FLAN: Fine-tuned 언어 모델을 활용한 Zero-Shot 학습
이 논문은 instruction tuning이라는 간단한 방법으로 언어 모델의 zero-shot 학습 능력을 향상시키는 방법을 제안합니다. 이 방법은 자연어 instruction으로 설명된 데이터셋 모음으로 언어 모델을 finetuning하는 것입니다. 137B 파라미터의 pretrained 언어 모델을 60개 이상의 NLP 데이터셋에서 instruction tuning하여 FLAN(Finetuned Language Net)이라는 모델을 만들었습니다. FLAN은 이전에 보지 못한 task에 대해 기존 모델보다 훨씬 향상된 성능을 보였으며, 평가한 25개 데이터셋 중 20개에서 zero-shot 175B GPT-3를 능가했습니다. 논문 제목: Finetuned Language Models Are Zero-Shot Learners
Wei, Jason, et al. "Finetuned language models are zero-shot learners." arXiv preprint arXiv:2109.01652 (2021).
Finetuned Language Models Are Zero-Shot Learners
Jason Wei*, Maarten Bosma*, Vincent Y. Zhao*, Kelvin Guu*, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le<br>Google Research
Abstract
본 논문은 언어 모델의 zero-shot 학습 능력을 향상시키기 위한 간단한 방법을 탐구한다. 우리는 instruction tuning—즉, instruction을 통해 설명된 데이터셋 컬렉션으로 언어 모델을 fine-tuning하는 것—이 이전에 보지 못한(unseen) task에 대한 zero-shot 성능을 크게 향상시킨다는 것을 보여준다.
우리는 137B 파라미터의 사전학습된 언어 모델을 가져와, 자연어 instruction 템플릿을 통해 verbalize된 60개 이상의 NLP 데이터셋으로 instruction tuning을 수행한다. 우리는 이 **instruction-tuned 모델(FLAN)**을 이전에 보지 못한 task 유형에 대해 평가한다.
FLAN은 수정되지 않은 원본 모델의 성능을 크게 향상시키며, 우리가 평가한 25개 데이터셋 중 20개에서 zero-shot 175B GPT-3를 능가한다. FLAN은 심지어 ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, StoryCloze에서는 few-shot GPT-3보다도 훨씬 뛰어난 성능을 보인다.
Ablation study 결과, fine-tuning 데이터셋의 수, 모델 규모, 그리고 자연어 instruction이 instruction tuning 성공의 핵심 요소임이 밝혀졌다.
 Figure 1: 상단: instruction tuning과 FLAN의 개요. Instruction tuning은 instruction 형태로 표현된 다양한 task들의 혼합 데이터셋으로 사전학습된 언어 모델을 fine-tuning한다. 추론 시에는 이전에 보지 못한 task 유형에 대해 평가한다. 예를 들어, instruction tuning 과정에서 NLI task를 전혀 보지 못했더라도, 자연어 추론(NLI) task에 대해 모델을 평가할 수 있다. 하단: 우리가 평가한 10가지 task 유형 중, instruction tuning이 성능을 크게 향상시킨 3가지 unseen task 유형에 대한 zero-shot FLAN의 성능을 zero-shot 및 few-shot GPT-3와 비교한 결과. NLI 데이터셋: ANLI R1-R3, CB, RTE. Reading comprehension 데이터셋: BoolQ, MultiRC, OBQA. Closed-book QA 데이터셋: ARC-easy, ARC-challenge, NQ, TriviaQA.
Figure 1: 상단: instruction tuning과 FLAN의 개요. Instruction tuning은 instruction 형태로 표현된 다양한 task들의 혼합 데이터셋으로 사전학습된 언어 모델을 fine-tuning한다. 추론 시에는 이전에 보지 못한 task 유형에 대해 평가한다. 예를 들어, instruction tuning 과정에서 NLI task를 전혀 보지 못했더라도, 자연어 추론(NLI) task에 대해 모델을 평가할 수 있다. 하단: 우리가 평가한 10가지 task 유형 중, instruction tuning이 성능을 크게 향상시킨 3가지 unseen task 유형에 대한 zero-shot FLAN의 성능을 zero-shot 및 few-shot GPT-3와 비교한 결과. NLI 데이터셋: ANLI R1-R3, CB, RTE. Reading comprehension 데이터셋: BoolQ, MultiRC, OBQA. Closed-book QA 데이터셋: ARC-easy, ARC-challenge, NQ, TriviaQA.
1 Introduction
GPT-3 (Brown et al., 2020)와 같은 대규모 Language Model (LM)은 few-shot learning에서 놀라운 성능을 보여주었다. 그러나 zero-shot learning에서는 성공적이지 못했다. 예를 들어, GPT-3의 zero-shot 성능은 독해, 질문 응답, 자연어 추론과 같은 task에서 few-shot 성능보다 훨씬 낮다. 한 가지 잠재적인 이유는 few-shot 예시가 없으면, 사전학습 데이터 형식과 유사하지 않은 prompt에 대해 모델이 좋은 성능을 내기 어렵기 때문이다.
본 논문에서는 대규모 language model의 zero-shot 성능을 향상시키는 간단한 방법을 탐구하며, 이는 더 넓은 사용자층에게 LM의 활용 범위를 확장할 수 있을 것이다. 우리는 NLP task가 "이 영화 리뷰의 감정은 긍정적인가 부정적인가?" 또는 "'how are you'를 중국어로 번역하시오"와 같은 자연어 지시(natural language instructions)를 통해 설명될 수 있다는 직관을 활용한다. 우리는 137B 파라미터의 사전학습된 language model을 가져와 instruction tuning을 수행한다. 이는 60개 이상의 NLP 데이터셋을 자연어 지시 형태로 표현한 혼합 데이터셋으로 모델을 fine-tuning하는 것이다. 이 결과 모델을 **FLAN (Finetuned Language Net)**이라고 부른다.
FLAN의 미학습(unseen) task에 대한 zero-shot 성능을 평가하기 위해, 우리는 NLP 데이터셋을 task 유형에 따라 클러스터로 그룹화하고, FLAN을 다른 모든 클러스터로 instruction tuning하는 동안 각 클러스터를 평가용으로 보류한다. 예를 들어, Figure 1에서 보여주듯이, FLAN의 자연어 추론 능력을 평가하기 위해, 우리는 상식 추론, 번역, 감성 분석과 같은 다양한 다른 NLP task로 모델을 instruction tuning한다. 이 설정은 FLAN이 instruction tuning에서 어떤 자연어 추론 task도 보지 못했음을 보장하므로, 우리는 FLAN의 zero-shot 자연어 추론 능력을 평가한다.
우리의 평가는 FLAN이 기본 137B 파라미터 모델의 zero-shot 성능을 크게 향상시킨다는 것을 보여준다. FLAN의 zero-shot 성능은 우리가 평가한 25개 데이터셋 중 20개에서 175B 파라미터 GPT-3의 zero-shot 성능을 능가하며, 심지어 ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, StoryCloze에서는 GPT-3의 few-shot 성능보다도 훨씬 뛰어난 성능을 보인다. ablation study에서 우리는 instruction tuning에서 task 클러스터 수를 늘리면 미학습 task에 대한 성능이 향상되며, instruction tuning의 이점은 충분한 모델 규모에서만 나타난다는 것을 발견했다.
Instruction tuning은 Figure 2에 묘사된 바와 같이, fine-tuning을 통한 supervision을 사용하여 추론 시 텍스트 상호작용에 대한 language model의 응답을 개선함으로써, pretrain-finetune 및 prompting 패러다임의 매력적인 측면을 결합하는 간단한 방법이다. 우리의 실증적 결과는 지시만으로 설명된 task를 수행하는 language model의 유망한 능력을 보여준다. FLAN에 사용된 instruction tuning 데이터셋을 로드하기 위한 소스 코드는 https://github.com/google-research/flan에서 공개적으로 이용 가능하다.
(A) Pretrain-finetune (BERT, T5)
 Figure 2: Instruction tuning과 pretrain-finetune, 그리고 prompting 방식의 비교.
Figure 2: Instruction tuning과 pretrain-finetune, 그리고 prompting 방식의 비교.
2 FLAN: Instruction Tuning Improves Zero-Shot Learning
Instruction tuning의 동기는 언어 모델(LM)이 NLP instruction에 응답하는 능력을 향상시키는 것이다. 이 아이디어는 LM이 instruction을 통해 설명된 task를 수행하도록 지도 학습(supervision)을 사용하여 가르치면, LM이 instruction을 따르는 방법을 학습하고, 심지어 이전에 보지 못한(unseen) task에 대해서도 이를 수행할 수 있게 될 것이라는 것이다. Unseen task에 대한 성능을 평가하기 위해, 우리는 데이터셋을 task 유형별로 클러스터링하고, 각 task 클러스터를 평가용으로 따로 분리한 다음, 나머지 모든 클러스터에 대해 instruction tuning을 수행한다.
2.1 Tasks & Templates
많은 task를 포함하는 instruction tuning 데이터셋을 처음부터 구축하는 것은 자원 집약적이기 때문에, 우리는 기존 연구 커뮤니티의 데이터셋을 instructional format으로 변환하였다. 우리는 Tensorflow Datasets에서 공개적으로 사용 가능한 62개의 텍스트 데이터셋을 단일 혼합물로 통합했으며, 여기에는 언어 이해(language understanding) 및 언어 생성(language generation) task가 모두 포함된다. Figure 3은 이 데이터셋들을 보여준다. 각 데이터셋은 12개의 task cluster 중 하나로 분류되며, 주어진 cluster 내의 데이터셋들은 동일한 task 유형을 가진다. 각 데이터셋의 설명, 크기 및 예시는 Appendix G에 제시되어 있다.
 Figure 3: 본 논문에서 사용된 데이터셋 및 task cluster (파란색은 NLU task; 청록색은 NLG task).
Figure 3: 본 논문에서 사용된 데이터셋 및 task cluster (파란색은 NLU task; 청록색은 NLG task).
각 데이터셋에 대해 우리는 자연어 지시(natural language instruction)를 사용하여 해당 데이터셋의 task를 설명하는 10개의 고유한 템플릿을 수동으로 구성하였다. 10개의 템플릿 대부분은 원래 task를 설명하지만, 다양성을 높이기 위해 각 데이터셋에 대해 "task를 뒤집는" 최대 3개의 템플릿도 포함하였다 (예: 감성 분류(sentiment classification)의 경우 영화 리뷰를 생성하도록 요청하는 템플릿을 포함). 그런 다음, 사전학습된 language model을 모든 데이터셋의 혼합물에 대해 instruction tuning하였으며, 각 데이터셋의 예시는 해당 데이터셋에 대해 무작위로 선택된 instruction 템플릿을 통해 형식화되었다. Figure 4는 자연어 추론(natural language inference) 데이터셋에 대한 여러 instruction 템플릿을 보여준다.
 Figure 4: 자연어 추론 task를 설명하는 여러 instruction 템플릿.
Figure 4: 자연어 추론 task를 설명하는 여러 instruction 템플릿.
2.2 Evaluation Splits
우리는 FLAN이 instruction tuning에서 보지 못한 task에서 어떻게 수행되는지에 관심이 있으므로, '보지 못한 task'가 무엇을 의미하는지 정의하는 것이 중요하다. 일부 이전 연구에서는 동일한 데이터셋이 학습에 나타나는 것을 허용하지 않음으로써 보지 못한 task를 정의했지만, 우리는 Figure 3의 task cluster를 활용하는 더 보수적인 정의를 사용한다.
본 연구에서는 데이터셋 가 속한 어떤 task cluster의 데이터셋도 instruction tuning 중에 사용되지 않았을 때만 평가 시점에 를 보지 못한 task로 간주한다. 예를 들어, 가 entailment task라면, instruction tuning에는 어떤 entailment 데이터셋도 포함되지 않았고, 우리는 다른 모든 cluster에 대해 instruction tuning을 수행한다.
따라서 개의 task cluster에 대해 zero-shot FLAN을 평가하기 위해 개의 모델을 instruction tuning하며, 각 모델은 평가를 위해 서로 다른 task cluster를 제외한다.
2.3 Classification with Options
주어진 task의 출력 공간은 **여러 클래스 중 하나(분류)**이거나 **자유 형식 텍스트(생성)**이다. FLAN은 decoder-only language model의 instruction-tuned 버전이므로, 자연스럽게 자유 형식 텍스트로 응답하며, 따라서 생성 task에는 추가적인 수정이 필요하지 않다.
분류 task의 경우, 이전 연구(Brown et al., 2020)에서는 rank classification 접근 방식을 사용했다. 예를 들어, "yes"와 "no" 두 가지 출력만 고려하고, 더 높은 확률을 가진 쪽을 모델의 예측으로 선택하는 방식이다. 이 절차는 논리적으로 타당하지만, 각 답변을 표현하는 다양한 방식들 사이에 확률 분포가 의도치 않게 분산될 수 있다는 점에서 완벽하지 않다 (예: "yes"를 표현하는 많은 대안적 방식들이 "yes"에 할당된 확률 질량을 낮출 수 있다). 따라서 우리는 options suffix를 포함한다. 이는 분류 task의 끝에 options 토큰과 함께 해당 task의 출력 클래스 목록을 추가하는 방식이다. 이를 통해 모델은 분류 task에 응답할 때 어떤 선택지가 요구되는지 인식하게 된다. options의 사용 예시는 Figure 1의 NLI 및 commonsense 예시에서 확인할 수 있다.
2.4 Training Details
모델 아키텍처 및 사전학습 (Model architecture and pretraining)
우리의 실험에서는 137B 파라미터를 가진 dense left-to-right, decoder-only Transformer language model인 LaMDA-PT를 사용한다 (Thoppilan et al., 2022). 이 모델은 웹 문서(컴퓨터 코드 포함), 대화 데이터, 위키피디아를 포함하는 데이터셋으로 사전학습되었으며, **SentencePiece 라이브러리 (Kudo & Richardson, 2018)**를 사용하여 32k 어휘의 2.49T BPE 토큰으로 토큰화되었다. 사전학습 데이터의 약 10%는 비영어권 데이터였다. LaMDA-PT는 language model 사전학습만 수행되었으며 (대화에 대해 fine-tuning된 LaMDA와는 다름), 이 점에 유의해야 한다.
Instruction tuning 절차 (Instruction tuning procedure)
FLAN은 LaMDA-PT의 instruction-tuned 버전이다. 우리의 instruction tuning 파이프라인은 모든 데이터셋을 혼합하고 각 데이터셋에서 무작위로 샘플링한다. 다양한 데이터셋 크기의 균형을 맞추기 위해, 우리는 데이터셋당 학습 예시 수를 30k로 제한하고, **최대 3k의 혼합 비율을 가진 examples-proportional mixing scheme (Raffel et al., 2020)**을 따른다. 우리는 모든 모델을 30k gradient step 동안 batch size 8,192 토큰으로 fine-tuning하며, **Adafactor Optimizer (Shazeer & Stern, 2018)**와 3e-5의 learning rate를 사용한다. fine-tuning에 사용된 입력 및 타겟 시퀀스 길이는 각각 1024와 256이다. 우리는 **packing (Raffel et al., 2020)**을 사용하여 여러 학습 예시를 단일 시퀀스로 결합하고, 특수 EOS 토큰을 사용하여 입력과 타겟을 분리한다. 이 instruction tuning은 128 코어를 가진 TPUv3에서 약 60시간이 소요된다. 모든 평가에서 우리는 30k step 동안 학습된 최종 체크포인트의 결과를 보고한다.
3 Results
우리는 자연어 추론(natural language inference), 독해(reading comprehension), 폐쇄형 QA(closed-book QA), 번역(translation), 상식 추론(commonsense reasoning), 공참조 해결(coreference resolution), 그리고 struct-to-text task에 대해 FLAN을 평가한다.
§2.2에서 설명했듯이, 우리는 데이터셋을 task 클러스터로 그룹화하고, 각 클러스터를 평가용으로 보류한 채 나머지 모든 클러스터로 instruction tuning을 수행함으로써 미학습 task에 대한 평가를 진행한다 (즉, 각 평가 task 클러스터는 다른 체크포인트를 사용한다).
각 데이터셋에 대해, 우리는 모든 템플릿의 평균 성능을 평가하는데, 이는 일반적인 자연어 instruction이 주어졌을 때 예상되는 성능을 대리한다.
때로는 수동 프롬프트 엔지니어링을 위해 dev set이 사용 가능하므로 (Brown et al., 2020), 각 데이터셋에 대해 가장 좋은 dev set 성능을 보인 템플릿을 사용하여 test set 성능도 측정한다.
비교를 위해, 우리는 GPT-3와 동일한 프롬프트를 사용한 LaMDA-PT의 zero-shot 및 few-shot 결과를 보고한다 (LaMDA-PT는 instruction tuning 없이는 자연어 instruction에 적합하지 않기 때문이다). 이 baseline은 instruction tuning이 얼마나 도움이 되는지에 대한 가장 직접적인 ablation을 제공한다. Instruction tuning은 대부분의 데이터셋에서 LaMDA-PT의 성능을 크게 향상시킨다.
또한, 우리는 GPT-3 175B (Brown et al. 2020)와 GLaM 64B/64E (Du et al., 2021)의 zero-shot 성능을 각 논문에서 보고된 바와 같이 제시한다.
최고의 dev 템플릿을 사용했을 때, zero-shot FLAN은 25개 데이터셋 중 20개에서 zero-shot GPT-3를 능가하며, 10개 데이터셋에서는 GPT-3의 few-shot 성능마저 뛰어넘는다.
최고의 dev 템플릿을 사용했을 때, zero-shot FLAN은 19개 사용 가능한 데이터셋 중 13개에서 zero-shot GLaM을 능가하고, 19개 데이터셋 중 11개에서 one-shot GLaM을 능가한다.
전반적으로, 우리는 instruction tuning이 자연스럽게 instruction으로 표현되는 task (예: NLI, QA, 번역, struct-to-text)에서 매우 효과적이며, instruction이 대체로 불필요한 언어 모델링으로 직접 공식화된 task (예: 불완전한 문장이나 단락을 완성하는 형태로 구성된 상식 추론 및 공참조 해결 task)에서는 덜 효과적임을 관찰한다.
자연어 추론, 독해, 폐쇄형 QA, 번역에 대한 결과는 Figure 5에 요약되어 있으며 아래에서 설명한다.
 Figure 5: 자연어 추론, 독해, 폐쇄형 QA, 번역 task에서 FLAN의 zero-shot 성능을 LaMDA-PT 137B, GPT-3 175B, GLaM 64B/64E와 비교한 그래프. FLAN의 성능은 task당 최대 10개의 instructional template의 평균이다. Supervised 모델은 T5, BERT 또는 번역 모델이었다 (Appendix의 Table 2 및 Table 1에 명시).
Figure 5: 자연어 추론, 독해, 폐쇄형 QA, 번역 task에서 FLAN의 zero-shot 성능을 LaMDA-PT 137B, GPT-3 175B, GLaM 64B/64E와 비교한 그래프. FLAN의 성능은 task당 최대 10개의 instructional template의 평균이다. Supervised 모델은 T5, BERT 또는 번역 모델이었다 (Appendix의 Table 2 및 Table 1에 명시).
자연어 추론 (NLI).
모델이 주어진 전제(premise)에 대해 가설(hypothesis)이 참인지 거짓인지 판단해야 하는 5개의 NLI 데이터셋에서 FLAN은 모든 baseline을 큰 차이로 능가한다. Brown et al. (2020)이 언급했듯이, GPT-3가 NLI에서 어려움을 겪는 한 가지 이유는 NLI 예시가 비지도 학습 데이터셋에 자연스럽게 나타날 가능성이 낮아 문장의 연속으로 어색하게 표현되기 때문일 수 있다. FLAN의 경우, 우리는 NLI를 "Does <premise> mean that <hypothesis>?"와 같은 보다 자연스러운 질문으로 표현하여 훨씬 높은 성능을 달성한다.
독해 (Reading comprehension).
모델이 제공된 지문에 대한 질문에 답해야 하는 독해 task에서 FLAN은 MultiRC (Khashabi et al., 2018) 및 OBQA (Mihaylov et al., 2018)에 대한 baseline을 능가한다. BoolQ (Clark et al., 2019a)에서는 FLAN이 GPT-3를 큰 차이로 능가하지만, LaMDA-PT는 이미 BoolQ에서 높은 성능을 달성한다.
폐쇄형 QA (Closed-book QA).
모델이 답변을 포함하는 특정 정보에 접근하지 않고 세상에 대한 질문에 답해야 하는 폐쇄형 QA의 경우, FLAN은 4개의 모든 데이터셋에서 GPT-3를 능가한다. GLaM과 비교했을 때, FLAN은 ARC-e 및 ARC-c (Clark et al., 2018)에서 더 나은 성능을 보이며, NQ (Lee et al., 2019; Kwiatkowski et al., 2019) 및 TQA (Joshi et al., 2017)에서는 약간 낮은 성능을 보인다.
번역 (Translation).
GPT-3와 유사하게, LaMDA-PT의 학습 데이터는 약 90%가 영어이며, 기계 번역을 위해 특별히 사용되지 않은 다른 언어의 텍스트도 일부 포함한다. 우리는 또한 GPT-3 논문에서 평가된 세 가지 데이터셋에 대해 FLAN의 기계 번역 성능을 평가한다: WMT'14의 프랑스어-영어 (Bojar et al., 2014), 그리고 WMT'16의 독일어-영어 및 루마니아어-영어 (Bojar et al., 2016).
GPT-3와 비교했을 때, FLAN은 6개의 모든 평가에서 zero-shot GPT-3를 능가하지만, 대부분의 경우 few-shot GPT-3보다는 낮은 성능을 보인다. GPT-3와 유사하게, FLAN은 영어로 번역하는 데 강력한 결과를 보이며, supervised 번역 baseline과 비교하여 우수한 성능을 나타낸다. 그러나 영어를 다른 언어로 번역하는 것은 상대적으로 약했는데, 이는 FLAN이 영어 sentencepiece tokenizer를 사용하고 사전학습 데이터의 대부분이 영어라는 점을 고려할 때 예상할 수 있는 결과이다.
추가 task (Additional tasks).
위에서 언급된 task 클러스터에서 강력한 결과를 보였지만, instruction tuning의 한계점 중 하나는 많은 언어 모델링 task (예: 문장 완성 형태로 공식화된 상식 추론 또는 공참조 해결 task)에서 성능 향상을 가져오지 못한다는 점이다.
7개의 상식 추론 및 공참조 해결 task (Appendix의 Table 2 참조)에서 FLAN은 7개 task 중 3개에서만 LaMDA-PT를 능가한다. 이 부정적인 결과는 다운스트림 task가 원래의 언어 모델링 사전학습 목표와 동일할 때 (즉, instruction이 대체로 불필요한 경우), instruction tuning이 유용하지 않음을 나타낸다.
마지막으로, 감성 분석(sentiment analysis), paraphrase detection, struct-to-text에 대한 결과와 GPT-3 결과가 없는 추가 데이터셋에 대한 결과는 Appendix의 Table 2 및 Table 1에 보고되어 있다.
일반적으로, zero-shot FLAN은 zero-shot LaMDA-PT를 능가하며, few-shot LaMDA-PT와 비슷하거나 더 나은 성능을 보인다.
4 Ablation Studies & Further Analysis
4.1 Number of instruction tuning clusters
본 논문의 핵심 질문은 instruction tuning이 모델의 미학습(unseen) task에 대한 zero-shot 성능을 어떻게 향상시키는가이므로, 첫 번째 ablation 연구에서는 instruction tuning에 사용되는 클러스터 및 task의 개수가 성능에 미치는 영향을 조사한다.
이 설정에서는 NLI, closed-book QA, commonsense reasoning 클러스터를 평가용으로 제외하고, 나머지 7개 클러스터를 instruction tuning에 사용한다. 우리는 1개에서 7개까지의 instruction tuning 클러스터에 대한 결과를 보여주며, 클러스터는 클러스터당 task 수가 많은 순서대로 추가된다.
Figure 6은 이러한 결과를 보여준다. 예상대로, instruction tuning에 추가적인 클러스터와 task를 더할수록 (감성 분석 클러스터 제외) 세 개의 held-out 클러스터 전반에 걸친 평균 성능이 향상되는 것을 관찰할 수 있다. 이는 새로운 task에 대한 zero-shot 성능에서 우리가 제안한 instruction tuning 접근 방식의 이점을 확인시켜 준다.
또한, 우리가 테스트한 7개 클러스터의 경우 성능이 포화되지 않는 것으로 보이며, 이는 instruction tuning에 더 많은 클러스터를 추가하면 성능이 더욱 향상될 수 있음을 시사한다. 주목할 점은, 이 ablation 연구가 각 instruction tuning 클러스터가 각 평가 클러스터에 가장 크게 기여하는 바에 대한 결론을 내릴 수는 없지만, 감성 분석 클러스터의 추가 가치는 미미하다는 것을 확인할 수 있다는 것이다.
 Figure 6: instruction tuning에 추가 task 클러스터를 추가하면 held-out task 클러스터에 대한 zero-shot 성능이 향상된다. 평가 task는 다음과 같다.
Commonsense: CoPA, HellaSwag, PiQA, StoryCloze.
NLI: ANLI R1-R3, QNLI, RTE, SNLI, WNLI.
Closed-book QA: ARC easy, ARC challenge, Natural Questions, TriviaQA.
Figure 6: instruction tuning에 추가 task 클러스터를 추가하면 held-out task 클러스터에 대한 zero-shot 성능이 향상된다. 평가 task는 다음과 같다.
Commonsense: CoPA, HellaSwag, PiQA, StoryCloze.
NLI: ANLI R1-R3, QNLI, RTE, SNLI, WNLI.
Closed-book QA: ARC easy, ARC challenge, Natural Questions, TriviaQA.
4.2 Scaling laws
Brown et al. (2020)의 연구에서 언어 모델의 zero-shot 및 few-shot 능력이 모델 규모가 커질수록 크게 향상됨을 보여주었듯이, 우리는 다음으로 instruction tuning의 이점이 모델 규모에 따라 어떻게 영향을 받는지를 탐구한다. 이전 ablation study와 동일한 클러스터 분할을 사용하여, 4억 2,200만, 20억, 80억, 680억, 1,370억 파라미터 규모의 모델에 대한 instruction tuning의 효과를 평가한다.
Figure 7은 이러한 결과를 보여준다. 우리는 1,000억 파라미터 규모의 두 모델의 경우, 본 논문의 이전 결과에서 예상했듯이 instruction tuning이 held-out task에 대한 성능을 크게 향상시킨다는 것을 확인했다. 그러나 80억 파라미터 이하의 모델에서 held-out task에 대한 동작은 다음과 같은 시사점을 준다.
 Figure 7: Instruction tuning은 대규모 모델이 새로운 task에 일반화하는 데 도움이 되지만, 소규모 모델의 경우 오히려 보지 못한 task에 대한 일반화 능력을 저해한다. 이는 모델의 모든 용량이 instruction tuning task들의 혼합을 학습하는 데 사용되기 때문일 수 있다.
Figure 7: Instruction tuning은 대규모 모델이 새로운 task에 일반화하는 데 도움이 되지만, 소규모 모델의 경우 오히려 보지 못한 task에 대한 일반화 능력을 저해한다. 이는 모델의 모든 용량이 instruction tuning task들의 혼합을 학습하는 데 사용되기 때문일 수 있다.
4.3 Role of instructions
최종 ablation study에서는 fine-tuning 과정에서 instruction의 역할을 탐구한다. 이는 성능 향상이 전적으로 multi-task fine-tuning에서 비롯되며, instruction 없이도 모델이 동일하게 잘 작동할 수 있다는 가능성을 고려하기 위함이다.
따라서 우리는 instruction이 없는 두 가지 fine-tuning 설정을 고려한다.
- No template 설정: 모델에 입력과 출력만 제공된다 (예: 번역 task의 경우 입력은 "The dog runs."이고 출력은 "Le chien court."이다).
- Dataset name 설정: 각 입력 앞에 task 및 데이터셋 이름이 추가된다 (예: 프랑스어 번역의 경우 입력은 "[Translation: WMT'14 to French] The dog runs."이다).
이 두 가지 ablation 설정을, 자연어 instruction을 사용한 FLAN의 fine-tuning 절차와 비교한다 (예: "Please translate this sentence to French: 'The dog
 Figure 8: fine-tuning(FT)에서 instruction을 제거한 모델을 사용한 ablation study 결과.
Figure 8: fine-tuning(FT)에서 instruction을 제거한 모델을 사용한 ablation study 결과.
4.4 Instructions with Few-Shot Exemplars
지금까지 우리는 zero-shot 설정에서의 instruction tuning에 초점을 맞추었다. 여기서는 추론 시 few-shot exemplar를 사용할 수 있을 때 instruction tuning이 어떻게 활용될 수 있는지를 연구한다. few-shot 설정의 형식은 zero-shot 형식을 기반으로 한다. 어떤 입력 와 출력 에 대해, zero-shot instruction을 instruct 라고 하자. 이때 개의 few-shot exemplar 와 새로운 입력 가 주어지면, few-shot 설정의 instruction 형식은 다음과 같다: "instruct " 여기서 는 구분자(delimiter) 토큰이 삽입된 문자열 연결을 의미한다. 학습 및 추론 시, exemplar는 학습 세트에서 무작위로 추출되며, exemplar의 수는 16개로 제한되고 전체 시퀀스 길이가 960 토큰 미만이 되도록 한다. 우리의 실험은 §3과 동일한 task 분할 및 평가 절차를 사용하며, 미학습 task에 대한 few-shot exemplar는 추론 시에만 사용된다.
Figure 9에서 볼 수 있듯이, few-shot exemplar는 zero-shot FLAN에 비해 모든 task 클러스터에서 성능을 향상시킨다. Exemplar는 특히 struct to text, translation, closed-book QA와 같이 출력 공간이 크거나 복잡한 task에서 효과적인데, 이는 exemplar가 모델이 출력 형식을 더 잘 이해하도록 돕기 때문일 수 있다. 또한, 모든 task 클러스터에서 few-shot FLAN의 템플릿 간 표준 편차가 더 낮게 나타나, prompt engineering에 대한 민감도가 감소했음을 보여준다.
 Figure 9: FLAN에 few-shot exemplar를 추가하는 것은 instruction-tuned 모델의 성능을 향상시키는 보완적인 방법이다. 주황색 막대는 템플릿 간 표준 편차를 나타내며, 각 task 클러스터에 대해 데이터셋 수준에서 평균화된 값이다.
Figure 9: FLAN에 few-shot exemplar를 추가하는 것은 instruction-tuned 모델의 성능을 향상시키는 보완적인 방법이다. 주황색 막대는 템플릿 간 표준 편차를 나타내며, 각 task 클러스터에 대해 데이터셋 수준에서 평균화된 값이다.
4.5 Instruction Tuning Facilitates Prompt Tuning
우리는 instruction tuning이 모델의 instruction 응답 능력을 향상시킨다는 것을 확인했다. 따라서, 만약 FLAN이 NLP task 수행에 더 적합하다면, prompt tuning을 통해 최적화된 연속 변수(soft prompt)를 사용하여 추론을 수행할 때 더 나은 성능을 달성해야 한다 (Li & Liang, 2021; Lester et al., 2021).
추가 분석으로, 우리는 SuperGLUE (Wang et al., 2019a)의 각 task에 대해 연속적인 prompt를 학습시켰다. 이는 §2.2의 클러스터 분할에 따라 수행되었으며, task 에 대해 prompt-tuning을 수행할 때, 와 동일한 클러스터에 속하는 task는 instruction tuning 중에 학습되지 않도록 했다.
우리의 prompt tuning 설정은 Lester et al. (2021)의 절차를 따르지만, prompt 길이를 10으로, weight decay를 1e-4로 설정하고, attention score에 dropout을 사용하지 않았다는 차이점이 있다. 예비 실험에서 이러한 변경 사항이 LaMDA-PT의 성능을 향상시키는 것을 확인했다.
Figure 10은 완전 supervised 학습 세트와 32개의 학습 예시만 사용하는 low-resource 설정 모두에 대한 이러한 prompt tuning 실험 결과를 보여준다. 우리는 모든 시나리오에서 다음과 같은 점을 확인했다.
 Figure 10: Instruction-tuned 모델은 prompt tuning을 통한 연속적인 입력에 더 잘 반응한다. 주어진 데이터셋에 대해 prompt tuning을 수행할 때, 해당 데이터셋과 동일한 클러스터에 속하는 task는 instruction tuning 중에 학습되지 않았다. 표시된 성능은 SuperGLUE dev set의 평균이다.
Figure 10: Instruction-tuned 모델은 prompt tuning을 통한 연속적인 입력에 더 잘 반응한다. 주어진 데이터셋에 대해 prompt tuning을 수행할 때, 해당 데이터셋과 동일한 클러스터에 속하는 task는 instruction tuning 중에 학습되지 않았다. 표시된 성능은 SuperGLUE dev set의 평균이다.
5 Related Work
우리의 연구는 zero-shot learning, prompting, multi-task learning, 그리고 NLP 애플리케이션을 위한 language model을 포함한 여러 광범위한 연구 분야와 관련이 있다 (Radford et al., 2019; Raffel et al., 2020; Brown et al., 2020, Efrat & Levy, 2020, Aghajanyan et al., 2021; Li & Liang, 2021, inter alia). 이러한 광범위한 분야에 대한 선행 연구는 확장된 관련 연구 섹션(Appendix D)에서 설명하며, 여기서는 우리 연구와 가장 밀접하게 관련된 두 가지 더 좁은 범위의 하위 분야를 설명한다.
우리가 모델에게 지시에 응답하도록 요청하는 방식은 **QA 기반 task 정식화(formulation)**와 유사하다 (Kumar et al., 2016; McCann et al., 2018). 이는 NLP task들을 context에 대한 QA로 변환하여 통합하는 것을 목표로 한다. 이러한 방법들은 우리와 매우 유사하지만, 주로 zero-shot learning보다는 multi-task learning에 초점을 맞추고 있으며, Liu et al. (2021)이 지적했듯이, 사전학습된 LM의 기존 지식을 활용하는 데 크게 동기 부여되지 않는다. 또한, 우리 연구는 모델 규모와 task 범위 면에서 Chai et al. (2020) 및 Zhong et al. (2021)과 같은 최근 연구들을 능가한다.
Language model의 성공은 모델이 지시를 따르는 능력에 대한 초기 연구로 이어졌다. 가장 최근에는 Mishra et al. (2021)이 140M 파라미터 BART를 few-shot exemplar를 포함한 지시로 fine-tuning하고, 미학습 task에 대한 few-shot 능력을 평가했다. 이는 §4.4의 few-shot instruction tuning 결과와 유사하다. 이 유망한 결과(지시를 크게 강조하지 않은 Ye et al. (2021)의 결과도 포함)는 여러 task에 대한 fine-tuning이 더 작은 모델 규모에서도 미학습 task에 대한 few-shot 성능을 향상시킨다는 것을 시사한다. Sanh et al. (2021)은 우리와 유사한 설정으로 T5를 fine-tuning하여, 11B 파라미터 모델에서 zero-shot learning이 향상될 수 있음을 발견했다. 우리와 유사한 모델 규모에서, OpenAI의 InstructGPT 모델은 fine-tuning과 reinforcement learning을 통해 학습되어 인간 평가자가 더 선호하는 출력을 생성한다 (Ouyang et al., 2022).
6 Discussion
본 논문은 zero-shot prompting에서 제기되는 간단한 질문을 탐구했다: 명령어(instruction) 형태로 표현된 여러 task들에 대해 모델을 fine-tuning하는 것이, 이전에 보지 못한(unseen) task에서의 성능을 향상시키는가? 우리는 instruction tuning이라는 간단한 방법을 통해 이 질문을 구체화했으며, 이 방법은 pretrain-finetune 패러다임과 prompting 패러다임의 매력적인 측면들을 결합한다. 우리가 instruction tuning한 모델인 FLAN은 튜닝되지 않은 모델보다 성능이 향상되었고, 우리가 평가한 대부분의 task에서 zero-shot GPT-3를 능가했다.
Ablation study 결과, unseen task에서의 성능은 instruction tuning task cluster의 수가 증가할수록 향상되었으며, 흥미롭게도 instruction tuning으로 인한 성능 향상은 충분한 모델 규모에서만 나타났다. 또한, instruction tuning은 few-shot prompting 및 prompt tuning과 같은 다른 prompting 방법들과 결합될 수 있다.
대규모 언어 모델의 다양한 능력은 전문가 모델(task당 하나의 모델)과 일반화 모델(여러 task에 하나의 모델; Arivazhagan et al. 2019, Pratap et al., 2020) 간의 trade-off에 대한 관심을 불러일으켰으며, 우리의 연구는 이에 대한 잠재적인 함의를 가진다. 레이블링된 데이터가 전문가 모델의 성능 향상에 가장 자연스러운 역할을 할 것이라고 예상할 수 있지만, instruction tuning은 레이블링된 데이터가 대규모 언어 모델이 많은 unseen task를 수행하는 데 어떻게 도움을 줄 수 있는지를 보여준다. 즉, instruction tuning이 cross-task generalization에 미치는 긍정적인 효과는 task-specific 학습이 일반 언어 모델링과 상호 보완적임을 보여주며, 일반화 모델에 대한 추가 연구를 촉진한다.
우리 연구의 한계점으로는 task를 cluster에 할당하는 데 주관적인 요소가 있다는 점(문헌에서 통용되는 분류를 사용하려고 노력했지만), 그리고 일반적으로 단일 문장으로 된 비교적 짧은 instruction만 탐구했다는 점(크라우드 워커에게 주어지는 상세한 instruction과 비교)이 있다. 평가의 한계점으로는 개별 예시가 모델의 사전학습 데이터(웹 문서 포함)에 포함되었을 가능성이 있지만, 사후 분석(Appendix C)에서 데이터 중복이 결과에 실질적으로 영향을 미쳤다는 증거는 찾지 못했다. 마지막으로, FLAN 137B의 규모는 서비스 비용이 많이 든다. instruction tuning에 대한 향후 연구는 fine-tuning을 위한 더 많은 task cluster 수집/생성, cross-lingual 실험, FLAN을 사용하여 다운스트림 분류기 학습을 위한 데이터 생성, 그리고 fine-tuning을 통해 편향 및 공정성 측면에서 모델 동작 개선(Solaiman & Dennison, 2021) 등을 포함할 수 있다.
7 Conclusions
본 논문에서는 대규모 language model이 지시(instruction)에만 기반하여 zero-shot task를 수행하는 능력을 향상시키는 간단한 방법을 탐구하였다. 우리가 제안한 instruction-tuned 모델인 FLAN은 GPT-3와 비교하여 우수한 성능을 보였으며, 이는 대규모 language model이 지시를 따를 수 있는 잠재력을 시사한다. 우리는 본 논문이 instruction 기반 NLP, zero-shot learning, 그리고 labeled data를 활용한 대규모 language model 개선에 대한 추가 연구를 촉진하기를 기대한다.
Ethical Considerations
본 연구는 언어 모델을 사용하며, 이에 대한 위험과 잠재적 해악은 Bender & Koller (2020), Brown et al. (2020), Bender et al. (2021), Patterson et al. (2021) 등의 연구에서 논의되었다. 본 논문의 기여는 사전학습된 언어 모델 자체가 아니라, instruction tuning이 언어 모델의 미학습(unseen) task에 대한 zero-shot 성능에 어떻게 영향을 미치는지에 대한 실증 연구이므로, 우리는 추가적으로 두 가지 관련 윤리적 고려 사항을 강조한다.
첫째, 우리가 fine-tuning에 사용하는 것과 같은 labeled dataset은 바람직하지 않은 편향을 포함할 수 있으며, 이러한 편향은 다운스트림 task에서 모델의 zero-shot 적용으로 전파될 수 있다.
둘째, instruction-tuned 모델은 사용에 필요한 데이터와 전문 지식이 적을 수 있다. 이러한 접근 장벽의 하향은 해당 모델의 이점과 관련 위험을 모두 증가시킬 수 있다.
Environmental Considerations
우리는 Austin et al. (2021)과 동일한 사전학습된 language model을 사용한다. 사전학습된 모델들의 에너지 비용과 탄소 발자국은 각각 451 MWh와 26 tCO2e였다. FLAN fine-tuning을 위한 추가적인 instruction tuning gradient-step은 사전학습 step 수의 2% 미만이므로, 추정되는 추가 에너지 비용은 상대적으로 작다.
Author Contributions
Maarten Bosma는 FLAN의 초기 아이디어를 구상하고 첫 버전을 구현했다. Vincent Zhao는 학습 및 평가 파이프라인과 rank classification을 프로토타입으로 만들었다. Kelvin Guu는 task cluster 개념과 inter-cluster split을 사용한 평가 아이디어를 제안하고 구현했다. Jason Wei, Maarten Bosma, Vincent Zhao, Adams Wei Yu는 NLP task를 구현했다. Jason Wei, Vincent Zhao, Adams Wei Yu는 대부분의 실험을 수행하고 관리했다. Jason Wei는 ablation study를 설계하고 실행했다. Jason Wei, Maarten Bosma, Quoc V. Le는 논문의 대부분을 작성했다. Jason Wei, Maarten Bosma, Nan Du는 zero-shot 및 few-shot baseline을 얻었다. Vincent Zhao와 Kelvin Guu는 few-shot FLAN 실험을 설계, 구현, 수행했다. Maarten Bosma와 Jason Wei는 데이터 오염 분석을 실행했다. Brian Lester는 prompt tuning 실험을 실행했다. Quoc V. Le와 Andrew M. Dai는 자문, 고수준 지침 제공, 논문 편집을 도왔다.
Acknowledgements
우리는 원고에 대한 피드백을 제공해 준 Ed Chi, Slav Petrov, Dan Garrette, Ruibo Liu, Clara Meister에게 감사드린다. 모델 디버깅을 도와준 Adam Roberts, Liam Fedus, Hyung Won Chung, Noam Shazeer에게 감사드린다. 프로젝트 중반 단계에서 연구 설계에 대한 피드백을 준 Ellie Pavlick에게 감사드린다. 프로젝트 시작을 돕고, 대형 language model에 대한 조언을 제공하며, 일부 컴퓨팅 자원에 대한 접근을 허락해 준 Daniel De Freitas Adiwardana에게 감사드린다. 마지막으로, LaMDA-PT 사전학습에 참여한 팀인 Daniel De Freitas Adiwardana, Noam Shazeer, Yanping Huang, Dmitry Lepikhin, Dehao Chen, Yuanzhong Xu, Zhifeng Chen에게 감사드린다.
A Additional Results
이 섹션에서는 우리가 평가한 모든 데이터셋에 대한 전체 결과를 보여준다. 번역(translation) 및 struct-to-text 결과는 Table 1에, 8개 NLU task cluster 결과는 Table 2에 제시되어 있다.
우리는 최대 10개의 instruction template 중 가장 좋은 성능을 보인 것과 dev set에서 가장 좋은 성능을 보인 template을 사용하여 FLAN의 성능을 보여준다. LaMDA-PT의 경우, Brown et al. (2020)에서 GPT-3에 최적화된 template을 사용했으며, 우리 모델에 최적화하기 위한 어떠한 prompt engineering도 수행하지 않았다. 단순화를 위해, 모든 생성 task에 대해 greedy search를 사용했다 (Brown et al. (2020)에서 사용된 beam search와 비교). GPT-3가 dev set 성능을 통해 few-shot exemplar의 수 를 선택하는 것과 달리, few-shot LaMDA-PT의 경우 context 길이 1024 토큰에 맞는 가장 높은 를 중에서 선택했다.
DROP (Dua et al., 2019) 및 SQuADv2 (Rajpurkar et al., 2018)의 경우, Brown et al. (2020)과의 이메일 교신에 따르면, 그들의 zero-shot 정의는 우리와 다르다. 그들은 실제로 exemplar를 사용하지만, 추론 질문과 동일한 passage에서만 exemplar를 사용한다 (각 passage에는 하나 이상의 질문이 있음). 따라서 GPT-3의 DROP 및 SQuADv2에 대한 zero-shot 결과는 우리 결과와 직접적으로 비교할 수 없다. 우리는 이러한 결과에 기호를 표시한다. 또한, 이 두 데이터셋에서 답변의 끝을 어떻게 파싱해야 할지 불분명하므로, 우리는 중괄호 구분자 {와 }를 사용하며, 여기서 }는 답변의 끝을 나타낸다고 가정한다.
struct-to-text의 경우, 보고된 T5/mT5 결과는 GEM 벤치마크 논문 (Gehrmann et al., 2021)에서 가져왔다. 다만, DART에 대한 결과는 보고하지 않는데, 저자들과의 교신을 통해 DART 결과가 정확하지 않음을 확인했기 때문이다. instruction tuning 동안 요약(summarization) task cluster를 사용했지만, 대부분의 요약 데이터셋 입력 길이가 FLAN의 입력 길이인 1024 토큰을 초과하므로, 요약 평가는 향후 연구로 남겨둔다.
| | Metric | Supervised Model | LaMDA-PT | | GPT-3 175B | | FLAN 137B | | | | | | | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | | | | | | | zero-shot | few-shot | | | | | | | | zeroshot | fewshot | | | zeroshot | fewshot | average template | best dev template | average template | best dev template | [k] | | | Translation | | | | | | | | | | | | | | WMT '14 En Fr | BLEU | | 11.2 | 31.5 [5] | 25.2 | 32.6 [64] | | 33.9 | | 33.8 | [9] | 5 | | WMT '14 Fr En | BLEU | | 7.2 | 34.7 [5] | 21.2 | 39.2 [64] | | 35.9 | | 37.9 | [9] | 3 | | WMT '16 En De | BLEU | | 7.7 | 26.7 [5] | 24.6 | 29.7 [64] | | 27.0 | | 26.1 | [11] | 5 | | WMT '16 De- En | BLEU | | 20.8 | 36.8 [5] | 27.2 | 40.6 [64] | | 38.9 | | 40.7 | [11] | 3 | | WMT '16 En Ro | BLEU | | 3.5 | 22.9 [5] | 14.1 | | | 18.9 | | 20.5 | [9] | 5 | | WMT '16 Ro En | BLEU | | 9.7 | 37.5 [5] | 19.9 | 39.5 [64] | | 37.3 | | 38.1 | [9] | 3 | | Struct to Text | | | | | | | | | | | | | | CommonGen | Rouge-1 | | 3.9 | 56.7 [3] | - | - | | 56.3 | | 56.4 | [16] | 6 | | | Rouge-2 | | 1.5 | 29.6 [3] | - | - | | 27.6 | | 29.9 | [16] | 6 | | | Rouge-L | | 3.2 | 48.5 [3] | - | - | | 48.7 | | 51.0 | [16] | 6 | | DART | Rouge-1 | - | 11.3 | | - | - | | 48.9 | | 59.2 | [11] | 7 | | | Rouge-2 | - | 1.5 | 29.6 [3] | - | - | | 30.0 | | 36.2 | [11] | 7 | | | Rouge-L | - | 3.2 | 48.5 [3] | - | - | | 43.4 | | 48.2 | [11] | 7 | | E2ENLG | Rouge-1 | | 6.2 | 56.7 [3] | - | - | | 51.4 | | 59.7 | [12] | 9 | | | Rouge-2 | | 2.5 | 31.4 [3] | - | - | | 30.1 | | 33.6 | [12] | 9 | | | Rouge-L | | 4.9 | 41.1 [3] | - | - | | 42.4 | | 45.1 | [12] | 9 | | WebNLG | Rouge-1 | | 13.9 | 68.3 [3] | - | - | | 57.7 | | 71.2 | [10] | 8 | | | Rouge-2 | | 6.9 | 46.0 [3] | - | - | | 35.4 | | 49.8 | [10] | 8 | | | Rouge-L | | 11.8 | 56.5 [3] | - | - | | 49.7 | | 60.2 | [10] | 8 |
Table 1: 번역 및 struct-to-text task 결과. 는 few-shot exemplar의 수를 나타낸다. #t는 FLAN이 평가된 template의 수를 나타낸다. T5-11B, Edunov et al. (2018), Durrani et al. (2014), Wang et al. (2019b), Sennrich et al. (2016), Liu et al. (2020).
| GLaM <br> LaMDA-PT | GPT-3 175B | FLAN 137B | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| zero-shot | few-shot | ||||||||||||
| Random S Guess | Supervised Model | zero- oneshot shot | zeroshot | fewshot | zeroshot | fewshot | average template | ||||||
| NLI | |||||||||||||
| ANLI R1 | 33.3 | 40.9 | 42.4 | 39.6 | 34.6 | 36.8 [50] | 46.4 | 47.9 | [6] | ||||
| ANLI R2 | 33.3 | 38.2 | 40.0 | 39.9 | 37.5 [5] | 35.4 | 34.0 [50] | 44.0 | 41.1 | [6] | |||
| ANLI R3 | 33.3 | 40.9 | 40.8 | 39.3 | 40.7 [5] | 34.5 | 40.2 [50] | 48.5 | 46.8 | [6] | |||
| CB | 33.3 | 33.9 | 73.2 | 42.9 | 34.4 [5] | 46.4 | 82.1 [32] | 83.9 | 82.1 | [7] | |||
| MNLI-m | 33.3 | - | - | 35.7 | 43.7 [5] | - | - | 61.2 | 63.5 | [10] 1 | |||
| MNLI-mm | 33.3 | - | - | 37.0 | 43.8 [5] | - | - | 62.4 | 63.5 | [10] | |||
| QNLI | 50.0 | - | - | 50.6 | - | - | 66.4 | 63.3 | [12] | ||||
| RTE | 50.0 | 68.8 | 71.5 | 73.3 | 70.8 [5] | 63.5 | 84.1 | 84.5 | [8] | ||||
| SNLI | 33.3 | - | - | 33.3 | 54.7 [5] | - | - | 53.4 | 65.6 | [15] | |||
| WNLI | 50.0 | - | - | 56.3 | 64.8 [5] | - | - | 74.6 | 70.4 | [14] 10 | |||
| Reading Comp. | |||||||||||||
| BoolQ | 50.0 | 83.0 | 82.8 | 81.0 | 80.0 [1] | 60.5 | 77.5 [32] | 82.9 | 84.6 | [4] | |||
| DROP | - | 54.9 | 55.2 | 3.8 | 36.5 [20] | 22.7 | 23.9 | [2] | |||||
| MultiRC | - | 45.1 | 62.0 | 60.0 | 59.6 [5] | 72.9 | 77.5 | 72.1 | [1] | ||||
| OBQA | 25.0 | 53.0 | 55.2 | 41.8 | 50.6 [10] | 57.6 | 78.4 | 78.2 | [16] | ||||
| SQuADv1 | - | - | - | 22.7 | 50.2 [3] | - | - | 80.1 | 82.7 | [4] | |||
| SQuADv2 | - | 68.3 | 70.0 | 11.1 | 34.9 [3] | 69.8 [16] | 44.2 | 43.1 | [3] | ||||
| Closed-Book QA | |||||||||||||
| ARC-c | 25.0 | 48.2 | 50.3 | 42.0 | 49.4 [10] | 51.4 | 51.5 [50] | 63.1 | 63.8 | [13] | |||
| ARC-e | 25.0 | 71.9 | 76.6 | 76.4 | 80.9 [10] | 68.8 | 70.1 [50] | 79.6 | 80.7 | [14] | |||
| NQ | - | 21.5 | 23.9 | 3.2 | 22.1 [5] | 14.6 | 29.9 [64] | 20.7 | 27.6 | [16] 10 | |||
| TQA (wiki) | - | 68.8 | 71.5 | 21.9 | 63.3 [10] | 64.3 | 71.2 [64] | 68.1 | 67.3 | [16] 10 | |||
| TQA (fds-dev) | - | - | - | 18.4 | 55.1 [10] | - | - | 56.7 | 57.8 | [16] 10 | |||
| Commonsense | |||||||||||||
| COPA | 50.0 | 90.0 | 92.0 | 90.0 | 89.0 [10] | 91.0 | 92.0 [32] | 91.0 | 87.0 | [16] | |||
| HellaSwag | 25.0 | 77.1 | 76.8 | 57.0 | 78.9 | 79.3 [20] | 56.7 | 59.2 | [3] | ||||
| PIQA | 50.0 | 80.4 | 81.4 | 80.3* | 80.2* [10] | 81.0 | 82.3 [50] | 80.5* | 81.7* | [10] | |||
| StoryCloze | 50.0 | 82.5 | 84.0 | 79.5 | 83.2 | 87.7 [70] | 93.4 | 94.7 | [10] | ||||
| Sentiment | |||||||||||||
| IMDB | 50.0 | - | - | 76.9 | - | - | 94.3 | 95.0 | [2] | ||||
| Sent140 | 50.0 | - | - | 41.4 | 63.3 [5] | - | - | 73.5 | 69.3 | [16] | |||
| SST-2 | 50.0 | - | - | 51.0 | 92.3 [5] | 71.6 | 95.6 [8] | 94.6 | 94.6 | [16] | |||
| Yelp | 50.0 | - | - | 84.7 | 89.6 [3] | - | - | 98.1 | 98.0 | [4] | |||
| Paraphrase | |||||||||||||
| MRPC | 50.0 | - | - | 53.7 | - | - | 69.1 | 67.2 | [10] 10 | ||||
| QQP | 50.0 | - | - | 34.9 | 58.9 [3] | - | - | 75.9 | 75.9 | [16] | |||
| PAWS Wiki | 50.0 | - | - | 45.5 | 53.5 [5] | - | - | 69.4 | 70.2 | [10] 10 | |||
| Coreference | |||||||||||||
| DPR | 50.0 | - | - | 54.6 | 57.3 [5] | - | - | 66.8 | 63.3 | [16] 10 | |||
| Winogrande | 50.0 | 73.4 | 73.0 | 68.3 | 68.4 [10] | 70.2 | 77.7 [50] | 71.2 | 72.8 | [16] 10 | |||
| WSC273 | 50.0 | 86.8 | 83.9 | 81.0 | 61.5 [5] | 88.3 | 88.5 [32] | - | - - | - | [-] 10 | ||
| Read. Comp. w/ Commonsense | |||||||||||||
| CosmosQA | 25.0 | - | - | 34.1 | 33.8 [5] | - | - | 60.6 | 56.0 | [5] | |||
| ReCoRD | - | 90.3 | 90.3 | 87.8* | 87.6* | 90.2 | 89.0 [32] | 72.5* | 79.0* | [1] 10 |
Table 2: 8개 NLU task cluster 결과. 표시된 모든 값은 정확도(accuracy) 또는 exact match이며, DROP, MultiRC, SQuAD v1 및 v2는 F1 점수이다. 는 few-shot exemplar의 수를 나타낸다. #t는 FLAN이 평가된 template의 수를 나타낸다. T5-11B, BERT-large. *데이터 오염(Appendix C) 참조. WSC273 (Levesque et al., 2012)은 학습 또는 검증 세트가 없으므로, FLAN에 대한 few-shot 결과는 계산하지 않았다. Trivia QA (TQA)의 경우, GPT-3와 비교하기 위해 dev set의 wikipedia subset에 대한 exact match (EM)와 전체 TFDS dev set에 대한 EM을 모두 보고한다.
B Further Ablation Studies and Analysis
B. 1 Datasets per Task Cluster & Templates per Dataset
우리의 주요 가설은 다양한 task에 대한 instruction tuning이 이전에 보지 못한(unseen) task의 성능을 향상시킨다는 것이다. §4.1에서는 더 많은 task cluster를 추가하는 것이 성능을 향상시킨다는 것을 보여주었다. 여기서는 task cluster의 수를 일정하게 유지했을 때, 추가적인 데이터셋을 추가하는 것이 성능을 향상시키는지를 추가로 탐구한다.
우리는 §4.1과 동일한 분할을 사용하며, NLI, commonsense reasoning, closed-book QA cluster는 held-out으로 유지하고, 나머지 7개의 task cluster는 instruction tuning에 사용한다. 이 7개의 task cluster에 대해, 우리는 task cluster당 하나의 데이터셋만 사용한 모델과 task cluster당 4개의 데이터셋을 사용한 모델을 instruction tuning한다 (4개의 task를 가지지 않는 task cluster의 경우, 사용 가능한 모든 task를 사용했다).
또한, 우리는 데이터셋당 instruction template의 수의 역할을 동시에 탐구한다. §2.1에서 언급했듯이, 각 데이터셋에 대해 수동으로 10개의 instruction template을 구성하여 instruction tuning에 사용했다. 여기서는 데이터셋당 1개, 4개, 10개의 template을 사용하여 모델을 instruction tuning한다.
Figure 11은 이러한 결과를 보여준다. cluster당 더 많은 데이터셋을 사용하는 것은 3개의 held-out cluster에서 평균적으로 거의 10%의 성능 향상을 가져왔다. 그러나 데이터셋당 더 많은 template을 사용하는 것은 cluster당 하나의 task가 있을 때 성능에 비교적 미미한 영향을 미쳤으며, cluster당 4개의 task가 있을 때는 그 영향이 사라졌다.
template의 작은 효과는, 각 task당 10개의 template을 구성하는 것이 특정 template에 대한 overfitting을 완화할 것이라는 우리의 원래 동기를 고려할 때 놀랍다. 그러나 이 결과는 대규모 language model을 fine-tuning하는 것의 예측 불가능성을 강조한다. 한 가지 가설은 이러한 규모의 모델은 단일 task에 쉽게 overfit되지 않는다는 것이다.
 Figure 11: task cluster당 데이터셋 수와 데이터셋당 template 수가 3개의 held-out cluster(NLI, commonsense reasoning, closed-book QA) 성능에 미치는 영향.
Figure 11: task cluster당 데이터셋 수와 데이터셋당 template 수가 3개의 held-out cluster(NLI, commonsense reasoning, closed-book QA) 성능에 미치는 영향.
task cluster당 더 많은 데이터셋을 추가하는 것은 성능을 크게 향상시킨다. 그러나 데이터셋당 더 많은 template을 사용하는 것은 성능에 매우 작은 영향만을 미쳤으며, task cluster당 충분한 데이터셋이 있을 때는 그 영향이 사라졌다.
B. 2 Role of instructions during finetuning
Table 3에서는 4.3절의 ablation study에 대한 클러스터별 결과가 제시되어 있다.
B. 3 Further Analysis: Instruction Tuning Facilitates Prompt Tuning
Table 4에는 Section 4.5의 분석에 대한 데이터셋별 결과가 제시되어 있다. 위의 task들은 모두 분류(classification) task이므로, 향후 연구에서는 요약(summarization)이나 질문 응답(question answering)과 같은 task를 포함하거나, supervised 데이터셋을 사용하여 모델을 fine-tuning하는 방향으로 진행될 수 있다.
C Data Contamination Analysis
한 가지 합리적인 우려는 FLAN의 사전학습 코퍼스가 2조 개 이상의 토큰을 포함하고 있기 때문에, 주어진 평가 데이터셋의 예시가 사전학습 중에 모델에 의해 이미 그대로 학습되었을 가능성이 있다는 점이다. 이는 우리의 zero-shot 모델의 성능을 과대평가할 수 있다.
이러한 우려를 해소하기 위해, GPT-3 (Brown et al., 2020)와 마찬가지로 우리는 **사후 데이터 오염 분석(post-hoc data contamination analysis)**을 수행하여,
| Finetuning prompt | Inference prompt | Zero-shot performance on unseen task cluster | ||||
|---|---|---|---|---|---|---|
| NLI | Read. Comp. | ClosedBook QA | Translation | Four-Task Average | ||
| Natural instructions (= FLAN) | Natural instructions | 56.2 | 77.4 | 56.6 | 30.7 | 55.2 |
| No template | Natural instructions | 50.5 | 58.2 | 25.5 | 15.0 | 37.3 |
| Task/dataset name | Natural instructions | 52.8 | 63.0 | 44.8 | 25.9 | 46.6 |
| Task/dataset name | Task/dataset name | 60.2 | 64.9 | 40.8 | 21.9 | 47.0 |
Table 3: finetuning 과정에서 instruction이 제거된 모델을 사용한 ablation study 결과. "no template"의 경우, 입력과 출력만 주어져 multi-task finetuning 중 task를 구분하지 않는다. "task/dataset name"의 경우, multi-task finetuning 중 입력 앞에 task 및 데이터셋 이름이 추가된다 (예: "[Translation: WMT'14 to French] The dog runs"). NLI 데이터셋: ANLI R1-R3, CB, RTE; reading comprehension 데이터셋: BoolQ, MultiRC, OpenbookQA; closed-book QA 데이터셋: ARC-c, ARC-e, NQ, TQA; translation 데이터셋: WMT'14 Fr En, WMT'16 De En, WMT'16 Ro En. 특히, task/dataset name으로 학습한 경우 높은 NLI 점수를 달성했는데, 이는 CB 데이터셋에서 83.9점을 기록했기 때문이다. CB 데이터셋의 validation set은 56개의 예시만 포함한다 (FLAN도 최고의 dev template으로 83.9점을 얻었지만, 평균 template은 64.1점에 불과했다).
| Prompt tuning train. examples | Prompt Tuning Analysis | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BoolQ acc. | CB acc. | CoPA acc. | MultiRC F1 | ReCoRD acc. | RTE acc. | WiC acc. | WSC acc. | ||
| LaMDA-PT | 55.5 | 55.4 | 87.0 | 65.4 | 78.0 | 52.4 | 51.6 | 65.4 | |
| FLAN | 32 | 77.5 | 87.5 | 91.0 | 76.8 | 80.8 | 83.0 | 57.8 | 70.2 |
| LaMDA-PT | full | 82.8 | 87.5 | 90.0 | 78.6 | 84.8 | 82.0 | 54.9 | 72.7 |
| FLAN | dataset | 86.3 | 98.2 | 94.0 | 83.4 | 85.1 | 91.7 | 74.0 | 86.5 |
Table 4: FLAN (instruction tuning)은 LaMDA-PT (no instruction tuning)보다 prompt tuning을 통해 얻은 연속적인 입력에 더 잘 반응한다. 주어진 데이터셋에 대해 prompt tuning을 수행할 때, instruction tuning 중에는 해당 데이터셋과 동일한 클러스터의 task는 학습되지 않았다.
모델의 성능이 실제로 사전학습 데이터셋에 포함된 예시들을 평가함으로써 과대평가되었는지 조사한다.
우리의 데이터 오염 분석 절차는 Brown et al. (2020)의 설정을 따른다. 이 절차는 각 벤치마크에 대해 "clean" 버전을 생성하는데, 이는 사전학습 코퍼스 내의 어떤 -gram ( 은 데이터셋마다 다르지만 대략 13)과 겹치는 모든 잠재적으로 유출된 예시들을 제거한 것이다. 우리는 Brown et al. (2020)과 동일한 데이터셋별 을 사용하고, 공백을 기준으로 분할한다. 그런 다음, 원래 데이터셋(clean + dirty)에서의 모델 성능과 비교하여 이 clean subset에서 모델을 평가한다. clean subset에서 성능이 낮게 나타난다면, 데이터 오염이 결과 과대평가로 이어졌음을 시사한다.
Figure 12는 이러한 결과를 요약하며, 정확한 수치는 Table 5에 제시되어 있다. 우리는 GPT-3 논문과 매우 유사한 몇 가지 경향을 발견했다: (1) 많은 데이터셋이 사전학습 데이터와 상당수의 겹치는 예시를 가졌다. (2) 모든 데이터셋에서 clean 데이터로 평가하는 것이 전체 데이터셋으로 평가하는 것보다 성능이 나빠진다는 상관관계는 발견되지 않았다. (3) clean 예시가 적은 데이터셋일수록 성능 변화율의 분산이 더 높았다 (이는 clean 예시 수가 적기 때문일 가능성이 높다).
 Figure 12: GPT-3와 마찬가지로, 우리는 FLAN의 사전학습 데이터에 포함되지 않았을 것이라고 높은 신뢰도를 가진 "clean" 버전의 데이터셋에 대해서도 성능을 측정했다. FLAN이 사전학습 데이터에 예시가 더 자주 나타난 평가 세트에서 더 나은 성능을 보인다는 상관관계는 발견되지 않았다. clean 데이터의 비율이 매우 작을 때는 clean 성능을 계산하기 위한 예시 수가 적어 분산이 높게 나타난다.
Figure 12: GPT-3와 마찬가지로, 우리는 FLAN의 사전학습 데이터에 포함되지 않았을 것이라고 높은 신뢰도를 가진 "clean" 버전의 데이터셋에 대해서도 성능을 측정했다. FLAN이 사전학습 데이터에 예시가 더 자주 나타난 평가 세트에서 더 나은 성능을 보인다는 상관관계는 발견되지 않았다. clean 데이터의 비율이 매우 작을 때는 clean 성능을 계산하기 위한 예시 수가 적어 분산이 높게 나타난다.
GPT-3와 마찬가지로, 우리는 DROP과 SQuADv2가 사전학습 데이터와 거의 완전히 겹친다는 것을 발견했다. 우리는 그들의 절차를 따라 데이터를 수동으로 검사했으며, 대부분의 겹치는 -gram이 예시의 context에만 존재한다는 것을 확인했다 (DROP의 경우 99.6%, SQuADv2의 경우 97.2%). DROP의 경우 질문과 답변 모두에서 겹치는 부분이 전혀 없었으며, SQuADv2의 경우 11,153개의 평가 예시 중 5개에서만 질문과 답변 모두에서 겹치는 부분이 발생했다. 따라서 이 두 데이터셋의 경우,
모델은 배경 정보만 얻을 뿐 특정 질문에 대한 답변을 암기할 수 없다 (SQuADv2의 5개 예외 제외).
ANLI R1과 R2 (Nie et al., 2020) 또한 GPT-3보다 훨씬 높은 수준으로 거의 완전한 데이터 오염을 보였다. 추가 검사 결과, 대부분의 겹치는 부분이 예시 context에 발생하며 가설(hypothesis)에는 발생하지 않는다는 것을 확인했다 (ANLI R1의 경우 97.3%, ANLI R2의 경우 98.2%). ANLI R1과 R2는 전적으로 Wikipedia 예시를 기반으로 하므로 (R3는 아님), GPT-3의 사전학습 데이터셋에 비해 우리의 사전학습 데이터셋에서 오염 정도가 더 높은 것은 ANLI R1과 R2에 사용된 context를 포함하는 더 최신 버전의 Wikipedia를 사용했기 때문일 수 있다 (이들은 2019년에 수집됨). 사전학습에서 특정 context를 보는 것이 새로운, 보지 못한 문장이 주어졌을 때 NLI task에 도움이 되지 않으므로, 이러한 겹침이 두 데이터셋의 성능에 영향을 미쳤을 가능성은 낮다고 생각한다.
나머지 데이터셋 중에서는 ReCoRD와 PIQA만이 clean subset 성능이 전체 평가 세트 성능보다 1% 이상 낮았다. 이 두 데이터셋은 언어 모델링(즉, "이 문장의 가장 좋은 다음 부분은 무엇인가?") task이므로, 이전 task들에 비해 사전학습 데이터에서 완전한 문장을 보는 것이 모델이 다운스트림 평가에서 올바른 답변을 예측하는 데 도움이 될 가능성이 더 높다. PIQA의 경우, 1,838개의 평가 예시 중 93개에서 목표(goal)와 해결책(solution) 모두에 겹치는 부분이 있었고, ReCoRD의 경우 10,000개의 학습 예시 중 2,320개에서 쿼리에 겹치는 부분이 있었다. 따라서 우리는 Table 2에서 이 결과들을 별표 *로 표시한다. Brown et al. (2020) 또한 이 두 데이터셋에 대해 상당한 오염률을 보고했으며 (ReCoRD의 경우 61% dirty, PIQA의 경우 29%), PIQA를 별표로 표시했다.
이러한 겹침 분석은 Brown et al. (2020)에서 수행된 것을 따르므로, 동일한 주의사항을 다시 강조한다: 우리의 -gram 매칭 절차의 보수적인 특성은 추가적인 **오탐(false positives)**을 유발할 수 있다. clean subset이 전체 subset과 동일한 분포에서 추출되었다는 보장은 없으며, 테스트 오염을 정확하게 감지하는 것은 확립된 모범 사례가 없는 비교적 새로운 연구 분야이다. 더욱이, 우리의 사전학습 코퍼스는 GPT-3에 사용된 것(500B 토큰)보다 거의 5배 크기 때문에, dirty 데이터를 감지하는 데 더 많은 오탐이 발생할 가능성이 있다.
| Dataset | Metric | Total count | Total acc/F1/BLEU | Clean count | Clean acc/F1/BLEU | % clean | % Diff (clean overall) |
|---|---|---|---|---|---|---|---|
| DROP | F1 | 9,536 | 22.4 | 61 | 33.0 | 0.6 | 47.4 |
| SQuADv2 | F1 | 11,873 | 41.3 | 106 | 38.7 | 0.9 | -6.2 |
| ANLI R1 | acc | 1,000 | 48.1 | 14 | 57.1 | 1.4 | 18.8 |
| ANLI R2 | acc | 1,000 | 42.9 | 21 | 38.1 | 2.1 | -11.2 |
| ReCoRD | acc | 10,000 | 4.6 | 3,203 | 4.5 | 32.0 | -2.7 |
| MultiRC | acc | 4,848 | 75.4 | 1,972 | 75.7 | 40.7 | 0.5 |
| PIQA | acc | 1,838 | 23.7 | 896 | 23.3 | 48.7 | -1.7 |
| ANLI R3 | acc | 1,200 | 44.2 | 718 | 45.3 | 59.8 | 2.5 |
| HellaSwag | acc | 10,042 | 28.5 | 6,578 | 28.7 | 65.5 | 0.7 |
| RTE | acc | 2,77 | 84.1 | 183 | 84.2 | 66.1 | 0.0 |
| WMT' | BLEU | 3,003 | 31.3 | 2,243 | 31.5 | 74.7 | 0.9 |
| WMT'14 Fr En | BLEU | 3,003 | 34.0 | 2,243 | 34.1 | 74.7 | 0.2 |
| BoolQ | acc | 3,270 | 76.5 | 2,515 | 76.3 | 76.9 | -0.4 |
| TQA (tfds-dev) | F1 | 11,313 | 62.2 | 8,731 | 62.0 | 77.2 | -0.2 |
| ARC Easy | acc | 2,365 | 79.5 | 1,888 | 79.0 | 79.8 | -0.6 |
| ARC Challenge | acc | 1,165 | 63.1 | 983 | 64.2 | 84.4 | 1.7 |
| OpenbookQA | acc | 500 | 74.6 | 425 | 74.8 | 85.0 | 0.3 |
| WMT'16 En De | BLEU | 2,999 | 22.7 | 2,569 | 23.0 | 85.7 | 1.4 |
| WMT'16 De En | BLEU | 2,999 | 38.6 | 2,569 | 38.7 | 85.7 | 0.2 |
| WMT'16 En Ro | BLEU | 1,999 | 15.5 | 1,752 | 15.4 | 87.6 | -0.7 |
| WMT' 16 Ro En | BLEU | 1,999 | 36.7 | 1,752 | 36.8 | 87.6 | 0.1 |
| COPA | acc | 100 | 88.0 | 91 | 87.9 | 91.0 | -0.1 |
| CB | acc | 56 | 41.1 | 53 | 41.5 | 94.6 | 1.1 |
| NQ | F1 | 3,610 | 24.5 | 3,495 | 24.3 | 96.8 | -0.5 |
| StoryCloze | acc | 1,871 | 92.1 | 1,864 | 92.1 | 99.6 | 0.0 |
| Winogrande | acc | 1,267 | 39.4 | 1,265 | 39.4 | 99.8 | 0.2 |
Table 5: GPT-3에서도 사용된 데이터셋의 부분집합에 대한 겹침 통계. 가장 오염된 데이터셋부터 가장 깨끗한 데이터셋 순으로 정렬되어 있다. 평가 예시가 사전학습 코퍼스와 -gram 충돌이 발생하면 dirty로 간주되었다. 이 결과는 각 데이터셋에 대해 단일 template만을 사용하여 FLAN의 성능을 계산했으므로, 모든 template에 대한 평균 성능 결과와는 약간 다를 수 있다.
D Extended Related Work
D. 1 Language Models and Multi-task Learning
우리의 연구는 NLP 애플리케이션을 위한 언어 모델에 대한 오랜 선행 연구들(Dai & Le, 2015, Peters et al., 2018, Howard & Ruder, 2018, Radford et al., 2018, 2019, inter alia)에서 폭넓게 영감을 받았다. Instruction tuning은 **Multitask Learning (MTL)**의 한 형태로 볼 수 있으며, 이는 딥러닝 분야에서 잘 확립된 영역이다(Collobert et al., 2011, Luong et al., 2016, Ruder, 2017, Velay & Daniel, 2018, Clark et al., 2019b, Liu et al., 2019b, inter alia). NLP 분야의 MTL에 대한 최근 조사는 Worsham & Kalita (2020)를 참조하라. 훈련 task 전반의 성능 향상(Raffel et al., 2020, Aghajanyan et al., 2021) 또는 새로운 도메인으로의 일반화(Axelrod et al., 2011)에 초점을 맞춘 기존 MTL 연구와 달리, 우리의 연구는 훈련 시 보지 못한 task에 대한 zero-shot generalization을 개선하는 데 동기를 둔다.
D. 2 Zero-Shot Learning and Meta-Learning
우리의 연구는 또한 zero-shot learning이라는 잘 정립된 범주에 속한다. zero-shot learning은 역사적으로 학습되지 않은(unseen) 범주 집합 내에서 인스턴스를 분류하는 것을 지칭하는 데 사용되어 왔다 [Lampert et al., 2009; Romera-Paredes & Torr, 2015, Srivastava et al., 2018, Yin et al., 2019, inter alia]. NLP 분야에서 zero-shot learning 연구는 다음과 같은 영역을 포함한다:
- 학습되지 않은 언어 쌍 간의 번역 [Johnson et al., 2017, Pham et al., 2019],
- 학습되지 않은 언어에 대한 language modeling [Lauscher et al., 2020],
- 다양한 NLP 응용 분야 [Liu et al., 2019a; Corazza et al., 2020; Wang et al., 2021].
가장 최근에는 언어 모델의 emergent ability [Brown et al., 2020]가 부각되면서, 모델이 학습되지 않은 task에 어떻게 일반화되는지에 대한 관심이 증가했다. 이는 본 논문에서 사용된 zero-shot learning의 정의와 일치한다. 또한, meta-learning [Finn et al., 2017, Vanschoren, 2018, inter alia] 역시 소수의 예시를 기반으로 학습되지 않은 task에 빠르게 적응하는 모델을 훈련하는 것을 목표로 한다.
D. 3 Prompting
Instruction tuning은 대규모 language model이 상당한 세계 지식을 포함하고 있으며 다양한 NLP task를 수행할 수 있다는 직관을 활용한다 (Brown et al., 2020; Bommasani et al. (2021) 참조). 이와 유사한 목표를 공유하는 또 다른 연구 방향은 backpropagation을 통해 최적화된 continuous input으로 모델에 prompt를 주어 성능을 크게 향상시키는 방식이다 (Li & Liang, 2021; Lester et al., 2021; Qin & Eisner, 2021). 또한, 모델이 특정 출력을 생성하도록 prompt를 주는 연구도 있다 (Wei et al., 2022). 이러한 접근 방식의 성공은 모델 규모에 크게 의존하며 (Lester et al., 2021), 대규모 모델은 서비스 비용이 많이 들 수 있지만, 단일 대규모 모델이 여러 task를 수행할 수 있는 능력은 이러한 부담을 다소 완화시켜 준다. Section 4.5의 실험에서 보여주듯이, prompt tuning은 instruction tuning이 추가적으로 성능을 향상시킬 수 있는 직교적인(orthogonal) 방법이다. Reif et al. (2021)의 연구는 관련 task를 사용하여 zero-shot learning을 개선한다는 점에서 우리 연구와 유사하지만, context 내에서만 관련 task를 사용하고 (fine-tuning하지 않음), 텍스트 스타일 변환(text style transfer) 애플리케이션에 중점을 둔다는 점에서 차이가 있다.
우리 연구는 각 task별로 별도의 checkpoint를 생성하지 않고, 추론 시 텍스트 상호작용을 사용하여 단일 모델에 prompt를 준다는 점에서 prompting과 유사한 동기를 공유한다. GPT-3와 같은 prompting 연구는 사전학습 중에 볼 수 있을 법한 텍스트를 의도적으로 모방하는 prompt를 작성하기 위해 prompt engineering을 사용한다 (예: MultiRC의 경우 GPT-3는 정답 키가 있는 시험을 모방하는 prompt를 시도한다). 반면, 우리는 문장 완성 대신 자연어 지시에 응답하도록 모델을 fine-tuning함으로써 이러한 대규모 모델이 비전문 사용자에게 더 쉽게 접근할 수 있도록 만들고자 한다.
D. 4 Finetuning Large Language Models
사전학습된 language model을 fine-tuning하는 것은 NLP 분야에서 잘 확립된 방법이며, 지금까지의 많은 연구는 100M에서 10B 파라미터 범위의 모델에서 이루어졌다 (Dai & Le, 2015; Devlin et al., 2019; Raffel et al., 2020; Lewis et al., 2020 등). O(100B) 파라미터 규모의 모델의 경우, 최근 연구에서는 프로그램 합성 (Austin et al., 2021; Chen et al., 2021), 요약 (Wu et al., 2021)을 위한 task-specific 모델을 fine-tuning했으며, bias 및 fairness 행동 개선 (Solaiman & Dennison, 2021)도 이루어졌다. 전통적인 "dense" 모델 외에도, 1T 파라미터 이상에 달하는 sparse Mixture of Experts (MoE) 모델이 학습되고 fine-tuning되었다 (Lepikhin et al., 2020; Fedus et al., 2021). 동일한 다운스트림 task에서 fine-tuning하고 평가하는 이전 연구들과 비교하여, 우리의 설정은 instruction tuning이 미학습 task (unseen tasks) 수행 능력에 미치는 영향을 연구한다.
D. 5 Multi-task Question Answering
우리가 instruction tuning에 사용하는 지침은 QA 기반 task 정식화(formulation) 연구와 유사하다. 이 연구는 context에 대한 질문-답변(question-answering) 형태로 NLP task들을 통합하는 것을 목표로 한다. 예를 들어, McCann et al. (2018)은 10개의 NLP task를 QA로 정식화하고, 자연어 prompt로 구성된 task 모음으로 모델을 학습시킨다. 그들은 fine-tuning task에서 transfer learning 이득과 SNLI (Bowman et al., 2015) 및 Amazon/Yelp Reviews (Kotzias et al., 2015)에 대한 zero-shot domain adaptation 결과를 보고한다. McCann et al. (2018)은 unsupervised pre-training을 활용하지 않고 보지 못한 domain으로의 zero-shot transfer만 보고하는 반면, 우리 연구는 사전학습된 LM을 사용하고 보지 못한 task cluster에 대한 zero-shot 성능에 초점을 맞춘다. UnifiedQA (Khashabi et al., 2020)는 20개 데이터셋에 걸쳐 McCann et al. (2018)과 유사한 transfer learning 이득을 보이며, 4가지 유형의 QA에 걸쳐 보지 못한 task에 대한 우수한 일반화 성능을 보고한다. 이진 텍스트 분류에 초점을 맞춘 Zhong et al. (2021)은 43개의 task를 예/아니오 질문으로 표현하여 T5-770M을 fine-tuning하고, 보지 못한 task에 대한 zero-shot 성능을 연구한다. 이에 비해 우리 논문은 훨씬 더 넓은 범위에서, 훨씬 더 큰 모델로 다양한 task에 대한 아이디어를 실증적으로 보여준다. 다른 연구에서는 semantic role labeling (He et al., 2015), relation extraction (Levy et al., 2017), coreference resolution (Wu et al., 2020), named entity recognition (Li et al., 2020)과 같은 보다 특정 응용 분야에 대해 QA 기반 task 정식화를 사용해왔다.
D. 6 Instructions-Based NLP
언어 모델 능력의 최근 발전은 instructions 기반 NLP라는 새로운 분야에 대한 관심을 증가시켰다 (Goldwasser & Roth, 2014; McCarthy, 1960 참조). Schick & Schütze (2021) (Gao et al., 2021; Tam et al., 2021도 참조)는 cloze-style 구문으로 task 설명을 사용하여 언어 모델이 few-shot 및 semi-supervised learning을 위한 soft label을 할당하도록 돕는다. 하지만 이 연구는 각 다운스트림 task마다 새로운 checkpoint를 fine-tuning한다. Efrat & Levy (2020)는 GPT-2 (Radford et al., 2019)를 문장의 번째 단어를 검색하는 것부터 SQuAD 예시를 생성하는 것까지 다양한 간단한 task에 대해 평가했으며, GPT-2가 모든 task에서 저조한 성능을 보인다고 결론지었다.
많은 task에 대해 fine-tuning하고 보지 못한 task에 대해 평가하는 설정 측면에서, 최근 두 논문이 우리 연구와 유사하다. Mishra et al. (2021)은 BART (Lewis et al., 2020)를 instructions와 few-shot 예시를 사용하여 질문 응답, 텍스트 분류, 텍스트 수정과 같은 task에 대해 fine-tuning했으며, 이러한 instructions를 사용한 few-shot fine-tuning이 보지 못한 task에서 성능을 향상시킨다는 것을 발견했다. Ye et al. (2021)은 cross-task few-shot learning을 위한 설정을 도입하여, MAML (Finn et al. 2017)을 사용한 multi-task meta-learning이 보지 못한 다운스트림 task에서 BART의 few-shot 능력을 향상시킨다는 것을 발견했다. 우리 연구는 이 두 논문과 달리 zero-shot learning에 중점을 두며, 이를 위해 모델 규모의 결정적인 중요성을 관찰한다 (FLAN은 BART-base보다 1,000배 크다).
아마도 우리 연구와 가장 관련이 깊은 논문은 우리의 초기 preprint 이후에 발표된 Sanh et al. (2021)과 Min et al. (2021)일 것이다. Min et al. (2021)은 GPT-2 Large (770M 파라미터)를 few-shot learner로 fine-tuning하는데, 이는 Section 4.3의 우리 실험과 동일한 접근 방식이다. 우리 결론과 유사하게, 그들도 few-shot exemplars와 instruction tuning을 포함하는 것이 성능을 향상시키는 상호 보완적인 방법임을 관찰했다. Sanh et al. (2021)은 T5-11B를 prompt에 응답하도록 fine-tuning할 것을 제안하며, 그들도 zero-shot learning에서 성능 향상을 보고한다. 이 두 논문과 우리 연구는 모두 instructions를 사용한 fine-tuning을 연구하지만, Min et al. (2021)이 언급했듯이, 모델 크기, 모델 유형 (decoder-only vs encoder-decoder), 사전학습 데이터, task 혼합, instructions 유형 (Sanh et al. (2021)은 그들의 instructions가 더 다양하다고 말함)의 차이로 인해 결과를 직접 비교하기는 어렵다.
마지막으로, OpenAI에는 InstructGPT (Ouyang et al., 2022)라는 모델이 있다. InstructGPT는 사람의 주석을 사용하여 fine-tuning과 강화 학습을 통해 원하는 모델 동작을 유도하며, InstructGPT가 수정되지 않은 GPT-3보다 사람 평가자들에게 더 선호된다는 것을 발견했다.
E Frequently Asked Questions
How do the FLAN instructions differ from GPT-3 or T5 prompts?
GPT-3 prompting은 모델이 사전학습된 데이터와 유사한 형태로 prompt를 구성하여, 모델이 그 뒤를 이어서 완성하도록 하는 방식이다. T5 prompt는 대부분 데이터셋을 나타내는 단순한 태그에 불과하며, 이는 zero-shot 설정에서는 작동하지 않는다. 이와 대조적으로, FLAN에서 사용하는 prompt는 사람에게 task를 수행하도록 요청할 때 사용되는 방식과 유사하다.
예를 들어, NLI task의 입력이 주어졌을 때, prompt는 다음과 같다.
T5 prompt:
cb hypothesis: At my age you will probably have learnt one lesson.
premise: It's not certain how many lessons you'll learn by your
thirties.
GPT-3 prompt:
At my age you will probably have learnt one lesson.
question: It's not certain how many lessons you'll learn by your
thirties. true, false, or neither? answer:
FLAN prompt:
Premise: At my age you will probably have learnt one lesson.
Hypothesis: It's not certain how many lessons you'll learn by your
thirties.
Does the premise entail the hypothesis?
따라서 FLAN prompt는 지시에 응답하는 형태로 구성되어 있기 때문에, fine-tuning 없이는 사전학습된 language model에서 잘 작동하지 않는다. 대부분의 생성 task에서 성능은 거의 0에 가까웠다. 예를 들어, "'The dog runs.' Translate this sentence to French."라는 입력이 주어졌을 때, LaMDA-PT는 문장을 실제로 번역하는 대신 "The dog runs after the cat"이라고 이어서 생성한다. 이러한 이유로, 우리는 LaMDA-PT baseline에 기존의 GPT-3 prompt를 사용하였다.
What are some limitations/failure cases of FLAN?
FLAN이 대부분의 task에 잘 반응한다는 것을 정성적으로 확인했지만, 일부 간단한 task에서는 실패하기도 한다. 예를 들어, Figure 22에서 보듯이 FLAN은 문장에서 두 번째 단어를 반환하는 매우 간단한 task에서 실패하며, 덴마크어로 질문에 답하라고 요청했을 때 질문을 덴마크어로 잘못 번역하기도 한다. 추가적인 한계점으로는 1024 토큰의 짧은 context 길이(대부분의 요약 task에는 충분하지 않음)와 모델이 주로 영어 데이터로 학습되었다는 점이 있다.
Can FLAN be used when large amounts of training data are available?
본 연구에서는 zero-shot task에 대한 cross-task generalization에 초점을 맞추지만, instruction tuning이 task 혼합에 따라 학습된(seen) task들 간의 긍정적인 task transfer를 유도할 수 있다고 믿는다 (이는 향후 연구로 남겨둔다). §4.5에서 FLAN checkpoint에 prompt tuning을 적용했을 때, supervised setting에서 긍정적인 task transfer를 시사하는 유망한 결과를 확인하였다.
Are the ten unique templates per dataset or per task cluster?
10개의 고유한 템플릿은 각 데이터셋에 대해 개별적으로 적용되며, task cluster 전체에 적용되는 것이 아니다. 이는 동일한 task cluster 내의 데이터셋이라 할지라도 미묘한 차이가 있었기 때문이다 (예: "이 영화 리뷰는 긍정적인가?" vs "이 옐프 리뷰는 긍정적인가?").
In Figure 74 A, why does the untuned LaMDA-PT model see worse performance with more parameters for reading comprehension and sentiment analysis?
Figure 7A는 Figure 7B의 정확성을 확인하기 위한 검증 과정이다. Figure 7A는 예상대로 instruction tuning 과정에서 학습된 task에 대해서는 모델 규모(scale)가 성능을 향상시킨다는 것을 확인시켜준다. Figure 7A에 표시된 untuned LaMDA-PT 모델의 성능은 단지 완전성을 위해 제시된 것이다.
그럼에도 불구하고, 모델 규모가 untuned LaMDA-PT의 zero-shot 성능을 항상 향상시키지는 않는다는 사실은 흥미로운 결과이다. 우리는 처음에 놀랐는데, 이는 Brown et al. (2020)이 모델 규모가 많은 task에서 전반적으로 성능을 향상시킨다고 보고했기 때문이다.
결과적으로, 모델 규모가 특정 task에서는 성능을 향상시키지 않는다는 것이 밝혀졌다. 이는 특히 zero-shot learning에서 두드러지며, 우리가 평가한 독해(reading comprehension) 및 감성 분석(sentiment analysis) task에서 이러한 현상이 나타난다고 생각한다. GPT-3 논문 자체도 BoolQ와 DROP의 zero-shot 성능이 13B에서 175B 파라미터로 증가할 때 오히려 감소한다고 보고한다. GPT-3 논문은 감성 분석에 대한 결과를 보여주지 않지만, Holtzman et al. (2021)은 SST-2의 zero-shot 성능 또한 13B에서 175B 파라미터로 증가할 때 악화된다는 것을 발견했다. 따라서 이러한 현상은 GPT-3와 우리가 사용한 모델 모두에서 일관되게 나타나는 결과이다.
이러한 현상은 분명히 추가 연구 가치가 있지만, instruction tuning의 범위를 벗어난다. 이상적으로는 단일 분할(single split) 대신 교차 검증(cross-validation)을 사용하여 Figure 7의 ablation을 수행했어야 하며, 그렇게 했다면 이러한 현상이 완화되었을 것이다.
F Qualitative Examples
이 섹션에서는 FLAN이 다양한 prompt에 응답하는 질적(qualitative) 예시를 보여준다.

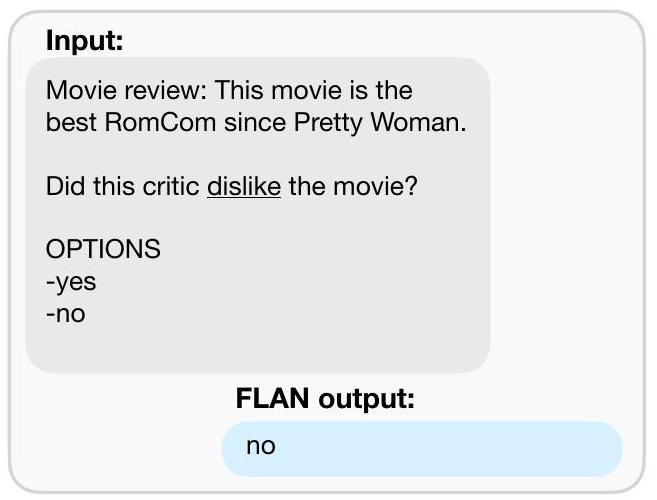
Figure 13: **감성 분석(sentiment analysis)**의 경우, 질문이 뒤집히면 FLAN은 그에 맞춰 답변을 적절하게 변경한다.
 Figure 14: **질문 응답(question answering)**의 경우, FLAN은 지시를 받으면 다른 언어로 질문에 답변할 수 있다. 여러 FLAN 출력은 temperature 0.9, top 40으로 무작위 샘플링을 통해 생성되었다.
Figure 14: **질문 응답(question answering)**의 경우, FLAN은 지시를 받으면 다른 언어로 질문에 답변할 수 있다. 여러 FLAN 출력은 temperature 0.9, top 40으로 무작위 샘플링을 통해 생성되었다.
Input:
Input:
John은 논문을 읽고 있다. John은 논문을 읽고 있다. "Finetuned Language Models are "Finetuned Language Models are Zero-Shot Learners." Zero-Shot Learners." 과거 시제로 변경. 수동태로 변경.
FLAN output:
FLAN output:
John은 논문을 읽고 있었다. "Finetuned Language Models are Zero-Shot Learners"라는 논문이 John에 의해 읽히고 있다.
Input:
Input:
John은 논문을 읽고 있다. John은 논문을 읽고 있다. "Finetuned Language Models are "Finetuned Language Models are Zero-Shot Learners." Zero-Shot Learners." 동사를 '먹다'로 바꾸시오. 동사를 '먹다'로, 주어를 'Noam Chomsky'로 바꾸시오.
FLAN output:
John은 "Finetuned Language Models are"라는 논문을 읽고 있다.
FLAN output:
Noam Chomsky is eating the pape Zero-Shot Learners." "Finetuned Language Models are Zero-Shot Learners."
Figure 15: FLAN은 zero-shot rule-based manipulation을 수행할 수 있다.
Input:
Input: Recommend fun activities to do on Recommend activities to do on a a rainy night in Seattle. sunny weekend in Copenhagen.
FLAN output:
FLAN 출력:
- Christiania 방문
- Pacific Science Center 방문
- Copenhagen Zoo
- 외식하기
- Tivoli Gardens 방문
- 코미디 클럽 가기
- 운하 투어하기
- 담요 요새 만들기
- 박물관
- Space Needle 가기
- The Little Mermaid Statue 방문
- 지하 투어 가기
- Copenhagen Zoo 방문
- 노래방 찾기
- Danish Maritime Museum 방문
Figure 16: FLAN은 zero-shot 추천을 할 수 있다. 여러 FLAN 출력은 temperature 0.9, top 40으로 무작위 샘플링하여 생성되었다.
 Figure 17: FLAN은 zero-shot 방식으로 데이터를 생성하는 데 사용될 수 있으며, 이는 주어진 의도(intent)와 일치하는 발화(utterance)와 같은 형태이다. 여러 FLAN 출력은 temperature 0.9, top 40으로 무작위 샘플링하여 생성되었다.
Figure 17: FLAN은 zero-shot 방식으로 데이터를 생성하는 데 사용될 수 있으며, 이는 주어진 의도(intent)와 일치하는 발화(utterance)와 같은 형태이다. 여러 FLAN 출력은 temperature 0.9, top 40으로 무작위 샘플링하여 생성되었다.
 Figure 18: FLAN은 zero-shot query expansion에 사용될 수 있다. 여러 FLAN 출력은 temperature 0.9, top 40으로 무작위 샘플링하여 생성되었다.
Figure 18: FLAN은 zero-shot query expansion에 사용될 수 있다. 여러 FLAN 출력은 temperature 0.9, top 40으로 무작위 샘플링하여 생성되었다.
Input:
요세미티로 가는 길에 앞 타이어가 터졌다. 이야기를 완성하고, 해피 엔딩으로 마무리하세요.
FLAN output (cherrypicked):
- 우리는 타이어를 교체했다. 정비사는 정직하고 친절하며 도움이 되었다. 그 후 우리는 남은 여행 내내 순조롭게 이동했다. 우리의 여행은 즐거움과 설렘으로 가득했다. - 우리는 견인차를 세 시간 기다렸지만, 멋진 피크닉을 즐겼다. 견인차 운전기사가 스페어 타이어를 장착하는 것을 도와주었고, 우리는 예약된 저녁 식사 시간 전에 요세미티에 도착했다.
 Figure 19: FLAN은 보조 작문(assisted-writing) 애플리케이션과 관련된 zero-shot task를 수행할 수 있다. 여러 FLAN 출력은 온도(temperature) 0.9, top 40으로 무작위 샘플링하여 생성되었다.
Figure 19: FLAN은 보조 작문(assisted-writing) 애플리케이션과 관련된 zero-shot task를 수행할 수 있다. 여러 FLAN 출력은 온도(temperature) 0.9, top 40으로 무작위 샘플링하여 생성되었다.
 Figure 20: FLAN은 **zero-shot 단어 형성(word formation)**에 사용될 수 있다. 여러 FLAN 출력은 온도(temperature) 0.9, top 40으로 무작위 샘플링하여 생성되었다.
Figure 20: FLAN은 **zero-shot 단어 형성(word formation)**에 사용될 수 있다. 여러 FLAN 출력은 온도(temperature) 0.9, top 40으로 무작위 샘플링하여 생성되었다.

 Figure 21: FLAN의 open-ended 생성 task 예시. 당근 이야기는 최소 길이 150으로 16개의 출력을 샘플링한 후, 가장 높은 확률의 출력을 선택한 결과이다.
Figure 21: FLAN의 open-ended 생성 task 예시. 당근 이야기는 최소 길이 150으로 16개의 출력을 샘플링한 후, 가장 높은 확률의 출력을 선택한 결과이다.
 Figure 22: FLAN의 실패 사례 예시.
왼쪽: FLAN이 번째 단어를 반환하는 간단한 task를 수행하지 못한다.
오른쪽: FLAN이 질문에 답하는 대신 질문을 번역한다.
여러 FLAN 출력은 온도(temperature) 0.9, top 40으로 무작위 샘플링하여 생성되었다.
Figure 22: FLAN의 실패 사례 예시.
왼쪽: FLAN이 번째 단어를 반환하는 간단한 task를 수행하지 못한다.
오른쪽: FLAN이 질문에 답하는 대신 질문을 번역한다.
여러 FLAN 출력은 온도(temperature) 0.9, top 40으로 무작위 샘플링하여 생성되었다.
Changes from V4 to V5
- 메인 그림의 표를 그림으로 대체하여 공간을 덜 차지하고 zero-shot 성능에 집중하도록 변경했다.
- GLaM 64B/64E를 baseline으로 추가했다.
- 명령어의 역할과 prompt tuning에 대한 ablation을 본 논문으로 옮기고 (그림을 압축하여) 내용을 요약했다.
Changes to V4 from V3
- 자주 묻는 질문(FAQ) 섹션을 추가하였다 (Appendix E).
- 정성적 예시 섹션을 추가하였다 (Appendix F).
- fine-tuning 시 instruction의 역할에 대한 추가 ablation study를 추가하였다 (Appendix B.2).
- 초기 preprint 이후 arxiv에 게시된 논문들을 반영하여 관련 연구(related work) 섹션을 업데이트하였다 (Appendix D).
Changes to V3 from V2
- 사전학습에 사용된 token 수는 2.81T에서 2.49T token으로 수정되었다.
Changes to V2 from V1
- 용어를 "datasets"와 "task clusters"로 업데이트하였다.
- 이전의 "open-domain QA" task cluster를 "closed-book QA"로 이름을 변경하였다.
- 관련 연구(related work) 섹션을 확장하고 Appendix D로 이동시켰으며, 본문에는 더 짧은 버전을 사용하였다.
- GPT-3 결과가 보고되지 않은 추가 데이터셋에 대해 FLAN 및 LaMDA-PT 결과를 추가하였다.
- TriviaQA의 경우, v1에서는 11,313개의 예시로 구성된 tfds dev set에 대한 결과를 보고하였다. 그러나 GPT-3는 실제로 7,993개의 예시로 구성된 wikipedia dev set으로 평가를 수행하므로, GPT-3의 성능과 비교하기 위해 해당 dev set에 대한 추가 평가를 진행하였다. 그 결과, zero-shot FLAN이 해당 task에서 zero-shot GPT-3를 능가하는 성능을 보였다 (따라서 25개 task 중 20개에서 우세). GPT-3와 비교할 결과는 없지만, 원래 결과는 여전히 Table 2에 표시되어 있다.
- 상식 추론(commonsense reasoning)과 공참조 해결(coreference resolution) 섹션을 본문에서 Appendix로 이동시켰다.
- prompt tuning 섹션을 본문에서 §4.5로 이동시켰다.
- 데이터 오염(data contamination) 분석을 추가하였다 (Appendix C).
- few-shot instruction tuning을 추가하였다 (§4.4).
- Appendix G에 추가 데이터셋을 인용하였다.
- 사전학습에 사용된 토큰 수가 2.81T에서 2.49T 토큰으로 수정되었다.
G Tasks and Datasets
본 Appendix에서는 본 논문에서 사용된 데이터셋에 대해 더 자세히 설명한다. 데이터셋은 다음 task cluster 중 하나로 분류된다:
-
Natural language inference는 두 문장이 어떻게 관련되는지에 대한 것으로, 일반적으로 첫 번째 문장이 주어졌을 때 두 번째 문장이 참, 거짓 또는 가능성이 있는 참인지 묻는다. 우리는 다음 데이터셋을 사용한다:
- ANLI (Nie et al., 2020)
- CB (De Marneffe et al., 2019)
- MNLI (Williams et al. 2018)
- QNLI (Rajpurkar et al., 2018)
- SNLI (Bowman et al., 2015)
- WNLI (Levesque et al., 2012)
- RTE (Dagan et al., 2005, Haim et al., 2006, Giampiccolo et al., 2007, Bentivogli et al., 2009)
-
Reading comprehension은 답변이 포함된 지문이 주어졌을 때 질문에 답하는 능력을 테스트한다. 우리는 다음 데이터셋을 사용한다:
- BoolQ Clark et al. (2019a)
- DROP (Dua et al., 2019)
- MultiRC (Khashabi et al., 2018)
- OBQA (Mihaylov et al., 2018)
- SQuADv1 (Rajpurkar et al., 2016)
- SQuADv2 (Rajpurkar et al., 2018)
-
Commonsense reasoning은 상식적인 요소를 포함하여 물리적 또는 과학적 추론을 수행하는 능력을 평가한다. 우리는 다음 데이터셋을 사용한다:
- COPA (Roemmele et al., 2011)
- HellaSwag (Zellers et al., 2019)
- PiQA (Bisk et al., 2020)
- StoryCloze (Mostafazadeh et al., 2016)
-
Sentiment analysis는 텍스트의 내용이 긍정적인지 부정적인지 이해하는 것을 목표로 하는 고전적인 NLP task이다. 우리는 다음 데이터셋을 사용한다:
- IMDB (Maas et al., 2011)
- Sentiment 140 (Go et al., 2009)
- SST-2 (Socher et al., 2013)
- Yelp (Fast.AI)
-
Closed-book QA는 모델이 답변을 포함하는 정보에 대한 특정 접근 없이 세상에 대한 질문에 답하도록 요구한다. 우리는 다음 데이터셋을 사용한다:
- ARC (Clark et al., 2018)
- NQ (Lee et al., 2019, Kwiatkowski et al., 2019)
- TriviaQA Joshi et al. (2017)
-
Paraphrase detection은 두 문장이 의미론적으로 동등한지 모델이 판단하도록 요구한다. 우리는 다음 데이터셋을 사용한다:
- MRPC (Dolan & Brockett, 2005)
- QQP (Wang et al., 2018, see)
- Paws Wiki (Zhang et al. 2019)
-
Coreference resolution은 주어진 텍스트에서 동일한 개체를 나타내는 표현을 식별하는 능력을 테스트한다. 우리는 다음 데이터셋을 사용한다:
- DPR (Rahman & Ng, 2012)
- Winogrande (Sakaguchi et al. 2020)
- WSC273 (Levesque et al., 2012)
-
Reading comprehension with commonsense는 독해와 상식의 요소를 결합한다. 우리는 다음 데이터셋을 사용한다:
- CosmosQA (Huang et al., 2019)
- ReCoRD (Zhang et al., 2018)
-
Struct to text는 자연어를 사용하여 일부 구조화된 데이터를 설명하는 능력을 테스트한다. 우리는 다음 데이터셋을 사용한다:
- CommonGen (Lin et al., 2020)
- DART (Nan et al., 2021)
- E2ENLG (Dušek et al., 2019)
- WebNLG (Gardent et al., 2017)
-
Translation은 한 언어의 텍스트를 다른 언어로 번역하는 task이다. 우리는 다음 데이터셋을 사용한다:
- WMT'14의 En-Fr (Bojar et al., 2014)
- WMT'16의 En-De, En-Tr, En-Cs, En-Fi, En-Ro, En-Ru (Bojar et al., 2016)
- Paracrawl의 En-Es (Bañón et al., 2020)
-
Summarization은 모델이 텍스트를 읽고 요약본을 생성하도록 요구한다. 우리는 다음 데이터셋을 사용한다:
- AESLC (Zhang & Tetreault, 2019)
- CNN-DM (See et al., 2017)
- Gigaword (Napoles et al., 2012)
- MultiNews (Fabbri et al., 2019)
- Newsroom (Grusky et al., 2018)
- Samsum (Gliwa et al., 2019)
- XSum (Narayan et al., 2018)
- AG News (Zhang et al., 2015)
- Opinion Abstracts - Rotten Tomatoes (Wang & Ling, 2016)
- Opinion Abstracts - iDebate (Wang & Ling, 2016)
- Wiki Lingua English (Ladhak et al., 2020)
-
기타 task cluster에 할당된 추가 데이터셋은 다음과 같다:
- 대화형 질문-답변: QuAC (Choi et al., 2018) 및 CoQA (Reddy et al., 2019)
- 문맥-문장 단어 의미 평가: WiC (Pilehvar & Camacho-Collados, 2019)
- 질문 분류: TREC (Li & Roth, 2002, Hovy et al., 2001)
- 언어적 수용성: CoLA (Warstadt et al., 2019)
- 수학 질문 (Saxton et al., 2019)
모든 task에 대해 우리의 fine-tuning 및 평가 코드는 **tensorflow datasets (TFDS)**를 사용하여 데이터셋을 로드하고 처리한다. 데이터셋당 훈련 예시 수와 관련하여, 우리는 데이터셋당 훈련 세트 크기를 30,000개로 제한하여 어떤 데이터셋도 fine-tuning 분포를 지배하지 않도록 했다. TFDS에서 레이블이 있는 테스트 세트를 사용할 수 있는 경우 이를 사용했으며, 그렇지 않은 경우 TFDS 검증 세트를 테스트 세트로 사용하고 훈련 세트를 훈련 및 개발 세트로 분할했다.
다음 페이지에서는 GPT-3와 비교한 평가 task에 대한 입력 및 출력을 보여준다. 다른 모든 데이터셋에 대한 템플릿은 첨부된 보충 자료를 참조하라.
G. 1 Natural Language Inference
Input
Joey Heindle (1993년 5월 14일 뮌헨 출생)는 독일의 가수이다. 그는 게임 쇼 "Ich bin ein Star - Holt mich hier raus!"의 일곱 번째 시즌에서 우승하고, 매주 심사위원들로부터 만장일치로 부정적인 평가를 받았음에도 불구하고 "Deutschland sucht den Superstar" 시즌 9에서 5위를 차지한 것으로 가장 잘 알려져 있다.
위 단락을 바탕으로 "Joey Heindle은 텔레비전에서 사람들에게 매우 싫어했다."라고 결론 내릴 수 있는가?
OPTIONS:
- Yes
- It's impossible to say
- No
Target Yes
Table 6: Adversarial NLI (ANLI)의 입력 및 타겟 예시. ANLI (Nie et al., 2020)는 사람과 모델이 반복적으로 상호작용하며 수집된 adversarial example을 포함하는 대규모 NLI 벤치마크이다. 이 task는 가설(hypothesis)이 전제(premise)에 의해 추론되는지 여부를 판단하는 것이다 (entailment, not entailment, or impossible to say). 총 세 라운드(R1-R3)가 있으며, 각각 16,946개, 45,460개, 100,459개의 예시로 구성된 세 가지 훈련 세트 중, 우리는 훈련용으로 16,946개, 30,000개, 30,000개를 사용하고, 개발용(dev)으로는 세 TFDS validation 세트에서 각각 200개를 사용한다. TFDS "test" 세트의 1,000개, 1,000개, 1,200개 예시를 최종 결과 보고를 위한 테스트 세트로 사용한다.
Input
A: 그래서 저는 물고기를 보거나, 뭐든 저를 계속 바쁘게 할 수 있는 일을 해요. TV를 켜두는 걸 좋아하는데, 그게 보통 저를 더 바쁘게 만들거든요. 시간이 빨리 가는 것 같고, 제가 자전거를 탈 때만 TV를 본다는 걸 깨닫지 못해요. 그리고 보통 자전거를 다 타고 나면, 몸을 식히기 위해 산책을 해요. 그러면 좀 덜 피곤해지는 것 같아요. 하지만 확실히 힘든 일이에요. B: 그렇게 생각하세요? A: 제가 정말 즐긴다고는 말할 수 없어요.
위 단락을 바탕으로 "그녀가 정말 즐긴다"고 결론 내릴 수 있을까요? OPTIONS:
- Yes
- No
- It's impossible to say
Target
Table 7: Commitment Bank (CB)의 입력 및 타겟 예시.
CB (De Marneffe et al., 2019)는 전제(premise)로부터 가설(hypothesis)이 추출된 텍스트 코퍼스이며, task는 가설이 전제에 의해 추론되는지 여부(entailment, not entailment, impossible to say)를 판단하는 것이다.
250개의 예시로 구성된 학습 세트 중, 200개는 학습용으로, 50개는 개발용으로 사용한다.
TFDS validation 세트의 56개 예시는 수치 보고를 위한 테스트 세트로 사용한다.
| Input <br> After years of study, the Vatican's doctrinal congregation has sent church leaders a confidential document concluding that "sex-change" procedures do not change a person's gender in the eyes of the church. |
|---|
| Based on the paragraph above can we conclude that "Sex-change operations become more common."? |
| OPTIONS: <br> - yes <br> - no |
| Target <br> no |
Table 8: Recognizing Textual Entailment (RTE)의 입력 및 타겟 예시.
RTE (Dagan et al. 2005, Haim et al., 2006, Giampiccolo et al., 2007; Bentivogli et al., 2009)는 두 번째 문장이 첫 번째 문장에 의해 추론되는지 여부(이진 분류, entailed 또는 not entailed)를 묻는 task이다.
2490개의 예시로 구성된 학습 세트 중, 2,290개는 학습용으로, 200개는 개발용으로 사용한다.
TFDS validation 세트의 277개 예시는 수치 보고를 위한 테스트 세트로 사용한다.
G. 2 Reading Comprehension
INPUT
개인이 캐나다 시민권을 취득할 수 있는 방법은 네 가지이다: 캐나다 영토에서 태어나는 경우(출생); 캐나다인 부모에게서 태어나는 경우(혈통); 캐나다 정부의 승인을 받는 경우(귀화); 그리고 입양을 통한 경우이다. 이 중 출생에 의한 시민권만이 제한적인 예외를 제외하고 자동으로 부여되며, 혈통 또는 입양에 의한 시민권은 명시된 조건이 충족되면 자동으로 취득된다. 반면, 귀화에 의한 시민권은 이민, 난민 및 시민권부 장관의 승인을 받아야 한다.
할아버지가 캐나다인이었다면 캐나다 시민권을 얻을 수 있다고 결론 내릴 수 있을까? OPTIONS:
- no
- yes
Target no
Table 9: Boolean Questions (BoolQ)의 입력 및 타겟 예시. BoolQ Clark et al. (2019a)는 주어진 지문과 질문에 대해 yes/no 질문에 답하는 task이다. 9,427개의 훈련 세트 예시 중 9,227개는 훈련에, 200개는 개발(dev)에 사용한다. TFDS 검증 세트의 3,270개 예시는 결과 보고를 위한 테스트 세트로 사용한다.
Input
Imagine you are standing in a farm field in central Illinois. The land is so flat you can see for miles and miles. On a clear day, you might see a grain silo 20 miles away. You might think to yourself, it sure is flat around here. If you drive one hundred miles to the south, the landscape changes. In southern Illinois, there are rolling hills. Why do you think this is? What could have caused these features? There are no big rivers that may have eroded and deposited this material. The ground is capable of supporting grass and trees, so wind erosion would not explain it. To answer the question, you need to go back 12,000 years. Around 12,000 years ago, a giant ice sheet covered much of the Midwest United States. Springfield, Illinois, was covered by over a mile of ice. Its hard to imagine a mile thick sheet of ice. The massive ice sheet, called a glacier, caused the features on the land you see today. Where did glaciers go? Where can you see them today? Glaciers are masses of flowing ice.
Question: "How big were the glaciers?" Response: "One mile" Does the response correctly answer the question? OPTIONS:
- no
- yes
Target yes
Table 10: Multi-Sentence Reading Comprehension (MultiRC)의 입력 및 타겟 예시. MultiRC Khashabi et al. (2018)은 주어진 단락에 답이 포함된 open-ended 질문을 묻는다. 27,243개의 훈련 세트 중 27,043개는 훈련용으로, 200개는 개발용으로 사용한다. TFDS 검증 세트의 4,848개 예시는 수치 보고를 위한 테스트 세트로 사용한다.
Input
soil is a renewable resource for growing plants A plant that needs to expand will be able to have an endless resource in OPTIONS:
- dirt
- pesticides
- pay
- beans
Target dirt
Table 11: Openbook Question Answering (OBQA)의 입력 및 타겟 예시. OBQA (Mihaylov et al. 2018)는 사실 기반의 4지선다형 질문을 제시한다. 4,957개의 학습 세트 예시 중, 우리는 모든 데이터를 학습에 사용하고, 500개의 TFDS validation 세트 중 200개를 개발(dev) 세트로 사용한다. 수치 보고를 위한 테스트 세트로는 500개의 TFDS 테스트 세트를 사용한다.
G. 3 Commonsense Reasoning
INPUT
나는 내 짐을 쌌다. 원인은 무엇인가?
OPTIONS:
- 나는 새 아파트를 찾고 있었다.
- 나는 내 아파트에서 이사하고 있었다.
Target
나는 아파트에서 이사하고 있었다. Table 12: COPA (Choice of Plausible Alternatives)의 입력 및 타겟 예시. COPA (Roemmele et al., 2011)는 인과 관계 추론 task로, 두 가지 선택지 중에서 주어진 전제(premise)의 원인(cause) 또는 결과(effect)를 추론하도록 요구한다. 400개의 학습 세트 예시 중 350개는 학습용으로, 50개는 개발용으로 사용한다. TFDS validation set의 100개 예시는 결과 보고를 위한 테스트 세트로 사용한다.
Input
이 단락 다음에 이어질 내용은 무엇인가? Once the rope is inside the hook, he begins moving up the wall but shortly after he stops and begins talking. The male then begins talking about the clip again and goes back up the wall. as he OPTIONS:
- progresses, there are hooks everywhere on the wall and when he gets near them, he puts his rope inside of it for support and safety.
- changes time, an instant replay of his initial move is shown a second time.
- continues to talk, another male speaks about the move and shows another closeup of the plex by the male.
- continues, other people start to arrive and begin to hang out with him as he makes a few parts of the rope.
Target
진행하면서 벽에는 갈고리가 곳곳에 있고, 그가 갈고리 근처에 다다르면 지지와 안전을 위해 밧줄을 그 안에 넣는다.
Table 13: Example input and target for Commonsense Sentence Completion (HellaSwag). HellaSwag
(Zellers et al., 2019)는 상식(common sense)을 요구하는 문장 완성 task를 평가하며, 네 가지 문맥이 주어졌을 때 가장 가능성 있는 결말을 묻는다. 총 39,905개의 예시로 구성된 학습 세트 중, 우리는 30,000개를 학습용으로, **200개를 개발용(dev)**으로 사용한다. 최종 성능 보고를 위한 테스트 세트로는 TFDS validation set의 10,042개 예시를 사용한다.
Input
Here is a goal: Remove smell from garbage disposal. How would you accomplish this goal? OPTIONS:
- Create soda ice cubes and grind through disposal.
- Create vinegar ice cubes and grind through disposal.
Target Create vinegar ice cubes and grind through disposal. Table 14: Physical Question Answering (PiQA)의 입력 및 타겟 예시. PiQA (Bisk et al. 2020)는 상식적인 물리 추론을 위한 commonsense QA 벤치마크로, 주어진 목표에 대한 두 가지 해결책 중 하나를 선택해야 한다. 16,113개의 학습 세트 예시 중 16,013개는 학습용으로, 100개는 개발용으로 사용한다. TFDS validation 세트의 1,838개 예시는 수치 보고를 위한 테스트 세트로 사용한다.
Input
Caroline은 탄산음료를 절대 마시지 않는다. 친구들은 그 때문에 그녀를 놀린다. 어느 날 친구들은 그녀에게 탄산음료를 마시라고 도전했다. Caroline은 그 도전을 이기고 싶었다.
다음 문장을 예측하시오. OPTIONS:
- Caroline은 탄산음료를 따는 것을 거부했다.
- Caroline은 탄산음료를 따서 단숨에 다 마셨다!
Target Caroline은 탄산음료를 따서 단숨에 다 마셨다! Table 15: The Story Cloze Test (StoryCloze)의 입력 및 타겟 예시. StoryCloze (Mostafazadeh et al., 2016)는 네 문장으로 된 이야기의 올바른 결말을 시스템이 선택하는 상식 추론(commonsense reasoning) 기반의 이야기 생성 프레임워크이다. 우리는 TFDS에 있는 2016년 버전을 사용한다. 1,871개의 예시로 구성된 validation set (training set은 제공되지 않음) 중 1,671개는 학습용으로, 200개는 개발용으로 사용한다. TFDS의 test set 1,871개 예시는 결과 보고를 위한 test set으로 사용한다.
G. 4 Closed-Book QA
| Input <br> What season is the Northern Hemisphere experiencing when it is tilted directly toward the Sun? <br> OPTIONS: <br> - fall <br> - winter <br> - spring <br> - summer |
|---|
| Target <br> summer |
Table 16: The AI2 Reasoning Challenge (ARC)의 입력 및 타겟 예시.
ARC (Clark et al. 2018)는 초등학생 수준의 4지선다형 과학 질문을 제시한다. 이 데이터셋은 challenge set과 easy set으로 나뉘며, challenge set의 질문들은 retrieval 기반 알고리즘과 co-occurrence 알고리즘 모두가 오답을 낸 문제들로 구성되어 있다.
학습 세트의 경우, challenge set은 1,119개, easy set은 2,251개의 예시로 구성되어 있으며, 우리는 이 중 각각 919개와 2,051개를 학습용으로, 200개씩을 개발용(dev)으로 사용한다.
성능 보고를 위한 테스트 세트로는 **TFDS의 테스트 세트(challenge 1,172개, easy 2,376개)**를 사용한다.
| INPUT |
|---|
| Question: who is the girl in more than you know?? |
| Answer: |
| TARGET |
| Romi Van Renterghem. |
Table 17: Natural Questions (Open) (NQ)의 입력 및 타겟 예시.
NQ (Lee et al., 2019; Kwiatkowski et al., 2019)는 질문에 대한 open-ended 답변을 요구하며, 모든 질문은 Wikipedia의 내용을 사용하여 답변할 수 있다.
총 87,925개의 예시로 구성된 학습 세트 중, 우리는 30,000개를 학습용으로, 200개를 개발용(dev)으로 사용한다.
성능 보고를 위한 테스트 세트로는 TFDS의 validation set 3,610개를 사용한다.
| Input <br> Please answer this question: Henry Croft, an orphan street sweeper who collected money for charity, is associated with what organised charitable tradition of working class culture in London, England? |
|---|
| Target <br> pearly kings and queens |
Table 18: Trivia Question Answering (TriviaQA)의 입력 및 타겟 예시.
TriviaQA (Joshi et al. 2017)는 퀴즈 애호가들이 작성한 질문-답변 쌍을 포함한다.
총 87,622개의 예시로 구성된 학습 세트 중, 우리는 30,000개를 학습용으로, 200개를 개발용(dev)으로 사용한다.
성능 보고를 위한 테스트 세트로는 TFDS validation set의 11,313개 예시 중 Wikipedia에서 가져온 7,993개 예시를 사용한다. 이는 (Brown et al. 2020)에서 사용된 validation set과 동일하다.
G. 5 Coreference Resolution
INPUT
문장이 어떻게 끝날까요? Elena wanted to move out of her parents fast but Victoria wanted to stay for a while, OPTIONS:
- Elena went to school.
- Victoria went to school.
Target
Victoria went to school.
Table 19: Adversarial Winograd Schema Challenge (Winogrande)의 입력 및 타겟 예시.
Winogrande (Sakaguchi et al., 2020)는 문장 내 마스킹된 토큰을 두 가지 옵션 중 하나로 채워 넣도록 모델에 요청하여 coreference resolution 능력을 테스트한다. XL training set의 40.4k 예시 중, 우리는 30,000개를 학습용으로, 200개를 개발용으로 사용한다. TFDS validation set 1,267개를 테스트 세트로 사용하여 결과를 보고한다.
| Input <br> Jane knocked on Susan's door, but there was no answer. <br> OPTIONS: <br> - Jane was out. <br> - Susan was out. |
|---|
| TARGET <br> Susan was out. |
Table 20: Winograd Schema Challenge (WSC273)의 입력 및 타겟 예시.
WSC273 (Levesque et al. 2012)은 문장 내 개체(entity)를 이해해야만 문장을 완성할 수 있도록 모델에 요청하여 coreference resolution 능력을 테스트한다. training set에는 예시가 없으므로 (WSC273은 테스트 세트 전용), 학습용과 개발용으로 사용된 예시는 없다. TFDS test set을 테스트 세트로 사용하여 결과를 보고한다.
G. 6 Reading Comprehension with Commonsense
INPUT <br> Complete the passage.
(CNN) - 언뜻 보기에 "The Flat"은 이스라엘판 "Hoarders" 에피소드처럼 보일 수 있다. 이 다큐멘터리 영화는 텔아비브에서 한 노파가 사망한 후 시작된다. 그녀의 손주들은 먼지 쌓인 책들, 빈티지 의류(예를 들어 수십 켤레의 고급 장갑), 백화점을 채울 만큼 많은 핸드백, 보석, 기념품, 그리고 잡동사니로 가득 찬 벽장들로 꽉 찬 그녀의 아파트를 정리하기 위해 모인다. 그러나 그들은 그 잔해 속에서 조부모와 중요한 나치 인물을 연결하는 놀랍고도 신비로운 문서를 우연히 발견한다. 1930년대 초 고국 독일을 떠난 열렬한 Zionists였던 그들이 어떻게 Leopold von Mildenstein과 같은 SS 장교와 연루될 수 있었을까?
"제가 알아낸 것은 이 여정, 즉 (Leopold von Mildenstein)과 그의 아내가 제 조부모와 동행했다는 것이었습니다." Goldfinger는 CNN에 말했다.
TARGET
Leopold von Mildenstein)과 그의 아내가 나의 조부모님과 동행했다"고 Goldfinger는 CNN에 말했다.
Table 21: Reading Comprehension with Commonsense Reasoning (ReCoRD)의 입력 및 타겟 예시. ReCoRD (Zhang et al., 2018)는 개체가 마스킹된 cloze-style 질문에 대한 답변을 요구한다. 100,730개의 학습 세트 예시 중 30,000개는 학습용으로, 200개는 개발용으로 사용한다. TFDS validation 세트의 10,000개 예시를 테스트 세트로 사용하여 수치를 보고한다.
G. 7 Translation (7 languages)
Input
여기에 이 지역의 가장 큰 도시인 Nordenham이 위치해 있으며, Weser강 어귀에서 Bremerhaven 맞은편에 있다.
Target
B 211 도로변 Loyermoor에는 약 30미터의 고도 차이를 보이는 "Geest-Abbruch"라고 불리는 지형이 있다.
Table 22: 번역을 위한 입력 및 출력 예시. 이 예시는 WMT'16 영어-독일어 데이터에서 가져왔으며, 모든 언어는 동일한 번역 템플릿을 사용한다.