AVIGATE: Gated Attention으로 오디오를 효과적으로 활용하는 Video-Text Retrieval
Video-text retrieval에서 기존 방법들은 오디오 정보를 무시하거나, 관련 없는 오디오 신호가 오히려 성능을 저하시키는 문제가 있었습니다. AVIGATE는 gated attention 메커니즘을 통해 유용한 오디오 정보는 선택적으로 활용하고 불필요한 노이즈는 필터링하여 비디오 표현을 효과적으로 학습하는 새로운 프레임워크입니다. 또한, adaptive margin-based contrastive loss를 도입하여 비디오와 텍스트 간의 정렬을 개선합니다. 이를 통해 AVIGATE는 주요 벤치마크에서 최고 수준의 검색 성능을 달성하며 오디오를 활용한 검색의 새로운 가능성을 제시합니다. 논문 제목: Learning Audio-guided Video Representation with Gated Attention for Video-Text Retrieval
Jeong, Boseung, et al. "Learning Audio-guided Video Representation with Gated Attention for Video-Text Retrieval." Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
Learning Audio-guided Video Representation with Gated Attention for Video-Text Retrieval
Abstract
Video-text retrieval은 텍스트 쿼리를 기반으로 비디오를 검색하거나 그 반대로 수행하는 task로, 비디오 이해 및 멀티모달 정보 검색에 매우 중요하다. 이 분야의 최근 방법들은 주로 시각 및 텍스트 feature에 의존하며, 오디오가 비디오 콘텐츠의 전반적인 이해를 향상시키는 데 도움이 됨에도 불구하고 종종 오디오를 무시한다. 더욱이, 오디오를 통합하는 전통적인 모델들은 오디오 입력이 유용한지 여부와 관계없이 맹목적으로 오디오 입력을 활용하여, 최적화되지 않은 비디오 표현을 초래한다. 이러한 한계점을 해결하기 위해, 우리는 **Audio-guided VIdeo representation learning with GATEd attention (AVIGATE)**이라는 새로운 video-text retrieval 프레임워크를 제안한다. AVIGATE는 gated attention mechanism을 통해 오디오 신호 중 정보성이 낮은 부분을 선택적으로 필터링하여 오디오 단서를 효과적으로 활용한다. 또한, 우리는 비디오와 텍스트 간의 본질적으로 불분명한 긍정-부정 관계를 다루기 위해 adaptive margin-based contrastive loss를 제안하며, 이는 더 나은 video-text alignment 학습을 촉진한다. 우리의 광범위한 실험은 AVIGATE가 모든 공개 벤치마크에서 state-of-the-art 성능을 달성함을 보여준다.
1. Introduction
비디오-텍스트 검색(video-text retrieval)은 텍스트 쿼리에 해당하는 비디오를 찾거나 그 반대의 작업을 수행하는 task로, 비디오 이해 및 멀티모달 정보 검색 분야의 다양한 응용 분야에서 큰 관심을 받고 있다. 이 분야의 대부분 기존 방법들은 주로 비디오의 시각 정보와 함께 제공되는 메타데이터 또는 캡션의 텍스트 정보를 활용하는 데 중점을 두었다 [6, 9, 10, 14, 21, 24, 25, 26, 34]. 이러한 방법들이 비디오-텍스트 검색을 크게 발전시켰지만, 여전히 중요한 한계점을 가지고 있다: 바로 비디오의 오디오 정보를 간과한다는 점이다. 오디오 정보는 화자의 신원, 배경 소음, 감정적 뉘앙스와 같이 비디오를 포괄적으로 이해하는 데 필수적인 '보이지 않지만 들리는' 단서를 제공한다. Figure 1(a)에서 보여주듯이, 비디오 표현 학습에서 오디오 정보를 활용하는 것은 더욱 풍부한 멀티모달 비디오 표현을 제공함으로써 검색 성능을 크게 향상시킬 잠재력을 가지고 있다.
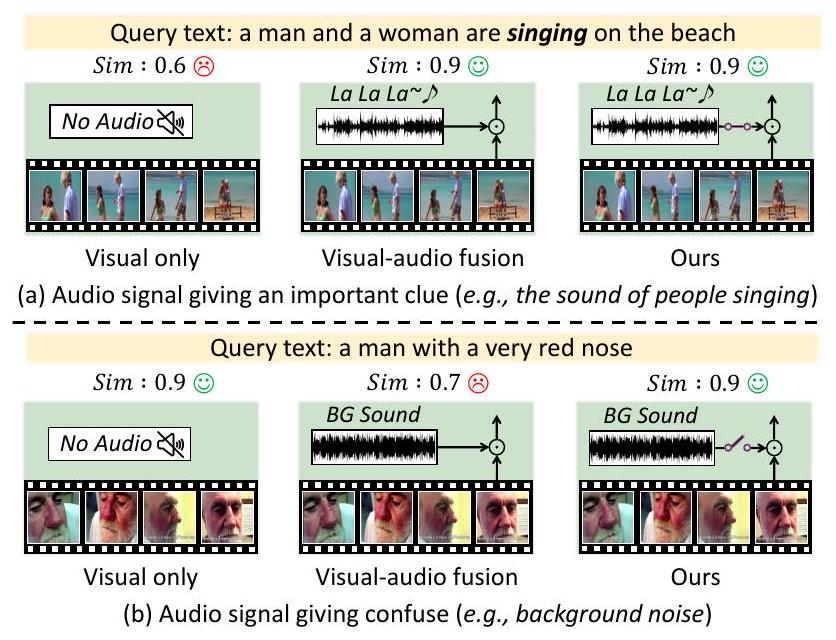
Figure 1. 시각 전용, 오디오-비디오 융합, 그리고 우리가 제안하는 gated fusion 접근 방식을 사용한 다양한 시나리오의 비교 그림. (a) 오디오 신호가 유용한 정보를 제공하는 경우, 오디오-비디오 융합과 우리의 gated fusion은 높은 유사도 점수를 달성한다. (b) 오디오 신호가 오해의 소지가 있는 경우, 전통적인 융합 방법은 성능을 저하시킨다. 이와 대조적으로, 우리의 gated fusion 메커니즘은 관련 없는 오디오 단서를 성공적으로 필터링하여 시각 전용의 경우처럼 높은 유사도 점수를 유지한다.
그럼에도 불구하고, 최근 몇몇 연구들만이 [15, 22] 비디오-텍스트 검색 task에서 오디오 정보의 활용을 탐구했다. ECLIPSE [22]는 cross-modal attention 메커니즘을 사용하여 오디오 및 시각 모달리티를 융합하여 통합된 표현을 생성한다. 반면 TEFAL [15]은 cross-attention 메커니즘을 기반으로 오디오 및 텍스트 모달리티뿐만 아니라 시각 및 텍스트 모달리티에 대해서도 **텍스트 조건부 feature 정렬(text-conditioned feature alignment)**을 제안한다. 이러한 방법들은 일반적으로 오디오가 비디오 표현을 향상시키는 데 긍정적으로 기여한다고 가정하지만, 항상 그런 것은 아니다. 관련 없는 오디오가 시각 정보와 함께 처리될 때 (예: 관련 없는 배경 음악 및 소음), 이는 비디오 표현을 손상시키고 cross-modal 정렬에 부정적인 영향을 미칠 수 있다. Figure 1(b)에서 보여주듯이, ECLIPSE와 TEFAL은 이 문제를 해결하지 못하고 오디오 모달리티를 맹목적으로 활용한다. 더욱이 TEFAL은 비디오(오디오 포함)와 텍스트 설명이 함께 처리되어야 비디오 프레임과 오디오의 표현을 생성할 수 있으므로, 새로운 쿼리가 수신될 때마다 전체 데이터베이스를 재처리해야 하는 등 검색 시스템에 상당한 계산 부담을 초래한다.
이러한 문제들을 해결하기 위해 우리는 오디오 입력이 유용한지 동적으로 판단하고, **비디오(오디오 포함)와 텍스트 설명을 독립적으로 처리하여 효율적인 검색을 가능하게 하는 새로운 프레임워크인 Audio-guided VIdeo representation learning with GATEd attention (AVIGATE)**을 소개한다. 전체 아키텍처는 Figure 2에 나와 있다. AVIGATE는 각 모달리티를 위한 세 가지 인코더를 기반으로 구축된다: 오디오 입력을 위한 Audio Spectrogram Transformer (AST) [13], 시각 입력을 위한 CLIP image encoder, 그리고 텍스트 입력을 위한 CLIP text encoder이다. 모델은 AST를 사용하여 오디오를 인코딩하여 dense audio embedding을 생성하는 것으로 시작한다. 이 embedding은 오디오 리샘플러(audio resampler)에 의해 처리되어 풍부한 오디오 정보를 보존하면서도 고정된 수의 embedding으로 리샘플링하여 중복성을 줄인다. 비디오는 CLIP image encoder에 의해 제공되는 frame embedding으로 표현되며, 텍스트는 CLIP text encoder에 의해 인코딩된다.
오디오 및 frame embedding은 gated fusion Transformer에 의해 융합된다. 이 모듈은 각 모달리티의 영향을 조절하는 adaptive gating function을 사용하여 오디오 및 frame embedding을 통합한다. 구체적으로, gate function은 오디오 embedding의 기여도를 동적으로 결정하여, Transformer가 관련성이 있을 때 보완적인 오디오 정보를 활용하고, 잠재적으로 노이즈가 있는 오디오의 영향을 최소화하여 frame embedding을 유지하도록 한다. gated fusion Transformer의 출력, 즉 최종 비디오 표현은 텍스트 embedding과 정렬된다.
비디오-텍스트 정렬의 판별 능력(discriminative capability)을 향상시키기 위해, 우리는 전통적인 contrastive loss [27, 31]를 확장하여 각 negative pair에 대한 추가적인 margin을 통합하는 adaptive margin-based contrastive learning 접근 방식을 제안한다. 이 margin은 텍스트 및 시각 모달리티 내의 intra-modal dissimilarity를 기반으로 결정되며, 이를 통해 의미적으로 유사한 쌍들 간의 내재된 관계를 암묵적으로 탐색할 수 있다. 제안된 loss에서 사용되는 비디오 표현과 텍스트 embedding 간의 입력 유사도 점수는 전체적인 의미론적 맥락과 미세한 세부 사항을 모두 포착할 수 있는 multi-grained alignment scheme [9, 21, 26, 34]를 통해 계산된다. 결과적으로, multi-grained alignment scheme을 포함한 제안된 loss는 더욱 판별적이고 일반화 가능한 cross-modal embedding space를 학습하도록 유도하여 더 나은 비디오-텍스트 정렬을 이끌어낸다.
우리의 방법은 두 가지 공개 벤치마크 [33, 35]에서 평가 및 비교되었으며, 효율적인 검색을 가능하게 하면서 모든 기존 방법들을 능가하는 성능을 보였다. 본 논문의 주요 기여는 세 가지이다:
- 우리는 오디오 입력의 가치를 동적으로 판단하면서 오디오 및 시각 정보를 융합하는 효과적인 오디오-비디오 융합 프레임워크인 AVIGATE를 제안한다.
- 우리는 의미적으로 유사한 쌍들 간의 내재된 관계를 고려하여 cross-modal embedding space가 더욱 판별적이고 일반화되도록 하는 새로운 adaptive margin-based contrastive loss를 제안한다.
- 우리의 방법은 비디오-텍스트 검색을 위한 세 가지 공개 벤치마크에서 최고의 성능을 달성하며, 테스트 중 높은 검색 효율성을 보장한다.
2. Related Work
2.1. Video-Text Retrieval
Video-text retrieval은 주어진 텍스트 쿼리에 대해 가장 의미적으로 관련성 높은 비디오를 검색하는 것을 목표로 하는 vision-language 분야의 핵심 주제이다. 이 분야의 초기 연구들은 주로 cross-modal alignment를 위해 dense fusion 메커니즘을 사용하여, 모달리티 간 feature를 긴밀하게 통합하는 데 중점을 두었다 [36, 37]. 그러나 대규모 text-video 데이터셋이 도입되면서, 최근 접근 방식들은 모델이 비디오와 텍스트 feature를 공동으로 학습할 수 있도록 하는 end-to-end 사전학습 전략으로 전환되었다.
이러한 발전을 더욱 촉진하기 위해, **ClipBERT [20] 및 Frozen [2]**와 같은 주목할 만한 방법들은 sparse sampling 및 curriculum learning과 같은 효율적인 학습 기법을 제안하여, 대규모 데이터셋 처리의 실현 가능성을 높였다. 또한, 최근 방법들은 CLIP [28]과 같이 대규모 이미지-텍스트 쌍으로 사전학습된 모델을 활용하여, 강력한 visual-textual alignment 능력의 이점을 얻고 있다. **CLIP4Clip [25]**은 CLIP의 사전학습된 feature 공간 내에서 frame-level alignment를 적용하여 비디오 검색 성능을 크게 향상시켰다.
CLIP4Clip을 확장하여, 최근 연구들은 시각 및 텍스트 모달리티 간의 정밀한 alignment 달성을 강조한다. **X-Pool [14]**은 텍스트와 비디오 프레임 간의 cross-attention 가중치를 계산하여 텍스트 조건부 비디오 표현(text-conditioned video representation)을 추출하는데, 이 과정에서 비디오 인코딩은 두 모달리티 데이터를 모두 포함해야 하므로 상당한 계산 비용이 발생한다. 한편, 일련의 연구들 [9, 21, 26, 34]은 더 정확한 검색을 달성하기 위해 multi-grained alignment scheme을 탐구하고 활용해왔다. **UCOFiA [34]**는 patch-word, frame-sentence, video-sentence 수준에 걸쳐 계층적 alignment 전략을 사용한다. **UATVR [9]**은 token-wise word-frame 매칭으로 시작하여, 모달리티별 분포를 모델링하는 분포 매칭(distribution matching) 방법을 도입함으로써 비디오-텍스트 쌍의 의미적 불확실성을 해결하고, 더욱 견고하고 적응적인 매칭을 가능하게 한다. 이러한 정신을 따라, CLIP4Clip의 원리를 기반으로 하는 우리의 방법 또한 naïve한 방식으로 multi-grained alignment scheme을 활용한다.
2.2. Audio-Enhanced Video-Text Retrieval
비디오-텍스트 검색(video-text retrieval)은 상당한 발전을 이루었지만, 비디오 콘텐츠에서 쉽게 사용할 수 있지만 종종 간과되는 오디오 정보를 통합함으로써 개선의 여지가 남아 있다. Liu et al. [23]의 초기 연구는 사전학습된 오디오 전문가(audio expert)의 표현을 다른 모달리티의 표현과 통합하여 비디오-텍스트 검색에 오디오 정보를 활용한다.
최근 연구들은 오디오를 다른 모달리티와 융합하는 표현 학습에 초점을 맞추고 있다. ECLIPSE [22]는 오디오와 비디오 간의 cross-attention을 사용하여 오디오 가이드 비디오 표현을 생성하는 융합 방법을 소개한다. 반면, TEFAL [15]은 텍스트와 오디오 간, 그리고 텍스트와 비디오 간의 cross-attention을 적용하여 텍스트 가이드 오디오 및 비디오 표현을 생성한다. 이 과정은 막대한 계산 비용을 요구하여 효율적인 검색을 방해한다.
더욱이, 기존의 융합 방법들은 배경 소음과 같이 관련 없는 오디오를 처리하지 못한다는 한계를 가지고 있으며, 이는 비디오 표현을 저하시키고 cross-modal 정렬을 방해할 수 있다. 이러한 문제들을 해결하기 위해, 우리는 오디오 입력의 관련성을 동적으로 평가하고 비디오와 텍스트 설명을 독립적으로 처리함으로써 효율적인 검색 시스템을 가능하게 하는 새로운 융합 방법을 제시한다.
3. Proposed Method
이 섹션에서는 우리의 비디오-텍스트 검색 프레임워크인 AVIGATE에 대한 세부 사항을 제시한다. 전체 아키텍처는 Figure 2에 나타나 있다. 먼저 Sec. 3.1에서 각 modality에 대한 embedding 추출 과정을 설명하고, 이어서 Sec. 3.2에서 gated fusion Transformer에 대해 자세히 다룬다. 마지막으로 Sec. 3.3에서는 adaptive margin-based contrastive learning 전략을 소개한다.
3.1. Embedding Extraction
AVIGATE는 각 modality를 처리하기 위해 세 가지 사전학습된 encoder를 활용한다: 비디오 프레임과 텍스트 설명을 위한 두 개의 CLIP encoder [28], 그리고 오디오 신호를 위한 Audio Spectrogram Transformer (AST) [13]이다.
프레임 임베딩 (Frame Embeddings): 우리는 각 비디오의 프레임 임베딩을 추출하기 위해 사전학습된 CLIP image encoder [28]를 사용한다. 입력 비디오 가 주어지면, 먼저 개의 프레임이 균일하게 샘플링되어 으로 표현된다. 각 프레임은 겹치지 않는 patch로 분할된 후, 선형 투영(linear projection)을 통해 변환된다. 이 patch 시퀀스 앞에는 [CLS] token이 추가되며, 결합된 시퀀스는 CLIP image encoder에 입력된다. [CLS] token에 해당하는 출력이 프레임 임베딩으로 사용된다. 마지막으로, 이 프레임 임베딩들은 연결되어 프레임 임베딩 시퀀스 를 형성하며, 여기서 는 임베딩의 차원을 나타낸다.
텍스트 임베딩 (Text Embeddings): 텍스트 임베딩 추출은 프레임 임베딩 추출과 마찬가지로 CLIP text encoder [28]에 의해 수행된다. 텍스트 입력 가 주어지면, 텍스트 내의 모든 단어는 토큰화되고, 문장의 시작과 끝을 나타내는 특수 토큰 **[SOS]**와 **[EOS]**로 둘러싸인다. 이 완전한 시퀀스는 CLIP text encoder를 통과한다. 그런 다음, [EOS] token에 해당하는 출력이 텍스트 임베딩 으로 간주되며, 이는 입력 텍스트의 전반적인 의미를 포착한다.
오디오 임베딩 (Audio Embeddings): 우리는 이전 연구 [13, 15]를 따라 AST [13]를 오디오 encoder로 사용한다. 비디오 에서 얻은 오디오 입력 는 먼저 Mel spectrogram으로 변환되어 시간 및 주파수 전반의 주요 오디오 feature를 포착한다. AST는 이 spectrogram을 개의 patch 시퀀스로 처리하며, Transformer layer를 사용하여 상세한 오디오 임베딩 세트를 생성한다. 그러나 오디오 신호는 비디오 프레임에 비해 훨씬 더 조밀하게 샘플링되므로, 모든 개의 오디오 임베딩을 프레임 임베딩과 직접 융합하는 것은 계산 비용이 많이 든다. 이를 해결하기 위해, 우리는 개의 학습 가능한 query 임베딩을 사용하는 cross-attention mechanism을 갖춘 추가적인 query-based Transformer (즉, audio resampler) [1, 4, 16]를 사용한다. 이 설계는 오디오 임베딩의 수를 고정된 길이 으로 줄여 를 형성하며, 필수적인 오디오 정보를 유지하면서 시각 modality와의 후속 융합을 위한 계산 부하를 크게 낮춘다. 우리는 학습 중에 사전학습된 AST 파라미터를 고정하여, fine-tuning의 높은 계산 비용을 피한다. 아키텍처 세부 사항은 보충 자료에 제공된다.
3.2. Gated Fusion Transformer
오디오 임베딩 와 프레임 임베딩 를 효과적으로 융합하기 위해, gated fusion transformer는 오디오의 비디오 관련성에 따라 오디오의 기여도를 동적으로 조절하도록 설계되었다. 이 Transformer는 게이팅 점수(gating scores)를 사용하여 오디오 feature가 비디오 표현에 미치는 영향을 조절함으로써 적응형 융합(adaptive fusion)을 달성한다. 이는 관련 없는 오디오 신호의 영향을 줄여 시각 콘텐츠의 무결성을 보존하는 역할을 한다.
gated fusion transformer는 개의 layer로 구성되며, 각 layer는 게이팅 점수를 적용하여 융합 과정을 제어하는 gated fusion block을 포함한다. 각 블록 내에서 **Multi-Head Attention (MHA)**과 **Feed-Forward Network (FFN)**는 오디오 및 프레임 임베딩을 혼합하며, 적응형 게이팅 함수(adaptive gating function)는 게이팅 점수( 및 )를 제공하여 이들의 영향력을 조절한다. 이러한 게이팅 점수는 오디오 임베딩의 기여도를 제어하여, Transformer가 관련성이 있을 때 보완적인 오디오 단서를 통합하고 잠재적으로 노이즈가 있는 오디오의 영향을 최소화할 수 있도록 한다. 이어서 **Multi-Head Self-Attention (MHSA)**과 **Feed-Forward Network (FFN)**가 표현을 정제하는 데 사용된다.
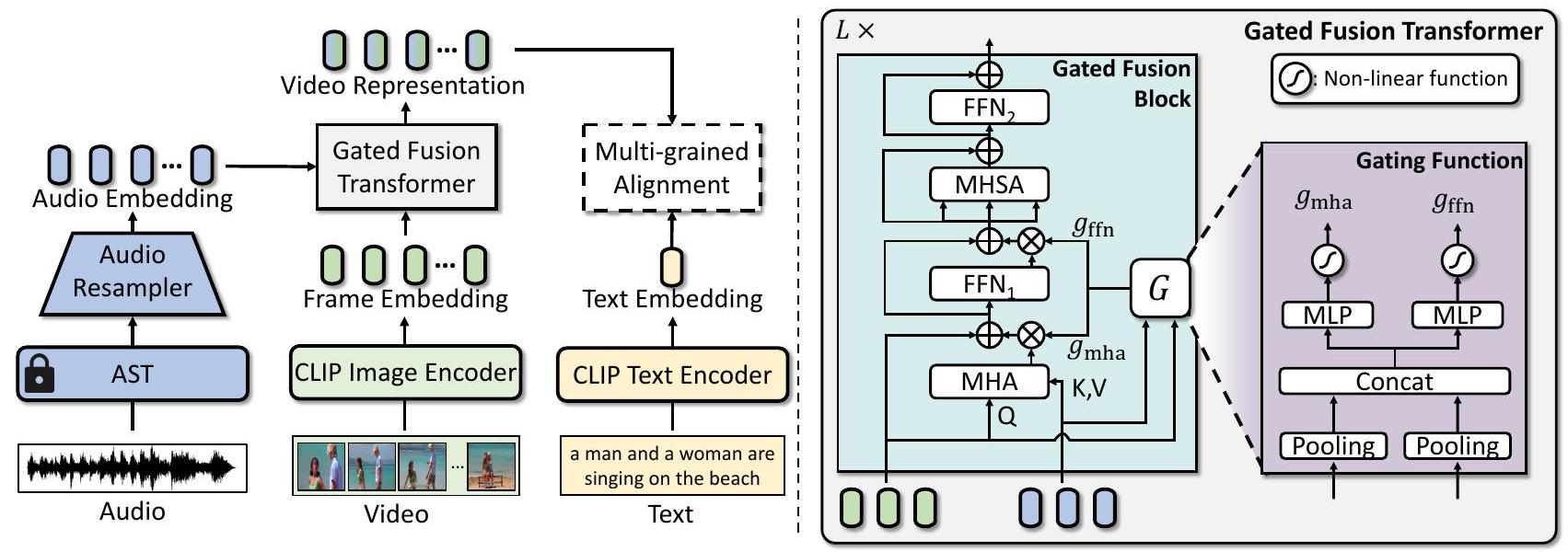
Figure 2. (왼쪽) AVIGATE의 전체 아키텍처. 오디오 입력은 **Audio Spectrogram Transformer (AST)**를 통해 처리되고, **오디오 리샘플러(audio resampler)**에 의해 추가적으로 정제되어 고정된 크기의 오디오 임베딩을 생성한다. 프레임 임베딩은 CLIP Image Encoder를 사용하여 비디오에서 추출되며, 텍스트 임베딩은 CLIP Text Encoder에 의해 추출된다. 이러한 오디오 및 프레임 임베딩은 gated fusion transformer에 의해 융합되며, 이는 오디오의 기여도를 동적으로 결정한다. 최종 비디오 표현은 multi-grained alignment scheme을 사용하여 텍스트 임베딩과 정렬되어, 효과적인 비디오-텍스트 검색(retrieval) 과정을 용이하게 한다. (오른쪽) gated fusion transformer는 gated fusion block과 **게이팅 함수(gating function)**로 구성된다.
게이팅 점수가 높을 때, 오디오 단서가 강조되어 보완적인 오디오 세부 정보를 포착함으로써 표현을 향상시킨다. 반대로, 게이팅 점수가 낮을 때, 관련 없는 오디오 간섭에 대한 시각 콘텐츠의 견고성(robustness)을 우선시한다. 이러한 **선택적 융합(selective fusion)**은 더욱 문맥에 민감하고 판별력 있는 비디오 표현으로 이어지며, 이는 비디오-텍스트 검색 성능을 향상시킨다. 다음에서는 gated fusion transformer의 두 가지 핵심 구성 요소인 gated fusion block과 게이팅 함수에 대한 아키텍처 세부 정보를 제공한다.
3.2.1 Gated Fusion Block
gated fusion block은 오디오 임베딩 와 프레임 임베딩 를 입력으로 받아, 융합(fusion) 과정과 정제(refining) 과정을 거쳐 비디오 표현을 출력한다. 구체적으로, 개의 layer를 통해 프레임 임베딩 는 오디오 임베딩 와의 crossmodal 상호작용을 포착하여 정제된 로 진화한다. 여기서 CLIP image encoder에서 직접 얻은 는 초기 입력 으로 간주된다. 정제된 은 최종 비디오 표현 으로 사용된다.
융합(fusion) 과정에서는 이 **residual connection을 포함하는 MHA(Multi-Head Attention)**를 통해 와 융합된다. 이 출력은 gating function (Sec. 3.2.2)에 의해 생성된 gating score 로 조절되어, 융합 과정에서 오디오 임베딩의 기여도를 결정한다. 그 다음, 이 출력은 **residual connection을 포함하는 FFN(Feed-Forward Network)**에 입력되며, 이 FFN의 출력 또한 gating score 으로 조절되어 gating mechanism에 기반한 선택적 강화를 보장한다. 융합 과정은 다음과 같이 정식화된다:
여기서 LN은 layer normalization을 나타낸다. MHA는 -head attention 연산을 포함하며, 다음과 같이 정식화된다:
여기서 는 concatenation을 나타내며, 는 으로 설정된다. 및 는 선형 투영(linear projection) 행렬이다.
융합된 표현 은 전반적인 비디오 표현을 강화하기 위한 정제(refining) 과정을 거친다. 구체적으로, 은 residual connection을 포함하는 Multi-Head Self-Attention (MHSA) 모듈에 입력된다. 그 다음, MHSA의 출력에 residual connection을 포함하는 두 번째 FFN이 적용되어 정제된 프레임 임베딩 을 생성한다. 정제 과정은 다음과 같이 정식화된다:
MHA와 유사하게, MHSA는 -head self-attention 연산을 포함하며, 여기서 이다.
3.2.2 Gating Function
각 layer 에서 **gating function **은 두 개의 **gating score 과 **을 생성하며, 이들은 각각 gated fusion block 내의 MHA와 출력을 조절한다. 이를 위해, **오디오 임베딩 와 프레임 임베딩 **은 먼저 **평균 풀링(average pooling)**을 사용하여 집계되며, 그 결과 각각 와 가 된다. 이 집계된 임베딩들은 이어서 **연결(concatenate)되어 결합 표현(joint representation) **을 형성한다. **결합 임베딩 **은 두 개의 **별개의 Multi-Layer Perceptron (MLP)**을 통과한 후, 비선형 함수를 거쳐 MHA와 출력에 대한 gating score를 계산한다. **Gating function **은 다음과 같이 공식화된다:
여기서 는 **비선형 함수(예: )**이다.
3.3. Adaptive Margin-based Contrastive Learning
gated fusion Transformer의 출력인 비디오 표현 는 텍스트 임베딩 와 정렬된다. 이러한 **비디오-텍스트 정렬(video-text alignment)**은 일반적으로 cross-modal contrastive learning [14, 25, 26, 28]을 통해 달성되었으며, 이는 긍정 쌍(positive pairs)의 유사도 점수(예: 코사인 유사도)를 최대화하고 부정 쌍(negative pairs)의 유사도 점수를 최소화한다.
contrastive learning의 판별 능력(discriminative ability)을 더욱 향상시키기 위해, 우리는 intra-modal semantic similarity를 기반으로 각 부정 쌍에 대한 margin을 동적으로 조정하는 adaptive margin-based contrastive loss를 도입한다. 우리 방법의 핵심 아이디어는 각 시각 및 텍스트 모달리티 내의 의미론적 관계가 적절한 margin을 결정하는 암묵적인 단서를 제공한다는 것이다. 예를 들어, 두 비디오가 시각적으로 유사하거나 두 텍스트가 높은 텍스트 유사도를 가진다면, 그들의 cross-modal counterpart 또한 어느 정도의 의미론적 관련성을 가질 가능성이 높다. 모든 부정 쌍에 동일한 margin을 적용하는 고정 margin contrastive loss [8, 17, 18]와 달리, 우리 방법은 부정 쌍 간의 다양한 의미론적 유사도 정도를 고려한다. 이러한 적응성은 모델이 의미론적으로 유사한 쌍들 간의 내재된 관계를 고려함으로써 강력한 일반화 능력을 유지하면서 판별적인 feature를 학습할 수 있도록 한다.
이러한 특성에 따라, 개의 비디오-텍스트 쌍 을 포함하는 배치(batch)가 주어졌을 때, 우리는 각 부정 쌍 ()에 대한 **adaptive margin **를 시각 및 텍스트 모달리티 모두에서 intra-modal similarity의 평균에 따라 정의한다. 먼저, 프레임 임베딩 는 **평균 풀링(average pooled)**되어 시각 모달리티의 전체적인 임베딩인 를 얻는다. 와 간의 코사인 유사도를 로, 와 간의 코사인 유사도를 로 나타낸다. adaptive margin은 다음과 같이 얻어진다:
여기서 는 **스케일링 팩터(scaling factor)**이고, 는 과도하게 큰 margin을 방지하기 위한 최대 margin이다. 연산은 margin이 를 초과하지 않도록 보장한다. adaptive margin 는 contrastive loss 함수에서 부정 쌍의 유사도 점수에 다음과 같이 추가된다:
adaptive margin을 contrastive loss에 통합함으로써, 우리 방법은 내재된 intra-modality 관계를 고려하는 보다 판별적이고 일반화 가능한 cross-modal 임베딩 공간을 촉진하여 검색 성능 향상으로 이어진다.
유사도 점수를 계산하기 위해 단순히 코사인 유사도를 활용하는 대신, 우리는 비디오와 텍스트 표현 간의 전역적(global) 및 지역적(local) 관계를 모두 포착하는 향상된 방법을 사용한다. 이러한 조합은 상호 보완적인 정보를 포착하여 이전 연구들 [9, 21, 26, 34]에서 관찰된 바와 같이 검색 성능을 향상시킨다. 먼저, **전역 정렬(global alignment)**을 위해, 우리는 최종 비디오 임베딩 에 **평균 풀링(average pooling)**을 적용하여 포괄적인 비디오 표현을 도출한다. 여기서 은 프레임 세그먼트의 수를 나타낸다. 이 풀링된 표현 은 비디오의 전체적인 내용을 포착한다. 비디오의 전역 표현 와 텍스트 임베딩 간의 비디오-텍스트 유사도 점수 는 다음과 같이 계산된다:
다음으로, **지역 정렬(local alignment)**을 위해, 우리는 각 프레임 세그먼트 임베딩 를 텍스트 임베딩 와 매칭하여 프레임-텍스트 유사도 를 계산한다. 이러한 프레임-텍스트 유사도는 log-sum-exp (LSE) 함수를 사용하여 집계된다:
여기서 는 최대 연산의 부드러움(smoothness)을 제어하는 스케일링 파라미터이다. 전역 및 지역 관점을 모두 결합한 최종 유사도 점수 는 와 을 평균하여 계산된다:
최종 유사도 점수 는 Eq. (6)의 adaptive margin-based contrastive loss에 활용된다. 이 multi-grained alignment scheme은 모델이 전체적인(holistic) 세부 사항과 미세한(fine-grained) 세부 사항을 모두 포착할 수 있도록 하여 비디오-텍스트 검색 정확도를 향상시킨다.
| Methods | Modality | Text-to-Video Retrieval | Video-to-Text Retrieval | RSum | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| CLIP ViT-B/32 | ||||||||
| CLIP4Clip [25] | V+T | 43.1 | 70.4 | 80.8 | 43.1 | 70.5 | 81.2 | 389.1 |
| CLIP4Clip [25] | V+T | 44.5 | 71.4 | 81.6 | 42.7 | 70.9 | 80.6 | 391.7 |
| ECLIPSE [22] | A+V+T | 44.9 | 71.3 | 81.6 | 44.7 | 71.9 | 82.8 | 397.2 |
| X-Pool [14] | V+T | 46.9 | 72.8 | 82.2 | 44.4 | 73.3 | 84.0 | 403.6 |
| TS2-Net [24] | V+T | 47.0 | 74.5 | 83.8 | 45.3 | 74.1 | 83.7 | 408.4 |
| UATVR [9] | V+T | 47.5 | 73.9 | 83.5 | 46.9 | 73.8 | 83.8 | 409.4 |
| ProST [21] | V+T | 48.2 | 74.6 | 83.4 | 46.3 | 74.2 | 83.2 | 409.9 |
| [34] | V+T | 49.4 | 72.1 | 83.5 | 47.1 | 74.3 | 83.0 | 409.4 |
| TEFAL [15] | 49.4 | 75.9 | 83.9 | 47.1 | 75.1 | 84.9 | 416.3 | |
| AVIGATE (Ours) | 50.2 | 74.3 | 83.2 | 49.7 | 75.3 | 83.7 | 416.4 | |
| CLIP ViT-B/16 | ||||||||
| X-Pool [14] | V+T | 48.2 | 73.7 | 82.6 | 46.4 | 73.9 | 84.1 | 408.9 |
| TS2-Net [24] | V+T | 49.4 | 75.6 | 85.3 | 46.6 | 75.9 | 84.9 | 417.7 |
| ProST [21] | V+T | 49.5 | 75.0 | 84.0 | 48.0 | 75.9 | 85.2 | 417.6 |
| [34] | V+T | 49.8 | 74.6 | 83.5 | 49.1 | 77.0 | 83.8 | 417.8 |
| TEFAL [15] | A+V+T | 49.9 | 76.2 | 84.4 | - | - | - | - |
| UATVR [9] | V+T | 50.8 | 76.3 | 85.5 | 48.1 | 76.3 | 85.4 | 422.4 |
| AVIGATE (Ours) | A+V+T | 52.1 | 76.4 | 85.2 | 51.2 | 77.9 | 86.2 | 429.0 |
Table 1. MSR-VTT 9k split에서의 Text-to-video 및 video-to-text 검색 결과. 는 후처리(post-processing) 기법의 사용을 나타낸다.
4. Experiments
이 섹션에서는 제안된 프레임워크인 AVIGATE에 대한 포괄적인 평가를 제시한다. 먼저, Section 4.1에서 데이터셋, 평가 지표, 구현 세부 사항을 포함한 실험 설정을 설명한다. 다음으로, Section 4.2에서 AVIGATE의 효과를 state-of-the-art 방법들과 비교하여 정량적 결과를 제공한다. 이어서, Section 4.3에서는 AVIGATE의 정성적 결과를 포함한다. 또한, Section 4.4에서는 AVIGATE 구성 요소의 영향을 분석하기 위한 ablation study를 수행한다. 마지막으로, Section 4.5에서는 계산 비용 분석을 통해 AVIGATE의 효율성을 기존 방법들과 비교하여 보여준다.
4.1. Experimental Setup
데이터셋 (Datasets)
우리는 MSR-VTT [35], VATEX [33], Charades [29] 세 가지 공개 벤치마크에서 우리 방법의 성능을 이전 방법들과 비교 평가한다.
MSR-VTT는 비디오-텍스트 검색에 가장 일반적으로 사용되는 데이터셋으로, 오디오 신호를 포함하는 10,000개의 웹 수집 비디오로 구성된다. 각 비디오는 10초에서 32초 길이이며, 20개의 해당 텍스트 설명을 가지고 있다. [11, 25]의 데이터 분할 방식을 따라, 우리는 AVIGATE를 9,000개의 비디오(180,000개의 비디오-텍스트 쌍)로 학습시키고, 선택된 1,000개의 비디오-텍스트 쌍으로 평가한다. 10,000개의 비디오 중 9,582개는 오디오를 포함하고 있으며, 우리는 이를 우리 방법에서 활용한다.
VATEX는 각 비디오에 대해 여러 텍스트 설명을 포함하는 34,991개의 비디오로 구성된다. 우리는 [5]의 분할 프로토콜을 따라 25,991개의 비디오를 학습용으로, 1,500개의 비디오를 검증용으로, 1,500개의 비디오를 테스트용으로 사용한다.
Charades는 9,848개의 비디오로 구성되며, 각 비디오는 하나의 텍스트 설명과 쌍을 이룬다. 우리는 [15, 22]의 분할 프로토콜을 따른다.
평가 지표 (Evaluation Metric)
우리는 텍스트-투-비디오 및 비디오-투-텍스트 검색 task 모두에 대해 검색 성능을 평가하기 위해 표준 지표인 **recall at (, )**를 사용한다. 두 경우 모두, 샘플은 쿼리와의 유사도(Eq. (9) 참조)를 기반으로 순위가 매겨진다. 우리는 또한 모든 지표의 합인 RSUM도 보고한다. 검색은 Top-K 위치 내에 최소 하나의 관련 항목이 나타나면 성공적인 것으로 간주된다.
구현 세부 사항 (Implementation Details)
우리는 OpenAI [28]의 사전학습된 CLIP 모델을 ViT-B/32 및 ViT-B/16의 두 가지 다른 크기의 image encoder와 함께 사용한다. 또한, 우리는 ImageNet [7] 및 AudioSet [12]에서 DeiT [32] backbone으로 사전학습된 AST를 채택한다. 오디오 신호를 포함하지 않는 비디오의 경우, 오디오 입력을 zero vector로 설정한다. 구현에 대한 더 자세한 내용은 보충 자료(Sec. B 참조)에 제시되어 있다.
4.2. Quantitative Results
우리는 MSR-VTT 9k split [35], VATEX [33], Charades [29] 데이터셋에 대해 기존 video-text retrieval 방법들과 AVIGATE를 비교했으며, 그 결과는 각각 Table 1, Table 2, Table 3에 제시되어 있다. 각 테이블은 video-text retrieval에 사용된 **모달리티(visual (V), textual (T), audio (A))**를 나타내며, 각 CLIP ViT backbone 크기별로 결과가 보고된다.
이 테이블들은 AVIGATE가 모든 데이터셋과 CLIP ViT backbone 크기에서 R@1 기준으로 모든 이전 방법들을 능가함을 보여준다. 구체적으로, MSR-VTT에서 AVIGATE는 TEFAL [15] (오디오 포함 SOTA) 대비 text-to-video retrieval에서 0.8%p, video-to-text retrieval에서 2.6%p 향상을 달성했다. 또한, VATEX에서는 UATVR [9] (오디오 미포함 SOTA) 대비 R@1에서 1.8%p라는 큰 차이로 우위를 점했다. Charades에서도 AVIGATE는 TEFAL보다 R@1에서 0.8%p 더 높은 성능을 보였다.
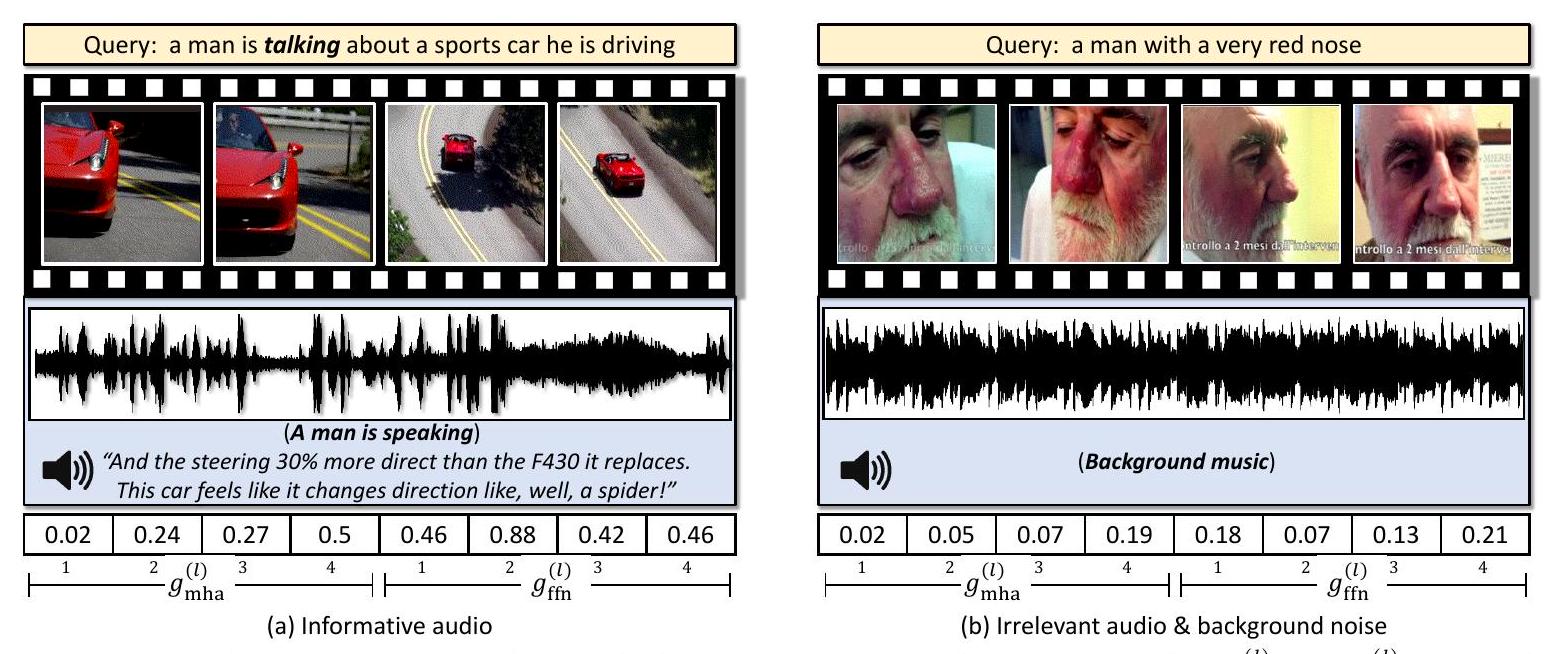
Figure 3. MSR-VTT에서 우리 방법의 Top-1 text-to-video retrieval 결과로, 실제 매칭된 사례들이다. 와 은 gated fusion Transformer의 -번째 layer에 대한 gating score를 나타낸다. 쿼리 텍스트의 "a man is talking" 부분이 시각적으로 보이지 않는 경우에도 오디오는 정확한 retrieval을 위한 유익한 단서를 제공한다 (a). 관련 없는 오디오는 gated fusion Transformer에 의해 필터링되어 정확한 retrieval 결과로 이어진다 (b).
| Methods | Modality | Text-to-Video Retrieval | ||
|---|---|---|---|---|
| R@1 | R@5 | R@10 | ||
| CLIP ViT-B/32 | ||||
| ECLIPSE [22] | 57.8 | 88.4 | 94.3 | |
| X-Pool [14] | V+T | 60.0 | 90.0 | 95.0 |
| ProST [21] | V+T | 60.6 | 90.5 | 95.4 |
| TEFAL [15] | A+V+T | 61.0 | 90.0 | 95.0 |
| [34] | V+T | 61.1 | 90.5 | - |
| UATVR [9] | V+T | 61.3 | 91.0 | 95.6 |
| AVIGATE (Ours) | A+V+T | 63.1 | 90.7 | 95.5 |
| CLIP ViT-B/16 | ||||
| X-Pool [14] | V+T | 62.6 | 91.7 | 96.0 |
| ProST [21] | V+T | 64.0 | 92.2 | 96.3 |
| UATVR [9] | V+T | 64.5 | 92.6 | 96.8 |
| AVIGATE (Ours) | A+V+T | 67.5 | 93.2 | 96.7 |
Table 2. VATEX에서의 Text-to-video retrieval 결과.
AVIGATE의 성능 향상은 더 큰 backbone을 사용할 때 더욱 두드러진다. 특히, MSR-VTT에서 AVIGATE는 text-to-video retrieval에서 1.3%p, video-to-text retrieval에서 3.1%p 향상을 달성했으며, VATEX의 text-to-video retrieval에서는 3.0%p 향상을 이루었다. 또한, 우리 방법은 RSum에서도 MSR-VTT에서 6.6%p 향상이라는 상당한 개선을 보여준다. AVIGATE의 우수한 성능은 정보성 오디오 단서를 선택적으로 통합하고, 비디오와 텍스트 간의 의미론적 정렬을 동적으로 조정하는 능력 덕분이며, 이는 더욱 판별력 있고 일반화 가능한 cross-modal representation으로 이어진다.
4.3. Qualitative Results
Figure 3은 주어진 텍스트 쿼리에 대한 우리 방법의 Top-1 검색 비디오 결과와 함께, 페어링된 오디오 신호 및 layer별 gating score를 보여준다. Figure 3(a)의 쿼리에 대해 우리 모델은 쿼리 내용과 일치하는 유익한 오디오 단서에 의해 뒷받침되는 올바른 비디오를 검색한다. 이 예시에서 오디오는 layer 전반에 걸쳐 을 제외하고 비교적 높은 gating score ( 및 )로 반영되는 귀중한 정보를 제공하며, 융합에서 오디오의 기여를 강조한다. 반대로, Figure 3(b)의 쿼리에 대해 성공적으로 검색된 비디오에는 관련 없는 배경 음악이 포함되어 있다. gating 메커니즘은 이에 따라 관련 없는 오디오 신호의 영향을 억제하기 위해 낮은 gating score를 할당한다. 이러한 동작은 gated fusion Transformer가 오디오가 긍정적으로 기여할 때만 비디오의 멀티모달 특성을 사용하면서 관련 없는 오디오를 성공적으로 필터링한다는 것을 보여준다.
| Methods | Modality | Text-to-Video Retrieval | ||
|---|---|---|---|---|
| R@1 | R@5 | R@10 | ||
| CLIP ViT-B/32 | ||||
| X-Pool [14] | V+T | 16.1 | 35.2 | 44.9 |
| TEFAL [15] | 18.2 | 37.3 | 48.6 | |
| AVIGATE (Ours) | 18.8 | 40.0 | 51.8 | |
| CLIP ViT-B/16 | ||||
| AVIGATE (Ours) | A+V+T | 24.1 | 48.5 | 61.3 |
Table 3. Charades 데이터셋에 대한 Text-to-video retrieval 결과.
4.4. Ablation Studies
우리는 포괄적인 실험을 통해 AVIGATE에서 제안된 구성 요소들의 효과를 평가한다. ablation study를 위해, 우리는 CLIP ViT-B/32 [28]를 사용하여 MSR-VTT 데이터셋 [35]에 대한 text-to-video retrieval 결과를 보고한다.
AVIGATE의 구성 요소: Table 4에서 우리는 우리 모델의 주요 구성 요소에 대한 ablation study 결과를 제시한다. 우리는 먼저 비디오 및 텍스트 임베딩을 위한 CLIP encoder만 포함하는 baseline을 구축하며, 이는 기존의 cross-modal contrastive loss를 통해 학습된다. 그런 다음, 이 baseline은 오디오 모달리티를 활용하기 위해 우리의 gated fusion Transformer에서 gating mechanism이 없는 단순화된 fusion Transformer를 도입하여 확장된다 (Base-
| Methods | Gate | Margin | Text-to-Video Retrieval | |||
|---|---|---|---|---|---|---|
| Fixed | Adaptive | R@1 | R@5 | R@10 | ||
| Baseline | 45.4 | 72.2 | 81.6 | |||
| + Audio | 47.1 | 73.4 | 81.9 | |||
| Adaptive Margin | 48.9 | 74.8 | 83.7 | |||
| Gated Fusion | 48.0 | 75.1 | 83.4 | |||
| + Fixed Margin | 49.0 | 74.1 | 83.5 | |||
| AVIGATE (Ours) | 50.2 | 74.3 | 83.2 |
Table 4. 우리 방법의 핵심 구성 요소에 대한 ablation study.
| Text-to-Video Retrieval | |||
|---|---|---|---|
| Ablated Setting | |||
| Granularity of alignment scheme | |||
| Global only | 46.1 | 73.4 | 82.4 |
| Local only | 48.5 | 73.7 | 82.8 |
| Global-Local | 50.2 | 74.3 | 83.2 |
Table 5. alignment scheme에 대한 ablation study.
line + Audio). 확장된 baseline은 전반적인 성능을 향상시키며, 특히 R@1에서 1.7%p의 주목할 만한 개선을 보여주어 오디오가 text-to-video retrieval에 긍정적으로 기여함을 입증한다. 이어서, gated fusion Transformer 및 adaptive margin을 포함한 우리의 주요 구성 요소들을 개별적으로 적용했을 때, 각 구성 요소는 확장된 baseline을 모든 지표에서 일관되게 향상시킨다. 이러한 관찰은 오디오의 기여도를 동적으로 조절하는 gated fusion Transformer의 효과와 adaptive margin을 사용한 contrastive learning의 이점을 강조한다. 우리 방법의 전체 구성은 R@1에서 50.2%로 최고의 성능을 달성하며, gated fusion Transformer와 adaptive margin 기반 contrastive loss 간의 상호 보완적인 시너지 효과를 보여주면서 일관된 개선을 입증한다. gated fusion Transformer와 함께 고정된 margin( in Eq. (5)는 0.1로 고정)을 사용하는 것이 R@1에서 적당한 성능 향상을 가져오지만, margin이 adaptive하게 적용될 때 가장 중요한 개선이 나타난다는 점은 주목할 만하다.
Alignment Scheme의 세분성: Table 5에서 우리는 세분성 측면에서 alignment scheme을 분석하며, global-local multi-grained alignment scheme이 전반적인 의미론적 맥락과 세부 정보를 포착하는 능력 덕분에 모든 지표에서 성능을 향상시킨다는 것을 보여준다.
4.5. Computational Cost Analysis
를 각각 텍스트 쿼리, 비디오, 오디오의 개수라고 하자. 여기서 인데, 이는 각 오디오가 해당 비디오와 연관되어 있지만 모든 비디오에 오디오가 포함된 것은 아니기 때문이다. Table 6은 AVIGATE의 효율성을 입증하기 위해 이전 방법들 [14, 15, 25]과 비교하여 계산 복잡도와 지연 시간(latency)을 보여준다. AVIGATE는 의 시간 복잡도로 효율적인 검색 프로세스를 달성하는 반면, TEFAL은 의 복잡도로 추가적인 계산 부담을 발생시킨다. 우리는 또한 텍스트-비디오 검색을 위해 사전 추출된 대규모 비디오 표현 집합에 대해 단일 텍스트 쿼리를 처리하는 데 필요한 평균 지연 시간을 평가한다. 특히, 우리는 **MSR-VTT-9k test split [35]**을 활용하는데, 이는 1,000개의 비디오-텍스트 쌍으로 구성되어 있으며, 비디오 표현은 미리 추출되어 저장되어 있어 검색 과정에서 실시간 계산이 필요 없다. 텍스트 쿼리가 도착하면, 시스템은 텍스트 임베딩과 전체 비디오 표현 집합 간의 유사도 점수를 계산한다. 총 지연 시간은 텍스트 임베딩 추출과 텍스트 임베딩 및 모든 비디오 표현 간의 유사도 점수 계산을 포함한다. AVIGATE는 TEFAL보다 14배 이상 빠르고, X-Pool보다 6배 이상 빠르다. 이는 TEFAL과 X-Pool이 최종 표현을 생성하기 위해 각 텍스트 쿼리에 대해 모든 비디오와 반복적으로 cross-modal interaction 프로세스를 필요로 하여 상당한 지연 시간 오버헤드를 발생시키기 때문이다. 반면, 우리 모델은 multi-grained alignment로 인해 CLIP4Clip에 비해 약간의 추가 비용만 발생한다.
| Methods | Time Complexity | Performance | Latency (ms) | |||
|---|---|---|---|---|---|---|
| R@1 | RSum | Total | ||||
| Modality: Video and Text | ||||||
| CLIP4Clip [25] | 44.5 | 391.7 | 0.02 | 9.74 | 9.76 | |
| X-Pool [14] | 46.9 | 403.6 | 56.57 | 9.74 | 66.31 | |
| Modality: Audio, Video and Text | ||||||
| TEFAL [15] | 49.4 | 416.3 | 130.83 | 9.74 | 140.57 | |
| AVIGATE | 50.2 | 416.4 | 0.16 | 9.74 | 9.90 |
Table 6. 우리 방법의 효율성을 기존 연구들과 비교 분석한 결과. 과 는 각각 유사도 계산과 쿼리 임베딩 추출의 지연 시간을 나타낸다. 모든 방법이 동일한 text encoder를 사용하므로 는 동일하다. 지연 시간은 단일 RTX3090 카드에서 측정되었다.
5. Conclusion
우리는 gated attention mechanism을 통해 오디오 신호를 효과적으로 활용하는 새로운 비디오-텍스트 검색 프레임워크인 AVIGATE를 소개했다. AVIGATE는 정보성이 낮은 오디오 신호를 선택적으로 필터링하여 비디오 표현을 향상시키고, 이를 통해 비디오 콘텐츠에 대한 보다 포괄적인 이해를 가능하게 한다. 또한, 우리는 시각 및 텍스트 모달리티 간의 내재된 긍정-부정 관계를 다루기 위해 adaptive margin-based contrastive loss를 제안했다. 이 손실 함수는 모달리티 내(intra-modal) 의미적 비유사성(semantic dissimilarity)에 따라 margin을 동적으로 조정함으로써, 더욱 판별적이고 일반화된 cross-modal embedding space를 구축하는 데 기여한다. 공개 벤치마크에 대한 광범위한 실험 결과, AVIGATE가 state-of-the-art 성능을 달성하고 효율적인 검색을 보장함을 입증했다. 감사의 글 (Acknowledgement). 본 연구는 한국 과학기술정보통신부의 NRF 그랜트(RS-2021-NR059830-30%) 및 IITP 그랜트(RS-2022-II220290-30%, RS-2024-00509258-30%, RS-2019-II191906-10%) 지원을 받아 수행되었습니다.
A. Appendix
이 보충 자료는 본 논문에 포함하지 못했던 오디오 resampler 및 실험 결과에 대한 추가 세부 정보를 제공한다.
먼저, query-based Transformer [1, 4, 16]를 사용하여 오디오 임베딩의 수를 고정된 길이로 줄이는 오디오 resampler의 세부 사항과, 본 논문의 Eq. (4)에 있는 MLP의 세부 사항을 Sec. A.1에서 설명한다. 또한, 우리 방법의 구현 세부 사항을 Sec. A.2에서 제공한다.
이어서, 후처리(post-processing)의 효과와 VATEX [33] 및 Charades [29] 데이터셋에 대한 전체 비디오-텍스트 검색 결과를 포함한 추가 정량적 결과를 Sec. A.3에서 제시한다.
또한, gated fusion Transformer의 layer 깊이, 스케일링 팩터, 본 논문의 Eq. (5)에 있는 최대 마진, gate 메커니즘의 유형, 그리고 modality encoder 고정(freezing)의 효과와 같은 하이퍼파라미터에 대한 추가 ablation study를 Sec. A.4에서 수행한다.
마지막으로, AVIGATE의 효과를 더욱 명확히 보여주는 추가 정성적 결과를 Sec. A.5에서 제공한다.
A.1. More Architectural Details
오디오 임베딩과 프레임 임베딩을 효율적으로 융합하고 계산 오버헤드를 줄이기 위해, 우리는 개의 학습 가능한 query embedding을 활용하는 cross-attention 메커니즘을 사용하는 query-based Transformer 프레임워크 [1, 4, 16] 기반의 오디오 resampler를 도입한다.
구체적으로, 오디오 입력은 Audio Spectrogram Transformer (AST) [13]에 입력되고, 그 출력은 필수 정보를 보존하면서 오디오 임베딩의 수를 고정된 길이 으로 줄이기 위해 오디오 resampler로 전달된다.
Figure 4에서 볼 수 있듯이, 오디오 resampler는 개의 오디오 resampler 블록으로 구성되며, 각 블록은 **multi-head self-attention (MHSA), multi-head cross-attention (MHA), 그리고 feedforward network (FFN)**을 포함한다. 우리는 기본적으로 를 4로 설정한다.
MHSA는 먼저 학습 가능한 query embedding들이 상호작용하여 그들 간의 문맥적 관계를 포착하고 초기 표현을 정제하도록 한다. 이어서 MHA가 수행되는데, 여기서 query embedding들은 AST의 출력에 attend하여 고정된 길이 의 오디오 임베딩을 추출한다. 그 후 FFN이 오디오 임베딩을 처리하여 정제한다. 이러한 일련의 연산은 오디오 resampler가 핵심 정보를 보존하면서 오디오 임베딩의 수를 효율적으로 줄일 수 있게 하며, 후속 단계에서 프레임 임베딩과의 원활한 융합을 용이하게 한다.
Eq. (4)의 MLP는 및 차원의 두 개 layer로 구성되며, 그 사이에 QuickGELU를 비선형 활성화 함수로 사용한다.
A.2. More Implementation Details
우리의 방법론에 대한 데이터셋별 학습 설정 세부사항은 Table 7에 제시되어 있다. 우리는 대부분의 설정, 예를 들어 image encoder, 학습 epoch, optimizer, batch size, max frames, max words, CLIP encoder의 learning rate, 그리고 temperature 등에 대해 [22, 25]를 따른다.
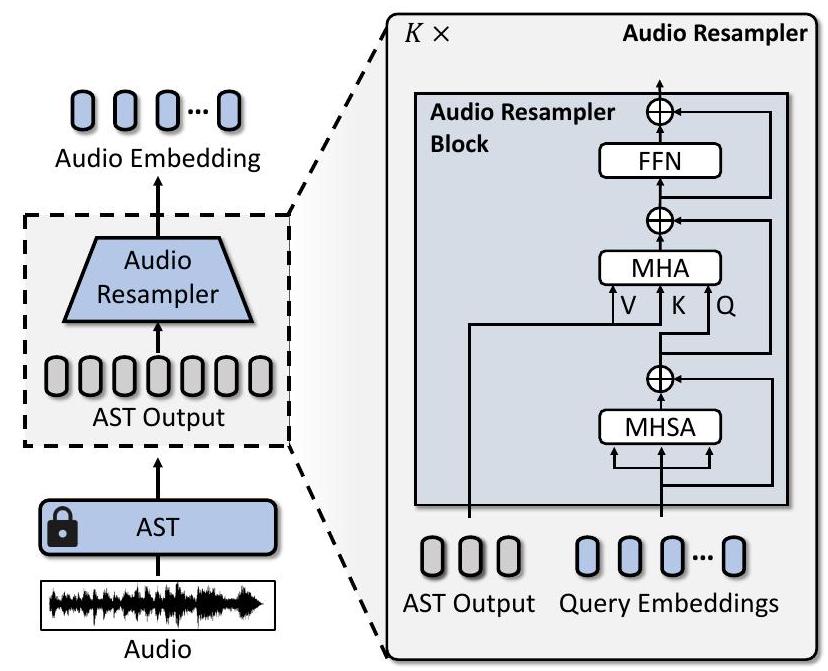
Figure 4. audio resampler의 전체 아키텍처.
A.3. More Quantitative Results
후처리(Post-Processing)의 효과: 후처리 기법은 유사도 점수를 정제하여 성능을 향상시키기 위해 비디오-텍스트 검색 분야에서 널리 채택되어 왔다. 이전 방법들 [6, 9, 15, 24, 34]은 검색 정확도를 더욱 높이기 위해 Dual Softmax Loss (DSL) [6], Querybank Norm (QB-Norm) [3], 그리고 **Sinkhorn-Knopp algorithm (SKNorm)**과 같은 후처리 기법들을 사용한다. 우리도 추론 시 inverted softmax [30]를 적용하는 DSL을 채택하여 후처리 기법의 효과를 탐구한다. 우리는 기존 방법들과 비교하여 후처리 적용 여부에 따른 AVIGATE의 검색 성능을 Table 8에 보고한다.
우리 모델인 AVIGATE는 text-to-video 및 video-to-text 검색 task 모두에서 모든 평가 지표에 걸쳐 일관되게 우수한 성능을 달성하며, 이전의 모든 방법들을 상당한 차이로 능가한다. 특히, CLIP ViT-B/32 backbone의 경우, 후처리를 적용한 AVIGATE는 text-to-video 검색에서 R@1 53.9%를 달성한다. 또한, video-to-text 검색에서는 DSL을 적용한 AVIGATE가 R@1 53.0%를 달성한다. 유사하게, CLIP ViT-B/16 backbone의 경우, AVIGATE는 기존 방법들 대비 상당한 성능 향상을 이룬다. 후처리를 사용했을 때, 우리 방법은 text-to-video 검색에서 R@1 56.3%를 달성하며, 이는 TS2-Net [24] 대비 2.3%p의 상당한 개선을 나타낸다. video-to-text 검색에서도 AVIGATE는 R@1 57.4%로 다른 방법들을 능가한다.
VATEX [33] 및 Charades [29]에서의 전체 성능: 우리는 VATEX 및 Charades 데이터셋에 대한 완전한 비디오-텍스트 검색 결과를 Table 9에 제시하며, 여기에는 text-to-video 및 video-to-text 검색 결과가 모두 포함된다. 결과는 다음을 사용하여 보고된다.
| Source dataset | MSR-VTT [35] | VATEX [33] | Charades [29] |
|---|---|---|---|
| Image encoder | 2 CLIP-ViTs (B/32 and B/16) | ||
| Total epochs | 5 | ||
| Optimizer | Adam [19] | ||
| Embedding dimension | 512 | ||
| Batch size | 128 | 128 | 64 |
| Max frames | 12 | 12 | 32 |
| Max words | 32 | 32 | 64 |
| Resampled audio length | 12 | ||
| Depth of Gated Fusion Transformer | 4 | ||
| Learning rate for Non-CLIP parameters | |||
| Learning rate for CLIP encoders | |||
| Temperature in Eq.(6) | Learnable (After training: 0.01) | ||
| Maximum margin in Eq.(5) | 0.1 | 0.05 | 0.1 |
| Scaling factor in Eq.(5) | 0.2 | ||
| Scaling factor in Eq.(8) | 50 |
Table 7. 다양한 데이터셋의 학습 설정.
| Methods | Modality | Text-to-Video Retrieval | Video-to-Text Retrieval | RSum | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| CLIP ViT-B/32 | ||||||||
| CAMoE [6] | V+T | 44.6 | 72.6 | 81.8 | 45.1 | 72.4 | 83.1 | 399.6 |
| +DSL | V+T | 47.3 (+2.7) | 74.2 (+1.6) | 84.5 (+2.7) | 49.1 (+4.0) | 74.3 (+1.9) | 84.3 (+1.2) | 413.7 (+14.1) |
| TS2-Net [24] | V+T | 47.0 | 74.5 | 83.8 | 45.3 | 74.1 | 83.7 | 408.4 |
| +DSL | V+T | 51.1 (+4.1) | 76.9 (+2.4) | 85.6 (+1.8) | - | - | - | - |
| UATVR [9] | V+T | 47.5 | 73.9 | 83.5 | 46.9 | 73.8 | 83.8 | 409.4 |
| +DSL | V+T | 49.8 (+2.3) | 76.1 (+2.2) | 85.5 (+2.0) | 51.1 (+4.2) | 74.8 (+1.0) | 85.1 (+1.3) | 422.4 (+13.0) |
| UCoFiA [34] | V+T | 48.2 | 73.3 | 82.3 | - | - | - | - |
| +SK norm | V+T | 49.4 (+1.2) | 72.1 (-0.9) | 83.5 (+1.2) | 47.1 | 74.3 | 83.0 | 409.4 |
| AVIGATE (Ours) | 50.2 | 74.3 | 83.2 | 49.7 | 75.3 | 83.7 | 416.4 | |
| +DSL | 53.9 (+3.7) | 77.0 (+2.7) | 86.0 (+2.8) | 53.0 (+3.3) | 78.2 (+2.9) | 85.4 (+1.7) | 433.5 (+16.9) | |
| CLIP ViT-B/16 | ||||||||
| TS2-Net [24] | V+T | 49.4 | 75.6 | 85.3 | 46.6 | 75.9 | 84.9 | 417.7 |
| +DSL | V+T | 54.0 (+4.6) | 79.3 (+3.7) | 87.4 (+2.1) | - | - | - | - |
| TEFAL [15] | 49.9 | 76.2 | 84.4 | - | - | - | - | |
| +DSL+QB-Norm | 52.0 (+2.1) | 76.6 (+0.4) | 86.1 (+1.7) | - | - | - | - | |
| UATVR [9] | V+T | 50.8 | 76.3 | 85.5 | 48.1 | 76.3 | 85.4 | 422.4 |
| +DSL | V+T | 53.5 (+2.7) | 79.5 (+3.2) | 88.1 (+2.7) | 54.5 (+6.4) | 79.1 (+2.8) | 87.9 (+2.5) | 442.6 (+20.2) |
| AVIGATE (Ours) | 52.1 | 76.4 | 85.2 | 51.2 | 77.9 | 86.2 | 429.0 | |
| +DSL | 56.3 (+4.2) | 80.8 (+4.4) | 88.1 (+2.9) | 57.4 (+6.2) | 80.2 (+2.3) | 87.4 (+1.2) | 450.2 (+21.2) |
Table 8. MSR-VTT 9k split에서의 text-to-video 및 video-to-text 검색 결과. DSL [6], QB-Norm [3], SK norm과 같은 후처리 기법들이 추가적인 성능 향상을 위해 사용되었다.
CLIP ViT backbone의 두 가지 변형인 CLIP ViT-B/32와 CLIP ViT-B/16을 사용한다. 또한, 우리는 추가적인 성능 향상을 위한 후처리 기법인 DSL [6]의 효과를 평가한다.
VATEX에서 CLIP ViT-B/32 backbone을 사용했을 때, AVIGATE는 text-to-video 검색에서 R@1 63.1%, **video-to-text 검색에서 R@1 76.6%**라는 주목할 만한 결과를 달성한다. DSL을 적용하면 모든 지표에서 상당한 개선을 관찰할 수 있다. 특히, text-to-video 검색에서 R@1 7.6%p, video-to-text 검색에서 R@1 8.7%p로 AVIGATE의 성능을 크게 향상시킨다. 더 큰 CLIP ViT-B/16 backbone을 사용했을 때, AVIGATE는 text-to-video 검색에서 R@1 67.5%, **video-to-text 검색에서 R@1 80.7%**를 달성하며, 다양한 backbone 크기에 걸친 확장성을 보여준다. 또한, DSL의 사용은 전반적인 검색 정확도를 꾸준히 향상시키며, RSum에서 20.2%p의 개선을 이룬다.
Charades에서 CLIP ViT-B/32 backbone을 사용했을 때, AVIGATE는 text-to-video 검색에서 R@1 18.8%, **video-to-text 검색에서 R@1 17.2%**를 달성하며, DSL을 적용하면 각각 21.3%와 20.0%로 소폭 증가한다. 더 큰 CLIP ViT-B/16 backbone을 사용하면, AVIGATE는 text-to-video 검색에서 R@1 24.1%, **video-to-text 검색에서 R@1 22.9%**를 달성하며, DSL은 이 수치를 각각 27.5%와 27.1%로 향상시킨다.
A.4. More Ablation Studies
우리는 AVIGATE에서 다양한 하이퍼파라미터를 사용하여 추가적인 ablation study를 수행한다. 본 논문의 주요 내용과 유사하게, 우리는
| Methods | Modality | Text-to-Video Retrieval | Video-to-Text Retrieval | RSum | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| CLIP ViT-B/32 | ||||||||
| AVIGATE (Ours) | 63.1 | 90.7 | 95.5 | 76.6 | 97.3 | 98.8 | 522.0 | |
| +DSL | 70.7 (+7.6) | 93.4 (+2.7) | 95.5 (+1.4) | 85.3 (+8.7) | 99.1 (+1.8) | 99.8 (+1.0) | 545.2 (+23.2) | |
| CLIP ViT-B/16 | ||||||||
| AVIGATE (Ours) | 67.5 | 93.2 | 96.7 | 80.7 | 97.8 | 99.5 | 535.4 | |
| +DSL | 74.6 (+7.1) | 95.3 (+2.1) | 97.8 (+1.1) | 88.7 (+8.0) | 99.3 (+1.5) | 99.9 (+0.3) | 555.6 (+20.2) |
Table 9. VATEX 데이터셋에 대한 Text-to-video 및 video-to-text retrieval 결과. 후처리 기법인 DSL [6]은 추가적인 성능 향상을 위해 사용되었다.
| Methods | Modality | Text-to-Video Retrieval | Video-to-Text Retrieval | RSum | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| CLIP ViT-B/32 | ||||||||
| AVIGATE (Ours) | 18.8 | 40.0 | 51.8 | 17.2 | 40.4 | 51.7 | 219.9 | |
| +DSL | 21.3 (+2.5) | 42.4 (+2.4) | 54.4 (+2.7) | 20.0 (+2.8) | 43.0 (+2.6) | 54.9 (+3.2) | 236.0 (+16.1) | |
| CLIP ViT-B/16 | ||||||||
| AVIGATE (Ours) | 24.1 | 48.5 | 61.3 | 22.9 | 48.4 | 61.0 | 266.2 | |
| +DSL | 27.5 (+3.4) | 52.7 (+4.2) | 64.5 (+3.2) | 27.1 (+4.2) | 52.7 (+4.3) | 65.0 (+4.0) | 289.5 (+23.3) |
Table 10. Charades 데이터셋에 대한 Text-to-video 및 video-to-text retrieval 결과. 후처리 기법인 DSL [6]은 추가적인 성능 향상을 위해 사용되었다. CLIP ViT-B/32를 사용하여 MSR-VTT 데이터셋 [35]에 대한 text-to-video retrieval 결과를 보고한다. Table 11은 ablation study의 전체 결과를 보여준다.
Gated Fusion Transformer의 Layer Depth: Table 11(a)에서 gated fusion Transformer의 layer 수()가 미치는 영향을 제시하며, 까지 성능이 점진적으로 향상되어 최적의 성능을 달성함을 관찰한다.
Eq. (5)의 하이퍼파라미터 및 : 우리는 논문의 Eq. (5)에 있는 스케일링 팩터 와 최대 마진 의 영향을 조사한다. Eq. (5)의 adaptive margin은 또는 가 0으로 설정되면 0이 되어, Eq. (6)의 loss가 기존의 contrastive loss로 이어진다는 점에 주목할 필요가 있다. Table 11(b)에서 보듯이, 가 0.2로 설정되었을 때 모델은 최상의 성능을 보인다. 한편, 를 0.1로 설정하면 성능이 약간 감소하는데, 이는 더 작은 스케일링 팩터가 충분한 마진 조정을 제공하지 못할 수 있음을 나타낸다. 그러나 를 0.3으로 증가시켜도 추가적인 개선은 이루어지지 않는다. 유사하게, Table 11(c)는 최대 마진 를 변화시켰을 때의 효과를 보여준다. 우리는 까지 성능이 점진적으로 향상됨을 관찰한다. 를 0.1 이상으로 증가시키면 과도하게 큰 마진이 negative pair를 너무 멀리 밀어내어 성능이 저하된다.
Gate Mechanism Type: 우리의 방법은 soft gate mechanism을 사용하며, 이는 융합 과정에서 오디오의 기여도를 연속적으로 조절할 수 있게 한다. soft gate mechanism의 효과를 평가하기 위해, 우리는 사전 정의된 임계값을 초과하면 1, 그렇지 않으면 0의 gating score를 할당하는 hard gate mechanism과 soft gate를 비교한다. Table 11(d)에서 보듯이, hard gate를 사용하면 우리의 방법보다 성능이 떨어진다. hard gate mechanism을 사용하는 것과 달리, 우리의 방법은 관련 없는 또는 노이즈가 있는 오디오 신호의 영향을 최소화하면서 관련 오디오 단서를 효과적으로 활용할 수 있도록 돕는다. 이는 모델이 정보성 오디오를 더 정확하게 활용하여 retrieval 정확도를 향상시킨다.
| Text-to-Video Retrieval | |||
|---|---|---|---|
| Ablated Setting | R@1 | R@5 | R@10 |
| (a) Layer depth of Gated Fusion Transformer: | |||
| 49.0 | 74.0 | 82.6 | |
| 49.8 | 74.0 | 83.0 | |
| 50.2 | 74.3 | 83.2 | |
| 49.5 | 74.2 | 82.6 | |
| (b) Scaling factor in Eq.(5): | |||
| 48.0 | 75.1 | 83.4 | |
| 49.4 | 74.8 | 83.8 | |
| 50.2 | 74.3 | 83.2 | |
| 50.0 | 74.4 | 83.2 | |
| (c) Maximum margin in Eq.(5): | |||
| 48.0 | 75.1 | 83.4 | |
| 49.4 | 75.1 | 83.6 | |
| 50.2 | 74.3 | 83.2 | |
| 49.3 | 74.8 | 83.8 | |
| 48.3 | 74.4 | 83.9 | |
| (d) Gate mechanism type | |||
| Hard Gate | 49.3 | 75.0 | 82.5 |
| Soft Gate | 50.2 | 74.3 | 83.2 |
| (e) Effect of freezing AST (Batch size:32) | |||
| Freezing | 48.2 | 75.3 | 83.7 |
| Fine-tuning | 48.0 | 73.5 | 83.4 |
| (f) Effect of freezing CLIP encoders | |||
| Freezing | 41.1 | 68.5 | 78.2 |
| Fine-tuning | 50.2 | 74.3 | 83.2 |
Table 11. 하이퍼파라미터에 대한 Ablation study. 회색은 기본 설정을 나타낸다. AST 고정의 효과: 우리는 학습 비용을 줄이기 위해 AST를 고정한다. AST를 fine-tuning하는 것은 비실용적이다. 왜냐하면 AST는 입력 오디오당 1,214개의 토큰을 처리하는데, 이는 ViT-B/32의 각 비디오 프레임에 대한 50개의 토큰보다 훨씬 많기 때문이다. 해결책은 batch size를 크게 줄이는 것이지만, contrastive loss는 batch size에 크게 의존하므로 성능이 저하된다. AST를 고정하고 매우 작은 입력 batch로 fine-tuning한 결과는 Table 11(e)에 보고되어 있으며, AST를 고정하는 것이 fine-tuning하는 것보다 우수한 성능을 보인다. 이러한 결과는 오디오 분류 데이터셋으로 사전학습된 AST의 특성에 기인하며, 오디오 입력에서 판별적인 embedding을 추출할 수 있게 한다. 따라서 우리는 계산 및 메모리 비용 부담이 큰 fine-tuning 대신 AST를 고정하기로 결정했다.
CLIP 이미지 및 텍스트 인코더 모두 고정: Table 11(f)에서 보듯이, CLIP 이미지 및 텍스트 인코더를 고정하면 성능이 현저히 낮아지며, 이는 CLIP4Clip [25]과 같은 이전 연구에서도 입증되었듯이 두 인코더를 fine-tuning하는 것의 중요성을 강조한다. Fine-tuning은 task-specific 비디오 및 텍스트 정보를 포착하고 그들 간의 정렬을 개선하는 데 필수적이다.
A.5. More Qualitative Results
우리는 텍스트-투-비디오 검색(text-to-video retrieval)에서 오디오 정보 활용의 효과를 보여주는 추가적인 정성적 결과들을 제시한다. Figure 5는 AVIGATE가 검색한 Top-1 비디오와 해당 오디오 신호를 보여주며, 오디오 단서가 검색 결과에 어떻게 영향을 미치는지를 강조한다.
Figure 5(a)와 (b)에서는 오디오가 검색 성능 향상에 중요한 정보를 제공하는 시나리오를 보여준다. gated fusion Transformer를 통해 오디오를 통합한 AVIGATE는 텍스트 쿼리에 해당하는 올바른 비디오를 성공적으로 검색한다. 이와 대조적으로, **오디오 정보가 없는 방법(즉, w/o Audio)**은 실제 일치하는 비디오를 검색하지 못한다. 이 비교는 유익한 오디오 단서를 활용하는 것의 이점을 명확히 보여준다.
반대로, Figure 5(c)와 (d)는 오디오 입력에 배경 소음과 같은 관련 없는 정보가 포함된 또 다른 시나리오를 제시한다. AVIGATE는 gating mechanism을 통해 정보성이 없는 오디오 신호를 효과적으로 필터링한다. gating function은 낮은 gating score를 할당하여 모델이 시각적 단서에만 집중할 수 있도록 한다. 그 결과, AVIGATE는 올바른 비디오를 성공적으로 검색한다. 이와 대조적으로, **gating function이 없는 방법(즉, w/o Gate)**은 노이즈가 있는 오디오의 영향을 받아 실제 일치하는 비디오를 검색하지 못한다.
이러한 정성적 결과들은 gated fusion Transformer가 오디오가 긍정적으로 기여할 때 유용한 오디오 정보를 활용하면서도 관련 없는 오디오를 성공적으로 필터링한다는 것을 보여준다.

Figure 5. MSR-VTT 데이터셋에서 우리 방법의 Top-1 텍스트-투-비디오 검색 결과 (실제 일치하는 경우). 오디오는 정확한 검색을 위한 유익한 단서를 제공한다. 예를 들어, 쿼리 텍스트의 "a man is talking"은 시각적으로 보이지 않지만 (a), "talk san diego"는 시각적으로 보이지 않아도 들을 수 있다 (b). 그러나 이러한 유익한 오디오 신호를 무시하면(즉, w/o Audio) 실제 일치하는 비디오를 검색하지 못한다. 한편, 관련 없는 오디오는 gated fusion Transformer에 의해 필터링되어 정확한 검색 결과로 이어진다 (c) 및 (d). gating mechanism이 없으면(즉, w/o Gate) 관련 없는 오디오로 인해 잘못된 비디오를 검색하게 된다.