Audio Spectrogram Transformer (AST): CNN을 넘어선 오디오 분류의 새로운 접근
Audio Spectrogram Transformer(AST)는 오디오 분류를 위해 제안된 최초의 Convolution-free, 순수 attention 기반 모델입니다. 기존 CNN 기반 모델과 달리, AST는 오디오 Spectrogram에서 직접적으로 장거리 전역 컨텍스트를 학습하여 AudioSet, ESC-50, Speech Commands V2와 같은 주요 벤치마크에서 SOTA(State-of-the-Art) 성능을 달성했습니다. ImageNet으로 사전 학습된 Vision Transformer (ViT)의 지식을 활용하여 성능을 크게 향상시키는 방법 또한 제안합니다. 논문 제목: AST: Audio Spectrogram Transformer
논문 요약: AST: Audio Spectrogram Transformer
- 논문 링크: https://arxiv.org/abs/2104.01778
- 저자: Yuan Gong, Yu-An Chung, James Glass (MIT Computer Science and Artificial Intelligence Laboratory)
- 발표 시기: 2021년 (arXiv preprint)
- 주요 키워드: 오디오 분류, Transformer, Self-Attention, Convolution-free
1. 연구 배경 및 문제 정의
- 문제 정의:
기존 오디오 분류 모델은 주로 CNN 기반이었으나, CNN의 의존성이 필수적인지, 그리고 순수 Attention 기반 모델로도 오디오 분류에서 좋은 성능을 얻을 수 있는지에 대한 의문이 제기되었습니다. 특히, CNN은 지역적 특징 추출에 강하지만 장거리 전역 컨텍스트(long-range global context) 포착에는 한계가 있었습니다. - 기존 접근 방식:
지난 10년간 오디오 분류 연구는 수작업 특징 기반 모델에서 오디오 스펙트로그램을 직접 레이블에 매핑하는 종단간(end-to-end) 모델로 발전했습니다. 특히 CNN은 공간적 지역성 및 번역 등변성 등의 이점으로 널리 사용되었습니다. 최근에는 장거리 전역 컨텍스트를 더 잘 포착하기 위해 CNN 위에 Self-Attention 메커니즘을 추가한 CNN-Attention 하이브리드 모델이 최첨단(SOTA) 성능을 달성했습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 오디오 분류를 위한 최초의 Convolution-free, 순수 Attention 기반 모델인 Audio Spectrogram Transformer (AST)를 제안했습니다.
- AudioSet, ESC-50, Speech Commands V2와 같은 주요 오디오 분류 벤치마크에서 새로운 SOTA 성능을 달성했습니다.
- 가변 길이 오디오 입력을 자연스럽게 지원하며, 아키텍처 변경 없이 다양한 오디오 분류 작업에 적용 가능한 일반화 능력을 입증했습니다.
- 기존 CNN-Attention 하이브리드 모델 대비 더 적은 매개변수, 더 간단한 아키텍처, 그리고 더 빠른 훈련 수렴 속도를 보여주었습니다.
- ImageNet으로 사전 학습된 Vision Transformer (ViT)의 지식을 AST로 효과적으로 전이 학습하는 방법을 제안하여 성능을 크게 향상시켰습니다.
- 제안 방법:
- 모델 아키텍처:
- 입력 오디오 파형을 128차원 로그 멜 필터뱅크(fbank) 특징의 2D 스펙트로그램으로 변환합니다.
- 스펙트로그램을 시간 및 주파수 차원에서 6의 중첩을 갖는 크기의 패치 시퀀스로 분할합니다.
- 각 패치를 선형 투영하여 768차원의 1D 패치 임베딩으로 변환하고, 학습 가능한 위치 임베딩 및 [CLS] 토큰을 추가합니다.
- 이 시퀀스를 표준 Transformer 인코더(768 임베딩 차원, 12 레이어, 12 헤드)에 입력합니다.
- [CLS] 토큰의 Transformer 인코더 출력은 오디오 스펙트로그램 표현으로 사용되며, 최종 선형 레이어를 통해 분류됩니다.
- 패치 임베딩 레이어와 Transformer 블록 내 투영 레이어는 컨볼루션과 유사하지만, 여러 레이어와 작은 커널을 사용하는 기존 CNN과 달리 순수 Attention 기반으로 간주됩니다.
- ImageNet 사전 학습:
- 오디오 데이터셋의 부족 문제를 해결하기 위해 이미지와 오디오 스펙트로그램의 유사성을 활용하여 교차 모달리티 전이 학습을 적용합니다.
- 사전 학습된 Vision Transformer (ViT) 가중치를 AST에 전이합니다.
- ViT의 3채널 입력 가중치를 AST의 단일 채널 스펙트로그램에 맞게 평균화하여 사용합니다.
- 가변 길이 오디오 스펙트로그램에 맞게 ViT의 위치 임베딩을 잘라내기 및 이중 선형 보간을 통해 적응시킵니다.
- ViT의 최종 분류 레이어는 버리고 AST에 맞게 새로 초기화합니다.
- 특히, 데이터 효율적인 이미지 Transformer (DeiT) 모델의 사전 학습된 가중치를 활용하여 성능을 향상시켰습니다.
- 모델 아키텍처:
3. 실험 결과
- 데이터셋:
- AudioSet: 2백만 개 이상의 10초 오디오 클립과 527개의 레이블로 구성된 대규모 약하게 레이블링된 오디오 이벤트 분류 데이터셋.
- ESC-50: 50개 클래스로 구성된 2,000개의 5초 환경 오디오 녹음 데이터셋.
- Speech Commands V2: 35개의 일반적인 음성 명령에 대한 105,829개의 1초 녹음 데이터셋.
- 실험 환경: ImageNet 사전 학습, 데이터 증강 (Mixup, 스펙트로그램 마스킹), 모델 앙상블 및 가중치 평균 사용. Adam 옵티마이저, 이진 교차 엔트로피 손실 (AudioSet).
- 주요 결과:
- AudioSet: 전체 데이터셋에서 0.485 mAP를 달성하여 기존 SOTA 모델을 능가했습니다. 또한, AST 훈련은 기존 CNN-Attention 하이브리드 모델(30 에포크)보다 훨씬 빠른 5 에포크 만에 수렴하는 효율성을 보였습니다. ImageNet 사전 학습이 성능 향상에 크게 기여했습니다.
- ESC-50: ImageNet 사전 학습만으로 88.7% 정확도, AudioSet 사전 학습 추가 시 95.6% 정확도를 달성하여 동일 설정에서 SOTA 모델을 모두 능가했습니다.
- Speech Commands V2: ImageNet 사전 학습만으로 98.11% 정확도를 달성하여 SOTA 모델을 능가했습니다. 이 작업에서는 AudioSet 사전 학습이 불필요함을 확인했습니다.
- 일반화 능력: 입력 오디오 길이가 1초(Speech Commands)에서 10초(AudioSet)까지 다양하고 내용이 음성(Speech Commands)에서 비음성(AudioSet 및 ESC-50)까지 다양함에도 불구하고, 고정된 AST 아키텍처를 사용하여 모든 벤치마크에서 SOTA 결과를 달성하며 뛰어난 일반화 능력을 입증했습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 오디오 분류 분야에서 CNN의 지배적인 위치를 깨고 순수 Transformer 모델만으로도 SOTA 성능을 달성할 수 있음을 보여준 점이 인상 깊습니다.
- 다양한 오디오 분류 벤치마크에서 뛰어난 성능과 함께, 아키텍처 변경 없이 가변 길이 입력과 다양한 오디오 콘텐츠에 적용 가능한 뛰어난 일반화 능력을 가진 점이 큰 장점입니다.
- ImageNet으로 사전 학습된 ViT의 지식을 오디오 스펙트로그램에 효과적으로 전이 학습하여 데이터 부족 문제를 해결하고 성능을 크게 향상시킨 아이디어가 매우 영리합니다.
- 기존 CNN-Attention 하이브리드 모델 대비 더 간단한 아키텍처, 적은 매개변수, 그리고 훨씬 빠른 훈련 수렴 속도를 가진다는 점에서 실용적인 가치가 높습니다.
- 단점/한계:
- Transformer 모델의 일반적인 단점인 대규모 데이터 필요성(ImageNet 사전 학습으로 완화되긴 했지만)은 여전히 존재합니다.
- 패치 중첩을 늘릴수록 성능은 향상되지만, Transformer의 2차 계산 복잡도로 인해 계산 오버헤드가 증가하는 trade-off가 있습니다.
- 오디오 스펙트로그램에 최적화된 패치 모양(예: 128x2 직사각형)이 존재할 수 있음에도 불구하고, ImageNet 사전 학습 모델의 제약으로 인해 16x16 정사각형 패치를 사용해야 하는 한계가 있습니다. 이는 향후 오디오 특화 Transformer 사전 학습 연구의 필요성을 시사합니다.
- 응용 가능성:
- 환경음 분류: 스마트 홈 기기, 도시 소음 모니터링, 야생 동물 감지 등 다양한 환경 소리 분석에 활용될 수 있습니다.
- 음성 명령 인식: 음성 비서, IoT 기기 제어, 차량 내 음성 인식 시스템 등에서 정확하고 효율적인 음성 명령 처리에 적용될 수 있습니다.
- 오디오 이벤트 감지: 보안 시스템의 이상음 감지, 산업 현장의 기계 고장 예측, 의료 분야의 비정상적인 신체음(예: 기침, 심장 소리) 분석 등 광범위한 분야에 적용 가능합니다.
- 음악 정보 검색: 음악 장르 분류, 악기 식별, 오디오 콘텐츠 기반 추천 시스템 등에도 활용될 잠재력이 있습니다.
5. 추가 참고 자료
Gong, Yuan, Yu-An Chung, and James Glass. "Ast: Audio spectrogram transformer." arXiv preprint arXiv:2104.01778 (2021).
AST: Audio Spectrogram Transformer
Yuan Gong, Yu-An Chung, James Glass<br>MIT Computer Science and Artificial Intelligence Laboratory, Cambridge, MA 02139, USA<br>{yuangong, andyyuan, glass}@mit.edu
Abstract
지난 10년간, convolutional neural networks (CNNs)는 오디오 스펙트로그램에서 해당 레이블로 직접 매핑하는 것을 목표로 하는 종단간 오디오 분류 모델의 주요 구성 요소로 널리 채택되었습니다. 더 나은 장거리 전역 컨텍스트를 포착하기 위해 최근의 추세는 CNN 위에 self-attention 메커니즘을 추가하여 CNN-attention 하이브리드 모델을 형성하는 것입니다. 그러나 CNN에 대한 의존이 필수적인지, 그리고 순수하게 attention에 기반한 신경망이 오디오 분류에서 좋은 성능을 얻기에 충분한지는 불분명합니다. 본 논문에서는 오디오 분류를 위한 최초의 convolution-free, 순수 attention 기반 모델인 Audio Spectrogram Transformer (AST)를 소개함으로써 이 질문에 답합니다. 우리는 다양한 오디오 분류 벤치마크에서 AST를 평가했으며, AudioSet에서 0.485 mAP, ESC-50에서 95.6% 정확도, Speech Commands V2에서 98.1% 정확도라는 새로운 최첨단 결과를 달성했습니다. 색인 용어: 오디오 분류, self-attention, Transformer
1. Introduction
딥 뉴럴 네트워크의 출현으로, 지난 10년간 오디오 분류 연구는 수작업으로 만든 특징에 기반한 모델[1, 2]에서 오디오 스펙트로그램을 직접 해당 레이블에 매핑하는 종단간 모델[3, 4, 5]로 이동했습니다. 특히, convolutional neural networks (CNNs) [6]는 공간적 지역성 및 번역 등변성과 같은 CNN에 내재된 귀납적 편향이 도움이 될 것으로 여겨져 원시 스펙트로그램으로부터 표현을 학습하기 위해 종단간 모델링에 널리 사용되어 왔습니다. 장거리 전역 컨텍스트를 더 잘 포착하기 위해 최근의 추세는 CNN 위에 self-attention 메커니즘을 추가하는 것입니다. 이러한 CNN-attention 하이브리드 모델은 오디오 이벤트 분류[7, 8], 음성 명령 인식[9], 감정 인식[10]과 같은 많은 오디오 분류 작업에서 최첨단(SOTA) 결과를 달성했습니다. 그러나 비전 분야[11, 12, 13]에서 순수 attention 기반 모델의 성공에 동기를 부여받아, 오디오 분류에 CNN이 여전히 필수적인지 묻는 것은 합리적입니다. []
이 질문에 답하기 위해, 우리는 오디오 스펙트로그램에 직접 적용되고 가장 낮은 레이어에서도 장거리 전역 컨텍스트를 포착할 수 있는 convolution-free, 순수 attention 기반 모델인 Audio Spectrogram Transformer(AST)를 소개합니다. 또한, ImageNet[14]에서 사전 훈련된 Vision Transformer(ViT)[12]의 지식을 AST로 전달하는 접근 방식을 제안하며, 이는 성능을 크게 향상시킬 수 있습니다. AST의 장점은 세 가지입니다. 첫째, AST는 우수한 성능을 가집니다: 우리는 AudioSet[15], ESC-50[16] 및 Speech Commands[17]를 포함한 다양한 오디오 분류 작업 및 데이터셋에서 AST를 평가합니다. AST는 이러한 모든 데이터셋에서 최첨단 시스템을 능가합니다. 둘째, AST는 자연스럽게 가변 길이 입력을 지원하며 아키텍처 변경 없이 다른 작업에 적용될 수 있습니다. 구체적으로,
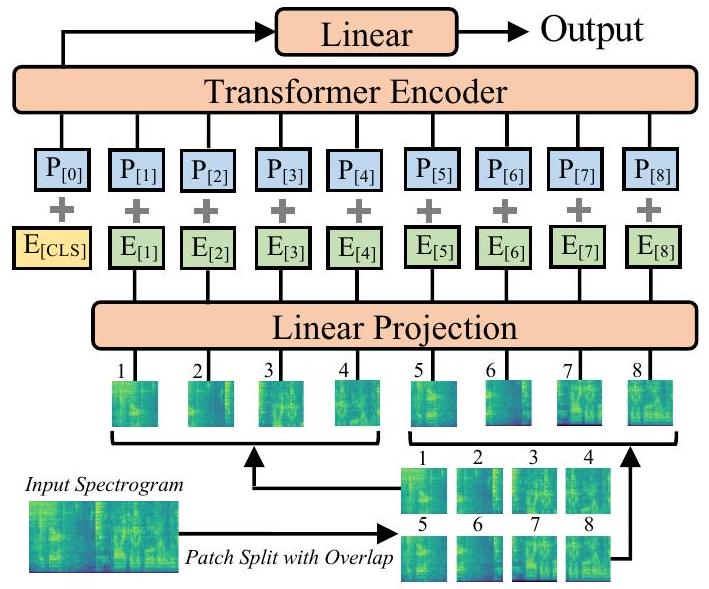
그림 1: 제안된 audio spectrogram transformer (AST) 아키텍처. 2D 오디오 스펙트로그램은 중첩이 있는 패치 시퀀스로 분할된 다음, 1차원 패치 임베딩 시퀀스로 선형 투영됩니다. 각 패치 임베딩에는 학습 가능한 위치 임베딩이 추가됩니다. 추가적인 분류 토큰이 시퀀스 앞에 추가됩니다. 출력 임베딩은 Transformer에 입력되고, 분류 토큰의 출력은 선형 레이어로 분류에 사용됩니다.
앞서 언급한 모든 작업에 사용하는 모델은 입력 길이가 1초(Speech Commands)에서 10초(AudioSet)까지 다양하지만 동일한 아키텍처를 가집니다. 반면, CNN 기반 모델은 일반적으로 다른 작업에 대한 최적의 성능을 얻기 위해 아키텍처 튜닝이 필요합니다. 셋째, SOTA CNN-attention 하이브리드 모델과 비교할 때, AST는 더 적은 매개변수를 가진 더 간단한 아키텍처를 특징으로 하며 훈련 중에 더 빨리 수렴합니다. 우리가 아는 한, AST는 최초의 순수 attention 기반 오디오 분류 모델입니다.
Related Work 제안된 Audio Spectrogram Transformer는 이름에서 알 수 있듯이 자연어 처리 작업을 위해 원래 제안된 Transformer 아키텍처[18]를 기반으로 합니다. 최근 Transformer는 오디오 처리에도 적용되었지만 일반적으로 CNN[19, 20, 21]과 함께 사용됩니다. [19, 20]에서 저자들은 CNN 위에 Transformer를 쌓았고, [21]에서는 저자들이 각 모델 블록에서 Transformer와 CNN을 결합했습니다. 다른 연구들은 CNN을 더 간단한 attention 모듈[8, 7, 9]과 결합합니다. 제안된 AST는 convolution-free이며 순수하게 attention 메커니즘에 기반한다는 점에서 이러한 연구들과 다릅니다. 우리 연구와 가장 가까운 작업은 비전 작업을 위한 Transformer 아키텍처인 Vision Transformer (ViT)[11, 12, 13]입니다. AST와 ViT는 유사한 아키텍처를 가지고 있지만 ViT는 고정 차원 입력(이미지)에만 적용된 반면 AST는 가변 길이 오디오 입력을 처리할 수 있습니다. 또한, 우리는 ImageNet 사전 훈련된 ViT에서 AST로 지식을 전달하는 접근법을 제안합니다. 또한 오디오 작업에 대한 AST의 설계 선택을 보여주기 위해 광범위한 실험을 수행합니다.
2. Audio Spectrogram Transformer
2.1. Model Architecture
그림 1은 제안된 Audio Spectrogram Transformer (AST) 아키텍처를 보여줍니다. 먼저, t초의 입력 오디오 파형은 25ms Hamming 윈도우로 10ms마다 계산된 128차원 로그 멜 필터뱅크(fbank) 특징의 시퀀스로 변환됩니다. 이것은 AST에 대한 입력으로 스펙트로그램을 생성합니다. 그런 다음 스펙트로그램을 시간 및 주파수 차원에서 6의 중첩을 갖는 개의 패치 시퀀스로 분할합니다. 여기서 는 패치의 수이고 Transformer에 대한 유효 입력 시퀀스 길이입니다. 우리는 각 패치를 선형 투영 레이어를 사용하여 크기 768의 1D 패치 임베딩으로 평탄화합니다. 이 선형 투영 레이어를 패치 임베딩 레이어라고 합니다. Transformer 아키텍처는 입력 순서 정보를 포착하지 않고 패치 시퀀스도 시간 순서가 아니므로, 모델이 2D 오디오 스펙트로그램의 공간 구조를 포착할 수 있도록 각 패치 임베딩에 학습 가능한 위치 임베딩(역시 크기 768)을 추가합니다.
[22]와 유사하게, 시퀀스의 시작 부분에 [CLS] 토큰을 추가합니다. 결과 시퀀스는 Transformer에 입력됩니다. Transformer는 여러 인코더 및 디코더 레이어로 구성됩니다. AST는 분류 작업을 위해 설계되었으므로 Transformer의 인코더만 사용합니다. 의도적으로, 우리는 수정 없이 원래의 Transformer 인코더[18] 아키텍처를 사용합니다. 이 간단한 설정의 장점은 1) 표준 Transformer 아키텍처는 TensorFlow 및 PyTorch에서 바로 사용할 수 있으므로 구현 및 재현이 쉽고, 2) AST에 전이 학습을 적용하려는 의도가 있으며, 표준 아키텍처는 전이 학습을 더 쉽게 만듭니다. 구체적으로, 우리가 사용하는 Transformer 인코더는 768의 임베딩 차원, 12개의 레이어, 12개의 헤드를 가지며, 이는 [12, 11]의 것과 동일합니다. [CLS] 토큰의 Transformer 인코더 출력은 오디오 스펙트로그램 표현으로 사용됩니다. 시그모이드 활성화를 갖는 선형 레이어는 오디오 스펙트로그램 표현을 분류를 위한 레이블에 매핑합니다.
엄밀히 말하면, 패치 임베딩 레이어는 큰 커널과 스트라이드 크기를 가진 단일 컨볼루션 레이어로 볼 수 있으며, 각 Transformer 블록의 투영 레이어는 컨볼루션과 동일합니다. 그러나 이 디자인은 여러 레이어와 작은 커널 및 스트라이드 크기를 가진 기존의 CNN과 다릅니다. 이러한 Transformer 모델은 일반적으로 CNN과 구별하기 위해 convolution-free라고 불립니다[11, 12].
2.2. ImageNet Pretraining
CNN에 비해 Transformer의 한 가지 단점은 훈련에 더 많은 데이터가 필요하다는 것입니다[11]. [11]에서 저자들은 이미지 분류 작업에서 데이터 양이 1,400만 개를 초과할 때 Transformer가 CNN을 능가하기 시작한다고 지적합니다. 그러나 오디오 데이터셋은 일반적으로 그렇게 많은 양의 데이터를 가지고 있지 않으므로, 이미지와 오디오 스펙트로그램이 유사한 형식을 가지고 있기 때문에 AST에 교차 모달리티 전이 학습을 적용하도록 동기를 부여합니다. 비전 작업에서 오디오 작업으로의 전이 학습은 이전에 [23, 24, 25, 8]에서 연구되었지만, CNN 기반 모델에만 해당되었으며, ImageNet 사전 훈련된 CNN 가중치가 오디오 분류 훈련을 위한 초기 CNN 가중치로 사용되었습니다. 실제로, 최첨단 비전 모델을 훈련시키는 것은 계산 비용이 많이 들지만, 많은 일반적으로 사용되는 아키텍처(예: ResNet [26], EfficientNet [27])는 TensorFlow 및 PyTorch 모두에 대해 바로 사용할 수 있는 ImageNet 사전 훈련 모델을 가지고 있어 전이 학습을 훨씬 쉽게 만듭니다. 우리도 이 방식을 따라 사전 훈련된 Vision Transformer(ViT)를 AST에 적용합니다.
ViT와 AST는 유사한 아키텍처(예: 둘 다 표준 Transformer, 동일한 패치 크기, 동일한 임베딩 크기 사용)를 가지고 있지만 동일하지는 않습니다. 따라서 적응을 위해 몇 가지 수정이 필요합니다. 첫째, ViT의 입력은 3채널 이미지인 반면 AST의 입력은 단일 채널 스펙트로그램이므로, ViT 패치 임베딩 레이어의 세 입력 채널 각각에 해당하는 가중치를 평균하여 AST 패치 임베딩 레이어의 가중치로 사용합니다. 이는 단일 채널 스펙트로그램을 동일한 내용의 3채널로 확장하는 것과 동일하지만 계산적으로 더 효율적입니다. 또한 입력 오디오 스펙트로그램을 데이터셋 평균 및 표준 편차가 각각 0과 0.5가 되도록 정규화합니다. 둘째, ViT의 입력 모양은 고정되어 있으며( 또는 ), 이는 일반적인 오디오 스펙트로그램과 다릅니다. 또한 오디오 스펙트로그램의 길이는 가변적일 수 있습니다. Transformer는 자연스럽게 가변 입력 길이를 지원하고 ViT에서 AST로 직접 전송될 수 있지만, 위치 임베딩은 ImageNet 훈련 중에 공간 정보를 인코딩하도록 학습되므로 신중하게 처리해야 합니다. 우리는 위치 임베딩 적응을 위해 잘라내기 및 이중 선형 보간 방법을 제안합니다. 예를 들어, 이미지 입력을 사용하고 의 패치 크기를 사용하는 ViT의 경우, 패치 수와 해당 위치 임베딩은 입니다(ViT는 중첩 없이 패치를 분할함). 10초 오디오 입력을 받는 AST는 개의 패치를 가지며, 각 패치에는 위치 임베딩이 필요합니다. 따라서 우리는 ViT 위치 임베딩의 첫 번째 차원을 자르고 두 번째 차원을 으로 보간하여 AST의 위치 임베딩으로 사용합니다. [CLS] 토큰에 대한 위치 임베딩은 직접 재사용합니다. 이렇게 함으로써 입력 모양이 다르더라도 사전 훈련된 ViT에서 AST로 2D 공간 지식을 전달할 수 있습니다. 마지막으로, 분류 작업이 본질적으로 다르기 때문에 ViT의 마지막 분류 레이어를 버리고 AST를 위해 새 레이어를 다시 초기화합니다. 이 적응 프레임워크를 통해 AST는 초기화를 위해 다양한 사전 훈련된 ViT 가중치를 사용할 수 있습니다. 이 연구에서는 CNN 지식 증류, 이미지로 훈련되고 8,700만 개의 매개변수를 가지며 ImageNet 2012에서 의 top-1 정확도를 달성하는 데이터 효율적인 이미지 Transformer(DeiT)[12]의 사전 훈련된 가중치를 사용합니다. ImageNet 훈련 중에 DeiT는 두 개의 [CLS] 토큰을 가집니다. 우리는 이들을 평균하여 오디오 훈련을 위한 단일 [CLS] 토큰으로 사용합니다.
3. Experiments
이 섹션에서는 약하게 레이블링된 오디오 이벤트 분류가 가장 어려운 오디오 분류 작업 중 하나이므로 AudioSet에서 AST를 평가하는 데 중점을 둡니다(섹션 3.1). 섹션 3.1.2 및 섹션 3.1.3에서 각각 주요 AudioSet 결과 및 절제 연구를 제시합니다. 그런 다음 섹션 3.2에서 ESC-50 및 Speech Commands V2에 대한 실험을 제시합니다.
3.1. AudioSet Experiments
3.1.1. Dataset and Training Details
AudioSet [15]은 YouTube 동영상에서 잘라낸 2백만 개 이상의 10초 오디오 클립 모음으로, 527개의 레이블 세트에서 클립에 포함된 소리로 레이블이 지정됩니다. 균형 잡힌 훈련, 전체 훈련 및 평가 세트에는 각각 22k, 2M 및 20k 샘플이 포함됩니다. AudioSet 실험의 경우 [8]과 정확히 동일한 훈련 파이프라인을 사용합니다. 구체적으로, 우리는 ImageNet 사전 훈련(섹션 2.2에서 설명), 균형 샘플링(전체 세트 실험에만 해당), 데이터 증강
표 1: AudioSet에서 AST와 이전 방법의 성능 비교.
| Model Architecture | Balanced mAP | Full mAP | |
|---|---|---|---|
| Baseline [15] | CNN+MLP | - | 0.314 |
| PANNs [7] | CNN+Attention | 0.278 | 0.439 |
| PSLA [8] (Single) | CNN+Attention | 0.319 | 0.444 |
| PSLA (Ensemble-S) | CNN+Attention | 0.345 | 0.464 |
| PSLA (Ensemble-M) | CNN+Attention | 0.362 | 0.474 |
| 0.347 | 0.459 | ||
| AST (Single) | Pure Attention | ||
| AST (Ensemble-S) | Pure Attention | 0.363 | 0.475 |
| AST (Ensemble-M) | Pure Attention | 0.378 | 0.485 |
(mixup [28] (mixup 비율 = 0.5) 및 스펙트로그램 마스킹 [29] (최대 시간 마스크 길이 192 프레임, 최대 주파수 마스크 길이 48 빈) 포함) 및 모델 집계(가중치 평균 [30] 및 앙상블 [31] 포함)를 사용합니다. 배치 크기 12, Adam 옵티마이저[32]로 모델을 훈련하고 이진 교차 엔트로피 손실을 사용합니다. 공식 균형 및 전체 훈련 세트에서 실험을 수행하고 AudioSet 평가 세트에서 평가합니다. 균형 세트 실험의 경우 초기 학습률 5e-5를 사용하고 모델을 25 에포크 동안 훈련하며, 학습률은 10번째 에포크 이후 5 에포크마다 절반으로 줄입니다. 전체 세트 실험의 경우 초기 학습률 1e-5를 사용하고 모델을 5 에포크 동안 훈련하며, 학습률은 2번째 에포크 이후 매 에포크마다 절반으로 줄입니다. 주요 평가 지표로 평균 평균 정밀도(mAP)를 사용합니다.
3.1.2. AudioSet Results
각 실험을 동일한 설정이지만 다른 랜덤 시드로 세 번 반복하고 평균과 표준 편차를 보고합니다. AST가 전체 AudioSet으로 훈련될 때 마지막 에포크의 mAP는 입니다. [8]에서와 같이 가중치 평균[30] 및 앙상블[31] 전략을 사용하여 AST의 성능을 더욱 향상시킵니다. 구체적으로, 가중치 평균의 경우 첫 번째부터 마지막 에포크까지의 모델 체크포인트의 모든 가중치를 평균합니다. 가중치 평균 모델은 mAP 을 달성하며, 이는 우리의 최상의 단일 모델입니다(가중치 평균은 모델 크기를 증가시키지 않음). 앙상블의 경우 두 가지 설정을 평가합니다: 1) Ensemble-S: 정확히 동일한 설정으로 실험을 세 번 실행하되 다른 랜덤 시드를 사용합니다. 그런 다음 각 실행의 마지막 체크포인트 모델의 출력을 평균합니다. 이 설정에서 앙상블 모델은 0.475의 mAP를 달성합니다; 2) Ensemble-M: 다른 설정으로 훈련된 모델을 앙상블합니다. 구체적으로, Ensemble-S의 세 모델과 다른 패치 분할 전략(섹션 3.1.3에서 설명하고 표 5에 표시됨)으로 훈련된 다른 세 모델을 함께 앙상블합니다. 이 설정에서 앙상블 모델은 0.485의 mAP를 달성하며, 이것이 AudioSet에 대한 우리의 최상의 전체 모델입니다. 표 1에서 볼 수 있듯이 제안된 AST는 모든 설정에서 [8]의 이전 최고 시스템을 능가합니다. [8]과 동일한 훈련 파이프라인을 사용하고 [8]도 ImageNet 사전 훈련을 사용하므로 공정한 비교입니다. 또한, 우리는 최상의 앙상블 모델에 8보다 적은 모델(6개)을 사용합니다. 마지막으로, AST 훈련이 빠르게 수렴한다는 점을 언급할 가치가 있습니다. AST는 5번의 훈련 에포크만 필요하지만 [8]에서는 CNN-attention 하이브리드 모델이 30 에포크 동안 훈련됩니다.
또한 AST의 성능을 평가하기 위해 균형 잡힌 AudioSet(전체 세트의 약 1%)으로 실험을 수행했습니다. 가중치 평균의 경우,
표 2: ImageNet 사전 훈련으로 인한 성능 영향. "Used"는 최적의 AST 모델에서 사용된 설정을 나타냅니다.
| Balanced Set | Full Set | |
|---|---|---|
| No Pretrain | 0.148 | 0.366 |
| ImageNet Pretrain (Used) | 0.347 | 0.459 |
표 3: 균형 잡힌 AudioSet에서 다른 ViT 가중치로 초기화된 AST 모델의 성능 및 해당 ViT 모델의 ImageNet 2012에서의 top-1 정확도. (* 모델은 메모리 제한으로 인해 패치 분할 중첩 없이 훈련되었습니다.)
| # Params | ImageNet | AudioSet | |
|---|---|---|---|
| ViT Base [11] | 86 M | 0.846 | 0.320 |
| ViT Large [11] | 307 M | 0.851 | 0.330 |
| DeiT w/o Distill [12] | 86 M | 0.829 | 0.330 |
| DeiT w/ Distill (Used) | 87 M | 0.852 | 0.347 |
마지막 20 에포크의 모델 체크포인트의 모든 가중치를 평균합니다. Ensemble-S의 경우, 전체 AudioSet 실험에 사용된 동일한 설정을 따릅니다. Ensemble-M의 경우, 다른 랜덤 시드(표 1), 다른 사전 훈련된 가중치(표 3), 다른 위치 임베딩 보간(표 4), 다른 패치 분할 전략(표 5)으로 훈련된 11개의 모델을 포함합니다. 단일, Ensemble-S, Ensemble-M 모델은 각각 을 달성하며, 모두 이전 최고의 시스템을 능가합니다. 이는 훈련 세트가 상대적으로 작을 때에도 AST가 CNN-attention 하이브리드 모델보다 더 잘 작동할 수 있음을 보여줍니다.
3.1.3. Ablation Study
AST의 설계 선택을 설명하기 위해 일련의 절제 연구를 수행합니다. 계산을 절약하기 위해 주로 균형 잡힌 AudioSet으로 절제 연구를 수행합니다. 모든 실험에서 가중치 평균을 사용하지만 앙상블은 사용하지 않습니다. ImageNet 사전 훈련의 영향. ImageNet 사전 훈련된 AST와 무작위로 초기화된 AST를 비교합니다. 표 2에서 볼 수 있듯이, ImageNet 사전 훈련된 AST는 균형 및 전체 AudioSet 실험 모두에서 무작위로 초기화된 AST보다 눈에 띄게 우수합니다. ImageNet 사전 훈련의 성능 향상은 훈련 데이터 양이 적을수록 더 중요하며, 이는 ImageNet 사전 훈련이 AST에 대한 도메인 내 오디오 데이터의 수요를 크게 줄일 수 있음을 보여줍니다. 사용된 사전 훈련 가중치의 영향을 더 연구합니다. 표 3에서 볼 수 있듯이, ViT-Base, ViT-Large 및 DeiT 모델의 사전 훈련된 가중치로 초기화된 AST 모델의 성능을 비교합니다. 이 모델들은 유사한 아키텍처를 가지고 있지만 다른 설정으로 훈련되었습니다. 가중치를 재사용하기 위해 AST에 필요한 아키텍처 수정을 했습니다. ImageNet2012에서 가장 좋은 성능을 보인 증류 방식의 DeiT 모델 가중치를 사용한 AST가 AudioSet에서도 가장 좋은 성능을 보인다는 것을 발견했습니다. 위치 임베딩 적응의 영향. 섹션 2.2에서 언급했듯이, Vision Transformer에서 AST로 지식을 전달할 때 위치 임베딩 적응을 위해 잘라내기 및 이중 선형 보간 접근 방식을 사용합니다. 이를 무작위로 초기화된 위치 임베딩을 가진 사전 훈련된 AST 모델과 비교합니다. 표 4에서 볼 수 있듯이, 위치 임베딩을 다시 초기화하는 것이 사전 훈련된 모델을 완전히 깨뜨리지는 않지만(모델이 완전히 무작위로 다시 초기화된 모델보다 여전히 성능이 우수함), 제안된 적응 접근 방식에 비해 눈에 띄는 성능 저하를 초래합니다. 이는 공간적 지식 전달의 중요성을 보여줍니다.
표 4: 다양한 위치 임베딩 적응 설정으로 인한 성능 영향.
| Balanced Set | |
|---|---|
| Reinitialize | 0.305 |
| Nearest Neighbor Interpolation | 0.346 |
| Bilinear Interpolation (Used) | 0.347 |
표 5: 다양한 패치 중첩 크기로 인한 성능 영향.
| # Patches | Balanced Set | Full Set | |
|---|---|---|---|
| No Overlap | 512 | 0.336 | 0.451 |
| Overlap-2 | 657 | 0.342 | 0.456 |
| Overlap-4 | 850 | 0.344 | 0.455 |
| Overlap-6 (Used) | 1212 | 0.347 | 0.459 |
표 6: 다양한 패치 모양 및 크기로 인한 성능 영향. 모든 모델은 패치 분할 중첩 없이 훈련되었습니다.
| # Patches | w/o Pretrain | w/ Pretrain | |
|---|---|---|---|
| 512 | 0.154 | - | |
| (Used) | 512 | 0.143 | 0.336 |
| 128 | 0.139 | - |
이중 선형 보간과 최근접 이웃 보간은 큰 차이를 보이지 않습니다. 패치 분할 중첩의 영향. 다른 패치 분할 중첩[13]으로 훈련된 모델의 성능을 비교합니다. 표 5에서 볼 수 있듯이, 균형 및 전체 세트 실험 모두에서 중첩 크기에 따라 성능이 향상됩니다. 그러나 중첩을 늘리면 Transformer에 대한 패치 시퀀스 입력이 길어져 계산 오버헤드가 이차적으로 증가합니다. 패치 분할 중첩이 없어도 AST는 [8]의 이전 최고 시스템을 능가할 수 있습니다. 패치 모양 및 크기의 영향. 섹션 2.1에서 언급했듯이 오디오 스펙트로그램을 정사각형 패치로 분할하므로 Transformer에 대한 입력 시퀀스는 시간 순서일 수 없습니다. 위치 임베딩이 2D 공간 정보를 인코딩하도록 학습되기를 바랍니다. 패치를 분할하는 다른 방법은 시간 순서대로 오디오 스펙트로그램을 직사각형 패치로 슬라이싱하는 것입니다. 표 6에서 두 방법을 비교하는데, 패치의 면적이 같을 때(256), 두 모델 모두 처음부터 훈련될 때 정사각형 패치를 사용하는 것보다 직사각형 패치를 사용하는 것이 더 나은 성능을 보입니다. 그러나 패치 기반의 ImageNet 사전 훈련 모델이 없다는 점을 고려하면, 패치를 사용하는 것이 현재 최적의 솔루션입니다. 또한 다른 크기의 패치를 사용하는 것을 비교하는데, 작은 크기의 패치가 더 나은 성능을 보입니다.
3.2. Results on ESC-50 and Speech Commands
ESC-50 [16] 데이터셋은 50개의 클래스로 구성된 2,000개의 5초 환경 오디오 녹음으로 구성됩니다. ESC-50의 현재 최고 결과는 86.5%의 정확도(처음부터 훈련, SOTA-S) [33]와 94.7%의 정확도(AudioSet 사전 훈련, SOTA-P) [7]입니다. 우리는 이 두 가지 설정에서 AST를 SOTA 모델과 비교합니다. 구체적으로, ImageNet 사전 훈련만 있는 AST 모델(AST-S)과 ImageNet 및 AudioSet 사전 훈련이 있는 AST 모델(AST-P)을 훈련합니다. 두 모델 모두 주파수/시간 마스킹[29] 데이터 증강, 배치 크기 48, Adam 옵티마이저[32]를 사용하여 20 에포크 동안 훈련합니다.
표 7: ESC-50 및 Speech Commands에서 AST와 SOTA 모델 비교. "- S"와 "- P"는 각각 추가 오디오 데이터 없이 및 추가 오디오 데이터로 훈련된 모델을 나타냅니다.
| ESC-50 | Speech Commands V2 (35 classes) | |
|---|---|---|
| SOTA-S | ||
| SOTA-P | ||
| AST-S | ||
| AST-P |
ASTS와 AST-P에 대해 각각 초기 학습률 1e-4와 1e-5를 사용하고, 5번째 에포크 이후 매 에포크마다 학습률을 0.85배 감소시킵니다. 표준 5겹 교차 검증에 따라 모델을 평가하고, 각 실험을 세 번 반복하여 평균과 표준 편차를 보고합니다. 표 7에서 볼 수 있듯이 AST-S는 , AST-P는 를 달성하여 동일한 설정에서 SOTA 모델을 모두 능가합니다. 주목할 점은, ESC-50이 각 폴드에 1,600개의 훈련 샘플을 가지고 있음에도 불구하고, AST는 AudioSet 사전 훈련 없이도 적은 양의 데이터로 잘 작동한다는 것입니다.
Speech Commands V2 [17]는 35개의 일반적인 음성 명령에 대한 105,829개의 1초 녹음으로 구성된 데이터셋입니다. 훈련, 검증 및 테스트 세트는 각각 84,843, 9,981 및 11,005개의 샘플을 포함합니다. 우리는 35개 클래스 분류 작업에 중점을 둡니다. 추가 오디오 데이터 사전 훈련 없이 Speech Commands V2(35개 클래스 분류)에서 SOTA 모델은 시간-채널 분리 가능한 컨볼루션 신경망[34]으로, 테스트 세트에서 97.4%를 달성합니다. [35]에서는 추가 2억 개의 YouTube 오디오로 사전 훈련된 CNN 모델이 테스트 세트에서 97.7%를 달성합니다. 우리도 이 두 가지 설정에서 AST를 평가합니다. 구체적으로, ImageNet 사전 훈련만 있는 AST 모델(AST-S)과 ImageNet 및 AudioSet 사전 훈련이 있는 AST 모델(AST-P)을 훈련합니다. 두 모델 모두 주파수 및 시간 마스킹[29], 무작위 노이즈 및 mixup[28] 증강, 배치 크기 128 및 Adam 옵티마이저[32]로 훈련합니다. 초기 학습률 2.5e-4를 사용하고 5번째 에포크 이후 매 에포크마다 학습률을 0.85배 감소시킵니다. 모델을 최대 20 에포크까지 훈련하고 검증 세트를 사용하여 최상의 모델을 선택하고 테스트 세트의 정확도를 보고합니다. 각 실험을 세 번 반복하고 평균과 표준 편차를 보고합니다. AST-S 모델은 를 달성하여 [9]의 SOTA 모델을 능가합니다. 또한, AST-S가 AST-P를 능가하므로 음성 명령 분류 작업에는 AudioSet 사전 훈련이 불필요하다는 것을 발견했습니다. 요약하자면, 입력 오디오 길이는 1초(Speech Commands), 5초(ESC-50)에서 10초(AudioSet)까지 다양하고 내용은 음성(Speech Commands)에서 비음성(AudioSet 및 ESC-50)까지 다양하지만, 세 가지 벤치마크 모두에 대해 고정된 AST 아키텍처를 사용하고 모든 벤치마크에서 SOTA 결과를 달성했습니다. 이는 AST가 일반적인 오디오 분류기로 사용될 가능성을 나타냅니다.
4. Conclusions
지난 10년 동안 CNN은 오디오 분류를 위한 일반적인 모델 구성 요소가 되었습니다. 이 연구에서 우리는 CNN이 필수 불가결하지 않다는 것을 발견하고, 간단한 아키텍처와 우수한 성능을 특징으로 하는 오디오 분류를 위한 convolution-free, 순수 attention 기반 모델인 Audio Spectrogram Transformer(AST)를 소개합니다.
5. Acknowledgements
이 연구는 Signify의 부분적인 지원을 받았습니다.
6. References
[1] F. Eyben, F. Weninger, F. Gross, and B. Schuller, "Recent developments in openSMILE, the Munich open-source multimedia feature extractor," in Multimedia, 2013. [2] B. Schuller, S. Steidl, A. Batliner, A. Vinciarelli, K. Scherer, F. Ringeval, M. Chetouani, F. Weninger, F. Eyben, E. Marchi, M. Mortillaro, H. Salamin, A. Polychroniou, F. Valente, and S. K. Kim, "The Interspeech 2013 computational paralinguistics challenge: Social signals, conflict, emotion, autism," in Interspeech, 2013. [3] N. Jaitly and G. Hinton, "Learning a better representation of speech soundwaves using restricted boltzmann machines," in ICASSP, 2011. [4] S. Dieleman and B. Schrauwen, "End-to-end learning for music audio," in ICASSP, 2014. [5] G. Trigeorgis, F. Ringeval, R. Brueckner, E. Marchi, M. A. Nicolaou, B. Schuller, and S. Zafeiriou, "Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network," in ICASSP, 2016. [6] Y. LeCun and Y. Bengio, "Convolutional networks for images, speech, and time series," The Handbook of Brain Theory and Neural Networks, vol. 3361, no. 10, p. 1995, 1995. [7] Q. Kong, Y. Cao, T. Iqbal, Y. Wang, W. Wang, and M. D. Plumbley, "PANNs: Large-scale pretrained audio neural networks for audio pattern recognition," IEEE/ACM TASLP, vol. 28, pp. 28802894, 2020. [8] Y. Gong, Y.-A. Chung, and J. Glass, "PSLA: Improving audio event classification with pretraining, sampling, labeling, and aggregation," arXiv preprint arXiv:2102.01243, 2021. [9] O. Rybakov, N. Kononenko, N. Subrahmanya, M. Visontai, and S. Laurenzo, "Streaming keyword spotting on mobile devices," in Interspeech, 2020. [10] P. Li, Y. Song, I. V. McLoughlin, W. Guo, and L.-R. Dai, "An attention pooling based representation learning method for speech emotion recognition," in Interspeech, 2018. [11] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, "An image is worth 16x16 words: Transformers for image recognition at scale," in , 2021. [12] H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jégou, "Training data-efficient image transformers & distillation through attention," arXiv preprint arXiv:2012.12877, 2020. [13] L. Yuan, Y. Chen, T. Wang, W. Yu, Y. Shi, F. E. Tay, J. Feng, and S. Yan, "Tokens-to-token ViT: Training vision transformers from scratch on ImageNet," arXiv preprint arXiv:2101.11986, 2021. [14] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, "ImageNet: A large-scale hierarchical image database," in CVPR, 2009. [15] J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, "Audio Set: An ontology and human-labeled dataset for audio events," in ICASSP, 2017. [16] K. J. Piczak, "ESC: Dataset for environmental sound classification," in Multimedia, 2015. [17] P. Warden, "Speech commands: A dataset for limited-vocabulary speech recognition," arXiv preprint arXiv:1804.03209, 2018. [18] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, "Attention is all you need," in NIPS, 2017. [19] K. Miyazaki, T. Komatsu, T. Hayashi, S. Watanabe, T. Toda, and K. Takeda, "Convolution augmented transformer for semisupervised sound event detection," in DCASE, 2020. [20] Q. Kong, Y. Xu, W. Wang, and M. D. Plumbley, "Sound event detection of weakly labelled data with CNN-transformer and automatic threshold optimization," IEEE/ACM TASLP, vol. 28, pp. 2450-2460, 2020. [21] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu, and R. Pang, "Conformer: Convolution-augmented transformer for speech recognition," in Interspeech, 2020. [22] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, "BERT: Pretraining of deep bidirectional transformers for language understanding," in NAACL-HLT, 2019. [23] G. Gwardys and D. M. Grzywczak, "Deep image features in music information retrieval," IJET, vol. 60, no. 4, pp. 321-326, 2014. [24] A. Guzhov, F. Raue, J. Hees, and A. Dengel, "ESResNet: Environmental sound classification based on visual domain models," in ICPR, 2020. [25] K. Palanisamy, D. Singhania, and A. Yao, "Rethinking CNN models for audio classification," arXiv preprint arXiv:2007.11154, 2020. [26] K. He, X. Zhang, S. Ren, and J. Sun, "Deep residual learning for image recognition," in CVPR, 2016. [27] M. Tan and Q. V. Le, "EfficientNet: Rethinking model scaling for convolutional neural networks," in ICML, 2019. [28] Y. Tokozume, Y. Ushiku, and T. Harada, "Learning from betweenclass examples for deep sound recognition," in ICLR, 2018. [29] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, "SpecAugment: A simple data augmentation method for automatic speech recognition," in Interspeech, 2019. [30] P. Izmailov, D. Podoprikhin, T. Garipov, D. Vetrov, and A. G. Wilson, "Averaging weights leads to wider optima and better generalization," in UAI, 2018. [31] L. Breiman, "Bagging predictors," Machine Learning, vol. 24, no. 2, pp. 123-140, 1996. [32] D. P. Kingma and J. Ba, "Adam: A method for stochastic optimization," in ICLR, 2015. [33] H. B. Sailor, D. M. Agrawal, and H. A. Patil, "Unsupervised filterbank learning using convolutional restricted boltzmann machine for environmental sound classification." in Interspeech, 2017. [34] S. Majumdar and B. Ginsburg, "Matchboxnet-1d time-channel separable convolutional neural network architecture for speech commands recognition," arXiv preprint arXiv:2004.08531, 2020. [35] J. Lin, K. Kilgour, D. Roblek, and M. Sharifi, "Training keyword spotters with limited and synthesized speech data," in ICASSP, 2020.
Footnotes
-
Code at https://github.com/YuanGongND/ast ↩