A²FA & F²SGD: 앵커 프레임과 2D 유사도 공간을 활용한 Video Moment Retrieval
본 논문은 Video Moment Retrieval (VMR) 작업의 두 가지 주요 과제인 쿼리와 비디오 프레임 간의 정확한 정렬 및 시간 경계 예측을 해결하기 위한 새로운 프레임워크를 제안합니다. 제안된 A²FA (Anchor-Aware Feature Alignment)는 VLM을 통해 쿼리와 가장 관련성이 높은 '앵커 프레임'을 식별하고, 이를 중심으로 의미적으로 응집된 세그먼트를 구성하여 관련 프레임에 대한 쿼리 정렬을 유도합니다. 이 과정을 통해 관련 프레임 간의 유사도가 높아지며, F²SGD (Frame-Frame Similarity Guided Detection)는 이를 활용해 시간 경계 예측 문제를 2D 유사도 공간에서의 단일 지점 탐지 문제로 변환합니다. 이 접근 방식은 프레임 의미와 시간 경계 간의 정보 격차를 효과적으로 해소하여 기존 방법론들보다 뛰어난 성능을 달성합니다. 논문 제목: Anchor-Aware Similarity Cohesion in Target Frames Enables Predicting Temporal Moment Boundaries in 2D
Tan, Jiawei, et al. "Anchor-Aware Similarity Cohesion in Target Frames Enables Predicting Temporal Moment Boundaries in 2D." Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
Anchor-Aware Similarity Cohesion in Target Frames Enables Predicting Temporal Moment Boundaries in 2D
Jiawei Tan , Hongxing Wang , Junwu Weng , Jiaxin Li , Zhilong Ou , Kang Dang <br> School of Big Data and Software Engineering, Chongqing University, China<br> Key Laboratory of Dependable Service Computing in Cyber Physical Society (Chongqing University), Ministry of Education, China<br> ByteDance Intelligent Creation<br> School of AI and Advanced Computing, XJTLU Entrepreneur College (Taicang), Xi'an Jiaotong-Liverpool University, Suzhou, China<br>{jwtan, ihxwang}@cqu.edu.cn, we0001wu@e.ntu.edu.sg, jiaxin_li@cqu.edu.cn, zlou@stu.edu.cn, Kang.Dang@xjtlu.edu.cn
Abstract
**비디오 모먼트 검색(Video moment retrieval)**은 쿼리 텍스트에 따라 비디오에서 특정 모먼트를 찾는 것을 목표로 한다. 이 task는 두 가지 주요 과제를 제시한다: i) 쿼리와 비디오 프레임을 feature 수준에서 정렬(align)하는 것, ii) 쿼리 정렬된 프레임 feature를 일치하는 구간의 시작 및 끝 경계로 투영(project)하는 것.
기존 연구들은 일반적으로 모든 프레임을 feature 정렬에 포함시켜, 쿼리와 관련 없는 프레임이 정렬되는 문제를 쉽게 야기했다. 또한, 시각 feature를 구간 경계에 강제로 매핑했지만, 그들 사이의 정보 격차(information gap)를 무시하여 최적화되지 않은 성능을 보였다.
본 연구에서는 관련 없는 프레임으로부터의 방해를 줄이기 위해, 기존의 Vision-Language Model로 측정된 최대 쿼리-프레임 관련성(relevance)을 가진 프레임을 앵커 프레임(anchor frame)으로 지정한다. 앵커 프레임과 다른 프레임들 간의 유사도 비교를 통해, 우리는 앵커 프레임 주변에 의미적으로 응집된 세그먼트(semantically compact segment)를 생성한다. 이 세그먼트는 쿼리와 관련 프레임의 feature를 정렬하는 가이드 역할을 한다.
우리는 이러한 feature 정렬이 타겟 프레임들 간의 유사도를 응집력 있게 만들 것이며, 이를 통해 프레임의 2D semantic similarity 공간에서 단일 지점 감지(single point detection)를 통해 구간 경계를 예측할 수 있음을 관찰했다. 이는 프레임 의미론과 시간적 경계 사이의 정보 격차를 효과적으로 해소한다.
다양한 데이터셋에 걸친 실험 결과는 우리의 접근 방식이 쿼리와 비디오 프레임 간의 정렬을 크게 개선하는 동시에 시간적 모먼트 경계를 효과적으로 예측함을 보여준다. 특히, QVHighlights Test 및 ActivityNet Captions 데이터셋에서 우리의 제안된 접근 방식은 현재 state-of-the-art R1@.7 성능보다 각각 3.8% 및 7.4% 더 높은 성능을 달성했다. 코드는 https://github.com/ExMorgan-Alter/AFAFSGD에서 확인할 수 있다.
1. Introduction
Video Moment Retrieval (VMR)은 자연어 쿼리를 기반으로 비디오에서 의미적으로 가장 관련성이 높은 세그먼트의 시작 및 종료 타임스탬프를 찾는 것을 목표로 한다. 이는 비디오 하이라이트 감지 [24] 및 비디오 요약 [12]을 포함한 광범위한 응용 분야를 가진다.
비디오와 텍스트 간의 **모달리티 간극(modality gap)**으로 인해 VMR은 공유 feature space에서 두 모달리티를 정렬해야 한다. 이를 위해 대부분의 기존 방법들 [17, 25, 26]은 **Vision-Language Model (VLM)**에 의존하여 쿼리 텍스트 feature를 프레임 feature에 임베딩한다. 그러나 이들은 텍스트 정보를 모든 비디오 프레임에 주입하는 경향이 있어, 관련 없는 프레임이 텍스트와 정렬되는 문제를 겪기 쉽다. 쿼리 텍스트와 실제로 관련 있는 프레임이 무엇인지 알 수 없기 때문에, 관련 없는 프레임 선택을 완화하는 것은 어려운 일이다. 본 연구에서는 Figure 1에서 보듯이, 쿼리와 가장 관련성이 높은 비디오 프레임이 VLM 기반의 쿼리-프레임 유사도 랭킹을 통해 다른 프레임들보다 두드러지게 나타나는 경향이 있음을 관찰했다. 이는 이전 VLM 관련 방법들 [17, 18, 27, 35, 36]에서 간과되었던 점이다. 쿼리 관련 프레임을 더 많이 포착하기 위해, 우리는 가장 높은 순위의 관련 프레임을 앵커(anchor)로 설정하여, 각 프레임이 앵커 프레임과 강한 시각-텍스트 유사도를 가지는 의미적으로 응집된 세그먼트(semantically compact segment)를 선택한다. 이 의미적으로 응집된 세그먼트는 풍부한 의미적 가이드를 제공하여, feature space에서 향상된 쿼리-프레임 정렬을 위한 집중적인 attention을 가능하게 한다. 이러한 맥락에서, 우리는 비디오 프레임 표현을 쿼리 표현과 더 잘 정렬되도록 적응시키기 위한 앵커 인식 feature 정렬(anchor-aware feature alignment, ) 스킴(Figure 3 및 4)을 제안한다.
비디오 모멘트는 시작부터 끝 경계까지의 시간 간격으로 결정되므로, feature space에서의 쿼리-프레임 정렬만으로는 두 시간 경계를 얻을 때까지 VMR의 목표를 달성할 수 없다. 기존 방법들은 프레임 feature에 의존하여 후보 간격이 목표 간격일 확률을 추정하거나 [9, 33, 40], 프레임 feature를 간격 경계로 직접 회귀시킨다 [18, 20, 35, 39]. 그러나 이들은 프레임의 의미와 시간 경계 간의 본질적인 정보 이질성(information heterogeneity)을 무시하고 프레임 feature를 시간 경계로 강제로 변환하여, 최적화되지 않은 검색 성능을 초래한다. 이러한 간극을 해소하기 위해, 우리는 정렬된 프레임 feature의 속성을 feature space에서 시간 경계 space로 나아가는 디딤돌로 탐색한다. Figure 2에서 예시된 바와 같이, 정렬되지 않은 프레임 feature와 비교할 때, 쿼리 관련 정렬된 프레임 feature는 서로 높은 유사성을 보인다. 높은 유사도 값을 가진 블록의 오른쪽 상단 모서리 위치 좌표는 매칭 간격의 시작 시간과 종료 시간을 정확히 암시한다. 이러한 관찰은 Frame-Frame Similarity Guided Detection (F SGD) (Figure 3)를 설계하도록 영감을 주었으며, 여기서는 간격 경계 예측을 2D 유사도 space에서의 단일 지점 감지 문제로 재구성한다. 이러한 방식으로, feature와 시간 경계 간의 정보 이질성은 프레임 간의 유사도를 기반으로 자연스럽게 보상된다. 특히, 우리의 방법은 1D 쿼리-프레임 유사도 space에서 간격 경계 감지를 수행하는 것을 피한다. 1D 공간에서는 시작 및 종료 경계 감지를 분리하여 수행하고 추가적인 후처리(post-processing)가 필요하기 때문이다. 대신, 시작 및 종료 타임스탬프가 결합된 2D 유사도 space에서 작동함으로써, 우리의 접근 방식은 후처리 필요성을 제거한다.
Query: A group of young people check into their AirBnB and love it.
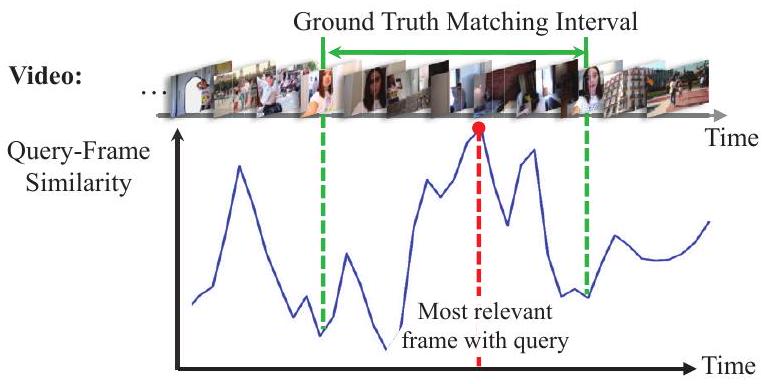
Figure 1. 인기 VLM인 CLIP [29]을 통해 얻은 쿼리-프레임 유사도. ground-truth 매칭 간격 내의 모든 프레임이 쿼리와 높은 유사도를 보이는 것은 아니지만, 가장 관련성이 높은 프레임은 거의 항상 ground-truth 내에 나타난다. 또한, 매칭 프레임들은 의미적으로 서로 관련되어 있으며, 이는 쿼리와 비디오 프레임 간의 더 나은 모달리티 정렬을 위해, 쿼리 관련성이 가장 높은 프레임(우리는 이를 앵커(anchor)라고 지칭)으로부터 나머지 프레임으로 유사도를 전파하도록 동기를 부여한다.
 Figure 2. VMR이 2D 유사도 space에서 단일 지점 감지로 변환되는 방식에 대한 설명. 쿼리 관련 정렬된 프레임 feature는 정렬되지 않은 프레임 feature에 비해 서로 높은 유사도를 보인다. 쿼리에 대한 목표 매칭 간격 의 경우, 시작 시간 와 종료 시간 는 프레임-프레임 유사도 행렬에서 높은 값 블록의 오른쪽 상단 모서리의 2D 좌표 ()와 정확히 일치한다. 이러한 관찰은 프레임 feature와 시간 경계 간의 정보 간극을 좁힐 수 있게 한다.
Figure 2. VMR이 2D 유사도 space에서 단일 지점 감지로 변환되는 방식에 대한 설명. 쿼리 관련 정렬된 프레임 feature는 정렬되지 않은 프레임 feature에 비해 서로 높은 유사도를 보인다. 쿼리에 대한 목표 매칭 간격 의 경우, 시작 시간 와 종료 시간 는 프레임-프레임 유사도 행렬에서 높은 값 블록의 오른쪽 상단 모서리의 2D 좌표 ()와 정확히 일치한다. 이러한 관찰은 프레임 feature와 시간 경계 간의 정보 간극을 좁힐 수 있게 한다.
요약하자면, 우리의 기여는 다음과 같다:
- 우리는 를 제안한다. 이는 확립된 VLM에 의해 식별된 앵커 프레임을 의미적으로 관련된 프레임과 연결하여, feature space에서 쿼리 텍스트와 관련 비디오 프레임의 **표적화된 정렬(targeted alignment)**을 가능하게 한다.
- VMR 분야에서, 우리는 프레임 feature와 시간 경계 간의 정보 간극을 해소하기 위해, 프레임 feature space가 아닌 2D 유사도 space에서 시간 경계 감지를 수행한 최초의 연구이다.
- 우리는 세 가지 VMR 데이터셋인 QVHighlights [18], CharadesSTA [8], ActivityNet Captions [16]에 대해 포괄적인 평가를 수행했다. 우리의 제안 방법은 이전 접근 방식들을 큰 폭으로 능가한다.
2. Related Work
비디오 모먼트 검색(Video moment retrieval)은 주어진 쿼리 문장에 대해 의미적으로 일관된 비디오 클립을 식별하고 해당 클립의 시작 및 끝 경계를 출력하는 것을 목표로 한다. 이를 달성하기 위해서는 텍스트와 비디오 모달리티를 정렬할 뿐만 아니라, 정렬된 시각적 표현을 클립의 시간적 좌표에 매핑해야 한다. 아래에서는 이 두 가지 측면에서 관련 방법들을 논의한다.
Video-Text Modality Alignment는 쿼리 텍스트와 관련 프레임의 feature 간 유사성을 향상시키는 것을 목표로 한다. 이를 위해 이전 방법들 [3, 4, 38]은 쿼리 텍스트 feature를 관련 프레임 feature에 임베딩한다. 비디오 이해를 위한 Vision-Language Model (VLM) 채택의 최근 성공 [10, 14]에 힘입어, 많은 방법들 [20, 22, 32, 34]이 VLM에서 얻은 프레임별 feature를 기반으로 구축된다. 대부분의 방법들 [23, 25, 27, 30, 37]은 cross-attention 메커니즘 [31]을 사용하여 쿼리 텍스트 feature를 관련 프레임 feature에 주입한다. 그러나 이들은 모든 프레임을 쿼리 텍스트 정보로 임베딩하여, 관련 없는 프레임까지 쿼리 텍스트와 정렬시키는 결과를 초래한다. 관련 없는 프레임의 개입을 완화하기 위해, 우리는 이전 VLM 방법들 [9, 13, 23, 25, 26, 35]이 간과했던 사실을 활용한다: 쿼리와 가장 관련 있는 비디오 프레임은 VLM 기반 쿼리-프레임 유사도 랭킹을 통해 다른 비디오 프레임들로부터 두드러질 수 있다. 이러한 방식으로, 우리는 상위 랭크된 관련 프레임과 나머지 프레임 간의 의미적 관계를 기반으로 의미적으로 압축된 세그먼트를 취하여, feature 수준에서 텍스트를 비디오 프레임과 정렬하는 의미적 가이드로 사용한다.
 Figure 3. 비디오 모먼트 검색을 위한 제안된 방법. Anchor-Aware Feature Alignment (A²FA, 자세한 내용은 Fig. 4 참조)를 통해 쿼리 텍스트와 비디오 프레임 간의 feature 공간 정렬을 강화하여, 쿼리 관련 프레임 간의 높은 유사도를 유도한다. 이는 다시 **Frame-Frame Similarity Guided Detection (F²SGD)**을 통해 프레임 feature를 정밀한 시간적 경계로 변환하는 것을 용이하게 한다. (M)은 행렬 곱셈을 나타낸다.
Figure 3. 비디오 모먼트 검색을 위한 제안된 방법. Anchor-Aware Feature Alignment (A²FA, 자세한 내용은 Fig. 4 참조)를 통해 쿼리 텍스트와 비디오 프레임 간의 feature 공간 정렬을 강화하여, 쿼리 관련 프레임 간의 높은 유사도를 유도한다. 이는 다시 **Frame-Frame Similarity Guided Detection (F²SGD)**을 통해 프레임 feature를 정밀한 시간적 경계로 변환하는 것을 용이하게 한다. (M)은 행렬 곱셈을 나타낸다.
Moment Localization은 정렬된 프레임 feature를 일치하는 구간의 시작 및 끝 타임스탬프에 투영하는 것을 포함한다. 열거 기반(Enumeration-based) [9, 40] 및 앵커 기반(anchor-based) 방법들 [21, 22]은 후보 구간이 쿼리와 일치하는지 평가하는 반면, 회귀 기반(regression-based) 방법들 [36, 39]은 feature를 해당 시간적 쌍에 직접 투영한다. 그러나 이러한 방법들은 정렬 feature를 구간 좌표에 강제로 매핑하여, 시각적 의미와 좌표 간의 정보 이질성을 무시함으로써 최적의 검색 성능을 달성하지 못한다. 이와 대조적으로, 우리는 프레임 feature 간의 유사도를 통해 프레임 feature와 시간적 경계 사이의 간극을 연결한다. 우리는 2D 프레임 유사도 공간에서 높은 유사도를 가진 블록의 우상단 모서리 위치 좌표를 식별하여 대상 구간의 시작 및 끝 경계를 결정한다.
3. Method
3.1. Problem Formulation
주어진 untrimmed video ( 개의 샘플링된 프레임 포함)와 query sentence 에 대해, **비디오 세그먼트 검색(video segment retrieval)**은 query와 관련된 프레임으로 구성된 세그먼트의 시작 와 끝 경계를 식별하는 detector 를 학습하는 것을 목표로 한다.
query의 도움 없이는 query와 관련된 프레임이 전체 비디오에서 두드러지지 않기 때문에, query 정보를 query와 관련된 프레임에 주입하여 **더욱 판별력 있는 정렬된 프레임 feature 를 생성하는 메커니즘 **가 필요하다. 이를 통해 는 에 작용하여 더 나은 경계 탐지를 수행할 수 있다.
본 연구에서는 Fig. 3에 나타난 바와 같이, 를 위해 **Anchor-Aware Feature Alignment ()**를, 를 위해 **Frame-Frame Similarity Guided Detection ()**를 제안한다.
3.2. Anchor-Aware Feature Alignment
서로 다른 modality의 비디오 와 쿼리 를 표현하기 위해, 우리는 frozen pre-trained CLIP [29] 인코딩을 모두에 사용하는 널리 사용되는 방식을 따른다. CLIP 인코딩을 통해, 비디오에 대해서는 개의 프레임 -차원 feature 를 얻고, 쿼리 문장에 대해서는 문장 수준의 쿼리 feature 를 얻는다.
시각 및 텍스트 modality 간의 이질성을 고려할 때, 쿼리 문장을 일치하는 비디오 프레임과 feature 수준에서 정렬(align)하는 것이 필수적이다. 정렬의 핵심은 일치하는 프레임과 쿼리 문장 간의 유사성을 최대화하는 것이다. 이를 위해 우리는 **anchor-aware feature alignment (A²FA)**를 제안한다. 이는 비디오에서 anchor-aware segment를 가져와 비디오 모먼트 검색에서 modality 정렬을 안내한다.
Anchor-Aware Mask 생성. 우리는 잠재적으로 일치하는 프레임에 초점을 맞추기 위해 anchor-aware mask를 설계한다. 일치하는 프레임은 시각적 및 텍스트적 수준 모두에서 서로 의미적으로 유사해야 하므로, 우리는 다음 query-frame 유사도 가중치를 기반으로 쿼리 feature 를 프레임 feature 에 임베딩하여, query-embedded visual feature 를 얻는다:
여기서 는 입력 feature 간의 코사인 유사도를 나타낸다.
그런 다음 우리는 에 의존하여 anchor-aware mask를 생성한다. 먼저, 쿼리와 가장 유사한 anchor frame을 식별하며, 이는 다음으로 인덱싱된다:
 Figure 4. 제안된 A²FA에서 re-weighting 및 aligning 단계의 세부 사항. 우리는 query-aggregated visual feature를 비교하여 프레임 feature를 재가중한다. 재가중 후, 프레임 feature는 frame-text 점수를 기반으로 쿼리 feature와 더 잘 정렬된다.
Figure 4. 제안된 A²FA에서 re-weighting 및 aligning 단계의 세부 사항. 우리는 query-aggregated visual feature를 비교하여 프레임 feature를 재가중한다. 재가중 후, 프레임 feature는 frame-text 점수를 기반으로 쿼리 feature와 더 잘 정렬된다.
직관적으로, anchor frame과 의미적으로 관련된 프레임은 쿼리와 일치할 가능성이 높다. 이를 위해 우리는 **dynamic time warping (DTW)**을 적용하여 각 구간 및 에서 **의미적 전환점(semantic transition point)**을 감지한다. 이를 통해 의미적 전환점의 양쪽에서 의미적 연결을 최대화할 수 있다 [28]. 우리는 두 의미적 전환점을 과 로 나타내며, 이는 다음을 통해 얻을 수 있다:
결과적으로, 우리는 anchor frame 에 의미적으로 관련된 구간을 얻는다:
이는 쿼리에 대한 후보 일치(candidate matching)에 대한 대략적인 추정치를 제공하며, 예측 결과로 직접 사용될 수는 없다.
을 기반으로, 우리는 다음으로 anchor-aware mask 을 정의한다. 이는 anchor frame과 의미적으로 관련 없는 프레임을 마스킹하고, 의미적으로 관련된 프레임은 쿼리-프레임 feature 정렬 동안 마스킹되지 않도록 유지한다.
프레임 Feature 재가중(Re-weighting). 내의 일부 프레임은 쿼리와 관련이 없을 수 있다. 이 문제를 해결하기 위해, Fig. 4에 나타난 바와 같이, 우리는 query-aggregated visual feature를 각 프레임과 비교하여 프레임 수준 feature를 재가중한다. 구체적으로, 우리는 cross-attention 메커니즘을 사용하여 문장 feature 를 attention query로 매핑하고, 프레임 feature 를 attention key 및 value로 매핑하여 집계 과정을 안내한다. 이 과정은 쿼리와 관련된 프레임 feature를 융합하여 query-aggregated visual feature 를 형성한다:
여기서 , 는 학습 가능한 행렬이다. 우리는 쿼리와 관련된 프레임에 높은 점수를 할당하기 위해 를 각 시각적 표현과 추가로 비교하여 쿼리 관련성 점수 를 얻는다:
여기서 및 는 학습 가능한 행렬이고, 및 는 학습 가능한 스케일이며, 는 hyperbolic tangent 활성화 함수이다. 재가중된 프레임 feature 는 다음으로 계산된다:
쿼리 및 프레임 표현 정렬(Aligning Query and Frame Representations). 을 얻은 후, 우리는 이를 쿼리 feature 와 정렬하는 과정을 진행한다. Fig. 4에 나타난 바와 같이, 우리는 재가중된 프레임 feature와 쿼리 텍스트 간의 관계를 다음과 같이 평가한다:
여기서 는 frame-text 일치 점수를 나타내고, 및 는 학습 가능한 행렬이다.
그 후, 우리는 를 기반으로 쿼리 정보를 프레임 수준 feature에 임베딩하여 정렬된 프레임 feature 를 다음과 같이 얻는다:
가 1에 가까울수록, -번째 프레임의 정렬된 시각 feature는 쿼리 feature 에 더 가까워지며, 이를 통해 -번째 프레임의 정렬된 시각 feature와 쿼리 feature 간의 유사성이 최대화된다.
3.3. Frame-Frame Similarity Guided Detection
관련 프레임들이 쿼리 텍스트 정보로 풍부해지고 비디오 프레임 feature 시퀀스에서 더 잘 구별되더라도, 이러한 프레임 feature와 VMR이 요구하는 구간의 시작 및 끝 좌표 사이에는 정보 격차가 존재한다. 프레임 feature를 시간적 경계로 원활하게 변환하기 위해, 우리는 정렬된 프레임 feature의 특성을 활용하여 새로운 detector인 **frame-frame similarity guided detection (FSGD)**를 제안한다. 구체적으로, 정렬된 프레임 feature는 매칭되는 구간 내 프레임 간의 유사도를 자연스럽게 높이는 반면, 매칭되는 프레임과 매칭되지 않는 프레임 간의 유사도는 약화시킨다. Fig. 2에서 보여진 바와 같이, 매칭되는 구간 내의 프레임들은 프레임 간 유사도 행렬(inter-frame similarity matrix)에서 높은 값의 블록으로 표현된다. 우연히도, 높은 값의 정사각형 블록의 오른쪽 상단 모서리는 매칭되는 구간의 시작 및 끝 타임스탬프에 해당한다.
공식적으로, Fig. 3에 나타난 바와 같이, 와 사이의 코사인 유사도인 를 항목으로 하는 정렬된 프레임 유사도 행렬 가 주어졌을 때, 우리는 높은 값의 정사각형 블록의 오른쪽 상단 꼭짓점(vertex)을 감지하는 것을 목표로 한다. 이를 달성하기 위해, 우리는 에 CNN 기반 네트워크를 적용하고, 이어서 다층 퍼셉트론(MLP)을 사용하여 의 각 위치가 높은 값의 정사각형의 오른쪽 상단 꼭짓점일 확률을 추정하여 꼭짓점 점수 행렬 을 얻는다:
여기서 는 커널 크기가 인 두 개의 convolutional layer로 구성되며, 는 MLP classifier이다.
3.4. Training and Inference
학습을 위해 우리는 예측된 vertex score matrix와 ground truth 간의 제곱 원소별 차이(squared element-wise differences)에 페널티를 부여하는 평균 제곱 오차(MSE) loss를 사용하며, 이는 다음과 같이 정의된다:
여기서 는 ground truth matrix이며, ground truth 시작 및 종료 타임스탬프 에 해당하는 값은 1로 설정되고, 나머지 모든 요소는 0이다.
추론 시에는 에서 상위 개 값의 인덱스를 예측된 구간 경계 로 선택한다:
여기서 는 후보 구간의 개수이다. 여러 비디오 세그먼트를 검색할 때는 이고, 그렇지 않은 경우에는 이다.
4. Experiments
4.1. Settings
데이터셋 (Datasets)
우리는 세 가지 대규모 Video Moment Retrieval (VMR) 벤치마크 데이터셋으로 우리의 방법을 평가한다:
- QVHighlights [18]: 10,148개의 비디오를 포함하며, 각 비디오는 약 150초 길이이다. 모든 비디오에는 최소 하나의 query가 주석되어 있으며, 평균 query 길이는 11.3단어이다. 각 query의 목표 moment는 평균 24.6초의 지속 시간을 가진다. 이 데이터셋은 학습용 7,218개 query, 검증용(줄여서 val) 1,150개 query, 테스트용 1,542개 query로 구성된다. 테스트 세트는 공정한 비교를 위해 Codalab에 보관되어 있다. [18, 25, 27]을 따라, 우리는 학습용으로 training split을 사용하고, val 및 test split을 모두 테스트용으로 사용하며, val split을 ablation 연구용으로 사용한다.
- ActivityNet Captions [16]: 20,000개의 비디오로 구성되며, 각 비디오는 평균 2분 길이이고, 72,000개의 query-segment 쌍을 포함한다. 각 query는 평균 13.5단어를 포함한다. 이 데이터셋은 training (37,421쌍), val-1 (17,505쌍), val-2 (17,031쌍) 서브셋으로 나뉜다. 이전 연구들 [1, 35]을 따라, 우리는 training set을 학습용으로, val-1을 검증용으로, val-2를 테스트용으로 사용한다.
- Charades-STA [8]: 9,848개의 실내 비디오로 구성되며, 각 비디오는 평균 30.6초 길이이다. 16,128개의 query-moment 쌍을 포함하며, 학습 세트 12,408쌍과 테스트 세트 3,720쌍으로 나뉜다.
평가 지표 (Metrics)
VMR에 가장 일반적으로 사용되는 지표는 **R1@**와 **mAP@**이다.
**R1@**는 상위 1개로 검색된 moment 중 IoU(Intersection over Union)가 보다 큰 비율을 측정한다. 우리는 값이 0.5와 0.7일 때의 R1@ 결과를 보고한다.
**mAP@**는 특정 값(IoU 임계값)에서의 평균 정밀도(AP)를 계산하며, mAP@Avg는 여러 값에 대한 평균 정밀도(mAP)의 평균을 반환한다. 우리는 mAP@에 대해 를 사용하고, mAP@Avg에 대해서는 범위를 0.5부터 0.95까지 0.05 단위로 증가시키며 사용한다.
구현 세부 사항 (Implementation details)
프레임 샘플링 빈도는 이전 방법들 [17, 18, 26]과 일치한다.
QVHighlights 및 ActivityNet Captions 데이터셋의 경우, 2초마다 한 프레임을 추출한다.
Charades-STA의 경우, 비디오 길이가 더 짧기 때문에 초당 한 프레임을 추출한다.
프레임 feature는 **CLIP visual extractor (ViT-B/32)**를 사용하여 인코딩되며, 문장 feature는 CLIP text extractor를 사용하여 얻는다.
Eq. (13)의 convolution size 는 QVHighlights 데이터셋의 경우 21이고, Charades-STA 및 ActivityNet Captions 데이터셋의 경우 27이다.
이전 방법들 [18, 25, 26]을 따라, QVHighlights 데이터셋에서 candidate interval의 수 는 10이고, 다른 데이터셋에서는 1이다.
모델 가중치는 Xavier [7]로 초기화된다. 우리는 **Adam optimizer [15]**를 batch size 128로 사용한다.
총 10 epoch의 학습 동안, 선형 warm-up 전략을 적용하여 초기 단계에서 학습률을 0.0001로 점진적으로 증가시킨 다음, 나머지 단계에서는 cosine schedule에 따라 학습률을 감소시킨다.
우리는 NVIDIA RTX 3060 GPU에서 모델을 학습시킨다.
4.2. Comparison with State-of-the-Art Methods
QVHighlights 결과
Table 1에서 볼 수 있듯이, QVHighlights 벤치마크에서 우리의 방법은 모든 지표에서 다른 모든 state-of-the-art (SOTA) 방법들을 크게 능가한다. 특히, CLIP backbone encoder를 활용하는 방법들 중에서는 우리의 방법이 SOTA 방법 [25]보다 test split에서 R1@.5에서 12.1%, R1@.7에서 12.2%, mAP@Avg에서 15.8% 더 우수한 성능을 보인다. 이러한 뛰어난 성능은 쿼리 텍스트 feature와 비디오 프레임 feature 간의 향상된 정렬(alignment), 그리고 프레임 feature와 temporal boundary 간의 정보 격차 해소에서 비롯된다. 주목할 점은, 우리의 방법이 쿼리와 관련 없는 프레임이 modality alignment에 참여하는 것을 방지하는 것을 목표로 하는 CG-DETR [26]을 능가한다는 것이다. 이는 우리의 feature alignment 의 우수성을 강조한다. 심지어 더 발전된 backbone encoder를 활용하는 Mr. BLIP [1]과 비교했을 때도, 우리의 방법은 test split에서 R1@0.5에서 6.0%, R1@0.7에서 3.8%, mAP@0.75에서 10.9%의 성능 향상을 보여준다. 이는 우리가 제안한 방법의 우수성을 더욱 부각시킨다.
| Method | Backbone | Val | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R1 | mAP | R1 | mAP | ||||||
| @. 5 | @. 7 | @. 75 | avg | @. 5 | @. 7 | @. 75 | Avg | ||
| Moment DETR [18] (NIPS'21) | CLIP | 53.5 | 34.1 | 30.8 | 32.4 | 55.8 | 33.8 | 31.2 | 32.7 |
| QD-DETR [27] (CVPR'23) | CLIP | 59.7 | 42.3 | 37.5 | 37.5 | 60.8 | 41.8 | 37.1 | 38.3 |
| EaTR [11] (ICCV'23) | CLIP | 54.9 | 36.0 | 33.5 | 34.1 | 54.6 | 34.0 | 32.6 | 33.2 |
| TR-DETR [30] (AAAI'24) | CLIP | 63.6 | 43.9 | 39.7 | 39.6 | 60.2 | 41.4 | 37.0 | 37.2 |
| UVCOM [34] (CVPR'24) | CLIP | 64.8 | 48.0 | 42.7 | 42.3 | 62.7 | 46.9 | 42.6 | 42.1 |
| CG-DETR [26] (CoRR'23) | CLIP | 66.6 | 49.9 | 44.2 | 43.9 | 64.5 | 46.0 | 41.6 | 41.8 |
| QD-VMR [6] (CoRR'24) | CLIP | 67.7 | 52.3 | 48.1 | 46.2 | 66.7 | 48.6 | 42.8 | 43.1 |
| BAM-DETR [17] (ECCV'24) | CLIP+SF | 65.1 | 51.6 | 48.6 | 47.6 | 62.7 | 48.6 | 46.3 | 45.4 |
| -Tuning [25] (ECCV'24) | CLIP | 67.7 | 51.9 | - | 47.9 | 68.7 | 52.1 | - | 47.6 |
| Mr. BLIP [1] (CoRR'24) | BLIP-2 | 76.1 | 63.4 | 55.8 | - | 74.8 | 60.5 | 53.4 | - |
| Ours | CLIP | 79.4 | 64.8 | 64.1 | 63.0 | 80.8 | 64.3 | 64.3 | 63.4 |
Table 1. QVHighlights val 및 test split에서 우리의 결과와 이전에 보고된 결과 비교. CLIP 또는 BLIP-2는 각각 CLIP [29] 또는 BLIP-2 [19]가 visual 및 text encoder로 적용되었음을 나타낸다. SF는 motion feature extractor SlowFast [5]를 의미한다. 가장 좋은 결과는 굵게 표시되었다. "-"는 결과가 공개되지 않았음을 의미한다.
ActivityNet Captions 결과
Table 2는 우리의 방법이 ActivityNet Captions 데이터셋에서 보고된 모든 SOTA 결과들을 능가하며, 그 효과를 입증한다. 더 나은 backbone을 사용하는 Mr. BLIP [1]과 비교했을 때도, 우리의 모델은 모든 지표에서 상당한 개선을 달성한다. 이 데이터셋에서의 결과는 QVHighlights 결과에서 도출된 결론과 일치한다.
| Method | Backbone | R1@.5 | R1@. 7 |
|---|---|---|---|
| Moment DETR [18] (NIPS'21) | CLIP | 36.1 | 20.4 |
| QD-DETR [27] (CVPR'23) | CLIP | 36.9 | 21.4 |
| UVCOM [34] (CVPR'24) | CLIP | 37.0 | 21.5 |
| CG-DETR [26] (CoRR'23) | CLIP | 38.8 | 22.6 |
| UnLoc-L [35] (ICCV'23) | CLIP | 48.3 | 30.2 |
| Mr. BLIP [1] (CoRR'24) | BLIP-2 | 53.9 | 35.6 |
| Ours | CLIP | 71.1 | 43.0 |
Table 2. ActivityNet Captions에서 우리의 결과와 이전에 보고된 결과 비교. CLIP 또는 BLIP-2는 각각 CLIP [29] 또는 BLIP-2 [19]가 visual 및 text encoder로 적용되었음을 나타낸다.
Charades-STA 결과
Table 3에서 볼 수 있듯이, 우리의 방법은 Charades-STA에서 다른 SOTA들을 능가한다. 그러나 QVHighlights 및 ActivityNet Captions에 비해 성능 향상 폭은 덜 유의미하다. 이는 Charades-STA 비디오의 짧은 비디오 길이 때문일 수 있으며, 이로 인해 타겟 구간을 구별하고 정확하게 지역화하는 것이 더 어려워진다. 그럼에도 불구하고, 우리의 모델은 경쟁력 있는 결과를 달성하며, 다양한 VMR 데이터 환경에서의 다재다능함을 보여준다.
| Method | Backbone | R1@.5 | R1@. 7 |
|---|---|---|---|
| Moment DETR [18] (NIPS'21) | SF+CLIP | 52.1 | 30.6 |
| QD-DETR [27] (CVPR'23) | SF+CLIP | 57.3 | 32.6 |
| UVCOM [34] (CVPR'24) | SF+CLIP | 59.3 | 36.6 |
| CG-DETR [26] (CoRR'23) | SF+CLIP | 58.4 | 36.3 |
| BAM-DETR [17] (ECCV'24) | SF+CLIP | 59.9 | 39.4 |
| -Tuning [25] (ECCV'24) | CLIP | 59.8 | 37.0 |
| UnLoc-L [35] (ICCV'23) | CLIP | 60.8 | 38.4 |
| UniMD+Sync. [39] (ECCV'24) | I3D+CLIP | 63.9 | 44.5 |
| Mr. BLIP [1] (CoRR’24) | BLIP-2 | 69.3 | 49.2 |
| Ours | CLIP | 83.8 | 50.1 |
Table 3. Charades-STA test split에서 우리의 결과와 이전에 보고된 결과 비교. CLIP 또는 BLIP-2는 각각 CLIP [29] 또는 BLIP-2 [19]가 visual 및 text encoder로 적용되었음을 나타낸다. SF 및 I3D는 motion feature extractor SlowFast [5] 및 I3D network [2]를 의미한다.
4.3. Ablation Studies
우리는 비디오 모먼트 검색(video moment retrieval)을 위한 제안 방법의 효과를 평가하기 위해 QVHighlights val 데이터셋에 대한 ablation study를 수행한다. 실험에서는 더 도전적인 R1@.7 및 mAP@Avg 지표를 사용한다. 또한, 모델 파라미터 비교 및 시각화와 같은 추가 결과는 supplementary에 포함되어 있다.
 Figure 5. QVHighlights val split에서 쿼리와 매칭 구간 또는 비매칭 구간 간의 코사인 유사도 분포를 보여준다. (a) 정렬 전, (b) CG-DETR [26]에 의한 정렬, (c) 우리의 에 의한 정렬을 포함한다.
Figure 5. QVHighlights val split에서 쿼리와 매칭 구간 또는 비매칭 구간 간의 코사인 유사도 분포를 보여준다. (a) 정렬 전, (b) CG-DETR [26]에 의한 정렬, (c) 우리의 에 의한 정렬을 포함한다.
유사도를 응집력 있게 만드는 제안된 의 효과.
Fig. 5는 정렬 전후의 쿼리와 매칭 또는 비매칭 구간 간의 유사도 분포를 보여준다. 정렬 후 결과를 더 잘 비교하기 위해, 관련 없는 프레임 정렬을 제거하는 데 특화된 SOTA 방법인 CG-DETR [26]의 유사도 분포를 함께 제시한다. CG-DETR 정렬 후에도 두 분포가 여전히 겹치는 반면, 우리의 방법은 두 분포를 명확하게 분리시킨다. 이는 우리의 가 프레임 feature 공간에서 매칭 구간과 비매칭 구간을 효과적으로 구별함을 보여준다.
2D 유사도 공간을 사용하여 시간적 경계를 감지하는 장점.
Fig. 6은 2D 유사도 공간 기반의 제안된 SGD 방법과 프레임 feature를 시간적 경계로 강제 매핑하는 일부 대표적인 detector들을 비교한다. 구체적으로, TAN [40]은 열거된 구간이 쿼리와 일치할 확률을 추정하는 반면, DETR-like 방법 [18]은 Transformer를 사용하여 매칭 구간의 중심과 길이를 예측한다. BR [20]은 convolutional network를 사용하여 시작 및 끝 경계를 회귀한다. 제안된 SGD는 이러한 경쟁 방법들을 능가하며, 2D 유사도 공간에서 시간적 경계 감지의 장점을 입증한다.
다양한 VLM에 의해 생성된 anchor-aware masks ()의 영향.
Table 4는 Eq. (6)에 정의된 생성에 사용되는 CLIP [29] 및 BLIP-2 [19]를 포함한 다양한 VLM의 성능을 비교한다. BLIP-2와 같은 더 발전된 VLM이 생성에 사용될수록 우리 방법의 성능이 더 우수하며, 이는 생성 방법이 다양한 VLM과 호환됨을 나타낸다. 또한, encoder로서의 VLM 선택보다 생성용 VLM 선택이 방법 성능에 더 큰 영향을 미친다.
Eq. (5)로부터 구간을 정제할 필요성.
Table 5는 Eq. (5)에 의해 대략적으로 추정된 의 예측 능력과 Eq. (15)에 의해 최종적으로 정제된 결과를 비교한다. 만으로는 대상 구간을 정확하게 매칭할 수 없지만, 이를 마스크로 우리 방법에 통합하면 성능이 크게 향상되며, 이는 후속 정제에서 우리 방법의 필요성을 강조한다.
 Figure 6. TAN [40], DETR [18], boundary regression (BR) [20]을 포함하여 프레임 feature를 좌표로 강제 변환하는 다른 detector들과 우리의 를 비교한다.
Figure 6. TAN [40], DETR [18], boundary regression (BR) [20]을 포함하여 프레임 feature를 좌표로 강제 변환하는 다른 detector들과 우리의 를 비교한다.
| Backbone | Avg | ||
|---|---|---|---|
| CLIP | CLIP | 64.8 | 63.0 |
| BLIP-2 | 66.0 | 65.1 | |
| BLIP-2 | CLIP | 64.8 | 63.1 |
| BLIP-2 | 66.1 | 65.6 |
Table 4. 다양한 VLM에 의해 생성된 anchor-aware masks ()의 성능.
| Method | R1@.7 | mAP@Avg |
|---|---|---|
| Intermediate results by Eq. (5) | 23.8 | 31.4 |
| Final results by Eq. (15) | 64.8 | 63.0 |
Table 5. Eq. (5)의 중간 결과와 Eq. (15)의 최종 결과 비교.
구성 요소 ablation.
Table 6은 우리 방법의 각 구성 요소가 전체 성능에 기여하는 바를 평가한 결과를 보여준다. 첫 번째 행은 모먼트 검색에 프레임-쿼리 유사도만 사용한 baseline 결과를 나타낸다. 제안된 모듈을 도입한 후, R1@0.7 및 mAP@Avg는 각각 34.4%와 35.7%로 증가하며, 이는 2D 유사도 공간에서 시간적 경계를 감지하는 것의 중요성을 강조한다. 'Align' 모듈을 추가하여 지표가 개선된 것은 쿼리 관련 프레임과 관련 없는 프레임 간의 관계를 고려하는 것의 이점을 더욱 강조한다. 'Reweight' 모듈은 최적의 성능을 달성하기 위해 추가되었다.
 Figure 7. 제안된 방법과 SOTA 방법인 TaskWeave [36] 및 UVCOM [34]의 시각화된 비교. GT는 참조를 위한 ground-truth 매칭 구간을 나타낸다.
Figure 7. 제안된 방법과 SOTA 방법인 TaskWeave [36] 및 UVCOM [34]의 시각화된 비교. GT는 참조를 위한 ground-truth 매칭 구간을 나타낸다.
| A FA | F SGD | R1@.7 | mAP@Avg | |
|---|---|---|---|---|
| Reweight | Align | |||
| - | - | - | 5.2 | 7.7 |
| - | - | 39.6 | 43.3 | |
| - | 57.6 | 56.4 | ||
| 64.8 | 63.0 |
Table 6. Sec. 3.2의 와 Sec. 3.3의 의 다양한 포함에 대한 제안 방법의 ablation study. 는 "포함됨"을, -는 "제외됨"을 의미한다.
| Method | Alignment | R1@.7 | mAP@Avg |
|---|---|---|---|
| MRNet-S [9] | Original | 46.6 | 41.6 |
| 47.7 | 46.8 | ||
| Moment-DETR [18] | Orignal | 34.1 | 32.4 |
| 49.1 | 48.1 | ||
| UniVTG [20] | Original | 40.9 | 35.5 |
| 55.8 | 55.4 |
Table 7. 다양한 방법들의 정렬 모듈을 우리의 로 대체했을 때의 성능.
의 플러그인 가능성.
Table 7은 Sec. 3.2에서 언급된 경쟁 방법들과 우리의 제안된 를 TAN [40], DETR [18], Regression [20]을 포함한 다양한 detector와 결합했을 때의 성능을 보고한다. 모든 조합에서 FA는 경쟁 방법들을 능가하며, 그 우수성과 플러그 앤 플레이 호환성을 입증한다.
SGD의 플러그인 가능성.
Table 8은 다양한 정렬 방법과 결합했을 때의 제안된 SGD의 성능을 보여준다. 결과는 SGD가 원래의 대안들보다 일관되게 성능을 향상시키며, 이는 어떤 정렬 방법에도 적용 가능한 일반성과 다양한 정렬 기술 전반에 걸친 이점을 강조한다.
SGD의 Convolution kernel size.
Table 9는 에서 convolution kernel size 를 변화시켰을 때의 영향을 보고한다. kernel size가 21로 설정되었을 때 모든 성능 지표가 최고점을 찍으며, 이는 SGD가 QVHighlights 데이터셋에서 다양한 길이의 매칭 구간을 효과적으로 인지할 수 있도록 한다.
| Method | Detection | R1@.7 | mAP@Avg |
|---|---|---|---|
| UVCOM [34] | Original | 47.5 | 43.2 |
| SGD | 51.1 | 49.1 | |
| CG-DETR [26] | Original | 52.1 | 44.9 |
| SGD | 55.8 | 49.6 | |
| TaskWeave [36] | Original | 50.1 | 45.4 |
| SGD | 52.4 | 47.8 |
Table 8. 다양한 방법들의 원래 시간적 경계 감지 모듈을 우리의 SGD로 대체했을 때의 비교.
| 17 | 21 | 25 | 29 | |
|---|---|---|---|---|
| R1@.7 | 63.9 | 64.8 | 64.1 | 63.6 |
| mAP@Avg | 62.4 | 63.0 | 62.3 | 62.4 |
Table 9. 의 convolution kernel size 의 영향.
검색 결과 시각화.
Fig. 7에서는 QVHighlights val 데이터셋에 대한 VMR의 샘플 결과를 제시한다. 참조를 위해 ground-truth annotation을 제공하며, 비교를 위해 이전 state-of-the-art 방법인 **TaskWeave [36] 및 UVCOM [34]**도 포함한다. TaskWeave와 UVCOM 모두 VLM을 feature extractor로만 사용하고 프레임 feature를 대상 구간 경계로 직접 회귀시키므로, 정확하지 않은 구간 경계 위치를 초래한다. 이와 대조적으로, 우리 방법이 예측한 구간은 대상 구간과 높은 중첩을 보이며, 이는 우리의 목표 모달리티 정렬과 프레임 feature와 시간적 경계 간의 정보 격차를 해소하는 능력 덕분이다.
5. Conclusion
우리는 VMR을 위한 새로운 프레임워크를 제안한다. 제안하는 는 anchor-aware mask를 통해 feature modality를 정렬하여, 쿼리 관련 프레임 유사도(query-related frame similarities)의 응집력을 높인다. 이는 우리의 SGD가 2D 유사도 공간에서 temporal boundary를 효과적으로 감지하도록 하여, 프레임 feature와 temporal boundary 사이의 간극을 좁힌다. 공개 데이터셋에서의 실험 결과는 제안된 접근 방식이 이전 SOTA보다 효과적이고 우수함을 보여준다.
Acknowledgments
본 연구는 중국 국가자연과학기금(National Natural Science Foundation of China)의 61976029번 과제와 충칭 기술 혁신 및 응용 개발 핵심 프로젝트(Key Project of Chongqing Technology Innovation and Application Development)의 cstc2021jscxgksbX0033번 과제의 지원을 받아 수행되었다.