B2T: 키워드 설명을 통한 시각적 편향 발견 및 완화 프레임워크
B2T(Bias-to-Text)는 computer vision 모델의 시각적 편향을 키워드로 해석하여 설명하는 프레임워크입니다. 잘못 예측된 이미지의 캡션에서 공통 키워드를 추출하여 잠재적 편향을 식별하고, CLIP과 같은 vision-language 모델을 사용하여 해당 키워드와 이미지의 유사도를 측정하여 편향을 검증합니다. B2T는 CelebA의 성별 편향이나 Waterbirds의 배경 편향과 같은 기존에 알려진 편향뿐만 아니라, ImageNet에서의 "벌"과 "꽃" 사이의 문맥적 편향과 같은 새로운 편향도 발견할 수 있습니다. 이렇게 발견된 키워드는 debiased training, CLIP prompting, 모델 비교 등 다양한 애플리케이션에 활용될 수 있습니다. 논문 제목: Discovering and Mitigating Visual Biases through Keyword Explanation
Kim, Younghyun, et al. "Discovering and mitigating visual biases through keyword explanation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
Discovering and Mitigating Visual Biases through Keyword Explanation
Abstract
컴퓨터 비전 모델의 편향(bias)을 해결하는 것은 실제 AI 배포에 매우 중요하다. 그러나 시각적 편향은 설명하기 어려운 특성 때문에 완화하기가 어렵다. 이러한 편향은 종종 시각화나 샘플 통계를 통해 간접적으로 식별되며, 이는 해석을 위해 추가적인 사람의 감독(human supervision)을 필요로 한다.
이 문제를 해결하기 위해 우리는 시각적 편향을 키워드로 해석하는 Bias-to-Text (B2T) 프레임워크를 제안한다. 구체적으로, 우리는 잘못 예측된 이미지들의 캡션에서 공통 키워드를 추출하여 모델의 잠재적 편향을 식별한다. 그런 다음, vision-language scoring model을 사용하여 이 키워드들과 잘못 예측된 이미지들 간의 유사도를 측정함으로써 키워드를 검증한다.
시각적 편향을 키워드 설명 형태로 제공하는 것은 여러 장점을 제공한다. 예를 들어, 편향 발견을 위한 명확한 그룹 이름 지정과 이 그룹 이름을 활용한 편향 완화(debiasing)를 위한 자연스러운 확장이 가능하다.
우리의 실험은 B2T가 CelebA의 성별 편향, Waterbirds의 배경 편향, ImageNet-R/C의 분포 변화와 같은 알려진 편향들을 식별할 수 있음을 보여준다. 또한, B2T는 Dollar Street 및 ImageNet과 같은 대규모 데이터셋에서 새로운 편향들을 발견한다. 예를 들어, 우리는 ImageNet에서 "bee"와 "flower" 사이의 맥락적 편향(contextual bias)을 발견했다. 우리는 또한 debiased training, CLIP prompting, 모델 비교 등 B2T 키워드의 다양한 응용 분야를 강조한다.
1. Introduction
Biased dataset은 이미지 분류기에서 오류를 유발하여 모델 성능을 저하시키고 공정성 문제를 야기할 수 있다 [76]. 이러한 모델 오류는 특정 그룹이 모델 오류에 기여하는 spurious correlation [71]으로 나타나거나, 테스트 분포가 학습 분포와 다른 distribution shift [63]로 나타날 수 있다. 예를 들어, 얼굴 데이터셋에서 금발 이미지가 주로 여성과 연관되어 있다면, 이미지 분류기는 금발 얼굴을 여성으로 잘못 분류하여 공정성 문제를 초래할 수 있다 [6]. 더욱이 이러한 편향은 성별 균형이 잡힌 금발 데이터셋과 같은 다른 시나리오에서 평가될 때 모델 성능에 영향을 미칠 수 있다 [21]. 따라서 모델의 편향을 인식하고 해결하기 위한 광범위한 노력이 이루어져 왔다 [9, 48].
 Figure 1. 개념. 우리의 Bias-to-Text (B2T) 프레임워크는 이미지 분류기의 시각적 편향을 키워드 설명 형태로 밝혀낸다. 예를 들어, B2T는 ImageNet [14]에서 새로운 편향을 식별했다. 특히, "flower" 키워드는 분류기가 "ant" 이미지를 "bee"와 연관시킨다는 것을 의미하며, 이는 **맥락적 편향(contextual bias)**을 나타낸다.
Figure 1. 개념. 우리의 Bias-to-Text (B2T) 프레임워크는 이미지 분류기의 시각적 편향을 키워드 설명 형태로 밝혀낸다. 예를 들어, B2T는 ImageNet [14]에서 새로운 편향을 식별했다. 특히, "flower" 키워드는 분류기가 "ant" 이미지를 "bee"와 연관시킨다는 것을 의미하며, 이는 **맥락적 편향(contextual bias)**을 나타낸다.
이전 연구들은 문제성 샘플 [44, 55, 74] 또는 문제성 속성 [29, 72, 73]을 분석하여 시각적 편향을 식별하려고 시도했다. 그러나 이러한 방법들은 편향을 간접적으로 정의하며, 종종 시각화나 특정 통계를 가진 샘플 그룹에 의존하고, 설명 가능한 형태로 표현하기 위해 **인간의 감독(human supervision)**을 필요로 한다. 이 문제를 해결하기 위해 최근 연구는 vision-language model을 사용하여 편향을 해석하는 것을 목표로 했다 [59]. 그럼에도 불구하고, 이러한 연구들은 새로운 편향을 발견하고 완화하는 데 한계가 있다. 일부 연구 [17, 30]는 미리 정의된 어휘집에서 가장 가까운 단어를 검색하여 알려진 편향으로 발견을 제한한다. 다른 연구들은 뉴런 [27] 또는 생성 모델에 의해 합성된 이미지 [80]를 분석하여 편향을 이해한다. 그러나 이들은 활성화된 뉴런이나 실패 예시를 설명하는 상세한 캡션을 생성하는 데 중점을 두며, 이는 개별 사례를 이해하는 데 도움이 될 수 있지만 디바이싱(debiasing)에 활용하기는 어렵다.
대신, 우리의 주요 아이디어는 문제성 이미지의 언어 설명에서 공통적인 특징을 집계하여 시각적 편향을 키워드로 설명하는 것이다. Figure 1은 우리의 개념을 보여주는데, "flower" 키워드는 "bee"로 잘못 예측된 "ant" 클래스 이미지의 독특한 속성을 포착한다. 이 키워드 형태는 각 편향 그룹에 자연스러운 이름을 제공하고, 이러한 그룹 이름을 사용하여 디바이싱 기술과 쉽게 통합될 수 있다는 여러 장점을 제공한다.
Step 1. Bias keywords generation Step 2. Various applications of keywords

Figure 2. 방법. (Step 1) B2T는 잘못 예측된 이미지로부터 언어 설명을 생성하고 공통 키워드를 추출한다. 그런 다음 CLIP [59]과 같은 vision-language model을 사용하여 잘못 예측된 이미지와의 유사도를 측정함으로써 이러한 키워드가 편향을 나타내는지 확인한다. (Step 2) 발견된 키워드는 디바이싱 학습, CLIP prompting, 모델 비교를 포함한 다양한 응용 분야에 활용될 수 있다.
기여 (Contribution). 우리는 시각적 편향을 키워드로 식별하는 Bias-to-Text (B2T) 프레임워크를 소개한다. 이를 위해 먼저 잘못 예측된 이미지로부터 언어 설명을 생성하고, 이러한 설명에서 잠재적 편향을 시사하는 공통 키워드를 추출한다. 그런 다음 CLIP [59]과 같은 vision-language scoring model을 사용하여 잘못 예측된 이미지와의 유사도를 측정함으로써 이러한 키워드가 편향을 나타내는지 검증한다. 키워드가 올바른 이미지보다 오분류된 이미지와 더 밀접하게 일치하는지 확인함으로써, 우리는 그것이 편향임을 확인할 수 있다.
우리는 B2T가 다양한 데이터셋으로 학습된 이미지 분류기에서 편향을 발견할 수 있음을 입증한다 (Section 4):
- 알려진 편향 (Known bias). B2T는 CelebA [46]의 성별 편향, Waterbirds [66]의 배경 편향, ImageNet-R [26] 및 ImageNetC [25]의 **분포 변화(distribution shift)**와 같은 널리 알려진 편향을 감지한다. B2T 키워드는 Waterbirds의 육지 배경을 나타내는 "bamboo"와 같이 각 편향에 대한 더 세분화된 정보를 제공한다. 또한, 이러한 키워드는 샘플별 편향 레이블을 추론할 수 있어 이전의 편향 발견 접근 방식 [17, 30]을 능가한다.
- 새로운 편향 (Novel bias). B2T는 Dollar Street [64]의 지리적 편향과 ImageNet [14]의 맥락적 편향과 같은 더 큰 데이터셋에서 새로운 편향을 발견한다. 예를 들어, ImageNet에서 "flower" 키워드를 가진 이미지는 "ant" 대신 "bee"로 예측되는데, 이는 벌이 개미보다 꽃과 더 흔하게 연관된다는 맥락적 편향을 나타낸다.
그런 다음 우리는 편향 키워드가 다양한 응용 분야에 사용될 수 있음을 보여준다 (Section 5):
- 디바이싱 학습 (Debiased training). 키워드는 CLIP 분류기를 사용하여 각 샘플에 대한 편향 레이블을 추론하는 데 사용될 수 있다. 이러한 레이블은 분포적으로 강건한 최적화(distributionally robust optimization, DRO) [66]와 같은 디바이싱 학습에 사용되며, 이전의 디바이싱 접근 방식보다 우수한 성능을 보인다.
- CLIP prompting. 키워드는 CLIP zero-shot 분류기를 개선하는 데 사용될 수 있다. 세분화된 B2T 키워드(예: "bamboo")로 prompting하는 것은 그룹 이름(예: "land")을 사용하는 이전 전략보다 우수한 성능을 보인다.
- 모델 비교 (Model comparison). 키워드는 다른 모델의 실패를 비교하는 데 사용될 수 있다. 예를 들어, ResNet [22]은 ViT [16]에 비해 "work out"과 같은 추상적인 키워드가 나타내는 것처럼 복잡한 장면에서 더 어려움을 겪는다.
- 레이블 진단 (Label diagnosis). B2T는 오분류 또는 레이블 모호성과 같은 레이블 문제를 감지할 수 있다. 예를 들어, ImageNet에서 "bee"가 종종 "fly"로 잘못 레이블링되어 있음을 발견했다.
마지막으로, 우리는 우리의 bias-to-text 접근 방식의 견고성과 다용도성을 강조한다. 첫째, B2T 키워드가 다양한 캡셔닝 및 유사도 스코어링 모델에서 합리적인 견고성을 보임을 확인했지만 (Section 6), GPT-4 [58]와 같은 고급 vision-language model을 사용하면 개선될 수 있다. 또한, B2T는 이미지 분류를 넘어 text-to-image generative model (Appendix B) 및 객체 감지와 같은 다른 컴퓨터 비전 task로 확장될 수 있다.
2. Related Work
편향(Bias)과 공정성(Fairness)
데이터셋과 모델의 편향은 컴퓨터 비전 및 머신러닝 분야에서 오랫동안 제기되어 온 문제이다 [48]. 우리의 목표는 특정 속성이나 그룹에 대한 분류기(classifier)의 실패, 즉 spurious correlation [71]을 연구하는 것이다. 이러한 실패는 모델이 특정 성별 [6, 24, 90]이나 인종 [32, 37]에 대해 낮은 성능을 보이는 공정성 문제와 밀접하게 관련되어 있다. 이러한 편향은 데이터셋 불균형 [33, 75]이나 표현 편향(representational bias) [3, 77, 89]과 같은 다양한 원인에서 비롯되며, 이는 모델 학습 과정에서 더욱 악화된다. B2T는 이러한 공정성 문제를 식별하는 것을 목표로 하며, CelebA [66]의 "blond" 클래스에 대해 "man"을 편향 키워드로 제공하는 예시를 보여준다.
편향은 공정성 문제와 관련될 뿐만 아니라, 특히 분포 변화(distribution shift)가 있을 때 일반화(generalization)에 상당한 영향을 미친다 [54]. 다수(majority)와 소수(minority) 샘플의 비율은 다양하게 나타날 수 있으며, 이는 모델이 구성 변화에 취약하게 만든다. 이는 모델이 핵심 feature보다는 spurious feature에 과도하게 의존하는 shortcut learning과 밀접하게 연결되어 있다 [21]. texture bias [20], background bias [83], scene bias [50] 등 다양한 유형의 shortcut이 존재한다. B2T는 ImageNet-R의 "illustration", Waterbirds의 "forest", ImageNet의 "ant" 클래스에 대한 "flower"와 같이 다양한 유형의 shortcut을 발견할 수 있다.
편향 발견 (Bias discovery)
이전 연구들은 문제성 있는 샘플을 분석하여 편향을 식별하려고 시도했다 [4, 5, 15, 31, 36, 38, 61, 82]. 구체적으로, 이들은 오분류된 이미지들을 단순히 검색하거나 [44] embedding 또는 gradient를 활용하여 [1, 55, 74] 편향된 샘플을 감지했다. 알려지지 않은 편향을 발견하기 위해, 이전 연구들은 discoverer와 classifier를 반복적으로 학습시키거나 [43] 두 개의 보조 편향 모델을 사용하여 신뢰도 높은 샘플을 선택했다 [88]. 또 다른 연구 방향은 문제성 있는 속성(attribute)을 분석하여 spurious correlation을 해석하고, 특정 영역을 강조하거나 [29, 72, 73] 속성과 함께 traversal 이미지를 생성하여 시각화했다 [42]. 그러나 이러한 방법들은 실패 사례들 간의 공통적인 특성을 이해하기 위해 여전히 사람의 감독이 필요하며, 실용적인 키워드 설명을 제공하는 B2T와는 차이가 있다.
언어를 이용한 편향 발견 (Bias discovery with language)
최근 연구들은 CLIP [59]과 같은 사전학습된 vision-language model을 사용하여 편향을 설명한다. 이들은 편향을 joint image-text embedding 공간에서의 outlier (또는 slice)로 정의한다 [17, 30, 87]. 그러나 이들은 outlier를 미리 정의된 편향 어휘(bias vocabulary)에 맞춰야 하므로, 단일한 알려진 편향을 감지하는 능력에 한계가 있다. 이와 대조적으로, B2T는 이미지로부터 직접 캡션을 생성하며, 이는 encoder embedding보다 더 상세한 설명을 포함할 수 있다. 따라서 B2T는 반복적인 발견 절차 없이도 여러 가지 세분화된 편향을 효과적으로 발견한다.
다른 연구들은 뉴런 [27]이나 생성 모델에 의해 합성된 이미지 [80]를 분석하여 편향을 이해한다. 특히 Wiles et al. [80]은 B2T와 유사하게 합성된 이미지에서 캡션을 추출한다. 그러나 이들은 상세한 문장 설명을 제공하는데, 이는 유익하지만 편향 제거(debiasing)에 직접적으로 적용하기는 어렵다. 이와 대조적으로, B2T의 키워드 설명은 편향 제거와 같은 응용 분야에서 입증되었듯이 더 실용적이다. 또한, 이들은 참(true) 클래스와 오분류된(mispredicted) 대상 클래스 쌍을 지정해야 하는데, 클래스가 많을 경우 확장하기 어려울 수 있다. 반면 B2T는 모든 실패 사례에 대해 편향 키워드를 동시에 찾을 수 있다.
분류기 편향 제거 (Debiasing classifier)
분류기의 편향을 완화하기 위한 수많은 노력이 이루어져 왔다. DRO [60, 66]는 모든 편향 그룹에 대한 손실을 최소화하는 인기 있는 접근 방식이다. 그러나 DRO는 모든 샘플에 대한 편향 주석(bias annotation)을 필요로 한다. 일부 연구는 비지도 방식으로 편향 그룹 레이블을 추론하여 이 문제를 해결했다 [44, 55]. 우리는 B2T의 키워드 설명이 CLIP과 같은 zero-shot classifier를 사용하여 편향 레이블을 추론할 수 있음을 보여준다. 이는 이전 방법들에 비해 더 정확한 편향 그룹 추정 및 향상된 편향 제거 학습을 가능하게 하며, Section 5.1에서 입증된다.
또한, 우리는 B2T 키워드를 사용하여 CLIP의 편향을 제거하는 prompting 전략을 제시한다. 이 키워드들은 Section 5.2에서 보여주듯이 이전 연구 [85]의 키워드보다 더 세분화되어 있다.
3. Bias-to-Text (B2T) Framework
이 섹션에서는 먼저 우리가 다루고자 하는 편향(bias)을 정의하는 것으로 시작한다 (3.1). 다음으로, captioning model을 사용하여 편향 키워드를 제공하고 scoring model로 이를 검증하는 Bias-to-Text (B2T) 프레임워크를 소개한다 (3.2). 마지막으로, scoring model의 효과를 검증하여, 높은 점수를 받은 키워드들이 더 강한 편향을 보이는 경향이 있음을 보여준다 (3.3).
3.1. Problem formulation
이미지 분류기는 이미지 에 대해 클래스 를 예측한다. 만약 속성 를 가진 이미지가 원래 클래스 로부터 자주 오분류된다면, 우리는 속성 를 클래스 와 관련된 **편향(bias)**이라고 정의한다. 우리의 목표는 이러한 편향된 속성 를 키워드 설명 형태로 식별하는 것이다.
편향 속성에는 spurious correlation [71] 또는 distribution shift [70]가 포함된다. Spurious correlation은 모델이 의도치 않은 결정 규칙에 의존하게 만든다 (예: "금발" 머리색을 "남자"와 연관시키는 것). 이는 해당 규칙이 적용되지 않을 때 잘못된 예측을 초래한다 [66]. 반면에 distribution shift (예: "일러스트레이션"과 같은 스타일 변환)는 모델이 보지 못한 샘플에 대한 일반화 능력을 저해할 수 있다 [26].
3.2. Discovering bias keywords
Bias keywords. 우리의 핵심 아이디어는 편향(bias)을 나타내는 키워드를 추출하는 것이다. 이를 위해, 우리는 클래스별로 잘못 예측된 이미지들의 언어 설명에서 공통적인 키워드를 추출한다. 소수 하위 그룹(minority subgroups)은 원래 클래스 에서 오분류된 이미지들이므로, 이러한 설명에 자주 나타난다. 예를 들어, "금발 vs. 비금발" 분류기의 경우, "금발" 클래스에서 잘못 예측된 이미지 설명에 "man"이라는 키워드가 자주 등장할 수 있다. 우리는 사전학습된 captioning 모델 [41, 84]을 사용하여 설명을 생성하고, 거기서 공통 키워드를 추출한다. 기본 captioning 모델로는 **ClipCap [52]**를 선택했는데, 이는 강력한 성능과 빠른 추론 속도 때문이다 (Table 4 참조). 키워드 추출에는 YAKE [7] 알고리즘을 적용한다.
CLIP score. 우리는 추출된 키워드가 편향을 나타내는지 검증한다. 이를 위해 CLIP [59]과 같은 vision-language scoring 모델을 사용하여 키워드와 잘못 예측된 이미지 간의 유사도를 측정한다. CLIP score는 편향된 개념과 관련된 키워드가 높은 CLIP score를 가지는 반면, 그렇지 않은 키워드는 낮은 점수를 가지도록 한다. 구체적으로, 우리는 키워드 와 및 에 속한 이미지 간의 CLIP embedding 유사도를 비교한다. 여기서 과 는 각각 분류기에 의해 잘못 예측된 이미지와 올바르게 예측된 이미지로 구성된 클래스별 validation set 의 부분집합이다. 공식적으로 CLIP score는 다음과 같이 정의된다:
여기서 는 키워드 와 데이터셋 간의 유사도를 나타내며, 이는 단어 와 에 속한 이미지 의 정규화된 embedding 간의 평균 코사인 유사도로 계산된다:
 Figure 3. CLIP score의 효과 (waterbird 클래스).
(a) CLIP score는 잘못된 편향 키워드를 식별할 수 있으며, "species"와 같은 비편향 키워드에 대해서는 0에 가까운 낮은 CLIP score를 보여준다.
(b) ROC 곡선은 **하위 그룹 정확도(subgroup accuracy)**를 나타낸다. 이 하위 그룹은 특정 키워드와 높은 CLIP 유사도를 가진 이미지들을 기반으로 정의되며, 임계값(threshold)을 변화시키면서 측정된다. 범례는 B2T 키워드와 해당 CLIP score(괄호 안)를 표시하며, 각 곡선의 AUROC는 등호 뒤에 표기된다. 높은 CLIP score를 가진 키워드는 낮은 하위 그룹 정확도를 보이는 경향이 있으며, 이는 해당 키워드가 편향임을 시사한다.
(c) 색깔 있는 점들은 CLIP score와 B2T 키워드에 대한 하위 그룹 정확도의 AUROC 간의 음의 상관관계를 보여준다. 이는 CLIP score가 높을수록 편향이 강하다는 것을 의미한다.
Figure 3. CLIP score의 효과 (waterbird 클래스).
(a) CLIP score는 잘못된 편향 키워드를 식별할 수 있으며, "species"와 같은 비편향 키워드에 대해서는 0에 가까운 낮은 CLIP score를 보여준다.
(b) ROC 곡선은 **하위 그룹 정확도(subgroup accuracy)**를 나타낸다. 이 하위 그룹은 특정 키워드와 높은 CLIP 유사도를 가진 이미지들을 기반으로 정의되며, 임계값(threshold)을 변화시키면서 측정된다. 범례는 B2T 키워드와 해당 CLIP score(괄호 안)를 표시하며, 각 곡선의 AUROC는 등호 뒤에 표기된다. 높은 CLIP score를 가진 키워드는 낮은 하위 그룹 정확도를 보이는 경향이 있으며, 이는 해당 키워드가 편향임을 시사한다.
(c) 색깔 있는 점들은 CLIP score와 B2T 키워드에 대한 하위 그룹 정확도의 AUROC 간의 음의 상관관계를 보여준다. 이는 CLIP score가 높을수록 편향이 강하다는 것을 의미한다.
우리는 기본적으로 CLIP을 사용했기 때문에 이를 CLIP score라고 명명했지만, 다른 vision-language 모델들 [10, 40]도 잘 작동한다는 점에 유의해야 한다 (Table 5 참조).
추가적인 실험 세부 사항은 Appendix A에 제공된다. 본 논문에서는 주로 이미지 분류기에 초점을 맞추지만, 시각적 편향을 키워드로 해석하는 우리의 원칙은 Appendix B에서 논의된 바와 같이 text-to-image 생성 모델과 같은 다른 컴퓨터 비전 task에도 확장될 수 있다.
3.3. Validation of the CLIP score
우리는 키워드가 편향을 나타내는지 검증하는 데 있어 CLIP score의 효과를 입증한다. Figure 3은 Waterbirds [66] 데이터셋의 waterbird 클래스를 사용하여 CLIP score에 대한 여러 분석을 보여준다. 패널 (a)는 CLIP score가 잘못된 편향 키워드를 식별하는 방식을 보여준다. 예를 들어, 캡셔닝 모델이 "species" 또는 "bird"와 같은 용어를 생성할 때, CLIP score는 이 용어들이 올바르게 예측된 이미지와 잘못 예측된 이미지 모두에 존재하기 때문에 비편향 키워드로 분류하며, 그 결과 낮은 CLIP score를 나타낸다.
패널 (b)는 **각 키워드에 대한 하위 그룹 정확도(subgroup accuracy)**를 보여준다. 우리는 각 키워드와 관련된 개별 샘플의 **CLIP 유사도(similarity)**를 사용하여 하위 그룹을 정의한다. 여기서 하위 그룹 정확도는 CLIP 유사도의 다양한 임계값(threshold)에 걸쳐 계산된 AUROC로 정의된다. 높은 CLIP score를 가진 키워드(괄호 안)는 낮은 하위 그룹 정확도(등호 뒤)를 보인다. 예를 들어, "bamboo" 키워드는 CLIP score가 2.85이고 하위 그룹 정확도는 0.29이다. 이와 대조적으로, CLIP score가 0에 가까운 일반적인 키워드(예: "bird")는 무작위 추측(회색 점선)과 유사한 성능을 보여주며, 이는 해당 키워드들이 편향되지 않았음을 시사한다.
패널 (c)는 B2T 키워드에 대한 CLIP score와 하위 그룹 정확도(AUROC) 간의 상관관계를 시각화한다. 이 지표들은 -0.95의 높은 상관계수를 가지며, 이는 CLIP score가 키워드의 편향 심각도를 반영함을 나타낸다. 추가 평가는 Appendix D를 참조하라.
4. Discovering Biases in Image Classifiers
우리는 B2T가 다양한 데이터셋으로 학습된 이미지 분류기에서 시각적 편향(visual bias)을 발견할 수 있음을 입증한다. 첫째, B2T가 벤치마크 데이터셋에서 알려진 편향을 식별할 수 있음을 보여준다 (4.1). 둘째, CLIP 분류기를 사용하여 bias 키워드가 샘플별 편향 레이블을 어떻게 추론하는지를 보여주며, 이는 기존 방법보다 우수한 성능을 보인다 (4.2). 마지막으로, B2T가 더 큰 데이터셋에서 새로운 편향을 발견하는 능력을 탐구한다 (4.3).
4.1. Can B2T identify the known biases?
Spurious correlation (허위 상관관계)
우리는 CelebA [46] 및 Waterbirds [66] 데이터셋에서 성별 및 배경 편향을 분석하기 위해 B2T를 사용한다. CelebA는 속성 주석이 있는 유명인의 얼굴 이미지를 포함한다. Sagawa et al. [66]에 따라, 우리는 머리 색깔을 "금발" 또는 "금발 아님"으로 분류하는 데 초점을 맞춘다. Waterbirds는 육지 또는 물 배경에 있는 물새와 육지새 이미지를 포함한다. 여기서 우리는 허위 상관관계에 의해 영향을 받는 것으로 알려진 ERM(empirical risk minimization) 분류기 [66]에 B2T를 적용한다.
Figure 4 (a, b)는 편향 키워드를 보여준다. B2T는 CelebA 금발에 대해 "man"을, Waterbirds에 대해 "forest"와 "ocean"을 포착하여 각 데이터셋의 성별 및 배경 편향을 드러낸다. 또한 B2T는 "bamboo"와 같은 세분화된 키워드를 찾아내어, 원래의 "land" 배경 주석보다 더 자세한 정보를 제공한다.
Distribution shifts (분포 변화)
B2T는 ImageNet 변형 데이터셋인 ImageNet-R (rendition) [26] (ImageNet 클래스의 예술적 이미지를 포함)과 ImageNet-C (corruption) [25] (ImageNet 클래스의 노이즈가 있는 이미지를 포함)에서 분포 변화를 감지할 수 있다. 우리는 ImageNet으로 학습된 supervised ResNet-50 [22] 분류기를 사용하는데, 이 분류기는 이들 데이터셋에 대해 일반화하는 데 어려움을 겪는 경우가 많으며, 이는 학습 데이터에 대한 편향을 나타낸다. 우리는 분류기의 실패를 식별하기 위해 ImageNet과 각 변형 데이터셋의 합집합(클래스별이 아님)에 B2T를 적용한다.
Figure 4 (c, d)는 편향 키워드를 보여준다. ImageNet-
| (a) CelebA blond | (b) Waterbirds | (c) ImageNet-R | (d) ImageNet-C snow / frost | |||||
|---|---|---|---|---|---|---|---|---|
| Keyword | Man | Forest | Ocean | Illustration | Drawing | Snow | Window | |
| Samples |  |  |  |  |  |  |  | |
| Actual | blond | blond | waterbird | landbird | backpack | white shark | airliner | American egret |
| Pred. | not blond | not blond | landbird | waterbird | maze | envelope | damselfly | quill |
| Caption | person, a man with a beard. | actor as a young man. | a bird in the forest. | a bird in the ocean. | hand drawn illustration of a backpack. | a drawing of a shark attacking [...] | airliner in the snow, photo. | a bird on a frozen window. |
| (e) Dollar Street | (f) ImageNet | |||||||
| Keyword | Cave | Fire | Bucket | Hole | Flower | Playground | Baby | Interior |
| Samples |  |  | 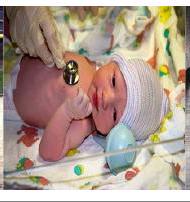 |  | ||||
| Actual | wardrobe | stove | plate rack | toilet seat | ant | horizontal bar | stethoscope | monastery |
| Pred. | poncho | caldron | oil filter | wheelbarrow | bee | swing | baby pacifier | arched ceiling |
| Caption | the cave is full of surprises. | a fire in the kitchen. | a bucket of water and a few tools. | the hole in the ground. | a yellow flower with a black head. | person on a swing in the playground. | a newborn baby boy in a stethoscope. | the interior of the church. |
Figure 4. 이미지 분류기에서 발견된 편향. 잘못 예측된 이미지의 시각적 예시와 해당 편향 키워드, 캡션, 실제 클래스 및 예측 클래스. B2T는 (a) CelebA 금발의 성별 편향, (b) Waterbirds의 배경 편향, (c) ImageNet-R의 다양한 스타일 분포 변화, (d) ImageNet-C의 자연적 손상 분포 변화와 같은 알려진 편향을 성공적으로 식별했다. 또한 B2T는 더 큰 데이터셋에서 새로운 편향을 발견했는데, 예를 들어 (e) "cave" 키워드와 옷장 클래스 간의 허위 상관관계는 Dollar Street의 지리적 편향을 나타내고, (f) "flower" 키워드와 개미 클래스 간의 허위 상관관계는 ImageNet의 맥락적 편향을 나타낸다.
R의 경우, B2T는 "illustration" 및 "drawing"과 같은 키워드를 포착하며, "hand-drawn" 및 "vector art"와 같은 더 자세한 정보를 제공한다. ImageNet-C의 경우, B2T는 눈 손상에 대해 "snow"와 같은 키워드를, 서리 손상에 대해 "window"와 같은 키워드를 포착한다. 여기서 "window" 키워드는 얼어붙은 이미지가 시각적으로 창문 뒤의 이미지와 유사하다는 것을 암시한다.
4.2. Sample-wise bias labeling
우리는 CLIP zero-shot classifier에 bias 키워드를 적용하여 샘플별 bias (또는 그룹) 레이블을 추론할 수 있다. 구체적으로, 우리는 **"[group]의 사진"**과 같은 prompt를 생성하는데, 여기서 "[group]"은 bias 키워드를 나타낸다. 그리고 각 이미지의 레이블을 가장 가까운 그룹에 할당한다.
우리는 이 샘플별 bias 레이블링을 ground-truth bias 레이블이 사용 가능한 CelebA 및 Waterbirds 데이터셋에서 평가한다. B2T를 기존의 비지도 bias 발견 방법인 **JTT [44], Domino [17], Failure Direction [30]**과 비교한다. 이 방법들은 각각 ERM confidence, GMM, SVM을 사용하여 bias 레이블을 예측한다. Figure 5는 B2T가 기존 방법들을 크게 능가하며, 고려된 모든 시나리오에서 거의 최적의 성능을 달성함을 보여준다.
4.3. Exploring novel biases in larger datasets
우리는 B2T를 적용하여 더 큰 데이터셋에서 새로운 편향(bias)을 발견한다. 주목할 점은 B2T가 captioning 모델로부터 zero-shot 방식으로 키워드를 생성하므로, 기존 연구들 [17, 30]과는 달리 사전에 정의된 잠재적 편향 키워드 세트가 필요하지 않다는 것이다.
Dollar Street. **Dollar Street [64]**는 다양한 소득 수준의 국가에서 수집된 객체 이미지를 포함한다. 이전 연구들은 분류기가 저소득 국가의 객체에 대해 낮은 성능을 보인다는 것을 입증했다 [13]. 우리는 ImageNet [14] 분류기를 사용하여 Dollar Street의 validation set에 B2T를 적용함으로써 이러한 **지리적 편향(geographic bias)**을 더 자세히 조사하고자 한다. 분류기는 고소득 국가의 객체에 대해서는 레이블을 정확하게 예측했지만, 저소득 국가의 객체에 대해서는 실패했다.
Figure 4 (e)는 편향 키워드를 보여준다. 여기서 B2T는 "wardrobe" 클래스에 대해 "cave", **"stove" 클래스에 대해 "fire"**와 같은 편향 키워드를 발견한다. 저소득 국가의 옷장은 종종 동굴과 유사한 어두운 곳에 있으며, 저소득 국가의 스토브는 종종 불을 사용하는 전통적인 디자인을 가지고 있다.
 Figure 5. 편향 발견 방법 비교. (a) CelebA blond (male) 및 (b) Waterbirds (waterbirds on land)에 대한 AUROC 곡선이며, 괄호 안은 해당 소수 그룹을 나타낸다. B2T는 기존 연구들보다 훨씬 뛰어난 성능을 보인다.
Figure 5. 편향 발견 방법 비교. (a) CelebA blond (male) 및 (b) Waterbirds (waterbirds on land)에 대한 AUROC 곡선이며, 괄호 안은 해당 소수 그룹을 나타낸다. B2T는 기존 연구들보다 훨씬 뛰어난 성능을 보인다.
"plate rack" 클래스에 대한 "bucket" 키워드는 양동이가 접시를 쌓는 데 흔히 사용될 수 있음을 시사하며, "toilet seat" 클래스에 대한 "hole" 키워드는 분류기가 쪼그려 앉는 변기(squat toilets)에 익숙하지 않음을 시사한다. 국가별 객체의 이러한 차이는 지리적 편향으로 이어진다.
ImageNet. 우리는 CLIP [59] zero-shot 분류기를 사용하여 ImageNet [14] 학습 세트에 B2T를 적용한다. CLIP 논문을 따라 80-prompts 앙상블 전략을 사용한다. 우리는 특정 클래스로 자주 오분류되는 혼란스러운 클래스를 조사하는 데 중점을 둔다.
Figure 4 (f)는 편향 키워드를 보여준다. 우리는 장면 내 객체들 간의 맥락적 편향(contextual biases)을 발견한다. 예를 들어, 분류기는 "flower" 키워드와 함께 "ant"를 "bee"로 예측하는데, 이는 꽃과 벌 사이에 개미보다 더 강한 연관성이 있음을 나타낸다. "playground" 키워드는 분류기가 놀이터의 "horizontal bar"를 "swing"으로 혼동함을 의미한다. 분류기는 "baby" 키워드와 함께 "stethoscope"를 "baby pacifier"로 혼동하는데, 이는 외형이 유사하기 때문에 합리적이다. 또한, 우리는 "plastic bag" 클래스에 대한 "street" 키워드와 "notebook" 클래스에 대한 "office" 키워드를 발견했는데, 이는 분류기가 여러 객체가 있는 복잡한 장면에서 어려움을 겪음을 시사한다.
더 많은 예시. 추가적인 시각적 예시는 Appendix G에, B2T 키워드 목록은 Appendix H에 제공되어 있다.
5. Applications of the B2T Keywords
우리는 B2T의 키워드 형태가 debiased DRO training, CLIP zeroshot prompting, 모델 비교, 레이블 진단 등 다양한 응용 분야에 활용될 수 있음을 보여준다.
5.1. Debiased DRO training
Bias keyword는 debiased classifier를 학습시키는 데 사용될 수 있다. 구체적으로, 우리는 Section 4.2에서 설명한 대로 샘플별 bias label을 추론하고, 이를 DRO [66] 학습에 적용한다. 우리는 우리의 DRO-B2T를 다양한 baseline과 비교한다. 여기에는 ERM, ground-truth (GT) bias label을 사용한 DRO, 그리고 그룹 label을 unsupervised 방식으로 추론하는 debiased 학습 방법들인 **LfF [55], GEORGE [74], JTT [44]**가 포함된다.
Table 1. Debiased DRO 학습. 우리의 debiased classifier (DRO-B2T)와 기존 연구들의 worst-group 및 평균 정확도(%)를 보여준다. GT는 학습에 ground-truth bias label을 사용했음을 나타내며, 굵은 글씨는 가장 좋은 worst-group 정확도를 의미한다. B2T keyword는 정확한 bias label 예측을 가능하게 하여 효과적인 DRO 학습을 촉진한다.
| Method | GT | CelebA blond | Waterbirds | ||
|---|---|---|---|---|---|
| Worst | Avg. | Worst | Avg. | ||
| ERM | - | 94.9 | 97.3 | ||
| LfF [55] | - | 77.2 | 85.1 | 78.0 | 91.2 |
| GEORGE [74] | - | 94.6 | 95.7 | ||
| JTT [44] | - | 88.1 | 89.3 | ||
| CNC [86] | - | 89.9 | 90.9 | ||
| DRO-B2T (ours) | - | 93.2 | 92.1 | ||
| DRO [66] | 93.3 | 91.5 |
Table 2. CLIP zero-shot prompting. CLIP zero-shot classifier의 worst-group 및 평균 정확도(%)를 보여준다. 이는 기본 prompt, 또는 확장된 prompt (기본 그룹 이름(group) 사용, 또는 긍정적(B2T-pos) 또는 부정적(B2T-neg) CLIP 점수를 가진 B2T keyword 사용)를 사용한 결과이다. 굵은 글씨는 가장 좋은 worst-group 정확도를 나타낸다. B2T-pos는 worst-group 정확도를 향상시키는 반면, B2T-neg는 해를 끼친다. 이는 prompt에 적절한 keyword를 추가하는 것이 CLIP zero-shot 추론의 debiased 정확도를 향상시킨다는 것을 의미한다.
| CelebA blond | Waterbirds | ||||
|---|---|---|---|---|---|
| Worst | Avg. | Worst | Avg. | ||
| CLIP zero-shot | 76.2 | 85.2 | 50.3 | 72.7 | |
| + Group prompt [85] | 76.7 | 87.0 | 53.7 | 78.0 | |
| + B2T-neg prompt | 72.9 | 88.0 | 45.4 | 70.8 | |
| + B2T-pos prompt (ours) | 87.2 | 76.9 |
그리고 **CNC [86]**가 있다. 우리는 CNC 논문에서 값을 발췌하였다. Table 1은 worst-group 및 평균 정확도를 보여준다. DRO-B2T는 그룹 label을 unsupervised 방식으로 추론하는 기존 방법들보다 우수한 성능을 보이며, 이는 B2T keyword의 영향을 확인시켜준다. DRO-B2T는 GT label을 사용한 DRO보다도 뛰어난 성능을 보이는데, 이는 GT annotation의 노이즈 때문일 가능성이 있다. 추가적인 DRO 실험은 Appendix C를 참조하라.
5.2. CLIP zero-shot prompting
Bias keyword는 prompt에 통합함으로써 CLIP zero-shot classifier의 성능을 향상시킬 수 있다. 원래 CLIP의 prompt template은 "a photo of a [class]"이다. 우리는 이 prompt에 "a photo of a [class] in the [group]"와 같이 키워드를 추가하여 수정한다. 여기서 키워드는 Waterbirds의 경우처럼 그룹 이름을 나타낸다. 여기서 우리는 모든 그룹에 걸쳐 prompt의 평균 텍스트 임베딩을 계산하여 class 임베딩을 얻고, 이미지를 가장 가까운 class에 할당한다.
우리는 다양한 키워드 세트로 prompt를 보강하여 그 중요성을 평가한다. 구체적으로, 우리는 양수 또는 음수 CLIP 점수를 가진 B2T 키워드를 사용하며, 이를 각각 B2T-pos 및 B2T-neg라고 부른다.
| Keyword | Work | Supermarket | ||
|---|---|---|---|---|
| Samples |  |  |  | |
| ViT-B | O | O | O | O |
| RN50 | O | X | O | X |
| Actual (RN50) | dumbbell | dumbbell | shopping basket | shopping basket |
| Pred (RN50) | dumbbell | horizontal bar | shopping basket | grocery store |
| Caption | a set of dumbbells with weights. | person works out in the gym. | a basket full of food. | woman shopping in a supermarket. |
Figure 6. 모델 비교: ResNet vs. ViT. 우리는 ImageNet으로 학습 및 평가된 ResNet과 ViT의 예측을 비교한다. ResNet의 예측 레이블과 B2T 키워드를 보고한다. ViT는 ResNet보다 전역적인 맥락을 이해하고 세분화된 클래스를 처리하는 데 탁월하다. 예를 들어, ResNet은 "work out" 및 "supermarket"과 같은 추상적인 맥락을 나타내는 B2T 키워드를 가진 복잡한 이미지에서 어려움을 겪는다.
예를 들어, Waterbirds의 경우, 우리는 B2T-pos에 "ocean"을, B2T-neg에 "bird"를 사용한다. B2T-pos 키워드는 소수 하위 그룹을 나타내며, 이들을 인식하는 데 도움을 줄 수 있다. 우리는 이 접근 방식을 Zhang and Ré [85]에서 제안한 "water" 배경과 같은 기본 그룹 이름을 사용하는 방식과 비교한다.
Table 2는 CLIP classifier의 worst-group 및 평균 정확도를 보여준다. B2T-pos 키워드는 worst-group 및 평균 정확도를 모두 향상시킨다. 반면, 기본 그룹 이름은 도움이 덜 되며, B2T-neg 키워드는 worst-group 정확도를 오히려 감소시킨다. 이는 prompt에 적절한 키워드를 추가하는 것이 CLIP zero-shot 추론의 debiased 정확도를 향상시킨다는 것을 시사한다.
5.3. Model comparison
Bias keyword는 다양한 분류기(classifier)를 해당 키워드를 기반으로 분석하고 비교하는 데 사용될 수 있다.
아키텍처: ResNet vs. ViT.
우리는 ResNet [22]과 ViT [16] 아키텍처를 비교한다. 최근 연구들은 ViT가 ResNet보다 객체 형태 이해에 더 뛰어나다고 주장한다 [57]. 우리는 bias keyword를 조사하여 이를 추가적으로 탐구한다. 모델은 ImageNet에서 학습 및 평가된다.
Figure 6은 비교 결과를 보여준다. ViT는 ResNet에 비해 전역적인 맥락(global contexts)과 세분화된 클래스(fine-grained classes)를 이해하는 데 탁월하다. 예를 들어, ViT는 "work out"과 같은 추상적인 bias keyword를 포함하는 복잡한 이미지를 성공적으로 예측한다. 우리는 이러한 능력이 ViT의 global self-attention 덕분이며, 이는 더 넓은 맥락을 고려할 수 있게 한다고 설명한다.
Debiased training: ERM vs. DRO.
우리는 CelebA와 Waterbirds 데이터셋에서 편향된(biased) 학습 방법인 ERM과 **편향 제거(debiased) 학습 방법인 DRO [66]**를 비교한다. ERM에서 추출된 bias keyword는 다음과 같다.
Table 3. 모델 비교: ERM vs. DRO.
우리는 CelebA와 Waterbirds 데이터셋에서 편향된 분류기(ERM)와 편향 제거된 분류기(DRO)를 비교한다. ERM, DRO의 CLIP 점수와 그 차이(gap)를 제시한다. bias keyword가 발견되지 않은 경우 로 표시한다. DRO에서는 bias keyword가 아예 없거나 그 점수가 감소한다. 예를 들어, CelebA blond 클래스에서는 "man" 키워드가 더 이상 나타나지 않는다.
| Keyword | ERM | DRO | Gap | |
|---|---|---|---|---|
| CelebA blond | man | 1.06 | ||
| Waterbird | bamboo forest | 3.61 | ||
| bamboo | 2.85 | |||
| forest | 2.27 | 1.97 | -0.30 | |
| woods | 2.24 | 1.88 | -0.36 | |
| Landbird | seagull | 3.10 | 1.85 | -1.24 |
| beach | 2.45 | 1.15 | -1.30 | |
| water | 1.51 | 0.67 | -0.84 | |
| lake | 1.25 |




Figure 7. Label 진단. 우리는 bias keyword를 사용하여 ImageNet에서 잘못된 라벨링(mislabeling) 및 라벨 모호성(label ambiguities)과 같은 라벨링 오류를 식별한다. 예를 들어, "bee"라는 키워드는 "fly" 클래스로 라벨링된 이미지가 실제로는 잘못 라벨링되었음을 시사한다. 반면에 "desk" 키워드는 이미지가 "computer mouse"와 "desktop computer"를 포함한 여러 객체를 책상 위에 담고 있어, 적절한 클래스를 할당하기 어렵다는 것을 나타낸다.
CLIP 점수는 1.0보다 높다. Table 3은 ERM, DRO의 CLIP 점수와 그 차이를 보여준다. 키워드가 발견되지 않은 경우 로 표시한다. DRO는 실제로 bias keyword를 더 적게 생성한다. 예를 들어, "man" 키워드는 CelebA blond 클래스에서 나타나지 않으며, 편향이 높은 키워드의 CLIP 점수는 감소한다. 예를 들어, landbird 클래스에서 "seagull"의 점수는 3.10에서 1.85로 감소한다.
추가 모델 비교.
우리는 분류기의 분포 변화(distribution shifts)에 대한 강건성(robustness)을 조사하는 추가 결과를 Appendix E에 제시한다. 우리의 연구 결과는 멀티모달 학습에서 CLIP이 ERM보다 더 강건하며, self-supervised learning에서는 MAE [23]가 더 나은 강건성을 보이고, DINO [8]는 ERM과 유사한 특성을 나타낸다는 것을 보여준다.
5.4. Label diagnosis
B2T는 오분류(mislabeling) 및 **레이블 모호성(label ambiguities)**과 같은 일반적인 레이블링 오류를 진단할 수 있다. 이전 연구들에서도 ImageNet에 레이블 오류가 포함되어 있음이 밝혀졌다 [68]. 우리는 Section 4.3의 설정에 따라 이러한 오류들을 분석한다.
Figure 7은 그 예시들을 시각화한다. 우리는 "bee" 이미지가 "fly"로, "boar" 이미지가 "pig"으로 잘못 레이블링된 경우와 같은 오분류된 이미지들을 발견했다. 또한, "desk"와 "market" 키워드로 표시된 모호한 레이블을 가진 이미지들도 발견했다. 이들은 장면에 여러 객체가 포함되어 있어 레이블이 모호하다.
6. Ablation Study
우리는 B2T 프레임워크에서 다양한 captioning 및 scoring 모델을 사용하는 효과를 연구한다. 각 모델에 사용된 아키텍처와 같은 세부 정보는 Appendix A에 명시되어 있다.
Captioning 모델. 우리는 ClipCap [52], BLIP [40], BLIP-2 [41], CoCa [84], LLaVA [45] 등 다양한 captioning 모델에 걸쳐 **bias 키워드의 견고성(robustness)**을 연구한다. Table 4는 그 결과를 보여준다. 서로 다른 captioning 모델들은 심각한 bias에 대해서는 일치된 의견을 보이지만, 다양한 세분화된 키워드를 제공한다. 예를 들어, 모든 모델은 "man", "forest", "beach"와 같은 주요 키워드를 포착한다. 반대로, "rainforest" 또는 "lake"와 같은 다양한 세분화된 키워드를 제공하므로, 몇몇 captioning 모델을 앙상블하면 발견되는 biased 키워드를 다양화할 수 있다. 우리는 강력한 성능과 빠른 추론 시간을 고려하여 ClipCap을 기본 선택으로 사용한다. 그러나 향상된 captioning을 위해 GPT-4 [58]와 같은 고급 모델을 선택할 수도 있다.
Scoring 모델. 우리는 다양한 vision-language 모델에 걸쳐 CLIP score의 견고성을 연구한다. 특히, 우리는 서로 다른 데이터셋으로 학습된 CLIP (예: LAION [67] 데이터셋으로 학습된 OpenCLIP [10])과 서로 다른 아키텍처를 가진 모델 (예: BLIP [40] 및 BLIP-2 [41])을 테스트한다. Table 5는 그 결과를 보여준다. Scoring 모델들은 "man" 또는 "bamboo forest"와 같은 키워드에 대해 높은 점수를 부여하며 일관된 순위를 제공한다. 우리는 CLIP을 기본 선택으로 사용하지만, 고급 모델도 고려할 수 있다.
키워드 추출 (Keyword extraction). 우리는 실험에서 **YAKE [7]**를 사용하지만, 고빈도 단어와 같은 다른 키워드 추출 전략도 잘 작동한다 (Appendix D 참조).
7. Conclusion
우리는 키워드 설명을 통해 편향을 식별하고 완화하기 위한 프레임워크인 B2T를 제안한다. 키워드 사용은 편향 완화 학습(debiased training) 및 모델 비교와 같은 여러 장점을 제공한다. 우리의 B2T 프레임워크가 이미지 인식의 책임감 있는 사용에 도움이 되기를 바란다.
한계점 (Limitations)
B2T는 사전학습된 captioning 및 scoring model을 활용하는 vision-language model의 최근 발전에 의존한다. 그러나 이러한 모델들이 완벽하지 않을 수 있다. 예를 들어, 웹 크롤링 데이터로 학습된 captioning model은 의료 및 위성 이미지와 같은 흔치 않은 도메인에서는 유익한 설명을 생성하지 못할 수 있다. 마찬가지로, scoring model은 학습 데이터의 한계로 인해 이미지-텍스트 유사도를 적절하게 포착하지 못할 수 있다.
Table 4. 다양한 captioning model에 대한 ablation 결과.
다양한 captioning model에 의해 발견된 B2T 키워드. 모델 이름과 함께 단일 이미지에서 caption을 추출하는 평균 추론 시간(RTX 3090 GPU에서 초 단위)을 보고한다. 모델들은 "man", "forest", "beach"와 같은 매우 편향된 키워드를 일관되게 포착하는 반면, "rainforest" 또는 "lake"와 같은 다양한 세분화된 키워드는 모델마다 다르게 발견할 수 있다.
| Inference time | ClipCap | BLIP | CoCa | BLIP-2 | LLaVA | |
|---|---|---|---|---|---|---|
| 0.13 sec | 0.20 sec | 0.34 sec | 0.56 sec | 1.90 sec | ||
| CelebA blond | man | O | O | O | O | O |
| Waterbird | forest | O | O | O | O | O |
| bamboo | O | O | O | O | O | |
| woods | O | - | - | O | - | |
| rainforest | O | - | - | - | - | |
| Landbird | beach | O | O | O | O | O |
| ocean | - | O | O | O | - | |
| boat | - | O | O | O | O | |
| lake | O | - | - | - | - |
Table 5. 다양한 scoring model에 대한 ablation 결과.
다양한 scoring model을 사용한 B2T 키워드와 그 점수. 모델들은 "man" 또는 "bamboo forest"와 같은 키워드에 대해 높은 점수를 부여하며 일관된 순위를 제공하여, 그 신뢰성을 뒷받침한다.
| CLIP | OpenCLIP | BLIP | BLIP-2 | ||
|---|---|---|---|---|---|
| CelebA blond | man | 1.06 | 2.23 | 1.19 | 4.04 |
| player | 0.35 | 1.30 | 0.74 | 2.67 | |
| face | -0.28 | 0.44 | 0.49 | 1.46 | |
| actress | -1.63 | -2.48 | -1.68 | -4.25 | |
| Waterbird | bamboo forest | 3.61 | 4.68 | 5.22 | 9.85 |
| woods | 2.24 | 4.43 | 3.47 | 7.08 | |
| bird | -0.09 | 0.67 | -0.03 | -0.70 | |
| pond | -0.27 | -0.63 | -0.92 | -1.69 |
그럼에도 불구하고, 두 모델 모두 다양한 시나리오에서 좋은 성능을 보여주며, 이는 B2T 프레임워크의 실용적인 장점을 강조한다. 한계점에 대한 추가 논의는 Appendix F에서 찾을 수 있다.
광범위한 영향 (Broader impacts)
편향 및 공정성 연구는 본질적으로 잠재적인 부정적 사회적 영향을 가질 수 있다. 우리는 B2T가 편향 발견을 완전히 자동화하는 것을 목표로 하는 것이 아니라, 편향 키워드를 기반으로 인간이 의사결정을 내리는 것을 돕는 것임을 강조한다. 최종 판단은 사용자에게 맡겨지며, 이들은 교차 검증 시스템에 의해 모니터링되어야 한다.
우리는 성별 및 지리적 편향과 같은 민감한 예시를 제시한다. 우리의 의도는 실제 데이터에서 잠재적인 위험을 인식하고 완화하는 것임을 강조한다.
Acknowledgements
본 연구는 정보통신기획평가원(IITP)의 지원을 받아 수행되었습니다 (한국 정부(MSIT) 기금, No.2019-0-00075, 인공지능 대학원 프로그램(KAIST); No. 2022-0-00184, 진화하는 윤리 정책에 저비용으로 순응하는 AI 기술 개발 및 연구). 건설적인 논의에 도움을 주신 김은지님께 감사드립니다.
Discovering and Mitigating Visual Biases through Keyword Explanation
Appendix
Contents
A Implementation Details ..... 13 A.1. Bias discovery ..... 13 A. 2 Debiasing classifiers ..... 14 A.3. Ablation studies ..... 14 B. Extension to Generative Models ..... 17 B.1. B2T for text-to-image (T2I) generative models ..... 17 B.2. Experimental results ..... 17 C. Additional DRO Results ..... 19 C.1. Multi-class debiasing ..... 19 C.2. Nonsensical groups ..... 19 D Additional Analyses ..... 20 D.1. Validation of the CLIP score ..... 20 D. 2 Comparison of bias discovery methods ..... 20 D.3. Keyword extraction ..... 21 E Additional Model Comparisons ..... 22 F. Further Discussion of Limitations ..... 23 G Additional Visual Examples ..... 24 H Complete Lists of the B2T Keywords ..... 26
A. Implementation Details
연산 비용 (Computation cost)
단일 RTX 3090 GPU를 사용하여, 19,867개의 이미지를 포함하는 CelebA validation set에 대한 caption을 생성하는 데 약 30분이 소요되었다.
키워드 추출에는 5초, CLIP 점수 도출에는 33초가 걸렸다.
A.1. Bias discovery
A.1.1 Dataset details
CelebA blond. CelebA [46] 데이터셋은 19,867개의 validation 이미지를 포함하며, 우리는 DRO repository의 ResNet-50 [22] 분류기를 사용한다. 특히, 우리는 learning rate 0.0001, batch size 128로 학습된 ERM 및 DRO 모델을 사용했으며, 이들은 blond 클래스에 대해 각각 95.44% 및 90.40%의 정확도를 달성했다.
Waterbirds. Waterbirds [66] 데이터셋은 1,199개의 validation 이미지를 포함하며, 우리는 DRO repository의 ResNet-50 분류기를 사용한다. 특히, 우리는 learning rate 0.001, batch size 128로 학습된 ERM 및 DRO 모델을 사용했다. ERM은 waterbird 및 landbird 클래스에 대해 각각 86.66% 및 91.24%의 정확도를 달성했다.
Dollar Street. Dollar Street [64] 데이터셋은 2019년 7월 30일 기준 원본 웹페이지의 스냅샷을 포함하며, 우리는 ImageNet으로 학습된 ResNet-50 분류기를 평가에 사용한다. Dollar Street의 클래스 이름은 Table 6에 제시된 매핑을 사용하여 ImageNet 이름으로 변환한다.
Table 6. Dollar Street의 클래스 이름을 ImageNet 클래스 이름으로 변환.
| Dollar Street | ImageNet |
|---|---|
| books | bookcase |
| computers | desktop computer |
| cups | tea cup |
| diapers | diaper |
| dish_racks | plate rack |
| dishwashers | dishwasher |
| necklaces | necklace |
| stoves | stove |
| tables_with_food | dining table |
| toilet_paper | toilet paper |
| toilets | toilet seat |
| wall_clocks | wall clock |
| wardrobes | wardrobe |
| wheel_barrows | barrow |
| wrist_watches | digital watch |
ImageNet 및 변형 데이터셋. ImageNet [14]은 1,000개 클래스에 걸쳐 1,281,167개의 training 이미지를 포함한다. 우리는 CLIP 논문을 따라 80-prompts 앙상블 전략과 클래스 이름을 사용하는 CLIP zero-shot 분류기를 사용한다. 특히, ResNet-50 아키텍처를 사용했을 때, 이 분류기는 vanilla ImageNet에 대해 60.56%의 정확도를 달성한다. 우리는 분류기가 가장 낮은 정확도를 보이는 가장 어려운 클래스에 B2T를 적용한다.
ImageNet-R [26]은 ImageNet 클래스의 예술적 표현을 나타내는 30,000개의 validation 이미지를 포함한다. 우리는 1,000개 클래스 전체를 사용하여 분류기를 추론하지만, ImageNet-R 샘플은 200개 ImageNet 클래스의 부분집합에 속한다. ImageNet-C [25]는 ImageNet validation set의 손상된(corrupted) 버전을 포함하며, 눈(snow) 및 서리(frost) 손상 등이 있다. 각 손상된 데이터셋은 vanilla ImageNet에 해당하는 50,000개의 이미지를 포함한다. B2T 키워드를 추출하기 위해, 우리는 각 validation set의 10%를 샘플링하고, 이를 원본 vanilla ImageNet의 동일한 수의 샘플과 결합한다.
우리는 PyTorch 모델 허브의 classic training recipe (V1)로 vanilla ImageNet에 대해 학습된 ResNet-50 분류기를 사용했으며, 이 분류기는 vanilla ImageNet에 대해 76.15%의 정확도를 달성했다. 이 분류기는 ImageNet-R, ImageNet-C snow, ImageNet-C frost에 대해 각각 52.8%, 64.6%, 67.7%의 정확도를 달성한다.
A.1.2 Inferring bias labels
Domino. Domino [17]는 CLIP embedding 공간에서 Gaussian mixture model (GMM)을 사용하여 "slice"라고 불리는 저성능 하위 그룹을 식별한다. 논문에서 제안된 파라미터에 따라, 우리는 와 에 대해 로그-likelihood 가중치 10을 사용하고, slice의 개수를 2로 설정한다. 각 클래스에 대해 validation 데이터로 slicing 함수를 학습시킨 다음, 이 학습된 slicing 함수를 test 데이터에 적용하여 soft slice 할당을 얻는다. 이 soft slice 할당은 AUROC 곡선을 구성하는 데 활용된다.
Failure Direction. Failure Direction [30]은 선형 Support Vector Machine (SVM)을 사용하여 모델의 실패 모드를 추출하고, 이를 CLIP feature 공간 내의 방향으로 표현한다. 우리는 validation 데이터로 클래스별 SVM을 학습시켜 test 데이터에 대한 decision value를 얻고, 이를 사용하여 AUROC 곡선을 구성한다.
B2T (ours). CelebA 데이터셋의 경우, 우리는 학습 샘플이 "man" 그룹에 속하는지 여부를 판단한다. Waterbirds 데이터셋의 경우, 학습 샘플의 배경이 "land" 또는 "water"인지 여부를 판단한다. zero-shot classifier를 효과적으로 활용하기 위해 여러 기술을 사용한다. 첫째, 공식 CLIP ImageNet zero-shot classification에서 제공하는 일반 템플릿을 사용한다. 둘째, 정보 추출 개선을 위해 데이터셋별 템플릿을 통합한다. 마지막으로, 다양한 B2T 키워드를 그룹 이름으로 사용하여 분류한다. 프롬프트는 "[일반 템플릿] + [데이터셋별 템플릿] + [그룹 이름]" 형식으로 생성되며, 예를 들어 "a photo of a bird in a forest"와 같다. 우리는 CLIP ResNet-50 모델을 사용한다. Table 7은 사용된 프롬프트 템플릿과 그룹 이름의 전체 목록을 보여준다.
A.2. Debiasing classifiers
Debiased DRO training.
우리는 [66]의 프로토콜에 따라 DRO-B2T 모델을 학습시킨다.
두 데이터셋 모두에 대해 ImageNet으로 사전학습된 ResNet-50 모델을 학습시키기 위해 momentum 0.9의 SGD optimizer를 활용한다.
CelebA 데이터셋의 경우, batch size 64, learning rate , weight decay 0.1, group adjustment 0로 설정하고 50 epoch 동안 학습한다.
Waterbirds 데이터셋의 경우, batch size 128로 설정하고 300 epoch 동안 학습한다.
하이퍼파라미터(learning rate, weight decay, group adjustment)는 validation worst-group accuracy를 기준으로 다음 탐색 공간에서 탐색한다:
.
우리는 가장 좋은 validation worst-group accuracy를 보인 epoch에서의 평균 및 worst-group test accuracy를 보고한다.
CLIP zero-shot prompting.
우리는 B2T로 추론된 bias 키워드를 prompt 템플릿의 끝에 추가하여 템플릿을 확장한다.
또한, CLIP zero-shot classifier를 활용하기 위해 ImageNet zero-shot 분류를 위해 제공된 일반 템플릿과 데이터셋별 템플릿을 사용한다.
Table 8은 양의 CLIP 점수를 가진 bias 키워드가 추가된 완전한 확장 템플릿을 보여준다.
예를 들어, Waterbirds 데이터셋의 landbird 클래스에 대한 prompt는 "a photo of a landbird in the forest."이다.
우리는 그룹 레이블을 추론하면서 가능한 모든 prompt 조합의 앙상블을 생성한다.
ResNet-50 image encoder가 포함된 사전학습된 CLIP 모델을 사용한다.
A.3. Ablation studies
Captioning 모델. 특별히 명시되지 않는 한, 우리는 Conceptual Captions [69]로 학습된 ClipCap [52] 모델을 빔 서치 없이 캡셔닝 모델로 사용한다. 또한, COCO로 학습된 BLIP [40] base 캡셔닝 모델과 LAVIS repository에서 제공하는 OPT-2.7b 아키텍처를 활용한 BLIP-2를 사용한다. CoCa [84]의 경우, open CLIP repository에서 제공하는 LAION-2b 데이터셋으로 사전학습된 ViT-L-14 backbone을 사용하며, LLaVA [45]의 경우, 2023년 9월에 학습된 v1.5-13B 모델을 사용한다.
Scoring 모델. 우리는 CLIP repository에서 제공하는 ViT-L/14 backbone을 가진 CLIP 모델을 사용한다. 또한, **LAION-2b 데이터셋 [67]으로 학습된 ViT-L/14 backbone을 가진 OpenCLIP [10]**과 LAVIS repository에서 제공하는 BLIP [40]의 base 버전 및 BLIP-2 [41]의 pretrain 버전을 사용한다.
키워드 추출. 우리는 YAKE [7] 알고리즘을 적용하여 잘못 예측되거나 생성된 샘플 코퍼스에서 편향 키워드를 추출한다. 최대 n-gram 크기는 3이며, 중복 제거 임계값 0.9를 사용하여 최대 20개의 키워드를 선택한다. 고빈도 단어의 경우, WordNet [49]을 사용하여 각 단어를 표제어(lemmatize)로 변환하여 단어를 계산한다.
Table 7. 그룹 레이블 추론을 위한 프롬프트 디자인.
| Dataset | Dataset-wise Template | Group Name |
|---|---|---|
| CelebA | - [group name] <br> - [group name] celebrity | 1. Male <br> - man <br> - male <br> 2. Non-male <br> - Empty string " " |
| Waterbirds | - [group name] <br> - bird on [group name] <br> - bird on a [group name] <br> - bird and a [group name] <br> - fowl on [group name] <br> - fowl on a [group name] <br> - fowl and a [group name] | 1. Land background <br> - forest <br> - woods <br> - tree <br> - branch <br> 2. Water background <br> - ocean <br> - beach <br> - surfer <br> - boat <br> - dock <br> - water <br> - lake |
Table 8. Zero-shot 분류기 편향 완화를 위한 프롬프트 디자인.
| Dataset | Dataset-wise Template | Class Name |
|---|---|---|
| CelebA | - [class name] <br> - [class name] man <br> - [class name] player <br> - [class name] person <br> - [class name] artist <br> - [class name] comedy <br> - [class name] film <br> - [class name] actor <br> - [class name] face | 1. Blond <br> - blond hair <br> - celebrity of blond hair <br> 2. Non blond <br> - non blond hair <br> - celebrity of non blond hair |
| Waterbirds | - [class name] <br> - [class name] on the forest <br> - [class name] with woods <br> - [class name] on a tree <br> - [class name] on a branch <br> - [class name] in the forest <br> - [class name] on the tree <br> - [class name] on the ocean <br> - [class name] on a beach <br> - [class name] on the lake <br> - [class name] with a surfer <br> - [class name] on the water <br> - [class name] on a boat <br> - [class name] on the dock <br> - [class name] on the rocks <br> - [class name] in the sunset <br> - [class name] with a kite <br> - [class name] on the sky <br> - [class name] is on flight <br> - [class name] is on flies | 1. Landbird <br> - landbird <br> 2. Waterbird <br> - waterbird |
B. Extension to Generative Models
우리는 B2T 프레임워크를 text-to-image (T2I) 생성 모델 [65]로 확장한다. 여기서 우리는 **편향(bias)**을 입력 조건과 생성된 속성 간의 spurious correlation [56]으로 정의한다. 즉, prompt를 통해 명시적으로 지정되지 않은 의도치 않은 속성들을 의미한다.
B.1. B2T for text-to-image (T2I) generative models
T2I generative model은 주어진 텍스트 설명 로부터 이미지 를 생성한다. 우리의 목표는 입력 prompt와 허위 상관관계(spuriously correlated)를 가지는 편향된 속성(biased attribute) 를 식별하는 것이다. 즉, 에 명시적으로 설명되어 있지 않음에도 불구하고, 생성된 이미지 가 편향된 속성 를 포함하는 경우를 말한다. 예를 들어, generative model이 "blond"라는 조건에 대해 여성 이미지만 생성한다면, 이는 "woman"이라는 속성이 "blond"라는 prompt와 허위 상관관계를 가질 수 있음을 시사한다.
Bias keywords. 편향된 속성 를 식별하기 위해, 우리는 분류기에서 잘못 예측된 키워드가 아닌, 생성된 이미지의 캡션에서 공통 키워드를 추출한다. 생성된 이미지에 나타나는 키워드는 의도된 텍스트 일 수도 있고, 의도치 않은 편향 일 수도 있으며, 사용자는 편향된 키워드의 후보군을 추론할 수 있다. "blond"라는 prompt에 조건화된 generative model의 경우, "woman"이라는 키워드(뿐만 아니라 "blond"도)가 자주 나타날 것이다.
SD score. 키워드가 편향을 나타내는지 검증하기 위해, 우리는 CLIP score와 유사한 점수를 정의한다. 우리의 점수는 기반 generative model이 T2I diffusion model [28]이라는 전제에 의존하지만, 원칙적으로 다른 generative model로 확장될 수 있다. 실험에서는 Stable Diffusion (SD) [65]을 사용하며, 우리의 metric을 SD score라고 부른다.
SD score는 생성된 이미지와 원본 prompt 또는 bias keyword 간의 diffusion score를 측정한다. 이는 생성된 이미지에 이미 존재하는 키워드(따라서 편향된 속성과 관련될 수 있는 키워드)만이 낮은 SD score를 가지도록 보장한다. 이 점수를 계산하기 위해, 우리는 원본 prompt 또는 bias keyword 에 조건화된 생성 이미지 의 diffusion score를 비교한다. 직관적으로, 생성된 이미지 가 이미 bias keyword를 반영하고 있다면, 조건 와 에 대한 diffusion score는 유사할 것이다. SD score는 다음과 같이 주어진다:
여기서 는 텍스트 에 조건화되어 생성된 이미지들의 집합이고, 는 텍스트 에 조건화된 이미지 의 diffusion score(즉, 이미지 를 조건 에 따르도록 업데이트하기 위한 데이터 공간에서의 gradient)이며, 는 -norm을 나타낸다. SD score는 generative model 자체의 diffusion score를 사용하므로, 기성 captioning model의 편향에 영향을 받지 않는다. 또한, SD score는 [12, 39]에서 탐구된 바와 같이, T2I diffusion model을 사용하여 이미지 가 클래스 와 에 대해 가지는 분류 신뢰도를 비교하는 분류기로 해석될 수 있다.
B.2. Experimental results
편향 발견 (Bias discovery)
우리는 [19, 47]의 prompt를 사용하여 Stable Diffusion [65]에 B2T를 적용했으며, 그 결과 불공정한 이미지 생성이 발생했다. B2T는 직업과 성별 또는 인종 간의 허위 상관관계와 같은 알려진 편향을 찾아낸다. 예를 들어, Figure 8에서 보듯이, Stable Diffusion은 간호사를 "여성"과, 건설 노동자를 "남성"과 연관시키는데, 이는 성별 편향을 나타낸다. 또한 하녀를 "아시아인"과 연관시키는 것은 인종 편향을 나타낸다.
더 나아가, B2T는 동일한 prompt에서 알려지지 않은 편향도 밝혀낸다. 예를 들어, 간호사를 "청진기"와, 건설 노동자를 "모자"와, 아메리카 원주민을 "깃털"과 연관시키는 것은, 모델이 특정 직업과 민족의 외모에 기반한 고정관념을 가지고 있음을 시사한다.
T2I diffusion 모델의 편향 제거 (Debiasing T2I diffusion)
우리는 발견된 편향 키워드를 사용하여 T2I diffusion 모델인 Stable Diffusion [65]의 편향을 제거한다. 이를 위해 Fair Diffusion [19] 알고리즘을 적용하는데, 이 알고리즘은 생성 과정에서 이미지를 업데이트하는 데 사용되는 diffusion score를 조정하여, 지정된 키워드의 영향을 조절한다. Figure 9는 B2T가 발견한 편향 키워드를 활용한 Fair Diffusion이 앞서 언급된 편향들을 효과적으로 제거함을 보여준다. 우리의 접근 방식은 이미지의 불공정한 생성을 균형 있게 조절한다. 우리는 B2T가 공정한 T2I 생성 모델의 바람직한 사용을 촉진할 수 있다고 믿는다.
| Prompt | "a photo of a face of a nurse" | "a photo of a face of a maid" | "a photo of a face of a construction worker" | "a photo of a face of a native American" |
|---|---|---|---|---|
| Generated images |  |  |  |  |
| B2T keywords | woman, stethoscope | woman, girl, young, asian | man, hardhat, site | man, Indian, feathers |
Figure 8. T2I 생성 모델에서 편향 발견. 생성된 이미지와 해당 편향 키워드 및 prompt의 시각적 예시. B2T는 직업과 허위로 연결되는 성별 및 인종과 같은 알려진 편향을 성공적으로 찾아낸다 [19, 47]. 또한 B2T는 "청진기"와 "간호사"의 짝짓기와 같은 새로운 허위 상관관계도 발견하는데, 이는 모델이 특정 직업이나 민족의 외모에 기반한 고정관념을 가지고 있음을 시사한다.
 Figure 9. T2I diffusion 모델의 편향 제거. B2T가 발견한 편향 키워드를 사용하여 Stable Diffusion의 허위 상관관계를 제거한다. B2T는 불공정한 속성인 "청진기" 또는 "(안전)모자"의 생성을 효과적으로 균형 있게 조절한다.
Figure 9. T2I diffusion 모델의 편향 제거. B2T가 발견한 편향 키워드를 사용하여 Stable Diffusion의 허위 상관관계를 제거한다. B2T는 불공정한 속성인 "청진기" 또는 "(안전)모자"의 생성을 효과적으로 균형 있게 조절한다.
C. Additional DRO Results
C.1. Multi-class debiasing
우리는 더 많은 클래스를 가진 데이터셋에 대해 추가 실험을 수행한다. 우리는 MetaShift [81] 데이터셋의 2-클래스 및 10-클래스 설정을 사용하는데, 이 데이터셋은 각각 고양이와 개 클래스 간의 실내(indoor) 및 실외(outdoor) 속성과 관련된 spurious correlation을 다루는 것을 목표로 한다.
먼저, 우리는 ERM classifier에 B2T를 적용하여 고양이의 경우 "street", "parked"와 같은 실외 키워드를, 개의 경우 "room", "sleeping"과 같은 실내 키워드를 얻는다.
그 다음, 이 키워드들을 사용하여 DRO 학습을 수행하고, 이를 baseline ERM 및 ground-truth label을 사용하는 oracle DRO와 비교한다. 아래 표는 worst-group accuracy를 보여주며, 소수 하위 그룹의 가중치 변화를 나타낸다 (낮은 값은 더 강한 bias를 의미한다). DRO-B2T (우리의 방법)는 2-클래스 및 10-클래스 시나리오 모두에서 좋은 성능을 보인다.
Table 9. 다중 클래스 디바이징 (Multi-class debiasing). DRO-B2T (우리의 방법)는 다중 클래스 디바이징 시나리오에서도 작동한다.
| 2 Class | 10 Class | |||||||
|---|---|---|---|---|---|---|---|---|
| GT | ||||||||
| ERM | - | 50.00 | 47.92 | 37.50 | 68.58 | 67.01 | 63.19 | |
| DRO-B2T (ours) | - | 74.54 | 69.91 | 51.62 | 70.08 | 69.33 | 65.16 | |
| DRO | 77.78 | 70.60 | 52.55 | 68.75 | 70.66 | 66.32 |
C.2. Nonsensical groups
키워드를 통한 DRO subgroup 정의는 사람의 감독 없이도 문제가 되지 않는다.
- CLIP 점수가 높은 키워드는 소수 그룹을 잘 대표하므로, 감독 없이도 의미 있는 subgroup을 정의할 수 있다.
- 키워드가 무의미하더라도, subgroup은 무작위로 샘플링된 부분집합이 되므로, DRO 결과에 영향을 미치지 않는다.
이를 검증하기 위해, 우리는 CelebA blond 데이터셋에 대해 추가적인 DRO 실험을 수행했다. 이 실험에서는 편향 키워드 "man"과 함께 무의미한 키워드 "face"를 사용했다. 표에서 보듯이, 무의미한 키워드는 결과에 아무런 영향도 미치지 않았다. 마지막으로, 편향의 주관적인 특성 때문에 인간의 모니터링은 여전히 필요하며, 우리의 목표는 인간을 대체하는 것이 아니라 보조하는 것이다.
Table 10. 무의미한 그룹 (Nonsensical groups). DRO-B2T (우리의 모델)은 무의미한 그룹 키워드를 사용해도 잘 작동한다.
| Keyword | Worst-group | Average |
|---|---|---|
| man | ||
| man+face |
D. Additional Analyses
D.1. Validation of the CLIP score
우리는 Figure 10에서 CelebA 데이터셋의 blond 클래스를, Figure 11에서 Waterbirds 데이터셋의 landbird 클래스를 사용하여 CLIP score의 효과를 보여준다.
 Figure 10. CLIP score의 효과 (CelebA의 blond 클래스). waterbird 클래스에서도 유사한 경향을 관찰할 수 있다.
Figure 10. CLIP score의 효과 (CelebA의 blond 클래스). waterbird 클래스에서도 유사한 경향을 관찰할 수 있다.
 Figure 11. CLIP score의 효과 (landbird 클래스). waterbird 클래스에서도 유사한 경향을 관찰할 수 있다.
Figure 11. CLIP score의 효과 (landbird 클래스). waterbird 클래스에서도 유사한 경향을 관찰할 수 있다.
D.2. Comparison of bias discovery methods
우리는 B2T를 기존의 비지도 편향 발견(unsupervised bias discovery) 방법인 JTT [44], Domino [17], Failure Direction [30]과 비교한다. Figure 12는 B2T가 기존 방법들을 크게 능가하며, 고려된 모든 시나리오에서 거의 최적에 가까운 성능을 달성함을 보여준다.
 Figure 12. 편향 발견 방법 비교.
(a) CelebA blond (male), (b) Waterbird (waterbird on land), (c) Landbird (landbird on water) 클래스에 대한 AUROC 곡선이며, 괄호 안은 해당 **소수 그룹(minority group)**을 나타낸다. B2T는 기존 연구들보다 훨씬 뛰어난 성능을 보인다.
Figure 12. 편향 발견 방법 비교.
(a) CelebA blond (male), (b) Waterbird (waterbird on land), (c) Landbird (landbird on water) 클래스에 대한 AUROC 곡선이며, 괄호 안은 해당 **소수 그룹(minority group)**을 나타낸다. B2T는 기존 연구들보다 훨씬 뛰어난 성능을 보인다.
D.3. Keyword extraction
우리는 YAKE 알고리즘을 단순한 high-frequency 방식 및 또 다른 인기 있는 키워드 추출 알고리즘인 FRAKE와 비교한다. Table 11에 나타난 바와 같이, 추출된 키워드들은 대부분의 방법에서 서로 공유된다. 모든 키워드 추출 방법에서 CelebA blond 클래스에서는 "man"과 같은, Waterbirds의 waterbird 및 landbird 클래스에서는 각각 "forest"와 "water"와 같은 **상당한 편향(bias)**이 관찰된다. 각 방법별 20개의 키워드는 Table 11에 보고되어 있다.
Table 11. 다양한 키워드 추출 방법
| (a) High Frequency | |
|---|---|
| Keywords | |
| CelebA blond | actor, person, hair, film, premiere, player, actress, face, model, comedy, former, love, woman, like, artist, style, man, want, first, contestant |
| Waterbird | specie, biological, bird, tree, garden, person, forest, saw, prey, one, wood, bamboo, wild, rainforest, paradise, pond, rock, wall, selected, art |
| Landbird | specie, biological, beach, bird, person, water, fly, seagull, rock, sky, dog, seen, lake, city, pond, parrot, yellow, one, saw, sunset |
| (b) FRAKE | |
| Keywords | |
| CelebA blond | actor person, actor premiere comedy film, person model actress, actor, person, want hair like, hair, player, film, premiere, actress, model, face, comedy, love, man, like, style, artist, contestant |
| Waterbird | biological species bird prey, biological bamboo forest, species bamboo forest, biological, species, bird tree, bird, tree, person, rainforest, saw, garden, forest, photo, wild, bamboo, trees, pond, prey, woods |
| Landbird | biological species beach, bird flies water, bird beach, person beach, species, biological, bird, beach, person, water, flies, seagull, sits, sky, sunset, sea, paraglider, rocks, flight, city |
E. Additional Model Comparisons
Multimodal learning: ERM vs. CLIP.
Table 12는 ERM과 CLIP으로 학습된 ViT-B 모델을 사용하여 ImageNet-R에서 얻은 bias keyword를 비교한 결과이다. ERM은 "illustration" 및 "drawing"과 같은 분포 변화(distribution shift)를 bias keyword로 식별하며, 이들은 높은 CLIP 점수를 보인다. 반면, CLIP은 "dog"와 같은 다른 bias keyword를 식별하며, 낮은 CLIP 점수를 나타낸다. 이는 CLIP이 ERM에 비해 분포 변화의 영향을 덜 받음을 시사한다.
Table 12. ERM vs. CLIP 비교.
(a) ERM
| Score | |
|---|---|
| hand drawn illustration | 2.02 |
| drawing | 1.61 |
| hand drawn | 1.42 |
| vector illustration | 1.38 |
| tattoo | 1.27 |
| white vector illustration | 1.22 |
| illustration | 1.09 |
| sketch | 1.02 |
| step by step | 0.53 |
| digital art | 0.31 |
(b) CLIP
| Score | |
|---|---|
| dog | 0.64 |
| art | 0.55 |
| art selected | 0.53 |
| person | 0.48 |
| tattoo | 0.48 |
| drawing | 0.45 |
| painting | 0.42 |
| step by step | 0.36 |
| made | 0.31 |
| digital art selected | 0.30 |
Self-supervised learning: ERM vs. DINO vs. MAE.
Table 13은 ImageNet-R을 사용하여 학습된 DINO [8] 및 MAE [23] 기반 ViT-B 모델과 앞서 언급된 ERM에서 얻은 bias keyword를 비교한 결과이다. DINO는 ERM과 유사한 bias keyword를 제공하는 반면, MAE는 CLIP 점수가 낮은 keyword를 제공한다. 직관적으로, ERM과 DINO 모두 MAE보다 분포 변화(distribution shift)에 대한 강건성(robustness)이 떨어진다는 것을 알 수 있다.
Table 13. DINO vs. MAE 비교.
| (a) DINO | (b) MAE | ||
|---|---|---|---|
| Score | Score | ||
| hand drawn illustration | 2.13 | drawn vector illustration | 1.69 |
| drawn vector illustration | 2.06 | cartoon illustration | 1.61 |
| cartoon illustration | 1.86 | tattoo | 1.45 |
| white vector illustration | 1.70 | white vector illustration | 1.31 |
| vector art illustration | 1.63 | vector art illustration | 1.27 |
| vector illustration | 1.53 | vector illustration | 1.20 |
| tattoo | 1.48 | drawing | 1.20 |
| white background vector | 1.38 | white background vector | 1.05 |
| art | 0.97 | art | 0.84 |
| digital art | 0.90 | person | 0.78 |
F. Further Discussion of Limitations
우리는 **captioning 모델(예: ClipCap [52])**과 **scoring 모델(예: CLIP [59])**을 사용하여 이미지 분류기의 편향을 발견한다. 그러나 이러한 모델들 자체도 편향될 위험이 존재한다 [2, 18]. 따라서 사용자는 추출된 caption에 전적으로 의존해서는 안 되며, 공정한 머신러닝 시스템 개발에는 여전히 인간 심사위원의 참여가 필수적이다.
예를 들어, ClipCap과 CLIP은 대부분 자연 이미지(natural images)로 학습되었기 때문에, 의료 또는 위성 이미지와 같은 전문 분야 [51]에서는 효과가 떨어진다. 이를 확인하기 위해 우리는 B2T를 ChestX-ray14 [78] 및 FMoW [11] 데이터셋에 적용한다. 분류기로는 ChexNet [62] 및 WILDS [35] 코드베이스에 공개된 분류기를 사용하며, FMoW의 경우 ERM classifier seed 0을 활용한다.
Figure 13은 이미지와 해당 caption을 시각화한 것이다. ClipCap은 흉부 이미지에 대해 "broken nose"와 같은 무의미한 caption을 생성하거나, 항공 뷰 이미지에 대해 "city from the air"와 같은 피상적인(trivial) caption을 생성한다. 결과적으로, B2T를 효과적으로 적용하려면 전문화된 captioning 모델을 학습해야 한다.
| (a) ChestX-14ray | (b) FMoW | |||
|---|---|---|---|---|
| Samples |  |  |  | |
| Actual | no disease | disease | crop field | Parking lot or garage |
| Pred. | disease | no disease | debris or rubble | place of worship |
| Caption | a picture of a patient with a broken nose. | a picture of a woman with a broken neck. | a small village in the middle of the desert. | a city from the air. |
Figure 13. (a) ChestX-ray 14 및 (b) FMoW 데이터셋의 시각적 예시.
G. Additional Visual Examples
| (a) CelebA blond | (b) Waterbirds | |||||||
|---|---|---|---|---|---|---|---|---|
| Keyword | Man | Player | Bamboo | Woods | Beach | Water | ||
| Samples |  |  |  |  |  | |||
| Actual | blond | blond | blond | blond | waterbird | waterbird | landbird | landbird |
| Pred. | not blond | not blond | not blond | not blond | landbird | landbird | waterbird | waterbird |
| Caption | actor is a man of many talents. | actor, the man behind the voices. | the most important player in the history of hockey. | football player has been named the player of the year. | biological species in a bamboo forest. | biological species - i saw one of these in the woods. | biological species on the beach. | a bird in the water. |
Figure 14. CelebA 및 Waterbirds의 추가 시각적 예시.
| Keyword | Illustration | Drawing | ||
|---|---|---|---|---|
| Samples |  |  | 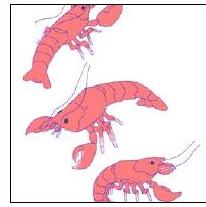 |  |
| Actual | African chameleon | basketball | American lobster | bee |
| Pred. | oscilloscope | knee pad | handkerchief | necklace |
| Caption | vector illustration of a frog. | cartoon illustration of a basketball [...] | a drawing of a crab. | a drawing of a bee. |
Figure 15. ImageNet-R의 추가 시각적 예시.
| (a) ImageNet-C snow | (b) ImageNet-C frost | |||||||
|---|---|---|---|---|---|---|---|---|
| Keyword | Snow | Rain | Window | Glass | ||||
| Samples |  |  |  |  |  |  | ||
| Actual | Afghan hound | Afghan hound | mosquito net | mosquito net | grasshopper | grasshopper | green snake | green snake |
| Pred. | fountain | Afghan hound | shower cap | mosquito net | African chameleon | grasshopper | rock beauty | green snake |
| Caption | a horse in the snow. | person, the dog of the day. | the umbrella in the rain. | the baby in the tent. | a green chameleon on a window sill. | a green grasshopper on my finger. | a frog in a glass of water. | a green frog in the jungle. |
Figure 16. ImageNet-C의 추가 시각적 예시.
| Keyword | - | Cave | - | Fire | - | Bucket | - | Hole |
|---|---|---|---|---|---|---|---|---|
| Samples |  |  |  |  |  |  | ||
| Actual | wardrobe | wardrobe | stove | stove | plate rack | plate rack | toilet seat | toilet seat |
| Pred. | wardrobe | poncho | stove | caldron | plate rack | oil filter | toilet seat | wheelbarrow |
| Caption | the back of the wardrobe. | the cave is full of surprises. | a stove for the kitchen. | a fire in the kitchen. | a man is putting a lot of plates in the dishwasher. | a bucket of water and a few tools. | a toilet in the bathroom. | the hole in the ground. |
| Country (Income) | Romania ($6256/month) | Tanzania ($32/month) | United States ($855/month) | Togo ($321/month) | India ($2499/month) | Cote d'Ivoire ($8/month) | Mexico ($898/month) | Cameroon ($137/month) |
Figure 17. Dollar Street 클래스의 시각적 예시.
| Keyword | Baby | Red <br> Pendant | Fighter | |
|---|---|---|---|---|
| Samples |  |  |  |  |
| Actual | Christmas stocking | mushroom | chain | military aircraft |
| Pred. | baby bib | agaric | necklace | airplane wing |
| Caption | how to make a christmas sweater for your baby. | a red mushroom in the grass. | a bracelet made from a recycled pendant. | a fighter jet in flight. |
| Keyword | Street | Office | Dish | Concert |
| Samples |  |  |  |  |
| Actual | plastic bag | notebook | broccoli | electric guitar |
| Pred. | poncho | desk | plate | stage |
| Caption | a homeless man begging on the streets. | the office of person, who is now. | the finished dish with a side of broccoli. | the band performs a live concert. |
Figure 18. ImageNet 클래스의 추가 시각적 예시.
H. Complete Lists of the B2T Keywords
이미지 분류기의 **편향 키워드(bias keywords)**와 그에 해당하는 CLIP 점수(scores) 및 하위 그룹 정확도(subgroup accuracies). CLIP 점수가 높을수록, 하위 그룹 정확도가 낮을수록 편향이 더 심각함을 나타낸다.
Table 14. CelebA blond에 대한 편향 키워드 후보.
| (a) Blond (base acc.: 86.0) | ||
|---|---|---|
| Score | Acc. | |
| man | 1.22 | 38.2 |
| player | 0.42 | 27.8 |
| person | 0.17 | 79.8 |
| artist | 0.16 | 69.6 |
| comedy | 0.16 | 88.2 |
| film | 0.13 | 88.3 |
| actor | 0.08 | 88.2 |
| face | 0.06 | 88.5 |
| love | 0.06 | 91.3 |
| clothing | 0.05 | 93.5 |
| outfit | 0.05 | 93.5 |
| hair | 0.02 | 91.2 |
| style | 0.00 | 92.2 |
| weight | -0.06 | 93.6 |
| clothing style | -0.08 | 93.5 |
| model | -0.19 | 95.5 |
| premiere | -0.52 | 89.1 |
| premiere of comedy | -0.63 | 86.2 |
| model and actress | -1.00 | 82.7 |
| actress | -1.28 | 83.3 |
| (b) Not blond (base acc.: 97.2) | ||
|---|---|---|
| Score | Acc. | |
| model | 0.50 | 96.9 |
| favorite outfit | 0.34 | 94.8 |
| hair | 0.33 | 94.4 |
| love | 0.17 | 96.7 |
| style | 0.14 | 94.7 |
| premiere | 0.11 | 98.0 |
| clothing style | 0.09 | 94.8 |
| outfit | 0.08 | 94.8 |
| favorite | 0.08 | 94.8 |
| feet size | 0.06 | 94.8 |
| clothing | 0.06 | 94.8 |
| film | 0.00 | 98.3 |
| weight | -0.03 | 94.8 |
| face | -0.05 | 97.3 |
| feet | -0.06 | 94.8 |
| size | -0.08 | 94.8 |
| comedy | -0.25 | 96.5 |
| person | -0.28 | 97.5 |
| bob | -0.50 | 93.2 |
| actor | -0.98 | 97.5 |
Table 15. Waterbirds에 대한 편향 키워드 후보.
| (a) Waterbird (base acc.: 75.6) | (b) Landbird (base acc.: 89.9) | ||||
|---|---|---|---|---|---|
| Score | Acc. | Score | Acc. | ||
| forest | 2.12 | 61.5 | ocean | 3.41 | 44.4 |
| woods | 1.94 | 62.5 | beach | 2.83 | 74.7 |
| tree | 1.45 | 41.7 | surfer | 2.73 | 55.6 |
| branch | 1.20 | 35.7 | boat | 2.16 | 64.7 |
| prey | 0.20 | 70.0 | dock | 1.56 | 75.0 |
| wild | 0.19 | 75.0 | water | 1.38 | 75.0 |
| bird of prey | -0.03 | 66.7 | lake | 1.17 | 80.0 |
| species | -0.05 | 74.2 | rocks | 1.02 | 76.5 |
| area | -0.09 | 0.0 | sunset | 0.88 | 70.0 |
| biological species | -0.11 | 74.2 | kite | 0.67 | 64.6 |
| bird in flight | -0.27 | 50.0 | sky | 0.28 | 84.2 |
| biological | -0.28 | 74.2 | flight | 0.23 | 62.5 |
| bird | -0.36 | 62.5 | flies | -0.17 | 73.3 |
| person | -0.41 | 81.3 | person | -0.38 | 86.9 |
| bird flying | -0.42 | 75.0 | pond | -0.47 | 87.0 |
| eagle | -0.69 | 95.5 | biological species | -0.48 | 95.5 |
| bald | -0.69 | 60.0 | biological | -0.55 | 93.4 |
| snow | -0.80 | 66.7 | species in flight | -0.92 | 44.4 |
| great bird | -0.80 | 0.0 | species | -0.97 | 93.4 |
| large bird | -1.05 | 50.0 | bird | -1.64 | 93.8 |
Table 16. ImageNet-R 및 ImageNet-C에 대한 편향 키워드 후보.
(a) ImageNet-R (base acc.: 52.8)
| Score | Acc. | |
|---|---|---|
| hand drawn illustration | 2.02 | 19.4 |
| drawing | 1.61 | 29.2 |
| hand drawn | 1.42 | 20.2 |
| vector illustration | 1.38 | 26.1 |
| tattoo | 1.27 | 12.2 |
| white vector illustration | 1.22 | 29.2 |
| illustration | 1.09 | 20.5 |
| sketch | 1.02 | 16.2 |
| step by step | 0.53 | 25.8 |
| digital art | 0.31 | 23.2 |
(b) ImageNet-C snow (base acc.: 64.6)
| Score | Acc. | |
|---|---|---|
| snow falling | 3.05 | 27.9 |
| rain falling | 2.58 | 0.9 |
| rain drops falling | 2.52 | 26.1 |
| rain drops | 2.25 | 26.7 |
| rain | 2.14 | 51.6 |
| snow | 1.83 | 54.2 |
| water drops | 1.52 | 32.3 |
| falling | 1.33 | 27.5 |
| water | 1.02 | 51.1 |
| day | 0.53 | 67.9 |
(c) ImageNet-C frost (base acc.: 67.7)
| Score | Acc. | |
|---|---|---|
| room | 0.97 | 53.4 |
| glass | 0.83 | 47.1 |
| window | 0.81 | 55.9 |
| snow | 0.70 | 70.8 |
| water | 0.58 | 65.5 |
| person playing | 0.52 | 65.3 |
| tree | 0.39 | 72.2 |
| person | 0.33 | 65.7 |
| dogs playing | 0.31 | 50.0 |
| car | 0.31 | 62.4 |
Table 17. Dollar Street에 대한 편향 키워드 후보.
(a) Wardrobe (base acc.: 60.7)
| Score | Acc. | |
|---|---|---|
| cave | 1.83 | 0.0 |
| laundry | 1.05 | 33.3 |
| man | 0.67 | 0.0 |
| pile | 0.34 | 50.0 |
| sleeps | 0.30 | 0.0 |
| living | -0.01 | 0.0 |
| shed | -0.48 | 0.0 |
| clothes | -0.99 | 72.7 |
| full | -1.10 | 71.4 |
| room | -1.22 | 58.3 |
(c) Plate rack (base acc.: 24.3)
| Score | Acc. | |
|---|---|---|
| bucket | 0.78 | 3.8 |
| water | 0.78 | 3.0 |
| small | 0.13 | 25.0 |
| sink | 0.03 | 29.5 |
| food | -0.02 | 11.8 |
| full | -0.51 | 21.6 |
| laundry | -0.52 | 22.2 |
| kitchen | -1.13 | 32.3 |
| dishes | -1.41 | 25.0 |
| collection | -1.42 | 21.1 |
(b) Stove (base acc.: 50.0)
| Score | Acc. | |
|---|---|---|
| burns | 0.90 | 0.0 |
| fire | 0.80 | 0.0 |
| fireplace | 0.05 | 0.0 |
| cat | 0.04 | 0.0 |
| sits | -0.17 | 0.0 |
| room | -0.17 | 0.0 |
| small | -0.51 | 50.0 |
| sink | -0.62 | 0.0 |
| kitchen | -1.60 | 50.0 |
| stove | -1.64 | 61.5 |
(d) Toillet seat (base acc.: 46.0)
| Score | Acc. | |
|---|---|---|
| hole | 0.65 | 0.0 |
| house | 0.10 | 62.3 |
| property | 0.04 | 80.0 |
| basement | -0.09 | 42.9 |
| man | -0.17 | 42.9 |
| image | -1.03 | 81.6 |
| small | -1.03 | 23.5 |
| room | -1.50 | 58.1 |
| bathroom | -3.50 | 59.6 |
| toilet | -4.70 | 71.4 |
Table 18. ImageNet에 대한 편향 키워드 후보.
(a) Ant (base acc.: 30.0)
| Score | Acc. | |
|---|---|---|
| flowers | 1.08 | 14.7 |
| flower | 1.03 | 20.9 |
| bee | 0.99 | 12.9 |
| tree | 0.86 | 19.1 |
| spider | 0.78 | 29.5 |
| fly | 0.75 | 24.2 |
| beetle | 0.58 | 30.4 |
| leaf | 0.32 | 27.3 |
| close | 0.12 | 33.3 |
| black | 0.10 | 18.1 |
(c) Stethoscope (base acc.: 69.1)
| Score | Acc. | |
|---|---|---|
| baby | 1.23 | 24.4 |
| boy | 1.23 | 28.0 |
| girl | 0.71 | 36.2 |
| person | 0.51 | 36.2 |
| student | 0.44 | 30.4 |
| nurse | 0.01 | 72.9 |
| doctor | -0.81 | 88.4 |
| hospital | -0.87 | 56.1 |
| medical | -0.99 | 88.3 |
| stethoscope | -3.04 | 93.3 |
(b) Horizontal bar (base acc.: 70.8)
| Score | Acc. | |
|---|---|---|
| swings | 7.01 | 6.3 |
| playground | 5.09 | 9.5 |
| park | 4.63 | 3.6 |
| swing | 4.31 | 12.5 |
| child | 3.47 | 27.7 |
| plays | 2.83 | 20.7 |
| girl | 2.52 | 22.0 |
| playing | 2.14 | 4.1 |
| person | 1.35 | 65.2 |
| boy | 1.10 | 20.0 |
(d) Monastery (base acc.: 53.0)
| Score | Acc. | |
|---|---|---|
| interior | 1.12 | 17.6 |
| built | 0.53 | 54.2 |
| cathedral | 0.35 | 36.7 |
| person | 0.29 | 60.5 |
| century | 0.06 | 58.8 |
| city | 0.03 | 56.7 |
| church | -0.01 | 53.3 |
| temple | -0.16 | 46.9 |
| courtyard | -0.50 | 58.5 |
| town | -0.64 | 60.6 |