Flamingo: a Visual Language Model for Few-Shot Learning
Flamingo는 이미지와 텍스트가 혼합된 입력을 처리할 수 있으며, few-shot 학습 환경에서도 높은 성능을 보이는 Visual Language Model (VLM)이다. Flamingo는 pretrained된 vision-only 및 language-only 모델을 효과적으로 연결하고, 임의의 순서로 interleaved된 이미지 및 텍스트 시퀀스를 처리할 수 있도록 설계되었다. 이 모델은 이미지와 텍스트가 섞인 대규모 웹 데이터로 학습되며, in-context few-shot 학습 능력을 통해 다양한 multimodal task (예: visual question answering, image captioning 등)에 빠르게 적응하는 성능을 보여준다. 논문 제목: Flamingo: a Visual Language Model for Few-Shot Learning
논문 요약: Flamingo: a Visual Language Model for Few-Shot Learning
- 논문 링크: https://arxiv.org/abs/2204.14198
- 저자: Jean-Baptiste Alayrac et al. (DeepMind)
- 발표 시기: 2022년, NeurIPS (Advances in neural information processing systems 35)
- 주요 키워드: VLM, Visual Language Model, Few-shot Learning, Multimodal, In-context learning, NLP
1. 연구 배경 및 문제 정의
- 문제 정의: 새로운 멀티모달(이미지/비디오 + 텍스트) task에 대해 소수의 주석된 예시만으로도 빠르게 적응하고, 특히 자유 형식의 텍스트를 생성할 수 있는 모델을 구축하는 것이 멀티모달 머신러닝의 주요 도전 과제입니다.
- 기존 접근 방식:
- Fine-tuning: 대규모 주석 데이터로 사전학습 후 특정 task에 미세 조정하는 방식이 일반적이지만, 수천 개 이상의 데이터와 많은 자원, 세심한 하이퍼파라미터 튜닝이 필요합니다.
- Contrastive VLM (예: CLIP): 이미지와 텍스트 간의 유사도 점수를 제공하여 zero-shot 분류는 가능하지만, 언어 생성 능력이 없어 캡셔닝이나 시각 질문 응답과 같은 개방형(open-ended) task에는 부적합합니다.
- 시각 조건부 언어 생성 모델: 소량의 데이터로 학습하는 few-shot 환경에서 성능이 좋지 않았습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 새로운 VLM 계열 'Flamingo' 제안: 소수의 입출력 예시(few-shot)만으로도 캡셔닝, 시각 대화, 시각 질문 응답 등 다양한 멀티모달 task를 수행할 수 있는 Visual Language Model (VLM)인 Flamingo를 소개합니다.
- 혁신적인 아키텍처 설계: 텍스트와 시각 데이터(이미지/비디오)가 임의로 섞인 시퀀스를 효율적으로 처리하고 자유 형식의 텍스트를 생성할 수 있도록 설계되었습니다.
- 압도적인 Few-shot SOTA 달성: 16개의 멀티모달 task에서 few-shot 학습 기준으로 새로운 SOTA를 달성했으며, 6개 task에서는 단 32개의 예시만으로 기존 fine-tuned SOTA 모델보다 뛰어난 성능을 보였습니다.
- 제안 방법:
Flamingo는 사전학습된 Vision-only 모델과 Language-only 모델을 효과적으로 연결하여 시각 정보를 조건으로 받아들이는 자기회귀(autoregressive) 텍스트 생성 모델입니다.
- Perceiver Resampler: 사전학습된 Vision Encoder(NFNet)로부터 추출된 가변 크기의 시각 특징(이미지 또는 비디오)을 고정된 개수(64개)의 visual token으로 효율적으로 변환합니다. 이는 cross-attention의 연산 복잡도를 줄여줍니다.
- GATED XATTN-DENSE Layer: 사전학습된 Language Model(LM) 블록들 사이에 새로 학습되는 cross-attention layer를 삽입합니다. 이 레이어는 LM이 시각 정보를 유연하게 통합하도록 하며, 0으로 초기화된 tanh-gating 메커니즘을 통해 LM의 사전학습 지식을 보존하고 학습 안정성을 높입니다.
- Multi-visual Input Support: 텍스트와 이미지/비디오가 섞인 시퀀스를 처리할 수 있습니다. 각 텍스트 토큰은 바로 직전에 등장한 시각 입력에만 cross-attention을 수행하지만, LM 내부의 self-attention을 통해 간접적으로 모든 이전 시각 정보와의 종속성을 유지합니다. 이는 추론 시 다양한 개수의 시각 입력에 유연하게 일반화될 수 있도록 합니다.
- 대규모 멀티모달 데이터 학습: 이미지와 텍스트가 임의로 섞인 대규모 웹 코퍼스(M3W), 이미지-텍스트 쌍 데이터셋(ALIGN, LTIP), 비디오-텍스트 쌍 데이터셋(VTP)의 혼합으로 학습됩니다. 특히 M3W는 in-context few-shot learning 능력 습득에 핵심적인 역할을 합니다.
- In-context Few-shot Learning: GPT-3와 유사하게, (이미지, 텍스트) 또는 (비디오, 텍스트) 형태의 support example들을 쿼리 시각 입력 앞에 연결하여 prompt를 구성함으로써 새로운 task에 빠르게 적응합니다.
3. 실험 결과
- 데이터셋:
- 평가 벤치마크: COCO, OKVQA, VQAv2, MSVDQA, VATEX, Flickr30k, VizWiz, TextVQA, VisDial, HatefulMemes, Kinetics700, MSVDQA, YouCook2, MSRVTTQA, iVQA, RareAct, NextQA, STAR 등 총 16개의 이미지/비디오 및 언어 벤치마크.
- 학습 데이터셋: MultiModal MassiveWeb (M3W, 4,300만 웹페이지), ALIGN (18억 이미지-alt-text 쌍), LTIP (3억 1,200만 이미지-텍스트 쌍), VTP (2,700만 비디오-텍스트 쌍).
- 모델 크기: Flamingo-3B, Flamingo-9B, Flamingo-80B (각각 Chinchilla 1.4B, 7B, 70B LM 기반).
- 학습 환경: 가장 큰 Flamingo-80B 모델은 1,536개의 TPUv4 칩에서 15일간 학습되었습니다.
- 주요 결과:
- Few-shot 성능: Flamingo는 16개 벤치마크 전반에 걸쳐 기존의 모든 zero-shot 및 few-shot 방법들을 큰 차이로 능가합니다. 특히, 단 4개의 예시만으로도 뛰어난 성능을 보였습니다.
- Fine-tuned SOTA 능가: 6개 task에서 Flamingo는 단 32개의 task-specific 예시와 고정된 모델 가중치만으로, 수천 개의 주석 데이터로 fine-tuning된 기존 SOTA 모델보다 더 나은 성능을 달성했습니다.
- 확장성: 모델 크기가 클수록, 그리고 few-shot 예시의 수가 많아질수록 성능이 향상되는 경향을 보였습니다. 특히 가장 큰 모델이 더 많은 shot 수를 활용하는 데 능숙했습니다.
- Fine-tuning 결과: few-shot 학습만으로 SOTA를 달성하지 못한 9개 task 중 5개(VQAv2, VATEX, VizWiz, MSRVTTQA, HatefulMemes)에서 fine-tuning을 통해 새로운 SOTA를 달성했습니다.
- Ablation Study 주요 발견:
- M3W를 포함한 학습 데이터셋 혼합의 중요성.
- 제안된 GATED XATTN-DENSE layer가 다른 조건화 아키텍처보다 우수함.
- 사전학습된 LM 레이어를 고정(freeze)하는 것이 파국적 망각(catastrophic forgetting)을 방지하고 계산 효율성을 높이는 데 중요함.
- Perceiver Resampler가 MLP나 Transformer보다 우수함.
- 각 텍스트 토큰이 바로 직전 이미지에만 cross-attention하는 방식이 더 효과적임.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 뛰어난 Few-shot 학습 능력: 적은 데이터만으로도 다양한 멀티모달 task에 빠르게 적응하는 능력이 매우 인상적입니다. 이는 실제 응용에서 데이터 수집 및 주석 비용을 크게 줄일 수 있습니다.
- 범용성과 유연성: 이미지와 텍스트가 섞인 복합적인 입력을 자연스럽게 처리하고 자유 형식의 텍스트를 생성할 수 있어, 기존의 제한적인 VLM보다 훨씬 넓은 범위의 응용이 가능합니다.
- 기존 모델 재활용: 강력한 사전학습된 언어 모델과 시각 모델을 고정된 상태로 활용하여 새로운 모달리티를 통합하는 방식은 계산 효율성 측면에서 매우 중요하며, 향후 대규모 모델 개발의 방향성을 제시합니다.
- 대화형 인터페이스 가능성: 시각 대화 예시에서 보여주듯이, "채팅"과 유사한 개방형 대화 인터페이스를 통해 비전문 사용자도 쉽게 접근하고 활용할 수 있는 잠재력이 있습니다.
- 단점/한계:
- 기반 LM의 한계 계승: 환각(hallucination)이나 근거 없는 추측, 학습 시퀀스보다 훨씬 긴 입력에 대한 일반화 성능 저하 등 기반 언어 모델의 약점을 그대로 물려받습니다.
- 분류 성능의 상대적 열세: 특정 분류 task에서는 contrastive 학습 기반의 전문 모델보다 성능이 뒤처지는 한계가 있습니다.
- In-context learning의 민감도: 프롬프트 구성(예시 순서, 형식)에 민감하며, shot 수가 일정 수준(약 32개)을 넘어서면 성능 향상이 정체되고 추론 비용이 증가할 수 있습니다.
- 사회적 위험: 대규모 언어 모델과 유사하게 유해한 언어 생성, 사회적 편향(성별, 인종 등) 확산, 민감한 정보 유출 등의 위험이 존재합니다.
- 응용 가능성:
- 범용 시각 이해 시스템: 다양한 시각 이해 task(캡셔닝, VQA, 시각 대화)를 위한 단일 모델로 활용될 수 있습니다.
- 저자원 환경의 문제 해결: 데이터가 부족한 환경에서 시각 인식 기술을 적용해야 하는 문제(예: 시각 장애인을 위한 VizWiz 챌린지)에 효과적으로 사용될 수 있습니다.
- 대화형 AI 및 챗봇: 이미지나 비디오를 이해하고 이에 기반하여 자연스러운 대화를 생성하는 대화형 AI 시스템 개발에 기여할 수 있습니다.
- 유해 콘텐츠 필터링: 모델의 적응 능력을 활용하여 유해하거나 편향된 샘플을 필터링하는 데 응용될 가능성도 있습니다.
Alayrac, Jean-Baptiste, et al. "Flamingo: a visual language model for few-shot learning." Advances in neural information processing systems 35 (2022): 23716-23736.
Flamingo: a Visual Language Model for Few-Shot Learning
DeepMind
Abstract
새로운 task에 대해 소수의 annotated example만으로도 빠르게 적응할 수 있는 모델을 구축하는 것은 멀티모달 머신러닝 연구에서 여전히 해결되지 않은 도전 과제이다. 우리는 이러한 능력을 갖춘 Visual Language Model(VLM) 계열인 Flamingo를 소개한다. 우리는 다음과 같은 주요 아키텍처 혁신을 제안한다: (i) 강력한 사전학습된 vision-only 모델과 language-only 모델을 연결하는 구조, (ii) 시각 및 텍스트 데이터가 임의로 섞여 있는 시퀀스를 처리할 수 있는 구조, (iii) 이미지 또는 비디오를 입력으로 자연스럽게 수용할 수 있는 구조.
이러한 유연성 덕분에 Flamingo 모델은 텍스트와 이미지가 임의로 섞여 있는 대규모 멀티모달 웹 코퍼스를 학습에 활용할 수 있으며, 이는 in-context few-shot learning 능력을 갖추는 데 핵심적인 요소이다.
우리는 다양한 이미지 및 비디오 task에 대한 Flamingo 모델의 빠른 적응 능력을 탐구하고 측정하며, 철저한 평가를 수행한다. 여기에는 다음과 같은 open-ended task가 포함된다:
- Visual Question Answering (VQA): 모델이 질문을 받고 그에 대한 답을 생성해야 하는 task,
- Captioning: 장면이나 이벤트를 설명하는 능력을 평가하는 task.
또한 다음과 같은 close-ended task도 포함된다:
- Multiple-choice VQA: 여러 선택지 중 정답을 고르는 형식의 task.
이 스펙트럼 어디에 위치한 task든지, 단일 Flamingo 모델은 task-specific 예시를 prompt로 주는 것만으로 few-shot learning 방식으로 새로운 state-of-the-art 성능을 달성할 수 있다. 많은 벤치마크에서 Flamingo는 수천 배 더 많은 task-specific 데이터로 fine-tuning된 모델보다 더 나은 성능을 보여준다.

Figure 1: Flamingo-80B로부터 얻은 입력과 출력의 선택된 예시. Flamingo는 few-shot prompting만으로 다양한 이미지/비디오 이해 task에 빠르게 적응할 수 있다 (상단). 또한 Flamingo는 별도의 fine-tuning 없이도 multi-image visual dialogue를 수행할 수 있는 능력을 갖추고 있다 (하단). 더 많은 예시는 Appendix C에 제시되어 있다.

Figure 2: Flamingo 결과 개요. 왼쪽: 우리의 가장 큰 모델인 Flamingo는 fine-tuning 없이도 우리가 다룬 16개의 task 중 6개에서 state-of-the-art로 fine-tuned된 모델보다 더 뛰어난 성능을 보인다. 또한, few-shot 결과가 공개된 9개의 task에서는 Flamingo가 새로운 few-shot state-of-the-art 성능을 기록한다. 참고로, 16번째 벤치마크인 RareAct는 비교할 수 있는 fine-tuned 결과가 없는 zero-shot 벤치마크이므로 생략하였다. 오른쪽: Flamingo의 성능은 모델 크기와 few-shot 예시의 개수가 많아질수록 향상된다.
1 Introduction
지능의 핵심적인 측면 중 하나는 간단한 지시만으로 새로운 task를 빠르게 학습하는 능력이다 [33, 70]. 컴퓨터 비전 분야에서도 이러한 능력에 대한 초기적인 진전이 있었지만, 여전히 가장 널리 사용되는 접근 방식은 대규모 supervised 데이터로 모델을 사전학습한 뒤, 관심 있는 task에 대해 fine-tuning을 수행하는 것이다 [66, 118, 143]. 하지만 이러한 fine-tuning은 수천 개 이상의 annotated data가 필요하며, 각 task별로 세심한 하이퍼파라미터 튜닝이 요구되고, 많은 자원이 소모된다는 단점이 있다.
최근에는 contrastive objective로 학습된 multimodal vision-language model들이 등장하면서, fine-tuning 없이도 새로운 task에 zero-shot으로 적응하는 것이 가능해졌다 [50, 85]. 하지만 이러한 모델들은 단순히 텍스트와 이미지 간의 유사도 점수만 제공하기 때문에, **미리 정의된 제한된 결과 집합(class label)**이 있는 분류 문제와 같은 제한된 use case에만 사용할 수 있다. 이들은 언어 생성 능력이 없어, captioning이나 visual question answering과 같은 open-ended task에는 적합하지 않다. 이에 반해, 몇몇 연구들은 **시각 정보에 조건을 거는 언어 생성(visual-conditioned language generation)**을 시도했으나 [17, 114, 119, 124, 132], 소량의 데이터로 학습하는 few-shot setting에서는 성능이 좋지 않았다.
우리는 이러한 문제를 해결하고자 Flamingo를 소개한다. Flamingo는 **Visual Language Model (VLM)**로서, Figure 1에서 보여주듯 소수의 input/output 예시만으로 prompt를 구성하는 것만으로도, 다양한 open-ended vision-language task에서 새로운 few-shot state-of-the-art 성능을 달성한다. 우리가 다룬 16개의 task 중 6개에서는 기존 fine-tuned SOTA보다 더 뛰어난 성능을 보이며, 이는 Flamingo가 훨씬 적은 task-specific training data를 사용함에도 불구하고 달성한 성과이다 (Figure 2 참조).
이를 가능하게 하기 위해 Flamingo는 **few-shot 학습에서 우수한 성능을 보인 최신 대형 language model (LM)**들의 구조에서 영감을 받았다 [11, 18, 42, 86]. 이러한 LMs는 텍스트 기반의 interface를 통해 다양한 task를 수행할 수 있으며, 소수의 예시들과 쿼리 입력을 prompt로 주면, 해당 쿼리에 대한 예측 결과를 생성할 수 있다. 우리는 이러한 방식이 **이미지와 비디오 이해 task들(예: 분류, 캡셔닝, 질문응답 등)**에도 적용될 수 있음을 보인다. 이들 task는 시각 정보에 기반한 텍스트 생성 문제로 변환될 수 있다.
LM과의 차이점은, Flamingo는 텍스트와 이미지/비디오가 섞여 있는 multimodal prompt를 처리할 수 있어야 한다는 점이다. Flamingo는 이러한 요구를 충족하는 모델로, 시각 정보를 조건으로 받아들이는 autoregressive text generation model이다. 즉, 텍스트 token과 이미지/비디오가 섞여 있는 시퀀스를 입력받아 텍스트를 출력할 수 있다.
Flamingo는 두 개의 사전학습된 모델을 조합하여 활용한다:
- 시각 정보를 인지(perceive)할 수 있는 vision model,
- 기초적인 reasoning을 수행할 수 있는 대형 language model.
이 둘 사이에 새로운 아키텍처 구성 요소를 삽입하여, 각 모델이 사전학습 동안 축적한 지식을 그대로 유지한 채 연결되도록 설계되었다.
또한 Flamingo는 **Perceiver 기반 아키텍처 [48]**를 통해 고해상도의 이미지나 비디오도 효율적으로 처리할 수 있다. 이 구조는 큰 규모의 시각 입력으로부터 고정된 수의 visual token을 생성할 수 있어, 다양한 크기의 이미지/비디오 입력을 수용 가능하게 한다.
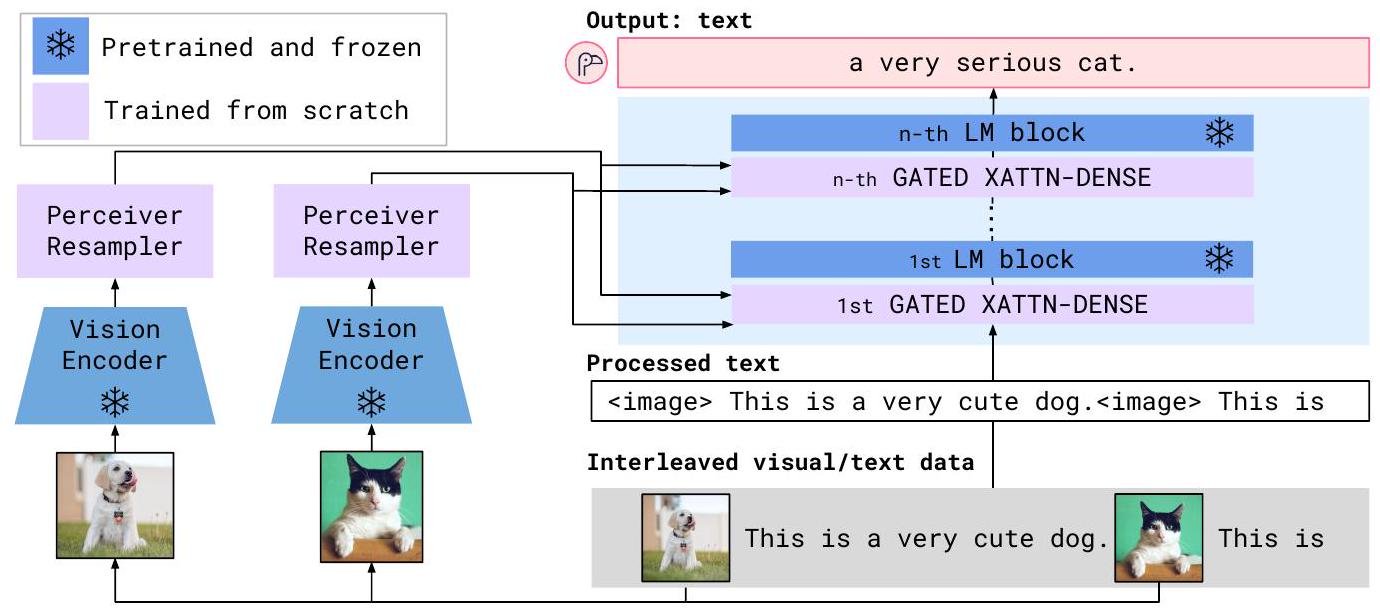
Figure 3: Flamingo 아키텍처 개요. Flamingo는 텍스트와 섞여 있는 시각적 데이터를 입력으로 받아 자유형식의 텍스트를 출력하는 Visual Language Model (VLM) 계열의 모델이다.
대형 Language Model (LM)의 성능에 있어 핵심적인 요소 중 하나는 방대한 양의 텍스트 데이터로 학습되었다는 점이다. 이러한 학습은 범용적인 텍스트 생성 능력을 모델에 부여하며, task 예시만으로도 뛰어난 성능을 발휘할 수 있게 해준다. 이와 유사하게, Flamingo 모델의 학습 방식 또한 최종 성능에 매우 중요한 역할을 한다는 것을 우리는 실험적으로 보여준다. Flamingo 모델은 기계학습을 위해 별도로 주석 처리되지 않은, 웹에서 수집한 다양한 대규모 멀티모달 데이터로 구성된 **신중하게 설계된 데이터 혼합(mixture)**을 이용해 학습된다. 이러한 학습을 거친 후 Flamingo는 어떠한 task-specific 튜닝 없이도, 단순한 few-shot prompting만으로 시각적 task에 직접 활용 가능하다.
기여 사항 (Contributions)
요약하면, 본 논문의 주요 기여는 다음과 같다:
(i) 우리는 **Flamingo 계열의 Visual Language Model (VLM)**을 소개한다. 이 모델은 few-shot input/output 예시만으로도 captioning, visual dialogue, visual question-answering과 같은 다양한 멀티모달 task를 수행할 수 있다. 아키텍처적 혁신 덕분에, Flamingo는 텍스트와 시각 데이터를 임의로 섞은 입력을 효율적으로 수용하고, 자유형식의 텍스트를 생성할 수 있다.
(ii) 우리는 Flamingo 모델이 다양한 task에 대해 few-shot learning을 통해 어떻게 적응 가능한지를 정량적으로 평가한다. 특히, 우리는 이 접근법의 디자인 결정이나 하이퍼파라미터 튜닝에 전혀 사용되지 않은 대규모의 held-out 벤치마크 세트를 따로 보존하여, 편향되지 않은 few-shot 성능을 추정하는 데 활용한다.
(iii) Flamingo는 언어 및 이미지/비디오 이해와 관련된 16개의 멀티모달 task에서 few-shot learning 기준으로 새로운 state of the art을 달성한다. 이 중 6개 task에서는 단 32개의 task-specific 예시만을 사용하고도, 기존 fine-tuned SOTA 모델보다 더 나은 성능을 보여준다. 이는 기존 SOTA보다 약 1000배 적은 task-specific training data를 사용한 결과다. 또한, 더 큰 어노테이션 budget이 주어진다면, Flamingo는 VQAv2, VATEX, VizWiz, MSRVTTQA, HatefulMemes와 같은 5개의 추가적인 고난이도 벤치마크에서도 새로운 SOTA 성능을 fine-tuning을 통해 달성할 수 있다.
2 Approach
이 섹션에서는 Flamingo를 설명한다. Flamingo는 텍스트와 이미지/비디오가 섞인(interleaved) 입력을 받아 자유 형식의 텍스트를 출력하는 Visual Language Model이다. Figure 3에 나타난 핵심 아키텍처 구성 요소들은 사전학습된 vision 및 language model을 효과적으로 연결하기 위해 설계되었다.
첫째, Perceiver Resampler(Section 2.1)는 Vision Encoder로부터 얻은 시공간(spatio-temporal) feature들을 입력받아(입력은 이미지 또는 비디오일 수 있음), 고정된 개수의 visual token을 출력한다.
둘째, 이렇게 생성된 visual token들은 사전학습된 Language Model(LM) 내부에 새롭게 초기화된 cross-attention layer를 삽입하여 언어 생성에 조건(condition)으로 활용된다 (Section 2.2). 이 cross-attention layer는 다음 token을 예측하는 과정에서 LM이 시각 정보를 유연하게 통합할 수 있도록 해주는 강력한 구조이다.
Flamingo는 이미지/비디오와 섞인 텍스트 시퀀스가 주어졌을 때, 텍스트 의 확률 분포를 다음과 같이 모델링한다:
여기서
- 은 입력 텍스트의 -번째 language token,
- 은 -번째 token 이전의 모든 token,
- 은 이전에 등장한 이미지/비디오들의 집합,
- 는 Flamingo 모델에 의해 parameterized된 확률 분포이다.
이처럼 텍스트와 시각 정보가 섞인 시퀀스를 처리할 수 있는 능력(Section 2.3)은 Flamingo를 GPT-3의 few-shot prompting과 유사하게 in-context few-shot learning에 자연스럽게 적용할 수 있게 만든다. 본 모델은 다양한 dataset의 혼합으로 학습되며, 이에 대한 자세한 내용은 Section 2.4에서 설명한다.
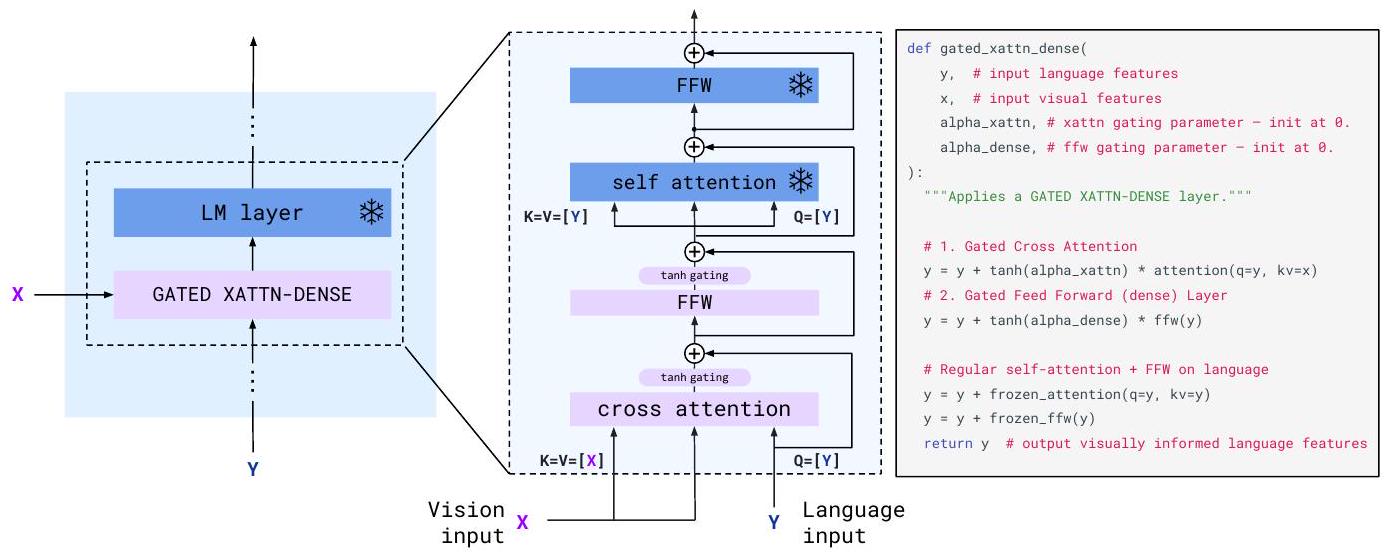
Figure 4: GATED XATTN-DENSE layer.
Language Model(LM)에 시각 정보를 조건으로 제공하기 위해, 우리는 기존의 사전학습된 고정된 LM layer 사이에 새로운 cross-attention layer를 삽입한다. 이 cross-attention layer에서 key와 value는 vision feature로부터 얻어지고, query는 language input으로부터 유도된다.
cross-attention 뒤에는 dense feed-forward layer가 이어진다.
이러한 layer들은 gate로 제어되며, 이를 통해 초기화 시점에서 LM의 본래 구조를 손상시키지 않고 안정성과 성능을 향상시킬 수 있다.
2.1 Visual processing and the Perceiver Resampler
Vision Encoder: 픽셀로부터 feature 추출
우리의 vision encoder는 사전학습된 Normalizer-Free ResNet (NFNet) [10]이며, F6 모델을 사용한다. 이 vision encoder는 이미지-텍스트 쌍으로 구성된 데이터셋을 기반으로, Radford et al. [85]의 two-term contrastive loss를 이용한 contrastive objective로 사전학습되었다.
Encoder의 출력은 2D 공간상의 feature grid이며, 이는 **1D 시퀀스로 평탄화(flatten)**되어 사용된다.
비디오 입력의 경우, 초당 1프레임(FPS)으로 프레임을 샘플링하고, 각 프레임은 개별적으로 인코딩된다. 이를 통해 3D spatio-temporal feature grid가 생성되며, 여기에 학습된 temporal embedding이 더해진다. 이렇게 얻은 feature는 1D 시퀀스로 평탄화된 후 Perceiver Resampler에 입력된다.
contrastive 모델 학습 및 성능에 대한 자세한 내용은 각각 Appendix B.1.3과 Appendix B.3.2에서 설명되어 있다.
Perceiver Resampler: 크기가 다양한 대형 feature map을 소수의 visual token으로 변환
이 모듈은 Figure 3에서 보여지듯, vision encoder와 고정된(frozen) language model을 연결하는 역할을 한다.
Perceiver Resampler는 vision encoder로부터 추출된 이미지 또는 비디오 feature들을 입력으로 받아, 고정된 개수(64개)의 visual output을 생성한다. 이는 vision-text cross-attention의 연산 복잡도를 효과적으로 줄여준다.
Perceiver [48] 및 DETR [13]에서와 유사하게, 우리는 사전에 정의된 개수의 latent input query를 학습하며, 이들은 Transformer에 입력되어 시각적 feature에 cross-attention을 수행한다.
ablation study (Section 3.3)에서는 이러한 vision-language resampler 모듈이 단순한 Transformer나 MLP보다 더 우수한 성능을 보인다는 것을 입증한다.
이 모듈에 대한 시각적 예시, 아키텍처 세부사항, 그리고 pseudo-code는 Appendix A.1.1에 제시되어 있다.
2.2 Conditioning frozen language models on visual representations
텍스트 생성(text generation)은 Perceiver Resampler가 생성한 시각 표현(visual representation)을 조건으로 하는 Transformer decoder에 의해 수행된다. 우리는 사전학습된 고정(frozen)된 텍스트 전용 LM 블록들과, Perceiver Resampler의 시각 출력을 cross-attend하는 방식으로 새로 학습되는 블록들을 교차(interleave)하여 배치한다.
Interleaving new GATED XATTN-DENSE layers within a frozen pretrained LM
우리는 **사전학습된 LM 블록들은 그대로 고정(freeze)**시키고, 새로 학습되는 gated cross-attention dense block(Figure 4 참조)을 기존 layer들 사이에 삽입한다.
초기화 시, 조건부(conditioned) 모델의 출력이 기존 language model의 출력과 동일하도록 하기 위해, 우리는 tanh-gating mechanism을 사용한다 [41]. 이 방식에서는 새로 삽입된 layer의 출력에 대해 를 곱한 후, residual connection을 통해 들어온 입력에 더한다. 여기서 는 layer마다 개별적으로 학습되는 scalar 파라미터이며, 초기값은 0으로 설정된다 [4].
따라서 초기 시점에서는 모델의 출력이 기존 사전학습된 LM과 동일하게 되며, 학습 안정성 및 최종 성능 향상에 기여한다.
ablation study (Section 3.3)에서는 제안된 GATED XATTN-DENSE layer와 최근 대안들 [22, 68]을 비교하고, 이러한 layer를 얼마나 자주 삽입할지를 조절함으로써 효율성과 표현력 간의 trade-off를 탐구한다. 자세한 내용은 Appendix A.1.2를 참조하라.
다양한 모델 크기 (Varying model sizes).
우리는 세 가지 모델 크기에서 실험을 수행하였으며, 이는 각각 Chinchilla 모델 [42]의 1.4B, 7B, 70B 파라미터 버전을 기반으로 한다. 이들을 각각 Flamingo-3B, Flamingo-9B, Flamingo-80B로 명명하였다. 본 논문 전체에서는 가장 큰 Flamingo-80B를 간단히 Flamingo라고 부른다.
Frozen된 LM의 파라미터 수와 trainable한 vision-text GATED XATTN-DENSE 모듈의 규모는 모델 크기에 따라 증가시키되,
**vision encoder(frozen)**와 **Perceiver Resampler(trainable)**는 모든 모델에서 동일한 크기로 고정되어 있으며, 이는 전체 모델 크기에 비해 상대적으로 작다.
자세한 구성은 Appendix B.1.1을 참조하라.
2.3 Multi-visual input support: per-image/video attention masking
Equation (1)에서 도입된 image-causal modeling은 전체 **text-to-image cross-attention 행렬을 마스킹(masking)**함으로써 구현되며, 이를 통해 각 텍스트 토큰이 볼 수 있는 시각 토큰의 범위를 제한한다.
즉, 주어진 텍스트 토큰에서 모델은 interleaved 시퀀스 내에서 바로 직전에 등장한 이미지의 시각 토큰만을 attend하며, 그 이전의 모든 이미지에는 직접적으로 attend하지 않는다 (이에 대한 공식화 및 도식은 Appendix A.1.3 참조).
하지만 모델은 한 번에 하나의 이미지에만 직접 attend하더라도, **LM 내부의 self-attention을 통해 간접적으로 모든 이전 이미지들과의 종속성(dependency)**을 유지하게 된다.
이러한 single-image cross-attention 방식은 중요한 장점이 있다.
즉, 훈련 시 사용된 이미지 수와 관계없이, 어떤 개수의 시각 입력에도 자연스럽게 일반화할 수 있다는 점이다.
실제로 우리는 학습 시 interleaved dataset에서 시퀀스당 최대 5장의 이미지만을 사용했음에도, **평가 시에는 이미지/비디오-텍스트 쌍(pair)**을 최대 32개까지 포함하는 시퀀스에서도 성능 향상이 가능함을 확인했다.
Section 3.3에서는 이 방식이, 모델이 이전 모든 이미지에 직접 cross-attend하도록 하는 방식보다 더 효과적이라는 것을 실험적으로 보여준다.
2.4 Training on a mixture of vision and language datasets
우리는 Flamingo 모델을 웹에서 수집한 세 가지 종류의 데이터셋 혼합물로 학습시킨다:
- 웹페이지로부터 추출된 이미지-텍스트가 섞여 있는(interleaved) 데이터셋,
- 이미지-텍스트 쌍 데이터셋,
- 비디오-텍스트 쌍 데이터셋.
M3W: 이미지-텍스트가 섞인(interleaved) 데이터셋
Flamingo 모델의 few-shot 능력은 텍스트와 이미지가 섞여 있는 데이터로의 학습에 기반한다. 이를 위해 우리는 MultiModal MassiveWeb (M3W) 데이터셋을 구축하였다.
약 4,300만 개의 웹페이지 HTML로부터 텍스트와 이미지를 추출하였으며, 문서의 DOM(Document Object Model) 구조 내에서 텍스트와 이미지 요소의 상대적인 위치를 기준으로 이미지의 텍스트 내 위치를 결정하였다.
하나의 예시는 다음과 같이 구성된다:
- 페이지 내 이미지 위치에
<image>태그를 일반 텍스트에 삽입하고, - 각 이미지 앞과 문서 끝에는 학습 가능한 특수 토큰
<EOC>(end of chunk)를 삽입한다.
각 문서로부터 임의로 256개의 토큰으로 구성된 subsequence를 샘플링하고, 해당 시퀀스에 포함된 처음 5개 이미지까지만 사용한다. 연산 비용 절약을 위해 그 이후의 이미지는 제거한다. 자세한 내용은 Appendix A.3에 설명되어 있다.
이미지/비디오-텍스트 쌍 데이터셋 (Pairs of image/video and text)
이미지-텍스트 쌍 데이터셋으로는 먼저 ALIGN [50] 데이터셋을 활용하는데, 이는 약 18억 개의 이미지와 alt-text 쌍으로 구성되어 있다. 이와 보완적으로, 우리는 **보다 긴 설명과 높은 품질을 목표로 하는 이미지-텍스트 쌍 데이터셋 LTIP (Long Text & Image Pairs)**을 새롭게 수집하였고, 이는 3억 1,200만 쌍으로 구성된다.
또한, **정지 이미지 대신 비디오를 포함하는 데이터셋인 VTP (Video & Text Pairs)**도 수집하였다.
VTP는 평균 22초 분량의 짧은 비디오 2,700만 개와 그에 대응되는 문장 단위의 설명 텍스트로 이루어져 있다.
이러한 paired 데이터셋들은 M3W와 문법(syntax)을 일치시키기 위해, 각 caption 앞에는 <image>를 붙이고, 끝에는 <EOC>를 추가하였다 (자세한 내용은 Appendix A.3.3 참조).
다중 목적 학습 및 최적화 전략 (Multi-objective training and optimisation strategy)
모델은 각 데이터셋에 대해 다음과 같은 **시각 입력이 주어진 상태에서의 텍스트 생성 확률에 대한 expected negative log-likelihood의 가중합(weighted sum)**을 최소화하도록 학습된다:
여기서 은 번째 데이터셋, 은 해당 데이터셋의 가중치이다.
각 데이터셋별 가중치 를 조정하는 것이 성능에 핵심적인 요소이다.
우리는 모든 데이터셋에 걸쳐 gradient를 누적하는 방식을 사용했으며, 이는 [17]에서 제안된 round-robin 방식보다 우수한 성능을 보였다.
추가적인 학습 세부사항 및 ablation은 Appendix B.1.2에 수록되어 있다.
2.5 Task adaptation with few-shot in-context learning
Flamingo를 학습시킨 이후, 우리는 이를 멀티모달 interleaved prompt를 조건으로 하여 다양한 시각적 task에 적용한다. 우리는 GPT-3 [11]에서와 유사하게, Flamingo 모델이 in-context learning을 통해 새로운 task에 얼마나 빠르게 적응하는지를 평가한다. 이를 위해 (image, text) 또는 (video, text) 형태의 support example 쌍들을 interleave한 후, 그 뒤에 **쿼리 시각 입력(query visual input)**을 추가하여 prompt를 구성한다 (자세한 구성은 Appendix A.2 참조).
- open-ended 평가는 beam search를 활용한 decoding으로 수행되고,
- close-ended 평가는 모델이 각 정답 후보에 대해 계산한 log-likelihood 점수를 이용해 수행된다.
또한 우리는 zero-shot generalization도 탐구하는데, 이때는 해당 task의 텍스트 예시 2개만으로 prompt를 구성하고 시각 정보는 포함하지 않는다.
평가 시 사용한 하이퍼파라미터 및 추가적인 세부 사항은 Appendix B.1.5에 설명되어 있다.
| Method | FT | Shot | OKVQA (I) | VQAv2 (I) | COCO (I) | MSVDQA (V) | VATEX (V) | VizWiz (I) | Flick30K (I) | MSRVTTQA (V) | iVQA (V) | YouCook2 (V) | STAR (V) | VisDial (I) | TextVQA (I) | NextQA (I) | HatefulMemes (I) | RareAct (V) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero/Few shot SOTA | [34] | [114] | [124] | [58] | [58] | [135] | [143] | [79] | [85] | [85] | ||||||||
| 43.3 | 38.2 | 32.2 | 35.2 | - | - | - | 19.2 | 12.2 | - | 39.4 | 11.6 | - | - | 66.1 | 40.7 | |||
| (X) | (16) | (4) | (0) | (0) | (0) | (0) | (0) | (0) | (0) | (0) | ||||||||
| Flamingo-3B | 0 | 41.2 | 49.2 | 73.0 | 27.5 | 40.1 | 28.9 | 60.6 | 11.0 | 32.7 | 55.8 | 39.6 | 46.1 | 30.1 | 21.3 | 53.7 | 58.4 | |
| 4 | 43.3 | 53.2 | 85.0 | 33.0 | 50.0 | 34.0 | 72.0 | 14.9 | 35.7 | 64.6 | 41.3 | 47.3 | 32.7 | 22.4 | 53.6 | - | ||
| 32 | 45.9 | 57.1 | 99.0 | 42.6 | 59.2 | 45.5 | 71.2 | 25.6 | 37.7 | 76.7 | 41.6 | 47.3 | 30.6 | 26.1 | 56.3 | - | ||
| Flamingo-9B | 0 | 44.7 | 51.8 | 79.4 | 30.2 | 39.5 | 28.8 | 61.5 | 13.7 | 35.2 | 55.0 | 41.8 | 48.0 | 31.8 | 23.0 | 57.0 | 57.9 | |
| 4 | 49.3 | 56.3 | 93.1 | 36.2 | 51.7 | 34.9 | 72.6 | 18.2 | 37.7 | 70.8 | 42.8 | 50.4 | 33.6 | 24.7 | 62.7 | - | ||
| 32 | 51.0 | 60.4 | 106.3 | 47.2 | 57.4 | 44.0 | 72.8 | 29.4 | 40.7 | 77.3 | 41.2 | 50.4 | 32.6 | 28.4 | 63.5 | - | ||
| Flamingo | 0 | 50.6 | 56.3 | 84.3 | 35.6 | 46.7 | 31.6 | 67.2 | 17.4 | 40.7 | 60.1 | 39.7 | 52.0 | 35.0 | 26.7 | 46.4 | 60.8 | |
| 4 | 57.4 | 63.1 | 103.2 | 41.7 | 56.0 | 39.6 | 75.1 | 23.9 | 44.1 | 74.5 | 42.4 | 55.6 | 36.5 | 30.8 | 68.6 | - | ||
| 32 | 57.8 | 67.6 | 113.8 | 52.3 | 65.1 | 49.8 | 75.4 | 31.0 | 45.3 | 86.8 | 42.2 | 55.6 | 37.9 | 33.5 | 70.0 | - | ||
| 54.4 | 80.2 | 143.3 | 47.9 | 76.3 | 57.2 | 67.4 | 46.8 | 35.4 | 138.7 | 36.7 | 75.2 | 54.7 | 25.2 | 79.1 | ||||
| Pretrained FT SOTA | [34] | [140] | [124] | [28] | [153] | [65] | [150] | [51] | [135] | [132] | [128] | [79] | [137] | [129] | [62] | - | ||
| (X) | ( 10 K ) | ( 444 K ) | ( 500 K ) | ( 27 K ) | ( 500 K ) | (20K) | ( 30 K ) | ( 130 K ) | (6K) | ( 10 K ) | (46K) | ( 123 K ) | (20K) | (38K) | (9K) |
Table 1: 기존 state-of-the-art와의 비교
단일 Flamingo 모델은 다양한 이미지(I) 및 비디오(V) 이해 task에 대해 few-shot learning만으로도 state-of-the-art 성능을 달성하며, 기존의 zero-shot 및 few-shot 방법들을 단 4개의 예시만으로도 크게 능가한다.
더 중요한 것은, 단 32개의 예시만 사용하고 모델 가중치를 전혀 업데이트하지 않은 상태로도, Flamingo는 수천 개의 annotated example로 fine-tuning된 기존 최고 성능의 방법들을 7개 task에서 능가한다는 점이다.
표에서 가장 뛰어난 few-shot 성능은 굵게(bold), **전체 최고 성능은 밑줄(underline)**로 표시되어 있다.
3 Experiments
우리의 목표는 다양하고 도전적인 task에 빠르게 적응할 수 있는 모델을 개발하는 것이다. 이를 위해 우리는 총 16개의 대표적인 멀티모달 이미지/비디오 및 언어 벤치마크를 고려한다.
프로젝트 진행 중 모델 설계 결정을 검증하기 위해, 이 중 5개의 벤치마크는 개발용(DEV) 세트로 사용되었다:
COCO, OKVQA, VQAv2, MSVDQA, VATEX.
이러한 DEV 벤치마크에 대한 성능 추정치는 모델 선택 과정에서의 편향이 존재할 수 있음에 유의해야 한다. 이는 유사한 벤치마크를 설계 검증 및 ablation에 활용한 기존 연구들에서도 동일하게 나타나는 현상이다.
이를 보완하기 위해 우리는 captioning, video question-answering, 그리고 visual dialogue 및 multi-choice question-answering과 같은 잘 탐색되지 않은 영역을 포함한 추가적인 11개의 벤치마크에서의 성능도 함께 보고한다.
이 평가용 벤치마크들에 대한 설명은 Appendix B.1.4에 제시되어 있다.
우리는 모든 벤치마크에서 동일한 evaluation 하이퍼파라미터를 사용하며, task에 따라 총 4가지 few-shot prompt 템플릿 중 하나를 선택해 적용한다 (자세한 내용은 Appendix B.1.5 참조).
우리는 특히 강조한다: 이 11개의 평가용 벤치마크에서는 어떠한 설계 결정도 검증하지 않았으며, 모델의 편향 없는 few-shot 학습 성능을 추정하는 목적으로만 사용하였다.
보다 구체적으로 말하자면, 모델의 few-shot 학습 성능을 평가할 때는 support 샘플들을 prompt로 주고, query 샘플에 대해 성능을 측정한다.
설계 결정 및 하이퍼파라미터 검증에 사용된 DEV 벤치마크에서는 다음 4개의 subset을 사용한다:
- validation support, validation query, test support, test query
반면, 그 외의 벤치마크에서는 test support와 test query만 사용하면 된다.
이러한 subset 구성 방식은 Appendix B.1.4에 설명되어 있다.
Section 3.1에서는 Flamingo 모델의 few-shot 학습 성능을 보고하고, Section 3.2에서는 fine-tuning 결과를 제시하며, Section 3.3에서는 ablation study를 제공한다.
추가적인 실험 결과는 Appendix B.2에 포함되어 있으며, 여기에는 ImageNet 및 Kinetics700 분류 task에서의 성능과 Flamingo의 contrastive 모델 성능이 포함된다.
Appendix C에는 추가적인 qualitative 결과도 수록되어 있다.
3.1 Few-shot learning on vision-language tasks
Few-shot 결과
결과는 Table 1에 제시되어 있다.
Flamingo는 16개의 벤치마크 전반에 걸쳐 기존의 모든 zero-shot 및 few-shot 방법들을 큰 차이로 능가한다.
이는 task당 단 4개의 예시만으로 달성된 성과로, vision 모델이 새로운 task에 실용적이고 효율적으로 적응할 수 있음을 보여준다.
더 중요한 점은, Flamingo가 수십만 개의 annotated example로 추가 fine-tuning된 state-of-the-art 방법들과도 종종 경쟁력 있는 성능을 보인다는 것이다.
심지어 6개의 task에서는 Flamingo가 단 하나의 고정된 모델 가중치와 32개의 task-specific 예시만을 사용하고도 fine-tuned SotA를 능가하는 성능을 기록했다.
| Method | VQAV2 test-dev test-std | COCO test | VATEX test | VizWiz test-dev test-std | MSRVTTQA test | VisDial valid test-std | YouCook2 valid | TextVQA valid test-std | HatefulMemes test seen | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| shots | 67.6 | - | 113.8 | 65.1 | 49.8 | - | 31.0 | 56.8 | - | 86.8 | 36.0 | - | 70.0 |
| Fine-tuned | 82.0 | 138.1 | 84.2 | 65.7 | 65.4 | 47.4 | 61.8 | 59.7 | 118.6 | 57.1 | 54.1 | ||
| SotA | [133] | [133] | 149.6 [119] | [153] | [65] | [65] | 46.8 [51] | 75.2 [79] | [123] | 138.7 [132] | 54.7 [137] | 73.7 [84] | [152] |
Table 2: Flamingo fine-tuning 시 SotA와의 비교
우리는 few-shot learning만으로 SotA를 달성하지 못한 9개의 task에 대해 Flamingo를 fine-tuning하였다.
그 결과, 그 중 5개의 task에서 Flamingo가 새로운 SotA를 달성하였으며,
이는 모델 앙상블, domain-specific metric 최적화 (예: CIDEr 최적화) 등의 **특수 기법을 사용하는 기존 방법들(† 표시)**보다도 뛰어난 성능을 보인다.
| Ablated setting | Flamingo-3B original value | Changed value | Param. count | Step time | COCO CIDEr | OKVQA top1 | VQAv2 top1 | MSVDQA top1 | VATEX CIDEr | Overall score | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Flamingo-3B model | 3.2B | 1.74s | 86.5 | 42.1 | 55.8 | 36.3 | 53.4 | 70.7 | |||
| (i) | Training data | All data | w/o Video-Text pairs | 3.2B | 1.42s | 84.2 | 43.0 | 53.9 | 34.5 | 46.0 | 67.3 |
| w/o Image-Text pairs | 3.2B | 0.95s | 66.3 | 39.2 | 51.6 | 32.0 | 41.6 | 60.9 | |||
| Image-Text pairs LAION | 3.2B | 1.74s | 79.5 | 41.4 | 53.5 | 33.9 | 47.6 | 66.4 | |||
| w/o M3W | 3.2B | 1.02 s | 54.1 | 36.5 | 52.7 | 31.4 | 23.5 | 53.4 | |||
| (ii) | Optimisation | Accumulation | Round Robin | 3.2B | 1.68s | 76.1 | 39.8 | 52.1 | 33.2 | 40.8 | 62.9 |
| (iii) | Tanh gating | 3.2B | 1.74s | 78.4 | 40.5 | 52.9 | 35.9 | 47.5 | 66.5 | ||
| (iv) | GATED XATTN-DENSE | Vanilla Xattn | 2.4B | 1.16s | 80.6 | 41.5 | 53.4 | 32.9 | 50.7 | 66.9 | |
| Cross-attention architecture | Grafting | 3.3 B | 1.74 s | 79.2 | 36.1 | 50.8 | 32.2 | 47.8 | 63.1 | ||
| (v) | Cross-attention frequency | Every | Single in middle | 2.0 B | 0.87s | 71.5 | 38.1 | 50.2 | 29.1 | 42.3 | 59.8 |
| Every 4th | 2.3 B | 1.02s | 82.3 | 42.7 | 55.1 | 34.6 | 50.8 | 68.8 | |||
| Every 2nd | 2.6 B | 1.24s | 83.7 | 41.0 | 55.8 | 34.5 | 49.7 | 68.2 | |||
| (vi) | Resampler | Perceiver | MLP | 3.2B | 1.85s | 78.6 | 42.2 | 54.7 | 35.2 | 44.7 | 66.6 |
| Transformer | 3.2 B | 1.81s | 83.2 | 41.7 | 55.6 | 31.5 | 48.3 | 66.7 | |||
| (vii) | Vision encoder | NFNet-F6 | CLIP ViT-L/14 | 3.1B | 1.58s | 76.5 | 41.6 | 53.4 | 33.2 | 44.5 | 64.9 |
| NFNet-F0 | 2.9 B | 1.45s | 73.8 | 40.5 | 52.8 | 31.1 | 42.9 | 62.7 | |||
| (viii) | Freezing LM | (random init) | 3.2B | 2.42s | 74.8 | 31.5 | 45.6 | 26.9 | 50.1 | 57.8 | |
| (pretrained) | 3.2 B | 2.42 s | 81.2 | 33.7 | 47.4 | 31.0 | 53.9 | 62.7 |
Table 3: Ablation study 결과
각 행은 **baseline Flamingo 실행 결과(맨 위 행)**와 비교해야 한다.
여기서 Step time은 모든 학습 데이터셋에 대해 gradient update를 수행하는 데 소요된 시간을 나타낸다.
마지막으로, 우리는 설계 결정을 위해 DEV 벤치마크만을 사용했음에도 불구하고, 우리의 결과는 다른 벤치마크들에도 잘 일반화되었으며, 이는 우리 접근 방식의 범용성을 입증한다.
파라미터 수 및 shot 수에 따른 확장성(Scaling)
Figure 2에서 보여주듯이, 모델이 클수록 few-shot 성능이 더 우수하며, 이는 GPT-3 [11]와 유사한 경향이다. 또한, shot 수가 많아질수록 성능도 향상된다.
우리는 특히, 가장 큰 모델이 더 많은 shot 수를 활용하는 데에 더 능숙하다는 것을 발견했다.
흥미롭게도, Flamingo 모델은 M3W에서 최대 5개의 이미지로 제한된 시퀀스로 학습되었음에도, 추론 시에는 최대 32개의 이미지나 비디오로부터 성능 향상을 얻을 수 있다.
이는 Flamingo 아키텍처가 다양한 개수의 이미지나 비디오를 유연하게 처리할 수 있는 구조임을 보여주는 결과이다.
3.2 Fine-tuning Flamingo as a pretrained vision-language model
비록 본 연구의 주요 초점은 아니지만, 우리는 더 많은 데이터가 주어졌을 때 Flamingo 모델을 fine-tuning을 통해 특정 task에 적응시킬 수 있음을 확인하였다.
Table 2에서는 어노테이션 예산에 제한 없이 주어진 task에 대해 가장 큰 Flamingo 모델을 fine-tuning하는 실험을 다룬다.
구체적으로는, 짧은 학습 스케줄과 작은 learning rate를 사용해 모델을 fine-tuning하며,
더 높은 입력 해상도를 수용하기 위해 vision backbone도 함께 unfreeze한다 (자세한 내용은 Appendix B.2.2 참조).
그 결과, 이전에 제시한 in-context few-shot 학습 성능을 능가하는 결과를 얻었으며,
다음 5개 task에서 새로운 state of the art를 달성하였다:
VQAv2, VATEX, VizWiz, MSRVTTQA, HatefulMemes.
3.3 Ablation studies
Table 3에서는 Flamingo-3B를 사용해, 4-shot 설정에서 5개의 DEV 벤치마크의 validation subset에 대해 수행한 ablation 실험 결과를 보고한다. 이 실험에서는 최종 모델과 비교해 더 작은 batch size와 더 짧은 학습 스케줄을 사용하였다. Overall 점수는 각 벤치마크의 성능을 Table 1의 SotA 성능으로 나눈 뒤 평균을 취해 계산하였다. 추가적인 세부사항과 결과는 Appendix B.3 및 Table 10에 제시되어 있다.
학습 데이터 구성의 중요성
(i)번 실험에서 보듯이, 적절한 학습 데이터 선택은 성능에 결정적인 영향을 미친다.
interleaved 이미지-텍스트 데이터셋 M3W를 제거하면 성능이 17% 이상 하락하며, 전통적인 paired 이미지-텍스트 데이터셋을 제거해도 성능이 9.8% 감소한다.
이는 서로 다른 유형의 데이터셋이 모두 중요함을 보여준다.
또한, 비디오-텍스트 데이터셋을 제거하면 모든 비디오 관련 task에서 성능이 하락하였다.
우리는 또한 자체 수집한 이미지-텍스트 쌍 데이터셋(ITP)을 공개된 LAION-400M [96]으로 대체하는 ablation도 수행했으며,
이 경우에도 성능이 약간 저하됨을 확인했다.
(ii)번 실험에서는 우리가 제안한 gradient accumulation 전략이 round-robin 업데이트 방식 [17]보다 더 효과적임을 보여준다.
Frozen LM의 시각 조건화(Visual Conditioning)
(iii)번 실험에서는 cross-attention 출력을 frozen LM에 병합할 때 사용하는 0으로 초기화된 tanh gating의 효과를 확인한다.
이를 제거할 경우 overall 점수가 4.2% 감소하며, 학습 안정성도 악화됨을 관찰했다.
(iv)번 실험에서는 다양한 조건화 아키텍처를 비교했다.
VANILLA XATTN은 오리지널 Transformer decoder [115]의 기본 cross-attention 구조이며,
**GRAFTING [68]**은 LM 자체는 그대로 사용하고, 그 출력 위에 새로운 self-attention 및 cross-attention layer 스택을 추가로 학습하는 방식이다.
이들에 비해 GATED XATTN-DENSE 방식이 가장 우수한 성능을 보였다.
성능 대비 연산/메모리 효율 (Compute/Memory vs. Performance Trade-offs)
(v)번 실험에서는 GATED XATTN-DENSE block을 삽입하는 빈도에 따른 trade-off를 분석하였다.
모든 layer에 삽입하면 성능은 좋지만 학습 시간이 증가하며,
4번째마다 삽입하는 경우, 학습 속도가 66% 빨라지면서도 overall 성능은 단 1.9%만 감소했다.
이러한 trade-off를 고려하여,
Flamingo-9B에는 4번째마다,
Flamingo-80B에는 7번째마다 GATED XATTN-DENSE를 삽입한다.
(vi)번 실험에서는 Perceiver Resampler를 MLP 또는 vanilla Transformer로 대체했을 때를 비교하였다.
두 대안 모두 성능이 더 낮고 속도도 느림을 확인했다.
Vision Encoder
(vii)번 실험에서는 우리의 contrastive 학습된 NFNet-F6 vision encoder와 공개된 CLIP ViT-L/14 [85] (224 해상도),
그리고 더 작은 NFNet-F0를 비교했다.
그 결과, NFNet-F6은 CLIP ViT-L/14보다 +5.8%, NFNet-F0보다 +8.0% 더 우수한 성능을 보였다.
이는 강력한 vision backbone의 중요성을 강조한다.
LM 고정(freezing)의 중요성: catastrophic forgetting 방지
(viii)번 실험에서는 학습 시 LM layer를 고정시키는 것이 얼마나 중요한지를 검증하였다.
LM을 scratch부터 학습시키면 성능이 12.9% 급감하며, 사전학습된 LM을 fine-tuning하더라도 성능이 8.0% 감소한다.
이는 학습 중 모델이 사전학습에서 얻은 지식을 점점 잊어버리는 "catastrophic forgetting" [71] 현상이 발생함을 의미한다.
우리 실험에서는 LM을 고정(freeze)시키는 것이, pretraining 데이터셋(MassiveText)을 혼합하여 함께 학습시키는 것보다도 더 효과적인 대안이었다.
4 Related work
Language modelling과 few-shot adaption
Transformer [115]의 등장 이후, 언어 모델링은 상당한 발전을 이루어왔다. 대규모 데이터로 먼저 사전학습(pretraining)을 수행한 후, 다운스트림 task에 적응(adaptation)하는 패러다임은 이제 표준으로 자리 잡았다 [11, 23, 32, 44, 52, 75, 87, 108]. 본 연구에서는 Flamingo의 기반 언어 모델로 70B 규모의 Chinchilla 모델 [42]을 사용하였다. 몇몇 선행 연구에서는 언어 모델을 소수의 예시만으로 새로운 task에 적응시키는 다양한 방법들을 탐구해왔다. 예를 들어, 작은 adapter 모듈을 삽입하거나 [43], LM의 일부만 fine-tuning 하거나 [141], in-context 예시를 prompt에 삽입하거나 [11], 또는 gradient descent를 통해 prompt 자체를 최적화하는 방식 [56, 60] 등이 있다. 본 논문에서는 metric learning 기반 few-shot 학습 [24, 103, 112, 117]이나 meta-learning 기반 접근법 [6, 7, 27, 31, 91, 155]처럼 복잡한 방식이 아닌, GPT-3에서 소개된 in-context few-shot learning 기법 [11]에서 영감을 받아 이를 Flamingo에 적용하였다.
언어와 비전의 만남
이러한 언어 모델의 발전은 vision-language 모델링에도 큰 영향을 끼쳤다. 특히 BERT [23]는 다수의 vision-language 관련 연구들 [16, 28, 29, 38, 59, 61, 66, 101, 106, 107, 109, 118, 121, 142, 143, 151]에 영감을 주었다. 그러나 Flamingo는 이들과 달리 새로운 task에 대해 fine-tuning을 요구하지 않는 점에서 차별화된다. 또 다른 vision-language 모델 계열은 contrastive learning 기반 모델이다 [2, 5, 49, 50, 57, 74, 82, 85, 138, 140, 146]. Flamingo는 이들과 달리 텍스트를 생성할 수 있다는 점에서 차별되며, Flamingo의 vision encoder는 이러한 contrastive 모델에 기반해 설계되었다. 본 연구와 유사하게, 일부 VLM은 autoregressive 방식으로 텍스트를 생성할 수 있도록 설계되어 있다 [19, 25, 45, 67, 116]. 최근에는 여러 vision task들을 텍스트 생성 문제로 정식화하려는 연구도 진행되고 있다 [17, 58, 119, 124, 154]. 사전학습된 대형 언어 모델을 기반으로 vision-language 모델을 구축하는 방향 역시 여러 연구들에서 탐색되고 있으며, 그중 일부 [26, 68, 78, 114, 136, 144]는 **catastrophic forgetting [71]을 방지하기 위해 언어 모델 가중치를 고정(freeze)**하는 방식을 제안한다. 우리도 이러한 접근을 따르며, Chinchilla LM의 layer를 freeze하고 그 내부에 학습 가능한 layer들을 삽입하였다. 그러나 기존 연구들과 달리, 우리는 임의로 섞여 있는 이미지, 비디오, 텍스트를 모두 입력으로 수용할 수 있는 최초의 LM을 제안한다는 점에서 차별성을 가진다.
웹 규모의 비전-언어 학습 데이터셋
수작업으로 주석된 vision-language 데이터셋은 제작 비용이 매우 크기 때문에 규모가 상대적으로 작으며, 일반적으로 1만~10만 개 수준이다 [3, 15, 69, 122, 129, 139]. 이러한 데이터 부족 문제를 해결하기 위해, 여러 연구 [14, 50, 98, 110]에서는 웹에서 쉽게 수집 가능한 이미지-텍스트 쌍 데이터를 자동으로 수집하는 방식이 제안되어 왔다. 본 연구는 이러한 paired 데이터 외에도, 이미지와 텍스트가 섞여 있는(multimodal interleaved) 전체 웹페이지를 하나의 시퀀스로 학습하는 것의 중요성을 강조한다. 동시 진행된 연구인 CM3 [1]에서는 웹페이지를 HTML 마크업으로 생성하는 방식을 택하였지만, 우리는 텍스트 생성 문제를 단순화하기 위해 plain text만을 생성 대상으로 설정하였다. 또한 우리는 few-shot 학습 및 vision task 성능을 중점적으로 평가한 반면, CM3 [1]은 zero-shot 또는 fine-tuning된 언어 전용 벤치마크를 중심으로 평가를 진행하였다.
5 Discussion
한계점
첫째, 우리의 모델은 사전학습된 언어 모델(LM)에 기반하고 있으며, 이로 인해 해당 언어 모델의 약점을 그대로 물려받는다는 부작용이 있다. 예를 들어, LM의 사전 지식(prior)은 일반적으로 유용하지만, 가끔 환각(hallucination)이나 근거 없는 추측을 야기할 수 있다. 또한, LM은 학습 시 사용된 시퀀스보다 긴 입력에 대해 일반화 성능이 낮으며, 훈련 시 sample efficiency도 떨어지는 문제를 가지고 있다. 이러한 문제들을 해결한다면, 본 분야의 발전을 가속화하고 Flamingo와 같은 VLM의 성능을 더욱 향상시킬 수 있을 것이다.
둘째, Flamingo는 이미지 분류(classification) 성능에 있어서 최신 contrastive 학습 기반 모델들 [82, 85]보다 뒤처진다. 해당 contrastive 모델들은 text-image retrieval을 직접적으로 최적화하는데, 이는 분류 문제의 특수한 형태에 해당한다. 반면, Flamingo는 보다 다양한 형태의 open-ended task를 다룰 수 있도록 설계되었다. 이러한 두 방식의 장점을 결합하는 unified 접근법은 앞으로 중요한 연구 방향이 될 수 있다.
셋째, in-context learning은 gradient 기반 few-shot 학습 방법에 비해 여러 장점이 있지만, 적용 대상 task의 특성에 따라 단점도 존재한다. 본 논문에서는 수십 개 수준의 적은 예시만 주어졌을 때 in-context learning이 효과적임을 입증하였다. 또한, in-context learning은 추론(inference)만으로 동작하며, 일반적으로 하이퍼파라미터 튜닝 없이도 손쉬운 배포가 가능하다는 이점이 있다. 그러나, in-context learning은 demonstration 구성의 다양한 요소에 매우 민감한 것으로 알려져 있으며 [80, 148], shot 수가 일정 수준 이상으로 늘어날 경우 계산 비용과 절대 성능이 비효율적으로 증가한다. 따라서, 서로 보완적인 few-shot 학습 기법들을 결합하는 방법에 가능성이 있다. 이와 관련된 한계점은 Appendix D.1에서 더 상세히 논의한다.
사회적 영향
Flamingo는 여러 긍정적인 잠재력을 가지고 있지만, 동시에 일정한 위험성도 수반한다. Flamingo는 적은 데이터로도 다양한 task에 빠르게 적응하는 능력을 가지며, 이는 비전문 사용자도 데이터 부족 환경에서 높은 성능을 달성할 수 있게 해준다.
이러한 특성은 유익한 활용뿐 아니라 악의적인 용도에도 악용될 수 있는 가능성을 내포한다.
Flamingo는 기존 대형 언어 모델과 동일한 위험, 예를 들어 모욕적인 언어 생성, 사회적 편향 및 고정관념의 확산, 민감한 정보 누출 등의 위험에 노출되어 있다 [42, 126]. 더 나아가, Flamingo는 시각 입력을 처리할 수 있는 능력으로 인해, 입력 이미지의 내용에 따라 성별, 인종과 관련된 편향을 초래할 수 있는 위험성 또한 내포하고 있다. 이러한 위험은 기존의 여러 시각 인식 시스템에서 관찰된 바 있다 [12, 21, 37, 97, 147].
우리는 본 연구의 긍정적, 부정적 사회적 영향에 대한 보다 자세한 논의와 함께, 성별 및 인종 편향, 유해 출력에 대한 위험성의 조기 탐색 및 대응 전략을 Appendix D.2에 정리해 두었다.
마지막으로, 이전의 언어 모델 연구들 [72, 81, 111]에서 보여주었듯, Flamingo의 few-shot 능력은 이러한 위험을 완화하는 데에도 긍정적인 역할을 할 수 있는 잠재력이 있음을 언급한다.
결론
우리는 본 논문에서 Flamingo를 제안하였다. Flamingo는 최소한의 task-specific 학습 데이터만으로 이미지 및 비디오 task에 적용 가능한 범용 모델 계열이다. 또한 우리는 Flamingo의 "대화"와 같은 상호작용적 능력을 정성적으로 탐구하였으며, 이는 전통적인 비전 벤치마크를 넘어서는 유연성을 보여준다.
우리의 결과는, 강력한 사전학습된 언어 모델과 시각 모델을 연결하는 것이 범용 시각 이해 모델로 가는 중요한 단계임을 시사한다.
감사의 말 및 연구 자금 지원 명시
본 연구는 DeepMind의 지원을 받아 수행되었다. 우리는 아래 동료들에게 유익한 논의, 제안, 피드백, 조언을 제공해 준 것에 감사드린다:
Samuel Albanie, Relja Arandjelović, Kareem Ayoub, Lorrayne Bennett, Adria Recasens Continente, Tom Eccles, Nando de Freitas, Sander Dieleman, Conor Durkan, Aleksa Gordić, Raia Hadsell, Will Hawkins, Lisa Anne Hendricks, Felix Hill, Jordan Hoffmann, Geoffrey Irving, Drew Jaegle, Koray Kavukcuoglu, Agustin Dal Lago, Mateusz Malinowski, Soňa Mokrá, Gaby Pearl, Toby Pohlen, Jack Rae, Laurent Sifre, Francis Song, Maria Tsimpoukelli, Gregory Wayne, 그리고 Boxi Wu.
Checklist
1 모든 저자에 대하여...
(a) 초록 및 서론에서 제시한 주요 주장들이 논문의 기여 및 범위와 정확히 일치하나요? [예]
(b) 연구의 한계점을 기술했나요? [예] Section 5 참조.
(c) 연구의 잠재적인 부정적 사회적 영향에 대해 논의했나요? [예] 간략한 논의는 Section 5에, 전체 논의는 Appendix D.2에 포함되어 있음.
(d) 윤리 심사 가이드라인을 읽고, 논문이 이에 부합하는지 확인했나요? [예]
2 이론적 결과를 포함하는 경우...
(a) 모든 이론적 결과에 대한 전제 조건을 명확히 기술했나요? [해당 없음]
(b) 모든 이론적 결과에 대한 완전한 증명을 포함했나요? [해당 없음]
3 실험을 수행한 경우...
(a) 주요 실험 결과를 재현할 수 있도록 코드, 데이터, 사용 방법 등을 (부록이나 URL을 통해) 제공했나요? [아니오] 코드와 데이터는 독점적 자산임.
(b) 학습 세부사항(예: 데이터 분할, 하이퍼파라미터, 선택 방법 등)을 명시했나요? [예] Section 3 및 Appendix B 참조.
(c) 오차 막대(error bar)를 보고했나요? (예: 여러 번 실험 수행 후 random seed에 따른 변동성 등) [아니오] 실험 반복에 따른 분산이 크지 않았으며, 가장 큰 모델의 경우 계산 자원 제약으로 인해 여러 번의 학습은 현실적으로 어렵다고 판단함.
(d) 총 연산량 및 사용된 리소스 종류(GPU 종류, 내부 클러스터, 클라우드 제공업체 등)를 명시했나요? [예] 자세한 내용은 Appendix B.1.2에 있으며, 요약하면 가장 큰 실험은 TPU 1536개로 15일간 학습됨.
4 기존 자산(코드, 데이터, 모델 등)을 사용하거나 새롭게 구축/공개한 경우...
(a) 기존 자산을 사용했다면, 해당 제작자를 인용했나요? [예] 우리의 연구가 기반한 이전 방법과 적절한 경우 관련된 기존 데이터셋(예: ALIGN)을 적절히 인용함.
(b) 사용한 자산의 라이선스를 언급했나요? [해당 없음] 사용한 자산은 인용한 논문에서 나온 것이며, 논문 내 도표에 사용된 시각 자료의 라이선스는 Appendix G에서 언급함.
(c) 새로운 자산을 supplemental 자료나 URL을 통해 포함했나요? [아니오]
(d) 사용/수집한 데이터가 개인 정보 또는 타인의 데이터인 경우, 이에 대한 동의 여부를 논의했나요? [예] 우리의 데이터는 수백만 개의 웹페이지로부터 자동 수집된 것이며, 자세한 내용은 Appendix F의 Datasheets [30]에 있음.
(e) 사용/수집한 데이터에 개인정보 또는 불쾌감을 줄 수 있는 콘텐츠가 포함되어 있는지 여부를 논의했나요? [예] Appendix F의 Datasheets [30]에 기술되어 있음.
5 크라우드소싱을 사용하거나 사람을 대상으로 한 연구를 수행한 경우...
(a) 참가자에게 제공된 전체 지시사항과 스크린샷(해당되는 경우)을 포함했나요? [해당 없음]
(b) 참가자에게 발생할 수 있는 위험과 관련된 IRB 승인 여부 및 링크를 기술했나요? [해당 없음]
(c) 참가자에게 지급된 시간당 보상금과 총 보상액을 명시했나요? [해당 없음]
Appendix
다음은 Appendix에 대한 개요이다.
Method (Appendix A)
먼저 Appendix A.1에서는 모델에 대한 추가적인 세부 사항을 제공한다:
- Perceiver Resampler(Section 2.1에 설명됨)의 도식 및 pseudo-code는 Appendix A.1.1과 Figure 5에 수록되어 있다.
- GATED XATTN-DENSE layer(Section 2.2에 설명됨)의 유사한 도식은 Appendix A.1.2와 Figure 4에 포함되어 있다.
- 다중 이미지/비디오 attention 메커니즘(Section 2.3)의 구현 세부 사항은 Appendix A.1.3에 설명되어 있다.
- 모든 모델 아키텍처에 대한 하이퍼파라미터는 Appendix A.1.4에 제시되어 있다.
이후, in-context few-shot learning을 이용해 모델을 평가하는 방법을 Appendix A.2에서 설명한다. 여기에는 few-shot prompt를 구성하는 방법, open-ended 및 close-ended task에 대한 예측을 수행하는 방식, zero-shot 수치 추정 방식, 그리고 더 많은 annotated 예시를 활용하기 위한 retrieval 및 ensembling 기법이 포함된다.
마지막으로, Appendix A.3에서는 학습 데이터셋에 대한 자세한 설명을 제공한다:
- M3W 수집 과정은 Appendix A.3.1에,
- 학습 중 M3W 샘플 처리 방식은 Appendix A.3.2에,
- LTIP 및 VTP 수집 과정은 Appendix A.3.3에,
- 학습/평가 데이터셋 간 누수 방지를 위한 중복 제거 전략은 Appendix A.3.4에 각각 기술되어 있다.
Experiments (Appendix B)
먼저 Appendix B.1에서는 학습 및 평가 관련 세부사항을 추가로 설명한다:
- Flamingo-3B, Flamingo-9B, Flamingo 모델 구성은 Appendix B.1.1에,
- 학습 하이퍼파라미터는 Appendix B.1.2에,
- Contrastive 모델 사전학습 세부 정보는 Appendix B.1.3에,
- 평가 벤치마크 및 데이터 분할은 Appendix B.1.4에,
- few-shot 학습 시의 하이퍼파라미터 설정은 Appendix B.1.5에,
- Figure 1 및 Figure 11의 정성적 대화 예시에서 사용된 대화 prompt는 Appendix B.1.6에 각각 수록되어 있다.
다음으로, Appendix B.2에서는 Flamingo 모델의 추가 실험 결과를 제시한다. 여기에는 분류 task에 대한 Flamingo 성능 (Appendix B.2.1), fine-tuning 결과 (Appendix B.2.2), **contrastive 모델의 zero-shot 결과 (Appendix B.2.3)**가 포함된다.
마지막으로, Appendix B.3에서는 Flamingo 모델 (Appendix B.3.1)과 사전학습된 contrastive Visual Encoder (Appendix B.3.2)에 대한 추가적인 ablation study를 제공한다.
Qualitative results (Appendix C)
Appendix C에서는 추가적인 정성적 결과들을 제시한다.
여기에는 Figure 10 (단일 이미지 예시), Figure 11 (대화 예시), **Figure 12 (비디오 예시)**가 포함된다.
Discussion (Appendix D)
Appendix D에서는 본 연구의 한계, 실패 사례, 광범위한 영향 및 사회적 영향에 대해 보다 심도 있게 논의한다.
Model card (Appendix E)
Appendix E에는 Flamingo의 model card가 포함되어 있다.
Datasheets (Appendix F)
Appendix F.1에는 M3W, Appendix F.2.1에는 LTIP, Appendix F.2.2에는 VTP에 대한 datasheet가 각각 수록되어 있다.
Credit for visual content (Appendix G)
논문에 사용된 모든 시각 자료에 대한 출처 및 저작권 표기는 Appendix G에 제공된다.

def perceiver_resampler(
x_f, # The [T, S, d] visual features (T=time, S=space)
time_embeddings, # The [T, 1, d] time pos embeddings.
x, # R learned latents of shape [R, d]
num_layers, # Number of layers
):
"""The Perceiver Resampler model."""
# Add the time position embeddings and flatten.
x_f = x_f + time_embeddings
x_f = flatten(x_f) # [T, S, d] -> [T * S, d]
# Apply the Perceiver Resampler layers.
for i in range(num_layers):
# Attention.
x = x + attention_i(q=x, kv=concat([x_f, x]))
# Feed forward.
x = x + ffw_i(x)
return x
Figure 5:
Perceiver Resampler 모듈은 Vision Encoder로부터 출력된 가변 크기의 시공간(spatio-temporal) 시각 feature grid를 고정된 개수의 output token(그림에서는 5개)으로 매핑한다.
이 과정은 입력 이미지의 해상도나 입력 비디오 프레임 수와 무관하게 동작한다.
이 Transformer 구조에서는 학습된 latent vector 집합이 query로 사용되며,
**key와 value는 시공간 시각 feature와 학습된 latent vector를 결합(concatenate)**한 것으로 구성된다.
A Method
A. 1 Model details
A.1.1 Perceiver Resampler
Section 2.1에서 간략히 설명한 내용을 확장하여, Figure 5는 Perceiver Resampler가 비디오 예시를 처리하는 과정을 시각적으로 보여주며, 함께 pseudo-code도 제공한다.
우리의 Perceiver Resampler는 Jaegle et al. [48]이 제안한 Perceiver 모델들과 유사한 철학을 따른다.
우리는 사전 정의된 개수의 latent input query를 학습하고, 이를 **평탄화(flatten)된 시각 feature **에 대해 cross-attention을 수행한다.
이 시각 feature 는 다음과 같은 방식으로 생성된다.
비디오의 각 프레임(이미지의 경우 단일 프레임 비디오로 간주)의 feature에 대해 학습된 temporal position encoding을 추가한다.
주의할 점은, 우리는 temporal encoding만 사용하고, 명시적인 spatial grid position encoding은 사용하지 않았다는 것이다.
후자를 사용했을 때 성능 향상이 관찰되지 않았기 때문이다.
그 배경에는 다음과 같은 이유가 있다:
NFNet encoder와 같은 CNN은 채널 차원에서 암묵적으로 공간 정보를 내포하고 있는 것으로 알려져 있기 때문이다 [47].
이후 시각 feature는 **평탄화(flatten)되어 하나의 시퀀스로 연결(concatenate)**되며, 이 과정은 Figure 5에 시각적으로 설명되어 있다.
Perceiver Resampler의 출력 token 수는 학습된 latent query의 수와 동일하다.
DETR나 기존 Perceiver와는 달리,
우리는 **학습된 latent로부터 계산한 key와 value를, 시각 feature 로부터 계산한 key와 value에 추가(concatenate)**하는 방식으로 사용하며,
이 방식이 약간 더 나은 성능을 보이는 것을 확인하였다.
A.1.2 GATED XATTN-DENSE details
우리는 Figure 4에서 GATED XATTN-DENSE 블록의 구조와 그것이 frozen된 LM 블록에 어떻게 연결되는지, 그리고 해당 구조의 pseudo-code를 함께 제공한다.
또한, Figure 6에서는 Flamingo-3B 모델의 24개 LM layer에 대해, 학습 진행률(0%에서 100%)에 따른 tanh gating 값의 절대값 변화 추이를 시각화하였다.
모든 frozen LM layer에서, tanh gating 값의 절대값이 초기값인 0에서 빠르게 증가하는 양상을 보이며,
이를 통해 각 layer가 시각 정보를 적극적으로 활용하고 있음을 유추할 수 있다.
또한, layer의 깊이에 따라 tanh gating 값의 절대값도 증가하는 경향이 관찰되지만,
이는 단정적인 결론을 내리기 어려운 현상이다.
그 이유는 gating 이전의 activation의 scale 자체도 layer 깊이에 따라 달라질 수 있기 때문이다.
이러한 추가 layer들이 최적화 동역학(optimization dynamics) 및 모델 자체에 미치는 영향을 보다 깊이 이해하기 위해서는 추가적인 후속 연구가 필요하다.

Figure 6: Flamingo-3B의 서로 다른 layer에서 tanh gating의 절대값 변화 추이

Figure 7: 섞여 있는(interleaved) 시각 데이터와 텍스트 지원 방식
웹페이지와 같이 이미지/비디오가 텍스트 사이에 섞여 있는 경우, 우리는 먼저 텍스트 내 시각 데이터의 위치에 <image> 태그를 삽입하고,
시퀀스 시작을 나타내는 <BOS> 토큰과 chunk 종료를 나타내는 <EOC> 토큰과 같은 특수 토큰도 함께 삽입한다.
이미지들은 **Vision Encoder와 Perceiver Resampler를 통해 개별적으로 처리되어 시각 토큰(visual token)**으로 변환된다.
모델은 각 텍스트 토큰에서, 그보다 앞서 등장한 마지막 이미지/비디오에 해당하는 시각 토큰만을 cross-attention으로 참조한다.
는 각 텍스트 토큰이 참조할 수 있는 이미지/비디오를 나타내며, 앞선 시각 정보가 없는 경우에는 0으로 표시된다.
실제로 이러한 선택적 cross-attention은 마스킹(masking)을 통해 구현되며,
그 예시는 그림에서 진한 파란색(마스킹 해제 / 볼 수 있음), **연한 파란색(마스킹됨 / 볼 수 없음)**으로 시각화되어 있다.
A.1.3 Multi-visual input support
우리는 Figure 7에서 특정 텍스트 토큰이 볼 수 있는 시각 토큰의 수를 제한하기 위해 사용하는 마스킹 방식을 시각적으로 설명한다. 또한, 이미지/비디오와 텍스트가 섞인(interleaved) 시퀀스에 대한 표기법도 공식화한다.
시각 데이터와 텍스트가 섞인 시퀀스 (Interleaved sequences of visual data and text)
우리는 이미지/비디오와 텍스트가 섞여 있는 예시를 다룬다.
각 예시는 다음 세 가지로 구성된다:
- 텍스트 시퀀스 ,
- 이미지/비디오 시퀀스 ,
- 텍스트 내에서 이미지가 등장하는 위치에 대한 시퀀스.
시각 데이터의 위치를 기준으로, 우리는 다음과 같은 **함수 **를 정의한다. 이 함수는 각 텍스트 위치 에 대해, 그 위치 이전에 등장한 마지막 이미지/비디오의 인덱스를 반환한다. 만약 그 위치 이전에 어떤 시각 데이터도 등장하지 않았다면 이다.
이 함수 는 **Equation (1)에서 텍스트 토큰 **을 예측할 때 어떤 시각 입력을 사용할 수 있는지를 정의한다:
- 앞선 텍스트 토큰들의 집합은 ,
- 앞선 이미지/비디오들의 집합은 이다.
A.1.4 Transformer architecture
Table 4에는 Flamingo 모델의 각 Transformer 구성 요소에 대해 다음 항목들을 정리하였다:
레이어 수 , hidden dimension , 헤드 수 , 그리고 Feed-Forward(FFW)에서 사용하는 활성화 함수(Act.)이다.
각 구성에서 key와 value의 차원은 로 설정되며, Perceiver Resampler의 경우 96, GATED XATTN-DENSE와 frozen LM의 경우에는 128이다.
또한, 각 feed-forward MLP의 hidden dimension은 로 설정되어 있다.
참고로, **frozen LM은 GeLU activation [39]**으로 사전학습되었으며,
나머지 **학습 가능한 Transformer layer들에는 Squared ReLU activation [104]**을 사용한다.
우리는 실험을 통해 Squared ReLU가 GeLU보다 더 나은 성능을 보인다는 사실을 확인하였다.
| Perceiver Resampler | GATED XATTN-DENSE | Frozen LM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L | D | H | Act. | L | D | H | Act. | L | D | H | Act. | |
| Flamingo-3B | 6 | 1536 | 16 | Sq. ReLU | 24 | 2048 | 16 | Sq. ReLU | 24 | 2048 | 16 | GeLU |
| Flamingo-9B | 6 | 1536 | 16 | Sq. ReLU | 10 | 4096 | 32 | Sq. ReLU | 40 | 4096 | 32 | GeLU |
| Flamingo | 6 | 1536 | 16 | Sq. ReLU | 12 | 8192 | 64 | Sq. ReLU | 80 | 8192 | 64 | GeLU |
Table 4: Flamingo 모델의 Transformer에 대한 하이퍼파라미터
각 feedforward MLP의 hidden 크기는 이다.
: 레이어 수, : Transformer hidden 크기, : 헤드 수, Act.: Feed-Forward에서 사용하는 활성화 함수,
Sq. ReLU: Squared ReLU [104].

Figure 8: Few-shot interleaved prompt 생성 방식
Flamingo가 예측을 수행해야 하는 쿼리와 함께, 몇 개의 task-specific few-shot 예시(즉, support example)가 주어졌을 때, 우리는 이미지와 해당 텍스트를 번갈아(interleave) 배치하여 prompt를 구성한다.
이를 위해 특정 포맷을 도입하며,
vision-to-text task의 경우에는 예상 응답 앞에 "Output:"을 붙이고,
visual question-answering task의 경우에는
"Question: {질문} Answer: {답변}" 형식으로 prompt를 구성한다.
A. 2 In-context few-shot evaluation details
Flamingo 모델을 활용한 In-context learning
우리는 GPT-3 [11]에서 사용된 접근 방식과 유사하게, Flamingo 모델이 새로운 task에 빠르게 적응할 수 있는지 in-context learning을 통해 평가한다.
구체적으로, (image, text) 또는 (video, text) 형태의 support example 집합이 주어지며, 여기서 image 또는 video는 시각 입력이고, text는 **예상되는 응답 또는 추가적인 task-specific 정보(예: 질문)**이다.
또한, 모델이 예측을 수행해야 하는 단일 visual query도 함께 제공된다.
이러한 정보를 바탕으로, 우리는 Figure 8에서 보여주듯, support example들을 시각 쿼리 앞에 연결(concatenate)하여 멀티모달 prompt를 구성한다.
별도의 명시가 없는 한, example들의 연결 순서는 무작위로 선택한다.
Open-ended 및 Close-ended 평가 방식
Open-ended 설정에서는, 모델이 쿼리 이미지 이후에 생성한 텍스트를 해당 이미지에 대한 예측으로 간주하며, 첫 번째 <EOC>(end of chunk) 토큰이 생성될 때까지 텍스트 생성을 진행한다.
특별한 언급이 없는 한, 우리는 항상 beam size 3의 beam search를 사용한다.
Close-ended 설정에서는, 모든 후보 응답들을 쿼리 이미지 뒤에 독립적으로 덧붙인 후,
각 시퀀스에 대해 모델이 계산한 log-likelihood를 기반으로 점수화한다.
이 점수들을 이용해 **후보 응답들을 신뢰도 순(높은 → 낮은)**으로 정렬한다.

Figure 9: 학습 데이터셋
서로 다른 형식의 학습 데이터셋으로 구성된 혼합 구조를 나타낸다.
은 하나의 예시에 포함된 시각 입력(이미지 또는 비디오)의 개수를 의미하며, **paired image (또는 video)-text 데이터셋에서는 **이다.
는 비디오 프레임 수를 의미하며, **이미지의 경우 **이다.
는 각각 **높이(height), 너비(width), 색상 채널 수(channel)**를 나타낸다.
Zero-shot generalization
few-shot 예시가 없는 상황에서는, 모델이 inference 시 task에 적절한 자연어 설명을 조건으로 활용하도록 하는 prompt engineering 기법이 일반적으로 사용된다 [85].
하지만 이러한 prompt를 검증하고 선택하는 과정은 성능에 큰 영향을 줄 수 있음에도 불구하고, annotated 예시를 필요로 하므로 진정한 의미의 zero-shot으로 간주될 수 없다.
게다가, Perez et al. [80]는 validation 과정에서 예시 수가 적을 경우, 성능이 쉽게 불안정해짐을 실험적으로 보였다.
우리의 연구에서는 zero-shot 성능을 평가하기 위해, 다운스트림 task에서 가져온 예시 중 해당 이미지 또는 비디오를 제거하여 텍스트만 포함된 2개의 예시로 prompt를 구성하였다.
예를 들어, Figure 8 상단에 나오는 task의 경우, prompt는 다음과 같이 구성된다:
<BOS>Output: This is a cat wearing sunglasses.<EOC>Output: Three elephants walking in the savanna.<EOC><image> Output:
이때, 모델에는 support 이미지가 제공되지 않는다.
우리는 텍스트 예시를 1개만 제공하는 경우, 모델이 그 예시와 유사한 형식의 응답을 생성하는 경향이 강해져 성능이 크게 저하됨을 확인했다.
반면, 2개를 제공하는 것이 실용성과 성능 간 균형 측면에서 가장 효과적이었으며, 2개 이상을 제공하는 것은 성능을 약간만 향상시킬 뿐이었다.
따라서 모든 zero-shot 결과에서는 텍스트 예시 2개만을 사용하였다.
실제로 이는 주어진 task에 대해 적절한 자연어 설명을 찾는 것보다 더 번거롭지 않다고 판단된다.
이러한 접근은 recent finding인 demonstration의 구성 방식이 성능에 미치는 주요 요인이라는 연구 [76]와도 관련이 있다.
Close-ended task의 경우, 후보 정답들에 대해 모델이 점수를 매기는 방식이므로, zero-shot prompt에 단일 텍스트 예시조차 포함할 필요가 없다.
Retrieval-based In-Context Example Selection (RICES) [136]
support set의 크기가 일정 수준을 넘어서게 되면, in-context learning으로 모든 예시를 효과적으로 활용하는 것이 어려워질 수 있다.
그 이유는 크게 두 가지다:
첫째, 모든 예시를 prompt에 넣기엔 너무 많은 연산 비용이 발생하며,
둘째, prompt의 길이가 학습 시 사용된 시퀀스 길이를 초과하면 일반화 성능이 저하될 위험이 있기 때문이다 [83].
이런 경우, prompt selection 기법을 사용하면 prompt 길이를 줄이고, 동시에 품질도 향상시켜 성능을 개선할 수 있다 [63].
우리는 이러한 접근 중 하나인 Retrieval-based In-Context Example Selection (RICES) 기법 [136]을 따른다.
구체적으로는, 쿼리 이미지가 주어졌을 때,
사전학습된 frozen visual encoder로부터 추출한 시각 feature를 기준으로 support set 내에서 유사한 이미지들을 검색한다.
그 후, 가장 유사한 상위 개 예시를 연결하여 prompt를 구성한다.
또한, language model은 prompt에서 **최근 등장한 정보에 민감(recency bias)**하므로 [148],
유사도가 낮은 예시부터 높은 예시 순으로 정렬하여 가장 유사한 예시가 쿼리 바로 앞에 오도록 구성한다.
우리는 특히 수백 개 이상의 class가 존재하는 분류 task 설정에서 이 접근의 효과를 보여준다 (Appendix B.2.1 참조).
이 설정에서는 class마다 여러 개의 이미지/비디오가 주어지기 때문에, 예시 수가 prompt 길이를 초과하는 경우가 많다.
Prompt ensembling
우리는 close-ended setting에서 여러 개의 prompt에 대해 모델 출력을 앙상블하는 방법도 실험하였다.
이 방식은 RICES와도 결합 가능하며, 유사한 예시들의 순서를 여러 가지로 섞어 생성한 prompt에 대해 모델 출력을 평균하는 식으로 동작한다.
구체적으로는, 선택된 few-shot 예시의 6가지 무작위 순열에 대해,
각 정답 후보의 log-likelihood를 모델이 계산한 뒤 평균을 취해 최종 점수를 산출한다.
A. 3 Training dataset details
우리는 Figure 9에 시각적으로 나타나 있고, 아래에 설명된 다양한 데이터셋의 조합을 신중하게 선택하여 Flamingo 모델을 학습시켰다.
A.3.1 collection
****의 웹페이지 수집 및 크롤링 과정은 MassiveWeb 데이터셋 [86]을 수집할 때 사용된 방식과 유사한 절차를 따른다.
우리는 먼저 영어가 아닌 문서들을 필터링하여 제외하고,
이미지, 비디오, 텍스트에 걸쳐 explicit 콘텐츠를 식별하는 내부 필터를 통과하지 못한 문서들 또한 제거한다.
그 이후, 우리는 텍스트와 이미지가 섞인 형태의 평문 콘텐츠를 추출하기 위해 커스텀 크롤러를 사용하며,
이 과정은 Section 2.4에서 설명한 방식과 동일하다.
의 텍스트는 MassiveWeb과 유사한 방식으로 수집되지만,
우리는 여기에 추가로 HTML 트리 상에서 동일한 수준에 위치한 이미지들도 함께 수집한다.
스크래핑된 결과에서 이미지가 포함되지 않은 문서들은 제거한다.
그 다음, 우리는 텍스트 품질을 높이기 위해 반복적이거나 품질이 낮은 문서를 제거하고, 다음과 같은 조건에 해당하는 이미지를 제거하는 이미지 필터링 절차도 적용한다:
- 이미지의 너비 또는 높이가 64픽셀 미만인 경우
- 이미지의 가로세로 비율이 3 이상으로 지나치게 넓거나 좁은 경우
- 단색 이미지와 같이 품질이 명확히 낮은 이미지
이러한 필터링 이후에도 이미지가 남아 있지 않은 문서들은 최종적으로 모두 폐기한다.
A.3.2 image-placement augmentation
Flamingo 모델을 평가할 때는 이미지를 입력으로 제공하고 해당 이미지에 대한 텍스트를 생성하도록 프롬프트를 구성한다. 이는 자연스럽게 추론 시 이미지가 먼저 오고, 그에 따른 텍스트가 이어지는 순서로 이어진다.
하지만, interleaved된 M3W 데이터셋(Section 2.4 참조)에서는 이미지와 텍스트 간의 명확한 대응 관계가 일반적으로 알려져 있지 않으며,
일부 경우에는 그 관계 자체가 명확하게 정의되지 않을 수도 있다.
이를 설명하기 위한 동기 부여 예시로, 단순한 웹페이지 구조는 다음 두 가지 형태 중 하나일 수 있다:
(a) This is my dog! <dog image> This is my cat! <cat image>
(b) <dog image> That was my dog! <cat image> That was my cat!
이때 **텍스트에 대응되는 이미지의 인덱스(index)**는 이상적으로는 해당 텍스트와 의미적으로 가장 관련이 깊은 이미지를 가리키는 것이 바람직하다.
예를 들어 (a)에서는 다음 이미지가, (b)에서는 이전 이미지가 해당 텍스트와 관련 있을 것이다.
그러나 실제 웹페이지들에서는 이러한 의미적 일치를 일반적으로 판별하는 방법이 없기 때문에, 우리는 다음과 같은 단순화된 가정을 적용한다:
텍스트의 각 위치에서 가장 관련 있는 이미지는 직전에 등장한 이미지이거나 직후에 등장하는 이미지 중 하나라는 것이다.
위 예시 구조들을 고려하여, 인덱스는 이러한 규칙에 따라 결정된다.
학습 과정에서는 각 웹페이지 샘플에 대해, 텍스트가 이전 이미지와 대응되는지 또는 다음 이미지와 대응되는지를
확률 로 무작위로 결정한다.
이 방식은 불가피하게 (a)의 경우에서처럼 "This is my cat!"이라는 문장이 강아지 이미지와 잘못 연결되는 비자연적인 결과를 약 절반의 확률로 만들게 된다.
Section 3.3에서 이 선택에 대한 ablation 실험을 수행한 결과,
으로 설정하는 것이 항상 이전 이미지(index=0) 또는 항상 다음 이미지(index=1) 를 선택하는 것보다 성능 면에서 약간의 이점을 가지는 것으로 나타났다.
이는 이 무작위 선택 방식이 일종의 "데이터 증강(data augmentation)" 효과를 제공할 수 있음을 시사한다.
A.3.3 LTIP and VTP: Visual data paired with text
우리의 interleaved image-text 데이터셋과 함께, 학습을 위해 여러 개의 paired vision-text 웹 데이터셋을 추가로 사용한다. 이 중 하나는 ALIGN [50]으로, alt-text와 함께 제공되는 18억 개의 이미지로 구성되어 있다. ALIGN은 규모는 크지만 노이즈가 많고 이미지에 한정된다는 단점이 있다. 예를 들어, 이미지에 대한 alt-text 주석은 종종 부정확하거나 부실하다.
이러한 한계를 보완하기 위해 두 가지 데이터셋을 추가로 사용한다:
LTIP (Long Text & Image Pairs) 데이터셋은 3억 1,200만 개의 이미지와 더 길고 풍부한 설명을 포함하며,
VTP (Video & Text Pairs) 데이터셋은 약 22초 분량의 짧은 영상 2,700만 개와 문장 수준의 캡션으로 구성되어 있다.
참고로, ALIGN 데이터셋에서 이미지 한 장당 평균 텍스트 길이는 12.4 토큰이지만, LTIP에서는 평균 20.5 토큰으로 더 자세한 설명을 포함한다.
LTIP와 VTP는 고품질의 풍부한 이미지 설명을 제공하는 웹사이트 수십 개에서 수집되었으며, 이는 ALIGN보다 훨씬 적은 수의 웹사이트를 대상으로 한다.
이들 single-image 및 single-video 기반의 데이터셋은 앞서 설명한 M3W의 전처리 방식과 유사하게 전처리되었는데, 시퀀스 시작 부분(<BOS>) 바로 뒤에 <image> 태그를 삽입하고, 텍스트 뒤에는 <EOC> 토큰을 추가한 후 <EOS>로 마무리한다.
또한 이 데이터셋들은 우리가 사용하는 모든 벤치마크(학습 및 평가 세트 모두)에 대해 중복을 제거하였다. 중복 제거는 Appendix A.3.4에서 설명된 바와 같이 이미지 유사도를 기반으로 수행되었다.
LTIP와 VTP에 대한 데이터시트는 각각 Appendix F.2.1 및 Appendix F.2.2에 수록되어 있다.
| Requires model sharding | Frozen | Trainable | Total count | |||
|---|---|---|---|---|---|---|
| Language | Vision | GATED XATTN-DENSE | Resampler | |||
| Flamingo-3B | 1.4 B | 435 M | 1.2 B (every) | 194 M | 3.2B | |
| Flamingo-9B | 7.1 B | 435 M | 1.6B (every 4th) | 194 M | 9.3B | |
| Flamingo | 70 B | 435 M | 10B (every 7th) | 194 M | 80B |
표 5: Flamingo 모델의 파라미터 수
우리는 frozen된 language model(LM)과 학습 가능한 vision-text GATED XATTN-DENSE 모듈의 파라미터 수를 증가시키는 데 중점을 두었으며, frozen vision encoder와 학습 가능한 Resampler는 모든 모델에서 고정된 작고 일정한 크기로 유지하였다.
표에서 괄호 안의 수치는 GATED XATTN-DENSE가 원래 language model 블록에 삽입되는 빈도수를 나타낸다.
A.3.4 Dataset deduplication against evaluation tasks
우리는 내부 deduplication 도구를 사용하여 학습 데이터셋과 평가 데이터셋 간의 중복 제거를 수행했다. 이 deduplication 파이프라인은 잠재적 중복일 가능성이 있는 이미지들의 임베딩을 서로 가깝게 매핑하도록 학습된 visual encoder를 기반으로 한다. 이미지 임베딩이 계산된 후, 학습 이미지에 대해 빠른 근사 최근접 이웃 탐색을 수행하여 평가 데이터셋으로부터 중복 후보를 검색한다.
paired image-text 데이터셋에 대해서는, LTIP 및 ALIGN 학습 이미지들을 다음과 비교하여 deduplication을 수행했다: ImageNet (train, val), COCO (train, valid, test), OK-VQA (train, valid, test), VQAv2 (train, valid, test), Flickr30k (train, valid, test), VisDial (train, valid, test).
우리는 VizWiz, HatefulMemes, TextVQA 데이터셋과는 이미지 중복 제거를 수행하지 않았는데, 이는 Flamingo 모델의 학습이 완료된 이후에 해당 평가들을 진행했기 때문이다. 그러나 이러한 결정이 결과에 영향을 주지는 않았다고 판단한다. 그 이유는 이들 데이터셋의 이미지는 웹에서 수집된 것이 아닐 가능성이 높기 때문이다. VizWiz의 이미지는 특정 모바일 앱을 통해 수집되어서 다운로드를 통해서만 얻을 수 있고, HatefulMemes는 연구자들이 생성한 밈이며, TextVQA는 OpenImages로부터 가져온 이미지이기 때문이다.
한편, 데이터셋에 대해서는 deduplication을 수행하지 않았다. 그 이유는 해당 데이터셋의 하나의 학습 샘플이 여러 개의 이미지를 포함하는 전체 웹페이지이기 때문에, 벤치마크에 사용되는 이미지들과 중복될 가능성이 낮다고 보았기 때문이다. 이 가설을 검증하기 위해 우리는 의 1억 8,500만 개의 개별 이미지에 대해 중복 탐지를 수행했으며, 그 결과는 다음과 같다: ImageNet, COCO, OK-VQA, VQAv2, Flickr30k, VisDial의 validation 및 test split으로부터 총 1,314개의 잠재적 중복 후보가 발견되었으며, 그 중 정확히 일치하는 중복은 단 125개뿐이었다.
비디오 데이터셋에 대해서는 VTP (2,700만 개의 비디오)에 대해 별도의 중복 제거를 수행하지 않았다. 이는 우리가 수집한 VTP 비디오가 YouTube나 Flickr에서 가져온 것이 아니며, 반면 우리가 사용한 모든 비디오 평가 데이터셋은 인터넷에서 수집된 YouTube 혹은 Flickr 기반의 것이기 때문이다.
B Experiments
B. 1 Training and evaluation details
B.1.1 Models
우리는 세 가지 모델 크기에 걸쳐 실험을 수행하였으며, 고정된 language model의 크기를 1.4B에서 7B, 70B로 확장하면서, 그에 따라 다른 구성 요소들의 파라미터 수도 조정하였다. 모든 실험에서 vision encoder는 고정된 pretrained 모델을 사용하였고, 별도로 명시된 경우를 제외하면 contrastive 방식으로 학습된 NFNet-F6 모델을 사용하였다(자세한 내용은 Appendix B.1.3 참조). Perceiver Resampler는 모든 모델 크기에서 약 2억 개의 파라미터를 갖도록 유지하였다.
GATED XATTN-DENSE layer를 얼마나 자주 삽입할 것인가는 메모리 제약과 downstream 성능 간의 trade-off에 의해 결정된다. 우리는 이 trade-off의 최적 지점을 작은 규모의 모델에서 식별한 후, 그 결과를 대규모 모델 아키텍처로 전이시켰다.
최종적으로 우리는 다음과 같은 세 가지 모델을 구성하였다: Flamingo-3B, Flamingo-9B, 그리고 Flamingo-80B.
- Flamingo-3B는 [42]의 1.4B 크기의 frozen language model 위에 구축되었으며, 각 Transformer block 앞에 visual input을 참조하는 GATED XATTN-DENSE layer를 추가하였다. 이로 인해 약 14억 개의 추가 학습 파라미터가 발생한다.
- Flamingo-9B는 [42]의 7B frozen language model 위에 구축되었으며, 가장 첫 번째 layer부터 시작하여 매 4번째 Transformer block 앞에 GATED XATTN-DENSE layer를 추가하였다. 이로 인해 약 18억 개의 추가 학습 파라미터가 발생한다.
- Flamingo-80B는 고정된 Chinchilla 70B language model [42] 위에 구축되었으며, 가장 첫 번째 layer부터 시작하여 매 7번째 Transformer block 앞에 GATED XATTN-DENSE layer를 추가하였다. 이로 인해 약 100억 개의 추가 학습 파라미터가 발생한다. 논문 전반에서는 이 모델을 간단히 Flamingo로 지칭한다.
Table 5에는 각 모델 구성 요소의 파라미터 수와 모델 분산 학습(sharding) 요구사항이 정리되어 있으며, Transformer 아키텍처에 대한 보다 구체적인 세부 사항은 Appendix A.1.4에 제공되어 있다. 또한, Flamingo 모델 카드 [77]는 Appendix E에 포함되어 있다.
B.1.2 Training details for the Flamingo models
데이터 증강 및 전처리 실험적으로 우리는 paired dataset의 텍스트 샘플 앞에 확률 0.5로 공백 문자 하나를 무작위로 추가하는 것이 효과적이라는 것을 발견했다. 이는 subword tokenizer가 단어 앞에 공백이 있느냐 없느냐에 따라 서로 다른 토큰으로 매핑한다는 사실에서 기인한다. 이러한 방식은 tokenizer의 이 인공적인 특성(tokenizer artifact)에 대한 불변성을 학습시킬 수 있도록 도와주며, 많은 샘플에서 이미 문장 부호가 부족한 점을 고려했을 때 문장의 정확도에 크게 영향을 주지 않는다. 이 처리는 다양한 태스크 전반에서 성능 향상을 이끌어냈다.
시각적 입력은 해상도 으로 조정되며, 종횡비는 유지된다. 필요한 경우, 평균값으로 패딩이 추가된다. 이 해상도는 Vision Encoder의 contrastive pretraining에서 사용된 보다 더 높은 해상도이다 (Appendix B.1.3 참고). 최종 학습 단계에서 해상도를 높인 이유는, CNN 기반 모델은 테스트 시점에 더 높은 해상도를 사용하면 성능이 향상될 수 있다는 기존 연구 [113]에 기반한다. 이는 frozen Vision Encoder에 대해 backpropagation을 수행하지 않기 때문에 계산량 및 메모리 비용을 적당한 수준으로 유지하면서 성능 향상을 얻을 수 있다. 또한, 우리는 random left/right flip과 색상 변화(color augmentation)도 적용한다.
Interleaved dataset (Section 2.4 참조)의 경우, 에서 샘플을 선택할 때 선택된 이미지 인덱스 를 확률 로 가볍게 무작위화하여 증강한다. 이 증강 기법은 Appendix A.3.2에 자세히 설명되어 있으며, 우리가 선택한 값은 Appendix B.3.1에서 ablation 실험을 통해 분석되었다. 비디오 학습에서는 각 학습 비디오에서 1초 간격으로 8프레임을 샘플링하여 사용한다. 모델은 학습 시 8개의 고정된 프레임을 사용했지만, 추론 시에는 3 FPS로 30프레임을 입력으로 넣는다. 이는 Perceiver Resampler의 학습된 temporal position embedding을 선형 보간하여 구현된다.
손실 함수 및 최적화 모든 모델은 AdamW optimizer를 사용해 학습되었고, gradient의 global norm은 1로 clipping되며, Perceiver Resampler에 대해서는 weight decay를 적용하지 않고, 나머지 학습 가능한 파라미터에는 0.1의 weight decay를 사용했다. learning rate는 처음 5,000 step 동안 선형적으로 까지 증가시키고 이후에는 일정하게 유지된다 (학습률을 감소시켜도 성능 개선은 관찰되지 않음). 별도로 명시되지 않는 한, 모델은 총 50만 step 동안 학습된다. 학습에는 네 개의 데이터셋인 , ALIGN, LTIP, VTP가 사용되며, 각 데이터셋의 가중치 는 각각 이다. 이 가중치는 소규모 모델에서의 실험을 통해 결정되었고, 이후 모든 실험에서 동일하게 유지되었다. 배치 크기는 실험 조건에 따라 달라지며, 이는 이후 섹션에서 명시된다.
인프라 및 구현 모델 및 관련 인프라는 JAX [8]와 Haiku [40]를 사용해 구현되었다. 학습 및 평가 과정은 TPUv4 인스턴스에서 수행되었다. 가장 큰 모델(파라미터 수 800억)은 총 1,536개의 TPU 칩에서 15일간 학습되었으며, 16개의 디바이스에 걸쳐 sharding되었다. Embedding, Self-Attention, Cross-Attention, FFW layer들은 모두 16-way Megatron 방식 [99]으로 모델 병렬화되었으며, Vision encoder인 NFNet은 병렬화되지 않았다. optimizer state는 ZeRO stage 1 [88]을 이용해 sharding되었다. 모든 학습 가능한 파라미터와 optimizer 누적값은 float32로 저장 및 업데이트되며, activation과 gradient는 파라미터를 float32에서 bfloat16으로 변환한 후 bfloat16으로 계산된다. frozen 파라미터는 bfloat16 형식으로 저장 및 적용된다.
B.1.3 Contrastive model details
Vision encoder는 language encoder와 함께 처음부터 학습되며, 이 두 encoder를 사용해 이미지와 텍스트 쌍을 각각 인코딩한 뒤, 공통 임베딩 공간으로 투영하고 L2 normalization을 수행한다. 이렇게 얻어진 임베딩을 바탕으로, 정답 쌍의 임베딩 간 유사도는 최대화하고, 잘못된 쌍의 유사도는 최소화하도록 학습한다. 이를 위해 multi-class cross-entropy loss를 사용하며, 정답 쌍의 이미지-텍스트는 positive example로 간주되고, 같은 배치 내의 나머지 쌍들은 negative example로 처리된다. 이 loss는 CLIP [85]에서 사용한 것과 동일하며, text-to-image와 image-to-text 방향의 두 개의 contrastive loss로 구성되어 있다. 최종 log-softmax 레이어에는 학습 가능한 temperature 파라미터를 사용한다 [9].
text-to-image loss는 다음과 같이 정의된다:
image-to-text loss는 이와 유사하게 다음과 같다:
이 두 loss의 합을 최소화하도록 학습된다. 여기서 와 는 각각 vision과 language encoder가 생성한 번째 샘플의 normalized embedding을 의미하며, 는 학습 가능한 inverse temperature 파라미터이고, 은 배치 크기이다. language encoder로는 BERT [23] 아키텍처를 사용한다. language encoder와 vision encoder의 출력은 각각 token 단위와 spatial 위치 단위로 평균을 내는 mean pooling을 거친 후, 공통 임베딩 공간으로 투영된다. Flamingo 본 모델에는 이 contrastive 방식으로 학습된 vision encoder만 사용된다.
Vision encoder는 ALIGN과 LTIP 데이터셋으로 사전학습되며, 학습 이미지 해상도는 이다. 공통 임베딩 공간의 크기는 1376이고, 배치 사이즈는 16,384이다. 총 120만 step 동안 학습되며, 각 step은 2회의 gradient 계산으로 구성된다. 학습은 512개의 TPUv4 칩 위에서 이루어졌고, learning rate는 에서 선형적으로 0까지 감소시킨다. 학습 중에는 이미지에 대해 색상 변화(color augmentation)와 수평 뒤집기(random horizontal flip)를 적용한다. tokenizer는 Jia et al. [50]에서 사용한 것을 따른다. optimizer로는 Adam을 사용하며, label smoothing 0.1을 적용한다. NFNet encoder에는 의 adaptive gradient clipping (AGC) [10]을, BERT encoder에는 global norm gradient clipping 10을 적용한다.
사전학습된 모델의 성능을 평가하기 위해 zero-shot image classification과 retrieval을 추적한다. zero-shot classification의 경우, 이미지와 클래스 이름 간의 image-text retrieval을 수행한다. Radford et al. [85]를 따라, "A photo of a {class_name}"과 같은 템플릿을 사용해 여러 개의 문장을 임베딩한 후 평균을 취하는 prompt ensembling 기법을 사용한다.
B.1.4 Evaluation benchmarks
우리의 목표는 few-shot 설정에서 다양하고 도전적인 task에 빠르게 적응할 수 있는 모델을 개발하는 것이다. 이를 위해 우리는 Table 6에 요약된 인기 있는 이미지 및 비디오 벤치마크들을 광범위하게 고려한다. 총 16개의 멀티모달 이미지/비디오 및 언어 벤치마크를 선택하였으며, 여기에는 **언어 이해 능력이 필요한 task(visual question answering, captioning, visual dialogue)와 더불어, 이미지 및 비디오 분류를 위한 두 가지 표준 벤치마크(ImageNet, Kinetics)**가 포함된다. YouTube에서 수집된 비디오 데이터셋(NextQA 및 STAR 제외 모든 비디오 데이터셋)의 경우, 2022년 4월 기준으로 공개된 모든 비디오에 대해 모델 성능을 평가하였다.
DEV 벤치마크
프로젝트 진행 과정에서 모델의 설계 결정을 검증하기 위해, 우리는 16개의 멀티모달 이미지/비디오 및 언어 벤치마크와 더불어 분류를 위한 ImageNet 및 Kinetics 중에서 **가장 도전적이고 널리 연구된 벤치마크들을 선택하여 개발 세트(DEV)**로 지정하였다.
캡셔닝, visual question-answering, 분류 task에 대해 이미지와 비디오 모두를 포함하도록 선정하였다.
DEV 벤치마크의 데이터셋 분할
구체적으로, 모델의 few-shot 학습 성능을 평가하는 것은 support 샘플 세트에 모델을 적응시키고, query 샘플 세트에 대해 평가하는 것으로 구성된다. 결과적으로, 모든 평가 세트는 support 샘플과 query 샘플을 각각 포함하는 두 개의 분리된 subset으로 구성되어야 한다.
우리는 설계 결정 및 하이퍼파라미터 검증, 그리고 최종 성능 보고에 모두 사용되는 DEV 벤치마크에 대해 다음과 같은 네 개의 subset을 사용한다:
- validation support: 검증을 위한 support 샘플 포함
- validation query: 검증을 위한 query 샘플 포함
- test support: 최종 성능 추정을 위한 support 샘플 포함
- test query: 최종 성능 추정을 위한 query 샘플 포함
실제로는, **test query subset에 대해 prior work에서 결과를 보고한 subset을 사용하여 직접적인 비교(apples-to-apples comparison)**를 수행한다. 검증 세트(validation set)가 validation query subset에 자연스러운 선택지가 될 수 있지만, 일부 벤치마크는 공식적인 검증 세트가 없거나(예: OKVQA), 검증 세트가 최종 성능 보고에 흔히 사용되기 때문에(예: ImageNet, COCO) 모든 벤치마크에 대해 이러한 방식이 불가능함을 명시한다. 단순화를 위해, 우리는 원본 학습 세트의 일부를 validation query subset으로 사용한다. 마지막으로, 우리는 학습 세트의 추가적인 분리된 subset을 validation support subset 및 test support subset으로 각각 사용한다.
이제 나머지 세 개의 subset을 구성하는 방법에 대해 더 자세히 설명한다. 캡셔닝 task의 경우, open-ended 평가가 효율적이므로 많은 샘플에 대해 평가한다. 구체적으로 COCO의 경우, 평가 세트로 사용된 Karpathy split과 동일한 수의 샘플(5000개)을 사용한다. VATEX의 경우, 학습 세트 크기가 제한적이므로 1024개의 샘플에 대해서만 평가하고 나머지는 support 세트로 남겨둔다. 질문 응답 task의 경우, open-ended 및 close-ended 평가 모두 합리적으로 빠르게 수행하기 위해 1024개의 샘플에 대해 평가한다. 이미지 분류 task의 경우, 클래스당 10개의 이미지를 평가에 사용하며, ImageNet의 경우 10,000개, Kinetics700의 경우 7000개의 샘플을 사용한다. support 세트의 경우, 검증 및 최종 성능 추정 모두에 대해 모든 task에 걸쳐 2048개의 샘플을 사용하지만, 분류 task의 경우 각 클래스에 대한 기대 성능을 더 잘 추정하기 위해 이를 클래스당 32개의 샘플로 조정한다.
| Dataset | DEV | Gen. | Custom prompt | Task description | Eval set | Metric | |
|---|---|---|---|---|---|---|---|
| ImageNet-1k [94] | Object classification | Val | Top-1 acc. | ||||
| MS-COCO [15] | Scene description | Test | CIDEr | ||||
| VQAv2 [3] | Scene understanding QA | Test-dev | VQA acc. [3] | ||||
| OKVQA [69] | External knowledge QA | Val | VQA acc. [3] | ||||
| Flickr30k [139] | Scene description | Test (Karpathy) | CIDEr | ||||
| VizWiz [35] | Scene understanding QA | Test-dev | VQA acc. [3] | ||||
| TextVQA [100] | Text reading QA | Val | VQA acc. [3] | ||||
| VisDial [20] | Visual Dialogue | Val | NDCG | ||||
| HatefulMemes [54] | Meme classification | Seen Test | ROC AUC | ||||
| Video | Kinetics700 2020 [102] | Action classification | Val | Top-1/5 avg | |||
| VATEX [122] | Event description | Test | CIDEr | ||||
| MSVDQA [130] | Event understanding QA | Test | Top-1 acc. | ||||
| YouCook2 [149] | Event description | Val | CIDEr | ||||
| MSRVTTQA [130] | Event understanding QA | Test | Top-1 acc. | ||||
| iVQA [135] | Event understanding QA | Test | iVQA acc. [135] | ||||
| RareAct [73] | Composite action retrieval | Test | mWAP | ||||
| NextQA [129] | Temporal/Causal QA | Test | WUPS | ||||
| STAR [128] | Multiple-choice QA | Test | Top-1 acc. |
Table 6: 평가 벤치마크 요약
DEV 벤치마크는 Flamingo 모델의 일반적인 설계 결정 검증에 사용되었다.
Gen.은 생성(generative) task를 의미하며, 이 경우 VLM으로부터 텍스트를 샘플링한다.
만약 task가 비생성적(non-generative)이라면, VLM을 사용하여 주어진 유한한 집합 내에서 답변의 점수를 매기는 데 사용한다.
대부분의 task에서는 일반적인 기본 prompt를 사용하여 task-specific 튜닝을 최소화하였다 (Appendix B.1.5 참조).
편향되지 않은 few-shot 성능 추정
DEV 벤치마크에 대한 few-shot 학습 성능 추정치는 프로젝트 진행 과정에서 이러한 벤치마크의 성능을 기반으로 설계 결정이 이루어졌다는 점에서 편향될 수 있음을 인지해야 한다.
이는 이러한 벤치마크를 사용하여 자체 설계 결정을 검증하고 ablation을 수행한 기존 연구들에서도 마찬가지이다.
이러한 편향을 설명하고 편향되지 않은 few-shot 학습 성능 추정치를 제공하기 위해, 우리는 나머지 11개의 벤치마크 세트에 대한 성능을 보고한다.
이 중 일부는 DEV 벤치마크와 동일한 open-ended 이미지 및 비디오 task(캡셔닝, visual question-answering)를 포함한다.
그러나 우리는 또한 덜 탐색된 능력을 탐구하기 위해 보다 특정한 벤치마크들을 살펴본다.
여기에는 특히 다음이 포함된다:
- TextVQA [100]: 질문 응답을 통해 OCR 능력을 특별히 평가한다.
- VisDial [20]: 시각 대화 벤치마크이다.
- HatefulMemes [54]: 비전 및 텍스트 분류 벤치마크이다.
- NextQA [129]: 특히 인과 관계 및 시간 관계에 초점을 맞춘다.
- STAR [128]: 객관식 질문 응답 task이다.
- RareAct [73]: 행동 인식에서의 복합성(compositionality)을 측정하는 벤치마크이다. 우리는 이러한 벤치마크에 대해 어떠한 설계 결정도 검증하지 않았으며, Flamingo 학습이 완료된 후 편향되지 않은 few-shot 학습 성능을 추정하는 목적으로만 사용함을 강조한다.
B.1.5 Few-shot learning evaluation hyperparameters
Few-shot learning에서 하이퍼파라미터 선택은 추가적인 검증 예시를 필요로 하므로, 암묵적으로 shot 수를 증가시킨다. 실제 사례에서 흔히 그렇듯 이러한 점을 고려하지 않으면, few-shot 성능이 과대평가될 수 있다 [80]. 마찬가지로, prompt와 같은 벤치마크별 하이퍼파라미터의 cross-validation은 shot 집합에 대해 task-specific prompt를 선택하는, 특히 기본적인 few-shot learning 방법으로 간주되어야 한다. 그러나 다른 학습 접근법은 이러한 레이블이 지정된 예시를 활용하는 데 더 효과적일 수 있다. [80]에서 보고된 cross-validation의 견고성 측면에서의 부정적인 결과와 달리, 달리 언급되지 않는 한 모든 벤치마크는 prompt를 포함한 단일 평가 하이퍼파라미터 세트를 사용하여 실행된다. 우리는 DEV 벤치마크의 검증 subset 전반에 걸쳐 하이퍼파라미터를 공동으로 최적화하며, 다음에서 자세히 설명하듯이 몇 가지 예외를 제외하고는 벤치마크별 하이퍼파라미터 cross-validation을 수행하지 않는다.
HatefulMemes와 RareAct를 제외하고, 모든 질문 응답(question-answering) / 시각 대화(visual dialogue) task에는 "Question: {question} Answer: {answer}" 프롬프트를 사용하고, 다른 모든 task에는 "Output: {output}" 프롬프트를 사용한다. 특히 VisDial [20]의 경우, 위에서 설명한 프롬프트를 사용하여 대화의 각 질문/답변을 인코딩하고, 제공된 이미지 캡션은 프롬프트 없이 대화 기록 앞에 추가된다. HatefulMemes [54]의 경우, 입력으로 제공되는 OCR 정보를 통합하기 위해 다음과 같은 특정 프롬프트를 사용한다: "is an image with written: "{meme_text}" on it. Is it hateful? Answer: {answer}", 여기서 답변은 yes 또는 no이다. 이는 Flamingo 모델에 OCR 텍스트 "meme_text"를 명시적으로 입력으로 제공하는 유일한 데이터셋임을 주목하라. TextVQA의 경우, 제공된 OCR 전사본을 사용하지 않고 대신 Flamingo 모델의 off-the-shelf OCR 기능을 직접 활용한다. RareAct는 zero-shot 벤치마크이며, 동사 이름을 3인칭으로 변경하고 각 명사 앞에 관사를 추가하며 "Caption: a person {verb + object}" 프롬프트를 사용한다.
B.1.6 Dialogue prompt
[Korean Translation] Figures 1과 11의 대화 예시에서는 다음과 같은 prompt가 사용되었다:
This is a conversation between a human, User, and an intelligent
visual AI, Flamingo. User sends images, and Flamingo describes
them.
User: <a cat image>
Flamingo: That is a cat. It's a tiny kitten with really cute big
ears.
User: <a dinner image>
Flamingo: This is a picture of a group of people having dinner.
They are having a great time!
User: Can you guess what are they celebrating?
Flamingo: They might be celebrating the end of a successful
project or maybe a birthday?
User: <a graph image>
Flamingo: This is a graph, it looks like a cumulative density
function graph.
| Model | Method | Prompt size | shots/class | ImageNet top 1 | Kinetics700 avg top1/5 |
|---|---|---|---|---|---|
| SotA | Fine-tuned | - | full | 90.9 [127] | 89.0 [134] |
| SotA | Contrastive | - | 0 | 85.7 [82] | 69.6 [85] |
| NFNetF6 | Our contrastive | - | 0 | 77.9 | 62.9 |
| Flamingo-3B | RICES | 8 | 1 | 70.9 | 55.9 |
| 16 | 1 | 71.0 | 56.9 | ||
| 16 | 5 | 72.7 | 58.3 | ||
| Flamingo-9B | RICES | 8 | 1 | 71.2 | 58.0 |
| 16 | 1 | 71.7 | 59.4 | ||
| 16 | 5 | 75.2 | 60.9 | ||
| Flamingo-80B | Random | 16 | 66.4 | 51.2 | |
| RICES | 8 | 1 | 71.9 | 60.4 | |
| 16 | 1 | 71.7 | 62.7 | ||
| 16 | 5 | 76.0 | 63.5 | ||
| RICES+ensembling | 16 | 5 | 77.3 | 64.2 |
Table 7: 분류 task에 대한 Few-shot 결과
Flamingo 모델은 표준 분류 task에도 활용될 수 있다. 특히, 우리는 현재 prompt가 수용할 수 있는 것보다 더 큰 support set (최대 5000개의 support 예시 사용)에 접근하는 경우를 탐구하였다. 이러한 환경에서는 RICS 방법 [136]과 prompt ensembling을 사용함으로써 큰 성능 향상을 얻을 수 있었다. 또한, 우리는 vision-language 벤치마크에서 관찰된 것과 동일한 추세를 발견하였다: 더 큰 모델이 더 나은 성능을 보이며, 더 많은 shot 수가 도움이 된다.
B. 2 Additional performance results
B.2.1 Few-shot learning on classification tasks
우리는 Flamingo 모델을 ImageNet 또는 Kinetics700과 같이 잘 연구된 분류 벤치마크에 적용하는 것을 고려한다. 결과는 Table 7에 제시되어 있다. 우리는 다른 실험과 유사한 패턴을 관찰하는데, 더 큰 모델이 더 나은 성능을 보이는 경향이 있다. 둘째, few-shot 분류 task는 종종 더 많은 훈련 예시를 수반한다는 점을 감안할 때 (예: ImageNet의 경우 클래스당 1개의 예시로 1000개), 더 큰 support set으로 확장하는 방법론을 사용하는 것이 유리하다. RICES (Retrieval In-Context Example Selection [136], Appendix A.2에서 설명됨)는 prompt에 포함될 예시를 무작위로 선택하는 것보다 훨씬 더 나은 성능을 보인다. 실제로 Flamingo는 ImageNet 분류에서 5000개 중 16개의 support 예시를 RICES를 사용하여 선택했을 때, 무작위로 동일한 수의 예시를 선택하는 것에 비해 9.2%의 성능 향상을 달성한다. 여러 prompt를 앙상블하는 것은 성능을 더욱 향상시킨다. 그러나 Flamingo 모델은 분류 task에 대한 현재 지배적인 contrastive 패러다임보다 성능이 떨어진다는 점에 유의해야 한다. 특히, 이는 vision encoder로 사용된 contrastive 모델보다 성능이 떨어진다 (Flamingo의 한계점에 대한 자세한 내용은 Appendix D.1 참조). 마지막으로, BASIC [82] 및 LiT [146]와 같은 ImageNet에 대한 최신 zero-shot 모델은 JFT-3B [145]라는 레이블이 있는 이미지 데이터셋으로 훈련되었기 때문에 분류 task에 특히 최적화되어 있다. 분류 task에서 Flamingo와 같은 VLM의 성능을 향상시키는 것은 향후 연구를 위한 흥미로운 방향이다.
B.2.2 Fine-tuning Flamingo as a pretrained vision-language model
Flamingo 모델을 다운스트림 task에 fine-tuning하기 위해, 우리는 Section 2.4에서 설명한 단일 이미지/비디오 데이터셋과 동일한 형식의 데이터 배치(batch)를 사용하여 관심 있는 task에 대해 학습시킨다.
고정(Freezing) 및 하이퍼파라미터 Flamingo를 fine-tuning할 때, 우리는 기반 LM layer들은 고정(frozen)된 상태로 유지하고, 사전학습 시와 동일한 Flamingo layer들을 학습시킨다. 또한, 입력 이미지의 해상도를 에서 으로 높인다. 사전학습 단계와 달리, 우리는 기반이 되는 vision encoder 또한 fine-tuning하며, 이는 입력 해상도 증가에 부분적으로 기인하여 일반적으로 성능을 향상시킨다는 것을 발견했다.
우리는 학습 데이터셋의 validation subset (또는 공식/표준 validation set이 사용 가능한 경우 해당 데이터셋)에 대한 grid search를 통해 task별로 특정 하이퍼파라미터를 선택한다. 이러한 하이퍼파라미터에는 학습률(learning rate, 에서 범위), decay schedule (10배씩 지수적 감소), 학습 스텝 수, 배치 크기(8 또는 16), 그리고 시각 데이터 증강(color augmentation, random horizontal flips) 사용 여부가 포함된다.
결과 Table 8에서는 task별 Flamingo fine-tuning에 대한 추가 결과를 제시한다. 수천 개의 예시를 포함하는 대규모 task-specific 데이터셋에 접근할 수 있을 때, 우리는 이전에 제시했던 in-context few-shot learning 결과보다 성능을 향상시킬 수 있으며, VQAv2, VATEX, VizWiz, MSRVTTQA, HatefulMemes의 5개 task에서 새로운 state of the art를 달성한다. 예를 들어, VQAv2에서는 의 성능 향상을 관찰하였으며, 이는 32-shot in-context learning으로 달성한 결과()와 이전 state of the art(, Yan et al. [133])를 능가하는 수치이다.
이러한 fine-tuning 결과는 이전에 제시된 in-context few-shot learning 결과에 비해 높은 계산 비용을 수반하며, 하이퍼파라미터 튜닝과 같은 다른 어려움도 있지만, 이는 대량의 task-specific 학습 데이터가 존재하는 상황에서도 시각적 이해를 위한 VLM 사전학습의 강력함을 더욱 입증한다. 일부 경우, 우리의 결과는 단순히 log-likelihood를 최적화하고 COCO captioning을 위한 CIDEr 최적화 [64, 90]와 같은 일반적인 task-specific metric 최적화 기법을 사용하지 않는다는 사실에 부분적으로 기인하여 state of the art에 미치지 못할 수 있다. 예를 들어, Murahari et al. [79]는 이러한 dense annotation fine-tuning을 통해 VisDial에서 NDCG 점수를 10% 상대적으로 개선했다고 보고한다.
B.2.3 Zero-shot performance of the pretrained contrastive model
Our approach의 핵심적인 부분은 Vision Encoder이며, 이는 **contrastive learning을 사용하여 별도로 사전학습되었고, Flamingo 모델 학습 시에는 고정(frozen)**됩니다.
ImageNet, Kinetics700에서의 zero-shot 이미지 분류 결과와 Flick30K 및 COCO에서의 retrieval 결과를 보고합니다. 분류 결과는 Table 7에 제시되어 있으며, retrieval 결과는 Table 9에 제시되어 있습니다.
Retrieval task의 경우, 우리의 모델은 최신 state-of-the-art contrastive dual encoder 접근법인 CLIP [85], ALIGN [50], Florence [140]을 능가합니다.
그러나, Kinetics700 (CLIP) 및 ImageNet (BASIC)에서의 zero-shot state-of-the-art 성능에는 미치지 못합니다. 하지만 앞서 언급했듯이, BASIC [82]은 특히 분류에 최적화되어 있으며, 이는 캡션 대신 레이블과 유사한 이미지를 포함하는 JFT-3B [145] 데이터셋으로 학습되었기 때문입니다. 우리는 이미지와 레이블과 유사한 짧은 텍스트 설명으로 학습하는 것이 ImageNet에는 크게 도움이 되지만, 풍부한 장면 설명을 포착해야 하는 retrieval 벤치마크에는 해롭다는 것을 발견했습니다.
우리의 목표는 Flamingo 모델을 위한 feature extractor로 Vision Encoder를 사용하여, 주요 객체뿐만 아니라 전체 장면을 포착하는 것이므로, 분류 지표보다는 retrieval 지표를 선호합니다.
contrastive 사전학습에 대한 자세한 내용은 Appendix B.1.3에서 제공합니다.
Table 8: Flamingo fine-tuning 시 SotA와의 비교
우리는 few-shot learning만으로 SotA를 달성하지 못한 9개의 task에 대해 Flamingo를 fine-tuning하였다.
그 결과, 그 중 5개의 task에서 Flamingo가 새로운 SotA를 달성하였으며, 이는 모델 앙상블과 같은 알려진 성능 최적화 트릭을 사용하는 방법들보다도 뛰어난 성능을 보이기도 한다 (VQAv2, VATEX, VizWiz, HatefulMemes).
제한된 SotA 중에서 가장 뛰어난 성능은 굵게(bold) 표시되어 있으며, 전체 최고 성능은 **밑줄(underline)**로 표시되어 있다.
**제한된 SotA**는 단일 모델(앙상블 제외)을 사용하고 테스트 지표를 직접 최적화하지 않는(CIDEr 최적화 없음) 방법들만 포함한다.
| Method | VQAV2 test-dev test-std | COCO test | VATEX test | VizWiz test-dev test-std | MSRVTTQA test | VisDial valid test-std | YouCook2 valid | TextVQA valid test-std | HatefulMemes test seen | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flamingo - 32 shots | 67.6 | - | 113.8 | 65.1 | 49.8 | - | 31.0 | 56.8 | - | 86.8 | 36.0 | - | 70.0 |
| SimVLM [124] | 80.0 | 80.3 | 143.3 | - | - | - | - | - | - | - | - | - | - |
| OFA [119] | 79.9 | 80.0 | 149.6 | - | - | - | - | - | - | - | - | - | - |
| Florence [140] | 80.2 | 80.4 | - | - | - | - | - | - | - | - | - | - | - |
| Flamingo Fine-tuned | 138.1 | 84.2 | 65.7 | 65.4 | 47.4 | 61.8 | 59.7 | 118.6 | 57.1 | 54.1 | 86.6 | ||
| Restricted SotA | 80.2 [140] | 80.4 [140] | 143.3 [124] | 76.3 [153] | -- | -- | 46.8 [51] | [79] | 74.5 [79] | 138.7 [132] | 54.7 [137] | 73.7 [84] | 79.1 [62] |
| Unrestricted SotA | 81.3 [133] | 81.3 [133] | 149.6 [119] | 81.4 [153] | 57.2 [65] | 60.6 [65] | -- | -- | [123] | -- | -- | -- | 84.6 [152] |
| Flickr30K | COCO | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| image-to-text text-to-image | image-to-text | text-to-image | ||||||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| Florence [140] | 90.9 | 99.1 | - | 76.7 | 93.6 | - | 64.7 | 85.9 | - | 47.2 | 71.4 | - |
| ALIGN [50] | 88.6 | 98.7 | 99.7 | 75.7 | 93.8 | 96.8 | 58.6 | 83.0 | 89.7 | 45.6 | 69.8 | 78.6 |
| CLIP [85] | 88.0 | 98.7 | 99.4 | 68.7 | 90.6 | 95.2 | 58.4 | 81.5 | 88.1 | 37.7 | 62.4 | 72.2 |
| Ours | 89.3 | 98.8 | 99.7 | 79.5 | 95.3 | 97.9 | 65.9 | 87.3 | 92.9 | 48.0 | 73.3 | 82.1 |
Table 9: Zero-shot contrastive pretraining 평가
우리의 사전학습된 contrastive 모델과 state-of-the-art dual encoder contrastive 모델들과의 zero-shot 이미지-텍스트 retrieval 평가 비교.
| Ablated setting | Flamingo 3B value | Changed value | Param. count | Step time | COCO CIDEr | OKVQA top | VQAv2 top | MSVDQA top1 | VATEX CIDEr | Overall score | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Flamingo 3B model (short training) | 3.2 B | 1.74s | 86.5 | 42.1 | 55.8 | 36.3 | 53.4 | 70.7 | |||
| (i) | Vision encoder | NFNet-F6 | CLIP ViT-L/14 | 3.1 B | 1.58s | 81.1 | 40.4 | 54.1 | 36.0 | 50.2 | 67.9 |
| Resampler size | Medium | Small Large | 3.4B | 1.87 s | 84.4 | 42.2 | 54.4 | 35.1 | 51.4 | 69.0 | |
| (ii) | Multi-Img att. | Only last | All previous | 3.2 B | 1.74s | 70.0 | 40.9 | 52.0 | 32.1 | 46.8 | 63.5 |
| (iii) | Tanh gating init | 0.5 | 0.0 | 3.2B | 1.74s | 85.0 | 41.6 | 55.2 | 36.7 | 50.6 | 69.6 |
| 1.0 | 3.2 B | 1.74s | 81.3 | 43.3 | 55.6 | 36.8 | 52.7 | 70.4 | |||
| (iv) | LM pretraining | MassiveText | C4 | 3.2B | 1.74s | 81.3 | 34.4 | 47.1 | 60.6 | 53.9 | 62.8 |
| (v) | Freezing Vision | (random init) | 3.2 B | 4.70s* | 74.5 | 41.6 | 52.7 | 31.4 | 35.8 | 61.4 | |
| (pretrained) | 3.2 B | 4.70s* | 83.5 | 40.6 | 55.1 | 34.6 | 50.7 | 68.1 | |||
| (vi) | Co-train LM | (random init) | 3.2 B | 5.34s* | 69.3 | 29.9 | 46.1 | 28.1 | 45.5 | 55.9 | |
| on MassiveText | (pretrained) | 3.2 B | 5.34s* | 83.0 | 42.5 | 53.3 | 35.1 | 51.1 | 68.6 | ||
| (vii) | Dataset | M3W+ITP+VTP | LAION400M and CLIP | 3.1 B | 0.86s | 61.4 | 37.9 | 50.9 | 27.9 | 29.7 | 54.7 |
| and Vision encoder | and NFNetF6 | M3W+LAION400M+VTP and CLIP | 3.1 B | 1.58s | 76.3 | 41.5 | 53.4 | 32.5 | 46.1 | 64.9 |
Table 10: 추가 Ablation study
이 ablation study 테이블의 각 행은 테이블 상단에 보고된 baseline Flamingo 실행 결과와 비교해야 한다.
Step time은 모든 학습 데이터셋에 대해 gradient update를 수행하는 데 소요된 시간을 나타낸다.
(*): 더 높은 메모리 사용량으로 인해, 이 모델들은 4배 더 많은 TPU 칩을 사용하여 학습되었다. 따라서 얻어진 누적 step time은 4배로 곱해졌다.
B. 3 Extended ablation studies
B.3.1 Flamingo
[Korean Translation] Ablation study 실험 설정. Table 10과 마찬가지로, 4-shot 설정에서 5개의 DEV 멀티모달 벤치마크의 validation subset에 대한 task별 결과와 Overall 점수(Section 3.3 참조)를 Table 10에 보고한다. Ablation은 의 경우 batch size 256, ALIGN의 경우 512, LTIP의 경우 512, VTP의 경우 64를 사용하여 수행한다. 모델은 1백만 gradient step 동안 학습된다 (이는 기본 모델의 경우 250,000 gradient update를 의미하며, 4개 데이터셋에 걸쳐 gradient를 누적하기 때문이다).
Resampler 크기. Table 10의 (i)번 행에서 Resampler의 아키텍처 설계를 추가로 조사한다. Resampler의 크기를 Small, Medium (모든 Flamingo 모델의 기본값), Large 세 가지 옵션으로 ablation한다. Medium 크기의 Resampler를 사용할 때 가장 좋은 성능을 달성함을 알 수 있다. 또한, frozen LM과 함께 확장할 때 Perceiver Resampler의 크기를 늘리면 학습이 불안정해지는 것을 관찰했다. 따라서 우리는 모든 Flamingo 모델에 대해 동일한 Medium 크기의 Resampler를 유지하는 보수적인 선택을 하였다.
교차 참석하는 이미지 수의 영향. Interleaved 이미지-텍스트 시나리오에서, 모델이 가장 최근의 단일 이전 이미지에만 참석할 수 있는지, 아니면 모든 이전 이미지에 참석할 수 있는지에 대한 ablation을 수행한다 (Table 10의 (ii)번 행). 단일 이미지 경우가 훨씬 더 나은 결과를 가져옴을 알 수 있다 (Overall 점수에서 7.2% 더 높음). 한 가지 가능한 설명은 모든 이전 이미지에 참석할 때, 교차 참석 입력 간의 이미지 구별을 명확하게 하는 방법이 없다는 것이다. 그럼에도 불구하고, 최근 연구에서는 이러한 구별이 인과적 참석 메커니즘 [36]을 통해 암묵적으로 여전히 가능함을 보여주었다. 우리는 또한 이미지 태그에 인덱스를 포함시키거나 (<image 1>, <image 2> 등) 그리고/또는 각 이미지에 대한 교차 참석 특징에 추가된 절대 인덱스 임베딩을 학습함으로써, 모든 이전 이미지에 참석하면서 이를 가능하게 하는 명시적인 방법을 탐구하였다. 이러한 전략들은 훈련과 테스트 시퀀스당 이미지 수가 변경될 때 우리의 방법만큼 견고하지 못했다. 이러한 속성은 효율성을 높이기 위해 훈련 시 시퀀스당 이미지 수를 줄이는 것(훈련 시 N=5 사용)과 동시에, few-shot 평가를 위해 많은 이미지로 일반화하는 것(테스트 시 N=32까지 사용)에 바람직하다. 이러한 이유로 우리는 Flamingo 모델에 대해 단일 이미지 교차 참석 전략을 유지한다. 이 마스킹 전략으로 인해 모델이 명시적으로 모든 이전 이미지에 참석할 수는 없지만, 이전 텍스트 토큰을 통해 모든 이전 이미지의 특징을 전달하는 언어 전용 self-attention을 통해 암묵적으로 참석할 수 있음을 유의해야 한다.
M3W 이미지 배치 데이터 증강. 웹페이지가 주어졌을 때, 페이지의 텍스트가 페이지의 2차원 레이아웃에서 이전 또는 다음 이미지를 언급할지 미리 알 수 없다. 이러한 이유로, 우리는 주어진 텍스트 토큰이 이전 또는 다음 이미지에 참석하는지 여부를 나타내는 에 의해 제어되는 에 대한 데이터 증강을 탐구한다 (Appendix A.3.2에서 더 자세한 내용 참조). 기본값 는 샘플링된 각 웹페이지에 대해, 모델이 이전 또는 다음 이미지에 참석할지 여부를 균일하게 무작위로 결정한다는 것을 의미한다. 은 모델이 항상 이전 이미지에 참석함을 의미하고, 은 모델이 항상 다음 이미지에 참석함을 의미한다. 결과(Table 10의 (iii)번 행)는 이러한 무작위화 사용이 유익함을 보여준다.
Language model 사전학습. 텍스트 사전학습의 중요성을 측정하기 위해, 우리는 MassiveText(주요 모델)로 사전학습되었거나 C4 데이터셋 [87]으로 사전학습된 frozen decoder-only Transformer를 사용하는 성능을 비교한다 (Table 10의 (iv)번 행). C4 데이터셋(MassiveText보다 작고 필터링이 덜 된 데이터셋)을 훈련에 사용하는 것은 성능에 상당한 손실(전체적으로 -7.9%)을 초래한다. 특히 언어 이해가 더 많이 필요한 task(OKVQA, VQAv2 및 MSVDQA)에서는 성능이 눈에 띄게 감소하는 반면, 언어 이해가 덜 필요한 task(COCO, VATEX)에서는 성능이 비슷한 수준을 유지함을 주목한다. 이는 고품질 텍스트 전용 데이터셋으로 LM을 사전학습하는 것의 중요성을 강조한다.
Vision encoder 고정. Flamingo 훈련 중, 우리는 사전학습된 구성 요소(Vision Encoder 및 LM layer)를 고정(freeze)하는 동안 새로 추가된 구성 요소를 처음부터(from scratch) 훈련시킨다. 우리는 Table 10의 (v)번 항목에서 Vision Encoder 가중치를 처음부터 훈련시키거나 대조 학습 비전-언어 task로 초기화하는 이 고정 결정을 ablation한다. 처음부터 훈련시키면 성능이 -9.3%의 큰 폭으로 감소함을 관찰한다. 사전학습된 가중치로 시작하는 것은 성능을 -2.6% 감소시키면서도 훈련의 계산 비용을 증가시킨다.
MassiveText에서의 공동 훈련을 통한 LM 고정의 대안. Catastrophic forgetting을 방지하는 또 다른 접근 방식은 언어 모델을 사전학습하는 데 사용된 데이터셋인 MassiveText [86]로 공동 훈련하는 것이다. 구체적으로, 우리는 훈련 혼합물에 MassiveText를 가중치 1.0(작은 그리드 검색 후 최상의 성능)으로 추가하고, 시퀀스 길이 2048과 Chinchilla [42]의 사전학습과 정확히 동일한 설정을 사용하여 텍스트 전용 훈련 손실을 계산한다. MassiveText로 공동 훈련하려면 언어 모델을 unfreeze해야 하지만, vision encoder는 고정된 상태로 유지한다. 우리는 Table 10의 (vi)번 항목에서 두 가지 ablation을 수행한다: 사전학습된 언어 모델에서 시작하는 것(LM 가중치의 0.1 학습률 승수 사용) 대 처음부터 초기화하는 것(모든 곳에서 동일한 학습률 사용). 두 경우 모두, 전체 점수는 MassiveText로 사전학습되고 훈련 내내 고정된 상태로 유지되는 언어 모델에서 시작하는 우리의 기본 모델보다 낮다. 이는 언어 모델을 고정하여 catastrophic forgetting을 피하는 전략이 유익함을 시사한다. 더 중요한 것은, LM을 고정하는 것이 계산적으로 더 저렴하다는 점이다. 왜냐하면 LM 가중치에 대한 gradient 업데이트가 필요하지 않고 추가 데이터셋으로 훈련할 필요도 없기 때문이다. 이러한 계산적 논증은 전체 가중치의 거의 90%를 고정하는 가장 큰 모델인 Flamingo-80B에 대해 더욱 관련성이 높다.
LAION400M 데이터셋을 사용한 추가 실험. 공개적으로 사용 가능한 데이터셋과 네트워크 가중치를 사용하여 더 쉽게 재현할 수 있는 참조 번호를 제공하기 위해, 우리는 Table 10의 (vii)번 항목에서 CLIP ViT L-14 가중치 [85]와 LAION400M 데이터셋 [96]을 사용하는 두 가지 추가적인 ablation을 제공한다.
B.3.2 Dataset mixing strategies for the contrastive pretraining
[Korean Translation] ALIGN과 함께 LTIP를 새로운 데이터셋으로 학습에 포함시킨 것이 강력한 결과를 달성하는 데 중요한 요소였습니다. LTIP는 ALIGN보다 6배 작은 데이터셋임에도 불구하고, LTIP만으로 학습된 contrastive 모델은 우리가 평가하는 지표에서 ALIGN만으로 학습된 모델보다 더 나은 성능을 보였습니다. 이는 우리가 운영하는 환경에서는 데이터셋의 규모보다 품질이 더 중요할 수 있음을 시사합니다. 또한, ALIGN과 LTIP 두 데이터셋 모두로 학습된 모델이 개별 데이터셋으로 학습된 모델보다 더 나은 성능을 보이며, 데이터셋을 결합하는 방식 또한 중요하다는 것을 발견했습니다.
이를 입증하기 위해, 우리는 NFNet-F0 vision encoder, BERT-mini language encoder를 사용하고 배치 크기를 2048으로 설정하여 ALIGN, LTIP, 그리고 이 둘을 혼합한 데이터셋으로 1백만 번의 gradient-calculation step 동안 작은 모델을 학습시켰습니다. 결과는 Table 11에 제시되어 있습니다. 이 표는 세 가지 다른 병합 방식(merging regimes)을 사용하여 결합된 데이터셋으로 모델을 학습시킨 결과들을 보여줍니다:
- Data merged: 각 데이터셋의 예시들을 하나의 배치로 병합하여 배치를 구성합니다.
- Round-robin: 각 데이터셋의 배치를 번갈아 사용하며, 각 배치마다 파라미터를 업데이트합니다.
- Accumulation: 각 데이터셋의 배치로부터 gradient를 계산합니다. 이 gradient들은 가중치를 부여받아 합산된 후 파라미터 업데이트에 사용됩니다.
모든 평가 지표에서, 우리는 Accumulation 방식이 다른 데이터셋 결합 방식보다 더 우수한 성능을 보인다는 것을 발견했습니다. LTIP 데이터셋이 ALIGN 데이터셋보다 5배 작음에도 불구하고, 이 ablation study는 학습 데이터의 품질이 그 풍부함보다 더 중요할 수 있음을 시사합니다.
| Dataset | Combination strategy | ImageNet accuracy top-1 | COCO | |||||
|---|---|---|---|---|---|---|---|---|
| image-to-text | text-to-image | |||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| LTIP | None | 40.8 | 38.6 | 66.4 | 76.4 | 31.1 | 57.4 | 68.4 |
| ALIGN | None | 35.2 | 32.2 | 58.9 | 70.6 | 23.7 | 47.7 | 59.4 |
| LTIP + ALIGN | Accumulation | 45.6 | 42.3 | 68.3 | 78.4 | 31.5 | 58.3 | 69.0 |
| LTIP + ALIGN | Data merged | 38.6 | 36.9 | 65.8 | 76.5 | 15.2 | 40.8 | 55.7 |
| LTIP + ALIGN | Round-robin | 41.2 | 40.1 | 66.7 | 77.6 | 29.2 | 55.1 | 66.6 |
Table 11: Contrastive pretraining 데이터셋 및 조합 전략의 효과 첫 두 행은 LTIP와 ALIGN만으로 작은 모델을 학습시킨 효과를 보여줍니다. 마지막 세 행은 이 데이터셋들의 조합으로 학습된 작은 모델의 결과를 보여주며, 다양한 조합 전략을 비교합니다.
C Qualitative results
Figure 1에 제시된 샘플 외에도, 본 섹션에서는 Figure 10, 11, 12를 통해 다양한 상호작용 양식(interaction modalities)을 포괄하는 샘플들을 제공한다. 디코딩 시 beam width 3의 beam search를 사용하는 정량적 벤치마크 결과와 달리, 본 섹션에 제시된 모든 정성적 결과는 더 빠른 샘플링을 위해 greedy decoding을 사용하였다.
Figure 10은 가장 단순한 형태의 상호작용을 보여준다. 단일 이미지가 제공되고, 질문 또는 caption의 시작 형태인 텍스트 prompt가 이어진다. 모델이 질문 및 답변 형식에 대해 특별히 학습되지 않았음에도 불구하고, 사전학습된 언어 모델의 능력은 이러한 적응을 가능하게 한다. 이러한 샘플들 중 다수에서 Flamingo는 최소한 한 단계의 암묵적 추론(implicit inference)을 수행할 수 있다. 일부 객체는 prompt에 이름이 명시되지 않았지만, 해당 객체의 속성에 대해 직접 질문이 이루어진다. 모델은 시각적 입력을 기반으로, 언급된 객체와 관련된 지식을 기억해내어 올바른 답변을 생성한다. contrastive 학습으로 훈련된 Vision network는 문자 인식 능력(character recognition capabilities)을 학습하는 것으로 알려져 있다 [85]. 우리는 Flamingo가 전체 모델에서 이러한 능력을 보존하며, 때로는 이미지 크기에 비해 상당히 작은 텍스트에 대해서도 이러한 능력을 발휘함을 관찰하였다.
우리의 모델은 임의의 시퀀스 형태의 시각 정보와 언어를 입력으로 받을 수 있으므로, 이미지와 텍스트가 섞인 확장된 대화를 유지하는 능력을 테스트하였다. Figure 11은 짧은 대화(Appendix B.1.6)로 모델을 prompt한 후, 이미지 삽입을 포함한 사용자 상호작용을 통해 생성된 샘플들을 보여준다. 여러 차례의 상호작용 후에도 Flamingo는 여전히 이미지를 성공적으로 attend하고, 언어만으로는 추측할 수 없는 질문에 답변할 수 있다. 우리는 여러 이미지가 개별적으로 attend될 수 있음을 관찰하였다: 단순 비교 및 추론이 적절하게 처리된다.
마지막으로, 이미지에 비해 추가적인 어려움을 제시하는 비디오 입력에 대해서도 유사한 능력을 조사하였다. Figure 12는 몇 가지 선택된 샘플을 보여준다. 그림에서 볼 수 있듯이, 일부 경우
Flamingo는 여러 프레임의 정보를 성공적으로 통합하고 (예: 장면을 스캔하는 비디오 또는 텍스트), 시간적 이해를 포함하는 질문에 답변할 수 있다 (예: 마지막 샘플에서 "after"라는 단어를 사용하여).
D Discussion
D. 1 Limitations, failure cases and opportunities
5 Discussion
한계점 및 개선 기회
본 섹션에서는 모델의 한계점과 실패 사례, 그리고 모델 개선 및 능력 확장을 위한 기회에 대해 논의한다.
분류 성능 (Classification performance)
우리의 Visual Language Model(VLM)은 contrastive model에 비해 few-shot learning 및 open-ended generation과 같은 중요한 장점을 가지고 있지만, 분류 task에서는 contrastive model에 비해 성능이 뒤처진다. 이는 contrastive 학습의 목적 함수가 text-image retrieval을 직접적으로 최적화하는 반면, 우리의 VLM은 language modeling objective를 사용하기 때문으로 보인다. 실제로 분류 task의 평가 절차는 image-to-text retrieval의 특수한 경우로 간주될 수 있다 [85].
특히 Zhao et al. [148]은 언어 모델이 학습 데이터 분포, prompt에 사용된 샘플 집합, 그리고 그 순서로부터 발생하는 다양한 편향에 취약하다는 것을 보여주었다. 또한, 이러한 문제들은 특정 사전 분포(예: uniform 분포)를 가정할 수 있다면 calibration 기법을 통해 완화될 수 있음을 입증하였다. 그러나 이러한 가정은 일반적이지 않으며, few-shot setting에서 이러한 문제를 해결하기 위한 추가적인 연구가 필요하다. 더 나아가, 이 두 종류의 모델 간의 성능 격차를 해소할 수 있는 objective, architecture, 또는 평가 절차를 찾는 것은 유망한 연구 방향이 될 수 있다.
언어 모델의 유산 (Legacies of language models)
우리의 모델은 강력한 사전학습된 causal language model에 기반하며, 이로 인해 해당 모델의 약점을 그대로 물려받는다. 예를 들어, 조건부 입력에 대한 causal modeling은 bidirectional modeling보다 표현력이 떨어진다. 이러한 맥락에서, 최근 연구들은 non-causal masked language modeling adaptation [120]과 multitask fine-tuning [95, 125, 131]을 결합하면 causal decoder-only language model의 zero-shot 성능을 효율적으로 향상시킬 수 있음을 보여주었다.
또한, Transformer 기반 언어 모델은 학습 시퀀스보다 훨씬 긴 테스트 시퀀스에 대해 일반화 성능이 떨어지는 경향이 있다 [83]. 예를 들어, 예상되는 텍스트 출력이 매우 길어지는 경우, few-shot learning을 위해 충분한 shot을 활용하는 모델의 능력이 저하될 수 있다. VisDial dataset [20]의 경우, 단일 shot은 이미지와 함께 21개의 문장으로 구성된 긴 대화로 이루어진다. 따라서 32개의 VisDial shot으로 구성된 시퀀스는 최소 개의 문장으로 이루어지며, 이는 실제로는 prompt 길이가 4096에서 8192 토큰 범위에 해당한다. 이는 우리의 LM이 학습된 최대 시퀀스 길이(2048)보다 훨씬 길다 [42]. 이러한 이유로, 우리는 VisDial에 대한 보고 결과를 최대 16 shot으로 제한하였다.
다른 한편으로, 우리의 ablation study는 고정된(frozen) 언어 모델로부터 물려받은 언어 모델 prior의 중요성을 보여주지만, open-ended 대화 설정에서 간혹 발생하는 환각(hallucination) 및 근거 없는 추측(ungrounded guesses)의 원인이 될 수 있다고 추측한다. 이러한 행동의 예시는 Figure 13에서 분석하여 제공한다. 마지막으로, 언어 모델링은 사전학습 시 sample efficiency가 낮다는 문제가 있다 [11]. 이 문제를 완화하면 대규모 학습 실행의 처리 시간을 개선하고, 더 나아가 대규모에서의 체계적인 설계 결정 탐색의 실현 가능성을 높여, 본 분야의 발전을 크게 가속화할 잠재력이 있다. 대형 LM의 일반적인 약점에 대한 추가적인 논의는 [11, 86]에서 찾아볼 수 있다.
Few-shot 학습 방법의 Trade-off
본 논문에서는 우리의 "주력" few-shot 학습 방법으로 in-context learning을 사용한다 (Section 2.5 참조). 이 방법은 fine-tuning과 같은 gradient 기반 접근 방식에 비해 주목할 만한 장점을 가진다. 실제로 in-context learning은 하이퍼파라미터 튜닝이 거의 필요 없으며, 매우 적은 데이터(수십 개 예시) 환경에서도 합리적인 성능을 보이고, 추론만으로도 작동하여 배포를 단순화한다. 반면, gradient 기반 접근 방식은 과적합을 피하기 위해 신중하게 튜닝된 설계 결정(적절한 learning rate 스케줄 또는 아키텍처 설계 [43] 등)이 필요하며, 좋은 성능을 내기 위해서는 더 많은 데이터(수천 개)가 필요한 경우가 많다. 이러한 이유로 우리는 in-context learning에 집중하였지만, 이 접근 방식에는 우리가 다음에서 논의할 단점들도 존재한다.
추론 연산 비용 (Inference compute cost)
Transformer 모델을 사용한 in-context learning의 연산 비용은, few-shot prompt를 여러 쿼리 샘플에 재사용할 수 있다면 (key와 value를 캐싱함으로써) shot 수에 대해 선형적으로 증가하며, 그렇지 않다면 제곱으로 증가한다. 반면, gradient 기반 few-shot 학습 접근 방식 [43]은 추론 시 shot 수에 대해 일정한 복잡도를 가진다.
Prompt 민감도 (Prompt sensitivity)
In-context learning은 또한 demonstration의 다양한 측면, 예를 들어 샘플의 순서 [148]나 형식에 대해 놀랍도록 민감한 것으로 나타났다.
더 많은 shot 활용 (Leveraging more shots)
In-context learning을 사용할 때, few-shot 샘플 수가 32개를 넘어서면 성능이 빠르게 정체된다. 이는 학습된 데이터의 양이 성능에 중요한 요소인 일반적인 gradient 기반 방법들과는 대조적인 결과이다. 우리는 RICES (Retrieval In-Context Example Selection [136], Appendix A.2 참조)가 분류 task에 대해 이 문제를 효과적으로 완화하지만 (Appendix B.2.1 참조), 클래스당 소수의 예시를 넘어서면 유사한 문제에 직면한다는 점에 주목한다.
Task 위치 (Task location)
In-context learning을 효과적으로 만드는 요인에 대한 최근 연구는, 왜 더 많은 shot이 항상 도움이 되지 않는지에 대한 가능한 설명을 제공한다 [76, 92]. 더 자세히 설명하자면, Brown et al. [11]은 in-context learning이 실제로 추론 시 제공된 입력-출력 매핑을 기반으로 새로운 task를 "학습"하는지, 아니면 단순히 학습 중에 배운 task를 인식하고 식별하는지에 대한 질문을 제기한다. 이 질문에 대해, Reynolds and McDonell [92]의 연구 결과는 후자가 다양한 설정에서 성능의 주요 동인임을 시사하며, 이를 "task location"이라고 지칭한다. 유사하게, Min et al. [76]은 입력과 출력 간의 매핑이 예시의 전반적인 형식을 지정하는 것과는 대조적으로, few-shot 성능에 미치는 영향이 제한적임을 보여준다. 이러한 연구 결과와 일치하여, 우리는 이미지 없이 prompt를 사용하는 경우에도 상당한 zero-shot 성능을 관찰했으며, 이는 task 형식이 중요하다는 점을 강조한다. 직관적으로, 소수의 샘플만으로도 task location을 잘 수행할 수 있지만, 모델은 일반적으로 추론 시 추가 샘플을 활용하여 행동을 개선하지 못할 수 있다.

Figure 13: Open-ended visual question answering에서의 환각 및 근거 없는 추측. 왼쪽: 모델이 때때로 텍스트만으로는 그럴듯해 보이지만, 추가적인 입력으로 이미지를 고려하면 틀린 답을 생성하는 환각 현상을 보인다. 중간: 관련 없는 질문으로 모델을 적대적으로 prompt하여 유사한 환각을 유발할 수 있다. 오른쪽: 모델이 입력만으로는 답을 결정할 수 없을 때 근거 없는 추측을 하는 더 흔한 함정이 발생한다. Few-shot 예시와 더 정교한 prompt 설계는 이러한 문제를 완화하는 데 사용될 수 있다. 더 넓게는, 이러한 문제를 해결하는 것은 open-ended visual dialogue 설정에서 모델의 응용을 개선하기 위한 중요한 연구 방향이다.
요약하자면, 모든 시나리오에서 잘 작동하는 "황금률"의 few-shot 방법은 존재하지 않는다. 특히, few-shot 학습 방법의 최적 선택은 응용 프로그램의 특성에 크게 의존하며, 그중 중요한 하나는 annotated 샘플의 수이다. 본 연구에서 우리는 in-context learning이 매우 적은 데이터(32개 이하의 샘플) 환경에서 매우 효과적임을 입증한다. 특히 수백 개의 샘플과 같이 데이터 제약이 덜한 환경을 목표로 할 때, 상호 보완적인 이점을 활용하기 위해 다양한 방법을 결합할 기회가 있을 수 있다.
시각 및 텍스트 인터페이스 확장 (Extending the visual and text interface)
자연어는 모델에 시각적 task에 대한 설명을 제공하고, 출력을 생성하거나 가능한 출력에 대한 조건부 확률을 추정하는 강력하고 다재다능한 인터페이스이다. 그러나 이는 bounding box (또는 그 시간적, 시공간적 대응물)와 같이 더 구조화된 출력을 조건으로 하거나 예측하는 task, 그리고 공간적(또는 시간적, 시공간적)으로 밀집된 예측을 수행하는 task에는 번거로운 인터페이스일 수 있다. 또한, 광학 흐름 예측과 같은 일부 시각 task는 연속적인 공간에서의 예측을 포함하며, 이는 우리 모델이 기본적으로 처리하도록 설계되지 않은 것이다. 마지막으로, 시각 외에 상호 보완적일 수 있는 오디오와 같은 추가적인 양식을 고려할 수 있다. 이러한 모든 방향은 우리 모델이 처리할 수 있는 task의 범위를 확장할 잠재력을 가지고 있으며, 상응하는 능력 간의 시너지를 통해 우리가 집중하는 task의 성능을 향상시킬 수도 있다.
Vision-Language 모델의 Scaling Law
본 연구에서는 Flamingo 모델을 최대 80B 파라미터까지 확장하고, Figure 2에 요약된 평가 벤치마크 전반에 걸친 확장 행동에 대한 초기 통찰력을 제공한다. 언어 분야에서는 중요한 연구 흐름이 언어 모델의 scaling law [42, 53]를 확립하는 데 초점을 맞춰왔다. 비전 분야에서는 Zhai et al. [145]가 이 방향으로 한 걸음 나아갔다. 그러나 contrastive 모델과 같은 비전-언어 모델, 그리고 우리가 제안하는 것과 같은 시각 언어 모델에 대해서는 유사한 노력이 아직 이루어지지 않았다. 언어 모델링 scaling law 연구가 perplexity를 주요 지표로 삼는 데 초점을 맞춘 반면, 우리는 aggregate downstream 평가 task 성능 측면에서 이러한 추세를 확립하는 것이 우리 목적에 더 직접적으로 유용할 수 있다고 추측한다.
D. 2 Benefits, risks and mitigation strategies
D.2.1 Benefits
Accessibility
Flamingo와 같은 시스템은 여러 잠재적인 사회적 이점을 제공하며, 그중 일부는 이 섹션에서 논의할 것이다. 광범위하게 말하자면, Flamingo는 task 일반화 능력을 갖추고 있어 역사적으로 비전 연구의 초점이 아니었던 사용 사례에도 적합하다. 일반적인 비전 시스템은 수동으로 주석 처리된 특정 task에 대한 대규모 데이터베이스로 학습되기 때문에, 의도적으로 훈련된 좁은 사용 사례 외의 응용에는 부적합하다. 반면에 Flamingo는 최소한의 제약 조건 하에서 학습되어 강력한 few-shot task 유도 능력을 갖추고 있다. 우리의 정성적 예시(Appendix C)에서 보여주었듯이, Flamingo는 개방형 대화를 위한 "채팅"과 유사한 인터페이스를 통해 사용될 수도 있다. 이러한 능력은 비전문 사용자도 적은 양의 task-specific 학습 데이터만 수집되었거나, 다양한 형식과 문체로 질의가 이루어질 수 있는 저자원 문제에도 Flamingo와 같은 모델을 적용할 수 있게 해줄 것이다. 이러한 맥락에서, 우리는 Flamingo가 시각 장애인을 지원하기 위한 시각 인식 기술을 촉진하는 VizWiz 챌린지에서 강력한 성능을 달성했음을 보여주었다. 또한 대화 인터페이스는 시각 언어 모델에 대한 더 나은 이해와 해석 가능성을 증진시킬 수 있다. 이는 모델이 학습 데이터로부터 습득할 수 있는 편향, 공정성, 독성 문제들을 강조하는 데 도움이 될 수 있다. 전반적으로, 우리는 Flamingo가 최신 시각 인식 기술을 보다 광범위하게 접근 가능하고 유용하게 만들어 다양한 응용 분야에 기여하는 중요한 단계를 나타낸다고 믿는다.
Model recycling
모델링 관점에서 볼 때, Flamingo는 학습에 계산 비용이 많이 들지만, 사전학습된 고정된(frozen) 언어 모델과 시각 인코더를 활용한다는 중요한 이점이 있다. 우리는 새로운 모달리티를 고정된 모델에 도입하여 값비싼 재학습을 피할 수 있음을 입증하였다. 이러한 모델들이 크기와 계산 요구 사항이 계속 증가함에 따라, Larochelle [55]에서 설명하고 Strubell et al. [105]에서 언어 모델에 대해 탐구한 바와 같이, 환경적 관점(그리고 실용적인 관점)에서 이들을 "재활용"하는 것이 점점 더 중요해질 것이다. 우리는 이러한 결과가 기존 모델을 처음부터 학습시키는 대신 효율적으로 재활용하는 방법에 대한 추가 연구에 영감을 주기를 희망한다.
D.2.2 Risks and mitigation strategies
[Korean Translation] 이 섹션에서는 Flamingo와 같은 모델이 가질 수 있는 잠재적 위험에 대한 초기 조사 결과를 제공한다. 본 연구는 예비적인 것이며, 이러한 위험을 더 잘 평가하기 위해 추가적인 연구 노력이 필요할 것으로 예상된다. 또한 이러한 모델을 안전하게 배포하기 위한 잠재적인 완화 전략에 대해서도 논의한다. 참고로, 본 모델은 연구 목적으로만 개발되었으며, 적절한 위험 분석 및 완화 전략 탐구가 선행되지 않는 한 특정 애플리케이션에 사용되어서는 안 된다는 점을 우리의 Model Card [77] (Appendix E 참조)에서 설명하였다.
구조적으로 Flamingo는 대형 언어 모델(Large LM)의 위험성을 그대로 계승한다. 우리 모델의 상당 부분이 기존 언어 모델 [42]의 가중치를 고정하여 얻어진다는 점을 상기하자. 특히, 이미지가 주어지지 않으면 Flamingo는 언어 모델의 행동으로 되돌아간다. 따라서 Flamingo는 대형 언어 모델과 동일한 위험에 노출된다: 잠재적으로 불쾌감을 주는 언어를 출력하거나, 사회적 편견과 고정관념을 확산시키거나, 개인 정보를 유출할 수 있다 [126]. 특히, Chinchilla 논문 (Hoffmann et al. [42], Section 4.2.7)에서 제시된 Winogender 데이터셋 [93]에 대한 성별 편향 분석을 참조하기 바란다. 이 분석은 해당 모델이 이전 모델 [86]보다 성별 편향이 적음에도 불구하고, 성별 편향이 여전히 존재함을 보여준다. 또한, 프롬프트 없이 발생하는 독성(unprompted toxicity)에 관해서는 Chinchilla [42]의 분석을 참조하기 바란다. 이 분석은 PerspectiveAPI 독성 점수를 25,000개의 샘플에 대해 계산한 결과, 프롬프트 없이 독성 출력을 생성하려는 모델의 경향이 전반적으로 상당히 낮다는 점을 강조한다. Weidinger et al. [126]은 이러한 위험에 대한 가능한 장기적인 완화 전략을 상세히 설명한다. 여기에는 규제 프레임워크 및 가이드라인 생성과 같은 사회적 또는 공공 정책 개입, 사용자 인터페이스 결정과 관련된 신중한 제품 설계, 그리고 더 나은 벤치마크 구축 및 완화 전략 개선과 같은 AI 윤리 및 NLP의 교차점에서 이루어지는 연구 등이 포함된다. 단기적으로는, 프롬프트를 활용하여 편향 및 유해한 출력을 완화하는 효과적인 접근 방식이 있다 [86]. 다음으로, Flamingo의 추가적인 시각 입력 기능으로 인해 발생하는 위험을 탐구한다.
1| | CIDEr 차이 | | CIDEr 전체 | | :--- | :--- | :--- | :--- | | | 여성 - 남성 | 어두운 피부 - 밝은 피부 | | | AoANet [46] | - | +0.0019 | 1.198 | | Oscar [61] | - | +0.0030 | 1.278 | | Flamingo, 0 shot | | | 0.843 | | Flamingo, 32 shots | | | 1.138 |
Table 12: COCO 캡셔닝에 대한 Flamingo의 편향 평가. 우리는 Zhao et al. [147]에서 제공한 성별 및 피부톤에 따른 COCO 데이터셋 분할에 대한 결과를 보고한다.
이미지로 프롬프트될 때의 성별 및 인종 편향. 이전 연구에서는 캡셔닝 시스템에 존재하는 편향을 연구해왔다 [37, 147]. 이러한 모델링 편향은 부주의하게 배포될 경우 실제적인 피해를 초래할 수 있다. AI 시스템이 사회 전체에 유용하려면, 그 성능은 인식된 피부톤이나 피사체의 성별에 의존해서는 안 된다. 즉, 모든 인구 집단에 대해 동등하게 잘 작동해야 한다. 그러나 현재 자동화된 비전 시스템의 성능은 인종, 성별에 따라 다르거나, 다양한 인구 통계 및 지리적 영역에 걸쳐 적용될 때 달라진다고 보고되었다 [12, 21, 97]. Flamingo의 성능이 인구 집단 간에 어떻게 달라지는지를 평가하는 예비 연구로서, 우리는 Zhao et al. [147]에서 제안한 연구를 따라, COCO에서의 모델 캡셔닝 성능이 성별 및 인종에 따라 어떻게 달라지는지를 보고한다. 참고로, 우리는 Zhao et al. [147]에서 제안한 평가 프로토콜과 다른 평가 프로토콜을 사용한다. 그 연구에서는 5개의 사전학습된 모델에 대한 결과를 측정하고, 모델별 집계 점수에 대한 신뢰 구간을 계산했다. 여기서는 (높은 학습 비용으로 인해) 모델 복사본이 하나뿐이므로, 대신 Zhao et al. [147]의 분할에서 샘플별 CIDEr 점수에 대한 통계적 검정을 수행한다. 결과를 Table 12에 보고한다.
전반적으로, 여성으로 레이블링된 이미지와 남성으로 레이블링된 이미지 간의 CIDEr 점수를 집계하여 비교할 때, 그리고 어두운 피부와 밝은 피부를 비교할 때, 샘플별 CIDEr 점수에는 통계적으로 유의미한 차이가 없음을 발견했다. 두 샘플 집단을 비교하기 위해 우리는 등분산이 아닌 이분산 t-검정을 사용했으며, 고려된 네 가지 비교 중에서 가장 낮은 p-값은 로, 일반적인 통계적 유의성 임계값(예: 일반적인 기각 임계값은 일 수 있음)보다 훨씬 높다. 이는 점수 간의 차이가 평균 점수가 동일하다는 귀무 가설 하에서 무작위 변동과 구별할 수 없음을 시사한다. 귀무 가설을 기각하지 못하고 유의미한 차이를 입증하지 못한다고 해서 유의미한 차이가 없다는 것을 의미하지는 않는다는 점에 유의해야 한다. 예를 들어, 더 큰 표본 크기를 통해 입증될 수 있는 차이가 존재할 수 있다. 그러나 이러한 예비 결과는 그럼에도 불구하고 고무적이다.
이미지로 프롬프트될 때의 독성. 우리는 또한 COCO 테스트 세트의 이미지를 프롬프트로 사용하여 모델이 생성한 캡션의 독성을 평가하기 위해 Perspective API를 사용하여 Flamingo의 독성을 평가한다. 일부 캡션이 분류기에 의해 잠재적으로 독성이 있는 것으로 레이블링됨을 관찰했지만, 수동으로 검사했을 때 명확한 독성은 관찰되지 않았다. 즉, 출력 캡션은 제공된 이미지에 적합했다. 전반적으로, 프로젝트 진행 중에 시스템과 상호 작용한 경험에 따르면, "안전한(safe-for-work)" 이미지가 주어졌을 때 독성 출력을 관찰하지 못했다. 그러나 이것이 모델이 독성 출력을 생성할 수 없다는 것을 의미하지는 않으며, 특히 "안전하지 않은(not-safe-for-work)" 이미지 및/또는 독성 텍스트로 프롬프트될 경우 더욱 그렇다. 이러한 모델이 생산에 투입된다면 보다 철저한 탐색과 연구가 필요할 것이다.
완화 전략을 위한 Flamingo 적용. 저자원 환경에서 빠르게 적응하는 능력 덕분에, Flamingo 자체를 위에서 설명한 일부 문제를 해결하는 데 적용할 수 있다. 예를 들어, Thoppilan et al. [111]에 따라, 적절하게 조건화되거나 fine-tuning된 Flamingo 모델을 학습 데이터에서 독성 또는 유해한 샘플을 필터링하는 목적으로 사용할 수 있다. 그들의 연구에서는 결과 데이터에 fine-tuning했을 때 안전성 및 품질 측면에서 상당한 개선이 있음을 관찰했다. 또한, 평가 중에 이러한 적응된 모델을 사용하여 공격적이거나, 사회적 편견 및 고정관념을 조장하거나, 개인 정보를 유출할 수 있는 출력을 순위 하락시키거나 제외함으로써, 저자원 작업에서도 이 방향으로의 발전을 가속화할 수 있다. HatefulMemes 벤치마크에 대한 우리의 결과는 이 방향으로의 유망한 단계를 나타낸다. 언어 모델링 분야의 최근 연구에서는 LM을 "레드팀(red team)" 역할을 하도록 훈련시켜 테스트 케이스를 생성함으로써, 다른 대상 LM이 유해하게 작동하는 경우를 자동으로 찾는 데 성공했다 [81]. 유사한 접근 방식을 우리 설정에도 적용할 수 있다.
2 시각 입력 내 특정 위치 또는 외부 검증된 인용을 참조하여 출력을 지원하는 기능 또한 흥미로운 방향이다 [72, 111]. 마지막으로, Figure 11에서는 Flamingo가 자체 출력에 대해 설명할 수 있음을 보여주는 정성적 예시를 제공하며, 이는 모델의 텍스트 인터페이스를 사용하여 설명 가능성 및 해석 가능성을 위한 길을 제시한다.
E Flamingo Model Card
[Korean Translation] 우리는 Mitchell et al. [77]에서 제시된 프레임워크에 따라 Flamingo에 대한 모델 카드(model card)를 Table 13에 제시한다.
| Model Details | |
|---|---|
| Model Date | March 2022 |
| Model Type | Transformer 기반의 autoregressive language model이며, convnet 기반 encoder로부터 얻은 시각적 특징(visual features)에 의해 조건화된다. 추가적인 Transformer 기반 cross-attention layer는 언어 모델의 텍스트 예측에 시각적 특징을 통합한다. (자세한 내용은 Section 2 참조.) |
| Intended Uses | |
| Primary Intended Uses | 주요 용도는 다음과 같은 visual language model (VLM) 연구이다: 분류, 캡셔닝, visual question answering과 같은 VLM 응용 연구, 강력한 VLM이 AGI에 어떻게 기여할 수 있는지 이해, 멀티모달 연구 분야에서의 공정성(fairness) 및 안전성 연구 발전, 그리고 현재 대형 VLM의 한계점 이해. |
| Out-of-Scope Uses | 유해하거나 기만적인 환경에서 시각 정보에 의해 조건화된 언어 생성을 위해 모델을 사용하는 것. 광범위하게 말하자면, 각 응용 분야에 특화된 추가적인 안전 및 공정성 완화 조치 없이 모델을 다운스트림 응용에 사용하는 것은 지양해야 한다. |
| Factors | |
| Card Prompts - Relevant Factor | 관련 요인에는 사용되는 언어가 포함된다. 우리 모델은 영어 데이터로 학습되었다. 우리 모델은 연구를 위해 설계되었다. 제안된 다운스트림 응용 분야의 요인에 대한 추가 분석 없이 모델을 다운스트림 응용에 사용하는 것은 지양해야 한다. |
| Card Prompts - Evaluation Factors | Flamingo는 Chinchilla에 기반하며 (Chinchilla 가중치의 상당 부분이 사용됨), 본 연구의 언어 전용 구성 요소에 대한 분석은 [42, 86]을 참조한다. 모델이 이미지에 의해 조건화될 때의 독성(toxicity) 분석에 대해서는 Appendix D.2.2에 제시된 연구를 참조한다. |
| Metrics |
| Model Performance Measures | 우리는 주로 이미지 입력 시 관련 언어를 예측하는 모델의 능력에 초점을 맞춘다. 이를 위해 분류(ImageNet, Kinetics700, HatefulMemes), 이미지 및 비디오 캡셔닝(COCO, VATEX, Flickr30K, YouCook2, RareAct), visual question answering(OKVQA, VizWiz, TextVQA, VQAv2, MSRVTTQA, MSVDQA, iVQA, STAR, NextQA), 그리고 visual dialog(VisDiag)와 같이 다양한 비전 및 언어 task를 포괄하는 총 18개의 서로 다른 벤치마크를 사용하였다. 이는 Flamingo가 언어를 생성하고 그 출력을 ground truth와 비교하는 open ended 설정 또는 모델의 likelihood를 사용하여 다양한 결과를 직접 평가하는 close ended 설정에서 테스트되었다. |
|---|---|
| Decision thresholds | 해당 없음 |
| Approaches to Uncertainty and Variability | Flamingo 학습 비용으로 인해 여러 번 학습시킬 수 없다. 그러나 다양한 종류의 task에 대한 광범위한 평가를 통해 모델의 전반적인 성능을 합리적으로 추정할 수 있다. |
| Evaluation Data | |
| Datasets | 자세한 목록은 Table 6을 참조하라. |
| Motivation | Flamingo가 이미지 입력 시 관련 텍스트를 생성하는 능력을 정확하게 평가하기 위해, 우리는 다양한 비전 및 언어 task를 포괄하는 중요한 범위의 평가 데이터셋을 선택하였다. |
| Preprocessing | 입력 텍스트는 32,000개의 어휘 크기를 가진 SentencePiece tokenizer를 사용하여 토큰화된다. 이미지는 각각 평균과 분산이 0과 1이 되도록 처리된다. |
| Training Data | |
| See [50], the Datasheet in Appendix F.1, Appendix F.2.1, Appendix F.2.2 | |
| Quantitative Analyses | |
| Unitary Results | Flamingo는 광범위한 open-ended 비전 및 언어 task에서 few-shot learning 기준으로 새로운 state of the art를 달성한다. 우리가 고려한 16개 task 중, Flamingo는 수십 배 적은 task-specific 학습 데이터를 사용했음에도 불구하고 6개 task에서 fine-tuned state-of-the-art를 능가한다. 우리의 정량적 연구에 대한 전체 세부 사항은 Section 3을 참조하라. |
| Intersectional Results | 교차적 편향(intersectional biases)을 조사하지 않았다. |
| Ethical Considerations | |
| Data | 데이터는 다양한 출처에서 수집되었으며, 일부는 웹 콘텐츠에서 비롯되었다. 성적으로 노골적인 콘텐츠는 필터링되었지만, 데이터셋에는 인종차별적, 성차별적 또는 기타 유해한 콘텐츠가 포함되어 있다. |
| Human Life | 이 모델은 인간의 삶이나 번영에 중요한 문제에 대한 결정을 내리는 데 사용될 의도가 없다. |
| Mitigations | 성적으로 노골적인 콘텐츠를 제거하는 것 외에, Rae et al. [86]의 논리에 따라 유해한(toxic) 콘텐츠를 필터링하지 않았다. Weidinger et al. [126]에서 논의된 바와 같이, 유해한 콘텐츠 및 언어 모델과 관련된 기타 유형의 위험에 대한 완화(mitigation) 접근 방식에 대한 추가적인 연구가 필요하다. |
|---|---|
| Risks and Harms | 데이터는 인터넷에서 수집되었으므로, 우리 모델 학습에 사용된 데이터셋에는 의심할 여지 없이 유해하고 편향된 콘텐츠가 포함되어 있다. 또한, 우리 모델 학습에 사용된 데이터셋에 개인 정보가 포함되어 있을 가능성이 높다. Weidinger et al. [126]에 제시된 보다 상세한 논의를 참조한다. |
| Use Cases | 특히 문제가 될 수 있는 사용 사례에는 사실과 다른 정보를 의도적으로 배포하거나, 인종차별적, 성차별적 또는 기타 유해한 텍스트를 악의적인 의도로 생성하기 위해 모델을 사용하는 것이 포함된다. 해를 끼칠 수 있는 더 많은 사용 사례가 존재한다. 이러한 악의적인 사용에 대한 응용은 Weidinger et al. [126]에서 자세히 논의된다. |
Table 13: Flamingo Model Card. Mitchell et al. [77]에서 제시된 프레임워크를 따른다.
F Datasheets
F. 1 M3W dataset
Gebru et al. [30]에서 정의한 프레임워크를 따라, 에 대한 Datasheet를 Table 14에 제시한다.
| Motivation | |
|---|---|
| For what purpose was the dataset created? Who created the dataset? Who funded the creation of the dataset? | 이 데이터셋은 vision-language 모델 사전학습을 목적으로 생성되었으며, 연구원 및 엔지니어들이 만들었다. |
| Any other comments? | 없음. |
| Composition | |
| What do the instances that comprise the dataset represent (e.g., documents, photos, people, countries)? | 이 데이터셋의 모든 인스턴스는 웹에서 수집된, 텍스트와 이미지가 섞여 있는(interleaved) 문서들이다. |
| How many instances are there in total (of each type, if appropriate)? | 총 4,330만 개의 인스턴스(문서)가 있으며, 총 1억 8,500만 개의 이미지가 포함되어 있고, 텍스트 용량은 182GB이다. |
| Does the dataset contain all possible instances or is it a sample (not necessarily random) of instances from a larger set? | 이 데이터셋은 더 큰 집합에서 추출된 샘플이다. |
| What data does each instance consist of? | 각 인스턴스는 문서의 텍스트를 인코딩하는 UTF-8 바이트 시퀀스, 텍스트 내 이미지 위치를 나타내는 정수 시퀀스, 그리고 압축된 형식의 이미지 자체로 구성된다 (Section 2.4 참조). |
| Is there a label or target associated with each instance? | 아니요, 각 인스턴스와 연관된 레이블은 없다. |
| Is any information missing from individual instances? | 아니요. |
|---|---|
| Are relationships between individual instances made explicit? | 이 데이터셋 내의 개별 인스턴스 간에는 어떠한 관계도 명시되어 있지 않다. |
| Are there recommended data splits? | 훈련 및 개발 세트에 대해 무작위 분할(random splits)을 사용한다. |
| Are there any errors, sources of noise, or redundancies in the dataset? | 문서 하위 수준(sub-document level)에서 상당한 중복(redundancy)이 존재한다. |
| Is the dataset self-contained, or does it link to or otherwise rely on external resources? | 이 데이터셋은 자체 포함적(self-contained)이다. |
| Does the dataset contain data that might be considered confidential? | 아니요. |
| Does the dataset contain data that, if viewed directly, might be offensive, insulting, threatening, or might otherwise cause anxiety? | 이 데이터셋은 웹에 만연한 특성상, 불쾌감을 주거나, 모욕적이거나, 위협적이거나, 또는 불안을 유발할 수 있는 데이터를 일부 포함하고 있을 가능성이 높다. 우리는 명시적인 콘텐츠를 제외하고는 이러한 콘텐츠를 필터링하려고 시도하지 않았으며, 명시적인 콘텐츠는 전용 필터를 사용하여 식별한다. |
| Collection Process | |
| How was the data associated with each instance acquired? | 데이터는 웹에서 공개적으로 이용 가능하다. |
| What mechanisms or procedures were used to collect the data? | 원시 텍스트와 이미지를 추출하고 정리하기 위해 다양한 소프트웨어 프로그램이 사용되었다. |
| If the dataset is a sample from a larger set, what was the sampling strategy? | 문서를 무작위로 하위 샘플링(subsample)한다. |
| Over what timeframe was the data collected? | 데이터는 2021년 몇 달에 걸쳐 수집되었다. 생성 날짜를 기준으로 소스를 필터링하지 않는다. |
| Were any ethical review processes conducted? | 아니요. |
| Preprocessing/cleaning/labeling | |
| Was any preprocessing/Cleaning/Labeling of the data done (e.g., discretization or bucketing, tokenization, part-of-speech tagging, SIFT feature extraction, removal of instances, processing of missing values)? | 예 - 전처리 세부 사항은 Appendix A.3.1에서 논의된다. |
| Is the software used to preprocess/clean/label the instances available? | 아니요. |
| Uses | |
| Has the dataset been used for any tasks already? | 예, 이 데이터셋은 멀티모달 언어 및 비전 모델 사전학습에 사용된다. |
| Is there a repository that links to any or all papers or systems that use the dataset? | 아니요, 이 데이터셋은 본 논문의 모델들을 학습시키는 데에만 사용되었다. |
| What (other) tasks could the dataset be used for? | 현재 단계에서는 다른 용도를 예상하지 않는다. |
|---|---|
| Is there anything about the composition of the dataset or the way it was collected and preprocessed/cleaned/labeled that might impact future uses? | 이 데이터셋은 정적이므로 시간이 지남에 따라 점차 "오래된" 데이터가 될 것이다. 예를 들어, 시간이 지남에 따라 진화하는 새로운 언어와 규범을 반영하지 못할 것이다. 그러나 데이터셋의 특성상 최신 버전의 데이터를 수집하는 비용은 상대적으로 저렴하다. |
| Are there tasks for which the dataset should not be used? | 본 논문에서 설명된 데이터셋은 거의 전적으로 영어 텍스트를 포함하므로, 다국어 기능을 갖춘 모델을 훈련하는 데에는 사용해서는 안 된다. |
| Distribution | |
| Will the dataset be distributed to third parties outside of the entity (e.g., company, institution, organization) on behalf of which the dataset was created? | 아니요. |
Table 14: M3W Datasheet. Gebru et al. [30]에서 제시된 프레임워크를 따른다.
F. 2 Image and video text pair datasets
F.2.1 Datasheet for LTIP
| 동기 (Motivation) | |
|---|---|
| 데이터셋은 어떤 목적으로 생성되었습니까? 데이터셋은 누가 생성했습니까? 데이터셋 생성 자금은 누가 지원했습니까? | 데이터셋은 vision-language 모델 사전학습을 위해 생성되었으며, 연구원 및 엔지니어들이 생성했습니다. |
| 기타 언급할 사항이 있습니까? | 없음. |
| 구성 (Composition) | |
| 데이터셋을 구성하는 인스턴스들은 무엇을 나타냅니까 (예: 문서, 사진, 사람, 국가)? | 데이터셋의 모든 인스턴스는 이미지-텍스트 쌍입니다. |
| 총 인스턴스 수는 몇 개입니까 (해당하는 경우 각 유형별로)? | 데이터셋은 3억 1,200만 개의 이미지-텍스트 쌍을 포함합니다. |
| 데이터셋은 가능한 모든 인스턴스를 포함합니까, 아니면 더 큰 세트에서 추출된 샘플입니까 (반드시 무작위는 아님)? | 데이터셋은 더 큰 세트에서 추출된 샘플입니다. |
| 각 인스턴스는 어떤 데이터로 구성됩니까? | 각 인스턴스는 문서의 텍스트를 인코딩하는 UTF-8 바이트 시퀀스와 압축된 형식의 이미지로 구성됩니다 (Appendix A.3.3 참조). |
| 각 인스턴스에 레이블 또는 타겟이 연관되어 있습니까? | 아니요, 각 인스턴스에 연관된 레이블은 없습니다. |
| 개별 인스턴스에서 누락된 정보가 있습니까? | 아니요. |
| 개별 인스턴스 간의 관계가 명시되어 있습니까? | 데이터셋 내의 다른 인스턴스 간에는 관계가 없습니다. |
| 권장되는 데이터 분할이 있습니까? | 학습 및 개발 세트에 대해 무작위 분할을 사용합니다. |
| 데이터셋에 오류, 노이즈 소스 또는 중복이 있습니까? | 데이터는 비교적 품질이 높지만, 일부 인스턴스가 여러 번 반복될 가능성이 있습니다. |
| 데이터셋은 자체 포함되어 있습니까, 아니면 외부 리소스에 연결되거나 의존합니까? | 데이터셋은 자체 포함되어 있습니다. |
| 데이터셋에 기밀로 간주될 수 있는 데이터가 포함되어 있습니까? | 아니요. |
| 데이터셋에 직접 보면 불쾌하거나, 모욕적이거나, 위협적이거나, 또는 다른 방식으로 불안을 유발할 수 있는 데이터가 포함되어 있습니까? | 이 데이터셋에 사용된 웹사이트는 그러한 콘텐츠를 피하기 위해 신중하게 선택되었습니다. 그러나 데이터의 규모를 고려할 때 일부 데이터가 불쾌하거나 모욕적인 것으로 간주될 수 있습니다. |
| 수집 과정 (Collection Process) | |
| 각 인스턴스에 연관된 데이터는 어떻게 획득되었습니까? | 데이터는 웹에서 공개적으로 이용 가능합니다. |
| 데이터를 수집하기 위해 어떤 메커니즘이나 절차가 사용되었습니까? | 원시 텍스트와 이미지를 추출하고 정리하기 위해 다양한 소프트웨어 프로그램이 사용되었습니다. |
| 데이터셋이 더 큰 세트에서 추출된 샘플인 경우, 샘플링 전략은 무엇이었습니까? | 해당 없음 (N.A.). |
| :--- | :--- |
| 데이터는 어떤 기간 동안 수집되었습니까? | 데이터는 2021년 몇 달에 걸쳐 수집되었습니다. 생성 날짜를 기준으로 소스를 필터링하지 않습니다. |
| 윤리 검토 절차가 수행되었습니까? | 아니요. |
| 전처리/정리/레이블링 (Preprocessing/cleaning/labeling) | |
| 데이터에 대한 전처리/정리/레이블링이 수행되었습니까 (예: 이산화 또는 버킷화, 토큰화, 품사 태깅, SIFT 특징 추출, 인스턴스 제거, 누락된 값 처리)? | 일부 자동 텍스트 서식 지정이 적용되어, 학습 목표와 관련 없는 날짜 및 위치 정보를 캡션에서 제거했습니다. |
| 인스턴스를 전처리/정리/레이블링하는 데 사용된 소프트웨어를 사용할 수 있습니까? | 아니요. |
| 용도 (Uses) | |
| 데이터셋이 이미 어떤 작업에 사용되었습니까? | 예, 멀티모달 언어 및 비전 모델 사전학습에 데이터셋을 사용합니다. |
| 데이터셋을 사용한 모든 논문 또는 시스템을 연결하는 저장소가 있습니까? | 아니요, 데이터셋은 본 논문의 모델을 학습시키는 데에만 사용되었습니다. |
| 데이터셋은 어떤 (다른) 작업에 사용될 수 있습니까? | 이 단계에서는 다른 용도를 예상하지 않습니다. |
| 데이터셋의 구성 또는 수집 및 전처리/정리/레이블링 방식에 향후 사용에 영향을 미칠 수 있는 점이 있습니까? | 데이터셋은 정적이므로 점진적으로 "오래된" 것이 될 것입니다. 예를 들어, 시간이 지남에 따라 진화하는 새로운 언어와 규범을 반영하지 못할 것입니다. 그러나 데이터의 특성상 최신 버전의 데이터를 수집하는 것은 비교적 저렴합니다. |
| 데이터셋을 사용해서는 안 되는 작업이 있습니까? | 본 논문에서 설명된 데이터셋은 거의 전적으로 영어 텍스트를 포함하므로, 다국어 기능을 갖춘 모델을 학습시키는 데 사용해서는 안 됩니다. |
| 배포 (Distribution) | |
| 데이터셋이 데이터셋이 생성된 주체(예: 회사, 기관, 조직) 외의 제3자에게 배포될 것입니까? | 아니요. |
Table 15: LTIP Datasheet. Gebru et al. [30]에서 제시된 프레임워크를 따릅니다.
F.2.2 Datasheet for VTP
| 동기 (Motivation) | |
|---|---|
| 데이터셋은 어떤 목적으로 생성되었습니까? 데이터셋은 누가 생성했습니까? 데이터셋 생성 자금은 누가 지원했습니까? | 데이터셋은 vision-language 모델 사전학습을 위해 생성되었으며, 연구원 및 엔지니어들이 생성했습니다. |
| 기타 참고사항이 있습니까? | 없음. |
| 구성 (Composition) | |
| 데이터셋을 구성하는 인스턴스들은 무엇을 나타냅니까 (예: 문서, 사진, 사람, 국가)? | 데이터셋의 모든 인스턴스는 비디오-텍스트 쌍입니다. |
| 총 인스턴스 수는 몇 개입니까 (해당하는 경우 각 유형별로)? | 데이터셋은 2,700만 개의 비디오-텍스트 쌍을 포함합니다. |
| 데이터셋은 가능한 모든 인스턴스를 포함합니까, 아니면 더 큰 집합에서 추출된 샘플입니까 (반드시 무작위는 아님)? | 데이터셋은 더 큰 집합에서 추출된 샘플입니다. |
| 각 인스턴스는 어떤 데이터로 구성되어 있습니까? | 각 인스턴스는 문서의 텍스트를 인코딩하는 UTF-8 바이트 시퀀스와 압축된 형식의 비디오로 구성됩니다 (Appendix A.3.3 참조). |
| 각 인스턴스에 레이블 또는 타겟이 연관되어 있습니까? | 아니요, 각 인스턴스에 연관된 레이블은 없습니다. |
| 개별 인스턴스에서 누락된 정보가 있습니까? | 아니요. |
| 개별 인스턴스 간의 관계가 명시되어 있습니까? | 데이터셋 내의 다른 인스턴스 간에는 관계가 없습니다. |
| 권장되는 데이터 분할이 있습니까? | 학습 및 개발 세트에 무작위 분할을 사용합니다. |
| 데이터셋에 오류, 노이즈 소스 또는 중복이 있습니까? | 데이터는 비교적 품질이 높지만, 일부 인스턴스가 여러 번 반복될 가능성이 있습니다. |
| 데이터셋은 자체 포함되어 있습니까, 아니면 외부 리소스에 연결되거나 의존합니까? | 데이터셋은 자체 포함되어 있습니다. |
| 데이터셋에 기밀로 간주될 수 있는 데이터가 포함되어 있습니까? | 아니요. |
| 데이터셋에 직접 보면 공격적이거나, 모욕적이거나, 위협적이거나, 또는 불안감을 유발할 수 있는 데이터가 포함되어 있습니까? | 이 데이터셋에 사용된 웹사이트는 그러한 콘텐츠를 피하기 위해 신중하게 선택되었습니다. 그러나 데이터의 규모를 고려할 때 일부 데이터가 공격적이거나 모욕적이라고 간주될 수 있습니다. |
| 수집 과정 (Collection Process) | |
| 각 인스턴스에 연관된 데이터는 어떻게 획득되었습니까? | 데이터는 웹에서 공개적으로 이용 가능합니다. |
| 데이터를 수집하기 위해 어떤 메커니즘이나 절차가 사용되었습니까? | 원시 텍스트와 비디오를 추출하고 정리하기 위해 다양한 소프트웨어 프로그램이 사용되었습니다. |
| 데이터셋이 더 큰 집합의 샘플인 경우, 샘플링 전략은 무엇이었습니까? | 해당 없음 (N.A.). |
| :--- | :--- |
| 데이터는 어떤 기간 동안 수집되었습니까? | 데이터는 2021년 몇 달에 걸쳐 수집되었습니다. 생성 날짜를 기준으로 소스를 필터링하지 않습니다. |
| 윤리 검토 절차가 수행되었습니까? | 아니요. |
| 전처리/정제/레이블링 (Preprocessing/cleaning/labeling) | |
| 데이터에 대한 전처리/정제/레이블링이 수행되었습니까 (예: 이산화 또는 버킷화, 토큰화, 품사 태깅, SIFT 특징 추출, 인스턴스 제거, 누락된 값 처리)? | 학습 목표와 관련 없는 날짜 및 위치를 캡션에서 제거하기 위해 일부 자동 텍스트 서식이 적용되었습니다. |
| 인스턴스를 전처리/정제/레이블링하는 데 사용된 소프트웨어를 사용할 수 있습니까? | 아니요. |
| 용도 (Uses) | |
| 데이터셋이 이미 어떤 작업에 사용되었습니까? | 예, 멀티모달 언어 및 비전 모델 사전학습에 사용됩니다. |
| 데이터셋을 사용하는 모든 논문 또는 시스템을 연결하는 저장소가 있습니까? | 아니요, 이 데이터셋은 본 논문의 모델을 학습시키는 데에만 사용되었습니다. |
| 데이터셋은 어떤 (다른) 작업에 사용될 수 있습니까? | 이 단계에서는 다른 용도를 예상하지 않습니다. |
| 데이터셋의 구성 또는 수집 및 전처리/정제/레이블링 방식에 향후 사용에 영향을 미칠 수 있는 점이 있습니까? | 데이터셋은 정적이므로 시간이 지남에 따라 점차 "오래된" 것이 됩니다. 예를 들어, 시간이 지남에 따라 진화하는 새로운 언어와 규범을 반영하지 못할 것입니다. 그러나 데이터의 특성상 최신 버전의 데이터를 수집하는 것은 비교적 저렴합니다. |
| 데이터셋을 사용해서는 안 되는 작업이 있습니까? | 본 논문에서 설명된 데이터셋은 거의 전적으로 영어 텍스트를 포함하므로, 다국어 기능을 갖춘 모델을 학습시키는 데 사용해서는 안 됩니다. |
| 배포 (Distribution) | |
| 데이터셋이 데이터셋이 생성된 주체(예: 회사, 기관, 조직) 외의 제3자에게 배포될 것입니까? | 아니요. |
Table 16: VTP Datasheet. Gebru et al. [30]에서 제시된 프레임워크를 따릅니다.
G Credit for visual content
- Figure 1:
- Row 1: 모든 이미지는 Unsplash 라이선스 하에 제공됩니다.
- Row 2: 모든 이미지는 퍼블릭 도메인입니다.
- Row 3: 처음 두 이미지는 Unsplash 라이선스 하에 제공됩니다.
- Row 5: DALL•E 2 [89]에서 사용 가능합니다.
- Row 6: 처음 두 이미지는 Unsplash 라이선스 하에 제공되며, 세 번째 이미지는 CC BY-ND 2.0 라이선스 하에 Wikimedia Commons에서 제공됩니다.
- Row 7: 이미지는 CC BY-ND 2.0 라이선스 하에 Wikimedia Commons에서 제공됩니다.
- Row 8: 이미지는 CC BY-ND 2.0 라이선스 하에 Wikimedia Commons에서 제공됩니다.
- Row 9: 이 비디오는 CC BY-ND 2.0 라이선스 하에 YFCC100M에서 제공됩니다.
- Dialogue 1: DALL•E 2 [89]에서 사용 가능합니다.
- Dialogue 2: 첫 번째 아이콘은 Flaticon 라이선스 하에 제공되며, 두 번째 이미지는 Unsplash 라이선스 하에 제공되며, 세 번째 이미지는 Sketchfab 라이선스 하에 제공됩니다.
- Dialogue 3: CLIP [85]에서 사용 가능합니다.
- Dialogue 4: 시카고와 도쿄 사진은 Unsplash에서 얻었습니다.
- Model Figures 3, 7, 9 and 8: 모든 이미지는 Unsplash 라이선스 하에 제공됩니다.
- Qualitative Figures 10, 11, 12, and 13: 모든 시각 자료는 COCO 데이터셋, CC BY-ND 2.0 라이선스 하에 제공되는 Wikimedia Commons, 또는 DALL•E 2 [89]에서 사용 가능한 자료를 포함한 다양한 출처에서 가져왔습니다.