인식을 통해, 인식을 위한 계층적 이미지 분할 학습 (CAST)
이미지 분할(Segmentation)과 인식(Recognition)을 별개의 작업으로 다루던 기존 방식과 달리, 이 논문은 두 과정을 상호 보완적인 시각적 파싱(visual parsing)의 연속체로 봅니다. CAST(Concurrently learns segmentation and recognition using Adaptive Segment Tokens)라는 모델을 제안하여, 계층적 분할(hierarchical segmentation)을 인식 과정에 내장합니다. 이 모델은 고정된 사각 패치 대신 이미지 윤곽에 맞는 adaptive segment token (superpixels)을 사용하고, graph pooling을 통해 세그먼트를 점진적으로 병합하여 부분-전체 관계를 학습합니다. 핵심은, 전체 모델이 오직 이미지 수준의 인식(image-level recognition) 목표만으로 학습된다는 점입니다. 이를 통해 별도의 분할 레이블 없이도 계층적 분할을 '공짜로' 학습하며, 심지어 SAM과 같은 대규모 모델을 능가하는 성능을 보입니다. 논문 제목: Learning Hierarchical Image Segmentation For Recognition and By Recognition
Ke, Tsung-Wei, Sangwoo Mo, and Stella X. Yu. "Learning hierarchical image segmentation for recognition and by recognition." arXiv preprint arXiv:2210.00314 (2022).
Learning Hierarchical Image Segmentation For Recognition and By Recognition
Abstract
이미지-텍스트 연관성을 통해 직접 학습된 대규모 vision-language 모델은 종종 세부적인 시각적 근거(visual substantiation)가 부족하며, 이미지 분할(segmentation) task는 인식(recognition)과 별개로 취급되어 상호 연결 없이 supervised 방식으로 학습된다.
우리의 핵심 관찰은 다음과 같다:
- 이미지는 여러 방식으로 인식될 수 있지만,
- 각 인식 방식은 일관된 부분-전체(part-and-whole) 시각적 구성을 가진다.
따라서 segmentation은 supervised learning을 통해 숙달해야 할 최종 task가 아니라, 인식이라는 궁극적인 목표와 함께 진화하고 이를 지원하는 내부 프로세스로 다루어져야 한다.
우리는 계층적 segmenter를 인식 프로세스에 통합하고, 전체 모델을 이미지 레벨 인식 objective만으로 학습 및 적응시키는 방법을 제안한다.
이를 통해 우리는 인식과 함께 계층적 segmentation을 무료로 학습하며, 인식을 뒷받침할 뿐만 아니라 향상시키는 부분-전체 관계를 자동으로 발견한다.
adaptive segment token과 graph pooling으로 Vision Transformer (ViT)를 강화한 우리 모델은 비지도 부분-전체 발견, semantic segmentation, 이미지 분류, 그리고 효율성 측면에서 ViT를 능가한다.
특히, 우리 모델(레이블 없는 1M ImageNet 이미지로 학습)은 PartImageNet 객체 segmentation에서 SAM(1,100만 이미지와 10억 개의 마스크로 학습)을 mIoU에서 절대 8%p 차이로 능가한다.
1 Introduction
CLIP (Radford et al., 2021) 및 GPT-4 (Achiam et al., 2023)에서 입증되었듯이, 이미지와 텍스트 설명을 연관시켜 시각적 인식을 학습하는 방식은 상당한 성공을 거두었다. 그러나 이미지를 의미론에 직접 연결하는 supervised 학습은 종종 "무엇이 어디에 있는지"에 대한 시각적 근거(visual substantiation)를 제공하지 못한다. 예를 들어, 모델은 Fig. 1의 이미지를 잉크(ink), 소녀(girl), 또는 여성(woman)으로 분류하도록 학습될 수 있지만, 이 이미지에서 이러한 범주들이 어떻게 다른지는 이해하지 못할 수 있다. 유사하게, 시각적 분할(visual segmentation)은 여러 granularities의 마스크를 사용하여 학습될 수 있지만 (Kirillov et al., 2023), 이러한 모델들은 세그먼트들이 서로, 그리고 전체 이미지 인식과 어떻게 관련되어 있는지 파악하지 못할 수 있다.
 Figure 1: 우리의 통찰은 이미지 분할(segmentation)과 인식(recognition)이 시각적 파싱(visual parsing)의 연속체를 형성하며, 개별 텍스트 레이블보다 그 일관성(consistency)이 인식에 더 필수적이라는 것이다. 우리는 이 이미지를 잉크(ink), 소녀(girl), 또는 여성(woman)으로 인식할 수 있다. 전경(색칠된 영역)은 달라질 수 있지만, 항상 **일관된 계층적 분할(hierarchical segmentation)**을 가진다: 사람이 인식되지 않을 때는 세 개의 개별 blob, 또는 소녀나 여성으로 인식될 때는 사람의 부분(얼굴, 머리카락)이다. 우리는 분할과 인식을 별개의 task로 취급하는 대신, 인식 과정에 분할을 포함시켜 이들을 동시에 모델링한다. 이미지 수준에서만 인식 목표를 설정함으로써, 계층적 분할을 무료로 학습할 수 있을 뿐만 아니라, 이러한 내부적인 부분-전체(part-to-whole) 일관성으로부터 더 좋고 근거 있는 인식이 발생한다.
Figure 1: 우리의 통찰은 이미지 분할(segmentation)과 인식(recognition)이 시각적 파싱(visual parsing)의 연속체를 형성하며, 개별 텍스트 레이블보다 그 일관성(consistency)이 인식에 더 필수적이라는 것이다. 우리는 이 이미지를 잉크(ink), 소녀(girl), 또는 여성(woman)으로 인식할 수 있다. 전경(색칠된 영역)은 달라질 수 있지만, 항상 **일관된 계층적 분할(hierarchical segmentation)**을 가진다: 사람이 인식되지 않을 때는 세 개의 개별 blob, 또는 소녀나 여성으로 인식될 때는 사람의 부분(얼굴, 머리카락)이다. 우리는 분할과 인식을 별개의 task로 취급하는 대신, 인식 과정에 분할을 포함시켜 이들을 동시에 모델링한다. 이미지 수준에서만 인식 목표를 설정함으로써, 계층적 분할을 무료로 학습할 수 있을 뿐만 아니라, 이러한 내부적인 부분-전체(part-to-whole) 일관성으로부터 더 좋고 근거 있는 인식이 발생한다.
 Figure 2: 기존 연구들은 패치(patch)를 시각 단위로 사용하고 분할과 인식을 별개의 supervised task로, 각각 다른 모델과 데이터로 처리하는 반면, 우리의 연구는 superpixel을 시각 단위로 사용하고 계층적 분할을 인식 과정에 통합하여, 단일 인식 목표로부터 내부적으로 학습한다. ViT (Dosovitskiy et al., 2020)와 같은 Classifier는 이미지 수준 레이블로부터 인식을 학습한다. Segmenter (Strudel et al., 2021)와 같은 Semantic Segmenter는 픽셀 수준 클래스 레이블로부터 객체 세그먼트를 학습하지만, 부분-전체(part-whole) granularity가 부족하다. SAM (Kirillov et al., 2023)과 같은 Boundary Segmenter는 경계 레이블로부터 여러 granularity의 영역을 학습하지만, 계층적 조직이 없다. 이와 대조적으로, 우리의 **Segmenter for Recognition (CAST)**는 미세-거친(fine-to-coarse) 세그먼트 계층을 인식 과정에 직접 통합한다. 세그먼트 토큰에 대한 graph-pooling을 통해, 시각적 파싱 연속체 내에서 이 세 가지 task를 동시에 효과적으로 해결한다.
Figure 2: 기존 연구들은 패치(patch)를 시각 단위로 사용하고 분할과 인식을 별개의 supervised task로, 각각 다른 모델과 데이터로 처리하는 반면, 우리의 연구는 superpixel을 시각 단위로 사용하고 계층적 분할을 인식 과정에 통합하여, 단일 인식 목표로부터 내부적으로 학습한다. ViT (Dosovitskiy et al., 2020)와 같은 Classifier는 이미지 수준 레이블로부터 인식을 학습한다. Segmenter (Strudel et al., 2021)와 같은 Semantic Segmenter는 픽셀 수준 클래스 레이블로부터 객체 세그먼트를 학습하지만, 부분-전체(part-whole) granularity가 부족하다. SAM (Kirillov et al., 2023)과 같은 Boundary Segmenter는 경계 레이블로부터 여러 granularity의 영역을 학습하지만, 계층적 조직이 없다. 이와 대조적으로, 우리의 **Segmenter for Recognition (CAST)**는 미세-거친(fine-to-coarse) 세그먼트 계층을 인식 과정에 직접 통합한다. 세그먼트 토큰에 대한 graph-pooling을 통해, 시각적 파싱 연속체 내에서 이 세 가지 task를 동시에 효과적으로 해결한다.
우리의 첫 번째 통찰은 분할(segmentation)과 인식(recognition)이 시각적 파싱(visual parsing)의 연속체를 형성하며, 개념을 주로 텍스트 레이블을 통해서가 아니라 시각적 조직(visual organization)을 통해 구체화한다는 것이다. Fig. 1의 이미지에 대해:
- 잉크(ink) 인식은 검은색 픽셀을 잉크 그룹을 형성하는 세 개의 개별 blob으로 조직화하는 것과 동시에 일어난다.
- 소녀(girl) 인식은 측면 얼굴과 검은 머리카락을 소녀의 머리를 형성하는 것으로 조직화하는 것과 동시에 일어난다.
- 여성(woman) 인식은 4분의 3 얼굴과 검은 머리카락을 여성의 머리를 형성하는 것으로 조직화하는 것과 동시에 일어난다. 전체(whole)에 대한 인식은 그것의 부분(part)으로의 분할에 의해 검증된다. 항상 전체 인식과 일관된 부분 분할 계층이 존재하며, 각각은 서로와 연관되어 변화한다. 우리는 이미지를 소녀로 인식하면서 동시에 여성의 코를 인식할 수는 없다. 다시 말해, 인식의 실제 의미론이 중요하지 않을 수 있지만, 분할과 인식 사이의 동시성(concurrency)과 일관성(consistency)은 중요하다. 인간의 시각에서는 독특한 부분들의 구성이 장면 이해를 촉진할 수 있으며 (Biederman, 1987), 거친 인식은 연결된 부분들을 설명하는 데 도움을 줄 수 있다 (Maurer et al., 2002). 부분과 전체 사이에서 정보는 양방향으로 흐르며, 최종적으로 일관된 지각(percept)에서 서로를 명확히 한다 (Tanaka & Farah, 1993; Tanaka & Simonyi, 2016; Tanaka et al., 2019).
컴퓨터 비전에서 기존 연구들(Fig. 2 상단)은 분할과 인식 task를 별개로 취급하며, 각각 고유한 모델과 주석된 학습 데이터를 사용한다.
- 인식 모델은 범주(category) 또는 인스턴스(instance)를 구별하는 이미지 수준 레이블을 사용하여 학습된다 (Deng et al., 2009; Wu et al., 2018). 각 이미지는 전역 feature 벡터로 인코딩되며 (He et al., 2016; Dosovitskiy et al., 2020), 이는 일반적으로 인식에 가장 판별적인 부분들을 강조한다 (Selvaraju et al., 2017).
- 분할 모델은 픽셀 수준 레이블을 사용하여 학습되며 (Long et al., 2015; Kirillov et al., 2023), 다양한 공간 해상도와 커버리지 영역에 걸쳐 정보를 전파하기 위해 skip connection을 사용한다 (Lin et al., 2017; Cheng et al., 2021).
- 서로 다른 아키텍처 설계로 인해, 인식 모델은 분할 task에 직접 사용될 수 없다. 대신, 아키텍처 수정 및 분할 레이블을 사용한 fine-tuning이 종종 필요하다 (Ahn & Kwak, 2018).
우리의 두 번째 통찰은 분할과 인식이 시각적 파싱의 연속체에 있을 때, 분할은 외부 supervised learning을 통해 숙달해야 할 최종 task가 아니라, 인식이라는 궁극적인 목표와 함께 진화하고 이를 지원하는 내부 프로세스로 취급되어야 한다는 것이다. 우리는 계층적 분할을 인식 과정에 통합할 것을 제안한다 (Fig. 2 하단). 이는 우리의 인식 모델이 분할과 인식 사이의 원하는 일관성과 동시성을 달성하도록 자연스럽게 보장한다. 구체적으로, 우리의 모델은 부분-전체(part-to-whole) 관계와 상관관계가 있는 미세-거친(fine-to-coarse) 분할을 통해 입력 이미지를 처리하며, 전체 이미지를 캡슐화하는 전역 feature 벡터로 귀결된다. 이 분할은 인식 프로세스의 내부적인 부분이며 그 자체가 최종 목표가 아니며, 궁극적으로 시각적 공간 파싱을 통해 인식을 향상시킨다.
 Figure 3: 우리의 모델은 테스트 시점 적응(test-time adaptation) 동안 분할과 인식을 동시에 수행한다: feedforward 계층의 초기 예측은 "한눈에 보는 시각(vision at a glance)"을 포착하는 반면, 역방향 계층의 개선은 "정밀하게 보는 시각(vision with scrutiny)"을 포착한다. 이 모델은 개, 사람, 자동차 이미지를 feed-forward 계층으로 처리하며, 처음에는 개의 등 부분만을 기반으로 54% 활성화로 개를 인식한다.
Figure 3: 우리의 모델은 테스트 시점 적응(test-time adaptation) 동안 분할과 인식을 동시에 수행한다: feedforward 계층의 초기 예측은 "한눈에 보는 시각(vision at a glance)"을 포착하는 반면, 역방향 계층의 개선은 "정밀하게 보는 시각(vision with scrutiny)"을 포착한다. 이 모델은 개, 사람, 자동차 이미지를 feed-forward 계층으로 처리하며, 처음에는 개의 등 부분만을 기반으로 54% 활성화로 개를 인식한다. dog 활성화를 높이기 위해 역전파(backpropagating)한 후, 모델은 역방향 계층에서 테스트 시점 적응(TTA)을 수행한다. 이 조정은 다음 feed-forward 프로세스가 전체 개를 발견하고 dog 활성화를 97%까지 높이도록 한다! 따라서 우리의 분할과 인식은 상호 영향을 미치고 서로를 향상시킨다.
결과적으로, 우리의 모델은 최종 전역 feature 벡터를 사용하여 인식을 위해 직접 최적화될 수 있으며, 동시에 인식을 이미지 내에서 공간적으로 grounding하는 계층적 분할을 무료로 개발할 수 있다.
우리의 개념은 **"인식의 분할(Segmentation Of Recognition), 인식에 의한 분할(By Recognition), 인식을 위한 분할(For Recognition)"**이라는 문구로 요약될 수 있다. **"Of"**는 인식 과정에 분할을 포함시키는 것을 의미한다. **"By"**는 내부 분할의 학습 과정이 어떠한 세그먼트 수준의 supervision 없이 이미지 수준 인식 목표에 의해 주도된다는 것을 나타낸다. **"For"**는 우리 모델의 결과가 인식을 grounding할 뿐만 아니라 향상시키는 부분-전체(part-to-whole) 관계를 자동으로 밝혀낸다는 것을 반영한다.
우리는 Vision Transformer (ViT) (Dosovitskiy et al., 2020)를 두 가지 측면에서 혁신하여 우리의 개념을 구현한다.
- 정규 그리드 상의 정사각형 패치 대신 임의의 모양을 가진 superpixel을 ViT 토큰의 시각 단위로 사용한다.
- graph-pooling을 사용하여 이러한 세그먼트 토큰들을 인식 방향으로 연속적으로 그룹화하여, 부분-전체(part-to-whole) 관계를 반영하는 미세-거친(fine-to-coarse) 분할 계층을 형성한다. 전체 모델은 비지도(unsupervised) (Wu et al., 2018; He et al., 2020) 또는 지도(supervised) (Touvron et al., 2021) 이미지 인식 목표로부터만 학습된다. 우리 모델은 **Adaptive Segment Tokens를 사용하여 분할과 인식을 동시에 학습(Concurrently learns segmentation and recognition using Adaptive Segment Tokens)**한다는 의미에서 CAST로 약칭된다. 정규 패치를 시각적 단어로 활용하는 전통적인 텍스트 기반 Vision Transformer와 달리, 우리의 비전 기반 CAST는 시각적 윤곽선에 충실한 superpixel을 시각적 단어로 사용한다. 이러한 의미에서 우리의 CAST는 진정한 Vision Transformer 모델을 구현한다.
계층적 분할을 인식 과정에 통합함으로써, CAST는 네 가지 주요 결과를 제공한다.
- CAST는 세그먼트 토큰을 미세(fine)에서 거친(coarse) 수준으로 그룹화하여 계층적 분할을 도출한다. 1,100만 개의 이미지와 10억 개의 마스크로 다중 스케일 분할을 위해 학습된 SAM (Kirillov et al., 2023)은 부분-전체(part-to-whole) 관계를 파악하고 계층적 분할을 생성하는 데 실패한다.
- CAST는 이미지 인식 목표로부터 직접 분할을 무료로 학습한다. 학습 중에는 우리 모델이 최종 이미지 인식을 최적화하기 위해 내부 분할을 조정한다. 테스트 중에는 feed-forward 계층으로 이미지를 처리하여, "한눈에 보는 시각(vision at a glance)"을 포착하는 초기 예측을 수행한다 (Ahissar et al., 2009). 불확실한 인식의 경우, 우리 모델은 테스트 시점 적응(TTA) (Sun et al., 2020)을 계속하여 인식을 확고히 할 수 있다. 역방향 계층에서 역전파되는 목표 피드백을 통해, 최종 인식 개선과 함께 내부 부분-전체 분할을 정제하여 "정밀하게 보는 시각(vision with scrutiny)"을 포착한다 (Fig. 3 및 Appx. C).
- CAST는 분할과 인식을 동시에 수행하며, 계층적 분할을 위한 HSG (Ke et al., 2022) 및 분류를 위한 Swin Transformer (Liu et al., 2021)와 같은 기존 방법들과 동등하거나 그 이상의 성능을 보인다. 이러한 방법들은 각 task에 특화된 아키텍처를 필요로 하는 반면, CAST는 단일 통합 모델을 사용하여 이 두 가지를 효율적으로 관리한다.
- CAST는 정사각형 패치 대신 superpixel을 시각 단위로 활용하여 Vision Transformer 설계의 자연스러운 진화를 나타낸다. 이 접근 방식은 우리 모델이 패치 기반 ViT에 비해 더 정확한 분할을 달성하도록 한다. 이는 비지도 및 지도 의미론적 분할(semantic segmentation)뿐만 아니라 attention 기반 figure-ground 분할을 포함한 여러 task에서 뛰어난 성능을 보인다.
2 Related Works
**동시 분할 및 인식(Concurrent segmentation and recognition)**은 딥러닝 시대 이전에 탐구되었다. 이전에는 모델들이 호환 가능한 패치들을 그룹화하여 인식을 수행하고, **감지된 픽셀-패치 관계를 통해 시각적으로 유사한 픽셀들을 그룹화하여 분할(segmentation)**을 동시에 수행했다. 이러한 접근 방식은 객체별 분할(object-specific segmentation) (Yu et al., 2002; Yu & Shi, 2003b) 및 전경-배경 분할(figure-ground segmentation) (Maire, 2010; Maire et al., 2011)로 이어졌다. 그러나 이러한 방법들은 수동으로 설계된 feature와 사전학습된 객체 부분 감지기(object part detector)에 의존했다. 이와 대조적으로, 우리 모델은 완전히 데이터 기반이며 scratch부터 학습된다.
Vision Transformer는 ViT (Dosovitskiy et al., 2020) 도입 이후 상당한 발전을 이루었다 (Han et al., 2022). 효율성을 높이기 위한 두 가지 주요 전략이 존재한다: 하나는 계층적 convolution의 원리를 활용하여 공간 풀링(spatial pooling)을 통해 토큰 수를 줄이는 것 (Liu et al., 2021; Heo et al., 2021; Dong et al., 2022; Ma et al., 2023)이고, 다른 하나는 토큰의 중요도를 평가하여 토큰을 선택적으로 가지치기(prune)하는 것 (Goyal et al., 2020; Rao et al., 2021; Marin et al., 2021; Zeng et al., 2022; Bolya et al., 2023)이다. 우리의 접근 방식은 이들 방법과 두 가지 근본적인 면에서 다르다:
- 우리의 token pooling은 시각적 파싱 계층(visual parsing hierarchy) 내에서 분할-인식 연속체(segmentation-recognition continuum)를 지원하도록 설계되었으며, 효율성은 단지 유익한 부산물로 나타난다.
- 다른 어떤 ViT 모델과도 달리, 우리 모델은 일관된 계층적 분할(hierarchical segmentation)을 생성한다.
**계층적 이미지 분할(Hierarchical image segmentation)**은 여러 세분화 수준(multiple granularities)에 걸쳐 픽셀들을 일관되게 그룹화하는 것을 목표로 한다. 대표적인 접근 방식은 응집형 클러스터링(agglomerative clustering) (Sharon et al., 2006; Arbelaez et al., 2010)으로, 픽셀 feature를 추출하고 클러스터를 초기화한 다음 feature 유사성을 기반으로 병합하는 방식으로 시작한다. 최근 연구들은 종종 하향식 분해(top-down decomposition)를 사용하여 거친 의미론적 인스턴스(coarse semantic instances)를 감지하고 이를 더 미세한 의미론적 부분으로 분해하는 supervised 접근 방식을 채택한다 (de Geus et al., 2021; Wei et al., 2024; Li et al., 2022b;a). 부분 주석(part annotations)을 피하기 위해, self-supervised learning은 교차 이미지 픽셀 대응(cross-image pixel correspondence) (Sun et al., 2023) 또는 feature clustering (Pan et al., 2023)을 통해 새로운 범주에 대한 부분 분할(part segmentation)을 향상시키는 데 사용된다. 또 다른 접근 방식은 부분(part) 및 객체(object) 수준 분할을 별도로 예측하는데 (Li et al., 2023; Wang et al., 2024; Qi et al., 2024), 이는 종종 세분화 수준에 걸쳐 분할이 정렬되지 않는(misaligned) 결과를 초래한다. 이와 대조적으로, 우리 연구는 표현 학습(representation learning), 계층적 분할(hierarchical segmentation), 이미지 인식(image recognition)을 Transformer 아키텍처 내에 통합하여 응집형 접근 방식을 현대화한다.
Superpixel 및 클러스터링 방법에 대한 추가 관련 연구는 Appx. D에서 찾을 수 있다.
3 Our Hierarchical Segmenter and Recognizer on A Continuum
우리의 목표는 계층적 분할(hierarchical segmentation)과 인식(recognition)을 연속적인 시각 파싱(visual parsing) 프레임워크에 통합하는 것이다. 이 프레임워크에서는 segmenter가 recognizer 내부에 존재하며 인식 프로세스를 지원한다 (Fig. 2).
학습 과정에서 segmenter는 recognizer와 함께 개발되며, 두 모듈 모두 이미지 레벨의 인식 목표(image-level recognition objective)에 의해서만 유도된다.
테스트 시에는 recognizer의 winning activation을 최대화하여 recognizer를 최적화하는데, 이 과정에서 발생하는 역전파(backpropagation)가 segmenter를 정제한다 (Fig. 3).
우리의 동시 분할 및 인식 프레임워크인 CAST에서는 분할이 인식을 뒷받침할 뿐만 아니라 인식에 의해 지시되므로, 두 프로세스가 상호 보완적으로 서로를 향상시킨다.
우리는 인식 task에 널리 사용되는 ViT를 활용하는 것부터 시작하며, 이를 계층적 분할에 적용하는 데 있어 두 가지 주요 과제를 식별했다 (Fig. 4):
- 고정된 형태의 패치(fixed-shape patches) 사용은 복잡한 시각적 윤곽(visual contours)을 제대로 특성화하지 못한다 (Bolya et al., 2022).
- 명시적인 분할(explicit segmentation)의 부재로 인해 다양한 세분성(granularities)에 걸쳐 일관된 픽셀 그룹화를 강제하기 어렵다.
 Figure 4: 우리의 모델은 적응형 세그먼트 토큰(adaptive segment tokens)과 점진적 그래프 풀링(progressive graph pooling)을 통해 ViT를 혁신함으로써 시각 파싱에서 동시성(concurrency)과 일관성(consistency) 개념을 구현한다. 이 모델은 정사각형 패치 대신 superpixel로 시작하여, 그래프 풀링을 적용하여 미세 세그먼트 를 거친 세그먼트 로 병합한다. 세그먼트 전환 확률 과 세그먼트 feature 은 모두 이미지 레벨의 인식 목표를 최적화하도록 학습되며, 이는 self-supervised instance discrimination 또는 supervised image classification이 될 수 있다. 어떠한 외부 감독(external supervision) 없이도, 우리는 작은 세부 요소(귀)와 얇은 구조(다리)와 함께 객체의 전체(개)를 발견하여, 우리 개념의 효과를 입증한다.
Figure 4: 우리의 모델은 적응형 세그먼트 토큰(adaptive segment tokens)과 점진적 그래프 풀링(progressive graph pooling)을 통해 ViT를 혁신함으로써 시각 파싱에서 동시성(concurrency)과 일관성(consistency) 개념을 구현한다. 이 모델은 정사각형 패치 대신 superpixel로 시작하여, 그래프 풀링을 적용하여 미세 세그먼트 를 거친 세그먼트 로 병합한다. 세그먼트 전환 확률 과 세그먼트 feature 은 모두 이미지 레벨의 인식 목표를 최적화하도록 학습되며, 이는 self-supervised instance discrimination 또는 supervised image classification이 될 수 있다. 어떠한 외부 감독(external supervision) 없이도, 우리는 작은 세부 요소(귀)와 얇은 구조(다리)와 함께 객체의 전체(개)를 발견하여, 우리 개념의 효과를 입증한다.
우리의 해결책은 다음과 같다:
- 고정된 형태의 패치(fixed-shape patches)를 시각적 윤곽에 맞춰 적응하는 세그먼트(adaptive segments)로 대체하는 것,
- 세그먼트 위에 그래프 풀링(graph pooling)을 적용하여 점진적으로 파싱 계층(parsing hierarchy)을 구축하는 것.
Fig. 4에서 우리 모델은 세그먼트를 시각 단위로 활용하며, 세그먼트 feature를 추출하는 Transformer encoder 블록과 미세 세그먼트를 거친 세그먼트로 병합하는 그래프 풀링 모듈을 번갈아 적용한다. 적응형 세그먼트와 그래프 풀링에 대해서는 아래에서 설명하며, 알고리즘은 Appx. E.1에 제시되어 있다.
3.1 Adaptive Segment Tokens from Superpixels
세그먼트는 임의의 픽셀 그룹으로 구성된다. 효과적인 계층적 세분화를 위해서는 **세그먼트의 픽셀 그룹화()**와 세그먼트 feature() 모두에 대한 표현이 필요하며, 이는 미세한 수준에서 거친 수준까지 여러 레벨에 걸쳐 적용된다.
우리의 초기 세분화인 는 영역 내의 저수준 feature와 일치하고 시각적 윤곽선에 정렬되는 superpixel을 사용한다. 이를 위해 우리는 **SEEDS (Bergh et al., 2012)**를 활용하는데, 이는 이미지를 색상 일관성이 있고 지역적으로 연결된 영역으로 분할한다. superpixel 방법 선택에 대한 논의는 Appx A.2에서 찾을 수 있다. 그런 다음 이 superpixel들을 더 큰 세그먼트로 결합하여, Fig. 4 상단에 표시된 것처럼 정확하게 윤곽선이 그려진 세분화 계층을 형성한다.
우리의 초기 세그먼트 feature인 는 시각적 feature와 공간적 feature를 모두 사용한다. 먼저 입력 이미지에 convolutional layer를 적용하여 **픽셀 수준 feature()**를 생성한다. 각 superpixel의 시각적 feature인 는 해당 superpixel 내의 픽셀 feature 의 평균이다. 마찬가지로, 각 superpixel의 **위치 인코딩()**은 해당 superpixel 내의 픽셀 위치 인코딩의 평균이며, 이는 과 동일한 해상도로 설정된다. 초기 세그먼트 feature인 는 이 두 superpixel feature에 ViT의 일반적인 class token 를 추가한 합이다: .
의 superpixel부터 시작하여, 이 가장 미세한 세그먼트 token 를 개의 더 거친 세그먼트 token() 레벨로 그룹화하여 점진적으로 더 전역적인 시각적 맥락을 포착한다. 이러한 적응형 세그먼트 token은 각 픽셀의 세그먼트 인덱스로부터 이미지 세분화()를 직접 도출할 수 있게 하여, 후처리(post-processing)의 필요성을 없앤다. 우리의 접근 방식은 SegSort (Hwang et al., 2019) 및 HSG (Ke et al., 2022)와 같은 이전 방법들과 대조된다. 이들 방법은 전체 모델에서 이미지 세분화와 feature 추출을 분리하여 유지한다.
3.2 Graph Pooling for Hierarchical Segmentation
우리는 adaptive segment token에 graph pooling을 적용하여 계층적 segmentation을 구축하며, 이를 **fine-to-coarse 레벨로 점진적으로 집계(aggregate)**한다. 이 집계 과정은 **soft assignment probability **을 활용하는데, 이는 레벨 의 fine segment 를 레벨 의 coarser segment 로 매핑한다. 우리는 fine segment token 의 중심(centroid)을 샘플링하여 segment 및 feature channel 수로 차원화된 coarse segment 를 초기화한다. feature 유사도 함수 sim으로 측정했을 때, segment 가 feature 공간에서 segment 에 가까울수록 를 에 할당할 확률 은 커진다:
픽셀 및 segment 수로 차원화된 이진 분할 행렬로 초기 segmentation 를 표현하면, 점진적인 segment 멤버십 전환을 기반으로 하는 segmentation 계층 구조를 다음과 같이 도출할 수 있다:
이 이진(binary)인 반면, 은 soft segmentation이며, 이는 일반적인 winner-take-all 전략을 통해 hard segmentation으로 변환될 수 있다. Segment token 은 에 따라 업데이트되는데, 을 사용하여 을 평균하고, 이를 MLP head와 함께 이전에 초기화된 값에 더한다. 여기서 ./는 element-wise division을 나타낸다.
우리의 superpixel과 계층적 segmenter가 인식 성능을 어떻게 향상시키는지 보여주기 위해, 우리는 CAST를 ViT와 비교한다. ViT는 patch를 사용하며 모델 전체에서 동일한 수의 token을 유지한다. 비교를 위해, 우리는 이미 학습된 ViT token으로부터 K-means clustering을 일관된 fine-to-coarse 방식으로 적용하여 계층적 segmentation을 도출했다 (자세한 내용은 Appx. E.5 참조). Figure 5는 superpixel의 사용이 우리의 segmentation이 시각적 윤곽을 더 가깝게 따르도록 할 뿐만 아니라, 다양한 granularity에 걸쳐 segmentation 일관성을 강제하는 것이 CAST가 coarse segmentation에서도 작은 세부 사항과 얇은 구조를 보존할 수 있게 함을 보여준다. 결과적으로, ViT와 CAST가 동일한 unlabeled 데이터로 학습되었음에도 불구하고, CAST는 어떠한 supervision 없이도 전체 객체를 발견하는 데 훨씬 뛰어난 성능을 보여주며, 이는 우리의 superpixel과 token pooling의 이점을 입증한다.
 Figure 5: CAST는 superpixel뿐만 아니라 점진적인 token pooling 덕분에 복잡한 윤곽을 가진 객체를 발견한다. 우리는 **MoCo objective (He et al., 2020)**를 사용하여 unlabeled ImageNet 데이터로 ViT와 CAST를 학습시켰다. 각 행의 Column 1에 있는 ImageNet 이미지에 대해, Column 2-9는 각각 ViT가 사용하는 정사각형 patch, fine-to-coarse K-means clustering을 통해 ViT token에서 파생된 32, 16, 8-way segmentation, CAST가 사용하는 superpixel, 그리고 CAST가 생성한 32, 16, 8-way segmentation을 보여준다. 우리의 색 구성표는 coarse-to-fine 일관성을 가진다: 8-way segmentation의 색상은 ViT와 CAST 간에 일치하며, 16(32)-way segmentation의 색상은 8-way와 동일한 색조를 가지지만, 더 미세한 세부 사항을 반영하기 위해 채도(saturation) 및 명도(value)가 다르다. 우리의 결과는 시각적 윤곽을 더 가깝게 따르며, 목, 얇은 다리, 긴 귀와 같은 세부 사항을 포함한 전체 객체를 성공적으로 발견한다.
Figure 5: CAST는 superpixel뿐만 아니라 점진적인 token pooling 덕분에 복잡한 윤곽을 가진 객체를 발견한다. 우리는 **MoCo objective (He et al., 2020)**를 사용하여 unlabeled ImageNet 데이터로 ViT와 CAST를 학습시켰다. 각 행의 Column 1에 있는 ImageNet 이미지에 대해, Column 2-9는 각각 ViT가 사용하는 정사각형 patch, fine-to-coarse K-means clustering을 통해 ViT token에서 파생된 32, 16, 8-way segmentation, CAST가 사용하는 superpixel, 그리고 CAST가 생성한 32, 16, 8-way segmentation을 보여준다. 우리의 색 구성표는 coarse-to-fine 일관성을 가진다: 8-way segmentation의 색상은 ViT와 CAST 간에 일치하며, 16(32)-way segmentation의 색상은 8-way와 동일한 색조를 가지지만, 더 미세한 세부 사항을 반영하기 위해 채도(saturation) 및 명도(value)가 다르다. 우리의 결과는 시각적 윤곽을 더 가깝게 따르며, 목, 얇은 다리, 긴 귀와 같은 세부 사항을 포함한 전체 객체를 성공적으로 발견한다.
우리의 모델은 또한 추론 시 segmentation granularity에 대한 유연성을 제공한다. 이는 GroupViT (Xu et al., 2022) 및 **HSG (Ke et al., 2022)**와는 다르다. 이들은 학습 후 변경할 수 없는 고정된 수의 학습 가능한 쿼리에 의존하여 다음 레벨 segment를 생성한다. 우리의 접근 방식에서는 clustering centroid의 수가 segmentation granularity를 결정하며, 이는 학습 구성과 다를 수 있다. 특히, 우리는 **Farthest Point Sampling (FPS) (Qi et al., 2017)**을 사용하여 token feature의 부분 집합을 초기 centroid로 선택한다. 이 전략은 지배적인 feature에 대한 편향 없이 feature 공간의 최대 커버리지를 보장하여 더욱 견고한 segmentation을 이끌어낸다 (Appx. F).
아키텍처 및 학습 (Architecture and Training). CAST는 기존 ViT 아키텍처에 patch encoder를 segment encoder로 교체하고 ViT 블록 내에 graph pooling 모듈을 삽입하여 통합될 수 있다. 우리는 SEEDS를 사용하여 superpixel을 추출하고 (Xiao et al., 2021)의 convolutional layer를 적용하여 초기 segment feature를 얻음으로써 ViT와의 공정한 비교를 보장한다. 원래 ViT 아키텍처를 따라, 우리는 우리 모델을 **ViT-(S/B)에 해당하는 CAST-(S/B)**로 명명한다. Segmentation granularity는 각각 3, 3, 3, 2개의 encoder 블록 이후에 64, 32, 16, 8로 설정된다. Segment는 레벨-0의 196개 superpixel부터 시작하여 레벨-1, 2, 3, 4 segment로 지칭된다. CAST는 DeiT (Touvron et al., 2021) 및 **Segmenter (Strudel et al., 2021)**와 같이 supervised learning으로 학습되거나, ImageNet (Deng et al., 2009) 및 **COCO (Lin et al., 2014)**에서 **MoCo (He et al., 2020)**와 같이 self-supervised learning으로 학습될 수 있다.
4 Experiments on Hierarchical/Flat Segmentation & Recognition
우리 모델은 인식(recognition)을 위한 내부 계층적 segmenter를 가지고 있으며, 오직 이미지 인식 objective만을 사용하여 학습될 수 있다. 우리는 다음 세 가지 task에서 모델의 성능과 이점을 연구한다:
- 비지도 계층적 분할(unsupervised hierarchical segmentation) 및 부분-전체(part-whole) 관계 발견,
- 평면 의미론적 분할(flat semantic segmentation),
- 인식(recognition).
추가적인 ablation, 결과, 실험 세부사항 및 시각화 자료는 Appendix에서 확인할 수 있다.
4.1 Unsupervised Hierarchical Segmentation and Part-Whole Discovery
우리는 CAST에 대한 세 가지 흥미로운 baseline으로 ViT (Dosovitskiy et al., 2020), HSG (Ke et al., 2022), 그리고 **SAM (Kirillov et al., 2023)**을 고려한다.
- CAST, ViT, HSG는 모두 동일한 unlabeled 데이터로 학습될 수 있다. 이와 대조적으로, SAM은 대규모의 픽셀 단위로 레이블링된 이미지로 사전학습되었으며 직접 사용 가능하다. 경계 분할기(boundary segmenter)로서 SAM은 이미지 내에 어떤 segment가 있는지(what)는 모르고 어디에 있는지(where)만 안다.
- ViT는 계층적 분할(hierarchical segmentation)을 생성하지 않는다. 우리는 multiscale parsing 없이 학습되었고 detection (Li et al., 2022c) 및 segmentation (Kirillov et al., 2023)에 효과적임이 입증된 ViT의 최종 레이어 토큰에 대해 fine-to-coarse K-means clustering을 적용하여 계층 구조를 구축한다.
- HSG와 CAST는 모두 superpixel 기반의 일관된 계층적 분할을 생성한다. 그러나 HSG는 segmentation을 위해 설계된 반면, CAST는 recognition을 위해 설계되었다. HSG가 ResNet50을 사용하므로, 우리는 HSG를 유사한 크기의 CAST-S와 비교한다.
- SAM은 여러 granularities에서 segmentation을 출력하지만, 그들 간의 일관성을 강제하지 않는다. 우리는 가장 큰 모델인 SAM-H와 ViT-B 및 CAST-B와 크기가 일치하는 가장 작은 모델인 SAM-B에 대해 보고한다.
 Figure 6: CAST는 비지도 학습으로 부분들을 전체로 묶는 계층적 분할을 통해 recognition 성능을 향상시키는 반면, ViT와 SAM은 성능이 좋지 않다: 이들은 시각적 세부 사항을 포착하는 superpixel과 recognition을 단순화하는 계층적 분할기가 부족하다. SAM은 1,100만 개의 이미지와 10억 개의 마스크로 사전학습되었고, ViT와 CAST는 100만 개의 ImageNet 이미지로 self-supervised 학습되었으며, 모두 PartImageNet에서 의미론(semantics) 없이 segmentation을 생성한다. 우리는 평가를 위해 OVSeg (Liang et al., 2023)를 사용하여 각 segment의 이름을 지정한다. Column 1 Row 2의 SAM-H 출력의 경우, 우리는 먼저 객체 어휘(object vocabulary)를 사용하여 크기 내림차순으로 segment의 이름을 지정한 다음, 식별된 객체를 기반으로 부분의 이름을 지정한다. ViT의 경우, 마지막 레이어 토큰에 fine-to-coarse K-means clustering을 적용하여 계층적 분할을 도출한다. ViT와 CAST의 경우, 객체 어휘를 사용하여 8-way segmentation의 이름을 지정하고, 부분 어휘(part vocabulary)를 사용하여 16-way segmentation의 이름을 지정한다. 여기서 물고기는 뚜렷한 머리와 몸통으로 이어지는 지느러미를 가지고 있으며, 배경과의 대비는 몸통을 따라 다양하게 변한다. SAM은 물고기를 부분으로 분할하는 데 어려움을 겪고, ViT는 물고기를 배경과 분리하지 못하여 recognition을 오도한다. 이와 대조적으로, 우리의 비지도 학습 CAST는 뚜렷한 부분(머리, 몸통, 지느러미)을 가진 전체 물고기를 정확하게 발견한다.
Figure 6: CAST는 비지도 학습으로 부분들을 전체로 묶는 계층적 분할을 통해 recognition 성능을 향상시키는 반면, ViT와 SAM은 성능이 좋지 않다: 이들은 시각적 세부 사항을 포착하는 superpixel과 recognition을 단순화하는 계층적 분할기가 부족하다. SAM은 1,100만 개의 이미지와 10억 개의 마스크로 사전학습되었고, ViT와 CAST는 100만 개의 ImageNet 이미지로 self-supervised 학습되었으며, 모두 PartImageNet에서 의미론(semantics) 없이 segmentation을 생성한다. 우리는 평가를 위해 OVSeg (Liang et al., 2023)를 사용하여 각 segment의 이름을 지정한다. Column 1 Row 2의 SAM-H 출력의 경우, 우리는 먼저 객체 어휘(object vocabulary)를 사용하여 크기 내림차순으로 segment의 이름을 지정한 다음, 식별된 객체를 기반으로 부분의 이름을 지정한다. ViT의 경우, 마지막 레이어 토큰에 fine-to-coarse K-means clustering을 적용하여 계층적 분할을 도출한다. ViT와 CAST의 경우, 객체 어휘를 사용하여 8-way segmentation의 이름을 지정하고, 부분 어휘(part vocabulary)를 사용하여 16-way segmentation의 이름을 지정한다. 여기서 물고기는 뚜렷한 머리와 몸통으로 이어지는 지느러미를 가지고 있으며, 배경과의 대비는 몸통을 따라 다양하게 변한다. SAM은 물고기를 부분으로 분할하는 데 어려움을 겪고, ViT는 물고기를 배경과 분리하지 못하여 recognition을 오도한다. 이와 대조적으로, 우리의 비지도 학습 CAST는 뚜렷한 부분(머리, 몸통, 지느러미)을 가진 전체 물고기를 정확하게 발견한다.
 Figure 7: 비지도 계층적 분할은 HSG보다 CAST에서 의미론(semantics)과 더 밀접하게 일치한다. 우리는 32, 16, 8-way segmentation을 각각 fine, coarse, whole person parsing과 비교한다. 색상으로 일관된 계층 구조를 시각화하기 위해, 우리는 먼저 8-way segmentation을 1-label ground truth에 색조(hue)로 일치시킨 다음, 16-way에 대해 채도(saturation)를, 32-way에 대해 명도(value)를 변경한다. 전반적으로, CAST는 모든 수준에서 사람의 몸을 배경과 분리하는 데 DensePose에서 HSG보다 우수하다.
Figure 7: 비지도 계층적 분할은 HSG보다 CAST에서 의미론(semantics)과 더 밀접하게 일치한다. 우리는 32, 16, 8-way segmentation을 각각 fine, coarse, whole person parsing과 비교한다. 색상으로 일관된 계층 구조를 시각화하기 위해, 우리는 먼저 8-way segmentation을 1-label ground truth에 색조(hue)로 일치시킨 다음, 16-way에 대해 채도(saturation)를, 32-way에 대해 명도(value)를 변경한다. 전반적으로, CAST는 모든 수준에서 사람의 몸을 배경과 분리하는 데 DensePose에서 HSG보다 우수하다.
Figure 5는 CAST가 복잡한 윤곽선과 미세한 세부 사항을 가진 객체를 발견하는 데 ViT를 능가함을 보여주었다. 이제 우리는 변형 가능한(deformable) 및 강체(rigid) 객체 parsing을 위해 PartImageNet에서 비지도 학습 CAST를 SAM 및 ViT와 비교하고 (Figure 6), 인체 parsing을 위해 DensePose에서 HSG와 비교한다 (Figure 7).
**PartImageNet (He et al., 2022)**은 ImageNet의 하위 집합으로, 11개의 객체(예: Biped)와 40개의 부분(예: Biped Head)이 추가로 주석되어 있다 (자세한 내용은 Appendix B.1 참조). 우리는 **PartImageNet에서 SAM (있는 그대로), ViT 및 CAST (ImageNet에서 self-supervised 학습)**를 벤치마크한다. 이들 모두 클래스 레이블 없이 segmentation을 생성하므로, 평가를 위해 open-vocabulary segment classifier인 OVSeg (Liang et al., 2023)를 사용하여 각 segment의 이름을 지정한다. SAM의 경우, 기본 설정을 사용하여 겹칠 수 있는 일련의 이진 마스크를 생성한다. 더 큰 segment는 전체 객체일 가능성이 높고, 더 작은 segment는 부분일 가능성이 높으므로, 우리는 PartImageNet 객체 어휘를 사용하여 한 번에 segment의 이름을 지정한다. 가장 큰 마스크부터 이름을 지정하고, 더 작은 마스크는 겹치는 부분을 제거하도록 조정한다. 두 번째 단계에서는 PartImageNet 부분 어휘를 사용하여 식별된 각 segment의 이름을 지정한다. ViT와 CAST의 경우, 먼저 거친(8-way) segmentation에서 객체의 이름을 지정한 다음, 세밀한(16-way) segmentation에서 각 객체 내의 부분 이름을 지정한다. 자세한 내용은 Appendix E.3을 참조하라. Figure 6은 비지도 학습 CAST가 시각적 세부 사항을 더 큰 전체로 그룹화하여 객체를 배경과 분리함으로써 정확한 segment 이름 지정이 가능하게 함을 보여준다. SAM과 ViT는 학습 중에 granularities 간의 segmentation 일관성을 유지하지 못하여, 오류가 발생하기 쉽고, 최종적으로 recognition을 단순화하기보다는 경쟁하는 거친(coarse) 및 세밀한(fine) segmentation을 초래한다.
Table 1: 비지도 학습 CAST는 PartImageNet에서 객체 부분 및 전체를 분할하는 정확도와 효율성 면에서 SAM 및 ViT를 능가한다. 우리는 region mIoU와 boundary F-score를 객체 수준과 부분 수준에서 측정한다. SA-1B에서 픽셀 단위 레이블로 대규모 고해상도 이미지로 사전학습된 SAM은 경계 식별에 탁월하다: 객체(부분) 수준에서 SAM은 CAST보다 10(5)% 우수하고, CAST는 ViT보다 11(1)% 우수하다. 그러나 region 정확도 면에서는 CAST가 SAM (ViT)을 객체에 대해 8(4)%, 부분에 대해 1(1)% 능가하며, GFLOPS는 4(72)%에 불과하다.
| model | GFLOPS | region mIoU | boundary | F-score | |
|---|---|---|---|---|---|
| SAM-B | 677 | 18.03 | 10.15 | 20.71 | 7.25 |
| SAM-H | 3166 | 21.97 | 12.07 | ||
| ViT-B | 18 | 25.34 | 11.74 | 10.92 | 4.64 |
| CAST-B | 22.32 | 6.52 |
Table 2: CAST는 segmentation보다는 recognition에 중점을 두었음에도 불구하고, DensePose에서 비지도 계층적 의미론적 분할(unsupervised hierarchical semantic segmentation)에서 HSG를 능가한다. unlabeled COCO 데이터로 CAST-S와 HSG를 학습시킨 후, 우리는 DensePose에서 ground-truth 14, 4, 1-label 인체 parsing에 대해 32, 16, 8-way segmentation을 평가한다. 우리는 segmentation과 ground-truth 인체 간의 정밀도(P), 재현율(R), F-score (F)를 측정한다. CAST는 특히 전체 몸통 재현율에서 일관되게 우수하다.
| P R F | 14 labels | 4 labels | 1 label | ||||||
|---|---|---|---|---|---|---|---|---|---|
| HSG | 20.7 | 18.6 | 19.6 | 24.1 | 30.6 | 26.9 | 20.5 | 36.1 | 26.2 |
| CAST | |||||||||
| gain | 0.4 | 5.5 | 2.9 | 0.7 | 2.6 | 1.5 | 5.8 | 8.8 | 7.0 |
Table 1은 우리의 비지도 학습 CAST가 mIoU에서 ViT를 4% 능가할 뿐만 아니라, SAM을 객체 segmentation에서 8% 능가함을 보여준다. SAM은 SA-1B에서 supervised 학습되었고 GFLOPS는 243배 더 크다! SAM은 고품질 segmentation을 생성할 수 있지만, 이러한 segment를 조직화하고 recognition을 위해 단순화하지 못한다. 특히 PartImageNet은 이미지에서 단 하나의 두드러진 객체만 주석하기 때문이다. Figure 6의 인체 segment는 가려진 물고기 모양의 경계로 인해 OVSeg에 의해 biped 대신 Category fish로 오인된다. 이러한 경계 소유권(border-ownership)의 간섭은 인간 지각 연구에서 Bregman의 scrambled B illusion (Bregman, 1981)으로 예시되듯이 오랫동안 인정되어 왔다. 또한, CAST는 훨씬 더 효율적이다. SAM은 1) 고차원 feature 공간에서 픽셀-segment 할당을 예측하는 추가 마스크 디코더와 2) 다양한 point prompt에 의해 안내되는 여러 추론을 필요로 한다. CAST는 단일 추론 패스에서 색상 feature로부터 segment 계층 구조를 생성하며, SAM-H GFLOPS의 4%만 사용한다! **DensePose (Alp Güler et al., 2018)**는 복잡한 다중 인물 장면을 포함하며, 각 개인은 14개의 신체 부분으로 주석되어 있다. 우리는 이 레이블들을 4가지 범주(머리, 몸통, 상지, 하지)로 그룹화한다. 우리는 COCO (Lin et al., 2014)에서 HSG와 CAST-S를 self-supervised 학습시키고, DensePose에서 fine (14 labels), coarse (4 labels), whole person (1 label) parsing에 대해 32, 16, 8-way segmentation을 각각 비교한다 (Figure 7). Table 2는 CAST가 모든 수준에서 정밀도와 재현율 모두에서 HSG를 능가함을 보여준다. HSG는 모든 수준에서 segment 간의 feature 구별을 최적화하는 반면, CAST는 이 최적화를 최종 이미지 수준에만 집중한다. 따라서 계층적 segmentation을 독립적인 목표가 아닌 recognition의 필수적인 부분으로 접근하는 것이 실제로 segmentation을 향상시킨다!
4.2 Semantic Segmentation
이제 우리는 픽셀 단위의 레이블링 없이, 이미지 레벨의 인식(recognition) objective만으로 이미지 분할(segmentation)을 학습할 수 있다. 우리는 이러한 segmenter를 다운스트림 semantic segmentation task에 활용하는 데 있어 CAST와 ViT를 비교한다 (Table 3).
- 먼저 두 모델을 unlabeled COCO 데이터로 학습시킨 후, PASCAL VOC (Everingham et al., 2010)에서 fine-tuning하기 전과 후의 분할 성능을 평가한다.
- 먼저 두 모델을 labeled ImageNet 데이터로 학습시킨 후, Segmenter (Strudel et al., 2021)로 fine-tuning하고 ADE20K (Zhou et al., 2019) 및 PASCAL Context (Mottaghi et al., 2014)에서 테스트한다.
Table 3: CAST는 superpixel과 token pooling을 활용하여 비지도 또는 지도 학습 기반의 flat semantic segmentation에서 ViT를 능가한다. 우리는 CAST-S와 ViT-S를 벤치마크하기 위해 region mIoU와 boundary F-score를 모두 보고한다: a) unlabeled COCO로 학습한 후 PASCAL-VOC에서 테스트한 결과, b) labeled ImageNet으로 학습한 후 튜닝을 거쳐 ADE20K 및 PASCAL-Context에서 테스트한 결과. 우리는 기존 patch를 superpixel로 대체하고, token 축소를 위해 graph pooling을 적용한 ViT 변형 모델들을 탐색한다. CAST는 두 가지 수정 사항의 효능을 입증하며 일관되게 더 나은 성능을 보인다.
a) COCO에서 self-supervised 학습
| PASCAL-VOC에서 테스트 | 튜닝 전 | 튜닝 후 | ||
|---|---|---|---|---|
| ViT-S | 30.9 | 16.1 | 65.8 | 40.7 |
| ViT-S (superpixel 적용) | 32.2 | 21.2 | 66.5 | 46.7 |
| ViT-S (token pooling 적용) | 34.5 | 19.8 | 67.2 | 41.9 |
| CAST-S |
b) ImageNet에서 supervised 학습, 튜닝 후
| ADE20K | P-Context | |||
|---|---|---|---|---|
| ViT-S | 41.7 | 33.9 | 48.3 | 42.0 |
| - | - | - | - | - |
| - | - | - | - | - |
| CAST-S |
 Figure 8: 인식(recognition)을 위해 사전학습된 CAST는 semantic segmentation으로 ViT보다 더 잘 일반화된다. ViT-S와 CAST-S 모두 labeled ImageNet으로 사전학습되었으며, ADE20K 또는 PASCAL-Context에서 semantic segmentation을 위해 fine-tuning되었다. ViT와 달리, CAST는 큰 객체(집, 바닥)를 인식하고 분할할 수 있을 뿐만 아니라, 작은 객체(개)의 시각적 윤곽선에도 밀접하게 부착된다.
Figure 8: 인식(recognition)을 위해 사전학습된 CAST는 semantic segmentation으로 ViT보다 더 잘 일반화된다. ViT-S와 CAST-S 모두 labeled ImageNet으로 사전학습되었으며, ADE20K 또는 PASCAL-Context에서 semantic segmentation을 위해 fine-tuning되었다. ViT와 달리, CAST는 큰 객체(집, 바닥)를 인식하고 분할할 수 있을 뿐만 아니라, 작은 객체(개)의 시각적 윤곽선에도 밀접하게 부착된다.
우리는 비지도 평가를 위해 SegSort (Hwang et al., 2019)의 segment retrieval 방식을 따르며, 지도 평가를 위해 pixel-wise softmax classifier와 함께 모델을 fine-tuning한다.
Table 3은 CAST가 일관되게 ViT를 능가하며, 우리의 두 가지 구성 요소인 superpixel과 token pooling이 성능 향상에 기여함을 보여준다. 특히 fine-tuning 전에는 region mIoU에서 8%, boundary F-score에서 11% 증가하는 두드러진 개선을 보인다. Figure 8은 CAST가 supervised 학습 및 fine-tuning 후에도 이러한 이점을 유지하며, 전체 객체와 세부 사항을 모두 더 정확하게 인식하고 분할함을 보여준다.
4.3 Recognition and Refinement of Segmentation through Feedback
이제 우리는 CAST의 인식(recognition) 성능과 세그멘테이션(segmentation)과의 피드백 연결에 대해 연구한다.
분류 (Classification)
우리는 CAST-S를 ViT-S 및 Swin Transformer (Liu et al., 2021)의 Swin-T와 비교한다. 이 두 모델은 오직 인식만을 위해 설계되었으며, 유사한 GFLOPS를 가진다. 세 모델 모두 IN-1K에서 self-supervised 학습되었고, IN-1K 및 IN-100에서 linear probing을 사용하여 테스트되었다. Table 4는 계층적 token pooling을 통해 CAST가 ViT 및 Swin보다 30% 더 적은 GFLOPS로 더 나은 성능을 보임을 보여준다. 특히, CAST만이 계층적 세그멘테이션을 직접 출력할 수 있으며, 더 강력한 객체 중심의 attention을 가진다 (Appx. A.5).
| Model | GFLOPS | IN-100 | IN-1K |
|---|---|---|---|
| ViT-S | 4.7 | 78.1 | 67.9 |
| Swin-T | 4.5 | 78.3 | 63.0 |
| CAST-S |
Table 4: CAST는 더 높은 효율성으로 ImageNet 분류에서 ViT 및 Swin을 능가한다. 우리는 IN-1K에서 self-supervised 학습되고 IN-100/1K에서 테스트된 ViT, Swin, CAST의 top-1 linear probing 정확도를 보고한다. CAST는 약 30% 더 적은 GFLOPS를 사용하여 더 높은 정확도를 달성한다.
테스트 시간 적응 (Test-time adaptation)
CAST는 인식을 위한 feed-forward 계층 구조에서 내부 segmenter를 학습할 뿐만 아니라, 피드백 역 계층 구조에서 segmenter를 수정하여 세그멘테이션과 인식 모두를 동시에 향상시킬 수 있다 (Fig. 3). Fig. 9는 모호한 인식(ambiguous recognition)이 winning activation을 최대화함으로써 강화될 수 있으며, 이는 세그멘테이션을 수정하고 결과적으로 세그멘테이션과 인식 모두를 동시에 향상시킨다는 것을 보여준다. 더 자세한 내용은 Appx. C를 참조하라.
 Figure 9: CAST는 테스트 시간 동안 모호한 인식을 강화하고 세그멘테이션을 정제하기 위해 적응될 수 있다. Fig. 3에 표시된 PartImageNet의 이진 개 분류 task에 대해, 우리는 적응 전후 (Fig. 3) CAST의 8-way 세그멘테이션과 ground-truth 개 마스크에 대한 PartImageNet의 영역 mIoU를 평가한다. mIoU가 초기 임계값 0.8 (수직선)보다 낮을 때, 대부분 크고 긍정적인 이득을 얻는다 (대각선 위의 빨간 점). 적응이 가장 (필요하지 않을) 때, 초기 세그멘테이션이 좋지 않으면 평균 이득 (검은 선)은 크다 (0). 이 적응 과정에서 우리의 동시 세그멘테이션 및 인식이 서로를 향상시킨다.
Figure 9: CAST는 테스트 시간 동안 모호한 인식을 강화하고 세그멘테이션을 정제하기 위해 적응될 수 있다. Fig. 3에 표시된 PartImageNet의 이진 개 분류 task에 대해, 우리는 적응 전후 (Fig. 3) CAST의 8-way 세그멘테이션과 ground-truth 개 마스크에 대한 PartImageNet의 영역 mIoU를 평가한다. mIoU가 초기 임계값 0.8 (수직선)보다 낮을 때, 대부분 크고 긍정적인 이득을 얻는다 (대각선 위의 빨간 점). 적응이 가장 (필요하지 않을) 때, 초기 세그멘테이션이 좋지 않으면 평균 이득 (검은 선)은 크다 (0). 이 적응 과정에서 우리의 동시 세그멘테이션 및 인식이 서로를 향상시킨다.
요약 (Summary)
우리는 세그멘테이션을 인식의 일부로 포함하고, 이미지 인식 목표를 통해 이를 학습하며, 인식과 동시에 그리고 인식을 위해 이를 추론하는 방식을 제안한다. 우리는 superpixel과 token pooling을 활용하여 모델 CAST를 개발하였다. CAST는 부분(parts)과 전체(wholes)를 발견하며, 다양한 세그멘테이션 및 인식 task에서 정확도와 효율성 모두에서 SAM, HSG, ViT를 능가한다.
Acknowledgements
본 연구는 UC Berkeley와 University of Michigan의 S. Yu에게 지원된 미국 NSF 2131111, NSF 2215542, NSF 2313151 및 Bosch 기부금의 부분적인 지원을 받았다. 이 연구로 이어진 초기 통찰력 있는 논의를 제공해 준 Jyh-Jing Hwang에게 감사드린다.
Ethics Statement
우리의 CAST는 부분-전체 구조에 대한 세밀한 이해를 제공하여 새로운 가능성을 열어주지만, 동시에 오용의 가능성도 내포하고 있다. 예를 들어, 인간 자세와 같은 상세한 구조 정보는 DeepFake 비디오의 품질을 향상시키는 데 사용될 수 있다 (Masood et al., 2023). 그러나 기술 자체가 문제가 아니며, 그 기술을 사용하는 사람에게 책임이 있다는 점을 강조하는 것이 중요하다. 우리는 우리의 CAST가 이러한 잠재적 위험보다 더 많은 이점을 가져오기를 기대한다.
Reproducibility Statement
우리는 방법론 및 실험 세부 사항을 Appx. E와 Appx. F에 제공하며, 코드는 GitHub에서 확인할 수 있다.
A Ablation Studies and Analyses
A. 1 Ablation Study on Design Choices
Table 5는 우리 프레임워크의 설계 선택에 대한 ablation study 결과를 제시한다. (a) 다양한 token pooling 방법을 탐색했으며, 그중 GraphPool 모듈이 가장 뛰어난 성능을 보였다. 특히 FINCH (Sarfraz et al., 2019)는 성능이 뒤처져 adaptive pooling의 어려움을 보여준다. (b) 다양한 centroid 초기화 방법을 조사했으며, Farthest Point Sampling (FPS)이 다른 방법들보다 훨씬 우수한 성능을 나타냈다. FPS는 정보성 있는 token을 샘플링할 뿐만 아니라, fine-grained 시각 정보를 보존하면서 discriminative token 선택을 향상시킨다. (c) 모델 효율성과 task 성능 간의 균형을 맞추기 위해 학습 및 추론 모두에 고정된 최적의 segment granularity를 탐구했다. (d) 학습된 모델이 추론 시 다양한 segment granularity에 적응할 수 있음을 보여준다.
Table 5: (a) token pooling, (b) 클러스터 centroid 초기화, (c) 학습 및 테스트에 동일하게 적용된 token granularity, 그리고 (d) 학습된 모델의 테스트 시 변경된 token granularity에 대한 설계 선택을 비교한다. 우리는 IN-100에서 MoCo로 학습된 CAST-S의 linear probing 정확도를 보고한다. 는 해당 방법들이 재구현되었음을 나타낸다.
| (a) Pooling | Acc. | (c) Token granularity (Train=Test) | GFLOPS | Acc. |
|---|---|---|---|---|
| Graph Pooling | 79.9 | 196, 32, 16, 8 | 3.0 | 78.8 |
| Random Sampling | 55.8 | 196, 64, 32, 16 | 3.4 | 79.9 |
| K-Means | 73.9 | 196, 128, 64, 32 | 4.3 | 79.9 |
| K-Medoids | 72.3 | 324, 64, 32, 16 | 4.6 | 79.8 |
| (Sarfraz et al., 2019) | 63.3 | 324, 128, 64, 32 | 5.4 | 80.4 |
| Token Pooling (Marin et al., 2021) | 75.8 | |||
| CTM (Zeng et al., 2022) | 72.2 | |||
| ToMe (Bolya et al., 2023) | 78.1 | (d) Token granularity (Train Test ) | GFLOPS | Acc. |
| Train: 196, 64, 32, 16 | 3.4 | 79.9 | ||
| Acc. | Test: 196, 32, 16, 8 | 3.0 | 79.2 | |
| Farthest Point Sampling | 79.9 | Test: 196, 128, 64, 32 | 4.3 | 79.5 |
| Random Sampling | 71.2 | Test: 324,64,32,16 | 4.6 | 78.8 |
| PoWER-BERT (Goyal et al., 2020) | 71.6 | Test: 324, 128, 64, 32 | 5.4 | 79.3 |
A. 2 Ablation Study on Superpixel Methods
우리는 서로 다른 알고리즘으로 생성된 superpixel을 사용하여 **CAST의 견고성(robustness)**을 테스트한다. 특히, 분류 및 semantic segmentation task에서 SEEDS (Bergh et al., 2012)와 SLIC (Achanta et al., 2012)를 비교한다. 우리는 분류 및 segmentation을 위해 IN-1K 및 COCO 데이터셋에서 self-supervised learning 방식으로 CAST를 학습시킨다. Table 6에서 볼 수 있듯이, 우리는 ImageNet-1K에서의 linear probing 정확도와 VOC에서의 fine-tuning 전(왼쪽) 및 후(오른쪽) mIoU를 보고한다. 우리의 방법은 superpixel 알고리즘 선택에 견고하며, SEEDS가 SLIC보다 더 나은 성능을 달성한다.
Table 6: SEEDS는 분류 및 semantic segmentation에서 SLIC보다 우수한 성능을 보인다. 우리는 IN-1K에서의 분류 top-1 정확도와 VOC에서의 fine-tuning 전/후 segmentation mIoU를 보고한다. 우리의 CAST는 SEEDS로 생성된 superpixel을 사용하여 더 나은 성능을 달성한다.
| Classification | Segmentation | |
|---|---|---|
| SEEDS | 68.1 | |
| SLIC | 65.6 |
Figure 10은 SEEDS와 SLIC를 사용하여 얻은 superpixel을 보여준다. SEEDS superpixel은 SLIC에 비해 객체 경계, 특히 작은 객체에 대해 더 우수한 정렬을 보인다. 이러한 개선은 SEEDS가 경계 개선 알고리즘으로, superpixel을 반복적으로 업데이트하여 엣지를 더 잘 포착하기 때문이다. 반면, SLIC는 색상 및 연결 구성 요소 제약 조건에 기반한 K-Means 클러스터링에 의존하며, 이는 경계를 포착하는 데 덜 효과적일 수 있다. 결과적으로, 우리는 SEEDS superpixel이 우수한 형태 정보를 통해 CAST에 더 설득력 있는 계층적 segmentation을 생성한다고 결론 내릴 수 있다.
 Figure 10: 왼쪽에서 오른쪽으로, **SEEDS 및 SLIC 알고리즘으로 생성된 superpixel (흰색 윤곽선)**을 원본 이미지와 ground-truth semantic segmentation (색상 영역) 위에 겹쳐서 보여준다. SEEDS로 생성된 superpixel은 SLIC로 생성된 superpixel보다 객체 경계, 특히 작은 객체에 더 정확하게 정렬된다. feature 학습과 함께 superpixel을 생성하는 방법을 학습하면 더 정확한 superpixel 분할이 가능해지고 segmentation 성능이 향상될 것이다.
Figure 10: 왼쪽에서 오른쪽으로, **SEEDS 및 SLIC 알고리즘으로 생성된 superpixel (흰색 윤곽선)**을 원본 이미지와 ground-truth semantic segmentation (색상 영역) 위에 겹쳐서 보여준다. SEEDS로 생성된 superpixel은 SLIC로 생성된 superpixel보다 객체 경계, 특히 작은 객체에 더 정확하게 정렬된다. feature 학습과 함께 superpixel을 생성하는 방법을 학습하면 더 정확한 superpixel 분할이 가능해지고 segmentation 성능이 향상될 것이다.
A. 3 Limitations of Superpixels and Failure Cases
우리의 방법은 Cityscapes 데이터셋에서 ViT baseline보다 성능이 떨어진다. 이는 기존의 superpixel 알고리즘을 사용하는 것의 한계를 보여준다. **ViT-S는 74.6%**를 달성하는 반면, **CAST-S와 CAST-SD는 벤치마크에서 각각 72.1%와 74.2%**를 달성한다.
Fig. 11에서 볼 수 있듯이, 기존 superpixel 방법들은 장면에서 가로등 기둥이나 강철 파이프와 같은 얇은 구조물을 제대로 추출하지 못한다. 한 가지 가능한 이유는 이러한 방법들이 객체 중심 데이터셋(BSDS)에서만 개발 및 테스트되었기 때문이다. 이러한 superpixel 알고리즘을 학습 가능한(learnable) 접근 방식으로 대체하면 이러한 문제를 해결하는 데 도움이 될 수 있다.
 Figure 11: 왼쪽부터 오른쪽으로, 이미지와 해당 superpixel (흰색 윤곽선)을 보여준다. 거리 장면에는 가로등 기둥이나 강철 파이프와 같이 얇은 구조물이 많으며, superpixel 알고리즘은 종종 이를 제대로 추출하지 못한다. superpixel을 생성하는 방법을 학습하는 것이 이러한 문제를 해결하는 데 도움이 될 수 있다.
Figure 11: 왼쪽부터 오른쪽으로, 이미지와 해당 superpixel (흰색 윤곽선)을 보여준다. 거리 장면에는 가로등 기둥이나 강철 파이프와 같이 얇은 구조물이 많으며, superpixel 알고리즘은 종종 이를 제대로 추출하지 못한다. superpixel을 생성하는 방법을 학습하는 것이 이러한 문제를 해결하는 데 도움이 될 수 있다.
A. 4 Ablation Study on Inference Latency
superpixel 생성 및 graph pooling의 연산 비용은 self-attention 계산에 필요한 token 수가 감소함에 따라 줄어들 수 있다. 이러한 장점은 self-attention 블록이 전체 비용의 대부분을 차지하는 대규모 모델을 사용할 때 더욱 두드러진다.
이를 검증하기 위해, 우리는 **모델 추론(inference) 및 superpixel 생성의 지연 시간(latency)**을 분석한다. 우리의 시스템은 32GB Nvidia Titan V GPU 카드 1개와 Intel(R) Xeon(R) CPU E5-2630 v4 프로세서 2개(총 20개 CPU 코어)로 구성되어 있다. 우리는 PyTorch 머신러닝 프레임워크를 사용하며, 24개의 worker, 64의 batch size, 그리고 의 이미지 해상도를 설정하였다. 우리 시스템에서 CAST-B는 ViT-B의 273ms에 비해 더 낮은 평균 추론 지연 시간인 217ms를 달성한다. SEEDS는 이미지 배치로부터 superpixel을 생성하는 데 73ms가 소요된다. 그러나 현재 SEEDS 구현은 완전히 최적화되지 않았다는 점을 언급한다. GPU 구현을 활용하거나 더 많은 CPU 코어로 프로세스를 병렬화하면 superpixel 생성의 병목 현상을 완화할 수 있다. 또한, superpixel 생성 비용은 일반적으로 사용되는 대규모 모델에서 덜 중요해진다.
또한, 우리는 token 수가 감소함에 따라 self-attention 및 graph pooling의 비용이 감소함을 보여준다. Table 7은 layer별 graph pooling의 연산 비용을 보여주며, layer당 token 수가 감소함에 따라 비용이 크게 줄어듦을 나타낸다.
Table 7: 우리 graph pool 모듈의 FPS는 추가적인 연산을 필요로 한다. 우리는 IN-100에서 384 채널 차원과 256 batch size를 사용하여 각 모듈의 추론 시간(ms)을 보고한다. 모델 효율성을 높이기 위한 token sampling 기술 최적화는 우리의 향후 연구이다.
| #. of Tokens | Encoder Blocks | GraphPool (FPS) |
|---|---|---|
| 196 | 86.43 | |
| 64 | 25.4 | |
| 32 | 12.9 | |
| 16 | 5 |
A. 5 Visualization of Attention Maps
CAST는 ViT보다 더 객체 중심적인(object-centric) attention을 제공한다. 우리는 IN-1K에서 self-supervised 학습된 모델들을 비교하고, Pascal VOC에서 평가를 수행했다. Joulin et al. (2010)의 방법을 따라 multi-head attention으로부터 figure-ground segmentation을 생성하고, 실제 segmentation과의 mIoU를 측정했다. Figure 12는 attention map의 예시와 각 모델의 mIoU를 시각화한 것이다.
 Figure 12: CAST의 attention은 ViT보다 더 객체 중심적이다. 우리는 ViT와 CAST의 figure-grounded attention map을 시각화했다. 괄호 안의 숫자는 attention과 실제 segmentation 간의 mIoU를 나타낸다. CAST의 attention map은 양 전체를 포괄하는 반면, ViT는 양의 일부만을 포착한다.
Figure 12: CAST의 attention은 ViT보다 더 객체 중심적이다. 우리는 ViT와 CAST의 figure-grounded attention map을 시각화했다. 괄호 안의 숫자는 attention과 실제 segmentation 간의 mIoU를 나타낸다. CAST의 attention map은 양 전체를 포괄하는 반면, ViT는 양의 일부만을 포착한다.
B Additional Part-to-whole Results
B. 1 Examples for PartImageNet
우리는 PartImageNet의 어노테이션 목록과 시각적 예시를 제시한다. 이 데이터셋은 2개의 카테고리(동물 vs. 사물)에서 11개의 객체 클래스를 포함하며, 각 객체 클래스는 여러 부분(part) 클래스를 포함하여 총 40개의 부분으로 구성된다. 부분 세그먼트는 객체 세그먼트의 하위 영역으로 제한된다.
Table 8: PartImageNet은 11개의 객체와 40개의 부분 어노테이션을 포함한다. 각 객체 세그먼트는 부분 세그먼트로 분할된다. 예를 들어, 사족보행 동물(quadruped) 세그먼트는 사족보행 동물의 머리(quadruped head), 몸통(quadruped body), 발(quadruped foot), 꼬리(quadruped tail) 세그먼트로 구성된다. 우리의 실험에서는 먼저 객체 레이블을 예측한 다음, 일관된 예측을 강제하기 위해 객체에 조건화된 부분 레이블을 예측한다. 즉, 사족보행 동물의 하위 영역은 머리, 몸통, 발 또는 꼬리 중 하나여야 한다.
| Category | Object | Part |
|---|---|---|
| Animal | Quadruped | Head, Body, Foot, Tail |
| Biped | Head, Body, Hand, Foot, Tail | |
| Fish | Head, Body, Fin, Tail | |
| Bird | Head, Body, Wing, Foot, Tail | |
| Snake | Head, Body | |
| Reptile | Head, Body, Foot, Tail | |
| Things | Car | Body, Tire, Side Mirror |
| Bicycle | Head, Body, Seat, Tire | |
| Boat | Body, Sail | |
| Aeroplane | Head, Body, Wing, Engine, Tail | |
| Bottle | Body, Mouth |
 Figure 13: PartImageNet의 예시 이미지. 원본 논문 (He et al., 2022)의 Figure 1을 복사하였다. 사족보행 동물(개) 세그먼트는 머리, 몸통, 발, 꼬리 부분 세그먼트로 구성된다.
Figure 13: PartImageNet의 예시 이미지. 원본 논문 (He et al., 2022)의 Figure 1을 복사하였다. 사족보행 동물(개) 세그먼트는 머리, 몸통, 발, 꼬리 부분 세그먼트로 구성된다.
B. 2 Class-wise Performance
우리는 Table 9에서 PartImageNet에 대한 part-to-whole recognition의 클래스별 성능을 제시한다. CAST는 reptile과 bottle 클래스를 제외한 대부분의 클래스에서 SAM과 ViT를 능가한다. 이를 더 자세히 조사하기 위해, Figure 14에서는 다음 세 가지 시각적 예시를 보여준다:
- CAST가 우수한 성능을 보이는 경우 (quadruped),
- ViT가 우수한 성능을 보이는 경우 (reptile),
- SAM이 우수한 성능을 보이는 경우 (bottle).
Table 9: CAST는 대부분의 클래스에서 SAM과 ViT를 능가한다.
우리는 PartImageNet의 각 클래스에 대해 SAM, ViT, CAST의 객체 어노테이션에 대한 region mIoU를 보고하며, 각 Animal 또는 Things 카테고리 내 클래스들의 평균도 함께 제시한다. 굵은 글씨는 해당 방법들 중 최고 값을 나타낸다. Aeroplane 클래스는 validation set에 포함되어 있지 않으므로 모든 방법에서 '-'로 표시된다.
| Animal | |||||||
|---|---|---|---|---|---|---|---|
| Quadruped | Biped | Fish | Bird | Snake | Reptile | Avg. | |
| SAM-B | 18.18 | 14.98 | 16.09 | 24.55 | 19.87 | 14.78 | 18.08 |
| SAM-H | 29.00 | 17.25 | 19.97 | 21.35 | 20.57 | 13.05 | 20.20 |
| ViT-B | 29.61 | 15.17 | 24.34 | 30.02 | 22.97 | 23.79 | |
| CAST-B | 20.34 |
| Things | ||||||
|---|---|---|---|---|---|---|
| Car | Bicycle | Boat | Aeroplane | Bottle | Avg. | |
| SAM-B | 15.89 | 15.16 | 12.14 | - | 31.30 | 18.62 |
| SAM-H | 29.09 | 14.20 | 9.34 | - | 22.03 | |
| ViT-B | 32.15 | 18.33 | 20.19 | - | 31.59 | 25.57 |
| CAST-B | - | 27.36 |
 Figure 14: SAM, ViT, CAST를 사용한 PartImageNet의 객체 및 부분 분할(segmentation) 시각적 예시.
Figure 14: SAM, ViT, CAST를 사용한 PartImageNet의 객체 및 부분 분할(segmentation) 시각적 예시.
각 모델이 뛰어난 성능을 보이는 세 가지 경우를 보여준다.
- CAST는 quadruped에서 뛰어난 성능을 보인다. 여기에서 CAST는 머리, 몸통, 발과 같은 부분을 적절하게 포착하는 데 성공한다. SAM은 개를 포착할 수 있었지만, 머리와 같은 부분을 분할하는 데 실패한다.
- ViT는 reptile에서 뛰어난 성능을 보인다. SAM은 위장(camouflage) 때문에 reptile을 포착하는 데 실패했다. CAST는 몸통을 포착했지만 발을 놓쳤다. 이와 대조적으로, ViT는 상세한 경계를 제공하지는 않지만, reptile의 전체 몸통을 덮어 다른 모델보다 더 나은 region mIoU를 제공한다.
- SAM은 bottle에서 뛰어난 성능을 보인다. 여기에서 SAM은 bottle의 경계를 명확하게 설명한다. 그러나 CAST는 실수로 마우스를 bottle과 함께 군집화한다.
C Extension to Test-time Adaptation
CAST는 학습 중에 인식(recognition) 목표에 따라 top-down 경로만을 고려한다. 이 지식은 모델에 인코딩되어 추론 시 bottom-up 경로를 반영한다. 이러한 방식은 모델이 일반적인 top-down 요소를 학습하도록 하지만, 추론 시 top layer의 예측에 따라 segmentation 결과가 변경되지는 않는다.
추론 시 top-down 경로를 통합하여 CAST를 확장하기 위해, 우리는 test-time adaptation (TTA) (Sun et al., 2020), 특히 TENT (Wang et al., 2021a)를 사용한다. 이때 CAST backbone 위에 학습된 classifier를 활용한다. 우리는 각 샘플에 TENT를 적용하여 모델을 적응시키고 예측 신뢰도를 최대화한다. 결과적으로 CAST는 초기 예측(initial belief)에 맞춰 객체 segment를 정제한다: "이 이미지가 예측된 클래스를 나타낸다면, 어떤 부분이 이 예측에 기여하는가?"
C. 1 Implementation Details
우리는 MoCo objective로 ImageNet에서 사전학습된 CAST 모델을 기본 모델로 사용한다. 우리는 PartImageNet 학습 데이터로 개(dog)와 비개(non-dog) 분류기를 학습시키고, 이를 validation split에서 평가한다. 분류기는 해당 클래스에 속하는 학습 데이터의 정규화된 embedding 평균으로 정의된다. 즉, 우리는 각 클래스에 대한 학습 데이터의 중심(center)을 클래스 벡터로 정의한다. 클래스를 추론하기 위해, 테스트 embedding과 클래스 벡터 간의 cosine similarity를 계산하고, 이 cosine similarity를 logit으로 사용하여 softmax 분류기에 0.07의 temperature를 적용한다.
각 샘플에 대해 예측 entropy loss를 계산하고, 의 단일 SGD를 사용하여 모델을 업데이트한다. 우리는 TTA(Test-Time Adaptation)의 관행에 따라 다른 파라미터는 고정(frozen)한 채 normalization layer만 업데이트한다. 이 과정에서 어떠한 레이블이나 배치 정보도 사용되지 않으며, 모델은 단일 인스턴스의 추론에만 기반하여 업데이트된다.
우리는 TTA 전후의 segmentation 변화를 평가한다. 이를 위해, 각 segment에 레이블을 할당하여 객체 segmentation mask를 계산한다. 이 segment 레이블은 ground-truth segmentation mask를 사용하여 픽셀 레이블의 다수결로 정의한다. 우리는 단순화를 위해 이 전략을 선택했지만, 앞서 논의했듯이 OVSeg를 사용하여 segment 레이블을 예측할 수도 있다. 우리는 전경(개)과 배경을 두 개의 클래스로 간주하여 mIoU의 평균을 측정한다.
C. 2 Visual Examples Before and After TTA
Fig. 15는 TTA가 CAST segmentation을 어떻게 개선하는지를 보여준다. TTA는 객체 형태를 더 정확하게 포착하고 관련 없는 세부 사항에 대한 attention을 최소화함으로써 segmentation 성능을 향상시킨다. 이러한 개선은 원래 CAST가 제대로 작동하지 못하는 어려운 샘플에서 특히 두드러진다.
이를 검증하기 위해, 우리는 TTA 적용 전후로 mIoU가 크게 증가한 성공 사례(1-3행)와 mIoU가 감소한 실패 사례(4-5행)를 모두 제시한다. 실패 사례에서는 TTA가 CAST로 하여금 개의 가장 뚜렷한 부분에만 집중하게 하여, 개의 일부를 배경과 함께 클러스터링하도록 잘못 유도한다.
 Figure 15: test-time-adaptation (TTA) 적용 전후의 CAST 모델을 사용한 학습된 클러스터(왼쪽) 및 예측된 개 객체 segmentation(오른쪽)의 시각적 예시.
Figure 15: test-time-adaptation (TTA) 적용 전후의 CAST 모델을 사용한 학습된 클러스터(왼쪽) 및 예측된 개 객체 segmentation(오른쪽)의 시각적 예시.
segmentation은 GT 픽셀 레이블을 사용하여 다수결 투표(majority vote) 방식으로 각 segment에 레이블을 할당하여 얻어진다. 우리는 성공 사례(1-3행)와 실패 사례(4-5행)를 모두 보여준다.
TTA는 객체 형태 포착을 개선함으로써 CAST segmentation을 향상시킨다. 예를 들어, 1-3행에서는 놓쳤던 다리 부분을 피하고, 3행에서는 창문 프레임과 같은 불필요한 세부 사항에 대한 attention을 줄인다. 그러나 실패 사례에서는 TTA 적용 후 CAST가 뚜렷한 부분에만 집중하고 다른 부분들을 배경과 병합하는 경향을 보인다.
D Additional Related Works
**이미지 분할(Image segmentation)**은 이미지를 일관성 있는 영역으로 나눈다. 고전적인 방법들은 두 단계로 구성된다:
- 로컬 feature 추출
- 모드 찾기(mode-finding) (Comaniciu & Meer, 2002; Banerjee et al., 2005) 또는 그래프 분할(graph partitioning) (Felzenszwalb & Huttenlocher, 2004; Shi & Malik, 2000; Malik et al., 2001; Yu & Shi, 2003a; 2004)과 같은 기준에 기반한 클러스터링.
이러한 방법들은 종종 인간의 인지 비교를 위해 **계층적 분할(hierarchical segmentation)**을 출력한다 (Arbelaez et al., 2010). 객체 경계의 모호성을 방지하기 위해, 일반적인 접근 방식은 **윤곽선 감지(contour detection)**에 의존하거나 (Hwang & Liu, 2015; Xie & Tu, 2015), **다중 스케일 분할(multi-scale segmentation)**을 위해 윤곽선을 반복적으로 제거한다 (Arbelaez et al., 2010). 이와 대조적으로, 우리의 연구는 윤곽선 프록시(contour proxies)를 사용하지 않고 세그먼트(segment)에 직접 작동하여 적절한 경계를 제공한다.
Self-supervised segmentation 및 representation learning은 사람이 주석을 달지 않은 이미지로부터 이미지를 분할하는 방법을 학습하는 것을 목표로 하며, 종종 해당 feature도 함께 학습한다. 최근 연구들은 세 가지 범주로 나눌 수 있다:
- Self-supervised image recognition을 활용하여, 위치 민감도(location sensitivity)를 높이거나 (Wu et al., 2018; He et al., 2020; Chen et al., 2020; Wang et al., 2021c), 다양한 뷰(views)에 걸쳐 contrastive loss를 구현하거나 (Wang et al., 2021b), 더 강력한 증강(augmentation) 및 제약된 크롭(constrained cropping)을 적용하여 (Selvaraju et al., 2021; Mo et al., 2021) 모델을 segmentation으로 전이시킨다.
- Pixel-wise cluster predictor를 학습하여, 동일한 인스턴스의 증강된 뷰에서 해당 픽셀의 클러스터 예측 간의 상호 정보(mutual information)를 최대화한다 (Ji et al., 2019; Ouali et al., 2020).
- Pixel-level feature encoder를 학습하여, 윤곽선으로 유도된 세그먼트 (Hwang et al., 2019), 사전 계산된 영역 계층 (Zhang & Maire, 2020), 또는 feature로 유도된 계층적 그룹화 (Ke et al., 2022)를 기반으로 픽셀 간의 차별성(discrimination)을 최대화하고, 픽셀 feature 유사성으로부터 segmentation을 도출한다.
우리의 연구는 첫 번째와 세 번째 접근 방식을 통합하여, self-supervised image recognition 프레임워크로 CAST를 학습시키면서도 계층적 segmentation을 추가 비용 없이 얻는다.
Object-centric learning은 객체를 배경으로부터 분리하는 이미지의 구조화된 표현을 학습하는 것을 목표로 한다 (Eslami et al., 2016; Mo et al., 2019). 여러 선행 연구들은 이 개념을 attention mechanism에 통합하려고 시도했으며, 예를 들어 vision Transformer와 결합하는 방식이 있다 (Locatello et al., 2020; Xu et al., 2022; Kang et al., 2022; Shi et al., 2023). 이 접근 방식은 객체 segmentation을 발견할 뿐만 아니라, 분포 변화(distribution shifts)에 대한 강건성(robustness)도 향상시킨다. 그러나 대부분의 선행 연구는 객체 수준에만 초점을 맞춘다. 우리의 프레임워크는 object-centric learning을 더 세분화된 방식으로 확장하여, 부분-전체(part-to-whole) 관계의 연속체(continuum)를 발견한다.
Superpixel은 색상(colors)과 같은 일관성 있는 구조를 캡슐화하는 지역적으로 연결된 픽셀들의 집합이다 (Ren & Malik, 2003). Superpixel은 부분 파싱(part parsing) (Mori et al., 2004), 주목도 감지(saliency detection) (Ren et al., 2013), 이미지 분할(image segmentation) (Gould et al., 2008; Fulkerson et al., 2009; Sharma et al., 2014; Gadde et al., 2016; Wei et al., 2018)을 포함한 다양한 밀집 레이블링(densely labeling) task에서 활용되어 왔다. 최근에는 Zhang et al. (2022)이 ViT 아키텍처에서 패치(patches)를 superpixel token으로 대체하여 semantic segmentation 문제를 해결했다. 우리의 모델은 세그먼트 계층(segment hierarchy)을 구축하고 segmentation과 classification을 동시에 수행함으로써 한 단계 더 나아간다.
Token pooling은 (vision) Transformer의 token을 병합하거나 가지치기(prune)하는 것을 목표로 한다. 수많은 방법들이 제안되었지만, 그 주된 목표는 효율성을 향상시키는 것이었으며, 이들은 일반적으로 정사각형 패치(square patches)를 사용했다 (Sarfraz et al., 2019; Marin et al., 2021; Zeng et al., 2022). 이와 대조적으로, 우리의 CAST는 superpixel을 시각 단위(visual units)로 사용하며, 이는 계층적 segmentation을 추가 비용 없이 생성하는 독특한 이점을 제공한다. 또한, 우리의 ablation study는 제안된 graph pooling이 우리의 목적에 있어 ToMe (Bolya et al., 2023)와 같은 state-of-the-art token pooling 방법보다 우수함을 입증한다.
E Additional Method Details
E. 1 Algorithm
우리는 Graph Pooling 모듈과 우리의 CAST 프레임워크의 pseudo code를 제시한다.
- FPS: Farthest Point Sampling.
- MSA: Multi-headed Self-Attention.
- MLP: MultiLayer Perceptron
- FC: Fully Connected Layer.
- : Concatenation operator.
Algorithm 1: GraphPool
Input: Feature \(Z\) and number of clusters \(N\)
Output: Coarse feature \(Y\) and assignments \(P\)
Centroid indices \(C \leftarrow \operatorname{FPS}(Z, N)\)
Refined feature \(U \leftarrow \operatorname{MSA}(Z)+Z\)
Normalized feature
\(U \leftarrow U-\operatorname{mean}(U)+\) bias
Centroid feature \(V \leftarrow\{U[c] \mid c \in C\}\)
\(P \leftarrow \operatorname{softmax}\left(\kappa \frac{U V^{\top}}{\|U\|\|V\|}\right)\)
Project feature \(Z \leftarrow \operatorname{MLP}(Z)\)
Average pooled feature \(Z^{\prime} \leftarrow P^{\top} Z^{\prime} . / P^{\top} 1\)
New centroid feature \(Y \leftarrow\{Z[c] \mid c \in C\}\)
Updated centroid feature \(Y \leftarrow Y+Z^{\prime}\)
Algorithm 1: GraphPool
Updated centroid feature \(Y \leftarrow Y+Z^{\prime}\)
\(\frac{\text { Algorithm 1: GraphPool }}{\text { Input: Feature } Z \text { and number of clusters } N}\)
concatenation operator.
```
image 1, CNN features \(X_{\mathrm{cnn}}\), class
, position encoding \(E_{\text {pos }}, \#\) of
segments \(N_{l}\) at level \(l\)
Output: Feature \(\mathbf{f}_{\text {class }}\) or \(\mathbf{f}_{\text {seg }}\)
Input segmentation \(S_{0} \leftarrow \operatorname{Superpixel}\left(I, N_{0}\right)\)
Input tokens \(X_{s} \leftarrow\left\{\left.\frac{1}{|a|} \sum_{i \in a} X_{\text {cnn }}[i] \right\rvert\, a \in S_{0}\right\}\)
for \(l=0 \ldots L\) do
if \(l=0\) then
Initial segment features
\(Z_{0} \leftarrow\left[X_{s}+E_{\text {pos }} ; X_{\text {class }}\right]\)
else
Coarsened segment features and
clustering assignments
\(Z_{l}, P_{l} \leftarrow \operatorname{GraphPool}\left(Z_{l-1}, N_{l}\right)\)
Coarsened segmentation
\(S_{l} \leftarrow S_{l-1} \times P_{l}\)
end
\(Z_{l} \leftarrow \operatorname{ViT} \_\operatorname{Encoders}\left(Z_{l}\right)\)
end
Class token \(\mathbf{f}_{\text {class }} \leftarrow Z_{L}[0]\)
Multi-level segment tokens \(\mathbf{f}_{\text {seg }} \leftarrow \mathrm{FC}\left(\oplus\left(Z_{0}[1:\right.\)
\(\left.\left.\left.N_{0}\right], \ldots, \operatorname{Unpool}\left(Z_{L}\left[1: N_{L}\right]\right)\right)\right)\)
Algorithm 2: Overall framework Input: Input image (I), CNN features (X_{\text {cn }}) token (X_{\text {class }}), position encoding (E_{\text {pos }}), # of token (X_{\text {class }}), position ent Input segmentation (S_{0} \leftarrow \operatorname{Superpixel}\left(I, N_{0}\right)) Input tokens (X_{s} \leftarrow\left{\left.\frac{1}{|a|} \sum_{i \in a} X_{\mathrm{cnn}}[i] \right\rvert, a \in S_{0}\right}) (l=0 \ldots L) do end (\left.\left.\left.N_{0}\right], \ldots, \operatorname{Unpool}\left(Z_{L}\left[1: N_{L}\right]\right)\right)\right))
**Multi-level segment token**을 얻기 위해, 우리는 **coarse token**을 해당 **fine segment**로 **unpool**하고, **unpooled feature**를 **fine token**과 **concatenate**한다. **Segment token $Z_l$**은 관련 **fine segment**로 **scatter**된다:
$$
Z_{l-1}^{\text {unpool }}[a]=Z_{l}[c], c=\operatorname{argmax}_{c \in C} P_{l}[a, c] .
$$
## E. 2 Comparison with ViT
우리는 Figure 16과 Figure 17에서 **CNN, ViT, Token Pooling**을 포함한 기존 연구들과 **우리의 CAST 간의 기술적 차이점**을 강조한다.
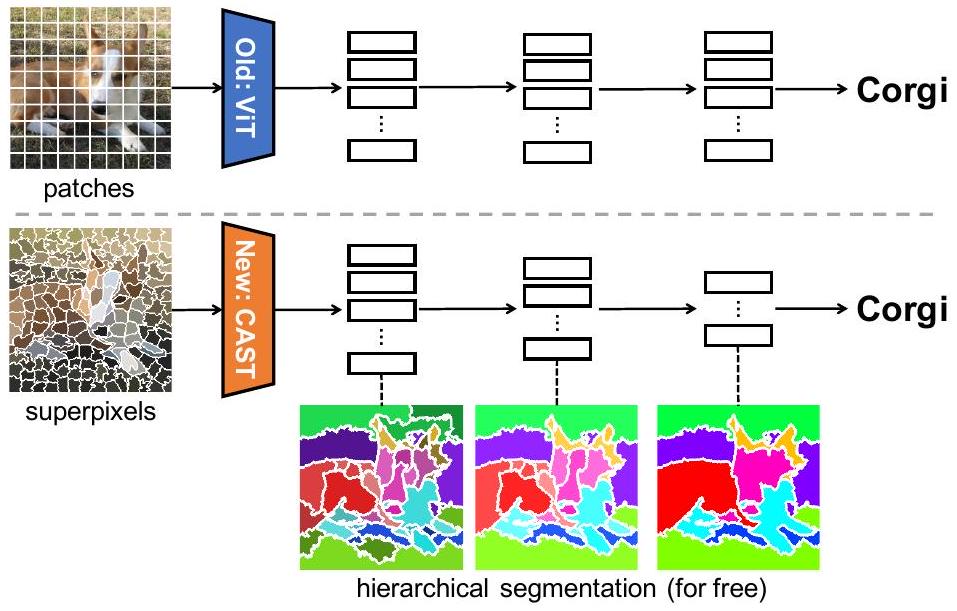
Figure 16: **ViT**는 **patch token**을 입력으로 받아 모든 **encoder block**에서 동일하게 많은 수의 token을 유지하는 반면, **우리의 CAST**는 **segment token**을 입력으로 받아 이를 **계층적으로 더 적고 큰 region token으로 coarsening**한다. 이러한 **segment token**은 이미지에 적응하며 모양이 가변적이다.
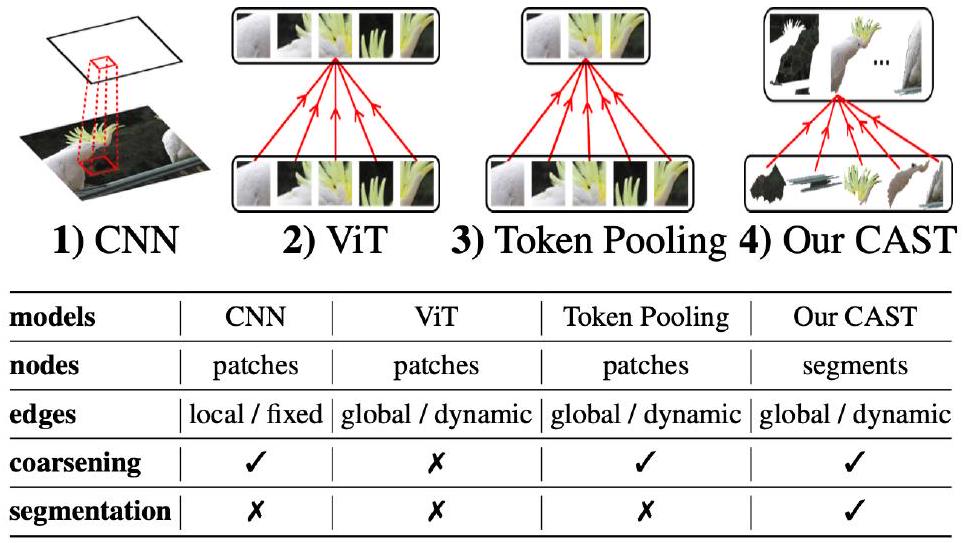
Figure 17: 우리는 **다양한 모델들이 어떤 대상을 기반으로 작동하는지, 그리고 local-to-global 정보를 어떻게 추출하는지**에 따라 비교한다.
* **CNN**은 **grid** 상에서 feature를 계산하고 **spatial downsampling**을 통해 global 정보를 처리한다.
* **ViT**는 **정규화된(regularly shaped) patch**를 입력으로 받아 **attention**을 사용하여 feature를 업데이트한다.
* **Token Pooling**은 token의 **중요도 점수(significance scores)**에 따라 token을 subsample한다.
* **우리의 CAST**는 **segment token**을 입력으로 받아 이를 **더 큰 region token으로 coarsening**하며, 이 **region token**은 이미지에 적응한다.
## E. 3 Open-vocabulary Segmentation
우리는 제공된 segment로부터 **부분-전체(part-to-whole) 예측**을 도출하기 위해 **open-vocabulary segmentation 방법인 OVSeg** (Liang et al., 2023)를 사용한다. OVSeg는 **CLIP** (Radford et al., 2021) 분류기를 활용하는데, 이때 **관심 segment만 포함하고 다른 영역은 회색으로 마스킹된 이미지**에 대해 분류를 수행한다. 주어진 전경(foreground) 레이블 외에 **"Background" 클래스**가 추가로 도입된다. 예를 들어, **PartImageNet** (He et al., 2022)은 11개의 객체(예: Biped)와 40개의 부분(예: Biped Head)으로 구성되어 있으며, 각각 12-way 및 41-way 분류가 필요하다. 우리는 **거친(coarse) segment로부터 카테고리와 객체를 예측**하고, **미세한(fine) segment로부터 부분을 예측**한다. OpenAI에서 공개한 **사전학습된 가중치를 가진 ViT-B-16 모델**을 사용하며, 마스킹된 이미지로 fine-tuning하지 않는다.
**CAST** 및 **ViT segment**는 본질적으로 계층 구조를 가지고 있으므로, 우리는 **부모 segment의 객체 클래스에 기반하여 부분 인식 어휘(part recognition vocabulary)를 제한**한다. 반면, **SAM segment**는 이러한 계층 구조가 부족하여 **부모 클래스를 제약하기 위한 우회적인 방법**이 필요하다. 각 경우에 대한 구체적인 절차는 아래에 설명되어 있다. 우리는 **segmentation을 부드럽게 하기 위해 커널 크기 $7 \times 7$의 GaussianBlur**를 적용했다.
**CAST (및 ViT)**. CAST는 layer가 진행됨에 따라 segment를 점진적으로 클러스터링하여 여러 수준의 segment를 생성한다. 이 맥락에서 우리는 **객체 인식을 위해 8개의 segment를 가진 가장 높은 수준(level 4)**을 활용하고, **부분 인식을 위해 16개의 segment를 가진 그 하위 수준(level 3)**을 활용한다. **ViT**의 경우에도 동일한 전략을 사용하는데, 여기서 segment는 **동일한 수준의 embedding에 대한 K-means clustering**을 사용하여 생성된다. 따라서 CAST와 ViT segment 모두 일관된 계층 구조를 따른다.
**SAM**. **Segment Anything (SAM)** (Kirillov et al., 2023)은 다양한 수준의 segment를 제공하지만, 그들의 계층 구조는 고려하지 않는다. 구체적으로, SAM은 조건이 주어지지 않았을 때 원본 이미지를 파싱하기 위해 **다양한 수준의 64개 segment를 생성**한다. 여기서 우리는 **segment를 면적의 내림차순으로 정렬**하는 것으로 시작하는데, 이는 앞쪽 segment가 객체를 나타내는 경향이 있고 뒤쪽 segment가 부분을 나타내는 경향이 있음을 의미한다. 우리는 **빈 semantic mask로 시작하여 정렬된 segment를 처리하여 마스크를 반복적으로 채워 semantic segmentation을 얻는다.**
동일한 절차를 따르지만, **객체 인식과 부분 인식 사이에는 중요한 차이점**이 발생한다. **객체 인식**에서는 **이전 객체 segment가 이미 픽셀을 할당했으므로, 해당 픽셀이 이미 채워져 있다면 업데이트를 건너뛴다.** 반대로, **부분 인식**에서는 **새로운 부분 segment로 픽셀을 덮어쓴다.** 이는 OVSeg가 SAM에 의해 생성된 **미세한(fine-grained) segment를 고려**할 수 있도록 한다. 우리는 다양한 접근 방식을 테스트했으며, 이 전략이 가장 좋은 결과를 가져왔다.
## E. 4 Comparison with Hierarchical Segment Grouping
**Hierarchical Segment Grouping (HSG)** (Ke et al., 2022)는 **픽셀 feature 유사성**을 기반으로 그룹화 계층(grouping hierarchy)을 유도하는 **비지도 계층적 semantic segmentation 프레임워크**이다. 우리의 **CAST**는 **세그먼트를 점진적으로 병합하는 방식으로 계층적 그룹화를 추론**한다는 점에서 HSG와 유사하다. 두 방법 모두 **fine-grained 세그먼트를 다음 레벨의 coarse-grained 영역에 매핑하기 위해 soft assigned 확률을 예측**한다. 모든 레벨에 걸쳐 세그먼트 할당을 연결함으로써 **multi-scale 이미지 segmentation이 유도**된다.
그러나 우리의 CAST는 HSG와 여러 측면에서 차이가 있다.
1) HSG는 **비지도 semantic segmentation을 위해 특별히 설계**되었다. 이와는 대조적으로, 우리의 CAST는 **분류, 이미지 segmentation, detection과 같은 다양한 다운스트림 task를 위한 일반적인 backbone 아키텍처**이다. 또한, 우리 모델은 **지도 학습 및 비지도 학습 모두로 훈련**될 수 있다.
2) 우리의 **계층적 이미지 segmentation은 multi-scale feature 추출에 직접적으로 관여**한다. 모델의 초기 단계부터 **모든 token feature는 다른 스케일의 이미지 세그먼트에 해당**한다. 이와 대조적으로, HSG는 **CNN backbone 위에 구축**되며, segmentation은 **모델의 최종 단계에서만 추론**된다.
3) 우리의 CAST는 **계층적 segmentation과 이미지 인식을 동시에 수행**함으로써 **우수한 모델 효율성**을 보여준다. Segmentation은 **모델 아키텍처로부터 직접 유도**된다. HSG는 이미지 segmentation을 추론하기 위해 **추가적인 Transformer 모듈**을 필요로 한다.
## E. 5 Generating Segments from Vit
우리는 **ViT의 최종 출력 token에 K-Means 클러스터링을 적용하여 segment를 생성**한다. feature map을 **이중 선형 보간(bilinearly upscale)**한 다음, **픽셀 수준 feature에 K-Means를 적용**하여 segment를 입력 이미지 해상도에 맞춘다. CAST와 유사하게, **계층적 이미지 분할(hierarchical image segmentation)을 달성하기 위해 여러 수준(level)에 걸쳐 클러스터링 할당을 교차 참조**한다. 일관된 클러스터 계층 구조를 유지하기 위해, **이전 iteration의 클러스터들을 더 거친(coarser) 클러스터로 그룹화하여 클러스터 수를 줄이는 방식으로 K-Means를 반복적으로 실행**한다.
## E. 6 Token Pooling Methods
우리는 제안하는 Graph Pooling과의 비교를 위해 기존의 token pooling 방법들인 **FINCH (Sarfraz et al., 2019), Token Pooling (Marin et al., 2021), CTM (Zeng et al., 2022), ToMe (Bolya et al., 2023)**을 재구현하였다. 모든 방법에서 **superpixel token**을 사용했으며, **token pooling layer만 수정**하였다.
* **FINCH**와 **Token Pooling**의 경우, 해당 논문에서 제안된 **클러스터링 알고리즘**을 구현하였다.
* **TCFormer**의 경우, 공식 코드베이스에서 제공하는 **Clustering-based Token Merge (CTM) 모듈**을 활용하여 ${ }^{1}$, **superpixel token에 적용하기 위해 convolutional layer를 제거**하였다.
* **ToMe**의 경우, 공식 코드베이스 ${ }^{2}$를 사용했으며, 다른 방법들과의 **latency를 맞추기 위해 layer당 token 수를 16개로 줄였다.**
## F Additional Experimental Details
## F. 1 Summary of Models Used in Experiments
우리는 CAST 모델을 **ImageNet 및 COCO 데이터셋**에서 **self-supervised 및 supervised 방식**으로 사전학습한다. 우리의 실험에서는 **다양한 모델 아키텍처와 사전학습 objective**를 사용한다. 명확한 설명을 위해, 각 실험에 사용된 **backbone 모델**을 **Table 10**에 요약하였다.
**Table 10: 각 실험에 사용된 사전학습된 backbone 모델.**
| Experiment | Pre-training objective | Model |
| :--- | :--- | :--- |
| Hierarchical segmentation: ImageNet (Fig. 5) | self-supervised: IN-1K | CAST-S |
| Hierarchical segmentation: PartImageNet (Fig. 6 & Table 1) | self-supervised: IN-1K | CAST-B |
| Hierarchical segmentation: DensePose (Fig. 7 & Table 2) | self-supervised: COCO | CAST-S |
| Semantic segmentation: VOC (Table 3 a) | self-supervised: COCO | CAST-S |
| Semantic segmentation: ADE20K (Table 3 b) | supervised: IN-1K | CAST-S |
| Semantic segmentation: Pascal Context (Table 3 b) | supervised: IN-1K | CAST-S |
| Classification: ImageNet (Table 4) | self-supervised: IN-1K | CAST-S |
| Test-time adaptation: PartImageNet (Fig. 9 & Fig. 15) | self-supervised: IN-1K | CAST-B |
| Object-centric attention: VOC (Fig. 12) | self-supervised: IN-1K | CAST-S |
## F. 2 Classification and Segmentation Datasets
**분류 데이터셋 (Classification Datasets)**
**ImageNet** (Deng et al., 2009)은 1,000개의 객체 카테고리(IN-1K)로 주석된 일반적인 이미지 분류 데이터셋이다. 학습 세트와 검증 세트는 각각 128만 개와 5만 개의 이미지를 포함한다. 우리는 Tian et al. (2020)을 따라 100개의 객체 카테고리를 샘플링하여 **IN-100**을 생성한다. 이 서브셋은 학습용 12만 7천 개, 테스트용 5천 개의 이미지를 포함한다.
**분할 데이터셋 (Segmentation Datasets)**
1) **Pascal VOC 2012** (Everingham et al., 2010)는 20개의 객체 카테고리와 배경 클래스를 포함하는 객체 중심의 semantic segmentation 데이터셋이다. 우리는 10,582개의 이미지를 포함하는 증강된 학습 세트 (Hariharan et al., 2011)와 1,449개의 이미지를 포함하는 검증 세트를 사용한다.
2) **MSCOCO** (Lin et al., 2014)는 복잡한 맥락을 가진 일반적인 장면 데이터셋으로, VOC보다 각 이미지에 더 많은 객체(7.3개 vs. 2.3개)를 포함한다. Van Gansbeke et al. (2021)을 따라, 우리는 train2017 분할의 118,287개 이미지로 학습하고 VOC 검증 세트로 테스트한다.
3) **ADE20K** (Zhou et al., 2019)는 150개의 객체 카테고리로 주석된 복잡한 장면 데이터셋이다. 이 데이터셋은 학습용 20,210개, 검증용 2,000개의 이미지를 포함한다.
4) **Pascal Context**는 또한 59개의 객체 카테고리와 배경 클래스로 레이블링된 장면 데이터셋으로, 학습용 4,996개, 검증용 5,104개의 이미지를 포함한다.
## F. 3 Image Resolution and Number of Tokens
우리는 분류 및 분할을 위한 이미지 해상도 설정을 위해 (Chen et al., 2021; Touvron et al., 2021; Van Gansbeke et al., 2021; Caron et al., 2021)의 방식을 면밀히 따른다.
**ViT baseline**의 경우, **ImageNet**에서는 `crop_size`를 224로 설정하여 196개의 입력 patch token을 얻는다.
**VOC**에서는 semantic segmentation을 위해 $512 \times 512$ 크기의 입력 이미지와 이에 상응하는 1024개의 patch token을 사용한다.
**ADE20K** 및 **Pascal Context** 실험에서는 (Strudel et al., 2021)과 동일한 설정을 따른다.
**ADE20K**에서는 $512 \times 512$ 크기의 sliding window를 사용하고 `stride`를 512로 설정한다.
**Pascal Context**에서는 $480 \times 480$ 크기의 sliding window를 사용하고 `stride`를 320으로 설정한다.
우리의 **CAST** 모델의 경우, 동일한 이미지 해상도 설정을 채택하고 **superpixel의 granularity를 조정**하여 **ViT baseline과 동일한 수의 입력 token**을 맞춘다.
## F. 4 Hyper-parameters for Training
우리는 MoCo 및 DeiT 프레임워크를 사용하여 학습할 때의 하이퍼파라미터를 Table 11과 Table 12에 나열한다. 대부분 각 프레임워크에서 사용된 기본 하이퍼파라미터를 따랐다. batch_size와 total_epochs는 우리의 CAST 및 ViT baseline과 동일하게 설정했다. 모든 실험은 8개의 TitanX (12 GB) 또는 2개의 A100 (45 GB) Nvidia 그래픽 카드를 사용하여 수행되었다.
Table 11: IN-100, IN-1K, COCO 데이터셋에서 우리의 CAST, ViT, Swin을 학습하기 위한 하이퍼파라미터. 연산 제약으로 인해 batch_size와 total_epoch를 조정했다. 그 외에는 MoCo (Chen et al., 2021)와 거의 동일한 설정을 따랐다.
| Parameter | IN-100 | IN-1K | COCO |
| :--- | :--- | :--- | :--- |
| batch_size | 256 | 256 | 256 |
| crop_size | 224 | 224 | 224 |
| learning_rate | $1.5 e^{-4}$ | $1.5 e^{-4}$ | $1.5 e^{-4}$ |
| weight_decay | 0.1 | 0.1 | 0.1 |
| momentum | 0.9 | 0.9 | 0.9 |
| total_epochs | 200 | 100 | 400 |
| warmup_epochs | 20 | 10 | 40 |
| optimizer | Adam | Adam | Adam |
| learning_rate_policy | Cosine decay | Cosine decay | Cosine decay |
| MOCO : temperature | 0.2 | 0.2 | 0.2 |
| MOCO : output_dimension | 256 | 256 | 256 |
| MOCO : momentum_coefficients | 0.99 | 0.99 | 0.99 |
| MOCO : MLP hidden dimension | 4096 | 4096 | 4096 |
| ViT: \# Tokens | $[196]_{\times 11}$ <br> $\stackrel{[196] \times 11}{[196]_{\times 3},[64]_{\times 3},[32]_{\times 3},[16]_{\times 2}}$ | | |
| CAST-S/B: \# Tokens | | | |
Table 12: IN-1K 데이터셋에서 우리의 CAST 및 ViT를 학습하기 위한 하이퍼파라미터. DeiT (Touvron et al., 2021)와 거의 동일한 설정을 따랐다.
| Parameter | IN-1K |
| :--- | :--- |
| batch_size | 1024 |
| crop_size | 224 |
| learning_rate | $5 e^{-4}$ |
| weight_decay | 0.05 |
| momentum | 0.9 |
| total_epochs | 300 |
| warmup_epochs | 5 |
| warmup_learning_rate | $1 e^{-6}$ |
| optimizer | Adam |
| learning_rate_policy | Cosine decay |
| augmentation | $\operatorname{RandAug}(9,0.5)$ (Cubuk et al., 2020) |
| label_smoothing (Szegedy et al., 2016) | 0.1 |
| mixup (Zhang et al., 2017) | 0.8 |
| cutmix (Yun et al., 2019) | 1.0 |
| ViT: \# Tokens | $[196]_{\times 3},[196]_{\times 11}[64]_{\times 3},[32]_{\times 3},[16]_{\times 2}$ |
| CAST-S: \# Tokens | |
## F. 5 Inference and Evaluation on Imagenet and VOC
ImageNet에서의 이미지 분류(Fig. 18)의 경우, 평가를 위해 **linear probing 절차**를 적용한다. VOC에서의 semantic segmentation(Fig. 19)의 경우, 모델 성능 평가를 위해 **segment retrieval 및 transfer learning 절차**를 사용한다.
**이미지 분류: linear probing.**
비지도 분류의 경우, **MoCo-v3 (Chen et al., 2021)**를 따라 **linear probing 프로토콜**을 사용하여 이미지별 판별 모델 성능을 평가한다. 우리는 학습된 모델 가중치를 고정하고, 3-layer MLP head를 무작위로 초기화된 linear projection layer로 대체하여 classifier로 사용한다. linear classifier는 ground-truth label로 학습시키고 **top-1 accuracy**를 보고한다. Chen et al. (2021)에 따라, ImageNet 데이터셋에서 90 epoch 동안 linear classifier를 학습시킨다. 모든 실험에서 momentum은 0.9, weight_decay는 0으로 설정한다. IN-1K에서는 batch_size를 1024, learning_rate를 30으로 설정하고, IN-100에서는 batch_size를 256, learning_rate를 0.8로 설정한다. optimizer로는 SGD를 사용한다.
**Semantic segmentation: segment retrieval.**
Hwang et al. (2019); Van Gansbeke et al. (2021); Ke et al. (2022)를 따라 **segment retrieval**을 사용하여 semantic segmentation을 평가한다. 이미지를 여러 segment로 분할하고, 각 segment의 label을 예측하기 위해 **nearest neighbor search**를 수행한다. 검색된 20개 segment에서 **다수결 label**을 할당한다.
ViT baseline의 경우, 각 token에 MLP head를 적용하여 unit-length output feature를 생성하고, feature map을 입력 이미지의 원래 해상도로 upsample한다. 이어서 **spherical K-Means clustering 알고리즘**을 사용하여 출력 feature를 기반으로 이미지를 40개의 segment로 분할한다.
우리의 CAST는 추가적인 upsampling 및 K-Means clustering을 필요로 하지 않는다. segmentation을 위해, 우리 모델은 **Hypercolumn 디자인 (Hariharan et al., 2015)**을 따라 multi-level segment token을 unpool하고 융합한다. 우리 모델은 superpixel과 동일한 수의 출력 token을 생성한다. superpixel index를 기반으로 출력 token에서 픽셀 feature를 수집한다. spherical K-Means clustering 없이, 우리의 CAST는 **graph pooling module**을 사용하여 이미지 segmentation을 예측한다. 이러한 이미지 segmentation에 따라 정규화된 segment feature를 계산한다.
**Semantic segmentation: transfer learning.**
Van Gansbeke et al. (2021)을 따라 **transfer learning 프로토콜**을 사용하여 모델 성능을 평가한다. 모든 모델은 MSCOCO에서 비지도 학습되고, Pascal VOC에서 지도 학습으로 fine-tuning된다. 3-layer MLP head를 2-layer $1 \times 1$ convolutional layer로 대체한다. ViT baseline 학습을 위해, bilinear interpolation을 사용하여 patch token을 입력 이미지 해상도로 다시 upscale한다. 우리의 CAST 학습을 위해, superpixel index를 사용하여 segment token을 per-pixel feature로 scatter한다. 두 방법 모두 학습을 위해 per-pixel ground-truth label을 사용한다. 학습 단계는 30K, learning_rate는 0.003, weight_decay는 0.0001, batch_size는 16, crop_size는 512로 설정한다. Chen et al. (2016)을 따라, base learning rate에 $1-\frac{\text { iter }}{\text { max_iter }}^{0.9}$를 곱하는 **poly learning rate policy**를 채택한다. SGD optimizer를 사용한다. 추론에는 단일 스케일 이미지만 사용한다.
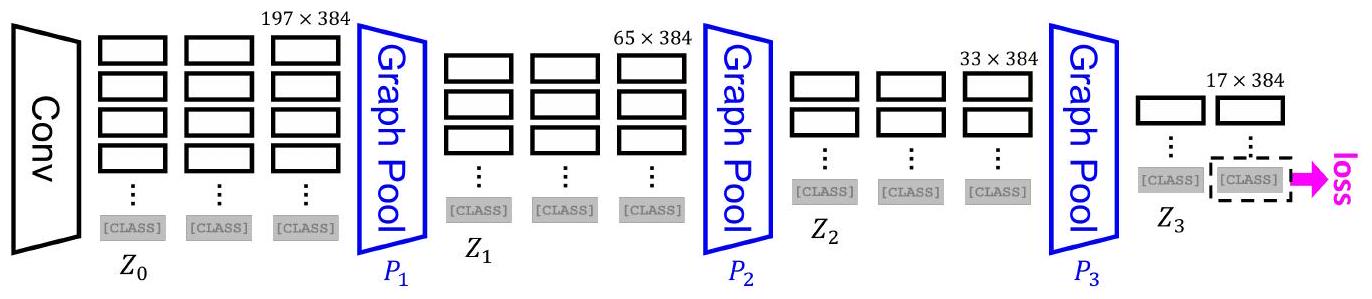
Figure 18: 분류를 위한 상세 모델 아키텍처. 우리의 CAST는 각 superpixel 내에서 convolutional feature를 **average pooling**하여 segment token을 집계하고, **Transformer encoder block**으로 segment token을 contextualize하며, **Graph Pooling module**로 더 적은 수의 region token으로 coarsening한다.
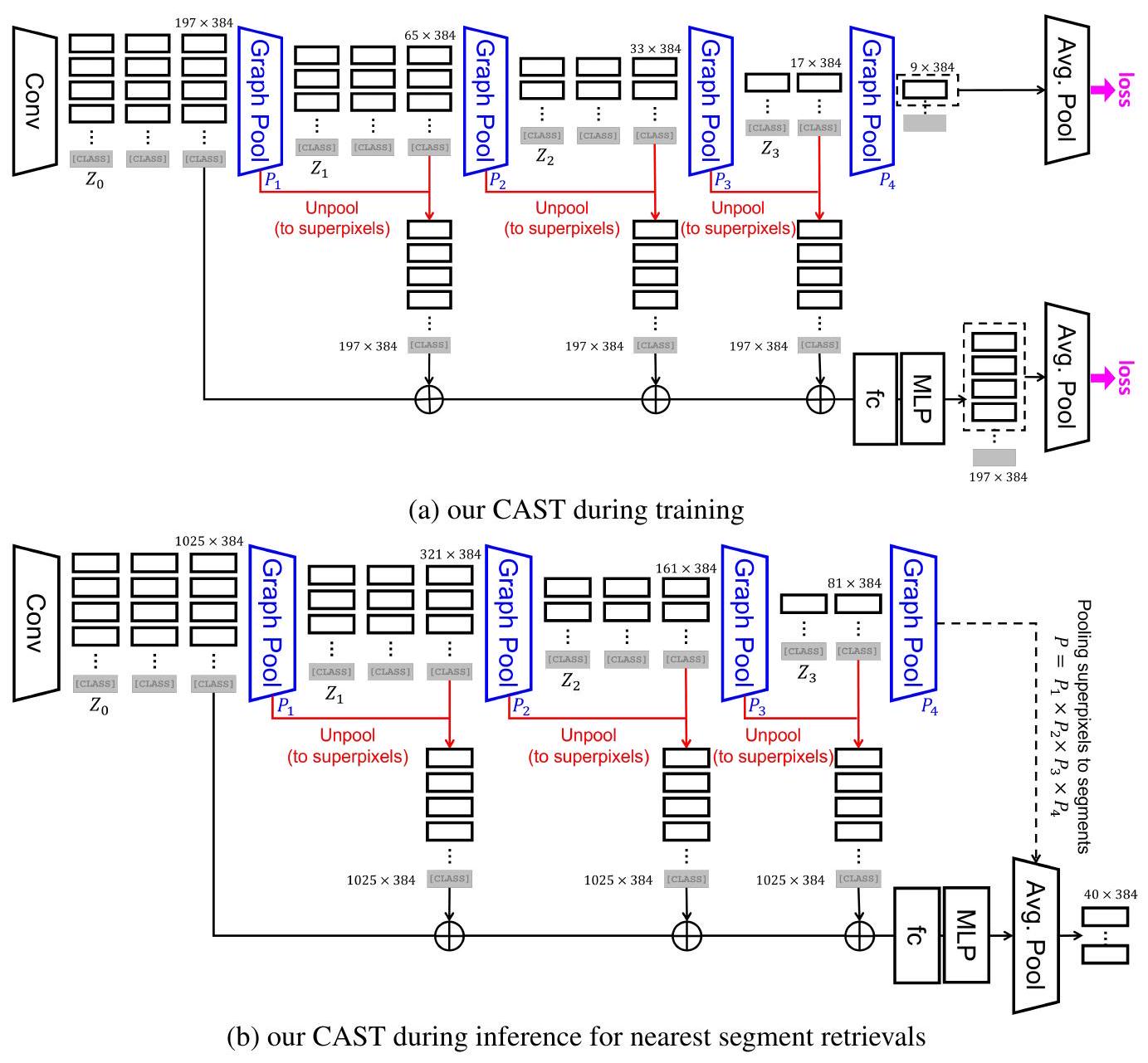
Figure 19: Semantic segmentation을 위한 상세 모델 아키텍처. 우리의 CAST는 각 superpixel 내에서 convolutional feature를 **average pooling**하여 segment token을 집계하고, **Transformer encoder block**으로 segment token을 contextualize하며, **Graph Pooling module**로 더 적은 수의 region token으로 coarsening한다. (a) 학습 중인 우리의 CAST-S. (b) segment retrieval을 위한 추론 중인 우리의 CAST-S. 우리는 입력 superpixel에 대한 grouping index를 기준으로 coarsened segment token을 unpool한다. 여러 스케일에 걸쳐 unpooled segment token을 concatenate($\oplus$)하고, fully_connected layer를 사용하여 융합한 다음, 3-layer MLP head를 적용한다. transfer learning의 경우, 3-layer MLP head를 융합된 token 위에 2-layer $1 \times 1$ convolutional layer로 대체한다. 또한 최종 average pooling layer를 제거한다. segment retrieval을 위해, 우리는 coarse segmentation을 예측하고 nearest-neighbor retrieval을 위한 출력으로 token을 average pooling하기 위해 추가적인 Graph Pooling module을 학습한다.
## G Additional Visualizations
## G. 1 Visual Results on Hierarchical Segmentation
우리는 ViT와 우리의 CAST에 의해 유도된 계층적 분할(hierarchical segmentation)에 대한 추가적인 시각화를 제시한다 (Fig. 20). CAST는 이미지 경계와 의미론을 더 정확하게 포착한다.
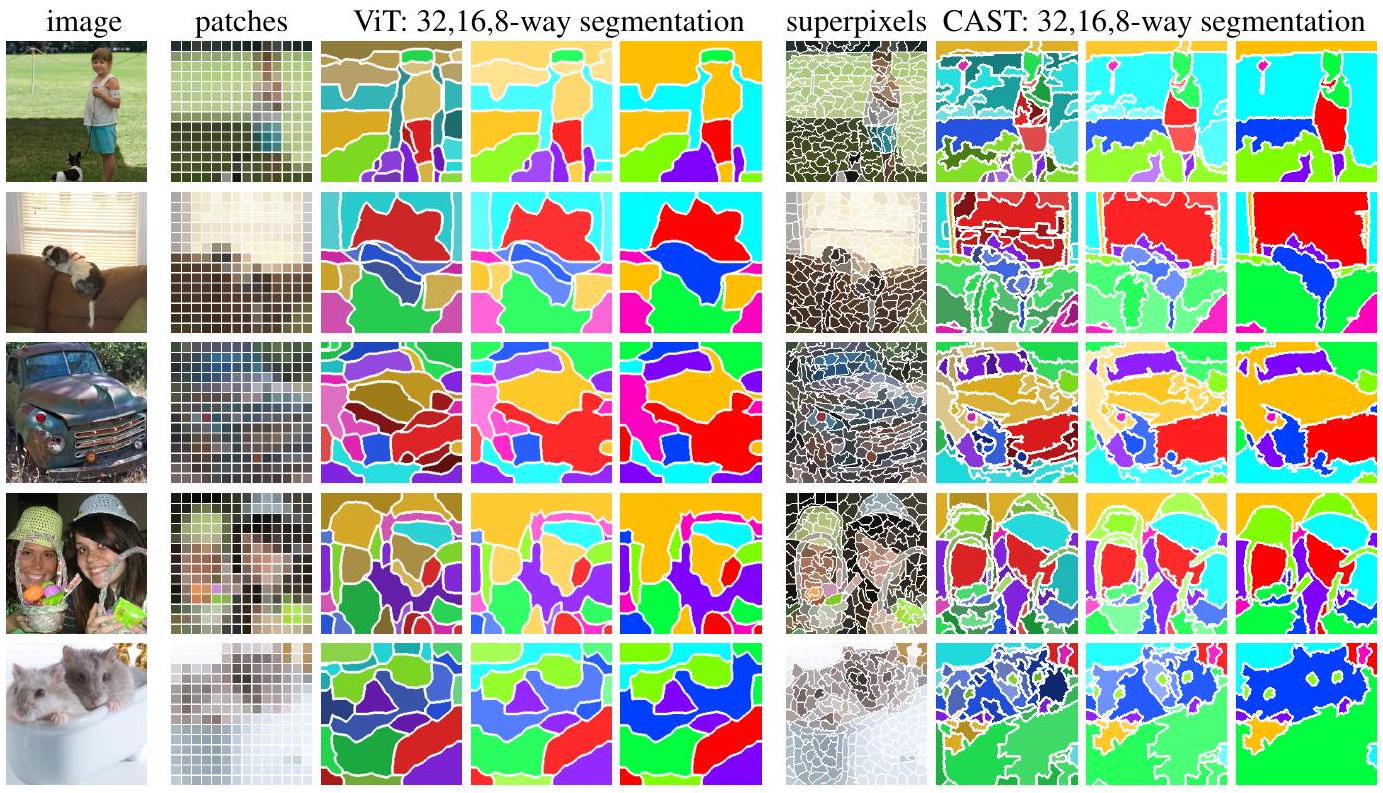
Figure 20: 계층적 분할에 대한 추가 시각화 결과는 우리 모델이 ViT보다 더 나은 윤곽선과 전체 분할을 포착함을 보여준다.
## G. 2 Visual Results on Semantic Segmentation
우리는 VOC 데이터셋에 대한 **fine-tuning 전후의 semantic segmentation 시각화 결과**를 추가로 제시한다 (Fig. 21).
ViT baseline과 비교했을 때, 우리 모델은 **더 정확한 segmentation 결과**를 생성한다.
특히, **추가적인 CRF 후처리 없이도 객체 윤곽선에 정확하게 일치하는 결과**를 보여준다.

Figure 21: 우리 모델은 **patch token 기반의 segmentation보다 훨씬 더 정밀한 segmentation**을 유도한다.
Segmentation은 **segment-wise nearest neighbor retrieval (첫 번째 행 이미지)** 및 **fine-tuned 모델 (두 번째 행 이미지)**을 기반으로 예측된다.
**patch token 대신 segment token을 사용함으로써 예측된 segmentation이 크게 향상**된다.
특히, 우리 방법은 **segment retrieval을 위한 추가적인 K-Means clustering 없이도 명시적으로 segmentation을 생성**한다.
## G. 3 Visual Results on Figure-ground Segmentation
우리는 VOC 데이터셋에서 **multi-head attention map**으로부터 생성된 **figure-ground segmentation**의 시각적 결과를 추가로 제시한다. 우리의 **CAST**는 **ViT**보다 **전경(foreground) 의미에 더 정확하게 attend**하며, 생성된 **segmentation**은 **객체 경계를 더 정확하게 보존**한다. Figure 22를 참조하라.
**CAST (상단) vs. ViT (하단)**

Figure 22: 우리의 **CAST (상단 행)**는 VOC 데이터셋에서 **ViT (하단 행)** 및 **DINO (Caron et al., 2021)**보다 **전경(foreground) 의미에 더 정확하게 attend**한다. 우리는 **DINO와 동일한 절차**를 사용하여 **latent multi-head attention map**으로부터 **전경 segmentation mask**를 생성한다. 모든 모델은 **IN-1K 데이터셋으로 scratch부터 학습**되었다. 우리의 **CAST와 ViT는 MoCo-v3 (Chen et al., 2021)를 기반으로 학습**되었다.
## G. 4 Visual Results on Multi-head Attention Maps
우리는 vision Transformer에서 **\[CLASS] token이 다른 모든 segment token에 대해 가지는 multi-head attention map**을 시각화한다. **\[CLASS] token은 이미지 단위의 판별(image-wise discrimination)을 위해 최적화**되므로, 이러한 attention map은 **가장 판별적인 이미지 단위 표현을 유도하는 segment들의 가장 유익한 그룹화**를 나타낸다. 우리는 **figure-ground segmentation을 생성하는 데 사용된 것과 동일한 attention map**을 시각화하며, 이는 **9번째 Transformer encoder block**에 있는 것들이다. 이 layer는 **32개의 coarsened segment token**을 입력으로 받아, **12개의 head로 구성된 $32 \times 32$ attention map**을 생성한다. 우리는 **DINO (Caron et al., 2021)와 동일한 절차**를 따라 **이진화된(binarized) attention map**을 표시한다. **임계값(threshold)은 mass의 60%를 유지하도록 조정**된다. 자세한 내용은 Caron et al. (2021)을 참조하라.
Fig. 23에서 보듯이, 우리의 attention map은 **이미지의 전체-부분(parts-of-the-whole) 정보**를 드러낸다. 우리는 **동일한 객체 부분들이 동일한 attention head에서 함께 attend되는 것을 관찰**한다. 예를 들어, 개의 얼굴, 귀, 코 등이 그러하다. 이는 **이미지 단위 인식에 전체-부분 정보가 필요함**을 시사한다. 또한, 우리 모델은 **patch token이 아닌 segment token을 layer들을 통해 전달**하므로, **객체 경계에 더 잘 정렬된 attention map**을 생성한다.

Figure 23: 우리의 multi-head attention map은 **IN-100 이미지에서 전체-부분 정보**를 드러낸다. 왼쪽에서 오른쪽으로: 입력 이미지와 해당 **\[CLASS] token이 다른 모든 segment에 대해 가지는 12개의 attention map head**이다. 우리는 **DINO (Caron et al., 2021)를 따라 attention map을 이진화**한다. 우리는 **동일한 객체 부분들이 동일한 head에서 함께 attend되는 것을 보여준다**. 예를 들어, 개의 얼굴, 귀, 코 등이 그러하다. 우리 모델은 **segment token을 입력으로 받아 객체 경계에 더 잘 정렬된 attention map**을 생성한다.