DEIM: DETR의 빠른 수렴을 위한 개선된 매칭 기법
DEIM은 Transformer 기반 객체 탐지 모델(DETR)의 느린 수렴 문제를 해결하기 위한 효율적인 훈련 프레임워크입니다. 이 방법은 Dense O2O 매칭 전략을 사용하여 훈련 중 양성 샘플 수를 늘리고, Matchability-Aware Loss(MAL)라는 새로운 손실 함수를 도입하여 다양한 품질의 매칭을 최적화합니다. 이를 통해 RT-DETR과 같은 기존 모델의 훈련 시간을 절반으로 줄이면서도 성능을 향상시킵니다. 논문 제목: DEIM: DETR with Improved Matching for Fast Convergence
논문 요약: DEIM: DETR with Improved Matching for Fast Convergence
- 논문 링크: https://arxiv.org/abs/2412.04234
- 저자: Shihua Huang 외 5명 (Intellindust AI Lab, City University of Hong Kong, Great Bay University, Hefei Normal University)
- 발표 시기: 2025년, CVPR (Computer Vision and Pattern Recognition Conference)
- 주요 키워드: 객체 탐지, DETR, Transformer, 실시간 탐지, 수렴 가속화
1. 연구 배경 및 문제 정의
- 문제 정의:
Transformer 기반 객체 탐지 모델(DETR)은 NMS(Non-Maximum Suppression)가 필요 없는 엔드투엔드 프레임워크를 제공하지만, 느린 수렴 속도가 주요 한계로 지적됩니다. 이는 주로 두 가지 원인 때문입니다:- 희소한 지도(Sparse Supervision): DETR의 일대일(O2O) 매칭 메커니즘은 타겟당 하나의 양성(positive) 샘플만 할당하여, 기존 일대다(O2M) 방식에 비해 지도 신호가 매우 희소합니다.
- 저품질 매치: 무작위로 초기화된 쿼리들이 타겟과의 공간적 정렬이 부족하여, IoU(Intersection over Union)는 낮지만 신뢰도 점수는 높은 저품질 매치를 다수 생성합니다.
- 기존 접근 방식:
- YOLO 계열 모델: 일대다(O2M) 할당 전략을 사용하여 밀도 높은 지도 신호를 제공하고 빠른 수렴을 달성하지만, 중복된 경계 상자 제거를 위해 NMS 후처리가 필수적입니다.
- 기존 DETR 개선 연구: Group DETR, Co-DETR 등은 추가적인 디코더나 헤드를 도입하여 양성 샘플 수를 늘리려 했으나, 이는 계산 오버헤드를 증가시키고 중복 예측을 생성할 위험이 있습니다.
- 쿼리 초기화 개선 시도: Anchor-DETR, DAB-DETR, DN-DETR, DINO 등은 쿼리 초기화를 개선하여 타겟 주변에 쿼리를 집중시켰지만, 여전히 저품질 매치 문제는 남아있습니다.
- 기존 손실 함수(VFL): Varifocal Loss(VFL)는 주로 고품질 매치에 초점을 맞추며, 저품질 매치(낮은 IoU)의 경우 손실 값이 작게 유지되어 효과적인 최적화가 어렵습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 실시간 객체 탐지를 위한 간단하고 유연한 학습 프레임워크인 DEIM을 제안합니다.
- DEIM은 Dense O2O 매칭과 Matchability-Aware Loss(MAL)를 통해 매칭의 양과 질을 동시에 개선하여 수렴 속도를 가속화합니다.
- 제안된 방법은 기존 실시간 DETR 모델의 학습 비용을 절반으로 줄이면서도 성능을 향상시키며, YOLO 모델을 능가하는 새로운 실시간 객체 탐지 SoTA(State-of-the-Art)를 달성합니다.
- 제안 방법:
DEIM은 DETR의 느린 수렴 문제를 해결하기 위해 두 가지 핵심 전략을 제안합니다.- Dense O2O 매칭:
- DETR의 일대일(O2O) 매칭 구조(타겟당 하나의 예측)를 유지하면서, 학습 이미지당 타겟의 수를 늘려 전체 양성 샘플 수를 증가시킵니다.
- 이를 위해 Mosaic 및 Mixup과 같은 표준 데이터 증강 기술을 활용하여 추가적인 계산 오버헤드 없이 밀도 높은 지도 신호를 제공합니다. 이는 기존 O2M 방식에 필적하는 수준의 감독을 O2O 프레임워크 내에서 가능하게 합니다.
- Matchability-Aware Loss (MAL):
- 기존 VFL의 한계를 극복하기 위해 제안된 새로운 손실 함수입니다.
- 매치된 쿼리와 타겟 간의 IoU를 분류 신뢰도와 직접 통합하여 매치 가능성에 따라 패널티를 조정합니다.
- 특히 저품질 매치(낮은 IoU)에 더 큰 가중치를 부여하여, 모델이 이러한 매치에 대한 예측을 효과적으로 개선하도록 돕습니다.
- VFL보다 간단한 수학적 공식을 가지며, 고품질 매치에 대한 성능 저하 없이 학습 효율성을 향상시킵니다.
- Dense O2O 매칭:
3. 실험 결과
- 데이터셋:
MS-COCO 2017 데이터셋 (train2017으로 학습, val2017으로 검증) 및 CrowdHuman 데이터셋을 사용했습니다. - 주요 결과:
- 수렴 속도 및 성능 향상: RT-DETR 및 D-FINE과 통합되었을 때, DEIM은 학습 시간을 50% 단축하면서도 일관되게 성능을 향상시켰습니다 (RT-DETRv2 0.2 AP, D-FINE 0.6 AP 향상).
- SoTA 달성: RT-DETRv2와 결합된 DEIM은 NVIDIA 4090 GPU에서 단 하루(약 24 에포크) 학습으로 53.2% AP를 달성했습니다. DEIM-D-FINE-L 및 DEIM-D-FINE-X는 각각 124 FPS, 78 FPS에서 54.7%, 56.5% AP를 달성하며, YOLOv11을 포함한 기존 실시간 탐지기들을 능가하는 새로운 SoTA를 확립했습니다.
- 작은 객체 탐지 개선: CrowdHuman 데이터셋에서 D-FINE-L 대비 1.5 AP 개선을 보였으며, 특히 작은 객체(APs) 및 고품질 탐지(AP75)에서 3% 이상의 상당한 성능 향상을 보여주었습니다.
- 개별 구성 요소의 효과: Dense O2O는 모델 수렴을 크게 가속화하여 기존 모델의 72 에포크 대비 36 에포크 만에 유사한 성능을 달성하게 했으며, MAL은 저품질 매치 최적화를 통해 상자 품질을 개선하여 추가적인 성능 향상을 가져왔습니다.
- 학습 효율성: DEIM은 기존 모델과 거의 동일한 에포크당 학습 시간을 유지하면서도, 더 적은 총 학습 시간(RT-DETRv2-R50 기준 85시간 -> 71시간)으로 더 높은 성능에 도달했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- DETR의 고질적인 문제였던 느린 수렴 문제를 Dense O2O와 MAL이라는 두 가지 독창적인 방법으로 효과적으로 해결했습니다.
- 기존 데이터 증강 기법(Mosaic, Mixup)을 활용하여 추가적인 계산 오버헤드 없이 Dense O2O를 구현한 점이 매우 인상적입니다. 이는 실용적인 측면에서 큰 장점입니다.
- 저품질 매치에 대한 손실 함수(MAL)를 개선하여 전반적인 탐지 성능, 특히 작은 객체 탐지 성능을 향상시킨 점은 실제 환경에서의 적용 가능성을 높입니다.
- 학습 시간을 절반으로 줄이면서도 SoTA 성능을 달성하여, 제한된 컴퓨팅 자원을 가진 연구자나 개발자에게 큰 이점을 제공할 수 있습니다.
- 단점/한계:
- 논문에서도 언급했듯이, YOLO 모델 대비 작은 객체 AP에서 여전히 약간의 격차가 존재합니다. 이는 DETR 아키텍처 자체의 작은 객체 탐지 한계일 수 있으며, 추가 연구가 필요합니다.
- Dense O2O에서 이미지당 객체 수가 너무 많아지면 성능이 오히려 감소할 수 있다는 분석 결과는, 최적의 데이터 증강 전략 및 객체 밀도에 대한 추가적인 연구가 필요함을 시사합니다.
- MAL의 γ 값 튜닝이 필요하며, 최적의 값은 실험적으로 찾아야 한다는 점은 일반적인 하이퍼파라미터 튜닝의 한계로 볼 수 있습니다.
- 응용 가능성:
- 자율 주행, 로봇 내비게이션, 보안 감시 등 실시간 객체 탐지가 필수적인 다양한 산업 분야에 즉시 적용될 수 있습니다.
- 클라우드 컴퓨팅 자원이 제한적이거나 온디바이스(On-device) AI 구현이 필요한 환경에서 고성능 DETR 모델을 빠르게 학습하고 배포하는 데 매우 유용할 것입니다.
- DETR뿐만 아니라 다른 Transformer 기반 비전 모델의 학습 효율성 개선에도 Dense O2O 및 MAL과 같은 아이디어를 확장 적용할 수 있는 잠재력이 있습니다.
5. 추가 참고 자료
- DEIM 프로젝트 페이지: https://www.shihuahuang.cn/DEIM/
Huang, Shihua, et al. "Deim: Detr with improved matching for fast convergence." Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
DEIM: DETR with Improved Matching for Fast Convergence
Shihua Huang Zhichao Lu Xiaodong Cun Yongjun Yu Xiao Zhou Xi Shen <br> Intellindust AI Lab City University of Hong Kong Great Bay University Hefei Normal University<br> Corresponding author: shenxiluc@gmail.com; Project lead.
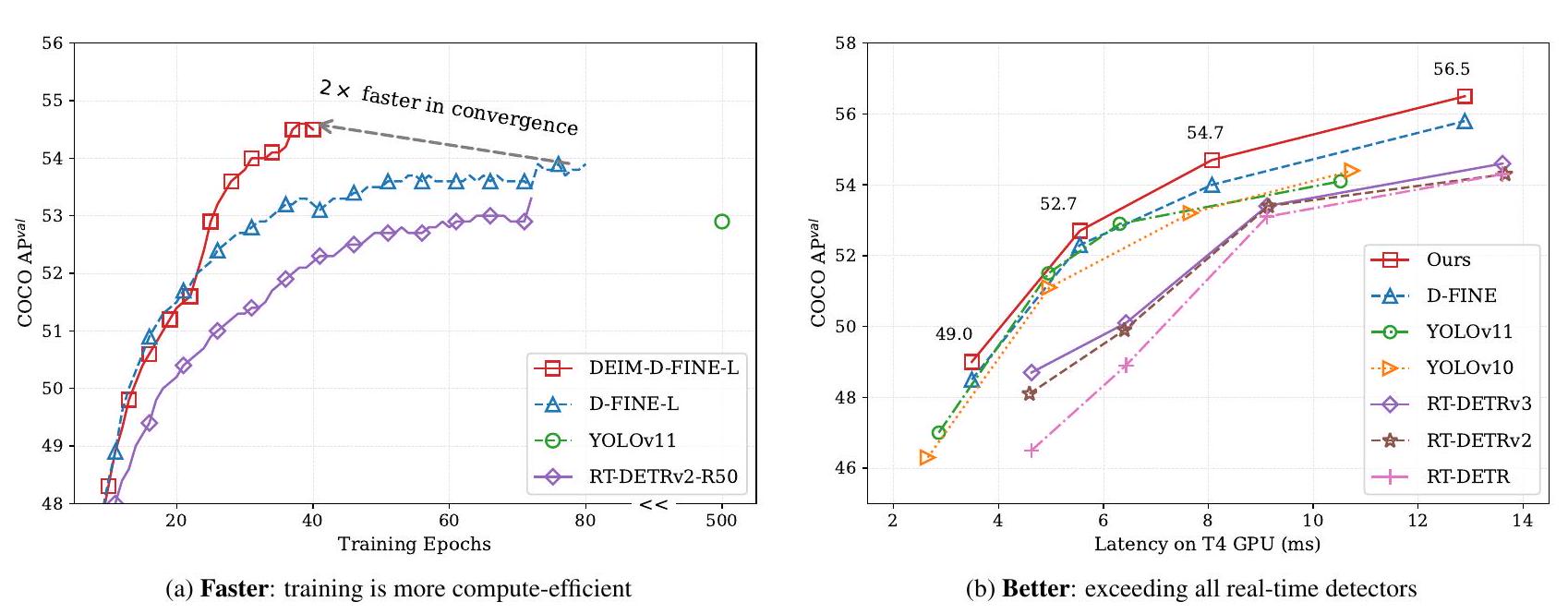
Figure 1. Comparison with state-of-the-art real-time object detectors on COCO [20]. The proposed DEIM achieves faster convergence (a) and superior performance in terms of average precision (AP) and latency (b) when compared to state-of-the-art real-time object detectors.
Abstract
우리는 Transformer 기반 아키텍처(DETR)를 사용하는 실시간 객체 탐지에서 수렴 속도를 가속화하도록 설계된 혁신적이고 효율적인 학습 프레임워크인 DEIM을 소개합니다. DETR 모델의 일대일(O2O) 매칭에 내재된 희소한 지도(sparse supervision) 문제를 완화하기 위해, DEIM은 Dense O2O 매칭 전략을 사용합니다. 이 접근법은 표준 데이터 증강 기술을 사용하여 추가적인 타겟을 통합함으로써 이미지당 포지티브 샘플의 수를 증가시킵니다. Dense O2O 매칭은 수렴 속도를 높이지만, 성능에 영향을 줄 수 있는 수많은 저품질 매치를 유발하기도 합니다. 이 문제를 해결하기 위해, 우리는 다양한 품질 수준의 매치를 최적화하여 Dense O2O의 효과를 향상시키는 새로운 손실 함수인 Matchability-Aware Loss(MAL)를 제안합니다. COCO 데이터셋에 대한 광범위한 실험은 DEIM의 효능을 입증합니다. RT-DETR 및 D-FINE과 통합되었을 때, DEIM은 학습 시간을 50% 단축하면서도 일관되게 성능을 향상시킵니다. 특히, RT-DETRv2와 결합된 DEIM은 NVIDIA 4090 GPU에서 단 하루의 학습으로 53.2%의 AP를 달성합니다. 또한, DEIM으로 학습된 실시간 모델들은 선두적인 실시간 객체 탐지기들을 능가하며, DEIM-D-FINE-L과 DEIM-D-FINE-X는 추가 데이터 없이 NVIDIA T4 GPU에서 각각 124 FPS와 78 FPS에서 54.7%와 56.5%의 AP를 달성합니다. 우리는 DEIM이 실시간 객체 탐지의 발전을 위한 새로운 기준선을 설정한다고 믿습니다. 우리의 코드와 사전 학습된 모델은 https://www.shihuahuang.cn/DEIM/ 에서 확인할 수 있습니다.
1. Introduction
객체 탐지는 자율 주행 [5, 6], 로봇 내비게이션 [9] 등과 같은 분야에서 널리 적용되는 컴퓨터 비전의 근본적인 과제입니다. 효율적인 탐지기에 대한 수요가 증가하면서 실시간 탐지 방법의 개발이 촉진되었습니다. 특히, YOLO는 지연 시간과 정확도 사이의 강력한 트레이드오프 덕분에 실시간 객체 탐지를 위한 주요 패러다임 중 하나로 부상했습니다 [1, 28, 32, 34, 44]. YOLO 모델은 컨볼루션 신경망을 기반으로 하는 1단계 탐지기로 널리 알려져 있습니다. 일대다(O2M) 할당 전략은 YOLO 시리즈 [1, 28, 34, 44]에서 널리 사용되어 왔으며, 각 타겟 상자는 여러 앵커와 연결됩니다. 이 전략은 밀도 높은 지도 신호(dense supervision signals)를 제공하여 수렴을 가속화하고 성능을 향상시키기 때문에 효과적인 것으로 알려져 있습니다 [44]. 그러나 이 방법은 객체당 여러 개의 겹치는 경계 상자를 생성하므로, 중복을 제거하기 위해 수작업으로 만든 Non-Maximum Suppression(NMS)이 필요하며, 이로 인해 지연 시간과 불안정성이 발생합니다 [32, 43].
Transformer 기반 탐지(DETR) 패러다임 [3]의 등장은 멀티헤드 어텐션을 활용하여 전역적 맥락을 포착함으로써 위치 파악 및 분류를 향상시켜 상당한 주목을 받았습니다 [4, 39, 46]. DETR은 헝가리안 [16] 알고리즘을 활용하여 학습 중에 예측된 상자와 실제 객체 간의 고유한 대응 관계를 설정하는 일대일(O2O) 매칭 전략을 채택하여 NMS의 필요성을 제거합니다. 이 엔드투엔드 프레임워크는 실시간 객체 탐지를 위한 강력한 대안을 제공합니다.
그러나 느린 수렴은 DETR의 주요 한계 중 하나로 남아 있으며, 우리는 그 이유가 두 가지라고 가정합니다. 1 희소한 지도(Sparse supervision): O2O 매칭 메커니즘은 타겟당 하나의 포지티브 샘플만 할당하므로 포지티브 샘플의 수를 크게 제한합니다. 반면, O2M은 몇 배 더 많은 포지티브 샘플을 생성합니다. 이러한 포지티브 샘플의 부족은 밀도 높은 지도를 제한하여 효과적인 모델 학습을 방해합니다. 특히 작은 객체의 경우 밀도 높은 지도가 성능에 중요합니다. (2) 저품질 매치: 밀도 높은 앵커(보통 >8000개)에 의존하는 기존 방법과 달리, DETR은 적은 수(100 또는 300개)의 무작위로 초기화된 쿼리를 사용합니다. 이러한 쿼리는 타겟과의 공간적 정렬이 부족하여 학습 중에 수많은 저품질 매치를 유발하며, 여기서 매치된 상자는 타겟과의 IoU는 낮지만 신뢰도 점수는 높습니다.
DETR의 지도 부족 문제를 해결하기 위해, 최근 연구들은 O2O 학습에 O2M 할당을 통합하여 O2O 매칭의 제약을 완화함으로써, 지도를 늘리기 위해 타겟당 보조 포지티브 샘플을 도입했습니다. Group DETR [4]은 여러 쿼리 그룹을 사용하여 이를 달성하며, 각 그룹은 독립적인 O2O 매칭을 수행합니다. 반면 Co-DETR [46]은 Faster R-CNN [29] 및 FCOS [31]와 같은 객체 탐지기의 O2M 방법을 통합합니다. 이러한 접근 방식은 성공적으로 포지티브 샘플 수를 늘리지만, 추가적인 디코더가 필요하여 계산 오버헤드를 증가시키고 기존 탐지기처럼 중복된 고품질 예측을 생성할 위험이 있습니다. 대조적으로, 우리는 dense one-to-one (Dense O2O) 매칭이라는 새롭고 간단한 접근법을 제안합니다. 우리의 핵심 아이디어는 각 학습 이미지의 타겟 수를 늘려 학습 중에 더 많은 포지티브 샘플을 생성하는 것입니다. 주목할 점은, 이는 mosaic [1] 및 mixup [38] 증강과 같은 고전적인 기술을 사용하여 쉽게 달성할 수 있으며, 이는 일대일 매칭 프레임워크를 유지하면서 이미지당 추가 포지티브 샘플을 생성합니다. Dense O2O 매칭은 일반적으로 O2M 방법과 관련된 추가적인 복잡성과 오버헤드 없이 O2M 접근법에 필적하는 수준의 지도를 제공할 수 있습니다.
사전 정보 [18, 39, 43, 45]를 사용하여 쿼리 초기화를 개선하려는 시도에도 불구하고, 이는 객체 주변에 더 효과적인 쿼리 분포를 가능하게 합니다. 이러한 개선된 초기화 방법은 종종 인코더 [39, 43]에서 추출된 제한된 특징 정보에 의존하여 몇몇 눈에 띄는 객체 주위에 쿼리를 집중시키는 경향이 있습니다. 반면, 대부분의 눈에 띄지 않는 객체는 근처에 쿼리가 부족하여 저품질 매치로 이어집니다. 이 문제는 Dense O2O를 사용할 때 더욱 두드러집니다. 타겟 수가 증가함에 따라 눈에 띄는 타겟과 그렇지 않은 타겟 간의 격차가 커져 전체 매칭 양이 증가함에도 불구하고 저품질 매치가 증가하게 됩니다. 이 경우, 손실 함수가 이러한 저품질 매치를 처리하는 데 한계가 있다면 이 격차는 지속되어 모델이 더 나은 성능을 달성하는 것을 방해할 것입니다.
Varifocal Loss (VFL) [40]와 같은 DETR의 기존 손실 함수 [19, 40]는 저품질 매치의 수가 비교적 적은 밀도 높은 앵커에 맞춰져 있습니다. 이들은 주로 고품질 매치, 특히 높은 IoU를 가졌지만 낮은 신뢰도를 가진 매치에 불이익을 주고 저품질 매치는 폐기합니다. 저품질 매치를 해결하고 Dense O2O를 더욱 개선하기 위해, 우리는 Matchability-Aware Loss (MAL)를 제안합니다. MAL은 매치된 쿼리와 타겟 간의 IoU를 분류 신뢰도와 통합하여 매치 가능성에 따라 패널티를 조정합니다. MAL은 고품질 매치에 대해서는 VFL과 유사하게 수행되지만 저품질 매치에 더 큰 중점을 두어 학습 중 제한된 포지티브 샘플의 활용도를 향상시킵니다. 또한, MAL은 VFL보다 더 간단한 수학적 공식을 제공합니다.
제안된 DEIM은 Dense O2O와 MAL을 결합하여 효과적인 학습 프레임워크를 만듭니다. 우리는 COCO [20] 데이터셋에서 광범위한 실험을 수행하여 DEIM의 효과를 평가했습니다. 그림 1 (a)의 결과는 DEIM이 RTDETRv2 [24]와 D-FINE [27]의 수렴을 상당히 가속화하고 개선된 성능을 달성함을 보여줍니다. 구체적으로, 학습 에포크 수를 절반만 사용했음에도 불구하고 우리 방법은 RT-DETRv2와 D-FINE을 각각 0.2 AP와 0.6 AP 만큼 능가합니다. 또한, 우리의 접근 방식은 단일 4090 GPU에서 ResNet50 기반 DETR 모델을 학습할 수 있게 하여, 단 하루(약 24 에포크) 만에 53.2% mAP를 달성합니다. 더 효율적인 모델을 통합함으로써, 우리는 또한 최신 YOLOv11 [13]을 포함한 기존 모델을 능가하는 새로운 실시간 탐지기 세트를 도입하여 실시간 객체 탐지를 위한 새로운 최고 수준(SoTA)을 설정합니다(그림 1 (b)).
이 작업의 주요 기여는 다음과 같이 요약됩니다:
- 우리는 실시간 객체 탐지를 위한 간단하고 유연한 학습 프레임워크인 DEIM을 소개합니다.
- DEIM은 각각 Dense O2O와 MAL로 매칭의 양과 질을 개선하여 수렴을 가속화합니다.
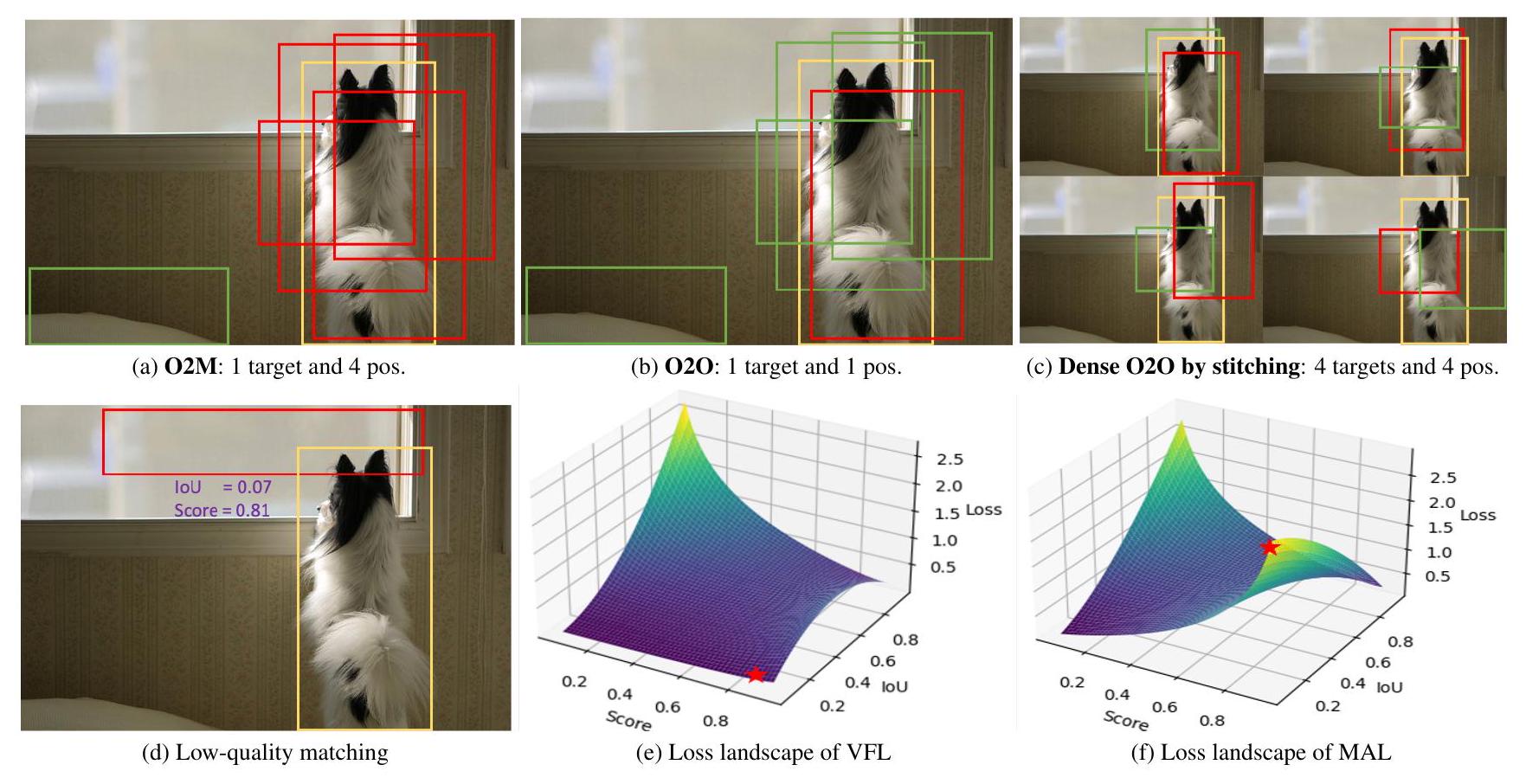
Figure 2. An illustration of our proposed DEIM. Yellow, red, and green boxes represent the GT, positive and negative samples, respectively. 'pos.' denotes the positive samples. Top: Our Dense O2O (Fig. 2c) can provide the same quality of positive samples as O2M (Fig. 2a). Bottom: For the low-quality matching, its loss values when using VFL [40] and MAL are marked by , indicating MAL can optimize those cases more effectively.
- 우리의 방법을 통해 기존 실시간 DETR은 학습 비용을 절반으로 줄이면서 더 나은 성능을 달성합니다. 구체적으로, 우리 방법은 D-FINE의 효율적인 모델과 결합된 후 YOLOs를 능가하고 실시간 객체 탐지에서 새로운 SoTA를 확립합니다.
2. Related Work
Object detection with transformer (DETR) [3]은 전통적인 CNN 아키텍처에서 트랜스포머로의 전환을 나타냅니다. 헝가리안 [16] 알고리즘을 일대일 매칭에 사용하여, DETR은 후처리로서의 수작업 NMS의 필요성을 없애고 엔드투엔드 객체 탐지를 가능하게 합니다. 그러나, 이는 느린 수렴과 밀집된 계산으로 어려움을 겪습니다.
포지티브 샘플 증가. 일대일 매칭은 각 타겟을 단일 포지티브 샘플로 제한하여 O2M보다 훨씬 적은 감독을 제공하고 최적화를 방해합니다. 일부 연구는 O2O 프레임워크 내에서 감독을 늘리는 방법을 탐구했습니다. 예를 들어, Group DETR [4]은 "그룹" 개념을 사용하여 O2M을 근사화합니다. 이는 K개의 쿼리 그룹을 사용하며, 여기서 K > 1이고, 각 그룹 내에서 독립적으로 O2O 매칭을 수행합니다. 이를 통해 각 타겟에 K개의 포지티브 샘플이 할당될 수 있습니다. 그러나 그룹 간의 통신을 방지하기 위해 각 그룹은 별도의 디코더 레이어가 필요하며, 궁극적으로 K개의 병렬 디코더가 발생합니다. H-DETR [15]의 하이브리드 매칭 방식은 Group DETR과 유사하게 작동합니다. Co-DETR [46]은 일대다 할당 방식이 모델이 더 독특한 특징 정보를 배우는 데 도움이 된다는 것을 밝혀냈고, 그래서 Faster R-CNN [29] 및 FCOS [31]와 같은 일대다 레이블 할당을 사용하는 보조 헤드를 통해 인코더 표현을 향상시키는 협력적 하이브리드 할당 방식을 제안했습니다. 기존 방법들은 감독을 강화하기 위해 타겟당 포지티브 샘플의 수를 늘리는 것을 목표로 합니다. 대조적으로, 우리의 Dense O2O는 다른 방향을 탐색합니다 - 감독을 효과적으로 증대시키기 위해 학습 이미지당 타겟의 수를 늘리는 것입니다. 추가적인 디코더나 헤드가 필요하고 따라서 학습 자원 소모를 증가시키는 기존 방법들과 달리, 우리의 접근 방식은 계산 비용이 없습니다.
저품질 매치 최적화. 희소하고 무작위로 초기화된 쿼리는 타겟과의 공간적 정렬이 부족하여 모델 수렴을 방해하는 높은 비율의 저품질 매치를 발생시킵니다. 여러 방법들이 앵커 쿼리 [35], DAB-DETR [21], DN-DETR [18], 그리고 밀집된 구별 쿼리 [41]와 같이 쿼리 초기화에 사전 지식을 도입했습니다. 더 최근에는 2단계 패러다임 [29, 45]에서 영감을 받아, DINO [39]와 RTDETR [43]과 같은 방법들이 인코더의 밀집된 출력에서 상위 순위 예측을 활용하여 디코더 쿼리를 개선합니다 [36]. 이러한 전략들은 타겟 영역에 더 가까운 효과적인 쿼리 초기화를 가능하게 합니다. 그러나 저품질 매치는 여전히 중요한 도전 과제로 남아있습니다 [22]. RT-DETR [43]에서는 분류 신뢰도와 상자 품질 사이의 불확실성을 줄여 실시간 성능을 향상시키기 위해 Varifocal Loss(VFL)가 사용됩니다. 그러나 VFL은 주로 저품질 매치가 적은 전통적인 탐지기를 위해 설계되었으며 높은 IoU 최적화에 초점을 맞추고 있어, 최소하고 평평한 손실 값 때문에 낮은 IoU 매치는 최적화되지 않은 상태로 남습니다. 이러한 고급 초기화를 기반으로, 우리는 다양한 품질 수준의 매치를 더 잘 최적화하기 위해 매치 가능성 인식 손실(matchability-aware loss)을 도입하여 Dense O2O 매칭의 효과를 크게 향상시킵니다.
계산 비용 절감. 표준 어텐션 메커니즘은 밀집 계산을 포함합니다. 효율성을 개선하고 다중 스케일 특징과의 상호 작용을 용이하게 하기 위해, 변형 가능한 어텐션 [45], 다중 스케일 변형 가능한 어텐션 [42], 동적 어텐션 [7], 그리고 캐스케이드 윈도우 어텐션 [37]과 같은 여러 고급 어텐션이 개발되었습니다. 또한, 최근 연구는 더 효율적인 인코더를 만드는 데 초점을 맞추고 있습니다. 예를 들어, Lite DETR [17]은 높은 수준과 낮은 수준의 특징 사이의 업데이트를 번갈아 수행하는 인코더 블록을 도입했으며, RTDETR [43]은 인코더에 CNN과 셀프 어텐션을 결합했습니다. 두 설계 모두 자원 소비를 크게 줄이며, 특히 RT-DETR이 그렇습니다. RT-DETR은 DETR 프레임워크 내에서 최초의 실시간 객체 탐지 모델입니다. 이 하이브리드 인코더를 기반으로, D-FINE [27]은 추가 모듈로 RTDETR을 더욱 최적화하고 고정된 좌표를 예측하는 대신 확률 분포를 반복적으로 업데이트하여 회귀 과정을 개선합니다. 이 접근 방식을 통해 D-FINE은 지연 시간과 성능 사이에서 더 유리한 절충을 달성하여 최근 YOLO 모델을 약간 능가합니다. 실시간 DETR의 이러한 발전을 활용하여, 우리 방법은 감소된 학습 비용으로 인상적인 성능을 달성하여 실시간 객체 탐지에서 YOLO 모델을 상당한 차이로 능가합니다.
3. Method
3.1. Preliminaries
O2M vs. O2O. O2M 할당 전략 [10, 44]은 전통적인 객체 탐지기에서 널리 채택되며, 그 감독은 다음과 같이 공식화될 수 있습니다:
여기서 N은 총 타겟 수, Mi는 i번째 타겟에 대한 매치 수, ŷij는 i번째 타겟에 대한 j번째 매치를 나타내며, yi는 i번째 정답 레이블을, f는 손실 함수를 나타냅니다. O2M은 Mi를 증가시켜, 즉 각 타겟에 여러 쿼리를 할당하여(Mi > 1) 감독을 강화하고 따라서 그림 2a에서 설명된 것처럼 밀집된 감독을 제공합니다. 대조적으로, O2O 할당은 각 타겟을 헝가리안 알고리즘을 통해 결정된 단일 최상의 예측과만 쌍을 이루며, 이는 분류 및 위치 파악 오류를 균형 있게 하는 비용 함수를 최소화합니다(그림 2b). O2O는 모든 타겟에 대해 Mi=1인 O2M의 특별한 경우로 간주될 수 있습니다.
Focal loss. Focal loss (FL) [19]는 학습 중에 많은 수의 쉬운 네거티브 샘플이 탐지기를 압도하는 것을 방지하기 위해 도입되었으며, 대신 희소한 어려운 예제에 초점을 맞춥니다. 이는 DETR [39, 45]에서 기본 분류 손실로 사용되며 다음과 같이 정의됩니다:
여기서 y ∈ {0, 1}은 정답 클래스를 지정하고 p ∈ [0, 1]은 전경 클래스에 대한 예측 확률을 나타냅니다. 매개변수 γ는 쉬운 샘플과 어려운 샘플 사이의 균형을 제어하고, α는 전경 클래스와 배경 클래스 간의 가중치를 조정합니다. FL에서는 샘플의 클래스와 신뢰도만 고려되며, 경계 상자 품질, 즉 위치 파악에는 주의를 기울이지 않습니다.
3.2. Improving matching efficiency: Dense
DETR 기반 모델에서 일반적으로 사용되는 일대일(O2O) 매칭 방식은 각 타겟을 단 하나의 예측된 쿼리에만 매칭합니다. 헝가리안 알고리즘 [16]을 통해 구현된 이 접근 방식은 엔드투엔드 학습을 가능하게 하고 NMS의 필요성을 제거합니다. 그러나 O2O의 주요 한계는 SimOTA [44]와 같은 전통적인 일대다(O2M) 방법에 비해 훨씬 적은 수의 포지티브 샘플을 생성한다는 것입니다. 이는 희소한 감독으로 이어져 학습 중 수렴을 늦출 수 있습니다.
이 문제를 더 잘 이해하기 위해, 우리는 MS COCO 데이터셋 [20]에서 ResNet50 백본으로 RTDETRv2 [24]를 학습시켰습니다. 우리는 헝가리안(O2O)과 SimOTA(O2M) 전략 모두에 의해 생성된 포지티브 매치의 수를 비교했습니다. 그림 3a에서 볼 수 있듯이, O2O는 이미지당 10개 미만의 포지티브 매치에서 날카로운 피크를 생성하는 반면, O2M은 훨씬 더 많은 포지티브 매치를 가진 더 넓은 분포를 생성하며, 때로는 단일 이미지에 대해 80개가 넘는 포지티브 샘플을 초과하기도 합니다. 그림 3b는 극단적인 경우 SimOTA가 O2O보다 약 10배 더 많은 매치를 생성함을 더욱 강조합니다. 이는 O2O가 더 적은 포지티브 매치를 가지고 있어 최적화를 늦출 수 있음을 보여줍니다.
우리는 효율적인 대안으로 Dense O2O를 제안합니다. 이 전략은 O2O의 일대일 매칭 구조(Mi=1)를 유지하면서 이미지당 타겟 수(N)를 늘려 더 밀도 높은 감독을 달성합니다. 예를 들어, 그림 2c에서 보듯이, 우리는 원본 이미지를 네 개의 사분면으로 복제하고 이를 원본 이미지 차원을 유지하면서 단일 합성 이미지로 결합합니다. 이는 타겟 수를 1에서 4로 늘려, 매칭 구조를 변경하지 않고 식 1의 감독 수준을 높입니다. Dense O2O는 추가적인 복잡성과 계산 오버헤드 없이 O2M에 필적하는 수준의 감독을 달성합니다.
3.3. Improving matching quality: MatchabilityAware Loss
VFL의 한계. FL [19]을 기반으로 구축된 VariFocal Loss(VFL) [40]는 특히 DETR 모델 [2, 24, 43]에서 객체 탐지 성능을 향상시키는 것으로 나타났습니다. VFL 손실은 다음과 같이 표현됩니다:
여기서 q는 예측된 경계 상자와 그 타겟 상자 간의 IoU를 나타냅니다. 전경 샘플(q > 0)의 경우, 타겟 레이블은 q로 설정되는 반면, 배경 샘플(q = 0)은 타겟 레이블이 0입니다. VFL은 DETR [43]에서 쿼리의 품질을 향상시키기 위해 IoU를 통합합니다.
그러나 VFL은 저품질 매치를 최적화할 때 두 가지 주요 한계를 가집니다: i). 저품질 매치. VFL은 주로 고품질 매치(높은 IoU)에 초점을 맞춥니다. 저품질 매치(낮은 IoU)의 경우, 손실은 작게 유지되어 모델이 저품질 상자에 대한 예측을 개선하는 것을 막습니다. 저품질 매칭(낮은 IoU, 예: 그림 2d)의 경우, 그러나 손실은 최소한으로 유지됩니다(그림 2e에서 ★로 표시됨). ii) 네거티브 샘플. VFL은 겹침이 없는 매치를 네거티브 샘플로 처리하여 포지티브 샘플 수를 줄이고 효과적인 학습을 제한합니다.
이러한 문제들은 밀집된 앵커와 일대다 할당 전략 때문에 전통적인 탐지기에서는 덜 문제가 됩니다. 그러나 쿼리가 희소하고 매칭이 더 엄격한 DETR 프레임워크에서는 이러한 한계가 더욱 두드러집니다.
Matchability-Aware Loss. 이러한 문제를 해결하기 위해, 우리는 VFL의 장점을 확장하면서 단점을 완화하는 Matchability-Aware Loss(MAL)를 제안합니다. MAL은 매칭 품질을 손실 함수에 직접 통합하여 저품질 매치에 더 민감하게 만듭니다.
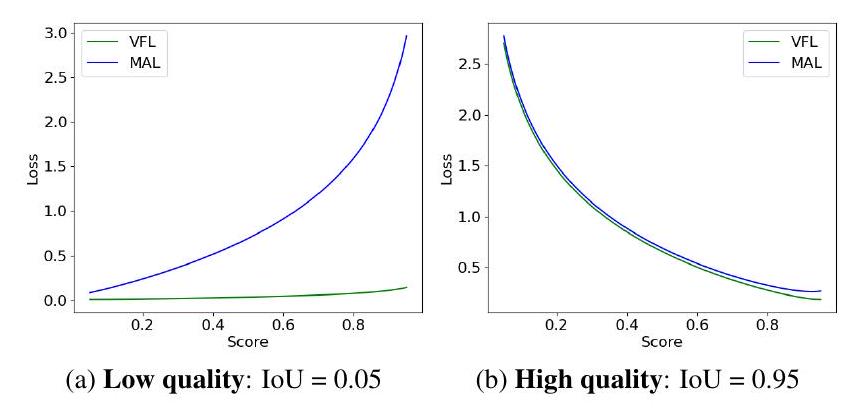
Figure 4. VFL vs. MAL Comparison. Comparison of VFL and our MAL for low-quality ( , Fig. 4a) and high-quality ( , Fig. 4b) matching cases. MAL의 공식은 다음과 같습니다:
VFL과 비교하여, 우리는 몇 가지 작지만 중요한 변경을 도입했습니다. 구체적으로, 타겟 레이블은 q에서 q^γ로 수정되어 포지티브 샘플과 네거티브 샘플에 대한 손실 가중치를 단순화하고 포지티브 샘플과 네거티브 샘플의 균형을 맞추기 위해 사용되는 하이퍼파라미터 α를 제거했습니다. 이 변경은 고품질 상자에 대한 과도한 강조를 피하고 전반적인 학습 과정을 개선하는 데 도움이 됩니다. 이는 VFL(그림 2e)과 MAL(그림 2f) 사이의 손실 지형에서 쉽게 볼 수 있습니다. γ의 영향은 섹션 4.5에서 제공됩니다.
VFL과의 비교. 우리는 MAL과 VFL을 저품질 및 고품질 매치 모두를 처리하는 데 있어서 비교합니다. 저품질 매치의 경우(IoU=0.05, 그림 4a), MAL은 예측 신뢰도가 증가함에 따라 손실이 더 급격하게 증가하는 것을 보여주며, 이는 거의 변하지 않는 VFL과 대조됩니다. 고품질 매치의 경우(IoU=0.95, 그림 4b), MAL과 VFL 모두 유사하게 수행되어, MAL이 고품질 매치에 대한 성능을 저하시키지 않으면서 학습 효율성을 향상시킨다는 것을 확인시켜 줍니다.
4. Experiments
4.1. Training details
Dense O2O를 위해, 우리는 이미지당 추가 포지티브 샘플을 생성하기 위해 모자이크 증강 [1]과 믹스업 증강 [38]을 적용합니다. 이러한 증강의 영향은 섹션 4.5에서 논의됩니다. 우리는 MS-COCO 데이터셋 [20]에서 AdamW 옵티마이저 [23]를 사용하여 모델을 학습합니다. RT-DETR [24, 43] 및 D-FINE [27]에서와 같이 색상 지터 및 줌아웃과 같은 표준 데이터 증강이 사용됩니다. 우리는 플랫 코사인 학습률 스케줄러 [25]를 사용하고 새로운 데이터 증강 스케줄러를 제안합니다. 어텐션 학습을 단순화하기 위해 처음 몇 번의 학습 에포크(보통 4번)에서 데이터 증강 워밍업 전략이 사용됩니다.
Table 1. Comparison with real-time object detectors on COCO [20] val2017. By integrating our method into D-FINE-L [27] and D-FINE-X [27], we build DEIM-D-FINE-L and DEIM-D-FINE-X. We compare our method with YOLO-based and DETR-based real-time object detectors. indicates that the NMS is tuned with a confidence threshold of 0.01 .
| Model | #Epochs | #Params | GFLOPs | Latency (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| YOLO-based Real-time Object Detectors | ||||||||||
| YOLOv8-L [12] | 500 | 43 | 165 | 12.31 | 52.9 | 69.8 | 57.5 | 35.3 | 58.3 | 69.8 |
| YOLOv8-X [12] | 500 | 68 | 257 | 16.59 | 53.9 | 71.0 | 58.7 | 35.7 | 59.3 | 70.7 |
| YOLOv9-C [34] | 500 | 25 | 102 | 10.66 | 53.0 | 70.2 | 57.8 | 36.2 | 58.5 | 69.3 |
| YOLOv9-E [34] | 500 | 57 | 189 | 20.53 | 55.6 | 72.8 | 60.6 | 40.2 | 61.0 | 71.4 |
| Gold-YOLO-L [33] | 300 | 75 | 152 | 9.21 | 53.3 | 70.9 | - | 33.8 | 58.9 | 69.9 |
| YOLOv10-L* [32] | 500 | 24 | 120 | 7.66 | 53.2 | 70.1 | 58.1 | 35.8 | 58.5 | 69.4 |
| YOLOv10-X [32] | 500 | 30 | 160 | 10.74 | 54.4 | 71.3 | 59.3 | 37.0 | 59.8 | 70.9 |
| YOLO11-L* [13] | 500 | 25 | 87 | 6.31 | 52.9 | 69.4 | 57.7 | 35.2 | 58.7 | 68.8 |
| YOLO11-X* [13] | 500 | 57 | 195 | 10.52 | 54.1 | 70.8 | 58.9 | 37.0 | 59.2 | 69.7 |
| DETR-based Real-time Object Detectors | ||||||||||
| RT-DETR-HG-L [43] | 72 | 32 | 107 | 8.77 | 53.0 | 71.7 | 57.3 | 34.6 | 57.4 | 71.2 |
| RT-DETR-HG-X [43] | 72 | 67 | 234 | 13.51 | 54.8 | 73.1 | 59.4 | 35.7 | 59.6 | 72.9 |
| D-FINE-L [27] | 72 | 31 | 91 | 8.07 | 54.0 | 71.6 | 58.4 | 36.5 | 58.0 | 71.9 |
| DEIM-D-FINE-L | 50 | 31 | 91 | 8.07 | 54.7 | 72.4 | 59.4 | 36.9 | 59.6 | 71.8 |
| D-FINE-X [27] | 72 | 62 | 202 | 12.89 | 55.8 | 73.7 | 60.2 | 37.3 | 60.5 | 73.4 |
| DEIM-D-FINE-X | 50 | 62 | 202 | 12.89 | 56.5 | 74.0 | 61.5 | 38.8 | 61.4 | 74.2 |
학습 에포크의 50% 이후에 Dense O2O를 비활성화하면 더 나은 결과를 얻을 수 있습니다. RT-DETRv2 [43]를 따라, 우리는 마지막 두 에포크에서 데이터 증강을 끕니다. 우리의 LR 및 DataAug 스케줄러는 그림 5에 구체적으로 묘사되어 있습니다. 우리의 백본은 ImageNet1k [8]에서 사전 학습되었습니다. 우리는 MS-COCO 검증 세트에서 640x640 해상도로 모델을 평가합니다. 하이퍼파라미터에 대한 추가 세부 정보는 보충 자료에 제공됩니다.
4.2. Comparisons with real-time detectors
우리는 우리의 방법을 D-FINE-L [27] 및 D-FINEX [27]에 통합하여 DEIM-D-FINE-L 및 DEIM-D-FINEX를 구축합니다. 그런 다음 이러한 모델을 평가하고 YOLOv8 [12], YOLOv9 [34], YOLOv10 [34], YOLOv11 [13]과 같은 최첨단 모델과 RT-DETRv2 [24] 및 D-FINE [27]과 같은 DETR 기반 모델에 대한 실시간 객체 탐지 성능을 벤치마킹합니다. 표 1은 에포크, 파라미터, GFLOPs, 지연 시간 및 탐지 정확도 측면에서 모델을 비교합니다. 더 작은 모델 변형(S 및 M)의 추가 비교는 보충 자료에 포함되어 있습니다.
우리의 방법은 학습 비용, 추론 지연 시간, 탐지 정확도 측면에서 현재 최첨단 모델을 능가하며, 실시간 객체 탐지를 위한 새로운 벤치마크를 설정합니다. D-FINE [27]은 증류 및 경계 상자 개선을 통합하여 RT-DETRv2 [24]의 성능을 향상시켜 선도적인 실시간 탐지기로 자리매김한 매우 최근의 연구라는 점에 유의하십시오. 우리의 DEIM은 D-FINE의 성능을 더욱 향상시켜 추론 지연 시간을 추가하지 않으면서 학습 비용을 30% 줄이면서 0.7 AP 이득을 달성합니다. 가장 큰 개선은 작은 객체 탐지에서 관찰되며, D-FINE-X [27]는 우리 방법으로 학습했을 때 DEIM-D-FINE-X로서 1.5 AP 이득을 달성합니다.
YOLOv11-X [13]와 직접 비교했을 때, 우리의 DEIM-D-FINE-L은 이 SoTA 모델을 능가하여 약간 더 높은 성능(54.7 대 54.1 AP)을 달성하고 추론 시간을 20%(8.07ms 대 10.74ms) 단축합니다. YOLOv10 [34]이 하이브리드 O2M 및 O2O 할당 전략을 사용하지만, 우리 모델은 일관되게 YOLOv10을 능가하여 Dense O2O의 효과를 입증합니다.
다른 DETR 기반 모델에 비해 작은 객체 탐지에서 상당한 개선이 있었음에도 불구하고, 우리 접근 방식은 YOLO 모델에 비해 작은 객체 AP에서 약간의 감소를 보입니다. 예를 들어, YOLOv9-E [34]는 작은 객체에서 D-FINEL [27]을 약 1.4 AP 능가하지만, 우리 모델은 더 높은 전체 AP(56.5 대 55.6)를 달성합니다. 이 격차는 DETR 아키텍처 내에서 작은 객체 탐지의 지속적인 과제를 강조하고 추가 개선을 위한 잠재적인 영역을 시사합니다.
4.3. Comparisons with ResNet [14]-based DETRs
대부분의 DETR 연구는 ResNet [14]을 백본으로 사용하며, 기존 DETR 변형 전반에 걸친 포괄적인 비교를 가능하게 하기 위해, 우리는 최첨단 DETR 변형인 RTDETRv2 [24]에도 우리의 방법을 적용했습니다. 결과는 표 2에 요약되어 있습니다. 효과적인 학습을 위해 500 에포크가 필요한 원래의 DETR과 달리, 우리를 포함한 최근 DETR 변형은 모델 성능을 향상시키면서 학습 시간을 단축합니다. 우리 방법은 가장 큰 개선을 보여주며, 단 36 에포크 만에 모든 변형을 능가합니다. 구체적으로, DEIM은 학습 시간을 절반으로 줄이고 ResNet-50 [14] 및 ResNet-101 [14] 백본을 사용한 RT-DETRv2 [24]에서 AP를 각각 0.5 및 0.9 증가시킵니다. 더욱이, ResNet-50 [14] 백본을 사용하면 DINO-DeformableDETR [39]을 2.7 AP 능가합니다.
Table 2. Comparison with ResNet-based DETRs on COCO [20] val2017. By integrating our method into ResNet50 [14] and ResNet101 [14], we build DEIM-RT-DETRv2-R50 and DEIM-RT-DETRv2-R101. We compare our method with competitive DETRbased object detectors that use ResNet50 [14] or ResNet101 [14] as backbones.
| Model | #Epochs | #Params | GFLOPs | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ResNet50 [14]-based | |||||||||
| DETR-DC5 [3] | 500 | 41 | 187 | 43.3 | 63.1 | 45.9 | 22.5 | 47.3 | 61.1 |
| Anchor-DETR-DC5 [35] | 50 | 39 | 172 | 44.2 | 64.7 | 47.5 | 24.7 | 48.2 | 60.6 |
| Conditional-DETR-DC5 [26] | 108 | 44 | 195 | 45.1 | 65.4 | 48.5 | 25.3 | 49.0 | 62.2 |
| Efficient-DETR [36] | 36 | 35 | 210 | 45.1 | 63.1 | 49.1 | 28.3 | 48.4 | 59.0 |
| SMCA-DETR [11] | 108 | 40 | 152 | 45.6 | 65.5 | 49.1 | 25.9 | 49.3 | 62.6 |
| Deformable-DETR [45] | 50 | 40 | 173 | 46.2 | 65.2 | 50.0 | 28.8 | 49.2 | 61.7 |
| DAB-Deformable-DETR [21] | 50 | 48 | 195 | 46.9 | 66.0 | 50.8 | 30.1 | 50.4 | 62.5 |
| DN-Deformable-DETR [18] | 50 | 48 | 195 | 48.6 | 67.4 | 52.7 | 31.0 | 52.0 | 63.7 |
| DINO-Deformable-DETR [39] | 36 | 47 | 279 | 50.9 | 69.0 | 55.3 | 34.6 | 54.1 | 64.6 |
| RT-DETR [43] | 72 | 42 | 136 | 53.1 | 71.3 | 57.7 | 34.8 | 58.0 | 70.0 |
| RT-DETRv2 [24] | 72 | 42 | 136 | 53.4 | 71.6 | 57.4 | 36.1 | 57.9 | 70.8 |
| DEIM-RT-DETRv2 | 36 | 42 | 136 | 53.9 | 71.7 | 58.6 | 36.7 | 58.9 | 70.9 |
| DEIM-RT-DETRv2 | 60 | 42 | 136 | 54.3 | 72.3 | 58.8 | 37.5 | 58.7 | 70.8 |
| ResNet101 [14]-based | |||||||||
| DETR-DC5 [3] | 500 | 60 | 253 | 44.9 | 64.7 | 47.7 | 23.7 | 49.5 | 62.3 |
| Anchor-DETR-DC5 [35] | 50 | - | - | 45.1 | 65.7 | 48.8 | 25.8 | 49.4 | 61.6 |
| Conditional-DETR-DC5 [26] | 108 | 63 | 262 | 45.9 | 66.8 | 49.5 | 27.2 | 50.3 | 63.3 |
| Efficient-DETR [36] | 36 | 54 | 289 | 45.7 | 64.1 | 49.5 | 28.2 | 49.1 | 60.2 |
| SMCA-DETR [11] | 108 | 58 | 218 | 46.3 | 66.6 | 50.2 | 27.2 | 50.5 | 63.2 |
| RT-DETR [43] | 72 | 76 | 259 | 54.3 | 72.7 | 58.6 | 36.0 | 58.8 | 72.1 |
| RT-DETRv2 [24] | 72 | 76 | 259 | 54.3 | 72.8 | 58.8 | 35.8 | 58.8 | 72.1 |
| DEIM-RT-DETRv2 | 36 | 76 | 259 | 55.2 | 73.3 | 59.9 | 37.8 | 59.6 | 72.8 |
| DEIM-RT-DETRv2 | 60 | 76 | 259 | 55.5 | 73.5 | 60.3 | 37.9 | 59.9 | 73.0 |
Table 3. Comparison of the D-FINE and when with our DEIM on CrowdHuman [30]. Both are trained with 120 epochs.
| Method | AP | |||||
|---|---|---|---|---|---|---|
| D-FINE-L | 56.0 | 87.2 | 59.4 | 29.0 | 46.1 | 54.6 |
| w/ DEIM |
DEIM은 또한 작은 객체 감지를 크게 향상시킵니다. 예를 들어, RT-DETRv2 [24]와 비슷한 전체 AP를 달성하면서도, 우리의 DEIM-RT-DETRv2-R50은 작은 객체에서 RT-DETRv2를 1.3 AP 능가합니다. 이 개선은 더 큰 ResNet101 백본에서 더욱 두드러지며, 우리의 DEIM-RT-DETRv2-R101은 작은 객체에서 RT-DETRv2-R101을 2.1 AP 능가합니다. 72 에포크로 학습을 연장하면 전체 성능이 더욱 향상되며, 특히 ResNet-50 백본에서 그렇습니다. 이는 더 작은 모델이 추가 학습으로부터 이점을 얻는다는 것을 나타냅니다.
4.4. Comparisons on CrowdHuman
CrowdHuman [30]은 밀집된 군중 시나리오에서 객체 탐지기를 평가하기 위해 설계된 벤치마크 데이터셋입니다. 우리는 D-FINE에 제공된 구성을 따라 D-FINE과 제안된 방법을 CrowdHuman 데이터셋에 모두 적용했습니다. 표 3에서 볼 수 있듯이, 우리의 접근 방식(DEIM으로 강화된 D-FINE-L)은 D-FINE-L에 비해 1.5 AP의 눈에 띄는 개선을 달성합니다. 특히, 우리 방법은 작은 객체(APs)와 고품질 탐지(AP75)에서 상당한 성능 향상(3% 이상의 개선)을 제공하여, 도전적인 시나리오에서 객체를 더 정확하게 탐지하는 능력을 보여줍니다.
Table 4. Comparison of Dense O2O methods with different combinations of mosaic and mixup augmentation strategies. The probability values denote the likelihood of applying mosaic and mixup in each mini-batch during training.
| Mosaic Prob. | Mixup Prob. | AP | |||||
|---|---|---|---|---|---|---|---|
| Training 12 Epochs | |||||||
| 0.0 | 0.0 | 49.6 | 67.1 | 53.6 | 31.3 | 54.2 | 67.8 |
| 0.5 | 0.0 | 50.4 | 68.4 | 54.5 | 32.7 | 54.6 | 68.1 |
| 0.0 | 0.5 | 50.1 | 67.7 | 54.0 | 31.1 | 54.5 | 68.7 |
| 0.5 | 0.5 | 50.4 | 68.1 | 54.2 | 32.7 | 54.7 | 68.2 |
| Training 24 Epochs | |||||||
| 0.0 | 0.0 | 51.7 | 69.5 | 55.8 | 32.8 | 56.4 | 69.7 |
| 0.5 | 0.0 | 51.9 | 70.1 | 55.9 | 34.9 | 56.1 | 69.3 |
| 0.0 | 0.5 | 51.5 | 69.4 | 55.5 | 33.2 | 56.3 | 69.3 |
| 0.5 | 0.5 | 52.5 | 70.6 | 56.7 | 34.9 | 57.1 | 70.1 |
게다가, 이 실험은 다양한 데이터셋에 걸친 DEIM의 강력한 일반화 능력을 강조하며 그 견고함을 확인시켜 줍니다.
4.5. Analysis
다음 연구에서는 RT-DETRv2 [24]와 ResNet50 [14]을 쌍으로 사용하여 실험을 수행하고, 별도의 명시가 없는 한 MS-COCO val2017의 성능을 기본 설정으로 보고합니다.
Dense O2O를 달성하는 방법. 우리는 Dense O2O를 구현하기 위해 두 가지 접근 방식, 즉 mosaic [1]과 mixup [38]을 탐색했습니다. Mosaic은 네 개의 이미지를 하나로 결합하는 데이터 증강 기법이며, mixup은 두 이미지를 임의의 비율로 겹치는 기법입니다. 두 방법 모두 이미지당 타겟 수를 효과적으로 증가시켜 학습 중 감독을 강화합니다.
표 4에서 볼 수 있듯이, mosaic과 mixup 모두 타겟 증강 없이 학습한 경우에 비해 12 에포크 후에 상당한 개선을 보이며, 이는 Dense O2O의 효과를 강조합니다. 더욱이, mosaic과 mixup을 결합하면 모델 수렴이 가속화되어 증강된 감독의 이점을 더욱 강조합니다. 우리는 또한 한 번의 학습 에포크 동안 이미지당 포지티브 샘플의 수를 추적했으며, 결과는 그림 6에 나와 있습니다. 전통적인 O2O에 비해 Dense O2O는 포지티브 샘플을 크게 증가시킵니다.
전반적으로, Dense O2O는 이미지당 타겟 수를 늘려 감독을 강화하고, 이는 더 빠른 모델 수렴으로 이어집니다. Mosaic과 mixup은 이 목표를 달성하는 간단하고 계산적으로 효율적인 기술이며, 그 효과는 학습 중 타겟 수를 늘리기 위한 다른 방법을 탐색할 추가적인 잠재력을 시사합니다.
MAL에서 γ의 영향(식 4). 표 5의 결과는 24 에포크 후 MAL에 대한 다른 γ 값의 영향을 보여줍니다. 이 실험들을 바탕으로, 우리는 γ를 1.5로 경험적으로 설정했는데, 이것이 최상의 성능을 내기 때문입니다.
Table 5. Impact of in MAL(Eqn. 4). We report the performance on COCO [20] val2017 for 24 epochs.
| 1.3 | 1.5 | 1.8 | 2.0 | |
|---|---|---|---|---|
| AP | 52.2 | 52.1 | 51.9 |
Table 6. Impact of Dense O2O and MAL. We conduct experiments with RT-DETRv2-R50 [24] and D-FINE-L [27].
| Epochs | Dense O2O | MAL | AP | ||
|---|---|---|---|---|---|
| RT-DETRv2-R50 [24] | |||||
| 72 | 53.4 | 71.6 | 57.4 | ||
| 36 | 53.6 | 71.9 | 58.2 | ||
| 53.9 | 71.7 | 58.6 | |||
| D-FINE-L [27] | |||||
| 72 | 54.0 | 71.6 | 58.4 | ||
| 36 | 54.2 | 72.1 | 58.9 | ||
| 54.6 | 72.2 | 59.5 |
Dense O2O와 MAL의 효과. 표 6은 두 가지 핵심 구성 요소인 Dense O2O와 MAL의 효과를 보여줍니다. Dense O2O는 모델 수렴을 크게 가속화하여, 원래 모델에 필요한 72 에포크와 대조적으로 단 36 에포크 만에 기준선과 유사한 성능을 달성합니다. MAL과 결합하면 우리 방법은 성능을 더욱 향상시킵니다. 이 개선은 주로 더 나은 상자 품질에 의해 주도되며, 이는 저품질 매치를 최적화하여 고품질 상자 예측을 개선하려는 우리의 목표와 일치합니다. 전반적으로, Dense O2O와 MAL은 RT-DETRv2와 DFINE 모두에서 일관되게 성능 향상을 제공하여 견고성과 일반화 가능성을 보여줍니다.
Table 7. Training time in GPU hours.
| Method | Epoch | #GPU hr | AP |
|---|---|---|---|
| RT-DETRv2-R50 | 1 | 1.181 | - |
| w/ DEIM | 1 | 1.183 | - |
| RT-DETRv2-R50 | 72 | 53.4 | |
| w/ DEIM |
Table 8. Fine-tuned results from Object365 pre-training.
| Method | Epoch | AP | ||
|---|---|---|---|---|
| D-FINE-X | 32 | 59.3 | 64.6 | |
| w/ DEIM | 76.4 |
학습 속도. 우리는 캐싱이 있는 Mosaic과 배치 내 Mixup을 사용하여 효율적인 구현을 제공합니다. 표 7은 단일 4090 GPU에서의 1-에포크 학습 시간을 보여주며, 여기서 DEIM은 기준선(1.183 대 1.181)과 거의 같은 속도이며 수렴하는 데 더 적은 학습 시간(71 대 85 시간)이 필요합니다. 이는 우리의 접근 방식이 효율성을 유지하면서 수렴을 개선함을 강조합니다.
Object365에서의 파인튜닝. 우리는 D-FINE의 사전 학습된 Object365 가중치를 직접 사용하고 DEIM 유무에 따른 파인튜닝 결과를 비교합니다. 표 8에서 볼 수 있듯이, DEIM은 더 적은 파인튜닝 에포크로 더 나은 성능을 달성합니다. 이는 DEIM이 더 큰 데이터셋에서 사전 학습되었을 때에도 일관된 이득을 제공함을 더욱 검증합니다.
5. Conclusion
본 논문에서는 매칭 개선을 통해 DETR 기반 실시간 객체 탐지기의 수렴을 가속화하도록 설계된 방법인 DEIM을 제시합니다. DEIM은 이미지당 포지티브 샘플 수를 늘리는 Dense O2O 매칭과, 다양한 품질의 매치를 최적화하고 특히 저품질 매치를 향상시키도록 설계된 새로운 손실 함수인 MAL을 통합합니다. 이 조합은 학습 효율성을 크게 향상시켜 DEIM이 YOLOv11과 같은 모델에 비해 더 적은 에포크로 우수한 성능을 달성할 수 있도록 합니다. DEIM은 RT-DETR 및 D-FINE과 같은 SoTA DETR 모델에 비해 명백한 이점을 보여주며, 추론 지연 시간을 손상시키지 않으면서 탐지 정확도 및 학습 속도에서 측정 가능한 이득을 보여줍니다. 이러한 속성들은 DEIM을 실시간 애플리케이션을 위한 매우 효과적인 솔루션으로 확립하며, 다른 고성능 탐지 작업 전반에 걸쳐 추가적인 개선 및 적용 가능성을 가지고 있습니다.
감사의 말. 귀중한 논의를 해주신 Xuanlong Yu, Longfei Liu, Haiyang Xie 님께 감사드립니다. 이 연구는 허페이 사범대학교의 수평 프로젝트(No. HXXM2022236)와 안후이성 대학의 국가 자연 과학 재단 주요 프로젝트(No. 2023AH051302)의 지원을 받았습니다.
References
[1] Alexey Bochkovskiy, Chien-Yao Wang, and HongYuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv, 2020. 1, 2, 5, 7 [2] Zhi Cai, Songtao Liu, Guodong Wang, Zheng Ge, Xiangyu Zhang, and Di Huang. Align-detr: Improving detr with simple iou-aware bce loss. In BMVC, 2024. 5 [3] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In , 3, 4, 7 [4] Qiang Chen, Xiaokang Chen, Jian Wang, Shan Zhang, Kun Yao, Haocheng Feng, Junyu Han, Errui Ding, Gang Zeng, and Jingdong Wang. Group detr: Fast detr training with group-wise one-to-many assignment. In ICCV, 2023. 2, 3 [5] Xiaozhi Chen, Kaustav Kundu, Ziyu Zhang, Huimin Ma, Sanja Fidler, and Raquel Urtasun. Monocular 3d object detection for autonomous driving. In CVPR, 2016. 1 [6] Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. Multi-view 3d object detection network for autonomous driving. In CVPR, 2017. 1 [7] Xiyang Dai, Yinpeng Chen, Jianwei Yang, Pengchuan Zhang, Lu Yuan, and Lei Zhang. Dynamic detr: End-toend object detection with dynamic attention. In ICCV, 2021. 4 [8] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009. 6 [9] Andreas Ess, Konrad Schindler, Bastian Leibe, and Luc Van Gool. Object detection and tracking for autonomous navigation in dynamic environments. The International Journal of Robotics Research, 2010. 1 [10] Chengjian Feng, Yujie Zhong, Yu Gao, Matthew R Scott, and Weilin Huang. Tood: Task-aligned one-stage object detection. In ICCV, 2021. 4 [11] Peng Gao, Minghang Zheng, Xiaogang Wang, Jifeng Dai, and Hongsheng Li. Fast convergence of detr with spatially modulated co-attention. In ICCV, 2021. 7 [12] Jocher Glenn. Yolov8. https://docs.ultralytics. com/models/yolov8/, 2023. 6, 2 [13] Jocher Glenn. Yolo11. https://docs.ultralytics. com/models/yololl/, 2024. 2, 6 [14] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016. 6, 7 [15] Ding Jia, Yuhui Yuan, Haodi He, Xiaopei Wu, Haojun Yu, Weihong Lin, Lei Sun, Chao Zhang, and Han Hu. Detrs with hybrid matching. In CVPR, 2023. 3 [16] Harold W Kuhn. The hungarian method for the assignment problem. Naval research logistics quarterly, 1955. 2, 3, 4 [17] Feng Li, Ailing Zeng, Shilong Liu, Hao Zhang, Hongyang Li, Lei Zhang, and Lionel M Ni. Lite detr: An interleaved multi-scale encoder for efficient detr. In CVPR, 2023. 4 [18] Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. Dn-detr: Accelerate detr training by introducing query denoising. In CVPR, 2022. 2, 3, 7 [19] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In ICCV, 2017. 2, 4, 5 [20] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. 1, 2, 4, 5, 6, 7, 8 [21] Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. Dab-detr: Dynamic anchor boxes are better queries for detr. In ICLR, 2022. 3, 7 [22] Shilong Liu, Tianhe Ren, Jiayu Chen, Zhaoyang Zeng, Hao Zhang, Feng Li, Hongyang Li, Jun Huang, Hang Su, Jun Zhu, et al. Detection transformer with stable matching. In ICCV, 2023. 4 [23] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2017. 5 [24] Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, and Yi Liu. Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer. arXiv, 2024. 2, 4, 5, 6, 7, 8, 1 [25] Chengqi Lyu, Wenwei Zhang, Haian Huang, Yue Zhou, Yudong Wang, Yanyi Liu, Shilong Zhang, and Kai Chen. Rtmdet: An empirical study of designing real-time object detectors. arXiv, 2022. 5, 1 [26] Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, and Jingdong Wang. Conditional detr for fast training convergence. In ICCV, 2021.7 [27] Yansong Peng, Hebei Li, Peixi Wu, Yueyi Zhang, Xiaoyan Sun, and Feng Wu. D-fine: Redefine regression task in detrs as fine-grained distribution refinement. arXiv, 2024. 2, 4, 5, 6, 8, 1 [28] J Redmon. You only look once: Unified, real-time object detection. In CVPR, 2016. 1 [29] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. TPAMI, 2016. 2, 3 [30] Shuai Shao, Zijian Zhao, Boxun Li, Tete Xiao, Gang Yu, Xiangyu Zhang, and Jian Sun. Crowdhuman: A benchmark for detecting human in a crowd. arXiv, 2018. 7 [31] Zhi Tian, Xiangxiang Chu, Xiaoming Wang, Xiaolin Wei, and Chunhua Shen. Fully convolutional one-stage 3d object detection on lidar range images. In NIPS, 2022. 2, 3 [32] Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Yolov10: Real-time end-toend object detection. 2024. 1, 2, 6 [33] Chengcheng Wang, Wei He, Ying Nie, Jianyuan Guo, Chuanjian Liu, Yunhe Wang, and Kai Han. Gold-yolo: Efficient object detector via gather-and-distribute mechanism. NeurIPS, 2023. 6, 2 [34] Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao. Yolov9: Learning what you want to learn using programmable gradient information. arXiv, 2024. 1, 6, 2 [35] Yingming Wang, Xiangyu Zhang, Tong Yang, and Jian Sun. Anchor detr: Query design for transformer-based detector. In AAAI, 2022. 3, 7 [36] Zhuyu Yao, Jiangbo Ai, Boxun Li, and Chi Zhang. Efficient detr: improving end-to-end object detector with dense prior. arXiv, 2021. 3, 7 [37] Mingqiao Ye, Lei Ke, Siyuan Li, Yu-Wing Tai, Chi-Keung Tang, Martin Danelljan, and Fisher Yu. Cascade-detr: delv- ing into high-quality universal object detection. In , 2023. 4 [38] Hongyi Zhang. mixup: Beyond empirical risk minimization. In ICLR, 2017. 2, 5, 7 [39] Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. In ICLR, 2023. 2, 3, 4, 6, 7 [40] Haoyang Zhang, Ying Wang, Feras Dayoub, and Niko Sunderhauf. Varifocalnet: An iou-aware dense object detector. In CVPR, 2021. 2, 3, 5 [41] Shilong Zhang, Xinjiang Wang, Jiaqi Wang, Jiangmiao Pang, Chengqi Lyu, Wenwei Zhang, Ping Luo, and Kai Chen. Dense distinct query for end-to-end object detection. In CVPR, 2023. 3 [42] Chuyang Zhao, Yifan Sun, Wenhao Wang, Qiang Chen, Errui Ding, Yi Yang, and Jingdong Wang. Ms-detr: Efficient detr training with mixed supervision. In CVPR, 2024. 4 [43] Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. Detrs beat yolos on real-time object detection. In CVPR, 2024. 2, 3, 4, 5, 6, 7, 1 [44] Ge Zheng, Liu Songtao, Wang Feng, Li Zeming, and Sun Jian. Yolox: Exceeding yolo series in 2021. arXiv, 2021. 1, 2, 4 [45] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. In ICLR, 2021. 2, 3, 4, 7 [46] Zhuofan Zong, Guanglu Song, and Yu Liu. Detrs with collaborative hybrid assignments training. In ICCV, 2023. 2, 3
DEIM: DETR with Improved Matching for Fast Convergence
Supplementary Material
1. Experimental Settings
데이터셋 및 메트릭. 우리는 COCO [20] 데이터셋에서 우리의 방법을 평가하고, train2017에서 DEIM을 학습시키고 val2017에서 검증합니다. 표준 COCO 메트릭이 보고되며, 여기에는 IoU 임계값 0.50에서 0.95까지 0.05 단계 크기로 평균화된 AP, AP50, AP75, 그리고 다른 객체 스케일에서의 AP: AP_S, AP_M, AP_L이 포함됩니다.
Table 9. Different hyperparameters for D-FINE models trained with DEIM.
| D-FINE | X | L | M | S |
|---|---|---|---|---|
| Base LR | 5e-4 | 5e-4 | ||
| Min LR | 2.5e-4 | 2.5e-4 | ||
| Backbone LR | 5e-6 | |||
| Backbone MinLR | 2.5e-6 | |||
| Weight of MAL | 1 | 1 | 1 | 1 |
| in MAL | 1.5 | 1.5 | 1.5 | 1.5 |
| Freeze Backbone BN | False | False | False | False |
| Decoder Act. | SiLU | SiLU | SiLU | SiLU |
| Epochs | 50 | 50 | 90 | 120 |
Table 10. Different hyperparameters for RT-DETRv2 models trained with DEIM.
| RT-DETRv2 | |||||
|---|---|---|---|---|---|
| Base LR | |||||
| Min LR | |||||
| Backbone LR | |||||
| Backbone MinLR | |||||
| Weight of MAL | 1 | 1 | 1 | 1 | 1 |
| in MAL | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 |
| Freeze Backbone BN | False | False | False | False | False |
| Decoder Act. | SiLU | SiLU | SiLU | SiLU | SiLU |
| Epochs | 60 | 60 | 60 | 120 | 120 |
구현 세부사항. 우리는 D-FINE [27] 및 RT-DETRv2 [24, 43] 프레임워크를 사용하여 우리의 방법을 구현하고 검증합니다. 대부분의 하이퍼파라미터는 원래 설정을 따르며, 차이점은 각각 표 9와 표 10에 자세히 설명되어 있습니다. RTMDet [25]의 FlatCosine LR 스케줄러에서 영감을 받아, 우리는 Dense O2O에 맞춰진 새로운 데이터 증강 스케줄러를 제안합니다. DETR의 어텐션 메커니즘은 위치 파악 및 분류를 위한 정확한 객체 특징을 추출하는 데 중요합니다. 그러나 유도적 편향 없이 처음부터 어텐션을 학습하는 것은 어려울 수 있습니다. 이를 완화하기 위해, 우리는 초기 에포크 동안 고급 데이터 증강을 비활성화하여 학습을 단순화하는 데이터 증강 워밍업 전략(DataAug Warmup)을 도입합니다.
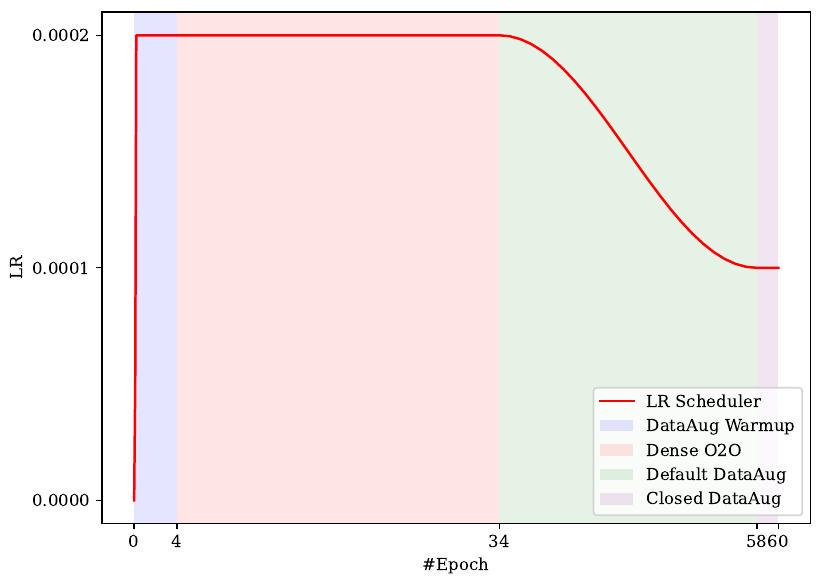
Figure 5. An illustrated example of our proposed novel training scheme for learning rate and data augmentation scheduler. 60번의 학습 에포크에 대한 FlatCosine LR 및 제안된 DataAug 스케줄러의 예는 그림 5에 나와 있습니다.
2. Comparison with Lighter YOLO Detectors
우리는 표 11에서 더 가벼운 실시간 모델(S 및 M 크기)과의 비교 결과를 제시합니다. 강력한 실시간 탐지기인 RTDETRv2 [24] 및 D-FINE [27]을 기반으로, 우리의 DEIM은 전반적으로 상당한 개선을 달성합니다. 특히, RTDETRv2에서는 세 가지 모델 크기 모두 약 1 AP의 개선을 보이며, DEIM-RT-DETRv2-M*은 1.3 AP의 놀라운 이득을 달성합니다. 다른 방법에 비해 우리의 접근 방식은 최신 기술 수준의 결과를 달성합니다.
3. Additional Results
사소한 수정의 효과. 우리는 백본의 BN 레이어 고정 해제, FlatCosine LR 스케줄러 채택, 디코더 활성화 함수를 SiLU로 교체하는 등 사소한 수정을 D-FINE-L과 D-FINE-X 모두에 통합했습니다. 36 에포크 동안 학습한 후, 이러한 변경 사항이 D-FINE-L에는 영향을 미치지 않았지만 D-FINE-X에서는 0.1 AP 개선(55.4 대 55.5)을 가져왔다는 것을 관찰했습니다. 이 구성은 우리 실험의 새로운 기준선으로 사용됩니다.
Dense O2O 사용 여부에 따른 포지티브 샘플 수. 한 에포크의 학습 동안, 우리는 동일한 학습 이미지에서 포지티브 샘플 수를 비교했습니다.
Table 11. Comparison with S and M sized real-time object detectors on COCO [20] val2017. * indicates that the NMS is tuned with a confidence threshold of 0.01 .
| Model | #Epochs | #Params. | GFLOPs | Latency (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| YOLO-based Real-time Object Detectors | ||||||||||
| YOLOv8-S [12] | 500 | 11 | 29 | 6.96 | 44.9 | 61.8 | 48.6 | 25.7 | 49.9 | 61.0 |
| YOLOv8-M [12] | 500 | 26 | 79 | 9.66 | 50.2 | 67.2 | 54.6 | 32.0 | 55.7 | 66.4 |
| YOLOv9-S [34] | 500 | 7 | 26 | 8.02 | 46.8 | 61.8 | 48.6 | 25.7 | 49.9 | 61.0 |
| YOLOv9-M [34] | 500 | 20 | 76 | 10.15 | 51.4 | 67.2 | 54.6 | 32.0 | 55.7 | 66.4 |
| Gold-YOLO-S [33] | 300 | 22 | 46 | 2.01 | 46.4 | 63.4 | - | 25.3 | 51.3 | 63.6 |
| Gold-YOLO-M [33] | 300 | 41 | 88 | 3.21 | 51.1 | 68.5 | - | 32.3 | 56.1 | 68.6 |
| YOLOv10-S [32] | 500 | 7 | 22 | 2.65 | 46.3 | 63.0 | 50.4 | 26.8 | 51.0 | 63.8 |
| YOLOv10-M [32] | 500 | 15 | 59 | 4.97 | 51.1 | 68.1 | 55.8 | 33.8 | 56.5 | 67.0 |
| YOLO11-S* [13] | 500 | 9 | 22 | 2.86 | 47.0 | 63.9 | 50.7 | 29.0 | 51.7 | 64.4 |
| YOLO11-M [13] | 500 | 20 | 68 | 4.95 | 51.5 | 68.5 | 55.7 | 33.4 | 57.1 | 67.9 |
| DETR-based Real-time Object Detectors | ||||||||||
| RT-DETR-R18 [43] | 72 | 20 | 61 | 4.63 | 46.5 | 63.8 | 50.4 | 28.4 | 49.8 | 63.0 |
| RT-DETR-R34 [43] | 72 | 31 | 93 | 6.43 | 48.9 | 66.8 | 52.9 | 30.6 | 52.4 | 66.3 |
| RT-DETRv2-S [24] | 120 | 20 | 60 | 4.59 | 48.1 | 65.1 | 57.4 | 36.1 | 57.9 | 70.8 |
| DEIM-RT-DETRv2-S | 120 | 20 | 60 | 4.59 | 49.0 | 66.1 | 53.3 | 32.6 | 52.5 | 64.1 |
| RT-DETRv2-M [24] | 120 | 31 | 92 | 6.40 | 49.9 | 67.5 | 58.6 | 35.8 | 58.6 | 72.1 |
| DEIM-RT-DETRv2-M | 120 | 31 | 92 | 6.40 | 50.9 | 68.6 | 55.2 | 34.3 | 54.4 | 67.1 |
| RT-DETRv2-M* [24] | 72 | 33 | 100 | 6.90 | 51.9 | 69.9 | 56.5 | 33.5 | 56.8 | 69.2 |
| DEIM-RT-DETRv2-M* | 60 | 33 | 100 | 6.90 | 53.2 | 71.2 | 57.8 | 35.3 | 57.6 | 70.2 |
| D-FINE-Nano [27] | 148 | 4 | 7 | 2.12 | 42.8 | 60.3 | 45.5 | 22.9 | 46.8 | 62.1 |
| DEIM-D-FINE-Nano | 148 | 4 | 7 | 2.12 | 43.0 | 60.4 | 46.2 | 24.5 | 47.1 | 62.1 |
| D-FINE-S [27] | 120 | 10 | 25 | 3.49 | 48.5 | 65.6 | 52.6 | 29.1 | 52.2 | 65.4 |
| DEIM-D-FINE-S | 120 | 10 | 25 | 3.49 | 49.0 | 65.9 | 53.1 | 30.4 | 52.6 | 65.7 |
| D-FINE-M [27] | 120 | 19 | 57 | 5.55 | 52.3 | 69.8 | 56.4 | 33.2 | 56.5 | 70.2 |
| DEIM-D-FINE-M | 90 | 19 | 57 | 5.55 | 52.7 | 70.0 | 57.3 | 35.3 | 56.7 | 69.5 |
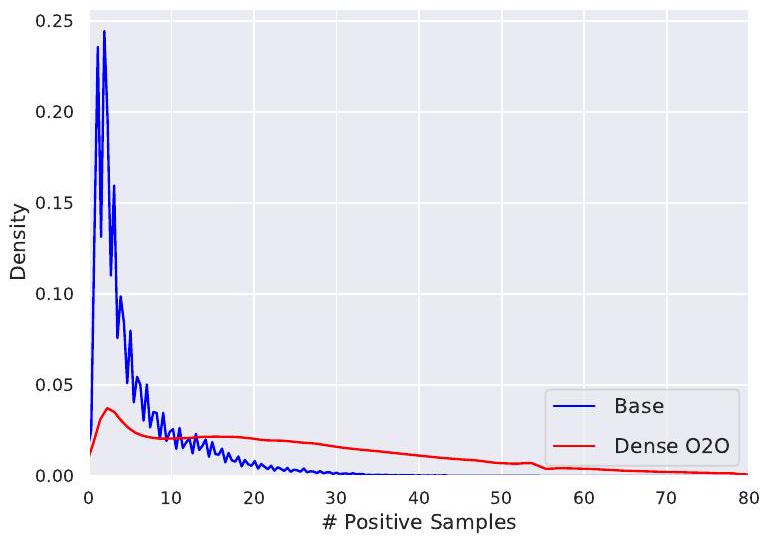
Figure 6. # Positive Samples with and without Dense in One Epoch of Training. Base indicates without Dense O2O. Dense O2O 사용 여부에 따라, 그림 6과 같이 비교했습니다. Dense O2O를 통합한 후, 포지티브 샘플의 수가 크게 증가했습니다. 이는 Dense O2O가 효과적으로 감독을 강화한다는 우리의 주장을 더욱 뒷받침합니다.
포지티브 샘플 수에 대한 연구. 우리는 학습 중 이미지당 평균 객체 수를 조정하여
Table 12. Varying the number of objects per training image.
| Avg # objects | AP | ||
|---|---|---|---|
| Training 24 Epochs | |||
| 51.7 | 69.5 | 55.8 | |
| 52.5 | 70.6 | 56.7 | |
| 52.2 | 70.1 | 56.4 |
Table 13. Training and validation accuracy.
| Model | ||
|---|---|---|
| RT-DETRv2-R50 | 53.4 | |
| w/ DEIM | 64.8 |
Dense O2O를 수정했습니다. 표 12에서 볼 수 있듯이, 객체 수가 10개(Dense O2O 없음)에서 25개(기본 Dense O2O)로 증가했을 때 성능이 크게 향상되었지만 50개(최대 Dense O2O)에서는 떨어졌습니다. 이 감소는 포지티브-네거티브 비율의 불균형과 너무 많은 객체로 인한 데이터 분포 이동 때문일 가능성이 높습니다. 주목할 점은, 평균 25개의 객체가 이 연구에서 사용된 기본 실험 설정과 일치하며, 이는 기본 Dense O2O 구성에 해당합니다.
학습 대 검증 정확도. 표 13에서 볼 수 있듯이, DEIM은 더 높은 검증 정확도와 약간 낮은 학습 정확도를 달성하여 학습 세트에 대한 과적합 감소와 새로운 샘플에 대한 적응력 향상을 나타냅니다.
4. Visualizations
우리는 그림 7에서 정성적 비교 결과를 제시합니다. 이 결과들은 DEIM이 D-FINE-L이 직면한 두 가지 중요한 문제, 즉 높은 신뢰도의 중복 예측과 거짓 양성을 효과적으로 해결한다는 것을 보여줍니다. 예를 들어, 상단 행에서 단일 연이 각각 높은 신뢰도 점수를 가진 네 개의 매우 겹치는 경계 상자에 잘못 할당되었습니다. 또한, 하단 행에서 볼 수 있듯이, D-FINEL은 소켓과 벽에 장착된 물체를 시계로 잘못 분류하면서 병을 감지하지 못했습니다. 학습 중에 DEIM을 통합함으로써, 탐지기는 이러한 문제들을 성공적으로 해결합니다. 이 시각화는 DEIM에 의해 가능해진 상당한 발전을 강조하며, 탐지 정확도 향상에 대한 잠재력을 보여줍니다.

Figure 7. Qualitative Comparison between D-FINE-L and DEIM. In each paired image, the left is from D-FINE-L while the right is predicted by DEIM-D-FINE-L (Score threshold ).