를 혼합하여 학습하는 것이 두 설정 모두에서 훨씬 더 나은 성능을 가져옴을 보여준다 (Section 3.2).
- 방법론적: 효과적인 instruction tuning을 위한 핵심 기법들을 측정하고 입증한다: 스케일링 (Section 3.3), 입력 반전을 통한 task 다양성 증대 (Section 3.4), chain-of-thought 학습 데이터 추가, 그리고 다양한 데이터 소스 균형 조정 (Section 3.5).
- 결과: 이러한 기술적 선택이 기존 오픈 소스 instruction tuning Collection에 비해 Held-Out task에서 3-17%의 성능 향상을 가져옴을 입증한다 (Figure 1).
- 결과: Flan-T5가 단일 task fine-tuning을 위한 더 강력하고 계산 효율적인 시작 체크포인트 역할을 함을 입증한다 (Section 4).
- 새로운 Flan 2022 task Collection, 템플릿 및 방법들을 공개 연구를 위해 오픈 소스로 제공한다.
2 Public Instruction Tuning Collections
 Figure 2: Public Instruction Tuning Collections의 타임라인은 각 컬렉션의 출시일, fine-tuned 모델에 대한 상세 정보(base model, 모델 크기, 모델의 공개 여부(Public (P) 또는 Not Public (NP))), 학습된 prompt 사양(zero-shot, few-shot, 또는 Chain-of-Thought), Flan 2022 Collection에 포함된 task 수(본 연구와 함께 출시됨), 그리고 각 연구의 핵심 방법론적 기여를 명시한다.
task 수와 예시 수는 가정에 따라 달라지므로 추정치임을 유의해야 한다. 예를 들어, "task"와 "task category"의 정의는 연구마다 다르며, 하나의 온톨로지로 쉽게 단순화될 수 없다. 보고된 task 수는 각 연구에서 사용된 task 정의를 기준으로 한다.
는 동시 진행 연구를 나타낸다.
Figure 2: Public Instruction Tuning Collections의 타임라인은 각 컬렉션의 출시일, fine-tuned 모델에 대한 상세 정보(base model, 모델 크기, 모델의 공개 여부(Public (P) 또는 Not Public (NP))), 학습된 prompt 사양(zero-shot, few-shot, 또는 Chain-of-Thought), Flan 2022 Collection에 포함된 task 수(본 연구와 함께 출시됨), 그리고 각 연구의 핵심 방법론적 기여를 명시한다.
task 수와 예시 수는 가정에 따라 달라지므로 추정치임을 유의해야 한다. 예를 들어, "task"와 "task category"의 정의는 연구마다 다르며, 하나의 온톨로지로 쉽게 단순화될 수 없다. 보고된 task 수는 각 연구에서 사용된 task 정의를 기준으로 한다.
는 동시 진행 연구를 나타낸다.
Large Language Model Instruction tuning은 대규모 언어 모델(LLM)과 그 능력을 대화형 상호작용 및 기능적 task에 더욱 유용하게 만드는 도구로 부상했다. 이전 연구들(Raffel et al., 2020; Liu et al., 2019; Aghajanyan et al., 2021; Aribandi et al., 2021)은 대규모 multi-task fine-tuning을 실험하여 다운스트림의 단일 타겟 fine-tuning 성능을 개선했지만, instruction prompt는 사용하지 않았다. UnifiedQA 및 기타 연구들(Khashabi et al., 2020; McCann et al., 2018; Keskar et al., 2019)은 다양한 NLP task를 단일 generative question answering 형식으로 통합했으며, multi-task fine-tuning 및 평가를 위해 prompt instruction을 사용했다.
첫 번째 물결 (The First Wave)
2020년 이후, Figure 2에 요약된 바와 같이 여러 instruction tuning task collection이 빠르게 연이어 출시되었다. Natural Instructions (Mishra et al., 2021), Flan 2021 (Wei et al., 2021), P3 (the Public Pool of Prompts, Bach et al., 2022)는 대규모 NLP task collection을 통합하고 instruction(zero-shot prompting)을 사용하여 템플릿화했으며, 특히 모델이 보지 못한 instruction에 일반화되도록 fine-tuning하는 데 중점을 두었다. MetaICL (Min et al., 2022)은 다른 task collection들(Ye et al., 2021; Khashabi et al., 2020)을 통합하여 모델이 "in-context"로 task를 학습하도록 훈련했다. 이는 few-shot prompting으로 알려진 여러 입력-출력 예시를 통해 학습하는 방식이지만, 이 경우에는 instruction이 없었다. 이들 각 연구는 task 및 템플릿 다양성의 스케일링 이점을 확인했으며, 일부는 템플릿에서 입력과 출력을 뒤집어 새로운 task를 생성하는 것("noisy channel" in Min et al., 2022)에서 강력한 이점을 보고했다.
두 번째 물결 (The Second Wave)
instruction tuning collection의 두 번째 물결은 이전 자원들을 확장했다: Super-Natural Instructions (Wang et al., 2022c) 또는 OPT-IML (Iyer et al., 2022)처럼 더 많은 데이터셋과 task를 하나의 자원으로 결합하고, xP3 (Muennighoff et al., 2022)에서 다국어 instruction tuning을 추가했으며, Flan 2022 (Chung et al., 2022)에서는 Chain-of-Thought training prompt를 도입했다. Flan Collection과 OPT-IML 모두 이전 collection에 포함된 대부분의 task를 포함한다. 우리의 연구는 여기에 위치하며, 이러한 대부분의 collection(collection들의 collection)과 그 방법론들을 통합하여 향후 오픈 소스 연구를 위한 가장 강력한 출발점을 제공한다.
새로운 방향 (New Directions)
동시 진행 중인 연구 및 향후 연구는 두 가지 새로운 방향을 탐색하기 시작했다:
(a) 합성 데이터 생성을 통해 task 다양성을 더욱 공격적으로 확장하는 것, 특히 창의적이고 open-ended 대화 분야에서 (Wang et al., 2022b; Honovich et al., 2022; Ye et al., 2022; Gupta et al., 2022),
(b) 모델 응답에 대한 인간 피드백 신호를 제공하는 것 (Ouyang et al., 2022; Glaese et al., 2022; Bai et al., 2022a; Nakano et al., 2021; Bai et al., 2022b).
우리는 이러한 새로운 방향들이 instruction tuning 방법론의 기반에 추가될 가능성이 높다고 본다.
인간 피드백을 통한 튜닝 (Tuning with Human Feedback)
인간 피드백을 통한 instruction tuning은 open-ended task에서 강력한 결과를 보여주었지만, 다양한 전통적인 NLP task에서는 성능 저하를 초래했다 (Ouyang et al., 2022; Glaese et al., 2022; Bai et al., 2022a; Nakano et al., 2021). (Ouyang et al. (2022)의 "alignment tax"에 대한 논의를 참조하라.) 우리의 연구는 두 가지 이유로 인간 피드백 없이 instruction generalization에 특별히 초점을 맞춘다. 첫째, 인간 피드백 데이터셋은 instruction tuning 데이터셋보다 공개적으로 훨씬 덜 이용 가능하며 (모델별로 다를 수 있음), 둘째, instruction generalization 자체만으로도 open-ended task에서 인간이 선호하는 응답을 향상시키고 전통적인 NLP metric을 개선하는 데 큰 가능성을 보여준다 (Chung et al., 2022). 비용이 많이 드는 인간 응답 demonstration이나 평가 없이 달성할 수 있는 발전의 정도는 여전히 미해결 질문이며, 공개 연구와 비공개 연구 간의 격차를 좁히기 위한 중요한 추구이다.
오픈 소스의 중요성 (The Importance of Open Source)
GPT-3 및 기타 모델(Ouyang et al., 2022; Glaese et al., 2022)의 경우처럼, 주목할 만한 연구는 점점 더 비공개 데이터에 의해 주도되고 있다. 이러한 자원에 대한 접근성 부족은 연구 커뮤니티가 공개 도메인에서 이러한 방법론을 분석하고 개선할 수 있는 능력을 저해한다. 우리는 연구 접근성을 민주화하려는 목표에 따라 오픈 소스 및 접근 가능한 데이터 collection에 초점을 맞춘다.
3 Flan 2022 Instruction Tuning Experiments
최근 연구들은 다양한 task, 모델 크기, 목표 입력 형식을 모두 다루면서도 통일된 기술 집합으로 수렴하지 못하고 있다. 우리는 Chung et al. (2022)에서 처음 소개된 새로운 컬렉션인 "Flan 2022"를 오픈 소스로 공개한다. 이 컬렉션은 Flan 2021, P3++[^3], Super-Natural Instructions에 추가적인 reasoning, dialog, program synthesis 데이터셋을 결합한 것이다. 템플릿화 및 데이터 수집에 대한 자세한 내용은 Chung et al. (2022)를 참조하며, 본 연구에서는 주요 방법론 개선 사항을 심층적으로 살펴보고, 기존 컬렉션과 동일한 모델 크기에서 Flan 2022를 비교한다.
이 섹션에서는 Flan의 설계 결정 사항을 평가하고, 특히 instruction tuning 성능을 크게 향상시키는 네 가지 요소에 대해 논의한다. Section 2에서 설명된 이러한 설계 구성 요소는 다음과 같다: (I) 학습 시 zero-shot, few-shot, Chain-of-Thought 템플릿을 혼합하여 사용하는 것 (Section 3.2), (II) T5 크기 모델을 1800개 이상의 task로 확장하는 것 (Section 3.3), (III) input inversion을 통해 task를 풍부하게 만드는 것 (Section 3.4), (IV) 이러한 task 혼합의 균형을 맞추는 것 (Section 3.5). Section 3.1에서는 각 구성 요소의 가치를 측정하고, 최종 모델을 다른 instruction tuning 컬렉션(및 그 방법론)과 비교하는 것으로 시작한다. [^2] 각 연구는 데이터셋, task, task 카테고리를 다르게 정의한다. 단순화를 위해 Section 2에서는 각 연구의 정의를 따른다. [^3] "P3++"는 Public Pool of Prompts (P3)의 모든 데이터셋을 지칭하는 우리의 표기법이다: https://huggingface.co/datasets/bigscience/P3
실험 설정 (Experimental Setup)
별도로 명시되지 않는 한, 우리는 일관성을 위해 모든 모델에 대해 XL (3B) 크기의 prefix language model adapted T5-LM (Lester et al., 2021)을 fine-tuning한다. 다른 크기의 Flan-T5도 사용 가능하지만, XL 크기가 대규모 체계적인 ablation을 수행하기에 적절하고, 일반적인 결론을 도출하기에 충분히 크다고 판단했다. 우리는 다음 세 가지 벤치마크에서 평가를 수행한다:
(a) 1800개 이상의 학습 task 컬렉션 내에 포함된 8개의 "Held-In" task 스위트 (4개의 question answering 및 4개의 natural language inference validation set),
(b) Chain-of-Thought (CoT) task (5개의 validation set),
(c) Flan 2022 fine-tuning에 포함되지 않은 "Held-Out" task 세트인 MMLU (Hendrycks et al., 2020) 및 BBH (Suzgun et al., 2022) 벤치마크.
Massively Multitask Language Understanding (MMLU) 벤치마크는 과학, 사회 과학, 인문학, 비즈니스, 건강 등 다양한 분야의 57개 task에 걸쳐 reasoning 및 지식 능력을 광범위하게 테스트한다. **BIG-Bench Hard (BBH)**는 BIG-Bench (Srivastava et al., 2022)에서 가져온 23개의 도전적인 task를 포함하며, 여기서 PaLM은 인간 평가자보다 낮은 성능을 보였다. 우리의 ablation 연구에서는 Chung et al. (2022)에 따라 Chain-of-Thought 입력을 사용하여 BBH를 평가한다. 추가적인 fine-tuning 및 평가 세부 사항은 Appendix A에 제공된다.
3.1 Ablation Studies
Table 1은 Held-in, Held-out, Chain-of-thought task에 대한 각 방법론의 평균 기여도를 보여준다. 이는 개별적으로 다음 방법들을 제외했을 때의 성능 변화를 나타낸다:
- mixture weight balancing ("- Mixture Balancing"),
- Chain-of-thought task ("- CoT"),
- mixed prompt settings ("- Few Shot Templates"),
- Input Inversion ("- Input Inversion").
Flan-T5 XL은 이 네 가지 방법을 모두 함께 활용한다. 또한 비교를 위해 Flan 2021, P3++, Super-Natural Instructions를 포함한 다른 컬렉션으로 T5-XL-LM을 fine-tuning했다.
| Model | Held-In | CoT | MMLU | BBH | BBH-CoT |
|---|---|---|---|---|---|
| T5-XL Flan 2022 | 73.8 / 74.8 | 35.8 / 34.1 | 50.3 / 52.4 | 26.2 / 39.3 | 33.9 / 35.2 |
| - CoT | 73.3 / 73.2 | 28.8 / 24.6 | 47.5 / 46.9 | 18.2 / 30.0 | 18.2 / 12.0 |
| - Input Inversion | 73.8 / 74.1 | 32.2 / 23.5 | 41.7 / 41.2 | 18.4 / 24.2 | 15.7 / 13.0 |
| - Mixture Balancing | 71.2 / 73.1 | 32.3 / 30.5 | 45.4 / 45.8 | 15.1 / 24.3 | 13.8 / 15.4 |
| - Few Shot Templates | 72.5 / 62.2 | 38.9 / 28.6 | 47.3 / 38.7 | 27.6 / 30.8 | 18.6 / 23.3 |
| T5-XL Flan 2021 | 68.4 / 56.3 | 24.6 / 22.7 | 41.4 / 34.8 | 28.1 / 28.3 | 26.0 / 26.9 |
| T5-XL P3++ | 70.5 / 62.8 | 25.6 / 25.6 | 46.1 / 34.1 | 26.0 / 30.8 | 23.4 / 26.1 |
| T5-XL Super-Natural Inst. | 50.3 / 42.2 | 13.8 / 14.3 | 35.6 / 31.1 | 10.4 / 15.6 | 8.0 / 12.5 |
| GLM-130B | - | - | - / 44.8 | - | - |
| OPT-IML-Max | - | - | 46.3 / 43.2 | - / 30.9 | - |
| OPT-IML-Max | - | - | 49.1 / 47.1 | - / 35.7 | - |
| Flan 2022 - Next Best T5-XL | +3.3 / +12 | +10.2 / +8.5 | +4.2 / +17.6 | -1.9 / +8.5 | +7.9 / +8.3 |
**Table 1: 방법론 Ablation (상단)**은 Flan-T5 XL에 대한 각 방법론의 중요성을 보여준다. **컬렉션 Ablation (하단)**은 Flan-T5 XL을 FLAN 2021, P3++, Super-Natural Instructions와 같은 다른 instruction tuning 컬렉션으로 fine-tuning된 T5-XL과 비교하여 평가한다. Flan 2022 - Next Best T5-XL은 Flan-T5 XL이 다른 컬렉션으로 fine-tuning된 다음으로 우수한 T5-XL (비교 가능한 크기) 모델 대비 개선된 성능을 나타낸다. Held-In, Chain-of-Thought, Held-Out (MMLU, BBH) task에 걸쳐 zero-shot / few-shot 설정 모두에서 지표가 보고된다. 우리는 또한 OPT-IML (Iyer et al., 2022) 및 **GLM-130B (Zeng et al., 2022)**에서 보고된 결과도 포함한다.
Flan의 각 ablation된 구성 요소는 서로 다른 지표에 개선을 가져온다:
- Chain-of-Thought 학습은 Chain-of-Thought 평가에,
- input inversion은 **Held-Out 평가 (MMLU 및 BBH)**에,
- few-shot prompt 학습은 few-shot 평가에,
- mixture balancing은 모든 지표에 기여한다.
Flan은 대안적인 instruction tuning 컬렉션(및 해당 방법론)으로 학습된 T5-XL 모델들과 비교했을 때, 거의 모든 설정에서 우수한 성능을 보인다. 이전 컬렉션들이 zero-shot prompt에 특화되어 튜닝된 반면, Flan-T5 XL은 zero-shot 또는 few-shot prompt 모두에 튜닝되었다. 이로 인해 대부분의 zero-shot 설정에서 +3~10%의 성능 향상을 보이며, few-shot 설정에서는 8~17%의 향상을 가져온다. 가장 인상적인 점은 Flan 2022가 OPT-IML-Max의 훨씬 더 큰 (10배) 30B 및 (58배) 175B 모델보다 우수한 성능을 보인다는 것이다. 다음으로, Flan 2022의 ablation된 방법들을 개별적으로 분리하여 각 방법의 이점을 살펴본다.
3.2 Training with Mixed Prompt Settings
기존 연구에서는 task별로 다양한 입력 템플릿을 사용하는 것이 성능을 향상시킬 수 있음을 보여주었다. 그러나 이러한 기존 LLM들은 지시 템플릿의 문구와는 별개로, 단일 prompt 설정에 맞춰진 템플릿 세트로 주로 튜닝되었다:
- zero-shot prompting의 경우 (Wei et al., 2021; Sanh et al., 2021; Aghajanyan et al., 2021; Aribandi et al., 2021),
- few-shot prompting의 경우 (Min et al., 2022; Wang et al., 2022c).
InstructGPT (Ouyang et al., 2022)에서 과소평가되었던 설계 결정 중 하나는 단일 설정만을 목표로 하는 대신, 각 prompt 설정에 대한 학습 템플릿을 혼합한 것이었다. 그러나 Ouyang et al. (2022)은 이러한 선택을 자세히 검토하지 않았기 때문에, 우리는 zero-shot 또는 few-shot prompting 성능을 위한 fine-tuning에서 성능 trade-off가 있을 것으로 예상했다. 특히 더 작은 모델의 경우 더욱 그러할 것으로 보았다.
하지만 예상과 달리, 우리는 zero-shot 및 few-shot prompt를 혼합하여 학습하는 것이 두 설정 모두에서 성능을 크게 향상시킨다는 것을 발견했다. 가장 놀라운 점은 3B 파라미터의 작은 모델에서도 이러한 개선이 나타났다는 것이다.
 Figure 3: zero-shot 및 few-shot prompt 템플릿을 함께 학습하는 것이 Held-In 및 Held-Out task 모두에서 성능을 향상시킨다. 별표는 각 설정에서의 최고 성능을 나타낸다.
Figure 3: zero-shot 및 few-shot prompt 템플릿을 함께 학습하는 것이 Held-In 및 Held-Out task 모두에서 성능을 향상시킨다. 별표는 각 설정에서의 최고 성능을 나타낸다.
Figure 3은 다음을 보여준다: (1) 5%만큼 적은 few-shot 학습 템플릿을 추가하는 것만으로도 zero-shot 성능을 극적으로 향상시킬 수 있으며, (2) 10% 이상의 zero-shot 데이터를 추가하는 것이 few-shot 성능 또한 향상시킨다. Held-In 및 Held-Out task 모두 few-shot 데이터 비율이 10-90% 사이에서 최고 성능을 보이지만, 이 범위는 단일 prompt 설정으로만 학습했을 때보다 일관되게 더 높다.
3.3 Scaling Small Models to + Tasks
가장 최근의 공개된 instruction tuning 연구들인 Flan 2022와 같은 노력들은 수천 개의 task로 학습되지만 (Wang et al., 2022c; Iyer et al., 2022), 서로 다른 task 구성과 근본적인 학습 방식을 사용한다. Flan 2022 컬렉션에 대해 모델 크기 및 task 스케일링의 영향을 측정하기 위해, 우리는 **T5-LM adapted 모델(Small, Base, Large, XL, XXL)**을 **무작위로 선택된 task subset(8, 25, 50, 100, 200, 400, 800, 전체 1873개)**으로 fine-tuning했다. 모든 fine-tuning 실행에는 Held-In task가 반드시 포함되도록 하여, task 스케일링이 모델이 이미 학습한 task에 대한 성능 유지 능력에 어떻게 영향을 미 미치는지를 추정할 수 있었다.
Figure 4는 Held-In task와 Held-Out task 모두 수백 개의 fine-tuning task를 추가함으로써 이점을 얻는다는 것을 보여준다. Held-In task 평가는 총 200개 task 부근에서 정점을 찍고, 더 많은 task가 추가될수록 성능이 감소하지만, 더 큰 모델은 더 늦게 정점을 찍고 감소폭도 적다. Held-Out task 성능은 task 수에 따라 log-linear하게 증가하며, 전체 1836개 task에서 가장 높은 성능을 달성한다.
 Figure 4: fine-tuning task 수와 모델 크기에 대한 성능 스케일링 법칙. Held-In 성능(왼쪽)과 Held-Out MMLU 성능(오른쪽)이 표시되어 있다. 금색 별은 해당 모델 크기의 최고 성능을 나타낸다.
Figure 4: fine-tuning task 수와 모델 크기에 대한 성능 스케일링 법칙. Held-In 성능(왼쪽)과 Held-Out MMLU 성능(오른쪽)이 표시되어 있다. 금색 별은 해당 모델 크기의 최고 성능을 나타낸다.
놀랍게도, T5-Small만이 1836개 task 이전에 Held-Out task 성능을 초과하는 것으로 나타났으며, 더 큰 모델 크기는 계속해서 성능이 향상되었다. 이러한 결과는 (a) T5-Base조차도 수천 개의 task로도 그 능력을 모두 소진하지 않았을 수 있으며, (b) 가장 큰 LMs는 Held-In 및 Held-Out task 성능을 위해 수천 개의 task가 더 필요할 수 있음을 시사한다.
이 분석의 필수적인 가정 중 하나는 모든 task가 동일하게 정의되고 계산된다는 것이다. Section 3.5에서는 모든 task 소스가 학습에 동일하게 유익하지 않으며, 하나의 소스에서 너무 많은 task를 사용하면 모델 성능이 포화될 수 있음(예: Super-Natural Instructions)을 보여준다. 우리는 task 다양성과 품질에 주의를 기울이지 않고 1800개 이상의 task 스케일링이 수익 증가로 이어질 것이라는 결론에 대해 신중해야 한다고 경고한다.
3.4 Task Enrichment with Input Inversion
이전의 instruction tuning 연구들은 supervised task에서 입력-출력 쌍을 **반전(inverting)**시켜 task의 다양성을 풍부하게 만들었다. 이는 P3 (Bach et al., 2022)에서는 "원래 task를 위한 것이 아닌 prompt"로, MetaICL (Min et al., 2022)에서는 "noisy channel"로 언급되었다. 예를 들어, 어떤 데이터셋은 원래 질문 가 주어졌을 때 모델이 를 답변할 수 있는지 평가하도록 설계되었을 수 있다. 하지만 **입력 반전(input inversion)**은 모델에 답변 를 주고 질문 를 생성하도록 학습시킨다. 이는 제한된 데이터 소스만 있을 때 task 다양성을 높이는 쉬운 방법이다. 그러나 이미 수백 개의 고유한 데이터 소스와 수천 개의 task가 있는 상황에서도 이 방법이 여전히 유용한지는 명확하지 않다.
이를 평가하기 위해, 우리는 입력 반전된 task로 데이터 혼합을 풍부하게 만들고 (자세한 내용 및 예시는 Appendix B 참조) 그 효과를 측정했다. Table 1에서 우리는 이 방법이 Held-In 성능에는 도움이 되지 않지만, Held-Out 성능에는 강력하게 유익하다는 것을 발견했다. 이러한 이점은 LLM fine-tuning을 위한 데이터 증강(data augmentation) 기법의 전망을 고무시킨다. 데이터 증강은 이전에 모델이 사전학습될수록 효과가 감소하는 것으로 나타났었다 (Longpre et al., 2020).
3.5 Balancing Data Sources
아키텍처 크기와 task 수를 확장하는 것은 효과적이지만, 우리의 결과는 결과 최적화를 위해 mixture weighting에도 그만큼의 관심이 필요함을 시사한다. 균형 잡힌 가중치를 찾기 위해, 우리는 다양한 task 소스 세트(Flan 2021, T0-SF, Super-Natural Instructions, Chain-of-Thought, Dialog, Program Synthesis)를 한 번에 하나씩 제외하고, MMLU 벤치마크에 대한 기여도를 평가했다.
| Train Mixtures | Metrics | ||
|---|---|---|---|
| Held-In | CoT | MMLU | |
| All (Equal) | 64.9 | 41.4 | 47.3 |
| All - Flan 2021 | 55.3 | 38.6 | 45.7 |
| All - T0-SF | 63.2 | 43.4 | 44.7 |
| All - Super-Nat. Inst. | 65.9 | 42.2 | 46.8 |
| All - CoT | 65.6 | 29.1 | 46.8 |
| All - Prog. Synth. | 66.9 | 42.3 | 46.8 |
| All - Dialog | 65.4 | 40.3 | 47.1 |
| All (Weighted) | 66.4 | 40.1 | 48.1 |
Table 2: 동일하게 가중치가 부여된 mixture에서 task의 일부를 제외하여 그 중요도를 측정하였다. T0-SF와 Flan 2021 fine-tuning은 MMLU에 가장 중요하며, Chain-of-Thought (CoT) fine-tuning은 Chain-of-Thought 평가에 가장 중요하다.
Table 2에서 볼 수 있듯이, Flan 2021과 T0-SF는 가장 유익한 mixture 중 하나이며, 그 다음으로 Super-Natural Instructions와 Chain-of-Thought, 그리고 Dialog와 Program Synthesis 순으로 나타났다. 이러한 결과는 데이터 혼합 비율을 광범위하게 테스트하고 Flan 2021, T0-SF, T5 mixture가 가장 광범위하게 유익하다는 것을 확인한 Iyer et al. (2022)의 연구와도 일치한다. 또한, 그들은 Super-Natural Instructions가 Held-Out task 성능에 제한적인 확장 이점을 가지며, 이는 고유한 입력 형식과 지시 설계와 관련이 있다고 밝혔다. 특히, Chain-of-Thought fine-tuning은 Flan 2021, T0-SF 또는 Natural Instructions보다 훨씬 적은 task를 포함함에도 불구하고 모든 평가 설정에서 유익한 것으로 나타났다.
우리는 이러한 발견을 활용하여 mixture weights 탐색 공간을 크게 좁혔고, 그 이후에는 실무자의 직관을 사용했다. 이 전략은 Table 1에서 보여주듯이 간단하지만 효과적이며, 미래의 더 정교한 연구를 위한 충분한 여지를 남긴다.
3.6 Discussion
OPT-IML (Iyer et al., 2022)은 본 연구와 가장 유사한 비교 대상이며, 유사한 task, 예시, 기법들을 포함한다. 그러나 OPT-IML에서 사용된 task들은 모두 공개된 소스에서 가져왔지만, 템플릿, 처리 방식, 예시 혼합 방식 등을 포함한 그들의 데이터셋은 공개되지 않아 쉽게 비교할 수 없다. Iyer et al. (2022)은 Flan-T5-XL (3B) 및 XXL (11B)이 MMLU와 BBH 모두에서 OPT-IML-Max 175B를 능가한다고 보고한다. 그들이 논의하듯이, 이러한 차이는 사전학습, 모델 아키텍처, instruction tuning의 어떤 조합에서든 발생할 수 있다. instruction tuning 이전의 모델 아키텍처와 사전학습은 중요한 역할을 할 수 있다 (Wang et al., 2022a). 하지만 Flan 2022와 OPT-IML 사이에는 instruction tuning에서 달라질 수 있는 많은 다른 세부 사항들이 있다. 유력한 후보들은 다음과 같다: 예시 템플릿화(templatization), 학습 시 혼합된 입력 prompting 절차 사용 방식, 그리고 task 구성이다.
이러한 차이점들이 얼마나 중요한가? OPT-IML이 Flan 2022보다 더 많은 task를 포함하고 있지만, 우리는 약 94% (2067/2207)가 Flan 2022 컬렉션에도 사용되었으며, Flan 2022의 task 중 OPT-IML에 어떤 형식으로든 포함되지 않은 task는 거의 없다고 추정한다. 이는 "task"에 대한 공통된 정의를 사용할 때 task 다양성의 전반적인 차이가 크지 않음을 시사한다. Task 혼합 비율 또한 Flan 2022와 OPT-IML 각각에 대해 Flan 2021 (46% 대 20%), PromptSource/P3 (28% 대 45%), Super-Natural Instructions (25% 대 25%)를 포함하여 유사한 소스를 강조한다. OPT-IML의 다른 컬렉션(Crossfit, ExMix, T5, U-SKG)은 크게 가중되지 않는다: 각각 4%, 2%, 2%, 2%이다.
Flan Held-In Tasks
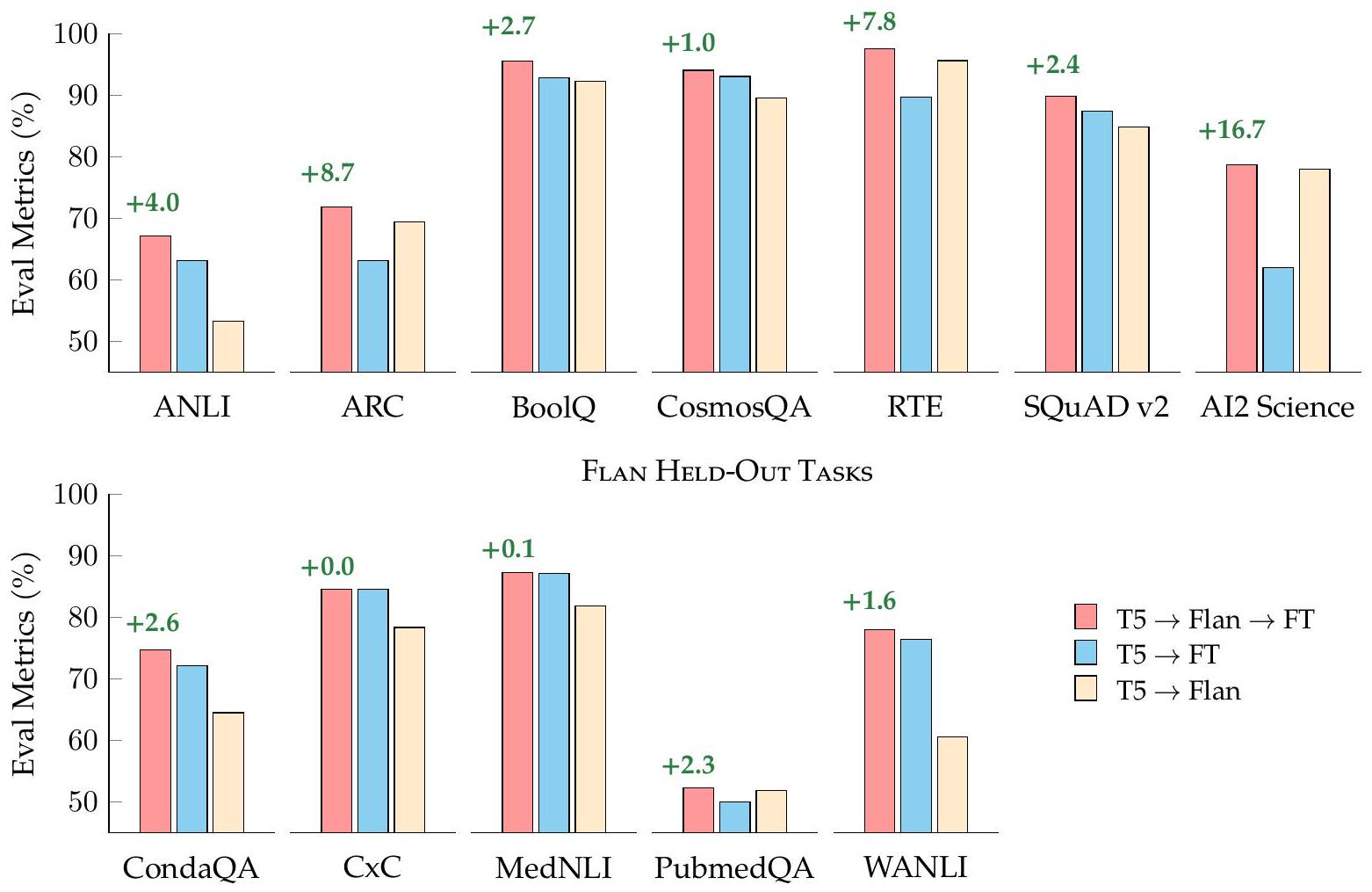
Figure 5: Flan-T5는 단일 task fine-tuning에서 T5를 능가한다. 우리는 단일 task로 fine-tuned된 T5, 단일 task로 fine-tuned된 Flan-T5, 그리고 추가 fine-tuning 없이 Flan-T5를 비교한다.
우리는 예시 템플릿화와 혼합 prompt 형식이 OPT-IML의 instruction tuning과 가장 큰 차이를 보일 수 있다고 생각한다. 우리의 템플릿 저장소는 Flan 2021에서 크게 업데이트되어, instruction뿐만 아니라 다양한 차원에서 다양성을 추가했다. 예를 들어, 템플릿화 절차는 instruction이 배치되는 위치(few-shot prompt 이전 또는 이후), few-shot 및 Chain-of-Thought prompt 사이의 간격 및 구분자, 그리고 객관식 예시의 답변 옵션(및 그 대상)의 형식 순열을 다양화하며, 이는 때로는 입력 또는 예시에 답변 옵션을 포함하고 때로는 제외한다. 우리는 많은 개발 반복을 비교하는 전용 실험은 없지만, 이러한 절차들이 입력 다양성을 극적으로 증가시키고 반복적인 성능 향상을 보였다는 것을 발견했다. 우리의 예시 템플릿화 절차는 검토 및 향후 작업을 위해 오픈 소스로 공개되어 있다.
4 Instruction Tuning Enhances Single-Task Finetuning
응용 환경에서 머신러닝 실무자들은 단일 목표 task에 특화되어 **fine-tuning (FT)**된 NLP 모델을 배포하며, 일반적으로 fine-tuning 데이터는 이미 사용 가능하다. 이전 연구들에서 intermediate fine-tuning (Pruksachatkun et al., 2020; Vu et al., 2020) 또는 multi-task fine-tuning (Aghajanyan et al., 2021; Aribandi et al., 2021)이 다운스트림 task에 미치는 이점을 보여주었지만, 이는 instruction-tuned 모델에 대해서는 광범위하게 연구되지 않았다.
우리는 Flan 2022 instruction tuning을 단일 목표 fine-tuning 이전의 중간 단계로 평가하여, Flan-T5가 실무자들에게 더 나은 시작 체크포인트 역할을 할 수 있는지를 이해하고자 한다. 우리는 세 가지 설정에서 평가를 수행한다.
 Figure 6: Flan fine-tuning의 5가지 Held-Out task 각각에 대해, Flan-T5는 T5보다 단일 task fine-tuning에서 더 빠르게 수렴한다.
Figure 6: Flan fine-tuning의 5가지 Held-Out task 각각에 대해, Flan-T5는 T5보다 단일 task fine-tuning에서 더 빠르게 수렴한다.
Figure 5:
- 기존 baseline으로서 T5를 목표 task에 직접 fine-tuning하는 경우 (파란색 막대),
- Flan-T5를 추가 fine-tuning 없이 사용하는 경우 (베이지색 막대),
- Flan-T5를 목표 task에 추가 fine-tuning하는 경우 (빨간색 막대).
단일 Task Fine-tuning에 대한 파레토 개선 (Pareto Improvements to Single Task Finetuning)
조사된 Held-In 및 Held-Out task 모두에서, Flan-T5를 fine-tuning하는 것은 T5를 직접 fine-tuning하는 것보다 파레토 개선을 제공한다. 일부 경우, 특히 task에 대한 fine-tuning 데이터가 제한적일 때, 추가 fine-tuning 없는 Flan-T5가 task fine-tuning을 거친 T5보다 더 나은 성능을 보인다.
더 빠른 수렴 및 계산상의 이점 (Faster Convergence & Computational Benefits)
Flan-T5를 시작 체크포인트로 사용하는 것은 학습 효율성 측면에서 추가적인 이점을 제공한다. Figure 6에서 보여주듯이, Flan-T5는 단일 목표 fine-tuning 과정에서 T5보다 훨씬 빠르게 수렴하며, 더 높은 정확도에서 최고 성능을 보인다. 이러한 수렴 결과는 NLP 커뮤니티가 단일 task fine-tuning을 위해 기존의 instruction-tuned되지 않은 모델 대신 Flan-T5와 같은 instruction-tuned 모델을 채택해야 하는 강력한 green-AI 인센티브가 있음을 시사한다. instruction tuning은 단일 task fine-tuning보다 계산 비용이 더 많이 들지만, 이는 일회성 비용이다. 반대로, 광범위한 fine-tuning이 필요한 사전학습 모델은 수백만 개의 추가 학습 단계를 합산할 때 더 많은 비용이 발생한다 (Wu et al., 2022; Bommasani et al., 2021). instruction-tuned 모델은 단일 task fine-tuning의 새로운 표준 시작점으로 채택될 경우, 광범위한 task에 걸쳐 fine-tuning 단계의 양을 크게 줄일 수 있는 유망한 해결책을 제공한다.
5 Related Work
Large Language Models
instruction tuning의 기반으로서, 여러 다운스트림 task에 유용한 하나의 범용 언어 표현을 사전학습하는 방식은 Mikolov et al. (2013) 및 Dai and Le (2015)까지 거슬러 올라가는 오랜 전통을 가지고 있다. 2018년 Peters et al. (2018)과 Devlin et al. (2019)는 대규모 비지도 코퍼스에서 대형 모델을 사전학습하는 패러다임을 확립했으며, NLP 분야는 빠르게 이러한 모델들을 사용하게 되었다. 이 모델들은 사전학습되지 않은 task-specific LSTM 모델의 기존 성능을 모든 task에서 크게 능가했다. 그러나 사전학습된 모델에 인코딩된 고품질의 구문 및 의미론적 지식에 접근하는 지배적인 방식은 명령(instruction)으로 prompt를 주는 것이 아니라, 모델 활성화(activation)를 수치적 class label로 매핑하는 추가적인 task-specific 선형 layer를 학습시키는 것이었다.
불과 1년 후, Radford et al. (2019), Raffel et al. (2020), Lewis et al. (2020)는 사전학습된 LM head를 직접 사용하여 자연어로 답변을 생성함으로써(task-specific 수치적 class label과 대조적으로) 다운스트림 task들, 그리고 여러 task들을 공동으로 학습할 수 있다는 개념을 대중화했다. 이러한 생성 모델의 task-general한 특성은 많은 멀티태스크 전이 학습 연구(McCann et al., 2018; Khashabi et al., 2020; Ye et al., 2021; Vu et al., 2020)의 전조가 되었고, 이는 다시 Section 2에서 설명된 instruction tuning의 첫 번째 물결로 이어졌다.
LM의 사전학습 코퍼스, 아키텍처 및 사전학습 목표에 대한 지속적인 연구 발전 또한 instruction tuning에 큰 영향을 미친다. 2022년 현재, decoder-only left-to-right causal Transformer는 100B보다 큰 모델 시장을 지배하고 있으며 (Brown et al., 2020; Thoppilan et al., 2022; Rae et al., 2021; Chowdhery et al., 2022; Hoffmann et al., 2022), 완전히 공개된 모델 파라미터를 가진 이러한 크기 클래스의 모든 모델은 decoder-only이다 (Wang and Komatsuzaki, 2021; Le Scao et al., 2022; Zhang et al., 2022). 이러한 결정은 종종 더 나은 하드웨어 및 소프트웨어 프레임워크 지원 때문인 경우가 많다. 그러나 Raffel et al. (2020), Lewis et al. (2020), Tay et al. (2022a)는 left-to-right causal language modeling이 최적이 아닌 목표임을 지속적으로 발견했으며, Tay et al. (2022b) 및 Wang et al. (2022a)는 특히 비순차적 목표의 혼합이 zero-shot 및 few-shot prompting을 사용하는 다운스트림 task에 훨씬 우수함을 보여주었다.
여전히 덜 탐구된 추가적인 요소는 사전학습 코퍼스, instruction tuning, 그리고 다운스트림 능력 간의 관계이다. 일반적으로 공개 모델들은 몇몇 공개 코퍼스 중 하나로 학습된다: C4 (Raffel et al., 2020), The Pile (Gao et al., 2020), 또는 ROOTs (Laurençon et al., 2022).
Instruction Tuning
Section 2에서는 instruction tuning의 주요 발전을 설명한다. 다른 중요한 발전으로는 parameter-efficient tuning을 통해 few-shot in-context learning(현재 사전학습 및 instruction-tuned 모델을 평가하는 지배적인 방법)을 보완하거나 대체할 가능성이 포함된다. 100B보다 큰 모델의 표준 fine-tuning은 적절한 상호 연결을 갖춘 많은 수의 가속기를 필요로 하며, 이는 많은 산업 연구소에서도 너무 비싼 경우가 많다. 이러한 상황에서 **parameter-efficient tuning (일명 continuous 또는 soft "prompt tuning")**은 모델 파라미터의 작은 부분집합만 업데이트해도 모든 모델 파라미터를 완전히 튜닝하는 것과 유사한 성능에 도달할 수 있음을 보여준다 (Lester et al., 2021; Vu et al., 2022; Hu et al., 2021; 자세한 분석은 He et al., 2022 참조).
특히 Liu et al. (2022b)는 few-shot ICL의 긴 시퀀스 길이와 모든 예시를 평가하기 위해 few-shot exemplars를 반복적으로 추론해야 한다는 점 때문에, parameter-efficient tuning이 in-context learning보다 계산적으로 더 저렴하고 성능이 더 높을 수 있음을 보여준다.
더 나아가 Liu et al. (2022b), Vu et al. (2022), Wei et al. (2021), Singhal et al. (2022)는 단일 task 및 멀티태스크 parameter-efficient tuning 모두 instruction tuning과 생산적으로 결합될 수 있음을 종합적으로 보여준다. 이는 일반적인 전체 모델 instruction tuning 전후에 적용될 수 있다. 이러한 연구 방향은 다른 연구자들이 일반 도메인 instruction-tuned 모델을 기반으로 자신들의 용도에 맞는 맞춤형 instruction-tuning 혼합을 수집하는 것을 용이하게 한다. 예를 들어, 여러 모달리티(Ahn et al., 2022; Huang et al., 2022; Xu et al., 2022) 또는 과학 및 의학 같은 특수 도메인(Lewkowycz et al., 2022; Singhal et al., 2022)에서 활용될 수 있다.
Instruction Tuning 및 Alignment 기법으로 해결되는 문제
instruction tuning은 언어 모델을 **더 유용한 목표와 인간의 선호도에 "정렬(align)"**시키기 위해 고안된 연구의 일환이다. 이러한 방법이 없을 경우, 언어 모델은 유해한 행동(toxic/harmful behaviour)을 보이거나 (Sheng et al., 2019; Liang et al., 2021; Wallace et al., 2019), 사실과 다른 정보(non-factual information)를 생성하고 (Maynez et al., 2020; Longpre et al., 2021; Devaraj et al., 2022), 배포 및 평가에서 다른 문제점들을 야기하는 것으로 알려져 있다 (Zellers et al., 2019; McGuffie and Newhouse, 2020; Talat et al., 2022). 이러한 문제들을 분석, 평가 및 완화하는 것은 미래 연구를 위한 유망한 방향을 제시한다 (Gao et al., 2022; Ganguli et al., 2022). instruction tuning은 Chung et al. (2022)에서 보여주듯이 NLP 편향 지표를 줄이는 데 고무적인 해결책임이 이미 입증되었으므로, 더 많은 조사가 필요하다.
6 Conclusions
새로운 Flan 2022 instruction tuning collection은 기존의 가장 인기 있는 공개 collection들과 그 방법들을 통합하는 동시에, 새로운 템플릿과 mixed prompt setting으로 학습하는 것과 같은 간단한 개선 사항들을 추가하였다. 그 결과, 이 collection은 Held-In QA, NLI, Chain-of-Thought task 및 Held-Out MMLU, BBH에서 Flan 2021, P3++, Super-Natural Instructions, OPT-IML-Max 175B를 종종 큰 차이로 능가하는 성능을 보여준다. 이러한 결과는 이 새로운 collection이 새로운 instruction에 대한 일반화 또는 단일 새로운 task에 대한 fine-tuning에 관심 있는 연구자와 실무자에게 더욱 경쟁력 있는 출발점이 될 수 있음을 시사한다.