비타겟 클래스 학습을 통한 Semi-Supervised Temporal Action Localization 성능 향상
Semi-Supervised Temporal Action Localization (SS-TAL)의 기존 연구들은 신뢰도가 가장 높은 타겟 클래스에만 집중하여 비타겟 클래스에 포함된 유용한 정보를 간과하는 한계가 있었습니다. 이 논문은 비타겟 클래스로부터 학습하는 새로운 관점을 제시합니다. 제안된 방법은 예측된 클래스 확률 분포의 레이블 공간을 타겟 클래스, positive 클래스, negative 클래스, 그리고 모호한 클래스로 분할합니다. 이를 통해 타겟 클래스에는 없는 긍정적, 부정적 의미 정보를 모두 활용하고, 모호한 클래스는 학습에서 제외합니다. 모델의 신뢰도와 순위를 기반으로 고품질의 positive 및 negative 클래스를 적응적으로 선택하는 전략과, 예측을 positive 클래스에 가깝게, negative 클래스에서 멀어지게 하는 새로운 positive 및 negative loss를 도입합니다. 이 hybrid positive-negative learning 프레임워크는 레이블이 있거나 없는 비디오 모두에서 비타겟 클래스를 효과적으로 활용하여 SS-TAL 성능을 크게 향상시킵니다. 논문 제목: Boosting Semi-Supervised Temporal Action Localization by Learning from Non-Target Classes
Xia, Kun, et al. "Boosting semi-supervised temporal action localization by learning from non-target classes." arXiv preprint arXiv:2403.11189 (2024).
Boosting Semi-Supervised Temporal Action Localization by Learning from Non-Target Classes
Abstract
**Semi-supervised temporal action localization (SSTAL)**의 핵심은 풍부한 unlabeled 비디오에서 가치 있는 정보를 발굴하는 데 있다. 그러나 현재 접근 방식들은 주로 오류가 발생하기 쉬운 target class (즉, 가장 높은 confidence를 가진 예측 클래스)에 강건한 모델을 구축하는 데 집중하며, non-target class 내의 유익한 의미론적 정보는 무시하고 있다.
본 논문은 non-target class로부터 학습하는 것을 옹호함으로써, 기존의 target class에만 초점을 맞추던 관습을 넘어선 새로운 관점에서 SS-TAL에 접근한다. 제안하는 접근 방식은 예측된 클래스 분포의 레이블 공간을 명확한 하위 공간으로 분할하는 것을 포함한다:
- target class
- positive classes
- negative classes
- ambiguous classes
이는 target class에는 없는 긍정적(positive) 및 부정적(negative) 의미론적 정보를 모두 발굴하는 동시에, ambiguous class는 제외하는 것을 목표로 한다.
이를 위해, 우리는 먼저 클래스의 confidence와 rank를 target class의 그것들과 관련지어 모델링함으로써, 레이블 공간에서 고품질의 positive 및 negative class를 적응적으로 선택하는 혁신적인 전략을 고안한다. 그런 다음, 학습 과정을 안내하도록 설계된 새로운 positive 및 negative loss를 도입하여, 예측을 positive class에 더 가깝게 만들고 negative class로부터 멀어지게 유도한다. 마지막으로, positive 및 negative 과정은 하이브리드 positive-negative 학습 프레임워크로 통합되어, labeled 및 unlabeled 비디오 모두에서 non-target class의 활용을 촉진한다.
THUMOS14 및 ActivityNet v1.3에 대한 실험 결과는 제안된 방법이 이전의 state-of-the-art 접근 방식보다 우수함을 입증한다.
1 Introduction
Temporal Action Localization (TAL)은 정리되지 않은(untrimmed) 비디오에서 관심 있는 action instance를 시간적으로 찾아내고 인식하는 task이다. 이는 컴퓨터 비전 분야의 근본적이면서도 도전적인 task이며, **보안 감시 [7, 36] 및 인간 행동 분석 [8, 26]**과 같은 광범위한 응용 분야를 가지고 있다. 전통적인 TAL 접근 방식은 대규모의 잘 주석된 데이터셋에 크게 의존하는데, 이는 실제로 지루하고 시간이 많이 소요되는 과정이다. 이러한 문제에 대응하여, 최근에는 제한된 수의 labeled sample과 상당량의 unlabeled data만을 사용하여 모델을 학습시키는 것을 목표로 하는 Semi-Supervised Temporal Action Localization (SS-TAL) 연구가 진행되고 있다.
 Fig. 1: Unlabeled 비디오 스니펫에 대한 신뢰할 수 없는 예측(unreliable prediction) 예시. 일반적인 관행은 가장 높은 confidence를 가진 action class, 즉 "Putting on Shoes"를 모델 최적화를 위한 target class로 취급하는 것이다. 반면, ground truth label인 "Sailing"은 non-target class들 속에 묻혀 있다.
Fig. 1: Unlabeled 비디오 스니펫에 대한 신뢰할 수 없는 예측(unreliable prediction) 예시. 일반적인 관행은 가장 높은 confidence를 가진 action class, 즉 "Putting on Shoes"를 모델 최적화를 위한 target class로 취급하는 것이다. 반면, ground truth label인 "Sailing"은 non-target class들 속에 묻혀 있다.
최근 SS-TAL [11, 21, 31, 32]의 발전은 두 가지 잘 알려진 semi-supervised learning 패러다임인 consistency regularization과 self-training을 활용하여 주목할 만한 성공을 거두었다. **Consistency regularization 접근 방식 [11, 31]**은 teacher model을 통해 신뢰할 수 있는 예측을 생성하여 student model의 학습 과정을 안내하는 것을 목표로 한다. 그러나 제한된 labeled data로 괜찮은 teacher model을 학습하는 것은 SS-TAL task 자체만큼이나 어려운 일이다. 최근에는 SS-TAL에 특화된 **self-training 접근 방식 [21, 32]**이 이 분야를 지배하며 state-of-the-art 성능을 달성하고 있다. 이러한 접근 방식은 현재 모델을 반복적으로 사용하여 unlabeled 비디오에 pseudo label을 할당하고, labeled 비디오와 pseudo-labeled 비디오 모두를 사용하여 새로운 모델을 학습시킨다.
유망한 결과를 달성했음에도 불구하고, 기존 접근 방식은 단순히 target class (즉, 가장 높은 confidence를 가진 예측 클래스)를 pseudo label로 활용하는데, 이는 두 가지 중요한 단점을 가진다. 첫째, 모델이 제한된 양의 labeled data로 학습되었기 때문에 target class는 매우 노이즈가 많을 가능성이 있다. 둘째, non-target class들은 종종 action에 대한 귀중한 단서를 포함하고 있음에도 불구하고 완전히 무시된다. Figure 1에 설명적인 예시가 나와 있다. "Sailing" 비디오 스니펫이 self-training을 위해 실수로 "Putting on Shoes"라는 target class로 할당되어 노이즈가 많은 pseudo label로 이어진다. 반면, ground truth label의 의미는 무시된 non-target class들 사이에 묻혀 있다.
본 논문에서는 target class에만 집중하는 전통적인 방식을 넘어, non-target class로부터 유익한 의미론적 정보(informative semantics)를 학습함으로써 Semi-Supervised Temporal Action Localization에 대한 새로운 관점으로 접근한다. unlabeled data에 대한 예측된 클래스 확률 분포가 주어졌을 때, 우리는 종종 두 가지 현상을 관찰한다. 첫째, ground truth label이 target class와 일치하지 않을 때, 종종 예측에서 다른 상위 랭크 클래스 내에 포함되는 경우가 많다. 둘째, 낮은 confidence를 가진 하위 랭크 클래스들이 ground truth label을 포함할 가능성은 매우 낮다.
이러한 관찰을 바탕으로, 우리는 예측된 클래스 확률 분포의 label space를 네 가지 하위 공간으로 분할한다: target class, positive classes, negative classes, 그리고 ambiguous classes. 앞서 언급했듯이, target class는 가장 높은 confidence를 가진 클래스로 정의된다. Positive classes는 높은 confidence를 가진 non-target class들을 포함하며, 종종 ground truth class를 포함한다. Negative classes는 낮은 confidence를 가진 non-target class들로 구성되며, ground truth class를 포함할 가능성이 낮다. 나머지 non-target class들은 ambiguous classes를 형성한다.
non-target class로부터 학습한다는 아이디어는 흥미롭지만, 두 가지 주요 과제를 해결해야 한다: non-target class, 특히 positive class와 negative class를 예측된 클래스 분포에서 어떻게 식별해야 하는가? 그리고 모델이 이러한 non-target class로부터 어떻게 효과적으로 학습할 수 있는가? 첫 번째 과제에 대응하여, 우리는 label space에서 고품질의 positive class와 negative class를 적응적으로 선택하기 위한 혁신적인 전략을 고안한다. 이는 target class와 관련하여 클래스의 confidence와 rank를 모두 모델링하는 것을 포함한다. 두 번째 과제를 해결하기 위해, 우리는 예측을 positive class에 더 가깝게 만들고 negative class에서 멀어지게 하도록 설계된 새로운 positive loss와 negative loss를 도입한다. 결과적으로, positive learning은 모델이 실제 클래스와 관련이 있지만 target class에는 없는 더 풍부한 의미론적 정보를 추출하도록 돕고, negative learning은 어떤 클래스가 올바르지 않은지에 대한 모델의 확신을 강화한다. ambiguous class와 관련된 높은 불확실성과 노이즈를 고려하여, 우리는 이들을 학습 과정에서 제외한다. 마지막으로, 우리는 positive learning과 negative learning 과정을 하이브리드 positive-negative learning 프레임워크에 통합하여 labeled 및 unlabeled 비디오 모두에서 non-target class를 활용한다.
본 논문의 주요 기여는 다음과 같이 요약된다:
- 본 논문은 target class에만 집중하는 기존의 관점을 넘어, non-target class로부터 학습하는 것을 강조함으로써 SS-TAL을 위한 새로운 패러다임을 제시한다. 이 접근 방식은 예측된 클래스 분포의 label space를 다른 하위 공간으로 분할하여, target class에는 없는 positive 및 negative 의미론적 정보를 모두 발굴하고, ambiguous class는 제외하는 것을 목표로 한다.
- 이 새로운 패러다임의 핵심 측면은 positive class와 negative class를 식별하고 이러한 non-target class로부터 학습하는 것이다. 본 논문은 label space에서 고품질의 positive class와 negative class를 적응적으로 선택하기 위한 혁신적인 전략을 도입한다. 또한, non-target learning을 효과적으로 안내하기 위해 새로운 positive loss와 negative loss를 제안한다. 이러한 과정들은 하이브리드 positive-negative learning 프레임워크에 통합되어 labeled 및 unlabeled 비디오 모두에서 non-target class의 활용을 촉진한다.
- 우리는 THUMOS14 및 ActivityNet v1.3 데이터셋에 대해 다양한 학습 설정에서 제안된 접근 방식을 평가한다. 광범위한 실험을 통해 우리의 접근 방식이 이전의 state-of-the-art 방법들을 능가함을 입증한다.
2 Related Work
Fully-Supervised Temporal Action Localization은 풍부하게 잘 주석된 비디오를 활용하여 최근 몇 년간 상당한 발전을 이루었다. 구체적으로, 초기 anchor-based method [5, 30, 35]는 일반적으로 multi-scale anchor를 사용하고, classification head와 boundary regression head를 부착하여 이러한 사전 정의된 anchor를 정제한다. Anchor-free method [17, 18, 22, 33, 40]는 복잡성을 줄이기 위해 boundary location을 직접 회귀하거나 frame-level action classification을 수행한다. 현재 널리 사용되는 Transformer-based method [14, 20, 24, 39]는 Transformer encoder-decoder 프레임워크에서 temporal action localization을 다루며, action instance를 학습 가능한 action query 집합으로 모델링한다.
Semi-Supervised Temporal Action Localization은 낮은 주석 비용으로 unlabeled data에서 귀중한 정보를 활용한다. 기존 연구들 [9, 11, 21, 31, 32]은 일반적인 semi-supervised learning [25, 27]의 발전에 힘입어 consistency regularization과 self-training이라는 두 가지 프레임워크를 따른다. Ji et al. [11]은 teacher 모델과 student 모델 모두에 대해 일관된 action proposal 예측을 생성하기 위해 두 가지 필수적인 유형의 sequential perturbation을 설계한다. Nag et al. [21]은 localization error propagation 문제를 해결하기 위해 proposal-free temporal masking model을 개발한다. Xia et al. [32]는 label noise 문제를 해결하고, 엄격하게 선별된 신뢰할 수 있는 pseudo label로 모델을 업데이트하는 noise-tolerant 프레임워크를 제시한다.
Pseudo Label 학습은 semi-supervised learning에서 중요하면서도 핵심적인 기술이다. 그러나 대부분의 접근 방식 [6, 13, 16, 23, 41]은 target class로부터 직접 학습하는 데 제한되어 있어, 모델이 noisy pseudo label에 의해 오도될 수밖에 없다. Chen et al. [6]은 pseudo label 할당을 위한 proposal self-assignment를 제시하는데, 이는 student 모델의 proposal을 teacher 모델에 주입하고, 그에 따라 student 모델의 각 proposal과 일치하는 정확한 pseudo label을 생성한다. 위 방법들 외에도, complementary label은 샘플이 속하지 않는 클래스를 지정하는 데 사용되어 왔다 [10]. Yu et al. [37]은 편향된 complementary label 문제를 이론적으로 분석하고, 편향 없이 transition probability를 추정하는 방법을 제안한다. Kim et al. [15]은 ground truth label을 가진 clean data를 학습하는 동시에, 무작위로 선택된 label을 complementary label로 사용하여 noise data를 학습하는 것을 목표로 한다.
기존 방법들과 달리, 우리는 target class의 confidence를 기반으로 더 풍부한 negative class를 적응적으로 선택하는 새로운 negative learning 접근 방식을 소개한다. 이러한 negative class는 더 많은 정보를 제공하여 true label을 선택할 위험을 줄인다. 또한, 우리의 새로운 positive learning 방법은 target class에 없을 수 있는 true class와 관련된 추가적인 의미론적 정보(semantics)를 추출한다.
3 Method
3.1 Preliminaries
문제 설정 (Problem Setting)
개의 labeled 비디오 와 개의 unlabeled 비디오 가 주어졌을 때, **semi-supervised temporal action localization (SS-TAL)**은 labeled 및 unlabeled 데이터 모두로부터 효과적으로 학습하여 액션 감지(action detection) 성능을 향상시키는 것을 목표로 한다. 각 labeled 비디오의 어노테이션 은 각 액션 인스턴스의 시작 시간, 종료 시간, 그리고 액션 카테고리를 포함한다.
 Fig. 2: 제안하는 Non-target Classes Learning 프레임워크의 개요. 이는 self-training 패러다임을 따르며, 현재 모델을 사용하여 unlabeled 비디오에 pseudo label을 할당하고, labeled 비디오와 pseudo-labeled 비디오 모두에 대해 새로운 모델을 학습하는 과정을 반복한다. unlabeled 비디오 스니펫이 주어지면, 현재 모델은 모든 클래스에 대한 확률 분포를 예측한다. 우리의 방법은 target class에 대한 신뢰도(confidence)와 순위(rank)를 모두 모델링하여, 레이블 공간 를 target class , positive classes , negative classes , 그리고 ambiguous classes 로 적응적으로 분할한다. 이러한 레이블 공간 분할을 기반으로, 우리는 새로운 positive learning loss 와 negative learning loss 를 설계하여, ambiguous classes를 제외하면서 target class에 없는 positive 및 negative 의미론(semantics)을 발굴한다.
Fig. 2: 제안하는 Non-target Classes Learning 프레임워크의 개요. 이는 self-training 패러다임을 따르며, 현재 모델을 사용하여 unlabeled 비디오에 pseudo label을 할당하고, labeled 비디오와 pseudo-labeled 비디오 모두에 대해 새로운 모델을 학습하는 과정을 반복한다. unlabeled 비디오 스니펫이 주어지면, 현재 모델은 모든 클래스에 대한 확률 분포를 예측한다. 우리의 방법은 target class에 대한 신뢰도(confidence)와 순위(rank)를 모두 모델링하여, 레이블 공간 를 target class , positive classes , negative classes , 그리고 ambiguous classes 로 적응적으로 분할한다. 이러한 레이블 공간 분할을 기반으로, 우리는 새로운 positive learning loss 와 negative learning loss 를 설계하여, ambiguous classes를 제외하면서 target class에 없는 positive 및 negative 의미론(semantics)을 발굴한다.
Feature Embedding
비디오 에 대해, 기존 연구들 [22, 28]의 관례에 따라, 우리는 fine-tuned된 two-stream network를 통해 연속적인 프레임으로부터 스니펫 수준의 feature 를 추출한다. 여기서 는 비디오 스니펫의 개수이다.
Baseline Model
최근 연구들 [21, 32]은 SS-TAL을 스니펫 수준의 분류(classification) task로 정식화한다. 우리의 방법 또한 SS-TAL을 위한 self-training 기반의 proposal-free 프레임워크를 채택하며, 이는 이전 연구들 [21, 32]과 같이 classification head와 mask head를 통해 액션 인스턴스를 탐지한다. 학습 목표는 다음 손실 함수를 최소화하는 것이다:
여기서 와 는 각각 labeled 비디오와 unlabeled 비디오에 적용되는 supervised loss와 unsupervised loss를 나타내며, 는 하이퍼파라미터이다. 액션 감지 모델의 주된 목적은 labeled 및 unlabeled 데이터 모두에 대해 cross-entropy (CE) 손실 함수를 최적화하여 모델 의 파라미터 를 학습하는 것이다:
여기서 과 는 각각 labeled 비디오와 unlabeled 비디오의 -번째 스니펫 feature 벡터이다. 과 는 각각 ground truth 레이블과 pseudo 레이블의 one-hot 벡터이며, 개의 액션 클래스와 하나의 배경 클래스를 포함한다.
3.2 Motivation
기존 접근 방식들은 단순히 **target class (즉, 가장 높은 confidence를 가진 예측 클래스)**를 pseudo label로 활용한다. 하지만 모델이 제한된 양의 labeled data로 학습되었기 때문에, target class는 높은 노이즈를 포함하는 경향이 있으며, 이는 self-training 성능을 크게 저하시킨다.
본 논문은 이러한 전통적인 target class 중심의 접근 방식에서 벗어나, non-target class로부터 유익한 의미론적 정보(informative semantics)를 학습함으로써 SS-TAL 문제를 새로운 관점에서 해결한다.
우리의 접근 방식은 unlabeled 데이터에 대한 예측 클래스 확률 분포에 대한 두 가지 주요 관찰에서 비롯된다.
첫째, ground truth label이 target class와 일치하지 않을 때, 해당 label은 예측에서 종종 다른 상위 랭크 클래스들 내에 포함된다.
둘째, 낮은 confidence를 가진 클래스나 하위 랭크 클래스들이 ground truth label을 포함할 가능성은 매우 낮다.
이러한 관찰을 바탕으로, 우리는 unlabeled 비디오 스니펫에 대한 예측 클래스 확률 분포의 label space를 다음 네 가지 하위 공간으로 나눈다:
여기서 는 target class만을 포함하며, , , 는 각각 positive classes, negative classes, ambiguous classes를 나타낸다.
Positive classes는 높은 confidence를 가진 non-target class들을 포함하며, 종종 ground truth class를 포함한다.
Negative classes는 낮은 confidence를 가진 non-target class들로 구성되며, ground truth class를 포함할 가능성이 낮다.
나머지 non-target class들은 ambiguous classes를 형성한다.
전통적인 **target class 기반 학습(Sec. 3.3)**과 상호 보완적으로, **negative learning(Sec. 3.4)**은 모델이 어떤 클래스가 올바르지 않은지에 대한 확신을 강화하는 반면, **positive learning(Sec. 3.5)**은 모델이 실제 클래스와 관련이 있지만 target class에는 없는 더 풍부한 의미론적 정보를 추출할 수 있도록 돕는다.
ambiguous classes와 관련된 높은 불확실성과 노이즈를 고려하여, 우리는 이들을 self-training에서 제외한다.
3.3 Learning from Target Class
기존 접근 방식들은 먼저 레이블이 없는 스니펫 로부터 확률 분포 를 얻은 다음, 를 해당 스니펫의 **타겟 클래스(target class)**로 사용하여 one-hot pseudo label 벡터 를 구성한다. 학습 목표는 모델 예측과 타겟 클래스 간의 cross-entropy loss로 다음과 같이 공식화된다:
여기서 는 액션 클래스의 수이며, 는 타겟 클래스의 존재 여부를 나타낸다. 모델은 타겟 클래스의 log-likelihood를 최대화하는 방향으로 학습된다.
3.4 Learning from Negative Classes
Sec. 3.2에서 이전에 논의했듯이, 모델은 비디오 스니펫이 노이즈가 있는 target class에 속하는지 여부에 대해 불확실성을 보일 수 있지만, negative class에는 속하지 않는다고 상당히 확신할 수 있다. negative 정보를 효과적으로 학습하기 위해, non-target class 중에서 negative class를 선택하고, 모델은 다음의 negative learning loss를 사용하여 학습된다:
이는 negative class에 대한 log-likelihood를 최소화하는 것을 목표로 한다. 그러나 적절한 negative class를 선택하는 것은 어렵다. 한편으로는, 하나의 negative class만 선택하는 것은 가치 있는 negative 정보를 학습하기에 불충분하다. 다른 한편으로는, 모든 non-target class를 negative class로 간주하는 것은 non-target class에 숨겨진 ground truth semantics를 negative하게 학습할 위험을 수반한다. 따라서 우리는 이러한 도전을 해결하기 위해 adaptive negative learning 전략을 설계한다.
구체적으로, 레이블이 없는 비디오 스니펫에 대해 예측된 class 확률 분포를 라고 하자. 그런 다음, 이를 신뢰도(confidence)의 오름차순으로 정렬한다:
여기서 는 target class의 신뢰도에 해당한다. 가 높을수록 모델은 target class가 ground truth class와 일치한다고 더 확신한다. 이는 또한 더 많은 non-target class를 negative 정보를 학습하기 위한 negative class로 취급할 수 있음을 의미한다. 이러한 추론은 target class의 신뢰도를 기준으로 adaptive negative learning 전략을 설계하도록 동기를 부여한다. 구체적으로, 우리는 먼저 하위 개 class의 누적 확률을 계산한다. 만약 누적 확률이 보다 작으면, 이 개 class는 negative learning에 동등하게 기여하는 negative class로 취급되며, 이는 다음과 같이 공식화될 수 있다:
여기서 는 위의 기준을 충족하는 개의 negative class를 포함한다. 가 매우 높을 때는, 낮은 신뢰도의 class들이 ground truth semantics를 포함할 위험이 낮다는 것을 시사한다. 따라서 모델은 negative learning을 위해 더 많은 낮은 신뢰도의 class들을 에 포함시킬 것이다. 가 매우 낮을 때는, ground truth semantics가 낮은 신뢰도의 class들에 숨겨져 있을 가능성이 더 높다. 따라서 하위 개 class의 누적 확률이 작기 때문에 모델은 소수의 negative class만 선택할 것이다. 이러한 negative class들을 기반으로, 우리는 negative learning loss를 다음과 같이 재구성한다:
우리가 제안하는 adaptive negative learning은 모델이 가능한 한 많은 negative class로부터 근본적인 negative 정보를 효과적으로 학습할 수 있도록 할 것이다.
3.5 Learning from Positive Classes
나머지 비타겟 클래스(음성 클래스 제외)로부터 학습하는 것은 흥미로운데, 그 이유는 ground truth 의미론이 그들 사이에 숨겨져 있기 때문이다. 그러나 모든 나머지 비타겟 클래스로부터 긍정적인 정보(positive information)를 학습하는 것은 최적의 방법이 아니다. 모호한 클래스들이 모델을 혼란스럽게 할 수 있기 때문이다. 따라서 우리는 타겟 클래스의 confidence를 정보성 지표로 활용하여 긍정 클래스(positive classes)를 선택한다:
여기서 는 위 기준을 충족하는 개의 긍정 클래스를 포함하며, 는 하이퍼파라미터이다. 이러한 방식으로 모델은 confidence가 타겟 클래스와 유사한 클래스만을 선택하게 되는데, 이는 ground truth 클래스와 관련된 유사한 정보를 공유할 가능성이 높기 때문이다. 이 긍정 클래스들을 기반으로, 우리는 **긍정 학습 손실(positive learning loss)**을 다음과 같이 정의한다:
이 **긍정 학습(positive learning)**은 모델이 실제 클래스와 관련이 있지만 타겟 클래스에는 없는 더 풍부한 의미론을 추출할 수 있도록 한다.
3.6 Hybrid Positive-Negative Learning
마지막으로, 우리는 제안된 negative learning과 positive learning을 우리의 semi-supervised TAL 프레임워크에 통합한다.
학습 시, 모든 labeled data에 대해 ground truth label은 의심할 여지 없이 target class로 간주된다. 나머지 class들, 즉 모든 non-target class들은 ground truth label과 완전히 무관하므로 negative learning을 위한 negative class로 작용한다. 따라서 우리는 모든 labeled data에 대해 cross-entropy loss와 negative loss를 적용한다.
unlabeled data의 경우, target class에 대해 cross-entropy loss를 적용하고, 위에서 언급했듯이 positive class와 negative class에 대해 각각 positive loss와 negative loss를 적용한다.
전체 손실 함수는 다음과 같다:
여기서 supervised loss 는 cross-entropy loss 와 negative learning loss 를 포함한다. unsupervised loss 는 positive learning loss를 포함한다.
Table 1: THUMOS14 및 ActivityNet v1.3 데이터셋에서 labeled video의 비율을 다르게 했을 때의 주요 결과. Baseline은 positive 및 negative learning loss가 없는 기본 모델을 의미한다. 특히, SSP와 SSTAP는 proposal classification을 위해 100% class label로 학습된 UntrimmedNet [28]을 사용한다.
| Label | Method | Backbone | THUMOS14 (%) | ActivityNet v1.3 (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | Avg. | 0.5 | 0.75 | 0.95 | Avg. | |||
| 10% | SSP [11] | TSN | 44.2 | 34.1 | 24.6 | 16.9 | 9.3 | 25.8 | 38.9 | 28.7 | 8.4 | 27.6 |
| SSTAP [31] | TSN | 45.6 | 35.2 | 26.3 | 17.5 | 10.7 | 27.0 | 40.7 | 29.6 | 9.0 | 28.2 | |
| SPOT [21] | TSN | 49.4 | 40.4 | 31.5 | 22.9 | 12.4 | 31.3 | 49.9 | 31.1 | 8.3 | 32.1 | |
| NPL [32] | TSN | 50.0 | 41.7 | 33.5 | 23.6 | 13.4 | 32.4 | 50.9 | 32.0 | 7.9 | 32.6 | |
| Baseline | TSN | 49.2 | 40.2 | 32.8 | 22.4 | 12.5 | 31.4 | 51.2 | 31.8 | 7.3 | 32.1 | |
| Ours | TSN | 50.9 | 42.3 | 34.9 | 24.7 | 14.6 | 33.5 | 53.0 | 34.4 | 9.2 | 34.5 | |
| 20% | SPOT [21] | TSN | 52.6 | 43.9 | 34.1 | 25.2 | 16.2 | 34.4 | 51.7 | 32.0 | 6.9 | 32.3 |
| NPL [32] | TSN | 53.9 | 45.6 | 36.2 | 26.9 | 16.5 | 35.8 | 52.1 | 32.9 | 7.9 | 32.9 | |
| Baseline | TSN | 52.8 | 44.0 | 34.2 | 25.4 | 16.0 | 34.5 | 51.8 | 32.2 | 7.0 | 32.4 | |
| Ours | TSN | 54.6 | 46.4 | 37.0 | 27.2 | 17.1 | 36.5 | 53.5 | 34.7 | 9.4 | 34.8 | |
| 40% | SPOT [21] | TSN | 54.4 | 45.8 | 37.2 | 29.7 | 19.4 | 37.3 | 53.3 | 33.0 | 6.6 | 33.2 |
| NPL [32] | TSN | 56.2 | 46.7 | 38.8 | 30.3 | 19.5 | 38.3 | 53.4 | 33.9 | 8.1 | 33.8 | |
| Baseline | TSN | 54.8 | 45.9 | 37.3 | 29.9 | 19.1 | 37.4 | 53.5 | 33.2 | 6.9 | 33.4 | |
| Ours | TSN | 57.5 | 48.0 | 39.6 | 31.5 | 21.4 | 39.6 | 54.1 | 35.6 | 9.4 | 35.4 | |
| 60% | SSP [11] | TSN | 53.2 | 46.8 | 39.3 | 29.7 | 19.8 | 37.8 | 49.8 | 34.5 | 7.0 | 33.5 |
| SSTAP [31] | TSN | 56.4 | 49.5 | 41.0 | 30.9 | 21.6 | 39.9 | 50.1 | 34.9 | 7.4 | 34.0 | |
| SPOT [21] | TSN | 58.9 | 50.1 | 42.3 | 33.5 | 22.9 | 41.5 | 52.8 | 35.0 | 8.1 | 35.2 | |
| NPL [32] | TSN | 59.0 | 51.4 | 42.9 | 34.3 | 23.3 | 42.2 | 53.9 | 35.8 | 8.5 | 35.7 | |
| Baseline | TSN | 58.7 | 50.0 | 42.6 | 33.7 | 23.0 | 41.6 | 52.9 | 34.9 | 7.9 | 35.0 | |
| Ours | TSN | 59.9 | 52.6 | 43.9 | 35.7 | 24.0 | 43.2 | 54.4 | 35.8 | 9.5 | 35.9 |
와 negative learning loss 뿐만 아니라 도 포함한다. 또한, SS-TAL 모델은 주로 classification head와 mask head로 구성되며, [21, 32]에서와 같이 mask learning loss , refinement loss , 그리고 feature reconstruction loss 에 의해 추가적으로 최적화된다.
추론 시, 모델은 SPOT [21]에서와 같이 classification 및 mask prediction을 통해 각 테스트 비디오에 대한 action instance prediction을 생성한다. 더 구체적으로, 우리는 classification head와 mask head에 각각 classification threshold와 localization threshold를 적용하여 candidate snippet을 얻을 수 있다. 따라서 높은 class probability와 mask score를 가진 비디오 snippet만 top scoring snippet으로 선택된다. 우리는 충분한 candidate를 생성하기 위해 여러 threshold 세트를 사용한다. 각 candidate에 대해 classification probability와 mask score를 곱하여 confidence score를 계산한다. 후처리 단계에서는 Soft-NMS [2]가 최종적으로 적용되어 top scoring 결과를 얻는다.
4 Experiments
4.1 Datasets and Metrics
평가 데이터셋 (Evaluation Datasets)
기존의 관례 [22, 39]에 따라, 우리는 제안하는 방법을 두 가지 도전적인 TAL(Temporal Action Localization) 벤치마크, 즉 **THUMOS14 [12]와 ActivityNet v1.3 [3]**에서 평가한다.
**THUMOS14 [12]**는 200개의 validation 비디오와 213개의 testing 비디오를 포함하며, 20가지 액션 카테고리로 구성된다. 각 비디오에 15개 이상의 액션 인스턴스가 포함되어 있어 매우 도전적인 데이터셋이다. 일반적인 설정 [38]에 따라, 우리는 validation 세트를 학습에 사용하고 testing 세트에서 평가를 수행한다.
**ActivityNet v1.3 [3]**은 비디오 기반 액션 localization을 위한 대규모 벤치마크이다. 이 데이터셋은 10,000개의 training 비디오와 5,000개의 validation 비디오를 포함하며, 200가지의 다른 액션에 해당한다. 표준 관행 [19]에 따라, 우리는 training 세트에서 방법을 학습시키고 validation 세트에서 테스트한다.
평가 지표 (Evaluation Metrics)
우리는 **mAP(mean Average Precision)**를 평가 지표로 사용한다.
tIoU(temporal Intersection over Union) 임계값은 THUMOS14의 경우 [0.3: 0.1: 0.7]이고, ActivityNet v1.3의 경우 [0.5: 0.05: 0.95]이다.
ActivityNet v1.3에서는 IoU 임계값 0.5부터 0.95까지 0.05 간격으로 측정한 mAP의 평균을 보고한다. 또한, THUMOS14에서는 tIoU 임계값 0.3부터 0.7까지의 mAP 평균을 제시한다.
4.2 Implementation Details
기존의 설정 [14, 21, 31]에 따라, 우리는 Kinetics [34]로 사전학습된 TSN [29]을 사용하여 고정된 연속 프레임마다 각 비디오 스니펫 feature를 추출한다. ActivityNet v1.3과 THUMOS14의 시간 차원(temporal dimension)은 각각 100과 256으로 고정된다. 우리의 action localization 프레임워크는 인기 있는 proposal-free 접근 방식인 SPOT [21]을 채택하며, 이는 주로 classification head와 mask head로 구성된다. 우리의 주요 기여는 원래 target class에 대해 cross-entropy loss를 채택하는 classification head에 집중되어 있다. 또한, 공정한 비교를 위해 I3D backbone [4]을 사용하는 또 다른 anchor-free 접근 방식인 Actionformer [39]를 사용한다.
Semi-supervised 설정의 경우, 우리는 먼저 학습 세트에서 12 epoch 동안 모델을 사전학습한 다음, ActivityNet v1.3의 경우 , THUMOS14의 경우 의 learning rate로 15 epoch 동안 사전학습된 모델을 fine-tuning하며, cosine learning rate decay가 사용된다. SPOT [21]을 따라, 우리는 mask에 대해 동일한 label sharpening operator와 threshold set을 채택한다. Soft-NMS [2]는 ActivityNet v1.3과 THUMOS14에서 각각 0.6과 0.4의 threshold로 수행된다. 이다. 라벨링 비율에 대해, 우리는 서로 다른 라벨 크기를 가진 네 가지 SS-TAL 설정을 도입한다. NPL [32]을 따라, 우리는 학습 비디오의 를 라벨링된 세트로 무작위로 선택하고, 나머지는 라벨링되지 않은 세트로 지정한다. 라벨링된 세트와 라벨링되지 않은 세트 모두 SS-TAL 모델 학습에 사용 가능하다.
4.3 Comparison with State-of-the-art Methods
주요 결과는 Table 1에 보고되어 있으며, 여기서는 다양한 tIoU 임계값에서의 mAP와 평균 mAP를 제시한다. 우리의 방법이 두 데이터셋의 모든 데이터 분할에서 이전 연구들에 비해 안정적인 성능 향상을 달성했음을 확인할 수 있다. 또한, Table 1에는 우리의 baseline 모델 성능도 제시되어 있다. 우리의 주요 기여가 제안된 프레임워크의 우수성 덕분에 상당한 성능 향상을 이루었음을 알 수 있다.
구체적으로, THUMOS14 데이터셋의 경우, 밀집된 action instance와 모호한 의미론(ambiguous semantics)으로 인해 도전적인 TAL 벤치마크이다. 우리의 방법은 모든 labeled 비율에서 다른 모든 비교 가능한 방법들을 여전히 능가하며, 이는 우리의 긍정적(positive) 및 부정적(negative) 학습 전략으로부터 얻은 성능 향상을 나타낸다. 특히, labeled 데이터의 수가 매우 제한적일 때 (labeled 비디오가 10% 또는 20%에 불과할 때) 우리의 방법은 놀라운 성능을 얻는다. 이는 우리의 방법이 non-target 클래스로부터 잠재적인 가치 있는 정보를 학습할 수 있음을 보여준다.
제안된 방법의 우수성은 ActivityNet v1.3에서 더욱 강조된다. ActivityNet v1.3은 더 큰 규모의 비디오 데이터셋으로, 효과적인 hybrid positive-negative learning을 위한 더 넓은 label space를 제공한다. Table 1에 나타난 바와 같이, 우리의 방법은 다른 모든 방법들과 비교하여 뚜렷한 개선을 보여준다. 또한, 이러한 개선은 긍정적 및 부정적 클래스로부터 간접적으로 학습하는 것이 SS-TAL에 추가적인 이점을 제공함을 시사한다.
Table 2: THUMOS14 및 ActivityNet v1.3 데이터셋에서 10% label을 사용한 다양한 loss에 대한 ablation study. 여기서 는 snippet-level action classification을 위한 vanilla cross-entropy loss이며, 와 는 상호 보완적인 정보 발굴을 위해 제안된 negative 및 positive learning loss이다.
| THUMOS14 (%) | ActivityNet v1.3 (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.3 | 0.5 | 0.7 | Avg. | 0.5 | 0.75 | 0.95 | Avg. | |||
| 49.2 | 32.8 | 12.5 | 31.4 | 51.2 | 31.8 | 7.3 | 32.1 | |||
| 50.1 | 34.0 | 13.9 | 32.7 | 52.3 | 32.7 | 8.3 | 33.4 | |||
4.4 Ablation Study
Loss term의 효과. 우리의 핵심 통찰, 즉 비타겟 클래스(non-target classes)로부터 유익한 잠재적 의미(underlying informative semantics)를 학습하는 것을 입증하기 위해, Table 2에서 각 loss를 단계별로 제거하는 실험을 수행했다. 무엇보다도, 우리는 로 학습된 모델을 baseline으로 사용했으며, 이 모델은 THUMOS14에서 평균 mAP 31.4%, ActivityNet v1.3에서 32.1%를 달성했다. 제안된 를 적용하면 두 벤치마크 모두에서 baseline 성능이 크게 향상되는데, 이는 잠재적인 negative 정보가 snippet-level의 semantic discrimination을 개선하기 때문이라고 볼 수 있다. 또한, 제안된 역시 positive 클래스에서 ground truth label과 관련된 의미를 발굴함으로써 모델의 성능을 크게 향상시킨다.
다른 backbone 및 detector. 제안된 방법은 각 비디오 snippet의 label space로부터 상호 보완적인 정보(complementary information)를 학습하기 위한 hybrid positive-negative learning loss를 특징으로 하며, 이는 feature-agnostic하고 model-agnostic하다. 이 점을 검증하기 위해, 우리는 우리의 방법을 TAL에서 인기 있는 또 다른 I3D [4] backbone과 강력한 **detector인 Actionformer [39]**와 결합했으며, 그 결과는 Table 3에 제시되어 있다. 성능 향상은 우리의 주장을 뒷받침하며, 우리 방법의 우수성이 feature-agnostic하고 model-agnostic하다는 것을 확인시켜준다.
하이퍼파라미터 의 실증적 연구. Ground truth 클래스는 종종 positive 클래스 내에 숨겨져 있으며, 이는 target-class 기반 학습 방법에서는 무시되는 부분이다. 이와 대조적으로, 우리는 샘플의 confidence에 기반하여 positive 클래스의 수를 적응적으로 선택하는 하이퍼파라미터 를 도입한다. 이어서, 우리는 값을 변화시키며 그 성능에 미치는 영향을 심층적으로 분석하는 ablation study를 수행했다. Table 4에서 볼 수 있듯이, 더 높은 값으로 더 적은 positive 클래스를 선택하는 것은 positive learning을 통해 유익한 의미를 완전히 학습하기 어렵게 만들 수 있다. 반면, 더 낮은 값으로 더 많은 클래스를 positive 클래스로 선택하는 것은 신뢰할 수 없는 모호한 클래스를 포함할 위험이 있다.
Table 4: THUMOS14에서 10% 레이블을 사용하여 하이퍼파라미터 에 대한 실증적 연구. 는 positive learning을 위한 positive 클래스 수에 영향을 미친다. Table 3: THUMOS14에서 I3D feature와 Actionformer [39]를 사용한 SS-TAL 결과의 ablation study. 레이블 비율은 10%이며, 는 레이블된 비디오만 사용했음을 나타낸다.
| Method | $\left.\right | _{\text {Bkb }}$ | THUMOS14 (%) | |||
|---|---|---|---|---|---|---|
| 0.3 | 0.5 | 0.7 | Avg. | |||
| ActF | I3D | 28.5 | 14.1 | 4.1 | 15.6 | |
| NPL (ActF) [32] | I3D | 32.8 | 20.1 | 7.2 | 20.3 | |
| Ours (ActF) | I3D |
Table 4: THUMOS14에서 10% 레이블을 사용하여 하이퍼파라미터 에 대한 실증적 연구. 는 positive learning을 위한 positive 클래스 수에 영향을 미친다. Table 3: THUMOS14에서 I3D feature와 Actionformer [39]를 사용한 SS-TAL 결과의 ablation study. 레이블 비율은 10%이며, 는 레이블된 비디오만 사용했음을 나타낸다.
| value | THUMOS14 (%) | |||
|---|---|---|---|---|
| 0.3 | 0.5 | 0.7 | Avg. | |
| 0.90 | 50.6 | 34.8 | 14.3 | 33.2 |
| 0.85 | ||||
| 0.80 | 50.2 | 34.3 | 14.1 | 33.0 |
| 0.75 | 50.0 | 34.1 | 14.0 | 32.9 |
 Fig. 3: foreground-background subtask에 대한 우리 방법의 효과. 레이블되지 않은 THUMOS14 비디오에서 foreground feature와 background feature의 시각화를 제시한다.
Fig. 3: foreground-background subtask에 대한 우리 방법의 효과. 레이블되지 않은 THUMOS14 비디오에서 foreground feature와 background feature의 시각화를 제시한다.
 Fig. 4: foreground-instance subtask에 대한 우리 방법의 효과. THUMOS14에서 네 가지 도전적인 클래스의 feature 시각화를 제시한다.
Fig. 4: foreground-instance subtask에 대한 우리 방법의 효과. THUMOS14에서 네 가지 도전적인 클래스의 feature 시각화를 제시한다.
Positive 및 negative learning의 정성적 분석. 비타겟 클래스(non-target classes)로부터 상호 보완적인 정보(complementary information)를 학습하는 것은 클래스 수준의 표현(class-level representation)을 개선하는 데 기여한다. 이 점을 검증하기 위해, Figure 3과 Figure 4에서 각각 foreground-background feature와 foreground-instance feature의 시각화를 제시한다. 한편, Figure 3에서 제안된 hybrid positive-negative learning은 positive 클래스에 숨겨진 ground truth 의미를 발굴함으로써 foreground와 background feature를 더 명확하게 분리한다. 다른 한편, Figure 4에서 우리는 hybrid positive-negative learning을 통해 모델이 각 클래스의 훨씬 더 명확한 경계를 생성한다는 것을 관찰할 수 있다. 이는 우리 방법이 모델의 일반화 능력(generalization ability)을 향상시킬 수 있음을 보여준다.
Label space의 정량적 평가. 제안된 방법은 전체 label space를 target class, positive classes, ambiguous classes, negative classes로 적응적으로 분할한 다음, positive 및 negative learning을 수행하여 ground truth 의미와 잠재적인 negative 정보를 발굴할 수 있다. 성능 향상의 핵심은 positive 클래스가 ground truth label을 포함하는지 여부와 negative 클래스가 ground truth label을 포함할 위험이 낮은지 여부이다. 따라서, 우리는 Figure 5에 나타난 바와 같이, ground truth label이 이 네 가지 클래스 부분 공간에 위치할 평균 확률을 계산한다. 우리 방법이 positive 클래스를 효과적으로 사용하여 ground truth 의미를 발굴하고, negative 클래스를 활용하여 모델을 최대한 개선할 수 있음을 관찰할 수 있다.
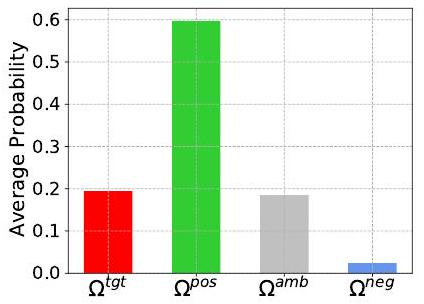
Fig. 5: Ground truth label이 다른 label subspace, 즉 target class , positive classes , ambiguous classes , negative classes 에 위치할 평균 확률. 이 실험은 90% 레이블되지 않은 THUMOS14에서 수행되었다.
Table 5: soft pseudo-label 방법 [1] 및 complementary label [10]과의 비교. 비교 결과는 이전의 semi-supervised 기술에 대한 우리 방법의 우수성을 검증한다.
| Method | THUMOS14 (%) | |||
|---|---|---|---|---|
| 0.3 | 0.5 | 0.7 | Avg. | |
| soft pseudo label | 49.5 | 33.2 | 12.7 | 31.7 |
| complementary label | 50.0 | 33.5 | 13.1 | 32.1 |
| Ours |
다른 semi-supervised 접근법과의 비교. 이전의 semi-supervised 기술에 대한 우리 방법의 우수성을 검증하기 위해, 우리는 **soft pseudo-label 방법 [1]과 complementary label 방법 [10] (무작위 비타겟 클래스에서 학습)**을 탐구했다. 우리는 이들의 주요 아이디어를 우리 연구에 통합했다. Table 5의 비교 결과는 모델에 의해 생성된 soft pseudo-label이 상당히 노이즈가 많고, target label 외에 제한적인 추가 지식만을 포함한다는 것을 보여준다. complementary label과 대조적으로, 우리의 hybrid positive-negative learning은 레이블되지 않은 비디오에서 더 풍부하고 유익한 action semantics를 적응적으로 추출하는 동시에, 진정한 레이블을 선택할 위험을 줄일 수 있다.
 Fig. 6: (a) THUMOS14 및 (b) ActivityNet v1.3의 두 untrimmed 비디오에서 제안된 방법과 SPOT [21]의 정성적 SS-TAL 결과 비교.
Fig. 6: (a) THUMOS14 및 (b) ActivityNet v1.3의 두 untrimmed 비디오에서 제안된 방법과 SPOT [21]의 정성적 SS-TAL 결과 비교.
4.5 Visualization results
Figure 6에서 볼 수 있듯이, 우리는 이전 연구인 SPOT [21]과 우리의 접근 방식에 대한 정성적 결과를 제시한다. 여기서 모델은 THUMOS14와 ActivityNet v1.3 모두에서 10% 및 40%의 labeled data로 학습되었다. 비타겟 클래스(non-target classes)를 활용하는 이점 덕분에, 우리의 방법은 타겟 액션(target actions)을 더 정확하게 찾아내고 인식할 수 있으며, 이는 우리 방법의 우수성을 보여준다.
5 Limitation
본 논문은 타겟 클래스(target class)뿐만 아니라 비타겟 클래스(non-target class)로부터도 유익한 의미론적 정보(informative semantics)를 학습하는 방법을 제안하며, 이는 레이블 공간(label space)에 숨겨진 풍부한 정보를 활용한다. 따라서 제안된 방법은 학습 세트와 레이블 공간이 작을 때 상당한 성능 향상을 달성하기 어렵다. 또한, 본 연구는 학습 과정에서 모든 모호한 클래스(ambiguous classes)를 완전히 제외하는데, 이는 일부 지시적인 정보(indicative information)가 낭비될 수 있다는 결과를 초래할 수 있다. 따라서 모호한 클래스를 활용하여 모델을 개선하는 것은 향후 연구의 일부가 될 것이다.
6 Conclusion
본 논문에서는 non-target class로부터 학습하는 것을 강조함으로써, SS-TAL(Semi-Supervised Temporal Action Localization)을 위한 새로운 패러다임을 제시한다. 이는 기존의 target class에만 집중하는 방식을 넘어선다. 우리의 접근 방식은 다음과 같다: 먼저, 예측된 class 분포의 전체 label space를 여러 subspace로 분할한다. 이는 target class에는 없지만 유용한 positive 및 negative semantic 정보를 발굴하고, 모호한(ambiguous) class는 제외하는 것을 목표로 한다. 다음으로, label space에서 고품질의 positive 및 negative class를 적응적으로 선택하기 위한 혁신적인 전략을 개발한다. 또한, non-target 학습을 효과적으로 유도하기 위해 새로운 positive 및 negative loss를 제안한다. 두 가지 인기 있는 벤치마크에서 수행된 광범위한 실험을 통해 일관된 성능 향상을 입증하였으며, 이는 우리 방법의 효과성을 보여준다.