DiscreteBERT: Self-Supervised Pre-Training을 통한 음성 인식의 혁신
이 논문은 음성 데이터를 명시적으로 양자화하는 방식과 그렇지 않은 Self-Supervised 표현 학습 알고리즘을 비교합니다. vq-wav2vec을 통해 음성 데이터의 어휘를 구축하고 BERT로 학습하는 방식이 더 효과적임을 보여줍니다. 특히, 사전 학습된 BERT 모델을 Connectionist Temporal Classification (CTC) loss를 사용하여 직접 fine-tuning함으로써, 단 10분의 레이블 데이터만으로도 높은 음성 인식 성능을 달성할 수 있음을 입증했습니다. 이는 Self-Supervision이 거의 제로에 가까운 전사 데이터로도 음성 인식 시스템을 가능하게 함을 보여줍니다. 논문 제목: EFFECTIVENESS OF SELF-SUPERVISED PRE-TRAINING FOR SPEECH RECOGNITION
논문 요약: EFFECTIVENESS OF SELF-SUPERVISED PRE-TRAINING FOR SPEECH RECOGNITION
- 논문 링크: arXiv:1911.03912
- 저자: Alexei Baevski, Michael Auli, Abdelrahman Mohamed (Facebook AI Research)
- 발표 시기: 2019년 (arXiv)
- 주요 키워드: Self-supervised Learning, Speech Recognition, BERT, Wav2Vec, Discrete Representation, CTC
1. 연구 배경 및 문제 정의
- 문제 정의:
자동 음성 인식(ASR) 시스템 구축은 일반적으로 방대한 양의 레이블된 음성 데이터(전사 데이터)를 필요로 한다. 이는 데이터 수집 및 전사 비용이 매우 높고, 특히 저자원 언어나 새로운 환경에서는 시스템 구축이 어렵다는 한계를 가진다. 이 논문은 이러한 레이블 데이터 의존성을 줄이면서도 높은 성능을 달성하는 ASR 시스템을 목표로 한다. - 기존 접근 방식:
기존 연구들은 제한된 자원 조건에서 ASR 시스템을 구축하기 위해 준지도(semi-supervised) 및 약지도(weakly-supervised) 학습 기술, 또는 비지도 음성 인식 및 표현 학습에 대한 연구를 진행해왔다. 하지만 이전의 자기 지도(self-supervised) 사전 학습 모델들은 주로 학습된 표현(representation)을 별도의 태스크별 아키텍처에 입력하는 방식이었으며, 사전 학습된 모델 자체를 직접 파인튜닝하는 방식은 드물었다. 또한, 음성 데이터를 명시적으로 양자화하는 방식과 그렇지 않은 방식 간의 효과적인 비교 연구가 부족했다.
2. 주요 기여 및 제안 방법
-
논문의 주요 기여:
- 음성 데이터에 대한 다양한 자기 지도 사전 학습(self-supervised pre-training) 접근 방식(명시적 양자화 vs. 비양자화)을 체계적으로 비교하고, 명시적 양자화 방식이 더 효과적임을 입증했다.
- vq-wav2vec을 통해 음성 데이터의 이산적인 어휘(discrete vocabulary)를 구축한 후, 이 이산 단위에 대해 BERT 모델을 사전 학습하는 방식(Discrete BERT)이 더 정확하고 효과적인 표현을 학습함을 보여주었다.
- 사전 학습된 BERT 모델을 Connectionist Temporal Classification (CTC) 손실을 사용하여 전사된 음성 데이터에 직접 파인튜닝하는 새로운 접근 방식을 제안하여, 기존의 표현 공급 방식보다 우수한 성능을 달성했다.
- 연속적인 오디오 데이터로부터 직접 학습하는 BERT 스타일 모델(Continuous BERT)을 제안하고, 원시 오디오 및 스펙트럼 특징에 대한 사전 학습 효과를 비교했다.
-
제안 방법:
논문은 크게 두 가지 자기 지도 사전 학습 접근 방식을 제안하고 비교한다.- Discrete BERT:
- 이산 단위 생성: vq-wav2vec [1]을 사용하여 원시 오디오 데이터를 13.5k개의 고유 코드워드로 양자화하여 이산적인 음향 단위를 생성한다. (대안으로 MFCC 및 FBANK 특징에 K-Means 클러스터링을 적용하여 이산 단위를 생성하는 방식도 탐색)
- BERT 사전 학습: 생성된 이산 단위 시퀀스에 대해 표준 BERT 모델 [19]을 마스킹된 언어 모델링(Masked Language Modeling, MLM) 방식으로 사전 학습한다. BERT의 고정 위치 임베딩은 단일 그룹 컨볼루션 레이어로 대체하여 파라미터 수를 줄인다.
- Continuous BERT:
- 연속 특징 사용: wav2vec [12] 특징, MFCC 또는 FBANK 특징과 같은 연속적인 오디오 표현을 직접 입력으로 사용한다.
- BERT 스타일 사전 학습: 마스킹된 입력 부분을 예측하는 방식으로 모델을 학습시키며, InfoNCE 손실 [11]을 사용하여 마스킹된 긍정 예제를 부정 예제 집합 중에서 분류하도록 최적화한다. 상대적 위치 임베딩을 사용하여 긴 시퀀스를 처리한다.
공통 파인튜닝:
- 사전 학습된 BERT 모델은 ASR 태스크를 위해 CTC 손실을 사용하여 전사된 음성 데이터에 직접 파인튜닝된다.
- 모델의 어휘를 나타내는 선형 투영 레이어가 BERT 출력 위에 추가된다.
- 과적합을 방지하고 성능을 향상시키기 위해 SpecAugment [29]와 유사한 마스킹 정책을 적용한다.
- Adam optimizer와 tri-state learning scheduler를 사용하여 학습한다.
- Discrete BERT:
3. 실험 결과
- 데이터셋:
- 사전 학습: Librispeech [21]의 960시간 오디오 전용(레이블 없음) 데이터셋.
- 파인튜닝: Libri-light [22]의 제한된 자원 지도 학습 세트(10시간, 1시간, 10분) 및 Librispeech "train-clean-100" (100시간) 부분집합.
- 평가: 표준 Librispeech 개발 및 테스트 분할(dev-clean, dev-other, test-clean, test-other).
- 주요 결과:
- Discrete BERT의 우수성: 모든 설정에서 Discrete BERT가 Continuous BERT를 능가하며, 의미 있는 이산 단위에 대한 사전 학습이 연속적인 레이블 없는 데이터로부터 직접 표현을 학습하는 것보다 우수함을 입증했다.
- 최적의 입력 특징: Discrete BERT의 경우 vq-wav2vec을 통한 자기 지도 학습이, Continuous BERT의 경우 wav2vec 특징이 가장 좋은 성능을 보였다. 특히 vq-wav2vec 기반 Discrete BERT는 클러스터링된 MFCC 및 FBANK 특징 대비 약 40%의 상대적 오류 감소를 달성했다.
- 사전 학습의 효과: 사전 학습은 레이블된 데이터가 적을수록 더욱 큰 이점을 제공했다. 100시간에서 10시간으로 레이블 데이터를 줄였을 때, vq-wav2vec 기반 Discrete BERT의 WER 증가는 미미했다.
- 저자원 환경에서의 뛰어난 성능: 단 10분의 레이블된 데이터만으로도 vq-wav2vec 기반 Discrete BERT는 test-clean에서 16.3%, test-other에서 25.2%의 WER을 달성하며, 거의 제로에 가까운 전사 데이터로도 음성 인식 시스템이 가능함을 보여주었다.
- 기존 SOTA 대비 성능: 단 10시간의 레이블 데이터로 파인튜닝된 Discrete BERT는 test-clean에서 100시간 레이블 데이터로 학습된 기존 최고 시스템에 필적하며, test-other에서는 25%의 상대적 WER 감소를 달성했다. 100시간 레이블 데이터 사용 시에는 test-other에서 35%, test-clean에서 22%의 상대적 WER 감소를 보였다.
- 어블레이션 연구: BERT 사전 학습 단계가 이산 입력에 필수적이며, 2단계 사전 학습(wav2vec + Continuous BERT)이 단일 단계(wav2vec만 사용)보다 훨씬 우수한 성능을 제공함을 확인했다.
4. 개인적인 생각 및 응용 가능성
- 장점:
이 논문의 가장 인상 깊었던 점은 음성 데이터를 이산적인 단위로 양자화한 후 BERT를 적용하는 아이디어가 연속적인 특징에 직접 BERT를 적용하는 것보다 훨씬 효과적임을 명확히 보여주었다는 점입니다. 특히, vq-wav2vec을 통해 의미 있는 음성 어휘를 구축하고 이를 BERT의 마스킹된 언어 모델링에 활용하는 방식은 음성 데이터의 특성을 잘 이해하고 NLP의 성공적인 모델을 접목한 훌륭한 접근이라고 생각합니다. 또한, 사전 학습된 BERT 모델을 ASR 태스크에 직접 파인튜닝하여, 기존 SOTA 시스템보다 훨씬 적은 레이블 데이터(10시간 또는 10분)만으로도 경쟁력 있는 성능을 달성한 것은 매우 고무적입니다. 이는 레이블 데이터 부족 문제를 겪는 저자원 언어 ASR 개발에 큰 돌파구가 될 수 있습니다. - 단점/한계:
논문 자체에서 명시적인 한계점을 언급하지는 않았지만, 몇 가지 생각해 볼 점이 있습니다. 첫째, vq-wav2vec을 통한 이산 단위 생성 단계가 별도로 필요하다는 점에서 완전한 단일 엔드-투-엔드(end-to-end) 학습 파이프라인은 아닙니다. 둘째, 10분 데이터셋과 같은 매우 적은 데이터로 파인튜닝할 경우, 일부 시드에서 조기 과적합이 발생하여 학습이 실패하는 경우가 있었다는 점은 모델의 안정성 측면에서 개선의 여지가 있을 수 있습니다. 마지막으로, Continuous BERT 방식이 Discrete BERT에 비해 성능이 현저히 낮았다는 점은 연속적인 음성 특징에서 효과적인 이산적 의미 단위를 학습하는 것이 여전히 도전 과제임을 시사합니다. - 응용 가능성:
- 저자원 언어 ASR: 전사 데이터가 부족한 언어에 대한 음성 인식 시스템을 빠르고 효율적으로 구축하는 데 핵심적인 역할을 할 수 있습니다.
- 도메인 적응: 특정 도메인이나 환경에 맞는 ASR 시스템을 구축할 때, 적은 양의 도메인 특화 데이터만으로도 기존 시스템을 빠르게 개선할 수 있습니다.
- 음성 기반 파운데이션 모델: 텍스트 분야의 BERT처럼, 음성 분야에서도 다양한 다운스트림 태스크에 활용될 수 있는 강력한 범용 음성 표현 모델의 기반이 될 수 있습니다.
- 음성 이해 및 분석: ASR 외에도 화자 인식, 감정 인식, 음성 검색 등 음성 기반의 다양한 인공지능 애플리케이션에 활용될 수 있습니다.
Baevski, Alexei, Michael Auli, and Abdelrahman Mohamed. "Effectiveness of self-supervised pre-training for speech recognition." arXiv preprint arXiv:1911.03912 (2019).
EFFECTIVENESS OF SELF-SUPERVISED PRE-TRAINING FOR SPEECH RECOGNITION
Alexei Baevski, Michael Auli, Abdelrahman Mohamed<br>Facebook AI Research<br>{abaevski, michaelauli, abdo}@fb.com
Abstract
우리는 오디오 데이터를 명시적으로 양자화하거나 양자화 없이 representation을 학습하는 self-supervised representation learning 알고리즘을 비교합니다. 우리는 전자가 더 정확하다는 것을 발견했는데, 이는 vq-wav2vec [1]을 통해 데이터의 좋은 어휘집을 구축하여 후속 BERT training에서 효과적인 representation을 학습할 수 있게 하기 때문입니다. 이전 연구와 달리, 우리는 pre-trained된 BERT 모델을 task-specific 모델에 representation을 공급하는 대신 Connectionist Temporal Classification (CTC) 손실을 사용하여 전사된 speech에 직접 fine-tune합니다. 또한 우리는 연속적인 오디오 데이터로부터 직접 학습하는 BERT 스타일 모델을 제안하고 원시 오디오와 스펙트럼 특징에 대한 pre-training을 비교합니다. vq-wav2vec 어휘집을 사용하여 10시간의 레이블이 지정된 Librispeech 데이터에 BERT 모델을 fine-tuning하는 것은 test-clean에서 100시간의 레이블된 데이터로 학습된 가장 잘 알려진 보고된 시스템만큼 거의 우수하며, test-other에서는 의 WER 감소를 달성합니다. 단 10분의 레이블된 데이터를 사용할 경우, test-other에서 WER은 25.2, test-clean에서 16.3입니다. 이는 self-supervision이 거의 제로에 가까운 전사된 데이터로 학습된 speech recognition 시스템을 가능하게 할 수 있음을 보여줍니다.
1 Introduction
Representation learning은 30년 이상 동안 활발한 연구 분야였으며[2], 입력 데이터로 표현되는 현상의 다양한 설명 요인을 분리하는 높은 수준의 representation을 학습하는 것을 목표로 합니다[3, 4]. 자동 음성 인식(Automatic Speech Recognition, ASR) 시스템을 구축하는 것은 일반적으로 음성 신호 생성에 기여하는 다양한 요인, 예를 들어 배경 소음, 녹음 채널, 화자 신원, 억양, 감정 상태, 토론 중인 주제 및 의사소통에 사용되는 언어 등을 나타내기 위해 대량의 학습 데이터가 필요합니다. 제한된 자원으로 새로운 조건에 맞는 ASR 시스템을 구축해야 하는 실용적인 필요성은 실제 시나리오에서 필요한 supervised 데이터를 줄이기 위한 semi-supervised 및 weakly-supervised 학습 기술[13, 14, 15, 16, 17, 18] 외에도, 비지도 음성 인식 및 representation learning에 대한 많은 연구를 촉발시켰습니다[5, 6, 7, 8, 9, 10, 11, 12].
최근 NLP 및 speech 분야에서 self-supervised learning을 통해 다양한 downstream tasks에 일반화되는 representation learning에 대한 인상적인 결과가 보고되었습니다[19, 20, 11, 12, 1]. Self-supervised representation learning 작업에는 입력의 마스킹된 부분 예측, 낮은 비트 전송률 채널을 통한 입력 재구성, 또는 유사한 데이터 포인트를 다른 것과 대조하는 것이 포함됩니다.
이 연구에서 우리는 speech 데이터에 대한 다양한 self-supervised pre-training 접근법을 비교합니다. 우리는 self-supervision [1]을 통해 또는 스펙트럼 특징을 클러스터링하여 오디오 데이터를 나타내는 이산 단위를 학습한 후, 이 단위들에 대해 양방향 transformer (BERT) 모델 [19]을 사용하여 pre-training하는 것을 고려합니다. 이는 원시 오디오뿐만 아니라 스펙트럼 특징에 대해 명시적인 양자화 없이 직접 representation을 학습하는 것과 비교됩니다. 이전 연구에서는 pre-trained 모델의 representation을 원시 파형 대신 speech recognition을 위한 task-specific 아키텍처에 입력했습니다[12, 1]. 대신 우리는 CTC 손실을 사용하여 전사된 speech 데이터에 pre-trained BERT 모델을 직접 fine-tune합니다. 우리의 실험은 이산 단위 발견 후 BERT training을 수행하는 것이 명시적인 양자화 없이 학습된 representation보다 더 나은 결과를 달성함을 보여줍니다. 음향 단위 발견을 그것들 사이의 순차적 관계 학습과 분리함으로써, 데이터의 더 나은 representation을 가능하게 하여 결과적으로 down-stream 모델 정확도를 향상시킵니다.
우리는 레이블이 없는 960시간의 Librispeech [21] 데이터에 모델을 pre-train하고, Libri-light [22]의 제한된 리소스 supervised 학습 세트인 10시간, 1시간, 10분을 따릅니다. 단 1시간의 레이블된 데이터로 fine-tune된 우리의 최고 모델은 표준 Librispeech test-other 서브셋에서 100시간의 레이블된 데이터에 의존하는 문헌상 가장 잘 알려진 결과를 능가할 수 있습니다[23]. 단 10분의 레이블된 데이터를 사용할 경우, 이 접근법은 test-clean/other에서 16.3/25.2 WER을 달성합니다.
2 Preliminaries
2.1 BERT
self-supervision을 사용하여, 깊은 양방향 transformer 모델인 BERT [19]는 다른 downstream NLP 작업에 일반화되는 내부 언어 representation을 구축합니다. 전체 입력 단어 시퀀스에 대한 self-attention은 BERT가 데이터의 왼쪽 및 오른쪽 문맥을 동시에 조건화할 수 있게 합니다. 학습을 위해, 모델이 예측하도록 일부 입력 단어를 무작위로 제거하는 masked language model 손실과, 문서에서 다음 문장을 무작위로 선택된 문장과 구별하기 위한 contrastive loss를 모두 사용합니다.
2.2 Wav2Vec
Wav2Vec [12]은 word2vec [24, 11]과 동일한 손실 함수를 사용하여 self-supervised 문맥 예측 작업을 해결함으로써 오디오 데이터의 representation을 학습합니다. 이 모델은 두 개의 convolutional neural networks를 기반으로 하며, encoder 는 100 Hz의 속도로 각 시간 단계 에 대한 representation 를 생성하고, aggregator 는 여러 encoder 시간 단계를 결합하여 각 시간 단계 에 대한 새로운 representation 를 만듭니다. 가 주어지면, 모델은 단계 미래의 샘플 를 분포 에서 추출한 방해 샘플 과 구별하도록 학습되며, 이는 단계에 대해 contrastive loss를 최소화함으로써 이루어집니다:
여기서 는 시퀀스 길이, 이며, 는 가 실제 샘플일 확률입니다. 단계별 아핀 변환 가 에 적용됩니다[11]. 손실 는 다른 단계 크기에 대해 (1)을 합산하여 최적화됩니다. 문맥 네트워크 에 의해 생성된 학습된 높은 수준의 특징은 표준 스펙트럼 특징과 비교하여 speech recognition에 더 나은 음향 representation임이 입증되었습니다.
2.3 vq-wav2vec
vq-wav2vec [1]은 미래 시간 단계 예측 작업을 사용하여 오디오 데이터의 vector quantized (VQ) representation을 학습합니다. Wav2Vec과 유사하게, 특징 추출 및 집계를 위한 컨볼루션 encoder 및 디코더 네트워크 와 가 있습니다. 그러나 그 사이에는 이산 representation을 구축하기 위한 양자화 모듈 이 있으며, 이는 aggregator에 입력됩니다.
먼저, 원시 speech의 30ms 세그먼트는 encoder 를 사용하여 10ms의 스트라이드로 밀집된 특징 representation 에 매핑됩니다. 다음으로, quantizer (q)는 이러한 밀집된 representation을 이산 인덱스로 변환하고, 이는 원본 representation 의 재구성 에 매핑됩니다. 는 aggregator 에 공급되고, 모델은 wav2vec과 동일한 문맥 예측 작업을 통해 최적화됩니다 (참조: § 2.2). 양자화 모듈은 원래 representation 를 고정된 크기의 코드북 에서 가져온 로 대체하며, 이 코드북에는 크기가 인 개의 representation이 포함되어 있습니다.
3 Approach
3.1 Discrete BERT
우리의 연구는 [1]에서 최근 제안된 연구를 기반으로 하며, 오디오는 contrastive loss를 사용하여 양자화된 다음, BERT 모델 [19]에 의해 그 위에 특징이 학습됩니다. vq-wav2vec 양자화를 위해, 우리는 [1]에 설명된 것과 동일한 설정의 gumbel-softmax 변형을 사용합니다. 이 모델은 Librispeech 데이터셋을 13.5k개의 고유 코드로 양자화합니다.
vq-wav2vec [1]의 이산 음향 representation의 영향을 이해하기 위해, 대안으로 표준 mel-frequency cepstral coefficients (MFCC) 및 log-mel filterbanks coefficients (FBANK)를 양자화하는 것을 탐색합니다. GPU 메모리에 들어갈 만큼 작은 부분집합을 선택하고, (vq-wav2vec 설정과 일치시키기 위해) 13.5k개의 중심점을 가진 k-means를 수렴할 때까지 실행합니다. 그런 다음 각 시간 단계를 나타내기 위해 가장 가까운 중심점의 인덱스를 할당합니다.
우리는 [1]에서 설명된 것과 유사한 방식으로 각 입력 세트에 대해 masked language modeling 작업만으로 표준 BERT 모델 [19, 25]을 학습시킵니다. 즉, 0.05의 확률로 마스킹할 토큰을 선택하고, 선택된 각 토큰을 평균 10, 표준편차 10의 정규 분포에서 샘플링된 길이의 스팬으로 확장하며(스팬은 겹칠 수 있음), 그런 다음 마스킹된 각 토큰에 대해 실제 토큰을 예측할 가능성을 최대화하려는 cross-entropy loss를 계산합니다(그림 1a).
[26]을 따라, 우리는 BERT 모델의 고정된 위치 임베딩을 transformer 블록 이전에 임베딩에 직접 적용되는 단일 그룹 컨볼루션 레이어로 대체합니다. 컨볼루션 레이어는 커널 크기 128과 그룹 크기 16을 가지며 추가되는 파라미터 수를 줄입니다.
3.2 Continuous BERT
masked language modeling 작업은 연속적인 입력과 출력으로는 수행될 수 없는데, 마스킹된 토큰 대신 예측할 대상이 없기 때문입니다. [27]에서처럼 입력을 재구성하는 대신, 우리는 마스킹된 긍정 예제를 부정 예제 집합 중에서 분류합니다. 모델에 대한 입력은 10ms의 오디오 데이터를 나타내는 밀집된 wav2vec 특징[12], MFCC 또는 FBANK 특징입니다. 이러한 입력 중 일부는 mask embedding으로 대체된 다음 transformer encoder에 공급됩니다. 그런 다음 우리는 각 마스킹된 입력에 해당하는 출력, 마스킹된 실제 입력, 그리고 동일한 배치 내의 다른 마스킹된 입력에서 샘플링된 부정 예제 집합 간의 내적을 계산합니다. 모델은 InfoNCE loss [11]로 최적화되며, 하나의 긍정 샘플 와 개의 부정 샘플 이 주어졌을 때 다음을 최소화합니다:
여기서 각 샘플 는 모델의 시간 단계 에서의 출력과 시간 단계 에서의 긍정 예제의 실제 마스킹되지 않은 값 또는 무작위로 샘플링된 부정 예제의 내적으로 계산됩니다. 학습을 안정화하기 위해, 우리는 내적으로 생성된 logits의 제곱 합을 손실에 더한 다음, 각 logit 에 대해 soft clamp 를 적용하여 학습 중에 모델이 logits의 크기를 계속 증가시키는 경향을 방지합니다[28]. 우리는 섹션 3.1에서 설명한 것과 동일한 종류의 컨볼루션 위치 레이어를 사용합니다.
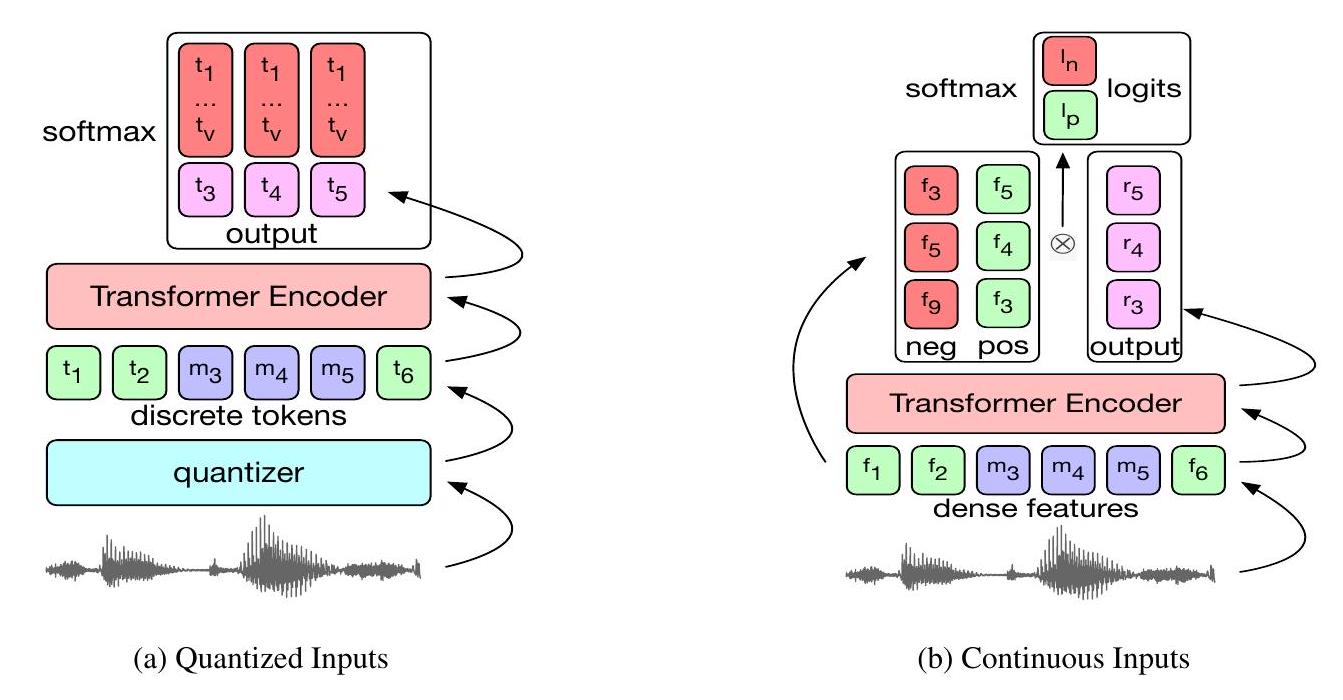
그림 1: BERT pre-training의 그림. 는 각 순전파 동안 무작위로 선택된 마스킹된 시간 단계를 나타냅니다. (a) 입력은 vq-wav2vec quantizer로 양자화되거나, MFCC 및 FBANK 변형의 경우 가장 가까운 중심점을 찾아 양자화된 후 masked language model 목표로 BERT 모델을 학습하는 데 사용됩니다. (b) wav2vec, MFCC 또는 FBANK 입력이 마스킹되고, transformer로 인코딩된 다음, 각 시간 단계에서 어떤 특징이 마스킹되었는지 예측하기 위해 분류기에 공급됩니다.
3.3 Supervised fine-tuning
pre-trained 모델은 transformer 모델에 의해 계산된 특징 위에 작업의 어휘를 나타내는 클래스로 무작위로 초기화된 선형 투영을 추가하여 ASR 작업을 수행하도록 fine-tune됩니다. 어휘는 문자 대상을 위한 29개의 토큰과 단어 경계 토큰으로 구성됩니다. 모델은 CTC 손실을 최소화하여 최적화됩니다. 우리는 학습 중에 시간 단계와 채널에 SpecAugment [29]에서 영감을 받은 마스킹을 적용하여 과적합을 지연시키고 특히 가장 작은 부분 집합에서 최종 정확도를 크게 향상시킵니다.
우리는 10분짜리 부분집합을 제외한 모든 부분집합에 대해 단일 시드로 학습하며, 10분짜리의 경우 5개의 시드로 학습하여 가장 좋은 것을 선택합니다. 10분짜리 부분집합의 경우, 일부 시드는 매우 초기에 과적합 상태에 들어가 실패합니다. 우리는 Adam optimizer와 tri-state learning scheduler를 사용하여 단일 GPU에서 학습하며, 학습률은 첫 번째 단계에서 에서 로 선형적으로 증가하고, 두 번째 단계에서 로 유지되며, 마지막으로 세 번째 단계에서 0으로 선형적으로 감소합니다. 1시간 및 10분 부분집합의 경우 각 단계에서 1250 / 6600 / 12150 업데이트를, 10시간 부분집합의 경우 5000 / 16500 / 28500 업데이트를, 100시간의 경우 8000 / 52800 / 91200 업데이트를 학습합니다. 우리는 100시간 부분집합에 대해 6144 타임스텝(61.44초 분량의 오디오)의 배치 크기를 사용하고 다른 부분집합에 대해서는 3072 타임스텝을 사용합니다.
fine-tuning 동안, 우리는 수정된 SpecAugment [29] 정책을 적용합니다. 여기서 우리는 마스킹할 시작 타임스텝의 수를 무작위로 선택하며, 각 타임스텝은 선택될 확률이 입니다. 선택된 각 위치에서 시작하는 20 타임스텝의 스팬은 비지도 학습 중에 사용된 mask embedding으로 대체됩니다(스팬은 겹칠 수 있음). 우리는 또한 채널 마스킹을 적용하는데, 모든 채널에서 시작 채널 인덱스를 의 확률로 선택하고, 채널 마스크의 길이는 평균 64, 표준편차 64인 정규 분포에서 샘플링하여 결정합니다. 선택된 (그리고 아마도 겹치는) 채널 스팬은 0으로 처리됩니다.
우리는 10분 및 1시간 설정에 대해 transformer의 모든 레이어에 0.1의 dropout을 적용하지만, 위에서 설명한 마스킹이 충분한 정규화를 제공하는 것으로 보이므로 다른 부분집합에 대해서는 이를 비활성화합니다.
4 Experiments
우리는 fairseq [30] 툴킷에서 모델을 구현합니다.
4.1 Data
모든 실험은 Librispeech [21] 학습 세트의 960시간 오디오 전용 데이터에 대해 pre-training하고, Libri-light [22]의 제한된 자원 supervised 학습 세트인 10시간(24명 화자), 1시간(24명 화자), 10분(4명 화자)에 대해 fine-tuning하여 수행됩니다. Libri-light 학습 세트는 깨끗한 부분과 잡음이 있는 부분에서 동일하게 샘플링되었으며, 남성 및 여성 화자의 균형을 맞췄습니다. 우리는 또한 "train-clean-100" 부분집합을 따라 100시간에 fine-tune된 모델의 결과를 보고합니다. 모든 모델은 표준 Librispeech 개발 및 테스트 분할에서 평가됩니다.
4.2 Models
4.2.1 Quantized Inputs Training
먼저 우리는 [1]에 설명된 gumbel-softmax 설정을 따라 vq-wav2vec 양자화 모델을 학습합니다. 960시간의 Librispeech에서 이 모델을 학습하고 학습 데이터셋을 양자화한 후, 13.5k개의 고유 코드워드 조합이 남습니다.
Kaldi [31] 툴킷을 사용하여 추출된 MFCC 및 FBANK 특징을 양자화하기 위해, 우리는 32GB 메모리를 갖춘 8개의 Volta GPU를 사용하여 vq-wav2vec 모델에 의해 생성된 고유 토큰 수와 일치하는 13.5k개의 K-Means 중심점을 계산합니다. GPU 메모리에 맞추기 위해, 우리는 클러스터링 알고리즘을 실행하기 전에 학습 세트에서 MFCC 특징의 와 FBANK 특징의 를 서브샘플링합니다.
masked language modeling 작업을 위해 사용하는 모델은 12개의 transformer 레이어, 모델 차원 768, 내부 차원(FFN) 3072, 12개의 어텐션 헤드를 가진 표준 BERT 모델입니다[19]. 학습률은 처음 10,000 업데이트 동안 최대값 까지 예열된 후, 총 250k 업데이트에 걸쳐 선형적으로 감소합니다. 우리는 GPU당 3072개의 토큰 배치 크기로 128개의 GPU에서 학습하여 총 배치 크기는 393k 토큰이 되며[32], 여기서 각 토큰은 10ms의 오디오 데이터를 나타냅니다.
입력 시퀀스를 마스킹하기 위해, 우리는 [1]을 따라 모든 토큰의 를 시작 인덱스로 무작위로 샘플링하고(중복 없음), 샘플링된 모든 인덱스에서 개의 연속적인 토큰을 마스킹합니다; 스팬은 겹칠 수 있습니다. 은 과 인 가우시안 분포에서 샘플링되며, 0보다 크거나 같은 가장 가까운 정수로 반올림됩니다.
[1]과 달리, 우리는 학습을 위한 예제를 형성하기 위해 다른 발화를 연결하지 않습니다. 대신 각 발화는 단일 예제로 처리되는데, 이 접근 방식이 fine-tuning 후 더 나은 결과를 생성한다는 것을 발견했기 때문입니다.
4.2.2 Continuous Inputs Training
밀집된 특징에 대한 학습을 위해, 우리는 양자화된 입력 학습에 사용된 것과 동일한 파라미터화를 가진 표준 BERT 모델과 유사한 모델을 사용하지만, wav2vec, MFCC 또는 FBANK 입력을 직접 사용합니다. 우리는 더 긴 예제를 더 쉽게 처리하기 위해 고정된 위치 임베딩 대신 모든 multi-head attention 블록에 128개의 상대적 위치 임베딩을 추가합니다[33]. 우리는 GPU당 9,600개의 입력 배치 크기로 8개의 GPU에서 이 모델을 학습하여 총 배치 크기는 76,800이 됩니다. GPU 수를 늘리는 것(실질적인 배치 크기를 증가시킴)이 이 특정 설정에서 더 나은 결과로 이어지지 않는다는 것을 발견했습니다.
Wav2vec 특징은 512차원인 반면, MFCC 특징은 39차원, FBANK 특징은 80차원입니다. 우리는 모든 모델에 대해 특징 차원에서 BERT 차원(768)으로의 간단한 선형 투영을 도입합니다.
4.2.1과 유사하게, 우리는 모든 시간 단계의 를 시작 인덱스로 무작위로 샘플링하여(중복 없음) 시간 단계를 마스킹하고, 샘플링된 모든 인덱스에서 개의 연속적인 시간 단계를 마스킹합니다. 스팬은 겹칠 수 있으며, 은 과 인 가우시안 분포에서 샘플링되어 0보다 크거나 같은 가장 가까운 정수로 반올림됩니다. 우리는 동일한 예제의 다른 마스킹된 시간 단계에서 10개의 부정적인 예제를 샘플링하고, 배치 내 어디에서나 발생하는 마스킹된 시간 단계에서 추가로 10개의 부정적인 예제를 샘플링합니다. 우리는 원래 특징과 BERT 모델에 의해 처리된 후 동일한 시간 단계에 해당하는 출력 사이의 내적을 계산합니다. 우리는 이러한 계산에서 나온 logits의 제곱 합에 를 곱하여 손실에 더한 다음, 각 logit 을 다시 계산하여 부드러운 클램프를 적용합니다.
학습률은 처음 10,000 업데이트 동안 최고 값 까지 예열된 후, 총 250k 업데이트에 걸쳐 선형적으로 감쇠됩니다.
4.3 Methodology
양자화된 입력의 경우, gumbel-softmax 기반 vq-wav2vec 모델을 사용하여 토큰 인덱스를 계산합니다. MFCC 및 FBANK 특징의 경우, Librispeech 데이터셋의 각 해당 특징에 대해 최소 유클리드 거리를 찾아 가장 가까운 중심점의 인덱스를 사용합니다. 그런 다음 § 4.2.1에서 설명한 대로 BERT 모델을 학습시킵니다.
wav2vec 연속 입력의 경우, 특징 추출기에 6개의 컨볼루션 블록과 집계 모듈에 11개의 컨볼루션 블록을 포함하는 공개적으로 사용 가능한 wav2vec [12] 모델에서 추출한 특징을 사용합니다. 우리는 집계기의 출력을 특징으로 사용합니다. MFCC 및 FBANK의 경우, 모델 차원으로 업샘플링하기 위해 단일 선형 투영을 적용한 후 해당 특징을 직접 사용합니다.
우리는 pre-trained 모델을 Librispeech train-clean-100 부분집합의 100시간, 또는 Libri-light [22]의 제한된 학습 세트를 따라 10시간, 1시간, 10분의 레이블된 데이터에 fine-tune합니다. 우리는 표준 CTC 손실을 사용하고 최대 20k 업데이트 동안 학습합니다. 우리는 pre-trained 모델이 약 4k 업데이트 후에만 수렴하는 반면, 처음부터 학습된 모델은 약 18k 업데이트 후에 훨씬 늦게 수렴하는 경향이 있음을 발견했습니다. 우리는 모든 모델을 0.0001의 학습률로 fine-tune하며, 이는 처음 2k 업데이트 동안 선형적으로 예열된 다음 마지막 18k 업데이트 동안 코사인 학습률 스케줄에 따라 어닐링됩니다. 우리는 pre-trained BERT 모델의 dropout을 0.1로 설정하고, 최종 투영 레이어 이전의 BERT 모델 출력의 dropout에 대해 0.0에서 0.4까지 0.1씩 증가시키며 스윕합니다. 각 모델에 대해, 우리는 dev-clean과 dev-other 표준 Librispeech 분할의 조합인 검증 세트에서 가장 좋은 손실을 가진 단일 최상의 체크포인트를 선택합니다.
우리는 공식 Librispeech 4-gram 언어 모델과 함께 Fairseq 프레임워크에 통합된 공개적으로 사용 가능한 wav2letter++ [34] 디코더를 사용합니다. 우리는 각 모델에 대해 언어 모델 점수, 단어 점수 및 무음 토큰 가중치에 대한 스윕을 실행하며, 여기서 매개변수는 무작위로 선택되고 dev-other Librispeech 세트에서 평가됩니다. 우리는 이러한 스윕에서 찾은 가중치를 사용하여 다른 모든 분할에 대한 결과를 평가하고 보고합니다. 스윕은 빔 크기 250으로 실행되며, 최종 디코딩은 빔 크기 1500을 사용합니다.
4.4 Results
첫 번째 실험에서는 100시간에서 10분까지 다양한 시뮬레이션된 레이블 데이터 시나리오에서 결과 이산 단위에 대한 BERT 학습(Discrete BERT)을 오디오 입력에서 직접 representation을 학습하는 것(Continuous BERT)과 비교합니다. 우리는
| 모델 | 입력 특징 | dev | test | ||
|---|---|---|---|---|---|
| clean | other | clean | other | ||
| 10분의 레이블 데이터 | |||||
| Discrete BERT | vq-wav2vec | 15.7 | 24.1 | 16.3 | 25.2 |
| MFCC | 30.3 | 48.8 | 31.5 | 49.1 | |
| FBANK | 35.7 | 53.9 | 35.5 | 55.0 | |
| Continuous BERT | wav2vec | 49.1 | 66.0 | 49.5 | 66.3 |
| MFCC | 82.2 | 91.7 | 80.4 | 90.4 | |
| FBANK | 92.9 | 96.1 | 92.3 | 95.9 | |
| 1시간의 레이블 데이터 | |||||
| Discrete BERT | vq-wav2vec | 8.5 | 16.4 | 9.0 | 17.6 |
| MFCC | 14.1 | 32.1 | 14.3 | 32.5 | |
| FBANK | 14.2 | 30.6 | 14.6 | 31.7 | |
| Continuous BERT | wav2vec | 22.1 | 42.0 | 22.4 | 44.0 |
| MFCC | 53.8 | 75.0 | 52.8 | 74.5 | |
| FBANK | 56.7 | 76.2 | 55.0 | 76.1 | |
| 10시간의 레이블 데이터 | |||||
| Discrete BERT | vq-wav2vec | 5.3 | 13.2 | 5.9 | 14.1 |
| MFCC | 9.8 | 26.6 | 9.9 | 27.8 | |
| FBANK | 9.8 | 25.7 | 10.1 | 26.6 | |
| Continuous BERT | wav2vec | 13.6 | 31.7 | 14.1 | 34.3 |
| MFCC | 27.5 | 54.2 | 27.4 | 55.7 | |
| FBANK | 25.0 | 50.2 | 24.9 | 51.7 | |
| 100시간의 레이블 데이터 | |||||
| Discrete BERT | vq-wav2vec | 4.0 | 10.9 | 4.5 | 12.1 |
| MFCC | 7.6 | 24.2 | 7.8 | 24.4 | |
| FBANK | 7.2 | 22.8 | 7.8 | 23.3 | |
| Continuous BERT | wav2vec | 11.3 | 26.4 | 11.8 | 28.3 |
| MFCC | 11.6 | 34.0 | 12.4 | 35.5 | |
| FBANK | 10.1 | 30.9 | 11.0 | 31.8 |
표 1: 이산화되거나 연속적인 입력 특징을 사용하는 BERT 모델의 Librispeech WER: 이산화된 BERT의 경우 vq-wav2vec 또는 MFCC/FBANK 특징의 k-means 클러스터링을 통해 양자화된 입력 단위를 얻습니다; 연속 BERT의 경우 wav2vec 특징은 [12]를 따라 학습됩니다. Pre-trained 모델은 다양한 크기의 레이블 데이터에 fine-tune됩니다.
vq-wav2vec을 사용한 양자화를 클러스터링된 MFCC 및 FBANK 특징과 비교합니다. 연속 BERT 변형은 명시적인 양자화 없이 오디오 representation에서 직접 학습하며, wav2vec, MFCC 및 FBANK 특징을 입력하는 실험을 진행합니다.
표 1은 표준 Librispeech clean 및 other 부분 집합에서 다양한 입력 특징과 pre-training 방법의 WER을 비교합니다. 첫 번째 관찰은 Discrete BERT가 모든 설정에서 Continuous BERT를 능가한다는 것입니다. 이는 의미 있는 이산 단위에 대한 pre-training이 연속적인 레이블 없는 데이터로부터 직접 representation을 학습하는 것보다 우수함을 보여줍니다. 초기 단위 발견은 후속 BERT pre-training을 더 효과적으로 만드는 어휘를 구축합니다.
최상의 입력 특징은 Discrete BERT의 경우 vq-wav2vec [1]을 통한 self-supervised learning을 통해, Continuous BERT의 경우 wav2vec [12]를 통해 얻어집니다.
Discrete BERT의 경우, vq-wav2vec은 모든 학습 세트 크기에 걸쳐 클러스터링된 스펙트럼 특징에 비해 두 테스트 부분 집합 모두에서 약 의 상대적 오류 감소를 제공하며, 잡음이 많은 test-other 부분 집합에서 더 큰 이득을 보입니다.
Pre-training은 명백한 이점을 가져옵니다: 레이블이 있는 학습 데이터를 100시간에서 10시간으로 줄였을 때, vq-wav2vec 입력을 사용하는 Discrete BERT의 경우 test-other에서 WER이 2, test-clean에서 WER이 1.4만큼만 증가했습니다. 이는 pre-training이 효과적이며 특히 레이블이 있는 데이터가 거의 없을 때 더욱 그렇다는 것을 보여줍니다. 레이블이 있는 데이터를 단 10분으로 줄였을 때, va-wav2vec 입력을 사용한 Discrete BERT는 여전히 test-clean/other에서 16.3/25.2의 WER을 달성할 수 있습니다.
| 레이블된 테스트 | |||
|---|---|---|---|
| 데이터 | clean other | ||
| Wang et al. (2019) [35] | 960 h | 2.6 | 5.6 |
| Irie et al. (2019) [36] (No LM) | 100 h | 12.9 | 35.5 |
| Kahn et al. (2019) [37] (Conv LM) | 100 h | 5.9 | 24.1 |
| Panayotov et al. (2015) [21] | 100 h | 6.6 | 22.5 |
| Lscher et al. (2019) [23] | 100 h | 5.8 | 18.6 |
| Kawakami et al. (2019) [38] | 96 h | 9.4 | 26.8 |
| vq-wav2vec + Discrete BERT (Ours) | 10 m | 16.3 | 25.2 |
| 1 h | 9.0 | 17.6 | |
| 10 h | 5.9 | 14.1 | |
| 100 h | 4.5 | 12.1 |
표 2: Librispeech에서 WER 측면에서 이전에 발표된 결과와의 비교. 모든 결과는 4-gram 언어 모델을 사용하며, [36, 37]은 예외입니다.
표 2는 Discrete BERT와 문헌의 결과를 비교한 것입니다. 단 10시간의 레이블 데이터로 Discrete BERT를 fine-tuning하면, test-clean에서 100시간의 레이블된 Librispeech 데이터 [23]에 대한 가장 잘 알려진 결과와 거의 일치할 수 있으며, test-other에서는 의 상대적 WER 감소를 달성합니다. 더욱이, fine-tuning을 위해 동일한 train-clean-100 부분집합을 사용할 때, vq-wav2vec 입력을 사용한 Discrete BERT는 [23]에 비해 test-other에서 6.5 WER (35% 상대적 WER 감소), test-clean에서 1.3 WER (22% 상대적 WER 감소) 향상됩니다.
우리와 가장 가까운 설정은 [38]로, CPC [11]를 사용하여 representation을 학습한 다음 약 96시간의 레이블 데이터로 학습된 ASR 시스템에 이를 공급합니다. 이 시스템은 10분 및 1시간에 fine-tune된 vq-wav2vec representation으로 학습된 우리의 Discrete-BERT 모델에 의해 test-clean에서 능가됩니다.
| 입력 <br> 특징 | dev | test | |||||
|---|---|---|---|---|---|---|---|
| clean | other | clean | |||||
| 이산 | 입력 (BERT 없음 | pre-training) | |||||
| vq-wav2vec | 99.7 | 99.3 | 99.3 | 99.4 | |||
| MFCC | 100.0 | 100.0 | 99.9 | 100.0 | |||
| FBANK | 98.8 | 99.6 | 98.9 | 99.0 | |||
| 연속 입력 (BERT 없음 | pre-training) | ||||||
| wav2vec | 27.5 | 47.2 | 28.4 | 48.5 | |||
| MFCC | 30.6 | 56.7 | 32.2 | 58.2 | |||
| FBANK | 20.2 | 47.6 | 21.3 | 49.2 |
표 3: 100시간의 레이블된 데이터에서 연속 및 이산 입력 특징에 대한 pre-training이 없는 Librispeech의 WER.
| Pre-training | dev | test | |||
|---|---|---|---|---|---|
| clean | other | clean | other | ||
| wav2vec | 51.1 | 71.4 | 52.6 | 71.9 | |
| + Continuous BERT | 13.3 | 31.9 | 14.0 | 35.0 |
표 4: 단일 단계 pre-training(wav2vec)과 2단계 pre-training(wav2vec + Continuous BERT) 비교. wav2vec은 10시간의 레이블 데이터에 fine-tune되었으며, wav2vec 입력을 사용한 Continuous BERT 모델도 마찬가지입니다.
4.5 Ablations
representation learning 접근법에서 BERT pre-training의 영향을 더 잘 이해하기 위해, 우리는 BERT pre-training 단계를 제거하고 이산 입력에 대해서는 vqwav2vec를 통한 단위 발견만 수행하고, 이산 및 연속 입력 모두에 대해 10시간 레이블 설정에서 fine-tuning만 수행합니다. 이산 입력에 대한 어휘는 여전히 레이블이 없는 데이터에서 구축됩니다. 표 3은 이산 입력으로 학습하면 실패한다는 것을 보여줍니다. 이는 입력 이산 단위의 representation이 무작위이고 레이블이 있는 데이터에 대한 학습이 충분하지 않기 때문일 가능성이 높습니다. 연속 입력은 이 문제로 고통받지 않습니다.
다음으로, 2단계 pre-training 접근법이 단일 단계 접근법과 어떻게 비교되는지 조명합니다. 구체적으로, 우리는 wav2vec 입력 특징을 사용하는 Continuous BERT(wav2vec 특징의 별도 학습 필요)를 레이블된 데이터에 CTC 손실로 fine-tune된 wav2vec 특징과 비교합니다. 결과(표 4)는 Continuous BERT + wav2vec가 상당한 이득을 제공한다는 것을 보여줍니다. 두 번째 representation learning 단계는 WER을 절반 이상으로 줄였으며, "clean" 부분 집합에서 더 많은 이득이 관찰되었습니다(참조 4.4).
5 Discussion and Related Work
BERT [19]와 Word2Vec [24]의 NLP 작업에서의 성공은 음향 단어 임베딩 및 비지도 음향 특징 representation을 위한 self-supervised 접근법에 대한 더 많은 연구를 동기 부여했습니다[39, 40, 41, 42, 10, 43, 12, 11, 44, 1]. 이는 마스킹된 이산 또는 연속 입력을 예측하거나, 원격 감독 또는 오디오 신호 내 근접성을 유사성의 지표로 사용하여 이웃하거나 유사하게 들리는 세그먼트를 대조적으로 예측함으로써 이루어집니다. [45]에서는 동적 시간 왜곡 정렬을 사용하여 유사한 세그먼트 쌍을 발견합니다.
우리의 연구는 비지도 단위 발견 및 음향 representation 학습[5, 6, 7, 8, 9]을 통해 ASR 시스템 구축에 대한 레이블 데이터 의존도를 줄이는 연구 노력과, 저자원 조건에서의 다국어 및 교차 언어 전이 학습[46, 47, 48, 49, 50, 51], 그리고 semi-supervised learning[13, 14, 15, 16]에서 영감을 받았습니다.
6 Conclusion and Future work
우리는 speech recognition을 위한 self-supervised pre-training 접근법의 체계적인 비교를 제시했습니다. 가장 효과적인 방법은 먼저 vq-wav2vec로 데이터의 이산 어휘를 학습한 다음, 이 이산 단위에 대해 표준 BERT training을 수행하는 것입니다. 이는 연속적인 오디오 데이터로부터 직접 학습하는 것보다 훨씬 더 나은 성능을 보입니다. task-specific ASR 모델에 의존했던 이전 연구와 달리, 우리는 결과적인 BERT 모델을 전사된 speech 데이터에 직접 fine-tune하여 speech recognition 모델로 작동하도록 합니다. 이 접근법은 100시간의 레이블된 데이터로 얻은 가장 잘 알려진 결과보다 test-other에서 더 나은 정확도를 달성하면서도 두 자릿수나 적은 레이블 데이터에 의존합니다. 모델이 단 10분의 데이터로 fine-tune되었을 때, 여전히 test-other에서 WER 25.2, test-clean에서 WER 16.3을 달성할 수 있습니다.
7 References
[1] Alexei Baevski, Steffen Schneider, and Michael Auli, "vq-wav2vec: Self-supervised learning of discrete speech representations," in Proc. of ICLR, 2020. [2] G. E. Hinton, J. L. McClelland, and D. E. Rumelhart, Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Vol. 1, MIT Press, 1986. [3] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton, "Deep learning," Nature Cell Biology, 2015. [4] Yoshua Bengio, Aaron Courville, and Pascal Vincent, "Representation learning: A review and new perspectives," IEEE Trans. Pattern Anal. Mach. Intell., 2013. [5] A. Park and J. Glass, "Unsupervised pattern discovery in speech," IEEE TASLP, vol. 16, no. 1, pp. 186-197, 2008. [6] Aren Jansen, Kenneth Church, and Hynek Hermansky, "Towards spoken term discovery at scale with zero resources.," in Proc. of Interspeech, 2010. [7] J. Glass, "Towards unsupervised speech processing," in ISSPA, 2012. [8] Aren Jansen, Emmanuel Dupoux, Sharon Goldwater, Mark Johnson, Sanjeev Khudanpur, Kenneth Church, Naomi Feldman, Hynek Hermansky, Florian Metze, Richard Rose, et al., "A summary of the 2012 JHU CLSP workshop on zero resource speech technologies and models of early language acquisition," in Proc. of ICASSP, 2013. [9] Odette Scharenborg, Laurent Besacier, Alan Black, Mark HasegawaJohnson, Florian Metze, Graham Neubig, Sebastian Stüker, Pierre Godard, Markus Müller, Lucas Ondel, et al., "Linguistic unit discovery from multi-modal inputs in unwritten languages: Summary of the "speaking rosetta" JSALT 2017 workshop," in Proc. of ICASSP, 2018. [10] Yu-An Chung and James Glass, "Speech2vec: A sequence-to-sequence framework for learning word embeddings from speech," in Proc. of Interspeech, 2018. [11] Aäron van den Oord, Yazhe Li, and Oriol Vinyals, "Representation learning with contrastive predictive coding," arXiv, 2018. [12] Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli, "wav2vec: Unsupervised pre-training for speech recognition," in Proc. of Interspeech, 2020. [13] K. Vesely, M. Hannemann, and L. Burget, "Semi-supervised training of deep neural networks," in Proc. of ASRU, 2013. [14] Sheng Li, Xugang Lu, Shinsuke Sakai, Masato Mimura, and Tatsuya Kawahara, "Semi-supervised ensemble dnn acoustic model training," in Proc. of ICASSP, 2017. [15] S. Krishnan Parthasarathi and N. Strom, "Lessons from building acoustic models with a million hours of speech," in Proc. of ICASSP, 2019. [16] Bo Li, Ruoming Pang, Tara Sainath, and Zelin Wu, "Semi-supervised training for end-to-end models via weak distillation," in Proc. of ICASSP, 2019. [17] Grzegorz Chrupała, Lieke Gelderloos, and Afra Alishahi, "Representations of language in a model of visually grounded speech signal," in Proc. of ACL, 2017. [18] Herman Kamper, Shane Settle, Gregory Shakhnarovich, and Karen Livescu, "Visually grounded learning of keyword prediction from untranscribed speech," in Proc. of Interspeech, 2017. [19] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, "Bert: Pre-training of deep bidirectional transformers for language understanding," in Proc. of NAACL, 2019. [20] Alexei Baevski, Sergey Edunov, Yinhan Liu, Luke Zettlemoyer, and Michael Auli, "Cloze-driven pretraining of self-attention networks," in Proc. of EMNLP, 2019. [21] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur, "Librispeech: An asr corpus based on public domain audio books," in Proc. of ICASSP, 2015. [22] Jacob Kahn et al., "Libri-light: A benchmark for asr with limited or no supervision," arXiv preprint arXiv:1912.07875, 2019. [23] Christoph Lscher, Eugen Beck, Kazuki Irie, Markus Kitza, Wilfried Michel, Albert Zeyer, Ralf Schlter, and Hermann Ney, "Rwth asr systems for librispeech: Hybrid vs attention," in Interspeech 2019, 2019. [24] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean, "Distributed representations of words and phrases and their compositionality," in Proc. of NIPS, 2013. [25] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov, "Roberta: A robustly optimized bert pretraining approach," arXiv, vol. abs/1907.11692, 2019. [26] Abdelrahman Mohamed, Dmytro Okhonko, and Luke Zettlemoyer, "Transformers with convolutional context for asr," arXiv, 2019. [27] Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu, "Neural discrete representation learning," arXiv, vol. abs/1711.00937, 2017. [28] Philip Bachman, R Devon Hjelm, and William Buchwalter, "Learning representations by maximizing mutual information across views," arXiv, vol. abs/1906.00910, 2019. [29] Daniel S. Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D. Cubuk, and Quoc V. Le, "Specaugment: A simple data augmentation method for automatic speech recognition," in Proc. of Interspeech. 2019, ISCA. [30] Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli, "fairseq: A fast, extensible toolkit for sequence modeling," in Proc. of NAACL System Demonstrations, 2019. [31] Daniel Povey, Arnab Ghoshal, Gilles Boulianne, Lukas Burget, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Petr Motlicek, Yanmin Qian, Petr Schwarz, Jan Silovsky, Georg Stemmer, and Karel Vesely, "The kaldi speech recognition toolkit," in Proc. of ASRU, 2011. [32] Myle Ott, Sergey Edunov, David Grangier, and Michael Auli, "Scaling neural machine translation," in Proc. of WMT, 2018. [33] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, and Ruslan Salakhutdinov, "Transformer-xl: Attentive language models beyond a fixed-length context," arXiv, vol. abs/1901.02860, 2019. [34] V. Pratap, A. Hannun, Q. Xu, J. Cai, J. Kahn, G. Synnaeve, V. Liptchinsky, and R. Collobert, "Wav2letter++: A fast open-source speech recognition system," in Proc. of ICASSP, 2019. [35] Yongqiang Wang, Abdelrahman Mohamed, Duc Le, Chunxi Liu, Alex Xiao, Jay Mahadeokar, Hongzhao Huang, Andros Tjandra, Xiaohui Zhang, Frank Zhang, Christian Fuegen, Geoffrey Zweig, and Michael L. Seltzer, "Transformer-based acoustic modeling for hybrid speech recognition," arXiv, vol. abs/1910.09799, 2019. [36] Kazuki Irie, Rohit Prabhavalkar, Anjuli Kannan, Antoine Bruguier, David Rybach, and Patrick Nguyen, "On the choice of modeling unit for sequence-to-sequence speech recognition," in Interspeech 2019, 2019. [37] Jacob Kahn, Ann Lee, and Awni Hannun, "Self-training for end-to-end speech recognition," arXiv, vol. abs/1909.09116, 2019. [38] Kazuya Kawakami, Luyu Wang, Chris Dyer, Phil Blunsom, and Aaron van den Oord, "Unsupervised learning of efficient and robust speech representations," 2019. [39] Samy Bengio and Georg Heigold, "Word embeddings for speech recognition," in Proc. of Interspeech, 2014. [40] Keith Levin, Katharine Henry, Aren Jansen, and K. Livescu, "Fixeddimensional acoustic embeddings of variable-length segments in lowresource settings," in Proc. of ASRU, 2013. [41] Yu-An Chung, Chao-Chung Wu, Chia-Hao Shen, Hung yi Lee, and L. Lee, "Audio word2vec: Unsupervised learning of audio segment representations using sequence-to-sequence autoencoder," in Proc. of Interspeech, 2016. [42] Wanjia He, Weiran Wang, and Karen Livescu, "Multi-view recurrent neural acoustic word embeddings," in Proc. of ICLR, 2016. [43] Shane Settle, Kartik Audhkhasi, Karen Livescu, and Michael Picheny, "Acoustically grounded word embeddings for improved acoustics-toword speech recognition," in Proc. of ICASSP, 2019. [44] Yu-An Chung, Wei-Ning Hsu, Hao Tang, and James R. Glass, "An unsupervised autoregressive model for speech representation learning," in Proc. of Interspeech, 2019. [45] Herman Kamper, Micha Elsner, Aren Jansen, and Sharon Goldwater, "Unsupervised neural network based feature extraction using weak topdown constraints," in Proc. of ICASSP, 2015. [46] Haihua Xu, Hang Su, Chongjia Ni, Xiong Xiao, Hao Huang, Eng Siong Chng, and Haizhou Li, "Semi-supervised and cross-lingual knowledge transfer learnings for dnn hybrid acoustic models under low-resource conditions," in Proc. of Interspeech, 2016. [47] Jia Cui, Brian Kingsbury, Bhuvana Ramabhadran, Abhinav Sethy, Kartik Audhkhasi, Xiaodong Cui, Ellen Kislal, Lidia Mangu, Markus Nussbaum-Thom, Michael Picheny, et al., "Multilingual representations for low resource speech recognition and keyword search," in Proc. of ASRU, 2015. [48] Georg Heigold, Vincent Vanhoucke, Alan Senior, Patrick Nguyen, MarcAurelio Ranzato, Matthieu Devin, and Jeffrey Dean, "Multilingual acoustic models using distributed deep neural networks," in Proc. of ICASSP, 2013. [49] A. Ghoshal, P. Swietojanski, and S. Renals, "Multilingual training of deep neural networks," in Proc. of ICASSP, 2013. [50] Jui-Ting Huang, Jinyu Li, Dong Yu, Li Deng, and Yifan Gong, "Crosslanguage knowledge transfer using multilingual deep neural network with shared hidden layers," in Proc. of ICASSP, 2013. [51] Ngoc Thang Vu et. al., "Multilingual deep neural network based acoustic modeling for rapid language adaptation," in Proc. of ICASSP, 2014.