BLIP-2: Frozen Image Encoder와 LLM을 활용한 효율적인 Vision-Language Pre-training
BLIP-2는 사전 학습된 frozen image encoder와 frozen large language model (LLM)을 효율적으로 활용하는 새로운 vision-language pre-training 전략입니다. 이 모델은 경량의 Querying Transformer (Q-Former)를 사용하여 두 모델 간의 modality 차이를 해소하며, 두 단계의 pre-training을 통해 학습됩니다. 첫 번째 단계에서는 vision-language representation learning을, 두 번째 단계에서는 vision-to-language generative learning을 수행합니다. BLIP-2는 기존 모델들보다 훨씬 적은 학습 파라미터로 다양한 vision-language 태스크에서 최고 수준의 성능을 달성했으며, 특히 zero-shot VQAv2 태스크에서 Flamingo-80B 모델보다 8.7% 높은 성능을 보여주었습니다. 또한 자연어 지시를 따르는 zero-shot image-to-text 생성 능력도 갖추고 있습니다. 논문 제목: BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
논문 요약: BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 논문 링크: https://arxiv.org/abs/2301.12597
- 저자: Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi (Salesforce Research)
- 발표 시기: 2023년, International Conference on Machine Learning (ICML)
- 주요 키워드: Vision-Language Model, LLM, 효율적인 Pre-training, 멀티모달
1. 연구 배경 및 문제 정의
- 문제 정의: 대규모 모델의 end-to-end 학습으로 인해 Vision-Language Pre-training (VLP) 비용이 점점 더 감당하기 어려워지고 있습니다. 또한, 이미 사전학습된 고품질의 이미지 인코더와 강력한 언어 생성 및 zero-shot 전이 능력을 가진 대규모 언어 모델(LLM)을 효율적으로 활용하고, 이들 간의 모달리티 간극(modality gap)을 효과적으로 연결하는 것이 중요한 과제입니다. 특히, LLM은 사전학습 동안 이미지를 본 적이 없으므로, 고정된(frozen) 상태에서 시각-언어 정렬을 달성하는 것이 어렵습니다.
- 기존 접근 방식: 대부분의 기존 VLP 방법은 대규모 이미지-텍스트 쌍 데이터셋을 사용하여 end-to-end 사전학습을 수행하여 높은 연산 비용을 발생시킵니다. 일부 모듈형 VLP 방법(예: Frozen, Flamingo)은 기성 사전학습 모델을 활용하고 VLP 동안 이들을 고정시키지만, 시각-언어 정렬을 위해 이미지 인코더를 fine-tuning하거나 LLM 내부에 새로운 cross-attention 레이어를 삽입하는 방식에 의존하며, 이는 모달리티 간극을 메우기에 불충분하거나 여전히 많은 학습 파라미터를 요구하는 한계가 있었습니다.
2. 주요 기여 및 제안 방법
-
논문의 주요 기여:
- 고정된 사전학습 이미지 인코더와 LLM을 모두 효과적이고 효율적으로 활용하는 새로운 VLP 전략인 BLIP-2를 제안합니다.
- 경량의 Querying Transformer (Q-Former)와 2단계 사전학습 전략을 통해 모달리티 간의 간극을 성공적으로 연결합니다.
- 기존 SOTA 모델 대비 현저히 적은 학습 가능한 파라미터로 다양한 Vision-Language 태스크에서 최고 수준의 성능을 달성합니다 (예: zero-shot VQAv2에서 Flamingo80B보다 8.7% 높은 성능).
- 자연어 지시를 따르는 zero-shot 이미지-텍스트 생성이라는 새로운 능력을 입증하여 시각적 지식 추론, 시각적 대화 등 광범위한 응용 가능성을 제시합니다.
-
제안 방법: BLIP-2는 고정된 이미지 인코더와 고정된 LLM 사이의 간극을 연결하는 학습 가능한 경량 모듈인 **Querying Transformer (Q-Former)**를 제안합니다. Q-Former는 학습 가능한 고정된 수의 쿼리 임베딩을 사용하여 이미지 인코더로부터 시각적 특징을 추출하며, 이는 LLM이 원하는 텍스트를 출력하는 데 가장 유용한 시각적 정보를 제공하는 정보 병목(information bottleneck) 역할을 합니다.
BLIP-2는 두 단계의 사전학습을 통해 학습됩니다:
- 1단계: Vision-Language Representation Learning: Q-Former를 고정된 이미지 인코더에 연결하고 이미지-텍스트 쌍을 사용하여 사전학습합니다. 이 단계에서는 Q-Former가 텍스트에 가장 유익한 시각적 표현을 추출하도록 학습시키기 위해 세 가지 목적 함수(Image-Text Contrastive Learning, Image-grounded Text Generation, Image-Text Matching)를 공동으로 최적화합니다.
- 2단계: Vision-to-Language Generative Learning: Q-Former의 출력을 고정된 LLM에 연결하여 LLM의 생성 언어 능력을 활용합니다. Q-Former의 출력은 LLM의 입력 텍스트 임베딩 앞에 추가되어 LLM을 시각적 표현에 조건화하는 soft visual prompt 역할을 합니다. 이 단계에서는 Q-Former가 생성하는 시각적 표현이 LLM에 의해 해석될 수 있도록 학습시키며, 이는 LLM이 vision-language 정렬을 학습하는 부담을 줄여 catastrophic forgetting 문제를 완화합니다. 이 단계는 decoder 기반 LLM (OPT)과 encoder-decoder 기반 LLM (FlanT5) 모두에 적용 가능합니다.
3. 실험 결과
- 데이터셋:
- 사전학습: COCO, Visual Genome, CC3M, CC12M, SBU, LAION400M을 포함한 총 1억 2,900만 개의 이미지-텍스트 쌍 데이터셋을 사용했으며, CapFilt 방법을 통해 합성 캡션을 생성하여 활용했습니다.
- 평가: VQAv2, GQA, OK-VQA (Zero-shot VQA), NoCaps, COCO (Image Captioning), Flickr30K, COCO (Image-Text Retrieval) 데이터셋에서 평가를 수행했습니다.
- 사용된 모델: 고정된 이미지 인코더로는 CLIP ViT-L/14 및 EVA-CLIP ViT-g/14를, 고정된 LLM으로는 OPT (decoder 기반) 및 FlanT5 (encoder-decoder 기반) 모델 계열을 사용했습니다.
- 주요 결과:
- Zero-shot VQA: BLIP-2는 VQAv2 및 GQA 데이터셋에서 SOTA 결과를 달성했습니다. 특히, Flamingo80B보다 54배 적은 학습 가능한 파라미터로 zero-shot VQAv2에서 8.7% 더 높은 성능(65.0% vs 56.3%)을 보였습니다. OK-VQA에서는 Flamingo80B 다음으로 좋은 성능을 보였습니다.
- Image Captioning: NoCaps에서 기존 방법론 대비 상당한 개선을 통해 SOTA 성능을 달성하며, out-domain 이미지에 대한 강력한 일반화 능력을 입증했습니다.
- Image-Text Retrieval: zero-shot 및 fine-tuned 이미지-텍스트 검색 모두에서 SOTA 성능을 달성했습니다.
- 효율성: 가장 큰 모델(ViT-g와 FlanT5-XXL)도 단일 16-A100 (40G) 머신에서 1단계에 6일 미만, 2단계에 3일 미만이 소요되어 기존 대규모 VLP 방법보다 계산적으로 효율적임을 입증했습니다.
- 모듈의 중요성: 1단계의 representation learning이 없으면 zero-shot VQA 성능이 현저히 낮아지고 catastrophic forgetting 현상이 발생함을 보여주어, Q-Former의 2단계 사전학습 전략의 중요성을 강조했습니다. 또한, Image-grounded Text Generation (ITG) loss가 이미지-텍스트 검색 성능 향상에 기여함을 입증했습니다.
- 확장성: 강력한 이미지 인코더(ViT-g > ViT-L)와 강력한 LLM(더 큰 모델, instruction-tuned FlanT5 > 비지도 학습된 OPT)이 모두 더 나은 성능으로 이어진다는 것을 확인하여, BLIP-2가 발전된 unimodal 모델을 활용할 수 있는 범용적인 방법임을 보여주었습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 기존의 방대한 사전학습된 단일 모달 모델(이미지 인코더, LLM)을 '고정'시킨 채로 활용하여 VLP의 막대한 연산 비용을 획기적으로 절감했다는 점이 가장 인상 깊습니다. 이는 연구 및 개발의 진입 장벽을 낮추는 데 크게 기여할 것입니다.
- 경량의 Q-Former와 체계적인 2단계 사전학습 전략을 통해 서로 다른 모달리티 간의 간극을 효과적으로 메우고, LLM의 강점을 최대한 활용할 수 있도록 설계된 점이 뛰어납니다.
- 적은 학습 파라미터로도 다양한 zero-shot 및 fine-tuned 멀티모달 태스크에서 SOTA 성능을 달성했다는 것은 BLIP-2의 효율성과 효과성을 명확히 보여줍니다. 특히, zero-shot VQA에서 Flamingo와 같은 거대 모델을 압도하는 성능은 매우 고무적입니다.
- 자연어 지시를 따르는 이미지-텍스트 생성 능력은 단순한 캡셔닝을 넘어 시각적 대화, 지식 추론 등 복잡한 멀티모달 AI 에이전트 개발의 가능성을 열어줍니다.
- 단점/한계:
- 논문에서 언급된 한계점 중 하나는 in-context learning 능력의 부족입니다. 이는 사전학습 데이터셋이 단일 이미지-텍스트 쌍으로 구성되어 LLM이 여러 쌍 간의 상관관계를 학습하기 어려웠기 때문으로 보입니다. 향후 interleaved 데이터셋 구축을 통해 개선될 여지가 있습니다.
- LLM의 부정확한 지식, 잘못된 추론, 최신 정보 부족 등으로 인해 이미지-텍스트 생성 결과가 만족스럽지 않을 수 있다는 점은 여전히 해결해야 할 과제입니다.
- 고정된 LLM을 사용하기 때문에 LLM이 가진 잠재적인 위험(공격적 언어, 사회적 편견, 개인 정보 유출)을 그대로 계승한다는 점도 중요한 한계입니다. 이는 모델의 생성 유도 지시문 사용이나 유해 콘텐츠 필터링된 데이터셋 학습 등으로 완화될 수 있습니다.
- 응용 가능성:
- BLIP-2는 멀티모달 대화형 AI 에이전트, 즉 이미지와 텍스트를 모두 이해하고 자연어로 소통할 수 있는 챗봇이나 가상 비서 개발에 핵심적인 기반 기술이 될 수 있습니다.
- 시각적 지식 추론, 시각적 상식 추론, 스토리텔링, 개인화된 이미지-텍스트 생성 등 다양한 고급 멀티모달 애플리케이션에 적용될 수 있습니다.
- 기존의 고품질 단일 모달 모델들을 재활용하여 새로운 멀티모달 모델을 효율적으로 구축하는 방법론을 제시함으로써, 향후 멀티모달 AI 연구 및 상용화에 큰 영향을 미칠 것으로 기대됩니다.
5. 추가 참고 자료
Li, Junnan, et al. "Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models." International conference on machine learning. PMLR, 2023.
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Junnan Li Dongxu Li Silvio Savarese Steven Hoi Salesforce Research<br>https://github.com/salesforce/LAVIS/tree/main/projects/blip2
Abstract
대규모 모델의 end-to-end 학습으로 인해 vision-and-language pre-training 비용이 점점 더 감당하기 어려워지고 있다. 본 논문은 BLIP-2를 제안한다. BLIP-2는 기존의 사전학습된 이미지 인코더(frozen pre-trained image encoder)와 대규모 언어 모델(frozen large language model)을 활용하여 vision-language pre-training을 부트스트랩하는 일반적이고 효율적인 전략이다. BLIP-2는 경량의 Querying Transformer를 통해 모달리티 간의 간극(modality gap)을 연결하며, 이 Querying Transformer는 두 단계로 사전학습된다.
- 첫 번째 단계에서는 frozen image encoder로부터 vision-language representation learning을 부트스트랩한다.
- 두 번째 단계에서는 frozen language model로부터 vision-to-language generative learning을 부트스트랩한다.
BLIP-2는 기존 방법론에 비해 학습 가능한 파라미터 수가 현저히 적음에도 불구하고, 다양한 vision-language task에서 state-of-the-art 성능을 달성한다. 예를 들어, 우리 모델은 Flamingo80B보다 54배 적은 학습 가능한 파라미터로 zero-shot VQAv2에서 8.7% 더 높은 성능을 보인다. 또한 우리는 자연어 지시를 따를 수 있는 zero-shot image-to-text generation의 새로운 능력도 입증한다.
1. Introduction
Vision-language pre-training (VLP) 연구는 지난 몇 년간 급속한 발전을 이루었으며, 점점 더 큰 규모의 사전학습 모델들이 개발되어 다양한 다운스트림 task에서 지속적으로 state-of-the-art를 경신해왔다 (Radford et al., 2021; Li et al., 2021; 2022; Wang et al., 2022a; Alayrac et al., 2022; Wang et al., 2022b). 그러나 대부분의 state-of-the-art vision-language 모델은 대규모 모델과 데이터셋을 사용한 end-to-end 학습으로 인해 사전학습 시 높은 연산 비용을 발생시킨다.
Vision-language 연구는 vision과 language의 교차점에 위치하므로, vision-language 모델이 vision 및 자연어 커뮤니티에서 이미 사용 가능한 unimodal 모델로부터 이점을 얻을 수 있을 것으로 자연스럽게 기대된다. 본 논문에서는 기존의 사전학습된 vision 모델과 language 모델을 활용하여 일반적이고 연산 효율적인 VLP 방법을 제안한다. 사전학습된 vision 모델은 고품질의 시각적 표현을 제공하며, 특히 대규모 language model (LLM)은 강력한 언어 생성 및 zero-shot transfer 능력을 제공한다. 연산 비용을 줄이고 catastrophic forgetting 문제에 대응하기 위해, unimodal 사전학습 모델들은 사전학습 동안 고정(frozen)된 상태를 유지한다.
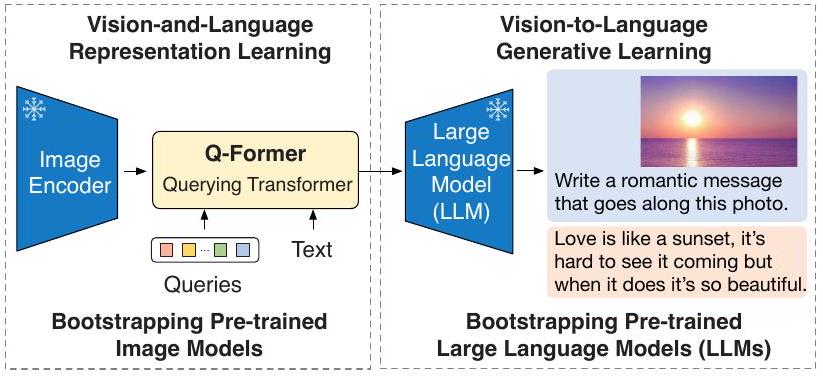
Figure 1. BLIP-2 프레임워크 개요. 우리는 경량 Querying Transformer를 두 단계 전략으로 사전학습하여 모달리티 간의 간극(modality gap)을 연결한다. 첫 번째 단계는 고정된 image encoder로부터 vision-language representation learning을 부트스트랩한다. 두 번째 단계는 고정된 LLM으로부터 vision-to-language generative learning을 부트스트랩하며, 이는 zero-shot instructed image-to-text generation을 가능하게 한다 (더 많은 예시는 Figure 4 참조).
VLP를 위해 사전학습된 unimodal 모델을 활용하려면 cross-modal alignment를 촉진하는 것이 핵심이다. 그러나 LLM은 unimodal 사전학습 동안 이미지를 본 적이 없으므로, 이들을 고정(freezing)하는 것은 vision-language alignment를 특히 어렵게 만든다. 이와 관련하여 기존 방법들(예: Frozen (Tsimpoukelli et al., 2021), Flamingo (Alayrac et al., 2022))은 image-to-text generation loss에 의존하지만, 우리는 이것만으로는 모달리티 간의 간극(modality gap)을 메우기에 불충분하다는 것을 보여준다.
고정된 unimodal 모델을 사용하여 효과적인 vision-language alignment를 달성하기 위해, 우리는 **새로운 2단계 사전학습 전략으로 학습되는 Querying Transformer (Q-Former)**를 제안한다. Figure 1에서 보듯이, Q-Former는 일련의 학습 가능한 query vector를 사용하여 고정된 image encoder로부터 시각적 feature를 추출하는 경량 Transformer이다. Q-Former는 고정된 image encoder와 고정된 LLM 사이의 정보 병목(information bottleneck) 역할을 하며, LLM이 원하는 텍스트를 출력하는 데 가장 유용한 시각적 feature를 제공한다.
- 첫 번째 사전학습 단계에서는 vision-language representation learning을 수행하여 Q-Former가 텍스트와 가장 관련성이 높은 시각적 표현을 학습하도록 한다.
- 두 번째 사전학습 단계에서는 Q-Former의 출력을 고정된 LLM에 연결하여 vision-to-language generative learning을 수행하며, Q-Former가 생성하는 시각적 표현이 LLM에 의해 해석될 수 있도록 학습시킨다.
우리는 우리의 VLP 프레임워크를 BLIP-2: Bootstrapping Language-Image Pre-training with frozen unimodal models라고 명명한다. BLIP-2의 주요 장점은 다음과 같다:
- BLIP-2는 고정된 사전학습 image model과 language model을 모두 효과적으로 활용한다. 우리는 representation learning 단계와 generative learning 단계의 두 단계로 사전학습된 Q-Former를 사용하여 모달리티 간의 간극을 연결한다. BLIP-2는 visual question answering, image captioning, image-text retrieval을 포함한 다양한 vision-language task에서 state-of-the-art 성능을 달성한다.
- LLM (예: OPT (Zhang et al., 2022), FlanT5 (Chung et al., 2022))의 지원을 받아, BLIP-2는 자연어 지시를 따르는 zero-shot image-to-text generation을 수행하도록 prompt될 수 있으며, 이는 시각적 지식 추론, 시각적 대화 등과 같은 새로운 기능을 가능하게 한다 (예시는 Figure 4 참조).
- 고정된 unimodal 모델과 경량 Q-Former를 사용하기 때문에, BLIP-2는 기존 state-of-the-art 모델보다 연산 효율적이다. 예를 들어, BLIP-2는 Flamingo (Alayrac et al., 2022)보다 zero-shot VQAv2에서 8.7% 더 우수한 성능을 보이면서도, 학습 가능한 파라미터 수는 54배 더 적다. 또한, 우리의 결과는 BLIP-2가 더 나은 VLP 성능을 위해 더 발전된 unimodal 모델을 활용할 수 있는 일반적인 방법임을 보여준다.
2. Related Work
2.1. End-to-end Vision-Language Pre-training
Vision-language pre-training은 다양한 vision-and-language task에서 향상된 성능을 보이는 멀티모달 foundation model을 학습하는 것을 목표로 한다. 다운스트림 task에 따라 다양한 모델 아키텍처가 제안되어 왔다. 여기에는 dual-encoder 아키텍처 (Radford et al., 2021; Jia et al., 2021), fusion-encoder 아키텍처 (Tan & Bansal, 2019; Li et al., 2021), encoder-decoder 아키텍처 (Cho et al., 2021; Wang et al., 2021b; Chen et al., 2022b), 그리고 최근에는 unified transformer 아키텍처 (Li et al., 2022; Wang et al., 2022b) 등이 포함된다. 또한 수년에 걸쳐 다양한 pre-training objective가 제안되었으며, 점차적으로 몇 가지 검증된 방식으로 수렴되었다: image-text contrastive learning (Radford et al., 2021; Yao et al., 2022; Li et al., 2021; 2022), image-text matching (Li et al., 2021; 2022; Wang et al., 2021a), 그리고 (masked) language modeling (Li et al., 2021; 2022; Yu et al., 2022; Wang et al., 2022b) 등이 그것이다.
대부분의 VLP(Vision-Language Pre-training) 방법은 대규모 image-text pair 데이터셋을 사용하여 end-to-end pre-training을 수행한다. 모델 크기가 계속 증가함에 따라, pre-training은 극도로 높은 연산 비용을 발생시킬 수 있다. 더욱이, end-to-end로 사전학습된 모델은 LLM(Large Language Model) (Brown et al., 2020; Zhang et al., 2022; Chung et al., 2022)과 같이 이미 사용 가능한 unimodal 사전학습 모델을 활용하는 데 유연성이 떨어진다.
2.2. Modular Vision-Language Pre-training
우리와 더 유사한 방법들은 기성(off-the-shelf) 사전학습 모델을 활용하고 VLP(Vision-Language Pre-training) 동안 이들을 고정(frozen)시키는 방식이다. 일부 방법은 이미지 인코더를 고정시키는데, 여기에는 고정된 object detector를 사용하여 시각 feature를 추출하는 초기 연구들 (Chen et al., 2020; Li et al., 2020; Zhang et al., 2021)과, **CLIP (Radford et al., 2021) 사전학습을 위해 고정된 사전학습 이미지 인코더를 사용하는 최근의 LiT (Zhai et al., 2022)**가 포함된다. 또 다른 방법들은 LLM(Large Language Model)의 지식을 vision-to-language 생성 task에 활용하기 위해 language model을 고정시킨다 (Tsimpoukelli et al., 2021; Alayrac et al., 2022; Chen et al., 2022a; Mañas et al., 2023; Tiong et al., 2022; Guo et al., 2022). 고정된 LLM을 사용하는 데 있어 핵심적인 과제는 시각 feature를 텍스트 공간에 정렬(align)하는 것이다. 이를 위해 **Frozen (Tsimpoukelli et al., 2021)**은 이미지 인코더를 fine-tuning하며, 이 인코더의 출력은 LLM의 soft prompt로 직접 사용된다. **Flamingo (Alayrac et al., 2022)**는 LLM 내부에 새로운 cross-attention layer를 삽입하여 시각 feature를 주입하고, 수십억 개의 이미지-텍스트 쌍으로 이 새로운 layer들을 사전학습한다. 두 방법 모두 language modeling loss를 채택하며, 여기서 language model은 이미지를 조건으로 텍스트를 생성한다.
기존 방법들과 달리, BLIP-2는 고정된 이미지 인코더와 고정된 LLM을 모두 효과적이고 효율적으로 활용하여 다양한 vision-language task를 수행하며, 더 낮은 연산 비용으로 더 강력한 성능을 달성한다.
3. Method
우리는 BLIP-2를 제안한다. 이는 사전학습된 unimodal 모델들을 활용(bootstraps)하는 새로운 vision-language pre-training 방법이다. 모달리티 간의 간극(modality gap)을 연결하기 위해, 우리는 **두 단계로 사전학습되는 Querying Transformer (Q-Former)**를 제안한다: (1) frozen된 image encoder를 활용한 vision-language representation learning 단계, (2) frozen된 LLM을 활용한 vision-to-language generative learning 단계.
본 섹션에서는 먼저 Q-Former의 모델 아키텍처를 소개하고, 이어서 두 단계의 pre-training 절차를 설명한다.
3.1. Model Architecture
우리는 frozen image encoder와 frozen LLM 사이의 간극을 연결하는 학습 가능한 모듈로 Q-Former를 제안한다. Q-Former는 입력 이미지 해상도와 무관하게 image encoder로부터 고정된 수의 출력 feature를 추출한다. Figure 2에서 보듯이, Q-Former는 동일한 self-attention layer를 공유하는 두 개의 Transformer 서브모듈로 구성된다:
- Image Transformer: frozen image encoder와 상호작용하여 시각 feature를 추출한다.
- Text Transformer: 텍스트 encoder와 텍스트 decoder 역할을 모두 수행할 수 있다.
우리는 학습 가능한 고정된 수의 query embedding을 image Transformer의 입력으로 사용한다. 이 query들은 self-attention layer를 통해 서로 상호작용하며, cross-attention layer(다른 Transformer 블록마다 삽입됨)를 통해 frozen image feature와 상호작용한다. Query들은 동일한 self-attention layer를 통해 텍스트와도 추가적으로 상호작용할 수 있다. 사전학습 task에 따라, 우리는 query-텍스트 상호작용을 제어하기 위해 다른 self-attention mask를 적용한다. 우리는 Q-Former를 사전학습된 (Devlin et al., 2019)의 가중치로 초기화하며, cross-attention layer는 무작위로 초기화된다. 총 188M개의 파라미터를 포함한다. Query는 모델 파라미터로 간주된다.
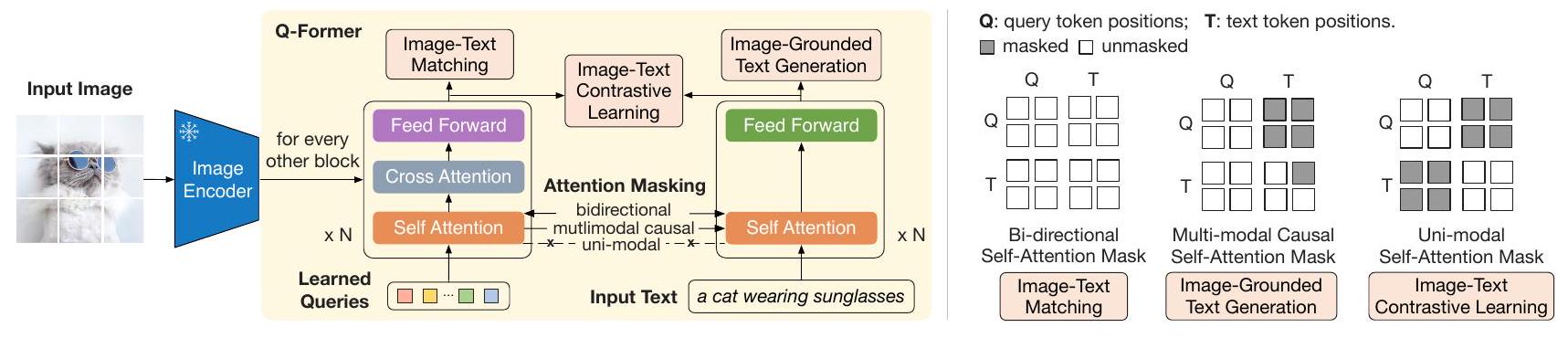
Figure 2. (왼쪽) Q-Former의 모델 아키텍처 및 BLIP-2의 1단계 vision-language representation learning objective. 우리는 query(학습 가능한 embedding 집합)가 텍스트와 가장 관련성이 높은 시각적 표현을 추출하도록 강제하는 세 가지 objective를 공동으로 최적화한다. (오른쪽) 각 objective에 대한 self-attention masking 전략으로 query-텍스트 상호작용을 제어한다.
실험에서 우리는 각 query의 차원이 768(Q-Former의 hidden dimension과 동일)인 32개의 query를 사용한다. 출력 query 표현은 로 표기한다. 의 크기()는 frozen image feature의 크기(예: ViT-L/14의 경우 )보다 훨씬 작다. 이러한 병목(bottleneck) 아키텍처는 우리의 사전학습 objective와 함께 작동하여 query가 텍스트와 가장 관련성이 높은 시각 정보를 추출하도록 강제한다.
3.2. Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
표현 학습(representation learning) 단계에서 우리는 Q-Former를 frozen image encoder에 연결하고 이미지-텍스트 쌍을 사용하여 사전학습을 수행한다. 우리의 목표는 쿼리가 텍스트에 가장 유익한 시각적 표현을 추출하도록 Q-Former를 학습시키는 것이다. BLIP (Li et al., 2022)에서 영감을 받아, 우리는 동일한 입력 형식과 모델 파라미터를 공유하는 세 가지 사전학습 objective를 공동으로 최적화한다. 각 objective는 쿼리와 텍스트 간의 다른 attention masking 전략을 사용하여 상호작용을 제어한다 (Figure 2 참조).
**Image-Text Contrastive Learning (ITC)**은 이미지 표현과 텍스트 표현을 정렬하여 상호 정보(mutual information)를 최대화하도록 학습한다. 이는 긍정 쌍(positive pair)의 이미지-텍스트 유사도를 부정 쌍(negative pair)의 유사도와 대조함으로써 달성된다. 우리는 image Transformer의 출력 쿼리 표현 를 text Transformer의 텍스트 표현 와 정렬한다. 여기서 는 [CLS] 토큰의 출력 임베딩이다. 는 여러 출력 임베딩(각 쿼리에서 하나씩)을 포함하므로, 우리는 먼저 각 쿼리 출력과 사이의 쌍별 유사도를 계산한 다음, 가장 높은 값을 이미지-텍스트 유사도로 선택한다. 정보 유출을 방지하기 위해, 우리는 쿼리와 텍스트가 서로를 볼 수 없도록 하는 unimodal self-attention mask를 사용한다. frozen image encoder를 사용하기 때문에, end-to-end 방식에 비해 GPU당 더 많은 샘플을 처리할 수 있다. 따라서 우리는 BLIP의 momentum queue 대신 in-batch negatives를 사용한다.
Image-grounded Text Generation (ITG) loss는 입력 이미지를 조건으로 텍스트를 생성하도록 Q-Former를 학습시킨다. Q-Former의 아키텍처는 frozen image encoder와 텍스트 토큰 간의 직접적인 상호작용을 허용하지 않으므로, 텍스트 생성에 필요한 정보는 먼저 쿼리에 의해 추출된 다음, self-attention layer를 통해 텍스트 토큰으로 전달되어야 한다. 따라서 쿼리는 텍스트에 대한 모든 정보를 포착하는 시각적 feature를 추출하도록 강제된다. 우리는 UniLM (Dong et al., 2019)에서 사용된 것과 유사한 multimodal causal self-attention mask를 사용하여 쿼리-텍스트 상호작용을 제어한다. 쿼리는 서로에게 attend할 수 있지만 텍스트 토큰에는 attend할 수 없다. 각 텍스트 토큰은 모든 쿼리와 이전 텍스트 토큰에 attend할 수 있다. 또한 우리는 디코딩 task를 알리기 위해 첫 번째 텍스트 토큰으로 [CLS] 토큰을 새로운 [DEC] 토큰으로 대체한다.
**Image-Text Matching (ITM)**은 이미지 및 텍스트 표현 간의 fine-grained alignment를 학습하는 것을 목표로 한다. 이는 모델이 이미지-텍스트 쌍이 긍정(일치)인지 부정(불일치)인지 예측하도록 요청받는 이진 분류 task이다. 우리는 모든 쿼리와 텍스트가 서로에게 attend할 수 있는 bi-directional self-attention mask를 사용한다. 따라서 출력 쿼리 임베딩 는 멀티모달 정보를 포착한다. 우리는 각 출력 쿼리 임베딩을 두 클래스 선형 분류기(two-class linear classifier)에 입력하여 logit을 얻고, 모든 쿼리의 logit을 평균하여 출력 매칭 점수(matching score)로 사용한다. 우리는 정보성 있는 부정 쌍을 생성하기 위해 Li et al. (2021; 2022)의 hard negative mining 전략을 채택한다.
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
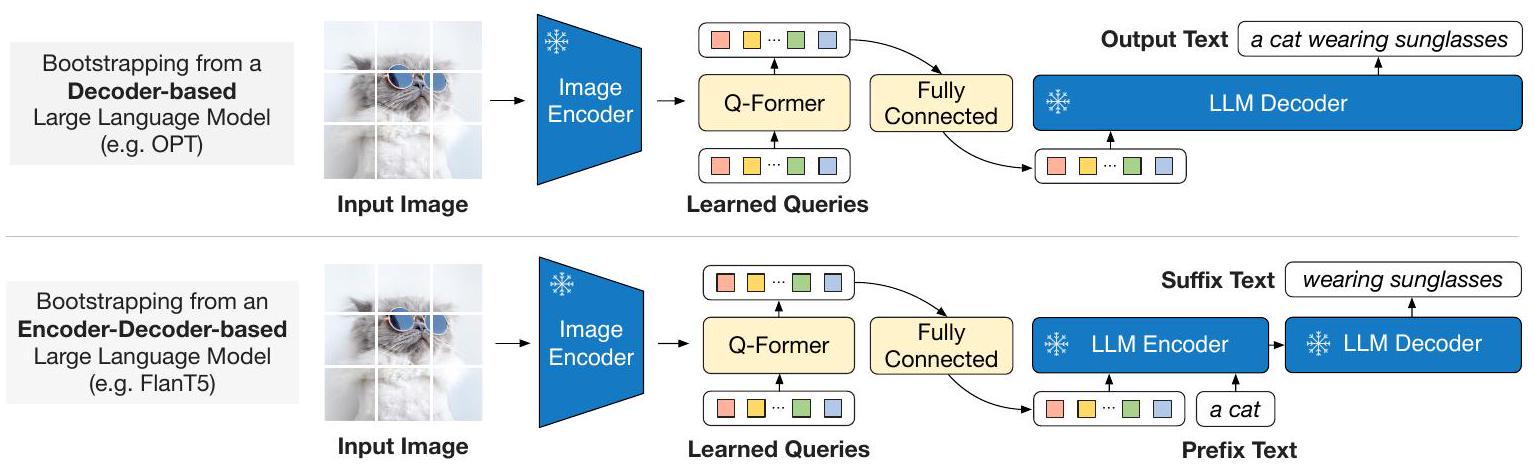
Figure 3. BLIP-2의 2단계 vision-to-language 생성 사전학습(generative pre-training)으로, frozen large language model (LLM)을 활용한다. (상단) decoder 기반 LLM (예: OPT)을 활용하는 방식. (하단) encoder-decoder 기반 LLM (예: FlanT5)을 활용하는 방식. fully-connected layer는 Q-Former의 출력 차원을 선택된 LLM의 입력 차원에 맞게 조정한다.
3.3. Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
생성 사전학습(generative pre-training) 단계에서는 **Q-Former(고정된 image encoder가 연결된 상태)**를 고정된 LLM에 연결하여 LLM의 생성 언어 능력을 활용한다. Figure 3에서 볼 수 있듯이, 우리는 완전 연결(FC) layer를 사용하여 **출력 query embedding 를 LLM의 텍스트 embedding과 동일한 차원으로 선형 투영(linearly project)**한다. 투영된 query embedding은 입력 텍스트 embedding 앞에 추가된다. 이들은 Q-Former가 추출한 시각적 표현에 LLM을 조건화하는 soft visual prompt 역할을 한다. Q-Former는 언어 정보가 풍부한 시각적 표현을 추출하도록 사전학습되었기 때문에, 가장 유용한 정보를 LLM에 제공하면서 관련 없는 시각 정보를 제거하는 정보 병목(information bottleneck) 역할을 효과적으로 수행한다. 이는 LLM이 vision-language alignment를 학습하는 부담을 줄여주어 catastrophic forgetting 문제를 완화한다.
우리는 두 가지 유형의 LLM으로 실험한다: decoder 기반 LLM과 encoder-decoder 기반 LLM. decoder 기반 LLM의 경우, Q-Former의 시각적 표현을 조건으로 텍스트를 생성하도록 LLM에 task를 부여하는 language modeling loss로 사전학습한다. encoder-decoder 기반 LLM의 경우, 텍스트를 두 부분으로 나누는 prefix language modeling loss로 사전학습한다. prefix 텍스트는 시각적 표현과 연결되어 LLM의 encoder 입력으로 사용된다. suffix 텍스트는 LLM의 decoder를 위한 생성 목표로 사용된다.
3.4. Model Pre-training
사전학습 데이터 (Pre-training data)
우리는 BLIP과 동일한 사전학습 데이터셋을 사용하며, 총 1억 2,900만 개의 이미지를 포함한다. 이 데이터셋은 COCO (Lin et al., 2014), Visual Genome (Krishna et al., 2017), CC3M (Sharma et al., 2018), CC12M (Changpinyo et al., 2021), SBU (Ordonez et al., 2011), 그리고 LAION400M 데이터셋 (Schuhmann et al., 2021)에서 가져온 1억 1,500만 개의 이미지로 구성된다.
우리는 **CapFilt 방법 (Li et al., 2022)**을 채택하여 웹 이미지에 대한 **합성 캡션(synthetic captions)**을 생성한다. 구체적으로, BLIP 캡셔닝 모델을 사용하여 10개의 캡션을 생성하고, CLIP ViT-L/14 모델이 생성한 이미지-텍스트 유사도를 기반으로 합성 캡션과 원본 웹 캡션의 순위를 매긴다. 우리는 이미지당 상위 2개의 캡션을 학습 데이터로 유지하고, 각 사전학습 단계에서 무작위로 하나를 샘플링한다.
사전학습된 이미지 인코더 및 LLM (Pre-trained image encoder and LLM)
고정된(frozen) 이미지 인코더로는 두 가지 state-of-the-art 사전학습된 vision Transformer 모델을 탐색한다:
(1) CLIP의 ViT-L/14 (Radford et al., 2021)
(2) EVA-CLIP의 ViT-g/14 (Fang et al., 2022)
우리는 ViT의 마지막 레이어를 제거하고 두 번째 마지막 레이어의 출력 feature를 사용하는데, 이는 약간 더 나은 성능을 가져온다.
고정된(frozen) 언어 모델로는 **decoder 기반 LLM을 위해 비지도 학습된 OPT 모델 계열 (Zhang et al., 2022)**을, **encoder-decoder 기반 LLM을 위해 instruction-trained FlanT5 모델 계열 (Chung et al., 2022)**을 탐색한다.
사전학습 설정 (Pre-training settings)
우리는 1단계에서 250k 스텝, 2단계에서 80k 스텝 동안 사전학습을 진행한다.
1단계에서는 ViT-L/ViT-g에 대해 2320/1680의 배치 크기를 사용하고, 2단계에서는 OPT/FlanT5에 대해 1920/1520의 배치 크기를 사용한다.
사전학습 동안, 고정된 ViT와 LLM의 파라미터는 FP16으로 변환하며, FlanT5의 경우 BFloat16을 사용한다.
우리는 32비트 모델을 사용하는 것과 비교하여 성능 저하가 없음을 확인했다.
고정된 모델을 사용하기 때문에, 우리의 사전학습은 기존의 대규모 VLP 방법보다 계산적으로 효율적이다.
예를 들어, 단일 16-A100 (40G) 머신을 사용하여, ViT-g와 FlanT5-XXL을 사용하는 가장 큰 모델은 1단계에 6일 미만, 2단계에 3일 미만이 소요된다.
모든 모델에 대해 동일한 사전학습 하이퍼파라미터 세트를 사용한다. AdamW (Loshchilov & Hutter, 2017) optimizer를 사용하며, , 그리고 0.05의 weight decay를 설정한다. **최대 학습률 1e-4와 2k 스텝의 선형 웜업(linear warmup)**을 가진 **코사인 학습률 감쇠(cosine learning rate decay)**를 사용한다. 2단계에서의 최소 학습률은 5e-5이다. 224x224 크기의 이미지를 사용하며, 무작위 크기 조정 크롭(random resized cropping) 및 수평 뒤집기(horizontal flipping)로 증강한다.

Figure 4. ViT-g 및 FlanT5을 사용한 BLIP-2 모델의 지시 기반 zero-shot 이미지-텍스트 생성의 선택된 예시. 이 모델은 시각적 대화, 시각적 지식 추론, 시각적 상식 추론, 스토리텔링, 개인화된 이미지-텍스트 생성 등 광범위한 능력을 보여준다.
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
| Models | #Trainable Params | Opensourced? | Visual Question Answering VQAv2 (test-dev) VQA acc. | Image Captioning NoCaps (val) | Image-Text Retrieval Flickr (test) | ||
|---|---|---|---|---|---|---|---|
| CIDEr | SPICE | TR@1 | IR@1 | ||||
| BLIP (Li et al., 2022) | 583 M | - | 113.2 | 14.8 | 96.7 | 86.7 | |
| SimVLM (Wang et al., 2021b) | 1.4 B | - | 112.2 | - | - | - | |
| BEIT-3 (Wang et al., 2022b) | 1.9 B | - | - | - | 94.9 | 81.5 | |
| Flamingo (Alayrac et al., 2022) | 10.2B | 56.3 | - | - | - | - | |
| BLIP-2 | 188 M | 65.0 | 121.6 | 15.8 | 97.6 | 89.7 |
Table 1. 다양한 zero-shot vision-language task에 대한 BLIP-2 결과 개요. 기존의 state-of-the-art 모델들과 비교했을 때, BLIP-2는 가장 적은 수의 학습 가능한 파라미터를 필요로 하면서도 가장 높은 zero-shot 성능을 달성한다.
| Models | #Trainable | #Total | VQAv2 | OK-VQA | GQA | |
|---|---|---|---|---|---|---|
| Params | Params | val | test-dev | test | test-dev | |
| VL-T5 | 224 M | 269 M | 13.5 | - | 5.8 | 6.3 |
| FewVLM (Jin et al., 2022) | 740M | 785 M | 47.7 | - | 16.5 | 29.3 |
| Frozen (Tsimpoukelli et al., 2021) | 40M | 7.1 B | 29.6 | - | 5.9 | - |
| VLKD (Dai et al., 2022) | 406M | 832 M | 42.6 | 44.5 | 13.3 | - |
| Flamingo3B (Alayrac et al., 2022) | 1.4 B | 3.2B | - | 49.2 | 41.2 | - |
| Flamingo9B (Alayrac et al., 2022) | 1.8 B | 9.3 B | - | 51.8 | 44.7 | - |
| Flamingo80B (Alayrac et al., 2022) | 10.2 B | 80B | - | 56.3 | 50.6 | - |
| BLIP-2 ViT-L OPT | 104 M | 3.1 B | 50.1 | 49.7 | 30.2 | 33.9 |
| BLIP-2 ViT-g OPT | 107 M | 3.8 B | 53.5 | 52.3 | 31.7 | 34.6 |
| BLIP-2 ViT-g OPT | 108M | 7.8 B | 54.3 | 52.6 | 36.4 | 36.4 |
| BLIP-2 ViT-L FlanT5 | 103 M | 3.4 B | 62.6 | 62.3 | 39.4 | |
| BLIP-2 ViT-g FlanT5 | 107M | 4.1 B | 63.1 | 40.7 | 44.2 | |
| BLIP-2 ViT-g FlanT5 | 108M | 12.1 B | 65.2 | 65.0 | 44.7 |
Table 2. Zero-shot visual question answering에 대한 state-of-the-art 방법들과의 비교.
4. Experiment
Table 1은 다양한 zero-shot vision-language task에서 BLIP-2의 성능 개요를 제공한다. BLIP-2는 기존 state-of-the-art 모델들과 비교하여 향상된 성능을 달성했으며, 동시에 vision-language 사전학습 과정에서 훨씬 적은 수의 trainable parameter를 필요로 한다.
4.1. Instructed Zero-shot Image-to-Text Generation
BLIP-2는 LLM이 이미지(image)를 이해하는 동시에 텍스트 prompt를 따르는 능력을 보존하여, 지시(instruction)를 통해 이미지-텍스트 생성(image-to-text generation)을 제어할 수 있게 한다. 우리는 단순히 시각 prompt 뒤에 텍스트 prompt를 LLM의 입력으로 추가한다. Figure 4는 시각 지식 추론(visual knowledge reasoning), 시각 상식 추론(visual commonsense reasoning), 시각 대화(visual conversation), 개인화된 이미지-텍스트 생성 등 광범위한 zero-shot 이미지-텍스트 능력을 보여주는 예시들을 나타낸다.
Zero-shot VQA. 우리는 zero-shot visual question answering task에 대한 정량적 평가를 수행한다. OPT 모델의 경우, "Question: {} Answer:" prompt를 사용한다. FlanT5 모델의 경우, "Question: {} Short answer:" prompt를 사용한다. 생성 시에는 beam width가 5인 beam search를 사용한다. 또한 length-penalty를 -1로 설정하여 인간의 주석과 더 잘 일치하는 짧은 답변을 유도한다.
Table 2에서 보듯이, BLIP-2는 VQAv2 (Goyal et al., 2017) 및 GQA (Hudson & Manning, 2019) 데이터셋에서 state-of-the-art 결과를 달성한다. 학습 가능한 파라미터 수가 54배 적음에도 불구하고 VQAv2에서 Flamingo80B보다 8.7% 더 나은 성능을 보인다. OK-VQA (Marino et al., 2019) 데이터셋에서는 BLIP-2가 Flamingo80B에 이어 두 번째로 좋은 성능을 보인다. 우리는 이 현상이 OK-VQA가 시각적 이해보다는 개방형 세계 지식(open-world knowledge)에 더 중점을 두기 때문이며, Flamingo80B의 70B Chinchilla (Hoffmann et al., 2022) language model이 11B FlanT5XXL보다 더 많은 지식을 가지고 있기 때문이라고 가정한다.
Table 2에서 우리는 강력한 image encoder 또는 강력한 LLM이 모두 더 나은 성능으로 이어진다는 유망한 관찰을 했다. 이 관찰은 여러 사실에 의해 뒷받침된다: (1) ViT-g는 OPT와 FlanT5 모두에서 ViT-L보다 우수한 성능을 보인다. (2) 동일한 LLM 계열 내에서, 더 큰 모델이 더 작은 모델보다 우수한 성능을 보인다. (3) instruction-tuned LLM인 FlanT5는 VQA에서 비지도 학습된 OPT보다 우수한 성능을 보인다. 이러한 관찰은 BLIP-2가 vision 및 자연어 커뮤니티의 빠른 발전을 효율적으로 활용할 수 있는 범용적인 vision-language pre-training 방법임을 입증한다.
Effect of Vision-Language Representation Learning.
첫 번째 단계인 representation learning은 QFormer가 텍스트와 관련된 시각적 feature를 학습하도록 사전학습하여, LLM이 vision-language alignment를 학습하는 부담을 줄여준다. Representation learning 단계가 없으면, Q-
BLIP-2: Frozen Image Encoder와 Large Language Model을 활용한 언어-이미지 사전학습 부트스트래핑
| Models | #Trainable Params | in-domain | near-domain | out-domain | overall | COCO Fine-tuned Karpathy test | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| C | S | C | S | C | S | C | S | B@4 | C | ||
| OSCAR (Li et al., 2020) | 345 M | - | - | - | - | - | - | 80.9 | 11.3 | 37.4 | 127.8 |
| VinVL (Zhang et al., 2021) | 345 M | 103.1 | 14.2 | 96.1 | 13.8 | 88.3 | 12.1 | 95.5 | 13.5 | 38.2 | 129.3 |
| BLIP (Li et al., 2022) | 446M | 114.9 | 15.2 | 112.1 | 14.9 | 115.3 | 14.4 | 113.2 | 14.8 | 40.4 | 136.7 |
| OFA (Wang et al., 2022a) | 930 M | - | - | - | - | - | - | - | - | 43.9 | |
| Flamingo (Alayrac et al., 2022) | 10.6 B | - | - | - | - | - | - | - | - | - | 138.1 |
| SimVLM (Wang et al., 2021b) | 113.7 | - | 110.9 | - | 115.2 | - | 112.2 | - | 40.6 | 143.3 | |
| BLIP-2 ViT-g OPT | 1.1 B | 117.8 | 123.4 | 15.1 | 119.7 | 43.7 | 145.8 | ||||
| BLIP-2 ViT-g OPT | 1.1 B | 123.7 | 15.8 | 119.2 | 15.3 | 14.8 | 121.0 | 15.3 | 43.5 | 145.2 | |
| BLIP-2 ViT-g FlanT5 | 1.1 B | 123.7 | 16.3 | 120.2 | 15.9 | 124.8 | 15.1 | 121.6 | 15.8 | 42.4 | 144.5 |
Table 3. NoCaps 및 COCO Caption에서 state-of-the-art 이미지 캡셔닝 방법들과의 비교. 모든 방법은 fine-tuning 동안 cross-entropy loss를 최적화한다. C: CIDEr, S: SPICE, B@4: BLEU@4.
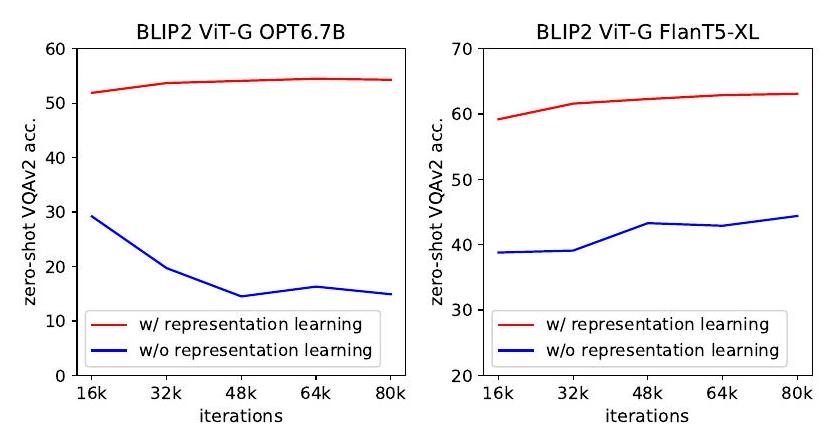
Figure 5. vision-language representation learning이 vision-to-language generative learning에 미치는 영향. representation learning이 없으면 Q-Former는 modality 간의 간극을 메우지 못하여 zero-shot VQA 성능이 현저히 낮아진다.
Former는 modality 간의 간극을 메우기 위해 vision-to-language generative learning에만 의존하게 되는데, 이는 Flamingo의 Perceiver Resampler와 유사하다. Figure 5는 representation learning이 generative learning에 미치는 영향을 보여준다. representation learning이 없으면, 두 가지 유형의 LLM 모두 zero-shot VQA에서 상당히 낮은 성능을 보인다. 특히, OPT는 학습이 진행됨에 따라 성능이 급격히 저하되는 catastrophic forgetting 현상을 겪는다.
4.2. Image Captioning
우리는 BLIP-2 모델을 이미지 캡셔닝 task를 위해 fine-tuning한다. 이 task는 모델에게 이미지의 시각적 내용에 대한 텍스트 설명을 생성하도록 요구한다. 우리는 LLM의 초기 입력으로 "a photo of"라는 prompt를 사용하고, language modeling loss를 사용하여 캡션을 생성하도록 모델을 학습시킨다. fine-tuning 동안 LLM은 frozen 상태로 유지하며, Q-Former의 파라미터와 이미지 encoder의 파라미터를 함께 업데이트한다. 우리는 ViT-g와 다양한 LLM을 사용하여 실험한다. 자세한 하이퍼파라미터는 appendix에서 확인할 수 있다. 우리는 COCO 데이터셋으로 fine-tuning을 수행하고, COCO test set과 NoCaps (Agrawal et al., 2019) validation set에 대한 zero-shot transfer 성능을 모두 평가한다.
결과는 Table 3에 제시되어 있다. BLIP-2는 기존 방법론 대비 NoCaps에서 상당한 개선을 통해 state-of-the-art 성능을 달성하며, out-domain 이미지에 대한 강력한 일반화 능력을 보여준다.
| Models | #Trainable | VQAv2 | |
|---|---|---|---|
| Params | test-dev | test-std | |
| Open-ended generation models | |||
| ALBEF (Li et al., 2021) | 314M | 75.84 | 76.04 |
| BLIP (Li et al., 2022) | 385 M | 78.25 | 78.32 |
| OFA (Wang et al., 2022a) | 930 M | 82.00 | 82.00 |
| Flamingo80B (Alayrac et al., 2022) | 10.6 B | 82.00 | 82.10 |
| BLIP-2 ViT-g FlanT5 | 1.2B | 81.55 | 81.66 |
| BLIP-2 ViT-g OPT | 1.2B | 81.59 | 81.74 |
| BLIP-2 ViT-g OPT | 1.2B | 82.19 | 82.30 |
| Closed-ended classification models | |||
| VinVL | 345M | 76.52 | 76.60 |
| SimVLM (Wang et al., 2021b) | 80.03 | 80.34 | |
| CoCa (Yu et al., 2022) | 2.1B | 82.30 | 82.30 |
| BEIT-3 (Wang et al., 2022b) | 1.9 B | 84.19 | 84.03 |
Table 4. Visual Question Answering을 위해 fine-tuning된 state-of-the-art 모델들과의 비교.
4.3. Visual Question Answering
주석이 달린 VQA 데이터가 주어졌을 때, 우리는 LLM을 고정(frozen)시킨 채 Q-Former와 image encoder의 파라미터를 fine-tuning한다. fine-tuning은 open-ended answer generation loss를 사용하여 수행된다. 이 과정에서 LLM은 Q-Former의 출력과 질문을 입력으로 받아 답변을 생성하도록 요청받는다. 질문에 더 관련성 높은 이미지 feature를 추출하기 위해, 우리는 **Q-Former에도 질문을 추가적으로 조건화(condition)**한다. 구체적으로, 질문 토큰은 Q-Former의 입력으로 주어지고 self-attention layer를 통해 쿼리(query)와 상호작용한다. 이는 Q-Former의 cross-attention layer가 더 유익한 이미지 영역에 집중하도록 유도할 수 있다.
BLIP을 따라, 우리의 VQA 데이터는 VQAv2의 training 및 validation split과 Visual Genome의 training sample을 포함한다. Table 4는 open-ended generation model 중 BLIP-2의 state-of-the-art 결과를 보여준다.
BLIP-2: Frozen Image Encoder와 Large Language Model을 활용한 Language-Image Pre-training 부트스트래핑
| Model | #Trainable Params | Flickr30K Zero-shot ( 1 K test set) | COCO Fine-tuned ( 5 K test set) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Image Text | Text Image | Image Text | Text Image | ||||||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| Dual-encoder models | |||||||||||||
| CLIP (Radford et al., 2021) | 428M | 88.0 | 98.7 | 99.4 | 68.7 | 90.6 | 95.2 | - | - | - | - | - | - |
| ALIGN (Jia et al., 2021) | 820 M | 88.6 | 98.7 | 99.7 | 75.7 | 93.8 | 96.8 | 77.0 | 93.5 | 96.9 | 59.9 | 83.3 | 89.8 |
| FILIP (Yao et al., 2022) | 417 M | 89.8 | 99.2 | 99.8 | 75.0 | 93.4 | 96.3 | 78.9 | 94.4 | 97.4 | 61.2 | 84.3 | 90.6 |
| Florence (Yuan et al., 2021) | 893M | 90.9 | 99.1 | - | 76.7 | 93.6 | - | 81.8 | 95.2 | - | 63.2 | 85.7 | - |
| BEIT-3(Wang et al., 2022b) | 1.9 B | 94.9 | 99.9 | 100.0 | 81.5 | 95.6 | 97.8 | 84.8 | 96.5 | 98.3 | 67.2 | 87.7 | 92.8 |
| Fusion-encoder models | |||||||||||||
| UNITER (Chen et al., 2020) | 303M | 83.6 | 95.7 | 97.7 | 68.7 | 89.2 | 93.9 | 65.7 | 88.6 | 93.8 | 52.9 | 79.9 | 88.0 |
| OSCAR (Li et al., 2020) | 345 M | - | - | - | - | - | - | 70.0 | 91.1 | 95.5 | 54.0 | 80.8 | 88.5 |
| VinVL (Zhang et al., 2021) | 345 M | - | - | - | - | - | - | 75.4 | 92.9 | 96.2 | 58.8 | 83.5 | 90.3 |
| Dual encoder + Fusion encoder reranking | |||||||||||||
| ALBEF (Li et al., 2021) | 233 M | 94.1 | 99.5 | 99.7 | 82.8 | 96.3 | 98.1 | 77.6 | 94.3 | 97.2 | 60.7 | 84.3 | 90.5 |
| BLIP (Li et al., 2022) | 446М | 96.7 | 100.0 | 100.0 | 86.7 | 97.3 | 98.7 | 82.4 | 95.4 | 97.9 | 65.1 | 86.3 | 91.8 |
| BLIP-2 ViT-L | 474M | 96.9 | 100.0 | 100.0 | 88.6 | 97.6 | 98.9 | 83.5 | 96.0 | 98.0 | 66.3 | 86.5 | 91.8 |
| BLIP-2 ViT-g | 1.2 B | 97.6 | 100.0 | 100.0 | 89.7 | 98.1 | 98.9 | 85.4 | 97.0 | 98.5 | 68.3 | 87.7 | 92.6 |
Table 5. COCO로 fine-tuning하고 Flickr30K로 zero-shot 전이 학습한 state-of-the-art 이미지-텍스트 검색 방법들과의 비교.
| COCO finetuning <br> objectives | Image Text | Text Image | ||
|---|---|---|---|---|
| R@1 | R@5 | R@1 | R@5 | |
| ITC + ITM | 84.5 | 96.2 | 67.2 | 87.1 |
| ITC + ITM + ITG | 85.4 | 97.0 | 68.3 | 87.7 |
Table 6. Image-grounded text generation (ITG) loss는 쿼리가 언어와 관련된 시각적 feature를 추출하도록 강제함으로써 이미지-텍스트 검색 성능을 향상시킨다.
4.4. Image-Text Retrieval
이미지-텍스트 검색은 언어 생성을 포함하지 않으므로, 우리는 LLM 없이 1단계 사전학습 모델을 직접 fine-tuning한다. 구체적으로, 사전학습과 동일한 objective(즉, ITC, ITM, ITG)를 사용하여 COCO 데이터셋에서 Q-Former와 함께 image encoder를 fine-tuning한다. 그런 다음 COCO 및 Flickr30K (Plummer et al., 2015) 데이터셋에서 image-to-text 검색과 text-to-image 검색 모두에 대해 모델을 평가한다. 추론 시에는 Li et al. (2021; 2022)의 방식을 따르는데, 이 방식은 먼저 이미지-텍스트 feature 유사도를 기반으로 개의 후보를 선택한 다음, pairwise ITM 점수를 기반으로 재순위화(re-ranking)한다. 우리는 ViT-L과 ViT-g를 image encoder로 사용하여 실험한다. 자세한 하이퍼파라미터는 부록에서 확인할 수 있다.
결과는 Table 5에 나와 있다. BLIP-2는 zero-shot image-text 검색에서 기존 방법들보다 상당한 개선을 통해 state-of-the-art 성능을 달성한다.
ITC 및 ITM loss는 이미지-텍스트 유사도를 직접 학습하므로 이미지-텍스트 검색에 필수적이다. Table 6에서 우리는 ITG (image-grounded text generation) loss 또한 이미지-텍스트 검색에 유익하다는 것을 보여준다. 이 결과는 표현 학습 objective를 설계하는 우리의 직관을 뒷받침한다: ITG loss는 쿼리가 텍스트와 가장 관련성이 높은 시각적 feature를 추출하도록 강제하여 vision-language alignment를 향상시킨다.
5. Limitation
최근의 LLM은 few-shot 예시가 주어졌을 때 in-context learning을 수행할 수 있다. 그러나 BLIP-2를 이용한 우리의 실험에서는 LLM에 in-context VQA 예시를 제공했을 때 VQA 성능 향상이 관찰되지 않았다. 우리는 이러한 in-context learning 능력의 부족이 사전학습 데이터셋에 기인한다고 본다. 우리의 데이터셋은 샘플당 단일 이미지-텍스트 쌍만을 포함하고 있어, LLM이 단일 시퀀스 내에서 여러 이미지-텍스트 쌍 간의 상관관계를 학습할 수 없었다. 이러한 동일한 관찰은 Flamingo 논문에서도 보고되었는데, Flamingo는 시퀀스당 여러 이미지-텍스트 쌍을 포함하는 비공개 interleaved 이미지 및 텍스트 데이터셋(M3W)을 사용한다. 우리는 향후 연구에서 이와 유사한 데이터셋을 구축하는 것을 목표로 한다.
BLIP-2의 이미지-텍스트 생성 결과는 LLM의 부정확한 지식, 잘못된 추론 경로 활성화, 또는 새로운 이미지 콘텐츠에 대한 최신 정보 부족 등 다양한 이유로 만족스럽지 않을 수 있다 (Figure 7 참조). 또한, frozen 모델을 사용하기 때문에 BLIP-2는 공격적인 언어 출력, 사회적 편견 전파, 개인 정보 유출과 같은 LLM의 위험을 그대로 계승한다. 이러한 문제에 대한 해결책으로는 모델의 생성을 유도하는 지시문 사용 또는 유해 콘텐츠가 제거된 필터링된 데이터셋으로 학습하는 방법 등이 있다.
6. Conclusion
우리는 사전학습된(frozen) image encoder와 LLM을 활용하는 범용적이고 연산 효율적인 vision-language pre-training 방법인 BLIP-2를 제안한다. BLIP-2는 pre-training 시 적은 수의 trainable parameter만을 사용하면서도, 다양한 vision-language task에서 state-of-the-art 성능을 달성한다. 또한 BLIP-2는 zero-shot instructed image-to-text generation에서 새로운 능력을 보여준다. 우리는 BLIP-2가 멀티모달 대화형 AI 에이전트를 구축하는 데 중요한 단계라고 생각한다.
| LLM | FlanT5xx | ||
|---|---|---|---|
| Fine-tuning epochs | 5 | ||
| Warmup steps | 1000 | ||
| Learning rate | |||
| Batch size | 256 | ||
| AdamW | (0.9,0.999) | ||
| Weight decay | 0.05 | ||
| Drop path | 0 | ||
| Image resolution | 364 | ||
| Prompt | "a photo of" | ||
| Inference beam size | 5 | ||
| Layer-wise learning rate decay for ViT | 1 | 1 | 0.95 |
Table 7. COCO captioning에서 ViT-g와 함께 BLIP-2를 fine-tuning하기 위한 하이퍼파라미터.
| LLM | FlanT5xl | OPT | OPT |
|---|---|---|---|
| Fine-tuning epochs | 5 | ||
| Warmup steps | 1000 | ||
| Learning rate | |||
| Batch size | 128 | ||
| AdamW | (0.9,0.999) | ||
| Weight decay | 0.05 | ||
| Drop path | 0 | ||
| Image resolution | 490 | ||
| Prompt | "Question: {} Answer:" | ||
| Inference beam size | 5 | ||
| Layer-wise learning rate decay for ViT | 0.95 | 0.95 | 0.9 |
Table 8. VQA에서 ViT-g와 함께 BLIP-2를 fine-tuning하기 위한 하이퍼파라미터.
| Image Encoder | ViT-L/14 | ViT-g/14 |
|---|---|---|
| Fine-tuning epochs | 5 | |
| Warmup steps | 1000 | |
| Learning rate | 5e-6 | |
| Batch size | 224 | |
| AdamW | (0.9,0.98) | (0.9,0.999) |
| Weight decay | 0.05 | |
| Drop path | 0 | |
| Image resolution | 364 | |
| Layer-wise learning rate decay for ViT | 1 | 0.95 |
Table 9. COCO image-text retrieval에서 BLIP-2를 fine-tuning하기 위한 하이퍼파라미터.
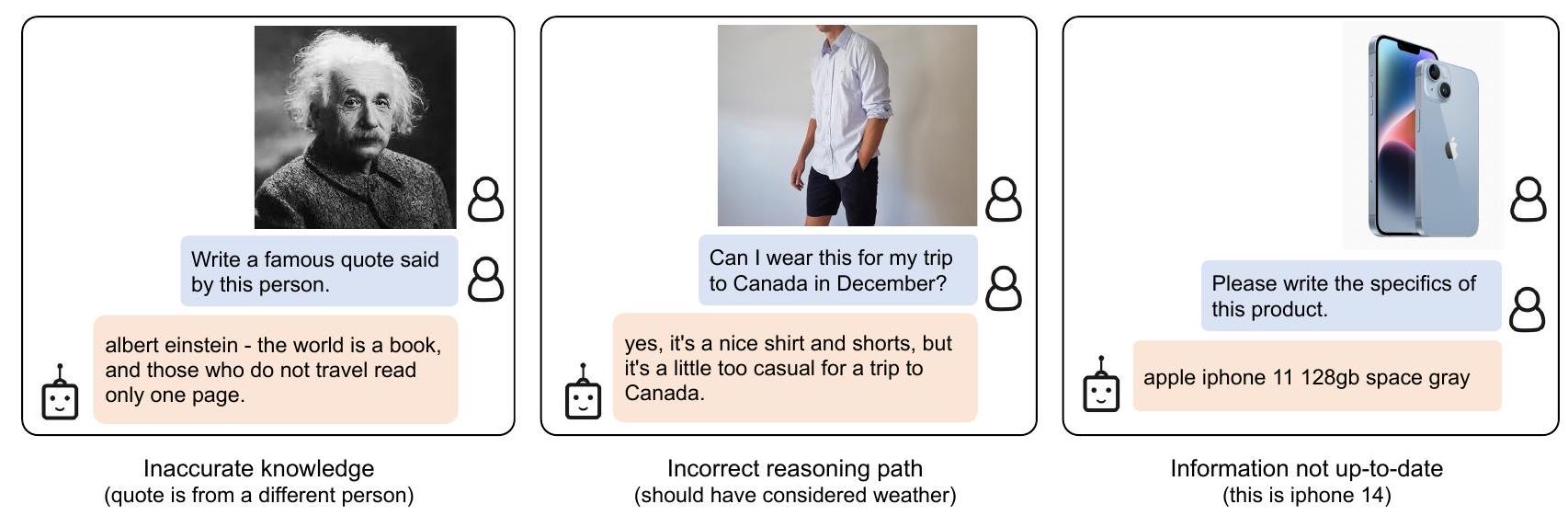
Figure 6. ViT-g와 FlanT5xxl을 사용하는 BLIP-2 모델의 instructed zero-shot image-to-text generation에 대한 오류 출력 예시.
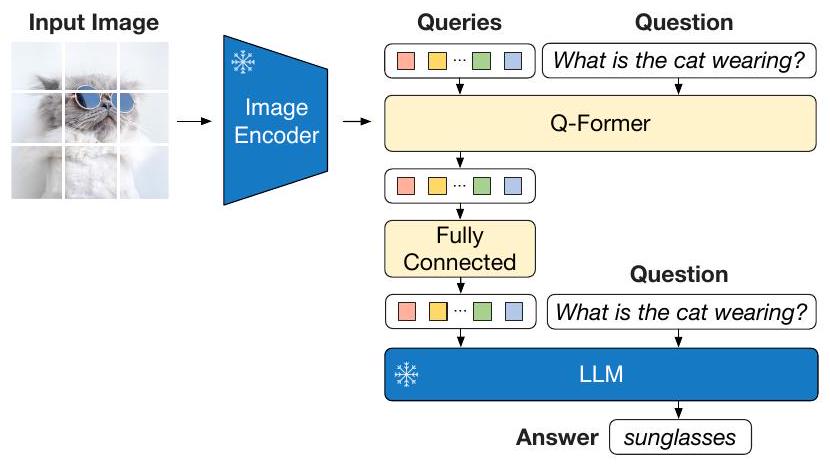
Figure 7. VQA fine-tuning을 위한 모델 아키텍처. 여기서 LLM은 Q-Former의 출력과 질문을 입력으로 받아 답변을 예측한다. 추출된 이미지 feature가 질문과 더 관련성을 갖도록, 질문을 Q-Former에 대한 조건으로도 제공한다.