ELIP: 이미지 검색 성능을 향상시키는 시각-언어 기반 모델
ELIP (Enhanced Language-Image Pre-training)은 대규모 사전 학습 시각-언어 모델의 텍스트-이미지 검색 성능을 향상시키기 위한 새로운 프레임워크입니다. 이 접근법은 텍스트 쿼리를 사용하여 ViT 이미지 인코딩을 조건화하는 시각적 프롬프트 세트를 예측하며, 기존의 CLIP, SigLIP, BLIP-2와 같은 모델에 쉽게 적용할 수 있는 경량 아키텍처를 특징으로 합니다. ELIP은 제한된 컴퓨팅 자원으로 효율적인 학습이 가능하도록 데이터 큐레이션 전략을 제안하며, 텍스트-이미지 재순위화(re-ranking) 단계에서 성능을 크게 향상시켜 기존 모델들을 능가하는 결과를 보여줍니다. 논문 제목: ELIP: Enhanced Visual-Language Foundation Models for Image Retrieval
논문 요약: ELIP: Enhanced Visual-Language Foundation Models for Image Retrieval
- 논문 링크: arXiv:2502.15682
- 저자: Guanqi Zhan, Yuanpei Liu, Kai Han, Weidi Xie, Andrew Zisserman (VGG, University of Oxford; The University of Hong Kong; Shanghai Jiao Tong University)
- 발표 시기: 2025 (arXiv preprint)
- 주요 키워드: Image Retrieval, Visual-Language Model, Multimodal, NLP
1. 연구 배경 및 문제 정의
- 문제 정의:
텍스트 쿼리에 대한 이미지 인스턴스의 관련성을 순위화하는 text-to-image retrieval 성능을 향상시키는 것이 목표이다. 특히, 초기 검색 후 상위 개 후보를 정제하는 재순위화(re-ranking) 단계의 성능 개선에 초점을 맞춘다. - 기존 접근 방식:
CLIP, ALIGN, BLIP-2와 같은 기존 대규모 시각-언어 모델들은 주로 첫 번째 검색 단계(초기 순위 제공)에 중점을 두어 인상적인 일반화 능력을 보여주었다. 그러나 재순위화 단계는 상대적으로 덜 탐구되었으며, 기존의 재순위화 방법(예: 텍스트 조건화된 이미지의 로그-가능도 추정)은 학습 및 추론 모두에서 계산 비용이 많이 들어 느리다는 한계가 있었다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- CLIP, SigLIP, BLIP-2 등 가장 인기 있는 대규모 사전학습 시각-언어 모델의 텍스트 기반 이미지 검색 성능을 개선하기 위한 새로운 경량 아키텍처를 제안한다.
- 제한된 컴퓨팅 자원으로 아키텍처를 효율적으로 학습하기 위한 '학생 친화적인' 모범 사례(Global hard sample mining 및 학습 가능성 기반 데이터 큐레이션)를 제안한다.
- text-to-image retrieval 모델의 OOD(Out-of-Distribution) 도메인에 대한 일반화 능력을 평가하기 위해, Occluded COCO와 ImageNet-R이라는 두 가지 새로운 벤치마크를 설정한다.
- ELIP가 CLIP/SigLIP/BLIP-2의 이미지 검색 성능을 크게 향상시키고, OOD 데이터셋에 효율적으로 적응시킬 수 있음을 입증한다.
- 제안 방법:
논문은 **ELIP (Enhanced Language-Image Pre-training)**이라는 새로운 프레임워크를 제안한다. 핵심 아이디어는 경량의 텍스트-가이드 시각 프롬프팅 모듈을 도입하는 것이다.- MLP Mapping Network: 텍스트 쿼리의 [CLS] 토큰 임베딩을 입력받아, 이를 시각 임베딩 공간 내의 시각 프롬프트 벡터 세트(visual prompt vector set)로 투영한다. 이 MLP 네트워크는 3개의 선형 레이어와 GELU 활성화 함수로 구성된다.
- 프롬프트 통합: 예측된 시각 프롬프트 벡터는 Vision Transformer (ViT) 이미지 인코더의 첫 번째 레이어에 추가 토큰으로 통합된다. 이로써 이미지 인코더는 텍스트 쿼리를 인지하게 되어, 텍스트 조건화된 이미지 임베딩을 재계산한다.
- 모델 적용: ELIP는 CLIP (ELIP-C), SigLIP/SigLIP-2 (ELIP-S/ELIP-S-2), BLIP-2 (ELIP-B) 등 기존의 사전학습된 시각-언어 모델에 쉽게 적용될 수 있다.
- 학습 전략:
- Global Hard Sample Mining: 작은 배치 크기로도 학습 효과를 높이기 위해, 사전학습된 CLIP 인코더를 사용하여 참조 텍스트와 높은 유사도를 가진 이미지-텍스트 쌍들을 그룹화하여 학습 배치를 구성한다.
- 대규모 데이터셋 큐레이션: JEST에서 영감을 받아, 학습자 모델(ELIP-B)의 손실과 참조 모델(BLIP-2)의 손실 간의 차이로 계산되는 '학습 가능성'이 가장 높은 상위 10%의 배치만 선택하여 학습 효율성을 극대화한다.
- 추론 시 재순위화: 초기 검색 모델이 제공한 상위 개 후보에 대해, ELIP 모델로 재계산된 이미지 feature와 텍스트 feature의 유사도 점수를 활용하여 최종 순위를 결정한다. BLIP-2 기반의 ELIP-B의 경우, Image-Text Matching (ITM) Head가 예측한 점수를 활용한다.
3. 실험 결과
- 데이터셋:
- 학습 데이터셋: Conceptual Captions (CC3M), DataCompDR12M.
- 평가 데이터셋:
- 표준 벤치마크: COCO, Flickr30k (평가 지표: Recall@1, Recall@5, Recall@10).
- Out-of-Distribution (OOD) 벤치마크: Occluded COCO (가려진 객체 검색), ImageNet-R (만화, 스케치 등 다양한 비정형 도메인 객체 검색) (평가 지표: mAP).
- 주요 결과:
- 표준 벤치마크 성능 향상: ELIP-C/ELIP-S/ELIP-S-2는 CLIP/SigLIP/SigLIP-2의 text-to-image retrieval 성능을 COCO 및 Flickr 벤치마크에서 크게 향상시켰다. 특히, ELIP-B는 DataCompDR12M으로 학습했을 때 기존 BLIP-2 기반의 최신 연구를 능가하며 text-to-image retrieval에서 새로운 state-of-the-art를 달성했다.
- OOD 일반화 능력: ELIP는 Occluded COCO 및 ImageNet-R OOD 벤치마크에서 모든 모델(CLIP, SigLIP 시리즈, BLIP-2)에 걸쳐 주목할 만한 zero-shot 성능 향상을 달성하며 강력한 일반화 능력을 입증했다. 또한, 관련 데이터셋(COCO, ImageNet)으로 매핑 네트워크를 fine-tuning함으로써 성능이 더욱 증폭될 수 있음을 보여주었다.
- 효율성: ELIP는 학습 가능한 MLP 매핑 네트워크로 인한 FLOPS 증가가 미미함에도 불구하고, 학습 시간, GPU 요구 사항, 배치 크기 측면에서 기존 모델의 사전학습 대비 효율성을 크게 향상시켰다.
- 정성적 분석 및 시각화: ELIP는 ground-truth 이미지와 hard negative 이미지 간의 구별 능력을 향상시켜 더 나은 검색 성능을 달성했다. 어텐션 맵 시각화를 통해 ELIP가 텍스트 쿼리와 관련된 이미지 feature에 더 효과적으로 집중하도록 돕는다는 것을 입증했다.
4. 개인적인 생각 및 응용 가능성
- 장점:
ELIP는 기존의 강력한 시각-언어 모델에 플러그-앤-플레이 방식으로 쉽게 적용될 수 있는 경량 아키텍처라는 점이 인상 깊다. 특히, 제한된 컴퓨팅 자원으로도 효율적인 학습이 가능하도록 데이터 큐레이션 및 hard sample mining 전략을 제안하여, 대규모 모델의 성능 향상을 위한 실용적인 접근법을 제시했다. 표준 벤치마크뿐만 아니라, 가려진 객체나 비정형 도메인과 같은 OOD 시나리오에서도 뛰어난 일반화 능력과 성능 향상을 보여준 점은 실제 응용 가능성을 높인다. 어텐션 맵 시각화를 통해 모델이 텍스트 쿼리에 따라 이미지의 관련 부분에 집중하는 방식이 개선됨을 명확히 보여준 점도 강점이다. - 단점/한계:
ELIP는 재순위화 단계에 초점을 맞추므로, 초기 검색 후 추가적인 계산 비용이 발생한다. 논문에서는 이를 "더 비용이 많이 드는 모델"이라고 언급하며, 이는 매우 빠른 실시간 검색이 필요한 시나리오에서는 여전히 고려해야 할 한계가 될 수 있다. 또한, 데이터 큐레이션 전략이 학습 효율성을 높이지만, 여전히 대규모 데이터셋(예: DataCompDR12M)으로 학습하는 데는 상당한 시간(약 200 GPU-days)이 소요된다는 점은 여전히 높은 자원 요구 사항을 시사한다. - 응용 가능성:
ELIP는 텍스트 기반 이미지 검색 시스템의 성능을 크게 향상시킬 수 있어, 전자상거래, 콘텐츠 추천, 디지털 아카이빙, 의료 영상 분석 등 다양한 분야에서 사용자 질의에 대한 이미지 검색 정확도를 개선하는 데 활용될 수 있다. 또한, 논문에서 언급된 바와 같이, ELIP와 유사한 아이디어를 생성형 멀티모달 대규모 언어 모델(Generative Multimodal Large Language Model)에 적용하여 텍스트-가이드 시각 어텐션 및 인코딩을 개선하는 방향으로 확장될 가능성이 크다.
Zhan, Guanqi, et al. "ELIP: Enhanced Visual-Language Foundation Models for Image Retrieval." arXiv preprint arXiv:2502.15682 (2025).
ELIP: Enhanced Visual-Language Foundation Models for Image Retrieval
Guanqi Zhan , Yuanpei Liu , Kai Han , Weidi Xie , Andrew Zisserman <br> VGG, University of Oxford The University of Hong Kong Shanghai Jiao Tong University<br>{guanqi, weidi, az}@robots.ox.ac.uk<br>ypliu0@connect.hku.hk kaihanx@hku.hk
 Figure 1. ELIP 아키텍처.
왼쪽: 우리는 CLIP, SigLIP, SigLIP-2, BLIP-2와 같은 사전학습되고 고정된(frozen) vision-language foundation model에 적용하여 text-to-image retrieval 성능을 향상시킬 수 있는 새로운 아키텍처를 제안한다. 핵심 아이디어는 텍스트 쿼리를 사용하여 일련의 visual prompt vector를 정의하고, 이를 이미지 인코더에 통합하여 임베딩을 생성할 때 쿼리를 인지하도록 만드는 것이다. MLP는 텍스트 공간에서 ViT 인코더 입력의 시각 공간으로 매핑한다. 이 아키텍처는 **경량(lightweight)**이며, 우리의 데이터 큐레이션 전략은 제한된 자원으로도 효율적이고 효과적인 학습을 가능하게 한다.
오른쪽: COCO 벤치마크의 retrieval 예시에서, ELIP 모델은 'People on bicycles ride down a busy street'라는 텍스트 쿼리에 대해 상위 개 이미지를 재순위화한다. 쿼리와 일치하는 ground truth 이미지는 초기 CLIP 순위에서 상위 5개 이미지에 포함되지 않았지만, 재순위화 후에는 상위 1위(점선 상자로 강조)로 순위가 매겨졌다.
Figure 1. ELIP 아키텍처.
왼쪽: 우리는 CLIP, SigLIP, SigLIP-2, BLIP-2와 같은 사전학습되고 고정된(frozen) vision-language foundation model에 적용하여 text-to-image retrieval 성능을 향상시킬 수 있는 새로운 아키텍처를 제안한다. 핵심 아이디어는 텍스트 쿼리를 사용하여 일련의 visual prompt vector를 정의하고, 이를 이미지 인코더에 통합하여 임베딩을 생성할 때 쿼리를 인지하도록 만드는 것이다. MLP는 텍스트 공간에서 ViT 인코더 입력의 시각 공간으로 매핑한다. 이 아키텍처는 **경량(lightweight)**이며, 우리의 데이터 큐레이션 전략은 제한된 자원으로도 효율적이고 효과적인 학습을 가능하게 한다.
오른쪽: COCO 벤치마크의 retrieval 예시에서, ELIP 모델은 'People on bicycles ride down a busy street'라는 텍스트 쿼리에 대해 상위 개 이미지를 재순위화한다. 쿼리와 일치하는 ground truth 이미지는 초기 CLIP 순위에서 상위 5개 이미지에 포함되지 않았지만, 재순위화 후에는 상위 1위(점선 상자로 강조)로 순위가 매겨졌다.
Abstract
본 논문의 목표는 text-to-image retrieval 성능을 향상시키는 것이다. 이를 위해 우리는 대규모 사전학습된 vision-language model의 성능을 향상시켜 text-to-image re-ranking에 활용할 수 있는 새로운 프레임워크를 소개한다. **Enhanced Language-Image Pre-training (ELIP)**이라는 이 접근 방식은 간단한 MLP 매핑 네트워크를 통해 텍스트 쿼리를 사용하여 ViT 이미지 인코딩을 조건화할 시각적 prompt 세트를 예측한다. ELIP는 일반적으로 사용되는 CLIP, SigLIP, BLIP-2 네트워크에 쉽게 적용될 수 있다. 제한된 컴퓨팅 자원으로 아키텍처를 학습시키기 위해, 우리는 global hard sample mining과 대규모 데이터셋 큐레이션을 포함하는 'student friendly'한 모범 사례를 개발한다. 평가 측면에서는, 모델의 zero-shot 일반화 능력을 다른 도메인에서 평가하기 위해 Occluded COCO와 ImageNet-R이라는 두 가지 새로운 out-of-distribution (OOD) 벤치마크를 설정한다. 결과는 ELIP가 CLIP/SigLIP/SigLIP-2의 text-to-image retrieval 성능을 크게 향상시키고, 여러 벤치마크에서 BLIP-2를 능가하며, OOD 데이터셋에 쉽게 적응할 수 있는 방법을 제공함을 보여준다.
1. Introduction
본 논문은 텍스트 쿼리에 대한 이미지 인스턴스의 관련성을 순위화하는 것을 목표로 하는 text-to-image retrieval 문제를 다룬다. 효과적인 검색은 일반적으로 두 단계로 구성된다: 첫 번째 단계는 빠르고 효율적인 방식으로 초기 순위를 제공하고, 두 번째 단계(re-ranking이라고 함)는 더 비용이 많이 드는 모델로 텍스트 쿼리와 상위 순위 후보 각각 간의 관련성 점수를 재계산하여 이 순위를 정제한다.
text-to-image retrieval의 최근 발전은 주로 첫 번째 단계에 초점을 맞추었다. CLIP [68] 및 ALIGN [41]과 같은 주목할 만한 모델들은 대규모 이미지-텍스트 쌍에 대한 contrastive learning [63]을 활용하여 joint representation을 학습함으로써, cross-modal retrieval task에서 인상적인 일반화 능력을 보여주었다.
우리의 주요 기여는 검색 파이프라인의 두 번째 단계, 즉 re-ranking에 중점을 둔다. 구체적으로, 우리의 목표는 기성(off-the-shelf) vision-language foundation model의 성능을 향상시켜, 빠른 검색 프로세스에서 얻은 상위 개 후보를 re-ranking하는 데 재활용할 수 있도록 하는 것이다. 우리가 개발한 접근 방식은 **Enhanced Language-Image Pre-training (ELIP)**이라고 불리며, 소수의 학습 가능한 파라미터만을 필요로 하며, '학생 친화적인' 자원과 데이터로 효율적으로 학습을 수행할 수 있다. 우리는 ELIP가 사전학습된 CLIP [68], SigLIP [99], SigLIP-2 [81] 및 BLIP-2 [48]의 cross-modal retrieval 성능을 향상시킬 수 있음을 입증한다.
이 목표를 달성하기 위해, 우리는 먼저 경량의 텍스트-가이드 시각 프롬프팅 모듈을 도입한다. Figure 1에서 보듯이, 쿼리 텍스트는 일련의 visual prompt vector [42]로 매핑되며, 이들은 이미지 encoder의 [CLS] 및 patch embedding과 연결된다. 이렇게 증강된 embedding은 frozen vision encoder로 전달되어 이미지 representation을 재계산한다. 결과적으로 얻어지는 이미지 embedding은 텍스트 조건화(text conditioning)를 인지하게 되며, 이는 re-ranking 성능을 향상시킨다.
두 번째 기여로, 우리는 대규모 vision-language model 학습의 두 가지 주요 과제를 다룬다: 첫째, 데이터 크기 - 강력한 일반화 능력을 위해서는 수백만 또는 수십억 개의 이미지로 학습해야 하지만, 이는 비용이 많이 든다. 둘째, 배치 크기 - 모델의 판별 능력을 향상시키기 위해서는 큰 배치 크기로 학습하는 것이 중요하지만, 이는 많은 수의 GPU를 필요로 한다. 우리는 최대 정보를 가진 학습 데이터셋을 선택하고 큐레이션하는 전략을 도입하고, 작은 배치 크기로도 효과적인 학습을 위해 어려운 샘플들을 배치 내에서 함께 그룹화하는 모범 사례를 개발한다.
제안된 ELIP 모델의 re-ranking 성능을 평가하기 위해, 우리는 표준 COCO [50] 및 Flickr30k [66] text-to-image retrieval 벤치마크에서 실험한다. 추가적인 도전 과제로, 우리는 ELIP로 향상된 모델의 out-of-distribution 도메인에 대한 일반화 능력도 평가한다. 이를 위해, Occluded COCO [45] 및 ImageNet-R [34] 데이터셋을 text-to-image retrieval 벤치마크로 재활용한다.
요약하자면, 우리는 다음 네 가지 기여를 했다: 첫째, 우리는 가장 인기 있는 CLIP/SigLIP 아키텍처와 state-of-the-art BLIP-2 아키텍처를 포함한 대규모 사전학습된 vision-language model에서 텍스트 기반 이미지 검색을 개선하기 위한 새로운 아키텍처를 제안한다. 둘째, 제한된 자원으로 우리 아키텍처를 효율적으로 학습하기 위한 모범 사례를 제안한다. 셋째, text-to-image retrieval 모델의 out-of-distribution 도메인에 대한 일반화 능력을 평가하기 위해, Occluded COCO와 ImageNet-R이라는 두 가지 새로운 text-to-image retrieval 벤치마크를 설정한다. 넷째, 그리고 가장 중요하게, 우리는 ELIP가 CLIP 및 SigLIP 아키텍처의 이미지 검색 성능을 크게 향상시키고, state-of-the-art BLIP-2 아키텍처를 능가함을 입증한다. 또한, 이는 CLIP, SigLIP, SigLIP-2 및 BLIP-2에 엄청난 향상을 제공하면서, 이러한 아키텍처를 OOD 데이터셋에 적응시키는 효율적인 방법을 제공한다.
2. Related Work
Text-to-Image Retrieval은 cross-modal learning에서 매우 중요하고 많이 연구된 task이다 [12-17, 20, 21, 23, 26, 30, 36, 39, 40, 43, 44, 46, 47, 49, 52, 53, 68, 75, 78, 84-88, 90, 91, 95, 97, 98, 101-105]. CLIP [37, 68], ALIGN [41], BLIP-2 [48], SigLIP [99], SigLIP-2 [81]와 같이 강력한 zero-shot 능력을 가진 대규모 vision language model들은 이제 openset text-based image retrieval의 사실상 표준 방법이 되었다. 가장 최근 연구 [74]는 object detector의 출력 또는 detection bounding box의 annotation을 통합하여 BLIP-2보다 약간의 성능 향상을 보여주었다. 이는 이미지 내의 작지만 의미적으로 중요한 객체가 모델에 의해 제대로 이해되지 않는 실패 사례를 극복하는 데 성공했다. 우리는 이 모델과 비교하여 더 우수한 성능을 보여준다.
CIR 및 Universal Retrieval
Composed Image Retrieval (CIR) [5, 29, 55, 83]에서는 쿼리가 이미지와 텍스트의 조합으로 지정되며, 텍스트는 이미지가 어떻게 변경되어야 하는지를 명시한다. 예를 들어, 쿼리 이미지는 엎드려 있는 개의 사진일 수 있고, 쿼리 텍스트는 '공을 가지고 노는'일 수 있다. 이 조합된 쿼리는 갤러리에서 검색할 대상 이미지를 정의한다. 이는 쿼리가 텍스트로만 지정되고, 텍스트만으로 갤러리에서 검색할 대상 이미지를 정의하는 우리의 task와는 다르다. 더 일반적인 설정은 'universal retrieval' [56, 89]로, 쿼리가 이미지, 텍스트, 지시의 조합일 수 있으며, 대상은 이미지 단독, 텍스트 단독, 또는 이미지와 텍스트의 조합일 수 있다.
Post-Retrieval Re-ranking
쿼리가 이미지인 단일 모달리티 이미지 검색의 경우, 초기 랭킹에서 상위 개의 이미지를 'query expansion', 'geometric verification' 또는 이 둘의 조합과 같은 고전적인 컴퓨터 비전 알고리즘 [4, 18, 19, 38, 65, 80]뿐만 아니라 학습 기반 알고리즘 [6, 10, 22, 33, 77]을 통해 재랭킹하는 일련의 연구들이 있었다. Re-ranking 알고리즘은 text-to-image retrieval에서는 상대적으로 덜 탐구되었다 [57, 67, 96]. [60]은 이미지에 조건화된 텍스트의 log-likelihood를 추정하여 이미지와 텍스트 쿼리 간의 유사도 점수를 계산하는 방법을 도입했다. 이 접근 방식은 강력한 성능을 보여주었지만, 학습 및 추론 모두에서 계산 비용이 많이 들어 느린 프로세스이다. 우리 논문 또한 re-ranking 단계에 초점을 맞추고 있으며, 원래 검색 모델이 구별하기 어려운 이미지들에 대해 더 나은 랭킹을 제공하기 위해 visual-language foundation model의 더 강력한 버전을 개발한다.
Multi-Modal Datasets
강력한 일반화 능력을 가진 multi-modal foundation model을 얻기 위해서는 대규모 multi-modal dataset으로 학습하는 것이 중요하다. 따라서 최근 몇 년 동안 COCO [50], SBU [64], Conceptual Captions [72], LAION [70], DataComp [28]와 같이 이미지-텍스트 쌍을 제공하는 multi-modal vision-language dataset의 수와 규모가 크게 증가했다. multi-modal dataset의 크기 증가는 더 강력한 visual-language foundation model의 학습을 가능하게 한다. 최근에는 DataCompDR [82]이 대규모 사전학습된 이미지 캡셔닝 모델의 사전 지식을 활용하여 DataComp 이미지에 대한 합성 캡션(synthetic captions)을 생성하는데, 이는 원래 DataComp dataset과 같이 웹에서 수집된 dataset보다 노이즈가 적은 캡션을 생성한다. 우리 논문에서는 Conceptual Captions [72]와 DataCompDR [82]을 사용하여 모델을 학습시키는 실험을 진행했다.
Multi-Modal Data Curation
multi-modal dataset에 대한 **데이터 큐레이션(data curation)**은 특히 자원이 제한된 상황에서 더 효율적이고 효과적인 학습을 가능하게 하므로 필수적이다. 데이터 큐레이션에는 오프라인 예시-레벨 데이터 가지치기(offline example-level data pruning) [8, 11, 27, 28, 35, 41, 59, 93], 오프라인 클러스터-레벨 데이터 가지치기(offline cluster-level data pruning) [1, 2, 9, 31, 76], 그리고 모델 기반 스코어링을 통한 온라인 데이터 큐레이션(online data curation with model-based scoring) [24, 51, 58, 61]과 같은 지속적인 노력이 있었다. 가장 최근 연구인 JEST [25]는 학습자 모델(learner model)과 참조 모델(reference model) 쌍을 활용하여 모델이 학습할 수 있지만 아직 학습되지 않은 데이터 배치(batch)를 선택한다. 이는 BLIP-2에서 우리 아키텍처를 학습시키기 위한 가장 효율적인 배치를 선택하는 데 영감을 주었다. 우리와 관련된 또 다른 일련의 연구는 hard negative mining으로, 이는 고전적인 metric learning [7, 32, 62, 73, 92, 94]과 현대적인 contrastive learning [69, 79] 모두에서 탐구되었다.
3. Preliminaries
이미지 검색에서의 재순위화 (Re-Ranking in Image Retrieval)
주어진 입력 쿼리에 대해 검색 시스템의 목표는 데이터셋 내의 모든 인스턴스를 쿼리와의 관련성을 기반으로 순위를 매기는 것이다. 텍스트-이미지 검색의 경우, 쿼리는 **텍스트(T)**로 지정되며, 이상적인 결과는 관련 이미지가 관련 없는 이미지보다 더 높은 순위로 매겨진 집합 이다. 일반적으로 효과적인 검색 시스템은 두 단계로 진행된다:
첫 번째 단계는 빠르고 효율적인 방식으로 초기 순위를 제공한다. 두 번째 단계는 **재순위화(re-ranking)**라고 불리며, 더 강력하고(일반적으로 더 비용이 많이 드는) 순위 모델을 사용하여 텍스트 쿼리와 상위 개 후보 각각 간의 관련성 점수를 재계산함으로써 이 순위를 정제한다. 여기서 는 일반적으로 모든 관련 이미지에 대해 높은 recall을 보장하도록 선택된다. 본 논문에서 우리의 독창성은 첫 번째 단계 결과에서 상위 개 후보를 재순위화하는 것을 목표로 하는 두 번째 단계에 있다.
 Figure 2. ELIP-C / ELIP-S의 아키텍처. 학습 시, 텍스트-이미지 쌍의 배치(batch)가 아키텍처에 입력된다. 텍스트 feature는 MLP mapping network를 통해 prompt vector 집합으로 시각 임베딩 공간에 매핑된 다음, 이미지 feature의 인코딩을 안내한다. 우리는 [CLS] token, patch token, 그리고 텍스트로부터 생성된 visual token에 대해 색상 코딩을 사용한다. 이 아키텍처는 **InfoNCE loss (ELIP-C용) 및 Sigmoid loss (ELIP-S/ELIP-S-2용)**로 학습되어, 텍스트 feature를 해당 재계산된 이미지 feature와 정렬시킨다.
Figure 2. ELIP-C / ELIP-S의 아키텍처. 학습 시, 텍스트-이미지 쌍의 배치(batch)가 아키텍처에 입력된다. 텍스트 feature는 MLP mapping network를 통해 prompt vector 집합으로 시각 임베딩 공간에 매핑된 다음, 이미지 feature의 인코딩을 안내한다. 우리는 [CLS] token, patch token, 그리고 텍스트로부터 생성된 visual token에 대해 색상 코딩을 사용한다. 이 아키텍처는 **InfoNCE loss (ELIP-C용) 및 Sigmoid loss (ELIP-S/ELIP-S-2용)**로 학습되어, 텍스트 feature를 해당 재계산된 이미지 feature와 정렬시킨다.
Visual Prompt Tuning (VPT) [42]는 Transformer layer에 추가적인 학습 가능한 prompt를 삽입하여 ViT 이미지 인코더를 향상시키는 방법이다. 이는 학습 가능한 prompt의 소수 파라미터만 학습하면 되므로 ViT의 효율적인 적응을 가능하게 한다. VPT는 VPT-Shallow와 VPT-Deep의 두 가지 변형이 있다. VPT-Shallow는 첫 번째 Transformer layer에만 추가적인 visual prompt를 삽입하는 반면, VPT-Deep은 모든 Transformer layer의 입력 공간에 prompt를 도입한다. 우리는 생성된 visual prompt vector 집합을 ViT의 첫 번째 Transformer layer에 삽입하는데, 이는 VPT-Shallow와 유사하다.
4. The ELIP Architecture
이 섹션에서는 ELIP text-to-visual prompt mapping network에 대해 설명한다. 이 네트워크는 일반적으로 사용되는 CLIP/SigLIP 아키텍처뿐만 아니라, 더 정교한 BLIP-2 아키텍처에도 효율적으로 적용되어 re-ranking을 수행할 수 있다. 먼저 Section 4.1에서 네트워크의 아키텍처를 소개하고, Section 4.2와 4.3에서 각각 학습 및 추론 전략을 설명한다. 우리는 이 네트워크가 CLIP에 적용될 경우 ELIP-C, SigLIP/SigLIP-2에 적용될 경우 ELIP-S/ELIP-S-2, 그리고 BLIP-2에 적용될 경우 ELIP-B라고 지칭한다.
4.1. Text-Guided MLP Mapping Network
여기서 우리는 텍스트 쿼리의 embedding을 시각 embedding 공간 내의 prompt vector 집합으로 투영하는 mapping network를 제안한다. 이 prompt vector 집합은 Vision Transformer (ViT) 이미지 encoder의 첫 번째 layer에 추가적인 token으로 통합되어 시각 embedding을 재계산하는 데 사용된다:
여기서 는 쿼리 텍스트를 나타내며, 이는 먼저 사전학습되고 고정된(frozen) text encoder ()로 인코딩되어 개의 embedding을 생성한다. [CLS] token은 다시 학습 가능한 mapping network에 입력되어 prompt vector를 생성하며, 이 prompt vector는 개의 이미지 embedding ()과 연결(concatenate)된 후, 사전학습되고 고정된 visual encoder ()에 전달된다. MLP Mapping Network는 3개의 linear layer로 구성되며, 두 linear layer 사이에 GELU 활성화 함수가 적용된다. ELIP 아키텍처는 Figure 2와 Figure 3에 나타나 있다.
4.2. Training and Testing ELIP-C/ELIP-S
텍스트 기반 Contrastive Training (Text-Guided Contrastive Training)
학습 시, 우리는 **텍스트 쿼리의 [CLS] token embedding ()**과 쿼리 텍스트에 의해 재계산된 이미지 feature들(, 여기서 는 batch size) 간의 **내적(dot product)**을 계산한다.
ELIP-C의 경우, 표준 InfoNCE loss를 사용하여 batch 단위로 학습을 진행한다.
ELIP-S/ELIP-S-2의 경우, pairwise Sigmoid loss를 사용하여 학습한다.
Section 5.1에서는 global hard sample mining을 통한 batch 선택 방식에 대한 자세한 내용을 제공한다.
추론 시 재랭킹 (Re-Ranking at Inference Time)
추론 시, 각 텍스트 쿼리에 대해 먼저 원본 CLIP/SigLIP 모델이 계산한 visual-language embedding 간의 유사도 점수를 계산하여 모든 이미지의 초기 랭킹을 얻는다.
그 다음, 상위 개의 후보를 선택하여 추가적인 재랭킹을 수행한다. 이때, mapping network로부터 얻은 prompted vector를 통합하여 visual feature를 재계산한다.
최종 랭킹은 재계산된 이미지 feature와 텍스트 feature의 내적을 통해 얻어진다.
4.3. Training and Testing ELIP-B
Figure 3는 BLIP-2에 우리 아키텍처를 적용한 것을 보여준다. CLIP 유형 모델에 대해 설명된 것과의 유일한 차이점은 BLIP-2 re-ranking이 dual encoder를 사용하지 않고, 대신 이미지 및 텍스트 encoder가 서로 cross-attention한다는 점이다. 그러나 우리 mapping network의 목적과 학습 방식은 본질적으로 변하지 않는다.
Text-Guided Image-Text Matching Loss.
학습 시, 우리는 **텍스트 쿼리(T)**와 쿼리 텍스트를 prompt로 사용하여 재계산된 이미지 feature, 즉 (는 positive image, 는 negative image)를 Q-Former에 입력하고, 이어서 Image-Text Matching (ITM) Head에 전달하여 텍스트와 이미지가 일치하는지 여부를 나타내는 점수를 예측한다. ITM head의 출력은 binary cross entropy loss로 학습된다.
 Figure 3. ELIP-B의 아키텍처. CLIP/SigLIP의 아키텍처와 유사하게, MLP Mapping Network는 텍스트 feature를 visual embedding space로 매핑한다. 유일한 차이점은 텍스트 가이드 이미지 feature가 Q-Former에 추가로 입력되어 입력 텍스트와 cross-attend한 다음, Image-Text Matching (ITM) Head를 통과하여 이미지와 텍스트가 일치하는지 여부를 예측한다는 점이다. ITM head에 대한 입력 이미지 feature가 변경되었으므로, 우리는 경량 MLP 네트워크인 ITM head도 fine-tune한다. 이 네트워크는 학습 시 텍스트와 positive/negative 이미지 feature 쌍을 입력받아 binary cross entropy loss로 학습된다.
Figure 3. ELIP-B의 아키텍처. CLIP/SigLIP의 아키텍처와 유사하게, MLP Mapping Network는 텍스트 feature를 visual embedding space로 매핑한다. 유일한 차이점은 텍스트 가이드 이미지 feature가 Q-Former에 추가로 입력되어 입력 텍스트와 cross-attend한 다음, Image-Text Matching (ITM) Head를 통과하여 이미지와 텍스트가 일치하는지 여부를 예측한다는 점이다. ITM head에 대한 입력 이미지 feature가 변경되었으므로, 우리는 경량 MLP 네트워크인 ITM head도 fine-tune한다. 이 네트워크는 학습 시 텍스트와 positive/negative 이미지 feature 쌍을 입력받아 binary cross entropy loss로 학습된다.
추론 시 Re-Ranking (Inference Time Re-Ranking).
각 텍스트 쿼리에 대해, 우리는 먼저 원래 BLIP-2 이미지 및 텍스트 encoder에 의해 계산된 visual-language embedding 간의 유사도 점수를 계산하여 모든 이미지의 초기 순위(initial ranking)를 얻는다. 그런 다음, mapping network에서 prompt된 벡터를 통합하여 visual feature를 재계산한 후, 추가 re-ranking을 위해 상위 개의 후보를 선택한다. 최종 순위는 초기 계산된 유사도 점수와 재계산된 이미지 feature 및 텍스트 쿼리를 기반으로 ITM head가 예측한 점수의 합을 통해 얻어진다.
5. Best Practice for Data Curation & Training
최근의 visual-language foundation model들은 수십억 개에 달하는 방대한 양의 이미지-캡션 쌍 샘플로 학습되며, 이 과정에서 상당한 컴퓨팅 자원이 소모된다. 본 연구에서는 제한된 자원으로 대규모 visual-language model의 성능을 향상시킬 수 있는, '학생 친화적인(student friendly)' 데이터 큐레이션 모범 사례를 탐구한다. 구체적으로 해결해야 할 두 가지 주요 과제는 다음과 같다: (i) GPU 메모리 제약으로 인해 큰 batch size로 학습하기 어렵다. (ii) 수십억 개의 샘플로 학습하는 것은 계산 비용 측면에서 엄청나게 비싸다.
Section 5.1에서는 작은 batch size로도 학습 효과를 높이기 위한 global hard sample mining 전략을 논의한다. Section 5.2에서는 최대 정보량을 가진 이미지-텍스트 학습 데이터셋을 선택하고 큐레이션하는 절차를 상세히 설명한다.
5.1. Global Hard Sample Mining
CLIP, SigLIP, BLIP-2와 같은 모델을 학습시킬 때 큰 batch size가 요구되는 경우가 많다. 이는 hard training sample을 포함할 가능성을 높여 모델의 contrastive 및 discriminative 능력을 향상시키기 때문이다. 본 연구에서는 global hard sample mining 전략을 채택하여 hard sample들을 batch로 묶어 작은 batch size로도 학습을 더 효과적으로 만들었다.
 Figure 4. Global hard sample mining을 통해 생성된 학습 batch의 예시. 각 행에서 첫 번째 샘플은 다른 샘플들을 그룹화하는 데 사용된다.
1행의 캡션 (왼쪽에서 오른쪽으로): 'a wooden table with no base'; 'a wooden table with a couple of folding legs on it'; 'a table that has a metal base with an olive wood top'; 'small table outdoors sitting on top of the asphalt'.
2행의 캡션 (왼쪽에서 오른쪽으로): 'a huge body of blue ice floats in a mountain stream'; 'the big chunk of glacier is falling off of the cliff'; 'there is a broken piece of glass that has been broken from the ground'; 'a body of water surrounded by a forest near a mountain'.
이미지와 캡션이 서로 매우 유사하며, 무작위 batch의 이미지와 캡션보다 훨씬 더 가깝다는 것을 확인할 수 있다.
Figure 4. Global hard sample mining을 통해 생성된 학습 batch의 예시. 각 행에서 첫 번째 샘플은 다른 샘플들을 그룹화하는 데 사용된다.
1행의 캡션 (왼쪽에서 오른쪽으로): 'a wooden table with no base'; 'a wooden table with a couple of folding legs on it'; 'a table that has a metal base with an olive wood top'; 'small table outdoors sitting on top of the asphalt'.
2행의 캡션 (왼쪽에서 오른쪽으로): 'a huge body of blue ice floats in a mountain stream'; 'the big chunk of glacier is falling off of the cliff'; 'there is a broken piece of glass that has been broken from the ground'; 'a body of water surrounded by a forest near a mountain'.
이미지와 캡션이 서로 매우 유사하며, 무작위 batch의 이미지와 캡션보다 훨씬 더 가깝다는 것을 확인할 수 있다.
더 구체적으로, 각 이미지-텍스트 쌍 와 에 대해, 우리는 사전학습된 CLIP image encoder와 text encoder를 사용하여 이미지 및 텍스트 feature를 계산한다. 그런 다음, 참조 텍스트 와 높은 CLIP feature 유사도 점수를 가진 이미지-텍스트 쌍들을 수집하여 batch를 그룹화한다. Figure 4는 이렇게 생성된 학습 batch의 예시를 보여준다. 학습 batch size가 이고 원본 데이터셋에 개의 이미지-텍스트 쌍이 있다고 가정하면, 이 알고리즘은 개의 학습 샘플을 batch로 그룹화하여 제공한다. 실제로는 이 중 무작위 subset을 선택하여 모델을 학습시킨다.
5.2. Selection and Curation of Large-Scale Dataset
문헌에는 CC3M [72], DataComp [28] 등과 같은 대규모 이미지-텍스트 학습 데이터셋이 다수 소개되었다. 최근의 한 연구 [82]는 대규모 사전학습된 이미지 캡셔닝 모델을 활용하여 DataComp 이미지에 대한 합성 캡션(synthetic caption)을 생성함으로써, 학습에 더 많은 정보를 제공하였다. 실험 [82]에 따르면, 생성된 DataCompDR12M 데이터셋으로 CLIP을 학습시키는 것이 DataComp1B로 학습시키는 것보다 더 나은 성능을 달성했으며, 이는 단 1%의 데이터 샘플만 사용했음에도 불구하고 얻어진 결과이다. 그러나 우리의 경우, DataCompDR12M을 사용하여 모델을 학습시키는 데에도 A6000/A40 GPU로 12M 데이터에 대해 ELIP-B를 학습시키는 데 약 200 GPU-days라는 엄청난 시간이 소요되었다.
ELIP-B 학습 속도를 높이기 위해, 우리는 JEST [25]에서 영감을 받아 학습 가능성(learnability)에 따라 배치를 구성하는 배치 선택 전략을 채택한다. 구체적으로, 우리는 Section 5.1에서 설명한 global hard sample mining 전략에 따라 그룹화된 배치에 대해 ELIP-B (학습자 모델)와 사전학습된 BLIP-2 모델 (참조 모델)을 모두 실행한다.
 Figure 5. out-of-distribution 벤치마크 예시. 왼쪽은 Occluded COCO, 오른쪽은 ImageNet-R이다. 두 벤치마크 모두에서, 긍정 이미지(positive images)는 텍스트 쿼리가 설명하는 객체를 포함하고, 부정 이미지(negative images)는 해당 객체를 포함하지 않는다. 첫 번째 행에는 긍정 이미지를, 두 번째 행에는 부정 이미지를 표시하였다. Occluded COCO의 경우, 이미지 내의 대상 객체가 가려져 있어 검색하기가 더 어렵다. 예를 들어, Occluded COCO에서 "Bicycle" 텍스트 쿼리에 대해, 긍정 이미지는 가려진 자전거(점선 상자로 강조 표시)를 포함하고, 부정 이미지는 자전거를 포함하지 않는다. ImageNet-R에서 "Goldfish" 텍스트 쿼리에 대해, 긍정 이미지는 금붕어를 포함하고, 부정 이미지는 금붕어를 포함하지 않는다.
Figure 5. out-of-distribution 벤치마크 예시. 왼쪽은 Occluded COCO, 오른쪽은 ImageNet-R이다. 두 벤치마크 모두에서, 긍정 이미지(positive images)는 텍스트 쿼리가 설명하는 객체를 포함하고, 부정 이미지(negative images)는 해당 객체를 포함하지 않는다. 첫 번째 행에는 긍정 이미지를, 두 번째 행에는 부정 이미지를 표시하였다. Occluded COCO의 경우, 이미지 내의 대상 객체가 가려져 있어 검색하기가 더 어렵다. 예를 들어, Occluded COCO에서 "Bicycle" 텍스트 쿼리에 대해, 긍정 이미지는 가려진 자전거(점선 상자로 강조 표시)를 포함하고, 부정 이미지는 자전거를 포함하지 않는다. ImageNet-R에서 "Goldfish" 텍스트 쿼리에 대해, 긍정 이미지는 금붕어를 포함하고, 부정 이미지는 금붕어를 포함하지 않는다.
따라서 우리는 가장 높은 학습 가능성을 가진 상위 10%의 배치를 선택한다. 여기서 배치의 학습 가능성은 우리 모델의 손실(loss)과 참조 모델의 손실 간의 차이로 계산된다.
6. Evaluation Datasets
우리는 모델을 표준 text-to-image retrieval 벤치마크인 COCO [50]와 Flickr [66] (Section 6.1) 뿐만 아니라, 새롭게 설정한 out-of-distribution 벤치마크 (Section 6.2) 에 대해서도 평가한다.
6.1. Standard Benchmarks
COCO [50]는 객체 탐지(object detection), 분할(segmentation), 캡셔닝(captioning) 연구를 위한 대규모 데이터셋이다. 캡셔닝 측면에서 각 이미지는 5개의 다른 caption으로 주석되어 있다. 이전 연구들은 text-to-image retrieval 평가를 위해 5,000개의 이미지와 25,010개의 caption으로 구성된 test split을 사용한다.
Flickr30k Dataset [66]은 Flickr에서 수집된 이미지와 함께 인간 주석자가 제공한 5개의 참조 문장을 포함한다. text-to-image retrieval을 위한 test set은 1,000개의 이미지와 5,000개의 caption으로 구성된다.
평가 지표 (Evaluation Metrics)
우리는 retrieval 성능 평가를 위한 표준 지표인 Recall@1, Recall@5, Recall@10을 사용한다. Recall@k는 각 텍스트 쿼리에 대해 상위 개 결과 내에서 성공적으로 검색된 관련 이미지의 비율을 나타낸다.
6.2. Out-of-Distribution Benchmarks
모델의 text-to-image retrieval 능력을 out-of-distribution (OOD) 시나리오에서 평가하기 위해, 우리는 두 가지 새로운 벤치마크를 설정하였다.
| Setting | Architecture | Training Dataset | Hard Sample Mining | Multiple Prompts | COCO | Avg. | Flickr | Avg. | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||||||
| CLIP | - | 40.2 | 66.0 | 75.6 | 60.6 | 67.6 | 88.3 | 93.0 | 83.0 | |||
| ELIP-C | CC3M [72] | 40.7 | 66.2 | 76.1 | 61.0 | 68.8 | 88.9 | 93.8 | 83.8 | |||
| C | ELIP-C | CC3M [72] | 41.8 | 67.5 | 77.5 | 62.3 | 69.5 | 89.7 | 94.1 | 84.4 | ||
| ELIP-C | DataCompDR [82] | 44.2 | 70.0 | 79.5 | 64.6 | 71.3 | 90.6 | 94.4 | 85.4 | |||
| ELIP-C | DataCompDR [82] | 45.6 | 71.1 | 80.4 | 65.7 | 72.3 | 90.6 | 94.7 | 85.9 |
Table 1. ELIP-C에 대한 학습 데이터셋 선택, hard sample mining, 생성되는 prompt vector 수에 대한 ablation study.
| Model | Year | COCO | Average | Flickr | Average | ||||
|---|---|---|---|---|---|---|---|---|---|
| Recall@1 | Recall@5 | Recall@10 | Recall@1 | Recall@5 | Recall@10 | ||||
| CLIP [37, 68] | 2021 | 40.16 | 65.95 | 75.62 | 60.58 | 67.56 | 88.34 | 93.00 | 82.97 |
| ELIP-C(Ours) | - | 45.61 | 71.08 | 80.43 | 65.71 | 72.30 | 90.62 | 94.68 | 85.87 |
| SigLIP [99] | 2023 | 54.21 | 76.78 | 84.24 | 71.74 | 82.96 | 96.10 | 98.04 | 92.37 |
| ELIP-S(Ours) | - | 61.03 | 82.62 | 88.70 | 77.45 | 87.62 | 98.16 | 99.16 | 94.98 |
| SigLIP-2 [81] | 2025 | 56.87 | 78.79 | 85.49 | 73.72 | 83.94 | 96.62 | 98.20 | 92.92 |
| ELIP-S-2(Ours) | - | 62.91 | 83.86 | 89.70 | 78.82 | 87.74 | 97.96 | 98.94 | 94.88 |
| BLIP-2* [48] | 2023 | 68.25 | 87.72 | 92.63 | 82.87 | 89.74 | 98.18 | 98.94 | 95.62 |
| Q-Pert.(E)* [74] | 2024 | 68.34 | 87.76 | 92.63 | 82.91 | 89.82 | 98.20 | 99.04 | 95.69 |
| Q-Pert.(D)* [74] | 2024 | 68.35 | 87.72 | 92.65 | 82.91 | 89.86 | 98.20 | 99.06 | 95.71 |
| ELIP-B(Ours)* | - | 68.41 | 87.88 | 92.78 | 83.02 | 90.08 | 98.34 | 99.22 | 95.88 |
Table 2. 최신 state-of-the-art 방법들과의 비교. 상단: CLIP 기반 모델들; 중간: SigLIP 기반 모델들; 하단: BLIP-2 기반 모델들. ELIP-C/ELIP-S는 CLIP/SigLIP 아키텍처의 zero-shot 성능을 크게 향상시키며, ELIP-B는 state-of-the-art BLIP-2 모델을 능가한다. * 표시가 없는 모델의 결과는 zero-shot이며, * 표시가 있는 모델의 결과는 Flickr에서만 zero-shot이다. 이는 BLIP-2 모델이 COCO에서 fine-tuning되었고, * 모델들이 BLIP-2를 기반으로 하기 때문이다. 그러나 우리의 방법은 DataCompDR로 학습했을 때 두 벤치마크 모두에서 BLIP-2보다 향상된 성능을 보인다.
특히, Occluded COCO는 가려진(occluded) 객체 검색에 초점을 맞추고, ImageNet-R은 만화, 스케치 등 다양한 비정형(unusual) 도메인에서 객체를 검색하는 데 중점을 둔다. Figure 5는 Occluded COCO 및 ImageNet-R 벤치마크의 예시를 보여준다.
Occluded COCO는 [45]의 어노테이션을 활용하여 [100]에 설명된 방식으로 큐레이션되었으며, 가려짐(occlusion) 관계를 활용하여 가려진 객체를 포함하는 이미지를 수집한다. 이 데이터셋은 모델이 가려진 대상 객체를 포함하는 이미지를, 대상 객체가 없는 이미지와 구별하여 검색하는 성능을 평가하는 것을 목표로 한다.
ImageNet-R은 [34]의 어노테이션을 사용하여 생성되었으며, 예술, 만화, deviantart, 그래피티, 자수, 그래픽, 종이접기, 그림, 패턴, 플라스틱 객체, 봉제 인형, 조각, 스케치, 문신, 장난감, 비디오 게임 등 다양한 도메인에 걸쳐 모델의 검색 성능을 검증하는 것을 목표로 한다.
평가 지표 (Evaluation Metrics)
여기서는 **mAP(mean Average Precision)**를 평가 지표로 사용한다. 이는 각 텍스트 쿼리에 대해 여러 개의 긍정(positive) 이미지가 있을 수 있기 때문이다.
7. Experiment
구현 세부 사항 (Implementation Details)
연산 자원 제약으로 인해, 우리는 ELIP-C 모델을 batch size 40으로, ELIP-S 모델을 batch size 10으로, ELIP-B 모델을 batch size 12로 학습시켰다.
초기 learning rate는 ELIP-C, ELIP-S, ELIP-S-2의 경우 으로, ELIP-B의 경우 으로 설정되었다.
모든 모델은 기본적으로 DataCompDR 데이터셋으로 학습되었으며, ablation study를 위해 더 작은 CC3M 데이터셋에 대한 추가 실험도 수행되었다.
학습은 두 대의 A6000 또는 A40 GPU에서 진행되었다.
re-ranking을 위해, 우리는 데이터셋과 모델에 따라 상위 개의 샘플을 선택한다:
- ELIP-C: COCO 및 Flickr의 경우 , Occluded COCO의 경우 , ImageNet-R의 경우 .
- ELIP-S 및 ELIP-S-2: COCO 및 Flickr의 경우 , Occluded COCO의 경우 , ImageNet-R의 경우 .
- ELIP-B: COCO 및 Flickr의 경우 , Occluded COCO의 경우 , ImageNet-R의 경우 .
값은 원래 랭킹에서 높은 recall을 유지하면서 빠른 추론 속도를 보장하도록 선택되었다. CLIP, SigLIP, BLIP-2의 기존 사전학습 접근 방식과 비교할 때, 우리 방법은 학습 가능한 MLP mapping network에 의해 도입되는 FLOPS의 미미한 증가만으로도, 학습 시간, GPU 요구 사항, batch size 측면에서 학습 효율성을 크게 향상시킨다. 더 자세한 내용은 appendix에 제공된다.
7.1. Results on COCO and Flickr Benchmarks
Ablation Study.
Table 1에서는 CLIP을 위한 ELIP 프레임워크의 각 구성 요소가 기여하는 바를 평가한다.
Setting 와 의 비교는 원래 CLIP 대비 ELIP-C의 성능 향상 효과를 보여준다.
Setting 와 의 비교는 작은 batch size로 학습할 때 hard sample mining의 중요성을 입증한다.
**Setting 와 **는 노이즈가 적은 caption을 가진 더 큰 데이터셋으로 학습하는 것의 이점을 보여준다.
마지막으로, Setting 와 의 비교는 단일 prompt를 생성하는 것보다 여러 개의 visual prompt를 생성하는 것(예: 본 연구에서는 10개의 prompt)이 더 유익함을 나타낸다.
생성된 prompt 수에 대한 추가 ablation study는 appendix에 자세히 설명되어 있다.
State-of-the-Art와의 비교.
Table 2에서 우리는 우리의 모델들(ELIP-C, ELIP-S, ELIP-S-2, ELIP-B)을 기존의 state-of-the-art 방법들과 비교한다.
DataCompDR12M으로 학습했을 때, 우리의 방법은 CLIP, SigLIP, SigLIP-2, BLIP-2에 대해 COCO 및 Flickr 벤치마크에서 zero-shot 성능 향상을 보여준다.
특히, ELIP-B는 가장 최근 연구 [74]를 능가하며 BLIP-2 backbone에서 text-to-image retrieval의 새로운 state-of-the-art를 수립한다.
또한, 우리의 ELIP-S는 SigLIP 및 SigLIP-2에 적용되었을 때 BLIP-2와 필적하는 성능을 달성한다.
Recall Top- Curves.
**Figure 6 (오른쪽)**은 COCO 벤치마크에서 원본 CLIP 모델과 우리의 ELIP-C에 대한 Recall@Top- 곡선을 보여준다.
이 곡선들은 다양한 Top- 임계값에 따른 Recall 값을 플로팅하여 생성된다.
두 모델 간에는 상당한 성능 차이가 있으며, 이는 ELIP-C reranking이 다양한 값에 걸쳐 text-to-image retrieval 성능을 일관되게 향상시킨다는 것을 입증한다.
Qualitative Results.
Figure 7은 COCO (왼쪽) 및 Flickr (오른쪽) 벤치마크에서 CLIP 모델이 생성한 초기 랭킹과 ELIP-C로 재랭킹된 결과 간의 정성적 비교를 제공한다.
두 경우 모두, ELIP-C는 ground-truth 이미지(점선 상자로 강조 표시)를 랭킹 1위로 끌어올려 랭킹을 크게 향상시킨다.
추가적인 정성적 결과는 appendix에 제공된다.
Attention Map 시각화.
Figure 8은 COCO에서 CLIP과 ELIP-C 모두에 대한 patch token에 대한 [CLS] token의 cross-attention map을 시각화한다.
이미지가 텍스트 쿼리와 일치할 때(Figure 8 왼쪽), 우리가 생성한
 Figure 6. Before/after comparisons.
왼쪽: Occluded COCO retrieval에 대한 Precision-Recall 곡선으로, SigLIP-2의 초기 랭킹과 ELIP-S-2에 의한 재랭킹을 비교한다.
오른쪽: COCO retrieval에 대한 Recall Top- 곡선으로, CLIP의 초기 랭킹과 ELIP-C에 의한 재랭킹을 비교한다.
Figure 6. Before/after comparisons.
왼쪽: Occluded COCO retrieval에 대한 Precision-Recall 곡선으로, SigLIP-2의 초기 랭킹과 ELIP-S-2에 의한 재랭킹을 비교한다.
오른쪽: COCO retrieval에 대한 Recall Top- 곡선으로, CLIP의 초기 랭킹과 ELIP-C에 의한 재랭킹을 비교한다.
 Figure 7. CLIP 초기 랭킹과 ELIP-C 재랭킹 간의 정성적 비교.
COCO: 1-2열; Flickr: 3-4열. 각 쿼리에 대한 ground-truth 이미지는 점선 상자로 강조 표시되어 있으며, 상위 5개 검색된 이미지가 표시된다.
COCO 쿼리 "A large wooden pole with a green street sign hanging from it"에 대해 CLIP은 나무가 아닌 기둥을 top-1으로 랭크하는 반면, ELIP-C는 큰 나무 기둥을 정확하게 top-1으로 재랭크한다.
Flickr 쿼리 "A man wearing bathing trunks is parasailing in the water"에 대해 CLIP은 웨이크보드를 타는 사람을 top-1으로 랭크하는 반면, ELIP-C는 수영복을 입고 파라세일링하는 남자를 정확하게 top-1으로 재랭크한다.
Figure 7. CLIP 초기 랭킹과 ELIP-C 재랭킹 간의 정성적 비교.
COCO: 1-2열; Flickr: 3-4열. 각 쿼리에 대한 ground-truth 이미지는 점선 상자로 강조 표시되어 있으며, 상위 5개 검색된 이미지가 표시된다.
COCO 쿼리 "A large wooden pole with a green street sign hanging from it"에 대해 CLIP은 나무가 아닌 기둥을 top-1으로 랭크하는 반면, ELIP-C는 큰 나무 기둥을 정확하게 top-1으로 재랭크한다.
Flickr 쿼리 "A man wearing bathing trunks is parasailing in the water"에 대해 CLIP은 웨이크보드를 타는 사람을 top-1으로 랭크하는 반면, ELIP-C는 수영복을 입고 파라세일링하는 남자를 정확하게 top-1으로 재랭크한다.
visual prompt vector는 쿼리와 관련된 이미지 feature의 선택을 효과적으로 향상시킨다. 이러한 개선은
 Figure 8. CLIP과 ELIP-C에 대한 patch token의 [CLS] token cross-attention map을 비교하는 attention map 시각화.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
일치하는 쿼리의 경우, ELIP-C는 텍스트와 관련된 이미지 feature에 대한 attention을 향상시킨다.
예를 들어: (1행) "A young woman holding a giant tennis racket" 쿼리에 대해 ELIP-C는 거대한 테니스 라켓과 젊은 여성에 더 집중한다; (2행) "A baby in plaid shirt eating a frosted cake" 쿼리에 대해 ELIP-C는 케이크, 아기, 셔츠를 강조한다.
이미지가 쿼리와 일치하지 않을 때는 차이가 미미하다 (4-6열).
Figure 8. CLIP과 ELIP-C에 대한 patch token의 [CLS] token cross-attention map을 비교하는 attention map 시각화.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
일치하는 쿼리의 경우, ELIP-C는 텍스트와 관련된 이미지 feature에 대한 attention을 향상시킨다.
예를 들어: (1행) "A young woman holding a giant tennis racket" 쿼리에 대해 ELIP-C는 거대한 테니스 라켓과 젊은 여성에 더 집중한다; (2행) "A baby in plaid shirt eating a frosted cake" 쿼리에 대해 ELIP-C는 케이크, 아기, 셔츠를 강조한다.
이미지가 쿼리와 일치하지 않을 때는 차이가 미미하다 (4-6열).
ELIP-C의 early fusion 접근 방식 덕분이다. 이 방식은 이미지 encoder 초기에 텍스트 feature를 통합하여, 모델이 쿼리 텍스트와 더 밀접하게 정렬된 이미지 embedding을 생성할 수 있도록 한다. 이러한 시각화는 이 가설을 강력하게 뒷받침하는 증거를 제공한다.
| Model | Occluded COCO | ImageNet-R | Average |
|---|---|---|---|
| CLIP | 47.47 | 76.01 | 61.74 |
| ELIP-C (zero-shot) | 48.89 | 76.81 | 62.85 |
| ELIP-C (fine-tuned) | 59.88 | 81.44 | 70.66 |
| SigLIP | 61.74 | 92.11 | 76.93 |
| ELIP-S (zero-shot) | 64.58 | 92.42 | 78.50 |
| ELIP-S (fine-tuned) | 71.99 | 92.86 | 82.43 |
| SigLIP-2 | 66.40 | 92.66 | 79.53 |
| ELIP-S-2 (zero-shot) | 67.42 | 92.74 | 80.08 |
| ELIP-S-2 (fine-tuned) | 76.10 | 94.00 | 85.05 |
| BLIP-2 | 62.73 | 82.31 | 72.52 |
| ELIP-B (zero-shot) | 63.40 | 82.99 | 73.20 |
| ELIP-B (fine-tuned) | 70.49 | 83.68 | 77.09 |
Table 3. OOD 데이터셋에 대한 mAP 결과. ELIP prompting은 CLIP, SigLIP 시리즈, BLIP-2에 대해 주목할 만한 zero-shot 성능 향상을 달성한다. 이러한 성능 향상은 관련 데이터셋에 대한 fine-tuning을 통해 더욱 증폭된다. 예를 들어, Occluded COCO에 적응하기 위해 ELIP 모델은 COCO에서 fine-tuning된다. 유사하게, ImageNet에서 fine-tuning하면 ELIP는 ImageNet-R에 적응한다. 이러한 결과는 ELIP가 모델을 새로운 데이터셋에 효율적으로 적응시키는 능력을 보여준다.
7.2. Results on OOD Benchmarks
out-of-distribution (OOD) 벤치마크에 대한 결과는 Table 3에 제시되어 있다. ELIP은 OOD 벤치마크인 Occluded COCO와 ImageNet-R에서 모든 모델에 걸쳐 주목할 만한 zero-shot 성능 향상을 달성했으며, 이는 ELIP 모델의 강력한 일반화 능력을 보여준다. 성능은 적절한 데이터셋으로 mapping network를 fine-tuning함으로써 더욱 향상될 수 있다 (이때 이미지 및 텍스트 encoder는 고정된다). Occluded COCO (데이터 샘플이 매우 적음)와 ImageNet-R (평가 전용)은 fine-tuning이 불가능하므로, Occluded COCO retrieval의 경우 원본 COCO 데이터셋으로 fine-tuning을 수행하고, ImageNet-R retrieval의 경우 ImageNet으로 fine-tuning을 수행한다. Table 3에서 볼 수 있듯이, 이러한 fine-tuning을 통해 모든 모델의 성능이 크게 향상된다. 이는 ELIP의 fine-tuning이 모델을 새로운 데이터셋에 효율적으로 적응시킬 수 있음을 보여준다. ELIP이 만들어내는 상당한 성능 차이는 **Figure 6 (왼쪽)**에서도 확인할 수 있다. fine-tuning에 대한 자세한 내용은 appendix를 참조하라.
8. Conclusion
결론
본 논문에서는 텍스트 기반 이미지 검색을 위한 visual-language foundation model의 성능을 향상시키는 방법인 **Enhance Language-Image Pretraining (ELIP)**을 소개하였다. ELIP는 사전학습된 visual-language foundation model에 간단히 적용할 수 있는 plug-and-play 방식의 수정으로, zero-shot 성능을 크게 향상시킨다. 또한, mapping network를 fine-tuning하여 OOD(Out-Of-Distribution) 데이터셋에 효율적으로 적응시킬 수 있으며, 이를 통해 추가적인 성능 향상을 이끌어낼 수 있다. 우리는 또한 attention map을 시각화하여, ELIP가 image encoder가 더 관련성 높은 세부 정보에 집중할 수 있도록 돕는다는 것을 입증하였다.
향후 연구에서는 ELIP와 유사한 아이디어를 적용하여 generative Multimodal Large Language Model의 성능을 향상시킬 수 있을 것이다. 이는 decoder-only 아키텍처 [54]와 cross-attention 기반 아키텍처 [3] 모두에 대해 더 효과적인 text-guided visual attention 및 인코딩을 도입함으로써 가능하다.
감사의 글 (Acknowledgements)
본 연구는 EPSRC Programme Grant VisualAI EP/T028572/1, Royal Society Research Professorship RP\R1\191132, China Oxford Scholarship, 그리고 Hong Kong Research Grants Council - General Research Fund (Grant No.: 17211024)의 지원을 받았다. 프로젝트에 도움과 지원을 주신 Minghao Chen, Jindong Gu, Zhongrui Gui, Zhenqi He, João Henriques, Zeren Jiang, Zihang Lai, Horace Lee, Kun-Yu Lin, Xianzheng Ma, Christian Rupprecht, Ashish Thandavan, Jianyuan Wang, Kaiyan Zhang, Chuanxia Zheng, Liang Zheng께 감사드린다.
Appendix
A. Additional Implementation Details
이 섹션에서는 다음 내용에 대한 추가 구현 세부 정보를 제공한다:
- Section 7에서 언급된 Section A.1의 re-ranking을 위한 값 선택
- Section 5.1 및 Section 7에서 언급된 Section A.2의 일반 실험
- Section 7.2에서 언급된 Section A.3의 fine-tuning 실험
- Section 6.2에서 언급된 Section A.4의 Occluded COCO 벤치마크
A.1. Choice of for re-ranking
| CLIP | |||||
|---|---|---|---|---|---|
| Dataset | Top-20 | Top-50 | Top-100 | Top-200 | Top-500 |
| COCO | 84.25 | 93.30 | 97.67 | 99.12 | 99.65 |
| Flickr | 95.90 | 98.32 | 99.24 | 99.82 | 99.98 |
| Dataset | Top-100 | Top-200 | Top-500 | Top-1000 | Top-2000 |
| Occluded COCO | 65.31 | 72.00 | 81.14 | 87.66 | 93.71 |
| ImageNet-R | 57.33 | 77.83 | 91.13 | 95.05 | 97.18 |
| SigLIP | |||||
| Dataset | Top-20 | Top-50 | Top-100 | Top-200 | Top-500 |
| COCO | 90.14 | 96.07 | 98.77 | 99.44 | 99.78 |
| Flickr | 98.98 | 99.64 | 99.82 | 99.92 | 100.00 |
| Dataset | Top-50 | Top-100 | Top-200 | Top-500 | Top-1000 |
| Occluded COCO | 68.84 | 75.90 | 81.18 | 86.96 | 91.94 |
| ImageNet-R | 39.22 | 67.46 | 90.46 | 98.14 | 99.04 |
| SigLIP-2 | |||||
| Dataset | Top-20 | Top-50 | Top-100 | Top-200 | Top-500 |
| COCO | 91.10 | 96.59 | 98.85 | 99.55 | 99.80 |
| Flickr | 99.34 | 99.80 | 99.92 | 99.94 | 100.00 |
| Dataset | Top-50 | Top-100 | Top-200 | Top-500 | Top-1000 |
| Occluded COCO | 70.69 | 79.57 | 85.67 | 91.28 | 95.34 |
| ImageNet-R | 39.39 | 67.74 | 90.90 | 98.24 | 99.10 |
| BLIP-2 | |||||
| Dataset | Top-5 | Top-10 | Top-20 | Top-50 | Top-100 |
| COCO | 86.08 | 91.85 | 95.96 | 98.80 | 99.63 |
| Flickr | 97.64 | 99.06 | 99.52 | 99.82 | 99.86 |
| Dataset | Top-50 | Top-100 | Top-200 | Top-500 | Top-1000 |
| Occluded COCO | 68.67 | 77.40 | 82.12 | 88.17 | 92.67 |
| ImageNet-R | 35.97 | 61.21 | 82.81 | 92.88 | 94.99 |
Table 4. CLIP, SigLIP, BLIP-2 초기 랭킹에 대한 Recall @ Different 값. 자세한 내용은 본문을 참조하라.
Section 7에서 언급된 re-ranking을 위한 top- 값 선택과 관련하여, 값은 초기 랭킹에서 해당 에서의 recall이 높고, 동시에 추론 속도가 빠르도록 선택된다. ELIP-C의 경우, COCO와 Flickr에서는 를 100으로, Occluded COCO에서는 500으로, ImageNet-R에서는 1000으로 설정한다. ELIP-S 및 ELIP-S-2의 경우, COCO와 Flickr에서는 를 100으로, Occluded COCO에서는 500으로, ImageNet-R에서는 200으로 설정한다. ELIP-B의 경우, COCO와 Flickr에서는 를 20으로, Occluded COCO에서는 100으로, ImageNet-R에서는 200으로 설정한다.
더 구체적으로, Table 4에서 보듯이:
- CLIP의 경우, COCO/Flickr의 recall@100은 95% 이상, Occluded COCO의 recall@500은 80% 이상, ImageNet-R의 recall@1000은 95% 이상이다.
- SigLIP/SigLIP-2의 경우, COCO/Flickr의 recall@100은 95% 이상, Occluded COCO의 recall@500은 85% 이상, ImageNet-R의 recall@200은 90% 이상이다.
- BLIP-2의 경우, COCO/Flickr의 recall@20은 95% 이상, Occluded COCO의 recall@100은 75% 이상, ImageNet-R의 recall@200은 80% 이상이다.
우리는 re-ranking을 위해 를 증가시키는 실험을 수행했지만, 계산 비용이 훨씬 높아지는 반면 성능 향상은 미미했다.
A.2. Implementation Details for General Experiments
Section 5.1에서 언급했듯이, 실제로는 ELIP-C/ELIP-S 학습을 위해 600만 개의 샘플 중 무작위 부분집합을 사용하고, ELIP-B 학습을 위해 100만 개의 샘플 중 무작위 부분집합을 사용한다. ELIP-B의 경우, Section 5.2에서 설명한 대로 학습 가능성(learnability)이 가장 높은 상위 10%의 샘플을 먼저 선택한 다음, 선택된 학습 샘플로 ELIP-B 아키텍처를 학습시킨다. ELIP-C의 경우, 제한된 컴퓨팅 자원과 ablation 연구를 위해 **기본 backbone (ViT-B)**을 사용한다. 반면 ELIP-S와 ELIP-B의 경우, 우리 방법의 **state-of-the-art 모델 대비 효과를 보여주기 위해 최고의 backbone (BLIP-2 및 SigLIP-2에는 ViT-G, SigLIP에는 ViT-SO400M)**을 사용한다. ELIP-S에 큰 backbone을 사용하면 GPU 메모리가 증가하므로, ELIP-C 학습 데이터셋의 40개 샘플 배치에서 매 학습 배치마다 10개의 샘플을 추출하여 사용한다.
MLP Mapping Network는 세 개의 linear layer로 구성되며, 각 layer 쌍 사이에 GELU 활성화 함수가 적용된다. 개의 토큰을 생성할 때 출력 차원을 배로 확장한 다음, 생성된 벡터를 개의 토큰으로 나눈다. 우리는 Mapping Network에 대해 Transformer layer, 다양한 수의 MLP layer, linear network 등 다른 아키텍처도 탐색했지만, 유의미한 성능 이점은 발견되지 않았다. 따라서 우리는 간단하면서도 효과적인 현재 아키텍처를 사용한다.
A.3. Implementation Details for Fine-Tuning on COCO and ImageNet
Section 7.2에서 언급했듯이, 우리는 DataCompDR로 사전학습된 모델들을 각각 COCO와 ImageNet 데이터셋에 대해 추가 fine-tuning했다. 두 데이터셋 모두에서, 우리는 먼저 Section 5.1에 설명된 방법을 사용하여 어려운 샘플들을 배치로 그룹화했다. 이미지에 대한 캡션은 카테고리 이름이며, 학습 시 노이즈가 발생하지 않도록 한 배치 내에서 한 카테고리가 한 번만 나타나도록 했다. 우리는 ELIP-C, ELIP-S, ELIP-B 모델을 초기 학습률 로 10,000 iteration 동안 fine-tuning했다. COCO와 Occluded COCO, ImageNet과 ImageNet-R 사이에 여전히 domain gap이 존재하지만, 캡션 도메인이 더 가깝기 때문에 COCO와 ImageNet으로 fine-tuning하는 것만으로도 Occluded COCO와 ImageNet-R에서의 성능 향상을 가져올 수 있음을 확인했다. Occluded COCO는 데이터 샘플이 매우 적고 ImageNet-R은 평가용으로 설계되었기 때문에, 이들 데이터셋으로 fine-tuning하는 것은 현실적으로 불가능하다.
A.4. Implementation Details for Setting up the Occluded COCO Benchmark
Section 6.2에서 언급했듯이, 우리는 [45]의 annotation을 사용하여 Occluded COCO 벤치마크를 구축했다. 더 구체적으로, 각 COCO category에 대해 두 가지 목록을 수집했다:
- 해당 category의 가려진(occluded) 객체를 포함하는 이미지 목록
- 해당 category의 객체가 없는 이미지 목록
가려진 객체를 포함하는 이미지의 경우, 다음 기준을 충족하는 이미지를 선택했다:
- 해당 이미지는 해당 category의 객체를 포함한다.
- 해당 category의 모든 instance는 적어도 하나 이상의 다른 instance에 의해 가려져 있다. 즉, [45]의 annotation에서 다른 instance와 occludee-occluder 관계를 가진다.
가려진 instance를 포함하는 이미지를 수집하는 아이디어는 occlusion 관계를 활용하는 [100]과 유사하다.
B. Additional Qualitative Results
이 섹션에서는 본 논문의 Section 7에서 언급된 추가적인 정성적 결과들을 제공한다. 여기에는 다음 내용이 포함된다:
- CLIP과 ELIP-C의 COCO (Figure 9), Flickr (Figure 10), Occluded COCO (Figure 11), ImageNet-R (Figure 12) 데이터셋에서의 랭킹 정성적 비교.
- SigLIP/SigLIP-2와 ELIP-S/ELIP-S-2의 COCO (Figure 13), Flickr (Figure 14), Occluded COCO (Figure 15), ImageNet-R (Figure 16) 데이터셋에서의 랭킹 정성적 비교.
- BLIP-2와 ELIP-B의 COCO (Figure 17), Flickr (Figure 18), Occluded COCO (Figure 19), ImageNet-R (Figure 20) 데이터셋에서의 랭킹 정성적 비교.
- CLIP과 ELIP-C의 attention map (Figure 21 및 Figure 22).
- SigLIP/SigLIP-2와 ELIP-S/ELIP-S-2의 attention map (Figure 23 및 Figure 24).
- BLIP-2와 ELIP-B의 attention map (Figure 25 및 Figure 26).
B.1. Qualitative Comparison of CLIP and ELIP-C
Figure 9는 COCO 데이터셋에서 CLIP 초기 랭킹과 ELIP-C 재랭킹 간의 정성적 비교를 추가로 보여준다.
 Figure 9. CLIP과 ELIP-C의 COCO 데이터셋에 대한 정성적 비교. 각 예시마다 상위 5개 랭킹(왼쪽에서 오른쪽으로)을 보여주며, 정답 이미지는 검은색 점선 상자로 강조 표시했다. 첫 번째와 두 번째 예시(위에서 아래로)에서 텍스트 쿼리는 각각 'Two young men playing a game of soccer'와 'A man cuts into a small cake with his sharp knife'이며, 정답 이미지는 CLIP 초기 랭킹의 상위 5개 이미지에 포함되지 않았지만, ELIP-C 재랭킹에서는 상위 1위로 랭크되었다.
Figure 9. CLIP과 ELIP-C의 COCO 데이터셋에 대한 정성적 비교. 각 예시마다 상위 5개 랭킹(왼쪽에서 오른쪽으로)을 보여주며, 정답 이미지는 검은색 점선 상자로 강조 표시했다. 첫 번째와 두 번째 예시(위에서 아래로)에서 텍스트 쿼리는 각각 'Two young men playing a game of soccer'와 'A man cuts into a small cake with his sharp knife'이며, 정답 이미지는 CLIP 초기 랭킹의 상위 5개 이미지에 포함되지 않았지만, ELIP-C 재랭킹에서는 상위 1위로 랭크되었다.
Figure 10은 Flickr 데이터셋에서 CLIP 초기 랭킹과 ELIP-C 재랭킹 간의 정성적 비교를 추가로 보여준다.
 Figure 10. CLIP과 ELIP-C의 Flickr 데이터셋에 대한 정성적 비교. 각 예시마다 상위 5개 랭킹(왼쪽에서 오른쪽으로)을 보여주며, 정답 이미지는 검은색 점선 상자로 강조 표시했다. 첫 번째 예시에서 텍스트 쿼리는 'A man in blue overalls and red shirt holding a chainsaw'이며, 정답 이미지는 초기 랭킹에서 상위 3위였지만, 우리의 재랭킹에서는 상위 1위로 랭크되었다. 두 번째 예시에서 텍스트 쿼리는 'A muzzled greyhound dog wearing yellow and black is running on the track'이며, 정답 이미지는 CLIP 초기 랭킹의 상위 5개 이미지에 포함되지 않았지만, 우리의 ELIP-C 재랭킹에서는 상위 1위로 랭크되었다.
Figure 10. CLIP과 ELIP-C의 Flickr 데이터셋에 대한 정성적 비교. 각 예시마다 상위 5개 랭킹(왼쪽에서 오른쪽으로)을 보여주며, 정답 이미지는 검은색 점선 상자로 강조 표시했다. 첫 번째 예시에서 텍스트 쿼리는 'A man in blue overalls and red shirt holding a chainsaw'이며, 정답 이미지는 초기 랭킹에서 상위 3위였지만, 우리의 재랭킹에서는 상위 1위로 랭크되었다. 두 번째 예시에서 텍스트 쿼리는 'A muzzled greyhound dog wearing yellow and black is running on the track'이며, 정답 이미지는 CLIP 초기 랭킹의 상위 5개 이미지에 포함되지 않았지만, 우리의 ELIP-C 재랭킹에서는 상위 1위로 랭크되었다.
Figure 11은 Occluded COCO 데이터셋에서 CLIP 초기 랭킹과 우리의 ELIP-C 재랭킹의 정성적 비교를 보여준다.

Figure 11. CLIP과 ELIP-C의 Occluded COCO 데이터셋에 대한 정성적 비교. 상위 5개 검색된 이미지를 보여준다. 오답(errors)은 주황색 실선 상자로 강조 표시했다. 첫 번째 예시에서 텍스트 쿼리는 'bowl'이며, CLIP은 상위 5개 검색된 이미지에서 'frisbee', 'toilet', 'plate'와 혼동한다. 두 번째 예시에서 텍스트 쿼리는 'boat'이며, CLIP은 상위 5개 검색된 이미지에서 'surfboard'와 혼동한다.
Figure 12는 ImageNet-R 데이터셋에서 CLIP 초기 랭킹과 우리의 ELIP-C 재랭킹의 정성적 비교를 보여준다.
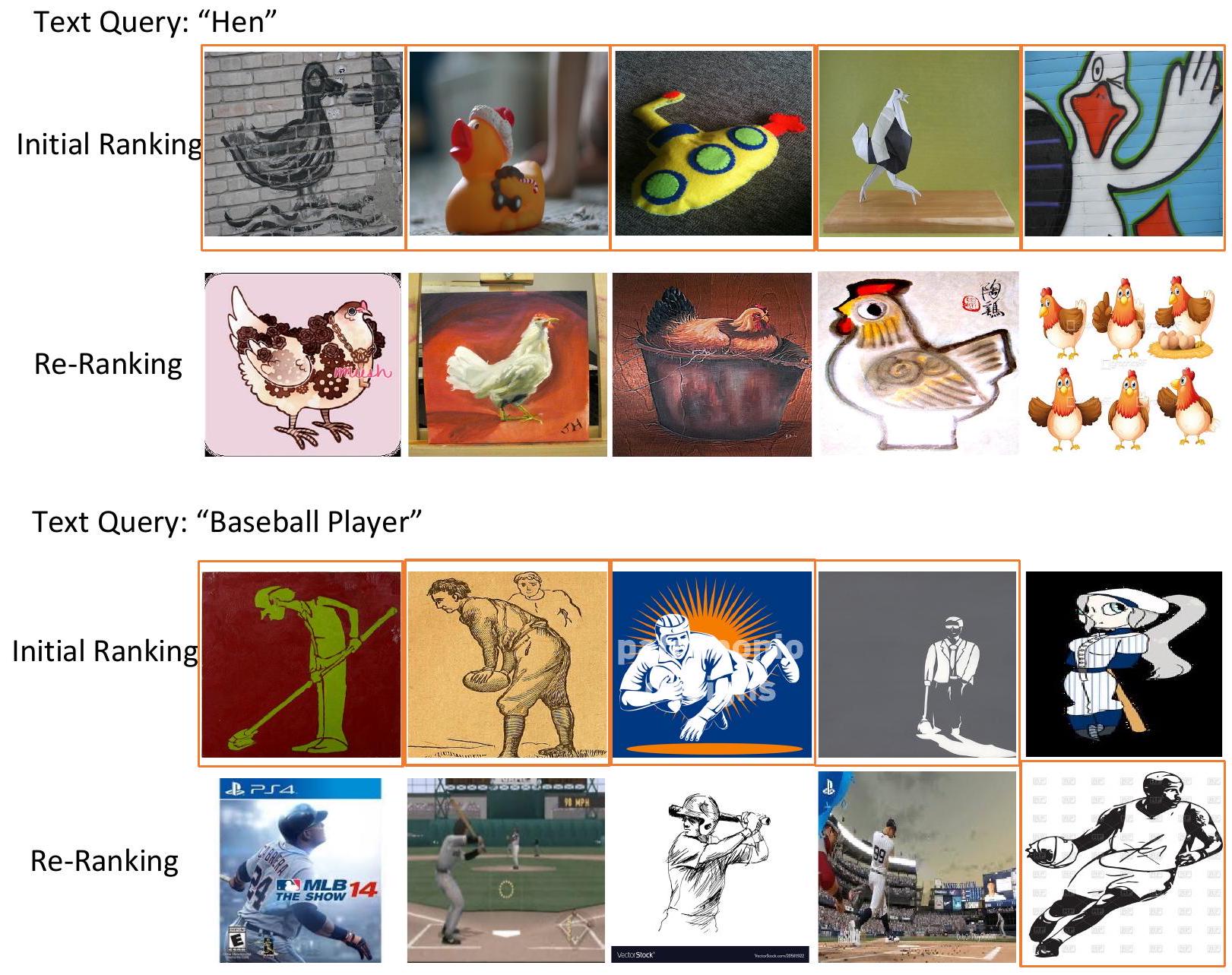
Figure 12. CLIP과 ELIP-C의 ImageNet-R 데이터셋에 대한 정성적 비교. 상위 100개 랭킹에서 두 모델 간에 차이가 있는 예시, 즉 한 모델은 긍정 샘플을 검색하고 다른 모델은 부정 샘플을 검색하는 경우를 보여준다. 이는 상위 100개 검색된 샘플의 대부분이 긍정 샘플이기 때문이다. 일반적으로 ELIP-C는 CLIP보다 상위 100개 이미지에서 더 많은 긍정 샘플을 검색한다. 오답(errors)은 주황색 실선 상자로 강조 표시했다. 첫 번째 예시에서 텍스트 쿼리는 'hen'이며, CLIP은 상위 100개 검색된 이미지에서 일부 'duck'을 검색한다. 두 번째 예시에서 텍스트 쿼리는 'baseball player'이며, CLIP은 상위 100개 검색된 이미지에서 다른 구기 종목의 선수들을 검색하는 반면, 우리의 ELIP-C는 상위 100개 이미지에서 농구 선수를 검색한다.
결론적으로, 이러한 결과들은 초기 CLIP 모델이 관련 이미지를 대략적으로 검색할 수 있지만, 상위 검색된 이미지들 간의 미세한 차이를 구별하는 능력은 떨어진다는 것을 보여준다. 반면, 우리의 재랭킹 모델은 정답 이미지와 hard negative 이미지 간의 구별 능력을 더욱 향상시켜 더 나은 검색 성능을 달성한다.
B.2. Qualitative Comparison of SigLIP/SigLIP-2 and ELIP-S/ELIP-S-2
Figure 13은 COCO 데이터셋에서 SigLIP/SigLIP-2의 초기 랭킹과 ELIP-S/ELIP-S-2의 재랭킹 간의 정성적 비교를 추가로 보여준다.
Text Query: "A small blue plane sitting on top of a field"

Text Query: "Assortment of doughnuts and other snack items on a serving tray"

Figure 13. COCO 데이터셋에서 SigLIP과 ELIP-S (상단), SigLIP-2와 ELIP-S-2 (하단)의 정성적 비교. 각 예시에서 상위 5개 랭킹(왼쪽에서 오른쪽으로)을 모두 보여주며, ground truth 이미지는 검은색 점선 상자로 강조 표시한다. 첫 번째(SigLIP 대 ELIP-S) 및 두 번째(SigLIP-2 대 ELIP-S-2) 예시(위에서 아래로)에서, 텍스트 쿼리는 각각 'A small blue plane sitting on top of a field'와 'Assortment of doughnuts and other snack items on a serving tray'이다. ground truth 이미지는 SigLIP/SigLIP-2의 초기 랭킹에서는 상위 5개 이미지에 포함되지 않았지만, 우리의 ELIP-S/ELIP-S-2 재랭킹에서는 상위 1위로 랭크되었다.
Figure 14는 Flickr 데이터셋에서 SigLIP/SigLIP-2의 초기 랭킹과 ELIP-S/ELIP-S-2의 재랭킹 간의 정성적 비교를 추가로 보여준다.
Text Query: "A man wearing bathing trunks is parasailing in the water"

Text Query: "A group of mountain bikers race each other down a dirt hill"

Figure 14. Flickr 데이터셋에서 SigLIP과 ELIP-S (상단), SigLIP-2와 ELIP-S-2 (하단)의 정성적 비교. 각 예시에서 상위 5개 랭킹(왼쪽에서 오른쪽으로)을 모두 보여주며, ground truth 이미지는 검은색 점선 상자로 강조 표시한다. 첫 번째 예시에서 텍스트 쿼리는 'A man wearing bathing trunks is parasailing in the water'이며, ground truth 이미지는 SigLIP 초기 랭킹에서 상위 3위였지만, 우리의 ELIP-S 재랭킹에서는 상위 1위로 랭크되었다. 두 번째 예시에서 텍스트 쿼리는 'A group of mountain bikers race each other down a dirt hill'이며, ground truth 이미지는 SigLIP-2 초기 랭킹에서 상위 3위였지만, 우리의 ELIP-S-2 재랭킹에서는 상위 1위로 랭크되었다.
Figure 15는 Occluded COCO 데이터셋에서 SigLIP/SigLIP-2의 초기 랭킹과 우리의 ELIP-S/ELIP-S-2 재랭킹 간의 정성적 비교를 보여준다.
Text Query: "bowl"

Figure 15. Occluded COCO 데이터셋에서 SigLIP과 ELIP-S (상단), SigLIP-2와 ELIP-S-2 (하단)의 정성적 비교. Figure 12와 유사하게, 두 모델 간에 차이가 있는 상위 100개 랭킹의 예시를 보여준다. 즉, 한 모델은 positive sample을 검색하고 다른 모델은 negative sample을 검색하는 경우이다. 일반적으로 ELIP-S/ELIP-S-2는 SigLIP/SigLIP-2보다 상위 100개 이미지에서 더 많은 positive sample을 검색한다. **Negative sample (오류)**은 주황색 실선 상자로 강조 표시된다. 첫 번째 예시에서 텍스트 쿼리는 'bowl'이며, SigLIP은 상위 100개 검색 이미지에서 'roller skating rink', 'plate', 'frisbee'와 혼동하는 반면, ELIP-S는 'cup'과 혼동한다. 두 번째 예시에서 텍스트 쿼리는 'TV'이며, SigLIP-2는 상위 100개 검색 이미지에서 'cell phone', 'laptop', 'remote control'과 혼동한다.
Figure 16은 ImageNet-R 데이터셋에서 SigLIP/SigLIP-2의 초기 랭킹과 우리의 ELIP-S/ELIP-S-2 재랭킹 간의 정성적 비교를 보여준다.
Text Query: "Duck"

Figure 16. ImageNet-R 데이터셋에서 SigLIP과 ELIP-S (상단), SigLIP-2와 ELIP-S-2 (하단)의 정성적 비교. 상위 100개 검색 이미지의 대부분이 positive sample이므로, 두 모델 간에 차이가 있는 상위 100개 랭킹의 예시를 보여준다. 즉, 한 모델은 positive sample을 검색하고 다른 모델은 negative sample을 검색하는 경우이다. 일반적으로 ELIP-S/ELIP-S-2는 SigLIP/SigLIP-2보다 상위 100개 이미지에서 더 많은 positive sample을 검색한다. **Negative sample (오류)**은 주황색 실선 상자로 강조 표시된다. 첫 번째 예시에서 텍스트 쿼리는 'duck'이며, SigLIP은 상위 100개 검색 이미지에서 일부 'goose'를 검색하는 반면, 우리의 ELIP-S는 상위 100개 이미지에서 'goose'를 검색한다. 두 번째 예시에서 텍스트 쿼리는 'centipede'이며, SigLIP-2는 상위 100개 검색 이미지에서 다른 곤충들을 검색한다.
결론적으로, 이러한 결과들은 초기 SigLIP/SigLIP-2 모델이 관련 이미지를 대략적으로 검색할 수 있지만, 상위 검색 이미지들 간의 미세한 차이를 구별하는 능력은 떨어진다는 것을 보여준다. 반면, 우리의 재랭킹 모델은 ground truth 이미지와 hard negative 이미지 간의 구별 능력을 더욱 향상시켜 더 나은 검색 성능을 달성한다.
B.3. Qualitative Comparison of BLIP and ELIP-B
Figure 17은 COCO 데이터셋에서 BLIP-2 랭킹과 ELIP-B 재랭킹 간의 정성적 비교를 추가로 보여준다.
Text Query: "There is dust coming out of the catcher's glove as a boy prepares to bat"

Text Query: "Park scene, park bench, light pole and building in background, probably city park area"

Figure 17. BLIP-2와 ELIP-B의 COCO 정성적 비교. 각 예시에서 우리는 상위 5개 랭킹(왼쪽에서 오른쪽으로)을 모두 보여주며, 정답 이미지를 검은색 점선 상자로 강조 표시한다. 첫 번째와 두 번째 예시에서 텍스트 쿼리는 각각 'There is dust coming out of the catcher's glove as a boy prepares to bat'와 'Park scene, park bench, light pole and building in background, probably city park area'이며, 정답 이미지는 BLIP-2에 의해 각각 상위 5위 / 상위 4위로 랭크되었지만, ELIP-B에 의해 상위 1위로 랭크되었다.
Figure 18은 Flickr 데이터셋에서 BLIP-2 랭킹과 ELIP-B 재랭킹 간의 정성적 비교를 추가로 보여준다.
 Figure 18. BLIP-2와 ELIP-B의 Flickr 정성적 비교. 각 예시에서 우리는 상위 5개 랭킹(왼쪽에서 오른쪽으로)을 모두 보여주며, 정답 이미지를 검은색 점선 상자로 강조 표시한다. 첫 번째와 두 번째 예시에서 텍스트 쿼리는 'A brown dog waits for the frisbee to come down before catching it'와 'A crowd is present at a bar'이며, 정답 이미지는 BLIP-2 랭킹에서 상위 2위였지만, ELIP-B 랭킹에서는 상위 1위였다.
Figure 18. BLIP-2와 ELIP-B의 Flickr 정성적 비교. 각 예시에서 우리는 상위 5개 랭킹(왼쪽에서 오른쪽으로)을 모두 보여주며, 정답 이미지를 검은색 점선 상자로 강조 표시한다. 첫 번째와 두 번째 예시에서 텍스트 쿼리는 'A brown dog waits for the frisbee to come down before catching it'와 'A crowd is present at a bar'이며, 정답 이미지는 BLIP-2 랭킹에서 상위 2위였지만, ELIP-B 랭킹에서는 상위 1위였다.
Text Query: "A crowd is present at a bar"

Figure 19는 Occluded COCO 데이터셋에서 BLIP-2 초기 랭킹과 ELIP-B 재랭킹의 정성적 비교를 보여준다.
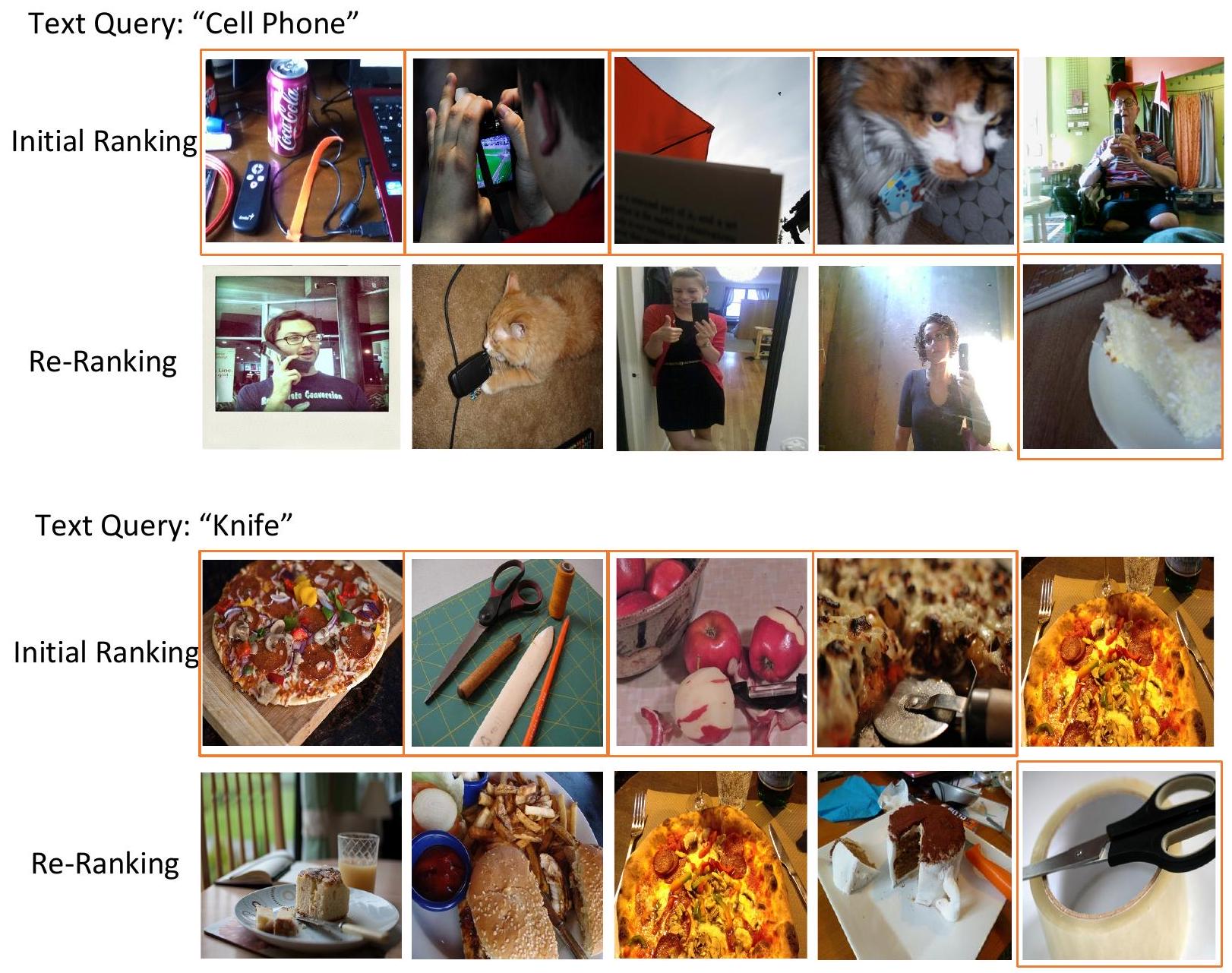
Figure 19. BLIP-2와 ELIP-B의 Occluded COCO 정성적 비교. Figure 12와 유사하게, 두 모델 간에 차이가 있는 상위 100개 랭킹의 예시를 보여준다. 즉, 한 모델은 긍정 샘플을 검색하고 다른 모델은 부정 샘플을 검색하는 경우이다. 일반적으로 ELIP-B는 BLIP-2보다 상위 100개 이미지에서 더 많은 긍정 샘플을 검색한다. 부정 샘플(오류)은 주황색 실선 상자로 강조 표시된다. 첫 번째 예시에서 텍스트 쿼리는 'cell phone'이며, BLIP-2는 상위 100개 검색 이미지에서 'remote control' 및 'camera'와 혼동하는 반면, ELIP-B는 'keyboard'와 혼동한다. 두 번째 예시에서 텍스트 쿼리는 'knife'이며, BLIP-2는 상위 100개 검색 이미지에서 'scissors', 'fruit peeler' 및 'pizza cutter'와 혼동하는 반면, ELIP-B는 'scissors'와 혼동한다.
Figure 20은 ImageNet-R 데이터셋에서 BLIP-2 초기 랭킹과 ELIP-B 재랭킹의 정성적 비교를 보여준다.
 Figure 20. BLIP-2와 ELIP-B의 ImageNet-R 정성적 비교. 마찬가지로, 두 모델 간에 차이가 있는 상위 100개 랭킹의 예시를 보여준다. 즉, 한 모델은 긍정 샘플을 검색하고 다른 모델은 부정 샘플을 검색하는 경우이다. 일반적으로 ELIP-B는 BLIP-2보다 상위 100개 이미지에서 더 많은 긍정 샘플을 검색한다. 부정 샘플(오류)은 주황색 실선 상자로 강조 표시된다. 세 번째 예시에서 텍스트 쿼리는 'hammerhead'이며, BLIP-2는 상위 100개 검색 이미지에서 일부 'hammer'를 검색한다. 네 번째 예시에서 텍스트 쿼리는 'mitten'이며, BLIP-2는 상위 100개 검색 이미지에서 'mitten'과 유사한 재료로 만들어진 다른 객체들을 검색하는 반면, ELIP-B는 유사한 실수를 하지만 총 오류 수는 더 적다.
Figure 20. BLIP-2와 ELIP-B의 ImageNet-R 정성적 비교. 마찬가지로, 두 모델 간에 차이가 있는 상위 100개 랭킹의 예시를 보여준다. 즉, 한 모델은 긍정 샘플을 검색하고 다른 모델은 부정 샘플을 검색하는 경우이다. 일반적으로 ELIP-B는 BLIP-2보다 상위 100개 이미지에서 더 많은 긍정 샘플을 검색한다. 부정 샘플(오류)은 주황색 실선 상자로 강조 표시된다. 세 번째 예시에서 텍스트 쿼리는 'hammerhead'이며, BLIP-2는 상위 100개 검색 이미지에서 일부 'hammer'를 검색한다. 네 번째 예시에서 텍스트 쿼리는 'mitten'이며, BLIP-2는 상위 100개 검색 이미지에서 'mitten'과 유사한 재료로 만들어진 다른 객체들을 검색하는 반면, ELIP-B는 유사한 실수를 하지만 총 오류 수는 더 적다.
결론적으로, 이러한 결과는 ELIP-B 재랭킹 모델이 긍정 이미지와 어려운 부정 이미지 간의 구별 능력(discrimination capability)을 향상시켜, 원래 BLIP-2 모델보다 더 나은 검색 성능을 달성함을 보여준다.
B.4. Attention Map of CLIP and ELIP-C
Figure 21은 COCO (1-2행) 및 Flickr (3-4행) 데이터셋에서 CLIP과 우리의 ELIP-C 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다. 왼쪽에는 이미지가 텍스트 쿼리와 일치하는 경우를, 오른쪽에는 일치하지 않는 경우를 나타냈다. 시각화는 [71]의 코드베이스를 기반으로 하며, 따뜻한 색상일수록 더 높은 활성화를 의미한다.
 Figure 21. CLIP과 ELIP-C의 attention map 시각화는 COCO와 Flickr 데이터셋에서 CLIP과 우리의 ELIP-C 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
COCO: 1-2행; Flickr: 3-4행.
이미지가 텍스트 쿼리와 일치할 때, 우리의 생성된 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다:
예를 들어, 텍스트 쿼리가 'A person wearing a banana headdress and necklace'일 때 (1행), CLIP과 ELIP-C의 attention map을 비교하면 ELIP-C가 바나나 머리 장식과 목걸이에 더 많은 attention을 집중시키는 것을 볼 수 있다.
텍스트 쿼리가 'A cute cat laying down in a sink'일 때 (2행), ELIP-C가 고양이에 훨씬 더 많은 attention을 부여하는 것을 확인할 수 있다.
텍스트 쿼리가 'A black and white dog is running in a grassy garden surrounded by a white fence'일 때 (3행), ELIP-C가 흑백 개와 흰색 울타리에 대한 attention을 크게 증가시키는 것을 알 수 있다.
텍스트 쿼리가 'A group of young people are listening to a man in a blue shirt telling them about Brazil'일 때 (4행), ELIP-C가 파란 셔츠를 입고 말하는 남성, 브라질 국기, 그리고 듣고 있는 사람들에게 더 집중적으로 attention을 부여하는 것을 확인할 수 있다.
이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 크지 않다.
Figure 21. CLIP과 ELIP-C의 attention map 시각화는 COCO와 Flickr 데이터셋에서 CLIP과 우리의 ELIP-C 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
COCO: 1-2행; Flickr: 3-4행.
이미지가 텍스트 쿼리와 일치할 때, 우리의 생성된 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다:
예를 들어, 텍스트 쿼리가 'A person wearing a banana headdress and necklace'일 때 (1행), CLIP과 ELIP-C의 attention map을 비교하면 ELIP-C가 바나나 머리 장식과 목걸이에 더 많은 attention을 집중시키는 것을 볼 수 있다.
텍스트 쿼리가 'A cute cat laying down in a sink'일 때 (2행), ELIP-C가 고양이에 훨씬 더 많은 attention을 부여하는 것을 확인할 수 있다.
텍스트 쿼리가 'A black and white dog is running in a grassy garden surrounded by a white fence'일 때 (3행), ELIP-C가 흑백 개와 흰색 울타리에 대한 attention을 크게 증가시키는 것을 알 수 있다.
텍스트 쿼리가 'A group of young people are listening to a man in a blue shirt telling them about Brazil'일 때 (4행), ELIP-C가 파란 셔츠를 입고 말하는 남성, 브라질 국기, 그리고 듣고 있는 사람들에게 더 집중적으로 attention을 부여하는 것을 확인할 수 있다.
이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 크지 않다.
Figure 22는 Occluded COCO (1-2행) 및 ImageNet-R (3-4행) 데이터셋에서 CLIP과 우리의 ELIP-C 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다. 왼쪽에는 이미지가 텍스트 쿼리와 일치하는 경우를, 오른쪽에는 일치하지 않는 경우를 나타냈다. 시각화는 [71]의 코드베이스를 기반으로 하며, 따뜻한 색상일수록 더 높은 활성화를 의미한다.
 Figure 22. CLIP과 ELIP-C의 attention map 시각화는 Occluded COCO와 ImageNet-R 데이터셋에서 CLIP과 우리의 ELIP-C 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
Occluded COCO: 1-2행; ImageNet-R: 3-4행.
이미지가 텍스트 쿼리와 일치할 때, 우리의 생성된 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다:
예를 들어, 텍스트 쿼리가 'banana'일 때 (1행), ELIP-C가 다른 영역보다 바나나에 더 많은 attention을 집중시키는 것을 볼 수 있다.
텍스트 쿼리가 'baseball bat'일 때 (2행), ELIP-C가 야구 방망이에 더 많은 attention을 집중시키는 것을 확인할 수 있다.
텍스트 쿼리가 'baboon' (3행) 및 'ant' (4행)일 때, ELIP-C가 각각 비비와 개미에 더 집중적으로 attention을 부여하는 것을 확인할 수 있다.
이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 크지 않다.
Figure 22. CLIP과 ELIP-C의 attention map 시각화는 Occluded COCO와 ImageNet-R 데이터셋에서 CLIP과 우리의 ELIP-C 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
Occluded COCO: 1-2행; ImageNet-R: 3-4행.
이미지가 텍스트 쿼리와 일치할 때, 우리의 생성된 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다:
예를 들어, 텍스트 쿼리가 'banana'일 때 (1행), ELIP-C가 다른 영역보다 바나나에 더 많은 attention을 집중시키는 것을 볼 수 있다.
텍스트 쿼리가 'baseball bat'일 때 (2행), ELIP-C가 야구 방망이에 더 많은 attention을 집중시키는 것을 확인할 수 있다.
텍스트 쿼리가 'baboon' (3행) 및 'ant' (4행)일 때, ELIP-C가 각각 비비와 개미에 더 집중적으로 attention을 부여하는 것을 확인할 수 있다.
이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 크지 않다.
B.5. Attention Map of SigLIP/SigLIP-2 and ELIP-S/ELIP-S-2
Figure 23은 COCO (1행 및 3행)와 Flickr (2행 및 4행)에서 SigLIP/SigLIP-2와 우리의 ELIP-S/ELIP-S2 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다. 왼쪽에는 이미지와 텍스트 쿼리가 일치하는 경우를, 오른쪽에는 일치하지 않는 경우를 나타냈다. 시각화는 [71]의 코드베이스를 기반으로 하며, 따뜻한 색상일수록 더 높은 활성화를 의미한다.
 Figure 23. SigLIP/SigLIP-2 및 ELIP-S/ELIP-S-2의 attention map 시각화는 COCO 및 Flickr에서 SigLIP/SigLIP-2와 우리의 ELIP-S/ELIP-S-2 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다.
상단: SigLIP 대 ELIP-S; 하단: SigLIP-2 대 ELIP-S-2.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
COCO: 1행 및 3행; Flickr: 2행 및 4행.
이미지가 텍스트 쿼리와 일치할 때, 우리가 생성한 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다.
예를 들어, 텍스트 쿼리가 'A basket ball player is posing in front of a basket'일 때 (1행), SigLIP과 ELIP-S의 attention map을 비교하면, ELIP-S가 농구공, 농구 골대, 그리고 선수에 더 많은 attention을 집중시키는 것을 볼 수 있다.
텍스트 쿼리가 'A black dog is slowly crossing a fallen log that is outstretched over a stream of water'일 때 (2행), ELIP-S가 검은 개와 통나무에 훨씬 더 많은 attention을 부여하는 것을 확인할 수 있다.
텍스트 쿼리가 'A dark skinned child getting ready to be pushed on a swing'일 때 (3행), ELIP-S-2가 아이와 그네에 대한 attention을 크게 증가시키는 것을 알 수 있다.
텍스트 쿼리가 'A boy is hanging out of the window of a yellow taxi'일 때 (4행), ELIP-S-2가 창문 밖의 소년에 더 집중하도록 attention을 유도하는 것을 확인할 수 있다.
이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 유의미하지 않다.
Figure 23. SigLIP/SigLIP-2 및 ELIP-S/ELIP-S-2의 attention map 시각화는 COCO 및 Flickr에서 SigLIP/SigLIP-2와 우리의 ELIP-S/ELIP-S-2 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다.
상단: SigLIP 대 ELIP-S; 하단: SigLIP-2 대 ELIP-S-2.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
COCO: 1행 및 3행; Flickr: 2행 및 4행.
이미지가 텍스트 쿼리와 일치할 때, 우리가 생성한 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다.
예를 들어, 텍스트 쿼리가 'A basket ball player is posing in front of a basket'일 때 (1행), SigLIP과 ELIP-S의 attention map을 비교하면, ELIP-S가 농구공, 농구 골대, 그리고 선수에 더 많은 attention을 집중시키는 것을 볼 수 있다.
텍스트 쿼리가 'A black dog is slowly crossing a fallen log that is outstretched over a stream of water'일 때 (2행), ELIP-S가 검은 개와 통나무에 훨씬 더 많은 attention을 부여하는 것을 확인할 수 있다.
텍스트 쿼리가 'A dark skinned child getting ready to be pushed on a swing'일 때 (3행), ELIP-S-2가 아이와 그네에 대한 attention을 크게 증가시키는 것을 알 수 있다.
텍스트 쿼리가 'A boy is hanging out of the window of a yellow taxi'일 때 (4행), ELIP-S-2가 창문 밖의 소년에 더 집중하도록 attention을 유도하는 것을 확인할 수 있다.
이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 유의미하지 않다.
Figure 24는 Occluded COCO (1행 및 3행)와 ImageNet-R (2행 및 4행)에서 SigLIP/SigLIP-2와 우리의 ELIP-S/ELIP-S-2 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다. 왼쪽에는 이미지와 텍스트 쿼리가 일치하는 경우를, 오른쪽에는 일치하지 않는 경우를 나타냈다. 시각화는 [71]의 코드베이스를 기반으로 하며, 따뜻한 색상일수록 더 높은 활성화를 의미한다.
 Figure 24. SigLIP/SigLIP-2 및 ELIP-S/ELIP-S-2의 attention map 시각화는 Occluded COCO 및 ImageNet-R에서 SigLIP/SigLIP-2와 우리의 ELIP-S/ELIP-S-2 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다.
상단: SigLIP 대 ELIP-S; 하단: SigLIP-2 대 ELIP-S-2.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
Occluded COCO: 1행 및 3행; ImageNet-R: 2행 및 4행.
이미지가 텍스트 쿼리와 일치할 때, 우리가 생성한 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다.
예를 들어, 텍스트 쿼리가 'bird'일 때 (1행), ELIP-S가 새에 대한 attention 집중도를 높이는 것을 볼 수 있다.
텍스트 쿼리가 'beagle'일 때 (2행), ELIP-S가 비글에 더 많은 attention을 가져오는 것을 관찰할 수 있다.
텍스트 쿼리가 'book' (3행) 및 'chow chow' (4행)일 때, ELIP-S-2가 각각 책과 차우차우에 더 집중하도록 attention을 유도한다.
이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 유의미하지 않다.
Figure 24. SigLIP/SigLIP-2 및 ELIP-S/ELIP-S-2의 attention map 시각화는 Occluded COCO 및 ImageNet-R에서 SigLIP/SigLIP-2와 우리의 ELIP-S/ELIP-S-2 모델에 대한 [CLS] token의 patch token에 대한 cross-attention map을 보여준다.
상단: SigLIP 대 ELIP-S; 하단: SigLIP-2 대 ELIP-S-2.
왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우.
Occluded COCO: 1행 및 3행; ImageNet-R: 2행 및 4행.
이미지가 텍스트 쿼리와 일치할 때, 우리가 생성한 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다.
예를 들어, 텍스트 쿼리가 'bird'일 때 (1행), ELIP-S가 새에 대한 attention 집중도를 높이는 것을 볼 수 있다.
텍스트 쿼리가 'beagle'일 때 (2행), ELIP-S가 비글에 더 많은 attention을 가져오는 것을 관찰할 수 있다.
텍스트 쿼리가 'book' (3행) 및 'chow chow' (4행)일 때, ELIP-S-2가 각각 책과 차우차우에 더 집중하도록 attention을 유도한다.
이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 유의미하지 않다.
B.6. Attention Map of BLIP-2 and ELIP-B
Figure 25는 COCO (1-2행) 및 Flickr (3-4행) 데이터셋에서 BLIP-2와 ELIP-B 모두에 대한 ITM head의 query token이 patch token에 대해 수행하는 cross-attention map을 보여준다. 총 32개의 query token이 있으며, 이 32개 query token의 평균값을 사용하여 attention map을 시각화하였다. attention map은 어떤 위치의 이미지 feature가 선택되고 집중되는지를 나타낸다. 왼쪽에는 이미지가 텍스트 쿼리와 일치하는 상황을, 오른쪽에는 이미지가 텍스트 쿼리와 일치하지 않는 상황을 표시하였다. 시각화는 [71]의 코드베이스를 기반으로 하며, 따뜻한 색상일수록 더 높은 활성화를 나타낸다.
 Figure 25. BLIP-2와 ELIP-B의 attention map 시각화는 COCO 및 Flickr 데이터셋에서 BLIP-2와 ELIP-B 모두에 대한 ITM head의 query token이 patch token에 대해 수행하는 cross-attention map을 보여준다. 총 32개의 query token이 있으며, 이 32개 query token의 평균값을 사용하여 attention map을 시각화하였다. attention map은 어떤 위치의 이미지 feature가 선택되고 집중되는지를 나타낸다. 왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우. COCO: 1-2행; Flickr: 3-4행.
이미지가 텍스트 쿼리와 일치할 때, 우리가 생성한 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다. 예를 들어, 텍스트 쿼리가 'A baseball player holding a bat while standing in a field' (1행)일 때, BLIP-2와 ELIP-B의 attention map을 비교하면 ELIP-B가 야구 방망이에 더 많은 attention을 집중시키는 것을 관찰할 수 있다. 텍스트 쿼리가 'A brown and white dog wearing a neck tie' (2행)일 때, ELIP-B가 넥타이와 개에 더 많은 attention을 준다는 것을 알 수 있다. 텍스트 쿼리가 'A bunch of beer pull tabs at a bar with Christmas lights on the ceiling' (3행)일 때, ELIP-B가 천장의 크리스마스 조명과 맥주 캔 따개 뭉치에 대한 attention을 크게 증가시키는 것을 확인할 수 있다. 텍스트 쿼리가 'A father and daughter holding a young tree upright, ready to be planted, as the son stands to their side wielding a shovel' (4행)일 때, ELIP-B가 아버지, 딸, 아들, 그리고 나무에 더 집중적으로 attention을 준다는 것을 알 수 있다. 이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 크지 않다.
Figure 25. BLIP-2와 ELIP-B의 attention map 시각화는 COCO 및 Flickr 데이터셋에서 BLIP-2와 ELIP-B 모두에 대한 ITM head의 query token이 patch token에 대해 수행하는 cross-attention map을 보여준다. 총 32개의 query token이 있으며, 이 32개 query token의 평균값을 사용하여 attention map을 시각화하였다. attention map은 어떤 위치의 이미지 feature가 선택되고 집중되는지를 나타낸다. 왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우. COCO: 1-2행; Flickr: 3-4행.
이미지가 텍스트 쿼리와 일치할 때, 우리가 생성한 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다. 예를 들어, 텍스트 쿼리가 'A baseball player holding a bat while standing in a field' (1행)일 때, BLIP-2와 ELIP-B의 attention map을 비교하면 ELIP-B가 야구 방망이에 더 많은 attention을 집중시키는 것을 관찰할 수 있다. 텍스트 쿼리가 'A brown and white dog wearing a neck tie' (2행)일 때, ELIP-B가 넥타이와 개에 더 많은 attention을 준다는 것을 알 수 있다. 텍스트 쿼리가 'A bunch of beer pull tabs at a bar with Christmas lights on the ceiling' (3행)일 때, ELIP-B가 천장의 크리스마스 조명과 맥주 캔 따개 뭉치에 대한 attention을 크게 증가시키는 것을 확인할 수 있다. 텍스트 쿼리가 'A father and daughter holding a young tree upright, ready to be planted, as the son stands to their side wielding a shovel' (4행)일 때, ELIP-B가 아버지, 딸, 아들, 그리고 나무에 더 집중적으로 attention을 준다는 것을 알 수 있다. 이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 크지 않다.
Figure 26은 Occluded COCO (1-2행) 및 ImageNet-R (3-4행) 데이터셋에서 BLIP-2와 ELIP-B 모두에 대한 ITM head의 query token이 patch token에 대해 수행하는 cross-attention map을 보여준다. 총 32개의 query token이 있으며, 이 32개 query token의 평균값을 사용하여 attention map을 시각화하였다. attention map은 어떤 위치의 이미지 feature가 선택되고 집중되는지를 나타낸다. 왼쪽에는 이미지가 텍스트 쿼리와 일치하는 상황을, 오른쪽에는 이미지가 텍스트 쿼리와 일치하지 않는 상황을 표시하였다. 시각화는 [71]의 코드베이스를 기반으로 하며, 따뜻한 색상일수록 더 높은 활성화를 나타낸다.
 Figure 26. BLIP-2와 ELIP-B의 attention map 시각화는 Occluded COCO 및 ImageNet-R 데이터셋에서 BLIP-2와 ELIP-B 모두에 대한 ITM head의 query token이 patch token에 대해 수행하는 cross-attention map을 보여준다. 총 32개의 query token이 있으며, 이 32개 query token의 평균값을 사용하여 attention map을 시각화하였다. attention map은 어떤 위치의 이미지 feature가 선택되고 집중되는지를 나타낸다. 왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우. Occluded COCO: 1-2행; ImageNet-R: 3-4행.
이미지가 텍스트 쿼리와 일치할 때, 우리가 생성한 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다. 예를 들어, 텍스트 쿼리가 'pizza' (1행)일 때, ELIP-B가 피자에 더 많은 attention을 집중시키는 것을 관찰할 수 있다. 텍스트 쿼리가 'surfboard' (2행)일 때, ELIP-B가 서핑보드에 더 많은 attention을 준다는 것을 알 수 있다. 텍스트 쿼리가 'bee' (3행) 및 'basketball' (4행)일 때, ELIP-B가 각각 벌과 농구공에 더 집중적으로 attention을 준다는 것을 알 수 있다. 이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 크지 않다.
Figure 26. BLIP-2와 ELIP-B의 attention map 시각화는 Occluded COCO 및 ImageNet-R 데이터셋에서 BLIP-2와 ELIP-B 모두에 대한 ITM head의 query token이 patch token에 대해 수행하는 cross-attention map을 보여준다. 총 32개의 query token이 있으며, 이 32개 query token의 평균값을 사용하여 attention map을 시각화하였다. attention map은 어떤 위치의 이미지 feature가 선택되고 집중되는지를 나타낸다. 왼쪽: 이미지가 텍스트 쿼리와 일치하는 경우; 오른쪽: 이미지가 텍스트 쿼리와 일치하지 않는 경우. Occluded COCO: 1-2행; ImageNet-R: 3-4행.
이미지가 텍스트 쿼리와 일치할 때, 우리가 생성한 visual prompt vector가 텍스트 쿼리와 관련된 이미지 feature의 선택을 효과적으로 증폭시킬 수 있음을 확인할 수 있다. 예를 들어, 텍스트 쿼리가 'pizza' (1행)일 때, ELIP-B가 피자에 더 많은 attention을 집중시키는 것을 관찰할 수 있다. 텍스트 쿼리가 'surfboard' (2행)일 때, ELIP-B가 서핑보드에 더 많은 attention을 준다는 것을 알 수 있다. 텍스트 쿼리가 'bee' (3행) 및 'basketball' (4행)일 때, ELIP-B가 각각 벌과 농구공에 더 집중적으로 attention을 준다는 것을 알 수 있다. 이미지가 쿼리와 일치하지 않는 경우(4-6열)에는 그 차이가 크지 않다.
C. Ablation Study for Different Number of Generated Visual Prompt Tokens
| Settings | #Generated Tokens | COCO | Flickr | ||||
|---|---|---|---|---|---|---|---|
| Recall@1 | Recall@5 | Recall@10 | Recall@1 | Recall@5 | Recall@10 | ||
| A | 0 | 40.2 | 66.0 | 75.6 | 67.6 | 88.3 | 93.0 |
| 1 | 44.2 | 70.0 | 79.5 | 71.3 | 90.6 | 94.4 | |
| C | 2 | 44.7 | 70.2 | 79.8 | 71.4 | 90.5 | 94.1 |
| 5 | 45.2 | 70.5 | 80.0 | 72.4 | 90.5 | 94.6 | |
| 10 | 45.6 | 71.1 | 80.4 | 72.3 | 90.6 | 94.7 |
Table 5. 생성된 visual prompt token 수에 대한 ablation study.
본 논문의 Table 1에 따라, ablation study의 baseline으로 CLIP을 사용한다.
0은 CLIP baseline을 의미하며, 0이 아닌 숫자는 다양한 수의 생성된 visual prompt vector를 사용한 ELIP-C 아키텍처를 의미한다.
Section 7.1에서 언급했듯이, 여기서는 생성된 visual prompt token의 수가 달라짐에 따른 성능 변화를 연구한다. 결과는 Table 5에 나타나 있으며, 여러 개의 token을 생성하는 것(예: 2개 토큰(Setting ), 5개 토큰(Setting ), 10개 토큰(Setting ))이 단 1개의 토큰을 생성하는 것(Setting )보다 성능 향상을 가져옴을 확인할 수 있다. 특히 Setting 가 가장 좋은 성능을 보인다. 따라서 우리는 모든 실험에서 10개의 token을 생성한다.
D. Further Ablation Study for ELIP-B
| Settings | Fine-tune ITM Head | JEST Selection | COCO | Flickr | ||||
|---|---|---|---|---|---|---|---|---|
| Recall@1 | Recall@5 | Recall@10 | Recall@1 | Recall@5 | Recall@10 | |||
| - | - | 68.25 | 87.72 | 92.63 | 89.74 | 98.18 | 98.94 | |
| 68.26 | 87.86 | 92.78 | 89.80 | 98.26 | 99.14 | |||
| C | 67.35 | 87.38 | 92.53 | 89.08 | 98.06 | 99.08 | ||
| 68.41 | 87.88 | 92.78 | 90.08 | 98.34 | 99.22 |
Table 6. JEST [25]에서 영감을 받은 학습 데이터 선택 및 ITM head fine-tuning에 대한 ELIP-B의 ablation study.
Setting 는 baseline BLIP-2이다. Setting 는 Setting 및 와 동일한 크기의 무작위 subset으로 학습되었다.
ITM head를 fine-tuning하는 전략과 JEST에 의해 선택된 subset으로 학습하는 전략 모두 ELIP-B의 성능 향상에 기여함을 확인할 수 있다.
이 섹션에서는 ELIP-B에 대한 추가적인 ablation study를 수행하여, Section 5.2에서 설명된 JEST [25]에서 영감을 받은 전략을 사용하여 학습 데이터를 선택하는 것의 효과와, 본 논문의 Figure 3에서와 같이 ITM head를 fine-tuning하는 것의 효과를 보여준다. 이 두 가지는 우리가 BLIP-2에만 적용한 고유한 요소이기 때문이다.
Table 6에서 다음을 관찰할 수 있다:
- Setting 와 를 비교하면, 무작위로 batch를 선택하는 것과 비교하여 JEST로 선택된 학습 batch로 학습하는 것의 효과를 알 수 있다.
- Setting 와 를 비교하면, ELIP-B에서 ITM head로의 입력 feature가 변경되었기 때문에 경량 ITM head를 fine-tuning하는 것 또한 중요하다는 것을 추론할 수 있다.
E. Efficiency of ELIP Pre-Training
| Model | GPU Hours | #GPU | BS | FLOPS | FLOPS |
|---|---|---|---|---|---|
| CLIP | 10736 A100 | A100 | 33792 | 33.7G | - |
| ELIP-C | 144 A40 | A40 | 40 | 35.8G | 2.1G |
| SigLIP | 1152 TPUv4 | TPUv4 | 32768 | 604.5G | - |
| ELIP-S | 144 A40 | A40 | 10 | 613.3G | 8.8G |
| SigLIP-2 | * | TPUv5e | 32768 | 1.31 T | - |
| ELIP-S-2 | 144 A40 | A40 | 10 | 1.34 T | 0.03T |
| BLIP-2 | 2304 A100 | A100 | 1680 | 1.33 T | - |
| ELIP-B | 48 A40 | A40 | 12 | 1.35 T | 0.02T |
Table 7. ELIP 사전학습의 효율성 비교 (원본 사전학습 대비)
우리의 방법은 학습 시간, GPU 요구 사항, 배치 크기 측면에서 효율성을 크게 향상시키며, 학습 가능한 MLP 매핑 네트워크로 인한 FLOPS 증가는 미미하다.
*SigLIP-2의 원본 학습 시간은 논문에 제공되지 않았다.
Section 7에서 언급했듯이, 아래 표는 학습 시간, GPU 요구 사항, 배치 크기, FLOPS 측면에서 우리의 방법과 CLIP, SigLIP, SigLIP-2, BLIP-2의 원본 사전학습을 비교한 것이다. 우리의 방법이 학습 시간, GPU 요구 사항, 배치 크기 측면에서 효율성을 크게 향상시키는 반면, 학습 가능한 MLP 매핑 네트워크로 인한 FLOPS 증가는 미미하다는 것을 확인할 수 있다.